
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_35965 | rasdani/github-patches | git_diff | ethereum__web3.py-914 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Erorr in websockets.py: '<=' not supported between instances of 'int' and 'NoneType'
* web3 (4.3.0)
* websockets (4.0.1)
* Python: 3.6
* OS: osx HighSierra
### What was wrong?
`web3 = Web3(Web3.WebsocketProvider("ws://10.224.12.6:8546"))`
`web3.eth.syncing //returns data`
The websocket is clearly open but when I run a filter which is supposed to have many entries, I get the following error trace:
Upon running: `data = web3.eth.getFilterLogs(new_block_filter.filter_id)`, I get:
```
~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/web3/providers/websocket.py in make_request(self, method, params)
81 WebsocketProvider._loop
82 )
---> 83 return future.result()
/anaconda3/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)
430 raise CancelledError()
431 elif self._state == FINISHED:
--> 432 return self.__get_result()
433 else:
434 raise TimeoutError()
/anaconda3/lib/python3.6/concurrent/futures/_base.py in __get_result(self)
382 def __get_result(self):
383 if self._exception:
--> 384 raise self._exception
385 else:
386 return self._result
~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/web3/providers/websocket.py in coro_make_request(self, request_data)
71 async with self.conn as conn:
72 await conn.send(request_data)
---> 73 return json.loads(await conn.recv())
74
75 def make_request(self, method, params):
~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/websockets/protocol.py in recv(self)
321 next_message.cancel()
322 if not self.legacy_recv:
--> 323 raise ConnectionClosed(self.close_code, self.close_reason)
324
325 @asyncio.coroutine
~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/websockets/exceptions.py in __init__(self, code, reason)
145 self.reason = reason
146 message = "WebSocket connection is closed: "
--> 147 if 3000 <= code < 4000:
148 explanation = "registered"
149 elif 4000 <= code < 5000:
TypeError: '<=' not supported between instances of 'int' and 'NoneType'
```
The same filter runs fine (albeit a bit slow) using `Web3.HTTPProvider()`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/providers/websocket.py`
Content:
```
1 import asyncio
2 import json
3 import logging
4 import os
5 from threading import (
6 Thread,
7 )
8
9 import websockets
10
11 from web3.providers.base import (
12 JSONBaseProvider,
13 )
14
15
16 def _start_event_loop(loop):
17 asyncio.set_event_loop(loop)
18 loop.run_forever()
19 loop.close()
20
21
22 def _get_threaded_loop():
23 new_loop = asyncio.new_event_loop()
24 thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)
25 thread_loop.start()
26 return new_loop
27
28
29 def get_default_endpoint():
30 return os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546')
31
32
33 class PersistentWebSocket:
34
35 def __init__(self, endpoint_uri, loop):
36 self.ws = None
37 self.endpoint_uri = endpoint_uri
38 self.loop = loop
39
40 async def __aenter__(self):
41 if self.ws is None:
42 self.ws = await websockets.connect(uri=self.endpoint_uri, loop=self.loop)
43 return self.ws
44
45 async def __aexit__(self, exc_type, exc_val, exc_tb):
46 if exc_val is not None:
47 try:
48 await self.ws.close()
49 except Exception:
50 pass
51 self.ws = None
52
53
54 class WebsocketProvider(JSONBaseProvider):
55 logger = logging.getLogger("web3.providers.WebsocketProvider")
56 _loop = None
57
58 def __init__(self, endpoint_uri=None):
59 self.endpoint_uri = endpoint_uri
60 if self.endpoint_uri is None:
61 self.endpoint_uri = get_default_endpoint()
62 if WebsocketProvider._loop is None:
63 WebsocketProvider._loop = _get_threaded_loop()
64 self.conn = PersistentWebSocket(self.endpoint_uri, WebsocketProvider._loop)
65 super().__init__()
66
67 def __str__(self):
68 return "WS connection {0}".format(self.endpoint_uri)
69
70 async def coro_make_request(self, request_data):
71 async with self.conn as conn:
72 await conn.send(request_data)
73 return json.loads(await conn.recv())
74
75 def make_request(self, method, params):
76 self.logger.debug("Making request WebSocket. URI: %s, "
77 "Method: %s", self.endpoint_uri, method)
78 request_data = self.encode_rpc_request(method, params)
79 future = asyncio.run_coroutine_threadsafe(
80 self.coro_make_request(request_data),
81 WebsocketProvider._loop
82 )
83 return future.result()
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/web3/providers/websocket.py b/web3/providers/websocket.py
--- a/web3/providers/websocket.py
+++ b/web3/providers/websocket.py
@@ -8,10 +8,15 @@
import websockets
+from web3.exceptions import (
+ ValidationError,
+)
from web3.providers.base import (
JSONBaseProvider,
)
+RESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}
+
def _start_event_loop(loop):
asyncio.set_event_loop(loop)
@@ -32,14 +37,17 @@
class PersistentWebSocket:
- def __init__(self, endpoint_uri, loop):
+ def __init__(self, endpoint_uri, loop, websocket_kwargs):
self.ws = None
self.endpoint_uri = endpoint_uri
self.loop = loop
+ self.websocket_kwargs = websocket_kwargs
async def __aenter__(self):
if self.ws is None:
- self.ws = await websockets.connect(uri=self.endpoint_uri, loop=self.loop)
+ self.ws = await websockets.connect(
+ uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs
+ )
return self.ws
async def __aexit__(self, exc_type, exc_val, exc_tb):
@@ -55,13 +63,26 @@
logger = logging.getLogger("web3.providers.WebsocketProvider")
_loop = None
- def __init__(self, endpoint_uri=None):
+ def __init__(self, endpoint_uri=None, websocket_kwargs=None):
self.endpoint_uri = endpoint_uri
if self.endpoint_uri is None:
self.endpoint_uri = get_default_endpoint()
if WebsocketProvider._loop is None:
WebsocketProvider._loop = _get_threaded_loop()
- self.conn = PersistentWebSocket(self.endpoint_uri, WebsocketProvider._loop)
+ if websocket_kwargs is None:
+ websocket_kwargs = {}
+ else:
+ found_restricted_keys = set(websocket_kwargs.keys()).intersection(
+ RESTRICTED_WEBSOCKET_KWARGS
+ )
+ if found_restricted_keys:
+ raise ValidationError(
+ '{0} are not allowed in websocket_kwargs, '
+ 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)
+ )
+ self.conn = PersistentWebSocket(
+ self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs
+ )
super().__init__()
def __str__(self):
| {"golden_diff": "diff --git a/web3/providers/websocket.py b/web3/providers/websocket.py\n--- a/web3/providers/websocket.py\n+++ b/web3/providers/websocket.py\n@@ -8,10 +8,15 @@\n \n import websockets\n \n+from web3.exceptions import (\n+ ValidationError,\n+)\n from web3.providers.base import (\n JSONBaseProvider,\n )\n \n+RESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}\n+\n \n def _start_event_loop(loop):\n asyncio.set_event_loop(loop)\n@@ -32,14 +37,17 @@\n \n class PersistentWebSocket:\n \n- def __init__(self, endpoint_uri, loop):\n+ def __init__(self, endpoint_uri, loop, websocket_kwargs):\n self.ws = None\n self.endpoint_uri = endpoint_uri\n self.loop = loop\n+ self.websocket_kwargs = websocket_kwargs\n \n async def __aenter__(self):\n if self.ws is None:\n- self.ws = await websockets.connect(uri=self.endpoint_uri, loop=self.loop)\n+ self.ws = await websockets.connect(\n+ uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n+ )\n return self.ws\n \n async def __aexit__(self, exc_type, exc_val, exc_tb):\n@@ -55,13 +63,26 @@\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n \n- def __init__(self, endpoint_uri=None):\n+ def __init__(self, endpoint_uri=None, websocket_kwargs=None):\n self.endpoint_uri = endpoint_uri\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n- self.conn = PersistentWebSocket(self.endpoint_uri, WebsocketProvider._loop)\n+ if websocket_kwargs is None:\n+ websocket_kwargs = {}\n+ else:\n+ found_restricted_keys = set(websocket_kwargs.keys()).intersection(\n+ RESTRICTED_WEBSOCKET_KWARGS\n+ )\n+ if found_restricted_keys:\n+ raise ValidationError(\n+ '{0} are not allowed in websocket_kwargs, '\n+ 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n+ )\n+ self.conn = PersistentWebSocket(\n+ self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n+ )\n super().__init__()\n \n def __str__(self):\n", "issue": "Erorr in websockets.py: '<=' not supported between instances of 'int' and 'NoneType'\n* web3 (4.3.0)\r\n* websockets (4.0.1)\r\n* Python: 3.6\r\n* OS: osx HighSierra\r\n\r\n\r\n### What was wrong?\r\n\r\n`web3 = Web3(Web3.WebsocketProvider(\"ws://10.224.12.6:8546\"))`\r\n`web3.eth.syncing //returns data`\r\n\r\nThe websocket is clearly open but when I run a filter which is supposed to have many entries, I get the following error trace:\r\n\r\nUpon running: `data = web3.eth.getFilterLogs(new_block_filter.filter_id)`, I get:\r\n\r\n```\r\n~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/web3/providers/websocket.py in make_request(self, method, params)\r\n 81 WebsocketProvider._loop\r\n 82 )\r\n---> 83 return future.result()\r\n\r\n/anaconda3/lib/python3.6/concurrent/futures/_base.py in result(self, timeout)\r\n 430 raise CancelledError()\r\n 431 elif self._state == FINISHED:\r\n--> 432 return self.__get_result()\r\n 433 else:\r\n 434 raise TimeoutError()\r\n\r\n/anaconda3/lib/python3.6/concurrent/futures/_base.py in __get_result(self)\r\n 382 def __get_result(self):\r\n 383 if self._exception:\r\n--> 384 raise self._exception\r\n 385 else:\r\n 386 return self._result\r\n\r\n~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/web3/providers/websocket.py in coro_make_request(self, request_data)\r\n 71 async with self.conn as conn:\r\n 72 await conn.send(request_data)\r\n---> 73 return json.loads(await conn.recv())\r\n 74 \r\n 75 def make_request(self, method, params):\r\n\r\n~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/websockets/protocol.py in recv(self)\r\n 321 next_message.cancel()\r\n 322 if not self.legacy_recv:\r\n--> 323 raise ConnectionClosed(self.close_code, self.close_reason)\r\n 324 \r\n 325 @asyncio.coroutine\r\n\r\n~/Desktop/contracts-py/contracts/lib/python3.6/site-packages/websockets/exceptions.py in __init__(self, code, reason)\r\n 145 self.reason = reason\r\n 146 message = \"WebSocket connection is closed: \"\r\n--> 147 if 3000 <= code < 4000:\r\n 148 explanation = \"registered\"\r\n 149 elif 4000 <= code < 5000:\r\n\r\nTypeError: '<=' not supported between instances of 'int' and 'NoneType'\r\n```\r\n\r\nThe same filter runs fine (albeit a bit slow) using `Web3.HTTPProvider()`\r\n\r\n\n", "before_files": [{"content": "import asyncio\nimport json\nimport logging\nimport os\nfrom threading import (\n Thread,\n)\n\nimport websockets\n\nfrom web3.providers.base import (\n JSONBaseProvider,\n)\n\n\ndef _start_event_loop(loop):\n asyncio.set_event_loop(loop)\n loop.run_forever()\n loop.close()\n\n\ndef _get_threaded_loop():\n new_loop = asyncio.new_event_loop()\n thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)\n thread_loop.start()\n return new_loop\n\n\ndef get_default_endpoint():\n return os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546')\n\n\nclass PersistentWebSocket:\n\n def __init__(self, endpoint_uri, loop):\n self.ws = None\n self.endpoint_uri = endpoint_uri\n self.loop = loop\n\n async def __aenter__(self):\n if self.ws is None:\n self.ws = await websockets.connect(uri=self.endpoint_uri, loop=self.loop)\n return self.ws\n\n async def __aexit__(self, exc_type, exc_val, exc_tb):\n if exc_val is not None:\n try:\n await self.ws.close()\n except Exception:\n pass\n self.ws = None\n\n\nclass WebsocketProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n\n def __init__(self, endpoint_uri=None):\n self.endpoint_uri = endpoint_uri\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n self.conn = PersistentWebSocket(self.endpoint_uri, WebsocketProvider._loop)\n super().__init__()\n\n def __str__(self):\n return \"WS connection {0}\".format(self.endpoint_uri)\n\n async def coro_make_request(self, request_data):\n async with self.conn as conn:\n await conn.send(request_data)\n return json.loads(await conn.recv())\n\n def make_request(self, method, params):\n self.logger.debug(\"Making request WebSocket. URI: %s, \"\n \"Method: %s\", self.endpoint_uri, method)\n request_data = self.encode_rpc_request(method, params)\n future = asyncio.run_coroutine_threadsafe(\n self.coro_make_request(request_data),\n WebsocketProvider._loop\n )\n return future.result()\n", "path": "web3/providers/websocket.py"}], "after_files": [{"content": "import asyncio\nimport json\nimport logging\nimport os\nfrom threading import (\n Thread,\n)\n\nimport websockets\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.providers.base import (\n JSONBaseProvider,\n)\n\nRESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}\n\n\ndef _start_event_loop(loop):\n asyncio.set_event_loop(loop)\n loop.run_forever()\n loop.close()\n\n\ndef _get_threaded_loop():\n new_loop = asyncio.new_event_loop()\n thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)\n thread_loop.start()\n return new_loop\n\n\ndef get_default_endpoint():\n return os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546')\n\n\nclass PersistentWebSocket:\n\n def __init__(self, endpoint_uri, loop, websocket_kwargs):\n self.ws = None\n self.endpoint_uri = endpoint_uri\n self.loop = loop\n self.websocket_kwargs = websocket_kwargs\n\n async def __aenter__(self):\n if self.ws is None:\n self.ws = await websockets.connect(\n uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n )\n return self.ws\n\n async def __aexit__(self, exc_type, exc_val, exc_tb):\n if exc_val is not None:\n try:\n await self.ws.close()\n except Exception:\n pass\n self.ws = None\n\n\nclass WebsocketProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n\n def __init__(self, endpoint_uri=None, websocket_kwargs=None):\n self.endpoint_uri = endpoint_uri\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n if websocket_kwargs is None:\n websocket_kwargs = {}\n else:\n found_restricted_keys = set(websocket_kwargs.keys()).intersection(\n RESTRICTED_WEBSOCKET_KWARGS\n )\n if found_restricted_keys:\n raise ValidationError(\n '{0} are not allowed in websocket_kwargs, '\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n )\n super().__init__()\n\n def __str__(self):\n return \"WS connection {0}\".format(self.endpoint_uri)\n\n async def coro_make_request(self, request_data):\n async with self.conn as conn:\n await conn.send(request_data)\n return json.loads(await conn.recv())\n\n def make_request(self, method, params):\n self.logger.debug(\"Making request WebSocket. URI: %s, \"\n \"Method: %s\", self.endpoint_uri, method)\n request_data = self.encode_rpc_request(method, params)\n future = asyncio.run_coroutine_threadsafe(\n self.coro_make_request(request_data),\n WebsocketProvider._loop\n )\n return future.result()\n", "path": "web3/providers/websocket.py"}]} | 1,632 | 544 |
gh_patches_debug_34363 | rasdani/github-patches | git_diff | localstack__localstack-1082 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Localstack Elasticsearch plugin Ingest User Agent Processor not available
Plugin `Ingest User Agent Processor` is installed by default for Elasticsearch (ELK) on AWS. It is not the case in Localstack and think we basically expect it.
In addition, I was not able to install it manually through command `bin/elasticsearch-plugin install ingest-user-agent` as bin/elasticsearch-plugin is missing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `localstack/constants.py`
Content:
```
1 import os
2 import localstack_client.config
3
4 # LocalStack version
5 VERSION = '0.8.10'
6
7 # default AWS region
8 if 'DEFAULT_REGION' not in os.environ:
9 os.environ['DEFAULT_REGION'] = 'us-east-1'
10 DEFAULT_REGION = os.environ['DEFAULT_REGION']
11
12 # constant to represent the "local" region, i.e., local machine
13 REGION_LOCAL = 'local'
14
15 # dev environment
16 ENV_DEV = 'dev'
17
18 # backend service ports, for services that are behind a proxy (counting down from 4566)
19 DEFAULT_PORT_APIGATEWAY_BACKEND = 4566
20 DEFAULT_PORT_KINESIS_BACKEND = 4565
21 DEFAULT_PORT_DYNAMODB_BACKEND = 4564
22 DEFAULT_PORT_S3_BACKEND = 4563
23 DEFAULT_PORT_SNS_BACKEND = 4562
24 DEFAULT_PORT_SQS_BACKEND = 4561
25 DEFAULT_PORT_ELASTICSEARCH_BACKEND = 4560
26 DEFAULT_PORT_CLOUDFORMATION_BACKEND = 4559
27
28 DEFAULT_PORT_WEB_UI = 8080
29
30 LOCALHOST = 'localhost'
31
32 # version of the Maven dependency with Java utility code
33 LOCALSTACK_MAVEN_VERSION = '0.1.15'
34
35 # map of default service APIs and ports to be spun up (fetch map from localstack_client)
36 DEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()
37
38 # host to bind to when starting the services
39 BIND_HOST = '0.0.0.0'
40
41 # AWS user account ID used for tests
42 TEST_AWS_ACCOUNT_ID = '000000000000'
43 os.environ['TEST_AWS_ACCOUNT_ID'] = TEST_AWS_ACCOUNT_ID
44
45 # root code folder
46 LOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(os.path.dirname(os.path.realpath(__file__)), '..'))
47
48 # virtualenv folder
49 LOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, '.venv')
50 if not os.path.isdir(LOCALSTACK_VENV_FOLDER):
51 # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/
52 LOCALSTACK_VENV_FOLDER = os.path.realpath(os.path.join(LOCALSTACK_ROOT_FOLDER, '..', '..', '..'))
53
54 # API Gateway path to indicate a user request sent to the gateway
55 PATH_USER_REQUEST = '_user_request_'
56
57 # name of LocalStack Docker image
58 DOCKER_IMAGE_NAME = 'localstack/localstack'
59
60 # environment variable name to tag local test runs
61 ENV_INTERNAL_TEST_RUN = 'LOCALSTACK_INTERNAL_TEST_RUN'
62
63 # content types
64 APPLICATION_AMZ_JSON_1_0 = 'application/x-amz-json-1.0'
65 APPLICATION_AMZ_JSON_1_1 = 'application/x-amz-json-1.1'
66 APPLICATION_JSON = 'application/json'
67
68 # Lambda defaults
69 LAMBDA_TEST_ROLE = 'arn:aws:iam::%s:role/lambda-test-role' % TEST_AWS_ACCOUNT_ID
70
71 # installation constants
72 ELASTICSEARCH_JAR_URL = 'https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.0.zip'
73 DYNAMODB_JAR_URL = 'https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip'
74 ELASTICMQ_JAR_URL = 'https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-0.14.2.jar'
75 STS_JAR_URL = 'http://central.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar'
76
77 # API endpoint for analytics events
78 API_ENDPOINT = 'https://api.localstack.cloud/v1'
79
```
Path: `localstack/services/install.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4 import sys
5 import glob
6 import shutil
7 import logging
8 import tempfile
9 from localstack.constants import (DEFAULT_SERVICE_PORTS, ELASTICMQ_JAR_URL, STS_JAR_URL,
10 ELASTICSEARCH_JAR_URL, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)
11 from localstack.utils.common import download, parallelize, run, mkdir, save_file, unzip, rm_rf, chmod_r
12
13 THIS_PATH = os.path.dirname(os.path.realpath(__file__))
14 ROOT_PATH = os.path.realpath(os.path.join(THIS_PATH, '..'))
15
16 INSTALL_DIR_INFRA = '%s/infra' % ROOT_PATH
17 INSTALL_DIR_NPM = '%s/node_modules' % ROOT_PATH
18 INSTALL_DIR_ES = '%s/elasticsearch' % INSTALL_DIR_INFRA
19 INSTALL_DIR_DDB = '%s/dynamodb' % INSTALL_DIR_INFRA
20 INSTALL_DIR_KCL = '%s/amazon-kinesis-client' % INSTALL_DIR_INFRA
21 INSTALL_DIR_ELASTICMQ = '%s/elasticmq' % INSTALL_DIR_INFRA
22 INSTALL_PATH_LOCALSTACK_FAT_JAR = '%s/localstack-utils-fat.jar' % INSTALL_DIR_INFRA
23 TMP_ARCHIVE_ES = os.path.join(tempfile.gettempdir(), 'localstack.es.zip')
24 TMP_ARCHIVE_DDB = os.path.join(tempfile.gettempdir(), 'localstack.ddb.zip')
25 TMP_ARCHIVE_STS = os.path.join(tempfile.gettempdir(), 'aws-java-sdk-sts.jar')
26 TMP_ARCHIVE_ELASTICMQ = os.path.join(tempfile.gettempdir(), 'elasticmq-server.jar')
27 URL_LOCALSTACK_FAT_JAR = ('http://central.maven.org/maven2/' +
28 'cloud/localstack/localstack-utils/{v}/localstack-utils-{v}-fat.jar').format(v=LOCALSTACK_MAVEN_VERSION)
29
30 # set up logger
31 LOGGER = logging.getLogger(__name__)
32
33
34 def install_elasticsearch():
35 if not os.path.exists(INSTALL_DIR_ES):
36 LOGGER.info('Downloading and installing local Elasticsearch server. This may take some time.')
37 mkdir(INSTALL_DIR_INFRA)
38 # download and extract archive
39 download_and_extract_with_retry(ELASTICSEARCH_JAR_URL, TMP_ARCHIVE_ES, INSTALL_DIR_INFRA)
40 elasticsearch_dir = glob.glob(os.path.join(INSTALL_DIR_INFRA, 'elasticsearch*'))
41 if not elasticsearch_dir:
42 raise Exception('Unable to find Elasticsearch folder in %s' % INSTALL_DIR_INFRA)
43 shutil.move(elasticsearch_dir[0], INSTALL_DIR_ES)
44
45 for dir_name in ('data', 'logs', 'modules', 'plugins', 'config/scripts'):
46 dir_path = '%s/%s' % (INSTALL_DIR_ES, dir_name)
47 mkdir(dir_path)
48 chmod_r(dir_path, 0o777)
49
50
51 def install_elasticmq():
52 if not os.path.exists(INSTALL_DIR_ELASTICMQ):
53 LOGGER.info('Downloading and installing local ElasticMQ server. This may take some time.')
54 mkdir(INSTALL_DIR_ELASTICMQ)
55 # download archive
56 if not os.path.exists(TMP_ARCHIVE_ELASTICMQ):
57 download(ELASTICMQ_JAR_URL, TMP_ARCHIVE_ELASTICMQ)
58 shutil.copy(TMP_ARCHIVE_ELASTICMQ, INSTALL_DIR_ELASTICMQ)
59
60
61 def install_kinesalite():
62 target_dir = '%s/kinesalite' % INSTALL_DIR_NPM
63 if not os.path.exists(target_dir):
64 LOGGER.info('Downloading and installing local Kinesis server. This may take some time.')
65 run('cd "%s" && npm install' % ROOT_PATH)
66
67
68 def install_dynamodb_local():
69 if not os.path.exists(INSTALL_DIR_DDB):
70 LOGGER.info('Downloading and installing local DynamoDB server. This may take some time.')
71 mkdir(INSTALL_DIR_DDB)
72 # download and extract archive
73 download_and_extract_with_retry(DYNAMODB_JAR_URL, TMP_ARCHIVE_DDB, INSTALL_DIR_DDB)
74
75 # fix for Alpine, otherwise DynamoDBLocal fails with:
76 # DynamoDBLocal_lib/libsqlite4java-linux-amd64.so: __memcpy_chk: symbol not found
77 if is_alpine():
78 ddb_libs_dir = '%s/DynamoDBLocal_lib' % INSTALL_DIR_DDB
79 patched_marker = '%s/alpine_fix_applied' % ddb_libs_dir
80 if not os.path.exists(patched_marker):
81 patched_lib = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +
82 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/libsqlite4java-linux-amd64.so')
83 patched_jar = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +
84 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/sqlite4java.jar')
85 run("curl -L -o %s/libsqlite4java-linux-amd64.so '%s'" % (ddb_libs_dir, patched_lib))
86 run("curl -L -o %s/sqlite4java.jar '%s'" % (ddb_libs_dir, patched_jar))
87 save_file(patched_marker, '')
88
89 # fix logging configuration for DynamoDBLocal
90 log4j2_config = """<Configuration status="WARN">
91 <Appenders>
92 <Console name="Console" target="SYSTEM_OUT">
93 <PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
94 </Console>
95 </Appenders>
96 <Loggers>
97 <Root level="WARN"><AppenderRef ref="Console"/></Root>
98 </Loggers>
99 </Configuration>"""
100 log4j2_file = os.path.join(INSTALL_DIR_DDB, 'log4j2.xml')
101 save_file(log4j2_file, log4j2_config)
102 run('cd "%s" && zip -u DynamoDBLocal.jar log4j2.xml || true' % INSTALL_DIR_DDB)
103
104
105 def install_amazon_kinesis_client_libs():
106 # install KCL/STS JAR files
107 if not os.path.exists(INSTALL_DIR_KCL):
108 mkdir(INSTALL_DIR_KCL)
109 if not os.path.exists(TMP_ARCHIVE_STS):
110 download(STS_JAR_URL, TMP_ARCHIVE_STS)
111 shutil.copy(TMP_ARCHIVE_STS, INSTALL_DIR_KCL)
112 # Compile Java files
113 from localstack.utils.kinesis import kclipy_helper
114 classpath = kclipy_helper.get_kcl_classpath()
115 java_files = '%s/utils/kinesis/java/com/atlassian/*.java' % ROOT_PATH
116 class_files = '%s/utils/kinesis/java/com/atlassian/*.class' % ROOT_PATH
117 if not glob.glob(class_files):
118 run('javac -cp "%s" %s' % (classpath, java_files))
119
120
121 def install_lambda_java_libs():
122 # install LocalStack "fat" JAR file (contains all dependencies)
123 if not os.path.exists(INSTALL_PATH_LOCALSTACK_FAT_JAR):
124 LOGGER.info('Downloading and installing LocalStack Java libraries. This may take some time.')
125 download(URL_LOCALSTACK_FAT_JAR, INSTALL_PATH_LOCALSTACK_FAT_JAR)
126
127
128 def install_component(name):
129 if name == 'kinesis':
130 install_kinesalite()
131 elif name == 'dynamodb':
132 install_dynamodb_local()
133 elif name == 'es':
134 install_elasticsearch()
135 elif name == 'sqs':
136 install_elasticmq()
137
138
139 def install_components(names):
140 parallelize(install_component, names)
141 install_lambda_java_libs()
142
143
144 def install_all_components():
145 install_components(DEFAULT_SERVICE_PORTS.keys())
146
147
148 # -----------------
149 # HELPER FUNCTIONS
150 # -----------------
151
152
153 def is_alpine():
154 try:
155 run('cat /etc/issue | grep Alpine', print_error=False)
156 return True
157 except Exception:
158 return False
159
160
161 def download_and_extract_with_retry(archive_url, tmp_archive, target_dir):
162
163 def download_and_extract():
164 if not os.path.exists(tmp_archive):
165 download(archive_url, tmp_archive)
166 unzip(tmp_archive, target_dir)
167
168 try:
169 download_and_extract()
170 except Exception:
171 # try deleting and re-downloading the zip file
172 LOGGER.info('Unable to extract file, re-downloading ZIP archive: %s' % tmp_archive)
173 rm_rf(tmp_archive)
174 download_and_extract()
175
176
177 if __name__ == '__main__':
178
179 if len(sys.argv) > 1:
180 if sys.argv[1] == 'libs':
181 print('Initializing installation.')
182 logging.basicConfig(level=logging.INFO)
183 logging.getLogger('requests').setLevel(logging.WARNING)
184 install_all_components()
185 print('Done.')
186 elif sys.argv[1] == 'testlibs':
187 # Install additional libraries for testing
188 install_amazon_kinesis_client_libs()
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/localstack/constants.py b/localstack/constants.py
--- a/localstack/constants.py
+++ b/localstack/constants.py
@@ -70,6 +70,9 @@
# installation constants
ELASTICSEARCH_JAR_URL = 'https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.0.zip'
+# https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html
+ELASTICSEARCH_PLUGIN_LIST = ['analysis-icu', 'ingest-attachment', 'ingest-user-agent', 'analysis-kuromoji',
+ 'mapper-murmur3', 'mapper-size', 'analysis-phonetic', 'analysis-smartcn', 'analysis-stempel', 'analysis-ukrainian']
DYNAMODB_JAR_URL = 'https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip'
ELASTICMQ_JAR_URL = 'https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-0.14.2.jar'
STS_JAR_URL = 'http://central.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar'
diff --git a/localstack/services/install.py b/localstack/services/install.py
--- a/localstack/services/install.py
+++ b/localstack/services/install.py
@@ -7,7 +7,7 @@
import logging
import tempfile
from localstack.constants import (DEFAULT_SERVICE_PORTS, ELASTICMQ_JAR_URL, STS_JAR_URL,
- ELASTICSEARCH_JAR_URL, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)
+ ELASTICSEARCH_JAR_URL, ELASTICSEARCH_PLUGIN_LIST, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)
from localstack.utils.common import download, parallelize, run, mkdir, save_file, unzip, rm_rf, chmod_r
THIS_PATH = os.path.dirname(os.path.realpath(__file__))
@@ -47,6 +47,14 @@
mkdir(dir_path)
chmod_r(dir_path, 0o777)
+ # install default plugins
+ for plugin in ELASTICSEARCH_PLUGIN_LIST:
+ if is_alpine():
+ # https://github.com/pires/docker-elasticsearch/issues/56
+ os.environ['ES_TMPDIR'] = '/tmp'
+ plugin_binary = os.path.join(INSTALL_DIR_ES, 'bin', 'elasticsearch-plugin')
+ run('%s install %s' % (plugin_binary, plugin))
+
def install_elasticmq():
if not os.path.exists(INSTALL_DIR_ELASTICMQ):
| {"golden_diff": "diff --git a/localstack/constants.py b/localstack/constants.py\n--- a/localstack/constants.py\n+++ b/localstack/constants.py\n@@ -70,6 +70,9 @@\n \n # installation constants\n ELASTICSEARCH_JAR_URL = 'https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.0.zip'\n+# https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html\n+ELASTICSEARCH_PLUGIN_LIST = ['analysis-icu', 'ingest-attachment', 'ingest-user-agent', 'analysis-kuromoji',\n+ 'mapper-murmur3', 'mapper-size', 'analysis-phonetic', 'analysis-smartcn', 'analysis-stempel', 'analysis-ukrainian']\n DYNAMODB_JAR_URL = 'https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip'\n ELASTICMQ_JAR_URL = 'https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-0.14.2.jar'\n STS_JAR_URL = 'http://central.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar'\ndiff --git a/localstack/services/install.py b/localstack/services/install.py\n--- a/localstack/services/install.py\n+++ b/localstack/services/install.py\n@@ -7,7 +7,7 @@\n import logging\n import tempfile\n from localstack.constants import (DEFAULT_SERVICE_PORTS, ELASTICMQ_JAR_URL, STS_JAR_URL,\n- ELASTICSEARCH_JAR_URL, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)\n+ ELASTICSEARCH_JAR_URL, ELASTICSEARCH_PLUGIN_LIST, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)\n from localstack.utils.common import download, parallelize, run, mkdir, save_file, unzip, rm_rf, chmod_r\n \n THIS_PATH = os.path.dirname(os.path.realpath(__file__))\n@@ -47,6 +47,14 @@\n mkdir(dir_path)\n chmod_r(dir_path, 0o777)\n \n+ # install default plugins\n+ for plugin in ELASTICSEARCH_PLUGIN_LIST:\n+ if is_alpine():\n+ # https://github.com/pires/docker-elasticsearch/issues/56\n+ os.environ['ES_TMPDIR'] = '/tmp'\n+ plugin_binary = os.path.join(INSTALL_DIR_ES, 'bin', 'elasticsearch-plugin')\n+ run('%s install %s' % (plugin_binary, plugin))\n+\n \n def install_elasticmq():\n if not os.path.exists(INSTALL_DIR_ELASTICMQ):\n", "issue": "Localstack Elasticsearch plugin Ingest User Agent Processor not available\nPlugin `Ingest User Agent Processor` is installed by default for Elasticsearch (ELK) on AWS. It is not the case in Localstack and think we basically expect it.\r\n\r\nIn addition, I was not able to install it manually through command `bin/elasticsearch-plugin install ingest-user-agent` as bin/elasticsearch-plugin is missing.\n", "before_files": [{"content": "import os\nimport localstack_client.config\n\n# LocalStack version\nVERSION = '0.8.10'\n\n# default AWS region\nif 'DEFAULT_REGION' not in os.environ:\n os.environ['DEFAULT_REGION'] = 'us-east-1'\nDEFAULT_REGION = os.environ['DEFAULT_REGION']\n\n# constant to represent the \"local\" region, i.e., local machine\nREGION_LOCAL = 'local'\n\n# dev environment\nENV_DEV = 'dev'\n\n# backend service ports, for services that are behind a proxy (counting down from 4566)\nDEFAULT_PORT_APIGATEWAY_BACKEND = 4566\nDEFAULT_PORT_KINESIS_BACKEND = 4565\nDEFAULT_PORT_DYNAMODB_BACKEND = 4564\nDEFAULT_PORT_S3_BACKEND = 4563\nDEFAULT_PORT_SNS_BACKEND = 4562\nDEFAULT_PORT_SQS_BACKEND = 4561\nDEFAULT_PORT_ELASTICSEARCH_BACKEND = 4560\nDEFAULT_PORT_CLOUDFORMATION_BACKEND = 4559\n\nDEFAULT_PORT_WEB_UI = 8080\n\nLOCALHOST = 'localhost'\n\n# version of the Maven dependency with Java utility code\nLOCALSTACK_MAVEN_VERSION = '0.1.15'\n\n# map of default service APIs and ports to be spun up (fetch map from localstack_client)\nDEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()\n\n# host to bind to when starting the services\nBIND_HOST = '0.0.0.0'\n\n# AWS user account ID used for tests\nTEST_AWS_ACCOUNT_ID = '000000000000'\nos.environ['TEST_AWS_ACCOUNT_ID'] = TEST_AWS_ACCOUNT_ID\n\n# root code folder\nLOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(os.path.dirname(os.path.realpath(__file__)), '..'))\n\n# virtualenv folder\nLOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, '.venv')\nif not os.path.isdir(LOCALSTACK_VENV_FOLDER):\n # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/\n LOCALSTACK_VENV_FOLDER = os.path.realpath(os.path.join(LOCALSTACK_ROOT_FOLDER, '..', '..', '..'))\n\n# API Gateway path to indicate a user request sent to the gateway\nPATH_USER_REQUEST = '_user_request_'\n\n# name of LocalStack Docker image\nDOCKER_IMAGE_NAME = 'localstack/localstack'\n\n# environment variable name to tag local test runs\nENV_INTERNAL_TEST_RUN = 'LOCALSTACK_INTERNAL_TEST_RUN'\n\n# content types\nAPPLICATION_AMZ_JSON_1_0 = 'application/x-amz-json-1.0'\nAPPLICATION_AMZ_JSON_1_1 = 'application/x-amz-json-1.1'\nAPPLICATION_JSON = 'application/json'\n\n# Lambda defaults\nLAMBDA_TEST_ROLE = 'arn:aws:iam::%s:role/lambda-test-role' % TEST_AWS_ACCOUNT_ID\n\n# installation constants\nELASTICSEARCH_JAR_URL = 'https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.0.zip'\nDYNAMODB_JAR_URL = 'https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip'\nELASTICMQ_JAR_URL = 'https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-0.14.2.jar'\nSTS_JAR_URL = 'http://central.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar'\n\n# API endpoint for analytics events\nAPI_ENDPOINT = 'https://api.localstack.cloud/v1'\n", "path": "localstack/constants.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport glob\nimport shutil\nimport logging\nimport tempfile\nfrom localstack.constants import (DEFAULT_SERVICE_PORTS, ELASTICMQ_JAR_URL, STS_JAR_URL,\n ELASTICSEARCH_JAR_URL, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)\nfrom localstack.utils.common import download, parallelize, run, mkdir, save_file, unzip, rm_rf, chmod_r\n\nTHIS_PATH = os.path.dirname(os.path.realpath(__file__))\nROOT_PATH = os.path.realpath(os.path.join(THIS_PATH, '..'))\n\nINSTALL_DIR_INFRA = '%s/infra' % ROOT_PATH\nINSTALL_DIR_NPM = '%s/node_modules' % ROOT_PATH\nINSTALL_DIR_ES = '%s/elasticsearch' % INSTALL_DIR_INFRA\nINSTALL_DIR_DDB = '%s/dynamodb' % INSTALL_DIR_INFRA\nINSTALL_DIR_KCL = '%s/amazon-kinesis-client' % INSTALL_DIR_INFRA\nINSTALL_DIR_ELASTICMQ = '%s/elasticmq' % INSTALL_DIR_INFRA\nINSTALL_PATH_LOCALSTACK_FAT_JAR = '%s/localstack-utils-fat.jar' % INSTALL_DIR_INFRA\nTMP_ARCHIVE_ES = os.path.join(tempfile.gettempdir(), 'localstack.es.zip')\nTMP_ARCHIVE_DDB = os.path.join(tempfile.gettempdir(), 'localstack.ddb.zip')\nTMP_ARCHIVE_STS = os.path.join(tempfile.gettempdir(), 'aws-java-sdk-sts.jar')\nTMP_ARCHIVE_ELASTICMQ = os.path.join(tempfile.gettempdir(), 'elasticmq-server.jar')\nURL_LOCALSTACK_FAT_JAR = ('http://central.maven.org/maven2/' +\n 'cloud/localstack/localstack-utils/{v}/localstack-utils-{v}-fat.jar').format(v=LOCALSTACK_MAVEN_VERSION)\n\n# set up logger\nLOGGER = logging.getLogger(__name__)\n\n\ndef install_elasticsearch():\n if not os.path.exists(INSTALL_DIR_ES):\n LOGGER.info('Downloading and installing local Elasticsearch server. This may take some time.')\n mkdir(INSTALL_DIR_INFRA)\n # download and extract archive\n download_and_extract_with_retry(ELASTICSEARCH_JAR_URL, TMP_ARCHIVE_ES, INSTALL_DIR_INFRA)\n elasticsearch_dir = glob.glob(os.path.join(INSTALL_DIR_INFRA, 'elasticsearch*'))\n if not elasticsearch_dir:\n raise Exception('Unable to find Elasticsearch folder in %s' % INSTALL_DIR_INFRA)\n shutil.move(elasticsearch_dir[0], INSTALL_DIR_ES)\n\n for dir_name in ('data', 'logs', 'modules', 'plugins', 'config/scripts'):\n dir_path = '%s/%s' % (INSTALL_DIR_ES, dir_name)\n mkdir(dir_path)\n chmod_r(dir_path, 0o777)\n\n\ndef install_elasticmq():\n if not os.path.exists(INSTALL_DIR_ELASTICMQ):\n LOGGER.info('Downloading and installing local ElasticMQ server. This may take some time.')\n mkdir(INSTALL_DIR_ELASTICMQ)\n # download archive\n if not os.path.exists(TMP_ARCHIVE_ELASTICMQ):\n download(ELASTICMQ_JAR_URL, TMP_ARCHIVE_ELASTICMQ)\n shutil.copy(TMP_ARCHIVE_ELASTICMQ, INSTALL_DIR_ELASTICMQ)\n\n\ndef install_kinesalite():\n target_dir = '%s/kinesalite' % INSTALL_DIR_NPM\n if not os.path.exists(target_dir):\n LOGGER.info('Downloading and installing local Kinesis server. This may take some time.')\n run('cd \"%s\" && npm install' % ROOT_PATH)\n\n\ndef install_dynamodb_local():\n if not os.path.exists(INSTALL_DIR_DDB):\n LOGGER.info('Downloading and installing local DynamoDB server. This may take some time.')\n mkdir(INSTALL_DIR_DDB)\n # download and extract archive\n download_and_extract_with_retry(DYNAMODB_JAR_URL, TMP_ARCHIVE_DDB, INSTALL_DIR_DDB)\n\n # fix for Alpine, otherwise DynamoDBLocal fails with:\n # DynamoDBLocal_lib/libsqlite4java-linux-amd64.so: __memcpy_chk: symbol not found\n if is_alpine():\n ddb_libs_dir = '%s/DynamoDBLocal_lib' % INSTALL_DIR_DDB\n patched_marker = '%s/alpine_fix_applied' % ddb_libs_dir\n if not os.path.exists(patched_marker):\n patched_lib = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +\n 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/libsqlite4java-linux-amd64.so')\n patched_jar = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +\n 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/sqlite4java.jar')\n run(\"curl -L -o %s/libsqlite4java-linux-amd64.so '%s'\" % (ddb_libs_dir, patched_lib))\n run(\"curl -L -o %s/sqlite4java.jar '%s'\" % (ddb_libs_dir, patched_jar))\n save_file(patched_marker, '')\n\n # fix logging configuration for DynamoDBLocal\n log4j2_config = \"\"\"<Configuration status=\"WARN\">\n <Appenders>\n <Console name=\"Console\" target=\"SYSTEM_OUT\">\n <PatternLayout pattern=\"%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n\"/>\n </Console>\n </Appenders>\n <Loggers>\n <Root level=\"WARN\"><AppenderRef ref=\"Console\"/></Root>\n </Loggers>\n </Configuration>\"\"\"\n log4j2_file = os.path.join(INSTALL_DIR_DDB, 'log4j2.xml')\n save_file(log4j2_file, log4j2_config)\n run('cd \"%s\" && zip -u DynamoDBLocal.jar log4j2.xml || true' % INSTALL_DIR_DDB)\n\n\ndef install_amazon_kinesis_client_libs():\n # install KCL/STS JAR files\n if not os.path.exists(INSTALL_DIR_KCL):\n mkdir(INSTALL_DIR_KCL)\n if not os.path.exists(TMP_ARCHIVE_STS):\n download(STS_JAR_URL, TMP_ARCHIVE_STS)\n shutil.copy(TMP_ARCHIVE_STS, INSTALL_DIR_KCL)\n # Compile Java files\n from localstack.utils.kinesis import kclipy_helper\n classpath = kclipy_helper.get_kcl_classpath()\n java_files = '%s/utils/kinesis/java/com/atlassian/*.java' % ROOT_PATH\n class_files = '%s/utils/kinesis/java/com/atlassian/*.class' % ROOT_PATH\n if not glob.glob(class_files):\n run('javac -cp \"%s\" %s' % (classpath, java_files))\n\n\ndef install_lambda_java_libs():\n # install LocalStack \"fat\" JAR file (contains all dependencies)\n if not os.path.exists(INSTALL_PATH_LOCALSTACK_FAT_JAR):\n LOGGER.info('Downloading and installing LocalStack Java libraries. This may take some time.')\n download(URL_LOCALSTACK_FAT_JAR, INSTALL_PATH_LOCALSTACK_FAT_JAR)\n\n\ndef install_component(name):\n if name == 'kinesis':\n install_kinesalite()\n elif name == 'dynamodb':\n install_dynamodb_local()\n elif name == 'es':\n install_elasticsearch()\n elif name == 'sqs':\n install_elasticmq()\n\n\ndef install_components(names):\n parallelize(install_component, names)\n install_lambda_java_libs()\n\n\ndef install_all_components():\n install_components(DEFAULT_SERVICE_PORTS.keys())\n\n\n# -----------------\n# HELPER FUNCTIONS\n# -----------------\n\n\ndef is_alpine():\n try:\n run('cat /etc/issue | grep Alpine', print_error=False)\n return True\n except Exception:\n return False\n\n\ndef download_and_extract_with_retry(archive_url, tmp_archive, target_dir):\n\n def download_and_extract():\n if not os.path.exists(tmp_archive):\n download(archive_url, tmp_archive)\n unzip(tmp_archive, target_dir)\n\n try:\n download_and_extract()\n except Exception:\n # try deleting and re-downloading the zip file\n LOGGER.info('Unable to extract file, re-downloading ZIP archive: %s' % tmp_archive)\n rm_rf(tmp_archive)\n download_and_extract()\n\n\nif __name__ == '__main__':\n\n if len(sys.argv) > 1:\n if sys.argv[1] == 'libs':\n print('Initializing installation.')\n logging.basicConfig(level=logging.INFO)\n logging.getLogger('requests').setLevel(logging.WARNING)\n install_all_components()\n print('Done.')\n elif sys.argv[1] == 'testlibs':\n # Install additional libraries for testing\n install_amazon_kinesis_client_libs()\n", "path": "localstack/services/install.py"}], "after_files": [{"content": "import os\nimport localstack_client.config\n\n# LocalStack version\nVERSION = '0.8.10'\n\n# default AWS region\nif 'DEFAULT_REGION' not in os.environ:\n os.environ['DEFAULT_REGION'] = 'us-east-1'\nDEFAULT_REGION = os.environ['DEFAULT_REGION']\n\n# constant to represent the \"local\" region, i.e., local machine\nREGION_LOCAL = 'local'\n\n# dev environment\nENV_DEV = 'dev'\n\n# backend service ports, for services that are behind a proxy (counting down from 4566)\nDEFAULT_PORT_APIGATEWAY_BACKEND = 4566\nDEFAULT_PORT_KINESIS_BACKEND = 4565\nDEFAULT_PORT_DYNAMODB_BACKEND = 4564\nDEFAULT_PORT_S3_BACKEND = 4563\nDEFAULT_PORT_SNS_BACKEND = 4562\nDEFAULT_PORT_SQS_BACKEND = 4561\nDEFAULT_PORT_ELASTICSEARCH_BACKEND = 4560\nDEFAULT_PORT_CLOUDFORMATION_BACKEND = 4559\n\nDEFAULT_PORT_WEB_UI = 8080\n\nLOCALHOST = 'localhost'\n\n# version of the Maven dependency with Java utility code\nLOCALSTACK_MAVEN_VERSION = '0.1.15'\n\n# map of default service APIs and ports to be spun up (fetch map from localstack_client)\nDEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()\n\n# host to bind to when starting the services\nBIND_HOST = '0.0.0.0'\n\n# AWS user account ID used for tests\nTEST_AWS_ACCOUNT_ID = '000000000000'\nos.environ['TEST_AWS_ACCOUNT_ID'] = TEST_AWS_ACCOUNT_ID\n\n# root code folder\nLOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(os.path.dirname(os.path.realpath(__file__)), '..'))\n\n# virtualenv folder\nLOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, '.venv')\nif not os.path.isdir(LOCALSTACK_VENV_FOLDER):\n # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/\n LOCALSTACK_VENV_FOLDER = os.path.realpath(os.path.join(LOCALSTACK_ROOT_FOLDER, '..', '..', '..'))\n\n# API Gateway path to indicate a user request sent to the gateway\nPATH_USER_REQUEST = '_user_request_'\n\n# name of LocalStack Docker image\nDOCKER_IMAGE_NAME = 'localstack/localstack'\n\n# environment variable name to tag local test runs\nENV_INTERNAL_TEST_RUN = 'LOCALSTACK_INTERNAL_TEST_RUN'\n\n# content types\nAPPLICATION_AMZ_JSON_1_0 = 'application/x-amz-json-1.0'\nAPPLICATION_AMZ_JSON_1_1 = 'application/x-amz-json-1.1'\nAPPLICATION_JSON = 'application/json'\n\n# Lambda defaults\nLAMBDA_TEST_ROLE = 'arn:aws:iam::%s:role/lambda-test-role' % TEST_AWS_ACCOUNT_ID\n\n# installation constants\nELASTICSEARCH_JAR_URL = 'https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.0.zip'\n# https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html\nELASTICSEARCH_PLUGIN_LIST = ['analysis-icu', 'ingest-attachment', 'ingest-user-agent', 'analysis-kuromoji',\n 'mapper-murmur3', 'mapper-size', 'analysis-phonetic', 'analysis-smartcn', 'analysis-stempel', 'analysis-ukrainian']\nDYNAMODB_JAR_URL = 'https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip'\nELASTICMQ_JAR_URL = 'https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-0.14.2.jar'\nSTS_JAR_URL = 'http://central.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar'\n\n# API endpoint for analytics events\nAPI_ENDPOINT = 'https://api.localstack.cloud/v1'\n", "path": "localstack/constants.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport glob\nimport shutil\nimport logging\nimport tempfile\nfrom localstack.constants import (DEFAULT_SERVICE_PORTS, ELASTICMQ_JAR_URL, STS_JAR_URL,\n ELASTICSEARCH_JAR_URL, ELASTICSEARCH_PLUGIN_LIST, DYNAMODB_JAR_URL, LOCALSTACK_MAVEN_VERSION)\nfrom localstack.utils.common import download, parallelize, run, mkdir, save_file, unzip, rm_rf, chmod_r\n\nTHIS_PATH = os.path.dirname(os.path.realpath(__file__))\nROOT_PATH = os.path.realpath(os.path.join(THIS_PATH, '..'))\n\nINSTALL_DIR_INFRA = '%s/infra' % ROOT_PATH\nINSTALL_DIR_NPM = '%s/node_modules' % ROOT_PATH\nINSTALL_DIR_ES = '%s/elasticsearch' % INSTALL_DIR_INFRA\nINSTALL_DIR_DDB = '%s/dynamodb' % INSTALL_DIR_INFRA\nINSTALL_DIR_KCL = '%s/amazon-kinesis-client' % INSTALL_DIR_INFRA\nINSTALL_DIR_ELASTICMQ = '%s/elasticmq' % INSTALL_DIR_INFRA\nINSTALL_PATH_LOCALSTACK_FAT_JAR = '%s/localstack-utils-fat.jar' % INSTALL_DIR_INFRA\nTMP_ARCHIVE_ES = os.path.join(tempfile.gettempdir(), 'localstack.es.zip')\nTMP_ARCHIVE_DDB = os.path.join(tempfile.gettempdir(), 'localstack.ddb.zip')\nTMP_ARCHIVE_STS = os.path.join(tempfile.gettempdir(), 'aws-java-sdk-sts.jar')\nTMP_ARCHIVE_ELASTICMQ = os.path.join(tempfile.gettempdir(), 'elasticmq-server.jar')\nURL_LOCALSTACK_FAT_JAR = ('http://central.maven.org/maven2/' +\n 'cloud/localstack/localstack-utils/{v}/localstack-utils-{v}-fat.jar').format(v=LOCALSTACK_MAVEN_VERSION)\n\n# set up logger\nLOGGER = logging.getLogger(__name__)\n\n\ndef install_elasticsearch():\n if not os.path.exists(INSTALL_DIR_ES):\n LOGGER.info('Downloading and installing local Elasticsearch server. This may take some time.')\n mkdir(INSTALL_DIR_INFRA)\n # download and extract archive\n download_and_extract_with_retry(ELASTICSEARCH_JAR_URL, TMP_ARCHIVE_ES, INSTALL_DIR_INFRA)\n elasticsearch_dir = glob.glob(os.path.join(INSTALL_DIR_INFRA, 'elasticsearch*'))\n if not elasticsearch_dir:\n raise Exception('Unable to find Elasticsearch folder in %s' % INSTALL_DIR_INFRA)\n shutil.move(elasticsearch_dir[0], INSTALL_DIR_ES)\n\n for dir_name in ('data', 'logs', 'modules', 'plugins', 'config/scripts'):\n dir_path = '%s/%s' % (INSTALL_DIR_ES, dir_name)\n mkdir(dir_path)\n chmod_r(dir_path, 0o777)\n\n # install default plugins\n for plugin in ELASTICSEARCH_PLUGIN_LIST:\n if is_alpine():\n # https://github.com/pires/docker-elasticsearch/issues/56\n os.environ['ES_TMPDIR'] = '/tmp'\n plugin_binary = os.path.join(INSTALL_DIR_ES, 'bin', 'elasticsearch-plugin')\n run('%s install %s' % (plugin_binary, plugin))\n\n\ndef install_elasticmq():\n if not os.path.exists(INSTALL_DIR_ELASTICMQ):\n LOGGER.info('Downloading and installing local ElasticMQ server. This may take some time.')\n mkdir(INSTALL_DIR_ELASTICMQ)\n # download archive\n if not os.path.exists(TMP_ARCHIVE_ELASTICMQ):\n download(ELASTICMQ_JAR_URL, TMP_ARCHIVE_ELASTICMQ)\n shutil.copy(TMP_ARCHIVE_ELASTICMQ, INSTALL_DIR_ELASTICMQ)\n\n\ndef install_kinesalite():\n target_dir = '%s/kinesalite' % INSTALL_DIR_NPM\n if not os.path.exists(target_dir):\n LOGGER.info('Downloading and installing local Kinesis server. This may take some time.')\n run('cd \"%s\" && npm install' % ROOT_PATH)\n\n\ndef install_dynamodb_local():\n if not os.path.exists(INSTALL_DIR_DDB):\n LOGGER.info('Downloading and installing local DynamoDB server. This may take some time.')\n mkdir(INSTALL_DIR_DDB)\n # download and extract archive\n download_and_extract_with_retry(DYNAMODB_JAR_URL, TMP_ARCHIVE_DDB, INSTALL_DIR_DDB)\n\n # fix for Alpine, otherwise DynamoDBLocal fails with:\n # DynamoDBLocal_lib/libsqlite4java-linux-amd64.so: __memcpy_chk: symbol not found\n if is_alpine():\n ddb_libs_dir = '%s/DynamoDBLocal_lib' % INSTALL_DIR_DDB\n patched_marker = '%s/alpine_fix_applied' % ddb_libs_dir\n if not os.path.exists(patched_marker):\n patched_lib = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +\n 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/libsqlite4java-linux-amd64.so')\n patched_jar = ('https://rawgit.com/bhuisgen/docker-alpine/master/alpine-dynamodb/' +\n 'rootfs/usr/local/dynamodb/DynamoDBLocal_lib/sqlite4java.jar')\n run(\"curl -L -o %s/libsqlite4java-linux-amd64.so '%s'\" % (ddb_libs_dir, patched_lib))\n run(\"curl -L -o %s/sqlite4java.jar '%s'\" % (ddb_libs_dir, patched_jar))\n save_file(patched_marker, '')\n\n # fix logging configuration for DynamoDBLocal\n log4j2_config = \"\"\"<Configuration status=\"WARN\">\n <Appenders>\n <Console name=\"Console\" target=\"SYSTEM_OUT\">\n <PatternLayout pattern=\"%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n\"/>\n </Console>\n </Appenders>\n <Loggers>\n <Root level=\"WARN\"><AppenderRef ref=\"Console\"/></Root>\n </Loggers>\n </Configuration>\"\"\"\n log4j2_file = os.path.join(INSTALL_DIR_DDB, 'log4j2.xml')\n save_file(log4j2_file, log4j2_config)\n run('cd \"%s\" && zip -u DynamoDBLocal.jar log4j2.xml || true' % INSTALL_DIR_DDB)\n\n\ndef install_amazon_kinesis_client_libs():\n # install KCL/STS JAR files\n if not os.path.exists(INSTALL_DIR_KCL):\n mkdir(INSTALL_DIR_KCL)\n if not os.path.exists(TMP_ARCHIVE_STS):\n download(STS_JAR_URL, TMP_ARCHIVE_STS)\n shutil.copy(TMP_ARCHIVE_STS, INSTALL_DIR_KCL)\n # Compile Java files\n from localstack.utils.kinesis import kclipy_helper\n classpath = kclipy_helper.get_kcl_classpath()\n java_files = '%s/utils/kinesis/java/com/atlassian/*.java' % ROOT_PATH\n class_files = '%s/utils/kinesis/java/com/atlassian/*.class' % ROOT_PATH\n if not glob.glob(class_files):\n run('javac -cp \"%s\" %s' % (classpath, java_files))\n\n\ndef install_lambda_java_libs():\n # install LocalStack \"fat\" JAR file (contains all dependencies)\n if not os.path.exists(INSTALL_PATH_LOCALSTACK_FAT_JAR):\n LOGGER.info('Downloading and installing LocalStack Java libraries. This may take some time.')\n download(URL_LOCALSTACK_FAT_JAR, INSTALL_PATH_LOCALSTACK_FAT_JAR)\n\n\ndef install_component(name):\n if name == 'kinesis':\n install_kinesalite()\n elif name == 'dynamodb':\n install_dynamodb_local()\n elif name == 'es':\n install_elasticsearch()\n elif name == 'sqs':\n install_elasticmq()\n\n\ndef install_components(names):\n parallelize(install_component, names)\n install_lambda_java_libs()\n\n\ndef install_all_components():\n install_components(DEFAULT_SERVICE_PORTS.keys())\n\n\n# -----------------\n# HELPER FUNCTIONS\n# -----------------\n\n\ndef is_alpine():\n try:\n run('cat /etc/issue | grep Alpine', print_error=False)\n return True\n except Exception:\n return False\n\n\ndef download_and_extract_with_retry(archive_url, tmp_archive, target_dir):\n\n def download_and_extract():\n if not os.path.exists(tmp_archive):\n download(archive_url, tmp_archive)\n unzip(tmp_archive, target_dir)\n\n try:\n download_and_extract()\n except Exception:\n # try deleting and re-downloading the zip file\n LOGGER.info('Unable to extract file, re-downloading ZIP archive: %s' % tmp_archive)\n rm_rf(tmp_archive)\n download_and_extract()\n\n\nif __name__ == '__main__':\n\n if len(sys.argv) > 1:\n if sys.argv[1] == 'libs':\n print('Initializing installation.')\n logging.basicConfig(level=logging.INFO)\n logging.getLogger('requests').setLevel(logging.WARNING)\n install_all_components()\n print('Done.')\n elif sys.argv[1] == 'testlibs':\n # Install additional libraries for testing\n install_amazon_kinesis_client_libs()\n", "path": "localstack/services/install.py"}]} | 3,646 | 591 |
gh_patches_debug_19160 | rasdani/github-patches | git_diff | marshmallow-code__webargs-368 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: module 'typing' has no attribute 'NoReturn' with Python 3.5.3
I get this error when running the tests with Python 3.5.3.
```
tests/test_py3/test_aiohttpparser_async_functions.py:6: in <module>
from webargs.aiohttpparser import parser, use_args, use_kwargs
webargs/aiohttpparser.py:72: in <module>
class AIOHTTPParser(AsyncParser):
webargs/aiohttpparser.py:148: in AIOHTTPParser
) -> typing.NoReturn:
E AttributeError: module 'typing' has no attribute 'NoReturn'
```
The docs say [`typing.NoReturn`](https://docs.python.org/3/library/typing.html#typing.NoReturn) was added in 3.6.5. However, [the tests pass on Travis](https://travis-ci.org/marshmallow-code/webargs/jobs/486701760) with Python 3.5.6.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `webargs/aiohttpparser.py`
Content:
```
1 """aiohttp request argument parsing module.
2
3 Example: ::
4
5 import asyncio
6 from aiohttp import web
7
8 from webargs import fields
9 from webargs.aiohttpparser import use_args
10
11
12 hello_args = {
13 'name': fields.Str(required=True)
14 }
15 @asyncio.coroutine
16 @use_args(hello_args)
17 def index(request, args):
18 return web.Response(
19 body='Hello {}'.format(args['name']).encode('utf-8')
20 )
21
22 app = web.Application()
23 app.router.add_route('GET', '/', index)
24 """
25 import typing
26
27 from aiohttp import web
28 from aiohttp.web import Request
29 from aiohttp import web_exceptions
30 from marshmallow import Schema, ValidationError
31 from marshmallow.fields import Field
32
33 from webargs import core
34 from webargs.core import json
35 from webargs.asyncparser import AsyncParser
36
37
38 def is_json_request(req: Request) -> bool:
39 content_type = req.content_type
40 return core.is_json(content_type)
41
42
43 class HTTPUnprocessableEntity(web.HTTPClientError):
44 status_code = 422
45
46
47 # Mapping of status codes to exception classes
48 # Adapted from werkzeug
49 exception_map = {422: HTTPUnprocessableEntity}
50
51
52 def _find_exceptions() -> None:
53 for name in web_exceptions.__all__:
54 obj = getattr(web_exceptions, name)
55 try:
56 is_http_exception = issubclass(obj, web_exceptions.HTTPException)
57 except TypeError:
58 is_http_exception = False
59 if not is_http_exception or obj.status_code is None:
60 continue
61 old_obj = exception_map.get(obj.status_code, None)
62 if old_obj is not None and issubclass(obj, old_obj):
63 continue
64 exception_map[obj.status_code] = obj
65
66
67 # Collect all exceptions from aiohttp.web_exceptions
68 _find_exceptions()
69 del _find_exceptions
70
71
72 class AIOHTTPParser(AsyncParser):
73 """aiohttp request argument parser."""
74
75 __location_map__ = dict(
76 match_info="parse_match_info", **core.Parser.__location_map__
77 )
78
79 def parse_querystring(self, req: Request, name: str, field: Field) -> typing.Any:
80 """Pull a querystring value from the request."""
81 return core.get_value(req.query, name, field)
82
83 async def parse_form(self, req: Request, name: str, field: Field) -> typing.Any:
84 """Pull a form value from the request."""
85 post_data = self._cache.get("post")
86 if post_data is None:
87 self._cache["post"] = await req.post()
88 return core.get_value(self._cache["post"], name, field)
89
90 async def parse_json(self, req: Request, name: str, field: Field) -> typing.Any:
91 """Pull a json value from the request."""
92 json_data = self._cache.get("json")
93 if json_data is None:
94 if not (req.body_exists and is_json_request(req)):
95 return core.missing
96 try:
97 json_data = await req.json(loads=json.loads)
98 except json.JSONDecodeError as e:
99 if e.doc == "":
100 return core.missing
101 else:
102 return self.handle_invalid_json_error(e, req)
103 self._cache["json"] = json_data
104 return core.get_value(json_data, name, field, allow_many_nested=True)
105
106 def parse_headers(self, req: Request, name: str, field: Field) -> typing.Any:
107 """Pull a value from the header data."""
108 return core.get_value(req.headers, name, field)
109
110 def parse_cookies(self, req: Request, name: str, field: Field) -> typing.Any:
111 """Pull a value from the cookiejar."""
112 return core.get_value(req.cookies, name, field)
113
114 def parse_files(self, req: Request, name: str, field: Field) -> None:
115 raise NotImplementedError(
116 "parse_files is not implemented. You may be able to use parse_form for "
117 "parsing upload data."
118 )
119
120 def parse_match_info(self, req: Request, name: str, field: Field) -> typing.Any:
121 """Pull a value from the request's ``match_info``."""
122 return core.get_value(req.match_info, name, field)
123
124 def get_request_from_view_args(
125 self, view: typing.Callable, args: typing.Iterable, kwargs: typing.Mapping
126 ) -> Request:
127 """Get request object from a handler function or method. Used internally by
128 ``use_args`` and ``use_kwargs``.
129 """
130 req = None
131 for arg in args:
132 if isinstance(arg, web.Request):
133 req = arg
134 break
135 elif isinstance(arg, web.View):
136 req = arg.request
137 break
138 assert isinstance(req, web.Request), "Request argument not found for handler"
139 return req
140
141 def handle_error(
142 self,
143 error: ValidationError,
144 req: Request,
145 schema: Schema,
146 error_status_code: typing.Union[int, None] = None,
147 error_headers: typing.Union[typing.Mapping[str, str], None] = None,
148 ) -> typing.NoReturn:
149 """Handle ValidationErrors and return a JSON response of error messages
150 to the client.
151 """
152 error_class = exception_map.get(
153 error_status_code or self.DEFAULT_VALIDATION_STATUS
154 )
155 if not error_class:
156 raise LookupError("No exception for {0}".format(error_status_code))
157 headers = error_headers
158 raise error_class(
159 body=json.dumps(error.messages).encode("utf-8"),
160 headers=headers,
161 content_type="application/json",
162 )
163
164 def handle_invalid_json_error(
165 self, error: json.JSONDecodeError, req: Request, *args, **kwargs
166 ) -> typing.NoReturn:
167 error_class = exception_map[400]
168 messages = {"json": ["Invalid JSON body."]}
169 raise error_class(
170 body=json.dumps(messages).encode("utf-8"), content_type="application/json"
171 )
172
173
174 parser = AIOHTTPParser()
175 use_args = parser.use_args # type: typing.Callable
176 use_kwargs = parser.use_kwargs # type: typing.Callable
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/webargs/aiohttpparser.py b/webargs/aiohttpparser.py
--- a/webargs/aiohttpparser.py
+++ b/webargs/aiohttpparser.py
@@ -145,7 +145,7 @@
schema: Schema,
error_status_code: typing.Union[int, None] = None,
error_headers: typing.Union[typing.Mapping[str, str], None] = None,
- ) -> typing.NoReturn:
+ ) -> "typing.NoReturn":
"""Handle ValidationErrors and return a JSON response of error messages
to the client.
"""
@@ -163,7 +163,7 @@
def handle_invalid_json_error(
self, error: json.JSONDecodeError, req: Request, *args, **kwargs
- ) -> typing.NoReturn:
+ ) -> "typing.NoReturn":
error_class = exception_map[400]
messages = {"json": ["Invalid JSON body."]}
raise error_class(
| {"golden_diff": "diff --git a/webargs/aiohttpparser.py b/webargs/aiohttpparser.py\n--- a/webargs/aiohttpparser.py\n+++ b/webargs/aiohttpparser.py\n@@ -145,7 +145,7 @@\n schema: Schema,\n error_status_code: typing.Union[int, None] = None,\n error_headers: typing.Union[typing.Mapping[str, str], None] = None,\n- ) -> typing.NoReturn:\n+ ) -> \"typing.NoReturn\":\n \"\"\"Handle ValidationErrors and return a JSON response of error messages\n to the client.\n \"\"\"\n@@ -163,7 +163,7 @@\n \n def handle_invalid_json_error(\n self, error: json.JSONDecodeError, req: Request, *args, **kwargs\n- ) -> typing.NoReturn:\n+ ) -> \"typing.NoReturn\":\n error_class = exception_map[400]\n messages = {\"json\": [\"Invalid JSON body.\"]}\n raise error_class(\n", "issue": "AttributeError: module 'typing' has no attribute 'NoReturn' with Python 3.5.3\nI get this error when running the tests with Python 3.5.3.\r\n\r\n```\r\ntests/test_py3/test_aiohttpparser_async_functions.py:6: in <module>\r\n from webargs.aiohttpparser import parser, use_args, use_kwargs\r\nwebargs/aiohttpparser.py:72: in <module>\r\n class AIOHTTPParser(AsyncParser):\r\nwebargs/aiohttpparser.py:148: in AIOHTTPParser\r\n ) -> typing.NoReturn:\r\nE AttributeError: module 'typing' has no attribute 'NoReturn'\r\n```\r\n\r\nThe docs say [`typing.NoReturn`](https://docs.python.org/3/library/typing.html#typing.NoReturn) was added in 3.6.5. However, [the tests pass on Travis](https://travis-ci.org/marshmallow-code/webargs/jobs/486701760) with Python 3.5.6.\n", "before_files": [{"content": "\"\"\"aiohttp request argument parsing module.\n\nExample: ::\n\n import asyncio\n from aiohttp import web\n\n from webargs import fields\n from webargs.aiohttpparser import use_args\n\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n @asyncio.coroutine\n @use_args(hello_args)\n def index(request, args):\n return web.Response(\n body='Hello {}'.format(args['name']).encode('utf-8')\n )\n\n app = web.Application()\n app.router.add_route('GET', '/', index)\n\"\"\"\nimport typing\n\nfrom aiohttp import web\nfrom aiohttp.web import Request\nfrom aiohttp import web_exceptions\nfrom marshmallow import Schema, ValidationError\nfrom marshmallow.fields import Field\n\nfrom webargs import core\nfrom webargs.core import json\nfrom webargs.asyncparser import AsyncParser\n\n\ndef is_json_request(req: Request) -> bool:\n content_type = req.content_type\n return core.is_json(content_type)\n\n\nclass HTTPUnprocessableEntity(web.HTTPClientError):\n status_code = 422\n\n\n# Mapping of status codes to exception classes\n# Adapted from werkzeug\nexception_map = {422: HTTPUnprocessableEntity}\n\n\ndef _find_exceptions() -> None:\n for name in web_exceptions.__all__:\n obj = getattr(web_exceptions, name)\n try:\n is_http_exception = issubclass(obj, web_exceptions.HTTPException)\n except TypeError:\n is_http_exception = False\n if not is_http_exception or obj.status_code is None:\n continue\n old_obj = exception_map.get(obj.status_code, None)\n if old_obj is not None and issubclass(obj, old_obj):\n continue\n exception_map[obj.status_code] = obj\n\n\n# Collect all exceptions from aiohttp.web_exceptions\n_find_exceptions()\ndel _find_exceptions\n\n\nclass AIOHTTPParser(AsyncParser):\n \"\"\"aiohttp request argument parser.\"\"\"\n\n __location_map__ = dict(\n match_info=\"parse_match_info\", **core.Parser.__location_map__\n )\n\n def parse_querystring(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.query, name, field)\n\n async def parse_form(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a form value from the request.\"\"\"\n post_data = self._cache.get(\"post\")\n if post_data is None:\n self._cache[\"post\"] = await req.post()\n return core.get_value(self._cache[\"post\"], name, field)\n\n async def parse_json(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n if not (req.body_exists and is_json_request(req)):\n return core.missing\n try:\n json_data = await req.json(loads=json.loads)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n self._cache[\"json\"] = json_data\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_headers(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req: Request, name: str, field: Field) -> None:\n raise NotImplementedError(\n \"parse_files is not implemented. You may be able to use parse_form for \"\n \"parsing upload data.\"\n )\n\n def parse_match_info(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the request's ``match_info``.\"\"\"\n return core.get_value(req.match_info, name, field)\n\n def get_request_from_view_args(\n self, view: typing.Callable, args: typing.Iterable, kwargs: typing.Mapping\n ) -> Request:\n \"\"\"Get request object from a handler function or method. Used internally by\n ``use_args`` and ``use_kwargs``.\n \"\"\"\n req = None\n for arg in args:\n if isinstance(arg, web.Request):\n req = arg\n break\n elif isinstance(arg, web.View):\n req = arg.request\n break\n assert isinstance(req, web.Request), \"Request argument not found for handler\"\n return req\n\n def handle_error(\n self,\n error: ValidationError,\n req: Request,\n schema: Schema,\n error_status_code: typing.Union[int, None] = None,\n error_headers: typing.Union[typing.Mapping[str, str], None] = None,\n ) -> typing.NoReturn:\n \"\"\"Handle ValidationErrors and return a JSON response of error messages\n to the client.\n \"\"\"\n error_class = exception_map.get(\n error_status_code or self.DEFAULT_VALIDATION_STATUS\n )\n if not error_class:\n raise LookupError(\"No exception for {0}\".format(error_status_code))\n headers = error_headers\n raise error_class(\n body=json.dumps(error.messages).encode(\"utf-8\"),\n headers=headers,\n content_type=\"application/json\",\n )\n\n def handle_invalid_json_error(\n self, error: json.JSONDecodeError, req: Request, *args, **kwargs\n ) -> typing.NoReturn:\n error_class = exception_map[400]\n messages = {\"json\": [\"Invalid JSON body.\"]}\n raise error_class(\n body=json.dumps(messages).encode(\"utf-8\"), content_type=\"application/json\"\n )\n\n\nparser = AIOHTTPParser()\nuse_args = parser.use_args # type: typing.Callable\nuse_kwargs = parser.use_kwargs # type: typing.Callable\n", "path": "webargs/aiohttpparser.py"}], "after_files": [{"content": "\"\"\"aiohttp request argument parsing module.\n\nExample: ::\n\n import asyncio\n from aiohttp import web\n\n from webargs import fields\n from webargs.aiohttpparser import use_args\n\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n @asyncio.coroutine\n @use_args(hello_args)\n def index(request, args):\n return web.Response(\n body='Hello {}'.format(args['name']).encode('utf-8')\n )\n\n app = web.Application()\n app.router.add_route('GET', '/', index)\n\"\"\"\nimport typing\n\nfrom aiohttp import web\nfrom aiohttp.web import Request\nfrom aiohttp import web_exceptions\nfrom marshmallow import Schema, ValidationError\nfrom marshmallow.fields import Field\n\nfrom webargs import core\nfrom webargs.core import json\nfrom webargs.asyncparser import AsyncParser\n\n\ndef is_json_request(req: Request) -> bool:\n content_type = req.content_type\n return core.is_json(content_type)\n\n\nclass HTTPUnprocessableEntity(web.HTTPClientError):\n status_code = 422\n\n\n# Mapping of status codes to exception classes\n# Adapted from werkzeug\nexception_map = {422: HTTPUnprocessableEntity}\n\n\ndef _find_exceptions() -> None:\n for name in web_exceptions.__all__:\n obj = getattr(web_exceptions, name)\n try:\n is_http_exception = issubclass(obj, web_exceptions.HTTPException)\n except TypeError:\n is_http_exception = False\n if not is_http_exception or obj.status_code is None:\n continue\n old_obj = exception_map.get(obj.status_code, None)\n if old_obj is not None and issubclass(obj, old_obj):\n continue\n exception_map[obj.status_code] = obj\n\n\n# Collect all exceptions from aiohttp.web_exceptions\n_find_exceptions()\ndel _find_exceptions\n\n\nclass AIOHTTPParser(AsyncParser):\n \"\"\"aiohttp request argument parser.\"\"\"\n\n __location_map__ = dict(\n match_info=\"parse_match_info\", **core.Parser.__location_map__\n )\n\n def parse_querystring(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.query, name, field)\n\n async def parse_form(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a form value from the request.\"\"\"\n post_data = self._cache.get(\"post\")\n if post_data is None:\n self._cache[\"post\"] = await req.post()\n return core.get_value(self._cache[\"post\"], name, field)\n\n async def parse_json(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n if not (req.body_exists and is_json_request(req)):\n return core.missing\n try:\n json_data = await req.json(loads=json.loads)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n self._cache[\"json\"] = json_data\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_headers(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req: Request, name: str, field: Field) -> None:\n raise NotImplementedError(\n \"parse_files is not implemented. You may be able to use parse_form for \"\n \"parsing upload data.\"\n )\n\n def parse_match_info(self, req: Request, name: str, field: Field) -> typing.Any:\n \"\"\"Pull a value from the request's ``match_info``.\"\"\"\n return core.get_value(req.match_info, name, field)\n\n def get_request_from_view_args(\n self, view: typing.Callable, args: typing.Iterable, kwargs: typing.Mapping\n ) -> Request:\n \"\"\"Get request object from a handler function or method. Used internally by\n ``use_args`` and ``use_kwargs``.\n \"\"\"\n req = None\n for arg in args:\n if isinstance(arg, web.Request):\n req = arg\n break\n elif isinstance(arg, web.View):\n req = arg.request\n break\n assert isinstance(req, web.Request), \"Request argument not found for handler\"\n return req\n\n def handle_error(\n self,\n error: ValidationError,\n req: Request,\n schema: Schema,\n error_status_code: typing.Union[int, None] = None,\n error_headers: typing.Union[typing.Mapping[str, str], None] = None,\n ) -> \"typing.NoReturn\":\n \"\"\"Handle ValidationErrors and return a JSON response of error messages\n to the client.\n \"\"\"\n error_class = exception_map.get(\n error_status_code or self.DEFAULT_VALIDATION_STATUS\n )\n if not error_class:\n raise LookupError(\"No exception for {0}\".format(error_status_code))\n headers = error_headers\n raise error_class(\n body=json.dumps(error.messages).encode(\"utf-8\"),\n headers=headers,\n content_type=\"application/json\",\n )\n\n def handle_invalid_json_error(\n self, error: json.JSONDecodeError, req: Request, *args, **kwargs\n ) -> \"typing.NoReturn\":\n error_class = exception_map[400]\n messages = {\"json\": [\"Invalid JSON body.\"]}\n raise error_class(\n body=json.dumps(messages).encode(\"utf-8\"), content_type=\"application/json\"\n )\n\n\nparser = AIOHTTPParser()\nuse_args = parser.use_args # type: typing.Callable\nuse_kwargs = parser.use_kwargs # type: typing.Callable\n", "path": "webargs/aiohttpparser.py"}]} | 2,246 | 222 |
gh_patches_debug_3699 | rasdani/github-patches | git_diff | plone__Products.CMFPlone-2982 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PasswordResetView::getErrors function never called.
## BUG
<!--
Read https://plone.org/support/bugs first!
Please use the labels at Github, at least one of the types: bug, regression, question, enhancement.
Please include tracebacks, screenshots, code of debugging sessions or code that reproduces the issue if possible.
The best reproductions are in plain Plone installations without addons or at least with minimal needed addons installed.
-->
### What I did:
I am trying to reset the password, using a normal Plone user and I made a PDB inside https://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/browser/login/password_reset.py#L159
URL: {site url}/passwordreset/e3127df738bc41e1976cc36cc9832132?userid=local_manager
### What I expect to happen:
I expected a call `RegistrationTool.testPasswordValidity(password, password2)
` as I have some business logic inside testPasswordValidity but I saw code never coming here
### What actually happened:
As I see inside ''getErrors'' method, there is a call to registration tool testPasswordValidity method but the ''getErrors'' never called.
### What version of Plone/ Addons I am using:
Plone 5.2.5rc
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/browser/login/password_reset.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from AccessControl.SecurityManagement import getSecurityManager
3 from email.header import Header
4 from plone.app.layout.navigation.interfaces import INavigationRoot
5 from plone.memoize import view
6 from plone.registry.interfaces import IRegistry
7 from Products.CMFCore.utils import getToolByName
8 from Products.CMFPlone import PloneMessageFactory as _
9 from Products.CMFPlone.interfaces import IPasswordResetToolView
10 from Products.CMFPlone.interfaces.controlpanel import IMailSchema
11 from Products.CMFPlone.PasswordResetTool import ExpiredRequestError
12 from Products.CMFPlone.PasswordResetTool import InvalidRequestError
13 from Products.CMFPlone.utils import safe_unicode
14 from Products.CMFPlone.utils import safeToInt
15 from Products.Five import BrowserView
16 from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
17 from Products.PlonePAS.events import UserInitialLoginInEvent
18 from Products.PlonePAS.events import UserLoggedInEvent
19 from Products.PluggableAuthService.interfaces.plugins import ICredentialsUpdatePlugin # noqa
20 from Products.statusmessages.interfaces import IStatusMessage
21 from zope.component import getMultiAdapter
22 from zope.component import getUtility
23 from zope.event import notify
24 from zope.i18n import translate
25 from zope.interface import implementer
26 from zope.publisher.interfaces import IPublishTraverse
27
28
29 @implementer(IPasswordResetToolView)
30 class PasswordResetToolView(BrowserView):
31
32 @view.memoize_contextless
33 def portal_state(self):
34 """ return portal_state of plone.app.layout
35 """
36 return getMultiAdapter((self.context, self.request),
37 name=u"plone_portal_state")
38
39 def encode_mail_header(self, text):
40 """ Encodes text into correctly encoded email header """
41 return Header(safe_unicode(text), 'utf-8')
42
43 def encoded_mail_sender(self):
44 """ returns encoded version of Portal name <portal_email> """
45 registry = getUtility(IRegistry)
46 mail_settings = registry.forInterface(IMailSchema, prefix="plone")
47 from_ = mail_settings.email_from_name
48 mail = mail_settings.email_from_address
49 return '"%s" <%s>' % (self.encode_mail_header(from_).encode(), mail)
50
51 def registered_notify_subject(self):
52 portal_name = self.portal_state().portal_title()
53 return translate(
54 _(
55 u'mailtemplate_user_account_info',
56 default=u'User Account Information for ${portal_name}',
57 mapping={'portal_name': safe_unicode(portal_name)},
58 ),
59 context=self.request,
60 )
61
62 def mail_password_subject(self):
63 return translate(
64 _(
65 u'mailtemplate_subject_resetpasswordrequest',
66 default=u'Password reset request',
67 ),
68 context=self.request,
69 )
70
71 def construct_url(self, randomstring):
72 return '%s/passwordreset/%s' % (
73 self.portal_state().navigation_root_url(), randomstring)
74
75 def expiration_timeout(self):
76 pw_tool = getToolByName(self.context, 'portal_password_reset')
77 timeout = int(pw_tool.getExpirationTimeout() or 0)
78 return timeout * 24 # timeout is in days, but templates want in hours.
79
80
81 @implementer(IPublishTraverse)
82 class PasswordResetView(BrowserView):
83 """ """
84
85 invalid = ViewPageTemplateFile('templates/pwreset_invalid.pt')
86 expired = ViewPageTemplateFile('templates/pwreset_expired.pt')
87 finish = ViewPageTemplateFile('templates/pwreset_finish.pt')
88 form = ViewPageTemplateFile('templates/pwreset_form.pt')
89 subpath = None
90
91 def _auto_login(self, userid, password):
92 aclu = getToolByName(self.context, 'acl_users')
93 for name, plugin in aclu.plugins.listPlugins(ICredentialsUpdatePlugin):
94 plugin.updateCredentials(
95 self.request,
96 self.request.response,
97 userid,
98 password
99 )
100 user = getSecurityManager().getUser()
101 login_time = user.getProperty('login_time', None)
102 if login_time is None:
103 notify(UserInitialLoginInEvent(user))
104 else:
105 notify(UserLoggedInEvent(user))
106
107 IStatusMessage(self.request).addStatusMessage(
108 _(
109 'password_reset_successful',
110 default='Password reset successful, '
111 'you are logged in now!',
112 ),
113 'info',
114 )
115 url = INavigationRoot(self.context).absolute_url()
116 self.request.response.redirect(url)
117 return
118
119 def _reset_password(self, pw_tool, randomstring):
120 userid = self.request.form.get('userid')
121 password = self.request.form.get('password')
122 try:
123 pw_tool.resetPassword(userid, randomstring, password)
124 except ExpiredRequestError:
125 return self.expired()
126 except InvalidRequestError:
127 return self.invalid()
128 except RuntimeError:
129 return self.invalid()
130 registry = getUtility(IRegistry)
131 if registry.get('plone.autologin_after_password_reset', False):
132 return self._auto_login(userid, password)
133 return self.finish()
134
135 def __call__(self):
136 if self.subpath:
137 # Try traverse subpath first:
138 randomstring = self.subpath[0]
139 else:
140 randomstring = self.request.get('key', None)
141
142 pw_tool = getToolByName(self.context, 'portal_password_reset')
143 if self.request.method == 'POST':
144 return self._reset_password(pw_tool, randomstring)
145 try:
146 pw_tool.verifyKey(randomstring)
147 except InvalidRequestError:
148 return self.invalid()
149 except ExpiredRequestError:
150 return self.expired()
151 return self.form()
152
153 def publishTraverse(self, request, name):
154 if self.subpath is None:
155 self.subpath = []
156 self.subpath.append(name)
157 return self
158
159 def getErrors(self):
160 if self.request.method != 'POST':
161 return
162 password = self.request.form.get('password')
163 password2 = self.request.form.get('password2')
164 userid = self.request.form.get('userid')
165 reg_tool = getToolByName(self.context, 'portal_registration')
166 pw_fail = reg_tool.testPasswordValidity(password, password2)
167 state = {}
168 if pw_fail:
169 state['password'] = pw_fail
170
171 # Determine if we're checking userids or not
172 pw_tool = getToolByName(self.context, 'portal_password_reset')
173 if not pw_tool.checkUser():
174 return state
175
176 if not userid:
177 state['userid'] = _(
178 'This field is required, please provide some information.',
179 )
180 if state:
181 state['status'] = 'failure'
182 state['portal_status_message'] = _(
183 'Please correct the indicated errors.',
184 )
185 return state
186
187 def login_url(self):
188 portal_state = getMultiAdapter((self.context, self.request),
189 name=u"plone_portal_state")
190 return '{0}/login?__ac_name={1}'.format(
191 portal_state.navigation_root_url(),
192 self.request.form.get('userid', ''))
193
194 def expiration_timeout(self):
195 pw_tool = getToolByName(self.context, 'portal_password_reset')
196 timeout = int(pw_tool.getExpirationTimeout() or 0)
197 return timeout * 24 # timeout is in days, but templates want in hours.
198
199
200 class ExplainPWResetToolView(BrowserView):
201 """ """
202
203 def timeout_days(self):
204 return self.context.getExpirationTimeout()
205
206 def user_check(self):
207 return self.context._user_check and 'checked' or None
208
209 @property
210 def stats(self):
211 """Return a dictionary like so:
212 {"open":3, "expired":0}
213 about the number of open and expired reset requests.
214 """
215 # count expired reset requests by creating a list of it
216 bad = len([1 for expiry in self.context._requests.values()
217 if self.context.expired(expiry)])
218 # open reset requests are all requests without the expired ones
219 good = len(self.context._requests) - bad
220 return {"open": good, "expired": bad}
221
222 def __call__(self):
223 if self.request.method == 'POST':
224 timeout_days = safeToInt(self.request.get('timeout_days'), 7)
225 self.context.setExpirationTimeout(timeout_days)
226 self.context._user_check = bool(
227 self.request.get('user_check', False),
228 )
229 return self.index()
230
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/Products/CMFPlone/browser/login/password_reset.py b/Products/CMFPlone/browser/login/password_reset.py
--- a/Products/CMFPlone/browser/login/password_reset.py
+++ b/Products/CMFPlone/browser/login/password_reset.py
@@ -117,6 +117,9 @@
return
def _reset_password(self, pw_tool, randomstring):
+ state = self.getErrors()
+ if state:
+ return self.form()
userid = self.request.form.get('userid')
password = self.request.form.get('password')
try:
| {"golden_diff": "diff --git a/Products/CMFPlone/browser/login/password_reset.py b/Products/CMFPlone/browser/login/password_reset.py\n--- a/Products/CMFPlone/browser/login/password_reset.py\n+++ b/Products/CMFPlone/browser/login/password_reset.py\n@@ -117,6 +117,9 @@\n return\n \n def _reset_password(self, pw_tool, randomstring):\n+ state = self.getErrors()\n+ if state:\n+ return self.form()\n userid = self.request.form.get('userid')\n password = self.request.form.get('password')\n try:\n", "issue": "PasswordResetView::getErrors function never called.\n## BUG\r\n\r\n<!--\r\n\r\nRead https://plone.org/support/bugs first!\r\n\r\nPlease use the labels at Github, at least one of the types: bug, regression, question, enhancement.\r\n\r\nPlease include tracebacks, screenshots, code of debugging sessions or code that reproduces the issue if possible.\r\nThe best reproductions are in plain Plone installations without addons or at least with minimal needed addons installed.\r\n\r\n-->\r\n\r\n### What I did:\r\nI am trying to reset the password, using a normal Plone user and I made a PDB inside https://github.com/plone/Products.CMFPlone/blob/master/Products/CMFPlone/browser/login/password_reset.py#L159\r\n\r\nURL: {site url}/passwordreset/e3127df738bc41e1976cc36cc9832132?userid=local_manager\r\n\r\n### What I expect to happen:\r\nI expected a call `RegistrationTool.testPasswordValidity(password, password2)\r\n` as I have some business logic inside testPasswordValidity but I saw code never coming here\r\n\r\n### What actually happened:\r\nAs I see inside ''getErrors'' method, there is a call to registration tool testPasswordValidity method but the ''getErrors'' never called.\r\n### What version of Plone/ Addons I am using:\r\nPlone 5.2.5rc\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl.SecurityManagement import getSecurityManager\nfrom email.header import Header\nfrom plone.app.layout.navigation.interfaces import INavigationRoot\nfrom plone.memoize import view\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.interfaces import IPasswordResetToolView\nfrom Products.CMFPlone.interfaces.controlpanel import IMailSchema\nfrom Products.CMFPlone.PasswordResetTool import ExpiredRequestError\nfrom Products.CMFPlone.PasswordResetTool import InvalidRequestError\nfrom Products.CMFPlone.utils import safe_unicode\nfrom Products.CMFPlone.utils import safeToInt\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom Products.PlonePAS.events import UserInitialLoginInEvent\nfrom Products.PlonePAS.events import UserLoggedInEvent\nfrom Products.PluggableAuthService.interfaces.plugins import ICredentialsUpdatePlugin # noqa\nfrom Products.statusmessages.interfaces import IStatusMessage\nfrom zope.component import getMultiAdapter\nfrom zope.component import getUtility\nfrom zope.event import notify\nfrom zope.i18n import translate\nfrom zope.interface import implementer\nfrom zope.publisher.interfaces import IPublishTraverse\n\n\n@implementer(IPasswordResetToolView)\nclass PasswordResetToolView(BrowserView):\n\n @view.memoize_contextless\n def portal_state(self):\n \"\"\" return portal_state of plone.app.layout\n \"\"\"\n return getMultiAdapter((self.context, self.request),\n name=u\"plone_portal_state\")\n\n def encode_mail_header(self, text):\n \"\"\" Encodes text into correctly encoded email header \"\"\"\n return Header(safe_unicode(text), 'utf-8')\n\n def encoded_mail_sender(self):\n \"\"\" returns encoded version of Portal name <portal_email> \"\"\"\n registry = getUtility(IRegistry)\n mail_settings = registry.forInterface(IMailSchema, prefix=\"plone\")\n from_ = mail_settings.email_from_name\n mail = mail_settings.email_from_address\n return '\"%s\" <%s>' % (self.encode_mail_header(from_).encode(), mail)\n\n def registered_notify_subject(self):\n portal_name = self.portal_state().portal_title()\n return translate(\n _(\n u'mailtemplate_user_account_info',\n default=u'User Account Information for ${portal_name}',\n mapping={'portal_name': safe_unicode(portal_name)},\n ),\n context=self.request,\n )\n\n def mail_password_subject(self):\n return translate(\n _(\n u'mailtemplate_subject_resetpasswordrequest',\n default=u'Password reset request',\n ),\n context=self.request,\n )\n\n def construct_url(self, randomstring):\n return '%s/passwordreset/%s' % (\n self.portal_state().navigation_root_url(), randomstring)\n\n def expiration_timeout(self):\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n timeout = int(pw_tool.getExpirationTimeout() or 0)\n return timeout * 24 # timeout is in days, but templates want in hours.\n\n\n@implementer(IPublishTraverse)\nclass PasswordResetView(BrowserView):\n \"\"\" \"\"\"\n\n invalid = ViewPageTemplateFile('templates/pwreset_invalid.pt')\n expired = ViewPageTemplateFile('templates/pwreset_expired.pt')\n finish = ViewPageTemplateFile('templates/pwreset_finish.pt')\n form = ViewPageTemplateFile('templates/pwreset_form.pt')\n subpath = None\n\n def _auto_login(self, userid, password):\n aclu = getToolByName(self.context, 'acl_users')\n for name, plugin in aclu.plugins.listPlugins(ICredentialsUpdatePlugin):\n plugin.updateCredentials(\n self.request,\n self.request.response,\n userid,\n password\n )\n user = getSecurityManager().getUser()\n login_time = user.getProperty('login_time', None)\n if login_time is None:\n notify(UserInitialLoginInEvent(user))\n else:\n notify(UserLoggedInEvent(user))\n\n IStatusMessage(self.request).addStatusMessage(\n _(\n 'password_reset_successful',\n default='Password reset successful, '\n 'you are logged in now!',\n ),\n 'info',\n )\n url = INavigationRoot(self.context).absolute_url()\n self.request.response.redirect(url)\n return\n\n def _reset_password(self, pw_tool, randomstring):\n userid = self.request.form.get('userid')\n password = self.request.form.get('password')\n try:\n pw_tool.resetPassword(userid, randomstring, password)\n except ExpiredRequestError:\n return self.expired()\n except InvalidRequestError:\n return self.invalid()\n except RuntimeError:\n return self.invalid()\n registry = getUtility(IRegistry)\n if registry.get('plone.autologin_after_password_reset', False):\n return self._auto_login(userid, password)\n return self.finish()\n\n def __call__(self):\n if self.subpath:\n # Try traverse subpath first:\n randomstring = self.subpath[0]\n else:\n randomstring = self.request.get('key', None)\n\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n if self.request.method == 'POST':\n return self._reset_password(pw_tool, randomstring)\n try:\n pw_tool.verifyKey(randomstring)\n except InvalidRequestError:\n return self.invalid()\n except ExpiredRequestError:\n return self.expired()\n return self.form()\n\n def publishTraverse(self, request, name):\n if self.subpath is None:\n self.subpath = []\n self.subpath.append(name)\n return self\n\n def getErrors(self):\n if self.request.method != 'POST':\n return\n password = self.request.form.get('password')\n password2 = self.request.form.get('password2')\n userid = self.request.form.get('userid')\n reg_tool = getToolByName(self.context, 'portal_registration')\n pw_fail = reg_tool.testPasswordValidity(password, password2)\n state = {}\n if pw_fail:\n state['password'] = pw_fail\n\n # Determine if we're checking userids or not\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n if not pw_tool.checkUser():\n return state\n\n if not userid:\n state['userid'] = _(\n 'This field is required, please provide some information.',\n )\n if state:\n state['status'] = 'failure'\n state['portal_status_message'] = _(\n 'Please correct the indicated errors.',\n )\n return state\n\n def login_url(self):\n portal_state = getMultiAdapter((self.context, self.request),\n name=u\"plone_portal_state\")\n return '{0}/login?__ac_name={1}'.format(\n portal_state.navigation_root_url(),\n self.request.form.get('userid', ''))\n\n def expiration_timeout(self):\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n timeout = int(pw_tool.getExpirationTimeout() or 0)\n return timeout * 24 # timeout is in days, but templates want in hours.\n\n\nclass ExplainPWResetToolView(BrowserView):\n \"\"\" \"\"\"\n\n def timeout_days(self):\n return self.context.getExpirationTimeout()\n\n def user_check(self):\n return self.context._user_check and 'checked' or None\n\n @property\n def stats(self):\n \"\"\"Return a dictionary like so:\n {\"open\":3, \"expired\":0}\n about the number of open and expired reset requests.\n \"\"\"\n # count expired reset requests by creating a list of it\n bad = len([1 for expiry in self.context._requests.values()\n if self.context.expired(expiry)])\n # open reset requests are all requests without the expired ones\n good = len(self.context._requests) - bad\n return {\"open\": good, \"expired\": bad}\n\n def __call__(self):\n if self.request.method == 'POST':\n timeout_days = safeToInt(self.request.get('timeout_days'), 7)\n self.context.setExpirationTimeout(timeout_days)\n self.context._user_check = bool(\n self.request.get('user_check', False),\n )\n return self.index()\n", "path": "Products/CMFPlone/browser/login/password_reset.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom AccessControl.SecurityManagement import getSecurityManager\nfrom email.header import Header\nfrom plone.app.layout.navigation.interfaces import INavigationRoot\nfrom plone.memoize import view\nfrom plone.registry.interfaces import IRegistry\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.CMFPlone.interfaces import IPasswordResetToolView\nfrom Products.CMFPlone.interfaces.controlpanel import IMailSchema\nfrom Products.CMFPlone.PasswordResetTool import ExpiredRequestError\nfrom Products.CMFPlone.PasswordResetTool import InvalidRequestError\nfrom Products.CMFPlone.utils import safe_unicode\nfrom Products.CMFPlone.utils import safeToInt\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom Products.PlonePAS.events import UserInitialLoginInEvent\nfrom Products.PlonePAS.events import UserLoggedInEvent\nfrom Products.PluggableAuthService.interfaces.plugins import ICredentialsUpdatePlugin # noqa\nfrom Products.statusmessages.interfaces import IStatusMessage\nfrom zope.component import getMultiAdapter\nfrom zope.component import getUtility\nfrom zope.event import notify\nfrom zope.i18n import translate\nfrom zope.interface import implementer\nfrom zope.publisher.interfaces import IPublishTraverse\n\n\n@implementer(IPasswordResetToolView)\nclass PasswordResetToolView(BrowserView):\n\n @view.memoize_contextless\n def portal_state(self):\n \"\"\" return portal_state of plone.app.layout\n \"\"\"\n return getMultiAdapter((self.context, self.request),\n name=u\"plone_portal_state\")\n\n def encode_mail_header(self, text):\n \"\"\" Encodes text into correctly encoded email header \"\"\"\n return Header(safe_unicode(text), 'utf-8')\n\n def encoded_mail_sender(self):\n \"\"\" returns encoded version of Portal name <portal_email> \"\"\"\n registry = getUtility(IRegistry)\n mail_settings = registry.forInterface(IMailSchema, prefix=\"plone\")\n from_ = mail_settings.email_from_name\n mail = mail_settings.email_from_address\n return '\"%s\" <%s>' % (self.encode_mail_header(from_).encode(), mail)\n\n def registered_notify_subject(self):\n portal_name = self.portal_state().portal_title()\n return translate(\n _(\n u'mailtemplate_user_account_info',\n default=u'User Account Information for ${portal_name}',\n mapping={'portal_name': safe_unicode(portal_name)},\n ),\n context=self.request,\n )\n\n def mail_password_subject(self):\n return translate(\n _(\n u'mailtemplate_subject_resetpasswordrequest',\n default=u'Password reset request',\n ),\n context=self.request,\n )\n\n def construct_url(self, randomstring):\n return '%s/passwordreset/%s' % (\n self.portal_state().navigation_root_url(), randomstring)\n\n def expiration_timeout(self):\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n timeout = int(pw_tool.getExpirationTimeout() or 0)\n return timeout * 24 # timeout is in days, but templates want in hours.\n\n\n@implementer(IPublishTraverse)\nclass PasswordResetView(BrowserView):\n \"\"\" \"\"\"\n\n invalid = ViewPageTemplateFile('templates/pwreset_invalid.pt')\n expired = ViewPageTemplateFile('templates/pwreset_expired.pt')\n finish = ViewPageTemplateFile('templates/pwreset_finish.pt')\n form = ViewPageTemplateFile('templates/pwreset_form.pt')\n subpath = None\n\n def _auto_login(self, userid, password):\n aclu = getToolByName(self.context, 'acl_users')\n for name, plugin in aclu.plugins.listPlugins(ICredentialsUpdatePlugin):\n plugin.updateCredentials(\n self.request,\n self.request.response,\n userid,\n password\n )\n user = getSecurityManager().getUser()\n login_time = user.getProperty('login_time', None)\n if login_time is None:\n notify(UserInitialLoginInEvent(user))\n else:\n notify(UserLoggedInEvent(user))\n\n IStatusMessage(self.request).addStatusMessage(\n _(\n 'password_reset_successful',\n default='Password reset successful, '\n 'you are logged in now!',\n ),\n 'info',\n )\n url = INavigationRoot(self.context).absolute_url()\n self.request.response.redirect(url)\n return\n\n def _reset_password(self, pw_tool, randomstring):\n state = self.getErrors()\n if state:\n return self.form()\n userid = self.request.form.get('userid')\n password = self.request.form.get('password')\n try:\n pw_tool.resetPassword(userid, randomstring, password)\n except ExpiredRequestError:\n return self.expired()\n except InvalidRequestError:\n return self.invalid()\n except RuntimeError:\n return self.invalid()\n registry = getUtility(IRegistry)\n if registry.get('plone.autologin_after_password_reset', False):\n return self._auto_login(userid, password)\n return self.finish()\n\n def __call__(self):\n if self.subpath:\n # Try traverse subpath first:\n randomstring = self.subpath[0]\n else:\n randomstring = self.request.get('key', None)\n\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n if self.request.method == 'POST':\n return self._reset_password(pw_tool, randomstring)\n try:\n pw_tool.verifyKey(randomstring)\n except InvalidRequestError:\n return self.invalid()\n except ExpiredRequestError:\n return self.expired()\n return self.form()\n\n def publishTraverse(self, request, name):\n if self.subpath is None:\n self.subpath = []\n self.subpath.append(name)\n return self\n\n def getErrors(self):\n if self.request.method != 'POST':\n return\n password = self.request.form.get('password')\n password2 = self.request.form.get('password2')\n userid = self.request.form.get('userid')\n reg_tool = getToolByName(self.context, 'portal_registration')\n pw_fail = reg_tool.testPasswordValidity(password, password2)\n state = {}\n if pw_fail:\n state['password'] = pw_fail\n\n # Determine if we're checking userids or not\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n if not pw_tool.checkUser():\n return state\n\n if not userid:\n state['userid'] = _(\n 'This field is required, please provide some information.',\n )\n if state:\n state['status'] = 'failure'\n state['portal_status_message'] = _(\n 'Please correct the indicated errors.',\n )\n return state\n\n def login_url(self):\n portal_state = getMultiAdapter((self.context, self.request),\n name=u\"plone_portal_state\")\n return '{0}/login?__ac_name={1}'.format(\n portal_state.navigation_root_url(),\n self.request.form.get('userid', ''))\n\n def expiration_timeout(self):\n pw_tool = getToolByName(self.context, 'portal_password_reset')\n timeout = int(pw_tool.getExpirationTimeout() or 0)\n return timeout * 24 # timeout is in days, but templates want in hours.\n\n\nclass ExplainPWResetToolView(BrowserView):\n \"\"\" \"\"\"\n\n def timeout_days(self):\n return self.context.getExpirationTimeout()\n\n def user_check(self):\n return self.context._user_check and 'checked' or None\n\n @property\n def stats(self):\n \"\"\"Return a dictionary like so:\n {\"open\":3, \"expired\":0}\n about the number of open and expired reset requests.\n \"\"\"\n # count expired reset requests by creating a list of it\n bad = len([1 for expiry in self.context._requests.values()\n if self.context.expired(expiry)])\n # open reset requests are all requests without the expired ones\n good = len(self.context._requests) - bad\n return {\"open\": good, \"expired\": bad}\n\n def __call__(self):\n if self.request.method == 'POST':\n timeout_days = safeToInt(self.request.get('timeout_days'), 7)\n self.context.setExpirationTimeout(timeout_days)\n self.context._user_check = bool(\n self.request.get('user_check', False),\n )\n return self.index()\n", "path": "Products/CMFPlone/browser/login/password_reset.py"}]} | 2,921 | 132 |
gh_patches_debug_6782 | rasdani/github-patches | git_diff | learningequality__kolibri-1761 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The mastery completion sign updates only after a page refresh and not real time.
## Summary
A learner had completed and came out of the exercise and found the green completed tick did not get updated real time, but after refreshing the page the completed tick appeared.
## System information
- Version: Kolibri 0.4.0beta10
- Operating system: Ubuntu 14.04 LTS
- Browser: Chrome
## How to reproduce
1. Attempt an exercise or master it.
2. Come out of the exercise.
3. The completed or In progress stamp is not updated real time.
## Screenshots
Learner has mastered the topic.

He exited the exercise and the completed sign on the thumbnail is not update:

But on refreshing the page the thumbnail has the completed sign.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/auth/backends.py`
Content:
```
1 """
2 Implements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and
3 DeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication
4 backends are checked in the order they're listed.
5 """
6
7 from kolibri.auth.models import DeviceOwner, FacilityUser
8
9
10 class FacilityUserBackend(object):
11 """
12 A class that implements authentication for FacilityUsers.
13 """
14
15 def authenticate(self, username=None, password=None, facility=None):
16 """
17 Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.
18
19 :param username: a string
20 :param password: a string
21 :param facility: a Facility
22 :return: A FacilityUser instance if successful, or None if authentication failed.
23 """
24 users = FacilityUser.objects.filter(username=username)
25 if facility:
26 users = users.filter(facility=facility)
27 for user in users:
28 if user.check_password(password):
29 return user
30 # Allow login without password for learners for facilities that allow this.
31 # Must specify the facility, to prevent accidental logins
32 elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():
33 return user
34 return None
35
36 def get_user(self, user_id):
37 """
38 Gets a user. Auth backends are required to implement this.
39
40 :param user_id: A FacilityUser pk
41 :return: A FacilityUser instance if a BaseUser with that pk is found, else None.
42 """
43 try:
44 return FacilityUser.objects.get(pk=user_id)
45 except FacilityUser.DoesNotExist:
46 return None
47
48
49 class DeviceOwnerBackend(object):
50 """
51 A class that implements authentication for DeviceOwners.
52 """
53
54 def authenticate(self, username=None, password=None, **kwargs):
55 """
56 Authenticates the user if the credentials correspond to a DeviceOwner.
57
58 :param username: a string
59 :param password: a string
60 :return: A DeviceOwner instance if successful, or None if authentication failed.
61 """
62 try:
63 user = DeviceOwner.objects.get(username=username)
64 if user.check_password(password):
65 return user
66 else:
67 return None
68 except DeviceOwner.DoesNotExist:
69 return None
70
71 def get_user(self, user_id):
72 """
73 Gets a user. Auth backends are required to implement this.
74
75 :param user_id: A BaseUser pk
76 :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.
77 """
78 try:
79 return DeviceOwner.objects.get(pk=user_id)
80 except DeviceOwner.DoesNotExist:
81 return None
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py
--- a/kolibri/auth/backends.py
+++ b/kolibri/auth/backends.py
@@ -21,7 +21,7 @@
:param facility: a Facility
:return: A FacilityUser instance if successful, or None if authentication failed.
"""
- users = FacilityUser.objects.filter(username=username)
+ users = FacilityUser.objects.filter(username__iexact=username)
if facility:
users = users.filter(facility=facility)
for user in users:
| {"golden_diff": "diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py\n--- a/kolibri/auth/backends.py\n+++ b/kolibri/auth/backends.py\n@@ -21,7 +21,7 @@\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n- users = FacilityUser.objects.filter(username=username)\n+ users = FacilityUser.objects.filter(username__iexact=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n", "issue": "The mastery completion sign updates only after a page refresh and not real time.\n## Summary\r\n\r\nA learner had completed and came out of the exercise and found the green completed tick did not get updated real time, but after refreshing the page the completed tick appeared. \r\n\r\n## System information\r\n - Version: Kolibri 0.4.0beta10\r\n - Operating system: Ubuntu 14.04 LTS\r\n - Browser: Chrome\r\n\r\n\r\n## How to reproduce\r\n1. Attempt an exercise or master it.\r\n2. Come out of the exercise.\r\n3. The completed or In progress stamp is not updated real time.\r\n\r\n## Screenshots\r\nLearner has mastered the topic.\r\n\r\n\r\nHe exited the exercise and the completed sign on the thumbnail is not update:\r\n\r\n\r\nBut on refreshing the page the thumbnail has the completed sign.\n", "before_files": [{"content": "\"\"\"\nImplements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and\nDeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication\nbackends are checked in the order they're listed.\n\"\"\"\n\nfrom kolibri.auth.models import DeviceOwner, FacilityUser\n\n\nclass FacilityUserBackend(object):\n \"\"\"\n A class that implements authentication for FacilityUsers.\n \"\"\"\n\n def authenticate(self, username=None, password=None, facility=None):\n \"\"\"\n Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.\n\n :param username: a string\n :param password: a string\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n users = FacilityUser.objects.filter(username=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n if user.check_password(password):\n return user\n # Allow login without password for learners for facilities that allow this.\n # Must specify the facility, to prevent accidental logins\n elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():\n return user\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A FacilityUser pk\n :return: A FacilityUser instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return FacilityUser.objects.get(pk=user_id)\n except FacilityUser.DoesNotExist:\n return None\n\n\nclass DeviceOwnerBackend(object):\n \"\"\"\n A class that implements authentication for DeviceOwners.\n \"\"\"\n\n def authenticate(self, username=None, password=None, **kwargs):\n \"\"\"\n Authenticates the user if the credentials correspond to a DeviceOwner.\n\n :param username: a string\n :param password: a string\n :return: A DeviceOwner instance if successful, or None if authentication failed.\n \"\"\"\n try:\n user = DeviceOwner.objects.get(username=username)\n if user.check_password(password):\n return user\n else:\n return None\n except DeviceOwner.DoesNotExist:\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A BaseUser pk\n :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return DeviceOwner.objects.get(pk=user_id)\n except DeviceOwner.DoesNotExist:\n return None\n", "path": "kolibri/auth/backends.py"}], "after_files": [{"content": "\"\"\"\nImplements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and\nDeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication\nbackends are checked in the order they're listed.\n\"\"\"\n\nfrom kolibri.auth.models import DeviceOwner, FacilityUser\n\n\nclass FacilityUserBackend(object):\n \"\"\"\n A class that implements authentication for FacilityUsers.\n \"\"\"\n\n def authenticate(self, username=None, password=None, facility=None):\n \"\"\"\n Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.\n\n :param username: a string\n :param password: a string\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n users = FacilityUser.objects.filter(username__iexact=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n if user.check_password(password):\n return user\n # Allow login without password for learners for facilities that allow this.\n # Must specify the facility, to prevent accidental logins\n elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():\n return user\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A FacilityUser pk\n :return: A FacilityUser instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return FacilityUser.objects.get(pk=user_id)\n except FacilityUser.DoesNotExist:\n return None\n\n\nclass DeviceOwnerBackend(object):\n \"\"\"\n A class that implements authentication for DeviceOwners.\n \"\"\"\n\n def authenticate(self, username=None, password=None, **kwargs):\n \"\"\"\n Authenticates the user if the credentials correspond to a DeviceOwner.\n\n :param username: a string\n :param password: a string\n :return: A DeviceOwner instance if successful, or None if authentication failed.\n \"\"\"\n try:\n user = DeviceOwner.objects.get(username=username)\n if user.check_password(password):\n return user\n else:\n return None\n except DeviceOwner.DoesNotExist:\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A BaseUser pk\n :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return DeviceOwner.objects.get(pk=user_id)\n except DeviceOwner.DoesNotExist:\n return None\n", "path": "kolibri/auth/backends.py"}]} | 1,318 | 126 |
gh_patches_debug_30951 | rasdani/github-patches | git_diff | fail2ban__fail2ban-1503 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Wrong install path `/usr/share/doc/` for some platform (install fails on Mac OS 10.11 "El Capitan")
Due to El Capitan's new "System Integrity Protection", there is no way to create the directory at /usr/share/doc/fail2ban, even as root:
> % sudo python setup.py install
> running install
> Checking .pth file support in /Library/Python/2.7/site-packages/
> ...
> running install_data
> creating /usr/share/doc/fail2ban
> error: could not create '/usr/share/doc/fail2ban': Operation not permitted
However, /usr/local is modifiable, so changing line 151 of setup.py from
> '/usr/share/doc/fail2ban'
to
> '/usr/local/doc/fail2ban'
allowed the installer to proceed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/python
2 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-
3 # vi: set ft=python sts=4 ts=4 sw=4 noet :
4
5 # This file is part of Fail2Ban.
6 #
7 # Fail2Ban is free software; you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation; either version 2 of the License, or
10 # (at your option) any later version.
11 #
12 # Fail2Ban is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with Fail2Ban; if not, write to the Free Software
19 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
20
21 __author__ = "Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko"
22 __copyright__ = "Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors"
23 __license__ = "GPL"
24
25 try:
26 import setuptools
27 from setuptools import setup
28 except ImportError:
29 setuptools = None
30 from distutils.core import setup
31
32 try:
33 # python 3.x
34 from distutils.command.build_py import build_py_2to3 as build_py
35 from distutils.command.build_scripts \
36 import build_scripts_2to3 as build_scripts
37 except ImportError:
38 # python 2.x
39 from distutils.command.build_py import build_py
40 from distutils.command.build_scripts import build_scripts
41 import os
42 from os.path import isfile, join, isdir, realpath
43 import sys
44 import warnings
45 from glob import glob
46
47 if setuptools and "test" in sys.argv:
48 import logging
49 logSys = logging.getLogger("fail2ban")
50 hdlr = logging.StreamHandler(sys.stdout)
51 fmt = logging.Formatter("%(asctime)-15s %(message)s")
52 hdlr.setFormatter(fmt)
53 logSys.addHandler(hdlr)
54 if set(["-q", "--quiet"]) & set(sys.argv):
55 logSys.setLevel(logging.CRITICAL)
56 warnings.simplefilter("ignore")
57 sys.warnoptions.append("ignore")
58 elif set(["-v", "--verbose"]) & set(sys.argv):
59 logSys.setLevel(logging.DEBUG)
60 else:
61 logSys.setLevel(logging.INFO)
62 elif "test" in sys.argv:
63 print("python distribute required to execute fail2ban tests")
64 print("")
65
66 longdesc = '''
67 Fail2Ban scans log files like /var/log/pwdfail or
68 /var/log/apache/error_log and bans IP that makes
69 too many password failures. It updates firewall rules
70 to reject the IP address or executes user defined
71 commands.'''
72
73 if setuptools:
74 setup_extra = {
75 'test_suite': "fail2ban.tests.utils.gatherTests",
76 'use_2to3': True,
77 }
78 else:
79 setup_extra = {}
80
81 data_files_extra = []
82 if os.path.exists('/var/run'):
83 # if we are on the system with /var/run -- we are to use it for having fail2ban/
84 # directory there for socket file etc.
85 # realpath is used to possibly resolve /var/run -> /run symlink
86 data_files_extra += [(realpath('/var/run/fail2ban'), '')]
87
88 # Get version number, avoiding importing fail2ban.
89 # This is due to tests not functioning for python3 as 2to3 takes place later
90 exec(open(join("fail2ban", "version.py")).read())
91
92 setup(
93 name = "fail2ban",
94 version = version,
95 description = "Ban IPs that make too many password failures",
96 long_description = longdesc,
97 author = "Cyril Jaquier & Fail2Ban Contributors",
98 author_email = "[email protected]",
99 url = "http://www.fail2ban.org",
100 license = "GPL",
101 platforms = "Posix",
102 cmdclass = {'build_py': build_py, 'build_scripts': build_scripts},
103 scripts = [
104 'bin/fail2ban-client',
105 'bin/fail2ban-server',
106 'bin/fail2ban-regex',
107 'bin/fail2ban-testcases',
108 ],
109 packages = [
110 'fail2ban',
111 'fail2ban.client',
112 'fail2ban.server',
113 'fail2ban.tests',
114 'fail2ban.tests.action_d',
115 ],
116 package_data = {
117 'fail2ban.tests':
118 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
119 for w in os.walk('fail2ban/tests/files')
120 for f in w[2]] +
121 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
122 for w in os.walk('fail2ban/tests/config')
123 for f in w[2]] +
124 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
125 for w in os.walk('fail2ban/tests/action_d')
126 for f in w[2]]
127 },
128 data_files = [
129 ('/etc/fail2ban',
130 glob("config/*.conf")
131 ),
132 ('/etc/fail2ban/filter.d',
133 glob("config/filter.d/*.conf")
134 ),
135 ('/etc/fail2ban/filter.d/ignorecommands',
136 glob("config/filter.d/ignorecommands/*")
137 ),
138 ('/etc/fail2ban/action.d',
139 glob("config/action.d/*.conf") +
140 glob("config/action.d/*.py")
141 ),
142 ('/etc/fail2ban/fail2ban.d',
143 ''
144 ),
145 ('/etc/fail2ban/jail.d',
146 ''
147 ),
148 ('/var/lib/fail2ban',
149 ''
150 ),
151 ('/usr/share/doc/fail2ban',
152 ['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',
153 'doc/run-rootless.txt']
154 )
155 ] + data_files_extra,
156 **setup_extra
157 )
158
159 # Do some checks after installation
160 # Search for obsolete files.
161 obsoleteFiles = []
162 elements = {
163 "/etc/":
164 [
165 "fail2ban.conf"
166 ],
167 "/usr/bin/":
168 [
169 "fail2ban.py"
170 ],
171 "/usr/lib/fail2ban/":
172 [
173 "version.py",
174 "protocol.py"
175 ]
176 }
177
178 for directory in elements:
179 for f in elements[directory]:
180 path = join(directory, f)
181 if isfile(path):
182 obsoleteFiles.append(path)
183
184 if obsoleteFiles:
185 print("")
186 print("Obsolete files from previous Fail2Ban versions were found on "
187 "your system.")
188 print("Please delete them:")
189 print("")
190 for f in obsoleteFiles:
191 print("\t" + f)
192 print("")
193
194 if isdir("/usr/lib/fail2ban"):
195 print("")
196 print("Fail2ban is not installed under /usr/lib anymore. The new "
197 "location is under /usr/share. Please remove the directory "
198 "/usr/lib/fail2ban and everything under this directory.")
199 print("")
200
201 # Update config file
202 if sys.argv[1] == "install":
203 print("")
204 print("Please do not forget to update your configuration files.")
205 print("They are in /etc/fail2ban/.")
206 print("")
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -19,9 +19,11 @@
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
__author__ = "Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko"
-__copyright__ = "Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors"
+__copyright__ = "Copyright (c) 2004 Cyril Jaquier, 2008-2016 Fail2Ban Contributors"
__license__ = "GPL"
+import platform
+
try:
import setuptools
from setuptools import setup
@@ -85,6 +87,18 @@
# realpath is used to possibly resolve /var/run -> /run symlink
data_files_extra += [(realpath('/var/run/fail2ban'), '')]
+# Installing documentation files only under Linux or other GNU/ systems
+# (e.g. GNU/kFreeBSD), since others might have protective mechanisms forbidding
+# installation there (see e.g. #1233)
+platform_system = platform.system().lower()
+doc_files = ['README.md', 'DEVELOP', 'FILTERS', 'doc/run-rootless.txt']
+if platform_system in ('solaris', 'sunos'):
+ doc_files.append('README.Solaris')
+if platform_system in ('linux', 'solaris', 'sunos') or platform_system.startswith('gnu'):
+ data_files_extra.append(
+ ('/usr/share/doc/fail2ban', doc_files)
+ )
+
# Get version number, avoiding importing fail2ban.
# This is due to tests not functioning for python3 as 2to3 takes place later
exec(open(join("fail2ban", "version.py")).read())
@@ -148,10 +162,6 @@
('/var/lib/fail2ban',
''
),
- ('/usr/share/doc/fail2ban',
- ['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',
- 'doc/run-rootless.txt']
- )
] + data_files_extra,
**setup_extra
)
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -19,9 +19,11 @@\n # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n \n __author__ = \"Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko\"\n-__copyright__ = \"Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors\"\n+__copyright__ = \"Copyright (c) 2004 Cyril Jaquier, 2008-2016 Fail2Ban Contributors\"\n __license__ = \"GPL\"\n \n+import platform\n+\n try:\n \timport setuptools\n \tfrom setuptools import setup\n@@ -85,6 +87,18 @@\n \t# realpath is used to possibly resolve /var/run -> /run symlink\n \tdata_files_extra += [(realpath('/var/run/fail2ban'), '')]\n \n+# Installing documentation files only under Linux or other GNU/ systems\n+# (e.g. GNU/kFreeBSD), since others might have protective mechanisms forbidding\n+# installation there (see e.g. #1233)\n+platform_system = platform.system().lower()\n+doc_files = ['README.md', 'DEVELOP', 'FILTERS', 'doc/run-rootless.txt']\n+if platform_system in ('solaris', 'sunos'):\n+\tdoc_files.append('README.Solaris')\n+if platform_system in ('linux', 'solaris', 'sunos') or platform_system.startswith('gnu'):\n+\tdata_files_extra.append(\n+\t\t('/usr/share/doc/fail2ban', doc_files)\n+\t)\n+\n # Get version number, avoiding importing fail2ban.\n # This is due to tests not functioning for python3 as 2to3 takes place later\n exec(open(join(\"fail2ban\", \"version.py\")).read())\n@@ -148,10 +162,6 @@\n \t\t('/var/lib/fail2ban',\n \t\t\t''\n \t\t),\n-\t\t('/usr/share/doc/fail2ban',\n-\t\t\t['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',\n-\t\t\t 'doc/run-rootless.txt']\n-\t\t)\n \t] + data_files_extra,\n \t**setup_extra\n )\n", "issue": "Wrong install path `/usr/share/doc/` for some platform (install fails on Mac OS 10.11 \"El Capitan\")\nDue to El Capitan's new \"System Integrity Protection\", there is no way to create the directory at /usr/share/doc/fail2ban, even as root:\n\n> % sudo python setup.py install\n> running install\n> Checking .pth file support in /Library/Python/2.7/site-packages/\n> ...\n> running install_data\n> creating /usr/share/doc/fail2ban\n> error: could not create '/usr/share/doc/fail2ban': Operation not permitted\n\nHowever, /usr/local is modifiable, so changing line 151 of setup.py from\n\n> '/usr/share/doc/fail2ban'\n\nto\n\n> '/usr/local/doc/fail2ban'\n\nallowed the installer to proceed.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-\n# vi: set ft=python sts=4 ts=4 sw=4 noet :\n\n# This file is part of Fail2Ban.\n#\n# Fail2Ban is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# Fail2Ban is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Fail2Ban; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n__author__ = \"Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko\"\n__copyright__ = \"Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors\"\n__license__ = \"GPL\"\n\ntry:\n\timport setuptools\n\tfrom setuptools import setup\nexcept ImportError:\n\tsetuptools = None\n\tfrom distutils.core import setup\n\ntry:\n\t# python 3.x\n\tfrom distutils.command.build_py import build_py_2to3 as build_py\n\tfrom distutils.command.build_scripts \\\n\t\timport build_scripts_2to3 as build_scripts\nexcept ImportError:\n\t# python 2.x\n\tfrom distutils.command.build_py import build_py\n\tfrom distutils.command.build_scripts import build_scripts\nimport os\nfrom os.path import isfile, join, isdir, realpath\nimport sys\nimport warnings\nfrom glob import glob\n\nif setuptools and \"test\" in sys.argv:\n\timport logging\n\tlogSys = logging.getLogger(\"fail2ban\")\n\thdlr = logging.StreamHandler(sys.stdout)\n\tfmt = logging.Formatter(\"%(asctime)-15s %(message)s\")\n\thdlr.setFormatter(fmt)\n\tlogSys.addHandler(hdlr)\n\tif set([\"-q\", \"--quiet\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.CRITICAL)\n\t\twarnings.simplefilter(\"ignore\")\n\t\tsys.warnoptions.append(\"ignore\")\n\telif set([\"-v\", \"--verbose\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.DEBUG)\n\telse:\n\t\tlogSys.setLevel(logging.INFO)\nelif \"test\" in sys.argv:\n\tprint(\"python distribute required to execute fail2ban tests\")\n\tprint(\"\")\n\nlongdesc = '''\nFail2Ban scans log files like /var/log/pwdfail or\n/var/log/apache/error_log and bans IP that makes\ntoo many password failures. It updates firewall rules\nto reject the IP address or executes user defined\ncommands.'''\n\nif setuptools:\n\tsetup_extra = {\n\t\t'test_suite': \"fail2ban.tests.utils.gatherTests\",\n\t\t'use_2to3': True,\n\t}\nelse:\n\tsetup_extra = {}\n\ndata_files_extra = []\nif os.path.exists('/var/run'):\n\t# if we are on the system with /var/run -- we are to use it for having fail2ban/\n\t# directory there for socket file etc.\n\t# realpath is used to possibly resolve /var/run -> /run symlink\n\tdata_files_extra += [(realpath('/var/run/fail2ban'), '')]\n\n# Get version number, avoiding importing fail2ban.\n# This is due to tests not functioning for python3 as 2to3 takes place later\nexec(open(join(\"fail2ban\", \"version.py\")).read())\n\nsetup(\n\tname = \"fail2ban\",\n\tversion = version,\n\tdescription = \"Ban IPs that make too many password failures\",\n\tlong_description = longdesc,\n\tauthor = \"Cyril Jaquier & Fail2Ban Contributors\",\n\tauthor_email = \"[email protected]\",\n\turl = \"http://www.fail2ban.org\",\n\tlicense = \"GPL\",\n\tplatforms = \"Posix\",\n\tcmdclass = {'build_py': build_py, 'build_scripts': build_scripts},\n\tscripts = [\n\t\t'bin/fail2ban-client',\n\t\t'bin/fail2ban-server',\n\t\t'bin/fail2ban-regex',\n\t\t'bin/fail2ban-testcases',\n\t],\n\tpackages = [\n\t\t'fail2ban',\n\t\t'fail2ban.client',\n\t\t'fail2ban.server',\n\t\t'fail2ban.tests',\n\t\t'fail2ban.tests.action_d',\n\t],\n\tpackage_data = {\n\t\t'fail2ban.tests':\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/files')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/config')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/action_d')\n\t\t\t\tfor f in w[2]]\n\t},\n\tdata_files = [\n\t\t('/etc/fail2ban',\n\t\t\tglob(\"config/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/filter.d',\n\t\t\tglob(\"config/filter.d/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/filter.d/ignorecommands',\n\t\t\tglob(\"config/filter.d/ignorecommands/*\")\n\t\t),\n\t\t('/etc/fail2ban/action.d',\n\t\t\tglob(\"config/action.d/*.conf\") +\n\t\t\tglob(\"config/action.d/*.py\")\n\t\t),\n\t\t('/etc/fail2ban/fail2ban.d',\n\t\t\t''\n\t\t),\n\t\t('/etc/fail2ban/jail.d',\n\t\t\t''\n\t\t),\n\t\t('/var/lib/fail2ban',\n\t\t\t''\n\t\t),\n\t\t('/usr/share/doc/fail2ban',\n\t\t\t['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',\n\t\t\t 'doc/run-rootless.txt']\n\t\t)\n\t] + data_files_extra,\n\t**setup_extra\n)\n\n# Do some checks after installation\n# Search for obsolete files.\nobsoleteFiles = []\nelements = {\n\t\"/etc/\":\n\t\t[\n\t\t\t\"fail2ban.conf\"\n\t\t],\n\t\"/usr/bin/\":\n\t\t[\n\t\t\t\"fail2ban.py\"\n\t\t],\n\t\"/usr/lib/fail2ban/\":\n\t\t[\n\t\t\t\"version.py\",\n\t\t\t\"protocol.py\"\n\t\t]\n}\n\nfor directory in elements:\n\tfor f in elements[directory]:\n\t\tpath = join(directory, f)\n\t\tif isfile(path):\n\t\t\tobsoleteFiles.append(path)\n\nif obsoleteFiles:\n\tprint(\"\")\n\tprint(\"Obsolete files from previous Fail2Ban versions were found on \"\n\t\t \"your system.\")\n\tprint(\"Please delete them:\")\n\tprint(\"\")\n\tfor f in obsoleteFiles:\n\t\tprint(\"\\t\" + f)\n\tprint(\"\")\n\nif isdir(\"/usr/lib/fail2ban\"):\n\tprint(\"\")\n\tprint(\"Fail2ban is not installed under /usr/lib anymore. The new \"\n\t\t \"location is under /usr/share. Please remove the directory \"\n\t\t \"/usr/lib/fail2ban and everything under this directory.\")\n\tprint(\"\")\n\n# Update config file\nif sys.argv[1] == \"install\":\n\tprint(\"\")\n\tprint(\"Please do not forget to update your configuration files.\")\n\tprint(\"They are in /etc/fail2ban/.\")\n\tprint(\"\")\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/python\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-\n# vi: set ft=python sts=4 ts=4 sw=4 noet :\n\n# This file is part of Fail2Ban.\n#\n# Fail2Ban is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# Fail2Ban is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Fail2Ban; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n__author__ = \"Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko\"\n__copyright__ = \"Copyright (c) 2004 Cyril Jaquier, 2008-2016 Fail2Ban Contributors\"\n__license__ = \"GPL\"\n\nimport platform\n\ntry:\n\timport setuptools\n\tfrom setuptools import setup\nexcept ImportError:\n\tsetuptools = None\n\tfrom distutils.core import setup\n\ntry:\n\t# python 3.x\n\tfrom distutils.command.build_py import build_py_2to3 as build_py\n\tfrom distutils.command.build_scripts \\\n\t\timport build_scripts_2to3 as build_scripts\nexcept ImportError:\n\t# python 2.x\n\tfrom distutils.command.build_py import build_py\n\tfrom distutils.command.build_scripts import build_scripts\nimport os\nfrom os.path import isfile, join, isdir, realpath\nimport sys\nimport warnings\nfrom glob import glob\n\nif setuptools and \"test\" in sys.argv:\n\timport logging\n\tlogSys = logging.getLogger(\"fail2ban\")\n\thdlr = logging.StreamHandler(sys.stdout)\n\tfmt = logging.Formatter(\"%(asctime)-15s %(message)s\")\n\thdlr.setFormatter(fmt)\n\tlogSys.addHandler(hdlr)\n\tif set([\"-q\", \"--quiet\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.CRITICAL)\n\t\twarnings.simplefilter(\"ignore\")\n\t\tsys.warnoptions.append(\"ignore\")\n\telif set([\"-v\", \"--verbose\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.DEBUG)\n\telse:\n\t\tlogSys.setLevel(logging.INFO)\nelif \"test\" in sys.argv:\n\tprint(\"python distribute required to execute fail2ban tests\")\n\tprint(\"\")\n\nlongdesc = '''\nFail2Ban scans log files like /var/log/pwdfail or\n/var/log/apache/error_log and bans IP that makes\ntoo many password failures. It updates firewall rules\nto reject the IP address or executes user defined\ncommands.'''\n\nif setuptools:\n\tsetup_extra = {\n\t\t'test_suite': \"fail2ban.tests.utils.gatherTests\",\n\t\t'use_2to3': True,\n\t}\nelse:\n\tsetup_extra = {}\n\ndata_files_extra = []\nif os.path.exists('/var/run'):\n\t# if we are on the system with /var/run -- we are to use it for having fail2ban/\n\t# directory there for socket file etc.\n\t# realpath is used to possibly resolve /var/run -> /run symlink\n\tdata_files_extra += [(realpath('/var/run/fail2ban'), '')]\n\n# Installing documentation files only under Linux or other GNU/ systems\n# (e.g. GNU/kFreeBSD), since others might have protective mechanisms forbidding\n# installation there (see e.g. #1233)\nplatform_system = platform.system().lower()\ndoc_files = ['README.md', 'DEVELOP', 'FILTERS', 'doc/run-rootless.txt']\nif platform_system in ('solaris', 'sunos'):\n\tdoc_files.append('README.Solaris')\nif platform_system in ('linux', 'solaris', 'sunos') or platform_system.startswith('gnu'):\n\tdata_files_extra.append(\n\t\t('/usr/share/doc/fail2ban', doc_files)\n\t)\n\n# Get version number, avoiding importing fail2ban.\n# This is due to tests not functioning for python3 as 2to3 takes place later\nexec(open(join(\"fail2ban\", \"version.py\")).read())\n\nsetup(\n\tname = \"fail2ban\",\n\tversion = version,\n\tdescription = \"Ban IPs that make too many password failures\",\n\tlong_description = longdesc,\n\tauthor = \"Cyril Jaquier & Fail2Ban Contributors\",\n\tauthor_email = \"[email protected]\",\n\turl = \"http://www.fail2ban.org\",\n\tlicense = \"GPL\",\n\tplatforms = \"Posix\",\n\tcmdclass = {'build_py': build_py, 'build_scripts': build_scripts},\n\tscripts = [\n\t\t'bin/fail2ban-client',\n\t\t'bin/fail2ban-server',\n\t\t'bin/fail2ban-regex',\n\t\t'bin/fail2ban-testcases',\n\t],\n\tpackages = [\n\t\t'fail2ban',\n\t\t'fail2ban.client',\n\t\t'fail2ban.server',\n\t\t'fail2ban.tests',\n\t\t'fail2ban.tests.action_d',\n\t],\n\tpackage_data = {\n\t\t'fail2ban.tests':\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/files')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/config')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/action_d')\n\t\t\t\tfor f in w[2]]\n\t},\n\tdata_files = [\n\t\t('/etc/fail2ban',\n\t\t\tglob(\"config/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/filter.d',\n\t\t\tglob(\"config/filter.d/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/filter.d/ignorecommands',\n\t\t\tglob(\"config/filter.d/ignorecommands/*\")\n\t\t),\n\t\t('/etc/fail2ban/action.d',\n\t\t\tglob(\"config/action.d/*.conf\") +\n\t\t\tglob(\"config/action.d/*.py\")\n\t\t),\n\t\t('/etc/fail2ban/fail2ban.d',\n\t\t\t''\n\t\t),\n\t\t('/etc/fail2ban/jail.d',\n\t\t\t''\n\t\t),\n\t\t('/var/lib/fail2ban',\n\t\t\t''\n\t\t),\n\t] + data_files_extra,\n\t**setup_extra\n)\n\n# Do some checks after installation\n# Search for obsolete files.\nobsoleteFiles = []\nelements = {\n\t\"/etc/\":\n\t\t[\n\t\t\t\"fail2ban.conf\"\n\t\t],\n\t\"/usr/bin/\":\n\t\t[\n\t\t\t\"fail2ban.py\"\n\t\t],\n\t\"/usr/lib/fail2ban/\":\n\t\t[\n\t\t\t\"version.py\",\n\t\t\t\"protocol.py\"\n\t\t]\n}\n\nfor directory in elements:\n\tfor f in elements[directory]:\n\t\tpath = join(directory, f)\n\t\tif isfile(path):\n\t\t\tobsoleteFiles.append(path)\n\nif obsoleteFiles:\n\tprint(\"\")\n\tprint(\"Obsolete files from previous Fail2Ban versions were found on \"\n\t\t \"your system.\")\n\tprint(\"Please delete them:\")\n\tprint(\"\")\n\tfor f in obsoleteFiles:\n\t\tprint(\"\\t\" + f)\n\tprint(\"\")\n\nif isdir(\"/usr/lib/fail2ban\"):\n\tprint(\"\")\n\tprint(\"Fail2ban is not installed under /usr/lib anymore. The new \"\n\t\t \"location is under /usr/share. Please remove the directory \"\n\t\t \"/usr/lib/fail2ban and everything under this directory.\")\n\tprint(\"\")\n\n# Update config file\nif sys.argv[1] == \"install\":\n\tprint(\"\")\n\tprint(\"Please do not forget to update your configuration files.\")\n\tprint(\"They are in /etc/fail2ban/.\")\n\tprint(\"\")\n", "path": "setup.py"}]} | 2,661 | 522 |
gh_patches_debug_36757 | rasdani/github-patches | git_diff | huggingface__trl-398 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Llama Reward Model is incorrectly merged
As mentioned in #287, `merge_peft_adapter` saves the Llama RM as a `LlamaForCausalLM` see [here](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/merge_peft_adapter.py#L35)
But the reward model is trained and should be a `LlamaForSequenceClassification` and running `rl_training.py` gives the obvious warnings
```
Some weights of the model checkpoint at ./llama-7b-se-rm were not used when initializing LlamaForSequenceClassification: ['lm_head.weight']
- This IS expected if you are initializing LlamaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing LlamaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of LlamaForSequenceClassification were not initialized from the model checkpoint at /home/toolkit/huggingface/llama-7b-rm and are newly initialized: ['score.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
We should instead check whether we are merging the rm and then save as a the correct model
Also the `score.weight` is not being loaded as mentioned in #297 , see more info below
--- update --
It seems that `merge_peft_adapter` should be using `merge_and_unload()` which correctly overrides the score. But I haven't yet managed to get good results using the adapter weights on the hub
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/stack_llama/scripts/merge_peft_adapter.py`
Content:
```
1 from dataclasses import dataclass, field
2 from typing import Optional
3
4 import peft
5 import torch
6 from peft import PeftConfig, PeftModel
7 from peft.utils import _get_submodules
8 from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, HfArgumentParser
9
10
11 DEFAULT_PAD_TOKEN = "[PAD]"
12 DEFAULT_EOS_TOKEN = "</s>"
13 DEFAULT_BOS_TOKEN = "</s>"
14 DEFAULT_UNK_TOKEN = "</s>"
15
16
17 @dataclass
18 class ScriptArguments:
19 """
20 The name of the Casual LM model we wish to fine with PPO
21 """
22
23 adapter_model_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
24 base_model_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
25 output_name: Optional[str] = field(default=None, metadata={"help": "the model name"})
26
27
28 parser = HfArgumentParser(ScriptArguments)
29 script_args = parser.parse_args_into_dataclasses()[0]
30 assert script_args.adapter_model_name is not None, "please provide the name of the Adapter you would like to merge"
31 assert script_args.base_model_name is not None, "please provide the name of the Base model"
32 assert script_args.base_model_name is not None, "please provide the output name of the merged model"
33
34 peft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)
35 model = AutoModelForCausalLM.from_pretrained(script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16)
36 tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)
37 config = AutoConfig.from_pretrained(script_args.base_model_name)
38 architecture = config.architectures[0]
39 if "Llama" in architecture:
40 print("Setting EOS, BOS, and UNK tokens for LLama tokenizer")
41 tokenizer.add_special_tokens(
42 {
43 "eos_token": DEFAULT_EOS_TOKEN,
44 "bos_token": DEFAULT_BOS_TOKEN,
45 "unk_token": DEFAULT_UNK_TOKEN,
46 "pad_token": DEFAULT_PAD_TOKEN,
47 }
48 )
49
50 # Load the Lora model
51 model = PeftModel.from_pretrained(model, script_args.adapter_model_name)
52 model.eval()
53
54 key_list = [key for key, _ in model.base_model.model.named_modules() if "lora" not in key]
55 for key in key_list:
56 parent, target, target_name = _get_submodules(model.base_model.model, key)
57 if isinstance(target, peft.tuners.lora.Linear):
58 bias = target.bias is not None
59 new_module = torch.nn.Linear(target.in_features, target.out_features, bias=bias)
60 model.base_model._replace_module(parent, target_name, new_module, target)
61
62 model = model.base_model.model
63
64 model.save_pretrained(f"{script_args.output_name}")
65 tokenizer.save_pretrained(f"{script_args.output_name}")
66 model.push_to_hub(f"{script_args.output_name}", use_temp_dir=False)
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/stack_llama/scripts/merge_peft_adapter.py b/examples/stack_llama/scripts/merge_peft_adapter.py
--- a/examples/stack_llama/scripts/merge_peft_adapter.py
+++ b/examples/stack_llama/scripts/merge_peft_adapter.py
@@ -1,17 +1,9 @@
from dataclasses import dataclass, field
from typing import Optional
-import peft
import torch
from peft import PeftConfig, PeftModel
-from peft.utils import _get_submodules
-from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, HfArgumentParser
-
-
-DEFAULT_PAD_TOKEN = "[PAD]"
-DEFAULT_EOS_TOKEN = "</s>"
-DEFAULT_BOS_TOKEN = "</s>"
-DEFAULT_UNK_TOKEN = "</s>"
+from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer, HfArgumentParser
@dataclass
@@ -32,34 +24,23 @@
assert script_args.base_model_name is not None, "please provide the output name of the merged model"
peft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)
-model = AutoModelForCausalLM.from_pretrained(script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16)
-tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)
-config = AutoConfig.from_pretrained(script_args.base_model_name)
-architecture = config.architectures[0]
-if "Llama" in architecture:
- print("Setting EOS, BOS, and UNK tokens for LLama tokenizer")
- tokenizer.add_special_tokens(
- {
- "eos_token": DEFAULT_EOS_TOKEN,
- "bos_token": DEFAULT_BOS_TOKEN,
- "unk_token": DEFAULT_UNK_TOKEN,
- "pad_token": DEFAULT_PAD_TOKEN,
- }
+if peft_config.task_type == "SEQ_CLS":
+ # peft is for reward model so load sequence classification
+ model = AutoModelForSequenceClassification.from_pretrained(
+ script_args.base_model_name, num_labels=1, torch_dtype=torch.bfloat16
+ )
+else:
+ model = AutoModelForCausalLM.from_pretrained(
+ script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16
)
+tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)
+
# Load the Lora model
model = PeftModel.from_pretrained(model, script_args.adapter_model_name)
model.eval()
-key_list = [key for key, _ in model.base_model.model.named_modules() if "lora" not in key]
-for key in key_list:
- parent, target, target_name = _get_submodules(model.base_model.model, key)
- if isinstance(target, peft.tuners.lora.Linear):
- bias = target.bias is not None
- new_module = torch.nn.Linear(target.in_features, target.out_features, bias=bias)
- model.base_model._replace_module(parent, target_name, new_module, target)
-
-model = model.base_model.model
+model = model.merge_and_unload()
model.save_pretrained(f"{script_args.output_name}")
tokenizer.save_pretrained(f"{script_args.output_name}")
| {"golden_diff": "diff --git a/examples/stack_llama/scripts/merge_peft_adapter.py b/examples/stack_llama/scripts/merge_peft_adapter.py\n--- a/examples/stack_llama/scripts/merge_peft_adapter.py\n+++ b/examples/stack_llama/scripts/merge_peft_adapter.py\n@@ -1,17 +1,9 @@\n from dataclasses import dataclass, field\n from typing import Optional\n \n-import peft\n import torch\n from peft import PeftConfig, PeftModel\n-from peft.utils import _get_submodules\n-from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, HfArgumentParser\n-\n-\n-DEFAULT_PAD_TOKEN = \"[PAD]\"\n-DEFAULT_EOS_TOKEN = \"</s>\"\n-DEFAULT_BOS_TOKEN = \"</s>\"\n-DEFAULT_UNK_TOKEN = \"</s>\"\n+from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer, HfArgumentParser\n \n \n @dataclass\n@@ -32,34 +24,23 @@\n assert script_args.base_model_name is not None, \"please provide the output name of the merged model\"\n \n peft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)\n-model = AutoModelForCausalLM.from_pretrained(script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16)\n-tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)\n-config = AutoConfig.from_pretrained(script_args.base_model_name)\n-architecture = config.architectures[0]\n-if \"Llama\" in architecture:\n- print(\"Setting EOS, BOS, and UNK tokens for LLama tokenizer\")\n- tokenizer.add_special_tokens(\n- {\n- \"eos_token\": DEFAULT_EOS_TOKEN,\n- \"bos_token\": DEFAULT_BOS_TOKEN,\n- \"unk_token\": DEFAULT_UNK_TOKEN,\n- \"pad_token\": DEFAULT_PAD_TOKEN,\n- }\n+if peft_config.task_type == \"SEQ_CLS\":\n+ # peft is for reward model so load sequence classification\n+ model = AutoModelForSequenceClassification.from_pretrained(\n+ script_args.base_model_name, num_labels=1, torch_dtype=torch.bfloat16\n+ )\n+else:\n+ model = AutoModelForCausalLM.from_pretrained(\n+ script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16\n )\n \n+tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)\n+\n # Load the Lora model\n model = PeftModel.from_pretrained(model, script_args.adapter_model_name)\n model.eval()\n \n-key_list = [key for key, _ in model.base_model.model.named_modules() if \"lora\" not in key]\n-for key in key_list:\n- parent, target, target_name = _get_submodules(model.base_model.model, key)\n- if isinstance(target, peft.tuners.lora.Linear):\n- bias = target.bias is not None\n- new_module = torch.nn.Linear(target.in_features, target.out_features, bias=bias)\n- model.base_model._replace_module(parent, target_name, new_module, target)\n-\n-model = model.base_model.model\n+model = model.merge_and_unload()\n \n model.save_pretrained(f\"{script_args.output_name}\")\n tokenizer.save_pretrained(f\"{script_args.output_name}\")\n", "issue": "Llama Reward Model is incorrectly merged\nAs mentioned in #287, `merge_peft_adapter` saves the Llama RM as a `LlamaForCausalLM` see [here](https://github.com/lvwerra/trl/blob/main/examples/stack_llama/scripts/merge_peft_adapter.py#L35)\r\n\r\nBut the reward model is trained and should be a `LlamaForSequenceClassification` and running `rl_training.py` gives the obvious warnings\r\n```\r\nSome weights of the model checkpoint at ./llama-7b-se-rm were not used when initializing LlamaForSequenceClassification: ['lm_head.weight']\r\n- This IS expected if you are initializing LlamaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\r\n- This IS NOT expected if you are initializing LlamaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\r\nSome weights of LlamaForSequenceClassification were not initialized from the model checkpoint at /home/toolkit/huggingface/llama-7b-rm and are newly initialized: ['score.weight']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n```\r\n\r\nWe should instead check whether we are merging the rm and then save as a the correct model \r\n\r\nAlso the `score.weight` is not being loaded as mentioned in #297 , see more info below\r\n\r\n\r\n--- update --\r\n\r\nIt seems that `merge_peft_adapter` should be using `merge_and_unload()` which correctly overrides the score. But I haven't yet managed to get good results using the adapter weights on the hub\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional\n\nimport peft\nimport torch\nfrom peft import PeftConfig, PeftModel\nfrom peft.utils import _get_submodules\nfrom transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, HfArgumentParser\n\n\nDEFAULT_PAD_TOKEN = \"[PAD]\"\nDEFAULT_EOS_TOKEN = \"</s>\"\nDEFAULT_BOS_TOKEN = \"</s>\"\nDEFAULT_UNK_TOKEN = \"</s>\"\n\n\n@dataclass\nclass ScriptArguments:\n \"\"\"\n The name of the Casual LM model we wish to fine with PPO\n \"\"\"\n\n adapter_model_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n base_model_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n output_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n\n\nparser = HfArgumentParser(ScriptArguments)\nscript_args = parser.parse_args_into_dataclasses()[0]\nassert script_args.adapter_model_name is not None, \"please provide the name of the Adapter you would like to merge\"\nassert script_args.base_model_name is not None, \"please provide the name of the Base model\"\nassert script_args.base_model_name is not None, \"please provide the output name of the merged model\"\n\npeft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)\nmodel = AutoModelForCausalLM.from_pretrained(script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16)\ntokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)\nconfig = AutoConfig.from_pretrained(script_args.base_model_name)\narchitecture = config.architectures[0]\nif \"Llama\" in architecture:\n print(\"Setting EOS, BOS, and UNK tokens for LLama tokenizer\")\n tokenizer.add_special_tokens(\n {\n \"eos_token\": DEFAULT_EOS_TOKEN,\n \"bos_token\": DEFAULT_BOS_TOKEN,\n \"unk_token\": DEFAULT_UNK_TOKEN,\n \"pad_token\": DEFAULT_PAD_TOKEN,\n }\n )\n\n# Load the Lora model\nmodel = PeftModel.from_pretrained(model, script_args.adapter_model_name)\nmodel.eval()\n\nkey_list = [key for key, _ in model.base_model.model.named_modules() if \"lora\" not in key]\nfor key in key_list:\n parent, target, target_name = _get_submodules(model.base_model.model, key)\n if isinstance(target, peft.tuners.lora.Linear):\n bias = target.bias is not None\n new_module = torch.nn.Linear(target.in_features, target.out_features, bias=bias)\n model.base_model._replace_module(parent, target_name, new_module, target)\n\nmodel = model.base_model.model\n\nmodel.save_pretrained(f\"{script_args.output_name}\")\ntokenizer.save_pretrained(f\"{script_args.output_name}\")\nmodel.push_to_hub(f\"{script_args.output_name}\", use_temp_dir=False)\n", "path": "examples/stack_llama/scripts/merge_peft_adapter.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional\n\nimport torch\nfrom peft import PeftConfig, PeftModel\nfrom transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer, HfArgumentParser\n\n\n@dataclass\nclass ScriptArguments:\n \"\"\"\n The name of the Casual LM model we wish to fine with PPO\n \"\"\"\n\n adapter_model_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n base_model_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n output_name: Optional[str] = field(default=None, metadata={\"help\": \"the model name\"})\n\n\nparser = HfArgumentParser(ScriptArguments)\nscript_args = parser.parse_args_into_dataclasses()[0]\nassert script_args.adapter_model_name is not None, \"please provide the name of the Adapter you would like to merge\"\nassert script_args.base_model_name is not None, \"please provide the name of the Base model\"\nassert script_args.base_model_name is not None, \"please provide the output name of the merged model\"\n\npeft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)\nif peft_config.task_type == \"SEQ_CLS\":\n # peft is for reward model so load sequence classification\n model = AutoModelForSequenceClassification.from_pretrained(\n script_args.base_model_name, num_labels=1, torch_dtype=torch.bfloat16\n )\nelse:\n model = AutoModelForCausalLM.from_pretrained(\n script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16\n )\n\ntokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)\n\n# Load the Lora model\nmodel = PeftModel.from_pretrained(model, script_args.adapter_model_name)\nmodel.eval()\n\nmodel = model.merge_and_unload()\n\nmodel.save_pretrained(f\"{script_args.output_name}\")\ntokenizer.save_pretrained(f\"{script_args.output_name}\")\nmodel.push_to_hub(f\"{script_args.output_name}\", use_temp_dir=False)\n", "path": "examples/stack_llama/scripts/merge_peft_adapter.py"}]} | 1,391 | 704 |
gh_patches_debug_10391 | rasdani/github-patches | git_diff | streamlit__streamlit-5168 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Uncaught exception: TypeError: Protocols cannot be instantiated
### Summary
TypeError: Protocols cannot be instantiated in 1.12.0
After upgrading from 1.11.1 to 1.12.0, streamlit server keeps raising exceptions and clients get stuck at loading page 'please wait...'
### Steps to reproduce
server error snippet:
```
Traceback (most recent call last):
File "/home/xx/.local/lib/python3.9/site-packages/tornado/http1connection.py", line 276, in _read_message
delegate.finish()
File "/home/xx/.local/lib/python3.9/site-packages/tornado/routing.py", line 268, in finish
self.delegate.finish()
File "/home/xx/.local/lib/python3.9/site-packages/tornado/web.py", line 2322, in finish
self.execute()
File "/home/xx/.local/lib/python3.9/site-packages/tornado/web.py", line 2344, in execute
self.handler = self.handler_class(
File "/home/xx/.local/lib/python3.9/site-packages/tornado/websocket.py", line 224, in __init__
super().__init__(application, request, **kwargs)
File "/home/xx/.local/lib/python3.9/site-packages/tornado/web.py", line 215, in __init__
super().__init__()
File "/usr/local/python3/lib/python3.9/typing.py", line 1083, in _no_init
raise TypeError('Protocols cannot be instantiated')
TypeError: Protocols cannot be instantiated
```
**Actual behavior:**
Get stuck at loading page 'please wait...'
### Debug info
- Streamlit version: 1.12.0
- Python version: 3.9.7
- Using Conda? PipEnv? PyEnv? Pex? using venv
- OS version: Debian 10
- Browser version: Chrome 104 and Safari 15
### Additional information
Roll back to streamlit version 1.11.1, everything works fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/setup.py`
Content:
```
1 # Copyright 2018-2022 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import setuptools
17 import sys
18
19 from setuptools.command.install import install
20
21
22 VERSION = "1.12.0" # PEP-440
23
24 NAME = "streamlit"
25
26 DESCRIPTION = "The fastest way to build data apps in Python"
27
28 LONG_DESCRIPTION = (
29 "Streamlit's open-source app framework is the easiest way "
30 "for data scientists and machine learning engineers to "
31 "create beautiful, performant apps in only a few hours! "
32 "All in pure Python. All for free."
33 )
34
35 # IMPORTANT: We should try very hard *not* to add dependencies to Streamlit.
36 # And if you do add one, make the required version as general as possible.
37 # But include relevant lower bounds for any features we use from our dependencies.
38 INSTALL_REQUIRES = [
39 "altair>=3.2.0",
40 "blinker>=1.0.0",
41 "cachetools>=4.0",
42 "click>=7.0",
43 # 1.4 introduced the functionality found in python 3.8's importlib.metadata module
44 "importlib-metadata>=1.4",
45 "numpy",
46 "packaging>=14.1",
47 "pandas>=0.21.0",
48 "pillow>=6.2.0",
49 "protobuf<4,>=3.12",
50 "pyarrow>=4.0",
51 "pydeck>=0.1.dev5",
52 "pympler>=0.9",
53 "python-dateutil",
54 "requests>=2.4",
55 "rich>=10.11.0",
56 "semver",
57 "toml",
58 # 5.0 has a fix for etag header: https://github.com/tornadoweb/tornado/issues/2262
59 "tornado>=5.0",
60 "typing-extensions>=3.10.0.0",
61 "tzlocal>=1.1",
62 "validators>=0.2",
63 # Don't require watchdog on MacOS, since it'll fail without xcode tools.
64 # Without watchdog, we fallback to a polling file watcher to check for app changes.
65 "watchdog; platform_system != 'Darwin'",
66 ]
67
68 # We want to exclude some dependencies in our internal conda distribution of
69 # Streamlit.
70 CONDA_OPTIONAL_DEPENDENCIES = [
71 "gitpython!=3.1.19",
72 ]
73
74 # NOTE: ST_CONDA_BUILD is used here (even though CONDA_BUILD is set
75 # automatically when using the `conda build` command) because the
76 # `load_setup_py_data()` conda build helper function does not have the
77 # CONDA_BUILD environment variable set when it runs to generate our build
78 # recipe from meta.yaml.
79 if not os.getenv("ST_CONDA_BUILD"):
80 INSTALL_REQUIRES.extend(CONDA_OPTIONAL_DEPENDENCIES)
81
82
83 class VerifyVersionCommand(install):
84 """Custom command to verify that the git tag matches our version"""
85
86 description = "verify that the git tag matches our version"
87
88 def run(self):
89 tag = os.getenv("CIRCLE_TAG")
90
91 if tag != VERSION:
92 info = "Git tag: {0} does not match the version of this app: {1}".format(
93 tag, VERSION
94 )
95 sys.exit(info)
96
97
98 setuptools.setup(
99 name=NAME,
100 version=VERSION,
101 description=DESCRIPTION,
102 long_description=LONG_DESCRIPTION,
103 url="https://streamlit.io",
104 project_urls={
105 "Source": "https://github.com/streamlit/streamlit",
106 },
107 author="Streamlit Inc",
108 author_email="[email protected]",
109 python_requires=">=3.7",
110 license="Apache 2",
111 # PEP 561: https://mypy.readthedocs.io/en/stable/installed_packages.html
112 package_data={"streamlit": ["py.typed", "hello/**/*.py"]},
113 packages=setuptools.find_packages(exclude=["tests", "tests.*"]),
114 # Requirements
115 install_requires=INSTALL_REQUIRES,
116 zip_safe=False, # install source files not egg
117 include_package_data=True, # copy html and friends
118 entry_points={"console_scripts": ["streamlit = streamlit.web.cli:main"]},
119 # For Windows so that streamlit * commands work ie.
120 # - streamlit version
121 # - streamlit hello
122 scripts=["bin/streamlit.cmd"],
123 cmdclass={
124 "verify": VerifyVersionCommand,
125 },
126 )
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/setup.py b/lib/setup.py
--- a/lib/setup.py
+++ b/lib/setup.py
@@ -106,7 +106,10 @@
},
author="Streamlit Inc",
author_email="[email protected]",
- python_requires=">=3.7",
+ # We exclude Python 3.9.7 from our compatible versions due to a bug in that version
+ # with typing.Protocol. See https://github.com/streamlit/streamlit/issues/5140 and
+ # https://bugs.python.org/issue45121
+ python_requires=">=3.7, !=3.9.7",
license="Apache 2",
# PEP 561: https://mypy.readthedocs.io/en/stable/installed_packages.html
package_data={"streamlit": ["py.typed", "hello/**/*.py"]},
| {"golden_diff": "diff --git a/lib/setup.py b/lib/setup.py\n--- a/lib/setup.py\n+++ b/lib/setup.py\n@@ -106,7 +106,10 @@\n },\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n- python_requires=\">=3.7\",\n+ # We exclude Python 3.9.7 from our compatible versions due to a bug in that version\n+ # with typing.Protocol. See https://github.com/streamlit/streamlit/issues/5140 and\n+ # https://bugs.python.org/issue45121\n+ python_requires=\">=3.7, !=3.9.7\",\n license=\"Apache 2\",\n # PEP 561: https://mypy.readthedocs.io/en/stable/installed_packages.html\n package_data={\"streamlit\": [\"py.typed\", \"hello/**/*.py\"]},\n", "issue": "Uncaught exception: TypeError: Protocols cannot be instantiated\n### Summary\r\n\r\nTypeError: Protocols cannot be instantiated in 1.12.0\r\nAfter upgrading from 1.11.1 to 1.12.0, streamlit server keeps raising exceptions and clients get stuck at loading page 'please wait...'\r\n\r\n### Steps to reproduce\r\n\r\nserver error snippet:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/http1connection.py\", line 276, in _read_message\r\n delegate.finish()\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/routing.py\", line 268, in finish\r\n self.delegate.finish()\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/web.py\", line 2322, in finish\r\n self.execute()\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/web.py\", line 2344, in execute\r\n self.handler = self.handler_class(\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/websocket.py\", line 224, in __init__\r\n super().__init__(application, request, **kwargs)\r\n File \"/home/xx/.local/lib/python3.9/site-packages/tornado/web.py\", line 215, in __init__\r\n super().__init__()\r\n File \"/usr/local/python3/lib/python3.9/typing.py\", line 1083, in _no_init\r\n raise TypeError('Protocols cannot be instantiated')\r\nTypeError: Protocols cannot be instantiated\r\n```\r\n\r\n**Actual behavior:**\r\n\r\nGet stuck at loading page 'please wait...' \r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.12.0\r\n- Python version: 3.9.7\r\n- Using Conda? PipEnv? PyEnv? Pex? using venv\r\n- OS version: Debian 10 \r\n- Browser version: Chrome 104 and Safari 15\r\n\r\n### Additional information\r\n\r\nRoll back to streamlit version 1.11.1, everything works fine.\r\n\n", "before_files": [{"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport setuptools\nimport sys\n\nfrom setuptools.command.install import install\n\n\nVERSION = \"1.12.0\" # PEP-440\n\nNAME = \"streamlit\"\n\nDESCRIPTION = \"The fastest way to build data apps in Python\"\n\nLONG_DESCRIPTION = (\n \"Streamlit's open-source app framework is the easiest way \"\n \"for data scientists and machine learning engineers to \"\n \"create beautiful, performant apps in only a few hours! \"\n \"All in pure Python. All for free.\"\n)\n\n# IMPORTANT: We should try very hard *not* to add dependencies to Streamlit.\n# And if you do add one, make the required version as general as possible.\n# But include relevant lower bounds for any features we use from our dependencies.\nINSTALL_REQUIRES = [\n \"altair>=3.2.0\",\n \"blinker>=1.0.0\",\n \"cachetools>=4.0\",\n \"click>=7.0\",\n # 1.4 introduced the functionality found in python 3.8's importlib.metadata module\n \"importlib-metadata>=1.4\",\n \"numpy\",\n \"packaging>=14.1\",\n \"pandas>=0.21.0\",\n \"pillow>=6.2.0\",\n \"protobuf<4,>=3.12\",\n \"pyarrow>=4.0\",\n \"pydeck>=0.1.dev5\",\n \"pympler>=0.9\",\n \"python-dateutil\",\n \"requests>=2.4\",\n \"rich>=10.11.0\",\n \"semver\",\n \"toml\",\n # 5.0 has a fix for etag header: https://github.com/tornadoweb/tornado/issues/2262\n \"tornado>=5.0\",\n \"typing-extensions>=3.10.0.0\",\n \"tzlocal>=1.1\",\n \"validators>=0.2\",\n # Don't require watchdog on MacOS, since it'll fail without xcode tools.\n # Without watchdog, we fallback to a polling file watcher to check for app changes.\n \"watchdog; platform_system != 'Darwin'\",\n]\n\n# We want to exclude some dependencies in our internal conda distribution of\n# Streamlit.\nCONDA_OPTIONAL_DEPENDENCIES = [\n \"gitpython!=3.1.19\",\n]\n\n# NOTE: ST_CONDA_BUILD is used here (even though CONDA_BUILD is set\n# automatically when using the `conda build` command) because the\n# `load_setup_py_data()` conda build helper function does not have the\n# CONDA_BUILD environment variable set when it runs to generate our build\n# recipe from meta.yaml.\nif not os.getenv(\"ST_CONDA_BUILD\"):\n INSTALL_REQUIRES.extend(CONDA_OPTIONAL_DEPENDENCIES)\n\n\nclass VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n\n description = \"verify that the git tag matches our version\"\n\n def run(self):\n tag = os.getenv(\"CIRCLE_TAG\")\n\n if tag != VERSION:\n info = \"Git tag: {0} does not match the version of this app: {1}\".format(\n tag, VERSION\n )\n sys.exit(info)\n\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=\"https://streamlit.io\",\n project_urls={\n \"Source\": \"https://github.com/streamlit/streamlit\",\n },\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n python_requires=\">=3.7\",\n license=\"Apache 2\",\n # PEP 561: https://mypy.readthedocs.io/en/stable/installed_packages.html\n package_data={\"streamlit\": [\"py.typed\", \"hello/**/*.py\"]},\n packages=setuptools.find_packages(exclude=[\"tests\", \"tests.*\"]),\n # Requirements\n install_requires=INSTALL_REQUIRES,\n zip_safe=False, # install source files not egg\n include_package_data=True, # copy html and friends\n entry_points={\"console_scripts\": [\"streamlit = streamlit.web.cli:main\"]},\n # For Windows so that streamlit * commands work ie.\n # - streamlit version\n # - streamlit hello\n scripts=[\"bin/streamlit.cmd\"],\n cmdclass={\n \"verify\": VerifyVersionCommand,\n },\n)\n", "path": "lib/setup.py"}], "after_files": [{"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport setuptools\nimport sys\n\nfrom setuptools.command.install import install\n\n\nVERSION = \"1.12.0\" # PEP-440\n\nNAME = \"streamlit\"\n\nDESCRIPTION = \"The fastest way to build data apps in Python\"\n\nLONG_DESCRIPTION = (\n \"Streamlit's open-source app framework is the easiest way \"\n \"for data scientists and machine learning engineers to \"\n \"create beautiful, performant apps in only a few hours! \"\n \"All in pure Python. All for free.\"\n)\n\n# IMPORTANT: We should try very hard *not* to add dependencies to Streamlit.\n# And if you do add one, make the required version as general as possible.\n# But include relevant lower bounds for any features we use from our dependencies.\nINSTALL_REQUIRES = [\n \"altair>=3.2.0\",\n \"blinker>=1.0.0\",\n \"cachetools>=4.0\",\n \"click>=7.0\",\n # 1.4 introduced the functionality found in python 3.8's importlib.metadata module\n \"importlib-metadata>=1.4\",\n \"numpy\",\n \"packaging>=14.1\",\n \"pandas>=0.21.0\",\n \"pillow>=6.2.0\",\n \"protobuf<4,>=3.12\",\n \"pyarrow>=4.0\",\n \"pydeck>=0.1.dev5\",\n \"pympler>=0.9\",\n \"python-dateutil\",\n \"requests>=2.4\",\n \"rich>=10.11.0\",\n \"semver\",\n \"toml\",\n # 5.0 has a fix for etag header: https://github.com/tornadoweb/tornado/issues/2262\n \"tornado>=5.0\",\n \"typing-extensions>=3.10.0.0\",\n \"tzlocal>=1.1\",\n \"validators>=0.2\",\n # Don't require watchdog on MacOS, since it'll fail without xcode tools.\n # Without watchdog, we fallback to a polling file watcher to check for app changes.\n \"watchdog; platform_system != 'Darwin'\",\n]\n\n# We want to exclude some dependencies in our internal conda distribution of\n# Streamlit.\nCONDA_OPTIONAL_DEPENDENCIES = [\n \"gitpython!=3.1.19\",\n]\n\n# NOTE: ST_CONDA_BUILD is used here (even though CONDA_BUILD is set\n# automatically when using the `conda build` command) because the\n# `load_setup_py_data()` conda build helper function does not have the\n# CONDA_BUILD environment variable set when it runs to generate our build\n# recipe from meta.yaml.\nif not os.getenv(\"ST_CONDA_BUILD\"):\n INSTALL_REQUIRES.extend(CONDA_OPTIONAL_DEPENDENCIES)\n\n\nclass VerifyVersionCommand(install):\n \"\"\"Custom command to verify that the git tag matches our version\"\"\"\n\n description = \"verify that the git tag matches our version\"\n\n def run(self):\n tag = os.getenv(\"CIRCLE_TAG\")\n\n if tag != VERSION:\n info = \"Git tag: {0} does not match the version of this app: {1}\".format(\n tag, VERSION\n )\n sys.exit(info)\n\n\nsetuptools.setup(\n name=NAME,\n version=VERSION,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=\"https://streamlit.io\",\n project_urls={\n \"Source\": \"https://github.com/streamlit/streamlit\",\n },\n author=\"Streamlit Inc\",\n author_email=\"[email protected]\",\n # We exclude Python 3.9.7 from our compatible versions due to a bug in that version\n # with typing.Protocol. See https://github.com/streamlit/streamlit/issues/5140 and\n # https://bugs.python.org/issue45121\n python_requires=\">=3.7, !=3.9.7\",\n license=\"Apache 2\",\n # PEP 561: https://mypy.readthedocs.io/en/stable/installed_packages.html\n package_data={\"streamlit\": [\"py.typed\", \"hello/**/*.py\"]},\n packages=setuptools.find_packages(exclude=[\"tests\", \"tests.*\"]),\n # Requirements\n install_requires=INSTALL_REQUIRES,\n zip_safe=False, # install source files not egg\n include_package_data=True, # copy html and friends\n entry_points={\"console_scripts\": [\"streamlit = streamlit.web.cli:main\"]},\n # For Windows so that streamlit * commands work ie.\n # - streamlit version\n # - streamlit hello\n scripts=[\"bin/streamlit.cmd\"],\n cmdclass={\n \"verify\": VerifyVersionCommand,\n },\n)\n", "path": "lib/setup.py"}]} | 2,100 | 199 |
gh_patches_debug_6809 | rasdani/github-patches | git_diff | PyGithub__PyGithub-1641 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
KeyError while trying to fetch an unbounded PaginatedList's count
Accessing the `totalCount` attribute on a `PaginatedList` returned from the `get_repos` method throws a KeyError
Trace
```py
repos = github_client.get_repos()
repos.totalCount
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-42-68d28c2d7948> in <module>
----> 1 repos.totalCount
e:\software\python36\lib\site-packages\github\PaginatedList.py in totalCount(self)
164 links = self.__parseLinkHeader(headers)
165 lastUrl = links.get("last")
--> 166 self.__totalCount = int(parse_qs(lastUrl)["page"][0])
167 return self.__totalCount
168
KeyError: 'page'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `github/PaginatedList.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 ############################ Copyrights and license ############################
4 # #
5 # Copyright 2012 Vincent Jacques <[email protected]> #
6 # Copyright 2012 Zearin <[email protected]> #
7 # Copyright 2013 AKFish <[email protected]> #
8 # Copyright 2013 Bill Mill <[email protected]> #
9 # Copyright 2013 Vincent Jacques <[email protected]> #
10 # Copyright 2013 davidbrai <[email protected]> #
11 # Copyright 2014 Thialfihar <[email protected]> #
12 # Copyright 2014 Vincent Jacques <[email protected]> #
13 # Copyright 2015 Dan Vanderkam <[email protected]> #
14 # Copyright 2015 Eliot Walker <[email protected]> #
15 # Copyright 2016 Peter Buckley <[email protected]> #
16 # Copyright 2017 Jannis Gebauer <[email protected]> #
17 # Copyright 2018 Gilad Shefer <[email protected]> #
18 # Copyright 2018 Joel Koglin <[email protected]> #
19 # Copyright 2018 Wan Liuyang <[email protected]> #
20 # Copyright 2018 sfdye <[email protected]> #
21 # #
22 # This file is part of PyGithub. #
23 # http://pygithub.readthedocs.io/ #
24 # #
25 # PyGithub is free software: you can redistribute it and/or modify it under #
26 # the terms of the GNU Lesser General Public License as published by the Free #
27 # Software Foundation, either version 3 of the License, or (at your option) #
28 # any later version. #
29 # #
30 # PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #
31 # WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #
32 # FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #
33 # details. #
34 # #
35 # You should have received a copy of the GNU Lesser General Public License #
36 # along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #
37 # #
38 ################################################################################
39
40 from urllib.parse import parse_qs
41
42
43 class PaginatedListBase:
44 def __init__(self):
45 self.__elements = list()
46
47 def __getitem__(self, index):
48 assert isinstance(index, (int, slice))
49 if isinstance(index, int):
50 self.__fetchToIndex(index)
51 return self.__elements[index]
52 else:
53 return self._Slice(self, index)
54
55 def __iter__(self):
56 for element in self.__elements:
57 yield element
58 while self._couldGrow():
59 newElements = self._grow()
60 for element in newElements:
61 yield element
62
63 def _isBiggerThan(self, index):
64 return len(self.__elements) > index or self._couldGrow()
65
66 def __fetchToIndex(self, index):
67 while len(self.__elements) <= index and self._couldGrow():
68 self._grow()
69
70 def _grow(self):
71 newElements = self._fetchNextPage()
72 self.__elements += newElements
73 return newElements
74
75 class _Slice:
76 def __init__(self, theList, theSlice):
77 self.__list = theList
78 self.__start = theSlice.start or 0
79 self.__stop = theSlice.stop
80 self.__step = theSlice.step or 1
81
82 def __iter__(self):
83 index = self.__start
84 while not self.__finished(index):
85 if self.__list._isBiggerThan(index):
86 yield self.__list[index]
87 index += self.__step
88 else:
89 return
90
91 def __finished(self, index):
92 return self.__stop is not None and index >= self.__stop
93
94
95 class PaginatedList(PaginatedListBase):
96 """
97 This class abstracts the `pagination of the API <http://developer.github.com/v3/#pagination>`_.
98
99 You can simply enumerate through instances of this class::
100
101 for repo in user.get_repos():
102 print(repo.name)
103
104 If you want to know the total number of items in the list::
105
106 print(user.get_repos().totalCount)
107
108 You can also index them or take slices::
109
110 second_repo = user.get_repos()[1]
111 first_repos = user.get_repos()[:10]
112
113 If you want to iterate in reversed order, just do::
114
115 for repo in user.get_repos().reversed:
116 print(repo.name)
117
118 And if you really need it, you can explicitly access a specific page::
119
120 some_repos = user.get_repos().get_page(0)
121 some_other_repos = user.get_repos().get_page(3)
122 """
123
124 def __init__(
125 self,
126 contentClass,
127 requester,
128 firstUrl,
129 firstParams,
130 headers=None,
131 list_item="items",
132 ):
133 super().__init__()
134 self.__requester = requester
135 self.__contentClass = contentClass
136 self.__firstUrl = firstUrl
137 self.__firstParams = firstParams or ()
138 self.__nextUrl = firstUrl
139 self.__nextParams = firstParams or {}
140 self.__headers = headers
141 self.__list_item = list_item
142 if self.__requester.per_page != 30:
143 self.__nextParams["per_page"] = self.__requester.per_page
144 self._reversed = False
145 self.__totalCount = None
146
147 @property
148 def totalCount(self):
149 if not self.__totalCount:
150 params = {} if self.__nextParams is None else self.__nextParams.copy()
151 # set per_page = 1 so the totalCount is just the number of pages
152 params.update({"per_page": 1})
153 headers, data = self.__requester.requestJsonAndCheck(
154 "GET", self.__firstUrl, parameters=params, headers=self.__headers
155 )
156 if "link" not in headers:
157 if data and "total_count" in data:
158 self.__totalCount = data["total_count"]
159 elif data:
160 self.__totalCount = len(data)
161 else:
162 self.__totalCount = 0
163 else:
164 links = self.__parseLinkHeader(headers)
165 lastUrl = links.get("last")
166 self.__totalCount = int(parse_qs(lastUrl)["page"][0])
167 return self.__totalCount
168
169 def _getLastPageUrl(self):
170 headers, data = self.__requester.requestJsonAndCheck(
171 "GET", self.__firstUrl, parameters=self.__nextParams, headers=self.__headers
172 )
173 links = self.__parseLinkHeader(headers)
174 lastUrl = links.get("last")
175 return lastUrl
176
177 @property
178 def reversed(self):
179 r = PaginatedList(
180 self.__contentClass,
181 self.__requester,
182 self.__firstUrl,
183 self.__firstParams,
184 self.__headers,
185 self.__list_item,
186 )
187 r.__reverse()
188 return r
189
190 def __reverse(self):
191 self._reversed = True
192 lastUrl = self._getLastPageUrl()
193 if lastUrl:
194 self.__nextUrl = lastUrl
195
196 def _couldGrow(self):
197 return self.__nextUrl is not None
198
199 def _fetchNextPage(self):
200 headers, data = self.__requester.requestJsonAndCheck(
201 "GET", self.__nextUrl, parameters=self.__nextParams, headers=self.__headers
202 )
203 data = data if data else []
204
205 self.__nextUrl = None
206 if len(data) > 0:
207 links = self.__parseLinkHeader(headers)
208 if self._reversed:
209 if "prev" in links:
210 self.__nextUrl = links["prev"]
211 elif "next" in links:
212 self.__nextUrl = links["next"]
213 self.__nextParams = None
214
215 if self.__list_item in data:
216 self.__totalCount = data.get("total_count")
217 data = data[self.__list_item]
218
219 content = [
220 self.__contentClass(self.__requester, headers, element, completed=False)
221 for element in data
222 if element is not None
223 ]
224 if self._reversed:
225 return content[::-1]
226 return content
227
228 def __parseLinkHeader(self, headers):
229 links = {}
230 if "link" in headers:
231 linkHeaders = headers["link"].split(", ")
232 for linkHeader in linkHeaders:
233 url, rel, *rest = linkHeader.split("; ")
234 url = url[1:-1]
235 rel = rel[5:-1]
236 links[rel] = url
237 return links
238
239 def get_page(self, page):
240 params = dict(self.__firstParams)
241 if page != 0:
242 params["page"] = page + 1
243 if self.__requester.per_page != 30:
244 params["per_page"] = self.__requester.per_page
245 headers, data = self.__requester.requestJsonAndCheck(
246 "GET", self.__firstUrl, parameters=params, headers=self.__headers
247 )
248
249 if self.__list_item in data:
250 self.__totalCount = data.get("total_count")
251 data = data[self.__list_item]
252
253 return [
254 self.__contentClass(self.__requester, headers, element, completed=False)
255 for element in data
256 ]
257
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/github/PaginatedList.py b/github/PaginatedList.py
--- a/github/PaginatedList.py
+++ b/github/PaginatedList.py
@@ -163,7 +163,10 @@
else:
links = self.__parseLinkHeader(headers)
lastUrl = links.get("last")
- self.__totalCount = int(parse_qs(lastUrl)["page"][0])
+ if lastUrl:
+ self.__totalCount = int(parse_qs(lastUrl)["page"][0])
+ else:
+ self.__totalCount = 0
return self.__totalCount
def _getLastPageUrl(self):
| {"golden_diff": "diff --git a/github/PaginatedList.py b/github/PaginatedList.py\n--- a/github/PaginatedList.py\n+++ b/github/PaginatedList.py\n@@ -163,7 +163,10 @@\n else:\n links = self.__parseLinkHeader(headers)\n lastUrl = links.get(\"last\")\n- self.__totalCount = int(parse_qs(lastUrl)[\"page\"][0])\n+ if lastUrl:\n+ self.__totalCount = int(parse_qs(lastUrl)[\"page\"][0])\n+ else:\n+ self.__totalCount = 0\n return self.__totalCount\n \n def _getLastPageUrl(self):\n", "issue": "KeyError while trying to fetch an unbounded PaginatedList's count \nAccessing the `totalCount` attribute on a `PaginatedList` returned from the `get_repos` method throws a KeyError\r\n\r\nTrace\r\n```py\r\nrepos = github_client.get_repos()\r\n\r\nrepos.totalCount\r\n---------------------------------------------------------------------------\r\nKeyError Traceback (most recent call last)\r\n<ipython-input-42-68d28c2d7948> in <module>\r\n----> 1 repos.totalCount\r\n\r\ne:\\software\\python36\\lib\\site-packages\\github\\PaginatedList.py in totalCount(self)\r\n 164 links = self.__parseLinkHeader(headers)\r\n 165 lastUrl = links.get(\"last\")\r\n--> 166 self.__totalCount = int(parse_qs(lastUrl)[\"page\"][0])\r\n 167 return self.__totalCount\r\n 168 \r\n\r\nKeyError: 'page'\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2012 Vincent Jacques <[email protected]> #\n# Copyright 2012 Zearin <[email protected]> #\n# Copyright 2013 AKFish <[email protected]> #\n# Copyright 2013 Bill Mill <[email protected]> #\n# Copyright 2013 Vincent Jacques <[email protected]> #\n# Copyright 2013 davidbrai <[email protected]> #\n# Copyright 2014 Thialfihar <[email protected]> #\n# Copyright 2014 Vincent Jacques <[email protected]> #\n# Copyright 2015 Dan Vanderkam <[email protected]> #\n# Copyright 2015 Eliot Walker <[email protected]> #\n# Copyright 2016 Peter Buckley <[email protected]> #\n# Copyright 2017 Jannis Gebauer <[email protected]> #\n# Copyright 2018 Gilad Shefer <[email protected]> #\n# Copyright 2018 Joel Koglin <[email protected]> #\n# Copyright 2018 Wan Liuyang <[email protected]> #\n# Copyright 2018 sfdye <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nfrom urllib.parse import parse_qs\n\n\nclass PaginatedListBase:\n def __init__(self):\n self.__elements = list()\n\n def __getitem__(self, index):\n assert isinstance(index, (int, slice))\n if isinstance(index, int):\n self.__fetchToIndex(index)\n return self.__elements[index]\n else:\n return self._Slice(self, index)\n\n def __iter__(self):\n for element in self.__elements:\n yield element\n while self._couldGrow():\n newElements = self._grow()\n for element in newElements:\n yield element\n\n def _isBiggerThan(self, index):\n return len(self.__elements) > index or self._couldGrow()\n\n def __fetchToIndex(self, index):\n while len(self.__elements) <= index and self._couldGrow():\n self._grow()\n\n def _grow(self):\n newElements = self._fetchNextPage()\n self.__elements += newElements\n return newElements\n\n class _Slice:\n def __init__(self, theList, theSlice):\n self.__list = theList\n self.__start = theSlice.start or 0\n self.__stop = theSlice.stop\n self.__step = theSlice.step or 1\n\n def __iter__(self):\n index = self.__start\n while not self.__finished(index):\n if self.__list._isBiggerThan(index):\n yield self.__list[index]\n index += self.__step\n else:\n return\n\n def __finished(self, index):\n return self.__stop is not None and index >= self.__stop\n\n\nclass PaginatedList(PaginatedListBase):\n \"\"\"\n This class abstracts the `pagination of the API <http://developer.github.com/v3/#pagination>`_.\n\n You can simply enumerate through instances of this class::\n\n for repo in user.get_repos():\n print(repo.name)\n\n If you want to know the total number of items in the list::\n\n print(user.get_repos().totalCount)\n\n You can also index them or take slices::\n\n second_repo = user.get_repos()[1]\n first_repos = user.get_repos()[:10]\n\n If you want to iterate in reversed order, just do::\n\n for repo in user.get_repos().reversed:\n print(repo.name)\n\n And if you really need it, you can explicitly access a specific page::\n\n some_repos = user.get_repos().get_page(0)\n some_other_repos = user.get_repos().get_page(3)\n \"\"\"\n\n def __init__(\n self,\n contentClass,\n requester,\n firstUrl,\n firstParams,\n headers=None,\n list_item=\"items\",\n ):\n super().__init__()\n self.__requester = requester\n self.__contentClass = contentClass\n self.__firstUrl = firstUrl\n self.__firstParams = firstParams or ()\n self.__nextUrl = firstUrl\n self.__nextParams = firstParams or {}\n self.__headers = headers\n self.__list_item = list_item\n if self.__requester.per_page != 30:\n self.__nextParams[\"per_page\"] = self.__requester.per_page\n self._reversed = False\n self.__totalCount = None\n\n @property\n def totalCount(self):\n if not self.__totalCount:\n params = {} if self.__nextParams is None else self.__nextParams.copy()\n # set per_page = 1 so the totalCount is just the number of pages\n params.update({\"per_page\": 1})\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=params, headers=self.__headers\n )\n if \"link\" not in headers:\n if data and \"total_count\" in data:\n self.__totalCount = data[\"total_count\"]\n elif data:\n self.__totalCount = len(data)\n else:\n self.__totalCount = 0\n else:\n links = self.__parseLinkHeader(headers)\n lastUrl = links.get(\"last\")\n self.__totalCount = int(parse_qs(lastUrl)[\"page\"][0])\n return self.__totalCount\n\n def _getLastPageUrl(self):\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=self.__nextParams, headers=self.__headers\n )\n links = self.__parseLinkHeader(headers)\n lastUrl = links.get(\"last\")\n return lastUrl\n\n @property\n def reversed(self):\n r = PaginatedList(\n self.__contentClass,\n self.__requester,\n self.__firstUrl,\n self.__firstParams,\n self.__headers,\n self.__list_item,\n )\n r.__reverse()\n return r\n\n def __reverse(self):\n self._reversed = True\n lastUrl = self._getLastPageUrl()\n if lastUrl:\n self.__nextUrl = lastUrl\n\n def _couldGrow(self):\n return self.__nextUrl is not None\n\n def _fetchNextPage(self):\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__nextUrl, parameters=self.__nextParams, headers=self.__headers\n )\n data = data if data else []\n\n self.__nextUrl = None\n if len(data) > 0:\n links = self.__parseLinkHeader(headers)\n if self._reversed:\n if \"prev\" in links:\n self.__nextUrl = links[\"prev\"]\n elif \"next\" in links:\n self.__nextUrl = links[\"next\"]\n self.__nextParams = None\n\n if self.__list_item in data:\n self.__totalCount = data.get(\"total_count\")\n data = data[self.__list_item]\n\n content = [\n self.__contentClass(self.__requester, headers, element, completed=False)\n for element in data\n if element is not None\n ]\n if self._reversed:\n return content[::-1]\n return content\n\n def __parseLinkHeader(self, headers):\n links = {}\n if \"link\" in headers:\n linkHeaders = headers[\"link\"].split(\", \")\n for linkHeader in linkHeaders:\n url, rel, *rest = linkHeader.split(\"; \")\n url = url[1:-1]\n rel = rel[5:-1]\n links[rel] = url\n return links\n\n def get_page(self, page):\n params = dict(self.__firstParams)\n if page != 0:\n params[\"page\"] = page + 1\n if self.__requester.per_page != 30:\n params[\"per_page\"] = self.__requester.per_page\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=params, headers=self.__headers\n )\n\n if self.__list_item in data:\n self.__totalCount = data.get(\"total_count\")\n data = data[self.__list_item]\n\n return [\n self.__contentClass(self.__requester, headers, element, completed=False)\n for element in data\n ]\n", "path": "github/PaginatedList.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n############################ Copyrights and license ############################\n# #\n# Copyright 2012 Vincent Jacques <[email protected]> #\n# Copyright 2012 Zearin <[email protected]> #\n# Copyright 2013 AKFish <[email protected]> #\n# Copyright 2013 Bill Mill <[email protected]> #\n# Copyright 2013 Vincent Jacques <[email protected]> #\n# Copyright 2013 davidbrai <[email protected]> #\n# Copyright 2014 Thialfihar <[email protected]> #\n# Copyright 2014 Vincent Jacques <[email protected]> #\n# Copyright 2015 Dan Vanderkam <[email protected]> #\n# Copyright 2015 Eliot Walker <[email protected]> #\n# Copyright 2016 Peter Buckley <[email protected]> #\n# Copyright 2017 Jannis Gebauer <[email protected]> #\n# Copyright 2018 Gilad Shefer <[email protected]> #\n# Copyright 2018 Joel Koglin <[email protected]> #\n# Copyright 2018 Wan Liuyang <[email protected]> #\n# Copyright 2018 sfdye <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nfrom urllib.parse import parse_qs\n\n\nclass PaginatedListBase:\n def __init__(self):\n self.__elements = list()\n\n def __getitem__(self, index):\n assert isinstance(index, (int, slice))\n if isinstance(index, int):\n self.__fetchToIndex(index)\n return self.__elements[index]\n else:\n return self._Slice(self, index)\n\n def __iter__(self):\n for element in self.__elements:\n yield element\n while self._couldGrow():\n newElements = self._grow()\n for element in newElements:\n yield element\n\n def _isBiggerThan(self, index):\n return len(self.__elements) > index or self._couldGrow()\n\n def __fetchToIndex(self, index):\n while len(self.__elements) <= index and self._couldGrow():\n self._grow()\n\n def _grow(self):\n newElements = self._fetchNextPage()\n self.__elements += newElements\n return newElements\n\n class _Slice:\n def __init__(self, theList, theSlice):\n self.__list = theList\n self.__start = theSlice.start or 0\n self.__stop = theSlice.stop\n self.__step = theSlice.step or 1\n\n def __iter__(self):\n index = self.__start\n while not self.__finished(index):\n if self.__list._isBiggerThan(index):\n yield self.__list[index]\n index += self.__step\n else:\n return\n\n def __finished(self, index):\n return self.__stop is not None and index >= self.__stop\n\n\nclass PaginatedList(PaginatedListBase):\n \"\"\"\n This class abstracts the `pagination of the API <http://developer.github.com/v3/#pagination>`_.\n\n You can simply enumerate through instances of this class::\n\n for repo in user.get_repos():\n print(repo.name)\n\n If you want to know the total number of items in the list::\n\n print(user.get_repos().totalCount)\n\n You can also index them or take slices::\n\n second_repo = user.get_repos()[1]\n first_repos = user.get_repos()[:10]\n\n If you want to iterate in reversed order, just do::\n\n for repo in user.get_repos().reversed:\n print(repo.name)\n\n And if you really need it, you can explicitly access a specific page::\n\n some_repos = user.get_repos().get_page(0)\n some_other_repos = user.get_repos().get_page(3)\n \"\"\"\n\n def __init__(\n self,\n contentClass,\n requester,\n firstUrl,\n firstParams,\n headers=None,\n list_item=\"items\",\n ):\n super().__init__()\n self.__requester = requester\n self.__contentClass = contentClass\n self.__firstUrl = firstUrl\n self.__firstParams = firstParams or ()\n self.__nextUrl = firstUrl\n self.__nextParams = firstParams or {}\n self.__headers = headers\n self.__list_item = list_item\n if self.__requester.per_page != 30:\n self.__nextParams[\"per_page\"] = self.__requester.per_page\n self._reversed = False\n self.__totalCount = None\n\n @property\n def totalCount(self):\n if not self.__totalCount:\n params = {} if self.__nextParams is None else self.__nextParams.copy()\n # set per_page = 1 so the totalCount is just the number of pages\n params.update({\"per_page\": 1})\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=params, headers=self.__headers\n )\n if \"link\" not in headers:\n if data and \"total_count\" in data:\n self.__totalCount = data[\"total_count\"]\n elif data:\n self.__totalCount = len(data)\n else:\n self.__totalCount = 0\n else:\n links = self.__parseLinkHeader(headers)\n lastUrl = links.get(\"last\")\n if lastUrl:\n self.__totalCount = int(parse_qs(lastUrl)[\"page\"][0])\n else:\n self.__totalCount = 0\n return self.__totalCount\n\n def _getLastPageUrl(self):\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=self.__nextParams, headers=self.__headers\n )\n links = self.__parseLinkHeader(headers)\n lastUrl = links.get(\"last\")\n return lastUrl\n\n @property\n def reversed(self):\n r = PaginatedList(\n self.__contentClass,\n self.__requester,\n self.__firstUrl,\n self.__firstParams,\n self.__headers,\n self.__list_item,\n )\n r.__reverse()\n return r\n\n def __reverse(self):\n self._reversed = True\n lastUrl = self._getLastPageUrl()\n if lastUrl:\n self.__nextUrl = lastUrl\n\n def _couldGrow(self):\n return self.__nextUrl is not None\n\n def _fetchNextPage(self):\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__nextUrl, parameters=self.__nextParams, headers=self.__headers\n )\n data = data if data else []\n\n self.__nextUrl = None\n if len(data) > 0:\n links = self.__parseLinkHeader(headers)\n if self._reversed:\n if \"prev\" in links:\n self.__nextUrl = links[\"prev\"]\n elif \"next\" in links:\n self.__nextUrl = links[\"next\"]\n self.__nextParams = None\n\n if self.__list_item in data:\n self.__totalCount = data.get(\"total_count\")\n data = data[self.__list_item]\n\n content = [\n self.__contentClass(self.__requester, headers, element, completed=False)\n for element in data\n if element is not None\n ]\n if self._reversed:\n return content[::-1]\n return content\n\n def __parseLinkHeader(self, headers):\n links = {}\n if \"link\" in headers:\n linkHeaders = headers[\"link\"].split(\", \")\n for linkHeader in linkHeaders:\n url, rel, *rest = linkHeader.split(\"; \")\n url = url[1:-1]\n rel = rel[5:-1]\n links[rel] = url\n return links\n\n def get_page(self, page):\n params = dict(self.__firstParams)\n if page != 0:\n params[\"page\"] = page + 1\n if self.__requester.per_page != 30:\n params[\"per_page\"] = self.__requester.per_page\n headers, data = self.__requester.requestJsonAndCheck(\n \"GET\", self.__firstUrl, parameters=params, headers=self.__headers\n )\n\n if self.__list_item in data:\n self.__totalCount = data.get(\"total_count\")\n data = data[self.__list_item]\n\n return [\n self.__contentClass(self.__requester, headers, element, completed=False)\n for element in data\n ]\n", "path": "github/PaginatedList.py"}]} | 3,234 | 138 |
gh_patches_debug_4453 | rasdani/github-patches | git_diff | translate__pootle-4350 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Editor templates broken in non-debug mode
Since switching to Django 1.8 in master, the [scripts section of the editor templates](https://github.com/translate/pootle/blob/master/pootle/templates/editor/_scripts.html) doesn't render when `DEBUG = False`.
I might be doing something wrong, but I tried removing any template customizations we have, also clearing out caches, trying different browsers, always with the same result. I can reproduce this locally and in our staging server.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_store/templatetags/store_tags.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright (C) Pootle contributors.
5 #
6 # This file is a part of the Pootle project. It is distributed under the GPL3
7 # or later license. See the LICENSE file for a copy of the license and the
8 # AUTHORS file for copyright and authorship information.
9
10 import re
11
12 from diff_match_patch import diff_match_patch
13 from translate.misc.multistring import multistring
14 from translate.storage.placeables import general
15
16 from django import template
17 from django.core.exceptions import ObjectDoesNotExist
18 from django.template.defaultfilters import stringfilter
19 from django.template.loader import get_template
20 from django.utils.safestring import mark_safe
21 from django.utils.translation import ugettext as _
22
23 from pootle_store.fields import list_empty
24
25
26 register = template.Library()
27
28
29 IMAGE_URL_RE = re.compile("(https?://[^\s]+\.(png|jpe?g|gif))", re.IGNORECASE)
30
31
32 @register.filter
33 def image_urls(text):
34 """Return a list of image URLs extracted from `text`."""
35 return map(lambda x: x[0], IMAGE_URL_RE.findall(text))
36
37
38 ESCAPE_RE = re.compile('<[^<]*?>|\\\\|\r\n|[\r\n\t&<>]')
39
40
41 def fancy_escape(text):
42 """Replace special chars with entities, and highlight XML tags and
43 whitespaces.
44 """
45 def replace(match):
46 escape_highlight = ('<span class="highlight-escape '
47 'js-editor-copytext">%s</span>')
48 submap = {
49 '\r\n': (escape_highlight % '\\r\\n') + '<br/>\n',
50 '\r': (escape_highlight % '\\r') + '<br/>\n',
51 '\n': (escape_highlight % '\\n') + '<br/>\n',
52 '\t': (escape_highlight % '\\t'),
53 '&': '&',
54 '<': '<',
55 '>': '>',
56 '\\': (escape_highlight % '\\\\'),
57 }
58 try:
59 return submap[match.group()]
60 except KeyError:
61 html_highlight = ('<span class="highlight-html '
62 'js-editor-copytext"><%s></span>')
63 return html_highlight % fancy_escape(match.group()[1:-1])
64
65 return ESCAPE_RE.sub(replace, text)
66
67
68 WHITESPACE_RE = re.compile('^ +| +$|[\r\n\t] +| {2,}')
69
70
71 def fancy_spaces(text):
72 """Highlight spaces to make them easily visible."""
73 def replace(match):
74 fancy_space = '<span class="translation-space"> </span>'
75 if match.group().startswith(' '):
76 return fancy_space * len(match.group())
77 return match.group()[0] + fancy_space * (len(match.group()) - 1)
78 return WHITESPACE_RE.sub(replace, text)
79
80
81 PUNCTUATION_RE = general.PunctuationPlaceable().regex
82
83
84 def fancy_punctuation_chars(text):
85 """Wrap punctuation chars found in the ``text`` around tags."""
86 def replace(match):
87 fancy_special_char = ('<span class="highlight-punctuation '
88 'js-editor-copytext">%s</span>')
89 return fancy_special_char % match.group()
90
91 return PUNCTUATION_RE.sub(replace, text)
92
93
94 @register.filter
95 @stringfilter
96 def fancy_highlight(text):
97 return mark_safe(fancy_punctuation_chars(fancy_spaces(fancy_escape(text))))
98
99
100 def call_highlight(old, new):
101 """Calls diff highlighting code only if the target is set.
102 Otherwise, highlight as a normal unit.
103 """
104 if isinstance(old, multistring):
105 old_value = old.strings
106 else:
107 old_value = old
108
109 if list_empty(old_value):
110 return fancy_highlight(new)
111
112 return highlight_diffs(old, new)
113
114
115 differencer = diff_match_patch()
116
117
118 def highlight_diffs(old, new):
119 """Highlight the differences between old and new."""
120
121 textdiff = u"" # to store the final result
122 removed = u"" # the removed text that we might still want to add
123 diff = differencer.diff_main(old, new)
124 differencer.diff_cleanupSemantic(diff)
125 for op, text in diff:
126 if op == 0: # equality
127 if removed:
128 textdiff += '<span class="diff-delete">%s</span>' % \
129 fancy_escape(removed)
130 removed = u""
131 textdiff += fancy_escape(text)
132 elif op == 1: # insertion
133 if removed:
134 # this is part of a substitution, not a plain insertion. We
135 # will format this differently.
136 textdiff += '<span class="diff-replace">%s</span>' % \
137 fancy_escape(text)
138 removed = u""
139 else:
140 textdiff += '<span class="diff-insert">%s</span>' % \
141 fancy_escape(text)
142 elif op == -1: # deletion
143 removed = text
144 if removed:
145 textdiff += '<span class="diff-delete">%s</span>' % \
146 fancy_escape(removed)
147 return mark_safe(textdiff)
148
149
150 @register.filter('pluralize_source')
151 def pluralize_source(unit):
152 if not unit.hasplural():
153 return [(0, unit.source, None)]
154
155 count = len(unit.source.strings)
156 if count == 1:
157 return [(0, unit.source.strings[0], "%s+%s" % (_('Singular'),
158 _('Plural')))]
159
160 if count == 2:
161 return [(0, unit.source.strings[0], _('Singular')),
162 (1, unit.source.strings[1], _('Plural'))]
163
164 forms = []
165 for i, source in enumerate(unit.source.strings):
166 forms.append((i, source, _('Plural Form %d', i)))
167 return forms
168
169
170 @register.filter('pluralize_target')
171 def pluralize_target(unit, nplurals=None):
172 if not unit.hasplural():
173 return [(0, unit.target, None)]
174
175 if nplurals is None:
176 try:
177 nplurals = unit.store.translation_project.language.nplurals
178 except ObjectDoesNotExist:
179 pass
180 forms = []
181 if nplurals is None:
182 for i, target in enumerate(unit.target.strings):
183 forms.append((i, target, _('Plural Form %d', i)))
184 else:
185 for i in range(nplurals):
186 try:
187 target = unit.target.strings[i]
188 except IndexError:
189 target = ''
190 forms.append((i, target, _('Plural Form %d', i)))
191
192 return forms
193
194
195 @register.filter('pluralize_diff_sugg')
196 def pluralize_diff_sugg(sugg):
197 unit = sugg.unit
198 if not unit.hasplural():
199 return [
200 (0, sugg.target, call_highlight(unit.target, sugg.target), None)
201 ]
202
203 forms = []
204 for i, target in enumerate(sugg.target.strings):
205 if i < len(unit.target.strings):
206 sugg_text = unit.target.strings[i]
207 else:
208 sugg_text = ''
209
210 forms.append((
211 i, target, call_highlight(sugg_text, target),
212 _('Plural Form %d', i)
213 ))
214
215 return forms
216
217
218 @register.tag(name="include_raw")
219 def do_include_raw(parser, token):
220 """
221 Performs a template include without parsing the context, just dumps
222 the template in.
223 Source: http://djangosnippets.org/snippets/1684/
224 """
225 bits = token.split_contents()
226 if len(bits) != 2:
227 raise template.TemplateSyntaxError(
228 "%r tag takes one argument: the name of the template "
229 "to be included" % bits[0]
230 )
231
232 template_name = bits[1]
233 if (template_name[0] in ('"', "'") and
234 template_name[-1] == template_name[0]):
235 template_name = template_name[1:-1]
236
237 source, path = get_template(
238 template_name).origin.loader(template_name)
239
240 return template.base.TextNode(source)
241
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pootle/apps/pootle_store/templatetags/store_tags.py b/pootle/apps/pootle_store/templatetags/store_tags.py
--- a/pootle/apps/pootle_store/templatetags/store_tags.py
+++ b/pootle/apps/pootle_store/templatetags/store_tags.py
@@ -234,7 +234,8 @@
template_name[-1] == template_name[0]):
template_name = template_name[1:-1]
- source, path = get_template(
- template_name).origin.loader(template_name)
-
- return template.base.TextNode(source)
+ return template.base.TextNode(
+ u"\n".join(
+ [x.s
+ for x
+ in get_template(template_name).template.nodelist]))
| {"golden_diff": "diff --git a/pootle/apps/pootle_store/templatetags/store_tags.py b/pootle/apps/pootle_store/templatetags/store_tags.py\n--- a/pootle/apps/pootle_store/templatetags/store_tags.py\n+++ b/pootle/apps/pootle_store/templatetags/store_tags.py\n@@ -234,7 +234,8 @@\n template_name[-1] == template_name[0]):\n template_name = template_name[1:-1]\n \n- source, path = get_template(\n- template_name).origin.loader(template_name)\n-\n- return template.base.TextNode(source)\n+ return template.base.TextNode(\n+ u\"\\n\".join(\n+ [x.s\n+ for x\n+ in get_template(template_name).template.nodelist]))\n", "issue": "Editor templates broken in non-debug mode\nSince switching to Django 1.8 in master, the [scripts section of the editor templates](https://github.com/translate/pootle/blob/master/pootle/templates/editor/_scripts.html) doesn't render when `DEBUG = False`.\n\nI might be doing something wrong, but I tried removing any template customizations we have, also clearing out caches, trying different browsers, always with the same result. I can reproduce this locally and in our staging server.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport re\n\nfrom diff_match_patch import diff_match_patch\nfrom translate.misc.multistring import multistring\nfrom translate.storage.placeables import general\n\nfrom django import template\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.template.defaultfilters import stringfilter\nfrom django.template.loader import get_template\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext as _\n\nfrom pootle_store.fields import list_empty\n\n\nregister = template.Library()\n\n\nIMAGE_URL_RE = re.compile(\"(https?://[^\\s]+\\.(png|jpe?g|gif))\", re.IGNORECASE)\n\n\[email protected]\ndef image_urls(text):\n \"\"\"Return a list of image URLs extracted from `text`.\"\"\"\n return map(lambda x: x[0], IMAGE_URL_RE.findall(text))\n\n\nESCAPE_RE = re.compile('<[^<]*?>|\\\\\\\\|\\r\\n|[\\r\\n\\t&<>]')\n\n\ndef fancy_escape(text):\n \"\"\"Replace special chars with entities, and highlight XML tags and\n whitespaces.\n \"\"\"\n def replace(match):\n escape_highlight = ('<span class=\"highlight-escape '\n 'js-editor-copytext\">%s</span>')\n submap = {\n '\\r\\n': (escape_highlight % '\\\\r\\\\n') + '<br/>\\n',\n '\\r': (escape_highlight % '\\\\r') + '<br/>\\n',\n '\\n': (escape_highlight % '\\\\n') + '<br/>\\n',\n '\\t': (escape_highlight % '\\\\t'),\n '&': '&',\n '<': '<',\n '>': '>',\n '\\\\': (escape_highlight % '\\\\\\\\'),\n }\n try:\n return submap[match.group()]\n except KeyError:\n html_highlight = ('<span class=\"highlight-html '\n 'js-editor-copytext\"><%s></span>')\n return html_highlight % fancy_escape(match.group()[1:-1])\n\n return ESCAPE_RE.sub(replace, text)\n\n\nWHITESPACE_RE = re.compile('^ +| +$|[\\r\\n\\t] +| {2,}')\n\n\ndef fancy_spaces(text):\n \"\"\"Highlight spaces to make them easily visible.\"\"\"\n def replace(match):\n fancy_space = '<span class=\"translation-space\"> </span>'\n if match.group().startswith(' '):\n return fancy_space * len(match.group())\n return match.group()[0] + fancy_space * (len(match.group()) - 1)\n return WHITESPACE_RE.sub(replace, text)\n\n\nPUNCTUATION_RE = general.PunctuationPlaceable().regex\n\n\ndef fancy_punctuation_chars(text):\n \"\"\"Wrap punctuation chars found in the ``text`` around tags.\"\"\"\n def replace(match):\n fancy_special_char = ('<span class=\"highlight-punctuation '\n 'js-editor-copytext\">%s</span>')\n return fancy_special_char % match.group()\n\n return PUNCTUATION_RE.sub(replace, text)\n\n\[email protected]\n@stringfilter\ndef fancy_highlight(text):\n return mark_safe(fancy_punctuation_chars(fancy_spaces(fancy_escape(text))))\n\n\ndef call_highlight(old, new):\n \"\"\"Calls diff highlighting code only if the target is set.\n Otherwise, highlight as a normal unit.\n \"\"\"\n if isinstance(old, multistring):\n old_value = old.strings\n else:\n old_value = old\n\n if list_empty(old_value):\n return fancy_highlight(new)\n\n return highlight_diffs(old, new)\n\n\ndifferencer = diff_match_patch()\n\n\ndef highlight_diffs(old, new):\n \"\"\"Highlight the differences between old and new.\"\"\"\n\n textdiff = u\"\" # to store the final result\n removed = u\"\" # the removed text that we might still want to add\n diff = differencer.diff_main(old, new)\n differencer.diff_cleanupSemantic(diff)\n for op, text in diff:\n if op == 0: # equality\n if removed:\n textdiff += '<span class=\"diff-delete\">%s</span>' % \\\n fancy_escape(removed)\n removed = u\"\"\n textdiff += fancy_escape(text)\n elif op == 1: # insertion\n if removed:\n # this is part of a substitution, not a plain insertion. We\n # will format this differently.\n textdiff += '<span class=\"diff-replace\">%s</span>' % \\\n fancy_escape(text)\n removed = u\"\"\n else:\n textdiff += '<span class=\"diff-insert\">%s</span>' % \\\n fancy_escape(text)\n elif op == -1: # deletion\n removed = text\n if removed:\n textdiff += '<span class=\"diff-delete\">%s</span>' % \\\n fancy_escape(removed)\n return mark_safe(textdiff)\n\n\[email protected]('pluralize_source')\ndef pluralize_source(unit):\n if not unit.hasplural():\n return [(0, unit.source, None)]\n\n count = len(unit.source.strings)\n if count == 1:\n return [(0, unit.source.strings[0], \"%s+%s\" % (_('Singular'),\n _('Plural')))]\n\n if count == 2:\n return [(0, unit.source.strings[0], _('Singular')),\n (1, unit.source.strings[1], _('Plural'))]\n\n forms = []\n for i, source in enumerate(unit.source.strings):\n forms.append((i, source, _('Plural Form %d', i)))\n return forms\n\n\[email protected]('pluralize_target')\ndef pluralize_target(unit, nplurals=None):\n if not unit.hasplural():\n return [(0, unit.target, None)]\n\n if nplurals is None:\n try:\n nplurals = unit.store.translation_project.language.nplurals\n except ObjectDoesNotExist:\n pass\n forms = []\n if nplurals is None:\n for i, target in enumerate(unit.target.strings):\n forms.append((i, target, _('Plural Form %d', i)))\n else:\n for i in range(nplurals):\n try:\n target = unit.target.strings[i]\n except IndexError:\n target = ''\n forms.append((i, target, _('Plural Form %d', i)))\n\n return forms\n\n\[email protected]('pluralize_diff_sugg')\ndef pluralize_diff_sugg(sugg):\n unit = sugg.unit\n if not unit.hasplural():\n return [\n (0, sugg.target, call_highlight(unit.target, sugg.target), None)\n ]\n\n forms = []\n for i, target in enumerate(sugg.target.strings):\n if i < len(unit.target.strings):\n sugg_text = unit.target.strings[i]\n else:\n sugg_text = ''\n\n forms.append((\n i, target, call_highlight(sugg_text, target),\n _('Plural Form %d', i)\n ))\n\n return forms\n\n\[email protected](name=\"include_raw\")\ndef do_include_raw(parser, token):\n \"\"\"\n Performs a template include without parsing the context, just dumps\n the template in.\n Source: http://djangosnippets.org/snippets/1684/\n \"\"\"\n bits = token.split_contents()\n if len(bits) != 2:\n raise template.TemplateSyntaxError(\n \"%r tag takes one argument: the name of the template \"\n \"to be included\" % bits[0]\n )\n\n template_name = bits[1]\n if (template_name[0] in ('\"', \"'\") and\n template_name[-1] == template_name[0]):\n template_name = template_name[1:-1]\n\n source, path = get_template(\n template_name).origin.loader(template_name)\n\n return template.base.TextNode(source)\n", "path": "pootle/apps/pootle_store/templatetags/store_tags.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport re\n\nfrom diff_match_patch import diff_match_patch\nfrom translate.misc.multistring import multistring\nfrom translate.storage.placeables import general\n\nfrom django import template\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.template.defaultfilters import stringfilter\nfrom django.template.loader import get_template\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext as _\n\nfrom pootle_store.fields import list_empty\n\n\nregister = template.Library()\n\n\nIMAGE_URL_RE = re.compile(\"(https?://[^\\s]+\\.(png|jpe?g|gif))\", re.IGNORECASE)\n\n\[email protected]\ndef image_urls(text):\n \"\"\"Return a list of image URLs extracted from `text`.\"\"\"\n return map(lambda x: x[0], IMAGE_URL_RE.findall(text))\n\n\nESCAPE_RE = re.compile('<[^<]*?>|\\\\\\\\|\\r\\n|[\\r\\n\\t&<>]')\n\n\ndef fancy_escape(text):\n \"\"\"Replace special chars with entities, and highlight XML tags and\n whitespaces.\n \"\"\"\n def replace(match):\n escape_highlight = ('<span class=\"highlight-escape '\n 'js-editor-copytext\">%s</span>')\n submap = {\n '\\r\\n': (escape_highlight % '\\\\r\\\\n') + '<br/>\\n',\n '\\r': (escape_highlight % '\\\\r') + '<br/>\\n',\n '\\n': (escape_highlight % '\\\\n') + '<br/>\\n',\n '\\t': (escape_highlight % '\\\\t'),\n '&': '&',\n '<': '<',\n '>': '>',\n '\\\\': (escape_highlight % '\\\\\\\\'),\n }\n try:\n return submap[match.group()]\n except KeyError:\n html_highlight = ('<span class=\"highlight-html '\n 'js-editor-copytext\"><%s></span>')\n return html_highlight % fancy_escape(match.group()[1:-1])\n\n return ESCAPE_RE.sub(replace, text)\n\n\nWHITESPACE_RE = re.compile('^ +| +$|[\\r\\n\\t] +| {2,}')\n\n\ndef fancy_spaces(text):\n \"\"\"Highlight spaces to make them easily visible.\"\"\"\n def replace(match):\n fancy_space = '<span class=\"translation-space\"> </span>'\n if match.group().startswith(' '):\n return fancy_space * len(match.group())\n return match.group()[0] + fancy_space * (len(match.group()) - 1)\n return WHITESPACE_RE.sub(replace, text)\n\n\nPUNCTUATION_RE = general.PunctuationPlaceable().regex\n\n\ndef fancy_punctuation_chars(text):\n \"\"\"Wrap punctuation chars found in the ``text`` around tags.\"\"\"\n def replace(match):\n fancy_special_char = ('<span class=\"highlight-punctuation '\n 'js-editor-copytext\">%s</span>')\n return fancy_special_char % match.group()\n\n return PUNCTUATION_RE.sub(replace, text)\n\n\[email protected]\n@stringfilter\ndef fancy_highlight(text):\n return mark_safe(fancy_punctuation_chars(fancy_spaces(fancy_escape(text))))\n\n\ndef call_highlight(old, new):\n \"\"\"Calls diff highlighting code only if the target is set.\n Otherwise, highlight as a normal unit.\n \"\"\"\n if isinstance(old, multistring):\n old_value = old.strings\n else:\n old_value = old\n\n if list_empty(old_value):\n return fancy_highlight(new)\n\n return highlight_diffs(old, new)\n\n\ndifferencer = diff_match_patch()\n\n\ndef highlight_diffs(old, new):\n \"\"\"Highlight the differences between old and new.\"\"\"\n\n textdiff = u\"\" # to store the final result\n removed = u\"\" # the removed text that we might still want to add\n diff = differencer.diff_main(old, new)\n differencer.diff_cleanupSemantic(diff)\n for op, text in diff:\n if op == 0: # equality\n if removed:\n textdiff += '<span class=\"diff-delete\">%s</span>' % \\\n fancy_escape(removed)\n removed = u\"\"\n textdiff += fancy_escape(text)\n elif op == 1: # insertion\n if removed:\n # this is part of a substitution, not a plain insertion. We\n # will format this differently.\n textdiff += '<span class=\"diff-replace\">%s</span>' % \\\n fancy_escape(text)\n removed = u\"\"\n else:\n textdiff += '<span class=\"diff-insert\">%s</span>' % \\\n fancy_escape(text)\n elif op == -1: # deletion\n removed = text\n if removed:\n textdiff += '<span class=\"diff-delete\">%s</span>' % \\\n fancy_escape(removed)\n return mark_safe(textdiff)\n\n\[email protected]('pluralize_source')\ndef pluralize_source(unit):\n if not unit.hasplural():\n return [(0, unit.source, None)]\n\n count = len(unit.source.strings)\n if count == 1:\n return [(0, unit.source.strings[0], \"%s+%s\" % (_('Singular'),\n _('Plural')))]\n\n if count == 2:\n return [(0, unit.source.strings[0], _('Singular')),\n (1, unit.source.strings[1], _('Plural'))]\n\n forms = []\n for i, source in enumerate(unit.source.strings):\n forms.append((i, source, _('Plural Form %d', i)))\n return forms\n\n\[email protected]('pluralize_target')\ndef pluralize_target(unit, nplurals=None):\n if not unit.hasplural():\n return [(0, unit.target, None)]\n\n if nplurals is None:\n try:\n nplurals = unit.store.translation_project.language.nplurals\n except ObjectDoesNotExist:\n pass\n forms = []\n if nplurals is None:\n for i, target in enumerate(unit.target.strings):\n forms.append((i, target, _('Plural Form %d', i)))\n else:\n for i in range(nplurals):\n try:\n target = unit.target.strings[i]\n except IndexError:\n target = ''\n forms.append((i, target, _('Plural Form %d', i)))\n\n return forms\n\n\[email protected]('pluralize_diff_sugg')\ndef pluralize_diff_sugg(sugg):\n unit = sugg.unit\n if not unit.hasplural():\n return [\n (0, sugg.target, call_highlight(unit.target, sugg.target), None)\n ]\n\n forms = []\n for i, target in enumerate(sugg.target.strings):\n if i < len(unit.target.strings):\n sugg_text = unit.target.strings[i]\n else:\n sugg_text = ''\n\n forms.append((\n i, target, call_highlight(sugg_text, target),\n _('Plural Form %d', i)\n ))\n\n return forms\n\n\[email protected](name=\"include_raw\")\ndef do_include_raw(parser, token):\n \"\"\"\n Performs a template include without parsing the context, just dumps\n the template in.\n Source: http://djangosnippets.org/snippets/1684/\n \"\"\"\n bits = token.split_contents()\n if len(bits) != 2:\n raise template.TemplateSyntaxError(\n \"%r tag takes one argument: the name of the template \"\n \"to be included\" % bits[0]\n )\n\n template_name = bits[1]\n if (template_name[0] in ('\"', \"'\") and\n template_name[-1] == template_name[0]):\n template_name = template_name[1:-1]\n\n return template.base.TextNode(\n u\"\\n\".join(\n [x.s\n for x\n in get_template(template_name).template.nodelist]))\n", "path": "pootle/apps/pootle_store/templatetags/store_tags.py"}]} | 2,727 | 182 |
gh_patches_debug_21408 | rasdani/github-patches | git_diff | aws-cloudformation__cfn-lint-1063 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
String misinterpreted as an int results in error on E2015
```
cfn-lint --version
cfn-lint 0.19.1
```
*Description of issue.*
The following template
```
Parameters:
CentralAccountId:
Default: 112233445566
MaxLength: 12
MinLength: 12
Type: String
```
result in the error:
```
E0002 Unknown exception while processing rule E2015: object of type 'int' has no len()
application-account-initial-setup.yaml:1:1
```
It is solved by putting quotes on the default value. However it is valid to not putting the quotes.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/parameters/Default.py`
Content:
```
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 import six
19 from cfnlint import CloudFormationLintRule
20 from cfnlint import RuleMatch
21
22
23 class Default(CloudFormationLintRule):
24 """Check if Parameters are configured correctly"""
25 id = 'E2015'
26 shortdesc = 'Default value is within parameter constraints'
27 description = 'Making sure the parameters have a default value inside AllowedValues, MinValue, MaxValue, AllowedPattern'
28 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html'
29 tags = ['parameters']
30
31 def check_allowed_pattern(self, allowed_value, allowed_pattern, path):
32 """
33 Check allowed value against allowed pattern
34 """
35 message = 'Default should be allowed by AllowedPattern'
36 try:
37 if not re.match(allowed_pattern, str(allowed_value)):
38 return([RuleMatch(path, message)])
39 except re.error as ex:
40 self.logger.debug('Regex pattern "%s" isn\'t supported by Python: %s', allowed_pattern, ex)
41
42 return []
43
44 def check_min_value(self, allowed_value, min_value, path):
45 """
46 Check allowed value against min value
47 """
48 message = 'Default should be equal to or higher than MinValue'
49
50 if isinstance(allowed_value, six.integer_types) and isinstance(min_value, six.integer_types):
51 if allowed_value < min_value:
52 return([RuleMatch(path, message)])
53
54 return []
55
56 def check_max_value(self, allowed_value, max_value, path):
57 """
58 Check allowed value against max value
59 """
60 message = 'Default should be less than or equal to MaxValue'
61
62 if isinstance(allowed_value, six.integer_types) and isinstance(max_value, six.integer_types):
63 if allowed_value > max_value:
64 return([RuleMatch(path, message)])
65
66 return []
67
68 def check_allowed_values(self, allowed_value, allowed_values, path):
69 """
70 Check allowed value against allowed values
71 """
72 message = 'Default should be a value within AllowedValues'
73
74 if allowed_value not in allowed_values:
75 return([RuleMatch(path, message)])
76
77 return []
78
79 def check_min_length(self, allowed_value, min_length, path):
80 """
81 Check allowed value against MinLength
82 """
83 message = 'Default should have a length above or equal to MinLength'
84
85 if isinstance(min_length, six.integer_types):
86 if len(allowed_value) < min_length:
87 return([RuleMatch(path, message)])
88
89 return []
90
91 def check_max_length(self, allowed_value, max_length, path):
92 """
93 Check allowed value against MaxLength
94 """
95 message = 'Default should have a length below or equal to MaxLength'
96
97 if isinstance(max_length, six.integer_types):
98 if len(allowed_value) > max_length:
99 return([RuleMatch(path, message)])
100
101 return []
102
103 def match(self, cfn):
104 """Check CloudFormation Parameters"""
105
106 matches = []
107
108 for paramname, paramvalue in cfn.get_parameters().items():
109 default_value = paramvalue.get('Default')
110 if default_value is not None:
111 path = ['Parameters', paramname, 'Default']
112 allowed_pattern = paramvalue.get('AllowedPattern')
113 if allowed_pattern:
114 matches.extend(
115 self.check_allowed_pattern(
116 default_value, allowed_pattern, path
117 )
118 )
119 min_value = paramvalue.get('MinValue')
120 if min_value:
121 matches.extend(
122 self.check_min_value(
123 default_value, min_value, path
124 )
125 )
126 max_value = paramvalue.get('MaxValue')
127 if max_value is not None:
128 matches.extend(
129 self.check_max_value(
130 default_value, max_value, path
131 )
132 )
133 allowed_values = paramvalue.get('AllowedValues')
134 if allowed_values:
135 matches.extend(
136 self.check_allowed_values(
137 default_value, allowed_values, path
138 )
139 )
140 min_length = paramvalue.get('MinLength')
141 if min_length is not None:
142 matches.extend(
143 self.check_min_length(
144 default_value, min_length, path
145 )
146 )
147 max_length = paramvalue.get('MaxLength')
148 if max_length is not None:
149 matches.extend(
150 self.check_max_length(
151 default_value, max_length, path
152 )
153 )
154
155 return matches
156
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/cfnlint/rules/parameters/Default.py b/src/cfnlint/rules/parameters/Default.py
--- a/src/cfnlint/rules/parameters/Default.py
+++ b/src/cfnlint/rules/parameters/Default.py
@@ -82,8 +82,9 @@
"""
message = 'Default should have a length above or equal to MinLength'
+ value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)
if isinstance(min_length, six.integer_types):
- if len(allowed_value) < min_length:
+ if len(value) < min_length:
return([RuleMatch(path, message)])
return []
@@ -94,8 +95,9 @@
"""
message = 'Default should have a length below or equal to MaxLength'
+ value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)
if isinstance(max_length, six.integer_types):
- if len(allowed_value) > max_length:
+ if len(value) > max_length:
return([RuleMatch(path, message)])
return []
| {"golden_diff": "diff --git a/src/cfnlint/rules/parameters/Default.py b/src/cfnlint/rules/parameters/Default.py\n--- a/src/cfnlint/rules/parameters/Default.py\n+++ b/src/cfnlint/rules/parameters/Default.py\n@@ -82,8 +82,9 @@\n \"\"\"\n message = 'Default should have a length above or equal to MinLength'\n \n+ value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)\n if isinstance(min_length, six.integer_types):\n- if len(allowed_value) < min_length:\n+ if len(value) < min_length:\n return([RuleMatch(path, message)])\n \n return []\n@@ -94,8 +95,9 @@\n \"\"\"\n message = 'Default should have a length below or equal to MaxLength'\n \n+ value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)\n if isinstance(max_length, six.integer_types):\n- if len(allowed_value) > max_length:\n+ if len(value) > max_length:\n return([RuleMatch(path, message)])\n \n return []\n", "issue": "String misinterpreted as an int results in error on E2015\n```\r\ncfn-lint --version\r\ncfn-lint 0.19.1\r\n```\r\n\r\n*Description of issue.*\r\nThe following template\r\n```\r\nParameters:\r\n CentralAccountId:\r\n Default: 112233445566\r\n MaxLength: 12\r\n MinLength: 12\r\n Type: String\r\n```\r\nresult in the error:\r\n```\r\nE0002 Unknown exception while processing rule E2015: object of type 'int' has no len()\r\napplication-account-initial-setup.yaml:1:1\r\n```\r\n\r\nIt is solved by putting quotes on the default value. However it is valid to not putting the quotes.\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Default(CloudFormationLintRule):\n \"\"\"Check if Parameters are configured correctly\"\"\"\n id = 'E2015'\n shortdesc = 'Default value is within parameter constraints'\n description = 'Making sure the parameters have a default value inside AllowedValues, MinValue, MaxValue, AllowedPattern'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html'\n tags = ['parameters']\n\n def check_allowed_pattern(self, allowed_value, allowed_pattern, path):\n \"\"\"\n Check allowed value against allowed pattern\n \"\"\"\n message = 'Default should be allowed by AllowedPattern'\n try:\n if not re.match(allowed_pattern, str(allowed_value)):\n return([RuleMatch(path, message)])\n except re.error as ex:\n self.logger.debug('Regex pattern \"%s\" isn\\'t supported by Python: %s', allowed_pattern, ex)\n\n return []\n\n def check_min_value(self, allowed_value, min_value, path):\n \"\"\"\n Check allowed value against min value\n \"\"\"\n message = 'Default should be equal to or higher than MinValue'\n\n if isinstance(allowed_value, six.integer_types) and isinstance(min_value, six.integer_types):\n if allowed_value < min_value:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_max_value(self, allowed_value, max_value, path):\n \"\"\"\n Check allowed value against max value\n \"\"\"\n message = 'Default should be less than or equal to MaxValue'\n\n if isinstance(allowed_value, six.integer_types) and isinstance(max_value, six.integer_types):\n if allowed_value > max_value:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_allowed_values(self, allowed_value, allowed_values, path):\n \"\"\"\n Check allowed value against allowed values\n \"\"\"\n message = 'Default should be a value within AllowedValues'\n\n if allowed_value not in allowed_values:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_min_length(self, allowed_value, min_length, path):\n \"\"\"\n Check allowed value against MinLength\n \"\"\"\n message = 'Default should have a length above or equal to MinLength'\n\n if isinstance(min_length, six.integer_types):\n if len(allowed_value) < min_length:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_max_length(self, allowed_value, max_length, path):\n \"\"\"\n Check allowed value against MaxLength\n \"\"\"\n message = 'Default should have a length below or equal to MaxLength'\n\n if isinstance(max_length, six.integer_types):\n if len(allowed_value) > max_length:\n return([RuleMatch(path, message)])\n\n return []\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Parameters\"\"\"\n\n matches = []\n\n for paramname, paramvalue in cfn.get_parameters().items():\n default_value = paramvalue.get('Default')\n if default_value is not None:\n path = ['Parameters', paramname, 'Default']\n allowed_pattern = paramvalue.get('AllowedPattern')\n if allowed_pattern:\n matches.extend(\n self.check_allowed_pattern(\n default_value, allowed_pattern, path\n )\n )\n min_value = paramvalue.get('MinValue')\n if min_value:\n matches.extend(\n self.check_min_value(\n default_value, min_value, path\n )\n )\n max_value = paramvalue.get('MaxValue')\n if max_value is not None:\n matches.extend(\n self.check_max_value(\n default_value, max_value, path\n )\n )\n allowed_values = paramvalue.get('AllowedValues')\n if allowed_values:\n matches.extend(\n self.check_allowed_values(\n default_value, allowed_values, path\n )\n )\n min_length = paramvalue.get('MinLength')\n if min_length is not None:\n matches.extend(\n self.check_min_length(\n default_value, min_length, path\n )\n )\n max_length = paramvalue.get('MaxLength')\n if max_length is not None:\n matches.extend(\n self.check_max_length(\n default_value, max_length, path\n )\n )\n\n return matches\n", "path": "src/cfnlint/rules/parameters/Default.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Default(CloudFormationLintRule):\n \"\"\"Check if Parameters are configured correctly\"\"\"\n id = 'E2015'\n shortdesc = 'Default value is within parameter constraints'\n description = 'Making sure the parameters have a default value inside AllowedValues, MinValue, MaxValue, AllowedPattern'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html'\n tags = ['parameters']\n\n def check_allowed_pattern(self, allowed_value, allowed_pattern, path):\n \"\"\"\n Check allowed value against allowed pattern\n \"\"\"\n message = 'Default should be allowed by AllowedPattern'\n try:\n if not re.match(allowed_pattern, str(allowed_value)):\n return([RuleMatch(path, message)])\n except re.error as ex:\n self.logger.debug('Regex pattern \"%s\" isn\\'t supported by Python: %s', allowed_pattern, ex)\n\n return []\n\n def check_min_value(self, allowed_value, min_value, path):\n \"\"\"\n Check allowed value against min value\n \"\"\"\n message = 'Default should be equal to or higher than MinValue'\n\n if isinstance(allowed_value, six.integer_types) and isinstance(min_value, six.integer_types):\n if allowed_value < min_value:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_max_value(self, allowed_value, max_value, path):\n \"\"\"\n Check allowed value against max value\n \"\"\"\n message = 'Default should be less than or equal to MaxValue'\n\n if isinstance(allowed_value, six.integer_types) and isinstance(max_value, six.integer_types):\n if allowed_value > max_value:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_allowed_values(self, allowed_value, allowed_values, path):\n \"\"\"\n Check allowed value against allowed values\n \"\"\"\n message = 'Default should be a value within AllowedValues'\n\n if allowed_value not in allowed_values:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_min_length(self, allowed_value, min_length, path):\n \"\"\"\n Check allowed value against MinLength\n \"\"\"\n message = 'Default should have a length above or equal to MinLength'\n\n value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)\n if isinstance(min_length, six.integer_types):\n if len(value) < min_length:\n return([RuleMatch(path, message)])\n\n return []\n\n def check_max_length(self, allowed_value, max_length, path):\n \"\"\"\n Check allowed value against MaxLength\n \"\"\"\n message = 'Default should have a length below or equal to MaxLength'\n\n value = allowed_value if isinstance(allowed_value, six.string_types) else str(allowed_value)\n if isinstance(max_length, six.integer_types):\n if len(value) > max_length:\n return([RuleMatch(path, message)])\n\n return []\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Parameters\"\"\"\n\n matches = []\n\n for paramname, paramvalue in cfn.get_parameters().items():\n default_value = paramvalue.get('Default')\n if default_value is not None:\n path = ['Parameters', paramname, 'Default']\n allowed_pattern = paramvalue.get('AllowedPattern')\n if allowed_pattern:\n matches.extend(\n self.check_allowed_pattern(\n default_value, allowed_pattern, path\n )\n )\n min_value = paramvalue.get('MinValue')\n if min_value:\n matches.extend(\n self.check_min_value(\n default_value, min_value, path\n )\n )\n max_value = paramvalue.get('MaxValue')\n if max_value is not None:\n matches.extend(\n self.check_max_value(\n default_value, max_value, path\n )\n )\n allowed_values = paramvalue.get('AllowedValues')\n if allowed_values:\n matches.extend(\n self.check_allowed_values(\n default_value, allowed_values, path\n )\n )\n min_length = paramvalue.get('MinLength')\n if min_length is not None:\n matches.extend(\n self.check_min_length(\n default_value, min_length, path\n )\n )\n max_length = paramvalue.get('MaxLength')\n if max_length is not None:\n matches.extend(\n self.check_max_length(\n default_value, max_length, path\n )\n )\n\n return matches\n", "path": "src/cfnlint/rules/parameters/Default.py"}]} | 1,923 | 248 |
gh_patches_debug_29460 | rasdani/github-patches | git_diff | aimhubio__aim-2671 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Extend `aim.ext.tensorboard_tracker.run.Run` to also allow system stats, parameters, and stdout capture.
## 🚀 Feature
Allow capturing of system parameters and terminal logs by the `aim.ext.tensorboard_tracker.run.Run`, as this is great feature shouldn't be only available to the default `Run`.
### Motivation
The new feature of allowing continuous syncing from `tensorboard` files to `aim` is really nice, but because `aim.ext.tensorboard_tracker.run.Run` inherits from `BasicRun` rather than `Run`, it misses out on the ability to log the standard out, system stats and system parameters. Since `aim.ext.tensorboard_tracker.run.Run` should be a possible replacement for `Run`, I don't see a reason why this behaviour shouldn't be allowed.
It has been highlighted in Discord by @mihran113:
> The reason behind inheriting from basic run is exactly to avoid terminal log tracking and system param tracking actually, cause we don’t want to add anything else rather than what’s tracked via tensorboard. Cause there can be times when live tracking is done from a different process, and catching that process’s terminal logs and system params won’t make any sense I guess. If you’re interested you can open a PR to address those points, cause adding the possibility to enable those won’t make any harm as well.
so I believe the *default* arguments should *not* do this extra logging, but still optionally allow this behaviour.
### Pitch
Have `aim.ext.tensorboard_tracker.run.Run` inherit from `aim.sdk.run.Run` instead of `aim.sdk.run.BasicRun`, so that it can utilise it's extra capabilities.
### Alternatives
Instead of inheritance we could change the system resource tracking be a mixin?
Extend `aim.ext.tensorboard_tracker.run.Run` to also allow system stats, parameters, and stdout capture.
## 🚀 Feature
Allow capturing of system parameters and terminal logs by the `aim.ext.tensorboard_tracker.run.Run`, as this is great feature shouldn't be only available to the default `Run`.
### Motivation
The new feature of allowing continuous syncing from `tensorboard` files to `aim` is really nice, but because `aim.ext.tensorboard_tracker.run.Run` inherits from `BasicRun` rather than `Run`, it misses out on the ability to log the standard out, system stats and system parameters. Since `aim.ext.tensorboard_tracker.run.Run` should be a possible replacement for `Run`, I don't see a reason why this behaviour shouldn't be allowed.
It has been highlighted in Discord by @mihran113:
> The reason behind inheriting from basic run is exactly to avoid terminal log tracking and system param tracking actually, cause we don’t want to add anything else rather than what’s tracked via tensorboard. Cause there can be times when live tracking is done from a different process, and catching that process’s terminal logs and system params won’t make any sense I guess. If you’re interested you can open a PR to address those points, cause adding the possibility to enable those won’t make any harm as well.
so I believe the *default* arguments should *not* do this extra logging, but still optionally allow this behaviour.
### Pitch
Have `aim.ext.tensorboard_tracker.run.Run` inherit from `aim.sdk.run.Run` instead of `aim.sdk.run.BasicRun`, so that it can utilise it's extra capabilities.
### Alternatives
Instead of inheritance we could change the system resource tracking be a mixin?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aim/ext/tensorboard_tracker/run.py`
Content:
```
1 from typing import Optional, Union
2
3 from aim.sdk.run import BasicRun
4 from aim.ext.tensorboard_tracker.tracker import TensorboardTracker
5
6 from typing import TYPE_CHECKING
7
8 if TYPE_CHECKING:
9 from aim.sdk.repo import Repo
10
11
12 class Run(BasicRun):
13 def __init__(self, run_hash: Optional[str] = None, *,
14 sync_tensorboard_log_dir: str,
15 repo: Optional[Union[str, 'Repo']] = None,
16 experiment: Optional[str] = None,
17 force_resume: Optional[bool] = False,
18 ):
19 super().__init__(run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume)
20 self['tb_log_directory'] = sync_tensorboard_log_dir
21 self._tensorboard_tracker = TensorboardTracker(self._tracker, sync_tensorboard_log_dir)
22 self._tensorboard_tracker.start()
23 self._resources.add_extra_resource(self._tensorboard_tracker)
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/aim/ext/tensorboard_tracker/run.py b/aim/ext/tensorboard_tracker/run.py
--- a/aim/ext/tensorboard_tracker/run.py
+++ b/aim/ext/tensorboard_tracker/run.py
@@ -1,6 +1,6 @@
from typing import Optional, Union
-from aim.sdk.run import BasicRun
+from aim.sdk.run import Run as SdkRun
from aim.ext.tensorboard_tracker.tracker import TensorboardTracker
from typing import TYPE_CHECKING
@@ -9,14 +9,23 @@
from aim.sdk.repo import Repo
-class Run(BasicRun):
- def __init__(self, run_hash: Optional[str] = None, *,
- sync_tensorboard_log_dir: str,
- repo: Optional[Union[str, 'Repo']] = None,
- experiment: Optional[str] = None,
- force_resume: Optional[bool] = False,
- ):
- super().__init__(run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume)
+class Run(SdkRun):
+ def __init__(
+ self, run_hash: Optional[str] = None, *,
+ sync_tensorboard_log_dir: str,
+ repo: Optional[Union[str, 'Repo']] = None,
+ experiment: Optional[str] = None,
+ force_resume: Optional[bool] = False,
+ system_tracking_interval: Optional[Union[int, float]] = None,
+ log_system_params: Optional[bool] = False,
+ capture_terminal_logs: Optional[bool] = False,
+ ):
+ super().__init__(
+ run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume,
+ system_tracking_interval=system_tracking_interval, log_system_params=log_system_params,
+ capture_terminal_logs=capture_terminal_logs
+ )
+
self['tb_log_directory'] = sync_tensorboard_log_dir
self._tensorboard_tracker = TensorboardTracker(self._tracker, sync_tensorboard_log_dir)
self._tensorboard_tracker.start()
| {"golden_diff": "diff --git a/aim/ext/tensorboard_tracker/run.py b/aim/ext/tensorboard_tracker/run.py\n--- a/aim/ext/tensorboard_tracker/run.py\n+++ b/aim/ext/tensorboard_tracker/run.py\n@@ -1,6 +1,6 @@\n from typing import Optional, Union\n \n-from aim.sdk.run import BasicRun\n+from aim.sdk.run import Run as SdkRun\n from aim.ext.tensorboard_tracker.tracker import TensorboardTracker\n \n from typing import TYPE_CHECKING\n@@ -9,14 +9,23 @@\n from aim.sdk.repo import Repo\n \n \n-class Run(BasicRun):\n- def __init__(self, run_hash: Optional[str] = None, *,\n- sync_tensorboard_log_dir: str,\n- repo: Optional[Union[str, 'Repo']] = None,\n- experiment: Optional[str] = None,\n- force_resume: Optional[bool] = False,\n- ):\n- super().__init__(run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume)\n+class Run(SdkRun):\n+ def __init__(\n+ self, run_hash: Optional[str] = None, *,\n+ sync_tensorboard_log_dir: str,\n+ repo: Optional[Union[str, 'Repo']] = None,\n+ experiment: Optional[str] = None,\n+ force_resume: Optional[bool] = False,\n+ system_tracking_interval: Optional[Union[int, float]] = None,\n+ log_system_params: Optional[bool] = False,\n+ capture_terminal_logs: Optional[bool] = False,\n+ ):\n+ super().__init__(\n+ run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume,\n+ system_tracking_interval=system_tracking_interval, log_system_params=log_system_params,\n+ capture_terminal_logs=capture_terminal_logs\n+ )\n+\n self['tb_log_directory'] = sync_tensorboard_log_dir\n self._tensorboard_tracker = TensorboardTracker(self._tracker, sync_tensorboard_log_dir)\n self._tensorboard_tracker.start()\n", "issue": "Extend `aim.ext.tensorboard_tracker.run.Run` to also allow system stats, parameters, and stdout capture.\n## \ud83d\ude80 Feature\r\n\r\nAllow capturing of system parameters and terminal logs by the `aim.ext.tensorboard_tracker.run.Run`, as this is great feature shouldn't be only available to the default `Run`.\r\n\r\n### Motivation\r\n\r\nThe new feature of allowing continuous syncing from `tensorboard` files to `aim` is really nice, but because `aim.ext.tensorboard_tracker.run.Run` inherits from `BasicRun` rather than `Run`, it misses out on the ability to log the standard out, system stats and system parameters. Since `aim.ext.tensorboard_tracker.run.Run` should be a possible replacement for `Run`, I don't see a reason why this behaviour shouldn't be allowed.\r\n\r\nIt has been highlighted in Discord by @mihran113:\r\n\r\n> The reason behind inheriting from basic run is exactly to avoid terminal log tracking and system param tracking actually, cause we don\u2019t want to add anything else rather than what\u2019s tracked via tensorboard. Cause there can be times when live tracking is done from a different process, and catching that process\u2019s terminal logs and system params won\u2019t make any sense I guess. If you\u2019re interested you can open a PR to address those points, cause adding the possibility to enable those won\u2019t make any harm as well.\r\n\r\nso I believe the *default* arguments should *not* do this extra logging, but still optionally allow this behaviour. \r\n\r\n### Pitch\r\n\r\nHave `aim.ext.tensorboard_tracker.run.Run` inherit from `aim.sdk.run.Run` instead of `aim.sdk.run.BasicRun`, so that it can utilise it's extra capabilities.\r\n\r\n### Alternatives\r\n\r\nInstead of inheritance we could change the system resource tracking be a mixin? \r\n\nExtend `aim.ext.tensorboard_tracker.run.Run` to also allow system stats, parameters, and stdout capture.\n## \ud83d\ude80 Feature\r\n\r\nAllow capturing of system parameters and terminal logs by the `aim.ext.tensorboard_tracker.run.Run`, as this is great feature shouldn't be only available to the default `Run`.\r\n\r\n### Motivation\r\n\r\nThe new feature of allowing continuous syncing from `tensorboard` files to `aim` is really nice, but because `aim.ext.tensorboard_tracker.run.Run` inherits from `BasicRun` rather than `Run`, it misses out on the ability to log the standard out, system stats and system parameters. Since `aim.ext.tensorboard_tracker.run.Run` should be a possible replacement for `Run`, I don't see a reason why this behaviour shouldn't be allowed.\r\n\r\nIt has been highlighted in Discord by @mihran113:\r\n\r\n> The reason behind inheriting from basic run is exactly to avoid terminal log tracking and system param tracking actually, cause we don\u2019t want to add anything else rather than what\u2019s tracked via tensorboard. Cause there can be times when live tracking is done from a different process, and catching that process\u2019s terminal logs and system params won\u2019t make any sense I guess. If you\u2019re interested you can open a PR to address those points, cause adding the possibility to enable those won\u2019t make any harm as well.\r\n\r\nso I believe the *default* arguments should *not* do this extra logging, but still optionally allow this behaviour. \r\n\r\n### Pitch\r\n\r\nHave `aim.ext.tensorboard_tracker.run.Run` inherit from `aim.sdk.run.Run` instead of `aim.sdk.run.BasicRun`, so that it can utilise it's extra capabilities.\r\n\r\n### Alternatives\r\n\r\nInstead of inheritance we could change the system resource tracking be a mixin? \r\n\n", "before_files": [{"content": "from typing import Optional, Union\n\nfrom aim.sdk.run import BasicRun\nfrom aim.ext.tensorboard_tracker.tracker import TensorboardTracker\n\nfrom typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from aim.sdk.repo import Repo\n\n\nclass Run(BasicRun):\n def __init__(self, run_hash: Optional[str] = None, *,\n sync_tensorboard_log_dir: str,\n repo: Optional[Union[str, 'Repo']] = None,\n experiment: Optional[str] = None,\n force_resume: Optional[bool] = False,\n ):\n super().__init__(run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume)\n self['tb_log_directory'] = sync_tensorboard_log_dir\n self._tensorboard_tracker = TensorboardTracker(self._tracker, sync_tensorboard_log_dir)\n self._tensorboard_tracker.start()\n self._resources.add_extra_resource(self._tensorboard_tracker)\n", "path": "aim/ext/tensorboard_tracker/run.py"}], "after_files": [{"content": "from typing import Optional, Union\n\nfrom aim.sdk.run import Run as SdkRun\nfrom aim.ext.tensorboard_tracker.tracker import TensorboardTracker\n\nfrom typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from aim.sdk.repo import Repo\n\n\nclass Run(SdkRun):\n def __init__(\n self, run_hash: Optional[str] = None, *,\n sync_tensorboard_log_dir: str,\n repo: Optional[Union[str, 'Repo']] = None,\n experiment: Optional[str] = None,\n force_resume: Optional[bool] = False,\n system_tracking_interval: Optional[Union[int, float]] = None,\n log_system_params: Optional[bool] = False,\n capture_terminal_logs: Optional[bool] = False,\n ):\n super().__init__(\n run_hash, repo=repo, read_only=False, experiment=experiment, force_resume=force_resume,\n system_tracking_interval=system_tracking_interval, log_system_params=log_system_params,\n capture_terminal_logs=capture_terminal_logs\n )\n\n self['tb_log_directory'] = sync_tensorboard_log_dir\n self._tensorboard_tracker = TensorboardTracker(self._tracker, sync_tensorboard_log_dir)\n self._tensorboard_tracker.start()\n self._resources.add_extra_resource(self._tensorboard_tracker)\n", "path": "aim/ext/tensorboard_tracker/run.py"}]} | 1,232 | 448 |
gh_patches_debug_4710 | rasdani/github-patches | git_diff | nerfstudio-project__nerfstudio-1180 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Feature extraction/matching doesn't work when using all the frames from a video with COLMAP and ns-process-data
**Describe the bug**
COLMAP isn't able to run feature extraction and subsequent bundle adjustment when I use all the frames from a video. Everything works fine when I use the default ~300 input frames. Have anynone experienced the same?
For every image it tries to extract features from it exits with `ERROR: Failed to read image file format.`, although the file format is PNG. I see that the resulting files are 2-3 times larger (totalling ~11Mb) than what the ones extracted with the thumbnail-option is. Is there possibly an issue with convert_video_to_images and the ffmpeg_cmd?
**To Reproduce**
Steps to reproduce the behavior:
1. Run `ns-process-data video` with an input-video and `--num-frames-target` equal (or approx. equal) to the video's number of frames. And `--verbose`
2. This results in `spacing` in `process_data_utils.py` to be 1
3. Observe that all phases before Feature extraction works as expected
4. Observe that for each line of "Processed file" during feature extraction, an error `ERROR: Failed to read image file format.` is logged.
5. Observe that `/colmap/sparse/0` isn't generated which causes the Bundle adjustment step to fail.
**Expected behavior**
Feature extraction should generate features and match them, resulting in a `/colmap/sparse/0`-dir that bundle adjustment can operate on.
**Screenshots**
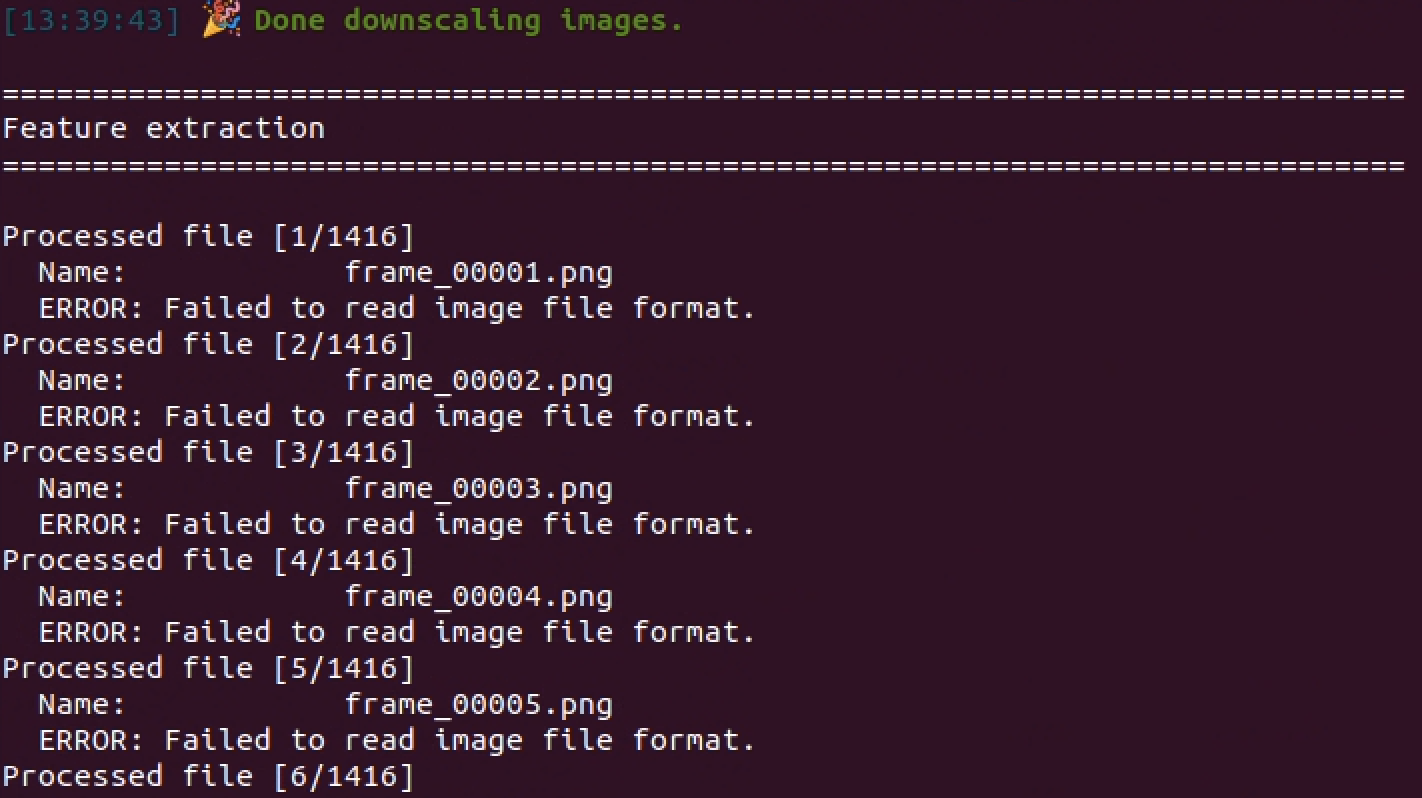
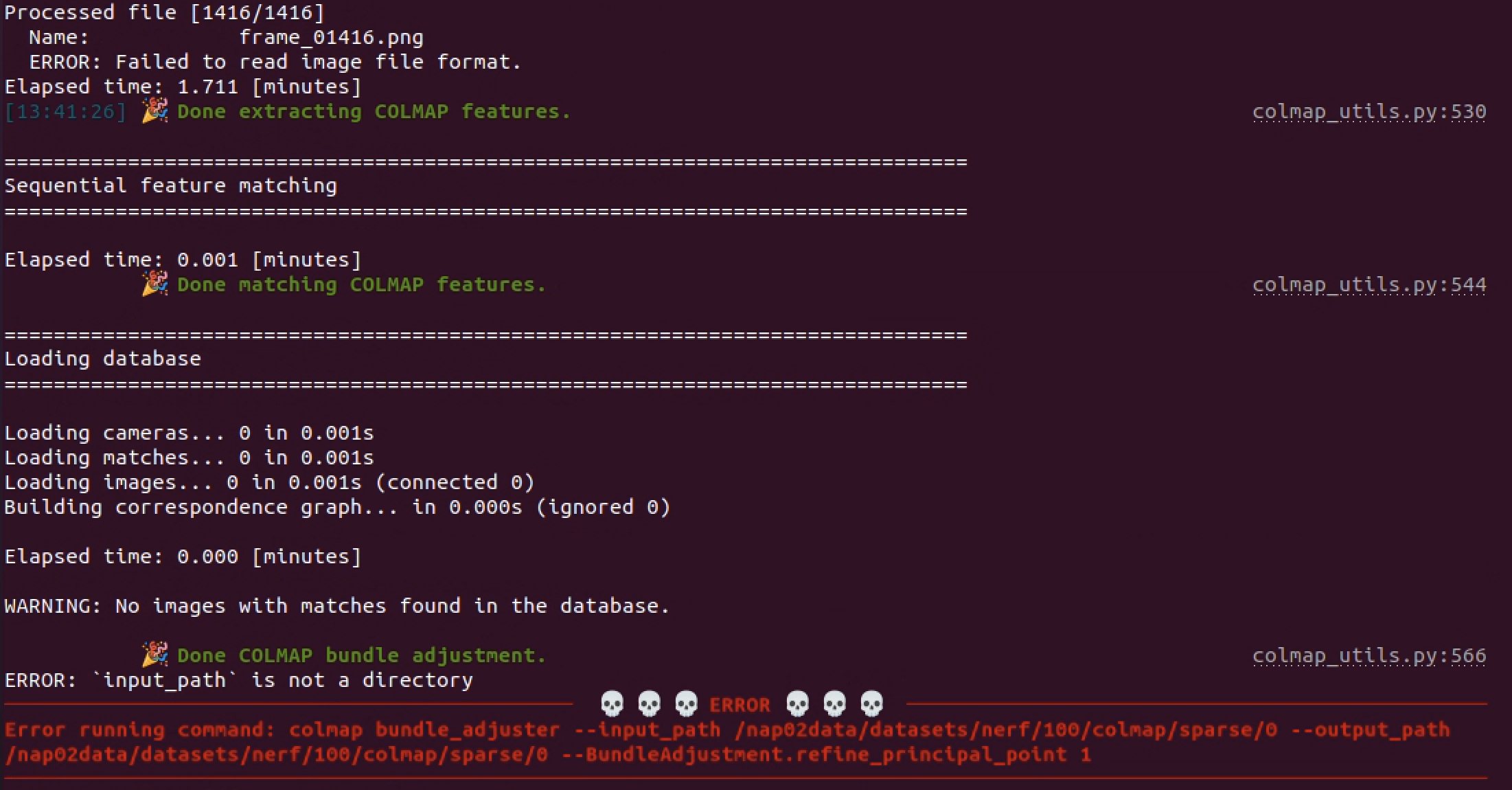
**Additional context**
- COLMAP version: 3.6
- FFMPEG version: 4.2.2
- The video contains 1416 frames, captured at 30Hz.
- I have tried running the ffmpeg_cmd with -r 30
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nerfstudio/process_data/process_data_utils.py`
Content:
```
1 # Copyright 2022 The Nerfstudio Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helper utils for processing data into the nerfstudio format."""
16
17 import shutil
18 import sys
19 from enum import Enum
20 from pathlib import Path
21 from typing import List, Optional, Tuple
22
23 from rich.console import Console
24 from typing_extensions import Literal
25
26 from nerfstudio.utils.rich_utils import status
27 from nerfstudio.utils.scripts import run_command
28
29 CONSOLE = Console(width=120)
30
31
32 class CameraModel(Enum):
33 """Enum for camera types."""
34
35 OPENCV = "OPENCV"
36 OPENCV_FISHEYE = "OPENCV_FISHEYE"
37
38
39 CAMERA_MODELS = {
40 "perspective": CameraModel.OPENCV,
41 "fisheye": CameraModel.OPENCV_FISHEYE,
42 }
43
44
45 def get_num_frames_in_video(video: Path) -> int:
46 """Returns the number of frames in a video.
47
48 Args:
49 video: Path to a video.
50
51 Returns:
52 The number of frames in a video.
53 """
54 cmd = f"ffprobe -v error -select_streams v:0 -count_packets \
55 -show_entries stream=nb_read_packets -of csv=p=0 {video}"
56 output = run_command(cmd)
57 assert output is not None
58 output = output.strip(" ,\t\n\r")
59 return int(output)
60
61
62 def convert_video_to_images(
63 video_path: Path, image_dir: Path, num_frames_target: int, verbose: bool = False
64 ) -> Tuple[List[str], int]:
65 """Converts a video into a sequence of images.
66
67 Args:
68 video_path: Path to the video.
69 output_dir: Path to the output directory.
70 num_frames_target: Number of frames to extract.
71 verbose: If True, logs the output of the command.
72 Returns:
73 A tuple containing summary of the conversion and the number of extracted frames.
74 """
75
76 with status(msg="Converting video to images...", spinner="bouncingBall", verbose=verbose):
77 # delete existing images in folder
78 for img in image_dir.glob("*.png"):
79 if verbose:
80 CONSOLE.log(f"Deleting {img}")
81 img.unlink()
82
83 num_frames = get_num_frames_in_video(video_path)
84 if num_frames == 0:
85 CONSOLE.print(f"[bold red]Error: Video has no frames: {video_path}")
86 sys.exit(1)
87 print("Number of frames in video:", num_frames)
88
89 out_filename = image_dir / "frame_%05d.png"
90 ffmpeg_cmd = f"ffmpeg -i {video_path}"
91 spacing = num_frames // num_frames_target
92
93 if spacing > 1:
94 ffmpeg_cmd += f" -vf thumbnail={spacing},setpts=N/TB -r 1"
95 else:
96 CONSOLE.print("[bold red]Can't satify requested number of frames. Extracting all frames.")
97
98 ffmpeg_cmd += f" {out_filename}"
99
100 run_command(ffmpeg_cmd, verbose=verbose)
101
102 num_final_frames = len(list(image_dir.glob("*.png")))
103 summary_log = []
104 summary_log.append(f"Starting with {num_frames} video frames")
105 summary_log.append(f"We extracted {num_final_frames} images")
106 CONSOLE.log("[bold green]:tada: Done converting video to images.")
107
108 return summary_log, num_final_frames
109
110
111 def copy_images_list(
112 image_paths: List[Path], image_dir: Path, crop_border_pixels: Optional[int] = None, verbose: bool = False
113 ) -> List[Path]:
114 """Copy all images in a list of Paths. Useful for filtering from a directory.
115 Args:
116 image_paths: List of Paths of images to copy to a new directory.
