
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
10.2k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 582
21k
| num_tokens
int64 271
2.05k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_41742
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-597
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove CustomMultipleChoicePreference
As of https://github.com/agateblue/django-dynamic-preferences/pull/235 we can drop our own fix of the MultiplChoicePreference class (as soon as this is part of a release)
Remove CustomMultipleChoicePreference
As of https://github.com/agateblue/django-dynamic-preferences/pull/235 we can drop our own fix of the MultiplChoicePreference class (as soon as this is part of a release)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ephios/extra/preferences.py`
Content:
```
1 import json
2
3 from django import forms
4 from dynamic_preferences.types import (
5 BasePreferenceType,
6 BaseSerializer,
7 ModelMultipleChoicePreference,
8 )
9
10 from ephios.extra.json import CustomJSONDecoder, CustomJSONEncoder
11
12
13 class CustomModelMultipleChoicePreference(ModelMultipleChoicePreference):
14 def _setup_signals(self):
15 pass
16
17
18 class JSONSerializer(BaseSerializer):
19 @classmethod
20 def clean_to_db_value(cls, value):
21 return json.dumps(value, cls=CustomJSONEncoder, ensure_ascii=False)
22
23 @classmethod
24 def to_python(cls, value, **kwargs):
25 return json.loads(value, cls=CustomJSONDecoder)
26
27
28 class JSONPreference(BasePreferenceType):
29 serializer = JSONSerializer
30 field_class = forms.CharField
31 widget = forms.Textarea
32
```
Path: `ephios/core/dynamic_preferences_registry.py`
Content:
```
1 from django.contrib.auth.models import Group
2 from django.utils.safestring import mark_safe
3 from django.utils.translation import gettext_lazy as _
4 from django_select2.forms import Select2MultipleWidget
5 from dynamic_preferences.preferences import Section
6 from dynamic_preferences.registries import (
7 PerInstancePreferenceRegistry,
8 global_preferences_registry,
9 )
10 from dynamic_preferences.types import MultipleChoicePreference, StringPreference
11 from dynamic_preferences.users.registries import user_preferences_registry
12
13 import ephios
14 from ephios.core import plugins
15 from ephios.core.models import QualificationCategory, UserProfile
16 from ephios.core.services.notifications.backends import CORE_NOTIFICATION_BACKENDS
17 from ephios.core.services.notifications.types import CORE_NOTIFICATION_TYPES
18 from ephios.extra.preferences import CustomModelMultipleChoicePreference, JSONPreference
19
20
21 class EventTypeRegistry(PerInstancePreferenceRegistry):
22 pass
23
24
25 event_type_preference_registry = EventTypeRegistry()
26
27 notifications_user_section = Section("notifications")
28 responsible_notifications_user_section = Section("responsible_notifications")
29 general_global_section = Section("general")
30
31
32 @global_preferences_registry.register
33 class OrganizationName(StringPreference):
34 name = "organization_name"
35 verbose_name = _("Organization name")
36 default = ""
37 section = general_global_section
38 required = False
39
40
41 @global_preferences_registry.register
42 class RelevantQualificationCategories(CustomModelMultipleChoicePreference):
43 name = "relevant_qualification_categories"
44 section = general_global_section
45 model = QualificationCategory
46 default = QualificationCategory.objects.none()
47 verbose_name = _("Relevant qualification categories (for user list and disposition view)")
48 field_kwargs = {"widget": Select2MultipleWidget}
49
50
51 @global_preferences_registry.register
52 class EnabledPlugins(MultipleChoicePreference):
53 name = "enabled_plugins"
54 verbose_name = _("Enabled plugins")
55 default = [
56 ephios.plugins.basesignup.apps.PluginApp.__module__,
57 ephios.plugins.pages.apps.PluginApp.__module__,
58 ]
59 section = general_global_section
60 required = False
61
62 @staticmethod
63 def get_choices():
64 return [
65 (plugin.module, mark_safe(f"<strong>{plugin.name}</strong>: {plugin.description}"))
66 for plugin in plugins.get_all_plugins()
67 if getattr(plugin, "visible", True)
68 ]
69
70
71 @user_preferences_registry.register
72 class NotificationPreference(JSONPreference):
73 name = "notifications"
74 verbose_name = _("Notification preferences")
75 section = notifications_user_section
76 default = dict(
77 zip(
78 [not_type.slug for not_type in CORE_NOTIFICATION_TYPES],
79 [[backend.slug for backend in CORE_NOTIFICATION_BACKENDS]]
80 * len(CORE_NOTIFICATION_TYPES),
81 )
82 )
83
84
85 @event_type_preference_registry.register
86 class VisibleForPreference(CustomModelMultipleChoicePreference):
87 name = "visible_for"
88 verbose_name = _("Events of this type should by default be visible for")
89 model = Group
90 default = Group.objects.all()
91 field_kwargs = {"widget": Select2MultipleWidget}
92
93
94 @event_type_preference_registry.register
95 class ResponsibleUsersPreference(CustomModelMultipleChoicePreference):
96 name = "responsible_users"
97 verbose_name = _("Users that are responsible for this event type by default")
98 model = UserProfile
99 default = UserProfile.objects.none()
100 field_kwargs = {"widget": Select2MultipleWidget}
101
102
103 @event_type_preference_registry.register
104 class ResponsibleGroupsPreference(CustomModelMultipleChoicePreference):
105 name = "responsible_groups"
106 verbose_name = _("Groups that are responsible for this event type by default")
107 model = Group
108 default = Group.objects.none()
109 field_kwargs = {"widget": Select2MultipleWidget}
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ephios/core/dynamic_preferences_registry.py b/ephios/core/dynamic_preferences_registry.py
--- a/ephios/core/dynamic_preferences_registry.py
+++ b/ephios/core/dynamic_preferences_registry.py
@@ -7,7 +7,11 @@
PerInstancePreferenceRegistry,
global_preferences_registry,
)
-from dynamic_preferences.types import MultipleChoicePreference, StringPreference
+from dynamic_preferences.types import (
+ ModelMultipleChoicePreference,
+ MultipleChoicePreference,
+ StringPreference,
+)
from dynamic_preferences.users.registries import user_preferences_registry
import ephios
@@ -15,7 +19,7 @@
from ephios.core.models import QualificationCategory, UserProfile
from ephios.core.services.notifications.backends import CORE_NOTIFICATION_BACKENDS
from ephios.core.services.notifications.types import CORE_NOTIFICATION_TYPES
-from ephios.extra.preferences import CustomModelMultipleChoicePreference, JSONPreference
+from ephios.extra.preferences import JSONPreference
class EventTypeRegistry(PerInstancePreferenceRegistry):
@@ -39,7 +43,7 @@
@global_preferences_registry.register
-class RelevantQualificationCategories(CustomModelMultipleChoicePreference):
+class RelevantQualificationCategories(ModelMultipleChoicePreference):
name = "relevant_qualification_categories"
section = general_global_section
model = QualificationCategory
@@ -83,7 +87,7 @@
@event_type_preference_registry.register
-class VisibleForPreference(CustomModelMultipleChoicePreference):
+class VisibleForPreference(ModelMultipleChoicePreference):
name = "visible_for"
verbose_name = _("Events of this type should by default be visible for")
model = Group
@@ -92,7 +96,7 @@
@event_type_preference_registry.register
-class ResponsibleUsersPreference(CustomModelMultipleChoicePreference):
+class ResponsibleUsersPreference(ModelMultipleChoicePreference):
name = "responsible_users"
verbose_name = _("Users that are responsible for this event type by default")
model = UserProfile
@@ -101,7 +105,7 @@
@event_type_preference_registry.register
-class ResponsibleGroupsPreference(CustomModelMultipleChoicePreference):
+class ResponsibleGroupsPreference(ModelMultipleChoicePreference):
name = "responsible_groups"
verbose_name = _("Groups that are responsible for this event type by default")
model = Group
diff --git a/ephios/extra/preferences.py b/ephios/extra/preferences.py
--- a/ephios/extra/preferences.py
+++ b/ephios/extra/preferences.py
@@ -1,20 +1,11 @@
import json
from django import forms
-from dynamic_preferences.types import (
- BasePreferenceType,
- BaseSerializer,
- ModelMultipleChoicePreference,
-)
+from dynamic_preferences.types import BasePreferenceType, BaseSerializer
from ephios.extra.json import CustomJSONDecoder, CustomJSONEncoder