117 image_dir: Path to the output directory.
118 crop_border_pixels: If not None, crops each edge by the specified number of pixels.
119 verbose: If True, print extra logging.
120 Returns:
121 A list of the copied image Paths.
122 """
123
124 # Remove original directory only if we provide a proper image folder path
125 if image_dir.is_dir() and len(image_paths):
126 shutil.rmtree(image_dir, ignore_errors=True)
127 image_dir.mkdir(exist_ok=True, parents=True)
128
129 copied_image_paths = []
130
131 # Images should be 1-indexed for the rest of the pipeline.
132 for idx, image_path in enumerate(image_paths):
133 if verbose:
134 CONSOLE.log(f"Copying image {idx + 1} of {len(image_paths)}...")
135 copied_image_path = image_dir / f"frame_{idx + 1:05d}{image_path.suffix}"
136 shutil.copy(image_path, copied_image_path)
137 copied_image_paths.append(copied_image_path)
138
139 if crop_border_pixels is not None:
140 file_type = image_paths[0].suffix
141 filename = f"frame_%05d{file_type}"
142 crop = f"crop=iw-{crop_border_pixels*2}:ih-{crop_border_pixels*2}"
143 ffmpeg_cmd = f"ffmpeg -y -i {image_dir / filename} -q:v 2 -vf {crop} {image_dir / filename}"
144 run_command(ffmpeg_cmd, verbose=verbose)
145
146 num_frames = len(image_paths)
147
148 if num_frames == 0:
149 CONSOLE.log("[bold red]:skull: No usable images in the data folder.")
150 else:
151 CONSOLE.log("[bold green]:tada: Done copying images.")
152
153 return copied_image_paths
154
155
156 def copy_images(data: Path, image_dir: Path, verbose) -> int:
157 """Copy images from a directory to a new directory.
158
159 Args:
160 data: Path to the directory of images.
161 image_dir: Path to the output directory.
162 verbose: If True, print extra logging.
163 Returns:
164 The number of images copied.
165 """
166 with status(msg="[bold yellow]Copying images...", spinner="bouncingBall", verbose=verbose):
167 allowed_exts = [".jpg", ".jpeg", ".png", ".tif", ".tiff"]
168 image_paths = sorted([p for p in data.glob("[!.]*") if p.suffix.lower() in allowed_exts])
169
170 if len(image_paths) == 0:
171 CONSOLE.log("[bold red]:skull: No usable images in the data folder.")
172 sys.exit(1)
173
174 num_frames = len(copy_images_list(image_paths, image_dir, verbose))
175
176 return num_frames
177
178
179 def downscale_images(image_dir: Path, num_downscales: int, verbose: bool = False) -> str:
180 """Downscales the images in the directory. Uses FFMPEG.
181
182 Assumes images are named frame_00001.png, frame_00002.png, etc.
183
184 Args:
185 image_dir: Path to the directory containing the images.
186 num_downscales: Number of times to downscale the images. Downscales by 2 each time.
187 verbose: If True, logs the output of the command.
188
189 Returns:
190 Summary of downscaling.
191 """
192
193 if num_downscales == 0:
194 return "No downscaling performed."
195
196 with status(msg="[bold yellow]Downscaling images...", spinner="growVertical", verbose=verbose):
197 downscale_factors = [2**i for i in range(num_downscales + 1)[1:]]
198 for downscale_factor in downscale_factors:
199 assert downscale_factor > 1
200 assert isinstance(downscale_factor, int)
201 downscale_dir = image_dir.parent / f"images_{downscale_factor}"
202 downscale_dir.mkdir(parents=True, exist_ok=True)
203 file_type = image_dir.glob("frame_*").__next__().suffix
204 filename = f"frame_%05d{file_type}"
205 ffmpeg_cmd = [
206 f"ffmpeg -i {image_dir / filename} ",
207 f"-q:v 2 -vf scale=iw/{downscale_factor}:ih/{downscale_factor} ",
208 f"{downscale_dir / filename}",
209 ]
210 ffmpeg_cmd = " ".join(ffmpeg_cmd)
211 run_command(ffmpeg_cmd, verbose=verbose)
212
213 CONSOLE.log("[bold green]:tada: Done downscaling images.")
214 downscale_text = [f"[bold blue]{2**(i+1)}x[/bold blue]" for i in range(num_downscales)]
215 downscale_text = ", ".join(downscale_text[:-1]) + " and " + downscale_text[-1]
216 return f"We downsampled the images by {downscale_text}"
217
218
219 def find_tool_feature_matcher_combination(
220 sfm_tool: Literal["any", "colmap", "hloc"],
221 feature_type: Literal[
222 "any",
223 "sift",
224 "superpoint",
225 "superpoint_aachen",
226 "superpoint_max",
227 "superpoint_inloc",
228 "r2d2",
229 "d2net-ss",
230 "sosnet",
231 "disk",
232 ],
233 matcher_type: Literal[
234 "any", "NN", "superglue", "superglue-fast", "NN-superpoint", "NN-ratio", "NN-mutual", "adalam"
235 ],
236 ):
237 """Find a valid combination of sfm tool, feature type, and matcher type.
238 Basically, replace the default parameters 'any' by usable value
239
240 Args:
241 sfm_tool: Sfm tool name (any, colmap, hloc)
242 feature_type: Type of image features (any, sift, superpoint, ...)
243 matcher_type: Type of matching algorithm (any, NN, superglue,...)
244
245 Returns:
246 Tuple of sfm tool, feature type, and matcher type.
247 Returns (None,None,None) if no valid combination can be found
248 """
249 if sfm_tool == "any":
250 if (feature_type in ("any", "sift")) and (matcher_type in ("any", "NN")):
251 sfm_tool = "colmap"
252 else:
253 sfm_tool = "hloc"
254
255 if sfm_tool == "colmap":
256 if (feature_type not in ("any", "sift")) or (matcher_type not in ("any", "NN")):
257 return (None, None, None)
258 return ("colmap", "sift", "NN")
259 if sfm_tool == "hloc":
260 if feature_type in ("any", "superpoint"):
261 feature_type = "superpoint_aachen"
262
263 if matcher_type == "any":
264 matcher_type = "superglue"
265 elif matcher_type == "NN":
266 matcher_type = "NN-mutual"
267
268 return (sfm_tool, feature_type, matcher_type)
269 return (None, None, None)
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nerfstudio/process_data/process_data_utils.py b/nerfstudio/process_data/process_data_utils.py
--- a/nerfstudio/process_data/process_data_utils.py
+++ b/nerfstudio/process_data/process_data_utils.py
@@ -94,6 +94,7 @@
ffmpeg_cmd += f" -vf thumbnail={spacing},setpts=N/TB -r 1"
else:
CONSOLE.print("[bold red]Can't satify requested number of frames. Extracting all frames.")
+ ffmpeg_cmd += " -pix_fmt bgr8"
ffmpeg_cmd += f" {out_filename}"
| {"golden_diff": "diff --git a/nerfstudio/process_data/process_data_utils.py b/nerfstudio/process_data/process_data_utils.py\n--- a/nerfstudio/process_data/process_data_utils.py\n+++ b/nerfstudio/process_data/process_data_utils.py\n@@ -94,6 +94,7 @@\n ffmpeg_cmd += f\" -vf thumbnail={spacing},setpts=N/TB -r 1\"\n else:\n CONSOLE.print(\"[bold red]Can't satify requested number of frames. Extracting all frames.\")\n+ ffmpeg_cmd += \" -pix_fmt bgr8\"\n \n ffmpeg_cmd += f\" {out_filename}\"\n", "issue": "Feature extraction/matching doesn't work when using all the frames from a video with COLMAP and ns-process-data\n**Describe the bug**\r\nCOLMAP isn't able to run feature extraction and subsequent bundle adjustment when I use all the frames from a video. Everything works fine when I use the default ~300 input frames. Have anynone experienced the same?\r\n\r\nFor every image it tries to extract features from it exits with `ERROR: Failed to read image file format.`, although the file format is PNG. I see that the resulting files are 2-3 times larger (totalling ~11Mb) than what the ones extracted with the thumbnail-option is. Is there possibly an issue with convert_video_to_images and the ffmpeg_cmd?\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Run `ns-process-data video` with an input-video and `--num-frames-target` equal (or approx. equal) to the video's number of frames. And `--verbose`\r\n2. This results in `spacing` in `process_data_utils.py` to be 1\r\n3. Observe that all phases before Feature extraction works as expected\r\n4. Observe that for each line of \"Processed file\" during feature extraction, an error `ERROR: Failed to read image file format.` is logged.\r\n5. Observe that `/colmap/sparse/0` isn't generated which causes the Bundle adjustment step to fail.\r\n\r\n**Expected behavior**\r\nFeature extraction should generate features and match them, resulting in a `/colmap/sparse/0`-dir that bundle adjustment can operate on.\r\n\r\n**Screenshots**\r\n\r\n\r\n\r\n\r\n\r\n**Additional context**\r\n- COLMAP version: 3.6\r\n- FFMPEG version: 4.2.2\r\n- The video contains 1416 frames, captured at 30Hz.\r\n- I have tried running the ffmpeg_cmd with -r 30 \n", "before_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper utils for processing data into the nerfstudio format.\"\"\"\n\nimport shutil\nimport sys\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import List, Optional, Tuple\n\nfrom rich.console import Console\nfrom typing_extensions import Literal\n\nfrom nerfstudio.utils.rich_utils import status\nfrom nerfstudio.utils.scripts import run_command\n\nCONSOLE = Console(width=120)\n\n\nclass CameraModel(Enum):\n \"\"\"Enum for camera types.\"\"\"\n\n OPENCV = \"OPENCV\"\n OPENCV_FISHEYE = \"OPENCV_FISHEYE\"\n\n\nCAMERA_MODELS = {\n \"perspective\": CameraModel.OPENCV,\n \"fisheye\": CameraModel.OPENCV_FISHEYE,\n}\n\n\ndef get_num_frames_in_video(video: Path) -> int:\n \"\"\"Returns the number of frames in a video.\n\n Args:\n video: Path to a video.\n\n Returns:\n The number of frames in a video.\n \"\"\"\n cmd = f\"ffprobe -v error -select_streams v:0 -count_packets \\\n -show_entries stream=nb_read_packets -of csv=p=0 {video}\"\n output = run_command(cmd)\n assert output is not None\n output = output.strip(\" ,\\t\\n\\r\")\n return int(output)\n\n\ndef convert_video_to_images(\n video_path: Path, image_dir: Path, num_frames_target: int, verbose: bool = False\n) -> Tuple[List[str], int]:\n \"\"\"Converts a video into a sequence of images.\n\n Args:\n video_path: Path to the video.\n output_dir: Path to the output directory.\n num_frames_target: Number of frames to extract.\n verbose: If True, logs the output of the command.\n Returns:\n A tuple containing summary of the conversion and the number of extracted frames.\n \"\"\"\n\n with status(msg=\"Converting video to images...\", spinner=\"bouncingBall\", verbose=verbose):\n # delete existing images in folder\n for img in image_dir.glob(\"*.png\"):\n if verbose:\n CONSOLE.log(f\"Deleting {img}\")\n img.unlink()\n\n num_frames = get_num_frames_in_video(video_path)\n if num_frames == 0:\n CONSOLE.print(f\"[bold red]Error: Video has no frames: {video_path}\")\n sys.exit(1)\n print(\"Number of frames in video:\", num_frames)\n\n out_filename = image_dir / \"frame_%05d.png\"\n ffmpeg_cmd = f\"ffmpeg -i {video_path}\"\n spacing = num_frames // num_frames_target\n\n if spacing > 1:\n ffmpeg_cmd += f\" -vf thumbnail={spacing},setpts=N/TB -r 1\"\n else:\n CONSOLE.print(\"[bold red]Can't satify requested number of frames. Extracting all frames.\")\n\n ffmpeg_cmd += f\" {out_filename}\"\n\n run_command(ffmpeg_cmd, verbose=verbose)\n\n num_final_frames = len(list(image_dir.glob(\"*.png\")))\n summary_log = []\n summary_log.append(f\"Starting with {num_frames} video frames\")\n summary_log.append(f\"We extracted {num_final_frames} images\")\n CONSOLE.log(\"[bold green]:tada: Done converting video to images.\")\n\n return summary_log, num_final_frames\n\n\ndef copy_images_list(\n image_paths: List[Path], image_dir: Path, crop_border_pixels: Optional[int] = None, verbose: bool = False\n) -> List[Path]:\n \"\"\"Copy all images in a list of Paths. Useful for filtering from a directory.\n Args:\n image_paths: List of Paths of images to copy to a new directory.\n image_dir: Path to the output directory.\n crop_border_pixels: If not None, crops each edge by the specified number of pixels.\n verbose: If True, print extra logging.\n Returns:\n A list of the copied image Paths.\n \"\"\"\n\n # Remove original directory only if we provide a proper image folder path\n if image_dir.is_dir() and len(image_paths):\n shutil.rmtree(image_dir, ignore_errors=True)\n image_dir.mkdir(exist_ok=True, parents=True)\n\n copied_image_paths = []\n\n # Images should be 1-indexed for the rest of the pipeline.\n for idx, image_path in enumerate(image_paths):\n if verbose:\n CONSOLE.log(f\"Copying image {idx + 1} of {len(image_paths)}...\")\n copied_image_path = image_dir / f\"frame_{idx + 1:05d}{image_path.suffix}\"\n shutil.copy(image_path, copied_image_path)\n copied_image_paths.append(copied_image_path)\n\n if crop_border_pixels is not None:\n file_type = image_paths[0].suffix\n filename = f\"frame_%05d{file_type}\"\n crop = f\"crop=iw-{crop_border_pixels*2}:ih-{crop_border_pixels*2}\"\n ffmpeg_cmd = f\"ffmpeg -y -i {image_dir / filename} -q:v 2 -vf {crop} {image_dir / filename}\"\n run_command(ffmpeg_cmd, verbose=verbose)\n\n num_frames = len(image_paths)\n\n if num_frames == 0:\n CONSOLE.log(\"[bold red]:skull: No usable images in the data folder.\")\n else:\n CONSOLE.log(\"[bold green]:tada: Done copying images.\")\n\n return copied_image_paths\n\n\ndef copy_images(data: Path, image_dir: Path, verbose) -> int:\n \"\"\"Copy images from a directory to a new directory.\n\n Args:\n data: Path to the directory of images.\n image_dir: Path to the output directory.\n verbose: If True, print extra logging.\n Returns:\n The number of images copied.\n \"\"\"\n with status(msg=\"[bold yellow]Copying images...\", spinner=\"bouncingBall\", verbose=verbose):\n allowed_exts = [\".jpg\", \".jpeg\", \".png\", \".tif\", \".tiff\"]\n image_paths = sorted([p for p in data.glob(\"[!.]*\") if p.suffix.lower() in allowed_exts])\n\n if len(image_paths) == 0:\n CONSOLE.log(\"[bold red]:skull: No usable images in the data folder.\")\n sys.exit(1)\n\n num_frames = len(copy_images_list(image_paths, image_dir, verbose))\n\n return num_frames\n\n\ndef downscale_images(image_dir: Path, num_downscales: int, verbose: bool = False) -> str:\n \"\"\"Downscales the images in the directory. Uses FFMPEG.\n\n Assumes images are named frame_00001.png, frame_00002.png, etc.\n\n Args:\n image_dir: Path to the directory containing the images.\n num_downscales: Number of times to downscale the images. Downscales by 2 each time.\n verbose: If True, logs the output of the command.\n\n Returns:\n Summary of downscaling.\n \"\"\"\n\n if num_downscales == 0:\n return \"No downscaling performed.\"\n\n with status(msg=\"[bold yellow]Downscaling images...\", spinner=\"growVertical\", verbose=verbose):\n downscale_factors = [2**i for i in range(num_downscales + 1)[1:]]\n for downscale_factor in downscale_factors:\n assert downscale_factor > 1\n assert isinstance(downscale_factor, int)\n downscale_dir = image_dir.parent / f\"images_{downscale_factor}\"\n downscale_dir.mkdir(parents=True, exist_ok=True)\n file_type = image_dir.glob(\"frame_*\").__next__().suffix\n filename = f\"frame_%05d{file_type}\"\n ffmpeg_cmd = [\n f\"ffmpeg -i {image_dir / filename} \",\n f\"-q:v 2 -vf scale=iw/{downscale_factor}:ih/{downscale_factor} \",\n f\"{downscale_dir / filename}\",\n ]\n ffmpeg_cmd = \" \".join(ffmpeg_cmd)\n run_command(ffmpeg_cmd, verbose=verbose)\n\n CONSOLE.log(\"[bold green]:tada: Done downscaling images.\")\n downscale_text = [f\"[bold blue]{2**(i+1)}x[/bold blue]\" for i in range(num_downscales)]\n downscale_text = \", \".join(downscale_text[:-1]) + \" and \" + downscale_text[-1]\n return f\"We downsampled the images by {downscale_text}\"\n\n\ndef find_tool_feature_matcher_combination(\n sfm_tool: Literal[\"any\", \"colmap\", \"hloc\"],\n feature_type: Literal[\n \"any\",\n \"sift\",\n \"superpoint\",\n \"superpoint_aachen\",\n \"superpoint_max\",\n \"superpoint_inloc\",\n \"r2d2\",\n \"d2net-ss\",\n \"sosnet\",\n \"disk\",\n ],\n matcher_type: Literal[\n \"any\", \"NN\", \"superglue\", \"superglue-fast\", \"NN-superpoint\", \"NN-ratio\", \"NN-mutual\", \"adalam\"\n ],\n):\n \"\"\"Find a valid combination of sfm tool, feature type, and matcher type.\n Basically, replace the default parameters 'any' by usable value\n\n Args:\n sfm_tool: Sfm tool name (any, colmap, hloc)\n feature_type: Type of image features (any, sift, superpoint, ...)\n matcher_type: Type of matching algorithm (any, NN, superglue,...)\n\n Returns:\n Tuple of sfm tool, feature type, and matcher type.\n Returns (None,None,None) if no valid combination can be found\n \"\"\"\n if sfm_tool == \"any\":\n if (feature_type in (\"any\", \"sift\")) and (matcher_type in (\"any\", \"NN\")):\n sfm_tool = \"colmap\"\n else:\n sfm_tool = \"hloc\"\n\n if sfm_tool == \"colmap\":\n if (feature_type not in (\"any\", \"sift\")) or (matcher_type not in (\"any\", \"NN\")):\n return (None, None, None)\n return (\"colmap\", \"sift\", \"NN\")\n if sfm_tool == \"hloc\":\n if feature_type in (\"any\", \"superpoint\"):\n feature_type = \"superpoint_aachen\"\n\n if matcher_type == \"any\":\n matcher_type = \"superglue\"\n elif matcher_type == \"NN\":\n matcher_type = \"NN-mutual\"\n\n return (sfm_tool, feature_type, matcher_type)\n return (None, None, None)\n", "path": "nerfstudio/process_data/process_data_utils.py"}], "after_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper utils for processing data into the nerfstudio format.\"\"\"\n\nimport shutil\nimport sys\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import List, Optional, Tuple\n\nfrom rich.console import Console\nfrom typing_extensions import Literal\n\nfrom nerfstudio.utils.rich_utils import status\nfrom nerfstudio.utils.scripts import run_command\n\nCONSOLE = Console(width=120)\n\n\nclass CameraModel(Enum):\n \"\"\"Enum for camera types.\"\"\"\n\n OPENCV = \"OPENCV\"\n OPENCV_FISHEYE = \"OPENCV_FISHEYE\"\n\n\nCAMERA_MODELS = {\n \"perspective\": CameraModel.OPENCV,\n \"fisheye\": CameraModel.OPENCV_FISHEYE,\n}\n\n\ndef get_num_frames_in_video(video: Path) -> int:\n \"\"\"Returns the number of frames in a video.\n\n Args:\n video: Path to a video.\n\n Returns:\n The number of frames in a video.\n \"\"\"\n cmd = f\"ffprobe -v error -select_streams v:0 -count_packets \\\n -show_entries stream=nb_read_packets -of csv=p=0 {video}\"\n output = run_command(cmd)\n assert output is not None\n output = output.strip(\" ,\\t\\n\\r\")\n return int(output)\n\n\ndef convert_video_to_images(\n video_path: Path, image_dir: Path, num_frames_target: int, verbose: bool = False\n) -> Tuple[List[str], int]:\n \"\"\"Converts a video into a sequence of images.\n\n Args:\n video_path: Path to the video.\n output_dir: Path to the output directory.\n num_frames_target: Number of frames to extract.\n verbose: If True, logs the output of the command.\n Returns:\n A tuple containing summary of the conversion and the number of extracted frames.\n \"\"\"\n\n with status(msg=\"Converting video to images...\", spinner=\"bouncingBall\", verbose=verbose):\n # delete existing images in folder\n for img in image_dir.glob(\"*.png\"):\n if verbose:\n CONSOLE.log(f\"Deleting {img}\")\n img.unlink()\n\n num_frames = get_num_frames_in_video(video_path)\n if num_frames == 0:\n CONSOLE.print(f\"[bold red]Error: Video has no frames: {video_path}\")\n sys.exit(1)\n print(\"Number of frames in video:\", num_frames)\n\n out_filename = image_dir / \"frame_%05d.png\"\n ffmpeg_cmd = f\"ffmpeg -i {video_path}\"\n spacing = num_frames // num_frames_target\n\n if spacing > 1:\n ffmpeg_cmd += f\" -vf thumbnail={spacing},setpts=N/TB -r 1\"\n else:\n CONSOLE.print(\"[bold red]Can't satify requested number of frames. Extracting all frames.\")\n ffmpeg_cmd += \" -pix_fmt bgr8\"\n\n ffmpeg_cmd += f\" {out_filename}\"\n\n run_command(ffmpeg_cmd, verbose=verbose)\n\n num_final_frames = len(list(image_dir.glob(\"*.png\")))\n summary_log = []\n summary_log.append(f\"Starting with {num_frames} video frames\")\n summary_log.append(f\"We extracted {num_final_frames} images\")\n CONSOLE.log(\"[bold green]:tada: Done converting video to images.\")\n\n return summary_log, num_final_frames\n\n\ndef copy_images_list(\n image_paths: List[Path], image_dir: Path, crop_border_pixels: Optional[int] = None, verbose: bool = False\n) -> List[Path]:\n \"\"\"Copy all images in a list of Paths. Useful for filtering from a directory.\n Args:\n image_paths: List of Paths of images to copy to a new directory.\n image_dir: Path to the output directory.\n crop_border_pixels: If not None, crops each edge by the specified number of pixels.\n verbose: If True, print extra logging.\n Returns:\n A list of the copied image Paths.\n \"\"\"\n\n # Remove original directory only if we provide a proper image folder path\n if image_dir.is_dir() and len(image_paths):\n shutil.rmtree(image_dir, ignore_errors=True)\n image_dir.mkdir(exist_ok=True, parents=True)\n\n copied_image_paths = []\n\n # Images should be 1-indexed for the rest of the pipeline.\n for idx, image_path in enumerate(image_paths):\n if verbose:\n CONSOLE.log(f\"Copying image {idx + 1} of {len(image_paths)}...\")\n copied_image_path = image_dir / f\"frame_{idx + 1:05d}{image_path.suffix}\"\n shutil.copy(image_path, copied_image_path)\n copied_image_paths.append(copied_image_path)\n\n if crop_border_pixels is not None:\n file_type = image_paths[0].suffix\n filename = f\"frame_%05d{file_type}\"\n crop = f\"crop=iw-{crop_border_pixels*2}:ih-{crop_border_pixels*2}\"\n ffmpeg_cmd = f\"ffmpeg -y -i {image_dir / filename} -q:v 2 -vf {crop} {image_dir / filename}\"\n run_command(ffmpeg_cmd, verbose=verbose)\n\n num_frames = len(image_paths)\n\n if num_frames == 0:\n CONSOLE.log(\"[bold red]:skull: No usable images in the data folder.\")\n else:\n CONSOLE.log(\"[bold green]:tada: Done copying images.\")\n\n return copied_image_paths\n\n\ndef copy_images(data: Path, image_dir: Path, verbose) -> int:\n \"\"\"Copy images from a directory to a new directory.\n\n Args:\n data: Path to the directory of images.\n image_dir: Path to the output directory.\n verbose: If True, print extra logging.\n Returns:\n The number of images copied.\n \"\"\"\n with status(msg=\"[bold yellow]Copying images...\", spinner=\"bouncingBall\", verbose=verbose):\n allowed_exts = [\".jpg\", \".jpeg\", \".png\", \".tif\", \".tiff\"]\n image_paths = sorted([p for p in data.glob(\"[!.]*\") if p.suffix.lower() in allowed_exts])\n\n if len(image_paths) == 0:\n CONSOLE.log(\"[bold red]:skull: No usable images in the data folder.\")\n sys.exit(1)\n\n num_frames = len(copy_images_list(image_paths, image_dir, verbose))\n\n return num_frames\n\n\ndef downscale_images(image_dir: Path, num_downscales: int, verbose: bool = False) -> str:\n \"\"\"Downscales the images in the directory. Uses FFMPEG.\n\n Assumes images are named frame_00001.png, frame_00002.png, etc.\n\n Args:\n image_dir: Path to the directory containing the images.\n num_downscales: Number of times to downscale the images. Downscales by 2 each time.\n verbose: If True, logs the output of the command.\n\n Returns:\n Summary of downscaling.\n \"\"\"\n\n if num_downscales == 0:\n return \"No downscaling performed.\"\n\n with status(msg=\"[bold yellow]Downscaling images...\", spinner=\"growVertical\", verbose=verbose):\n downscale_factors = [2**i for i in range(num_downscales + 1)[1:]]\n for downscale_factor in downscale_factors:\n assert downscale_factor > 1\n assert isinstance(downscale_factor, int)\n downscale_dir = image_dir.parent / f\"images_{downscale_factor}\"\n downscale_dir.mkdir(parents=True, exist_ok=True)\n file_type = image_dir.glob(\"frame_*\").__next__().suffix\n filename = f\"frame_%05d{file_type}\"\n ffmpeg_cmd = [\n f\"ffmpeg -i {image_dir / filename} \",\n f\"-q:v 2 -vf scale=iw/{downscale_factor}:ih/{downscale_factor} \",\n f\"{downscale_dir / filename}\",\n ]\n ffmpeg_cmd = \" \".join(ffmpeg_cmd)\n run_command(ffmpeg_cmd, verbose=verbose)\n\n CONSOLE.log(\"[bold green]:tada: Done downscaling images.\")\n downscale_text = [f\"[bold blue]{2**(i+1)}x[/bold blue]\" for i in range(num_downscales)]\n downscale_text = \", \".join(downscale_text[:-1]) + \" and \" + downscale_text[-1]\n return f\"We downsampled the images by {downscale_text}\"\n\n\ndef find_tool_feature_matcher_combination(\n sfm_tool: Literal[\"any\", \"colmap\", \"hloc\"],\n feature_type: Literal[\n \"any\",\n \"sift\",\n \"superpoint\",\n \"superpoint_aachen\",\n \"superpoint_max\",\n \"superpoint_inloc\",\n \"r2d2\",\n \"d2net-ss\",\n \"sosnet\",\n \"disk\",\n ],\n matcher_type: Literal[\n \"any\", \"NN\", \"superglue\", \"superglue-fast\", \"NN-superpoint\", \"NN-ratio\", \"NN-mutual\", \"adalam\"\n ],\n):\n \"\"\"Find a valid combination of sfm tool, feature type, and matcher type.\n Basically, replace the default parameters 'any' by usable value\n\n Args:\n sfm_tool: Sfm tool name (any, colmap, hloc)\n feature_type: Type of image features (any, sift, superpoint, ...)\n matcher_type: Type of matching algorithm (any, NN, superglue,...)\n\n Returns:\n Tuple of sfm tool, feature type, and matcher type.\n Returns (None,None,None) if no valid combination can be found\n \"\"\"\n if sfm_tool == \"any\":\n if (feature_type in (\"any\", \"sift\")) and (matcher_type in (\"any\", \"NN\")):\n sfm_tool = \"colmap\"\n else:\n sfm_tool = \"hloc\"\n\n if sfm_tool == \"colmap\":\n if (feature_type not in (\"any\", \"sift\")) or (matcher_type not in (\"any\", \"NN\")):\n return (None, None, None)\n return (\"colmap\", \"sift\", \"NN\")\n if sfm_tool == \"hloc\":\n if feature_type in (\"any\", \"superpoint\"):\n feature_type = \"superpoint_aachen\"\n\n if matcher_type == \"any\":\n matcher_type = \"superglue\"\n elif matcher_type == \"NN\":\n matcher_type = \"NN-mutual\"\n\n return (sfm_tool, feature_type, matcher_type)\n return (None, None, None)\n", "path": "nerfstudio/process_data/process_data_utils.py"}]} | 3,984 | 135 |
gh_patches_debug_42129 | rasdani/github-patches | git_diff | conan-io__conan-center-index-1204 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] cgal/all: review options applied
Comming from https://github.com/conan-io/conan-center-index/pull/965#issuecomment-590802910
Seems that the recipe might require some work regarding the options and flags
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/cgal/all/conanfile.py`
Content:
```
1 import os
2 from conans import ConanFile, CMake, tools
3
4
5 class CgalConan(ConanFile):
6 name = "cgal"
7 license = "LGPL-3.0-or-later"
8 url = "https://github.com/conan-io/conan-center-index"
9 homepage = "https://github.com/CGAL/cgal"
10 description = "C++ library that aims to provide easy access to efficient and reliable algorithms"\
11 "in computational geometry."
12 topics = ("geometry", "algorithms")
13 settings = "os", "compiler", "build_type", "arch"
14 requires = "mpir/3.0.0", "mpfr/4.0.2", "boost/1.72.0", "eigen/3.3.7"
15 generators = "cmake"
16
17 _source_subfolder = "source_subfolder"
18 _cmake = None
19
20 options = {
21 "with_cgal_core": [True, False],
22 "with_cgal_qt5": [True, False],
23 "with_cgal_imageio": [True, False]
24 }
25
26 default_options = {
27 "with_cgal_core": True,
28 "with_cgal_qt5": False,
29 "with_cgal_imageio": True
30 }
31
32 def _configure_cmake(self):
33 if not self._cmake:
34 self._cmake = CMake(self)
35 self._cmake.definitions["WITH_CGAL_Core"] = self.options.with_cgal_core
36 self._cmake.definitions["WITH_CGAL_Qt5"] = self.options.with_cgal_qt5
37 self._cmake.definitions["WITH_CGAL_ImageIO"] = self.options.with_cgal_imageio
38 self._cmake.configure(source_folder=self._source_subfolder)
39 return self._cmake
40
41 def _patch_sources(self):
42 tools.replace_in_file(
43 os.path.join(self._source_subfolder, "CMakeLists.txt"),
44 "project(CGAL CXX C)", '''project(CGAL CXX C)
45 include(${CMAKE_BINARY_DIR}/conanbuildinfo.cmake)
46 conan_basic_setup()''')
47
48 def source(self):
49 tools.get(**self.conan_data["sources"][self.version])
50 extracted_dir = "CGAL-{}".format(self.version)
51 os.rename(extracted_dir, self._source_subfolder)
52
53 def build(self):
54 self._patch_sources()
55 cmake = self._configure_cmake()
56 cmake.build()
57
58 def package(self):
59 self.copy("LICENSE*", dst="licenses", src=self._source_subfolder)
60 cmake = self._configure_cmake()
61 cmake.install()
62 tools.rmdir(os.path.join(self.package_folder, "share"))
63 tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
64 tools.rmdir(os.path.join(self.package_folder, "bin"))
65
66 def package_info(self):
67 self.cpp_info.names["cmake_find_package"] = "CGAL"
68 self.cpp_info.names["cmake_find_package_multi"] = "CGAL"
69
70 def package_id(self):
71 self.info.header_only()
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/recipes/cgal/all/conanfile.py b/recipes/cgal/all/conanfile.py
--- a/recipes/cgal/all/conanfile.py
+++ b/recipes/cgal/all/conanfile.py
@@ -1,5 +1,6 @@
import os
from conans import ConanFile, CMake, tools
+from conans.errors import ConanInvalidConfiguration
class CgalConan(ConanFile):
@@ -13,20 +14,26 @@
settings = "os", "compiler", "build_type", "arch"
requires = "mpir/3.0.0", "mpfr/4.0.2", "boost/1.72.0", "eigen/3.3.7"
generators = "cmake"
+ exports_sources = "CMakeLists.txt"
_source_subfolder = "source_subfolder"
+ _build_subfolder = "build_subfolder"
_cmake = None
options = {
"with_cgal_core": [True, False],
"with_cgal_qt5": [True, False],
- "with_cgal_imageio": [True, False]
+ "with_cgal_imageio": [True, False],
+ "shared": [True, False],
+ "header_only": [True, False]
}
default_options = {
"with_cgal_core": True,
"with_cgal_qt5": False,
- "with_cgal_imageio": True
+ "with_cgal_imageio": True,
+ "shared": False,
+ "header_only": True
}
def _configure_cmake(self):
@@ -35,15 +42,19 @@
self._cmake.definitions["WITH_CGAL_Core"] = self.options.with_cgal_core
self._cmake.definitions["WITH_CGAL_Qt5"] = self.options.with_cgal_qt5
self._cmake.definitions["WITH_CGAL_ImageIO"] = self.options.with_cgal_imageio
- self._cmake.configure(source_folder=self._source_subfolder)
+ self._cmake.definitions["CGAL_HEADER_ONLY"] = self.options.header_only
+ self._cmake.configure(build_folder=self._build_subfolder)
return self._cmake
def _patch_sources(self):
- tools.replace_in_file(
- os.path.join(self._source_subfolder, "CMakeLists.txt"),
- "project(CGAL CXX C)", '''project(CGAL CXX C)
-include(${CMAKE_BINARY_DIR}/conanbuildinfo.cmake)
-conan_basic_setup()''')
+ tools.replace_in_file(os.path.join(self._source_subfolder, "CMakeLists.txt"),
+ "CMAKE_SOURCE_DIR", "CMAKE_CURRENT_SOURCE_DIR")
+
+ def configure(self):
+ if self.options.with_cgal_qt5:
+ raise ConanInvalidConfiguration("Qt Conan package is not available yet.")
+ if self.options.header_only:
+ del self.options.shared
def source(self):
tools.get(**self.conan_data["sources"][self.version])
@@ -61,11 +72,20 @@
cmake.install()
tools.rmdir(os.path.join(self.package_folder, "share"))
tools.rmdir(os.path.join(self.package_folder, "lib", "cmake"))
- tools.rmdir(os.path.join(self.package_folder, "bin"))
+ if self.options.get_safe("shared"):
+ for root, _, filenames in os.walk(os.path.join(self.package_folder, "bin")):
+ for filename in filenames:
+ if not filename.endswith(".dll"):
+ os.unlink(os.path.join(root, filename))
+ else:
+ tools.rmdir(os.path.join(self.package_folder, "bin"))
def package_info(self):
+ if not self.options.header_only:
+ self.cpp_info.libs = tools.collect_libs(self)
self.cpp_info.names["cmake_find_package"] = "CGAL"
self.cpp_info.names["cmake_find_package_multi"] = "CGAL"
def package_id(self):
- self.info.header_only()
+ if self.options.header_only:
+ self.info.header_only()
| {"golden_diff": "diff --git a/recipes/cgal/all/conanfile.py b/recipes/cgal/all/conanfile.py\n--- a/recipes/cgal/all/conanfile.py\n+++ b/recipes/cgal/all/conanfile.py\n@@ -1,5 +1,6 @@\n import os\n from conans import ConanFile, CMake, tools\n+from conans.errors import ConanInvalidConfiguration\n \n \n class CgalConan(ConanFile):\n@@ -13,20 +14,26 @@\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n requires = \"mpir/3.0.0\", \"mpfr/4.0.2\", \"boost/1.72.0\", \"eigen/3.3.7\"\n generators = \"cmake\"\n+ exports_sources = \"CMakeLists.txt\"\n \n _source_subfolder = \"source_subfolder\"\n+ _build_subfolder = \"build_subfolder\"\n _cmake = None\n \n options = {\n \"with_cgal_core\": [True, False],\n \"with_cgal_qt5\": [True, False],\n- \"with_cgal_imageio\": [True, False]\n+ \"with_cgal_imageio\": [True, False],\n+ \"shared\": [True, False],\n+ \"header_only\": [True, False]\n }\n \n default_options = {\n \"with_cgal_core\": True,\n \"with_cgal_qt5\": False,\n- \"with_cgal_imageio\": True\n+ \"with_cgal_imageio\": True,\n+ \"shared\": False,\n+ \"header_only\": True\n }\n \n def _configure_cmake(self):\n@@ -35,15 +42,19 @@\n self._cmake.definitions[\"WITH_CGAL_Core\"] = self.options.with_cgal_core\n self._cmake.definitions[\"WITH_CGAL_Qt5\"] = self.options.with_cgal_qt5\n self._cmake.definitions[\"WITH_CGAL_ImageIO\"] = self.options.with_cgal_imageio\n- self._cmake.configure(source_folder=self._source_subfolder)\n+ self._cmake.definitions[\"CGAL_HEADER_ONLY\"] = self.options.header_only\n+ self._cmake.configure(build_folder=self._build_subfolder)\n return self._cmake\n \n def _patch_sources(self):\n- tools.replace_in_file(\n- os.path.join(self._source_subfolder, \"CMakeLists.txt\"),\n- \"project(CGAL CXX C)\", '''project(CGAL CXX C)\n-include(${CMAKE_BINARY_DIR}/conanbuildinfo.cmake)\n-conan_basic_setup()''')\n+ tools.replace_in_file(os.path.join(self._source_subfolder, \"CMakeLists.txt\"),\n+ \"CMAKE_SOURCE_DIR\", \"CMAKE_CURRENT_SOURCE_DIR\")\n+\n+ def configure(self):\n+ if self.options.with_cgal_qt5:\n+ raise ConanInvalidConfiguration(\"Qt Conan package is not available yet.\")\n+ if self.options.header_only:\n+ del self.options.shared\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n@@ -61,11 +72,20 @@\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n- tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n+ if self.options.get_safe(\"shared\"):\n+ for root, _, filenames in os.walk(os.path.join(self.package_folder, \"bin\")):\n+ for filename in filenames:\n+ if not filename.endswith(\".dll\"):\n+ os.unlink(os.path.join(root, filename))\n+ else:\n+ tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n \n def package_info(self):\n+ if not self.options.header_only:\n+ self.cpp_info.libs = tools.collect_libs(self)\n self.cpp_info.names[\"cmake_find_package\"] = \"CGAL\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"CGAL\"\n \n def package_id(self):\n- self.info.header_only()\n+ if self.options.header_only:\n+ self.info.header_only()\n", "issue": "[package] cgal/all: review options applied\nComming from https://github.com/conan-io/conan-center-index/pull/965#issuecomment-590802910\r\n\r\nSeems that the recipe might require some work regarding the options and flags\n", "before_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\n\n\nclass CgalConan(ConanFile):\n name = \"cgal\"\n license = \"LGPL-3.0-or-later\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/CGAL/cgal\"\n description = \"C++ library that aims to provide easy access to efficient and reliable algorithms\"\\\n \"in computational geometry.\"\n topics = (\"geometry\", \"algorithms\")\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n requires = \"mpir/3.0.0\", \"mpfr/4.0.2\", \"boost/1.72.0\", \"eigen/3.3.7\"\n generators = \"cmake\"\n\n _source_subfolder = \"source_subfolder\"\n _cmake = None\n\n options = {\n \"with_cgal_core\": [True, False],\n \"with_cgal_qt5\": [True, False],\n \"with_cgal_imageio\": [True, False]\n }\n\n default_options = {\n \"with_cgal_core\": True,\n \"with_cgal_qt5\": False,\n \"with_cgal_imageio\": True\n }\n\n def _configure_cmake(self):\n if not self._cmake:\n self._cmake = CMake(self)\n self._cmake.definitions[\"WITH_CGAL_Core\"] = self.options.with_cgal_core\n self._cmake.definitions[\"WITH_CGAL_Qt5\"] = self.options.with_cgal_qt5\n self._cmake.definitions[\"WITH_CGAL_ImageIO\"] = self.options.with_cgal_imageio\n self._cmake.configure(source_folder=self._source_subfolder)\n return self._cmake\n\n def _patch_sources(self):\n tools.replace_in_file(\n os.path.join(self._source_subfolder, \"CMakeLists.txt\"),\n \"project(CGAL CXX C)\", '''project(CGAL CXX C)\ninclude(${CMAKE_BINARY_DIR}/conanbuildinfo.cmake)\nconan_basic_setup()''')\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = \"CGAL-{}\".format(self.version)\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n\n def package_info(self):\n self.cpp_info.names[\"cmake_find_package\"] = \"CGAL\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"CGAL\"\n\n def package_id(self):\n self.info.header_only()\n", "path": "recipes/cgal/all/conanfile.py"}], "after_files": [{"content": "import os\nfrom conans import ConanFile, CMake, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nclass CgalConan(ConanFile):\n name = \"cgal\"\n license = \"LGPL-3.0-or-later\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/CGAL/cgal\"\n description = \"C++ library that aims to provide easy access to efficient and reliable algorithms\"\\\n \"in computational geometry.\"\n topics = (\"geometry\", \"algorithms\")\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n requires = \"mpir/3.0.0\", \"mpfr/4.0.2\", \"boost/1.72.0\", \"eigen/3.3.7\"\n generators = \"cmake\"\n exports_sources = \"CMakeLists.txt\"\n\n _source_subfolder = \"source_subfolder\"\n _build_subfolder = \"build_subfolder\"\n _cmake = None\n\n options = {\n \"with_cgal_core\": [True, False],\n \"with_cgal_qt5\": [True, False],\n \"with_cgal_imageio\": [True, False],\n \"shared\": [True, False],\n \"header_only\": [True, False]\n }\n\n default_options = {\n \"with_cgal_core\": True,\n \"with_cgal_qt5\": False,\n \"with_cgal_imageio\": True,\n \"shared\": False,\n \"header_only\": True\n }\n\n def _configure_cmake(self):\n if not self._cmake:\n self._cmake = CMake(self)\n self._cmake.definitions[\"WITH_CGAL_Core\"] = self.options.with_cgal_core\n self._cmake.definitions[\"WITH_CGAL_Qt5\"] = self.options.with_cgal_qt5\n self._cmake.definitions[\"WITH_CGAL_ImageIO\"] = self.options.with_cgal_imageio\n self._cmake.definitions[\"CGAL_HEADER_ONLY\"] = self.options.header_only\n self._cmake.configure(build_folder=self._build_subfolder)\n return self._cmake\n\n def _patch_sources(self):\n tools.replace_in_file(os.path.join(self._source_subfolder, \"CMakeLists.txt\"),\n \"CMAKE_SOURCE_DIR\", \"CMAKE_CURRENT_SOURCE_DIR\")\n\n def configure(self):\n if self.options.with_cgal_qt5:\n raise ConanInvalidConfiguration(\"Qt Conan package is not available yet.\")\n if self.options.header_only:\n del self.options.shared\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n extracted_dir = \"CGAL-{}\".format(self.version)\n os.rename(extracted_dir, self._source_subfolder)\n\n def build(self):\n self._patch_sources()\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n self.copy(\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n cmake = self._configure_cmake()\n cmake.install()\n tools.rmdir(os.path.join(self.package_folder, \"share\"))\n tools.rmdir(os.path.join(self.package_folder, \"lib\", \"cmake\"))\n if self.options.get_safe(\"shared\"):\n for root, _, filenames in os.walk(os.path.join(self.package_folder, \"bin\")):\n for filename in filenames:\n if not filename.endswith(\".dll\"):\n os.unlink(os.path.join(root, filename))\n else:\n tools.rmdir(os.path.join(self.package_folder, \"bin\"))\n\n def package_info(self):\n if not self.options.header_only:\n self.cpp_info.libs = tools.collect_libs(self)\n self.cpp_info.names[\"cmake_find_package\"] = \"CGAL\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"CGAL\"\n\n def package_id(self):\n if self.options.header_only:\n self.info.header_only()\n", "path": "recipes/cgal/all/conanfile.py"}]} | 1,133 | 922 |
gh_patches_debug_11580 | rasdani/github-patches | git_diff | electricitymaps__electricitymaps-contrib-1631 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FR: key coal has negative value -9.0
```
invalid point: {'zoneKey': 'FR', 'datetime': datetime.datetime(2018, 10, 9, 11, 15, tzinfo=tzoffset(None, 7200)), 'production': {'nuclear': 41740.0, 'coal': -9.0, 'gas': 4057.0, 'oil': 188.0, 'wind': 1158.0, 'solar': 2762.0, 'biomass': 861.0, 'hydro': 3366.0}, 'storage': {'hydro': -1024.0}, 'source': 'opendata.reseaux-energies.fr', 'schemaVersion': 1}, reason:FR: key coal has negative value -9.0
```
Probably a good idea to set small negative values to 0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/FR.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import arrow
4 import json
5 import logging
6 import os
7 import math
8
9 import pandas as pd
10 import requests
11 import xml.etree.ElementTree as ET
12
13 API_ENDPOINT = 'https://opendata.reseaux-energies.fr/api/records/1.0/search/'
14
15 MAP_GENERATION = {
16 'nucleaire': 'nuclear',
17 'charbon': 'coal',
18 'gaz': 'gas',
19 'fioul': 'oil',
20 'eolien': 'wind',
21 'solaire': 'solar',
22 'bioenergies': 'biomass'
23 }
24
25 MAP_HYDRO = [
26 'hydraulique_fil_eau_eclusee',
27 'hydraulique_lacs',
28 'hydraulique_step_turbinage',
29 'pompage'
30 ]
31
32 def is_not_nan_and_truthy(v):
33 if isinstance(v, float) and math.isnan(v):
34 return False
35 return bool(v)
36
37
38 def fetch_production(zone_key='FR', session=None, target_datetime=None,
39 logger=logging.getLogger(__name__)):
40 if target_datetime:
41 to = arrow.get(target_datetime, 'Europe/Paris')
42 else:
43 to = arrow.now(tz='Europe/Paris')
44
45 # setup request
46 r = session or requests.session()
47 formatted_from = to.shift(days=-1).format('YYYY-MM-DDTHH:mm')
48 formatted_to = to.format('YYYY-MM-DDTHH:mm')
49
50 params = {
51 'dataset': 'eco2mix-national-tr',
52 'q': 'date_heure >= {} AND date_heure <= {}'.format(
53 formatted_from, formatted_to),
54 'timezone': 'Europe/Paris',
55 'rows': 100
56 }
57
58 if 'RESEAUX_ENERGIES_TOKEN' not in os.environ:
59 raise Exception(
60 'No RESEAUX_ENERGIES_TOKEN found! Please add it into secrets.env!')
61 params['apikey'] = os.environ['RESEAUX_ENERGIES_TOKEN']
62
63 # make request and create dataframe with response
64 response = r.get(API_ENDPOINT, params=params)
65 data = json.loads(response.content)
66 data = [d['fields'] for d in data['records']]
67 df = pd.DataFrame(data)
68
69 # filter out desired columns and convert values to float
70 value_columns = list(MAP_GENERATION.keys()) + MAP_HYDRO
71 df = df[['date_heure'] + value_columns]
72 df[value_columns] = df[value_columns].astype(float)
73
74 datapoints = list()
75 for row in df.iterrows():
76 production = dict()
77 for key, value in MAP_GENERATION.items():
78 production[value] = row[1][key]
79
80 # Hydro is a special case!
81 production['hydro'] = row[1]['hydraulique_lacs'] + row[1]['hydraulique_fil_eau_eclusee']
82 storage = {
83 'hydro': row[1]['pompage'] * -1 + row[1]['hydraulique_step_turbinage'] * -1
84 }
85
86 # if all production values are null, ignore datapoint
87 if not any([is_not_nan_and_truthy(v)
88 for k, v in production.items()]):
89 continue
90
91 datapoints.append({
92 'zoneKey': zone_key,
93 'datetime': arrow.get(row[1]['date_heure']).datetime,
94 'production': production,
95 'storage': storage,
96 'source': 'opendata.reseaux-energies.fr'
97 })
98
99 return datapoints
100
101
102 def fetch_price(zone_key, session=None, target_datetime=None,
103 logger=logging.getLogger(__name__)):
104 if target_datetime:
105 now = arrow.get(target_datetime, tz='Europe/Paris')
106 else:
107 now = arrow.now(tz='Europe/Paris')
108
109 r = session or requests.session()
110 formatted_from = now.shift(days=-1).format('DD/MM/YYYY')
111 formatted_to = now.format('DD/MM/YYYY')
112
113 url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&da' \
114 'teDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)
115 response = r.get(url)
116 obj = ET.fromstring(response.content)
117 datas = {}
118
119 for donnesMarche in obj:
120 if donnesMarche.tag != 'donneesMarche':
121 continue
122
123 start_date = arrow.get(arrow.get(donnesMarche.attrib['date']).datetime, 'Europe/Paris')
124
125 for item in donnesMarche:
126 if item.get('granularite') != 'Global':
127 continue
128 country_c = item.get('perimetre')
129 if zone_key != country_c:
130 continue
131 value = None
132 for value in item:
133 if value.text == 'ND':
134 continue
135 period = int(value.attrib['periode'])
136 datetime = start_date.replace(hours=+period).datetime
137 if not datetime in datas:
138 datas[datetime] = {
139 'zoneKey': zone_key,
140 'currency': 'EUR',
141 'datetime': datetime,
142 'source': 'rte-france.com',
143 }
144 data = datas[datetime]
145 data['price'] = float(value.text)
146
147 return list(datas.values())
148
149
150 if __name__ == '__main__':
151 print(fetch_production())
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/parsers/FR.py b/parsers/FR.py
--- a/parsers/FR.py
+++ b/parsers/FR.py
@@ -75,7 +75,12 @@
for row in df.iterrows():
production = dict()
for key, value in MAP_GENERATION.items():
- production[value] = row[1][key]
+ # Set small negative values to 0
+ if row[1][key] < 0 and row[1][key] > -50:
+ logger.warning('Setting small value of %s (%s) to 0.' % (key, value))
+ production[value] = 0
+ else:
+ production[value] = row[1][key]
# Hydro is a special case!
production['hydro'] = row[1]['hydraulique_lacs'] + row[1]['hydraulique_fil_eau_eclusee']
| {"golden_diff": "diff --git a/parsers/FR.py b/parsers/FR.py\n--- a/parsers/FR.py\n+++ b/parsers/FR.py\n@@ -75,7 +75,12 @@\n for row in df.iterrows():\n production = dict()\n for key, value in MAP_GENERATION.items():\n- production[value] = row[1][key]\n+ # Set small negative values to 0\n+ if row[1][key] < 0 and row[1][key] > -50:\n+ logger.warning('Setting small value of %s (%s) to 0.' % (key, value))\n+ production[value] = 0\n+ else:\n+ production[value] = row[1][key]\n \n # Hydro is a special case!\n production['hydro'] = row[1]['hydraulique_lacs'] + row[1]['hydraulique_fil_eau_eclusee']\n", "issue": "FR: key coal has negative value -9.0\n```\r\ninvalid point: {'zoneKey': 'FR', 'datetime': datetime.datetime(2018, 10, 9, 11, 15, tzinfo=tzoffset(None, 7200)), 'production': {'nuclear': 41740.0, 'coal': -9.0, 'gas': 4057.0, 'oil': 188.0, 'wind': 1158.0, 'solar': 2762.0, 'biomass': 861.0, 'hydro': 3366.0}, 'storage': {'hydro': -1024.0}, 'source': 'opendata.reseaux-energies.fr', 'schemaVersion': 1}, reason:FR: key coal has negative value -9.0\r\n```\r\n\r\nProbably a good idea to set small negative values to 0\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport json\nimport logging\nimport os\nimport math\n\nimport pandas as pd\nimport requests\nimport xml.etree.ElementTree as ET\n\nAPI_ENDPOINT = 'https://opendata.reseaux-energies.fr/api/records/1.0/search/'\n\nMAP_GENERATION = {\n 'nucleaire': 'nuclear',\n 'charbon': 'coal',\n 'gaz': 'gas',\n 'fioul': 'oil',\n 'eolien': 'wind',\n 'solaire': 'solar',\n 'bioenergies': 'biomass'\n}\n\nMAP_HYDRO = [\n 'hydraulique_fil_eau_eclusee',\n 'hydraulique_lacs',\n 'hydraulique_step_turbinage',\n 'pompage'\n]\n\ndef is_not_nan_and_truthy(v):\n if isinstance(v, float) and math.isnan(v):\n return False\n return bool(v)\n\n\ndef fetch_production(zone_key='FR', session=None, target_datetime=None,\n logger=logging.getLogger(__name__)):\n if target_datetime:\n to = arrow.get(target_datetime, 'Europe/Paris')\n else:\n to = arrow.now(tz='Europe/Paris')\n\n # setup request\n r = session or requests.session()\n formatted_from = to.shift(days=-1).format('YYYY-MM-DDTHH:mm')\n formatted_to = to.format('YYYY-MM-DDTHH:mm')\n\n params = {\n 'dataset': 'eco2mix-national-tr',\n 'q': 'date_heure >= {} AND date_heure <= {}'.format(\n formatted_from, formatted_to),\n 'timezone': 'Europe/Paris',\n 'rows': 100\n }\n\n if 'RESEAUX_ENERGIES_TOKEN' not in os.environ:\n raise Exception(\n 'No RESEAUX_ENERGIES_TOKEN found! Please add it into secrets.env!')\n params['apikey'] = os.environ['RESEAUX_ENERGIES_TOKEN']\n\n # make request and create dataframe with response\n response = r.get(API_ENDPOINT, params=params)\n data = json.loads(response.content)\n data = [d['fields'] for d in data['records']]\n df = pd.DataFrame(data)\n\n # filter out desired columns and convert values to float\n value_columns = list(MAP_GENERATION.keys()) + MAP_HYDRO\n df = df[['date_heure'] + value_columns]\n df[value_columns] = df[value_columns].astype(float)\n\n datapoints = list()\n for row in df.iterrows():\n production = dict()\n for key, value in MAP_GENERATION.items():\n production[value] = row[1][key]\n\n # Hydro is a special case!\n production['hydro'] = row[1]['hydraulique_lacs'] + row[1]['hydraulique_fil_eau_eclusee']\n storage = {\n 'hydro': row[1]['pompage'] * -1 + row[1]['hydraulique_step_turbinage'] * -1\n }\n\n # if all production values are null, ignore datapoint\n if not any([is_not_nan_and_truthy(v)\n for k, v in production.items()]):\n continue\n\n datapoints.append({\n 'zoneKey': zone_key,\n 'datetime': arrow.get(row[1]['date_heure']).datetime,\n 'production': production,\n 'storage': storage,\n 'source': 'opendata.reseaux-energies.fr'\n })\n\n return datapoints\n\n\ndef fetch_price(zone_key, session=None, target_datetime=None,\n logger=logging.getLogger(__name__)):\n if target_datetime:\n now = arrow.get(target_datetime, tz='Europe/Paris')\n else:\n now = arrow.now(tz='Europe/Paris')\n\n r = session or requests.session()\n formatted_from = now.shift(days=-1).format('DD/MM/YYYY')\n formatted_to = now.format('DD/MM/YYYY')\n\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&da' \\\n 'teDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n datas = {}\n\n for donnesMarche in obj:\n if donnesMarche.tag != 'donneesMarche':\n continue\n\n start_date = arrow.get(arrow.get(donnesMarche.attrib['date']).datetime, 'Europe/Paris')\n\n for item in donnesMarche:\n if item.get('granularite') != 'Global':\n continue\n country_c = item.get('perimetre')\n if zone_key != country_c:\n continue\n value = None\n for value in item:\n if value.text == 'ND':\n continue\n period = int(value.attrib['periode'])\n datetime = start_date.replace(hours=+period).datetime\n if not datetime in datas:\n datas[datetime] = {\n 'zoneKey': zone_key,\n 'currency': 'EUR',\n 'datetime': datetime,\n 'source': 'rte-france.com',\n }\n data = datas[datetime]\n data['price'] = float(value.text)\n\n return list(datas.values())\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/FR.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport json\nimport logging\nimport os\nimport math\n\nimport pandas as pd\nimport requests\nimport xml.etree.ElementTree as ET\n\nAPI_ENDPOINT = 'https://opendata.reseaux-energies.fr/api/records/1.0/search/'\n\nMAP_GENERATION = {\n 'nucleaire': 'nuclear',\n 'charbon': 'coal',\n 'gaz': 'gas',\n 'fioul': 'oil',\n 'eolien': 'wind',\n 'solaire': 'solar',\n 'bioenergies': 'biomass'\n}\n\nMAP_HYDRO = [\n 'hydraulique_fil_eau_eclusee',\n 'hydraulique_lacs',\n 'hydraulique_step_turbinage',\n 'pompage'\n]\n\ndef is_not_nan_and_truthy(v):\n if isinstance(v, float) and math.isnan(v):\n return False\n return bool(v)\n\n\ndef fetch_production(zone_key='FR', session=None, target_datetime=None,\n logger=logging.getLogger(__name__)):\n if target_datetime:\n to = arrow.get(target_datetime, 'Europe/Paris')\n else:\n to = arrow.now(tz='Europe/Paris')\n\n # setup request\n r = session or requests.session()\n formatted_from = to.shift(days=-1).format('YYYY-MM-DDTHH:mm')\n formatted_to = to.format('YYYY-MM-DDTHH:mm')\n\n params = {\n 'dataset': 'eco2mix-national-tr',\n 'q': 'date_heure >= {} AND date_heure <= {}'.format(\n formatted_from, formatted_to),\n 'timezone': 'Europe/Paris',\n 'rows': 100\n }\n\n if 'RESEAUX_ENERGIES_TOKEN' not in os.environ:\n raise Exception(\n 'No RESEAUX_ENERGIES_TOKEN found! Please add it into secrets.env!')\n params['apikey'] = os.environ['RESEAUX_ENERGIES_TOKEN']\n\n # make request and create dataframe with response\n response = r.get(API_ENDPOINT, params=params)\n data = json.loads(response.content)\n data = [d['fields'] for d in data['records']]\n df = pd.DataFrame(data)\n\n # filter out desired columns and convert values to float\n value_columns = list(MAP_GENERATION.keys()) + MAP_HYDRO\n df = df[['date_heure'] + value_columns]\n df[value_columns] = df[value_columns].astype(float)\n\n datapoints = list()\n for row in df.iterrows():\n production = dict()\n for key, value in MAP_GENERATION.items():\n # Set small negative values to 0\n if row[1][key] < 0 and row[1][key] > -50:\n logger.warning('Setting small value of %s (%s) to 0.' % (key, value))\n production[value] = 0\n else:\n production[value] = row[1][key]\n\n # Hydro is a special case!\n production['hydro'] = row[1]['hydraulique_lacs'] + row[1]['hydraulique_fil_eau_eclusee']\n storage = {\n 'hydro': row[1]['pompage'] * -1 + row[1]['hydraulique_step_turbinage'] * -1\n }\n\n # if all production values are null, ignore datapoint\n if not any([is_not_nan_and_truthy(v)\n for k, v in production.items()]):\n continue\n\n datapoints.append({\n 'zoneKey': zone_key,\n 'datetime': arrow.get(row[1]['date_heure']).datetime,\n 'production': production,\n 'storage': storage,\n 'source': 'opendata.reseaux-energies.fr'\n })\n\n return datapoints\n\n\ndef fetch_price(zone_key, session=None, target_datetime=None,\n logger=logging.getLogger(__name__)):\n if target_datetime:\n now = arrow.get(target_datetime, tz='Europe/Paris')\n else:\n now = arrow.now(tz='Europe/Paris')\n\n r = session or requests.session()\n formatted_from = now.shift(days=-1).format('DD/MM/YYYY')\n formatted_to = now.format('DD/MM/YYYY')\n\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&da' \\\n 'teDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n datas = {}\n\n for donnesMarche in obj:\n if donnesMarche.tag != 'donneesMarche':\n continue\n\n start_date = arrow.get(arrow.get(donnesMarche.attrib['date']).datetime, 'Europe/Paris')\n\n for item in donnesMarche:\n if item.get('granularite') != 'Global':\n continue\n country_c = item.get('perimetre')\n if zone_key != country_c:\n continue\n value = None\n for value in item:\n if value.text == 'ND':\n continue\n period = int(value.attrib['periode'])\n datetime = start_date.replace(hours=+period).datetime\n if not datetime in datas:\n datas[datetime] = {\n 'zoneKey': zone_key,\n 'currency': 'EUR',\n 'datetime': datetime,\n 'source': 'rte-france.com',\n }\n data = datas[datetime]\n data['price'] = float(value.text)\n\n return list(datas.values())\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/FR.py"}]} | 2,002 | 206 |
gh_patches_debug_40863 | rasdani/github-patches | git_diff | dotkom__onlineweb4-712 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mandatory phone number in profile
It has been requested from arrkom among others and decided in HS that phone numbers in the user profile should be mandatory for people attending events. So we need to implement functionality similar to the one used for "prikkeregler".
If users hide this in their profile the info could behave as allergies and only show up when events are exported to pdf.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/events/views.py`
Content:
```
1 #-*- coding: utf-8 -*-
2
3 import datetime
4
5 from django.utils import timezone
6
7 from django.conf import settings
8 from django.contrib import messages
9 from django.contrib.auth.decorators import login_required, user_passes_test
10 from django.core.urlresolvers import reverse
11 from django.http import HttpResponseRedirect
12 from django.shortcuts import render, get_object_or_404, redirect
13 from django.utils.translation import ugettext as _
14
15 import watson
16
17 from apps.events.forms import CaptchaForm
18 from apps.events.models import Event, AttendanceEvent, Attendee
19 from apps.events.pdf_generator import EventPDF
20
21
22 def index(request):
23 return render(request, 'events/index.html', {})
24
25 def details(request, event_id, event_slug):
26 event = get_object_or_404(Event, pk=event_id)
27
28 is_attendance_event = False
29 user_anonymous = True
30 user_attending = False
31 place_on_wait_list = 0
32 will_be_on_wait_list = False
33 rules = []
34 user_status = False
35
36 try:
37 attendance_event = AttendanceEvent.objects.get(pk=event_id)
38 is_attendance_event = True
39 form = CaptchaForm(user=request.user)
40
41 if attendance_event.rule_bundles:
42 for rule_bundle in attendance_event.rule_bundles.all():
43 rules.append(rule_bundle.get_rule_strings)
44
45 if request.user.is_authenticated():
46 user_anonymous = False
47 if attendance_event.is_attendee(request.user):
48 user_attending = True
49
50
51 will_be_on_wait_list = attendance_event.will_i_be_on_wait_list
52
53 user_status = event.is_eligible_for_signup(request.user)
54
55 # Check if this user is on the waitlist
56 place_on_wait_list = event.what_place_is_user_on_wait_list(request.user)
57
58 except AttendanceEvent.DoesNotExist:
59 pass
60
61 if is_attendance_event:
62 context = {
63 'now': timezone.now(),
64 'event': event,
65 'attendance_event': attendance_event,
66 'user_anonymous': user_anonymous,
67 'user_attending': user_attending,
68 'will_be_on_wait_list': will_be_on_wait_list,
69 'rules': rules,
70 'user_status': user_status,
71 'place_on_wait_list': int(place_on_wait_list),
72 #'position_in_wait_list': position_in_wait_list,
73 'captcha_form': form,
74 }
75
76 return render(request, 'events/details.html', context)
77 else:
78 return render(request, 'events/details.html', {'event': event})
79
80
81 def get_attendee(attendee_id):
82 return get_object_or_404(Attendee, pk=attendee_id)
83
84 @login_required
85 def attendEvent(request, event_id):
86
87 event = get_object_or_404(Event, pk=event_id)
88
89 if not request.POST:
90 messages.error(request, _(u'Vennligst fyll ut skjemaet.'))
91 return redirect(event)
92 form = CaptchaForm(request.POST, user=request.user)
93
94 if not form.is_valid():
95 if not 'mark_rules' in request.POST and not request.user.mark_rules:
96 error_message = u'Du må godta prikkreglene for å melde deg på.'
97 else:
98 error_message = u'Du klarte ikke captcha-en. Er du en bot?'
99 messages.error(request, _(error_message))
100 return redirect(event)
101
102 # Check if the user is eligible to attend this event.
103 # If not, an error message will be present in the returned dict
104 attendance_event = event.attendance_event
105
106 response = event.is_eligible_for_signup(request.user);
107
108 if response['status']:
109 # First time accepting mark rules
110 if 'mark_rules' in form.cleaned_data:
111 request.user.mark_rules = True
112 request.user.save()
113 Attendee(event=attendance_event, user=request.user).save()
114 messages.success(request, _(u"Du er nå påmeldt på arrangementet!"))
115 return redirect(event)
116 else:
117 messages.error(request, response['message'])
118 return redirect(event)
119
120 @login_required
121 def unattendEvent(request, event_id):
122
123 event = get_object_or_404(Event, pk=event_id)
124 attendance_event = event.attendance_event
125
126 # Check if the deadline for unattending has passed
127 if attendance_event.unattend_deadline < timezone.now():
128 messages.error(request, _(u"Avmeldingsfristen for dette arrangementet har utløpt."))
129 return redirect(event)
130
131 event.notify_waiting_list(host=request.META['HTTP_HOST'], unattended_user=request.user)
132 Attendee.objects.get(event=attendance_event, user=request.user).delete()
133
134 messages.success(request, _(u"Du ble meldt av arrangementet."))
135 return redirect(event)
136
137 def search_events(request):
138 query = request.GET.get('query')
139 filters = {
140 'future' : request.GET.get('future'),
141 'myevents' : request.GET.get('myevents')
142 }
143 events = _search_indexed(request, query, filters)
144
145 return render(request, 'events/search.html', {'events': events})
146
147
148 def _search_indexed(request, query, filters):
149 results = []
150 kwargs = {}
151
152 if filters['future'] == 'true':
153 kwargs['event_start__gte'] = timezone.now()
154
155 if filters['myevents'] == 'true':
156 kwargs['attendance_event__attendees'] = request.user
157
158 events = Event.objects.filter(**kwargs).order_by('event_start').prefetch_related(
159 'attendance_event', 'attendance_event__attendees')
160
161 if query:
162 for result in watson.search(query, models=(events,)):
163 results.append(result.object)
164 return results[:10]
165
166 return events
167
168
169 @login_required()
170 @user_passes_test(lambda u: u.groups.filter(name='Komiteer').count() == 1)
171 def generate_pdf(request, event_id):
172
173 event = get_object_or_404(Event, pk=event_id)
174
175 groups = request.user.groups.all()
176 if not (groups.filter(name='dotKom').count() == 1 or groups.filter(name='Hovedstyret').count() == 1):
177 if event.event_type == 1 and not groups.filter(name='arrKom').count() == 1:
178 messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))
179 return redirect(event)
180
181 if event.event_type == 2 and not groups.filter(name='bedKom').count() == 1:
182 messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))
183 return redirect(event)
184
185 if event.event_type == 3 and not groups.filter(name='fagKom').count() == 1:
186 messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))
187 return redirect(event)
188
189 return EventPDF(event).render_pdf()
190
```
Path: `apps/events/forms.py`
Content:
```
1 from django import forms
2 from captcha.fields import CaptchaField
3
4 class CaptchaForm(forms.Form):
5 def __init__(self, *args, **kwargs):
6 user = kwargs.pop('user', None)
7 super(CaptchaForm, self).__init__(*args, **kwargs)
8 # Removing mark rules field if user has already accepted the rules
9 if user and user.is_authenticated() and user.mark_rules:
10 del self.fields['mark_rules']
11 mark_rules = forms.BooleanField(label=u'Jeg godtar <a href="/profile/#marks" target="_blank">prikkreglene</a>')
12 captcha = CaptchaField()
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/apps/events/forms.py b/apps/events/forms.py
--- a/apps/events/forms.py
+++ b/apps/events/forms.py
@@ -1,12 +1,48 @@
+#-*- coding: utf-8 -*-
+
from django import forms
from captcha.fields import CaptchaField
+from django.utils.translation import ugettext as _
class CaptchaForm(forms.Form):
+
+ phone_number = forms.CharField(label=_(u'Telefonnummer er påkrevd for å være påmeldt et arrangement.'),
+ error_messages={'required' : _(u'Telefonnummer er påkrevd!')})
+ mark_rules = forms.BooleanField(label=_(u'Jeg godtar <a href="/profile/#marks" target="_blank">prikkreglene</a>'),
+ error_messages={'required' : _(u'Du må godta prikkereglene!')})
+ captcha = CaptchaField(error_messages={'required' : _(u'Du klarte ikke captchaen! Er du en bot?')})
+
def __init__(self, *args, **kwargs):
- user = kwargs.pop('user', None)
+ self.user = kwargs.pop('user', None)
super(CaptchaForm, self).__init__(*args, **kwargs)
+
# Removing mark rules field if user has already accepted the rules
- if user and user.is_authenticated() and user.mark_rules:
- del self.fields['mark_rules']
- mark_rules = forms.BooleanField(label=u'Jeg godtar <a href="/profile/#marks" target="_blank">prikkreglene</a>')
- captcha = CaptchaField()
+ if self.user and self.user.is_authenticated():
+ if self.user.mark_rules:
+ del self.fields['mark_rules']
+
+ if self.user.phone_number:
+ del self.fields['phone_number']
+
+
+ def clean(self):
+ super(CaptchaForm, self).clean()
+ cleaned_data = self.cleaned_data
+
+ if 'mark_rules' in self.fields:
+ if 'mark_rules' in cleaned_data:
+ mark_rules = cleaned_data['mark_rules']
+
+ if mark_rules:
+ self.user.mark_rules = True
+ self.user.save()
+
+ if 'phone_number' in self.fields:
+ if 'phone_number' in cleaned_data:
+ phone_number = cleaned_data['phone_number']
+
+ if phone_number:
+ self.user.phone_number = phone_number
+ self.user.save()
+
+ return cleaned_data
\ No newline at end of file
diff --git a/apps/events/views.py b/apps/events/views.py
--- a/apps/events/views.py
+++ b/apps/events/views.py
@@ -89,14 +89,14 @@
if not request.POST:
messages.error(request, _(u'Vennligst fyll ut skjemaet.'))
return redirect(event)
+
form = CaptchaForm(request.POST, user=request.user)
if not form.is_valid():
- if not 'mark_rules' in request.POST and not request.user.mark_rules:
- error_message = u'Du må godta prikkreglene for å melde deg på.'
- else:
- error_message = u'Du klarte ikke captcha-en. Er du en bot?'
- messages.error(request, _(error_message))
+ for field,errors in form.errors.items():
+ for error in errors:
+ messages.error(request, error)
+
return redirect(event)
# Check if the user is eligible to attend this event.
@@ -106,10 +106,6 @@
response = event.is_eligible_for_signup(request.user);
if response['status']:
- # First time accepting mark rules
- if 'mark_rules' in form.cleaned_data:
- request.user.mark_rules = True
- request.user.save()
Attendee(event=attendance_event, user=request.user).save()
messages.success(request, _(u"Du er nå påmeldt på arrangementet!"))
return redirect(event)
| {"golden_diff": "diff --git a/apps/events/forms.py b/apps/events/forms.py\n--- a/apps/events/forms.py\n+++ b/apps/events/forms.py\n@@ -1,12 +1,48 @@\n+#-*- coding: utf-8 -*-\n+\n from django import forms\n from captcha.fields import CaptchaField\n+from django.utils.translation import ugettext as _\n \n class CaptchaForm(forms.Form):\n+\n+ phone_number = forms.CharField(label=_(u'Telefonnummer er p\u00e5krevd for \u00e5 v\u00e6re p\u00e5meldt et arrangement.'),\n+ error_messages={'required' : _(u'Telefonnummer er p\u00e5krevd!')})\n+ mark_rules = forms.BooleanField(label=_(u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>'),\n+ error_messages={'required' : _(u'Du m\u00e5 godta prikkereglene!')})\n+ captcha = CaptchaField(error_messages={'required' : _(u'Du klarte ikke captchaen! Er du en bot?')})\n+\n def __init__(self, *args, **kwargs):\n- user = kwargs.pop('user', None)\n+ self.user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n+\n # Removing mark rules field if user has already accepted the rules\n- if user and user.is_authenticated() and user.mark_rules:\n- del self.fields['mark_rules']\n- mark_rules = forms.BooleanField(label=u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>')\n- captcha = CaptchaField()\n+ if self.user and self.user.is_authenticated():\n+ if self.user.mark_rules:\n+ del self.fields['mark_rules']\n+\n+ if self.user.phone_number:\n+ del self.fields['phone_number']\n+\n+\n+ def clean(self):\n+ super(CaptchaForm, self).clean()\n+ cleaned_data = self.cleaned_data\n+\n+ if 'mark_rules' in self.fields:\n+ if 'mark_rules' in cleaned_data:\n+ mark_rules = cleaned_data['mark_rules']\n+\n+ if mark_rules:\n+ self.user.mark_rules = True\n+ self.user.save()\n+\n+ if 'phone_number' in self.fields:\n+ if 'phone_number' in cleaned_data:\n+ phone_number = cleaned_data['phone_number']\n+\n+ if phone_number:\n+ self.user.phone_number = phone_number\n+ self.user.save()\n+\n+ return cleaned_data\n\\ No newline at end of file\ndiff --git a/apps/events/views.py b/apps/events/views.py\n--- a/apps/events/views.py\n+++ b/apps/events/views.py\n@@ -89,14 +89,14 @@\n if not request.POST:\n messages.error(request, _(u'Vennligst fyll ut skjemaet.'))\n return redirect(event)\n+\n form = CaptchaForm(request.POST, user=request.user)\n \n if not form.is_valid():\n- if not 'mark_rules' in request.POST and not request.user.mark_rules:\n- error_message = u'Du m\u00e5 godta prikkreglene for \u00e5 melde deg p\u00e5.'\n- else:\n- error_message = u'Du klarte ikke captcha-en. Er du en bot?'\n- messages.error(request, _(error_message))\n+ for field,errors in form.errors.items():\n+ for error in errors:\n+ messages.error(request, error)\n+\n return redirect(event)\n \n # Check if the user is eligible to attend this event.\n@@ -106,10 +106,6 @@\n response = event.is_eligible_for_signup(request.user);\n \n if response['status']: \n- # First time accepting mark rules\n- if 'mark_rules' in form.cleaned_data:\n- request.user.mark_rules = True\n- request.user.save()\n Attendee(event=attendance_event, user=request.user).save()\n messages.success(request, _(u\"Du er n\u00e5 p\u00e5meldt p\u00e5 arrangementet!\"))\n return redirect(event)\n", "issue": "Mandatory phone number in profile\nIt has been requested from arrkom among others and decided in HS that phone numbers in the user profile should be mandatory for people attending events. So we need to implement functionality similar to the one used for \"prikkeregler\". \n\nIf users hide this in their profile the info could behave as allergies and only show up when events are exported to pdf. \n\n", "before_files": [{"content": "#-*- coding: utf-8 -*-\n\nimport datetime\n\nfrom django.utils import timezone\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required, user_passes_test\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.utils.translation import ugettext as _\n\nimport watson\n\nfrom apps.events.forms import CaptchaForm\nfrom apps.events.models import Event, AttendanceEvent, Attendee\nfrom apps.events.pdf_generator import EventPDF\n\n\ndef index(request):\n return render(request, 'events/index.html', {})\n\ndef details(request, event_id, event_slug):\n event = get_object_or_404(Event, pk=event_id)\n\n is_attendance_event = False\n user_anonymous = True\n user_attending = False\n place_on_wait_list = 0\n will_be_on_wait_list = False\n rules = []\n user_status = False\n\n try:\n attendance_event = AttendanceEvent.objects.get(pk=event_id)\n is_attendance_event = True\n form = CaptchaForm(user=request.user)\n\n if attendance_event.rule_bundles:\n for rule_bundle in attendance_event.rule_bundles.all():\n rules.append(rule_bundle.get_rule_strings)\n\n if request.user.is_authenticated():\n user_anonymous = False\n if attendance_event.is_attendee(request.user):\n user_attending = True\n\n \n will_be_on_wait_list = attendance_event.will_i_be_on_wait_list\n\n user_status = event.is_eligible_for_signup(request.user)\n\n # Check if this user is on the waitlist\n place_on_wait_list = event.what_place_is_user_on_wait_list(request.user)\n\n except AttendanceEvent.DoesNotExist:\n pass\n\n if is_attendance_event:\n context = {\n 'now': timezone.now(),\n 'event': event,\n 'attendance_event': attendance_event,\n 'user_anonymous': user_anonymous,\n 'user_attending': user_attending,\n 'will_be_on_wait_list': will_be_on_wait_list,\n 'rules': rules,\n 'user_status': user_status,\n 'place_on_wait_list': int(place_on_wait_list),\n #'position_in_wait_list': position_in_wait_list,\n 'captcha_form': form,\n }\n \n return render(request, 'events/details.html', context)\n else:\n return render(request, 'events/details.html', {'event': event})\n\n\ndef get_attendee(attendee_id):\n return get_object_or_404(Attendee, pk=attendee_id)\n\n@login_required\ndef attendEvent(request, event_id):\n \n event = get_object_or_404(Event, pk=event_id)\n\n if not request.POST:\n messages.error(request, _(u'Vennligst fyll ut skjemaet.'))\n return redirect(event)\n form = CaptchaForm(request.POST, user=request.user)\n\n if not form.is_valid():\n if not 'mark_rules' in request.POST and not request.user.mark_rules:\n error_message = u'Du m\u00e5 godta prikkreglene for \u00e5 melde deg p\u00e5.'\n else:\n error_message = u'Du klarte ikke captcha-en. Er du en bot?'\n messages.error(request, _(error_message))\n return redirect(event)\n\n # Check if the user is eligible to attend this event.\n # If not, an error message will be present in the returned dict\n attendance_event = event.attendance_event\n\n response = event.is_eligible_for_signup(request.user);\n\n if response['status']: \n # First time accepting mark rules\n if 'mark_rules' in form.cleaned_data:\n request.user.mark_rules = True\n request.user.save()\n Attendee(event=attendance_event, user=request.user).save()\n messages.success(request, _(u\"Du er n\u00e5 p\u00e5meldt p\u00e5 arrangementet!\"))\n return redirect(event)\n else:\n messages.error(request, response['message'])\n return redirect(event)\n\n@login_required\ndef unattendEvent(request, event_id):\n\n event = get_object_or_404(Event, pk=event_id)\n attendance_event = event.attendance_event\n\n # Check if the deadline for unattending has passed\n if attendance_event.unattend_deadline < timezone.now():\n messages.error(request, _(u\"Avmeldingsfristen for dette arrangementet har utl\u00f8pt.\"))\n return redirect(event)\n\n event.notify_waiting_list(host=request.META['HTTP_HOST'], unattended_user=request.user)\n Attendee.objects.get(event=attendance_event, user=request.user).delete()\n\n messages.success(request, _(u\"Du ble meldt av arrangementet.\"))\n return redirect(event)\n\ndef search_events(request):\n query = request.GET.get('query')\n filters = {\n 'future' : request.GET.get('future'),\n 'myevents' : request.GET.get('myevents')\n }\n events = _search_indexed(request, query, filters)\n\n return render(request, 'events/search.html', {'events': events})\n\n\ndef _search_indexed(request, query, filters):\n results = []\n kwargs = {}\n\n if filters['future'] == 'true':\n kwargs['event_start__gte'] = timezone.now()\n\n if filters['myevents'] == 'true':\n kwargs['attendance_event__attendees'] = request.user\n\n events = Event.objects.filter(**kwargs).order_by('event_start').prefetch_related(\n 'attendance_event', 'attendance_event__attendees')\n\n if query:\n for result in watson.search(query, models=(events,)):\n results.append(result.object)\n return results[:10]\n\n return events\n\n\n@login_required()\n@user_passes_test(lambda u: u.groups.filter(name='Komiteer').count() == 1)\ndef generate_pdf(request, event_id):\n\n event = get_object_or_404(Event, pk=event_id)\n\n groups = request.user.groups.all()\n if not (groups.filter(name='dotKom').count() == 1 or groups.filter(name='Hovedstyret').count() == 1):\n if event.event_type == 1 and not groups.filter(name='arrKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))\n return redirect(event)\n\n if event.event_type == 2 and not groups.filter(name='bedKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))\n return redirect(event)\n\n if event.event_type == 3 and not groups.filter(name='fagKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.')) \n return redirect(event)\n\n return EventPDF(event).render_pdf()\n", "path": "apps/events/views.py"}, {"content": "from django import forms\nfrom captcha.fields import CaptchaField\n\nclass CaptchaForm(forms.Form):\n def __init__(self, *args, **kwargs):\n user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n # Removing mark rules field if user has already accepted the rules\n if user and user.is_authenticated() and user.mark_rules:\n del self.fields['mark_rules']\n mark_rules = forms.BooleanField(label=u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>')\n captcha = CaptchaField()\n", "path": "apps/events/forms.py"}], "after_files": [{"content": "#-*- coding: utf-8 -*-\n\nimport datetime\n\nfrom django.utils import timezone\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required, user_passes_test\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.utils.translation import ugettext as _\n\nimport watson\n\nfrom apps.events.forms import CaptchaForm\nfrom apps.events.models import Event, AttendanceEvent, Attendee\nfrom apps.events.pdf_generator import EventPDF\n\n\ndef index(request):\n return render(request, 'events/index.html', {})\n\ndef details(request, event_id, event_slug):\n event = get_object_or_404(Event, pk=event_id)\n\n is_attendance_event = False\n user_anonymous = True\n user_attending = False\n place_on_wait_list = 0\n will_be_on_wait_list = False\n rules = []\n user_status = False\n\n try:\n attendance_event = AttendanceEvent.objects.get(pk=event_id)\n is_attendance_event = True\n form = CaptchaForm(user=request.user)\n\n if attendance_event.rule_bundles:\n for rule_bundle in attendance_event.rule_bundles.all():\n rules.append(rule_bundle.get_rule_strings)\n\n if request.user.is_authenticated():\n user_anonymous = False\n if attendance_event.is_attendee(request.user):\n user_attending = True\n\n \n will_be_on_wait_list = attendance_event.will_i_be_on_wait_list\n\n user_status = event.is_eligible_for_signup(request.user)\n\n # Check if this user is on the waitlist\n place_on_wait_list = event.what_place_is_user_on_wait_list(request.user)\n\n except AttendanceEvent.DoesNotExist:\n pass\n\n if is_attendance_event:\n context = {\n 'now': timezone.now(),\n 'event': event,\n 'attendance_event': attendance_event,\n 'user_anonymous': user_anonymous,\n 'user_attending': user_attending,\n 'will_be_on_wait_list': will_be_on_wait_list,\n 'rules': rules,\n 'user_status': user_status,\n 'place_on_wait_list': int(place_on_wait_list),\n #'position_in_wait_list': position_in_wait_list,\n 'captcha_form': form,\n }\n \n return render(request, 'events/details.html', context)\n else:\n return render(request, 'events/details.html', {'event': event})\n\n\ndef get_attendee(attendee_id):\n return get_object_or_404(Attendee, pk=attendee_id)\n\n@login_required\ndef attendEvent(request, event_id):\n \n event = get_object_or_404(Event, pk=event_id)\n\n if not request.POST:\n messages.error(request, _(u'Vennligst fyll ut skjemaet.'))\n return redirect(event)\n\n form = CaptchaForm(request.POST, user=request.user)\n\n if not form.is_valid():\n for field,errors in form.errors.items():\n for error in errors:\n messages.error(request, error)\n\n return redirect(event)\n\n # Check if the user is eligible to attend this event.\n # If not, an error message will be present in the returned dict\n attendance_event = event.attendance_event\n\n response = event.is_eligible_for_signup(request.user);\n\n if response['status']: \n Attendee(event=attendance_event, user=request.user).save()\n messages.success(request, _(u\"Du er n\u00e5 p\u00e5meldt p\u00e5 arrangementet!\"))\n return redirect(event)\n else:\n messages.error(request, response['message'])\n return redirect(event)\n\n@login_required\ndef unattendEvent(request, event_id):\n\n event = get_object_or_404(Event, pk=event_id)\n attendance_event = event.attendance_event\n\n # Check if the deadline for unattending has passed\n if attendance_event.unattend_deadline < timezone.now():\n messages.error(request, _(u\"Avmeldingsfristen for dette arrangementet har utl\u00f8pt.\"))\n return redirect(event)\n \n Attendee.objects.get(event=attendance_event, user=request.user).delete()\n\n messages.success(request, _(u\"Du ble meldt av arrangementet.\"))\n return redirect(event)\n\ndef search_events(request):\n query = request.GET.get('query')\n filters = {\n 'future' : request.GET.get('future'),\n 'myevents' : request.GET.get('myevents')\n }\n events = _search_indexed(request, query, filters)\n\n return render(request, 'events/search.html', {'events': events})\n\n\ndef _search_indexed(request, query, filters):\n results = []\n kwargs = {}\n\n if filters['future'] == 'true':\n kwargs['event_start__gte'] = timezone.now()\n\n if filters['myevents'] == 'true':\n kwargs['attendance_event__attendees'] = request.user\n\n events = Event.objects.filter(**kwargs).order_by('event_start').prefetch_related(\n 'attendance_event', 'attendance_event__attendees')\n\n if query:\n for result in watson.search(query, models=(events,)):\n results.append(result.object)\n return results[:10]\n\n return events\n\n\n@login_required()\n@user_passes_test(lambda u: u.groups.filter(name='Komiteer').count() == 1)\ndef generate_pdf(request, event_id):\n\n event = get_object_or_404(Event, pk=event_id)\n\n groups = request.user.groups.all()\n if not (groups.filter(name='dotKom').count() == 1 or groups.filter(name='Hovedstyret').count() == 1):\n if event.event_type == 1 and not groups.filter(name='arrKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))\n return redirect(event)\n\n if event.event_type == 2 and not groups.filter(name='bedKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.'))\n return redirect(event)\n\n if event.event_type == 3 and not groups.filter(name='fagKom').count() == 1:\n messages.error(request, _(u'Du har ikke tilgang til listen for dette arrangementet.')) \n return redirect(event)\n\n return EventPDF(event).render_pdf()\n", "path": "apps/events/views.py"}, {"content": "#-*- coding: utf-8 -*-\n\nfrom django import forms\nfrom captcha.fields import CaptchaField\nfrom django.utils.translation import ugettext as _\n\nclass CaptchaForm(forms.Form):\n\n phone_number = forms.CharField(label=_(u'Telefonnummer er p\u00e5krevd for \u00e5 v\u00e6re p\u00e5meldt et arrangement.'),\n error_messages={'required' : _(u'Telefonnummer er p\u00e5krevd!')})\n mark_rules = forms.BooleanField(label=_(u'Jeg godtar <a href=\"/profile/#marks\" target=\"_blank\">prikkreglene</a>'),\n error_messages={'required' : _(u'Du m\u00e5 godta prikkereglene!')})\n captcha = CaptchaField(error_messages={'required' : _(u'Du klarte ikke captchaen! Er du en bot?')})\n\n def __init__(self, *args, **kwargs):\n self.user = kwargs.pop('user', None)\n super(CaptchaForm, self).__init__(*args, **kwargs)\n\n # Removing mark rules field if user has already accepted the rules\n if self.user and self.user.is_authenticated():\n if self.user.mark_rules:\n del self.fields['mark_rules']\n\n if self.user.phone_number:\n del self.fields['phone_number']\n\n\n def clean(self):\n super(CaptchaForm, self).clean()\n cleaned_data = self.cleaned_data\n\n if 'mark_rules' in self.fields:\n if 'mark_rules' in cleaned_data:\n mark_rules = cleaned_data['mark_rules']\n\n if mark_rules:\n self.user.mark_rules = True\n self.user.save()\n\n if 'phone_number' in self.fields:\n if 'phone_number' in cleaned_data:\n phone_number = cleaned_data['phone_number']\n\n if phone_number:\n self.user.phone_number = phone_number\n self.user.save()\n\n return cleaned_data", "path": "apps/events/forms.py"}]} | 2,458 | 880 |
gh_patches_debug_26159 | rasdani/github-patches | git_diff | keras-team__keras-7330 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
skipgram seed parameter got removed in a documentation patch, seed parameter should be readded
Patch 0af6b6c7f5cbad394673bc962dd248f50fd821ff removed the seed parameter from skipgrams. Having a seed parameter makes it easier to vary the results from``skipgram`` in a controlled way.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/preprocessing/sequence.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import
3
4 import numpy as np
5 import random
6 from six.moves import range
7
8
9 def pad_sequences(sequences, maxlen=None, dtype='int32',
10 padding='pre', truncating='pre', value=0.):
11 """Pads each sequence to the same length (length of the longest sequence).
12
13 If maxlen is provided, any sequence longer
14 than maxlen is truncated to maxlen.
15 Truncation happens off either the beginning (default) or
16 the end of the sequence.
17
18 Supports post-padding and pre-padding (default).
19
20 # Arguments
21 sequences: list of lists where each element is a sequence
22 maxlen: int, maximum length
23 dtype: type to cast the resulting sequence.
24 padding: 'pre' or 'post', pad either before or after each sequence.
25 truncating: 'pre' or 'post', remove values from sequences larger than
26 maxlen either in the beginning or in the end of the sequence
27 value: float, value to pad the sequences to the desired value.
28
29 # Returns
30 x: numpy array with dimensions (number_of_sequences, maxlen)
31
32 # Raises
33 ValueError: in case of invalid values for `truncating` or `padding`,
34 or in case of invalid shape for a `sequences` entry.
35 """
36 if not hasattr(sequences, '__len__'):
37 raise ValueError('`sequences` must be iterable.')
38 lengths = []
39 for x in sequences:
40 if not hasattr(x, '__len__'):
41 raise ValueError('`sequences` must be a list of iterables. '
42 'Found non-iterable: ' + str(x))
43 lengths.append(len(x))
44
45 num_samples = len(sequences)
46 if maxlen is None:
47 maxlen = np.max(lengths)
48
49 # take the sample shape from the first non empty sequence
50 # checking for consistency in the main loop below.
51 sample_shape = tuple()
52 for s in sequences:
53 if len(s) > 0:
54 sample_shape = np.asarray(s).shape[1:]
55 break
56
57 x = (np.ones((num_samples, maxlen) + sample_shape) * value).astype(dtype)
58 for idx, s in enumerate(sequences):
59 if not len(s):
60 continue # empty list/array was found
61 if truncating == 'pre':
62 trunc = s[-maxlen:]
63 elif truncating == 'post':
64 trunc = s[:maxlen]
65 else:
66 raise ValueError('Truncating type "%s" not understood' % truncating)
67
68 # check `trunc` has expected shape
69 trunc = np.asarray(trunc, dtype=dtype)
70 if trunc.shape[1:] != sample_shape:
71 raise ValueError('Shape of sample %s of sequence at position %s is different from expected shape %s' %
72 (trunc.shape[1:], idx, sample_shape))
73
74 if padding == 'post':
75 x[idx, :len(trunc)] = trunc
76 elif padding == 'pre':
77 x[idx, -len(trunc):] = trunc
78 else:
79 raise ValueError('Padding type "%s" not understood' % padding)
80 return x
81
82
83 def make_sampling_table(size, sampling_factor=1e-5):
84 """Generates a word rank-based probabilistic sampling table.
85
86 This generates an array where the ith element
87 is the probability that a word of rank i would be sampled,
88 according to the sampling distribution used in word2vec.
89
90 The word2vec formula is:
91 p(word) = min(1, sqrt(word.frequency/sampling_factor) / (word.frequency/sampling_factor))
92
93 We assume that the word frequencies follow Zipf's law (s=1) to derive
94 a numerical approximation of frequency(rank):
95 frequency(rank) ~ 1/(rank * (log(rank) + gamma) + 1/2 - 1/(12*rank))
96 where gamma is the Euler-Mascheroni constant.
97
98 # Arguments
99 size: int, number of possible words to sample.
100 sampling_factor: the sampling factor in the word2vec formula.
101
102 # Returns
103 A 1D Numpy array of length `size` where the ith entry
104 is the probability that a word of rank i should be sampled.
105 """
106 gamma = 0.577
107 rank = np.arange(size)
108 rank[0] = 1
109 inv_fq = rank * (np.log(rank) + gamma) + 0.5 - 1. / (12. * rank)
110 f = sampling_factor * inv_fq
111
112 return np.minimum(1., f / np.sqrt(f))
113
114
115 def skipgrams(sequence, vocabulary_size,
116 window_size=4, negative_samples=1., shuffle=True,
117 categorical=False, sampling_table=None):
118 """Generates skipgram word pairs.
119
120 Takes a sequence (list of indexes of words),
121 returns couples of [word_index, other_word index] and labels (1s or 0s),
122 where label = 1 if 'other_word' belongs to the context of 'word',
123 and label=0 if 'other_word' is randomly sampled
124
125 # Arguments
126 sequence: a word sequence (sentence), encoded as a list
127 of word indices (integers). If using a `sampling_table`,
128 word indices are expected to match the rank
129 of the words in a reference dataset (e.g. 10 would encode
130 the 10-th most frequently occurring token).
131 Note that index 0 is expected to be a non-word and will be skipped.
132 vocabulary_size: int. maximum possible word index + 1
133 window_size: int. actually half-window.
134 The window of a word wi will be [i-window_size, i+window_size+1]
135 negative_samples: float >= 0. 0 for no negative (=random) samples.
136 1 for same number as positive samples. etc.
137 shuffle: whether to shuffle the word couples before returning them.
138 categorical: bool. if False, labels will be
139 integers (eg. [0, 1, 1 .. ]),
140 if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]
141 sampling_table: 1D array of size `vocabulary_size` where the entry i
142 encodes the probabibily to sample a word of rank i.
143
144 # Returns
145 couples, labels: where `couples` are int pairs and
146 `labels` are either 0 or 1.
147
148 # Note
149 By convention, index 0 in the vocabulary is
150 a non-word and will be skipped.
151 """
152 couples = []
153 labels = []
154 for i, wi in enumerate(sequence):
155 if not wi:
156 continue
157 if sampling_table is not None:
158 if sampling_table[wi] < random.random():
159 continue
160
161 window_start = max(0, i - window_size)
162 window_end = min(len(sequence), i + window_size + 1)
163 for j in range(window_start, window_end):
164 if j != i:
165 wj = sequence[j]
166 if not wj:
167 continue
168 couples.append([wi, wj])
169 if categorical:
170 labels.append([0, 1])
171 else:
172 labels.append(1)
173
174 if negative_samples > 0:
175 num_negative_samples = int(len(labels) * negative_samples)
176 words = [c[0] for c in couples]
177 random.shuffle(words)
178
179 couples += [[words[i % len(words)],
180 random.randint(1, vocabulary_size - 1)] for i in range(num_negative_samples)]
181 if categorical:
182 labels += [[1, 0]] * num_negative_samples
183 else:
184 labels += [0] * num_negative_samples
185
186 if shuffle:
187 seed = random.randint(0, 10e6)
188 random.seed(seed)
189 random.shuffle(couples)
190 random.seed(seed)
191 random.shuffle(labels)
192
193 return couples, labels
194
195
196 def _remove_long_seq(maxlen, seq, label):
197 """Removes sequences that exceed the maximum length.
198
199 # Arguments
200 maxlen: int, maximum length
201 seq: list of lists where each sublist is a sequence
202 label: list where each element is an integer
203
204 # Returns
205 new_seq, new_label: shortened lists for `seq` and `label`.
206 """
207 new_seq, new_label = [], []
208 for x, y in zip(seq, label):
209 if len(x) < maxlen:
210 new_seq.append(x)
211 new_label.append(y)
212 return new_seq, new_label
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/keras/preprocessing/sequence.py b/keras/preprocessing/sequence.py
--- a/keras/preprocessing/sequence.py
+++ b/keras/preprocessing/sequence.py
@@ -114,7 +114,7 @@
def skipgrams(sequence, vocabulary_size,
window_size=4, negative_samples=1., shuffle=True,
- categorical=False, sampling_table=None):
+ categorical=False, sampling_table=None, seed=None):
"""Generates skipgram word pairs.
Takes a sequence (list of indexes of words),
@@ -140,6 +140,7 @@
if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]
sampling_table: 1D array of size `vocabulary_size` where the entry i
encodes the probabibily to sample a word of rank i.
+ seed: random seed.
# Returns
couples, labels: where `couples` are int pairs and
@@ -184,7 +185,8 @@
labels += [0] * num_negative_samples
if shuffle:
- seed = random.randint(0, 10e6)
+ if seed is None:
+ seed = random.randint(0, 10e6)
random.seed(seed)
random.shuffle(couples)
random.seed(seed)
| {"golden_diff": "diff --git a/keras/preprocessing/sequence.py b/keras/preprocessing/sequence.py\n--- a/keras/preprocessing/sequence.py\n+++ b/keras/preprocessing/sequence.py\n@@ -114,7 +114,7 @@\n \n def skipgrams(sequence, vocabulary_size,\n window_size=4, negative_samples=1., shuffle=True,\n- categorical=False, sampling_table=None):\n+ categorical=False, sampling_table=None, seed=None):\n \"\"\"Generates skipgram word pairs.\n \n Takes a sequence (list of indexes of words),\n@@ -140,6 +140,7 @@\n if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]\n sampling_table: 1D array of size `vocabulary_size` where the entry i\n encodes the probabibily to sample a word of rank i.\n+ seed: random seed.\n \n # Returns\n couples, labels: where `couples` are int pairs and\n@@ -184,7 +185,8 @@\n labels += [0] * num_negative_samples\n \n if shuffle:\n- seed = random.randint(0, 10e6)\n+ if seed is None:\n+ seed = random.randint(0, 10e6)\n random.seed(seed)\n random.shuffle(couples)\n random.seed(seed)\n", "issue": "skipgram seed parameter got removed in a documentation patch, seed parameter should be readded\nPatch 0af6b6c7f5cbad394673bc962dd248f50fd821ff removed the seed parameter from skipgrams. Having a seed parameter makes it easier to vary the results from``skipgram`` in a controlled way.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\n\nimport numpy as np\nimport random\nfrom six.moves import range\n\n\ndef pad_sequences(sequences, maxlen=None, dtype='int32',\n padding='pre', truncating='pre', value=0.):\n \"\"\"Pads each sequence to the same length (length of the longest sequence).\n\n If maxlen is provided, any sequence longer\n than maxlen is truncated to maxlen.\n Truncation happens off either the beginning (default) or\n the end of the sequence.\n\n Supports post-padding and pre-padding (default).\n\n # Arguments\n sequences: list of lists where each element is a sequence\n maxlen: int, maximum length\n dtype: type to cast the resulting sequence.\n padding: 'pre' or 'post', pad either before or after each sequence.\n truncating: 'pre' or 'post', remove values from sequences larger than\n maxlen either in the beginning or in the end of the sequence\n value: float, value to pad the sequences to the desired value.\n\n # Returns\n x: numpy array with dimensions (number_of_sequences, maxlen)\n\n # Raises\n ValueError: in case of invalid values for `truncating` or `padding`,\n or in case of invalid shape for a `sequences` entry.\n \"\"\"\n if not hasattr(sequences, '__len__'):\n raise ValueError('`sequences` must be iterable.')\n lengths = []\n for x in sequences:\n if not hasattr(x, '__len__'):\n raise ValueError('`sequences` must be a list of iterables. '\n 'Found non-iterable: ' + str(x))\n lengths.append(len(x))\n\n num_samples = len(sequences)\n if maxlen is None:\n maxlen = np.max(lengths)\n\n # take the sample shape from the first non empty sequence\n # checking for consistency in the main loop below.\n sample_shape = tuple()\n for s in sequences:\n if len(s) > 0:\n sample_shape = np.asarray(s).shape[1:]\n break\n\n x = (np.ones((num_samples, maxlen) + sample_shape) * value).astype(dtype)\n for idx, s in enumerate(sequences):\n if not len(s):\n continue # empty list/array was found\n if truncating == 'pre':\n trunc = s[-maxlen:]\n elif truncating == 'post':\n trunc = s[:maxlen]\n else:\n raise ValueError('Truncating type \"%s\" not understood' % truncating)\n\n # check `trunc` has expected shape\n trunc = np.asarray(trunc, dtype=dtype)\n if trunc.shape[1:] != sample_shape:\n raise ValueError('Shape of sample %s of sequence at position %s is different from expected shape %s' %\n (trunc.shape[1:], idx, sample_shape))\n\n if padding == 'post':\n x[idx, :len(trunc)] = trunc\n elif padding == 'pre':\n x[idx, -len(trunc):] = trunc\n else:\n raise ValueError('Padding type \"%s\" not understood' % padding)\n return x\n\n\ndef make_sampling_table(size, sampling_factor=1e-5):\n \"\"\"Generates a word rank-based probabilistic sampling table.\n\n This generates an array where the ith element\n is the probability that a word of rank i would be sampled,\n according to the sampling distribution used in word2vec.\n\n The word2vec formula is:\n p(word) = min(1, sqrt(word.frequency/sampling_factor) / (word.frequency/sampling_factor))\n\n We assume that the word frequencies follow Zipf's law (s=1) to derive\n a numerical approximation of frequency(rank):\n frequency(rank) ~ 1/(rank * (log(rank) + gamma) + 1/2 - 1/(12*rank))\n where gamma is the Euler-Mascheroni constant.\n\n # Arguments\n size: int, number of possible words to sample.\n sampling_factor: the sampling factor in the word2vec formula.\n\n # Returns\n A 1D Numpy array of length `size` where the ith entry\n is the probability that a word of rank i should be sampled.\n \"\"\"\n gamma = 0.577\n rank = np.arange(size)\n rank[0] = 1\n inv_fq = rank * (np.log(rank) + gamma) + 0.5 - 1. / (12. * rank)\n f = sampling_factor * inv_fq\n\n return np.minimum(1., f / np.sqrt(f))\n\n\ndef skipgrams(sequence, vocabulary_size,\n window_size=4, negative_samples=1., shuffle=True,\n categorical=False, sampling_table=None):\n \"\"\"Generates skipgram word pairs.\n\n Takes a sequence (list of indexes of words),\n returns couples of [word_index, other_word index] and labels (1s or 0s),\n where label = 1 if 'other_word' belongs to the context of 'word',\n and label=0 if 'other_word' is randomly sampled\n\n # Arguments\n sequence: a word sequence (sentence), encoded as a list\n of word indices (integers). If using a `sampling_table`,\n word indices are expected to match the rank\n of the words in a reference dataset (e.g. 10 would encode\n the 10-th most frequently occurring token).\n Note that index 0 is expected to be a non-word and will be skipped.\n vocabulary_size: int. maximum possible word index + 1\n window_size: int. actually half-window.\n The window of a word wi will be [i-window_size, i+window_size+1]\n negative_samples: float >= 0. 0 for no negative (=random) samples.\n 1 for same number as positive samples. etc.\n shuffle: whether to shuffle the word couples before returning them.\n categorical: bool. if False, labels will be\n integers (eg. [0, 1, 1 .. ]),\n if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]\n sampling_table: 1D array of size `vocabulary_size` where the entry i\n encodes the probabibily to sample a word of rank i.\n\n # Returns\n couples, labels: where `couples` are int pairs and\n `labels` are either 0 or 1.\n\n # Note\n By convention, index 0 in the vocabulary is\n a non-word and will be skipped.\n \"\"\"\n couples = []\n labels = []\n for i, wi in enumerate(sequence):\n if not wi:\n continue\n if sampling_table is not None:\n if sampling_table[wi] < random.random():\n continue\n\n window_start = max(0, i - window_size)\n window_end = min(len(sequence), i + window_size + 1)\n for j in range(window_start, window_end):\n if j != i:\n wj = sequence[j]\n if not wj:\n continue\n couples.append([wi, wj])\n if categorical:\n labels.append([0, 1])\n else:\n labels.append(1)\n\n if negative_samples > 0:\n num_negative_samples = int(len(labels) * negative_samples)\n words = [c[0] for c in couples]\n random.shuffle(words)\n\n couples += [[words[i % len(words)],\n random.randint(1, vocabulary_size - 1)] for i in range(num_negative_samples)]\n if categorical:\n labels += [[1, 0]] * num_negative_samples\n else:\n labels += [0] * num_negative_samples\n\n if shuffle:\n seed = random.randint(0, 10e6)\n random.seed(seed)\n random.shuffle(couples)\n random.seed(seed)\n random.shuffle(labels)\n\n return couples, labels\n\n\ndef _remove_long_seq(maxlen, seq, label):\n \"\"\"Removes sequences that exceed the maximum length.\n\n # Arguments\n maxlen: int, maximum length\n seq: list of lists where each sublist is a sequence\n label: list where each element is an integer\n\n # Returns\n new_seq, new_label: shortened lists for `seq` and `label`.\n \"\"\"\n new_seq, new_label = [], []\n for x, y in zip(seq, label):\n if len(x) < maxlen:\n new_seq.append(x)\n new_label.append(y)\n return new_seq, new_label\n", "path": "keras/preprocessing/sequence.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\n\nimport numpy as np\nimport random\nfrom six.moves import range\n\n\ndef pad_sequences(sequences, maxlen=None, dtype='int32',\n padding='pre', truncating='pre', value=0.):\n \"\"\"Pads each sequence to the same length (length of the longest sequence).\n\n If maxlen is provided, any sequence longer\n than maxlen is truncated to maxlen.\n Truncation happens off either the beginning (default) or\n the end of the sequence.\n\n Supports post-padding and pre-padding (default).\n\n # Arguments\n sequences: list of lists where each element is a sequence\n maxlen: int, maximum length\n dtype: type to cast the resulting sequence.\n padding: 'pre' or 'post', pad either before or after each sequence.\n truncating: 'pre' or 'post', remove values from sequences larger than\n maxlen either in the beginning or in the end of the sequence\n value: float, value to pad the sequences to the desired value.\n\n # Returns\n x: numpy array with dimensions (number_of_sequences, maxlen)\n\n # Raises\n ValueError: in case of invalid values for `truncating` or `padding`,\n or in case of invalid shape for a `sequences` entry.\n \"\"\"\n if not hasattr(sequences, '__len__'):\n raise ValueError('`sequences` must be iterable.')\n lengths = []\n for x in sequences:\n if not hasattr(x, '__len__'):\n raise ValueError('`sequences` must be a list of iterables. '\n 'Found non-iterable: ' + str(x))\n lengths.append(len(x))\n\n num_samples = len(sequences)\n if maxlen is None:\n maxlen = np.max(lengths)\n\n # take the sample shape from the first non empty sequence\n # checking for consistency in the main loop below.\n sample_shape = tuple()\n for s in sequences:\n if len(s) > 0:\n sample_shape = np.asarray(s).shape[1:]\n break\n\n x = (np.ones((num_samples, maxlen) + sample_shape) * value).astype(dtype)\n for idx, s in enumerate(sequences):\n if not len(s):\n continue # empty list/array was found\n if truncating == 'pre':\n trunc = s[-maxlen:]\n elif truncating == 'post':\n trunc = s[:maxlen]\n else:\n raise ValueError('Truncating type \"%s\" not understood' % truncating)\n\n # check `trunc` has expected shape\n trunc = np.asarray(trunc, dtype=dtype)\n if trunc.shape[1:] != sample_shape:\n raise ValueError('Shape of sample %s of sequence at position %s is different from expected shape %s' %\n (trunc.shape[1:], idx, sample_shape))\n\n if padding == 'post':\n x[idx, :len(trunc)] = trunc\n elif padding == 'pre':\n x[idx, -len(trunc):] = trunc\n else:\n raise ValueError('Padding type \"%s\" not understood' % padding)\n return x\n\n\ndef make_sampling_table(size, sampling_factor=1e-5):\n \"\"\"Generates a word rank-based probabilistic sampling table.\n\n This generates an array where the ith element\n is the probability that a word of rank i would be sampled,\n according to the sampling distribution used in word2vec.\n\n The word2vec formula is:\n p(word) = min(1, sqrt(word.frequency/sampling_factor) / (word.frequency/sampling_factor))\n\n We assume that the word frequencies follow Zipf's law (s=1) to derive\n a numerical approximation of frequency(rank):\n frequency(rank) ~ 1/(rank * (log(rank) + gamma) + 1/2 - 1/(12*rank))\n where gamma is the Euler-Mascheroni constant.\n\n # Arguments\n size: int, number of possible words to sample.\n sampling_factor: the sampling factor in the word2vec formula.\n\n # Returns\n A 1D Numpy array of length `size` where the ith entry\n is the probability that a word of rank i should be sampled.\n \"\"\"\n gamma = 0.577\n rank = np.arange(size)\n rank[0] = 1\n inv_fq = rank * (np.log(rank) + gamma) + 0.5 - 1. / (12. * rank)\n f = sampling_factor * inv_fq\n\n return np.minimum(1., f / np.sqrt(f))\n\n\ndef skipgrams(sequence, vocabulary_size,\n window_size=4, negative_samples=1., shuffle=True,\n categorical=False, sampling_table=None, seed=None):\n \"\"\"Generates skipgram word pairs.\n\n Takes a sequence (list of indexes of words),\n returns couples of [word_index, other_word index] and labels (1s or 0s),\n where label = 1 if 'other_word' belongs to the context of 'word',\n and label=0 if 'other_word' is randomly sampled\n\n # Arguments\n sequence: a word sequence (sentence), encoded as a list\n of word indices (integers). If using a `sampling_table`,\n word indices are expected to match the rank\n of the words in a reference dataset (e.g. 10 would encode\n the 10-th most frequently occurring token).\n Note that index 0 is expected to be a non-word and will be skipped.\n vocabulary_size: int. maximum possible word index + 1\n window_size: int. actually half-window.\n The window of a word wi will be [i-window_size, i+window_size+1]\n negative_samples: float >= 0. 0 for no negative (=random) samples.\n 1 for same number as positive samples. etc.\n shuffle: whether to shuffle the word couples before returning them.\n categorical: bool. if False, labels will be\n integers (eg. [0, 1, 1 .. ]),\n if True labels will be categorical eg. [[1,0],[0,1],[0,1] .. ]\n sampling_table: 1D array of size `vocabulary_size` where the entry i\n encodes the probabibily to sample a word of rank i.\n seed: random seed.\n\n # Returns\n couples, labels: where `couples` are int pairs and\n `labels` are either 0 or 1.\n\n # Note\n By convention, index 0 in the vocabulary is\n a non-word and will be skipped.\n \"\"\"\n couples = []\n labels = []\n for i, wi in enumerate(sequence):\n if not wi:\n continue\n if sampling_table is not None:\n if sampling_table[wi] < random.random():\n continue\n\n window_start = max(0, i - window_size)\n window_end = min(len(sequence), i + window_size + 1)\n for j in range(window_start, window_end):\n if j != i:\n wj = sequence[j]\n if not wj:\n continue\n couples.append([wi, wj])\n if categorical:\n labels.append([0, 1])\n else:\n labels.append(1)\n\n if negative_samples > 0:\n num_negative_samples = int(len(labels) * negative_samples)\n words = [c[0] for c in couples]\n random.shuffle(words)\n\n couples += [[words[i % len(words)],\n random.randint(1, vocabulary_size - 1)] for i in range(num_negative_samples)]\n if categorical:\n labels += [[1, 0]] * num_negative_samples\n else:\n labels += [0] * num_negative_samples\n\n if shuffle:\n if seed is None:\n seed = random.randint(0, 10e6)\n random.seed(seed)\n random.shuffle(couples)\n random.seed(seed)\n random.shuffle(labels)\n\n return couples, labels\n\n\ndef _remove_long_seq(maxlen, seq, label):\n \"\"\"Removes sequences that exceed the maximum length.\n\n # Arguments\n maxlen: int, maximum length\n seq: list of lists where each sublist is a sequence\n label: list where each element is an integer\n\n # Returns\n new_seq, new_label: shortened lists for `seq` and `label`.\n \"\"\"\n new_seq, new_label = [], []\n for x, y in zip(seq, label):\n if len(x) < maxlen:\n new_seq.append(x)\n new_label.append(y)\n return new_seq, new_label\n", "path": "keras/preprocessing/sequence.py"}]} | 2,744 | 306 |
gh_patches_debug_31395 | rasdani/github-patches | git_diff | aio-libs__aiohttp-4058 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Drop aiodns < 1.1
aiodns 1.1.1 was released on Oct 14, 2016
Let's drop aiodns 1.0 in aiohttp 4.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aiohttp/resolver.py`
Content:
```
1 import socket
2 from typing import Any, Dict, List
3
4 from .abc import AbstractResolver
5 from .helpers import get_running_loop
6
7 __all__ = ('ThreadedResolver', 'AsyncResolver', 'DefaultResolver')
8
9 try:
10 import aiodns
11 # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')
12 except ImportError: # pragma: no cover
13 aiodns = None
14
15 aiodns_default = False
16
17
18 class ThreadedResolver(AbstractResolver):
19 """Use Executor for synchronous getaddrinfo() calls, which defaults to
20 concurrent.futures.ThreadPoolExecutor.
21 """
22
23 def __init__(self) -> None:
24 self._loop = get_running_loop()
25
26 async def resolve(self, host: str, port: int=0,
27 family: int=socket.AF_INET) -> List[Dict[str, Any]]:
28 infos = await self._loop.getaddrinfo(
29 host, port, type=socket.SOCK_STREAM, family=family)
30
31 hosts = []
32 for family, _, proto, _, address in infos:
33 hosts.append(
34 {'hostname': host,
35 'host': address[0], 'port': address[1],
36 'family': family, 'proto': proto,
37 'flags': socket.AI_NUMERICHOST})
38
39 return hosts
40
41 async def close(self) -> None:
42 pass
43
44
45 class AsyncResolver(AbstractResolver):
46 """Use the `aiodns` package to make asynchronous DNS lookups"""
47
48 def __init__(self, *args: Any, **kwargs: Any) -> None:
49 if aiodns is None:
50 raise RuntimeError("Resolver requires aiodns library")
51
52 self._loop = get_running_loop()
53 self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)
54
55 if not hasattr(self._resolver, 'gethostbyname'):
56 # aiodns 1.1 is not available, fallback to DNSResolver.query
57 self.resolve = self._resolve_with_query # type: ignore
58
59 async def resolve(self, host: str, port: int=0,
60 family: int=socket.AF_INET) -> List[Dict[str, Any]]:
61 try:
62 resp = await self._resolver.gethostbyname(host, family)
63 except aiodns.error.DNSError as exc:
64 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
65 raise OSError(msg) from exc
66 hosts = []
67 for address in resp.addresses:
68 hosts.append(
69 {'hostname': host,
70 'host': address, 'port': port,
71 'family': family, 'proto': 0,
72 'flags': socket.AI_NUMERICHOST})
73
74 if not hosts:
75 raise OSError("DNS lookup failed")
76
77 return hosts
78
79 async def _resolve_with_query(
80 self, host: str, port: int=0,
81 family: int=socket.AF_INET) -> List[Dict[str, Any]]:
82 if family == socket.AF_INET6:
83 qtype = 'AAAA'
84 else:
85 qtype = 'A'
86
87 try:
88 resp = await self._resolver.query(host, qtype)
89 except aiodns.error.DNSError as exc:
90 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
91 raise OSError(msg) from exc
92
93 hosts = []
94 for rr in resp:
95 hosts.append(
96 {'hostname': host,
97 'host': rr.host, 'port': port,
98 'family': family, 'proto': 0,
99 'flags': socket.AI_NUMERICHOST})
100
101 if not hosts:
102 raise OSError("DNS lookup failed")
103
104 return hosts
105
106 async def close(self) -> None:
107 return self._resolver.cancel()
108
109
110 DefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver
111
```
Path: `setup.py`
Content:
```
1 import codecs
2 import os
3 import pathlib
4 import re
5 import sys
6 from distutils.command.build_ext import build_ext
7 from distutils.errors import (CCompilerError, DistutilsExecError,
8 DistutilsPlatformError)
9
10 from setuptools import Extension, setup
11
12
13 if sys.version_info < (3, 5, 3):
14 raise RuntimeError("aiohttp 3.x requires Python 3.5.3+")
15
16
17 NO_EXTENSIONS = bool(os.environ.get('AIOHTTP_NO_EXTENSIONS')) # type: bool
18
19 if sys.implementation.name != "cpython":
20 NO_EXTENSIONS = True
21
22
23 here = pathlib.Path(__file__).parent
24
25 if (here / '.git').exists() and not (here / 'vendor/http-parser/README.md').exists():
26 print("Install submodules when building from git clone", file=sys.stderr)
27 print("Hint:", file=sys.stderr)
28 print(" git submodule update --init", file=sys.stderr)
29 sys.exit(2)
30
31
32 # NOTE: makefile cythonizes all Cython modules
33
34 extensions = [Extension('aiohttp._websocket', ['aiohttp/_websocket.c']),
35 Extension('aiohttp._http_parser',
36 ['aiohttp/_http_parser.c',
37 'vendor/http-parser/http_parser.c',
38 'aiohttp/_find_header.c'],
39 define_macros=[('HTTP_PARSER_STRICT', 0)],
40 ),
41 Extension('aiohttp._frozenlist',
42 ['aiohttp/_frozenlist.c']),
43 Extension('aiohttp._helpers',
44 ['aiohttp/_helpers.c']),
45 Extension('aiohttp._http_writer',
46 ['aiohttp/_http_writer.c'])]
47
48
49 class BuildFailed(Exception):
50 pass
51
52
53 class ve_build_ext(build_ext):
54 # This class allows C extension building to fail.
55
56 def run(self):
57 try:
58 build_ext.run(self)
59 except (DistutilsPlatformError, FileNotFoundError):
60 raise BuildFailed()
61
62 def build_extension(self, ext):
63 try:
64 build_ext.build_extension(self, ext)
65 except (CCompilerError, DistutilsExecError,
66 DistutilsPlatformError, ValueError):
67 raise BuildFailed()
68
69
70
71 txt = (here / 'aiohttp' / '__init__.py').read_text('utf-8')
72 try:
73 version = re.findall(r"^__version__ = '([^']+)'\r?$",
74 txt, re.M)[0]
75 except IndexError:
76 raise RuntimeError('Unable to determine version.')
77
78 install_requires = [
79 'attrs>=17.3.0',
80 'chardet>=2.0,<4.0',
81 'multidict>=4.0,<5.0',
82 'async_timeout>=3.0,<4.0',
83 'yarl>=1.0,<2.0',
84 'idna-ssl>=1.0; python_version<"3.7"',
85 'typing_extensions>=3.6.5',
86 ]
87
88
89 def read(f):
90 return (here / f).read_text('utf-8').strip()
91
92
93 args = dict(
94 name='aiohttp',
95 version=version,
96 description='Async http client/server framework (asyncio)',
97 long_description='\n\n'.join((read('README.rst'), read('CHANGES.rst'))),
98 long_description_content_type="text/x-rst",
99 classifiers=[
100 'License :: OSI Approved :: Apache Software License',
101 'Intended Audience :: Developers',
102 'Programming Language :: Python',
103 'Programming Language :: Python :: 3',
104 'Programming Language :: Python :: 3.5',
105 'Programming Language :: Python :: 3.6',
106 'Programming Language :: Python :: 3.7',
107 'Development Status :: 5 - Production/Stable',
108 'Operating System :: POSIX',
109 'Operating System :: MacOS :: MacOS X',
110 'Operating System :: Microsoft :: Windows',
111 'Topic :: Internet :: WWW/HTTP',
112 'Framework :: AsyncIO',
113 ],
114 author='Nikolay Kim',
115 author_email='[email protected]',
116 maintainer=', '.join(('Nikolay Kim <[email protected]>',
117 'Andrew Svetlov <[email protected]>')),
118 maintainer_email='[email protected]',
119 url='https://github.com/aio-libs/aiohttp',
120 project_urls={
121 'Chat: Gitter': 'https://gitter.im/aio-libs/Lobby',
122 'CI: AppVeyor': 'https://ci.appveyor.com/project/aio-libs/aiohttp',
123 'CI: Circle': 'https://circleci.com/gh/aio-libs/aiohttp',
124 'CI: Shippable': 'https://app.shippable.com/github/aio-libs/aiohttp',
125 'CI: Travis': 'https://travis-ci.com/aio-libs/aiohttp',
126 'Coverage: codecov': 'https://codecov.io/github/aio-libs/aiohttp',
127 'Docs: RTD': 'https://docs.aiohttp.org',
128 'GitHub: issues': 'https://github.com/aio-libs/aiohttp/issues',
129 'GitHub: repo': 'https://github.com/aio-libs/aiohttp',
130 },
131 license='Apache 2',
132 packages=['aiohttp'],
133 python_requires='>=3.5.3',
134 install_requires=install_requires,
135 extras_require={
136 'speedups': [
137 'aiodns',
138 'Brotli',
139 'cchardet',
140 ],
141 },
142 include_package_data=True,
143 )
144
145 if not NO_EXTENSIONS:
146 print("**********************")
147 print("* Accellerated build *")
148 print("**********************")
149 setup(ext_modules=extensions,
150 cmdclass=dict(build_ext=ve_build_ext),
151 **args)
152 else:
153 print("*********************")
154 print("* Pure Python build *")
155 print("*********************")
156 setup(**args)
157
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py
--- a/aiohttp/resolver.py
+++ b/aiohttp/resolver.py
@@ -52,10 +52,6 @@
self._loop = get_running_loop()
self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)
- if not hasattr(self._resolver, 'gethostbyname'):
- # aiodns 1.1 is not available, fallback to DNSResolver.query
- self.resolve = self._resolve_with_query # type: ignore
-
async def resolve(self, host: str, port: int=0,
family: int=socket.AF_INET) -> List[Dict[str, Any]]:
try:
@@ -76,33 +72,6 @@
return hosts
- async def _resolve_with_query(
- self, host: str, port: int=0,
- family: int=socket.AF_INET) -> List[Dict[str, Any]]:
- if family == socket.AF_INET6:
- qtype = 'AAAA'
- else:
- qtype = 'A'
-
- try:
- resp = await self._resolver.query(host, qtype)
- except aiodns.error.DNSError as exc:
- msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
- raise OSError(msg) from exc
-
- hosts = []
- for rr in resp:
- hosts.append(
- {'hostname': host,
- 'host': rr.host, 'port': port,
- 'family': family, 'proto': 0,
- 'flags': socket.AI_NUMERICHOST})
-
- if not hosts:
- raise OSError("DNS lookup failed")
-
- return hosts
-
async def close(self) -> None:
return self._resolver.cancel()
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -134,7 +134,7 @@
install_requires=install_requires,
extras_require={
'speedups': [
- 'aiodns',
+ 'aiodns>=1.1',
'Brotli',
'cchardet',
],
| {"golden_diff": "diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py\n--- a/aiohttp/resolver.py\n+++ b/aiohttp/resolver.py\n@@ -52,10 +52,6 @@\n self._loop = get_running_loop()\n self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)\n \n- if not hasattr(self._resolver, 'gethostbyname'):\n- # aiodns 1.1 is not available, fallback to DNSResolver.query\n- self.resolve = self._resolve_with_query # type: ignore\n-\n async def resolve(self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n try:\n@@ -76,33 +72,6 @@\n \n return hosts\n \n- async def _resolve_with_query(\n- self, host: str, port: int=0,\n- family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n- if family == socket.AF_INET6:\n- qtype = 'AAAA'\n- else:\n- qtype = 'A'\n-\n- try:\n- resp = await self._resolver.query(host, qtype)\n- except aiodns.error.DNSError as exc:\n- msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n- raise OSError(msg) from exc\n-\n- hosts = []\n- for rr in resp:\n- hosts.append(\n- {'hostname': host,\n- 'host': rr.host, 'port': port,\n- 'family': family, 'proto': 0,\n- 'flags': socket.AI_NUMERICHOST})\n-\n- if not hosts:\n- raise OSError(\"DNS lookup failed\")\n-\n- return hosts\n-\n async def close(self) -> None:\n return self._resolver.cancel()\n \ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -134,7 +134,7 @@\n install_requires=install_requires,\n extras_require={\n 'speedups': [\n- 'aiodns',\n+ 'aiodns>=1.1',\n 'Brotli',\n 'cchardet',\n ],\n", "issue": "Drop aiodns < 1.1\naiodns 1.1.1 was released on Oct 14, 2016\r\nLet's drop aiodns 1.0 in aiohttp 4.0\n", "before_files": [{"content": "import socket\nfrom typing import Any, Dict, List\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = ('ThreadedResolver', 'AsyncResolver', 'DefaultResolver')\n\ntry:\n import aiodns\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self) -> None:\n self._loop = get_running_loop()\n\n async def resolve(self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n host, port, type=socket.SOCK_STREAM, family=family)\n\n hosts = []\n for family, _, proto, _, address in infos:\n hosts.append(\n {'hostname': host,\n 'host': address[0], 'port': address[1],\n 'family': family, 'proto': proto,\n 'flags': socket.AI_NUMERICHOST})\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop()\n self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)\n\n if not hasattr(self._resolver, 'gethostbyname'):\n # aiodns 1.1 is not available, fallback to DNSResolver.query\n self.resolve = self._resolve_with_query # type: ignore\n\n async def resolve(self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {'hostname': host,\n 'host': address, 'port': port,\n 'family': family, 'proto': 0,\n 'flags': socket.AI_NUMERICHOST})\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def _resolve_with_query(\n self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n if family == socket.AF_INET6:\n qtype = 'AAAA'\n else:\n qtype = 'A'\n\n try:\n resp = await self._resolver.query(host, qtype)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n\n hosts = []\n for rr in resp:\n hosts.append(\n {'hostname': host,\n 'host': rr.host, 'port': port,\n 'family': family, 'proto': 0,\n 'flags': socket.AI_NUMERICHOST})\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}, {"content": "import codecs\nimport os\nimport pathlib\nimport re\nimport sys\nfrom distutils.command.build_ext import build_ext\nfrom distutils.errors import (CCompilerError, DistutilsExecError,\n DistutilsPlatformError)\n\nfrom setuptools import Extension, setup\n\n\nif sys.version_info < (3, 5, 3):\n raise RuntimeError(\"aiohttp 3.x requires Python 3.5.3+\")\n\n\nNO_EXTENSIONS = bool(os.environ.get('AIOHTTP_NO_EXTENSIONS')) # type: bool\n\nif sys.implementation.name != \"cpython\":\n NO_EXTENSIONS = True\n\n\nhere = pathlib.Path(__file__).parent\n\nif (here / '.git').exists() and not (here / 'vendor/http-parser/README.md').exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n sys.exit(2)\n\n\n# NOTE: makefile cythonizes all Cython modules\n\nextensions = [Extension('aiohttp._websocket', ['aiohttp/_websocket.c']),\n Extension('aiohttp._http_parser',\n ['aiohttp/_http_parser.c',\n 'vendor/http-parser/http_parser.c',\n 'aiohttp/_find_header.c'],\n define_macros=[('HTTP_PARSER_STRICT', 0)],\n ),\n Extension('aiohttp._frozenlist',\n ['aiohttp/_frozenlist.c']),\n Extension('aiohttp._helpers',\n ['aiohttp/_helpers.c']),\n Extension('aiohttp._http_writer',\n ['aiohttp/_http_writer.c'])]\n\n\nclass BuildFailed(Exception):\n pass\n\n\nclass ve_build_ext(build_ext):\n # This class allows C extension building to fail.\n\n def run(self):\n try:\n build_ext.run(self)\n except (DistutilsPlatformError, FileNotFoundError):\n raise BuildFailed()\n\n def build_extension(self, ext):\n try:\n build_ext.build_extension(self, ext)\n except (CCompilerError, DistutilsExecError,\n DistutilsPlatformError, ValueError):\n raise BuildFailed()\n\n\n\ntxt = (here / 'aiohttp' / '__init__.py').read_text('utf-8')\ntry:\n version = re.findall(r\"^__version__ = '([^']+)'\\r?$\",\n txt, re.M)[0]\nexcept IndexError:\n raise RuntimeError('Unable to determine version.')\n\ninstall_requires = [\n 'attrs>=17.3.0',\n 'chardet>=2.0,<4.0',\n 'multidict>=4.0,<5.0',\n 'async_timeout>=3.0,<4.0',\n 'yarl>=1.0,<2.0',\n 'idna-ssl>=1.0; python_version<\"3.7\"',\n 'typing_extensions>=3.6.5',\n]\n\n\ndef read(f):\n return (here / f).read_text('utf-8').strip()\n\n\nargs = dict(\n name='aiohttp',\n version=version,\n description='Async http client/server framework (asyncio)',\n long_description='\\n\\n'.join((read('README.rst'), read('CHANGES.rst'))),\n long_description_content_type=\"text/x-rst\",\n classifiers=[\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Development Status :: 5 - Production/Stable',\n 'Operating System :: POSIX',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Topic :: Internet :: WWW/HTTP',\n 'Framework :: AsyncIO',\n ],\n author='Nikolay Kim',\n author_email='[email protected]',\n maintainer=', '.join(('Nikolay Kim <[email protected]>',\n 'Andrew Svetlov <[email protected]>')),\n maintainer_email='[email protected]',\n url='https://github.com/aio-libs/aiohttp',\n project_urls={\n 'Chat: Gitter': 'https://gitter.im/aio-libs/Lobby',\n 'CI: AppVeyor': 'https://ci.appveyor.com/project/aio-libs/aiohttp',\n 'CI: Circle': 'https://circleci.com/gh/aio-libs/aiohttp',\n 'CI: Shippable': 'https://app.shippable.com/github/aio-libs/aiohttp',\n 'CI: Travis': 'https://travis-ci.com/aio-libs/aiohttp',\n 'Coverage: codecov': 'https://codecov.io/github/aio-libs/aiohttp',\n 'Docs: RTD': 'https://docs.aiohttp.org',\n 'GitHub: issues': 'https://github.com/aio-libs/aiohttp/issues',\n 'GitHub: repo': 'https://github.com/aio-libs/aiohttp',\n },\n license='Apache 2',\n packages=['aiohttp'],\n python_requires='>=3.5.3',\n install_requires=install_requires,\n extras_require={\n 'speedups': [\n 'aiodns',\n 'Brotli',\n 'cchardet',\n ],\n },\n include_package_data=True,\n)\n\nif not NO_EXTENSIONS:\n print(\"**********************\")\n print(\"* Accellerated build *\")\n print(\"**********************\")\n setup(ext_modules=extensions,\n cmdclass=dict(build_ext=ve_build_ext),\n **args)\nelse:\n print(\"*********************\")\n print(\"* Pure Python build *\")\n print(\"*********************\")\n setup(**args)\n", "path": "setup.py"}], "after_files": [{"content": "import socket\nfrom typing import Any, Dict, List\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = ('ThreadedResolver', 'AsyncResolver', 'DefaultResolver')\n\ntry:\n import aiodns\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self) -> None:\n self._loop = get_running_loop()\n\n async def resolve(self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n host, port, type=socket.SOCK_STREAM, family=family)\n\n hosts = []\n for family, _, proto, _, address in infos:\n hosts.append(\n {'hostname': host,\n 'host': address[0], 'port': address[1],\n 'family': family, 'proto': proto,\n 'flags': socket.AI_NUMERICHOST})\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop()\n self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)\n\n async def resolve(self, host: str, port: int=0,\n family: int=socket.AF_INET) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {'hostname': host,\n 'host': address, 'port': port,\n 'family': family, 'proto': 0,\n 'flags': socket.AI_NUMERICHOST})\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}, {"content": "import codecs\nimport os\nimport pathlib\nimport re\nimport sys\nfrom distutils.command.build_ext import build_ext\nfrom distutils.errors import (CCompilerError, DistutilsExecError,\n DistutilsPlatformError)\n\nfrom setuptools import Extension, setup\n\n\nif sys.version_info < (3, 5, 3):\n raise RuntimeError(\"aiohttp 3.x requires Python 3.5.3+\")\n\n\nNO_EXTENSIONS = bool(os.environ.get('AIOHTTP_NO_EXTENSIONS')) # type: bool\n\nif sys.implementation.name != \"cpython\":\n NO_EXTENSIONS = True\n\n\nhere = pathlib.Path(__file__).parent\n\nif (here / '.git').exists() and not (here / 'vendor/http-parser/README.md').exists():\n print(\"Install submodules when building from git clone\", file=sys.stderr)\n print(\"Hint:\", file=sys.stderr)\n print(\" git submodule update --init\", file=sys.stderr)\n sys.exit(2)\n\n\n# NOTE: makefile cythonizes all Cython modules\n\nextensions = [Extension('aiohttp._websocket', ['aiohttp/_websocket.c']),\n Extension('aiohttp._http_parser',\n ['aiohttp/_http_parser.c',\n 'vendor/http-parser/http_parser.c',\n 'aiohttp/_find_header.c'],\n define_macros=[('HTTP_PARSER_STRICT', 0)],\n ),\n Extension('aiohttp._frozenlist',\n ['aiohttp/_frozenlist.c']),\n Extension('aiohttp._helpers',\n ['aiohttp/_helpers.c']),\n Extension('aiohttp._http_writer',\n ['aiohttp/_http_writer.c'])]\n\n\nclass BuildFailed(Exception):\n pass\n\n\nclass ve_build_ext(build_ext):\n # This class allows C extension building to fail.\n\n def run(self):\n try:\n build_ext.run(self)\n except (DistutilsPlatformError, FileNotFoundError):\n raise BuildFailed()\n\n def build_extension(self, ext):\n try:\n build_ext.build_extension(self, ext)\n except (CCompilerError, DistutilsExecError,\n DistutilsPlatformError, ValueError):\n raise BuildFailed()\n\n\n\ntxt = (here / 'aiohttp' / '__init__.py').read_text('utf-8')\ntry:\n version = re.findall(r\"^__version__ = '([^']+)'\\r?$\",\n txt, re.M)[0]\nexcept IndexError:\n raise RuntimeError('Unable to determine version.')\n\ninstall_requires = [\n 'attrs>=17.3.0',\n 'chardet>=2.0,<4.0',\n 'multidict>=4.0,<5.0',\n 'async_timeout>=3.0,<4.0',\n 'yarl>=1.0,<2.0',\n 'idna-ssl>=1.0; python_version<\"3.7\"',\n 'typing_extensions>=3.6.5',\n]\n\n\ndef read(f):\n return (here / f).read_text('utf-8').strip()\n\n\nargs = dict(\n name='aiohttp',\n version=version,\n description='Async http client/server framework (asyncio)',\n long_description='\\n\\n'.join((read('README.rst'), read('CHANGES.rst'))),\n long_description_content_type=\"text/x-rst\",\n classifiers=[\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Developers',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Development Status :: 5 - Production/Stable',\n 'Operating System :: POSIX',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Topic :: Internet :: WWW/HTTP',\n 'Framework :: AsyncIO',\n ],\n author='Nikolay Kim',\n author_email='[email protected]',\n maintainer=', '.join(('Nikolay Kim <[email protected]>',\n 'Andrew Svetlov <[email protected]>')),\n maintainer_email='[email protected]',\n url='https://github.com/aio-libs/aiohttp',\n project_urls={\n 'Chat: Gitter': 'https://gitter.im/aio-libs/Lobby',\n 'CI: AppVeyor': 'https://ci.appveyor.com/project/aio-libs/aiohttp',\n 'CI: Circle': 'https://circleci.com/gh/aio-libs/aiohttp',\n 'CI: Shippable': 'https://app.shippable.com/github/aio-libs/aiohttp',\n 'CI: Travis': 'https://travis-ci.com/aio-libs/aiohttp',\n 'Coverage: codecov': 'https://codecov.io/github/aio-libs/aiohttp',\n 'Docs: RTD': 'https://docs.aiohttp.org',\n 'GitHub: issues': 'https://github.com/aio-libs/aiohttp/issues',\n 'GitHub: repo': 'https://github.com/aio-libs/aiohttp',\n },\n license='Apache 2',\n packages=['aiohttp'],\n python_requires='>=3.5.3',\n install_requires=install_requires,\n extras_require={\n 'speedups': [\n 'aiodns>=1.1',\n 'Brotli',\n 'cchardet',\n ],\n },\n include_package_data=True,\n)\n\nif not NO_EXTENSIONS:\n print(\"**********************\")\n print(\"* Accellerated build *\")\n print(\"**********************\")\n setup(ext_modules=extensions,\n cmdclass=dict(build_ext=ve_build_ext),\n **args)\nelse:\n print(\"*********************\")\n print(\"* Pure Python build *\")\n print(\"*********************\")\n setup(**args)\n", "path": "setup.py"}]} | 3,030 | 505 |
gh_patches_debug_4345 | rasdani/github-patches | git_diff | netbox-community__netbox-16037 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unable to run scripts from CLI in v4.0
### Deployment Type
Self-hosted
### NetBox Version
v4.0.0
### Python Version
3.11
### Steps to Reproduce
1. Create a script
2. Run it with `python manage.py runscript 'module.ScriptName' inside the NetBox instance
### Expected Behavior
Script should run.
### Observed Behavior
Script fails with:
> AttributeError: 'Script' object has no attribute 'full_name'
Running the same script from GUI works fine, have tried multiple scripts, and haven't been able to run any via CLI in v4.
Seems to be this line that fails: https://github.com/netbox-community/netbox/blob/develop/netbox/extras/management/commands/runscript.py#L104
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netbox/extras/management/commands/runscript.py`
Content:
```
1 import json
2 import logging
3 import sys
4 import traceback
5 import uuid
6
7 from django.contrib.auth import get_user_model
8 from django.core.management.base import BaseCommand, CommandError
9 from django.db import transaction
10
11 from core.choices import JobStatusChoices
12 from core.models import Job
13 from extras.context_managers import event_tracking
14 from extras.scripts import get_module_and_script
15 from extras.signals import clear_events
16 from utilities.exceptions import AbortTransaction
17 from utilities.request import NetBoxFakeRequest
18
19
20 class Command(BaseCommand):
21 help = "Run a script in NetBox"
22
23 def add_arguments(self, parser):
24 parser.add_argument(
25 '--loglevel',
26 help="Logging Level (default: info)",
27 dest='loglevel',
28 default='info',
29 choices=['debug', 'info', 'warning', 'error', 'critical'])
30 parser.add_argument('--commit', help="Commit this script to database", action='store_true')
31 parser.add_argument('--user', help="User script is running as")
32 parser.add_argument('--data', help="Data as a string encapsulated JSON blob")
33 parser.add_argument('script', help="Script to run")
34
35 def handle(self, *args, **options):
36
37 def _run_script():
38 """
39 Core script execution task. We capture this within a subfunction to allow for conditionally wrapping it with
40 the event_tracking context manager (which is bypassed if commit == False).
41 """
42 try:
43 try:
44 with transaction.atomic():
45 script.output = script.run(data=data, commit=commit)
46 if not commit:
47 raise AbortTransaction()
48 except AbortTransaction:
49 script.log_info("Database changes have been reverted automatically.")
50 clear_events.send(request)
51 job.data = script.get_job_data()
52 job.terminate()
53 except Exception as e:
54 stacktrace = traceback.format_exc()
55 script.log_failure(
56 f"An exception occurred: `{type(e).__name__}: {e}`\n```\n{stacktrace}\n```"
57 )
58 script.log_info("Database changes have been reverted due to error.")
59 logger.error(f"Exception raised during script execution: {e}")
60 clear_events.send(request)
61 job.data = script.get_job_data()
62 job.terminate(status=JobStatusChoices.STATUS_ERRORED, error=repr(e))
63
64 # Print any test method results
65 for test_name, attrs in job.data['tests'].items():
66 self.stdout.write(
67 "\t{}: {} success, {} info, {} warning, {} failure".format(
68 test_name, attrs['success'], attrs['info'], attrs['warning'], attrs['failure']
69 )
70 )
71
72 logger.info(f"Script completed in {job.duration}")
73
74 User = get_user_model()
75
76 # Params
77 script = options['script']
78 loglevel = options['loglevel']
79 commit = options['commit']
80
81 try:
82 data = json.loads(options['data'])
83 except TypeError:
84 data = {}
85
86 module_name, script_name = script.split('.', 1)
87 module, script = get_module_and_script(module_name, script_name)
88
89 # Take user from command line if provided and exists, other
90 if options['user']:
91 try:
92 user = User.objects.get(username=options['user'])
93 except User.DoesNotExist:
94 user = User.objects.filter(is_superuser=True).order_by('pk')[0]
95 else:
96 user = User.objects.filter(is_superuser=True).order_by('pk')[0]
97
98 # Setup logging to Stdout
99 formatter = logging.Formatter(f'[%(asctime)s][%(levelname)s] - %(message)s')
100 stdouthandler = logging.StreamHandler(sys.stdout)
101 stdouthandler.setLevel(logging.DEBUG)
102 stdouthandler.setFormatter(formatter)
103
104 logger = logging.getLogger(f"netbox.scripts.{script.full_name}")
105 logger.addHandler(stdouthandler)
106
107 try:
108 logger.setLevel({
109 'critical': logging.CRITICAL,
110 'debug': logging.DEBUG,
111 'error': logging.ERROR,
112 'fatal': logging.FATAL,
113 'info': logging.INFO,
114 'warning': logging.WARNING,
115 }[loglevel])
116 except KeyError:
117 raise CommandError(f"Invalid log level: {loglevel}")
118
119 # Initialize the script form
120 script = script()
121 form = script.as_form(data, None)
122
123 # Create the job
124 job = Job.objects.create(
125 object=module,
126 name=script.class_name,
127 user=User.objects.filter(is_superuser=True).order_by('pk')[0],
128 job_id=uuid.uuid4()
129 )
130
131 request = NetBoxFakeRequest({
132 'META': {},
133 'POST': data,
134 'GET': {},
135 'FILES': {},
136 'user': user,
137 'path': '',
138 'id': job.job_id
139 })
140
141 if form.is_valid():
142 job.status = JobStatusChoices.STATUS_RUNNING
143 job.save()
144
145 logger.info(f"Running script (commit={commit})")
146 script.request = request
147
148 # Execute the script. If commit is True, wrap it with the event_tracking context manager to ensure we process
149 # change logging, webhooks, etc.
150 with event_tracking(request):
151 _run_script()
152 else:
153 logger.error('Data is not valid:')
154 for field, errors in form.errors.get_json_data().items():
155 for error in errors:
156 logger.error(f'\t{field}: {error.get("message")}')
157 job.status = JobStatusChoices.STATUS_ERRORED
158 job.save()
159
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/netbox/extras/management/commands/runscript.py b/netbox/extras/management/commands/runscript.py
--- a/netbox/extras/management/commands/runscript.py
+++ b/netbox/extras/management/commands/runscript.py
@@ -85,6 +85,7 @@
module_name, script_name = script.split('.', 1)
module, script = get_module_and_script(module_name, script_name)
+ script = script.python_class
# Take user from command line if provided and exists, other
if options['user']:
| {"golden_diff": "diff --git a/netbox/extras/management/commands/runscript.py b/netbox/extras/management/commands/runscript.py\n--- a/netbox/extras/management/commands/runscript.py\n+++ b/netbox/extras/management/commands/runscript.py\n@@ -85,6 +85,7 @@\n \n module_name, script_name = script.split('.', 1)\n module, script = get_module_and_script(module_name, script_name)\n+ script = script.python_class\n \n # Take user from command line if provided and exists, other\n if options['user']:\n", "issue": "Unable to run scripts from CLI in v4.0\n### Deployment Type\n\nSelf-hosted\n\n### NetBox Version\n\nv4.0.0\n\n### Python Version\n\n3.11\n\n### Steps to Reproduce\n\n1. Create a script\r\n2. Run it with `python manage.py runscript 'module.ScriptName' inside the NetBox instance\r\n\n\n### Expected Behavior\n\nScript should run.\n\n### Observed Behavior\n\nScript fails with:\r\n> AttributeError: 'Script' object has no attribute 'full_name'\r\n\r\nRunning the same script from GUI works fine, have tried multiple scripts, and haven't been able to run any via CLI in v4. \r\n\r\nSeems to be this line that fails: https://github.com/netbox-community/netbox/blob/develop/netbox/extras/management/commands/runscript.py#L104\n", "before_files": [{"content": "import json\nimport logging\nimport sys\nimport traceback\nimport uuid\n\nfrom django.contrib.auth import get_user_model\nfrom django.core.management.base import BaseCommand, CommandError\nfrom django.db import transaction\n\nfrom core.choices import JobStatusChoices\nfrom core.models import Job\nfrom extras.context_managers import event_tracking\nfrom extras.scripts import get_module_and_script\nfrom extras.signals import clear_events\nfrom utilities.exceptions import AbortTransaction\nfrom utilities.request import NetBoxFakeRequest\n\n\nclass Command(BaseCommand):\n help = \"Run a script in NetBox\"\n\n def add_arguments(self, parser):\n parser.add_argument(\n '--loglevel',\n help=\"Logging Level (default: info)\",\n dest='loglevel',\n default='info',\n choices=['debug', 'info', 'warning', 'error', 'critical'])\n parser.add_argument('--commit', help=\"Commit this script to database\", action='store_true')\n parser.add_argument('--user', help=\"User script is running as\")\n parser.add_argument('--data', help=\"Data as a string encapsulated JSON blob\")\n parser.add_argument('script', help=\"Script to run\")\n\n def handle(self, *args, **options):\n\n def _run_script():\n \"\"\"\n Core script execution task. We capture this within a subfunction to allow for conditionally wrapping it with\n the event_tracking context manager (which is bypassed if commit == False).\n \"\"\"\n try:\n try:\n with transaction.atomic():\n script.output = script.run(data=data, commit=commit)\n if not commit:\n raise AbortTransaction()\n except AbortTransaction:\n script.log_info(\"Database changes have been reverted automatically.\")\n clear_events.send(request)\n job.data = script.get_job_data()\n job.terminate()\n except Exception as e:\n stacktrace = traceback.format_exc()\n script.log_failure(\n f\"An exception occurred: `{type(e).__name__}: {e}`\\n```\\n{stacktrace}\\n```\"\n )\n script.log_info(\"Database changes have been reverted due to error.\")\n logger.error(f\"Exception raised during script execution: {e}\")\n clear_events.send(request)\n job.data = script.get_job_data()\n job.terminate(status=JobStatusChoices.STATUS_ERRORED, error=repr(e))\n\n # Print any test method results\n for test_name, attrs in job.data['tests'].items():\n self.stdout.write(\n \"\\t{}: {} success, {} info, {} warning, {} failure\".format(\n test_name, attrs['success'], attrs['info'], attrs['warning'], attrs['failure']\n )\n )\n\n logger.info(f\"Script completed in {job.duration}\")\n\n User = get_user_model()\n\n # Params\n script = options['script']\n loglevel = options['loglevel']\n commit = options['commit']\n\n try:\n data = json.loads(options['data'])\n except TypeError:\n data = {}\n\n module_name, script_name = script.split('.', 1)\n module, script = get_module_and_script(module_name, script_name)\n\n # Take user from command line if provided and exists, other\n if options['user']:\n try:\n user = User.objects.get(username=options['user'])\n except User.DoesNotExist:\n user = User.objects.filter(is_superuser=True).order_by('pk')[0]\n else:\n user = User.objects.filter(is_superuser=True).order_by('pk')[0]\n\n # Setup logging to Stdout\n formatter = logging.Formatter(f'[%(asctime)s][%(levelname)s] - %(message)s')\n stdouthandler = logging.StreamHandler(sys.stdout)\n stdouthandler.setLevel(logging.DEBUG)\n stdouthandler.setFormatter(formatter)\n\n logger = logging.getLogger(f\"netbox.scripts.{script.full_name}\")\n logger.addHandler(stdouthandler)\n\n try:\n logger.setLevel({\n 'critical': logging.CRITICAL,\n 'debug': logging.DEBUG,\n 'error': logging.ERROR,\n 'fatal': logging.FATAL,\n 'info': logging.INFO,\n 'warning': logging.WARNING,\n }[loglevel])\n except KeyError:\n raise CommandError(f\"Invalid log level: {loglevel}\")\n\n # Initialize the script form\n script = script()\n form = script.as_form(data, None)\n\n # Create the job\n job = Job.objects.create(\n object=module,\n name=script.class_name,\n user=User.objects.filter(is_superuser=True).order_by('pk')[0],\n job_id=uuid.uuid4()\n )\n\n request = NetBoxFakeRequest({\n 'META': {},\n 'POST': data,\n 'GET': {},\n 'FILES': {},\n 'user': user,\n 'path': '',\n 'id': job.job_id\n })\n\n if form.is_valid():\n job.status = JobStatusChoices.STATUS_RUNNING\n job.save()\n\n logger.info(f\"Running script (commit={commit})\")\n script.request = request\n\n # Execute the script. If commit is True, wrap it with the event_tracking context manager to ensure we process\n # change logging, webhooks, etc.\n with event_tracking(request):\n _run_script()\n else:\n logger.error('Data is not valid:')\n for field, errors in form.errors.get_json_data().items():\n for error in errors:\n logger.error(f'\\t{field}: {error.get(\"message\")}')\n job.status = JobStatusChoices.STATUS_ERRORED\n job.save()\n", "path": "netbox/extras/management/commands/runscript.py"}], "after_files": [{"content": "import json\nimport logging\nimport sys\nimport traceback\nimport uuid\n\nfrom django.contrib.auth import get_user_model\nfrom django.core.management.base import BaseCommand, CommandError\nfrom django.db import transaction\n\nfrom core.choices import JobStatusChoices\nfrom core.models import Job\nfrom extras.context_managers import event_tracking\nfrom extras.scripts import get_module_and_script\nfrom extras.signals import clear_events\nfrom utilities.exceptions import AbortTransaction\nfrom utilities.request import NetBoxFakeRequest\n\n\nclass Command(BaseCommand):\n help = \"Run a script in NetBox\"\n\n def add_arguments(self, parser):\n parser.add_argument(\n '--loglevel',\n help=\"Logging Level (default: info)\",\n dest='loglevel',\n default='info',\n choices=['debug', 'info', 'warning', 'error', 'critical'])\n parser.add_argument('--commit', help=\"Commit this script to database\", action='store_true')\n parser.add_argument('--user', help=\"User script is running as\")\n parser.add_argument('--data', help=\"Data as a string encapsulated JSON blob\")\n parser.add_argument('script', help=\"Script to run\")\n\n def handle(self, *args, **options):\n\n def _run_script():\n \"\"\"\n Core script execution task. We capture this within a subfunction to allow for conditionally wrapping it with\n the event_tracking context manager (which is bypassed if commit == False).\n \"\"\"\n try:\n try:\n with transaction.atomic():\n script.output = script.run(data=data, commit=commit)\n if not commit:\n raise AbortTransaction()\n except AbortTransaction:\n script.log_info(\"Database changes have been reverted automatically.\")\n clear_events.send(request)\n job.data = script.get_job_data()\n job.terminate()\n except Exception as e:\n stacktrace = traceback.format_exc()\n script.log_failure(\n f\"An exception occurred: `{type(e).__name__}: {e}`\\n```\\n{stacktrace}\\n```\"\n )\n script.log_info(\"Database changes have been reverted due to error.\")\n logger.error(f\"Exception raised during script execution: {e}\")\n clear_events.send(request)\n job.data = script.get_job_data()\n job.terminate(status=JobStatusChoices.STATUS_ERRORED, error=repr(e))\n\n # Print any test method results\n for test_name, attrs in job.data['tests'].items():\n self.stdout.write(\n \"\\t{}: {} success, {} info, {} warning, {} failure\".format(\n test_name, attrs['success'], attrs['info'], attrs['warning'], attrs['failure']\n )\n )\n\n logger.info(f\"Script completed in {job.duration}\")\n\n User = get_user_model()\n\n # Params\n script = options['script']\n loglevel = options['loglevel']\n commit = options['commit']\n\n try:\n data = json.loads(options['data'])\n except TypeError:\n data = {}\n\n module_name, script_name = script.split('.', 1)\n module, script = get_module_and_script(module_name, script_name)\n script = script.python_class\n\n # Take user from command line if provided and exists, other\n if options['user']:\n try:\n user = User.objects.get(username=options['user'])\n except User.DoesNotExist:\n user = User.objects.filter(is_superuser=True).order_by('pk')[0]\n else:\n user = User.objects.filter(is_superuser=True).order_by('pk')[0]\n\n # Setup logging to Stdout\n formatter = logging.Formatter(f'[%(asctime)s][%(levelname)s] - %(message)s')\n stdouthandler = logging.StreamHandler(sys.stdout)\n stdouthandler.setLevel(logging.DEBUG)\n stdouthandler.setFormatter(formatter)\n\n logger = logging.getLogger(f\"netbox.scripts.{script.full_name}\")\n logger.addHandler(stdouthandler)\n\n try:\n logger.setLevel({\n 'critical': logging.CRITICAL,\n 'debug': logging.DEBUG,\n 'error': logging.ERROR,\n 'fatal': logging.FATAL,\n 'info': logging.INFO,\n 'warning': logging.WARNING,\n }[loglevel])\n except KeyError:\n raise CommandError(f\"Invalid log level: {loglevel}\")\n\n # Initialize the script form\n script = script()\n form = script.as_form(data, None)\n\n # Create the job\n job = Job.objects.create(\n object=module,\n name=script.class_name,\n user=User.objects.filter(is_superuser=True).order_by('pk')[0],\n job_id=uuid.uuid4()\n )\n\n request = NetBoxFakeRequest({\n 'META': {},\n 'POST': data,\n 'GET': {},\n 'FILES': {},\n 'user': user,\n 'path': '',\n 'id': job.job_id\n })\n\n if form.is_valid():\n job.status = JobStatusChoices.STATUS_RUNNING\n job.save()\n\n logger.info(f\"Running script (commit={commit})\")\n script.request = request\n\n # Execute the script. If commit is True, wrap it with the event_tracking context manager to ensure we process\n # change logging, webhooks, etc.\n with event_tracking(request):\n _run_script()\n else:\n logger.error('Data is not valid:')\n for field, errors in form.errors.get_json_data().items():\n for error in errors:\n logger.error(f'\\t{field}: {error.get(\"message\")}')\n job.status = JobStatusChoices.STATUS_ERRORED\n job.save()\n", "path": "netbox/extras/management/commands/runscript.py"}]} | 1,970 | 125 |
gh_patches_debug_63273 | rasdani/github-patches | git_diff | weecology__retriever-400 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't download and extract Gentry dataset
If trying to download "Gentry Forest Transect Dataset" the retriever seems to download the data, but gets stuck when it comes in extracting AVALANCH.xls
Moreover force quit seems the only way to close the program.
OS: OS X El Capitan Version 10.11.3 (15D21)
Machine: Macbook Pro Early 2015 13"
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/download_manager.py`
Content:
```
1 """This class manages dataset downloads concurrently and processes progress
2 output."""
3
4 import wx
5 from retriever.lib.download import DownloadThread
6
7
8 class DownloadManager:
9 def __init__(self, parent):
10 self.dialog = None
11 self.worker = None
12 self.queue = []
13 self.downloaded = set()
14 self.errors = set()
15 self.warnings = set()
16 self.Parent = parent
17 self.timer = wx.Timer(parent, -1)
18 self.timer.interval = 10
19 parent.Bind(wx.EVT_TIMER, self.update, self.timer)
20
21 def Download(self, script):
22 if not script in self.queue and not (self.worker and self.worker.script == script):
23 self.queue.append(script)
24 self.downloaded.add(script)
25 if script in self.errors:
26 self.errors.remove(script)
27 self.warnings.remove(script)
28 self.Parent.script_list.RefreshMe(None)
29 if not self.timer.IsRunning() and not self.worker and len(self.queue) < 2:
30 self.timer.Start(self.timer.interval)
31 return True
32 return False
33
34 def update(self, evt):
35 self.timer.Stop()
36 terminate = False
37 if self.worker:
38 script = self.worker.script
39 if self.worker.finished() and len(self.worker.output) == 0:
40 if hasattr(script, 'warnings') and script.warnings:
41 self.warnings.add(script)
42 self.Parent.SetStatusText('\n'.join(str(w) for w in script.warnings))
43 else:
44 self.Parent.SetStatusText("")
45 self.worker = None
46 self.Parent.script_list.RefreshMe(None)
47 self.timer.Start(self.timer.interval)
48 else:
49 self.worker.output_lock.acquire()
50 while len(self.worker.output) > 0 and not terminate:
51 if "Error:" in self.worker.output[0] and script in self.downloaded:
52 self.downloaded.remove(script)
53 self.errors.add(script)
54 if self.write(self.worker) == False:
55 terminate = True
56 self.worker.output = self.worker.output[1:]
57 #self.gauge.SetValue(100 * ((self.worker.scriptnum) /
58 # (self.worker.progress_max + 1.0)))
59 self.worker.output_lock.release()
60 if terminate:
61 self.Parent.Quit(None)
62 else:
63 self.timer.Start(self.timer.interval)
64 elif self.queue:
65 script = self.queue[0]
66 self.queue = self.queue[1:]
67 self.worker = DownloadThread(self.Parent.engine, script)
68 self.worker.parent = self
69 self.worker.start()
70 self.timer.Start(10)
71
72 def flush(self):
73 pass
74
75 def write(self, worker):
76 s = worker.output[0]
77
78 if '\b' in s:
79 s = s.replace('\b', '')
80 if not self.dialog:
81 wx.GetApp().Yield()
82 self.dialog = wx.ProgressDialog("Download Progress",
83 "Downloading datasets . . .\n"
84 + " " * len(s),
85 maximum=1000,
86 parent=None,
87 style=wx.PD_SMOOTH
88 | wx.DIALOG_NO_PARENT
89 | wx.PD_CAN_ABORT
90 | wx.PD_AUTO_HIDE
91 | wx.PD_REMAINING_TIME
92 )
93 def progress(s):
94 if ' / ' in s:
95 s = s.split(' / ')
96 total = float(s[1])
97 current = float(s[0].split(': ')[1])
98 progress = int((current / total) * 1000)
99 return (progress if progress > 1 else 1)
100 else:
101 return None
102
103 current_progress = progress(s)
104 if current_progress:
105 (keepgoing, skip) = self.dialog.Update(current_progress, s)
106 else:
107 (keepgoing, skip) = self.dialog.Pulse(s)
108
109 if not keepgoing:
110 return False
111 else:
112 if self.dialog:
113 self.dialog.Update(1000, "")
114 self.dialog.Destroy()
115 self.dialog = None
116
117 if '...' in s:
118 self.Parent.SetStatusText(s)
119 else:
120 self.Parent.script_list.SetStatus(worker.script.name, s)
121
122 wx.GetApp().Yield()
123 return True
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/download_manager.py b/app/download_manager.py
--- a/app/download_manager.py
+++ b/app/download_manager.py
@@ -102,8 +102,9 @@
current_progress = progress(s)
if current_progress:
- (keepgoing, skip) = self.dialog.Update(current_progress, s)
- else:
+ # download progress remaining-time disabled. causes bottle neck on Gentry ref: #396.
+ # (keepgoing, skip) = self.dialog.Update(current_progress, s)
+ # else:
(keepgoing, skip) = self.dialog.Pulse(s)
if not keepgoing:
| {"golden_diff": "diff --git a/app/download_manager.py b/app/download_manager.py\n--- a/app/download_manager.py\n+++ b/app/download_manager.py\n@@ -102,8 +102,9 @@\n \n current_progress = progress(s)\n if current_progress:\n- (keepgoing, skip) = self.dialog.Update(current_progress, s)\n- else:\n+ # download progress remaining-time disabled. causes bottle neck on Gentry ref: #396.\n+ # (keepgoing, skip) = self.dialog.Update(current_progress, s)\n+ # else:\n (keepgoing, skip) = self.dialog.Pulse(s)\n \n if not keepgoing:\n", "issue": "Can't download and extract Gentry dataset\nIf trying to download \"Gentry Forest Transect Dataset\" the retriever seems to download the data, but gets stuck when it comes in extracting AVALANCH.xls\nMoreover force quit seems the only way to close the program. \nOS: OS X El Capitan Version 10.11.3 (15D21)\nMachine: Macbook Pro Early 2015 13\"\n\n", "before_files": [{"content": "\"\"\"This class manages dataset downloads concurrently and processes progress\noutput.\"\"\"\n\nimport wx\nfrom retriever.lib.download import DownloadThread\n\n\nclass DownloadManager:\n def __init__(self, parent):\n self.dialog = None\n self.worker = None\n self.queue = []\n self.downloaded = set()\n self.errors = set()\n self.warnings = set()\n self.Parent = parent\n self.timer = wx.Timer(parent, -1)\n self.timer.interval = 10\n parent.Bind(wx.EVT_TIMER, self.update, self.timer)\n\n def Download(self, script):\n if not script in self.queue and not (self.worker and self.worker.script == script):\n self.queue.append(script)\n self.downloaded.add(script)\n if script in self.errors:\n self.errors.remove(script)\n self.warnings.remove(script)\n self.Parent.script_list.RefreshMe(None)\n if not self.timer.IsRunning() and not self.worker and len(self.queue) < 2:\n self.timer.Start(self.timer.interval)\n return True\n return False\n\n def update(self, evt):\n self.timer.Stop()\n terminate = False\n if self.worker:\n script = self.worker.script\n if self.worker.finished() and len(self.worker.output) == 0:\n if hasattr(script, 'warnings') and script.warnings:\n self.warnings.add(script)\n self.Parent.SetStatusText('\\n'.join(str(w) for w in script.warnings))\n else:\n self.Parent.SetStatusText(\"\")\n self.worker = None\n self.Parent.script_list.RefreshMe(None)\n self.timer.Start(self.timer.interval)\n else:\n self.worker.output_lock.acquire()\n while len(self.worker.output) > 0 and not terminate:\n if \"Error:\" in self.worker.output[0] and script in self.downloaded:\n self.downloaded.remove(script)\n self.errors.add(script)\n if self.write(self.worker) == False:\n terminate = True\n self.worker.output = self.worker.output[1:]\n #self.gauge.SetValue(100 * ((self.worker.scriptnum) /\n # (self.worker.progress_max + 1.0)))\n self.worker.output_lock.release()\n if terminate:\n self.Parent.Quit(None)\n else:\n self.timer.Start(self.timer.interval)\n elif self.queue:\n script = self.queue[0]\n self.queue = self.queue[1:]\n self.worker = DownloadThread(self.Parent.engine, script)\n self.worker.parent = self\n self.worker.start()\n self.timer.Start(10)\n\n def flush(self):\n pass\n\n def write(self, worker):\n s = worker.output[0]\n\n if '\\b' in s:\n s = s.replace('\\b', '')\n if not self.dialog:\n wx.GetApp().Yield()\n self.dialog = wx.ProgressDialog(\"Download Progress\",\n \"Downloading datasets . . .\\n\"\n + \" \" * len(s),\n maximum=1000,\n parent=None,\n style=wx.PD_SMOOTH\n | wx.DIALOG_NO_PARENT\n | wx.PD_CAN_ABORT\n | wx.PD_AUTO_HIDE\n | wx.PD_REMAINING_TIME\n )\n def progress(s):\n if ' / ' in s:\n s = s.split(' / ')\n total = float(s[1])\n current = float(s[0].split(': ')[1])\n progress = int((current / total) * 1000)\n return (progress if progress > 1 else 1)\n else:\n return None\n\n current_progress = progress(s)\n if current_progress:\n (keepgoing, skip) = self.dialog.Update(current_progress, s)\n else:\n (keepgoing, skip) = self.dialog.Pulse(s)\n\n if not keepgoing:\n return False\n else:\n if self.dialog:\n self.dialog.Update(1000, \"\")\n self.dialog.Destroy()\n self.dialog = None\n\n if '...' in s:\n self.Parent.SetStatusText(s)\n else:\n self.Parent.script_list.SetStatus(worker.script.name, s)\n\n wx.GetApp().Yield()\n return True\n", "path": "app/download_manager.py"}], "after_files": [{"content": "\"\"\"This class manages dataset downloads concurrently and processes progress\noutput.\"\"\"\n\nimport wx\nfrom retriever.lib.download import DownloadThread\n\n\nclass DownloadManager:\n def __init__(self, parent):\n self.dialog = None\n self.worker = None\n self.queue = []\n self.downloaded = set()\n self.errors = set()\n self.warnings = set()\n self.Parent = parent\n self.timer = wx.Timer(parent, -1)\n self.timer.interval = 10\n parent.Bind(wx.EVT_TIMER, self.update, self.timer)\n\n def Download(self, script):\n if not script in self.queue and not (self.worker and self.worker.script == script):\n self.queue.append(script)\n self.downloaded.add(script)\n if script in self.errors:\n self.errors.remove(script)\n self.warnings.remove(script)\n self.Parent.script_list.RefreshMe(None)\n if not self.timer.IsRunning() and not self.worker and len(self.queue) < 2:\n self.timer.Start(self.timer.interval)\n return True\n return False\n\n def update(self, evt):\n self.timer.Stop()\n terminate = False\n if self.worker:\n script = self.worker.script\n if self.worker.finished() and len(self.worker.output) == 0:\n if hasattr(script, 'warnings') and script.warnings:\n self.warnings.add(script)\n self.Parent.SetStatusText('\\n'.join(str(w) for w in script.warnings))\n else:\n self.Parent.SetStatusText(\"\")\n self.worker = None\n self.Parent.script_list.RefreshMe(None)\n self.timer.Start(self.timer.interval)\n else:\n self.worker.output_lock.acquire()\n while len(self.worker.output) > 0 and not terminate:\n if \"Error:\" in self.worker.output[0] and script in self.downloaded:\n self.downloaded.remove(script)\n self.errors.add(script)\n if self.write(self.worker) == False:\n terminate = True\n self.worker.output = self.worker.output[1:]\n #self.gauge.SetValue(100 * ((self.worker.scriptnum) /\n # (self.worker.progress_max + 1.0)))\n self.worker.output_lock.release()\n if terminate:\n self.Parent.Quit(None)\n else:\n self.timer.Start(self.timer.interval)\n elif self.queue:\n script = self.queue[0]\n self.queue = self.queue[1:]\n self.worker = DownloadThread(self.Parent.engine, script)\n self.worker.parent = self\n self.worker.start()\n self.timer.Start(10)\n\n def flush(self):\n pass\n\n def write(self, worker):\n s = worker.output[0]\n\n if '\\b' in s:\n s = s.replace('\\b', '')\n if not self.dialog:\n wx.GetApp().Yield()\n self.dialog = wx.ProgressDialog(\"Download Progress\",\n \"Downloading datasets . . .\\n\"\n + \" \" * len(s),\n maximum=1000,\n parent=None,\n style=wx.PD_SMOOTH\n | wx.DIALOG_NO_PARENT\n | wx.PD_CAN_ABORT\n | wx.PD_AUTO_HIDE\n | wx.PD_REMAINING_TIME\n )\n def progress(s):\n if ' / ' in s:\n s = s.split(' / ')\n total = float(s[1])\n current = float(s[0].split(': ')[1])\n progress = int((current / total) * 1000)\n return (progress if progress > 1 else 1)\n else:\n return None\n\n current_progress = progress(s)\n if current_progress:\n # download progress remaining-time disabled. causes bottle neck on Gentry ref: #396.\n # (keepgoing, skip) = self.dialog.Update(current_progress, s)\n # else:\n (keepgoing, skip) = self.dialog.Pulse(s)\n\n if not keepgoing:\n return False\n else:\n if self.dialog:\n self.dialog.Update(1000, \"\")\n self.dialog.Destroy()\n self.dialog = None\n\n if '...' in s:\n self.Parent.SetStatusText(s)\n else:\n self.Parent.script_list.SetStatus(worker.script.name, s)\n\n wx.GetApp().Yield()\n return True\n", "path": "app/download_manager.py"}]} | 1,507 | 143 |
gh_patches_debug_22153 | rasdani/github-patches | git_diff | svthalia__concrexit-1794 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Display warning in admin for age restricted orders for under age members
https://github.com/svthalia/concrexit/blob/8244e4bd50db6e64a63aa1605756acc2fb413094/website/sales/admin/order_admin.py#L334
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/sales/admin/order_admin.py`
Content:
```
1 from functools import partial
2
3 from admin_auto_filters.filters import AutocompleteFilter
4 from django.contrib import admin, messages
5 from django.contrib.admin import register, SimpleListFilter
6 from django.forms import Field
7 from django.http import HttpRequest
8 from django.urls import resolve
9 from django.utils import timezone
10
11 from django.utils.translation import gettext_lazy as _
12
13 from payments.widgets import PaymentWidget
14 from sales.models.order import Order, OrderItem
15 from sales.models.shift import Shift
16 from sales.services import is_manager
17
18
19 class OrderItemInline(admin.TabularInline):
20 model = OrderItem
21 extra = 0
22
23 fields = ("product", "amount", "total")
24
25 def get_readonly_fields(self, request: HttpRequest, obj: Order = None):
26 default_fields = self.readonly_fields
27
28 if not (request.member and request.member.has_perm("sales.custom_prices")):
29 default_fields += ("total",)
30
31 return default_fields
32
33 def get_queryset(self, request):
34 queryset = super().get_queryset(request)
35 queryset = queryset.prefetch_related("product", "product__product")
36 return queryset
37
38 def has_add_permission(self, request, obj):
39 if obj and obj.shift.locked:
40 return False
41
42 if obj and obj.payment:
43 return False
44
45 parent = self.get_parent_object_from_request(request)
46 if not parent:
47 return False
48
49 return super().has_add_permission(request, obj)
50
51 def has_change_permission(self, request, obj=None):
52 if obj and obj.payment:
53 return False
54 if obj and obj.shift.locked:
55 return False
56 if obj and not is_manager(request.member, obj.shift):
57 return False
58 return True
59
60 def has_delete_permission(self, request, obj=None):
61 if obj and obj.payment:
62 return False
63 if obj and obj.shift.locked:
64 return False
65 if obj and not is_manager(request.member, obj.shift):
66 return False
67 return True
68
69 def get_parent_object_from_request(self, request):
70 """Get parent object to determine product list."""
71 resolved = resolve(request.path_info)
72 if resolved.kwargs:
73 parent = self.parent_model.objects.get(pk=resolved.kwargs["object_id"])
74 return parent
75 return None
76
77 def formfield_for_foreignkey(self, db_field, request=None, **kwargs):
78 """Limit product list items to items of order's shift."""
79 field = super().formfield_for_foreignkey(db_field, request, **kwargs)
80
81 if db_field.name == "product":
82 if request is not None:
83 parent = self.get_parent_object_from_request(request)
84 if parent:
85 field.queryset = parent.shift.product_list.product_items
86 else:
87 field.queryset = field.queryset.none()
88
89 return field
90
91
92 class OrderShiftFilter(AutocompleteFilter):
93 title = _("shift")
94 field_name = "shift"
95 rel_model = Order
96
97 def queryset(self, request, queryset):
98 if self.value():
99 return queryset.filter(shift=self.value())
100 return queryset
101
102
103 class OrderMemberFilter(AutocompleteFilter):
104 title = _("member")
105 field_name = "payer"
106 rel_model = Order
107
108 def queryset(self, request, queryset):
109 if self.value():
110 return queryset.filter(payer=self.value())
111 return queryset
112
113
114 class OrderPaymentFilter(SimpleListFilter):
115 title = _("payment")
116 parameter_name = "payment"
117
118 def lookups(self, request, model_admin):
119 return (
120 ("not_required", _("No payment required")),
121 ("paid", _("Paid")),
122 ("unpaid", _("Unpaid")),
123 )
124
125 def queryset(self, request, queryset):
126 if self.value() is None:
127 return queryset
128 if self.value() == "paid":
129 return queryset.filter(payment__isnull=False)
130 if self.value() == "unpaid":
131 return queryset.filter(payment__isnull=True, total_amount__gt=0)
132 return queryset.filter(total_amount__exact=0)
133
134
135 class OrderProductFilter(SimpleListFilter):
136 title = _("product")
137 parameter_name = "product"
138
139 def lookups(self, request, model_admin):
140 qs = model_admin.get_queryset(request)
141 types = qs.filter(order_items__product__product__isnull=False).values_list(
142 "order_items__product__product__id", "order_items__product__product__name"
143 )
144 return list(types.order_by("order_items__product__product__id").distinct())
145
146 def queryset(self, request, queryset):
147 if self.value() is None:
148 return queryset
149 return queryset.filter(order_items__product__product__id__contains=self.value())
150
151
152 @register(Order)
153 class OrderAdmin(admin.ModelAdmin):
154 class Media:
155 pass
156
157 inlines = [
158 OrderItemInline,
159 ]
160 ordering = ("-created_at",)
161 date_hierarchy = "created_at"
162 search_fields = (
163 "id",
164 "payer__username",
165 "payer__first_name",
166 "payer__last_name",
167 "payer__profile__nickname",
168 )
169
170 list_display = (
171 "id",
172 "shift",
173 "created_at",
174 "order_description",
175 "num_items",
176 "discount",
177 "total_amount",
178 "paid",
179 "payer",
180 )
181 list_filter = [
182 OrderShiftFilter,
183 OrderMemberFilter,
184 OrderPaymentFilter,
185 OrderProductFilter,
186 ]
187
188 fields = (
189 "shift",
190 "created_at",
191 "order_description",
192 "num_items",
193 "age_restricted",
194 "subtotal",
195 "discount",
196 "total_amount",
197 "payer",
198 "payment",
199 "payment_url",
200 )
201
202 readonly_fields = (
203 "created_at",
204 "order_description",
205 "num_items",
206 "subtotal",
207 "total_amount",
208 "age_restricted",
209 "payment_url",
210 )
211
212 def get_readonly_fields(self, request: HttpRequest, obj: Order = None):
213 """Disallow changing shift when selected."""
214 default_fields = self.readonly_fields
215
216 if not (request.member and request.member.has_perm("sales.custom_prices")):
217 default_fields += ("discount",)
218
219 if obj and obj.shift:
220 default_fields += ("shift",)
221
222 return default_fields
223
224 def get_queryset(self, request):
225 queryset = super().get_queryset(request)
226
227 if not request.member:
228 queryset = queryset.none()
229 elif not request.member.has_perm("sales.override_manager"):
230 queryset = queryset.filter(
231 shift__managers__in=request.member.get_member_groups()
232 ).distinct()
233
234 queryset = queryset.select_properties(
235 "total_amount", "subtotal", "num_items", "age_restricted"
236 )
237 queryset = queryset.prefetch_related(
238 "shift", "shift__event", "shift__product_list"
239 )
240 queryset = queryset.prefetch_related(
241 "order_items", "order_items__product", "order_items__product__product"
242 )
243 queryset = queryset.prefetch_related("payment")
244 queryset = queryset.prefetch_related("payer")
245 return queryset
246
247 def has_add_permission(self, request):
248 if not request.member:
249 return False
250 elif not request.member.has_perm("sales.override_manager"):
251 if (
252 Shift.objects.filter(
253 start__lte=timezone.now(),
254 locked=False,
255 managers__in=request.member.get_member_groups(),
256 ).count()
257 == 0
258 ):
259 return False
260 return super().has_view_permission(request)
261
262 def has_view_permission(self, request, obj=None):
263 if obj and not is_manager(request.member, obj.shift):
264 return False
265 return super().has_view_permission(request, obj)
266
267 def has_change_permission(self, request, obj=None):
268 if obj and obj.shift.locked:
269 return False
270 if obj and obj.payment:
271 return False
272
273 if obj and not is_manager(request.member, obj.shift):
274 return False
275
276 return super().has_change_permission(request, obj)
277
278 def has_delete_permission(self, request, obj=None):
279 if obj and obj.shift.locked:
280 return False
281 if obj and obj.payment:
282 return False
283
284 if obj and not is_manager(request.member, obj.shift):
285 return False
286
287 return super().has_delete_permission(request, obj)
288
289 def get_form(self, request, obj=None, **kwargs):
290 """Override get form to use payment widget."""
291 return super().get_form(
292 request,
293 obj,
294 formfield_callback=partial(
295 self.formfield_for_dbfield, request=request, obj=obj
296 ),
297 **kwargs,
298 )
299
300 def formfield_for_dbfield(self, db_field, request, obj=None, **kwargs):
301 """Use payment widget for payments."""
302 field = super().formfield_for_dbfield(db_field, request, **kwargs)
303 if db_field.name == "payment":
304 return Field(
305 widget=PaymentWidget(obj=obj), initial=field.initial, required=False
306 )
307 if db_field.name == "shift":
308 field.queryset = Shift.objects.filter(locked=False)
309 if not request.member:
310 field.queryset = field.queryset.none()
311 elif not request.member.has_perm("sales.override_manager"):
312 field.queryset = field.queryset.filter(
313 managers__in=request.member.get_member_groups()
314 )
315 return field
316
317 def changelist_view(self, request, extra_context=None):
318 if not (request.member and request.member.has_perm("sales.override_manager")):
319 self.message_user(
320 request,
321 _("You are only seeing orders that are relevant to you."),
322 messages.WARNING,
323 )
324 return super().changelist_view(request, extra_context)
325
326 def change_view(self, request, object_id, form_url="", extra_context=None):
327 object_id
328 return super().change_view(request, object_id, form_url, extra_context)
329
330 def order_description(self, obj):
331 if obj.order_description:
332 return obj.order_description
333 return "-"
334
335 def num_items(self, obj):
336 return obj.num_items
337
338 def subtotal(self, obj):
339 if obj.subtotal:
340 return f"€{obj.subtotal:.2f}"
341 return "-"
342
343 def discount(self, obj):
344 if obj.discount:
345 return f"€{obj.discount:.2f}"
346 return "-"
347
348 def total_amount(self, obj):
349 if obj.total_amount:
350 return f"€{obj.total_amount:.2f}"
351 return "-"
352
353 def paid(self, obj):
354 if obj.total_amount is None or obj.total_amount == 0:
355 return None
356 return obj.payment is not None
357
358 paid.boolean = True
359
360 def age_restricted(self, obj):
361 return bool(obj.age_restricted) if obj else None
362
363 age_restricted.boolean = True
364
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/website/sales/admin/order_admin.py b/website/sales/admin/order_admin.py
--- a/website/sales/admin/order_admin.py
+++ b/website/sales/admin/order_admin.py
@@ -11,6 +11,7 @@
from django.utils.translation import gettext_lazy as _
from payments.widgets import PaymentWidget
+from sales import services
from sales.models.order import Order, OrderItem
from sales.models.shift import Shift
from sales.services import is_manager
@@ -221,6 +222,19 @@
return default_fields
+ def changeform_view(self, request, object_id=None, form_url="", extra_context=None):
+ if object_id:
+ obj = self.model.objects.get(pk=object_id)
+ if obj.age_restricted and obj.payer and not services.is_adult(obj.payer):
+ self.message_user(
+ request,
+ _(
+ "The payer for this order is under-age while the order is age restricted!"
+ ),
+ messages.WARNING,
+ )
+ return super().changeform_view(request, object_id, form_url, extra_context)
+
def get_queryset(self, request):
queryset = super().get_queryset(request)
| {"golden_diff": "diff --git a/website/sales/admin/order_admin.py b/website/sales/admin/order_admin.py\n--- a/website/sales/admin/order_admin.py\n+++ b/website/sales/admin/order_admin.py\n@@ -11,6 +11,7 @@\n from django.utils.translation import gettext_lazy as _\n \n from payments.widgets import PaymentWidget\n+from sales import services\n from sales.models.order import Order, OrderItem\n from sales.models.shift import Shift\n from sales.services import is_manager\n@@ -221,6 +222,19 @@\n \n return default_fields\n \n+ def changeform_view(self, request, object_id=None, form_url=\"\", extra_context=None):\n+ if object_id:\n+ obj = self.model.objects.get(pk=object_id)\n+ if obj.age_restricted and obj.payer and not services.is_adult(obj.payer):\n+ self.message_user(\n+ request,\n+ _(\n+ \"The payer for this order is under-age while the order is age restricted!\"\n+ ),\n+ messages.WARNING,\n+ )\n+ return super().changeform_view(request, object_id, form_url, extra_context)\n+\n def get_queryset(self, request):\n queryset = super().get_queryset(request)\n", "issue": "Display warning in admin for age restricted orders for under age members\nhttps://github.com/svthalia/concrexit/blob/8244e4bd50db6e64a63aa1605756acc2fb413094/website/sales/admin/order_admin.py#L334\n", "before_files": [{"content": "from functools import partial\n\nfrom admin_auto_filters.filters import AutocompleteFilter\nfrom django.contrib import admin, messages\nfrom django.contrib.admin import register, SimpleListFilter\nfrom django.forms import Field\nfrom django.http import HttpRequest\nfrom django.urls import resolve\nfrom django.utils import timezone\n\nfrom django.utils.translation import gettext_lazy as _\n\nfrom payments.widgets import PaymentWidget\nfrom sales.models.order import Order, OrderItem\nfrom sales.models.shift import Shift\nfrom sales.services import is_manager\n\n\nclass OrderItemInline(admin.TabularInline):\n model = OrderItem\n extra = 0\n\n fields = (\"product\", \"amount\", \"total\")\n\n def get_readonly_fields(self, request: HttpRequest, obj: Order = None):\n default_fields = self.readonly_fields\n\n if not (request.member and request.member.has_perm(\"sales.custom_prices\")):\n default_fields += (\"total\",)\n\n return default_fields\n\n def get_queryset(self, request):\n queryset = super().get_queryset(request)\n queryset = queryset.prefetch_related(\"product\", \"product__product\")\n return queryset\n\n def has_add_permission(self, request, obj):\n if obj and obj.shift.locked:\n return False\n\n if obj and obj.payment:\n return False\n\n parent = self.get_parent_object_from_request(request)\n if not parent:\n return False\n\n return super().has_add_permission(request, obj)\n\n def has_change_permission(self, request, obj=None):\n if obj and obj.payment:\n return False\n if obj and obj.shift.locked:\n return False\n if obj and not is_manager(request.member, obj.shift):\n return False\n return True\n\n def has_delete_permission(self, request, obj=None):\n if obj and obj.payment:\n return False\n if obj and obj.shift.locked:\n return False\n if obj and not is_manager(request.member, obj.shift):\n return False\n return True\n\n def get_parent_object_from_request(self, request):\n \"\"\"Get parent object to determine product list.\"\"\"\n resolved = resolve(request.path_info)\n if resolved.kwargs:\n parent = self.parent_model.objects.get(pk=resolved.kwargs[\"object_id\"])\n return parent\n return None\n\n def formfield_for_foreignkey(self, db_field, request=None, **kwargs):\n \"\"\"Limit product list items to items of order's shift.\"\"\"\n field = super().formfield_for_foreignkey(db_field, request, **kwargs)\n\n if db_field.name == \"product\":\n if request is not None:\n parent = self.get_parent_object_from_request(request)\n if parent:\n field.queryset = parent.shift.product_list.product_items\n else:\n field.queryset = field.queryset.none()\n\n return field\n\n\nclass OrderShiftFilter(AutocompleteFilter):\n title = _(\"shift\")\n field_name = \"shift\"\n rel_model = Order\n\n def queryset(self, request, queryset):\n if self.value():\n return queryset.filter(shift=self.value())\n return queryset\n\n\nclass OrderMemberFilter(AutocompleteFilter):\n title = _(\"member\")\n field_name = \"payer\"\n rel_model = Order\n\n def queryset(self, request, queryset):\n if self.value():\n return queryset.filter(payer=self.value())\n return queryset\n\n\nclass OrderPaymentFilter(SimpleListFilter):\n title = _(\"payment\")\n parameter_name = \"payment\"\n\n def lookups(self, request, model_admin):\n return (\n (\"not_required\", _(\"No payment required\")),\n (\"paid\", _(\"Paid\")),\n (\"unpaid\", _(\"Unpaid\")),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n if self.value() == \"paid\":\n return queryset.filter(payment__isnull=False)\n if self.value() == \"unpaid\":\n return queryset.filter(payment__isnull=True, total_amount__gt=0)\n return queryset.filter(total_amount__exact=0)\n\n\nclass OrderProductFilter(SimpleListFilter):\n title = _(\"product\")\n parameter_name = \"product\"\n\n def lookups(self, request, model_admin):\n qs = model_admin.get_queryset(request)\n types = qs.filter(order_items__product__product__isnull=False).values_list(\n \"order_items__product__product__id\", \"order_items__product__product__name\"\n )\n return list(types.order_by(\"order_items__product__product__id\").distinct())\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n return queryset.filter(order_items__product__product__id__contains=self.value())\n\n\n@register(Order)\nclass OrderAdmin(admin.ModelAdmin):\n class Media:\n pass\n\n inlines = [\n OrderItemInline,\n ]\n ordering = (\"-created_at\",)\n date_hierarchy = \"created_at\"\n search_fields = (\n \"id\",\n \"payer__username\",\n \"payer__first_name\",\n \"payer__last_name\",\n \"payer__profile__nickname\",\n )\n\n list_display = (\n \"id\",\n \"shift\",\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"discount\",\n \"total_amount\",\n \"paid\",\n \"payer\",\n )\n list_filter = [\n OrderShiftFilter,\n OrderMemberFilter,\n OrderPaymentFilter,\n OrderProductFilter,\n ]\n\n fields = (\n \"shift\",\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"age_restricted\",\n \"subtotal\",\n \"discount\",\n \"total_amount\",\n \"payer\",\n \"payment\",\n \"payment_url\",\n )\n\n readonly_fields = (\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"subtotal\",\n \"total_amount\",\n \"age_restricted\",\n \"payment_url\",\n )\n\n def get_readonly_fields(self, request: HttpRequest, obj: Order = None):\n \"\"\"Disallow changing shift when selected.\"\"\"\n default_fields = self.readonly_fields\n\n if not (request.member and request.member.has_perm(\"sales.custom_prices\")):\n default_fields += (\"discount\",)\n\n if obj and obj.shift:\n default_fields += (\"shift\",)\n\n return default_fields\n\n def get_queryset(self, request):\n queryset = super().get_queryset(request)\n\n if not request.member:\n queryset = queryset.none()\n elif not request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n shift__managers__in=request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n queryset = queryset.prefetch_related(\"payer\")\n return queryset\n\n def has_add_permission(self, request):\n if not request.member:\n return False\n elif not request.member.has_perm(\"sales.override_manager\"):\n if (\n Shift.objects.filter(\n start__lte=timezone.now(),\n locked=False,\n managers__in=request.member.get_member_groups(),\n ).count()\n == 0\n ):\n return False\n return super().has_view_permission(request)\n\n def has_view_permission(self, request, obj=None):\n if obj and not is_manager(request.member, obj.shift):\n return False\n return super().has_view_permission(request, obj)\n\n def has_change_permission(self, request, obj=None):\n if obj and obj.shift.locked:\n return False\n if obj and obj.payment:\n return False\n\n if obj and not is_manager(request.member, obj.shift):\n return False\n\n return super().has_change_permission(request, obj)\n\n def has_delete_permission(self, request, obj=None):\n if obj and obj.shift.locked:\n return False\n if obj and obj.payment:\n return False\n\n if obj and not is_manager(request.member, obj.shift):\n return False\n\n return super().has_delete_permission(request, obj)\n\n def get_form(self, request, obj=None, **kwargs):\n \"\"\"Override get form to use payment widget.\"\"\"\n return super().get_form(\n request,\n obj,\n formfield_callback=partial(\n self.formfield_for_dbfield, request=request, obj=obj\n ),\n **kwargs,\n )\n\n def formfield_for_dbfield(self, db_field, request, obj=None, **kwargs):\n \"\"\"Use payment widget for payments.\"\"\"\n field = super().formfield_for_dbfield(db_field, request, **kwargs)\n if db_field.name == \"payment\":\n return Field(\n widget=PaymentWidget(obj=obj), initial=field.initial, required=False\n )\n if db_field.name == \"shift\":\n field.queryset = Shift.objects.filter(locked=False)\n if not request.member:\n field.queryset = field.queryset.none()\n elif not request.member.has_perm(\"sales.override_manager\"):\n field.queryset = field.queryset.filter(\n managers__in=request.member.get_member_groups()\n )\n return field\n\n def changelist_view(self, request, extra_context=None):\n if not (request.member and request.member.has_perm(\"sales.override_manager\")):\n self.message_user(\n request,\n _(\"You are only seeing orders that are relevant to you.\"),\n messages.WARNING,\n )\n return super().changelist_view(request, extra_context)\n\n def change_view(self, request, object_id, form_url=\"\", extra_context=None):\n object_id\n return super().change_view(request, object_id, form_url, extra_context)\n\n def order_description(self, obj):\n if obj.order_description:\n return obj.order_description\n return \"-\"\n\n def num_items(self, obj):\n return obj.num_items\n\n def subtotal(self, obj):\n if obj.subtotal:\n return f\"\u20ac{obj.subtotal:.2f}\"\n return \"-\"\n\n def discount(self, obj):\n if obj.discount:\n return f\"\u20ac{obj.discount:.2f}\"\n return \"-\"\n\n def total_amount(self, obj):\n if obj.total_amount:\n return f\"\u20ac{obj.total_amount:.2f}\"\n return \"-\"\n\n def paid(self, obj):\n if obj.total_amount is None or obj.total_amount == 0:\n return None\n return obj.payment is not None\n\n paid.boolean = True\n\n def age_restricted(self, obj):\n return bool(obj.age_restricted) if obj else None\n\n age_restricted.boolean = True\n", "path": "website/sales/admin/order_admin.py"}], "after_files": [{"content": "from functools import partial\n\nfrom admin_auto_filters.filters import AutocompleteFilter\nfrom django.contrib import admin, messages\nfrom django.contrib.admin import register, SimpleListFilter\nfrom django.forms import Field\nfrom django.http import HttpRequest\nfrom django.urls import resolve\nfrom django.utils import timezone\n\nfrom django.utils.translation import gettext_lazy as _\n\nfrom payments.widgets import PaymentWidget\nfrom sales import services\nfrom sales.models.order import Order, OrderItem\nfrom sales.models.shift import Shift\nfrom sales.services import is_manager\n\n\nclass OrderItemInline(admin.TabularInline):\n model = OrderItem\n extra = 0\n\n fields = (\"product\", \"amount\", \"total\")\n\n def get_readonly_fields(self, request: HttpRequest, obj: Order = None):\n default_fields = self.readonly_fields\n\n if not (request.member and request.member.has_perm(\"sales.custom_prices\")):\n default_fields += (\"total\",)\n\n return default_fields\n\n def get_queryset(self, request):\n queryset = super().get_queryset(request)\n queryset = queryset.prefetch_related(\"product\", \"product__product\")\n return queryset\n\n def has_add_permission(self, request, obj):\n if obj and obj.shift.locked:\n return False\n\n if obj and obj.payment:\n return False\n\n parent = self.get_parent_object_from_request(request)\n if not parent:\n return False\n\n return super().has_add_permission(request, obj)\n\n def has_change_permission(self, request, obj=None):\n if obj and obj.payment:\n return False\n if obj and obj.shift.locked:\n return False\n if obj and not is_manager(request.member, obj.shift):\n return False\n return True\n\n def has_delete_permission(self, request, obj=None):\n if obj and obj.payment:\n return False\n if obj and obj.shift.locked:\n return False\n if obj and not is_manager(request.member, obj.shift):\n return False\n return True\n\n def get_parent_object_from_request(self, request):\n \"\"\"Get parent object to determine product list.\"\"\"\n resolved = resolve(request.path_info)\n if resolved.kwargs:\n parent = self.parent_model.objects.get(pk=resolved.kwargs[\"object_id\"])\n return parent\n return None\n\n def formfield_for_foreignkey(self, db_field, request=None, **kwargs):\n \"\"\"Limit product list items to items of order's shift.\"\"\"\n field = super().formfield_for_foreignkey(db_field, request, **kwargs)\n\n if db_field.name == \"product\":\n if request is not None:\n parent = self.get_parent_object_from_request(request)\n if parent:\n field.queryset = parent.shift.product_list.product_items\n else:\n field.queryset = field.queryset.none()\n\n return field\n\n\nclass OrderShiftFilter(AutocompleteFilter):\n title = _(\"shift\")\n field_name = \"shift\"\n rel_model = Order\n\n def queryset(self, request, queryset):\n if self.value():\n return queryset.filter(shift=self.value())\n return queryset\n\n\nclass OrderMemberFilter(AutocompleteFilter):\n title = _(\"member\")\n field_name = \"payer\"\n rel_model = Order\n\n def queryset(self, request, queryset):\n if self.value():\n return queryset.filter(payer=self.value())\n return queryset\n\n\nclass OrderPaymentFilter(SimpleListFilter):\n title = _(\"payment\")\n parameter_name = \"payment\"\n\n def lookups(self, request, model_admin):\n return (\n (\"not_required\", _(\"No payment required\")),\n (\"paid\", _(\"Paid\")),\n (\"unpaid\", _(\"Unpaid\")),\n )\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n if self.value() == \"paid\":\n return queryset.filter(payment__isnull=False)\n if self.value() == \"unpaid\":\n return queryset.filter(payment__isnull=True, total_amount__gt=0)\n return queryset.filter(total_amount__exact=0)\n\n\nclass OrderProductFilter(SimpleListFilter):\n title = _(\"product\")\n parameter_name = \"product\"\n\n def lookups(self, request, model_admin):\n qs = model_admin.get_queryset(request)\n types = qs.filter(order_items__product__product__isnull=False).values_list(\n \"order_items__product__product__id\", \"order_items__product__product__name\"\n )\n return list(types.order_by(\"order_items__product__product__id\").distinct())\n\n def queryset(self, request, queryset):\n if self.value() is None:\n return queryset\n return queryset.filter(order_items__product__product__id__contains=self.value())\n\n\n@register(Order)\nclass OrderAdmin(admin.ModelAdmin):\n class Media:\n pass\n\n inlines = [\n OrderItemInline,\n ]\n ordering = (\"-created_at\",)\n date_hierarchy = \"created_at\"\n search_fields = (\n \"id\",\n \"payer__username\",\n \"payer__first_name\",\n \"payer__last_name\",\n \"payer__profile__nickname\",\n )\n\n list_display = (\n \"id\",\n \"shift\",\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"discount\",\n \"total_amount\",\n \"paid\",\n \"payer\",\n )\n list_filter = [\n OrderShiftFilter,\n OrderMemberFilter,\n OrderPaymentFilter,\n OrderProductFilter,\n ]\n\n fields = (\n \"shift\",\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"age_restricted\",\n \"subtotal\",\n \"discount\",\n \"total_amount\",\n \"payer\",\n \"payment\",\n \"payment_url\",\n )\n\n readonly_fields = (\n \"created_at\",\n \"order_description\",\n \"num_items\",\n \"subtotal\",\n \"total_amount\",\n \"age_restricted\",\n \"payment_url\",\n )\n\n def get_readonly_fields(self, request: HttpRequest, obj: Order = None):\n \"\"\"Disallow changing shift when selected.\"\"\"\n default_fields = self.readonly_fields\n\n if not (request.member and request.member.has_perm(\"sales.custom_prices\")):\n default_fields += (\"discount\",)\n\n if obj and obj.shift:\n default_fields += (\"shift\",)\n\n return default_fields\n\n def changeform_view(self, request, object_id=None, form_url=\"\", extra_context=None):\n if object_id:\n obj = self.model.objects.get(pk=object_id)\n if obj.age_restricted and obj.payer and not services.is_adult(obj.payer):\n self.message_user(\n request,\n _(\n \"The payer for this order is under-age while the order is age restricted!\"\n ),\n messages.WARNING,\n )\n return super().changeform_view(request, object_id, form_url, extra_context)\n\n def get_queryset(self, request):\n queryset = super().get_queryset(request)\n\n if not request.member:\n queryset = queryset.none()\n elif not request.member.has_perm(\"sales.override_manager\"):\n queryset = queryset.filter(\n shift__managers__in=request.member.get_member_groups()\n ).distinct()\n\n queryset = queryset.select_properties(\n \"total_amount\", \"subtotal\", \"num_items\", \"age_restricted\"\n )\n queryset = queryset.prefetch_related(\n \"shift\", \"shift__event\", \"shift__product_list\"\n )\n queryset = queryset.prefetch_related(\n \"order_items\", \"order_items__product\", \"order_items__product__product\"\n )\n queryset = queryset.prefetch_related(\"payment\")\n queryset = queryset.prefetch_related(\"payer\")\n return queryset\n\n def has_add_permission(self, request):\n if not request.member:\n return False\n elif not request.member.has_perm(\"sales.override_manager\"):\n if (\n Shift.objects.filter(\n start__lte=timezone.now(),\n locked=False,\n managers__in=request.member.get_member_groups(),\n ).count()\n == 0\n ):\n return False\n return super().has_view_permission(request)\n\n def has_view_permission(self, request, obj=None):\n if obj and not is_manager(request.member, obj.shift):\n return False\n return super().has_view_permission(request, obj)\n\n def has_change_permission(self, request, obj=None):\n if obj and obj.shift.locked:\n return False\n if obj and obj.payment:\n return False\n\n if obj and not is_manager(request.member, obj.shift):\n return False\n\n return super().has_change_permission(request, obj)\n\n def has_delete_permission(self, request, obj=None):\n if obj and obj.shift.locked:\n return False\n if obj and obj.payment:\n return False\n\n if obj and not is_manager(request.member, obj.shift):\n return False\n\n return super().has_delete_permission(request, obj)\n\n def get_form(self, request, obj=None, **kwargs):\n \"\"\"Override get form to use payment widget.\"\"\"\n return super().get_form(\n request,\n obj,\n formfield_callback=partial(\n self.formfield_for_dbfield, request=request, obj=obj\n ),\n **kwargs,\n )\n\n def formfield_for_dbfield(self, db_field, request, obj=None, **kwargs):\n \"\"\"Use payment widget for payments.\"\"\"\n field = super().formfield_for_dbfield(db_field, request, **kwargs)\n if db_field.name == \"payment\":\n return Field(\n widget=PaymentWidget(obj=obj), initial=field.initial, required=False\n )\n if db_field.name == \"shift\":\n field.queryset = Shift.objects.filter(locked=False)\n if not request.member:\n field.queryset = field.queryset.none()\n elif not request.member.has_perm(\"sales.override_manager\"):\n field.queryset = field.queryset.filter(\n managers__in=request.member.get_member_groups()\n )\n return field\n\n def changelist_view(self, request, extra_context=None):\n if not (request.member and request.member.has_perm(\"sales.override_manager\")):\n self.message_user(\n request,\n _(\"You are only seeing orders that are relevant to you.\"),\n messages.WARNING,\n )\n return super().changelist_view(request, extra_context)\n\n def change_view(self, request, object_id, form_url=\"\", extra_context=None):\n object_id\n return super().change_view(request, object_id, form_url, extra_context)\n\n def order_description(self, obj):\n if obj.order_description:\n return obj.order_description\n return \"-\"\n\n def num_items(self, obj):\n return obj.num_items\n\n def subtotal(self, obj):\n if obj.subtotal:\n return f\"\u20ac{obj.subtotal:.2f}\"\n return \"-\"\n\n def discount(self, obj):\n if obj.discount:\n return f\"\u20ac{obj.discount:.2f}\"\n return \"-\"\n\n def total_amount(self, obj):\n if obj.total_amount:\n return f\"\u20ac{obj.total_amount:.2f}\"\n return \"-\"\n\n def paid(self, obj):\n if obj.total_amount is None or obj.total_amount == 0:\n return None\n return obj.payment is not None\n\n paid.boolean = True\n\n def age_restricted(self, obj):\n return bool(obj.age_restricted) if obj else None\n\n age_restricted.boolean = True\n", "path": "website/sales/admin/order_admin.py"}]} | 3,627 | 265 |
gh_patches_debug_26761 | rasdani/github-patches | git_diff | feast-dev__feast-2356 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Snowflake login support private key or web browser authentication
The current snowflake support seems only allow password authentication but we are using Azure AD login without password for the account.
Can we add functionality to allow different mechanism of authentication?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sdk/python/feast/infra/utils/snowflake_utils.py`
Content:
```
1 import configparser
2 import os
3 import random
4 import string
5 from logging import getLogger
6 from tempfile import TemporaryDirectory
7 from typing import Dict, Iterator, List, Optional, Tuple, cast
8
9 import pandas as pd
10 from tenacity import (
11 retry,
12 retry_if_exception_type,
13 stop_after_attempt,
14 wait_exponential,
15 )
16
17 from feast.errors import SnowflakeIncompleteConfig, SnowflakeQueryUnknownError
18
19 try:
20 import snowflake.connector
21 from snowflake.connector import ProgrammingError, SnowflakeConnection
22 from snowflake.connector.cursor import SnowflakeCursor
23 except ImportError as e:
24 from feast.errors import FeastExtrasDependencyImportError
25
26 raise FeastExtrasDependencyImportError("snowflake", str(e))
27
28
29 getLogger("snowflake.connector.cursor").disabled = True
30 getLogger("snowflake.connector.connection").disabled = True
31 getLogger("snowflake.connector.network").disabled = True
32 logger = getLogger(__name__)
33
34
35 def execute_snowflake_statement(conn: SnowflakeConnection, query) -> SnowflakeCursor:
36 cursor = conn.cursor().execute(query)
37 if cursor is None:
38 raise SnowflakeQueryUnknownError(query)
39 return cursor
40
41
42 def get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:
43 if config.type == "snowflake.offline":
44 config_header = "connections.feast_offline_store"
45
46 config = dict(config)
47
48 # read config file
49 config_reader = configparser.ConfigParser()
50 config_reader.read([config["config_path"]])
51 if config_reader.has_section(config_header):
52 kwargs = dict(config_reader[config_header])
53 else:
54 kwargs = {}
55
56 kwargs.update((k, v) for k, v in config.items() if v is not None)
57
58 try:
59 conn = snowflake.connector.connect(
60 account=kwargs["account"],
61 user=kwargs["user"],
62 password=kwargs["password"],
63 role=f'''"{kwargs['role']}"''',
64 warehouse=f'''"{kwargs['warehouse']}"''',
65 database=f'''"{kwargs['database']}"''',
66 schema=f'''"{kwargs['schema_']}"''',
67 application="feast",
68 autocommit=autocommit,
69 )
70
71 return conn
72 except KeyError as e:
73 raise SnowflakeIncompleteConfig(e)
74
75
76 # TO DO -- sfc-gh-madkins
77 # Remove dependency on write_pandas function by falling back to native snowflake python connector
78 # Current issue is datetime[ns] types are read incorrectly in Snowflake, need to coerce to datetime[ns, UTC]
79 def write_pandas(
80 conn: SnowflakeConnection,
81 df: pd.DataFrame,
82 table_name: str,
83 database: Optional[str] = None,
84 schema: Optional[str] = None,
85 chunk_size: Optional[int] = None,
86 compression: str = "gzip",
87 on_error: str = "abort_statement",
88 parallel: int = 4,
89 quote_identifiers: bool = True,
90 auto_create_table: bool = False,
91 create_temp_table: bool = False,
92 ):
93 """Allows users to most efficiently write back a pandas DataFrame to Snowflake.
94
95 It works by dumping the DataFrame into Parquet files, uploading them and finally copying their data into the table.
96
97 Returns whether all files were ingested correctly, number of chunks uploaded, and number of rows ingested
98 with all of the COPY INTO command's output for debugging purposes.
99
100 Example usage:
101 import pandas
102 from snowflake.connector.pandas_tools import write_pandas
103
104 df = pandas.DataFrame([('Mark', 10), ('Luke', 20)], columns=['name', 'balance'])
105 success, nchunks, nrows, _ = write_pandas(cnx, df, 'customers')
106
107 Args:
108 conn: Connection to be used to communicate with Snowflake.
109 df: Dataframe we'd like to write back.
110 table_name: Table name where we want to insert into.
111 database: Database schema and table is in, if not provided the default one will be used (Default value = None).
112 schema: Schema table is in, if not provided the default one will be used (Default value = None).
113 chunk_size: Number of elements to be inserted once, if not provided all elements will be dumped once
114 (Default value = None).
115 compression: The compression used on the Parquet files, can only be gzip, or snappy. Gzip gives supposedly a
116 better compression, while snappy is faster. Use whichever is more appropriate (Default value = 'gzip').
117 on_error: Action to take when COPY INTO statements fail, default follows documentation at:
118 https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#copy-options-copyoptions
119 (Default value = 'abort_statement').
120 parallel: Number of threads to be used when uploading chunks, default follows documentation at:
121 https://docs.snowflake.com/en/sql-reference/sql/put.html#optional-parameters (Default value = 4).
122 quote_identifiers: By default, identifiers, specifically database, schema, table and column names
123 (from df.columns) will be quoted. If set to False, identifiers are passed on to Snowflake without quoting.
124 I.e. identifiers will be coerced to uppercase by Snowflake. (Default value = True)
125 auto_create_table: When true, will automatically create a table with corresponding columns for each column in
126 the passed in DataFrame. The table will not be created if it already exists
127 create_temp_table: Will make the auto-created table as a temporary table
128 """
129 if database is not None and schema is None:
130 raise ProgrammingError(
131 "Schema has to be provided to write_pandas when a database is provided"
132 )
133 # This dictionary maps the compression algorithm to Snowflake put copy into command type
134 # https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#type-parquet
135 compression_map = {"gzip": "auto", "snappy": "snappy"}
136 if compression not in compression_map.keys():
137 raise ProgrammingError(
138 "Invalid compression '{}', only acceptable values are: {}".format(
139 compression, compression_map.keys()
140 )
141 )
142 if quote_identifiers:
143 location = (
144 (('"' + database + '".') if database else "")
145 + (('"' + schema + '".') if schema else "")
146 + ('"' + table_name + '"')
147 )
148 else:
149 location = (
150 (database + "." if database else "")
151 + (schema + "." if schema else "")
152 + (table_name)
153 )
154 if chunk_size is None:
155 chunk_size = len(df)
156 cursor: SnowflakeCursor = conn.cursor()
157 stage_name = create_temporary_sfc_stage(cursor)
158
159 with TemporaryDirectory() as tmp_folder:
160 for i, chunk in chunk_helper(df, chunk_size):
161 chunk_path = os.path.join(tmp_folder, "file{}.txt".format(i))
162 # Dump chunk into parquet file
163 chunk.to_parquet(
164 chunk_path,
165 compression=compression,
166 use_deprecated_int96_timestamps=True,
167 )
168 # Upload parquet file
169 upload_sql = (
170 "PUT /* Python:snowflake.connector.pandas_tools.write_pandas() */ "
171 "'file://{path}' @\"{stage_name}\" PARALLEL={parallel}"
172 ).format(
173 path=chunk_path.replace("\\", "\\\\").replace("'", "\\'"),
174 stage_name=stage_name,
175 parallel=parallel,
176 )
177 logger.debug(f"uploading files with '{upload_sql}'")
178 cursor.execute(upload_sql, _is_internal=True)
179 # Remove chunk file
180 os.remove(chunk_path)
181 if quote_identifiers:
182 columns = '"' + '","'.join(list(df.columns)) + '"'
183 else:
184 columns = ",".join(list(df.columns))
185
186 if auto_create_table:
187 file_format_name = create_file_format(compression, compression_map, cursor)
188 infer_schema_sql = f"SELECT COLUMN_NAME, TYPE FROM table(infer_schema(location=>'@\"{stage_name}\"', file_format=>'{file_format_name}'))"
189 logger.debug(f"inferring schema with '{infer_schema_sql}'")
190 result_cursor = cursor.execute(infer_schema_sql, _is_internal=True)
191 if result_cursor is None:
192 raise SnowflakeQueryUnknownError(infer_schema_sql)
193 result = cast(List[Tuple[str, str]], result_cursor.fetchall())
194 column_type_mapping: Dict[str, str] = dict(result)
195 # Infer schema can return the columns out of order depending on the chunking we do when uploading
196 # so we have to iterate through the dataframe columns to make sure we create the table with its
197 # columns in order
198 quote = '"' if quote_identifiers else ""
199 create_table_columns = ", ".join(
200 [f"{quote}{c}{quote} {column_type_mapping[c]}" for c in df.columns]
201 )
202 create_table_sql = (
203 f"CREATE {'TEMP ' if create_temp_table else ''}TABLE IF NOT EXISTS {location} "
204 f"({create_table_columns})"
205 f" /* Python:snowflake.connector.pandas_tools.write_pandas() */ "
206 )
207 logger.debug(f"auto creating table with '{create_table_sql}'")
208 cursor.execute(create_table_sql, _is_internal=True)
209 drop_file_format_sql = f"DROP FILE FORMAT IF EXISTS {file_format_name}"
210 logger.debug(f"dropping file format with '{drop_file_format_sql}'")
211 cursor.execute(drop_file_format_sql, _is_internal=True)
212
213 # in Snowflake, all parquet data is stored in a single column, $1, so we must select columns explicitly
214 # see (https://docs.snowflake.com/en/user-guide/script-data-load-transform-parquet.html)
215 if quote_identifiers:
216 parquet_columns = "$1:" + ",$1:".join(f'"{c}"' for c in df.columns)
217 else:
218 parquet_columns = "$1:" + ",$1:".join(df.columns)
219 copy_into_sql = (
220 "COPY INTO {location} /* Python:snowflake.connector.pandas_tools.write_pandas() */ "
221 "({columns}) "
222 'FROM (SELECT {parquet_columns} FROM @"{stage_name}") '
223 "FILE_FORMAT=(TYPE=PARQUET COMPRESSION={compression}) "
224 "PURGE=TRUE ON_ERROR={on_error}"
225 ).format(
226 location=location,
227 columns=columns,
228 parquet_columns=parquet_columns,
229 stage_name=stage_name,
230 compression=compression_map[compression],
231 on_error=on_error,
232 )
233 logger.debug("copying into with '{}'".format(copy_into_sql))
234 # Snowflake returns the original cursor if the query execution succeeded.
235 result_cursor = cursor.execute(copy_into_sql, _is_internal=True)
236 if result_cursor is None:
237 raise SnowflakeQueryUnknownError(copy_into_sql)
238 result_cursor.close()
239
240
241 @retry(
242 wait=wait_exponential(multiplier=1, max=4),
243 retry=retry_if_exception_type(ProgrammingError),
244 stop=stop_after_attempt(5),
245 reraise=True,
246 )
247 def create_file_format(
248 compression: str, compression_map: Dict[str, str], cursor: SnowflakeCursor
249 ) -> str:
250 file_format_name = (
251 '"' + "".join(random.choice(string.ascii_lowercase) for _ in range(5)) + '"'
252 )
253 file_format_sql = (
254 f"CREATE FILE FORMAT {file_format_name} "
255 f"/* Python:snowflake.connector.pandas_tools.write_pandas() */ "
256 f"TYPE=PARQUET COMPRESSION={compression_map[compression]}"
257 )
258 logger.debug(f"creating file format with '{file_format_sql}'")
259 cursor.execute(file_format_sql, _is_internal=True)
260 return file_format_name
261
262
263 @retry(
264 wait=wait_exponential(multiplier=1, max=4),
265 retry=retry_if_exception_type(ProgrammingError),
266 stop=stop_after_attempt(5),
267 reraise=True,
268 )
269 def create_temporary_sfc_stage(cursor: SnowflakeCursor) -> str:
270 stage_name = "".join(random.choice(string.ascii_lowercase) for _ in range(5))
271 create_stage_sql = (
272 "create temporary stage /* Python:snowflake.connector.pandas_tools.write_pandas() */ "
273 '"{stage_name}"'
274 ).format(stage_name=stage_name)
275 logger.debug(f"creating stage with '{create_stage_sql}'")
276 result_cursor = cursor.execute(create_stage_sql, _is_internal=True)
277 if result_cursor is None:
278 raise SnowflakeQueryUnknownError(create_stage_sql)
279 result_cursor.fetchall()
280 return stage_name
281
282
283 def chunk_helper(lst: pd.DataFrame, n: int) -> Iterator[Tuple[int, pd.DataFrame]]:
284 """Helper generator to chunk a sequence efficiently with current index like if enumerate was called on sequence."""
285 for i in range(0, len(lst), n):
286 yield int(i / n), lst[i : i + n]
287
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sdk/python/feast/infra/utils/snowflake_utils.py b/sdk/python/feast/infra/utils/snowflake_utils.py
--- a/sdk/python/feast/infra/utils/snowflake_utils.py
+++ b/sdk/python/feast/infra/utils/snowflake_utils.py
@@ -43,29 +43,27 @@
if config.type == "snowflake.offline":
config_header = "connections.feast_offline_store"
- config = dict(config)
+ config_dict = dict(config)
# read config file
config_reader = configparser.ConfigParser()
- config_reader.read([config["config_path"]])
+ config_reader.read([config_dict["config_path"]])
if config_reader.has_section(config_header):
kwargs = dict(config_reader[config_header])
else:
kwargs = {}
- kwargs.update((k, v) for k, v in config.items() if v is not None)
+ kwargs.update((k, v) for k, v in config_dict.items() if v is not None)
+ [
+ kwargs.update({k: '"' + v + '"'})
+ for k, v in kwargs.items()
+ if k in ["role", "warehouse", "database", "schema_"]
+ ]
+ kwargs["schema"] = kwargs.pop("schema_")
try:
conn = snowflake.connector.connect(
- account=kwargs["account"],
- user=kwargs["user"],
- password=kwargs["password"],
- role=f'''"{kwargs['role']}"''',
- warehouse=f'''"{kwargs['warehouse']}"''',
- database=f'''"{kwargs['database']}"''',
- schema=f'''"{kwargs['schema_']}"''',
- application="feast",
- autocommit=autocommit,
+ application="feast", autocommit=autocommit, **kwargs
)
return conn
| {"golden_diff": "diff --git a/sdk/python/feast/infra/utils/snowflake_utils.py b/sdk/python/feast/infra/utils/snowflake_utils.py\n--- a/sdk/python/feast/infra/utils/snowflake_utils.py\n+++ b/sdk/python/feast/infra/utils/snowflake_utils.py\n@@ -43,29 +43,27 @@\n if config.type == \"snowflake.offline\":\n config_header = \"connections.feast_offline_store\"\n \n- config = dict(config)\n+ config_dict = dict(config)\n \n # read config file\n config_reader = configparser.ConfigParser()\n- config_reader.read([config[\"config_path\"]])\n+ config_reader.read([config_dict[\"config_path\"]])\n if config_reader.has_section(config_header):\n kwargs = dict(config_reader[config_header])\n else:\n kwargs = {}\n \n- kwargs.update((k, v) for k, v in config.items() if v is not None)\n+ kwargs.update((k, v) for k, v in config_dict.items() if v is not None)\n+ [\n+ kwargs.update({k: '\"' + v + '\"'})\n+ for k, v in kwargs.items()\n+ if k in [\"role\", \"warehouse\", \"database\", \"schema_\"]\n+ ]\n+ kwargs[\"schema\"] = kwargs.pop(\"schema_\")\n \n try:\n conn = snowflake.connector.connect(\n- account=kwargs[\"account\"],\n- user=kwargs[\"user\"],\n- password=kwargs[\"password\"],\n- role=f'''\"{kwargs['role']}\"''',\n- warehouse=f'''\"{kwargs['warehouse']}\"''',\n- database=f'''\"{kwargs['database']}\"''',\n- schema=f'''\"{kwargs['schema_']}\"''',\n- application=\"feast\",\n- autocommit=autocommit,\n+ application=\"feast\", autocommit=autocommit, **kwargs\n )\n \n return conn\n", "issue": "Snowflake login support private key or web browser authentication\nThe current snowflake support seems only allow password authentication but we are using Azure AD login without password for the account.\r\nCan we add functionality to allow different mechanism of authentication?\n", "before_files": [{"content": "import configparser\nimport os\nimport random\nimport string\nfrom logging import getLogger\nfrom tempfile import TemporaryDirectory\nfrom typing import Dict, Iterator, List, Optional, Tuple, cast\n\nimport pandas as pd\nfrom tenacity import (\n retry,\n retry_if_exception_type,\n stop_after_attempt,\n wait_exponential,\n)\n\nfrom feast.errors import SnowflakeIncompleteConfig, SnowflakeQueryUnknownError\n\ntry:\n import snowflake.connector\n from snowflake.connector import ProgrammingError, SnowflakeConnection\n from snowflake.connector.cursor import SnowflakeCursor\nexcept ImportError as e:\n from feast.errors import FeastExtrasDependencyImportError\n\n raise FeastExtrasDependencyImportError(\"snowflake\", str(e))\n\n\ngetLogger(\"snowflake.connector.cursor\").disabled = True\ngetLogger(\"snowflake.connector.connection\").disabled = True\ngetLogger(\"snowflake.connector.network\").disabled = True\nlogger = getLogger(__name__)\n\n\ndef execute_snowflake_statement(conn: SnowflakeConnection, query) -> SnowflakeCursor:\n cursor = conn.cursor().execute(query)\n if cursor is None:\n raise SnowflakeQueryUnknownError(query)\n return cursor\n\n\ndef get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:\n if config.type == \"snowflake.offline\":\n config_header = \"connections.feast_offline_store\"\n\n config = dict(config)\n\n # read config file\n config_reader = configparser.ConfigParser()\n config_reader.read([config[\"config_path\"]])\n if config_reader.has_section(config_header):\n kwargs = dict(config_reader[config_header])\n else:\n kwargs = {}\n\n kwargs.update((k, v) for k, v in config.items() if v is not None)\n\n try:\n conn = snowflake.connector.connect(\n account=kwargs[\"account\"],\n user=kwargs[\"user\"],\n password=kwargs[\"password\"],\n role=f'''\"{kwargs['role']}\"''',\n warehouse=f'''\"{kwargs['warehouse']}\"''',\n database=f'''\"{kwargs['database']}\"''',\n schema=f'''\"{kwargs['schema_']}\"''',\n application=\"feast\",\n autocommit=autocommit,\n )\n\n return conn\n except KeyError as e:\n raise SnowflakeIncompleteConfig(e)\n\n\n# TO DO -- sfc-gh-madkins\n# Remove dependency on write_pandas function by falling back to native snowflake python connector\n# Current issue is datetime[ns] types are read incorrectly in Snowflake, need to coerce to datetime[ns, UTC]\ndef write_pandas(\n conn: SnowflakeConnection,\n df: pd.DataFrame,\n table_name: str,\n database: Optional[str] = None,\n schema: Optional[str] = None,\n chunk_size: Optional[int] = None,\n compression: str = \"gzip\",\n on_error: str = \"abort_statement\",\n parallel: int = 4,\n quote_identifiers: bool = True,\n auto_create_table: bool = False,\n create_temp_table: bool = False,\n):\n \"\"\"Allows users to most efficiently write back a pandas DataFrame to Snowflake.\n\n It works by dumping the DataFrame into Parquet files, uploading them and finally copying their data into the table.\n\n Returns whether all files were ingested correctly, number of chunks uploaded, and number of rows ingested\n with all of the COPY INTO command's output for debugging purposes.\n\n Example usage:\n import pandas\n from snowflake.connector.pandas_tools import write_pandas\n\n df = pandas.DataFrame([('Mark', 10), ('Luke', 20)], columns=['name', 'balance'])\n success, nchunks, nrows, _ = write_pandas(cnx, df, 'customers')\n\n Args:\n conn: Connection to be used to communicate with Snowflake.\n df: Dataframe we'd like to write back.\n table_name: Table name where we want to insert into.\n database: Database schema and table is in, if not provided the default one will be used (Default value = None).\n schema: Schema table is in, if not provided the default one will be used (Default value = None).\n chunk_size: Number of elements to be inserted once, if not provided all elements will be dumped once\n (Default value = None).\n compression: The compression used on the Parquet files, can only be gzip, or snappy. Gzip gives supposedly a\n better compression, while snappy is faster. Use whichever is more appropriate (Default value = 'gzip').\n on_error: Action to take when COPY INTO statements fail, default follows documentation at:\n https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#copy-options-copyoptions\n (Default value = 'abort_statement').\n parallel: Number of threads to be used when uploading chunks, default follows documentation at:\n https://docs.snowflake.com/en/sql-reference/sql/put.html#optional-parameters (Default value = 4).\n quote_identifiers: By default, identifiers, specifically database, schema, table and column names\n (from df.columns) will be quoted. If set to False, identifiers are passed on to Snowflake without quoting.\n I.e. identifiers will be coerced to uppercase by Snowflake. (Default value = True)\n auto_create_table: When true, will automatically create a table with corresponding columns for each column in\n the passed in DataFrame. The table will not be created if it already exists\n create_temp_table: Will make the auto-created table as a temporary table\n \"\"\"\n if database is not None and schema is None:\n raise ProgrammingError(\n \"Schema has to be provided to write_pandas when a database is provided\"\n )\n # This dictionary maps the compression algorithm to Snowflake put copy into command type\n # https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#type-parquet\n compression_map = {\"gzip\": \"auto\", \"snappy\": \"snappy\"}\n if compression not in compression_map.keys():\n raise ProgrammingError(\n \"Invalid compression '{}', only acceptable values are: {}\".format(\n compression, compression_map.keys()\n )\n )\n if quote_identifiers:\n location = (\n (('\"' + database + '\".') if database else \"\")\n + (('\"' + schema + '\".') if schema else \"\")\n + ('\"' + table_name + '\"')\n )\n else:\n location = (\n (database + \".\" if database else \"\")\n + (schema + \".\" if schema else \"\")\n + (table_name)\n )\n if chunk_size is None:\n chunk_size = len(df)\n cursor: SnowflakeCursor = conn.cursor()\n stage_name = create_temporary_sfc_stage(cursor)\n\n with TemporaryDirectory() as tmp_folder:\n for i, chunk in chunk_helper(df, chunk_size):\n chunk_path = os.path.join(tmp_folder, \"file{}.txt\".format(i))\n # Dump chunk into parquet file\n chunk.to_parquet(\n chunk_path,\n compression=compression,\n use_deprecated_int96_timestamps=True,\n )\n # Upload parquet file\n upload_sql = (\n \"PUT /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n \"'file://{path}' @\\\"{stage_name}\\\" PARALLEL={parallel}\"\n ).format(\n path=chunk_path.replace(\"\\\\\", \"\\\\\\\\\").replace(\"'\", \"\\\\'\"),\n stage_name=stage_name,\n parallel=parallel,\n )\n logger.debug(f\"uploading files with '{upload_sql}'\")\n cursor.execute(upload_sql, _is_internal=True)\n # Remove chunk file\n os.remove(chunk_path)\n if quote_identifiers:\n columns = '\"' + '\",\"'.join(list(df.columns)) + '\"'\n else:\n columns = \",\".join(list(df.columns))\n\n if auto_create_table:\n file_format_name = create_file_format(compression, compression_map, cursor)\n infer_schema_sql = f\"SELECT COLUMN_NAME, TYPE FROM table(infer_schema(location=>'@\\\"{stage_name}\\\"', file_format=>'{file_format_name}'))\"\n logger.debug(f\"inferring schema with '{infer_schema_sql}'\")\n result_cursor = cursor.execute(infer_schema_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(infer_schema_sql)\n result = cast(List[Tuple[str, str]], result_cursor.fetchall())\n column_type_mapping: Dict[str, str] = dict(result)\n # Infer schema can return the columns out of order depending on the chunking we do when uploading\n # so we have to iterate through the dataframe columns to make sure we create the table with its\n # columns in order\n quote = '\"' if quote_identifiers else \"\"\n create_table_columns = \", \".join(\n [f\"{quote}{c}{quote} {column_type_mapping[c]}\" for c in df.columns]\n )\n create_table_sql = (\n f\"CREATE {'TEMP ' if create_temp_table else ''}TABLE IF NOT EXISTS {location} \"\n f\"({create_table_columns})\"\n f\" /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n )\n logger.debug(f\"auto creating table with '{create_table_sql}'\")\n cursor.execute(create_table_sql, _is_internal=True)\n drop_file_format_sql = f\"DROP FILE FORMAT IF EXISTS {file_format_name}\"\n logger.debug(f\"dropping file format with '{drop_file_format_sql}'\")\n cursor.execute(drop_file_format_sql, _is_internal=True)\n\n # in Snowflake, all parquet data is stored in a single column, $1, so we must select columns explicitly\n # see (https://docs.snowflake.com/en/user-guide/script-data-load-transform-parquet.html)\n if quote_identifiers:\n parquet_columns = \"$1:\" + \",$1:\".join(f'\"{c}\"' for c in df.columns)\n else:\n parquet_columns = \"$1:\" + \",$1:\".join(df.columns)\n copy_into_sql = (\n \"COPY INTO {location} /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n \"({columns}) \"\n 'FROM (SELECT {parquet_columns} FROM @\"{stage_name}\") '\n \"FILE_FORMAT=(TYPE=PARQUET COMPRESSION={compression}) \"\n \"PURGE=TRUE ON_ERROR={on_error}\"\n ).format(\n location=location,\n columns=columns,\n parquet_columns=parquet_columns,\n stage_name=stage_name,\n compression=compression_map[compression],\n on_error=on_error,\n )\n logger.debug(\"copying into with '{}'\".format(copy_into_sql))\n # Snowflake returns the original cursor if the query execution succeeded.\n result_cursor = cursor.execute(copy_into_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(copy_into_sql)\n result_cursor.close()\n\n\n@retry(\n wait=wait_exponential(multiplier=1, max=4),\n retry=retry_if_exception_type(ProgrammingError),\n stop=stop_after_attempt(5),\n reraise=True,\n)\ndef create_file_format(\n compression: str, compression_map: Dict[str, str], cursor: SnowflakeCursor\n) -> str:\n file_format_name = (\n '\"' + \"\".join(random.choice(string.ascii_lowercase) for _ in range(5)) + '\"'\n )\n file_format_sql = (\n f\"CREATE FILE FORMAT {file_format_name} \"\n f\"/* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n f\"TYPE=PARQUET COMPRESSION={compression_map[compression]}\"\n )\n logger.debug(f\"creating file format with '{file_format_sql}'\")\n cursor.execute(file_format_sql, _is_internal=True)\n return file_format_name\n\n\n@retry(\n wait=wait_exponential(multiplier=1, max=4),\n retry=retry_if_exception_type(ProgrammingError),\n stop=stop_after_attempt(5),\n reraise=True,\n)\ndef create_temporary_sfc_stage(cursor: SnowflakeCursor) -> str:\n stage_name = \"\".join(random.choice(string.ascii_lowercase) for _ in range(5))\n create_stage_sql = (\n \"create temporary stage /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n '\"{stage_name}\"'\n ).format(stage_name=stage_name)\n logger.debug(f\"creating stage with '{create_stage_sql}'\")\n result_cursor = cursor.execute(create_stage_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(create_stage_sql)\n result_cursor.fetchall()\n return stage_name\n\n\ndef chunk_helper(lst: pd.DataFrame, n: int) -> Iterator[Tuple[int, pd.DataFrame]]:\n \"\"\"Helper generator to chunk a sequence efficiently with current index like if enumerate was called on sequence.\"\"\"\n for i in range(0, len(lst), n):\n yield int(i / n), lst[i : i + n]\n", "path": "sdk/python/feast/infra/utils/snowflake_utils.py"}], "after_files": [{"content": "import configparser\nimport os\nimport random\nimport string\nfrom logging import getLogger\nfrom tempfile import TemporaryDirectory\nfrom typing import Dict, Iterator, List, Optional, Tuple, cast\n\nimport pandas as pd\nfrom tenacity import (\n retry,\n retry_if_exception_type,\n stop_after_attempt,\n wait_exponential,\n)\n\nfrom feast.errors import SnowflakeIncompleteConfig, SnowflakeQueryUnknownError\n\ntry:\n import snowflake.connector\n from snowflake.connector import ProgrammingError, SnowflakeConnection\n from snowflake.connector.cursor import SnowflakeCursor\nexcept ImportError as e:\n from feast.errors import FeastExtrasDependencyImportError\n\n raise FeastExtrasDependencyImportError(\"snowflake\", str(e))\n\n\ngetLogger(\"snowflake.connector.cursor\").disabled = True\ngetLogger(\"snowflake.connector.connection\").disabled = True\ngetLogger(\"snowflake.connector.network\").disabled = True\nlogger = getLogger(__name__)\n\n\ndef execute_snowflake_statement(conn: SnowflakeConnection, query) -> SnowflakeCursor:\n cursor = conn.cursor().execute(query)\n if cursor is None:\n raise SnowflakeQueryUnknownError(query)\n return cursor\n\n\ndef get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:\n if config.type == \"snowflake.offline\":\n config_header = \"connections.feast_offline_store\"\n\n config_dict = dict(config)\n\n # read config file\n config_reader = configparser.ConfigParser()\n config_reader.read([config_dict[\"config_path\"]])\n if config_reader.has_section(config_header):\n kwargs = dict(config_reader[config_header])\n else:\n kwargs = {}\n\n kwargs.update((k, v) for k, v in config_dict.items() if v is not None)\n [\n kwargs.update({k: '\"' + v + '\"'})\n for k, v in kwargs.items()\n if k in [\"role\", \"warehouse\", \"database\", \"schema_\"]\n ]\n kwargs[\"schema\"] = kwargs.pop(\"schema_\")\n\n try:\n conn = snowflake.connector.connect(\n application=\"feast\", autocommit=autocommit, **kwargs\n )\n\n return conn\n except KeyError as e:\n raise SnowflakeIncompleteConfig(e)\n\n\n# TO DO -- sfc-gh-madkins\n# Remove dependency on write_pandas function by falling back to native snowflake python connector\n# Current issue is datetime[ns] types are read incorrectly in Snowflake, need to coerce to datetime[ns, UTC]\ndef write_pandas(\n conn: SnowflakeConnection,\n df: pd.DataFrame,\n table_name: str,\n database: Optional[str] = None,\n schema: Optional[str] = None,\n chunk_size: Optional[int] = None,\n compression: str = \"gzip\",\n on_error: str = \"abort_statement\",\n parallel: int = 4,\n quote_identifiers: bool = True,\n auto_create_table: bool = False,\n create_temp_table: bool = False,\n):\n \"\"\"Allows users to most efficiently write back a pandas DataFrame to Snowflake.\n\n It works by dumping the DataFrame into Parquet files, uploading them and finally copying their data into the table.\n\n Returns whether all files were ingested correctly, number of chunks uploaded, and number of rows ingested\n with all of the COPY INTO command's output for debugging purposes.\n\n Example usage:\n import pandas\n from snowflake.connector.pandas_tools import write_pandas\n\n df = pandas.DataFrame([('Mark', 10), ('Luke', 20)], columns=['name', 'balance'])\n success, nchunks, nrows, _ = write_pandas(cnx, df, 'customers')\n\n Args:\n conn: Connection to be used to communicate with Snowflake.\n df: Dataframe we'd like to write back.\n table_name: Table name where we want to insert into.\n database: Database schema and table is in, if not provided the default one will be used (Default value = None).\n schema: Schema table is in, if not provided the default one will be used (Default value = None).\n chunk_size: Number of elements to be inserted once, if not provided all elements will be dumped once\n (Default value = None).\n compression: The compression used on the Parquet files, can only be gzip, or snappy. Gzip gives supposedly a\n better compression, while snappy is faster. Use whichever is more appropriate (Default value = 'gzip').\n on_error: Action to take when COPY INTO statements fail, default follows documentation at:\n https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#copy-options-copyoptions\n (Default value = 'abort_statement').\n parallel: Number of threads to be used when uploading chunks, default follows documentation at:\n https://docs.snowflake.com/en/sql-reference/sql/put.html#optional-parameters (Default value = 4).\n quote_identifiers: By default, identifiers, specifically database, schema, table and column names\n (from df.columns) will be quoted. If set to False, identifiers are passed on to Snowflake without quoting.\n I.e. identifiers will be coerced to uppercase by Snowflake. (Default value = True)\n auto_create_table: When true, will automatically create a table with corresponding columns for each column in\n the passed in DataFrame. The table will not be created if it already exists\n create_temp_table: Will make the auto-created table as a temporary table\n \"\"\"\n if database is not None and schema is None:\n raise ProgrammingError(\n \"Schema has to be provided to write_pandas when a database is provided\"\n )\n # This dictionary maps the compression algorithm to Snowflake put copy into command type\n # https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html#type-parquet\n compression_map = {\"gzip\": \"auto\", \"snappy\": \"snappy\"}\n if compression not in compression_map.keys():\n raise ProgrammingError(\n \"Invalid compression '{}', only acceptable values are: {}\".format(\n compression, compression_map.keys()\n )\n )\n if quote_identifiers:\n location = (\n (('\"' + database + '\".') if database else \"\")\n + (('\"' + schema + '\".') if schema else \"\")\n + ('\"' + table_name + '\"')\n )\n else:\n location = (\n (database + \".\" if database else \"\")\n + (schema + \".\" if schema else \"\")\n + (table_name)\n )\n if chunk_size is None:\n chunk_size = len(df)\n cursor: SnowflakeCursor = conn.cursor()\n stage_name = create_temporary_sfc_stage(cursor)\n\n with TemporaryDirectory() as tmp_folder:\n for i, chunk in chunk_helper(df, chunk_size):\n chunk_path = os.path.join(tmp_folder, \"file{}.txt\".format(i))\n # Dump chunk into parquet file\n chunk.to_parquet(\n chunk_path,\n compression=compression,\n use_deprecated_int96_timestamps=True,\n )\n # Upload parquet file\n upload_sql = (\n \"PUT /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n \"'file://{path}' @\\\"{stage_name}\\\" PARALLEL={parallel}\"\n ).format(\n path=chunk_path.replace(\"\\\\\", \"\\\\\\\\\").replace(\"'\", \"\\\\'\"),\n stage_name=stage_name,\n parallel=parallel,\n )\n logger.debug(f\"uploading files with '{upload_sql}'\")\n cursor.execute(upload_sql, _is_internal=True)\n # Remove chunk file\n os.remove(chunk_path)\n if quote_identifiers:\n columns = '\"' + '\",\"'.join(list(df.columns)) + '\"'\n else:\n columns = \",\".join(list(df.columns))\n\n if auto_create_table:\n file_format_name = create_file_format(compression, compression_map, cursor)\n infer_schema_sql = f\"SELECT COLUMN_NAME, TYPE FROM table(infer_schema(location=>'@\\\"{stage_name}\\\"', file_format=>'{file_format_name}'))\"\n logger.debug(f\"inferring schema with '{infer_schema_sql}'\")\n result_cursor = cursor.execute(infer_schema_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(infer_schema_sql)\n result = cast(List[Tuple[str, str]], result_cursor.fetchall())\n column_type_mapping: Dict[str, str] = dict(result)\n # Infer schema can return the columns out of order depending on the chunking we do when uploading\n # so we have to iterate through the dataframe columns to make sure we create the table with its\n # columns in order\n quote = '\"' if quote_identifiers else \"\"\n create_table_columns = \", \".join(\n [f\"{quote}{c}{quote} {column_type_mapping[c]}\" for c in df.columns]\n )\n create_table_sql = (\n f\"CREATE {'TEMP ' if create_temp_table else ''}TABLE IF NOT EXISTS {location} \"\n f\"({create_table_columns})\"\n f\" /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n )\n logger.debug(f\"auto creating table with '{create_table_sql}'\")\n cursor.execute(create_table_sql, _is_internal=True)\n drop_file_format_sql = f\"DROP FILE FORMAT IF EXISTS {file_format_name}\"\n logger.debug(f\"dropping file format with '{drop_file_format_sql}'\")\n cursor.execute(drop_file_format_sql, _is_internal=True)\n\n # in Snowflake, all parquet data is stored in a single column, $1, so we must select columns explicitly\n # see (https://docs.snowflake.com/en/user-guide/script-data-load-transform-parquet.html)\n if quote_identifiers:\n parquet_columns = \"$1:\" + \",$1:\".join(f'\"{c}\"' for c in df.columns)\n else:\n parquet_columns = \"$1:\" + \",$1:\".join(df.columns)\n copy_into_sql = (\n \"COPY INTO {location} /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n \"({columns}) \"\n 'FROM (SELECT {parquet_columns} FROM @\"{stage_name}\") '\n \"FILE_FORMAT=(TYPE=PARQUET COMPRESSION={compression}) \"\n \"PURGE=TRUE ON_ERROR={on_error}\"\n ).format(\n location=location,\n columns=columns,\n parquet_columns=parquet_columns,\n stage_name=stage_name,\n compression=compression_map[compression],\n on_error=on_error,\n )\n logger.debug(\"copying into with '{}'\".format(copy_into_sql))\n # Snowflake returns the original cursor if the query execution succeeded.\n result_cursor = cursor.execute(copy_into_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(copy_into_sql)\n result_cursor.close()\n\n\n@retry(\n wait=wait_exponential(multiplier=1, max=4),\n retry=retry_if_exception_type(ProgrammingError),\n stop=stop_after_attempt(5),\n reraise=True,\n)\ndef create_file_format(\n compression: str, compression_map: Dict[str, str], cursor: SnowflakeCursor\n) -> str:\n file_format_name = (\n '\"' + \"\".join(random.choice(string.ascii_lowercase) for _ in range(5)) + '\"'\n )\n file_format_sql = (\n f\"CREATE FILE FORMAT {file_format_name} \"\n f\"/* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n f\"TYPE=PARQUET COMPRESSION={compression_map[compression]}\"\n )\n logger.debug(f\"creating file format with '{file_format_sql}'\")\n cursor.execute(file_format_sql, _is_internal=True)\n return file_format_name\n\n\n@retry(\n wait=wait_exponential(multiplier=1, max=4),\n retry=retry_if_exception_type(ProgrammingError),\n stop=stop_after_attempt(5),\n reraise=True,\n)\ndef create_temporary_sfc_stage(cursor: SnowflakeCursor) -> str:\n stage_name = \"\".join(random.choice(string.ascii_lowercase) for _ in range(5))\n create_stage_sql = (\n \"create temporary stage /* Python:snowflake.connector.pandas_tools.write_pandas() */ \"\n '\"{stage_name}\"'\n ).format(stage_name=stage_name)\n logger.debug(f\"creating stage with '{create_stage_sql}'\")\n result_cursor = cursor.execute(create_stage_sql, _is_internal=True)\n if result_cursor is None:\n raise SnowflakeQueryUnknownError(create_stage_sql)\n result_cursor.fetchall()\n return stage_name\n\n\ndef chunk_helper(lst: pd.DataFrame, n: int) -> Iterator[Tuple[int, pd.DataFrame]]:\n \"\"\"Helper generator to chunk a sequence efficiently with current index like if enumerate was called on sequence.\"\"\"\n for i in range(0, len(lst), n):\n yield int(i / n), lst[i : i + n]\n", "path": "sdk/python/feast/infra/utils/snowflake_utils.py"}]} | 3,824 | 422 |
gh_patches_debug_30074 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-266 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Duplicate schema creation
**Describe the bug**
We are currently able to create a new schema with an existing schema name, creating duplicates on our mathesar_schema table.
**Expected behavior**
* Schema name should be unique per db in mathesar_schema table.
* If a new schema creation is attempted with the same name as an existing schema, a 400 should be thrown with proper error message.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/views/api.py`
Content:
```
1 import logging
2 from rest_framework import status, viewsets
3 from rest_framework.exceptions import NotFound, ValidationError
4 from rest_framework.mixins import ListModelMixin, RetrieveModelMixin, CreateModelMixin
5 from rest_framework.response import Response
6 from django.core.cache import cache
7 from django_filters import rest_framework as filters
8
9
10 from mathesar.database.utils import get_non_default_database_keys
11 from mathesar.models import Table, Schema, DataFile
12 from mathesar.pagination import DefaultLimitOffsetPagination, TableLimitOffsetPagination
13 from mathesar.serializers import TableSerializer, SchemaSerializer, RecordSerializer, DataFileSerializer
14 from mathesar.utils.schemas import create_schema_and_object, reflect_schemas_from_database
15 from mathesar.utils.tables import reflect_tables_from_schema
16 from mathesar.utils.api import create_table_from_datafile, create_datafile
17 from mathesar.filters import SchemaFilter, TableFilter
18
19 logger = logging.getLogger(__name__)
20
21 DB_REFLECTION_KEY = 'database_reflected_recently'
22 DB_REFLECTION_INTERVAL = 60 * 5 # we reflect DB changes every 5 minutes
23
24
25 def reflect_db_objects():
26 if not cache.get(DB_REFLECTION_KEY):
27 for database_key in get_non_default_database_keys():
28 reflect_schemas_from_database(database_key)
29 for schema in Schema.objects.all():
30 reflect_tables_from_schema(schema)
31 cache.set(DB_REFLECTION_KEY, True, DB_REFLECTION_INTERVAL)
32
33
34 class SchemaViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):
35 def get_queryset(self):
36 reflect_db_objects()
37 return Schema.objects.all().order_by('-created_at')
38
39 serializer_class = SchemaSerializer
40 pagination_class = DefaultLimitOffsetPagination
41 filter_backends = (filters.DjangoFilterBackend,)
42 filterset_class = SchemaFilter
43
44 def create(self, request):
45 schema = create_schema_and_object(request.data['name'], request.data['database'])
46 serializer = SchemaSerializer(schema)
47 return Response(serializer.data, status=status.HTTP_201_CREATED)
48
49
50 class TableViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin,
51 CreateModelMixin):
52 def get_queryset(self):
53 reflect_db_objects()
54 return Table.objects.all().order_by('-created_at')
55
56 serializer_class = TableSerializer
57 pagination_class = DefaultLimitOffsetPagination
58 filter_backends = (filters.DjangoFilterBackend,)
59 filterset_class = TableFilter
60
61 def create(self, request):
62 serializer = TableSerializer(data=request.data, context={'request': request})
63 if serializer.is_valid():
64 return create_table_from_datafile(request, serializer.validated_data)
65 else:
66 raise ValidationError(serializer.errors)
67
68
69 class RecordViewSet(viewsets.ViewSet):
70 # There is no "update" method.
71 # We're not supporting PUT requests because there aren't a lot of use cases
72 # where the entire record needs to be replaced, PATCH suffices for updates.
73 queryset = Table.objects.all().order_by('-created_at')
74
75 def list(self, request, table_pk=None):
76 paginator = TableLimitOffsetPagination()
77 records = paginator.paginate_queryset(self.queryset, request, table_pk)
78 serializer = RecordSerializer(records, many=True)
79 return paginator.get_paginated_response(serializer.data)
80
81 def retrieve(self, request, pk=None, table_pk=None):
82 table = Table.objects.get(id=table_pk)
83 record = table.get_record(pk)
84 if not record:
85 raise NotFound
86 serializer = RecordSerializer(record)
87 return Response(serializer.data)
88
89 def create(self, request, table_pk=None):
90 table = Table.objects.get(id=table_pk)
91 # We only support adding a single record through the API.