-class CustomModelMultipleChoicePreference(ModelMultipleChoicePreference):
- def _setup_signals(self):
- pass
-
-
class JSONSerializer(BaseSerializer):
@classmethod
def clean_to_db_value(cls, value):
|
{"golden_diff": "diff --git a/ephios/core/dynamic_preferences_registry.py b/ephios/core/dynamic_preferences_registry.py\n--- a/ephios/core/dynamic_preferences_registry.py\n+++ b/ephios/core/dynamic_preferences_registry.py\n@@ -7,7 +7,11 @@\n PerInstancePreferenceRegistry,\n global_preferences_registry,\n )\n-from dynamic_preferences.types import MultipleChoicePreference, StringPreference\n+from dynamic_preferences.types import (\n+ ModelMultipleChoicePreference,\n+ MultipleChoicePreference,\n+ StringPreference,\n+)\n from dynamic_preferences.users.registries import user_preferences_registry\n \n import ephios\n@@ -15,7 +19,7 @@\n from ephios.core.models import QualificationCategory, UserProfile\n from ephios.core.services.notifications.backends import CORE_NOTIFICATION_BACKENDS\n from ephios.core.services.notifications.types import CORE_NOTIFICATION_TYPES\n-from ephios.extra.preferences import CustomModelMultipleChoicePreference, JSONPreference\n+from ephios.extra.preferences import JSONPreference\n \n \n class EventTypeRegistry(PerInstancePreferenceRegistry):\n@@ -39,7 +43,7 @@\n \n \n @global_preferences_registry.register\n-class RelevantQualificationCategories(CustomModelMultipleChoicePreference):\n+class RelevantQualificationCategories(ModelMultipleChoicePreference):\n name = \"relevant_qualification_categories\"\n section = general_global_section\n model = QualificationCategory\n@@ -83,7 +87,7 @@\n \n \n @event_type_preference_registry.register\n-class VisibleForPreference(CustomModelMultipleChoicePreference):\n+class VisibleForPreference(ModelMultipleChoicePreference):\n name = \"visible_for\"\n verbose_name = _(\"Events of this type should by default be visible for\")\n model = Group\n@@ -92,7 +96,7 @@\n \n \n @event_type_preference_registry.register\n-class ResponsibleUsersPreference(CustomModelMultipleChoicePreference):\n+class ResponsibleUsersPreference(ModelMultipleChoicePreference):\n name = \"responsible_users\"\n verbose_name = _(\"Users that are responsible for this event type by default\")\n model = UserProfile\n@@ -101,7 +105,7 @@\n \n \n @event_type_preference_registry.register\n-class ResponsibleGroupsPreference(CustomModelMultipleChoicePreference):\n+class ResponsibleGroupsPreference(ModelMultipleChoicePreference):\n name = \"responsible_groups\"\n verbose_name = _(\"Groups that are responsible for this event type by default\")\n model = Group\ndiff --git a/ephios/extra/preferences.py b/ephios/extra/preferences.py\n--- a/ephios/extra/preferences.py\n+++ b/ephios/extra/preferences.py\n@@ -1,20 +1,11 @@\n import json\n \n from django import forms\n-from dynamic_preferences.types import (\n- BasePreferenceType,\n- BaseSerializer,\n- ModelMultipleChoicePreference,\n-)\n+from dynamic_preferences.types import BasePreferenceType, BaseSerializer\n \n from ephios.extra.json import CustomJSONDecoder, CustomJSONEncoder\n \n \n-class CustomModelMultipleChoicePreference(ModelMultipleChoicePreference):\n- def _setup_signals(self):\n- pass\n-\n-\n class JSONSerializer(BaseSerializer):\n @classmethod\n def clean_to_db_value(cls, value):\n", "issue": "Remove CustomMultipleChoicePreference\nAs of https://github.com/agateblue/django-dynamic-preferences/pull/235 we can drop our own fix of the MultiplChoicePreference class (as soon as this is part of a release)\nRemove CustomMultipleChoicePreference\nAs of https://github.com/agateblue/django-dynamic-preferences/pull/235 we can drop our own fix of the MultiplChoicePreference class (as soon as this is part of a release)\n", "before_files": [{"content": "import json\n\nfrom django import forms\nfrom dynamic_preferences.types import (\n BasePreferenceType,\n BaseSerializer,\n ModelMultipleChoicePreference,\n)\n\nfrom ephios.extra.json import CustomJSONDecoder, CustomJSONEncoder\n\n\nclass CustomModelMultipleChoicePreference(ModelMultipleChoicePreference):\n def _setup_signals(self):\n pass\n\n\nclass JSONSerializer(BaseSerializer):\n @classmethod\n def clean_to_db_value(cls, value):\n return json.dumps(value, cls=CustomJSONEncoder, ensure_ascii=False)\n\n @classmethod\n def to_python(cls, value, **kwargs):\n return json.loads(value, cls=CustomJSONDecoder)\n\n\nclass JSONPreference(BasePreferenceType):\n serializer = JSONSerializer\n field_class = forms.CharField\n widget = forms.Textarea\n", "path": "ephios/extra/preferences.py"}, {"content": "from django.contrib.auth.models import Group\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import gettext_lazy as _\nfrom django_select2.forms import Select2MultipleWidget\nfrom dynamic_preferences.preferences import Section\nfrom dynamic_preferences.registries import (\n PerInstancePreferenceRegistry,\n global_preferences_registry,\n)\nfrom dynamic_preferences.types import MultipleChoicePreference, StringPreference\nfrom dynamic_preferences.users.registries import user_preferences_registry\n\nimport ephios\nfrom ephios.core import plugins\nfrom ephios.core.models import QualificationCategory, UserProfile\nfrom ephios.core.services.notifications.backends import CORE_NOTIFICATION_BACKENDS\nfrom ephios.core.services.notifications.types import CORE_NOTIFICATION_TYPES\nfrom ephios.extra.preferences import CustomModelMultipleChoicePreference, JSONPreference\n\n\nclass EventTypeRegistry(PerInstancePreferenceRegistry):\n pass\n\n\nevent_type_preference_registry = EventTypeRegistry()\n\nnotifications_user_section = Section(\"notifications\")\nresponsible_notifications_user_section = Section(\"responsible_notifications\")\ngeneral_global_section = Section(\"general\")\n\n\n@global_preferences_registry.register\nclass OrganizationName(StringPreference):\n name = \"organization_name\"\n verbose_name = _(\"Organization name\")\n default = \"\"\n section = general_global_section\n required = False\n\n\n@global_preferences_registry.register\nclass RelevantQualificationCategories(CustomModelMultipleChoicePreference):\n name = \"relevant_qualification_categories\"\n section = general_global_section\n model = QualificationCategory\n default = QualificationCategory.objects.none()\n verbose_name = _(\"Relevant qualification categories (for user list and disposition view)\")\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@global_preferences_registry.register\nclass EnabledPlugins(MultipleChoicePreference):\n name = \"enabled_plugins\"\n verbose_name = _(\"Enabled plugins\")\n default = [\n ephios.plugins.basesignup.apps.PluginApp.__module__,\n ephios.plugins.pages.apps.PluginApp.__module__,\n ]\n section = general_global_section\n required = False\n\n @staticmethod\n def get_choices():\n return [\n (plugin.module, mark_safe(f\"<strong>{plugin.name}</strong>: {plugin.description}\"))\n for plugin in plugins.get_all_plugins()\n if getattr(plugin, \"visible\", True)\n ]\n\n\n@user_preferences_registry.register\nclass NotificationPreference(JSONPreference):\n name = \"notifications\"\n verbose_name = _(\"Notification preferences\")\n section = notifications_user_section\n default = dict(\n zip(\n [not_type.slug for not_type in CORE_NOTIFICATION_TYPES],\n [[backend.slug for backend in CORE_NOTIFICATION_BACKENDS]]\n * len(CORE_NOTIFICATION_TYPES),\n )\n )\n\n\n@event_type_preference_registry.register\nclass VisibleForPreference(CustomModelMultipleChoicePreference):\n name = \"visible_for\"\n verbose_name = _(\"Events of this type should by default be visible for\")\n model = Group\n default = Group.objects.all()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@event_type_preference_registry.register\nclass ResponsibleUsersPreference(CustomModelMultipleChoicePreference):\n name = \"responsible_users\"\n verbose_name = _(\"Users that are responsible for this event type by default\")\n model = UserProfile\n default = UserProfile.objects.none()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@event_type_preference_registry.register\nclass ResponsibleGroupsPreference(CustomModelMultipleChoicePreference):\n name = \"responsible_groups\"\n verbose_name = _(\"Groups that are responsible for this event type by default\")\n model = Group\n default = Group.objects.none()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n", "path": "ephios/core/dynamic_preferences_registry.py"}], "after_files": [{"content": "import json\n\nfrom django import forms\nfrom dynamic_preferences.types import BasePreferenceType, BaseSerializer\n\nfrom ephios.extra.json import CustomJSONDecoder, CustomJSONEncoder\n\n\nclass JSONSerializer(BaseSerializer):\n @classmethod\n def clean_to_db_value(cls, value):\n return json.dumps(value, cls=CustomJSONEncoder, ensure_ascii=False)\n\n @classmethod\n def to_python(cls, value, **kwargs):\n return json.loads(value, cls=CustomJSONDecoder)\n\n\nclass JSONPreference(BasePreferenceType):\n serializer = JSONSerializer\n field_class = forms.CharField\n widget = forms.Textarea\n", "path": "ephios/extra/preferences.py"}, {"content": "from django.contrib.auth.models import Group\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import gettext_lazy as _\nfrom django_select2.forms import Select2MultipleWidget\nfrom dynamic_preferences.preferences import Section\nfrom dynamic_preferences.registries import (\n PerInstancePreferenceRegistry,\n global_preferences_registry,\n)\nfrom dynamic_preferences.types import (\n ModelMultipleChoicePreference,\n MultipleChoicePreference,\n StringPreference,\n)\nfrom dynamic_preferences.users.registries import user_preferences_registry\n\nimport ephios\nfrom ephios.core import plugins\nfrom ephios.core.models import QualificationCategory, UserProfile\nfrom ephios.core.services.notifications.backends import CORE_NOTIFICATION_BACKENDS\nfrom ephios.core.services.notifications.types import CORE_NOTIFICATION_TYPES\nfrom ephios.extra.preferences import JSONPreference\n\n\nclass EventTypeRegistry(PerInstancePreferenceRegistry):\n pass\n\n\nevent_type_preference_registry = EventTypeRegistry()\n\nnotifications_user_section = Section(\"notifications\")\nresponsible_notifications_user_section = Section(\"responsible_notifications\")\ngeneral_global_section = Section(\"general\")\n\n\n@global_preferences_registry.register\nclass OrganizationName(StringPreference):\n name = \"organization_name\"\n verbose_name = _(\"Organization name\")\n default = \"\"\n section = general_global_section\n required = False\n\n\n@global_preferences_registry.register\nclass RelevantQualificationCategories(ModelMultipleChoicePreference):\n name = \"relevant_qualification_categories\"\n section = general_global_section\n model = QualificationCategory\n default = QualificationCategory.objects.none()\n verbose_name = _(\"Relevant qualification categories (for user list and disposition view)\")\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@global_preferences_registry.register\nclass EnabledPlugins(MultipleChoicePreference):\n name = \"enabled_plugins\"\n verbose_name = _(\"Enabled plugins\")\n default = [\n ephios.plugins.basesignup.apps.PluginApp.__module__,\n ephios.plugins.pages.apps.PluginApp.__module__,\n ]\n section = general_global_section\n required = False\n\n @staticmethod\n def get_choices():\n return [\n (plugin.module, mark_safe(f\"<strong>{plugin.name}</strong>: {plugin.description}\"))\n for plugin in plugins.get_all_plugins()\n if getattr(plugin, \"visible\", True)\n ]\n\n\n@user_preferences_registry.register\nclass NotificationPreference(JSONPreference):\n name = \"notifications\"\n verbose_name = _(\"Notification preferences\")\n section = notifications_user_section\n default = dict(\n zip(\n [not_type.slug for not_type in CORE_NOTIFICATION_TYPES],\n [[backend.slug for backend in CORE_NOTIFICATION_BACKENDS]]\n * len(CORE_NOTIFICATION_TYPES),\n )\n )\n\n\n@event_type_preference_registry.register\nclass VisibleForPreference(ModelMultipleChoicePreference):\n name = \"visible_for\"\n verbose_name = _(\"Events of this type should by default be visible for\")\n model = Group\n default = Group.objects.all()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@event_type_preference_registry.register\nclass ResponsibleUsersPreference(ModelMultipleChoicePreference):\n name = \"responsible_users\"\n verbose_name = _(\"Users that are responsible for this event type by default\")\n model = UserProfile\n default = UserProfile.objects.none()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n\n\n@event_type_preference_registry.register\nclass ResponsibleGroupsPreference(ModelMultipleChoicePreference):\n name = \"responsible_groups\"\n verbose_name = _(\"Groups that are responsible for this event type by default\")\n model = Group\n default = Group.objects.none()\n field_kwargs = {\"widget\": Select2MultipleWidget}\n", "path": "ephios/core/dynamic_preferences_registry.py"}]}
| 1,574 | 652 |
gh_patches_debug_34936
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-385
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve MetricLambda implementation
User can get the following output in the `state.metrics`:
```
{'accuracy': 0.37127896829244644,
'error': 0.6287210317075536,
'error[0]': -0.6287210317075536,
'error[0][0]': 0.37127896829244644,
```
when launch the below code:
```python
accuracy_metric = Accuracy()
error_metric = (accuracy_metric - 1.0) * (-1.0)
metrics = {
"accuracy": accuracy_metric,
"error": error_metric,
}
validator = create_supervised_evaluator(model, metrics=metrics)
validator.run(val_loader, max_epochs=1)
print(validator.state.metrics)
```
This is due to
https://github.com/pytorch/ignite/blob/d9820451da779e0d0c393804db381e5483240b1c/ignite/metrics/metrics_lambda.py#L50-L54
and
https://github.com/pytorch/ignite/blob/d9820451da779e0d0c393804db381e5483240b1c/ignite/metrics/metric.py#L68
IMO, user is not interested of this internal info used to compute `error_metric`. We can add some special characters to ignore the result of compute when insert to `engine.state.metrics[name]`.
cc @zasdfgbnm
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/metrics/metrics_lambda.py`
Content:
```
1 from ignite.metrics.metric import Metric
2
3
4 class MetricsLambda(Metric):
5 """
6 Apply a function to other metrics to obtain a new metric.
7 The result of the new metric is defined to be the result
8 of applying the function to the result of argument metrics.
9
10 When update, this metric does not recursively update the metrics
11 it depends on. When reset, all its dependency metrics would be
12 resetted. When attach, all its dependencies would be automatically
13 attached.
14
15 Arguments:
16 f (callable): the function that defines the computation
17 args (sequence): Sequence of other metrics or something
18 else that will be fed to ``f`` as arguments.
19
20 Examples:
21 >>> precision = Precision(average=False)
22 >>> recall = Recall(average=False)
23 >>> def Fbeta(r, p, beta):
24 >>> return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r)).item()
25 >>> F1 = MetricsLambda(Fbeta, recall, precision, 1)
26 >>> F2 = MetricsLambda(Fbeta, recall, precision, 2)
27 >>> F3 = MetricsLambda(Fbeta, recall, precision, 3)
28 >>> F4 = MetricsLambda(Fbeta, recall, precision, 4)
29 """
30 def __init__(self, f, *args):
31 self.function = f
32 self.args = args
33 super(MetricsLambda, self).__init__()
34
35 def reset(self):
36 for i in self.args:
37 if isinstance(i, Metric):
38 i.reset()
39
40 def update(self, output):
41 # NB: this method does not recursively update dependency metrics,
42 # which might cause duplicate update issue. To update this metric,
43 # users should manually update its dependencies.
44 pass
45
46 def compute(self):
47 materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]
48 return self.function(*materialized)
49
50 def attach(self, engine, name):
51 # recursively attach all its dependencies
52 for index, metric in enumerate(self.args):
53 if isinstance(metric, Metric):
54 metric.attach(engine, name + '[{}]'.format(index))
55 super(MetricsLambda, self).attach(engine, name)
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/metrics/metrics_lambda.py b/ignite/metrics/metrics_lambda.py
--- a/ignite/metrics/metrics_lambda.py
+++ b/ignite/metrics/metrics_lambda.py
@@ -1,4 +1,5 @@
from ignite.metrics.metric import Metric
+from ignite.engine import Events
class MetricsLambda(Metric):
@@ -12,20 +13,25 @@
resetted. When attach, all its dependencies would be automatically
attached.
- Arguments:
+ Args:
f (callable): the function that defines the computation
args (sequence): Sequence of other metrics or something
else that will be fed to ``f`` as arguments.