92 assert isinstance((request.data), dict)
93 record = table.create_record_or_records(request.data)
94 serializer = RecordSerializer(record)
95 return Response(serializer.data, status=status.HTTP_201_CREATED)
96
97 def partial_update(self, request, pk=None, table_pk=None):
98 table = Table.objects.get(id=table_pk)
99 record = table.update_record(pk, request.data)
100 serializer = RecordSerializer(record)
101 return Response(serializer.data)
102
103 def destroy(self, request, pk=None, table_pk=None):
104 table = Table.objects.get(id=table_pk)
105 table.delete_record(pk)
106 return Response(status=status.HTTP_204_NO_CONTENT)
107
108
109 class DatabaseKeyViewSet(viewsets.ViewSet):
110 def list(self, request):
111 return Response(get_non_default_database_keys())
112
113
114 class DataFileViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin, CreateModelMixin):
115 queryset = DataFile.objects.all().order_by('-created_at')
116 serializer_class = DataFileSerializer
117 pagination_class = DefaultLimitOffsetPagination
118
119 def create(self, request):
120 serializer = DataFileSerializer(data=request.data, context={'request': request})
121 if serializer.is_valid():
122 return create_datafile(request, serializer.validated_data['file'])
123 else:
124 raise ValidationError(serializer.errors)
125
```
Path: `mathesar/utils/schemas.py`
Content:
```
1 from db.schemas import (
2 create_schema, get_schema_oid_from_name, get_mathesar_schemas_with_oids
3 )
4 from mathesar.database.base import create_mathesar_engine
5 from mathesar.models import Schema
6
7
8 def create_schema_and_object(name, database):
9 engine = create_mathesar_engine(database)
10 create_schema(name, engine)
11 schema_oid = get_schema_oid_from_name(name, engine)
12 schema = Schema.objects.create(oid=schema_oid, database=database)
13 return schema
14
15
16 def reflect_schemas_from_database(database):
17 engine = create_mathesar_engine(database)
18 db_schema_oids = {
19 schema["oid"] for schema in get_mathesar_schemas_with_oids(engine)
20 }
21 schemas = [
22 Schema.objects.get_or_create(oid=oid, database=database)
23 for oid in db_schema_oids
24 ]
25 for schema in Schema.objects.all():
26 if schema.oid not in db_schema_oids:
27 schema.delete()
28 return schemas
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mathesar/utils/schemas.py b/mathesar/utils/schemas.py
--- a/mathesar/utils/schemas.py
+++ b/mathesar/utils/schemas.py
@@ -1,5 +1,8 @@
+from rest_framework.exceptions import ValidationError
+
from db.schemas import (
- create_schema, get_schema_oid_from_name, get_mathesar_schemas_with_oids
+ create_schema, get_schema_oid_from_name, get_mathesar_schemas,
+ get_mathesar_schemas_with_oids
)
from mathesar.database.base import create_mathesar_engine
from mathesar.models import Schema
@@ -7,6 +10,11 @@
def create_schema_and_object(name, database):
engine = create_mathesar_engine(database)
+
+ all_schemas = get_mathesar_schemas(engine)
+ if name in all_schemas:
+ raise ValidationError({"name": "Schema name is not unique"})
+
create_schema(name, engine)
schema_oid = get_schema_oid_from_name(name, engine)
schema = Schema.objects.create(oid=schema_oid, database=database)
diff --git a/mathesar/views/api.py b/mathesar/views/api.py
--- a/mathesar/views/api.py
+++ b/mathesar/views/api.py
@@ -42,9 +42,13 @@
filterset_class = SchemaFilter
def create(self, request):
- schema = create_schema_and_object(request.data['name'], request.data['database'])
- serializer = SchemaSerializer(schema)
- return Response(serializer.data, status=status.HTTP_201_CREATED)
+ serializer = SchemaSerializer(data=request.data)
+ if serializer.is_valid():
+ schema = create_schema_and_object(request.data['name'], request.data['database'])
+ serializer = SchemaSerializer(schema)
+ return Response(serializer.data, status=status.HTTP_201_CREATED)
+ else:
+ raise ValidationError(serializer.errors)
class TableViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin,
| {"golden_diff": "diff --git a/mathesar/utils/schemas.py b/mathesar/utils/schemas.py\n--- a/mathesar/utils/schemas.py\n+++ b/mathesar/utils/schemas.py\n@@ -1,5 +1,8 @@\n+from rest_framework.exceptions import ValidationError\n+\n from db.schemas import (\n- create_schema, get_schema_oid_from_name, get_mathesar_schemas_with_oids\n+ create_schema, get_schema_oid_from_name, get_mathesar_schemas,\n+ get_mathesar_schemas_with_oids\n )\n from mathesar.database.base import create_mathesar_engine\n from mathesar.models import Schema\n@@ -7,6 +10,11 @@\n \n def create_schema_and_object(name, database):\n engine = create_mathesar_engine(database)\n+\n+ all_schemas = get_mathesar_schemas(engine)\n+ if name in all_schemas:\n+ raise ValidationError({\"name\": \"Schema name is not unique\"})\n+\n create_schema(name, engine)\n schema_oid = get_schema_oid_from_name(name, engine)\n schema = Schema.objects.create(oid=schema_oid, database=database)\ndiff --git a/mathesar/views/api.py b/mathesar/views/api.py\n--- a/mathesar/views/api.py\n+++ b/mathesar/views/api.py\n@@ -42,9 +42,13 @@\n filterset_class = SchemaFilter\n \n def create(self, request):\n- schema = create_schema_and_object(request.data['name'], request.data['database'])\n- serializer = SchemaSerializer(schema)\n- return Response(serializer.data, status=status.HTTP_201_CREATED)\n+ serializer = SchemaSerializer(data=request.data)\n+ if serializer.is_valid():\n+ schema = create_schema_and_object(request.data['name'], request.data['database'])\n+ serializer = SchemaSerializer(schema)\n+ return Response(serializer.data, status=status.HTTP_201_CREATED)\n+ else:\n+ raise ValidationError(serializer.errors)\n \n \n class TableViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin,\n", "issue": "Duplicate schema creation\n**Describe the bug**\r\nWe are currently able to create a new schema with an existing schema name, creating duplicates on our mathesar_schema table.\r\n\r\n**Expected behavior**\r\n* Schema name should be unique per db in mathesar_schema table.\r\n* If a new schema creation is attempted with the same name as an existing schema, a 400 should be thrown with proper error message.\n", "before_files": [{"content": "import logging\nfrom rest_framework import status, viewsets\nfrom rest_framework.exceptions import NotFound, ValidationError\nfrom rest_framework.mixins import ListModelMixin, RetrieveModelMixin, CreateModelMixin\nfrom rest_framework.response import Response\nfrom django.core.cache import cache\nfrom django_filters import rest_framework as filters\n\n\nfrom mathesar.database.utils import get_non_default_database_keys\nfrom mathesar.models import Table, Schema, DataFile\nfrom mathesar.pagination import DefaultLimitOffsetPagination, TableLimitOffsetPagination\nfrom mathesar.serializers import TableSerializer, SchemaSerializer, RecordSerializer, DataFileSerializer\nfrom mathesar.utils.schemas import create_schema_and_object, reflect_schemas_from_database\nfrom mathesar.utils.tables import reflect_tables_from_schema\nfrom mathesar.utils.api import create_table_from_datafile, create_datafile\nfrom mathesar.filters import SchemaFilter, TableFilter\n\nlogger = logging.getLogger(__name__)\n\nDB_REFLECTION_KEY = 'database_reflected_recently'\nDB_REFLECTION_INTERVAL = 60 * 5 # we reflect DB changes every 5 minutes\n\n\ndef reflect_db_objects():\n if not cache.get(DB_REFLECTION_KEY):\n for database_key in get_non_default_database_keys():\n reflect_schemas_from_database(database_key)\n for schema in Schema.objects.all():\n reflect_tables_from_schema(schema)\n cache.set(DB_REFLECTION_KEY, True, DB_REFLECTION_INTERVAL)\n\n\nclass SchemaViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):\n def get_queryset(self):\n reflect_db_objects()\n return Schema.objects.all().order_by('-created_at')\n\n serializer_class = SchemaSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = SchemaFilter\n\n def create(self, request):\n schema = create_schema_and_object(request.data['name'], request.data['database'])\n serializer = SchemaSerializer(schema)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n\nclass TableViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin,\n CreateModelMixin):\n def get_queryset(self):\n reflect_db_objects()\n return Table.objects.all().order_by('-created_at')\n\n serializer_class = TableSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = TableFilter\n\n def create(self, request):\n serializer = TableSerializer(data=request.data, context={'request': request})\n if serializer.is_valid():\n return create_table_from_datafile(request, serializer.validated_data)\n else:\n raise ValidationError(serializer.errors)\n\n\nclass RecordViewSet(viewsets.ViewSet):\n # There is no \"update\" method.\n # We're not supporting PUT requests because there aren't a lot of use cases\n # where the entire record needs to be replaced, PATCH suffices for updates.\n queryset = Table.objects.all().order_by('-created_at')\n\n def list(self, request, table_pk=None):\n paginator = TableLimitOffsetPagination()\n records = paginator.paginate_queryset(self.queryset, request, table_pk)\n serializer = RecordSerializer(records, many=True)\n return paginator.get_paginated_response(serializer.data)\n\n def retrieve(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n record = table.get_record(pk)\n if not record:\n raise NotFound\n serializer = RecordSerializer(record)\n return Response(serializer.data)\n\n def create(self, request, table_pk=None):\n table = Table.objects.get(id=table_pk)\n # We only support adding a single record through the API.\n assert isinstance((request.data), dict)\n record = table.create_record_or_records(request.data)\n serializer = RecordSerializer(record)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n def partial_update(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n record = table.update_record(pk, request.data)\n serializer = RecordSerializer(record)\n return Response(serializer.data)\n\n def destroy(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n table.delete_record(pk)\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\nclass DatabaseKeyViewSet(viewsets.ViewSet):\n def list(self, request):\n return Response(get_non_default_database_keys())\n\n\nclass DataFileViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin, CreateModelMixin):\n queryset = DataFile.objects.all().order_by('-created_at')\n serializer_class = DataFileSerializer\n pagination_class = DefaultLimitOffsetPagination\n\n def create(self, request):\n serializer = DataFileSerializer(data=request.data, context={'request': request})\n if serializer.is_valid():\n return create_datafile(request, serializer.validated_data['file'])\n else:\n raise ValidationError(serializer.errors)\n", "path": "mathesar/views/api.py"}, {"content": "from db.schemas import (\n create_schema, get_schema_oid_from_name, get_mathesar_schemas_with_oids\n)\nfrom mathesar.database.base import create_mathesar_engine\nfrom mathesar.models import Schema\n\n\ndef create_schema_and_object(name, database):\n engine = create_mathesar_engine(database)\n create_schema(name, engine)\n schema_oid = get_schema_oid_from_name(name, engine)\n schema = Schema.objects.create(oid=schema_oid, database=database)\n return schema\n\n\ndef reflect_schemas_from_database(database):\n engine = create_mathesar_engine(database)\n db_schema_oids = {\n schema[\"oid\"] for schema in get_mathesar_schemas_with_oids(engine)\n }\n schemas = [\n Schema.objects.get_or_create(oid=oid, database=database)\n for oid in db_schema_oids\n ]\n for schema in Schema.objects.all():\n if schema.oid not in db_schema_oids:\n schema.delete()\n return schemas\n", "path": "mathesar/utils/schemas.py"}], "after_files": [{"content": "import logging\nfrom rest_framework import status, viewsets\nfrom rest_framework.exceptions import NotFound, ValidationError\nfrom rest_framework.mixins import ListModelMixin, RetrieveModelMixin, CreateModelMixin\nfrom rest_framework.response import Response\nfrom django.core.cache import cache\nfrom django_filters import rest_framework as filters\n\n\nfrom mathesar.database.utils import get_non_default_database_keys\nfrom mathesar.models import Table, Schema, DataFile\nfrom mathesar.pagination import DefaultLimitOffsetPagination, TableLimitOffsetPagination\nfrom mathesar.serializers import TableSerializer, SchemaSerializer, RecordSerializer, DataFileSerializer\nfrom mathesar.utils.schemas import create_schema_and_object, reflect_schemas_from_database\nfrom mathesar.utils.tables import reflect_tables_from_schema\nfrom mathesar.utils.api import create_table_from_datafile, create_datafile\nfrom mathesar.filters import SchemaFilter, TableFilter\n\nlogger = logging.getLogger(__name__)\n\nDB_REFLECTION_KEY = 'database_reflected_recently'\nDB_REFLECTION_INTERVAL = 60 * 5 # we reflect DB changes every 5 minutes\n\n\ndef reflect_db_objects():\n if not cache.get(DB_REFLECTION_KEY):\n for database_key in get_non_default_database_keys():\n reflect_schemas_from_database(database_key)\n for schema in Schema.objects.all():\n reflect_tables_from_schema(schema)\n cache.set(DB_REFLECTION_KEY, True, DB_REFLECTION_INTERVAL)\n\n\nclass SchemaViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin):\n def get_queryset(self):\n reflect_db_objects()\n return Schema.objects.all().order_by('-created_at')\n\n serializer_class = SchemaSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = SchemaFilter\n\n def create(self, request):\n serializer = SchemaSerializer(data=request.data)\n if serializer.is_valid():\n schema = create_schema_and_object(request.data['name'], request.data['database'])\n serializer = SchemaSerializer(schema)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n else:\n raise ValidationError(serializer.errors)\n\n\nclass TableViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin,\n CreateModelMixin):\n def get_queryset(self):\n reflect_db_objects()\n return Table.objects.all().order_by('-created_at')\n\n serializer_class = TableSerializer\n pagination_class = DefaultLimitOffsetPagination\n filter_backends = (filters.DjangoFilterBackend,)\n filterset_class = TableFilter\n\n def create(self, request):\n serializer = TableSerializer(data=request.data, context={'request': request})\n if serializer.is_valid():\n return create_table_from_datafile(request, serializer.validated_data)\n else:\n raise ValidationError(serializer.errors)\n\n\nclass RecordViewSet(viewsets.ViewSet):\n # There is no \"update\" method.\n # We're not supporting PUT requests because there aren't a lot of use cases\n # where the entire record needs to be replaced, PATCH suffices for updates.\n queryset = Table.objects.all().order_by('-created_at')\n\n def list(self, request, table_pk=None):\n paginator = TableLimitOffsetPagination()\n records = paginator.paginate_queryset(self.queryset, request, table_pk)\n serializer = RecordSerializer(records, many=True)\n return paginator.get_paginated_response(serializer.data)\n\n def retrieve(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n record = table.get_record(pk)\n if not record:\n raise NotFound\n serializer = RecordSerializer(record)\n return Response(serializer.data)\n\n def create(self, request, table_pk=None):\n table = Table.objects.get(id=table_pk)\n # We only support adding a single record through the API.\n assert isinstance((request.data), dict)\n record = table.create_record_or_records(request.data)\n serializer = RecordSerializer(record)\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\n def partial_update(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n record = table.update_record(pk, request.data)\n serializer = RecordSerializer(record)\n return Response(serializer.data)\n\n def destroy(self, request, pk=None, table_pk=None):\n table = Table.objects.get(id=table_pk)\n table.delete_record(pk)\n return Response(status=status.HTTP_204_NO_CONTENT)\n\n\nclass DatabaseKeyViewSet(viewsets.ViewSet):\n def list(self, request):\n return Response(get_non_default_database_keys())\n\n\nclass DataFileViewSet(viewsets.GenericViewSet, ListModelMixin, RetrieveModelMixin, CreateModelMixin):\n queryset = DataFile.objects.all().order_by('-created_at')\n serializer_class = DataFileSerializer\n pagination_class = DefaultLimitOffsetPagination\n\n def create(self, request):\n serializer = DataFileSerializer(data=request.data, context={'request': request})\n if serializer.is_valid():\n return create_datafile(request, serializer.validated_data['file'])\n else:\n raise ValidationError(serializer.errors)\n", "path": "mathesar/views/api.py"}, {"content": "from rest_framework.exceptions import ValidationError\n\nfrom db.schemas import (\n create_schema, get_schema_oid_from_name, get_mathesar_schemas,\n get_mathesar_schemas_with_oids\n)\nfrom mathesar.database.base import create_mathesar_engine\nfrom mathesar.models import Schema\n\n\ndef create_schema_and_object(name, database):\n engine = create_mathesar_engine(database)\n\n all_schemas = get_mathesar_schemas(engine)\n if name in all_schemas:\n raise ValidationError({\"name\": \"Schema name is not unique\"})\n\n create_schema(name, engine)\n schema_oid = get_schema_oid_from_name(name, engine)\n schema = Schema.objects.create(oid=schema_oid, database=database)\n return schema\n\n\ndef reflect_schemas_from_database(database):\n engine = create_mathesar_engine(database)\n db_schema_oids = {\n schema[\"oid\"] for schema in get_mathesar_schemas_with_oids(engine)\n }\n schemas = [\n Schema.objects.get_or_create(oid=oid, database=database)\n for oid in db_schema_oids\n ]\n for schema in Schema.objects.all():\n if schema.oid not in db_schema_oids:\n schema.delete()\n return schemas\n", "path": "mathesar/utils/schemas.py"}]} | 1,917 | 422 |
gh_patches_debug_27609 | rasdani/github-patches | git_diff | fossasia__open-event-server-6473 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add celery, redis and SQLAlchemy integrations in sentry
- [ ] Celery integration
- [ ] Redis Integration
- [ ] SQLAlchemy Integration
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/__init__.py`
Content:
```
1 from celery.signals import after_task_publish
2 import logging
3 import os.path
4 from envparse import env
5
6 import sys
7 from flask import Flask, json, make_response
8 from flask_celeryext import FlaskCeleryExt
9 from app.settings import get_settings, get_setts
10 from flask_migrate import Migrate, MigrateCommand
11 from flask_script import Manager
12 from flask_login import current_user
13 from flask_jwt_extended import JWTManager
14 from flask_limiter import Limiter
15 from datetime import timedelta
16 from flask_cors import CORS
17 from flask_rest_jsonapi.errors import jsonapi_errors
18 from flask_rest_jsonapi.exceptions import JsonApiException
19 from healthcheck import HealthCheck
20 from apscheduler.schedulers.background import BackgroundScheduler
21 from elasticsearch_dsl.connections import connections
22 from pytz import utc
23
24 import sqlalchemy as sa
25
26 import stripe
27 from app.settings import get_settings
28 from app.models import db
29 from app.api.helpers.jwt import jwt_user_loader
30 from app.api.helpers.cache import cache
31 from werkzeug.middleware.profiler import ProfilerMiddleware
32 from app.views import BlueprintsManager
33 from app.api.helpers.auth import AuthManager, is_token_blacklisted
34 from app.api.helpers.scheduled_jobs import send_after_event_mail, send_event_fee_notification, \
35 send_event_fee_notification_followup, change_session_state_on_event_completion, \
36 expire_pending_tickets, send_monthly_event_invoice, event_invoices_mark_due
37 from app.models.event import Event
38 from app.models.role_invite import RoleInvite
39 from app.views.healthcheck import health_check_celery, health_check_db, health_check_migrations, check_migrations
40 from app.views.elastic_search import client
41 from app.views.elastic_cron_helpers import sync_events_elasticsearch, cron_rebuild_events_elasticsearch
42 from app.views.redis_store import redis_store
43 from app.views.celery_ import celery
44 from app.templates.flask_ext.jinja.filters import init_filters
45 import sentry_sdk
46 from sentry_sdk.integrations.flask import FlaskIntegration
47
48
49 BASE_DIR = os.path.dirname(os.path.abspath(__file__))
50
51 static_dir = os.path.dirname(os.path.dirname(__file__)) + "/static"
52 template_dir = os.path.dirname(__file__) + "/templates"
53 app = Flask(__name__, static_folder=static_dir, template_folder=template_dir)
54 limiter = Limiter(app)
55 env.read_envfile()
56
57
58 class ReverseProxied:
59 """
60 ReverseProxied flask wsgi app wrapper from http://stackoverflow.com/a/37842465/1562480 by aldel
61 """
62
63 def __init__(self, app):
64 self.app = app
65
66 def __call__(self, environ, start_response):
67 scheme = environ.get('HTTP_X_FORWARDED_PROTO')
68 if scheme:
69 environ['wsgi.url_scheme'] = scheme
70 if os.getenv('FORCE_SSL', 'no') == 'yes':
71 environ['wsgi.url_scheme'] = 'https'
72 return self.app(environ, start_response)
73
74
75 app.wsgi_app = ReverseProxied(app.wsgi_app)
76
77 app_created = False
78
79
80 def create_app():
81 global app_created
82 if not app_created:
83 BlueprintsManager.register(app)
84 Migrate(app, db)
85
86 app.config.from_object(env('APP_CONFIG', default='config.ProductionConfig'))
87 db.init_app(app)
88 _manager = Manager(app)
89 _manager.add_command('db', MigrateCommand)
90
91 if app.config['CACHING']:
92 cache.init_app(app, config={'CACHE_TYPE': 'simple'})
93 else:
94 cache.init_app(app, config={'CACHE_TYPE': 'null'})
95
96 stripe.api_key = 'SomeStripeKey'
97 app.secret_key = 'super secret key'
98 app.config['JSONIFY_PRETTYPRINT_REGULAR'] = False
99 app.config['FILE_SYSTEM_STORAGE_FILE_VIEW'] = 'static'
100
101 app.logger.addHandler(logging.StreamHandler(sys.stdout))
102 app.logger.setLevel(logging.ERROR)
103
104 # set up jwt
105 app.config['JWT_HEADER_TYPE'] = 'JWT'
106 app.config['JWT_ACCESS_TOKEN_EXPIRES'] = timedelta(days=1)
107 app.config['JWT_REFRESH_TOKEN_EXPIRES'] = timedelta(days=365)
108 app.config['JWT_ERROR_MESSAGE_KEY'] = 'error'
109 app.config['JWT_TOKEN_LOCATION'] = ['cookies', 'headers']
110 app.config['JWT_REFRESH_COOKIE_PATH'] = '/v1/auth/token/refresh'
111 app.config['JWT_SESSION_COOKIE'] = False
112 app.config['JWT_BLACKLIST_ENABLED'] = True
113 app.config['JWT_BLACKLIST_TOKEN_CHECKS'] = ['refresh']
114 _jwt = JWTManager(app)
115 _jwt.user_loader_callback_loader(jwt_user_loader)
116 _jwt.token_in_blacklist_loader(is_token_blacklisted)
117
118 # setup celery
119 app.config['CELERY_BROKER_URL'] = app.config['REDIS_URL']
120 app.config['CELERY_RESULT_BACKEND'] = app.config['CELERY_BROKER_URL']
121 app.config['CELERY_ACCEPT_CONTENT'] = ['json', 'application/text']
122
123 CORS(app, resources={r"/*": {"origins": "*"}})
124 AuthManager.init_login(app)
125
126 if app.config['TESTING'] and app.config['PROFILE']:
127 # Profiling
128 app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions=[30])
129
130 # development api
131 with app.app_context():
132 from app.api.admin_statistics_api.events import event_statistics
133 from app.api.auth import auth_routes
134 from app.api.attendees import attendee_misc_routes
135 from app.api.bootstrap import api_v1
136 from app.api.celery_tasks import celery_routes
137 from app.api.event_copy import event_copy
138 from app.api.exports import export_routes
139 from app.api.imports import import_routes
140 from app.api.uploads import upload_routes
141 from app.api.users import user_misc_routes
142 from app.api.orders import order_misc_routes
143 from app.api.role_invites import role_invites_misc_routes
144 from app.api.auth import ticket_blueprint, authorised_blueprint
145 from app.api.admin_translations import admin_blueprint
146 from app.api.orders import alipay_blueprint
147 from app.api.settings import admin_misc_routes
148
149 app.register_blueprint(api_v1)
150 app.register_blueprint(event_copy)
151 app.register_blueprint(upload_routes)
152 app.register_blueprint(export_routes)
153 app.register_blueprint(import_routes)
154 app.register_blueprint(celery_routes)
155 app.register_blueprint(auth_routes)
156 app.register_blueprint(event_statistics)
157 app.register_blueprint(user_misc_routes)
158 app.register_blueprint(attendee_misc_routes)
159 app.register_blueprint(order_misc_routes)
160 app.register_blueprint(role_invites_misc_routes)
161 app.register_blueprint(ticket_blueprint)
162 app.register_blueprint(authorised_blueprint)
163 app.register_blueprint(admin_blueprint)
164 app.register_blueprint(alipay_blueprint)
165 app.register_blueprint(admin_misc_routes)
166
167 sa.orm.configure_mappers()
168
169 if app.config['SERVE_STATIC']:
170 app.add_url_rule('/static/<path:filename>',
171 endpoint='static',
172 view_func=app.send_static_file)
173
174 # sentry
175 if not app_created and 'SENTRY_DSN' in app.config:
176 sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration()])
177
178 # redis
179 redis_store.init_app(app)
180
181 # elasticsearch
182 if app.config['ENABLE_ELASTICSEARCH']:
183 client.init_app(app)
184 connections.add_connection('default', client.elasticsearch)
185 with app.app_context():
186 try:
187 cron_rebuild_events_elasticsearch.delay()
188 except Exception:
189 pass
190
191 app_created = True
192 return app, _manager, db, _jwt
193
194
195 current_app, manager, database, jwt = create_app()
196 init_filters(app)
197
198
199 # http://stackoverflow.com/questions/26724623/
200 @app.before_request
201 def track_user():
202 if current_user.is_authenticated:
203 current_user.update_lat()
204
205
206 def make_celery(app=None):
207 app = app or create_app()[0]
208 celery.conf.update(app.config)
209 ext = FlaskCeleryExt(app)
210 return ext.celery
211
212
213 # Health-check
214 health = HealthCheck(current_app, "/health-check")
215 health.add_check(health_check_celery)
216 health.add_check(health_check_db)
217 with current_app.app_context():
218 current_app.config['MIGRATION_STATUS'] = check_migrations()
219 health.add_check(health_check_migrations)
220
221
222 # http://stackoverflow.com/questions/9824172/find-out-whether-celery-task-exists
223 @after_task_publish.connect
224 def update_sent_state(sender=None, headers=None, **kwargs):
225 # the task may not exist if sent using `send_task` which
226 # sends tasks by name, so fall back to the default result backend
227 # if that is the case.
228 task = celery.tasks.get(sender)
229 backend = task.backend if task else celery.backend
230 backend.store_result(headers['id'], None, 'WAITING')
231
232
233 # register celery tasks. removing them will cause the tasks to not function. so don't remove them
234 # it is important to register them after celery is defined to resolve circular imports
235
236 from .api.helpers import tasks
237
238 # import helpers.tasks
239
240
241 scheduler = BackgroundScheduler(timezone=utc)
242 # scheduler.add_job(send_mail_to_expired_orders, 'interval', hours=5)
243 # scheduler.add_job(empty_trash, 'cron', hour=5, minute=30)
244 if app.config['ENABLE_ELASTICSEARCH']:
245 scheduler.add_job(sync_events_elasticsearch, 'interval', minutes=60)
246 scheduler.add_job(cron_rebuild_events_elasticsearch, 'cron', day=7)
247
248 scheduler.add_job(send_after_event_mail, 'cron', hour=5, minute=30)
249 scheduler.add_job(send_event_fee_notification, 'cron', day=1)
250 scheduler.add_job(send_event_fee_notification_followup, 'cron', day=1, month='1-12')
251 scheduler.add_job(change_session_state_on_event_completion, 'cron', hour=5, minute=30)
252 scheduler.add_job(expire_pending_tickets, 'cron', minute=45)
253 scheduler.add_job(send_monthly_event_invoice, 'cron', day=1, month='1-12')
254 scheduler.add_job(event_invoices_mark_due, 'cron', hour=5)
255 scheduler.start()
256
257
258 @app.errorhandler(500)
259 def internal_server_error(error):
260 if current_app.config['PROPOGATE_ERROR'] is True:
261 exc = JsonApiException({'pointer': ''}, str(error))
262 else:
263 exc = JsonApiException({'pointer': ''}, 'Unknown error')
264 return make_response(json.dumps(jsonapi_errors([exc.to_dict()])), exc.status,
265 {'Content-Type': 'application/vnd.api+json'})
266
267
268 if __name__ == '__main__':
269 current_app.run()
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/__init__.py b/app/__init__.py
--- a/app/__init__.py
+++ b/app/__init__.py
@@ -6,6 +6,12 @@
import sys
from flask import Flask, json, make_response
from flask_celeryext import FlaskCeleryExt
+import sentry_sdk
+from sentry_sdk.integrations.flask import FlaskIntegration
+from sentry_sdk.integrations.celery import CeleryIntegration
+from sentry_sdk.integrations.redis import RedisIntegration
+from sentry_sdk.integrations.sqlalchemy import SqlalchemyIntegration
+
from app.settings import get_settings, get_setts
from flask_migrate import Migrate, MigrateCommand
from flask_script import Manager
@@ -42,8 +48,6 @@
from app.views.redis_store import redis_store
from app.views.celery_ import celery
from app.templates.flask_ext.jinja.filters import init_filters
-import sentry_sdk
-from sentry_sdk.integrations.flask import FlaskIntegration
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
@@ -173,7 +177,8 @@
# sentry
if not app_created and 'SENTRY_DSN' in app.config:
- sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration()])
+ sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration(), RedisIntegration(),
+ CeleryIntegration(), SqlalchemyIntegration()])
# redis
redis_store.init_app(app)
| {"golden_diff": "diff --git a/app/__init__.py b/app/__init__.py\n--- a/app/__init__.py\n+++ b/app/__init__.py\n@@ -6,6 +6,12 @@\n import sys\n from flask import Flask, json, make_response\n from flask_celeryext import FlaskCeleryExt\n+import sentry_sdk\n+from sentry_sdk.integrations.flask import FlaskIntegration\n+from sentry_sdk.integrations.celery import CeleryIntegration\n+from sentry_sdk.integrations.redis import RedisIntegration\n+from sentry_sdk.integrations.sqlalchemy import SqlalchemyIntegration\n+\n from app.settings import get_settings, get_setts\n from flask_migrate import Migrate, MigrateCommand\n from flask_script import Manager\n@@ -42,8 +48,6 @@\n from app.views.redis_store import redis_store\n from app.views.celery_ import celery\n from app.templates.flask_ext.jinja.filters import init_filters\n-import sentry_sdk\n-from sentry_sdk.integrations.flask import FlaskIntegration\n \n \n BASE_DIR = os.path.dirname(os.path.abspath(__file__))\n@@ -173,7 +177,8 @@\n \n # sentry\n if not app_created and 'SENTRY_DSN' in app.config:\n- sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration()])\n+ sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration(), RedisIntegration(),\n+ CeleryIntegration(), SqlalchemyIntegration()])\n \n # redis\n redis_store.init_app(app)\n", "issue": "Add celery, redis and SQLAlchemy integrations in sentry\n- [ ] Celery integration\r\n- [ ] Redis Integration\r\n- [ ] SQLAlchemy Integration\n", "before_files": [{"content": "from celery.signals import after_task_publish\nimport logging\nimport os.path\nfrom envparse import env\n\nimport sys\nfrom flask import Flask, json, make_response\nfrom flask_celeryext import FlaskCeleryExt\nfrom app.settings import get_settings, get_setts\nfrom flask_migrate import Migrate, MigrateCommand\nfrom flask_script import Manager\nfrom flask_login import current_user\nfrom flask_jwt_extended import JWTManager\nfrom flask_limiter import Limiter\nfrom datetime import timedelta\nfrom flask_cors import CORS\nfrom flask_rest_jsonapi.errors import jsonapi_errors\nfrom flask_rest_jsonapi.exceptions import JsonApiException\nfrom healthcheck import HealthCheck\nfrom apscheduler.schedulers.background import BackgroundScheduler\nfrom elasticsearch_dsl.connections import connections\nfrom pytz import utc\n\nimport sqlalchemy as sa\n\nimport stripe\nfrom app.settings import get_settings\nfrom app.models import db\nfrom app.api.helpers.jwt import jwt_user_loader\nfrom app.api.helpers.cache import cache\nfrom werkzeug.middleware.profiler import ProfilerMiddleware\nfrom app.views import BlueprintsManager\nfrom app.api.helpers.auth import AuthManager, is_token_blacklisted\nfrom app.api.helpers.scheduled_jobs import send_after_event_mail, send_event_fee_notification, \\\n send_event_fee_notification_followup, change_session_state_on_event_completion, \\\n expire_pending_tickets, send_monthly_event_invoice, event_invoices_mark_due\nfrom app.models.event import Event\nfrom app.models.role_invite import RoleInvite\nfrom app.views.healthcheck import health_check_celery, health_check_db, health_check_migrations, check_migrations\nfrom app.views.elastic_search import client\nfrom app.views.elastic_cron_helpers import sync_events_elasticsearch, cron_rebuild_events_elasticsearch\nfrom app.views.redis_store import redis_store\nfrom app.views.celery_ import celery\nfrom app.templates.flask_ext.jinja.filters import init_filters\nimport sentry_sdk\nfrom sentry_sdk.integrations.flask import FlaskIntegration\n\n\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n\nstatic_dir = os.path.dirname(os.path.dirname(__file__)) + \"/static\"\ntemplate_dir = os.path.dirname(__file__) + \"/templates\"\napp = Flask(__name__, static_folder=static_dir, template_folder=template_dir)\nlimiter = Limiter(app)\nenv.read_envfile()\n\n\nclass ReverseProxied:\n \"\"\"\n ReverseProxied flask wsgi app wrapper from http://stackoverflow.com/a/37842465/1562480 by aldel\n \"\"\"\n\n def __init__(self, app):\n self.app = app\n\n def __call__(self, environ, start_response):\n scheme = environ.get('HTTP_X_FORWARDED_PROTO')\n if scheme:\n environ['wsgi.url_scheme'] = scheme\n if os.getenv('FORCE_SSL', 'no') == 'yes':\n environ['wsgi.url_scheme'] = 'https'\n return self.app(environ, start_response)\n\n\napp.wsgi_app = ReverseProxied(app.wsgi_app)\n\napp_created = False\n\n\ndef create_app():\n global app_created\n if not app_created:\n BlueprintsManager.register(app)\n Migrate(app, db)\n\n app.config.from_object(env('APP_CONFIG', default='config.ProductionConfig'))\n db.init_app(app)\n _manager = Manager(app)\n _manager.add_command('db', MigrateCommand)\n\n if app.config['CACHING']:\n cache.init_app(app, config={'CACHE_TYPE': 'simple'})\n else:\n cache.init_app(app, config={'CACHE_TYPE': 'null'})\n\n stripe.api_key = 'SomeStripeKey'\n app.secret_key = 'super secret key'\n app.config['JSONIFY_PRETTYPRINT_REGULAR'] = False\n app.config['FILE_SYSTEM_STORAGE_FILE_VIEW'] = 'static'\n\n app.logger.addHandler(logging.StreamHandler(sys.stdout))\n app.logger.setLevel(logging.ERROR)\n\n # set up jwt\n app.config['JWT_HEADER_TYPE'] = 'JWT'\n app.config['JWT_ACCESS_TOKEN_EXPIRES'] = timedelta(days=1)\n app.config['JWT_REFRESH_TOKEN_EXPIRES'] = timedelta(days=365)\n app.config['JWT_ERROR_MESSAGE_KEY'] = 'error'\n app.config['JWT_TOKEN_LOCATION'] = ['cookies', 'headers']\n app.config['JWT_REFRESH_COOKIE_PATH'] = '/v1/auth/token/refresh'\n app.config['JWT_SESSION_COOKIE'] = False\n app.config['JWT_BLACKLIST_ENABLED'] = True\n app.config['JWT_BLACKLIST_TOKEN_CHECKS'] = ['refresh']\n _jwt = JWTManager(app)\n _jwt.user_loader_callback_loader(jwt_user_loader)\n _jwt.token_in_blacklist_loader(is_token_blacklisted)\n\n # setup celery\n app.config['CELERY_BROKER_URL'] = app.config['REDIS_URL']\n app.config['CELERY_RESULT_BACKEND'] = app.config['CELERY_BROKER_URL']\n app.config['CELERY_ACCEPT_CONTENT'] = ['json', 'application/text']\n\n CORS(app, resources={r\"/*\": {\"origins\": \"*\"}})\n AuthManager.init_login(app)\n\n if app.config['TESTING'] and app.config['PROFILE']:\n # Profiling\n app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions=[30])\n\n # development api\n with app.app_context():\n from app.api.admin_statistics_api.events import event_statistics\n from app.api.auth import auth_routes\n from app.api.attendees import attendee_misc_routes\n from app.api.bootstrap import api_v1\n from app.api.celery_tasks import celery_routes\n from app.api.event_copy import event_copy\n from app.api.exports import export_routes\n from app.api.imports import import_routes\n from app.api.uploads import upload_routes\n from app.api.users import user_misc_routes\n from app.api.orders import order_misc_routes\n from app.api.role_invites import role_invites_misc_routes\n from app.api.auth import ticket_blueprint, authorised_blueprint\n from app.api.admin_translations import admin_blueprint\n from app.api.orders import alipay_blueprint\n from app.api.settings import admin_misc_routes\n\n app.register_blueprint(api_v1)\n app.register_blueprint(event_copy)\n app.register_blueprint(upload_routes)\n app.register_blueprint(export_routes)\n app.register_blueprint(import_routes)\n app.register_blueprint(celery_routes)\n app.register_blueprint(auth_routes)\n app.register_blueprint(event_statistics)\n app.register_blueprint(user_misc_routes)\n app.register_blueprint(attendee_misc_routes)\n app.register_blueprint(order_misc_routes)\n app.register_blueprint(role_invites_misc_routes)\n app.register_blueprint(ticket_blueprint)\n app.register_blueprint(authorised_blueprint)\n app.register_blueprint(admin_blueprint)\n app.register_blueprint(alipay_blueprint)\n app.register_blueprint(admin_misc_routes)\n\n sa.orm.configure_mappers()\n\n if app.config['SERVE_STATIC']:\n app.add_url_rule('/static/<path:filename>',\n endpoint='static',\n view_func=app.send_static_file)\n\n # sentry\n if not app_created and 'SENTRY_DSN' in app.config:\n sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration()])\n\n # redis\n redis_store.init_app(app)\n\n # elasticsearch\n if app.config['ENABLE_ELASTICSEARCH']:\n client.init_app(app)\n connections.add_connection('default', client.elasticsearch)\n with app.app_context():\n try:\n cron_rebuild_events_elasticsearch.delay()\n except Exception:\n pass\n\n app_created = True\n return app, _manager, db, _jwt\n\n\ncurrent_app, manager, database, jwt = create_app()\ninit_filters(app)\n\n\n# http://stackoverflow.com/questions/26724623/\[email protected]_request\ndef track_user():\n if current_user.is_authenticated:\n current_user.update_lat()\n\n\ndef make_celery(app=None):\n app = app or create_app()[0]\n celery.conf.update(app.config)\n ext = FlaskCeleryExt(app)\n return ext.celery\n\n\n# Health-check\nhealth = HealthCheck(current_app, \"/health-check\")\nhealth.add_check(health_check_celery)\nhealth.add_check(health_check_db)\nwith current_app.app_context():\n current_app.config['MIGRATION_STATUS'] = check_migrations()\nhealth.add_check(health_check_migrations)\n\n\n# http://stackoverflow.com/questions/9824172/find-out-whether-celery-task-exists\n@after_task_publish.connect\ndef update_sent_state(sender=None, headers=None, **kwargs):\n # the task may not exist if sent using `send_task` which\n # sends tasks by name, so fall back to the default result backend\n # if that is the case.\n task = celery.tasks.get(sender)\n backend = task.backend if task else celery.backend\n backend.store_result(headers['id'], None, 'WAITING')\n\n\n# register celery tasks. removing them will cause the tasks to not function. so don't remove them\n# it is important to register them after celery is defined to resolve circular imports\n\nfrom .api.helpers import tasks\n\n# import helpers.tasks\n\n\nscheduler = BackgroundScheduler(timezone=utc)\n# scheduler.add_job(send_mail_to_expired_orders, 'interval', hours=5)\n# scheduler.add_job(empty_trash, 'cron', hour=5, minute=30)\nif app.config['ENABLE_ELASTICSEARCH']:\n scheduler.add_job(sync_events_elasticsearch, 'interval', minutes=60)\n scheduler.add_job(cron_rebuild_events_elasticsearch, 'cron', day=7)\n\nscheduler.add_job(send_after_event_mail, 'cron', hour=5, minute=30)\nscheduler.add_job(send_event_fee_notification, 'cron', day=1)\nscheduler.add_job(send_event_fee_notification_followup, 'cron', day=1, month='1-12')\nscheduler.add_job(change_session_state_on_event_completion, 'cron', hour=5, minute=30)\nscheduler.add_job(expire_pending_tickets, 'cron', minute=45)\nscheduler.add_job(send_monthly_event_invoice, 'cron', day=1, month='1-12')\nscheduler.add_job(event_invoices_mark_due, 'cron', hour=5)\nscheduler.start()\n\n\[email protected](500)\ndef internal_server_error(error):\n if current_app.config['PROPOGATE_ERROR'] is True:\n exc = JsonApiException({'pointer': ''}, str(error))\n else:\n exc = JsonApiException({'pointer': ''}, 'Unknown error')\n return make_response(json.dumps(jsonapi_errors([exc.to_dict()])), exc.status,\n {'Content-Type': 'application/vnd.api+json'})\n\n\nif __name__ == '__main__':\n current_app.run()\n", "path": "app/__init__.py"}], "after_files": [{"content": "from celery.signals import after_task_publish\nimport logging\nimport os.path\nfrom envparse import env\n\nimport sys\nfrom flask import Flask, json, make_response\nfrom flask_celeryext import FlaskCeleryExt\nimport sentry_sdk\nfrom sentry_sdk.integrations.flask import FlaskIntegration\nfrom sentry_sdk.integrations.celery import CeleryIntegration\nfrom sentry_sdk.integrations.redis import RedisIntegration\nfrom sentry_sdk.integrations.sqlalchemy import SqlalchemyIntegration\n\nfrom app.settings import get_settings, get_setts\nfrom flask_migrate import Migrate, MigrateCommand\nfrom flask_script import Manager\nfrom flask_login import current_user\nfrom flask_jwt_extended import JWTManager\nfrom flask_limiter import Limiter\nfrom datetime import timedelta\nfrom flask_cors import CORS\nfrom flask_rest_jsonapi.errors import jsonapi_errors\nfrom flask_rest_jsonapi.exceptions import JsonApiException\nfrom healthcheck import HealthCheck\nfrom apscheduler.schedulers.background import BackgroundScheduler\nfrom elasticsearch_dsl.connections import connections\nfrom pytz import utc\n\nimport sqlalchemy as sa\n\nimport stripe\nfrom app.settings import get_settings\nfrom app.models import db\nfrom app.api.helpers.jwt import jwt_user_loader\nfrom app.api.helpers.cache import cache\nfrom werkzeug.middleware.profiler import ProfilerMiddleware\nfrom app.views import BlueprintsManager\nfrom app.api.helpers.auth import AuthManager, is_token_blacklisted\nfrom app.api.helpers.scheduled_jobs import send_after_event_mail, send_event_fee_notification, \\\n send_event_fee_notification_followup, change_session_state_on_event_completion, \\\n expire_pending_tickets, send_monthly_event_invoice, event_invoices_mark_due\nfrom app.models.event import Event\nfrom app.models.role_invite import RoleInvite\nfrom app.views.healthcheck import health_check_celery, health_check_db, health_check_migrations, check_migrations\nfrom app.views.elastic_search import client\nfrom app.views.elastic_cron_helpers import sync_events_elasticsearch, cron_rebuild_events_elasticsearch\nfrom app.views.redis_store import redis_store\nfrom app.views.celery_ import celery\nfrom app.templates.flask_ext.jinja.filters import init_filters\n\n\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n\nstatic_dir = os.path.dirname(os.path.dirname(__file__)) + \"/static\"\ntemplate_dir = os.path.dirname(__file__) + \"/templates\"\napp = Flask(__name__, static_folder=static_dir, template_folder=template_dir)\nlimiter = Limiter(app)\nenv.read_envfile()\n\n\nclass ReverseProxied:\n \"\"\"\n ReverseProxied flask wsgi app wrapper from http://stackoverflow.com/a/37842465/1562480 by aldel\n \"\"\"\n\n def __init__(self, app):\n self.app = app\n\n def __call__(self, environ, start_response):\n scheme = environ.get('HTTP_X_FORWARDED_PROTO')\n if scheme:\n environ['wsgi.url_scheme'] = scheme\n if os.getenv('FORCE_SSL', 'no') == 'yes':\n environ['wsgi.url_scheme'] = 'https'\n return self.app(environ, start_response)\n\n\napp.wsgi_app = ReverseProxied(app.wsgi_app)\n\napp_created = False\n\n\ndef create_app():\n global app_created\n if not app_created:\n BlueprintsManager.register(app)\n Migrate(app, db)\n\n app.config.from_object(env('APP_CONFIG', default='config.ProductionConfig'))\n db.init_app(app)\n _manager = Manager(app)\n _manager.add_command('db', MigrateCommand)\n\n if app.config['CACHING']:\n cache.init_app(app, config={'CACHE_TYPE': 'simple'})\n else:\n cache.init_app(app, config={'CACHE_TYPE': 'null'})\n\n stripe.api_key = 'SomeStripeKey'\n app.secret_key = 'super secret key'\n app.config['JSONIFY_PRETTYPRINT_REGULAR'] = False\n app.config['FILE_SYSTEM_STORAGE_FILE_VIEW'] = 'static'\n\n app.logger.addHandler(logging.StreamHandler(sys.stdout))\n app.logger.setLevel(logging.ERROR)\n\n # set up jwt\n app.config['JWT_HEADER_TYPE'] = 'JWT'\n app.config['JWT_ACCESS_TOKEN_EXPIRES'] = timedelta(days=1)\n app.config['JWT_REFRESH_TOKEN_EXPIRES'] = timedelta(days=365)\n app.config['JWT_ERROR_MESSAGE_KEY'] = 'error'\n app.config['JWT_TOKEN_LOCATION'] = ['cookies', 'headers']\n app.config['JWT_REFRESH_COOKIE_PATH'] = '/v1/auth/token/refresh'\n app.config['JWT_SESSION_COOKIE'] = False\n app.config['JWT_BLACKLIST_ENABLED'] = True\n app.config['JWT_BLACKLIST_TOKEN_CHECKS'] = ['refresh']\n _jwt = JWTManager(app)\n _jwt.user_loader_callback_loader(jwt_user_loader)\n _jwt.token_in_blacklist_loader(is_token_blacklisted)\n\n # setup celery\n app.config['CELERY_BROKER_URL'] = app.config['REDIS_URL']\n app.config['CELERY_RESULT_BACKEND'] = app.config['CELERY_BROKER_URL']\n app.config['CELERY_ACCEPT_CONTENT'] = ['json', 'application/text']\n\n CORS(app, resources={r\"/*\": {\"origins\": \"*\"}})\n AuthManager.init_login(app)\n\n if app.config['TESTING'] and app.config['PROFILE']:\n # Profiling\n app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions=[30])\n\n # development api\n with app.app_context():\n from app.api.admin_statistics_api.events import event_statistics\n from app.api.auth import auth_routes\n from app.api.attendees import attendee_misc_routes\n from app.api.bootstrap import api_v1\n from app.api.celery_tasks import celery_routes\n from app.api.event_copy import event_copy\n from app.api.exports import export_routes\n from app.api.imports import import_routes\n from app.api.uploads import upload_routes\n from app.api.users import user_misc_routes\n from app.api.orders import order_misc_routes\n from app.api.role_invites import role_invites_misc_routes\n from app.api.auth import ticket_blueprint, authorised_blueprint\n from app.api.admin_translations import admin_blueprint\n from app.api.orders import alipay_blueprint\n from app.api.settings import admin_misc_routes\n\n app.register_blueprint(api_v1)\n app.register_blueprint(event_copy)\n app.register_blueprint(upload_routes)\n app.register_blueprint(export_routes)\n app.register_blueprint(import_routes)\n app.register_blueprint(celery_routes)\n app.register_blueprint(auth_routes)\n app.register_blueprint(event_statistics)\n app.register_blueprint(user_misc_routes)\n app.register_blueprint(attendee_misc_routes)\n app.register_blueprint(order_misc_routes)\n app.register_blueprint(role_invites_misc_routes)\n app.register_blueprint(ticket_blueprint)\n app.register_blueprint(authorised_blueprint)\n app.register_blueprint(admin_blueprint)\n app.register_blueprint(alipay_blueprint)\n app.register_blueprint(admin_misc_routes)\n\n sa.orm.configure_mappers()\n\n if app.config['SERVE_STATIC']:\n app.add_url_rule('/static/<path:filename>',\n endpoint='static',\n view_func=app.send_static_file)\n\n # sentry\n if not app_created and 'SENTRY_DSN' in app.config:\n sentry_sdk.init(app.config['SENTRY_DSN'], integrations=[FlaskIntegration(), RedisIntegration(),\n CeleryIntegration(), SqlalchemyIntegration()])\n\n # redis\n redis_store.init_app(app)\n\n # elasticsearch\n if app.config['ENABLE_ELASTICSEARCH']:\n client.init_app(app)\n connections.add_connection('default', client.elasticsearch)\n with app.app_context():\n try:\n cron_rebuild_events_elasticsearch.delay()\n except Exception:\n pass\n\n app_created = True\n return app, _manager, db, _jwt\n\n\ncurrent_app, manager, database, jwt = create_app()\ninit_filters(app)\n\n\n# http://stackoverflow.com/questions/26724623/\[email protected]_request\ndef track_user():\n if current_user.is_authenticated:\n current_user.update_lat()\n\n\ndef make_celery(app=None):\n app = app or create_app()[0]\n celery.conf.update(app.config)\n ext = FlaskCeleryExt(app)\n return ext.celery\n\n\n# Health-check\nhealth = HealthCheck(current_app, \"/health-check\")\nhealth.add_check(health_check_celery)\nhealth.add_check(health_check_db)\nwith current_app.app_context():\n current_app.config['MIGRATION_STATUS'] = check_migrations()\nhealth.add_check(health_check_migrations)\n\n\n# http://stackoverflow.com/questions/9824172/find-out-whether-celery-task-exists\n@after_task_publish.connect\ndef update_sent_state(sender=None, headers=None, **kwargs):\n # the task may not exist if sent using `send_task` which\n # sends tasks by name, so fall back to the default result backend\n # if that is the case.\n task = celery.tasks.get(sender)\n backend = task.backend if task else celery.backend\n backend.store_result(headers['id'], None, 'WAITING')\n\n\n# register celery tasks. removing them will cause the tasks to not function. so don't remove them\n# it is important to register them after celery is defined to resolve circular imports\n\nfrom .api.helpers import tasks\n\n# import helpers.tasks\n\n\nscheduler = BackgroundScheduler(timezone=utc)\n# scheduler.add_job(send_mail_to_expired_orders, 'interval', hours=5)\n# scheduler.add_job(empty_trash, 'cron', hour=5, minute=30)\nif app.config['ENABLE_ELASTICSEARCH']:\n scheduler.add_job(sync_events_elasticsearch, 'interval', minutes=60)\n scheduler.add_job(cron_rebuild_events_elasticsearch, 'cron', day=7)\n\nscheduler.add_job(send_after_event_mail, 'cron', hour=5, minute=30)\nscheduler.add_job(send_event_fee_notification, 'cron', day=1)\nscheduler.add_job(send_event_fee_notification_followup, 'cron', day=1, month='1-12')\nscheduler.add_job(change_session_state_on_event_completion, 'cron', hour=5, minute=30)\nscheduler.add_job(expire_pending_tickets, 'cron', minute=45)\nscheduler.add_job(send_monthly_event_invoice, 'cron', day=1, month='1-12')\nscheduler.add_job(event_invoices_mark_due, 'cron', hour=5)\nscheduler.start()\n\n\[email protected](500)\ndef internal_server_error(error):\n if current_app.config['PROPOGATE_ERROR'] is True:\n exc = JsonApiException({'pointer': ''}, str(error))\n else:\n exc = JsonApiException({'pointer': ''}, 'Unknown error')\n return make_response(json.dumps(jsonapi_errors([exc.to_dict()])), exc.status,\n {'Content-Type': 'application/vnd.api+json'})\n\n\nif __name__ == '__main__':\n current_app.run()\n", "path": "app/__init__.py"}]} | 3,293 | 340 |
gh_patches_debug_3794 | rasdani/github-patches | git_diff | digitalfabrik__integreat-cms-515 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Language tree node form not working
### Describe the Bug
<!-- A clear and concise description of what the bug is. -->
Since commit 928dec60b79ba47366099ca4227b2abe0acb2de7, the language node form is not working anymore.
### Steps to Reproduce
1. Go to a region
2. Open language tree
3. Open language tree node
4. Click on save
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
The language tree node should be saved
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
the following error appears:
```
MultipleObjectsReturned at /augsburg/language-tree/4/edit
get() returned more than one LanguageTreeNode -- it returned 3!
```
### Additional Information
<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->
<details>
<summary>Debug Stacktrace</summary>
Environment:
Request Method: POST
Request URL: http://localhost:8000/augsburg/language-tree/4/edit
Django Version: 2.2.16
Python Version: 3.7.9
Installed Applications:
['cms.apps.CmsConfig',
'gvz_api.apps.GvzApiConfig',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.messages',
'django.contrib.sessions',
'django.contrib.sitemaps',
'django.contrib.staticfiles',
'compressor',
'compressor_toolkit',
'corsheaders',
'widget_tweaks',
'easy_thumbnails',
'filer',
'mptt',
'rules.apps.AutodiscoverRulesConfig']
Installed Middleware:
['corsheaders.middleware.CorsMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.locale.LocaleMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware']
Traceback:
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/exception.py" in inner
34. response = get_response(request)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py" in _get_response
115. response = self.process_exception_by_middleware(e, request)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py" in _get_response
113. response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py" in view
71. return self.dispatch(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py" in _wrapper
45. return bound_method(*args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/decorators.py" in _wrapped_view
21. return view_func(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py" in _wrapper
45. return bound_method(*args, **kwargs)
File "/home/timo/job/integreat/django/src/cms/decorators.py" in wrap
53. return function(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/mixins.py" in dispatch
85. return super().dispatch(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py" in dispatch
97. return handler(request, *args, **kwargs)
File "/home/timo/job/integreat/django/src/cms/views/language_tree/language_tree_node_view.py" in post
58. if not language_tree_node_form.is_valid():
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in is_valid
185. return self.is_bound and not self.errors
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in errors
180. self.full_clean()
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in full_clean
381. self._clean_fields()
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in _clean_fields
399. value = field.clean(value)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/fields.py" in clean
148. value = self.to_python(value)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/models.py" in to_python
1248. value = self.queryset.get(**{key: value})
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/db/models/query.py" in get
412. (self.model._meta.object_name, num)
Exception Type: MultipleObjectsReturned at /augsburg/language-tree/4/edit
Exception Value: get() returned more than one LanguageTreeNode -- it returned 3!
</details>
I assume that this is a bug in the mptt library - TreeQuerySets don't seem to work properly with the `difference()`-method...
Language tree node form not working
### Describe the Bug
<!-- A clear and concise description of what the bug is. -->
Since commit 928dec60b79ba47366099ca4227b2abe0acb2de7, the language node form is not working anymore.
### Steps to Reproduce
1. Go to a region
2. Open language tree
3. Open language tree node
4. Click on save
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
The language tree node should be saved
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
the following error appears:
```
MultipleObjectsReturned at /augsburg/language-tree/4/edit
get() returned more than one LanguageTreeNode -- it returned 3!
```
### Additional Information
<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->
<details>
<summary>Debug Stacktrace</summary>
Environment:
Request Method: POST
Request URL: http://localhost:8000/augsburg/language-tree/4/edit
Django Version: 2.2.16
Python Version: 3.7.9
Installed Applications:
['cms.apps.CmsConfig',
'gvz_api.apps.GvzApiConfig',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.messages',
'django.contrib.sessions',
'django.contrib.sitemaps',
'django.contrib.staticfiles',
'compressor',
'compressor_toolkit',
'corsheaders',
'widget_tweaks',
'easy_thumbnails',
'filer',
'mptt',
'rules.apps.AutodiscoverRulesConfig']
Installed Middleware:
['corsheaders.middleware.CorsMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.locale.LocaleMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware']
Traceback:
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/exception.py" in inner
34. response = get_response(request)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py" in _get_response
115. response = self.process_exception_by_middleware(e, request)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py" in _get_response
113. response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py" in view
71. return self.dispatch(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py" in _wrapper
45. return bound_method(*args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/decorators.py" in _wrapped_view
21. return view_func(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py" in _wrapper
45. return bound_method(*args, **kwargs)
File "/home/timo/job/integreat/django/src/cms/decorators.py" in wrap
53. return function(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/mixins.py" in dispatch
85. return super().dispatch(request, *args, **kwargs)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py" in dispatch
97. return handler(request, *args, **kwargs)
File "/home/timo/job/integreat/django/src/cms/views/language_tree/language_tree_node_view.py" in post
58. if not language_tree_node_form.is_valid():
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in is_valid
185. return self.is_bound and not self.errors
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in errors
180. self.full_clean()
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in full_clean
381. self._clean_fields()
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py" in _clean_fields
399. value = field.clean(value)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/fields.py" in clean
148. value = self.to_python(value)
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/models.py" in to_python
1248. value = self.queryset.get(**{key: value})
File "/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/db/models/query.py" in get
412. (self.model._meta.object_name, num)
Exception Type: MultipleObjectsReturned at /augsburg/language-tree/4/edit
Exception Value: get() returned more than one LanguageTreeNode -- it returned 3!
</details>
I assume that this is a bug in the mptt library - TreeQuerySets don't seem to work properly with the `difference()`-method...
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cms/forms/language_tree/language_tree_node_form.py`
Content:
```
1 import logging
2
3 from django import forms
4 from django.utils.translation import ugettext_lazy as _
5
6 from ...models import Language, LanguageTreeNode
7
8
9 logger = logging.getLogger(__name__)
10
11
12 class LanguageField(forms.ModelChoiceField):
13 """
14 Form field helper class to overwrite the label function (which would otherwise call __str__)
15 """
16
17 def label_from_instance(self, obj):
18 return obj.translated_name
19
20
21 class LanguageTreeNodeForm(forms.ModelForm):
22 """
23 Form for creating and modifying language tree node objects
24 """
25
26 class Meta:
27 model = LanguageTreeNode
28 fields = ["language", "parent", "active"]
29 field_classes = {
30 "language": LanguageField,
31 "parent": LanguageField,
32 }
33
34 def __init__(self, *args, **kwargs):
35 logger.info(
36 "LanguageTreeNodeForm instantiated with data %s and instance %s",
37 kwargs.get("data"),
38 kwargs.get("instance"),
39 )
40
41 # current region
42 region = kwargs.pop("region", None)
43
44 super().__init__(*args, **kwargs)
45
46 parent_queryset = region.language_tree_nodes
47 excluded_languages = region.languages.exclude(language_tree_nodes=self.instance)
48
49 if self.instance.id:
50 children = self.instance.get_descendants(include_self=True)
51 parent_queryset = parent_queryset.difference(children)
52 else:
53 self.instance.region = region
54
55 # limit possible parents to nodes of current region
56 self.fields["parent"].queryset = parent_queryset
57 # limit possible languages to those which are not yet included in the tree
58 self.fields["language"].queryset = Language.objects.exclude(
59 id__in=excluded_languages
60 )
61
62 def save(self, commit=True):
63 """
64 Function to create or update a language tree node
65 """
66 logger.info(
67 "LanguageTreeNodeForm saved with cleaned data %s and changed data %s",
68 self.cleaned_data,
69 self.changed_data,
70 )
71
72 return super().save(commit=commit)
73
74 def clean(self):
75 """
76 Don't allow multiple root nodes for one region:
77 If self is a root node and the region already has a default language,
78 raise a validation error.
79 """
80 cleaned_data = super().clean()
81 logger.info("LanguageTreeNodeForm cleaned with cleaned data %s", cleaned_data)
82 default_language = self.instance.region.default_language
83 # There are two cases in which this error is thrown.
84 # Both cases include that the parent field is None.
85 # 1. The instance does exist:
86 # - The default language is different from the instance language
87 # 2. The instance does not exist:
88 # - The default language exists
89 if not cleaned_data.get("parent") and (
90 (self.instance.id and default_language != self.instance.language)
91 or (not self.instance.id and default_language)
92 ):
93 self.add_error(
94 "parent",
95 forms.ValidationError(
96 _(
97 "This region has already a default language."
98 "Please specify a source language for this language."
99 ),
100 code="invalid",
101 ),
102 )
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/cms/forms/language_tree/language_tree_node_form.py b/src/cms/forms/language_tree/language_tree_node_form.py
--- a/src/cms/forms/language_tree/language_tree_node_form.py
+++ b/src/cms/forms/language_tree/language_tree_node_form.py
@@ -48,7 +48,7 @@
if self.instance.id:
children = self.instance.get_descendants(include_self=True)
- parent_queryset = parent_queryset.difference(children)
+ parent_queryset = parent_queryset.exclude(id__in=children)
else:
self.instance.region = region
| {"golden_diff": "diff --git a/src/cms/forms/language_tree/language_tree_node_form.py b/src/cms/forms/language_tree/language_tree_node_form.py\n--- a/src/cms/forms/language_tree/language_tree_node_form.py\n+++ b/src/cms/forms/language_tree/language_tree_node_form.py\n@@ -48,7 +48,7 @@\n \n if self.instance.id:\n children = self.instance.get_descendants(include_self=True)\n- parent_queryset = parent_queryset.difference(children)\n+ parent_queryset = parent_queryset.exclude(id__in=children)\n else:\n self.instance.region = region\n", "issue": "Language tree node form not working\n### Describe the Bug\r\n<!-- A clear and concise description of what the bug is. -->\r\nSince commit 928dec60b79ba47366099ca4227b2abe0acb2de7, the language node form is not working anymore.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Go to a region\r\n2. Open language tree\r\n3. Open language tree node\r\n4. Click on save\r\n\r\n### Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe language tree node should be saved\r\n\r\n### Actual Behavior\r\n<!-- A clear and concise description of what actually happened. -->\r\nthe following error appears:\r\n```\r\nMultipleObjectsReturned at /augsburg/language-tree/4/edit\r\n\r\nget() returned more than one LanguageTreeNode -- it returned 3!\r\n```\r\n### Additional Information\r\n<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->\r\n<details>\r\n <summary>Debug Stacktrace</summary>\r\n\r\n\r\nEnvironment:\r\n\r\n\r\nRequest Method: POST\r\nRequest URL: http://localhost:8000/augsburg/language-tree/4/edit\r\n\r\nDjango Version: 2.2.16\r\nPython Version: 3.7.9\r\nInstalled Applications:\r\n['cms.apps.CmsConfig',\r\n 'gvz_api.apps.GvzApiConfig',\r\n 'django.contrib.admin',\r\n 'django.contrib.auth',\r\n 'django.contrib.contenttypes',\r\n 'django.contrib.messages',\r\n 'django.contrib.sessions',\r\n 'django.contrib.sitemaps',\r\n 'django.contrib.staticfiles',\r\n 'compressor',\r\n 'compressor_toolkit',\r\n 'corsheaders',\r\n 'widget_tweaks',\r\n 'easy_thumbnails',\r\n 'filer',\r\n 'mptt',\r\n 'rules.apps.AutodiscoverRulesConfig']\r\nInstalled Middleware:\r\n['corsheaders.middleware.CorsMiddleware',\r\n 'django.middleware.security.SecurityMiddleware',\r\n 'django.contrib.sessions.middleware.SessionMiddleware',\r\n 'django.middleware.locale.LocaleMiddleware',\r\n 'django.middleware.common.CommonMiddleware',\r\n 'django.middleware.csrf.CsrfViewMiddleware',\r\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\r\n 'django.contrib.messages.middleware.MessageMiddleware',\r\n 'django.middleware.clickjacking.XFrameOptionsMiddleware']\r\n\r\n\r\n\r\nTraceback:\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/exception.py\" in inner\r\n 34. response = get_response(request)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py\" in _get_response\r\n 115. response = self.process_exception_by_middleware(e, request)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py\" in _get_response\r\n 113. response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py\" in view\r\n 71. return self.dispatch(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py\" in _wrapper\r\n 45. return bound_method(*args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/decorators.py\" in _wrapped_view\r\n 21. return view_func(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py\" in _wrapper\r\n 45. return bound_method(*args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/src/cms/decorators.py\" in wrap\r\n 53. return function(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/mixins.py\" in dispatch\r\n 85. return super().dispatch(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py\" in dispatch\r\n 97. return handler(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/src/cms/views/language_tree/language_tree_node_view.py\" in post\r\n 58. if not language_tree_node_form.is_valid():\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in is_valid\r\n 185. return self.is_bound and not self.errors\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in errors\r\n 180. self.full_clean()\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in full_clean\r\n 381. self._clean_fields()\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in _clean_fields\r\n 399. value = field.clean(value)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/fields.py\" in clean\r\n 148. value = self.to_python(value)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/models.py\" in to_python\r\n 1248. value = self.queryset.get(**{key: value})\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/db/models/query.py\" in get\r\n 412. (self.model._meta.object_name, num)\r\n\r\nException Type: MultipleObjectsReturned at /augsburg/language-tree/4/edit\r\nException Value: get() returned more than one LanguageTreeNode -- it returned 3!\r\n</details>\r\n\r\nI assume that this is a bug in the mptt library - TreeQuerySets don't seem to work properly with the `difference()`-method...\nLanguage tree node form not working\n### Describe the Bug\r\n<!-- A clear and concise description of what the bug is. -->\r\nSince commit 928dec60b79ba47366099ca4227b2abe0acb2de7, the language node form is not working anymore.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Go to a region\r\n2. Open language tree\r\n3. Open language tree node\r\n4. Click on save\r\n\r\n### Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe language tree node should be saved\r\n\r\n### Actual Behavior\r\n<!-- A clear and concise description of what actually happened. -->\r\nthe following error appears:\r\n```\r\nMultipleObjectsReturned at /augsburg/language-tree/4/edit\r\n\r\nget() returned more than one LanguageTreeNode -- it returned 3!\r\n```\r\n### Additional Information\r\n<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->\r\n<details>\r\n <summary>Debug Stacktrace</summary>\r\n\r\n\r\nEnvironment:\r\n\r\n\r\nRequest Method: POST\r\nRequest URL: http://localhost:8000/augsburg/language-tree/4/edit\r\n\r\nDjango Version: 2.2.16\r\nPython Version: 3.7.9\r\nInstalled Applications:\r\n['cms.apps.CmsConfig',\r\n 'gvz_api.apps.GvzApiConfig',\r\n 'django.contrib.admin',\r\n 'django.contrib.auth',\r\n 'django.contrib.contenttypes',\r\n 'django.contrib.messages',\r\n 'django.contrib.sessions',\r\n 'django.contrib.sitemaps',\r\n 'django.contrib.staticfiles',\r\n 'compressor',\r\n 'compressor_toolkit',\r\n 'corsheaders',\r\n 'widget_tweaks',\r\n 'easy_thumbnails',\r\n 'filer',\r\n 'mptt',\r\n 'rules.apps.AutodiscoverRulesConfig']\r\nInstalled Middleware:\r\n['corsheaders.middleware.CorsMiddleware',\r\n 'django.middleware.security.SecurityMiddleware',\r\n 'django.contrib.sessions.middleware.SessionMiddleware',\r\n 'django.middleware.locale.LocaleMiddleware',\r\n 'django.middleware.common.CommonMiddleware',\r\n 'django.middleware.csrf.CsrfViewMiddleware',\r\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\r\n 'django.contrib.messages.middleware.MessageMiddleware',\r\n 'django.middleware.clickjacking.XFrameOptionsMiddleware']\r\n\r\n\r\n\r\nTraceback:\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/exception.py\" in inner\r\n 34. response = get_response(request)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py\" in _get_response\r\n 115. response = self.process_exception_by_middleware(e, request)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/core/handlers/base.py\" in _get_response\r\n 113. response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py\" in view\r\n 71. return self.dispatch(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py\" in _wrapper\r\n 45. return bound_method(*args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/decorators.py\" in _wrapped_view\r\n 21. return view_func(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/utils/decorators.py\" in _wrapper\r\n 45. return bound_method(*args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/src/cms/decorators.py\" in wrap\r\n 53. return function(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/contrib/auth/mixins.py\" in dispatch\r\n 85. return super().dispatch(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/views/generic/base.py\" in dispatch\r\n 97. return handler(request, *args, **kwargs)\r\n\r\nFile \"/home/timo/job/integreat/django/src/cms/views/language_tree/language_tree_node_view.py\" in post\r\n 58. if not language_tree_node_form.is_valid():\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in is_valid\r\n 185. return self.is_bound and not self.errors\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in errors\r\n 180. self.full_clean()\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in full_clean\r\n 381. self._clean_fields()\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/forms.py\" in _clean_fields\r\n 399. value = field.clean(value)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/fields.py\" in clean\r\n 148. value = self.to_python(value)\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/forms/models.py\" in to_python\r\n 1248. value = self.queryset.get(**{key: value})\r\n\r\nFile \"/home/timo/job/integreat/django/.venv/lib/python3.7/site-packages/django/db/models/query.py\" in get\r\n 412. (self.model._meta.object_name, num)\r\n\r\nException Type: MultipleObjectsReturned at /augsburg/language-tree/4/edit\r\nException Value: get() returned more than one LanguageTreeNode -- it returned 3!\r\n</details>\r\n\r\nI assume that this is a bug in the mptt library - TreeQuerySets don't seem to work properly with the `difference()`-method...\n", "before_files": [{"content": "import logging\n\nfrom django import forms\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ...models import Language, LanguageTreeNode\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass LanguageField(forms.ModelChoiceField):\n \"\"\"\n Form field helper class to overwrite the label function (which would otherwise call __str__)\n \"\"\"\n\n def label_from_instance(self, obj):\n return obj.translated_name\n\n\nclass LanguageTreeNodeForm(forms.ModelForm):\n \"\"\"\n Form for creating and modifying language tree node objects\n \"\"\"\n\n class Meta:\n model = LanguageTreeNode\n fields = [\"language\", \"parent\", \"active\"]\n field_classes = {\n \"language\": LanguageField,\n \"parent\": LanguageField,\n }\n\n def __init__(self, *args, **kwargs):\n logger.info(\n \"LanguageTreeNodeForm instantiated with data %s and instance %s\",\n kwargs.get(\"data\"),\n kwargs.get(\"instance\"),\n )\n\n # current region\n region = kwargs.pop(\"region\", None)\n\n super().__init__(*args, **kwargs)\n\n parent_queryset = region.language_tree_nodes\n excluded_languages = region.languages.exclude(language_tree_nodes=self.instance)\n\n if self.instance.id:\n children = self.instance.get_descendants(include_self=True)\n parent_queryset = parent_queryset.difference(children)\n else:\n self.instance.region = region\n\n # limit possible parents to nodes of current region\n self.fields[\"parent\"].queryset = parent_queryset\n # limit possible languages to those which are not yet included in the tree\n self.fields[\"language\"].queryset = Language.objects.exclude(\n id__in=excluded_languages\n )\n\n def save(self, commit=True):\n \"\"\"\n Function to create or update a language tree node\n \"\"\"\n logger.info(\n \"LanguageTreeNodeForm saved with cleaned data %s and changed data %s\",\n self.cleaned_data,\n self.changed_data,\n )\n\n return super().save(commit=commit)\n\n def clean(self):\n \"\"\"\n Don't allow multiple root nodes for one region:\n If self is a root node and the region already has a default language,\n raise a validation error.\n \"\"\"\n cleaned_data = super().clean()\n logger.info(\"LanguageTreeNodeForm cleaned with cleaned data %s\", cleaned_data)\n default_language = self.instance.region.default_language\n # There are two cases in which this error is thrown.\n # Both cases include that the parent field is None.\n # 1. The instance does exist:\n # - The default language is different from the instance language\n # 2. The instance does not exist:\n # - The default language exists\n if not cleaned_data.get(\"parent\") and (\n (self.instance.id and default_language != self.instance.language)\n or (not self.instance.id and default_language)\n ):\n self.add_error(\n \"parent\",\n forms.ValidationError(\n _(\n \"This region has already a default language.\"\n \"Please specify a source language for this language.\"\n ),\n code=\"invalid\",\n ),\n )\n", "path": "src/cms/forms/language_tree/language_tree_node_form.py"}], "after_files": [{"content": "import logging\n\nfrom django import forms\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ...models import Language, LanguageTreeNode\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass LanguageField(forms.ModelChoiceField):\n \"\"\"\n Form field helper class to overwrite the label function (which would otherwise call __str__)\n \"\"\"\n\n def label_from_instance(self, obj):\n return obj.translated_name\n\n\nclass LanguageTreeNodeForm(forms.ModelForm):\n \"\"\"\n Form for creating and modifying language tree node objects\n \"\"\"\n\n class Meta:\n model = LanguageTreeNode\n fields = [\"language\", \"parent\", \"active\"]\n field_classes = {\n \"language\": LanguageField,\n \"parent\": LanguageField,\n }\n\n def __init__(self, *args, **kwargs):\n logger.info(\n \"LanguageTreeNodeForm instantiated with data %s and instance %s\",\n kwargs.get(\"data\"),\n kwargs.get(\"instance\"),\n )\n\n # current region\n region = kwargs.pop(\"region\", None)\n\n super().__init__(*args, **kwargs)\n\n parent_queryset = region.language_tree_nodes\n excluded_languages = region.languages.exclude(language_tree_nodes=self.instance)\n\n if self.instance.id:\n children = self.instance.get_descendants(include_self=True)\n parent_queryset = parent_queryset.exclude(id__in=children)\n else:\n self.instance.region = region\n\n # limit possible parents to nodes of current region\n self.fields[\"parent\"].queryset = parent_queryset\n # limit possible languages to those which are not yet included in the tree\n self.fields[\"language\"].queryset = Language.objects.exclude(\n id__in=excluded_languages\n )\n\n def save(self, commit=True):\n \"\"\"\n Function to create or update a language tree node\n \"\"\"\n logger.info(\n \"LanguageTreeNodeForm saved with cleaned data %s and changed data %s\",\n self.cleaned_data,\n self.changed_data,\n )\n\n return super().save(commit=commit)\n\n def clean(self):\n \"\"\"\n Don't allow multiple root nodes for one region:\n If self is a root node and the region already has a default language,\n raise a validation error.\n \"\"\"\n cleaned_data = super().clean()\n logger.info(\"LanguageTreeNodeForm cleaned with cleaned data %s\", cleaned_data)\n default_language = self.instance.region.default_language\n # There are two cases in which this error is thrown.\n # Both cases include that the parent field is None.\n # 1. The instance does exist:\n # - The default language is different from the instance language\n # 2. The instance does not exist:\n # - The default language exists\n if not cleaned_data.get(\"parent\") and (\n (self.instance.id and default_language != self.instance.language)\n or (not self.instance.id and default_language)\n ):\n self.add_error(\n \"parent\",\n forms.ValidationError(\n _(\n \"This region has already a default language.\"\n \"Please specify a source language for this language.\"\n ),\n code=\"invalid\",\n ),\n )\n", "path": "src/cms/forms/language_tree/language_tree_node_form.py"}]} | 3,865 | 118 |
gh_patches_debug_36849 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-1024 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
get_correlations return value should be immutable
According to the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/correlationcontext/api.md#get-correlations):
> the returned value can be either an immutable collection or an immutable iterator
Currently, we return a `dict` ([link](https://github.com/open-telemetry/opentelemetry-python/blob/3cae0775ba12a2f7b4214b8b8c062c5e81002a19/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py#L34-L37)):
```python
correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)
if isinstance(correlations, dict):
return correlations.copy()
return {}
```
This was mentioned in the PR but not definitively addressed https://github.com/open-telemetry/opentelemetry-python/pull/471#discussion_r392369812, so I thought it might be worth bringing up again before GA.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 import typing
16 import urllib.parse
17
18 from opentelemetry import correlationcontext
19 from opentelemetry.context import get_current
20 from opentelemetry.context.context import Context
21 from opentelemetry.trace.propagation import httptextformat
22
23
24 class CorrelationContextPropagator(httptextformat.HTTPTextFormat):
25 MAX_HEADER_LENGTH = 8192
26 MAX_PAIR_LENGTH = 4096
27 MAX_PAIRS = 180
28 _CORRELATION_CONTEXT_HEADER_NAME = "otcorrelationcontext"
29
30 def extract(
31 self,
32 get_from_carrier: httptextformat.Getter[
33 httptextformat.HTTPTextFormatT
34 ],
35 carrier: httptextformat.HTTPTextFormatT,
36 context: typing.Optional[Context] = None,
37 ) -> Context:
38 """Extract CorrelationContext from the carrier.
39
40 See
41 `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.extract`
42 """
43
44 if context is None:
45 context = get_current()
46
47 header = _extract_first_element(
48 get_from_carrier(carrier, self._CORRELATION_CONTEXT_HEADER_NAME)
49 )
50
51 if not header or len(header) > self.MAX_HEADER_LENGTH:
52 return context
53
54 correlations = header.split(",")
55 total_correlations = self.MAX_PAIRS
56 for correlation in correlations:
57 if total_correlations <= 0:
58 return context
59 total_correlations -= 1
60 if len(correlation) > self.MAX_PAIR_LENGTH:
61 continue
62 try:
63 name, value = correlation.split("=", 1)
64 except Exception: # pylint: disable=broad-except
65 continue
66 context = correlationcontext.set_correlation(
67 urllib.parse.unquote(name).strip(),
68 urllib.parse.unquote(value).strip(),
69 context=context,
70 )
71
72 return context
73
74 def inject(
75 self,
76 set_in_carrier: httptextformat.Setter[httptextformat.HTTPTextFormatT],
77 carrier: httptextformat.HTTPTextFormatT,
78 context: typing.Optional[Context] = None,
79 ) -> None:
80 """Injects CorrelationContext into the carrier.
81
82 See
83 `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.inject`
84 """
85 correlations = correlationcontext.get_correlations(context=context)
86 if not correlations:
87 return
88
89 correlation_context_string = _format_correlations(correlations)
90 set_in_carrier(
91 carrier,
92 self._CORRELATION_CONTEXT_HEADER_NAME,
93 correlation_context_string,
94 )
95
96
97 def _format_correlations(correlations: typing.Dict[str, object]) -> str:
98 return ",".join(
99 key + "=" + urllib.parse.quote_plus(str(value))
100 for key, value in correlations.items()
101 )
102
103
104 def _extract_first_element(
105 items: typing.Iterable[httptextformat.HTTPTextFormatT],
106 ) -> typing.Optional[httptextformat.HTTPTextFormatT]:
107 if items is None:
108 return None
109 return next(iter(items), None)
110
```
Path: `opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import typing
16
17 from opentelemetry.context import get_value, set_value
18 from opentelemetry.context.context import Context
19
20 _CORRELATION_CONTEXT_KEY = "correlation-context"
21
22
23 def get_correlations(
24 context: typing.Optional[Context] = None,
25 ) -> typing.Dict[str, object]:
26 """Returns the name/value pairs in the CorrelationContext
27
28 Args:
29 context: The Context to use. If not set, uses current Context
30
31 Returns:
32 Name/value pairs in the CorrelationContext
33 """
34 correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)
35 if isinstance(correlations, dict):
36 return correlations.copy()
37 return {}
38
39
40 def get_correlation(
41 name: str, context: typing.Optional[Context] = None
42 ) -> typing.Optional[object]:
43 """Provides access to the value for a name/value pair in the
44 CorrelationContext
45
46 Args:
47 name: The name of the value to retrieve
48 context: The Context to use. If not set, uses current Context
49
50 Returns:
51 The value associated with the given name, or null if the given name is
52 not present.
53 """
54 return get_correlations(context=context).get(name)
55
56
57 def set_correlation(
58 name: str, value: object, context: typing.Optional[Context] = None
59 ) -> Context:
60 """Sets a value in the CorrelationContext
61
62 Args:
63 name: The name of the value to set
64 value: The value to set
65 context: The Context to use. If not set, uses current Context
66
67 Returns:
68 A Context with the value updated
69 """
70 correlations = get_correlations(context=context)
71 correlations[name] = value
72 return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)
73
74
75 def remove_correlation(
76 name: str, context: typing.Optional[Context] = None
77 ) -> Context:
78 """Removes a value from the CorrelationContext
79
80 Args:
81 name: The name of the value to remove
82 context: The Context to use. If not set, uses current Context
83
84 Returns:
85 A Context with the name/value removed
86 """
87 correlations = get_correlations(context=context)
88 correlations.pop(name, None)
89
90 return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)
91
92
93 def clear_correlations(context: typing.Optional[Context] = None) -> Context:
94 """Removes all values from the CorrelationContext
95
96 Args:
97 context: The Context to use. If not set, uses current Context
98
99 Returns:
100 A Context with all correlations removed
101 """
102 return set_value(_CORRELATION_CONTEXT_KEY, {}, context=context)
103
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py b/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py
--- a/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py
@@ -13,6 +13,7 @@
# limitations under the License.
import typing
+from types import MappingProxyType
from opentelemetry.context import get_value, set_value
from opentelemetry.context.context import Context
@@ -22,7 +23,7 @@
def get_correlations(
context: typing.Optional[Context] = None,
-) -> typing.Dict[str, object]:
+) -> typing.Mapping[str, object]:
"""Returns the name/value pairs in the CorrelationContext
Args:
@@ -33,8 +34,8 @@
"""
correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)
if isinstance(correlations, dict):
- return correlations.copy()
- return {}
+ return MappingProxyType(correlations.copy())
+ return MappingProxyType({})
def get_correlation(
@@ -67,7 +68,7 @@
Returns:
A Context with the value updated
"""
- correlations = get_correlations(context=context)
+ correlations = dict(get_correlations(context=context))
correlations[name] = value
return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)
@@ -84,7 +85,7 @@
Returns:
A Context with the name/value removed
"""
- correlations = get_correlations(context=context)
+ correlations = dict(get_correlations(context=context))
correlations.pop(name, None)
return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)
diff --git a/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py b/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py
--- a/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py
@@ -94,7 +94,7 @@
)
-def _format_correlations(correlations: typing.Dict[str, object]) -> str:
+def _format_correlations(correlations: typing.Mapping[str, object]) -> str:
return ",".join(
key + "=" + urllib.parse.quote_plus(str(value))
for key, value in correlations.items()
| {"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py b/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py\n@@ -13,6 +13,7 @@\n # limitations under the License.\n \n import typing\n+from types import MappingProxyType\n \n from opentelemetry.context import get_value, set_value\n from opentelemetry.context.context import Context\n@@ -22,7 +23,7 @@\n \n def get_correlations(\n context: typing.Optional[Context] = None,\n-) -> typing.Dict[str, object]:\n+) -> typing.Mapping[str, object]:\n \"\"\"Returns the name/value pairs in the CorrelationContext\n \n Args:\n@@ -33,8 +34,8 @@\n \"\"\"\n correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)\n if isinstance(correlations, dict):\n- return correlations.copy()\n- return {}\n+ return MappingProxyType(correlations.copy())\n+ return MappingProxyType({})\n \n \n def get_correlation(\n@@ -67,7 +68,7 @@\n Returns:\n A Context with the value updated\n \"\"\"\n- correlations = get_correlations(context=context)\n+ correlations = dict(get_correlations(context=context))\n correlations[name] = value\n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\n \n@@ -84,7 +85,7 @@\n Returns:\n A Context with the name/value removed\n \"\"\"\n- correlations = get_correlations(context=context)\n+ correlations = dict(get_correlations(context=context))\n correlations.pop(name, None)\n \n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\ndiff --git a/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py b/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py\n@@ -94,7 +94,7 @@\n )\n \n \n-def _format_correlations(correlations: typing.Dict[str, object]) -> str:\n+def _format_correlations(correlations: typing.Mapping[str, object]) -> str:\n return \",\".join(\n key + \"=\" + urllib.parse.quote_plus(str(value))\n for key, value in correlations.items()\n", "issue": "get_correlations return value should be immutable\nAccording to the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/correlationcontext/api.md#get-correlations):\r\n\r\n> the returned value can be either an immutable collection or an immutable iterator\r\n\r\nCurrently, we return a `dict` ([link](https://github.com/open-telemetry/opentelemetry-python/blob/3cae0775ba12a2f7b4214b8b8c062c5e81002a19/opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py#L34-L37)): \r\n```python\r\ncorrelations = get_value(_CORRELATION_CONTEXT_KEY, context=context)\r\nif isinstance(correlations, dict):\r\n return correlations.copy()\r\nreturn {}\r\n```\r\n\r\nThis was mentioned in the PR but not definitively addressed https://github.com/open-telemetry/opentelemetry-python/pull/471#discussion_r392369812, so I thought it might be worth bringing up again before GA.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport typing\nimport urllib.parse\n\nfrom opentelemetry import correlationcontext\nfrom opentelemetry.context import get_current\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.trace.propagation import httptextformat\n\n\nclass CorrelationContextPropagator(httptextformat.HTTPTextFormat):\n MAX_HEADER_LENGTH = 8192\n MAX_PAIR_LENGTH = 4096\n MAX_PAIRS = 180\n _CORRELATION_CONTEXT_HEADER_NAME = \"otcorrelationcontext\"\n\n def extract(\n self,\n get_from_carrier: httptextformat.Getter[\n httptextformat.HTTPTextFormatT\n ],\n carrier: httptextformat.HTTPTextFormatT,\n context: typing.Optional[Context] = None,\n ) -> Context:\n \"\"\"Extract CorrelationContext from the carrier.\n\n See\n `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.extract`\n \"\"\"\n\n if context is None:\n context = get_current()\n\n header = _extract_first_element(\n get_from_carrier(carrier, self._CORRELATION_CONTEXT_HEADER_NAME)\n )\n\n if not header or len(header) > self.MAX_HEADER_LENGTH:\n return context\n\n correlations = header.split(\",\")\n total_correlations = self.MAX_PAIRS\n for correlation in correlations:\n if total_correlations <= 0:\n return context\n total_correlations -= 1\n if len(correlation) > self.MAX_PAIR_LENGTH:\n continue\n try:\n name, value = correlation.split(\"=\", 1)\n except Exception: # pylint: disable=broad-except\n continue\n context = correlationcontext.set_correlation(\n urllib.parse.unquote(name).strip(),\n urllib.parse.unquote(value).strip(),\n context=context,\n )\n\n return context\n\n def inject(\n self,\n set_in_carrier: httptextformat.Setter[httptextformat.HTTPTextFormatT],\n carrier: httptextformat.HTTPTextFormatT,\n context: typing.Optional[Context] = None,\n ) -> None:\n \"\"\"Injects CorrelationContext into the carrier.\n\n See\n `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.inject`\n \"\"\"\n correlations = correlationcontext.get_correlations(context=context)\n if not correlations:\n return\n\n correlation_context_string = _format_correlations(correlations)\n set_in_carrier(\n carrier,\n self._CORRELATION_CONTEXT_HEADER_NAME,\n correlation_context_string,\n )\n\n\ndef _format_correlations(correlations: typing.Dict[str, object]) -> str:\n return \",\".join(\n key + \"=\" + urllib.parse.quote_plus(str(value))\n for key, value in correlations.items()\n )\n\n\ndef _extract_first_element(\n items: typing.Iterable[httptextformat.HTTPTextFormatT],\n) -> typing.Optional[httptextformat.HTTPTextFormatT]:\n if items is None:\n return None\n return next(iter(items), None)\n", "path": "opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\n\nfrom opentelemetry.context import get_value, set_value\nfrom opentelemetry.context.context import Context\n\n_CORRELATION_CONTEXT_KEY = \"correlation-context\"\n\n\ndef get_correlations(\n context: typing.Optional[Context] = None,\n) -> typing.Dict[str, object]:\n \"\"\"Returns the name/value pairs in the CorrelationContext\n\n Args:\n context: The Context to use. If not set, uses current Context\n\n Returns:\n Name/value pairs in the CorrelationContext\n \"\"\"\n correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)\n if isinstance(correlations, dict):\n return correlations.copy()\n return {}\n\n\ndef get_correlation(\n name: str, context: typing.Optional[Context] = None\n) -> typing.Optional[object]:\n \"\"\"Provides access to the value for a name/value pair in the\n CorrelationContext\n\n Args:\n name: The name of the value to retrieve\n context: The Context to use. If not set, uses current Context\n\n Returns:\n The value associated with the given name, or null if the given name is\n not present.\n \"\"\"\n return get_correlations(context=context).get(name)\n\n\ndef set_correlation(\n name: str, value: object, context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"Sets a value in the CorrelationContext\n\n Args:\n name: The name of the value to set\n value: The value to set\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with the value updated\n \"\"\"\n correlations = get_correlations(context=context)\n correlations[name] = value\n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\n\n\ndef remove_correlation(\n name: str, context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"Removes a value from the CorrelationContext\n\n Args:\n name: The name of the value to remove\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with the name/value removed\n \"\"\"\n correlations = get_correlations(context=context)\n correlations.pop(name, None)\n\n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\n\n\ndef clear_correlations(context: typing.Optional[Context] = None) -> Context:\n \"\"\"Removes all values from the CorrelationContext\n\n Args:\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with all correlations removed\n \"\"\"\n return set_value(_CORRELATION_CONTEXT_KEY, {}, context=context)\n", "path": "opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py"}], "after_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport typing\nimport urllib.parse\n\nfrom opentelemetry import correlationcontext\nfrom opentelemetry.context import get_current\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.trace.propagation import httptextformat\n\n\nclass CorrelationContextPropagator(httptextformat.HTTPTextFormat):\n MAX_HEADER_LENGTH = 8192\n MAX_PAIR_LENGTH = 4096\n MAX_PAIRS = 180\n _CORRELATION_CONTEXT_HEADER_NAME = \"otcorrelationcontext\"\n\n def extract(\n self,\n get_from_carrier: httptextformat.Getter[\n httptextformat.HTTPTextFormatT\n ],\n carrier: httptextformat.HTTPTextFormatT,\n context: typing.Optional[Context] = None,\n ) -> Context:\n \"\"\"Extract CorrelationContext from the carrier.\n\n See\n `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.extract`\n \"\"\"\n\n if context is None:\n context = get_current()\n\n header = _extract_first_element(\n get_from_carrier(carrier, self._CORRELATION_CONTEXT_HEADER_NAME)\n )\n\n if not header or len(header) > self.MAX_HEADER_LENGTH:\n return context\n\n correlations = header.split(\",\")\n total_correlations = self.MAX_PAIRS\n for correlation in correlations:\n if total_correlations <= 0:\n return context\n total_correlations -= 1\n if len(correlation) > self.MAX_PAIR_LENGTH:\n continue\n try:\n name, value = correlation.split(\"=\", 1)\n except Exception: # pylint: disable=broad-except\n continue\n context = correlationcontext.set_correlation(\n urllib.parse.unquote(name).strip(),\n urllib.parse.unquote(value).strip(),\n context=context,\n )\n\n return context\n\n def inject(\n self,\n set_in_carrier: httptextformat.Setter[httptextformat.HTTPTextFormatT],\n carrier: httptextformat.HTTPTextFormatT,\n context: typing.Optional[Context] = None,\n ) -> None:\n \"\"\"Injects CorrelationContext into the carrier.\n\n See\n `opentelemetry.trace.propagation.httptextformat.HTTPTextFormat.inject`\n \"\"\"\n correlations = correlationcontext.get_correlations(context=context)\n if not correlations:\n return\n\n correlation_context_string = _format_correlations(correlations)\n set_in_carrier(\n carrier,\n self._CORRELATION_CONTEXT_HEADER_NAME,\n correlation_context_string,\n )\n\n\ndef _format_correlations(correlations: typing.Mapping[str, object]) -> str:\n return \",\".join(\n key + \"=\" + urllib.parse.quote_plus(str(value))\n for key, value in correlations.items()\n )\n\n\ndef _extract_first_element(\n items: typing.Iterable[httptextformat.HTTPTextFormatT],\n) -> typing.Optional[httptextformat.HTTPTextFormatT]:\n if items is None:\n return None\n return next(iter(items), None)\n", "path": "opentelemetry-api/src/opentelemetry/correlationcontext/propagation/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\nfrom types import MappingProxyType\n\nfrom opentelemetry.context import get_value, set_value\nfrom opentelemetry.context.context import Context\n\n_CORRELATION_CONTEXT_KEY = \"correlation-context\"\n\n\ndef get_correlations(\n context: typing.Optional[Context] = None,\n) -> typing.Mapping[str, object]:\n \"\"\"Returns the name/value pairs in the CorrelationContext\n\n Args:\n context: The Context to use. If not set, uses current Context\n\n Returns:\n Name/value pairs in the CorrelationContext\n \"\"\"\n correlations = get_value(_CORRELATION_CONTEXT_KEY, context=context)\n if isinstance(correlations, dict):\n return MappingProxyType(correlations.copy())\n return MappingProxyType({})\n\n\ndef get_correlation(\n name: str, context: typing.Optional[Context] = None\n) -> typing.Optional[object]:\n \"\"\"Provides access to the value for a name/value pair in the\n CorrelationContext\n\n Args:\n name: The name of the value to retrieve\n context: The Context to use. If not set, uses current Context\n\n Returns:\n The value associated with the given name, or null if the given name is\n not present.\n \"\"\"\n return get_correlations(context=context).get(name)\n\n\ndef set_correlation(\n name: str, value: object, context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"Sets a value in the CorrelationContext\n\n Args:\n name: The name of the value to set\n value: The value to set\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with the value updated\n \"\"\"\n correlations = dict(get_correlations(context=context))\n correlations[name] = value\n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\n\n\ndef remove_correlation(\n name: str, context: typing.Optional[Context] = None\n) -> Context:\n \"\"\"Removes a value from the CorrelationContext\n\n Args:\n name: The name of the value to remove\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with the name/value removed\n \"\"\"\n correlations = dict(get_correlations(context=context))\n correlations.pop(name, None)\n\n return set_value(_CORRELATION_CONTEXT_KEY, correlations, context=context)\n\n\ndef clear_correlations(context: typing.Optional[Context] = None) -> Context:\n \"\"\"Removes all values from the CorrelationContext\n\n Args:\n context: The Context to use. If not set, uses current Context\n\n Returns:\n A Context with all correlations removed\n \"\"\"\n return set_value(_CORRELATION_CONTEXT_KEY, {}, context=context)\n", "path": "opentelemetry-api/src/opentelemetry/correlationcontext/__init__.py"}]} | 2,445 | 564 |
gh_patches_debug_137 | rasdani/github-patches | git_diff | google__flax-3089 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Imcompatibility with Flax Official ImageNet example with jax version >= 0.4.7
Hi,
I was testing the [official flax example](https://github.com/google/flax/tree/main/examples/imagenet/) on Colab with jax and jaxlib version >= 0.4.7 on the colab pro+ environment with V100. After installing the requirements with `pip install -r requirements.txt` and with the following command `python main.py --workdir=./imagenet --config=configs/v100_x8.py`, the error is
```
File "/content/FlaxImageNet/main.py", line 29, in <module>
import train
File "/content/FlaxImageNet/train.py", line 30, in <module>
from flax.training import checkpoints
File "/usr/local/lib/python3.10/dist-packages/flax/training/checkpoints.py", line 34,
in <module>
from jax.experimental.global_device_array import GlobalDeviceArray
ModuleNotFoundError: No module named 'jax.experimental.global_device_array'
```
According to [this StackOverflow answer](https://stackoverflow.com/questions/76191911/no-module-named-jax-experimental-global-device-array-when-running-the-official/76192120#76192120), it seems that 'jax.experimental.global_device_array' is removed.
Therefore, it would be great if one can fix the official example so that it works on newer version of jax.
Unavailable to import checkpoints
Provide as much information as possible. At least, this should include a description of your issue and steps to reproduce the problem. If possible also provide a summary of what steps or workarounds you have already tried.
### System information
- Flax, jax, jaxlib versions (obtain with `pip show flax jax jaxlib`: All to its latest, also orbitax
Name: flax
Version: 0.6.9
Summary: Flax: A neural network library for JAX designed for flexibility
Home-page:
Author:
Author-email: Flax team <[email protected]>
License:
Location: /home/fernanda/.local/lib/python3.8/site-packages
Requires: jax, msgpack, numpy, optax, orbax-checkpoint, PyYAML, rich, tensorstore, typing-extensions
Required-by:
---
Name: jax
Version: 0.4.8
Summary: Differentiate, compile, and transform Numpy code.
Home-page: https://github.com/google/jax
Author: JAX team
Author-email: [email protected]
License: Apache-2.0
Location: /home/fernanda/.local/lib/python3.8/site-packages
Requires: ml-dtypes, numpy, opt-einsum, scipy
Required-by: chex, diffrax, equinox, flax, optax, orbax, orbax-checkpoint, richmol
---
Name: jaxlib
Version: 0.4.7
Summary: XLA library for JAX
Home-page: https://github.com/google/jax
Author: JAX team
Author-email: [email protected]
License: Apache-2.0
Location: /home/fernanda/.local/lib/python3.8/site-packages
Requires: ml-dtypes, numpy, scipy
Required-by: chex, optax, orbax, orbax-checkpoint
---
Name: orbax
Version: 0.1.7
Summary: Orbax
Home-page:
Author:
Author-email: Orbax Authors <[email protected]>
License:
Location: /home/fernanda/.local/lib/python3.8/site-packages
Requires: absl-py, cached_property, etils, importlib_resources, jax, jaxlib, msgpack, nest_asyncio, numpy, pyyaml, tensorstore, typing_extensions
- Python version: 3.8
### Problem you have encountered:
When importing checkpoints, get the following error:
"""
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-1-0eac7b685376> in <module>
11 config.update("jax_enable_x64", True)
12 from flax import serialization
---> 13 from flax.training import checkpoints
14 from jax import numpy as jnp
15 import jax
/gpfs/cfel/group/cmi/common/psi4/psi4conda/lib//python3.8/site-packages/flax/training/checkpoints.py in <module>
37 from jax import process_index
38 from jax import sharding
---> 39 from jax.experimental.global_device_array import GlobalDeviceArray
40 from jax.experimental.multihost_utils import sync_global_devices
41 import orbax.checkpoint as orbax
ModuleNotFoundError: No module named 'jax.experimental.global_device_array'
"""
I guess it is a compatibility problem between jax and flax.
### What you expected to happen:
Usual importing
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flax/version.py`
Content:
```
1 # Copyright 2023 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Current Flax version at head on Github."""
16 __version__ = "0.6.9"
17
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/flax/version.py b/flax/version.py
--- a/flax/version.py
+++ b/flax/version.py
@@ -13,5 +13,5 @@
# limitations under the License.
"""Current Flax version at head on Github."""
-__version__ = "0.6.9"
+__version__ = "0.6.10"
| {"golden_diff": "diff --git a/flax/version.py b/flax/version.py\n--- a/flax/version.py\n+++ b/flax/version.py\n@@ -13,5 +13,5 @@\n # limitations under the License.\n \n \"\"\"Current Flax version at head on Github.\"\"\"\n-__version__ = \"0.6.9\"\n+__version__ = \"0.6.10\"\n", "issue": "Imcompatibility with Flax Official ImageNet example with jax version >= 0.4.7\nHi, \r\n\r\nI was testing the [official flax example](https://github.com/google/flax/tree/main/examples/imagenet/) on Colab with jax and jaxlib version >= 0.4.7 on the colab pro+ environment with V100. After installing the requirements with `pip install -r requirements.txt` and with the following command `python main.py --workdir=./imagenet --config=configs/v100_x8.py`, the error is \r\n\r\n```\r\nFile \"/content/FlaxImageNet/main.py\", line 29, in <module>\r\nimport train\r\nFile \"/content/FlaxImageNet/train.py\", line 30, in <module>\r\nfrom flax.training import checkpoints\r\nFile \"/usr/local/lib/python3.10/dist-packages/flax/training/checkpoints.py\", line 34, \r\nin <module>\r\nfrom jax.experimental.global_device_array import GlobalDeviceArray\r\nModuleNotFoundError: No module named 'jax.experimental.global_device_array'\r\n```\r\n\r\nAccording to [this StackOverflow answer](https://stackoverflow.com/questions/76191911/no-module-named-jax-experimental-global-device-array-when-running-the-official/76192120#76192120), it seems that 'jax.experimental.global_device_array' is removed. \r\n\r\nTherefore, it would be great if one can fix the official example so that it works on newer version of jax. \nUnavailable to import checkpoints\nProvide as much information as possible. At least, this should include a description of your issue and steps to reproduce the problem. If possible also provide a summary of what steps or workarounds you have already tried.\r\n\r\n### System information\r\n- Flax, jax, jaxlib versions (obtain with `pip show flax jax jaxlib`: All to its latest, also orbitax\r\n\r\nName: flax\r\nVersion: 0.6.9\r\nSummary: Flax: A neural network library for JAX designed for flexibility\r\nHome-page: \r\nAuthor: \r\nAuthor-email: Flax team <[email protected]>\r\nLicense: \r\nLocation: /home/fernanda/.local/lib/python3.8/site-packages\r\nRequires: jax, msgpack, numpy, optax, orbax-checkpoint, PyYAML, rich, tensorstore, typing-extensions\r\nRequired-by: \r\n---\r\nName: jax\r\nVersion: 0.4.8\r\nSummary: Differentiate, compile, and transform Numpy code.\r\nHome-page: https://github.com/google/jax\r\nAuthor: JAX team\r\nAuthor-email: [email protected]\r\nLicense: Apache-2.0\r\nLocation: /home/fernanda/.local/lib/python3.8/site-packages\r\nRequires: ml-dtypes, numpy, opt-einsum, scipy\r\nRequired-by: chex, diffrax, equinox, flax, optax, orbax, orbax-checkpoint, richmol\r\n---\r\nName: jaxlib\r\nVersion: 0.4.7\r\nSummary: XLA library for JAX\r\nHome-page: https://github.com/google/jax\r\nAuthor: JAX team\r\nAuthor-email: [email protected]\r\nLicense: Apache-2.0\r\nLocation: /home/fernanda/.local/lib/python3.8/site-packages\r\nRequires: ml-dtypes, numpy, scipy\r\nRequired-by: chex, optax, orbax, orbax-checkpoint\r\n---\r\nName: orbax\r\nVersion: 0.1.7\r\nSummary: Orbax\r\nHome-page: \r\nAuthor: \r\nAuthor-email: Orbax Authors <[email protected]>\r\nLicense: \r\nLocation: /home/fernanda/.local/lib/python3.8/site-packages\r\nRequires: absl-py, cached_property, etils, importlib_resources, jax, jaxlib, msgpack, nest_asyncio, numpy, pyyaml, tensorstore, typing_extensions\r\n\r\n- Python version: 3.8\r\n\r\n\r\n### Problem you have encountered:\r\nWhen importing checkpoints, get the following error:\r\n \"\"\" \r\n---------------------------------------------------------------------------\r\nModuleNotFoundError Traceback (most recent call last)\r\n<ipython-input-1-0eac7b685376> in <module>\r\n 11 config.update(\"jax_enable_x64\", True)\r\n 12 from flax import serialization\r\n---> 13 from flax.training import checkpoints\r\n 14 from jax import numpy as jnp\r\n 15 import jax\r\n\r\n/gpfs/cfel/group/cmi/common/psi4/psi4conda/lib//python3.8/site-packages/flax/training/checkpoints.py in <module>\r\n 37 from jax import process_index\r\n 38 from jax import sharding\r\n---> 39 from jax.experimental.global_device_array import GlobalDeviceArray\r\n 40 from jax.experimental.multihost_utils import sync_global_devices\r\n 41 import orbax.checkpoint as orbax\r\n\r\nModuleNotFoundError: No module named 'jax.experimental.global_device_array'\r\n\r\n\"\"\"\r\n\r\nI guess it is a compatibility problem between jax and flax.\r\n\r\n### What you expected to happen:\r\n\r\nUsual importing\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Current Flax version at head on Github.\"\"\"\n__version__ = \"0.6.9\"\n\n", "path": "flax/version.py"}], "after_files": [{"content": "# Copyright 2023 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Current Flax version at head on Github.\"\"\"\n__version__ = \"0.6.10\"\n\n", "path": "flax/version.py"}]} | 1,558 | 82 |
gh_patches_debug_42084 | rasdani/github-patches | git_diff | opensearch-project__opensearch-build-765 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: Distribution builds can have path collisions
Distribution builds are not namespace'd based on the type of artifact produced so an OpenSearch and OpenSearch Dashboard build could collide.
### Actual
The current path generated is `https://ci.opensearch.org/ci/dbc/builds/1.1.0/328/x64/manifest.yml`.
### Expected
It should have the distribution type in the path like `https://ci.opensearch.org/ci/dbc/opensearch/builds/1.1.0/328/x64/manifest.yml` and `https://ci.opensearch.org/ci/dbc/opensearch-dashboards/builds/1.1.0/328/x64/manifest.yml`
### Required changes
- [x] Update the build jobs to include the build type in the url for the generated manifests, see [bundle_recorder.py](https://github.com/opensearch-project/opensearch-build/blob/main/src/assemble_workflow/bundle_recorder.py).
- [x] Update the jenkinsfile to upload to a destination based on the build type, see [Jenkinsfile](https://github.com/opensearch-project/opensearch-build/blob/main/Jenkinsfile#L127).
### Other changes
- [ ] Migrate/ update existing artifacts to the new destination
- [x] Update the [roles](https://github.com/opensearch-project/opensearch-build/blob/main/deployment/lib/identities.ts#L11) to be separate between jobs to prevent any possible conflicts, then update the jenkins jobs to build to the correct destination.
- [x] https://github.com/opensearch-project/opensearch-build/issues/661
- [x] https://github.com/opensearch-project/opensearch-build/issues/714
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/run_assemble.py`
Content:
```
1 #!/usr/bin/env python
2
3 # SPDX-License-Identifier: Apache-2.0
4 #
5 # The OpenSearch Contributors require contributions made to
6 # this file be licensed under the Apache-2.0 license or a
7 # compatible open source license.
8
9 import argparse
10 import logging
11 import os
12 import sys
13
14 from assemble_workflow.bundle_recorder import BundleRecorder
15 from assemble_workflow.bundles import Bundles
16 from manifests.build_manifest import BuildManifest
17 from system import console
18 from system.temporary_directory import TemporaryDirectory
19
20
21 def main():
22 parser = argparse.ArgumentParser(description="Assemble an OpenSearch Bundle")
23 parser.add_argument("manifest", type=argparse.FileType("r"), help="Manifest file.")
24 parser.add_argument(
25 "-v",
26 "--verbose",
27 help="Show more verbose output.",
28 action="store_const",
29 default=logging.INFO,
30 const=logging.DEBUG,
31 dest="logging_level",
32 )
33 args = parser.parse_args()
34
35 console.configure(level=args.logging_level)
36
37 build_manifest = BuildManifest.from_file(args.manifest)
38 build = build_manifest.build
39 artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))
40 output_dir = os.path.join(os.getcwd(), "bundle")
41 os.makedirs(output_dir, exist_ok=True)
42
43 with TemporaryDirectory() as work_dir:
44 logging.info(f"Bundling {build.name} ({build.architecture}) on {build.platform} into {output_dir} ...")
45
46 os.chdir(work_dir.name)
47
48 bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)
49
50 bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)
51
52 bundle.install_min()
53 bundle.install_plugins()
54 logging.info(f"Installed plugins: {bundle.installed_plugins}")
55
56 # Save a copy of the manifest inside of the tar
57 bundle_recorder.write_manifest(bundle.archive_path)
58 bundle.build_tar(output_dir)
59
60 bundle_recorder.write_manifest(output_dir)
61
62 logging.info("Done.")
63
64
65 if __name__ == "__main__":
66 sys.exit(main())
67
```
Path: `src/assemble_workflow/bundle_recorder.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import os
8 from urllib.parse import urljoin
9
10 from manifests.bundle_manifest import BundleManifest
11
12
13 class BundleRecorder:
14 def __init__(self, build, output_dir, artifacts_dir):
15 self.output_dir = output_dir
16 self.build_id = build.id
17 self.public_url = os.getenv("PUBLIC_ARTIFACT_URL", None)
18 self.version = build.version
19 self.tar_name = self.__get_tar_name(build)
20 self.artifacts_dir = artifacts_dir
21 self.architecture = build.architecture
22 self.bundle_manifest = self.BundleManifestBuilder(
23 build.id,
24 build.name,
25 build.version,
26 build.platform,
27 build.architecture,
28 self.__get_tar_location(),
29 )
30
31 def __get_tar_name(self, build):
32 parts = [
33 build.name.lower().replace(" ", "-"),
34 build.version,
35 build.platform,
36 build.architecture,
37 ]
38 return "-".join(parts) + ".tar.gz"
39
40 def __get_public_url_path(self, folder, rel_path):
41 path = "/".join((folder, self.version, self.build_id, self.architecture, rel_path))
42 return urljoin(self.public_url + "/", path)
43
44 def __get_location(self, folder_name, rel_path, abs_path):
45 if self.public_url:
46 return self.__get_public_url_path(folder_name, rel_path)
47 return abs_path
48
49 # Assembled bundles are expected to be served from a separate "bundles" folder
50 # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id
51 def __get_tar_location(self):
52 return self.__get_location("bundles", self.tar_name, os.path.join(self.output_dir, self.tar_name))
53
54 # Build artifacts are expected to be served from a "builds" folder
55 # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>
56 def __get_component_location(self, component_rel_path):
57 abs_path = os.path.join(self.artifacts_dir, component_rel_path)
58 return self.__get_location("builds", component_rel_path, abs_path)
59
60 def record_component(self, component, rel_path):
61 self.bundle_manifest.append_component(
62 component.name,
63 component.repository,
64 component.ref,
65 component.commit_id,
66 self.__get_component_location(rel_path),
67 )
68
69 def get_manifest(self):
70 return self.bundle_manifest.to_manifest()
71
72 def write_manifest(self, folder):
73 manifest_path = os.path.join(folder, "manifest.yml")
74 self.get_manifest().to_file(manifest_path)
75
76 class BundleManifestBuilder:
77 def __init__(self, build_id, name, version, platform, architecture, location):
78 self.data = {}
79 self.data["build"] = {}
80 self.data["build"]["id"] = build_id
81 self.data["build"]["name"] = name
82 self.data["build"]["version"] = str(version)
83 self.data["build"]["platform"] = platform
84 self.data["build"]["architecture"] = architecture
85 self.data["build"]["location"] = location
86 self.data["schema-version"] = "1.1"
87 # We need to store components as a hash so that we can append artifacts by component name
88 # When we convert to a BundleManifest this will get converted back into a list
89 self.data["components"] = []
90
91 def append_component(self, name, repository_url, ref, commit_id, location):
92 component = {
93 "name": name,
94 "repository": repository_url,
95 "ref": ref,
96 "commit_id": commit_id,
97 "location": location,
98 }
99 self.data["components"].append(component)
100
101 def to_manifest(self):
102 return BundleManifest(self.data)
103
```
Path: `src/run_build.py`
Content:
```
1 #!/usr/bin/env python
2
3 # SPDX-License-Identifier: Apache-2.0
4 #
5 # The OpenSearch Contributors require contributions made to
6 # this file be licensed under the Apache-2.0 license or a
7 # compatible open source license.
8
9 import logging
10 import os
11 import sys
12
13 from build_workflow.build_args import BuildArgs
14 from build_workflow.build_recorder import BuildRecorder
15 from build_workflow.build_target import BuildTarget
16 from build_workflow.builder import Builder
17 from git.git_repository import GitRepository
18 from manifests.input_manifest import InputManifest
19 from system import console
20 from system.temporary_directory import TemporaryDirectory
21
22
23 def main():
24 args = BuildArgs()
25 console.configure(level=args.logging_level)
26 manifest = InputManifest.from_file(args.manifest)
27
28 with TemporaryDirectory(keep=args.keep) as work_dir:
29 output_dir = os.path.join(os.getcwd(), "artifacts")
30
31 logging.info(f"Building in {work_dir.name}")
32
33 os.chdir(work_dir.name)
34
35 target = BuildTarget(
36 name=manifest.build.name,
37 version=manifest.build.version,
38 snapshot=args.snapshot,
39 output_dir=output_dir,
40 platform=args.platform,
41 architecture=args.architecture,
42 )
43
44 os.makedirs(target.output_dir, exist_ok=True)
45
46 build_recorder = BuildRecorder(target)
47
48 logging.info(
49 f"Building {manifest.build.name} ({target.architecture}) into {target.output_dir}"
50 )
51
52 for component in manifest.components:
53
54 if args.component and args.component != component.name:
55 logging.info(f"Skipping {component.name}")
56 continue
57
58 logging.info(f"Building {component.name}")
59
60 with GitRepository(
61 component.repository,
62 component.ref,
63 os.path.join(work_dir.name, component.name),
64 component.working_directory,
65 ) as repo:
66 try:
67 builder = Builder(component.name, repo, build_recorder)
68 builder.build(target)
69 builder.export_artifacts()
70 except:
71 logging.error(f"Error building {component.name}, retry with: {args.component_command(component.name)}")
72 raise
73
74 build_recorder.write_manifest()
75
76 logging.info("Done.")
77
78
79 if __name__ == "__main__":
80 sys.exit(main())
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/assemble_workflow/bundle_recorder.py b/src/assemble_workflow/bundle_recorder.py
--- a/src/assemble_workflow/bundle_recorder.py
+++ b/src/assemble_workflow/bundle_recorder.py
@@ -11,10 +11,10 @@
class BundleRecorder:
- def __init__(self, build, output_dir, artifacts_dir):
+ def __init__(self, build, output_dir, artifacts_dir, base_url):
self.output_dir = output_dir
self.build_id = build.id
- self.public_url = os.getenv("PUBLIC_ARTIFACT_URL", None)
+ self.base_url = base_url
self.version = build.version
self.tar_name = self.__get_tar_name(build)
self.artifacts_dir = artifacts_dir
@@ -38,18 +38,18 @@
return "-".join(parts) + ".tar.gz"
def __get_public_url_path(self, folder, rel_path):
- path = "/".join((folder, self.version, self.build_id, self.architecture, rel_path))
- return urljoin(self.public_url + "/", path)
+ path = "/".join((folder, rel_path))
+ return urljoin(self.base_url + "/", path)
def __get_location(self, folder_name, rel_path, abs_path):
- if self.public_url:
+ if self.base_url:
return self.__get_public_url_path(folder_name, rel_path)
return abs_path
# Assembled bundles are expected to be served from a separate "bundles" folder
# Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id
def __get_tar_location(self):
- return self.__get_location("bundles", self.tar_name, os.path.join(self.output_dir, self.tar_name))
+ return self.__get_location("dist", self.tar_name, os.path.join(self.output_dir, self.tar_name))
# Build artifacts are expected to be served from a "builds" folder
# Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>
diff --git a/src/run_assemble.py b/src/run_assemble.py
--- a/src/run_assemble.py
+++ b/src/run_assemble.py
@@ -30,6 +30,7 @@
const=logging.DEBUG,
dest="logging_level",
)
+ parser.add_argument("-b", "--base-url", dest='base_url', help="The base url to download the artifacts.")
args = parser.parse_args()
console.configure(level=args.logging_level)
@@ -37,7 +38,7 @@
build_manifest = BuildManifest.from_file(args.manifest)
build = build_manifest.build
artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))
- output_dir = os.path.join(os.getcwd(), "bundle")
+ output_dir = os.path.join(os.getcwd(), "dist")
os.makedirs(output_dir, exist_ok=True)
with TemporaryDirectory() as work_dir:
@@ -45,7 +46,7 @@
os.chdir(work_dir.name)
- bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)
+ bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir, args.base_url)
bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)
diff --git a/src/run_build.py b/src/run_build.py
--- a/src/run_build.py
+++ b/src/run_build.py
@@ -26,7 +26,7 @@
manifest = InputManifest.from_file(args.manifest)
with TemporaryDirectory(keep=args.keep) as work_dir:
- output_dir = os.path.join(os.getcwd(), "artifacts")
+ output_dir = os.path.join(os.getcwd(), "builds")
logging.info(f"Building in {work_dir.name}")
| {"golden_diff": "diff --git a/src/assemble_workflow/bundle_recorder.py b/src/assemble_workflow/bundle_recorder.py\n--- a/src/assemble_workflow/bundle_recorder.py\n+++ b/src/assemble_workflow/bundle_recorder.py\n@@ -11,10 +11,10 @@\n \n \n class BundleRecorder:\n- def __init__(self, build, output_dir, artifacts_dir):\n+ def __init__(self, build, output_dir, artifacts_dir, base_url):\n self.output_dir = output_dir\n self.build_id = build.id\n- self.public_url = os.getenv(\"PUBLIC_ARTIFACT_URL\", None)\n+ self.base_url = base_url\n self.version = build.version\n self.tar_name = self.__get_tar_name(build)\n self.artifacts_dir = artifacts_dir\n@@ -38,18 +38,18 @@\n return \"-\".join(parts) + \".tar.gz\"\n \n def __get_public_url_path(self, folder, rel_path):\n- path = \"/\".join((folder, self.version, self.build_id, self.architecture, rel_path))\n- return urljoin(self.public_url + \"/\", path)\n+ path = \"/\".join((folder, rel_path))\n+ return urljoin(self.base_url + \"/\", path)\n \n def __get_location(self, folder_name, rel_path, abs_path):\n- if self.public_url:\n+ if self.base_url:\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n \n # Assembled bundles are expected to be served from a separate \"bundles\" folder\n # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id\n def __get_tar_location(self):\n- return self.__get_location(\"bundles\", self.tar_name, os.path.join(self.output_dir, self.tar_name))\n+ return self.__get_location(\"dist\", self.tar_name, os.path.join(self.output_dir, self.tar_name))\n \n # Build artifacts are expected to be served from a \"builds\" folder\n # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>\ndiff --git a/src/run_assemble.py b/src/run_assemble.py\n--- a/src/run_assemble.py\n+++ b/src/run_assemble.py\n@@ -30,6 +30,7 @@\n const=logging.DEBUG,\n dest=\"logging_level\",\n )\n+ parser.add_argument(\"-b\", \"--base-url\", dest='base_url', help=\"The base url to download the artifacts.\")\n args = parser.parse_args()\n \n console.configure(level=args.logging_level)\n@@ -37,7 +38,7 @@\n build_manifest = BuildManifest.from_file(args.manifest)\n build = build_manifest.build\n artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))\n- output_dir = os.path.join(os.getcwd(), \"bundle\")\n+ output_dir = os.path.join(os.getcwd(), \"dist\")\n os.makedirs(output_dir, exist_ok=True)\n \n with TemporaryDirectory() as work_dir:\n@@ -45,7 +46,7 @@\n \n os.chdir(work_dir.name)\n \n- bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)\n+ bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir, args.base_url)\n \n bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)\n \ndiff --git a/src/run_build.py b/src/run_build.py\n--- a/src/run_build.py\n+++ b/src/run_build.py\n@@ -26,7 +26,7 @@\n manifest = InputManifest.from_file(args.manifest)\n \n with TemporaryDirectory(keep=args.keep) as work_dir:\n- output_dir = os.path.join(os.getcwd(), \"artifacts\")\n+ output_dir = os.path.join(os.getcwd(), \"builds\")\n \n logging.info(f\"Building in {work_dir.name}\")\n", "issue": "[Bug]: Distribution builds can have path collisions\nDistribution builds are not namespace'd based on the type of artifact produced so an OpenSearch and OpenSearch Dashboard build could collide.\r\n\r\n### Actual\r\nThe current path generated is `https://ci.opensearch.org/ci/dbc/builds/1.1.0/328/x64/manifest.yml`.\r\n\r\n### Expected\r\nIt should have the distribution type in the path like `https://ci.opensearch.org/ci/dbc/opensearch/builds/1.1.0/328/x64/manifest.yml` and `https://ci.opensearch.org/ci/dbc/opensearch-dashboards/builds/1.1.0/328/x64/manifest.yml`\r\n\r\n### Required changes\r\n- [x] Update the build jobs to include the build type in the url for the generated manifests, see [bundle_recorder.py](https://github.com/opensearch-project/opensearch-build/blob/main/src/assemble_workflow/bundle_recorder.py).\r\n- [x] Update the jenkinsfile to upload to a destination based on the build type, see [Jenkinsfile](https://github.com/opensearch-project/opensearch-build/blob/main/Jenkinsfile#L127).\r\n\r\n### Other changes\r\n- [ ] Migrate/ update existing artifacts to the new destination\r\n- [x] Update the [roles](https://github.com/opensearch-project/opensearch-build/blob/main/deployment/lib/identities.ts#L11) to be separate between jobs to prevent any possible conflicts, then update the jenkins jobs to build to the correct destination.\r\n- [x] https://github.com/opensearch-project/opensearch-build/issues/661\r\n- [x] https://github.com/opensearch-project/opensearch-build/issues/714\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport argparse\nimport logging\nimport os\nimport sys\n\nfrom assemble_workflow.bundle_recorder import BundleRecorder\nfrom assemble_workflow.bundles import Bundles\nfrom manifests.build_manifest import BuildManifest\nfrom system import console\nfrom system.temporary_directory import TemporaryDirectory\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Assemble an OpenSearch Bundle\")\n parser.add_argument(\"manifest\", type=argparse.FileType(\"r\"), help=\"Manifest file.\")\n parser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"Show more verbose output.\",\n action=\"store_const\",\n default=logging.INFO,\n const=logging.DEBUG,\n dest=\"logging_level\",\n )\n args = parser.parse_args()\n\n console.configure(level=args.logging_level)\n\n build_manifest = BuildManifest.from_file(args.manifest)\n build = build_manifest.build\n artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))\n output_dir = os.path.join(os.getcwd(), \"bundle\")\n os.makedirs(output_dir, exist_ok=True)\n\n with TemporaryDirectory() as work_dir:\n logging.info(f\"Bundling {build.name} ({build.architecture}) on {build.platform} into {output_dir} ...\")\n\n os.chdir(work_dir.name)\n\n bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir)\n\n bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)\n\n bundle.install_min()\n bundle.install_plugins()\n logging.info(f\"Installed plugins: {bundle.installed_plugins}\")\n\n # Save a copy of the manifest inside of the tar\n bundle_recorder.write_manifest(bundle.archive_path)\n bundle.build_tar(output_dir)\n\n bundle_recorder.write_manifest(output_dir)\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_assemble.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom urllib.parse import urljoin\n\nfrom manifests.bundle_manifest import BundleManifest\n\n\nclass BundleRecorder:\n def __init__(self, build, output_dir, artifacts_dir):\n self.output_dir = output_dir\n self.build_id = build.id\n self.public_url = os.getenv(\"PUBLIC_ARTIFACT_URL\", None)\n self.version = build.version\n self.tar_name = self.__get_tar_name(build)\n self.artifacts_dir = artifacts_dir\n self.architecture = build.architecture\n self.bundle_manifest = self.BundleManifestBuilder(\n build.id,\n build.name,\n build.version,\n build.platform,\n build.architecture,\n self.__get_tar_location(),\n )\n\n def __get_tar_name(self, build):\n parts = [\n build.name.lower().replace(\" \", \"-\"),\n build.version,\n build.platform,\n build.architecture,\n ]\n return \"-\".join(parts) + \".tar.gz\"\n\n def __get_public_url_path(self, folder, rel_path):\n path = \"/\".join((folder, self.version, self.build_id, self.architecture, rel_path))\n return urljoin(self.public_url + \"/\", path)\n\n def __get_location(self, folder_name, rel_path, abs_path):\n if self.public_url:\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n\n # Assembled bundles are expected to be served from a separate \"bundles\" folder\n # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id\n def __get_tar_location(self):\n return self.__get_location(\"bundles\", self.tar_name, os.path.join(self.output_dir, self.tar_name))\n\n # Build artifacts are expected to be served from a \"builds\" folder\n # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>\n def __get_component_location(self, component_rel_path):\n abs_path = os.path.join(self.artifacts_dir, component_rel_path)\n return self.__get_location(\"builds\", component_rel_path, abs_path)\n\n def record_component(self, component, rel_path):\n self.bundle_manifest.append_component(\n component.name,\n component.repository,\n component.ref,\n component.commit_id,\n self.__get_component_location(rel_path),\n )\n\n def get_manifest(self):\n return self.bundle_manifest.to_manifest()\n\n def write_manifest(self, folder):\n manifest_path = os.path.join(folder, \"manifest.yml\")\n self.get_manifest().to_file(manifest_path)\n\n class BundleManifestBuilder:\n def __init__(self, build_id, name, version, platform, architecture, location):\n self.data = {}\n self.data[\"build\"] = {}\n self.data[\"build\"][\"id\"] = build_id\n self.data[\"build\"][\"name\"] = name\n self.data[\"build\"][\"version\"] = str(version)\n self.data[\"build\"][\"platform\"] = platform\n self.data[\"build\"][\"architecture\"] = architecture\n self.data[\"build\"][\"location\"] = location\n self.data[\"schema-version\"] = \"1.1\"\n # We need to store components as a hash so that we can append artifacts by component name\n # When we convert to a BundleManifest this will get converted back into a list\n self.data[\"components\"] = []\n\n def append_component(self, name, repository_url, ref, commit_id, location):\n component = {\n \"name\": name,\n \"repository\": repository_url,\n \"ref\": ref,\n \"commit_id\": commit_id,\n \"location\": location,\n }\n self.data[\"components\"].append(component)\n\n def to_manifest(self):\n return BundleManifest(self.data)\n", "path": "src/assemble_workflow/bundle_recorder.py"}, {"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\nimport os\nimport sys\n\nfrom build_workflow.build_args import BuildArgs\nfrom build_workflow.build_recorder import BuildRecorder\nfrom build_workflow.build_target import BuildTarget\nfrom build_workflow.builder import Builder\nfrom git.git_repository import GitRepository\nfrom manifests.input_manifest import InputManifest\nfrom system import console\nfrom system.temporary_directory import TemporaryDirectory\n\n\ndef main():\n args = BuildArgs()\n console.configure(level=args.logging_level)\n manifest = InputManifest.from_file(args.manifest)\n\n with TemporaryDirectory(keep=args.keep) as work_dir:\n output_dir = os.path.join(os.getcwd(), \"artifacts\")\n\n logging.info(f\"Building in {work_dir.name}\")\n\n os.chdir(work_dir.name)\n\n target = BuildTarget(\n name=manifest.build.name,\n version=manifest.build.version,\n snapshot=args.snapshot,\n output_dir=output_dir,\n platform=args.platform,\n architecture=args.architecture,\n )\n\n os.makedirs(target.output_dir, exist_ok=True)\n\n build_recorder = BuildRecorder(target)\n\n logging.info(\n f\"Building {manifest.build.name} ({target.architecture}) into {target.output_dir}\"\n )\n\n for component in manifest.components:\n\n if args.component and args.component != component.name:\n logging.info(f\"Skipping {component.name}\")\n continue\n\n logging.info(f\"Building {component.name}\")\n\n with GitRepository(\n component.repository,\n component.ref,\n os.path.join(work_dir.name, component.name),\n component.working_directory,\n ) as repo:\n try:\n builder = Builder(component.name, repo, build_recorder)\n builder.build(target)\n builder.export_artifacts()\n except:\n logging.error(f\"Error building {component.name}, retry with: {args.component_command(component.name)}\")\n raise\n\n build_recorder.write_manifest()\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_build.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport argparse\nimport logging\nimport os\nimport sys\n\nfrom assemble_workflow.bundle_recorder import BundleRecorder\nfrom assemble_workflow.bundles import Bundles\nfrom manifests.build_manifest import BuildManifest\nfrom system import console\nfrom system.temporary_directory import TemporaryDirectory\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Assemble an OpenSearch Bundle\")\n parser.add_argument(\"manifest\", type=argparse.FileType(\"r\"), help=\"Manifest file.\")\n parser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"Show more verbose output.\",\n action=\"store_const\",\n default=logging.INFO,\n const=logging.DEBUG,\n dest=\"logging_level\",\n )\n parser.add_argument(\"-b\", \"--base-url\", dest='base_url', help=\"The base url to download the artifacts.\")\n args = parser.parse_args()\n\n console.configure(level=args.logging_level)\n\n build_manifest = BuildManifest.from_file(args.manifest)\n build = build_manifest.build\n artifacts_dir = os.path.dirname(os.path.realpath(args.manifest.name))\n output_dir = os.path.join(os.getcwd(), \"dist\")\n os.makedirs(output_dir, exist_ok=True)\n\n with TemporaryDirectory() as work_dir:\n logging.info(f\"Bundling {build.name} ({build.architecture}) on {build.platform} into {output_dir} ...\")\n\n os.chdir(work_dir.name)\n\n bundle_recorder = BundleRecorder(build, output_dir, artifacts_dir, args.base_url)\n\n bundle = Bundles.create(build_manifest, artifacts_dir, bundle_recorder)\n\n bundle.install_min()\n bundle.install_plugins()\n logging.info(f\"Installed plugins: {bundle.installed_plugins}\")\n\n # Save a copy of the manifest inside of the tar\n bundle_recorder.write_manifest(bundle.archive_path)\n bundle.build_tar(output_dir)\n\n bundle_recorder.write_manifest(output_dir)\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_assemble.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom urllib.parse import urljoin\n\nfrom manifests.bundle_manifest import BundleManifest\n\n\nclass BundleRecorder:\n def __init__(self, build, output_dir, artifacts_dir, base_url):\n self.output_dir = output_dir\n self.build_id = build.id\n self.base_url = base_url\n self.version = build.version\n self.tar_name = self.__get_tar_name(build)\n self.artifacts_dir = artifacts_dir\n self.architecture = build.architecture\n self.bundle_manifest = self.BundleManifestBuilder(\n build.id,\n build.name,\n build.version,\n build.platform,\n build.architecture,\n self.__get_tar_location(),\n )\n\n def __get_tar_name(self, build):\n parts = [\n build.name.lower().replace(\" \", \"-\"),\n build.version,\n build.platform,\n build.architecture,\n ]\n return \"-\".join(parts) + \".tar.gz\"\n\n def __get_public_url_path(self, folder, rel_path):\n path = \"/\".join((folder, rel_path))\n return urljoin(self.base_url + \"/\", path)\n\n def __get_location(self, folder_name, rel_path, abs_path):\n if self.base_url:\n return self.__get_public_url_path(folder_name, rel_path)\n return abs_path\n\n # Assembled bundles are expected to be served from a separate \"bundles\" folder\n # Example: https://artifacts.opensearch.org/bundles/1.0.0/<build-id\n def __get_tar_location(self):\n return self.__get_location(\"dist\", self.tar_name, os.path.join(self.output_dir, self.tar_name))\n\n # Build artifacts are expected to be served from a \"builds\" folder\n # Example: https://artifacts.opensearch.org/builds/1.0.0/<build-id>\n def __get_component_location(self, component_rel_path):\n abs_path = os.path.join(self.artifacts_dir, component_rel_path)\n return self.__get_location(\"builds\", component_rel_path, abs_path)\n\n def record_component(self, component, rel_path):\n self.bundle_manifest.append_component(\n component.name,\n component.repository,\n component.ref,\n component.commit_id,\n self.__get_component_location(rel_path),\n )\n\n def get_manifest(self):\n return self.bundle_manifest.to_manifest()\n\n def write_manifest(self, folder):\n manifest_path = os.path.join(folder, \"manifest.yml\")\n self.get_manifest().to_file(manifest_path)\n\n class BundleManifestBuilder:\n def __init__(self, build_id, name, version, platform, architecture, location):\n self.data = {}\n self.data[\"build\"] = {}\n self.data[\"build\"][\"id\"] = build_id\n self.data[\"build\"][\"name\"] = name\n self.data[\"build\"][\"version\"] = str(version)\n self.data[\"build\"][\"platform\"] = platform\n self.data[\"build\"][\"architecture\"] = architecture\n self.data[\"build\"][\"location\"] = location\n self.data[\"schema-version\"] = \"1.1\"\n # We need to store components as a hash so that we can append artifacts by component name\n # When we convert to a BundleManifest this will get converted back into a list\n self.data[\"components\"] = []\n\n def append_component(self, name, repository_url, ref, commit_id, location):\n component = {\n \"name\": name,\n \"repository\": repository_url,\n \"ref\": ref,\n \"commit_id\": commit_id,\n \"location\": location,\n }\n self.data[\"components\"].append(component)\n\n def to_manifest(self):\n return BundleManifest(self.data)\n", "path": "src/assemble_workflow/bundle_recorder.py"}, {"content": "#!/usr/bin/env python\n\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\nimport os\nimport sys\n\nfrom build_workflow.build_args import BuildArgs\nfrom build_workflow.build_recorder import BuildRecorder\nfrom build_workflow.build_target import BuildTarget\nfrom build_workflow.builder import Builder\nfrom git.git_repository import GitRepository\nfrom manifests.input_manifest import InputManifest\nfrom system import console\nfrom system.temporary_directory import TemporaryDirectory\n\n\ndef main():\n args = BuildArgs()\n console.configure(level=args.logging_level)\n manifest = InputManifest.from_file(args.manifest)\n\n with TemporaryDirectory(keep=args.keep) as work_dir:\n output_dir = os.path.join(os.getcwd(), \"builds\")\n\n logging.info(f\"Building in {work_dir.name}\")\n\n os.chdir(work_dir.name)\n\n target = BuildTarget(\n name=manifest.build.name,\n version=manifest.build.version,\n snapshot=args.snapshot,\n output_dir=output_dir,\n platform=args.platform,\n architecture=args.architecture,\n )\n\n os.makedirs(target.output_dir, exist_ok=True)\n\n build_recorder = BuildRecorder(target)\n\n logging.info(\n f\"Building {manifest.build.name} ({target.architecture}) into {target.output_dir}\"\n )\n\n for component in manifest.components:\n\n if args.component and args.component != component.name:\n logging.info(f\"Skipping {component.name}\")\n continue\n\n logging.info(f\"Building {component.name}\")\n\n with GitRepository(\n component.repository,\n component.ref,\n os.path.join(work_dir.name, component.name),\n component.working_directory,\n ) as repo:\n try:\n builder = Builder(component.name, repo, build_recorder)\n builder.build(target)\n builder.export_artifacts()\n except:\n logging.error(f\"Error building {component.name}, retry with: {args.component_command(component.name)}\")\n raise\n\n build_recorder.write_manifest()\n\n logging.info(\"Done.\")\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "src/run_build.py"}]} | 2,904 | 843 |
gh_patches_debug_21264 | rasdani/github-patches | git_diff | inventree__InvenTree-6250 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
News Feed task doesn't work behind proxy, impacting performance
### Please verify that this bug has NOT been raised before.
- [X] I checked and didn't find a similar issue
### Describe the bug*
The `update_news_feed` task attempts to fetch the RSS/Atom feed once daily. This, however, doesn't work behind a proxy server.
The result is that these tasks occupy workers all the time, and never complete.
Each worker is terminated roughly every 90 seconds due to this.
### Steps to Reproduce
1. Put the InvenTree backend on a network unable to reach `INVENTREE_NEWS_URL`
2. Trigger the task
3. Task will lead to continuous timeout termination of workers
### Expected behaviour
Task should finish with no new News entries added if URL is unreachable.
### Deployment Method
- [ ] Docker
- [X] Bare metal
### Version Information
0.12.10
### Please verify if you can reproduce this bug on the demo site.
- [ ] I can reproduce this bug on the demo site.
### Relevant log output
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `InvenTree/common/tasks.py`
Content:
```
1 """Tasks (processes that get offloaded) for common app."""
2
3 import logging
4 import os
5 from datetime import datetime, timedelta
6
7 from django.conf import settings
8 from django.core.exceptions import AppRegistryNotReady
9 from django.db.utils import IntegrityError, OperationalError
10 from django.utils import timezone
11
12 import feedparser
13
14 from InvenTree.helpers_model import getModelsWithMixin
15 from InvenTree.models import InvenTreeNotesMixin
16 from InvenTree.tasks import ScheduledTask, scheduled_task
17
18 logger = logging.getLogger('inventree')
19
20
21 @scheduled_task(ScheduledTask.DAILY)
22 def delete_old_notifications():
23 """Remove old notifications from the database.
24
25 Anything older than ~3 months is removed
26 """
27 try:
28 from common.models import NotificationEntry
29 except AppRegistryNotReady: # pragma: no cover
30 logger.info(
31 "Could not perform 'delete_old_notifications' - App registry not ready"
32 )
33 return
34
35 before = timezone.now() - timedelta(days=90)
36
37 # Delete notification records before the specified date
38 NotificationEntry.objects.filter(updated__lte=before).delete()
39
40
41 @scheduled_task(ScheduledTask.DAILY)
42 def update_news_feed():
43 """Update the newsfeed."""
44 try:
45 from common.models import NewsFeedEntry
46 except AppRegistryNotReady: # pragma: no cover
47 logger.info("Could not perform 'update_news_feed' - App registry not ready")
48 return
49
50 # Fetch and parse feed
51 try:
52 d = feedparser.parse(settings.INVENTREE_NEWS_URL)
53 except Exception as entry: # pragma: no cover
54 logger.warning('update_news_feed: Error parsing the newsfeed', entry)
55 return
56
57 # Get a reference list
58 id_list = [a.feed_id for a in NewsFeedEntry.objects.all()]
59
60 # Iterate over entries
61 for entry in d.entries:
62 # Check if id already exists
63 if entry.id in id_list:
64 continue
65
66 # Create entry
67 try:
68 NewsFeedEntry.objects.create(
69 feed_id=entry.id,
70 title=entry.title,
71 link=entry.link,
72 published=entry.published,
73 author=entry.author,
74 summary=entry.summary,
75 )
76 except (IntegrityError, OperationalError):
77 # Sometimes errors-out on database start-up
78 pass
79
80 logger.info('update_news_feed: Sync done')
81
82
83 @scheduled_task(ScheduledTask.DAILY)
84 def delete_old_notes_images():
85 """Remove old notes images from the database.
86
87 Anything older than ~3 months is removed, unless it is linked to a note
88 """
89 try:
90 from common.models import NotesImage
91 except AppRegistryNotReady:
92 logger.info(
93 "Could not perform 'delete_old_notes_images' - App registry not ready"
94 )
95 return
96
97 # Remove any notes which point to non-existent image files
98 for note in NotesImage.objects.all():
99 if not os.path.exists(note.image.path):
100 logger.info('Deleting note %s - image file does not exist', note.image.path)
101 note.delete()
102
103 note_classes = getModelsWithMixin(InvenTreeNotesMixin)
104 before = datetime.now() - timedelta(days=90)
105
106 for note in NotesImage.objects.filter(date__lte=before):
107 # Find any images which are no longer referenced by a note
108
109 found = False
110
111 img = note.image.name
112
113 for model in note_classes:
114 if model.objects.filter(notes__icontains=img).exists():
115 found = True
116 break
117
118 if not found:
119 logger.info('Deleting note %s - image file not linked to a note', img)
120 note.delete()
121
122 # Finally, remove any images in the notes dir which are not linked to a note
123 notes_dir = os.path.join(settings.MEDIA_ROOT, 'notes')
124
125 try:
126 images = os.listdir(notes_dir)
127 except FileNotFoundError:
128 # Thrown if the directory does not exist
129 images = []
130
131 all_notes = NotesImage.objects.all()
132
133 for image in images:
134 found = False
135 for note in all_notes:
136 img_path = os.path.basename(note.image.path)
137 if img_path == image:
138 found = True
139 break
140
141 if not found:
142 logger.info('Deleting note %s - image file not linked to a note', image)
143 os.remove(os.path.join(notes_dir, image))
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/InvenTree/common/tasks.py b/InvenTree/common/tasks.py
--- a/InvenTree/common/tasks.py
+++ b/InvenTree/common/tasks.py
@@ -10,6 +10,7 @@
from django.utils import timezone
import feedparser
+import requests
from InvenTree.helpers_model import getModelsWithMixin
from InvenTree.models import InvenTreeNotesMixin
@@ -47,11 +48,16 @@
logger.info("Could not perform 'update_news_feed' - App registry not ready")
return
+ # News feed isn't defined, no need to continue
+ if not settings.INVENTREE_NEWS_URL or type(settings.INVENTREE_NEWS_URL) != str:
+ return
+
# Fetch and parse feed
try:
- d = feedparser.parse(settings.INVENTREE_NEWS_URL)
- except Exception as entry: # pragma: no cover
- logger.warning('update_news_feed: Error parsing the newsfeed', entry)
+ feed = requests.get(settings.INVENTREE_NEWS_URL)
+ d = feedparser.parse(feed.content)
+ except Exception: # pragma: no cover
+ logger.warning('update_news_feed: Error parsing the newsfeed')
return
# Get a reference list
| {"golden_diff": "diff --git a/InvenTree/common/tasks.py b/InvenTree/common/tasks.py\n--- a/InvenTree/common/tasks.py\n+++ b/InvenTree/common/tasks.py\n@@ -10,6 +10,7 @@\n from django.utils import timezone\n \n import feedparser\n+import requests\n \n from InvenTree.helpers_model import getModelsWithMixin\n from InvenTree.models import InvenTreeNotesMixin\n@@ -47,11 +48,16 @@\n logger.info(\"Could not perform 'update_news_feed' - App registry not ready\")\n return\n \n+ # News feed isn't defined, no need to continue\n+ if not settings.INVENTREE_NEWS_URL or type(settings.INVENTREE_NEWS_URL) != str:\n+ return\n+\n # Fetch and parse feed\n try:\n- d = feedparser.parse(settings.INVENTREE_NEWS_URL)\n- except Exception as entry: # pragma: no cover\n- logger.warning('update_news_feed: Error parsing the newsfeed', entry)\n+ feed = requests.get(settings.INVENTREE_NEWS_URL)\n+ d = feedparser.parse(feed.content)\n+ except Exception: # pragma: no cover\n+ logger.warning('update_news_feed: Error parsing the newsfeed')\n return\n \n # Get a reference list\n", "issue": "News Feed task doesn't work behind proxy, impacting performance\n### Please verify that this bug has NOT been raised before.\n\n- [X] I checked and didn't find a similar issue\n\n### Describe the bug*\n\nThe `update_news_feed` task attempts to fetch the RSS/Atom feed once daily. This, however, doesn't work behind a proxy server.\r\n\r\nThe result is that these tasks occupy workers all the time, and never complete.\r\nEach worker is terminated roughly every 90 seconds due to this.\n\n### Steps to Reproduce\n\n1. Put the InvenTree backend on a network unable to reach `INVENTREE_NEWS_URL`\r\n2. Trigger the task\r\n3. Task will lead to continuous timeout termination of workers\n\n### Expected behaviour\n\nTask should finish with no new News entries added if URL is unreachable.\n\n### Deployment Method\n\n- [ ] Docker\n- [X] Bare metal\n\n### Version Information\n\n0.12.10\n\n### Please verify if you can reproduce this bug on the demo site.\n\n- [ ] I can reproduce this bug on the demo site.\n\n### Relevant log output\n\n_No response_\n", "before_files": [{"content": "\"\"\"Tasks (processes that get offloaded) for common app.\"\"\"\n\nimport logging\nimport os\nfrom datetime import datetime, timedelta\n\nfrom django.conf import settings\nfrom django.core.exceptions import AppRegistryNotReady\nfrom django.db.utils import IntegrityError, OperationalError\nfrom django.utils import timezone\n\nimport feedparser\n\nfrom InvenTree.helpers_model import getModelsWithMixin\nfrom InvenTree.models import InvenTreeNotesMixin\nfrom InvenTree.tasks import ScheduledTask, scheduled_task\n\nlogger = logging.getLogger('inventree')\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef delete_old_notifications():\n \"\"\"Remove old notifications from the database.\n\n Anything older than ~3 months is removed\n \"\"\"\n try:\n from common.models import NotificationEntry\n except AppRegistryNotReady: # pragma: no cover\n logger.info(\n \"Could not perform 'delete_old_notifications' - App registry not ready\"\n )\n return\n\n before = timezone.now() - timedelta(days=90)\n\n # Delete notification records before the specified date\n NotificationEntry.objects.filter(updated__lte=before).delete()\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef update_news_feed():\n \"\"\"Update the newsfeed.\"\"\"\n try:\n from common.models import NewsFeedEntry\n except AppRegistryNotReady: # pragma: no cover\n logger.info(\"Could not perform 'update_news_feed' - App registry not ready\")\n return\n\n # Fetch and parse feed\n try:\n d = feedparser.parse(settings.INVENTREE_NEWS_URL)\n except Exception as entry: # pragma: no cover\n logger.warning('update_news_feed: Error parsing the newsfeed', entry)\n return\n\n # Get a reference list\n id_list = [a.feed_id for a in NewsFeedEntry.objects.all()]\n\n # Iterate over entries\n for entry in d.entries:\n # Check if id already exists\n if entry.id in id_list:\n continue\n\n # Create entry\n try:\n NewsFeedEntry.objects.create(\n feed_id=entry.id,\n title=entry.title,\n link=entry.link,\n published=entry.published,\n author=entry.author,\n summary=entry.summary,\n )\n except (IntegrityError, OperationalError):\n # Sometimes errors-out on database start-up\n pass\n\n logger.info('update_news_feed: Sync done')\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef delete_old_notes_images():\n \"\"\"Remove old notes images from the database.\n\n Anything older than ~3 months is removed, unless it is linked to a note\n \"\"\"\n try:\n from common.models import NotesImage\n except AppRegistryNotReady:\n logger.info(\n \"Could not perform 'delete_old_notes_images' - App registry not ready\"\n )\n return\n\n # Remove any notes which point to non-existent image files\n for note in NotesImage.objects.all():\n if not os.path.exists(note.image.path):\n logger.info('Deleting note %s - image file does not exist', note.image.path)\n note.delete()\n\n note_classes = getModelsWithMixin(InvenTreeNotesMixin)\n before = datetime.now() - timedelta(days=90)\n\n for note in NotesImage.objects.filter(date__lte=before):\n # Find any images which are no longer referenced by a note\n\n found = False\n\n img = note.image.name\n\n for model in note_classes:\n if model.objects.filter(notes__icontains=img).exists():\n found = True\n break\n\n if not found:\n logger.info('Deleting note %s - image file not linked to a note', img)\n note.delete()\n\n # Finally, remove any images in the notes dir which are not linked to a note\n notes_dir = os.path.join(settings.MEDIA_ROOT, 'notes')\n\n try:\n images = os.listdir(notes_dir)\n except FileNotFoundError:\n # Thrown if the directory does not exist\n images = []\n\n all_notes = NotesImage.objects.all()\n\n for image in images:\n found = False\n for note in all_notes:\n img_path = os.path.basename(note.image.path)\n if img_path == image:\n found = True\n break\n\n if not found:\n logger.info('Deleting note %s - image file not linked to a note', image)\n os.remove(os.path.join(notes_dir, image))\n", "path": "InvenTree/common/tasks.py"}], "after_files": [{"content": "\"\"\"Tasks (processes that get offloaded) for common app.\"\"\"\n\nimport logging\nimport os\nfrom datetime import datetime, timedelta\n\nfrom django.conf import settings\nfrom django.core.exceptions import AppRegistryNotReady\nfrom django.db.utils import IntegrityError, OperationalError\nfrom django.utils import timezone\n\nimport feedparser\nimport requests\n\nfrom InvenTree.helpers_model import getModelsWithMixin\nfrom InvenTree.models import InvenTreeNotesMixin\nfrom InvenTree.tasks import ScheduledTask, scheduled_task\n\nlogger = logging.getLogger('inventree')\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef delete_old_notifications():\n \"\"\"Remove old notifications from the database.\n\n Anything older than ~3 months is removed\n \"\"\"\n try:\n from common.models import NotificationEntry\n except AppRegistryNotReady: # pragma: no cover\n logger.info(\n \"Could not perform 'delete_old_notifications' - App registry not ready\"\n )\n return\n\n before = timezone.now() - timedelta(days=90)\n\n # Delete notification records before the specified date\n NotificationEntry.objects.filter(updated__lte=before).delete()\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef update_news_feed():\n \"\"\"Update the newsfeed.\"\"\"\n try:\n from common.models import NewsFeedEntry\n except AppRegistryNotReady: # pragma: no cover\n logger.info(\"Could not perform 'update_news_feed' - App registry not ready\")\n return\n\n # News feed isn't defined, no need to continue\n if not settings.INVENTREE_NEWS_URL or type(settings.INVENTREE_NEWS_URL) != str:\n return\n\n # Fetch and parse feed\n try:\n feed = requests.get(settings.INVENTREE_NEWS_URL)\n d = feedparser.parse(feed.content)\n except Exception: # pragma: no cover\n logger.warning('update_news_feed: Error parsing the newsfeed')\n return\n\n # Get a reference list\n id_list = [a.feed_id for a in NewsFeedEntry.objects.all()]\n\n # Iterate over entries\n for entry in d.entries:\n # Check if id already exists\n if entry.id in id_list:\n continue\n\n # Create entry\n try:\n NewsFeedEntry.objects.create(\n feed_id=entry.id,\n title=entry.title,\n link=entry.link,\n published=entry.published,\n author=entry.author,\n summary=entry.summary,\n )\n except (IntegrityError, OperationalError):\n # Sometimes errors-out on database start-up\n pass\n\n logger.info('update_news_feed: Sync done')\n\n\n@scheduled_task(ScheduledTask.DAILY)\ndef delete_old_notes_images():\n \"\"\"Remove old notes images from the database.\n\n Anything older than ~3 months is removed, unless it is linked to a note\n \"\"\"\n try:\n from common.models import NotesImage\n except AppRegistryNotReady:\n logger.info(\n \"Could not perform 'delete_old_notes_images' - App registry not ready\"\n )\n return\n\n # Remove any notes which point to non-existent image files\n for note in NotesImage.objects.all():\n if not os.path.exists(note.image.path):\n logger.info('Deleting note %s - image file does not exist', note.image.path)\n note.delete()\n\n note_classes = getModelsWithMixin(InvenTreeNotesMixin)\n before = datetime.now() - timedelta(days=90)\n\n for note in NotesImage.objects.filter(date__lte=before):\n # Find any images which are no longer referenced by a note\n\n found = False\n\n img = note.image.name\n\n for model in note_classes:\n if model.objects.filter(notes__icontains=img).exists():\n found = True\n break\n\n if not found:\n logger.info('Deleting note %s - image file not linked to a note', img)\n note.delete()\n\n # Finally, remove any images in the notes dir which are not linked to a note\n notes_dir = os.path.join(settings.MEDIA_ROOT, 'notes')\n\n try:\n images = os.listdir(notes_dir)\n except FileNotFoundError:\n # Thrown if the directory does not exist\n images = []\n\n all_notes = NotesImage.objects.all()\n\n for image in images:\n found = False\n for note in all_notes:\n img_path = os.path.basename(note.image.path)\n if img_path == image:\n found = True\n break\n\n if not found:\n logger.info('Deleting note %s - image file not linked to a note', image)\n os.remove(os.path.join(notes_dir, image))\n", "path": "InvenTree/common/tasks.py"}]} | 1,762 | 284 |
gh_patches_debug_55968 | rasdani/github-patches | git_diff | bridgecrewio__checkov-2740 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check Azure Front Door WAF enabled fails even when a WAF is correctly assigned
**Describe the issue**
[`CKV_AZURE_121`](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py) fails despite a Web Application Firewall policy being correctly applied.
WAF policies are applied by specifying a value for `web_application_firewall_policy_link_id` inside a `frontend_endpoint` block within the `azurerm_frontdoor` resource itself.
The [documentation](https://docs.bridgecrew.io/docs/ensure-that-azure-front-door-enables-waf) seems to expect that the `web_application_firewall_policy_link_id` attribute is defined in the resource block itself, rather than in a sub-block (`frontend_endpoint`).
- [`azurerm_frontdoor` resource documentation reference](https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/frontdoor#web_application_firewall_policy_link_id)
**Examples**
```terraform
resource "azurerm_frontdoor" "test" {
name = "test-front-door"
resource_group_name = var.resource_group_name
enforce_backend_pools_certificate_name_check = false
tags = var.tags
frontend_endpoint {
name = "DefaultFrontend"
host_name = "test-front-door.azurefd.net"
web_application_firewall_policy_link_id = azurerm_frontdoor_firewall_policy.test.id
}
# ...
```
**Version (please complete the following information):**
- Checkov Version: 2.0.930
**Additional context**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py`
Content:
```
1 from checkov.common.models.consts import ANY_VALUE
2 from checkov.common.models.enums import CheckCategories
3 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
4
5
6 class AzureFrontDoorEnablesWAF(BaseResourceValueCheck):
7 def __init__(self):
8 name = "Ensure that Azure Front Door enables WAF"
9 id = "CKV_AZURE_121"
10 supported_resources = ['azurerm_frontdoor']
11 categories = [CheckCategories.NETWORKING]
12 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
13
14 def get_inspected_key(self):
15 return "web_application_firewall_policy_link_id"
16
17 def get_expected_value(self):
18 return ANY_VALUE
19
20
21 check = AzureFrontDoorEnablesWAF()
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py b/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py
--- a/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py
+++ b/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py
@@ -12,7 +12,7 @@
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
def get_inspected_key(self):
- return "web_application_firewall_policy_link_id"
+ return "frontend_endpoint/[0]/web_application_firewall_policy_link_id"
def get_expected_value(self):
return ANY_VALUE
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py b/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py\n--- a/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py\n+++ b/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py\n@@ -12,7 +12,7 @@\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n def get_inspected_key(self):\n- return \"web_application_firewall_policy_link_id\"\n+ return \"frontend_endpoint/[0]/web_application_firewall_policy_link_id\"\n \n def get_expected_value(self):\n return ANY_VALUE\n", "issue": "Check Azure Front Door WAF enabled fails even when a WAF is correctly assigned\n**Describe the issue**\r\n[`CKV_AZURE_121`](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py) fails despite a Web Application Firewall policy being correctly applied. \r\n\r\nWAF policies are applied by specifying a value for `web_application_firewall_policy_link_id` inside a `frontend_endpoint` block within the `azurerm_frontdoor` resource itself.\r\n\r\nThe [documentation](https://docs.bridgecrew.io/docs/ensure-that-azure-front-door-enables-waf) seems to expect that the `web_application_firewall_policy_link_id` attribute is defined in the resource block itself, rather than in a sub-block (`frontend_endpoint`).\r\n\r\n- [`azurerm_frontdoor` resource documentation reference](https://registry.terraform.io/providers/hashicorp/azurerm/latest/docs/resources/frontdoor#web_application_firewall_policy_link_id)\r\n\r\n**Examples**\r\n```terraform\r\nresource \"azurerm_frontdoor\" \"test\" {\r\n name = \"test-front-door\"\r\n resource_group_name = var.resource_group_name\r\n enforce_backend_pools_certificate_name_check = false\r\n tags = var.tags\r\n\r\n frontend_endpoint {\r\n name = \"DefaultFrontend\"\r\n host_name = \"test-front-door.azurefd.net\"\r\n web_application_firewall_policy_link_id = azurerm_frontdoor_firewall_policy.test.id\r\n }\r\n\r\n # ... \r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version: 2.0.930\r\n\r\n**Additional context**\r\n\n", "before_files": [{"content": "from checkov.common.models.consts import ANY_VALUE\nfrom checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AzureFrontDoorEnablesWAF(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that Azure Front Door enables WAF\"\n id = \"CKV_AZURE_121\"\n supported_resources = ['azurerm_frontdoor']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"web_application_firewall_policy_link_id\"\n\n def get_expected_value(self):\n return ANY_VALUE\n\n\ncheck = AzureFrontDoorEnablesWAF()\n", "path": "checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py"}], "after_files": [{"content": "from checkov.common.models.consts import ANY_VALUE\nfrom checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AzureFrontDoorEnablesWAF(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that Azure Front Door enables WAF\"\n id = \"CKV_AZURE_121\"\n supported_resources = ['azurerm_frontdoor']\n categories = [CheckCategories.NETWORKING]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"frontend_endpoint/[0]/web_application_firewall_policy_link_id\"\n\n def get_expected_value(self):\n return ANY_VALUE\n\n\ncheck = AzureFrontDoorEnablesWAF()\n", "path": "checkov/terraform/checks/resource/azure/AzureFrontDoorEnablesWAF.py"}]} | 833 | 168 |
gh_patches_debug_1917 | rasdani/github-patches | git_diff | freqtrade__freqtrade-2082 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plot_dataframe.py
## Step 1: Have you search for this issue before posting it?
Couldn't find similar issue, so starting a new issue.
## Step 2: Describe your environment
* Python Version: Python 3.6.8
* CCXT version: ccxt==1.18.992
* Branch: Master
* Last Commit ID: b8713a515e960f1ffadcf1c7ee62c4bee80b506c
## Step 3: Describe the problem:
Unable to plot my backtest results.
*Explain the problem you have encountered*
Executing the following command results in error.
Error
### Steps to reproduce:
`
Command: python3 scripts/plot_dataframe.py -s EMACrossHTF1h --export
EMACrossHTF1h_results.json -p BTC/USDT --datadir user_data/data/binance/
`
### Observed Results:
Error is thrown.
### Relevant code exceptions or logs:
`
File "scripts/plot_dataframe.py", line 113, in <module>
main(sys.argv[1:])
File "scripts/plot_dataframe.py", line 107, in main
plot_parse_args(sysargv)
File "scripts/plot_dataframe.py", line 58, in analyse_and_plot_pairs
plot_elements = init_plotscript(config)
File "/home/ubuntu/freqtrade/freqtrade/plot/plotting.py", line 57, in init_plotscript
trades = load_trades(config)
File "/home/ubuntu/freqtrade/freqtrade/data/btanalysis.py", line 113, in load_trades
return load_backtest_data(Path(config["exportfilename"]))
File "/home/ubuntu/freqtrade/freqtrade/data/btanalysis.py", line 33, in load_backtest_data
raise ValueError("File {filename} does not exist.")
ValueError: File {filename} does not exist.
`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/data/btanalysis.py`
Content:
```
1 """
2 Helpers when analyzing backtest data
3 """
4 import logging
5 from pathlib import Path
6 from typing import Dict
7
8 import numpy as np
9 import pandas as pd
10 import pytz
11
12 from freqtrade import persistence
13 from freqtrade.misc import json_load
14 from freqtrade.persistence import Trade
15
16 logger = logging.getLogger(__name__)
17
18 # must align with columns in backtest.py
19 BT_DATA_COLUMNS = ["pair", "profitperc", "open_time", "close_time", "index", "duration",
20 "open_rate", "close_rate", "open_at_end", "sell_reason"]
21
22
23 def load_backtest_data(filename) -> pd.DataFrame:
24 """
25 Load backtest data file.
26 :param filename: pathlib.Path object, or string pointing to the file.
27 :return: a dataframe with the analysis results
28 """
29 if isinstance(filename, str):
30 filename = Path(filename)
31
32 if not filename.is_file():
33 raise ValueError("File {filename} does not exist.")
34
35 with filename.open() as file:
36 data = json_load(file)
37
38 df = pd.DataFrame(data, columns=BT_DATA_COLUMNS)
39
40 df['open_time'] = pd.to_datetime(df['open_time'],
41 unit='s',
42 utc=True,
43 infer_datetime_format=True
44 )
45 df['close_time'] = pd.to_datetime(df['close_time'],
46 unit='s',
47 utc=True,
48 infer_datetime_format=True
49 )
50 df['profitabs'] = df['close_rate'] - df['open_rate']
51 df = df.sort_values("open_time").reset_index(drop=True)
52 return df
53
54
55 def evaluate_result_multi(results: pd.DataFrame, freq: str, max_open_trades: int) -> pd.DataFrame:
56 """
57 Find overlapping trades by expanding each trade once per period it was open
58 and then counting overlaps
59 :param results: Results Dataframe - can be loaded
60 :param freq: Frequency used for the backtest
61 :param max_open_trades: parameter max_open_trades used during backtest run
62 :return: dataframe with open-counts per time-period in freq
63 """
64 dates = [pd.Series(pd.date_range(row[1].open_time, row[1].close_time, freq=freq))
65 for row in results[['open_time', 'close_time']].iterrows()]
66 deltas = [len(x) for x in dates]
67 dates = pd.Series(pd.concat(dates).values, name='date')
68 df2 = pd.DataFrame(np.repeat(results.values, deltas, axis=0), columns=results.columns)
69
70 df2 = pd.concat([dates, df2], axis=1)
71 df2 = df2.set_index('date')
72 df_final = df2.resample(freq)[['pair']].count()
73 return df_final[df_final['pair'] > max_open_trades]
74
75
76 def load_trades_from_db(db_url: str) -> pd.DataFrame:
77 """
78 Load trades from a DB (using dburl)
79 :param db_url: Sqlite url (default format sqlite:///tradesv3.dry-run.sqlite)
80 :return: Dataframe containing Trades
81 """
82 trades: pd.DataFrame = pd.DataFrame([], columns=BT_DATA_COLUMNS)
83 persistence.init(db_url, clean_open_orders=False)
84 columns = ["pair", "profit", "open_time", "close_time",
85 "open_rate", "close_rate", "duration", "sell_reason",
86 "max_rate", "min_rate"]
87
88 trades = pd.DataFrame([(t.pair, t.calc_profit(),
89 t.open_date.replace(tzinfo=pytz.UTC),
90 t.close_date.replace(tzinfo=pytz.UTC) if t.close_date else None,
91 t.open_rate, t.close_rate,
92 t.close_date.timestamp() - t.open_date.timestamp()
93 if t.close_date else None,
94 t.sell_reason,
95 t.max_rate,
96 t.min_rate,
97 )
98 for t in Trade.query.all()],
99 columns=columns)
100
101 return trades
102
103
104 def load_trades(config) -> pd.DataFrame:
105 """
106 Based on configuration option "trade_source":
107 * loads data from DB (using `db_url`)
108 * loads data from backtestfile (using `exportfilename`)
109 """
110 if config["trade_source"] == "DB":
111 return load_trades_from_db(config["db_url"])
112 elif config["trade_source"] == "file":
113 return load_backtest_data(Path(config["exportfilename"]))
114
115
116 def extract_trades_of_period(dataframe: pd.DataFrame, trades: pd.DataFrame) -> pd.DataFrame:
117 """
118 Compare trades and backtested pair DataFrames to get trades performed on backtested period
119 :return: the DataFrame of a trades of period
120 """
121 trades = trades.loc[(trades['open_time'] >= dataframe.iloc[0]['date']) &
122 (trades['close_time'] <= dataframe.iloc[-1]['date'])]
123 return trades
124
125
126 def combine_tickers_with_mean(tickers: Dict[str, pd.DataFrame], column: str = "close"):
127 """
128 Combine multiple dataframes "column"
129 :param tickers: Dict of Dataframes, dict key should be pair.
130 :param column: Column in the original dataframes to use
131 :return: DataFrame with the column renamed to the dict key, and a column
132 named mean, containing the mean of all pairs.
133 """
134 df_comb = pd.concat([tickers[pair].set_index('date').rename(
135 {column: pair}, axis=1)[pair] for pair in tickers], axis=1)
136
137 df_comb['mean'] = df_comb.mean(axis=1)
138
139 return df_comb
140
141
142 def create_cum_profit(df: pd.DataFrame, trades: pd.DataFrame, col_name: str) -> pd.DataFrame:
143 """
144 Adds a column `col_name` with the cumulative profit for the given trades array.
145 :param df: DataFrame with date index
146 :param trades: DataFrame containing trades (requires columns close_time and profitperc)
147 :return: Returns df with one additional column, col_name, containing the cumulative profit.
148 """
149 df[col_name] = trades.set_index('close_time')['profitperc'].cumsum()
150 # Set first value to 0
151 df.loc[df.iloc[0].name, col_name] = 0
152 # FFill to get continuous
153 df[col_name] = df[col_name].ffill()
154 return df
155
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/freqtrade/data/btanalysis.py b/freqtrade/data/btanalysis.py
--- a/freqtrade/data/btanalysis.py
+++ b/freqtrade/data/btanalysis.py
@@ -30,7 +30,7 @@
filename = Path(filename)
if not filename.is_file():
- raise ValueError("File {filename} does not exist.")
+ raise ValueError(f"File {filename} does not exist.")
with filename.open() as file:
data = json_load(file)
| {"golden_diff": "diff --git a/freqtrade/data/btanalysis.py b/freqtrade/data/btanalysis.py\n--- a/freqtrade/data/btanalysis.py\n+++ b/freqtrade/data/btanalysis.py\n@@ -30,7 +30,7 @@\n filename = Path(filename)\n \n if not filename.is_file():\n- raise ValueError(\"File {filename} does not exist.\")\n+ raise ValueError(f\"File {filename} does not exist.\")\n \n with filename.open() as file:\n data = json_load(file)\n", "issue": "plot_dataframe.py\n## Step 1: Have you search for this issue before posting it?\r\n\r\nCouldn't find similar issue, so starting a new issue.\r\n\r\n## Step 2: Describe your environment\r\n\r\n * Python Version: Python 3.6.8\r\n * CCXT version: ccxt==1.18.992\r\n * Branch: Master \r\n * Last Commit ID: b8713a515e960f1ffadcf1c7ee62c4bee80b506c\r\n \r\n## Step 3: Describe the problem:\r\nUnable to plot my backtest results.\r\n\r\n*Explain the problem you have encountered*\r\nExecuting the following command results in error.\r\nError\r\n### Steps to reproduce:\r\n\r\n`\r\n Command: python3 scripts/plot_dataframe.py -s EMACrossHTF1h --export \r\n EMACrossHTF1h_results.json -p BTC/USDT --datadir user_data/data/binance/\r\n`\r\n \r\n### Observed Results:\r\n\r\nError is thrown. \r\n\r\n### Relevant code exceptions or logs:\r\n`\r\n File \"scripts/plot_dataframe.py\", line 113, in <module>\r\n main(sys.argv[1:])\r\n File \"scripts/plot_dataframe.py\", line 107, in main\r\n plot_parse_args(sysargv)\r\n File \"scripts/plot_dataframe.py\", line 58, in analyse_and_plot_pairs\r\n plot_elements = init_plotscript(config)\r\n File \"/home/ubuntu/freqtrade/freqtrade/plot/plotting.py\", line 57, in init_plotscript\r\n trades = load_trades(config)\r\n File \"/home/ubuntu/freqtrade/freqtrade/data/btanalysis.py\", line 113, in load_trades\r\n return load_backtest_data(Path(config[\"exportfilename\"]))\r\n File \"/home/ubuntu/freqtrade/freqtrade/data/btanalysis.py\", line 33, in load_backtest_data\r\n raise ValueError(\"File {filename} does not exist.\")\r\n ValueError: File {filename} does not exist.\r\n`\r\n\n", "before_files": [{"content": "\"\"\"\nHelpers when analyzing backtest data\n\"\"\"\nimport logging\nfrom pathlib import Path\nfrom typing import Dict\n\nimport numpy as np\nimport pandas as pd\nimport pytz\n\nfrom freqtrade import persistence\nfrom freqtrade.misc import json_load\nfrom freqtrade.persistence import Trade\n\nlogger = logging.getLogger(__name__)\n\n# must align with columns in backtest.py\nBT_DATA_COLUMNS = [\"pair\", \"profitperc\", \"open_time\", \"close_time\", \"index\", \"duration\",\n \"open_rate\", \"close_rate\", \"open_at_end\", \"sell_reason\"]\n\n\ndef load_backtest_data(filename) -> pd.DataFrame:\n \"\"\"\n Load backtest data file.\n :param filename: pathlib.Path object, or string pointing to the file.\n :return: a dataframe with the analysis results\n \"\"\"\n if isinstance(filename, str):\n filename = Path(filename)\n\n if not filename.is_file():\n raise ValueError(\"File {filename} does not exist.\")\n\n with filename.open() as file:\n data = json_load(file)\n\n df = pd.DataFrame(data, columns=BT_DATA_COLUMNS)\n\n df['open_time'] = pd.to_datetime(df['open_time'],\n unit='s',\n utc=True,\n infer_datetime_format=True\n )\n df['close_time'] = pd.to_datetime(df['close_time'],\n unit='s',\n utc=True,\n infer_datetime_format=True\n )\n df['profitabs'] = df['close_rate'] - df['open_rate']\n df = df.sort_values(\"open_time\").reset_index(drop=True)\n return df\n\n\ndef evaluate_result_multi(results: pd.DataFrame, freq: str, max_open_trades: int) -> pd.DataFrame:\n \"\"\"\n Find overlapping trades by expanding each trade once per period it was open\n and then counting overlaps\n :param results: Results Dataframe - can be loaded\n :param freq: Frequency used for the backtest\n :param max_open_trades: parameter max_open_trades used during backtest run\n :return: dataframe with open-counts per time-period in freq\n \"\"\"\n dates = [pd.Series(pd.date_range(row[1].open_time, row[1].close_time, freq=freq))\n for row in results[['open_time', 'close_time']].iterrows()]\n deltas = [len(x) for x in dates]\n dates = pd.Series(pd.concat(dates).values, name='date')\n df2 = pd.DataFrame(np.repeat(results.values, deltas, axis=0), columns=results.columns)\n\n df2 = pd.concat([dates, df2], axis=1)\n df2 = df2.set_index('date')\n df_final = df2.resample(freq)[['pair']].count()\n return df_final[df_final['pair'] > max_open_trades]\n\n\ndef load_trades_from_db(db_url: str) -> pd.DataFrame:\n \"\"\"\n Load trades from a DB (using dburl)\n :param db_url: Sqlite url (default format sqlite:///tradesv3.dry-run.sqlite)\n :return: Dataframe containing Trades\n \"\"\"\n trades: pd.DataFrame = pd.DataFrame([], columns=BT_DATA_COLUMNS)\n persistence.init(db_url, clean_open_orders=False)\n columns = [\"pair\", \"profit\", \"open_time\", \"close_time\",\n \"open_rate\", \"close_rate\", \"duration\", \"sell_reason\",\n \"max_rate\", \"min_rate\"]\n\n trades = pd.DataFrame([(t.pair, t.calc_profit(),\n t.open_date.replace(tzinfo=pytz.UTC),\n t.close_date.replace(tzinfo=pytz.UTC) if t.close_date else None,\n t.open_rate, t.close_rate,\n t.close_date.timestamp() - t.open_date.timestamp()\n if t.close_date else None,\n t.sell_reason,\n t.max_rate,\n t.min_rate,\n )\n for t in Trade.query.all()],\n columns=columns)\n\n return trades\n\n\ndef load_trades(config) -> pd.DataFrame:\n \"\"\"\n Based on configuration option \"trade_source\":\n * loads data from DB (using `db_url`)\n * loads data from backtestfile (using `exportfilename`)\n \"\"\"\n if config[\"trade_source\"] == \"DB\":\n return load_trades_from_db(config[\"db_url\"])\n elif config[\"trade_source\"] == \"file\":\n return load_backtest_data(Path(config[\"exportfilename\"]))\n\n\ndef extract_trades_of_period(dataframe: pd.DataFrame, trades: pd.DataFrame) -> pd.DataFrame:\n \"\"\"\n Compare trades and backtested pair DataFrames to get trades performed on backtested period\n :return: the DataFrame of a trades of period\n \"\"\"\n trades = trades.loc[(trades['open_time'] >= dataframe.iloc[0]['date']) &\n (trades['close_time'] <= dataframe.iloc[-1]['date'])]\n return trades\n\n\ndef combine_tickers_with_mean(tickers: Dict[str, pd.DataFrame], column: str = \"close\"):\n \"\"\"\n Combine multiple dataframes \"column\"\n :param tickers: Dict of Dataframes, dict key should be pair.\n :param column: Column in the original dataframes to use\n :return: DataFrame with the column renamed to the dict key, and a column\n named mean, containing the mean of all pairs.\n \"\"\"\n df_comb = pd.concat([tickers[pair].set_index('date').rename(\n {column: pair}, axis=1)[pair] for pair in tickers], axis=1)\n\n df_comb['mean'] = df_comb.mean(axis=1)\n\n return df_comb\n\n\ndef create_cum_profit(df: pd.DataFrame, trades: pd.DataFrame, col_name: str) -> pd.DataFrame:\n \"\"\"\n Adds a column `col_name` with the cumulative profit for the given trades array.\n :param df: DataFrame with date index\n :param trades: DataFrame containing trades (requires columns close_time and profitperc)\n :return: Returns df with one additional column, col_name, containing the cumulative profit.\n \"\"\"\n df[col_name] = trades.set_index('close_time')['profitperc'].cumsum()\n # Set first value to 0\n df.loc[df.iloc[0].name, col_name] = 0\n # FFill to get continuous\n df[col_name] = df[col_name].ffill()\n return df\n", "path": "freqtrade/data/btanalysis.py"}], "after_files": [{"content": "\"\"\"\nHelpers when analyzing backtest data\n\"\"\"\nimport logging\nfrom pathlib import Path\nfrom typing import Dict\n\nimport numpy as np\nimport pandas as pd\nimport pytz\n\nfrom freqtrade import persistence\nfrom freqtrade.misc import json_load\nfrom freqtrade.persistence import Trade\n\nlogger = logging.getLogger(__name__)\n\n# must align with columns in backtest.py\nBT_DATA_COLUMNS = [\"pair\", \"profitperc\", \"open_time\", \"close_time\", \"index\", \"duration\",\n \"open_rate\", \"close_rate\", \"open_at_end\", \"sell_reason\"]\n\n\ndef load_backtest_data(filename) -> pd.DataFrame:\n \"\"\"\n Load backtest data file.\n :param filename: pathlib.Path object, or string pointing to the file.\n :return: a dataframe with the analysis results\n \"\"\"\n if isinstance(filename, str):\n filename = Path(filename)\n\n if not filename.is_file():\n raise ValueError(f\"File {filename} does not exist.\")\n\n with filename.open() as file:\n data = json_load(file)\n\n df = pd.DataFrame(data, columns=BT_DATA_COLUMNS)\n\n df['open_time'] = pd.to_datetime(df['open_time'],\n unit='s',\n utc=True,\n infer_datetime_format=True\n )\n df['close_time'] = pd.to_datetime(df['close_time'],\n unit='s',\n utc=True,\n infer_datetime_format=True\n )\n df['profitabs'] = df['close_rate'] - df['open_rate']\n df = df.sort_values(\"open_time\").reset_index(drop=True)\n return df\n\n\ndef evaluate_result_multi(results: pd.DataFrame, freq: str, max_open_trades: int) -> pd.DataFrame:\n \"\"\"\n Find overlapping trades by expanding each trade once per period it was open\n and then counting overlaps\n :param results: Results Dataframe - can be loaded\n :param freq: Frequency used for the backtest\n :param max_open_trades: parameter max_open_trades used during backtest run\n :return: dataframe with open-counts per time-period in freq\n \"\"\"\n dates = [pd.Series(pd.date_range(row[1].open_time, row[1].close_time, freq=freq))\n for row in results[['open_time', 'close_time']].iterrows()]\n deltas = [len(x) for x in dates]\n dates = pd.Series(pd.concat(dates).values, name='date')\n df2 = pd.DataFrame(np.repeat(results.values, deltas, axis=0), columns=results.columns)\n\n df2 = pd.concat([dates, df2], axis=1)\n df2 = df2.set_index('date')\n df_final = df2.resample(freq)[['pair']].count()\n return df_final[df_final['pair'] > max_open_trades]\n\n\ndef load_trades_from_db(db_url: str) -> pd.DataFrame:\n \"\"\"\n Load trades from a DB (using dburl)\n :param db_url: Sqlite url (default format sqlite:///tradesv3.dry-run.sqlite)\n :return: Dataframe containing Trades\n \"\"\"\n trades: pd.DataFrame = pd.DataFrame([], columns=BT_DATA_COLUMNS)\n persistence.init(db_url, clean_open_orders=False)\n columns = [\"pair\", \"profit\", \"open_time\", \"close_time\",\n \"open_rate\", \"close_rate\", \"duration\", \"sell_reason\",\n \"max_rate\", \"min_rate\"]\n\n trades = pd.DataFrame([(t.pair, t.calc_profit(),\n t.open_date.replace(tzinfo=pytz.UTC),\n t.close_date.replace(tzinfo=pytz.UTC) if t.close_date else None,\n t.open_rate, t.close_rate,\n t.close_date.timestamp() - t.open_date.timestamp()\n if t.close_date else None,\n t.sell_reason,\n t.max_rate,\n t.min_rate,\n )\n for t in Trade.query.all()],\n columns=columns)\n\n return trades\n\n\ndef load_trades(config) -> pd.DataFrame:\n \"\"\"\n Based on configuration option \"trade_source\":\n * loads data from DB (using `db_url`)\n * loads data from backtestfile (using `exportfilename`)\n \"\"\"\n if config[\"trade_source\"] == \"DB\":\n return load_trades_from_db(config[\"db_url\"])\n elif config[\"trade_source\"] == \"file\":\n return load_backtest_data(Path(config[\"exportfilename\"]))\n\n\ndef extract_trades_of_period(dataframe: pd.DataFrame, trades: pd.DataFrame) -> pd.DataFrame:\n \"\"\"\n Compare trades and backtested pair DataFrames to get trades performed on backtested period\n :return: the DataFrame of a trades of period\n \"\"\"\n trades = trades.loc[(trades['open_time'] >= dataframe.iloc[0]['date']) &\n (trades['close_time'] <= dataframe.iloc[-1]['date'])]\n return trades\n\n\ndef combine_tickers_with_mean(tickers: Dict[str, pd.DataFrame], column: str = \"close\"):\n \"\"\"\n Combine multiple dataframes \"column\"\n :param tickers: Dict of Dataframes, dict key should be pair.\n :param column: Column in the original dataframes to use\n :return: DataFrame with the column renamed to the dict key, and a column\n named mean, containing the mean of all pairs.\n \"\"\"\n df_comb = pd.concat([tickers[pair].set_index('date').rename(\n {column: pair}, axis=1)[pair] for pair in tickers], axis=1)\n\n df_comb['mean'] = df_comb.mean(axis=1)\n\n return df_comb\n\n\ndef create_cum_profit(df: pd.DataFrame, trades: pd.DataFrame, col_name: str) -> pd.DataFrame:\n \"\"\"\n Adds a column `col_name` with the cumulative profit for the given trades array.\n :param df: DataFrame with date index\n :param trades: DataFrame containing trades (requires columns close_time and profitperc)\n :return: Returns df with one additional column, col_name, containing the cumulative profit.\n \"\"\"\n df[col_name] = trades.set_index('close_time')['profitperc'].cumsum()\n # Set first value to 0\n df.loc[df.iloc[0].name, col_name] = 0\n # FFill to get continuous\n df[col_name] = df[col_name].ffill()\n return df\n", "path": "freqtrade/data/btanalysis.py"}]} | 2,417 | 113 |
gh_patches_debug_23532 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-29 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Configure flake8 & GitHub Action correctly
Our flake8 setup has a couple of issues:
- Failures on the GitHub Action don't actually block merge.
- We need to set up our style guide for flake8.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/forms/widgets.py`
Content:
```
1 from django.forms.widgets import TextInput
2
3 class DataListInput(TextInput):
4 """
5 Widget that adds a <data_list> element to the standard text input widget.
6 See TextInput for further details.
7
8 Attributes:
9 data_list: List of strings, where each string is a data_list value, or
10 a callable that returns a list of the same form
11 data_list_id: ID of the data_list, generated when render() is called.
12 Of the form [widget_id | widget_name]_data_list
13 """
14 template_name = "mathesar/widgets/data_list.html"
15
16 def __init__(self, data_list, attrs=None):
17 super().__init__(attrs=attrs)
18 self.data_list = data_list
19 self.data_list_id = "_data_list"
20
21 def get_context(self, name, value, attrs):
22 context = super().get_context(name, value, attrs)
23 if callable(self.data_list):
24 context["widget"]["data_list"] = self.data_list()
25 else:
26 context["widget"]["data_list"] = self.data_list
27 context["widget"]["data_list_id"] = self.data_list_id
28 return context
29
30 def render(self, name, value, attrs=None, renderer=None):
31 # In practice, there should always be an ID attribute, but we fallback
32 # to using widget name if ID is missing
33 if attrs and "id" in attrs:
34 self.data_list_id = attrs["id"] + "_data_list"
35 else:
36 self.data_list_id = name + "_data_list"
37 attrs = {} if attrs is None else attrs
38 attrs["list"] = self.data_list_id
39 return super().render(name, value, attrs, renderer)
40
41
```
Path: `mathesar/forms/forms.py`
Content:
```
1 from django import forms
2 from django.core.exceptions import ValidationError
3
4 from mathesar.database.schemas import get_all_schemas
5 from mathesar.forms.widgets import DataListInput
6
7 def validate_csv(value):
8 if not value.name.lower().endswith(".csv"):
9 raise ValidationError(f"{value.name} is not a CSV file")
10
11 class UploadFileForm(forms.Form):
12 collection_name = forms.CharField(min_length=1, label="Collection Name")
13
14 application_name = forms.CharField(
15 min_length=1, label="Application Name",
16 widget=DataListInput(get_all_schemas)
17 )
18
19 file = forms.FileField(validators=[validate_csv], label="CSV File")
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mathesar/forms/forms.py b/mathesar/forms/forms.py
--- a/mathesar/forms/forms.py
+++ b/mathesar/forms/forms.py
@@ -4,10 +4,12 @@
from mathesar.database.schemas import get_all_schemas
from mathesar.forms.widgets import DataListInput
+
def validate_csv(value):
if not value.name.lower().endswith(".csv"):
raise ValidationError(f"{value.name} is not a CSV file")
+
class UploadFileForm(forms.Form):
collection_name = forms.CharField(min_length=1, label="Collection Name")
diff --git a/mathesar/forms/widgets.py b/mathesar/forms/widgets.py
--- a/mathesar/forms/widgets.py
+++ b/mathesar/forms/widgets.py
@@ -1,5 +1,6 @@
from django.forms.widgets import TextInput
+
class DataListInput(TextInput):
"""
Widget that adds a <data_list> element to the standard text input widget.
@@ -37,4 +38,3 @@
attrs = {} if attrs is None else attrs
attrs["list"] = self.data_list_id
return super().render(name, value, attrs, renderer)
-
| {"golden_diff": "diff --git a/mathesar/forms/forms.py b/mathesar/forms/forms.py\n--- a/mathesar/forms/forms.py\n+++ b/mathesar/forms/forms.py\n@@ -4,10 +4,12 @@\n from mathesar.database.schemas import get_all_schemas\n from mathesar.forms.widgets import DataListInput\n \n+\n def validate_csv(value):\n if not value.name.lower().endswith(\".csv\"):\n raise ValidationError(f\"{value.name} is not a CSV file\")\n \n+\n class UploadFileForm(forms.Form):\n collection_name = forms.CharField(min_length=1, label=\"Collection Name\")\n \ndiff --git a/mathesar/forms/widgets.py b/mathesar/forms/widgets.py\n--- a/mathesar/forms/widgets.py\n+++ b/mathesar/forms/widgets.py\n@@ -1,5 +1,6 @@\n from django.forms.widgets import TextInput\n \n+\n class DataListInput(TextInput):\n \"\"\"\n Widget that adds a <data_list> element to the standard text input widget.\n@@ -37,4 +38,3 @@\n attrs = {} if attrs is None else attrs\n attrs[\"list\"] = self.data_list_id\n return super().render(name, value, attrs, renderer)\n-\n", "issue": "Configure flake8 & GitHub Action correctly\nOur flake8 setup has a couple of issues:\r\n- Failures on the GitHub Action don't actually block merge.\r\n- We need to set up our style guide for flake8.\n", "before_files": [{"content": "from django.forms.widgets import TextInput\n\nclass DataListInput(TextInput):\n \"\"\"\n Widget that adds a <data_list> element to the standard text input widget.\n See TextInput for further details.\n\n Attributes:\n data_list: List of strings, where each string is a data_list value, or\n a callable that returns a list of the same form\n data_list_id: ID of the data_list, generated when render() is called.\n Of the form [widget_id | widget_name]_data_list\n \"\"\"\n template_name = \"mathesar/widgets/data_list.html\"\n\n def __init__(self, data_list, attrs=None):\n super().__init__(attrs=attrs)\n self.data_list = data_list\n self.data_list_id = \"_data_list\"\n\n def get_context(self, name, value, attrs):\n context = super().get_context(name, value, attrs)\n if callable(self.data_list):\n context[\"widget\"][\"data_list\"] = self.data_list()\n else:\n context[\"widget\"][\"data_list\"] = self.data_list\n context[\"widget\"][\"data_list_id\"] = self.data_list_id\n return context\n\n def render(self, name, value, attrs=None, renderer=None):\n # In practice, there should always be an ID attribute, but we fallback\n # to using widget name if ID is missing\n if attrs and \"id\" in attrs:\n self.data_list_id = attrs[\"id\"] + \"_data_list\"\n else:\n self.data_list_id = name + \"_data_list\"\n attrs = {} if attrs is None else attrs\n attrs[\"list\"] = self.data_list_id\n return super().render(name, value, attrs, renderer)\n\n", "path": "mathesar/forms/widgets.py"}, {"content": "from django import forms\nfrom django.core.exceptions import ValidationError\n\nfrom mathesar.database.schemas import get_all_schemas\nfrom mathesar.forms.widgets import DataListInput\n\ndef validate_csv(value):\n if not value.name.lower().endswith(\".csv\"):\n raise ValidationError(f\"{value.name} is not a CSV file\")\n\nclass UploadFileForm(forms.Form):\n collection_name = forms.CharField(min_length=1, label=\"Collection Name\")\n\n application_name = forms.CharField(\n min_length=1, label=\"Application Name\",\n widget=DataListInput(get_all_schemas)\n )\n\n file = forms.FileField(validators=[validate_csv], label=\"CSV File\")\n", "path": "mathesar/forms/forms.py"}], "after_files": [{"content": "from django.forms.widgets import TextInput\n\n\nclass DataListInput(TextInput):\n \"\"\"\n Widget that adds a <data_list> element to the standard text input widget.\n See TextInput for further details.\n\n Attributes:\n data_list: List of strings, where each string is a data_list value, or\n a callable that returns a list of the same form\n data_list_id: ID of the data_list, generated when render() is called.\n Of the form [widget_id | widget_name]_data_list\n \"\"\"\n template_name = \"mathesar/widgets/data_list.html\"\n\n def __init__(self, data_list, attrs=None):\n super().__init__(attrs=attrs)\n self.data_list = data_list\n self.data_list_id = \"_data_list\"\n\n def get_context(self, name, value, attrs):\n context = super().get_context(name, value, attrs)\n if callable(self.data_list):\n context[\"widget\"][\"data_list\"] = self.data_list()\n else:\n context[\"widget\"][\"data_list\"] = self.data_list\n context[\"widget\"][\"data_list_id\"] = self.data_list_id\n return context\n\n def render(self, name, value, attrs=None, renderer=None):\n # In practice, there should always be an ID attribute, but we fallback\n # to using widget name if ID is missing\n if attrs and \"id\" in attrs:\n self.data_list_id = attrs[\"id\"] + \"_data_list\"\n else:\n self.data_list_id = name + \"_data_list\"\n attrs = {} if attrs is None else attrs\n attrs[\"list\"] = self.data_list_id\n return super().render(name, value, attrs, renderer)\n", "path": "mathesar/forms/widgets.py"}, {"content": "from django import forms\nfrom django.core.exceptions import ValidationError\n\nfrom mathesar.database.schemas import get_all_schemas\nfrom mathesar.forms.widgets import DataListInput\n\n\ndef validate_csv(value):\n if not value.name.lower().endswith(\".csv\"):\n raise ValidationError(f\"{value.name} is not a CSV file\")\n\n\nclass UploadFileForm(forms.Form):\n collection_name = forms.CharField(min_length=1, label=\"Collection Name\")\n\n application_name = forms.CharField(\n min_length=1, label=\"Application Name\",\n widget=DataListInput(get_all_schemas)\n )\n\n file = forms.FileField(validators=[validate_csv], label=\"CSV File\")\n", "path": "mathesar/forms/forms.py"}]} | 932 | 248 |
gh_patches_debug_6566 | rasdani/github-patches | git_diff | GPflow__GPflow-175 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
error while importing GPflow
I can not import GPflow. I instelled it by `python setup.py develop` on virtualenv. Tests are also failing to run.
### Import error
```
In [2]: import GPflow
---------------------------------------------------------------------------
NotFoundError Traceback (most recent call last)
<ipython-input-2-d5391a053bbd> in <module>()
----> 1 import GPflow
/home/me/<...>/GPflow/GPflow/__init__.py in <module>()
15
16 # flake8: noqa
---> 17 from . import likelihoods, kernels, param, model, gpmc, sgpmc, priors, gpr, svgp, vgp, sgpr
18 from ._version import __version__
/home/me/<...>/GPflow/GPflow/likelihoods.py in <module>()
17 import tensorflow as tf
18 import numpy as np
---> 19 from .param import Parameterized, Param
20 from . import transforms
21 hermgauss = np.polynomial.hermite.hermgauss
/home/me/<...>/GPflow/GPflow/param.py in <module>()
17 import pandas as pd
18 import tensorflow as tf
---> 19 from . import transforms
20 from contextlib import contextmanager
21 from functools import wraps
/home/me/<...>/GPflow/GPflow/transforms.py in <module>()
16 import numpy as np
17 import tensorflow as tf
---> 18 import GPflow.tf_hacks as tfh
19
20
/home/me/<...>/GPflow/GPflow/tf_hacks.py in <module>()
28
29
---> 30 _custom_op_module = tf.load_op_library(os.path.join(os.path.dirname(__file__), 'tfops', 'matpackops.so'))
31 vec_to_tri = _custom_op_module.vec_to_tri
32 tri_to_vec = _custom_op_module.tri_to_vec
/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/tensorflow/python/framework/load_library.pyc in load_op_library(library_filename)
73 return _OP_LIBRARY_MAP[library_filename]
74 # pylint: disable=protected-access
---> 75 raise errors._make_specific_exception(None, None, error_msg, error_code)
76 # pylint: enable=protected-access
77 finally:
NotFoundError: GPflow/tfops/matpackops.so: undefined symbol: _ZN10tensorflow7strings6StrCatB5cxx11ERKNS0_8AlphaNumE
```
### Test error
```
running test
running egg_info
writing requirements to GPflow.egg-info/requires.txt
writing GPflow.egg-info/PKG-INFO
writing top-level names to GPflow.egg-info/top_level.txt
writing dependency_links to GPflow.egg-info/dependency_links.txt
reading manifest file 'GPflow.egg-info/SOURCES.txt'
writing manifest file 'GPflow.egg-info/SOURCES.txt'
running build_ext
Traceback (most recent call last):
File "setup.py", line 50, in <module>
'Topic :: Scientific/Engineering :: Artificial Intelligence']
File "/usr/lib64/python2.7/distutils/core.py", line 151, in setup
dist.run_commands()
File "/usr/lib64/python2.7/distutils/dist.py", line 953, in run_commands
self.run_command(cmd)
File "/usr/lib64/python2.7/distutils/dist.py", line 972, in run_command
cmd_obj.run()
File "/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py", line 172, in run
self.run_tests()
File "/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py", line 193, in run_tests
testRunner=self._resolve_as_ep(self.test_runner),
File "/usr/lib64/python2.7/unittest/main.py", line 94, in __init__
self.parseArgs(argv)
File "/usr/lib64/python2.7/unittest/main.py", line 149, in parseArgs
self.createTests()
File "/usr/lib64/python2.7/unittest/main.py", line 158, in createTests
self.module)
File "/usr/lib64/python2.7/unittest/loader.py", line 130, in loadTestsFromNames
suites = [self.loadTestsFromName(name, module) for name in names]
File "/usr/lib64/python2.7/unittest/loader.py", line 103, in loadTestsFromName
return self.loadTestsFromModule(obj)
File "/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py", line 40, in loadTestsFromModule
tests.append(self.loadTestsFromName(submodule))
File "/usr/lib64/python2.7/unittest/loader.py", line 100, in loadTestsFromName
parent, obj = obj, getattr(obj, part)
AttributeError: 'module' object has no attribute 'test_variational'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import print_function
4 from setuptools import setup
5 import re
6 import os
7 import sys
8
9 # load version form _version.py
10 VERSIONFILE = "GPflow/_version.py"
11 verstrline = open(VERSIONFILE, "rt").read()
12 VSRE = r"^__version__ = ['\"]([^'\"]*)['\"]"
13 mo = re.search(VSRE, verstrline, re.M)
14 if mo:
15 verstr = mo.group(1)
16 else:
17 raise RuntimeError("Unable to find version string in %s." % (VERSIONFILE,))
18
19 # Compile the bespoke TensorFlow ops in-place. Not sure how this would work if this script wasn't executed as `develop`.
20 compile_command = "g++ -std=c++11 -shared ./GPflow/tfops/vec_to_tri.cc " \
21 "GPflow/tfops/tri_to_vec.cc -o GPflow/tfops/matpackops.so " \
22 "-fPIC -I $(python -c 'import tensorflow as tf; print(tf.sysconfig.get_include())')"
23 if sys.platform == "darwin":
24 # Additional command for Macs, as instructed by the TensorFlow docs
25 compile_command += " -undefined dynamic_lookup"
26 os.system(compile_command)
27
28 setup(name='GPflow',
29 version=verstr,
30 author="James Hensman, Alex Matthews",
31 author_email="[email protected]",
32 description=("Gaussian process methods in tensorflow"),
33 license="BSD 3-clause",
34 keywords="machine-learning gaussian-processes kernels tensorflow",
35 url="http://github.com/gpflow/gpflow",
36 package_data={'GPflow': ['GPflow/tfops/*.so']},
37 include_package_data=True,
38 ext_modules=[],
39 packages=["GPflow"],
40 package_dir={'GPflow': 'GPflow'},
41 py_modules=['GPflow.__init__'],
42 test_suite='testing',
43 install_requires=['numpy>=1.9', 'scipy>=0.16', 'tensorflow>=0.10.0rc0'],
44 classifiers=['License :: OSI Approved :: BSD License',
45 'Natural Language :: English',
46 'Operating System :: MacOS :: MacOS X',
47 'Operating System :: Microsoft :: Windows',
48 'Operating System :: POSIX :: Linux',
49 'Programming Language :: Python :: 2.7',
50 'Topic :: Scientific/Engineering :: Artificial Intelligence']
51 )
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,6 +23,10 @@
if sys.platform == "darwin":
# Additional command for Macs, as instructed by the TensorFlow docs
compile_command += " -undefined dynamic_lookup"
+elif sys.platform.startswith("linux"):
+ gcc_version = int(re.search('\d+.', os.popen("gcc --version").read()).group()[0])
+ if gcc_version == 5:
+ compile_command += " -D_GLIBCXX_USE_CXX11_ABI=0"
os.system(compile_command)
setup(name='GPflow',
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,6 +23,10 @@\n if sys.platform == \"darwin\":\n # Additional command for Macs, as instructed by the TensorFlow docs\n compile_command += \" -undefined dynamic_lookup\"\n+elif sys.platform.startswith(\"linux\"):\n+ gcc_version = int(re.search('\\d+.', os.popen(\"gcc --version\").read()).group()[0])\n+ if gcc_version == 5:\n+ compile_command += \" -D_GLIBCXX_USE_CXX11_ABI=0\"\n os.system(compile_command)\n \n setup(name='GPflow',\n", "issue": "error while importing GPflow \nI can not import GPflow. I instelled it by `python setup.py develop` on virtualenv. Tests are also failing to run.\n### Import error\n\n```\nIn [2]: import GPflow\n---------------------------------------------------------------------------\nNotFoundError Traceback (most recent call last)\n<ipython-input-2-d5391a053bbd> in <module>()\n----> 1 import GPflow\n\n/home/me/<...>/GPflow/GPflow/__init__.py in <module>()\n 15 \n 16 # flake8: noqa\n---> 17 from . import likelihoods, kernels, param, model, gpmc, sgpmc, priors, gpr, svgp, vgp, sgpr\n 18 from ._version import __version__\n\n/home/me/<...>/GPflow/GPflow/likelihoods.py in <module>()\n 17 import tensorflow as tf\n 18 import numpy as np\n---> 19 from .param import Parameterized, Param\n 20 from . import transforms\n 21 hermgauss = np.polynomial.hermite.hermgauss\n\n/home/me/<...>/GPflow/GPflow/param.py in <module>()\n 17 import pandas as pd\n 18 import tensorflow as tf\n---> 19 from . import transforms\n 20 from contextlib import contextmanager\n 21 from functools import wraps\n\n/home/me/<...>/GPflow/GPflow/transforms.py in <module>()\n 16 import numpy as np\n 17 import tensorflow as tf\n---> 18 import GPflow.tf_hacks as tfh\n 19 \n 20 \n\n/home/me/<...>/GPflow/GPflow/tf_hacks.py in <module>()\n 28 \n 29 \n---> 30 _custom_op_module = tf.load_op_library(os.path.join(os.path.dirname(__file__), 'tfops', 'matpackops.so'))\n 31 vec_to_tri = _custom_op_module.vec_to_tri\n 32 tri_to_vec = _custom_op_module.tri_to_vec\n\n/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/tensorflow/python/framework/load_library.pyc in load_op_library(library_filename)\n 73 return _OP_LIBRARY_MAP[library_filename]\n 74 # pylint: disable=protected-access\n---> 75 raise errors._make_specific_exception(None, None, error_msg, error_code)\n 76 # pylint: enable=protected-access\n 77 finally:\n\nNotFoundError: GPflow/tfops/matpackops.so: undefined symbol: _ZN10tensorflow7strings6StrCatB5cxx11ERKNS0_8AlphaNumE\n\n```\n### Test error\n\n```\nrunning test\nrunning egg_info\nwriting requirements to GPflow.egg-info/requires.txt\nwriting GPflow.egg-info/PKG-INFO\nwriting top-level names to GPflow.egg-info/top_level.txt\nwriting dependency_links to GPflow.egg-info/dependency_links.txt\nreading manifest file 'GPflow.egg-info/SOURCES.txt'\nwriting manifest file 'GPflow.egg-info/SOURCES.txt'\nrunning build_ext\nTraceback (most recent call last):\n File \"setup.py\", line 50, in <module>\n 'Topic :: Scientific/Engineering :: Artificial Intelligence']\n File \"/usr/lib64/python2.7/distutils/core.py\", line 151, in setup\n dist.run_commands()\n File \"/usr/lib64/python2.7/distutils/dist.py\", line 953, in run_commands\n self.run_command(cmd)\n File \"/usr/lib64/python2.7/distutils/dist.py\", line 972, in run_command\n cmd_obj.run()\n File \"/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py\", line 172, in run\n self.run_tests()\n File \"/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py\", line 193, in run_tests\n testRunner=self._resolve_as_ep(self.test_runner),\n File \"/usr/lib64/python2.7/unittest/main.py\", line 94, in __init__\n self.parseArgs(argv)\n File \"/usr/lib64/python2.7/unittest/main.py\", line 149, in parseArgs\n self.createTests()\n File \"/usr/lib64/python2.7/unittest/main.py\", line 158, in createTests\n self.module)\n File \"/usr/lib64/python2.7/unittest/loader.py\", line 130, in loadTestsFromNames\n suites = [self.loadTestsFromName(name, module) for name in names]\n File \"/usr/lib64/python2.7/unittest/loader.py\", line 103, in loadTestsFromName\n return self.loadTestsFromModule(obj)\n File \"/home/me/.virtualenvs/tf_0_10/lib/python2.7/site-packages/setuptools/command/test.py\", line 40, in loadTestsFromModule\n tests.append(self.loadTestsFromName(submodule))\n File \"/usr/lib64/python2.7/unittest/loader.py\", line 100, in loadTestsFromName\n parent, obj = obj, getattr(obj, part)\nAttributeError: 'module' object has no attribute 'test_variational'\n\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import print_function\nfrom setuptools import setup\nimport re\nimport os\nimport sys\n\n# load version form _version.py\nVERSIONFILE = \"GPflow/_version.py\"\nverstrline = open(VERSIONFILE, \"rt\").read()\nVSRE = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\nmo = re.search(VSRE, verstrline, re.M)\nif mo:\n verstr = mo.group(1)\nelse:\n raise RuntimeError(\"Unable to find version string in %s.\" % (VERSIONFILE,))\n\n# Compile the bespoke TensorFlow ops in-place. Not sure how this would work if this script wasn't executed as `develop`.\ncompile_command = \"g++ -std=c++11 -shared ./GPflow/tfops/vec_to_tri.cc \" \\\n \"GPflow/tfops/tri_to_vec.cc -o GPflow/tfops/matpackops.so \" \\\n \"-fPIC -I $(python -c 'import tensorflow as tf; print(tf.sysconfig.get_include())')\"\nif sys.platform == \"darwin\":\n # Additional command for Macs, as instructed by the TensorFlow docs\n compile_command += \" -undefined dynamic_lookup\"\nos.system(compile_command)\n\nsetup(name='GPflow',\n version=verstr,\n author=\"James Hensman, Alex Matthews\",\n author_email=\"[email protected]\",\n description=(\"Gaussian process methods in tensorflow\"),\n license=\"BSD 3-clause\",\n keywords=\"machine-learning gaussian-processes kernels tensorflow\",\n url=\"http://github.com/gpflow/gpflow\",\n package_data={'GPflow': ['GPflow/tfops/*.so']},\n include_package_data=True,\n ext_modules=[],\n packages=[\"GPflow\"],\n package_dir={'GPflow': 'GPflow'},\n py_modules=['GPflow.__init__'],\n test_suite='testing',\n install_requires=['numpy>=1.9', 'scipy>=0.16', 'tensorflow>=0.10.0rc0'],\n classifiers=['License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence']\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import print_function\nfrom setuptools import setup\nimport re\nimport os\nimport sys\n\n# load version form _version.py\nVERSIONFILE = \"GPflow/_version.py\"\nverstrline = open(VERSIONFILE, \"rt\").read()\nVSRE = r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\"\nmo = re.search(VSRE, verstrline, re.M)\nif mo:\n verstr = mo.group(1)\nelse:\n raise RuntimeError(\"Unable to find version string in %s.\" % (VERSIONFILE,))\n\n# Compile the bespoke TensorFlow ops in-place. Not sure how this would work if this script wasn't executed as `develop`.\ncompile_command = \"g++ -std=c++11 -shared ./GPflow/tfops/vec_to_tri.cc \" \\\n \"GPflow/tfops/tri_to_vec.cc -o GPflow/tfops/matpackops.so \" \\\n \"-fPIC -I $(python -c 'import tensorflow as tf; print(tf.sysconfig.get_include())')\"\nif sys.platform == \"darwin\":\n # Additional command for Macs, as instructed by the TensorFlow docs\n compile_command += \" -undefined dynamic_lookup\"\nelif sys.platform.startswith(\"linux\"):\n gcc_version = int(re.search('\\d+.', os.popen(\"gcc --version\").read()).group()[0])\n if gcc_version == 5:\n compile_command += \" -D_GLIBCXX_USE_CXX11_ABI=0\"\nos.system(compile_command)\n\nsetup(name='GPflow',\n version=verstr,\n author=\"James Hensman, Alex Matthews\",\n author_email=\"[email protected]\",\n description=(\"Gaussian process methods in tensorflow\"),\n license=\"BSD 3-clause\",\n keywords=\"machine-learning gaussian-processes kernels tensorflow\",\n url=\"http://github.com/gpflow/gpflow\",\n package_data={'GPflow': ['GPflow/tfops/*.so']},\n include_package_data=True,\n ext_modules=[],\n packages=[\"GPflow\"],\n package_dir={'GPflow': 'GPflow'},\n py_modules=['GPflow.__init__'],\n test_suite='testing',\n install_requires=['numpy>=1.9', 'scipy>=0.16', 'tensorflow>=0.10.0rc0'],\n classifiers=['License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence']\n )\n", "path": "setup.py"}]} | 2,090 | 142 |
gh_patches_debug_22492 | rasdani/github-patches | git_diff | pyjanitor-devs__pyjanitor-1153 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[INF] Set multi-test env to compat dependency and system
<!-- Thank you for your PR!
BEFORE YOU CONTINUE! Please add the appropriate three-letter abbreviation to your title.
The abbreviations can be:
- [DOC]: Documentation fixes.
- [ENH]: Code contributions and new features.
- [TST]: Test-related contributions.
- [INF]: Infrastructure-related contributions.
Also, do not forget to tag the relevant issue here as well.
Finally, as commits come in, don't forget to regularly rebase!
-->
# PR Description
Please describe the changes proposed in the pull request:
Aim:
- Set multi-test environment
- Compat different dependencies and systems
ToDo/Doing:
- [x] Set latest env: test pyjanitor work with the latest dependencies to get the minimal python version
- [ ] Set minimal env: get the minimal version of dependencies
Part of #1133
# PR Checklist
<!-- This checklist exists for newcomers who are not yet familiar with our requirements. If you are experienced with
the project, please feel free to delete this section. -->
Please ensure that you have done the following:
1. [x] PR in from a fork off your branch. Do not PR from `<your_username>`:`dev`, but rather from `<your_username>`:`<feature-branch_name>`.
<!-- Doing this helps us keep the commit history much cleaner than it would otherwise be. -->
2. [x] If you're not on the contributors list, add yourself to `AUTHORS.md`.
<!-- We'd like to acknowledge your contributions! -->
3. [x] Add a line to `CHANGELOG.md` under the latest version header (i.e. the one that is "on deck") describing the contribution.
- Do use some discretion here; if there are multiple PRs that are related, keep them in a single line.
# Automatic checks
There will be automatic checks run on the PR. These include:
- Building a preview of the docs on Netlify
- Automatically linting the code
- Making sure the code is documented
- Making sure that all tests are passed
- Making sure that code coverage doesn't go down.
# Relevant Reviewers
<!-- Finally, please tag relevant maintainers to review. -->
Please tag maintainers to review.
- @ericmjl
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `janitor/functions/encode_categorical.py`
Content:
```
1 import warnings
2 from enum import Enum
3 from typing import Hashable, Iterable, Union
4
5 import pandas_flavor as pf
6 import pandas as pd
7 from pandas.api.types import is_list_like
8
9 from janitor.utils import check, check_column, deprecated_alias
10
11
12 @pf.register_dataframe_method
13 @deprecated_alias(columns="column_names")
14 def encode_categorical(
15 df: pd.DataFrame,
16 column_names: Union[str, Iterable[str], Hashable] = None,
17 **kwargs,
18 ) -> pd.DataFrame:
19 """Encode the specified columns with Pandas' [category dtype][cat].
20
21 [cat]: http://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html
22
23 It is syntactic sugar around `pd.Categorical`.
24
25 This method does not mutate the original DataFrame.
26
27 Simply pass a string, or a sequence of column names to `column_names`;
28 alternatively, you can pass kwargs, where the keys are the column names
29 and the values can either be None, `sort`, `appearance`
30 or a 1-D array-like object.
31
32 - None: column is cast to an unordered categorical.
33 - `sort`: column is cast to an ordered categorical,
34 with the order defined by the sort-order of the categories.
35 - `appearance`: column is cast to an ordered categorical,
36 with the order defined by the order of appearance
37 in the original column.
38 - 1d-array-like object: column is cast to an ordered categorical,
39 with the categories and order as specified
40 in the input array.
41
42 `column_names` and `kwargs` parameters cannot be used at the same time.
43
44 Example: Using `column_names`
45
46 >>> import pandas as pd
47 >>> import janitor
48 >>> df = pd.DataFrame({
49 ... "foo": ["b", "b", "a", "c", "b"],
50 ... "bar": range(4, 9),
51 ... })
52 >>> df
53 foo bar
54 0 b 4
55 1 b 5
56 2 a 6
57 3 c 7
58 4 b 8
59 >>> df.dtypes
60 foo object
61 bar int64
62 dtype: object
63 >>> enc_df = df.encode_categorical(column_names="foo")
64 >>> enc_df.dtypes
65 foo category
66 bar int64
67 dtype: object
68 >>> enc_df["foo"].cat.categories
69 Index(['a', 'b', 'c'], dtype='object')
70 >>> enc_df["foo"].cat.ordered
71 False
72
73 Example: Using `kwargs` to specify an ordered categorical.
74
75 >>> import pandas as pd
76 >>> import janitor
77 >>> df = pd.DataFrame({
78 ... "foo": ["b", "b", "a", "c", "b"],
79 ... "bar": range(4, 9),
80 ... })
81 >>> df.dtypes
82 foo object
83 bar int64
84 dtype: object
85 >>> enc_df = df.encode_categorical(foo="appearance")
86 >>> enc_df.dtypes
87 foo category
88 bar int64
89 dtype: object
90 >>> enc_df["foo"].cat.categories
91 Index(['b', 'a', 'c'], dtype='object')
92 >>> enc_df["foo"].cat.ordered
93 True
94
95 :param df: A pandas DataFrame object.
96 :param column_names: A column name or an iterable (list or tuple)
97 of column names.
98 :param **kwargs: A mapping from column name to either `None`,
99 `'sort'` or `'appearance'`, or a 1-D array. This is useful
100 in creating categorical columns that are ordered, or
101 if the user needs to explicitly specify the categories.
102 :returns: A pandas DataFrame.
103 :raises ValueError: If both `column_names` and `kwargs` are provided.
104 """ # noqa: E501
105
106 if all((column_names, kwargs)):
107 raise ValueError(
108 "Only one of `column_names` or `kwargs` can be provided."
109 )
110 # column_names deal with only category dtype (unordered)
111 # kwargs takes care of scenarios where user wants an ordered category
112 # or user supplies specific categories to create the categorical
113 if column_names is not None:
114 check("column_names", column_names, [list, tuple, Hashable])
115 if isinstance(column_names, Hashable):
116 column_names = [column_names]
117 check_column(df, column_names)
118 dtypes = {col: "category" for col in column_names}
119 return df.astype(dtypes)
120
121 return _computations_as_categorical(df, **kwargs)
122
123
124 def _computations_as_categorical(df: pd.DataFrame, **kwargs) -> pd.DataFrame:
125 """
126 This function handles cases where
127 categorical columns are created with an order,
128 or specific values supplied for the categories.
129 It uses a kwarg, where the key is the column name,
130 and the value is either a string, or a 1D array.
131 The default for value is None and will return a categorical dtype
132 with no order and categories inferred from the column.
133 A DataFrame, with categorical columns, is returned.
134 """
135
136 categories_dict = _as_categorical_checks(df, **kwargs)
137
138 categories_dtypes = {}
139
140 for column_name, value in categories_dict.items():
141 if value is None:
142 cat_dtype = pd.CategoricalDtype()
143 elif isinstance(value, str):
144 if value == _CategoryOrder.SORT.value:
145 _, cat_dtype = df[column_name].factorize(sort=True)
146 else:
147 _, cat_dtype = df[column_name].factorize(sort=False)
148 if cat_dtype.empty:
149 raise ValueError(
150 "Kindly ensure there is at least "
151 f"one non-null value in {column_name}."
152 )
153 cat_dtype = pd.CategoricalDtype(categories=cat_dtype, ordered=True)
154
155 else: # 1-D array
156 cat_dtype = pd.CategoricalDtype(categories=value, ordered=True)
157
158 categories_dtypes[column_name] = cat_dtype
159
160 return df.astype(categories_dtypes)
161
162
163 def _as_categorical_checks(df: pd.DataFrame, **kwargs) -> dict:
164 """
165 This function raises errors if columns in `kwargs` are
166 absent from the dataframe's columns.
167 It also raises errors if the value in `kwargs`
168 is not a string (`'appearance'` or `'sort'`), or a 1D array.
169
170 This function is executed before proceeding to the computation phase.
171
172 If all checks pass, a dictionary of column names and value is returned.
173
174 :param df: The pandas DataFrame object.
175 :param **kwargs: A pairing of column name and value.
176 :returns: A dictionary.
177 :raises TypeError: If `value` is not a 1-D array, or a string.
178 :raises ValueError: If `value` is a 1-D array, and contains nulls,
179 or is non-unique.
180 """
181
182 check_column(df, kwargs)
183
184 categories_dict = {}
185
186 for column_name, value in kwargs.items():
187 # type check
188 if (value is not None) and not (
189 is_list_like(value) or isinstance(value, str)
190 ):
191 raise TypeError(f"{value} should be list-like or a string.")
192 if is_list_like(value):
193 if not hasattr(value, "shape"):
194 value = pd.Index([*value])
195
196 arr_ndim = value.ndim
197 if (arr_ndim != 1) or isinstance(value, pd.MultiIndex):
198 raise ValueError(
199 f"{value} is not a 1-D array. "
200 "Kindly provide a 1-D array-like object."
201 )
202
203 if not isinstance(value, (pd.Series, pd.Index)):
204 value = pd.Index(value)
205
206 if value.hasnans:
207 raise ValueError(
208 "Kindly ensure there are no nulls in the array provided."
209 )
210
211 if not value.is_unique:
212 raise ValueError(
213 "Kindly provide unique, "
214 "non-null values for the array provided."
215 )
216
217 if value.empty:
218 raise ValueError(
219 "Kindly ensure there is at least "
220 "one non-null value in the array provided."
221 )
222
223 # uniques, without nulls
224 uniques = df[column_name].factorize(sort=False)[-1]
225 if uniques.empty:
226 raise ValueError(
227 "Kindly ensure there is at least "
228 f"one non-null value in {column_name}."
229 )
230
231 missing = uniques.difference(value, sort=False)
232 if not missing.empty and (uniques.size > missing.size):
233 warnings.warn(
234 f"Values {tuple(missing)} are missing from "
235 f"the provided categories {value} "
236 f"for {column_name}; this may create nulls "
237 "in the new categorical column.",
238 UserWarning,
239 stacklevel=2,
240 )
241
242 elif uniques.equals(missing):
243 warnings.warn(
244 f"None of the values in {column_name} are in "
245 f"{value}; this might create nulls for all values "
246 f"in the new categorical column.",
247 UserWarning,
248 stacklevel=2,
249 )
250
251 elif isinstance(value, str):
252 category_order_types = {ent.value for ent in _CategoryOrder}
253 if value.lower() not in category_order_types:
254 raise ValueError(
255 "Argument should be one of 'appearance' or 'sort'."
256 )
257
258 categories_dict[column_name] = value
259
260 return categories_dict
261
262
263 class _CategoryOrder(Enum):
264 """
265 order types for encode_categorical.
266 """
267
268 SORT = "sort"
269 APPEARANCE = "appearance"
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/janitor/functions/encode_categorical.py b/janitor/functions/encode_categorical.py
--- a/janitor/functions/encode_categorical.py
+++ b/janitor/functions/encode_categorical.py
@@ -2,8 +2,9 @@
from enum import Enum
from typing import Hashable, Iterable, Union
-import pandas_flavor as pf
+import numpy as np
import pandas as pd
+import pandas_flavor as pf
from pandas.api.types import is_list_like
from janitor.utils import check, check_column, deprecated_alias
@@ -191,10 +192,9 @@
raise TypeError(f"{value} should be list-like or a string.")
if is_list_like(value):
if not hasattr(value, "shape"):
- value = pd.Index([*value])
+ value = np.asarray(value)
- arr_ndim = value.ndim
- if (arr_ndim != 1) or isinstance(value, pd.MultiIndex):
+ if (value.ndim != 1) or isinstance(value, pd.MultiIndex):
raise ValueError(
f"{value} is not a 1-D array. "
"Kindly provide a 1-D array-like object."
| {"golden_diff": "diff --git a/janitor/functions/encode_categorical.py b/janitor/functions/encode_categorical.py\n--- a/janitor/functions/encode_categorical.py\n+++ b/janitor/functions/encode_categorical.py\n@@ -2,8 +2,9 @@\n from enum import Enum\n from typing import Hashable, Iterable, Union\n \n-import pandas_flavor as pf\n+import numpy as np\n import pandas as pd\n+import pandas_flavor as pf\n from pandas.api.types import is_list_like\n \n from janitor.utils import check, check_column, deprecated_alias\n@@ -191,10 +192,9 @@\n raise TypeError(f\"{value} should be list-like or a string.\")\n if is_list_like(value):\n if not hasattr(value, \"shape\"):\n- value = pd.Index([*value])\n+ value = np.asarray(value)\n \n- arr_ndim = value.ndim\n- if (arr_ndim != 1) or isinstance(value, pd.MultiIndex):\n+ if (value.ndim != 1) or isinstance(value, pd.MultiIndex):\n raise ValueError(\n f\"{value} is not a 1-D array. \"\n \"Kindly provide a 1-D array-like object.\"\n", "issue": "[INF] Set multi-test env to compat dependency and system\n<!-- Thank you for your PR!\r\n\r\nBEFORE YOU CONTINUE! Please add the appropriate three-letter abbreviation to your title.\r\n\r\nThe abbreviations can be:\r\n- [DOC]: Documentation fixes.\r\n- [ENH]: Code contributions and new features.\r\n- [TST]: Test-related contributions.\r\n- [INF]: Infrastructure-related contributions.\r\n\r\nAlso, do not forget to tag the relevant issue here as well.\r\n\r\nFinally, as commits come in, don't forget to regularly rebase!\r\n-->\r\n\r\n# PR Description\r\n\r\nPlease describe the changes proposed in the pull request:\r\n\r\nAim:\r\n- Set multi-test environment\r\n- Compat different dependencies and systems\r\n\r\nToDo/Doing:\r\n- [x] Set latest env: test pyjanitor work with the latest dependencies to get the minimal python version\r\n- [ ] Set minimal env: get the minimal version of dependencies\r\n\r\nPart of #1133\r\n\r\n# PR Checklist\r\n\r\n<!-- This checklist exists for newcomers who are not yet familiar with our requirements. If you are experienced with\r\nthe project, please feel free to delete this section. -->\r\n\r\nPlease ensure that you have done the following:\r\n\r\n1. [x] PR in from a fork off your branch. Do not PR from `<your_username>`:`dev`, but rather from `<your_username>`:`<feature-branch_name>`.\r\n<!-- Doing this helps us keep the commit history much cleaner than it would otherwise be. -->\r\n2. [x] If you're not on the contributors list, add yourself to `AUTHORS.md`.\r\n<!-- We'd like to acknowledge your contributions! -->\r\n3. [x] Add a line to `CHANGELOG.md` under the latest version header (i.e. the one that is \"on deck\") describing the contribution.\r\n - Do use some discretion here; if there are multiple PRs that are related, keep them in a single line.\r\n\r\n# Automatic checks\r\n\r\nThere will be automatic checks run on the PR. These include:\r\n\r\n- Building a preview of the docs on Netlify\r\n- Automatically linting the code\r\n- Making sure the code is documented\r\n- Making sure that all tests are passed\r\n- Making sure that code coverage doesn't go down.\r\n\r\n# Relevant Reviewers\r\n\r\n<!-- Finally, please tag relevant maintainers to review. -->\r\n\r\nPlease tag maintainers to review.\r\n\r\n- @ericmjl\r\n\n", "before_files": [{"content": "import warnings\nfrom enum import Enum\nfrom typing import Hashable, Iterable, Union\n\nimport pandas_flavor as pf\nimport pandas as pd\nfrom pandas.api.types import is_list_like\n\nfrom janitor.utils import check, check_column, deprecated_alias\n\n\[email protected]_dataframe_method\n@deprecated_alias(columns=\"column_names\")\ndef encode_categorical(\n df: pd.DataFrame,\n column_names: Union[str, Iterable[str], Hashable] = None,\n **kwargs,\n) -> pd.DataFrame:\n \"\"\"Encode the specified columns with Pandas' [category dtype][cat].\n\n [cat]: http://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html\n\n It is syntactic sugar around `pd.Categorical`.\n\n This method does not mutate the original DataFrame.\n\n Simply pass a string, or a sequence of column names to `column_names`;\n alternatively, you can pass kwargs, where the keys are the column names\n and the values can either be None, `sort`, `appearance`\n or a 1-D array-like object.\n\n - None: column is cast to an unordered categorical.\n - `sort`: column is cast to an ordered categorical,\n with the order defined by the sort-order of the categories.\n - `appearance`: column is cast to an ordered categorical,\n with the order defined by the order of appearance\n in the original column.\n - 1d-array-like object: column is cast to an ordered categorical,\n with the categories and order as specified\n in the input array.\n\n `column_names` and `kwargs` parameters cannot be used at the same time.\n\n Example: Using `column_names`\n\n >>> import pandas as pd\n >>> import janitor\n >>> df = pd.DataFrame({\n ... \"foo\": [\"b\", \"b\", \"a\", \"c\", \"b\"],\n ... \"bar\": range(4, 9),\n ... })\n >>> df\n foo bar\n 0 b 4\n 1 b 5\n 2 a 6\n 3 c 7\n 4 b 8\n >>> df.dtypes\n foo object\n bar int64\n dtype: object\n >>> enc_df = df.encode_categorical(column_names=\"foo\")\n >>> enc_df.dtypes\n foo category\n bar int64\n dtype: object\n >>> enc_df[\"foo\"].cat.categories\n Index(['a', 'b', 'c'], dtype='object')\n >>> enc_df[\"foo\"].cat.ordered\n False\n\n Example: Using `kwargs` to specify an ordered categorical.\n\n >>> import pandas as pd\n >>> import janitor\n >>> df = pd.DataFrame({\n ... \"foo\": [\"b\", \"b\", \"a\", \"c\", \"b\"],\n ... \"bar\": range(4, 9),\n ... })\n >>> df.dtypes\n foo object\n bar int64\n dtype: object\n >>> enc_df = df.encode_categorical(foo=\"appearance\")\n >>> enc_df.dtypes\n foo category\n bar int64\n dtype: object\n >>> enc_df[\"foo\"].cat.categories\n Index(['b', 'a', 'c'], dtype='object')\n >>> enc_df[\"foo\"].cat.ordered\n True\n\n :param df: A pandas DataFrame object.\n :param column_names: A column name or an iterable (list or tuple)\n of column names.\n :param **kwargs: A mapping from column name to either `None`,\n `'sort'` or `'appearance'`, or a 1-D array. This is useful\n in creating categorical columns that are ordered, or\n if the user needs to explicitly specify the categories.\n :returns: A pandas DataFrame.\n :raises ValueError: If both `column_names` and `kwargs` are provided.\n \"\"\" # noqa: E501\n\n if all((column_names, kwargs)):\n raise ValueError(\n \"Only one of `column_names` or `kwargs` can be provided.\"\n )\n # column_names deal with only category dtype (unordered)\n # kwargs takes care of scenarios where user wants an ordered category\n # or user supplies specific categories to create the categorical\n if column_names is not None:\n check(\"column_names\", column_names, [list, tuple, Hashable])\n if isinstance(column_names, Hashable):\n column_names = [column_names]\n check_column(df, column_names)\n dtypes = {col: \"category\" for col in column_names}\n return df.astype(dtypes)\n\n return _computations_as_categorical(df, **kwargs)\n\n\ndef _computations_as_categorical(df: pd.DataFrame, **kwargs) -> pd.DataFrame:\n \"\"\"\n This function handles cases where\n categorical columns are created with an order,\n or specific values supplied for the categories.\n It uses a kwarg, where the key is the column name,\n and the value is either a string, or a 1D array.\n The default for value is None and will return a categorical dtype\n with no order and categories inferred from the column.\n A DataFrame, with categorical columns, is returned.\n \"\"\"\n\n categories_dict = _as_categorical_checks(df, **kwargs)\n\n categories_dtypes = {}\n\n for column_name, value in categories_dict.items():\n if value is None:\n cat_dtype = pd.CategoricalDtype()\n elif isinstance(value, str):\n if value == _CategoryOrder.SORT.value:\n _, cat_dtype = df[column_name].factorize(sort=True)\n else:\n _, cat_dtype = df[column_name].factorize(sort=False)\n if cat_dtype.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n f\"one non-null value in {column_name}.\"\n )\n cat_dtype = pd.CategoricalDtype(categories=cat_dtype, ordered=True)\n\n else: # 1-D array\n cat_dtype = pd.CategoricalDtype(categories=value, ordered=True)\n\n categories_dtypes[column_name] = cat_dtype\n\n return df.astype(categories_dtypes)\n\n\ndef _as_categorical_checks(df: pd.DataFrame, **kwargs) -> dict:\n \"\"\"\n This function raises errors if columns in `kwargs` are\n absent from the dataframe's columns.\n It also raises errors if the value in `kwargs`\n is not a string (`'appearance'` or `'sort'`), or a 1D array.\n\n This function is executed before proceeding to the computation phase.\n\n If all checks pass, a dictionary of column names and value is returned.\n\n :param df: The pandas DataFrame object.\n :param **kwargs: A pairing of column name and value.\n :returns: A dictionary.\n :raises TypeError: If `value` is not a 1-D array, or a string.\n :raises ValueError: If `value` is a 1-D array, and contains nulls,\n or is non-unique.\n \"\"\"\n\n check_column(df, kwargs)\n\n categories_dict = {}\n\n for column_name, value in kwargs.items():\n # type check\n if (value is not None) and not (\n is_list_like(value) or isinstance(value, str)\n ):\n raise TypeError(f\"{value} should be list-like or a string.\")\n if is_list_like(value):\n if not hasattr(value, \"shape\"):\n value = pd.Index([*value])\n\n arr_ndim = value.ndim\n if (arr_ndim != 1) or isinstance(value, pd.MultiIndex):\n raise ValueError(\n f\"{value} is not a 1-D array. \"\n \"Kindly provide a 1-D array-like object.\"\n )\n\n if not isinstance(value, (pd.Series, pd.Index)):\n value = pd.Index(value)\n\n if value.hasnans:\n raise ValueError(\n \"Kindly ensure there are no nulls in the array provided.\"\n )\n\n if not value.is_unique:\n raise ValueError(\n \"Kindly provide unique, \"\n \"non-null values for the array provided.\"\n )\n\n if value.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n \"one non-null value in the array provided.\"\n )\n\n # uniques, without nulls\n uniques = df[column_name].factorize(sort=False)[-1]\n if uniques.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n f\"one non-null value in {column_name}.\"\n )\n\n missing = uniques.difference(value, sort=False)\n if not missing.empty and (uniques.size > missing.size):\n warnings.warn(\n f\"Values {tuple(missing)} are missing from \"\n f\"the provided categories {value} \"\n f\"for {column_name}; this may create nulls \"\n \"in the new categorical column.\",\n UserWarning,\n stacklevel=2,\n )\n\n elif uniques.equals(missing):\n warnings.warn(\n f\"None of the values in {column_name} are in \"\n f\"{value}; this might create nulls for all values \"\n f\"in the new categorical column.\",\n UserWarning,\n stacklevel=2,\n )\n\n elif isinstance(value, str):\n category_order_types = {ent.value for ent in _CategoryOrder}\n if value.lower() not in category_order_types:\n raise ValueError(\n \"Argument should be one of 'appearance' or 'sort'.\"\n )\n\n categories_dict[column_name] = value\n\n return categories_dict\n\n\nclass _CategoryOrder(Enum):\n \"\"\"\n order types for encode_categorical.\n \"\"\"\n\n SORT = \"sort\"\n APPEARANCE = \"appearance\"\n", "path": "janitor/functions/encode_categorical.py"}], "after_files": [{"content": "import warnings\nfrom enum import Enum\nfrom typing import Hashable, Iterable, Union\n\nimport numpy as np\nimport pandas as pd\nimport pandas_flavor as pf\nfrom pandas.api.types import is_list_like\n\nfrom janitor.utils import check, check_column, deprecated_alias\n\n\[email protected]_dataframe_method\n@deprecated_alias(columns=\"column_names\")\ndef encode_categorical(\n df: pd.DataFrame,\n column_names: Union[str, Iterable[str], Hashable] = None,\n **kwargs,\n) -> pd.DataFrame:\n \"\"\"Encode the specified columns with Pandas' [category dtype][cat].\n\n [cat]: http://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html\n\n It is syntactic sugar around `pd.Categorical`.\n\n This method does not mutate the original DataFrame.\n\n Simply pass a string, or a sequence of column names to `column_names`;\n alternatively, you can pass kwargs, where the keys are the column names\n and the values can either be None, `sort`, `appearance`\n or a 1-D array-like object.\n\n - None: column is cast to an unordered categorical.\n - `sort`: column is cast to an ordered categorical,\n with the order defined by the sort-order of the categories.\n - `appearance`: column is cast to an ordered categorical,\n with the order defined by the order of appearance\n in the original column.\n - 1d-array-like object: column is cast to an ordered categorical,\n with the categories and order as specified\n in the input array.\n\n `column_names` and `kwargs` parameters cannot be used at the same time.\n\n Example: Using `column_names`\n\n >>> import pandas as pd\n >>> import janitor\n >>> df = pd.DataFrame({\n ... \"foo\": [\"b\", \"b\", \"a\", \"c\", \"b\"],\n ... \"bar\": range(4, 9),\n ... })\n >>> df\n foo bar\n 0 b 4\n 1 b 5\n 2 a 6\n 3 c 7\n 4 b 8\n >>> df.dtypes\n foo object\n bar int64\n dtype: object\n >>> enc_df = df.encode_categorical(column_names=\"foo\")\n >>> enc_df.dtypes\n foo category\n bar int64\n dtype: object\n >>> enc_df[\"foo\"].cat.categories\n Index(['a', 'b', 'c'], dtype='object')\n >>> enc_df[\"foo\"].cat.ordered\n False\n\n Example: Using `kwargs` to specify an ordered categorical.\n\n >>> import pandas as pd\n >>> import janitor\n >>> df = pd.DataFrame({\n ... \"foo\": [\"b\", \"b\", \"a\", \"c\", \"b\"],\n ... \"bar\": range(4, 9),\n ... })\n >>> df.dtypes\n foo object\n bar int64\n dtype: object\n >>> enc_df = df.encode_categorical(foo=\"appearance\")\n >>> enc_df.dtypes\n foo category\n bar int64\n dtype: object\n >>> enc_df[\"foo\"].cat.categories\n Index(['b', 'a', 'c'], dtype='object')\n >>> enc_df[\"foo\"].cat.ordered\n True\n\n :param df: A pandas DataFrame object.\n :param column_names: A column name or an iterable (list or tuple)\n of column names.\n :param **kwargs: A mapping from column name to either `None`,\n `'sort'` or `'appearance'`, or a 1-D array. This is useful\n in creating categorical columns that are ordered, or\n if the user needs to explicitly specify the categories.\n :returns: A pandas DataFrame.\n :raises ValueError: If both `column_names` and `kwargs` are provided.\n \"\"\" # noqa: E501\n\n if all((column_names, kwargs)):\n raise ValueError(\n \"Only one of `column_names` or `kwargs` can be provided.\"\n )\n # column_names deal with only category dtype (unordered)\n # kwargs takes care of scenarios where user wants an ordered category\n # or user supplies specific categories to create the categorical\n if column_names is not None:\n check(\"column_names\", column_names, [list, tuple, Hashable])\n if isinstance(column_names, Hashable):\n column_names = [column_names]\n check_column(df, column_names)\n dtypes = {col: \"category\" for col in column_names}\n return df.astype(dtypes)\n\n return _computations_as_categorical(df, **kwargs)\n\n\ndef _computations_as_categorical(df: pd.DataFrame, **kwargs) -> pd.DataFrame:\n \"\"\"\n This function handles cases where\n categorical columns are created with an order,\n or specific values supplied for the categories.\n It uses a kwarg, where the key is the column name,\n and the value is either a string, or a 1D array.\n The default for value is None and will return a categorical dtype\n with no order and categories inferred from the column.\n A DataFrame, with categorical columns, is returned.\n \"\"\"\n\n categories_dict = _as_categorical_checks(df, **kwargs)\n\n categories_dtypes = {}\n\n for column_name, value in categories_dict.items():\n if value is None:\n cat_dtype = pd.CategoricalDtype()\n elif isinstance(value, str):\n if value == _CategoryOrder.SORT.value:\n _, cat_dtype = df[column_name].factorize(sort=True)\n else:\n _, cat_dtype = df[column_name].factorize(sort=False)\n if cat_dtype.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n f\"one non-null value in {column_name}.\"\n )\n cat_dtype = pd.CategoricalDtype(categories=cat_dtype, ordered=True)\n\n else: # 1-D array\n cat_dtype = pd.CategoricalDtype(categories=value, ordered=True)\n\n categories_dtypes[column_name] = cat_dtype\n\n return df.astype(categories_dtypes)\n\n\ndef _as_categorical_checks(df: pd.DataFrame, **kwargs) -> dict:\n \"\"\"\n This function raises errors if columns in `kwargs` are\n absent from the dataframe's columns.\n It also raises errors if the value in `kwargs`\n is not a string (`'appearance'` or `'sort'`), or a 1D array.\n\n This function is executed before proceeding to the computation phase.\n\n If all checks pass, a dictionary of column names and value is returned.\n\n :param df: The pandas DataFrame object.\n :param **kwargs: A pairing of column name and value.\n :returns: A dictionary.\n :raises TypeError: If `value` is not a 1-D array, or a string.\n :raises ValueError: If `value` is a 1-D array, and contains nulls,\n or is non-unique.\n \"\"\"\n\n check_column(df, kwargs)\n\n categories_dict = {}\n\n for column_name, value in kwargs.items():\n # type check\n if (value is not None) and not (\n is_list_like(value) or isinstance(value, str)\n ):\n raise TypeError(f\"{value} should be list-like or a string.\")\n if is_list_like(value):\n if not hasattr(value, \"shape\"):\n value = np.asarray(value)\n\n if (value.ndim != 1) or isinstance(value, pd.MultiIndex):\n raise ValueError(\n f\"{value} is not a 1-D array. \"\n \"Kindly provide a 1-D array-like object.\"\n )\n\n if not isinstance(value, (pd.Series, pd.Index)):\n value = pd.Index(value)\n\n if value.hasnans:\n raise ValueError(\n \"Kindly ensure there are no nulls in the array provided.\"\n )\n\n if not value.is_unique:\n raise ValueError(\n \"Kindly provide unique, \"\n \"non-null values for the array provided.\"\n )\n\n if value.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n \"one non-null value in the array provided.\"\n )\n\n # uniques, without nulls\n uniques = df[column_name].factorize(sort=False)[-1]\n if uniques.empty:\n raise ValueError(\n \"Kindly ensure there is at least \"\n f\"one non-null value in {column_name}.\"\n )\n\n missing = uniques.difference(value, sort=False)\n if not missing.empty and (uniques.size > missing.size):\n warnings.warn(\n f\"Values {tuple(missing)} are missing from \"\n f\"the provided categories {value} \"\n f\"for {column_name}; this may create nulls \"\n \"in the new categorical column.\",\n UserWarning,\n stacklevel=2,\n )\n\n elif uniques.equals(missing):\n warnings.warn(\n f\"None of the values in {column_name} are in \"\n f\"{value}; this might create nulls for all values \"\n f\"in the new categorical column.\",\n UserWarning,\n stacklevel=2,\n )\n\n elif isinstance(value, str):\n category_order_types = {ent.value for ent in _CategoryOrder}\n if value.lower() not in category_order_types:\n raise ValueError(\n \"Argument should be one of 'appearance' or 'sort'.\"\n )\n\n categories_dict[column_name] = value\n\n return categories_dict\n\n\nclass _CategoryOrder(Enum):\n \"\"\"\n order types for encode_categorical.\n \"\"\"\n\n SORT = \"sort\"\n APPEARANCE = \"appearance\"\n", "path": "janitor/functions/encode_categorical.py"}]} | 3,556 | 259 |
gh_patches_debug_14801 | rasdani/github-patches | git_diff | scikit-hep__awkward-2274 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tests are failing in "Build Docs", possibly due to new Sphinx theme
Is pydata_sphinx_theme broken, perhaps? It had a 0.13 release 12 hours ago.
_Originally posted by @henryiii in https://github.com/scikit-hep/awkward/issues/2268#issuecomment-1448934363_
For example, https://github.com/scikit-hep/awkward/actions/runs/4297198800/jobs/7489883737
This open issue, https://github.com/pydata/pydata-sphinx-theme/issues/1149, has the same error message and they say
> I think it ought to be possible to run our basic dev commands (test, docs, docs-live) in the dev environment we recommend contributors to use
which sounds like something we do.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # This file only contains a selection of the most common options. For a full
4 # list see the documentation:
5 # https://www.sphinx-doc.org/en/master/usage/configuration.html
6
7 # -- Path setup --------------------------------------------------------------
8
9 # If extensions (or modules to document with autodoc) are in another directory,
10 # add these directories to sys.path here. If the directory is relative to the
11 # documentation root, use os.path.abspath to make it absolute, like shown here.
12 #
13 import awkward
14 import datetime
15 import os
16 import runpy
17 import pathlib
18
19 # -- Project information -----------------------------------------------------
20
21 project = "Awkward Array"
22 copyright = f"{datetime.datetime.now().year}, Awkward Array development team"
23 author = "Jim Pivarski"
24
25 parts = awkward.__version__.split(".")
26 version = ".".join(parts[:2])
27 release = ".".join(parts)
28
29 # -- General configuration ---------------------------------------------------
30
31 # Add any Sphinx extension module names here, as strings. They can be
32 # extensions coming with Sphinx (named "sphinx.ext.*") or your custom
33 # ones.
34 extensions = [
35 "sphinx_copybutton",
36 "sphinx_design",
37 "sphinx_external_toc",
38 "sphinx.ext.intersphinx",
39 "myst_nb",
40 # Preserve old links
41 "jupyterlite_sphinx",
42 "IPython.sphinxext.ipython_console_highlighting",
43 "IPython.sphinxext.ipython_directive",
44 ]
45
46 # Allow the CI to set version_match="main"
47 if "DOCS_VERSION" in os.environ:
48 version_match = os.environ["DOCS_VERSION"]
49 else:
50 version_match = version
51
52
53 # Specify a canonical version
54 if "DOCS_CANONICAL_VERSION" in os.environ:
55 canonical_version = os.environ["DOCS_CANONICAL_VERSION"]
56 html_baseurl = f"https://awkward-array.org/doc/{canonical_version}/"
57
58 # Build sitemap on main
59 if version_match == canonical_version:
60 extensions.append("sphinx_sitemap")
61 # Sitemap URLs are relative to `html_baseurl`
62 sitemap_url_scheme = "{link}"
63
64 # Add any paths that contain templates here, relative to this directory.
65 templates_path = ["_templates"]
66
67 # List of patterns, relative to source directory, that match files and
68 # directories to ignore when looking for source files.
69 # This pattern also affects html_static_path and html_extra_path.
70 exclude_patterns = ["_build", "_templates", "Thumbs.db", "jupyter_execute", ".*"]
71
72 # -- Options for HTML output -------------------------------------------------
73
74 # The theme to use for HTML and HTML Help pages. See the documentation for
75 # a list of builtin themes.
76
77 html_context = {
78 "github_user": "scikit-hep",
79 "github_repo": "awkward",
80 "github_version": "main",
81 "doc_path": "docs",
82 }
83 html_theme = "pydata_sphinx_theme"
84 html_show_sourcelink = True
85 html_theme_options = {
86 "logo": {
87 "image_light": "image/logo-300px.png",
88 "image_dark": "image/logo-300px-white.png",
89 },
90 "github_url": "https://github.com/scikit-hep/awkward",
91 # Add light/dark mode and documentation version switcher:
92 "navbar_end": ["theme-switcher", "navbar-icon-links"],
93 "footer_items": ["copyright", "sphinx-version", "funding"],
94 "icon_links": [
95 {
96 "name": "PyPI",
97 "url": "https://pypi.org/project/awkward",
98 "icon": "fab fa-python",
99 }
100 ],
101 "use_edit_page_button": True,
102 "external_links": [
103 {
104 "name": "Contributor guide",
105 "url": "https://github.com/scikit-hep/awkward/blob/main/CONTRIBUTING.md",
106 },
107 {
108 "name": "Release history",
109 "url": "https://github.com/scikit-hep/awkward/releases",
110 },
111 ],
112 }
113
114 # Disable analytics for previews
115 if "DOCS_REPORT_ANALYTICS" in os.environ:
116 html_theme_options["analytics"] = {
117 "plausible_analytics_domain": "awkward-array.org",
118 "plausible_analytics_url": "https://views.scientific-python.org/js/plausible.js",
119 }
120
121 # Don't show version for offline builds by default
122 if "DOCS_SHOW_VERSION" in os.environ:
123 html_theme_options["switcher"] = {
124 "json_url": "https://awkward-array.org/doc/switcher.json",
125 "version_match": version_match,
126 }
127 html_theme_options["navbar_start"] = ["navbar-logo", "version-switcher"]
128
129 # Add any paths that contain custom static files (such as style sheets) here,
130 # relative to this directory. They are copied after the builtin static files,
131 # so a file named "default.css" will overwrite the builtin "default.css".
132 html_static_path = ["_static"]
133 html_css_files = ["css/awkward.css"]
134
135 # MyST settings
136 myst_enable_extensions = ["colon_fence"]
137
138 nb_execution_mode = "cache"
139 nb_execution_raise_on_error = True
140 # unpkg is currently _very_ slow
141 nb_ipywidgets_js = {
142 # Load RequireJS, used by the IPywidgets for dependency management
143 "https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.4/require.min.js": {
144 "integrity": "sha256-Ae2Vz/4ePdIu6ZyI/5ZGsYnb+m0JlOmKPjt6XZ9JJkA=",
145 "crossorigin": "anonymous",
146 },
147 # Load IPywidgets bundle for embedding.
148 "https://cdn.jsdelivr.net/npm/@jupyter-widgets/[email protected]/dist/embed-amd.js": {
149 "data-jupyter-widgets-cdn": "https://cdn.jsdelivr.net/npm/",
150 "crossorigin": "anonymous",
151 },
152 }
153 nb_execution_show_tb = True
154
155 # Additional stuff
156 master_doc = "index"
157
158 # Cross-reference existing Python objects
159 intersphinx_mapping = {
160 "python": ("https://docs.python.org/3/", None),
161 "pandas": ("https://pandas.pydata.org/pandas-docs/stable", None),
162 "numpy": ("https://numpy.org/doc/stable", None),
163 "scipy": ("https://docs.scipy.org/doc/scipy", None),
164 "numba": ("https://numba.pydata.org/numba-doc/latest", None),
165 "arrow": ("https://arrow.apache.org/docs/", None),
166 "jax": ("https://jax.readthedocs.io/en/latest", None),
167 }
168
169
170 # JupyterLite configuration
171 jupyterlite_dir = "./lite"
172 # Don't override ipynb format
173 jupyterlite_bind_ipynb_suffix = False
174 # We've disabled localstorage, so we must provide the contents explicitly
175 jupyterlite_contents = ["getting-started/demo/*"]
176
177 linkcheck_ignore = [
178 r"^https?:\/\/github\.com\/.*$",
179 r"^getting-started\/try-awkward-array\.html$", # Relative link won't resolve
180 r"^https?:\/\/$", # Bare https:// allowed
181 ]
182 # Eventually we need to revisit these
183 if (datetime.date.today() - datetime.date(2022, 12, 13)) < datetime.timedelta(days=30):
184 linkcheck_ignore.extend(
185 [
186 r"^https:\/\/doi.org\/10\.1051\/epjconf\/202024505023$",
187 r"^https:\/\/doi.org\/10\.1051\/epjconf\/202125103002$",
188 ]
189 )
190
191 # Generate Python docstrings
192 HERE = pathlib.Path(__file__).parent
193 runpy.run_path(HERE / "prepare_docstrings.py", run_name="__main__")
194
195
196 # Sphinx doesn't usually want content to fit the screen, so we hack the styles for this page
197 def install_jupyterlite_styles(app, pagename, templatename, context, event_arg) -> None:
198 if pagename != "getting-started/try-awkward-array":
199 return
200
201 app.add_css_file("css/try-awkward-array.css")
202
203
204 def setup(app):
205 app.connect("html-page-context", install_jupyterlite_styles)
206
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -84,13 +84,13 @@
html_show_sourcelink = True
html_theme_options = {
"logo": {
- "image_light": "image/logo-300px.png",
- "image_dark": "image/logo-300px-white.png",
+ "image_light": "_static/image/logo-300px.png",
+ "image_dark": "_static/image/logo-300px-white.png",
},
"github_url": "https://github.com/scikit-hep/awkward",
# Add light/dark mode and documentation version switcher:
"navbar_end": ["theme-switcher", "navbar-icon-links"],
- "footer_items": ["copyright", "sphinx-version", "funding"],
+ "footer_start": ["copyright", "sphinx-version", "funding"],
"icon_links": [
{
"name": "PyPI",
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -84,13 +84,13 @@\n html_show_sourcelink = True\n html_theme_options = {\n \"logo\": {\n- \"image_light\": \"image/logo-300px.png\",\n- \"image_dark\": \"image/logo-300px-white.png\",\n+ \"image_light\": \"_static/image/logo-300px.png\",\n+ \"image_dark\": \"_static/image/logo-300px-white.png\",\n },\n \"github_url\": \"https://github.com/scikit-hep/awkward\",\n # Add light/dark mode and documentation version switcher:\n \"navbar_end\": [\"theme-switcher\", \"navbar-icon-links\"],\n- \"footer_items\": [\"copyright\", \"sphinx-version\", \"funding\"],\n+ \"footer_start\": [\"copyright\", \"sphinx-version\", \"funding\"],\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n", "issue": "Tests are failing in \"Build Docs\", possibly due to new Sphinx theme\n Is pydata_sphinx_theme broken, perhaps? It had a 0.13 release 12 hours ago.\r\n\r\n_Originally posted by @henryiii in https://github.com/scikit-hep/awkward/issues/2268#issuecomment-1448934363_\r\n\r\nFor example, https://github.com/scikit-hep/awkward/actions/runs/4297198800/jobs/7489883737\r\n\r\nThis open issue, https://github.com/pydata/pydata-sphinx-theme/issues/1149, has the same error message and they say\r\n\r\n> I think it ought to be possible to run our basic dev commands (test, docs, docs-live) in the dev environment we recommend contributors to use\r\n\r\nwhich sounds like something we do.\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport awkward\nimport datetime\nimport os\nimport runpy\nimport pathlib\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Awkward Array\"\ncopyright = f\"{datetime.datetime.now().year}, Awkward Array development team\"\nauthor = \"Jim Pivarski\"\n\nparts = awkward.__version__.split(\".\")\nversion = \".\".join(parts[:2])\nrelease = \".\".join(parts)\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named \"sphinx.ext.*\") or your custom\n# ones.\nextensions = [\n \"sphinx_copybutton\",\n \"sphinx_design\",\n \"sphinx_external_toc\",\n \"sphinx.ext.intersphinx\",\n \"myst_nb\",\n # Preserve old links\n \"jupyterlite_sphinx\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n]\n\n# Allow the CI to set version_match=\"main\"\nif \"DOCS_VERSION\" in os.environ:\n version_match = os.environ[\"DOCS_VERSION\"]\nelse:\n version_match = version\n\n\n# Specify a canonical version\nif \"DOCS_CANONICAL_VERSION\" in os.environ:\n canonical_version = os.environ[\"DOCS_CANONICAL_VERSION\"]\n html_baseurl = f\"https://awkward-array.org/doc/{canonical_version}/\"\n\n # Build sitemap on main\n if version_match == canonical_version:\n extensions.append(\"sphinx_sitemap\")\n # Sitemap URLs are relative to `html_baseurl`\n sitemap_url_scheme = \"{link}\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\"_build\", \"_templates\", \"Thumbs.db\", \"jupyter_execute\", \".*\"]\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nhtml_context = {\n \"github_user\": \"scikit-hep\",\n \"github_repo\": \"awkward\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs\",\n}\nhtml_theme = \"pydata_sphinx_theme\"\nhtml_show_sourcelink = True\nhtml_theme_options = {\n \"logo\": {\n \"image_light\": \"image/logo-300px.png\",\n \"image_dark\": \"image/logo-300px-white.png\",\n },\n \"github_url\": \"https://github.com/scikit-hep/awkward\",\n # Add light/dark mode and documentation version switcher:\n \"navbar_end\": [\"theme-switcher\", \"navbar-icon-links\"],\n \"footer_items\": [\"copyright\", \"sphinx-version\", \"funding\"],\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/awkward\",\n \"icon\": \"fab fa-python\",\n }\n ],\n \"use_edit_page_button\": True,\n \"external_links\": [\n {\n \"name\": \"Contributor guide\",\n \"url\": \"https://github.com/scikit-hep/awkward/blob/main/CONTRIBUTING.md\",\n },\n {\n \"name\": \"Release history\",\n \"url\": \"https://github.com/scikit-hep/awkward/releases\",\n },\n ],\n}\n\n# Disable analytics for previews\nif \"DOCS_REPORT_ANALYTICS\" in os.environ:\n html_theme_options[\"analytics\"] = {\n \"plausible_analytics_domain\": \"awkward-array.org\",\n \"plausible_analytics_url\": \"https://views.scientific-python.org/js/plausible.js\",\n }\n\n# Don't show version for offline builds by default\nif \"DOCS_SHOW_VERSION\" in os.environ:\n html_theme_options[\"switcher\"] = {\n \"json_url\": \"https://awkward-array.org/doc/switcher.json\",\n \"version_match\": version_match,\n }\n html_theme_options[\"navbar_start\"] = [\"navbar-logo\", \"version-switcher\"]\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\nhtml_css_files = [\"css/awkward.css\"]\n\n# MyST settings\nmyst_enable_extensions = [\"colon_fence\"]\n\nnb_execution_mode = \"cache\"\nnb_execution_raise_on_error = True\n# unpkg is currently _very_ slow\nnb_ipywidgets_js = {\n # Load RequireJS, used by the IPywidgets for dependency management\n \"https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.4/require.min.js\": {\n \"integrity\": \"sha256-Ae2Vz/4ePdIu6ZyI/5ZGsYnb+m0JlOmKPjt6XZ9JJkA=\",\n \"crossorigin\": \"anonymous\",\n },\n # Load IPywidgets bundle for embedding.\n \"https://cdn.jsdelivr.net/npm/@jupyter-widgets/[email protected]/dist/embed-amd.js\": {\n \"data-jupyter-widgets-cdn\": \"https://cdn.jsdelivr.net/npm/\",\n \"crossorigin\": \"anonymous\",\n },\n}\nnb_execution_show_tb = True\n\n# Additional stuff\nmaster_doc = \"index\"\n\n# Cross-reference existing Python objects\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable\", None),\n \"numpy\": (\"https://numpy.org/doc/stable\", None),\n \"scipy\": (\"https://docs.scipy.org/doc/scipy\", None),\n \"numba\": (\"https://numba.pydata.org/numba-doc/latest\", None),\n \"arrow\": (\"https://arrow.apache.org/docs/\", None),\n \"jax\": (\"https://jax.readthedocs.io/en/latest\", None),\n}\n\n\n# JupyterLite configuration\njupyterlite_dir = \"./lite\"\n# Don't override ipynb format\njupyterlite_bind_ipynb_suffix = False\n# We've disabled localstorage, so we must provide the contents explicitly\njupyterlite_contents = [\"getting-started/demo/*\"]\n\nlinkcheck_ignore = [\n r\"^https?:\\/\\/github\\.com\\/.*$\",\n r\"^getting-started\\/try-awkward-array\\.html$\", # Relative link won't resolve\n r\"^https?:\\/\\/$\", # Bare https:// allowed\n]\n# Eventually we need to revisit these\nif (datetime.date.today() - datetime.date(2022, 12, 13)) < datetime.timedelta(days=30):\n linkcheck_ignore.extend(\n [\n r\"^https:\\/\\/doi.org\\/10\\.1051\\/epjconf\\/202024505023$\",\n r\"^https:\\/\\/doi.org\\/10\\.1051\\/epjconf\\/202125103002$\",\n ]\n )\n\n# Generate Python docstrings\nHERE = pathlib.Path(__file__).parent\nrunpy.run_path(HERE / \"prepare_docstrings.py\", run_name=\"__main__\")\n\n\n# Sphinx doesn't usually want content to fit the screen, so we hack the styles for this page\ndef install_jupyterlite_styles(app, pagename, templatename, context, event_arg) -> None:\n if pagename != \"getting-started/try-awkward-array\":\n return\n\n app.add_css_file(\"css/try-awkward-array.css\")\n\n\ndef setup(app):\n app.connect(\"html-page-context\", install_jupyterlite_styles)\n", "path": "docs/conf.py"}], "after_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport awkward\nimport datetime\nimport os\nimport runpy\nimport pathlib\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Awkward Array\"\ncopyright = f\"{datetime.datetime.now().year}, Awkward Array development team\"\nauthor = \"Jim Pivarski\"\n\nparts = awkward.__version__.split(\".\")\nversion = \".\".join(parts[:2])\nrelease = \".\".join(parts)\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named \"sphinx.ext.*\") or your custom\n# ones.\nextensions = [\n \"sphinx_copybutton\",\n \"sphinx_design\",\n \"sphinx_external_toc\",\n \"sphinx.ext.intersphinx\",\n \"myst_nb\",\n # Preserve old links\n \"jupyterlite_sphinx\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"IPython.sphinxext.ipython_directive\",\n]\n\n# Allow the CI to set version_match=\"main\"\nif \"DOCS_VERSION\" in os.environ:\n version_match = os.environ[\"DOCS_VERSION\"]\nelse:\n version_match = version\n\n\n# Specify a canonical version\nif \"DOCS_CANONICAL_VERSION\" in os.environ:\n canonical_version = os.environ[\"DOCS_CANONICAL_VERSION\"]\n html_baseurl = f\"https://awkward-array.org/doc/{canonical_version}/\"\n\n # Build sitemap on main\n if version_match == canonical_version:\n extensions.append(\"sphinx_sitemap\")\n # Sitemap URLs are relative to `html_baseurl`\n sitemap_url_scheme = \"{link}\"\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\"_build\", \"_templates\", \"Thumbs.db\", \"jupyter_execute\", \".*\"]\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nhtml_context = {\n \"github_user\": \"scikit-hep\",\n \"github_repo\": \"awkward\",\n \"github_version\": \"main\",\n \"doc_path\": \"docs\",\n}\nhtml_theme = \"pydata_sphinx_theme\"\nhtml_show_sourcelink = True\nhtml_theme_options = {\n \"logo\": {\n \"image_light\": \"_static/image/logo-300px.png\",\n \"image_dark\": \"_static/image/logo-300px-white.png\",\n },\n \"github_url\": \"https://github.com/scikit-hep/awkward\",\n # Add light/dark mode and documentation version switcher:\n \"navbar_end\": [\"theme-switcher\", \"navbar-icon-links\"],\n \"footer_start\": [\"copyright\", \"sphinx-version\", \"funding\"],\n \"icon_links\": [\n {\n \"name\": \"PyPI\",\n \"url\": \"https://pypi.org/project/awkward\",\n \"icon\": \"fab fa-python\",\n }\n ],\n \"use_edit_page_button\": True,\n \"external_links\": [\n {\n \"name\": \"Contributor guide\",\n \"url\": \"https://github.com/scikit-hep/awkward/blob/main/CONTRIBUTING.md\",\n },\n {\n \"name\": \"Release history\",\n \"url\": \"https://github.com/scikit-hep/awkward/releases\",\n },\n ],\n}\n\n# Disable analytics for previews\nif \"DOCS_REPORT_ANALYTICS\" in os.environ:\n html_theme_options[\"analytics\"] = {\n \"plausible_analytics_domain\": \"awkward-array.org\",\n \"plausible_analytics_url\": \"https://views.scientific-python.org/js/plausible.js\",\n }\n\n# Don't show version for offline builds by default\nif \"DOCS_SHOW_VERSION\" in os.environ:\n html_theme_options[\"switcher\"] = {\n \"json_url\": \"https://awkward-array.org/doc/switcher.json\",\n \"version_match\": version_match,\n }\n html_theme_options[\"navbar_start\"] = [\"navbar-logo\", \"version-switcher\"]\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\nhtml_css_files = [\"css/awkward.css\"]\n\n# MyST settings\nmyst_enable_extensions = [\"colon_fence\"]\n\nnb_execution_mode = \"cache\"\nnb_execution_raise_on_error = True\n# unpkg is currently _very_ slow\nnb_ipywidgets_js = {\n # Load RequireJS, used by the IPywidgets for dependency management\n \"https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.4/require.min.js\": {\n \"integrity\": \"sha256-Ae2Vz/4ePdIu6ZyI/5ZGsYnb+m0JlOmKPjt6XZ9JJkA=\",\n \"crossorigin\": \"anonymous\",\n },\n # Load IPywidgets bundle for embedding.\n \"https://cdn.jsdelivr.net/npm/@jupyter-widgets/[email protected]/dist/embed-amd.js\": {\n \"data-jupyter-widgets-cdn\": \"https://cdn.jsdelivr.net/npm/\",\n \"crossorigin\": \"anonymous\",\n },\n}\nnb_execution_show_tb = True\n\n# Additional stuff\nmaster_doc = \"index\"\n\n# Cross-reference existing Python objects\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3/\", None),\n \"pandas\": (\"https://pandas.pydata.org/pandas-docs/stable\", None),\n \"numpy\": (\"https://numpy.org/doc/stable\", None),\n \"scipy\": (\"https://docs.scipy.org/doc/scipy\", None),\n \"numba\": (\"https://numba.pydata.org/numba-doc/latest\", None),\n \"arrow\": (\"https://arrow.apache.org/docs/\", None),\n \"jax\": (\"https://jax.readthedocs.io/en/latest\", None),\n}\n\n\n# JupyterLite configuration\njupyterlite_dir = \"./lite\"\n# Don't override ipynb format\njupyterlite_bind_ipynb_suffix = False\n# We've disabled localstorage, so we must provide the contents explicitly\njupyterlite_contents = [\"getting-started/demo/*\"]\n\nlinkcheck_ignore = [\n r\"^https?:\\/\\/github\\.com\\/.*$\",\n r\"^getting-started\\/try-awkward-array\\.html$\", # Relative link won't resolve\n r\"^https?:\\/\\/$\", # Bare https:// allowed\n]\n# Eventually we need to revisit these\nif (datetime.date.today() - datetime.date(2022, 12, 13)) < datetime.timedelta(days=30):\n linkcheck_ignore.extend(\n [\n r\"^https:\\/\\/doi.org\\/10\\.1051\\/epjconf\\/202024505023$\",\n r\"^https:\\/\\/doi.org\\/10\\.1051\\/epjconf\\/202125103002$\",\n ]\n )\n\n# Generate Python docstrings\nHERE = pathlib.Path(__file__).parent\nrunpy.run_path(HERE / \"prepare_docstrings.py\", run_name=\"__main__\")\n\n\n# Sphinx doesn't usually want content to fit the screen, so we hack the styles for this page\ndef install_jupyterlite_styles(app, pagename, templatename, context, event_arg) -> None:\n if pagename != \"getting-started/try-awkward-array\":\n return\n\n app.add_css_file(\"css/try-awkward-array.css\")\n\n\ndef setup(app):\n app.connect(\"html-page-context\", install_jupyterlite_styles)\n", "path": "docs/conf.py"}]} | 2,792 | 225 |
gh_patches_debug_50321 | rasdani/github-patches | git_diff | pwndbg__pwndbg-979 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add-symbol-file should not specify a base address
This happens when connecting to a remote target:
```
hacker@babyrop_level10:~$ gdb -ex 'target remote :1234'
...
add-symbol-file /tmp/tmp_yea7f3g/babyrop_level10.0 0x555555554000
...
pwndbg> b main
Breakpoint 1 at 0x555555555581 (2 locations)
pwndbg> info b
Num Type Disp Enb Address What
1 breakpoint keep y <MULTIPLE>
1.1 y 0x0000555555555581 <main>
1.2 y 0x00005555555567c1
```
This double breakpoint results in `\xcc` bytes incorrectly polluting memory, and I've seen this corrupt the GOT and crash my program as a result.
https://github.com/pwndbg/pwndbg/blob/05036defa01d4d47bfad56867f53470a29fcdc89/pwndbg/symbol.py#L261
Why is the base address being specified here? According to the help info for `add-symbol-file`, if anything is specified for `[ADDR]`, it should be the location of the `.text` section.
```
(gdb) help add-symbol-file
Load symbols from FILE, assuming FILE has been dynamically loaded.
Usage: add-symbol-file FILE [-readnow | -readnever] [-o OFF] [ADDR] [-s SECT-NAME SECT-ADDR]...
ADDR is the starting address of the file's text.
Each '-s' argument provides a section name and address, and
should be specified if the data and bss segments are not contiguous
with the text. SECT-NAME is a section name to be loaded at SECT-ADDR.
OFF is an optional offset which is added to the default load addresses
of all sections for which no other address was specified.
The '-readnow' option will cause GDB to read the entire symbol file
immediately. This makes the command slower, but may make future operations
faster.
The '-readnever' option will prevent GDB from reading the symbol file's
symbolic debug information.
```
If we just omit the address, `gdb` will automatically find the `.text` section and use that address. Things would probably fail if there isn't a `.text` section defined, but I'm not really sure what the correct solution would be in this case anyways.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/symbol.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Looking up addresses for function names / symbols, and
5 vice-versa.
6
7 Uses IDA when available if there isn't sufficient symbol
8 information available.
9 """
10 import os
11 import re
12 import shutil
13 import tempfile
14
15 import elftools.common.exceptions
16 import elftools.elf.constants
17 import elftools.elf.elffile
18 import elftools.elf.segments
19 import gdb
20
21 import pwndbg.arch
22 import pwndbg.elf
23 import pwndbg.events
24 import pwndbg.file
25 import pwndbg.ida
26 import pwndbg.memoize
27 import pwndbg.memory
28 import pwndbg.qemu
29 import pwndbg.remote
30 import pwndbg.stack
31 import pwndbg.vmmap
32
33
34 def get_directory():
35 """
36 Retrieve the debug file directory path.
37
38 The debug file directory path ('show debug-file-directory') is a comma-
39 separated list of directories which GDB will look in to find the binaries
40 currently loaded.