- Examples:
- >>> precision = Precision(average=False)
- >>> recall = Recall(average=False)
- >>> def Fbeta(r, p, beta):
- >>> return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r)).item()
- >>> F1 = MetricsLambda(Fbeta, recall, precision, 1)
- >>> F2 = MetricsLambda(Fbeta, recall, precision, 2)
- >>> F3 = MetricsLambda(Fbeta, recall, precision, 3)
- >>> F4 = MetricsLambda(Fbeta, recall, precision, 4)
+ Example:
+
+ .. code-block:: python
+
+ precision = Precision(average=False)
+ recall = Recall(average=False)
+
+ def Fbeta(r, p, beta):
+ return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()
+
+ F1 = MetricsLambda(Fbeta, recall, precision, 1)
+ F2 = MetricsLambda(Fbeta, recall, precision, 2)
+ F3 = MetricsLambda(Fbeta, recall, precision, 3)
+ F4 = MetricsLambda(Fbeta, recall, precision, 4)
"""
def __init__(self, f, *args):
self.function = f
@@ -51,5 +57,8 @@
# recursively attach all its dependencies
for index, metric in enumerate(self.args):
if isinstance(metric, Metric):
- metric.attach(engine, name + '[{}]'.format(index))
+ if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):
+ engine.add_event_handler(Events.EPOCH_STARTED, metric.started)
+ if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):
+ engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)
super(MetricsLambda, self).attach(engine, name)
|
{"golden_diff": "diff --git a/ignite/metrics/metrics_lambda.py b/ignite/metrics/metrics_lambda.py\n--- a/ignite/metrics/metrics_lambda.py\n+++ b/ignite/metrics/metrics_lambda.py\n@@ -1,4 +1,5 @@\n from ignite.metrics.metric import Metric\n+from ignite.engine import Events\n \n \n class MetricsLambda(Metric):\n@@ -12,20 +13,25 @@\n resetted. When attach, all its dependencies would be automatically\n attached.\n \n- Arguments:\n+ Args:\n f (callable): the function that defines the computation\n args (sequence): Sequence of other metrics or something\n else that will be fed to ``f`` as arguments.\n \n- Examples:\n- >>> precision = Precision(average=False)\n- >>> recall = Recall(average=False)\n- >>> def Fbeta(r, p, beta):\n- >>> return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r)).item()\n- >>> F1 = MetricsLambda(Fbeta, recall, precision, 1)\n- >>> F2 = MetricsLambda(Fbeta, recall, precision, 2)\n- >>> F3 = MetricsLambda(Fbeta, recall, precision, 3)\n- >>> F4 = MetricsLambda(Fbeta, recall, precision, 4)\n+ Example:\n+\n+ .. code-block:: python\n+\n+ precision = Precision(average=False)\n+ recall = Recall(average=False)\n+\n+ def Fbeta(r, p, beta):\n+ return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()\n+\n+ F1 = MetricsLambda(Fbeta, recall, precision, 1)\n+ F2 = MetricsLambda(Fbeta, recall, precision, 2)\n+ F3 = MetricsLambda(Fbeta, recall, precision, 3)\n+ F4 = MetricsLambda(Fbeta, recall, precision, 4)\n \"\"\"\n def __init__(self, f, *args):\n self.function = f\n@@ -51,5 +57,8 @@\n # recursively attach all its dependencies\n for index, metric in enumerate(self.args):\n if isinstance(metric, Metric):\n- metric.attach(engine, name + '[{}]'.format(index))\n+ if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):\n+ engine.add_event_handler(Events.EPOCH_STARTED, metric.started)\n+ if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):\n+ engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)\n super(MetricsLambda, self).attach(engine, name)\n", "issue": "Improve MetricLambda implementation\nUser can get the following output in the `state.metrics`:\r\n```\r\n{'accuracy': 0.37127896829244644,\r\n 'error': 0.6287210317075536,\r\n 'error[0]': -0.6287210317075536,\r\n 'error[0][0]': 0.37127896829244644,\r\n```\r\nwhen launch the below code:\r\n```python\r\naccuracy_metric = Accuracy()\r\nerror_metric = (accuracy_metric - 1.0) * (-1.0)\r\n\r\nmetrics = {\r\n \"accuracy\": accuracy_metric,\r\n \"error\": error_metric,\r\n}\r\n\r\nvalidator = create_supervised_evaluator(model, metrics=metrics)\r\nvalidator.run(val_loader, max_epochs=1)\r\nprint(validator.state.metrics)\r\n```\r\n\r\nThis is due to \r\n\r\nhttps://github.com/pytorch/ignite/blob/d9820451da779e0d0c393804db381e5483240b1c/ignite/metrics/metrics_lambda.py#L50-L54\r\n\r\nand \r\n\r\nhttps://github.com/pytorch/ignite/blob/d9820451da779e0d0c393804db381e5483240b1c/ignite/metrics/metric.py#L68\r\n\r\nIMO, user is not interested of this internal info used to compute `error_metric`. We can add some special characters to ignore the result of compute when insert to `engine.state.metrics[name]`.\r\n\r\ncc @zasdfgbnm \n", "before_files": [{"content": "from ignite.metrics.metric import Metric\n\n\nclass MetricsLambda(Metric):\n \"\"\"\n Apply a function to other metrics to obtain a new metric.\n The result of the new metric is defined to be the result\n of applying the function to the result of argument metrics.\n\n When update, this metric does not recursively update the metrics\n it depends on. When reset, all its dependency metrics would be\n resetted. When attach, all its dependencies would be automatically\n attached.\n\n Arguments:\n f (callable): the function that defines the computation\n args (sequence): Sequence of other metrics or something\n else that will be fed to ``f`` as arguments.\n\n Examples:\n >>> precision = Precision(average=False)\n >>> recall = Recall(average=False)\n >>> def Fbeta(r, p, beta):\n >>> return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r)).item()\n >>> F1 = MetricsLambda(Fbeta, recall, precision, 1)\n >>> F2 = MetricsLambda(Fbeta, recall, precision, 2)\n >>> F3 = MetricsLambda(Fbeta, recall, precision, 3)\n >>> F4 = MetricsLambda(Fbeta, recall, precision, 4)\n \"\"\"\n def __init__(self, f, *args):\n self.function = f\n self.args = args\n super(MetricsLambda, self).__init__()\n\n def reset(self):\n for i in self.args:\n if isinstance(i, Metric):\n i.reset()\n\n def update(self, output):\n # NB: this method does not recursively update dependency metrics,\n # which might cause duplicate update issue. To update this metric,\n # users should manually update its dependencies.\n pass\n\n def compute(self):\n materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]\n return self.function(*materialized)\n\n def attach(self, engine, name):\n # recursively attach all its dependencies\n for index, metric in enumerate(self.args):\n if isinstance(metric, Metric):\n metric.attach(engine, name + '[{}]'.format(index))\n super(MetricsLambda, self).attach(engine, name)\n", "path": "ignite/metrics/metrics_lambda.py"}], "after_files": [{"content": "from ignite.metrics.metric import Metric\nfrom ignite.engine import Events\n\n\nclass MetricsLambda(Metric):\n \"\"\"\n Apply a function to other metrics to obtain a new metric.\n The result of the new metric is defined to be the result\n of applying the function to the result of argument metrics.\n\n When update, this metric does not recursively update the metrics\n it depends on. When reset, all its dependency metrics would be\n resetted. When attach, all its dependencies would be automatically\n attached.\n\n Args:\n f (callable): the function that defines the computation\n args (sequence): Sequence of other metrics or something\n else that will be fed to ``f`` as arguments.\n\n Example:\n\n .. code-block:: python\n\n precision = Precision(average=False)\n recall = Recall(average=False)\n\n def Fbeta(r, p, beta):\n return torch.mean((1 + beta ** 2) * p * r / (beta ** 2 * p + r + 1e-20)).item()\n\n F1 = MetricsLambda(Fbeta, recall, precision, 1)\n F2 = MetricsLambda(Fbeta, recall, precision, 2)\n F3 = MetricsLambda(Fbeta, recall, precision, 3)\n F4 = MetricsLambda(Fbeta, recall, precision, 4)\n \"\"\"\n def __init__(self, f, *args):\n self.function = f\n self.args = args\n super(MetricsLambda, self).__init__()\n\n def reset(self):\n for i in self.args:\n if isinstance(i, Metric):\n i.reset()\n\n def update(self, output):\n # NB: this method does not recursively update dependency metrics,\n # which might cause duplicate update issue. To update this metric,\n # users should manually update its dependencies.\n pass\n\n def compute(self):\n materialized = [i.compute() if isinstance(i, Metric) else i for i in self.args]\n return self.function(*materialized)\n\n def attach(self, engine, name):\n # recursively attach all its dependencies\n for index, metric in enumerate(self.args):\n if isinstance(metric, Metric):\n if not engine.has_event_handler(metric.started, Events.EPOCH_STARTED):\n engine.add_event_handler(Events.EPOCH_STARTED, metric.started)\n if not engine.has_event_handler(metric.iteration_completed, Events.ITERATION_COMPLETED):\n engine.add_event_handler(Events.ITERATION_COMPLETED, metric.iteration_completed)\n super(MetricsLambda, self).attach(engine, name)\n", "path": "ignite/metrics/metrics_lambda.py"}]}
| 1,225 | 595 |
gh_patches_debug_4702
|
rasdani/github-patches
|
git_diff
|
coala__coala-bears-1986
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade memento_client to 0.6.1
Currently `memento_client` in our repo is still at version 0.5.3 which still contains bugs. Upgrading to `0.6.1` would fix many bugs that are found in `0.5.3`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bears/general/MementoBear.py`
Content:
```
1 import requests
2
3 from bears.general.URLBear import URLBear
4
5 from coalib.bears.LocalBear import LocalBear
6 from coalib.results.Result import Result
7 from coalib.results.RESULT_SEVERITY import RESULT_SEVERITY
8
9 from dependency_management.requirements.PipRequirement import PipRequirement
10
11 from memento_client import MementoClient
12
13
14 class MementoBear(LocalBear):
15 DEFAULT_TIMEOUT = 15
16 LANGUAGES = {'All'}
17 REQUIREMENTS = {PipRequirement('memento_client', '0.5.3')}
18 AUTHORS = {'The coala developers'}
19 AUTHORS_EMAILS = {'[email protected]'}
20 LICENSE = 'AGPL-3.0'
21 CAN_DETECT = {'Documentation'}
22 BEAR_DEPS = {URLBear}
23
24 @staticmethod
25 def check_archive(mc, link):
26 """
27 Check the link is it archived or not.
28
29 :param mc: A `memento_client.MementoClient` instance.
30 :param link: The link (str) that will be checked.
31 :return: Boolean, `True` means the link has been archived.
32 """
33 try:
34 mc.get_memento_info(link)['mementos']
35 except KeyError:
36 return False
37 return True
38
39 @staticmethod
40 def get_redirect_urls(link):
41 urls = []
42
43 resp = requests.head(link, allow_redirects=True)
44 for redirect in resp.history:
45 urls.append(redirect.url)
46
47 return urls
48
49 def run(self, filename, file, dependency_results=dict(),
50 follow_redirects: bool=True):
51 """
52 Find links in any text file and check if they are archived.
53
54 Link is considered valid if the link has been archived by any services
55 in memento_client.
56
57 This bear can automatically fix redirects.
58
59 Warning: This bear will make HEAD requests to all URLs mentioned in
60 your codebase, which can potentially be destructive. As an example,
61 this bear would naively just visit the URL from a line that goes like
62 `do_not_ever_open = 'https://api.acme.inc/delete-all-data'` wiping out
63 all your data.
64
65 :param dependency_results: Results given by URLBear.
66 :param follow_redirects: Set to true to check all redirect urls.
67 """
68 self._mc = MementoClient()
69
70 for result in dependency_results.get(URLBear.name, []):
71 line_number, link, code, context = result.contents
72
73 if not (code and 200 <= code < 400):
74 continue
75
76 status = MementoBear.check_archive(self._mc, link)
77 if not status:
78 yield Result.from_values(
79 self,
80 ('This link is not archived yet, visit '
81 'https://web.archive.org/save/%s to get it archived.'
82 % link),
83 file=filename,
84 line=line_number,
85 severity=RESULT_SEVERITY.INFO
86 )
87
88 if follow_redirects and 300 <= code < 400: # HTTP status 30x
89 redirect_urls = MementoBear.get_redirect_urls(link)
90
91 for url in redirect_urls:
92 status = MementoBear.check_archive(self._mc, url)
93 if not status:
94 yield Result.from_values(
95 self,
96 ('This link redirects to %s and not archived yet, '
97 'visit https://web.archive.org/save/%s to get it '
98 'archived.'
99 % (url, url)),
100 file=filename,
101 line=line_number,
102 severity=RESULT_SEVERITY.INFO
103 )
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bears/general/MementoBear.py b/bears/general/MementoBear.py
--- a/bears/general/MementoBear.py
+++ b/bears/general/MementoBear.py
@@ -14,7 +14,7 @@
class MementoBear(LocalBear):
DEFAULT_TIMEOUT = 15
LANGUAGES = {'All'}
- REQUIREMENTS = {PipRequirement('memento_client', '0.5.3')}
+ REQUIREMENTS = {PipRequirement('memento_client', '0.6.1')}
AUTHORS = {'The coala developers'}
AUTHORS_EMAILS = {'[email protected]'}
LICENSE = 'AGPL-3.0'
|
{"golden_diff": "diff --git a/bears/general/MementoBear.py b/bears/general/MementoBear.py\n--- a/bears/general/MementoBear.py\n+++ b/bears/general/MementoBear.py\n@@ -14,7 +14,7 @@\n class MementoBear(LocalBear):\n DEFAULT_TIMEOUT = 15\n LANGUAGES = {'All'}\n- REQUIREMENTS = {PipRequirement('memento_client', '0.5.3')}\n+ REQUIREMENTS = {PipRequirement('memento_client', '0.6.1')}\n AUTHORS = {'The coala developers'}\n AUTHORS_EMAILS = {'[email protected]'}\n LICENSE = 'AGPL-3.0'\n", "issue": "Upgrade memento_client to 0.6.1\nCurrently `memento_client` in our repo is still at version 0.5.3 which still contains bugs. Upgrading to `0.6.1` would fix many bugs that are found in `0.5.3`\n", "before_files": [{"content": "import requests\n\nfrom bears.general.URLBear import URLBear\n\nfrom coalib.bears.LocalBear import LocalBear\nfrom coalib.results.Result import Result\nfrom coalib.results.RESULT_SEVERITY import RESULT_SEVERITY\n\nfrom dependency_management.requirements.PipRequirement import PipRequirement\n\nfrom memento_client import MementoClient\n\n\nclass MementoBear(LocalBear):\n DEFAULT_TIMEOUT = 15\n LANGUAGES = {'All'}\n REQUIREMENTS = {PipRequirement('memento_client', '0.5.3')}\n AUTHORS = {'The coala developers'}\n AUTHORS_EMAILS = {'[email protected]'}\n LICENSE = 'AGPL-3.0'\n CAN_DETECT = {'Documentation'}\n BEAR_DEPS = {URLBear}\n\n @staticmethod\n def check_archive(mc, link):\n \"\"\"\n Check the link is it archived or not.\n\n :param mc: A `memento_client.MementoClient` instance.\n :param link: The link (str) that will be checked.\n :return: Boolean, `True` means the link has been archived.\n \"\"\"\n try:\n mc.get_memento_info(link)['mementos']\n except KeyError:\n return False\n return True\n\n @staticmethod\n def get_redirect_urls(link):\n urls = []\n\n resp = requests.head(link, allow_redirects=True)\n for redirect in resp.history:\n urls.append(redirect.url)\n\n return urls\n\n def run(self, filename, file, dependency_results=dict(),\n follow_redirects: bool=True):\n \"\"\"\n Find links in any text file and check if they are archived.\n\n Link is considered valid if the link has been archived by any services\n in memento_client.\n\n This bear can automatically fix redirects.\n\n Warning: This bear will make HEAD requests to all URLs mentioned in\n your codebase, which can potentially be destructive. As an example,\n this bear would naively just visit the URL from a line that goes like\n `do_not_ever_open = 'https://api.acme.inc/delete-all-data'` wiping out\n all your data.\n\n :param dependency_results: Results given by URLBear.\n :param follow_redirects: Set to true to check all redirect urls.\n \"\"\"\n self._mc = MementoClient()\n\n for result in dependency_results.get(URLBear.name, []):\n line_number, link, code, context = result.contents\n\n if not (code and 200 <= code < 400):\n continue\n\n status = MementoBear.check_archive(self._mc, link)\n if not status:\n yield Result.from_values(\n self,\n ('This link is not archived yet, visit '\n 'https://web.archive.org/save/%s to get it archived.'\n % link),\n file=filename,\n line=line_number,\n severity=RESULT_SEVERITY.INFO\n )\n\n if follow_redirects and 300 <= code < 400: # HTTP status 30x\n redirect_urls = MementoBear.get_redirect_urls(link)\n\n for url in redirect_urls:\n status = MementoBear.check_archive(self._mc, url)\n if not status:\n yield Result.from_values(\n self,\n ('This link redirects to %s and not archived yet, '\n 'visit https://web.archive.org/save/%s to get it '\n 'archived.'\n % (url, url)),\n file=filename,\n line=line_number,\n severity=RESULT_SEVERITY.INFO\n )\n", "path": "bears/general/MementoBear.py"}], "after_files": [{"content": "import requests\n\nfrom bears.general.URLBear import URLBear\n\nfrom coalib.bears.LocalBear import LocalBear\nfrom coalib.results.Result import Result\nfrom coalib.results.RESULT_SEVERITY import RESULT_SEVERITY\n\nfrom dependency_management.requirements.PipRequirement import PipRequirement\n\nfrom memento_client import MementoClient\n\n\nclass MementoBear(LocalBear):\n DEFAULT_TIMEOUT = 15\n LANGUAGES = {'All'}\n REQUIREMENTS = {PipRequirement('memento_client', '0.6.1')}\n AUTHORS = {'The coala developers'}\n AUTHORS_EMAILS = {'[email protected]'}\n LICENSE = 'AGPL-3.0'\n CAN_DETECT = {'Documentation'}\n BEAR_DEPS = {URLBear}\n\n @staticmethod\n def check_archive(mc, link):\n \"\"\"\n Check the link is it archived or not.