41 """
42 result = gdb.execute('show debug-file-directory', to_string=True, from_tty=False)
43 expr = r'The directory where separate debug symbols are searched for is "(.*)".\n'
44
45 match = re.search(expr, result)
46
47 if match:
48 return match.group(1)
49 return ''
50
51 def set_directory(d):
52 gdb.execute('set debug-file-directory %s' % d, to_string=True, from_tty=False)
53
54 def add_directory(d):
55 current = get_directory()
56 if current:
57 set_directory('%s:%s' % (current, d))
58 else:
59 set_directory(d)
60
61 remote_files = {}
62 remote_files_dir = None
63
64 @pwndbg.events.exit
65 def reset_remote_files():
66 global remote_files
67 global remote_files_dir
68 remote_files = {}
69 if remote_files_dir is not None:
70 shutil.rmtree(remote_files_dir)
71 remote_files_dir = None
72
73 @pwndbg.events.new_objfile
74 def autofetch():
75 """
76 """
77 global remote_files_dir
78 if not pwndbg.remote.is_remote():
79 return
80
81 if pwndbg.qemu.is_qemu_usermode():
82 return
83
84 if pwndbg.android.is_android():
85 return
86
87 if not remote_files_dir:
88 remote_files_dir = tempfile.mkdtemp()
89 add_directory(remote_files_dir)
90
91 searchpath = get_directory()
92
93 for mapping in pwndbg.vmmap.get():
94 objfile = mapping.objfile
95
96 # Don't attempt to download things like '[stack]' and '[heap]'
97 if not objfile.startswith('/'):
98 continue
99
100 # Don't re-download things that we have already downloaded
101 if not objfile or objfile in remote_files:
102 continue
103
104 msg = "Downloading %r from the remote server" % objfile
105 print(msg, end='')
106
107 try:
108 data = pwndbg.file.get(objfile)
109 print('\r' + msg + ': OK')
110 except OSError:
111 # The file could not be downloaded :(
112 print('\r' + msg + ': Failed')
113 return
114
115 filename = os.path.basename(objfile)
116 local_path = os.path.join(remote_files_dir, filename)
117
118 with open(local_path, 'wb+') as f:
119 f.write(data)
120
121 remote_files[objfile] = local_path
122
123 base = None
124 for mapping in pwndbg.vmmap.get():
125 if mapping.objfile != objfile:
126 continue
127
128 if base is None or mapping.vaddr < base.vaddr:
129 base = mapping
130
131 if not base:
132 continue
133
134 base = base.vaddr
135
136 try:
137 elf = elftools.elf.elffile.ELFFile(open(local_path, 'rb'))
138 except elftools.common.exceptions.ELFError:
139 continue
140
141 gdb_command = ['add-symbol-file', local_path, hex(int(base))]
142 for section in elf.iter_sections():
143 name = section.name #.decode('latin-1')
144 section = section.header
145 if not section.sh_flags & elftools.elf.constants.SH_FLAGS.SHF_ALLOC:
146 continue
147 gdb_command += ['-s', name, hex(int(base + section.sh_addr))]
148
149 print(' '.join(gdb_command))
150 # gdb.execute(' '.join(gdb_command), from_tty=False, to_string=True)
151
152 @pwndbg.memoize.reset_on_objfile
153 def get(address, gdb_only=False):
154 """
155 Retrieve the textual name for a symbol
156 """
157 # Fast path
158 if address < pwndbg.memory.MMAP_MIN_ADDR or address >= ((1 << 64)-1):
159 return ''
160
161 # Don't look up stack addresses
162 if pwndbg.stack.find(address):
163 return ''
164
165 # This sucks, but there's not a GDB API for this.
166 result = gdb.execute('info symbol %#x' % int(address), to_string=True, from_tty=False)
167
168 if not gdb_only and result.startswith('No symbol'):
169 address = int(address)
170 exe = pwndbg.elf.exe()
171 if exe:
172 exe_map = pwndbg.vmmap.find(exe.address)
173 if exe_map and address in exe_map:
174 res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)
175 return res or ''
176
177 # Expected format looks like this:
178 # main in section .text of /bin/bash
179 # main + 3 in section .text of /bin/bash
180 # system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6
181 # No symbol matches system-1.
182 a, b, c, _ = result.split(None, 3)
183
184
185 if b == '+':
186 return "%s+%s" % (a, c)
187 if b == 'in':
188 return a
189
190 return ''
191
192 @pwndbg.memoize.reset_on_objfile
193 def address(symbol, allow_unmapped=False):
194 if isinstance(symbol, int):
195 return symbol
196
197 try:
198 return int(symbol, 0)
199 except:
200 pass
201
202 try:
203 symbol_obj = gdb.lookup_symbol(symbol)[0]
204 if symbol_obj:
205 return int(symbol_obj.value().address)
206 except Exception:
207 pass
208
209 try:
210 result = gdb.execute('info address %s' % symbol, to_string=True, from_tty=False)
211 address = int(re.search('0x[0-9a-fA-F]+', result).group(), 0)
212
213 # The address found should lie in one of the memory maps
214 # There are cases when GDB shows offsets e.g.:
215 # pwndbg> info address tcache
216 # Symbol "tcache" is a thread-local variable at offset 0x40
217 # in the thread-local storage for `/lib/x86_64-linux-gnu/libc.so.6'.
218 if not allow_unmapped and not pwndbg.vmmap.find(address):
219 return None
220
221 return address
222
223 except gdb.error:
224 return None
225
226 try:
227 address = pwndbg.ida.LocByName(symbol)
228 if address:
229 return address
230 except Exception:
231 pass
232
233 @pwndbg.events.stop
234 @pwndbg.memoize.reset_on_start
235 def add_main_exe_to_symbols():
236 if not pwndbg.remote.is_remote():
237 return
238
239 if pwndbg.android.is_android():
240 return
241
242 exe = pwndbg.elf.exe()
243
244 if not exe:
245 return
246
247 addr = exe.address
248
249 if not addr:
250 return
251
252 addr = int(addr)
253
254 mmap = pwndbg.vmmap.find(addr)
255 if not mmap:
256 return
257
258 path = mmap.objfile
259 if path and (pwndbg.arch.endian == pwndbg.arch.native_endian):
260 try:
261 gdb.execute('add-symbol-file %s %#x' % (path, addr), from_tty=False, to_string=True)
262 except gdb.error:
263 pass
264
265
266 @pwndbg.memoize.reset_on_stop
267 @pwndbg.memoize.reset_on_start
268 def selected_frame_source_absolute_filename():
269 """
270 Retrieve the symbol table’s source absolute file name from the selected frame.
271
272 In case of missing symbol table or frame information, None is returned.
273 """
274 try:
275 frame = gdb.selected_frame()
276 except gdb.error:
277 return None
278
279 if not frame:
280 return None
281
282 sal = frame.find_sal()
283 if not sal:
284 return None
285
286 symtab = sal.symtab
287 if not symtab:
288 return None
289
290 return symtab.fullname()
291
292
293 if '/usr/lib/debug' not in get_directory():
294 set_directory(get_directory() + ':/usr/lib/debug')
295
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pwndbg/symbol.py b/pwndbg/symbol.py
--- a/pwndbg/symbol.py
+++ b/pwndbg/symbol.py
@@ -258,7 +258,7 @@
path = mmap.objfile
if path and (pwndbg.arch.endian == pwndbg.arch.native_endian):
try:
- gdb.execute('add-symbol-file %s %#x' % (path, addr), from_tty=False, to_string=True)
+ gdb.execute('add-symbol-file %s' % (path,), from_tty=False, to_string=True)
except gdb.error:
pass
| {"golden_diff": "diff --git a/pwndbg/symbol.py b/pwndbg/symbol.py\n--- a/pwndbg/symbol.py\n+++ b/pwndbg/symbol.py\n@@ -258,7 +258,7 @@\n path = mmap.objfile\n if path and (pwndbg.arch.endian == pwndbg.arch.native_endian):\n try:\n- gdb.execute('add-symbol-file %s %#x' % (path, addr), from_tty=False, to_string=True)\n+ gdb.execute('add-symbol-file %s' % (path,), from_tty=False, to_string=True)\n except gdb.error:\n pass\n", "issue": "add-symbol-file should not specify a base address\nThis happens when connecting to a remote target:\r\n```\r\nhacker@babyrop_level10:~$ gdb -ex 'target remote :1234'\r\n...\r\nadd-symbol-file /tmp/tmp_yea7f3g/babyrop_level10.0 0x555555554000\r\n...\r\npwndbg> b main\r\nBreakpoint 1 at 0x555555555581 (2 locations)\r\npwndbg> info b\r\nNum Type Disp Enb Address What\r\n1 breakpoint keep y <MULTIPLE> \r\n1.1 y 0x0000555555555581 <main>\r\n1.2 y 0x00005555555567c1 \r\n```\r\nThis double breakpoint results in `\\xcc` bytes incorrectly polluting memory, and I've seen this corrupt the GOT and crash my program as a result.\r\n\r\nhttps://github.com/pwndbg/pwndbg/blob/05036defa01d4d47bfad56867f53470a29fcdc89/pwndbg/symbol.py#L261\r\n\r\nWhy is the base address being specified here? According to the help info for `add-symbol-file`, if anything is specified for `[ADDR]`, it should be the location of the `.text` section.\r\n\r\n```\r\n(gdb) help add-symbol-file\r\nLoad symbols from FILE, assuming FILE has been dynamically loaded.\r\nUsage: add-symbol-file FILE [-readnow | -readnever] [-o OFF] [ADDR] [-s SECT-NAME SECT-ADDR]...\r\nADDR is the starting address of the file's text.\r\nEach '-s' argument provides a section name and address, and\r\nshould be specified if the data and bss segments are not contiguous\r\nwith the text. SECT-NAME is a section name to be loaded at SECT-ADDR.\r\nOFF is an optional offset which is added to the default load addresses\r\nof all sections for which no other address was specified.\r\nThe '-readnow' option will cause GDB to read the entire symbol file\r\nimmediately. This makes the command slower, but may make future operations\r\nfaster.\r\nThe '-readnever' option will prevent GDB from reading the symbol file's\r\nsymbolic debug information.\r\n```\r\n\r\nIf we just omit the address, `gdb` will automatically find the `.text` section and use that address. Things would probably fail if there isn't a `.text` section defined, but I'm not really sure what the correct solution would be in this case anyways.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nLooking up addresses for function names / symbols, and\nvice-versa.\n\nUses IDA when available if there isn't sufficient symbol\ninformation available.\n\"\"\"\nimport os\nimport re\nimport shutil\nimport tempfile\n\nimport elftools.common.exceptions\nimport elftools.elf.constants\nimport elftools.elf.elffile\nimport elftools.elf.segments\nimport gdb\n\nimport pwndbg.arch\nimport pwndbg.elf\nimport pwndbg.events\nimport pwndbg.file\nimport pwndbg.ida\nimport pwndbg.memoize\nimport pwndbg.memory\nimport pwndbg.qemu\nimport pwndbg.remote\nimport pwndbg.stack\nimport pwndbg.vmmap\n\n\ndef get_directory():\n \"\"\"\n Retrieve the debug file directory path.\n\n The debug file directory path ('show debug-file-directory') is a comma-\n separated list of directories which GDB will look in to find the binaries\n currently loaded.\n \"\"\"\n result = gdb.execute('show debug-file-directory', to_string=True, from_tty=False)\n expr = r'The directory where separate debug symbols are searched for is \"(.*)\".\\n'\n\n match = re.search(expr, result)\n\n if match:\n return match.group(1)\n return ''\n\ndef set_directory(d):\n gdb.execute('set debug-file-directory %s' % d, to_string=True, from_tty=False)\n\ndef add_directory(d):\n current = get_directory()\n if current:\n set_directory('%s:%s' % (current, d))\n else:\n set_directory(d)\n\nremote_files = {}\nremote_files_dir = None\n\[email protected]\ndef reset_remote_files():\n global remote_files\n global remote_files_dir\n remote_files = {}\n if remote_files_dir is not None:\n shutil.rmtree(remote_files_dir)\n remote_files_dir = None\n\[email protected]_objfile\ndef autofetch():\n \"\"\"\n \"\"\"\n global remote_files_dir\n if not pwndbg.remote.is_remote():\n return\n\n if pwndbg.qemu.is_qemu_usermode():\n return\n\n if pwndbg.android.is_android():\n return\n\n if not remote_files_dir:\n remote_files_dir = tempfile.mkdtemp()\n add_directory(remote_files_dir)\n\n searchpath = get_directory()\n\n for mapping in pwndbg.vmmap.get():\n objfile = mapping.objfile\n\n # Don't attempt to download things like '[stack]' and '[heap]'\n if not objfile.startswith('/'):\n continue\n\n # Don't re-download things that we have already downloaded\n if not objfile or objfile in remote_files:\n continue\n\n msg = \"Downloading %r from the remote server\" % objfile\n print(msg, end='')\n\n try:\n data = pwndbg.file.get(objfile)\n print('\\r' + msg + ': OK')\n except OSError:\n # The file could not be downloaded :(\n print('\\r' + msg + ': Failed')\n return\n\n filename = os.path.basename(objfile)\n local_path = os.path.join(remote_files_dir, filename)\n\n with open(local_path, 'wb+') as f:\n f.write(data)\n\n remote_files[objfile] = local_path\n\n base = None\n for mapping in pwndbg.vmmap.get():\n if mapping.objfile != objfile:\n continue\n\n if base is None or mapping.vaddr < base.vaddr:\n base = mapping\n\n if not base:\n continue\n\n base = base.vaddr\n\n try:\n elf = elftools.elf.elffile.ELFFile(open(local_path, 'rb'))\n except elftools.common.exceptions.ELFError:\n continue\n\n gdb_command = ['add-symbol-file', local_path, hex(int(base))]\n for section in elf.iter_sections():\n name = section.name #.decode('latin-1')\n section = section.header\n if not section.sh_flags & elftools.elf.constants.SH_FLAGS.SHF_ALLOC:\n continue\n gdb_command += ['-s', name, hex(int(base + section.sh_addr))]\n\n print(' '.join(gdb_command))\n # gdb.execute(' '.join(gdb_command), from_tty=False, to_string=True)\n\[email protected]_on_objfile\ndef get(address, gdb_only=False):\n \"\"\"\n Retrieve the textual name for a symbol\n \"\"\"\n # Fast path\n if address < pwndbg.memory.MMAP_MIN_ADDR or address >= ((1 << 64)-1):\n return ''\n\n # Don't look up stack addresses\n if pwndbg.stack.find(address):\n return ''\n\n # This sucks, but there's not a GDB API for this.\n result = gdb.execute('info symbol %#x' % int(address), to_string=True, from_tty=False)\n\n if not gdb_only and result.startswith('No symbol'):\n address = int(address)\n exe = pwndbg.elf.exe()\n if exe:\n exe_map = pwndbg.vmmap.find(exe.address)\n if exe_map and address in exe_map:\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or ''\n\n # Expected format looks like this:\n # main in section .text of /bin/bash\n # main + 3 in section .text of /bin/bash\n # system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6\n # No symbol matches system-1.\n a, b, c, _ = result.split(None, 3)\n\n\n if b == '+':\n return \"%s+%s\" % (a, c)\n if b == 'in':\n return a\n\n return ''\n\[email protected]_on_objfile\ndef address(symbol, allow_unmapped=False):\n if isinstance(symbol, int):\n return symbol\n\n try:\n return int(symbol, 0)\n except:\n pass\n\n try:\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n if symbol_obj:\n return int(symbol_obj.value().address)\n except Exception:\n pass\n\n try:\n result = gdb.execute('info address %s' % symbol, to_string=True, from_tty=False)\n address = int(re.search('0x[0-9a-fA-F]+', result).group(), 0)\n\n # The address found should lie in one of the memory maps\n # There are cases when GDB shows offsets e.g.:\n # pwndbg> info address tcache\n # Symbol \"tcache\" is a thread-local variable at offset 0x40\n # in the thread-local storage for `/lib/x86_64-linux-gnu/libc.so.6'.\n if not allow_unmapped and not pwndbg.vmmap.find(address):\n return None\n\n return address\n\n except gdb.error:\n return None\n\n try:\n address = pwndbg.ida.LocByName(symbol)\n if address:\n return address\n except Exception:\n pass\n\[email protected]\[email protected]_on_start\ndef add_main_exe_to_symbols():\n if not pwndbg.remote.is_remote():\n return\n\n if pwndbg.android.is_android():\n return\n\n exe = pwndbg.elf.exe()\n\n if not exe:\n return\n\n addr = exe.address\n\n if not addr:\n return\n\n addr = int(addr)\n\n mmap = pwndbg.vmmap.find(addr)\n if not mmap:\n return\n\n path = mmap.objfile\n if path and (pwndbg.arch.endian == pwndbg.arch.native_endian):\n try:\n gdb.execute('add-symbol-file %s %#x' % (path, addr), from_tty=False, to_string=True)\n except gdb.error:\n pass\n\n\[email protected]_on_stop\[email protected]_on_start\ndef selected_frame_source_absolute_filename():\n \"\"\"\n Retrieve the symbol table\u2019s source absolute file name from the selected frame.\n\n In case of missing symbol table or frame information, None is returned.\n \"\"\"\n try:\n frame = gdb.selected_frame()\n except gdb.error:\n return None\n\n if not frame:\n return None\n\n sal = frame.find_sal()\n if not sal:\n return None\n\n symtab = sal.symtab\n if not symtab:\n return None\n\n return symtab.fullname()\n\n\nif '/usr/lib/debug' not in get_directory():\n set_directory(get_directory() + ':/usr/lib/debug')\n", "path": "pwndbg/symbol.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nLooking up addresses for function names / symbols, and\nvice-versa.\n\nUses IDA when available if there isn't sufficient symbol\ninformation available.\n\"\"\"\nimport os\nimport re\nimport shutil\nimport tempfile\n\nimport elftools.common.exceptions\nimport elftools.elf.constants\nimport elftools.elf.elffile\nimport elftools.elf.segments\nimport gdb\n\nimport pwndbg.arch\nimport pwndbg.elf\nimport pwndbg.events\nimport pwndbg.file\nimport pwndbg.ida\nimport pwndbg.memoize\nimport pwndbg.memory\nimport pwndbg.qemu\nimport pwndbg.remote\nimport pwndbg.stack\nimport pwndbg.vmmap\n\n\ndef get_directory():\n \"\"\"\n Retrieve the debug file directory path.\n\n The debug file directory path ('show debug-file-directory') is a comma-\n separated list of directories which GDB will look in to find the binaries\n currently loaded.\n \"\"\"\n result = gdb.execute('show debug-file-directory', to_string=True, from_tty=False)\n expr = r'The directory where separate debug symbols are searched for is \"(.*)\".\\n'\n\n match = re.search(expr, result)\n\n if match:\n return match.group(1)\n return ''\n\ndef set_directory(d):\n gdb.execute('set debug-file-directory %s' % d, to_string=True, from_tty=False)\n\ndef add_directory(d):\n current = get_directory()\n if current:\n set_directory('%s:%s' % (current, d))\n else:\n set_directory(d)\n\nremote_files = {}\nremote_files_dir = None\n\[email protected]\ndef reset_remote_files():\n global remote_files\n global remote_files_dir\n remote_files = {}\n if remote_files_dir is not None:\n shutil.rmtree(remote_files_dir)\n remote_files_dir = None\n\[email protected]_objfile\ndef autofetch():\n \"\"\"\n \"\"\"\n global remote_files_dir\n if not pwndbg.remote.is_remote():\n return\n\n if pwndbg.qemu.is_qemu_usermode():\n return\n\n if pwndbg.android.is_android():\n return\n\n if not remote_files_dir:\n remote_files_dir = tempfile.mkdtemp()\n add_directory(remote_files_dir)\n\n searchpath = get_directory()\n\n for mapping in pwndbg.vmmap.get():\n objfile = mapping.objfile\n\n # Don't attempt to download things like '[stack]' and '[heap]'\n if not objfile.startswith('/'):\n continue\n\n # Don't re-download things that we have already downloaded\n if not objfile or objfile in remote_files:\n continue\n\n msg = \"Downloading %r from the remote server\" % objfile\n print(msg, end='')\n\n try:\n data = pwndbg.file.get(objfile)\n print('\\r' + msg + ': OK')\n except OSError:\n # The file could not be downloaded :(\n print('\\r' + msg + ': Failed')\n return\n\n filename = os.path.basename(objfile)\n local_path = os.path.join(remote_files_dir, filename)\n\n with open(local_path, 'wb+') as f:\n f.write(data)\n\n remote_files[objfile] = local_path\n\n base = None\n for mapping in pwndbg.vmmap.get():\n if mapping.objfile != objfile:\n continue\n\n if base is None or mapping.vaddr < base.vaddr:\n base = mapping\n\n if not base:\n continue\n\n base = base.vaddr\n\n try:\n elf = elftools.elf.elffile.ELFFile(open(local_path, 'rb'))\n except elftools.common.exceptions.ELFError:\n continue\n\n gdb_command = ['add-symbol-file', local_path, hex(int(base))]\n for section in elf.iter_sections():\n name = section.name #.decode('latin-1')\n section = section.header\n if not section.sh_flags & elftools.elf.constants.SH_FLAGS.SHF_ALLOC:\n continue\n gdb_command += ['-s', name, hex(int(base + section.sh_addr))]\n\n print(' '.join(gdb_command))\n # gdb.execute(' '.join(gdb_command), from_tty=False, to_string=True)\n\[email protected]_on_objfile\ndef get(address, gdb_only=False):\n \"\"\"\n Retrieve the textual name for a symbol\n \"\"\"\n # Fast path\n if address < pwndbg.memory.MMAP_MIN_ADDR or address >= ((1 << 64)-1):\n return ''\n\n # Don't look up stack addresses\n if pwndbg.stack.find(address):\n return ''\n\n # This sucks, but there's not a GDB API for this.\n result = gdb.execute('info symbol %#x' % int(address), to_string=True, from_tty=False)\n\n if not gdb_only and result.startswith('No symbol'):\n address = int(address)\n exe = pwndbg.elf.exe()\n if exe:\n exe_map = pwndbg.vmmap.find(exe.address)\n if exe_map and address in exe_map:\n res = pwndbg.ida.Name(address) or pwndbg.ida.GetFuncOffset(address)\n return res or ''\n\n # Expected format looks like this:\n # main in section .text of /bin/bash\n # main + 3 in section .text of /bin/bash\n # system + 1 in section .text of /lib/x86_64-linux-gnu/libc.so.6\n # No symbol matches system-1.\n a, b, c, _ = result.split(None, 3)\n\n\n if b == '+':\n return \"%s+%s\" % (a, c)\n if b == 'in':\n return a\n\n return ''\n\[email protected]_on_objfile\ndef address(symbol, allow_unmapped=False):\n if isinstance(symbol, int):\n return symbol\n\n try:\n return int(symbol, 0)\n except:\n pass\n\n try:\n symbol_obj = gdb.lookup_symbol(symbol)[0]\n if symbol_obj:\n return int(symbol_obj.value().address)\n except Exception:\n pass\n\n try:\n result = gdb.execute('info address %s' % symbol, to_string=True, from_tty=False)\n address = int(re.search('0x[0-9a-fA-F]+', result).group(), 0)\n\n # The address found should lie in one of the memory maps\n # There are cases when GDB shows offsets e.g.:\n # pwndbg> info address tcache\n # Symbol \"tcache\" is a thread-local variable at offset 0x40\n # in the thread-local storage for `/lib/x86_64-linux-gnu/libc.so.6'.\n if not allow_unmapped and not pwndbg.vmmap.find(address):\n return None\n\n return address\n\n except gdb.error:\n return None\n\n try:\n address = pwndbg.ida.LocByName(symbol)\n if address:\n return address\n except Exception:\n pass\n\[email protected]\[email protected]_on_start\ndef add_main_exe_to_symbols():\n if not pwndbg.remote.is_remote():\n return\n\n if pwndbg.android.is_android():\n return\n\n exe = pwndbg.elf.exe()\n\n if not exe:\n return\n\n addr = exe.address\n\n if not addr:\n return\n\n addr = int(addr)\n\n mmap = pwndbg.vmmap.find(addr)\n if not mmap:\n return\n\n path = mmap.objfile\n if path and (pwndbg.arch.endian == pwndbg.arch.native_endian):\n try:\n gdb.execute('add-symbol-file %s' % (path,), from_tty=False, to_string=True)\n except gdb.error:\n pass\n\n\[email protected]_on_stop\[email protected]_on_start\ndef selected_frame_source_absolute_filename():\n \"\"\"\n Retrieve the symbol table\u2019s source absolute file name from the selected frame.\n\n In case of missing symbol table or frame information, None is returned.\n \"\"\"\n try:\n frame = gdb.selected_frame()\n except gdb.error:\n return None\n\n if not frame:\n return None\n\n sal = frame.find_sal()\n if not sal:\n return None\n\n symtab = sal.symtab\n if not symtab:\n return None\n\n return symtab.fullname()\n\n\nif '/usr/lib/debug' not in get_directory():\n set_directory(get_directory() + ':/usr/lib/debug')\n", "path": "pwndbg/symbol.py"}]} | 3,533 | 139 |
gh_patches_debug_155 | rasdani/github-patches | git_diff | hylang__hy-1369 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Official support for evaluating strings of Hy code from Python
Is it possible to embed some hy code inside a python file? As opposed to having the whole file be full on hy?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/__init__.py`
Content:
```
1 __appname__ = 'hy'
2 try:
3 from hy.version import __version__
4 except ImportError:
5 __version__ = 'unknown'
6
7
8 from hy.models import HyExpression, HyInteger, HyKeyword, HyComplex, HyString, HyBytes, HySymbol, HyFloat, HyDict, HyList, HySet, HyCons # NOQA
9
10
11 import hy.importer # NOQA
12 # we import for side-effects.
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/hy/__init__.py b/hy/__init__.py
--- a/hy/__init__.py
+++ b/hy/__init__.py
@@ -10,3 +10,7 @@
import hy.importer # NOQA
# we import for side-effects.
+
+
+from hy.core.language import read, read_str # NOQA
+from hy.importer import hy_eval as eval # NOQA
| {"golden_diff": "diff --git a/hy/__init__.py b/hy/__init__.py\n--- a/hy/__init__.py\n+++ b/hy/__init__.py\n@@ -10,3 +10,7 @@\n \n import hy.importer # NOQA\n # we import for side-effects.\n+\n+\n+from hy.core.language import read, read_str # NOQA\n+from hy.importer import hy_eval as eval # NOQA\n", "issue": "Official support for evaluating strings of Hy code from Python\nIs it possible to embed some hy code inside a python file? As opposed to having the whole file be full on hy?\n", "before_files": [{"content": "__appname__ = 'hy'\ntry:\n from hy.version import __version__\nexcept ImportError:\n __version__ = 'unknown'\n\n\nfrom hy.models import HyExpression, HyInteger, HyKeyword, HyComplex, HyString, HyBytes, HySymbol, HyFloat, HyDict, HyList, HySet, HyCons # NOQA\n\n\nimport hy.importer # NOQA\n# we import for side-effects.\n", "path": "hy/__init__.py"}], "after_files": [{"content": "__appname__ = 'hy'\ntry:\n from hy.version import __version__\nexcept ImportError:\n __version__ = 'unknown'\n\n\nfrom hy.models import HyExpression, HyInteger, HyKeyword, HyComplex, HyString, HyBytes, HySymbol, HyFloat, HyDict, HyList, HySet, HyCons # NOQA\n\n\nimport hy.importer # NOQA\n# we import for side-effects.\n\n\nfrom hy.core.language import read, read_str # NOQA\nfrom hy.importer import hy_eval as eval # NOQA\n", "path": "hy/__init__.py"}]} | 405 | 97 |
gh_patches_debug_12260 | rasdani/github-patches | git_diff | pytorch__ignite-2217 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve doc examples rendering
Currently we are rendering our examples in the docs like this https://pytorch.org/ignite/generated/ignite.engine.engine.Engine.html#ignite.engine.engine.Engine which is not very neat.
What we want to do is to find a better way to make it more good looking, and update our docs examples

- Replace "Examples" with some sphinx tag or something else, for example, like scikit-image does:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/conf.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Configuration file for the Sphinx documentation builder.
4 #
5 # This file does only contain a selection of the most common options. For a
6 # full list see the documentation:
7 # http://www.sphinx-doc.org/en/stable/config
8
9 # -- Path setup --------------------------------------------------------------
10
11 # If extensions (or modules to document with autodoc) are in another directory,
12 # add these directories to sys.path here. If the directory is relative to the
13 # documentation root, use os.path.abspath to make it absolute, like shown here.
14 #
15 import os
16 import sys
17
18 sys.path.insert(0, os.path.abspath("../.."))
19 import ignite
20 import pytorch_sphinx_theme
21
22 from datetime import datetime
23
24 # -- Project information -----------------------------------------------------
25
26 project = "PyTorch-Ignite"
27 author = "PyTorch-Ignite Contributors"
28 copyright = f"{datetime.now().year}, {author}"
29
30 # The short X.Y version
31 try:
32 version = os.environ["code_version"]
33 except KeyError:
34 version = ignite.__version__
35
36 # The full version, including alpha/beta/rc tags
37 release = version
38
39
40 # -- General configuration ---------------------------------------------------
41
42 # If your documentation needs a minimal Sphinx version, state it here.
43 #
44 # needs_sphinx = '1.0'
45
46 # Add any Sphinx extension module names here, as strings. They can be
47 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
48 # ones.
49 extensions = [
50 "sphinx.ext.autodoc",
51 "sphinx.ext.autosummary",
52 "sphinx.ext.doctest",
53 "sphinx.ext.intersphinx",
54 "sphinx.ext.todo",
55 "sphinx.ext.coverage",
56 "sphinxcontrib.katex",
57 "sphinx.ext.napoleon",
58 "sphinx.ext.viewcode",
59 "sphinx.ext.autosectionlabel",
60 ]
61
62 # katex options
63 katex_prerender = True
64
65 # Add any paths that contain templates here, relative to this directory.
66 templates_path = ["_templates"]
67
68 # The suffix(es) of source filenames.
69 # You can specify multiple suffix as a list of string:
70 #
71 # source_suffix = ['.rst', '.md']
72 source_suffix = ".rst"
73
74 # The master toctree document.
75 master_doc = "index"
76
77 # The language for content autogenerated by Sphinx. Refer to documentation
78 # for a list of supported languages.
79 #
80 # This is also used if you do content translation via gettext catalogs.
81 # Usually you set "language" from the command line for these cases.
82 language = "en"
83
84 # List of patterns, relative to source directory, that match files and
85 # directories to ignore when looking for source files.
86 # This pattern also affects html_static_path and html_extra_path .
87 exclude_patterns = []
88
89 # The name of the Pygments (syntax highlighting) style to use.
90 pygments_style = "sphinx"
91
92
93 # -- Options for HTML output -------------------------------------------------
94
95 # The theme to use for HTML and HTML Help pages. See the documentation for
96 # a list of builtin themes.
97
98 html_title = f"{project} {version} Documentation"
99 html_theme = "pytorch_sphinx_theme"
100 html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
101
102 html_theme_options = {
103 "canonical_url": "https://pytorch.org/ignite/",
104 "collapse_navigation": False,
105 "display_version": True,
106 "logo_only": True,
107 "navigation_with_keys": True,
108 }
109
110 html_logo = "_templates/_static/img/ignite_logo.svg"
111
112 html_favicon = "_templates/_static/img/ignite_logomark.svg"
113
114 # Theme options are theme-specific and customize the look and feel of a theme
115 # further. For a list of options available for each theme, see the
116 # documentation.
117 #
118 # html_theme_options = {}
119
120 # Add any paths that contain custom static files (such as style sheets) here,
121 # relative to this directory. They are copied after the builtin static files,
122 # so a file named "default.css" will overwrite the builtin "default.css".
123 html_static_path = ["_static", "_templates/_static"]
124
125 html_context = {
126 "css_files": [
127 # 'https://fonts.googleapis.com/css?family=Lato',
128 # '_static/css/pytorch_theme.css'
129 "_static/css/ignite_theme.css",
130 "https://cdn.jsdelivr.net/npm/@docsearch/[email protected]/dist/style.min.css",
131 ],
132 }
133
134 html_last_updated_fmt = "%m/%d/%Y, %X"
135 html_add_permalinks = "#"
136
137 # -- Options for HTMLHelp output ---------------------------------------------
138
139 # Output file base name for HTML help builder.
140 htmlhelp_basename = "ignitedoc"
141
142
143 # -- Options for LaTeX output ------------------------------------------------
144
145 latex_elements = {
146 # The paper size ('letterpaper' or 'a4paper').
147 #
148 # 'papersize': 'letterpaper',
149 # The font size ('10pt', '11pt' or '12pt').
150 #
151 # 'pointsize': '10pt',
152 # Additional stuff for the LaTeX preamble.
153 #
154 # 'preamble': '',
155 # Latex figure (float) alignment
156 #
157 # 'figure_align': 'htbp',
158 }
159
160 # Grouping the document tree into LaTeX files. List of tuples
161 # (source start file, target name, title,
162 # author, documentclass [howto, manual, or own class]).
163 latex_documents = [
164 (master_doc, "ignite.tex", "ignite Documentation", "Torch Contributors", "manual"),
165 ]
166
167
168 # -- Options for manual page output ------------------------------------------
169
170 # One entry per manual page. List of tuples
171 # (source start file, name, description, authors, manual section).
172 man_pages = [(master_doc, "ignite", "ignite Documentation", [author], 1)]
173
174
175 # -- Options for Texinfo output ----------------------------------------------
176
177 # Grouping the document tree into Texinfo files. List of tuples
178 # (source start file, target name, title, author,
179 # dir menu entry, description, category)
180 texinfo_documents = [
181 (
182 master_doc,
183 "ignite",
184 "ignite Documentation",
185 author,
186 "ignite",
187 "One line description of project.",
188 "Miscellaneous",
189 ),
190 ]
191
192
193 # -- Extension configuration -------------------------------------------------
194
195 # -- Options for intersphinx extension ---------------------------------------
196
197 # Example configuration for intersphinx: refer to the Python standard library.
198 intersphinx_mapping = {
199 "python": ("https://docs.python.org/3", None),
200 "torch": ("https://pytorch.org/docs/stable/", None),
201 }
202
203 # -- Options for todo extension ----------------------------------------------
204
205 # If true, `todo` and `todoList` produce output, else they produce nothing.
206 todo_include_todos = True
207
208 # -- Type hints configs ------------------------------------------------------
209
210 autodoc_inherit_docstrings = True
211 autoclass_content = "both"
212 autodoc_typehints = "description"
213 napoleon_attr_annotations = True
214
215 # -- A patch that turns-off cross refs for type annotations ------------------
216
217 import sphinx.domains.python
218 from docutils import nodes
219 from sphinx import addnodes
220
221 # replaces pending_xref node with desc_type for type annotations
222 sphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type("", nodes.Text(t))
223
224 # -- Autosummary patch to get list of a classes, funcs automatically ----------
225
226 from importlib import import_module
227 from inspect import getmembers, isclass, isfunction
228 import sphinx.ext.autosummary
229 from sphinx.ext.autosummary import Autosummary
230 from docutils.parsers.rst import directives
231 from docutils.statemachine import StringList
232
233
234 class BetterAutosummary(Autosummary):
235 """Autosummary with autolisting for modules.
236
237 By default it tries to import all public names (__all__),
238 otherwise import all classes and/or functions in a module.
239
240 Options:
241 - :autolist: option to get list of classes and functions from currentmodule.
242 - :autolist-classes: option to get list of classes from currentmodule.
243 - :autolist-functions: option to get list of functions from currentmodule.
244
245 Example Usage:
246
247 .. currentmodule:: ignite.metrics
248
249 .. autosummary::
250 :nosignatures:
251 :autolist:
252 """
253
254 # Add new option
255 _option_spec = Autosummary.option_spec.copy()
256 _option_spec.update(
257 {
258 "autolist": directives.unchanged,
259 "autolist-classes": directives.unchanged,
260 "autolist-functions": directives.unchanged,
261 }
262 )
263 option_spec = _option_spec
264
265 def run(self):
266 for auto in ("autolist", "autolist-classes", "autolist-functions"):
267 if auto in self.options:
268 # Get current module name
269 module_name = self.env.ref_context.get("py:module")
270 # Import module
271 module = import_module(module_name)
272
273 # Get public names (if possible)
274 try:
275 names = getattr(module, "__all__")
276 except AttributeError:
277 # Get classes defined in the module
278 cls_names = [
279 name[0]
280 for name in getmembers(module, isclass)
281 if name[-1].__module__ == module_name and not (name[0].startswith("_"))
282 ]
283 # Get functions defined in the module
284 fn_names = [
285 name[0]
286 for name in getmembers(module, isfunction)
287 if (name[-1].__module__ == module_name) and not (name[0].startswith("_"))
288 ]
289 names = cls_names + fn_names
290 # It may happen that module doesn't have any defined class or func
291 if not names:
292 names = [name[0] for name in getmembers(module)]
293
294 # Filter out members w/o doc strings
295 names = [name for name in names if getattr(module, name).__doc__ is not None]
296
297 if auto == "autolist":
298 # Get list of all classes and functions inside module
299 names = [
300 name for name in names if (isclass(getattr(module, name)) or isfunction(getattr(module, name)))
301 ]
302 else:
303 if auto == "autolist-classes":
304 # Get only classes
305 check = isclass
306 elif auto == "autolist-functions":
307 # Get only functions
308 check = isfunction
309 else:
310 raise NotImplementedError
311
312 names = [name for name in names if check(getattr(module, name))]
313
314 # Update content
315 self.content = StringList(names)
316 return super().run()
317
318
319 # Patch original Autosummary
320 sphinx.ext.autosummary.Autosummary = BetterAutosummary
321
322 # --- autosummary config -----------------------------------------------------
323 autosummary_generate = True
324
325 # --- nitpicky config : check internal links are correct or not --------------
326 nitpicky = True
327 # ignore links which can't be referenced
328 nitpick_ignore = [
329 ("py:class", ".."),
330 ("py:class", "TextIO"),
331 ("py:class", "torch.device"),
332 ("py:class", "_MpDeviceLoader"),
333 ("py:class", "torch.nn.modules.module.Module"),
334 ("py:class", "torch.optim.optimizer.Optimizer"),
335 ("py:class", "torch.utils.data.dataset.Dataset"),
336 ("py:class", "torch.utils.data.sampler.BatchSampler"),
337 ("py:class", "torch.cuda.amp.grad_scaler.GradScaler"),
338 ("py:class", "torch.optim.lr_scheduler._LRScheduler"),
339 ("py:class", "torch.utils.data.dataloader.DataLoader"),
340 ]
341
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -57,6 +57,7 @@
"sphinx.ext.napoleon",
"sphinx.ext.viewcode",
"sphinx.ext.autosectionlabel",
+ "sphinx_copybutton",
]
# katex options
@@ -123,7 +124,7 @@
html_static_path = ["_static", "_templates/_static"]
html_context = {
- "css_files": [
+ "extra_css_files": [
# 'https://fonts.googleapis.com/css?family=Lato',
# '_static/css/pytorch_theme.css'
"_static/css/ignite_theme.css",
| {"golden_diff": "diff --git a/docs/source/conf.py b/docs/source/conf.py\n--- a/docs/source/conf.py\n+++ b/docs/source/conf.py\n@@ -57,6 +57,7 @@\n \"sphinx.ext.napoleon\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosectionlabel\",\n+ \"sphinx_copybutton\",\n ]\n \n # katex options\n@@ -123,7 +124,7 @@\n html_static_path = [\"_static\", \"_templates/_static\"]\n \n html_context = {\n- \"css_files\": [\n+ \"extra_css_files\": [\n # 'https://fonts.googleapis.com/css?family=Lato',\n # '_static/css/pytorch_theme.css'\n \"_static/css/ignite_theme.css\",\n", "issue": "Improve doc examples rendering\nCurrently we are rendering our examples in the docs like this https://pytorch.org/ignite/generated/ignite.engine.engine.Engine.html#ignite.engine.engine.Engine which is not very neat.\r\nWhat we want to do is to find a better way to make it more good looking, and update our docs examples\r\n\r\n\r\n\r\n- Replace \"Examples\" with some sphinx tag or something else, for example, like scikit-image does:\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"../..\"))\nimport ignite\nimport pytorch_sphinx_theme\n\nfrom datetime import datetime\n\n# -- Project information -----------------------------------------------------\n\nproject = \"PyTorch-Ignite\"\nauthor = \"PyTorch-Ignite Contributors\"\ncopyright = f\"{datetime.now().year}, {author}\"\n\n# The short X.Y version\ntry:\n version = os.environ[\"code_version\"]\nexcept KeyError:\n version = ignite.__version__\n\n# The full version, including alpha/beta/rc tags\nrelease = version\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinxcontrib.katex\",\n \"sphinx.ext.napoleon\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosectionlabel\",\n]\n\n# katex options\nkatex_prerender = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = \"en\"\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nhtml_title = f\"{project} {version} Documentation\"\nhtml_theme = \"pytorch_sphinx_theme\"\nhtml_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]\n\nhtml_theme_options = {\n \"canonical_url\": \"https://pytorch.org/ignite/\",\n \"collapse_navigation\": False,\n \"display_version\": True,\n \"logo_only\": True,\n \"navigation_with_keys\": True,\n}\n\nhtml_logo = \"_templates/_static/img/ignite_logo.svg\"\n\nhtml_favicon = \"_templates/_static/img/ignite_logomark.svg\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\", \"_templates/_static\"]\n\nhtml_context = {\n \"css_files\": [\n # 'https://fonts.googleapis.com/css?family=Lato',\n # '_static/css/pytorch_theme.css'\n \"_static/css/ignite_theme.css\",\n \"https://cdn.jsdelivr.net/npm/@docsearch/[email protected]/dist/style.min.css\",\n ],\n}\n\nhtml_last_updated_fmt = \"%m/%d/%Y, %X\"\nhtml_add_permalinks = \"#\"\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"ignitedoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"ignite.tex\", \"ignite Documentation\", \"Torch Contributors\", \"manual\"),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"ignite\", \"ignite Documentation\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"ignite\",\n \"ignite Documentation\",\n author,\n \"ignite\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n}\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n# -- Type hints configs ------------------------------------------------------\n\nautodoc_inherit_docstrings = True\nautoclass_content = \"both\"\nautodoc_typehints = \"description\"\nnapoleon_attr_annotations = True\n\n# -- A patch that turns-off cross refs for type annotations ------------------\n\nimport sphinx.domains.python\nfrom docutils import nodes\nfrom sphinx import addnodes\n\n# replaces pending_xref node with desc_type for type annotations\nsphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type(\"\", nodes.Text(t))\n\n# -- Autosummary patch to get list of a classes, funcs automatically ----------\n\nfrom importlib import import_module\nfrom inspect import getmembers, isclass, isfunction\nimport sphinx.ext.autosummary\nfrom sphinx.ext.autosummary import Autosummary\nfrom docutils.parsers.rst import directives\nfrom docutils.statemachine import StringList\n\n\nclass BetterAutosummary(Autosummary):\n \"\"\"Autosummary with autolisting for modules.\n\n By default it tries to import all public names (__all__),\n otherwise import all classes and/or functions in a module.\n\n Options:\n - :autolist: option to get list of classes and functions from currentmodule.\n - :autolist-classes: option to get list of classes from currentmodule.\n - :autolist-functions: option to get list of functions from currentmodule.\n\n Example Usage:\n\n .. currentmodule:: ignite.metrics\n\n .. autosummary::\n :nosignatures:\n :autolist:\n \"\"\"\n\n # Add new option\n _option_spec = Autosummary.option_spec.copy()\n _option_spec.update(\n {\n \"autolist\": directives.unchanged,\n \"autolist-classes\": directives.unchanged,\n \"autolist-functions\": directives.unchanged,\n }\n )\n option_spec = _option_spec\n\n def run(self):\n for auto in (\"autolist\", \"autolist-classes\", \"autolist-functions\"):\n if auto in self.options:\n # Get current module name\n module_name = self.env.ref_context.get(\"py:module\")\n # Import module\n module = import_module(module_name)\n\n # Get public names (if possible)\n try:\n names = getattr(module, \"__all__\")\n except AttributeError:\n # Get classes defined in the module\n cls_names = [\n name[0]\n for name in getmembers(module, isclass)\n if name[-1].__module__ == module_name and not (name[0].startswith(\"_\"))\n ]\n # Get functions defined in the module\n fn_names = [\n name[0]\n for name in getmembers(module, isfunction)\n if (name[-1].__module__ == module_name) and not (name[0].startswith(\"_\"))\n ]\n names = cls_names + fn_names\n # It may happen that module doesn't have any defined class or func\n if not names:\n names = [name[0] for name in getmembers(module)]\n\n # Filter out members w/o doc strings\n names = [name for name in names if getattr(module, name).__doc__ is not None]\n\n if auto == \"autolist\":\n # Get list of all classes and functions inside module\n names = [\n name for name in names if (isclass(getattr(module, name)) or isfunction(getattr(module, name)))\n ]\n else:\n if auto == \"autolist-classes\":\n # Get only classes\n check = isclass\n elif auto == \"autolist-functions\":\n # Get only functions\n check = isfunction\n else:\n raise NotImplementedError\n\n names = [name for name in names if check(getattr(module, name))]\n\n # Update content\n self.content = StringList(names)\n return super().run()\n\n\n# Patch original Autosummary\nsphinx.ext.autosummary.Autosummary = BetterAutosummary\n\n# --- autosummary config -----------------------------------------------------\nautosummary_generate = True\n\n# --- nitpicky config : check internal links are correct or not --------------\nnitpicky = True\n# ignore links which can't be referenced\nnitpick_ignore = [\n (\"py:class\", \"..\"),\n (\"py:class\", \"TextIO\"),\n (\"py:class\", \"torch.device\"),\n (\"py:class\", \"_MpDeviceLoader\"),\n (\"py:class\", \"torch.nn.modules.module.Module\"),\n (\"py:class\", \"torch.optim.optimizer.Optimizer\"),\n (\"py:class\", \"torch.utils.data.dataset.Dataset\"),\n (\"py:class\", \"torch.utils.data.sampler.BatchSampler\"),\n (\"py:class\", \"torch.cuda.amp.grad_scaler.GradScaler\"),\n (\"py:class\", \"torch.optim.lr_scheduler._LRScheduler\"),\n (\"py:class\", \"torch.utils.data.dataloader.DataLoader\"),\n]\n", "path": "docs/source/conf.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"../..\"))\nimport ignite\nimport pytorch_sphinx_theme\n\nfrom datetime import datetime\n\n# -- Project information -----------------------------------------------------\n\nproject = \"PyTorch-Ignite\"\nauthor = \"PyTorch-Ignite Contributors\"\ncopyright = f\"{datetime.now().year}, {author}\"\n\n# The short X.Y version\ntry:\n version = os.environ[\"code_version\"]\nexcept KeyError:\n version = ignite.__version__\n\n# The full version, including alpha/beta/rc tags\nrelease = version\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinxcontrib.katex\",\n \"sphinx.ext.napoleon\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx_copybutton\",\n]\n\n# katex options\nkatex_prerender = True\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = \"en\"\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n\nhtml_title = f\"{project} {version} Documentation\"\nhtml_theme = \"pytorch_sphinx_theme\"\nhtml_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]\n\nhtml_theme_options = {\n \"canonical_url\": \"https://pytorch.org/ignite/\",\n \"collapse_navigation\": False,\n \"display_version\": True,\n \"logo_only\": True,\n \"navigation_with_keys\": True,\n}\n\nhtml_logo = \"_templates/_static/img/ignite_logo.svg\"\n\nhtml_favicon = \"_templates/_static/img/ignite_logomark.svg\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\", \"_templates/_static\"]\n\nhtml_context = {\n \"extra_css_files\": [\n # 'https://fonts.googleapis.com/css?family=Lato',\n # '_static/css/pytorch_theme.css'\n \"_static/css/ignite_theme.css\",\n \"https://cdn.jsdelivr.net/npm/@docsearch/[email protected]/dist/style.min.css\",\n ],\n}\n\nhtml_last_updated_fmt = \"%m/%d/%Y, %X\"\nhtml_add_permalinks = \"#\"\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"ignitedoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, \"ignite.tex\", \"ignite Documentation\", \"Torch Contributors\", \"manual\"),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"ignite\", \"ignite Documentation\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"ignite\",\n \"ignite Documentation\",\n author,\n \"ignite\",\n \"One line description of project.\",\n \"Miscellaneous\",\n ),\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3\", None),\n \"torch\": (\"https://pytorch.org/docs/stable/\", None),\n}\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n# -- Type hints configs ------------------------------------------------------\n\nautodoc_inherit_docstrings = True\nautoclass_content = \"both\"\nautodoc_typehints = \"description\"\nnapoleon_attr_annotations = True\n\n# -- A patch that turns-off cross refs for type annotations ------------------\n\nimport sphinx.domains.python\nfrom docutils import nodes\nfrom sphinx import addnodes\n\n# replaces pending_xref node with desc_type for type annotations\nsphinx.domains.python.type_to_xref = lambda t, e=None: addnodes.desc_type(\"\", nodes.Text(t))\n\n# -- Autosummary patch to get list of a classes, funcs automatically ----------\n\nfrom importlib import import_module\nfrom inspect import getmembers, isclass, isfunction\nimport sphinx.ext.autosummary\nfrom sphinx.ext.autosummary import Autosummary\nfrom docutils.parsers.rst import directives\nfrom docutils.statemachine import StringList\n\n\nclass BetterAutosummary(Autosummary):\n \"\"\"Autosummary with autolisting for modules.\n\n By default it tries to import all public names (__all__),\n otherwise import all classes and/or functions in a module.\n\n Options:\n - :autolist: option to get list of classes and functions from currentmodule.\n - :autolist-classes: option to get list of classes from currentmodule.\n - :autolist-functions: option to get list of functions from currentmodule.\n\n Example Usage:\n\n .. currentmodule:: ignite.metrics\n\n .. autosummary::\n :nosignatures:\n :autolist:\n \"\"\"\n\n # Add new option\n _option_spec = Autosummary.option_spec.copy()\n _option_spec.update(\n {\n \"autolist\": directives.unchanged,\n \"autolist-classes\": directives.unchanged,\n \"autolist-functions\": directives.unchanged,\n }\n )\n option_spec = _option_spec\n\n def run(self):\n for auto in (\"autolist\", \"autolist-classes\", \"autolist-functions\"):\n if auto in self.options:\n # Get current module name\n module_name = self.env.ref_context.get(\"py:module\")\n # Import module\n module = import_module(module_name)\n\n # Get public names (if possible)\n try:\n names = getattr(module, \"__all__\")\n except AttributeError:\n # Get classes defined in the module\n cls_names = [\n name[0]\n for name in getmembers(module, isclass)\n if name[-1].__module__ == module_name and not (name[0].startswith(\"_\"))\n ]\n # Get functions defined in the module\n fn_names = [\n name[0]\n for name in getmembers(module, isfunction)\n if (name[-1].__module__ == module_name) and not (name[0].startswith(\"_\"))\n ]\n names = cls_names + fn_names\n # It may happen that module doesn't have any defined class or func\n if not names:\n names = [name[0] for name in getmembers(module)]\n\n # Filter out members w/o doc strings\n names = [name for name in names if getattr(module, name).__doc__ is not None]\n\n if auto == \"autolist\":\n # Get list of all classes and functions inside module\n names = [\n name for name in names if (isclass(getattr(module, name)) or isfunction(getattr(module, name)))\n ]\n else:\n if auto == \"autolist-classes\":\n # Get only classes\n check = isclass\n elif auto == \"autolist-functions\":\n # Get only functions\n check = isfunction\n else:\n raise NotImplementedError\n\n names = [name for name in names if check(getattr(module, name))]\n\n # Update content\n self.content = StringList(names)\n return super().run()\n\n\n# Patch original Autosummary\nsphinx.ext.autosummary.Autosummary = BetterAutosummary\n\n# --- autosummary config -----------------------------------------------------\nautosummary_generate = True\n\n# --- nitpicky config : check internal links are correct or not --------------\nnitpicky = True\n# ignore links which can't be referenced\nnitpick_ignore = [\n (\"py:class\", \"..\"),\n (\"py:class\", \"TextIO\"),\n (\"py:class\", \"torch.device\"),\n (\"py:class\", \"_MpDeviceLoader\"),\n (\"py:class\", \"torch.nn.modules.module.Module\"),\n (\"py:class\", \"torch.optim.optimizer.Optimizer\"),\n (\"py:class\", \"torch.utils.data.dataset.Dataset\"),\n (\"py:class\", \"torch.utils.data.sampler.BatchSampler\"),\n (\"py:class\", \"torch.cuda.amp.grad_scaler.GradScaler\"),\n (\"py:class\", \"torch.optim.lr_scheduler._LRScheduler\"),\n (\"py:class\", \"torch.utils.data.dataloader.DataLoader\"),\n]\n", "path": "docs/source/conf.py"}]} | 3,881 | 161 |
gh_patches_debug_22 | rasdani/github-patches | git_diff | RedHatInsights__insights-core-3114 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Futures python module is included in Python3
Insights-core currently installs the [futures module](https://pypi.org/project/futures/) in all cases for the [development] target in [setup.py](https://github.com/RedHatInsights/insights-core/blob/7dc392df90a2535014cc1ec7f5df9c03a9d3d95d/setup.py#L64). This module is only necessary for Python2 since it is included in Python3. This is only used in one place in [collect.py](https://github.com/RedHatInsights/insights-core/blob/7dc392df90a2535014cc1ec7f5df9c03a9d3d95d/insights/collect.py#L286).
The `futures` module states:
> It **does not** work on Python 3 due to Python 2 syntax being used in the codebase. Python 3 users should not attempt to install it, since the package is already included in the standard library.
When installed it causes the latest version of `pip` to fail when installing into a virtual environment:
```python
Installing build dependencies ... error
ERROR: Command errored out with exit status 1:
command: /home/bfahr/work/insights/insights-core/venv36/bin/python3.6 /home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-vujizkqz/overlay --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- 'setuptools>=40.8.0' wheel
cwd: None
Complete output (29 lines):
Traceback (most recent call last):
File "/usr/lib64/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib64/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/__main__.py", line 29, in <module>
from pip._internal.cli.main import main as _main
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/main.py", line 9, in <module>
from pip._internal.cli.autocompletion import autocomplete
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/autocompletion.py", line 10, in <module>
from pip._internal.cli.main_parser import create_main_parser
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/main_parser.py", line 8, in <module>
from pip._internal.cli import cmdoptions
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/cmdoptions.py", line 23, in <module>
from pip._internal.cli.parser import ConfigOptionParser
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/parser.py", line 12, in <module>
from pip._internal.configuration import Configuration, ConfigurationError
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/configuration.py", line 27, in <module>
from pip._internal.utils.misc import ensure_dir, enum
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/utils/misc.py", line 38, in <module>
from pip._vendor.tenacity import retry, stop_after_delay, wait_fixed
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_vendor/tenacity/__init__.py", line 35, in <module>
from concurrent import futures
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/concurrent/futures/__init__.py", line 8, in <module>
from concurrent.futures._base import (FIRST_COMPLETED,
File "/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/concurrent/futures/_base.py", line 357
raise type(self._exception), self._exception, self._traceback
^
SyntaxError: invalid syntax
----------------------------------------
```
It was only used to create a thread pool for parallel collection in the client. We don't currently use this feature and since `futures` is not installed by the client RPM it would never be used. It is included in the default python on RHEL8 so it could be used if so desired, but again we don't currently use it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 import sys
3 from setuptools import setup, find_packages
4
5 __here__ = os.path.dirname(os.path.abspath(__file__))
6
7 package_info = dict.fromkeys(["RELEASE", "COMMIT", "VERSION", "NAME"])
8
9 for name in package_info:
10 with open(os.path.join(__here__, "insights", name)) as f:
11 package_info[name] = f.read().strip()
12
13 entry_points = {
14 'console_scripts': [
15 'insights-collect = insights.collect:main',
16 'insights-run = insights:main',
17 'insights = insights.command_parser:main',
18 'insights-cat = insights.tools.cat:main',
19 'insights-dupkeycheck = insights.tools.dupkeycheck:main',
20 'insights-inspect = insights.tools.insights_inspect:main',
21 'insights-info = insights.tools.query:main',
22 'insights-ocpshell= insights.ocpshell:main',
23 'client = insights.client:run',
24 'mangle = insights.util.mangle:main'
25 ]
26 }
27
28 runtime = set([
29 'six',
30 'requests',
31 'redis',
32 'cachecontrol',
33 'cachecontrol[redis]',
34 'cachecontrol[filecache]',
35 'defusedxml',
36 'lockfile',
37 'jinja2<=2.11.3',
38 ])
39
40 if (sys.version_info < (2, 7)):
41 runtime.add('pyyaml>=3.10,<=3.13')
42 else:
43 runtime.add('pyyaml')
44
45
46 def maybe_require(pkg):
47 try:
48 __import__(pkg)
49 except ImportError:
50 runtime.add(pkg)
51
52
53 maybe_require("importlib")
54 maybe_require("argparse")
55
56
57 client = set([
58 'requests',
59 'python-gnupg==0.4.6',
60 'oyaml'
61 ])
62
63 develop = set([
64 'futures==3.0.5',
65 'wheel',
66 ])
67
68 docs = set([
69 'docutils',
70 'Sphinx',
71 'nbsphinx',
72 'sphinx_rtd_theme',
73 'ipython',
74 'colorama',
75 'jinja2<=2.11.3',
76 'Pygments',
77 'jedi<0.18.0', # Open issue with jedi 0.18.0 and iPython <= 7.19
78 # https://github.com/davidhalter/jedi/issues/1714
79 ])
80
81 testing = set([
82 'coverage==4.3.4',
83 'pytest==3.0.6',
84 'pytest-cov==2.4.0',
85 'mock==2.0.0',
86 ])
87
88 cluster = set([
89 'ansible',
90 'pandas',
91 'colorama',
92 ])
93
94 openshift = set([
95 'openshift'
96 ])
97
98 linting = set([
99 'flake8==2.6.2',
100 ])
101
102 optional = set([
103 'python-cjson',
104 'python-logstash',
105 'python-statsd',
106 'watchdog',
107 ])
108
109 if __name__ == "__main__":
110 # allows for runtime modification of rpm name
111 name = os.environ.get("INSIGHTS_CORE_NAME", package_info["NAME"])
112
113 setup(
114 name=name,
115 version=package_info["VERSION"],
116 description="Insights Core is a data collection and analysis framework",
117 long_description=open("README.rst").read(),
118 url="https://github.com/redhatinsights/insights-core",
119 author="Red Hat, Inc.",
120 author_email="[email protected]",
121 packages=find_packages(),
122 install_requires=list(runtime),
123 package_data={'': ['LICENSE']},
124 license='Apache 2.0',
125 extras_require={
126 'develop': list(runtime | develop | client | docs | linting | testing | cluster),
127 'develop26': list(runtime | develop | client | linting | testing | cluster),
128 'client': list(runtime | client),
129 'client-develop': list(runtime | develop | client | linting | testing),
130 'cluster': list(runtime | cluster),
131 'openshift': list(runtime | openshift),
132 'optional': list(optional),
133 'docs': list(docs),
134 'linting': list(linting | client),
135 'testing': list(testing | client)
136 },
137 classifiers=[
138 'Development Status :: 5 - Production/Stable',
139 'Intended Audience :: Developers',
140 'Natural Language :: English',
141 'License :: OSI Approved :: Apache Software License',
142 'Programming Language :: Python',
143 'Programming Language :: Python :: 2.6',
144 'Programming Language :: Python :: 2.7',
145 'Programming Language :: Python :: 3.3',
146 'Programming Language :: Python :: 3.4',
147 'Programming Language :: Python :: 3.5',
148 'Programming Language :: Python :: 3.6'
149 ],
150 entry_points=entry_points,
151 include_package_data=True
152 )
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -61,7 +61,6 @@
])
develop = set([
- 'futures==3.0.5',
'wheel',
])
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -61,7 +61,6 @@\n ])\n \n develop = set([\n- 'futures==3.0.5',\n 'wheel',\n ])\n", "issue": "Futures python module is included in Python3\nInsights-core currently installs the [futures module](https://pypi.org/project/futures/) in all cases for the [development] target in [setup.py](https://github.com/RedHatInsights/insights-core/blob/7dc392df90a2535014cc1ec7f5df9c03a9d3d95d/setup.py#L64). This module is only necessary for Python2 since it is included in Python3. This is only used in one place in [collect.py](https://github.com/RedHatInsights/insights-core/blob/7dc392df90a2535014cc1ec7f5df9c03a9d3d95d/insights/collect.py#L286).\r\n\r\nThe `futures` module states:\r\n\r\n> It **does not** work on Python 3 due to Python 2 syntax being used in the codebase. Python 3 users should not attempt to install it, since the package is already included in the standard library.\r\n\r\nWhen installed it causes the latest version of `pip` to fail when installing into a virtual environment:\r\n\r\n```python\r\n Installing build dependencies ... error\r\n ERROR: Command errored out with exit status 1:\r\n command: /home/bfahr/work/insights/insights-core/venv36/bin/python3.6 /home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip install --ignore-installed --no-user --prefix /tmp/pip-build-env-vujizkqz/overlay --no-warn-script-location --no-binary :none: --only-binary :none: -i https://pypi.org/simple -- 'setuptools>=40.8.0' wheel\r\n cwd: None\r\n Complete output (29 lines):\r\n Traceback (most recent call last):\r\n File \"/usr/lib64/python3.6/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/lib64/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/__main__.py\", line 29, in <module>\r\n from pip._internal.cli.main import main as _main\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/main.py\", line 9, in <module>\r\n from pip._internal.cli.autocompletion import autocomplete\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/autocompletion.py\", line 10, in <module>\r\n from pip._internal.cli.main_parser import create_main_parser\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/main_parser.py\", line 8, in <module>\r\n from pip._internal.cli import cmdoptions\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/cmdoptions.py\", line 23, in <module>\r\n from pip._internal.cli.parser import ConfigOptionParser\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/cli/parser.py\", line 12, in <module>\r\n from pip._internal.configuration import Configuration, ConfigurationError\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/configuration.py\", line 27, in <module>\r\n from pip._internal.utils.misc import ensure_dir, enum\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_internal/utils/misc.py\", line 38, in <module>\r\n from pip._vendor.tenacity import retry, stop_after_delay, wait_fixed\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/pip/_vendor/tenacity/__init__.py\", line 35, in <module>\r\n from concurrent import futures\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/concurrent/futures/__init__.py\", line 8, in <module>\r\n from concurrent.futures._base import (FIRST_COMPLETED,\r\n File \"/home/bfahr/work/insights/insights-core/venv36/lib64/python3.6/site-packages/concurrent/futures/_base.py\", line 357\r\n raise type(self._exception), self._exception, self._traceback\r\n ^\r\n SyntaxError: invalid syntax\r\n ----------------------------------------\r\n```\r\n\r\nIt was only used to create a thread pool for parallel collection in the client. We don't currently use this feature and since `futures` is not installed by the client RPM it would never be used. It is included in the default python on RHEL8 so it could be used if so desired, but again we don't currently use it.\n", "before_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\n\n__here__ = os.path.dirname(os.path.abspath(__file__))\n\npackage_info = dict.fromkeys([\"RELEASE\", \"COMMIT\", \"VERSION\", \"NAME\"])\n\nfor name in package_info:\n with open(os.path.join(__here__, \"insights\", name)) as f:\n package_info[name] = f.read().strip()\n\nentry_points = {\n 'console_scripts': [\n 'insights-collect = insights.collect:main',\n 'insights-run = insights:main',\n 'insights = insights.command_parser:main',\n 'insights-cat = insights.tools.cat:main',\n 'insights-dupkeycheck = insights.tools.dupkeycheck:main',\n 'insights-inspect = insights.tools.insights_inspect:main',\n 'insights-info = insights.tools.query:main',\n 'insights-ocpshell= insights.ocpshell:main',\n 'client = insights.client:run',\n 'mangle = insights.util.mangle:main'\n ]\n}\n\nruntime = set([\n 'six',\n 'requests',\n 'redis',\n 'cachecontrol',\n 'cachecontrol[redis]',\n 'cachecontrol[filecache]',\n 'defusedxml',\n 'lockfile',\n 'jinja2<=2.11.3',\n])\n\nif (sys.version_info < (2, 7)):\n runtime.add('pyyaml>=3.10,<=3.13')\nelse:\n runtime.add('pyyaml')\n\n\ndef maybe_require(pkg):\n try:\n __import__(pkg)\n except ImportError:\n runtime.add(pkg)\n\n\nmaybe_require(\"importlib\")\nmaybe_require(\"argparse\")\n\n\nclient = set([\n 'requests',\n 'python-gnupg==0.4.6',\n 'oyaml'\n])\n\ndevelop = set([\n 'futures==3.0.5',\n 'wheel',\n])\n\ndocs = set([\n 'docutils',\n 'Sphinx',\n 'nbsphinx',\n 'sphinx_rtd_theme',\n 'ipython',\n 'colorama',\n 'jinja2<=2.11.3',\n 'Pygments',\n 'jedi<0.18.0', # Open issue with jedi 0.18.0 and iPython <= 7.19\n # https://github.com/davidhalter/jedi/issues/1714\n])\n\ntesting = set([\n 'coverage==4.3.4',\n 'pytest==3.0.6',\n 'pytest-cov==2.4.0',\n 'mock==2.0.0',\n])\n\ncluster = set([\n 'ansible',\n 'pandas',\n 'colorama',\n])\n\nopenshift = set([\n 'openshift'\n])\n\nlinting = set([\n 'flake8==2.6.2',\n])\n\noptional = set([\n 'python-cjson',\n 'python-logstash',\n 'python-statsd',\n 'watchdog',\n])\n\nif __name__ == \"__main__\":\n # allows for runtime modification of rpm name\n name = os.environ.get(\"INSIGHTS_CORE_NAME\", package_info[\"NAME\"])\n\n setup(\n name=name,\n version=package_info[\"VERSION\"],\n description=\"Insights Core is a data collection and analysis framework\",\n long_description=open(\"README.rst\").read(),\n url=\"https://github.com/redhatinsights/insights-core\",\n author=\"Red Hat, Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n install_requires=list(runtime),\n package_data={'': ['LICENSE']},\n license='Apache 2.0',\n extras_require={\n 'develop': list(runtime | develop | client | docs | linting | testing | cluster),\n 'develop26': list(runtime | develop | client | linting | testing | cluster),\n 'client': list(runtime | client),\n 'client-develop': list(runtime | develop | client | linting | testing),\n 'cluster': list(runtime | cluster),\n 'openshift': list(runtime | openshift),\n 'optional': list(optional),\n 'docs': list(docs),\n 'linting': list(linting | client),\n 'testing': list(testing | client)\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6'\n ],\n entry_points=entry_points,\n include_package_data=True\n )\n", "path": "setup.py"}], "after_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\n\n__here__ = os.path.dirname(os.path.abspath(__file__))\n\npackage_info = dict.fromkeys([\"RELEASE\", \"COMMIT\", \"VERSION\", \"NAME\"])\n\nfor name in package_info:\n with open(os.path.join(__here__, \"insights\", name)) as f:\n package_info[name] = f.read().strip()\n\nentry_points = {\n 'console_scripts': [\n 'insights-collect = insights.collect:main',\n 'insights-run = insights:main',\n 'insights = insights.command_parser:main',\n 'insights-cat = insights.tools.cat:main',\n 'insights-dupkeycheck = insights.tools.dupkeycheck:main',\n 'insights-inspect = insights.tools.insights_inspect:main',\n 'insights-info = insights.tools.query:main',\n 'insights-ocpshell= insights.ocpshell:main',\n 'client = insights.client:run',\n 'mangle = insights.util.mangle:main'\n ]\n}\n\nruntime = set([\n 'six',\n 'requests',\n 'redis',\n 'cachecontrol',\n 'cachecontrol[redis]',\n 'cachecontrol[filecache]',\n 'defusedxml',\n 'lockfile',\n 'jinja2<=2.11.3',\n])\n\nif (sys.version_info < (2, 7)):\n runtime.add('pyyaml>=3.10,<=3.13')\nelse:\n runtime.add('pyyaml')\n\n\ndef maybe_require(pkg):\n try:\n __import__(pkg)\n except ImportError:\n runtime.add(pkg)\n\n\nmaybe_require(\"importlib\")\nmaybe_require(\"argparse\")\n\n\nclient = set([\n 'requests',\n 'python-gnupg==0.4.6',\n 'oyaml'\n])\n\ndevelop = set([\n 'wheel',\n])\n\ndocs = set([\n 'docutils',\n 'Sphinx',\n 'nbsphinx',\n 'sphinx_rtd_theme',\n 'ipython',\n 'colorama',\n 'jinja2<=2.11.3',\n 'Pygments',\n 'jedi<0.18.0', # Open issue with jedi 0.18.0 and iPython <= 7.19\n # https://github.com/davidhalter/jedi/issues/1714\n])\n\ntesting = set([\n 'coverage==4.3.4',\n 'pytest==3.0.6',\n 'pytest-cov==2.4.0',\n 'mock==2.0.0',\n])\n\ncluster = set([\n 'ansible',\n 'pandas',\n 'colorama',\n])\n\nopenshift = set([\n 'openshift'\n])\n\nlinting = set([\n 'flake8==2.6.2',\n])\n\noptional = set([\n 'python-cjson',\n 'python-logstash',\n 'python-statsd',\n 'watchdog',\n])\n\nif __name__ == \"__main__\":\n # allows for runtime modification of rpm name\n name = os.environ.get(\"INSIGHTS_CORE_NAME\", package_info[\"NAME\"])\n\n setup(\n name=name,\n version=package_info[\"VERSION\"],\n description=\"Insights Core is a data collection and analysis framework\",\n long_description=open(\"README.rst\").read(),\n url=\"https://github.com/redhatinsights/insights-core\",\n author=\"Red Hat, Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n install_requires=list(runtime),\n package_data={'': ['LICENSE']},\n license='Apache 2.0',\n extras_require={\n 'develop': list(runtime | develop | client | docs | linting | testing | cluster),\n 'develop26': list(runtime | develop | client | linting | testing | cluster),\n 'client': list(runtime | client),\n 'client-develop': list(runtime | develop | client | linting | testing),\n 'cluster': list(runtime | cluster),\n 'openshift': list(runtime | openshift),\n 'optional': list(optional),\n 'docs': list(docs),\n 'linting': list(linting | client),\n 'testing': list(testing | client)\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6'\n ],\n entry_points=entry_points,\n include_package_data=True\n )\n", "path": "setup.py"}]} | 2,903 | 55 |
gh_patches_debug_1165 | rasdani/github-patches | git_diff | AnalogJ__lexicon-1356 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug in create action for glesys provider
When creating an A record with the glesys provider, the full name is added instead of the host name.
```
lexicon_config = {
"provider_name" : "glesys",
"action": "create",
"domain": "somedomain.com",
"type": "A",
"name": "lexicon",
"content": "1.2.3.4",
"glesys": {
}
}
```
Results in the A-record:
`{'id': 2723410, 'type': 'A', 'name': 'lexicon.somedomain.com', 'ttl': 3600, 'content': '1.2.3.4'}`
While the expected result is:
`{'id': 2723410, 'type': 'A', 'name': 'lexicon', 'ttl': 3600, 'content': '1.2.3.4'}`
The request data sent to `domain/addrecord` :
`{'domainname': 'somedomain.com', 'host': 'lexicon.somedomain.com', 'type': 'A', 'data': '1.2.3.4', 'ttl': 3600}`
Expected request data to `domain/addrecord`:
`{'domainname': 'somedomain.com', 'host': 'lexicon', 'type': 'A', 'data': '1.2.3.4', 'ttl': 3600}`
Glesys API documentation:
```
domain/addrecord
Url: https://api.glesys.com/domain/addrecord
Method: Only Https POST
Required arguments: domainname , host , type , data
Optional arguments: ttl
Description: Adds a dns record to a domain
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lexicon/providers/glesys.py`
Content:
```
1 """Module provider for Glesys"""
2 import json
3
4 import requests
5
6 from lexicon.exceptions import AuthenticationError
7 from lexicon.providers.base import Provider as BaseProvider
8
9 NAMESERVER_DOMAINS = ["glesys.com"]
10
11
12 def provider_parser(subparser):
13 """Generate a subparser for Glesys"""
14 subparser.add_argument("--auth-username", help="specify username (CL12345)")
15 subparser.add_argument("--auth-token", help="specify API key")
16
17
18 class Provider(BaseProvider):
19 """Provider class for Glesys"""
20
21 def __init__(self, config):
22 super(Provider, self).__init__(config)
23 self.domain_id = None
24 self.api_endpoint = "https://api.glesys.com"
25
26 def _authenticate(self):
27 payload = self._get("/domain/list")
28 domains = payload["response"]["domains"]
29 for record in domains:
30 if record["domainname"] == self.domain:
31 # Domain records do not have any id.
32 # Since domain_id cannot be None, use domain name as id instead.
33 self.domain_id = record["domainname"]
34 break
35 else:
36 raise AuthenticationError("No domain found")
37
38 # Create record. If record already exists with the same content, do nothing.
39 def _create_record(self, rtype, name, content):
40 existing = self.list_records(rtype, name, content)
41 if existing:
42 # Already exists, do nothing.
43 return True
44
45 request_data = {
46 "domainname": self.domain,
47 "host": self._full_name(name),
48 "type": rtype,
49 "data": content,
50 }
51 self._addttl(request_data)
52
53 self._post("/domain/addrecord", data=request_data)
54 return True
55
56 # List all records. Return an empty list if no records found
57 # type, name and content are used to filter records.
58 # If possible filter during the query, otherwise filter after response is received.
59 def _list_records(self, rtype=None, name=None, content=None):
60 request_data = {"domainname": self.domain}
61 payload = self._post("/domain/listrecords", data=request_data)
62
63 # Convert from Glesys record structure to Lexicon structure.
64 processed_records = [
65 self._glesysrecord2lexiconrecord(r) for r in payload["response"]["records"]
66 ]
67
68 if rtype:
69 processed_records = [
70 record for record in processed_records if record["type"] == rtype
71 ]
72 if name:
73 processed_records = [
74 record
75 for record in processed_records
76 if record["name"] == self._full_name(name)
77 ]
78 if content:
79 processed_records = [
80 record
81 for record in processed_records
82 if record["content"].lower() == content.lower()
83 ]
84
85 return processed_records
86
87 # Update a record. Identifier must be specified.
88 def _update_record(self, identifier, rtype=None, name=None, content=None):
89 request_data = {"recordid": identifier}
90 if name:
91 request_data["host"] = name
92 if rtype:
93 request_data["type"] = rtype
94 if content:
95 request_data["data"] = content
96
97 self._addttl(request_data)
98 self._post("/domain/updaterecord", data=request_data)
99 return True
100
101 # Delete an existing record.
102 # If record does not exist, do nothing.
103 # If an identifier is specified, use it, otherwise do a lookup using type, name and content.
104 def _delete_record(self, identifier=None, rtype=None, name=None, content=None):
105 delete_record_id = []
106 if not identifier:
107 records = self._list_records(rtype, name, content)
108 delete_record_id = [record["id"] for record in records]
109 else:
110 delete_record_id.append(identifier)
111
112 for record_id in delete_record_id:
113 request_data = {"recordid": record_id}
114 self._post("/domain/deleterecord", data=request_data)
115
116 return True
117
118 # Helpers.
119 def _request(self, action="GET", url="/", data=None, query_params=None):
120 if data is None:
121 data = {}
122 if query_params is None:
123 query_params = {}
124
125 query_params["format"] = "json"
126 default_headers = {
127 "Accept": "application/json",
128 "Content-Type": "application/json",
129 }
130
131 credentials = (
132 self._get_provider_option("auth_username"),
133 self._get_provider_option("auth_token"),
134 )
135 response = requests.request(
136 action,
137 self.api_endpoint + url,
138 params=query_params,
139 data=json.dumps(data),
140 headers=default_headers,
141 auth=credentials,
142 )
143
144 # if the request fails for any reason, throw an error.
145 response.raise_for_status()
146 return response.json()
147
148 # Adds TTL parameter if passed as argument to lexicon.
149 def _addttl(self, request_data):
150 if self._get_lexicon_option("ttl"):
151 request_data["ttl"] = self._get_lexicon_option("ttl")
152
153 # From Glesys record structure: [u'domainname', u'recordid', u'type', u'host', u'ttl', u'data']
154 def _glesysrecord2lexiconrecord(self, glesys_record):
155 return {
156 "id": glesys_record["recordid"],
157 "type": glesys_record["type"],
158 "name": glesys_record["host"],
159 "ttl": glesys_record["ttl"],
160 "content": glesys_record["data"],
161 }
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lexicon/providers/glesys.py b/lexicon/providers/glesys.py
--- a/lexicon/providers/glesys.py
+++ b/lexicon/providers/glesys.py
@@ -44,7 +44,7 @@
request_data = {
"domainname": self.domain,
- "host": self._full_name(name),
+ "host": name,
"type": rtype,
"data": content,
}
| {"golden_diff": "diff --git a/lexicon/providers/glesys.py b/lexicon/providers/glesys.py\n--- a/lexicon/providers/glesys.py\n+++ b/lexicon/providers/glesys.py\n@@ -44,7 +44,7 @@\n \n request_data = {\n \"domainname\": self.domain,\n- \"host\": self._full_name(name),\n+ \"host\": name,\n \"type\": rtype,\n \"data\": content,\n }\n", "issue": "Bug in create action for glesys provider\nWhen creating an A record with the glesys provider, the full name is added instead of the host name. \r\n```\r\nlexicon_config = {\r\n \"provider_name\" : \"glesys\",\r\n \"action\": \"create\", \r\n \"domain\": \"somedomain.com\",\r\n \"type\": \"A\",\r\n \"name\": \"lexicon\",\r\n \"content\": \"1.2.3.4\",\r\n \"glesys\": {\r\n }\r\n}\r\n```\r\nResults in the A-record:\r\n`{'id': 2723410, 'type': 'A', 'name': 'lexicon.somedomain.com', 'ttl': 3600, 'content': '1.2.3.4'}`\r\n\r\nWhile the expected result is:\r\n`{'id': 2723410, 'type': 'A', 'name': 'lexicon', 'ttl': 3600, 'content': '1.2.3.4'}`\r\n\r\nThe request data sent to `domain/addrecord` :\r\n`{'domainname': 'somedomain.com', 'host': 'lexicon.somedomain.com', 'type': 'A', 'data': '1.2.3.4', 'ttl': 3600}`\r\n\r\nExpected request data to `domain/addrecord`: \r\n`{'domainname': 'somedomain.com', 'host': 'lexicon', 'type': 'A', 'data': '1.2.3.4', 'ttl': 3600}`\r\n\r\nGlesys API documentation:\r\n```\r\ndomain/addrecord\r\n\r\nUrl: https://api.glesys.com/domain/addrecord\r\n\r\nMethod: Only Https POST\r\n\r\nRequired arguments: domainname , host , type , data\r\n\r\nOptional arguments: ttl\r\n\r\nDescription: Adds a dns record to a domain\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Module provider for Glesys\"\"\"\nimport json\n\nimport requests\n\nfrom lexicon.exceptions import AuthenticationError\nfrom lexicon.providers.base import Provider as BaseProvider\n\nNAMESERVER_DOMAINS = [\"glesys.com\"]\n\n\ndef provider_parser(subparser):\n \"\"\"Generate a subparser for Glesys\"\"\"\n subparser.add_argument(\"--auth-username\", help=\"specify username (CL12345)\")\n subparser.add_argument(\"--auth-token\", help=\"specify API key\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Glesys\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = \"https://api.glesys.com\"\n\n def _authenticate(self):\n payload = self._get(\"/domain/list\")\n domains = payload[\"response\"][\"domains\"]\n for record in domains:\n if record[\"domainname\"] == self.domain:\n # Domain records do not have any id.\n # Since domain_id cannot be None, use domain name as id instead.\n self.domain_id = record[\"domainname\"]\n break\n else:\n raise AuthenticationError(\"No domain found\")\n\n # Create record. If record already exists with the same content, do nothing.\n def _create_record(self, rtype, name, content):\n existing = self.list_records(rtype, name, content)\n if existing:\n # Already exists, do nothing.\n return True\n\n request_data = {\n \"domainname\": self.domain,\n \"host\": self._full_name(name),\n \"type\": rtype,\n \"data\": content,\n }\n self._addttl(request_data)\n\n self._post(\"/domain/addrecord\", data=request_data)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n request_data = {\"domainname\": self.domain}\n payload = self._post(\"/domain/listrecords\", data=request_data)\n\n # Convert from Glesys record structure to Lexicon structure.\n processed_records = [\n self._glesysrecord2lexiconrecord(r) for r in payload[\"response\"][\"records\"]\n ]\n\n if rtype:\n processed_records = [\n record for record in processed_records if record[\"type\"] == rtype\n ]\n if name:\n processed_records = [\n record\n for record in processed_records\n if record[\"name\"] == self._full_name(name)\n ]\n if content:\n processed_records = [\n record\n for record in processed_records\n if record[\"content\"].lower() == content.lower()\n ]\n\n return processed_records\n\n # Update a record. Identifier must be specified.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n request_data = {\"recordid\": identifier}\n if name:\n request_data[\"host\"] = name\n if rtype:\n request_data[\"type\"] = rtype\n if content:\n request_data[\"data\"] = content\n\n self._addttl(request_data)\n self._post(\"/domain/updaterecord\", data=request_data)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n # If an identifier is specified, use it, otherwise do a lookup using type, name and content.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record[\"id\"] for record in records]\n else:\n delete_record_id.append(identifier)\n\n for record_id in delete_record_id:\n request_data = {\"recordid\": record_id}\n self._post(\"/domain/deleterecord\", data=request_data)\n\n return True\n\n # Helpers.\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n\n query_params[\"format\"] = \"json\"\n default_headers = {\n \"Accept\": \"application/json\",\n \"Content-Type\": \"application/json\",\n }\n\n credentials = (\n self._get_provider_option(\"auth_username\"),\n self._get_provider_option(\"auth_token\"),\n )\n response = requests.request(\n action,\n self.api_endpoint + url,\n params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=credentials,\n )\n\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n return response.json()\n\n # Adds TTL parameter if passed as argument to lexicon.\n def _addttl(self, request_data):\n if self._get_lexicon_option(\"ttl\"):\n request_data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n # From Glesys record structure: [u'domainname', u'recordid', u'type', u'host', u'ttl', u'data']\n def _glesysrecord2lexiconrecord(self, glesys_record):\n return {\n \"id\": glesys_record[\"recordid\"],\n \"type\": glesys_record[\"type\"],\n \"name\": glesys_record[\"host\"],\n \"ttl\": glesys_record[\"ttl\"],\n \"content\": glesys_record[\"data\"],\n }\n", "path": "lexicon/providers/glesys.py"}], "after_files": [{"content": "\"\"\"Module provider for Glesys\"\"\"\nimport json\n\nimport requests\n\nfrom lexicon.exceptions import AuthenticationError\nfrom lexicon.providers.base import Provider as BaseProvider\n\nNAMESERVER_DOMAINS = [\"glesys.com\"]\n\n\ndef provider_parser(subparser):\n \"\"\"Generate a subparser for Glesys\"\"\"\n subparser.add_argument(\"--auth-username\", help=\"specify username (CL12345)\")\n subparser.add_argument(\"--auth-token\", help=\"specify API key\")\n\n\nclass Provider(BaseProvider):\n \"\"\"Provider class for Glesys\"\"\"\n\n def __init__(self, config):\n super(Provider, self).__init__(config)\n self.domain_id = None\n self.api_endpoint = \"https://api.glesys.com\"\n\n def _authenticate(self):\n payload = self._get(\"/domain/list\")\n domains = payload[\"response\"][\"domains\"]\n for record in domains:\n if record[\"domainname\"] == self.domain:\n # Domain records do not have any id.\n # Since domain_id cannot be None, use domain name as id instead.\n self.domain_id = record[\"domainname\"]\n break\n else:\n raise AuthenticationError(\"No domain found\")\n\n # Create record. If record already exists with the same content, do nothing.\n def _create_record(self, rtype, name, content):\n existing = self.list_records(rtype, name, content)\n if existing:\n # Already exists, do nothing.\n return True\n\n request_data = {\n \"domainname\": self.domain,\n \"host\": name,\n \"type\": rtype,\n \"data\": content,\n }\n self._addttl(request_data)\n\n self._post(\"/domain/addrecord\", data=request_data)\n return True\n\n # List all records. Return an empty list if no records found\n # type, name and content are used to filter records.\n # If possible filter during the query, otherwise filter after response is received.\n def _list_records(self, rtype=None, name=None, content=None):\n request_data = {\"domainname\": self.domain}\n payload = self._post(\"/domain/listrecords\", data=request_data)\n\n # Convert from Glesys record structure to Lexicon structure.\n processed_records = [\n self._glesysrecord2lexiconrecord(r) for r in payload[\"response\"][\"records\"]\n ]\n\n if rtype:\n processed_records = [\n record for record in processed_records if record[\"type\"] == rtype\n ]\n if name:\n processed_records = [\n record\n for record in processed_records\n if record[\"name\"] == self._full_name(name)\n ]\n if content:\n processed_records = [\n record\n for record in processed_records\n if record[\"content\"].lower() == content.lower()\n ]\n\n return processed_records\n\n # Update a record. Identifier must be specified.\n def _update_record(self, identifier, rtype=None, name=None, content=None):\n request_data = {\"recordid\": identifier}\n if name:\n request_data[\"host\"] = name\n if rtype:\n request_data[\"type\"] = rtype\n if content:\n request_data[\"data\"] = content\n\n self._addttl(request_data)\n self._post(\"/domain/updaterecord\", data=request_data)\n return True\n\n # Delete an existing record.\n # If record does not exist, do nothing.\n # If an identifier is specified, use it, otherwise do a lookup using type, name and content.\n def _delete_record(self, identifier=None, rtype=None, name=None, content=None):\n delete_record_id = []\n if not identifier:\n records = self._list_records(rtype, name, content)\n delete_record_id = [record[\"id\"] for record in records]\n else:\n delete_record_id.append(identifier)\n\n for record_id in delete_record_id:\n request_data = {\"recordid\": record_id}\n self._post(\"/domain/deleterecord\", data=request_data)\n\n return True\n\n # Helpers.\n def _request(self, action=\"GET\", url=\"/\", data=None, query_params=None):\n if data is None:\n data = {}\n if query_params is None:\n query_params = {}\n\n query_params[\"format\"] = \"json\"\n default_headers = {\n \"Accept\": \"application/json\",\n \"Content-Type\": \"application/json\",\n }\n\n credentials = (\n self._get_provider_option(\"auth_username\"),\n self._get_provider_option(\"auth_token\"),\n )\n response = requests.request(\n action,\n self.api_endpoint + url,\n params=query_params,\n data=json.dumps(data),\n headers=default_headers,\n auth=credentials,\n )\n\n # if the request fails for any reason, throw an error.\n response.raise_for_status()\n return response.json()\n\n # Adds TTL parameter if passed as argument to lexicon.\n def _addttl(self, request_data):\n if self._get_lexicon_option(\"ttl\"):\n request_data[\"ttl\"] = self._get_lexicon_option(\"ttl\")\n\n # From Glesys record structure: [u'domainname', u'recordid', u'type', u'host', u'ttl', u'data']\n def _glesysrecord2lexiconrecord(self, glesys_record):\n return {\n \"id\": glesys_record[\"recordid\"],\n \"type\": glesys_record[\"type\"],\n \"name\": glesys_record[\"host\"],\n \"ttl\": glesys_record[\"ttl\"],\n \"content\": glesys_record[\"data\"],\n }\n", "path": "lexicon/providers/glesys.py"}]} | 2,258 | 103 |
gh_patches_debug_19577 | rasdani/github-patches | git_diff | googleapis__google-cloud-python-1182 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PubSub subscription with ack_deadline set causes HTTP 400
Page Name: pubsub-usage
Release: 0.7.1
This appears to return an API error:
```
subscription = topic.subscription('subscription_name', ack_deadline=600)
```
Here is what I am seeing:
```
...
File "/home/greg.taylor/workspace/aclima/sig-cassandra-extractor/aclima/cass_extractor/queue.py", line 42, in run
self.subscription.create()
File "/home/greg.taylor/.virtualenvs/cas-e/lib/python3.4/site-packages/gcloud/pubsub/subscription.py", line 121, in create
client.connection.api_request(method='PUT', path=self.path, data=data)
File "/home/greg.taylor/.virtualenvs/cas-e/lib/python3.4/site-packages/gcloud/connection.py", line 419, in api_request
error_info=method + ' ' + url)
gcloud.exceptions.BadRequest: 400 Invalid JSON payload received. Unknown name "ack_deadline": Cannot find field. (PUT https://pubsub.googleapis.com/v1/projects/aclima-gsa/subscriptions/cassandra_extractor)
```
If I remove the `ack_deadline` kwarg, all is well. We definitely want the ack_deadline, thoguh.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gcloud/pubsub/subscription.py`
Content:
```
1 # Copyright 2015 Google Inc. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Define API Subscriptions."""
16
17 from gcloud.exceptions import NotFound
18 from gcloud.pubsub._helpers import topic_name_from_path
19 from gcloud.pubsub.message import Message
20
21
22 class Subscription(object):
23 """Subscriptions receive messages published to their topics.
24
25 See:
26 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions
27
28 :type name: string
29 :param name: the name of the subscription
30
31 :type topic: :class:`gcloud.pubsub.topic.Topic`
32 :param topic: the topic to which the subscription belongs..
33
34 :type ack_deadline: int
35 :param ack_deadline: the deadline (in seconds) by which messages pulled
36 from the back-end must be acknowledged.
37
38 :type push_endpoint: string
39 :param push_endpoint: URL to which messages will be pushed by the back-end.
40 If not set, the application must pull messages.
41 """
42 def __init__(self, name, topic, ack_deadline=None, push_endpoint=None):
43 self.name = name
44 self.topic = topic
45 self.ack_deadline = ack_deadline
46 self.push_endpoint = push_endpoint
47
48 @classmethod
49 def from_api_repr(cls, resource, client, topics=None):
50 """Factory: construct a topic given its API representation
51
52 :type resource: dict
53 :param resource: topic resource representation returned from the API
54
55 :type client: :class:`gcloud.pubsub.client.Client`
56 :param client: Client which holds credentials and project
57 configuration for a topic.
58
59 :type topics: dict or None
60 :param topics: A mapping of topic names -> topics. If not passed,
61 the subscription will have a newly-created topic.
62
63 :rtype: :class:`gcloud.pubsub.subscription.Subscription`
64 :returns: Subscription parsed from ``resource``.
65 """
66 if topics is None:
67 topics = {}
68 topic_path = resource['topic']
69 topic = topics.get(topic_path)
70 if topic is None:
71 # NOTE: This duplicates behavior from Topic.from_api_repr to avoid
72 # an import cycle.
73 topic_name = topic_name_from_path(topic_path, client.project)
74 topic = topics[topic_path] = client.topic(topic_name)
75 _, _, _, name = resource['name'].split('/')
76 ack_deadline = resource.get('ackDeadlineSeconds')
77 push_config = resource.get('pushConfig', {})
78 push_endpoint = push_config.get('pushEndpoint')
79 return cls(name, topic, ack_deadline, push_endpoint)
80
81 @property
82 def path(self):
83 """URL path for the subscription's APIs"""
84 project = self.topic.project
85 return '/projects/%s/subscriptions/%s' % (project, self.name)
86
87 def _require_client(self, client):
88 """Check client or verify over-ride.
89
90 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
91 :param client: the client to use. If not passed, falls back to the
92 ``client`` stored on the topic of the
93 current subscription.
94
95 :rtype: :class:`gcloud.pubsub.client.Client`
96 :returns: The client passed in or the currently bound client.
97 """
98 if client is None:
99 client = self.topic._client
100 return client
101
102 def create(self, client=None):
103 """API call: create the subscription via a PUT request
104
105 See:
106 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/create
107
108 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
109 :param client: the client to use. If not passed, falls back to the
110 ``client`` stored on the current subscription's topic.
111 """
112 data = {'topic': self.topic.full_name}
113
114 if self.ack_deadline is not None:
115 data['ackDeadline'] = self.ack_deadline
116
117 if self.push_endpoint is not None:
118 data['pushConfig'] = {'pushEndpoint': self.push_endpoint}
119
120 client = self._require_client(client)
121 client.connection.api_request(method='PUT', path=self.path, data=data)
122
123 def exists(self, client=None):
124 """API call: test existence of the subscription via a GET request
125
126 See
127 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get
128
129 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
130 :param client: the client to use. If not passed, falls back to the
131 ``client`` stored on the current subscription's topic.
132 """
133 client = self._require_client(client)
134 try:
135 client.connection.api_request(method='GET', path=self.path)
136 except NotFound:
137 return False
138 else:
139 return True
140
141 def reload(self, client=None):
142 """API call: sync local subscription configuration via a GET request
143
144 See
145 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get
146
147 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
148 :param client: the client to use. If not passed, falls back to the
149 ``client`` stored on the current subscription's topic.
150 """
151 client = self._require_client(client)
152 data = client.connection.api_request(method='GET', path=self.path)
153 self.ack_deadline = data.get('ackDeadline')
154 push_config = data.get('pushConfig', {})
155 self.push_endpoint = push_config.get('pushEndpoint')
156
157 def modify_push_configuration(self, push_endpoint, client=None):
158 """API call: update the push endpoint for the subscription.
159
160 See:
161 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/modifyPushConfig
162
163 :type push_endpoint: string
164 :param push_endpoint: URL to which messages will be pushed by the
165 back-end. If None, the application must pull
166 messages.
167
168 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
169 :param client: the client to use. If not passed, falls back to the
170 ``client`` stored on the current subscription's topic.
171 """
172 client = self._require_client(client)
173 data = {}
174 config = data['pushConfig'] = {}
175 if push_endpoint is not None:
176 config['pushEndpoint'] = push_endpoint
177 client.connection.api_request(
178 method='POST', path='%s:modifyPushConfig' % (self.path,),
179 data=data)
180 self.push_endpoint = push_endpoint
181
182 def pull(self, return_immediately=False, max_messages=1, client=None):
183 """API call: retrieve messages for the subscription.
184
185 See:
186 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/pull
187
188 :type return_immediately: boolean
189 :param return_immediately: if True, the back-end returns even if no
190 messages are available; if False, the API
191 call blocks until one or more messages are
192 available.
193
194 :type max_messages: int
195 :param max_messages: the maximum number of messages to return.
196
197 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
198 :param client: the client to use. If not passed, falls back to the
199 ``client`` stored on the current subscription's topic.
200
201 :rtype: list of (ack_id, message) tuples
202 :returns: sequence of tuples: ``ack_id`` is the ID to be used in a
203 subsequent call to :meth:`acknowledge`, and ``message``
204 is an instance of :class:`gcloud.pubsub.message.Message`.
205 """
206 client = self._require_client(client)
207 data = {'returnImmediately': return_immediately,
208 'maxMessages': max_messages}
209 response = client.connection.api_request(
210 method='POST', path='%s:pull' % (self.path,), data=data)
211 return [(info['ackId'], Message.from_api_repr(info['message']))
212 for info in response.get('receivedMessages', ())]
213
214 def acknowledge(self, ack_ids, client=None):
215 """API call: acknowledge retrieved messages for the subscription.
216
217 See:
218 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge
219
220 :type ack_ids: list of string
221 :param ack_ids: ack IDs of messages being acknowledged
222
223 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
224 :param client: the client to use. If not passed, falls back to the
225 ``client`` stored on the current subscription's topic.
226 """
227 client = self._require_client(client)
228 data = {'ackIds': ack_ids}
229 client.connection.api_request(
230 method='POST', path='%s:acknowledge' % (self.path,), data=data)
231
232 def modify_ack_deadline(self, ack_id, ack_deadline, client=None):
233 """API call: update acknowledgement deadline for a retrieved message.
234
235 See:
236 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge
237
238 :type ack_id: string
239 :param ack_id: ack ID of message being updated
240
241 :type ack_deadline: int
242 :param ack_deadline: new deadline for the message, in seconds
243
244 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
245 :param client: the client to use. If not passed, falls back to the
246 ``client`` stored on the current subscription's topic.
247 """
248 client = self._require_client(client)
249 data = {'ackIds': [ack_id], 'ackDeadlineSeconds': ack_deadline}
250 client.connection.api_request(
251 method='POST', path='%s:modifyAckDeadline' % (self.path,),
252 data=data)
253
254 def delete(self, client=None):
255 """API call: delete the subscription via a DELETE request.
256
257 See:
258 https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/delete
259
260 :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``
261 :param client: the client to use. If not passed, falls back to the
262 ``client`` stored on the current subscription's topic.
263 """
264 client = self._require_client(client)
265 client.connection.api_request(method='DELETE', path=self.path)
266
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gcloud/pubsub/subscription.py b/gcloud/pubsub/subscription.py
--- a/gcloud/pubsub/subscription.py
+++ b/gcloud/pubsub/subscription.py
@@ -112,7 +112,7 @@
data = {'topic': self.topic.full_name}
if self.ack_deadline is not None:
- data['ackDeadline'] = self.ack_deadline
+ data['ackDeadlineSeconds'] = self.ack_deadline
if self.push_endpoint is not None:
data['pushConfig'] = {'pushEndpoint': self.push_endpoint}
@@ -150,7 +150,7 @@
"""
client = self._require_client(client)
data = client.connection.api_request(method='GET', path=self.path)
- self.ack_deadline = data.get('ackDeadline')
+ self.ack_deadline = data.get('ackDeadlineSeconds')
push_config = data.get('pushConfig', {})
self.push_endpoint = push_config.get('pushEndpoint')
| {"golden_diff": "diff --git a/gcloud/pubsub/subscription.py b/gcloud/pubsub/subscription.py\n--- a/gcloud/pubsub/subscription.py\n+++ b/gcloud/pubsub/subscription.py\n@@ -112,7 +112,7 @@\n data = {'topic': self.topic.full_name}\n \n if self.ack_deadline is not None:\n- data['ackDeadline'] = self.ack_deadline\n+ data['ackDeadlineSeconds'] = self.ack_deadline\n \n if self.push_endpoint is not None:\n data['pushConfig'] = {'pushEndpoint': self.push_endpoint}\n@@ -150,7 +150,7 @@\n \"\"\"\n client = self._require_client(client)\n data = client.connection.api_request(method='GET', path=self.path)\n- self.ack_deadline = data.get('ackDeadline')\n+ self.ack_deadline = data.get('ackDeadlineSeconds')\n push_config = data.get('pushConfig', {})\n self.push_endpoint = push_config.get('pushEndpoint')\n", "issue": "PubSub subscription with ack_deadline set causes HTTP 400\nPage Name: pubsub-usage\nRelease: 0.7.1\n\nThis appears to return an API error:\n\n```\nsubscription = topic.subscription('subscription_name', ack_deadline=600)\n```\n\nHere is what I am seeing:\n\n```\n...\n File \"/home/greg.taylor/workspace/aclima/sig-cassandra-extractor/aclima/cass_extractor/queue.py\", line 42, in run\n self.subscription.create()\n File \"/home/greg.taylor/.virtualenvs/cas-e/lib/python3.4/site-packages/gcloud/pubsub/subscription.py\", line 121, in create\n client.connection.api_request(method='PUT', path=self.path, data=data)\n File \"/home/greg.taylor/.virtualenvs/cas-e/lib/python3.4/site-packages/gcloud/connection.py\", line 419, in api_request\n error_info=method + ' ' + url)\ngcloud.exceptions.BadRequest: 400 Invalid JSON payload received. Unknown name \"ack_deadline\": Cannot find field. (PUT https://pubsub.googleapis.com/v1/projects/aclima-gsa/subscriptions/cassandra_extractor)\n```\n\nIf I remove the `ack_deadline` kwarg, all is well. We definitely want the ack_deadline, thoguh.\n\n", "before_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Define API Subscriptions.\"\"\"\n\nfrom gcloud.exceptions import NotFound\nfrom gcloud.pubsub._helpers import topic_name_from_path\nfrom gcloud.pubsub.message import Message\n\n\nclass Subscription(object):\n \"\"\"Subscriptions receive messages published to their topics.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions\n\n :type name: string\n :param name: the name of the subscription\n\n :type topic: :class:`gcloud.pubsub.topic.Topic`\n :param topic: the topic to which the subscription belongs..\n\n :type ack_deadline: int\n :param ack_deadline: the deadline (in seconds) by which messages pulled\n from the back-end must be acknowledged.\n\n :type push_endpoint: string\n :param push_endpoint: URL to which messages will be pushed by the back-end.\n If not set, the application must pull messages.\n \"\"\"\n def __init__(self, name, topic, ack_deadline=None, push_endpoint=None):\n self.name = name\n self.topic = topic\n self.ack_deadline = ack_deadline\n self.push_endpoint = push_endpoint\n\n @classmethod\n def from_api_repr(cls, resource, client, topics=None):\n \"\"\"Factory: construct a topic given its API representation\n\n :type resource: dict\n :param resource: topic resource representation returned from the API\n\n :type client: :class:`gcloud.pubsub.client.Client`\n :param client: Client which holds credentials and project\n configuration for a topic.\n\n :type topics: dict or None\n :param topics: A mapping of topic names -> topics. If not passed,\n the subscription will have a newly-created topic.\n\n :rtype: :class:`gcloud.pubsub.subscription.Subscription`\n :returns: Subscription parsed from ``resource``.\n \"\"\"\n if topics is None:\n topics = {}\n topic_path = resource['topic']\n topic = topics.get(topic_path)\n if topic is None:\n # NOTE: This duplicates behavior from Topic.from_api_repr to avoid\n # an import cycle.\n topic_name = topic_name_from_path(topic_path, client.project)\n topic = topics[topic_path] = client.topic(topic_name)\n _, _, _, name = resource['name'].split('/')\n ack_deadline = resource.get('ackDeadlineSeconds')\n push_config = resource.get('pushConfig', {})\n push_endpoint = push_config.get('pushEndpoint')\n return cls(name, topic, ack_deadline, push_endpoint)\n\n @property\n def path(self):\n \"\"\"URL path for the subscription's APIs\"\"\"\n project = self.topic.project\n return '/projects/%s/subscriptions/%s' % (project, self.name)\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the topic of the\n current subscription.\n\n :rtype: :class:`gcloud.pubsub.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self.topic._client\n return client\n\n def create(self, client=None):\n \"\"\"API call: create the subscription via a PUT request\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/create\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n data = {'topic': self.topic.full_name}\n\n if self.ack_deadline is not None:\n data['ackDeadline'] = self.ack_deadline\n\n if self.push_endpoint is not None:\n data['pushConfig'] = {'pushEndpoint': self.push_endpoint}\n\n client = self._require_client(client)\n client.connection.api_request(method='PUT', path=self.path, data=data)\n\n def exists(self, client=None):\n \"\"\"API call: test existence of the subscription via a GET request\n\n See\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n try:\n client.connection.api_request(method='GET', path=self.path)\n except NotFound:\n return False\n else:\n return True\n\n def reload(self, client=None):\n \"\"\"API call: sync local subscription configuration via a GET request\n\n See\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = client.connection.api_request(method='GET', path=self.path)\n self.ack_deadline = data.get('ackDeadline')\n push_config = data.get('pushConfig', {})\n self.push_endpoint = push_config.get('pushEndpoint')\n\n def modify_push_configuration(self, push_endpoint, client=None):\n \"\"\"API call: update the push endpoint for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/modifyPushConfig\n\n :type push_endpoint: string\n :param push_endpoint: URL to which messages will be pushed by the\n back-end. If None, the application must pull\n messages.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {}\n config = data['pushConfig'] = {}\n if push_endpoint is not None:\n config['pushEndpoint'] = push_endpoint\n client.connection.api_request(\n method='POST', path='%s:modifyPushConfig' % (self.path,),\n data=data)\n self.push_endpoint = push_endpoint\n\n def pull(self, return_immediately=False, max_messages=1, client=None):\n \"\"\"API call: retrieve messages for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/pull\n\n :type return_immediately: boolean\n :param return_immediately: if True, the back-end returns even if no\n messages are available; if False, the API\n call blocks until one or more messages are\n available.\n\n :type max_messages: int\n :param max_messages: the maximum number of messages to return.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n\n :rtype: list of (ack_id, message) tuples\n :returns: sequence of tuples: ``ack_id`` is the ID to be used in a\n subsequent call to :meth:`acknowledge`, and ``message``\n is an instance of :class:`gcloud.pubsub.message.Message`.\n \"\"\"\n client = self._require_client(client)\n data = {'returnImmediately': return_immediately,\n 'maxMessages': max_messages}\n response = client.connection.api_request(\n method='POST', path='%s:pull' % (self.path,), data=data)\n return [(info['ackId'], Message.from_api_repr(info['message']))\n for info in response.get('receivedMessages', ())]\n\n def acknowledge(self, ack_ids, client=None):\n \"\"\"API call: acknowledge retrieved messages for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge\n\n :type ack_ids: list of string\n :param ack_ids: ack IDs of messages being acknowledged\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {'ackIds': ack_ids}\n client.connection.api_request(\n method='POST', path='%s:acknowledge' % (self.path,), data=data)\n\n def modify_ack_deadline(self, ack_id, ack_deadline, client=None):\n \"\"\"API call: update acknowledgement deadline for a retrieved message.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge\n\n :type ack_id: string\n :param ack_id: ack ID of message being updated\n\n :type ack_deadline: int\n :param ack_deadline: new deadline for the message, in seconds\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {'ackIds': [ack_id], 'ackDeadlineSeconds': ack_deadline}\n client.connection.api_request(\n method='POST', path='%s:modifyAckDeadline' % (self.path,),\n data=data)\n\n def delete(self, client=None):\n \"\"\"API call: delete the subscription via a DELETE request.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/delete\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n client.connection.api_request(method='DELETE', path=self.path)\n", "path": "gcloud/pubsub/subscription.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Define API Subscriptions.\"\"\"\n\nfrom gcloud.exceptions import NotFound\nfrom gcloud.pubsub._helpers import topic_name_from_path\nfrom gcloud.pubsub.message import Message\n\n\nclass Subscription(object):\n \"\"\"Subscriptions receive messages published to their topics.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions\n\n :type name: string\n :param name: the name of the subscription\n\n :type topic: :class:`gcloud.pubsub.topic.Topic`\n :param topic: the topic to which the subscription belongs..\n\n :type ack_deadline: int\n :param ack_deadline: the deadline (in seconds) by which messages pulled\n from the back-end must be acknowledged.\n\n :type push_endpoint: string\n :param push_endpoint: URL to which messages will be pushed by the back-end.\n If not set, the application must pull messages.\n \"\"\"\n def __init__(self, name, topic, ack_deadline=None, push_endpoint=None):\n self.name = name\n self.topic = topic\n self.ack_deadline = ack_deadline\n self.push_endpoint = push_endpoint\n\n @classmethod\n def from_api_repr(cls, resource, client, topics=None):\n \"\"\"Factory: construct a topic given its API representation\n\n :type resource: dict\n :param resource: topic resource representation returned from the API\n\n :type client: :class:`gcloud.pubsub.client.Client`\n :param client: Client which holds credentials and project\n configuration for a topic.\n\n :type topics: dict or None\n :param topics: A mapping of topic names -> topics. If not passed,\n the subscription will have a newly-created topic.\n\n :rtype: :class:`gcloud.pubsub.subscription.Subscription`\n :returns: Subscription parsed from ``resource``.\n \"\"\"\n if topics is None:\n topics = {}\n topic_path = resource['topic']\n topic = topics.get(topic_path)\n if topic is None:\n # NOTE: This duplicates behavior from Topic.from_api_repr to avoid\n # an import cycle.\n topic_name = topic_name_from_path(topic_path, client.project)\n topic = topics[topic_path] = client.topic(topic_name)\n _, _, _, name = resource['name'].split('/')\n ack_deadline = resource.get('ackDeadlineSeconds')\n push_config = resource.get('pushConfig', {})\n push_endpoint = push_config.get('pushEndpoint')\n return cls(name, topic, ack_deadline, push_endpoint)\n\n @property\n def path(self):\n \"\"\"URL path for the subscription's APIs\"\"\"\n project = self.topic.project\n return '/projects/%s/subscriptions/%s' % (project, self.name)\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the topic of the\n current subscription.\n\n :rtype: :class:`gcloud.pubsub.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self.topic._client\n return client\n\n def create(self, client=None):\n \"\"\"API call: create the subscription via a PUT request\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/create\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n data = {'topic': self.topic.full_name}\n\n if self.ack_deadline is not None:\n data['ackDeadlineSeconds'] = self.ack_deadline\n\n if self.push_endpoint is not None:\n data['pushConfig'] = {'pushEndpoint': self.push_endpoint}\n\n client = self._require_client(client)\n client.connection.api_request(method='PUT', path=self.path, data=data)\n\n def exists(self, client=None):\n \"\"\"API call: test existence of the subscription via a GET request\n\n See\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n try:\n client.connection.api_request(method='GET', path=self.path)\n except NotFound:\n return False\n else:\n return True\n\n def reload(self, client=None):\n \"\"\"API call: sync local subscription configuration via a GET request\n\n See\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/get\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = client.connection.api_request(method='GET', path=self.path)\n self.ack_deadline = data.get('ackDeadlineSeconds')\n push_config = data.get('pushConfig', {})\n self.push_endpoint = push_config.get('pushEndpoint')\n\n def modify_push_configuration(self, push_endpoint, client=None):\n \"\"\"API call: update the push endpoint for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/modifyPushConfig\n\n :type push_endpoint: string\n :param push_endpoint: URL to which messages will be pushed by the\n back-end. If None, the application must pull\n messages.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {}\n config = data['pushConfig'] = {}\n if push_endpoint is not None:\n config['pushEndpoint'] = push_endpoint\n client.connection.api_request(\n method='POST', path='%s:modifyPushConfig' % (self.path,),\n data=data)\n self.push_endpoint = push_endpoint\n\n def pull(self, return_immediately=False, max_messages=1, client=None):\n \"\"\"API call: retrieve messages for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/pull\n\n :type return_immediately: boolean\n :param return_immediately: if True, the back-end returns even if no\n messages are available; if False, the API\n call blocks until one or more messages are\n available.\n\n :type max_messages: int\n :param max_messages: the maximum number of messages to return.\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n\n :rtype: list of (ack_id, message) tuples\n :returns: sequence of tuples: ``ack_id`` is the ID to be used in a\n subsequent call to :meth:`acknowledge`, and ``message``\n is an instance of :class:`gcloud.pubsub.message.Message`.\n \"\"\"\n client = self._require_client(client)\n data = {'returnImmediately': return_immediately,\n 'maxMessages': max_messages}\n response = client.connection.api_request(\n method='POST', path='%s:pull' % (self.path,), data=data)\n return [(info['ackId'], Message.from_api_repr(info['message']))\n for info in response.get('receivedMessages', ())]\n\n def acknowledge(self, ack_ids, client=None):\n \"\"\"API call: acknowledge retrieved messages for the subscription.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge\n\n :type ack_ids: list of string\n :param ack_ids: ack IDs of messages being acknowledged\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {'ackIds': ack_ids}\n client.connection.api_request(\n method='POST', path='%s:acknowledge' % (self.path,), data=data)\n\n def modify_ack_deadline(self, ack_id, ack_deadline, client=None):\n \"\"\"API call: update acknowledgement deadline for a retrieved message.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/acknowledge\n\n :type ack_id: string\n :param ack_id: ack ID of message being updated\n\n :type ack_deadline: int\n :param ack_deadline: new deadline for the message, in seconds\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n data = {'ackIds': [ack_id], 'ackDeadlineSeconds': ack_deadline}\n client.connection.api_request(\n method='POST', path='%s:modifyAckDeadline' % (self.path,),\n data=data)\n\n def delete(self, client=None):\n \"\"\"API call: delete the subscription via a DELETE request.\n\n See:\n https://cloud.google.com/pubsub/reference/rest/v1beta2/projects/subscriptions/delete\n\n :type client: :class:`gcloud.pubsub.client.Client` or ``NoneType``\n :param client: the client to use. If not passed, falls back to the\n ``client`` stored on the current subscription's topic.\n \"\"\"\n client = self._require_client(client)\n client.connection.api_request(method='DELETE', path=self.path)\n", "path": "gcloud/pubsub/subscription.py"}]} | 3,663 | 222 |
gh_patches_debug_11274 | rasdani/github-patches | git_diff | elastic__apm-agent-python-1021 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove Python 3.5 support
Python 3.5 hit EOL September 13, 2020. Support will be removed in our next major release.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30 import sys
31
32 from elasticapm.base import Client
33 from elasticapm.conf import setup_logging # noqa: F401
34 from elasticapm.instrumentation.control import instrument, uninstrument # noqa: F401
35 from elasticapm.traces import ( # noqa: F401
36 capture_span,
37 get_span_id,
38 get_trace_id,
39 get_transaction_id,
40 get_trace_parent_header,
41 label,
42 set_context,
43 set_custom_context,
44 set_transaction_name,
45 set_transaction_outcome,
46 set_transaction_result,
47 set_user_context,
48 tag,
49 )
50 from elasticapm.utils.disttracing import trace_parent_from_headers, trace_parent_from_string # noqa: F401
51
52 __all__ = ("VERSION", "Client")
53
54 try:
55 try:
56 VERSION = __import__("importlib.metadata").metadata.version("elastic-apm")
57 except ImportError:
58 VERSION = __import__("pkg_resources").get_distribution("elastic-apm").version
59 except Exception:
60 VERSION = "unknown"
61
62
63 if sys.version_info >= (3, 5):
64 from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/elasticapm/__init__.py b/elasticapm/__init__.py
--- a/elasticapm/__init__.py
+++ b/elasticapm/__init__.py
@@ -36,8 +36,8 @@
capture_span,
get_span_id,
get_trace_id,
- get_transaction_id,
get_trace_parent_header,
+ get_transaction_id,
label,
set_context,
set_custom_context,
@@ -60,5 +60,7 @@
VERSION = "unknown"
-if sys.version_info >= (3, 5):
- from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401
+if sys.version_info <= (3, 5):
+ raise DeprecationWarning("The Elastic APM agent requires Python 3.6+")
+
+from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401
| {"golden_diff": "diff --git a/elasticapm/__init__.py b/elasticapm/__init__.py\n--- a/elasticapm/__init__.py\n+++ b/elasticapm/__init__.py\n@@ -36,8 +36,8 @@\n capture_span,\n get_span_id,\n get_trace_id,\n- get_transaction_id,\n get_trace_parent_header,\n+ get_transaction_id,\n label,\n set_context,\n set_custom_context,\n@@ -60,5 +60,7 @@\n VERSION = \"unknown\"\n \n \n-if sys.version_info >= (3, 5):\n- from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401\n+if sys.version_info <= (3, 5):\n+ raise DeprecationWarning(\"The Elastic APM agent requires Python 3.6+\")\n+\n+from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401\n", "issue": "Remove Python 3.5 support\nPython 3.5 hit EOL September 13, 2020. Support will be removed in our next major release.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\nimport sys\n\nfrom elasticapm.base import Client\nfrom elasticapm.conf import setup_logging # noqa: F401\nfrom elasticapm.instrumentation.control import instrument, uninstrument # noqa: F401\nfrom elasticapm.traces import ( # noqa: F401\n capture_span,\n get_span_id,\n get_trace_id,\n get_transaction_id,\n get_trace_parent_header,\n label,\n set_context,\n set_custom_context,\n set_transaction_name,\n set_transaction_outcome,\n set_transaction_result,\n set_user_context,\n tag,\n)\nfrom elasticapm.utils.disttracing import trace_parent_from_headers, trace_parent_from_string # noqa: F401\n\n__all__ = (\"VERSION\", \"Client\")\n\ntry:\n try:\n VERSION = __import__(\"importlib.metadata\").metadata.version(\"elastic-apm\")\n except ImportError:\n VERSION = __import__(\"pkg_resources\").get_distribution(\"elastic-apm\").version\nexcept Exception:\n VERSION = \"unknown\"\n\n\nif sys.version_info >= (3, 5):\n from elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401\n", "path": "elasticapm/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\nimport sys\n\nfrom elasticapm.base import Client\nfrom elasticapm.conf import setup_logging # noqa: F401\nfrom elasticapm.instrumentation.control import instrument, uninstrument # noqa: F401\nfrom elasticapm.traces import ( # noqa: F401\n capture_span,\n get_span_id,\n get_trace_id,\n get_trace_parent_header,\n get_transaction_id,\n label,\n set_context,\n set_custom_context,\n set_transaction_name,\n set_transaction_outcome,\n set_transaction_result,\n set_user_context,\n tag,\n)\nfrom elasticapm.utils.disttracing import trace_parent_from_headers, trace_parent_from_string # noqa: F401\n\n__all__ = (\"VERSION\", \"Client\")\n\ntry:\n try:\n VERSION = __import__(\"importlib.metadata\").metadata.version(\"elastic-apm\")\n except ImportError:\n VERSION = __import__(\"pkg_resources\").get_distribution(\"elastic-apm\").version\nexcept Exception:\n VERSION = \"unknown\"\n\n\nif sys.version_info <= (3, 5):\n raise DeprecationWarning(\"The Elastic APM agent requires Python 3.6+\")\n\nfrom elasticapm.contrib.asyncio.traces import async_capture_span # noqa: F401\n", "path": "elasticapm/__init__.py"}]} | 1,020 | 211 |
gh_patches_debug_20263 | rasdani/github-patches | git_diff | learningequality__kolibri-1754 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
imports get stuck when server is restarted
* begin importing channel
* stop server
* start server
Transfer is stuck partway. It does not continue, and due to #1673 cannot be canceled:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/tasks/api.py`
Content:
```
1 import logging as logger
2
3 from django.apps.registry import AppRegistryNotReady
4
5 try:
6 from django.apps import apps
7
8 apps.check_apps_ready()
9 except AppRegistryNotReady:
10 import django
11
12 django.setup()
13
14 import requests
15 from django.core.management import call_command
16 from django.conf import settings
17 from django.http import Http404
18 from django.utils.translation import ugettext as _
19 from kolibri.content.models import ChannelMetadataCache
20 from kolibri.content.utils.channels import get_mounted_drives_with_channel_info
21 from kolibri.content.utils.paths import get_content_database_file_url
22 from rest_framework import serializers, viewsets
23 from rest_framework.decorators import list_route
24 from rest_framework.response import Response
25 from barbequeue.common.classes import State
26 from barbequeue.client import SimpleClient
27
28 from .permissions import IsDeviceOwnerOnly
29
30 logging = logger.getLogger(__name__)
31
32 client = SimpleClient(
33 app="kolibri", storage_path=settings.QUEUE_JOB_STORAGE_PATH)
34
35 # all tasks are marked as remote imports for nwo
36 TASKTYPE = "remoteimport"
37
38
39 class TasksViewSet(viewsets.ViewSet):
40 permission_classes = (IsDeviceOwnerOnly, )
41
42 def list(self, request):
43 jobs_response = [_job_to_response(j) for j in client.all_jobs()]
44 return Response(jobs_response)
45
46 def create(self, request):
47 # unimplemented. Call out to the task-specific APIs for now.
48 pass
49
50 def retrieve(self, request, pk=None):
51 task = _job_to_response(client.status(pk))
52 return Response(task)
53
54 def destroy(self, request, pk=None):
55 # unimplemented for now.
56 pass
57
58 @list_route(methods=['post'])
59 def startremoteimport(self, request):
60 '''Download a channel's database from the main curation server, and then
61 download its content.
62
63 '''
64
65 if "channel_id" not in request.data:
66 raise serializers.ValidationError(
67 "The 'channel_id' field is required.")
68
69 channel_id = request.data['channel_id']
70
71 # ensure the requested channel_id can be found on the central server, otherwise error
72 status = requests.head(
73 get_content_database_file_url(channel_id)).status_code
74 if status == 404:
75 raise Http404(
76 _("The requested channel does not exist on the content server")
77 )
78
79 task_id = client.schedule(
80 _networkimport, channel_id, track_progress=True)
81
82 # attempt to get the created Task, otherwise return pending status
83 resp = _job_to_response(client.status(task_id))
84
85 return Response(resp)
86
87 @list_route(methods=['post'])
88 def startlocalimport(self, request):
89 """
90 Import a channel from a local drive, and copy content to the local machine.
91 """
92 # Importing django/running setup because Windows...
93
94 if "drive_id" not in request.data:
95 raise serializers.ValidationError(
96 "The 'drive_id' field is required.")
97
98 job_id = client.schedule(
99 _localimport, request.data['drive_id'], track_progress=True)
100
101 # attempt to get the created Task, otherwise return pending status
102 resp = _job_to_response(client.status(job_id))
103
104 return Response(resp)
105
106 @list_route(methods=['post'])
107 def startlocalexport(self, request):
108 '''
109 Export a channel to a local drive, and copy content to the drive.
110
111 '''
112
113 if "drive_id" not in request.data:
114 raise serializers.ValidationError(
115 "The 'drive_id' field is required.")
116
117 job_id = client.schedule(
118 _localexport, request.data['drive_id'], track_progress=True)
119
120 # attempt to get the created Task, otherwise return pending status
121 resp = _job_to_response(client.status(job_id))
122
123 return Response(resp)
124
125 @list_route(methods=['post'])
126 def cleartask(self, request):
127 '''
128 Clears a task with its task id given in the task_id parameter.
129 '''
130
131 if 'task_id' not in request.data:
132 raise serializers.ValidationError(
133 "The 'task_id' field is required.")
134
135 client.clear(force=True)
136 return Response({})
137
138 @list_route(methods=['get'])
139 def localdrive(self, request):
140 drives = get_mounted_drives_with_channel_info()
141
142 # make sure everything is a dict, before converting to JSON
143 assert isinstance(drives, dict)
144 out = [mountdata._asdict() for mountdata in drives.values()]
145
146 return Response(out)
147
148
149 def _networkimport(channel_id, update_progress=None):
150 call_command("importchannel", "network", channel_id)
151 call_command(
152 "importcontent",
153 "network",
154 channel_id,
155 update_progress=update_progress)
156
157
158 def _localimport(drive_id, update_progress=None):
159 drives = get_mounted_drives_with_channel_info()
160 drive = drives[drive_id]
161 for channel in drive.metadata["channels"]:
162 call_command("importchannel", "local", channel["id"], drive.datafolder)
163 call_command(
164 "importcontent",
165 "local",
166 channel["id"],
167 drive.datafolder,
168 update_progress=update_progress)
169
170
171 def _localexport(drive_id, update_progress=None):
172 drives = get_mounted_drives_with_channel_info()
173 drive = drives[drive_id]
174 for channel in ChannelMetadataCache.objects.all():
175 call_command("exportchannel", channel.id, drive.datafolder)
176 call_command(
177 "exportcontent",
178 channel.id,
179 drive.datafolder,
180 update_progress=update_progress)
181
182
183 def _job_to_response(job):
184 if not job:
185 return {
186 "type": TASKTYPE,
187 "status": State.SCHEDULED,
188 "percentage": 0,
189 "progress": [],
190 "id": job.job_id,
191 }
192 else:
193 return {
194 "type": TASKTYPE,
195 "status": job.state,
196 "exception": str(job.exception),
197 "traceback": str(job.traceback),
198 "percentage": job.percentage_progress,
199 "id": job.job_id,
200 }
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kolibri/tasks/api.py b/kolibri/tasks/api.py
--- a/kolibri/tasks/api.py
+++ b/kolibri/tasks/api.py
@@ -13,7 +13,6 @@
import requests
from django.core.management import call_command
-from django.conf import settings
from django.http import Http404
from django.utils.translation import ugettext as _
from kolibri.content.models import ChannelMetadataCache
@@ -29,15 +28,14 @@
logging = logger.getLogger(__name__)
-client = SimpleClient(
- app="kolibri", storage_path=settings.QUEUE_JOB_STORAGE_PATH)
+client = SimpleClient(app="kolibri")
# all tasks are marked as remote imports for nwo
TASKTYPE = "remoteimport"
class TasksViewSet(viewsets.ViewSet):
- permission_classes = (IsDeviceOwnerOnly, )
+ permission_classes = (IsDeviceOwnerOnly,)
def list(self, request):
jobs_response = [_job_to_response(j) for j in client.all_jobs()]
| {"golden_diff": "diff --git a/kolibri/tasks/api.py b/kolibri/tasks/api.py\n--- a/kolibri/tasks/api.py\n+++ b/kolibri/tasks/api.py\n@@ -13,7 +13,6 @@\n \n import requests\n from django.core.management import call_command\n-from django.conf import settings\n from django.http import Http404\n from django.utils.translation import ugettext as _\n from kolibri.content.models import ChannelMetadataCache\n@@ -29,15 +28,14 @@\n \n logging = logger.getLogger(__name__)\n \n-client = SimpleClient(\n- app=\"kolibri\", storage_path=settings.QUEUE_JOB_STORAGE_PATH)\n+client = SimpleClient(app=\"kolibri\")\n \n # all tasks are marked as remote imports for nwo\n TASKTYPE = \"remoteimport\"\n \n \n class TasksViewSet(viewsets.ViewSet):\n- permission_classes = (IsDeviceOwnerOnly, )\n+ permission_classes = (IsDeviceOwnerOnly,)\n \n def list(self, request):\n jobs_response = [_job_to_response(j) for j in client.all_jobs()]\n", "issue": "imports get stuck when server is restarted\n\r\n* begin importing channel\r\n* stop server\r\n* start server\r\n\r\nTransfer is stuck partway. It does not continue, and due to #1673 cannot be canceled:\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import logging as logger\n\nfrom django.apps.registry import AppRegistryNotReady\n\ntry:\n from django.apps import apps\n\n apps.check_apps_ready()\nexcept AppRegistryNotReady:\n import django\n\n django.setup()\n\nimport requests\nfrom django.core.management import call_command\nfrom django.conf import settings\nfrom django.http import Http404\nfrom django.utils.translation import ugettext as _\nfrom kolibri.content.models import ChannelMetadataCache\nfrom kolibri.content.utils.channels import get_mounted_drives_with_channel_info\nfrom kolibri.content.utils.paths import get_content_database_file_url\nfrom rest_framework import serializers, viewsets\nfrom rest_framework.decorators import list_route\nfrom rest_framework.response import Response\nfrom barbequeue.common.classes import State\nfrom barbequeue.client import SimpleClient\n\nfrom .permissions import IsDeviceOwnerOnly\n\nlogging = logger.getLogger(__name__)\n\nclient = SimpleClient(\n app=\"kolibri\", storage_path=settings.QUEUE_JOB_STORAGE_PATH)\n\n# all tasks are marked as remote imports for nwo\nTASKTYPE = \"remoteimport\"\n\n\nclass TasksViewSet(viewsets.ViewSet):\n permission_classes = (IsDeviceOwnerOnly, )\n\n def list(self, request):\n jobs_response = [_job_to_response(j) for j in client.all_jobs()]\n return Response(jobs_response)\n\n def create(self, request):\n # unimplemented. Call out to the task-specific APIs for now.\n pass\n\n def retrieve(self, request, pk=None):\n task = _job_to_response(client.status(pk))\n return Response(task)\n\n def destroy(self, request, pk=None):\n # unimplemented for now.\n pass\n\n @list_route(methods=['post'])\n def startremoteimport(self, request):\n '''Download a channel's database from the main curation server, and then\n download its content.\n\n '''\n\n if \"channel_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'channel_id' field is required.\")\n\n channel_id = request.data['channel_id']\n\n # ensure the requested channel_id can be found on the central server, otherwise error\n status = requests.head(\n get_content_database_file_url(channel_id)).status_code\n if status == 404:\n raise Http404(\n _(\"The requested channel does not exist on the content server\")\n )\n\n task_id = client.schedule(\n _networkimport, channel_id, track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(task_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def startlocalimport(self, request):\n \"\"\"\n Import a channel from a local drive, and copy content to the local machine.\n \"\"\"\n # Importing django/running setup because Windows...\n\n if \"drive_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'drive_id' field is required.\")\n\n job_id = client.schedule(\n _localimport, request.data['drive_id'], track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(job_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def startlocalexport(self, request):\n '''\n Export a channel to a local drive, and copy content to the drive.\n\n '''\n\n if \"drive_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'drive_id' field is required.\")\n\n job_id = client.schedule(\n _localexport, request.data['drive_id'], track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(job_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def cleartask(self, request):\n '''\n Clears a task with its task id given in the task_id parameter.\n '''\n\n if 'task_id' not in request.data:\n raise serializers.ValidationError(\n \"The 'task_id' field is required.\")\n\n client.clear(force=True)\n return Response({})\n\n @list_route(methods=['get'])\n def localdrive(self, request):\n drives = get_mounted_drives_with_channel_info()\n\n # make sure everything is a dict, before converting to JSON\n assert isinstance(drives, dict)\n out = [mountdata._asdict() for mountdata in drives.values()]\n\n return Response(out)\n\n\ndef _networkimport(channel_id, update_progress=None):\n call_command(\"importchannel\", \"network\", channel_id)\n call_command(\n \"importcontent\",\n \"network\",\n channel_id,\n update_progress=update_progress)\n\n\ndef _localimport(drive_id, update_progress=None):\n drives = get_mounted_drives_with_channel_info()\n drive = drives[drive_id]\n for channel in drive.metadata[\"channels\"]:\n call_command(\"importchannel\", \"local\", channel[\"id\"], drive.datafolder)\n call_command(\n \"importcontent\",\n \"local\",\n channel[\"id\"],\n drive.datafolder,\n update_progress=update_progress)\n\n\ndef _localexport(drive_id, update_progress=None):\n drives = get_mounted_drives_with_channel_info()\n drive = drives[drive_id]\n for channel in ChannelMetadataCache.objects.all():\n call_command(\"exportchannel\", channel.id, drive.datafolder)\n call_command(\n \"exportcontent\",\n channel.id,\n drive.datafolder,\n update_progress=update_progress)\n\n\ndef _job_to_response(job):\n if not job:\n return {\n \"type\": TASKTYPE,\n \"status\": State.SCHEDULED,\n \"percentage\": 0,\n \"progress\": [],\n \"id\": job.job_id,\n }\n else:\n return {\n \"type\": TASKTYPE,\n \"status\": job.state,\n \"exception\": str(job.exception),\n \"traceback\": str(job.traceback),\n \"percentage\": job.percentage_progress,\n \"id\": job.job_id,\n }\n", "path": "kolibri/tasks/api.py"}], "after_files": [{"content": "import logging as logger\n\nfrom django.apps.registry import AppRegistryNotReady\n\ntry:\n from django.apps import apps\n\n apps.check_apps_ready()\nexcept AppRegistryNotReady:\n import django\n\n django.setup()\n\nimport requests\nfrom django.core.management import call_command\nfrom django.http import Http404\nfrom django.utils.translation import ugettext as _\nfrom kolibri.content.models import ChannelMetadataCache\nfrom kolibri.content.utils.channels import get_mounted_drives_with_channel_info\nfrom kolibri.content.utils.paths import get_content_database_file_url\nfrom rest_framework import serializers, viewsets\nfrom rest_framework.decorators import list_route\nfrom rest_framework.response import Response\nfrom barbequeue.common.classes import State\nfrom barbequeue.client import SimpleClient\n\nfrom .permissions import IsDeviceOwnerOnly\n\nlogging = logger.getLogger(__name__)\n\nclient = SimpleClient(app=\"kolibri\")\n\n# all tasks are marked as remote imports for nwo\nTASKTYPE = \"remoteimport\"\n\n\nclass TasksViewSet(viewsets.ViewSet):\n permission_classes = (IsDeviceOwnerOnly,)\n\n def list(self, request):\n jobs_response = [_job_to_response(j) for j in client.all_jobs()]\n return Response(jobs_response)\n\n def create(self, request):\n # unimplemented. Call out to the task-specific APIs for now.\n pass\n\n def retrieve(self, request, pk=None):\n task = _job_to_response(client.status(pk))\n return Response(task)\n\n def destroy(self, request, pk=None):\n # unimplemented for now.\n pass\n\n @list_route(methods=['post'])\n def startremoteimport(self, request):\n '''Download a channel's database from the main curation server, and then\n download its content.\n\n '''\n\n if \"channel_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'channel_id' field is required.\")\n\n channel_id = request.data['channel_id']\n\n # ensure the requested channel_id can be found on the central server, otherwise error\n status = requests.head(\n get_content_database_file_url(channel_id)).status_code\n if status == 404:\n raise Http404(\n _(\"The requested channel does not exist on the content server\")\n )\n\n task_id = client.schedule(\n _networkimport, channel_id, track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(task_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def startlocalimport(self, request):\n \"\"\"\n Import a channel from a local drive, and copy content to the local machine.\n \"\"\"\n # Importing django/running setup because Windows...\n\n if \"drive_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'drive_id' field is required.\")\n\n job_id = client.schedule(\n _localimport, request.data['drive_id'], track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(job_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def startlocalexport(self, request):\n '''\n Export a channel to a local drive, and copy content to the drive.\n\n '''\n\n if \"drive_id\" not in request.data:\n raise serializers.ValidationError(\n \"The 'drive_id' field is required.\")\n\n job_id = client.schedule(\n _localexport, request.data['drive_id'], track_progress=True)\n\n # attempt to get the created Task, otherwise return pending status\n resp = _job_to_response(client.status(job_id))\n\n return Response(resp)\n\n @list_route(methods=['post'])\n def cleartask(self, request):\n '''\n Clears a task with its task id given in the task_id parameter.\n '''\n\n if 'task_id' not in request.data:\n raise serializers.ValidationError(\n \"The 'task_id' field is required.\")\n\n client.clear(force=True)\n return Response({})\n\n @list_route(methods=['get'])\n def localdrive(self, request):\n drives = get_mounted_drives_with_channel_info()\n\n # make sure everything is a dict, before converting to JSON\n assert isinstance(drives, dict)\n out = [mountdata._asdict() for mountdata in drives.values()]\n\n return Response(out)\n\n\ndef _networkimport(channel_id, update_progress=None):\n call_command(\"importchannel\", \"network\", channel_id)\n call_command(\n \"importcontent\",\n \"network\",\n channel_id,\n update_progress=update_progress)\n\n\ndef _localimport(drive_id, update_progress=None):\n drives = get_mounted_drives_with_channel_info()\n drive = drives[drive_id]\n for channel in drive.metadata[\"channels\"]:\n call_command(\"importchannel\", \"local\", channel[\"id\"], drive.datafolder)\n call_command(\n \"importcontent\",\n \"local\",\n channel[\"id\"],\n drive.datafolder,\n update_progress=update_progress)\n\n\ndef _localexport(drive_id, update_progress=None):\n drives = get_mounted_drives_with_channel_info()\n drive = drives[drive_id]\n for channel in ChannelMetadataCache.objects.all():\n call_command(\"exportchannel\", channel.id, drive.datafolder)\n call_command(\n \"exportcontent\",\n channel.id,\n drive.datafolder,\n update_progress=update_progress)\n\n\ndef _job_to_response(job):\n if not job:\n return {\n \"type\": TASKTYPE,\n \"status\": State.SCHEDULED,\n \"percentage\": 0,\n \"progress\": [],\n \"id\": job.job_id,\n }\n else:\n return {\n \"type\": TASKTYPE,\n \"status\": job.state,\n \"exception\": str(job.exception),\n \"traceback\": str(job.traceback),\n \"percentage\": job.percentage_progress,\n \"id\": job.job_id,\n }\n", "path": "kolibri/tasks/api.py"}]} | 2,171 | 225 |
gh_patches_debug_36865 | rasdani/github-patches | git_diff | cookiecutter__cookiecutter-834 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplify cookiecutter.hooks.find_hooks
We should rename `cookiecutter.hooks.find_hooks` to `find_hook(hook_name)` and explicitly look for the requested hook, instead of processing all the files in the hooks directory.
See https://github.com/audreyr/cookiecutter/pull/768/files/9a94484093ca23e9d55d42a53f096f67535b0b63#r68646614
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cookiecutter/hooks.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 """Functions for discovering and executing various cookiecutter hooks."""
4
5 import io
6 import logging
7 import os
8 import subprocess
9 import sys
10 import tempfile
11
12 from jinja2 import Template
13
14 from cookiecutter import utils
15 from .exceptions import FailedHookException
16
17 logger = logging.getLogger(__name__)
18
19
20 _HOOKS = [
21 'pre_gen_project',
22 'post_gen_project',
23 # TODO: other hooks should be listed here
24 ]
25 EXIT_SUCCESS = 0
26
27
28 def find_hooks():
29 """Return a dict of all hook scripts provided.
30
31 Must be called with the project template as the current working directory.
32 Dict's key will be the hook/script's name, without extension, while values
33 will be the absolute path to the script. Missing scripts will not be
34 included in the returned dict.
35 """
36 hooks_dir = 'hooks'
37 hooks = {}
38 logger.debug('hooks_dir is {}'.format(hooks_dir))
39
40 if not os.path.isdir(hooks_dir):
41 logger.debug('No hooks/ dir in template_dir')
42 return hooks
43
44 for f in os.listdir(hooks_dir):
45 filename = os.path.basename(f)
46 basename = os.path.splitext(filename)[0]
47
48 if basename in _HOOKS and not filename.endswith('~'):
49 hooks[basename] = os.path.abspath(os.path.join(hooks_dir, f))
50 return hooks
51
52
53 def run_script(script_path, cwd='.'):
54 """Execute a script from a working directory.
55
56 :param script_path: Absolute path to the script to run.
57 :param cwd: The directory to run the script from.
58 """
59 run_thru_shell = sys.platform.startswith('win')
60 if script_path.endswith('.py'):
61 script_command = [sys.executable, script_path]
62 else:
63 script_command = [script_path]
64
65 utils.make_executable(script_path)
66
67 proc = subprocess.Popen(
68 script_command,
69 shell=run_thru_shell,
70 cwd=cwd
71 )
72 exit_status = proc.wait()
73 if exit_status != EXIT_SUCCESS:
74 raise FailedHookException(
75 "Hook script failed (exit status: %d)" % exit_status)
76
77
78 def run_script_with_context(script_path, cwd, context):
79 """Execute a script after rendering it with Jinja.
80
81 :param script_path: Absolute path to the script to run.
82 :param cwd: The directory to run the script from.
83 :param context: Cookiecutter project template context.
84 """
85 _, extension = os.path.splitext(script_path)
86
87 contents = io.open(script_path, 'r', encoding='utf-8').read()
88
89 with tempfile.NamedTemporaryFile(
90 delete=False,
91 mode='wb',
92 suffix=extension
93 ) as temp:
94 output = Template(contents).render(**context)
95 temp.write(output.encode('utf-8'))
96
97 run_script(temp.name, cwd)
98
99
100 def run_hook(hook_name, project_dir, context):
101 """
102 Try to find and execute a hook from the specified project directory.
103
104 :param hook_name: The hook to execute.
105 :param project_dir: The directory to execute the script from.
106 :param context: Cookiecutter project context.
107 """
108 script = find_hooks().get(hook_name)
109 if script is None:
110 logger.debug('No hooks found')
111 return
112 logger.debug('Running hook {}'.format(hook_name))
113 run_script_with_context(script, project_dir, context)
114
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cookiecutter/hooks.py b/cookiecutter/hooks.py
--- a/cookiecutter/hooks.py
+++ b/cookiecutter/hooks.py
@@ -16,38 +16,53 @@
logger = logging.getLogger(__name__)
-
_HOOKS = [
'pre_gen_project',
'post_gen_project',
- # TODO: other hooks should be listed here
]
EXIT_SUCCESS = 0
-def find_hooks():
+def valid_hook(hook_file, hook_name):
+ """Determine if a hook file is valid.
+
+ :param hook_file: The hook file to consider for validity
+ :param hook_name: The hook to find
+ :return: The hook file validity
+ """
+ filename = os.path.basename(hook_file)
+ basename = os.path.splitext(filename)[0]
+
+ matching_hook = basename == hook_name
+ supported_hook = basename in _HOOKS
+ backup_file = filename.endswith('~')
+
+ return matching_hook and supported_hook and not backup_file
+
+
+def find_hook(hook_name, hooks_dir='hooks'):
"""Return a dict of all hook scripts provided.
Must be called with the project template as the current working directory.
Dict's key will be the hook/script's name, without extension, while values
will be the absolute path to the script. Missing scripts will not be
included in the returned dict.
+
+ :param hook_name: The hook to find
+ :param hooks_dir: The hook directory in the template
+ :return: The absolute path to the hook script or None
"""
- hooks_dir = 'hooks'
- hooks = {}
- logger.debug('hooks_dir is {}'.format(hooks_dir))
+ logger.debug('hooks_dir is {}'.format(os.path.abspath(hooks_dir)))
if not os.path.isdir(hooks_dir):
logger.debug('No hooks/ dir in template_dir')
- return hooks
+ return None
- for f in os.listdir(hooks_dir):
- filename = os.path.basename(f)
- basename = os.path.splitext(filename)[0]
+ for hook_file in os.listdir(hooks_dir):
+ if valid_hook(hook_file, hook_name):
+ return os.path.abspath(os.path.join(hooks_dir, hook_file))
- if basename in _HOOKS and not filename.endswith('~'):
- hooks[basename] = os.path.abspath(os.path.join(hooks_dir, f))
- return hooks
+ return None
def run_script(script_path, cwd='.'):
@@ -105,7 +120,7 @@
:param project_dir: The directory to execute the script from.
:param context: Cookiecutter project context.
"""
- script = find_hooks().get(hook_name)
+ script = find_hook(hook_name)
if script is None:
logger.debug('No hooks found')
return
| {"golden_diff": "diff --git a/cookiecutter/hooks.py b/cookiecutter/hooks.py\n--- a/cookiecutter/hooks.py\n+++ b/cookiecutter/hooks.py\n@@ -16,38 +16,53 @@\n \n logger = logging.getLogger(__name__)\n \n-\n _HOOKS = [\n 'pre_gen_project',\n 'post_gen_project',\n- # TODO: other hooks should be listed here\n ]\n EXIT_SUCCESS = 0\n \n \n-def find_hooks():\n+def valid_hook(hook_file, hook_name):\n+ \"\"\"Determine if a hook file is valid.\n+\n+ :param hook_file: The hook file to consider for validity\n+ :param hook_name: The hook to find\n+ :return: The hook file validity\n+ \"\"\"\n+ filename = os.path.basename(hook_file)\n+ basename = os.path.splitext(filename)[0]\n+\n+ matching_hook = basename == hook_name\n+ supported_hook = basename in _HOOKS\n+ backup_file = filename.endswith('~')\n+\n+ return matching_hook and supported_hook and not backup_file\n+\n+\n+def find_hook(hook_name, hooks_dir='hooks'):\n \"\"\"Return a dict of all hook scripts provided.\n \n Must be called with the project template as the current working directory.\n Dict's key will be the hook/script's name, without extension, while values\n will be the absolute path to the script. Missing scripts will not be\n included in the returned dict.\n+\n+ :param hook_name: The hook to find\n+ :param hooks_dir: The hook directory in the template\n+ :return: The absolute path to the hook script or None\n \"\"\"\n- hooks_dir = 'hooks'\n- hooks = {}\n- logger.debug('hooks_dir is {}'.format(hooks_dir))\n+ logger.debug('hooks_dir is {}'.format(os.path.abspath(hooks_dir)))\n \n if not os.path.isdir(hooks_dir):\n logger.debug('No hooks/ dir in template_dir')\n- return hooks\n+ return None\n \n- for f in os.listdir(hooks_dir):\n- filename = os.path.basename(f)\n- basename = os.path.splitext(filename)[0]\n+ for hook_file in os.listdir(hooks_dir):\n+ if valid_hook(hook_file, hook_name):\n+ return os.path.abspath(os.path.join(hooks_dir, hook_file))\n \n- if basename in _HOOKS and not filename.endswith('~'):\n- hooks[basename] = os.path.abspath(os.path.join(hooks_dir, f))\n- return hooks\n+ return None\n \n \n def run_script(script_path, cwd='.'):\n@@ -105,7 +120,7 @@\n :param project_dir: The directory to execute the script from.\n :param context: Cookiecutter project context.\n \"\"\"\n- script = find_hooks().get(hook_name)\n+ script = find_hook(hook_name)\n if script is None:\n logger.debug('No hooks found')\n return\n", "issue": "Simplify cookiecutter.hooks.find_hooks\nWe should rename `cookiecutter.hooks.find_hooks` to `find_hook(hook_name)` and explicitly look for the requested hook, instead of processing all the files in the hooks directory.\n\nSee https://github.com/audreyr/cookiecutter/pull/768/files/9a94484093ca23e9d55d42a53f096f67535b0b63#r68646614\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Functions for discovering and executing various cookiecutter hooks.\"\"\"\n\nimport io\nimport logging\nimport os\nimport subprocess\nimport sys\nimport tempfile\n\nfrom jinja2 import Template\n\nfrom cookiecutter import utils\nfrom .exceptions import FailedHookException\n\nlogger = logging.getLogger(__name__)\n\n\n_HOOKS = [\n 'pre_gen_project',\n 'post_gen_project',\n # TODO: other hooks should be listed here\n]\nEXIT_SUCCESS = 0\n\n\ndef find_hooks():\n \"\"\"Return a dict of all hook scripts provided.\n\n Must be called with the project template as the current working directory.\n Dict's key will be the hook/script's name, without extension, while values\n will be the absolute path to the script. Missing scripts will not be\n included in the returned dict.\n \"\"\"\n hooks_dir = 'hooks'\n hooks = {}\n logger.debug('hooks_dir is {}'.format(hooks_dir))\n\n if not os.path.isdir(hooks_dir):\n logger.debug('No hooks/ dir in template_dir')\n return hooks\n\n for f in os.listdir(hooks_dir):\n filename = os.path.basename(f)\n basename = os.path.splitext(filename)[0]\n\n if basename in _HOOKS and not filename.endswith('~'):\n hooks[basename] = os.path.abspath(os.path.join(hooks_dir, f))\n return hooks\n\n\ndef run_script(script_path, cwd='.'):\n \"\"\"Execute a script from a working directory.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n \"\"\"\n run_thru_shell = sys.platform.startswith('win')\n if script_path.endswith('.py'):\n script_command = [sys.executable, script_path]\n else:\n script_command = [script_path]\n\n utils.make_executable(script_path)\n\n proc = subprocess.Popen(\n script_command,\n shell=run_thru_shell,\n cwd=cwd\n )\n exit_status = proc.wait()\n if exit_status != EXIT_SUCCESS:\n raise FailedHookException(\n \"Hook script failed (exit status: %d)\" % exit_status)\n\n\ndef run_script_with_context(script_path, cwd, context):\n \"\"\"Execute a script after rendering it with Jinja.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n :param context: Cookiecutter project template context.\n \"\"\"\n _, extension = os.path.splitext(script_path)\n\n contents = io.open(script_path, 'r', encoding='utf-8').read()\n\n with tempfile.NamedTemporaryFile(\n delete=False,\n mode='wb',\n suffix=extension\n ) as temp:\n output = Template(contents).render(**context)\n temp.write(output.encode('utf-8'))\n\n run_script(temp.name, cwd)\n\n\ndef run_hook(hook_name, project_dir, context):\n \"\"\"\n Try to find and execute a hook from the specified project directory.\n\n :param hook_name: The hook to execute.\n :param project_dir: The directory to execute the script from.\n :param context: Cookiecutter project context.\n \"\"\"\n script = find_hooks().get(hook_name)\n if script is None:\n logger.debug('No hooks found')\n return\n logger.debug('Running hook {}'.format(hook_name))\n run_script_with_context(script, project_dir, context)\n", "path": "cookiecutter/hooks.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Functions for discovering and executing various cookiecutter hooks.\"\"\"\n\nimport io\nimport logging\nimport os\nimport subprocess\nimport sys\nimport tempfile\n\nfrom jinja2 import Template\n\nfrom cookiecutter import utils\nfrom .exceptions import FailedHookException\n\nlogger = logging.getLogger(__name__)\n\n_HOOKS = [\n 'pre_gen_project',\n 'post_gen_project',\n]\nEXIT_SUCCESS = 0\n\n\ndef valid_hook(hook_file, hook_name):\n \"\"\"Determine if a hook file is valid.\n\n :param hook_file: The hook file to consider for validity\n :param hook_name: The hook to find\n :return: The hook file validity\n \"\"\"\n filename = os.path.basename(hook_file)\n basename = os.path.splitext(filename)[0]\n\n matching_hook = basename == hook_name\n supported_hook = basename in _HOOKS\n backup_file = filename.endswith('~')\n\n return matching_hook and supported_hook and not backup_file\n\n\ndef find_hook(hook_name, hooks_dir='hooks'):\n \"\"\"Return a dict of all hook scripts provided.\n\n Must be called with the project template as the current working directory.\n Dict's key will be the hook/script's name, without extension, while values\n will be the absolute path to the script. Missing scripts will not be\n included in the returned dict.\n\n :param hook_name: The hook to find\n :param hooks_dir: The hook directory in the template\n :return: The absolute path to the hook script or None\n \"\"\"\n logger.debug('hooks_dir is {}'.format(os.path.abspath(hooks_dir)))\n\n if not os.path.isdir(hooks_dir):\n logger.debug('No hooks/ dir in template_dir')\n return None\n\n for hook_file in os.listdir(hooks_dir):\n if valid_hook(hook_file, hook_name):\n return os.path.abspath(os.path.join(hooks_dir, hook_file))\n\n return None\n\n\ndef run_script(script_path, cwd='.'):\n \"\"\"Execute a script from a working directory.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n \"\"\"\n run_thru_shell = sys.platform.startswith('win')\n if script_path.endswith('.py'):\n script_command = [sys.executable, script_path]\n else:\n script_command = [script_path]\n\n utils.make_executable(script_path)\n\n proc = subprocess.Popen(\n script_command,\n shell=run_thru_shell,\n cwd=cwd\n )\n exit_status = proc.wait()\n if exit_status != EXIT_SUCCESS:\n raise FailedHookException(\n \"Hook script failed (exit status: %d)\" % exit_status)\n\n\ndef run_script_with_context(script_path, cwd, context):\n \"\"\"Execute a script after rendering it with Jinja.\n\n :param script_path: Absolute path to the script to run.\n :param cwd: The directory to run the script from.\n :param context: Cookiecutter project template context.\n \"\"\"\n _, extension = os.path.splitext(script_path)\n\n contents = io.open(script_path, 'r', encoding='utf-8').read()\n\n with tempfile.NamedTemporaryFile(\n delete=False,\n mode='wb',\n suffix=extension\n ) as temp:\n output = Template(contents).render(**context)\n temp.write(output.encode('utf-8'))\n\n run_script(temp.name, cwd)\n\n\ndef run_hook(hook_name, project_dir, context):\n \"\"\"\n Try to find and execute a hook from the specified project directory.\n\n :param hook_name: The hook to execute.\n :param project_dir: The directory to execute the script from.\n :param context: Cookiecutter project context.\n \"\"\"\n script = find_hook(hook_name)\n if script is None:\n logger.debug('No hooks found')\n return\n logger.debug('Running hook {}'.format(hook_name))\n run_script_with_context(script, project_dir, context)\n", "path": "cookiecutter/hooks.py"}]} | 1,354 | 640 |
gh_patches_debug_8339 | rasdani/github-patches | git_diff | google__turbinia-1012 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'message' referenced before assignment in recipe_helpers.validate_recipe
https://github.com/google/turbinia/blob/a756f4c625cf3796fc82d160f3c794c7e2039437/turbinia/lib/recipe_helpers.py#L169
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `turbinia/lib/recipe_helpers.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright 2021 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Library to contain recipe validation logic."""
16
17 import copy
18 import logging
19 import yaml
20 import os
21
22 from yaml import Loader
23 from yaml import load
24 from turbinia import config
25 from turbinia.lib.file_helpers import file_to_str
26 from turbinia.lib.file_helpers import file_to_list
27 from turbinia.task_utils import TaskLoader
28
29 log = logging.getLogger('turbinia')
30
31 #Attributes allowed on the 'globals' task recipe
32 DEFAULT_GLOBALS_RECIPE = {
33 'debug_tasks': False,
34 'jobs_allowlist': [],
35 'jobs_denylist': [],
36 'yara_rules': '',
37 'filter_patterns': [],
38 'sketch_id': None,
39 'group_id': ''
40 }
41
42 #Default recipes dict
43 DEFAULT_RECIPE = {'globals': DEFAULT_GLOBALS_RECIPE}
44
45
46 def load_recipe_from_file(recipe_file, validate=True):
47 """Load recipe from file.
48
49 Args:
50 recipe_file(str): Name of the recipe file to be read.
51
52 Returns:
53 dict: Validated and corrected recipe dictionary.
54 Empty dict if recipe is invalid.
55 """
56 if not recipe_file:
57 return copy.deepcopy(DEFAULT_RECIPE)
58 try:
59 log.info('Loading recipe file from {0:s}'.format(recipe_file))
60 with open(recipe_file, 'r') as r_file:
61 recipe_file_contents = r_file.read()
62 recipe_dict = load(recipe_file_contents, Loader=Loader)
63 if validate:
64 success, _ = validate_recipe(recipe_dict)
65 if success:
66 return recipe_dict
67 else:
68 return recipe_dict
69 except yaml.parser.ParserError as exception:
70 message = (
71 'Invalid YAML on recipe file {0:s}: {1!s}.'.format(
72 recipe_file, exception))
73 log.error(message)
74 except IOError as exception:
75 log.error(
76 'Failed to read recipe file {0:s}: {1!s}'.format(
77 recipe_file, exception))
78 return {}
79
80
81 def validate_globals_recipe(proposed_globals_recipe):
82 """Validate the 'globals' special task recipe.
83
84 Args:
85 proposed_globals_recipe(dict): globals task recipe in need of validation.
86
87 Returns:
88 Tuple(
89 bool: Whether the recipe has a valid format.
90 str: Error message if validation failed.
91 )
92 """
93 reference_globals_recipe = copy.deepcopy(DEFAULT_GLOBALS_RECIPE)
94 reference_globals_recipe.update(proposed_globals_recipe)
95
96 filter_patterns_file = proposed_globals_recipe.get(
97 'filter_patterns_file', None)
98 yara_rules_file = proposed_globals_recipe.get('yara_rules_file', None)
99 if filter_patterns_file:
100 proposed_globals_recipe['filter_patterns'] = file_to_list(
101 filter_patterns_file)
102 if yara_rules_file:
103 proposed_globals_recipe['yara_rules'] = file_to_str(yara_rules_file)
104 diff = set(proposed_globals_recipe) - set(DEFAULT_GLOBALS_RECIPE)
105 if diff:
106 message = (
107 'Invalid recipe: Unknown keys [{0:s}] found in globals recipe'.format(
108 str(diff)))
109 log.error(message)
110 return (False, message)
111
112 if (proposed_globals_recipe.get('jobs_allowlist') and
113 proposed_globals_recipe.get('jobs_denylist')):
114 message = 'Invalid recipe: Jobs cannot be in both the allow and deny lists'
115 log.error(message)
116 return (False, message)
117 return (True, '')
118
119
120 def validate_recipe(recipe_dict):
121 """Validate the 'recipe' dict supplied by the request recipe.
122
123 Args:
124 recipe_dict(dict): Turbinia recipe in need of validation
125 submitted along with the evidence.
126
127 Returns:
128 Tuple(
129 bool: Whether the recipe has a valid format.
130 str: Error message if validation failed.
131 )
132 """
133 tasks_with_recipe = []
134 #If not globals task recipe is specified create one.
135 if 'globals' not in recipe_dict:
136 recipe_dict['globals'] = copy.deepcopy(DEFAULT_RECIPE)
137 log.warning(
138 'No globals recipe specified, all recipes should include '
139 'a globals entry, the default values will be used')
140 else:
141 success, message = validate_globals_recipe(recipe_dict['globals'])
142 if not success:
143 log.error(message)
144 return (False, message)
145
146 for recipe_item, recipe_item_contents in recipe_dict.items():
147 if recipe_item in tasks_with_recipe:
148 message = (
149 'Two recipe items with the same name \"{0:s}\" have been found. '
150 'If you wish to specify several task runs of the same tool, '
151 'please include them in separate recipes.'.format(recipe_item))
152 log.error(message)
153 return (False, message)
154 if recipe_item != 'globals':
155 if 'task' not in recipe_item_contents:
156 message = (
157 'Recipe item \"{0:s}\" has no "task" key. All recipe items '
158 'must have a "task" key indicating the TurbiniaTask '
159 'to which it relates.'.format(recipe_item))
160 log.error(message)
161 return (False, message)
162 proposed_task = recipe_item_contents['task']
163
164 task_loader = TaskLoader()
165 if not task_loader.check_task_name(proposed_task):
166 log.error(
167 'Task {0:s} defined for task recipe {1:s} does not exist.'.format(
168 proposed_task, recipe_item))
169 return (False, message)
170 tasks_with_recipe.append(recipe_item)
171
172 return (True, '')
173
174
175 def get_recipe_path_from_name(recipe_name):
176 """Returns a recipe's path from a recipe name.
177
178 Args:
179 recipe_name (str): A recipe name.
180
181 Returns:
182 str: a recipe's file system path.
183 """
184 recipe_path = ''
185 if not recipe_name.endswith('.yaml'):
186 recipe_name = recipe_name + '.yaml'
187
188 if hasattr(config, 'RECIPE_FILE_DIR') and config.RECIPE_FILE_DIR:
189 recipe_path = os.path.join(config.RECIPE_FILE_DIR, recipe_name)
190 else:
191 recipe_path = os.path.realpath(__file__)
192 recipe_path = os.path.dirname(recipe_path)
193 recipe_path = os.path.join(recipe_path, 'config', 'recipes')
194 recipe_path = os.path.join(recipe_path, recipe_name)
195
196 return recipe_path
197
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/turbinia/lib/recipe_helpers.py b/turbinia/lib/recipe_helpers.py
--- a/turbinia/lib/recipe_helpers.py
+++ b/turbinia/lib/recipe_helpers.py
@@ -163,9 +163,10 @@
task_loader = TaskLoader()
if not task_loader.check_task_name(proposed_task):
- log.error(
- 'Task {0:s} defined for task recipe {1:s} does not exist.'.format(
- proposed_task, recipe_item))
+ message = (
+ 'Task {0:s} defined for task recipe {1:s} does not '
+ 'exist.'.format(proposed_task, recipe_item))
+ log.error(message)
return (False, message)
tasks_with_recipe.append(recipe_item)
| {"golden_diff": "diff --git a/turbinia/lib/recipe_helpers.py b/turbinia/lib/recipe_helpers.py\n--- a/turbinia/lib/recipe_helpers.py\n+++ b/turbinia/lib/recipe_helpers.py\n@@ -163,9 +163,10 @@\n \n task_loader = TaskLoader()\n if not task_loader.check_task_name(proposed_task):\n- log.error(\n- 'Task {0:s} defined for task recipe {1:s} does not exist.'.format(\n- proposed_task, recipe_item))\n+ message = (\n+ 'Task {0:s} defined for task recipe {1:s} does not '\n+ 'exist.'.format(proposed_task, recipe_item))\n+ log.error(message)\n return (False, message)\n tasks_with_recipe.append(recipe_item)\n", "issue": "'message' referenced before assignment in recipe_helpers.validate_recipe\nhttps://github.com/google/turbinia/blob/a756f4c625cf3796fc82d160f3c794c7e2039437/turbinia/lib/recipe_helpers.py#L169\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2021 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Library to contain recipe validation logic.\"\"\"\n\nimport copy\nimport logging\nimport yaml\nimport os\n\nfrom yaml import Loader\nfrom yaml import load\nfrom turbinia import config\nfrom turbinia.lib.file_helpers import file_to_str\nfrom turbinia.lib.file_helpers import file_to_list\nfrom turbinia.task_utils import TaskLoader\n\nlog = logging.getLogger('turbinia')\n\n#Attributes allowed on the 'globals' task recipe\nDEFAULT_GLOBALS_RECIPE = {\n 'debug_tasks': False,\n 'jobs_allowlist': [],\n 'jobs_denylist': [],\n 'yara_rules': '',\n 'filter_patterns': [],\n 'sketch_id': None,\n 'group_id': ''\n}\n\n#Default recipes dict\nDEFAULT_RECIPE = {'globals': DEFAULT_GLOBALS_RECIPE}\n\n\ndef load_recipe_from_file(recipe_file, validate=True):\n \"\"\"Load recipe from file.\n\n Args:\n recipe_file(str): Name of the recipe file to be read.\n\n Returns:\n dict: Validated and corrected recipe dictionary.\n Empty dict if recipe is invalid.\n \"\"\"\n if not recipe_file:\n return copy.deepcopy(DEFAULT_RECIPE)\n try:\n log.info('Loading recipe file from {0:s}'.format(recipe_file))\n with open(recipe_file, 'r') as r_file:\n recipe_file_contents = r_file.read()\n recipe_dict = load(recipe_file_contents, Loader=Loader)\n if validate:\n success, _ = validate_recipe(recipe_dict)\n if success:\n return recipe_dict\n else:\n return recipe_dict\n except yaml.parser.ParserError as exception:\n message = (\n 'Invalid YAML on recipe file {0:s}: {1!s}.'.format(\n recipe_file, exception))\n log.error(message)\n except IOError as exception:\n log.error(\n 'Failed to read recipe file {0:s}: {1!s}'.format(\n recipe_file, exception))\n return {}\n\n\ndef validate_globals_recipe(proposed_globals_recipe):\n \"\"\"Validate the 'globals' special task recipe.\n\n Args:\n proposed_globals_recipe(dict): globals task recipe in need of validation.\n\n Returns:\n Tuple(\n bool: Whether the recipe has a valid format.\n str: Error message if validation failed.\n )\n \"\"\"\n reference_globals_recipe = copy.deepcopy(DEFAULT_GLOBALS_RECIPE)\n reference_globals_recipe.update(proposed_globals_recipe)\n\n filter_patterns_file = proposed_globals_recipe.get(\n 'filter_patterns_file', None)\n yara_rules_file = proposed_globals_recipe.get('yara_rules_file', None)\n if filter_patterns_file:\n proposed_globals_recipe['filter_patterns'] = file_to_list(\n filter_patterns_file)\n if yara_rules_file:\n proposed_globals_recipe['yara_rules'] = file_to_str(yara_rules_file)\n diff = set(proposed_globals_recipe) - set(DEFAULT_GLOBALS_RECIPE)\n if diff:\n message = (\n 'Invalid recipe: Unknown keys [{0:s}] found in globals recipe'.format(\n str(diff)))\n log.error(message)\n return (False, message)\n\n if (proposed_globals_recipe.get('jobs_allowlist') and\n proposed_globals_recipe.get('jobs_denylist')):\n message = 'Invalid recipe: Jobs cannot be in both the allow and deny lists'\n log.error(message)\n return (False, message)\n return (True, '')\n\n\ndef validate_recipe(recipe_dict):\n \"\"\"Validate the 'recipe' dict supplied by the request recipe.\n\n Args:\n recipe_dict(dict): Turbinia recipe in need of validation\n submitted along with the evidence.\n\n Returns:\n Tuple(\n bool: Whether the recipe has a valid format.\n str: Error message if validation failed.\n )\n \"\"\"\n tasks_with_recipe = []\n #If not globals task recipe is specified create one.\n if 'globals' not in recipe_dict:\n recipe_dict['globals'] = copy.deepcopy(DEFAULT_RECIPE)\n log.warning(\n 'No globals recipe specified, all recipes should include '\n 'a globals entry, the default values will be used')\n else:\n success, message = validate_globals_recipe(recipe_dict['globals'])\n if not success:\n log.error(message)\n return (False, message)\n\n for recipe_item, recipe_item_contents in recipe_dict.items():\n if recipe_item in tasks_with_recipe:\n message = (\n 'Two recipe items with the same name \\\"{0:s}\\\" have been found. '\n 'If you wish to specify several task runs of the same tool, '\n 'please include them in separate recipes.'.format(recipe_item))\n log.error(message)\n return (False, message)\n if recipe_item != 'globals':\n if 'task' not in recipe_item_contents:\n message = (\n 'Recipe item \\\"{0:s}\\\" has no \"task\" key. All recipe items '\n 'must have a \"task\" key indicating the TurbiniaTask '\n 'to which it relates.'.format(recipe_item))\n log.error(message)\n return (False, message)\n proposed_task = recipe_item_contents['task']\n\n task_loader = TaskLoader()\n if not task_loader.check_task_name(proposed_task):\n log.error(\n 'Task {0:s} defined for task recipe {1:s} does not exist.'.format(\n proposed_task, recipe_item))\n return (False, message)\n tasks_with_recipe.append(recipe_item)\n\n return (True, '')\n\n\ndef get_recipe_path_from_name(recipe_name):\n \"\"\"Returns a recipe's path from a recipe name.\n\n Args:\n recipe_name (str): A recipe name.\n\n Returns:\n str: a recipe's file system path.\n \"\"\"\n recipe_path = ''\n if not recipe_name.endswith('.yaml'):\n recipe_name = recipe_name + '.yaml'\n\n if hasattr(config, 'RECIPE_FILE_DIR') and config.RECIPE_FILE_DIR:\n recipe_path = os.path.join(config.RECIPE_FILE_DIR, recipe_name)\n else:\n recipe_path = os.path.realpath(__file__)\n recipe_path = os.path.dirname(recipe_path)\n recipe_path = os.path.join(recipe_path, 'config', 'recipes')\n recipe_path = os.path.join(recipe_path, recipe_name)\n\n return recipe_path\n", "path": "turbinia/lib/recipe_helpers.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2021 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Library to contain recipe validation logic.\"\"\"\n\nimport copy\nimport logging\nimport yaml\nimport os\n\nfrom yaml import Loader\nfrom yaml import load\nfrom turbinia import config\nfrom turbinia.lib.file_helpers import file_to_str\nfrom turbinia.lib.file_helpers import file_to_list\nfrom turbinia.task_utils import TaskLoader\n\nlog = logging.getLogger('turbinia')\n\n#Attributes allowed on the 'globals' task recipe\nDEFAULT_GLOBALS_RECIPE = {\n 'debug_tasks': False,\n 'jobs_allowlist': [],\n 'jobs_denylist': [],\n 'yara_rules': '',\n 'filter_patterns': [],\n 'sketch_id': None,\n 'group_id': ''\n}\n\n#Default recipes dict\nDEFAULT_RECIPE = {'globals': DEFAULT_GLOBALS_RECIPE}\n\n\ndef load_recipe_from_file(recipe_file, validate=True):\n \"\"\"Load recipe from file.\n\n Args:\n recipe_file(str): Name of the recipe file to be read.\n\n Returns:\n dict: Validated and corrected recipe dictionary.\n Empty dict if recipe is invalid.\n \"\"\"\n if not recipe_file:\n return copy.deepcopy(DEFAULT_RECIPE)\n try:\n log.info('Loading recipe file from {0:s}'.format(recipe_file))\n with open(recipe_file, 'r') as r_file:\n recipe_file_contents = r_file.read()\n recipe_dict = load(recipe_file_contents, Loader=Loader)\n if validate:\n success, _ = validate_recipe(recipe_dict)\n if success:\n return recipe_dict\n else:\n return recipe_dict\n except yaml.parser.ParserError as exception:\n message = (\n 'Invalid YAML on recipe file {0:s}: {1!s}.'.format(\n recipe_file, exception))\n log.error(message)\n except IOError as exception:\n log.error(\n 'Failed to read recipe file {0:s}: {1!s}'.format(\n recipe_file, exception))\n return {}\n\n\ndef validate_globals_recipe(proposed_globals_recipe):\n \"\"\"Validate the 'globals' special task recipe.\n\n Args:\n proposed_globals_recipe(dict): globals task recipe in need of validation.\n\n Returns:\n Tuple(\n bool: Whether the recipe has a valid format.\n str: Error message if validation failed.\n )\n \"\"\"\n reference_globals_recipe = copy.deepcopy(DEFAULT_GLOBALS_RECIPE)\n reference_globals_recipe.update(proposed_globals_recipe)\n\n filter_patterns_file = proposed_globals_recipe.get(\n 'filter_patterns_file', None)\n yara_rules_file = proposed_globals_recipe.get('yara_rules_file', None)\n if filter_patterns_file:\n proposed_globals_recipe['filter_patterns'] = file_to_list(\n filter_patterns_file)\n if yara_rules_file:\n proposed_globals_recipe['yara_rules'] = file_to_str(yara_rules_file)\n diff = set(proposed_globals_recipe) - set(DEFAULT_GLOBALS_RECIPE)\n if diff:\n message = (\n 'Invalid recipe: Unknown keys [{0:s}] found in globals recipe'.format(\n str(diff)))\n log.error(message)\n return (False, message)\n\n if (proposed_globals_recipe.get('jobs_allowlist') and\n proposed_globals_recipe.get('jobs_denylist')):\n message = 'Invalid recipe: Jobs cannot be in both the allow and deny lists'\n log.error(message)\n return (False, message)\n return (True, '')\n\n\ndef validate_recipe(recipe_dict):\n \"\"\"Validate the 'recipe' dict supplied by the request recipe.\n\n Args:\n recipe_dict(dict): Turbinia recipe in need of validation\n submitted along with the evidence.\n\n Returns:\n Tuple(\n bool: Whether the recipe has a valid format.\n str: Error message if validation failed.\n )\n \"\"\"\n tasks_with_recipe = []\n #If not globals task recipe is specified create one.\n if 'globals' not in recipe_dict:\n recipe_dict['globals'] = copy.deepcopy(DEFAULT_RECIPE)\n log.warning(\n 'No globals recipe specified, all recipes should include '\n 'a globals entry, the default values will be used')\n else:\n success, message = validate_globals_recipe(recipe_dict['globals'])\n if not success:\n log.error(message)\n return (False, message)\n\n for recipe_item, recipe_item_contents in recipe_dict.items():\n if recipe_item in tasks_with_recipe:\n message = (\n 'Two recipe items with the same name \\\"{0:s}\\\" have been found. '\n 'If you wish to specify several task runs of the same tool, '\n 'please include them in separate recipes.'.format(recipe_item))\n log.error(message)\n return (False, message)\n if recipe_item != 'globals':\n if 'task' not in recipe_item_contents:\n message = (\n 'Recipe item \\\"{0:s}\\\" has no \"task\" key. All recipe items '\n 'must have a \"task\" key indicating the TurbiniaTask '\n 'to which it relates.'.format(recipe_item))\n log.error(message)\n return (False, message)\n proposed_task = recipe_item_contents['task']\n\n task_loader = TaskLoader()\n if not task_loader.check_task_name(proposed_task):\n message = (\n 'Task {0:s} defined for task recipe {1:s} does not '\n 'exist.'.format(proposed_task, recipe_item))\n log.error(message)\n return (False, message)\n tasks_with_recipe.append(recipe_item)\n\n return (True, '')\n\n\ndef get_recipe_path_from_name(recipe_name):\n \"\"\"Returns a recipe's path from a recipe name.\n\n Args:\n recipe_name (str): A recipe name.\n\n Returns:\n str: a recipe's file system path.\n \"\"\"\n recipe_path = ''\n if not recipe_name.endswith('.yaml'):\n recipe_name = recipe_name + '.yaml'\n\n if hasattr(config, 'RECIPE_FILE_DIR') and config.RECIPE_FILE_DIR:\n recipe_path = os.path.join(config.RECIPE_FILE_DIR, recipe_name)\n else:\n recipe_path = os.path.realpath(__file__)\n recipe_path = os.path.dirname(recipe_path)\n recipe_path = os.path.join(recipe_path, 'config', 'recipes')\n recipe_path = os.path.join(recipe_path, recipe_name)\n\n return recipe_path\n", "path": "turbinia/lib/recipe_helpers.py"}]} | 2,284 | 176 |
gh_patches_debug_22238 | rasdani/github-patches | git_diff | tensorflow__addons-2274 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Significant LazyAdam optimizer performance degradation since PR#1988
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Reproducible on Colab
- TensorFlow version and how it was installed (source or binary): TF 2.3.0
- TensorFlow-Addons version and how it was installed (source or binary): TF 0.11.2
- Python version: 3.6.9
- Is GPU used? (yes/no): no (but issue observed on GPU as well)
**Describe the bug**
PR [#1988](https://github.com/tensorflow/addons/pull/1988/files) replaces calls to resource scatter update/sub/add from `tf.raw_ops` with calls to similar methods from ancestor class [OptimizerV2](https://github.com/tensorflow/tensorflow/blob/v2.3.0/tensorflow/python/keras/optimizer_v2/optimizer_v2.py#L1149-L1157).
These differ in that the OptimizerV2 method calls `.value()` on the input resource and returns a `Tensor`, whereas the `raw_ops` method returns an `Operation`.
The result is a major performance penalty with both CPU and GPU runtimes (in fact when using a GPU I have observed GPU utilization to drop to near 0%).
**Code to reproduce the issue**
Issue reproduced in this Colab on a CPU runtime with both with the Keras API and the Estimator API:
https://colab.research.google.com/drive/1IxPrQiGQn9Wgn9MtMhVTh0rdLlgZkMYo?usp=sharing
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tensorflow_addons/optimizers/lazy_adam.py`
Content:
```
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Variant of the Adam optimizer that handles sparse updates more efficiently.
16
17 Compared with the original Adam optimizer, the one in this file can
18 provide a large improvement in model training throughput for some
19 applications. However, it provides slightly different semantics than the
20 original Adam algorithm, and may lead to different empirical results.
21 """
22
23 import tensorflow as tf
24 from tensorflow_addons.utils.types import FloatTensorLike
25
26 from typeguard import typechecked
27 from typing import Union, Callable
28
29
30 @tf.keras.utils.register_keras_serializable(package="Addons")
31 class LazyAdam(tf.keras.optimizers.Adam):
32 """Variant of the Adam optimizer that handles sparse updates more
33 efficiently.
34
35 The original Adam algorithm maintains two moving-average accumulators for
36 each trainable variable; the accumulators are updated at every step.
37 This class provides lazier handling of gradient updates for sparse
38 variables. It only updates moving-average accumulators for sparse variable
39 indices that appear in the current batch, rather than updating the
40 accumulators for all indices. Compared with the original Adam optimizer,
41 it can provide large improvements in model training throughput for some
42 applications. However, it provides slightly different semantics than the
43 original Adam algorithm, and may lead to different empirical results.
44
45 Note, amsgrad is currently not supported and the argument can only be
46 False.
47 """
48
49 @typechecked
50 def __init__(
51 self,
52 learning_rate: Union[FloatTensorLike, Callable] = 0.001,
53 beta_1: FloatTensorLike = 0.9,
54 beta_2: FloatTensorLike = 0.999,
55 epsilon: FloatTensorLike = 1e-7,
56 amsgrad: bool = False,
57 name: str = "LazyAdam",
58 **kwargs,
59 ):
60 """Constructs a new LazyAdam optimizer.
61
62 Args:
63 learning_rate: A `Tensor` or a floating point value. or a schedule
64 that is a `tf.keras.optimizers.schedules.LearningRateSchedule`
65 The learning rate.
66 beta_1: A `float` value or a constant `float` tensor.
67 The exponential decay rate for the 1st moment estimates.
68 beta_2: A `float` value or a constant `float` tensor.
69 The exponential decay rate for the 2nd moment estimates.
70 epsilon: A small constant for numerical stability.
71 This epsilon is "epsilon hat" in
72 [Adam: A Method for Stochastic Optimization. Kingma et al., 2014]
73 (http://arxiv.org/abs/1412.6980) (in the formula just
74 before Section 2.1), not the epsilon in Algorithm 1 of the paper.
75 amsgrad: `boolean`. Whether to apply AMSGrad variant of this
76 algorithm from the paper "On the Convergence of Adam and beyond".
77 Note that this argument is currently not supported and the
78 argument can only be `False`.
79 name: Optional name for the operations created when applying
80 gradients. Defaults to "LazyAdam".
81 **kwargs: keyword arguments. Allowed to be {`clipnorm`, `clipvalue`,
82 `lr`, `decay`}. `clipnorm` is clip gradients by norm; `clipvalue`
83 is clip gradients by value, `decay` is included for backward
84 compatibility to allow time inverse decay of learning rate. `lr`
85 is included for backward compatibility, recommended to use
86 `learning_rate` instead.
87 """
88 super().__init__(
89 learning_rate=learning_rate,
90 beta_1=beta_1,
91 beta_2=beta_2,
92 epsilon=epsilon,
93 amsgrad=amsgrad,
94 name=name,
95 **kwargs,
96 )
97
98 def _resource_apply_sparse(self, grad, var, indices):
99 var_dtype = var.dtype.base_dtype
100 lr_t = self._decayed_lr(var_dtype)
101 beta_1_t = self._get_hyper("beta_1", var_dtype)
102 beta_2_t = self._get_hyper("beta_2", var_dtype)
103 local_step = tf.cast(self.iterations + 1, var_dtype)
104 beta_1_power = tf.math.pow(beta_1_t, local_step)
105 beta_2_power = tf.math.pow(beta_2_t, local_step)
106 epsilon_t = tf.convert_to_tensor(self.epsilon, var_dtype)
107 lr = lr_t * tf.math.sqrt(1 - beta_2_power) / (1 - beta_1_power)
108
109 # \\(m := beta1 * m + (1 - beta1) * g_t\\)
110 m = self.get_slot(var, "m")
111 m_t_slice = beta_1_t * tf.gather(m, indices) + (1 - beta_1_t) * grad
112 m_update_op = self._resource_scatter_update(m, indices, m_t_slice)
113
114 # \\(v := beta2 * v + (1 - beta2) * (g_t * g_t)\\)
115 v = self.get_slot(var, "v")
116 v_t_slice = beta_2_t * tf.gather(v, indices) + (1 - beta_2_t) * tf.math.square(
117 grad
118 )
119 v_update_op = self._resource_scatter_update(v, indices, v_t_slice)
120
121 # \\(variable += -learning_rate * m_t / (epsilon_t + sqrt(v_t))\\)
122 var_slice = -lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)
123 var_update_op = self._resource_scatter_add(var, indices, var_slice)
124
125 return tf.group(*[var_update_op, m_update_op, v_update_op])
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tensorflow_addons/optimizers/lazy_adam.py b/tensorflow_addons/optimizers/lazy_adam.py
--- a/tensorflow_addons/optimizers/lazy_adam.py
+++ b/tensorflow_addons/optimizers/lazy_adam.py
@@ -119,7 +119,26 @@
v_update_op = self._resource_scatter_update(v, indices, v_t_slice)
# \\(variable += -learning_rate * m_t / (epsilon_t + sqrt(v_t))\\)
- var_slice = -lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)
- var_update_op = self._resource_scatter_add(var, indices, var_slice)
+ var_slice = lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)
+ var_update_op = self._resource_scatter_sub(var, indices, var_slice)
return tf.group(*[var_update_op, m_update_op, v_update_op])
+
+ def _resource_scatter_update(self, resource, indices, update):
+ return self._resource_scatter_operate(
+ resource, indices, update, tf.raw_ops.ResourceScatterUpdate
+ )
+
+ def _resource_scatter_sub(self, resource, indices, update):
+ return self._resource_scatter_operate(
+ resource, indices, update, tf.raw_ops.ResourceScatterSub
+ )
+
+ def _resource_scatter_operate(self, resource, indices, update, resource_scatter_op):
+ resource_update_kwargs = {
+ "resource": resource.handle,
+ "indices": indices,
+ "updates": update,
+ }
+
+ return resource_scatter_op(**resource_update_kwargs)
| {"golden_diff": "diff --git a/tensorflow_addons/optimizers/lazy_adam.py b/tensorflow_addons/optimizers/lazy_adam.py\n--- a/tensorflow_addons/optimizers/lazy_adam.py\n+++ b/tensorflow_addons/optimizers/lazy_adam.py\n@@ -119,7 +119,26 @@\n v_update_op = self._resource_scatter_update(v, indices, v_t_slice)\n \n # \\\\(variable += -learning_rate * m_t / (epsilon_t + sqrt(v_t))\\\\)\n- var_slice = -lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)\n- var_update_op = self._resource_scatter_add(var, indices, var_slice)\n+ var_slice = lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)\n+ var_update_op = self._resource_scatter_sub(var, indices, var_slice)\n \n return tf.group(*[var_update_op, m_update_op, v_update_op])\n+\n+ def _resource_scatter_update(self, resource, indices, update):\n+ return self._resource_scatter_operate(\n+ resource, indices, update, tf.raw_ops.ResourceScatterUpdate\n+ )\n+\n+ def _resource_scatter_sub(self, resource, indices, update):\n+ return self._resource_scatter_operate(\n+ resource, indices, update, tf.raw_ops.ResourceScatterSub\n+ )\n+\n+ def _resource_scatter_operate(self, resource, indices, update, resource_scatter_op):\n+ resource_update_kwargs = {\n+ \"resource\": resource.handle,\n+ \"indices\": indices,\n+ \"updates\": update,\n+ }\n+\n+ return resource_scatter_op(**resource_update_kwargs)\n", "issue": "Significant LazyAdam optimizer performance degradation since PR#1988\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Reproducible on Colab\r\n- TensorFlow version and how it was installed (source or binary): TF 2.3.0\r\n- TensorFlow-Addons version and how it was installed (source or binary): TF 0.11.2\r\n- Python version: 3.6.9\r\n- Is GPU used? (yes/no): no (but issue observed on GPU as well)\r\n\r\n**Describe the bug**\r\n\r\nPR [#1988](https://github.com/tensorflow/addons/pull/1988/files) replaces calls to resource scatter update/sub/add from `tf.raw_ops` with calls to similar methods from ancestor class [OptimizerV2](https://github.com/tensorflow/tensorflow/blob/v2.3.0/tensorflow/python/keras/optimizer_v2/optimizer_v2.py#L1149-L1157).\r\nThese differ in that the OptimizerV2 method calls `.value()` on the input resource and returns a `Tensor`, whereas the `raw_ops` method returns an `Operation`.\r\n\r\nThe result is a major performance penalty with both CPU and GPU runtimes (in fact when using a GPU I have observed GPU utilization to drop to near 0%).\r\n\r\n**Code to reproduce the issue**\r\n\r\nIssue reproduced in this Colab on a CPU runtime with both with the Keras API and the Estimator API:\r\nhttps://colab.research.google.com/drive/1IxPrQiGQn9Wgn9MtMhVTh0rdLlgZkMYo?usp=sharing\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Variant of the Adam optimizer that handles sparse updates more efficiently.\n\nCompared with the original Adam optimizer, the one in this file can\nprovide a large improvement in model training throughput for some\napplications. However, it provides slightly different semantics than the\noriginal Adam algorithm, and may lead to different empirical results.\n\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils.types import FloatTensorLike\n\nfrom typeguard import typechecked\nfrom typing import Union, Callable\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass LazyAdam(tf.keras.optimizers.Adam):\n \"\"\"Variant of the Adam optimizer that handles sparse updates more\n efficiently.\n\n The original Adam algorithm maintains two moving-average accumulators for\n each trainable variable; the accumulators are updated at every step.\n This class provides lazier handling of gradient updates for sparse\n variables. It only updates moving-average accumulators for sparse variable\n indices that appear in the current batch, rather than updating the\n accumulators for all indices. Compared with the original Adam optimizer,\n it can provide large improvements in model training throughput for some\n applications. However, it provides slightly different semantics than the\n original Adam algorithm, and may lead to different empirical results.\n\n Note, amsgrad is currently not supported and the argument can only be\n False.\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n learning_rate: Union[FloatTensorLike, Callable] = 0.001,\n beta_1: FloatTensorLike = 0.9,\n beta_2: FloatTensorLike = 0.999,\n epsilon: FloatTensorLike = 1e-7,\n amsgrad: bool = False,\n name: str = \"LazyAdam\",\n **kwargs,\n ):\n \"\"\"Constructs a new LazyAdam optimizer.\n\n Args:\n learning_rate: A `Tensor` or a floating point value. or a schedule\n that is a `tf.keras.optimizers.schedules.LearningRateSchedule`\n The learning rate.\n beta_1: A `float` value or a constant `float` tensor.\n The exponential decay rate for the 1st moment estimates.\n beta_2: A `float` value or a constant `float` tensor.\n The exponential decay rate for the 2nd moment estimates.\n epsilon: A small constant for numerical stability.\n This epsilon is \"epsilon hat\" in\n [Adam: A Method for Stochastic Optimization. Kingma et al., 2014]\n (http://arxiv.org/abs/1412.6980) (in the formula just\n before Section 2.1), not the epsilon in Algorithm 1 of the paper.\n amsgrad: `boolean`. Whether to apply AMSGrad variant of this\n algorithm from the paper \"On the Convergence of Adam and beyond\".\n Note that this argument is currently not supported and the\n argument can only be `False`.\n name: Optional name for the operations created when applying\n gradients. Defaults to \"LazyAdam\".\n **kwargs: keyword arguments. Allowed to be {`clipnorm`, `clipvalue`,\n `lr`, `decay`}. `clipnorm` is clip gradients by norm; `clipvalue`\n is clip gradients by value, `decay` is included for backward\n compatibility to allow time inverse decay of learning rate. `lr`\n is included for backward compatibility, recommended to use\n `learning_rate` instead.\n \"\"\"\n super().__init__(\n learning_rate=learning_rate,\n beta_1=beta_1,\n beta_2=beta_2,\n epsilon=epsilon,\n amsgrad=amsgrad,\n name=name,\n **kwargs,\n )\n\n def _resource_apply_sparse(self, grad, var, indices):\n var_dtype = var.dtype.base_dtype\n lr_t = self._decayed_lr(var_dtype)\n beta_1_t = self._get_hyper(\"beta_1\", var_dtype)\n beta_2_t = self._get_hyper(\"beta_2\", var_dtype)\n local_step = tf.cast(self.iterations + 1, var_dtype)\n beta_1_power = tf.math.pow(beta_1_t, local_step)\n beta_2_power = tf.math.pow(beta_2_t, local_step)\n epsilon_t = tf.convert_to_tensor(self.epsilon, var_dtype)\n lr = lr_t * tf.math.sqrt(1 - beta_2_power) / (1 - beta_1_power)\n\n # \\\\(m := beta1 * m + (1 - beta1) * g_t\\\\)\n m = self.get_slot(var, \"m\")\n m_t_slice = beta_1_t * tf.gather(m, indices) + (1 - beta_1_t) * grad\n m_update_op = self._resource_scatter_update(m, indices, m_t_slice)\n\n # \\\\(v := beta2 * v + (1 - beta2) * (g_t * g_t)\\\\)\n v = self.get_slot(var, \"v\")\n v_t_slice = beta_2_t * tf.gather(v, indices) + (1 - beta_2_t) * tf.math.square(\n grad\n )\n v_update_op = self._resource_scatter_update(v, indices, v_t_slice)\n\n # \\\\(variable += -learning_rate * m_t / (epsilon_t + sqrt(v_t))\\\\)\n var_slice = -lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)\n var_update_op = self._resource_scatter_add(var, indices, var_slice)\n\n return tf.group(*[var_update_op, m_update_op, v_update_op])\n", "path": "tensorflow_addons/optimizers/lazy_adam.py"}], "after_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Variant of the Adam optimizer that handles sparse updates more efficiently.\n\nCompared with the original Adam optimizer, the one in this file can\nprovide a large improvement in model training throughput for some\napplications. However, it provides slightly different semantics than the\noriginal Adam algorithm, and may lead to different empirical results.\n\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow_addons.utils.types import FloatTensorLike\n\nfrom typeguard import typechecked\nfrom typing import Union, Callable\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass LazyAdam(tf.keras.optimizers.Adam):\n \"\"\"Variant of the Adam optimizer that handles sparse updates more\n efficiently.\n\n The original Adam algorithm maintains two moving-average accumulators for\n each trainable variable; the accumulators are updated at every step.\n This class provides lazier handling of gradient updates for sparse\n variables. It only updates moving-average accumulators for sparse variable\n indices that appear in the current batch, rather than updating the\n accumulators for all indices. Compared with the original Adam optimizer,\n it can provide large improvements in model training throughput for some\n applications. However, it provides slightly different semantics than the\n original Adam algorithm, and may lead to different empirical results.\n\n Note, amsgrad is currently not supported and the argument can only be\n False.\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n learning_rate: Union[FloatTensorLike, Callable] = 0.001,\n beta_1: FloatTensorLike = 0.9,\n beta_2: FloatTensorLike = 0.999,\n epsilon: FloatTensorLike = 1e-7,\n amsgrad: bool = False,\n name: str = \"LazyAdam\",\n **kwargs,\n ):\n \"\"\"Constructs a new LazyAdam optimizer.\n\n Args:\n learning_rate: A `Tensor` or a floating point value. or a schedule\n that is a `tf.keras.optimizers.schedules.LearningRateSchedule`\n The learning rate.\n beta_1: A `float` value or a constant `float` tensor.\n The exponential decay rate for the 1st moment estimates.\n beta_2: A `float` value or a constant `float` tensor.\n The exponential decay rate for the 2nd moment estimates.\n epsilon: A small constant for numerical stability.\n This epsilon is \"epsilon hat\" in\n [Adam: A Method for Stochastic Optimization. Kingma et al., 2014]\n (http://arxiv.org/abs/1412.6980) (in the formula just\n before Section 2.1), not the epsilon in Algorithm 1 of the paper.\n amsgrad: `boolean`. Whether to apply AMSGrad variant of this\n algorithm from the paper \"On the Convergence of Adam and beyond\".\n Note that this argument is currently not supported and the\n argument can only be `False`.\n name: Optional name for the operations created when applying\n gradients. Defaults to \"LazyAdam\".\n **kwargs: keyword arguments. Allowed to be {`clipnorm`, `clipvalue`,\n `lr`, `decay`}. `clipnorm` is clip gradients by norm; `clipvalue`\n is clip gradients by value, `decay` is included for backward\n compatibility to allow time inverse decay of learning rate. `lr`\n is included for backward compatibility, recommended to use\n `learning_rate` instead.\n \"\"\"\n super().__init__(\n learning_rate=learning_rate,\n beta_1=beta_1,\n beta_2=beta_2,\n epsilon=epsilon,\n amsgrad=amsgrad,\n name=name,\n **kwargs,\n )\n\n def _resource_apply_sparse(self, grad, var, indices):\n var_dtype = var.dtype.base_dtype\n lr_t = self._decayed_lr(var_dtype)\n beta_1_t = self._get_hyper(\"beta_1\", var_dtype)\n beta_2_t = self._get_hyper(\"beta_2\", var_dtype)\n local_step = tf.cast(self.iterations + 1, var_dtype)\n beta_1_power = tf.math.pow(beta_1_t, local_step)\n beta_2_power = tf.math.pow(beta_2_t, local_step)\n epsilon_t = tf.convert_to_tensor(self.epsilon, var_dtype)\n lr = lr_t * tf.math.sqrt(1 - beta_2_power) / (1 - beta_1_power)\n\n # \\\\(m := beta1 * m + (1 - beta1) * g_t\\\\)\n m = self.get_slot(var, \"m\")\n m_t_slice = beta_1_t * tf.gather(m, indices) + (1 - beta_1_t) * grad\n m_update_op = self._resource_scatter_update(m, indices, m_t_slice)\n\n # \\\\(v := beta2 * v + (1 - beta2) * (g_t * g_t)\\\\)\n v = self.get_slot(var, \"v\")\n v_t_slice = beta_2_t * tf.gather(v, indices) + (1 - beta_2_t) * tf.math.square(\n grad\n )\n v_update_op = self._resource_scatter_update(v, indices, v_t_slice)\n\n # \\\\(variable += -learning_rate * m_t / (epsilon_t + sqrt(v_t))\\\\)\n var_slice = lr * m_t_slice / (tf.math.sqrt(v_t_slice) + epsilon_t)\n var_update_op = self._resource_scatter_sub(var, indices, var_slice)\n\n return tf.group(*[var_update_op, m_update_op, v_update_op])\n\n def _resource_scatter_update(self, resource, indices, update):\n return self._resource_scatter_operate(\n resource, indices, update, tf.raw_ops.ResourceScatterUpdate\n )\n\n def _resource_scatter_sub(self, resource, indices, update):\n return self._resource_scatter_operate(\n resource, indices, update, tf.raw_ops.ResourceScatterSub\n )\n\n def _resource_scatter_operate(self, resource, indices, update, resource_scatter_op):\n resource_update_kwargs = {\n \"resource\": resource.handle,\n \"indices\": indices,\n \"updates\": update,\n }\n\n return resource_scatter_op(**resource_update_kwargs)\n", "path": "tensorflow_addons/optimizers/lazy_adam.py"}]} | 2,264 | 388 |
gh_patches_debug_26507 | rasdani/github-patches | git_diff | airctic__icevision-960 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add more logging to the pytorch lighning models.
The feature consists of two parts:
1. Add the validation loss to the progress bar by default
2. Create boolean parameter for extended progress bar logging (showing the different components of the loss)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `icevision/engines/lightning/lightning_model_adapter.py`
Content:
```
1 __all__ = ["LightningModelAdapter"]
2
3 import pytorch_lightning as pl
4 from icevision.imports import *
5 from icevision.metrics import *
6
7
8 class LightningModelAdapter(pl.LightningModule, ABC):
9 def __init__(self, metrics: List[Metric] = None):
10 super().__init__()
11 self.metrics = metrics or []
12
13 def accumulate_metrics(self, preds):
14 for metric in self.metrics:
15 metric.accumulate(preds=preds)
16
17 def finalize_metrics(self) -> None:
18 for metric in self.metrics:
19 metric_logs = metric.finalize()
20 for k, v in metric_logs.items():
21 self.log(f"{metric.name}/{k}", v)
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/icevision/engines/lightning/lightning_model_adapter.py b/icevision/engines/lightning/lightning_model_adapter.py
--- a/icevision/engines/lightning/lightning_model_adapter.py
+++ b/icevision/engines/lightning/lightning_model_adapter.py
@@ -6,9 +6,21 @@
class LightningModelAdapter(pl.LightningModule, ABC):
- def __init__(self, metrics: List[Metric] = None):
+ def __init__(
+ self,
+ metrics: List[Metric] = None,
+ metrics_keys_to_log_to_prog_bar: List[tuple] = None,
+ ):
+ """
+ To show a metric in the progressbar a list of tupels can be provided for metrics_keys_to_log_to_prog_bar, the first
+ entry has to be the name of the metric to log and the second entry the display name in the progressbar. By default the
+ mAP is logged to the progressbar.
+ """
super().__init__()
self.metrics = metrics or []
+ self.metrics_keys_to_log_to_prog_bar = metrics_keys_to_log_to_prog_bar or [
+ ("AP (IoU=0.50:0.95) area=all", "COCOMetric")
+ ]
def accumulate_metrics(self, preds):
for metric in self.metrics:
@@ -18,4 +30,9 @@
for metric in self.metrics:
metric_logs = metric.finalize()
for k, v in metric_logs.items():
- self.log(f"{metric.name}/{k}", v)
+ for entry in self.metrics_keys_to_log_to_prog_bar:
+ if entry[0] == k:
+ self.log(entry[1], v, prog_bar=True)
+ self.log(f"{metric.name}/{k}", v)
+ else:
+ self.log(f"{metric.name}/{k}", v)
| {"golden_diff": "diff --git a/icevision/engines/lightning/lightning_model_adapter.py b/icevision/engines/lightning/lightning_model_adapter.py\n--- a/icevision/engines/lightning/lightning_model_adapter.py\n+++ b/icevision/engines/lightning/lightning_model_adapter.py\n@@ -6,9 +6,21 @@\n \n \n class LightningModelAdapter(pl.LightningModule, ABC):\n- def __init__(self, metrics: List[Metric] = None):\n+ def __init__(\n+ self,\n+ metrics: List[Metric] = None,\n+ metrics_keys_to_log_to_prog_bar: List[tuple] = None,\n+ ):\n+ \"\"\"\n+ To show a metric in the progressbar a list of tupels can be provided for metrics_keys_to_log_to_prog_bar, the first\n+ entry has to be the name of the metric to log and the second entry the display name in the progressbar. By default the\n+ mAP is logged to the progressbar.\n+ \"\"\"\n super().__init__()\n self.metrics = metrics or []\n+ self.metrics_keys_to_log_to_prog_bar = metrics_keys_to_log_to_prog_bar or [\n+ (\"AP (IoU=0.50:0.95) area=all\", \"COCOMetric\")\n+ ]\n \n def accumulate_metrics(self, preds):\n for metric in self.metrics:\n@@ -18,4 +30,9 @@\n for metric in self.metrics:\n metric_logs = metric.finalize()\n for k, v in metric_logs.items():\n- self.log(f\"{metric.name}/{k}\", v)\n+ for entry in self.metrics_keys_to_log_to_prog_bar:\n+ if entry[0] == k:\n+ self.log(entry[1], v, prog_bar=True)\n+ self.log(f\"{metric.name}/{k}\", v)\n+ else:\n+ self.log(f\"{metric.name}/{k}\", v)\n", "issue": "Add more logging to the pytorch lighning models.\nThe feature consists of two parts:\r\n 1. Add the validation loss to the progress bar by default\r\n 2. Create boolean parameter for extended progress bar logging (showing the different components of the loss)\n", "before_files": [{"content": "__all__ = [\"LightningModelAdapter\"]\n\nimport pytorch_lightning as pl\nfrom icevision.imports import *\nfrom icevision.metrics import *\n\n\nclass LightningModelAdapter(pl.LightningModule, ABC):\n def __init__(self, metrics: List[Metric] = None):\n super().__init__()\n self.metrics = metrics or []\n\n def accumulate_metrics(self, preds):\n for metric in self.metrics:\n metric.accumulate(preds=preds)\n\n def finalize_metrics(self) -> None:\n for metric in self.metrics:\n metric_logs = metric.finalize()\n for k, v in metric_logs.items():\n self.log(f\"{metric.name}/{k}\", v)\n", "path": "icevision/engines/lightning/lightning_model_adapter.py"}], "after_files": [{"content": "__all__ = [\"LightningModelAdapter\"]\n\nimport pytorch_lightning as pl\nfrom icevision.imports import *\nfrom icevision.metrics import *\n\n\nclass LightningModelAdapter(pl.LightningModule, ABC):\n def __init__(\n self,\n metrics: List[Metric] = None,\n metrics_keys_to_log_to_prog_bar: List[tuple] = None,\n ):\n \"\"\"\n To show a metric in the progressbar a list of tupels can be provided for metrics_keys_to_log_to_prog_bar, the first\n entry has to be the name of the metric to log and the second entry the display name in the progressbar. By default the\n mAP is logged to the progressbar.\n \"\"\"\n super().__init__()\n self.metrics = metrics or []\n self.metrics_keys_to_log_to_prog_bar = metrics_keys_to_log_to_prog_bar or [\n (\"AP (IoU=0.50:0.95) area=all\", \"COCOMetric\")\n ]\n\n def accumulate_metrics(self, preds):\n for metric in self.metrics:\n metric.accumulate(preds=preds)\n\n def finalize_metrics(self) -> None:\n for metric in self.metrics:\n metric_logs = metric.finalize()\n for k, v in metric_logs.items():\n for entry in self.metrics_keys_to_log_to_prog_bar:\n if entry[0] == k:\n self.log(entry[1], v, prog_bar=True)\n self.log(f\"{metric.name}/{k}\", v)\n else:\n self.log(f\"{metric.name}/{k}\", v)\n", "path": "icevision/engines/lightning/lightning_model_adapter.py"}]} | 502 | 417 |
gh_patches_debug_13791 | rasdani/github-patches | git_diff | DataDog__dd-trace-py-3409 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
app_key not passed to aiohttp_jinja2
When using aiohttp_admin the app_key value for the templating module differs from the default one.
This causes an error executing:
https://github.com/DataDog/dd-trace-py/blob/ec191a4a71ae71017b70d26111bba4489e617ae5/ddtrace/contrib/aiohttp/template.py#L21
As far as I understand this would solve the problem.
`env = aiohttp_jinja2.get_env(request.app, app_key=kwargs["app_key"])`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/contrib/aiohttp_jinja2/patch.py`
Content:
```
1 from ddtrace import Pin
2 from ddtrace import config
3
4 from ...ext import SpanTypes
5 from ...internal.utils import get_argument_value
6 from ..trace_utils import unwrap
7 from ..trace_utils import with_traced_module
8 from ..trace_utils import wrap
9
10
11 config._add(
12 "aiohttp_jinja2",
13 dict(),
14 )
15
16
17 @with_traced_module
18 def traced_render_template(aiohttp_jinja2, pin, func, instance, args, kwargs):
19 # original signature:
20 # render_template(template_name, request, context, *, app_key=APP_KEY, encoding='utf-8')
21 template_name = get_argument_value(args, kwargs, 0, "template_name")
22 request = get_argument_value(args, kwargs, 1, "request")
23 env = aiohttp_jinja2.get_env(request.app)
24
25 # the prefix is available only on PackageLoader
26 template_prefix = getattr(env.loader, "package_path", "")
27 template_meta = "%s/%s" % (template_prefix, template_name)
28
29 with pin.tracer.trace("aiohttp.template", span_type=SpanTypes.TEMPLATE) as span:
30 span.set_tag("aiohttp.template", template_meta)
31 return func(*args, **kwargs)
32
33
34 def _patch(aiohttp_jinja2):
35 Pin().onto(aiohttp_jinja2)
36 wrap("aiohttp_jinja2", "render_template", traced_render_template(aiohttp_jinja2))
37
38
39 def patch():
40 import aiohttp_jinja2
41
42 if getattr(aiohttp_jinja2, "_datadog_patch", False):
43 return
44
45 _patch(aiohttp_jinja2)
46
47 setattr(aiohttp_jinja2, "_datadog_patch", True)
48
49
50 def _unpatch(aiohttp_jinja2):
51 unwrap(aiohttp_jinja2, "render_template")
52
53
54 def unpatch():
55 import aiohttp_jinja2
56
57 if not getattr(aiohttp_jinja2, "_datadog_patch", False):
58 return
59
60 _unpatch(aiohttp_jinja2)
61
62 setattr(aiohttp_jinja2, "_datadog_patch", False)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ddtrace/contrib/aiohttp_jinja2/patch.py b/ddtrace/contrib/aiohttp_jinja2/patch.py
--- a/ddtrace/contrib/aiohttp_jinja2/patch.py
+++ b/ddtrace/contrib/aiohttp_jinja2/patch.py
@@ -20,7 +20,10 @@
# render_template(template_name, request, context, *, app_key=APP_KEY, encoding='utf-8')
template_name = get_argument_value(args, kwargs, 0, "template_name")
request = get_argument_value(args, kwargs, 1, "request")
- env = aiohttp_jinja2.get_env(request.app)
+ get_env_kwargs = {}
+ if "app_key" in kwargs:
+ get_env_kwargs["app_key"] = kwargs["app_key"]
+ env = aiohttp_jinja2.get_env(request.app, **get_env_kwargs)
# the prefix is available only on PackageLoader
template_prefix = getattr(env.loader, "package_path", "")
| {"golden_diff": "diff --git a/ddtrace/contrib/aiohttp_jinja2/patch.py b/ddtrace/contrib/aiohttp_jinja2/patch.py\n--- a/ddtrace/contrib/aiohttp_jinja2/patch.py\n+++ b/ddtrace/contrib/aiohttp_jinja2/patch.py\n@@ -20,7 +20,10 @@\n # render_template(template_name, request, context, *, app_key=APP_KEY, encoding='utf-8')\n template_name = get_argument_value(args, kwargs, 0, \"template_name\")\n request = get_argument_value(args, kwargs, 1, \"request\")\n- env = aiohttp_jinja2.get_env(request.app)\n+ get_env_kwargs = {}\n+ if \"app_key\" in kwargs:\n+ get_env_kwargs[\"app_key\"] = kwargs[\"app_key\"]\n+ env = aiohttp_jinja2.get_env(request.app, **get_env_kwargs)\n \n # the prefix is available only on PackageLoader\n template_prefix = getattr(env.loader, \"package_path\", \"\")\n", "issue": "app_key not passed to aiohttp_jinja2 \nWhen using aiohttp_admin the app_key value for the templating module differs from the default one.\r\n\r\nThis causes an error executing:\r\nhttps://github.com/DataDog/dd-trace-py/blob/ec191a4a71ae71017b70d26111bba4489e617ae5/ddtrace/contrib/aiohttp/template.py#L21\r\n\r\nAs far as I understand this would solve the problem.\r\n`env = aiohttp_jinja2.get_env(request.app, app_key=kwargs[\"app_key\"])`\n", "before_files": [{"content": "from ddtrace import Pin\nfrom ddtrace import config\n\nfrom ...ext import SpanTypes\nfrom ...internal.utils import get_argument_value\nfrom ..trace_utils import unwrap\nfrom ..trace_utils import with_traced_module\nfrom ..trace_utils import wrap\n\n\nconfig._add(\n \"aiohttp_jinja2\",\n dict(),\n)\n\n\n@with_traced_module\ndef traced_render_template(aiohttp_jinja2, pin, func, instance, args, kwargs):\n # original signature:\n # render_template(template_name, request, context, *, app_key=APP_KEY, encoding='utf-8')\n template_name = get_argument_value(args, kwargs, 0, \"template_name\")\n request = get_argument_value(args, kwargs, 1, \"request\")\n env = aiohttp_jinja2.get_env(request.app)\n\n # the prefix is available only on PackageLoader\n template_prefix = getattr(env.loader, \"package_path\", \"\")\n template_meta = \"%s/%s\" % (template_prefix, template_name)\n\n with pin.tracer.trace(\"aiohttp.template\", span_type=SpanTypes.TEMPLATE) as span:\n span.set_tag(\"aiohttp.template\", template_meta)\n return func(*args, **kwargs)\n\n\ndef _patch(aiohttp_jinja2):\n Pin().onto(aiohttp_jinja2)\n wrap(\"aiohttp_jinja2\", \"render_template\", traced_render_template(aiohttp_jinja2))\n\n\ndef patch():\n import aiohttp_jinja2\n\n if getattr(aiohttp_jinja2, \"_datadog_patch\", False):\n return\n\n _patch(aiohttp_jinja2)\n\n setattr(aiohttp_jinja2, \"_datadog_patch\", True)\n\n\ndef _unpatch(aiohttp_jinja2):\n unwrap(aiohttp_jinja2, \"render_template\")\n\n\ndef unpatch():\n import aiohttp_jinja2\n\n if not getattr(aiohttp_jinja2, \"_datadog_patch\", False):\n return\n\n _unpatch(aiohttp_jinja2)\n\n setattr(aiohttp_jinja2, \"_datadog_patch\", False)\n", "path": "ddtrace/contrib/aiohttp_jinja2/patch.py"}], "after_files": [{"content": "from ddtrace import Pin\nfrom ddtrace import config\n\nfrom ...ext import SpanTypes\nfrom ...internal.utils import get_argument_value\nfrom ..trace_utils import unwrap\nfrom ..trace_utils import with_traced_module\nfrom ..trace_utils import wrap\n\n\nconfig._add(\n \"aiohttp_jinja2\",\n dict(),\n)\n\n\n@with_traced_module\ndef traced_render_template(aiohttp_jinja2, pin, func, instance, args, kwargs):\n # original signature:\n # render_template(template_name, request, context, *, app_key=APP_KEY, encoding='utf-8')\n template_name = get_argument_value(args, kwargs, 0, \"template_name\")\n request = get_argument_value(args, kwargs, 1, \"request\")\n get_env_kwargs = {}\n if \"app_key\" in kwargs:\n get_env_kwargs[\"app_key\"] = kwargs[\"app_key\"]\n env = aiohttp_jinja2.get_env(request.app, **get_env_kwargs)\n\n # the prefix is available only on PackageLoader\n template_prefix = getattr(env.loader, \"package_path\", \"\")\n template_meta = \"%s/%s\" % (template_prefix, template_name)\n\n with pin.tracer.trace(\"aiohttp.template\", span_type=SpanTypes.TEMPLATE) as span:\n span.set_tag(\"aiohttp.template\", template_meta)\n return func(*args, **kwargs)\n\n\ndef _patch(aiohttp_jinja2):\n Pin().onto(aiohttp_jinja2)\n wrap(\"aiohttp_jinja2\", \"render_template\", traced_render_template(aiohttp_jinja2))\n\n\ndef patch():\n import aiohttp_jinja2\n\n if getattr(aiohttp_jinja2, \"_datadog_patch\", False):\n return\n\n _patch(aiohttp_jinja2)\n\n setattr(aiohttp_jinja2, \"_datadog_patch\", True)\n\n\ndef _unpatch(aiohttp_jinja2):\n unwrap(aiohttp_jinja2, \"render_template\")\n\n\ndef unpatch():\n import aiohttp_jinja2\n\n if not getattr(aiohttp_jinja2, \"_datadog_patch\", False):\n return\n\n _unpatch(aiohttp_jinja2)\n\n setattr(aiohttp_jinja2, \"_datadog_patch\", False)\n", "path": "ddtrace/contrib/aiohttp_jinja2/patch.py"}]} | 985 | 225 |
gh_patches_debug_4173 | rasdani/github-patches | git_diff | statsmodels__statsmodels-779 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
OLS residuals returned as Pandas series when endog and exog are Pandas series
When I fit OLS model with pandas series and try to do a Durbin-Watson test, the function returns nan. In that case the RegressionResult.resid attribute is a pandas series, rather than a numpy array- converting to a numpy array explicitly, the durbin_watson function works like a charm.
My instinct is this is something that should probably be changed in OLS (to guarantee the type of resid), hence the title of the issue, but I leave that to the judgement of our fearless leaders.
``` python
import statsmodels.api as sm
import numpy as np
from pandas import DataFrame
x=np.arange(1,11)
y=[num+np.random.normal() for num in np.arange(0,5, .5)]
linmod=sm.OLS(y, x).fit()
dw=sm.stats.stattools.durbin_watson(linmod.resid)
data=DataFrame({'x':x, 'y':y}, index=x)
linmod_pandas=sm.OLS(data.y, data.x).fit()
dw_pandas=sm.stats.stattools.durbin_watson(linmod_pandas.resid)
dw_pandas1=sm.stats.stattools.durbin_watson(array(linmod_pandas.resid))
print type(linmod_pandas.resid)
print dw, dw_pandas, dw_pandas1
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `statsmodels/stats/stattools.py`
Content:
```
1 """
2 Statistical tests to be used in conjunction with the models
3
4 Notes
5 -----
6 These functions haven't been formally tested.
7 """
8
9 from scipy import stats
10 import numpy as np
11
12
13 #TODO: these are pretty straightforward but they should be tested
14 def durbin_watson(resids):
15 """
16 Calculates the Durbin-Watson statistic
17
18 Parameters
19 -----------
20 resids : array-like
21
22 Returns
23 --------
24 Durbin Watson statistic. This is defined as
25 sum_(t=2)^(T)((e_t - e_(t-1))^(2))/sum_(t=1)^(T)e_t^(2)
26 """
27 diff_resids = np.diff(resids, 1)
28 dw = np.dot(diff_resids, diff_resids) / np.dot(resids, resids)
29 return dw
30
31 def omni_normtest(resids, axis=0):
32 """
33 Omnibus test for normality
34
35 Parameters
36 -----------
37 resid : array-like
38 axis : int, optional
39 Default is 0
40
41 Returns
42 -------
43 Chi^2 score, two-tail probability
44 """
45 #TODO: change to exception in summary branch and catch in summary()
46 #behavior changed between scipy 0.9 and 0.10
47 resids = np.asarray(resids)
48 n = resids.shape[axis]
49 if n < 8:
50 return np.nan, np.nan
51 return_shape = list(resids.shape)
52 del return_shape[axis]
53 return np.nan * np.zeros(return_shape), np.nan * np.zeros(return_shape)
54 raise ValueError(
55 "skewtest is not valid with less than 8 observations; %i samples"
56 " were given." % int(n))
57
58 return stats.normaltest(resids, axis=axis)
59
60 def jarque_bera(resids):
61 """
62 Calculate residual skewness, kurtosis, and do the JB test for normality
63
64 Parameters
65 -----------
66 resids : array-like
67
68 Returns
69 -------
70 JB, JBpv, skew, kurtosis
71
72 JB = n/6*(S^2 + (K-3)^2/4)
73
74 JBpv is the Chi^2 two-tail probability value
75
76 skew is the measure of skewness
77
78 kurtosis is the measure of kurtosis
79
80 """
81 resids = np.asarray(resids)
82 # Calculate residual skewness and kurtosis
83 skew = stats.skew(resids)
84 kurtosis = 3 + stats.kurtosis(resids)
85
86 # Calculate the Jarque-Bera test for normality
87 JB = (resids.shape[0] / 6.) * (skew**2 + (1 / 4.) * (kurtosis-3)**2)
88 JBpv = stats.chi2.sf(JB,2)
89
90 return JB, JBpv, skew, kurtosis
91
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/statsmodels/stats/stattools.py b/statsmodels/stats/stattools.py
--- a/statsmodels/stats/stattools.py
+++ b/statsmodels/stats/stattools.py
@@ -24,6 +24,7 @@
Durbin Watson statistic. This is defined as
sum_(t=2)^(T)((e_t - e_(t-1))^(2))/sum_(t=1)^(T)e_t^(2)
"""
+ resids=np.asarray(resids)
diff_resids = np.diff(resids, 1)
dw = np.dot(diff_resids, diff_resids) / np.dot(resids, resids)
return dw
| {"golden_diff": "diff --git a/statsmodels/stats/stattools.py b/statsmodels/stats/stattools.py\n--- a/statsmodels/stats/stattools.py\n+++ b/statsmodels/stats/stattools.py\n@@ -24,6 +24,7 @@\n Durbin Watson statistic. This is defined as\n sum_(t=2)^(T)((e_t - e_(t-1))^(2))/sum_(t=1)^(T)e_t^(2)\n \"\"\"\n+ resids=np.asarray(resids)\n diff_resids = np.diff(resids, 1)\n dw = np.dot(diff_resids, diff_resids) / np.dot(resids, resids)\n return dw\n", "issue": "OLS residuals returned as Pandas series when endog and exog are Pandas series\nWhen I fit OLS model with pandas series and try to do a Durbin-Watson test, the function returns nan. In that case the RegressionResult.resid attribute is a pandas series, rather than a numpy array- converting to a numpy array explicitly, the durbin_watson function works like a charm. \n\nMy instinct is this is something that should probably be changed in OLS (to guarantee the type of resid), hence the title of the issue, but I leave that to the judgement of our fearless leaders.\n\n``` python\nimport statsmodels.api as sm\nimport numpy as np\nfrom pandas import DataFrame\nx=np.arange(1,11)\ny=[num+np.random.normal() for num in np.arange(0,5, .5)]\nlinmod=sm.OLS(y, x).fit()\ndw=sm.stats.stattools.durbin_watson(linmod.resid)\ndata=DataFrame({'x':x, 'y':y}, index=x)\nlinmod_pandas=sm.OLS(data.y, data.x).fit()\ndw_pandas=sm.stats.stattools.durbin_watson(linmod_pandas.resid)\ndw_pandas1=sm.stats.stattools.durbin_watson(array(linmod_pandas.resid))\nprint type(linmod_pandas.resid)\nprint dw, dw_pandas, dw_pandas1\n```\n\n", "before_files": [{"content": "\"\"\"\nStatistical tests to be used in conjunction with the models\n\nNotes\n-----\nThese functions haven't been formally tested.\n\"\"\"\n\nfrom scipy import stats\nimport numpy as np\n\n\n#TODO: these are pretty straightforward but they should be tested\ndef durbin_watson(resids):\n \"\"\"\n Calculates the Durbin-Watson statistic\n\n Parameters\n -----------\n resids : array-like\n\n Returns\n --------\n Durbin Watson statistic. This is defined as\n sum_(t=2)^(T)((e_t - e_(t-1))^(2))/sum_(t=1)^(T)e_t^(2)\n \"\"\"\n diff_resids = np.diff(resids, 1)\n dw = np.dot(diff_resids, diff_resids) / np.dot(resids, resids)\n return dw\n\ndef omni_normtest(resids, axis=0):\n \"\"\"\n Omnibus test for normality\n\n Parameters\n -----------\n resid : array-like\n axis : int, optional\n Default is 0\n\n Returns\n -------\n Chi^2 score, two-tail probability\n \"\"\"\n #TODO: change to exception in summary branch and catch in summary()\n #behavior changed between scipy 0.9 and 0.10\n resids = np.asarray(resids)\n n = resids.shape[axis]\n if n < 8:\n return np.nan, np.nan\n return_shape = list(resids.shape)\n del return_shape[axis]\n return np.nan * np.zeros(return_shape), np.nan * np.zeros(return_shape)\n raise ValueError(\n \"skewtest is not valid with less than 8 observations; %i samples\"\n \" were given.\" % int(n))\n\n return stats.normaltest(resids, axis=axis)\n\ndef jarque_bera(resids):\n \"\"\"\n Calculate residual skewness, kurtosis, and do the JB test for normality\n\n Parameters\n -----------\n resids : array-like\n\n Returns\n -------\n JB, JBpv, skew, kurtosis\n\n JB = n/6*(S^2 + (K-3)^2/4)\n\n JBpv is the Chi^2 two-tail probability value\n\n skew is the measure of skewness\n\n kurtosis is the measure of kurtosis\n\n \"\"\"\n resids = np.asarray(resids)\n # Calculate residual skewness and kurtosis\n skew = stats.skew(resids)\n kurtosis = 3 + stats.kurtosis(resids)\n\n # Calculate the Jarque-Bera test for normality\n JB = (resids.shape[0] / 6.) * (skew**2 + (1 / 4.) * (kurtosis-3)**2)\n JBpv = stats.chi2.sf(JB,2)\n\n return JB, JBpv, skew, kurtosis\n\n", "path": "statsmodels/stats/stattools.py"}], "after_files": [{"content": "\"\"\"\nStatistical tests to be used in conjunction with the models\n\nNotes\n-----\nThese functions haven't been formally tested.\n\"\"\"\n\nfrom scipy import stats\nimport numpy as np\n\n\n#TODO: these are pretty straightforward but they should be tested\ndef durbin_watson(resids):\n \"\"\"\n Calculates the Durbin-Watson statistic\n\n Parameters\n -----------\n resids : array-like\n\n Returns\n --------\n Durbin Watson statistic. This is defined as\n sum_(t=2)^(T)((e_t - e_(t-1))^(2))/sum_(t=1)^(T)e_t^(2)\n \"\"\"\n resids=np.asarray(resids)\n diff_resids = np.diff(resids, 1)\n dw = np.dot(diff_resids, diff_resids) / np.dot(resids, resids)\n return dw\n\ndef omni_normtest(resids, axis=0):\n \"\"\"\n Omnibus test for normality\n\n Parameters\n -----------\n resid : array-like\n axis : int, optional\n Default is 0\n\n Returns\n -------\n Chi^2 score, two-tail probability\n \"\"\"\n #TODO: change to exception in summary branch and catch in summary()\n #behavior changed between scipy 0.9 and 0.10\n resids = np.asarray(resids)\n n = resids.shape[axis]\n if n < 8:\n return np.nan, np.nan\n return_shape = list(resids.shape)\n del return_shape[axis]\n return np.nan * np.zeros(return_shape), np.nan * np.zeros(return_shape)\n raise ValueError(\n \"skewtest is not valid with less than 8 observations; %i samples\"\n \" were given.\" % int(n))\n\n return stats.normaltest(resids, axis=axis)\n\ndef jarque_bera(resids):\n \"\"\"\n Calculate residual skewness, kurtosis, and do the JB test for normality\n\n Parameters\n -----------\n resids : array-like\n\n Returns\n -------\n JB, JBpv, skew, kurtosis\n\n JB = n/6*(S^2 + (K-3)^2/4)\n\n JBpv is the Chi^2 two-tail probability value\n\n skew is the measure of skewness\n\n kurtosis is the measure of kurtosis\n\n \"\"\"\n resids = np.asarray(resids)\n # Calculate residual skewness and kurtosis\n skew = stats.skew(resids)\n kurtosis = 3 + stats.kurtosis(resids)\n\n # Calculate the Jarque-Bera test for normality\n JB = (resids.shape[0] / 6.) * (skew**2 + (1 / 4.) * (kurtosis-3)**2)\n JBpv = stats.chi2.sf(JB,2)\n\n return JB, JBpv, skew, kurtosis\n\n", "path": "statsmodels/stats/stattools.py"}]} | 1,380 | 145 |
gh_patches_debug_2846 | rasdani/github-patches | git_diff | ESMCI__cime-3605 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NLCOMP fails with python3 because dictionaries no longer support `has_key`
When using python3, I get:
```
$ ./case.cmpgen_namelists
Comparing namelists with baselines 'lilac_0703a'
Generating namelists to baselines 'lilac_0703b'
Exception during namelist operations:
'dict' object has no attribute 'has_key'
Traceback (most recent call last):
File "/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/case/case_cmpgen_namelists.py", line 123, in case_cmpgen_namelists
success, output = _do_full_nl_comp(self, test_name, compare_name, baseline_root)
File "/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/case/case_cmpgen_namelists.py", line 45, in _do_full_nl_comp
success, current_comments = compare_runconfigfiles(baseline_counterpart, item, test)
File "/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/simple_compare.py", line 171, in compare_runconfigfiles
comments = findDiff(gold_dict, compare_dict, case=case)
File "/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/simple_compare.py", line 215, in findDiff
if not d2.has_key(k):
AttributeError: 'dict' object has no attribute 'has_key'
```
I have a fix incoming.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/lib/CIME/simple_compare.py`
Content:
```
1 import os, re
2
3 from CIME.utils import expect
4
5 ###############################################################################
6 def _normalize_string_value(value, case):
7 ###############################################################################
8 """
9 Some of the strings are inherently prone to diffs, like file
10 paths, etc. This function attempts to normalize that data so that
11 it will not cause diffs.
12 """
13 # Any occurance of case must be normalized because test-ids might not match
14 if (case is not None):
15 case_re = re.compile(r'{}[.]([GC])[.]([^./\s]+)'.format(case))
16 value = case_re.sub("{}.ACTION.TESTID".format(case), value)
17
18 if ("/" in value):
19 # File path, just return the basename
20 return os.path.basename(value)
21 elif ("username" in value):
22 return ''
23 elif (".log." in value):
24 # Remove the part that's prone to diff
25 components = value.split(".")
26 return os.path.basename(".".join(components[0:-1]))
27 else:
28 return value
29
30 ###############################################################################
31 def _skip_comments_and_whitespace(lines, idx):
32 ###############################################################################
33 """
34 Starting at idx, return next valid idx of lines that contains real data
35 """
36 if (idx == len(lines)):
37 return idx
38
39 comment_re = re.compile(r'^[#!]')
40
41 lines_slice = lines[idx:]
42 for line in lines_slice:
43 line = line.strip()
44 if (comment_re.match(line) is not None or line == ""):
45 idx += 1
46 else:
47 return idx
48
49 return idx
50
51 ###############################################################################
52 def _compare_data(gold_lines, comp_lines, case, offset_method=False):
53 ###############################################################################
54 """
55 >>> teststr = '''
56 ... data1
57 ... data2 data3
58 ... data4 data5 data6
59 ...
60 ... # Comment
61 ... data7 data8 data9 data10
62 ... '''
63 >>> _compare_data(teststr.splitlines(), teststr.splitlines(), None)
64 ('', 0)
65
66 >>> teststr2 = '''
67 ... data1
68 ... data2 data30
69 ... data4 data5 data6
70 ... data7 data8 data9 data10
71 ... data00
72 ... '''
73 >>> results,_ = _compare_data(teststr.splitlines(), teststr2.splitlines(), None)
74 >>> print(results)
75 Inequivalent lines data2 data3 != data2 data30
76 NORMALIZED: data2 data3 != data2 data30
77 Found extra lines
78 data00
79 <BLANKLINE>
80 >>> teststr3 = '''
81 ... data1
82 ... data4 data5 data6
83 ... data7 data8 data9 data10
84 ... data00
85 ... '''
86 >>> results,_ = _compare_data(teststr3.splitlines(), teststr2.splitlines(), None, offset_method=True)
87 >>> print(results)
88 Inequivalent lines data4 data5 data6 != data2 data30
89 NORMALIZED: data4 data5 data6 != data2 data30
90 <BLANKLINE>
91 """
92 comments = ""
93 cnt = 0
94 gidx, cidx = 0, 0
95 gnum, cnum = len(gold_lines), len(comp_lines)
96 while (gidx < gnum or cidx < cnum):
97 gidx = _skip_comments_and_whitespace(gold_lines, gidx)
98 cidx = _skip_comments_and_whitespace(comp_lines, cidx)
99
100 if (gidx == gnum):
101 if (cidx == cnum):
102 return comments, cnt
103 else:
104 comments += "Found extra lines\n"
105 comments += "\n".join(comp_lines[cidx:]) + "\n"
106 return comments, cnt
107 elif (cidx == cnum):
108 comments += "Missing lines\n"
109 comments += "\n".join(gold_lines[gidx:1]) + "\n"
110 return comments, cnt
111
112 gold_value = gold_lines[gidx].strip()
113 gold_value = gold_value.replace('"',"'")
114 comp_value = comp_lines[cidx].strip()
115 comp_value = comp_value.replace('"',"'")
116
117 norm_gold_value = _normalize_string_value(gold_value, case)
118 norm_comp_value = _normalize_string_value(comp_value, case)
119
120 if (norm_gold_value != norm_comp_value):
121 comments += "Inequivalent lines {} != {}\n".format(gold_value, comp_value)
122 comments += " NORMALIZED: {} != {}\n".format(norm_gold_value, norm_comp_value)
123 cnt += 1
124 if offset_method and (norm_gold_value != norm_comp_value):
125 if gnum > cnum:
126 gidx += 1
127 else:
128 cidx += 1
129 else:
130 gidx += 1
131 cidx += 1
132
133 return comments, cnt
134
135 ###############################################################################
136 def compare_files(gold_file, compare_file, case=None):
137 ###############################################################################
138 """
139 Returns true if files are the same, comments are returned too:
140 (success, comments)
141 """
142 expect(os.path.exists(gold_file), "File not found: {}".format(gold_file))
143 expect(os.path.exists(compare_file), "File not found: {}".format(compare_file))
144
145 comments, cnt = _compare_data(open(gold_file, "r").readlines(),
146 open(compare_file, "r").readlines(), case)
147
148 if cnt > 0:
149 comments2, cnt2 = _compare_data(open(gold_file, "r").readlines(),
150 open(compare_file, "r").readlines(),
151 case, offset_method=True)
152 if cnt2 < cnt:
153 comments = comments2
154
155 return comments == "", comments
156
157 ###############################################################################
158 def compare_runconfigfiles(gold_file, compare_file, case=None):
159 ###############################################################################
160 """
161 Returns true if files are the same, comments are returned too:
162 (success, comments)
163 """
164 expect(os.path.exists(gold_file), "File not found: {}".format(gold_file))
165 expect(os.path.exists(compare_file), "File not found: {}".format(compare_file))
166
167 #create dictionary's of the runconfig files and compare them
168 gold_dict = _parse_runconfig(gold_file)
169 compare_dict = _parse_runconfig(compare_file)
170
171 comments = findDiff(gold_dict, compare_dict, case=case)
172 comments = comments.replace(" d1", " " + gold_file)
173 comments = comments.replace(" d2", " " + compare_file)
174 # this picks up the case that an entry in compare is not in gold
175 if comments == "":
176 comments = findDiff(compare_dict, gold_dict, case=case)
177 comments = comments.replace(" d2", " " + gold_file)
178 comments = comments.replace(" d1", " " + compare_file)
179
180 return comments == "", comments
181
182 def _parse_runconfig(filename):
183 runconfig = {}
184 inrunseq = False
185 insubsection = None
186 subsection_re = re.compile(r'\s*(\S+)::')
187 group_re = re.compile(r'\s*(\S+)\s*:\s*(\S+)')
188 var_re = re.compile(r'\s*(\S+)\s*=\s*(\S+)')
189 with open(filename, "r") as fd:
190 for line in fd:
191 # remove comments
192 line = line.split('#')[0]
193 subsection_match = subsection_re.match(line)
194 group_match = group_re.match(line)
195 var_match = var_re.match(line)
196 if re.match(r'\s*runSeq\s*::', line):
197 runconfig['runSeq'] = []
198 inrunseq = True
199 elif re.match(r'\s*::\s*', line):
200 inrunseq = False
201 elif inrunseq:
202 runconfig['runSeq'].append(line)
203 elif subsection_match:
204 insubsection = subsection_match.group(1)
205 runconfig[insubsection] = {}
206 elif group_match:
207 runconfig[group_match.group(1)] = group_match.group(2)
208 elif insubsection and var_match:
209 runconfig[insubsection][var_match.group(1)] = var_match.group(2)
210 return runconfig
211
212 def findDiff(d1, d2, path="", case=None):
213 comment = ""
214 for k in d1.keys():
215 if not d2.has_key(k):
216 comment += path + ":\n"
217 comment += k + " as key not in d2\n"
218 else:
219 if type(d1[k]) is dict:
220 if path == "":
221 path = k
222 else:
223 path = path + "->" + k
224 comment += findDiff(d1[k],d2[k], path=path, case=case)
225 else:
226 if case in d1[k]:
227 pass
228 elif "username" in k:
229 pass
230 elif "logfile" in k:
231 pass
232 elif d1[k] != d2[k]:
233 comment += path+":\n"
234 comment += " - {} : {}\n".format(k,d1[k])
235 comment += " + {} : {}\n".format(k,d2[k])
236 return comment
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/scripts/lib/CIME/simple_compare.py b/scripts/lib/CIME/simple_compare.py
--- a/scripts/lib/CIME/simple_compare.py
+++ b/scripts/lib/CIME/simple_compare.py
@@ -212,7 +212,7 @@
def findDiff(d1, d2, path="", case=None):
comment = ""
for k in d1.keys():
- if not d2.has_key(k):
+ if not k in d2:
comment += path + ":\n"
comment += k + " as key not in d2\n"
else:
| {"golden_diff": "diff --git a/scripts/lib/CIME/simple_compare.py b/scripts/lib/CIME/simple_compare.py\n--- a/scripts/lib/CIME/simple_compare.py\n+++ b/scripts/lib/CIME/simple_compare.py\n@@ -212,7 +212,7 @@\n def findDiff(d1, d2, path=\"\", case=None):\n comment = \"\"\n for k in d1.keys():\n- if not d2.has_key(k):\n+ if not k in d2:\n comment += path + \":\\n\"\n comment += k + \" as key not in d2\\n\"\n else:\n", "issue": "NLCOMP fails with python3 because dictionaries no longer support `has_key`\nWhen using python3, I get:\r\n\r\n```\r\n$ ./case.cmpgen_namelists\r\nComparing namelists with baselines 'lilac_0703a'\r\nGenerating namelists to baselines 'lilac_0703b'\r\nException during namelist operations:\r\n'dict' object has no attribute 'has_key'\r\nTraceback (most recent call last):\r\n File \"/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/case/case_cmpgen_namelists.py\", line 123, in case_cmpgen_namelists\r\n success, output = _do_full_nl_comp(self, test_name, compare_name, baseline_root)\r\n File \"/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/case/case_cmpgen_namelists.py\", line 45, in _do_full_nl_comp\r\n success, current_comments = compare_runconfigfiles(baseline_counterpart, item, test)\r\n File \"/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/simple_compare.py\", line 171, in compare_runconfigfiles\r\n comments = findDiff(gold_dict, compare_dict, case=case)\r\n File \"/Users/sacks/ctsm/ctsm3/cime/scripts/Tools/../../scripts/lib/CIME/simple_compare.py\", line 215, in findDiff\r\n if not d2.has_key(k):\r\nAttributeError: 'dict' object has no attribute 'has_key'\r\n```\r\n\r\nI have a fix incoming.\n", "before_files": [{"content": "import os, re\n\nfrom CIME.utils import expect\n\n###############################################################################\ndef _normalize_string_value(value, case):\n###############################################################################\n \"\"\"\n Some of the strings are inherently prone to diffs, like file\n paths, etc. This function attempts to normalize that data so that\n it will not cause diffs.\n \"\"\"\n # Any occurance of case must be normalized because test-ids might not match\n if (case is not None):\n case_re = re.compile(r'{}[.]([GC])[.]([^./\\s]+)'.format(case))\n value = case_re.sub(\"{}.ACTION.TESTID\".format(case), value)\n\n if (\"/\" in value):\n # File path, just return the basename\n return os.path.basename(value)\n elif (\"username\" in value):\n return ''\n elif (\".log.\" in value):\n # Remove the part that's prone to diff\n components = value.split(\".\")\n return os.path.basename(\".\".join(components[0:-1]))\n else:\n return value\n\n###############################################################################\ndef _skip_comments_and_whitespace(lines, idx):\n###############################################################################\n \"\"\"\n Starting at idx, return next valid idx of lines that contains real data\n \"\"\"\n if (idx == len(lines)):\n return idx\n\n comment_re = re.compile(r'^[#!]')\n\n lines_slice = lines[idx:]\n for line in lines_slice:\n line = line.strip()\n if (comment_re.match(line) is not None or line == \"\"):\n idx += 1\n else:\n return idx\n\n return idx\n\n###############################################################################\ndef _compare_data(gold_lines, comp_lines, case, offset_method=False):\n###############################################################################\n \"\"\"\n >>> teststr = '''\n ... data1\n ... data2 data3\n ... data4 data5 data6\n ...\n ... # Comment\n ... data7 data8 data9 data10\n ... '''\n >>> _compare_data(teststr.splitlines(), teststr.splitlines(), None)\n ('', 0)\n\n >>> teststr2 = '''\n ... data1\n ... data2 data30\n ... data4 data5 data6\n ... data7 data8 data9 data10\n ... data00\n ... '''\n >>> results,_ = _compare_data(teststr.splitlines(), teststr2.splitlines(), None)\n >>> print(results)\n Inequivalent lines data2 data3 != data2 data30\n NORMALIZED: data2 data3 != data2 data30\n Found extra lines\n data00\n <BLANKLINE>\n >>> teststr3 = '''\n ... data1\n ... data4 data5 data6\n ... data7 data8 data9 data10\n ... data00\n ... '''\n >>> results,_ = _compare_data(teststr3.splitlines(), teststr2.splitlines(), None, offset_method=True)\n >>> print(results)\n Inequivalent lines data4 data5 data6 != data2 data30\n NORMALIZED: data4 data5 data6 != data2 data30\n <BLANKLINE>\n \"\"\"\n comments = \"\"\n cnt = 0\n gidx, cidx = 0, 0\n gnum, cnum = len(gold_lines), len(comp_lines)\n while (gidx < gnum or cidx < cnum):\n gidx = _skip_comments_and_whitespace(gold_lines, gidx)\n cidx = _skip_comments_and_whitespace(comp_lines, cidx)\n\n if (gidx == gnum):\n if (cidx == cnum):\n return comments, cnt\n else:\n comments += \"Found extra lines\\n\"\n comments += \"\\n\".join(comp_lines[cidx:]) + \"\\n\"\n return comments, cnt\n elif (cidx == cnum):\n comments += \"Missing lines\\n\"\n comments += \"\\n\".join(gold_lines[gidx:1]) + \"\\n\"\n return comments, cnt\n\n gold_value = gold_lines[gidx].strip()\n gold_value = gold_value.replace('\"',\"'\")\n comp_value = comp_lines[cidx].strip()\n comp_value = comp_value.replace('\"',\"'\")\n\n norm_gold_value = _normalize_string_value(gold_value, case)\n norm_comp_value = _normalize_string_value(comp_value, case)\n\n if (norm_gold_value != norm_comp_value):\n comments += \"Inequivalent lines {} != {}\\n\".format(gold_value, comp_value)\n comments += \" NORMALIZED: {} != {}\\n\".format(norm_gold_value, norm_comp_value)\n cnt += 1\n if offset_method and (norm_gold_value != norm_comp_value):\n if gnum > cnum:\n gidx += 1\n else:\n cidx += 1\n else:\n gidx += 1\n cidx += 1\n\n return comments, cnt\n\n###############################################################################\ndef compare_files(gold_file, compare_file, case=None):\n###############################################################################\n \"\"\"\n Returns true if files are the same, comments are returned too:\n (success, comments)\n \"\"\"\n expect(os.path.exists(gold_file), \"File not found: {}\".format(gold_file))\n expect(os.path.exists(compare_file), \"File not found: {}\".format(compare_file))\n\n comments, cnt = _compare_data(open(gold_file, \"r\").readlines(),\n open(compare_file, \"r\").readlines(), case)\n\n if cnt > 0:\n comments2, cnt2 = _compare_data(open(gold_file, \"r\").readlines(),\n open(compare_file, \"r\").readlines(),\n case, offset_method=True)\n if cnt2 < cnt:\n comments = comments2\n\n return comments == \"\", comments\n\n###############################################################################\ndef compare_runconfigfiles(gold_file, compare_file, case=None):\n###############################################################################\n \"\"\"\n Returns true if files are the same, comments are returned too:\n (success, comments)\n \"\"\"\n expect(os.path.exists(gold_file), \"File not found: {}\".format(gold_file))\n expect(os.path.exists(compare_file), \"File not found: {}\".format(compare_file))\n\n #create dictionary's of the runconfig files and compare them\n gold_dict = _parse_runconfig(gold_file)\n compare_dict = _parse_runconfig(compare_file)\n\n comments = findDiff(gold_dict, compare_dict, case=case)\n comments = comments.replace(\" d1\", \" \" + gold_file)\n comments = comments.replace(\" d2\", \" \" + compare_file)\n # this picks up the case that an entry in compare is not in gold\n if comments == \"\":\n comments = findDiff(compare_dict, gold_dict, case=case)\n comments = comments.replace(\" d2\", \" \" + gold_file)\n comments = comments.replace(\" d1\", \" \" + compare_file)\n\n return comments == \"\", comments\n\ndef _parse_runconfig(filename):\n runconfig = {}\n inrunseq = False\n insubsection = None\n subsection_re = re.compile(r'\\s*(\\S+)::')\n group_re = re.compile(r'\\s*(\\S+)\\s*:\\s*(\\S+)')\n var_re = re.compile(r'\\s*(\\S+)\\s*=\\s*(\\S+)')\n with open(filename, \"r\") as fd:\n for line in fd:\n # remove comments\n line = line.split('#')[0]\n subsection_match = subsection_re.match(line)\n group_match = group_re.match(line)\n var_match = var_re.match(line)\n if re.match(r'\\s*runSeq\\s*::', line):\n runconfig['runSeq'] = []\n inrunseq = True\n elif re.match(r'\\s*::\\s*', line):\n inrunseq = False\n elif inrunseq:\n runconfig['runSeq'].append(line)\n elif subsection_match:\n insubsection = subsection_match.group(1)\n runconfig[insubsection] = {}\n elif group_match:\n runconfig[group_match.group(1)] = group_match.group(2)\n elif insubsection and var_match:\n runconfig[insubsection][var_match.group(1)] = var_match.group(2)\n return runconfig\n\ndef findDiff(d1, d2, path=\"\", case=None):\n comment = \"\"\n for k in d1.keys():\n if not d2.has_key(k):\n comment += path + \":\\n\"\n comment += k + \" as key not in d2\\n\"\n else:\n if type(d1[k]) is dict:\n if path == \"\":\n path = k\n else:\n path = path + \"->\" + k\n comment += findDiff(d1[k],d2[k], path=path, case=case)\n else:\n if case in d1[k]:\n pass\n elif \"username\" in k:\n pass\n elif \"logfile\" in k:\n pass\n elif d1[k] != d2[k]:\n comment += path+\":\\n\"\n comment += \" - {} : {}\\n\".format(k,d1[k])\n comment += \" + {} : {}\\n\".format(k,d2[k])\n return comment\n", "path": "scripts/lib/CIME/simple_compare.py"}], "after_files": [{"content": "import os, re\n\nfrom CIME.utils import expect\n\n###############################################################################\ndef _normalize_string_value(value, case):\n###############################################################################\n \"\"\"\n Some of the strings are inherently prone to diffs, like file\n paths, etc. This function attempts to normalize that data so that\n it will not cause diffs.\n \"\"\"\n # Any occurance of case must be normalized because test-ids might not match\n if (case is not None):\n case_re = re.compile(r'{}[.]([GC])[.]([^./\\s]+)'.format(case))\n value = case_re.sub(\"{}.ACTION.TESTID\".format(case), value)\n\n if (\"/\" in value):\n # File path, just return the basename\n return os.path.basename(value)\n elif (\"username\" in value):\n return ''\n elif (\".log.\" in value):\n # Remove the part that's prone to diff\n components = value.split(\".\")\n return os.path.basename(\".\".join(components[0:-1]))\n else:\n return value\n\n###############################################################################\ndef _skip_comments_and_whitespace(lines, idx):\n###############################################################################\n \"\"\"\n Starting at idx, return next valid idx of lines that contains real data\n \"\"\"\n if (idx == len(lines)):\n return idx\n\n comment_re = re.compile(r'^[#!]')\n\n lines_slice = lines[idx:]\n for line in lines_slice:\n line = line.strip()\n if (comment_re.match(line) is not None or line == \"\"):\n idx += 1\n else:\n return idx\n\n return idx\n\n###############################################################################\ndef _compare_data(gold_lines, comp_lines, case, offset_method=False):\n###############################################################################\n \"\"\"\n >>> teststr = '''\n ... data1\n ... data2 data3\n ... data4 data5 data6\n ...\n ... # Comment\n ... data7 data8 data9 data10\n ... '''\n >>> _compare_data(teststr.splitlines(), teststr.splitlines(), None)\n ('', 0)\n\n >>> teststr2 = '''\n ... data1\n ... data2 data30\n ... data4 data5 data6\n ... data7 data8 data9 data10\n ... data00\n ... '''\n >>> results,_ = _compare_data(teststr.splitlines(), teststr2.splitlines(), None)\n >>> print(results)\n Inequivalent lines data2 data3 != data2 data30\n NORMALIZED: data2 data3 != data2 data30\n Found extra lines\n data00\n <BLANKLINE>\n >>> teststr3 = '''\n ... data1\n ... data4 data5 data6\n ... data7 data8 data9 data10\n ... data00\n ... '''\n >>> results,_ = _compare_data(teststr3.splitlines(), teststr2.splitlines(), None, offset_method=True)\n >>> print(results)\n Inequivalent lines data4 data5 data6 != data2 data30\n NORMALIZED: data4 data5 data6 != data2 data30\n <BLANKLINE>\n \"\"\"\n comments = \"\"\n cnt = 0\n gidx, cidx = 0, 0\n gnum, cnum = len(gold_lines), len(comp_lines)\n while (gidx < gnum or cidx < cnum):\n gidx = _skip_comments_and_whitespace(gold_lines, gidx)\n cidx = _skip_comments_and_whitespace(comp_lines, cidx)\n\n if (gidx == gnum):\n if (cidx == cnum):\n return comments, cnt\n else:\n comments += \"Found extra lines\\n\"\n comments += \"\\n\".join(comp_lines[cidx:]) + \"\\n\"\n return comments, cnt\n elif (cidx == cnum):\n comments += \"Missing lines\\n\"\n comments += \"\\n\".join(gold_lines[gidx:1]) + \"\\n\"\n return comments, cnt\n\n gold_value = gold_lines[gidx].strip()\n gold_value = gold_value.replace('\"',\"'\")\n comp_value = comp_lines[cidx].strip()\n comp_value = comp_value.replace('\"',\"'\")\n\n norm_gold_value = _normalize_string_value(gold_value, case)\n norm_comp_value = _normalize_string_value(comp_value, case)\n\n if (norm_gold_value != norm_comp_value):\n comments += \"Inequivalent lines {} != {}\\n\".format(gold_value, comp_value)\n comments += \" NORMALIZED: {} != {}\\n\".format(norm_gold_value, norm_comp_value)\n cnt += 1\n if offset_method and (norm_gold_value != norm_comp_value):\n if gnum > cnum:\n gidx += 1\n else:\n cidx += 1\n else:\n gidx += 1\n cidx += 1\n\n return comments, cnt\n\n###############################################################################\ndef compare_files(gold_file, compare_file, case=None):\n###############################################################################\n \"\"\"\n Returns true if files are the same, comments are returned too:\n (success, comments)\n \"\"\"\n expect(os.path.exists(gold_file), \"File not found: {}\".format(gold_file))\n expect(os.path.exists(compare_file), \"File not found: {}\".format(compare_file))\n\n comments, cnt = _compare_data(open(gold_file, \"r\").readlines(),\n open(compare_file, \"r\").readlines(), case)\n\n if cnt > 0:\n comments2, cnt2 = _compare_data(open(gold_file, \"r\").readlines(),\n open(compare_file, \"r\").readlines(),\n case, offset_method=True)\n if cnt2 < cnt:\n comments = comments2\n\n return comments == \"\", comments\n\n###############################################################################\ndef compare_runconfigfiles(gold_file, compare_file, case=None):\n###############################################################################\n \"\"\"\n Returns true if files are the same, comments are returned too:\n (success, comments)\n \"\"\"\n expect(os.path.exists(gold_file), \"File not found: {}\".format(gold_file))\n expect(os.path.exists(compare_file), \"File not found: {}\".format(compare_file))\n\n #create dictionary's of the runconfig files and compare them\n gold_dict = _parse_runconfig(gold_file)\n compare_dict = _parse_runconfig(compare_file)\n\n comments = findDiff(gold_dict, compare_dict, case=case)\n comments = comments.replace(\" d1\", \" \" + gold_file)\n comments = comments.replace(\" d2\", \" \" + compare_file)\n # this picks up the case that an entry in compare is not in gold\n if comments == \"\":\n comments = findDiff(compare_dict, gold_dict, case=case)\n comments = comments.replace(\" d2\", \" \" + gold_file)\n comments = comments.replace(\" d1\", \" \" + compare_file)\n\n return comments == \"\", comments\n\ndef _parse_runconfig(filename):\n runconfig = {}\n inrunseq = False\n insubsection = None\n subsection_re = re.compile(r'\\s*(\\S+)::')\n group_re = re.compile(r'\\s*(\\S+)\\s*:\\s*(\\S+)')\n var_re = re.compile(r'\\s*(\\S+)\\s*=\\s*(\\S+)')\n with open(filename, \"r\") as fd:\n for line in fd:\n # remove comments\n line = line.split('#')[0]\n subsection_match = subsection_re.match(line)\n group_match = group_re.match(line)\n var_match = var_re.match(line)\n if re.match(r'\\s*runSeq\\s*::', line):\n runconfig['runSeq'] = []\n inrunseq = True\n elif re.match(r'\\s*::\\s*', line):\n inrunseq = False\n elif inrunseq:\n runconfig['runSeq'].append(line)\n elif subsection_match:\n insubsection = subsection_match.group(1)\n runconfig[insubsection] = {}\n elif group_match:\n runconfig[group_match.group(1)] = group_match.group(2)\n elif insubsection and var_match:\n runconfig[insubsection][var_match.group(1)] = var_match.group(2)\n return runconfig\n\ndef findDiff(d1, d2, path=\"\", case=None):\n comment = \"\"\n for k in d1.keys():\n if not k in d2:\n comment += path + \":\\n\"\n comment += k + \" as key not in d2\\n\"\n else:\n if type(d1[k]) is dict:\n if path == \"\":\n path = k\n else:\n path = path + \"->\" + k\n comment += findDiff(d1[k],d2[k], path=path, case=case)\n else:\n if case in d1[k]:\n pass\n elif \"username\" in k:\n pass\n elif \"logfile\" in k:\n pass\n elif d1[k] != d2[k]:\n comment += path+\":\\n\"\n comment += \" - {} : {}\\n\".format(k,d1[k])\n comment += \" + {} : {}\\n\".format(k,d2[k])\n return comment\n", "path": "scripts/lib/CIME/simple_compare.py"}]} | 3,202 | 126 |
gh_patches_debug_15028 | rasdani/github-patches | git_diff | Pyomo__pyomo-1521 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Deprecate the pyomo install-extras subcommand
The conda pyomo.extras package supports this functionality more robustly. We should not duplicate this logic in separate places.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyomo/scripting/plugins/extras.py`
Content:
```
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 import six
12 from pyomo.scripting.pyomo_parser import add_subparser, CustomHelpFormatter
13
14 def get_packages():
15 packages = [
16 'sympy',
17 'xlrd',
18 'openpyxl',
19 #('suds-jurko', 'suds'),
20 ('PyYAML', 'yaml'),
21 'pypyodbc',
22 'pymysql',
23 #'openopt',
24 #'FuncDesigner',
25 #'DerApproximator',
26 ('ipython[notebook]', 'IPython'),
27 ('pyro4', 'Pyro4'),
28 ]
29 if six.PY2:
30 packages.append(('pyro','Pyro'))
31 return packages
32
33 def install_extras(args=[], quiet=False):
34 #
35 # Verify that pip is installed
36 #
37 try:
38 import pip
39 pip_version = pip.__version__.split('.')
40 for i,s in enumerate(pip_version):
41 try:
42 pip_version[i] = int(s)
43 except:
44 pass
45 pip_version = tuple(pip_version)
46 except ImportError:
47 print("You must have 'pip' installed to run this script.")
48 raise SystemExit
49
50 cmd = ['--disable-pip-version-check', 'install','--upgrade']
51 # Disable the PIP download cache
52 if pip_version[0] >= 6:
53 cmd.append('--no-cache-dir')
54 else:
55 cmd.append('--download-cache')
56 cmd.append('')
57
58 if not quiet:
59 print(' ')
60 print('-'*60)
61 print("Installation Output Logs")
62 print(" (A summary will be printed below)")
63 print('-'*60)
64 print(' ')
65
66 results = {}
67 for package in get_packages():
68 if type(package) is tuple:
69 package, pkg_import = package
70 else:
71 pkg_import = package
72 try:
73 # Allow the user to provide extra options
74 pip.main(cmd + args + [package])
75 __import__(pkg_import)
76 results[package] = True
77 except:
78 results[package] = False
79 try:
80 pip.logger.consumers = []
81 except AttributeError:
82 # old pip versions (prior to 6.0~104^2)
83 pip.log.consumers = []
84
85 if not quiet:
86 print(' ')
87 print(' ')
88 print('-'*60)
89 print("Installation Summary")
90 print('-'*60)
91 print(' ')
92 for package, result in sorted(six.iteritems(results)):
93 if result:
94 print("YES %s" % package)
95 else:
96 print("NO %s" % package)
97
98
99 def pyomo_subcommand(options):
100 return install_extras(options.args, quiet=options.quiet)
101
102
103 _parser = add_subparser(
104 'install-extras',
105 func=pyomo_subcommand,
106 help='Install "extra" packages that Pyomo can leverage.',
107 description="""
108 This pyomo subcommand uses PIP to install optional third-party Python
109 packages that Pyomo could leverage from PyPI. The installation of some
110 packages may fail, but this subcommand ignore these failures and
111 provides a summary describing which packages were installed.
112 """,
113 epilog="""
114 Since pip options begin with a dash, the --pip-args option can only be
115 used with the equals syntax. --pip-args may appear multiple times on
116 the command line. For example:\n\n
117 pyomo install-extras --pip-args="--upgrade"
118 """,
119 formatter_class=CustomHelpFormatter,
120 )
121
122 _parser.add_argument(
123 '-q', '--quiet',
124 action='store_true',
125 dest='quiet',
126 default=False,
127 help="Suppress some terminal output",
128 )
129 _parser.add_argument(
130 "--pip-args",
131 dest="args",
132 action="append",
133 help=("Arguments that are passed to the 'pip' command when "
134 "installing packages"),
135 )
136
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyomo/scripting/plugins/extras.py b/pyomo/scripting/plugins/extras.py
--- a/pyomo/scripting/plugins/extras.py
+++ b/pyomo/scripting/plugins/extras.py
@@ -11,6 +11,8 @@
import six
from pyomo.scripting.pyomo_parser import add_subparser, CustomHelpFormatter
+from pyomo.common.deprecation import deprecated
+
def get_packages():
packages = [
'sympy',
@@ -30,6 +32,11 @@
packages.append(('pyro','Pyro'))
return packages
+@deprecated(
+ "Use of the pyomo install-extras is deprecated."