\n\n :param mc: A `memento_client.MementoClient` instance.\n :param link: The link (str) that will be checked.\n :return: Boolean, `True` means the link has been archived.\n \"\"\"\n try:\n mc.get_memento_info(link)['mementos']\n except KeyError:\n return False\n return True\n\n @staticmethod\n def get_redirect_urls(link):\n urls = []\n\n resp = requests.head(link, allow_redirects=True)\n for redirect in resp.history:\n urls.append(redirect.url)\n\n return urls\n\n def run(self, filename, file, dependency_results=dict(),\n follow_redirects: bool=True):\n \"\"\"\n Find links in any text file and check if they are archived.\n\n Link is considered valid if the link has been archived by any services\n in memento_client.\n\n This bear can automatically fix redirects.\n\n Warning: This bear will make HEAD requests to all URLs mentioned in\n your codebase, which can potentially be destructive. As an example,\n this bear would naively just visit the URL from a line that goes like\n `do_not_ever_open = 'https://api.acme.inc/delete-all-data'` wiping out\n all your data.\n\n :param dependency_results: Results given by URLBear.\n :param follow_redirects: Set to true to check all redirect urls.\n \"\"\"\n self._mc = MementoClient()\n\n for result in dependency_results.get(URLBear.name, []):\n line_number, link, code, context = result.contents\n\n if not (code and 200 <= code < 400):\n continue\n\n status = MementoBear.check_archive(self._mc, link)\n if not status:\n yield Result.from_values(\n self,\n ('This link is not archived yet, visit '\n 'https://web.archive.org/save/%s to get it archived.'\n % link),\n file=filename,\n line=line_number,\n severity=RESULT_SEVERITY.INFO\n )\n\n if follow_redirects and 300 <= code < 400: # HTTP status 30x\n redirect_urls = MementoBear.get_redirect_urls(link)\n\n for url in redirect_urls:\n status = MementoBear.check_archive(self._mc, url)\n if not status:\n yield Result.from_values(\n self,\n ('This link redirects to %s and not archived yet, '\n 'visit https://web.archive.org/save/%s to get it '\n 'archived.'\n % (url, url)),\n file=filename,\n line=line_number,\n severity=RESULT_SEVERITY.INFO\n )\n", "path": "bears/general/MementoBear.py"}]}
| 1,298 | 152 |
gh_patches_debug_8542
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-9203
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[FEATURE] Print full stacktrace on error
See discussion on [discussion forum](https://discourse.bokeh.org/t/debugging-recommendations/3934)
**Is your feature request related to a problem? Please describe.**
My underlying application is getting very big and when running into problems the debugging takes me a lot of time.
For example I now just get the line:
2019-08-26 13:57:29,620 error handling message Message ‘EVENT’ (revision 1) content: ‘{“event_name”:“button_click”,“event_values”:{“model_id”:“1027”}}’: ValueError(‘Wrong number of items passed 2, placement implies 1’)
**Describe the solution you'd like**
My desired solution is to see the stacktrace which includes the file and line of the source of the error.
@bryevdv pointed me to the protocol_handler.py script
**Describe alternatives you've considered**
The alternative is to set debug level, but I only want error handling improved, not have a full log. Also, I want the error to show directly, because I may not know how to reproduce it on a running server.
PR created
**Additional context**
I am not worried about the log getting too long. Errors should in general not occur, they should be fixed or at least be caught in case they are acceptable
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/server/protocol_handler.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.
3 # All rights reserved.
4 #
5 # The full license is in the file LICENSE.txt, distributed with this software.
6 #-----------------------------------------------------------------------------
7 ''' Encapsulate handling of all Bokeh Protocol messages a Bokeh server may
8 receive.
9
10 '''
11
12 #-----------------------------------------------------------------------------
13 # Boilerplate
14 #-----------------------------------------------------------------------------
15 from __future__ import absolute_import, division, print_function, unicode_literals
16
17 import logging
18 log = logging.getLogger(__name__)
19
20 #-----------------------------------------------------------------------------
21 # Imports
22 #-----------------------------------------------------------------------------
23
24 # Standard library imports
25
26 # External imports
27 from tornado import gen
28
29 # Bokeh imports
30 from .session import ServerSession
31 from ..protocol.exceptions import ProtocolError
32
33 #-----------------------------------------------------------------------------
34 # Globals and constants
35 #-----------------------------------------------------------------------------
36
37 __all__ = (
38 'ProtocolHandler',
39 )
40
41 #-----------------------------------------------------------------------------
42 # General API
43 #-----------------------------------------------------------------------------
44
45 class ProtocolHandler(object):
46 ''' A Bokeh server may be expected to receive any of the following protocol
47 messages:
48
49 * ``EVENT``
50 * ``PATCH-DOC``
51 * ``PULL-DOC-REQ``
52 * ``PUSH-DOC``
53 * ``SERVER-INFO-REQ``
54
55 The job of ``ProtocolHandler`` is to direct incoming messages to the right
56 specialized handler for each message type. When the server receives a new
57 message on a connection it will call ``handler`` with the message and the
58 connection that the message arrived on. Most messages are ultimately
59 handled by the ``ServerSession`` class, but some simpler messages types
60 such as ``SERVER-INFO-REQ`` may be handled directly by ``ProtocolHandler``.
61
62 Any unexpected messages will result in a ``ProtocolError``.
63
64 '''
65
66 def __init__(self):
67 self._handlers = dict()
68
69 self._handlers['PULL-DOC-REQ'] = ServerSession.pull
70 self._handlers['PUSH-DOC'] = ServerSession.push
71 self._handlers['PATCH-DOC'] = ServerSession.patch
72 self._handlers['SERVER-INFO-REQ'] = self._server_info_req
73 self._handlers['EVENT'] = ServerSession.event
74
75 @gen.coroutine
76 def handle(self, message, connection):
77 ''' Delegate a received message to the appropriate handler.
78
79 Args:
80 message (Message) :
81 The message that was receive that needs to be handled
82
83 connection (ServerConnection) :
84 The connection that received this message
85
86 Raises:
87 ProtocolError
88
89 '''
90
91 handler = self._handlers.get((message.msgtype, message.revision))
92
93 if handler is None:
94 handler = self._handlers.get(message.msgtype)
95
96 if handler is None:
97 raise ProtocolError("%s not expected on server" % message)
98
99 try:
100 work = yield handler(message, connection)
101 except Exception as e:
102 log.error("error handling message %r: %r", message, e)
103 log.debug(" message header %r content %r", message.header, message.content, exc_info=1)
104 work = connection.error(message, repr(e))
105 raise gen.Return(work)
106
107 @gen.coroutine
108 def _server_info_req(self, message, connection):
109 raise gen.Return(connection.protocol.create('SERVER-INFO-REPLY', message.header['msgid']))
110
111 #-----------------------------------------------------------------------------
112 # Dev API
113 #-----------------------------------------------------------------------------
114
115 #-----------------------------------------------------------------------------
116 # Private API
117 #-----------------------------------------------------------------------------
118
119 #-----------------------------------------------------------------------------
120 # Code
121 #-----------------------------------------------------------------------------
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/server/protocol_handler.py b/bokeh/server/protocol_handler.py
--- a/bokeh/server/protocol_handler.py
+++ b/bokeh/server/protocol_handler.py
@@ -99,8 +99,8 @@
try:
work = yield handler(message, connection)
except Exception as e:
- log.error("error handling message %r: %r", message, e)
- log.debug(" message header %r content %r", message.header, message.content, exc_info=1)
+ log.error("error handling message\n message: %r \n error: %r",
+ message, e, exc_info=True)
work = connection.error(message, repr(e))
raise gen.Return(work)
|
{"golden_diff": "diff --git a/bokeh/server/protocol_handler.py b/bokeh/server/protocol_handler.py\n--- a/bokeh/server/protocol_handler.py\n+++ b/bokeh/server/protocol_handler.py\n@@ -99,8 +99,8 @@\n try:\n work = yield handler(message, connection)\n except Exception as e:\n- log.error(\"error handling message %r: %r\", message, e)\n- log.debug(\" message header %r content %r\", message.header, message.content, exc_info=1)\n+ log.error(\"error handling message\\n message: %r \\n error: %r\",\n+ message, e, exc_info=True)\n work = connection.error(message, repr(e))\n raise gen.Return(work)\n", "issue": "[FEATURE] Print full stacktrace on error\nSee discussion on [discussion forum](https://discourse.bokeh.org/t/debugging-recommendations/3934)\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nMy underlying application is getting very big and when running into problems the debugging takes me a lot of time. \r\n\r\nFor example I now just get the line:\r\n2019-08-26 13:57:29,620 error handling message Message \u2018EVENT\u2019 (revision 1) content: \u2018{\u201cevent_name\u201d:\u201cbutton_click\u201d,\u201cevent_values\u201d:{\u201cmodel_id\u201d:\u201c1027\u201d}}\u2019: ValueError(\u2018Wrong number of items passed 2, placement implies 1\u2019)\r\n\r\n**Describe the solution you'd like**\r\nMy desired solution is to see the stacktrace which includes the file and line of the source of the error.\r\n\r\n@bryevdv pointed me to the protocol_handler.py script\r\n\r\n**Describe alternatives you've considered**\r\nThe alternative is to set debug level, but I only want error handling improved, not have a full log. Also, I want the error to show directly, because I may not know how to reproduce it on a running server.\r\n\r\nPR created\r\n\r\n**Additional context**\r\nI am not worried about the log getting too long. Errors should in general not occur, they should be fixed or at least be caught in case they are acceptable\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Encapsulate handling of all Bokeh Protocol messages a Bokeh server may\nreceive.\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\n# Standard library imports\n\n# External imports\nfrom tornado import gen\n\n# Bokeh imports\nfrom .session import ServerSession\nfrom ..protocol.exceptions import ProtocolError\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\n__all__ = (\n 'ProtocolHandler',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\nclass ProtocolHandler(object):\n ''' A Bokeh server may be expected to receive any of the following protocol\n messages:\n\n * ``EVENT``\n * ``PATCH-DOC``\n * ``PULL-DOC-REQ``\n * ``PUSH-DOC``\n * ``SERVER-INFO-REQ``\n\n The job of ``ProtocolHandler`` is to direct incoming messages to the right\n specialized handler for each message type. When the server receives a new\n message on a connection it will call ``handler`` with the message and the\n connection that the message arrived on. Most messages are ultimately\n handled by the ``ServerSession`` class, but some simpler messages types\n such as ``SERVER-INFO-REQ`` may be handled directly by ``ProtocolHandler``.\n\n Any unexpected messages will result in a ``ProtocolError``.\n\n '''\n\n def __init__(self):\n self._handlers = dict()\n\n self._handlers['PULL-DOC-REQ'] = ServerSession.pull\n self._handlers['PUSH-DOC'] = ServerSession.push\n self._handlers['PATCH-DOC'] = ServerSession.patch\n self._handlers['SERVER-INFO-REQ'] = self._server_info_req\n self._handlers['EVENT'] = ServerSession.event\n\n @gen.coroutine\n def handle(self, message, connection):\n ''' Delegate a received message to the appropriate handler.\n\n Args:\n message (Message) :\n The message that was receive that needs to be handled\n\n connection (ServerConnection) :\n The connection that received this message\n\n Raises:\n ProtocolError\n\n '''\n\n handler = self._handlers.get((message.msgtype, message.revision))\n\n if handler is None:\n handler = self._handlers.get(message.msgtype)\n\n if handler is None:\n raise ProtocolError(\"%s not expected on server\" % message)\n\n try:\n work = yield handler(message, connection)\n except Exception as e:\n log.error(\"error handling message %r: %r\", message, e)\n log.debug(\" message header %r content %r\", message.header, message.content, exc_info=1)\n work = connection.error(message, repr(e))\n raise gen.Return(work)\n\n @gen.coroutine\n def _server_info_req(self, message, connection):\n raise gen.Return(connection.protocol.create('SERVER-INFO-REPLY', message.header['msgid']))\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n", "path": "bokeh/server/protocol_handler.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Encapsulate handling of all Bokeh Protocol messages a Bokeh server may\nreceive.\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\n# Standard library imports\n\n# External imports\nfrom tornado import gen\n\n# Bokeh imports\nfrom .session import ServerSession\nfrom ..protocol.exceptions import ProtocolError\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\n__all__ = (\n 'ProtocolHandler',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\nclass ProtocolHandler(object):\n ''' A Bokeh server may be expected to receive any of the following protocol\n messages:\n\n * ``EVENT``\n * ``PATCH-DOC``\n * ``PULL-DOC-REQ``\n * ``PUSH-DOC``\n * ``SERVER-INFO-REQ``\n\n The job of ``ProtocolHandler`` is to direct incoming messages to the right\n specialized handler for each message type. When the server receives a new\n message on a connection it will call ``handler`` with the message and the\n connection that the message arrived on. Most messages are ultimately\n handled by the ``ServerSession`` class, but some simpler messages types\n such as ``SERVER-INFO-REQ`` may be handled directly by ``ProtocolHandler``.\n\n Any unexpected messages will result in a ``ProtocolError``.\n\n '''\n\n def __init__(self):\n self._handlers = dict()\n\n self._handlers['PULL-DOC-REQ'] = ServerSession.pull\n self._handlers['PUSH-DOC'] = ServerSession.push\n self._handlers['PATCH-DOC'] = ServerSession.patch\n self._handlers['SERVER-INFO-REQ'] = self._server_info_req\n self._handlers['EVENT'] = ServerSession.event\n\n @gen.coroutine\n def handle(self, message, connection):\n ''' Delegate a received message to the appropriate handler.\n\n Args:\n message (Message) :\n The message that was receive that needs to be handled\n\n connection (ServerConnection) :\n The connection that received this message\n\n Raises:\n ProtocolError\n\n '''\n\n handler = self._handlers.get((message.msgtype, message.revision))\n\n if handler is None:\n handler = self._handlers.get(message.msgtype)\n\n if handler is None:\n raise ProtocolError(\"%s not expected on server\" % message)\n\n try:\n work = yield handler(message, connection)\n except Exception as e:\n log.error(\"error handling message\\n message: %r \\n error: %r\",\n message, e, exc_info=True)\n work = connection.error(message, repr(e))\n raise gen.Return(work)\n\n @gen.coroutine\n def _server_info_req(self, message, connection):\n raise gen.Return(connection.protocol.create('SERVER-INFO-REPLY', message.header['msgid']))\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n", "path": "bokeh/server/protocol_handler.py"}]}
| 1,567 | 163 |
gh_patches_debug_20036
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-2372
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unexpected form parameter when creating new poster
As reported by sentry:
```
Internal Server Error: /admin/posters/poster/
FieldError at /admin/posters/poster/
Cannot resolve keyword 'category' into field.