+ "The current recommended course of action is to manually install "
+ "optional dependencies as needed.",
+ version='TBD')
def install_extras(args=[], quiet=False):
#
# Verify that pip is installed
| {"golden_diff": "diff --git a/pyomo/scripting/plugins/extras.py b/pyomo/scripting/plugins/extras.py\n--- a/pyomo/scripting/plugins/extras.py\n+++ b/pyomo/scripting/plugins/extras.py\n@@ -11,6 +11,8 @@\n import six\n from pyomo.scripting.pyomo_parser import add_subparser, CustomHelpFormatter\n \n+from pyomo.common.deprecation import deprecated\n+\n def get_packages():\n packages = [\n 'sympy', \n@@ -30,6 +32,11 @@\n packages.append(('pyro','Pyro'))\n return packages\n \n+@deprecated(\n+ \"Use of the pyomo install-extras is deprecated.\"\n+ \"The current recommended course of action is to manually install \"\n+ \"optional dependencies as needed.\",\n+ version='TBD')\n def install_extras(args=[], quiet=False):\n #\n # Verify that pip is installed\n", "issue": "Deprecate the pyomo install-extras subcommand\nThe conda pyomo.extras package supports this functionality more robustly. We should not duplicate this logic in separate places.\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport six\nfrom pyomo.scripting.pyomo_parser import add_subparser, CustomHelpFormatter\n\ndef get_packages():\n packages = [\n 'sympy', \n 'xlrd', \n 'openpyxl', \n #('suds-jurko', 'suds'),\n ('PyYAML', 'yaml'),\n 'pypyodbc', \n 'pymysql', \n #'openopt', \n #'FuncDesigner', \n #'DerApproximator', \n ('ipython[notebook]', 'IPython'),\n ('pyro4', 'Pyro4'),\n ]\n if six.PY2:\n packages.append(('pyro','Pyro'))\n return packages\n\ndef install_extras(args=[], quiet=False):\n #\n # Verify that pip is installed\n #\n try:\n import pip\n pip_version = pip.__version__.split('.')\n for i,s in enumerate(pip_version):\n try:\n pip_version[i] = int(s)\n except:\n pass\n pip_version = tuple(pip_version)\n except ImportError:\n print(\"You must have 'pip' installed to run this script.\")\n raise SystemExit\n\n cmd = ['--disable-pip-version-check', 'install','--upgrade']\n # Disable the PIP download cache\n if pip_version[0] >= 6:\n cmd.append('--no-cache-dir')\n else:\n cmd.append('--download-cache')\n cmd.append('')\n\n if not quiet:\n print(' ')\n print('-'*60)\n print(\"Installation Output Logs\")\n print(\" (A summary will be printed below)\")\n print('-'*60)\n print(' ')\n\n results = {}\n for package in get_packages():\n if type(package) is tuple:\n package, pkg_import = package\n else:\n pkg_import = package\n try:\n # Allow the user to provide extra options\n pip.main(cmd + args + [package])\n __import__(pkg_import)\n results[package] = True\n except:\n results[package] = False\n try:\n pip.logger.consumers = []\n except AttributeError:\n # old pip versions (prior to 6.0~104^2)\n pip.log.consumers = []\n\n if not quiet:\n print(' ')\n print(' ')\n print('-'*60)\n print(\"Installation Summary\")\n print('-'*60)\n print(' ')\n for package, result in sorted(six.iteritems(results)):\n if result:\n print(\"YES %s\" % package)\n else:\n print(\"NO %s\" % package)\n\n\ndef pyomo_subcommand(options):\n return install_extras(options.args, quiet=options.quiet)\n\n\n_parser = add_subparser(\n 'install-extras',\n func=pyomo_subcommand,\n help='Install \"extra\" packages that Pyomo can leverage.',\n description=\"\"\"\nThis pyomo subcommand uses PIP to install optional third-party Python\npackages that Pyomo could leverage from PyPI. The installation of some\npackages may fail, but this subcommand ignore these failures and\nprovides a summary describing which packages were installed.\n\"\"\",\n epilog=\"\"\"\nSince pip options begin with a dash, the --pip-args option can only be\nused with the equals syntax. --pip-args may appear multiple times on\nthe command line. For example:\\n\\n\n pyomo install-extras --pip-args=\"--upgrade\"\n\"\"\",\n formatter_class=CustomHelpFormatter,\n)\n\n_parser.add_argument(\n '-q', '--quiet',\n action='store_true',\n dest='quiet',\n default=False,\n help=\"Suppress some terminal output\",\n)\n_parser.add_argument(\n \"--pip-args\",\n dest=\"args\",\n action=\"append\",\n help=(\"Arguments that are passed to the 'pip' command when \"\n \"installing packages\"),\n)\n\n", "path": "pyomo/scripting/plugins/extras.py"}], "after_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport six\nfrom pyomo.scripting.pyomo_parser import add_subparser, CustomHelpFormatter\n\nfrom pyomo.common.deprecation import deprecated\n\ndef get_packages():\n packages = [\n 'sympy', \n 'xlrd', \n 'openpyxl', \n #('suds-jurko', 'suds'),\n ('PyYAML', 'yaml'),\n 'pypyodbc', \n 'pymysql', \n #'openopt', \n #'FuncDesigner', \n #'DerApproximator', \n ('ipython[notebook]', 'IPython'),\n ('pyro4', 'Pyro4'),\n ]\n if six.PY2:\n packages.append(('pyro','Pyro'))\n return packages\n\n@deprecated(\n \"Use of the pyomo install-extras is deprecated.\"\n \"The current recommended course of action is to manually install \"\n \"optional dependencies as needed.\",\n version='TBD')\ndef install_extras(args=[], quiet=False):\n #\n # Verify that pip is installed\n #\n try:\n import pip\n pip_version = pip.__version__.split('.')\n for i,s in enumerate(pip_version):\n try:\n pip_version[i] = int(s)\n except:\n pass\n pip_version = tuple(pip_version)\n except ImportError:\n print(\"You must have 'pip' installed to run this script.\")\n raise SystemExit\n\n cmd = ['--disable-pip-version-check', 'install','--upgrade']\n # Disable the PIP download cache\n if pip_version[0] >= 6:\n cmd.append('--no-cache-dir')\n else:\n cmd.append('--download-cache')\n cmd.append('')\n\n if not quiet:\n print(' ')\n print('-'*60)\n print(\"Installation Output Logs\")\n print(\" (A summary will be printed below)\")\n print('-'*60)\n print(' ')\n\n results = {}\n for package in get_packages():\n if type(package) is tuple:\n package, pkg_import = package\n else:\n pkg_import = package\n try:\n # Allow the user to provide extra options\n pip.main(cmd + args + [package])\n __import__(pkg_import)\n results[package] = True\n except:\n results[package] = False\n try:\n pip.logger.consumers = []\n except AttributeError:\n # old pip versions (prior to 6.0~104^2)\n pip.log.consumers = []\n\n if not quiet:\n print(' ')\n print(' ')\n print('-'*60)\n print(\"Installation Summary\")\n print('-'*60)\n print(' ')\n for package, result in sorted(six.iteritems(results)):\n if result:\n print(\"YES %s\" % package)\n else:\n print(\"NO %s\" % package)\n\n\ndef pyomo_subcommand(options):\n return install_extras(options.args, quiet=options.quiet)\n\n\n_parser = add_subparser(\n 'install-extras',\n func=pyomo_subcommand,\n help='Install \"extra\" packages that Pyomo can leverage.',\n description=\"\"\"\nThis pyomo subcommand uses PIP to install optional third-party Python\npackages that Pyomo could leverage from PyPI. The installation of some\npackages may fail, but this subcommand ignore these failures and\nprovides a summary describing which packages were installed.\n\"\"\",\n epilog=\"\"\"\nSince pip options begin with a dash, the --pip-args option can only be\nused with the equals syntax. --pip-args may appear multiple times on\nthe command line. For example:\\n\\n\n pyomo install-extras --pip-args=\"--upgrade\"\n\"\"\",\n formatter_class=CustomHelpFormatter,\n)\n\n_parser.add_argument(\n '-q', '--quiet',\n action='store_true',\n dest='quiet',\n default=False,\n help=\"Suppress some terminal output\",\n)\n_parser.add_argument(\n \"--pip-args\",\n dest=\"args\",\n action=\"append\",\n help=(\"Arguments that are passed to the 'pip' command when \"\n \"installing packages\"),\n)\n\n", "path": "pyomo/scripting/plugins/extras.py"}]} | 1,546 | 195 |
gh_patches_debug_5294 | rasdani/github-patches | git_diff | OBOFoundry__OBOFoundry.github.io-2483 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JSON-LD context does not expand as intended
https://purl.obolibrary.org/meta/obo_context.jsonld
We can't have trailing underscores on expansions (and have it behave as expected). Sorry, I don't make the rules
More context here:
- https://github.com/w3c/json-ld-syntax/issues/329
These would all have to be modified to be nested
```json
"RO": {
"@id": "http://purl.obolibrary.org/obo/RO_",
"@prefix": true
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `util/processor.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import argparse
4 import datetime
5 import logging
6 import sys
7 import time
8 from contextlib import closing
9 from json import dumps
10
11 import requests
12 import yaml
13 from SPARQLWrapper import JSON, SPARQLWrapper
14
15 __author__ = "cjm"
16
17
18 def main():
19 parser = argparse.ArgumentParser(
20 description="Helper utils for OBO",
21 formatter_class=argparse.RawTextHelpFormatter,
22 )
23 parser.add_argument(
24 "-i", "--input", type=str, required=False, help="Input metadata file"
25 )
26 parser.add_argument(
27 "-v",
28 "--verbosity",
29 default=0,
30 action="count",
31 help="Increase output verbosity (min.: 0, max. 2)",
32 )
33 subparsers = parser.add_subparsers(dest="subcommand", help="sub-command help")
34
35 # SUBCOMMAND
36 parser_n = subparsers.add_parser("check-urls", help="Ensure PURLs resolve")
37 parser_n.set_defaults(function=check_urls)
38
39 parser_n = subparsers.add_parser(
40 "sparql-compare",
41 help="Run SPARQL commands against the db to generate a " "consistency report",
42 )
43 parser_n.set_defaults(function=sparql_compare_all)
44
45 parser_n = subparsers.add_parser("extract-context", help="Extracts JSON-LD context")
46 parser_n.set_defaults(function=extract_context)
47
48 parser_n = subparsers.add_parser(
49 "extract-contributors",
50 help="Queries github API for metadata about contributors",
51 )
52 parser_n.set_defaults(function=write_all_contributors)
53
54 args = parser.parse_args()
55 if args.verbosity >= 2:
56 logging.basicConfig(level=logging.DEBUG)
57 elif args.verbosity == 1:
58 logging.basicConfig(level=logging.INFO)
59 else:
60 logging.basicConfig(level=logging.WARNING)
61
62 with open(args.input, "r") as f:
63 obj = yaml.load(f, Loader=yaml.SafeLoader)
64 ontologies = obj["ontologies"]
65
66 func = args.function
67 func(ontologies, args)
68
69
70 def check_urls(ontologies, args):
71 """
72 Ensure PURLs resolve
73 """
74
75 def test_url(url):
76 try:
77 with closing(requests.get(url, stream=False)) as resp:
78 return resp.status_code == 200
79 except requests.exceptions.InvalidSchema as e:
80 # TODO: requests lib doesn't handle ftp. For now simply return True in that case.
81 if not format(e).startswith("No connection adapters were found for 'ftp:"):
82 raise
83 return True
84
85 failed_ids = []
86 for ont in ontologies:
87 for p in ont.get("products", []):
88 pid = p["id"]
89 if not test_url(p.get("ontology_purl")):
90 failed_ids.append(pid)
91 if len(failed_ids) > 0:
92 print("FAILURES:")
93 for pid in failed_ids:
94 print(pid, file=sys.stderr)
95 exit(1)
96
97
98 def extract_context(ontologies, args):
99 """
100 Writes to STDOUT a sorted JSON map from ontology prefixes to PURLs
101 """
102
103 def has_obo_prefix(obj):
104 return ("uri_prefix" not in obj) or (
105 obj["uri_prefix"] == "http://purl.obolibrary.org/obo/"
106 )
107
108 prefix_map = {}
109 for obj in ontologies:
110 if has_obo_prefix(obj):
111 prefix = obj.get("preferredPrefix") or obj["id"].upper()
112 prefix_map[prefix] = "http://purl.obolibrary.org/obo/" + prefix + "_"
113
114 print(
115 dumps(
116 {"@context": prefix_map}, sort_keys=True, indent=4, separators=(",", ": ")
117 )
118 )
119
120
121 def write_all_contributors(ontologies, args):
122 """
123 Query github API for all contributors to an ontology,
124 write results as json
125 """
126 results = []
127 for ont_obj in ontologies:
128 id = ont_obj["id"]
129 logging.info("Getting info for {}".format(id))
130 repo_path = get_repo_path(ont_obj)
131 if repo_path is not None:
132 contribs = list(get_ontology_contributors(repo_path))
133 print("CONTRIBS({})=={}".format(id, contribs))
134 for c in contribs:
135 print("#{}\t{}\n".format(id, c["login"]))
136 results.append(dict(id=id, contributors=contribs))
137 else:
138 logging.warn("No repo_path declared for {}".format(id))
139 print(dumps(results, sort_keys=True, indent=4, separators=(",", ": ")))
140
141
142 def get_ontology_contributors(repo_path):
143 """
144 Get individual contributors to a org/repo_path
145 repo_path is a string "org/repo"
146 """
147 url = "https://api.github.com/repos/{}/contributors".format(repo_path)
148 # TODO: allow use of oauth token;
149 # GH has a quota for non-logged in API calls
150 time.sleep(3)
151 with closing(requests.get(url, stream=False)) as resp:
152 ok = resp.status_code == 200
153 if ok:
154 results = resp.json()
155 logging.info("RESP={}".format(results))
156 return results
157 else:
158 logging.error("Failed: {}".format(url))
159 return []
160
161
162 def get_repo_path(ont_obj):
163 """
164 Extract the repository path for the given object
165 """
166 repo_path = None
167 if "repository" in ont_obj:
168 repo_path = ont_obj["repository"]
169 elif "tracker" in ont_obj:
170 tracker = ont_obj["tracker"]
171 if tracker is not None and "github" in tracker:
172 repo_path = tracker.replace("/issues", "")
173
174 if repo_path is not None:
175 repo_path = repo_path.replace("https://github.com/", "")
176 if repo_path.endswith("/"):
177 repo_path = repo_path[:-1]
178 return repo_path
179 else:
180 logging.warn("Could not get gh repo_path for ".format(ont_obj))
181 return None
182
183
184 def run_sparql(obj, p, expected_value, q):
185 """
186 Generate a SPARQL statement using query q and parameter p, and expect 'expected_value' as the
187 result. Print out a message indicating whether the there is or is not a match for the given object
188 """
189 sparql = SPARQLWrapper("http://sparql.hegroup.org/sparql")
190 sparql.setQuery(q)
191 sparql.setReturnFormat(JSON)
192 results = sparql.query().convert()
193
194 id = obj["id"]
195 got_value = False
196 is_match = False
197 vs = []
198
199 for result in results["results"]["bindings"]:
200 got_value = True
201 v = result[p]["value"]
202 vs.append(str(v))
203 if v == expected_value:
204 is_match = True
205
206 if got_value and is_match:
207 msg = "CONSISTENT"
208 elif got_value and not is_match:
209 if expected_value == "":
210 msg = "UNDECLARED_LOCAL: REMOTE:" + ",".join(vs)
211 else:
212 msg = "INCONSISTENT: REMOTE:" + ",".join(vs) + " != LOCAL:" + expected_value
213 else:
214 msg = "UNDECLARED_REMOTE"
215 print(id + " " + p + " " + msg)
216
217
218 def sparql_compare_ont(obj):
219 """
220 Some ontologies will directly declare some subset of the OBO metadata
221 directly in the ontology header. In the majority of cases we should
222 yield to the provider. However, we reserve the right to override. For
223 example, OBO may have particular guidelines about the length of the title,
224 required for coherency within the registry. All differences should be
225 discussed with the provider and an accomodation reached
226 """
227 if "ontology_purl" not in obj:
228 return
229
230 purl = obj["ontology_purl"]
231 # this could be made more declarative, or driven by the context.jsonld mapping;
232 # however, for now this is relatively simple and easy to understand:
233 run_sparql(
234 obj,
235 "license",
236 obj["license"]["url"] if "license" in obj else "",
237 "SELECT DISTINCT ?license WHERE {<"
238 + purl
239 + "> <http://purl.org/dc/elements/1.1/license> ?license}",
240 )
241 run_sparql(
242 obj,
243 "title",
244 obj["title"] if "title" in obj else "",
245 "SELECT DISTINCT ?title WHERE {<"
246 + purl
247 + "> <http://purl.org/dc/elements/1.1/title> ?title}",
248 )
249 run_sparql(
250 obj,
251 "description",
252 obj["description"] if "description" in obj else "",
253 "SELECT DISTINCT ?description WHERE {<"
254 + purl
255 + "> <http://purl.org/dc/elements/1.1/description> ?description}",
256 )
257 run_sparql(
258 obj,
259 "homepage",
260 obj["homepage"] if "homepage" in obj else "",
261 "SELECT DISTINCT ?homepage WHERE {<"
262 + purl
263 + "> <http://xmlns.com/foaf/0.1/homepage> ?homepage}",
264 )
265
266
267 def sparql_compare_all(ontologies, args):
268 """
269 Run sparql_compare_ont() on all the given ontologies.
270 """
271 # The `args` parameter is not used here but it is convenient to have it in our definition, since
272 # whether this function or one of the other main `subcommands` of this script is called is
273 # determine dynamically, and we want all of the subcommands to have a consistent signature.
274 for obj in ontologies:
275 sparql_compare_ont(obj)
276
277
278 if __name__ == "__main__":
279 main()
280
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/util/processor.py b/util/processor.py
--- a/util/processor.py
+++ b/util/processor.py
@@ -109,7 +109,10 @@
for obj in ontologies:
if has_obo_prefix(obj):
prefix = obj.get("preferredPrefix") or obj["id"].upper()
- prefix_map[prefix] = "http://purl.obolibrary.org/obo/" + prefix + "_"
+ prefix_map[prefix] = {
+ "@id": "http://purl.obolibrary.org/obo/" + prefix + "_",
+ "@prefix": True,
+ }
print(
dumps(
| {"golden_diff": "diff --git a/util/processor.py b/util/processor.py\n--- a/util/processor.py\n+++ b/util/processor.py\n@@ -109,7 +109,10 @@\n for obj in ontologies:\n if has_obo_prefix(obj):\n prefix = obj.get(\"preferredPrefix\") or obj[\"id\"].upper()\n- prefix_map[prefix] = \"http://purl.obolibrary.org/obo/\" + prefix + \"_\"\n+ prefix_map[prefix] = {\n+ \"@id\": \"http://purl.obolibrary.org/obo/\" + prefix + \"_\",\n+ \"@prefix\": True,\n+ }\n \n print(\n dumps(\n", "issue": "JSON-LD context does not expand as intended\nhttps://purl.obolibrary.org/meta/obo_context.jsonld\r\n\r\nWe can't have trailing underscores on expansions (and have it behave as expected). Sorry, I don't make the rules\r\n\r\nMore context here:\r\n\r\n- https://github.com/w3c/json-ld-syntax/issues/329\r\n\r\nThese would all have to be modified to be nested\r\n\r\n```json\r\n \"RO\": {\r\n \"@id\": \"http://purl.obolibrary.org/obo/RO_\",\r\n \"@prefix\": true\r\n }\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport datetime\nimport logging\nimport sys\nimport time\nfrom contextlib import closing\nfrom json import dumps\n\nimport requests\nimport yaml\nfrom SPARQLWrapper import JSON, SPARQLWrapper\n\n__author__ = \"cjm\"\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description=\"Helper utils for OBO\",\n formatter_class=argparse.RawTextHelpFormatter,\n )\n parser.add_argument(\n \"-i\", \"--input\", type=str, required=False, help=\"Input metadata file\"\n )\n parser.add_argument(\n \"-v\",\n \"--verbosity\",\n default=0,\n action=\"count\",\n help=\"Increase output verbosity (min.: 0, max. 2)\",\n )\n subparsers = parser.add_subparsers(dest=\"subcommand\", help=\"sub-command help\")\n\n # SUBCOMMAND\n parser_n = subparsers.add_parser(\"check-urls\", help=\"Ensure PURLs resolve\")\n parser_n.set_defaults(function=check_urls)\n\n parser_n = subparsers.add_parser(\n \"sparql-compare\",\n help=\"Run SPARQL commands against the db to generate a \" \"consistency report\",\n )\n parser_n.set_defaults(function=sparql_compare_all)\n\n parser_n = subparsers.add_parser(\"extract-context\", help=\"Extracts JSON-LD context\")\n parser_n.set_defaults(function=extract_context)\n\n parser_n = subparsers.add_parser(\n \"extract-contributors\",\n help=\"Queries github API for metadata about contributors\",\n )\n parser_n.set_defaults(function=write_all_contributors)\n\n args = parser.parse_args()\n if args.verbosity >= 2:\n logging.basicConfig(level=logging.DEBUG)\n elif args.verbosity == 1:\n logging.basicConfig(level=logging.INFO)\n else:\n logging.basicConfig(level=logging.WARNING)\n\n with open(args.input, \"r\") as f:\n obj = yaml.load(f, Loader=yaml.SafeLoader)\n ontologies = obj[\"ontologies\"]\n\n func = args.function\n func(ontologies, args)\n\n\ndef check_urls(ontologies, args):\n \"\"\"\n Ensure PURLs resolve\n \"\"\"\n\n def test_url(url):\n try:\n with closing(requests.get(url, stream=False)) as resp:\n return resp.status_code == 200\n except requests.exceptions.InvalidSchema as e:\n # TODO: requests lib doesn't handle ftp. For now simply return True in that case.\n if not format(e).startswith(\"No connection adapters were found for 'ftp:\"):\n raise\n return True\n\n failed_ids = []\n for ont in ontologies:\n for p in ont.get(\"products\", []):\n pid = p[\"id\"]\n if not test_url(p.get(\"ontology_purl\")):\n failed_ids.append(pid)\n if len(failed_ids) > 0:\n print(\"FAILURES:\")\n for pid in failed_ids:\n print(pid, file=sys.stderr)\n exit(1)\n\n\ndef extract_context(ontologies, args):\n \"\"\"\n Writes to STDOUT a sorted JSON map from ontology prefixes to PURLs\n \"\"\"\n\n def has_obo_prefix(obj):\n return (\"uri_prefix\" not in obj) or (\n obj[\"uri_prefix\"] == \"http://purl.obolibrary.org/obo/\"\n )\n\n prefix_map = {}\n for obj in ontologies:\n if has_obo_prefix(obj):\n prefix = obj.get(\"preferredPrefix\") or obj[\"id\"].upper()\n prefix_map[prefix] = \"http://purl.obolibrary.org/obo/\" + prefix + \"_\"\n\n print(\n dumps(\n {\"@context\": prefix_map}, sort_keys=True, indent=4, separators=(\",\", \": \")\n )\n )\n\n\ndef write_all_contributors(ontologies, args):\n \"\"\"\n Query github API for all contributors to an ontology,\n write results as json\n \"\"\"\n results = []\n for ont_obj in ontologies:\n id = ont_obj[\"id\"]\n logging.info(\"Getting info for {}\".format(id))\n repo_path = get_repo_path(ont_obj)\n if repo_path is not None:\n contribs = list(get_ontology_contributors(repo_path))\n print(\"CONTRIBS({})=={}\".format(id, contribs))\n for c in contribs:\n print(\"#{}\\t{}\\n\".format(id, c[\"login\"]))\n results.append(dict(id=id, contributors=contribs))\n else:\n logging.warn(\"No repo_path declared for {}\".format(id))\n print(dumps(results, sort_keys=True, indent=4, separators=(\",\", \": \")))\n\n\ndef get_ontology_contributors(repo_path):\n \"\"\"\n Get individual contributors to a org/repo_path\n repo_path is a string \"org/repo\"\n \"\"\"\n url = \"https://api.github.com/repos/{}/contributors\".format(repo_path)\n # TODO: allow use of oauth token;\n # GH has a quota for non-logged in API calls\n time.sleep(3)\n with closing(requests.get(url, stream=False)) as resp:\n ok = resp.status_code == 200\n if ok:\n results = resp.json()\n logging.info(\"RESP={}\".format(results))\n return results\n else:\n logging.error(\"Failed: {}\".format(url))\n return []\n\n\ndef get_repo_path(ont_obj):\n \"\"\"\n Extract the repository path for the given object\n \"\"\"\n repo_path = None\n if \"repository\" in ont_obj:\n repo_path = ont_obj[\"repository\"]\n elif \"tracker\" in ont_obj:\n tracker = ont_obj[\"tracker\"]\n if tracker is not None and \"github\" in tracker:\n repo_path = tracker.replace(\"/issues\", \"\")\n\n if repo_path is not None:\n repo_path = repo_path.replace(\"https://github.com/\", \"\")\n if repo_path.endswith(\"/\"):\n repo_path = repo_path[:-1]\n return repo_path\n else:\n logging.warn(\"Could not get gh repo_path for \".format(ont_obj))\n return None\n\n\ndef run_sparql(obj, p, expected_value, q):\n \"\"\"\n Generate a SPARQL statement using query q and parameter p, and expect 'expected_value' as the\n result. Print out a message indicating whether the there is or is not a match for the given object\n \"\"\"\n sparql = SPARQLWrapper(\"http://sparql.hegroup.org/sparql\")\n sparql.setQuery(q)\n sparql.setReturnFormat(JSON)\n results = sparql.query().convert()\n\n id = obj[\"id\"]\n got_value = False\n is_match = False\n vs = []\n\n for result in results[\"results\"][\"bindings\"]:\n got_value = True\n v = result[p][\"value\"]\n vs.append(str(v))\n if v == expected_value:\n is_match = True\n\n if got_value and is_match:\n msg = \"CONSISTENT\"\n elif got_value and not is_match:\n if expected_value == \"\":\n msg = \"UNDECLARED_LOCAL: REMOTE:\" + \",\".join(vs)\n else:\n msg = \"INCONSISTENT: REMOTE:\" + \",\".join(vs) + \" != LOCAL:\" + expected_value\n else:\n msg = \"UNDECLARED_REMOTE\"\n print(id + \" \" + p + \" \" + msg)\n\n\ndef sparql_compare_ont(obj):\n \"\"\"\n Some ontologies will directly declare some subset of the OBO metadata\n directly in the ontology header. In the majority of cases we should\n yield to the provider. However, we reserve the right to override. For\n example, OBO may have particular guidelines about the length of the title,\n required for coherency within the registry. All differences should be\n discussed with the provider and an accomodation reached\n \"\"\"\n if \"ontology_purl\" not in obj:\n return\n\n purl = obj[\"ontology_purl\"]\n # this could be made more declarative, or driven by the context.jsonld mapping;\n # however, for now this is relatively simple and easy to understand:\n run_sparql(\n obj,\n \"license\",\n obj[\"license\"][\"url\"] if \"license\" in obj else \"\",\n \"SELECT DISTINCT ?license WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/license> ?license}\",\n )\n run_sparql(\n obj,\n \"title\",\n obj[\"title\"] if \"title\" in obj else \"\",\n \"SELECT DISTINCT ?title WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/title> ?title}\",\n )\n run_sparql(\n obj,\n \"description\",\n obj[\"description\"] if \"description\" in obj else \"\",\n \"SELECT DISTINCT ?description WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/description> ?description}\",\n )\n run_sparql(\n obj,\n \"homepage\",\n obj[\"homepage\"] if \"homepage\" in obj else \"\",\n \"SELECT DISTINCT ?homepage WHERE {<\"\n + purl\n + \"> <http://xmlns.com/foaf/0.1/homepage> ?homepage}\",\n )\n\n\ndef sparql_compare_all(ontologies, args):\n \"\"\"\n Run sparql_compare_ont() on all the given ontologies.\n \"\"\"\n # The `args` parameter is not used here but it is convenient to have it in our definition, since\n # whether this function or one of the other main `subcommands` of this script is called is\n # determine dynamically, and we want all of the subcommands to have a consistent signature.\n for obj in ontologies:\n sparql_compare_ont(obj)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "util/processor.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport argparse\nimport datetime\nimport logging\nimport sys\nimport time\nfrom contextlib import closing\nfrom json import dumps\n\nimport requests\nimport yaml\nfrom SPARQLWrapper import JSON, SPARQLWrapper\n\n__author__ = \"cjm\"\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description=\"Helper utils for OBO\",\n formatter_class=argparse.RawTextHelpFormatter,\n )\n parser.add_argument(\n \"-i\", \"--input\", type=str, required=False, help=\"Input metadata file\"\n )\n parser.add_argument(\n \"-v\",\n \"--verbosity\",\n default=0,\n action=\"count\",\n help=\"Increase output verbosity (min.: 0, max. 2)\",\n )\n subparsers = parser.add_subparsers(dest=\"subcommand\", help=\"sub-command help\")\n\n # SUBCOMMAND\n parser_n = subparsers.add_parser(\"check-urls\", help=\"Ensure PURLs resolve\")\n parser_n.set_defaults(function=check_urls)\n\n parser_n = subparsers.add_parser(\n \"sparql-compare\",\n help=\"Run SPARQL commands against the db to generate a \" \"consistency report\",\n )\n parser_n.set_defaults(function=sparql_compare_all)\n\n parser_n = subparsers.add_parser(\"extract-context\", help=\"Extracts JSON-LD context\")\n parser_n.set_defaults(function=extract_context)\n\n parser_n = subparsers.add_parser(\n \"extract-contributors\",\n help=\"Queries github API for metadata about contributors\",\n )\n parser_n.set_defaults(function=write_all_contributors)\n\n args = parser.parse_args()\n if args.verbosity >= 2:\n logging.basicConfig(level=logging.DEBUG)\n elif args.verbosity == 1:\n logging.basicConfig(level=logging.INFO)\n else:\n logging.basicConfig(level=logging.WARNING)\n\n with open(args.input, \"r\") as f:\n obj = yaml.load(f, Loader=yaml.SafeLoader)\n ontologies = obj[\"ontologies\"]\n\n func = args.function\n func(ontologies, args)\n\n\ndef check_urls(ontologies, args):\n \"\"\"\n Ensure PURLs resolve\n \"\"\"\n\n def test_url(url):\n try:\n with closing(requests.get(url, stream=False)) as resp:\n return resp.status_code == 200\n except requests.exceptions.InvalidSchema as e:\n # TODO: requests lib doesn't handle ftp. For now simply return True in that case.\n if not format(e).startswith(\"No connection adapters were found for 'ftp:\"):\n raise\n return True\n\n failed_ids = []\n for ont in ontologies:\n for p in ont.get(\"products\", []):\n pid = p[\"id\"]\n if not test_url(p.get(\"ontology_purl\")):\n failed_ids.append(pid)\n if len(failed_ids) > 0:\n print(\"FAILURES:\")\n for pid in failed_ids:\n print(pid, file=sys.stderr)\n exit(1)\n\n\ndef extract_context(ontologies, args):\n \"\"\"\n Writes to STDOUT a sorted JSON map from ontology prefixes to PURLs\n \"\"\"\n\n def has_obo_prefix(obj):\n return (\"uri_prefix\" not in obj) or (\n obj[\"uri_prefix\"] == \"http://purl.obolibrary.org/obo/\"\n )\n\n prefix_map = {}\n for obj in ontologies:\n if has_obo_prefix(obj):\n prefix = obj.get(\"preferredPrefix\") or obj[\"id\"].upper()\n prefix_map[prefix] = {\n \"@id\": \"http://purl.obolibrary.org/obo/\" + prefix + \"_\",\n \"@prefix\": True,\n }\n\n print(\n dumps(\n {\"@context\": prefix_map}, sort_keys=True, indent=4, separators=(\",\", \": \")\n )\n )\n\n\ndef write_all_contributors(ontologies, args):\n \"\"\"\n Query github API for all contributors to an ontology,\n write results as json\n \"\"\"\n results = []\n for ont_obj in ontologies:\n id = ont_obj[\"id\"]\n logging.info(\"Getting info for {}\".format(id))\n repo_path = get_repo_path(ont_obj)\n if repo_path is not None:\n contribs = list(get_ontology_contributors(repo_path))\n print(\"CONTRIBS({})=={}\".format(id, contribs))\n for c in contribs:\n print(\"#{}\\t{}\\n\".format(id, c[\"login\"]))\n results.append(dict(id=id, contributors=contribs))\n else:\n logging.warn(\"No repo_path declared for {}\".format(id))\n print(dumps(results, sort_keys=True, indent=4, separators=(\",\", \": \")))\n\n\ndef get_ontology_contributors(repo_path):\n \"\"\"\n Get individual contributors to a org/repo_path\n repo_path is a string \"org/repo\"\n \"\"\"\n url = \"https://api.github.com/repos/{}/contributors\".format(repo_path)\n # TODO: allow use of oauth token;\n # GH has a quota for non-logged in API calls\n time.sleep(3)\n with closing(requests.get(url, stream=False)) as resp:\n ok = resp.status_code == 200\n if ok:\n results = resp.json()\n logging.info(\"RESP={}\".format(results))\n return results\n else:\n logging.error(\"Failed: {}\".format(url))\n return []\n\n\ndef get_repo_path(ont_obj):\n \"\"\"\n Extract the repository path for the given object\n \"\"\"\n repo_path = None\n if \"repository\" in ont_obj:\n repo_path = ont_obj[\"repository\"]\n elif \"tracker\" in ont_obj:\n tracker = ont_obj[\"tracker\"]\n if tracker is not None and \"github\" in tracker:\n repo_path = tracker.replace(\"/issues\", \"\")\n\n if repo_path is not None:\n repo_path = repo_path.replace(\"https://github.com/\", \"\")\n if repo_path.endswith(\"/\"):\n repo_path = repo_path[:-1]\n return repo_path\n else:\n logging.warn(\"Could not get gh repo_path for \".format(ont_obj))\n return None\n\n\ndef run_sparql(obj, p, expected_value, q):\n \"\"\"\n Generate a SPARQL statement using query q and parameter p, and expect 'expected_value' as the\n result. Print out a message indicating whether the there is or is not a match for the given object\n \"\"\"\n sparql = SPARQLWrapper(\"http://sparql.hegroup.org/sparql\")\n sparql.setQuery(q)\n sparql.setReturnFormat(JSON)\n results = sparql.query().convert()\n\n id = obj[\"id\"]\n got_value = False\n is_match = False\n vs = []\n\n for result in results[\"results\"][\"bindings\"]:\n got_value = True\n v = result[p][\"value\"]\n vs.append(str(v))\n if v == expected_value:\n is_match = True\n\n if got_value and is_match:\n msg = \"CONSISTENT\"\n elif got_value and not is_match:\n if expected_value == \"\":\n msg = \"UNDECLARED_LOCAL: REMOTE:\" + \",\".join(vs)\n else:\n msg = \"INCONSISTENT: REMOTE:\" + \",\".join(vs) + \" != LOCAL:\" + expected_value\n else:\n msg = \"UNDECLARED_REMOTE\"\n print(id + \" \" + p + \" \" + msg)\n\n\ndef sparql_compare_ont(obj):\n \"\"\"\n Some ontologies will directly declare some subset of the OBO metadata\n directly in the ontology header. In the majority of cases we should\n yield to the provider. However, we reserve the right to override. For\n example, OBO may have particular guidelines about the length of the title,\n required for coherency within the registry. All differences should be\n discussed with the provider and an accomodation reached\n \"\"\"\n if \"ontology_purl\" not in obj:\n return\n\n purl = obj[\"ontology_purl\"]\n # this could be made more declarative, or driven by the context.jsonld mapping;\n # however, for now this is relatively simple and easy to understand:\n run_sparql(\n obj,\n \"license\",\n obj[\"license\"][\"url\"] if \"license\" in obj else \"\",\n \"SELECT DISTINCT ?license WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/license> ?license}\",\n )\n run_sparql(\n obj,\n \"title\",\n obj[\"title\"] if \"title\" in obj else \"\",\n \"SELECT DISTINCT ?title WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/title> ?title}\",\n )\n run_sparql(\n obj,\n \"description\",\n obj[\"description\"] if \"description\" in obj else \"\",\n \"SELECT DISTINCT ?description WHERE {<\"\n + purl\n + \"> <http://purl.org/dc/elements/1.1/description> ?description}\",\n )\n run_sparql(\n obj,\n \"homepage\",\n obj[\"homepage\"] if \"homepage\" in obj else \"\",\n \"SELECT DISTINCT ?homepage WHERE {<\"\n + purl\n + \"> <http://xmlns.com/foaf/0.1/homepage> ?homepage}\",\n )\n\n\ndef sparql_compare_all(ontologies, args):\n \"\"\"\n Run sparql_compare_ont() on all the given ontologies.\n \"\"\"\n # The `args` parameter is not used here but it is convenient to have it in our definition, since\n # whether this function or one of the other main `subcommands` of this script is called is\n # determine dynamically, and we want all of the subcommands to have a consistent signature.\n for obj in ontologies:\n sparql_compare_ont(obj)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "util/processor.py"}]} | 3,239 | 147 |
gh_patches_debug_39322 | rasdani/github-patches | git_diff | carpentries__amy-583 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add event organizer info to the API
Compute Canada would like to be able to use the API to pull all the events it is hosting and then use this information to populate website.
Might be nice to have the EventBrite IDs there too.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `api/serializers.py`
Content:
```
1 from rest_framework import serializers
2
3 from workshops.models import Badge, Airport, Person, Event
4
5
6 class PersonUsernameSerializer(serializers.ModelSerializer):
7 name = serializers.CharField(source='get_full_name')
8 user = serializers.CharField(source='username')
9
10 class Meta:
11 model = Person
12 fields = ('name', 'user', )
13
14
15 class ExportBadgesSerializer(serializers.ModelSerializer):
16 persons = PersonUsernameSerializer(many=True, source='person_set')
17
18 class Meta:
19 model = Badge
20 fields = ('name', 'persons')
21
22
23 class ExportInstructorLocationsSerializer(serializers.ModelSerializer):
24 name = serializers.CharField(source='fullname')
25 instructors = PersonUsernameSerializer(many=True, source='person_set')
26
27 class Meta:
28 model = Airport
29 fields = ('name', 'latitude', 'longitude', 'instructors', 'country')
30
31
32 class EventSerializer(serializers.ModelSerializer):
33 humandate = serializers.SerializerMethodField()
34 country = serializers.CharField()
35 start = serializers.DateField(format=None)
36 end = serializers.DateField(format=None)
37 url = serializers.URLField(source='website_url')
38
39 def get_humandate(self, obj):
40 """Render start and end dates as human-readable short date."""
41 return EventSerializer.human_readable_date(obj.start, obj.end)
42
43 @staticmethod
44 def human_readable_date(date1, date2):
45 """Render start and end dates as human-readable short date."""
46 if date1 and not date2:
47 return '{:%b %d, %Y}-???'.format(date1)
48 elif date2 and not date1:
49 return '???-{:%b %d, %Y}'.format(date2)
50 elif not date2 and not date1:
51 return '???-???'
52
53 if date1.year == date2.year:
54 if date1.month == date2.month:
55 return '{:%b %d}-{:%d, %Y}'.format(date1, date2)
56 else:
57 return '{:%b %d}-{:%b %d, %Y}'.format(date1, date2)
58 else:
59 return '{:%b %d, %Y}-{:%b %d, %Y}'.format(date1, date2)
60
61 class Meta:
62 model = Event
63 fields = (
64 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',
65 'venue', 'address', 'latitude', 'longitude',
66 )
67
```
Path: `api/views.py`
Content:
```
1 from django.db.models import Q
2 from rest_framework.generics import ListAPIView
3 from rest_framework.permissions import IsAuthenticatedOrReadOnly
4 from rest_framework.response import Response
5 from rest_framework.reverse import reverse
6 from rest_framework.views import APIView
7
8 from workshops.models import Badge, Airport, Event
9
10 from .serializers import (
11 ExportBadgesSerializer,
12 ExportInstructorLocationsSerializer,
13 EventSerializer,
14 )
15
16
17 class ApiRoot(APIView):
18 def get(self, request, format=None):
19 return Response({
20 'export-badges': reverse('api:export-badges', request=request,
21 format=format),
22 'export-instructors': reverse('api:export-instructors',
23 request=request, format=format),
24 'events-published': reverse('api:events-published',
25 request=request, format=format),
26 })
27
28
29 class ExportBadgesView(ListAPIView):
30 """List all badges and people who have them."""
31 permission_classes = (IsAuthenticatedOrReadOnly, )
32 paginator = None # disable pagination
33
34 queryset = Badge.objects.prefetch_related('person_set')
35 serializer_class = ExportBadgesSerializer
36
37
38 class ExportInstructorLocationsView(ListAPIView):
39 """List all airports and instructors located near them."""
40 permission_classes = (IsAuthenticatedOrReadOnly, )
41 paginator = None # disable pagination
42
43 queryset = Airport.objects.exclude(person=None) \
44 .prefetch_related('person_set')
45 serializer_class = ExportInstructorLocationsSerializer
46
47
48 class PublishedEvents(ListAPIView):
49 # only events that have both a starting date and a URL
50 permission_classes = (IsAuthenticatedOrReadOnly, )
51 paginator = None # disable pagination
52
53 serializer_class = EventSerializer
54 queryset = Event.objects.published_events()
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/api/serializers.py b/api/serializers.py
--- a/api/serializers.py
+++ b/api/serializers.py
@@ -35,6 +35,7 @@
start = serializers.DateField(format=None)
end = serializers.DateField(format=None)
url = serializers.URLField(source='website_url')
+ eventbrite_id = serializers.CharField(source='reg_key')
def get_humandate(self, obj):
"""Render start and end dates as human-readable short date."""
@@ -62,5 +63,5 @@
model = Event
fields = (
'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',
- 'venue', 'address', 'latitude', 'longitude',
+ 'venue', 'address', 'latitude', 'longitude', 'eventbrite_id',
)
diff --git a/api/views.py b/api/views.py
--- a/api/views.py
+++ b/api/views.py
@@ -1,5 +1,6 @@
from django.db.models import Q
from rest_framework.generics import ListAPIView
+from rest_framework.metadata import SimpleMetadata
from rest_framework.permissions import IsAuthenticatedOrReadOnly
from rest_framework.response import Response
from rest_framework.reverse import reverse
@@ -14,6 +15,21 @@
)
+class QueryMetadata(SimpleMetadata):
+ """Additionally include info about query parameters."""
+
+ def determine_metadata(self, request, view):
+ print('doing something')
+ data = super().determine_metadata(request, view)
+
+ try:
+ data['query_params'] = view.get_query_params_description()
+ except AttributeError:
+ pass
+
+ return data
+
+
class ApiRoot(APIView):
def get(self, request, format=None):
return Response({
@@ -46,9 +62,34 @@
class PublishedEvents(ListAPIView):
+ """List published events."""
+
# only events that have both a starting date and a URL
permission_classes = (IsAuthenticatedOrReadOnly, )
paginator = None # disable pagination
serializer_class = EventSerializer
- queryset = Event.objects.published_events()
+
+ metadata_class = QueryMetadata
+
+ def get_queryset(self):
+ """Optionally restrict the returned event set to events hosted by
+ specific host or administered by specific admin."""
+ queryset = Event.objects.published_events()
+
+ administrator = self.request.query_params.get('administrator', None)
+ if administrator is not None:
+ queryset = queryset.filter(administrator__pk=administrator)
+
+ host = self.request.query_params.get('host', None)
+ if host is not None:
+ queryset = queryset.filter(host__pk=host)
+
+ return queryset
+
+ def get_query_params_description(self):
+ return {
+ 'administrator': 'ID of the organization responsible for admin '
+ 'work on events.',
+ 'host': 'ID of the organization hosting the event.',
+ }
| {"golden_diff": "diff --git a/api/serializers.py b/api/serializers.py\n--- a/api/serializers.py\n+++ b/api/serializers.py\n@@ -35,6 +35,7 @@\n start = serializers.DateField(format=None)\n end = serializers.DateField(format=None)\n url = serializers.URLField(source='website_url')\n+ eventbrite_id = serializers.CharField(source='reg_key')\n \n def get_humandate(self, obj):\n \"\"\"Render start and end dates as human-readable short date.\"\"\"\n@@ -62,5 +63,5 @@\n model = Event\n fields = (\n 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',\n- 'venue', 'address', 'latitude', 'longitude',\n+ 'venue', 'address', 'latitude', 'longitude', 'eventbrite_id',\n )\ndiff --git a/api/views.py b/api/views.py\n--- a/api/views.py\n+++ b/api/views.py\n@@ -1,5 +1,6 @@\n from django.db.models import Q\n from rest_framework.generics import ListAPIView\n+from rest_framework.metadata import SimpleMetadata\n from rest_framework.permissions import IsAuthenticatedOrReadOnly\n from rest_framework.response import Response\n from rest_framework.reverse import reverse\n@@ -14,6 +15,21 @@\n )\n \n \n+class QueryMetadata(SimpleMetadata):\n+ \"\"\"Additionally include info about query parameters.\"\"\"\n+\n+ def determine_metadata(self, request, view):\n+ print('doing something')\n+ data = super().determine_metadata(request, view)\n+\n+ try:\n+ data['query_params'] = view.get_query_params_description()\n+ except AttributeError:\n+ pass\n+\n+ return data\n+\n+\n class ApiRoot(APIView):\n def get(self, request, format=None):\n return Response({\n@@ -46,9 +62,34 @@\n \n \n class PublishedEvents(ListAPIView):\n+ \"\"\"List published events.\"\"\"\n+\n # only events that have both a starting date and a URL\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n \n serializer_class = EventSerializer\n- queryset = Event.objects.published_events()\n+\n+ metadata_class = QueryMetadata\n+\n+ def get_queryset(self):\n+ \"\"\"Optionally restrict the returned event set to events hosted by\n+ specific host or administered by specific admin.\"\"\"\n+ queryset = Event.objects.published_events()\n+\n+ administrator = self.request.query_params.get('administrator', None)\n+ if administrator is not None:\n+ queryset = queryset.filter(administrator__pk=administrator)\n+\n+ host = self.request.query_params.get('host', None)\n+ if host is not None:\n+ queryset = queryset.filter(host__pk=host)\n+\n+ return queryset\n+\n+ def get_query_params_description(self):\n+ return {\n+ 'administrator': 'ID of the organization responsible for admin '\n+ 'work on events.',\n+ 'host': 'ID of the organization hosting the event.',\n+ }\n", "issue": "Add event organizer info to the API\nCompute Canada would like to be able to use the API to pull all the events it is hosting and then use this information to populate website.\n\nMight be nice to have the EventBrite IDs there too.\n\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom workshops.models import Badge, Airport, Person, Event\n\n\nclass PersonUsernameSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='get_full_name')\n user = serializers.CharField(source='username')\n\n class Meta:\n model = Person\n fields = ('name', 'user', )\n\n\nclass ExportBadgesSerializer(serializers.ModelSerializer):\n persons = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Badge\n fields = ('name', 'persons')\n\n\nclass ExportInstructorLocationsSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='fullname')\n instructors = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Airport\n fields = ('name', 'latitude', 'longitude', 'instructors', 'country')\n\n\nclass EventSerializer(serializers.ModelSerializer):\n humandate = serializers.SerializerMethodField()\n country = serializers.CharField()\n start = serializers.DateField(format=None)\n end = serializers.DateField(format=None)\n url = serializers.URLField(source='website_url')\n\n def get_humandate(self, obj):\n \"\"\"Render start and end dates as human-readable short date.\"\"\"\n return EventSerializer.human_readable_date(obj.start, obj.end)\n\n @staticmethod\n def human_readable_date(date1, date2):\n \"\"\"Render start and end dates as human-readable short date.\"\"\"\n if date1 and not date2:\n return '{:%b %d, %Y}-???'.format(date1)\n elif date2 and not date1:\n return '???-{:%b %d, %Y}'.format(date2)\n elif not date2 and not date1:\n return '???-???'\n\n if date1.year == date2.year:\n if date1.month == date2.month:\n return '{:%b %d}-{:%d, %Y}'.format(date1, date2)\n else:\n return '{:%b %d}-{:%b %d, %Y}'.format(date1, date2)\n else:\n return '{:%b %d, %Y}-{:%b %d, %Y}'.format(date1, date2)\n\n class Meta:\n model = Event\n fields = (\n 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',\n 'venue', 'address', 'latitude', 'longitude',\n )\n", "path": "api/serializers.py"}, {"content": "from django.db.models import Q\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly\nfrom rest_framework.response import Response\nfrom rest_framework.reverse import reverse\nfrom rest_framework.views import APIView\n\nfrom workshops.models import Badge, Airport, Event\n\nfrom .serializers import (\n ExportBadgesSerializer,\n ExportInstructorLocationsSerializer,\n EventSerializer,\n)\n\n\nclass ApiRoot(APIView):\n def get(self, request, format=None):\n return Response({\n 'export-badges': reverse('api:export-badges', request=request,\n format=format),\n 'export-instructors': reverse('api:export-instructors',\n request=request, format=format),\n 'events-published': reverse('api:events-published',\n request=request, format=format),\n })\n\n\nclass ExportBadgesView(ListAPIView):\n \"\"\"List all badges and people who have them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Badge.objects.prefetch_related('person_set')\n serializer_class = ExportBadgesSerializer\n\n\nclass ExportInstructorLocationsView(ListAPIView):\n \"\"\"List all airports and instructors located near them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Airport.objects.exclude(person=None) \\\n .prefetch_related('person_set')\n serializer_class = ExportInstructorLocationsSerializer\n\n\nclass PublishedEvents(ListAPIView):\n # only events that have both a starting date and a URL\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n serializer_class = EventSerializer\n queryset = Event.objects.published_events()\n", "path": "api/views.py"}], "after_files": [{"content": "from rest_framework import serializers\n\nfrom workshops.models import Badge, Airport, Person, Event\n\n\nclass PersonUsernameSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='get_full_name')\n user = serializers.CharField(source='username')\n\n class Meta:\n model = Person\n fields = ('name', 'user', )\n\n\nclass ExportBadgesSerializer(serializers.ModelSerializer):\n persons = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Badge\n fields = ('name', 'persons')\n\n\nclass ExportInstructorLocationsSerializer(serializers.ModelSerializer):\n name = serializers.CharField(source='fullname')\n instructors = PersonUsernameSerializer(many=True, source='person_set')\n\n class Meta:\n model = Airport\n fields = ('name', 'latitude', 'longitude', 'instructors', 'country')\n\n\nclass EventSerializer(serializers.ModelSerializer):\n humandate = serializers.SerializerMethodField()\n country = serializers.CharField()\n start = serializers.DateField(format=None)\n end = serializers.DateField(format=None)\n url = serializers.URLField(source='website_url')\n eventbrite_id = serializers.CharField(source='reg_key')\n\n def get_humandate(self, obj):\n \"\"\"Render start and end dates as human-readable short date.\"\"\"\n return EventSerializer.human_readable_date(obj.start, obj.end)\n\n @staticmethod\n def human_readable_date(date1, date2):\n \"\"\"Render start and end dates as human-readable short date.\"\"\"\n if date1 and not date2:\n return '{:%b %d, %Y}-???'.format(date1)\n elif date2 and not date1:\n return '???-{:%b %d, %Y}'.format(date2)\n elif not date2 and not date1:\n return '???-???'\n\n if date1.year == date2.year:\n if date1.month == date2.month:\n return '{:%b %d}-{:%d, %Y}'.format(date1, date2)\n else:\n return '{:%b %d}-{:%b %d, %Y}'.format(date1, date2)\n else:\n return '{:%b %d, %Y}-{:%b %d, %Y}'.format(date1, date2)\n\n class Meta:\n model = Event\n fields = (\n 'slug', 'start', 'end', 'url', 'humandate', 'contact', 'country',\n 'venue', 'address', 'latitude', 'longitude', 'eventbrite_id',\n )\n", "path": "api/serializers.py"}, {"content": "from django.db.models import Q\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.metadata import SimpleMetadata\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly\nfrom rest_framework.response import Response\nfrom rest_framework.reverse import reverse\nfrom rest_framework.views import APIView\n\nfrom workshops.models import Badge, Airport, Event\n\nfrom .serializers import (\n ExportBadgesSerializer,\n ExportInstructorLocationsSerializer,\n EventSerializer,\n)\n\n\nclass QueryMetadata(SimpleMetadata):\n \"\"\"Additionally include info about query parameters.\"\"\"\n\n def determine_metadata(self, request, view):\n print('doing something')\n data = super().determine_metadata(request, view)\n\n try:\n data['query_params'] = view.get_query_params_description()\n except AttributeError:\n pass\n\n return data\n\n\nclass ApiRoot(APIView):\n def get(self, request, format=None):\n return Response({\n 'export-badges': reverse('api:export-badges', request=request,\n format=format),\n 'export-instructors': reverse('api:export-instructors',\n request=request, format=format),\n 'events-published': reverse('api:events-published',\n request=request, format=format),\n })\n\n\nclass ExportBadgesView(ListAPIView):\n \"\"\"List all badges and people who have them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Badge.objects.prefetch_related('person_set')\n serializer_class = ExportBadgesSerializer\n\n\nclass ExportInstructorLocationsView(ListAPIView):\n \"\"\"List all airports and instructors located near them.\"\"\"\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n queryset = Airport.objects.exclude(person=None) \\\n .prefetch_related('person_set')\n serializer_class = ExportInstructorLocationsSerializer\n\n\nclass PublishedEvents(ListAPIView):\n \"\"\"List published events.\"\"\"\n\n # only events that have both a starting date and a URL\n permission_classes = (IsAuthenticatedOrReadOnly, )\n paginator = None # disable pagination\n\n serializer_class = EventSerializer\n\n metadata_class = QueryMetadata\n\n def get_queryset(self):\n \"\"\"Optionally restrict the returned event set to events hosted by\n specific host or administered by specific admin.\"\"\"\n queryset = Event.objects.published_events()\n\n administrator = self.request.query_params.get('administrator', None)\n if administrator is not None:\n queryset = queryset.filter(administrator__pk=administrator)\n\n host = self.request.query_params.get('host', None)\n if host is not None:\n queryset = queryset.filter(host__pk=host)\n\n return queryset\n\n def get_query_params_description(self):\n return {\n 'administrator': 'ID of the organization responsible for admin '\n 'work on events.',\n 'host': 'ID of the organization hosting the event.',\n }\n", "path": "api/views.py"}]} | 1,429 | 653 |
gh_patches_debug_37480 | rasdani/github-patches | git_diff | translate__pootle-6669 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Localisation strings need to allow ordering
The following errors occur in `pootle makemessages` run via `make pot`. These are strings where we're using multiple `%s` variables without names, thus they can't be reordered if required by the language.
```
./pootle/apps/import_export/utils.py:57: warning: 'msgid' format string with unnamed arguments cannot be properly localized:
The translator cannot reorder the arguments.
Please consider using a format string with named arguments,
and a mapping instead of a tuple for the arguments.
./pootle/apps/pootle_profile/templatetags/profile_tags.py:35: warning: 'msgid' format string with unnamed arguments cannot be properly localized:
The translator cannot reorder the arguments.
Please consider using a format string with named arguments,
and a mapping instead of a tuple for the arguments.
./pootle/apps/pootle_profile/templatetags/profile_tags.py:52: warning: 'msgid' format string with unnamed arguments cannot be properly localized:
The translator cannot reorder the arguments.
Please consider using a format string with named arguments,
and a mapping instead of a tuple for the arguments.
./pootle/apps/pootle_profile/templatetags/profile_tags.py:56: warning: 'msgid' format string with unnamed arguments cannot be properly localized:
The translator cannot reorder the arguments.
Please consider using a format string with named arguments,
and a mapping instead of a tuple for the arguments.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_profile/templatetags/profile_tags.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import urllib
10
11 from django import template
12 from django.conf import settings
13 from django.core.urlresolvers import reverse
14 from django.utils.safestring import mark_safe
15
16 from pootle.i18n.gettext import ugettext_lazy as _
17
18
19 register = template.Library()
20
21
22 @register.filter
23 def gravatar(user, size):
24 return user.gravatar_url(size)
25
26
27 @register.inclusion_tag("user/includes/profile_score.html")
28 def profile_score(request, profile):
29 context = dict(profile=profile)
30 top_lang = profile.scores.top_language
31 context["own_profile"] = request.user == profile.user
32 if top_lang and not top_lang[0] == -1 and top_lang[1]:
33 if context["own_profile"]:
34 score_tweet_content = _(
35 "My current score at %s is %s"
36 % (settings.POOTLE_TITLE,
37 profile.scores.public_score))
38 context["score_tweet_message"] = _("Tweet this!")
39 context["score_tweet_link"] = (
40 "https://twitter.com/share?text=%s"
41 % urllib.quote_plus(score_tweet_content.encode("utf8")))
42 return context
43
44
45 @register.inclusion_tag("user/includes/profile_ranking.html")
46 def profile_ranking(request, profile):
47 context = dict(request=request, profile=profile)
48 top_lang = profile.scores.top_language
49 context["own_profile"] = request.user == profile.user
50 if top_lang and not top_lang[0] == -1 and top_lang[1]:
51 context["ranking_text"] = _(
52 "#%s contributor in %s in the last 30 days"
53 % (top_lang[0], top_lang[1].name))
54 if context["own_profile"]:
55 ranking_tweet_content = _(
56 "I am #%s contributor in %s in the last 30 days at %s!"
57 % (top_lang[0],
58 top_lang[1].name,
59 settings.POOTLE_TITLE))
60 context["ranking_tweet_link"] = (
61 "https://twitter.com/share?text=%s"
62 % urllib.quote_plus(ranking_tweet_content.encode("utf8")))
63 context["ranking_tweet_link_text"] = _("Tweet this!")
64 else:
65 context["no_ranking_text"] = _("No contributions in the last 30 days")
66 return context
67
68
69 @register.inclusion_tag("user/includes/profile_social.html")
70 def profile_social(profile):
71 links = []
72 if profile.user.website:
73 links.append(
74 dict(url=profile.user.website,
75 icon="icon-user-website",
76 text=_("My Website")))
77 if profile.user.twitter:
78 links.append(
79 dict(url=profile.user.twitter_url,
80 icon="icon-user-twitter",
81 text="@%s" % profile.user.twitter))
82 if profile.user.linkedin:
83 links.append(
84 dict(url=profile.user.linkedin,
85 icon="icon-user-linkedin",
86 text=_("My LinkedIn Profile")))
87 return dict(social_media_links=links)
88
89
90 @register.inclusion_tag("user/includes/profile_teams.html")
91 def profile_teams(request, profile):
92 teams = profile.membership.teams_and_roles
93 site_permissions = []
94 if not request.user.is_anonymous and profile.user.is_superuser:
95 site_permissions.append(_("Site administrator"))
96 for code, info in teams.items():
97 info["url"] = reverse(
98 "pootle-language-browse",
99 kwargs=dict(language_code=code))
100 teams_title = _(
101 "%s's language teams"
102 % profile.user.display_name)
103 no_teams_message = _(
104 "%s is not a member of any language teams"
105 % profile.user.display_name)
106 return dict(
107 anon_request=request.user.is_anonymous,
108 teams=teams,
109 teams_title=teams_title,
110 no_teams_message=no_teams_message,
111 site_permissions=site_permissions)
112
113
114 @register.inclusion_tag("user/includes/profile_user.html")
115 def profile_user(request, profile):
116 context = dict(request=request, profile=profile)
117 context['request_user_is_manager'] = (
118 request.user.has_manager_permissions())
119 if profile.user.is_anonymous:
120 context["bio"] = _(
121 "Some translations are provided by anonymous volunteers. "
122 "These are registered under this special meta-account.")
123 elif profile.user.is_system():
124 context["bio"] = _(
125 "Some translations are imported from external files. "
126 "These are registered under this special meta-account.")
127 else:
128 if request.user == profile.user:
129 context["can_edit_profile"] = True
130 context["should_edit_profile"] = (
131 not profile.user.has_contact_details
132 or not profile.user.bio)
133 if context["should_edit_profile"]:
134 context["edit_profile_message"] = mark_safe(
135 _("Show others who you are, tell about yourself<br/>"
136 "and make your public profile look gorgeous!"))
137 context["user_title"] = _(
138 "You can set or change your avatar image at www.gravatar.com")
139 if profile.user.bio:
140 context["bio"] = profile.user.bio
141 return context
142
143
144 @register.inclusion_tag("user/includes/profile_activity.html")
145 def profile_activity(profile, request_lang=None):
146 context = dict(profile=profile)
147 if profile.user.is_meta:
148 return context
149 context["user_last_event"] = (
150 context["profile"].user.last_event(locale=request_lang))
151 return context
152
```
Path: `pootle/apps/import_export/utils.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import logging
10 import os
11 from io import BytesIO
12 from zipfile import ZipFile
13
14 from translate.storage import tmx
15 from translate.storage.factory import getclass
16
17 from django.conf import settings
18 from django.utils.functional import cached_property
19
20 from pootle.core.delegate import revision
21 from pootle.core.url_helpers import urljoin
22 from pootle.i18n.gettext import ugettext_lazy as _
23 from pootle_app.models.permissions import check_user_permission
24 from pootle_statistics.models import SubmissionTypes
25 from pootle_store.constants import TRANSLATED
26 from pootle_store.models import Store
27
28 from .exceptions import (FileImportError, MissingPootlePathError,
29 MissingPootleRevError, UnsupportedFiletypeError)
30
31
32 logger = logging.getLogger(__name__)
33
34
35 def import_file(f, user=None):
36 ttk = getclass(f)(f.read())
37 if not hasattr(ttk, "parseheader"):
38 raise UnsupportedFiletypeError(_("Unsupported filetype '%s', only PO "
39 "files are supported at this time\n",
40 f.name))
41 header = ttk.parseheader()
42 pootle_path = header.get("X-Pootle-Path")
43 if not pootle_path:
44 raise MissingPootlePathError(_("File '%s' missing X-Pootle-Path "
45 "header\n", f.name))
46
47 rev = header.get("X-Pootle-Revision")
48 if not rev or not rev.isdigit():
49 raise MissingPootleRevError(_("File '%s' missing or invalid "
50 "X-Pootle-Revision header\n",
51 f.name))
52 rev = int(rev)
53
54 try:
55 store = Store.objects.get(pootle_path=pootle_path)
56 except Store.DoesNotExist as e:
57 raise FileImportError(_("Could not create '%s'. Missing "
58 "Project/Language? (%s)", (f.name, e)))
59
60 tp = store.translation_project
61 allow_add_and_obsolete = ((tp.project.checkstyle == 'terminology'
62 or tp.is_template_project)
63 and check_user_permission(user,
64 'administrate',
65 tp.directory))
66 try:
67 store.update(store=ttk, user=user,
68 submission_type=SubmissionTypes.UPLOAD,
69 store_revision=rev,
70 allow_add_and_obsolete=allow_add_and_obsolete)
71 except Exception as e:
72 # This should not happen!
73 logger.error("Error importing file: %s", str(e))
74 raise FileImportError(_("There was an error uploading your file"))
75
76
77 class TPTMXExporter(object):
78
79 def __init__(self, context):
80 self.context = context
81
82 @cached_property
83 def exported_revision(self):
84 return revision.get(self.context.__class__)(
85 self.context).get(key="pootle.offline.tm")
86
87 @cached_property
88 def revision(self):
89 return revision.get(self.context.__class__)(
90 self.context.directory).get(key="stats")[:10] or "0"
91
92 def get_url(self):
93 if self.exported_revision:
94 relative_path = "offline_tm/%s/%s" % (
95 self.context.language.code,
96 self.get_filename(self.exported_revision)
97 )
98 return urljoin(settings.MEDIA_URL, relative_path)
99 return None
100
101 def update_exported_revision(self):
102 if self.has_changes():
103 revision.get(self.context.__class__)(
104 self.context).set(keys=["pootle.offline.tm"],
105 value=self.revision)
106 if "exported_revision" in self.__dict__:
107 del self.__dict__["exported_revision"]
108
109 def has_changes(self):
110 return self.revision != self.exported_revision
111
112 def file_exists(self):
113 return os.path.exists(self.abs_filepath)
114
115 @property
116 def last_exported_file_path(self):
117 if not self.exported_revision:
118 return None
119 exported_filename = self.get_filename(self.exported_revision)
120 return os.path.join(self.directory, exported_filename)
121
122 def exported_file_exists(self):
123 if self.last_exported_file_path is None:
124 return False
125 return os.path.exists(self.last_exported_file_path)
126
127 @property
128 def directory(self):
129 return os.path.join(settings.MEDIA_ROOT,
130 'offline_tm',
131 self.context.language.code)
132
133 def get_filename(self, revision):
134 return ".".join([self.context.project.code,
135 self.context.language.code, revision, 'tmx',
136 'zip'])
137
138 def check_tp(self, filename):
139 """Check if filename relates to the context TP."""
140
141 return filename.startswith(".".join([
142 self.context.project.code,
143 self.context.language.code]))
144
145 @property
146 def filename(self):
147 return self.get_filename(self.revision)
148
149 @property
150 def abs_filepath(self):
151 return os.path.join(self.directory, self.filename)
152
153 def export(self, rotate=False):
154 source_language = self.context.project.source_language.code
155 target_language = self.context.language.code
156
157 if not os.path.exists(self.directory):
158 os.makedirs(self.directory)
159
160 tmxfile = tmx.tmxfile()
161 for store in self.context.stores.live().iterator():
162 for unit in store.units.filter(state=TRANSLATED):
163 tmxfile.addtranslation(unit.source, source_language,
164 unit.target, target_language,
165 unit.developer_comment)
166
167 bs = BytesIO()
168 tmxfile.serialize(bs)
169 with open(self.abs_filepath, "wb") as f:
170 with ZipFile(f, "w") as zf:
171 zf.writestr(self.filename.rstrip('.zip'), bs.getvalue())
172
173 last_exported_filepath = self.last_exported_file_path
174 self.update_exported_revision()
175
176 removed = []
177 if rotate:
178 for fn in os.listdir(self.directory):
179 # Skip files from other projects.
180 if not self.check_tp(fn):
181 continue
182 filepath = os.path.join(self.directory, fn)
183 if filepath not in [self.abs_filepath, last_exported_filepath]:
184 removed.append(filepath)
185 os.remove(filepath)
186
187 return self.abs_filepath, removed
188
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pootle/apps/import_export/utils.py b/pootle/apps/import_export/utils.py
--- a/pootle/apps/import_export/utils.py
+++ b/pootle/apps/import_export/utils.py
@@ -54,8 +54,10 @@
try:
store = Store.objects.get(pootle_path=pootle_path)
except Store.DoesNotExist as e:
- raise FileImportError(_("Could not create '%s'. Missing "
- "Project/Language? (%s)", (f.name, e)))
+ raise FileImportError(
+ _("Could not create '%(filename)s'. Missing "
+ "Project/Language? (%(error)s)",
+ dict(filename=f.name, error=e)))
tp = store.translation_project
allow_add_and_obsolete = ((tp.project.checkstyle == 'terminology'
diff --git a/pootle/apps/pootle_profile/templatetags/profile_tags.py b/pootle/apps/pootle_profile/templatetags/profile_tags.py
--- a/pootle/apps/pootle_profile/templatetags/profile_tags.py
+++ b/pootle/apps/pootle_profile/templatetags/profile_tags.py
@@ -32,9 +32,9 @@
if top_lang and not top_lang[0] == -1 and top_lang[1]:
if context["own_profile"]:
score_tweet_content = _(
- "My current score at %s is %s"
- % (settings.POOTLE_TITLE,
- profile.scores.public_score))
+ "My current score at %(pootle_title)s is %(score)s",
+ dict(pootle_title=settings.POOTLE_TITLE,
+ score=profile.scores.public_score))
context["score_tweet_message"] = _("Tweet this!")
context["score_tweet_link"] = (
"https://twitter.com/share?text=%s"
@@ -49,14 +49,15 @@
context["own_profile"] = request.user == profile.user
if top_lang and not top_lang[0] == -1 and top_lang[1]:
context["ranking_text"] = _(
- "#%s contributor in %s in the last 30 days"
- % (top_lang[0], top_lang[1].name))
+ "#%(rank)s contributor in %(language)s in the last 30 days",
+ dict(rank=top_lang[0], language=top_lang[1].name))
if context["own_profile"]:
ranking_tweet_content = _(
- "I am #%s contributor in %s in the last 30 days at %s!"
- % (top_lang[0],
- top_lang[1].name,
- settings.POOTLE_TITLE))
+ "I am #%(rank)s contributor in %(language)s in the last 30 "
+ "days at %(pootle_title)s!",
+ dict(rank=top_lang[0],
+ language=top_lang[1].name,
+ pootle_title=settings.POOTLE_TITLE))
context["ranking_tweet_link"] = (
"https://twitter.com/share?text=%s"
% urllib.quote_plus(ranking_tweet_content.encode("utf8")))
| {"golden_diff": "diff --git a/pootle/apps/import_export/utils.py b/pootle/apps/import_export/utils.py\n--- a/pootle/apps/import_export/utils.py\n+++ b/pootle/apps/import_export/utils.py\n@@ -54,8 +54,10 @@\n try:\n store = Store.objects.get(pootle_path=pootle_path)\n except Store.DoesNotExist as e:\n- raise FileImportError(_(\"Could not create '%s'. Missing \"\n- \"Project/Language? (%s)\", (f.name, e)))\n+ raise FileImportError(\n+ _(\"Could not create '%(filename)s'. Missing \"\n+ \"Project/Language? (%(error)s)\",\n+ dict(filename=f.name, error=e)))\n \n tp = store.translation_project\n allow_add_and_obsolete = ((tp.project.checkstyle == 'terminology'\ndiff --git a/pootle/apps/pootle_profile/templatetags/profile_tags.py b/pootle/apps/pootle_profile/templatetags/profile_tags.py\n--- a/pootle/apps/pootle_profile/templatetags/profile_tags.py\n+++ b/pootle/apps/pootle_profile/templatetags/profile_tags.py\n@@ -32,9 +32,9 @@\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n if context[\"own_profile\"]:\n score_tweet_content = _(\n- \"My current score at %s is %s\"\n- % (settings.POOTLE_TITLE,\n- profile.scores.public_score))\n+ \"My current score at %(pootle_title)s is %(score)s\",\n+ dict(pootle_title=settings.POOTLE_TITLE,\n+ score=profile.scores.public_score))\n context[\"score_tweet_message\"] = _(\"Tweet this!\")\n context[\"score_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n@@ -49,14 +49,15 @@\n context[\"own_profile\"] = request.user == profile.user\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n context[\"ranking_text\"] = _(\n- \"#%s contributor in %s in the last 30 days\"\n- % (top_lang[0], top_lang[1].name))\n+ \"#%(rank)s contributor in %(language)s in the last 30 days\",\n+ dict(rank=top_lang[0], language=top_lang[1].name))\n if context[\"own_profile\"]:\n ranking_tweet_content = _(\n- \"I am #%s contributor in %s in the last 30 days at %s!\"\n- % (top_lang[0],\n- top_lang[1].name,\n- settings.POOTLE_TITLE))\n+ \"I am #%(rank)s contributor in %(language)s in the last 30 \"\n+ \"days at %(pootle_title)s!\",\n+ dict(rank=top_lang[0],\n+ language=top_lang[1].name,\n+ pootle_title=settings.POOTLE_TITLE))\n context[\"ranking_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n % urllib.quote_plus(ranking_tweet_content.encode(\"utf8\")))\n", "issue": "Localisation strings need to allow ordering\nThe following errors occur in `pootle makemessages` run via `make pot`. These are strings where we're using multiple `%s` variables without names, thus they can't be reordered if required by the language.\r\n\r\n```\r\n./pootle/apps/import_export/utils.py:57: warning: 'msgid' format string with unnamed arguments cannot be properly localized:\r\n The translator cannot reorder the arguments.\r\n Please consider using a format string with named arguments,\r\n and a mapping instead of a tuple for the arguments.\r\n./pootle/apps/pootle_profile/templatetags/profile_tags.py:35: warning: 'msgid' format string with unnamed arguments cannot be properly localized:\r\n The translator cannot reorder the arguments.\r\n Please consider using a format string with named arguments,\r\n and a mapping instead of a tuple for the arguments.\r\n./pootle/apps/pootle_profile/templatetags/profile_tags.py:52: warning: 'msgid' format string with unnamed arguments cannot be properly localized:\r\n The translator cannot reorder the arguments.\r\n Please consider using a format string with named arguments,\r\n and a mapping instead of a tuple for the arguments.\r\n./pootle/apps/pootle_profile/templatetags/profile_tags.py:56: warning: 'msgid' format string with unnamed arguments cannot be properly localized:\r\n The translator cannot reorder the arguments.\r\n Please consider using a format string with named arguments,\r\n and a mapping instead of a tuple for the arguments.\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport urllib\n\nfrom django import template\nfrom django.conf import settings\nfrom django.core.urlresolvers import reverse\nfrom django.utils.safestring import mark_safe\n\nfrom pootle.i18n.gettext import ugettext_lazy as _\n\n\nregister = template.Library()\n\n\[email protected]\ndef gravatar(user, size):\n return user.gravatar_url(size)\n\n\[email protected]_tag(\"user/includes/profile_score.html\")\ndef profile_score(request, profile):\n context = dict(profile=profile)\n top_lang = profile.scores.top_language\n context[\"own_profile\"] = request.user == profile.user\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n if context[\"own_profile\"]:\n score_tweet_content = _(\n \"My current score at %s is %s\"\n % (settings.POOTLE_TITLE,\n profile.scores.public_score))\n context[\"score_tweet_message\"] = _(\"Tweet this!\")\n context[\"score_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n % urllib.quote_plus(score_tweet_content.encode(\"utf8\")))\n return context\n\n\[email protected]_tag(\"user/includes/profile_ranking.html\")\ndef profile_ranking(request, profile):\n context = dict(request=request, profile=profile)\n top_lang = profile.scores.top_language\n context[\"own_profile\"] = request.user == profile.user\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n context[\"ranking_text\"] = _(\n \"#%s contributor in %s in the last 30 days\"\n % (top_lang[0], top_lang[1].name))\n if context[\"own_profile\"]:\n ranking_tweet_content = _(\n \"I am #%s contributor in %s in the last 30 days at %s!\"\n % (top_lang[0],\n top_lang[1].name,\n settings.POOTLE_TITLE))\n context[\"ranking_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n % urllib.quote_plus(ranking_tweet_content.encode(\"utf8\")))\n context[\"ranking_tweet_link_text\"] = _(\"Tweet this!\")\n else:\n context[\"no_ranking_text\"] = _(\"No contributions in the last 30 days\")\n return context\n\n\[email protected]_tag(\"user/includes/profile_social.html\")\ndef profile_social(profile):\n links = []\n if profile.user.website:\n links.append(\n dict(url=profile.user.website,\n icon=\"icon-user-website\",\n text=_(\"My Website\")))\n if profile.user.twitter:\n links.append(\n dict(url=profile.user.twitter_url,\n icon=\"icon-user-twitter\",\n text=\"@%s\" % profile.user.twitter))\n if profile.user.linkedin:\n links.append(\n dict(url=profile.user.linkedin,\n icon=\"icon-user-linkedin\",\n text=_(\"My LinkedIn Profile\")))\n return dict(social_media_links=links)\n\n\[email protected]_tag(\"user/includes/profile_teams.html\")\ndef profile_teams(request, profile):\n teams = profile.membership.teams_and_roles\n site_permissions = []\n if not request.user.is_anonymous and profile.user.is_superuser:\n site_permissions.append(_(\"Site administrator\"))\n for code, info in teams.items():\n info[\"url\"] = reverse(\n \"pootle-language-browse\",\n kwargs=dict(language_code=code))\n teams_title = _(\n \"%s's language teams\"\n % profile.user.display_name)\n no_teams_message = _(\n \"%s is not a member of any language teams\"\n % profile.user.display_name)\n return dict(\n anon_request=request.user.is_anonymous,\n teams=teams,\n teams_title=teams_title,\n no_teams_message=no_teams_message,\n site_permissions=site_permissions)\n\n\[email protected]_tag(\"user/includes/profile_user.html\")\ndef profile_user(request, profile):\n context = dict(request=request, profile=profile)\n context['request_user_is_manager'] = (\n request.user.has_manager_permissions())\n if profile.user.is_anonymous:\n context[\"bio\"] = _(\n \"Some translations are provided by anonymous volunteers. \"\n \"These are registered under this special meta-account.\")\n elif profile.user.is_system():\n context[\"bio\"] = _(\n \"Some translations are imported from external files. \"\n \"These are registered under this special meta-account.\")\n else:\n if request.user == profile.user:\n context[\"can_edit_profile\"] = True\n context[\"should_edit_profile\"] = (\n not profile.user.has_contact_details\n or not profile.user.bio)\n if context[\"should_edit_profile\"]:\n context[\"edit_profile_message\"] = mark_safe(\n _(\"Show others who you are, tell about yourself<br/>\"\n \"and make your public profile look gorgeous!\"))\n context[\"user_title\"] = _(\n \"You can set or change your avatar image at www.gravatar.com\")\n if profile.user.bio:\n context[\"bio\"] = profile.user.bio\n return context\n\n\[email protected]_tag(\"user/includes/profile_activity.html\")\ndef profile_activity(profile, request_lang=None):\n context = dict(profile=profile)\n if profile.user.is_meta:\n return context\n context[\"user_last_event\"] = (\n context[\"profile\"].user.last_event(locale=request_lang))\n return context\n", "path": "pootle/apps/pootle_profile/templatetags/profile_tags.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nfrom io import BytesIO\nfrom zipfile import ZipFile\n\nfrom translate.storage import tmx\nfrom translate.storage.factory import getclass\n\nfrom django.conf import settings\nfrom django.utils.functional import cached_property\n\nfrom pootle.core.delegate import revision\nfrom pootle.core.url_helpers import urljoin\nfrom pootle.i18n.gettext import ugettext_lazy as _\nfrom pootle_app.models.permissions import check_user_permission\nfrom pootle_statistics.models import SubmissionTypes\nfrom pootle_store.constants import TRANSLATED\nfrom pootle_store.models import Store\n\nfrom .exceptions import (FileImportError, MissingPootlePathError,\n MissingPootleRevError, UnsupportedFiletypeError)\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef import_file(f, user=None):\n ttk = getclass(f)(f.read())\n if not hasattr(ttk, \"parseheader\"):\n raise UnsupportedFiletypeError(_(\"Unsupported filetype '%s', only PO \"\n \"files are supported at this time\\n\",\n f.name))\n header = ttk.parseheader()\n pootle_path = header.get(\"X-Pootle-Path\")\n if not pootle_path:\n raise MissingPootlePathError(_(\"File '%s' missing X-Pootle-Path \"\n \"header\\n\", f.name))\n\n rev = header.get(\"X-Pootle-Revision\")\n if not rev or not rev.isdigit():\n raise MissingPootleRevError(_(\"File '%s' missing or invalid \"\n \"X-Pootle-Revision header\\n\",\n f.name))\n rev = int(rev)\n\n try:\n store = Store.objects.get(pootle_path=pootle_path)\n except Store.DoesNotExist as e:\n raise FileImportError(_(\"Could not create '%s'. Missing \"\n \"Project/Language? (%s)\", (f.name, e)))\n\n tp = store.translation_project\n allow_add_and_obsolete = ((tp.project.checkstyle == 'terminology'\n or tp.is_template_project)\n and check_user_permission(user,\n 'administrate',\n tp.directory))\n try:\n store.update(store=ttk, user=user,\n submission_type=SubmissionTypes.UPLOAD,\n store_revision=rev,\n allow_add_and_obsolete=allow_add_and_obsolete)\n except Exception as e:\n # This should not happen!\n logger.error(\"Error importing file: %s\", str(e))\n raise FileImportError(_(\"There was an error uploading your file\"))\n\n\nclass TPTMXExporter(object):\n\n def __init__(self, context):\n self.context = context\n\n @cached_property\n def exported_revision(self):\n return revision.get(self.context.__class__)(\n self.context).get(key=\"pootle.offline.tm\")\n\n @cached_property\n def revision(self):\n return revision.get(self.context.__class__)(\n self.context.directory).get(key=\"stats\")[:10] or \"0\"\n\n def get_url(self):\n if self.exported_revision:\n relative_path = \"offline_tm/%s/%s\" % (\n self.context.language.code,\n self.get_filename(self.exported_revision)\n )\n return urljoin(settings.MEDIA_URL, relative_path)\n return None\n\n def update_exported_revision(self):\n if self.has_changes():\n revision.get(self.context.__class__)(\n self.context).set(keys=[\"pootle.offline.tm\"],\n value=self.revision)\n if \"exported_revision\" in self.__dict__:\n del self.__dict__[\"exported_revision\"]\n\n def has_changes(self):\n return self.revision != self.exported_revision\n\n def file_exists(self):\n return os.path.exists(self.abs_filepath)\n\n @property\n def last_exported_file_path(self):\n if not self.exported_revision:\n return None\n exported_filename = self.get_filename(self.exported_revision)\n return os.path.join(self.directory, exported_filename)\n\n def exported_file_exists(self):\n if self.last_exported_file_path is None:\n return False\n return os.path.exists(self.last_exported_file_path)\n\n @property\n def directory(self):\n return os.path.join(settings.MEDIA_ROOT,\n 'offline_tm',\n self.context.language.code)\n\n def get_filename(self, revision):\n return \".\".join([self.context.project.code,\n self.context.language.code, revision, 'tmx',\n 'zip'])\n\n def check_tp(self, filename):\n \"\"\"Check if filename relates to the context TP.\"\"\"\n\n return filename.startswith(\".\".join([\n self.context.project.code,\n self.context.language.code]))\n\n @property\n def filename(self):\n return self.get_filename(self.revision)\n\n @property\n def abs_filepath(self):\n return os.path.join(self.directory, self.filename)\n\n def export(self, rotate=False):\n source_language = self.context.project.source_language.code\n target_language = self.context.language.code\n\n if not os.path.exists(self.directory):\n os.makedirs(self.directory)\n\n tmxfile = tmx.tmxfile()\n for store in self.context.stores.live().iterator():\n for unit in store.units.filter(state=TRANSLATED):\n tmxfile.addtranslation(unit.source, source_language,\n unit.target, target_language,\n unit.developer_comment)\n\n bs = BytesIO()\n tmxfile.serialize(bs)\n with open(self.abs_filepath, \"wb\") as f:\n with ZipFile(f, \"w\") as zf:\n zf.writestr(self.filename.rstrip('.zip'), bs.getvalue())\n\n last_exported_filepath = self.last_exported_file_path\n self.update_exported_revision()\n\n removed = []\n if rotate:\n for fn in os.listdir(self.directory):\n # Skip files from other projects.\n if not self.check_tp(fn):\n continue\n filepath = os.path.join(self.directory, fn)\n if filepath not in [self.abs_filepath, last_exported_filepath]:\n removed.append(filepath)\n os.remove(filepath)\n\n return self.abs_filepath, removed\n", "path": "pootle/apps/import_export/utils.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport urllib\n\nfrom django import template\nfrom django.conf import settings\nfrom django.core.urlresolvers import reverse\nfrom django.utils.safestring import mark_safe\n\nfrom pootle.i18n.gettext import ugettext_lazy as _\n\n\nregister = template.Library()\n\n\[email protected]\ndef gravatar(user, size):\n return user.gravatar_url(size)\n\n\[email protected]_tag(\"user/includes/profile_score.html\")\ndef profile_score(request, profile):\n context = dict(profile=profile)\n top_lang = profile.scores.top_language\n context[\"own_profile\"] = request.user == profile.user\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n if context[\"own_profile\"]:\n score_tweet_content = _(\n \"My current score at %(pootle_title)s is %(score)s\",\n dict(pootle_title=settings.POOTLE_TITLE,\n score=profile.scores.public_score))\n context[\"score_tweet_message\"] = _(\"Tweet this!\")\n context[\"score_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n % urllib.quote_plus(score_tweet_content.encode(\"utf8\")))\n return context\n\n\[email protected]_tag(\"user/includes/profile_ranking.html\")\ndef profile_ranking(request, profile):\n context = dict(request=request, profile=profile)\n top_lang = profile.scores.top_language\n context[\"own_profile\"] = request.user == profile.user\n if top_lang and not top_lang[0] == -1 and top_lang[1]:\n context[\"ranking_text\"] = _(\n \"#%(rank)s contributor in %(language)s in the last 30 days\",\n dict(rank=top_lang[0], language=top_lang[1].name))\n if context[\"own_profile\"]:\n ranking_tweet_content = _(\n \"I am #%(rank)s contributor in %(language)s in the last 30 \"\n \"days at %(pootle_title)s!\",\n dict(rank=top_lang[0],\n language=top_lang[1].name,\n pootle_title=settings.POOTLE_TITLE))\n context[\"ranking_tweet_link\"] = (\n \"https://twitter.com/share?text=%s\"\n % urllib.quote_plus(ranking_tweet_content.encode(\"utf8\")))\n context[\"ranking_tweet_link_text\"] = _(\"Tweet this!\")\n else:\n context[\"no_ranking_text\"] = _(\"No contributions in the last 30 days\")\n return context\n\n\[email protected]_tag(\"user/includes/profile_social.html\")\ndef profile_social(profile):\n links = []\n if profile.user.website:\n links.append(\n dict(url=profile.user.website,\n icon=\"icon-user-website\",\n text=_(\"My Website\")))\n if profile.user.twitter:\n links.append(\n dict(url=profile.user.twitter_url,\n icon=\"icon-user-twitter\",\n text=\"@%s\" % profile.user.twitter))\n if profile.user.linkedin:\n links.append(\n dict(url=profile.user.linkedin,\n icon=\"icon-user-linkedin\",\n text=_(\"My LinkedIn Profile\")))\n return dict(social_media_links=links)\n\n\[email protected]_tag(\"user/includes/profile_teams.html\")\ndef profile_teams(request, profile):\n teams = profile.membership.teams_and_roles\n site_permissions = []\n if not request.user.is_anonymous and profile.user.is_superuser:\n site_permissions.append(_(\"Site administrator\"))\n for code, info in teams.items():\n info[\"url\"] = reverse(\n \"pootle-language-browse\",\n kwargs=dict(language_code=code))\n teams_title = _(\n \"%s's language teams\"\n % profile.user.display_name)\n no_teams_message = _(\n \"%s is not a member of any language teams\"\n % profile.user.display_name)\n return dict(\n anon_request=request.user.is_anonymous,\n teams=teams,\n teams_title=teams_title,\n no_teams_message=no_teams_message,\n site_permissions=site_permissions)\n\n\[email protected]_tag(\"user/includes/profile_user.html\")\ndef profile_user(request, profile):\n context = dict(request=request, profile=profile)\n context['request_user_is_manager'] = (\n request.user.has_manager_permissions())\n if profile.user.is_anonymous:\n context[\"bio\"] = _(\n \"Some translations are provided by anonymous volunteers. \"\n \"These are registered under this special meta-account.\")\n elif profile.user.is_system():\n context[\"bio\"] = _(\n \"Some translations are imported from external files. \"\n \"These are registered under this special meta-account.\")\n else:\n if request.user == profile.user:\n context[\"can_edit_profile\"] = True\n context[\"should_edit_profile\"] = (\n not profile.user.has_contact_details\n or not profile.user.bio)\n if context[\"should_edit_profile\"]:\n context[\"edit_profile_message\"] = mark_safe(\n _(\"Show others who you are, tell about yourself<br/>\"\n \"and make your public profile look gorgeous!\"))\n context[\"user_title\"] = _(\n \"You can set or change your avatar image at www.gravatar.com\")\n if profile.user.bio:\n context[\"bio\"] = profile.user.bio\n return context\n\n\[email protected]_tag(\"user/includes/profile_activity.html\")\ndef profile_activity(profile, request_lang=None):\n context = dict(profile=profile)\n if profile.user.is_meta:\n return context\n context[\"user_last_event\"] = (\n context[\"profile\"].user.last_event(locale=request_lang))\n return context\n", "path": "pootle/apps/pootle_profile/templatetags/profile_tags.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport logging\nimport os\nfrom io import BytesIO\nfrom zipfile import ZipFile\n\nfrom translate.storage import tmx\nfrom translate.storage.factory import getclass\n\nfrom django.conf import settings\nfrom django.utils.functional import cached_property\n\nfrom pootle.core.delegate import revision\nfrom pootle.core.url_helpers import urljoin\nfrom pootle.i18n.gettext import ugettext_lazy as _\nfrom pootle_app.models.permissions import check_user_permission\nfrom pootle_statistics.models import SubmissionTypes\nfrom pootle_store.constants import TRANSLATED\nfrom pootle_store.models import Store\n\nfrom .exceptions import (FileImportError, MissingPootlePathError,\n MissingPootleRevError, UnsupportedFiletypeError)\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef import_file(f, user=None):\n ttk = getclass(f)(f.read())\n if not hasattr(ttk, \"parseheader\"):\n raise UnsupportedFiletypeError(_(\"Unsupported filetype '%s', only PO \"\n \"files are supported at this time\\n\",\n f.name))\n header = ttk.parseheader()\n pootle_path = header.get(\"X-Pootle-Path\")\n if not pootle_path:\n raise MissingPootlePathError(_(\"File '%s' missing X-Pootle-Path \"\n \"header\\n\", f.name))\n\n rev = header.get(\"X-Pootle-Revision\")\n if not rev or not rev.isdigit():\n raise MissingPootleRevError(_(\"File '%s' missing or invalid \"\n \"X-Pootle-Revision header\\n\",\n f.name))\n rev = int(rev)\n\n try:\n store = Store.objects.get(pootle_path=pootle_path)\n except Store.DoesNotExist as e:\n raise FileImportError(\n _(\"Could not create '%(filename)s'. Missing \"\n \"Project/Language? (%(error)s)\",\n dict(filename=f.name, error=e)))\n\n tp = store.translation_project\n allow_add_and_obsolete = ((tp.project.checkstyle == 'terminology'\n or tp.is_template_project)\n and check_user_permission(user,\n 'administrate',\n tp.directory))\n try:\n store.update(store=ttk, user=user,\n submission_type=SubmissionTypes.UPLOAD,\n store_revision=rev,\n allow_add_and_obsolete=allow_add_and_obsolete)\n except Exception as e:\n # This should not happen!\n logger.error(\"Error importing file: %s\", str(e))\n raise FileImportError(_(\"There was an error uploading your file\"))\n\n\nclass TPTMXExporter(object):\n\n def __init__(self, context):\n self.context = context\n\n @cached_property\n def exported_revision(self):\n return revision.get(self.context.__class__)(\n self.context).get(key=\"pootle.offline.tm\")\n\n @cached_property\n def revision(self):\n return revision.get(self.context.__class__)(\n self.context.directory).get(key=\"stats\")[:10] or \"0\"\n\n def get_url(self):\n if self.exported_revision:\n relative_path = \"offline_tm/%s/%s\" % (\n self.context.language.code,\n self.get_filename(self.exported_revision)\n )\n return urljoin(settings.MEDIA_URL, relative_path)\n return None\n\n def update_exported_revision(self):\n if self.has_changes():\n revision.get(self.context.__class__)(\n self.context).set(keys=[\"pootle.offline.tm\"],\n value=self.revision)\n if \"exported_revision\" in self.__dict__:\n del self.__dict__[\"exported_revision\"]\n\n def has_changes(self):\n return self.revision != self.exported_revision\n\n def file_exists(self):\n return os.path.exists(self.abs_filepath)\n\n @property\n def last_exported_file_path(self):\n if not self.exported_revision:\n return None\n exported_filename = self.get_filename(self.exported_revision)\n return os.path.join(self.directory, exported_filename)\n\n def exported_file_exists(self):\n if self.last_exported_file_path is None:\n return False\n return os.path.exists(self.last_exported_file_path)\n\n @property\n def directory(self):\n return os.path.join(settings.MEDIA_ROOT,\n 'offline_tm',\n self.context.language.code)\n\n def get_filename(self, revision):\n return \".\".join([self.context.project.code,\n self.context.language.code, revision, 'tmx',\n 'zip'])\n\n def check_tp(self, filename):\n \"\"\"Check if filename relates to the context TP.\"\"\"\n\n return filename.startswith(\".\".join([\n self.context.project.code,\n self.context.language.code]))\n\n @property\n def filename(self):\n return self.get_filename(self.revision)\n\n @property\n def abs_filepath(self):\n return os.path.join(self.directory, self.filename)\n\n def export(self, rotate=False):\n source_language = self.context.project.source_language.code\n target_language = self.context.language.code\n\n if not os.path.exists(self.directory):\n os.makedirs(self.directory)\n\n tmxfile = tmx.tmxfile()\n for store in self.context.stores.live().iterator():\n for unit in store.units.filter(state=TRANSLATED):\n tmxfile.addtranslation(unit.source, source_language,\n unit.target, target_language,\n unit.developer_comment)\n\n bs = BytesIO()\n tmxfile.serialize(bs)\n with open(self.abs_filepath, \"wb\") as f:\n with ZipFile(f, \"w\") as zf:\n zf.writestr(self.filename.rstrip('.zip'), bs.getvalue())\n\n last_exported_filepath = self.last_exported_file_path\n self.update_exported_revision()\n\n removed = []\n if rotate:\n for fn in os.listdir(self.directory):\n # Skip files from other projects.\n if not self.check_tp(fn):\n continue\n filepath = os.path.join(self.directory, fn)\n if filepath not in [self.abs_filepath, last_exported_filepath]:\n removed.append(filepath)\n os.remove(filepath)\n\n return self.abs_filepath, removed\n", "path": "pootle/apps/import_export/utils.py"}]} | 3,974 | 693 |
gh_patches_debug_37874 | rasdani/github-patches | git_diff | microsoft__torchgeo-352 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Re-think how configs are handled in train.py
Currently configuration to `train.py` is handled with [OmegaConf](https://omegaconf.readthedocs.io/en/2.1_branch/usage.html). This made more sense when the tasks (and accompanying trainer code) were fragmented, as we could easily define per-task configuration. Now that the trainer code that we would like to include in base TorchGeo are being generalized into things like `ClassificationTask` and `SemanticSegmentationTask` _and_ it is clear that more complicated training configurations won't be supported by torchgeo proper, it might make sense to pull out the OmegaConf part, and go with a more simple `argparse` based approach. Bonus: this would also allow us to get rid of a dependency. I'm not sure how exactly the argparse approach would work in all cases but it is worth more thought!
Lightning has a few pieces of docs that can help with this:
- https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html#trainer-in-python-scripts
- https://pytorch-lightning.readthedocs.io/en/stable/common/hyperparameters.html
- https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_cli.html
Whatever we settle on here should definitely still allow passing arguments via a YAML config file. This allows reproducible benchmark experiment configurations to be saved in source control.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `train.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # Copyright (c) Microsoft Corporation. All rights reserved.
4 # Licensed under the MIT License.
5
6 """torchgeo model training script."""
7
8 import os
9 from typing import Any, Dict, Tuple, Type, cast
10
11 import pytorch_lightning as pl
12 from omegaconf import DictConfig, OmegaConf
13 from pytorch_lightning import loggers as pl_loggers
14 from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
15
16 from torchgeo.datamodules import (
17 BigEarthNetDataModule,
18 ChesapeakeCVPRDataModule,
19 COWCCountingDataModule,
20 CycloneDataModule,
21 ETCI2021DataModule,
22 EuroSATDataModule,
23 LandCoverAIDataModule,
24 NAIPChesapeakeDataModule,
25 OSCDDataModule,
26 RESISC45DataModule,
27 SEN12MSDataModule,
28 So2SatDataModule,
29 UCMercedDataModule,
30 )
31 from torchgeo.trainers import (
32 BYOLTask,
33 ClassificationTask,
34 MultiLabelClassificationTask,
35 RegressionTask,
36 SemanticSegmentationTask,
37 )
38
39 TASK_TO_MODULES_MAPPING: Dict[
40 str, Tuple[Type[pl.LightningModule], Type[pl.LightningDataModule]]
41 ] = {
42 "bigearthnet_all": (MultiLabelClassificationTask, BigEarthNetDataModule),
43 "bigearthnet_s1": (MultiLabelClassificationTask, BigEarthNetDataModule),
44 "bigearthnet_s2": (MultiLabelClassificationTask, BigEarthNetDataModule),
45 "byol": (BYOLTask, ChesapeakeCVPRDataModule),
46 "chesapeake_cvpr_5": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
47 "chesapeake_cvpr_7": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
48 "chesapeake_cvpr_prior": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
49 "cowc_counting": (RegressionTask, COWCCountingDataModule),
50 "cyclone": (RegressionTask, CycloneDataModule),
51 "eurosat": (ClassificationTask, EuroSATDataModule),
52 "etci2021": (SemanticSegmentationTask, ETCI2021DataModule),
53 "landcoverai": (SemanticSegmentationTask, LandCoverAIDataModule),
54 "naipchesapeake": (SemanticSegmentationTask, NAIPChesapeakeDataModule),
55 "oscd_all": (SemanticSegmentationTask, OSCDDataModule),
56 "oscd_rgb": (SemanticSegmentationTask, OSCDDataModule),
57 "resisc45": (ClassificationTask, RESISC45DataModule),
58 "sen12ms_all": (SemanticSegmentationTask, SEN12MSDataModule),
59 "sen12ms_s1": (SemanticSegmentationTask, SEN12MSDataModule),
60 "sen12ms_s2_all": (SemanticSegmentationTask, SEN12MSDataModule),
61 "sen12ms_s2_reduced": (SemanticSegmentationTask, SEN12MSDataModule),
62 "so2sat_supervised": (ClassificationTask, So2SatDataModule),
63 "so2sat_unsupervised": (ClassificationTask, So2SatDataModule),
64 "ucmerced": (ClassificationTask, UCMercedDataModule),
65 }
66
67
68 def set_up_omegaconf() -> DictConfig:
69 """Loads program arguments from either YAML config files or command line arguments.
70
71 This method loads defaults/a schema from "conf/defaults.yaml" as well as potential
72 arguments from the command line. If one of the command line arguments is
73 "config_file", then we additionally read arguments from that YAML file. One of the
74 config file based arguments or command line arguments must specify task.name. The
75 task.name value is used to grab a task specific defaults from its respective
76 trainer. The final configuration is given as merge(task_defaults, defaults,
77 config file, command line). The merge() works from the first argument to the last,
78 replacing existing values with newer values. Additionally, if any values are
79 merged into task_defaults without matching types, then there will be a runtime
80 error.
81
82 Returns:
83 an OmegaConf DictConfig containing all the validated program arguments
84
85 Raises:
86 FileNotFoundError: when ``config_file`` does not exist
87 ValueError: when ``task.name`` is not a valid task
88 """
89 conf = OmegaConf.load("conf/defaults.yaml")
90 command_line_conf = OmegaConf.from_cli()
91
92 if "config_file" in command_line_conf:
93 config_fn = command_line_conf.config_file
94 if not os.path.isfile(config_fn):
95 raise FileNotFoundError(f"config_file={config_fn} is not a valid file")
96
97 user_conf = OmegaConf.load(config_fn)
98 conf = OmegaConf.merge(conf, user_conf)
99
100 conf = OmegaConf.merge( # Merge in any arguments passed via the command line
101 conf, command_line_conf
102 )
103
104 # These OmegaConf structured configs enforce a schema at runtime, see:
105 # https://omegaconf.readthedocs.io/en/2.0_branch/structured_config.html#merging-with-other-configs
106 task_name = conf.experiment.task
107 task_config_fn = os.path.join("conf", "task_defaults", f"{task_name}.yaml")
108 if task_name == "test":
109 task_conf = OmegaConf.create()
110 elif os.path.exists(task_config_fn):
111 task_conf = cast(DictConfig, OmegaConf.load(task_config_fn))
112 else:
113 raise ValueError(
114 f"experiment.task={task_name} is not recognized as a valid task"
115 )
116
117 conf = OmegaConf.merge(task_conf, conf)
118 conf = cast(DictConfig, conf) # convince mypy that everything is alright
119
120 return conf
121
122
123 def main(conf: DictConfig) -> None:
124 """Main training loop."""
125 ######################################
126 # Setup output directory
127 ######################################
128
129 experiment_name = conf.experiment.name
130 task_name = conf.experiment.task
131 if os.path.isfile(conf.program.output_dir):
132 raise NotADirectoryError("`program.output_dir` must be a directory")
133 os.makedirs(conf.program.output_dir, exist_ok=True)
134
135 experiment_dir = os.path.join(conf.program.output_dir, experiment_name)
136 os.makedirs(experiment_dir, exist_ok=True)
137
138 if len(os.listdir(experiment_dir)) > 0:
139 if conf.program.overwrite:
140 print(
141 f"WARNING! The experiment directory, {experiment_dir}, already exists, "
142 + "we might overwrite data in it!"
143 )
144 else:
145 raise FileExistsError(
146 f"The experiment directory, {experiment_dir}, already exists and isn't "
147 + "empty. We don't want to overwrite any existing results, exiting..."
148 )
149
150 with open(os.path.join(experiment_dir, "experiment_config.yaml"), "w") as f:
151 OmegaConf.save(config=conf, f=f)
152
153 ######################################
154 # Choose task to run based on arguments or configuration
155 ######################################
156 # Convert the DictConfig into a dictionary so that we can pass as kwargs.
157 task_args = cast(Dict[str, Any], OmegaConf.to_object(conf.experiment.module))
158 datamodule_args = cast(
159 Dict[str, Any], OmegaConf.to_object(conf.experiment.datamodule)
160 )
161
162 datamodule: pl.LightningDataModule
163 task: pl.LightningModule
164 if task_name in TASK_TO_MODULES_MAPPING:
165 task_class, datamodule_class = TASK_TO_MODULES_MAPPING[task_name]
166 task = task_class(**task_args)
167 datamodule = datamodule_class(**datamodule_args)
168 else:
169 raise ValueError(
170 f"experiment.task={task_name} is not recognized as a valid task"
171 )
172
173 ######################################
174 # Setup trainer
175 ######################################
176 tb_logger = pl_loggers.TensorBoardLogger(conf.program.log_dir, name=experiment_name)
177
178 checkpoint_callback = ModelCheckpoint(
179 monitor="val_loss", dirpath=experiment_dir, save_top_k=1, save_last=True
180 )
181 early_stopping_callback = EarlyStopping(
182 monitor="val_loss", min_delta=0.00, patience=18
183 )
184
185 trainer_args = cast(Dict[str, Any], OmegaConf.to_object(conf.trainer))
186
187 trainer_args["callbacks"] = [checkpoint_callback, early_stopping_callback]
188 trainer_args["logger"] = tb_logger
189 trainer_args["default_root_dir"] = experiment_dir
190 trainer = pl.Trainer(**trainer_args)
191
192 if trainer_args.get("auto_lr_find"):
193 trainer.tune(model=task, datamodule=datamodule)
194
195 ######################################
196 # Run experiment
197 ######################################
198 trainer.fit(model=task, datamodule=datamodule)
199 trainer.test(model=task, datamodule=datamodule)
200
201
202 if __name__ == "__main__":
203 # Taken from https://github.com/pangeo-data/cog-best-practices
204 _rasterio_best_practices = {
205 "GDAL_DISABLE_READDIR_ON_OPEN": "EMPTY_DIR",
206 "AWS_NO_SIGN_REQUEST": "YES",
207 "GDAL_MAX_RAW_BLOCK_CACHE_SIZE": "200000000",
208 "GDAL_SWATH_SIZE": "200000000",
209 "VSI_CURL_CACHE_SIZE": "200000000",
210 }
211 os.environ.update(_rasterio_best_practices)
212
213 conf = set_up_omegaconf()
214
215 # Set random seed for reproducibility
216 # https://pytorch-lightning.readthedocs.io/en/latest/api/pytorch_lightning.utilities.seed.html#pytorch_lightning.utilities.seed.seed_everything
217 pl.seed_everything(conf.program.seed)
218
219 # Main training procedure
220 main(conf)
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/train.py b/train.py
--- a/train.py
+++ b/train.py
@@ -39,28 +39,19 @@
TASK_TO_MODULES_MAPPING: Dict[
str, Tuple[Type[pl.LightningModule], Type[pl.LightningDataModule]]
] = {
- "bigearthnet_all": (MultiLabelClassificationTask, BigEarthNetDataModule),
- "bigearthnet_s1": (MultiLabelClassificationTask, BigEarthNetDataModule),
- "bigearthnet_s2": (MultiLabelClassificationTask, BigEarthNetDataModule),
+ "bigearthnet": (MultiLabelClassificationTask, BigEarthNetDataModule),
"byol": (BYOLTask, ChesapeakeCVPRDataModule),
- "chesapeake_cvpr_5": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
- "chesapeake_cvpr_7": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
- "chesapeake_cvpr_prior": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
+ "chesapeake_cvpr": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),
"cowc_counting": (RegressionTask, COWCCountingDataModule),
"cyclone": (RegressionTask, CycloneDataModule),
"eurosat": (ClassificationTask, EuroSATDataModule),
"etci2021": (SemanticSegmentationTask, ETCI2021DataModule),
"landcoverai": (SemanticSegmentationTask, LandCoverAIDataModule),
"naipchesapeake": (SemanticSegmentationTask, NAIPChesapeakeDataModule),
- "oscd_all": (SemanticSegmentationTask, OSCDDataModule),
- "oscd_rgb": (SemanticSegmentationTask, OSCDDataModule),
+ "oscd": (SemanticSegmentationTask, OSCDDataModule),
"resisc45": (ClassificationTask, RESISC45DataModule),
- "sen12ms_all": (SemanticSegmentationTask, SEN12MSDataModule),
- "sen12ms_s1": (SemanticSegmentationTask, SEN12MSDataModule),
- "sen12ms_s2_all": (SemanticSegmentationTask, SEN12MSDataModule),
- "sen12ms_s2_reduced": (SemanticSegmentationTask, SEN12MSDataModule),
- "so2sat_supervised": (ClassificationTask, So2SatDataModule),
- "so2sat_unsupervised": (ClassificationTask, So2SatDataModule),
+ "sen12ms": (SemanticSegmentationTask, SEN12MSDataModule),
+ "so2sat": (ClassificationTask, So2SatDataModule),
"ucmerced": (ClassificationTask, UCMercedDataModule),
}
@@ -104,7 +95,7 @@
# These OmegaConf structured configs enforce a schema at runtime, see:
# https://omegaconf.readthedocs.io/en/2.0_branch/structured_config.html#merging-with-other-configs
task_name = conf.experiment.task
- task_config_fn = os.path.join("conf", "task_defaults", f"{task_name}.yaml")
+ task_config_fn = os.path.join("conf", f"{task_name}.yaml")
if task_name == "test":
task_conf = OmegaConf.create()
elif os.path.exists(task_config_fn):
| {"golden_diff": "diff --git a/train.py b/train.py\n--- a/train.py\n+++ b/train.py\n@@ -39,28 +39,19 @@\n TASK_TO_MODULES_MAPPING: Dict[\n str, Tuple[Type[pl.LightningModule], Type[pl.LightningDataModule]]\n ] = {\n- \"bigearthnet_all\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n- \"bigearthnet_s1\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n- \"bigearthnet_s2\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n+ \"bigearthnet\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n \"byol\": (BYOLTask, ChesapeakeCVPRDataModule),\n- \"chesapeake_cvpr_5\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n- \"chesapeake_cvpr_7\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n- \"chesapeake_cvpr_prior\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n+ \"chesapeake_cvpr\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n \"cowc_counting\": (RegressionTask, COWCCountingDataModule),\n \"cyclone\": (RegressionTask, CycloneDataModule),\n \"eurosat\": (ClassificationTask, EuroSATDataModule),\n \"etci2021\": (SemanticSegmentationTask, ETCI2021DataModule),\n \"landcoverai\": (SemanticSegmentationTask, LandCoverAIDataModule),\n \"naipchesapeake\": (SemanticSegmentationTask, NAIPChesapeakeDataModule),\n- \"oscd_all\": (SemanticSegmentationTask, OSCDDataModule),\n- \"oscd_rgb\": (SemanticSegmentationTask, OSCDDataModule),\n+ \"oscd\": (SemanticSegmentationTask, OSCDDataModule),\n \"resisc45\": (ClassificationTask, RESISC45DataModule),\n- \"sen12ms_all\": (SemanticSegmentationTask, SEN12MSDataModule),\n- \"sen12ms_s1\": (SemanticSegmentationTask, SEN12MSDataModule),\n- \"sen12ms_s2_all\": (SemanticSegmentationTask, SEN12MSDataModule),\n- \"sen12ms_s2_reduced\": (SemanticSegmentationTask, SEN12MSDataModule),\n- \"so2sat_supervised\": (ClassificationTask, So2SatDataModule),\n- \"so2sat_unsupervised\": (ClassificationTask, So2SatDataModule),\n+ \"sen12ms\": (SemanticSegmentationTask, SEN12MSDataModule),\n+ \"so2sat\": (ClassificationTask, So2SatDataModule),\n \"ucmerced\": (ClassificationTask, UCMercedDataModule),\n }\n \n@@ -104,7 +95,7 @@\n # These OmegaConf structured configs enforce a schema at runtime, see:\n # https://omegaconf.readthedocs.io/en/2.0_branch/structured_config.html#merging-with-other-configs\n task_name = conf.experiment.task\n- task_config_fn = os.path.join(\"conf\", \"task_defaults\", f\"{task_name}.yaml\")\n+ task_config_fn = os.path.join(\"conf\", f\"{task_name}.yaml\")\n if task_name == \"test\":\n task_conf = OmegaConf.create()\n elif os.path.exists(task_config_fn):\n", "issue": "Re-think how configs are handled in train.py\nCurrently configuration to `train.py` is handled with [OmegaConf](https://omegaconf.readthedocs.io/en/2.1_branch/usage.html). This made more sense when the tasks (and accompanying trainer code) were fragmented, as we could easily define per-task configuration. Now that the trainer code that we would like to include in base TorchGeo are being generalized into things like `ClassificationTask` and `SemanticSegmentationTask` _and_ it is clear that more complicated training configurations won't be supported by torchgeo proper, it might make sense to pull out the OmegaConf part, and go with a more simple `argparse` based approach. Bonus: this would also allow us to get rid of a dependency. I'm not sure how exactly the argparse approach would work in all cases but it is worth more thought!\r\n\r\nLightning has a few pieces of docs that can help with this:\r\n- https://pytorch-lightning.readthedocs.io/en/stable/common/trainer.html#trainer-in-python-scripts\r\n- https://pytorch-lightning.readthedocs.io/en/stable/common/hyperparameters.html\r\n- https://pytorch-lightning.readthedocs.io/en/latest/common/lightning_cli.html\r\n\r\nWhatever we settle on here should definitely still allow passing arguments via a YAML config file. This allows reproducible benchmark experiment configurations to be saved in source control.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"torchgeo model training script.\"\"\"\n\nimport os\nfrom typing import Any, Dict, Tuple, Type, cast\n\nimport pytorch_lightning as pl\nfrom omegaconf import DictConfig, OmegaConf\nfrom pytorch_lightning import loggers as pl_loggers\nfrom pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint\n\nfrom torchgeo.datamodules import (\n BigEarthNetDataModule,\n ChesapeakeCVPRDataModule,\n COWCCountingDataModule,\n CycloneDataModule,\n ETCI2021DataModule,\n EuroSATDataModule,\n LandCoverAIDataModule,\n NAIPChesapeakeDataModule,\n OSCDDataModule,\n RESISC45DataModule,\n SEN12MSDataModule,\n So2SatDataModule,\n UCMercedDataModule,\n)\nfrom torchgeo.trainers import (\n BYOLTask,\n ClassificationTask,\n MultiLabelClassificationTask,\n RegressionTask,\n SemanticSegmentationTask,\n)\n\nTASK_TO_MODULES_MAPPING: Dict[\n str, Tuple[Type[pl.LightningModule], Type[pl.LightningDataModule]]\n] = {\n \"bigearthnet_all\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n \"bigearthnet_s1\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n \"bigearthnet_s2\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n \"byol\": (BYOLTask, ChesapeakeCVPRDataModule),\n \"chesapeake_cvpr_5\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n \"chesapeake_cvpr_7\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n \"chesapeake_cvpr_prior\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n \"cowc_counting\": (RegressionTask, COWCCountingDataModule),\n \"cyclone\": (RegressionTask, CycloneDataModule),\n \"eurosat\": (ClassificationTask, EuroSATDataModule),\n \"etci2021\": (SemanticSegmentationTask, ETCI2021DataModule),\n \"landcoverai\": (SemanticSegmentationTask, LandCoverAIDataModule),\n \"naipchesapeake\": (SemanticSegmentationTask, NAIPChesapeakeDataModule),\n \"oscd_all\": (SemanticSegmentationTask, OSCDDataModule),\n \"oscd_rgb\": (SemanticSegmentationTask, OSCDDataModule),\n \"resisc45\": (ClassificationTask, RESISC45DataModule),\n \"sen12ms_all\": (SemanticSegmentationTask, SEN12MSDataModule),\n \"sen12ms_s1\": (SemanticSegmentationTask, SEN12MSDataModule),\n \"sen12ms_s2_all\": (SemanticSegmentationTask, SEN12MSDataModule),\n \"sen12ms_s2_reduced\": (SemanticSegmentationTask, SEN12MSDataModule),\n \"so2sat_supervised\": (ClassificationTask, So2SatDataModule),\n \"so2sat_unsupervised\": (ClassificationTask, So2SatDataModule),\n \"ucmerced\": (ClassificationTask, UCMercedDataModule),\n}\n\n\ndef set_up_omegaconf() -> DictConfig:\n \"\"\"Loads program arguments from either YAML config files or command line arguments.\n\n This method loads defaults/a schema from \"conf/defaults.yaml\" as well as potential\n arguments from the command line. If one of the command line arguments is\n \"config_file\", then we additionally read arguments from that YAML file. One of the\n config file based arguments or command line arguments must specify task.name. The\n task.name value is used to grab a task specific defaults from its respective\n trainer. The final configuration is given as merge(task_defaults, defaults,\n config file, command line). The merge() works from the first argument to the last,\n replacing existing values with newer values. Additionally, if any values are\n merged into task_defaults without matching types, then there will be a runtime\n error.\n\n Returns:\n an OmegaConf DictConfig containing all the validated program arguments\n\n Raises:\n FileNotFoundError: when ``config_file`` does not exist\n ValueError: when ``task.name`` is not a valid task\n \"\"\"\n conf = OmegaConf.load(\"conf/defaults.yaml\")\n command_line_conf = OmegaConf.from_cli()\n\n if \"config_file\" in command_line_conf:\n config_fn = command_line_conf.config_file\n if not os.path.isfile(config_fn):\n raise FileNotFoundError(f\"config_file={config_fn} is not a valid file\")\n\n user_conf = OmegaConf.load(config_fn)\n conf = OmegaConf.merge(conf, user_conf)\n\n conf = OmegaConf.merge( # Merge in any arguments passed via the command line\n conf, command_line_conf\n )\n\n # These OmegaConf structured configs enforce a schema at runtime, see:\n # https://omegaconf.readthedocs.io/en/2.0_branch/structured_config.html#merging-with-other-configs\n task_name = conf.experiment.task\n task_config_fn = os.path.join(\"conf\", \"task_defaults\", f\"{task_name}.yaml\")\n if task_name == \"test\":\n task_conf = OmegaConf.create()\n elif os.path.exists(task_config_fn):\n task_conf = cast(DictConfig, OmegaConf.load(task_config_fn))\n else:\n raise ValueError(\n f\"experiment.task={task_name} is not recognized as a valid task\"\n )\n\n conf = OmegaConf.merge(task_conf, conf)\n conf = cast(DictConfig, conf) # convince mypy that everything is alright\n\n return conf\n\n\ndef main(conf: DictConfig) -> None:\n \"\"\"Main training loop.\"\"\"\n ######################################\n # Setup output directory\n ######################################\n\n experiment_name = conf.experiment.name\n task_name = conf.experiment.task\n if os.path.isfile(conf.program.output_dir):\n raise NotADirectoryError(\"`program.output_dir` must be a directory\")\n os.makedirs(conf.program.output_dir, exist_ok=True)\n\n experiment_dir = os.path.join(conf.program.output_dir, experiment_name)\n os.makedirs(experiment_dir, exist_ok=True)\n\n if len(os.listdir(experiment_dir)) > 0:\n if conf.program.overwrite:\n print(\n f\"WARNING! The experiment directory, {experiment_dir}, already exists, \"\n + \"we might overwrite data in it!\"\n )\n else:\n raise FileExistsError(\n f\"The experiment directory, {experiment_dir}, already exists and isn't \"\n + \"empty. We don't want to overwrite any existing results, exiting...\"\n )\n\n with open(os.path.join(experiment_dir, \"experiment_config.yaml\"), \"w\") as f:\n OmegaConf.save(config=conf, f=f)\n\n ######################################\n # Choose task to run based on arguments or configuration\n ######################################\n # Convert the DictConfig into a dictionary so that we can pass as kwargs.\n task_args = cast(Dict[str, Any], OmegaConf.to_object(conf.experiment.module))\n datamodule_args = cast(\n Dict[str, Any], OmegaConf.to_object(conf.experiment.datamodule)\n )\n\n datamodule: pl.LightningDataModule\n task: pl.LightningModule\n if task_name in TASK_TO_MODULES_MAPPING:\n task_class, datamodule_class = TASK_TO_MODULES_MAPPING[task_name]\n task = task_class(**task_args)\n datamodule = datamodule_class(**datamodule_args)\n else:\n raise ValueError(\n f\"experiment.task={task_name} is not recognized as a valid task\"\n )\n\n ######################################\n # Setup trainer\n ######################################\n tb_logger = pl_loggers.TensorBoardLogger(conf.program.log_dir, name=experiment_name)\n\n checkpoint_callback = ModelCheckpoint(\n monitor=\"val_loss\", dirpath=experiment_dir, save_top_k=1, save_last=True\n )\n early_stopping_callback = EarlyStopping(\n monitor=\"val_loss\", min_delta=0.00, patience=18\n )\n\n trainer_args = cast(Dict[str, Any], OmegaConf.to_object(conf.trainer))\n\n trainer_args[\"callbacks\"] = [checkpoint_callback, early_stopping_callback]\n trainer_args[\"logger\"] = tb_logger\n trainer_args[\"default_root_dir\"] = experiment_dir\n trainer = pl.Trainer(**trainer_args)\n\n if trainer_args.get(\"auto_lr_find\"):\n trainer.tune(model=task, datamodule=datamodule)\n\n ######################################\n # Run experiment\n ######################################\n trainer.fit(model=task, datamodule=datamodule)\n trainer.test(model=task, datamodule=datamodule)\n\n\nif __name__ == \"__main__\":\n # Taken from https://github.com/pangeo-data/cog-best-practices\n _rasterio_best_practices = {\n \"GDAL_DISABLE_READDIR_ON_OPEN\": \"EMPTY_DIR\",\n \"AWS_NO_SIGN_REQUEST\": \"YES\",\n \"GDAL_MAX_RAW_BLOCK_CACHE_SIZE\": \"200000000\",\n \"GDAL_SWATH_SIZE\": \"200000000\",\n \"VSI_CURL_CACHE_SIZE\": \"200000000\",\n }\n os.environ.update(_rasterio_best_practices)\n\n conf = set_up_omegaconf()\n\n # Set random seed for reproducibility\n # https://pytorch-lightning.readthedocs.io/en/latest/api/pytorch_lightning.utilities.seed.html#pytorch_lightning.utilities.seed.seed_everything\n pl.seed_everything(conf.program.seed)\n\n # Main training procedure\n main(conf)\n", "path": "train.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"torchgeo model training script.\"\"\"\n\nimport os\nfrom typing import Any, Dict, Tuple, Type, cast\n\nimport pytorch_lightning as pl\nfrom omegaconf import DictConfig, OmegaConf\nfrom pytorch_lightning import loggers as pl_loggers\nfrom pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint\n\nfrom torchgeo.datamodules import (\n BigEarthNetDataModule,\n ChesapeakeCVPRDataModule,\n COWCCountingDataModule,\n CycloneDataModule,\n ETCI2021DataModule,\n EuroSATDataModule,\n LandCoverAIDataModule,\n NAIPChesapeakeDataModule,\n OSCDDataModule,\n RESISC45DataModule,\n SEN12MSDataModule,\n So2SatDataModule,\n UCMercedDataModule,\n)\nfrom torchgeo.trainers import (\n BYOLTask,\n ClassificationTask,\n MultiLabelClassificationTask,\n RegressionTask,\n SemanticSegmentationTask,\n)\n\nTASK_TO_MODULES_MAPPING: Dict[\n str, Tuple[Type[pl.LightningModule], Type[pl.LightningDataModule]]\n] = {\n \"bigearthnet\": (MultiLabelClassificationTask, BigEarthNetDataModule),\n \"byol\": (BYOLTask, ChesapeakeCVPRDataModule),\n \"chesapeake_cvpr\": (SemanticSegmentationTask, ChesapeakeCVPRDataModule),\n \"cowc_counting\": (RegressionTask, COWCCountingDataModule),\n \"cyclone\": (RegressionTask, CycloneDataModule),\n \"eurosat\": (ClassificationTask, EuroSATDataModule),\n \"etci2021\": (SemanticSegmentationTask, ETCI2021DataModule),\n \"landcoverai\": (SemanticSegmentationTask, LandCoverAIDataModule),\n \"naipchesapeake\": (SemanticSegmentationTask, NAIPChesapeakeDataModule),\n \"oscd\": (SemanticSegmentationTask, OSCDDataModule),\n \"resisc45\": (ClassificationTask, RESISC45DataModule),\n \"sen12ms\": (SemanticSegmentationTask, SEN12MSDataModule),\n \"so2sat\": (ClassificationTask, So2SatDataModule),\n \"ucmerced\": (ClassificationTask, UCMercedDataModule),\n}\n\n\ndef set_up_omegaconf() -> DictConfig:\n \"\"\"Loads program arguments from either YAML config files or command line arguments.\n\n This method loads defaults/a schema from \"conf/defaults.yaml\" as well as potential\n arguments from the command line. If one of the command line arguments is\n \"config_file\", then we additionally read arguments from that YAML file. One of the\n config file based arguments or command line arguments must specify task.name. The\n task.name value is used to grab a task specific defaults from its respective\n trainer. The final configuration is given as merge(task_defaults, defaults,\n config file, command line). The merge() works from the first argument to the last,\n replacing existing values with newer values. Additionally, if any values are\n merged into task_defaults without matching types, then there will be a runtime\n error.\n\n Returns:\n an OmegaConf DictConfig containing all the validated program arguments\n\n Raises:\n FileNotFoundError: when ``config_file`` does not exist\n ValueError: when ``task.name`` is not a valid task\n \"\"\"\n conf = OmegaConf.load(\"conf/defaults.yaml\")\n command_line_conf = OmegaConf.from_cli()\n\n if \"config_file\" in command_line_conf:\n config_fn = command_line_conf.config_file\n if not os.path.isfile(config_fn):\n raise FileNotFoundError(f\"config_file={config_fn} is not a valid file\")\n\n user_conf = OmegaConf.load(config_fn)\n conf = OmegaConf.merge(conf, user_conf)\n\n conf = OmegaConf.merge( # Merge in any arguments passed via the command line\n conf, command_line_conf\n )\n\n # These OmegaConf structured configs enforce a schema at runtime, see:\n # https://omegaconf.readthedocs.io/en/2.0_branch/structured_config.html#merging-with-other-configs\n task_name = conf.experiment.task\n task_config_fn = os.path.join(\"conf\", f\"{task_name}.yaml\")\n if task_name == \"test\":\n task_conf = OmegaConf.create()\n elif os.path.exists(task_config_fn):\n task_conf = cast(DictConfig, OmegaConf.load(task_config_fn))\n else:\n raise ValueError(\n f\"experiment.task={task_name} is not recognized as a valid task\"\n )\n\n conf = OmegaConf.merge(task_conf, conf)\n conf = cast(DictConfig, conf) # convince mypy that everything is alright\n\n return conf\n\n\ndef main(conf: DictConfig) -> None:\n \"\"\"Main training loop.\"\"\"\n ######################################\n # Setup output directory\n ######################################\n\n experiment_name = conf.experiment.name\n task_name = conf.experiment.task\n if os.path.isfile(conf.program.output_dir):\n raise NotADirectoryError(\"`program.output_dir` must be a directory\")\n os.makedirs(conf.program.output_dir, exist_ok=True)\n\n experiment_dir = os.path.join(conf.program.output_dir, experiment_name)\n os.makedirs(experiment_dir, exist_ok=True)\n\n if len(os.listdir(experiment_dir)) > 0:\n if conf.program.overwrite:\n print(\n f\"WARNING! The experiment directory, {experiment_dir}, already exists, \"\n + \"we might overwrite data in it!\"\n )\n else:\n raise FileExistsError(\n f\"The experiment directory, {experiment_dir}, already exists and isn't \"\n + \"empty. We don't want to overwrite any existing results, exiting...\"\n )\n\n with open(os.path.join(experiment_dir, \"experiment_config.yaml\"), \"w\") as f:\n OmegaConf.save(config=conf, f=f)\n\n ######################################\n # Choose task to run based on arguments or configuration\n ######################################\n # Convert the DictConfig into a dictionary so that we can pass as kwargs.\n task_args = cast(Dict[str, Any], OmegaConf.to_object(conf.experiment.module))\n datamodule_args = cast(\n Dict[str, Any], OmegaConf.to_object(conf.experiment.datamodule)\n )\n\n datamodule: pl.LightningDataModule\n task: pl.LightningModule\n if task_name in TASK_TO_MODULES_MAPPING:\n task_class, datamodule_class = TASK_TO_MODULES_MAPPING[task_name]\n task = task_class(**task_args)\n datamodule = datamodule_class(**datamodule_args)\n else:\n raise ValueError(\n f\"experiment.task={task_name} is not recognized as a valid task\"\n )\n\n ######################################\n # Setup trainer\n ######################################\n tb_logger = pl_loggers.TensorBoardLogger(conf.program.log_dir, name=experiment_name)\n\n checkpoint_callback = ModelCheckpoint(\n monitor=\"val_loss\", dirpath=experiment_dir, save_top_k=1, save_last=True\n )\n early_stopping_callback = EarlyStopping(\n monitor=\"val_loss\", min_delta=0.00, patience=18\n )\n\n trainer_args = cast(Dict[str, Any], OmegaConf.to_object(conf.trainer))\n\n trainer_args[\"callbacks\"] = [checkpoint_callback, early_stopping_callback]\n trainer_args[\"logger\"] = tb_logger\n trainer_args[\"default_root_dir\"] = experiment_dir\n trainer = pl.Trainer(**trainer_args)\n\n if trainer_args.get(\"auto_lr_find\"):\n trainer.tune(model=task, datamodule=datamodule)\n\n ######################################\n # Run experiment\n ######################################\n trainer.fit(model=task, datamodule=datamodule)\n trainer.test(model=task, datamodule=datamodule)\n\n\nif __name__ == \"__main__\":\n # Taken from https://github.com/pangeo-data/cog-best-practices\n _rasterio_best_practices = {\n \"GDAL_DISABLE_READDIR_ON_OPEN\": \"EMPTY_DIR\",\n \"AWS_NO_SIGN_REQUEST\": \"YES\",\n \"GDAL_MAX_RAW_BLOCK_CACHE_SIZE\": \"200000000\",\n \"GDAL_SWATH_SIZE\": \"200000000\",\n \"VSI_CURL_CACHE_SIZE\": \"200000000\",\n }\n os.environ.update(_rasterio_best_practices)\n\n conf = set_up_omegaconf()\n\n # Set random seed for reproducibility\n # https://pytorch-lightning.readthedocs.io/en/latest/api/pytorch_lightning.utilities.seed.html#pytorch_lightning.utilities.seed.seed_everything\n pl.seed_everything(conf.program.seed)\n\n # Main training procedure\n main(conf)\n", "path": "train.py"}]} | 3,221 | 756 |
gh_patches_debug_7093 | rasdani/github-patches | git_diff | ckan__ckan-260 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Recline does not preview datastore anymore
The new plugin does not evaluate `datastore_active`.
<!---
@huboard:{"order":247.0}
-->
Recline does not preview datastore anymore
The new plugin does not evaluate `datastore_active`.
<!---
@huboard:{"order":247.0}
-->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext/reclinepreview/plugin.py`
Content:
```
1 from logging import getLogger
2
3 import ckan.plugins as p
4 import ckan.plugins.toolkit as toolkit
5
6 log = getLogger(__name__)
7
8
9 class ReclinePreview(p.SingletonPlugin):
10 """This extension previews resources using recline
11
12 This extension implements two interfaces
13
14 - ``IConfigurer`` allows to modify the configuration
15 - ``IResourcePreview`` allows to add previews
16 """
17 p.implements(p.IConfigurer, inherit=True)
18 p.implements(p.IResourcePreview, inherit=True)
19
20 def update_config(self, config):
21 ''' Set up the resource library, public directory and
22 template directory for the preview
23 '''
24 toolkit.add_public_directory(config, 'theme/public')
25 toolkit.add_template_directory(config, 'theme/templates')
26 toolkit.add_resource('theme/public', 'ckanext-reclinepreview')
27
28 def can_preview(self, data_dict):
29 format_lower = data_dict['resource']['format'].lower()
30 return format_lower in ['csv', 'xls', 'tsv']
31
32 def preview_template(self, context, data_dict):
33 return 'recline.html'
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ckanext/reclinepreview/plugin.py b/ckanext/reclinepreview/plugin.py
--- a/ckanext/reclinepreview/plugin.py
+++ b/ckanext/reclinepreview/plugin.py
@@ -26,6 +26,9 @@
toolkit.add_resource('theme/public', 'ckanext-reclinepreview')
def can_preview(self, data_dict):
+ # if the resource is in the datastore then we can preview it with recline
+ if data_dict['resource'].get('datastore_active'):
+ return True
format_lower = data_dict['resource']['format'].lower()
return format_lower in ['csv', 'xls', 'tsv']
| {"golden_diff": "diff --git a/ckanext/reclinepreview/plugin.py b/ckanext/reclinepreview/plugin.py\n--- a/ckanext/reclinepreview/plugin.py\n+++ b/ckanext/reclinepreview/plugin.py\n@@ -26,6 +26,9 @@\n toolkit.add_resource('theme/public', 'ckanext-reclinepreview')\n \n def can_preview(self, data_dict):\n+ # if the resource is in the datastore then we can preview it with recline\n+ if data_dict['resource'].get('datastore_active'):\n+ return True\n format_lower = data_dict['resource']['format'].lower()\n return format_lower in ['csv', 'xls', 'tsv']\n", "issue": "Recline does not preview datastore anymore\nThe new plugin does not evaluate `datastore_active`.\n\n<!---\n@huboard:{\"order\":247.0}\n-->\n\nRecline does not preview datastore anymore\nThe new plugin does not evaluate `datastore_active`.\n\n<!---\n@huboard:{\"order\":247.0}\n-->\n\n", "before_files": [{"content": "from logging import getLogger\n\nimport ckan.plugins as p\nimport ckan.plugins.toolkit as toolkit\n\nlog = getLogger(__name__)\n\n\nclass ReclinePreview(p.SingletonPlugin):\n \"\"\"This extension previews resources using recline\n\n This extension implements two interfaces\n\n - ``IConfigurer`` allows to modify the configuration\n - ``IResourcePreview`` allows to add previews\n \"\"\"\n p.implements(p.IConfigurer, inherit=True)\n p.implements(p.IResourcePreview, inherit=True)\n\n def update_config(self, config):\n ''' Set up the resource library, public directory and\n template directory for the preview\n '''\n toolkit.add_public_directory(config, 'theme/public')\n toolkit.add_template_directory(config, 'theme/templates')\n toolkit.add_resource('theme/public', 'ckanext-reclinepreview')\n\n def can_preview(self, data_dict):\n format_lower = data_dict['resource']['format'].lower()\n return format_lower in ['csv', 'xls', 'tsv']\n\n def preview_template(self, context, data_dict):\n return 'recline.html'\n", "path": "ckanext/reclinepreview/plugin.py"}], "after_files": [{"content": "from logging import getLogger\n\nimport ckan.plugins as p\nimport ckan.plugins.toolkit as toolkit\n\nlog = getLogger(__name__)\n\n\nclass ReclinePreview(p.SingletonPlugin):\n \"\"\"This extension previews resources using recline\n\n This extension implements two interfaces\n\n - ``IConfigurer`` allows to modify the configuration\n - ``IResourcePreview`` allows to add previews\n \"\"\"\n p.implements(p.IConfigurer, inherit=True)\n p.implements(p.IResourcePreview, inherit=True)\n\n def update_config(self, config):\n ''' Set up the resource library, public directory and\n template directory for the preview\n '''\n toolkit.add_public_directory(config, 'theme/public')\n toolkit.add_template_directory(config, 'theme/templates')\n toolkit.add_resource('theme/public', 'ckanext-reclinepreview')\n\n def can_preview(self, data_dict):\n # if the resource is in the datastore then we can preview it with recline\n if data_dict['resource'].get('datastore_active'):\n return True\n format_lower = data_dict['resource']['format'].lower()\n return format_lower in ['csv', 'xls', 'tsv']\n\n def preview_template(self, context, data_dict):\n return 'recline.html'\n", "path": "ckanext/reclinepreview/plugin.py"}]} | 624 | 152 |
gh_patches_debug_1229 | rasdani/github-patches | git_diff | streamlit__streamlit-6348 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
experimental_get_query_params won't work before rerun
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
User can not get right query_params before rerun.
### Reproducible Code Example
```Python
import streamlit as st
st.experimental_set_query_params(param=3)
st.write(st.experimental_get_query_params())
```
### Steps To Reproduce
Run script, `{"param ": 3}` will not appear at first time until rerun script after querystring in browser already changed.
### Expected Behavior
Show `{"param ": 3}`
### Current Behavior
show empty dict
### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: 1.20.0
- Python version: 3.10.6
- Operating System: Linux
- Browser: Chrome
- Virtual environment: None
### Additional Information
In previous version `set_query_params` will set `ctx.query_string = parse.urlencode(query_params, doseq=True)` immediately.
But in 1.20, this line is removed while `get_query_params` still get if from `ctx.query_string` .
### Are you willing to submit a PR?
- [x] Yes, I am willing to submit a PR!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/commands/query_params.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import urllib.parse as parse
16 from typing import Any, Dict, List
17
18 from streamlit import util
19 from streamlit.errors import StreamlitAPIException
20 from streamlit.proto.ForwardMsg_pb2 import ForwardMsg
21 from streamlit.runtime.metrics_util import gather_metrics
22 from streamlit.runtime.scriptrunner import get_script_run_ctx
23
24 EMBED_QUERY_PARAM = "embed"
25 EMBED_OPTIONS_QUERY_PARAM = "embed_options"
26 EMBED_QUERY_PARAMS_KEYS = [EMBED_QUERY_PARAM, EMBED_OPTIONS_QUERY_PARAM]
27
28
29 @gather_metrics("experimental_get_query_params")
30 def get_query_params() -> Dict[str, List[str]]:
31 """Return the query parameters that is currently showing in the browser's URL bar.
32
33 Returns
34 -------
35 dict
36 The current query parameters as a dict. "Query parameters" are the part of the URL that comes
37 after the first "?".
38
39 Example
40 -------
41 Let's say the user's web browser is at
42 `http://localhost:8501/?show_map=True&selected=asia&selected=america`.
43 Then, you can get the query parameters using the following:
44
45 >>> import streamlit as st
46 >>>
47 >>> st.experimental_get_query_params()
48 {"show_map": ["True"], "selected": ["asia", "america"]}
49
50 Note that the values in the returned dict are *always* lists. This is
51 because we internally use Python's urllib.parse.parse_qs(), which behaves
52 this way. And this behavior makes sense when you consider that every item
53 in a query string is potentially a 1-element array.
54
55 """
56 ctx = get_script_run_ctx()
57 if ctx is None:
58 return {}
59 # Return new query params dict, but without embed, embed_options query params
60 return util.exclude_key_query_params(
61 parse.parse_qs(ctx.query_string), keys_to_exclude=EMBED_QUERY_PARAMS_KEYS
62 )
63
64
65 @gather_metrics("experimental_set_query_params")
66 def set_query_params(**query_params: Any) -> None:
67 """Set the query parameters that are shown in the browser's URL bar.
68
69 .. warning::
70 Query param `embed` cannot be set using this method.
71
72 Parameters
73 ----------
74 **query_params : dict
75 The query parameters to set, as key-value pairs.
76
77 Example
78 -------
79
80 To point the user's web browser to something like
81 "http://localhost:8501/?show_map=True&selected=asia&selected=america",
82 you would do the following:
83
84 >>> import streamlit as st
85 >>>
86 >>> st.experimental_set_query_params(
87 ... show_map=True,
88 ... selected=["asia", "america"],
89 ... )
90
91 """
92 ctx = get_script_run_ctx()
93 if ctx is None:
94 return
95
96 msg = ForwardMsg()
97 msg.page_info_changed.query_string = _ensure_no_embed_params(
98 query_params, ctx.query_string
99 )
100 ctx.enqueue(msg)
101
102
103 def _ensure_no_embed_params(
104 query_params: Dict[str, List[str]], query_string: str
105 ) -> str:
106 """Ensures there are no embed params set (raises StreamlitAPIException) if there is a try,
107 also makes sure old param values in query_string are preserved. Returns query_string : str."""
108 # Get query params dict without embed, embed_options params
109 query_params_without_embed = util.exclude_key_query_params(
110 query_params, keys_to_exclude=EMBED_QUERY_PARAMS_KEYS
111 )
112 if query_params != query_params_without_embed:
113 raise StreamlitAPIException(
114 "Query param embed and embed_options (case-insensitive) cannot be set using set_query_params method."
115 )
116
117 all_current_params = parse.parse_qs(query_string)
118 current_embed_params = parse.urlencode(
119 {
120 EMBED_QUERY_PARAM: [
121 param
122 for param in util.extract_key_query_params(
123 all_current_params, param_key=EMBED_QUERY_PARAM
124 )
125 ],
126 EMBED_OPTIONS_QUERY_PARAM: [
127 param
128 for param in util.extract_key_query_params(
129 all_current_params, param_key=EMBED_OPTIONS_QUERY_PARAM
130 )
131 ],
132 },
133 doseq=True,
134 )
135 query_string = parse.urlencode(query_params, doseq=True)
136
137 if query_string:
138 separator = "&" if current_embed_params else ""
139 return separator.join([query_string, current_embed_params])
140 return current_embed_params
141
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/streamlit/commands/query_params.py b/lib/streamlit/commands/query_params.py
--- a/lib/streamlit/commands/query_params.py
+++ b/lib/streamlit/commands/query_params.py
@@ -97,6 +97,7 @@
msg.page_info_changed.query_string = _ensure_no_embed_params(
query_params, ctx.query_string
)
+ ctx.query_string = msg.page_info_changed.query_string
ctx.enqueue(msg)
| {"golden_diff": "diff --git a/lib/streamlit/commands/query_params.py b/lib/streamlit/commands/query_params.py\n--- a/lib/streamlit/commands/query_params.py\n+++ b/lib/streamlit/commands/query_params.py\n@@ -97,6 +97,7 @@\n msg.page_info_changed.query_string = _ensure_no_embed_params(\n query_params, ctx.query_string\n )\n+ ctx.query_string = msg.page_info_changed.query_string\n ctx.enqueue(msg)\n", "issue": " experimental_get_query_params won't work before rerun \n### Checklist\n\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\n- [X] I added a very descriptive title to this issue.\n- [X] I have provided sufficient information below to help reproduce this issue.\n\n### Summary\n\nUser can not get right query_params before rerun.\n\n### Reproducible Code Example\n\n```Python\nimport streamlit as st\r\n\r\nst.experimental_set_query_params(param=3)\r\nst.write(st.experimental_get_query_params())\n```\n\n\n### Steps To Reproduce\n\nRun script, `{\"param \": 3}` will not appear at first time until rerun script after querystring in browser already changed.\n\n### Expected Behavior\n\nShow `{\"param \": 3}`\n\n### Current Behavior\n\nshow empty dict\n\n### Is this a regression?\n\n- [X] Yes, this used to work in a previous version.\n\n### Debug info\n\n- Streamlit version: 1.20.0\r\n- Python version: 3.10.6\r\n- Operating System: Linux\r\n- Browser: Chrome\r\n- Virtual environment: None\r\n\n\n### Additional Information\n\nIn previous version `set_query_params` will set `ctx.query_string = parse.urlencode(query_params, doseq=True)` immediately.\r\n\r\nBut in 1.20, this line is removed while `get_query_params` still get if from `ctx.query_string` .\n\n### Are you willing to submit a PR?\n\n- [x] Yes, I am willing to submit a PR!\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.parse as parse\nfrom typing import Any, Dict, List\n\nfrom streamlit import util\nfrom streamlit.errors import StreamlitAPIException\nfrom streamlit.proto.ForwardMsg_pb2 import ForwardMsg\nfrom streamlit.runtime.metrics_util import gather_metrics\nfrom streamlit.runtime.scriptrunner import get_script_run_ctx\n\nEMBED_QUERY_PARAM = \"embed\"\nEMBED_OPTIONS_QUERY_PARAM = \"embed_options\"\nEMBED_QUERY_PARAMS_KEYS = [EMBED_QUERY_PARAM, EMBED_OPTIONS_QUERY_PARAM]\n\n\n@gather_metrics(\"experimental_get_query_params\")\ndef get_query_params() -> Dict[str, List[str]]:\n \"\"\"Return the query parameters that is currently showing in the browser's URL bar.\n\n Returns\n -------\n dict\n The current query parameters as a dict. \"Query parameters\" are the part of the URL that comes\n after the first \"?\".\n\n Example\n -------\n Let's say the user's web browser is at\n `http://localhost:8501/?show_map=True&selected=asia&selected=america`.\n Then, you can get the query parameters using the following:\n\n >>> import streamlit as st\n >>>\n >>> st.experimental_get_query_params()\n {\"show_map\": [\"True\"], \"selected\": [\"asia\", \"america\"]}\n\n Note that the values in the returned dict are *always* lists. This is\n because we internally use Python's urllib.parse.parse_qs(), which behaves\n this way. And this behavior makes sense when you consider that every item\n in a query string is potentially a 1-element array.\n\n \"\"\"\n ctx = get_script_run_ctx()\n if ctx is None:\n return {}\n # Return new query params dict, but without embed, embed_options query params\n return util.exclude_key_query_params(\n parse.parse_qs(ctx.query_string), keys_to_exclude=EMBED_QUERY_PARAMS_KEYS\n )\n\n\n@gather_metrics(\"experimental_set_query_params\")\ndef set_query_params(**query_params: Any) -> None:\n \"\"\"Set the query parameters that are shown in the browser's URL bar.\n\n .. warning::\n Query param `embed` cannot be set using this method.\n\n Parameters\n ----------\n **query_params : dict\n The query parameters to set, as key-value pairs.\n\n Example\n -------\n\n To point the user's web browser to something like\n \"http://localhost:8501/?show_map=True&selected=asia&selected=america\",\n you would do the following:\n\n >>> import streamlit as st\n >>>\n >>> st.experimental_set_query_params(\n ... show_map=True,\n ... selected=[\"asia\", \"america\"],\n ... )\n\n \"\"\"\n ctx = get_script_run_ctx()\n if ctx is None:\n return\n\n msg = ForwardMsg()\n msg.page_info_changed.query_string = _ensure_no_embed_params(\n query_params, ctx.query_string\n )\n ctx.enqueue(msg)\n\n\ndef _ensure_no_embed_params(\n query_params: Dict[str, List[str]], query_string: str\n) -> str:\n \"\"\"Ensures there are no embed params set (raises StreamlitAPIException) if there is a try,\n also makes sure old param values in query_string are preserved. Returns query_string : str.\"\"\"\n # Get query params dict without embed, embed_options params\n query_params_without_embed = util.exclude_key_query_params(\n query_params, keys_to_exclude=EMBED_QUERY_PARAMS_KEYS\n )\n if query_params != query_params_without_embed:\n raise StreamlitAPIException(\n \"Query param embed and embed_options (case-insensitive) cannot be set using set_query_params method.\"\n )\n\n all_current_params = parse.parse_qs(query_string)\n current_embed_params = parse.urlencode(\n {\n EMBED_QUERY_PARAM: [\n param\n for param in util.extract_key_query_params(\n all_current_params, param_key=EMBED_QUERY_PARAM\n )\n ],\n EMBED_OPTIONS_QUERY_PARAM: [\n param\n for param in util.extract_key_query_params(\n all_current_params, param_key=EMBED_OPTIONS_QUERY_PARAM\n )\n ],\n },\n doseq=True,\n )\n query_string = parse.urlencode(query_params, doseq=True)\n\n if query_string:\n separator = \"&\" if current_embed_params else \"\"\n return separator.join([query_string, current_embed_params])\n return current_embed_params\n", "path": "lib/streamlit/commands/query_params.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport urllib.parse as parse\nfrom typing import Any, Dict, List\n\nfrom streamlit import util\nfrom streamlit.errors import StreamlitAPIException\nfrom streamlit.proto.ForwardMsg_pb2 import ForwardMsg\nfrom streamlit.runtime.metrics_util import gather_metrics\nfrom streamlit.runtime.scriptrunner import get_script_run_ctx\n\nEMBED_QUERY_PARAM = \"embed\"\nEMBED_OPTIONS_QUERY_PARAM = \"embed_options\"\nEMBED_QUERY_PARAMS_KEYS = [EMBED_QUERY_PARAM, EMBED_OPTIONS_QUERY_PARAM]\n\n\n@gather_metrics(\"experimental_get_query_params\")\ndef get_query_params() -> Dict[str, List[str]]:\n \"\"\"Return the query parameters that is currently showing in the browser's URL bar.\n\n Returns\n -------\n dict\n The current query parameters as a dict. \"Query parameters\" are the part of the URL that comes\n after the first \"?\".\n\n Example\n -------\n Let's say the user's web browser is at\n `http://localhost:8501/?show_map=True&selected=asia&selected=america`.\n Then, you can get the query parameters using the following:\n\n >>> import streamlit as st\n >>>\n >>> st.experimental_get_query_params()\n {\"show_map\": [\"True\"], \"selected\": [\"asia\", \"america\"]}\n\n Note that the values in the returned dict are *always* lists. This is\n because we internally use Python's urllib.parse.parse_qs(), which behaves\n this way. And this behavior makes sense when you consider that every item\n in a query string is potentially a 1-element array.\n\n \"\"\"\n ctx = get_script_run_ctx()\n if ctx is None:\n return {}\n # Return new query params dict, but without embed, embed_options query params\n return util.exclude_key_query_params(\n parse.parse_qs(ctx.query_string), keys_to_exclude=EMBED_QUERY_PARAMS_KEYS\n )\n\n\n@gather_metrics(\"experimental_set_query_params\")\ndef set_query_params(**query_params: Any) -> None:\n \"\"\"Set the query parameters that are shown in the browser's URL bar.\n\n .. warning::\n Query param `embed` cannot be set using this method.\n\n Parameters\n ----------\n **query_params : dict\n The query parameters to set, as key-value pairs.\n\n Example\n -------\n\n To point the user's web browser to something like\n \"http://localhost:8501/?show_map=True&selected=asia&selected=america\",\n you would do the following:\n\n >>> import streamlit as st\n >>>\n >>> st.experimental_set_query_params(\n ... show_map=True,\n ... selected=[\"asia\", \"america\"],\n ... )\n\n \"\"\"\n ctx = get_script_run_ctx()\n if ctx is None:\n return\n\n msg = ForwardMsg()\n msg.page_info_changed.query_string = _ensure_no_embed_params(\n query_params, ctx.query_string\n )\n ctx.query_string = msg.page_info_changed.query_string\n ctx.enqueue(msg)\n\n\ndef _ensure_no_embed_params(\n query_params: Dict[str, List[str]], query_string: str\n) -> str:\n \"\"\"Ensures there are no embed params set (raises StreamlitAPIException) if there is a try,\n also makes sure old param values in query_string are preserved. Returns query_string : str.\"\"\"\n # Get query params dict without embed, embed_options params\n query_params_without_embed = util.exclude_key_query_params(\n query_params, keys_to_exclude=EMBED_QUERY_PARAMS_KEYS\n )\n if query_params != query_params_without_embed:\n raise StreamlitAPIException(\n \"Query param embed and embed_options (case-insensitive) cannot be set using set_query_params method.\"\n )\n\n all_current_params = parse.parse_qs(query_string)\n current_embed_params = parse.urlencode(\n {\n EMBED_QUERY_PARAM: [\n param\n for param in util.extract_key_query_params(\n all_current_params, param_key=EMBED_QUERY_PARAM\n )\n ],\n EMBED_OPTIONS_QUERY_PARAM: [\n param\n for param in util.extract_key_query_params(\n all_current_params, param_key=EMBED_OPTIONS_QUERY_PARAM\n )\n ],\n },\n doseq=True,\n )\n query_string = parse.urlencode(query_params, doseq=True)\n\n if query_string:\n separator = \"&\" if current_embed_params else \"\"\n return separator.join([query_string, current_embed_params])\n return current_embed_params\n", "path": "lib/streamlit/commands/query_params.py"}]} | 1,997 | 98 |
gh_patches_debug_18458 | rasdani/github-patches | git_diff | mampfes__hacs_waste_collection_schedule-603 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
I miss one with C-Trace.de/WZV
Hello guys,
I just switched from ics to C-Trace.de. Since then, unfortunately, it no longer shows me all the bins. I'm missing the residual waste, everything else is displayed as usual. Can someone help me?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py`
Content:
```
1 import requests
2 from waste_collection_schedule import Collection # type: ignore[attr-defined]
3 from waste_collection_schedule.service.ICS import ICS
4
5 TITLE = "C-Trace"
6 DESCRIPTION = "Source for C-Trace.de."
7 URL = "https://c-trace.de/"
8 EXTRA_INFO = [
9 {
10 "title": "Bremener Stadreinigung",
11 "url": "https://www.die-bremer-stadtreinigung.de/",
12 },
13 {
14 "title": "AWB Landkreis Augsburg",
15 "url": "https://www.awb-landkreis-augsburg.de/",
16 },
17 {
18 "title": "WZV Kreis Segeberg",
19 "url": "https://www.wzv.de/",
20 },
21 ]
22 TEST_CASES = {
23 "Bremen": {"ort": "Bremen", "strasse": "Abbentorstraße", "hausnummer": 5},
24 "AugsburgLand": {
25 "ort": "Königsbrunn",
26 "strasse": "Marktplatz",
27 "hausnummer": 7,
28 "service": "augsburglandkreis",
29 },
30 }
31
32
33 BASE_URL = "https://web.c-trace.de"
34
35
36 class Source:
37 def __init__(self, ort, strasse, hausnummer, service=None):
38 # Compatibility handling for Bremen which was the first supported
39 # district and didn't require to set a service name.
40 if service is None:
41 if ort == "Bremen":
42 service = "bremenabfallkalender"
43 else:
44 raise Exception("service is missing")
45
46 self._service = service
47 self._ort = ort
48 self._strasse = strasse
49 self._hausnummer = hausnummer
50 self._ics = ICS(regex=r"Abfuhr: (.*)")
51
52 def fetch(self):
53 session = requests.session()
54
55 # get session url
56 r = session.get(
57 f"{BASE_URL}/{self._service}/Abfallkalender",
58 allow_redirects=False,
59 )
60 session_id = r.headers["location"].split("/")[
61 2
62 ] # session_id like "(S(r3bme50igdgsp2lstgxxhvs2))"
63
64 args = {
65 "Ort": self._ort,
66 "Gemeinde": self._ort,
67 "Strasse": self._strasse,
68 "Hausnr": self._hausnummer,
69 "Abfall": "|".join(str(i) for i in range(1, 99)), # return all waste types
70 }
71 r = session.get(
72 f"{BASE_URL}/{self._service}/{session_id}/abfallkalender/cal", params=args
73 )
74 r.raise_for_status()
75
76 # parse ics file
77 r.encoding = "utf-8"
78 dates = self._ics.convert(r.text)
79
80 entries = []
81 for d in dates:
82 entries.append(Collection(d[0], d[1]))
83 return entries
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py
@@ -27,6 +27,12 @@
"hausnummer": 7,
"service": "augsburglandkreis",
},
+ "WZV": {
+ "ort": "Bark",
+ "strasse": "Birkenweg",
+ "hausnummer": 1,
+ "service": "segebergwzv-abfallkalender",
+ },
}
@@ -66,7 +72,7 @@
"Gemeinde": self._ort,
"Strasse": self._strasse,
"Hausnr": self._hausnummer,
- "Abfall": "|".join(str(i) for i in range(1, 99)), # return all waste types
+ "Abfall": "|".join(str(i) for i in range(0, 99)), # return all waste types
}
r = session.get(
f"{BASE_URL}/{self._service}/{session_id}/abfallkalender/cal", params=args
| {"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py\n@@ -27,6 +27,12 @@\n \"hausnummer\": 7,\n \"service\": \"augsburglandkreis\",\n },\n+ \"WZV\": {\n+ \"ort\": \"Bark\",\n+ \"strasse\": \"Birkenweg\",\n+ \"hausnummer\": 1,\n+ \"service\": \"segebergwzv-abfallkalender\",\n+ },\n }\n \n \n@@ -66,7 +72,7 @@\n \"Gemeinde\": self._ort,\n \"Strasse\": self._strasse,\n \"Hausnr\": self._hausnummer,\n- \"Abfall\": \"|\".join(str(i) for i in range(1, 99)), # return all waste types\n+ \"Abfall\": \"|\".join(str(i) for i in range(0, 99)), # return all waste types\n }\n r = session.get(\n f\"{BASE_URL}/{self._service}/{session_id}/abfallkalender/cal\", params=args\n", "issue": "I miss one with C-Trace.de/WZV\nHello guys,\r\n\r\nI just switched from ics to C-Trace.de. Since then, unfortunately, it no longer shows me all the bins. I'm missing the residual waste, everything else is displayed as usual. Can someone help me?\r\n\r\n\n", "before_files": [{"content": "import requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"C-Trace\"\nDESCRIPTION = \"Source for C-Trace.de.\"\nURL = \"https://c-trace.de/\"\nEXTRA_INFO = [\n {\n \"title\": \"Bremener Stadreinigung\",\n \"url\": \"https://www.die-bremer-stadtreinigung.de/\",\n },\n {\n \"title\": \"AWB Landkreis Augsburg\",\n \"url\": \"https://www.awb-landkreis-augsburg.de/\",\n },\n {\n \"title\": \"WZV Kreis Segeberg\",\n \"url\": \"https://www.wzv.de/\",\n },\n]\nTEST_CASES = {\n \"Bremen\": {\"ort\": \"Bremen\", \"strasse\": \"Abbentorstra\u00dfe\", \"hausnummer\": 5},\n \"AugsburgLand\": {\n \"ort\": \"K\u00f6nigsbrunn\",\n \"strasse\": \"Marktplatz\",\n \"hausnummer\": 7,\n \"service\": \"augsburglandkreis\",\n },\n}\n\n\nBASE_URL = \"https://web.c-trace.de\"\n\n\nclass Source:\n def __init__(self, ort, strasse, hausnummer, service=None):\n # Compatibility handling for Bremen which was the first supported\n # district and didn't require to set a service name.\n if service is None:\n if ort == \"Bremen\":\n service = \"bremenabfallkalender\"\n else:\n raise Exception(\"service is missing\")\n\n self._service = service\n self._ort = ort\n self._strasse = strasse\n self._hausnummer = hausnummer\n self._ics = ICS(regex=r\"Abfuhr: (.*)\")\n\n def fetch(self):\n session = requests.session()\n\n # get session url\n r = session.get(\n f\"{BASE_URL}/{self._service}/Abfallkalender\",\n allow_redirects=False,\n )\n session_id = r.headers[\"location\"].split(\"/\")[\n 2\n ] # session_id like \"(S(r3bme50igdgsp2lstgxxhvs2))\"\n\n args = {\n \"Ort\": self._ort,\n \"Gemeinde\": self._ort,\n \"Strasse\": self._strasse,\n \"Hausnr\": self._hausnummer,\n \"Abfall\": \"|\".join(str(i) for i in range(1, 99)), # return all waste types\n }\n r = session.get(\n f\"{BASE_URL}/{self._service}/{session_id}/abfallkalender/cal\", params=args\n )\n r.raise_for_status()\n\n # parse ics file\n r.encoding = \"utf-8\"\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py"}], "after_files": [{"content": "import requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"C-Trace\"\nDESCRIPTION = \"Source for C-Trace.de.\"\nURL = \"https://c-trace.de/\"\nEXTRA_INFO = [\n {\n \"title\": \"Bremener Stadreinigung\",\n \"url\": \"https://www.die-bremer-stadtreinigung.de/\",\n },\n {\n \"title\": \"AWB Landkreis Augsburg\",\n \"url\": \"https://www.awb-landkreis-augsburg.de/\",\n },\n {\n \"title\": \"WZV Kreis Segeberg\",\n \"url\": \"https://www.wzv.de/\",\n },\n]\nTEST_CASES = {\n \"Bremen\": {\"ort\": \"Bremen\", \"strasse\": \"Abbentorstra\u00dfe\", \"hausnummer\": 5},\n \"AugsburgLand\": {\n \"ort\": \"K\u00f6nigsbrunn\",\n \"strasse\": \"Marktplatz\",\n \"hausnummer\": 7,\n \"service\": \"augsburglandkreis\",\n },\n \"WZV\": {\n \"ort\": \"Bark\",\n \"strasse\": \"Birkenweg\",\n \"hausnummer\": 1,\n \"service\": \"segebergwzv-abfallkalender\",\n },\n}\n\n\nBASE_URL = \"https://web.c-trace.de\"\n\n\nclass Source:\n def __init__(self, ort, strasse, hausnummer, service=None):\n # Compatibility handling for Bremen which was the first supported\n # district and didn't require to set a service name.\n if service is None:\n if ort == \"Bremen\":\n service = \"bremenabfallkalender\"\n else:\n raise Exception(\"service is missing\")\n\n self._service = service\n self._ort = ort\n self._strasse = strasse\n self._hausnummer = hausnummer\n self._ics = ICS(regex=r\"Abfuhr: (.*)\")\n\n def fetch(self):\n session = requests.session()\n\n # get session url\n r = session.get(\n f\"{BASE_URL}/{self._service}/Abfallkalender\",\n allow_redirects=False,\n )\n session_id = r.headers[\"location\"].split(\"/\")[\n 2\n ] # session_id like \"(S(r3bme50igdgsp2lstgxxhvs2))\"\n\n args = {\n \"Ort\": self._ort,\n \"Gemeinde\": self._ort,\n \"Strasse\": self._strasse,\n \"Hausnr\": self._hausnummer,\n \"Abfall\": \"|\".join(str(i) for i in range(0, 99)), # return all waste types\n }\n r = session.get(\n f\"{BASE_URL}/{self._service}/{session_id}/abfallkalender/cal\", params=args\n )\n r.raise_for_status()\n\n # parse ics file\n r.encoding = \"utf-8\"\n dates = self._ics.convert(r.text)\n\n entries = []\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/c_trace_de.py"}]} | 1,146 | 300 |
gh_patches_debug_24900 | rasdani/github-patches | git_diff | liberapay__liberapay.com-502 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add support for xmpp: uri in markdown syntax
When adding and XMPP uri in the following form:
`[[email protected]](xmpp:[email protected]?join)`
the uri syntax is shown raw instead of linking to the room as expected.
add support for xmpp: uri in markdown syntax
When adding and XMPP uri in the following form:
`[[email protected]](xmpp:[email protected]?join)`
the uri syntax is shown raw instead of linking to the room as expected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `liberapay/utils/markdown.py`
Content:
```
1 from markupsafe import Markup
2 import misaka as m # http://misaka.61924.nl/
3
4 def render(markdown):
5 return Markup(m.html(
6 markdown,
7 extensions=m.EXT_AUTOLINK | m.EXT_STRIKETHROUGH | m.EXT_NO_INTRA_EMPHASIS,
8 render_flags=m.HTML_SKIP_HTML | m.HTML_TOC | m.HTML_SMARTYPANTS | m.HTML_SAFELINK
9 ))
10
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/liberapay/utils/markdown.py b/liberapay/utils/markdown.py
--- a/liberapay/utils/markdown.py
+++ b/liberapay/utils/markdown.py
@@ -1,9 +1,41 @@
-from markupsafe import Markup
+from __future__ import absolute_import, division, print_function, unicode_literals
+
+import re
+
+from markupsafe import Markup, escape
import misaka as m # http://misaka.61924.nl/
+
+url_re = re.compile(r'^(https?|xmpp):')
+
+
+class CustomRenderer(m.HtmlRenderer):
+
+ def image(self, link, title='', alt=''):
+ if url_re.match(link):
+ maybe_alt = Markup(' alt="%s"') % alt if alt else ''
+ maybe_title = Markup(' title="%s"') % title if title else ''
+ return Markup('<img src="%s"%s%s />') % (link, maybe_alt, maybe_title)
+ else:
+ return escape("" % (alt, link))
+
+ def link(self, content, link, title=''):
+ if url_re.match(link):
+ maybe_title = Markup(' title="%s"') % title if title else ''
+ return Markup('<a href="%s"%s>%s</a>') % (link, maybe_title, content)
+ else:
+ return escape("[%s](%s)" % (content, link))
+
+ def autolink(self, link, is_email):
+ if url_re.match(link):
+ return Markup('<a href="%s">%s</a>') % (link, link)
+ else:
+ return escape('<%s>' % link)
+
+
+renderer = CustomRenderer(flags=m.HTML_SKIP_HTML)
+md = m.Markdown(renderer, extensions=('autolink', 'strikethrough', 'no-intra-emphasis'))
+
+
def render(markdown):
- return Markup(m.html(
- markdown,
- extensions=m.EXT_AUTOLINK | m.EXT_STRIKETHROUGH | m.EXT_NO_INTRA_EMPHASIS,
- render_flags=m.HTML_SKIP_HTML | m.HTML_TOC | m.HTML_SMARTYPANTS | m.HTML_SAFELINK
- ))
+ return Markup(md(markdown))
| {"golden_diff": "diff --git a/liberapay/utils/markdown.py b/liberapay/utils/markdown.py\n--- a/liberapay/utils/markdown.py\n+++ b/liberapay/utils/markdown.py\n@@ -1,9 +1,41 @@\n-from markupsafe import Markup\n+from __future__ import absolute_import, division, print_function, unicode_literals\n+\n+import re\n+\n+from markupsafe import Markup, escape\n import misaka as m # http://misaka.61924.nl/\n \n+\n+url_re = re.compile(r'^(https?|xmpp):')\n+\n+\n+class CustomRenderer(m.HtmlRenderer):\n+\n+ def image(self, link, title='', alt=''):\n+ if url_re.match(link):\n+ maybe_alt = Markup(' alt=\"%s\"') % alt if alt else ''\n+ maybe_title = Markup(' title=\"%s\"') % title if title else ''\n+ return Markup('<img src=\"%s\"%s%s />') % (link, maybe_alt, maybe_title)\n+ else:\n+ return escape(\"\" % (alt, link))\n+\n+ def link(self, content, link, title=''):\n+ if url_re.match(link):\n+ maybe_title = Markup(' title=\"%s\"') % title if title else ''\n+ return Markup('<a href=\"%s\"%s>%s</a>') % (link, maybe_title, content)\n+ else:\n+ return escape(\"[%s](%s)\" % (content, link))\n+\n+ def autolink(self, link, is_email):\n+ if url_re.match(link):\n+ return Markup('<a href=\"%s\">%s</a>') % (link, link)\n+ else:\n+ return escape('<%s>' % link)\n+\n+\n+renderer = CustomRenderer(flags=m.HTML_SKIP_HTML)\n+md = m.Markdown(renderer, extensions=('autolink', 'strikethrough', 'no-intra-emphasis'))\n+\n+\n def render(markdown):\n- return Markup(m.html(\n- markdown,\n- extensions=m.EXT_AUTOLINK | m.EXT_STRIKETHROUGH | m.EXT_NO_INTRA_EMPHASIS,\n- render_flags=m.HTML_SKIP_HTML | m.HTML_TOC | m.HTML_SMARTYPANTS | m.HTML_SAFELINK\n- ))\n+ return Markup(md(markdown))\n", "issue": "add support for xmpp: uri in markdown syntax\nWhen adding and XMPP uri in the following form:\r\n`[[email protected]](xmpp:[email protected]?join)`\r\nthe uri syntax is shown raw instead of linking to the room as expected.\nadd support for xmpp: uri in markdown syntax\nWhen adding and XMPP uri in the following form:\r\n`[[email protected]](xmpp:[email protected]?join)`\r\nthe uri syntax is shown raw instead of linking to the room as expected.\n", "before_files": [{"content": "from markupsafe import Markup\nimport misaka as m # http://misaka.61924.nl/\n\ndef render(markdown):\n return Markup(m.html(\n markdown,\n extensions=m.EXT_AUTOLINK | m.EXT_STRIKETHROUGH | m.EXT_NO_INTRA_EMPHASIS,\n render_flags=m.HTML_SKIP_HTML | m.HTML_TOC | m.HTML_SMARTYPANTS | m.HTML_SAFELINK\n ))\n", "path": "liberapay/utils/markdown.py"}], "after_files": [{"content": "from __future__ import absolute_import, division, print_function, unicode_literals\n\nimport re\n\nfrom markupsafe import Markup, escape\nimport misaka as m # http://misaka.61924.nl/\n\n\nurl_re = re.compile(r'^(https?|xmpp):')\n\n\nclass CustomRenderer(m.HtmlRenderer):\n\n def image(self, link, title='', alt=''):\n if url_re.match(link):\n maybe_alt = Markup(' alt=\"%s\"') % alt if alt else ''\n maybe_title = Markup(' title=\"%s\"') % title if title else ''\n return Markup('<img src=\"%s\"%s%s />') % (link, maybe_alt, maybe_title)\n else:\n return escape(\"\" % (alt, link))\n\n def link(self, content, link, title=''):\n if url_re.match(link):\n maybe_title = Markup(' title=\"%s\"') % title if title else ''\n return Markup('<a href=\"%s\"%s>%s</a>') % (link, maybe_title, content)\n else:\n return escape(\"[%s](%s)\" % (content, link))\n\n def autolink(self, link, is_email):\n if url_re.match(link):\n return Markup('<a href=\"%s\">%s</a>') % (link, link)\n else:\n return escape('<%s>' % link)\n\n\nrenderer = CustomRenderer(flags=m.HTML_SKIP_HTML)\nmd = m.Markdown(renderer, extensions=('autolink', 'strikethrough', 'no-intra-emphasis'))\n\n\ndef render(markdown):\n return Markup(md(markdown))\n", "path": "liberapay/utils/markdown.py"}]} | 497 | 512 |
gh_patches_debug_10069 | rasdani/github-patches | git_diff | mkdocs__mkdocs-276 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Multi-page documentaion does not work on Windows
Multi-page documentation did not work on Windows, possibly because of Windows usage of backward slash instead of forward slash for paths.

Should be similar to:

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/nav.py`
Content:
```
1 # coding: utf-8
2
3 """
4 Deals with generating the site-wide navigation.
5
6 This consists of building a set of interlinked page and header objects.
7 """
8
9 from mkdocs import utils
10 import posixpath
11 import os
12
13
14 def filename_to_title(filename):
15 """
16 Automatically generate a default title, given a filename.
17 """
18 if utils.is_homepage(filename):
19 return 'Home'
20
21 title = os.path.splitext(filename)[0]
22 title = title.replace('-', ' ').replace('_', ' ')
23 # Captialize if the filename was all lowercase, otherwise leave it as-is.
24 if title.lower() == title:
25 title = title.capitalize()
26 return title
27
28
29 class SiteNavigation(object):
30 def __init__(self, pages_config, use_directory_urls=True):
31 self.url_context = URLContext()
32 self.file_context = FileContext()
33 self.nav_items, self.pages = \
34 _generate_site_navigation(pages_config, self.url_context, use_directory_urls)
35 self.homepage = self.pages[0] if self.pages else None
36 self.use_directory_urls = use_directory_urls
37
38 def __str__(self):
39 return str(self.homepage) + ''.join([str(item) for item in self])
40
41 def __iter__(self):
42 return iter(self.nav_items)
43
44 def walk_pages(self):
45 """
46 Returns each page in the site in turn.
47
48 Additionally this sets the active status of the pages and headers,
49 in the site navigation, so that the rendered navbar can correctly
50 highlight the currently active page and/or header item.
51 """
52 page = self.homepage
53 page.set_active()
54 self.url_context.set_current_url(page.abs_url)
55 self.file_context.set_current_path(page.input_path)
56 yield page
57 while page.next_page:
58 page.set_active(False)
59 page = page.next_page
60 page.set_active()
61 self.url_context.set_current_url(page.abs_url)
62 self.file_context.set_current_path(page.input_path)
63 yield page
64 page.set_active(False)
65
66 @property
67 def source_files(self):
68 if not hasattr(self, '_source_files'):
69 self._source_files = set([page.input_path for page in self.pages])
70 return self._source_files
71
72
73 class URLContext(object):
74 """
75 The URLContext is used to ensure that we can generate the appropriate
76 relative URLs to other pages from any given page in the site.
77
78 We use relative URLs so that static sites can be deployed to any location
79 without having to specify what the path component on the host will be
80 if the documentation is not hosted at the root path.
81 """
82
83 def __init__(self):
84 self.base_path = '/'
85
86 def set_current_url(self, current_url):
87 self.base_path = posixpath.dirname(current_url)
88
89 def make_relative(self, url):
90 """
91 Given a URL path return it as a relative URL,
92 given the context of the current page.
93 """
94 suffix = '/' if (url.endswith('/') and len(url) > 1) else ''
95 # Workaround for bug on `posixpath.relpath()` in Python 2.6
96 if self.base_path == '/':
97 if url == '/':
98 # Workaround for static assets
99 return '.'
100 return url.lstrip('/')
101 relative_path = posixpath.relpath(url, start=self.base_path) + suffix
102
103 # Under Python 2.6, relative_path adds an extra '/' at the end.
104 return relative_path.rstrip('/')
105
106
107 class FileContext(object):
108 """
109 The FileContext is used to ensure that we can generate the appropriate
110 full path for other pages given their relative path from a particular page.
111
112 This is used when we have relative hyperlinks in the documentation, so that
113 we can ensure that they point to markdown documents that actually exist
114 in the `pages` config.
115 """
116 def __init__(self):
117 self.current_file = None
118 self.base_path = ''
119
120 def set_current_path(self, current_path):
121 self.current_file = current_path
122 self.base_path = os.path.dirname(current_path)
123
124 def make_absolute(self, path):
125 """
126 Given a relative file path return it as a POSIX-style
127 absolute filepath, given the context of the current page.
128 """
129 return posixpath.normpath(posixpath.join(self.base_path, path))
130
131
132 class Page(object):
133 def __init__(self, title, url, path, url_context):
134 self.title = title
135 self.abs_url = url
136 self.active = False
137 self.url_context = url_context
138
139 # Relative paths to the input markdown file and output html file.
140 self.input_path = path
141 self.output_path = utils.get_html_path(path)
142
143 # Links to related pages
144 self.previous_page = None
145 self.next_page = None
146 self.ancestors = []
147
148 @property
149 def url(self):
150 return self.url_context.make_relative(self.abs_url)
151
152 @property
153 def is_homepage(self):
154 return utils.is_homepage(self.input_path)
155
156 def __str__(self):
157 return self._indent_print()
158
159 def _indent_print(self, depth=0):
160 indent = ' ' * depth
161 active_marker = ' [*]' if self.active else ''
162 title = self.title if (self.title is not None) else '[blank]'
163 return '%s%s - %s%s\n' % (indent, title, self.abs_url, active_marker)
164
165 def set_active(self, active=True):
166 self.active = active
167 for ancestor in self.ancestors:
168 ancestor.active = active
169
170
171 class Header(object):
172 def __init__(self, title, children):
173 self.title, self.children = title, children
174 self.active = False
175
176 def __str__(self):
177 return self._indent_print()
178
179 def _indent_print(self, depth=0):
180 indent = ' ' * depth
181 active_marker = ' [*]' if self.active else ''
182 ret = '%s%s%s\n' % (indent, self.title, active_marker)
183 for item in self.children:
184 ret += item._indent_print(depth + 1)
185 return ret
186
187
188 def _generate_site_navigation(pages_config, url_context, use_directory_urls=True):
189 """
190 Returns a list of Page and Header instances that represent the
191 top level site navigation.
192 """
193 nav_items = []
194 pages = []
195 previous = None
196
197 for config_line in pages_config:
198 if isinstance(config_line, str):
199 path = config_line
200 title, child_title = None, None
201 elif len(config_line) in (1, 2, 3):
202 # Pad any items that don't exist with 'None'
203 padded_config = (list(config_line) + [None, None])[:3]
204 path, title, child_title = padded_config
205 else:
206 msg = (
207 "Line in 'page' config contained %d items. "
208 "Expected 1, 2 or 3 strings." % len(config_line)
209 )
210 assert False, msg
211
212 if title is None:
213 filename = path.split('/')[0]
214 title = filename_to_title(filename)
215 if child_title is None and '/' in path:
216 filename = path.split('/')[1]
217 child_title = filename_to_title(filename)
218
219 url = utils.get_url_path(path, use_directory_urls)
220
221 if not child_title:
222 # New top level page.
223 page = Page(title=title, url=url, path=path, url_context=url_context)
224 if not utils.is_homepage(path):
225 nav_items.append(page)
226 elif not nav_items or (nav_items[-1].title != title):
227 # New second level page.
228 page = Page(title=child_title, url=url, path=path, url_context=url_context)
229 header = Header(title=title, children=[page])
230 nav_items.append(header)
231 page.ancestors = [header]
232 else:
233 # Additional second level page.
234 page = Page(title=child_title, url=url, path=path, url_context=url_context)
235 header = nav_items[-1]
236 header.children.append(page)
237 page.ancestors = [header]
238
239 # Add in previous and next information.
240 if previous:
241 page.previous_page = previous
242 previous.next_page = page
243 previous = page
244
245 pages.append(page)
246
247 return (nav_items, pages)
248
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mkdocs/nav.py b/mkdocs/nav.py
--- a/mkdocs/nav.py
+++ b/mkdocs/nav.py
@@ -210,10 +210,11 @@
assert False, msg
if title is None:
- filename = path.split('/')[0]
+ filename = path.split(os.path.sep)[0]
title = filename_to_title(filename)
- if child_title is None and '/' in path:
- filename = path.split('/')[1]
+
+ if child_title is None and os.path.sep in path:
+ filename = path.split(os.path.sep)[-1]
child_title = filename_to_title(filename)
url = utils.get_url_path(path, use_directory_urls)
| {"golden_diff": "diff --git a/mkdocs/nav.py b/mkdocs/nav.py\n--- a/mkdocs/nav.py\n+++ b/mkdocs/nav.py\n@@ -210,10 +210,11 @@\n assert False, msg\n \n if title is None:\n- filename = path.split('/')[0]\n+ filename = path.split(os.path.sep)[0]\n title = filename_to_title(filename)\n- if child_title is None and '/' in path:\n- filename = path.split('/')[1]\n+\n+ if child_title is None and os.path.sep in path:\n+ filename = path.split(os.path.sep)[-1]\n child_title = filename_to_title(filename)\n \n url = utils.get_url_path(path, use_directory_urls)\n", "issue": "Multi-page documentaion does not work on Windows\nMulti-page documentation did not work on Windows, possibly because of Windows usage of backward slash instead of forward slash for paths.\n\n\n\nShould be similar to:\n\n\n\n", "before_files": [{"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the site-wide navigation.\n\nThis consists of building a set of interlinked page and header objects.\n\"\"\"\n\nfrom mkdocs import utils\nimport posixpath\nimport os\n\n\ndef filename_to_title(filename):\n \"\"\"\n Automatically generate a default title, given a filename.\n \"\"\"\n if utils.is_homepage(filename):\n return 'Home'\n\n title = os.path.splitext(filename)[0]\n title = title.replace('-', ' ').replace('_', ' ')\n # Captialize if the filename was all lowercase, otherwise leave it as-is.\n if title.lower() == title:\n title = title.capitalize()\n return title\n\n\nclass SiteNavigation(object):\n def __init__(self, pages_config, use_directory_urls=True):\n self.url_context = URLContext()\n self.file_context = FileContext()\n self.nav_items, self.pages = \\\n _generate_site_navigation(pages_config, self.url_context, use_directory_urls)\n self.homepage = self.pages[0] if self.pages else None\n self.use_directory_urls = use_directory_urls\n\n def __str__(self):\n return str(self.homepage) + ''.join([str(item) for item in self])\n\n def __iter__(self):\n return iter(self.nav_items)\n\n def walk_pages(self):\n \"\"\"\n Returns each page in the site in turn.\n\n Additionally this sets the active status of the pages and headers,\n in the site navigation, so that the rendered navbar can correctly\n highlight the currently active page and/or header item.\n \"\"\"\n page = self.homepage\n page.set_active()\n self.url_context.set_current_url(page.abs_url)\n self.file_context.set_current_path(page.input_path)\n yield page\n while page.next_page:\n page.set_active(False)\n page = page.next_page\n page.set_active()\n self.url_context.set_current_url(page.abs_url)\n self.file_context.set_current_path(page.input_path)\n yield page\n page.set_active(False)\n\n @property\n def source_files(self):\n if not hasattr(self, '_source_files'):\n self._source_files = set([page.input_path for page in self.pages])\n return self._source_files\n\n\nclass URLContext(object):\n \"\"\"\n The URLContext is used to ensure that we can generate the appropriate\n relative URLs to other pages from any given page in the site.\n\n We use relative URLs so that static sites can be deployed to any location\n without having to specify what the path component on the host will be\n if the documentation is not hosted at the root path.\n \"\"\"\n\n def __init__(self):\n self.base_path = '/'\n\n def set_current_url(self, current_url):\n self.base_path = posixpath.dirname(current_url)\n\n def make_relative(self, url):\n \"\"\"\n Given a URL path return it as a relative URL,\n given the context of the current page.\n \"\"\"\n suffix = '/' if (url.endswith('/') and len(url) > 1) else ''\n # Workaround for bug on `posixpath.relpath()` in Python 2.6\n if self.base_path == '/':\n if url == '/':\n # Workaround for static assets\n return '.'\n return url.lstrip('/')\n relative_path = posixpath.relpath(url, start=self.base_path) + suffix\n\n # Under Python 2.6, relative_path adds an extra '/' at the end.\n return relative_path.rstrip('/')\n\n\nclass FileContext(object):\n \"\"\"\n The FileContext is used to ensure that we can generate the appropriate\n full path for other pages given their relative path from a particular page.\n\n This is used when we have relative hyperlinks in the documentation, so that\n we can ensure that they point to markdown documents that actually exist\n in the `pages` config.\n \"\"\"\n def __init__(self):\n self.current_file = None\n self.base_path = ''\n\n def set_current_path(self, current_path):\n self.current_file = current_path\n self.base_path = os.path.dirname(current_path)\n\n def make_absolute(self, path):\n \"\"\"\n Given a relative file path return it as a POSIX-style\n absolute filepath, given the context of the current page.\n \"\"\"\n return posixpath.normpath(posixpath.join(self.base_path, path))\n\n\nclass Page(object):\n def __init__(self, title, url, path, url_context):\n self.title = title\n self.abs_url = url\n self.active = False\n self.url_context = url_context\n\n # Relative paths to the input markdown file and output html file.\n self.input_path = path\n self.output_path = utils.get_html_path(path)\n\n # Links to related pages\n self.previous_page = None\n self.next_page = None\n self.ancestors = []\n\n @property\n def url(self):\n return self.url_context.make_relative(self.abs_url)\n\n @property\n def is_homepage(self):\n return utils.is_homepage(self.input_path)\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n active_marker = ' [*]' if self.active else ''\n title = self.title if (self.title is not None) else '[blank]'\n return '%s%s - %s%s\\n' % (indent, title, self.abs_url, active_marker)\n\n def set_active(self, active=True):\n self.active = active\n for ancestor in self.ancestors:\n ancestor.active = active\n\n\nclass Header(object):\n def __init__(self, title, children):\n self.title, self.children = title, children\n self.active = False\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n active_marker = ' [*]' if self.active else ''\n ret = '%s%s%s\\n' % (indent, self.title, active_marker)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\ndef _generate_site_navigation(pages_config, url_context, use_directory_urls=True):\n \"\"\"\n Returns a list of Page and Header instances that represent the\n top level site navigation.\n \"\"\"\n nav_items = []\n pages = []\n previous = None\n\n for config_line in pages_config:\n if isinstance(config_line, str):\n path = config_line\n title, child_title = None, None\n elif len(config_line) in (1, 2, 3):\n # Pad any items that don't exist with 'None'\n padded_config = (list(config_line) + [None, None])[:3]\n path, title, child_title = padded_config\n else:\n msg = (\n \"Line in 'page' config contained %d items. \"\n \"Expected 1, 2 or 3 strings.\" % len(config_line)\n )\n assert False, msg\n\n if title is None:\n filename = path.split('/')[0]\n title = filename_to_title(filename)\n if child_title is None and '/' in path:\n filename = path.split('/')[1]\n child_title = filename_to_title(filename)\n\n url = utils.get_url_path(path, use_directory_urls)\n\n if not child_title:\n # New top level page.\n page = Page(title=title, url=url, path=path, url_context=url_context)\n if not utils.is_homepage(path):\n nav_items.append(page)\n elif not nav_items or (nav_items[-1].title != title):\n # New second level page.\n page = Page(title=child_title, url=url, path=path, url_context=url_context)\n header = Header(title=title, children=[page])\n nav_items.append(header)\n page.ancestors = [header]\n else:\n # Additional second level page.\n page = Page(title=child_title, url=url, path=path, url_context=url_context)\n header = nav_items[-1]\n header.children.append(page)\n page.ancestors = [header]\n\n # Add in previous and next information.\n if previous:\n page.previous_page = previous\n previous.next_page = page\n previous = page\n\n pages.append(page)\n\n return (nav_items, pages)\n", "path": "mkdocs/nav.py"}], "after_files": [{"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the site-wide navigation.\n\nThis consists of building a set of interlinked page and header objects.\n\"\"\"\n\nfrom mkdocs import utils\nimport posixpath\nimport os\n\n\ndef filename_to_title(filename):\n \"\"\"\n Automatically generate a default title, given a filename.\n \"\"\"\n if utils.is_homepage(filename):\n return 'Home'\n\n title = os.path.splitext(filename)[0]\n title = title.replace('-', ' ').replace('_', ' ')\n # Captialize if the filename was all lowercase, otherwise leave it as-is.\n if title.lower() == title:\n title = title.capitalize()\n return title\n\n\nclass SiteNavigation(object):\n def __init__(self, pages_config, use_directory_urls=True):\n self.url_context = URLContext()\n self.file_context = FileContext()\n self.nav_items, self.pages = \\\n _generate_site_navigation(pages_config, self.url_context, use_directory_urls)\n self.homepage = self.pages[0] if self.pages else None\n self.use_directory_urls = use_directory_urls\n\n def __str__(self):\n return str(self.homepage) + ''.join([str(item) for item in self])\n\n def __iter__(self):\n return iter(self.nav_items)\n\n def walk_pages(self):\n \"\"\"\n Returns each page in the site in turn.\n\n Additionally this sets the active status of the pages and headers,\n in the site navigation, so that the rendered navbar can correctly\n highlight the currently active page and/or header item.\n \"\"\"\n page = self.homepage\n page.set_active()\n self.url_context.set_current_url(page.abs_url)\n self.file_context.set_current_path(page.input_path)\n yield page\n while page.next_page:\n page.set_active(False)\n page = page.next_page\n page.set_active()\n self.url_context.set_current_url(page.abs_url)\n self.file_context.set_current_path(page.input_path)\n yield page\n page.set_active(False)\n\n @property\n def source_files(self):\n if not hasattr(self, '_source_files'):\n self._source_files = set([page.input_path for page in self.pages])\n return self._source_files\n\n\nclass URLContext(object):\n \"\"\"\n The URLContext is used to ensure that we can generate the appropriate\n relative URLs to other pages from any given page in the site.\n\n We use relative URLs so that static sites can be deployed to any location\n without having to specify what the path component on the host will be\n if the documentation is not hosted at the root path.\n \"\"\"\n\n def __init__(self):\n self.base_path = '/'\n\n def set_current_url(self, current_url):\n self.base_path = posixpath.dirname(current_url)\n\n def make_relative(self, url):\n \"\"\"\n Given a URL path return it as a relative URL,\n given the context of the current page.\n \"\"\"\n suffix = '/' if (url.endswith('/') and len(url) > 1) else ''\n # Workaround for bug on `posixpath.relpath()` in Python 2.6\n if self.base_path == '/':\n if url == '/':\n # Workaround for static assets\n return '.'\n return url.lstrip('/')\n relative_path = posixpath.relpath(url, start=self.base_path) + suffix\n\n # Under Python 2.6, relative_path adds an extra '/' at the end.\n return relative_path.rstrip('/')\n\n\nclass FileContext(object):\n \"\"\"\n The FileContext is used to ensure that we can generate the appropriate\n full path for other pages given their relative path from a particular page.\n\n This is used when we have relative hyperlinks in the documentation, so that\n we can ensure that they point to markdown documents that actually exist\n in the `pages` config.\n \"\"\"\n def __init__(self):\n self.current_file = None\n self.base_path = ''\n\n def set_current_path(self, current_path):\n self.current_file = current_path\n self.base_path = os.path.dirname(current_path)\n\n def make_absolute(self, path):\n \"\"\"\n Given a relative file path return it as a POSIX-style\n absolute filepath, given the context of the current page.\n \"\"\"\n return posixpath.normpath(posixpath.join(self.base_path, path))\n\n\nclass Page(object):\n def __init__(self, title, url, path, url_context):\n self.title = title\n self.abs_url = url\n self.active = False\n self.url_context = url_context\n\n # Relative paths to the input markdown file and output html file.\n self.input_path = path\n self.output_path = utils.get_html_path(path)\n\n # Links to related pages\n self.previous_page = None\n self.next_page = None\n self.ancestors = []\n\n @property\n def url(self):\n return self.url_context.make_relative(self.abs_url)\n\n @property\n def is_homepage(self):\n return utils.is_homepage(self.input_path)\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n active_marker = ' [*]' if self.active else ''\n title = self.title if (self.title is not None) else '[blank]'\n return '%s%s - %s%s\\n' % (indent, title, self.abs_url, active_marker)\n\n def set_active(self, active=True):\n self.active = active\n for ancestor in self.ancestors:\n ancestor.active = active\n\n\nclass Header(object):\n def __init__(self, title, children):\n self.title, self.children = title, children\n self.active = False\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n active_marker = ' [*]' if self.active else ''\n ret = '%s%s%s\\n' % (indent, self.title, active_marker)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\ndef _generate_site_navigation(pages_config, url_context, use_directory_urls=True):\n \"\"\"\n Returns a list of Page and Header instances that represent the\n top level site navigation.\n \"\"\"\n nav_items = []\n pages = []\n previous = None\n\n for config_line in pages_config:\n if isinstance(config_line, str):\n path = config_line\n title, child_title = None, None\n elif len(config_line) in (1, 2, 3):\n # Pad any items that don't exist with 'None'\n padded_config = (list(config_line) + [None, None])[:3]\n path, title, child_title = padded_config\n else:\n msg = (\n \"Line in 'page' config contained %d items. \"\n \"Expected 1, 2 or 3 strings.\" % len(config_line)\n )\n assert False, msg\n\n if title is None:\n filename = path.split(os.path.sep)[0]\n title = filename_to_title(filename)\n\n if child_title is None and os.path.sep in path:\n filename = path.split(os.path.sep)[-1]\n child_title = filename_to_title(filename)\n\n url = utils.get_url_path(path, use_directory_urls)\n\n if not child_title:\n # New top level page.\n page = Page(title=title, url=url, path=path, url_context=url_context)\n if not utils.is_homepage(path):\n nav_items.append(page)\n elif not nav_items or (nav_items[-1].title != title):\n # New second level page.\n page = Page(title=child_title, url=url, path=path, url_context=url_context)\n header = Header(title=title, children=[page])\n nav_items.append(header)\n page.ancestors = [header]\n else:\n # Additional second level page.\n page = Page(title=child_title, url=url, path=path, url_context=url_context)\n header = nav_items[-1]\n header.children.append(page)\n page.ancestors = [header]\n\n # Add in previous and next information.\n if previous:\n page.previous_page = previous\n previous.next_page = page\n previous = page\n\n pages.append(page)\n\n return (nav_items, pages)\n", "path": "mkdocs/nav.py"}]} | 2,862 | 160 |
gh_patches_debug_842 | rasdani/github-patches | git_diff | streamlit__streamlit-6377 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Streamlit logger working on root
### Summary
Upon import, Streamlit adds a new **global** log handler that dumps logs in text format. Packages should not be doing that, because it might break the logging convention of the host systems.
In our case for example, we dump logs in JSON format and push it all to our logging aggregation system. Streamlit's log message break the format and so it happens that the only service we can't debug properly is Streamlit.
### Steps to reproduce
Nothing special, logging comes out of the box.
**Expected behavior:**
Streamlit should attach its handler to a specific logger namespace (e.g. `streamlit`) instead of attaching it to the root logger.
**Actual behavior:**
Streamlit attaches a stream handler to the root logger
### Is this a regression?
That is, did this use to work the way you expected in the past?
no
### Debug info
- Streamlit version: 1.1.0
- Python version: 3.8
- Using Conda? PipEnv? PyEnv? Pex?
- OS version: Any
- Browser version: Irrelevant
---
Community voting on feature requests enables the Streamlit team to understand which features are most important to our users.
**If you'd like the Streamlit team to prioritize this feature request, please use the 👍 (thumbs up emoji) reaction in response to the initial post.**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/logger.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Logging module."""
16
17 import logging
18 import sys
19 from typing import Dict, Union
20
21 from typing_extensions import Final
22
23 DEFAULT_LOG_MESSAGE: Final = "%(asctime)s %(levelname) -7s " "%(name)s: %(message)s"
24
25 # Loggers for each name are saved here.
26 _loggers: Dict[str, logging.Logger] = {}
27
28 # The global log level is set here across all names.
29 _global_log_level = logging.INFO
30
31
32 def set_log_level(level: Union[str, int]) -> None:
33 """Set log level."""
34 logger = get_logger(__name__)
35
36 if isinstance(level, str):
37 level = level.upper()
38 if level == "CRITICAL" or level == logging.CRITICAL:
39 log_level = logging.CRITICAL
40 elif level == "ERROR" or level == logging.ERROR:
41 log_level = logging.ERROR
42 elif level == "WARNING" or level == logging.WARNING:
43 log_level = logging.WARNING
44 elif level == "INFO" or level == logging.INFO:
45 log_level = logging.INFO
46 elif level == "DEBUG" or level == logging.DEBUG:
47 log_level = logging.DEBUG
48 else:
49 msg = 'undefined log level "%s"' % level
50 logger.critical(msg)
51 sys.exit(1)
52
53 for log in _loggers.values():
54 log.setLevel(log_level)
55
56 global _global_log_level
57 _global_log_level = log_level
58
59
60 def setup_formatter(logger: logging.Logger) -> None:
61 """Set up the console formatter for a given logger."""
62 # Deregister any previous console loggers.
63 if hasattr(logger, "streamlit_console_handler"):
64 logger.removeHandler(logger.streamlit_console_handler)
65
66 logger.streamlit_console_handler = logging.StreamHandler() # type: ignore[attr-defined]
67
68 # Import here to avoid circular imports
69 from streamlit import config
70
71 if config._config_options:
72 # logger is required in ConfigOption.set_value
73 # Getting the config option before the config file has been parsed
74 # can create an infinite loop
75 message_format = config.get_option("logger.messageFormat")
76 else:
77 message_format = DEFAULT_LOG_MESSAGE
78 formatter = logging.Formatter(fmt=message_format)
79 formatter.default_msec_format = "%s.%03d"
80 logger.streamlit_console_handler.setFormatter(formatter) # type: ignore[attr-defined]
81
82 # Register the new console logger.
83 logger.addHandler(logger.streamlit_console_handler) # type: ignore[attr-defined]
84
85
86 def update_formatter() -> None:
87 for log in _loggers.values():
88 setup_formatter(log)
89
90
91 def init_tornado_logs() -> None:
92 """Set Tornado log levels.
93
94 This function does not import any Tornado code, so it's safe to call even
95 when Server is not running.
96 """
97 # http://www.tornadoweb.org/en/stable/log.html
98 for log in ("access", "application", "general"):
99 # get_logger will set the log level for the logger with the given name.
100 get_logger(f"tornado.{log}")
101
102
103 def get_logger(name: str) -> logging.Logger:
104 """Return a logger.
105
106 Parameters
107 ----------
108 name : str
109 The name of the logger to use. You should just pass in __name__.
110
111 Returns
112 -------
113 Logger
114
115 """
116 if name in _loggers.keys():
117 return _loggers[name]
118
119 if name == "root":
120 logger = logging.getLogger()
121 else:
122 logger = logging.getLogger(name)
123
124 logger.setLevel(_global_log_level)
125 logger.propagate = False
126 setup_formatter(logger)
127
128 _loggers[name] = logger
129
130 return logger
131
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/streamlit/logger.py b/lib/streamlit/logger.py
--- a/lib/streamlit/logger.py
+++ b/lib/streamlit/logger.py
@@ -117,7 +117,7 @@
return _loggers[name]
if name == "root":
- logger = logging.getLogger()
+ logger = logging.getLogger("streamlit")
else:
logger = logging.getLogger(name)
| {"golden_diff": "diff --git a/lib/streamlit/logger.py b/lib/streamlit/logger.py\n--- a/lib/streamlit/logger.py\n+++ b/lib/streamlit/logger.py\n@@ -117,7 +117,7 @@\n return _loggers[name]\n \n if name == \"root\":\n- logger = logging.getLogger()\n+ logger = logging.getLogger(\"streamlit\")\n else:\n logger = logging.getLogger(name)\n", "issue": "Streamlit logger working on root\n### Summary\r\n\r\nUpon import, Streamlit adds a new **global** log handler that dumps logs in text format. Packages should not be doing that, because it might break the logging convention of the host systems. \r\nIn our case for example, we dump logs in JSON format and push it all to our logging aggregation system. Streamlit's log message break the format and so it happens that the only service we can't debug properly is Streamlit.\r\n\r\n### Steps to reproduce\r\nNothing special, logging comes out of the box.\r\n\r\n**Expected behavior:**\r\nStreamlit should attach its handler to a specific logger namespace (e.g. `streamlit`) instead of attaching it to the root logger.\r\n\r\n**Actual behavior:**\r\n\r\nStreamlit attaches a stream handler to the root logger\r\n\r\n### Is this a regression?\r\n\r\nThat is, did this use to work the way you expected in the past?\r\nno\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.1.0\r\n- Python version: 3.8\r\n- Using Conda? PipEnv? PyEnv? Pex?\r\n- OS version: Any\r\n- Browser version: Irrelevant\r\n\r\n---\r\n\r\nCommunity voting on feature requests enables the Streamlit team to understand which features are most important to our users.\r\n\r\n**If you'd like the Streamlit team to prioritize this feature request, please use the \ud83d\udc4d (thumbs up emoji) reaction in response to the initial post.**\r\n\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Logging module.\"\"\"\n\nimport logging\nimport sys\nfrom typing import Dict, Union\n\nfrom typing_extensions import Final\n\nDEFAULT_LOG_MESSAGE: Final = \"%(asctime)s %(levelname) -7s \" \"%(name)s: %(message)s\"\n\n# Loggers for each name are saved here.\n_loggers: Dict[str, logging.Logger] = {}\n\n# The global log level is set here across all names.\n_global_log_level = logging.INFO\n\n\ndef set_log_level(level: Union[str, int]) -> None:\n \"\"\"Set log level.\"\"\"\n logger = get_logger(__name__)\n\n if isinstance(level, str):\n level = level.upper()\n if level == \"CRITICAL\" or level == logging.CRITICAL:\n log_level = logging.CRITICAL\n elif level == \"ERROR\" or level == logging.ERROR:\n log_level = logging.ERROR\n elif level == \"WARNING\" or level == logging.WARNING:\n log_level = logging.WARNING\n elif level == \"INFO\" or level == logging.INFO:\n log_level = logging.INFO\n elif level == \"DEBUG\" or level == logging.DEBUG:\n log_level = logging.DEBUG\n else:\n msg = 'undefined log level \"%s\"' % level\n logger.critical(msg)\n sys.exit(1)\n\n for log in _loggers.values():\n log.setLevel(log_level)\n\n global _global_log_level\n _global_log_level = log_level\n\n\ndef setup_formatter(logger: logging.Logger) -> None:\n \"\"\"Set up the console formatter for a given logger.\"\"\"\n # Deregister any previous console loggers.\n if hasattr(logger, \"streamlit_console_handler\"):\n logger.removeHandler(logger.streamlit_console_handler)\n\n logger.streamlit_console_handler = logging.StreamHandler() # type: ignore[attr-defined]\n\n # Import here to avoid circular imports\n from streamlit import config\n\n if config._config_options:\n # logger is required in ConfigOption.set_value\n # Getting the config option before the config file has been parsed\n # can create an infinite loop\n message_format = config.get_option(\"logger.messageFormat\")\n else:\n message_format = DEFAULT_LOG_MESSAGE\n formatter = logging.Formatter(fmt=message_format)\n formatter.default_msec_format = \"%s.%03d\"\n logger.streamlit_console_handler.setFormatter(formatter) # type: ignore[attr-defined]\n\n # Register the new console logger.\n logger.addHandler(logger.streamlit_console_handler) # type: ignore[attr-defined]\n\n\ndef update_formatter() -> None:\n for log in _loggers.values():\n setup_formatter(log)\n\n\ndef init_tornado_logs() -> None:\n \"\"\"Set Tornado log levels.\n\n This function does not import any Tornado code, so it's safe to call even\n when Server is not running.\n \"\"\"\n # http://www.tornadoweb.org/en/stable/log.html\n for log in (\"access\", \"application\", \"general\"):\n # get_logger will set the log level for the logger with the given name.\n get_logger(f\"tornado.{log}\")\n\n\ndef get_logger(name: str) -> logging.Logger:\n \"\"\"Return a logger.\n\n Parameters\n ----------\n name : str\n The name of the logger to use. You should just pass in __name__.\n\n Returns\n -------\n Logger\n\n \"\"\"\n if name in _loggers.keys():\n return _loggers[name]\n\n if name == \"root\":\n logger = logging.getLogger()\n else:\n logger = logging.getLogger(name)\n\n logger.setLevel(_global_log_level)\n logger.propagate = False\n setup_formatter(logger)\n\n _loggers[name] = logger\n\n return logger\n", "path": "lib/streamlit/logger.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Logging module.\"\"\"\n\nimport logging\nimport sys\nfrom typing import Dict, Union\n\nfrom typing_extensions import Final\n\nDEFAULT_LOG_MESSAGE: Final = \"%(asctime)s %(levelname) -7s \" \"%(name)s: %(message)s\"\n\n# Loggers for each name are saved here.\n_loggers: Dict[str, logging.Logger] = {}\n\n# The global log level is set here across all names.\n_global_log_level = logging.INFO\n\n\ndef set_log_level(level: Union[str, int]) -> None:\n \"\"\"Set log level.\"\"\"\n logger = get_logger(__name__)\n\n if isinstance(level, str):\n level = level.upper()\n if level == \"CRITICAL\" or level == logging.CRITICAL:\n log_level = logging.CRITICAL\n elif level == \"ERROR\" or level == logging.ERROR:\n log_level = logging.ERROR\n elif level == \"WARNING\" or level == logging.WARNING:\n log_level = logging.WARNING\n elif level == \"INFO\" or level == logging.INFO:\n log_level = logging.INFO\n elif level == \"DEBUG\" or level == logging.DEBUG:\n log_level = logging.DEBUG\n else:\n msg = 'undefined log level \"%s\"' % level\n logger.critical(msg)\n sys.exit(1)\n\n for log in _loggers.values():\n log.setLevel(log_level)\n\n global _global_log_level\n _global_log_level = log_level\n\n\ndef setup_formatter(logger: logging.Logger) -> None:\n \"\"\"Set up the console formatter for a given logger.\"\"\"\n # Deregister any previous console loggers.\n if hasattr(logger, \"streamlit_console_handler\"):\n logger.removeHandler(logger.streamlit_console_handler)\n\n logger.streamlit_console_handler = logging.StreamHandler() # type: ignore[attr-defined]\n\n # Import here to avoid circular imports\n from streamlit import config\n\n if config._config_options:\n # logger is required in ConfigOption.set_value\n # Getting the config option before the config file has been parsed\n # can create an infinite loop\n message_format = config.get_option(\"logger.messageFormat\")\n else:\n message_format = DEFAULT_LOG_MESSAGE\n formatter = logging.Formatter(fmt=message_format)\n formatter.default_msec_format = \"%s.%03d\"\n logger.streamlit_console_handler.setFormatter(formatter) # type: ignore[attr-defined]\n\n # Register the new console logger.\n logger.addHandler(logger.streamlit_console_handler) # type: ignore[attr-defined]\n\n\ndef update_formatter() -> None:\n for log in _loggers.values():\n setup_formatter(log)\n\n\ndef init_tornado_logs() -> None:\n \"\"\"Set Tornado log levels.\n\n This function does not import any Tornado code, so it's safe to call even\n when Server is not running.\n \"\"\"\n # http://www.tornadoweb.org/en/stable/log.html\n for log in (\"access\", \"application\", \"general\"):\n # get_logger will set the log level for the logger with the given name.\n get_logger(f\"tornado.{log}\")\n\n\ndef get_logger(name: str) -> logging.Logger:\n \"\"\"Return a logger.\n\n Parameters\n ----------\n name : str\n The name of the logger to use. You should just pass in __name__.\n\n Returns\n -------\n Logger\n\n \"\"\"\n if name in _loggers.keys():\n return _loggers[name]\n\n if name == \"root\":\n logger = logging.getLogger(\"streamlit\")\n else:\n logger = logging.getLogger(name)\n\n logger.setLevel(_global_log_level)\n logger.propagate = False\n setup_formatter(logger)\n\n _loggers[name] = logger\n\n return logger\n", "path": "lib/streamlit/logger.py"}]} | 1,784 | 88 |
gh_patches_debug_10826 | rasdani/github-patches | git_diff | hyperledger__aries-cloudagent-python-2897 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Connectionless OOB with attachments results in attribute error
As reported by @nodlesh after errors seen in AATH:
> Since approximately April 9th the AATH OOB tests have been failing. These tests have credential V1 or V2 or proof V1 or V2 attachments. There is an error that happens on the receiver/holder agent on the receive-invitation. I’m getting an internal server error. See stack trace below.
```python
2024-04-16 14:25:11,018 aiohttp.server ERROR Error handling request
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/aiohttp/web_protocol.py", line 452, in _handle_request
resp = await request_handler(request)
File "/usr/local/lib/python3.9/site-packages/aiohttp/web_app.py", line 543, in _handle
resp = await handler(request)
File "/usr/local/lib/python3.9/site-packages/aiohttp/web_middlewares.py", line 114, in impl
return await handler(request)
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py", line 181, in ready_middleware
return await handler(request)
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py", line 218, in debug_middleware
return await handler(request)
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py", line 451, in setup_context
return await task
File "/usr/local/lib/python3.9/asyncio/futures.py", line 284, in __await__
yield self # This tells Task to wait for completion.
File "/usr/local/lib/python3.9/asyncio/tasks.py", line 328, in __wakeup
future.result()
File "/usr/local/lib/python3.9/asyncio/futures.py", line 201, in result
raise self._exception
File "/usr/local/lib/python3.9/asyncio/tasks.py", line 256, in __step
result = coro.send(None)
File "/usr/local/lib/python3.9/site-packages/aiohttp_apispec/middlewares.py", line 45, in validation_middleware
return await handler(request)
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/routes.py", line 324, in invitation_receive
result = await oob_mgr.receive_invitation(
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/manager.py", line 817, in receive_invitation
await self._process_request_attach(oob_record)
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/manager.py", line 836, in _process_request_attach
await message_processor.handle_message(
File "/usr/local/lib/python3.9/site-packages/aries_cloudagent/core/oob_processor.py", line 360, in handle_message
oob_record.their_service = their_service.serialize()
AttributeError: can't set attribute
```
This is a result of changes made in 7f5eae76b1, part of #2862. The `setter` for an attribute turned into a property was omitted.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py`
Content:
```
1 """Record for out of band invitations."""
2
3 import json
4 from typing import Any, Mapping, Optional, Union
5
6 from marshmallow import fields, validate
7
8 from .....connections.models.conn_record import ConnRecord
9 from .....core.profile import ProfileSession
10 from .....messaging.decorators.service_decorator import (
11 ServiceDecorator,
12 ServiceDecoratorSchema,
13 )
14 from .....messaging.models.base_record import BaseExchangeRecord, BaseExchangeSchema
15 from .....messaging.valid import UUID4_EXAMPLE
16 from .....storage.base import BaseStorage
17 from .....storage.error import StorageNotFoundError
18 from .....storage.record import StorageRecord
19 from ..messages.invitation import InvitationMessage, InvitationMessageSchema
20
21
22 class OobRecord(BaseExchangeRecord):
23 """Represents an out of band record."""
24
25 class Meta:
26 """OobRecord metadata."""
27
28 schema_class = "OobRecordSchema"
29
30 RECORD_TYPE = "oob_record"
31 RECORD_TYPE_METADATA = ConnRecord.RECORD_TYPE_METADATA
32 RECORD_ID_NAME = "oob_id"
33 RECORD_TOPIC = "out_of_band"
34 TAG_NAMES = {
35 "invi_msg_id",
36 "attach_thread_id",
37 "our_recipient_key",
38 "connection_id",
39 "reuse_msg_id",
40 }
41
42 STATE_INITIAL = "initial"
43 STATE_PREPARE_RESPONSE = "prepare-response"
44 STATE_AWAIT_RESPONSE = "await-response"
45 STATE_NOT_ACCEPTED = "reuse-not-accepted"
46 STATE_ACCEPTED = "reuse-accepted"
47 STATE_DONE = "done"
48
49 ROLE_SENDER = "sender"
50 ROLE_RECEIVER = "receiver"
51
52 def __init__(
53 self,
54 *,
55 state: str,
56 invi_msg_id: str,
57 role: str,
58 invitation: Union[InvitationMessage, Mapping[str, Any]],
59 their_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,
60 connection_id: Optional[str] = None,
61 reuse_msg_id: Optional[str] = None,
62 oob_id: Optional[str] = None,
63 attach_thread_id: Optional[str] = None,
64 our_recipient_key: Optional[str] = None,
65 our_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,
66 multi_use: bool = False,
67 trace: bool = False,
68 **kwargs,
69 ):
70 """Initialize a new OobRecord."""
71 super().__init__(oob_id, state, trace=trace, **kwargs)
72 self._id = oob_id
73 self.state = state
74 self.invi_msg_id = invi_msg_id
75 self.role = role
76 self._invitation = InvitationMessage.serde(invitation)
77 self.connection_id = connection_id
78 self.reuse_msg_id = reuse_msg_id
79 self._their_service = ServiceDecorator.serde(their_service)
80 self._our_service = ServiceDecorator.serde(our_service)
81 self.attach_thread_id = attach_thread_id
82 self.our_recipient_key = our_recipient_key
83 self.multi_use = multi_use
84 self.trace = trace
85
86 @property
87 def oob_id(self) -> str:
88 """Accessor for the ID associated with this exchange."""
89 return self._id
90
91 @property
92 def invitation(self) -> Optional[InvitationMessage]:
93 """Accessor; get deserialized view."""
94 return None if self._invitation is None else self._invitation.de
95
96 @invitation.setter
97 def invitation(self, value):
98 """Setter; store de/serialized views."""
99 self._invitation = InvitationMessage.serde(value)
100
101 @property
102 def our_service(self) -> Optional[ServiceDecorator]:
103 """Accessor; get deserialized view."""
104 return None if self._our_service is None else self._our_service.de
105
106 @our_service.setter
107 def our_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):
108 """Setter; store de/serialized views."""
109 self._our_service = ServiceDecorator.serde(value)
110
111 @property
112 def their_service(self) -> Optional[ServiceDecorator]:
113 """Accessor; get deserialized view."""
114 return None if self._their_service is None else self._their_service.de
115
116 @property
117 def record_value(self) -> dict:
118 """Accessor for the JSON record value generated for this invitation."""
119 return {
120 **{
121 prop: getattr(self, prop)
122 for prop in (
123 "state",
124 "their_service",
125 "connection_id",
126 "role",
127 "invi_msg_id",
128 "multi_use",
129 )
130 },
131 **{
132 prop: getattr(self, f"_{prop}").ser
133 for prop in ("invitation", "our_service", "their_service")
134 if getattr(self, prop) is not None
135 },
136 }
137
138 async def delete_record(self, session: ProfileSession):
139 """Perform connection record deletion actions.
140
141 Args:
142 session (ProfileSession): session
143
144 """
145 await super().delete_record(session)
146
147 # Delete metadata
148 if self.connection_id:
149 storage = session.inject(BaseStorage)
150 await storage.delete_all_records(
151 self.RECORD_TYPE_METADATA,
152 {"connection_id": self.connection_id},
153 )
154
155 async def metadata_get(
156 self, session: ProfileSession, key: str, default: Any = None
157 ) -> Any:
158 """Retrieve arbitrary metadata associated with this connection.
159
160 Args:
161 session (ProfileSession): session used for storage
162 key (str): key identifying metadata
163 default (Any): default value to get; type should be a JSON
164 compatible value.
165
166 Returns:
167 Any: metadata stored by key
168
169 """
170 assert self.connection_id
171 storage: BaseStorage = session.inject(BaseStorage)
172 try:
173 record = await storage.find_record(
174 self.RECORD_TYPE_METADATA,
175 {"key": key, "connection_id": self.connection_id},
176 )
177 return json.loads(record.value)
178 except StorageNotFoundError:
179 return default
180
181 async def metadata_set(self, session: ProfileSession, key: str, value: Any):
182 """Set arbitrary metadata associated with this connection.
183
184 Args:
185 session (ProfileSession): session used for storage
186 key (str): key identifying metadata
187 value (Any): value to set
188 """
189 assert self.connection_id
190 value = json.dumps(value)
191 storage: BaseStorage = session.inject(BaseStorage)
192 try:
193 record = await storage.find_record(
194 self.RECORD_TYPE_METADATA,
195 {"key": key, "connection_id": self.connection_id},
196 )
197 await storage.update_record(record, value, record.tags)
198 except StorageNotFoundError:
199 record = StorageRecord(
200 self.RECORD_TYPE_METADATA,
201 value,
202 {"key": key, "connection_id": self.connection_id},
203 )
204 await storage.add_record(record)
205
206 async def metadata_delete(self, session: ProfileSession, key: str):
207 """Delete custom metadata associated with this connection.
208
209 Args:
210 session (ProfileSession): session used for storage
211 key (str): key of metadata to delete
212 """
213 assert self.connection_id
214 storage: BaseStorage = session.inject(BaseStorage)
215 try:
216 record = await storage.find_record(
217 self.RECORD_TYPE_METADATA,
218 {"key": key, "connection_id": self.connection_id},
219 )
220 await storage.delete_record(record)
221 except StorageNotFoundError as err:
222 raise KeyError(f"{key} not found in connection metadata") from err
223
224 async def metadata_get_all(self, session: ProfileSession) -> dict:
225 """Return all custom metadata associated with this connection.
226
227 Args:
228 session (ProfileSession): session used for storage
229
230 Returns:
231 dict: dictionary representation of all metadata values
232
233 """
234 assert self.connection_id
235 storage: BaseStorage = session.inject(BaseStorage)
236 records = await storage.find_all_records(
237 self.RECORD_TYPE_METADATA,
238 {"connection_id": self.connection_id},
239 )
240 return {record.tags["key"]: json.loads(record.value) for record in records}
241
242 def __eq__(self, other: Any) -> bool:
243 """Comparison between records."""
244 return super().__eq__(other)
245
246
247 class OobRecordSchema(BaseExchangeSchema):
248 """Schema to allow serialization/deserialization of invitation records."""
249
250 class Meta:
251 """OobRecordSchema metadata."""
252
253 model_class = OobRecord
254
255 oob_id = fields.Str(
256 required=True,
257 metadata={"description": "Oob record identifier", "example": UUID4_EXAMPLE},
258 )
259 state = fields.Str(
260 required=True,
261 validate=validate.OneOf(
262 OobRecord.get_attributes_by_prefix("STATE_", walk_mro=True)
263 ),
264 metadata={
265 "description": "Out of band message exchange state",
266 "example": OobRecord.STATE_AWAIT_RESPONSE,
267 },
268 )
269 invi_msg_id = fields.Str(
270 required=True,
271 metadata={
272 "description": "Invitation message identifier",
273 "example": UUID4_EXAMPLE,
274 },
275 )
276 invitation = fields.Nested(
277 InvitationMessageSchema(),
278 required=True,
279 metadata={"description": "Out of band invitation message"},
280 )
281
282 their_service = fields.Nested(ServiceDecoratorSchema(), required=False)
283
284 connection_id = fields.Str(
285 required=False,
286 metadata={
287 "description": "Connection record identifier",
288 "example": UUID4_EXAMPLE,
289 },
290 )
291
292 attach_thread_id = fields.Str(
293 required=False,
294 metadata={
295 "description": "Connection record identifier",
296 "example": UUID4_EXAMPLE,
297 },
298 )
299
300 our_recipient_key = fields.Str(
301 required=False,
302 metadata={
303 "description": "Recipient key used for oob invitation",
304 "example": UUID4_EXAMPLE,
305 },
306 )
307
308 role = fields.Str(
309 required=False,
310 validate=validate.OneOf(
311 OobRecord.get_attributes_by_prefix("ROLE_", walk_mro=False)
312 ),
313 metadata={"description": "OOB Role", "example": OobRecord.ROLE_RECEIVER},
314 )
315
316 multi_use = fields.Boolean(
317 required=False,
318 metadata={
319 "description": "Allow for multiple uses of the oobinvitation",
320 "example": True,
321 },
322 )
323
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py b/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py
--- a/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py
+++ b/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py
@@ -113,6 +113,11 @@
"""Accessor; get deserialized view."""
return None if self._their_service is None else self._their_service.de
+ @their_service.setter
+ def their_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):
+ """Setter; store de/serialized vies."""
+ self._their_service = ServiceDecorator.serde(value)
+
@property
def record_value(self) -> dict:
"""Accessor for the JSON record value generated for this invitation."""
| {"golden_diff": "diff --git a/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py b/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py\n--- a/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py\n+++ b/aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py\n@@ -113,6 +113,11 @@\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._their_service is None else self._their_service.de\n \n+ @their_service.setter\n+ def their_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):\n+ \"\"\"Setter; store de/serialized vies.\"\"\"\n+ self._their_service = ServiceDecorator.serde(value)\n+\n @property\n def record_value(self) -> dict:\n \"\"\"Accessor for the JSON record value generated for this invitation.\"\"\"\n", "issue": "Connectionless OOB with attachments results in attribute error\nAs reported by @nodlesh after errors seen in AATH:\r\n\r\n> Since approximately April 9th the AATH OOB tests have been failing. These tests have credential V1 or V2 or proof V1 or V2 attachments. There is an error that happens on the receiver/holder agent on the receive-invitation. I\u2019m getting an internal server error. See stack trace below.\r\n\r\n```python\r\n2024-04-16 14:25:11,018 aiohttp.server ERROR Error handling request\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/aiohttp/web_protocol.py\", line 452, in _handle_request\r\n resp = await request_handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aiohttp/web_app.py\", line 543, in _handle\r\n resp = await handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aiohttp/web_middlewares.py\", line 114, in impl\r\n return await handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py\", line 181, in ready_middleware\r\n return await handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py\", line 218, in debug_middleware\r\n return await handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/admin/server.py\", line 451, in setup_context\r\n return await task\r\n File \"/usr/local/lib/python3.9/asyncio/futures.py\", line 284, in __await__\r\n yield self # This tells Task to wait for completion.\r\n File \"/usr/local/lib/python3.9/asyncio/tasks.py\", line 328, in __wakeup\r\n future.result()\r\n File \"/usr/local/lib/python3.9/asyncio/futures.py\", line 201, in result\r\n raise self._exception\r\n File \"/usr/local/lib/python3.9/asyncio/tasks.py\", line 256, in __step\r\n result = coro.send(None)\r\n File \"/usr/local/lib/python3.9/site-packages/aiohttp_apispec/middlewares.py\", line 45, in validation_middleware\r\n return await handler(request)\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/routes.py\", line 324, in invitation_receive\r\n result = await oob_mgr.receive_invitation(\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/manager.py\", line 817, in receive_invitation\r\n await self._process_request_attach(oob_record)\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/protocols/out_of_band/v1_0/manager.py\", line 836, in _process_request_attach\r\n await message_processor.handle_message(\r\n File \"/usr/local/lib/python3.9/site-packages/aries_cloudagent/core/oob_processor.py\", line 360, in handle_message\r\n oob_record.their_service = their_service.serialize()\r\nAttributeError: can't set attribute\r\n```\r\n\r\nThis is a result of changes made in 7f5eae76b1, part of #2862. The `setter` for an attribute turned into a property was omitted.\n", "before_files": [{"content": "\"\"\"Record for out of band invitations.\"\"\"\n\nimport json\nfrom typing import Any, Mapping, Optional, Union\n\nfrom marshmallow import fields, validate\n\nfrom .....connections.models.conn_record import ConnRecord\nfrom .....core.profile import ProfileSession\nfrom .....messaging.decorators.service_decorator import (\n ServiceDecorator,\n ServiceDecoratorSchema,\n)\nfrom .....messaging.models.base_record import BaseExchangeRecord, BaseExchangeSchema\nfrom .....messaging.valid import UUID4_EXAMPLE\nfrom .....storage.base import BaseStorage\nfrom .....storage.error import StorageNotFoundError\nfrom .....storage.record import StorageRecord\nfrom ..messages.invitation import InvitationMessage, InvitationMessageSchema\n\n\nclass OobRecord(BaseExchangeRecord):\n \"\"\"Represents an out of band record.\"\"\"\n\n class Meta:\n \"\"\"OobRecord metadata.\"\"\"\n\n schema_class = \"OobRecordSchema\"\n\n RECORD_TYPE = \"oob_record\"\n RECORD_TYPE_METADATA = ConnRecord.RECORD_TYPE_METADATA\n RECORD_ID_NAME = \"oob_id\"\n RECORD_TOPIC = \"out_of_band\"\n TAG_NAMES = {\n \"invi_msg_id\",\n \"attach_thread_id\",\n \"our_recipient_key\",\n \"connection_id\",\n \"reuse_msg_id\",\n }\n\n STATE_INITIAL = \"initial\"\n STATE_PREPARE_RESPONSE = \"prepare-response\"\n STATE_AWAIT_RESPONSE = \"await-response\"\n STATE_NOT_ACCEPTED = \"reuse-not-accepted\"\n STATE_ACCEPTED = \"reuse-accepted\"\n STATE_DONE = \"done\"\n\n ROLE_SENDER = \"sender\"\n ROLE_RECEIVER = \"receiver\"\n\n def __init__(\n self,\n *,\n state: str,\n invi_msg_id: str,\n role: str,\n invitation: Union[InvitationMessage, Mapping[str, Any]],\n their_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,\n connection_id: Optional[str] = None,\n reuse_msg_id: Optional[str] = None,\n oob_id: Optional[str] = None,\n attach_thread_id: Optional[str] = None,\n our_recipient_key: Optional[str] = None,\n our_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,\n multi_use: bool = False,\n trace: bool = False,\n **kwargs,\n ):\n \"\"\"Initialize a new OobRecord.\"\"\"\n super().__init__(oob_id, state, trace=trace, **kwargs)\n self._id = oob_id\n self.state = state\n self.invi_msg_id = invi_msg_id\n self.role = role\n self._invitation = InvitationMessage.serde(invitation)\n self.connection_id = connection_id\n self.reuse_msg_id = reuse_msg_id\n self._their_service = ServiceDecorator.serde(their_service)\n self._our_service = ServiceDecorator.serde(our_service)\n self.attach_thread_id = attach_thread_id\n self.our_recipient_key = our_recipient_key\n self.multi_use = multi_use\n self.trace = trace\n\n @property\n def oob_id(self) -> str:\n \"\"\"Accessor for the ID associated with this exchange.\"\"\"\n return self._id\n\n @property\n def invitation(self) -> Optional[InvitationMessage]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._invitation is None else self._invitation.de\n\n @invitation.setter\n def invitation(self, value):\n \"\"\"Setter; store de/serialized views.\"\"\"\n self._invitation = InvitationMessage.serde(value)\n\n @property\n def our_service(self) -> Optional[ServiceDecorator]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._our_service is None else self._our_service.de\n\n @our_service.setter\n def our_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):\n \"\"\"Setter; store de/serialized views.\"\"\"\n self._our_service = ServiceDecorator.serde(value)\n\n @property\n def their_service(self) -> Optional[ServiceDecorator]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._their_service is None else self._their_service.de\n\n @property\n def record_value(self) -> dict:\n \"\"\"Accessor for the JSON record value generated for this invitation.\"\"\"\n return {\n **{\n prop: getattr(self, prop)\n for prop in (\n \"state\",\n \"their_service\",\n \"connection_id\",\n \"role\",\n \"invi_msg_id\",\n \"multi_use\",\n )\n },\n **{\n prop: getattr(self, f\"_{prop}\").ser\n for prop in (\"invitation\", \"our_service\", \"their_service\")\n if getattr(self, prop) is not None\n },\n }\n\n async def delete_record(self, session: ProfileSession):\n \"\"\"Perform connection record deletion actions.\n\n Args:\n session (ProfileSession): session\n\n \"\"\"\n await super().delete_record(session)\n\n # Delete metadata\n if self.connection_id:\n storage = session.inject(BaseStorage)\n await storage.delete_all_records(\n self.RECORD_TYPE_METADATA,\n {\"connection_id\": self.connection_id},\n )\n\n async def metadata_get(\n self, session: ProfileSession, key: str, default: Any = None\n ) -> Any:\n \"\"\"Retrieve arbitrary metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key identifying metadata\n default (Any): default value to get; type should be a JSON\n compatible value.\n\n Returns:\n Any: metadata stored by key\n\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n return json.loads(record.value)\n except StorageNotFoundError:\n return default\n\n async def metadata_set(self, session: ProfileSession, key: str, value: Any):\n \"\"\"Set arbitrary metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key identifying metadata\n value (Any): value to set\n \"\"\"\n assert self.connection_id\n value = json.dumps(value)\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.update_record(record, value, record.tags)\n except StorageNotFoundError:\n record = StorageRecord(\n self.RECORD_TYPE_METADATA,\n value,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.add_record(record)\n\n async def metadata_delete(self, session: ProfileSession, key: str):\n \"\"\"Delete custom metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key of metadata to delete\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.delete_record(record)\n except StorageNotFoundError as err:\n raise KeyError(f\"{key} not found in connection metadata\") from err\n\n async def metadata_get_all(self, session: ProfileSession) -> dict:\n \"\"\"Return all custom metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n\n Returns:\n dict: dictionary representation of all metadata values\n\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n records = await storage.find_all_records(\n self.RECORD_TYPE_METADATA,\n {\"connection_id\": self.connection_id},\n )\n return {record.tags[\"key\"]: json.loads(record.value) for record in records}\n\n def __eq__(self, other: Any) -> bool:\n \"\"\"Comparison between records.\"\"\"\n return super().__eq__(other)\n\n\nclass OobRecordSchema(BaseExchangeSchema):\n \"\"\"Schema to allow serialization/deserialization of invitation records.\"\"\"\n\n class Meta:\n \"\"\"OobRecordSchema metadata.\"\"\"\n\n model_class = OobRecord\n\n oob_id = fields.Str(\n required=True,\n metadata={\"description\": \"Oob record identifier\", \"example\": UUID4_EXAMPLE},\n )\n state = fields.Str(\n required=True,\n validate=validate.OneOf(\n OobRecord.get_attributes_by_prefix(\"STATE_\", walk_mro=True)\n ),\n metadata={\n \"description\": \"Out of band message exchange state\",\n \"example\": OobRecord.STATE_AWAIT_RESPONSE,\n },\n )\n invi_msg_id = fields.Str(\n required=True,\n metadata={\n \"description\": \"Invitation message identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n invitation = fields.Nested(\n InvitationMessageSchema(),\n required=True,\n metadata={\"description\": \"Out of band invitation message\"},\n )\n\n their_service = fields.Nested(ServiceDecoratorSchema(), required=False)\n\n connection_id = fields.Str(\n required=False,\n metadata={\n \"description\": \"Connection record identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n attach_thread_id = fields.Str(\n required=False,\n metadata={\n \"description\": \"Connection record identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n our_recipient_key = fields.Str(\n required=False,\n metadata={\n \"description\": \"Recipient key used for oob invitation\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n role = fields.Str(\n required=False,\n validate=validate.OneOf(\n OobRecord.get_attributes_by_prefix(\"ROLE_\", walk_mro=False)\n ),\n metadata={\"description\": \"OOB Role\", \"example\": OobRecord.ROLE_RECEIVER},\n )\n\n multi_use = fields.Boolean(\n required=False,\n metadata={\n \"description\": \"Allow for multiple uses of the oobinvitation\",\n \"example\": True,\n },\n )\n", "path": "aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py"}], "after_files": [{"content": "\"\"\"Record for out of band invitations.\"\"\"\n\nimport json\nfrom typing import Any, Mapping, Optional, Union\n\nfrom marshmallow import fields, validate\n\nfrom .....connections.models.conn_record import ConnRecord\nfrom .....core.profile import ProfileSession\nfrom .....messaging.decorators.service_decorator import (\n ServiceDecorator,\n ServiceDecoratorSchema,\n)\nfrom .....messaging.models.base_record import BaseExchangeRecord, BaseExchangeSchema\nfrom .....messaging.valid import UUID4_EXAMPLE\nfrom .....storage.base import BaseStorage\nfrom .....storage.error import StorageNotFoundError\nfrom .....storage.record import StorageRecord\nfrom ..messages.invitation import InvitationMessage, InvitationMessageSchema\n\n\nclass OobRecord(BaseExchangeRecord):\n \"\"\"Represents an out of band record.\"\"\"\n\n class Meta:\n \"\"\"OobRecord metadata.\"\"\"\n\n schema_class = \"OobRecordSchema\"\n\n RECORD_TYPE = \"oob_record\"\n RECORD_TYPE_METADATA = ConnRecord.RECORD_TYPE_METADATA\n RECORD_ID_NAME = \"oob_id\"\n RECORD_TOPIC = \"out_of_band\"\n TAG_NAMES = {\n \"invi_msg_id\",\n \"attach_thread_id\",\n \"our_recipient_key\",\n \"connection_id\",\n \"reuse_msg_id\",\n }\n\n STATE_INITIAL = \"initial\"\n STATE_PREPARE_RESPONSE = \"prepare-response\"\n STATE_AWAIT_RESPONSE = \"await-response\"\n STATE_NOT_ACCEPTED = \"reuse-not-accepted\"\n STATE_ACCEPTED = \"reuse-accepted\"\n STATE_DONE = \"done\"\n\n ROLE_SENDER = \"sender\"\n ROLE_RECEIVER = \"receiver\"\n\n def __init__(\n self,\n *,\n state: str,\n invi_msg_id: str,\n role: str,\n invitation: Union[InvitationMessage, Mapping[str, Any]],\n their_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,\n connection_id: Optional[str] = None,\n reuse_msg_id: Optional[str] = None,\n oob_id: Optional[str] = None,\n attach_thread_id: Optional[str] = None,\n our_recipient_key: Optional[str] = None,\n our_service: Optional[Union[ServiceDecorator, Mapping[str, Any]]] = None,\n multi_use: bool = False,\n trace: bool = False,\n **kwargs,\n ):\n \"\"\"Initialize a new OobRecord.\"\"\"\n super().__init__(oob_id, state, trace=trace, **kwargs)\n self._id = oob_id\n self.state = state\n self.invi_msg_id = invi_msg_id\n self.role = role\n self._invitation = InvitationMessage.serde(invitation)\n self.connection_id = connection_id\n self.reuse_msg_id = reuse_msg_id\n self._their_service = ServiceDecorator.serde(their_service)\n self._our_service = ServiceDecorator.serde(our_service)\n self.attach_thread_id = attach_thread_id\n self.our_recipient_key = our_recipient_key\n self.multi_use = multi_use\n self.trace = trace\n\n @property\n def oob_id(self) -> str:\n \"\"\"Accessor for the ID associated with this exchange.\"\"\"\n return self._id\n\n @property\n def invitation(self) -> Optional[InvitationMessage]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._invitation is None else self._invitation.de\n\n @invitation.setter\n def invitation(self, value):\n \"\"\"Setter; store de/serialized views.\"\"\"\n self._invitation = InvitationMessage.serde(value)\n\n @property\n def our_service(self) -> Optional[ServiceDecorator]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._our_service is None else self._our_service.de\n\n @our_service.setter\n def our_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):\n \"\"\"Setter; store de/serialized views.\"\"\"\n self._our_service = ServiceDecorator.serde(value)\n\n @property\n def their_service(self) -> Optional[ServiceDecorator]:\n \"\"\"Accessor; get deserialized view.\"\"\"\n return None if self._their_service is None else self._their_service.de\n\n @their_service.setter\n def their_service(self, value: Union[ServiceDecorator, Mapping[str, Any]]):\n \"\"\"Setter; store de/serialized vies.\"\"\"\n self._their_service = ServiceDecorator.serde(value)\n\n @property\n def record_value(self) -> dict:\n \"\"\"Accessor for the JSON record value generated for this invitation.\"\"\"\n return {\n **{\n prop: getattr(self, prop)\n for prop in (\n \"state\",\n \"their_service\",\n \"connection_id\",\n \"role\",\n \"invi_msg_id\",\n \"multi_use\",\n )\n },\n **{\n prop: getattr(self, f\"_{prop}\").ser\n for prop in (\"invitation\", \"our_service\", \"their_service\")\n if getattr(self, prop) is not None\n },\n }\n\n async def delete_record(self, session: ProfileSession):\n \"\"\"Perform connection record deletion actions.\n\n Args:\n session (ProfileSession): session\n\n \"\"\"\n await super().delete_record(session)\n\n # Delete metadata\n if self.connection_id:\n storage = session.inject(BaseStorage)\n await storage.delete_all_records(\n self.RECORD_TYPE_METADATA,\n {\"connection_id\": self.connection_id},\n )\n\n async def metadata_get(\n self, session: ProfileSession, key: str, default: Any = None\n ) -> Any:\n \"\"\"Retrieve arbitrary metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key identifying metadata\n default (Any): default value to get; type should be a JSON\n compatible value.\n\n Returns:\n Any: metadata stored by key\n\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n return json.loads(record.value)\n except StorageNotFoundError:\n return default\n\n async def metadata_set(self, session: ProfileSession, key: str, value: Any):\n \"\"\"Set arbitrary metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key identifying metadata\n value (Any): value to set\n \"\"\"\n assert self.connection_id\n value = json.dumps(value)\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.update_record(record, value, record.tags)\n except StorageNotFoundError:\n record = StorageRecord(\n self.RECORD_TYPE_METADATA,\n value,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.add_record(record)\n\n async def metadata_delete(self, session: ProfileSession, key: str):\n \"\"\"Delete custom metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n key (str): key of metadata to delete\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n try:\n record = await storage.find_record(\n self.RECORD_TYPE_METADATA,\n {\"key\": key, \"connection_id\": self.connection_id},\n )\n await storage.delete_record(record)\n except StorageNotFoundError as err:\n raise KeyError(f\"{key} not found in connection metadata\") from err\n\n async def metadata_get_all(self, session: ProfileSession) -> dict:\n \"\"\"Return all custom metadata associated with this connection.\n\n Args:\n session (ProfileSession): session used for storage\n\n Returns:\n dict: dictionary representation of all metadata values\n\n \"\"\"\n assert self.connection_id\n storage: BaseStorage = session.inject(BaseStorage)\n records = await storage.find_all_records(\n self.RECORD_TYPE_METADATA,\n {\"connection_id\": self.connection_id},\n )\n return {record.tags[\"key\"]: json.loads(record.value) for record in records}\n\n def __eq__(self, other: Any) -> bool:\n \"\"\"Comparison between records.\"\"\"\n return super().__eq__(other)\n\n\nclass OobRecordSchema(BaseExchangeSchema):\n \"\"\"Schema to allow serialization/deserialization of invitation records.\"\"\"\n\n class Meta:\n \"\"\"OobRecordSchema metadata.\"\"\"\n\n model_class = OobRecord\n\n oob_id = fields.Str(\n required=True,\n metadata={\"description\": \"Oob record identifier\", \"example\": UUID4_EXAMPLE},\n )\n state = fields.Str(\n required=True,\n validate=validate.OneOf(\n OobRecord.get_attributes_by_prefix(\"STATE_\", walk_mro=True)\n ),\n metadata={\n \"description\": \"Out of band message exchange state\",\n \"example\": OobRecord.STATE_AWAIT_RESPONSE,\n },\n )\n invi_msg_id = fields.Str(\n required=True,\n metadata={\n \"description\": \"Invitation message identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n invitation = fields.Nested(\n InvitationMessageSchema(),\n required=True,\n metadata={\"description\": \"Out of band invitation message\"},\n )\n\n their_service = fields.Nested(ServiceDecoratorSchema(), required=False)\n\n connection_id = fields.Str(\n required=False,\n metadata={\n \"description\": \"Connection record identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n attach_thread_id = fields.Str(\n required=False,\n metadata={\n \"description\": \"Connection record identifier\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n our_recipient_key = fields.Str(\n required=False,\n metadata={\n \"description\": \"Recipient key used for oob invitation\",\n \"example\": UUID4_EXAMPLE,\n },\n )\n\n role = fields.Str(\n required=False,\n validate=validate.OneOf(\n OobRecord.get_attributes_by_prefix(\"ROLE_\", walk_mro=False)\n ),\n metadata={\"description\": \"OOB Role\", \"example\": OobRecord.ROLE_RECEIVER},\n )\n\n multi_use = fields.Boolean(\n required=False,\n metadata={\n \"description\": \"Allow for multiple uses of the oobinvitation\",\n \"example\": True,\n },\n )\n", "path": "aries_cloudagent/protocols/out_of_band/v1_0/models/oob_record.py"}]} | 4,084 | 204 |
gh_patches_debug_24570 | rasdani/github-patches | git_diff | scikit-image__scikit-image-4329 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`skimage.filters.gaussian` doesn't use `output` parameter at all
## Description
`skimage.filters.gaussian` doesn't use the value of `output` parameter. It returns only the image of float64 dtype, even if explicitly specify the output dtype.
## Way to reproduce
Simply run the code snippet:
```python
from skimage.filters import gaussian
import numpy as np
image = np.arange(25, dtype=np.uint8).reshape((5,5))
# output is not specified
filtered_0 = gaussian(image, sigma=0.25)
print(filtered_0.dtype)
# return: float64
# output is specified
filtered_output = gaussian(image, output = np.uint8, sigma=0.25)
print(filtered_output.dtype)
# return: float64
```
This function is a wrapper around `scipy.ndi.gaussian_filter`. But the scikit-image `gaussian` doesn't pass the `output` to `scipy.ndi.gaussian_filter`.
`skimage.filters.gaussian` doesn't use `output` parameter at all
## Description
`skimage.filters.gaussian` doesn't use the value of `output` parameter. It returns only the image of float64 dtype, even if explicitly specify the output dtype.
## Way to reproduce
Simply run the code snippet:
```python
from skimage.filters import gaussian
import numpy as np
image = np.arange(25, dtype=np.uint8).reshape((5,5))
# output is not specified
filtered_0 = gaussian(image, sigma=0.25)
print(filtered_0.dtype)
# return: float64
# output is specified
filtered_output = gaussian(image, output = np.uint8, sigma=0.25)
print(filtered_output.dtype)
# return: float64
```
This function is a wrapper around `scipy.ndi.gaussian_filter`. But the scikit-image `gaussian` doesn't pass the `output` to `scipy.ndi.gaussian_filter`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/filters/_gaussian.py`
Content:
```
1 from collections.abc import Iterable
2 import numpy as np
3 from scipy import ndimage as ndi
4
5 from ..util import img_as_float
6 from .._shared.utils import warn, convert_to_float
7
8
9 __all__ = ['gaussian']
10
11
12 def gaussian(image, sigma=1, output=None, mode='nearest', cval=0,
13 multichannel=None, preserve_range=False, truncate=4.0):
14 """Multi-dimensional Gaussian filter.
15
16 Parameters
17 ----------
18 image : array-like
19 Input image (grayscale or color) to filter.
20 sigma : scalar or sequence of scalars, optional
21 Standard deviation for Gaussian kernel. The standard
22 deviations of the Gaussian filter are given for each axis as a
23 sequence, or as a single number, in which case it is equal for
24 all axes.
25 output : array, optional
26 The ``output`` parameter passes an array in which to store the
27 filter output.
28 mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional
29 The ``mode`` parameter determines how the array borders are
30 handled, where ``cval`` is the value when mode is equal to
31 'constant'. Default is 'nearest'.
32 cval : scalar, optional
33 Value to fill past edges of input if ``mode`` is 'constant'. Default
34 is 0.0
35 multichannel : bool, optional (default: None)
36 Whether the last axis of the image is to be interpreted as multiple
37 channels. If True, each channel is filtered separately (channels are
38 not mixed together). Only 3 channels are supported. If ``None``,
39 the function will attempt to guess this, and raise a warning if
40 ambiguous, when the array has shape (M, N, 3).
41 preserve_range : bool, optional
42 Whether to keep the original range of values. Otherwise, the input
43 image is converted according to the conventions of ``img_as_float``.
44 Also see
45 https://scikit-image.org/docs/dev/user_guide/data_types.html
46 truncate : float, optional
47 Truncate the filter at this many standard deviations.
48
49 Returns
50 -------
51 filtered_image : ndarray
52 the filtered array
53
54 Notes
55 -----
56 This function is a wrapper around :func:`scipy.ndi.gaussian_filter`.
57
58 Integer arrays are converted to float.
59
60 The multi-dimensional filter is implemented as a sequence of
61 one-dimensional convolution filters. The intermediate arrays are
62 stored in the same data type as the output. Therefore, for output
63 types with a limited precision, the results may be imprecise
64 because intermediate results may be stored with insufficient
65 precision.
66
67 Examples
68 --------
69
70 >>> a = np.zeros((3, 3))
71 >>> a[1, 1] = 1
72 >>> a
73 array([[0., 0., 0.],
74 [0., 1., 0.],
75 [0., 0., 0.]])
76 >>> gaussian(a, sigma=0.4) # mild smoothing
77 array([[0.00163116, 0.03712502, 0.00163116],
78 [0.03712502, 0.84496158, 0.03712502],
79 [0.00163116, 0.03712502, 0.00163116]])
80 >>> gaussian(a, sigma=1) # more smoothing
81 array([[0.05855018, 0.09653293, 0.05855018],
82 [0.09653293, 0.15915589, 0.09653293],
83 [0.05855018, 0.09653293, 0.05855018]])
84 >>> # Several modes are possible for handling boundaries
85 >>> gaussian(a, sigma=1, mode='reflect')
86 array([[0.08767308, 0.12075024, 0.08767308],
87 [0.12075024, 0.16630671, 0.12075024],
88 [0.08767308, 0.12075024, 0.08767308]])
89 >>> # For RGB images, each is filtered separately
90 >>> from skimage.data import astronaut
91 >>> image = astronaut()
92 >>> filtered_img = gaussian(image, sigma=1, multichannel=True)
93
94 """
95
96 spatial_dims = None
97 try:
98 spatial_dims = _guess_spatial_dimensions(image)
99 except ValueError:
100 spatial_dims = image.ndim
101 if spatial_dims is None and multichannel is None:
102 msg = ("Images with dimensions (M, N, 3) are interpreted as 2D+RGB "
103 "by default. Use `multichannel=False` to interpret as "
104 "3D image with last dimension of length 3.")
105 warn(RuntimeWarning(msg))
106 multichannel = True
107 if np.any(np.asarray(sigma) < 0.0):
108 raise ValueError("Sigma values less than zero are not valid")
109 if multichannel:
110 # do not filter across channels
111 if not isinstance(sigma, Iterable):
112 sigma = [sigma] * (image.ndim - 1)
113 if len(sigma) != image.ndim:
114 sigma = np.concatenate((np.asarray(sigma), [0]))
115 image = convert_to_float(image, preserve_range)
116 return ndi.gaussian_filter(image, sigma, mode=mode, cval=cval,
117 truncate=truncate)
118
119
120 def _guess_spatial_dimensions(image):
121 """Make an educated guess about whether an image has a channels dimension.
122
123 Parameters
124 ----------
125 image : ndarray
126 The input image.
127
128 Returns
129 -------
130 spatial_dims : int or None
131 The number of spatial dimensions of ``image``. If ambiguous, the value
132 is ``None``.
133
134 Raises
135 ------
136 ValueError
137 If the image array has less than two or more than four dimensions.
138 """
139 if image.ndim == 2:
140 return 2
141 if image.ndim == 3 and image.shape[-1] != 3:
142 return 3
143 if image.ndim == 3 and image.shape[-1] == 3:
144 return None
145 if image.ndim == 4 and image.shape[-1] == 3:
146 return 3
147 else:
148 raise ValueError("Expected 2D, 3D, or 4D array, got %iD." % image.ndim)
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/skimage/filters/_gaussian.py b/skimage/filters/_gaussian.py
--- a/skimage/filters/_gaussian.py
+++ b/skimage/filters/_gaussian.py
@@ -57,6 +57,10 @@
Integer arrays are converted to float.
+ The ``output`` should be floating point data type since gaussian converts
+ to float provided ``image``. If ``output`` is not provided, another array
+ will be allocated and returned as the result.
+
The multi-dimensional filter is implemented as a sequence of
one-dimensional convolution filters. The intermediate arrays are
stored in the same data type as the output. Therefore, for output
@@ -113,8 +117,13 @@
if len(sigma) != image.ndim:
sigma = np.concatenate((np.asarray(sigma), [0]))
image = convert_to_float(image, preserve_range)
- return ndi.gaussian_filter(image, sigma, mode=mode, cval=cval,
- truncate=truncate)
+ if output is None:
+ output = np.empty_like(image)
+ elif not np.issubdtype(output.dtype, np.floating):
+ raise ValueError("Provided output data type is not float")
+ ndi.gaussian_filter(image, sigma, output=output, mode=mode, cval=cval,
+ truncate=truncate)
+ return output
def _guess_spatial_dimensions(image):
| {"golden_diff": "diff --git a/skimage/filters/_gaussian.py b/skimage/filters/_gaussian.py\n--- a/skimage/filters/_gaussian.py\n+++ b/skimage/filters/_gaussian.py\n@@ -57,6 +57,10 @@\n \n Integer arrays are converted to float.\n \n+ The ``output`` should be floating point data type since gaussian converts\n+ to float provided ``image``. If ``output`` is not provided, another array\n+ will be allocated and returned as the result.\n+\n The multi-dimensional filter is implemented as a sequence of\n one-dimensional convolution filters. The intermediate arrays are\n stored in the same data type as the output. Therefore, for output\n@@ -113,8 +117,13 @@\n if len(sigma) != image.ndim:\n sigma = np.concatenate((np.asarray(sigma), [0]))\n image = convert_to_float(image, preserve_range)\n- return ndi.gaussian_filter(image, sigma, mode=mode, cval=cval,\n- truncate=truncate)\n+ if output is None:\n+ output = np.empty_like(image)\n+ elif not np.issubdtype(output.dtype, np.floating):\n+ raise ValueError(\"Provided output data type is not float\")\n+ ndi.gaussian_filter(image, sigma, output=output, mode=mode, cval=cval,\n+ truncate=truncate)\n+ return output\n \n \n def _guess_spatial_dimensions(image):\n", "issue": "`skimage.filters.gaussian` doesn't use `output` parameter at all\n## Description\r\n`skimage.filters.gaussian` doesn't use the value of `output` parameter. It returns only the image of float64 dtype, even if explicitly specify the output dtype. \r\n\r\n## Way to reproduce\r\nSimply run the code snippet:\r\n```python\r\nfrom skimage.filters import gaussian\r\nimport numpy as np\r\n\r\nimage = np.arange(25, dtype=np.uint8).reshape((5,5))\r\n\r\n# output is not specified\r\nfiltered_0 = gaussian(image, sigma=0.25)\r\nprint(filtered_0.dtype)\r\n# return: float64\r\n\r\n# output is specified\r\nfiltered_output = gaussian(image, output = np.uint8, sigma=0.25)\r\nprint(filtered_output.dtype)\r\n# return: float64\r\n```\r\nThis function is a wrapper around `scipy.ndi.gaussian_filter`. But the scikit-image `gaussian` doesn't pass the `output` to `scipy.ndi.gaussian_filter`.\r\n\r\n\n`skimage.filters.gaussian` doesn't use `output` parameter at all\n## Description\r\n`skimage.filters.gaussian` doesn't use the value of `output` parameter. It returns only the image of float64 dtype, even if explicitly specify the output dtype. \r\n\r\n## Way to reproduce\r\nSimply run the code snippet:\r\n```python\r\nfrom skimage.filters import gaussian\r\nimport numpy as np\r\n\r\nimage = np.arange(25, dtype=np.uint8).reshape((5,5))\r\n\r\n# output is not specified\r\nfiltered_0 = gaussian(image, sigma=0.25)\r\nprint(filtered_0.dtype)\r\n# return: float64\r\n\r\n# output is specified\r\nfiltered_output = gaussian(image, output = np.uint8, sigma=0.25)\r\nprint(filtered_output.dtype)\r\n# return: float64\r\n```\r\nThis function is a wrapper around `scipy.ndi.gaussian_filter`. But the scikit-image `gaussian` doesn't pass the `output` to `scipy.ndi.gaussian_filter`.\r\n\r\n\n", "before_files": [{"content": "from collections.abc import Iterable\nimport numpy as np\nfrom scipy import ndimage as ndi\n\nfrom ..util import img_as_float\nfrom .._shared.utils import warn, convert_to_float\n\n\n__all__ = ['gaussian']\n\n\ndef gaussian(image, sigma=1, output=None, mode='nearest', cval=0,\n multichannel=None, preserve_range=False, truncate=4.0):\n \"\"\"Multi-dimensional Gaussian filter.\n\n Parameters\n ----------\n image : array-like\n Input image (grayscale or color) to filter.\n sigma : scalar or sequence of scalars, optional\n Standard deviation for Gaussian kernel. The standard\n deviations of the Gaussian filter are given for each axis as a\n sequence, or as a single number, in which case it is equal for\n all axes.\n output : array, optional\n The ``output`` parameter passes an array in which to store the\n filter output.\n mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional\n The ``mode`` parameter determines how the array borders are\n handled, where ``cval`` is the value when mode is equal to\n 'constant'. Default is 'nearest'.\n cval : scalar, optional\n Value to fill past edges of input if ``mode`` is 'constant'. Default\n is 0.0\n multichannel : bool, optional (default: None)\n Whether the last axis of the image is to be interpreted as multiple\n channels. If True, each channel is filtered separately (channels are\n not mixed together). Only 3 channels are supported. If ``None``,\n the function will attempt to guess this, and raise a warning if\n ambiguous, when the array has shape (M, N, 3).\n preserve_range : bool, optional\n Whether to keep the original range of values. Otherwise, the input\n image is converted according to the conventions of ``img_as_float``.\n Also see\n https://scikit-image.org/docs/dev/user_guide/data_types.html\n truncate : float, optional\n Truncate the filter at this many standard deviations.\n\n Returns\n -------\n filtered_image : ndarray\n the filtered array\n\n Notes\n -----\n This function is a wrapper around :func:`scipy.ndi.gaussian_filter`.\n\n Integer arrays are converted to float.\n\n The multi-dimensional filter is implemented as a sequence of\n one-dimensional convolution filters. The intermediate arrays are\n stored in the same data type as the output. Therefore, for output\n types with a limited precision, the results may be imprecise\n because intermediate results may be stored with insufficient\n precision.\n\n Examples\n --------\n\n >>> a = np.zeros((3, 3))\n >>> a[1, 1] = 1\n >>> a\n array([[0., 0., 0.],\n [0., 1., 0.],\n [0., 0., 0.]])\n >>> gaussian(a, sigma=0.4) # mild smoothing\n array([[0.00163116, 0.03712502, 0.00163116],\n [0.03712502, 0.84496158, 0.03712502],\n [0.00163116, 0.03712502, 0.00163116]])\n >>> gaussian(a, sigma=1) # more smoothing\n array([[0.05855018, 0.09653293, 0.05855018],\n [0.09653293, 0.15915589, 0.09653293],\n [0.05855018, 0.09653293, 0.05855018]])\n >>> # Several modes are possible for handling boundaries\n >>> gaussian(a, sigma=1, mode='reflect')\n array([[0.08767308, 0.12075024, 0.08767308],\n [0.12075024, 0.16630671, 0.12075024],\n [0.08767308, 0.12075024, 0.08767308]])\n >>> # For RGB images, each is filtered separately\n >>> from skimage.data import astronaut\n >>> image = astronaut()\n >>> filtered_img = gaussian(image, sigma=1, multichannel=True)\n\n \"\"\"\n\n spatial_dims = None\n try:\n spatial_dims = _guess_spatial_dimensions(image)\n except ValueError:\n spatial_dims = image.ndim\n if spatial_dims is None and multichannel is None:\n msg = (\"Images with dimensions (M, N, 3) are interpreted as 2D+RGB \"\n \"by default. Use `multichannel=False` to interpret as \"\n \"3D image with last dimension of length 3.\")\n warn(RuntimeWarning(msg))\n multichannel = True\n if np.any(np.asarray(sigma) < 0.0):\n raise ValueError(\"Sigma values less than zero are not valid\")\n if multichannel:\n # do not filter across channels\n if not isinstance(sigma, Iterable):\n sigma = [sigma] * (image.ndim - 1)\n if len(sigma) != image.ndim:\n sigma = np.concatenate((np.asarray(sigma), [0]))\n image = convert_to_float(image, preserve_range)\n return ndi.gaussian_filter(image, sigma, mode=mode, cval=cval,\n truncate=truncate)\n\n\ndef _guess_spatial_dimensions(image):\n \"\"\"Make an educated guess about whether an image has a channels dimension.\n\n Parameters\n ----------\n image : ndarray\n The input image.\n\n Returns\n -------\n spatial_dims : int or None\n The number of spatial dimensions of ``image``. If ambiguous, the value\n is ``None``.\n\n Raises\n ------\n ValueError\n If the image array has less than two or more than four dimensions.\n \"\"\"\n if image.ndim == 2:\n return 2\n if image.ndim == 3 and image.shape[-1] != 3:\n return 3\n if image.ndim == 3 and image.shape[-1] == 3:\n return None\n if image.ndim == 4 and image.shape[-1] == 3:\n return 3\n else:\n raise ValueError(\"Expected 2D, 3D, or 4D array, got %iD.\" % image.ndim)\n", "path": "skimage/filters/_gaussian.py"}], "after_files": [{"content": "from collections.abc import Iterable\nimport numpy as np\nfrom scipy import ndimage as ndi\n\nfrom ..util import img_as_float\nfrom .._shared.utils import warn, convert_to_float\n\n\n__all__ = ['gaussian']\n\n\ndef gaussian(image, sigma=1, output=None, mode='nearest', cval=0,\n multichannel=None, preserve_range=False, truncate=4.0):\n \"\"\"Multi-dimensional Gaussian filter.\n\n Parameters\n ----------\n image : array-like\n Input image (grayscale or color) to filter.\n sigma : scalar or sequence of scalars, optional\n Standard deviation for Gaussian kernel. The standard\n deviations of the Gaussian filter are given for each axis as a\n sequence, or as a single number, in which case it is equal for\n all axes.\n output : array, optional\n The ``output`` parameter passes an array in which to store the\n filter output.\n mode : {'reflect', 'constant', 'nearest', 'mirror', 'wrap'}, optional\n The ``mode`` parameter determines how the array borders are\n handled, where ``cval`` is the value when mode is equal to\n 'constant'. Default is 'nearest'.\n cval : scalar, optional\n Value to fill past edges of input if ``mode`` is 'constant'. Default\n is 0.0\n multichannel : bool, optional (default: None)\n Whether the last axis of the image is to be interpreted as multiple\n channels. If True, each channel is filtered separately (channels are\n not mixed together). Only 3 channels are supported. If ``None``,\n the function will attempt to guess this, and raise a warning if\n ambiguous, when the array has shape (M, N, 3).\n preserve_range : bool, optional\n Whether to keep the original range of values. Otherwise, the input\n image is converted according to the conventions of ``img_as_float``.\n Also see\n https://scikit-image.org/docs/dev/user_guide/data_types.html\n truncate : float, optional\n Truncate the filter at this many standard deviations.\n\n Returns\n -------\n filtered_image : ndarray\n the filtered array\n\n Notes\n -----\n This function is a wrapper around :func:`scipy.ndi.gaussian_filter`.\n\n Integer arrays are converted to float.\n\n The ``output`` should be floating point data type since gaussian converts\n to float provided ``image``. If ``output`` is not provided, another array\n will be allocated and returned as the result.\n\n The multi-dimensional filter is implemented as a sequence of\n one-dimensional convolution filters. The intermediate arrays are\n stored in the same data type as the output. Therefore, for output\n types with a limited precision, the results may be imprecise\n because intermediate results may be stored with insufficient\n precision.\n\n Examples\n --------\n\n >>> a = np.zeros((3, 3))\n >>> a[1, 1] = 1\n >>> a\n array([[0., 0., 0.],\n [0., 1., 0.],\n [0., 0., 0.]])\n >>> gaussian(a, sigma=0.4) # mild smoothing\n array([[0.00163116, 0.03712502, 0.00163116],\n [0.03712502, 0.84496158, 0.03712502],\n [0.00163116, 0.03712502, 0.00163116]])\n >>> gaussian(a, sigma=1) # more smoothing\n array([[0.05855018, 0.09653293, 0.05855018],\n [0.09653293, 0.15915589, 0.09653293],\n [0.05855018, 0.09653293, 0.05855018]])\n >>> # Several modes are possible for handling boundaries\n >>> gaussian(a, sigma=1, mode='reflect')\n array([[0.08767308, 0.12075024, 0.08767308],\n [0.12075024, 0.16630671, 0.12075024],\n [0.08767308, 0.12075024, 0.08767308]])\n >>> # For RGB images, each is filtered separately\n >>> from skimage.data import astronaut\n >>> image = astronaut()\n >>> filtered_img = gaussian(image, sigma=1, multichannel=True)\n\n \"\"\"\n\n spatial_dims = None\n try:\n spatial_dims = _guess_spatial_dimensions(image)\n except ValueError:\n spatial_dims = image.ndim\n if spatial_dims is None and multichannel is None:\n msg = (\"Images with dimensions (M, N, 3) are interpreted as 2D+RGB \"\n \"by default. Use `multichannel=False` to interpret as \"\n \"3D image with last dimension of length 3.\")\n warn(RuntimeWarning(msg))\n multichannel = True\n if np.any(np.asarray(sigma) < 0.0):\n raise ValueError(\"Sigma values less than zero are not valid\")\n if multichannel:\n # do not filter across channels\n if not isinstance(sigma, Iterable):\n sigma = [sigma] * (image.ndim - 1)\n if len(sigma) != image.ndim:\n sigma = np.concatenate((np.asarray(sigma), [0]))\n image = convert_to_float(image, preserve_range)\n if output is None:\n output = np.empty_like(image)\n elif not np.issubdtype(output.dtype, np.floating):\n raise ValueError(\"Provided output data type is not float\")\n ndi.gaussian_filter(image, sigma, output=output, mode=mode, cval=cval,\n truncate=truncate)\n return output\n\n\ndef _guess_spatial_dimensions(image):\n \"\"\"Make an educated guess about whether an image has a channels dimension.\n\n Parameters\n ----------\n image : ndarray\n The input image.\n\n Returns\n -------\n spatial_dims : int or None\n The number of spatial dimensions of ``image``. If ambiguous, the value\n is ``None``.\n\n Raises\n ------\n ValueError\n If the image array has less than two or more than four dimensions.\n \"\"\"\n if image.ndim == 2:\n return 2\n if image.ndim == 3 and image.shape[-1] != 3:\n return 3\n if image.ndim == 3 and image.shape[-1] == 3:\n return None\n if image.ndim == 4 and image.shape[-1] == 3:\n return 3\n else:\n raise ValueError(\"Expected 2D, 3D, or 4D array, got %iD.\" % image.ndim)\n", "path": "skimage/filters/_gaussian.py"}]} | 2,566 | 322 |
gh_patches_debug_15043 | rasdani/github-patches | git_diff | freedomofpress__securedrop-5067 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Graphical updater "is already running" dialog during late stages of the update process
## Description
The graphical updater briefly shows an "is already running" dialog during the last stages of the process. The dialog can be dismissed and has no negative consequences.
Tested on Tails 3.16.
## Steps to Reproduce
Perform a full graphical update using the graphical updater, with the Tails admin password set.
## Expected Behavior
The graphical update completes without any unusual messages.
## Actual Behavior
An "already running" dialog briefly appears towards the end of the process.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `journalist_gui/journalist_gui/SecureDropUpdater.py`
Content:
```
1 #!/usr/bin/python
2 from PyQt5 import QtGui, QtWidgets
3 from PyQt5.QtCore import QThread, pyqtSignal
4 import subprocess
5 import os
6 import re
7 import pexpect
8 import socket
9 import sys
10
11 from journalist_gui import updaterUI, strings, resources_rc # noqa
12
13
14 FLAG_LOCATION = "/home/amnesia/Persistent/.securedrop/securedrop_update.flag" # noqa
15 ESCAPE_POD = re.compile(r'\x1B\[[0-?]*[ -/]*[@-~]')
16
17
18 def password_is_set():
19
20 pwd_flag = subprocess.check_output(['passwd', '--status']).decode('utf-8').split()[1]
21
22 if pwd_flag == 'NP':
23 return False
24 return True
25
26
27 def prevent_second_instance(app: QtWidgets.QApplication, name: str) -> None: # noqa
28
29 # Null byte triggers abstract namespace
30 IDENTIFIER = '\0' + name
31 ALREADY_BOUND_ERRNO = 98
32
33 app.instance_binding = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)
34 try:
35 app.instance_binding.bind(IDENTIFIER)
36 except OSError as e:
37 if e.errno == ALREADY_BOUND_ERRNO:
38 err_dialog = QtWidgets.QMessageBox()
39 err_dialog.setText(name + strings.app_is_already_running)
40 err_dialog.exec()
41 sys.exit()
42 else:
43 raise
44
45
46 class SetupThread(QThread):
47 signal = pyqtSignal('PyQt_PyObject')
48
49 def __init__(self):
50 QThread.__init__(self)
51 self.output = ""
52 self.update_success = False
53 self.failure_reason = ""
54
55 def run(self):
56 sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'
57 update_command = [sdadmin_path, 'setup']
58
59 # Create flag file to indicate we should resume failed updates on
60 # reboot. Don't create the flag if it already exists.
61 if not os.path.exists(FLAG_LOCATION):
62 open(FLAG_LOCATION, 'a').close()
63
64 try:
65 self.output = subprocess.check_output(
66 update_command,
67 stderr=subprocess.STDOUT).decode('utf-8')
68 if 'Failed to install' in self.output:
69 self.update_success = False
70 self.failure_reason = strings.update_failed_generic_reason
71 else:
72 self.update_success = True
73 except subprocess.CalledProcessError as e:
74 self.output += e.output.decode('utf-8')
75 self.update_success = False
76 self.failure_reason = strings.update_failed_generic_reason
77 result = {'status': self.update_success,
78 'output': self.output,
79 'failure_reason': self.failure_reason}
80 self.signal.emit(result)
81
82
83 # This thread will handle the ./securedrop-admin update command
84 class UpdateThread(QThread):
85 signal = pyqtSignal('PyQt_PyObject')
86
87 def __init__(self):
88 QThread.__init__(self)
89 self.output = ""
90 self.update_success = False
91 self.failure_reason = ""
92
93 def run(self):
94 sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'
95 update_command = [sdadmin_path, 'update']
96 try:
97 self.output = subprocess.check_output(
98 update_command,
99 stderr=subprocess.STDOUT).decode('utf-8')
100 if "Signature verification successful" in self.output:
101 self.update_success = True
102 else:
103 self.failure_reason = strings.update_failed_generic_reason
104 except subprocess.CalledProcessError as e:
105 self.update_success = False
106 self.output += e.output.decode('utf-8')
107 if 'Signature verification failed' in self.output:
108 self.failure_reason = strings.update_failed_sig_failure
109 else:
110 self.failure_reason = strings.update_failed_generic_reason
111 result = {'status': self.update_success,
112 'output': self.output,
113 'failure_reason': self.failure_reason}
114 self.signal.emit(result)
115
116
117 # This thread will handle the ./securedrop-admin tailsconfig command
118 class TailsconfigThread(QThread):
119 signal = pyqtSignal('PyQt_PyObject')
120
121 def __init__(self):
122 QThread.__init__(self)
123 self.output = ""
124 self.update_success = False
125 self.failure_reason = ""
126 self.sudo_password = ""
127
128 def run(self):
129 tailsconfig_command = ("/home/amnesia/Persistent/"
130 "securedrop/securedrop-admin "
131 "tailsconfig")
132 try:
133 child = pexpect.spawn(tailsconfig_command)
134 child.expect('SUDO password:')
135 self.output += child.before.decode('utf-8')
136 child.sendline(self.sudo_password)
137 child.expect(pexpect.EOF)
138 self.output += child.before.decode('utf-8')
139 child.close()
140
141 # For Tailsconfig to be considered a success, we expect no
142 # failures in the Ansible output.
143 if child.exitstatus:
144 self.update_success = False
145 self.failure_reason = strings.tailsconfig_failed_generic_reason # noqa
146 else:
147 self.update_success = True
148 except pexpect.exceptions.TIMEOUT:
149 self.update_success = False
150 self.failure_reason = strings.tailsconfig_failed_sudo_password
151
152 except subprocess.CalledProcessError:
153 self.update_success = False
154 self.failure_reason = strings.tailsconfig_failed_generic_reason
155 result = {'status': self.update_success,
156 'output': ESCAPE_POD.sub('', self.output),
157 'failure_reason': self.failure_reason}
158 self.signal.emit(result)
159
160
161 class UpdaterApp(QtWidgets.QMainWindow, updaterUI.Ui_MainWindow):
162
163 def __init__(self, parent=None):
164 super(UpdaterApp, self).__init__(parent)
165 self.setupUi(self)
166 self.statusbar.setSizeGripEnabled(False)
167 self.output = strings.initial_text_box
168 self.plainTextEdit.setPlainText(self.output)
169 self.update_success = False
170
171 pixmap = QtGui.QPixmap(":/images/static/banner.png")
172 self.label_2.setPixmap(pixmap)
173 self.label_2.setScaledContents(True)
174
175 self.progressBar.setProperty("value", 0)
176 self.setWindowTitle(strings.window_title)
177 self.setWindowIcon(QtGui.QIcon(':/images/static/securedrop_icon.png'))
178 self.label.setText(strings.update_in_progress)
179
180 self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab),
181 strings.main_tab)
182 self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_2),
183 strings.output_tab)
184
185 # Connect buttons to their functions.
186 self.pushButton.setText(strings.install_later_button)
187 self.pushButton.setStyleSheet("""background-color: lightgrey;
188 min-height: 2em;
189 border-radius: 10px""")
190 self.pushButton.clicked.connect(self.close)
191 self.pushButton_2.setText(strings.install_update_button)
192 self.pushButton_2.setStyleSheet("""background-color: #E6FFEB;
193 min-height: 2em;
194 border-radius: 10px;""")
195 self.pushButton_2.clicked.connect(self.update_securedrop)
196 self.update_thread = UpdateThread()
197 self.update_thread.signal.connect(self.update_status)
198 self.tails_thread = TailsconfigThread()
199 self.tails_thread.signal.connect(self.tails_status)
200 self.setup_thread = SetupThread()
201 self.setup_thread.signal.connect(self.setup_status)
202
203 # At the end of this function, we will try to do tailsconfig.
204 # A new slot will handle tailsconfig output
205 def setup_status(self, result):
206 "This is the slot for setup thread"
207 self.output += result['output']
208 self.update_success = result['status']
209 self.failure_reason = result['failure_reason']
210 self.progressBar.setProperty("value", 60)
211 self.plainTextEdit.setPlainText(self.output)
212 self.plainTextEdit.setReadOnly = True
213 if not self.update_success: # Failed to do setup
214 self.pushButton.setEnabled(True)
215 self.pushButton_2.setEnabled(True)
216 self.update_status_bar_and_output(self.failure_reason)
217 self.progressBar.setProperty("value", 0)
218 self.alert_failure(self.failure_reason)
219 return
220 self.progressBar.setProperty("value", 70)
221 self.call_tailsconfig()
222
223 # This will update the output text after the git commands.
224 def update_status(self, result):
225 "This is the slot for update thread"
226 self.output += result['output']
227 self.update_success = result['status']
228 self.failure_reason = result['failure_reason']
229 self.progressBar.setProperty("value", 40)
230 self.plainTextEdit.setPlainText(self.output)
231 self.plainTextEdit.setReadOnly = True
232 if not self.update_success: # Failed to do update
233 self.pushButton.setEnabled(True)
234 self.pushButton_2.setEnabled(True)
235 self.update_status_bar_and_output(self.failure_reason)
236 self.progressBar.setProperty("value", 0)
237 self.alert_failure(self.failure_reason)
238 return
239 self.progressBar.setProperty("value", 50)
240 self.update_status_bar_and_output(strings.doing_setup)
241 self.setup_thread.start()
242
243 def update_status_bar_and_output(self, status_message):
244 """This method updates the status bar and the output window with the
245 status_message."""
246 self.statusbar.showMessage(status_message)
247 self.output += status_message + '\n'
248 self.plainTextEdit.setPlainText(self.output)
249
250 def call_tailsconfig(self):
251 # Now let us work on tailsconfig part
252 if self.update_success:
253 # Get sudo password and add an enter key as tailsconfig command
254 # expects
255 sudo_password = self.get_sudo_password()
256 if not sudo_password:
257 self.update_success = False
258 self.failure_reason = strings.missing_sudo_password
259 self.on_failure()
260 return
261 self.tails_thread.sudo_password = sudo_password + '\n'
262 self.update_status_bar_and_output(strings.updating_tails_env)
263 self.tails_thread.start()
264 else:
265 self.on_failure()
266
267 def tails_status(self, result):
268 "This is the slot for Tailsconfig thread"
269 self.output += result['output']
270 self.update_success = result['status']
271 self.failure_reason = result['failure_reason']
272 self.plainTextEdit.setPlainText(self.output)
273 self.progressBar.setProperty("value", 80)
274 if self.update_success:
275 # Remove flag file indicating an update is in progress
276 os.remove(FLAG_LOCATION)
277 self.update_status_bar_and_output(strings.finished)
278 self.progressBar.setProperty("value", 100)
279 self.alert_success()
280 else:
281 self.on_failure()
282
283 def on_failure(self):
284 self.update_status_bar_and_output(self.failure_reason)
285 self.alert_failure(self.failure_reason)
286 # Now everything is done, enable the button.
287 self.pushButton.setEnabled(True)
288 self.pushButton_2.setEnabled(True)
289 self.progressBar.setProperty("value", 0)
290
291 def update_securedrop(self):
292 if password_is_set():
293 self.pushButton_2.setEnabled(False)
294 self.pushButton.setEnabled(False)
295 self.progressBar.setProperty("value", 10)
296 self.update_status_bar_and_output(strings.fetching_update)
297 self.update_thread.start()
298 else:
299 self.pushButton_2.setEnabled(False)
300 pwd_err_dialog = QtWidgets.QMessageBox()
301 pwd_err_dialog.setText(strings.no_password_set_message)
302 pwd_err_dialog.exec()
303
304 def alert_success(self):
305 self.success_dialog = QtWidgets.QMessageBox()
306 self.success_dialog.setIcon(QtWidgets.QMessageBox.Information)
307 self.success_dialog.setText(strings.finished_dialog_message)
308 self.success_dialog.setWindowTitle(strings.finished_dialog_title)
309 self.success_dialog.show()
310
311 def alert_failure(self, failure_reason):
312 self.error_dialog = QtWidgets.QMessageBox()
313 self.error_dialog.setIcon(QtWidgets.QMessageBox.Critical)
314 self.error_dialog.setText(self.failure_reason)
315 self.error_dialog.setWindowTitle(strings.update_failed_dialog_title)
316 self.error_dialog.show()
317
318 def get_sudo_password(self):
319 sudo_password, ok_is_pressed = QtWidgets.QInputDialog.getText(
320 self, "Tails Administrator password", strings.sudo_password_text,
321 QtWidgets.QLineEdit.Password, "")
322 if ok_is_pressed and sudo_password:
323 return sudo_password
324 else:
325 return None
326
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/journalist_gui/journalist_gui/SecureDropUpdater.py b/journalist_gui/journalist_gui/SecureDropUpdater.py
--- a/journalist_gui/journalist_gui/SecureDropUpdater.py
+++ b/journalist_gui/journalist_gui/SecureDropUpdater.py
@@ -7,6 +7,7 @@
import pexpect
import socket
import sys
+import syslog as log
from journalist_gui import updaterUI, strings, resources_rc # noqa
@@ -35,9 +36,7 @@
app.instance_binding.bind(IDENTIFIER)
except OSError as e:
if e.errno == ALREADY_BOUND_ERRNO:
- err_dialog = QtWidgets.QMessageBox()
- err_dialog.setText(name + strings.app_is_already_running)
- err_dialog.exec()
+ log.syslog(log.LOG_NOTICE, name + strings.app_is_already_running)
sys.exit()
else:
raise
| {"golden_diff": "diff --git a/journalist_gui/journalist_gui/SecureDropUpdater.py b/journalist_gui/journalist_gui/SecureDropUpdater.py\n--- a/journalist_gui/journalist_gui/SecureDropUpdater.py\n+++ b/journalist_gui/journalist_gui/SecureDropUpdater.py\n@@ -7,6 +7,7 @@\n import pexpect\n import socket\n import sys\n+import syslog as log\n \n from journalist_gui import updaterUI, strings, resources_rc # noqa\n \n@@ -35,9 +36,7 @@\n app.instance_binding.bind(IDENTIFIER)\n except OSError as e:\n if e.errno == ALREADY_BOUND_ERRNO:\n- err_dialog = QtWidgets.QMessageBox()\n- err_dialog.setText(name + strings.app_is_already_running)\n- err_dialog.exec()\n+ log.syslog(log.LOG_NOTICE, name + strings.app_is_already_running)\n sys.exit()\n else:\n raise\n", "issue": "Graphical updater \"is already running\" dialog during late stages of the update process\n## Description\r\n\r\nThe graphical updater briefly shows an \"is already running\" dialog during the last stages of the process. The dialog can be dismissed and has no negative consequences.\r\n\r\nTested on Tails 3.16.\r\n\r\n## Steps to Reproduce\r\n\r\nPerform a full graphical update using the graphical updater, with the Tails admin password set.\r\n\r\n## Expected Behavior\r\n\r\nThe graphical update completes without any unusual messages.\r\n\r\n## Actual Behavior\r\n\r\nAn \"already running\" dialog briefly appears towards the end of the process.\n", "before_files": [{"content": "#!/usr/bin/python\nfrom PyQt5 import QtGui, QtWidgets\nfrom PyQt5.QtCore import QThread, pyqtSignal\nimport subprocess\nimport os\nimport re\nimport pexpect\nimport socket\nimport sys\n\nfrom journalist_gui import updaterUI, strings, resources_rc # noqa\n\n\nFLAG_LOCATION = \"/home/amnesia/Persistent/.securedrop/securedrop_update.flag\" # noqa\nESCAPE_POD = re.compile(r'\\x1B\\[[0-?]*[ -/]*[@-~]')\n\n\ndef password_is_set():\n\n pwd_flag = subprocess.check_output(['passwd', '--status']).decode('utf-8').split()[1]\n\n if pwd_flag == 'NP':\n return False\n return True\n\n\ndef prevent_second_instance(app: QtWidgets.QApplication, name: str) -> None: # noqa\n\n # Null byte triggers abstract namespace\n IDENTIFIER = '\\0' + name\n ALREADY_BOUND_ERRNO = 98\n\n app.instance_binding = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)\n try:\n app.instance_binding.bind(IDENTIFIER)\n except OSError as e:\n if e.errno == ALREADY_BOUND_ERRNO:\n err_dialog = QtWidgets.QMessageBox()\n err_dialog.setText(name + strings.app_is_already_running)\n err_dialog.exec()\n sys.exit()\n else:\n raise\n\n\nclass SetupThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'setup']\n\n # Create flag file to indicate we should resume failed updates on\n # reboot. Don't create the flag if it already exists.\n if not os.path.exists(FLAG_LOCATION):\n open(FLAG_LOCATION, 'a').close()\n\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if 'Failed to install' in self.output:\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n else:\n self.update_success = True\n except subprocess.CalledProcessError as e:\n self.output += e.output.decode('utf-8')\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin update command\nclass UpdateThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'update']\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if \"Signature verification successful\" in self.output:\n self.update_success = True\n else:\n self.failure_reason = strings.update_failed_generic_reason\n except subprocess.CalledProcessError as e:\n self.update_success = False\n self.output += e.output.decode('utf-8')\n if 'Signature verification failed' in self.output:\n self.failure_reason = strings.update_failed_sig_failure\n else:\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin tailsconfig command\nclass TailsconfigThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n self.sudo_password = \"\"\n\n def run(self):\n tailsconfig_command = (\"/home/amnesia/Persistent/\"\n \"securedrop/securedrop-admin \"\n \"tailsconfig\")\n try:\n child = pexpect.spawn(tailsconfig_command)\n child.expect('SUDO password:')\n self.output += child.before.decode('utf-8')\n child.sendline(self.sudo_password)\n child.expect(pexpect.EOF)\n self.output += child.before.decode('utf-8')\n child.close()\n\n # For Tailsconfig to be considered a success, we expect no\n # failures in the Ansible output.\n if child.exitstatus:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason # noqa\n else:\n self.update_success = True\n except pexpect.exceptions.TIMEOUT:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_sudo_password\n\n except subprocess.CalledProcessError:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason\n result = {'status': self.update_success,\n 'output': ESCAPE_POD.sub('', self.output),\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\nclass UpdaterApp(QtWidgets.QMainWindow, updaterUI.Ui_MainWindow):\n\n def __init__(self, parent=None):\n super(UpdaterApp, self).__init__(parent)\n self.setupUi(self)\n self.statusbar.setSizeGripEnabled(False)\n self.output = strings.initial_text_box\n self.plainTextEdit.setPlainText(self.output)\n self.update_success = False\n\n pixmap = QtGui.QPixmap(\":/images/static/banner.png\")\n self.label_2.setPixmap(pixmap)\n self.label_2.setScaledContents(True)\n\n self.progressBar.setProperty(\"value\", 0)\n self.setWindowTitle(strings.window_title)\n self.setWindowIcon(QtGui.QIcon(':/images/static/securedrop_icon.png'))\n self.label.setText(strings.update_in_progress)\n\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab),\n strings.main_tab)\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_2),\n strings.output_tab)\n\n # Connect buttons to their functions.\n self.pushButton.setText(strings.install_later_button)\n self.pushButton.setStyleSheet(\"\"\"background-color: lightgrey;\n min-height: 2em;\n border-radius: 10px\"\"\")\n self.pushButton.clicked.connect(self.close)\n self.pushButton_2.setText(strings.install_update_button)\n self.pushButton_2.setStyleSheet(\"\"\"background-color: #E6FFEB;\n min-height: 2em;\n border-radius: 10px;\"\"\")\n self.pushButton_2.clicked.connect(self.update_securedrop)\n self.update_thread = UpdateThread()\n self.update_thread.signal.connect(self.update_status)\n self.tails_thread = TailsconfigThread()\n self.tails_thread.signal.connect(self.tails_status)\n self.setup_thread = SetupThread()\n self.setup_thread.signal.connect(self.setup_status)\n\n # At the end of this function, we will try to do tailsconfig.\n # A new slot will handle tailsconfig output\n def setup_status(self, result):\n \"This is the slot for setup thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 60)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do setup\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 70)\n self.call_tailsconfig()\n\n # This will update the output text after the git commands.\n def update_status(self, result):\n \"This is the slot for update thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 40)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do update\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 50)\n self.update_status_bar_and_output(strings.doing_setup)\n self.setup_thread.start()\n\n def update_status_bar_and_output(self, status_message):\n \"\"\"This method updates the status bar and the output window with the\n status_message.\"\"\"\n self.statusbar.showMessage(status_message)\n self.output += status_message + '\\n'\n self.plainTextEdit.setPlainText(self.output)\n\n def call_tailsconfig(self):\n # Now let us work on tailsconfig part\n if self.update_success:\n # Get sudo password and add an enter key as tailsconfig command\n # expects\n sudo_password = self.get_sudo_password()\n if not sudo_password:\n self.update_success = False\n self.failure_reason = strings.missing_sudo_password\n self.on_failure()\n return\n self.tails_thread.sudo_password = sudo_password + '\\n'\n self.update_status_bar_and_output(strings.updating_tails_env)\n self.tails_thread.start()\n else:\n self.on_failure()\n\n def tails_status(self, result):\n \"This is the slot for Tailsconfig thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.plainTextEdit.setPlainText(self.output)\n self.progressBar.setProperty(\"value\", 80)\n if self.update_success:\n # Remove flag file indicating an update is in progress\n os.remove(FLAG_LOCATION)\n self.update_status_bar_and_output(strings.finished)\n self.progressBar.setProperty(\"value\", 100)\n self.alert_success()\n else:\n self.on_failure()\n\n def on_failure(self):\n self.update_status_bar_and_output(self.failure_reason)\n self.alert_failure(self.failure_reason)\n # Now everything is done, enable the button.\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.progressBar.setProperty(\"value\", 0)\n\n def update_securedrop(self):\n if password_is_set():\n self.pushButton_2.setEnabled(False)\n self.pushButton.setEnabled(False)\n self.progressBar.setProperty(\"value\", 10)\n self.update_status_bar_and_output(strings.fetching_update)\n self.update_thread.start()\n else:\n self.pushButton_2.setEnabled(False)\n pwd_err_dialog = QtWidgets.QMessageBox()\n pwd_err_dialog.setText(strings.no_password_set_message)\n pwd_err_dialog.exec()\n\n def alert_success(self):\n self.success_dialog = QtWidgets.QMessageBox()\n self.success_dialog.setIcon(QtWidgets.QMessageBox.Information)\n self.success_dialog.setText(strings.finished_dialog_message)\n self.success_dialog.setWindowTitle(strings.finished_dialog_title)\n self.success_dialog.show()\n\n def alert_failure(self, failure_reason):\n self.error_dialog = QtWidgets.QMessageBox()\n self.error_dialog.setIcon(QtWidgets.QMessageBox.Critical)\n self.error_dialog.setText(self.failure_reason)\n self.error_dialog.setWindowTitle(strings.update_failed_dialog_title)\n self.error_dialog.show()\n\n def get_sudo_password(self):\n sudo_password, ok_is_pressed = QtWidgets.QInputDialog.getText(\n self, \"Tails Administrator password\", strings.sudo_password_text,\n QtWidgets.QLineEdit.Password, \"\")\n if ok_is_pressed and sudo_password:\n return sudo_password\n else:\n return None\n", "path": "journalist_gui/journalist_gui/SecureDropUpdater.py"}], "after_files": [{"content": "#!/usr/bin/python\nfrom PyQt5 import QtGui, QtWidgets\nfrom PyQt5.QtCore import QThread, pyqtSignal\nimport subprocess\nimport os\nimport re\nimport pexpect\nimport socket\nimport sys\nimport syslog as log\n\nfrom journalist_gui import updaterUI, strings, resources_rc # noqa\n\n\nFLAG_LOCATION = \"/home/amnesia/Persistent/.securedrop/securedrop_update.flag\" # noqa\nESCAPE_POD = re.compile(r'\\x1B\\[[0-?]*[ -/]*[@-~]')\n\n\ndef password_is_set():\n\n pwd_flag = subprocess.check_output(['passwd', '--status']).decode('utf-8').split()[1]\n\n if pwd_flag == 'NP':\n return False\n return True\n\n\ndef prevent_second_instance(app: QtWidgets.QApplication, name: str) -> None: # noqa\n\n # Null byte triggers abstract namespace\n IDENTIFIER = '\\0' + name\n ALREADY_BOUND_ERRNO = 98\n\n app.instance_binding = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)\n try:\n app.instance_binding.bind(IDENTIFIER)\n except OSError as e:\n if e.errno == ALREADY_BOUND_ERRNO:\n log.syslog(log.LOG_NOTICE, name + strings.app_is_already_running)\n sys.exit()\n else:\n raise\n\n\nclass SetupThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'setup']\n\n # Create flag file to indicate we should resume failed updates on\n # reboot. Don't create the flag if it already exists.\n if not os.path.exists(FLAG_LOCATION):\n open(FLAG_LOCATION, 'a').close()\n\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if 'Failed to install' in self.output:\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n else:\n self.update_success = True\n except subprocess.CalledProcessError as e:\n self.output += e.output.decode('utf-8')\n self.update_success = False\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin update command\nclass UpdateThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n\n def run(self):\n sdadmin_path = '/home/amnesia/Persistent/securedrop/securedrop-admin'\n update_command = [sdadmin_path, 'update']\n try:\n self.output = subprocess.check_output(\n update_command,\n stderr=subprocess.STDOUT).decode('utf-8')\n if \"Signature verification successful\" in self.output:\n self.update_success = True\n else:\n self.failure_reason = strings.update_failed_generic_reason\n except subprocess.CalledProcessError as e:\n self.update_success = False\n self.output += e.output.decode('utf-8')\n if 'Signature verification failed' in self.output:\n self.failure_reason = strings.update_failed_sig_failure\n else:\n self.failure_reason = strings.update_failed_generic_reason\n result = {'status': self.update_success,\n 'output': self.output,\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\n# This thread will handle the ./securedrop-admin tailsconfig command\nclass TailsconfigThread(QThread):\n signal = pyqtSignal('PyQt_PyObject')\n\n def __init__(self):\n QThread.__init__(self)\n self.output = \"\"\n self.update_success = False\n self.failure_reason = \"\"\n self.sudo_password = \"\"\n\n def run(self):\n tailsconfig_command = (\"/home/amnesia/Persistent/\"\n \"securedrop/securedrop-admin \"\n \"tailsconfig\")\n try:\n child = pexpect.spawn(tailsconfig_command)\n child.expect('SUDO password:')\n self.output += child.before.decode('utf-8')\n child.sendline(self.sudo_password)\n child.expect(pexpect.EOF)\n self.output += child.before.decode('utf-8')\n child.close()\n\n # For Tailsconfig to be considered a success, we expect no\n # failures in the Ansible output.\n if child.exitstatus:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason # noqa\n else:\n self.update_success = True\n except pexpect.exceptions.TIMEOUT:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_sudo_password\n\n except subprocess.CalledProcessError:\n self.update_success = False\n self.failure_reason = strings.tailsconfig_failed_generic_reason\n result = {'status': self.update_success,\n 'output': ESCAPE_POD.sub('', self.output),\n 'failure_reason': self.failure_reason}\n self.signal.emit(result)\n\n\nclass UpdaterApp(QtWidgets.QMainWindow, updaterUI.Ui_MainWindow):\n\n def __init__(self, parent=None):\n super(UpdaterApp, self).__init__(parent)\n self.setupUi(self)\n self.statusbar.setSizeGripEnabled(False)\n self.output = strings.initial_text_box\n self.plainTextEdit.setPlainText(self.output)\n self.update_success = False\n\n pixmap = QtGui.QPixmap(\":/images/static/banner.png\")\n self.label_2.setPixmap(pixmap)\n self.label_2.setScaledContents(True)\n\n self.progressBar.setProperty(\"value\", 0)\n self.setWindowTitle(strings.window_title)\n self.setWindowIcon(QtGui.QIcon(':/images/static/securedrop_icon.png'))\n self.label.setText(strings.update_in_progress)\n\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab),\n strings.main_tab)\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_2),\n strings.output_tab)\n\n # Connect buttons to their functions.\n self.pushButton.setText(strings.install_later_button)\n self.pushButton.setStyleSheet(\"\"\"background-color: lightgrey;\n min-height: 2em;\n border-radius: 10px\"\"\")\n self.pushButton.clicked.connect(self.close)\n self.pushButton_2.setText(strings.install_update_button)\n self.pushButton_2.setStyleSheet(\"\"\"background-color: #E6FFEB;\n min-height: 2em;\n border-radius: 10px;\"\"\")\n self.pushButton_2.clicked.connect(self.update_securedrop)\n self.update_thread = UpdateThread()\n self.update_thread.signal.connect(self.update_status)\n self.tails_thread = TailsconfigThread()\n self.tails_thread.signal.connect(self.tails_status)\n self.setup_thread = SetupThread()\n self.setup_thread.signal.connect(self.setup_status)\n\n # At the end of this function, we will try to do tailsconfig.\n # A new slot will handle tailsconfig output\n def setup_status(self, result):\n \"This is the slot for setup thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 60)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do setup\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 70)\n self.call_tailsconfig()\n\n # This will update the output text after the git commands.\n def update_status(self, result):\n \"This is the slot for update thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.progressBar.setProperty(\"value\", 40)\n self.plainTextEdit.setPlainText(self.output)\n self.plainTextEdit.setReadOnly = True\n if not self.update_success: # Failed to do update\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.update_status_bar_and_output(self.failure_reason)\n self.progressBar.setProperty(\"value\", 0)\n self.alert_failure(self.failure_reason)\n return\n self.progressBar.setProperty(\"value\", 50)\n self.update_status_bar_and_output(strings.doing_setup)\n self.setup_thread.start()\n\n def update_status_bar_and_output(self, status_message):\n \"\"\"This method updates the status bar and the output window with the\n status_message.\"\"\"\n self.statusbar.showMessage(status_message)\n self.output += status_message + '\\n'\n self.plainTextEdit.setPlainText(self.output)\n\n def call_tailsconfig(self):\n # Now let us work on tailsconfig part\n if self.update_success:\n # Get sudo password and add an enter key as tailsconfig command\n # expects\n sudo_password = self.get_sudo_password()\n if not sudo_password:\n self.update_success = False\n self.failure_reason = strings.missing_sudo_password\n self.on_failure()\n return\n self.tails_thread.sudo_password = sudo_password + '\\n'\n self.update_status_bar_and_output(strings.updating_tails_env)\n self.tails_thread.start()\n else:\n self.on_failure()\n\n def tails_status(self, result):\n \"This is the slot for Tailsconfig thread\"\n self.output += result['output']\n self.update_success = result['status']\n self.failure_reason = result['failure_reason']\n self.plainTextEdit.setPlainText(self.output)\n self.progressBar.setProperty(\"value\", 80)\n if self.update_success:\n # Remove flag file indicating an update is in progress\n os.remove(FLAG_LOCATION)\n self.update_status_bar_and_output(strings.finished)\n self.progressBar.setProperty(\"value\", 100)\n self.alert_success()\n else:\n self.on_failure()\n\n def on_failure(self):\n self.update_status_bar_and_output(self.failure_reason)\n self.alert_failure(self.failure_reason)\n # Now everything is done, enable the button.\n self.pushButton.setEnabled(True)\n self.pushButton_2.setEnabled(True)\n self.progressBar.setProperty(\"value\", 0)\n\n def update_securedrop(self):\n if password_is_set():\n self.pushButton_2.setEnabled(False)\n self.pushButton.setEnabled(False)\n self.progressBar.setProperty(\"value\", 10)\n self.update_status_bar_and_output(strings.fetching_update)\n self.update_thread.start()\n else:\n self.pushButton_2.setEnabled(False)\n pwd_err_dialog = QtWidgets.QMessageBox()\n pwd_err_dialog.setText(strings.no_password_set_message)\n pwd_err_dialog.exec()\n\n def alert_success(self):\n self.success_dialog = QtWidgets.QMessageBox()\n self.success_dialog.setIcon(QtWidgets.QMessageBox.Information)\n self.success_dialog.setText(strings.finished_dialog_message)\n self.success_dialog.setWindowTitle(strings.finished_dialog_title)\n self.success_dialog.show()\n\n def alert_failure(self, failure_reason):\n self.error_dialog = QtWidgets.QMessageBox()\n self.error_dialog.setIcon(QtWidgets.QMessageBox.Critical)\n self.error_dialog.setText(self.failure_reason)\n self.error_dialog.setWindowTitle(strings.update_failed_dialog_title)\n self.error_dialog.show()\n\n def get_sudo_password(self):\n sudo_password, ok_is_pressed = QtWidgets.QInputDialog.getText(\n self, \"Tails Administrator password\", strings.sudo_password_text,\n QtWidgets.QLineEdit.Password, \"\")\n if ok_is_pressed and sudo_password:\n return sudo_password\n else:\n return None\n", "path": "journalist_gui/journalist_gui/SecureDropUpdater.py"}]} | 3,816 | 199 |
gh_patches_debug_24425 | rasdani/github-patches | git_diff | conda__conda-5421 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
conda-env update error in 4.3.20
```
conda env update
An unexpected error has occurred.
Please consider posting the following information to the
conda GitHub issue tracker at:
https://github.com/conda/conda/issues
Current conda install:
platform : linux-64
conda version : 4.3.20
conda is private : False
conda-env version : 4.3.20
conda-build version : not installed
python version : 3.5.2.final.0
requests version : 2.14.2
root environment : /home/travis/miniconda (writable)
default environment : /home/travis/miniconda
envs directories : /home/travis/miniconda/envs
/home/travis/.conda/envs
package cache : /home/travis/miniconda/pkgs
/home/travis/.conda/pkgs
channel URLs : https://conda.anaconda.org/conda-canary/linux-64
https://conda.anaconda.org/conda-canary/noarch
https://repo.continuum.io/pkgs/free/linux-64
https://repo.continuum.io/pkgs/free/noarch
https://repo.continuum.io/pkgs/r/linux-64
https://repo.continuum.io/pkgs/r/noarch
https://repo.continuum.io/pkgs/pro/linux-64
https://repo.continuum.io/pkgs/pro/noarch
config file : /home/travis/.condarc
netrc file : None
offline mode : False
user-agent : conda/4.3.20 requests/2.14.2 CPython/3.5.2 Linux/4.4.0-51-generic debian/jessie/sid glibc/2.19
UID:GID : 1000:1000
`$ /home/travis/miniconda/bin/conda-env update`
Traceback (most recent call last):
File "/home/travis/miniconda/lib/python3.5/site-packages/conda/exceptions.py", line 632, in conda_exception_handler
return_value = func(*args, **kwargs)
File "/home/travis/miniconda/lib/python3.5/site-packages/conda_env/cli/main_update.py", line 82, in execute
if not (args.name or args.prefix):
AttributeError: 'Namespace' object has no attribute 'prefix'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_env/cli/main_update.py`
Content:
```
1 from argparse import RawDescriptionHelpFormatter
2 import os
3 import textwrap
4 import sys
5
6 from conda import config
7 from conda.cli import common
8 from conda.cli import install as cli_install
9 from conda.misc import touch_nonadmin
10 from ..installers.base import get_installer, InvalidInstaller
11 from .. import specs as install_specs
12 from .. import exceptions
13 # for conda env
14 from conda_env.cli.common import get_prefix
15 from ..exceptions import CondaEnvException
16 description = """
17 Update the current environment based on environment file
18 """
19
20 example = """
21 examples:
22 conda env update
23 conda env update -n=foo
24 conda env update -f=/path/to/environment.yml
25 conda env update --name=foo --file=environment.yml
26 conda env update vader/deathstar
27 """
28
29
30 def configure_parser(sub_parsers):
31 p = sub_parsers.add_parser(
32 'update',
33 formatter_class=RawDescriptionHelpFormatter,
34 description=description,
35 help=description,
36 epilog=example,
37 )
38 p.add_argument(
39 '-n', '--name',
40 action='store',
41 help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),
42 default=None,
43 )
44 p.add_argument(
45 '-f', '--file',
46 action='store',
47 help='environment definition (default: environment.yml)',
48 default='environment.yml',
49 )
50 p.add_argument(
51 '--prune',
52 action='store_true',
53 default=False,
54 help='remove installed packages not defined in environment.yml',
55 )
56 p.add_argument(
57 '-q', '--quiet',
58 action='store_true',
59 default=False,
60 )
61 p.add_argument(
62 'remote_definition',
63 help='remote environment definition / IPython notebook',
64 action='store',
65 default=None,
66 nargs='?'
67 )
68 common.add_parser_json(p)
69 p.set_defaults(func=execute)
70
71
72 def execute(args, parser):
73 name = args.remote_definition or args.name
74
75 try:
76 spec = install_specs.detect(name=name, filename=args.file,
77 directory=os.getcwd())
78 env = spec.environment
79 except exceptions.SpecNotFound:
80 raise
81
82 if not (args.name or args.prefix):
83 if not env.name:
84 # Note, this is a hack fofr get_prefix that assumes argparse results
85 # TODO Refactor common.get_prefix
86 name = os.environ.get('CONDA_DEFAULT_ENV', False)
87 if not name:
88 msg = "Unable to determine environment\n\n"
89 msg += textwrap.dedent("""
90 Please re-run this command with one of the following options:
91
92 * Provide an environment name via --name or -n
93 * Re-run this command inside an activated conda environment.""").lstrip()
94 # TODO Add json support
95 raise CondaEnvException(msg)
96
97 # Note: stubbing out the args object as all of the
98 # conda.cli.common code thinks that name will always
99 # be specified.
100 args.name = env.name
101
102 prefix = get_prefix(args, search=False)
103 # CAN'T Check with this function since it assumes we will create prefix.
104 # cli_install.check_prefix(prefix, json=args.json)
105
106 # TODO, add capability
107 # common.ensure_override_channels_requires_channel(args)
108 # channel_urls = args.channel or ()
109
110 for installer_type, specs in env.dependencies.items():
111 try:
112 installer = get_installer(installer_type)
113 installer.install(prefix, specs, args, env, prune=args.prune)
114 except InvalidInstaller:
115 sys.stderr.write(textwrap.dedent("""
116 Unable to install package for {0}.
117
118 Please double check and ensure you dependencies file has
119 the correct spelling. You might also try installing the
120 conda-env-{0} package to see if provides the required
121 installer.
122 """).lstrip().format(installer_type)
123 )
124 return -1
125
126 touch_nonadmin(prefix)
127 if not args.json:
128 print(cli_install.print_activate(args.name if args.name else prefix))
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py
--- a/conda_env/cli/main_update.py
+++ b/conda_env/cli/main_update.py
@@ -1,18 +1,16 @@
from argparse import RawDescriptionHelpFormatter
import os
-import textwrap
import sys
+import textwrap
-from conda import config
-from conda.cli import common
-from conda.cli import install as cli_install
+from conda.cli import common, install as cli_install
from conda.misc import touch_nonadmin
-from ..installers.base import get_installer, InvalidInstaller
-from .. import specs as install_specs
-from .. import exceptions
# for conda env
from conda_env.cli.common import get_prefix
+from .. import exceptions, specs as install_specs
from ..exceptions import CondaEnvException
+from ..installers.base import InvalidInstaller, get_installer
+
description = """
Update the current environment based on environment file
"""
@@ -35,12 +33,7 @@
help=description,
epilog=example,
)
- p.add_argument(
- '-n', '--name',
- action='store',
- help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),
- default=None,
- )
+ common.add_parser_prefix(p)
p.add_argument(
'-f', '--file',
action='store',
| {"golden_diff": "diff --git a/conda_env/cli/main_update.py b/conda_env/cli/main_update.py\n--- a/conda_env/cli/main_update.py\n+++ b/conda_env/cli/main_update.py\n@@ -1,18 +1,16 @@\n from argparse import RawDescriptionHelpFormatter\n import os\n-import textwrap\n import sys\n+import textwrap\n \n-from conda import config\n-from conda.cli import common\n-from conda.cli import install as cli_install\n+from conda.cli import common, install as cli_install\n from conda.misc import touch_nonadmin\n-from ..installers.base import get_installer, InvalidInstaller\n-from .. import specs as install_specs\n-from .. import exceptions\n # for conda env\n from conda_env.cli.common import get_prefix\n+from .. import exceptions, specs as install_specs\n from ..exceptions import CondaEnvException\n+from ..installers.base import InvalidInstaller, get_installer\n+\n description = \"\"\"\n Update the current environment based on environment file\n \"\"\"\n@@ -35,12 +33,7 @@\n help=description,\n epilog=example,\n )\n- p.add_argument(\n- '-n', '--name',\n- action='store',\n- help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),\n- default=None,\n- )\n+ common.add_parser_prefix(p)\n p.add_argument(\n '-f', '--file',\n action='store',\n", "issue": "conda-env update error in 4.3.20\n```\r\nconda env update\r\nAn unexpected error has occurred.\r\nPlease consider posting the following information to the\r\nconda GitHub issue tracker at:\r\n https://github.com/conda/conda/issues\r\nCurrent conda install:\r\n platform : linux-64\r\n conda version : 4.3.20\r\n conda is private : False\r\n conda-env version : 4.3.20\r\n conda-build version : not installed\r\n python version : 3.5.2.final.0\r\n requests version : 2.14.2\r\n root environment : /home/travis/miniconda (writable)\r\n default environment : /home/travis/miniconda\r\n envs directories : /home/travis/miniconda/envs\r\n /home/travis/.conda/envs\r\n package cache : /home/travis/miniconda/pkgs\r\n /home/travis/.conda/pkgs\r\n channel URLs : https://conda.anaconda.org/conda-canary/linux-64\r\n https://conda.anaconda.org/conda-canary/noarch\r\n https://repo.continuum.io/pkgs/free/linux-64\r\n https://repo.continuum.io/pkgs/free/noarch\r\n https://repo.continuum.io/pkgs/r/linux-64\r\n https://repo.continuum.io/pkgs/r/noarch\r\n https://repo.continuum.io/pkgs/pro/linux-64\r\n https://repo.continuum.io/pkgs/pro/noarch\r\n config file : /home/travis/.condarc\r\n netrc file : None\r\n offline mode : False\r\n user-agent : conda/4.3.20 requests/2.14.2 CPython/3.5.2 Linux/4.4.0-51-generic debian/jessie/sid glibc/2.19 \r\n UID:GID : 1000:1000\r\n`$ /home/travis/miniconda/bin/conda-env update`\r\n Traceback (most recent call last):\r\n File \"/home/travis/miniconda/lib/python3.5/site-packages/conda/exceptions.py\", line 632, in conda_exception_handler\r\n return_value = func(*args, **kwargs)\r\n File \"/home/travis/miniconda/lib/python3.5/site-packages/conda_env/cli/main_update.py\", line 82, in execute\r\n if not (args.name or args.prefix):\r\n AttributeError: 'Namespace' object has no attribute 'prefix'\r\n```\n", "before_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport textwrap\nimport sys\n\nfrom conda import config\nfrom conda.cli import common\nfrom conda.cli import install as cli_install\nfrom conda.misc import touch_nonadmin\nfrom ..installers.base import get_installer, InvalidInstaller\nfrom .. import specs as install_specs\nfrom .. import exceptions\n# for conda env\nfrom conda_env.cli.common import get_prefix\nfrom ..exceptions import CondaEnvException\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n p.add_argument(\n '-n', '--name',\n action='store',\n help='name of environment (in %s)' % os.pathsep.join(config.envs_dirs),\n default=None,\n )\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n common.add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}], "after_files": [{"content": "from argparse import RawDescriptionHelpFormatter\nimport os\nimport sys\nimport textwrap\n\nfrom conda.cli import common, install as cli_install\nfrom conda.misc import touch_nonadmin\n# for conda env\nfrom conda_env.cli.common import get_prefix\nfrom .. import exceptions, specs as install_specs\nfrom ..exceptions import CondaEnvException\nfrom ..installers.base import InvalidInstaller, get_installer\n\ndescription = \"\"\"\nUpdate the current environment based on environment file\n\"\"\"\n\nexample = \"\"\"\nexamples:\n conda env update\n conda env update -n=foo\n conda env update -f=/path/to/environment.yml\n conda env update --name=foo --file=environment.yml\n conda env update vader/deathstar\n\"\"\"\n\n\ndef configure_parser(sub_parsers):\n p = sub_parsers.add_parser(\n 'update',\n formatter_class=RawDescriptionHelpFormatter,\n description=description,\n help=description,\n epilog=example,\n )\n common.add_parser_prefix(p)\n p.add_argument(\n '-f', '--file',\n action='store',\n help='environment definition (default: environment.yml)',\n default='environment.yml',\n )\n p.add_argument(\n '--prune',\n action='store_true',\n default=False,\n help='remove installed packages not defined in environment.yml',\n )\n p.add_argument(\n '-q', '--quiet',\n action='store_true',\n default=False,\n )\n p.add_argument(\n 'remote_definition',\n help='remote environment definition / IPython notebook',\n action='store',\n default=None,\n nargs='?'\n )\n common.add_parser_json(p)\n p.set_defaults(func=execute)\n\n\ndef execute(args, parser):\n name = args.remote_definition or args.name\n\n try:\n spec = install_specs.detect(name=name, filename=args.file,\n directory=os.getcwd())\n env = spec.environment\n except exceptions.SpecNotFound:\n raise\n\n if not (args.name or args.prefix):\n if not env.name:\n # Note, this is a hack fofr get_prefix that assumes argparse results\n # TODO Refactor common.get_prefix\n name = os.environ.get('CONDA_DEFAULT_ENV', False)\n if not name:\n msg = \"Unable to determine environment\\n\\n\"\n msg += textwrap.dedent(\"\"\"\n Please re-run this command with one of the following options:\n\n * Provide an environment name via --name or -n\n * Re-run this command inside an activated conda environment.\"\"\").lstrip()\n # TODO Add json support\n raise CondaEnvException(msg)\n\n # Note: stubbing out the args object as all of the\n # conda.cli.common code thinks that name will always\n # be specified.\n args.name = env.name\n\n prefix = get_prefix(args, search=False)\n # CAN'T Check with this function since it assumes we will create prefix.\n # cli_install.check_prefix(prefix, json=args.json)\n\n # TODO, add capability\n # common.ensure_override_channels_requires_channel(args)\n # channel_urls = args.channel or ()\n\n for installer_type, specs in env.dependencies.items():\n try:\n installer = get_installer(installer_type)\n installer.install(prefix, specs, args, env, prune=args.prune)\n except InvalidInstaller:\n sys.stderr.write(textwrap.dedent(\"\"\"\n Unable to install package for {0}.\n\n Please double check and ensure you dependencies file has\n the correct spelling. You might also try installing the\n conda-env-{0} package to see if provides the required\n installer.\n \"\"\").lstrip().format(installer_type)\n )\n return -1\n\n touch_nonadmin(prefix)\n if not args.json:\n print(cli_install.print_activate(args.name if args.name else prefix))\n", "path": "conda_env/cli/main_update.py"}]} | 1,978 | 311 |
gh_patches_debug_22597 | rasdani/github-patches | git_diff | pwndbg__pwndbg-430 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pwndbg failing with GDB using language different than English
### Description
After installing pwndbg with a GDB that uses Spanish language we do fail on detecting whether `osabi` is Linux.
This happens after launching GDB:
https://prnt.sc/itwf3u
And this is the return of `show osabi` for GDB with spanish language:
```
(gdb) show osabi
El actual SO ABI es «auto» (actualmente «GNU/Linux»).
El SO ABI predeterminado es «GNU/Linux».
```
This is the code responsible for failure:
https://github.com/pwndbg/pwndbg/blob/dev/pwndbg/abi.py#L127-L140
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/abi.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import
3 from __future__ import division
4 from __future__ import print_function
5 from __future__ import unicode_literals
6
7 import functools
8 import re
9
10 import gdb
11
12 import pwndbg.arch
13 import pwndbg.color.message as M
14
15
16 class ABI(object):
17 """
18 Encapsulates information about a calling convention.
19 """
20 #: List or registers which should be filled with arguments before
21 #: spilling onto the stack.
22 register_arguments = []
23
24 #: Minimum alignment of the stack.
25 #: The value used is min(context.bytes, stack_alignment)
26 #: This is necessary as Windows x64 frames must be 32-byte aligned.
27 #: "Alignment" is considered with respect to the last argument on the stack.
28 arg_alignment = 1
29
30 #: Minimum number of stack slots used by a function call
31 #: This is necessary as Windows x64 requires using 4 slots on the stack
32 stack_minimum = 0
33
34 #: Indicates that this ABI returns to the next address on the slot
35 returns = True
36
37 def __init__(self, regs, align, minimum):
38 self.register_arguments = regs
39 self.arg_alignment = align
40 self.stack_minimum = minimum
41
42 @staticmethod
43 def default():
44 return {
45 (32, 'i386', 'linux'): linux_i386,
46 (64, 'x86-64', 'linux'): linux_amd64,
47 (64, 'aarch64', 'linux'): linux_aarch64,
48 (32, 'arm', 'linux'): linux_arm,
49 (32, 'thumb', 'linux'): linux_arm,
50 (32, 'mips', 'linux'): linux_mips,
51 (32, 'powerpc', 'linux'): linux_ppc,
52 (64, 'powerpc', 'linux'): linux_ppc64,
53 }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]
54
55 @staticmethod
56 def syscall():
57 return {
58 (32, 'i386', 'linux'): linux_i386_syscall,
59 (64, 'x86-64', 'linux'): linux_amd64_syscall,
60 (64, 'aarch64', 'linux'): linux_aarch64_syscall,
61 (32, 'arm', 'linux'): linux_arm_syscall,
62 (32, 'thumb', 'linux'): linux_arm_syscall,
63 (32, 'mips', 'linux'): linux_mips_syscall,
64 (32, 'powerpc', 'linux'): linux_ppc_syscall,
65 (64, 'powerpc', 'linux'): linux_ppc64_syscall,
66 }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]
67
68 @staticmethod
69 def sigreturn():
70 return {
71 (32, 'i386', 'linux'): linux_i386_sigreturn,
72 (64, 'x86-64', 'linux'): linux_amd64_sigreturn,
73 (32, 'arm', 'linux'): linux_arm_sigreturn,
74 (32, 'thumb', 'linux'): linux_arm_sigreturn,
75 }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]
76
77 class SyscallABI(ABI):
78 """
79 The syscall ABI treats the syscall number as the zeroth argument,
80 which must be loaded into the specified register.
81 """
82 def __init__(self, register_arguments, *a, **kw):
83 self.syscall_register = register_arguments.pop(0)
84 super(SyscallABI, self).__init__(register_arguments, *a, **kw)
85
86
87 class SigreturnABI(SyscallABI):
88 """
89 The sigreturn ABI is similar to the syscall ABI, except that
90 both PC and SP are loaded from the stack. Because of this, there
91 is no 'return' slot necessary on the stack.
92 """
93 returns = False
94
95
96 linux_i386 = ABI([], 4, 0)
97 linux_amd64 = ABI(['rdi','rsi','rdx','rcx','r8','r9'], 8, 0)
98 linux_arm = ABI(['r0', 'r1', 'r2', 'r3'], 8, 0)
99 linux_aarch64 = ABI(['x0', 'x1', 'x2', 'x3'], 16, 0)
100 linux_mips = ABI(['$a0','$a1','$a2','$a3'], 4, 0)
101 linux_ppc = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 4, 0)
102 linux_ppc64 = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 8, 0)
103
104 linux_i386_syscall = SyscallABI(['eax', 'ebx', 'ecx', 'edx', 'esi', 'edi', 'ebp'], 4, 0)
105 linux_amd64_syscall = SyscallABI(['rax','rdi', 'rsi', 'rdx', 'r10', 'r8', 'r9'], 8, 0)
106 linux_arm_syscall = SyscallABI(['r7', 'r0', 'r1', 'r2', 'r3', 'r4', 'r5', 'r6'], 4, 0)
107 linux_aarch64_syscall = SyscallABI(['x8', 'x0', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6'], 16, 0)
108 linux_mips_syscall = SyscallABI(['$v0', '$a0','$a1','$a2','$a3'], 4, 0)
109 linux_ppc_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 4, 0)
110 linux_ppc64_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 8, 0)
111
112 linux_i386_sigreturn = SigreturnABI(['eax'], 4, 0)
113 linux_amd64_sigreturn = SigreturnABI(['rax'], 4, 0)
114 linux_arm_sigreturn = SigreturnABI(['r7'], 4, 0)
115
116 # Fake ABIs used by SROP
117 linux_i386_srop = ABI(['eax'], 4, 0)
118 linux_amd64_srop = ABI(['rax'], 4, 0)
119 linux_arm_srop = ABI(['r7'], 4, 0)
120
121
122 @pwndbg.events.start
123 def update():
124 global abi
125 global linux
126
127 # Detect current ABI of client side by 'show osabi'
128 osabi_string = gdb.execute('show osabi', to_string=True)
129
130 # The return string will be:
131 # The current OS ABI is "auto" (currently "GNU/Linux").
132 match = re.search('currently "([^"]+)"', osabi_string)
133 if match:
134 # 'GNU/Linux': linux
135 # 'none': bare metal
136 abi = match.group(1)
137
138 linux = 'Linux' in abi
139
140 if not linux:
141 msg = M.warn(
142 "The bare metal debugging is enabled since the gdb's osabi is '%s' which is not 'GNU/Linux'.\n"
143 "Ex. the page resolving and memory de-referencing ONLY works on known pages.\n"
144 "This option is based ib gdb client compile arguments (by default) and will be corrected if you load an ELF which has the '.note.ABI-tag' section.\n"
145 "If you are debuging a program that runs on Linux ABI, please select the correct gdb client."
146 % abi
147 )
148 print(msg)
149
150
151 def LinuxOnly(default=None):
152 """Create a decorator that the function will be called when ABI is Linux.
153 Otherwise, return `default`.
154 """
155 def decorator(func):
156 @functools.wraps(func)
157 def caller(*args, **kwargs):
158 if linux:
159 return func(*args, **kwargs)
160 else:
161 return default
162 return caller
163
164 return decorator
165
166
167 # Update when starting the gdb to show warning message for non-Linux ABI user.
168 update()
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pwndbg/abi.py b/pwndbg/abi.py
--- a/pwndbg/abi.py
+++ b/pwndbg/abi.py
@@ -125,17 +125,23 @@
global linux
# Detect current ABI of client side by 'show osabi'
- osabi_string = gdb.execute('show osabi', to_string=True)
-
- # The return string will be:
- # The current OS ABI is "auto" (currently "GNU/Linux").
- match = re.search('currently "([^"]+)"', osabi_string)
- if match:
- # 'GNU/Linux': linux
- # 'none': bare metal
- abi = match.group(1)
-
- linux = 'Linux' in abi
+ #
+ # Examples of strings returned by `show osabi`:
+ # 'The current OS ABI is "auto" (currently "GNU/Linux").\nThe default OS ABI is "GNU/Linux".\n'
+ # 'The current OS ABI is "GNU/Linux".\nThe default OS ABI is "GNU/Linux".\n'
+ # 'El actual SO ABI es «auto» (actualmente «GNU/Linux»).\nEl SO ABI predeterminado es «GNU/Linux».\n'
+ # 'The current OS ABI is "auto" (currently "none")'
+ #
+ # As you can see, there might be GDBs with different language versions
+ # and so we have to support it there too.
+ # Lets assume and hope that `current osabi` is returned in first line in all languages...
+ current_osabi = gdb.execute('show osabi', to_string=True).split('\n')[0]
+
+ # Currently we support those osabis:
+ # 'GNU/Linux': linux
+ # 'none': bare metal
+
+ linux = 'GNU/Linux' in current_osabi
if not linux:
msg = M.warn(
| {"golden_diff": "diff --git a/pwndbg/abi.py b/pwndbg/abi.py\n--- a/pwndbg/abi.py\n+++ b/pwndbg/abi.py\n@@ -125,17 +125,23 @@\n global linux\n \n # Detect current ABI of client side by 'show osabi'\n- osabi_string = gdb.execute('show osabi', to_string=True)\n-\n- # The return string will be:\n- # The current OS ABI is \"auto\" (currently \"GNU/Linux\").\n- match = re.search('currently \"([^\"]+)\"', osabi_string)\n- if match:\n- # 'GNU/Linux': linux\n- # 'none': bare metal\n- abi = match.group(1)\n-\n- linux = 'Linux' in abi\n+ #\n+ # Examples of strings returned by `show osabi`:\n+ # 'The current OS ABI is \"auto\" (currently \"GNU/Linux\").\\nThe default OS ABI is \"GNU/Linux\".\\n'\n+ # 'The current OS ABI is \"GNU/Linux\".\\nThe default OS ABI is \"GNU/Linux\".\\n'\n+ # 'El actual SO ABI es \u00abauto\u00bb (actualmente \u00abGNU/Linux\u00bb).\\nEl SO ABI predeterminado es \u00abGNU/Linux\u00bb.\\n'\n+ # 'The current OS ABI is \"auto\" (currently \"none\")'\n+ #\n+ # As you can see, there might be GDBs with different language versions\n+ # and so we have to support it there too.\n+ # Lets assume and hope that `current osabi` is returned in first line in all languages...\n+ current_osabi = gdb.execute('show osabi', to_string=True).split('\\n')[0]\n+\n+ # Currently we support those osabis:\n+ # 'GNU/Linux': linux\n+ # 'none': bare metal\n+\n+ linux = 'GNU/Linux' in current_osabi\n \n if not linux:\n msg = M.warn(\n", "issue": "Pwndbg failing with GDB using language different than English\n### Description\r\n\r\nAfter installing pwndbg with a GDB that uses Spanish language we do fail on detecting whether `osabi` is Linux.\r\n\r\nThis happens after launching GDB:\r\nhttps://prnt.sc/itwf3u\r\n\r\nAnd this is the return of `show osabi` for GDB with spanish language:\r\n```\r\n(gdb) show osabi \r\nEl actual SO ABI es \u00abauto\u00bb (actualmente \u00abGNU/Linux\u00bb).\r\nEl SO ABI predeterminado es \u00abGNU/Linux\u00bb. \r\n```\r\n\r\nThis is the code responsible for failure:\r\nhttps://github.com/pwndbg/pwndbg/blob/dev/pwndbg/abi.py#L127-L140\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport functools\nimport re\n\nimport gdb\n\nimport pwndbg.arch\nimport pwndbg.color.message as M\n\n\nclass ABI(object):\n \"\"\"\n Encapsulates information about a calling convention.\n \"\"\"\n #: List or registers which should be filled with arguments before\n #: spilling onto the stack.\n register_arguments = []\n\n #: Minimum alignment of the stack.\n #: The value used is min(context.bytes, stack_alignment)\n #: This is necessary as Windows x64 frames must be 32-byte aligned.\n #: \"Alignment\" is considered with respect to the last argument on the stack.\n arg_alignment = 1\n\n #: Minimum number of stack slots used by a function call\n #: This is necessary as Windows x64 requires using 4 slots on the stack\n stack_minimum = 0\n\n #: Indicates that this ABI returns to the next address on the slot\n returns = True\n\n def __init__(self, regs, align, minimum):\n self.register_arguments = regs\n self.arg_alignment = align\n self.stack_minimum = minimum\n\n @staticmethod\n def default():\n return {\n (32, 'i386', 'linux'): linux_i386,\n (64, 'x86-64', 'linux'): linux_amd64,\n (64, 'aarch64', 'linux'): linux_aarch64,\n (32, 'arm', 'linux'): linux_arm,\n (32, 'thumb', 'linux'): linux_arm,\n (32, 'mips', 'linux'): linux_mips,\n (32, 'powerpc', 'linux'): linux_ppc,\n (64, 'powerpc', 'linux'): linux_ppc64,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\n @staticmethod\n def syscall():\n return {\n (32, 'i386', 'linux'): linux_i386_syscall,\n (64, 'x86-64', 'linux'): linux_amd64_syscall,\n (64, 'aarch64', 'linux'): linux_aarch64_syscall,\n (32, 'arm', 'linux'): linux_arm_syscall,\n (32, 'thumb', 'linux'): linux_arm_syscall,\n (32, 'mips', 'linux'): linux_mips_syscall,\n (32, 'powerpc', 'linux'): linux_ppc_syscall,\n (64, 'powerpc', 'linux'): linux_ppc64_syscall,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\n @staticmethod\n def sigreturn():\n return {\n (32, 'i386', 'linux'): linux_i386_sigreturn,\n (64, 'x86-64', 'linux'): linux_amd64_sigreturn,\n (32, 'arm', 'linux'): linux_arm_sigreturn,\n (32, 'thumb', 'linux'): linux_arm_sigreturn,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\nclass SyscallABI(ABI):\n \"\"\"\n The syscall ABI treats the syscall number as the zeroth argument,\n which must be loaded into the specified register.\n \"\"\"\n def __init__(self, register_arguments, *a, **kw):\n self.syscall_register = register_arguments.pop(0)\n super(SyscallABI, self).__init__(register_arguments, *a, **kw)\n\n\nclass SigreturnABI(SyscallABI):\n \"\"\"\n The sigreturn ABI is similar to the syscall ABI, except that\n both PC and SP are loaded from the stack. Because of this, there\n is no 'return' slot necessary on the stack.\n \"\"\"\n returns = False\n\n\nlinux_i386 = ABI([], 4, 0)\nlinux_amd64 = ABI(['rdi','rsi','rdx','rcx','r8','r9'], 8, 0)\nlinux_arm = ABI(['r0', 'r1', 'r2', 'r3'], 8, 0)\nlinux_aarch64 = ABI(['x0', 'x1', 'x2', 'x3'], 16, 0)\nlinux_mips = ABI(['$a0','$a1','$a2','$a3'], 4, 0)\nlinux_ppc = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 4, 0)\nlinux_ppc64 = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 8, 0)\n\nlinux_i386_syscall = SyscallABI(['eax', 'ebx', 'ecx', 'edx', 'esi', 'edi', 'ebp'], 4, 0)\nlinux_amd64_syscall = SyscallABI(['rax','rdi', 'rsi', 'rdx', 'r10', 'r8', 'r9'], 8, 0)\nlinux_arm_syscall = SyscallABI(['r7', 'r0', 'r1', 'r2', 'r3', 'r4', 'r5', 'r6'], 4, 0)\nlinux_aarch64_syscall = SyscallABI(['x8', 'x0', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6'], 16, 0)\nlinux_mips_syscall = SyscallABI(['$v0', '$a0','$a1','$a2','$a3'], 4, 0)\nlinux_ppc_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 4, 0)\nlinux_ppc64_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 8, 0)\n\nlinux_i386_sigreturn = SigreturnABI(['eax'], 4, 0)\nlinux_amd64_sigreturn = SigreturnABI(['rax'], 4, 0)\nlinux_arm_sigreturn = SigreturnABI(['r7'], 4, 0)\n\n# Fake ABIs used by SROP\nlinux_i386_srop = ABI(['eax'], 4, 0)\nlinux_amd64_srop = ABI(['rax'], 4, 0)\nlinux_arm_srop = ABI(['r7'], 4, 0)\n\n\[email protected]\ndef update():\n global abi\n global linux\n\n # Detect current ABI of client side by 'show osabi'\n osabi_string = gdb.execute('show osabi', to_string=True)\n\n # The return string will be:\n # The current OS ABI is \"auto\" (currently \"GNU/Linux\").\n match = re.search('currently \"([^\"]+)\"', osabi_string)\n if match:\n # 'GNU/Linux': linux\n # 'none': bare metal\n abi = match.group(1)\n\n linux = 'Linux' in abi\n\n if not linux:\n msg = M.warn(\n \"The bare metal debugging is enabled since the gdb's osabi is '%s' which is not 'GNU/Linux'.\\n\"\n \"Ex. the page resolving and memory de-referencing ONLY works on known pages.\\n\"\n \"This option is based ib gdb client compile arguments (by default) and will be corrected if you load an ELF which has the '.note.ABI-tag' section.\\n\"\n \"If you are debuging a program that runs on Linux ABI, please select the correct gdb client.\"\n % abi\n )\n print(msg)\n\n\ndef LinuxOnly(default=None):\n \"\"\"Create a decorator that the function will be called when ABI is Linux.\n Otherwise, return `default`.\n \"\"\"\n def decorator(func):\n @functools.wraps(func)\n def caller(*args, **kwargs):\n if linux:\n return func(*args, **kwargs)\n else:\n return default\n return caller\n\n return decorator\n\n\n# Update when starting the gdb to show warning message for non-Linux ABI user.\nupdate()\n", "path": "pwndbg/abi.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport functools\nimport re\n\nimport gdb\n\nimport pwndbg.arch\nimport pwndbg.color.message as M\n\n\nclass ABI(object):\n \"\"\"\n Encapsulates information about a calling convention.\n \"\"\"\n #: List or registers which should be filled with arguments before\n #: spilling onto the stack.\n register_arguments = []\n\n #: Minimum alignment of the stack.\n #: The value used is min(context.bytes, stack_alignment)\n #: This is necessary as Windows x64 frames must be 32-byte aligned.\n #: \"Alignment\" is considered with respect to the last argument on the stack.\n arg_alignment = 1\n\n #: Minimum number of stack slots used by a function call\n #: This is necessary as Windows x64 requires using 4 slots on the stack\n stack_minimum = 0\n\n #: Indicates that this ABI returns to the next address on the slot\n returns = True\n\n def __init__(self, regs, align, minimum):\n self.register_arguments = regs\n self.arg_alignment = align\n self.stack_minimum = minimum\n\n @staticmethod\n def default():\n return {\n (32, 'i386', 'linux'): linux_i386,\n (64, 'x86-64', 'linux'): linux_amd64,\n (64, 'aarch64', 'linux'): linux_aarch64,\n (32, 'arm', 'linux'): linux_arm,\n (32, 'thumb', 'linux'): linux_arm,\n (32, 'mips', 'linux'): linux_mips,\n (32, 'powerpc', 'linux'): linux_ppc,\n (64, 'powerpc', 'linux'): linux_ppc64,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\n @staticmethod\n def syscall():\n return {\n (32, 'i386', 'linux'): linux_i386_syscall,\n (64, 'x86-64', 'linux'): linux_amd64_syscall,\n (64, 'aarch64', 'linux'): linux_aarch64_syscall,\n (32, 'arm', 'linux'): linux_arm_syscall,\n (32, 'thumb', 'linux'): linux_arm_syscall,\n (32, 'mips', 'linux'): linux_mips_syscall,\n (32, 'powerpc', 'linux'): linux_ppc_syscall,\n (64, 'powerpc', 'linux'): linux_ppc64_syscall,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\n @staticmethod\n def sigreturn():\n return {\n (32, 'i386', 'linux'): linux_i386_sigreturn,\n (64, 'x86-64', 'linux'): linux_amd64_sigreturn,\n (32, 'arm', 'linux'): linux_arm_sigreturn,\n (32, 'thumb', 'linux'): linux_arm_sigreturn,\n }[(8*pwndbg.arch.ptrsize, pwndbg.arch.current, 'linux')]\n\nclass SyscallABI(ABI):\n \"\"\"\n The syscall ABI treats the syscall number as the zeroth argument,\n which must be loaded into the specified register.\n \"\"\"\n def __init__(self, register_arguments, *a, **kw):\n self.syscall_register = register_arguments.pop(0)\n super(SyscallABI, self).__init__(register_arguments, *a, **kw)\n\n\nclass SigreturnABI(SyscallABI):\n \"\"\"\n The sigreturn ABI is similar to the syscall ABI, except that\n both PC and SP are loaded from the stack. Because of this, there\n is no 'return' slot necessary on the stack.\n \"\"\"\n returns = False\n\n\nlinux_i386 = ABI([], 4, 0)\nlinux_amd64 = ABI(['rdi','rsi','rdx','rcx','r8','r9'], 8, 0)\nlinux_arm = ABI(['r0', 'r1', 'r2', 'r3'], 8, 0)\nlinux_aarch64 = ABI(['x0', 'x1', 'x2', 'x3'], 16, 0)\nlinux_mips = ABI(['$a0','$a1','$a2','$a3'], 4, 0)\nlinux_ppc = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 4, 0)\nlinux_ppc64 = ABI(['r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9', 'r10'], 8, 0)\n\nlinux_i386_syscall = SyscallABI(['eax', 'ebx', 'ecx', 'edx', 'esi', 'edi', 'ebp'], 4, 0)\nlinux_amd64_syscall = SyscallABI(['rax','rdi', 'rsi', 'rdx', 'r10', 'r8', 'r9'], 8, 0)\nlinux_arm_syscall = SyscallABI(['r7', 'r0', 'r1', 'r2', 'r3', 'r4', 'r5', 'r6'], 4, 0)\nlinux_aarch64_syscall = SyscallABI(['x8', 'x0', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6'], 16, 0)\nlinux_mips_syscall = SyscallABI(['$v0', '$a0','$a1','$a2','$a3'], 4, 0)\nlinux_ppc_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 4, 0)\nlinux_ppc64_syscall = ABI(['r0', 'r3', 'r4', 'r5', 'r6', 'r7', 'r8', 'r9'], 8, 0)\n\nlinux_i386_sigreturn = SigreturnABI(['eax'], 4, 0)\nlinux_amd64_sigreturn = SigreturnABI(['rax'], 4, 0)\nlinux_arm_sigreturn = SigreturnABI(['r7'], 4, 0)\n\n# Fake ABIs used by SROP\nlinux_i386_srop = ABI(['eax'], 4, 0)\nlinux_amd64_srop = ABI(['rax'], 4, 0)\nlinux_arm_srop = ABI(['r7'], 4, 0)\n\n\[email protected]\ndef update():\n global abi\n global linux\n\n # Detect current ABI of client side by 'show osabi'\n #\n # Examples of strings returned by `show osabi`:\n # 'The current OS ABI is \"auto\" (currently \"GNU/Linux\").\\nThe default OS ABI is \"GNU/Linux\".\\n'\n # 'The current OS ABI is \"GNU/Linux\".\\nThe default OS ABI is \"GNU/Linux\".\\n'\n # 'El actual SO ABI es \u00abauto\u00bb (actualmente \u00abGNU/Linux\u00bb).\\nEl SO ABI predeterminado es \u00abGNU/Linux\u00bb.\\n'\n # 'The current OS ABI is \"auto\" (currently \"none\")'\n #\n # As you can see, there might be GDBs with different language versions\n # and so we have to support it there too.\n # Lets assume and hope that `current osabi` is returned in first line in all languages...\n current_osabi = gdb.execute('show osabi', to_string=True).split('\\n')[0]\n\n # Currently we support those osabis:\n # 'GNU/Linux': linux\n # 'none': bare metal\n\n linux = 'GNU/Linux' in current_osabi\n\n if not linux:\n msg = M.warn(\n \"The bare metal debugging is enabled since the gdb's osabi is '%s' which is not 'GNU/Linux'.\\n\"\n \"Ex. the page resolving and memory de-referencing ONLY works on known pages.\\n\"\n \"This option is based ib gdb client compile arguments (by default) and will be corrected if you load an ELF which has the '.note.ABI-tag' section.\\n\"\n \"If you are debuging a program that runs on Linux ABI, please select the correct gdb client.\"\n % abi\n )\n print(msg)\n\n\ndef LinuxOnly(default=None):\n \"\"\"Create a decorator that the function will be called when ABI is Linux.\n Otherwise, return `default`.\n \"\"\"\n def decorator(func):\n @functools.wraps(func)\n def caller(*args, **kwargs):\n if linux:\n return func(*args, **kwargs)\n else:\n return default\n return caller\n\n return decorator\n\n\n# Update when starting the gdb to show warning message for non-Linux ABI user.\nupdate()\n", "path": "pwndbg/abi.py"}]} | 2,744 | 436 |
gh_patches_debug_4431 | rasdani/github-patches | git_diff | MycroftAI__mycroft-core-2528 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
mycroft "devices" web UI doesn't show core version
Version/setup same as MycroftAI/mycroft-core#2523 2523
## Try to provide steps that we can use to replicate the Issue
Hit up https://account.mycroft.ai/devices

## Provide log files or other output to help us see the error
N/A TBD (can help investigate let me know how) per the ref'd ticket the "self support" method didn't work
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/version/__init__.py`
Content:
```
1 # Copyright 2017 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 import json
16
17 from genericpath import exists, isfile
18 from os.path import join, expanduser
19
20 from mycroft.configuration import Configuration
21 from mycroft.util.log import LOG
22
23
24 # The following lines are replaced during the release process.
25 # START_VERSION_BLOCK
26 CORE_VERSION_MAJOR = 20
27 CORE_VERSION_MINOR = 2
28 CORE_VERSION_BUILD = 1
29 # END_VERSION_BLOCK
30
31 CORE_VERSION_TUPLE = (CORE_VERSION_MAJOR,
32 CORE_VERSION_MINOR,
33 CORE_VERSION_BUILD)
34 CORE_VERSION_STR = '.'.join(map(str, CORE_VERSION_TUPLE))
35
36
37 class VersionManager:
38 @staticmethod
39 def get():
40 data_dir = expanduser(Configuration.get()['data_dir'])
41 version_file = join(data_dir, 'version.json')
42 if exists(version_file) and isfile(version_file):
43 try:
44 with open(version_file) as f:
45 return json.load(f)
46 except Exception:
47 LOG.error("Failed to load version from '%s'" % version_file)
48 return {"coreVersion": None, "enclosureVersion": None}
49
50
51 def check_version(version_string):
52 """
53 Check if current version is equal or higher than the
54 version string provided to the function
55
56 Args:
57 version_string (string): version string ('Major.Minor.Build')
58 """
59 version_tuple = tuple(map(int, version_string.split('.')))
60 return CORE_VERSION_TUPLE >= version_tuple
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mycroft/version/__init__.py b/mycroft/version/__init__.py
--- a/mycroft/version/__init__.py
+++ b/mycroft/version/__init__.py
@@ -45,7 +45,7 @@
return json.load(f)
except Exception:
LOG.error("Failed to load version from '%s'" % version_file)
- return {"coreVersion": None, "enclosureVersion": None}
+ return {"coreVersion": CORE_VERSION_STR, "enclosureVersion": None}
def check_version(version_string):
| {"golden_diff": "diff --git a/mycroft/version/__init__.py b/mycroft/version/__init__.py\n--- a/mycroft/version/__init__.py\n+++ b/mycroft/version/__init__.py\n@@ -45,7 +45,7 @@\n return json.load(f)\n except Exception:\n LOG.error(\"Failed to load version from '%s'\" % version_file)\n- return {\"coreVersion\": None, \"enclosureVersion\": None}\n+ return {\"coreVersion\": CORE_VERSION_STR, \"enclosureVersion\": None}\n \n \n def check_version(version_string):\n", "issue": "mycroft \"devices\" web UI doesn't show core version\n\r\nVersion/setup same as MycroftAI/mycroft-core#2523 2523\r\n\r\n## Try to provide steps that we can use to replicate the Issue\r\n\r\nHit up https://account.mycroft.ai/devices\r\n\r\n\r\n## Provide log files or other output to help us see the error\r\n\r\nN/A TBD (can help investigate let me know how) per the ref'd ticket the \"self support\" method didn't work\n", "before_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport json\n\nfrom genericpath import exists, isfile\nfrom os.path import join, expanduser\n\nfrom mycroft.configuration import Configuration\nfrom mycroft.util.log import LOG\n\n\n# The following lines are replaced during the release process.\n# START_VERSION_BLOCK\nCORE_VERSION_MAJOR = 20\nCORE_VERSION_MINOR = 2\nCORE_VERSION_BUILD = 1\n# END_VERSION_BLOCK\n\nCORE_VERSION_TUPLE = (CORE_VERSION_MAJOR,\n CORE_VERSION_MINOR,\n CORE_VERSION_BUILD)\nCORE_VERSION_STR = '.'.join(map(str, CORE_VERSION_TUPLE))\n\n\nclass VersionManager:\n @staticmethod\n def get():\n data_dir = expanduser(Configuration.get()['data_dir'])\n version_file = join(data_dir, 'version.json')\n if exists(version_file) and isfile(version_file):\n try:\n with open(version_file) as f:\n return json.load(f)\n except Exception:\n LOG.error(\"Failed to load version from '%s'\" % version_file)\n return {\"coreVersion\": None, \"enclosureVersion\": None}\n\n\ndef check_version(version_string):\n \"\"\"\n Check if current version is equal or higher than the\n version string provided to the function\n\n Args:\n version_string (string): version string ('Major.Minor.Build')\n \"\"\"\n version_tuple = tuple(map(int, version_string.split('.')))\n return CORE_VERSION_TUPLE >= version_tuple\n", "path": "mycroft/version/__init__.py"}], "after_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport json\n\nfrom genericpath import exists, isfile\nfrom os.path import join, expanduser\n\nfrom mycroft.configuration import Configuration\nfrom mycroft.util.log import LOG\n\n\n# The following lines are replaced during the release process.\n# START_VERSION_BLOCK\nCORE_VERSION_MAJOR = 20\nCORE_VERSION_MINOR = 2\nCORE_VERSION_BUILD = 1\n# END_VERSION_BLOCK\n\nCORE_VERSION_TUPLE = (CORE_VERSION_MAJOR,\n CORE_VERSION_MINOR,\n CORE_VERSION_BUILD)\nCORE_VERSION_STR = '.'.join(map(str, CORE_VERSION_TUPLE))\n\n\nclass VersionManager:\n @staticmethod\n def get():\n data_dir = expanduser(Configuration.get()['data_dir'])\n version_file = join(data_dir, 'version.json')\n if exists(version_file) and isfile(version_file):\n try:\n with open(version_file) as f:\n return json.load(f)\n except Exception:\n LOG.error(\"Failed to load version from '%s'\" % version_file)\n return {\"coreVersion\": CORE_VERSION_STR, \"enclosureVersion\": None}\n\n\ndef check_version(version_string):\n \"\"\"\n Check if current version is equal or higher than the\n version string provided to the function\n\n Args:\n version_string (string): version string ('Major.Minor.Build')\n \"\"\"\n version_tuple = tuple(map(int, version_string.split('.')))\n return CORE_VERSION_TUPLE >= version_tuple\n", "path": "mycroft/version/__init__.py"}]} | 970 | 119 |
gh_patches_debug_32365 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-3541 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove unused API docs cruft
Since we're moving to the RPC endpoint style, we need to remove the remaining pieces of the REST API documentation infrastructure.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `config/settings/common_settings.py`
Content:
```
1 """
2 Base settings to build other settings files upon.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19
20 # We use a 'tuple' with pipes as delimiters as decople naively splits the global
21 # variables on commas when casting to Csv()
22 def pipe_delim(pipe_string):
23 # Remove opening and closing brackets
24 pipe_string = pipe_string[1:-1]
25 # Split on pipe delim
26 return pipe_string.split("|")
27
28
29 # Build paths inside the project like this: BASE_DIR / 'subdir'.
30 BASE_DIR = Path(__file__).resolve().parent.parent.parent
31
32 # Application definition
33
34 INSTALLED_APPS = [
35 "django.contrib.admin",
36 "django.contrib.auth",
37 "django.contrib.contenttypes",
38 "django.contrib.sessions",
39 "django.contrib.messages",
40 "whitenoise.runserver_nostatic",
41 "django.contrib.staticfiles",
42 "rest_framework",
43 "django_filters",
44 "django_property_filter",
45 "drf_spectacular",
46 "modernrpc",
47 "mathesar",
48 ]
49
50 MIDDLEWARE = [
51 "django.middleware.security.SecurityMiddleware",
52 "whitenoise.middleware.WhiteNoiseMiddleware",
53 "django.contrib.sessions.middleware.SessionMiddleware",
54 "django.middleware.locale.LocaleMiddleware",
55 "django.middleware.common.CommonMiddleware",
56 "django.middleware.csrf.CsrfViewMiddleware",
57 "django.contrib.auth.middleware.AuthenticationMiddleware",
58 "django.contrib.messages.middleware.MessageMiddleware",
59 "django.middleware.clickjacking.XFrameOptionsMiddleware",
60 "mathesar.middleware.CursorClosedHandlerMiddleware",
61 "mathesar.middleware.PasswordChangeNeededMiddleware",
62 'django_userforeignkey.middleware.UserForeignKeyMiddleware',
63 'django_request_cache.middleware.RequestCacheMiddleware',
64 ]
65
66 ROOT_URLCONF = "config.urls"
67
68 MODERNRPC_METHODS_MODULES = [
69 'mathesar.rpc.connections'
70 ]
71
72 TEMPLATES = [
73 {
74 "BACKEND": "django.template.backends.django.DjangoTemplates",
75 "DIRS": [],
76 "APP_DIRS": True,
77 "OPTIONS": {
78 "context_processors": [
79 "config.context_processors.frontend_settings",
80 "django.template.context_processors.debug",
81 "django.template.context_processors.request",
82 "django.contrib.auth.context_processors.auth",
83 "django.contrib.messages.context_processors.messages",
84 "mathesar.template_context_processors.base_template_extensions.script_extension_templates"
85 ],
86 },
87 },
88 ]
89
90 WSGI_APPLICATION = "config.wsgi.application"
91
92 # Database
93 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
94
95 # TODO: Add to documentation that database keys should not be than 128 characters.
96
97 # MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'
98 # See pipe_delim above for why we use pipes as delimiters
99 DATABASES = {
100 db_key: db_url(url_string)
101 for db_key, url_string in decouple_config('MATHESAR_DATABASES', default='', cast=Csv(pipe_delim))
102 }
103
104 # POSTGRES_DB, POSTGRES_USER, POSTGRES_PASSWORD, POSTGRES_HOST & POSTGRES_PORT are required env variables for forming a pg connection string for the django database
105 # lack of any one of these will result in the internal django database to be sqlite.
106 POSTGRES_DB = decouple_config('POSTGRES_DB', default=None)
107 POSTGRES_USER = decouple_config('POSTGRES_USER', default=None)
108 POSTGRES_PASSWORD = decouple_config('POSTGRES_PASSWORD', default=None)
109 POSTGRES_HOST = decouple_config('POSTGRES_HOST', default=None)
110 POSTGRES_PORT = decouple_config('POSTGRES_PORT', default=None)
111
112 if POSTGRES_DB and POSTGRES_USER and POSTGRES_PASSWORD and POSTGRES_HOST and POSTGRES_PORT:
113 DATABASES['default'] = db_url(f'postgres://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_HOST}:{POSTGRES_PORT}/{POSTGRES_DB}')
114 else:
115 DATABASES['default'] = db_url('sqlite:///db.sqlite3')
116
117 for db_key, db_dict in DATABASES.items():
118 # Engine should be '.postgresql' or '.postgresql_psycopg2' for all db(s),
119 # however for the internal 'default' db 'sqlite3' can be used.
120 if not db_dict['ENGINE'].startswith('django.db.backends.postgresql') and db_key != 'default':
121 raise ValueError(
122 f"{db_key} is not a PostgreSQL database. "
123 f"{db_dict['ENGINE']} found for {db_key}'s engine."
124 )
125
126 # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
127 # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
128 TEST = decouple_config('TEST', default=False, cast=bool)
129 if TEST:
130 for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):
131 DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}
132
133
134 # SECURITY WARNING: keep the secret key used in production secret!
135 SECRET_KEY = decouple_config('SECRET_KEY', default="2gr6ud88x=(p855_5nbj_+7^gw-iz&n7ldqv%94mjaecl+b9=4")
136
137 # SECURITY WARNING: don't run with debug turned on in production!
138 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
139
140 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv(), default=".localhost, 127.0.0.1, [::1]")
141
142 # Password validation
143 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
144
145 AUTH_PASSWORD_VALIDATORS = [
146 {
147 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
148 },
149 {
150 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
151 },
152 {
153 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
154 },
155 {
156 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
157 },
158 ]
159
160 # Internationalization
161 # https://docs.djangoproject.com/en/3.1/topics/i18n/
162
163 LANGUAGE_CODE = "en-us"
164
165 TIME_ZONE = "UTC"
166
167 USE_I18N = True
168
169 USE_L10N = True
170
171 USE_TZ = True
172
173 # Static files (CSS, JavaScript, Images)
174 # https://docs.djangoproject.com/en/3.1/howto/static-files/
175 # https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/
176
177 STATIC_URL = "/static/"
178
179 # When running with DEBUG=False, the webserver needs to serve files from this location
180 # python manage.py collectstatic has to be run to collect all static files into this location
181 # The files need to served in brotli or gzip compressed format
182 STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
183
184 # Media files (uploaded by the user)
185 DEFAULT_MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
186 MEDIA_ROOT = decouple_config('MEDIA_ROOT', default=DEFAULT_MEDIA_ROOT)
187
188 MEDIA_URL = "/media/"
189
190 # Update Authentication classes, removed BasicAuthentication
191 # Defaults: https://www.django-rest-framework.org/api-guide/settings/
192 REST_FRAMEWORK = {
193 'DEFAULT_AUTHENTICATION_CLASSES': [
194 'rest_framework.authentication.TokenAuthentication',
195 'rest_framework.authentication.SessionAuthentication'
196 ],
197 'DEFAULT_PERMISSION_CLASSES': [
198 'rest_framework.permissions.IsAuthenticated',
199 ],
200 'DEFAULT_PARSER_CLASSES': [
201 'rest_framework.parsers.JSONParser',
202 ],
203 'DEFAULT_FILTER_BACKENDS': (
204 'django_filters.rest_framework.DjangoFilterBackend',
205 'rest_framework.filters.OrderingFilter',
206 ),
207 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
208 'EXCEPTION_HANDLER':
209 'mathesar.exception_handlers.mathesar_exception_handler',
210 'DEFAULT_SCHEMA_CLASS': 'drf_spectacular.openapi.AutoSchema'
211 }
212 SPECTACULAR_SETTINGS = {
213 'TITLE': 'Mathesar API',
214 'DESCRIPTION': '',
215 'VERSION': '1.0.0',
216 'SERVE_INCLUDE_SCHEMA': False,
217 'PREPROCESSING_HOOKS': ['config.settings.openapi.custom_preprocessing_hook'],
218 'POSTPROCESSING_HOOKS': [
219 'config.settings.openapi.remove_url_prefix_hook',
220 ],
221 # OTHER SETTINGS
222 }
223 FRIENDLY_ERRORS = {
224 'FIELD_ERRORS': {
225 # By default drf-friendly-errors does contain error codes for ListSerializer type
226 'ListSerializer': {
227 'required': 2007,
228 'null': 2027,
229 'invalid_choice': 2083,
230 'not_a_list': 2123,
231 'empty': 2093
232 },
233 'PermittedPkRelatedField': {
234 'required': 2007,
235 'null': 2027,
236 'does_not_exist': 2151,
237 'incorrect_type': 2161
238 },
239 'PermittedSlugRelatedField': {
240 'required': 2007, 'invalid': 2002, 'null': 2027,
241 'does_not_exist': 2151, 'incorrect_type': 2161
242 },
243 },
244 'EXCEPTION_DICT': {
245 'Http404': 4005
246 }
247 }
248 # Mathesar settings
249 MATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')
250 MATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')
251 MATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')
252 MATHESAR_CLIENT_DEV_URL = decouple_config(
253 'MATHESAR_CLIENT_DEV_URL',
254 default='http://localhost:3000'
255 )
256 MATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')
257 MATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)
258 MATHESAR_STATIC_NON_CODE_FILES_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/non-code/')
259
260 # UI source files have to be served by Django in order for static assets to be included during dev mode
261 # https://vitejs.dev/guide/assets.html
262 # https://vitejs.dev/guide/backend-integration.html
263 STATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION]
264 STATICFILES_STORAGE = "whitenoise.storage.CompressedManifestStaticFilesStorage"
265
266 # Accounts
267 AUTH_USER_MODEL = 'mathesar.User'
268 LOGIN_URL = '/auth/login/'
269 LOGIN_REDIRECT_URL = '/'
270 LOGOUT_REDIRECT_URL = LOGIN_URL
271 DRF_ACCESS_POLICY = {
272 'reusable_conditions': ['mathesar.api.permission_conditions']
273 }
274 # List of Template names that contains additional script tags to be added to the base template
275 BASE_TEMPLATE_ADDITIONAL_SCRIPT_TEMPLATES = []
276
277 # i18n
278 LANGUAGES = [
279 ('en', 'English'),
280 ('ja', 'Japanese'),
281 ]
282 LOCALE_PATHS = [
283 'translations'
284 ]
285 LANGUAGE_COOKIE_NAME = 'display_language'
286 FALLBACK_LANGUAGE = 'en'
287
288 SALT_KEY = SECRET_KEY
289
```
Path: `config/settings/openapi.py`
Content:
```
1 def custom_preprocessing_hook(endpoints):
2 prefixes = [
3 "/api/db/v0/databases/",
4 "/api/db/v0/data_files/",
5 "/api/db/v0/schemas/",
6 "/api/db/v0/tables/",
7 "/api/db/v0/links/",
8 "/api/db/v0/queries/",
9 "/api/ui/v0/databases/",
10 "/api/ui/v0/users/",
11 "/api/ui/v0/database_roles/"
12 ]
13 filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]
14 return filtered
15
16
17 def remove_url_prefix_hook(result, **kwargs):
18 # Remove namespace and version URL prefix from the operation Id of the generated API schema
19 for path, path_info in result['paths'].items():
20 for method, operation in path_info.items():
21 operation_id = operation.get('operationId')
22 if operation_id:
23 if path.startswith('/api/db/v0/'):
24 operation['operationId'] = operation_id.replace('db_v0_', '')
25 elif path.startswith('/api/ui/v0/'):
26 operation['operationId'] = operation_id.replace('ui_v0_', '')
27
28 return result
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/config/settings/common_settings.py b/config/settings/common_settings.py
--- a/config/settings/common_settings.py
+++ b/config/settings/common_settings.py
@@ -42,7 +42,6 @@
"rest_framework",
"django_filters",
"django_property_filter",
- "drf_spectacular",
"modernrpc",
"mathesar",
]
@@ -207,18 +206,6 @@
'TEST_REQUEST_DEFAULT_FORMAT': 'json',
'EXCEPTION_HANDLER':
'mathesar.exception_handlers.mathesar_exception_handler',
- 'DEFAULT_SCHEMA_CLASS': 'drf_spectacular.openapi.AutoSchema'
-}
-SPECTACULAR_SETTINGS = {
- 'TITLE': 'Mathesar API',
- 'DESCRIPTION': '',
- 'VERSION': '1.0.0',
- 'SERVE_INCLUDE_SCHEMA': False,
- 'PREPROCESSING_HOOKS': ['config.settings.openapi.custom_preprocessing_hook'],
- 'POSTPROCESSING_HOOKS': [
- 'config.settings.openapi.remove_url_prefix_hook',
- ],
- # OTHER SETTINGS
}
FRIENDLY_ERRORS = {
'FIELD_ERRORS': {
diff --git a/config/settings/openapi.py b/config/settings/openapi.py
deleted file mode 100644
--- a/config/settings/openapi.py
+++ /dev/null
@@ -1,28 +0,0 @@
-def custom_preprocessing_hook(endpoints):
- prefixes = [
- "/api/db/v0/databases/",
- "/api/db/v0/data_files/",
- "/api/db/v0/schemas/",
- "/api/db/v0/tables/",
- "/api/db/v0/links/",
- "/api/db/v0/queries/",
- "/api/ui/v0/databases/",
- "/api/ui/v0/users/",
- "/api/ui/v0/database_roles/"
- ]
- filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]
- return filtered
-
-
-def remove_url_prefix_hook(result, **kwargs):
- # Remove namespace and version URL prefix from the operation Id of the generated API schema
- for path, path_info in result['paths'].items():
- for method, operation in path_info.items():
- operation_id = operation.get('operationId')
- if operation_id:
- if path.startswith('/api/db/v0/'):
- operation['operationId'] = operation_id.replace('db_v0_', '')
- elif path.startswith('/api/ui/v0/'):
- operation['operationId'] = operation_id.replace('ui_v0_', '')
-
- return result
| {"golden_diff": "diff --git a/config/settings/common_settings.py b/config/settings/common_settings.py\n--- a/config/settings/common_settings.py\n+++ b/config/settings/common_settings.py\n@@ -42,7 +42,6 @@\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n- \"drf_spectacular\",\n \"modernrpc\",\n \"mathesar\",\n ]\n@@ -207,18 +206,6 @@\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler',\n- 'DEFAULT_SCHEMA_CLASS': 'drf_spectacular.openapi.AutoSchema'\n-}\n-SPECTACULAR_SETTINGS = {\n- 'TITLE': 'Mathesar API',\n- 'DESCRIPTION': '',\n- 'VERSION': '1.0.0',\n- 'SERVE_INCLUDE_SCHEMA': False,\n- 'PREPROCESSING_HOOKS': ['config.settings.openapi.custom_preprocessing_hook'],\n- 'POSTPROCESSING_HOOKS': [\n- 'config.settings.openapi.remove_url_prefix_hook',\n- ],\n- # OTHER SETTINGS\n }\n FRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\ndiff --git a/config/settings/openapi.py b/config/settings/openapi.py\ndeleted file mode 100644\n--- a/config/settings/openapi.py\n+++ /dev/null\n@@ -1,28 +0,0 @@\n-def custom_preprocessing_hook(endpoints):\n- prefixes = [\n- \"/api/db/v0/databases/\",\n- \"/api/db/v0/data_files/\",\n- \"/api/db/v0/schemas/\",\n- \"/api/db/v0/tables/\",\n- \"/api/db/v0/links/\",\n- \"/api/db/v0/queries/\",\n- \"/api/ui/v0/databases/\",\n- \"/api/ui/v0/users/\",\n- \"/api/ui/v0/database_roles/\"\n- ]\n- filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]\n- return filtered\n-\n-\n-def remove_url_prefix_hook(result, **kwargs):\n- # Remove namespace and version URL prefix from the operation Id of the generated API schema\n- for path, path_info in result['paths'].items():\n- for method, operation in path_info.items():\n- operation_id = operation.get('operationId')\n- if operation_id:\n- if path.startswith('/api/db/v0/'):\n- operation['operationId'] = operation_id.replace('db_v0_', '')\n- elif path.startswith('/api/ui/v0/'):\n- operation['operationId'] = operation_id.replace('ui_v0_', '')\n-\n- return result\n", "issue": "Remove unused API docs cruft\nSince we're moving to the RPC endpoint style, we need to remove the remaining pieces of the REST API documentation infrastructure.\n", "before_files": [{"content": "\"\"\"\nBase settings to build other settings files upon.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n\n# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n# variables on commas when casting to Csv()\ndef pipe_delim(pipe_string):\n # Remove opening and closing brackets\n pipe_string = pipe_string[1:-1]\n # Split on pipe delim\n return pipe_string.split(\"|\")\n\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"whitenoise.runserver_nostatic\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"drf_spectacular\",\n \"modernrpc\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.locale.LocaleMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n \"mathesar.middleware.PasswordChangeNeededMiddleware\",\n 'django_userforeignkey.middleware.UserForeignKeyMiddleware',\n 'django_request_cache.middleware.RequestCacheMiddleware',\n]\n\nROOT_URLCONF = \"config.urls\"\n\nMODERNRPC_METHODS_MODULES = [\n 'mathesar.rpc.connections'\n]\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.frontend_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"mathesar.template_context_processors.base_template_extensions.script_extension_templates\"\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\n\n# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n# See pipe_delim above for why we use pipes as delimiters\nDATABASES = {\n db_key: db_url(url_string)\n for db_key, url_string in decouple_config('MATHESAR_DATABASES', default='', cast=Csv(pipe_delim))\n}\n\n# POSTGRES_DB, POSTGRES_USER, POSTGRES_PASSWORD, POSTGRES_HOST & POSTGRES_PORT are required env variables for forming a pg connection string for the django database\n# lack of any one of these will result in the internal django database to be sqlite.\nPOSTGRES_DB = decouple_config('POSTGRES_DB', default=None)\nPOSTGRES_USER = decouple_config('POSTGRES_USER', default=None)\nPOSTGRES_PASSWORD = decouple_config('POSTGRES_PASSWORD', default=None)\nPOSTGRES_HOST = decouple_config('POSTGRES_HOST', default=None)\nPOSTGRES_PORT = decouple_config('POSTGRES_PORT', default=None)\n\nif POSTGRES_DB and POSTGRES_USER and POSTGRES_PASSWORD and POSTGRES_HOST and POSTGRES_PORT:\n DATABASES['default'] = db_url(f'postgres://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_HOST}:{POSTGRES_PORT}/{POSTGRES_DB}')\nelse:\n DATABASES['default'] = db_url('sqlite:///db.sqlite3')\n\nfor db_key, db_dict in DATABASES.items():\n # Engine should be '.postgresql' or '.postgresql_psycopg2' for all db(s),\n # however for the internal 'default' db 'sqlite3' can be used.\n if not db_dict['ENGINE'].startswith('django.db.backends.postgresql') and db_key != 'default':\n raise ValueError(\n f\"{db_key} is not a PostgreSQL database. \"\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nTEST = decouple_config('TEST', default=False, cast=bool)\nif TEST:\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY', default=\"2gr6ud88x=(p855_5nbj_+7^gw-iz&n7ldqv%94mjaecl+b9=4\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv(), default=\".localhost, 127.0.0.1, [::1]\")\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\n\nSTATIC_URL = \"/static/\"\n\n# When running with DEBUG=False, the webserver needs to serve files from this location\n# python manage.py collectstatic has to be run to collect all static files into this location\n# The files need to served in brotli or gzip compressed format\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static/')\n\n# Media files (uploaded by the user)\nDEFAULT_MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\nMEDIA_ROOT = decouple_config('MEDIA_ROOT', default=DEFAULT_MEDIA_ROOT)\n\nMEDIA_URL = \"/media/\"\n\n# Update Authentication classes, removed BasicAuthentication\n# Defaults: https://www.django-rest-framework.org/api-guide/settings/\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.TokenAuthentication',\n 'rest_framework.authentication.SessionAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated',\n ],\n 'DEFAULT_PARSER_CLASSES': [\n 'rest_framework.parsers.JSONParser',\n ],\n 'DEFAULT_FILTER_BACKENDS': (\n 'django_filters.rest_framework.DjangoFilterBackend',\n 'rest_framework.filters.OrderingFilter',\n ),\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler',\n 'DEFAULT_SCHEMA_CLASS': 'drf_spectacular.openapi.AutoSchema'\n}\nSPECTACULAR_SETTINGS = {\n 'TITLE': 'Mathesar API',\n 'DESCRIPTION': '',\n 'VERSION': '1.0.0',\n 'SERVE_INCLUDE_SCHEMA': False,\n 'PREPROCESSING_HOOKS': ['config.settings.openapi.custom_preprocessing_hook'],\n 'POSTPROCESSING_HOOKS': [\n 'config.settings.openapi.remove_url_prefix_hook',\n ],\n # OTHER SETTINGS\n}\nFRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\n # By default drf-friendly-errors does contain error codes for ListSerializer type\n 'ListSerializer': {\n 'required': 2007,\n 'null': 2027,\n 'invalid_choice': 2083,\n 'not_a_list': 2123,\n 'empty': 2093\n },\n 'PermittedPkRelatedField': {\n 'required': 2007,\n 'null': 2027,\n 'does_not_exist': 2151,\n 'incorrect_type': 2161\n },\n 'PermittedSlugRelatedField': {\n 'required': 2007, 'invalid': 2002, 'null': 2027,\n 'does_not_exist': 2151, 'incorrect_type': 2161\n },\n },\n 'EXCEPTION_DICT': {\n 'Http404': 4005\n }\n}\n# Mathesar settings\nMATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')\nMATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')\nMATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')\nMATHESAR_CLIENT_DEV_URL = decouple_config(\n 'MATHESAR_CLIENT_DEV_URL',\n default='http://localhost:3000'\n)\nMATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')\nMATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)\nMATHESAR_STATIC_NON_CODE_FILES_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/non-code/')\n\n# UI source files have to be served by Django in order for static assets to be included during dev mode\n# https://vitejs.dev/guide/assets.html\n# https://vitejs.dev/guide/backend-integration.html\nSTATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION]\nSTATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n# Accounts\nAUTH_USER_MODEL = 'mathesar.User'\nLOGIN_URL = '/auth/login/'\nLOGIN_REDIRECT_URL = '/'\nLOGOUT_REDIRECT_URL = LOGIN_URL\nDRF_ACCESS_POLICY = {\n 'reusable_conditions': ['mathesar.api.permission_conditions']\n}\n# List of Template names that contains additional script tags to be added to the base template\nBASE_TEMPLATE_ADDITIONAL_SCRIPT_TEMPLATES = []\n\n# i18n\nLANGUAGES = [\n ('en', 'English'),\n ('ja', 'Japanese'),\n]\nLOCALE_PATHS = [\n 'translations'\n]\nLANGUAGE_COOKIE_NAME = 'display_language'\nFALLBACK_LANGUAGE = 'en'\n\nSALT_KEY = SECRET_KEY\n", "path": "config/settings/common_settings.py"}, {"content": "def custom_preprocessing_hook(endpoints):\n prefixes = [\n \"/api/db/v0/databases/\",\n \"/api/db/v0/data_files/\",\n \"/api/db/v0/schemas/\",\n \"/api/db/v0/tables/\",\n \"/api/db/v0/links/\",\n \"/api/db/v0/queries/\",\n \"/api/ui/v0/databases/\",\n \"/api/ui/v0/users/\",\n \"/api/ui/v0/database_roles/\"\n ]\n filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]\n return filtered\n\n\ndef remove_url_prefix_hook(result, **kwargs):\n # Remove namespace and version URL prefix from the operation Id of the generated API schema\n for path, path_info in result['paths'].items():\n for method, operation in path_info.items():\n operation_id = operation.get('operationId')\n if operation_id:\n if path.startswith('/api/db/v0/'):\n operation['operationId'] = operation_id.replace('db_v0_', '')\n elif path.startswith('/api/ui/v0/'):\n operation['operationId'] = operation_id.replace('ui_v0_', '')\n\n return result\n", "path": "config/settings/openapi.py"}], "after_files": [{"content": "\"\"\"\nBase settings to build other settings files upon.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n\n# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n# variables on commas when casting to Csv()\ndef pipe_delim(pipe_string):\n # Remove opening and closing brackets\n pipe_string = pipe_string[1:-1]\n # Split on pipe delim\n return pipe_string.split(\"|\")\n\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"whitenoise.runserver_nostatic\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"modernrpc\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.locale.LocaleMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n \"mathesar.middleware.PasswordChangeNeededMiddleware\",\n 'django_userforeignkey.middleware.UserForeignKeyMiddleware',\n 'django_request_cache.middleware.RequestCacheMiddleware',\n]\n\nROOT_URLCONF = \"config.urls\"\n\nMODERNRPC_METHODS_MODULES = [\n 'mathesar.rpc.connections'\n]\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.frontend_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"mathesar.template_context_processors.base_template_extensions.script_extension_templates\"\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\n\n# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n# See pipe_delim above for why we use pipes as delimiters\nDATABASES = {\n db_key: db_url(url_string)\n for db_key, url_string in decouple_config('MATHESAR_DATABASES', default='', cast=Csv(pipe_delim))\n}\n\n# POSTGRES_DB, POSTGRES_USER, POSTGRES_PASSWORD, POSTGRES_HOST & POSTGRES_PORT are required env variables for forming a pg connection string for the django database\n# lack of any one of these will result in the internal django database to be sqlite.\nPOSTGRES_DB = decouple_config('POSTGRES_DB', default=None)\nPOSTGRES_USER = decouple_config('POSTGRES_USER', default=None)\nPOSTGRES_PASSWORD = decouple_config('POSTGRES_PASSWORD', default=None)\nPOSTGRES_HOST = decouple_config('POSTGRES_HOST', default=None)\nPOSTGRES_PORT = decouple_config('POSTGRES_PORT', default=None)\n\nif POSTGRES_DB and POSTGRES_USER and POSTGRES_PASSWORD and POSTGRES_HOST and POSTGRES_PORT:\n DATABASES['default'] = db_url(f'postgres://{POSTGRES_USER}:{POSTGRES_PASSWORD}@{POSTGRES_HOST}:{POSTGRES_PORT}/{POSTGRES_DB}')\nelse:\n DATABASES['default'] = db_url('sqlite:///db.sqlite3')\n\nfor db_key, db_dict in DATABASES.items():\n # Engine should be '.postgresql' or '.postgresql_psycopg2' for all db(s),\n # however for the internal 'default' db 'sqlite3' can be used.\n if not db_dict['ENGINE'].startswith('django.db.backends.postgresql') and db_key != 'default':\n raise ValueError(\n f\"{db_key} is not a PostgreSQL database. \"\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nTEST = decouple_config('TEST', default=False, cast=bool)\nif TEST:\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY', default=\"2gr6ud88x=(p855_5nbj_+7^gw-iz&n7ldqv%94mjaecl+b9=4\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv(), default=\".localhost, 127.0.0.1, [::1]\")\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\n\nSTATIC_URL = \"/static/\"\n\n# When running with DEBUG=False, the webserver needs to serve files from this location\n# python manage.py collectstatic has to be run to collect all static files into this location\n# The files need to served in brotli or gzip compressed format\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static/')\n\n# Media files (uploaded by the user)\nDEFAULT_MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\nMEDIA_ROOT = decouple_config('MEDIA_ROOT', default=DEFAULT_MEDIA_ROOT)\n\nMEDIA_URL = \"/media/\"\n\n# Update Authentication classes, removed BasicAuthentication\n# Defaults: https://www.django-rest-framework.org/api-guide/settings/\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.TokenAuthentication',\n 'rest_framework.authentication.SessionAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated',\n ],\n 'DEFAULT_PARSER_CLASSES': [\n 'rest_framework.parsers.JSONParser',\n ],\n 'DEFAULT_FILTER_BACKENDS': (\n 'django_filters.rest_framework.DjangoFilterBackend',\n 'rest_framework.filters.OrderingFilter',\n ),\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler',\n}\nFRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\n # By default drf-friendly-errors does contain error codes for ListSerializer type\n 'ListSerializer': {\n 'required': 2007,\n 'null': 2027,\n 'invalid_choice': 2083,\n 'not_a_list': 2123,\n 'empty': 2093\n },\n 'PermittedPkRelatedField': {\n 'required': 2007,\n 'null': 2027,\n 'does_not_exist': 2151,\n 'incorrect_type': 2161\n },\n 'PermittedSlugRelatedField': {\n 'required': 2007, 'invalid': 2002, 'null': 2027,\n 'does_not_exist': 2151, 'incorrect_type': 2161\n },\n },\n 'EXCEPTION_DICT': {\n 'Http404': 4005\n }\n}\n# Mathesar settings\nMATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')\nMATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')\nMATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')\nMATHESAR_CLIENT_DEV_URL = decouple_config(\n 'MATHESAR_CLIENT_DEV_URL',\n default='http://localhost:3000'\n)\nMATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')\nMATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)\nMATHESAR_STATIC_NON_CODE_FILES_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/non-code/')\n\n# UI source files have to be served by Django in order for static assets to be included during dev mode\n# https://vitejs.dev/guide/assets.html\n# https://vitejs.dev/guide/backend-integration.html\nSTATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION]\nSTATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n# Accounts\nAUTH_USER_MODEL = 'mathesar.User'\nLOGIN_URL = '/auth/login/'\nLOGIN_REDIRECT_URL = '/'\nLOGOUT_REDIRECT_URL = LOGIN_URL\nDRF_ACCESS_POLICY = {\n 'reusable_conditions': ['mathesar.api.permission_conditions']\n}\n# List of Template names that contains additional script tags to be added to the base template\nBASE_TEMPLATE_ADDITIONAL_SCRIPT_TEMPLATES = []\n\n# i18n\nLANGUAGES = [\n ('en', 'English'),\n ('ja', 'Japanese'),\n]\nLOCALE_PATHS = [\n 'translations'\n]\nLANGUAGE_COOKIE_NAME = 'display_language'\nFALLBACK_LANGUAGE = 'en'\n\nSALT_KEY = SECRET_KEY\n", "path": "config/settings/common_settings.py"}, {"content": null, "path": "config/settings/openapi.py"}]} | 3,886 | 580 |
gh_patches_debug_37800 | rasdani/github-patches | git_diff | saleor__saleor-1541 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Variants displayed in product add to cart form even when product type has no variants
### What I'm trying to achieve
...Smaller form for products with no variants
### Steps to reproduce the problem
1. Create a product type with no variants
2. Create a product based on that product type
3. Open product details page in the consumer website
### What I expected to happen
...Variants field is not shown when product has no variants
### What happened instead/how it failed
...Variants field is displayed with SKU and price
(Please include a stack trace if this problem results in a crash.)

Mostly I'm wondering if this is expected behaviour? Displaying a product form containing only one option showing the SKU seems a bit odd for the enduser. In my app, I am probably going to set the product variant field to hidden in the product variant form for products with no variants.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/product/views.py`
Content:
```
1 import datetime
2 import json
3
4 from django.conf import settings
5 from django.http import HttpResponsePermanentRedirect, JsonResponse
6 from django.shortcuts import get_object_or_404, redirect
7 from django.template.response import TemplateResponse
8 from django.urls import reverse
9
10 from ..cart.utils import set_cart_cookie
11 from ..core.utils import get_paginator_items, serialize_decimal
12 from ..core.utils.filters import get_now_sorted_by, get_sort_by_choices
13 from .filters import ProductFilter, SORT_BY_FIELDS
14 from .models import Category
15 from .utils import (
16 get_availability, get_product_attributes_data, get_product_images,
17 get_variant_picker_data, handle_cart_form, product_json_ld,
18 products_for_cart, products_with_availability, products_with_details)
19
20
21 def product_details(request, slug, product_id, form=None):
22 """Product details page
23
24 The following variables are available to the template:
25
26 product:
27 The Product instance itself.
28
29 is_visible:
30 Whether the product is visible to regular users (for cases when an
31 admin is previewing a product before publishing).
32
33 form:
34 The add-to-cart form.
35
36 price_range:
37 The PriceRange for the product including all discounts.
38
39 undiscounted_price_range:
40 The PriceRange excluding all discounts.
41
42 discount:
43 Either a Price instance equal to the discount value or None if no
44 discount was available.
45
46 local_price_range:
47 The same PriceRange from price_range represented in user's local
48 currency. The value will be None if exchange rate is not available or
49 the local currency is the same as site's default currency.
50 """
51 products = products_with_details(user=request.user)
52 product = get_object_or_404(products, id=product_id)
53 if product.get_slug() != slug:
54 return HttpResponsePermanentRedirect(product.get_absolute_url())
55 today = datetime.date.today()
56 is_visible = (
57 product.available_on is None or product.available_on <= today)
58 if form is None:
59 form = handle_cart_form(request, product, create_cart=False)[0]
60 availability = get_availability(product, discounts=request.discounts,
61 local_currency=request.currency)
62 product_images = get_product_images(product)
63 variant_picker_data = get_variant_picker_data(
64 product, request.discounts, request.currency)
65 product_attributes = get_product_attributes_data(product)
66 show_variant_picker = all([v.attributes for v in product.variants.all()])
67 json_ld_data = product_json_ld(product, availability, product_attributes)
68 return TemplateResponse(
69 request, 'product/details.html',
70 {'is_visible': is_visible,
71 'form': form,
72 'availability': availability,
73 'product': product,
74 'product_attributes': product_attributes,
75 'product_images': product_images,
76 'show_variant_picker': show_variant_picker,
77 'variant_picker_data': json.dumps(
78 variant_picker_data, default=serialize_decimal),
79 'json_ld_product_data': json.dumps(
80 json_ld_data, default=serialize_decimal)})
81
82
83 def product_add_to_cart(request, slug, product_id):
84 # types: (int, str, dict) -> None
85
86 if not request.method == 'POST':
87 return redirect(reverse(
88 'product:details',
89 kwargs={'product_id': product_id, 'slug': slug}))
90
91 products = products_for_cart(user=request.user)
92 product = get_object_or_404(products, pk=product_id)
93 form, cart = handle_cart_form(request, product, create_cart=True)
94 if form.is_valid():
95 form.save()
96 if request.is_ajax():
97 response = JsonResponse({'next': reverse('cart:index')}, status=200)
98 else:
99 response = redirect('cart:index')
100 else:
101 if request.is_ajax():
102 response = JsonResponse({'error': form.errors}, status=400)
103 else:
104 response = product_details(request, slug, product_id, form)
105 if not request.user.is_authenticated:
106 set_cart_cookie(cart, response)
107 return response
108
109
110 def category_index(request, path, category_id):
111 category = get_object_or_404(Category, id=category_id)
112 actual_path = category.get_full_path()
113 if actual_path != path:
114 return redirect('product:category', permanent=True, path=actual_path,
115 category_id=category_id)
116 products = (products_with_details(user=request.user)
117 .filter(categories__id=category.id)
118 .order_by('name'))
119 product_filter = ProductFilter(
120 request.GET, queryset=products, category=category)
121 products_paginated = get_paginator_items(
122 product_filter.qs, settings.PAGINATE_BY, request.GET.get('page'))
123 products_and_availability = list(products_with_availability(
124 products_paginated, request.discounts, request.currency))
125 now_sorted_by = get_now_sorted_by(product_filter)
126 arg_sort_by = request.GET.get('sort_by')
127 is_descending = arg_sort_by.startswith('-') if arg_sort_by else False
128 ctx = {'category': category, 'filter_set': product_filter,
129 'products': products_and_availability,
130 'products_paginated': products_paginated,
131 'sort_by_choices': get_sort_by_choices(product_filter),
132 'now_sorted_by': now_sorted_by,
133 'is_descending': is_descending}
134 return TemplateResponse(request, 'category/index.html', ctx)
135
```
Path: `saleor/product/forms.py`
Content:
```
1 import json
2
3 from django import forms
4 from django.utils.encoding import smart_text
5 from django.utils.translation import pgettext_lazy
6 from django_prices.templatetags.prices_i18n import gross
7
8 from ..cart.forms import AddToCartForm
9
10
11 class VariantChoiceField(forms.ModelChoiceField):
12 discounts = None
13
14 def label_from_instance(self, obj):
15 variant_label = smart_text(obj)
16 label = pgettext_lazy(
17 'Variant choice field label',
18 '%(variant_label)s - %(price)s') % {
19 'variant_label': variant_label,
20 'price': gross(obj.get_price(discounts=self.discounts))}
21 return label
22
23
24 class ProductForm(AddToCartForm):
25 variant = VariantChoiceField(queryset=None)
26
27 def __init__(self, *args, **kwargs):
28 super().__init__(*args, **kwargs)
29 variant_field = self.fields['variant']
30 variant_field.queryset = self.product.variants
31 variant_field.discounts = self.cart.discounts
32 variant_field.empty_label = None
33 images_map = {variant.pk: [vi.image.image.url
34 for vi in variant.variant_images.all()]
35 for variant in self.product.variants.all()}
36 variant_field.widget.attrs['data-images'] = json.dumps(images_map)
37
38 def get_variant(self, cleaned_data):
39 return cleaned_data.get('variant')
40
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/saleor/product/forms.py b/saleor/product/forms.py
--- a/saleor/product/forms.py
+++ b/saleor/product/forms.py
@@ -11,6 +11,9 @@
class VariantChoiceField(forms.ModelChoiceField):
discounts = None
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
def label_from_instance(self, obj):
variant_label = smart_text(obj)
label = pgettext_lazy(
@@ -20,6 +23,20 @@
'price': gross(obj.get_price(discounts=self.discounts))}
return label
+ def update_field_data(self, variants, cart):
+ """ Function initializing fields custom data """
+ self.queryset = variants
+ self.discounts = cart.discounts
+ self.empty_label = None
+ images_map = {variant.pk: [vi.image.image.url
+ for vi in variant.variant_images.all()]
+ for variant in variants.all()}
+ self.widget.attrs['data-images'] = json.dumps(images_map)
+ # Don't display select input if there are less than two variants
+ if self.queryset.count() < 2:
+ self.widget = forms.HiddenInput(
+ {'value': variants.all()[0].pk})
+
class ProductForm(AddToCartForm):
variant = VariantChoiceField(queryset=None)
@@ -27,14 +44,7 @@
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
variant_field = self.fields['variant']
- variant_field.queryset = self.product.variants
- variant_field.discounts = self.cart.discounts
- variant_field.empty_label = None
- images_map = {variant.pk: [vi.image.image.url
- for vi in variant.variant_images.all()]
- for variant in self.product.variants.all()}
- variant_field.widget.attrs['data-images'] = json.dumps(images_map)
+ variant_field.update_field_data(self.product.variants, self.cart)
def get_variant(self, cleaned_data):
return cleaned_data.get('variant')
-
diff --git a/saleor/product/views.py b/saleor/product/views.py
--- a/saleor/product/views.py
+++ b/saleor/product/views.py
@@ -63,6 +63,7 @@
variant_picker_data = get_variant_picker_data(
product, request.discounts, request.currency)
product_attributes = get_product_attributes_data(product)
+ # show_variant_picker determines if variant picker is used or select input
show_variant_picker = all([v.attributes for v in product.variants.all()])
json_ld_data = product_json_ld(product, availability, product_attributes)
return TemplateResponse(
| {"golden_diff": "diff --git a/saleor/product/forms.py b/saleor/product/forms.py\n--- a/saleor/product/forms.py\n+++ b/saleor/product/forms.py\n@@ -11,6 +11,9 @@\n class VariantChoiceField(forms.ModelChoiceField):\n discounts = None\n \n+ def __init__(self, *args, **kwargs):\n+ super().__init__(*args, **kwargs)\n+\n def label_from_instance(self, obj):\n variant_label = smart_text(obj)\n label = pgettext_lazy(\n@@ -20,6 +23,20 @@\n 'price': gross(obj.get_price(discounts=self.discounts))}\n return label\n \n+ def update_field_data(self, variants, cart):\n+ \"\"\" Function initializing fields custom data \"\"\"\n+ self.queryset = variants\n+ self.discounts = cart.discounts\n+ self.empty_label = None\n+ images_map = {variant.pk: [vi.image.image.url\n+ for vi in variant.variant_images.all()]\n+ for variant in variants.all()}\n+ self.widget.attrs['data-images'] = json.dumps(images_map)\n+ # Don't display select input if there are less than two variants\n+ if self.queryset.count() < 2:\n+ self.widget = forms.HiddenInput(\n+ {'value': variants.all()[0].pk})\n+\n \n class ProductForm(AddToCartForm):\n variant = VariantChoiceField(queryset=None)\n@@ -27,14 +44,7 @@\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n variant_field = self.fields['variant']\n- variant_field.queryset = self.product.variants\n- variant_field.discounts = self.cart.discounts\n- variant_field.empty_label = None\n- images_map = {variant.pk: [vi.image.image.url\n- for vi in variant.variant_images.all()]\n- for variant in self.product.variants.all()}\n- variant_field.widget.attrs['data-images'] = json.dumps(images_map)\n+ variant_field.update_field_data(self.product.variants, self.cart)\n \n def get_variant(self, cleaned_data):\n return cleaned_data.get('variant')\n-\ndiff --git a/saleor/product/views.py b/saleor/product/views.py\n--- a/saleor/product/views.py\n+++ b/saleor/product/views.py\n@@ -63,6 +63,7 @@\n variant_picker_data = get_variant_picker_data(\n product, request.discounts, request.currency)\n product_attributes = get_product_attributes_data(product)\n+ # show_variant_picker determines if variant picker is used or select input\n show_variant_picker = all([v.attributes for v in product.variants.all()])\n json_ld_data = product_json_ld(product, availability, product_attributes)\n return TemplateResponse(\n", "issue": "Variants displayed in product add to cart form even when product type has no variants\n### What I'm trying to achieve\r\n\r\n...Smaller form for products with no variants\r\n\r\n### Steps to reproduce the problem\r\n\r\n1. Create a product type with no variants\r\n2. Create a product based on that product type\r\n3. Open product details page in the consumer website\r\n\r\n### What I expected to happen\r\n\r\n...Variants field is not shown when product has no variants\r\n\r\n### What happened instead/how it failed\r\n\r\n...Variants field is displayed with SKU and price\r\n\r\n(Please include a stack trace if this problem results in a crash.)\r\n\r\n\r\nMostly I'm wondering if this is expected behaviour? Displaying a product form containing only one option showing the SKU seems a bit odd for the enduser. In my app, I am probably going to set the product variant field to hidden in the product variant form for products with no variants.\n", "before_files": [{"content": "import datetime\nimport json\n\nfrom django.conf import settings\nfrom django.http import HttpResponsePermanentRedirect, JsonResponse\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\n\nfrom ..cart.utils import set_cart_cookie\nfrom ..core.utils import get_paginator_items, serialize_decimal\nfrom ..core.utils.filters import get_now_sorted_by, get_sort_by_choices\nfrom .filters import ProductFilter, SORT_BY_FIELDS\nfrom .models import Category\nfrom .utils import (\n get_availability, get_product_attributes_data, get_product_images,\n get_variant_picker_data, handle_cart_form, product_json_ld,\n products_for_cart, products_with_availability, products_with_details)\n\n\ndef product_details(request, slug, product_id, form=None):\n \"\"\"Product details page\n\n The following variables are available to the template:\n\n product:\n The Product instance itself.\n\n is_visible:\n Whether the product is visible to regular users (for cases when an\n admin is previewing a product before publishing).\n\n form:\n The add-to-cart form.\n\n price_range:\n The PriceRange for the product including all discounts.\n\n undiscounted_price_range:\n The PriceRange excluding all discounts.\n\n discount:\n Either a Price instance equal to the discount value or None if no\n discount was available.\n\n local_price_range:\n The same PriceRange from price_range represented in user's local\n currency. The value will be None if exchange rate is not available or\n the local currency is the same as site's default currency.\n \"\"\"\n products = products_with_details(user=request.user)\n product = get_object_or_404(products, id=product_id)\n if product.get_slug() != slug:\n return HttpResponsePermanentRedirect(product.get_absolute_url())\n today = datetime.date.today()\n is_visible = (\n product.available_on is None or product.available_on <= today)\n if form is None:\n form = handle_cart_form(request, product, create_cart=False)[0]\n availability = get_availability(product, discounts=request.discounts,\n local_currency=request.currency)\n product_images = get_product_images(product)\n variant_picker_data = get_variant_picker_data(\n product, request.discounts, request.currency)\n product_attributes = get_product_attributes_data(product)\n show_variant_picker = all([v.attributes for v in product.variants.all()])\n json_ld_data = product_json_ld(product, availability, product_attributes)\n return TemplateResponse(\n request, 'product/details.html',\n {'is_visible': is_visible,\n 'form': form,\n 'availability': availability,\n 'product': product,\n 'product_attributes': product_attributes,\n 'product_images': product_images,\n 'show_variant_picker': show_variant_picker,\n 'variant_picker_data': json.dumps(\n variant_picker_data, default=serialize_decimal),\n 'json_ld_product_data': json.dumps(\n json_ld_data, default=serialize_decimal)})\n\n\ndef product_add_to_cart(request, slug, product_id):\n # types: (int, str, dict) -> None\n\n if not request.method == 'POST':\n return redirect(reverse(\n 'product:details',\n kwargs={'product_id': product_id, 'slug': slug}))\n\n products = products_for_cart(user=request.user)\n product = get_object_or_404(products, pk=product_id)\n form, cart = handle_cart_form(request, product, create_cart=True)\n if form.is_valid():\n form.save()\n if request.is_ajax():\n response = JsonResponse({'next': reverse('cart:index')}, status=200)\n else:\n response = redirect('cart:index')\n else:\n if request.is_ajax():\n response = JsonResponse({'error': form.errors}, status=400)\n else:\n response = product_details(request, slug, product_id, form)\n if not request.user.is_authenticated:\n set_cart_cookie(cart, response)\n return response\n\n\ndef category_index(request, path, category_id):\n category = get_object_or_404(Category, id=category_id)\n actual_path = category.get_full_path()\n if actual_path != path:\n return redirect('product:category', permanent=True, path=actual_path,\n category_id=category_id)\n products = (products_with_details(user=request.user)\n .filter(categories__id=category.id)\n .order_by('name'))\n product_filter = ProductFilter(\n request.GET, queryset=products, category=category)\n products_paginated = get_paginator_items(\n product_filter.qs, settings.PAGINATE_BY, request.GET.get('page'))\n products_and_availability = list(products_with_availability(\n products_paginated, request.discounts, request.currency))\n now_sorted_by = get_now_sorted_by(product_filter)\n arg_sort_by = request.GET.get('sort_by')\n is_descending = arg_sort_by.startswith('-') if arg_sort_by else False\n ctx = {'category': category, 'filter_set': product_filter,\n 'products': products_and_availability,\n 'products_paginated': products_paginated,\n 'sort_by_choices': get_sort_by_choices(product_filter),\n 'now_sorted_by': now_sorted_by,\n 'is_descending': is_descending}\n return TemplateResponse(request, 'category/index.html', ctx)\n", "path": "saleor/product/views.py"}, {"content": "import json\n\nfrom django import forms\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import pgettext_lazy\nfrom django_prices.templatetags.prices_i18n import gross\n\nfrom ..cart.forms import AddToCartForm\n\n\nclass VariantChoiceField(forms.ModelChoiceField):\n discounts = None\n\n def label_from_instance(self, obj):\n variant_label = smart_text(obj)\n label = pgettext_lazy(\n 'Variant choice field label',\n '%(variant_label)s - %(price)s') % {\n 'variant_label': variant_label,\n 'price': gross(obj.get_price(discounts=self.discounts))}\n return label\n\n\nclass ProductForm(AddToCartForm):\n variant = VariantChoiceField(queryset=None)\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n variant_field = self.fields['variant']\n variant_field.queryset = self.product.variants\n variant_field.discounts = self.cart.discounts\n variant_field.empty_label = None\n images_map = {variant.pk: [vi.image.image.url\n for vi in variant.variant_images.all()]\n for variant in self.product.variants.all()}\n variant_field.widget.attrs['data-images'] = json.dumps(images_map)\n\n def get_variant(self, cleaned_data):\n return cleaned_data.get('variant')\n\n", "path": "saleor/product/forms.py"}], "after_files": [{"content": "import datetime\nimport json\n\nfrom django.conf import settings\nfrom django.http import HttpResponsePermanentRedirect, JsonResponse\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\n\nfrom ..cart.utils import set_cart_cookie\nfrom ..core.utils import get_paginator_items, serialize_decimal\nfrom ..core.utils.filters import get_now_sorted_by, get_sort_by_choices\nfrom .filters import ProductFilter, SORT_BY_FIELDS\nfrom .models import Category\nfrom .utils import (\n get_availability, get_product_attributes_data, get_product_images,\n get_variant_picker_data, handle_cart_form, product_json_ld,\n products_for_cart, products_with_availability, products_with_details)\n\n\ndef product_details(request, slug, product_id, form=None):\n \"\"\"Product details page\n\n The following variables are available to the template:\n\n product:\n The Product instance itself.\n\n is_visible:\n Whether the product is visible to regular users (for cases when an\n admin is previewing a product before publishing).\n\n form:\n The add-to-cart form.\n\n price_range:\n The PriceRange for the product including all discounts.\n\n undiscounted_price_range:\n The PriceRange excluding all discounts.\n\n discount:\n Either a Price instance equal to the discount value or None if no\n discount was available.\n\n local_price_range:\n The same PriceRange from price_range represented in user's local\n currency. The value will be None if exchange rate is not available or\n the local currency is the same as site's default currency.\n \"\"\"\n products = products_with_details(user=request.user)\n product = get_object_or_404(products, id=product_id)\n if product.get_slug() != slug:\n return HttpResponsePermanentRedirect(product.get_absolute_url())\n today = datetime.date.today()\n is_visible = (\n product.available_on is None or product.available_on <= today)\n if form is None:\n form = handle_cart_form(request, product, create_cart=False)[0]\n availability = get_availability(product, discounts=request.discounts,\n local_currency=request.currency)\n product_images = get_product_images(product)\n variant_picker_data = get_variant_picker_data(\n product, request.discounts, request.currency)\n product_attributes = get_product_attributes_data(product)\n # show_variant_picker determines if variant picker is used or select input\n show_variant_picker = all([v.attributes for v in product.variants.all()])\n json_ld_data = product_json_ld(product, availability, product_attributes)\n return TemplateResponse(\n request, 'product/details.html',\n {'is_visible': is_visible,\n 'form': form,\n 'availability': availability,\n 'product': product,\n 'product_attributes': product_attributes,\n 'product_images': product_images,\n 'show_variant_picker': show_variant_picker,\n 'variant_picker_data': json.dumps(\n variant_picker_data, default=serialize_decimal),\n 'json_ld_product_data': json.dumps(\n json_ld_data, default=serialize_decimal)})\n\n\ndef product_add_to_cart(request, slug, product_id):\n # types: (int, str, dict) -> None\n\n if not request.method == 'POST':\n return redirect(reverse(\n 'product:details',\n kwargs={'product_id': product_id, 'slug': slug}))\n\n products = products_for_cart(user=request.user)\n product = get_object_or_404(products, pk=product_id)\n form, cart = handle_cart_form(request, product, create_cart=True)\n if form.is_valid():\n form.save()\n if request.is_ajax():\n response = JsonResponse({'next': reverse('cart:index')}, status=200)\n else:\n response = redirect('cart:index')\n else:\n if request.is_ajax():\n response = JsonResponse({'error': form.errors}, status=400)\n else:\n response = product_details(request, slug, product_id, form)\n if not request.user.is_authenticated:\n set_cart_cookie(cart, response)\n return response\n\n\ndef category_index(request, path, category_id):\n category = get_object_or_404(Category, id=category_id)\n actual_path = category.get_full_path()\n if actual_path != path:\n return redirect('product:category', permanent=True, path=actual_path,\n category_id=category_id)\n products = (products_with_details(user=request.user)\n .filter(categories__id=category.id)\n .order_by('name'))\n product_filter = ProductFilter(\n request.GET, queryset=products, category=category)\n products_paginated = get_paginator_items(\n product_filter.qs, settings.PAGINATE_BY, request.GET.get('page'))\n products_and_availability = list(products_with_availability(\n products_paginated, request.discounts, request.currency))\n now_sorted_by = get_now_sorted_by(product_filter)\n arg_sort_by = request.GET.get('sort_by')\n is_descending = arg_sort_by.startswith('-') if arg_sort_by else False\n ctx = {'category': category, 'filter_set': product_filter,\n 'products': products_and_availability,\n 'products_paginated': products_paginated,\n 'sort_by_choices': get_sort_by_choices(product_filter),\n 'now_sorted_by': now_sorted_by,\n 'is_descending': is_descending}\n return TemplateResponse(request, 'category/index.html', ctx)\n", "path": "saleor/product/views.py"}, {"content": "import json\n\nfrom django import forms\nfrom django.utils.encoding import smart_text\nfrom django.utils.translation import pgettext_lazy\nfrom django_prices.templatetags.prices_i18n import gross\n\nfrom ..cart.forms import AddToCartForm\n\n\nclass VariantChoiceField(forms.ModelChoiceField):\n discounts = None\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n def label_from_instance(self, obj):\n variant_label = smart_text(obj)\n label = pgettext_lazy(\n 'Variant choice field label',\n '%(variant_label)s - %(price)s') % {\n 'variant_label': variant_label,\n 'price': gross(obj.get_price(discounts=self.discounts))}\n return label\n\n def update_field_data(self, variants, cart):\n \"\"\" Function initializing fields custom data \"\"\"\n self.queryset = variants\n self.discounts = cart.discounts\n self.empty_label = None\n images_map = {variant.pk: [vi.image.image.url\n for vi in variant.variant_images.all()]\n for variant in variants.all()}\n self.widget.attrs['data-images'] = json.dumps(images_map)\n # Don't display select input if there are less than two variants\n if self.queryset.count() < 2:\n self.widget = forms.HiddenInput(\n {'value': variants.all()[0].pk})\n\n\nclass ProductForm(AddToCartForm):\n variant = VariantChoiceField(queryset=None)\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n variant_field = self.fields['variant']\n variant_field.update_field_data(self.product.variants, self.cart)\n\n def get_variant(self, cleaned_data):\n return cleaned_data.get('variant')\n", "path": "saleor/product/forms.py"}]} | 2,316 | 603 |
gh_patches_debug_12730 | rasdani/github-patches | git_diff | dbt-labs__dbt-core-8050 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[CT-2804] Exclude `click==8.1.4` from dependencies
## Problem
When `click==8.1.4` was released, our code quality workflows using `mypy` began failing. An issue has been created on the [click repository](https://github.com/pallets/click/issues/2558).
## Solution
The solution is to exclude, for the time being, `click==8.1.4`. Currently our click dependency is set to `click>=7.0,<9.0`, this should become on main `click>=8.1.1,<8.1.4`.
## Backports
We need to backport this fix to `1.3.latest`, `1.4.latest`, and `1.5.latest`. For the backports we should update the dependency from `click>=7.0,<9.0` to `click>=7.0,<8.1.4`. The reason for the different specification in the backports is that we already support `click 7.x` in these earlier versions. Dropping support for `click 7.x` could be problematic if people are installing dbt-core alongside other dependencies which limit click to `7.x.`, then dropping support for `click 7.x` would represent a breaking change (and we shouldn't do this in a patch version).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/setup.py`
Content:
```
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 8):
6 print("Error: dbt does not support this version of Python.")
7 print("Please upgrade to Python 3.8 or higher.")
8 sys.exit(1)
9
10
11 from setuptools import setup
12
13 try:
14 from setuptools import find_namespace_packages
15 except ImportError:
16 # the user has a downlevel version of setuptools.
17 print("Error: dbt requires setuptools v40.1.0 or higher.")
18 print('Please upgrade setuptools with "pip install --upgrade setuptools" ' "and try again")
19 sys.exit(1)
20
21
22 this_directory = os.path.abspath(os.path.dirname(__file__))
23 with open(os.path.join(this_directory, "README.md")) as f:
24 long_description = f.read()
25
26
27 package_name = "dbt-core"
28 package_version = "1.6.0b8"
29 description = """With dbt, data analysts and engineers can build analytics \
30 the way engineers build applications."""
31
32
33 setup(
34 name=package_name,
35 version=package_version,
36 description=description,
37 long_description=long_description,
38 long_description_content_type="text/markdown",
39 author="dbt Labs",
40 author_email="[email protected]",
41 url="https://github.com/dbt-labs/dbt-core",
42 packages=find_namespace_packages(include=["dbt", "dbt.*"]),
43 include_package_data=True,
44 test_suite="test",
45 entry_points={
46 "console_scripts": ["dbt = dbt.cli.main:cli"],
47 },
48 install_requires=[
49 # ----
50 # dbt-core uses these packages deeply, throughout the codebase, and there have been breaking changes in past patch releases (even though these are major-version-one).
51 # Pin to the patch or minor version, and bump in each new minor version of dbt-core.
52 "agate~=1.7.0",
53 "Jinja2~=3.1.2",
54 "mashumaro[msgpack]~=3.8.1",
55 # ----
56 # Legacy: This package has not been updated since 2019, and it is unused in dbt's logging system (since v1.0)
57 # The dependency here will be removed along with the removal of 'legacy logging', in a future release of dbt-core
58 "logbook>=1.5,<1.6",
59 # ----
60 # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility
61 # with major versions in each new minor version of dbt-core.
62 "click>=7.0,<9",
63 "networkx>=2.3,<4",
64 # ----
65 # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)
66 # and check compatibility / bump in each new minor version of dbt-core.
67 "colorama>=0.3.9,<0.5",
68 "pathspec>=0.9,<0.12",
69 "isodate>=0.6,<0.7",
70 # ----
71 # There was a pin to below 0.4.4 for a while due to a bug in Ubuntu/sqlparse 0.4.4
72 "sqlparse>=0.2.3",
73 # ----
74 # These are major-version-0 packages also maintained by dbt-labs. Accept patches.
75 "dbt-extractor~=0.4.1",
76 "hologram~=0.0.16", # includes transitive dependencies on python-dateutil and jsonschema
77 "minimal-snowplow-tracker~=0.0.2",
78 # DSI is under active development, so we're pinning to specific dev versions for now.
79 # TODO: Before RC/final release, update to use ~= pinning.
80 "dbt-semantic-interfaces==0.1.0.dev8",
81 # ----
82 # Expect compatibility with all new versions of these packages, so lower bounds only.
83 "packaging>20.9",
84 "protobuf>=4.0.0",
85 "pytz>=2015.7",
86 "pyyaml>=6.0",
87 "typing-extensions>=3.7.4",
88 # ----
89 # Match snowflake-connector-python, to ensure compatibility in dbt-snowflake
90 "cffi>=1.9,<2.0.0",
91 "idna>=2.5,<4",
92 "requests<3.0.0",
93 "urllib3~=1.0",
94 # ----
95 ],
96 zip_safe=False,
97 classifiers=[
98 "Development Status :: 5 - Production/Stable",
99 "License :: OSI Approved :: Apache Software License",
100 "Operating System :: Microsoft :: Windows",
101 "Operating System :: MacOS :: MacOS X",
102 "Operating System :: POSIX :: Linux",
103 "Programming Language :: Python :: 3.8",
104 "Programming Language :: Python :: 3.9",
105 "Programming Language :: Python :: 3.10",
106 "Programming Language :: Python :: 3.11",
107 ],
108 python_requires=">=3.8",
109 )
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -59,7 +59,8 @@
# ----
# dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility
# with major versions in each new minor version of dbt-core.
- "click>=7.0,<9",
+ # temporarily pinning click for mypy failures: https://github.com/pallets/click/issues/2558
+ "click>=8.1.1,<8.1.4",
"networkx>=2.3,<4",
# ----
# These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)
| {"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -59,7 +59,8 @@\n # ----\n # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility\n # with major versions in each new minor version of dbt-core.\n- \"click>=7.0,<9\",\n+ # temporarily pinning click for mypy failures: https://github.com/pallets/click/issues/2558\n+ \"click>=8.1.1,<8.1.4\",\n \"networkx>=2.3,<4\",\n # ----\n # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)\n", "issue": "[CT-2804] Exclude `click==8.1.4` from dependencies\n## Problem\r\nWhen `click==8.1.4` was released, our code quality workflows using `mypy` began failing. An issue has been created on the [click repository](https://github.com/pallets/click/issues/2558). \r\n\r\n## Solution\r\nThe solution is to exclude, for the time being, `click==8.1.4`. Currently our click dependency is set to `click>=7.0,<9.0`, this should become on main `click>=8.1.1,<8.1.4`.\r\n\r\n## Backports\r\nWe need to backport this fix to `1.3.latest`, `1.4.latest`, and `1.5.latest`. For the backports we should update the dependency from `click>=7.0,<9.0` to `click>=7.0,<8.1.4`. The reason for the different specification in the backports is that we already support `click 7.x` in these earlier versions. Dropping support for `click 7.x` could be problematic if people are installing dbt-core alongside other dependencies which limit click to `7.x.`, then dropping support for `click 7.x` would represent a breaking change (and we shouldn't do this in a patch version).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 8):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.8 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.6.0b8\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\"dbt = dbt.cli.main:cli\"],\n },\n install_requires=[\n # ----\n # dbt-core uses these packages deeply, throughout the codebase, and there have been breaking changes in past patch releases (even though these are major-version-one).\n # Pin to the patch or minor version, and bump in each new minor version of dbt-core.\n \"agate~=1.7.0\",\n \"Jinja2~=3.1.2\",\n \"mashumaro[msgpack]~=3.8.1\",\n # ----\n # Legacy: This package has not been updated since 2019, and it is unused in dbt's logging system (since v1.0)\n # The dependency here will be removed along with the removal of 'legacy logging', in a future release of dbt-core\n \"logbook>=1.5,<1.6\",\n # ----\n # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility\n # with major versions in each new minor version of dbt-core.\n \"click>=7.0,<9\",\n \"networkx>=2.3,<4\",\n # ----\n # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)\n # and check compatibility / bump in each new minor version of dbt-core.\n \"colorama>=0.3.9,<0.5\",\n \"pathspec>=0.9,<0.12\",\n \"isodate>=0.6,<0.7\",\n # ----\n # There was a pin to below 0.4.4 for a while due to a bug in Ubuntu/sqlparse 0.4.4\n \"sqlparse>=0.2.3\",\n # ----\n # These are major-version-0 packages also maintained by dbt-labs. Accept patches.\n \"dbt-extractor~=0.4.1\",\n \"hologram~=0.0.16\", # includes transitive dependencies on python-dateutil and jsonschema\n \"minimal-snowplow-tracker~=0.0.2\",\n # DSI is under active development, so we're pinning to specific dev versions for now.\n # TODO: Before RC/final release, update to use ~= pinning.\n \"dbt-semantic-interfaces==0.1.0.dev8\",\n # ----\n # Expect compatibility with all new versions of these packages, so lower bounds only.\n \"packaging>20.9\",\n \"protobuf>=4.0.0\",\n \"pytz>=2015.7\",\n \"pyyaml>=6.0\",\n \"typing-extensions>=3.7.4\",\n # ----\n # Match snowflake-connector-python, to ensure compatibility in dbt-snowflake\n \"cffi>=1.9,<2.0.0\",\n \"idna>=2.5,<4\",\n \"requests<3.0.0\",\n \"urllib3~=1.0\",\n # ----\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n python_requires=\">=3.8\",\n)\n", "path": "core/setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 8):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.8 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.6.0b8\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\"dbt = dbt.cli.main:cli\"],\n },\n install_requires=[\n # ----\n # dbt-core uses these packages deeply, throughout the codebase, and there have been breaking changes in past patch releases (even though these are major-version-one).\n # Pin to the patch or minor version, and bump in each new minor version of dbt-core.\n \"agate~=1.7.0\",\n \"Jinja2~=3.1.2\",\n \"mashumaro[msgpack]~=3.8.1\",\n # ----\n # Legacy: This package has not been updated since 2019, and it is unused in dbt's logging system (since v1.0)\n # The dependency here will be removed along with the removal of 'legacy logging', in a future release of dbt-core\n \"logbook>=1.5,<1.6\",\n # ----\n # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility\n # with major versions in each new minor version of dbt-core.\n # temporarily pinning click for mypy failures: https://github.com/pallets/click/issues/2558\n \"click>=8.1.1,<8.1.4\",\n \"networkx>=2.3,<4\",\n # ----\n # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)\n # and check compatibility / bump in each new minor version of dbt-core.\n \"colorama>=0.3.9,<0.5\",\n \"pathspec>=0.9,<0.12\",\n \"isodate>=0.6,<0.7\",\n # ----\n # There was a pin to below 0.4.4 for a while due to a bug in Ubuntu/sqlparse 0.4.4\n \"sqlparse>=0.2.3\",\n # ----\n # These are major-version-0 packages also maintained by dbt-labs. Accept patches.\n \"dbt-extractor~=0.4.1\",\n \"hologram~=0.0.16\", # includes transitive dependencies on python-dateutil and jsonschema\n \"minimal-snowplow-tracker~=0.0.2\",\n # DSI is under active development, so we're pinning to specific dev versions for now.\n # TODO: Before RC/final release, update to use ~= pinning.\n \"dbt-semantic-interfaces==0.1.0.dev8\",\n # ----\n # Expect compatibility with all new versions of these packages, so lower bounds only.\n \"packaging>20.9\",\n \"protobuf>=4.0.0\",\n \"pytz>=2015.7\",\n \"pyyaml>=6.0\",\n \"typing-extensions>=3.7.4\",\n # ----\n # Match snowflake-connector-python, to ensure compatibility in dbt-snowflake\n \"cffi>=1.9,<2.0.0\",\n \"idna>=2.5,<4\",\n \"requests<3.0.0\",\n \"urllib3~=1.0\",\n # ----\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n python_requires=\">=3.8\",\n)\n", "path": "core/setup.py"}]} | 1,888 | 172 |
gh_patches_debug_27178 | rasdani/github-patches | git_diff | modin-project__modin-2836 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Test on Ray Nightly
It would be great if we could test on the Ray nightly wheels on each commit to the master branch. I think we can add it as a separate CI and add a badge to the README to track.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `modin/engines/ray/utils.py`
Content:
```
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 import builtins
15 import os
16 import sys
17
18 from modin.config import (
19 IsRayCluster,
20 RayRedisAddress,
21 CpuCount,
22 Memory,
23 RayPlasmaDir,
24 IsOutOfCore,
25 NPartitions,
26 )
27
28
29 def handle_ray_task_error(e):
30 for s in e.traceback_str.split("\n")[::-1]:
31 if "Error" in s or "Exception" in s:
32 try:
33 raise getattr(builtins, s.split(":")[0])("".join(s.split(":")[1:]))
34 except AttributeError as att_err:
35 if "module" in str(att_err) and builtins.__name__ in str(att_err):
36 pass
37 else:
38 raise att_err
39 raise e
40
41
42 # Register a fix import function to run on all_workers including the driver.
43 # This is a hack solution to fix #647, #746
44 def _move_stdlib_ahead_of_site_packages(*args):
45 site_packages_path = None
46 site_packages_path_index = -1
47 for i, path in enumerate(sys.path):
48 if sys.exec_prefix in path and path.endswith("site-packages"):
49 site_packages_path = path
50 site_packages_path_index = i
51 # break on first found
52 break
53
54 if site_packages_path is not None:
55 # stdlib packages layout as follows:
56 # - python3.x
57 # - typing.py
58 # - site-packages/
59 # - pandas
60 # So extracting the dirname of the site_packages can point us
61 # to the directory containing standard libraries.
62 sys.path.insert(site_packages_path_index, os.path.dirname(site_packages_path))
63
64
65 # Register a fix to import pandas on all workers before running tasks.
66 # This prevents a race condition between two threads deserializing functions
67 # and trying to import pandas at the same time.
68 def _import_pandas(*args):
69 import pandas # noqa F401
70
71
72 def initialize_ray(
73 override_is_cluster=False,
74 override_redis_address: str = None,
75 override_redis_password: str = None,
76 ):
77 """
78 Initializes ray based on parameters, environment variables and internal defaults.
79
80 Parameters
81 ----------
82 override_is_cluster: bool, optional
83 Whether to override the detection of Moding being run in a cluster
84 and always assume this runs on cluster head node.
85 This also overrides Ray worker detection and always runs the function,
86 not only from main thread.
87 If not specified, $MODIN_RAY_CLUSTER env variable is used.
88 override_redis_address: str, optional
89 What Redis address to connect to when running in Ray cluster.
90 If not specified, $MODIN_REDIS_ADDRESS is used.
91 override_redis_password: str, optional
92 What password to use when connecting to Redis.
93 If not specified, a new random one is generated.
94 """
95 import ray
96
97 if not ray.is_initialized() or override_is_cluster:
98 import secrets
99
100 cluster = override_is_cluster or IsRayCluster.get()
101 redis_address = override_redis_address or RayRedisAddress.get()
102 redis_password = override_redis_password or secrets.token_hex(32)
103
104 if cluster:
105 # We only start ray in a cluster setting for the head node.
106 ray.init(
107 address=redis_address or "auto",
108 include_dashboard=False,
109 ignore_reinit_error=True,
110 _redis_password=redis_password,
111 logging_level=100,
112 )
113 else:
114 from modin.error_message import ErrorMessage
115
116 # This string is intentionally formatted this way. We want it indented in
117 # the warning message.
118 ErrorMessage.not_initialized(
119 "Ray",
120 """
121 import ray
122 ray.init()
123 """,
124 )
125 object_store_memory = Memory.get()
126 plasma_directory = RayPlasmaDir.get()
127 if IsOutOfCore.get():
128 if plasma_directory is None:
129 from tempfile import gettempdir
130
131 plasma_directory = gettempdir()
132 # We may have already set the memory from the environment variable, we don't
133 # want to overwrite that value if we have.
134 if object_store_memory is None:
135 # Round down to the nearest Gigabyte.
136 try:
137 system_memory = ray._private.utils.get_system_memory()
138 except AttributeError: # Compatibility with Ray <= 1.2
139 system_memory = ray.utils.get_system_memory()
140 mem_bytes = system_memory // 10 ** 9 * 10 ** 9
141 # Default to 8x memory for out of core
142 object_store_memory = 8 * mem_bytes
143 # In case anything failed above, we can still improve the memory for Modin.
144 if object_store_memory is None:
145 # Round down to the nearest Gigabyte.
146 try:
147 system_memory = ray._private.utils.get_system_memory()
148 except AttributeError: # Compatibility with Ray <= 1.2
149 system_memory = ray.utils.get_system_memory()
150 object_store_memory = int(0.6 * system_memory // 10 ** 9 * 10 ** 9)
151 # If the memory pool is smaller than 2GB, just use the default in ray.
152 if object_store_memory == 0:
153 object_store_memory = None
154 else:
155 object_store_memory = int(object_store_memory)
156 ray.init(
157 num_cpus=CpuCount.get(),
158 include_dashboard=False,
159 ignore_reinit_error=True,
160 _plasma_directory=plasma_directory,
161 object_store_memory=object_store_memory,
162 address=redis_address,
163 _redis_password=redis_password,
164 logging_level=100,
165 _memory=object_store_memory,
166 _lru_evict=True,
167 )
168 _move_stdlib_ahead_of_site_packages()
169 ray.worker.global_worker.run_function_on_all_workers(
170 _move_stdlib_ahead_of_site_packages
171 )
172
173 ray.worker.global_worker.run_function_on_all_workers(_import_pandas)
174
175 num_cpus = int(ray.cluster_resources()["CPU"])
176 NPartitions.put_if_default(num_cpus)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/modin/engines/ray/utils.py b/modin/engines/ray/utils.py
--- a/modin/engines/ray/utils.py
+++ b/modin/engines/ray/utils.py
@@ -153,18 +153,26 @@
object_store_memory = None
else:
object_store_memory = int(object_store_memory)
- ray.init(
- num_cpus=CpuCount.get(),
- include_dashboard=False,
- ignore_reinit_error=True,
- _plasma_directory=plasma_directory,
- object_store_memory=object_store_memory,
- address=redis_address,
- _redis_password=redis_password,
- logging_level=100,
- _memory=object_store_memory,
- _lru_evict=True,
- )
+
+ ray_init_kwargs = {
+ "num_cpus": CpuCount.get(),
+ "include_dashboard": False,
+ "ignore_reinit_error": True,
+ "_plasma_directory": plasma_directory,
+ "object_store_memory": object_store_memory,
+ "address": redis_address,
+ "_redis_password": redis_password,
+ "logging_level": 100,
+ "_memory": object_store_memory,
+ "_lru_evict": True,
+ }
+ from packaging import version
+
+ # setting of `_lru_evict` parameter raises DeprecationWarning since ray 2.0.0.dev0
+ if version.parse(ray.__version__) >= version.parse("2.0.0.dev0"):
+ ray_init_kwargs.pop("_lru_evict")
+ ray.init(**ray_init_kwargs)
+
_move_stdlib_ahead_of_site_packages()
ray.worker.global_worker.run_function_on_all_workers(
_move_stdlib_ahead_of_site_packages
| {"golden_diff": "diff --git a/modin/engines/ray/utils.py b/modin/engines/ray/utils.py\n--- a/modin/engines/ray/utils.py\n+++ b/modin/engines/ray/utils.py\n@@ -153,18 +153,26 @@\n object_store_memory = None\n else:\n object_store_memory = int(object_store_memory)\n- ray.init(\n- num_cpus=CpuCount.get(),\n- include_dashboard=False,\n- ignore_reinit_error=True,\n- _plasma_directory=plasma_directory,\n- object_store_memory=object_store_memory,\n- address=redis_address,\n- _redis_password=redis_password,\n- logging_level=100,\n- _memory=object_store_memory,\n- _lru_evict=True,\n- )\n+\n+ ray_init_kwargs = {\n+ \"num_cpus\": CpuCount.get(),\n+ \"include_dashboard\": False,\n+ \"ignore_reinit_error\": True,\n+ \"_plasma_directory\": plasma_directory,\n+ \"object_store_memory\": object_store_memory,\n+ \"address\": redis_address,\n+ \"_redis_password\": redis_password,\n+ \"logging_level\": 100,\n+ \"_memory\": object_store_memory,\n+ \"_lru_evict\": True,\n+ }\n+ from packaging import version\n+\n+ # setting of `_lru_evict` parameter raises DeprecationWarning since ray 2.0.0.dev0\n+ if version.parse(ray.__version__) >= version.parse(\"2.0.0.dev0\"):\n+ ray_init_kwargs.pop(\"_lru_evict\")\n+ ray.init(**ray_init_kwargs)\n+\n _move_stdlib_ahead_of_site_packages()\n ray.worker.global_worker.run_function_on_all_workers(\n _move_stdlib_ahead_of_site_packages\n", "issue": "Test on Ray Nightly\nIt would be great if we could test on the Ray nightly wheels on each commit to the master branch. I think we can add it as a separate CI and add a badge to the README to track.\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\nimport builtins\nimport os\nimport sys\n\nfrom modin.config import (\n IsRayCluster,\n RayRedisAddress,\n CpuCount,\n Memory,\n RayPlasmaDir,\n IsOutOfCore,\n NPartitions,\n)\n\n\ndef handle_ray_task_error(e):\n for s in e.traceback_str.split(\"\\n\")[::-1]:\n if \"Error\" in s or \"Exception\" in s:\n try:\n raise getattr(builtins, s.split(\":\")[0])(\"\".join(s.split(\":\")[1:]))\n except AttributeError as att_err:\n if \"module\" in str(att_err) and builtins.__name__ in str(att_err):\n pass\n else:\n raise att_err\n raise e\n\n\n# Register a fix import function to run on all_workers including the driver.\n# This is a hack solution to fix #647, #746\ndef _move_stdlib_ahead_of_site_packages(*args):\n site_packages_path = None\n site_packages_path_index = -1\n for i, path in enumerate(sys.path):\n if sys.exec_prefix in path and path.endswith(\"site-packages\"):\n site_packages_path = path\n site_packages_path_index = i\n # break on first found\n break\n\n if site_packages_path is not None:\n # stdlib packages layout as follows:\n # - python3.x\n # - typing.py\n # - site-packages/\n # - pandas\n # So extracting the dirname of the site_packages can point us\n # to the directory containing standard libraries.\n sys.path.insert(site_packages_path_index, os.path.dirname(site_packages_path))\n\n\n# Register a fix to import pandas on all workers before running tasks.\n# This prevents a race condition between two threads deserializing functions\n# and trying to import pandas at the same time.\ndef _import_pandas(*args):\n import pandas # noqa F401\n\n\ndef initialize_ray(\n override_is_cluster=False,\n override_redis_address: str = None,\n override_redis_password: str = None,\n):\n \"\"\"\n Initializes ray based on parameters, environment variables and internal defaults.\n\n Parameters\n ----------\n override_is_cluster: bool, optional\n Whether to override the detection of Moding being run in a cluster\n and always assume this runs on cluster head node.\n This also overrides Ray worker detection and always runs the function,\n not only from main thread.\n If not specified, $MODIN_RAY_CLUSTER env variable is used.\n override_redis_address: str, optional\n What Redis address to connect to when running in Ray cluster.\n If not specified, $MODIN_REDIS_ADDRESS is used.\n override_redis_password: str, optional\n What password to use when connecting to Redis.\n If not specified, a new random one is generated.\n \"\"\"\n import ray\n\n if not ray.is_initialized() or override_is_cluster:\n import secrets\n\n cluster = override_is_cluster or IsRayCluster.get()\n redis_address = override_redis_address or RayRedisAddress.get()\n redis_password = override_redis_password or secrets.token_hex(32)\n\n if cluster:\n # We only start ray in a cluster setting for the head node.\n ray.init(\n address=redis_address or \"auto\",\n include_dashboard=False,\n ignore_reinit_error=True,\n _redis_password=redis_password,\n logging_level=100,\n )\n else:\n from modin.error_message import ErrorMessage\n\n # This string is intentionally formatted this way. We want it indented in\n # the warning message.\n ErrorMessage.not_initialized(\n \"Ray\",\n \"\"\"\n import ray\n ray.init()\n\"\"\",\n )\n object_store_memory = Memory.get()\n plasma_directory = RayPlasmaDir.get()\n if IsOutOfCore.get():\n if plasma_directory is None:\n from tempfile import gettempdir\n\n plasma_directory = gettempdir()\n # We may have already set the memory from the environment variable, we don't\n # want to overwrite that value if we have.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n try:\n system_memory = ray._private.utils.get_system_memory()\n except AttributeError: # Compatibility with Ray <= 1.2\n system_memory = ray.utils.get_system_memory()\n mem_bytes = system_memory // 10 ** 9 * 10 ** 9\n # Default to 8x memory for out of core\n object_store_memory = 8 * mem_bytes\n # In case anything failed above, we can still improve the memory for Modin.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n try:\n system_memory = ray._private.utils.get_system_memory()\n except AttributeError: # Compatibility with Ray <= 1.2\n system_memory = ray.utils.get_system_memory()\n object_store_memory = int(0.6 * system_memory // 10 ** 9 * 10 ** 9)\n # If the memory pool is smaller than 2GB, just use the default in ray.\n if object_store_memory == 0:\n object_store_memory = None\n else:\n object_store_memory = int(object_store_memory)\n ray.init(\n num_cpus=CpuCount.get(),\n include_dashboard=False,\n ignore_reinit_error=True,\n _plasma_directory=plasma_directory,\n object_store_memory=object_store_memory,\n address=redis_address,\n _redis_password=redis_password,\n logging_level=100,\n _memory=object_store_memory,\n _lru_evict=True,\n )\n _move_stdlib_ahead_of_site_packages()\n ray.worker.global_worker.run_function_on_all_workers(\n _move_stdlib_ahead_of_site_packages\n )\n\n ray.worker.global_worker.run_function_on_all_workers(_import_pandas)\n\n num_cpus = int(ray.cluster_resources()[\"CPU\"])\n NPartitions.put_if_default(num_cpus)\n", "path": "modin/engines/ray/utils.py"}], "after_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\nimport builtins\nimport os\nimport sys\n\nfrom modin.config import (\n IsRayCluster,\n RayRedisAddress,\n CpuCount,\n Memory,\n RayPlasmaDir,\n IsOutOfCore,\n NPartitions,\n)\n\n\ndef handle_ray_task_error(e):\n for s in e.traceback_str.split(\"\\n\")[::-1]:\n if \"Error\" in s or \"Exception\" in s:\n try:\n raise getattr(builtins, s.split(\":\")[0])(\"\".join(s.split(\":\")[1:]))\n except AttributeError as att_err:\n if \"module\" in str(att_err) and builtins.__name__ in str(att_err):\n pass\n else:\n raise att_err\n raise e\n\n\n# Register a fix import function to run on all_workers including the driver.\n# This is a hack solution to fix #647, #746\ndef _move_stdlib_ahead_of_site_packages(*args):\n site_packages_path = None\n site_packages_path_index = -1\n for i, path in enumerate(sys.path):\n if sys.exec_prefix in path and path.endswith(\"site-packages\"):\n site_packages_path = path\n site_packages_path_index = i\n # break on first found\n break\n\n if site_packages_path is not None:\n # stdlib packages layout as follows:\n # - python3.x\n # - typing.py\n # - site-packages/\n # - pandas\n # So extracting the dirname of the site_packages can point us\n # to the directory containing standard libraries.\n sys.path.insert(site_packages_path_index, os.path.dirname(site_packages_path))\n\n\n# Register a fix to import pandas on all workers before running tasks.\n# This prevents a race condition between two threads deserializing functions\n# and trying to import pandas at the same time.\ndef _import_pandas(*args):\n import pandas # noqa F401\n\n\ndef initialize_ray(\n override_is_cluster=False,\n override_redis_address: str = None,\n override_redis_password: str = None,\n):\n \"\"\"\n Initializes ray based on parameters, environment variables and internal defaults.\n\n Parameters\n ----------\n override_is_cluster: bool, optional\n Whether to override the detection of Moding being run in a cluster\n and always assume this runs on cluster head node.\n This also overrides Ray worker detection and always runs the function,\n not only from main thread.\n If not specified, $MODIN_RAY_CLUSTER env variable is used.\n override_redis_address: str, optional\n What Redis address to connect to when running in Ray cluster.\n If not specified, $MODIN_REDIS_ADDRESS is used.\n override_redis_password: str, optional\n What password to use when connecting to Redis.\n If not specified, a new random one is generated.\n \"\"\"\n import ray\n\n if not ray.is_initialized() or override_is_cluster:\n import secrets\n\n cluster = override_is_cluster or IsRayCluster.get()\n redis_address = override_redis_address or RayRedisAddress.get()\n redis_password = override_redis_password or secrets.token_hex(32)\n\n if cluster:\n # We only start ray in a cluster setting for the head node.\n ray.init(\n address=redis_address or \"auto\",\n include_dashboard=False,\n ignore_reinit_error=True,\n _redis_password=redis_password,\n logging_level=100,\n )\n else:\n from modin.error_message import ErrorMessage\n\n # This string is intentionally formatted this way. We want it indented in\n # the warning message.\n ErrorMessage.not_initialized(\n \"Ray\",\n \"\"\"\n import ray\n ray.init()\n\"\"\",\n )\n object_store_memory = Memory.get()\n plasma_directory = RayPlasmaDir.get()\n if IsOutOfCore.get():\n if plasma_directory is None:\n from tempfile import gettempdir\n\n plasma_directory = gettempdir()\n # We may have already set the memory from the environment variable, we don't\n # want to overwrite that value if we have.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n try:\n system_memory = ray._private.utils.get_system_memory()\n except AttributeError: # Compatibility with Ray <= 1.2\n system_memory = ray.utils.get_system_memory()\n mem_bytes = system_memory // 10 ** 9 * 10 ** 9\n # Default to 8x memory for out of core\n object_store_memory = 8 * mem_bytes\n # In case anything failed above, we can still improve the memory for Modin.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n try:\n system_memory = ray._private.utils.get_system_memory()\n except AttributeError: # Compatibility with Ray <= 1.2\n system_memory = ray.utils.get_system_memory()\n object_store_memory = int(0.6 * system_memory // 10 ** 9 * 10 ** 9)\n # If the memory pool is smaller than 2GB, just use the default in ray.\n if object_store_memory == 0:\n object_store_memory = None\n else:\n object_store_memory = int(object_store_memory)\n\n ray_init_kwargs = {\n \"num_cpus\": CpuCount.get(),\n \"include_dashboard\": False,\n \"ignore_reinit_error\": True,\n \"_plasma_directory\": plasma_directory,\n \"object_store_memory\": object_store_memory,\n \"address\": redis_address,\n \"_redis_password\": redis_password,\n \"logging_level\": 100,\n \"_memory\": object_store_memory,\n \"_lru_evict\": True,\n }\n from packaging import version\n\n # setting of `_lru_evict` parameter raises DeprecationWarning since ray 2.0.0.dev0\n if version.parse(ray.__version__) >= version.parse(\"2.0.0.dev0\"):\n ray_init_kwargs.pop(\"_lru_evict\")\n ray.init(**ray_init_kwargs)\n\n _move_stdlib_ahead_of_site_packages()\n ray.worker.global_worker.run_function_on_all_workers(\n _move_stdlib_ahead_of_site_packages\n )\n\n ray.worker.global_worker.run_function_on_all_workers(_import_pandas)\n\n num_cpus = int(ray.cluster_resources()[\"CPU\"])\n NPartitions.put_if_default(num_cpus)\n", "path": "modin/engines/ray/utils.py"}]} | 2,181 | 399 |
gh_patches_debug_6728 | rasdani/github-patches | git_diff | ydataai__ydata-profiling-1023 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incorrect duplicate rows count
### Current Behaviour
The duplicated rows count is different between pandas and pandas-profiling when there are nan's in columns
### Expected Behaviour
The count should be equal
### Data Description
I attach a simple example

### Code that reproduces the bug
```Python
import pandas as pd
import numpy as np
df = pd.DataFrame({"a": [np.nan, np.nan, 2], "b": [1, 1, 3]})
sum(df.duplicated())
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
```
### pandas-profiling version
3.2.0
### Dependencies
```Text
numpy==1.22.4
pandas==1.3.3
```
### OS
_No response_
### Checklist
- [X] There is not yet another bug report for this issue in the [issue tracker](https://github.com/ydataai/pandas-profiling/issues)
- [X] The problem is reproducible from this bug report. [This guide](http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) can help to craft a minimal bug report.
- [X] The issue has not been resolved by the entries listed under [Common Issues](https://pandas-profiling.ydata.ai/docs/master/pages/support_contrib/common_issues.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pandas_profiling/model/pandas/duplicates_pandas.py`
Content:
```
1 from typing import Any, Dict, Optional, Sequence, Tuple
2
3 import pandas as pd
4
5 from pandas_profiling.config import Settings
6 from pandas_profiling.model.duplicates import get_duplicates
7
8
9 @get_duplicates.register(Settings, pd.DataFrame, Sequence)
10 def pandas_get_duplicates(
11 config: Settings, df: pd.DataFrame, supported_columns: Sequence
12 ) -> Tuple[Dict[str, Any], Optional[pd.DataFrame]]:
13 """Obtain the most occurring duplicate rows in the DataFrame.
14
15 Args:
16 config: report Settings object
17 df: the Pandas DataFrame.
18 supported_columns: the columns to consider
19
20 Returns:
21 A subset of the DataFrame, ordered by occurrence.
22 """
23 n_head = config.duplicates.head
24
25 metrics: Dict[str, Any] = {}
26 if n_head > 0:
27 if supported_columns and len(df) > 0:
28 duplicates_key = config.duplicates.key
29 if duplicates_key in df.columns:
30 raise ValueError(
31 f"Duplicates key ({duplicates_key}) may not be part of the DataFrame. Either change the "
32 f" column name in the DataFrame or change the 'duplicates.key' parameter."
33 )
34
35 duplicated_rows = df.duplicated(subset=supported_columns, keep=False)
36 duplicated_rows = (
37 df[duplicated_rows]
38 .groupby(supported_columns)
39 .size()
40 .reset_index(name=duplicates_key)
41 )
42
43 metrics["n_duplicates"] = len(duplicated_rows[duplicates_key])
44 metrics["p_duplicates"] = metrics["n_duplicates"] / len(df)
45
46 return (
47 metrics,
48 duplicated_rows.nlargest(n_head, duplicates_key),
49 )
50 else:
51 metrics["n_duplicates"] = 0
52 metrics["p_duplicates"] = 0.0
53 return metrics, None
54 else:
55 return metrics, None
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/pandas_profiling/model/pandas/duplicates_pandas.py b/src/pandas_profiling/model/pandas/duplicates_pandas.py
--- a/src/pandas_profiling/model/pandas/duplicates_pandas.py
+++ b/src/pandas_profiling/model/pandas/duplicates_pandas.py
@@ -35,7 +35,7 @@
duplicated_rows = df.duplicated(subset=supported_columns, keep=False)
duplicated_rows = (
df[duplicated_rows]
- .groupby(supported_columns)
+ .groupby(supported_columns, dropna=False)
.size()
.reset_index(name=duplicates_key)
)
| {"golden_diff": "diff --git a/src/pandas_profiling/model/pandas/duplicates_pandas.py b/src/pandas_profiling/model/pandas/duplicates_pandas.py\n--- a/src/pandas_profiling/model/pandas/duplicates_pandas.py\n+++ b/src/pandas_profiling/model/pandas/duplicates_pandas.py\n@@ -35,7 +35,7 @@\n duplicated_rows = df.duplicated(subset=supported_columns, keep=False)\n duplicated_rows = (\n df[duplicated_rows]\n- .groupby(supported_columns)\n+ .groupby(supported_columns, dropna=False)\n .size()\n .reset_index(name=duplicates_key)\n )\n", "issue": "Incorrect duplicate rows count\n### Current Behaviour\n\nThe duplicated rows count is different between pandas and pandas-profiling when there are nan's in columns\n\n### Expected Behaviour\n\nThe count should be equal\n\n### Data Description\n\nI attach a simple example\r\n\r\n\r\n\n\n### Code that reproduces the bug\n\n```Python\nimport pandas as pd\r\nimport numpy as np\r\n\r\ndf = pd.DataFrame({\"a\": [np.nan, np.nan, 2], \"b\": [1, 1, 3]})\r\nsum(df.duplicated())\r\n\r\nfrom pandas_profiling import ProfileReport\r\n\r\nprofile = ProfileReport(df, title=\"Pandas Profiling Report\")\n```\n\n\n### pandas-profiling version\n\n3.2.0\n\n### Dependencies\n\n```Text\nnumpy==1.22.4\r\npandas==1.3.3\n```\n\n\n### OS\n\n_No response_\n\n### Checklist\n\n- [X] There is not yet another bug report for this issue in the [issue tracker](https://github.com/ydataai/pandas-profiling/issues)\n- [X] The problem is reproducible from this bug report. [This guide](http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports) can help to craft a minimal bug report.\n- [X] The issue has not been resolved by the entries listed under [Common Issues](https://pandas-profiling.ydata.ai/docs/master/pages/support_contrib/common_issues.html).\n", "before_files": [{"content": "from typing import Any, Dict, Optional, Sequence, Tuple\n\nimport pandas as pd\n\nfrom pandas_profiling.config import Settings\nfrom pandas_profiling.model.duplicates import get_duplicates\n\n\n@get_duplicates.register(Settings, pd.DataFrame, Sequence)\ndef pandas_get_duplicates(\n config: Settings, df: pd.DataFrame, supported_columns: Sequence\n) -> Tuple[Dict[str, Any], Optional[pd.DataFrame]]:\n \"\"\"Obtain the most occurring duplicate rows in the DataFrame.\n\n Args:\n config: report Settings object\n df: the Pandas DataFrame.\n supported_columns: the columns to consider\n\n Returns:\n A subset of the DataFrame, ordered by occurrence.\n \"\"\"\n n_head = config.duplicates.head\n\n metrics: Dict[str, Any] = {}\n if n_head > 0:\n if supported_columns and len(df) > 0:\n duplicates_key = config.duplicates.key\n if duplicates_key in df.columns:\n raise ValueError(\n f\"Duplicates key ({duplicates_key}) may not be part of the DataFrame. Either change the \"\n f\" column name in the DataFrame or change the 'duplicates.key' parameter.\"\n )\n\n duplicated_rows = df.duplicated(subset=supported_columns, keep=False)\n duplicated_rows = (\n df[duplicated_rows]\n .groupby(supported_columns)\n .size()\n .reset_index(name=duplicates_key)\n )\n\n metrics[\"n_duplicates\"] = len(duplicated_rows[duplicates_key])\n metrics[\"p_duplicates\"] = metrics[\"n_duplicates\"] / len(df)\n\n return (\n metrics,\n duplicated_rows.nlargest(n_head, duplicates_key),\n )\n else:\n metrics[\"n_duplicates\"] = 0\n metrics[\"p_duplicates\"] = 0.0\n return metrics, None\n else:\n return metrics, None\n", "path": "src/pandas_profiling/model/pandas/duplicates_pandas.py"}], "after_files": [{"content": "from typing import Any, Dict, Optional, Sequence, Tuple\n\nimport pandas as pd\n\nfrom pandas_profiling.config import Settings\nfrom pandas_profiling.model.duplicates import get_duplicates\n\n\n@get_duplicates.register(Settings, pd.DataFrame, Sequence)\ndef pandas_get_duplicates(\n config: Settings, df: pd.DataFrame, supported_columns: Sequence\n) -> Tuple[Dict[str, Any], Optional[pd.DataFrame]]:\n \"\"\"Obtain the most occurring duplicate rows in the DataFrame.\n\n Args:\n config: report Settings object\n df: the Pandas DataFrame.\n supported_columns: the columns to consider\n\n Returns:\n A subset of the DataFrame, ordered by occurrence.\n \"\"\"\n n_head = config.duplicates.head\n\n metrics: Dict[str, Any] = {}\n if n_head > 0:\n if supported_columns and len(df) > 0:\n duplicates_key = config.duplicates.key\n if duplicates_key in df.columns:\n raise ValueError(\n f\"Duplicates key ({duplicates_key}) may not be part of the DataFrame. Either change the \"\n f\" column name in the DataFrame or change the 'duplicates.key' parameter.\"\n )\n\n duplicated_rows = df.duplicated(subset=supported_columns, keep=False)\n duplicated_rows = (\n df[duplicated_rows]\n .groupby(supported_columns, dropna=False)\n .size()\n .reset_index(name=duplicates_key)\n )\n\n metrics[\"n_duplicates\"] = len(duplicated_rows[duplicates_key])\n metrics[\"p_duplicates\"] = metrics[\"n_duplicates\"] / len(df)\n\n return (\n metrics,\n duplicated_rows.nlargest(n_head, duplicates_key),\n )\n else:\n metrics[\"n_duplicates\"] = 0\n metrics[\"p_duplicates\"] = 0.0\n return metrics, None\n else:\n return metrics, None\n", "path": "src/pandas_profiling/model/pandas/duplicates_pandas.py"}]} | 1,122 | 140 |
gh_patches_debug_7812 | rasdani/github-patches | git_diff | qutebrowser__qutebrowser-3660 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Crash in schedule_completion_update because self._last_cursor_pos was None
From https://crashes.qutebrowser.org/view/2e422bf5
```
10:10:35 DEBUG commands command:run:485 command called: set-cmd-text ['-s', ':open -t']
10:10:35 DEBUG commands command:run:500 Calling qutebrowser.mainwindow.statusbar.command.Command.set_cmd_text_command(<qutebrowser.mainwindow.statusbar.command.Command>, ':open -t', None, True, False, False)
10:10:35 ERROR misc crashsignal:exception_hook:216 Uncaught exception
Traceback (most recent call last):
File "/usr/lib/python3.6/site-packages/qutebrowser/completion/completer.py", line 206, in schedule_completion_update
self._cmd.cursorPosition() > self._last_cursor_pos):
TypeError: '>' not supported between instances of 'int' and 'NoneType'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qutebrowser/completion/completer.py`
Content:
```
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2018 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Completer attached to a CompletionView."""
21
22 import attr
23 from PyQt5.QtCore import pyqtSlot, QObject, QTimer
24
25 from qutebrowser.config import config
26 from qutebrowser.commands import cmdutils, runners
27 from qutebrowser.utils import log, utils, debug
28 from qutebrowser.completion.models import miscmodels
29
30
31 @attr.s
32 class CompletionInfo:
33
34 """Context passed into all completion functions."""
35
36 config = attr.ib()
37 keyconf = attr.ib()
38 win_id = attr.ib()
39
40
41 class Completer(QObject):
42
43 """Completer which manages completions in a CompletionView.
44
45 Attributes:
46 _cmd: The statusbar Command object this completer belongs to.
47 _win_id: The id of the window that owns this object.
48 _timer: The timer used to trigger the completion update.
49 _last_cursor_pos: The old cursor position so we avoid double completion
50 updates.
51 _last_text: The old command text so we avoid double completion updates.
52 _last_completion_func: The completion function used for the last text.
53 """
54
55 def __init__(self, *, cmd, win_id, parent=None):
56 super().__init__(parent)
57 self._cmd = cmd
58 self._win_id = win_id
59 self._timer = QTimer()
60 self._timer.setSingleShot(True)
61 self._timer.setInterval(0)
62 self._timer.timeout.connect(self._update_completion)
63 self._last_cursor_pos = None
64 self._last_text = None
65 self._last_completion_func = None
66 self._cmd.update_completion.connect(self.schedule_completion_update)
67
68 def __repr__(self):
69 return utils.get_repr(self)
70
71 def _model(self):
72 """Convenience method to get the current completion model."""
73 completion = self.parent()
74 return completion.model()
75
76 def _get_new_completion(self, before_cursor, under_cursor):
77 """Get the completion function based on the current command text.
78
79 Args:
80 before_cursor: The command chunks before the cursor.
81 under_cursor: The command chunk under the cursor.
82
83 Return:
84 A completion model.
85 """
86 if '--' in before_cursor or under_cursor.startswith('-'):
87 # cursor on a flag or after an explicit split (--)
88 return None
89 log.completion.debug("Before removing flags: {}".format(before_cursor))
90 if not before_cursor:
91 # '|' or 'set|'
92 log.completion.debug('Starting command completion')
93 return miscmodels.command
94 try:
95 cmd = cmdutils.cmd_dict[before_cursor[0]]
96 except KeyError:
97 log.completion.debug("No completion for unknown command: {}"
98 .format(before_cursor[0]))
99 return None
100
101 before_cursor = [x for x in before_cursor if not x.startswith('-')]
102 log.completion.debug("After removing flags: {}".format(before_cursor))
103 argpos = len(before_cursor) - 1
104 try:
105 func = cmd.get_pos_arg_info(argpos).completion
106 except IndexError:
107 log.completion.debug("No completion in position {}".format(argpos))
108 return None
109 return func
110
111 def _quote(self, s):
112 """Quote s if it needs quoting for the commandline.
113
114 Note we don't use shlex.quote because that quotes a lot of shell
115 metachars we don't need to have quoted.
116 """
117 if not s:
118 return "''"
119 elif any(c in s for c in ' "\'\t\n\\'):
120 # use single quotes, and put single quotes into double quotes
121 # the string $'b is then quoted as '$'"'"'b'
122 return "'" + s.replace("'", "'\"'\"'") + "'"
123 else:
124 return s
125
126 def _partition(self):
127 """Divide the commandline text into chunks around the cursor position.
128
129 Return:
130 ([parts_before_cursor], 'part_under_cursor', [parts_after_cursor])
131 """
132 text = self._cmd.text()[len(self._cmd.prefix()):]
133 if not text or not text.strip():
134 # Only ":", empty part under the cursor with nothing before/after
135 return [], '', []
136 parser = runners.CommandParser()
137 result = parser.parse(text, fallback=True, keep=True)
138 parts = [x for x in result.cmdline if x]
139 pos = self._cmd.cursorPosition() - len(self._cmd.prefix())
140 pos = min(pos, len(text)) # Qt treats 2-byte UTF-16 chars as 2 chars
141 log.completion.debug('partitioning {} around position {}'.format(parts,
142 pos))
143 for i, part in enumerate(parts):
144 pos -= len(part)
145 if pos <= 0:
146 if part[pos-1:pos+1].isspace():
147 # cursor is in a space between two existing words
148 parts.insert(i, '')
149 prefix = [x.strip() for x in parts[:i]]
150 center = parts[i].strip()
151 # strip trailing whitepsace included as a separate token
152 postfix = [x.strip() for x in parts[i+1:] if not x.isspace()]
153 log.completion.debug(
154 "partitioned: {} '{}' {}".format(prefix, center, postfix))
155 return prefix, center, postfix
156
157 raise utils.Unreachable("Not all parts consumed: {}".format(parts))
158
159 @pyqtSlot(str)
160 def on_selection_changed(self, text):
161 """Change the completed part if a new item was selected.
162
163 Called from the views selectionChanged method.
164
165 Args:
166 text: Newly selected text.
167 """
168 if text is None:
169 return
170 before, center, after = self._partition()
171 log.completion.debug("Changing {} to '{}'".format(center, text))
172 try:
173 maxsplit = cmdutils.cmd_dict[before[0]].maxsplit
174 except (KeyError, IndexError):
175 maxsplit = None
176 if maxsplit is None:
177 text = self._quote(text)
178 model = self._model()
179 if model.count() == 1 and config.val.completion.quick:
180 # If we only have one item, we want to apply it immediately and go
181 # on to the next part, unless we are quick-completing the part
182 # after maxsplit, so that we don't keep offering completions
183 # (see issue #1519)
184 if maxsplit is not None and maxsplit < len(before):
185 self._change_completed_part(text, before, after)
186 else:
187 self._change_completed_part(text, before, after,
188 immediate=True)
189 else:
190 self._change_completed_part(text, before, after)
191
192 @pyqtSlot()
193 def schedule_completion_update(self):
194 """Schedule updating/enabling completion.
195
196 For performance reasons we don't want to block here, instead we do this
197 in the background.
198
199 We delay the update only if we've already input some text and ignore
200 updates if the text is shorter than completion.min_chars (unless we're
201 hitting backspace in which case updates won't be ignored).
202 """
203 _cmd, _sep, rest = self._cmd.text().partition(' ')
204 input_length = len(rest)
205 if (0 < input_length < config.val.completion.min_chars and
206 self._cmd.cursorPosition() > self._last_cursor_pos):
207 log.completion.debug("Ignoring update because the length of "
208 "the text is less than completion.min_chars.")
209 elif (self._cmd.cursorPosition() == self._last_cursor_pos and
210 self._cmd.text() == self._last_text):
211 log.completion.debug("Ignoring update because there were no "
212 "changes.")
213 else:
214 log.completion.debug("Scheduling completion update.")
215 start_delay = config.val.completion.delay if self._last_text else 0
216 self._timer.start(start_delay)
217 self._last_cursor_pos = self._cmd.cursorPosition()
218 self._last_text = self._cmd.text()
219
220 @pyqtSlot()
221 def _update_completion(self):
222 """Check if completions are available and activate them."""
223 completion = self.parent()
224
225 if self._cmd.prefix() != ':':
226 # This is a search or gibberish, so we don't need to complete
227 # anything (yet)
228 # FIXME complete searches
229 # https://github.com/qutebrowser/qutebrowser/issues/32
230 completion.set_model(None)
231 self._last_completion_func = None
232 return
233
234 before_cursor, pattern, after_cursor = self._partition()
235
236 log.completion.debug("Updating completion: {} {} {}".format(
237 before_cursor, pattern, after_cursor))
238
239 pattern = pattern.strip("'\"")
240 func = self._get_new_completion(before_cursor, pattern)
241
242 if func is None:
243 log.completion.debug('Clearing completion')
244 completion.set_model(None)
245 self._last_completion_func = None
246 return
247
248 if func != self._last_completion_func:
249 self._last_completion_func = func
250 args = (x for x in before_cursor[1:] if not x.startswith('-'))
251 with debug.log_time(log.completion, 'Starting {} completion'
252 .format(func.__name__)):
253 info = CompletionInfo(config=config.instance,
254 keyconf=config.key_instance,
255 win_id=self._win_id)
256 model = func(*args, info=info)
257 with debug.log_time(log.completion, 'Set completion model'):
258 completion.set_model(model)
259
260 completion.set_pattern(pattern)
261
262 def _change_completed_part(self, newtext, before, after, immediate=False):
263 """Change the part we're currently completing in the commandline.
264
265 Args:
266 text: The text to set (string) for the token under the cursor.
267 before: Commandline tokens before the token under the cursor.
268 after: Commandline tokens after the token under the cursor.
269 immediate: True if the text should be completed immediately
270 including a trailing space and we shouldn't continue
271 completing the current item.
272 """
273 text = self._cmd.prefix() + ' '.join(before + [newtext])
274 pos = len(text) + (1 if immediate else 0)
275 if after:
276 text += ' ' + ' '.join(after)
277 elif immediate:
278 # pad with a space if quick-completing the last entry
279 text += ' '
280 log.completion.debug("setting text = '{}', pos = {}".format(text, pos))
281
282 # generally, we don't want to let self._cmd emit cursorPositionChanged,
283 # because that'll schedule a completion update. That happens when
284 # tabbing through the completions, and we want to change the command
285 # text but we also want to keep the original completion list for the
286 # command the user manually entered. The exception is when we're
287 # immediately completing, in which case we *do* want to update the
288 # completion view so that we can start completing the next part
289 if not immediate:
290 self._cmd.blockSignals(True)
291
292 self._cmd.setText(text)
293 self._cmd.setCursorPosition(pos)
294 self._cmd.setFocus()
295
296 self._cmd.blockSignals(False)
297 self._cmd.show_cmd.emit()
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/qutebrowser/completion/completer.py b/qutebrowser/completion/completer.py
--- a/qutebrowser/completion/completer.py
+++ b/qutebrowser/completion/completer.py
@@ -60,7 +60,7 @@
self._timer.setSingleShot(True)
self._timer.setInterval(0)
self._timer.timeout.connect(self._update_completion)
- self._last_cursor_pos = None
+ self._last_cursor_pos = -1
self._last_text = None
self._last_completion_func = None
self._cmd.update_completion.connect(self.schedule_completion_update)
| {"golden_diff": "diff --git a/qutebrowser/completion/completer.py b/qutebrowser/completion/completer.py\n--- a/qutebrowser/completion/completer.py\n+++ b/qutebrowser/completion/completer.py\n@@ -60,7 +60,7 @@\n self._timer.setSingleShot(True)\n self._timer.setInterval(0)\n self._timer.timeout.connect(self._update_completion)\n- self._last_cursor_pos = None\n+ self._last_cursor_pos = -1\n self._last_text = None\n self._last_completion_func = None\n self._cmd.update_completion.connect(self.schedule_completion_update)\n", "issue": "Crash in schedule_completion_update because self._last_cursor_pos was None\nFrom https://crashes.qutebrowser.org/view/2e422bf5\r\n\r\n```\r\n10:10:35 DEBUG commands command:run:485 command called: set-cmd-text ['-s', ':open -t']\r\n10:10:35 DEBUG commands command:run:500 Calling qutebrowser.mainwindow.statusbar.command.Command.set_cmd_text_command(<qutebrowser.mainwindow.statusbar.command.Command>, ':open -t', None, True, False, False)\r\n10:10:35 ERROR misc crashsignal:exception_hook:216 Uncaught exception\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.6/site-packages/qutebrowser/completion/completer.py\", line 206, in schedule_completion_update\r\n self._cmd.cursorPosition() > self._last_cursor_pos):\r\nTypeError: '>' not supported between instances of 'int' and 'NoneType'\r\n```\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2018 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Completer attached to a CompletionView.\"\"\"\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QObject, QTimer\n\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdutils, runners\nfrom qutebrowser.utils import log, utils, debug\nfrom qutebrowser.completion.models import miscmodels\n\n\[email protected]\nclass CompletionInfo:\n\n \"\"\"Context passed into all completion functions.\"\"\"\n\n config = attr.ib()\n keyconf = attr.ib()\n win_id = attr.ib()\n\n\nclass Completer(QObject):\n\n \"\"\"Completer which manages completions in a CompletionView.\n\n Attributes:\n _cmd: The statusbar Command object this completer belongs to.\n _win_id: The id of the window that owns this object.\n _timer: The timer used to trigger the completion update.\n _last_cursor_pos: The old cursor position so we avoid double completion\n updates.\n _last_text: The old command text so we avoid double completion updates.\n _last_completion_func: The completion function used for the last text.\n \"\"\"\n\n def __init__(self, *, cmd, win_id, parent=None):\n super().__init__(parent)\n self._cmd = cmd\n self._win_id = win_id\n self._timer = QTimer()\n self._timer.setSingleShot(True)\n self._timer.setInterval(0)\n self._timer.timeout.connect(self._update_completion)\n self._last_cursor_pos = None\n self._last_text = None\n self._last_completion_func = None\n self._cmd.update_completion.connect(self.schedule_completion_update)\n\n def __repr__(self):\n return utils.get_repr(self)\n\n def _model(self):\n \"\"\"Convenience method to get the current completion model.\"\"\"\n completion = self.parent()\n return completion.model()\n\n def _get_new_completion(self, before_cursor, under_cursor):\n \"\"\"Get the completion function based on the current command text.\n\n Args:\n before_cursor: The command chunks before the cursor.\n under_cursor: The command chunk under the cursor.\n\n Return:\n A completion model.\n \"\"\"\n if '--' in before_cursor or under_cursor.startswith('-'):\n # cursor on a flag or after an explicit split (--)\n return None\n log.completion.debug(\"Before removing flags: {}\".format(before_cursor))\n if not before_cursor:\n # '|' or 'set|'\n log.completion.debug('Starting command completion')\n return miscmodels.command\n try:\n cmd = cmdutils.cmd_dict[before_cursor[0]]\n except KeyError:\n log.completion.debug(\"No completion for unknown command: {}\"\n .format(before_cursor[0]))\n return None\n\n before_cursor = [x for x in before_cursor if not x.startswith('-')]\n log.completion.debug(\"After removing flags: {}\".format(before_cursor))\n argpos = len(before_cursor) - 1\n try:\n func = cmd.get_pos_arg_info(argpos).completion\n except IndexError:\n log.completion.debug(\"No completion in position {}\".format(argpos))\n return None\n return func\n\n def _quote(self, s):\n \"\"\"Quote s if it needs quoting for the commandline.\n\n Note we don't use shlex.quote because that quotes a lot of shell\n metachars we don't need to have quoted.\n \"\"\"\n if not s:\n return \"''\"\n elif any(c in s for c in ' \"\\'\\t\\n\\\\'):\n # use single quotes, and put single quotes into double quotes\n # the string $'b is then quoted as '$'\"'\"'b'\n return \"'\" + s.replace(\"'\", \"'\\\"'\\\"'\") + \"'\"\n else:\n return s\n\n def _partition(self):\n \"\"\"Divide the commandline text into chunks around the cursor position.\n\n Return:\n ([parts_before_cursor], 'part_under_cursor', [parts_after_cursor])\n \"\"\"\n text = self._cmd.text()[len(self._cmd.prefix()):]\n if not text or not text.strip():\n # Only \":\", empty part under the cursor with nothing before/after\n return [], '', []\n parser = runners.CommandParser()\n result = parser.parse(text, fallback=True, keep=True)\n parts = [x for x in result.cmdline if x]\n pos = self._cmd.cursorPosition() - len(self._cmd.prefix())\n pos = min(pos, len(text)) # Qt treats 2-byte UTF-16 chars as 2 chars\n log.completion.debug('partitioning {} around position {}'.format(parts,\n pos))\n for i, part in enumerate(parts):\n pos -= len(part)\n if pos <= 0:\n if part[pos-1:pos+1].isspace():\n # cursor is in a space between two existing words\n parts.insert(i, '')\n prefix = [x.strip() for x in parts[:i]]\n center = parts[i].strip()\n # strip trailing whitepsace included as a separate token\n postfix = [x.strip() for x in parts[i+1:] if not x.isspace()]\n log.completion.debug(\n \"partitioned: {} '{}' {}\".format(prefix, center, postfix))\n return prefix, center, postfix\n\n raise utils.Unreachable(\"Not all parts consumed: {}\".format(parts))\n\n @pyqtSlot(str)\n def on_selection_changed(self, text):\n \"\"\"Change the completed part if a new item was selected.\n\n Called from the views selectionChanged method.\n\n Args:\n text: Newly selected text.\n \"\"\"\n if text is None:\n return\n before, center, after = self._partition()\n log.completion.debug(\"Changing {} to '{}'\".format(center, text))\n try:\n maxsplit = cmdutils.cmd_dict[before[0]].maxsplit\n except (KeyError, IndexError):\n maxsplit = None\n if maxsplit is None:\n text = self._quote(text)\n model = self._model()\n if model.count() == 1 and config.val.completion.quick:\n # If we only have one item, we want to apply it immediately and go\n # on to the next part, unless we are quick-completing the part\n # after maxsplit, so that we don't keep offering completions\n # (see issue #1519)\n if maxsplit is not None and maxsplit < len(before):\n self._change_completed_part(text, before, after)\n else:\n self._change_completed_part(text, before, after,\n immediate=True)\n else:\n self._change_completed_part(text, before, after)\n\n @pyqtSlot()\n def schedule_completion_update(self):\n \"\"\"Schedule updating/enabling completion.\n\n For performance reasons we don't want to block here, instead we do this\n in the background.\n\n We delay the update only if we've already input some text and ignore\n updates if the text is shorter than completion.min_chars (unless we're\n hitting backspace in which case updates won't be ignored).\n \"\"\"\n _cmd, _sep, rest = self._cmd.text().partition(' ')\n input_length = len(rest)\n if (0 < input_length < config.val.completion.min_chars and\n self._cmd.cursorPosition() > self._last_cursor_pos):\n log.completion.debug(\"Ignoring update because the length of \"\n \"the text is less than completion.min_chars.\")\n elif (self._cmd.cursorPosition() == self._last_cursor_pos and\n self._cmd.text() == self._last_text):\n log.completion.debug(\"Ignoring update because there were no \"\n \"changes.\")\n else:\n log.completion.debug(\"Scheduling completion update.\")\n start_delay = config.val.completion.delay if self._last_text else 0\n self._timer.start(start_delay)\n self._last_cursor_pos = self._cmd.cursorPosition()\n self._last_text = self._cmd.text()\n\n @pyqtSlot()\n def _update_completion(self):\n \"\"\"Check if completions are available and activate them.\"\"\"\n completion = self.parent()\n\n if self._cmd.prefix() != ':':\n # This is a search or gibberish, so we don't need to complete\n # anything (yet)\n # FIXME complete searches\n # https://github.com/qutebrowser/qutebrowser/issues/32\n completion.set_model(None)\n self._last_completion_func = None\n return\n\n before_cursor, pattern, after_cursor = self._partition()\n\n log.completion.debug(\"Updating completion: {} {} {}\".format(\n before_cursor, pattern, after_cursor))\n\n pattern = pattern.strip(\"'\\\"\")\n func = self._get_new_completion(before_cursor, pattern)\n\n if func is None:\n log.completion.debug('Clearing completion')\n completion.set_model(None)\n self._last_completion_func = None\n return\n\n if func != self._last_completion_func:\n self._last_completion_func = func\n args = (x for x in before_cursor[1:] if not x.startswith('-'))\n with debug.log_time(log.completion, 'Starting {} completion'\n .format(func.__name__)):\n info = CompletionInfo(config=config.instance,\n keyconf=config.key_instance,\n win_id=self._win_id)\n model = func(*args, info=info)\n with debug.log_time(log.completion, 'Set completion model'):\n completion.set_model(model)\n\n completion.set_pattern(pattern)\n\n def _change_completed_part(self, newtext, before, after, immediate=False):\n \"\"\"Change the part we're currently completing in the commandline.\n\n Args:\n text: The text to set (string) for the token under the cursor.\n before: Commandline tokens before the token under the cursor.\n after: Commandline tokens after the token under the cursor.\n immediate: True if the text should be completed immediately\n including a trailing space and we shouldn't continue\n completing the current item.\n \"\"\"\n text = self._cmd.prefix() + ' '.join(before + [newtext])\n pos = len(text) + (1 if immediate else 0)\n if after:\n text += ' ' + ' '.join(after)\n elif immediate:\n # pad with a space if quick-completing the last entry\n text += ' '\n log.completion.debug(\"setting text = '{}', pos = {}\".format(text, pos))\n\n # generally, we don't want to let self._cmd emit cursorPositionChanged,\n # because that'll schedule a completion update. That happens when\n # tabbing through the completions, and we want to change the command\n # text but we also want to keep the original completion list for the\n # command the user manually entered. The exception is when we're\n # immediately completing, in which case we *do* want to update the\n # completion view so that we can start completing the next part\n if not immediate:\n self._cmd.blockSignals(True)\n\n self._cmd.setText(text)\n self._cmd.setCursorPosition(pos)\n self._cmd.setFocus()\n\n self._cmd.blockSignals(False)\n self._cmd.show_cmd.emit()\n", "path": "qutebrowser/completion/completer.py"}], "after_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2018 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Completer attached to a CompletionView.\"\"\"\n\nimport attr\nfrom PyQt5.QtCore import pyqtSlot, QObject, QTimer\n\nfrom qutebrowser.config import config\nfrom qutebrowser.commands import cmdutils, runners\nfrom qutebrowser.utils import log, utils, debug\nfrom qutebrowser.completion.models import miscmodels\n\n\[email protected]\nclass CompletionInfo:\n\n \"\"\"Context passed into all completion functions.\"\"\"\n\n config = attr.ib()\n keyconf = attr.ib()\n win_id = attr.ib()\n\n\nclass Completer(QObject):\n\n \"\"\"Completer which manages completions in a CompletionView.\n\n Attributes:\n _cmd: The statusbar Command object this completer belongs to.\n _win_id: The id of the window that owns this object.\n _timer: The timer used to trigger the completion update.\n _last_cursor_pos: The old cursor position so we avoid double completion\n updates.\n _last_text: The old command text so we avoid double completion updates.\n _last_completion_func: The completion function used for the last text.\n \"\"\"\n\n def __init__(self, *, cmd, win_id, parent=None):\n super().__init__(parent)\n self._cmd = cmd\n self._win_id = win_id\n self._timer = QTimer()\n self._timer.setSingleShot(True)\n self._timer.setInterval(0)\n self._timer.timeout.connect(self._update_completion)\n self._last_cursor_pos = -1\n self._last_text = None\n self._last_completion_func = None\n self._cmd.update_completion.connect(self.schedule_completion_update)\n\n def __repr__(self):\n return utils.get_repr(self)\n\n def _model(self):\n \"\"\"Convenience method to get the current completion model.\"\"\"\n completion = self.parent()\n return completion.model()\n\n def _get_new_completion(self, before_cursor, under_cursor):\n \"\"\"Get the completion function based on the current command text.\n\n Args:\n before_cursor: The command chunks before the cursor.\n under_cursor: The command chunk under the cursor.\n\n Return:\n A completion model.\n \"\"\"\n if '--' in before_cursor or under_cursor.startswith('-'):\n # cursor on a flag or after an explicit split (--)\n return None\n log.completion.debug(\"Before removing flags: {}\".format(before_cursor))\n if not before_cursor:\n # '|' or 'set|'\n log.completion.debug('Starting command completion')\n return miscmodels.command\n try:\n cmd = cmdutils.cmd_dict[before_cursor[0]]\n except KeyError:\n log.completion.debug(\"No completion for unknown command: {}\"\n .format(before_cursor[0]))\n return None\n\n before_cursor = [x for x in before_cursor if not x.startswith('-')]\n log.completion.debug(\"After removing flags: {}\".format(before_cursor))\n argpos = len(before_cursor) - 1\n try:\n func = cmd.get_pos_arg_info(argpos).completion\n except IndexError:\n log.completion.debug(\"No completion in position {}\".format(argpos))\n return None\n return func\n\n def _quote(self, s):\n \"\"\"Quote s if it needs quoting for the commandline.\n\n Note we don't use shlex.quote because that quotes a lot of shell\n metachars we don't need to have quoted.\n \"\"\"\n if not s:\n return \"''\"\n elif any(c in s for c in ' \"\\'\\t\\n\\\\'):\n # use single quotes, and put single quotes into double quotes\n # the string $'b is then quoted as '$'\"'\"'b'\n return \"'\" + s.replace(\"'\", \"'\\\"'\\\"'\") + \"'\"\n else:\n return s\n\n def _partition(self):\n \"\"\"Divide the commandline text into chunks around the cursor position.\n\n Return:\n ([parts_before_cursor], 'part_under_cursor', [parts_after_cursor])\n \"\"\"\n text = self._cmd.text()[len(self._cmd.prefix()):]\n if not text or not text.strip():\n # Only \":\", empty part under the cursor with nothing before/after\n return [], '', []\n parser = runners.CommandParser()\n result = parser.parse(text, fallback=True, keep=True)\n parts = [x for x in result.cmdline if x]\n pos = self._cmd.cursorPosition() - len(self._cmd.prefix())\n pos = min(pos, len(text)) # Qt treats 2-byte UTF-16 chars as 2 chars\n log.completion.debug('partitioning {} around position {}'.format(parts,\n pos))\n for i, part in enumerate(parts):\n pos -= len(part)\n if pos <= 0:\n if part[pos-1:pos+1].isspace():\n # cursor is in a space between two existing words\n parts.insert(i, '')\n prefix = [x.strip() for x in parts[:i]]\n center = parts[i].strip()\n # strip trailing whitepsace included as a separate token\n postfix = [x.strip() for x in parts[i+1:] if not x.isspace()]\n log.completion.debug(\n \"partitioned: {} '{}' {}\".format(prefix, center, postfix))\n return prefix, center, postfix\n\n raise utils.Unreachable(\"Not all parts consumed: {}\".format(parts))\n\n @pyqtSlot(str)\n def on_selection_changed(self, text):\n \"\"\"Change the completed part if a new item was selected.\n\n Called from the views selectionChanged method.\n\n Args:\n text: Newly selected text.\n \"\"\"\n if text is None:\n return\n before, center, after = self._partition()\n log.completion.debug(\"Changing {} to '{}'\".format(center, text))\n try:\n maxsplit = cmdutils.cmd_dict[before[0]].maxsplit\n except (KeyError, IndexError):\n maxsplit = None\n if maxsplit is None:\n text = self._quote(text)\n model = self._model()\n if model.count() == 1 and config.val.completion.quick:\n # If we only have one item, we want to apply it immediately and go\n # on to the next part, unless we are quick-completing the part\n # after maxsplit, so that we don't keep offering completions\n # (see issue #1519)\n if maxsplit is not None and maxsplit < len(before):\n self._change_completed_part(text, before, after)\n else:\n self._change_completed_part(text, before, after,\n immediate=True)\n else:\n self._change_completed_part(text, before, after)\n\n @pyqtSlot()\n def schedule_completion_update(self):\n \"\"\"Schedule updating/enabling completion.\n\n For performance reasons we don't want to block here, instead we do this\n in the background.\n\n We delay the update only if we've already input some text and ignore\n updates if the text is shorter than completion.min_chars (unless we're\n hitting backspace in which case updates won't be ignored).\n \"\"\"\n _cmd, _sep, rest = self._cmd.text().partition(' ')\n input_length = len(rest)\n if (0 < input_length < config.val.completion.min_chars and\n self._cmd.cursorPosition() > self._last_cursor_pos):\n log.completion.debug(\"Ignoring update because the length of \"\n \"the text is less than completion.min_chars.\")\n elif (self._cmd.cursorPosition() == self._last_cursor_pos and\n self._cmd.text() == self._last_text):\n log.completion.debug(\"Ignoring update because there were no \"\n \"changes.\")\n else:\n log.completion.debug(\"Scheduling completion update.\")\n start_delay = config.val.completion.delay if self._last_text else 0\n self._timer.start(start_delay)\n self._last_cursor_pos = self._cmd.cursorPosition()\n self._last_text = self._cmd.text()\n\n @pyqtSlot()\n def _update_completion(self):\n \"\"\"Check if completions are available and activate them.\"\"\"\n completion = self.parent()\n\n if self._cmd.prefix() != ':':\n # This is a search or gibberish, so we don't need to complete\n # anything (yet)\n # FIXME complete searches\n # https://github.com/qutebrowser/qutebrowser/issues/32\n completion.set_model(None)\n self._last_completion_func = None\n return\n\n before_cursor, pattern, after_cursor = self._partition()\n\n log.completion.debug(\"Updating completion: {} {} {}\".format(\n before_cursor, pattern, after_cursor))\n\n pattern = pattern.strip(\"'\\\"\")\n func = self._get_new_completion(before_cursor, pattern)\n\n if func is None:\n log.completion.debug('Clearing completion')\n completion.set_model(None)\n self._last_completion_func = None\n return\n\n if func != self._last_completion_func:\n self._last_completion_func = func\n args = (x for x in before_cursor[1:] if not x.startswith('-'))\n with debug.log_time(log.completion, 'Starting {} completion'\n .format(func.__name__)):\n info = CompletionInfo(config=config.instance,\n keyconf=config.key_instance,\n win_id=self._win_id)\n model = func(*args, info=info)\n with debug.log_time(log.completion, 'Set completion model'):\n completion.set_model(model)\n\n completion.set_pattern(pattern)\n\n def _change_completed_part(self, newtext, before, after, immediate=False):\n \"\"\"Change the part we're currently completing in the commandline.\n\n Args:\n text: The text to set (string) for the token under the cursor.\n before: Commandline tokens before the token under the cursor.\n after: Commandline tokens after the token under the cursor.\n immediate: True if the text should be completed immediately\n including a trailing space and we shouldn't continue\n completing the current item.\n \"\"\"\n text = self._cmd.prefix() + ' '.join(before + [newtext])\n pos = len(text) + (1 if immediate else 0)\n if after:\n text += ' ' + ' '.join(after)\n elif immediate:\n # pad with a space if quick-completing the last entry\n text += ' '\n log.completion.debug(\"setting text = '{}', pos = {}\".format(text, pos))\n\n # generally, we don't want to let self._cmd emit cursorPositionChanged,\n # because that'll schedule a completion update. That happens when\n # tabbing through the completions, and we want to change the command\n # text but we also want to keep the original completion list for the\n # command the user manually entered. The exception is when we're\n # immediately completing, in which case we *do* want to update the\n # completion view so that we can start completing the next part\n if not immediate:\n self._cmd.blockSignals(True)\n\n self._cmd.setText(text)\n self._cmd.setCursorPosition(pos)\n self._cmd.setFocus()\n\n self._cmd.blockSignals(False)\n self._cmd.show_cmd.emit()\n", "path": "qutebrowser/completion/completer.py"}]} | 3,867 | 139 |
gh_patches_debug_9499 | rasdani/github-patches | git_diff | talonhub__community-1133 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`grave` command in dictation mode
The use of `grave` as an alternative to `backtick` is more rare (using backticks at all is rare), and some folks have complained about `grave` showing up in speech when they don't want it. I propose removing it from the keys list.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/keys/keys.py`
Content:
```
1 from talon import Context, Module, actions, app
2
3 from ..user_settings import get_list_from_csv
4
5
6 def setup_default_alphabet():
7 """set up common default alphabet.
8
9 no need to modify this here, change your alphabet using alphabet.csv"""
10 initial_default_alphabet = "air bat cap drum each fine gust harp sit jury crunch look made near odd pit quench red sun trap urge vest whale plex yank zip".split(
11 " "
12 )
13 initial_letters_string = "abcdefghijklmnopqrstuvwxyz"
14 initial_default_alphabet_dict = dict(
15 zip(initial_default_alphabet, initial_letters_string)
16 )
17
18 return initial_default_alphabet_dict
19
20
21 alphabet_list = get_list_from_csv(
22 "alphabet.csv", ("Letter", "Spoken Form"), setup_default_alphabet()
23 )
24
25 default_digits = "zero one two three four five six seven eight nine".split(" ")
26 numbers = [str(i) for i in range(10)]
27 default_f_digits = (
28 "one two three four five six seven eight nine ten eleven twelve".split(" ")
29 )
30
31 mod = Module()
32 mod.list("letter", desc="The spoken phonetic alphabet")
33 mod.list("symbol_key", desc="All symbols from the keyboard")
34 mod.list("arrow_key", desc="All arrow keys")
35 mod.list("number_key", desc="All number keys")
36 mod.list("modifier_key", desc="All modifier keys")
37 mod.list("function_key", desc="All function keys")
38 mod.list("special_key", desc="All special keys")
39 mod.list("punctuation", desc="words for inserting punctuation into text")
40
41
42 @mod.capture(rule="{self.modifier_key}+")
43 def modifiers(m) -> str:
44 "One or more modifier keys"
45 return "-".join(m.modifier_key_list)
46
47
48 @mod.capture(rule="{self.arrow_key}")
49 def arrow_key(m) -> str:
50 "One directional arrow key"
51 return m.arrow_key
52
53
54 @mod.capture(rule="<self.arrow_key>+")
55 def arrow_keys(m) -> str:
56 "One or more arrow keys separated by a space"
57 return str(m)
58
59
60 @mod.capture(rule="{self.number_key}")
61 def number_key(m) -> str:
62 "One number key"
63 return m.number_key
64
65
66 @mod.capture(rule="{self.letter}")
67 def letter(m) -> str:
68 "One letter key"
69 return m.letter
70
71
72 @mod.capture(rule="{self.special_key}")
73 def special_key(m) -> str:
74 "One special key"
75 return m.special_key
76
77
78 @mod.capture(rule="{self.symbol_key}")
79 def symbol_key(m) -> str:
80 "One symbol key"
81 return m.symbol_key
82
83
84 @mod.capture(rule="{self.function_key}")
85 def function_key(m) -> str:
86 "One function key"
87 return m.function_key
88
89
90 @mod.capture(rule="( <self.letter> | <self.number_key> | <self.symbol_key> )")
91 def any_alphanumeric_key(m) -> str:
92 "any alphanumeric key"
93 return str(m)
94
95
96 @mod.capture(
97 rule="( <self.letter> | <self.number_key> | <self.symbol_key> "
98 "| <self.arrow_key> | <self.function_key> | <self.special_key> )"
99 )
100 def unmodified_key(m) -> str:
101 "A single key with no modifiers"
102 return str(m)
103
104
105 @mod.capture(rule="{self.modifier_key}* <self.unmodified_key>")
106 def key(m) -> str:
107 "A single key with optional modifiers"
108 try:
109 mods = m.modifier_key_list
110 except AttributeError:
111 mods = []
112 return "-".join(mods + [m.unmodified_key])
113
114
115 @mod.capture(rule="<self.key>+")
116 def keys(m) -> str:
117 "A sequence of one or more keys with optional modifiers"
118 return " ".join(m.key_list)
119
120
121 @mod.capture(rule="{self.letter}+")
122 def letters(m) -> str:
123 "Multiple letter keys"
124 return "".join(m.letter_list)
125
126
127 ctx = Context()
128 modifier_keys = {
129 # If you find 'alt' is often misrecognized, try using 'alter'.
130 "alt": "alt", #'alter': 'alt',
131 "control": "ctrl", #'troll': 'ctrl',
132 "shift": "shift", #'sky': 'shift',
133 "super": "super",
134 }
135 if app.platform == "mac":
136 modifier_keys["command"] = "cmd"
137 modifier_keys["option"] = "alt"
138 ctx.lists["self.modifier_key"] = modifier_keys
139 ctx.lists["self.letter"] = alphabet_list
140
141 # `punctuation_words` is for words you want available BOTH in dictation and as key names in command mode.
142 # `symbol_key_words` is for key names that should be available in command mode, but NOT during dictation.
143 punctuation_words = {
144 # TODO: I'm not sure why we need these, I think it has something to do with
145 # Dragon. Possibly it has been fixed by later improvements to talon? -rntz
146 "`": "`",
147 ",": ",", # <== these things
148 "back tick": "`",
149 "grave": "`",
150 "comma": ",",
151 # Workaround for issue with conformer b-series; see #946
152 "coma": ",",
153 "period": ".",
154 "full stop": ".",
155 "semicolon": ";",
156 "colon": ":",
157 "forward slash": "/",
158 "question mark": "?",
159 "exclamation mark": "!",
160 "exclamation point": "!",
161 "asterisk": "*",
162 "hash sign": "#",
163 "number sign": "#",
164 "percent sign": "%",
165 "at sign": "@",
166 "and sign": "&",
167 "ampersand": "&",
168 # Currencies
169 "dollar sign": "$",
170 "pound sign": "£",
171 "hyphen": "-",
172 "L paren": "(",
173 "left paren": "(",
174 "R paren": ")",
175 "right paren": ")",
176 }
177 symbol_key_words = {
178 "dot": ".",
179 "point": ".",
180 "quote": "'",
181 "question": "?",
182 "apostrophe": "'",
183 "L square": "[",
184 "left square": "[",
185 "square": "[",
186 "R square": "]",
187 "right square": "]",
188 "slash": "/",
189 "backslash": "\\",
190 "minus": "-",
191 "dash": "-",
192 "equals": "=",
193 "plus": "+",
194 "tilde": "~",
195 "bang": "!",
196 "down score": "_",
197 "underscore": "_",
198 "paren": "(",
199 "brace": "{",
200 "left brace": "{",
201 "brack": "{",
202 "bracket": "{",
203 "left bracket": "{",
204 "r brace": "}",
205 "right brace": "}",
206 "r brack": "}",
207 "r bracket": "}",
208 "right bracket": "}",
209 "angle": "<",
210 "left angle": "<",
211 "less than": "<",
212 "rangle": ">",
213 "R angle": ">",
214 "right angle": ">",
215 "greater than": ">",
216 "star": "*",
217 "hash": "#",
218 "percent": "%",
219 "caret": "^",
220 "amper": "&",
221 "pipe": "|",
222 "dub quote": '"',
223 "double quote": '"',
224 # Currencies
225 "dollar": "$",
226 "pound": "£",
227 }
228
229 # make punctuation words also included in {user.symbol_keys}
230 symbol_key_words.update(punctuation_words)
231 ctx.lists["self.punctuation"] = punctuation_words
232 ctx.lists["self.symbol_key"] = symbol_key_words
233 ctx.lists["self.number_key"] = dict(zip(default_digits, numbers))
234 ctx.lists["self.arrow_key"] = {
235 "down": "down",
236 "left": "left",
237 "right": "right",
238 "up": "up",
239 }
240
241 simple_keys = [
242 "end",
243 "enter",
244 "escape",
245 "home",
246 "insert",
247 "pagedown",
248 "pageup",
249 "space",
250 "tab",
251 ]
252
253 alternate_keys = {
254 "wipe": "backspace",
255 "delete": "backspace",
256 #'junk': 'backspace',
257 "forward delete": "delete",
258 "page up": "pageup",
259 "page down": "pagedown",
260 }
261 # mac apparently doesn't have the menu key.
262 if app.platform in ("windows", "linux"):
263 alternate_keys["menu key"] = "menu"
264 alternate_keys["print screen"] = "printscr"
265
266 special_keys = {k: k for k in simple_keys}
267 special_keys.update(alternate_keys)
268 ctx.lists["self.special_key"] = special_keys
269 ctx.lists["self.function_key"] = {
270 f"F {default_f_digits[i]}": f"f{i + 1}" for i in range(12)
271 }
272
273
274 @mod.action_class
275 class Actions:
276 def move_cursor(s: str):
277 """Given a sequence of directions, eg. 'left left up', moves the cursor accordingly using edit.{left,right,up,down}."""
278 for d in s.split():
279 if d in ("left", "right", "up", "down"):
280 getattr(actions.edit, d)()
281 else:
282 raise RuntimeError(f"invalid arrow key: {d}")
283
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/keys/keys.py b/core/keys/keys.py
--- a/core/keys/keys.py
+++ b/core/keys/keys.py
@@ -146,7 +146,6 @@
"`": "`",
",": ",", # <== these things
"back tick": "`",
- "grave": "`",
"comma": ",",
# Workaround for issue with conformer b-series; see #946
"coma": ",",
@@ -191,6 +190,7 @@
"dash": "-",
"equals": "=",
"plus": "+",
+ "grave": "`",
"tilde": "~",
"bang": "!",
"down score": "_",
| {"golden_diff": "diff --git a/core/keys/keys.py b/core/keys/keys.py\n--- a/core/keys/keys.py\n+++ b/core/keys/keys.py\n@@ -146,7 +146,6 @@\n \"`\": \"`\",\n \",\": \",\", # <== these things\n \"back tick\": \"`\",\n- \"grave\": \"`\",\n \"comma\": \",\",\n # Workaround for issue with conformer b-series; see #946\n \"coma\": \",\",\n@@ -191,6 +190,7 @@\n \"dash\": \"-\",\n \"equals\": \"=\",\n \"plus\": \"+\",\n+ \"grave\": \"`\",\n \"tilde\": \"~\",\n \"bang\": \"!\",\n \"down score\": \"_\",\n", "issue": "`grave` command in dictation mode\nThe use of `grave` as an alternative to `backtick` is more rare (using backticks at all is rare), and some folks have complained about `grave` showing up in speech when they don't want it. I propose removing it from the keys list.\n", "before_files": [{"content": "from talon import Context, Module, actions, app\n\nfrom ..user_settings import get_list_from_csv\n\n\ndef setup_default_alphabet():\n \"\"\"set up common default alphabet.\n\n no need to modify this here, change your alphabet using alphabet.csv\"\"\"\n initial_default_alphabet = \"air bat cap drum each fine gust harp sit jury crunch look made near odd pit quench red sun trap urge vest whale plex yank zip\".split(\n \" \"\n )\n initial_letters_string = \"abcdefghijklmnopqrstuvwxyz\"\n initial_default_alphabet_dict = dict(\n zip(initial_default_alphabet, initial_letters_string)\n )\n\n return initial_default_alphabet_dict\n\n\nalphabet_list = get_list_from_csv(\n \"alphabet.csv\", (\"Letter\", \"Spoken Form\"), setup_default_alphabet()\n)\n\ndefault_digits = \"zero one two three four five six seven eight nine\".split(\" \")\nnumbers = [str(i) for i in range(10)]\ndefault_f_digits = (\n \"one two three four five six seven eight nine ten eleven twelve\".split(\" \")\n)\n\nmod = Module()\nmod.list(\"letter\", desc=\"The spoken phonetic alphabet\")\nmod.list(\"symbol_key\", desc=\"All symbols from the keyboard\")\nmod.list(\"arrow_key\", desc=\"All arrow keys\")\nmod.list(\"number_key\", desc=\"All number keys\")\nmod.list(\"modifier_key\", desc=\"All modifier keys\")\nmod.list(\"function_key\", desc=\"All function keys\")\nmod.list(\"special_key\", desc=\"All special keys\")\nmod.list(\"punctuation\", desc=\"words for inserting punctuation into text\")\n\n\[email protected](rule=\"{self.modifier_key}+\")\ndef modifiers(m) -> str:\n \"One or more modifier keys\"\n return \"-\".join(m.modifier_key_list)\n\n\[email protected](rule=\"{self.arrow_key}\")\ndef arrow_key(m) -> str:\n \"One directional arrow key\"\n return m.arrow_key\n\n\[email protected](rule=\"<self.arrow_key>+\")\ndef arrow_keys(m) -> str:\n \"One or more arrow keys separated by a space\"\n return str(m)\n\n\[email protected](rule=\"{self.number_key}\")\ndef number_key(m) -> str:\n \"One number key\"\n return m.number_key\n\n\[email protected](rule=\"{self.letter}\")\ndef letter(m) -> str:\n \"One letter key\"\n return m.letter\n\n\[email protected](rule=\"{self.special_key}\")\ndef special_key(m) -> str:\n \"One special key\"\n return m.special_key\n\n\[email protected](rule=\"{self.symbol_key}\")\ndef symbol_key(m) -> str:\n \"One symbol key\"\n return m.symbol_key\n\n\[email protected](rule=\"{self.function_key}\")\ndef function_key(m) -> str:\n \"One function key\"\n return m.function_key\n\n\[email protected](rule=\"( <self.letter> | <self.number_key> | <self.symbol_key> )\")\ndef any_alphanumeric_key(m) -> str:\n \"any alphanumeric key\"\n return str(m)\n\n\[email protected](\n rule=\"( <self.letter> | <self.number_key> | <self.symbol_key> \"\n \"| <self.arrow_key> | <self.function_key> | <self.special_key> )\"\n)\ndef unmodified_key(m) -> str:\n \"A single key with no modifiers\"\n return str(m)\n\n\[email protected](rule=\"{self.modifier_key}* <self.unmodified_key>\")\ndef key(m) -> str:\n \"A single key with optional modifiers\"\n try:\n mods = m.modifier_key_list\n except AttributeError:\n mods = []\n return \"-\".join(mods + [m.unmodified_key])\n\n\[email protected](rule=\"<self.key>+\")\ndef keys(m) -> str:\n \"A sequence of one or more keys with optional modifiers\"\n return \" \".join(m.key_list)\n\n\[email protected](rule=\"{self.letter}+\")\ndef letters(m) -> str:\n \"Multiple letter keys\"\n return \"\".join(m.letter_list)\n\n\nctx = Context()\nmodifier_keys = {\n # If you find 'alt' is often misrecognized, try using 'alter'.\n \"alt\": \"alt\", #'alter': 'alt',\n \"control\": \"ctrl\", #'troll': 'ctrl',\n \"shift\": \"shift\", #'sky': 'shift',\n \"super\": \"super\",\n}\nif app.platform == \"mac\":\n modifier_keys[\"command\"] = \"cmd\"\n modifier_keys[\"option\"] = \"alt\"\nctx.lists[\"self.modifier_key\"] = modifier_keys\nctx.lists[\"self.letter\"] = alphabet_list\n\n# `punctuation_words` is for words you want available BOTH in dictation and as key names in command mode.\n# `symbol_key_words` is for key names that should be available in command mode, but NOT during dictation.\npunctuation_words = {\n # TODO: I'm not sure why we need these, I think it has something to do with\n # Dragon. Possibly it has been fixed by later improvements to talon? -rntz\n \"`\": \"`\",\n \",\": \",\", # <== these things\n \"back tick\": \"`\",\n \"grave\": \"`\",\n \"comma\": \",\",\n # Workaround for issue with conformer b-series; see #946\n \"coma\": \",\",\n \"period\": \".\",\n \"full stop\": \".\",\n \"semicolon\": \";\",\n \"colon\": \":\",\n \"forward slash\": \"/\",\n \"question mark\": \"?\",\n \"exclamation mark\": \"!\",\n \"exclamation point\": \"!\",\n \"asterisk\": \"*\",\n \"hash sign\": \"#\",\n \"number sign\": \"#\",\n \"percent sign\": \"%\",\n \"at sign\": \"@\",\n \"and sign\": \"&\",\n \"ampersand\": \"&\",\n # Currencies\n \"dollar sign\": \"$\",\n \"pound sign\": \"\u00a3\",\n \"hyphen\": \"-\",\n \"L paren\": \"(\",\n \"left paren\": \"(\",\n \"R paren\": \")\",\n \"right paren\": \")\",\n}\nsymbol_key_words = {\n \"dot\": \".\",\n \"point\": \".\",\n \"quote\": \"'\",\n \"question\": \"?\",\n \"apostrophe\": \"'\",\n \"L square\": \"[\",\n \"left square\": \"[\",\n \"square\": \"[\",\n \"R square\": \"]\",\n \"right square\": \"]\",\n \"slash\": \"/\",\n \"backslash\": \"\\\\\",\n \"minus\": \"-\",\n \"dash\": \"-\",\n \"equals\": \"=\",\n \"plus\": \"+\",\n \"tilde\": \"~\",\n \"bang\": \"!\",\n \"down score\": \"_\",\n \"underscore\": \"_\",\n \"paren\": \"(\",\n \"brace\": \"{\",\n \"left brace\": \"{\",\n \"brack\": \"{\",\n \"bracket\": \"{\",\n \"left bracket\": \"{\",\n \"r brace\": \"}\",\n \"right brace\": \"}\",\n \"r brack\": \"}\",\n \"r bracket\": \"}\",\n \"right bracket\": \"}\",\n \"angle\": \"<\",\n \"left angle\": \"<\",\n \"less than\": \"<\",\n \"rangle\": \">\",\n \"R angle\": \">\",\n \"right angle\": \">\",\n \"greater than\": \">\",\n \"star\": \"*\",\n \"hash\": \"#\",\n \"percent\": \"%\",\n \"caret\": \"^\",\n \"amper\": \"&\",\n \"pipe\": \"|\",\n \"dub quote\": '\"',\n \"double quote\": '\"',\n # Currencies\n \"dollar\": \"$\",\n \"pound\": \"\u00a3\",\n}\n\n# make punctuation words also included in {user.symbol_keys}\nsymbol_key_words.update(punctuation_words)\nctx.lists[\"self.punctuation\"] = punctuation_words\nctx.lists[\"self.symbol_key\"] = symbol_key_words\nctx.lists[\"self.number_key\"] = dict(zip(default_digits, numbers))\nctx.lists[\"self.arrow_key\"] = {\n \"down\": \"down\",\n \"left\": \"left\",\n \"right\": \"right\",\n \"up\": \"up\",\n}\n\nsimple_keys = [\n \"end\",\n \"enter\",\n \"escape\",\n \"home\",\n \"insert\",\n \"pagedown\",\n \"pageup\",\n \"space\",\n \"tab\",\n]\n\nalternate_keys = {\n \"wipe\": \"backspace\",\n \"delete\": \"backspace\",\n #'junk': 'backspace',\n \"forward delete\": \"delete\",\n \"page up\": \"pageup\",\n \"page down\": \"pagedown\",\n}\n# mac apparently doesn't have the menu key.\nif app.platform in (\"windows\", \"linux\"):\n alternate_keys[\"menu key\"] = \"menu\"\n alternate_keys[\"print screen\"] = \"printscr\"\n\nspecial_keys = {k: k for k in simple_keys}\nspecial_keys.update(alternate_keys)\nctx.lists[\"self.special_key\"] = special_keys\nctx.lists[\"self.function_key\"] = {\n f\"F {default_f_digits[i]}\": f\"f{i + 1}\" for i in range(12)\n}\n\n\[email protected]_class\nclass Actions:\n def move_cursor(s: str):\n \"\"\"Given a sequence of directions, eg. 'left left up', moves the cursor accordingly using edit.{left,right,up,down}.\"\"\"\n for d in s.split():\n if d in (\"left\", \"right\", \"up\", \"down\"):\n getattr(actions.edit, d)()\n else:\n raise RuntimeError(f\"invalid arrow key: {d}\")\n", "path": "core/keys/keys.py"}], "after_files": [{"content": "from talon import Context, Module, actions, app\n\nfrom ..user_settings import get_list_from_csv\n\n\ndef setup_default_alphabet():\n \"\"\"set up common default alphabet.\n\n no need to modify this here, change your alphabet using alphabet.csv\"\"\"\n initial_default_alphabet = \"air bat cap drum each fine gust harp sit jury crunch look made near odd pit quench red sun trap urge vest whale plex yank zip\".split(\n \" \"\n )\n initial_letters_string = \"abcdefghijklmnopqrstuvwxyz\"\n initial_default_alphabet_dict = dict(\n zip(initial_default_alphabet, initial_letters_string)\n )\n\n return initial_default_alphabet_dict\n\n\nalphabet_list = get_list_from_csv(\n \"alphabet.csv\", (\"Letter\", \"Spoken Form\"), setup_default_alphabet()\n)\n\ndefault_digits = \"zero one two three four five six seven eight nine\".split(\" \")\nnumbers = [str(i) for i in range(10)]\ndefault_f_digits = (\n \"one two three four five six seven eight nine ten eleven twelve\".split(\" \")\n)\n\nmod = Module()\nmod.list(\"letter\", desc=\"The spoken phonetic alphabet\")\nmod.list(\"symbol_key\", desc=\"All symbols from the keyboard\")\nmod.list(\"arrow_key\", desc=\"All arrow keys\")\nmod.list(\"number_key\", desc=\"All number keys\")\nmod.list(\"modifier_key\", desc=\"All modifier keys\")\nmod.list(\"function_key\", desc=\"All function keys\")\nmod.list(\"special_key\", desc=\"All special keys\")\nmod.list(\"punctuation\", desc=\"words for inserting punctuation into text\")\n\n\[email protected](rule=\"{self.modifier_key}+\")\ndef modifiers(m) -> str:\n \"One or more modifier keys\"\n return \"-\".join(m.modifier_key_list)\n\n\[email protected](rule=\"{self.arrow_key}\")\ndef arrow_key(m) -> str:\n \"One directional arrow key\"\n return m.arrow_key\n\n\[email protected](rule=\"<self.arrow_key>+\")\ndef arrow_keys(m) -> str:\n \"One or more arrow keys separated by a space\"\n return str(m)\n\n\[email protected](rule=\"{self.number_key}\")\ndef number_key(m) -> str:\n \"One number key\"\n return m.number_key\n\n\[email protected](rule=\"{self.letter}\")\ndef letter(m) -> str:\n \"One letter key\"\n return m.letter\n\n\[email protected](rule=\"{self.special_key}\")\ndef special_key(m) -> str:\n \"One special key\"\n return m.special_key\n\n\[email protected](rule=\"{self.symbol_key}\")\ndef symbol_key(m) -> str:\n \"One symbol key\"\n return m.symbol_key\n\n\[email protected](rule=\"{self.function_key}\")\ndef function_key(m) -> str:\n \"One function key\"\n return m.function_key\n\n\[email protected](rule=\"( <self.letter> | <self.number_key> | <self.symbol_key> )\")\ndef any_alphanumeric_key(m) -> str:\n \"any alphanumeric key\"\n return str(m)\n\n\[email protected](\n rule=\"( <self.letter> | <self.number_key> | <self.symbol_key> \"\n \"| <self.arrow_key> | <self.function_key> | <self.special_key> )\"\n)\ndef unmodified_key(m) -> str:\n \"A single key with no modifiers\"\n return str(m)\n\n\[email protected](rule=\"{self.modifier_key}* <self.unmodified_key>\")\ndef key(m) -> str:\n \"A single key with optional modifiers\"\n try:\n mods = m.modifier_key_list\n except AttributeError:\n mods = []\n return \"-\".join(mods + [m.unmodified_key])\n\n\[email protected](rule=\"<self.key>+\")\ndef keys(m) -> str:\n \"A sequence of one or more keys with optional modifiers\"\n return \" \".join(m.key_list)\n\n\[email protected](rule=\"{self.letter}+\")\ndef letters(m) -> str:\n \"Multiple letter keys\"\n return \"\".join(m.letter_list)\n\n\nctx = Context()\nmodifier_keys = {\n # If you find 'alt' is often misrecognized, try using 'alter'.\n \"alt\": \"alt\", #'alter': 'alt',\n \"control\": \"ctrl\", #'troll': 'ctrl',\n \"shift\": \"shift\", #'sky': 'shift',\n \"super\": \"super\",\n}\nif app.platform == \"mac\":\n modifier_keys[\"command\"] = \"cmd\"\n modifier_keys[\"option\"] = \"alt\"\nctx.lists[\"self.modifier_key\"] = modifier_keys\nctx.lists[\"self.letter\"] = alphabet_list\n\n# `punctuation_words` is for words you want available BOTH in dictation and as key names in command mode.\n# `symbol_key_words` is for key names that should be available in command mode, but NOT during dictation.\npunctuation_words = {\n # TODO: I'm not sure why we need these, I think it has something to do with\n # Dragon. Possibly it has been fixed by later improvements to talon? -rntz\n \"`\": \"`\",\n \",\": \",\", # <== these things\n \"back tick\": \"`\",\n \"comma\": \",\",\n # Workaround for issue with conformer b-series; see #946\n \"coma\": \",\",\n \"period\": \".\",\n \"full stop\": \".\",\n \"semicolon\": \";\",\n \"colon\": \":\",\n \"forward slash\": \"/\",\n \"question mark\": \"?\",\n \"exclamation mark\": \"!\",\n \"exclamation point\": \"!\",\n \"asterisk\": \"*\",\n \"hash sign\": \"#\",\n \"number sign\": \"#\",\n \"percent sign\": \"%\",\n \"at sign\": \"@\",\n \"and sign\": \"&\",\n \"ampersand\": \"&\",\n # Currencies\n \"dollar sign\": \"$\",\n \"pound sign\": \"\u00a3\",\n \"hyphen\": \"-\",\n \"L paren\": \"(\",\n \"left paren\": \"(\",\n \"R paren\": \")\",\n \"right paren\": \")\",\n}\nsymbol_key_words = {\n \"dot\": \".\",\n \"point\": \".\",\n \"quote\": \"'\",\n \"question\": \"?\",\n \"apostrophe\": \"'\",\n \"L square\": \"[\",\n \"left square\": \"[\",\n \"square\": \"[\",\n \"R square\": \"]\",\n \"right square\": \"]\",\n \"slash\": \"/\",\n \"backslash\": \"\\\\\",\n \"minus\": \"-\",\n \"dash\": \"-\",\n \"equals\": \"=\",\n \"plus\": \"+\",\n \"grave\": \"`\",\n \"tilde\": \"~\",\n \"bang\": \"!\",\n \"down score\": \"_\",\n \"underscore\": \"_\",\n \"paren\": \"(\",\n \"brace\": \"{\",\n \"left brace\": \"{\",\n \"brack\": \"{\",\n \"bracket\": \"{\",\n \"left bracket\": \"{\",\n \"r brace\": \"}\",\n \"right brace\": \"}\",\n \"r brack\": \"}\",\n \"r bracket\": \"}\",\n \"right bracket\": \"}\",\n \"angle\": \"<\",\n \"left angle\": \"<\",\n \"less than\": \"<\",\n \"rangle\": \">\",\n \"R angle\": \">\",\n \"right angle\": \">\",\n \"greater than\": \">\",\n \"star\": \"*\",\n \"hash\": \"#\",\n \"percent\": \"%\",\n \"caret\": \"^\",\n \"amper\": \"&\",\n \"pipe\": \"|\",\n \"dub quote\": '\"',\n \"double quote\": '\"',\n # Currencies\n \"dollar\": \"$\",\n \"pound\": \"\u00a3\",\n}\n\n# make punctuation words also included in {user.symbol_keys}\nsymbol_key_words.update(punctuation_words)\nctx.lists[\"self.punctuation\"] = punctuation_words\nctx.lists[\"self.symbol_key\"] = symbol_key_words\nctx.lists[\"self.number_key\"] = dict(zip(default_digits, numbers))\nctx.lists[\"self.arrow_key\"] = {\n \"down\": \"down\",\n \"left\": \"left\",\n \"right\": \"right\",\n \"up\": \"up\",\n}\n\nsimple_keys = [\n \"end\",\n \"enter\",\n \"escape\",\n \"home\",\n \"insert\",\n \"pagedown\",\n \"pageup\",\n \"space\",\n \"tab\",\n]\n\nalternate_keys = {\n \"wipe\": \"backspace\",\n \"delete\": \"backspace\",\n #'junk': 'backspace',\n \"forward delete\": \"delete\",\n \"page up\": \"pageup\",\n \"page down\": \"pagedown\",\n}\n# mac apparently doesn't have the menu key.\nif app.platform in (\"windows\", \"linux\"):\n alternate_keys[\"menu key\"] = \"menu\"\n alternate_keys[\"print screen\"] = \"printscr\"\n\nspecial_keys = {k: k for k in simple_keys}\nspecial_keys.update(alternate_keys)\nctx.lists[\"self.special_key\"] = special_keys\nctx.lists[\"self.function_key\"] = {\n f\"F {default_f_digits[i]}\": f\"f{i + 1}\" for i in range(12)\n}\n\n\[email protected]_class\nclass Actions:\n def move_cursor(s: str):\n \"\"\"Given a sequence of directions, eg. 'left left up', moves the cursor accordingly using edit.{left,right,up,down}.\"\"\"\n for d in s.split():\n if d in (\"left\", \"right\", \"up\", \"down\"):\n getattr(actions.edit, d)()\n else:\n raise RuntimeError(f\"invalid arrow key: {d}\")\n", "path": "core/keys/keys.py"}]} | 3,104 | 169 |
gh_patches_debug_23376 | rasdani/github-patches | git_diff | goauthentik__authentik-8677 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow setting a custom attribute for oidc provider sub claim
**Is your feature request related to a problem? Please describe.**
I have an external auth source and I'm using authentik as an authentication hub between the source and other applications. That auth source has unique user ids that I save in authentik as a custom attribute. I would like to use it as the oidc subject.
**Describe the solution you'd like**
Add a subject mode option "Based on a user attribute" with a text field where one enter the attribute. Alternatively it could be an expression similar to property mappings.
This would be quite similar to the current "Based on the User's UPN" and it may even make sense to replace it entirely, but that would require migrating existing configurations to the new type with upn as the attribute.
**Describe alternatives you've considered**
I could set the external uid as the username in authentik as I'm not currently using the username for anything
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/providers/oauth2/views/userinfo.py`
Content:
```
1 """authentik OAuth2 OpenID Userinfo views"""
2
3 from typing import Any
4
5 from deepmerge import always_merger
6 from django.http import HttpRequest, HttpResponse
7 from django.http.response import HttpResponseBadRequest
8 from django.utils.decorators import method_decorator
9 from django.utils.translation import gettext_lazy as _
10 from django.views import View
11 from django.views.decorators.csrf import csrf_exempt
12 from structlog.stdlib import get_logger
13
14 from authentik.core.exceptions import PropertyMappingExpressionException
15 from authentik.events.models import Event, EventAction
16 from authentik.flows.challenge import PermissionDict
17 from authentik.providers.oauth2.constants import (
18 SCOPE_AUTHENTIK_API,
19 SCOPE_GITHUB_ORG_READ,
20 SCOPE_GITHUB_USER,
21 SCOPE_GITHUB_USER_EMAIL,
22 SCOPE_GITHUB_USER_READ,
23 SCOPE_OPENID,
24 )
25 from authentik.providers.oauth2.models import (
26 BaseGrantModel,
27 OAuth2Provider,
28 RefreshToken,
29 ScopeMapping,
30 )
31 from authentik.providers.oauth2.utils import TokenResponse, cors_allow, protected_resource_view
32
33 LOGGER = get_logger()
34
35
36 @method_decorator(csrf_exempt, name="dispatch")
37 @method_decorator(protected_resource_view([SCOPE_OPENID]), name="dispatch")
38 class UserInfoView(View):
39 """Create a dictionary with all the requested claims about the End-User.
40 See: http://openid.net/specs/openid-connect-core-1_0.html#UserInfoResponse"""
41
42 token: RefreshToken | None
43
44 def get_scope_descriptions(
45 self, scopes: list[str], provider: OAuth2Provider
46 ) -> list[PermissionDict]:
47 """Get a list of all Scopes's descriptions"""
48 scope_descriptions = []
49 for scope in ScopeMapping.objects.filter(scope_name__in=scopes, provider=provider).order_by(
50 "scope_name"
51 ):
52 scope_descriptions.append(PermissionDict(id=scope.scope_name, name=scope.description))
53 # GitHub Compatibility Scopes are handled differently, since they required custom paths
54 # Hence they don't exist as Scope objects
55 special_scope_map = {
56 SCOPE_GITHUB_USER: _("GitHub Compatibility: Access your User Information"),
57 SCOPE_GITHUB_USER_READ: _("GitHub Compatibility: Access your User Information"),
58 SCOPE_GITHUB_USER_EMAIL: _("GitHub Compatibility: Access you Email addresses"),
59 SCOPE_GITHUB_ORG_READ: _("GitHub Compatibility: Access your Groups"),
60 SCOPE_AUTHENTIK_API: _("authentik API Access on behalf of your user"),
61 }
62 for scope in scopes:
63 if scope in special_scope_map:
64 scope_descriptions.append(
65 PermissionDict(id=scope, name=str(special_scope_map[scope]))
66 )
67 return scope_descriptions
68
69 def get_claims(self, provider: OAuth2Provider, token: BaseGrantModel) -> dict[str, Any]:
70 """Get a dictionary of claims from scopes that the token
71 requires and are assigned to the provider."""
72
73 scopes_from_client = token.scope
74 final_claims = {}
75 for scope in ScopeMapping.objects.filter(
76 provider=provider, scope_name__in=scopes_from_client
77 ).order_by("scope_name"):
78 scope: ScopeMapping
79 value = None
80 try:
81 value = scope.evaluate(
82 user=token.user,
83 request=self.request,
84 provider=provider,
85 token=token,
86 )
87 except PropertyMappingExpressionException as exc:
88 Event.new(
89 EventAction.CONFIGURATION_ERROR,
90 message=f"Failed to evaluate property-mapping: '{scope.name}'",
91 provider=provider,
92 mapping=scope,
93 ).from_http(self.request)
94 LOGGER.warning("Failed to evaluate property mapping", exc=exc)
95 if value is None:
96 continue
97 if not isinstance(value, dict):
98 LOGGER.warning(
99 "Scope returned a non-dict value, ignoring",
100 scope=scope,
101 value=value,
102 )
103 continue
104 LOGGER.debug("updated scope", scope=scope)
105 always_merger.merge(final_claims, value)
106 return final_claims
107
108 def dispatch(self, request: HttpRequest, *args: Any, **kwargs: Any) -> HttpResponse:
109 self.token = kwargs.get("token", None)
110 response = super().dispatch(request, *args, **kwargs)
111 allowed_origins = []
112 if self.token:
113 allowed_origins = self.token.provider.redirect_uris.split("\n")
114 cors_allow(self.request, response, *allowed_origins)
115 return response
116
117 def options(self, request: HttpRequest) -> HttpResponse:
118 return TokenResponse({})
119
120 def get(self, request: HttpRequest, **kwargs) -> HttpResponse:
121 """Handle GET Requests for UserInfo"""
122 if not self.token:
123 return HttpResponseBadRequest()
124 claims = self.get_claims(self.token.provider, self.token)
125 claims["sub"] = self.token.id_token.sub
126 if self.token.id_token.nonce:
127 claims["nonce"] = self.token.id_token.nonce
128 response = TokenResponse(claims)
129 return response
130
131 def post(self, request: HttpRequest, **kwargs) -> HttpResponse:
132 """POST Requests behave the same as GET Requests, so the get handler is called here"""
133 return self.get(request, **kwargs)
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/authentik/providers/oauth2/views/userinfo.py b/authentik/providers/oauth2/views/userinfo.py
--- a/authentik/providers/oauth2/views/userinfo.py
+++ b/authentik/providers/oauth2/views/userinfo.py
@@ -101,8 +101,8 @@
value=value,
)
continue
- LOGGER.debug("updated scope", scope=scope)
always_merger.merge(final_claims, value)
+ LOGGER.debug("updated scope", scope=scope)
return final_claims
def dispatch(self, request: HttpRequest, *args: Any, **kwargs: Any) -> HttpResponse:
@@ -121,8 +121,9 @@
"""Handle GET Requests for UserInfo"""
if not self.token:
return HttpResponseBadRequest()
- claims = self.get_claims(self.token.provider, self.token)
- claims["sub"] = self.token.id_token.sub
+ claims = {}
+ claims.setdefault("sub", self.token.id_token.sub)
+ claims.update(self.get_claims(self.token.provider, self.token))
if self.token.id_token.nonce:
claims["nonce"] = self.token.id_token.nonce
response = TokenResponse(claims)
| {"golden_diff": "diff --git a/authentik/providers/oauth2/views/userinfo.py b/authentik/providers/oauth2/views/userinfo.py\n--- a/authentik/providers/oauth2/views/userinfo.py\n+++ b/authentik/providers/oauth2/views/userinfo.py\n@@ -101,8 +101,8 @@\n value=value,\n )\n continue\n- LOGGER.debug(\"updated scope\", scope=scope)\n always_merger.merge(final_claims, value)\n+ LOGGER.debug(\"updated scope\", scope=scope)\n return final_claims\n \n def dispatch(self, request: HttpRequest, *args: Any, **kwargs: Any) -> HttpResponse:\n@@ -121,8 +121,9 @@\n \"\"\"Handle GET Requests for UserInfo\"\"\"\n if not self.token:\n return HttpResponseBadRequest()\n- claims = self.get_claims(self.token.provider, self.token)\n- claims[\"sub\"] = self.token.id_token.sub\n+ claims = {}\n+ claims.setdefault(\"sub\", self.token.id_token.sub)\n+ claims.update(self.get_claims(self.token.provider, self.token))\n if self.token.id_token.nonce:\n claims[\"nonce\"] = self.token.id_token.nonce\n response = TokenResponse(claims)\n", "issue": "Allow setting a custom attribute for oidc provider sub claim\n**Is your feature request related to a problem? Please describe.**\r\nI have an external auth source and I'm using authentik as an authentication hub between the source and other applications. That auth source has unique user ids that I save in authentik as a custom attribute. I would like to use it as the oidc subject.\r\n\r\n**Describe the solution you'd like**\r\nAdd a subject mode option \"Based on a user attribute\" with a text field where one enter the attribute. Alternatively it could be an expression similar to property mappings.\r\n\r\nThis would be quite similar to the current \"Based on the User's UPN\" and it may even make sense to replace it entirely, but that would require migrating existing configurations to the new type with upn as the attribute.\r\n\r\n**Describe alternatives you've considered**\r\nI could set the external uid as the username in authentik as I'm not currently using the username for anything\n", "before_files": [{"content": "\"\"\"authentik OAuth2 OpenID Userinfo views\"\"\"\n\nfrom typing import Any\n\nfrom deepmerge import always_merger\nfrom django.http import HttpRequest, HttpResponse\nfrom django.http.response import HttpResponseBadRequest\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\nfrom django.views.decorators.csrf import csrf_exempt\nfrom structlog.stdlib import get_logger\n\nfrom authentik.core.exceptions import PropertyMappingExpressionException\nfrom authentik.events.models import Event, EventAction\nfrom authentik.flows.challenge import PermissionDict\nfrom authentik.providers.oauth2.constants import (\n SCOPE_AUTHENTIK_API,\n SCOPE_GITHUB_ORG_READ,\n SCOPE_GITHUB_USER,\n SCOPE_GITHUB_USER_EMAIL,\n SCOPE_GITHUB_USER_READ,\n SCOPE_OPENID,\n)\nfrom authentik.providers.oauth2.models import (\n BaseGrantModel,\n OAuth2Provider,\n RefreshToken,\n ScopeMapping,\n)\nfrom authentik.providers.oauth2.utils import TokenResponse, cors_allow, protected_resource_view\n\nLOGGER = get_logger()\n\n\n@method_decorator(csrf_exempt, name=\"dispatch\")\n@method_decorator(protected_resource_view([SCOPE_OPENID]), name=\"dispatch\")\nclass UserInfoView(View):\n \"\"\"Create a dictionary with all the requested claims about the End-User.\n See: http://openid.net/specs/openid-connect-core-1_0.html#UserInfoResponse\"\"\"\n\n token: RefreshToken | None\n\n def get_scope_descriptions(\n self, scopes: list[str], provider: OAuth2Provider\n ) -> list[PermissionDict]:\n \"\"\"Get a list of all Scopes's descriptions\"\"\"\n scope_descriptions = []\n for scope in ScopeMapping.objects.filter(scope_name__in=scopes, provider=provider).order_by(\n \"scope_name\"\n ):\n scope_descriptions.append(PermissionDict(id=scope.scope_name, name=scope.description))\n # GitHub Compatibility Scopes are handled differently, since they required custom paths\n # Hence they don't exist as Scope objects\n special_scope_map = {\n SCOPE_GITHUB_USER: _(\"GitHub Compatibility: Access your User Information\"),\n SCOPE_GITHUB_USER_READ: _(\"GitHub Compatibility: Access your User Information\"),\n SCOPE_GITHUB_USER_EMAIL: _(\"GitHub Compatibility: Access you Email addresses\"),\n SCOPE_GITHUB_ORG_READ: _(\"GitHub Compatibility: Access your Groups\"),\n SCOPE_AUTHENTIK_API: _(\"authentik API Access on behalf of your user\"),\n }\n for scope in scopes:\n if scope in special_scope_map:\n scope_descriptions.append(\n PermissionDict(id=scope, name=str(special_scope_map[scope]))\n )\n return scope_descriptions\n\n def get_claims(self, provider: OAuth2Provider, token: BaseGrantModel) -> dict[str, Any]:\n \"\"\"Get a dictionary of claims from scopes that the token\n requires and are assigned to the provider.\"\"\"\n\n scopes_from_client = token.scope\n final_claims = {}\n for scope in ScopeMapping.objects.filter(\n provider=provider, scope_name__in=scopes_from_client\n ).order_by(\"scope_name\"):\n scope: ScopeMapping\n value = None\n try:\n value = scope.evaluate(\n user=token.user,\n request=self.request,\n provider=provider,\n token=token,\n )\n except PropertyMappingExpressionException as exc:\n Event.new(\n EventAction.CONFIGURATION_ERROR,\n message=f\"Failed to evaluate property-mapping: '{scope.name}'\",\n provider=provider,\n mapping=scope,\n ).from_http(self.request)\n LOGGER.warning(\"Failed to evaluate property mapping\", exc=exc)\n if value is None:\n continue\n if not isinstance(value, dict):\n LOGGER.warning(\n \"Scope returned a non-dict value, ignoring\",\n scope=scope,\n value=value,\n )\n continue\n LOGGER.debug(\"updated scope\", scope=scope)\n always_merger.merge(final_claims, value)\n return final_claims\n\n def dispatch(self, request: HttpRequest, *args: Any, **kwargs: Any) -> HttpResponse:\n self.token = kwargs.get(\"token\", None)\n response = super().dispatch(request, *args, **kwargs)\n allowed_origins = []\n if self.token:\n allowed_origins = self.token.provider.redirect_uris.split(\"\\n\")\n cors_allow(self.request, response, *allowed_origins)\n return response\n\n def options(self, request: HttpRequest) -> HttpResponse:\n return TokenResponse({})\n\n def get(self, request: HttpRequest, **kwargs) -> HttpResponse:\n \"\"\"Handle GET Requests for UserInfo\"\"\"\n if not self.token:\n return HttpResponseBadRequest()\n claims = self.get_claims(self.token.provider, self.token)\n claims[\"sub\"] = self.token.id_token.sub\n if self.token.id_token.nonce:\n claims[\"nonce\"] = self.token.id_token.nonce\n response = TokenResponse(claims)\n return response\n\n def post(self, request: HttpRequest, **kwargs) -> HttpResponse:\n \"\"\"POST Requests behave the same as GET Requests, so the get handler is called here\"\"\"\n return self.get(request, **kwargs)\n", "path": "authentik/providers/oauth2/views/userinfo.py"}], "after_files": [{"content": "\"\"\"authentik OAuth2 OpenID Userinfo views\"\"\"\n\nfrom typing import Any\n\nfrom deepmerge import always_merger\nfrom django.http import HttpRequest, HttpResponse\nfrom django.http.response import HttpResponseBadRequest\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\nfrom django.views.decorators.csrf import csrf_exempt\nfrom structlog.stdlib import get_logger\n\nfrom authentik.core.exceptions import PropertyMappingExpressionException\nfrom authentik.events.models import Event, EventAction\nfrom authentik.flows.challenge import PermissionDict\nfrom authentik.providers.oauth2.constants import (\n SCOPE_AUTHENTIK_API,\n SCOPE_GITHUB_ORG_READ,\n SCOPE_GITHUB_USER,\n SCOPE_GITHUB_USER_EMAIL,\n SCOPE_GITHUB_USER_READ,\n SCOPE_OPENID,\n)\nfrom authentik.providers.oauth2.models import (\n BaseGrantModel,\n OAuth2Provider,\n RefreshToken,\n ScopeMapping,\n)\nfrom authentik.providers.oauth2.utils import TokenResponse, cors_allow, protected_resource_view\n\nLOGGER = get_logger()\n\n\n@method_decorator(csrf_exempt, name=\"dispatch\")\n@method_decorator(protected_resource_view([SCOPE_OPENID]), name=\"dispatch\")\nclass UserInfoView(View):\n \"\"\"Create a dictionary with all the requested claims about the End-User.\n See: http://openid.net/specs/openid-connect-core-1_0.html#UserInfoResponse\"\"\"\n\n token: RefreshToken | None\n\n def get_scope_descriptions(\n self, scopes: list[str], provider: OAuth2Provider\n ) -> list[PermissionDict]:\n \"\"\"Get a list of all Scopes's descriptions\"\"\"\n scope_descriptions = []\n for scope in ScopeMapping.objects.filter(scope_name__in=scopes, provider=provider).order_by(\n \"scope_name\"\n ):\n scope_descriptions.append(PermissionDict(id=scope.scope_name, name=scope.description))\n # GitHub Compatibility Scopes are handled differently, since they required custom paths\n # Hence they don't exist as Scope objects\n special_scope_map = {\n SCOPE_GITHUB_USER: _(\"GitHub Compatibility: Access your User Information\"),\n SCOPE_GITHUB_USER_READ: _(\"GitHub Compatibility: Access your User Information\"),\n SCOPE_GITHUB_USER_EMAIL: _(\"GitHub Compatibility: Access you Email addresses\"),\n SCOPE_GITHUB_ORG_READ: _(\"GitHub Compatibility: Access your Groups\"),\n SCOPE_AUTHENTIK_API: _(\"authentik API Access on behalf of your user\"),\n }\n for scope in scopes:\n if scope in special_scope_map:\n scope_descriptions.append(\n PermissionDict(id=scope, name=str(special_scope_map[scope]))\n )\n return scope_descriptions\n\n def get_claims(self, provider: OAuth2Provider, token: BaseGrantModel) -> dict[str, Any]:\n \"\"\"Get a dictionary of claims from scopes that the token\n requires and are assigned to the provider.\"\"\"\n\n scopes_from_client = token.scope\n final_claims = {}\n for scope in ScopeMapping.objects.filter(\n provider=provider, scope_name__in=scopes_from_client\n ).order_by(\"scope_name\"):\n scope: ScopeMapping\n value = None\n try:\n value = scope.evaluate(\n user=token.user,\n request=self.request,\n provider=provider,\n token=token,\n )\n except PropertyMappingExpressionException as exc:\n Event.new(\n EventAction.CONFIGURATION_ERROR,\n message=f\"Failed to evaluate property-mapping: '{scope.name}'\",\n provider=provider,\n mapping=scope,\n ).from_http(self.request)\n LOGGER.warning(\"Failed to evaluate property mapping\", exc=exc)\n if value is None:\n continue\n if not isinstance(value, dict):\n LOGGER.warning(\n \"Scope returned a non-dict value, ignoring\",\n scope=scope,\n value=value,\n )\n continue\n always_merger.merge(final_claims, value)\n LOGGER.debug(\"updated scope\", scope=scope)\n return final_claims\n\n def dispatch(self, request: HttpRequest, *args: Any, **kwargs: Any) -> HttpResponse:\n self.token = kwargs.get(\"token\", None)\n response = super().dispatch(request, *args, **kwargs)\n allowed_origins = []\n if self.token:\n allowed_origins = self.token.provider.redirect_uris.split(\"\\n\")\n cors_allow(self.request, response, *allowed_origins)\n return response\n\n def options(self, request: HttpRequest) -> HttpResponse:\n return TokenResponse({})\n\n def get(self, request: HttpRequest, **kwargs) -> HttpResponse:\n \"\"\"Handle GET Requests for UserInfo\"\"\"\n if not self.token:\n return HttpResponseBadRequest()\n claims = {}\n claims.setdefault(\"sub\", self.token.id_token.sub)\n claims.update(self.get_claims(self.token.provider, self.token))\n if self.token.id_token.nonce:\n claims[\"nonce\"] = self.token.id_token.nonce\n response = TokenResponse(claims)\n return response\n\n def post(self, request: HttpRequest, **kwargs) -> HttpResponse:\n \"\"\"POST Requests behave the same as GET Requests, so the get handler is called here\"\"\"\n return self.get(request, **kwargs)\n", "path": "authentik/providers/oauth2/views/userinfo.py"}]} | 1,862 | 263 |
gh_patches_debug_4588 | rasdani/github-patches | git_diff | saleor__saleor-541 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Drop cart partitioner from cart view
Currently the cart is partitioned every time it'd displayed. We really only need to do this when creating an order/payment. We do call it every time the cart is rendered but we then merge all of the partitions back into a single list.
- [ ] identify places where cart partitioner is called
- [ ] remove the unnecessary calls from places that don't absolutely need partitioning to work (checkout)
- [ ] simplify templates so they iterate over the cart instead of walking through a list of partitions that in turn contain items
- [ ] provide a brief description of the changes for the next release changelog
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/cart/views.py`
Content:
```
1 from __future__ import unicode_literals
2 from babeldjango.templatetags.babel import currencyfmt
3
4 from django.contrib import messages
5 from django.http import JsonResponse
6 from django.shortcuts import redirect
7 from django.template.response import TemplateResponse
8 from django.utils.translation import ugettext as _
9
10 from . import Cart
11 from .forms import ReplaceCartLineForm
12 from ..cart.utils import (
13 contains_unavailable_products, remove_unavailable_products)
14
15
16 def index(request, product_id=None):
17 if product_id is not None:
18 product_id = int(product_id)
19 cart = Cart.for_session_cart(request.cart, discounts=request.discounts)
20 if contains_unavailable_products(cart):
21 msg = _('Sorry. We don\'t have that many items in stock. '
22 'Quantity was set to maximum available for now.')
23 messages.warning(request, msg)
24 remove_unavailable_products(cart)
25 for line in cart:
26 data = None
27 if line.product.pk == product_id:
28 data = request.POST
29 initial = {'quantity': line.get_quantity()}
30 form = ReplaceCartLineForm(data, cart=cart, product=line.product,
31 initial=initial)
32 line.form = form
33 if form.is_valid():
34 form.save()
35 if request.is_ajax():
36 response = {
37 'productId': line.product.pk,
38 'subtotal': currencyfmt(
39 line.get_total().gross,
40 line.get_total().currency),
41 'total': 0}
42 if cart:
43 response['total'] = currencyfmt(
44 cart.get_total().gross, cart.get_total().currency)
45 return JsonResponse(response)
46 return redirect('cart:index')
47 elif data is not None:
48 if request.is_ajax():
49 response = {'error': form.errors}
50 return JsonResponse(response, status=400)
51 cart_partitioner = cart.partition()
52 return TemplateResponse(
53 request, 'cart/index.html', {
54 'cart': cart_partitioner})
55
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/saleor/cart/views.py b/saleor/cart/views.py
--- a/saleor/cart/views.py
+++ b/saleor/cart/views.py
@@ -48,7 +48,6 @@
if request.is_ajax():
response = {'error': form.errors}
return JsonResponse(response, status=400)
- cart_partitioner = cart.partition()
return TemplateResponse(
request, 'cart/index.html', {
- 'cart': cart_partitioner})
+ 'cart': cart})
| {"golden_diff": "diff --git a/saleor/cart/views.py b/saleor/cart/views.py\n--- a/saleor/cart/views.py\n+++ b/saleor/cart/views.py\n@@ -48,7 +48,6 @@\n if request.is_ajax():\n response = {'error': form.errors}\n return JsonResponse(response, status=400)\n- cart_partitioner = cart.partition()\n return TemplateResponse(\n request, 'cart/index.html', {\n- 'cart': cart_partitioner})\n+ 'cart': cart})\n", "issue": "Drop cart partitioner from cart view\nCurrently the cart is partitioned every time it'd displayed. We really only need to do this when creating an order/payment. We do call it every time the cart is rendered but we then merge all of the partitions back into a single list.\n- [ ] identify places where cart partitioner is called\n- [ ] remove the unnecessary calls from places that don't absolutely need partitioning to work (checkout)\n- [ ] simplify templates so they iterate over the cart instead of walking through a list of partitions that in turn contain items\n- [ ] provide a brief description of the changes for the next release changelog\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom babeldjango.templatetags.babel import currencyfmt\n\nfrom django.contrib import messages\nfrom django.http import JsonResponse\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import ugettext as _\n\nfrom . import Cart\nfrom .forms import ReplaceCartLineForm\nfrom ..cart.utils import (\n contains_unavailable_products, remove_unavailable_products)\n\n\ndef index(request, product_id=None):\n if product_id is not None:\n product_id = int(product_id)\n cart = Cart.for_session_cart(request.cart, discounts=request.discounts)\n if contains_unavailable_products(cart):\n msg = _('Sorry. We don\\'t have that many items in stock. '\n 'Quantity was set to maximum available for now.')\n messages.warning(request, msg)\n remove_unavailable_products(cart)\n for line in cart:\n data = None\n if line.product.pk == product_id:\n data = request.POST\n initial = {'quantity': line.get_quantity()}\n form = ReplaceCartLineForm(data, cart=cart, product=line.product,\n initial=initial)\n line.form = form\n if form.is_valid():\n form.save()\n if request.is_ajax():\n response = {\n 'productId': line.product.pk,\n 'subtotal': currencyfmt(\n line.get_total().gross,\n line.get_total().currency),\n 'total': 0}\n if cart:\n response['total'] = currencyfmt(\n cart.get_total().gross, cart.get_total().currency)\n return JsonResponse(response)\n return redirect('cart:index')\n elif data is not None:\n if request.is_ajax():\n response = {'error': form.errors}\n return JsonResponse(response, status=400)\n cart_partitioner = cart.partition()\n return TemplateResponse(\n request, 'cart/index.html', {\n 'cart': cart_partitioner})\n", "path": "saleor/cart/views.py"}], "after_files": [{"content": "from __future__ import unicode_literals\nfrom babeldjango.templatetags.babel import currencyfmt\n\nfrom django.contrib import messages\nfrom django.http import JsonResponse\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils.translation import ugettext as _\n\nfrom . import Cart\nfrom .forms import ReplaceCartLineForm\nfrom ..cart.utils import (\n contains_unavailable_products, remove_unavailable_products)\n\n\ndef index(request, product_id=None):\n if product_id is not None:\n product_id = int(product_id)\n cart = Cart.for_session_cart(request.cart, discounts=request.discounts)\n if contains_unavailable_products(cart):\n msg = _('Sorry. We don\\'t have that many items in stock. '\n 'Quantity was set to maximum available for now.')\n messages.warning(request, msg)\n remove_unavailable_products(cart)\n for line in cart:\n data = None\n if line.product.pk == product_id:\n data = request.POST\n initial = {'quantity': line.get_quantity()}\n form = ReplaceCartLineForm(data, cart=cart, product=line.product,\n initial=initial)\n line.form = form\n if form.is_valid():\n form.save()\n if request.is_ajax():\n response = {\n 'productId': line.product.pk,\n 'subtotal': currencyfmt(\n line.get_total().gross,\n line.get_total().currency),\n 'total': 0}\n if cart:\n response['total'] = currencyfmt(\n cart.get_total().gross, cart.get_total().currency)\n return JsonResponse(response)\n return redirect('cart:index')\n elif data is not None:\n if request.is_ajax():\n response = {'error': form.errors}\n return JsonResponse(response, status=400)\n return TemplateResponse(\n request, 'cart/index.html', {\n 'cart': cart})\n", "path": "saleor/cart/views.py"}]} | 895 | 113 |
gh_patches_debug_40361 | rasdani/github-patches | git_diff | optuna__optuna-931 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The doc of `optuna.integration.lightgbm.train` function cannot be generated if LightGBM isn't installed.
Due to the bug the title describes, [the current API reference doc](https://optuna.readthedocs.io/en/latest/) doesn't contain the entry of `optuna.integration.lightgbm.train` function.
# Expected behavior
The build of the function doc should be succeeded even if LightGBM isn't installed in the build environment.
## Error messages, stack traces, or logs
```console
$ cd optuna/docs
$ make html
...
WARNING: autodoc: failed to import function 'train' from module 'optuna.integration.lightgbm'; the following exception was raised:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/util/inspect.py", line 225, in safe_getattr
return getattr(obj, name, *defargs)
AttributeError: module 'optuna.integration.lightgbm' has no attribute 'train'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/importer.py", line 193, in import_object
obj = attrgetter(obj, attrname)
File "/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/__init__.py", line 290, in get_attr
return autodoc_attrgetter(self.env.app, obj, name, *defargs)
File "/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/__init__.py", line 1563, in autodoc_attrgetter
return safe_getattr(obj, name, *defargs)
File "/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/util/inspect.py", line 241, in safe_getattr
raise AttributeError(name)
AttributeError: train
...
```
## Steps to reproduce
1. Ensure that LightGBM isn't installed in the built environment.
2. `$ git clone git://github.com/optuna/optuna.git`
3. `$ cd optuna/docs`
4. `$ make html`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `optuna/integration/lightgbm.py`
Content:
```
1 import sys
2
3 import optuna
4
5 try:
6 import lightgbm as lgb # NOQA
7 _available = True
8 except ImportError as e:
9 _import_error = e
10 # LightGBMPruningCallback is disabled because LightGBM is not available.
11 _available = False
12
13
14 # Attach lightgbm API.
15 if _available:
16 # API from optuna integration.
17 from optuna.integration import lightgbm_tuner as tuner
18
19 # Workaround for mypy.
20 from lightgbm import Dataset # NOQA
21 from optuna.integration.lightgbm_tuner import LightGBMTuner # NOQA
22
23 _names_from_tuners = ['train', 'LGBMModel', 'LGBMClassifier', 'LGBMRegressor']
24
25 # API from lightgbm.
26 for api_name in lgb.__dict__['__all__']:
27 if api_name in _names_from_tuners:
28 continue
29 setattr(sys.modules[__name__], api_name, lgb.__dict__[api_name])
30
31 for api_name in _names_from_tuners:
32 setattr(sys.modules[__name__], api_name, tuner.__dict__[api_name])
33 else:
34 LightGBMTuner = object # type: ignore
35
36
37 class LightGBMPruningCallback(object):
38 """Callback for LightGBM to prune unpromising trials.
39
40 Example:
41
42 Add a pruning callback which observes validation scores to training of a LightGBM model.
43
44 .. code::
45
46 param = {'objective': 'binary', 'metric': 'binary_error'}
47 pruning_callback = LightGBMPruningCallback(trial, 'binary_error')
48 gbm = lgb.train(param, dtrain, valid_sets=[dtest], callbacks=[pruning_callback])
49
50 Args:
51 trial:
52 A :class:`~optuna.trial.Trial` corresponding to the current evaluation of
53 the objective function.
54 metric:
55 An evaluation metric for pruning, e.g., ``binary_error`` and ``multi_error``.
56 Please refer to
57 `LightGBM reference
58 <https://lightgbm.readthedocs.io/en/latest/Parameters.html#metric>`_
59 for further details.
60 valid_name:
61 The name of the target validation.
62 Validation names are specified by ``valid_names`` option of
63 `train method
64 <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.train>`_.
65 If omitted, ``valid_0`` is used which is the default name of the first validation.
66 Note that this argument will be ignored if you are calling
67 `cv method <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.cv>`_
68 instead of train method.
69 """
70
71 def __init__(self, trial, metric, valid_name='valid_0'):
72 # type: (optuna.trial.Trial, str, str) -> None
73
74 _check_lightgbm_availability()
75
76 self._trial = trial
77 self._valid_name = valid_name
78 self._metric = metric
79
80 def __call__(self, env):
81 # type: (lgb.callback.CallbackEnv) -> None
82
83 # If this callback has been passed to `lightgbm.cv` function,
84 # the value of `is_cv` becomes `True`. See also:
85 # https://github.com/Microsoft/LightGBM/blob/v2.2.2/python-package/lightgbm/engine.py#L329
86 # Note that `5` is not the number of folds but the length of sequence.
87 is_cv = len(env.evaluation_result_list) > 0 and len(env.evaluation_result_list[0]) == 5
88 if is_cv:
89 target_valid_name = 'cv_agg'
90 else:
91 target_valid_name = self._valid_name
92
93 for evaluation_result in env.evaluation_result_list:
94 valid_name, metric, current_score, is_higher_better = evaluation_result[:4]
95 if valid_name != target_valid_name or metric != self._metric:
96 continue
97
98 if is_higher_better:
99 if self._trial.storage.get_study_direction(self._trial.study._study_id) != \
100 optuna.structs.StudyDirection.MAXIMIZE:
101 raise ValueError(
102 "The intermediate values are inconsistent with the objective values in "
103 "terms of study directions. Please specify a metric to be minimized for "
104 "LightGBMPruningCallback.")
105 else:
106 if self._trial.storage.get_study_direction(self._trial.study._study_id) != \
107 optuna.structs.StudyDirection.MINIMIZE:
108 raise ValueError(
109 "The intermediate values are inconsistent with the objective values in "
110 "terms of study directions. Please specify a metric to be maximized for "
111 "LightGBMPruningCallback.")
112
113 self._trial.report(current_score, step=env.iteration)
114 if self._trial.should_prune():
115 message = "Trial was pruned at iteration {}.".format(env.iteration)
116 raise optuna.exceptions.TrialPruned(message)
117
118 return None
119
120 raise ValueError(
121 'The entry associated with the validation name "{}" and the metric name "{}" '
122 'is not found in the evaluation result list {}.'.format(
123 target_valid_name, self._metric, str(env.evaluation_result_list)))
124
125
126 def _check_lightgbm_availability():
127 # type: () -> None
128
129 if not _available:
130 raise ImportError(
131 'LightGBM is not available. Please install LightGBM to use this feature. '
132 'LightGBM can be installed by executing `$ pip install lightgbm`. '
133 'For further information, please refer to the installation guide of LightGBM. '
134 '(The actual import error is as follows: ' + str(_import_error) + ')')
135
```
Path: `setup.py`
Content:
```
1 import os
2 import sys
3
4 import pkg_resources
5 from setuptools import find_packages
6 from setuptools import setup
7
8 from typing import Dict # NOQA
9 from typing import List # NOQA
10 from typing import Optional # NOQA
11
12
13 def get_version():
14 # type: () -> str
15
16 version_filepath = os.path.join(os.path.dirname(__file__), 'optuna', 'version.py')
17 with open(version_filepath) as f:
18 for line in f:
19 if line.startswith('__version__'):
20 return line.strip().split()[-1][1:-1]
21 assert False
22
23
24 def get_long_description():
25 # type: () -> str
26
27 readme_filepath = os.path.join(os.path.dirname(__file__), 'README.md')
28 with open(readme_filepath) as f:
29 return f.read()
30
31
32 def get_install_requires():
33 # type: () -> List[str]
34
35 return [
36 'alembic',
37 'cliff',
38 'colorlog',
39 'numpy',
40 'scipy!=1.4.0',
41 'sqlalchemy>=1.1.0',
42 'tqdm',
43 'joblib',
44 ]
45
46
47 def get_tests_require():
48 # type: () -> List[str]
49
50 return get_extras_require()['testing']
51
52
53 def get_extras_require():
54 # type: () -> Dict[str, List[str]]
55
56 requirements = {
57 'checking': [
58 'autopep8',
59 'hacking',
60 'mypy',
61 ],
62 'codecov': [
63 'codecov',
64 'pytest-cov',
65 ],
66 'doctest': [
67 'pandas',
68 'scikit-learn>=0.19.0',
69 ],
70 'document': [
71 'lightgbm',
72 'sphinx',
73 'sphinx_rtd_theme',
74 ],
75 'example': [
76 'catboost',
77 'chainer',
78 'lightgbm',
79 'mlflow',
80 'mxnet',
81 'pytorch-ignite',
82 'scikit-image',
83 'scikit-learn',
84 'torch',
85 'torchvision>=0.5.0',
86 'xgboost',
87 ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])
88 + ([
89 'dask[dataframe]',
90 'dask-ml',
91 'keras',
92 'pytorch-lightning',
93 'tensorflow>=2.0.0',
94 ] if sys.version_info[:2] < (3, 8) else []),
95 'testing': [
96 'bokeh',
97 'chainer>=5.0.0',
98 'cma',
99 'lightgbm',
100 'mock',
101 'mpi4py',
102 'mxnet',
103 'pandas',
104 'plotly>=4.0.0',
105 'pytest',
106 'pytorch-ignite',
107 'scikit-learn>=0.19.0',
108 'scikit-optimize',
109 'torch',
110 'torchvision>=0.5.0',
111 'xgboost',
112 ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])
113 + ([
114 'keras',
115 'pytorch-lightning',
116 'tensorflow',
117 'tensorflow-datasets',
118 ] if sys.version_info[:2] < (3, 8) else []),
119 }
120
121 return requirements
122
123
124 def find_any_distribution(pkgs):
125 # type: (List[str]) -> Optional[pkg_resources.Distribution]
126
127 for pkg in pkgs:
128 try:
129 return pkg_resources.get_distribution(pkg)
130 except pkg_resources.DistributionNotFound:
131 pass
132 return None
133
134
135 pfnopt_pkg = find_any_distribution(['pfnopt'])
136 if pfnopt_pkg is not None:
137 msg = 'We detected that PFNOpt is installed in your environment.\n' \
138 'PFNOpt has been renamed Optuna. Please uninstall the old\n' \
139 'PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`).'
140 print(msg)
141 exit(1)
142
143 setup(
144 name='optuna',
145 version=get_version(),
146 description='A hyperparameter optimization framework',
147 long_description=get_long_description(),
148 long_description_content_type='text/markdown',
149 author='Takuya Akiba',
150 author_email='[email protected]',
151 url='https://optuna.org/',
152 packages=find_packages(),
153 package_data={
154 'optuna': [
155 'storages/rdb/alembic.ini',
156 'storages/rdb/alembic/*.*',
157 'storages/rdb/alembic/versions/*.*'
158 ]
159 },
160 install_requires=get_install_requires(),
161 tests_require=get_tests_require(),
162 extras_require=get_extras_require(),
163 entry_points={'console_scripts': ['optuna = optuna.cli:main']})
164
```
Path: `optuna/integration/lightgbm_tuner/__init__.py`
Content:
```
1 from typing import Any
2
3 from optuna._experimental import experimental
4 from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA
5 from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner
6
7
8 @experimental("0.18.0")
9 def train(*args: Any, **kwargs: Any) -> Any:
10 """Wrapper of LightGBM Training API to tune hyperparameters.
11
12 It tunes important hyperparameters (e.g., `min_child_samples` and `feature_fraction`) in a
13 stepwise manner. Arguments and keyword arguments for `lightgbm.train()
14 <https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html>`_ can be passed.
15 """
16
17 auto_booster = LightGBMTuner(*args, **kwargs)
18 booster = auto_booster.run()
19 return booster
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/optuna/integration/lightgbm.py b/optuna/integration/lightgbm.py
--- a/optuna/integration/lightgbm.py
+++ b/optuna/integration/lightgbm.py
@@ -2,6 +2,8 @@
import optuna
+from optuna.integration import lightgbm_tuner as tuner
+
try:
import lightgbm as lgb # NOQA
_available = True
@@ -13,10 +15,7 @@
# Attach lightgbm API.
if _available:
- # API from optuna integration.
- from optuna.integration import lightgbm_tuner as tuner
-
- # Workaround for mypy.
+ # To pass tests/integration_tests/lightgbm_tuner_tests/test_optimize.py.
from lightgbm import Dataset # NOQA
from optuna.integration.lightgbm_tuner import LightGBMTuner # NOQA
@@ -28,10 +27,12 @@
continue
setattr(sys.modules[__name__], api_name, lgb.__dict__[api_name])
+ # API from lightgbm_tuner.
for api_name in _names_from_tuners:
setattr(sys.modules[__name__], api_name, tuner.__dict__[api_name])
else:
- LightGBMTuner = object # type: ignore
+ # To create docstring of train.
+ setattr(sys.modules[__name__], 'train', tuner.__dict__['train'])
class LightGBMPruningCallback(object):
diff --git a/optuna/integration/lightgbm_tuner/__init__.py b/optuna/integration/lightgbm_tuner/__init__.py
--- a/optuna/integration/lightgbm_tuner/__init__.py
+++ b/optuna/integration/lightgbm_tuner/__init__.py
@@ -1,8 +1,20 @@
from typing import Any
from optuna._experimental import experimental
-from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA
-from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner
+from optuna import type_checking
+
+try:
+ from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA
+ from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner
+ _available = True
+except ImportError as e:
+ _import_error = e
+ # LightGBMTuner is disabled because LightGBM is not available.
+ _available = False
+
+
+if type_checking.TYPE_CHECKING:
+ from typing import Any # NOQA
@experimental("0.18.0")
@@ -13,7 +25,19 @@
stepwise manner. Arguments and keyword arguments for `lightgbm.train()
<https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html>`_ can be passed.
"""
+ _check_lightgbm_availability()
auto_booster = LightGBMTuner(*args, **kwargs)
booster = auto_booster.run()
return booster
+
+
+def _check_lightgbm_availability():
+ # type: () -> None
+
+ if not _available:
+ raise ImportError(
+ 'LightGBM is not available. Please install LightGBM to use this feature. '
+ 'LightGBM can be installed by executing `$ pip install lightgbm`. '
+ 'For further information, please refer to the installation guide of LightGBM. '
+ '(The actual import error is as follows: ' + str(_import_error) + ')')
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -68,7 +68,6 @@
'scikit-learn>=0.19.0',
],
'document': [
- 'lightgbm',
'sphinx',
'sphinx_rtd_theme',
],
| {"golden_diff": "diff --git a/optuna/integration/lightgbm.py b/optuna/integration/lightgbm.py\n--- a/optuna/integration/lightgbm.py\n+++ b/optuna/integration/lightgbm.py\n@@ -2,6 +2,8 @@\n \n import optuna\n \n+from optuna.integration import lightgbm_tuner as tuner\n+\n try:\n import lightgbm as lgb # NOQA\n _available = True\n@@ -13,10 +15,7 @@\n \n # Attach lightgbm API.\n if _available:\n- # API from optuna integration.\n- from optuna.integration import lightgbm_tuner as tuner\n-\n- # Workaround for mypy.\n+ # To pass tests/integration_tests/lightgbm_tuner_tests/test_optimize.py.\n from lightgbm import Dataset # NOQA\n from optuna.integration.lightgbm_tuner import LightGBMTuner # NOQA\n \n@@ -28,10 +27,12 @@\n continue\n setattr(sys.modules[__name__], api_name, lgb.__dict__[api_name])\n \n+ # API from lightgbm_tuner.\n for api_name in _names_from_tuners:\n setattr(sys.modules[__name__], api_name, tuner.__dict__[api_name])\n else:\n- LightGBMTuner = object # type: ignore\n+ # To create docstring of train.\n+ setattr(sys.modules[__name__], 'train', tuner.__dict__['train'])\n \n \n class LightGBMPruningCallback(object):\ndiff --git a/optuna/integration/lightgbm_tuner/__init__.py b/optuna/integration/lightgbm_tuner/__init__.py\n--- a/optuna/integration/lightgbm_tuner/__init__.py\n+++ b/optuna/integration/lightgbm_tuner/__init__.py\n@@ -1,8 +1,20 @@\n from typing import Any\n \n from optuna._experimental import experimental\n-from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA\n-from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner\n+from optuna import type_checking\n+\n+try:\n+ from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA\n+ from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner\n+ _available = True\n+except ImportError as e:\n+ _import_error = e\n+ # LightGBMTuner is disabled because LightGBM is not available.\n+ _available = False\n+\n+\n+if type_checking.TYPE_CHECKING:\n+ from typing import Any # NOQA\n \n \n @experimental(\"0.18.0\")\n@@ -13,7 +25,19 @@\n stepwise manner. Arguments and keyword arguments for `lightgbm.train()\n <https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html>`_ can be passed.\n \"\"\"\n+ _check_lightgbm_availability()\n \n auto_booster = LightGBMTuner(*args, **kwargs)\n booster = auto_booster.run()\n return booster\n+\n+\n+def _check_lightgbm_availability():\n+ # type: () -> None\n+\n+ if not _available:\n+ raise ImportError(\n+ 'LightGBM is not available. Please install LightGBM to use this feature. '\n+ 'LightGBM can be installed by executing `$ pip install lightgbm`. '\n+ 'For further information, please refer to the installation guide of LightGBM. '\n+ '(The actual import error is as follows: ' + str(_import_error) + ')')\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -68,7 +68,6 @@\n 'scikit-learn>=0.19.0',\n ],\n 'document': [\n- 'lightgbm',\n 'sphinx',\n 'sphinx_rtd_theme',\n ],\n", "issue": "The doc of `optuna.integration.lightgbm.train` function cannot be generated if LightGBM isn't installed.\nDue to the bug the title describes, [the current API reference doc](https://optuna.readthedocs.io/en/latest/) doesn't contain the entry of `optuna.integration.lightgbm.train` function.\r\n\r\n# Expected behavior\r\n\r\nThe build of the function doc should be succeeded even if LightGBM isn't installed in the build environment.\r\n\r\n## Error messages, stack traces, or logs\r\n\r\n```console\r\n$ cd optuna/docs\r\n$ make html\r\n...\r\nWARNING: autodoc: failed to import function 'train' from module 'optuna.integration.lightgbm'; the following exception was raised:\r\nTraceback (most recent call last):\r\n File \"/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/util/inspect.py\", line 225, in safe_getattr\r\n return getattr(obj, name, *defargs)\r\nAttributeError: module 'optuna.integration.lightgbm' has no attribute 'train'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/importer.py\", line 193, in import_object\r\n obj = attrgetter(obj, attrname)\r\n File \"/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/__init__.py\", line 290, in get_attr\r\n return autodoc_attrgetter(self.env.app, obj, name, *defargs)\r\n File \"/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/ext/autodoc/__init__.py\", line 1563, in autodoc_attrgetter\r\n return safe_getattr(obj, name, *defargs)\r\n File \"/home/docs/checkouts/readthedocs.org/user_builds/optuna/envs/latest/lib/python3.7/site-packages/sphinx/util/inspect.py\", line 241, in safe_getattr\r\n raise AttributeError(name)\r\nAttributeError: train\r\n...\r\n```\r\n\r\n## Steps to reproduce\r\n\r\n1. Ensure that LightGBM isn't installed in the built environment.\r\n2. `$ git clone git://github.com/optuna/optuna.git`\r\n3. `$ cd optuna/docs`\r\n4. `$ make html`\r\n\r\n\r\n\n", "before_files": [{"content": "import sys\n\nimport optuna\n\ntry:\n import lightgbm as lgb # NOQA\n _available = True\nexcept ImportError as e:\n _import_error = e\n # LightGBMPruningCallback is disabled because LightGBM is not available.\n _available = False\n\n\n# Attach lightgbm API.\nif _available:\n # API from optuna integration.\n from optuna.integration import lightgbm_tuner as tuner\n\n # Workaround for mypy.\n from lightgbm import Dataset # NOQA\n from optuna.integration.lightgbm_tuner import LightGBMTuner # NOQA\n\n _names_from_tuners = ['train', 'LGBMModel', 'LGBMClassifier', 'LGBMRegressor']\n\n # API from lightgbm.\n for api_name in lgb.__dict__['__all__']:\n if api_name in _names_from_tuners:\n continue\n setattr(sys.modules[__name__], api_name, lgb.__dict__[api_name])\n\n for api_name in _names_from_tuners:\n setattr(sys.modules[__name__], api_name, tuner.__dict__[api_name])\nelse:\n LightGBMTuner = object # type: ignore\n\n\nclass LightGBMPruningCallback(object):\n \"\"\"Callback for LightGBM to prune unpromising trials.\n\n Example:\n\n Add a pruning callback which observes validation scores to training of a LightGBM model.\n\n .. code::\n\n param = {'objective': 'binary', 'metric': 'binary_error'}\n pruning_callback = LightGBMPruningCallback(trial, 'binary_error')\n gbm = lgb.train(param, dtrain, valid_sets=[dtest], callbacks=[pruning_callback])\n\n Args:\n trial:\n A :class:`~optuna.trial.Trial` corresponding to the current evaluation of\n the objective function.\n metric:\n An evaluation metric for pruning, e.g., ``binary_error`` and ``multi_error``.\n Please refer to\n `LightGBM reference\n <https://lightgbm.readthedocs.io/en/latest/Parameters.html#metric>`_\n for further details.\n valid_name:\n The name of the target validation.\n Validation names are specified by ``valid_names`` option of\n `train method\n <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.train>`_.\n If omitted, ``valid_0`` is used which is the default name of the first validation.\n Note that this argument will be ignored if you are calling\n `cv method <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.cv>`_\n instead of train method.\n \"\"\"\n\n def __init__(self, trial, metric, valid_name='valid_0'):\n # type: (optuna.trial.Trial, str, str) -> None\n\n _check_lightgbm_availability()\n\n self._trial = trial\n self._valid_name = valid_name\n self._metric = metric\n\n def __call__(self, env):\n # type: (lgb.callback.CallbackEnv) -> None\n\n # If this callback has been passed to `lightgbm.cv` function,\n # the value of `is_cv` becomes `True`. See also:\n # https://github.com/Microsoft/LightGBM/blob/v2.2.2/python-package/lightgbm/engine.py#L329\n # Note that `5` is not the number of folds but the length of sequence.\n is_cv = len(env.evaluation_result_list) > 0 and len(env.evaluation_result_list[0]) == 5\n if is_cv:\n target_valid_name = 'cv_agg'\n else:\n target_valid_name = self._valid_name\n\n for evaluation_result in env.evaluation_result_list:\n valid_name, metric, current_score, is_higher_better = evaluation_result[:4]\n if valid_name != target_valid_name or metric != self._metric:\n continue\n\n if is_higher_better:\n if self._trial.storage.get_study_direction(self._trial.study._study_id) != \\\n optuna.structs.StudyDirection.MAXIMIZE:\n raise ValueError(\n \"The intermediate values are inconsistent with the objective values in \"\n \"terms of study directions. Please specify a metric to be minimized for \"\n \"LightGBMPruningCallback.\")\n else:\n if self._trial.storage.get_study_direction(self._trial.study._study_id) != \\\n optuna.structs.StudyDirection.MINIMIZE:\n raise ValueError(\n \"The intermediate values are inconsistent with the objective values in \"\n \"terms of study directions. Please specify a metric to be maximized for \"\n \"LightGBMPruningCallback.\")\n\n self._trial.report(current_score, step=env.iteration)\n if self._trial.should_prune():\n message = \"Trial was pruned at iteration {}.\".format(env.iteration)\n raise optuna.exceptions.TrialPruned(message)\n\n return None\n\n raise ValueError(\n 'The entry associated with the validation name \"{}\" and the metric name \"{}\" '\n 'is not found in the evaluation result list {}.'.format(\n target_valid_name, self._metric, str(env.evaluation_result_list)))\n\n\ndef _check_lightgbm_availability():\n # type: () -> None\n\n if not _available:\n raise ImportError(\n 'LightGBM is not available. Please install LightGBM to use this feature. '\n 'LightGBM can be installed by executing `$ pip install lightgbm`. '\n 'For further information, please refer to the installation guide of LightGBM. '\n '(The actual import error is as follows: ' + str(_import_error) + ')')\n", "path": "optuna/integration/lightgbm.py"}, {"content": "import os\nimport sys\n\nimport pkg_resources\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nfrom typing import Dict # NOQA\nfrom typing import List # NOQA\nfrom typing import Optional # NOQA\n\n\ndef get_version():\n # type: () -> str\n\n version_filepath = os.path.join(os.path.dirname(__file__), 'optuna', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ndef get_long_description():\n # type: () -> str\n\n readme_filepath = os.path.join(os.path.dirname(__file__), 'README.md')\n with open(readme_filepath) as f:\n return f.read()\n\n\ndef get_install_requires():\n # type: () -> List[str]\n\n return [\n 'alembic',\n 'cliff',\n 'colorlog',\n 'numpy',\n 'scipy!=1.4.0',\n 'sqlalchemy>=1.1.0',\n 'tqdm',\n 'joblib',\n ]\n\n\ndef get_tests_require():\n # type: () -> List[str]\n\n return get_extras_require()['testing']\n\n\ndef get_extras_require():\n # type: () -> Dict[str, List[str]]\n\n requirements = {\n 'checking': [\n 'autopep8',\n 'hacking',\n 'mypy',\n ],\n 'codecov': [\n 'codecov',\n 'pytest-cov',\n ],\n 'doctest': [\n 'pandas',\n 'scikit-learn>=0.19.0',\n ],\n 'document': [\n 'lightgbm',\n 'sphinx',\n 'sphinx_rtd_theme',\n ],\n 'example': [\n 'catboost',\n 'chainer',\n 'lightgbm',\n 'mlflow',\n 'mxnet',\n 'pytorch-ignite',\n 'scikit-image',\n 'scikit-learn',\n 'torch',\n 'torchvision>=0.5.0',\n 'xgboost',\n ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])\n + ([\n 'dask[dataframe]',\n 'dask-ml',\n 'keras',\n 'pytorch-lightning',\n 'tensorflow>=2.0.0',\n ] if sys.version_info[:2] < (3, 8) else []),\n 'testing': [\n 'bokeh',\n 'chainer>=5.0.0',\n 'cma',\n 'lightgbm',\n 'mock',\n 'mpi4py',\n 'mxnet',\n 'pandas',\n 'plotly>=4.0.0',\n 'pytest',\n 'pytorch-ignite',\n 'scikit-learn>=0.19.0',\n 'scikit-optimize',\n 'torch',\n 'torchvision>=0.5.0',\n 'xgboost',\n ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])\n + ([\n 'keras',\n 'pytorch-lightning',\n 'tensorflow',\n 'tensorflow-datasets',\n ] if sys.version_info[:2] < (3, 8) else []),\n }\n\n return requirements\n\n\ndef find_any_distribution(pkgs):\n # type: (List[str]) -> Optional[pkg_resources.Distribution]\n\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\npfnopt_pkg = find_any_distribution(['pfnopt'])\nif pfnopt_pkg is not None:\n msg = 'We detected that PFNOpt is installed in your environment.\\n' \\\n 'PFNOpt has been renamed Optuna. Please uninstall the old\\n' \\\n 'PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`).'\n print(msg)\n exit(1)\n\nsetup(\n name='optuna',\n version=get_version(),\n description='A hyperparameter optimization framework',\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n author='Takuya Akiba',\n author_email='[email protected]',\n url='https://optuna.org/',\n packages=find_packages(),\n package_data={\n 'optuna': [\n 'storages/rdb/alembic.ini',\n 'storages/rdb/alembic/*.*',\n 'storages/rdb/alembic/versions/*.*'\n ]\n },\n install_requires=get_install_requires(),\n tests_require=get_tests_require(),\n extras_require=get_extras_require(),\n entry_points={'console_scripts': ['optuna = optuna.cli:main']})\n", "path": "setup.py"}, {"content": "from typing import Any\n\nfrom optuna._experimental import experimental\nfrom optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA\nfrom optuna.integration.lightgbm_tuner.optimize import LightGBMTuner\n\n\n@experimental(\"0.18.0\")\ndef train(*args: Any, **kwargs: Any) -> Any:\n \"\"\"Wrapper of LightGBM Training API to tune hyperparameters.\n\n It tunes important hyperparameters (e.g., `min_child_samples` and `feature_fraction`) in a\n stepwise manner. Arguments and keyword arguments for `lightgbm.train()\n <https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html>`_ can be passed.\n \"\"\"\n\n auto_booster = LightGBMTuner(*args, **kwargs)\n booster = auto_booster.run()\n return booster\n", "path": "optuna/integration/lightgbm_tuner/__init__.py"}], "after_files": [{"content": "import sys\n\nimport optuna\n\nfrom optuna.integration import lightgbm_tuner as tuner\n\ntry:\n import lightgbm as lgb # NOQA\n _available = True\nexcept ImportError as e:\n _import_error = e\n # LightGBMPruningCallback is disabled because LightGBM is not available.\n _available = False\n\n\n# Attach lightgbm API.\nif _available:\n # To pass tests/integration_tests/lightgbm_tuner_tests/test_optimize.py.\n from lightgbm import Dataset # NOQA\n from optuna.integration.lightgbm_tuner import LightGBMTuner # NOQA\n\n _names_from_tuners = ['train', 'LGBMModel', 'LGBMClassifier', 'LGBMRegressor']\n\n # API from lightgbm.\n for api_name in lgb.__dict__['__all__']:\n if api_name in _names_from_tuners:\n continue\n setattr(sys.modules[__name__], api_name, lgb.__dict__[api_name])\n\n # API from lightgbm_tuner.\n for api_name in _names_from_tuners:\n setattr(sys.modules[__name__], api_name, tuner.__dict__[api_name])\nelse:\n # To create docstring of train.\n setattr(sys.modules[__name__], 'train', tuner.__dict__['train'])\n\n\nclass LightGBMPruningCallback(object):\n \"\"\"Callback for LightGBM to prune unpromising trials.\n\n Example:\n\n Add a pruning callback which observes validation scores to training of a LightGBM model.\n\n .. code::\n\n param = {'objective': 'binary', 'metric': 'binary_error'}\n pruning_callback = LightGBMPruningCallback(trial, 'binary_error')\n gbm = lgb.train(param, dtrain, valid_sets=[dtest], callbacks=[pruning_callback])\n\n Args:\n trial:\n A :class:`~optuna.trial.Trial` corresponding to the current evaluation of\n the objective function.\n metric:\n An evaluation metric for pruning, e.g., ``binary_error`` and ``multi_error``.\n Please refer to\n `LightGBM reference\n <https://lightgbm.readthedocs.io/en/latest/Parameters.html#metric>`_\n for further details.\n valid_name:\n The name of the target validation.\n Validation names are specified by ``valid_names`` option of\n `train method\n <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.train>`_.\n If omitted, ``valid_0`` is used which is the default name of the first validation.\n Note that this argument will be ignored if you are calling\n `cv method <https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.cv>`_\n instead of train method.\n \"\"\"\n\n def __init__(self, trial, metric, valid_name='valid_0'):\n # type: (optuna.trial.Trial, str, str) -> None\n\n _check_lightgbm_availability()\n\n self._trial = trial\n self._valid_name = valid_name\n self._metric = metric\n\n def __call__(self, env):\n # type: (lgb.callback.CallbackEnv) -> None\n\n # If this callback has been passed to `lightgbm.cv` function,\n # the value of `is_cv` becomes `True`. See also:\n # https://github.com/Microsoft/LightGBM/blob/v2.2.2/python-package/lightgbm/engine.py#L329\n # Note that `5` is not the number of folds but the length of sequence.\n is_cv = len(env.evaluation_result_list) > 0 and len(env.evaluation_result_list[0]) == 5\n if is_cv:\n target_valid_name = 'cv_agg'\n else:\n target_valid_name = self._valid_name\n\n for evaluation_result in env.evaluation_result_list:\n valid_name, metric, current_score, is_higher_better = evaluation_result[:4]\n if valid_name != target_valid_name or metric != self._metric:\n continue\n\n if is_higher_better:\n if self._trial.storage.get_study_direction(self._trial.study._study_id) != \\\n optuna.structs.StudyDirection.MAXIMIZE:\n raise ValueError(\n \"The intermediate values are inconsistent with the objective values in \"\n \"terms of study directions. Please specify a metric to be minimized for \"\n \"LightGBMPruningCallback.\")\n else:\n if self._trial.storage.get_study_direction(self._trial.study._study_id) != \\\n optuna.structs.StudyDirection.MINIMIZE:\n raise ValueError(\n \"The intermediate values are inconsistent with the objective values in \"\n \"terms of study directions. Please specify a metric to be maximized for \"\n \"LightGBMPruningCallback.\")\n\n self._trial.report(current_score, step=env.iteration)\n if self._trial.should_prune():\n message = \"Trial was pruned at iteration {}.\".format(env.iteration)\n raise optuna.exceptions.TrialPruned(message)\n\n return None\n\n raise ValueError(\n 'The entry associated with the validation name \"{}\" and the metric name \"{}\" '\n 'is not found in the evaluation result list {}.'.format(\n target_valid_name, self._metric, str(env.evaluation_result_list)))\n\n\ndef _check_lightgbm_availability():\n # type: () -> None\n\n if not _available:\n raise ImportError(\n 'LightGBM is not available. Please install LightGBM to use this feature. '\n 'LightGBM can be installed by executing `$ pip install lightgbm`. '\n 'For further information, please refer to the installation guide of LightGBM. '\n '(The actual import error is as follows: ' + str(_import_error) + ')')\n", "path": "optuna/integration/lightgbm.py"}, {"content": "import os\nimport sys\n\nimport pkg_resources\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nfrom typing import Dict # NOQA\nfrom typing import List # NOQA\nfrom typing import Optional # NOQA\n\n\ndef get_version():\n # type: () -> str\n\n version_filepath = os.path.join(os.path.dirname(__file__), 'optuna', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ndef get_long_description():\n # type: () -> str\n\n readme_filepath = os.path.join(os.path.dirname(__file__), 'README.md')\n with open(readme_filepath) as f:\n return f.read()\n\n\ndef get_install_requires():\n # type: () -> List[str]\n\n return [\n 'alembic',\n 'cliff',\n 'colorlog',\n 'numpy',\n 'scipy!=1.4.0',\n 'sqlalchemy>=1.1.0',\n 'tqdm',\n 'joblib',\n ]\n\n\ndef get_tests_require():\n # type: () -> List[str]\n\n return get_extras_require()['testing']\n\n\ndef get_extras_require():\n # type: () -> Dict[str, List[str]]\n\n requirements = {\n 'checking': [\n 'autopep8',\n 'hacking',\n 'mypy',\n ],\n 'codecov': [\n 'codecov',\n 'pytest-cov',\n ],\n 'doctest': [\n 'pandas',\n 'scikit-learn>=0.19.0',\n ],\n 'document': [\n 'sphinx',\n 'sphinx_rtd_theme',\n ],\n 'example': [\n 'catboost',\n 'chainer',\n 'lightgbm',\n 'mlflow',\n 'mxnet',\n 'pytorch-ignite',\n 'scikit-image',\n 'scikit-learn',\n 'torch',\n 'torchvision>=0.5.0',\n 'xgboost',\n ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])\n + ([\n 'dask[dataframe]',\n 'dask-ml',\n 'keras',\n 'pytorch-lightning',\n 'tensorflow>=2.0.0',\n ] if sys.version_info[:2] < (3, 8) else []),\n 'testing': [\n 'bokeh',\n 'chainer>=5.0.0',\n 'cma',\n 'lightgbm',\n 'mock',\n 'mpi4py',\n 'mxnet',\n 'pandas',\n 'plotly>=4.0.0',\n 'pytest',\n 'pytorch-ignite',\n 'scikit-learn>=0.19.0',\n 'scikit-optimize',\n 'torch',\n 'torchvision>=0.5.0',\n 'xgboost',\n ] + (['fastai<2'] if (3, 5) < sys.version_info[:2] < (3, 8) else [])\n + ([\n 'keras',\n 'pytorch-lightning',\n 'tensorflow',\n 'tensorflow-datasets',\n ] if sys.version_info[:2] < (3, 8) else []),\n }\n\n return requirements\n\n\ndef find_any_distribution(pkgs):\n # type: (List[str]) -> Optional[pkg_resources.Distribution]\n\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\npfnopt_pkg = find_any_distribution(['pfnopt'])\nif pfnopt_pkg is not None:\n msg = 'We detected that PFNOpt is installed in your environment.\\n' \\\n 'PFNOpt has been renamed Optuna. Please uninstall the old\\n' \\\n 'PFNOpt in advance (e.g. by executing `$ pip uninstall pfnopt`).'\n print(msg)\n exit(1)\n\nsetup(\n name='optuna',\n version=get_version(),\n description='A hyperparameter optimization framework',\n long_description=get_long_description(),\n long_description_content_type='text/markdown',\n author='Takuya Akiba',\n author_email='[email protected]',\n url='https://optuna.org/',\n packages=find_packages(),\n package_data={\n 'optuna': [\n 'storages/rdb/alembic.ini',\n 'storages/rdb/alembic/*.*',\n 'storages/rdb/alembic/versions/*.*'\n ]\n },\n install_requires=get_install_requires(),\n tests_require=get_tests_require(),\n extras_require=get_extras_require(),\n entry_points={'console_scripts': ['optuna = optuna.cli:main']})\n", "path": "setup.py"}, {"content": "from typing import Any\n\nfrom optuna._experimental import experimental\nfrom optuna import type_checking\n\ntry:\n from optuna.integration.lightgbm_tuner.sklearn import LGBMClassifier, LGBMModel, LGBMRegressor # NOQA\n from optuna.integration.lightgbm_tuner.optimize import LightGBMTuner\n _available = True\nexcept ImportError as e:\n _import_error = e\n # LightGBMTuner is disabled because LightGBM is not available.\n _available = False\n\n\nif type_checking.TYPE_CHECKING:\n from typing import Any # NOQA\n\n\n@experimental(\"0.18.0\")\ndef train(*args: Any, **kwargs: Any) -> Any:\n \"\"\"Wrapper of LightGBM Training API to tune hyperparameters.\n\n It tunes important hyperparameters (e.g., `min_child_samples` and `feature_fraction`) in a\n stepwise manner. Arguments and keyword arguments for `lightgbm.train()\n <https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html>`_ can be passed.\n \"\"\"\n _check_lightgbm_availability()\n\n auto_booster = LightGBMTuner(*args, **kwargs)\n booster = auto_booster.run()\n return booster\n\n\ndef _check_lightgbm_availability():\n # type: () -> None\n\n if not _available:\n raise ImportError(\n 'LightGBM is not available. Please install LightGBM to use this feature. '\n 'LightGBM can be installed by executing `$ pip install lightgbm`. '\n 'For further information, please refer to the installation guide of LightGBM. '\n '(The actual import error is as follows: ' + str(_import_error) + ')')\n", "path": "optuna/integration/lightgbm_tuner/__init__.py"}]} | 4,090 | 900 |
gh_patches_debug_16016 | rasdani/github-patches | git_diff | flairNLP__flair-531 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Get perplexity of a sentence.
Is it currently possible to get the perplexity (or probability) of a sentence using flair's language model.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flair/models/language_model.py`
Content:
```
1 from pathlib import Path
2
3 import torch.nn as nn
4 import torch
5 import math
6 from typing import Union, Tuple
7 from typing import List
8
9 from torch.optim import Optimizer
10
11 import flair
12 from flair.data import Dictionary
13
14
15 class LanguageModel(nn.Module):
16 """Container module with an encoder, a recurrent module, and a decoder."""
17
18 def __init__(self,
19 dictionary: Dictionary,
20 is_forward_lm: bool,
21 hidden_size: int,
22 nlayers: int,
23 embedding_size: int = 100,
24 nout=None,
25 dropout=0.1):
26
27 super(LanguageModel, self).__init__()
28
29 self.dictionary = dictionary
30 self.is_forward_lm: bool = is_forward_lm
31
32 self.dropout = dropout
33 self.hidden_size = hidden_size
34 self.embedding_size = embedding_size
35 self.nlayers = nlayers
36
37 self.drop = nn.Dropout(dropout)
38 self.encoder = nn.Embedding(len(dictionary), embedding_size)
39
40 if nlayers == 1:
41 self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers)
42 else:
43 self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers, dropout=dropout)
44
45 self.hidden = None
46
47 self.nout = nout
48 if nout is not None:
49 self.proj = nn.Linear(hidden_size, nout)
50 self.initialize(self.proj.weight)
51 self.decoder = nn.Linear(nout, len(dictionary))
52 else:
53 self.proj = None
54 self.decoder = nn.Linear(hidden_size, len(dictionary))
55
56 self.init_weights()
57
58 # auto-spawn on GPU if available
59 self.to(flair.device)
60
61 def init_weights(self):
62 initrange = 0.1
63 self.encoder.weight.detach().uniform_(-initrange, initrange)
64 self.decoder.bias.detach().fill_(0)
65 self.decoder.weight.detach().uniform_(-initrange, initrange)
66
67 def set_hidden(self, hidden):
68 self.hidden = hidden
69
70 def forward(self, input, hidden, ordered_sequence_lengths=None):
71 encoded = self.encoder(input)
72 emb = self.drop(encoded)
73
74 self.rnn.flatten_parameters()
75
76 output, hidden = self.rnn(emb, hidden)
77
78 if self.proj is not None:
79 output = self.proj(output)
80
81 output = self.drop(output)
82
83 decoded = self.decoder(output.view(output.size(0) * output.size(1), output.size(2)))
84
85 return decoded.view(output.size(0), output.size(1), decoded.size(1)), output, hidden
86
87 def init_hidden(self, bsz):
88 weight = next(self.parameters()).detach()
89 return (weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach(),
90 weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach())
91
92 def get_representation(self, strings: List[str], chars_per_chunk: int = 512):
93
94 # cut up the input into chunks of max charlength = chunk_size
95 longest = len(strings[0])
96 chunks = []
97 splice_begin = 0
98 for splice_end in range(chars_per_chunk, longest, chars_per_chunk):
99 chunks.append([text[splice_begin:splice_end] for text in strings])
100 splice_begin = splice_end
101
102 chunks.append([text[splice_begin:longest] for text in strings])
103 hidden = self.init_hidden(len(chunks[0]))
104
105 output_parts = []
106
107 # push each chunk through the RNN language model
108 for chunk in chunks:
109
110 sequences_as_char_indices: List[List[int]] = []
111 for string in chunk:
112 char_indices = [self.dictionary.get_idx_for_item(char) for char in string]
113 sequences_as_char_indices.append(char_indices)
114
115 batch = torch.LongTensor(sequences_as_char_indices).transpose(0, 1)
116 batch = batch.to(flair.device)
117
118 prediction, rnn_output, hidden = self.forward(batch, hidden)
119 rnn_output = rnn_output.detach()
120
121 output_parts.append(rnn_output)
122
123 # concatenate all chunks to make final output
124 output = torch.cat(output_parts)
125
126 return output
127
128 def get_output(self, text: str):
129 char_indices = [self.dictionary.get_idx_for_item(char) for char in text]
130 input_vector = torch.LongTensor([char_indices]).transpose(0, 1)
131
132 hidden = self.init_hidden(1)
133 prediction, rnn_output, hidden = self.forward(input_vector, hidden)
134
135 return self.repackage_hidden(hidden)
136
137 def repackage_hidden(self, h):
138 """Wraps hidden states in new Variables, to detach them from their history."""
139 if type(h) == torch.Tensor:
140 return h.clone().detach()
141 else:
142 return tuple(self.repackage_hidden(v) for v in h)
143
144 def initialize(self, matrix):
145 in_, out_ = matrix.size()
146 stdv = math.sqrt(3. / (in_ + out_))
147 matrix.detach().uniform_(-stdv, stdv)
148
149 @classmethod
150 def load_language_model(cls, model_file: Union[Path, str]):
151
152 state = torch.load(str(model_file), map_location=flair.device)
153
154 model = LanguageModel(state['dictionary'],
155 state['is_forward_lm'],
156 state['hidden_size'],
157 state['nlayers'],
158 state['embedding_size'],
159 state['nout'],
160 state['dropout'])
161 model.load_state_dict(state['state_dict'])
162 model.eval()
163 model.to(flair.device)
164
165 return model
166
167 @classmethod
168 def load_checkpoint(cls, model_file: Path):
169 state = torch.load(str(model_file), map_location=flair.device)
170
171 epoch = state['epoch'] if 'epoch' in state else None
172 split = state['split'] if 'split' in state else None
173 loss = state['loss'] if 'loss' in state else None
174 optimizer_state_dict = state['optimizer_state_dict'] if 'optimizer_state_dict' in state else None
175
176 model = LanguageModel(state['dictionary'],
177 state['is_forward_lm'],
178 state['hidden_size'],
179 state['nlayers'],
180 state['embedding_size'],
181 state['nout'],
182 state['dropout'])
183 model.load_state_dict(state['state_dict'])
184 model.eval()
185 model.to(flair.device)
186
187 return {'model': model, 'epoch': epoch, 'split': split, 'loss': loss,
188 'optimizer_state_dict': optimizer_state_dict}
189
190 def save_checkpoint(self, file: Path, optimizer: Optimizer, epoch: int, split: int, loss: float):
191 model_state = {
192 'state_dict': self.state_dict(),
193 'dictionary': self.dictionary,
194 'is_forward_lm': self.is_forward_lm,
195 'hidden_size': self.hidden_size,
196 'nlayers': self.nlayers,
197 'embedding_size': self.embedding_size,
198 'nout': self.nout,
199 'dropout': self.dropout,
200 'optimizer_state_dict': optimizer.state_dict(),
201 'epoch': epoch,
202 'split': split,
203 'loss': loss
204 }
205
206 torch.save(model_state, str(file), pickle_protocol=4)
207
208 def save(self, file: Path):
209 model_state = {
210 'state_dict': self.state_dict(),
211 'dictionary': self.dictionary,
212 'is_forward_lm': self.is_forward_lm,
213 'hidden_size': self.hidden_size,
214 'nlayers': self.nlayers,
215 'embedding_size': self.embedding_size,
216 'nout': self.nout,
217 'dropout': self.dropout
218 }
219
220 torch.save(model_state, str(file), pickle_protocol=4)
221
222 def generate_text(self, prefix: str = '\n', number_of_characters: int = 1000, temperature: float = 1.0,
223 break_on_suffix=None) -> Tuple[str, float]:
224
225 if prefix == '':
226 prefix = '\n'
227
228 with torch.no_grad():
229 characters = []
230
231 idx2item = self.dictionary.idx2item
232
233 # initial hidden state
234 hidden = self.init_hidden(1)
235
236 if len(prefix) > 1:
237
238 char_tensors = []
239 for character in prefix[:-1]:
240 char_tensors.append(
241 torch.tensor(self.dictionary.get_idx_for_item(character)).unsqueeze(0).unsqueeze(0))
242
243 input = torch.cat(char_tensors)
244 if torch.cuda.is_available():
245 input = input.cuda()
246
247 prediction, _, hidden = self.forward(input, hidden)
248
249 input = torch.tensor(self.dictionary.get_idx_for_item(prefix[-1])).unsqueeze(0).unsqueeze(0)
250
251 log_prob = 0.
252
253 for i in range(number_of_characters):
254
255 if torch.cuda.is_available():
256 input = input.cuda()
257
258 # get predicted weights
259 prediction, _, hidden = self.forward(input, hidden)
260 prediction = prediction.squeeze().detach()
261 decoder_output = prediction
262
263 # divide by temperature
264 prediction = prediction.div(temperature)
265
266 # to prevent overflow problem with small temperature values, substract largest value from all
267 # this makes a vector in which the largest value is 0
268 max = torch.max(prediction)
269 prediction -= max
270
271 # compute word weights with exponential function
272 word_weights = prediction.exp().cpu()
273
274 # try sampling multinomial distribution for next character
275 try:
276 word_idx = torch.multinomial(word_weights, 1)[0]
277 except:
278 word_idx = torch.tensor(0)
279
280 # print(word_idx)
281 prob = decoder_output[word_idx]
282 log_prob += prob
283
284 input = word_idx.detach().unsqueeze(0).unsqueeze(0)
285 word = idx2item[word_idx].decode('UTF-8')
286 characters.append(word)
287
288 if break_on_suffix is not None:
289 if ''.join(characters).endswith(break_on_suffix):
290 break
291
292 text = prefix + ''.join(characters)
293
294 log_prob = log_prob.item()
295 log_prob /= len(characters)
296
297 if not self.is_forward_lm:
298 text = text[::-1]
299
300 return text, log_prob
301
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/flair/models/language_model.py b/flair/models/language_model.py
--- a/flair/models/language_model.py
+++ b/flair/models/language_model.py
@@ -298,3 +298,27 @@
text = text[::-1]
return text, log_prob
+
+ def calculate_perplexity(self, text: str) -> float:
+
+ if not self.is_forward_lm:
+ text = text[::-1]
+
+ # input ids
+ input = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[:-1]]).unsqueeze(1)
+
+ # push list of character IDs through model
+ hidden = self.init_hidden(1)
+ prediction, _, hidden = self.forward(input, hidden)
+
+ # the target is always the next character
+ targets = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[1:]])
+
+ # use cross entropy loss to compare output of forward pass with targets
+ cross_entroy_loss = torch.nn.CrossEntropyLoss()
+ loss = cross_entroy_loss(prediction.view(-1, len(self.dictionary)), targets).item()
+
+ # exponentiate cross-entropy loss to calculate perplexity
+ perplexity = math.exp(loss)
+
+ return perplexity
| {"golden_diff": "diff --git a/flair/models/language_model.py b/flair/models/language_model.py\n--- a/flair/models/language_model.py\n+++ b/flair/models/language_model.py\n@@ -298,3 +298,27 @@\n text = text[::-1]\n \n return text, log_prob\n+\n+ def calculate_perplexity(self, text: str) -> float:\n+\n+ if not self.is_forward_lm:\n+ text = text[::-1]\n+\n+ # input ids\n+ input = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[:-1]]).unsqueeze(1)\n+\n+ # push list of character IDs through model\n+ hidden = self.init_hidden(1)\n+ prediction, _, hidden = self.forward(input, hidden)\n+\n+ # the target is always the next character\n+ targets = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[1:]])\n+\n+ # use cross entropy loss to compare output of forward pass with targets\n+ cross_entroy_loss = torch.nn.CrossEntropyLoss()\n+ loss = cross_entroy_loss(prediction.view(-1, len(self.dictionary)), targets).item()\n+\n+ # exponentiate cross-entropy loss to calculate perplexity\n+ perplexity = math.exp(loss)\n+\n+ return perplexity\n", "issue": "Get perplexity of a sentence.\nIs it currently possible to get the perplexity (or probability) of a sentence using flair's language model. \n", "before_files": [{"content": "from pathlib import Path\n\nimport torch.nn as nn\nimport torch\nimport math\nfrom typing import Union, Tuple\nfrom typing import List\n\nfrom torch.optim import Optimizer\n\nimport flair\nfrom flair.data import Dictionary\n\n\nclass LanguageModel(nn.Module):\n \"\"\"Container module with an encoder, a recurrent module, and a decoder.\"\"\"\n\n def __init__(self,\n dictionary: Dictionary,\n is_forward_lm: bool,\n hidden_size: int,\n nlayers: int,\n embedding_size: int = 100,\n nout=None,\n dropout=0.1):\n\n super(LanguageModel, self).__init__()\n\n self.dictionary = dictionary\n self.is_forward_lm: bool = is_forward_lm\n\n self.dropout = dropout\n self.hidden_size = hidden_size\n self.embedding_size = embedding_size\n self.nlayers = nlayers\n\n self.drop = nn.Dropout(dropout)\n self.encoder = nn.Embedding(len(dictionary), embedding_size)\n\n if nlayers == 1:\n self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers)\n else:\n self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers, dropout=dropout)\n\n self.hidden = None\n\n self.nout = nout\n if nout is not None:\n self.proj = nn.Linear(hidden_size, nout)\n self.initialize(self.proj.weight)\n self.decoder = nn.Linear(nout, len(dictionary))\n else:\n self.proj = None\n self.decoder = nn.Linear(hidden_size, len(dictionary))\n\n self.init_weights()\n\n # auto-spawn on GPU if available\n self.to(flair.device)\n\n def init_weights(self):\n initrange = 0.1\n self.encoder.weight.detach().uniform_(-initrange, initrange)\n self.decoder.bias.detach().fill_(0)\n self.decoder.weight.detach().uniform_(-initrange, initrange)\n\n def set_hidden(self, hidden):\n self.hidden = hidden\n\n def forward(self, input, hidden, ordered_sequence_lengths=None):\n encoded = self.encoder(input)\n emb = self.drop(encoded)\n\n self.rnn.flatten_parameters()\n\n output, hidden = self.rnn(emb, hidden)\n\n if self.proj is not None:\n output = self.proj(output)\n\n output = self.drop(output)\n\n decoded = self.decoder(output.view(output.size(0) * output.size(1), output.size(2)))\n\n return decoded.view(output.size(0), output.size(1), decoded.size(1)), output, hidden\n\n def init_hidden(self, bsz):\n weight = next(self.parameters()).detach()\n return (weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach(),\n weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach())\n\n def get_representation(self, strings: List[str], chars_per_chunk: int = 512):\n\n # cut up the input into chunks of max charlength = chunk_size\n longest = len(strings[0])\n chunks = []\n splice_begin = 0\n for splice_end in range(chars_per_chunk, longest, chars_per_chunk):\n chunks.append([text[splice_begin:splice_end] for text in strings])\n splice_begin = splice_end\n\n chunks.append([text[splice_begin:longest] for text in strings])\n hidden = self.init_hidden(len(chunks[0]))\n\n output_parts = []\n\n # push each chunk through the RNN language model\n for chunk in chunks:\n\n sequences_as_char_indices: List[List[int]] = []\n for string in chunk:\n char_indices = [self.dictionary.get_idx_for_item(char) for char in string]\n sequences_as_char_indices.append(char_indices)\n\n batch = torch.LongTensor(sequences_as_char_indices).transpose(0, 1)\n batch = batch.to(flair.device)\n\n prediction, rnn_output, hidden = self.forward(batch, hidden)\n rnn_output = rnn_output.detach()\n\n output_parts.append(rnn_output)\n\n # concatenate all chunks to make final output\n output = torch.cat(output_parts)\n\n return output\n\n def get_output(self, text: str):\n char_indices = [self.dictionary.get_idx_for_item(char) for char in text]\n input_vector = torch.LongTensor([char_indices]).transpose(0, 1)\n\n hidden = self.init_hidden(1)\n prediction, rnn_output, hidden = self.forward(input_vector, hidden)\n\n return self.repackage_hidden(hidden)\n\n def repackage_hidden(self, h):\n \"\"\"Wraps hidden states in new Variables, to detach them from their history.\"\"\"\n if type(h) == torch.Tensor:\n return h.clone().detach()\n else:\n return tuple(self.repackage_hidden(v) for v in h)\n\n def initialize(self, matrix):\n in_, out_ = matrix.size()\n stdv = math.sqrt(3. / (in_ + out_))\n matrix.detach().uniform_(-stdv, stdv)\n\n @classmethod\n def load_language_model(cls, model_file: Union[Path, str]):\n\n state = torch.load(str(model_file), map_location=flair.device)\n\n model = LanguageModel(state['dictionary'],\n state['is_forward_lm'],\n state['hidden_size'],\n state['nlayers'],\n state['embedding_size'],\n state['nout'],\n state['dropout'])\n model.load_state_dict(state['state_dict'])\n model.eval()\n model.to(flair.device)\n\n return model\n\n @classmethod\n def load_checkpoint(cls, model_file: Path):\n state = torch.load(str(model_file), map_location=flair.device)\n\n epoch = state['epoch'] if 'epoch' in state else None\n split = state['split'] if 'split' in state else None\n loss = state['loss'] if 'loss' in state else None\n optimizer_state_dict = state['optimizer_state_dict'] if 'optimizer_state_dict' in state else None\n\n model = LanguageModel(state['dictionary'],\n state['is_forward_lm'],\n state['hidden_size'],\n state['nlayers'],\n state['embedding_size'],\n state['nout'],\n state['dropout'])\n model.load_state_dict(state['state_dict'])\n model.eval()\n model.to(flair.device)\n\n return {'model': model, 'epoch': epoch, 'split': split, 'loss': loss,\n 'optimizer_state_dict': optimizer_state_dict}\n\n def save_checkpoint(self, file: Path, optimizer: Optimizer, epoch: int, split: int, loss: float):\n model_state = {\n 'state_dict': self.state_dict(),\n 'dictionary': self.dictionary,\n 'is_forward_lm': self.is_forward_lm,\n 'hidden_size': self.hidden_size,\n 'nlayers': self.nlayers,\n 'embedding_size': self.embedding_size,\n 'nout': self.nout,\n 'dropout': self.dropout,\n 'optimizer_state_dict': optimizer.state_dict(),\n 'epoch': epoch,\n 'split': split,\n 'loss': loss\n }\n\n torch.save(model_state, str(file), pickle_protocol=4)\n\n def save(self, file: Path):\n model_state = {\n 'state_dict': self.state_dict(),\n 'dictionary': self.dictionary,\n 'is_forward_lm': self.is_forward_lm,\n 'hidden_size': self.hidden_size,\n 'nlayers': self.nlayers,\n 'embedding_size': self.embedding_size,\n 'nout': self.nout,\n 'dropout': self.dropout\n }\n\n torch.save(model_state, str(file), pickle_protocol=4)\n\n def generate_text(self, prefix: str = '\\n', number_of_characters: int = 1000, temperature: float = 1.0,\n break_on_suffix=None) -> Tuple[str, float]:\n\n if prefix == '':\n prefix = '\\n'\n\n with torch.no_grad():\n characters = []\n\n idx2item = self.dictionary.idx2item\n\n # initial hidden state\n hidden = self.init_hidden(1)\n\n if len(prefix) > 1:\n\n char_tensors = []\n for character in prefix[:-1]:\n char_tensors.append(\n torch.tensor(self.dictionary.get_idx_for_item(character)).unsqueeze(0).unsqueeze(0))\n\n input = torch.cat(char_tensors)\n if torch.cuda.is_available():\n input = input.cuda()\n\n prediction, _, hidden = self.forward(input, hidden)\n\n input = torch.tensor(self.dictionary.get_idx_for_item(prefix[-1])).unsqueeze(0).unsqueeze(0)\n\n log_prob = 0.\n\n for i in range(number_of_characters):\n\n if torch.cuda.is_available():\n input = input.cuda()\n\n # get predicted weights\n prediction, _, hidden = self.forward(input, hidden)\n prediction = prediction.squeeze().detach()\n decoder_output = prediction\n\n # divide by temperature\n prediction = prediction.div(temperature)\n\n # to prevent overflow problem with small temperature values, substract largest value from all\n # this makes a vector in which the largest value is 0\n max = torch.max(prediction)\n prediction -= max\n\n # compute word weights with exponential function\n word_weights = prediction.exp().cpu()\n\n # try sampling multinomial distribution for next character\n try:\n word_idx = torch.multinomial(word_weights, 1)[0]\n except:\n word_idx = torch.tensor(0)\n\n # print(word_idx)\n prob = decoder_output[word_idx]\n log_prob += prob\n\n input = word_idx.detach().unsqueeze(0).unsqueeze(0)\n word = idx2item[word_idx].decode('UTF-8')\n characters.append(word)\n\n if break_on_suffix is not None:\n if ''.join(characters).endswith(break_on_suffix):\n break\n\n text = prefix + ''.join(characters)\n\n log_prob = log_prob.item()\n log_prob /= len(characters)\n\n if not self.is_forward_lm:\n text = text[::-1]\n\n return text, log_prob\n", "path": "flair/models/language_model.py"}], "after_files": [{"content": "from pathlib import Path\n\nimport torch.nn as nn\nimport torch\nimport math\nfrom typing import Union, Tuple\nfrom typing import List\n\nfrom torch.optim import Optimizer\n\nimport flair\nfrom flair.data import Dictionary\n\n\nclass LanguageModel(nn.Module):\n \"\"\"Container module with an encoder, a recurrent module, and a decoder.\"\"\"\n\n def __init__(self,\n dictionary: Dictionary,\n is_forward_lm: bool,\n hidden_size: int,\n nlayers: int,\n embedding_size: int = 100,\n nout=None,\n dropout=0.1):\n\n super(LanguageModel, self).__init__()\n\n self.dictionary = dictionary\n self.is_forward_lm: bool = is_forward_lm\n\n self.dropout = dropout\n self.hidden_size = hidden_size\n self.embedding_size = embedding_size\n self.nlayers = nlayers\n\n self.drop = nn.Dropout(dropout)\n self.encoder = nn.Embedding(len(dictionary), embedding_size)\n\n if nlayers == 1:\n self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers)\n else:\n self.rnn = nn.LSTM(embedding_size, hidden_size, nlayers, dropout=dropout)\n\n self.hidden = None\n\n self.nout = nout\n if nout is not None:\n self.proj = nn.Linear(hidden_size, nout)\n self.initialize(self.proj.weight)\n self.decoder = nn.Linear(nout, len(dictionary))\n else:\n self.proj = None\n self.decoder = nn.Linear(hidden_size, len(dictionary))\n\n self.init_weights()\n\n # auto-spawn on GPU if available\n self.to(flair.device)\n\n def init_weights(self):\n initrange = 0.1\n self.encoder.weight.detach().uniform_(-initrange, initrange)\n self.decoder.bias.detach().fill_(0)\n self.decoder.weight.detach().uniform_(-initrange, initrange)\n\n def set_hidden(self, hidden):\n self.hidden = hidden\n\n def forward(self, input, hidden, ordered_sequence_lengths=None):\n encoded = self.encoder(input)\n emb = self.drop(encoded)\n\n self.rnn.flatten_parameters()\n\n output, hidden = self.rnn(emb, hidden)\n\n if self.proj is not None:\n output = self.proj(output)\n\n output = self.drop(output)\n\n decoded = self.decoder(output.view(output.size(0) * output.size(1), output.size(2)))\n\n return decoded.view(output.size(0), output.size(1), decoded.size(1)), output, hidden\n\n def init_hidden(self, bsz):\n weight = next(self.parameters()).detach()\n return (weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach(),\n weight.new(self.nlayers, bsz, self.hidden_size).zero_().clone().detach())\n\n def get_representation(self, strings: List[str], chars_per_chunk: int = 512):\n\n # cut up the input into chunks of max charlength = chunk_size\n longest = len(strings[0])\n chunks = []\n splice_begin = 0\n for splice_end in range(chars_per_chunk, longest, chars_per_chunk):\n chunks.append([text[splice_begin:splice_end] for text in strings])\n splice_begin = splice_end\n\n chunks.append([text[splice_begin:longest] for text in strings])\n hidden = self.init_hidden(len(chunks[0]))\n\n output_parts = []\n\n # push each chunk through the RNN language model\n for chunk in chunks:\n\n sequences_as_char_indices: List[List[int]] = []\n for string in chunk:\n char_indices = [self.dictionary.get_idx_for_item(char) for char in string]\n sequences_as_char_indices.append(char_indices)\n\n batch = torch.LongTensor(sequences_as_char_indices).transpose(0, 1)\n batch = batch.to(flair.device)\n\n prediction, rnn_output, hidden = self.forward(batch, hidden)\n rnn_output = rnn_output.detach()\n\n output_parts.append(rnn_output)\n\n # concatenate all chunks to make final output\n output = torch.cat(output_parts)\n\n return output\n\n def get_output(self, text: str):\n char_indices = [self.dictionary.get_idx_for_item(char) for char in text]\n input_vector = torch.LongTensor([char_indices]).transpose(0, 1)\n\n hidden = self.init_hidden(1)\n prediction, rnn_output, hidden = self.forward(input_vector, hidden)\n\n return self.repackage_hidden(hidden)\n\n def repackage_hidden(self, h):\n \"\"\"Wraps hidden states in new Variables, to detach them from their history.\"\"\"\n if type(h) == torch.Tensor:\n return h.clone().detach()\n else:\n return tuple(self.repackage_hidden(v) for v in h)\n\n def initialize(self, matrix):\n in_, out_ = matrix.size()\n stdv = math.sqrt(3. / (in_ + out_))\n matrix.detach().uniform_(-stdv, stdv)\n\n @classmethod\n def load_language_model(cls, model_file: Union[Path, str]):\n\n state = torch.load(str(model_file), map_location=flair.device)\n\n model = LanguageModel(state['dictionary'],\n state['is_forward_lm'],\n state['hidden_size'],\n state['nlayers'],\n state['embedding_size'],\n state['nout'],\n state['dropout'])\n model.load_state_dict(state['state_dict'])\n model.eval()\n model.to(flair.device)\n\n return model\n\n @classmethod\n def load_checkpoint(cls, model_file: Path):\n state = torch.load(str(model_file), map_location=flair.device)\n\n epoch = state['epoch'] if 'epoch' in state else None\n split = state['split'] if 'split' in state else None\n loss = state['loss'] if 'loss' in state else None\n optimizer_state_dict = state['optimizer_state_dict'] if 'optimizer_state_dict' in state else None\n\n model = LanguageModel(state['dictionary'],\n state['is_forward_lm'],\n state['hidden_size'],\n state['nlayers'],\n state['embedding_size'],\n state['nout'],\n state['dropout'])\n model.load_state_dict(state['state_dict'])\n model.eval()\n model.to(flair.device)\n\n return {'model': model, 'epoch': epoch, 'split': split, 'loss': loss,\n 'optimizer_state_dict': optimizer_state_dict}\n\n def save_checkpoint(self, file: Path, optimizer: Optimizer, epoch: int, split: int, loss: float):\n model_state = {\n 'state_dict': self.state_dict(),\n 'dictionary': self.dictionary,\n 'is_forward_lm': self.is_forward_lm,\n 'hidden_size': self.hidden_size,\n 'nlayers': self.nlayers,\n 'embedding_size': self.embedding_size,\n 'nout': self.nout,\n 'dropout': self.dropout,\n 'optimizer_state_dict': optimizer.state_dict(),\n 'epoch': epoch,\n 'split': split,\n 'loss': loss\n }\n\n torch.save(model_state, str(file), pickle_protocol=4)\n\n def save(self, file: Path):\n model_state = {\n 'state_dict': self.state_dict(),\n 'dictionary': self.dictionary,\n 'is_forward_lm': self.is_forward_lm,\n 'hidden_size': self.hidden_size,\n 'nlayers': self.nlayers,\n 'embedding_size': self.embedding_size,\n 'nout': self.nout,\n 'dropout': self.dropout\n }\n\n torch.save(model_state, str(file), pickle_protocol=4)\n\n def generate_text(self, prefix: str = '\\n', number_of_characters: int = 1000, temperature: float = 1.0,\n break_on_suffix=None) -> Tuple[str, float]:\n\n if prefix == '':\n prefix = '\\n'\n\n with torch.no_grad():\n characters = []\n\n idx2item = self.dictionary.idx2item\n\n # initial hidden state\n hidden = self.init_hidden(1)\n\n if len(prefix) > 1:\n\n char_tensors = []\n for character in prefix[:-1]:\n char_tensors.append(\n torch.tensor(self.dictionary.get_idx_for_item(character)).unsqueeze(0).unsqueeze(0))\n\n input = torch.cat(char_tensors)\n if torch.cuda.is_available():\n input = input.cuda()\n\n prediction, _, hidden = self.forward(input, hidden)\n\n input = torch.tensor(self.dictionary.get_idx_for_item(prefix[-1])).unsqueeze(0).unsqueeze(0)\n\n log_prob = 0.\n\n for i in range(number_of_characters):\n\n if torch.cuda.is_available():\n input = input.cuda()\n\n # get predicted weights\n prediction, _, hidden = self.forward(input, hidden)\n prediction = prediction.squeeze().detach()\n decoder_output = prediction\n\n # divide by temperature\n prediction = prediction.div(temperature)\n\n # to prevent overflow problem with small temperature values, substract largest value from all\n # this makes a vector in which the largest value is 0\n max = torch.max(prediction)\n prediction -= max\n\n # compute word weights with exponential function\n word_weights = prediction.exp().cpu()\n\n # try sampling multinomial distribution for next character\n try:\n word_idx = torch.multinomial(word_weights, 1)[0]\n except:\n word_idx = torch.tensor(0)\n\n # print(word_idx)\n prob = decoder_output[word_idx]\n log_prob += prob\n\n input = word_idx.detach().unsqueeze(0).unsqueeze(0)\n word = idx2item[word_idx].decode('UTF-8')\n characters.append(word)\n\n if break_on_suffix is not None:\n if ''.join(characters).endswith(break_on_suffix):\n break\n\n text = prefix + ''.join(characters)\n\n log_prob = log_prob.item()\n log_prob /= len(characters)\n\n if not self.is_forward_lm:\n text = text[::-1]\n\n return text, log_prob\n\n def calculate_perplexity(self, text: str) -> float:\n\n if not self.is_forward_lm:\n text = text[::-1]\n\n # input ids\n input = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[:-1]]).unsqueeze(1)\n\n # push list of character IDs through model\n hidden = self.init_hidden(1)\n prediction, _, hidden = self.forward(input, hidden)\n\n # the target is always the next character\n targets = torch.tensor([self.dictionary.get_idx_for_item(char) for char in text[1:]])\n\n # use cross entropy loss to compare output of forward pass with targets\n cross_entroy_loss = torch.nn.CrossEntropyLoss()\n loss = cross_entroy_loss(prediction.view(-1, len(self.dictionary)), targets).item()\n\n # exponentiate cross-entropy loss to calculate perplexity\n perplexity = math.exp(loss)\n\n return perplexity\n", "path": "flair/models/language_model.py"}]} | 3,265 | 287 |
gh_patches_debug_25588 | rasdani/github-patches | git_diff | freqtrade__freqtrade-3205 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Crash on PrecisionFilter logic
Just got this crash from the PrecisionFilter on a develop based new branch, running it on FTX leveraged tokens. This error never happened before.
```
2020-03-28 00:43:49,891 - freqtrade.commands.trade_commands - INFO - worker found ... calling exit
2020-03-28 00:43:49,891 - freqtrade.rpc.rpc_manager - INFO - Sending rpc message: {'type': status, 'status': 'process died'}
2020-03-28 00:43:49,953 - freqtrade.freqtradebot - INFO - Cleaning up modules ...
2020-03-28 00:43:49,953 - freqtrade.rpc.rpc_manager - INFO - Cleaning up rpc modules ...
2020-03-28 00:44:05,419 - freqtrade - ERROR - Fatal exception!
Traceback (most recent call last):
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/main.py", line 36, in main
return_code = args['func'](args)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/commands/trade_commands.py", line 20, in start_trading
worker.run()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 66, in run
state = self._worker(old_state=state)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 104, in _worker
self._throttle(func=self._process_running, throttle_secs=self._throttle_secs)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 125, in _throttle
result = func(*args, **kwargs)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 139, in _process_running
self.freqtrade.process()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py", line 142, in process
self.active_pair_whitelist = self._refresh_whitelist(trades)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py", line 168, in _refresh_whitelist
self.pairlists.refresh_pairlist()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/pairlistmanager.py", line 91, in refresh_pairlist
pairlist = pl.filter_pairlist(pairlist, tickers)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py", line 59, in filter_pairlist
if not ticker or (stoploss and not self._validate_precision_filter(ticker, stoploss)):
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py", line 36, in _validate_precision_filter
stop_price = ticker['ask'] * stoploss
TypeError: unsupported operand type(s) for *: 'NoneType' and 'float'
```
Crash on PrecisionFilter logic
Just got this crash from the PrecisionFilter on a develop based new branch, running it on FTX leveraged tokens. This error never happened before.
```
2020-03-28 00:43:49,891 - freqtrade.commands.trade_commands - INFO - worker found ... calling exit
2020-03-28 00:43:49,891 - freqtrade.rpc.rpc_manager - INFO - Sending rpc message: {'type': status, 'status': 'process died'}
2020-03-28 00:43:49,953 - freqtrade.freqtradebot - INFO - Cleaning up modules ...
2020-03-28 00:43:49,953 - freqtrade.rpc.rpc_manager - INFO - Cleaning up rpc modules ...
2020-03-28 00:44:05,419 - freqtrade - ERROR - Fatal exception!
Traceback (most recent call last):
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/main.py", line 36, in main
return_code = args['func'](args)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/commands/trade_commands.py", line 20, in start_trading
worker.run()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 66, in run
state = self._worker(old_state=state)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 104, in _worker
self._throttle(func=self._process_running, throttle_secs=self._throttle_secs)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 125, in _throttle
result = func(*args, **kwargs)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py", line 139, in _process_running
self.freqtrade.process()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py", line 142, in process
self.active_pair_whitelist = self._refresh_whitelist(trades)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py", line 168, in _refresh_whitelist
self.pairlists.refresh_pairlist()
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/pairlistmanager.py", line 91, in refresh_pairlist
pairlist = pl.filter_pairlist(pairlist, tickers)
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py", line 59, in filter_pairlist
if not ticker or (stoploss and not self._validate_precision_filter(ticker, stoploss)):
File "/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py", line 36, in _validate_precision_filter
stop_price = ticker['ask'] * stoploss
TypeError: unsupported operand type(s) for *: 'NoneType' and 'float'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `freqtrade/pairlist/PriceFilter.py`
Content:
```
1 import logging
2 from copy import deepcopy
3 from typing import Any, Dict, List
4
5 from freqtrade.pairlist.IPairList import IPairList
6
7 logger = logging.getLogger(__name__)
8
9
10 class PriceFilter(IPairList):
11
12 def __init__(self, exchange, pairlistmanager,
13 config: Dict[str, Any], pairlistconfig: Dict[str, Any],
14 pairlist_pos: int) -> None:
15 super().__init__(exchange, pairlistmanager, config, pairlistconfig, pairlist_pos)
16
17 self._low_price_ratio = pairlistconfig.get('low_price_ratio', 0)
18
19 @property
20 def needstickers(self) -> bool:
21 """
22 Boolean property defining if tickers are necessary.
23 If no Pairlist requries tickers, an empty List is passed
24 as tickers argument to filter_pairlist
25 """
26 return True
27
28 def short_desc(self) -> str:
29 """
30 Short whitelist method description - used for startup-messages
31 """
32 return f"{self.name} - Filtering pairs priced below {self._low_price_ratio * 100}%."
33
34 def _validate_ticker_lowprice(self, ticker) -> bool:
35 """
36 Check if if one price-step (pip) is > than a certain barrier.
37 :param ticker: ticker dict as returned from ccxt.load_markets()
38 :return: True if the pair can stay, false if it should be removed
39 """
40 compare = ticker['last'] + self._exchange.price_get_one_pip(ticker['symbol'],
41 ticker['last'])
42 changeperc = (compare - ticker['last']) / ticker['last']
43 if changeperc > self._low_price_ratio:
44 self.log_on_refresh(logger.info, f"Removed {ticker['symbol']} from whitelist, "
45 f"because 1 unit is {changeperc * 100:.3f}%")
46 return False
47 return True
48
49 def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:
50
51 """
52 Filters and sorts pairlist and returns the whitelist again.
53 Called on each bot iteration - please use internal caching if necessary
54 :param pairlist: pairlist to filter or sort
55 :param tickers: Tickers (from exchange.get_tickers()). May be cached.
56 :return: new whitelist
57 """
58 # Copy list since we're modifying this list
59 for p in deepcopy(pairlist):
60 ticker = tickers.get(p)
61 if not ticker:
62 pairlist.remove(p)
63
64 # Filter out assets which would not allow setting a stoploss
65 if self._low_price_ratio and not self._validate_ticker_lowprice(ticker):
66 pairlist.remove(p)
67
68 return pairlist
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/freqtrade/pairlist/PriceFilter.py b/freqtrade/pairlist/PriceFilter.py
--- a/freqtrade/pairlist/PriceFilter.py
+++ b/freqtrade/pairlist/PriceFilter.py
@@ -37,6 +37,12 @@
:param ticker: ticker dict as returned from ccxt.load_markets()
:return: True if the pair can stay, false if it should be removed
"""
+ if ticker['last'] is None:
+
+ self.log_on_refresh(logger.info,
+ f"Removed {ticker['symbol']} from whitelist, because "
+ "ticker['last'] is empty (Usually no trade in the last 24h).")
+ return False
compare = ticker['last'] + self._exchange.price_get_one_pip(ticker['symbol'],
ticker['last'])
changeperc = (compare - ticker['last']) / ticker['last']
@@ -47,7 +53,6 @@
return True
def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:
-
"""
Filters and sorts pairlist and returns the whitelist again.
Called on each bot iteration - please use internal caching if necessary
| {"golden_diff": "diff --git a/freqtrade/pairlist/PriceFilter.py b/freqtrade/pairlist/PriceFilter.py\n--- a/freqtrade/pairlist/PriceFilter.py\n+++ b/freqtrade/pairlist/PriceFilter.py\n@@ -37,6 +37,12 @@\n :param ticker: ticker dict as returned from ccxt.load_markets()\n :return: True if the pair can stay, false if it should be removed\n \"\"\"\n+ if ticker['last'] is None:\n+\n+ self.log_on_refresh(logger.info,\n+ f\"Removed {ticker['symbol']} from whitelist, because \"\n+ \"ticker['last'] is empty (Usually no trade in the last 24h).\")\n+ return False\n compare = ticker['last'] + self._exchange.price_get_one_pip(ticker['symbol'],\n ticker['last'])\n changeperc = (compare - ticker['last']) / ticker['last']\n@@ -47,7 +53,6 @@\n return True\n \n def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:\n-\n \"\"\"\n Filters and sorts pairlist and returns the whitelist again.\n Called on each bot iteration - please use internal caching if necessary\n", "issue": "Crash on PrecisionFilter logic\nJust got this crash from the PrecisionFilter on a develop based new branch, running it on FTX leveraged tokens. This error never happened before.\r\n\r\n```\r\n2020-03-28 00:43:49,891 - freqtrade.commands.trade_commands - INFO - worker found ... calling exit\r\n2020-03-28 00:43:49,891 - freqtrade.rpc.rpc_manager - INFO - Sending rpc message: {'type': status, 'status': 'process died'}\r\n2020-03-28 00:43:49,953 - freqtrade.freqtradebot - INFO - Cleaning up modules ...\r\n2020-03-28 00:43:49,953 - freqtrade.rpc.rpc_manager - INFO - Cleaning up rpc modules ...\r\n2020-03-28 00:44:05,419 - freqtrade - ERROR - Fatal exception!\r\nTraceback (most recent call last):\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/main.py\", line 36, in main\r\n return_code = args['func'](args)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/commands/trade_commands.py\", line 20, in start_trading\r\n worker.run()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 66, in run\r\n state = self._worker(old_state=state)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 104, in _worker\r\n self._throttle(func=self._process_running, throttle_secs=self._throttle_secs)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 125, in _throttle\r\n result = func(*args, **kwargs)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 139, in _process_running\r\n self.freqtrade.process()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py\", line 142, in process\r\n self.active_pair_whitelist = self._refresh_whitelist(trades)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py\", line 168, in _refresh_whitelist\r\n self.pairlists.refresh_pairlist()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/pairlistmanager.py\", line 91, in refresh_pairlist\r\n pairlist = pl.filter_pairlist(pairlist, tickers)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py\", line 59, in filter_pairlist\r\n if not ticker or (stoploss and not self._validate_precision_filter(ticker, stoploss)):\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py\", line 36, in _validate_precision_filter\r\n stop_price = ticker['ask'] * stoploss\r\nTypeError: unsupported operand type(s) for *: 'NoneType' and 'float'\r\n```\nCrash on PrecisionFilter logic\nJust got this crash from the PrecisionFilter on a develop based new branch, running it on FTX leveraged tokens. This error never happened before.\r\n\r\n```\r\n2020-03-28 00:43:49,891 - freqtrade.commands.trade_commands - INFO - worker found ... calling exit\r\n2020-03-28 00:43:49,891 - freqtrade.rpc.rpc_manager - INFO - Sending rpc message: {'type': status, 'status': 'process died'}\r\n2020-03-28 00:43:49,953 - freqtrade.freqtradebot - INFO - Cleaning up modules ...\r\n2020-03-28 00:43:49,953 - freqtrade.rpc.rpc_manager - INFO - Cleaning up rpc modules ...\r\n2020-03-28 00:44:05,419 - freqtrade - ERROR - Fatal exception!\r\nTraceback (most recent call last):\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/main.py\", line 36, in main\r\n return_code = args['func'](args)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/commands/trade_commands.py\", line 20, in start_trading\r\n worker.run()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 66, in run\r\n state = self._worker(old_state=state)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 104, in _worker\r\n self._throttle(func=self._process_running, throttle_secs=self._throttle_secs)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 125, in _throttle\r\n result = func(*args, **kwargs)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/worker.py\", line 139, in _process_running\r\n self.freqtrade.process()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py\", line 142, in process\r\n self.active_pair_whitelist = self._refresh_whitelist(trades)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/freqtradebot.py\", line 168, in _refresh_whitelist\r\n self.pairlists.refresh_pairlist()\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/pairlistmanager.py\", line 91, in refresh_pairlist\r\n pairlist = pl.filter_pairlist(pairlist, tickers)\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py\", line 59, in filter_pairlist\r\n if not ticker or (stoploss and not self._validate_precision_filter(ticker, stoploss)):\r\n File \"/Users/yazeed/Sites/freqtradeLATEST/freqtrade/pairlist/PrecisionFilter.py\", line 36, in _validate_precision_filter\r\n stop_price = ticker['ask'] * stoploss\r\nTypeError: unsupported operand type(s) for *: 'NoneType' and 'float'\r\n```\n", "before_files": [{"content": "import logging\nfrom copy import deepcopy\nfrom typing import Any, Dict, List\n\nfrom freqtrade.pairlist.IPairList import IPairList\n\nlogger = logging.getLogger(__name__)\n\n\nclass PriceFilter(IPairList):\n\n def __init__(self, exchange, pairlistmanager,\n config: Dict[str, Any], pairlistconfig: Dict[str, Any],\n pairlist_pos: int) -> None:\n super().__init__(exchange, pairlistmanager, config, pairlistconfig, pairlist_pos)\n\n self._low_price_ratio = pairlistconfig.get('low_price_ratio', 0)\n\n @property\n def needstickers(self) -> bool:\n \"\"\"\n Boolean property defining if tickers are necessary.\n If no Pairlist requries tickers, an empty List is passed\n as tickers argument to filter_pairlist\n \"\"\"\n return True\n\n def short_desc(self) -> str:\n \"\"\"\n Short whitelist method description - used for startup-messages\n \"\"\"\n return f\"{self.name} - Filtering pairs priced below {self._low_price_ratio * 100}%.\"\n\n def _validate_ticker_lowprice(self, ticker) -> bool:\n \"\"\"\n Check if if one price-step (pip) is > than a certain barrier.\n :param ticker: ticker dict as returned from ccxt.load_markets()\n :return: True if the pair can stay, false if it should be removed\n \"\"\"\n compare = ticker['last'] + self._exchange.price_get_one_pip(ticker['symbol'],\n ticker['last'])\n changeperc = (compare - ticker['last']) / ticker['last']\n if changeperc > self._low_price_ratio:\n self.log_on_refresh(logger.info, f\"Removed {ticker['symbol']} from whitelist, \"\n f\"because 1 unit is {changeperc * 100:.3f}%\")\n return False\n return True\n\n def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:\n\n \"\"\"\n Filters and sorts pairlist and returns the whitelist again.\n Called on each bot iteration - please use internal caching if necessary\n :param pairlist: pairlist to filter or sort\n :param tickers: Tickers (from exchange.get_tickers()). May be cached.\n :return: new whitelist\n \"\"\"\n # Copy list since we're modifying this list\n for p in deepcopy(pairlist):\n ticker = tickers.get(p)\n if not ticker:\n pairlist.remove(p)\n\n # Filter out assets which would not allow setting a stoploss\n if self._low_price_ratio and not self._validate_ticker_lowprice(ticker):\n pairlist.remove(p)\n\n return pairlist\n", "path": "freqtrade/pairlist/PriceFilter.py"}], "after_files": [{"content": "import logging\nfrom copy import deepcopy\nfrom typing import Any, Dict, List\n\nfrom freqtrade.pairlist.IPairList import IPairList\n\nlogger = logging.getLogger(__name__)\n\n\nclass PriceFilter(IPairList):\n\n def __init__(self, exchange, pairlistmanager,\n config: Dict[str, Any], pairlistconfig: Dict[str, Any],\n pairlist_pos: int) -> None:\n super().__init__(exchange, pairlistmanager, config, pairlistconfig, pairlist_pos)\n\n self._low_price_ratio = pairlistconfig.get('low_price_ratio', 0)\n\n @property\n def needstickers(self) -> bool:\n \"\"\"\n Boolean property defining if tickers are necessary.\n If no Pairlist requries tickers, an empty List is passed\n as tickers argument to filter_pairlist\n \"\"\"\n return True\n\n def short_desc(self) -> str:\n \"\"\"\n Short whitelist method description - used for startup-messages\n \"\"\"\n return f\"{self.name} - Filtering pairs priced below {self._low_price_ratio * 100}%.\"\n\n def _validate_ticker_lowprice(self, ticker) -> bool:\n \"\"\"\n Check if if one price-step (pip) is > than a certain barrier.\n :param ticker: ticker dict as returned from ccxt.load_markets()\n :return: True if the pair can stay, false if it should be removed\n \"\"\"\n if ticker['last'] is None:\n\n self.log_on_refresh(logger.info,\n f\"Removed {ticker['symbol']} from whitelist, because \"\n \"ticker['last'] is empty (Usually no trade in the last 24h).\")\n return False\n compare = ticker['last'] + self._exchange.price_get_one_pip(ticker['symbol'],\n ticker['last'])\n changeperc = (compare - ticker['last']) / ticker['last']\n if changeperc > self._low_price_ratio:\n self.log_on_refresh(logger.info, f\"Removed {ticker['symbol']} from whitelist, \"\n f\"because 1 unit is {changeperc * 100:.3f}%\")\n return False\n return True\n\n def filter_pairlist(self, pairlist: List[str], tickers: Dict) -> List[str]:\n \"\"\"\n Filters and sorts pairlist and returns the whitelist again.\n Called on each bot iteration - please use internal caching if necessary\n :param pairlist: pairlist to filter or sort\n :param tickers: Tickers (from exchange.get_tickers()). May be cached.\n :return: new whitelist\n \"\"\"\n # Copy list since we're modifying this list\n for p in deepcopy(pairlist):\n ticker = tickers.get(p)\n if not ticker:\n pairlist.remove(p)\n\n # Filter out assets which would not allow setting a stoploss\n if self._low_price_ratio and not self._validate_ticker_lowprice(ticker):\n pairlist.remove(p)\n\n return pairlist\n", "path": "freqtrade/pairlist/PriceFilter.py"}]} | 2,479 | 272 |
gh_patches_debug_20754 | rasdani/github-patches | git_diff | googleapis__google-auth-library-python-435 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Set the default request timeout to something other than `None`
The [AuthorizedSession.requests()](https://github.com/googleapis/google-auth-library-python/blob/1b9de8dfbe4523f3170e47985ab523cb7865de48/google/auth/transport/requests.py#L242-L251) method does not specify a default timeout.
Since production code would almost always want to have some sort of a timeout, let's add one. The libraries that rely on `google-auth`, but do (yet) not specify a timeout themselves, would benefit from that.
Example: [storage issue](https://github.com/googleapis/google-cloud-python/issues/10182)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/auth/transport/requests.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Transport adapter for Requests."""
16
17 from __future__ import absolute_import
18
19 import functools
20 import logging
21 import numbers
22 import time
23
24 try:
25 import requests
26 except ImportError as caught_exc: # pragma: NO COVER
27 import six
28
29 six.raise_from(
30 ImportError(
31 "The requests library is not installed, please install the "
32 "requests package to use the requests transport."
33 ),
34 caught_exc,
35 )
36 import requests.adapters # pylint: disable=ungrouped-imports
37 import requests.exceptions # pylint: disable=ungrouped-imports
38 import six # pylint: disable=ungrouped-imports
39
40 from google.auth import exceptions
41 from google.auth import transport
42
43 _LOGGER = logging.getLogger(__name__)
44
45
46 class _Response(transport.Response):
47 """Requests transport response adapter.
48
49 Args:
50 response (requests.Response): The raw Requests response.
51 """
52
53 def __init__(self, response):
54 self._response = response
55
56 @property
57 def status(self):
58 return self._response.status_code
59
60 @property
61 def headers(self):
62 return self._response.headers
63
64 @property
65 def data(self):
66 return self._response.content
67
68
69 class TimeoutGuard(object):
70 """A context manager raising an error if the suite execution took too long.
71
72 Args:
73 timeout ([Union[None, float, Tuple[float, float]]]):
74 The maximum number of seconds a suite can run without the context
75 manager raising a timeout exception on exit. If passed as a tuple,
76 the smaller of the values is taken as a timeout. If ``None``, a
77 timeout error is never raised.
78 timeout_error_type (Optional[Exception]):
79 The type of the error to raise on timeout. Defaults to
80 :class:`requests.exceptions.Timeout`.
81 """
82
83 def __init__(self, timeout, timeout_error_type=requests.exceptions.Timeout):
84 self._timeout = timeout
85 self.remaining_timeout = timeout
86 self._timeout_error_type = timeout_error_type
87
88 def __enter__(self):
89 self._start = time.time()
90 return self
91
92 def __exit__(self, exc_type, exc_value, traceback):
93 if exc_value:
94 return # let the error bubble up automatically
95
96 if self._timeout is None:
97 return # nothing to do, the timeout was not specified
98
99 elapsed = time.time() - self._start
100 deadline_hit = False
101
102 if isinstance(self._timeout, numbers.Number):
103 self.remaining_timeout = self._timeout - elapsed
104 deadline_hit = self.remaining_timeout <= 0
105 else:
106 self.remaining_timeout = tuple(x - elapsed for x in self._timeout)
107 deadline_hit = min(self.remaining_timeout) <= 0
108
109 if deadline_hit:
110 raise self._timeout_error_type()
111
112
113 class Request(transport.Request):
114 """Requests request adapter.
115
116 This class is used internally for making requests using various transports
117 in a consistent way. If you use :class:`AuthorizedSession` you do not need
118 to construct or use this class directly.
119
120 This class can be useful if you want to manually refresh a
121 :class:`~google.auth.credentials.Credentials` instance::
122
123 import google.auth.transport.requests
124 import requests
125
126 request = google.auth.transport.requests.Request()
127
128 credentials.refresh(request)
129
130 Args:
131 session (requests.Session): An instance :class:`requests.Session` used
132 to make HTTP requests. If not specified, a session will be created.
133
134 .. automethod:: __call__
135 """
136
137 def __init__(self, session=None):
138 if not session:
139 session = requests.Session()
140
141 self.session = session
142
143 def __call__(
144 self, url, method="GET", body=None, headers=None, timeout=120, **kwargs
145 ):
146 """Make an HTTP request using requests.
147
148 Args:
149 url (str): The URI to be requested.
150 method (str): The HTTP method to use for the request. Defaults
151 to 'GET'.
152 body (bytes): The payload / body in HTTP request.
153 headers (Mapping[str, str]): Request headers.
154 timeout (Optional[int]): The number of seconds to wait for a
155 response from the server. If not specified or if None, the
156 requests default timeout will be used.
157 kwargs: Additional arguments passed through to the underlying
158 requests :meth:`~requests.Session.request` method.
159
160 Returns:
161 google.auth.transport.Response: The HTTP response.
162
163 Raises:
164 google.auth.exceptions.TransportError: If any exception occurred.
165 """
166 try:
167 _LOGGER.debug("Making request: %s %s", method, url)
168 response = self.session.request(
169 method, url, data=body, headers=headers, timeout=timeout, **kwargs
170 )
171 return _Response(response)
172 except requests.exceptions.RequestException as caught_exc:
173 new_exc = exceptions.TransportError(caught_exc)
174 six.raise_from(new_exc, caught_exc)
175
176
177 class AuthorizedSession(requests.Session):
178 """A Requests Session class with credentials.
179
180 This class is used to perform requests to API endpoints that require
181 authorization::
182
183 from google.auth.transport.requests import AuthorizedSession
184
185 authed_session = AuthorizedSession(credentials)
186
187 response = authed_session.request(
188 'GET', 'https://www.googleapis.com/storage/v1/b')
189
190 The underlying :meth:`request` implementation handles adding the
191 credentials' headers to the request and refreshing credentials as needed.
192
193 Args:
194 credentials (google.auth.credentials.Credentials): The credentials to
195 add to the request.
196 refresh_status_codes (Sequence[int]): Which HTTP status codes indicate
197 that credentials should be refreshed and the request should be
198 retried.
199 max_refresh_attempts (int): The maximum number of times to attempt to
200 refresh the credentials and retry the request.
201 refresh_timeout (Optional[int]): The timeout value in seconds for
202 credential refresh HTTP requests.
203 auth_request (google.auth.transport.requests.Request):
204 (Optional) An instance of
205 :class:`~google.auth.transport.requests.Request` used when
206 refreshing credentials. If not passed,
207 an instance of :class:`~google.auth.transport.requests.Request`
208 is created.
209 """
210
211 def __init__(
212 self,
213 credentials,
214 refresh_status_codes=transport.DEFAULT_REFRESH_STATUS_CODES,
215 max_refresh_attempts=transport.DEFAULT_MAX_REFRESH_ATTEMPTS,
216 refresh_timeout=None,
217 auth_request=None,
218 ):
219 super(AuthorizedSession, self).__init__()
220 self.credentials = credentials
221 self._refresh_status_codes = refresh_status_codes
222 self._max_refresh_attempts = max_refresh_attempts
223 self._refresh_timeout = refresh_timeout
224
225 if auth_request is None:
226 auth_request_session = requests.Session()
227
228 # Using an adapter to make HTTP requests robust to network errors.
229 # This adapter retrys HTTP requests when network errors occur
230 # and the requests seems safely retryable.
231 retry_adapter = requests.adapters.HTTPAdapter(max_retries=3)
232 auth_request_session.mount("https://", retry_adapter)
233
234 # Do not pass `self` as the session here, as it can lead to
235 # infinite recursion.
236 auth_request = Request(auth_request_session)
237
238 # Request instance used by internal methods (for example,
239 # credentials.refresh).
240 self._auth_request = auth_request
241
242 def request(
243 self,
244 method,
245 url,
246 data=None,
247 headers=None,
248 max_allowed_time=None,
249 timeout=None,
250 **kwargs
251 ):
252 """Implementation of Requests' request.
253
254 Args:
255 timeout (Optional[Union[float, Tuple[float, float]]]):
256 The amount of time in seconds to wait for the server response
257 with each individual request.
258
259 Can also be passed as a tuple (connect_timeout, read_timeout).
260 See :meth:`requests.Session.request` documentation for details.
261
262 max_allowed_time (Optional[float]):
263 If the method runs longer than this, a ``Timeout`` exception is
264 automatically raised. Unlike the ``timeout` parameter, this
265 value applies to the total method execution time, even if
266 multiple requests are made under the hood.
267
268 Mind that it is not guaranteed that the timeout error is raised
269 at ``max_allowed_time`. It might take longer, for example, if
270 an underlying request takes a lot of time, but the request
271 itself does not timeout, e.g. if a large file is being
272 transmitted. The timout error will be raised after such
273 request completes.
274 """
275 # pylint: disable=arguments-differ
276 # Requests has a ton of arguments to request, but only two
277 # (method, url) are required. We pass through all of the other
278 # arguments to super, so no need to exhaustively list them here.
279
280 # Use a kwarg for this instead of an attribute to maintain
281 # thread-safety.
282 _credential_refresh_attempt = kwargs.pop("_credential_refresh_attempt", 0)
283
284 # Make a copy of the headers. They will be modified by the credentials
285 # and we want to pass the original headers if we recurse.
286 request_headers = headers.copy() if headers is not None else {}
287
288 # Do not apply the timeout unconditionally in order to not override the
289 # _auth_request's default timeout.
290 auth_request = (
291 self._auth_request
292 if timeout is None
293 else functools.partial(self._auth_request, timeout=timeout)
294 )
295
296 remaining_time = max_allowed_time
297
298 with TimeoutGuard(remaining_time) as guard:
299 self.credentials.before_request(auth_request, method, url, request_headers)
300 remaining_time = guard.remaining_timeout
301
302 with TimeoutGuard(remaining_time) as guard:
303 response = super(AuthorizedSession, self).request(
304 method,
305 url,
306 data=data,
307 headers=request_headers,
308 timeout=timeout,
309 **kwargs
310 )
311 remaining_time = guard.remaining_timeout
312
313 # If the response indicated that the credentials needed to be
314 # refreshed, then refresh the credentials and re-attempt the
315 # request.
316 # A stored token may expire between the time it is retrieved and
317 # the time the request is made, so we may need to try twice.
318 if (
319 response.status_code in self._refresh_status_codes
320 and _credential_refresh_attempt < self._max_refresh_attempts
321 ):
322
323 _LOGGER.info(
324 "Refreshing credentials due to a %s response. Attempt %s/%s.",
325 response.status_code,
326 _credential_refresh_attempt + 1,
327 self._max_refresh_attempts,
328 )
329
330 # Do not apply the timeout unconditionally in order to not override the
331 # _auth_request's default timeout.
332 auth_request = (
333 self._auth_request
334 if timeout is None
335 else functools.partial(self._auth_request, timeout=timeout)
336 )
337
338 with TimeoutGuard(remaining_time) as guard:
339 self.credentials.refresh(auth_request)
340 remaining_time = guard.remaining_timeout
341
342 # Recurse. Pass in the original headers, not our modified set, but
343 # do pass the adjusted max allowed time (i.e. the remaining total time).
344 return self.request(
345 method,
346 url,
347 data=data,
348 headers=headers,
349 max_allowed_time=remaining_time,
350 timeout=timeout,
351 _credential_refresh_attempt=_credential_refresh_attempt + 1,
352 **kwargs
353 )
354
355 return response
356
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/google/auth/transport/requests.py b/google/auth/transport/requests.py
--- a/google/auth/transport/requests.py
+++ b/google/auth/transport/requests.py
@@ -42,6 +42,8 @@
_LOGGER = logging.getLogger(__name__)
+_DEFAULT_TIMEOUT = 120 # in seconds
+
class _Response(transport.Response):
"""Requests transport response adapter.
@@ -141,7 +143,13 @@
self.session = session
def __call__(
- self, url, method="GET", body=None, headers=None, timeout=120, **kwargs
+ self,
+ url,
+ method="GET",
+ body=None,
+ headers=None,
+ timeout=_DEFAULT_TIMEOUT,
+ **kwargs
):
"""Make an HTTP request using requests.
@@ -246,7 +254,7 @@
data=None,
headers=None,
max_allowed_time=None,
- timeout=None,
+ timeout=_DEFAULT_TIMEOUT,
**kwargs
):
"""Implementation of Requests' request.
| {"golden_diff": "diff --git a/google/auth/transport/requests.py b/google/auth/transport/requests.py\n--- a/google/auth/transport/requests.py\n+++ b/google/auth/transport/requests.py\n@@ -42,6 +42,8 @@\n \n _LOGGER = logging.getLogger(__name__)\n \n+_DEFAULT_TIMEOUT = 120 # in seconds\n+\n \n class _Response(transport.Response):\n \"\"\"Requests transport response adapter.\n@@ -141,7 +143,13 @@\n self.session = session\n \n def __call__(\n- self, url, method=\"GET\", body=None, headers=None, timeout=120, **kwargs\n+ self,\n+ url,\n+ method=\"GET\",\n+ body=None,\n+ headers=None,\n+ timeout=_DEFAULT_TIMEOUT,\n+ **kwargs\n ):\n \"\"\"Make an HTTP request using requests.\n \n@@ -246,7 +254,7 @@\n data=None,\n headers=None,\n max_allowed_time=None,\n- timeout=None,\n+ timeout=_DEFAULT_TIMEOUT,\n **kwargs\n ):\n \"\"\"Implementation of Requests' request.\n", "issue": "Set the default request timeout to something other than `None`\nThe [AuthorizedSession.requests()](https://github.com/googleapis/google-auth-library-python/blob/1b9de8dfbe4523f3170e47985ab523cb7865de48/google/auth/transport/requests.py#L242-L251) method does not specify a default timeout.\r\n\r\nSince production code would almost always want to have some sort of a timeout, let's add one. The libraries that rely on `google-auth`, but do (yet) not specify a timeout themselves, would benefit from that.\r\n\r\nExample: [storage issue](https://github.com/googleapis/google-cloud-python/issues/10182)\r\n\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Transport adapter for Requests.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport functools\nimport logging\nimport numbers\nimport time\n\ntry:\n import requests\nexcept ImportError as caught_exc: # pragma: NO COVER\n import six\n\n six.raise_from(\n ImportError(\n \"The requests library is not installed, please install the \"\n \"requests package to use the requests transport.\"\n ),\n caught_exc,\n )\nimport requests.adapters # pylint: disable=ungrouped-imports\nimport requests.exceptions # pylint: disable=ungrouped-imports\nimport six # pylint: disable=ungrouped-imports\n\nfrom google.auth import exceptions\nfrom google.auth import transport\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass _Response(transport.Response):\n \"\"\"Requests transport response adapter.\n\n Args:\n response (requests.Response): The raw Requests response.\n \"\"\"\n\n def __init__(self, response):\n self._response = response\n\n @property\n def status(self):\n return self._response.status_code\n\n @property\n def headers(self):\n return self._response.headers\n\n @property\n def data(self):\n return self._response.content\n\n\nclass TimeoutGuard(object):\n \"\"\"A context manager raising an error if the suite execution took too long.\n\n Args:\n timeout ([Union[None, float, Tuple[float, float]]]):\n The maximum number of seconds a suite can run without the context\n manager raising a timeout exception on exit. If passed as a tuple,\n the smaller of the values is taken as a timeout. If ``None``, a\n timeout error is never raised.\n timeout_error_type (Optional[Exception]):\n The type of the error to raise on timeout. Defaults to\n :class:`requests.exceptions.Timeout`.\n \"\"\"\n\n def __init__(self, timeout, timeout_error_type=requests.exceptions.Timeout):\n self._timeout = timeout\n self.remaining_timeout = timeout\n self._timeout_error_type = timeout_error_type\n\n def __enter__(self):\n self._start = time.time()\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value:\n return # let the error bubble up automatically\n\n if self._timeout is None:\n return # nothing to do, the timeout was not specified\n\n elapsed = time.time() - self._start\n deadline_hit = False\n\n if isinstance(self._timeout, numbers.Number):\n self.remaining_timeout = self._timeout - elapsed\n deadline_hit = self.remaining_timeout <= 0\n else:\n self.remaining_timeout = tuple(x - elapsed for x in self._timeout)\n deadline_hit = min(self.remaining_timeout) <= 0\n\n if deadline_hit:\n raise self._timeout_error_type()\n\n\nclass Request(transport.Request):\n \"\"\"Requests request adapter.\n\n This class is used internally for making requests using various transports\n in a consistent way. If you use :class:`AuthorizedSession` you do not need\n to construct or use this class directly.\n\n This class can be useful if you want to manually refresh a\n :class:`~google.auth.credentials.Credentials` instance::\n\n import google.auth.transport.requests\n import requests\n\n request = google.auth.transport.requests.Request()\n\n credentials.refresh(request)\n\n Args:\n session (requests.Session): An instance :class:`requests.Session` used\n to make HTTP requests. If not specified, a session will be created.\n\n .. automethod:: __call__\n \"\"\"\n\n def __init__(self, session=None):\n if not session:\n session = requests.Session()\n\n self.session = session\n\n def __call__(\n self, url, method=\"GET\", body=None, headers=None, timeout=120, **kwargs\n ):\n \"\"\"Make an HTTP request using requests.\n\n Args:\n url (str): The URI to be requested.\n method (str): The HTTP method to use for the request. Defaults\n to 'GET'.\n body (bytes): The payload / body in HTTP request.\n headers (Mapping[str, str]): Request headers.\n timeout (Optional[int]): The number of seconds to wait for a\n response from the server. If not specified or if None, the\n requests default timeout will be used.\n kwargs: Additional arguments passed through to the underlying\n requests :meth:`~requests.Session.request` method.\n\n Returns:\n google.auth.transport.Response: The HTTP response.\n\n Raises:\n google.auth.exceptions.TransportError: If any exception occurred.\n \"\"\"\n try:\n _LOGGER.debug(\"Making request: %s %s\", method, url)\n response = self.session.request(\n method, url, data=body, headers=headers, timeout=timeout, **kwargs\n )\n return _Response(response)\n except requests.exceptions.RequestException as caught_exc:\n new_exc = exceptions.TransportError(caught_exc)\n six.raise_from(new_exc, caught_exc)\n\n\nclass AuthorizedSession(requests.Session):\n \"\"\"A Requests Session class with credentials.\n\n This class is used to perform requests to API endpoints that require\n authorization::\n\n from google.auth.transport.requests import AuthorizedSession\n\n authed_session = AuthorizedSession(credentials)\n\n response = authed_session.request(\n 'GET', 'https://www.googleapis.com/storage/v1/b')\n\n The underlying :meth:`request` implementation handles adding the\n credentials' headers to the request and refreshing credentials as needed.\n\n Args:\n credentials (google.auth.credentials.Credentials): The credentials to\n add to the request.\n refresh_status_codes (Sequence[int]): Which HTTP status codes indicate\n that credentials should be refreshed and the request should be\n retried.\n max_refresh_attempts (int): The maximum number of times to attempt to\n refresh the credentials and retry the request.\n refresh_timeout (Optional[int]): The timeout value in seconds for\n credential refresh HTTP requests.\n auth_request (google.auth.transport.requests.Request):\n (Optional) An instance of\n :class:`~google.auth.transport.requests.Request` used when\n refreshing credentials. If not passed,\n an instance of :class:`~google.auth.transport.requests.Request`\n is created.\n \"\"\"\n\n def __init__(\n self,\n credentials,\n refresh_status_codes=transport.DEFAULT_REFRESH_STATUS_CODES,\n max_refresh_attempts=transport.DEFAULT_MAX_REFRESH_ATTEMPTS,\n refresh_timeout=None,\n auth_request=None,\n ):\n super(AuthorizedSession, self).__init__()\n self.credentials = credentials\n self._refresh_status_codes = refresh_status_codes\n self._max_refresh_attempts = max_refresh_attempts\n self._refresh_timeout = refresh_timeout\n\n if auth_request is None:\n auth_request_session = requests.Session()\n\n # Using an adapter to make HTTP requests robust to network errors.\n # This adapter retrys HTTP requests when network errors occur\n # and the requests seems safely retryable.\n retry_adapter = requests.adapters.HTTPAdapter(max_retries=3)\n auth_request_session.mount(\"https://\", retry_adapter)\n\n # Do not pass `self` as the session here, as it can lead to\n # infinite recursion.\n auth_request = Request(auth_request_session)\n\n # Request instance used by internal methods (for example,\n # credentials.refresh).\n self._auth_request = auth_request\n\n def request(\n self,\n method,\n url,\n data=None,\n headers=None,\n max_allowed_time=None,\n timeout=None,\n **kwargs\n ):\n \"\"\"Implementation of Requests' request.\n\n Args:\n timeout (Optional[Union[float, Tuple[float, float]]]):\n The amount of time in seconds to wait for the server response\n with each individual request.\n\n Can also be passed as a tuple (connect_timeout, read_timeout).\n See :meth:`requests.Session.request` documentation for details.\n\n max_allowed_time (Optional[float]):\n If the method runs longer than this, a ``Timeout`` exception is\n automatically raised. Unlike the ``timeout` parameter, this\n value applies to the total method execution time, even if\n multiple requests are made under the hood.\n\n Mind that it is not guaranteed that the timeout error is raised\n at ``max_allowed_time`. It might take longer, for example, if\n an underlying request takes a lot of time, but the request\n itself does not timeout, e.g. if a large file is being\n transmitted. The timout error will be raised after such\n request completes.\n \"\"\"\n # pylint: disable=arguments-differ\n # Requests has a ton of arguments to request, but only two\n # (method, url) are required. We pass through all of the other\n # arguments to super, so no need to exhaustively list them here.\n\n # Use a kwarg for this instead of an attribute to maintain\n # thread-safety.\n _credential_refresh_attempt = kwargs.pop(\"_credential_refresh_attempt\", 0)\n\n # Make a copy of the headers. They will be modified by the credentials\n # and we want to pass the original headers if we recurse.\n request_headers = headers.copy() if headers is not None else {}\n\n # Do not apply the timeout unconditionally in order to not override the\n # _auth_request's default timeout.\n auth_request = (\n self._auth_request\n if timeout is None\n else functools.partial(self._auth_request, timeout=timeout)\n )\n\n remaining_time = max_allowed_time\n\n with TimeoutGuard(remaining_time) as guard:\n self.credentials.before_request(auth_request, method, url, request_headers)\n remaining_time = guard.remaining_timeout\n\n with TimeoutGuard(remaining_time) as guard:\n response = super(AuthorizedSession, self).request(\n method,\n url,\n data=data,\n headers=request_headers,\n timeout=timeout,\n **kwargs\n )\n remaining_time = guard.remaining_timeout\n\n # If the response indicated that the credentials needed to be\n # refreshed, then refresh the credentials and re-attempt the\n # request.\n # A stored token may expire between the time it is retrieved and\n # the time the request is made, so we may need to try twice.\n if (\n response.status_code in self._refresh_status_codes\n and _credential_refresh_attempt < self._max_refresh_attempts\n ):\n\n _LOGGER.info(\n \"Refreshing credentials due to a %s response. Attempt %s/%s.\",\n response.status_code,\n _credential_refresh_attempt + 1,\n self._max_refresh_attempts,\n )\n\n # Do not apply the timeout unconditionally in order to not override the\n # _auth_request's default timeout.\n auth_request = (\n self._auth_request\n if timeout is None\n else functools.partial(self._auth_request, timeout=timeout)\n )\n\n with TimeoutGuard(remaining_time) as guard:\n self.credentials.refresh(auth_request)\n remaining_time = guard.remaining_timeout\n\n # Recurse. Pass in the original headers, not our modified set, but\n # do pass the adjusted max allowed time (i.e. the remaining total time).\n return self.request(\n method,\n url,\n data=data,\n headers=headers,\n max_allowed_time=remaining_time,\n timeout=timeout,\n _credential_refresh_attempt=_credential_refresh_attempt + 1,\n **kwargs\n )\n\n return response\n", "path": "google/auth/transport/requests.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Transport adapter for Requests.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport functools\nimport logging\nimport numbers\nimport time\n\ntry:\n import requests\nexcept ImportError as caught_exc: # pragma: NO COVER\n import six\n\n six.raise_from(\n ImportError(\n \"The requests library is not installed, please install the \"\n \"requests package to use the requests transport.\"\n ),\n caught_exc,\n )\nimport requests.adapters # pylint: disable=ungrouped-imports\nimport requests.exceptions # pylint: disable=ungrouped-imports\nimport six # pylint: disable=ungrouped-imports\n\nfrom google.auth import exceptions\nfrom google.auth import transport\n\n_LOGGER = logging.getLogger(__name__)\n\n_DEFAULT_TIMEOUT = 120 # in seconds\n\n\nclass _Response(transport.Response):\n \"\"\"Requests transport response adapter.\n\n Args:\n response (requests.Response): The raw Requests response.\n \"\"\"\n\n def __init__(self, response):\n self._response = response\n\n @property\n def status(self):\n return self._response.status_code\n\n @property\n def headers(self):\n return self._response.headers\n\n @property\n def data(self):\n return self._response.content\n\n\nclass TimeoutGuard(object):\n \"\"\"A context manager raising an error if the suite execution took too long.\n\n Args:\n timeout ([Union[None, float, Tuple[float, float]]]):\n The maximum number of seconds a suite can run without the context\n manager raising a timeout exception on exit. If passed as a tuple,\n the smaller of the values is taken as a timeout. If ``None``, a\n timeout error is never raised.\n timeout_error_type (Optional[Exception]):\n The type of the error to raise on timeout. Defaults to\n :class:`requests.exceptions.Timeout`.\n \"\"\"\n\n def __init__(self, timeout, timeout_error_type=requests.exceptions.Timeout):\n self._timeout = timeout\n self.remaining_timeout = timeout\n self._timeout_error_type = timeout_error_type\n\n def __enter__(self):\n self._start = time.time()\n return self\n\n def __exit__(self, exc_type, exc_value, traceback):\n if exc_value:\n return # let the error bubble up automatically\n\n if self._timeout is None:\n return # nothing to do, the timeout was not specified\n\n elapsed = time.time() - self._start\n deadline_hit = False\n\n if isinstance(self._timeout, numbers.Number):\n self.remaining_timeout = self._timeout - elapsed\n deadline_hit = self.remaining_timeout <= 0\n else:\n self.remaining_timeout = tuple(x - elapsed for x in self._timeout)\n deadline_hit = min(self.remaining_timeout) <= 0\n\n if deadline_hit:\n raise self._timeout_error_type()\n\n\nclass Request(transport.Request):\n \"\"\"Requests request adapter.\n\n This class is used internally for making requests using various transports\n in a consistent way. If you use :class:`AuthorizedSession` you do not need\n to construct or use this class directly.\n\n This class can be useful if you want to manually refresh a\n :class:`~google.auth.credentials.Credentials` instance::\n\n import google.auth.transport.requests\n import requests\n\n request = google.auth.transport.requests.Request()\n\n credentials.refresh(request)\n\n Args:\n session (requests.Session): An instance :class:`requests.Session` used\n to make HTTP requests. If not specified, a session will be created.\n\n .. automethod:: __call__\n \"\"\"\n\n def __init__(self, session=None):\n if not session:\n session = requests.Session()\n\n self.session = session\n\n def __call__(\n self,\n url,\n method=\"GET\",\n body=None,\n headers=None,\n timeout=_DEFAULT_TIMEOUT,\n **kwargs\n ):\n \"\"\"Make an HTTP request using requests.\n\n Args:\n url (str): The URI to be requested.\n method (str): The HTTP method to use for the request. Defaults\n to 'GET'.\n body (bytes): The payload / body in HTTP request.\n headers (Mapping[str, str]): Request headers.\n timeout (Optional[int]): The number of seconds to wait for a\n response from the server. If not specified or if None, the\n requests default timeout will be used.\n kwargs: Additional arguments passed through to the underlying\n requests :meth:`~requests.Session.request` method.\n\n Returns:\n google.auth.transport.Response: The HTTP response.\n\n Raises:\n google.auth.exceptions.TransportError: If any exception occurred.\n \"\"\"\n try:\n _LOGGER.debug(\"Making request: %s %s\", method, url)\n response = self.session.request(\n method, url, data=body, headers=headers, timeout=timeout, **kwargs\n )\n return _Response(response)\n except requests.exceptions.RequestException as caught_exc:\n new_exc = exceptions.TransportError(caught_exc)\n six.raise_from(new_exc, caught_exc)\n\n\nclass AuthorizedSession(requests.Session):\n \"\"\"A Requests Session class with credentials.\n\n This class is used to perform requests to API endpoints that require\n authorization::\n\n from google.auth.transport.requests import AuthorizedSession\n\n authed_session = AuthorizedSession(credentials)\n\n response = authed_session.request(\n 'GET', 'https://www.googleapis.com/storage/v1/b')\n\n The underlying :meth:`request` implementation handles adding the\n credentials' headers to the request and refreshing credentials as needed.\n\n Args:\n credentials (google.auth.credentials.Credentials): The credentials to\n add to the request.\n refresh_status_codes (Sequence[int]): Which HTTP status codes indicate\n that credentials should be refreshed and the request should be\n retried.\n max_refresh_attempts (int): The maximum number of times to attempt to\n refresh the credentials and retry the request.\n refresh_timeout (Optional[int]): The timeout value in seconds for\n credential refresh HTTP requests.\n auth_request (google.auth.transport.requests.Request):\n (Optional) An instance of\n :class:`~google.auth.transport.requests.Request` used when\n refreshing credentials. If not passed,\n an instance of :class:`~google.auth.transport.requests.Request`\n is created.\n \"\"\"\n\n def __init__(\n self,\n credentials,\n refresh_status_codes=transport.DEFAULT_REFRESH_STATUS_CODES,\n max_refresh_attempts=transport.DEFAULT_MAX_REFRESH_ATTEMPTS,\n refresh_timeout=None,\n auth_request=None,\n ):\n super(AuthorizedSession, self).__init__()\n self.credentials = credentials\n self._refresh_status_codes = refresh_status_codes\n self._max_refresh_attempts = max_refresh_attempts\n self._refresh_timeout = refresh_timeout\n\n if auth_request is None:\n auth_request_session = requests.Session()\n\n # Using an adapter to make HTTP requests robust to network errors.\n # This adapter retrys HTTP requests when network errors occur\n # and the requests seems safely retryable.\n retry_adapter = requests.adapters.HTTPAdapter(max_retries=3)\n auth_request_session.mount(\"https://\", retry_adapter)\n\n # Do not pass `self` as the session here, as it can lead to\n # infinite recursion.\n auth_request = Request(auth_request_session)\n\n # Request instance used by internal methods (for example,\n # credentials.refresh).\n self._auth_request = auth_request\n\n def request(\n self,\n method,\n url,\n data=None,\n headers=None,\n max_allowed_time=None,\n timeout=_DEFAULT_TIMEOUT,\n **kwargs\n ):\n \"\"\"Implementation of Requests' request.\n\n Args:\n timeout (Optional[Union[float, Tuple[float, float]]]):\n The amount of time in seconds to wait for the server response\n with each individual request.\n\n Can also be passed as a tuple (connect_timeout, read_timeout).\n See :meth:`requests.Session.request` documentation for details.\n\n max_allowed_time (Optional[float]):\n If the method runs longer than this, a ``Timeout`` exception is\n automatically raised. Unlike the ``timeout` parameter, this\n value applies to the total method execution time, even if\n multiple requests are made under the hood.\n\n Mind that it is not guaranteed that the timeout error is raised\n at ``max_allowed_time`. It might take longer, for example, if\n an underlying request takes a lot of time, but the request\n itself does not timeout, e.g. if a large file is being\n transmitted. The timout error will be raised after such\n request completes.\n \"\"\"\n # pylint: disable=arguments-differ\n # Requests has a ton of arguments to request, but only two\n # (method, url) are required. We pass through all of the other\n # arguments to super, so no need to exhaustively list them here.\n\n # Use a kwarg for this instead of an attribute to maintain\n # thread-safety.\n _credential_refresh_attempt = kwargs.pop(\"_credential_refresh_attempt\", 0)\n\n # Make a copy of the headers. They will be modified by the credentials\n # and we want to pass the original headers if we recurse.\n request_headers = headers.copy() if headers is not None else {}\n\n # Do not apply the timeout unconditionally in order to not override the\n # _auth_request's default timeout.\n auth_request = (\n self._auth_request\n if timeout is None\n else functools.partial(self._auth_request, timeout=timeout)\n )\n\n remaining_time = max_allowed_time\n\n with TimeoutGuard(remaining_time) as guard:\n self.credentials.before_request(auth_request, method, url, request_headers)\n remaining_time = guard.remaining_timeout\n\n with TimeoutGuard(remaining_time) as guard:\n response = super(AuthorizedSession, self).request(\n method,\n url,\n data=data,\n headers=request_headers,\n timeout=timeout,\n **kwargs\n )\n remaining_time = guard.remaining_timeout\n\n # If the response indicated that the credentials needed to be\n # refreshed, then refresh the credentials and re-attempt the\n # request.\n # A stored token may expire between the time it is retrieved and\n # the time the request is made, so we may need to try twice.\n if (\n response.status_code in self._refresh_status_codes\n and _credential_refresh_attempt < self._max_refresh_attempts\n ):\n\n _LOGGER.info(\n \"Refreshing credentials due to a %s response. Attempt %s/%s.\",\n response.status_code,\n _credential_refresh_attempt + 1,\n self._max_refresh_attempts,\n )\n\n # Do not apply the timeout unconditionally in order to not override the\n # _auth_request's default timeout.\n auth_request = (\n self._auth_request\n if timeout is None\n else functools.partial(self._auth_request, timeout=timeout)\n )\n\n with TimeoutGuard(remaining_time) as guard:\n self.credentials.refresh(auth_request)\n remaining_time = guard.remaining_timeout\n\n # Recurse. Pass in the original headers, not our modified set, but\n # do pass the adjusted max allowed time (i.e. the remaining total time).\n return self.request(\n method,\n url,\n data=data,\n headers=headers,\n max_allowed_time=remaining_time,\n timeout=timeout,\n _credential_refresh_attempt=_credential_refresh_attempt + 1,\n **kwargs\n )\n\n return response\n", "path": "google/auth/transport/requests.py"}]} | 3,958 | 244 |
gh_patches_debug_10288 | rasdani/github-patches | git_diff | Zeroto521__my-data-toolkit-585 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PERF: `to_set` speeds up especial to large data
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #542
- [x] whatsnew entry
Apply to index accessor
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/accessor/index/to_set.py`
Content:
```
1 import pandas as pd
2
3 from dtoolkit.accessor.register import register_index_method
4
5
6 @register_index_method
7 def to_set(index: pd.Index) -> set:
8 """
9 Return a :keyword:`set` of the values.
10
11 A sugary syntax wraps :keyword:`set`::
12
13 set(index)
14
15 Different to :meth:`~pandas.Index.unique`, it returns :class:`~pandas.Index`.
16
17 Returns
18 -------
19 set
20
21 See Also
22 --------
23 pandas.Index.unique
24
25 Examples
26 --------
27 >>> import dtoolkit.accessor
28 >>> import pandas as pd
29 >>> i = pd.Index([1, 2, 2])
30 >>> i
31 Int64Index([1, 2, 2], dtype='int64')
32 >>> i.to_set()
33 {1, 2}
34 """
35
36 return set(index.unique())
37
```
Path: `dtoolkit/accessor/series/to_set.py`
Content:
```
1 import pandas as pd
2
3 from dtoolkit.accessor.register import register_series_method
4
5
6 @register_series_method
7 def to_set(s: pd.Series) -> set:
8 """
9 Return a :keyword:`set` of the values.
10
11 A sugary syntax wraps :keyword:`set`::
12
13 set(s)
14
15 Different to :meth:`~pandas.Series.unique`, it returns :class:`~numpy.ndarray`.
16
17 Returns
18 -------
19 set
20
21 See Also
22 --------
23 pandas.Series.unique
24
25 Examples
26 --------
27 >>> import dtoolkit.accessor
28 >>> import pandas as pd
29 >>> s = pd.Series([1, 2, 2])
30 >>> s
31 0 1
32 1 2
33 2 2
34 dtype: int64
35 >>> s.to_set()
36 {1, 2}
37 """
38
39 return set(s.unique())
40
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/dtoolkit/accessor/index/to_set.py b/dtoolkit/accessor/index/to_set.py
--- a/dtoolkit/accessor/index/to_set.py
+++ b/dtoolkit/accessor/index/to_set.py
@@ -21,6 +21,7 @@
See Also
--------
pandas.Index.unique
+ dtoolkit.accessor.series.to_set
Examples
--------
diff --git a/dtoolkit/accessor/series/to_set.py b/dtoolkit/accessor/series/to_set.py
--- a/dtoolkit/accessor/series/to_set.py
+++ b/dtoolkit/accessor/series/to_set.py
@@ -21,6 +21,7 @@
See Also
--------
pandas.Series.unique
+ dtoolkit.accessor.index.to_set
Examples
--------
@@ -36,4 +37,4 @@
{1, 2}
"""
- return set(s.unique())
+ return set(s.to_list())
| {"golden_diff": "diff --git a/dtoolkit/accessor/index/to_set.py b/dtoolkit/accessor/index/to_set.py\n--- a/dtoolkit/accessor/index/to_set.py\n+++ b/dtoolkit/accessor/index/to_set.py\n@@ -21,6 +21,7 @@\n See Also\n --------\n pandas.Index.unique\n+ dtoolkit.accessor.series.to_set\n \n Examples\n --------\ndiff --git a/dtoolkit/accessor/series/to_set.py b/dtoolkit/accessor/series/to_set.py\n--- a/dtoolkit/accessor/series/to_set.py\n+++ b/dtoolkit/accessor/series/to_set.py\n@@ -21,6 +21,7 @@\n See Also\n --------\n pandas.Series.unique\n+ dtoolkit.accessor.index.to_set\n \n Examples\n --------\n@@ -36,4 +37,4 @@\n {1, 2}\n \"\"\"\n \n- return set(s.unique())\n+ return set(s.to_list())\n", "issue": "PERF: `to_set` speeds up especial to large data\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #542\r\n- [x] whatsnew entry\r\n\r\nApply to index accessor\n", "before_files": [{"content": "import pandas as pd\n\nfrom dtoolkit.accessor.register import register_index_method\n\n\n@register_index_method\ndef to_set(index: pd.Index) -> set:\n \"\"\"\n Return a :keyword:`set` of the values.\n\n A sugary syntax wraps :keyword:`set`::\n\n set(index)\n\n Different to :meth:`~pandas.Index.unique`, it returns :class:`~pandas.Index`.\n\n Returns\n -------\n set\n\n See Also\n --------\n pandas.Index.unique\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import pandas as pd\n >>> i = pd.Index([1, 2, 2])\n >>> i\n Int64Index([1, 2, 2], dtype='int64')\n >>> i.to_set()\n {1, 2}\n \"\"\"\n\n return set(index.unique())\n", "path": "dtoolkit/accessor/index/to_set.py"}, {"content": "import pandas as pd\n\nfrom dtoolkit.accessor.register import register_series_method\n\n\n@register_series_method\ndef to_set(s: pd.Series) -> set:\n \"\"\"\n Return a :keyword:`set` of the values.\n\n A sugary syntax wraps :keyword:`set`::\n\n set(s)\n\n Different to :meth:`~pandas.Series.unique`, it returns :class:`~numpy.ndarray`.\n\n Returns\n -------\n set\n\n See Also\n --------\n pandas.Series.unique\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import pandas as pd\n >>> s = pd.Series([1, 2, 2])\n >>> s\n 0 1\n 1 2\n 2 2\n dtype: int64\n >>> s.to_set()\n {1, 2}\n \"\"\"\n\n return set(s.unique())\n", "path": "dtoolkit/accessor/series/to_set.py"}], "after_files": [{"content": "import pandas as pd\n\nfrom dtoolkit.accessor.register import register_index_method\n\n\n@register_index_method\ndef to_set(index: pd.Index) -> set:\n \"\"\"\n Return a :keyword:`set` of the values.\n\n A sugary syntax wraps :keyword:`set`::\n\n set(index)\n\n Different to :meth:`~pandas.Index.unique`, it returns :class:`~pandas.Index`.\n\n Returns\n -------\n set\n\n See Also\n --------\n pandas.Index.unique\n dtoolkit.accessor.series.to_set\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import pandas as pd\n >>> i = pd.Index([1, 2, 2])\n >>> i\n Int64Index([1, 2, 2], dtype='int64')\n >>> i.to_set()\n {1, 2}\n \"\"\"\n\n return set(index.unique())\n", "path": "dtoolkit/accessor/index/to_set.py"}, {"content": "import pandas as pd\n\nfrom dtoolkit.accessor.register import register_series_method\n\n\n@register_series_method\ndef to_set(s: pd.Series) -> set:\n \"\"\"\n Return a :keyword:`set` of the values.\n\n A sugary syntax wraps :keyword:`set`::\n\n set(s)\n\n Different to :meth:`~pandas.Series.unique`, it returns :class:`~numpy.ndarray`.\n\n Returns\n -------\n set\n\n See Also\n --------\n pandas.Series.unique\n dtoolkit.accessor.index.to_set\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import pandas as pd\n >>> s = pd.Series([1, 2, 2])\n >>> s\n 0 1\n 1 2\n 2 2\n dtype: int64\n >>> s.to_set()\n {1, 2}\n \"\"\"\n\n return set(s.to_list())\n", "path": "dtoolkit/accessor/series/to_set.py"}]} | 1,014 | 215 |
gh_patches_debug_14623 | rasdani/github-patches | git_diff | ydataai__ydata-profiling-945 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Potential incompatiblity with Pandas 1.4.0
**Describe the bug**
Pandas version 1.4.0 was release few days ago and some tests start failing. I was able to reproduce with a minimum example which is failing with Pandas 1.4.0 and working with Pandas 1.3.5.
**To Reproduce**
```python
import pandas as pd
import pandas_profiling
data = {"col1": [1, 2], "col2": [3, 4]}
dataframe = pd.DataFrame(data=data)
profile = pandas_profiling.ProfileReport(dataframe, minimal=False)
profile.to_html()
```
When running with Pandas 1.4.0, I get the following traceback:
```
Traceback (most recent call last):
File "/tmp/bug.py", line 8, in <module>
profile.to_html()
File "/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py", line 368, in to_html
return self.html
File "/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py", line 185, in html
self._html = self._render_html()
File "/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py", line 287, in _render_html
report = self.report
File "/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py", line 179, in report
self._report = get_report_structure(self.config, self.description_set)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py", line 161, in description_set
self._description_set = describe_df(
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/describe.py", line 71, in describe
series_description = get_series_descriptions(
File "/vemv/lib/python3.9/site-packages/multimethod/__init__.py", line 303, in __call__
return func(*args, **kwargs)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py", line 92, in pandas_get_series_descriptions
for i, (column, description) in enumerate(
File "/home/lothiraldan/.pyenv/versions/3.9.1/lib/python3.9/multiprocessing/pool.py", line 870, in next
raise value
File "/home/lothiraldan/.pyenv/versions/3.9.1/lib/python3.9/multiprocessing/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py", line 72, in multiprocess_1d
return column, describe_1d(config, series, summarizer, typeset)
File "/vemv/lib/python3.9/site-packages/multimethod/__init__.py", line 303, in __call__
return func(*args, **kwargs)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py", line 50, in pandas_describe_1d
return summarizer.summarize(config, series, dtype=vtype)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/summarizer.py", line 37, in summarize
_, _, summary = self.handle(str(dtype), config, series, {"type": str(dtype)})
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py", line 62, in handle
return op(*args)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py", line 21, in func2
return f(*res)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py", line 21, in func2
return f(*res)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py", line 21, in func2
return f(*res)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py", line 17, in func2
res = g(*x)
File "/vemv/lib/python3.9/site-packages/multimethod/__init__.py", line 303, in __call__
return func(*args, **kwargs)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/summary_algorithms.py", line 65, in inner
return fn(config, series, summary)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/summary_algorithms.py", line 82, in inner
return fn(config, series, summary)
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/describe_categorical_pandas.py", line 205, in pandas_describe_categorical_1d
summary.update(length_summary_vc(value_counts))
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/describe_categorical_pandas.py", line 162, in length_summary_vc
"median_length": weighted_median(
File "/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/utils_pandas.py", line 13, in weighted_median
w_median = (data[weights == np.max(weights)])[0]
IndexError: only integers, slices (`:`), ellipsis (`...`), numpy.newaxis (`None`) and integer or boolean arrays are valid indices
```
If I try changing the `minimal` from `False` to `True`, the script is now passing.
**Version information:**
#### Failing environment
Python version: Python 3.9.1
Pip version: pip 21.3.1
Pandas and pandas-profiling versions: 1.4.0 | 3.1.0
Full pip list:
```
Package Version
--------------------- ---------
attrs 21.4.0
certifi 2021.10.8
charset-normalizer 2.0.10
cycler 0.11.0
fonttools 4.28.5
htmlmin 0.1.12
idna 3.3
ImageHash 4.2.1
Jinja2 3.0.3
joblib 1.0.1
kiwisolver 1.3.2
MarkupSafe 2.0.1
matplotlib 3.5.1
missingno 0.5.0
multimethod 1.6
networkx 2.6.3
numpy 1.22.1
packaging 21.3
pandas 1.4.0
pandas-profiling 3.1.0
phik 0.12.0
Pillow 9.0.0
pip 21.3.1
pydantic 1.9.0
pyparsing 3.0.7
python-dateutil 2.8.2
pytz 2021.3
PyWavelets 1.2.0
PyYAML 6.0
requests 2.27.1
scipy 1.7.3
seaborn 0.11.2
setuptools 60.0.5
six 1.16.0
tangled-up-in-unicode 0.1.0
tqdm 4.62.3
typing_extensions 4.0.1
urllib3 1.26.8
visions 0.7.4
wheel 0.37.1
```
#### Working environment
Python version: Python 3.9.1
Pip version: pip 21.3.1
Pandas and pandas-profiling versions: 1.3.5 | 3.1.0
Full pip list:
```
Package Version
--------------------- ---------
attrs 21.4.0
certifi 2021.10.8
charset-normalizer 2.0.10
cycler 0.11.0
fonttools 4.28.5
htmlmin 0.1.12
idna 3.3
ImageHash 4.2.1
Jinja2 3.0.3
joblib 1.0.1
kiwisolver 1.3.2
MarkupSafe 2.0.1
matplotlib 3.5.1
missingno 0.5.0
multimethod 1.6
networkx 2.6.3
numpy 1.22.1
packaging 21.3
pandas 1.3.5
pandas-profiling 3.1.0
phik 0.12.0
Pillow 9.0.0
pip 21.3.1
pydantic 1.9.0
pyparsing 3.0.7
python-dateutil 2.8.2
pytz 2021.3
PyWavelets 1.2.0
PyYAML 6.0
requests 2.27.1
scipy 1.7.3
seaborn 0.11.2
setuptools 60.0.5
six 1.16.0
tangled-up-in-unicode 0.1.0
tqdm 4.62.3
typing_extensions 4.0.1
urllib3 1.26.8
visions 0.7.4
wheel 0.37.1
```
Let me know if I can provide more details and thank you for your good work!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/pandas_profiling/model/pandas/utils_pandas.py`
Content:
```
1 import numpy as np
2
3
4 def weighted_median(data: np.ndarray, weights: np.ndarray) -> int:
5 """
6 Args:
7 data (list or numpy.array): data
8 weights (list or numpy.array): weights
9 """
10 s_data, s_weights = map(np.array, zip(*sorted(zip(data, weights))))
11 midpoint = 0.5 * sum(s_weights)
12 if any(weights > midpoint):
13 w_median = (data[weights == np.max(weights)])[0]
14 else:
15 cs_weights = np.cumsum(s_weights)
16 idx = np.where(cs_weights <= midpoint)[0][-1]
17 if cs_weights[idx] == midpoint:
18 w_median = np.mean(s_data[idx : idx + 2])
19 else:
20 w_median = s_data[idx + 1]
21 return w_median
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/pandas_profiling/model/pandas/utils_pandas.py b/src/pandas_profiling/model/pandas/utils_pandas.py
--- a/src/pandas_profiling/model/pandas/utils_pandas.py
+++ b/src/pandas_profiling/model/pandas/utils_pandas.py
@@ -7,10 +7,16 @@
data (list or numpy.array): data
weights (list or numpy.array): weights
"""
- s_data, s_weights = map(np.array, zip(*sorted(zip(data, weights))))
- midpoint = 0.5 * sum(s_weights)
- if any(weights > midpoint):
- w_median = (data[weights == np.max(weights)])[0]
+ if not isinstance(data, np.ndarray):
+ data = np.array(data)
+ if not isinstance(weights, np.ndarray):
+ weights = np.array(weights)
+
+ s_data, s_weights = map(np.sort, [data, weights])
+ midpoint = 0.5 * np.sum(s_weights)
+
+ if s_weights[-1] > midpoint:
+ w_median = data[weights == np.max(weights)][0]
else:
cs_weights = np.cumsum(s_weights)
idx = np.where(cs_weights <= midpoint)[0][-1]
| {"golden_diff": "diff --git a/src/pandas_profiling/model/pandas/utils_pandas.py b/src/pandas_profiling/model/pandas/utils_pandas.py\n--- a/src/pandas_profiling/model/pandas/utils_pandas.py\n+++ b/src/pandas_profiling/model/pandas/utils_pandas.py\n@@ -7,10 +7,16 @@\n data (list or numpy.array): data\n weights (list or numpy.array): weights\n \"\"\"\n- s_data, s_weights = map(np.array, zip(*sorted(zip(data, weights))))\n- midpoint = 0.5 * sum(s_weights)\n- if any(weights > midpoint):\n- w_median = (data[weights == np.max(weights)])[0]\n+ if not isinstance(data, np.ndarray):\n+ data = np.array(data)\n+ if not isinstance(weights, np.ndarray):\n+ weights = np.array(weights)\n+\n+ s_data, s_weights = map(np.sort, [data, weights])\n+ midpoint = 0.5 * np.sum(s_weights)\n+\n+ if s_weights[-1] > midpoint:\n+ w_median = data[weights == np.max(weights)][0]\n else:\n cs_weights = np.cumsum(s_weights)\n idx = np.where(cs_weights <= midpoint)[0][-1]\n", "issue": "Potential incompatiblity with Pandas 1.4.0\n**Describe the bug**\r\n\r\nPandas version 1.4.0 was release few days ago and some tests start failing. I was able to reproduce with a minimum example which is failing with Pandas 1.4.0 and working with Pandas 1.3.5.\r\n\r\n**To Reproduce**\r\n\r\n```python\r\nimport pandas as pd\r\nimport pandas_profiling\r\n\r\ndata = {\"col1\": [1, 2], \"col2\": [3, 4]}\r\ndataframe = pd.DataFrame(data=data)\r\n\r\nprofile = pandas_profiling.ProfileReport(dataframe, minimal=False)\r\nprofile.to_html()\r\n```\r\n\r\nWhen running with Pandas 1.4.0, I get the following traceback:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/tmp/bug.py\", line 8, in <module>\r\n profile.to_html()\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py\", line 368, in to_html\r\n return self.html\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py\", line 185, in html\r\n self._html = self._render_html()\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py\", line 287, in _render_html\r\n report = self.report\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py\", line 179, in report\r\n self._report = get_report_structure(self.config, self.description_set)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/profile_report.py\", line 161, in description_set\r\n self._description_set = describe_df(\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/describe.py\", line 71, in describe\r\n series_description = get_series_descriptions(\r\n File \"/vemv/lib/python3.9/site-packages/multimethod/__init__.py\", line 303, in __call__\r\n return func(*args, **kwargs)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py\", line 92, in pandas_get_series_descriptions\r\n for i, (column, description) in enumerate(\r\n File \"/home/lothiraldan/.pyenv/versions/3.9.1/lib/python3.9/multiprocessing/pool.py\", line 870, in next\r\n raise value\r\n File \"/home/lothiraldan/.pyenv/versions/3.9.1/lib/python3.9/multiprocessing/pool.py\", line 125, in worker\r\n result = (True, func(*args, **kwds))\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py\", line 72, in multiprocess_1d\r\n return column, describe_1d(config, series, summarizer, typeset)\r\n File \"/vemv/lib/python3.9/site-packages/multimethod/__init__.py\", line 303, in __call__\r\n return func(*args, **kwargs)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/summary_pandas.py\", line 50, in pandas_describe_1d\r\n return summarizer.summarize(config, series, dtype=vtype)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/summarizer.py\", line 37, in summarize\r\n _, _, summary = self.handle(str(dtype), config, series, {\"type\": str(dtype)})\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py\", line 62, in handle\r\n return op(*args)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py\", line 21, in func2\r\n return f(*res)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py\", line 21, in func2\r\n return f(*res)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py\", line 21, in func2\r\n return f(*res)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/handler.py\", line 17, in func2\r\n res = g(*x)\r\n File \"/vemv/lib/python3.9/site-packages/multimethod/__init__.py\", line 303, in __call__\r\n return func(*args, **kwargs)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/summary_algorithms.py\", line 65, in inner\r\n return fn(config, series, summary)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/summary_algorithms.py\", line 82, in inner\r\n return fn(config, series, summary)\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/describe_categorical_pandas.py\", line 205, in pandas_describe_categorical_1d\r\n summary.update(length_summary_vc(value_counts))\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/describe_categorical_pandas.py\", line 162, in length_summary_vc\r\n \"median_length\": weighted_median(\r\n File \"/vemv/lib/python3.9/site-packages/pandas_profiling/model/pandas/utils_pandas.py\", line 13, in weighted_median\r\n w_median = (data[weights == np.max(weights)])[0]\r\nIndexError: only integers, slices (`:`), ellipsis (`...`), numpy.newaxis (`None`) and integer or boolean arrays are valid indices\r\n```\r\n\r\nIf I try changing the `minimal` from `False` to `True`, the script is now passing.\r\n\r\n**Version information:**\r\n\r\n#### Failing environment\r\n\r\nPython version: Python 3.9.1\r\nPip version: pip 21.3.1\r\nPandas and pandas-profiling versions: 1.4.0 | 3.1.0\r\nFull pip list:\r\n```\r\nPackage Version\r\n--------------------- ---------\r\nattrs 21.4.0\r\ncertifi 2021.10.8\r\ncharset-normalizer 2.0.10\r\ncycler 0.11.0\r\nfonttools 4.28.5\r\nhtmlmin 0.1.12\r\nidna 3.3\r\nImageHash 4.2.1\r\nJinja2 3.0.3\r\njoblib 1.0.1\r\nkiwisolver 1.3.2\r\nMarkupSafe 2.0.1\r\nmatplotlib 3.5.1\r\nmissingno 0.5.0\r\nmultimethod 1.6\r\nnetworkx 2.6.3\r\nnumpy 1.22.1\r\npackaging 21.3\r\npandas 1.4.0\r\npandas-profiling 3.1.0\r\nphik 0.12.0\r\nPillow 9.0.0\r\npip 21.3.1\r\npydantic 1.9.0\r\npyparsing 3.0.7\r\npython-dateutil 2.8.2\r\npytz 2021.3\r\nPyWavelets 1.2.0\r\nPyYAML 6.0\r\nrequests 2.27.1\r\nscipy 1.7.3\r\nseaborn 0.11.2\r\nsetuptools 60.0.5\r\nsix 1.16.0\r\ntangled-up-in-unicode 0.1.0\r\ntqdm 4.62.3\r\ntyping_extensions 4.0.1\r\nurllib3 1.26.8\r\nvisions 0.7.4\r\nwheel 0.37.1\r\n```\r\n\r\n#### Working environment\r\n\r\nPython version: Python 3.9.1\r\nPip version: pip 21.3.1\r\nPandas and pandas-profiling versions: 1.3.5 | 3.1.0\r\nFull pip list:\r\n```\r\nPackage Version\r\n--------------------- ---------\r\nattrs 21.4.0\r\ncertifi 2021.10.8\r\ncharset-normalizer 2.0.10\r\ncycler 0.11.0\r\nfonttools 4.28.5\r\nhtmlmin 0.1.12\r\nidna 3.3\r\nImageHash 4.2.1\r\nJinja2 3.0.3\r\njoblib 1.0.1\r\nkiwisolver 1.3.2\r\nMarkupSafe 2.0.1\r\nmatplotlib 3.5.1\r\nmissingno 0.5.0\r\nmultimethod 1.6\r\nnetworkx 2.6.3\r\nnumpy 1.22.1\r\npackaging 21.3\r\npandas 1.3.5\r\npandas-profiling 3.1.0\r\nphik 0.12.0\r\nPillow 9.0.0\r\npip 21.3.1\r\npydantic 1.9.0\r\npyparsing 3.0.7\r\npython-dateutil 2.8.2\r\npytz 2021.3\r\nPyWavelets 1.2.0\r\nPyYAML 6.0\r\nrequests 2.27.1\r\nscipy 1.7.3\r\nseaborn 0.11.2\r\nsetuptools 60.0.5\r\nsix 1.16.0\r\ntangled-up-in-unicode 0.1.0\r\ntqdm 4.62.3\r\ntyping_extensions 4.0.1\r\nurllib3 1.26.8\r\nvisions 0.7.4\r\nwheel 0.37.1\r\n```\r\n\r\nLet me know if I can provide more details and thank you for your good work!\n", "before_files": [{"content": "import numpy as np\n\n\ndef weighted_median(data: np.ndarray, weights: np.ndarray) -> int:\n \"\"\"\n Args:\n data (list or numpy.array): data\n weights (list or numpy.array): weights\n \"\"\"\n s_data, s_weights = map(np.array, zip(*sorted(zip(data, weights))))\n midpoint = 0.5 * sum(s_weights)\n if any(weights > midpoint):\n w_median = (data[weights == np.max(weights)])[0]\n else:\n cs_weights = np.cumsum(s_weights)\n idx = np.where(cs_weights <= midpoint)[0][-1]\n if cs_weights[idx] == midpoint:\n w_median = np.mean(s_data[idx : idx + 2])\n else:\n w_median = s_data[idx + 1]\n return w_median\n", "path": "src/pandas_profiling/model/pandas/utils_pandas.py"}], "after_files": [{"content": "import numpy as np\n\n\ndef weighted_median(data: np.ndarray, weights: np.ndarray) -> int:\n \"\"\"\n Args:\n data (list or numpy.array): data\n weights (list or numpy.array): weights\n \"\"\"\n if not isinstance(data, np.ndarray):\n data = np.array(data)\n if not isinstance(weights, np.ndarray):\n weights = np.array(weights)\n\n s_data, s_weights = map(np.sort, [data, weights])\n midpoint = 0.5 * np.sum(s_weights)\n\n if s_weights[-1] > midpoint:\n w_median = data[weights == np.max(weights)][0]\n else:\n cs_weights = np.cumsum(s_weights)\n idx = np.where(cs_weights <= midpoint)[0][-1]\n if cs_weights[idx] == midpoint:\n w_median = np.mean(s_data[idx : idx + 2])\n else:\n w_median = s_data[idx + 1]\n return w_median\n", "path": "src/pandas_profiling/model/pandas/utils_pandas.py"}]} | 2,812 | 274 |
gh_patches_debug_9822 | rasdani/github-patches | git_diff | mitmproxy__mitmproxy-4532 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Passphrase given in the command line is visible in the process list
#### Problem Description
Mitmproxy accepts cert-passphrase as one of the command-line options. If the user gives a passphrase like this while running the mitmproxy, anyone having access to a command line on that server can see the passphrase by listing the running processes.
#### Steps to reproduce the behavior:
1. Create a self-signed certificate using openssl, make sure you give a passphrase for the certificate.
2. Run mitmproxy/mitmdump/mitmweb with the command line options as shown
mitmdump --certs *.mydomain.com=mycert.pem cert-passphrase abcd
3. Take a Linux terminal and issue the command ps -ef | grep mitm
4. You can see the passphrase given to mitmdump command in clear text
This is a security issue in my opinion. Some programs effectively hide such sensitive inputs that are given as command-line arguments. They do this by rewriting the command line args in an obfuscated manner and by rerunning the program by itself. In this way, the sensitive data that came along via command-line arguments will be visible for a split second, but that is still better than making them always visible as long as the program is running.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/options.py`
Content:
```
1 from typing import Optional, Sequence
2
3 from mitmproxy import optmanager
4
5 CONF_DIR = "~/.mitmproxy"
6 CONF_BASENAME = "mitmproxy"
7 LISTEN_PORT = 8080
8 CONTENT_VIEW_LINES_CUTOFF = 512
9 KEY_SIZE = 2048
10
11
12 class Options(optmanager.OptManager):
13
14 def __init__(self, **kwargs) -> None:
15 super().__init__()
16 self.add_option(
17 "server", bool, True,
18 "Start a proxy server. Enabled by default."
19 )
20 self.add_option(
21 "showhost", bool, False,
22 "Use the Host header to construct URLs for display."
23 )
24
25 # Proxy options
26 self.add_option(
27 "add_upstream_certs_to_client_chain", bool, False,
28 """
29 Add all certificates of the upstream server to the certificate chain
30 that will be served to the proxy client, as extras.
31 """
32 )
33 self.add_option(
34 "confdir", str, CONF_DIR,
35 "Location of the default mitmproxy configuration files."
36 )
37 self.add_option(
38 "certs", Sequence[str], [],
39 """
40 SSL certificates of the form "[domain=]path". The domain may include
41 a wildcard, and is equal to "*" if not specified. The file at path
42 is a certificate in PEM format. If a private key is included in the
43 PEM, it is used, else the default key in the conf dir is used. The
44 PEM file should contain the full certificate chain, with the leaf
45 certificate as the first entry.
46 """
47 )
48 self.add_option(
49 "cert_passphrase", Optional[str], None,
50 "Passphrase for decrypting the private key provided in the --cert option."
51 )
52 self.add_option(
53 "ciphers_client", Optional[str], None,
54 "Set supported ciphers for client connections using OpenSSL syntax."
55 )
56 self.add_option(
57 "ciphers_server", Optional[str], None,
58 "Set supported ciphers for server connections using OpenSSL syntax."
59 )
60 self.add_option(
61 "client_certs", Optional[str], None,
62 "Client certificate file or directory."
63 )
64 self.add_option(
65 "ignore_hosts", Sequence[str], [],
66 """
67 Ignore host and forward all traffic without processing it. In
68 transparent mode, it is recommended to use an IP address (range),
69 not the hostname. In regular mode, only SSL traffic is ignored and
70 the hostname should be used. The supplied value is interpreted as a
71 regular expression and matched on the ip or the hostname.
72 """
73 )
74 self.add_option(
75 "allow_hosts", Sequence[str], [],
76 "Opposite of --ignore-hosts."
77 )
78 self.add_option(
79 "listen_host", str, "",
80 "Address to bind proxy to."
81 )
82 self.add_option(
83 "listen_port", int, LISTEN_PORT,
84 "Proxy service port."
85 )
86 self.add_option(
87 "mode", str, "regular",
88 """
89 Mode can be "regular", "transparent", "socks5", "reverse:SPEC",
90 or "upstream:SPEC". For reverse and upstream proxy modes, SPEC
91 is host specification in the form of "http[s]://host[:port]".
92 """
93 )
94 self.add_option(
95 "upstream_cert", bool, True,
96 "Connect to upstream server to look up certificate details."
97 )
98
99 self.add_option(
100 "http2", bool, True,
101 "Enable/disable HTTP/2 support. "
102 "HTTP/2 support is enabled by default.",
103 )
104 self.add_option(
105 "websocket", bool, True,
106 "Enable/disable WebSocket support. "
107 "WebSocket support is enabled by default.",
108 )
109 self.add_option(
110 "rawtcp", bool, True,
111 "Enable/disable raw TCP connections. "
112 "TCP connections are enabled by default. "
113 )
114 self.add_option(
115 "ssl_insecure", bool, False,
116 "Do not verify upstream server SSL/TLS certificates."
117 )
118 self.add_option(
119 "ssl_verify_upstream_trusted_confdir", Optional[str], None,
120 """
121 Path to a directory of trusted CA certificates for upstream server
122 verification prepared using the c_rehash tool.
123 """
124 )
125 self.add_option(
126 "ssl_verify_upstream_trusted_ca", Optional[str], None,
127 "Path to a PEM formatted trusted CA certificate."
128 )
129 self.add_option(
130 "tcp_hosts", Sequence[str], [],
131 """
132 Generic TCP SSL proxy mode for all hosts that match the pattern.
133 Similar to --ignore-hosts, but SSL connections are intercepted.
134 The communication contents are printed to the log in verbose mode.
135 """
136 )
137 self.add_option(
138 "content_view_lines_cutoff", int, CONTENT_VIEW_LINES_CUTOFF,
139 """
140 Flow content view lines limit. Limit is enabled by default to
141 speedup flows browsing.
142 """
143 )
144 self.add_option(
145 "key_size", int, KEY_SIZE,
146 """
147 TLS key size for certificates and CA.
148 """
149 )
150
151 self.update(**kwargs)
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mitmproxy/options.py b/mitmproxy/options.py
--- a/mitmproxy/options.py
+++ b/mitmproxy/options.py
@@ -47,7 +47,12 @@
)
self.add_option(
"cert_passphrase", Optional[str], None,
- "Passphrase for decrypting the private key provided in the --cert option."
+ """
+ Passphrase for decrypting the private key provided in the --cert option.
+
+ Note that passing cert_passphrase on the command line makes your passphrase visible in your system's
+ process list. Specify it in config.yaml to avoid this.
+ """
)
self.add_option(
"ciphers_client", Optional[str], None,
| {"golden_diff": "diff --git a/mitmproxy/options.py b/mitmproxy/options.py\n--- a/mitmproxy/options.py\n+++ b/mitmproxy/options.py\n@@ -47,7 +47,12 @@\n )\n self.add_option(\n \"cert_passphrase\", Optional[str], None,\n- \"Passphrase for decrypting the private key provided in the --cert option.\"\n+ \"\"\"\n+ Passphrase for decrypting the private key provided in the --cert option.\n+\n+ Note that passing cert_passphrase on the command line makes your passphrase visible in your system's\n+ process list. Specify it in config.yaml to avoid this.\n+ \"\"\"\n )\n self.add_option(\n \"ciphers_client\", Optional[str], None,\n", "issue": "Passphrase given in the command line is visible in the process list \n#### Problem Description\r\nMitmproxy accepts cert-passphrase as one of the command-line options. If the user gives a passphrase like this while running the mitmproxy, anyone having access to a command line on that server can see the passphrase by listing the running processes.\r\n\r\n#### Steps to reproduce the behavior:\r\n1. Create a self-signed certificate using openssl, make sure you give a passphrase for the certificate. \r\n2. Run mitmproxy/mitmdump/mitmweb with the command line options as shown\r\nmitmdump --certs *.mydomain.com=mycert.pem cert-passphrase abcd \r\n3. Take a Linux terminal and issue the command ps -ef | grep mitm\r\n4. You can see the passphrase given to mitmdump command in clear text\r\n\r\nThis is a security issue in my opinion. Some programs effectively hide such sensitive inputs that are given as command-line arguments. They do this by rewriting the command line args in an obfuscated manner and by rerunning the program by itself. In this way, the sensitive data that came along via command-line arguments will be visible for a split second, but that is still better than making them always visible as long as the program is running.\r\n\r\n\n", "before_files": [{"content": "from typing import Optional, Sequence\n\nfrom mitmproxy import optmanager\n\nCONF_DIR = \"~/.mitmproxy\"\nCONF_BASENAME = \"mitmproxy\"\nLISTEN_PORT = 8080\nCONTENT_VIEW_LINES_CUTOFF = 512\nKEY_SIZE = 2048\n\n\nclass Options(optmanager.OptManager):\n\n def __init__(self, **kwargs) -> None:\n super().__init__()\n self.add_option(\n \"server\", bool, True,\n \"Start a proxy server. Enabled by default.\"\n )\n self.add_option(\n \"showhost\", bool, False,\n \"Use the Host header to construct URLs for display.\"\n )\n\n # Proxy options\n self.add_option(\n \"add_upstream_certs_to_client_chain\", bool, False,\n \"\"\"\n Add all certificates of the upstream server to the certificate chain\n that will be served to the proxy client, as extras.\n \"\"\"\n )\n self.add_option(\n \"confdir\", str, CONF_DIR,\n \"Location of the default mitmproxy configuration files.\"\n )\n self.add_option(\n \"certs\", Sequence[str], [],\n \"\"\"\n SSL certificates of the form \"[domain=]path\". The domain may include\n a wildcard, and is equal to \"*\" if not specified. The file at path\n is a certificate in PEM format. If a private key is included in the\n PEM, it is used, else the default key in the conf dir is used. The\n PEM file should contain the full certificate chain, with the leaf\n certificate as the first entry.\n \"\"\"\n )\n self.add_option(\n \"cert_passphrase\", Optional[str], None,\n \"Passphrase for decrypting the private key provided in the --cert option.\"\n )\n self.add_option(\n \"ciphers_client\", Optional[str], None,\n \"Set supported ciphers for client connections using OpenSSL syntax.\"\n )\n self.add_option(\n \"ciphers_server\", Optional[str], None,\n \"Set supported ciphers for server connections using OpenSSL syntax.\"\n )\n self.add_option(\n \"client_certs\", Optional[str], None,\n \"Client certificate file or directory.\"\n )\n self.add_option(\n \"ignore_hosts\", Sequence[str], [],\n \"\"\"\n Ignore host and forward all traffic without processing it. In\n transparent mode, it is recommended to use an IP address (range),\n not the hostname. In regular mode, only SSL traffic is ignored and\n the hostname should be used. The supplied value is interpreted as a\n regular expression and matched on the ip or the hostname.\n \"\"\"\n )\n self.add_option(\n \"allow_hosts\", Sequence[str], [],\n \"Opposite of --ignore-hosts.\"\n )\n self.add_option(\n \"listen_host\", str, \"\",\n \"Address to bind proxy to.\"\n )\n self.add_option(\n \"listen_port\", int, LISTEN_PORT,\n \"Proxy service port.\"\n )\n self.add_option(\n \"mode\", str, \"regular\",\n \"\"\"\n Mode can be \"regular\", \"transparent\", \"socks5\", \"reverse:SPEC\",\n or \"upstream:SPEC\". For reverse and upstream proxy modes, SPEC\n is host specification in the form of \"http[s]://host[:port]\".\n \"\"\"\n )\n self.add_option(\n \"upstream_cert\", bool, True,\n \"Connect to upstream server to look up certificate details.\"\n )\n\n self.add_option(\n \"http2\", bool, True,\n \"Enable/disable HTTP/2 support. \"\n \"HTTP/2 support is enabled by default.\",\n )\n self.add_option(\n \"websocket\", bool, True,\n \"Enable/disable WebSocket support. \"\n \"WebSocket support is enabled by default.\",\n )\n self.add_option(\n \"rawtcp\", bool, True,\n \"Enable/disable raw TCP connections. \"\n \"TCP connections are enabled by default. \"\n )\n self.add_option(\n \"ssl_insecure\", bool, False,\n \"Do not verify upstream server SSL/TLS certificates.\"\n )\n self.add_option(\n \"ssl_verify_upstream_trusted_confdir\", Optional[str], None,\n \"\"\"\n Path to a directory of trusted CA certificates for upstream server\n verification prepared using the c_rehash tool.\n \"\"\"\n )\n self.add_option(\n \"ssl_verify_upstream_trusted_ca\", Optional[str], None,\n \"Path to a PEM formatted trusted CA certificate.\"\n )\n self.add_option(\n \"tcp_hosts\", Sequence[str], [],\n \"\"\"\n Generic TCP SSL proxy mode for all hosts that match the pattern.\n Similar to --ignore-hosts, but SSL connections are intercepted.\n The communication contents are printed to the log in verbose mode.\n \"\"\"\n )\n self.add_option(\n \"content_view_lines_cutoff\", int, CONTENT_VIEW_LINES_CUTOFF,\n \"\"\"\n Flow content view lines limit. Limit is enabled by default to\n speedup flows browsing.\n \"\"\"\n )\n self.add_option(\n \"key_size\", int, KEY_SIZE,\n \"\"\"\n TLS key size for certificates and CA.\n \"\"\"\n )\n\n self.update(**kwargs)\n", "path": "mitmproxy/options.py"}], "after_files": [{"content": "from typing import Optional, Sequence\n\nfrom mitmproxy import optmanager\n\nCONF_DIR = \"~/.mitmproxy\"\nCONF_BASENAME = \"mitmproxy\"\nLISTEN_PORT = 8080\nCONTENT_VIEW_LINES_CUTOFF = 512\nKEY_SIZE = 2048\n\n\nclass Options(optmanager.OptManager):\n\n def __init__(self, **kwargs) -> None:\n super().__init__()\n self.add_option(\n \"server\", bool, True,\n \"Start a proxy server. Enabled by default.\"\n )\n self.add_option(\n \"showhost\", bool, False,\n \"Use the Host header to construct URLs for display.\"\n )\n\n # Proxy options\n self.add_option(\n \"add_upstream_certs_to_client_chain\", bool, False,\n \"\"\"\n Add all certificates of the upstream server to the certificate chain\n that will be served to the proxy client, as extras.\n \"\"\"\n )\n self.add_option(\n \"confdir\", str, CONF_DIR,\n \"Location of the default mitmproxy configuration files.\"\n )\n self.add_option(\n \"certs\", Sequence[str], [],\n \"\"\"\n SSL certificates of the form \"[domain=]path\". The domain may include\n a wildcard, and is equal to \"*\" if not specified. The file at path\n is a certificate in PEM format. If a private key is included in the\n PEM, it is used, else the default key in the conf dir is used. The\n PEM file should contain the full certificate chain, with the leaf\n certificate as the first entry.\n \"\"\"\n )\n self.add_option(\n \"cert_passphrase\", Optional[str], None,\n \"\"\"\n Passphrase for decrypting the private key provided in the --cert option.\n\n Note that passing cert_passphrase on the command line makes your passphrase visible in your system's\n process list. Specify it in config.yaml to avoid this.\n \"\"\"\n )\n self.add_option(\n \"ciphers_client\", Optional[str], None,\n \"Set supported ciphers for client connections using OpenSSL syntax.\"\n )\n self.add_option(\n \"ciphers_server\", Optional[str], None,\n \"Set supported ciphers for server connections using OpenSSL syntax.\"\n )\n self.add_option(\n \"client_certs\", Optional[str], None,\n \"Client certificate file or directory.\"\n )\n self.add_option(\n \"ignore_hosts\", Sequence[str], [],\n \"\"\"\n Ignore host and forward all traffic without processing it. In\n transparent mode, it is recommended to use an IP address (range),\n not the hostname. In regular mode, only SSL traffic is ignored and\n the hostname should be used. The supplied value is interpreted as a\n regular expression and matched on the ip or the hostname.\n \"\"\"\n )\n self.add_option(\n \"allow_hosts\", Sequence[str], [],\n \"Opposite of --ignore-hosts.\"\n )\n self.add_option(\n \"listen_host\", str, \"\",\n \"Address to bind proxy to.\"\n )\n self.add_option(\n \"listen_port\", int, LISTEN_PORT,\n \"Proxy service port.\"\n )\n self.add_option(\n \"mode\", str, \"regular\",\n \"\"\"\n Mode can be \"regular\", \"transparent\", \"socks5\", \"reverse:SPEC\",\n or \"upstream:SPEC\". For reverse and upstream proxy modes, SPEC\n is host specification in the form of \"http[s]://host[:port]\".\n \"\"\"\n )\n self.add_option(\n \"upstream_cert\", bool, True,\n \"Connect to upstream server to look up certificate details.\"\n )\n\n self.add_option(\n \"http2\", bool, True,\n \"Enable/disable HTTP/2 support. \"\n \"HTTP/2 support is enabled by default.\",\n )\n self.add_option(\n \"websocket\", bool, True,\n \"Enable/disable WebSocket support. \"\n \"WebSocket support is enabled by default.\",\n )\n self.add_option(\n \"rawtcp\", bool, True,\n \"Enable/disable raw TCP connections. \"\n \"TCP connections are enabled by default. \"\n )\n self.add_option(\n \"ssl_insecure\", bool, False,\n \"Do not verify upstream server SSL/TLS certificates.\"\n )\n self.add_option(\n \"ssl_verify_upstream_trusted_confdir\", Optional[str], None,\n \"\"\"\n Path to a directory of trusted CA certificates for upstream server\n verification prepared using the c_rehash tool.\n \"\"\"\n )\n self.add_option(\n \"ssl_verify_upstream_trusted_ca\", Optional[str], None,\n \"Path to a PEM formatted trusted CA certificate.\"\n )\n self.add_option(\n \"tcp_hosts\", Sequence[str], [],\n \"\"\"\n Generic TCP SSL proxy mode for all hosts that match the pattern.\n Similar to --ignore-hosts, but SSL connections are intercepted.\n The communication contents are printed to the log in verbose mode.\n \"\"\"\n )\n self.add_option(\n \"content_view_lines_cutoff\", int, CONTENT_VIEW_LINES_CUTOFF,\n \"\"\"\n Flow content view lines limit. Limit is enabled by default to\n speedup flows browsing.\n \"\"\"\n )\n self.add_option(\n \"key_size\", int, KEY_SIZE,\n \"\"\"\n TLS key size for certificates and CA.\n \"\"\"\n )\n\n self.update(**kwargs)\n", "path": "mitmproxy/options.py"}]} | 1,968 | 158 |
gh_patches_debug_33829 | rasdani/github-patches | git_diff | googleapis__google-auth-library-python-1430 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Broken link in Python37DeprecationWarning deprecation message
```
warnings.warn(message, Python37DeprecationWarning)
E google.auth.Python37DeprecationWarning: After January 1, 2024, new releases of this library will drop support for Python 3.7. More details about Python 3.7 support can be found at https://cloud.google.com/python/docs/python37-sunset/
```
The link https://cloud.google.com/python/docs/python37-sunset/ results in 404. We should remove it from the deprecation message.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/oauth2/__init__.py`
Content:
```
1 # Copyright 2016 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Google OAuth 2.0 Library for Python."""
16
17 import sys
18 import warnings
19
20
21 class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER
22 """
23 Deprecation warning raised when Python 3.7 runtime is detected.
24 Python 3.7 support will be dropped after January 1, 2024. See
25 https://cloud.google.com/python/docs/python37-sunset/ for more information.
26 """
27
28 pass
29
30
31 # Checks if the current runtime is Python 3.7.
32 if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER
33 message = (
34 "After January 1, 2024, new releases of this library will drop support "
35 "for Python 3.7. More details about Python 3.7 support "
36 "can be found at https://cloud.google.com/python/docs/python37-sunset/"
37 )
38 warnings.warn(message, Python37DeprecationWarning)
39
```
Path: `google/auth/__init__.py`
Content:
```
1 # Copyright 2016 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Google Auth Library for Python."""
16
17 import logging
18 import sys
19 import warnings
20
21 from google.auth import version as google_auth_version
22 from google.auth._default import (
23 default,
24 load_credentials_from_dict,
25 load_credentials_from_file,
26 )
27
28
29 __version__ = google_auth_version.__version__
30
31
32 __all__ = ["default", "load_credentials_from_file", "load_credentials_from_dict"]
33
34
35 class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER
36 """
37 Deprecation warning raised when Python 3.7 runtime is detected.
38 Python 3.7 support will be dropped after January 1, 2024. See
39 https://cloud.google.com/python/docs/python37-sunset/ for more information.
40 """
41
42 pass
43
44
45 # Checks if the current runtime is Python 3.7.
46 if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER
47 message = (
48 "After January 1, 2024, new releases of this library will drop support "
49 "for Python 3.7. More details about Python 3.7 support "
50 "can be found at https://cloud.google.com/python/docs/python37-sunset/"
51 )
52 warnings.warn(message, Python37DeprecationWarning)
53
54 # Set default logging handler to avoid "No handler found" warnings.
55 logging.getLogger(__name__).addHandler(logging.NullHandler())
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/google/auth/__init__.py b/google/auth/__init__.py
--- a/google/auth/__init__.py
+++ b/google/auth/__init__.py
@@ -35,8 +35,7 @@
class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER
"""
Deprecation warning raised when Python 3.7 runtime is detected.
- Python 3.7 support will be dropped after January 1, 2024. See
- https://cloud.google.com/python/docs/python37-sunset/ for more information.
+ Python 3.7 support will be dropped after January 1, 2024.
"""
pass
@@ -46,8 +45,7 @@
if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER
message = (
"After January 1, 2024, new releases of this library will drop support "
- "for Python 3.7. More details about Python 3.7 support "
- "can be found at https://cloud.google.com/python/docs/python37-sunset/"
+ "for Python 3.7."
)
warnings.warn(message, Python37DeprecationWarning)
diff --git a/google/oauth2/__init__.py b/google/oauth2/__init__.py
--- a/google/oauth2/__init__.py
+++ b/google/oauth2/__init__.py
@@ -21,8 +21,7 @@
class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER
"""
Deprecation warning raised when Python 3.7 runtime is detected.
- Python 3.7 support will be dropped after January 1, 2024. See
- https://cloud.google.com/python/docs/python37-sunset/ for more information.
+ Python 3.7 support will be dropped after January 1, 2024.
"""
pass
@@ -32,7 +31,6 @@
if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER
message = (
"After January 1, 2024, new releases of this library will drop support "
- "for Python 3.7. More details about Python 3.7 support "
- "can be found at https://cloud.google.com/python/docs/python37-sunset/"
+ "for Python 3.7."
)
warnings.warn(message, Python37DeprecationWarning)
| {"golden_diff": "diff --git a/google/auth/__init__.py b/google/auth/__init__.py\n--- a/google/auth/__init__.py\n+++ b/google/auth/__init__.py\n@@ -35,8 +35,7 @@\n class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n- Python 3.7 support will be dropped after January 1, 2024. See\n- https://cloud.google.com/python/docs/python37-sunset/ for more information.\n+ Python 3.7 support will be dropped after January 1, 2024.\n \"\"\"\n \n pass\n@@ -46,8 +45,7 @@\n if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n- \"for Python 3.7. More details about Python 3.7 support \"\n- \"can be found at https://cloud.google.com/python/docs/python37-sunset/\"\n+ \"for Python 3.7.\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n \ndiff --git a/google/oauth2/__init__.py b/google/oauth2/__init__.py\n--- a/google/oauth2/__init__.py\n+++ b/google/oauth2/__init__.py\n@@ -21,8 +21,7 @@\n class Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n- Python 3.7 support will be dropped after January 1, 2024. See\n- https://cloud.google.com/python/docs/python37-sunset/ for more information.\n+ Python 3.7 support will be dropped after January 1, 2024.\n \"\"\"\n \n pass\n@@ -32,7 +31,6 @@\n if sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n- \"for Python 3.7. More details about Python 3.7 support \"\n- \"can be found at https://cloud.google.com/python/docs/python37-sunset/\"\n+ \"for Python 3.7.\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n", "issue": "Broken link in Python37DeprecationWarning deprecation message\n```\r\n warnings.warn(message, Python37DeprecationWarning)\r\nE google.auth.Python37DeprecationWarning: After January 1, 2024, new releases of this library will drop support for Python 3.7. More details about Python 3.7 support can be found at https://cloud.google.com/python/docs/python37-sunset/\r\n```\r\nThe link https://cloud.google.com/python/docs/python37-sunset/ results in 404. We should remove it from the deprecation message.\n", "before_files": [{"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Google OAuth 2.0 Library for Python.\"\"\"\n\nimport sys\nimport warnings\n\n\nclass Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n Python 3.7 support will be dropped after January 1, 2024. See\n https://cloud.google.com/python/docs/python37-sunset/ for more information.\n \"\"\"\n\n pass\n\n\n# Checks if the current runtime is Python 3.7.\nif sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n \"for Python 3.7. More details about Python 3.7 support \"\n \"can be found at https://cloud.google.com/python/docs/python37-sunset/\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n", "path": "google/oauth2/__init__.py"}, {"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Google Auth Library for Python.\"\"\"\n\nimport logging\nimport sys\nimport warnings\n\nfrom google.auth import version as google_auth_version\nfrom google.auth._default import (\n default,\n load_credentials_from_dict,\n load_credentials_from_file,\n)\n\n\n__version__ = google_auth_version.__version__\n\n\n__all__ = [\"default\", \"load_credentials_from_file\", \"load_credentials_from_dict\"]\n\n\nclass Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n Python 3.7 support will be dropped after January 1, 2024. See\n https://cloud.google.com/python/docs/python37-sunset/ for more information.\n \"\"\"\n\n pass\n\n\n# Checks if the current runtime is Python 3.7.\nif sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n \"for Python 3.7. More details about Python 3.7 support \"\n \"can be found at https://cloud.google.com/python/docs/python37-sunset/\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n\n# Set default logging handler to avoid \"No handler found\" warnings.\nlogging.getLogger(__name__).addHandler(logging.NullHandler())\n", "path": "google/auth/__init__.py"}], "after_files": [{"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Google OAuth 2.0 Library for Python.\"\"\"\n\nimport sys\nimport warnings\n\n\nclass Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n Python 3.7 support will be dropped after January 1, 2024.\n \"\"\"\n\n pass\n\n\n# Checks if the current runtime is Python 3.7.\nif sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n \"for Python 3.7.\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n", "path": "google/oauth2/__init__.py"}, {"content": "# Copyright 2016 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Google Auth Library for Python.\"\"\"\n\nimport logging\nimport sys\nimport warnings\n\nfrom google.auth import version as google_auth_version\nfrom google.auth._default import (\n default,\n load_credentials_from_dict,\n load_credentials_from_file,\n)\n\n\n__version__ = google_auth_version.__version__\n\n\n__all__ = [\"default\", \"load_credentials_from_file\", \"load_credentials_from_dict\"]\n\n\nclass Python37DeprecationWarning(DeprecationWarning): # pragma: NO COVER\n \"\"\"\n Deprecation warning raised when Python 3.7 runtime is detected.\n Python 3.7 support will be dropped after January 1, 2024.\n \"\"\"\n\n pass\n\n\n# Checks if the current runtime is Python 3.7.\nif sys.version_info.major == 3 and sys.version_info.minor == 7: # pragma: NO COVER\n message = (\n \"After January 1, 2024, new releases of this library will drop support \"\n \"for Python 3.7.\"\n )\n warnings.warn(message, Python37DeprecationWarning)\n\n# Set default logging handler to avoid \"No handler found\" warnings.\nlogging.getLogger(__name__).addHandler(logging.NullHandler())\n", "path": "google/auth/__init__.py"}]} | 1,382 | 577 |
gh_patches_debug_14755 | rasdani/github-patches | git_diff | ansible__ansible-41206 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
aws_s3 is automaticly decrypting ansible-vault encrypted files before put
<!---
Verify first that your issue/request is not already reported on GitHub.
Also test if the latest release, and devel branch are affected too.
Always add information AFTER of these html comments. -->
##### ISSUE TYPE
- Bug Report
##### COMPONENT NAME
aws_s3
##### ANSIBLE VERSION
<!--- Paste, BELOW THIS COMMENT, verbatim output from "ansible --version" between quotes below -->
```
2.5.1
```
##### SUMMARY
- I'm trying to upload an ansible-vault encrypted file with aws_s3. But aws_s3 decrypts the src: file before uploading it to S3.
- aws_s3 in 2.4 didn't decrypt the src: parameter.
- The documentation for aws_s3 doesn't mention that the src: parameter is autodecrypted.
- The aws_s3 module doesn't accept the decrypt: argument.
##### STEPS TO REPRODUCE
<!--- Paste example playbooks or commands between quotes below -->
```yaml
- name: upload vault to s3
aws_s3:
bucket: "the bucket"
object: "file.txt"
src: "file.txt"
mode: put
```
1. The file.txt is encrypted with ansible-vault.
2. The playbook that runs this task is invoked with --vault-password and is able to decrypt the file because other tasks need the file decrypted.
##### EXPECTED RESULTS
Don't autodecrypt the src: argument or be able to specify decrypt: no.
##### ACTUAL RESULTS
The src: argument to aws_s3 is automagicly decrypted without documentation or a way to disable the feature like other modules (ex. copy).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/ansible/plugins/action/aws_s3.py`
Content:
```
1 # (c) 2012, Michael DeHaan <[email protected]>
2 # (c) 2018, Will Thames <[email protected]>
3 #
4 # This file is part of Ansible
5 #
6 # Ansible is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation, either version 3 of the License, or
9 # (at your option) any later version.
10 #
11 # Ansible is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
18 from __future__ import (absolute_import, division, print_function)
19 __metaclass__ = type
20
21 import os
22
23 from ansible.errors import AnsibleError, AnsibleAction, AnsibleActionFail, AnsibleFileNotFound
24 from ansible.module_utils._text import to_text
25 from ansible.plugins.action import ActionBase
26
27
28 class ActionModule(ActionBase):
29
30 TRANSFERS_FILES = True
31
32 def run(self, tmp=None, task_vars=None):
33 ''' handler for aws_s3 operations '''
34 if task_vars is None:
35 task_vars = dict()
36
37 result = super(ActionModule, self).run(tmp, task_vars)
38 del tmp # tmp no longer has any effect
39
40 source = self._task.args.get('src', None)
41
42 try:
43 new_module_args = self._task.args.copy()
44 if source:
45 source = os.path.expanduser(source)
46
47 # For backward compatibility check if the file exists on the remote; it should take precedence
48 if not self._remote_file_exists(source):
49 try:
50 source = self._loader.get_real_file(self._find_needle('files', source))
51 new_module_args['src'] = source
52 except AnsibleFileNotFound as e:
53 # module handles error message for nonexistent files
54 new_module_args['src'] = source
55 except AnsibleError as e:
56 raise AnsibleActionFail(to_text(e))
57
58 # execute the aws_s3 module now, with the updated args
59 result.update(self._execute_module(module_args=new_module_args, task_vars=task_vars))
60 except AnsibleAction as e:
61 result.update(e.result)
62 return result
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/ansible/plugins/action/aws_s3.py b/lib/ansible/plugins/action/aws_s3.py
--- a/lib/ansible/plugins/action/aws_s3.py
+++ b/lib/ansible/plugins/action/aws_s3.py
@@ -47,7 +47,7 @@
# For backward compatibility check if the file exists on the remote; it should take precedence
if not self._remote_file_exists(source):
try:
- source = self._loader.get_real_file(self._find_needle('files', source))
+ source = self._loader.get_real_file(self._find_needle('files', source), decrypt=False)
new_module_args['src'] = source
except AnsibleFileNotFound as e:
# module handles error message for nonexistent files
| {"golden_diff": "diff --git a/lib/ansible/plugins/action/aws_s3.py b/lib/ansible/plugins/action/aws_s3.py\n--- a/lib/ansible/plugins/action/aws_s3.py\n+++ b/lib/ansible/plugins/action/aws_s3.py\n@@ -47,7 +47,7 @@\n # For backward compatibility check if the file exists on the remote; it should take precedence\n if not self._remote_file_exists(source):\n try:\n- source = self._loader.get_real_file(self._find_needle('files', source))\n+ source = self._loader.get_real_file(self._find_needle('files', source), decrypt=False)\n new_module_args['src'] = source\n except AnsibleFileNotFound as e:\n # module handles error message for nonexistent files\n", "issue": "aws_s3 is automaticly decrypting ansible-vault encrypted files before put\n<!---\r\nVerify first that your issue/request is not already reported on GitHub.\r\nAlso test if the latest release, and devel branch are affected too.\r\nAlways add information AFTER of these html comments. -->\r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n\r\n##### COMPONENT NAME\r\naws_s3\r\n\r\n##### ANSIBLE VERSION\r\n<!--- Paste, BELOW THIS COMMENT, verbatim output from \"ansible --version\" between quotes below -->\r\n```\r\n2.5.1\r\n```\r\n\r\n##### SUMMARY\r\n- I'm trying to upload an ansible-vault encrypted file with aws_s3. But aws_s3 decrypts the src: file before uploading it to S3. \r\n- aws_s3 in 2.4 didn't decrypt the src: parameter.\r\n- The documentation for aws_s3 doesn't mention that the src: parameter is autodecrypted.\r\n- The aws_s3 module doesn't accept the decrypt: argument.\r\n\r\n##### STEPS TO REPRODUCE\r\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml\r\n- name: upload vault to s3\r\n aws_s3:\r\n bucket: \"the bucket\"\r\n object: \"file.txt\"\r\n src: \"file.txt\"\r\n mode: put\r\n```\r\n1. The file.txt is encrypted with ansible-vault. \r\n2. The playbook that runs this task is invoked with --vault-password and is able to decrypt the file because other tasks need the file decrypted.\r\n\r\n##### EXPECTED RESULTS\r\nDon't autodecrypt the src: argument or be able to specify decrypt: no.\r\n\r\n##### ACTUAL RESULTS\r\nThe src: argument to aws_s3 is automagicly decrypted without documentation or a way to disable the feature like other modules (ex. copy).\r\n\n", "before_files": [{"content": "# (c) 2012, Michael DeHaan <[email protected]>\n# (c) 2018, Will Thames <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport os\n\nfrom ansible.errors import AnsibleError, AnsibleAction, AnsibleActionFail, AnsibleFileNotFound\nfrom ansible.module_utils._text import to_text\nfrom ansible.plugins.action import ActionBase\n\n\nclass ActionModule(ActionBase):\n\n TRANSFERS_FILES = True\n\n def run(self, tmp=None, task_vars=None):\n ''' handler for aws_s3 operations '''\n if task_vars is None:\n task_vars = dict()\n\n result = super(ActionModule, self).run(tmp, task_vars)\n del tmp # tmp no longer has any effect\n\n source = self._task.args.get('src', None)\n\n try:\n new_module_args = self._task.args.copy()\n if source:\n source = os.path.expanduser(source)\n\n # For backward compatibility check if the file exists on the remote; it should take precedence\n if not self._remote_file_exists(source):\n try:\n source = self._loader.get_real_file(self._find_needle('files', source))\n new_module_args['src'] = source\n except AnsibleFileNotFound as e:\n # module handles error message for nonexistent files\n new_module_args['src'] = source\n except AnsibleError as e:\n raise AnsibleActionFail(to_text(e))\n\n # execute the aws_s3 module now, with the updated args\n result.update(self._execute_module(module_args=new_module_args, task_vars=task_vars))\n except AnsibleAction as e:\n result.update(e.result)\n return result\n", "path": "lib/ansible/plugins/action/aws_s3.py"}], "after_files": [{"content": "# (c) 2012, Michael DeHaan <[email protected]>\n# (c) 2018, Will Thames <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nimport os\n\nfrom ansible.errors import AnsibleError, AnsibleAction, AnsibleActionFail, AnsibleFileNotFound\nfrom ansible.module_utils._text import to_text\nfrom ansible.plugins.action import ActionBase\n\n\nclass ActionModule(ActionBase):\n\n TRANSFERS_FILES = True\n\n def run(self, tmp=None, task_vars=None):\n ''' handler for aws_s3 operations '''\n if task_vars is None:\n task_vars = dict()\n\n result = super(ActionModule, self).run(tmp, task_vars)\n del tmp # tmp no longer has any effect\n\n source = self._task.args.get('src', None)\n\n try:\n new_module_args = self._task.args.copy()\n if source:\n source = os.path.expanduser(source)\n\n # For backward compatibility check if the file exists on the remote; it should take precedence\n if not self._remote_file_exists(source):\n try:\n source = self._loader.get_real_file(self._find_needle('files', source), decrypt=False)\n new_module_args['src'] = source\n except AnsibleFileNotFound as e:\n # module handles error message for nonexistent files\n new_module_args['src'] = source\n except AnsibleError as e:\n raise AnsibleActionFail(to_text(e))\n\n # execute the aws_s3 module now, with the updated args\n result.update(self._execute_module(module_args=new_module_args, task_vars=task_vars))\n except AnsibleAction as e:\n result.update(e.result)\n return result\n", "path": "lib/ansible/plugins/action/aws_s3.py"}]} | 1,290 | 164 |
gh_patches_debug_22681 | rasdani/github-patches | git_diff | OpenNMT__OpenNMT-py-1188 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Source/Target length distinction
## Preprocess parameters
Removed parameter `-seq_length`
New parameters `-src_seq_length` and `-tgt_seq_length`
---
## Training speed token/s
In both LUA/PyTorch OpenNMT, the training process prints a speed, in token/sec, but:
* LUA OpenNMT is printing source token/sec
* PyOpenNMT is printing target token/sec
This can lead to important differences, especially when src/tgt sequence length are different (e.g. summarization), and therefore lead to false conclusion about performances.
See also: [pytoch/example/issue#75](https://github.com/pytorch/examples/issues/75)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `onmt/inputters/dataset_base.py`
Content:
```
1 # coding: utf-8
2
3 from itertools import chain
4 from collections import Counter
5 import codecs
6
7 import torch
8 from torchtext.data import Example, Dataset
9 from torchtext.vocab import Vocab
10
11
12 class DatasetBase(Dataset):
13 """
14 A dataset is an object that accepts sequences of raw data (sentence pairs
15 in the case of machine translation) and fields which describe how this
16 raw data should be processed to produce tensors. When a dataset is
17 instantiated, it applies the fields' preprocessing pipeline (but not
18 the bit that numericalizes it or turns it into batch tensors) to the raw
19 data, producing a list of torchtext.data.Example objects. torchtext's
20 iterators then know how to use these examples to make batches.
21
22 Datasets in OpenNMT take three positional arguments:
23
24 `fields`: a dict with the structure returned by inputters.get_fields().
25 keys match the keys of items yielded by the src_examples_iter or
26 tgt_examples_iter, while values are lists of (name, Field) pairs.
27 An attribute with this name will be created for each Example object,
28 and its value will be the result of applying the Field to the data
29 that matches the key. The advantage of having sequences of fields
30 for each piece of raw input is that it allows for the dataset to store
31 multiple `views` of each input, which allows for easy implementation
32 of token-level features, mixed word- and character-level models, and
33 so on.
34 `src_examples_iter`: a sequence of dicts. Each dict's keys should be a
35 subset of the keys in `fields`.
36 `tgt_examples_iter`: like `src_examples_iter`, but may be None (this is
37 the case at translation time if no target is specified).
38
39 `filter_pred` if specified, a function that accepts Example objects and
40 returns a boolean value indicating whether to include that example
41 in the dataset.
42
43 The resulting dataset will have three attributes (todo: also src_vocabs):
44
45 `examples`: a list of `torchtext.data.Example` objects with attributes as
46 described above.
47 `fields`: a dictionary whose keys are strings with the same names as the
48 attributes of the elements of `examples` and whose values are
49 the corresponding `torchtext.data.Field` objects. NOTE: this is not
50 the same structure as in the fields argument passed to the constructor.
51 """
52
53 def __getstate__(self):
54 return self.__dict__
55
56 def __setstate__(self, _d):
57 self.__dict__.update(_d)
58
59 def __reduce_ex__(self, proto):
60 # This is a hack. Something is broken with torch pickle.
61 return super(DatasetBase, self).__reduce_ex__()
62
63 def __init__(self, fields, src_examples_iter, tgt_examples_iter,
64 filter_pred=None):
65
66 dynamic_dict = 'src_map' in fields and 'alignment' in fields
67
68 if tgt_examples_iter is not None:
69 examples_iter = (self._join_dicts(src, tgt) for src, tgt in
70 zip(src_examples_iter, tgt_examples_iter))
71 else:
72 examples_iter = src_examples_iter
73
74 # self.src_vocabs is used in collapse_copy_scores and Translator.py
75 self.src_vocabs = []
76 examples = []
77 for ex_dict in examples_iter:
78 if dynamic_dict:
79 src_field = fields['src'][0][1]
80 tgt_field = fields['tgt'][0][1]
81 src_vocab, ex_dict = self._dynamic_dict(
82 ex_dict, src_field, tgt_field)
83 self.src_vocabs.append(src_vocab)
84 ex_fields = {k: v for k, v in fields.items() if k in ex_dict}
85 ex = Example.fromdict(ex_dict, ex_fields)
86 examples.append(ex)
87
88 # the dataset's self.fields should have the same attributes as examples
89 fields = dict(chain.from_iterable(ex_fields.values()))
90
91 super(DatasetBase, self).__init__(examples, fields, filter_pred)
92
93 def save(self, path, remove_fields=True):
94 if remove_fields:
95 self.fields = []
96 torch.save(self, path)
97
98 def _join_dicts(self, *args):
99 """
100 Args:
101 dictionaries with disjoint keys.
102
103 Returns:
104 a single dictionary that has the union of these keys.
105 """
106 return dict(chain(*[d.items() for d in args]))
107
108 def _dynamic_dict(self, example, src_field, tgt_field):
109 src = src_field.tokenize(example["src"])
110 # make a small vocab containing just the tokens in the source sequence
111 unk = src_field.unk_token
112 pad = src_field.pad_token
113 src_vocab = Vocab(Counter(src), specials=[unk, pad])
114 # Map source tokens to indices in the dynamic dict.
115 src_map = torch.LongTensor([src_vocab.stoi[w] for w in src])
116 example["src_map"] = src_map
117
118 if "tgt" in example:
119 tgt = tgt_field.tokenize(example["tgt"])
120 mask = torch.LongTensor(
121 [0] + [src_vocab.stoi[w] for w in tgt] + [0])
122 example["alignment"] = mask
123 return src_vocab, example
124
125 @property
126 def can_copy(self):
127 return False
128
129 @classmethod
130 def _read_file(cls, path):
131 with codecs.open(path, "r", "utf-8") as f:
132 for line in f:
133 yield line
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/onmt/inputters/dataset_base.py b/onmt/inputters/dataset_base.py
--- a/onmt/inputters/dataset_base.py
+++ b/onmt/inputters/dataset_base.py
@@ -50,16 +50,6 @@
the same structure as in the fields argument passed to the constructor.
"""
- def __getstate__(self):
- return self.__dict__
-
- def __setstate__(self, _d):
- self.__dict__.update(_d)
-
- def __reduce_ex__(self, proto):
- # This is a hack. Something is broken with torch pickle.
- return super(DatasetBase, self).__reduce_ex__()
-
def __init__(self, fields, src_examples_iter, tgt_examples_iter,
filter_pred=None):
@@ -90,6 +80,15 @@
super(DatasetBase, self).__init__(examples, fields, filter_pred)
+ def __getattr__(self, attr):
+ # avoid infinite recursion when fields isn't defined
+ if 'fields' not in vars(self):
+ raise AttributeError
+ if attr in self.fields:
+ return (getattr(x, attr) for x in self.examples)
+ else:
+ raise AttributeError
+
def save(self, path, remove_fields=True):
if remove_fields:
self.fields = []
| {"golden_diff": "diff --git a/onmt/inputters/dataset_base.py b/onmt/inputters/dataset_base.py\n--- a/onmt/inputters/dataset_base.py\n+++ b/onmt/inputters/dataset_base.py\n@@ -50,16 +50,6 @@\n the same structure as in the fields argument passed to the constructor.\n \"\"\"\n \n- def __getstate__(self):\n- return self.__dict__\n-\n- def __setstate__(self, _d):\n- self.__dict__.update(_d)\n-\n- def __reduce_ex__(self, proto):\n- # This is a hack. Something is broken with torch pickle.\n- return super(DatasetBase, self).__reduce_ex__()\n-\n def __init__(self, fields, src_examples_iter, tgt_examples_iter,\n filter_pred=None):\n \n@@ -90,6 +80,15 @@\n \n super(DatasetBase, self).__init__(examples, fields, filter_pred)\n \n+ def __getattr__(self, attr):\n+ # avoid infinite recursion when fields isn't defined\n+ if 'fields' not in vars(self):\n+ raise AttributeError\n+ if attr in self.fields:\n+ return (getattr(x, attr) for x in self.examples)\n+ else:\n+ raise AttributeError\n+\n def save(self, path, remove_fields=True):\n if remove_fields:\n self.fields = []\n", "issue": "Source/Target length distinction\n## Preprocess parameters\r\nRemoved parameter `-seq_length`\r\nNew parameters `-src_seq_length` and `-tgt_seq_length`\r\n\r\n---\r\n\r\n## Training speed token/s\r\nIn both LUA/PyTorch OpenNMT, the training process prints a speed, in token/sec, but:\r\n\r\n* LUA OpenNMT is printing source token/sec\r\n* PyOpenNMT is printing target token/sec\r\n\r\nThis can lead to important differences, especially when src/tgt sequence length are different (e.g. summarization), and therefore lead to false conclusion about performances.\r\n\r\nSee also: [pytoch/example/issue#75](https://github.com/pytorch/examples/issues/75)\n", "before_files": [{"content": "# coding: utf-8\n\nfrom itertools import chain\nfrom collections import Counter\nimport codecs\n\nimport torch\nfrom torchtext.data import Example, Dataset\nfrom torchtext.vocab import Vocab\n\n\nclass DatasetBase(Dataset):\n \"\"\"\n A dataset is an object that accepts sequences of raw data (sentence pairs\n in the case of machine translation) and fields which describe how this\n raw data should be processed to produce tensors. When a dataset is\n instantiated, it applies the fields' preprocessing pipeline (but not\n the bit that numericalizes it or turns it into batch tensors) to the raw\n data, producing a list of torchtext.data.Example objects. torchtext's\n iterators then know how to use these examples to make batches.\n\n Datasets in OpenNMT take three positional arguments:\n\n `fields`: a dict with the structure returned by inputters.get_fields().\n keys match the keys of items yielded by the src_examples_iter or\n tgt_examples_iter, while values are lists of (name, Field) pairs.\n An attribute with this name will be created for each Example object,\n and its value will be the result of applying the Field to the data\n that matches the key. The advantage of having sequences of fields\n for each piece of raw input is that it allows for the dataset to store\n multiple `views` of each input, which allows for easy implementation\n of token-level features, mixed word- and character-level models, and\n so on.\n `src_examples_iter`: a sequence of dicts. Each dict's keys should be a\n subset of the keys in `fields`.\n `tgt_examples_iter`: like `src_examples_iter`, but may be None (this is\n the case at translation time if no target is specified).\n\n `filter_pred` if specified, a function that accepts Example objects and\n returns a boolean value indicating whether to include that example\n in the dataset.\n\n The resulting dataset will have three attributes (todo: also src_vocabs):\n\n `examples`: a list of `torchtext.data.Example` objects with attributes as\n described above.\n `fields`: a dictionary whose keys are strings with the same names as the\n attributes of the elements of `examples` and whose values are\n the corresponding `torchtext.data.Field` objects. NOTE: this is not\n the same structure as in the fields argument passed to the constructor.\n \"\"\"\n\n def __getstate__(self):\n return self.__dict__\n\n def __setstate__(self, _d):\n self.__dict__.update(_d)\n\n def __reduce_ex__(self, proto):\n # This is a hack. Something is broken with torch pickle.\n return super(DatasetBase, self).__reduce_ex__()\n\n def __init__(self, fields, src_examples_iter, tgt_examples_iter,\n filter_pred=None):\n\n dynamic_dict = 'src_map' in fields and 'alignment' in fields\n\n if tgt_examples_iter is not None:\n examples_iter = (self._join_dicts(src, tgt) for src, tgt in\n zip(src_examples_iter, tgt_examples_iter))\n else:\n examples_iter = src_examples_iter\n\n # self.src_vocabs is used in collapse_copy_scores and Translator.py\n self.src_vocabs = []\n examples = []\n for ex_dict in examples_iter:\n if dynamic_dict:\n src_field = fields['src'][0][1]\n tgt_field = fields['tgt'][0][1]\n src_vocab, ex_dict = self._dynamic_dict(\n ex_dict, src_field, tgt_field)\n self.src_vocabs.append(src_vocab)\n ex_fields = {k: v for k, v in fields.items() if k in ex_dict}\n ex = Example.fromdict(ex_dict, ex_fields)\n examples.append(ex)\n\n # the dataset's self.fields should have the same attributes as examples\n fields = dict(chain.from_iterable(ex_fields.values()))\n\n super(DatasetBase, self).__init__(examples, fields, filter_pred)\n\n def save(self, path, remove_fields=True):\n if remove_fields:\n self.fields = []\n torch.save(self, path)\n\n def _join_dicts(self, *args):\n \"\"\"\n Args:\n dictionaries with disjoint keys.\n\n Returns:\n a single dictionary that has the union of these keys.\n \"\"\"\n return dict(chain(*[d.items() for d in args]))\n\n def _dynamic_dict(self, example, src_field, tgt_field):\n src = src_field.tokenize(example[\"src\"])\n # make a small vocab containing just the tokens in the source sequence\n unk = src_field.unk_token\n pad = src_field.pad_token\n src_vocab = Vocab(Counter(src), specials=[unk, pad])\n # Map source tokens to indices in the dynamic dict.\n src_map = torch.LongTensor([src_vocab.stoi[w] for w in src])\n example[\"src_map\"] = src_map\n\n if \"tgt\" in example:\n tgt = tgt_field.tokenize(example[\"tgt\"])\n mask = torch.LongTensor(\n [0] + [src_vocab.stoi[w] for w in tgt] + [0])\n example[\"alignment\"] = mask\n return src_vocab, example\n\n @property\n def can_copy(self):\n return False\n\n @classmethod\n def _read_file(cls, path):\n with codecs.open(path, \"r\", \"utf-8\") as f:\n for line in f:\n yield line\n", "path": "onmt/inputters/dataset_base.py"}], "after_files": [{"content": "# coding: utf-8\n\nfrom itertools import chain\nfrom collections import Counter\nimport codecs\n\nimport torch\nfrom torchtext.data import Example, Dataset\nfrom torchtext.vocab import Vocab\n\n\nclass DatasetBase(Dataset):\n \"\"\"\n A dataset is an object that accepts sequences of raw data (sentence pairs\n in the case of machine translation) and fields which describe how this\n raw data should be processed to produce tensors. When a dataset is\n instantiated, it applies the fields' preprocessing pipeline (but not\n the bit that numericalizes it or turns it into batch tensors) to the raw\n data, producing a list of torchtext.data.Example objects. torchtext's\n iterators then know how to use these examples to make batches.\n\n Datasets in OpenNMT take three positional arguments:\n\n `fields`: a dict with the structure returned by inputters.get_fields().\n keys match the keys of items yielded by the src_examples_iter or\n tgt_examples_iter, while values are lists of (name, Field) pairs.\n An attribute with this name will be created for each Example object,\n and its value will be the result of applying the Field to the data\n that matches the key. The advantage of having sequences of fields\n for each piece of raw input is that it allows for the dataset to store\n multiple `views` of each input, which allows for easy implementation\n of token-level features, mixed word- and character-level models, and\n so on.\n `src_examples_iter`: a sequence of dicts. Each dict's keys should be a\n subset of the keys in `fields`.\n `tgt_examples_iter`: like `src_examples_iter`, but may be None (this is\n the case at translation time if no target is specified).\n\n `filter_pred` if specified, a function that accepts Example objects and\n returns a boolean value indicating whether to include that example\n in the dataset.\n\n The resulting dataset will have three attributes (todo: also src_vocabs):\n\n `examples`: a list of `torchtext.data.Example` objects with attributes as\n described above.\n `fields`: a dictionary whose keys are strings with the same names as the\n attributes of the elements of `examples` and whose values are\n the corresponding `torchtext.data.Field` objects. NOTE: this is not\n the same structure as in the fields argument passed to the constructor.\n \"\"\"\n\n def __init__(self, fields, src_examples_iter, tgt_examples_iter,\n filter_pred=None):\n\n dynamic_dict = 'src_map' in fields and 'alignment' in fields\n\n if tgt_examples_iter is not None:\n examples_iter = (self._join_dicts(src, tgt) for src, tgt in\n zip(src_examples_iter, tgt_examples_iter))\n else:\n examples_iter = src_examples_iter\n\n # self.src_vocabs is used in collapse_copy_scores and Translator.py\n self.src_vocabs = []\n examples = []\n for ex_dict in examples_iter:\n if dynamic_dict:\n src_field = fields['src'][0][1]\n tgt_field = fields['tgt'][0][1]\n src_vocab, ex_dict = self._dynamic_dict(\n ex_dict, src_field, tgt_field)\n self.src_vocabs.append(src_vocab)\n ex_fields = {k: v for k, v in fields.items() if k in ex_dict}\n ex = Example.fromdict(ex_dict, ex_fields)\n examples.append(ex)\n\n # the dataset's self.fields should have the same attributes as examples\n fields = dict(chain.from_iterable(ex_fields.values()))\n\n super(DatasetBase, self).__init__(examples, fields, filter_pred)\n\n def __getattr__(self, attr):\n # avoid infinite recursion when fields isn't defined\n if 'fields' not in vars(self):\n raise AttributeError\n if attr in self.fields:\n return (getattr(x, attr) for x in self.examples)\n else:\n raise AttributeError\n\n def save(self, path, remove_fields=True):\n if remove_fields:\n self.fields = []\n torch.save(self, path)\n\n def _join_dicts(self, *args):\n \"\"\"\n Args:\n dictionaries with disjoint keys.\n\n Returns:\n a single dictionary that has the union of these keys.\n \"\"\"\n return dict(chain(*[d.items() for d in args]))\n\n def _dynamic_dict(self, example, src_field, tgt_field):\n src = src_field.tokenize(example[\"src\"])\n # make a small vocab containing just the tokens in the source sequence\n unk = src_field.unk_token\n pad = src_field.pad_token\n src_vocab = Vocab(Counter(src), specials=[unk, pad])\n # Map source tokens to indices in the dynamic dict.\n src_map = torch.LongTensor([src_vocab.stoi[w] for w in src])\n example[\"src_map\"] = src_map\n\n if \"tgt\" in example:\n tgt = tgt_field.tokenize(example[\"tgt\"])\n mask = torch.LongTensor(\n [0] + [src_vocab.stoi[w] for w in tgt] + [0])\n example[\"alignment\"] = mask\n return src_vocab, example\n\n @property\n def can_copy(self):\n return False\n\n @classmethod\n def _read_file(cls, path):\n with codecs.open(path, \"r\", \"utf-8\") as f:\n for line in f:\n yield line\n", "path": "onmt/inputters/dataset_base.py"}]} | 1,882 | 301 |
gh_patches_debug_4688 | rasdani/github-patches | git_diff | microsoft__playwright-python-624 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fix: handle cancelled tasks
prevents `InvalidStateError` when the task has been cancelled, here:
```python
callback.future.set_exception(parsed_error)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `playwright/_impl/_connection.py`
Content:
```
1 # Copyright (c) Microsoft Corporation.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import asyncio
16 import sys
17 import traceback
18 from pathlib import Path
19 from typing import Any, Callable, Dict, List, Optional, Union
20
21 from greenlet import greenlet
22 from pyee import AsyncIOEventEmitter
23
24 from playwright._impl._helper import ParsedMessagePayload, parse_error
25 from playwright._impl._transport import Transport
26
27
28 class Channel(AsyncIOEventEmitter):
29 def __init__(self, connection: "Connection", guid: str) -> None:
30 super().__init__()
31 self._connection: Connection = connection
32 self._guid = guid
33 self._object: Optional[ChannelOwner] = None
34
35 async def send(self, method: str, params: Dict = None) -> Any:
36 return await self.inner_send(method, params, False)
37
38 async def send_return_as_dict(self, method: str, params: Dict = None) -> Any:
39 return await self.inner_send(method, params, True)
40
41 async def inner_send(
42 self, method: str, params: Optional[Dict], return_as_dict: bool
43 ) -> Any:
44 if params is None:
45 params = {}
46 callback = self._connection._send_message_to_server(self._guid, method, params)
47 result = await callback.future
48 # Protocol now has named return values, assume result is one level deeper unless
49 # there is explicit ambiguity.
50 if not result:
51 return None
52 assert isinstance(result, dict)
53 if return_as_dict:
54 return result
55 if len(result) == 0:
56 return None
57 assert len(result) == 1
58 key = next(iter(result))
59 return result[key]
60
61 def send_no_reply(self, method: str, params: Dict = None) -> None:
62 if params is None:
63 params = {}
64 self._connection._send_message_to_server(self._guid, method, params)
65
66
67 class ChannelOwner(AsyncIOEventEmitter):
68 def __init__(
69 self,
70 parent: Union["ChannelOwner", "Connection"],
71 type: str,
72 guid: str,
73 initializer: Dict,
74 ) -> None:
75 super().__init__(loop=parent._loop)
76 self._loop: asyncio.AbstractEventLoop = parent._loop
77 self._dispatcher_fiber: Any = parent._dispatcher_fiber
78 self._type = type
79 self._guid = guid
80 self._connection: Connection = (
81 parent._connection if isinstance(parent, ChannelOwner) else parent
82 )
83 self._parent: Optional[ChannelOwner] = (
84 parent if isinstance(parent, ChannelOwner) else None
85 )
86 self._objects: Dict[str, "ChannelOwner"] = {}
87 self._channel = Channel(self._connection, guid)
88 self._channel._object = self
89 self._initializer = initializer
90
91 self._connection._objects[guid] = self
92 if self._parent:
93 self._parent._objects[guid] = self
94
95 def _wait_for_event_info_before(self, wait_id: str, name: str) -> None:
96 self._connection._send_message_to_server(
97 self._guid,
98 "waitForEventInfo",
99 {
100 "info": {
101 "name": name,
102 "waitId": wait_id,
103 "phase": "before",
104 "stack": capture_call_stack(),
105 }
106 },
107 )
108
109 def _wait_for_event_info_after(
110 self, wait_id: str, exception: Exception = None
111 ) -> None:
112 info = {"waitId": wait_id, "phase": "after"}
113 if exception:
114 info["error"] = str(exception)
115 self._connection._send_message_to_server(
116 self._guid,
117 "waitForEventInfo",
118 {"info": info},
119 )
120
121 def _dispose(self) -> None:
122 # Clean up from parent and connection.
123 if self._parent:
124 del self._parent._objects[self._guid]
125 del self._connection._objects[self._guid]
126
127 # Dispose all children.
128 for object in list(self._objects.values()):
129 object._dispose()
130 self._objects.clear()
131
132
133 class ProtocolCallback:
134 def __init__(self, loop: asyncio.AbstractEventLoop) -> None:
135 self.stack_trace: traceback.StackSummary = traceback.StackSummary()
136 self.future = loop.create_future()
137
138
139 class RootChannelOwner(ChannelOwner):
140 def __init__(self, connection: "Connection") -> None:
141 super().__init__(connection, "", "", {})
142
143
144 class Connection:
145 def __init__(
146 self, dispatcher_fiber: Any, object_factory: Any, driver_executable: Path
147 ) -> None:
148 self._dispatcher_fiber: Any = dispatcher_fiber
149 self._transport = Transport(driver_executable)
150 self._transport.on_message = lambda msg: self._dispatch(msg)
151 self._waiting_for_object: Dict[str, Any] = {}
152 self._last_id = 0
153 self._objects: Dict[str, ChannelOwner] = {}
154 self._callbacks: Dict[int, ProtocolCallback] = {}
155 self._object_factory = object_factory
156 self._is_sync = False
157 self._api_name = ""
158
159 async def run_as_sync(self) -> None:
160 self._is_sync = True
161 await self.run()
162
163 async def run(self) -> None:
164 self._loop = asyncio.get_running_loop()
165 self._root_object = RootChannelOwner(self)
166 await self._transport.run()
167
168 def stop_sync(self) -> None:
169 self._transport.stop()
170 self._dispatcher_fiber.switch()
171
172 async def stop_async(self) -> None:
173 self._transport.stop()
174 await self._transport.wait_until_stopped()
175
176 async def wait_for_object_with_known_name(self, guid: str) -> Any:
177 if guid in self._objects:
178 return self._objects[guid]
179 callback = self._loop.create_future()
180
181 def callback_wrapper(result: Any) -> None:
182 callback.set_result(result)
183
184 self._waiting_for_object[guid] = callback_wrapper
185 return await callback
186
187 def call_on_object_with_known_name(
188 self, guid: str, callback: Callable[[Any], None]
189 ) -> None:
190 self._waiting_for_object[guid] = callback
191
192 def _send_message_to_server(
193 self, guid: str, method: str, params: Dict
194 ) -> ProtocolCallback:
195 self._last_id += 1
196 id = self._last_id
197 callback = ProtocolCallback(self._loop)
198 task = asyncio.current_task(self._loop)
199 callback.stack_trace = getattr(task, "__pw_stack_trace__", None)
200 if not callback.stack_trace:
201 callback.stack_trace = traceback.extract_stack()
202
203 metadata = {"stack": serialize_call_stack(callback.stack_trace)}
204 api_name = getattr(task, "__pw_api_name__", None)
205 if api_name:
206 metadata["apiName"] = api_name
207
208 message = dict(
209 id=id,
210 guid=guid,
211 method=method,
212 params=self._replace_channels_with_guids(params, "params"),
213 metadata=metadata,
214 )
215 self._transport.send(message)
216 self._callbacks[id] = callback
217 return callback
218
219 def _dispatch(self, msg: ParsedMessagePayload) -> None:
220 id = msg.get("id")
221 if id:
222 callback = self._callbacks.pop(id)
223 error = msg.get("error")
224 if error:
225 parsed_error = parse_error(error["error"]) # type: ignore
226 parsed_error.stack = "".join(
227 traceback.format_list(callback.stack_trace)[-10:]
228 )
229 callback.future.set_exception(parsed_error)
230 else:
231 result = self._replace_guids_with_channels(msg.get("result"))
232 callback.future.set_result(result)
233 return
234
235 guid = msg["guid"]
236 method = msg.get("method")
237 params = msg["params"]
238 if method == "__create__":
239 parent = self._objects[guid]
240 self._create_remote_object(
241 parent, params["type"], params["guid"], params["initializer"]
242 )
243 return
244 if method == "__dispose__":
245 self._objects[guid]._dispose()
246 return
247
248 object = self._objects[guid]
249 try:
250 if self._is_sync:
251 for listener in object._channel.listeners(method):
252 g = greenlet(listener)
253 g.switch(self._replace_guids_with_channels(params))
254 else:
255 object._channel.emit(method, self._replace_guids_with_channels(params))
256 except Exception:
257 print(
258 "Error dispatching the event",
259 "".join(traceback.format_exception(*sys.exc_info())),
260 )
261
262 def _create_remote_object(
263 self, parent: ChannelOwner, type: str, guid: str, initializer: Dict
264 ) -> Any:
265 result: ChannelOwner
266 initializer = self._replace_guids_with_channels(initializer)
267 result = self._object_factory(parent, type, guid, initializer)
268 if guid in self._waiting_for_object:
269 self._waiting_for_object.pop(guid)(result)
270 return result
271
272 def _replace_channels_with_guids(self, payload: Any, param_name: str) -> Any:
273 if payload is None:
274 return payload
275 if isinstance(payload, Path):
276 return str(payload)
277 if isinstance(payload, list):
278 return list(
279 map(lambda p: self._replace_channels_with_guids(p, "index"), payload)
280 )
281 if isinstance(payload, Channel):
282 return dict(guid=payload._guid)
283 if isinstance(payload, dict):
284 result = {}
285 for key in payload:
286 result[key] = self._replace_channels_with_guids(payload[key], key)
287 return result
288 return payload
289
290 def _replace_guids_with_channels(self, payload: Any) -> Any:
291 if payload is None:
292 return payload
293 if isinstance(payload, list):
294 return list(map(lambda p: self._replace_guids_with_channels(p), payload))
295 if isinstance(payload, dict):
296 if payload.get("guid") in self._objects:
297 return self._objects[payload["guid"]]._channel
298 result = {}
299 for key in payload:
300 result[key] = self._replace_guids_with_channels(payload[key])
301 return result
302 return payload
303
304
305 def from_channel(channel: Channel) -> Any:
306 return channel._object
307
308
309 def from_nullable_channel(channel: Optional[Channel]) -> Optional[Any]:
310 return channel._object if channel else None
311
312
313 def serialize_call_stack(stack_trace: traceback.StackSummary) -> List[Dict]:
314 stack: List[Dict] = []
315 for frame in stack_trace:
316 if "_generated.py" in frame.filename:
317 break
318 stack.append(
319 {"file": frame.filename, "line": frame.lineno, "function": frame.name}
320 )
321 stack.reverse()
322 return stack
323
324
325 def capture_call_stack() -> List[Dict]:
326 return serialize_call_stack(traceback.extract_stack())
327
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/playwright/_impl/_connection.py b/playwright/_impl/_connection.py
--- a/playwright/_impl/_connection.py
+++ b/playwright/_impl/_connection.py
@@ -220,6 +220,8 @@
id = msg.get("id")
if id:
callback = self._callbacks.pop(id)
+ if callback.future.cancelled():
+ return
error = msg.get("error")
if error:
parsed_error = parse_error(error["error"]) # type: ignore
| {"golden_diff": "diff --git a/playwright/_impl/_connection.py b/playwright/_impl/_connection.py\n--- a/playwright/_impl/_connection.py\n+++ b/playwright/_impl/_connection.py\n@@ -220,6 +220,8 @@\n id = msg.get(\"id\")\n if id:\n callback = self._callbacks.pop(id)\n+ if callback.future.cancelled():\n+ return\n error = msg.get(\"error\")\n if error:\n parsed_error = parse_error(error[\"error\"]) # type: ignore\n", "issue": "fix: handle cancelled tasks\nprevents `InvalidStateError` when the task has been cancelled, here:\r\n\r\n```python\r\ncallback.future.set_exception(parsed_error)\r\n```\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport asyncio\nimport sys\nimport traceback\nfrom pathlib import Path\nfrom typing import Any, Callable, Dict, List, Optional, Union\n\nfrom greenlet import greenlet\nfrom pyee import AsyncIOEventEmitter\n\nfrom playwright._impl._helper import ParsedMessagePayload, parse_error\nfrom playwright._impl._transport import Transport\n\n\nclass Channel(AsyncIOEventEmitter):\n def __init__(self, connection: \"Connection\", guid: str) -> None:\n super().__init__()\n self._connection: Connection = connection\n self._guid = guid\n self._object: Optional[ChannelOwner] = None\n\n async def send(self, method: str, params: Dict = None) -> Any:\n return await self.inner_send(method, params, False)\n\n async def send_return_as_dict(self, method: str, params: Dict = None) -> Any:\n return await self.inner_send(method, params, True)\n\n async def inner_send(\n self, method: str, params: Optional[Dict], return_as_dict: bool\n ) -> Any:\n if params is None:\n params = {}\n callback = self._connection._send_message_to_server(self._guid, method, params)\n result = await callback.future\n # Protocol now has named return values, assume result is one level deeper unless\n # there is explicit ambiguity.\n if not result:\n return None\n assert isinstance(result, dict)\n if return_as_dict:\n return result\n if len(result) == 0:\n return None\n assert len(result) == 1\n key = next(iter(result))\n return result[key]\n\n def send_no_reply(self, method: str, params: Dict = None) -> None:\n if params is None:\n params = {}\n self._connection._send_message_to_server(self._guid, method, params)\n\n\nclass ChannelOwner(AsyncIOEventEmitter):\n def __init__(\n self,\n parent: Union[\"ChannelOwner\", \"Connection\"],\n type: str,\n guid: str,\n initializer: Dict,\n ) -> None:\n super().__init__(loop=parent._loop)\n self._loop: asyncio.AbstractEventLoop = parent._loop\n self._dispatcher_fiber: Any = parent._dispatcher_fiber\n self._type = type\n self._guid = guid\n self._connection: Connection = (\n parent._connection if isinstance(parent, ChannelOwner) else parent\n )\n self._parent: Optional[ChannelOwner] = (\n parent if isinstance(parent, ChannelOwner) else None\n )\n self._objects: Dict[str, \"ChannelOwner\"] = {}\n self._channel = Channel(self._connection, guid)\n self._channel._object = self\n self._initializer = initializer\n\n self._connection._objects[guid] = self\n if self._parent:\n self._parent._objects[guid] = self\n\n def _wait_for_event_info_before(self, wait_id: str, name: str) -> None:\n self._connection._send_message_to_server(\n self._guid,\n \"waitForEventInfo\",\n {\n \"info\": {\n \"name\": name,\n \"waitId\": wait_id,\n \"phase\": \"before\",\n \"stack\": capture_call_stack(),\n }\n },\n )\n\n def _wait_for_event_info_after(\n self, wait_id: str, exception: Exception = None\n ) -> None:\n info = {\"waitId\": wait_id, \"phase\": \"after\"}\n if exception:\n info[\"error\"] = str(exception)\n self._connection._send_message_to_server(\n self._guid,\n \"waitForEventInfo\",\n {\"info\": info},\n )\n\n def _dispose(self) -> None:\n # Clean up from parent and connection.\n if self._parent:\n del self._parent._objects[self._guid]\n del self._connection._objects[self._guid]\n\n # Dispose all children.\n for object in list(self._objects.values()):\n object._dispose()\n self._objects.clear()\n\n\nclass ProtocolCallback:\n def __init__(self, loop: asyncio.AbstractEventLoop) -> None:\n self.stack_trace: traceback.StackSummary = traceback.StackSummary()\n self.future = loop.create_future()\n\n\nclass RootChannelOwner(ChannelOwner):\n def __init__(self, connection: \"Connection\") -> None:\n super().__init__(connection, \"\", \"\", {})\n\n\nclass Connection:\n def __init__(\n self, dispatcher_fiber: Any, object_factory: Any, driver_executable: Path\n ) -> None:\n self._dispatcher_fiber: Any = dispatcher_fiber\n self._transport = Transport(driver_executable)\n self._transport.on_message = lambda msg: self._dispatch(msg)\n self._waiting_for_object: Dict[str, Any] = {}\n self._last_id = 0\n self._objects: Dict[str, ChannelOwner] = {}\n self._callbacks: Dict[int, ProtocolCallback] = {}\n self._object_factory = object_factory\n self._is_sync = False\n self._api_name = \"\"\n\n async def run_as_sync(self) -> None:\n self._is_sync = True\n await self.run()\n\n async def run(self) -> None:\n self._loop = asyncio.get_running_loop()\n self._root_object = RootChannelOwner(self)\n await self._transport.run()\n\n def stop_sync(self) -> None:\n self._transport.stop()\n self._dispatcher_fiber.switch()\n\n async def stop_async(self) -> None:\n self._transport.stop()\n await self._transport.wait_until_stopped()\n\n async def wait_for_object_with_known_name(self, guid: str) -> Any:\n if guid in self._objects:\n return self._objects[guid]\n callback = self._loop.create_future()\n\n def callback_wrapper(result: Any) -> None:\n callback.set_result(result)\n\n self._waiting_for_object[guid] = callback_wrapper\n return await callback\n\n def call_on_object_with_known_name(\n self, guid: str, callback: Callable[[Any], None]\n ) -> None:\n self._waiting_for_object[guid] = callback\n\n def _send_message_to_server(\n self, guid: str, method: str, params: Dict\n ) -> ProtocolCallback:\n self._last_id += 1\n id = self._last_id\n callback = ProtocolCallback(self._loop)\n task = asyncio.current_task(self._loop)\n callback.stack_trace = getattr(task, \"__pw_stack_trace__\", None)\n if not callback.stack_trace:\n callback.stack_trace = traceback.extract_stack()\n\n metadata = {\"stack\": serialize_call_stack(callback.stack_trace)}\n api_name = getattr(task, \"__pw_api_name__\", None)\n if api_name:\n metadata[\"apiName\"] = api_name\n\n message = dict(\n id=id,\n guid=guid,\n method=method,\n params=self._replace_channels_with_guids(params, \"params\"),\n metadata=metadata,\n )\n self._transport.send(message)\n self._callbacks[id] = callback\n return callback\n\n def _dispatch(self, msg: ParsedMessagePayload) -> None:\n id = msg.get(\"id\")\n if id:\n callback = self._callbacks.pop(id)\n error = msg.get(\"error\")\n if error:\n parsed_error = parse_error(error[\"error\"]) # type: ignore\n parsed_error.stack = \"\".join(\n traceback.format_list(callback.stack_trace)[-10:]\n )\n callback.future.set_exception(parsed_error)\n else:\n result = self._replace_guids_with_channels(msg.get(\"result\"))\n callback.future.set_result(result)\n return\n\n guid = msg[\"guid\"]\n method = msg.get(\"method\")\n params = msg[\"params\"]\n if method == \"__create__\":\n parent = self._objects[guid]\n self._create_remote_object(\n parent, params[\"type\"], params[\"guid\"], params[\"initializer\"]\n )\n return\n if method == \"__dispose__\":\n self._objects[guid]._dispose()\n return\n\n object = self._objects[guid]\n try:\n if self._is_sync:\n for listener in object._channel.listeners(method):\n g = greenlet(listener)\n g.switch(self._replace_guids_with_channels(params))\n else:\n object._channel.emit(method, self._replace_guids_with_channels(params))\n except Exception:\n print(\n \"Error dispatching the event\",\n \"\".join(traceback.format_exception(*sys.exc_info())),\n )\n\n def _create_remote_object(\n self, parent: ChannelOwner, type: str, guid: str, initializer: Dict\n ) -> Any:\n result: ChannelOwner\n initializer = self._replace_guids_with_channels(initializer)\n result = self._object_factory(parent, type, guid, initializer)\n if guid in self._waiting_for_object:\n self._waiting_for_object.pop(guid)(result)\n return result\n\n def _replace_channels_with_guids(self, payload: Any, param_name: str) -> Any:\n if payload is None:\n return payload\n if isinstance(payload, Path):\n return str(payload)\n if isinstance(payload, list):\n return list(\n map(lambda p: self._replace_channels_with_guids(p, \"index\"), payload)\n )\n if isinstance(payload, Channel):\n return dict(guid=payload._guid)\n if isinstance(payload, dict):\n result = {}\n for key in payload:\n result[key] = self._replace_channels_with_guids(payload[key], key)\n return result\n return payload\n\n def _replace_guids_with_channels(self, payload: Any) -> Any:\n if payload is None:\n return payload\n if isinstance(payload, list):\n return list(map(lambda p: self._replace_guids_with_channels(p), payload))\n if isinstance(payload, dict):\n if payload.get(\"guid\") in self._objects:\n return self._objects[payload[\"guid\"]]._channel\n result = {}\n for key in payload:\n result[key] = self._replace_guids_with_channels(payload[key])\n return result\n return payload\n\n\ndef from_channel(channel: Channel) -> Any:\n return channel._object\n\n\ndef from_nullable_channel(channel: Optional[Channel]) -> Optional[Any]:\n return channel._object if channel else None\n\n\ndef serialize_call_stack(stack_trace: traceback.StackSummary) -> List[Dict]:\n stack: List[Dict] = []\n for frame in stack_trace:\n if \"_generated.py\" in frame.filename:\n break\n stack.append(\n {\"file\": frame.filename, \"line\": frame.lineno, \"function\": frame.name}\n )\n stack.reverse()\n return stack\n\n\ndef capture_call_stack() -> List[Dict]:\n return serialize_call_stack(traceback.extract_stack())\n", "path": "playwright/_impl/_connection.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport asyncio\nimport sys\nimport traceback\nfrom pathlib import Path\nfrom typing import Any, Callable, Dict, List, Optional, Union\n\nfrom greenlet import greenlet\nfrom pyee import AsyncIOEventEmitter\n\nfrom playwright._impl._helper import ParsedMessagePayload, parse_error\nfrom playwright._impl._transport import Transport\n\n\nclass Channel(AsyncIOEventEmitter):\n def __init__(self, connection: \"Connection\", guid: str) -> None:\n super().__init__()\n self._connection: Connection = connection\n self._guid = guid\n self._object: Optional[ChannelOwner] = None\n\n async def send(self, method: str, params: Dict = None) -> Any:\n return await self.inner_send(method, params, False)\n\n async def send_return_as_dict(self, method: str, params: Dict = None) -> Any:\n return await self.inner_send(method, params, True)\n\n async def inner_send(\n self, method: str, params: Optional[Dict], return_as_dict: bool\n ) -> Any:\n if params is None:\n params = {}\n callback = self._connection._send_message_to_server(self._guid, method, params)\n result = await callback.future\n # Protocol now has named return values, assume result is one level deeper unless\n # there is explicit ambiguity.\n if not result:\n return None\n assert isinstance(result, dict)\n if return_as_dict:\n return result\n if len(result) == 0:\n return None\n assert len(result) == 1\n key = next(iter(result))\n return result[key]\n\n def send_no_reply(self, method: str, params: Dict = None) -> None:\n if params is None:\n params = {}\n self._connection._send_message_to_server(self._guid, method, params)\n\n\nclass ChannelOwner(AsyncIOEventEmitter):\n def __init__(\n self,\n parent: Union[\"ChannelOwner\", \"Connection\"],\n type: str,\n guid: str,\n initializer: Dict,\n ) -> None:\n super().__init__(loop=parent._loop)\n self._loop: asyncio.AbstractEventLoop = parent._loop\n self._dispatcher_fiber: Any = parent._dispatcher_fiber\n self._type = type\n self._guid = guid\n self._connection: Connection = (\n parent._connection if isinstance(parent, ChannelOwner) else parent\n )\n self._parent: Optional[ChannelOwner] = (\n parent if isinstance(parent, ChannelOwner) else None\n )\n self._objects: Dict[str, \"ChannelOwner\"] = {}\n self._channel = Channel(self._connection, guid)\n self._channel._object = self\n self._initializer = initializer\n\n self._connection._objects[guid] = self\n if self._parent:\n self._parent._objects[guid] = self\n\n def _wait_for_event_info_before(self, wait_id: str, name: str) -> None:\n self._connection._send_message_to_server(\n self._guid,\n \"waitForEventInfo\",\n {\n \"info\": {\n \"name\": name,\n \"waitId\": wait_id,\n \"phase\": \"before\",\n \"stack\": capture_call_stack(),\n }\n },\n )\n\n def _wait_for_event_info_after(\n self, wait_id: str, exception: Exception = None\n ) -> None:\n info = {\"waitId\": wait_id, \"phase\": \"after\"}\n if exception:\n info[\"error\"] = str(exception)\n self._connection._send_message_to_server(\n self._guid,\n \"waitForEventInfo\",\n {\"info\": info},\n )\n\n def _dispose(self) -> None:\n # Clean up from parent and connection.\n if self._parent:\n del self._parent._objects[self._guid]\n del self._connection._objects[self._guid]\n\n # Dispose all children.\n for object in list(self._objects.values()):\n object._dispose()\n self._objects.clear()\n\n\nclass ProtocolCallback:\n def __init__(self, loop: asyncio.AbstractEventLoop) -> None:\n self.stack_trace: traceback.StackSummary = traceback.StackSummary()\n self.future = loop.create_future()\n\n\nclass RootChannelOwner(ChannelOwner):\n def __init__(self, connection: \"Connection\") -> None:\n super().__init__(connection, \"\", \"\", {})\n\n\nclass Connection:\n def __init__(\n self, dispatcher_fiber: Any, object_factory: Any, driver_executable: Path\n ) -> None:\n self._dispatcher_fiber: Any = dispatcher_fiber\n self._transport = Transport(driver_executable)\n self._transport.on_message = lambda msg: self._dispatch(msg)\n self._waiting_for_object: Dict[str, Any] = {}\n self._last_id = 0\n self._objects: Dict[str, ChannelOwner] = {}\n self._callbacks: Dict[int, ProtocolCallback] = {}\n self._object_factory = object_factory\n self._is_sync = False\n self._api_name = \"\"\n\n async def run_as_sync(self) -> None:\n self._is_sync = True\n await self.run()\n\n async def run(self) -> None:\n self._loop = asyncio.get_running_loop()\n self._root_object = RootChannelOwner(self)\n await self._transport.run()\n\n def stop_sync(self) -> None:\n self._transport.stop()\n self._dispatcher_fiber.switch()\n\n async def stop_async(self) -> None:\n self._transport.stop()\n await self._transport.wait_until_stopped()\n\n async def wait_for_object_with_known_name(self, guid: str) -> Any:\n if guid in self._objects:\n return self._objects[guid]\n callback = self._loop.create_future()\n\n def callback_wrapper(result: Any) -> None:\n callback.set_result(result)\n\n self._waiting_for_object[guid] = callback_wrapper\n return await callback\n\n def call_on_object_with_known_name(\n self, guid: str, callback: Callable[[Any], None]\n ) -> None:\n self._waiting_for_object[guid] = callback\n\n def _send_message_to_server(\n self, guid: str, method: str, params: Dict\n ) -> ProtocolCallback:\n self._last_id += 1\n id = self._last_id\n callback = ProtocolCallback(self._loop)\n task = asyncio.current_task(self._loop)\n callback.stack_trace = getattr(task, \"__pw_stack_trace__\", None)\n if not callback.stack_trace:\n callback.stack_trace = traceback.extract_stack()\n\n metadata = {\"stack\": serialize_call_stack(callback.stack_trace)}\n api_name = getattr(task, \"__pw_api_name__\", None)\n if api_name:\n metadata[\"apiName\"] = api_name\n\n message = dict(\n id=id,\n guid=guid,\n method=method,\n params=self._replace_channels_with_guids(params, \"params\"),\n metadata=metadata,\n )\n self._transport.send(message)\n self._callbacks[id] = callback\n return callback\n\n def _dispatch(self, msg: ParsedMessagePayload) -> None:\n id = msg.get(\"id\")\n if id:\n callback = self._callbacks.pop(id)\n if callback.future.cancelled():\n return\n error = msg.get(\"error\")\n if error:\n parsed_error = parse_error(error[\"error\"]) # type: ignore\n parsed_error.stack = \"\".join(\n traceback.format_list(callback.stack_trace)[-10:]\n )\n callback.future.set_exception(parsed_error)\n else:\n result = self._replace_guids_with_channels(msg.get(\"result\"))\n callback.future.set_result(result)\n return\n\n guid = msg[\"guid\"]\n method = msg.get(\"method\")\n params = msg[\"params\"]\n if method == \"__create__\":\n parent = self._objects[guid]\n self._create_remote_object(\n parent, params[\"type\"], params[\"guid\"], params[\"initializer\"]\n )\n return\n if method == \"__dispose__\":\n self._objects[guid]._dispose()\n return\n\n object = self._objects[guid]\n try:\n if self._is_sync:\n for listener in object._channel.listeners(method):\n g = greenlet(listener)\n g.switch(self._replace_guids_with_channels(params))\n else:\n object._channel.emit(method, self._replace_guids_with_channels(params))\n except Exception:\n print(\n \"Error dispatching the event\",\n \"\".join(traceback.format_exception(*sys.exc_info())),\n )\n\n def _create_remote_object(\n self, parent: ChannelOwner, type: str, guid: str, initializer: Dict\n ) -> Any:\n result: ChannelOwner\n initializer = self._replace_guids_with_channels(initializer)\n result = self._object_factory(parent, type, guid, initializer)\n if guid in self._waiting_for_object:\n self._waiting_for_object.pop(guid)(result)\n return result\n\n def _replace_channels_with_guids(self, payload: Any, param_name: str) -> Any:\n if payload is None:\n return payload\n if isinstance(payload, Path):\n return str(payload)\n if isinstance(payload, list):\n return list(\n map(lambda p: self._replace_channels_with_guids(p, \"index\"), payload)\n )\n if isinstance(payload, Channel):\n return dict(guid=payload._guid)\n if isinstance(payload, dict):\n result = {}\n for key in payload:\n result[key] = self._replace_channels_with_guids(payload[key], key)\n return result\n return payload\n\n def _replace_guids_with_channels(self, payload: Any) -> Any:\n if payload is None:\n return payload\n if isinstance(payload, list):\n return list(map(lambda p: self._replace_guids_with_channels(p), payload))\n if isinstance(payload, dict):\n if payload.get(\"guid\") in self._objects:\n return self._objects[payload[\"guid\"]]._channel\n result = {}\n for key in payload:\n result[key] = self._replace_guids_with_channels(payload[key])\n return result\n return payload\n\n\ndef from_channel(channel: Channel) -> Any:\n return channel._object\n\n\ndef from_nullable_channel(channel: Optional[Channel]) -> Optional[Any]:\n return channel._object if channel else None\n\n\ndef serialize_call_stack(stack_trace: traceback.StackSummary) -> List[Dict]:\n stack: List[Dict] = []\n for frame in stack_trace:\n if \"_generated.py\" in frame.filename:\n break\n stack.append(\n {\"file\": frame.filename, \"line\": frame.lineno, \"function\": frame.name}\n )\n stack.reverse()\n return stack\n\n\ndef capture_call_stack() -> List[Dict]:\n return serialize_call_stack(traceback.extract_stack())\n", "path": "playwright/_impl/_connection.py"}]} | 3,632 | 115 |
gh_patches_debug_15780 | rasdani/github-patches | git_diff | conda-forge__staged-recipes-86 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Travis-CI failure on master
@pelson is this related to the latest `conda-smithy`?
See https://travis-ci.org/conda-forge/staged-recipes/jobs/115055485
```
Repository created, please edit conda-forge.yml to configure the upload channels
and afterwards call 'conda smithy register-github'
usage: a tool to help create, administer and manage feedstocks.
[-h]
{init,register-github,register-ci,regenerate,recipe-lint,rerender} ...
a tool to help create, administer and manage feedstocks.: error: invalid choice: 'github-create' (choose from 'init', 'register-github', 'register-ci', 'regenerate', 'recipe-lint', 'rerender')
Traceback (most recent call last):
File ".CI/create_feedstocks.py", line 118, in <module>
subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)
File "/Users/travis/miniconda/lib/python2.7/subprocess.py", line 540, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['conda', 'smithy', 'github-create', '/var/folders/gw/_2jq29095y7b__wtby9dg_5h0000gn/T/tmp_pPzpc__feedstocks/autoconf-feedstock', '--organization', 'conda-forge']' returned non-zero exit status 2
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `.CI/create_feedstocks.py`
Content:
```
1 #!/usr/bin/env python
2 """
3 Convert all recipes into feedstocks.
4
5 This script is to be run in a TravisCI context, with all secret environment variables defined (BINSTAR_TOKEN, GH_TOKEN)
6 Such as:
7
8 export GH_TOKEN=$(cat ~/.conda-smithy/github.token)
9
10 """
11 from __future__ import print_function
12
13 from conda_smithy.github import gh_token
14 from contextlib import contextmanager
15 from github import Github, GithubException
16 import os.path
17 import shutil
18 import subprocess
19 import tempfile
20
21
22 # Enable DEBUG to run the diagnostics, without actually creating new feedstocks.
23 DEBUG = False
24
25
26 def list_recipes():
27 recipe_directory_name = 'recipes'
28 if os.path.isdir(recipe_directory_name):
29 recipes = os.listdir(recipe_directory_name)
30 else:
31 recipes = []
32
33 for recipe_dir in recipes:
34 # We don't list the "example" feedstock. It is an example, and is there
35 # to be helpful.
36 if recipe_dir.startswith('example'):
37 continue
38 path = os.path.abspath(os.path.join(recipe_directory_name, recipe_dir))
39 yield path, recipe_dir
40
41
42 @contextmanager
43 def tmp_dir(*args, **kwargs):
44 temp_dir = tempfile.mkdtemp(*args, **kwargs)
45 try:
46 yield temp_dir
47 finally:
48 shutil.rmtree(temp_dir)
49
50
51 def repo_exists(organization, name):
52 token = gh_token()
53 gh = Github(token)
54 # Use the organization provided.
55 org = gh.get_organization(organization)
56 try:
57 org.get_repo(name)
58 return True
59 except GithubException as e:
60 if e.status == 404:
61 return False
62 raise
63
64
65 if __name__ == '__main__':
66 is_merged_pr = (os.environ.get('TRAVIS_BRANCH') == 'master' and os.environ.get('TRAVIS_PULL_REQUEST') == 'false')
67
68 smithy_conf = os.path.expanduser('~/.conda-smithy')
69 if not os.path.exists(smithy_conf):
70 os.mkdir(smithy_conf)
71
72 def write_token(name, token):
73 with open(os.path.join(smithy_conf, name + '.token'), 'w') as fh:
74 fh.write(token)
75 if 'APPVEYOR_TOKEN' in os.environ:
76 write_token('appveyor', os.environ['APPVEYOR_TOKEN'])
77 if 'CIRCLE_TOKEN' in os.environ:
78 write_token('circle', os.environ['CIRCLE_TOKEN'])
79 if 'GH_TOKEN' in os.environ:
80 write_token('github', os.environ['GH_TOKEN'])
81
82 owner_info = ['--organization', 'conda-forge']
83
84 print('Calculating the recipes which need to be turned into feedstocks.')
85 removed_recipes = []
86 with tmp_dir('__feedstocks') as feedstocks_dir:
87 feedstock_dirs = []
88 for recipe_dir, name in list_recipes():
89 feedstock_dir = os.path.join(feedstocks_dir, name + '-feedstock')
90 os.mkdir(feedstock_dir)
91 print('Making feedstock for {}'.format(name))
92
93 subprocess.check_call(['conda', 'smithy', 'recipe-lint', recipe_dir])
94
95 subprocess.check_call(['conda', 'smithy', 'init', recipe_dir,
96 '--feedstock-directory', feedstock_dir])
97 if not is_merged_pr:
98 # We just want to check that conda-smithy is doing its thing without having any metadata issues.
99 continue
100
101 feedstock_dirs.append([feedstock_dir, name, recipe_dir])
102
103 subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',
104 'https://conda-forge-admin:{}@github.com/conda-forge/{}'.format(os.environ['GH_TOKEN'],
105 os.path.basename(feedstock_dir))],
106 cwd=feedstock_dir)
107
108 # Sometimes we already have the feedstock created. We need to deal with that case.
109 if repo_exists('conda-forge', os.path.basename(feedstock_dir)):
110 subprocess.check_call(['git', 'fetch', 'upstream_with_token'], cwd=feedstock_dir)
111 subprocess.check_call(['git', 'branch', '-m', 'master', 'old'], cwd=feedstock_dir)
112 try:
113 subprocess.check_call(['git', 'checkout', '-b', 'master', 'upstream_with_token/master'], cwd=feedstock_dir)
114 except subprocess.CalledProcessError:
115 # Sometimes, we have a repo, but there are no commits on it! Just catch that case.
116 subprocess.check_call(['git', 'checkout', '-b' 'master'], cwd=feedstock_dir)
117 else:
118 subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)
119
120 # Break the previous loop to allow the TravisCI registering to take place only once per function call.
121 # Without this, intermittent failiures to synch the TravisCI repos ensue.
122 for feedstock_dir, name, recipe_dir in feedstock_dirs:
123 subprocess.check_call(['conda', 'smithy', 'register-feedstock-ci', feedstock_dir] + owner_info)
124
125 subprocess.check_call(['conda', 'smithy', 'rerender'], cwd=feedstock_dir)
126 subprocess.check_call(['git', 'commit', '-am', "Re-render the feedstock after CI registration."], cwd=feedstock_dir)
127 # Capture the output, as it may contain the GH_TOKEN.
128 out = subprocess.check_output(['git', 'push', 'upstream_with_token', 'master'], cwd=feedstock_dir,
129 stderr=subprocess.STDOUT)
130
131 # Remove this recipe from the repo.
132 removed_recipes.append(name)
133 if is_merged_pr:
134 subprocess.check_call(['git', 'rm', '-r', recipe_dir])
135
136 # Commit any removed packages.
137 subprocess.check_call(['git', 'status'])
138 if removed_recipes:
139 subprocess.check_call(['git', 'checkout', os.environ.get('TRAVIS_BRANCH')])
140 msg = ('Removed recipe{s} ({}) after converting into feedstock{s}.'
141 ''.format(', '.join(removed_recipes),
142 s=('s' if len(removed_recipes) > 1 else '')))
143 if is_merged_pr:
144 subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',
145 'https://conda-forge-admin:{}@github.com/conda-forge/staged-recipes'.format(os.environ['GH_TOKEN'])])
146 subprocess.check_call(['git', 'commit', '-m', msg])
147 # Capture the output, as it may contain the GH_TOKEN.
148 out = subprocess.check_output(['git', 'push', 'upstream_with_token', os.environ.get('TRAVIS_BRANCH')],
149 stderr=subprocess.STDOUT)
150 else:
151 print('Would git commit, with the following message: \n {}'.format(msg))
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/.CI/create_feedstocks.py b/.CI/create_feedstocks.py
--- a/.CI/create_feedstocks.py
+++ b/.CI/create_feedstocks.py
@@ -115,7 +115,7 @@
# Sometimes, we have a repo, but there are no commits on it! Just catch that case.
subprocess.check_call(['git', 'checkout', '-b' 'master'], cwd=feedstock_dir)
else:
- subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)
+ subprocess.check_call(['conda', 'smithy', 'register-github', feedstock_dir] + owner_info)
# Break the previous loop to allow the TravisCI registering to take place only once per function call.
# Without this, intermittent failiures to synch the TravisCI repos ensue.
| {"golden_diff": "diff --git a/.CI/create_feedstocks.py b/.CI/create_feedstocks.py\n--- a/.CI/create_feedstocks.py\n+++ b/.CI/create_feedstocks.py\n@@ -115,7 +115,7 @@\n # Sometimes, we have a repo, but there are no commits on it! Just catch that case.\n subprocess.check_call(['git', 'checkout', '-b' 'master'], cwd=feedstock_dir)\n else:\n- subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)\n+ subprocess.check_call(['conda', 'smithy', 'register-github', feedstock_dir] + owner_info)\n \n # Break the previous loop to allow the TravisCI registering to take place only once per function call.\n # Without this, intermittent failiures to synch the TravisCI repos ensue.\n", "issue": "Travis-CI failure on master\n@pelson is this related to the latest `conda-smithy`?\n\nSee https://travis-ci.org/conda-forge/staged-recipes/jobs/115055485\n\n```\nRepository created, please edit conda-forge.yml to configure the upload channels\nand afterwards call 'conda smithy register-github'\nusage: a tool to help create, administer and manage feedstocks.\n [-h]\n {init,register-github,register-ci,regenerate,recipe-lint,rerender} ...\na tool to help create, administer and manage feedstocks.: error: invalid choice: 'github-create' (choose from 'init', 'register-github', 'register-ci', 'regenerate', 'recipe-lint', 'rerender')\nTraceback (most recent call last):\n File \".CI/create_feedstocks.py\", line 118, in <module>\n subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)\n File \"/Users/travis/miniconda/lib/python2.7/subprocess.py\", line 540, in check_call\n raise CalledProcessError(retcode, cmd)\nsubprocess.CalledProcessError: Command '['conda', 'smithy', 'github-create', '/var/folders/gw/_2jq29095y7b__wtby9dg_5h0000gn/T/tmp_pPzpc__feedstocks/autoconf-feedstock', '--organization', 'conda-forge']' returned non-zero exit status 2\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nConvert all recipes into feedstocks.\n\nThis script is to be run in a TravisCI context, with all secret environment variables defined (BINSTAR_TOKEN, GH_TOKEN)\nSuch as:\n\n export GH_TOKEN=$(cat ~/.conda-smithy/github.token)\n\n\"\"\"\nfrom __future__ import print_function\n\nfrom conda_smithy.github import gh_token\nfrom contextlib import contextmanager\nfrom github import Github, GithubException\nimport os.path\nimport shutil\nimport subprocess\nimport tempfile\n\n\n# Enable DEBUG to run the diagnostics, without actually creating new feedstocks.\nDEBUG = False\n\n\ndef list_recipes():\n recipe_directory_name = 'recipes'\n if os.path.isdir(recipe_directory_name):\n recipes = os.listdir(recipe_directory_name)\n else:\n recipes = []\n\n for recipe_dir in recipes:\n # We don't list the \"example\" feedstock. It is an example, and is there\n # to be helpful.\n if recipe_dir.startswith('example'):\n continue\n path = os.path.abspath(os.path.join(recipe_directory_name, recipe_dir))\n yield path, recipe_dir\n\n\n@contextmanager\ndef tmp_dir(*args, **kwargs):\n temp_dir = tempfile.mkdtemp(*args, **kwargs)\n try:\n yield temp_dir\n finally:\n shutil.rmtree(temp_dir)\n\n\ndef repo_exists(organization, name):\n token = gh_token()\n gh = Github(token)\n # Use the organization provided.\n org = gh.get_organization(organization)\n try:\n org.get_repo(name)\n return True\n except GithubException as e:\n if e.status == 404:\n return False\n raise\n\n\nif __name__ == '__main__':\n is_merged_pr = (os.environ.get('TRAVIS_BRANCH') == 'master' and os.environ.get('TRAVIS_PULL_REQUEST') == 'false')\n\n smithy_conf = os.path.expanduser('~/.conda-smithy')\n if not os.path.exists(smithy_conf):\n os.mkdir(smithy_conf)\n\n def write_token(name, token):\n with open(os.path.join(smithy_conf, name + '.token'), 'w') as fh:\n fh.write(token)\n if 'APPVEYOR_TOKEN' in os.environ:\n write_token('appveyor', os.environ['APPVEYOR_TOKEN'])\n if 'CIRCLE_TOKEN' in os.environ:\n write_token('circle', os.environ['CIRCLE_TOKEN'])\n if 'GH_TOKEN' in os.environ:\n write_token('github', os.environ['GH_TOKEN'])\n\n owner_info = ['--organization', 'conda-forge']\n\n print('Calculating the recipes which need to be turned into feedstocks.')\n removed_recipes = []\n with tmp_dir('__feedstocks') as feedstocks_dir:\n feedstock_dirs = []\n for recipe_dir, name in list_recipes():\n feedstock_dir = os.path.join(feedstocks_dir, name + '-feedstock')\n os.mkdir(feedstock_dir)\n print('Making feedstock for {}'.format(name))\n\n subprocess.check_call(['conda', 'smithy', 'recipe-lint', recipe_dir])\n\n subprocess.check_call(['conda', 'smithy', 'init', recipe_dir,\n '--feedstock-directory', feedstock_dir])\n if not is_merged_pr:\n # We just want to check that conda-smithy is doing its thing without having any metadata issues.\n continue\n\n feedstock_dirs.append([feedstock_dir, name, recipe_dir])\n\n subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',\n 'https://conda-forge-admin:{}@github.com/conda-forge/{}'.format(os.environ['GH_TOKEN'],\n os.path.basename(feedstock_dir))],\n cwd=feedstock_dir)\n\n # Sometimes we already have the feedstock created. We need to deal with that case.\n if repo_exists('conda-forge', os.path.basename(feedstock_dir)):\n subprocess.check_call(['git', 'fetch', 'upstream_with_token'], cwd=feedstock_dir)\n subprocess.check_call(['git', 'branch', '-m', 'master', 'old'], cwd=feedstock_dir)\n try:\n subprocess.check_call(['git', 'checkout', '-b', 'master', 'upstream_with_token/master'], cwd=feedstock_dir)\n except subprocess.CalledProcessError:\n # Sometimes, we have a repo, but there are no commits on it! Just catch that case.\n subprocess.check_call(['git', 'checkout', '-b' 'master'], cwd=feedstock_dir)\n else:\n subprocess.check_call(['conda', 'smithy', 'github-create', feedstock_dir] + owner_info)\n\n # Break the previous loop to allow the TravisCI registering to take place only once per function call.\n # Without this, intermittent failiures to synch the TravisCI repos ensue.\n for feedstock_dir, name, recipe_dir in feedstock_dirs:\n subprocess.check_call(['conda', 'smithy', 'register-feedstock-ci', feedstock_dir] + owner_info)\n\n subprocess.check_call(['conda', 'smithy', 'rerender'], cwd=feedstock_dir)\n subprocess.check_call(['git', 'commit', '-am', \"Re-render the feedstock after CI registration.\"], cwd=feedstock_dir)\n # Capture the output, as it may contain the GH_TOKEN.\n out = subprocess.check_output(['git', 'push', 'upstream_with_token', 'master'], cwd=feedstock_dir,\n stderr=subprocess.STDOUT)\n\n # Remove this recipe from the repo.\n removed_recipes.append(name)\n if is_merged_pr:\n subprocess.check_call(['git', 'rm', '-r', recipe_dir])\n\n # Commit any removed packages.\n subprocess.check_call(['git', 'status'])\n if removed_recipes:\n subprocess.check_call(['git', 'checkout', os.environ.get('TRAVIS_BRANCH')])\n msg = ('Removed recipe{s} ({}) after converting into feedstock{s}.'\n ''.format(', '.join(removed_recipes),\n s=('s' if len(removed_recipes) > 1 else '')))\n if is_merged_pr:\n subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',\n 'https://conda-forge-admin:{}@github.com/conda-forge/staged-recipes'.format(os.environ['GH_TOKEN'])])\n subprocess.check_call(['git', 'commit', '-m', msg])\n # Capture the output, as it may contain the GH_TOKEN.\n out = subprocess.check_output(['git', 'push', 'upstream_with_token', os.environ.get('TRAVIS_BRANCH')],\n stderr=subprocess.STDOUT)\n else:\n print('Would git commit, with the following message: \\n {}'.format(msg))\n", "path": ".CI/create_feedstocks.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nConvert all recipes into feedstocks.\n\nThis script is to be run in a TravisCI context, with all secret environment variables defined (BINSTAR_TOKEN, GH_TOKEN)\nSuch as:\n\n export GH_TOKEN=$(cat ~/.conda-smithy/github.token)\n\n\"\"\"\nfrom __future__ import print_function\n\nfrom conda_smithy.github import gh_token\nfrom contextlib import contextmanager\nfrom github import Github, GithubException\nimport os.path\nimport shutil\nimport subprocess\nimport tempfile\n\n\n# Enable DEBUG to run the diagnostics, without actually creating new feedstocks.\nDEBUG = False\n\n\ndef list_recipes():\n recipe_directory_name = 'recipes'\n if os.path.isdir(recipe_directory_name):\n recipes = os.listdir(recipe_directory_name)\n else:\n recipes = []\n\n for recipe_dir in recipes:\n # We don't list the \"example\" feedstock. It is an example, and is there\n # to be helpful.\n if recipe_dir.startswith('example'):\n continue\n path = os.path.abspath(os.path.join(recipe_directory_name, recipe_dir))\n yield path, recipe_dir\n\n\n@contextmanager\ndef tmp_dir(*args, **kwargs):\n temp_dir = tempfile.mkdtemp(*args, **kwargs)\n try:\n yield temp_dir\n finally:\n shutil.rmtree(temp_dir)\n\n\ndef repo_exists(organization, name):\n token = gh_token()\n gh = Github(token)\n # Use the organization provided.\n org = gh.get_organization(organization)\n try:\n org.get_repo(name)\n return True\n except GithubException as e:\n if e.status == 404:\n return False\n raise\n\n\nif __name__ == '__main__':\n is_merged_pr = (os.environ.get('TRAVIS_BRANCH') == 'master' and os.environ.get('TRAVIS_PULL_REQUEST') == 'false')\n\n smithy_conf = os.path.expanduser('~/.conda-smithy')\n if not os.path.exists(smithy_conf):\n os.mkdir(smithy_conf)\n\n def write_token(name, token):\n with open(os.path.join(smithy_conf, name + '.token'), 'w') as fh:\n fh.write(token)\n if 'APPVEYOR_TOKEN' in os.environ:\n write_token('appveyor', os.environ['APPVEYOR_TOKEN'])\n if 'CIRCLE_TOKEN' in os.environ:\n write_token('circle', os.environ['CIRCLE_TOKEN'])\n if 'GH_TOKEN' in os.environ:\n write_token('github', os.environ['GH_TOKEN'])\n\n owner_info = ['--organization', 'conda-forge']\n\n print('Calculating the recipes which need to be turned into feedstocks.')\n removed_recipes = []\n with tmp_dir('__feedstocks') as feedstocks_dir:\n feedstock_dirs = []\n for recipe_dir, name in list_recipes():\n feedstock_dir = os.path.join(feedstocks_dir, name + '-feedstock')\n os.mkdir(feedstock_dir)\n print('Making feedstock for {}'.format(name))\n\n subprocess.check_call(['conda', 'smithy', 'recipe-lint', recipe_dir])\n\n subprocess.check_call(['conda', 'smithy', 'init', recipe_dir,\n '--feedstock-directory', feedstock_dir])\n if not is_merged_pr:\n # We just want to check that conda-smithy is doing its thing without having any metadata issues.\n continue\n\n feedstock_dirs.append([feedstock_dir, name, recipe_dir])\n\n subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',\n 'https://conda-forge-admin:{}@github.com/conda-forge/{}'.format(os.environ['GH_TOKEN'],\n os.path.basename(feedstock_dir))],\n cwd=feedstock_dir)\n\n # Sometimes we already have the feedstock created. We need to deal with that case.\n if repo_exists('conda-forge', os.path.basename(feedstock_dir)):\n subprocess.check_call(['git', 'fetch', 'upstream_with_token'], cwd=feedstock_dir)\n subprocess.check_call(['git', 'branch', '-m', 'master', 'old'], cwd=feedstock_dir)\n try:\n subprocess.check_call(['git', 'checkout', '-b', 'master', 'upstream_with_token/master'], cwd=feedstock_dir)\n except subprocess.CalledProcessError:\n # Sometimes, we have a repo, but there are no commits on it! Just catch that case.\n subprocess.check_call(['git', 'checkout', '-b' 'master'], cwd=feedstock_dir)\n else:\n subprocess.check_call(['conda', 'smithy', 'register-github', feedstock_dir] + owner_info)\n\n # Break the previous loop to allow the TravisCI registering to take place only once per function call.\n # Without this, intermittent failiures to synch the TravisCI repos ensue.\n for feedstock_dir, name, recipe_dir in feedstock_dirs:\n subprocess.check_call(['conda', 'smithy', 'register-feedstock-ci', feedstock_dir] + owner_info)\n\n subprocess.check_call(['conda', 'smithy', 'rerender'], cwd=feedstock_dir)\n subprocess.check_call(['git', 'commit', '-am', \"Re-render the feedstock after CI registration.\"], cwd=feedstock_dir)\n # Capture the output, as it may contain the GH_TOKEN.\n out = subprocess.check_output(['git', 'push', 'upstream_with_token', 'master'], cwd=feedstock_dir,\n stderr=subprocess.STDOUT)\n\n # Remove this recipe from the repo.\n removed_recipes.append(name)\n if is_merged_pr:\n subprocess.check_call(['git', 'rm', '-r', recipe_dir])\n\n # Commit any removed packages.\n subprocess.check_call(['git', 'status'])\n if removed_recipes:\n subprocess.check_call(['git', 'checkout', os.environ.get('TRAVIS_BRANCH')])\n msg = ('Removed recipe{s} ({}) after converting into feedstock{s}.'\n ''.format(', '.join(removed_recipes),\n s=('s' if len(removed_recipes) > 1 else '')))\n if is_merged_pr:\n subprocess.check_call(['git', 'remote', 'add', 'upstream_with_token',\n 'https://conda-forge-admin:{}@github.com/conda-forge/staged-recipes'.format(os.environ['GH_TOKEN'])])\n subprocess.check_call(['git', 'commit', '-m', msg])\n # Capture the output, as it may contain the GH_TOKEN.\n out = subprocess.check_output(['git', 'push', 'upstream_with_token', os.environ.get('TRAVIS_BRANCH')],\n stderr=subprocess.STDOUT)\n else:\n print('Would git commit, with the following message: \\n {}'.format(msg))\n", "path": ".CI/create_feedstocks.py"}]} | 2,400 | 187 |
gh_patches_debug_21995 | rasdani/github-patches | git_diff | openai__gym-1661 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove FireReset wrapper for atari environments
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gym/wrappers/atari_preprocessing.py`
Content:
```
1 import numpy as np
2
3 import gym
4 from gym.spaces import Box
5 from gym.wrappers import TimeLimit
6
7
8 class AtariPreprocessing(gym.Wrapper):
9 r"""Atari 2600 preprocessings.
10
11 This class follows the guidelines in
12 Machado et al. (2018), "Revisiting the Arcade Learning Environment:
13 Evaluation Protocols and Open Problems for General Agents".
14
15 Specifically:
16
17 * NoopReset: obtain initial state by taking random number of no-ops on reset.
18 * FireReset: take action on reset for environments that are fixed until firing.
19 * Frame skipping: 4 by default
20 * Max-pooling: most recent two observations
21 * Termination signal when a life is lost: turned off by default. Not recommended by Machado et al. (2018).
22 * Resize to a square image: 84x84 by default
23 * Grayscale observation: optional
24 * Scale observation: optional
25
26 Args:
27 env (Env): environment
28 noop_max (int): max number of no-ops
29 frame_skip (int): the frequency at which the agent experiences the game.
30 screen_size (int): resize Atari frame
31 terminal_on_life_loss (bool): if True, then step() returns done=True whenever a
32 life is lost.
33 grayscale_obs (bool): if True, then gray scale observation is returned, otherwise, RGB observation
34 is returned.
35 scale_obs (bool): if True, then observation normalized in range [0,1] is returned. It also limits memory
36 optimization benefits of FrameStack Wrapper.
37 """
38
39 def __init__(self, env, noop_max=30, frame_skip=4, screen_size=84, terminal_on_life_loss=False, grayscale_obs=True,
40 scale_obs=False):
41 super().__init__(env)
42 assert frame_skip > 0
43 assert screen_size > 0
44
45 self.noop_max = noop_max
46 assert env.unwrapped.get_action_meanings()[0] == 'NOOP'
47
48 self.frame_skip = frame_skip
49 self.screen_size = screen_size
50 self.terminal_on_life_loss = terminal_on_life_loss
51 self.grayscale_obs = grayscale_obs
52 self.scale_obs = scale_obs
53
54 # buffer of most recent two observations for max pooling
55 if grayscale_obs:
56 self.obs_buffer = [np.empty(env.observation_space.shape[:2], dtype=np.uint8),
57 np.empty(env.observation_space.shape[:2], dtype=np.uint8)]
58 else:
59 self.obs_buffer = [np.empty(env.observation_space.shape, dtype=np.uint8),
60 np.empty(env.observation_space.shape, dtype=np.uint8)]
61
62 self.ale = env.unwrapped.ale
63 self.lives = 0
64 self.game_over = False
65
66 _low, _high, _obs_dtype = (0, 255, np.uint8) if not scale_obs else (0, 1, np.float32)
67 if grayscale_obs:
68 self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size), dtype=_obs_dtype)
69 else:
70 self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size, 3), dtype=_obs_dtype)
71
72 def step(self, action):
73 R = 0.0
74
75 for t in range(self.frame_skip):
76 _, reward, done, info = self.env.step(action)
77 R += reward
78 self.game_over = done
79
80 if self.terminal_on_life_loss:
81 new_lives = self.ale.lives()
82 done = done or new_lives < self.lives
83 self.lives = new_lives
84
85 if done:
86 break
87 if t == self.frame_skip - 2:
88 if self.grayscale_obs:
89 self.ale.getScreenGrayscale(self.obs_buffer[0])
90 else:
91 self.ale.getScreenRGB2(self.obs_buffer[0])
92 elif t == self.frame_skip - 1:
93 if self.grayscale_obs:
94 self.ale.getScreenGrayscale(self.obs_buffer[1])
95 else:
96 self.ale.getScreenRGB2(self.obs_buffer[1])
97 return self._get_obs(), R, done, info
98
99 def reset(self, **kwargs):
100 # NoopReset
101 self.env.reset(**kwargs)
102 noops = self.env.unwrapped.np_random.randint(1, self.noop_max + 1) if self.noop_max > 0 else 0
103 for _ in range(noops):
104 _, _, done, _ = self.env.step(0)
105 if done:
106 self.env.reset(**kwargs)
107
108 # FireReset
109 action_meanings = self.env.unwrapped.get_action_meanings()
110 if action_meanings[1] == 'FIRE' and len(action_meanings) >= 3:
111 self.env.step(1)
112 self.env.step(2)
113
114 self.lives = self.ale.lives()
115 if self.grayscale_obs:
116 self.ale.getScreenGrayscale(self.obs_buffer[0])
117 else:
118 self.ale.getScreenRGB2(self.obs_buffer[0])
119 self.obs_buffer[1].fill(0)
120 return self._get_obs()
121
122 def _get_obs(self):
123 import cv2
124 if self.frame_skip > 1: # more efficient in-place pooling
125 np.maximum(self.obs_buffer[0], self.obs_buffer[1], out=self.obs_buffer[0])
126 obs = cv2.resize(self.obs_buffer[0], (self.screen_size, self.screen_size), interpolation=cv2.INTER_AREA)
127
128 if self.scale_obs:
129 obs = np.asarray(obs, dtype=np.float32) / 255.0
130 else:
131 obs = np.asarray(obs, dtype=np.uint8)
132 return obs
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gym/wrappers/atari_preprocessing.py b/gym/wrappers/atari_preprocessing.py
--- a/gym/wrappers/atari_preprocessing.py
+++ b/gym/wrappers/atari_preprocessing.py
@@ -15,7 +15,6 @@
Specifically:
* NoopReset: obtain initial state by taking random number of no-ops on reset.
- * FireReset: take action on reset for environments that are fixed until firing.
* Frame skipping: 4 by default
* Max-pooling: most recent two observations
* Termination signal when a life is lost: turned off by default. Not recommended by Machado et al. (2018).
@@ -105,12 +104,6 @@
if done:
self.env.reset(**kwargs)
- # FireReset
- action_meanings = self.env.unwrapped.get_action_meanings()
- if action_meanings[1] == 'FIRE' and len(action_meanings) >= 3:
- self.env.step(1)
- self.env.step(2)
-
self.lives = self.ale.lives()
if self.grayscale_obs:
self.ale.getScreenGrayscale(self.obs_buffer[0])
| {"golden_diff": "diff --git a/gym/wrappers/atari_preprocessing.py b/gym/wrappers/atari_preprocessing.py\n--- a/gym/wrappers/atari_preprocessing.py\n+++ b/gym/wrappers/atari_preprocessing.py\n@@ -15,7 +15,6 @@\n Specifically:\n \n * NoopReset: obtain initial state by taking random number of no-ops on reset. \n- * FireReset: take action on reset for environments that are fixed until firing. \n * Frame skipping: 4 by default\n * Max-pooling: most recent two observations\n * Termination signal when a life is lost: turned off by default. Not recommended by Machado et al. (2018).\n@@ -105,12 +104,6 @@\n if done:\n self.env.reset(**kwargs)\n \n- # FireReset\n- action_meanings = self.env.unwrapped.get_action_meanings()\n- if action_meanings[1] == 'FIRE' and len(action_meanings) >= 3:\n- self.env.step(1)\n- self.env.step(2)\n-\n self.lives = self.ale.lives()\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[0])\n", "issue": "Remove FireReset wrapper for atari environments\n\n", "before_files": [{"content": "import numpy as np\n\nimport gym\nfrom gym.spaces import Box\nfrom gym.wrappers import TimeLimit\n\n\nclass AtariPreprocessing(gym.Wrapper):\n r\"\"\"Atari 2600 preprocessings. \n\n This class follows the guidelines in \n Machado et al. (2018), \"Revisiting the Arcade Learning Environment: \n Evaluation Protocols and Open Problems for General Agents\".\n\n Specifically:\n\n * NoopReset: obtain initial state by taking random number of no-ops on reset. \n * FireReset: take action on reset for environments that are fixed until firing. \n * Frame skipping: 4 by default\n * Max-pooling: most recent two observations\n * Termination signal when a life is lost: turned off by default. Not recommended by Machado et al. (2018).\n * Resize to a square image: 84x84 by default\n * Grayscale observation: optional\n * Scale observation: optional\n\n Args:\n env (Env): environment\n noop_max (int): max number of no-ops\n frame_skip (int): the frequency at which the agent experiences the game. \n screen_size (int): resize Atari frame\n terminal_on_life_loss (bool): if True, then step() returns done=True whenever a\n life is lost. \n grayscale_obs (bool): if True, then gray scale observation is returned, otherwise, RGB observation\n is returned.\n scale_obs (bool): if True, then observation normalized in range [0,1] is returned. It also limits memory\n optimization benefits of FrameStack Wrapper.\n \"\"\"\n\n def __init__(self, env, noop_max=30, frame_skip=4, screen_size=84, terminal_on_life_loss=False, grayscale_obs=True,\n scale_obs=False):\n super().__init__(env)\n assert frame_skip > 0\n assert screen_size > 0\n\n self.noop_max = noop_max\n assert env.unwrapped.get_action_meanings()[0] == 'NOOP'\n\n self.frame_skip = frame_skip\n self.screen_size = screen_size\n self.terminal_on_life_loss = terminal_on_life_loss\n self.grayscale_obs = grayscale_obs\n self.scale_obs = scale_obs\n\n # buffer of most recent two observations for max pooling\n if grayscale_obs:\n self.obs_buffer = [np.empty(env.observation_space.shape[:2], dtype=np.uint8),\n np.empty(env.observation_space.shape[:2], dtype=np.uint8)]\n else:\n self.obs_buffer = [np.empty(env.observation_space.shape, dtype=np.uint8),\n np.empty(env.observation_space.shape, dtype=np.uint8)]\n\n self.ale = env.unwrapped.ale\n self.lives = 0\n self.game_over = False\n\n _low, _high, _obs_dtype = (0, 255, np.uint8) if not scale_obs else (0, 1, np.float32)\n if grayscale_obs:\n self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size), dtype=_obs_dtype)\n else:\n self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size, 3), dtype=_obs_dtype)\n\n def step(self, action):\n R = 0.0\n\n for t in range(self.frame_skip):\n _, reward, done, info = self.env.step(action)\n R += reward\n self.game_over = done\n\n if self.terminal_on_life_loss:\n new_lives = self.ale.lives()\n done = done or new_lives < self.lives\n self.lives = new_lives\n\n if done:\n break\n if t == self.frame_skip - 2:\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[0])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[0])\n elif t == self.frame_skip - 1:\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[1])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[1])\n return self._get_obs(), R, done, info\n\n def reset(self, **kwargs):\n # NoopReset\n self.env.reset(**kwargs)\n noops = self.env.unwrapped.np_random.randint(1, self.noop_max + 1) if self.noop_max > 0 else 0\n for _ in range(noops):\n _, _, done, _ = self.env.step(0)\n if done:\n self.env.reset(**kwargs)\n\n # FireReset\n action_meanings = self.env.unwrapped.get_action_meanings()\n if action_meanings[1] == 'FIRE' and len(action_meanings) >= 3:\n self.env.step(1)\n self.env.step(2)\n\n self.lives = self.ale.lives()\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[0])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[0])\n self.obs_buffer[1].fill(0)\n return self._get_obs()\n\n def _get_obs(self):\n import cv2\n if self.frame_skip > 1: # more efficient in-place pooling\n np.maximum(self.obs_buffer[0], self.obs_buffer[1], out=self.obs_buffer[0])\n obs = cv2.resize(self.obs_buffer[0], (self.screen_size, self.screen_size), interpolation=cv2.INTER_AREA)\n\n if self.scale_obs:\n obs = np.asarray(obs, dtype=np.float32) / 255.0\n else:\n obs = np.asarray(obs, dtype=np.uint8)\n return obs\n", "path": "gym/wrappers/atari_preprocessing.py"}], "after_files": [{"content": "import numpy as np\n\nimport gym\nfrom gym.spaces import Box\nfrom gym.wrappers import TimeLimit\n\n\nclass AtariPreprocessing(gym.Wrapper):\n r\"\"\"Atari 2600 preprocessings. \n\n This class follows the guidelines in \n Machado et al. (2018), \"Revisiting the Arcade Learning Environment: \n Evaluation Protocols and Open Problems for General Agents\".\n\n Specifically:\n\n * NoopReset: obtain initial state by taking random number of no-ops on reset. \n * Frame skipping: 4 by default\n * Max-pooling: most recent two observations\n * Termination signal when a life is lost: turned off by default. Not recommended by Machado et al. (2018).\n * Resize to a square image: 84x84 by default\n * Grayscale observation: optional\n * Scale observation: optional\n\n Args:\n env (Env): environment\n noop_max (int): max number of no-ops\n frame_skip (int): the frequency at which the agent experiences the game. \n screen_size (int): resize Atari frame\n terminal_on_life_loss (bool): if True, then step() returns done=True whenever a\n life is lost. \n grayscale_obs (bool): if True, then gray scale observation is returned, otherwise, RGB observation\n is returned.\n scale_obs (bool): if True, then observation normalized in range [0,1] is returned. It also limits memory\n optimization benefits of FrameStack Wrapper.\n \"\"\"\n\n def __init__(self, env, noop_max=30, frame_skip=4, screen_size=84, terminal_on_life_loss=False, grayscale_obs=True,\n scale_obs=False):\n super().__init__(env)\n assert frame_skip > 0\n assert screen_size > 0\n\n self.noop_max = noop_max\n assert env.unwrapped.get_action_meanings()[0] == 'NOOP'\n\n self.frame_skip = frame_skip\n self.screen_size = screen_size\n self.terminal_on_life_loss = terminal_on_life_loss\n self.grayscale_obs = grayscale_obs\n self.scale_obs = scale_obs\n\n # buffer of most recent two observations for max pooling\n if grayscale_obs:\n self.obs_buffer = [np.empty(env.observation_space.shape[:2], dtype=np.uint8),\n np.empty(env.observation_space.shape[:2], dtype=np.uint8)]\n else:\n self.obs_buffer = [np.empty(env.observation_space.shape, dtype=np.uint8),\n np.empty(env.observation_space.shape, dtype=np.uint8)]\n\n self.ale = env.unwrapped.ale\n self.lives = 0\n self.game_over = False\n\n _low, _high, _obs_dtype = (0, 255, np.uint8) if not scale_obs else (0, 1, np.float32)\n if grayscale_obs:\n self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size), dtype=_obs_dtype)\n else:\n self.observation_space = Box(low=_low, high=_high, shape=(screen_size, screen_size, 3), dtype=_obs_dtype)\n\n def step(self, action):\n R = 0.0\n\n for t in range(self.frame_skip):\n _, reward, done, info = self.env.step(action)\n R += reward\n self.game_over = done\n\n if self.terminal_on_life_loss:\n new_lives = self.ale.lives()\n done = done or new_lives < self.lives\n self.lives = new_lives\n\n if done:\n break\n if t == self.frame_skip - 2:\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[0])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[0])\n elif t == self.frame_skip - 1:\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[1])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[1])\n return self._get_obs(), R, done, info\n\n def reset(self, **kwargs):\n # NoopReset\n self.env.reset(**kwargs)\n noops = self.env.unwrapped.np_random.randint(1, self.noop_max + 1) if self.noop_max > 0 else 0\n for _ in range(noops):\n _, _, done, _ = self.env.step(0)\n if done:\n self.env.reset(**kwargs)\n\n self.lives = self.ale.lives()\n if self.grayscale_obs:\n self.ale.getScreenGrayscale(self.obs_buffer[0])\n else:\n self.ale.getScreenRGB2(self.obs_buffer[0])\n self.obs_buffer[1].fill(0)\n return self._get_obs()\n\n def _get_obs(self):\n import cv2\n if self.frame_skip > 1: # more efficient in-place pooling\n np.maximum(self.obs_buffer[0], self.obs_buffer[1], out=self.obs_buffer[0])\n obs = cv2.resize(self.obs_buffer[0], (self.screen_size, self.screen_size), interpolation=cv2.INTER_AREA)\n\n if self.scale_obs:\n obs = np.asarray(obs, dtype=np.float32) / 255.0\n else:\n obs = np.asarray(obs, dtype=np.uint8)\n return obs\n", "path": "gym/wrappers/atari_preprocessing.py"}]} | 1,839 | 281 |
gh_patches_debug_5738 | rasdani/github-patches | git_diff | quantumlib__Cirq-1673 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Two circuit diagram tests that rest in `contrib` are failing on Windows
See: https://travis-ci.com/quantumlib/Cirq/jobs/202641395
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq/contrib/paulistring/convert_to_pauli_string_phasors.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Optional, cast, TYPE_CHECKING
16
17 import numpy as np
18
19 from cirq import ops, optimizers, protocols, linalg
20 from cirq.circuits.circuit import Circuit
21 from cirq.circuits.optimization_pass import (
22 PointOptimizationSummary,
23 PointOptimizer,
24 )
25
26 if TYPE_CHECKING:
27 # pylint: disable=unused-import
28 from typing import List
29
30
31 class ConvertToPauliStringPhasors(PointOptimizer):
32 """Attempts to convert single-qubit gates into single-qubit
33 PauliStringPhasor operations.
34
35 Checks if the operation has a known unitary effect. If so, and the gate is a
36 1-qubit gate, then decomposes it into x, y, or z rotations and creates a
37 PauliStringPhasor for each.
38 """
39
40 def __init__(self,
41 ignore_failures: bool = False,
42 keep_clifford: bool = False,
43 atol: float = 0) -> None:
44 """
45 Args:
46 ignore_failures: If set, gates that fail to convert are forwarded
47 unchanged. If not set, conversion failures raise a TypeError.
48 keep_clifford: If set, single qubit rotations in the Clifford group
49 are converted to SingleQubitCliffordGates.
50 atol: Maximum absolute error tolerance. The optimization is
51 permitted to round angles with a threshold determined by this
52 tolerance.
53 """
54 super().__init__()
55 self.ignore_failures = ignore_failures
56 self.keep_clifford = keep_clifford
57 self.atol = atol
58
59 def _matrix_to_pauli_string_phasors(self,
60 mat: np.ndarray,
61 qubit: ops.Qid) -> ops.OP_TREE:
62 rotations = optimizers.single_qubit_matrix_to_pauli_rotations(
63 mat, self.atol)
64 out_ops = [] # type: List[ops.Operation]
65 for pauli, half_turns in rotations:
66 if (self.keep_clifford
67 and linalg.all_near_zero_mod(half_turns, 0.5)):
68 cliff_gate = ops.SingleQubitCliffordGate.from_quarter_turns(
69 pauli, round(half_turns * 2))
70 if out_ops and not isinstance(out_ops[-1],
71 ops.PauliStringPhasor):
72 op = cast(ops.GateOperation, out_ops[-1])
73 gate = cast(ops.SingleQubitCliffordGate, op.gate)
74 out_ops[-1] = gate.merged_with(cliff_gate)(qubit)
75 else:
76 out_ops.append(
77 cliff_gate(qubit))
78 else:
79 pauli_string = ops.PauliString.from_single(qubit, pauli)
80 out_ops.append(
81 ops.PauliStringPhasor(pauli_string,
82 exponent_neg=round(half_turns, 10)))
83 return out_ops
84
85 def _convert_one(self, op: ops.Operation) -> ops.OP_TREE:
86 # Don't change if it's already a ops.PauliStringPhasor
87 if isinstance(op, ops.PauliStringPhasor):
88 return op
89
90 if (self.keep_clifford
91 and isinstance(op, ops.GateOperation)
92 and isinstance(op.gate, ops.SingleQubitCliffordGate)):
93 return op
94
95 # Single qubit gate with known matrix?
96 if len(op.qubits) == 1:
97 mat = protocols.unitary(op, None)
98 if mat is not None:
99 return self._matrix_to_pauli_string_phasors(mat, op.qubits[0])
100
101 # Just let it be?
102 if self.ignore_failures:
103 return op
104
105 raise TypeError("Don't know how to work with {!r}. "
106 "It isn't a 1-qubit operation with a known unitary "
107 "effect.".format(op))
108
109 def convert(self, op: ops.Operation) -> ops.OP_TREE:
110 converted = self._convert_one(op)
111 if converted is op:
112 return converted
113 return [self.convert(cast(ops.Operation, e))
114 for e in ops.flatten_op_tree(converted)]
115
116 def optimization_at(self, circuit: Circuit, index: int, op: ops.Operation
117 ) -> Optional[PointOptimizationSummary]:
118 converted = self.convert(op)
119 if converted is op:
120 return None
121
122 return PointOptimizationSummary(
123 clear_span=1,
124 new_operations=converted,
125 clear_qubits=op.qubits)
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py b/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py
--- a/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py
+++ b/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py
@@ -40,7 +40,7 @@
def __init__(self,
ignore_failures: bool = False,
keep_clifford: bool = False,
- atol: float = 0) -> None:
+ atol: float = 1e-14) -> None:
"""
Args:
ignore_failures: If set, gates that fail to convert are forwarded
| {"golden_diff": "diff --git a/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py b/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py\n--- a/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py\n+++ b/cirq/contrib/paulistring/convert_to_pauli_string_phasors.py\n@@ -40,7 +40,7 @@\n def __init__(self,\n ignore_failures: bool = False,\n keep_clifford: bool = False,\n- atol: float = 0) -> None:\n+ atol: float = 1e-14) -> None:\n \"\"\"\n Args:\n ignore_failures: If set, gates that fail to convert are forwarded\n", "issue": "Two circuit diagram tests that rest in `contrib` are failing on Windows\nSee: https://travis-ci.com/quantumlib/Cirq/jobs/202641395\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Optional, cast, TYPE_CHECKING\n\nimport numpy as np\n\nfrom cirq import ops, optimizers, protocols, linalg\nfrom cirq.circuits.circuit import Circuit\nfrom cirq.circuits.optimization_pass import (\n PointOptimizationSummary,\n PointOptimizer,\n)\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n from typing import List\n\n\nclass ConvertToPauliStringPhasors(PointOptimizer):\n \"\"\"Attempts to convert single-qubit gates into single-qubit\n PauliStringPhasor operations.\n\n Checks if the operation has a known unitary effect. If so, and the gate is a\n 1-qubit gate, then decomposes it into x, y, or z rotations and creates a\n PauliStringPhasor for each.\n \"\"\"\n\n def __init__(self,\n ignore_failures: bool = False,\n keep_clifford: bool = False,\n atol: float = 0) -> None:\n \"\"\"\n Args:\n ignore_failures: If set, gates that fail to convert are forwarded\n unchanged. If not set, conversion failures raise a TypeError.\n keep_clifford: If set, single qubit rotations in the Clifford group\n are converted to SingleQubitCliffordGates.\n atol: Maximum absolute error tolerance. The optimization is\n permitted to round angles with a threshold determined by this\n tolerance.\n \"\"\"\n super().__init__()\n self.ignore_failures = ignore_failures\n self.keep_clifford = keep_clifford\n self.atol = atol\n\n def _matrix_to_pauli_string_phasors(self,\n mat: np.ndarray,\n qubit: ops.Qid) -> ops.OP_TREE:\n rotations = optimizers.single_qubit_matrix_to_pauli_rotations(\n mat, self.atol)\n out_ops = [] # type: List[ops.Operation]\n for pauli, half_turns in rotations:\n if (self.keep_clifford\n and linalg.all_near_zero_mod(half_turns, 0.5)):\n cliff_gate = ops.SingleQubitCliffordGate.from_quarter_turns(\n pauli, round(half_turns * 2))\n if out_ops and not isinstance(out_ops[-1],\n ops.PauliStringPhasor):\n op = cast(ops.GateOperation, out_ops[-1])\n gate = cast(ops.SingleQubitCliffordGate, op.gate)\n out_ops[-1] = gate.merged_with(cliff_gate)(qubit)\n else:\n out_ops.append(\n cliff_gate(qubit))\n else:\n pauli_string = ops.PauliString.from_single(qubit, pauli)\n out_ops.append(\n ops.PauliStringPhasor(pauli_string,\n exponent_neg=round(half_turns, 10)))\n return out_ops\n\n def _convert_one(self, op: ops.Operation) -> ops.OP_TREE:\n # Don't change if it's already a ops.PauliStringPhasor\n if isinstance(op, ops.PauliStringPhasor):\n return op\n\n if (self.keep_clifford\n and isinstance(op, ops.GateOperation)\n and isinstance(op.gate, ops.SingleQubitCliffordGate)):\n return op\n\n # Single qubit gate with known matrix?\n if len(op.qubits) == 1:\n mat = protocols.unitary(op, None)\n if mat is not None:\n return self._matrix_to_pauli_string_phasors(mat, op.qubits[0])\n\n # Just let it be?\n if self.ignore_failures:\n return op\n\n raise TypeError(\"Don't know how to work with {!r}. \"\n \"It isn't a 1-qubit operation with a known unitary \"\n \"effect.\".format(op))\n\n def convert(self, op: ops.Operation) -> ops.OP_TREE:\n converted = self._convert_one(op)\n if converted is op:\n return converted\n return [self.convert(cast(ops.Operation, e))\n for e in ops.flatten_op_tree(converted)]\n\n def optimization_at(self, circuit: Circuit, index: int, op: ops.Operation\n ) -> Optional[PointOptimizationSummary]:\n converted = self.convert(op)\n if converted is op:\n return None\n\n return PointOptimizationSummary(\n clear_span=1,\n new_operations=converted,\n clear_qubits=op.qubits)\n", "path": "cirq/contrib/paulistring/convert_to_pauli_string_phasors.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Optional, cast, TYPE_CHECKING\n\nimport numpy as np\n\nfrom cirq import ops, optimizers, protocols, linalg\nfrom cirq.circuits.circuit import Circuit\nfrom cirq.circuits.optimization_pass import (\n PointOptimizationSummary,\n PointOptimizer,\n)\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n from typing import List\n\n\nclass ConvertToPauliStringPhasors(PointOptimizer):\n \"\"\"Attempts to convert single-qubit gates into single-qubit\n PauliStringPhasor operations.\n\n Checks if the operation has a known unitary effect. If so, and the gate is a\n 1-qubit gate, then decomposes it into x, y, or z rotations and creates a\n PauliStringPhasor for each.\n \"\"\"\n\n def __init__(self,\n ignore_failures: bool = False,\n keep_clifford: bool = False,\n atol: float = 1e-14) -> None:\n \"\"\"\n Args:\n ignore_failures: If set, gates that fail to convert are forwarded\n unchanged. If not set, conversion failures raise a TypeError.\n keep_clifford: If set, single qubit rotations in the Clifford group\n are converted to SingleQubitCliffordGates.\n atol: Maximum absolute error tolerance. The optimization is\n permitted to round angles with a threshold determined by this\n tolerance.\n \"\"\"\n super().__init__()\n self.ignore_failures = ignore_failures\n self.keep_clifford = keep_clifford\n self.atol = atol\n\n def _matrix_to_pauli_string_phasors(self,\n mat: np.ndarray,\n qubit: ops.Qid) -> ops.OP_TREE:\n rotations = optimizers.single_qubit_matrix_to_pauli_rotations(\n mat, self.atol)\n out_ops = [] # type: List[ops.Operation]\n for pauli, half_turns in rotations:\n if (self.keep_clifford\n and linalg.all_near_zero_mod(half_turns, 0.5)):\n cliff_gate = ops.SingleQubitCliffordGate.from_quarter_turns(\n pauli, round(half_turns * 2))\n if out_ops and not isinstance(out_ops[-1],\n ops.PauliStringPhasor):\n op = cast(ops.GateOperation, out_ops[-1])\n gate = cast(ops.SingleQubitCliffordGate, op.gate)\n out_ops[-1] = gate.merged_with(cliff_gate)(qubit)\n else:\n out_ops.append(\n cliff_gate(qubit))\n else:\n pauli_string = ops.PauliString.from_single(qubit, pauli)\n out_ops.append(\n ops.PauliStringPhasor(pauli_string,\n exponent_neg=round(half_turns, 10)))\n return out_ops\n\n def _convert_one(self, op: ops.Operation) -> ops.OP_TREE:\n # Don't change if it's already a ops.PauliStringPhasor\n if isinstance(op, ops.PauliStringPhasor):\n return op\n\n if (self.keep_clifford\n and isinstance(op, ops.GateOperation)\n and isinstance(op.gate, ops.SingleQubitCliffordGate)):\n return op\n\n # Single qubit gate with known matrix?\n if len(op.qubits) == 1:\n mat = protocols.unitary(op, None)\n if mat is not None:\n return self._matrix_to_pauli_string_phasors(mat, op.qubits[0])\n\n # Just let it be?\n if self.ignore_failures:\n return op\n\n raise TypeError(\"Don't know how to work with {!r}. \"\n \"It isn't a 1-qubit operation with a known unitary \"\n \"effect.\".format(op))\n\n def convert(self, op: ops.Operation) -> ops.OP_TREE:\n converted = self._convert_one(op)\n if converted is op:\n return converted\n return [self.convert(cast(ops.Operation, e))\n for e in ops.flatten_op_tree(converted)]\n\n def optimization_at(self, circuit: Circuit, index: int, op: ops.Operation\n ) -> Optional[PointOptimizationSummary]:\n converted = self.convert(op)\n if converted is op:\n return None\n\n return PointOptimizationSummary(\n clear_span=1,\n new_operations=converted,\n clear_qubits=op.qubits)\n", "path": "cirq/contrib/paulistring/convert_to_pauli_string_phasors.py"}]} | 1,698 | 171 |
gh_patches_debug_10449 | rasdani/github-patches | git_diff | zestedesavoir__zds-site-5845 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Un simple membre ne peut pas ajouter une raison au masquage
Lorsqu'on est un simple membre, on n'a pas la possibilité d'ajouter une raison au masquage d'un message sur le forum (pour justifier => HS / déjà répondu / a côté de la plaque) alors qu'un staff peut ajouter un commentaire sur la raison du masquage.
Un simple membre ne peut pas ajouter une raison au masquage
Lorsqu'on est un simple membre, on n'a pas la possibilité d'ajouter une raison au masquage d'un message sur le forum (pour justifier => HS / déjà répondu / a côté de la plaque) alors qu'un staff peut ajouter un commentaire sur la raison du masquage.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zds/forum/commons.py`
Content:
```
1 from datetime import datetime
2
3 from django.contrib import messages
4 from django.core.exceptions import PermissionDenied
5 from django.http import Http404
6 from django.shortcuts import get_object_or_404
7 from django.utils.translation import ugettext as _
8 from django.views.generic.detail import SingleObjectMixin
9 from django.contrib.auth.decorators import permission_required
10
11 from zds.forum.models import Forum, Post, TopicRead
12 from zds.notification import signals
13 from zds.notification.models import TopicAnswerSubscription, Notification, NewTopicSubscription
14 from zds.utils.models import Alert, CommentEdit, get_hat_from_request
15
16
17 class ForumEditMixin(object):
18 @staticmethod
19 def perform_follow(forum_or_tag, user):
20 return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user).is_active
21
22 @staticmethod
23 def perform_follow_by_email(forum_or_tag, user):
24 return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user, True).is_active
25
26
27 class TopicEditMixin(object):
28 @staticmethod
29 def perform_follow(topic, user):
30 return TopicAnswerSubscription.objects.toggle_follow(topic, user)
31
32 @staticmethod
33 def perform_follow_by_email(topic, user):
34 return TopicAnswerSubscription.objects.toggle_follow(topic, user, True)
35
36 @staticmethod
37 def perform_solve_or_unsolve(user, topic):
38 if user == topic.author or user.has_perm('forum.change_topic'):
39 topic.solved_by = None if topic.solved_by else user
40 return topic.is_solved
41 else:
42 raise PermissionDenied
43
44 @staticmethod
45 @permission_required('forum.change_topic', raise_exception=True)
46 def perform_lock(request, topic):
47 topic.is_locked = request.POST.get('lock') == 'true'
48 if topic.is_locked:
49 success_message = _('Le sujet « {0} » est désormais verrouillé.').format(topic.title)
50 else:
51 success_message = _('Le sujet « {0} » est désormais déverrouillé.').format(topic.title)
52 messages.success(request, success_message)
53
54 @staticmethod
55 @permission_required('forum.change_topic', raise_exception=True)
56 def perform_sticky(request, topic):
57 topic.is_sticky = request.POST.get('sticky') == 'true'
58 if topic.is_sticky:
59 success_message = _('Le sujet « {0} » est désormais épinglé.').format(topic.title)
60 else:
61 success_message = _("Le sujet « {0} » n'est désormais plus épinglé.").format(topic.title)
62 messages.success(request, success_message)
63
64 def perform_move(self):
65 if self.request.user.has_perm('forum.change_topic'):
66 try:
67 forum_pk = int(self.request.POST.get('forum'))
68 except (KeyError, ValueError, TypeError) as e:
69 raise Http404('Forum not found', e)
70 forum = get_object_or_404(Forum, pk=forum_pk)
71 self.object.forum = forum
72
73 # Save topic to update update_index_date
74 self.object.save()
75
76 signals.edit_content.send(sender=self.object.__class__, instance=self.object, action='move')
77 message = _('Le sujet « {0} » a bien été déplacé dans « {1} ».').format(self.object.title, forum.title)
78 messages.success(self.request, message)
79 else:
80 raise PermissionDenied()
81
82 @staticmethod
83 def perform_edit_info(request, topic, data, editor):
84 topic.title = data.get('title')
85 topic.subtitle = data.get('subtitle')
86 topic.save()
87
88 PostEditMixin.perform_edit_post(request, topic.first_post(), editor, data.get('text'))
89
90 # add tags
91 topic.tags.clear()
92 if data.get('tags'):
93 topic.add_tags(data.get('tags').split(','))
94
95 return topic
96
97
98 class PostEditMixin(object):
99 @staticmethod
100 def perform_hide_message(request, post, user, data):
101 is_staff = user.has_perm('forum.change_post')
102 if post.author == user or is_staff:
103 for alert in post.alerts_on_this_comment.all():
104 alert.solve(user, _('Le message a été masqué.'))
105 post.is_visible = False
106 post.editor = user
107
108 if is_staff:
109 post.text_hidden = data.get('text_hidden', '')
110
111 messages.success(request, _('Le message est désormais masqué.'))
112 for user in Notification.objects.get_users_for_unread_notification_on(post):
113 signals.content_read.send(sender=post.topic.__class__, instance=post.topic, user=user)
114 else:
115 raise PermissionDenied
116
117 @staticmethod
118 @permission_required('forum.change_post', raise_exception=True)
119 def perform_show_message(request, post):
120 post.is_visible = True
121 post.text_hidden = ''
122
123 @staticmethod
124 def perform_alert_message(request, post, user, alert_text):
125 alert = Alert(
126 author=user,
127 comment=post,
128 scope='FORUM',
129 text=alert_text,
130 pubdate=datetime.now())
131 alert.save()
132
133 messages.success(request, _("Une alerte a été envoyée à l'équipe concernant ce message."))
134
135 @staticmethod
136 def perform_useful(post):
137 post.is_useful = not post.is_useful
138 post.save()
139
140 @staticmethod
141 def perform_unread_message(post, user):
142 """
143 Marks a post unread so we create a notification between the user and the topic host of the post.
144 But, if there is only one post in the topic, we mark the topic unread but we don't create a notification.
145 """
146 topic_read = TopicRead.objects.filter(topic=post.topic, user=user).first()
147 # issue 3227 proves that you can have post.position==1 AND topic_read to None
148 # it can happen whether on double click (the event "mark as not read" is therefore sent twice)
149 # or if you have two tabs in your browser.
150 if topic_read is None and post.position > 1:
151 unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()
152 topic_read = TopicRead(post=unread, topic=unread.topic, user=user)
153 topic_read.save()
154 else:
155 if post.position > 1:
156 unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()
157 topic_read.post = unread
158 topic_read.save()
159 elif topic_read:
160 topic_read.delete()
161
162 signals.answer_unread.send(sender=post.topic.__class__, instance=post, user=user)
163
164 @staticmethod
165 def perform_edit_post(request, post, user, text):
166 # create an archive
167 edit = CommentEdit()
168 edit.comment = post
169 edit.editor = user
170 edit.original_text = post.text
171 edit.save()
172
173 post.update_content(
174 text,
175 on_error=lambda m: messages.error(
176 request,
177 _('Erreur du serveur Markdown:\n{}').format('\n- '.join(m))))
178 post.hat = get_hat_from_request(request, post.author)
179 post.update = datetime.now()
180 post.editor = user
181 post.save()
182
183 if post.position == 1:
184 # Save topic to update update_index_date
185 post.topic.save()
186 return post
187
188
189 class SinglePostObjectMixin(SingleObjectMixin):
190 object = None
191
192 def get_object(self, queryset=None):
193 try:
194 post_pk = int(self.request.GET.get('message'))
195 except (KeyError, ValueError, TypeError):
196 raise Http404
197 return get_object_or_404(Post, pk=post_pk)
198
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/zds/forum/commons.py b/zds/forum/commons.py
--- a/zds/forum/commons.py
+++ b/zds/forum/commons.py
@@ -104,9 +104,7 @@
alert.solve(user, _('Le message a été masqué.'))
post.is_visible = False
post.editor = user
-
- if is_staff:
- post.text_hidden = data.get('text_hidden', '')
+ post.text_hidden = data.get('text_hidden', '')
messages.success(request, _('Le message est désormais masqué.'))
for user in Notification.objects.get_users_for_unread_notification_on(post):
| {"golden_diff": "diff --git a/zds/forum/commons.py b/zds/forum/commons.py\n--- a/zds/forum/commons.py\n+++ b/zds/forum/commons.py\n@@ -104,9 +104,7 @@\n alert.solve(user, _('Le message a \u00e9t\u00e9 masqu\u00e9.'))\n post.is_visible = False\n post.editor = user\n-\n- if is_staff:\n- post.text_hidden = data.get('text_hidden', '')\n+ post.text_hidden = data.get('text_hidden', '')\n \n messages.success(request, _('Le message est d\u00e9sormais masqu\u00e9.'))\n for user in Notification.objects.get_users_for_unread_notification_on(post):\n", "issue": "Un simple membre ne peut pas ajouter une raison au masquage\nLorsqu'on est un simple membre, on n'a pas la possibilit\u00e9 d'ajouter une raison au masquage d'un message sur le forum (pour justifier => HS / d\u00e9j\u00e0 r\u00e9pondu / a c\u00f4t\u00e9 de la plaque) alors qu'un staff peut ajouter un commentaire sur la raison du masquage.\nUn simple membre ne peut pas ajouter une raison au masquage\nLorsqu'on est un simple membre, on n'a pas la possibilit\u00e9 d'ajouter une raison au masquage d'un message sur le forum (pour justifier => HS / d\u00e9j\u00e0 r\u00e9pondu / a c\u00f4t\u00e9 de la plaque) alors qu'un staff peut ajouter un commentaire sur la raison du masquage.\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404\nfrom django.utils.translation import ugettext as _\nfrom django.views.generic.detail import SingleObjectMixin\nfrom django.contrib.auth.decorators import permission_required\n\nfrom zds.forum.models import Forum, Post, TopicRead\nfrom zds.notification import signals\nfrom zds.notification.models import TopicAnswerSubscription, Notification, NewTopicSubscription\nfrom zds.utils.models import Alert, CommentEdit, get_hat_from_request\n\n\nclass ForumEditMixin(object):\n @staticmethod\n def perform_follow(forum_or_tag, user):\n return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user).is_active\n\n @staticmethod\n def perform_follow_by_email(forum_or_tag, user):\n return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user, True).is_active\n\n\nclass TopicEditMixin(object):\n @staticmethod\n def perform_follow(topic, user):\n return TopicAnswerSubscription.objects.toggle_follow(topic, user)\n\n @staticmethod\n def perform_follow_by_email(topic, user):\n return TopicAnswerSubscription.objects.toggle_follow(topic, user, True)\n\n @staticmethod\n def perform_solve_or_unsolve(user, topic):\n if user == topic.author or user.has_perm('forum.change_topic'):\n topic.solved_by = None if topic.solved_by else user\n return topic.is_solved\n else:\n raise PermissionDenied\n\n @staticmethod\n @permission_required('forum.change_topic', raise_exception=True)\n def perform_lock(request, topic):\n topic.is_locked = request.POST.get('lock') == 'true'\n if topic.is_locked:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais verrouill\u00e9.').format(topic.title)\n else:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais d\u00e9verrouill\u00e9.').format(topic.title)\n messages.success(request, success_message)\n\n @staticmethod\n @permission_required('forum.change_topic', raise_exception=True)\n def perform_sticky(request, topic):\n topic.is_sticky = request.POST.get('sticky') == 'true'\n if topic.is_sticky:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais \u00e9pingl\u00e9.').format(topic.title)\n else:\n success_message = _(\"Le sujet \u00ab\u00a0{0}\u00a0\u00bb n'est d\u00e9sormais plus \u00e9pingl\u00e9.\").format(topic.title)\n messages.success(request, success_message)\n\n def perform_move(self):\n if self.request.user.has_perm('forum.change_topic'):\n try:\n forum_pk = int(self.request.POST.get('forum'))\n except (KeyError, ValueError, TypeError) as e:\n raise Http404('Forum not found', e)\n forum = get_object_or_404(Forum, pk=forum_pk)\n self.object.forum = forum\n\n # Save topic to update update_index_date\n self.object.save()\n\n signals.edit_content.send(sender=self.object.__class__, instance=self.object, action='move')\n message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb a bien \u00e9t\u00e9 d\u00e9plac\u00e9 dans \u00ab\u00a0{1}\u00a0\u00bb.').format(self.object.title, forum.title)\n messages.success(self.request, message)\n else:\n raise PermissionDenied()\n\n @staticmethod\n def perform_edit_info(request, topic, data, editor):\n topic.title = data.get('title')\n topic.subtitle = data.get('subtitle')\n topic.save()\n\n PostEditMixin.perform_edit_post(request, topic.first_post(), editor, data.get('text'))\n\n # add tags\n topic.tags.clear()\n if data.get('tags'):\n topic.add_tags(data.get('tags').split(','))\n\n return topic\n\n\nclass PostEditMixin(object):\n @staticmethod\n def perform_hide_message(request, post, user, data):\n is_staff = user.has_perm('forum.change_post')\n if post.author == user or is_staff:\n for alert in post.alerts_on_this_comment.all():\n alert.solve(user, _('Le message a \u00e9t\u00e9 masqu\u00e9.'))\n post.is_visible = False\n post.editor = user\n\n if is_staff:\n post.text_hidden = data.get('text_hidden', '')\n\n messages.success(request, _('Le message est d\u00e9sormais masqu\u00e9.'))\n for user in Notification.objects.get_users_for_unread_notification_on(post):\n signals.content_read.send(sender=post.topic.__class__, instance=post.topic, user=user)\n else:\n raise PermissionDenied\n\n @staticmethod\n @permission_required('forum.change_post', raise_exception=True)\n def perform_show_message(request, post):\n post.is_visible = True\n post.text_hidden = ''\n\n @staticmethod\n def perform_alert_message(request, post, user, alert_text):\n alert = Alert(\n author=user,\n comment=post,\n scope='FORUM',\n text=alert_text,\n pubdate=datetime.now())\n alert.save()\n\n messages.success(request, _(\"Une alerte a \u00e9t\u00e9 envoy\u00e9e \u00e0 l'\u00e9quipe concernant ce message.\"))\n\n @staticmethod\n def perform_useful(post):\n post.is_useful = not post.is_useful\n post.save()\n\n @staticmethod\n def perform_unread_message(post, user):\n \"\"\"\n Marks a post unread so we create a notification between the user and the topic host of the post.\n But, if there is only one post in the topic, we mark the topic unread but we don't create a notification.\n \"\"\"\n topic_read = TopicRead.objects.filter(topic=post.topic, user=user).first()\n # issue 3227 proves that you can have post.position==1 AND topic_read to None\n # it can happen whether on double click (the event \"mark as not read\" is therefore sent twice)\n # or if you have two tabs in your browser.\n if topic_read is None and post.position > 1:\n unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()\n topic_read = TopicRead(post=unread, topic=unread.topic, user=user)\n topic_read.save()\n else:\n if post.position > 1:\n unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()\n topic_read.post = unread\n topic_read.save()\n elif topic_read:\n topic_read.delete()\n\n signals.answer_unread.send(sender=post.topic.__class__, instance=post, user=user)\n\n @staticmethod\n def perform_edit_post(request, post, user, text):\n # create an archive\n edit = CommentEdit()\n edit.comment = post\n edit.editor = user\n edit.original_text = post.text\n edit.save()\n\n post.update_content(\n text,\n on_error=lambda m: messages.error(\n request,\n _('Erreur du serveur Markdown:\\n{}').format('\\n- '.join(m))))\n post.hat = get_hat_from_request(request, post.author)\n post.update = datetime.now()\n post.editor = user\n post.save()\n\n if post.position == 1:\n # Save topic to update update_index_date\n post.topic.save()\n return post\n\n\nclass SinglePostObjectMixin(SingleObjectMixin):\n object = None\n\n def get_object(self, queryset=None):\n try:\n post_pk = int(self.request.GET.get('message'))\n except (KeyError, ValueError, TypeError):\n raise Http404\n return get_object_or_404(Post, pk=post_pk)\n", "path": "zds/forum/commons.py"}], "after_files": [{"content": "from datetime import datetime\n\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404\nfrom django.utils.translation import ugettext as _\nfrom django.views.generic.detail import SingleObjectMixin\nfrom django.contrib.auth.decorators import permission_required\n\nfrom zds.forum.models import Forum, Post, TopicRead\nfrom zds.notification import signals\nfrom zds.notification.models import TopicAnswerSubscription, Notification, NewTopicSubscription\nfrom zds.utils.models import Alert, CommentEdit, get_hat_from_request\n\n\nclass ForumEditMixin(object):\n @staticmethod\n def perform_follow(forum_or_tag, user):\n return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user).is_active\n\n @staticmethod\n def perform_follow_by_email(forum_or_tag, user):\n return NewTopicSubscription.objects.toggle_follow(forum_or_tag, user, True).is_active\n\n\nclass TopicEditMixin(object):\n @staticmethod\n def perform_follow(topic, user):\n return TopicAnswerSubscription.objects.toggle_follow(topic, user)\n\n @staticmethod\n def perform_follow_by_email(topic, user):\n return TopicAnswerSubscription.objects.toggle_follow(topic, user, True)\n\n @staticmethod\n def perform_solve_or_unsolve(user, topic):\n if user == topic.author or user.has_perm('forum.change_topic'):\n topic.solved_by = None if topic.solved_by else user\n return topic.is_solved\n else:\n raise PermissionDenied\n\n @staticmethod\n @permission_required('forum.change_topic', raise_exception=True)\n def perform_lock(request, topic):\n topic.is_locked = request.POST.get('lock') == 'true'\n if topic.is_locked:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais verrouill\u00e9.').format(topic.title)\n else:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais d\u00e9verrouill\u00e9.').format(topic.title)\n messages.success(request, success_message)\n\n @staticmethod\n @permission_required('forum.change_topic', raise_exception=True)\n def perform_sticky(request, topic):\n topic.is_sticky = request.POST.get('sticky') == 'true'\n if topic.is_sticky:\n success_message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb est d\u00e9sormais \u00e9pingl\u00e9.').format(topic.title)\n else:\n success_message = _(\"Le sujet \u00ab\u00a0{0}\u00a0\u00bb n'est d\u00e9sormais plus \u00e9pingl\u00e9.\").format(topic.title)\n messages.success(request, success_message)\n\n def perform_move(self):\n if self.request.user.has_perm('forum.change_topic'):\n try:\n forum_pk = int(self.request.POST.get('forum'))\n except (KeyError, ValueError, TypeError) as e:\n raise Http404('Forum not found', e)\n forum = get_object_or_404(Forum, pk=forum_pk)\n self.object.forum = forum\n\n # Save topic to update update_index_date\n self.object.save()\n\n signals.edit_content.send(sender=self.object.__class__, instance=self.object, action='move')\n message = _('Le sujet \u00ab\u00a0{0}\u00a0\u00bb a bien \u00e9t\u00e9 d\u00e9plac\u00e9 dans \u00ab\u00a0{1}\u00a0\u00bb.').format(self.object.title, forum.title)\n messages.success(self.request, message)\n else:\n raise PermissionDenied()\n\n @staticmethod\n def perform_edit_info(request, topic, data, editor):\n topic.title = data.get('title')\n topic.subtitle = data.get('subtitle')\n topic.save()\n\n PostEditMixin.perform_edit_post(request, topic.first_post(), editor, data.get('text'))\n\n # add tags\n topic.tags.clear()\n if data.get('tags'):\n topic.add_tags(data.get('tags').split(','))\n\n return topic\n\n\nclass PostEditMixin(object):\n @staticmethod\n def perform_hide_message(request, post, user, data):\n is_staff = user.has_perm('forum.change_post')\n if post.author == user or is_staff:\n for alert in post.alerts_on_this_comment.all():\n alert.solve(user, _('Le message a \u00e9t\u00e9 masqu\u00e9.'))\n post.is_visible = False\n post.editor = user\n post.text_hidden = data.get('text_hidden', '')\n\n messages.success(request, _('Le message est d\u00e9sormais masqu\u00e9.'))\n for user in Notification.objects.get_users_for_unread_notification_on(post):\n signals.content_read.send(sender=post.topic.__class__, instance=post.topic, user=user)\n else:\n raise PermissionDenied\n\n @staticmethod\n @permission_required('forum.change_post', raise_exception=True)\n def perform_show_message(request, post):\n post.is_visible = True\n post.text_hidden = ''\n\n @staticmethod\n def perform_alert_message(request, post, user, alert_text):\n alert = Alert(\n author=user,\n comment=post,\n scope='FORUM',\n text=alert_text,\n pubdate=datetime.now())\n alert.save()\n\n messages.success(request, _(\"Une alerte a \u00e9t\u00e9 envoy\u00e9e \u00e0 l'\u00e9quipe concernant ce message.\"))\n\n @staticmethod\n def perform_useful(post):\n post.is_useful = not post.is_useful\n post.save()\n\n @staticmethod\n def perform_unread_message(post, user):\n \"\"\"\n Marks a post unread so we create a notification between the user and the topic host of the post.\n But, if there is only one post in the topic, we mark the topic unread but we don't create a notification.\n \"\"\"\n topic_read = TopicRead.objects.filter(topic=post.topic, user=user).first()\n # issue 3227 proves that you can have post.position==1 AND topic_read to None\n # it can happen whether on double click (the event \"mark as not read\" is therefore sent twice)\n # or if you have two tabs in your browser.\n if topic_read is None and post.position > 1:\n unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()\n topic_read = TopicRead(post=unread, topic=unread.topic, user=user)\n topic_read.save()\n else:\n if post.position > 1:\n unread = Post.objects.filter(topic=post.topic, position=(post.position - 1)).first()\n topic_read.post = unread\n topic_read.save()\n elif topic_read:\n topic_read.delete()\n\n signals.answer_unread.send(sender=post.topic.__class__, instance=post, user=user)\n\n @staticmethod\n def perform_edit_post(request, post, user, text):\n # create an archive\n edit = CommentEdit()\n edit.comment = post\n edit.editor = user\n edit.original_text = post.text\n edit.save()\n\n post.update_content(\n text,\n on_error=lambda m: messages.error(\n request,\n _('Erreur du serveur Markdown:\\n{}').format('\\n- '.join(m))))\n post.hat = get_hat_from_request(request, post.author)\n post.update = datetime.now()\n post.editor = user\n post.save()\n\n if post.position == 1:\n # Save topic to update update_index_date\n post.topic.save()\n return post\n\n\nclass SinglePostObjectMixin(SingleObjectMixin):\n object = None\n\n def get_object(self, queryset=None):\n try:\n post_pk = int(self.request.GET.get('message'))\n except (KeyError, ValueError, TypeError):\n raise Http404\n return get_object_or_404(Post, pk=post_pk)\n", "path": "zds/forum/commons.py"}]} | 2,529 | 136 |
gh_patches_debug_23156 | rasdani/github-patches | git_diff | hydroshare__hydroshare-5446 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Errors around the signup url
**Description of the bug**
We are seeing error in the logs around generating the signup url
Steps to reproduce the bug:
I'm not sure how to reproduce the bug but the stacktrace indicates a signup_url
**Expected behavior**
No errors in the log
**Additional information**
```
[27/Mar/2024 00:14:33] ERROR [django.request:224] Internal Server Error: /
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/django/core/handlers/exception.py", line 47, in inner
response = get_response(request)
File "/usr/local/lib/python3.9/site-packages/django/core/handlers/base.py", line 171, in _get_response
response = middleware_method(request, callback, callback_args, callback_kwargs)
File "/usr/local/lib/python3.9/site-packages/mezzanine/pages/middleware.py", line 90, in process_view
return view_func(request, *view_args, **view_kwargs)
File "/hydroshare/theme/views.py", line 607, in home_router
return render(request, "pages/homepage.html")
File "/usr/local/lib/python3.9/site-packages/django/shortcuts.py", line 19, in render
content = loader.render_to_string(template_name, context, request, using=using)
File "/usr/local/lib/python3.9/site-packages/django/template/loader.py", line 62, in render_to_string
return template.render(context, request)
File "/usr/local/lib/python3.9/site-packages/django/template/backends/django.py", line 61, in render
return self.template.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 170, in render
return self._render(context)
File "/usr/local/lib/python3.9/site-packages/django/test/utils.py", line 100, in instrumented_test_render
return self.nodelist.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py", line 150, in render
return compiled_parent._render(context)
File "/usr/local/lib/python3.9/site-packages/django/test/utils.py", line 100, in instrumented_test_render
return self.nodelist.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py", line 62, in render
result = block.nodelist.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py", line 62, in render
result = block.nodelist.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/defaulttags.py", line 315, in render
return nodelist.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 938, in render
bit = node.render_annotated(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 905, in render_annotated
return self.render(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 988, in render
output = self.filter_expression.resolve(context)
File "/usr/local/lib/python3.9/site-packages/django/template/base.py", line 698, in resolve
new_obj = func(obj, *arg_vals)
File "/hydroshare/hs_core/templatetags/hydroshare_tags.py", line 383, in signup_url
return build_oidc_url(request).replace('/auth?', '/registrations?')
File "/hydroshare/hs_core/authentication.py", line 43, in build_oidc_url
return redirect.url
AttributeError: 'HttpResponseNotAllowed' object has no attribute 'url'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hs_core/authentication.py`
Content:
```
1 import requests
2 import base64
3 from mozilla_django_oidc.auth import OIDCAuthenticationBackend
4 from hs_core.hydroshare import create_account
5 from django.urls import reverse, resolve
6 from django.conf import settings
7 from django.utils.http import urlencode
8 from django.contrib.auth.models import User
9 from rest_framework.authentication import BaseAuthentication
10 from keycloak.keycloak_openid import KeycloakOpenID
11
12
13 class HydroShareOIDCAuthenticationBackend(OIDCAuthenticationBackend):
14 def create_user(self, claims):
15 subject_areas = claims.get('subject_areas', '').split(";")
16 return create_account(
17 email=claims.get('email', ''),
18 username=claims.get('preferred_username', self.get_username(claims)),
19 first_name=claims.get('given_name', ''),
20 last_name=claims.get('family_name', ''),
21 superuser=False,
22 active=claims.get('email_verified', True),
23 organization=claims.get('organization', ''),
24 user_type=claims.get('user_type', ''),
25 country=claims.get('country', ''),
26 state=claims.get('state', ''),
27 subject_areas=subject_areas)
28
29
30 def build_oidc_url(request):
31 """Builds a link to OIDC service
32 To be called from within a view function
33
34 Args:
35 request: current request being processed by the view
36
37 Returns:
38 string: redirect URL for oidc service
39 """
40 view, args, kwargs = resolve(reverse('oidc_authentication_init'))
41 kwargs["request"] = request
42 redirect = view(*args, **kwargs)
43 return redirect.url
44
45
46 def provider_logout(request):
47 """ Create the user's OIDC logout URL."""
48 # User must confirm logout request with the default logout URL
49 # and is not redirected.
50 logout_url = settings.OIDC_OP_LOGOUT_ENDPOINT
51 redirect_url = settings.LOGOUT_REDIRECT_URL
52
53 # If we have the oidc_id_token, we can automatically redirect
54 # the user back to the application.
55 oidc_id_token = request.session.get('oidc_id_token', None)
56 if oidc_id_token:
57 data = {
58 "id_token_hint": oidc_id_token,
59 "post_logout_redirect_uri": request.build_absolute_uri(
60 location=redirect_url
61 )
62 }
63 res = requests.post(logout_url, data)
64 if not res.ok:
65 logout_url = logout_url + "?" + urlencode(data)
66 else:
67 logout_url = redirect_url
68 return logout_url
69
70
71 KEYCLOAK = KeycloakOpenID(
72 server_url=settings.OIDC_KEYCLOAK_URL,
73 client_id=settings.OIDC_RP_CLIENT_ID,
74 realm_name=settings.OIDC_KEYCLOAK_REALM,
75 client_secret_key=settings.OIDC_RP_CLIENT_SECRET,
76 )
77
78
79 class BasicOIDCAuthentication(BaseAuthentication):
80
81 def authenticate(self, request):
82 auth = request.headers.get('Authorization')
83 if not auth or 'Basic' not in auth:
84 return None
85 _, value, *_ = request.headers.get('Authorization').split()
86
87 decoded_username, decoded_password = (
88 base64.b64decode(value).decode("utf-8").split(":")
89 )
90 # authenticate against keycloak
91 try:
92 KEYCLOAK.token(decoded_username, decoded_password)
93 except Exception:
94 return None
95
96 user = User.objects.get(username=decoded_username)
97 return (user, None)
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/hs_core/authentication.py b/hs_core/authentication.py
--- a/hs_core/authentication.py
+++ b/hs_core/authentication.py
@@ -9,6 +9,9 @@
from rest_framework.authentication import BaseAuthentication
from keycloak.keycloak_openid import KeycloakOpenID
+import logging
+logger = logging.getLogger(__name__)
+
class HydroShareOIDCAuthenticationBackend(OIDCAuthenticationBackend):
def create_user(self, claims):
@@ -37,10 +40,22 @@
Returns:
string: redirect URL for oidc service
"""
- view, args, kwargs = resolve(reverse('oidc_authentication_init'))
+ oidc_init = reverse('oidc_authentication_init')
+ view, args, kwargs = resolve(oidc_init)
kwargs["request"] = request
- redirect = view(*args, **kwargs)
- return redirect.url
+ error = None
+ try:
+ redirect = view(*args, **kwargs)
+ if isinstance(redirect, Exception):
+ error = redirect
+ else:
+ return redirect.url
+ except Exception as e:
+ error = e
+
+ # If the OIDC URL could not be built, log the error and return the bare oidc_authentication_init url
+ logger.error(f"Error building OIDC URL: {error}")
+ return oidc_init
def provider_logout(request):
| {"golden_diff": "diff --git a/hs_core/authentication.py b/hs_core/authentication.py\n--- a/hs_core/authentication.py\n+++ b/hs_core/authentication.py\n@@ -9,6 +9,9 @@\n from rest_framework.authentication import BaseAuthentication\n from keycloak.keycloak_openid import KeycloakOpenID\n \n+import logging\n+logger = logging.getLogger(__name__)\n+\n \n class HydroShareOIDCAuthenticationBackend(OIDCAuthenticationBackend):\n def create_user(self, claims):\n@@ -37,10 +40,22 @@\n Returns:\n string: redirect URL for oidc service\n \"\"\"\n- view, args, kwargs = resolve(reverse('oidc_authentication_init'))\n+ oidc_init = reverse('oidc_authentication_init')\n+ view, args, kwargs = resolve(oidc_init)\n kwargs[\"request\"] = request\n- redirect = view(*args, **kwargs)\n- return redirect.url\n+ error = None\n+ try:\n+ redirect = view(*args, **kwargs)\n+ if isinstance(redirect, Exception):\n+ error = redirect\n+ else:\n+ return redirect.url\n+ except Exception as e:\n+ error = e\n+\n+ # If the OIDC URL could not be built, log the error and return the bare oidc_authentication_init url\n+ logger.error(f\"Error building OIDC URL: {error}\")\n+ return oidc_init\n \n \n def provider_logout(request):\n", "issue": "Errors around the signup url\n**Description of the bug**\r\nWe are seeing error in the logs around generating the signup url\r\n\r\nSteps to reproduce the bug:\r\nI'm not sure how to reproduce the bug but the stacktrace indicates a signup_url\r\n\r\n**Expected behavior**\r\nNo errors in the log\r\n\r\n**Additional information**\r\n```\r\n[27/Mar/2024 00:14:33] ERROR [django.request:224] Internal Server Error: /\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/handlers/exception.py\", line 47, in inner\r\n response = get_response(request)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/handlers/base.py\", line 171, in _get_response\r\n response = middleware_method(request, callback, callback_args, callback_kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/mezzanine/pages/middleware.py\", line 90, in process_view\r\n return view_func(request, *view_args, **view_kwargs)\r\n File \"/hydroshare/theme/views.py\", line 607, in home_router\r\n return render(request, \"pages/homepage.html\")\r\n File \"/usr/local/lib/python3.9/site-packages/django/shortcuts.py\", line 19, in render\r\n content = loader.render_to_string(template_name, context, request, using=using)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/loader.py\", line 62, in render_to_string\r\n return template.render(context, request)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/backends/django.py\", line 61, in render\r\n return self.template.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 170, in render\r\n return self._render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/test/utils.py\", line 100, in instrumented_test_render\r\n return self.nodelist.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py\", line 150, in render\r\n return compiled_parent._render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/test/utils.py\", line 100, in instrumented_test_render\r\n return self.nodelist.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py\", line 62, in render\r\n result = block.nodelist.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/loader_tags.py\", line 62, in render\r\n result = block.nodelist.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/defaulttags.py\", line 315, in render\r\n return nodelist.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 938, in render\r\n bit = node.render_annotated(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 905, in render_annotated\r\n return self.render(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 988, in render\r\n output = self.filter_expression.resolve(context)\r\n File \"/usr/local/lib/python3.9/site-packages/django/template/base.py\", line 698, in resolve\r\n new_obj = func(obj, *arg_vals)\r\n File \"/hydroshare/hs_core/templatetags/hydroshare_tags.py\", line 383, in signup_url\r\n return build_oidc_url(request).replace('/auth?', '/registrations?')\r\n File \"/hydroshare/hs_core/authentication.py\", line 43, in build_oidc_url\r\n return redirect.url\r\nAttributeError: 'HttpResponseNotAllowed' object has no attribute 'url'\r\n```\r\n\n", "before_files": [{"content": "import requests\nimport base64\nfrom mozilla_django_oidc.auth import OIDCAuthenticationBackend\nfrom hs_core.hydroshare import create_account\nfrom django.urls import reverse, resolve\nfrom django.conf import settings\nfrom django.utils.http import urlencode\nfrom django.contrib.auth.models import User\nfrom rest_framework.authentication import BaseAuthentication\nfrom keycloak.keycloak_openid import KeycloakOpenID\n\n\nclass HydroShareOIDCAuthenticationBackend(OIDCAuthenticationBackend):\n def create_user(self, claims):\n subject_areas = claims.get('subject_areas', '').split(\";\")\n return create_account(\n email=claims.get('email', ''),\n username=claims.get('preferred_username', self.get_username(claims)),\n first_name=claims.get('given_name', ''),\n last_name=claims.get('family_name', ''),\n superuser=False,\n active=claims.get('email_verified', True),\n organization=claims.get('organization', ''),\n user_type=claims.get('user_type', ''),\n country=claims.get('country', ''),\n state=claims.get('state', ''),\n subject_areas=subject_areas)\n\n\ndef build_oidc_url(request):\n \"\"\"Builds a link to OIDC service\n To be called from within a view function\n\n Args:\n request: current request being processed by the view\n\n Returns:\n string: redirect URL for oidc service\n \"\"\"\n view, args, kwargs = resolve(reverse('oidc_authentication_init'))\n kwargs[\"request\"] = request\n redirect = view(*args, **kwargs)\n return redirect.url\n\n\ndef provider_logout(request):\n \"\"\" Create the user's OIDC logout URL.\"\"\"\n # User must confirm logout request with the default logout URL\n # and is not redirected.\n logout_url = settings.OIDC_OP_LOGOUT_ENDPOINT\n redirect_url = settings.LOGOUT_REDIRECT_URL\n\n # If we have the oidc_id_token, we can automatically redirect\n # the user back to the application.\n oidc_id_token = request.session.get('oidc_id_token', None)\n if oidc_id_token:\n data = {\n \"id_token_hint\": oidc_id_token,\n \"post_logout_redirect_uri\": request.build_absolute_uri(\n location=redirect_url\n )\n }\n res = requests.post(logout_url, data)\n if not res.ok:\n logout_url = logout_url + \"?\" + urlencode(data)\n else:\n logout_url = redirect_url\n return logout_url\n\n\nKEYCLOAK = KeycloakOpenID(\n server_url=settings.OIDC_KEYCLOAK_URL,\n client_id=settings.OIDC_RP_CLIENT_ID,\n realm_name=settings.OIDC_KEYCLOAK_REALM,\n client_secret_key=settings.OIDC_RP_CLIENT_SECRET,\n)\n\n\nclass BasicOIDCAuthentication(BaseAuthentication):\n\n def authenticate(self, request):\n auth = request.headers.get('Authorization')\n if not auth or 'Basic' not in auth:\n return None\n _, value, *_ = request.headers.get('Authorization').split()\n\n decoded_username, decoded_password = (\n base64.b64decode(value).decode(\"utf-8\").split(\":\")\n )\n # authenticate against keycloak\n try:\n KEYCLOAK.token(decoded_username, decoded_password)\n except Exception:\n return None\n\n user = User.objects.get(username=decoded_username)\n return (user, None)\n", "path": "hs_core/authentication.py"}], "after_files": [{"content": "import requests\nimport base64\nfrom mozilla_django_oidc.auth import OIDCAuthenticationBackend\nfrom hs_core.hydroshare import create_account\nfrom django.urls import reverse, resolve\nfrom django.conf import settings\nfrom django.utils.http import urlencode\nfrom django.contrib.auth.models import User\nfrom rest_framework.authentication import BaseAuthentication\nfrom keycloak.keycloak_openid import KeycloakOpenID\n\nimport logging\nlogger = logging.getLogger(__name__)\n\n\nclass HydroShareOIDCAuthenticationBackend(OIDCAuthenticationBackend):\n def create_user(self, claims):\n subject_areas = claims.get('subject_areas', '').split(\";\")\n return create_account(\n email=claims.get('email', ''),\n username=claims.get('preferred_username', self.get_username(claims)),\n first_name=claims.get('given_name', ''),\n last_name=claims.get('family_name', ''),\n superuser=False,\n active=claims.get('email_verified', True),\n organization=claims.get('organization', ''),\n user_type=claims.get('user_type', ''),\n country=claims.get('country', ''),\n state=claims.get('state', ''),\n subject_areas=subject_areas)\n\n\ndef build_oidc_url(request):\n \"\"\"Builds a link to OIDC service\n To be called from within a view function\n\n Args:\n request: current request being processed by the view\n\n Returns:\n string: redirect URL for oidc service\n \"\"\"\n oidc_init = reverse('oidc_authentication_init')\n view, args, kwargs = resolve(oidc_init)\n kwargs[\"request\"] = request\n error = None\n try:\n redirect = view(*args, **kwargs)\n if isinstance(redirect, Exception):\n error = redirect\n else:\n return redirect.url\n except Exception as e:\n error = e\n\n # If the OIDC URL could not be built, log the error and return the bare oidc_authentication_init url\n logger.error(f\"Error building OIDC URL: {error}\")\n return oidc_init\n\n\ndef provider_logout(request):\n \"\"\" Create the user's OIDC logout URL.\"\"\"\n # User must confirm logout request with the default logout URL\n # and is not redirected.\n logout_url = settings.OIDC_OP_LOGOUT_ENDPOINT\n redirect_url = settings.LOGOUT_REDIRECT_URL\n\n # If we have the oidc_id_token, we can automatically redirect\n # the user back to the application.\n oidc_id_token = request.session.get('oidc_id_token', None)\n if oidc_id_token:\n data = {\n \"id_token_hint\": oidc_id_token,\n \"post_logout_redirect_uri\": request.build_absolute_uri(\n location=redirect_url\n )\n }\n res = requests.post(logout_url, data)\n if not res.ok:\n logout_url = logout_url + \"?\" + urlencode(data)\n else:\n logout_url = redirect_url\n return logout_url\n\n\nKEYCLOAK = KeycloakOpenID(\n server_url=settings.OIDC_KEYCLOAK_URL,\n client_id=settings.OIDC_RP_CLIENT_ID,\n realm_name=settings.OIDC_KEYCLOAK_REALM,\n client_secret_key=settings.OIDC_RP_CLIENT_SECRET,\n)\n\n\nclass BasicOIDCAuthentication(BaseAuthentication):\n\n def authenticate(self, request):\n auth = request.headers.get('Authorization')\n if not auth or 'Basic' not in auth:\n return None\n _, value, *_ = request.headers.get('Authorization').split()\n\n decoded_username, decoded_password = (\n base64.b64decode(value).decode(\"utf-8\").split(\":\")\n )\n # authenticate against keycloak\n try:\n KEYCLOAK.token(decoded_username, decoded_password)\n except Exception:\n return None\n\n user = User.objects.get(username=decoded_username)\n return (user, None)\n", "path": "hs_core/authentication.py"}]} | 2,335 | 311 |
gh_patches_debug_28145 | rasdani/github-patches | git_diff | dynamiqs__dynamiqs-216 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Propagator solvers are cached on slighlty changing `delta_t`
Both the `sesolve` and `mesolve` propagator solvers are cached on the time step `delta_t` to take, which should be constant for linearly spaced `t_save`. Thus, the propagator should be computed only once. However, due to numerical imprecisions, the `delta_t` changes slightly even when `t_save` is linearly spaced, resulting in frequent recomputations of the same quantity.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dynamiqs/solvers/propagator.py`
Content:
```
1 from abc import abstractmethod
2
3 from torch import Tensor
4
5 from .solver import AutogradSolver
6 from .utils.td_tensor import ConstantTDTensor
7 from .utils.utils import tqdm
8
9
10 class Propagator(AutogradSolver):
11 def __init__(self, *args, **kwargs):
12 super().__init__(*args, **kwargs)
13
14 # check that Hamiltonian is time-independent
15 if not isinstance(self.H, ConstantTDTensor):
16 raise TypeError(
17 'Solver `Propagator` requires a time-independent Hamiltonian.'
18 )
19 self.H = self.H(0.0)
20
21 def run_autograd(self):
22 y, t1 = self.y0, 0.0
23 for t2 in tqdm(self.t_stop.cpu().numpy(), disable=not self.options.verbose):
24 y = self.forward(t1, t2 - t1, y)
25 self.save(y)
26 t1 = t2
27
28 @abstractmethod
29 def forward(self, t: float, delta_t: float, y: Tensor):
30 pass
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/dynamiqs/solvers/propagator.py b/dynamiqs/solvers/propagator.py
--- a/dynamiqs/solvers/propagator.py
+++ b/dynamiqs/solvers/propagator.py
@@ -1,5 +1,8 @@
+from __future__ import annotations
+
from abc import abstractmethod
+import numpy as np
from torch import Tensor
from .solver import AutogradSolver
@@ -7,6 +10,19 @@
from .utils.utils import tqdm
+def round_truncate(x: np.float32 | np.float64) -> np.float32 | np.float64:
+ # round a strictly positive-valued float to remove numerical errors, and enable
+ # comparing floats for equality
+
+ # The mantissa of a float32 is stored using 23 bits. The following code rounds and
+ # truncates the float value to the 18 most significant bits of its mantissa. This
+ # removes any numerical error that may have accumulated in the 5 least significant
+ # bits of the mantissa.
+ leading = abs(int(np.log2(x)))
+ keep = leading + 18
+ return (x * 2**keep).round() / 2**keep
+
+
class Propagator(AutogradSolver):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
@@ -21,7 +37,10 @@
def run_autograd(self):
y, t1 = self.y0, 0.0
for t2 in tqdm(self.t_stop.cpu().numpy(), disable=not self.options.verbose):
- y = self.forward(t1, t2 - t1, y)
+ if t2 != 0.0:
+ # round time difference to avoid numerical errors when comparing floats
+ delta_t = round_truncate(t2 - t1)
+ y = self.forward(t1, delta_t, y)
self.save(y)
t1 = t2
| {"golden_diff": "diff --git a/dynamiqs/solvers/propagator.py b/dynamiqs/solvers/propagator.py\n--- a/dynamiqs/solvers/propagator.py\n+++ b/dynamiqs/solvers/propagator.py\n@@ -1,5 +1,8 @@\n+from __future__ import annotations\n+\n from abc import abstractmethod\n \n+import numpy as np\n from torch import Tensor\n \n from .solver import AutogradSolver\n@@ -7,6 +10,19 @@\n from .utils.utils import tqdm\n \n \n+def round_truncate(x: np.float32 | np.float64) -> np.float32 | np.float64:\n+ # round a strictly positive-valued float to remove numerical errors, and enable\n+ # comparing floats for equality\n+\n+ # The mantissa of a float32 is stored using 23 bits. The following code rounds and\n+ # truncates the float value to the 18 most significant bits of its mantissa. This\n+ # removes any numerical error that may have accumulated in the 5 least significant\n+ # bits of the mantissa.\n+ leading = abs(int(np.log2(x)))\n+ keep = leading + 18\n+ return (x * 2**keep).round() / 2**keep\n+\n+\n class Propagator(AutogradSolver):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n@@ -21,7 +37,10 @@\n def run_autograd(self):\n y, t1 = self.y0, 0.0\n for t2 in tqdm(self.t_stop.cpu().numpy(), disable=not self.options.verbose):\n- y = self.forward(t1, t2 - t1, y)\n+ if t2 != 0.0:\n+ # round time difference to avoid numerical errors when comparing floats\n+ delta_t = round_truncate(t2 - t1)\n+ y = self.forward(t1, delta_t, y)\n self.save(y)\n t1 = t2\n", "issue": "Propagator solvers are cached on slighlty changing `delta_t`\nBoth the `sesolve` and `mesolve` propagator solvers are cached on the time step `delta_t` to take, which should be constant for linearly spaced `t_save`. Thus, the propagator should be computed only once. However, due to numerical imprecisions, the `delta_t` changes slightly even when `t_save` is linearly spaced, resulting in frequent recomputations of the same quantity.\n", "before_files": [{"content": "from abc import abstractmethod\n\nfrom torch import Tensor\n\nfrom .solver import AutogradSolver\nfrom .utils.td_tensor import ConstantTDTensor\nfrom .utils.utils import tqdm\n\n\nclass Propagator(AutogradSolver):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n # check that Hamiltonian is time-independent\n if not isinstance(self.H, ConstantTDTensor):\n raise TypeError(\n 'Solver `Propagator` requires a time-independent Hamiltonian.'\n )\n self.H = self.H(0.0)\n\n def run_autograd(self):\n y, t1 = self.y0, 0.0\n for t2 in tqdm(self.t_stop.cpu().numpy(), disable=not self.options.verbose):\n y = self.forward(t1, t2 - t1, y)\n self.save(y)\n t1 = t2\n\n @abstractmethod\n def forward(self, t: float, delta_t: float, y: Tensor):\n pass\n", "path": "dynamiqs/solvers/propagator.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom abc import abstractmethod\n\nimport numpy as np\nfrom torch import Tensor\n\nfrom .solver import AutogradSolver\nfrom .utils.td_tensor import ConstantTDTensor\nfrom .utils.utils import tqdm\n\n\ndef round_truncate(x: np.float32 | np.float64) -> np.float32 | np.float64:\n # round a strictly positive-valued float to remove numerical errors, and enable\n # comparing floats for equality\n\n # The mantissa of a float32 is stored using 23 bits. The following code rounds and\n # truncates the float value to the 18 most significant bits of its mantissa. This\n # removes any numerical error that may have accumulated in the 5 least significant\n # bits of the mantissa.\n leading = abs(int(np.log2(x)))\n keep = leading + 18\n return (x * 2**keep).round() / 2**keep\n\n\nclass Propagator(AutogradSolver):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n # check that Hamiltonian is time-independent\n if not isinstance(self.H, ConstantTDTensor):\n raise TypeError(\n 'Solver `Propagator` requires a time-independent Hamiltonian.'\n )\n self.H = self.H(0.0)\n\n def run_autograd(self):\n y, t1 = self.y0, 0.0\n for t2 in tqdm(self.t_stop.cpu().numpy(), disable=not self.options.verbose):\n if t2 != 0.0:\n # round time difference to avoid numerical errors when comparing floats\n delta_t = round_truncate(t2 - t1)\n y = self.forward(t1, delta_t, y)\n self.save(y)\n t1 = t2\n\n @abstractmethod\n def forward(self, t: float, delta_t: float, y: Tensor):\n pass\n", "path": "dynamiqs/solvers/propagator.py"}]} | 649 | 461 |
gh_patches_debug_24161 | rasdani/github-patches | git_diff | pwndbg__pwndbg-588 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Context disasm crashes when trying to show dereferenced call address
Enhancing a disassembled instruction fails if it is an indirect call and the address cannot be dereferenced/retrieved.
The issue can be reproduced with a binary created from assembly:
```
global _start
_start:
call qword [r11+0x30]
```
Or, full testcase (assuming `nasm` is installed):
```
printf 'global _start\n_start:\ncall qword [r11+0x30]' > test.asm && nasm -f elf64 test.asm && ld test.o -o test && gdb ./test -ex entry
```
Current result:
```
Traceback (most recent call last):
File "/home/dc/pwndbg/pwndbg/commands/__init__.py", line 135, in __call__
return self.function(*args, **kwargs)
File "/home/dc/pwndbg/pwndbg/commands/__init__.py", line 226, in _OnlyWhenRunning
return function(*a, **kw)
File "/home/dc/pwndbg/pwndbg/commands/context.py", line 88, in context
result.extend(func())
File "/home/dc/pwndbg/pwndbg/commands/context.py", line 100, in context_regs
return [pwndbg.ui.banner("registers")] + get_regs()
File "/home/dc/pwndbg/pwndbg/commands/context.py", line 144, in get_regs
desc = pwndbg.chain.format(value)
File "/home/dc/pwndbg/pwndbg/chain.py", line 122, in format
enhanced = pwndbg.enhance.enhance(chain[-2] + offset, code=code)
File "/home/dc/pwndbg/pwndbg/enhance.py", line 102, in enhance
instr = pwndbg.disasm.one(value)
File "/home/dc/pwndbg/pwndbg/disasm/__init__.py", line 115, in one
for insn in get(address, 1):
File "/home/dc/pwndbg/pwndbg/disasm/__init__.py", line 135, in get
i = get_one_instruction(address)
File "/home/dc/pwndbg/pwndbg/memoize.py", line 48, in __call__
value = self.func(*args, **kwargs)
File "/home/dc/pwndbg/pwndbg/disasm/__init__.py", line 107, in get_one_instruction
pwndbg.disasm.arch.DisassemblyAssistant.enhance(ins)
File "/home/dc/pwndbg/pwndbg/disasm/arch.py", line 55, in enhance
enhancer.enhance_next(instruction)
File "/home/dc/pwndbg/pwndbg/disasm/arch.py", line 111, in enhance_next
instruction.target = self.next(instruction, call=True)
File "/home/dc/pwndbg/pwndbg/disasm/x86.py", line 112, in next
return super(DisassemblyAssistant, self).next(instruction, call)
File "/home/dc/pwndbg/pwndbg/disasm/arch.py", line 150, in next
addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))
File "/home/dc/pwndbg/pwndbg/inthook.py", line 40, in __new__
value = value.cast(pwndbg.typeinfo.ulong)
gdb.MemoryError: Cannot access memory at address 0x30
```
Expected result - display disasm:
```
call qword ptr [r11 + 0x30] # <INVALID>
```
or `INVALID DEREF` or sth like this.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwndbg/disasm/arch.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import absolute_import
4 from __future__ import division
5 from __future__ import print_function
6 from __future__ import unicode_literals
7
8 import collections
9
10 import capstone
11 from capstone import *
12
13 import pwndbg.memoize
14 import pwndbg.symbol
15
16 CS_OP_IMM
17
18 debug = False
19
20 groups = {v:k for k,v in globals().items() if k.startswith('CS_GRP_')}
21 ops = {v:k for k,v in globals().items() if k.startswith('CS_OP_')}
22 access = {v:k for k,v in globals().items() if k.startswith('CS_AC_')}
23
24 for value1, name1 in dict(access).items():
25 for value2, name2 in dict(access).items():
26 access.setdefault(value1 | value2, '%s | %s' % (name1, name2))
27
28
29 class DisassemblyAssistant(object):
30 # Registry of all instances, {architecture: instance}
31 assistants = {}
32
33 def __init__(self, architecture):
34 if architecture is not None:
35 self.assistants[architecture] = self
36
37 self.op_handlers = {
38 CS_OP_IMM: self.immediate,
39 CS_OP_REG: self.register,
40 CS_OP_MEM: self.memory
41 }
42
43 self.op_names = {
44 CS_OP_IMM: self.immediate_sz,
45 CS_OP_REG: self.register_sz,
46 CS_OP_MEM: self.memory_sz
47 }
48
49 @staticmethod
50 def enhance(instruction):
51 enhancer = DisassemblyAssistant.assistants.get(pwndbg.arch.current, generic_assistant)
52 enhancer.enhance_operands(instruction)
53 enhancer.enhance_symbol(instruction)
54 enhancer.enhance_conditional(instruction)
55 enhancer.enhance_next(instruction)
56
57 if debug:
58 print(enhancer.dump(instruction))
59
60 def enhance_conditional(self, instruction):
61 """
62 Adds a ``condition`` field to the instruction.
63
64 If the instruction is always executed unconditionally, the value
65 of the field is ``None``.
66
67 If the instruction is executed conditionally, and we can be absolutely
68 sure that it will be executed, the value of the field is ``True``.
69 Generally, this implies that it is the next instruction to be executed.
70
71 In all other cases, it is set to ``False``.
72 """
73 c = self.condition(instruction)
74
75 if c:
76 c = True
77 elif c is not None:
78 c = False
79
80 instruction.condition = c
81
82 def condition(self, instruction):
83 return False
84
85 def enhance_next(self, instruction):
86 """
87 Adds a ``next`` field to the instruction.
88
89 By default, it is set to the address of the next linear
90 instruction.
91
92 If the instruction is a non-"call" branch and either:
93
94 - Is unconditional
95 - Is conditional, but is known to be taken
96
97 And the target can be resolved, it is set to the address
98 of the jump target.
99 """
100 next_addr = None
101
102 if instruction.condition in (True, None):
103 next_addr = self.next(instruction)
104
105 instruction.target = None
106 instruction.target_const = None
107 instruction.next = None
108
109 if next_addr is None:
110 next_addr = instruction.address + instruction.size
111 instruction.target = self.next(instruction, call=True)
112
113
114 instruction.next = next_addr & pwndbg.arch.ptrmask
115
116 if instruction.target is None:
117 instruction.target = instruction.next
118
119 if instruction.operands and instruction.operands[0].int:
120 instruction.target_const = True
121
122
123 def next(self, instruction, call=False):
124 """
125 Architecture-specific hook point for enhance_next.
126 """
127 if CS_GRP_CALL in instruction.groups:
128 if not call:
129 return None
130
131 elif CS_GRP_JUMP not in instruction.groups:
132 return None
133
134 # At this point, all operands have been resolved.
135 # Assume only single-operand jumps.
136 if len(instruction.operands) != 1:
137 return None
138
139 # Memory operands must be dereferenced
140 op = instruction.operands[0]
141 addr = op.int
142 if addr:
143 addr &= pwndbg.arch.ptrmask
144 if op.type == CS_OP_MEM:
145 if addr is None:
146 addr = self.memory(instruction, op)
147
148 # self.memory may return none, so we need to check it here again
149 if addr is not None:
150 addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))
151 if op.type == CS_OP_REG:
152 addr = self.register(instruction, op)
153
154 # Evidently this can happen?
155 if addr is None:
156 return None
157
158 return int(addr)
159
160 def enhance_symbol(self, instruction):
161 """
162 Adds a ``symbol`` and ``symbol_addr`` fields to the instruction.
163
164 If, after parsing all of the operands, there is exactly one
165 value which resolved to a named symbol, it will be set to
166 that value.
167
168 In all other cases, the value is ``None``.
169 """
170 instruction.symbol = None
171 operands = [o for o in instruction.operands if o.symbol]
172
173 if len(operands) != 1:
174 return
175
176 o = operands[0]
177
178 instruction.symbol = o.symbol
179 instruction.symbol_addr = o.int
180
181 def enhance_operands(self, instruction):
182 """
183 Enhances all of the operands in the instruction, by adding the following
184 fields:
185
186 operand.str:
187 String of this operand, as it should appear in the
188 disassembly.
189
190 operand.int:
191 Integer value of the operand, if it can be resolved.
192
193 operand.symbol:
194 Resolved symbol name for this operand.
195 """
196 current = (instruction.address == pwndbg.regs.pc)
197
198 for i, op in enumerate(instruction.operands):
199 op.int = None
200 op.symbol = None
201
202 op.int = self.op_handlers.get(op.type, lambda *a: None)(instruction, op)
203 if op.int:
204 op.int &= pwndbg.arch.ptrmask
205 op.str = self.op_names.get(op.type, lambda *a: None)(instruction, op)
206
207 if op.int:
208 op.symbol = pwndbg.symbol.get(op.int)
209
210
211 def immediate(self, instruction, operand):
212 return operand.value.imm
213
214 def immediate_sz(self, instruction, operand):
215 value = operand.int
216
217 if abs(value) < 0x10:
218 return "%i" % value
219
220 return "%#x" % value
221
222 def register(self, instruction, operand):
223 if instruction.address != pwndbg.regs.pc:
224 return None
225
226 # # Don't care about registers which are only overwritten
227 # if operand.access & CS_AC_WRITE and not operand.access & CS_AC_READ:
228 # return None
229
230 reg = operand.value.reg
231 name = instruction.reg_name(reg)
232
233 return pwndbg.regs[name]
234
235 def register_sz(self, instruction, operand):
236 reg = operand.value.reg
237 return instruction.reg_name(reg).lower()
238
239 def memory(self, instruction, operand):
240 return None
241
242 def memory_sz(self, instruction, operand):
243 return None # raise NotImplementedError
244
245 def dump(self, instruction):
246 ins = instruction
247 rv = []
248 rv.append('%s %s' % (ins.mnemonic, ins.op_str))
249
250 for i, group in enumerate(ins.groups):
251 rv.append(' groups[%i] = %s' % (i, groups.get(group, group)))
252
253 rv.append(' next = %#x' % (ins.next))
254 rv.append(' condition = %r' % (ins.condition))
255
256 for i, op in enumerate(ins.operands):
257 rv.append(' operands[%i] = %s' % (i, ops.get(op.type, op.type)))
258 rv.append(' access = %s' % (access.get(op.access, op.access)))
259
260 if op.int is not None:
261 rv.append(' int = %#x' % (op.int))
262 if op.symbol is not None:
263 rv.append(' sym = %s' % (op.symbol))
264 if op.str is not None:
265 rv.append(' str = %s' % (op.str))
266
267 return '\n'.join(rv)
268
269 generic_assistant = DisassemblyAssistant(None)
270
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pwndbg/disasm/arch.py b/pwndbg/disasm/arch.py
--- a/pwndbg/disasm/arch.py
+++ b/pwndbg/disasm/arch.py
@@ -8,6 +8,7 @@
import collections
import capstone
+import gdb
from capstone import *
import pwndbg.memoize
@@ -147,7 +148,12 @@
# self.memory may return none, so we need to check it here again
if addr is not None:
- addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))
+ try:
+ # fails with gdb.MemoryError if the dereferenced address
+ # doesn't belong to any of process memory maps
+ addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))
+ except gdb.MemoryError:
+ return None
if op.type == CS_OP_REG:
addr = self.register(instruction, op)
@@ -243,6 +249,9 @@
return None # raise NotImplementedError
def dump(self, instruction):
+ """
+ Debug-only method.
+ """
ins = instruction
rv = []
rv.append('%s %s' % (ins.mnemonic, ins.op_str))
| {"golden_diff": "diff --git a/pwndbg/disasm/arch.py b/pwndbg/disasm/arch.py\n--- a/pwndbg/disasm/arch.py\n+++ b/pwndbg/disasm/arch.py\n@@ -8,6 +8,7 @@\n import collections\n \n import capstone\n+import gdb\n from capstone import *\n \n import pwndbg.memoize\n@@ -147,7 +148,12 @@\n \n # self.memory may return none, so we need to check it here again\n if addr is not None:\n- addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))\n+ try:\n+ # fails with gdb.MemoryError if the dereferenced address\n+ # doesn't belong to any of process memory maps\n+ addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))\n+ except gdb.MemoryError:\n+ return None\n if op.type == CS_OP_REG:\n addr = self.register(instruction, op)\n \n@@ -243,6 +249,9 @@\n return None # raise NotImplementedError\n \n def dump(self, instruction):\n+ \"\"\"\n+ Debug-only method.\n+ \"\"\"\n ins = instruction\n rv = []\n rv.append('%s %s' % (ins.mnemonic, ins.op_str))\n", "issue": "Context disasm crashes when trying to show dereferenced call address\nEnhancing a disassembled instruction fails if it is an indirect call and the address cannot be dereferenced/retrieved.\r\n\r\nThe issue can be reproduced with a binary created from assembly:\r\n```\r\nglobal _start\r\n_start:\r\ncall qword [r11+0x30]\r\n```\r\n\r\nOr, full testcase (assuming `nasm` is installed):\r\n```\r\nprintf 'global _start\\n_start:\\ncall qword [r11+0x30]' > test.asm && nasm -f elf64 test.asm && ld test.o -o test && gdb ./test -ex entry\r\n```\r\n\r\n\r\nCurrent result:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/dc/pwndbg/pwndbg/commands/__init__.py\", line 135, in __call__\r\n return self.function(*args, **kwargs)\r\n File \"/home/dc/pwndbg/pwndbg/commands/__init__.py\", line 226, in _OnlyWhenRunning\r\n return function(*a, **kw)\r\n File \"/home/dc/pwndbg/pwndbg/commands/context.py\", line 88, in context\r\n result.extend(func())\r\n File \"/home/dc/pwndbg/pwndbg/commands/context.py\", line 100, in context_regs\r\n return [pwndbg.ui.banner(\"registers\")] + get_regs()\r\n File \"/home/dc/pwndbg/pwndbg/commands/context.py\", line 144, in get_regs\r\n desc = pwndbg.chain.format(value)\r\n File \"/home/dc/pwndbg/pwndbg/chain.py\", line 122, in format\r\n enhanced = pwndbg.enhance.enhance(chain[-2] + offset, code=code)\r\n File \"/home/dc/pwndbg/pwndbg/enhance.py\", line 102, in enhance\r\n instr = pwndbg.disasm.one(value)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/__init__.py\", line 115, in one\r\n for insn in get(address, 1):\r\n File \"/home/dc/pwndbg/pwndbg/disasm/__init__.py\", line 135, in get\r\n i = get_one_instruction(address)\r\n File \"/home/dc/pwndbg/pwndbg/memoize.py\", line 48, in __call__\r\n value = self.func(*args, **kwargs)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/__init__.py\", line 107, in get_one_instruction\r\n pwndbg.disasm.arch.DisassemblyAssistant.enhance(ins)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/arch.py\", line 55, in enhance\r\n enhancer.enhance_next(instruction)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/arch.py\", line 111, in enhance_next\r\n instruction.target = self.next(instruction, call=True)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/x86.py\", line 112, in next\r\n return super(DisassemblyAssistant, self).next(instruction, call)\r\n File \"/home/dc/pwndbg/pwndbg/disasm/arch.py\", line 150, in next\r\n addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))\r\n File \"/home/dc/pwndbg/pwndbg/inthook.py\", line 40, in __new__\r\n value = value.cast(pwndbg.typeinfo.ulong)\r\ngdb.MemoryError: Cannot access memory at address 0x30\r\n```\r\n\r\nExpected result - display disasm:\r\n```\r\ncall qword ptr [r11 + 0x30] # <INVALID>\r\n```\r\n\r\nor `INVALID DEREF` or sth like this.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport collections\n\nimport capstone\nfrom capstone import *\n\nimport pwndbg.memoize\nimport pwndbg.symbol\n\nCS_OP_IMM\n\ndebug = False\n\ngroups = {v:k for k,v in globals().items() if k.startswith('CS_GRP_')}\nops = {v:k for k,v in globals().items() if k.startswith('CS_OP_')}\naccess = {v:k for k,v in globals().items() if k.startswith('CS_AC_')}\n\nfor value1, name1 in dict(access).items():\n for value2, name2 in dict(access).items():\n access.setdefault(value1 | value2, '%s | %s' % (name1, name2))\n\n\nclass DisassemblyAssistant(object):\n # Registry of all instances, {architecture: instance}\n assistants = {}\n\n def __init__(self, architecture):\n if architecture is not None:\n self.assistants[architecture] = self\n\n self.op_handlers = {\n CS_OP_IMM: self.immediate,\n CS_OP_REG: self.register,\n CS_OP_MEM: self.memory\n }\n\n self.op_names = {\n CS_OP_IMM: self.immediate_sz,\n CS_OP_REG: self.register_sz,\n CS_OP_MEM: self.memory_sz\n }\n\n @staticmethod\n def enhance(instruction):\n enhancer = DisassemblyAssistant.assistants.get(pwndbg.arch.current, generic_assistant)\n enhancer.enhance_operands(instruction)\n enhancer.enhance_symbol(instruction)\n enhancer.enhance_conditional(instruction)\n enhancer.enhance_next(instruction)\n\n if debug:\n print(enhancer.dump(instruction))\n\n def enhance_conditional(self, instruction):\n \"\"\"\n Adds a ``condition`` field to the instruction.\n\n If the instruction is always executed unconditionally, the value\n of the field is ``None``.\n\n If the instruction is executed conditionally, and we can be absolutely\n sure that it will be executed, the value of the field is ``True``.\n Generally, this implies that it is the next instruction to be executed.\n\n In all other cases, it is set to ``False``.\n \"\"\"\n c = self.condition(instruction)\n\n if c:\n c = True\n elif c is not None:\n c = False\n\n instruction.condition = c\n\n def condition(self, instruction):\n return False\n\n def enhance_next(self, instruction):\n \"\"\"\n Adds a ``next`` field to the instruction.\n\n By default, it is set to the address of the next linear\n instruction.\n\n If the instruction is a non-\"call\" branch and either:\n\n - Is unconditional\n - Is conditional, but is known to be taken\n\n And the target can be resolved, it is set to the address\n of the jump target.\n \"\"\"\n next_addr = None\n\n if instruction.condition in (True, None):\n next_addr = self.next(instruction)\n\n instruction.target = None\n instruction.target_const = None\n instruction.next = None\n\n if next_addr is None:\n next_addr = instruction.address + instruction.size\n instruction.target = self.next(instruction, call=True)\n\n\n instruction.next = next_addr & pwndbg.arch.ptrmask\n\n if instruction.target is None:\n instruction.target = instruction.next\n\n if instruction.operands and instruction.operands[0].int:\n instruction.target_const = True\n\n\n def next(self, instruction, call=False):\n \"\"\"\n Architecture-specific hook point for enhance_next.\n \"\"\"\n if CS_GRP_CALL in instruction.groups:\n if not call:\n return None\n\n elif CS_GRP_JUMP not in instruction.groups:\n return None\n\n # At this point, all operands have been resolved.\n # Assume only single-operand jumps.\n if len(instruction.operands) != 1:\n return None\n\n # Memory operands must be dereferenced\n op = instruction.operands[0]\n addr = op.int\n if addr:\n addr &= pwndbg.arch.ptrmask\n if op.type == CS_OP_MEM:\n if addr is None:\n addr = self.memory(instruction, op)\n\n # self.memory may return none, so we need to check it here again\n if addr is not None:\n addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))\n if op.type == CS_OP_REG:\n addr = self.register(instruction, op)\n\n # Evidently this can happen?\n if addr is None:\n return None\n\n return int(addr)\n\n def enhance_symbol(self, instruction):\n \"\"\"\n Adds a ``symbol`` and ``symbol_addr`` fields to the instruction.\n\n If, after parsing all of the operands, there is exactly one\n value which resolved to a named symbol, it will be set to\n that value.\n\n In all other cases, the value is ``None``.\n \"\"\"\n instruction.symbol = None\n operands = [o for o in instruction.operands if o.symbol]\n\n if len(operands) != 1:\n return\n\n o = operands[0]\n\n instruction.symbol = o.symbol\n instruction.symbol_addr = o.int\n\n def enhance_operands(self, instruction):\n \"\"\"\n Enhances all of the operands in the instruction, by adding the following\n fields:\n\n operand.str:\n String of this operand, as it should appear in the\n disassembly.\n\n operand.int:\n Integer value of the operand, if it can be resolved.\n\n operand.symbol:\n Resolved symbol name for this operand.\n \"\"\"\n current = (instruction.address == pwndbg.regs.pc)\n\n for i, op in enumerate(instruction.operands):\n op.int = None\n op.symbol = None\n\n op.int = self.op_handlers.get(op.type, lambda *a: None)(instruction, op)\n if op.int:\n op.int &= pwndbg.arch.ptrmask\n op.str = self.op_names.get(op.type, lambda *a: None)(instruction, op)\n\n if op.int:\n op.symbol = pwndbg.symbol.get(op.int)\n\n\n def immediate(self, instruction, operand):\n return operand.value.imm\n\n def immediate_sz(self, instruction, operand):\n value = operand.int\n\n if abs(value) < 0x10:\n return \"%i\" % value\n\n return \"%#x\" % value\n\n def register(self, instruction, operand):\n if instruction.address != pwndbg.regs.pc:\n return None\n\n # # Don't care about registers which are only overwritten\n # if operand.access & CS_AC_WRITE and not operand.access & CS_AC_READ:\n # return None\n\n reg = operand.value.reg\n name = instruction.reg_name(reg)\n\n return pwndbg.regs[name]\n\n def register_sz(self, instruction, operand):\n reg = operand.value.reg\n return instruction.reg_name(reg).lower()\n\n def memory(self, instruction, operand):\n return None\n\n def memory_sz(self, instruction, operand):\n return None # raise NotImplementedError\n\n def dump(self, instruction):\n ins = instruction\n rv = []\n rv.append('%s %s' % (ins.mnemonic, ins.op_str))\n\n for i, group in enumerate(ins.groups):\n rv.append(' groups[%i] = %s' % (i, groups.get(group, group)))\n\n rv.append(' next = %#x' % (ins.next))\n rv.append(' condition = %r' % (ins.condition))\n\n for i, op in enumerate(ins.operands):\n rv.append(' operands[%i] = %s' % (i, ops.get(op.type, op.type)))\n rv.append(' access = %s' % (access.get(op.access, op.access)))\n\n if op.int is not None:\n rv.append(' int = %#x' % (op.int))\n if op.symbol is not None:\n rv.append(' sym = %s' % (op.symbol))\n if op.str is not None:\n rv.append(' str = %s' % (op.str))\n\n return '\\n'.join(rv)\n\ngeneric_assistant = DisassemblyAssistant(None)\n", "path": "pwndbg/disasm/arch.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport collections\n\nimport capstone\nimport gdb\nfrom capstone import *\n\nimport pwndbg.memoize\nimport pwndbg.symbol\n\nCS_OP_IMM\n\ndebug = False\n\ngroups = {v:k for k,v in globals().items() if k.startswith('CS_GRP_')}\nops = {v:k for k,v in globals().items() if k.startswith('CS_OP_')}\naccess = {v:k for k,v in globals().items() if k.startswith('CS_AC_')}\n\nfor value1, name1 in dict(access).items():\n for value2, name2 in dict(access).items():\n access.setdefault(value1 | value2, '%s | %s' % (name1, name2))\n\n\nclass DisassemblyAssistant(object):\n # Registry of all instances, {architecture: instance}\n assistants = {}\n\n def __init__(self, architecture):\n if architecture is not None:\n self.assistants[architecture] = self\n\n self.op_handlers = {\n CS_OP_IMM: self.immediate,\n CS_OP_REG: self.register,\n CS_OP_MEM: self.memory\n }\n\n self.op_names = {\n CS_OP_IMM: self.immediate_sz,\n CS_OP_REG: self.register_sz,\n CS_OP_MEM: self.memory_sz\n }\n\n @staticmethod\n def enhance(instruction):\n enhancer = DisassemblyAssistant.assistants.get(pwndbg.arch.current, generic_assistant)\n enhancer.enhance_operands(instruction)\n enhancer.enhance_symbol(instruction)\n enhancer.enhance_conditional(instruction)\n enhancer.enhance_next(instruction)\n\n if debug:\n print(enhancer.dump(instruction))\n\n def enhance_conditional(self, instruction):\n \"\"\"\n Adds a ``condition`` field to the instruction.\n\n If the instruction is always executed unconditionally, the value\n of the field is ``None``.\n\n If the instruction is executed conditionally, and we can be absolutely\n sure that it will be executed, the value of the field is ``True``.\n Generally, this implies that it is the next instruction to be executed.\n\n In all other cases, it is set to ``False``.\n \"\"\"\n c = self.condition(instruction)\n\n if c:\n c = True\n elif c is not None:\n c = False\n\n instruction.condition = c\n\n def condition(self, instruction):\n return False\n\n def enhance_next(self, instruction):\n \"\"\"\n Adds a ``next`` field to the instruction.\n\n By default, it is set to the address of the next linear\n instruction.\n\n If the instruction is a non-\"call\" branch and either:\n\n - Is unconditional\n - Is conditional, but is known to be taken\n\n And the target can be resolved, it is set to the address\n of the jump target.\n \"\"\"\n next_addr = None\n\n if instruction.condition in (True, None):\n next_addr = self.next(instruction)\n\n instruction.target = None\n instruction.target_const = None\n instruction.next = None\n\n if next_addr is None:\n next_addr = instruction.address + instruction.size\n instruction.target = self.next(instruction, call=True)\n\n\n instruction.next = next_addr & pwndbg.arch.ptrmask\n\n if instruction.target is None:\n instruction.target = instruction.next\n\n if instruction.operands and instruction.operands[0].int:\n instruction.target_const = True\n\n\n def next(self, instruction, call=False):\n \"\"\"\n Architecture-specific hook point for enhance_next.\n \"\"\"\n if CS_GRP_CALL in instruction.groups:\n if not call:\n return None\n\n elif CS_GRP_JUMP not in instruction.groups:\n return None\n\n # At this point, all operands have been resolved.\n # Assume only single-operand jumps.\n if len(instruction.operands) != 1:\n return None\n\n # Memory operands must be dereferenced\n op = instruction.operands[0]\n addr = op.int\n if addr:\n addr &= pwndbg.arch.ptrmask\n if op.type == CS_OP_MEM:\n if addr is None:\n addr = self.memory(instruction, op)\n\n # self.memory may return none, so we need to check it here again\n if addr is not None:\n try:\n # fails with gdb.MemoryError if the dereferenced address\n # doesn't belong to any of process memory maps\n addr = int(pwndbg.memory.poi(pwndbg.typeinfo.ppvoid, addr))\n except gdb.MemoryError:\n return None\n if op.type == CS_OP_REG:\n addr = self.register(instruction, op)\n\n # Evidently this can happen?\n if addr is None:\n return None\n\n return int(addr)\n\n def enhance_symbol(self, instruction):\n \"\"\"\n Adds a ``symbol`` and ``symbol_addr`` fields to the instruction.\n\n If, after parsing all of the operands, there is exactly one\n value which resolved to a named symbol, it will be set to\n that value.\n\n In all other cases, the value is ``None``.\n \"\"\"\n instruction.symbol = None\n operands = [o for o in instruction.operands if o.symbol]\n\n if len(operands) != 1:\n return\n\n o = operands[0]\n\n instruction.symbol = o.symbol\n instruction.symbol_addr = o.int\n\n def enhance_operands(self, instruction):\n \"\"\"\n Enhances all of the operands in the instruction, by adding the following\n fields:\n\n operand.str:\n String of this operand, as it should appear in the\n disassembly.\n\n operand.int:\n Integer value of the operand, if it can be resolved.\n\n operand.symbol:\n Resolved symbol name for this operand.\n \"\"\"\n current = (instruction.address == pwndbg.regs.pc)\n\n for i, op in enumerate(instruction.operands):\n op.int = None\n op.symbol = None\n\n op.int = self.op_handlers.get(op.type, lambda *a: None)(instruction, op)\n if op.int:\n op.int &= pwndbg.arch.ptrmask\n op.str = self.op_names.get(op.type, lambda *a: None)(instruction, op)\n\n if op.int:\n op.symbol = pwndbg.symbol.get(op.int)\n\n\n def immediate(self, instruction, operand):\n return operand.value.imm\n\n def immediate_sz(self, instruction, operand):\n value = operand.int\n\n if abs(value) < 0x10:\n return \"%i\" % value\n\n return \"%#x\" % value\n\n def register(self, instruction, operand):\n if instruction.address != pwndbg.regs.pc:\n return None\n\n # # Don't care about registers which are only overwritten\n # if operand.access & CS_AC_WRITE and not operand.access & CS_AC_READ:\n # return None\n\n reg = operand.value.reg\n name = instruction.reg_name(reg)\n\n return pwndbg.regs[name]\n\n def register_sz(self, instruction, operand):\n reg = operand.value.reg\n return instruction.reg_name(reg).lower()\n\n def memory(self, instruction, operand):\n return None\n\n def memory_sz(self, instruction, operand):\n return None # raise NotImplementedError\n\n def dump(self, instruction):\n \"\"\"\n Debug-only method.\n \"\"\"\n ins = instruction\n rv = []\n rv.append('%s %s' % (ins.mnemonic, ins.op_str))\n\n for i, group in enumerate(ins.groups):\n rv.append(' groups[%i] = %s' % (i, groups.get(group, group)))\n\n rv.append(' next = %#x' % (ins.next))\n rv.append(' condition = %r' % (ins.condition))\n\n for i, op in enumerate(ins.operands):\n rv.append(' operands[%i] = %s' % (i, ops.get(op.type, op.type)))\n rv.append(' access = %s' % (access.get(op.access, op.access)))\n\n if op.int is not None:\n rv.append(' int = %#x' % (op.int))\n if op.symbol is not None:\n rv.append(' sym = %s' % (op.symbol))\n if op.str is not None:\n rv.append(' str = %s' % (op.str))\n\n return '\\n'.join(rv)\n\ngeneric_assistant = DisassemblyAssistant(None)\n", "path": "pwndbg/disasm/arch.py"}]} | 3,634 | 285 |
gh_patches_debug_52275 | rasdani/github-patches | git_diff | pytorch__vision-4283 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
a little problem when using some pretrained models
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
A little problem.
I used some pretrained models to do object detection.
However, when i used models whose name include others models' name, such as 'fasterrcnn_mobilenet_v3_large_320_fpn', (its name includes the name of model 'mobilenet_v3_large'), it will download the weight file of the short name models.
For example, when i used model 'fasterrcnn_mobilenet_v3_large_320_fpn', whenever the pretrained attribute is True or not, the weight file of model 'mobilenet_v3_large' will be downloaded.
This problem also happen in the models such as 'maskrcnn_resnet50_fpn' and many other models.
## To Reproduce
Steps to reproduce the behavior:
it's easy to reproduce. For example:
```bash
from torchvision.models.detection import *
model = fasterrcnn_mobilenet_v3_large_320_fpn()
```
excute the code above, the weight file of model "mobilenet_v3_large" will be downloaded.
you can change the model name to other this kind of model names.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
cc @fmassa @vfdev-5 @pmeier
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/models/segmentation/segmentation.py`
Content:
```
1 from .._utils import IntermediateLayerGetter
2 from ..._internally_replaced_utils import load_state_dict_from_url
3 from .. import mobilenetv3
4 from .. import resnet
5 from .deeplabv3 import DeepLabHead, DeepLabV3
6 from .fcn import FCN, FCNHead
7 from .lraspp import LRASPP
8
9
10 __all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101',
11 'deeplabv3_mobilenet_v3_large', 'lraspp_mobilenet_v3_large']
12
13
14 model_urls = {
15 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',
16 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',
17 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',
18 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',
19 'deeplabv3_mobilenet_v3_large_coco':
20 'https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth',
21 'lraspp_mobilenet_v3_large_coco': 'https://download.pytorch.org/models/lraspp_mobilenet_v3_large-d234d4ea.pth',
22 }
23
24
25 def _segm_model(name, backbone_name, num_classes, aux, pretrained_backbone=True):
26 if 'resnet' in backbone_name:
27 backbone = resnet.__dict__[backbone_name](
28 pretrained=pretrained_backbone,
29 replace_stride_with_dilation=[False, True, True])
30 out_layer = 'layer4'
31 out_inplanes = 2048
32 aux_layer = 'layer3'
33 aux_inplanes = 1024
34 elif 'mobilenet_v3' in backbone_name:
35 backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features
36
37 # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.
38 # The first and last blocks are always included because they are the C0 (conv1) and Cn.
39 stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "_is_cn", False)] + [len(backbone) - 1]
40 out_pos = stage_indices[-1] # use C5 which has output_stride = 16
41 out_layer = str(out_pos)
42 out_inplanes = backbone[out_pos].out_channels
43 aux_pos = stage_indices[-4] # use C2 here which has output_stride = 8
44 aux_layer = str(aux_pos)
45 aux_inplanes = backbone[aux_pos].out_channels
46 else:
47 raise NotImplementedError('backbone {} is not supported as of now'.format(backbone_name))
48
49 return_layers = {out_layer: 'out'}
50 if aux:
51 return_layers[aux_layer] = 'aux'
52 backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
53
54 aux_classifier = None
55 if aux:
56 aux_classifier = FCNHead(aux_inplanes, num_classes)
57
58 model_map = {
59 'deeplabv3': (DeepLabHead, DeepLabV3),
60 'fcn': (FCNHead, FCN),
61 }
62 classifier = model_map[name][0](out_inplanes, num_classes)
63 base_model = model_map[name][1]
64
65 model = base_model(backbone, classifier, aux_classifier)
66 return model
67
68
69 def _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):
70 if pretrained:
71 aux_loss = True
72 kwargs["pretrained_backbone"] = False
73 model = _segm_model(arch_type, backbone, num_classes, aux_loss, **kwargs)
74 if pretrained:
75 _load_weights(model, arch_type, backbone, progress)
76 return model
77
78
79 def _load_weights(model, arch_type, backbone, progress):
80 arch = arch_type + '_' + backbone + '_coco'
81 model_url = model_urls.get(arch, None)
82 if model_url is None:
83 raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))
84 else:
85 state_dict = load_state_dict_from_url(model_url, progress=progress)
86 model.load_state_dict(state_dict)
87
88
89 def _segm_lraspp_mobilenetv3(backbone_name, num_classes, pretrained_backbone=True):
90 backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features
91
92 # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.
93 # The first and last blocks are always included because they are the C0 (conv1) and Cn.
94 stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "_is_cn", False)] + [len(backbone) - 1]
95 low_pos = stage_indices[-4] # use C2 here which has output_stride = 8
96 high_pos = stage_indices[-1] # use C5 which has output_stride = 16
97 low_channels = backbone[low_pos].out_channels
98 high_channels = backbone[high_pos].out_channels
99
100 backbone = IntermediateLayerGetter(backbone, return_layers={str(low_pos): 'low', str(high_pos): 'high'})
101
102 model = LRASPP(backbone, low_channels, high_channels, num_classes)
103 return model
104
105
106 def fcn_resnet50(pretrained=False, progress=True,
107 num_classes=21, aux_loss=None, **kwargs):
108 """Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.
109
110 Args:
111 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
112 contains the same classes as Pascal VOC
113 progress (bool): If True, displays a progress bar of the download to stderr
114 num_classes (int): number of output classes of the model (including the background)
115 aux_loss (bool): If True, it uses an auxiliary loss
116 """
117 return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)
118
119
120 def fcn_resnet101(pretrained=False, progress=True,
121 num_classes=21, aux_loss=None, **kwargs):
122 """Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.
123
124 Args:
125 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
126 contains the same classes as Pascal VOC
127 progress (bool): If True, displays a progress bar of the download to stderr
128 num_classes (int): number of output classes of the model (including the background)
129 aux_loss (bool): If True, it uses an auxiliary loss
130 """
131 return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)
132
133
134 def deeplabv3_resnet50(pretrained=False, progress=True,
135 num_classes=21, aux_loss=None, **kwargs):
136 """Constructs a DeepLabV3 model with a ResNet-50 backbone.
137
138 Args:
139 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
140 contains the same classes as Pascal VOC
141 progress (bool): If True, displays a progress bar of the download to stderr
142 num_classes (int): number of output classes of the model (including the background)
143 aux_loss (bool): If True, it uses an auxiliary loss
144 """
145 return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)
146
147
148 def deeplabv3_resnet101(pretrained=False, progress=True,
149 num_classes=21, aux_loss=None, **kwargs):
150 """Constructs a DeepLabV3 model with a ResNet-101 backbone.
151
152 Args:
153 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
154 contains the same classes as Pascal VOC
155 progress (bool): If True, displays a progress bar of the download to stderr
156 num_classes (int): The number of classes
157 aux_loss (bool): If True, include an auxiliary classifier
158 """
159 return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)
160
161
162 def deeplabv3_mobilenet_v3_large(pretrained=False, progress=True,
163 num_classes=21, aux_loss=None, **kwargs):
164 """Constructs a DeepLabV3 model with a MobileNetV3-Large backbone.
165
166 Args:
167 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
168 contains the same classes as Pascal VOC
169 progress (bool): If True, displays a progress bar of the download to stderr
170 num_classes (int): number of output classes of the model (including the background)
171 aux_loss (bool): If True, it uses an auxiliary loss
172 """
173 return _load_model('deeplabv3', 'mobilenet_v3_large', pretrained, progress, num_classes, aux_loss, **kwargs)
174
175
176 def lraspp_mobilenet_v3_large(pretrained=False, progress=True, num_classes=21, **kwargs):
177 """Constructs a Lite R-ASPP Network model with a MobileNetV3-Large backbone.
178
179 Args:
180 pretrained (bool): If True, returns a model pre-trained on COCO train2017 which
181 contains the same classes as Pascal VOC
182 progress (bool): If True, displays a progress bar of the download to stderr
183 num_classes (int): number of output classes of the model (including the background)
184 """
185 if kwargs.pop("aux_loss", False):
186 raise NotImplementedError('This model does not use auxiliary loss')
187
188 backbone_name = 'mobilenet_v3_large'
189 model = _segm_lraspp_mobilenetv3(backbone_name, num_classes, **kwargs)
190
191 if pretrained:
192 _load_weights(model, 'lraspp', backbone_name, progress)
193
194 return model
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/torchvision/models/segmentation/segmentation.py b/torchvision/models/segmentation/segmentation.py
--- a/torchvision/models/segmentation/segmentation.py
+++ b/torchvision/models/segmentation/segmentation.py
@@ -186,6 +186,8 @@
raise NotImplementedError('This model does not use auxiliary loss')
backbone_name = 'mobilenet_v3_large'
+ if pretrained:
+ kwargs["pretrained_backbone"] = False
model = _segm_lraspp_mobilenetv3(backbone_name, num_classes, **kwargs)
if pretrained:
| {"golden_diff": "diff --git a/torchvision/models/segmentation/segmentation.py b/torchvision/models/segmentation/segmentation.py\n--- a/torchvision/models/segmentation/segmentation.py\n+++ b/torchvision/models/segmentation/segmentation.py\n@@ -186,6 +186,8 @@\n raise NotImplementedError('This model does not use auxiliary loss')\n \n backbone_name = 'mobilenet_v3_large'\n+ if pretrained:\n+ kwargs[\"pretrained_backbone\"] = False\n model = _segm_lraspp_mobilenetv3(backbone_name, num_classes, **kwargs)\n \n if pretrained:\n", "issue": "a little problem when using some pretrained models\n## \ud83d\udc1b Bug\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\nA little problem.\r\n\r\nI used some pretrained models to do object detection. \r\n\r\nHowever, when i used models whose name include others models' name, such as 'fasterrcnn_mobilenet_v3_large_320_fpn', (its name includes the name of model 'mobilenet_v3_large'), it will download the weight file of the short name models. \r\n\r\nFor example, when i used model 'fasterrcnn_mobilenet_v3_large_320_fpn', whenever the pretrained attribute is True or not, the weight file of model 'mobilenet_v3_large' will be downloaded. \r\n\r\nThis problem also happen in the models such as 'maskrcnn_resnet50_fpn' and many other models.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\nit's easy to reproduce. For example:\r\n```bash\r\nfrom torchvision.models.detection import *\r\nmodel = fasterrcnn_mobilenet_v3_large_320_fpn()\r\n```\r\nexcute the code above, the weight file of model \"mobilenet_v3_large\" will be downloaded.\r\nyou can change the model name to other this kind of model names.\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n\r\n\n\ncc @fmassa @vfdev-5 @pmeier\n", "before_files": [{"content": "from .._utils import IntermediateLayerGetter\nfrom ..._internally_replaced_utils import load_state_dict_from_url\nfrom .. import mobilenetv3\nfrom .. import resnet\nfrom .deeplabv3 import DeepLabHead, DeepLabV3\nfrom .fcn import FCN, FCNHead\nfrom .lraspp import LRASPP\n\n\n__all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101',\n 'deeplabv3_mobilenet_v3_large', 'lraspp_mobilenet_v3_large']\n\n\nmodel_urls = {\n 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',\n 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',\n 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',\n 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',\n 'deeplabv3_mobilenet_v3_large_coco':\n 'https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth',\n 'lraspp_mobilenet_v3_large_coco': 'https://download.pytorch.org/models/lraspp_mobilenet_v3_large-d234d4ea.pth',\n}\n\n\ndef _segm_model(name, backbone_name, num_classes, aux, pretrained_backbone=True):\n if 'resnet' in backbone_name:\n backbone = resnet.__dict__[backbone_name](\n pretrained=pretrained_backbone,\n replace_stride_with_dilation=[False, True, True])\n out_layer = 'layer4'\n out_inplanes = 2048\n aux_layer = 'layer3'\n aux_inplanes = 1024\n elif 'mobilenet_v3' in backbone_name:\n backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features\n\n # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.\n # The first and last blocks are always included because they are the C0 (conv1) and Cn.\n stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, \"_is_cn\", False)] + [len(backbone) - 1]\n out_pos = stage_indices[-1] # use C5 which has output_stride = 16\n out_layer = str(out_pos)\n out_inplanes = backbone[out_pos].out_channels\n aux_pos = stage_indices[-4] # use C2 here which has output_stride = 8\n aux_layer = str(aux_pos)\n aux_inplanes = backbone[aux_pos].out_channels\n else:\n raise NotImplementedError('backbone {} is not supported as of now'.format(backbone_name))\n\n return_layers = {out_layer: 'out'}\n if aux:\n return_layers[aux_layer] = 'aux'\n backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)\n\n aux_classifier = None\n if aux:\n aux_classifier = FCNHead(aux_inplanes, num_classes)\n\n model_map = {\n 'deeplabv3': (DeepLabHead, DeepLabV3),\n 'fcn': (FCNHead, FCN),\n }\n classifier = model_map[name][0](out_inplanes, num_classes)\n base_model = model_map[name][1]\n\n model = base_model(backbone, classifier, aux_classifier)\n return model\n\n\ndef _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):\n if pretrained:\n aux_loss = True\n kwargs[\"pretrained_backbone\"] = False\n model = _segm_model(arch_type, backbone, num_classes, aux_loss, **kwargs)\n if pretrained:\n _load_weights(model, arch_type, backbone, progress)\n return model\n\n\ndef _load_weights(model, arch_type, backbone, progress):\n arch = arch_type + '_' + backbone + '_coco'\n model_url = model_urls.get(arch, None)\n if model_url is None:\n raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))\n else:\n state_dict = load_state_dict_from_url(model_url, progress=progress)\n model.load_state_dict(state_dict)\n\n\ndef _segm_lraspp_mobilenetv3(backbone_name, num_classes, pretrained_backbone=True):\n backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features\n\n # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.\n # The first and last blocks are always included because they are the C0 (conv1) and Cn.\n stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, \"_is_cn\", False)] + [len(backbone) - 1]\n low_pos = stage_indices[-4] # use C2 here which has output_stride = 8\n high_pos = stage_indices[-1] # use C5 which has output_stride = 16\n low_channels = backbone[low_pos].out_channels\n high_channels = backbone[high_pos].out_channels\n\n backbone = IntermediateLayerGetter(backbone, return_layers={str(low_pos): 'low', str(high_pos): 'high'})\n\n model = LRASPP(backbone, low_channels, high_channels, num_classes)\n return model\n\n\ndef fcn_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef fcn_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): The number of classes\n aux_loss (bool): If True, include an auxiliary classifier\n \"\"\"\n return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_mobilenet_v3_large(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a MobileNetV3-Large backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('deeplabv3', 'mobilenet_v3_large', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef lraspp_mobilenet_v3_large(pretrained=False, progress=True, num_classes=21, **kwargs):\n \"\"\"Constructs a Lite R-ASPP Network model with a MobileNetV3-Large backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n \"\"\"\n if kwargs.pop(\"aux_loss\", False):\n raise NotImplementedError('This model does not use auxiliary loss')\n\n backbone_name = 'mobilenet_v3_large'\n model = _segm_lraspp_mobilenetv3(backbone_name, num_classes, **kwargs)\n\n if pretrained:\n _load_weights(model, 'lraspp', backbone_name, progress)\n\n return model\n", "path": "torchvision/models/segmentation/segmentation.py"}], "after_files": [{"content": "from .._utils import IntermediateLayerGetter\nfrom ..._internally_replaced_utils import load_state_dict_from_url\nfrom .. import mobilenetv3\nfrom .. import resnet\nfrom .deeplabv3 import DeepLabHead, DeepLabV3\nfrom .fcn import FCN, FCNHead\nfrom .lraspp import LRASPP\n\n\n__all__ = ['fcn_resnet50', 'fcn_resnet101', 'deeplabv3_resnet50', 'deeplabv3_resnet101',\n 'deeplabv3_mobilenet_v3_large', 'lraspp_mobilenet_v3_large']\n\n\nmodel_urls = {\n 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth',\n 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth',\n 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth',\n 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth',\n 'deeplabv3_mobilenet_v3_large_coco':\n 'https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth',\n 'lraspp_mobilenet_v3_large_coco': 'https://download.pytorch.org/models/lraspp_mobilenet_v3_large-d234d4ea.pth',\n}\n\n\ndef _segm_model(name, backbone_name, num_classes, aux, pretrained_backbone=True):\n if 'resnet' in backbone_name:\n backbone = resnet.__dict__[backbone_name](\n pretrained=pretrained_backbone,\n replace_stride_with_dilation=[False, True, True])\n out_layer = 'layer4'\n out_inplanes = 2048\n aux_layer = 'layer3'\n aux_inplanes = 1024\n elif 'mobilenet_v3' in backbone_name:\n backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features\n\n # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.\n # The first and last blocks are always included because they are the C0 (conv1) and Cn.\n stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, \"_is_cn\", False)] + [len(backbone) - 1]\n out_pos = stage_indices[-1] # use C5 which has output_stride = 16\n out_layer = str(out_pos)\n out_inplanes = backbone[out_pos].out_channels\n aux_pos = stage_indices[-4] # use C2 here which has output_stride = 8\n aux_layer = str(aux_pos)\n aux_inplanes = backbone[aux_pos].out_channels\n else:\n raise NotImplementedError('backbone {} is not supported as of now'.format(backbone_name))\n\n return_layers = {out_layer: 'out'}\n if aux:\n return_layers[aux_layer] = 'aux'\n backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)\n\n aux_classifier = None\n if aux:\n aux_classifier = FCNHead(aux_inplanes, num_classes)\n\n model_map = {\n 'deeplabv3': (DeepLabHead, DeepLabV3),\n 'fcn': (FCNHead, FCN),\n }\n classifier = model_map[name][0](out_inplanes, num_classes)\n base_model = model_map[name][1]\n\n model = base_model(backbone, classifier, aux_classifier)\n return model\n\n\ndef _load_model(arch_type, backbone, pretrained, progress, num_classes, aux_loss, **kwargs):\n if pretrained:\n aux_loss = True\n kwargs[\"pretrained_backbone\"] = False\n model = _segm_model(arch_type, backbone, num_classes, aux_loss, **kwargs)\n if pretrained:\n _load_weights(model, arch_type, backbone, progress)\n return model\n\n\ndef _load_weights(model, arch_type, backbone, progress):\n arch = arch_type + '_' + backbone + '_coco'\n model_url = model_urls.get(arch, None)\n if model_url is None:\n raise NotImplementedError('pretrained {} is not supported as of now'.format(arch))\n else:\n state_dict = load_state_dict_from_url(model_url, progress=progress)\n model.load_state_dict(state_dict)\n\n\ndef _segm_lraspp_mobilenetv3(backbone_name, num_classes, pretrained_backbone=True):\n backbone = mobilenetv3.__dict__[backbone_name](pretrained=pretrained_backbone, dilated=True).features\n\n # Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.\n # The first and last blocks are always included because they are the C0 (conv1) and Cn.\n stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, \"_is_cn\", False)] + [len(backbone) - 1]\n low_pos = stage_indices[-4] # use C2 here which has output_stride = 8\n high_pos = stage_indices[-1] # use C5 which has output_stride = 16\n low_channels = backbone[low_pos].out_channels\n high_channels = backbone[high_pos].out_channels\n\n backbone = IntermediateLayerGetter(backbone, return_layers={str(low_pos): 'low', str(high_pos): 'high'})\n\n model = LRASPP(backbone, low_channels, high_channels, num_classes)\n return model\n\n\ndef fcn_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('fcn', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef fcn_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a Fully-Convolutional Network model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('fcn', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet50(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-50 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('deeplabv3', 'resnet50', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_resnet101(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a ResNet-101 backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): The number of classes\n aux_loss (bool): If True, include an auxiliary classifier\n \"\"\"\n return _load_model('deeplabv3', 'resnet101', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef deeplabv3_mobilenet_v3_large(pretrained=False, progress=True,\n num_classes=21, aux_loss=None, **kwargs):\n \"\"\"Constructs a DeepLabV3 model with a MobileNetV3-Large backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n aux_loss (bool): If True, it uses an auxiliary loss\n \"\"\"\n return _load_model('deeplabv3', 'mobilenet_v3_large', pretrained, progress, num_classes, aux_loss, **kwargs)\n\n\ndef lraspp_mobilenet_v3_large(pretrained=False, progress=True, num_classes=21, **kwargs):\n \"\"\"Constructs a Lite R-ASPP Network model with a MobileNetV3-Large backbone.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on COCO train2017 which\n contains the same classes as Pascal VOC\n progress (bool): If True, displays a progress bar of the download to stderr\n num_classes (int): number of output classes of the model (including the background)\n \"\"\"\n if kwargs.pop(\"aux_loss\", False):\n raise NotImplementedError('This model does not use auxiliary loss')\n\n backbone_name = 'mobilenet_v3_large'\n if pretrained:\n kwargs[\"pretrained_backbone\"] = False\n model = _segm_lraspp_mobilenetv3(backbone_name, num_classes, **kwargs)\n\n if pretrained:\n _load_weights(model, 'lraspp', backbone_name, progress)\n\n return model\n", "path": "torchvision/models/segmentation/segmentation.py"}]} | 3,459 | 141 |
gh_patches_debug_13967 | rasdani/github-patches | git_diff | pyro-ppl__pyro-2828 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] CSIS error when parameters are not fully used
### Issue Description
For `pyro.infer.csis`
If some parameters are not used to produce the outputs, the gradients can be None. In this case, an error will be raised as following
```/usr/local/lib/python3.7/dist-packages/pyro/infer/csis.py in loss_and_grads(self, grads, batch, *args, **kwargs)
114 guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)
115 for guide_grad, guide_param in zip(guide_grads, guide_params):
--> 116 guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad
117
118 loss += torch_item(particle_loss)
TypeError: unsupported operand type(s) for +: 'Tensor' and 'NoneType'
```
I resolved this issue locally by checking None before updating gradients
```
if guide_grad is None:
continue
guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad
```
### Environment
- Python version: 3.7
- PyTorch version: 1.8.1+cu101
- Pyro version: 1.5.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyro/infer/csis.py`
Content:
```
1 # Copyright (c) 2017-2019 Uber Technologies, Inc.
2 # SPDX-License-Identifier: Apache-2.0
3
4 import itertools
5
6 import torch
7
8 import pyro
9 import pyro.poutine as poutine
10 from pyro.infer.importance import Importance
11 from pyro.infer.util import torch_item
12 from pyro.poutine.util import prune_subsample_sites
13 from pyro.util import check_model_guide_match, warn_if_nan
14
15
16 class CSIS(Importance):
17 """
18 Compiled Sequential Importance Sampling, allowing compilation of a guide
19 program to minimise KL(model posterior || guide), and inference with
20 importance sampling.
21
22 **Reference**
23 "Inference Compilation and Universal Probabilistic Programming" `pdf https://arxiv.org/pdf/1610.09900.pdf`
24
25 :param model: probabilistic model defined as a function. Must accept a
26 keyword argument named `observations`, in which observed values are
27 passed as, with the names of nodes as the keys.
28 :param guide: guide function which is used as an approximate posterior. Must
29 also accept `observations` as keyword argument.
30 :param optim: a Pyro optimizer
31 :type optim: pyro.optim.PyroOptim
32 :param num_inference_samples: The number of importance-weighted samples to
33 draw during inference.
34 :param training_batch_size: Number of samples to use to approximate the loss
35 before each gradient descent step during training.
36 :param validation_batch_size: Number of samples to use for calculating
37 validation loss (will only be used if `.validation_loss` is called).
38 """
39 def __init__(self,
40 model,
41 guide,
42 optim,
43 num_inference_samples=10,
44 training_batch_size=10,
45 validation_batch_size=20):
46 super().__init__(model, guide, num_inference_samples)
47 self.model = model
48 self.guide = guide
49 self.optim = optim
50 self.training_batch_size = training_batch_size
51 self.validation_batch_size = validation_batch_size
52 self.validation_batch = None
53
54 def set_validation_batch(self, *args, **kwargs):
55 """
56 Samples a batch of model traces and stores it as an object property.
57
58 Arguments are passed directly to model.
59 """
60 self.validation_batch = [self._sample_from_joint(*args, **kwargs)
61 for _ in range(self.validation_batch_size)]
62
63 def step(self, *args, **kwargs):
64 """
65 :returns: estimate of the loss
66 :rtype: float
67
68 Take a gradient step on the loss function. Arguments are passed to the
69 model and guide.
70 """
71 with poutine.trace(param_only=True) as param_capture:
72 loss = self.loss_and_grads(True, None, *args, **kwargs)
73
74 params = set(site["value"].unconstrained()
75 for site in param_capture.trace.nodes.values()
76 if site["value"].grad is not None)
77
78 self.optim(params)
79
80 pyro.infer.util.zero_grads(params)
81
82 return torch_item(loss)
83
84 def loss_and_grads(self, grads, batch, *args, **kwargs):
85 """
86 :returns: an estimate of the loss (expectation over p(x, y) of
87 -log q(x, y) ) - where p is the model and q is the guide
88 :rtype: float
89
90 If a batch is provided, the loss is estimated using these traces
91 Otherwise, a fresh batch is generated from the model.
92
93 If grads is True, will also call `backward` on loss.
94
95 `args` and `kwargs` are passed to the model and guide.
96 """
97 if batch is None:
98 batch = (self._sample_from_joint(*args, **kwargs)
99 for _ in range(self.training_batch_size))
100 batch_size = self.training_batch_size
101 else:
102 batch_size = len(batch)
103
104 loss = 0
105 for model_trace in batch:
106 with poutine.trace(param_only=True) as particle_param_capture:
107 guide_trace = self._get_matched_trace(model_trace, *args, **kwargs)
108 particle_loss = self._differentiable_loss_particle(guide_trace)
109 particle_loss /= batch_size
110
111 if grads:
112 guide_params = set(site["value"].unconstrained()
113 for site in particle_param_capture.trace.nodes.values())
114 guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)
115 for guide_grad, guide_param in zip(guide_grads, guide_params):
116 guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad
117
118 loss += torch_item(particle_loss)
119
120 warn_if_nan(loss, "loss")
121 return loss
122
123 def _differentiable_loss_particle(self, guide_trace):
124 return -guide_trace.log_prob_sum()
125
126 def validation_loss(self, *args, **kwargs):
127 """
128 :returns: loss estimated using validation batch
129 :rtype: float
130
131 Calculates loss on validation batch. If no validation batch is set,
132 will set one by calling `set_validation_batch`. Can be used to track
133 the loss in a less noisy way during training.
134
135 Arguments are passed to the model and guide.
136 """
137 if self.validation_batch is None:
138 self.set_validation_batch(*args, **kwargs)
139
140 return self.loss_and_grads(False, self.validation_batch, *args, **kwargs)
141
142 def _get_matched_trace(self, model_trace, *args, **kwargs):
143 """
144 :param model_trace: a trace from the model
145 :type model_trace: pyro.poutine.trace_struct.Trace
146 :returns: guide trace with sampled values matched to model_trace
147 :rtype: pyro.poutine.trace_struct.Trace
148
149 Returns a guide trace with values at sample and observe statements
150 matched to those in model_trace.
151
152 `args` and `kwargs` are passed to the guide.
153 """
154 kwargs["observations"] = {}
155 for node in itertools.chain(model_trace.stochastic_nodes, model_trace.observation_nodes):
156 if "was_observed" in model_trace.nodes[node]["infer"]:
157 model_trace.nodes[node]["is_observed"] = True
158 kwargs["observations"][node] = model_trace.nodes[node]["value"]
159
160 guide_trace = poutine.trace(poutine.replay(self.guide,
161 model_trace)
162 ).get_trace(*args, **kwargs)
163
164 check_model_guide_match(model_trace, guide_trace)
165 guide_trace = prune_subsample_sites(guide_trace)
166
167 return guide_trace
168
169 def _sample_from_joint(self, *args, **kwargs):
170 """
171 :returns: a sample from the joint distribution over unobserved and
172 observed variables
173 :rtype: pyro.poutine.trace_struct.Trace
174
175 Returns a trace of the model without conditioning on any observations.
176
177 Arguments are passed directly to the model.
178 """
179 unconditioned_model = pyro.poutine.uncondition(self.model)
180 return poutine.trace(unconditioned_model).get_trace(*args, **kwargs)
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyro/infer/csis.py b/pyro/infer/csis.py
--- a/pyro/infer/csis.py
+++ b/pyro/infer/csis.py
@@ -113,6 +113,8 @@
for site in particle_param_capture.trace.nodes.values())
guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)
for guide_grad, guide_param in zip(guide_grads, guide_params):
+ if guide_grad is None:
+ continue
guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad
loss += torch_item(particle_loss)
| {"golden_diff": "diff --git a/pyro/infer/csis.py b/pyro/infer/csis.py\n--- a/pyro/infer/csis.py\n+++ b/pyro/infer/csis.py\n@@ -113,6 +113,8 @@\n for site in particle_param_capture.trace.nodes.values())\n guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)\n for guide_grad, guide_param in zip(guide_grads, guide_params):\n+ if guide_grad is None:\n+ continue\n guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad\n \n loss += torch_item(particle_loss)\n", "issue": "[bug] CSIS error when parameters are not fully used\n### Issue Description\r\nFor `pyro.infer.csis`\r\nIf some parameters are not used to produce the outputs, the gradients can be None. In this case, an error will be raised as following\r\n```/usr/local/lib/python3.7/dist-packages/pyro/infer/csis.py in loss_and_grads(self, grads, batch, *args, **kwargs)\r\n 114 guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)\r\n 115 for guide_grad, guide_param in zip(guide_grads, guide_params):\r\n--> 116 guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad\r\n 117 \r\n 118 loss += torch_item(particle_loss)\r\n\r\nTypeError: unsupported operand type(s) for +: 'Tensor' and 'NoneType'\r\n```\r\nI resolved this issue locally by checking None before updating gradients\r\n```\r\nif guide_grad is None:\r\n continue\r\nguide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad\r\n```\r\n\r\n### Environment\r\n - Python version: 3.7\r\n - PyTorch version: 1.8.1+cu101\r\n - Pyro version: 1.5.1\n", "before_files": [{"content": "# Copyright (c) 2017-2019 Uber Technologies, Inc.\n# SPDX-License-Identifier: Apache-2.0\n\nimport itertools\n\nimport torch\n\nimport pyro\nimport pyro.poutine as poutine\nfrom pyro.infer.importance import Importance\nfrom pyro.infer.util import torch_item\nfrom pyro.poutine.util import prune_subsample_sites\nfrom pyro.util import check_model_guide_match, warn_if_nan\n\n\nclass CSIS(Importance):\n \"\"\"\n Compiled Sequential Importance Sampling, allowing compilation of a guide\n program to minimise KL(model posterior || guide), and inference with\n importance sampling.\n\n **Reference**\n \"Inference Compilation and Universal Probabilistic Programming\" `pdf https://arxiv.org/pdf/1610.09900.pdf`\n\n :param model: probabilistic model defined as a function. Must accept a\n keyword argument named `observations`, in which observed values are\n passed as, with the names of nodes as the keys.\n :param guide: guide function which is used as an approximate posterior. Must\n also accept `observations` as keyword argument.\n :param optim: a Pyro optimizer\n :type optim: pyro.optim.PyroOptim\n :param num_inference_samples: The number of importance-weighted samples to\n draw during inference.\n :param training_batch_size: Number of samples to use to approximate the loss\n before each gradient descent step during training.\n :param validation_batch_size: Number of samples to use for calculating\n validation loss (will only be used if `.validation_loss` is called).\n \"\"\"\n def __init__(self,\n model,\n guide,\n optim,\n num_inference_samples=10,\n training_batch_size=10,\n validation_batch_size=20):\n super().__init__(model, guide, num_inference_samples)\n self.model = model\n self.guide = guide\n self.optim = optim\n self.training_batch_size = training_batch_size\n self.validation_batch_size = validation_batch_size\n self.validation_batch = None\n\n def set_validation_batch(self, *args, **kwargs):\n \"\"\"\n Samples a batch of model traces and stores it as an object property.\n\n Arguments are passed directly to model.\n \"\"\"\n self.validation_batch = [self._sample_from_joint(*args, **kwargs)\n for _ in range(self.validation_batch_size)]\n\n def step(self, *args, **kwargs):\n \"\"\"\n :returns: estimate of the loss\n :rtype: float\n\n Take a gradient step on the loss function. Arguments are passed to the\n model and guide.\n \"\"\"\n with poutine.trace(param_only=True) as param_capture:\n loss = self.loss_and_grads(True, None, *args, **kwargs)\n\n params = set(site[\"value\"].unconstrained()\n for site in param_capture.trace.nodes.values()\n if site[\"value\"].grad is not None)\n\n self.optim(params)\n\n pyro.infer.util.zero_grads(params)\n\n return torch_item(loss)\n\n def loss_and_grads(self, grads, batch, *args, **kwargs):\n \"\"\"\n :returns: an estimate of the loss (expectation over p(x, y) of\n -log q(x, y) ) - where p is the model and q is the guide\n :rtype: float\n\n If a batch is provided, the loss is estimated using these traces\n Otherwise, a fresh batch is generated from the model.\n\n If grads is True, will also call `backward` on loss.\n\n `args` and `kwargs` are passed to the model and guide.\n \"\"\"\n if batch is None:\n batch = (self._sample_from_joint(*args, **kwargs)\n for _ in range(self.training_batch_size))\n batch_size = self.training_batch_size\n else:\n batch_size = len(batch)\n\n loss = 0\n for model_trace in batch:\n with poutine.trace(param_only=True) as particle_param_capture:\n guide_trace = self._get_matched_trace(model_trace, *args, **kwargs)\n particle_loss = self._differentiable_loss_particle(guide_trace)\n particle_loss /= batch_size\n\n if grads:\n guide_params = set(site[\"value\"].unconstrained()\n for site in particle_param_capture.trace.nodes.values())\n guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)\n for guide_grad, guide_param in zip(guide_grads, guide_params):\n guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad\n\n loss += torch_item(particle_loss)\n\n warn_if_nan(loss, \"loss\")\n return loss\n\n def _differentiable_loss_particle(self, guide_trace):\n return -guide_trace.log_prob_sum()\n\n def validation_loss(self, *args, **kwargs):\n \"\"\"\n :returns: loss estimated using validation batch\n :rtype: float\n\n Calculates loss on validation batch. If no validation batch is set,\n will set one by calling `set_validation_batch`. Can be used to track\n the loss in a less noisy way during training.\n\n Arguments are passed to the model and guide.\n \"\"\"\n if self.validation_batch is None:\n self.set_validation_batch(*args, **kwargs)\n\n return self.loss_and_grads(False, self.validation_batch, *args, **kwargs)\n\n def _get_matched_trace(self, model_trace, *args, **kwargs):\n \"\"\"\n :param model_trace: a trace from the model\n :type model_trace: pyro.poutine.trace_struct.Trace\n :returns: guide trace with sampled values matched to model_trace\n :rtype: pyro.poutine.trace_struct.Trace\n\n Returns a guide trace with values at sample and observe statements\n matched to those in model_trace.\n\n `args` and `kwargs` are passed to the guide.\n \"\"\"\n kwargs[\"observations\"] = {}\n for node in itertools.chain(model_trace.stochastic_nodes, model_trace.observation_nodes):\n if \"was_observed\" in model_trace.nodes[node][\"infer\"]:\n model_trace.nodes[node][\"is_observed\"] = True\n kwargs[\"observations\"][node] = model_trace.nodes[node][\"value\"]\n\n guide_trace = poutine.trace(poutine.replay(self.guide,\n model_trace)\n ).get_trace(*args, **kwargs)\n\n check_model_guide_match(model_trace, guide_trace)\n guide_trace = prune_subsample_sites(guide_trace)\n\n return guide_trace\n\n def _sample_from_joint(self, *args, **kwargs):\n \"\"\"\n :returns: a sample from the joint distribution over unobserved and\n observed variables\n :rtype: pyro.poutine.trace_struct.Trace\n\n Returns a trace of the model without conditioning on any observations.\n\n Arguments are passed directly to the model.\n \"\"\"\n unconditioned_model = pyro.poutine.uncondition(self.model)\n return poutine.trace(unconditioned_model).get_trace(*args, **kwargs)\n", "path": "pyro/infer/csis.py"}], "after_files": [{"content": "# Copyright (c) 2017-2019 Uber Technologies, Inc.\n# SPDX-License-Identifier: Apache-2.0\n\nimport itertools\n\nimport torch\n\nimport pyro\nimport pyro.poutine as poutine\nfrom pyro.infer.importance import Importance\nfrom pyro.infer.util import torch_item\nfrom pyro.poutine.util import prune_subsample_sites\nfrom pyro.util import check_model_guide_match, warn_if_nan\n\n\nclass CSIS(Importance):\n \"\"\"\n Compiled Sequential Importance Sampling, allowing compilation of a guide\n program to minimise KL(model posterior || guide), and inference with\n importance sampling.\n\n **Reference**\n \"Inference Compilation and Universal Probabilistic Programming\" `pdf https://arxiv.org/pdf/1610.09900.pdf`\n\n :param model: probabilistic model defined as a function. Must accept a\n keyword argument named `observations`, in which observed values are\n passed as, with the names of nodes as the keys.\n :param guide: guide function which is used as an approximate posterior. Must\n also accept `observations` as keyword argument.\n :param optim: a Pyro optimizer\n :type optim: pyro.optim.PyroOptim\n :param num_inference_samples: The number of importance-weighted samples to\n draw during inference.\n :param training_batch_size: Number of samples to use to approximate the loss\n before each gradient descent step during training.\n :param validation_batch_size: Number of samples to use for calculating\n validation loss (will only be used if `.validation_loss` is called).\n \"\"\"\n def __init__(self,\n model,\n guide,\n optim,\n num_inference_samples=10,\n training_batch_size=10,\n validation_batch_size=20):\n super().__init__(model, guide, num_inference_samples)\n self.model = model\n self.guide = guide\n self.optim = optim\n self.training_batch_size = training_batch_size\n self.validation_batch_size = validation_batch_size\n self.validation_batch = None\n\n def set_validation_batch(self, *args, **kwargs):\n \"\"\"\n Samples a batch of model traces and stores it as an object property.\n\n Arguments are passed directly to model.\n \"\"\"\n self.validation_batch = [self._sample_from_joint(*args, **kwargs)\n for _ in range(self.validation_batch_size)]\n\n def step(self, *args, **kwargs):\n \"\"\"\n :returns: estimate of the loss\n :rtype: float\n\n Take a gradient step on the loss function. Arguments are passed to the\n model and guide.\n \"\"\"\n with poutine.trace(param_only=True) as param_capture:\n loss = self.loss_and_grads(True, None, *args, **kwargs)\n\n params = set(site[\"value\"].unconstrained()\n for site in param_capture.trace.nodes.values()\n if site[\"value\"].grad is not None)\n\n self.optim(params)\n\n pyro.infer.util.zero_grads(params)\n\n return torch_item(loss)\n\n def loss_and_grads(self, grads, batch, *args, **kwargs):\n \"\"\"\n :returns: an estimate of the loss (expectation over p(x, y) of\n -log q(x, y) ) - where p is the model and q is the guide\n :rtype: float\n\n If a batch is provided, the loss is estimated using these traces\n Otherwise, a fresh batch is generated from the model.\n\n If grads is True, will also call `backward` on loss.\n\n `args` and `kwargs` are passed to the model and guide.\n \"\"\"\n if batch is None:\n batch = (self._sample_from_joint(*args, **kwargs)\n for _ in range(self.training_batch_size))\n batch_size = self.training_batch_size\n else:\n batch_size = len(batch)\n\n loss = 0\n for model_trace in batch:\n with poutine.trace(param_only=True) as particle_param_capture:\n guide_trace = self._get_matched_trace(model_trace, *args, **kwargs)\n particle_loss = self._differentiable_loss_particle(guide_trace)\n particle_loss /= batch_size\n\n if grads:\n guide_params = set(site[\"value\"].unconstrained()\n for site in particle_param_capture.trace.nodes.values())\n guide_grads = torch.autograd.grad(particle_loss, guide_params, allow_unused=True)\n for guide_grad, guide_param in zip(guide_grads, guide_params):\n if guide_grad is None:\n continue\n guide_param.grad = guide_grad if guide_param.grad is None else guide_param.grad + guide_grad\n\n loss += torch_item(particle_loss)\n\n warn_if_nan(loss, \"loss\")\n return loss\n\n def _differentiable_loss_particle(self, guide_trace):\n return -guide_trace.log_prob_sum()\n\n def validation_loss(self, *args, **kwargs):\n \"\"\"\n :returns: loss estimated using validation batch\n :rtype: float\n\n Calculates loss on validation batch. If no validation batch is set,\n will set one by calling `set_validation_batch`. Can be used to track\n the loss in a less noisy way during training.\n\n Arguments are passed to the model and guide.\n \"\"\"\n if self.validation_batch is None:\n self.set_validation_batch(*args, **kwargs)\n\n return self.loss_and_grads(False, self.validation_batch, *args, **kwargs)\n\n def _get_matched_trace(self, model_trace, *args, **kwargs):\n \"\"\"\n :param model_trace: a trace from the model\n :type model_trace: pyro.poutine.trace_struct.Trace\n :returns: guide trace with sampled values matched to model_trace\n :rtype: pyro.poutine.trace_struct.Trace\n\n Returns a guide trace with values at sample and observe statements\n matched to those in model_trace.\n\n `args` and `kwargs` are passed to the guide.\n \"\"\"\n kwargs[\"observations\"] = {}\n for node in itertools.chain(model_trace.stochastic_nodes, model_trace.observation_nodes):\n if \"was_observed\" in model_trace.nodes[node][\"infer\"]:\n model_trace.nodes[node][\"is_observed\"] = True\n kwargs[\"observations\"][node] = model_trace.nodes[node][\"value\"]\n\n guide_trace = poutine.trace(poutine.replay(self.guide,\n model_trace)\n ).get_trace(*args, **kwargs)\n\n check_model_guide_match(model_trace, guide_trace)\n guide_trace = prune_subsample_sites(guide_trace)\n\n return guide_trace\n\n def _sample_from_joint(self, *args, **kwargs):\n \"\"\"\n :returns: a sample from the joint distribution over unobserved and\n observed variables\n :rtype: pyro.poutine.trace_struct.Trace\n\n Returns a trace of the model without conditioning on any observations.\n\n Arguments are passed directly to the model.\n \"\"\"\n unconditioned_model = pyro.poutine.uncondition(self.model)\n return poutine.trace(unconditioned_model).get_trace(*args, **kwargs)\n", "path": "pyro/infer/csis.py"}]} | 2,506 | 144 |
gh_patches_debug_3483 | rasdani/github-patches | git_diff | Lightning-AI__torchmetrics-1302 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MatthewsCorrCoef has massive slow down on both CPU and especially GPU
## 🐛 Bug
It's extremely slow to compute the Matthew Correlation Coefficient since torchmetrics == 0.10.0.
### To Reproduce
During my testing, I am seeing massive slow down when computing the Matthew Correlation Coefficient, especially on the GPU (using pytorch-lightning to build, train and test a deep learning model's performance on this metric).
I have compiled a code sample (next section) and below shows the result over different versions of torchmetrics.
ON CPU:
torchmetrics 0.7.3: 0.93961 s
torchmetrics 0.8.0: 0.93549 s
torchmetrics 0.8.2: 0.94494 s
torchmetrics 0.9.0: 0.92856 s
torchmetrics 0.9.2: 0.93682 s
torchmetrics 0.10.0: 1.10903 s
ON GPU:
torchmetrics 0.7.3: 0.11444 s
torchmetrics 0.8.0: 0.11682 s
torchmetrics 0.8.2: 0.11425 s
torchmetrics 0.9.0: 0.11433 s
torchmetrics 0.9.2: 0.11410 s
torchmetrics 0.10.0: 359.30208 s
So yeah testing over thousands of batches now takes almost a week for me to complete :rofl: Please take a look at this soon.
#### Code sample
```
from tqdm.auto import tqdm
import time
import torch
from torchmetrics import MatthewsCorrCoef
torch.manual_seed(1)
b, h, w = 10, 1080, 1920
device = "cpu"
def generate(b, h, w):
prob = torch.rand(b, h, w).to(device)
truth = torch.randint(0, 2, (b, h, w)).to(device)
return prob, truth
batches = []
for _ in range(10):
batches.append(generate(b, h, w))
mcc = MatthewsCorrCoef(num_classes=2).to(device)
t1 = time.time()
for detections, targets in tqdm(batches):
mcc.update(detections, targets)
print(f"{time.time() - t1:.5f}")
```
### Expected behavior
It's supposed to be faster in the range of ~0.1 second for GPU and ~0.9 second for CPU in this naive benchmark.
### Environment
- GPU: NVIDIA RTX 3090
- TorchMetrics version (`pip`): 0.10.0
- Python & PyTorch Version (e.g., 1.0): python=3.9, pytorch=1.12.1
- Any other relevant information such as OS (e.g., Linux): ubuntu18.04, (same behavior with 20.04)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/torchmetrics/utilities/data.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, Callable, Dict, List, Mapping, Optional, Sequence, Union
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.utilities.imports import _TORCH_GREATER_EQUAL_1_12
20
21 METRIC_EPS = 1e-6
22
23
24 def dim_zero_cat(x: Union[Tensor, List[Tensor]]) -> Tensor:
25 """Concatenation along the zero dimension."""
26 x = x if isinstance(x, (list, tuple)) else [x]
27 x = [y.unsqueeze(0) if y.numel() == 1 and y.ndim == 0 else y for y in x]
28 if not x: # empty list
29 raise ValueError("No samples to concatenate")
30 return torch.cat(x, dim=0)
31
32
33 def dim_zero_sum(x: Tensor) -> Tensor:
34 """Summation along the zero dimension."""
35 return torch.sum(x, dim=0)
36
37
38 def dim_zero_mean(x: Tensor) -> Tensor:
39 """Average along the zero dimension."""
40 return torch.mean(x, dim=0)
41
42
43 def dim_zero_max(x: Tensor) -> Tensor:
44 """Max along the zero dimension."""
45 return torch.max(x, dim=0).values
46
47
48 def dim_zero_min(x: Tensor) -> Tensor:
49 """Min along the zero dimension."""
50 return torch.min(x, dim=0).values
51
52
53 def _flatten(x: Sequence) -> list:
54 """Flatten list of list into single list."""
55 return [item for sublist in x for item in sublist]
56
57
58 def _flatten_dict(x: Dict) -> Dict:
59 """Flatten dict of dicts into single dict."""
60 new_dict = {}
61 for key, value in x.items():
62 if isinstance(value, dict):
63 for k, v in value.items():
64 new_dict[k] = v
65 else:
66 new_dict[key] = value
67 return new_dict
68
69
70 def to_onehot(
71 label_tensor: Tensor,
72 num_classes: Optional[int] = None,
73 ) -> Tensor:
74 """Converts a dense label tensor to one-hot format.
75
76 Args:
77 label_tensor: dense label tensor, with shape [N, d1, d2, ...]
78 num_classes: number of classes C
79
80 Returns:
81 A sparse label tensor with shape [N, C, d1, d2, ...]
82
83 Example:
84 >>> x = torch.tensor([1, 2, 3])
85 >>> to_onehot(x)
86 tensor([[0, 1, 0, 0],
87 [0, 0, 1, 0],
88 [0, 0, 0, 1]])
89 """
90 if num_classes is None:
91 num_classes = int(label_tensor.max().detach().item() + 1)
92
93 tensor_onehot = torch.zeros(
94 label_tensor.shape[0],
95 num_classes,
96 *label_tensor.shape[1:],
97 dtype=label_tensor.dtype,
98 device=label_tensor.device,
99 )
100 index = label_tensor.long().unsqueeze(1).expand_as(tensor_onehot)
101 return tensor_onehot.scatter_(1, index, 1.0)
102
103
104 def select_topk(prob_tensor: Tensor, topk: int = 1, dim: int = 1) -> Tensor:
105 """Convert a probability tensor to binary by selecting top-k the highest entries.
106
107 Args:
108 prob_tensor: dense tensor of shape ``[..., C, ...]``, where ``C`` is in the
109 position defined by the ``dim`` argument
110 topk: number of the highest entries to turn into 1s
111 dim: dimension on which to compare entries
112
113 Returns:
114 A binary tensor of the same shape as the input tensor of type ``torch.int32``
115
116 Example:
117 >>> x = torch.tensor([[1.1, 2.0, 3.0], [2.0, 1.0, 0.5]])
118 >>> select_topk(x, topk=2)
119 tensor([[0, 1, 1],
120 [1, 1, 0]], dtype=torch.int32)
121 """
122 zeros = torch.zeros_like(prob_tensor)
123 if topk == 1: # argmax has better performance than topk
124 topk_tensor = zeros.scatter(dim, prob_tensor.argmax(dim=dim, keepdim=True), 1.0)
125 else:
126 topk_tensor = zeros.scatter(dim, prob_tensor.topk(k=topk, dim=dim).indices, 1.0)
127 return topk_tensor.int()
128
129
130 def to_categorical(x: Tensor, argmax_dim: int = 1) -> Tensor:
131 """Converts a tensor of probabilities to a dense label tensor.
132
133 Args:
134 x: probabilities to get the categorical label [N, d1, d2, ...]
135 argmax_dim: dimension to apply
136
137 Return:
138 A tensor with categorical labels [N, d2, ...]
139
140 Example:
141 >>> x = torch.tensor([[0.2, 0.5], [0.9, 0.1]])
142 >>> to_categorical(x)
143 tensor([1, 0])
144 """
145 return torch.argmax(x, dim=argmax_dim)
146
147
148 def apply_to_collection(
149 data: Any,
150 dtype: Union[type, tuple],
151 function: Callable,
152 *args: Any,
153 wrong_dtype: Optional[Union[type, tuple]] = None,
154 **kwargs: Any,
155 ) -> Any:
156 """Recursively applies a function to all elements of a certain dtype.
157
158 Args:
159 data: the collection to apply the function to
160 dtype: the given function will be applied to all elements of this dtype
161 function: the function to apply
162 *args: positional arguments (will be forwarded to call of ``function``)
163 wrong_dtype: the given function won't be applied if this type is specified and the given collections is of
164 the :attr:`wrong_type` even if it is of type :attr`dtype`
165 **kwargs: keyword arguments (will be forwarded to call of ``function``)
166
167 Returns:
168 the resulting collection
169
170 Example:
171 >>> apply_to_collection(torch.tensor([8, 0, 2, 6, 7]), dtype=Tensor, function=lambda x: x ** 2)
172 tensor([64, 0, 4, 36, 49])
173 >>> apply_to_collection([8, 0, 2, 6, 7], dtype=int, function=lambda x: x ** 2)
174 [64, 0, 4, 36, 49]
175 >>> apply_to_collection(dict(abc=123), dtype=int, function=lambda x: x ** 2)
176 {'abc': 15129}
177 """
178 elem_type = type(data)
179
180 # Breaking condition
181 if isinstance(data, dtype) and (wrong_dtype is None or not isinstance(data, wrong_dtype)):
182 return function(data, *args, **kwargs)
183
184 # Recursively apply to collection items
185 if isinstance(data, Mapping):
186 return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs) for k, v in data.items()})
187
188 if isinstance(data, tuple) and hasattr(data, "_fields"): # named tuple
189 return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))
190
191 if isinstance(data, Sequence) and not isinstance(data, str):
192 return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])
193
194 # data is neither of dtype, nor a collection
195 return data
196
197
198 def _squeeze_scalar_element_tensor(x: Tensor) -> Tensor:
199 return x.squeeze() if x.numel() == 1 else x
200
201
202 def _squeeze_if_scalar(data: Any) -> Any:
203 return apply_to_collection(data, Tensor, _squeeze_scalar_element_tensor)
204
205
206 def _bincount(x: Tensor, minlength: Optional[int] = None) -> Tensor:
207 """PyTorch currently does not support``torch.bincount`` for:
208
209 - deterministic mode on GPU.
210 - MPS devices
211
212 This implementation fallback to a for-loop counting occurrences in that case.
213
214 Args:
215 x: tensor to count
216 minlength: minimum length to count
217
218 Returns:
219 Number of occurrences for each unique element in x
220 """
221 if minlength is None:
222 minlength = len(torch.unique(x))
223 if torch.are_deterministic_algorithms_enabled() or _TORCH_GREATER_EQUAL_1_12 and x.is_mps:
224 output = torch.zeros(minlength, device=x.device, dtype=torch.long)
225 for i in range(minlength):
226 output[i] = (x == i).sum()
227 return output
228 z = torch.zeros(minlength, device=x.device, dtype=x.dtype)
229 return z.index_add_(0, x, torch.ones_like(x))
230
231
232 def _flexible_bincount(x: Tensor) -> Tensor:
233 """Similar to `_bincount`, but works also with tensor that do not contain continuous values.
234
235 Args:
236 x: tensor to count
237
238 Returns:
239 Number of occurrences for each unique element in x
240 """
241
242 # make sure elements in x start from 0
243 x = x - x.min()
244 unique_x = torch.unique(x)
245
246 output = _bincount(x, minlength=torch.max(unique_x) + 1)
247 # remove zeros from output tensor
248 return output[unique_x]
249
250
251 def allclose(tensor1: Tensor, tensor2: Tensor) -> bool:
252 """Wrapper of torch.allclose that is robust towards dtype difference."""
253 if tensor1.dtype != tensor2.dtype:
254 tensor2 = tensor2.to(dtype=tensor1.dtype)
255 return torch.allclose(tensor1, tensor2)
256
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/torchmetrics/utilities/data.py b/src/torchmetrics/utilities/data.py
--- a/src/torchmetrics/utilities/data.py
+++ b/src/torchmetrics/utilities/data.py
@@ -225,8 +225,7 @@
for i in range(minlength):
output[i] = (x == i).sum()
return output
- z = torch.zeros(minlength, device=x.device, dtype=x.dtype)
- return z.index_add_(0, x, torch.ones_like(x))
+ return torch.bincount(x, minlength=minlength)
def _flexible_bincount(x: Tensor) -> Tensor:
| {"golden_diff": "diff --git a/src/torchmetrics/utilities/data.py b/src/torchmetrics/utilities/data.py\n--- a/src/torchmetrics/utilities/data.py\n+++ b/src/torchmetrics/utilities/data.py\n@@ -225,8 +225,7 @@\n for i in range(minlength):\n output[i] = (x == i).sum()\n return output\n- z = torch.zeros(minlength, device=x.device, dtype=x.dtype)\n- return z.index_add_(0, x, torch.ones_like(x))\n+ return torch.bincount(x, minlength=minlength)\n \n \n def _flexible_bincount(x: Tensor) -> Tensor:\n", "issue": "MatthewsCorrCoef has massive slow down on both CPU and especially GPU\n## \ud83d\udc1b Bug\r\n\r\nIt's extremely slow to compute the Matthew Correlation Coefficient since torchmetrics == 0.10.0.\r\n\r\n### To Reproduce\r\n\r\nDuring my testing, I am seeing massive slow down when computing the Matthew Correlation Coefficient, especially on the GPU (using pytorch-lightning to build, train and test a deep learning model's performance on this metric).\r\n\r\nI have compiled a code sample (next section) and below shows the result over different versions of torchmetrics. \r\n\r\nON CPU:\r\ntorchmetrics 0.7.3: 0.93961 s\r\ntorchmetrics 0.8.0: 0.93549 s\r\ntorchmetrics 0.8.2: 0.94494 s\r\ntorchmetrics 0.9.0: 0.92856 s\r\ntorchmetrics 0.9.2: 0.93682 s\r\ntorchmetrics 0.10.0: 1.10903 s\r\n\r\nON GPU:\r\ntorchmetrics 0.7.3: 0.11444 s\r\ntorchmetrics 0.8.0: 0.11682 s\r\ntorchmetrics 0.8.2: 0.11425 s\r\ntorchmetrics 0.9.0: 0.11433 s\r\ntorchmetrics 0.9.2: 0.11410 s\r\ntorchmetrics 0.10.0: 359.30208 s\r\n\r\nSo yeah testing over thousands of batches now takes almost a week for me to complete :rofl: Please take a look at this soon.\r\n\r\n#### Code sample\r\n\r\n```\r\nfrom tqdm.auto import tqdm\r\nimport time\r\nimport torch\r\nfrom torchmetrics import MatthewsCorrCoef\r\n\r\ntorch.manual_seed(1)\r\n\r\nb, h, w = 10, 1080, 1920\r\ndevice = \"cpu\"\r\n\r\ndef generate(b, h, w):\r\n prob = torch.rand(b, h, w).to(device)\r\n truth = torch.randint(0, 2, (b, h, w)).to(device)\r\n return prob, truth\r\n\r\nbatches = []\r\nfor _ in range(10):\r\n batches.append(generate(b, h, w))\r\n\r\nmcc = MatthewsCorrCoef(num_classes=2).to(device)\r\n\r\nt1 = time.time()\r\nfor detections, targets in tqdm(batches):\r\n mcc.update(detections, targets)\r\nprint(f\"{time.time() - t1:.5f}\")\r\n```\r\n\r\n### Expected behavior\r\n\r\nIt's supposed to be faster in the range of ~0.1 second for GPU and ~0.9 second for CPU in this naive benchmark.\r\n\r\n### Environment\r\n\r\n- GPU: NVIDIA RTX 3090\r\n- TorchMetrics version (`pip`): 0.10.0\r\n- Python & PyTorch Version (e.g., 1.0): python=3.9, pytorch=1.12.1\r\n- Any other relevant information such as OS (e.g., Linux): ubuntu18.04, (same behavior with 20.04)\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Dict, List, Mapping, Optional, Sequence, Union\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.imports import _TORCH_GREATER_EQUAL_1_12\n\nMETRIC_EPS = 1e-6\n\n\ndef dim_zero_cat(x: Union[Tensor, List[Tensor]]) -> Tensor:\n \"\"\"Concatenation along the zero dimension.\"\"\"\n x = x if isinstance(x, (list, tuple)) else [x]\n x = [y.unsqueeze(0) if y.numel() == 1 and y.ndim == 0 else y for y in x]\n if not x: # empty list\n raise ValueError(\"No samples to concatenate\")\n return torch.cat(x, dim=0)\n\n\ndef dim_zero_sum(x: Tensor) -> Tensor:\n \"\"\"Summation along the zero dimension.\"\"\"\n return torch.sum(x, dim=0)\n\n\ndef dim_zero_mean(x: Tensor) -> Tensor:\n \"\"\"Average along the zero dimension.\"\"\"\n return torch.mean(x, dim=0)\n\n\ndef dim_zero_max(x: Tensor) -> Tensor:\n \"\"\"Max along the zero dimension.\"\"\"\n return torch.max(x, dim=0).values\n\n\ndef dim_zero_min(x: Tensor) -> Tensor:\n \"\"\"Min along the zero dimension.\"\"\"\n return torch.min(x, dim=0).values\n\n\ndef _flatten(x: Sequence) -> list:\n \"\"\"Flatten list of list into single list.\"\"\"\n return [item for sublist in x for item in sublist]\n\n\ndef _flatten_dict(x: Dict) -> Dict:\n \"\"\"Flatten dict of dicts into single dict.\"\"\"\n new_dict = {}\n for key, value in x.items():\n if isinstance(value, dict):\n for k, v in value.items():\n new_dict[k] = v\n else:\n new_dict[key] = value\n return new_dict\n\n\ndef to_onehot(\n label_tensor: Tensor,\n num_classes: Optional[int] = None,\n) -> Tensor:\n \"\"\"Converts a dense label tensor to one-hot format.\n\n Args:\n label_tensor: dense label tensor, with shape [N, d1, d2, ...]\n num_classes: number of classes C\n\n Returns:\n A sparse label tensor with shape [N, C, d1, d2, ...]\n\n Example:\n >>> x = torch.tensor([1, 2, 3])\n >>> to_onehot(x)\n tensor([[0, 1, 0, 0],\n [0, 0, 1, 0],\n [0, 0, 0, 1]])\n \"\"\"\n if num_classes is None:\n num_classes = int(label_tensor.max().detach().item() + 1)\n\n tensor_onehot = torch.zeros(\n label_tensor.shape[0],\n num_classes,\n *label_tensor.shape[1:],\n dtype=label_tensor.dtype,\n device=label_tensor.device,\n )\n index = label_tensor.long().unsqueeze(1).expand_as(tensor_onehot)\n return tensor_onehot.scatter_(1, index, 1.0)\n\n\ndef select_topk(prob_tensor: Tensor, topk: int = 1, dim: int = 1) -> Tensor:\n \"\"\"Convert a probability tensor to binary by selecting top-k the highest entries.\n\n Args:\n prob_tensor: dense tensor of shape ``[..., C, ...]``, where ``C`` is in the\n position defined by the ``dim`` argument\n topk: number of the highest entries to turn into 1s\n dim: dimension on which to compare entries\n\n Returns:\n A binary tensor of the same shape as the input tensor of type ``torch.int32``\n\n Example:\n >>> x = torch.tensor([[1.1, 2.0, 3.0], [2.0, 1.0, 0.5]])\n >>> select_topk(x, topk=2)\n tensor([[0, 1, 1],\n [1, 1, 0]], dtype=torch.int32)\n \"\"\"\n zeros = torch.zeros_like(prob_tensor)\n if topk == 1: # argmax has better performance than topk\n topk_tensor = zeros.scatter(dim, prob_tensor.argmax(dim=dim, keepdim=True), 1.0)\n else:\n topk_tensor = zeros.scatter(dim, prob_tensor.topk(k=topk, dim=dim).indices, 1.0)\n return topk_tensor.int()\n\n\ndef to_categorical(x: Tensor, argmax_dim: int = 1) -> Tensor:\n \"\"\"Converts a tensor of probabilities to a dense label tensor.\n\n Args:\n x: probabilities to get the categorical label [N, d1, d2, ...]\n argmax_dim: dimension to apply\n\n Return:\n A tensor with categorical labels [N, d2, ...]\n\n Example:\n >>> x = torch.tensor([[0.2, 0.5], [0.9, 0.1]])\n >>> to_categorical(x)\n tensor([1, 0])\n \"\"\"\n return torch.argmax(x, dim=argmax_dim)\n\n\ndef apply_to_collection(\n data: Any,\n dtype: Union[type, tuple],\n function: Callable,\n *args: Any,\n wrong_dtype: Optional[Union[type, tuple]] = None,\n **kwargs: Any,\n) -> Any:\n \"\"\"Recursively applies a function to all elements of a certain dtype.\n\n Args:\n data: the collection to apply the function to\n dtype: the given function will be applied to all elements of this dtype\n function: the function to apply\n *args: positional arguments (will be forwarded to call of ``function``)\n wrong_dtype: the given function won't be applied if this type is specified and the given collections is of\n the :attr:`wrong_type` even if it is of type :attr`dtype`\n **kwargs: keyword arguments (will be forwarded to call of ``function``)\n\n Returns:\n the resulting collection\n\n Example:\n >>> apply_to_collection(torch.tensor([8, 0, 2, 6, 7]), dtype=Tensor, function=lambda x: x ** 2)\n tensor([64, 0, 4, 36, 49])\n >>> apply_to_collection([8, 0, 2, 6, 7], dtype=int, function=lambda x: x ** 2)\n [64, 0, 4, 36, 49]\n >>> apply_to_collection(dict(abc=123), dtype=int, function=lambda x: x ** 2)\n {'abc': 15129}\n \"\"\"\n elem_type = type(data)\n\n # Breaking condition\n if isinstance(data, dtype) and (wrong_dtype is None or not isinstance(data, wrong_dtype)):\n return function(data, *args, **kwargs)\n\n # Recursively apply to collection items\n if isinstance(data, Mapping):\n return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs) for k, v in data.items()})\n\n if isinstance(data, tuple) and hasattr(data, \"_fields\"): # named tuple\n return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))\n\n if isinstance(data, Sequence) and not isinstance(data, str):\n return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])\n\n # data is neither of dtype, nor a collection\n return data\n\n\ndef _squeeze_scalar_element_tensor(x: Tensor) -> Tensor:\n return x.squeeze() if x.numel() == 1 else x\n\n\ndef _squeeze_if_scalar(data: Any) -> Any:\n return apply_to_collection(data, Tensor, _squeeze_scalar_element_tensor)\n\n\ndef _bincount(x: Tensor, minlength: Optional[int] = None) -> Tensor:\n \"\"\"PyTorch currently does not support``torch.bincount`` for:\n\n - deterministic mode on GPU.\n - MPS devices\n\n This implementation fallback to a for-loop counting occurrences in that case.\n\n Args:\n x: tensor to count\n minlength: minimum length to count\n\n Returns:\n Number of occurrences for each unique element in x\n \"\"\"\n if minlength is None:\n minlength = len(torch.unique(x))\n if torch.are_deterministic_algorithms_enabled() or _TORCH_GREATER_EQUAL_1_12 and x.is_mps:\n output = torch.zeros(minlength, device=x.device, dtype=torch.long)\n for i in range(minlength):\n output[i] = (x == i).sum()\n return output\n z = torch.zeros(minlength, device=x.device, dtype=x.dtype)\n return z.index_add_(0, x, torch.ones_like(x))\n\n\ndef _flexible_bincount(x: Tensor) -> Tensor:\n \"\"\"Similar to `_bincount`, but works also with tensor that do not contain continuous values.\n\n Args:\n x: tensor to count\n\n Returns:\n Number of occurrences for each unique element in x\n \"\"\"\n\n # make sure elements in x start from 0\n x = x - x.min()\n unique_x = torch.unique(x)\n\n output = _bincount(x, minlength=torch.max(unique_x) + 1)\n # remove zeros from output tensor\n return output[unique_x]\n\n\ndef allclose(tensor1: Tensor, tensor2: Tensor) -> bool:\n \"\"\"Wrapper of torch.allclose that is robust towards dtype difference.\"\"\"\n if tensor1.dtype != tensor2.dtype:\n tensor2 = tensor2.to(dtype=tensor1.dtype)\n return torch.allclose(tensor1, tensor2)\n", "path": "src/torchmetrics/utilities/data.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Dict, List, Mapping, Optional, Sequence, Union\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.imports import _TORCH_GREATER_EQUAL_1_12\n\nMETRIC_EPS = 1e-6\n\n\ndef dim_zero_cat(x: Union[Tensor, List[Tensor]]) -> Tensor:\n \"\"\"Concatenation along the zero dimension.\"\"\"\n x = x if isinstance(x, (list, tuple)) else [x]\n x = [y.unsqueeze(0) if y.numel() == 1 and y.ndim == 0 else y for y in x]\n if not x: # empty list\n raise ValueError(\"No samples to concatenate\")\n return torch.cat(x, dim=0)\n\n\ndef dim_zero_sum(x: Tensor) -> Tensor:\n \"\"\"Summation along the zero dimension.\"\"\"\n return torch.sum(x, dim=0)\n\n\ndef dim_zero_mean(x: Tensor) -> Tensor:\n \"\"\"Average along the zero dimension.\"\"\"\n return torch.mean(x, dim=0)\n\n\ndef dim_zero_max(x: Tensor) -> Tensor:\n \"\"\"Max along the zero dimension.\"\"\"\n return torch.max(x, dim=0).values\n\n\ndef dim_zero_min(x: Tensor) -> Tensor:\n \"\"\"Min along the zero dimension.\"\"\"\n return torch.min(x, dim=0).values\n\n\ndef _flatten(x: Sequence) -> list:\n \"\"\"Flatten list of list into single list.\"\"\"\n return [item for sublist in x for item in sublist]\n\n\ndef _flatten_dict(x: Dict) -> Dict:\n \"\"\"Flatten dict of dicts into single dict.\"\"\"\n new_dict = {}\n for key, value in x.items():\n if isinstance(value, dict):\n for k, v in value.items():\n new_dict[k] = v\n else:\n new_dict[key] = value\n return new_dict\n\n\ndef to_onehot(\n label_tensor: Tensor,\n num_classes: Optional[int] = None,\n) -> Tensor:\n \"\"\"Converts a dense label tensor to one-hot format.\n\n Args:\n label_tensor: dense label tensor, with shape [N, d1, d2, ...]\n num_classes: number of classes C\n\n Returns:\n A sparse label tensor with shape [N, C, d1, d2, ...]\n\n Example:\n >>> x = torch.tensor([1, 2, 3])\n >>> to_onehot(x)\n tensor([[0, 1, 0, 0],\n [0, 0, 1, 0],\n [0, 0, 0, 1]])\n \"\"\"\n if num_classes is None:\n num_classes = int(label_tensor.max().detach().item() + 1)\n\n tensor_onehot = torch.zeros(\n label_tensor.shape[0],\n num_classes,\n *label_tensor.shape[1:],\n dtype=label_tensor.dtype,\n device=label_tensor.device,\n )\n index = label_tensor.long().unsqueeze(1).expand_as(tensor_onehot)\n return tensor_onehot.scatter_(1, index, 1.0)\n\n\ndef select_topk(prob_tensor: Tensor, topk: int = 1, dim: int = 1) -> Tensor:\n \"\"\"Convert a probability tensor to binary by selecting top-k the highest entries.\n\n Args:\n prob_tensor: dense tensor of shape ``[..., C, ...]``, where ``C`` is in the\n position defined by the ``dim`` argument\n topk: number of the highest entries to turn into 1s\n dim: dimension on which to compare entries\n\n Returns:\n A binary tensor of the same shape as the input tensor of type ``torch.int32``\n\n Example:\n >>> x = torch.tensor([[1.1, 2.0, 3.0], [2.0, 1.0, 0.5]])\n >>> select_topk(x, topk=2)\n tensor([[0, 1, 1],\n [1, 1, 0]], dtype=torch.int32)\n \"\"\"\n zeros = torch.zeros_like(prob_tensor)\n if topk == 1: # argmax has better performance than topk\n topk_tensor = zeros.scatter(dim, prob_tensor.argmax(dim=dim, keepdim=True), 1.0)\n else:\n topk_tensor = zeros.scatter(dim, prob_tensor.topk(k=topk, dim=dim).indices, 1.0)\n return topk_tensor.int()\n\n\ndef to_categorical(x: Tensor, argmax_dim: int = 1) -> Tensor:\n \"\"\"Converts a tensor of probabilities to a dense label tensor.\n\n Args:\n x: probabilities to get the categorical label [N, d1, d2, ...]\n argmax_dim: dimension to apply\n\n Return:\n A tensor with categorical labels [N, d2, ...]\n\n Example:\n >>> x = torch.tensor([[0.2, 0.5], [0.9, 0.1]])\n >>> to_categorical(x)\n tensor([1, 0])\n \"\"\"\n return torch.argmax(x, dim=argmax_dim)\n\n\ndef apply_to_collection(\n data: Any,\n dtype: Union[type, tuple],\n function: Callable,\n *args: Any,\n wrong_dtype: Optional[Union[type, tuple]] = None,\n **kwargs: Any,\n) -> Any:\n \"\"\"Recursively applies a function to all elements of a certain dtype.\n\n Args:\n data: the collection to apply the function to\n dtype: the given function will be applied to all elements of this dtype\n function: the function to apply\n *args: positional arguments (will be forwarded to call of ``function``)\n wrong_dtype: the given function won't be applied if this type is specified and the given collections is of\n the :attr:`wrong_type` even if it is of type :attr`dtype`\n **kwargs: keyword arguments (will be forwarded to call of ``function``)\n\n Returns:\n the resulting collection\n\n Example:\n >>> apply_to_collection(torch.tensor([8, 0, 2, 6, 7]), dtype=Tensor, function=lambda x: x ** 2)\n tensor([64, 0, 4, 36, 49])\n >>> apply_to_collection([8, 0, 2, 6, 7], dtype=int, function=lambda x: x ** 2)\n [64, 0, 4, 36, 49]\n >>> apply_to_collection(dict(abc=123), dtype=int, function=lambda x: x ** 2)\n {'abc': 15129}\n \"\"\"\n elem_type = type(data)\n\n # Breaking condition\n if isinstance(data, dtype) and (wrong_dtype is None or not isinstance(data, wrong_dtype)):\n return function(data, *args, **kwargs)\n\n # Recursively apply to collection items\n if isinstance(data, Mapping):\n return elem_type({k: apply_to_collection(v, dtype, function, *args, **kwargs) for k, v in data.items()})\n\n if isinstance(data, tuple) and hasattr(data, \"_fields\"): # named tuple\n return elem_type(*(apply_to_collection(d, dtype, function, *args, **kwargs) for d in data))\n\n if isinstance(data, Sequence) and not isinstance(data, str):\n return elem_type([apply_to_collection(d, dtype, function, *args, **kwargs) for d in data])\n\n # data is neither of dtype, nor a collection\n return data\n\n\ndef _squeeze_scalar_element_tensor(x: Tensor) -> Tensor:\n return x.squeeze() if x.numel() == 1 else x\n\n\ndef _squeeze_if_scalar(data: Any) -> Any:\n return apply_to_collection(data, Tensor, _squeeze_scalar_element_tensor)\n\n\ndef _bincount(x: Tensor, minlength: Optional[int] = None) -> Tensor:\n \"\"\"PyTorch currently does not support``torch.bincount`` for:\n\n - deterministic mode on GPU.\n - MPS devices\n\n This implementation fallback to a for-loop counting occurrences in that case.\n\n Args:\n x: tensor to count\n minlength: minimum length to count\n\n Returns:\n Number of occurrences for each unique element in x\n \"\"\"\n if minlength is None:\n minlength = len(torch.unique(x))\n if torch.are_deterministic_algorithms_enabled() or _TORCH_GREATER_EQUAL_1_12 and x.is_mps:\n output = torch.zeros(minlength, device=x.device, dtype=torch.long)\n for i in range(minlength):\n output[i] = (x == i).sum()\n return output\n return torch.bincount(x, minlength=minlength)\n\n\ndef _flexible_bincount(x: Tensor) -> Tensor:\n \"\"\"Similar to `_bincount`, but works also with tensor that do not contain continuous values.\n\n Args:\n x: tensor to count\n\n Returns:\n Number of occurrences for each unique element in x\n \"\"\"\n\n # make sure elements in x start from 0\n x = x - x.min()\n unique_x = torch.unique(x)\n\n output = _bincount(x, minlength=torch.max(unique_x) + 1)\n # remove zeros from output tensor\n return output[unique_x]\n\n\ndef allclose(tensor1: Tensor, tensor2: Tensor) -> bool:\n \"\"\"Wrapper of torch.allclose that is robust towards dtype difference.\"\"\"\n if tensor1.dtype != tensor2.dtype:\n tensor2 = tensor2.to(dtype=tensor1.dtype)\n return torch.allclose(tensor1, tensor2)\n", "path": "src/torchmetrics/utilities/data.py"}]} | 3,881 | 141 |
gh_patches_debug_18665 | rasdani/github-patches | git_diff | CiviWiki__OpenCiviWiki-863 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove Sentry as a barrier to development
Our project currently will not start without configuring a SENTRY_ADDRESS. In general, development should be as quick and painless as possible -- and not be inhibited by production concerns.
For the time being, since we are not in production, remove the dependency on Sentry.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `project/civiwiki/settings.py`
Content:
```
1 """
2 Django settings for civiwiki project.
3 Darius Calliet May 12, 2016
4
5 Production settings file to select proper environment variables.
6 """
7 import os
8 import sentry_sdk
9 import environ
10
11 from django.core.exceptions import ImproperlyConfigured
12
13 from sentry_sdk.integrations.django import DjangoIntegration
14
15 env = environ.Env(
16 # set casting, default value
17 DEBUG=(bool, False)
18 )
19 # reading .env file
20 environ.Env.read_env()
21
22 # False if not in os.environ
23 DEBUG = env("DEBUG")
24
25 if not DEBUG:
26 SENTRY_ADDRESS = env("SENTRY_ADDRESS")
27 if SENTRY_ADDRESS:
28 sentry_sdk.init(dsn=SENTRY_ADDRESS, integrations=[DjangoIntegration()])
29
30 DJANGO_HOST = env("DJANGO_HOST", default="LOCALHOST")
31
32 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
33 SECRET_KEY = env("DJANGO_SECRET_KEY", default="TEST_KEY_FOR_DEVELOPMENT")
34 ALLOWED_HOSTS = [".herokuapp.com", ".civiwiki.org", "127.0.0.1", "localhost", "0.0.0.0"]
35
36 INSTALLED_APPS = (
37 "django.contrib.admin",
38 "django.contrib.auth",
39 "django.contrib.contenttypes",
40 "django.contrib.sessions",
41 "django.contrib.messages",
42 "django.contrib.staticfiles",
43 "django_extensions",
44 "storages",
45 "channels",
46 "civiwiki",
47 "api",
48 "rest_framework",
49 "authentication",
50 "frontend_views",
51 "notifications",
52 "corsheaders",
53 )
54
55 MIDDLEWARE = [
56 "corsheaders.middleware.CorsMiddleware",
57 "django.middleware.security.SecurityMiddleware",
58 "whitenoise.middleware.WhiteNoiseMiddleware",
59 "django.contrib.sessions.middleware.SessionMiddleware",
60 "django.middleware.common.CommonMiddleware",
61 "django.middleware.csrf.CsrfViewMiddleware",
62 "django.contrib.auth.middleware.AuthenticationMiddleware",
63 # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
64 "django.contrib.messages.middleware.MessageMiddleware",
65 "django.middleware.clickjacking.XFrameOptionsMiddleware",
66 ]
67
68 CSRF_USE_SESSIONS = (
69 True # Store the CSRF token in the users session instead of in a cookie
70 )
71
72 CORS_ORIGIN_ALLOW_ALL = True
73 ROOT_URLCONF = "civiwiki.urls"
74 LOGIN_URL = "/login"
75
76 # SSL Setup
77 if DJANGO_HOST != "LOCALHOST":
78 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
79 SECURE_SSL_REDIRECT = True
80 SESSION_COOKIE_SECURE = True
81 CSRF_COOKIE_SECURE = True
82
83 # Internationalization & Localization
84 LANGUAGE_CODE = "en-us"
85 TIME_ZONE = "UTC"
86 USE_I18N = True
87 USE_L10N = True
88 USE_TZ = True
89
90 TEMPLATES = [
91 {
92 "BACKEND": "django.template.backends.django.DjangoTemplates",
93 "DIRS": [
94 os.path.join(BASE_DIR, "webapp/templates")
95 ], # TODO: Add non-webapp template directory
96 "APP_DIRS": True,
97 "OPTIONS": {
98 "context_processors": [
99 "django.template.context_processors.debug",
100 "django.template.context_processors.request",
101 "django.contrib.auth.context_processors.auth",
102 "django.contrib.messages.context_processors.messages",
103 ],
104 },
105 },
106 ]
107
108 WSGI_APPLICATION = "civiwiki.wsgi.application"
109
110 # Global user privilege settings
111 CLOSED_BETA = env("CLOSED_BETA", default=False)
112
113 # Apex Contact for Production Errors
114 ADMINS = [("Development Team", "[email protected]")]
115
116 # API keys
117 SUNLIGHT_API_KEY = env("SUNLIGHT_API_KEY")
118 GOOGLE_API_KEY = env("GOOGLE_MAP_API_KEY")
119
120 # Channels Setup
121 REDIS_URL = env("REDIS_URL", default="redis://localhost:6379")
122 CHANNEL_LAYERS = {
123 "default": {
124 "BACKEND": "asgi_redis.RedisChannelLayer",
125 "CONFIG": {
126 "hosts": [REDIS_URL],
127 },
128 "ROUTING": "civiwiki.routing.channel_routing",
129 },
130 }
131
132 # Celery Task Runner Setup
133 CELERY_BROKER_URL = REDIS_URL + "/0"
134 CELERY_RESULT_BACKEND = CELERY_BROKER_URL
135 CELERY_ACCEPT_CONTENT = ["application/json"]
136 CELERY_TASK_SERIALIZER = "json"
137 CELERY_RESULT_SERIALIZER = "json"
138 CELERY_TIME_ZONE = TIME_ZONE
139
140 # AWS S3 Setup
141 if "AWS_STORAGE_BUCKET_NAME" not in os.environ:
142 MEDIA_URL = "/media/"
143 MEDIA_ROOT = os.path.join(BASE_DIR, "media")
144 else:
145 AWS_STORAGE_BUCKET_NAME = env("AWS_STORAGE_BUCKET_NAME")
146 AWS_S3_ACCESS_KEY_ID = env("AWS_S3_ACCESS_KEY_ID")
147 AWS_S3_SECRET_ACCESS_KEY = env("AWS_S3_SECRET_ACCESS_KEY")
148 DEFAULT_FILE_STORAGE = "storages.backends.s3boto.S3BotoStorage"
149 AWS_S3_SECURE_URLS = False
150 AWS_QUERYSTRING_AUTH = False
151
152 STATIC_URL = "/static/"
153 STATICFILES_DIRS = (os.path.join(BASE_DIR, "webapp/static"),)
154 STATIC_ROOT = os.path.join(BASE_DIR, "staticfiles")
155
156 # Database
157 if "CIVIWIKI_LOCAL_NAME" not in os.environ:
158 STATICFILES_STORAGE = "whitenoise.storage.CompressedManifestStaticFilesStorage"
159
160 DATABASES = {"default": env.db()}
161 else:
162 DATABASES = {
163 "default": {
164 "HOST": env("CIVIWIKI_LOCAL_DB_HOST", "localhost"),
165 "PORT": "5432",
166 "NAME": env("CIVIWIKI_LOCAL_NAME"),
167 "ENGINE": "django.db.backends.postgresql_psycopg2",
168 "USER": env("CIVIWIKI_LOCAL_USERNAME"),
169 "PASSWORD": env("CIVIWIKI_LOCAL_PASSWORD"),
170 },
171 }
172
173 # Email Backend Setup
174 if "EMAIL_HOST" not in os.environ:
175 EMAIL_BACKEND = "django.core.mail.backends.console.EmailBackend"
176 EMAIL_HOST_USER = "[email protected]"
177 else:
178 EMAIL_BACKEND = "django.core.mail.backends.smtp.EmailBackend"
179 EMAIL_HOST = env("EMAIL_HOST")
180 EMAIL_PORT = env("EMAIL_PORT")
181 EMAIL_HOST_USER = env("EMAIL_HOST_USER")
182 EMAIL_HOST_PASSWORD = env("EMAIL_HOST_PASSWORD")
183 EMAIL_USE_SSL = True
184 DEFAULT_FROM_EMAIL = EMAIL_HOST
185
186 # Notification API Settings
187 NOTIFICATIONS_SOFT_DELETE = True
188 NOTIFICATIONS_USE_JSONFIELD = True
189
190 # Django REST API Settings
191 DEFAULT_RENDERER_CLASSES = ("rest_framework.renderers.JSONRenderer",)
192
193 DEFAULT_AUTHENTICATION_CLASSES = ("rest_framework.authentication.BasicAuthentication",)
194
195 if DEBUG:
196 # Browsable HTML - Enabled only in Debug mode (dev)
197 DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (
198 "rest_framework.renderers.BrowsableAPIRenderer",
199 )
200
201 DEFAULT_AUTHENTICATION_CLASSES = (
202 "api.authentication.CsrfExemptSessionAuthentication",
203 ) + DEFAULT_AUTHENTICATION_CLASSES
204
205 REST_FRAMEWORK = {
206 "DEFAULT_PERMISSION_CLASSES": ("rest_framework.permissions.IsAuthenticated",),
207 "DEFAULT_RENDERER_CLASSES": DEFAULT_RENDERER_CLASSES,
208 "DEFAULT_AUTHENTICATION_CLASSES": DEFAULT_AUTHENTICATION_CLASSES,
209 }
210 # CORS Settings
211 CORS_ORIGIN_ALLOW_ALL = True
212 PROPUBLICA_API_KEY = env("PROPUBLICA_API_KEY", default="TEST")
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/project/civiwiki/settings.py b/project/civiwiki/settings.py
--- a/project/civiwiki/settings.py
+++ b/project/civiwiki/settings.py
@@ -5,13 +5,10 @@
Production settings file to select proper environment variables.
"""
import os
-import sentry_sdk
import environ
from django.core.exceptions import ImproperlyConfigured
-from sentry_sdk.integrations.django import DjangoIntegration
-
env = environ.Env(
# set casting, default value
DEBUG=(bool, False)
@@ -22,11 +19,6 @@
# False if not in os.environ
DEBUG = env("DEBUG")
-if not DEBUG:
- SENTRY_ADDRESS = env("SENTRY_ADDRESS")
- if SENTRY_ADDRESS:
- sentry_sdk.init(dsn=SENTRY_ADDRESS, integrations=[DjangoIntegration()])
-
DJANGO_HOST = env("DJANGO_HOST", default="LOCALHOST")
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
| {"golden_diff": "diff --git a/project/civiwiki/settings.py b/project/civiwiki/settings.py\n--- a/project/civiwiki/settings.py\n+++ b/project/civiwiki/settings.py\n@@ -5,13 +5,10 @@\n Production settings file to select proper environment variables.\n \"\"\"\n import os\n-import sentry_sdk\n import environ\n \n from django.core.exceptions import ImproperlyConfigured\n \n-from sentry_sdk.integrations.django import DjangoIntegration\n-\n env = environ.Env(\n # set casting, default value\n DEBUG=(bool, False)\n@@ -22,11 +19,6 @@\n # False if not in os.environ\n DEBUG = env(\"DEBUG\")\n \n-if not DEBUG:\n- SENTRY_ADDRESS = env(\"SENTRY_ADDRESS\")\n- if SENTRY_ADDRESS:\n- sentry_sdk.init(dsn=SENTRY_ADDRESS, integrations=[DjangoIntegration()])\n-\n DJANGO_HOST = env(\"DJANGO_HOST\", default=\"LOCALHOST\")\n \n BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n", "issue": "Remove Sentry as a barrier to development\nOur project currently will not start without configuring a SENTRY_ADDRESS. In general, development should be as quick and painless as possible -- and not be inhibited by production concerns.\r\n\r\nFor the time being, since we are not in production, remove the dependency on Sentry.\n", "before_files": [{"content": "\"\"\"\nDjango settings for civiwiki project.\nDarius Calliet May 12, 2016\n\nProduction settings file to select proper environment variables.\n\"\"\"\nimport os\nimport sentry_sdk\nimport environ\n\nfrom django.core.exceptions import ImproperlyConfigured\n\nfrom sentry_sdk.integrations.django import DjangoIntegration\n\nenv = environ.Env(\n # set casting, default value\n DEBUG=(bool, False)\n)\n# reading .env file\nenviron.Env.read_env()\n\n# False if not in os.environ\nDEBUG = env(\"DEBUG\")\n\nif not DEBUG:\n SENTRY_ADDRESS = env(\"SENTRY_ADDRESS\")\n if SENTRY_ADDRESS:\n sentry_sdk.init(dsn=SENTRY_ADDRESS, integrations=[DjangoIntegration()])\n\nDJANGO_HOST = env(\"DJANGO_HOST\", default=\"LOCALHOST\")\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nSECRET_KEY = env(\"DJANGO_SECRET_KEY\", default=\"TEST_KEY_FOR_DEVELOPMENT\")\nALLOWED_HOSTS = [\".herokuapp.com\", \".civiwiki.org\", \"127.0.0.1\", \"localhost\", \"0.0.0.0\"]\n\nINSTALLED_APPS = (\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"storages\",\n \"channels\",\n \"civiwiki\",\n \"api\",\n \"rest_framework\",\n \"authentication\",\n \"frontend_views\",\n \"notifications\",\n \"corsheaders\",\n)\n\nMIDDLEWARE = [\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCSRF_USE_SESSIONS = (\n True # Store the CSRF token in the users session instead of in a cookie\n)\n\nCORS_ORIGIN_ALLOW_ALL = True\nROOT_URLCONF = \"civiwiki.urls\"\nLOGIN_URL = \"/login\"\n\n# SSL Setup\nif DJANGO_HOST != \"LOCALHOST\":\n SECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n SECURE_SSL_REDIRECT = True\n SESSION_COOKIE_SECURE = True\n CSRF_COOKIE_SECURE = True\n\n# Internationalization & Localization\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\n os.path.join(BASE_DIR, \"webapp/templates\")\n ], # TODO: Add non-webapp template directory\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"civiwiki.wsgi.application\"\n\n# Global user privilege settings\nCLOSED_BETA = env(\"CLOSED_BETA\", default=False)\n\n# Apex Contact for Production Errors\nADMINS = [(\"Development Team\", \"[email protected]\")]\n\n# API keys\nSUNLIGHT_API_KEY = env(\"SUNLIGHT_API_KEY\")\nGOOGLE_API_KEY = env(\"GOOGLE_MAP_API_KEY\")\n\n# Channels Setup\nREDIS_URL = env(\"REDIS_URL\", default=\"redis://localhost:6379\")\nCHANNEL_LAYERS = {\n \"default\": {\n \"BACKEND\": \"asgi_redis.RedisChannelLayer\",\n \"CONFIG\": {\n \"hosts\": [REDIS_URL],\n },\n \"ROUTING\": \"civiwiki.routing.channel_routing\",\n },\n}\n\n# Celery Task Runner Setup\nCELERY_BROKER_URL = REDIS_URL + \"/0\"\nCELERY_RESULT_BACKEND = CELERY_BROKER_URL\nCELERY_ACCEPT_CONTENT = [\"application/json\"]\nCELERY_TASK_SERIALIZER = \"json\"\nCELERY_RESULT_SERIALIZER = \"json\"\nCELERY_TIME_ZONE = TIME_ZONE\n\n# AWS S3 Setup\nif \"AWS_STORAGE_BUCKET_NAME\" not in os.environ:\n MEDIA_URL = \"/media/\"\n MEDIA_ROOT = os.path.join(BASE_DIR, \"media\")\nelse:\n AWS_STORAGE_BUCKET_NAME = env(\"AWS_STORAGE_BUCKET_NAME\")\n AWS_S3_ACCESS_KEY_ID = env(\"AWS_S3_ACCESS_KEY_ID\")\n AWS_S3_SECRET_ACCESS_KEY = env(\"AWS_S3_SECRET_ACCESS_KEY\")\n DEFAULT_FILE_STORAGE = \"storages.backends.s3boto.S3BotoStorage\"\n AWS_S3_SECURE_URLS = False\n AWS_QUERYSTRING_AUTH = False\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = (os.path.join(BASE_DIR, \"webapp/static\"),)\nSTATIC_ROOT = os.path.join(BASE_DIR, \"staticfiles\")\n\n# Database\nif \"CIVIWIKI_LOCAL_NAME\" not in os.environ:\n STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n DATABASES = {\"default\": env.db()}\nelse:\n DATABASES = {\n \"default\": {\n \"HOST\": env(\"CIVIWIKI_LOCAL_DB_HOST\", \"localhost\"),\n \"PORT\": \"5432\",\n \"NAME\": env(\"CIVIWIKI_LOCAL_NAME\"),\n \"ENGINE\": \"django.db.backends.postgresql_psycopg2\",\n \"USER\": env(\"CIVIWIKI_LOCAL_USERNAME\"),\n \"PASSWORD\": env(\"CIVIWIKI_LOCAL_PASSWORD\"),\n },\n }\n\n# Email Backend Setup\nif \"EMAIL_HOST\" not in os.environ:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n EMAIL_HOST_USER = \"[email protected]\"\nelse:\n EMAIL_BACKEND = \"django.core.mail.backends.smtp.EmailBackend\"\n EMAIL_HOST = env(\"EMAIL_HOST\")\n EMAIL_PORT = env(\"EMAIL_PORT\")\n EMAIL_HOST_USER = env(\"EMAIL_HOST_USER\")\n EMAIL_HOST_PASSWORD = env(\"EMAIL_HOST_PASSWORD\")\n EMAIL_USE_SSL = True\n DEFAULT_FROM_EMAIL = EMAIL_HOST\n\n# Notification API Settings\nNOTIFICATIONS_SOFT_DELETE = True\nNOTIFICATIONS_USE_JSONFIELD = True\n\n# Django REST API Settings\nDEFAULT_RENDERER_CLASSES = (\"rest_framework.renderers.JSONRenderer\",)\n\nDEFAULT_AUTHENTICATION_CLASSES = (\"rest_framework.authentication.BasicAuthentication\",)\n\nif DEBUG:\n # Browsable HTML - Enabled only in Debug mode (dev)\n DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n )\n\n DEFAULT_AUTHENTICATION_CLASSES = (\n \"api.authentication.CsrfExemptSessionAuthentication\",\n ) + DEFAULT_AUTHENTICATION_CLASSES\n\nREST_FRAMEWORK = {\n \"DEFAULT_PERMISSION_CLASSES\": (\"rest_framework.permissions.IsAuthenticated\",),\n \"DEFAULT_RENDERER_CLASSES\": DEFAULT_RENDERER_CLASSES,\n \"DEFAULT_AUTHENTICATION_CLASSES\": DEFAULT_AUTHENTICATION_CLASSES,\n}\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\nPROPUBLICA_API_KEY = env(\"PROPUBLICA_API_KEY\", default=\"TEST\")\n", "path": "project/civiwiki/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for civiwiki project.\nDarius Calliet May 12, 2016\n\nProduction settings file to select proper environment variables.\n\"\"\"\nimport os\nimport environ\n\nfrom django.core.exceptions import ImproperlyConfigured\n\nenv = environ.Env(\n # set casting, default value\n DEBUG=(bool, False)\n)\n# reading .env file\nenviron.Env.read_env()\n\n# False if not in os.environ\nDEBUG = env(\"DEBUG\")\n\nDJANGO_HOST = env(\"DJANGO_HOST\", default=\"LOCALHOST\")\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nSECRET_KEY = env(\"DJANGO_SECRET_KEY\", default=\"TEST_KEY_FOR_DEVELOPMENT\")\nALLOWED_HOSTS = [\".herokuapp.com\", \".civiwiki.org\", \"127.0.0.1\", \"localhost\", \"0.0.0.0\"]\n\nINSTALLED_APPS = (\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"storages\",\n \"channels\",\n \"civiwiki\",\n \"api\",\n \"rest_framework\",\n \"authentication\",\n \"frontend_views\",\n \"notifications\",\n \"corsheaders\",\n)\n\nMIDDLEWARE = [\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n # 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCSRF_USE_SESSIONS = (\n True # Store the CSRF token in the users session instead of in a cookie\n)\n\nCORS_ORIGIN_ALLOW_ALL = True\nROOT_URLCONF = \"civiwiki.urls\"\nLOGIN_URL = \"/login\"\n\n# SSL Setup\nif DJANGO_HOST != \"LOCALHOST\":\n SECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n SECURE_SSL_REDIRECT = True\n SESSION_COOKIE_SECURE = True\n CSRF_COOKIE_SECURE = True\n\n# Internationalization & Localization\nLANGUAGE_CODE = \"en-us\"\nTIME_ZONE = \"UTC\"\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [\n os.path.join(BASE_DIR, \"webapp/templates\")\n ], # TODO: Add non-webapp template directory\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"civiwiki.wsgi.application\"\n\n# Global user privilege settings\nCLOSED_BETA = env(\"CLOSED_BETA\", default=False)\n\n# Apex Contact for Production Errors\nADMINS = [(\"Development Team\", \"[email protected]\")]\n\n# API keys\nSUNLIGHT_API_KEY = env(\"SUNLIGHT_API_KEY\")\nGOOGLE_API_KEY = env(\"GOOGLE_MAP_API_KEY\")\n\n# Channels Setup\nREDIS_URL = env(\"REDIS_URL\", default=\"redis://localhost:6379\")\nCHANNEL_LAYERS = {\n \"default\": {\n \"BACKEND\": \"asgi_redis.RedisChannelLayer\",\n \"CONFIG\": {\n \"hosts\": [REDIS_URL],\n },\n \"ROUTING\": \"civiwiki.routing.channel_routing\",\n },\n}\n\n# Celery Task Runner Setup\nCELERY_BROKER_URL = REDIS_URL + \"/0\"\nCELERY_RESULT_BACKEND = CELERY_BROKER_URL\nCELERY_ACCEPT_CONTENT = [\"application/json\"]\nCELERY_TASK_SERIALIZER = \"json\"\nCELERY_RESULT_SERIALIZER = \"json\"\nCELERY_TIME_ZONE = TIME_ZONE\n\n# AWS S3 Setup\nif \"AWS_STORAGE_BUCKET_NAME\" not in os.environ:\n MEDIA_URL = \"/media/\"\n MEDIA_ROOT = os.path.join(BASE_DIR, \"media\")\nelse:\n AWS_STORAGE_BUCKET_NAME = env(\"AWS_STORAGE_BUCKET_NAME\")\n AWS_S3_ACCESS_KEY_ID = env(\"AWS_S3_ACCESS_KEY_ID\")\n AWS_S3_SECRET_ACCESS_KEY = env(\"AWS_S3_SECRET_ACCESS_KEY\")\n DEFAULT_FILE_STORAGE = \"storages.backends.s3boto.S3BotoStorage\"\n AWS_S3_SECURE_URLS = False\n AWS_QUERYSTRING_AUTH = False\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = (os.path.join(BASE_DIR, \"webapp/static\"),)\nSTATIC_ROOT = os.path.join(BASE_DIR, \"staticfiles\")\n\n# Database\nif \"CIVIWIKI_LOCAL_NAME\" not in os.environ:\n STATICFILES_STORAGE = \"whitenoise.storage.CompressedManifestStaticFilesStorage\"\n\n DATABASES = {\"default\": env.db()}\nelse:\n DATABASES = {\n \"default\": {\n \"HOST\": env(\"CIVIWIKI_LOCAL_DB_HOST\", \"localhost\"),\n \"PORT\": \"5432\",\n \"NAME\": env(\"CIVIWIKI_LOCAL_NAME\"),\n \"ENGINE\": \"django.db.backends.postgresql_psycopg2\",\n \"USER\": env(\"CIVIWIKI_LOCAL_USERNAME\"),\n \"PASSWORD\": env(\"CIVIWIKI_LOCAL_PASSWORD\"),\n },\n }\n\n# Email Backend Setup\nif \"EMAIL_HOST\" not in os.environ:\n EMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n EMAIL_HOST_USER = \"[email protected]\"\nelse:\n EMAIL_BACKEND = \"django.core.mail.backends.smtp.EmailBackend\"\n EMAIL_HOST = env(\"EMAIL_HOST\")\n EMAIL_PORT = env(\"EMAIL_PORT\")\n EMAIL_HOST_USER = env(\"EMAIL_HOST_USER\")\n EMAIL_HOST_PASSWORD = env(\"EMAIL_HOST_PASSWORD\")\n EMAIL_USE_SSL = True\n DEFAULT_FROM_EMAIL = EMAIL_HOST\n\n# Notification API Settings\nNOTIFICATIONS_SOFT_DELETE = True\nNOTIFICATIONS_USE_JSONFIELD = True\n\n# Django REST API Settings\nDEFAULT_RENDERER_CLASSES = (\"rest_framework.renderers.JSONRenderer\",)\n\nDEFAULT_AUTHENTICATION_CLASSES = (\"rest_framework.authentication.BasicAuthentication\",)\n\nif DEBUG:\n # Browsable HTML - Enabled only in Debug mode (dev)\n DEFAULT_RENDERER_CLASSES = DEFAULT_RENDERER_CLASSES + (\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n )\n\n DEFAULT_AUTHENTICATION_CLASSES = (\n \"api.authentication.CsrfExemptSessionAuthentication\",\n ) + DEFAULT_AUTHENTICATION_CLASSES\n\nREST_FRAMEWORK = {\n \"DEFAULT_PERMISSION_CLASSES\": (\"rest_framework.permissions.IsAuthenticated\",),\n \"DEFAULT_RENDERER_CLASSES\": DEFAULT_RENDERER_CLASSES,\n \"DEFAULT_AUTHENTICATION_CLASSES\": DEFAULT_AUTHENTICATION_CLASSES,\n}\n# CORS Settings\nCORS_ORIGIN_ALLOW_ALL = True\nPROPUBLICA_API_KEY = env(\"PROPUBLICA_API_KEY\", default=\"TEST\")\n", "path": "project/civiwiki/settings.py"}]} | 2,415 | 218 |
gh_patches_debug_13607 | rasdani/github-patches | git_diff | python-poetry__poetry-1576 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Git w/ Non Standard Port Broken on Poetry 1.0.0b4
<!-- Checked checkbox should look like this: [x] -->
- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
- **OS version and name**: macOS 10.14.6
- **Poetry version**: 1.0.0b4
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: See Below
## Issue
I'm trying to use a git+ssh URL to a private repo using a non standard port, like this:
```toml
package = {git = "ssh://[email protected]:1234/repo/project.git"}
```
This leads to an error like this:
```
[ValueError]
Invalid git url ""
```
I think the issue may be here:
https://github.com/sdispater/poetry/blob/master/poetry/vcs/git.py#L16
Specifically, I think this regex is broken:
```python
r"(:?P<port>[\d]+)?"
```
Instead, I think it should look like:
```python
r"(?P<port>:[\d]+)?"
```
If someone doesn't beat me to it I'll likely submit a PR later today or tomorrow.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `poetry/puzzle/solver.py`
Content:
```
1 import time
2
3 from typing import Any
4 from typing import Dict
5 from typing import List
6
7 from poetry.mixology import resolve_version
8 from poetry.mixology.failure import SolveFailure
9 from poetry.packages import DependencyPackage
10 from poetry.packages import Package
11 from poetry.semver import parse_constraint
12 from poetry.version.markers import AnyMarker
13
14 from .exceptions import CompatibilityError
15 from .exceptions import SolverProblemError
16 from .operations import Install
17 from .operations import Uninstall
18 from .operations import Update
19 from .operations.operation import Operation
20 from .provider import Provider
21
22
23 class Solver:
24 def __init__(self, package, pool, installed, locked, io):
25 self._package = package
26 self._pool = pool
27 self._installed = installed
28 self._locked = locked
29 self._io = io
30 self._provider = Provider(self._package, self._pool, self._io)
31 self._branches = []
32
33 def solve(self, use_latest=None): # type: (...) -> List[Operation]
34 with self._provider.progress():
35 start = time.time()
36 packages, depths = self._solve(use_latest=use_latest)
37 end = time.time()
38
39 if len(self._branches) > 1:
40 self._provider.debug(
41 "Complete version solving took {:.3f} seconds for {} branches".format(
42 end - start, len(self._branches[1:])
43 )
44 )
45 self._provider.debug(
46 "Resolved for branches: {}".format(
47 ", ".join("({})".format(b) for b in self._branches[1:])
48 )
49 )
50
51 operations = []
52 for package in packages:
53 installed = False
54 for pkg in self._installed.packages:
55 if package.name == pkg.name:
56 installed = True
57
58 if pkg.source_type == "git" and package.source_type == "git":
59 from poetry.vcs.git import Git
60
61 # Trying to find the currently installed version
62 pkg_source_url = Git.normalize_url(pkg.source_url)
63 package_source_url = Git.normalize_url(package.source_url)
64 for locked in self._locked.packages:
65 locked_source_url = Git.normalize_url(locked.source_url)
66 if (
67 locked.name == pkg.name
68 and locked.source_type == pkg.source_type
69 and locked_source_url == pkg_source_url
70 and locked.source_reference == pkg.source_reference
71 ):
72 pkg = Package(pkg.name, locked.version)
73 pkg.source_type = "git"
74 pkg.source_url = locked.source_url
75 pkg.source_reference = locked.source_reference
76 break
77
78 if pkg_source_url != package_source_url or (
79 pkg.source_reference != package.source_reference
80 and not pkg.source_reference.startswith(
81 package.source_reference
82 )
83 ):
84 operations.append(Update(pkg, package))
85 else:
86 operations.append(
87 Install(package).skip("Already installed")
88 )
89 elif package.version != pkg.version:
90 # Checking version
91 operations.append(Update(pkg, package))
92 elif package.source_type != pkg.source_type:
93 operations.append(Update(pkg, package))
94 else:
95 operations.append(Install(package).skip("Already installed"))
96
97 break
98
99 if not installed:
100 operations.append(Install(package))
101
102 # Checking for removals
103 for pkg in self._locked.packages:
104 remove = True
105 for package in packages:
106 if pkg.name == package.name:
107 remove = False
108 break
109
110 if remove:
111 skip = True
112 for installed in self._installed.packages:
113 if installed.name == pkg.name:
114 skip = False
115 break
116
117 op = Uninstall(pkg)
118 if skip:
119 op.skip("Not currently installed")
120
121 operations.append(op)
122
123 return sorted(
124 operations,
125 key=lambda o: (
126 o.job_type == "uninstall",
127 # Packages to be uninstalled have no depth so we default to 0
128 # since it actually doesn't matter since removals are always on top.
129 -depths[packages.index(o.package)] if o.job_type != "uninstall" else 0,
130 o.package.name,
131 o.package.version,
132 ),
133 )
134
135 def solve_in_compatibility_mode(self, constraints, use_latest=None):
136 locked = {}
137 for package in self._locked.packages:
138 locked[package.name] = DependencyPackage(package.to_dependency(), package)
139
140 packages = []
141 depths = []
142 for constraint in constraints:
143 constraint = parse_constraint(constraint)
144 intersection = constraint.intersect(self._package.python_constraint)
145
146 self._provider.debug(
147 "<comment>Retrying dependency resolution "
148 "for Python ({}).</comment>".format(intersection)
149 )
150 with self._package.with_python_versions(str(intersection)):
151 _packages, _depths = self._solve(use_latest=use_latest)
152 for index, package in enumerate(_packages):
153 if package not in packages:
154 packages.append(package)
155 depths.append(_depths[index])
156 continue
157 else:
158 idx = packages.index(package)
159 pkg = packages[idx]
160 depths[idx] = max(depths[idx], _depths[index])
161 pkg.marker = pkg.marker.union(package.marker)
162
163 for dep in package.requires:
164 if dep not in pkg.requires:
165 pkg.requires.append(dep)
166
167 return packages, depths
168
169 def _solve(self, use_latest=None):
170 self._branches.append(self._package.python_versions)
171
172 locked = {}
173 for package in self._locked.packages:
174 locked[package.name] = DependencyPackage(package.to_dependency(), package)
175
176 try:
177 result = resolve_version(
178 self._package, self._provider, locked=locked, use_latest=use_latest
179 )
180
181 packages = result.packages
182 except CompatibilityError as e:
183 return self.solve_in_compatibility_mode(
184 e.constraints, use_latest=use_latest
185 )
186 except SolveFailure as e:
187 raise SolverProblemError(e)
188
189 graph = self._build_graph(self._package, packages)
190
191 depths = []
192 final_packages = []
193 for package in packages:
194 category, optional, marker, depth = self._get_tags_for_package(
195 package, graph
196 )
197
198 if marker is None:
199 marker = AnyMarker()
200 if marker.is_empty():
201 continue
202
203 package.category = category
204 package.optional = optional
205 package.marker = marker
206
207 depths.append(depth)
208 final_packages.append(package)
209
210 return final_packages, depths
211
212 def _build_graph(
213 self, package, packages, previous=None, previous_dep=None, dep=None
214 ): # type: (...) -> Dict[str, Any]
215 if not previous:
216 category = "dev"
217 optional = True
218 marker = package.marker
219 else:
220 category = dep.category
221 optional = dep.is_optional() and not dep.is_activated()
222 intersection = (
223 previous["marker"]
224 .without_extras()
225 .intersect(previous_dep.marker.without_extras())
226 )
227 intersection = intersection.intersect(package.marker.without_extras())
228
229 marker = intersection
230
231 childrens = [] # type: List[Dict[str, Any]]
232 graph = {
233 "name": package.name,
234 "category": category,
235 "optional": optional,
236 "marker": marker,
237 "children": childrens,
238 }
239
240 if previous_dep and previous_dep is not dep and previous_dep.name == dep.name:
241 return graph
242
243 for dependency in package.all_requires:
244 is_activated = True
245 if dependency.is_optional():
246 if not package.is_root() and (
247 not previous_dep or not previous_dep.extras
248 ):
249 continue
250
251 is_activated = False
252 for group, extra_deps in package.extras.items():
253 if dep:
254 extras = previous_dep.extras
255 elif package.is_root():
256 extras = package.extras
257 else:
258 extras = []
259
260 if group in extras and dependency.name in (
261 d.name for d in package.extras[group]
262 ):
263 is_activated = True
264 break
265
266 if previous and previous["name"] == dependency.name:
267 # We have a circular dependency.
268 # Since the dependencies are resolved we can
269 # simply skip it because we already have it
270 continue
271
272 for pkg in packages:
273 if pkg.name == dependency.name and dependency.constraint.allows(
274 pkg.version
275 ):
276 # If there is already a child with this name
277 # we merge the requirements
278 existing = None
279 for child in childrens:
280 if (
281 child["name"] == pkg.name
282 and child["category"] == dependency.category
283 ):
284 existing = child
285 continue
286
287 child_graph = self._build_graph(
288 pkg, packages, graph, dependency, dep or dependency
289 )
290
291 if not is_activated:
292 child_graph["optional"] = True
293
294 if existing:
295 existing["marker"] = existing["marker"].union(
296 child_graph["marker"]
297 )
298 continue
299
300 childrens.append(child_graph)
301
302 return graph
303
304 def _get_tags_for_package(self, package, graph, depth=0):
305 categories = ["dev"]
306 optionals = [True]
307 markers = []
308 _depths = [0]
309
310 children = graph["children"]
311 for child in children:
312 if child["name"] == package.name:
313 category = child["category"]
314 optional = child["optional"]
315 marker = child["marker"]
316 _depths.append(depth)
317 else:
318 (category, optional, marker, _depth) = self._get_tags_for_package(
319 package, child, depth=depth + 1
320 )
321
322 _depths.append(_depth)
323
324 categories.append(category)
325 optionals.append(optional)
326 if marker is not None:
327 markers.append(marker)
328
329 if "main" in categories:
330 category = "main"
331 else:
332 category = "dev"
333
334 optional = all(optionals)
335
336 depth = max(*(_depths + [0]))
337
338 if not markers:
339 marker = None
340 else:
341 marker = markers[0]
342 for m in markers[1:]:
343 marker = marker.union(m)
344
345 return category, optional, marker, depth
346
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/poetry/puzzle/solver.py b/poetry/puzzle/solver.py
--- a/poetry/puzzle/solver.py
+++ b/poetry/puzzle/solver.py
@@ -62,6 +62,9 @@
pkg_source_url = Git.normalize_url(pkg.source_url)
package_source_url = Git.normalize_url(package.source_url)
for locked in self._locked.packages:
+ if locked.name != pkg.name or locked.source_type != "git":
+ continue
+
locked_source_url = Git.normalize_url(locked.source_url)
if (
locked.name == pkg.name
| {"golden_diff": "diff --git a/poetry/puzzle/solver.py b/poetry/puzzle/solver.py\n--- a/poetry/puzzle/solver.py\n+++ b/poetry/puzzle/solver.py\n@@ -62,6 +62,9 @@\n pkg_source_url = Git.normalize_url(pkg.source_url)\n package_source_url = Git.normalize_url(package.source_url)\n for locked in self._locked.packages:\n+ if locked.name != pkg.name or locked.source_type != \"git\":\n+ continue\n+\n locked_source_url = Git.normalize_url(locked.source_url)\n if (\n locked.name == pkg.name\n", "issue": "Git w/ Non Standard Port Broken on Poetry 1.0.0b4\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.\r\n- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n- **OS version and name**: macOS 10.14.6\r\n- **Poetry version**: 1.0.0b4\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: See Below\r\n\r\n## Issue\r\nI'm trying to use a git+ssh URL to a private repo using a non standard port, like this:\r\n```toml\r\npackage = {git = \"ssh://[email protected]:1234/repo/project.git\"}\r\n```\r\nThis leads to an error like this:\r\n```\r\n[ValueError]\r\nInvalid git url \"\"\r\n```\r\n\r\nI think the issue may be here:\r\nhttps://github.com/sdispater/poetry/blob/master/poetry/vcs/git.py#L16\r\n\r\nSpecifically, I think this regex is broken:\r\n```python\r\nr\"(:?P<port>[\\d]+)?\"\r\n```\r\nInstead, I think it should look like:\r\n```python\r\nr\"(?P<port>:[\\d]+)?\"\r\n```\r\n\r\nIf someone doesn't beat me to it I'll likely submit a PR later today or tomorrow.\n", "before_files": [{"content": "import time\n\nfrom typing import Any\nfrom typing import Dict\nfrom typing import List\n\nfrom poetry.mixology import resolve_version\nfrom poetry.mixology.failure import SolveFailure\nfrom poetry.packages import DependencyPackage\nfrom poetry.packages import Package\nfrom poetry.semver import parse_constraint\nfrom poetry.version.markers import AnyMarker\n\nfrom .exceptions import CompatibilityError\nfrom .exceptions import SolverProblemError\nfrom .operations import Install\nfrom .operations import Uninstall\nfrom .operations import Update\nfrom .operations.operation import Operation\nfrom .provider import Provider\n\n\nclass Solver:\n def __init__(self, package, pool, installed, locked, io):\n self._package = package\n self._pool = pool\n self._installed = installed\n self._locked = locked\n self._io = io\n self._provider = Provider(self._package, self._pool, self._io)\n self._branches = []\n\n def solve(self, use_latest=None): # type: (...) -> List[Operation]\n with self._provider.progress():\n start = time.time()\n packages, depths = self._solve(use_latest=use_latest)\n end = time.time()\n\n if len(self._branches) > 1:\n self._provider.debug(\n \"Complete version solving took {:.3f} seconds for {} branches\".format(\n end - start, len(self._branches[1:])\n )\n )\n self._provider.debug(\n \"Resolved for branches: {}\".format(\n \", \".join(\"({})\".format(b) for b in self._branches[1:])\n )\n )\n\n operations = []\n for package in packages:\n installed = False\n for pkg in self._installed.packages:\n if package.name == pkg.name:\n installed = True\n\n if pkg.source_type == \"git\" and package.source_type == \"git\":\n from poetry.vcs.git import Git\n\n # Trying to find the currently installed version\n pkg_source_url = Git.normalize_url(pkg.source_url)\n package_source_url = Git.normalize_url(package.source_url)\n for locked in self._locked.packages:\n locked_source_url = Git.normalize_url(locked.source_url)\n if (\n locked.name == pkg.name\n and locked.source_type == pkg.source_type\n and locked_source_url == pkg_source_url\n and locked.source_reference == pkg.source_reference\n ):\n pkg = Package(pkg.name, locked.version)\n pkg.source_type = \"git\"\n pkg.source_url = locked.source_url\n pkg.source_reference = locked.source_reference\n break\n\n if pkg_source_url != package_source_url or (\n pkg.source_reference != package.source_reference\n and not pkg.source_reference.startswith(\n package.source_reference\n )\n ):\n operations.append(Update(pkg, package))\n else:\n operations.append(\n Install(package).skip(\"Already installed\")\n )\n elif package.version != pkg.version:\n # Checking version\n operations.append(Update(pkg, package))\n elif package.source_type != pkg.source_type:\n operations.append(Update(pkg, package))\n else:\n operations.append(Install(package).skip(\"Already installed\"))\n\n break\n\n if not installed:\n operations.append(Install(package))\n\n # Checking for removals\n for pkg in self._locked.packages:\n remove = True\n for package in packages:\n if pkg.name == package.name:\n remove = False\n break\n\n if remove:\n skip = True\n for installed in self._installed.packages:\n if installed.name == pkg.name:\n skip = False\n break\n\n op = Uninstall(pkg)\n if skip:\n op.skip(\"Not currently installed\")\n\n operations.append(op)\n\n return sorted(\n operations,\n key=lambda o: (\n o.job_type == \"uninstall\",\n # Packages to be uninstalled have no depth so we default to 0\n # since it actually doesn't matter since removals are always on top.\n -depths[packages.index(o.package)] if o.job_type != \"uninstall\" else 0,\n o.package.name,\n o.package.version,\n ),\n )\n\n def solve_in_compatibility_mode(self, constraints, use_latest=None):\n locked = {}\n for package in self._locked.packages:\n locked[package.name] = DependencyPackage(package.to_dependency(), package)\n\n packages = []\n depths = []\n for constraint in constraints:\n constraint = parse_constraint(constraint)\n intersection = constraint.intersect(self._package.python_constraint)\n\n self._provider.debug(\n \"<comment>Retrying dependency resolution \"\n \"for Python ({}).</comment>\".format(intersection)\n )\n with self._package.with_python_versions(str(intersection)):\n _packages, _depths = self._solve(use_latest=use_latest)\n for index, package in enumerate(_packages):\n if package not in packages:\n packages.append(package)\n depths.append(_depths[index])\n continue\n else:\n idx = packages.index(package)\n pkg = packages[idx]\n depths[idx] = max(depths[idx], _depths[index])\n pkg.marker = pkg.marker.union(package.marker)\n\n for dep in package.requires:\n if dep not in pkg.requires:\n pkg.requires.append(dep)\n\n return packages, depths\n\n def _solve(self, use_latest=None):\n self._branches.append(self._package.python_versions)\n\n locked = {}\n for package in self._locked.packages:\n locked[package.name] = DependencyPackage(package.to_dependency(), package)\n\n try:\n result = resolve_version(\n self._package, self._provider, locked=locked, use_latest=use_latest\n )\n\n packages = result.packages\n except CompatibilityError as e:\n return self.solve_in_compatibility_mode(\n e.constraints, use_latest=use_latest\n )\n except SolveFailure as e:\n raise SolverProblemError(e)\n\n graph = self._build_graph(self._package, packages)\n\n depths = []\n final_packages = []\n for package in packages:\n category, optional, marker, depth = self._get_tags_for_package(\n package, graph\n )\n\n if marker is None:\n marker = AnyMarker()\n if marker.is_empty():\n continue\n\n package.category = category\n package.optional = optional\n package.marker = marker\n\n depths.append(depth)\n final_packages.append(package)\n\n return final_packages, depths\n\n def _build_graph(\n self, package, packages, previous=None, previous_dep=None, dep=None\n ): # type: (...) -> Dict[str, Any]\n if not previous:\n category = \"dev\"\n optional = True\n marker = package.marker\n else:\n category = dep.category\n optional = dep.is_optional() and not dep.is_activated()\n intersection = (\n previous[\"marker\"]\n .without_extras()\n .intersect(previous_dep.marker.without_extras())\n )\n intersection = intersection.intersect(package.marker.without_extras())\n\n marker = intersection\n\n childrens = [] # type: List[Dict[str, Any]]\n graph = {\n \"name\": package.name,\n \"category\": category,\n \"optional\": optional,\n \"marker\": marker,\n \"children\": childrens,\n }\n\n if previous_dep and previous_dep is not dep and previous_dep.name == dep.name:\n return graph\n\n for dependency in package.all_requires:\n is_activated = True\n if dependency.is_optional():\n if not package.is_root() and (\n not previous_dep or not previous_dep.extras\n ):\n continue\n\n is_activated = False\n for group, extra_deps in package.extras.items():\n if dep:\n extras = previous_dep.extras\n elif package.is_root():\n extras = package.extras\n else:\n extras = []\n\n if group in extras and dependency.name in (\n d.name for d in package.extras[group]\n ):\n is_activated = True\n break\n\n if previous and previous[\"name\"] == dependency.name:\n # We have a circular dependency.\n # Since the dependencies are resolved we can\n # simply skip it because we already have it\n continue\n\n for pkg in packages:\n if pkg.name == dependency.name and dependency.constraint.allows(\n pkg.version\n ):\n # If there is already a child with this name\n # we merge the requirements\n existing = None\n for child in childrens:\n if (\n child[\"name\"] == pkg.name\n and child[\"category\"] == dependency.category\n ):\n existing = child\n continue\n\n child_graph = self._build_graph(\n pkg, packages, graph, dependency, dep or dependency\n )\n\n if not is_activated:\n child_graph[\"optional\"] = True\n\n if existing:\n existing[\"marker\"] = existing[\"marker\"].union(\n child_graph[\"marker\"]\n )\n continue\n\n childrens.append(child_graph)\n\n return graph\n\n def _get_tags_for_package(self, package, graph, depth=0):\n categories = [\"dev\"]\n optionals = [True]\n markers = []\n _depths = [0]\n\n children = graph[\"children\"]\n for child in children:\n if child[\"name\"] == package.name:\n category = child[\"category\"]\n optional = child[\"optional\"]\n marker = child[\"marker\"]\n _depths.append(depth)\n else:\n (category, optional, marker, _depth) = self._get_tags_for_package(\n package, child, depth=depth + 1\n )\n\n _depths.append(_depth)\n\n categories.append(category)\n optionals.append(optional)\n if marker is not None:\n markers.append(marker)\n\n if \"main\" in categories:\n category = \"main\"\n else:\n category = \"dev\"\n\n optional = all(optionals)\n\n depth = max(*(_depths + [0]))\n\n if not markers:\n marker = None\n else:\n marker = markers[0]\n for m in markers[1:]:\n marker = marker.union(m)\n\n return category, optional, marker, depth\n", "path": "poetry/puzzle/solver.py"}], "after_files": [{"content": "import time\n\nfrom typing import Any\nfrom typing import Dict\nfrom typing import List\n\nfrom poetry.mixology import resolve_version\nfrom poetry.mixology.failure import SolveFailure\nfrom poetry.packages import DependencyPackage\nfrom poetry.packages import Package\nfrom poetry.semver import parse_constraint\nfrom poetry.version.markers import AnyMarker\n\nfrom .exceptions import CompatibilityError\nfrom .exceptions import SolverProblemError\nfrom .operations import Install\nfrom .operations import Uninstall\nfrom .operations import Update\nfrom .operations.operation import Operation\nfrom .provider import Provider\n\n\nclass Solver:\n def __init__(self, package, pool, installed, locked, io):\n self._package = package\n self._pool = pool\n self._installed = installed\n self._locked = locked\n self._io = io\n self._provider = Provider(self._package, self._pool, self._io)\n self._branches = []\n\n def solve(self, use_latest=None): # type: (...) -> List[Operation]\n with self._provider.progress():\n start = time.time()\n packages, depths = self._solve(use_latest=use_latest)\n end = time.time()\n\n if len(self._branches) > 1:\n self._provider.debug(\n \"Complete version solving took {:.3f} seconds for {} branches\".format(\n end - start, len(self._branches[1:])\n )\n )\n self._provider.debug(\n \"Resolved for branches: {}\".format(\n \", \".join(\"({})\".format(b) for b in self._branches[1:])\n )\n )\n\n operations = []\n for package in packages:\n installed = False\n for pkg in self._installed.packages:\n if package.name == pkg.name:\n installed = True\n\n if pkg.source_type == \"git\" and package.source_type == \"git\":\n from poetry.vcs.git import Git\n\n # Trying to find the currently installed version\n pkg_source_url = Git.normalize_url(pkg.source_url)\n package_source_url = Git.normalize_url(package.source_url)\n for locked in self._locked.packages:\n if locked.name != pkg.name or locked.source_type != \"git\":\n continue\n\n locked_source_url = Git.normalize_url(locked.source_url)\n if (\n locked.name == pkg.name\n and locked.source_type == pkg.source_type\n and locked_source_url == pkg_source_url\n and locked.source_reference == pkg.source_reference\n ):\n pkg = Package(pkg.name, locked.version)\n pkg.source_type = \"git\"\n pkg.source_url = locked.source_url\n pkg.source_reference = locked.source_reference\n break\n\n if pkg_source_url != package_source_url or (\n pkg.source_reference != package.source_reference\n and not pkg.source_reference.startswith(\n package.source_reference\n )\n ):\n operations.append(Update(pkg, package))\n else:\n operations.append(\n Install(package).skip(\"Already installed\")\n )\n elif package.version != pkg.version:\n # Checking version\n operations.append(Update(pkg, package))\n elif package.source_type != pkg.source_type:\n operations.append(Update(pkg, package))\n else:\n operations.append(Install(package).skip(\"Already installed\"))\n\n break\n\n if not installed:\n operations.append(Install(package))\n\n # Checking for removals\n for pkg in self._locked.packages:\n remove = True\n for package in packages:\n if pkg.name == package.name:\n remove = False\n break\n\n if remove:\n skip = True\n for installed in self._installed.packages:\n if installed.name == pkg.name:\n skip = False\n break\n\n op = Uninstall(pkg)\n if skip:\n op.skip(\"Not currently installed\")\n\n operations.append(op)\n\n return sorted(\n operations,\n key=lambda o: (\n o.job_type == \"uninstall\",\n # Packages to be uninstalled have no depth so we default to 0\n # since it actually doesn't matter since removals are always on top.\n -depths[packages.index(o.package)] if o.job_type != \"uninstall\" else 0,\n o.package.name,\n o.package.version,\n ),\n )\n\n def solve_in_compatibility_mode(self, constraints, use_latest=None):\n locked = {}\n for package in self._locked.packages:\n locked[package.name] = DependencyPackage(package.to_dependency(), package)\n\n packages = []\n depths = []\n for constraint in constraints:\n constraint = parse_constraint(constraint)\n intersection = constraint.intersect(self._package.python_constraint)\n\n self._provider.debug(\n \"<comment>Retrying dependency resolution \"\n \"for Python ({}).</comment>\".format(intersection)\n )\n with self._package.with_python_versions(str(intersection)):\n _packages, _depths = self._solve(use_latest=use_latest)\n for index, package in enumerate(_packages):\n if package not in packages:\n packages.append(package)\n depths.append(_depths[index])\n continue\n else:\n idx = packages.index(package)\n pkg = packages[idx]\n depths[idx] = max(depths[idx], _depths[index])\n pkg.marker = pkg.marker.union(package.marker)\n\n for dep in package.requires:\n if dep not in pkg.requires:\n pkg.requires.append(dep)\n\n return packages, depths\n\n def _solve(self, use_latest=None):\n self._branches.append(self._package.python_versions)\n\n locked = {}\n for package in self._locked.packages:\n locked[package.name] = DependencyPackage(package.to_dependency(), package)\n\n try:\n result = resolve_version(\n self._package, self._provider, locked=locked, use_latest=use_latest\n )\n\n packages = result.packages\n except CompatibilityError as e:\n return self.solve_in_compatibility_mode(\n e.constraints, use_latest=use_latest\n )\n except SolveFailure as e:\n raise SolverProblemError(e)\n\n graph = self._build_graph(self._package, packages)\n\n depths = []\n final_packages = []\n for package in packages:\n category, optional, marker, depth = self._get_tags_for_package(\n package, graph\n )\n\n if marker is None:\n marker = AnyMarker()\n if marker.is_empty():\n continue\n\n package.category = category\n package.optional = optional\n package.marker = marker\n\n depths.append(depth)\n final_packages.append(package)\n\n return final_packages, depths\n\n def _build_graph(\n self, package, packages, previous=None, previous_dep=None, dep=None\n ): # type: (...) -> Dict[str, Any]\n if not previous:\n category = \"dev\"\n optional = True\n marker = package.marker\n else:\n category = dep.category\n optional = dep.is_optional() and not dep.is_activated()\n intersection = (\n previous[\"marker\"]\n .without_extras()\n .intersect(previous_dep.marker.without_extras())\n )\n intersection = intersection.intersect(package.marker.without_extras())\n\n marker = intersection\n\n childrens = [] # type: List[Dict[str, Any]]\n graph = {\n \"name\": package.name,\n \"category\": category,\n \"optional\": optional,\n \"marker\": marker,\n \"children\": childrens,\n }\n\n if previous_dep and previous_dep is not dep and previous_dep.name == dep.name:\n return graph\n\n for dependency in package.all_requires:\n is_activated = True\n if dependency.is_optional():\n if not package.is_root() and (\n not previous_dep or not previous_dep.extras\n ):\n continue\n\n is_activated = False\n for group, extra_deps in package.extras.items():\n if dep:\n extras = previous_dep.extras\n elif package.is_root():\n extras = package.extras\n else:\n extras = []\n\n if group in extras and dependency.name in (\n d.name for d in package.extras[group]\n ):\n is_activated = True\n break\n\n if previous and previous[\"name\"] == dependency.name:\n # We have a circular dependency.\n # Since the dependencies are resolved we can\n # simply skip it because we already have it\n continue\n\n for pkg in packages:\n if pkg.name == dependency.name and dependency.constraint.allows(\n pkg.version\n ):\n # If there is already a child with this name\n # we merge the requirements\n existing = None\n for child in childrens:\n if (\n child[\"name\"] == pkg.name\n and child[\"category\"] == dependency.category\n ):\n existing = child\n continue\n\n child_graph = self._build_graph(\n pkg, packages, graph, dependency, dep or dependency\n )\n\n if not is_activated:\n child_graph[\"optional\"] = True\n\n if existing:\n existing[\"marker\"] = existing[\"marker\"].union(\n child_graph[\"marker\"]\n )\n continue\n\n childrens.append(child_graph)\n\n return graph\n\n def _get_tags_for_package(self, package, graph, depth=0):\n categories = [\"dev\"]\n optionals = [True]\n markers = []\n _depths = [0]\n\n children = graph[\"children\"]\n for child in children:\n if child[\"name\"] == package.name:\n category = child[\"category\"]\n optional = child[\"optional\"]\n marker = child[\"marker\"]\n _depths.append(depth)\n else:\n (category, optional, marker, _depth) = self._get_tags_for_package(\n package, child, depth=depth + 1\n )\n\n _depths.append(_depth)\n\n categories.append(category)\n optionals.append(optional)\n if marker is not None:\n markers.append(marker)\n\n if \"main\" in categories:\n category = \"main\"\n else:\n category = \"dev\"\n\n optional = all(optionals)\n\n depth = max(*(_depths + [0]))\n\n if not markers:\n marker = None\n else:\n marker = markers[0]\n for m in markers[1:]:\n marker = marker.union(m)\n\n return category, optional, marker, depth\n", "path": "poetry/puzzle/solver.py"}]} | 3,743 | 134 |
gh_patches_debug_10 | rasdani/github-patches | git_diff | OCHA-DAP__hdx-ckan-770 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove text from home page
Please remove this text from homepage 'This is an early version of the HDX Repository. Initially, you will be able to find global datasets relevant to humanitarian work as well as local datasets from our three pilot locations - Colombia, Kenya and Yemen. You can also create an account and add your own data to the repository to share privately or publicly. Please have a look around and send us your feedback!' this will be covered in the about page. Not sure if yumi will want to adjusts the centering of the remaining HDX and tagline but we can ask her
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext-hdx_theme/ckanext/hdx_theme/version.py`
Content:
```
1 hdx_version='v0.2.6'
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py
+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
@@ -1 +1 @@
-hdx_version='v0.2.6'
\ No newline at end of file
+hdx_version='v0.3.0'
\ No newline at end of file
| {"golden_diff": "diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n@@ -1 +1 @@\n-hdx_version='v0.2.6'\n\\ No newline at end of file\n+hdx_version='v0.3.0'\n\\ No newline at end of file\n", "issue": "remove text from home page \nPlease remove this text from homepage 'This is an early version of the HDX Repository. Initially, you will be able to find global datasets relevant to humanitarian work as well as local datasets from our three pilot locations - Colombia, Kenya and Yemen. You can also create an account and add your own data to the repository to share privately or publicly. Please have a look around and send us your feedback!' this will be covered in the about page. Not sure if yumi will want to adjusts the centering of the remaining HDX and tagline but we can ask her\n\n", "before_files": [{"content": "hdx_version='v0.2.6'", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}], "after_files": [{"content": "hdx_version='v0.3.0'", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}]} | 401 | 120 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.