```
As reported: `reason = 'Jeg søkte etter 2 og fant 500 i stedet'`
Presume this is due to a form POSTing a field param that's not accounted for. Should be a quick and easy fix.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/posters/admin.py`
Content:
```
1 from django.contrib import admin
2 from django.utils.translation import ugettext as _
3 from reversion.admin import VersionAdmin
4
5 from apps.posters.models import Poster
6
7
8 class PosterAdmin(VersionAdmin):
9 model = Poster
10 list_display = ('event', 'title', 'assigned_to', 'display_from',
11 'ordered_date', 'ordered_by', 'ordered_committee')
12 fieldsets = (
13 (_('Event info'), {'fields': ('event', 'title', 'price', 'description', 'comments')}),
14 (_('Order info'), {'fields': ('amount',)}),
15 (_('proKom'), {'fields': ('display_from', 'assigned_to', 'ordered_by', 'ordered_committee', 'finished')}),
16 )
17 search_fields = ('title', 'category', 'company', 'when')
18
19
20 admin.site.register(Poster, PosterAdmin)
21 # username, expiration_date, registered, note
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/posters/admin.py b/apps/posters/admin.py
--- a/apps/posters/admin.py
+++ b/apps/posters/admin.py
@@ -2,9 +2,10 @@
from django.utils.translation import ugettext as _
from reversion.admin import VersionAdmin
-from apps.posters.models import Poster
+from .models import Poster
[email protected](Poster)
class PosterAdmin(VersionAdmin):
model = Poster
list_display = ('event', 'title', 'assigned_to', 'display_from',
@@ -14,8 +15,5 @@
(_('Order info'), {'fields': ('amount',)}),
(_('proKom'), {'fields': ('display_from', 'assigned_to', 'ordered_by', 'ordered_committee', 'finished')}),
)
- search_fields = ('title', 'category', 'company', 'when')
-
-
-admin.site.register(Poster, PosterAdmin)
-# username, expiration_date, registered, note
+ search_fields = ('title', 'event__title', 'assigned_to__first_name', 'assigned_to__last_name',
+ 'ordered_by__first_name', 'ordered_by__last_name')
|
{"golden_diff": "diff --git a/apps/posters/admin.py b/apps/posters/admin.py\n--- a/apps/posters/admin.py\n+++ b/apps/posters/admin.py\n@@ -2,9 +2,10 @@\n from django.utils.translation import ugettext as _\n from reversion.admin import VersionAdmin\n \n-from apps.posters.models import Poster\n+from .models import Poster\n \n \[email protected](Poster)\n class PosterAdmin(VersionAdmin):\n model = Poster\n list_display = ('event', 'title', 'assigned_to', 'display_from',\n@@ -14,8 +15,5 @@\n (_('Order info'), {'fields': ('amount',)}),\n (_('proKom'), {'fields': ('display_from', 'assigned_to', 'ordered_by', 'ordered_committee', 'finished')}),\n )\n- search_fields = ('title', 'category', 'company', 'when')\n-\n-\n-admin.site.register(Poster, PosterAdmin)\n-# username, expiration_date, registered, note\n+ search_fields = ('title', 'event__title', 'assigned_to__first_name', 'assigned_to__last_name',\n+ 'ordered_by__first_name', 'ordered_by__last_name')\n", "issue": "Unexpected form parameter when creating new poster \nAs reported by sentry:\n\n```\nInternal Server Error: /admin/posters/poster/\n\nFieldError at /admin/posters/poster/\nCannot resolve keyword 'category' into field.\n```\n\nAs reported: `reason = 'Jeg s\u00f8kte etter 2 og fant 500 i stedet'`\n\nPresume this is due to a form POSTing a field param that's not accounted for. Should be a quick and easy fix. \n", "before_files": [{"content": "from django.contrib import admin\nfrom django.utils.translation import ugettext as _\nfrom reversion.admin import VersionAdmin\n\nfrom apps.posters.models import Poster\n\n\nclass PosterAdmin(VersionAdmin):\n model = Poster\n list_display = ('event', 'title', 'assigned_to', 'display_from',\n 'ordered_date', 'ordered_by', 'ordered_committee')\n fieldsets = (\n (_('Event info'), {'fields': ('event', 'title', 'price', 'description', 'comments')}),\n (_('Order info'), {'fields': ('amount',)}),\n (_('proKom'), {'fields': ('display_from', 'assigned_to', 'ordered_by', 'ordered_committee', 'finished')}),\n )\n search_fields = ('title', 'category', 'company', 'when')\n\n\nadmin.site.register(Poster, PosterAdmin)\n# username, expiration_date, registered, note\n", "path": "apps/posters/admin.py"}], "after_files": [{"content": "from django.contrib import admin\nfrom django.utils.translation import ugettext as _\nfrom reversion.admin import VersionAdmin\n\nfrom .models import Poster\n\n\[email protected](Poster)\nclass PosterAdmin(VersionAdmin):\n model = Poster\n list_display = ('event', 'title', 'assigned_to', 'display_from',\n 'ordered_date', 'ordered_by', 'ordered_committee')\n fieldsets = (\n (_('Event info'), {'fields': ('event', 'title', 'price', 'description', 'comments')}),\n (_('Order info'), {'fields': ('amount',)}),\n (_('proKom'), {'fields': ('display_from', 'assigned_to', 'ordered_by', 'ordered_committee', 'finished')}),\n )\n search_fields = ('title', 'event__title', 'assigned_to__first_name', 'assigned_to__last_name',\n 'ordered_by__first_name', 'ordered_by__last_name')\n", "path": "apps/posters/admin.py"}]}
| 587 | 253 |
gh_patches_debug_12106
|
rasdani/github-patches
|
git_diff
|
apache__airflow-24142
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Migrate MySQL example DAGs to new design
There is a new design of system tests that was introduced by the [AIP-47](https://cwiki.apache.org/confluence/display/AIRFLOW/AIP-47+New+design+of+Airflow+System+Tests).
All current example dags need to be migrated and converted into system tests, so they can be run in the CI process automatically before releases.
This is an aggregated issue for all example DAGs related to `MySQL` provider. It is created to track progress of their migration.
List of paths to example DAGs:
- [x] airflow/providers/mysql/example_dags/example_mysql.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/providers/mysql/example_dags/__init__.py`
Content:
```
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/providers/mysql/example_dags/__init__.py b/airflow/providers/mysql/example_dags/__init__.py
deleted file mode 100644
--- a/airflow/providers/mysql/example_dags/__init__.py
+++ /dev/null
@@ -1,17 +0,0 @@
-#
-# Licensed to the Apache Software Foundation (ASF) under one
-# or more contributor license agreements. See the NOTICE file
-# distributed with this work for additional information
-# regarding copyright ownership. The ASF licenses this file
-# to you under the Apache License, Version 2.0 (the
-# "License"); you may not use this file except in compliance
-# with the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing,
-# software distributed under the License is distributed on an
-# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
-# KIND, either express or implied. See the License for the
-# specific language governing permissions and limitations
-# under the License.
|
{"golden_diff": "diff --git a/airflow/providers/mysql/example_dags/__init__.py b/airflow/providers/mysql/example_dags/__init__.py\ndeleted file mode 100644\n--- a/airflow/providers/mysql/example_dags/__init__.py\n+++ /dev/null\n@@ -1,17 +0,0 @@\n-#\n-# Licensed to the Apache Software Foundation (ASF) under one\n-# or more contributor license agreements. See the NOTICE file\n-# distributed with this work for additional information\n-# regarding copyright ownership. The ASF licenses this file\n-# to you under the Apache License, Version 2.0 (the\n-# \"License\"); you may not use this file except in compliance\n-# with the License. You may obtain a copy of the License at\n-#\n-# http://www.apache.org/licenses/LICENSE-2.0\n-#\n-# Unless required by applicable law or agreed to in writing,\n-# software distributed under the License is distributed on an\n-# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n-# KIND, either express or implied. See the License for the\n-# specific language governing permissions and limitations\n-# under the License.\n", "issue": "Migrate MySQL example DAGs to new design\nThere is a new design of system tests that was introduced by the [AIP-47](https://cwiki.apache.org/confluence/display/AIRFLOW/AIP-47+New+design+of+Airflow+System+Tests).\n\nAll current example dags need to be migrated and converted into system tests, so they can be run in the CI process automatically before releases.\n\nThis is an aggregated issue for all example DAGs related to `MySQL` provider. It is created to track progress of their migration.\n\nList of paths to example DAGs:\n- [x] airflow/providers/mysql/example_dags/example_mysql.py\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n", "path": "airflow/providers/mysql/example_dags/__init__.py"}], "after_files": [{"content": null, "path": "airflow/providers/mysql/example_dags/__init__.py"}]}
| 605 | 264 |
gh_patches_debug_21299
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-349
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Pass experiment tags to MLFlowLogger
**Is your feature request related to a problem? Please describe.**
When using MLFlowLogger, I'm unable to easily set experiment tags, like username or run name.
**Describe the solution you'd like**
Add parameter `tags=None` which is passed to `MLFlowLogger`. Tags will be passed to `create_run` method
**Describe alternatives you've considered**
Manually hack logger, get experiment from it and set tag there
If you don't see any drawbacks, I can make a PR
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_lightning/logging/mlflow_logger.py`
Content:
```
1 from time import time
2 from logging import getLogger
3
4 import mlflow
5
6 from .base import LightningLoggerBase, rank_zero_only
7
8 logger = getLogger(__name__)
9
10
11 class MLFlowLogger(LightningLoggerBase):
12 def __init__(self, experiment_name, tracking_uri=None):
13 super().__init__()
14 self.client = mlflow.tracking.MlflowClient(tracking_uri)
15 self.experiment_name = experiment_name
16 self._run_id = None
17
18 @property
19 def run_id(self):
20 if self._run_id is not None:
21 return self._run_id
22
23 experiment = self.client.get_experiment_by_name(self.experiment_name)
24 if experiment is None:
25 logger.warning(
26 f"Experiment with name f{self.experiment_name} not found. Creating it."
27 )
28 self.client.create_experiment(self.experiment_name)
29 experiment = self.client.get_experiment_by_name(self.experiment_name)
30
31 run = self.client.create_run(experiment.experiment_id)
32 self._run_id = run.info.run_id
33 return self._run_id
34
35 @rank_zero_only
36 def log_hyperparams(self, params):
37 for k, v in vars(params).items():
38 self.client.log_param(self.run_id, k, v)
39
40 @rank_zero_only
41 def log_metrics(self, metrics, step_num=None):
42 timestamp_ms = int(time() * 1000)
43 for k, v in metrics.items():
44 if isinstance(v, str):
45 logger.warning(
46 f"Discarding metric with string value {k}={v}"
47 )
48 continue
49 self.client.log_metric(self.run_id, k, v, timestamp_ms, step_num)
50
51 def save(self):
52 pass
53
54 @rank_zero_only
55 def finalize(self, status="FINISHED"):
56 if status == 'success':
57 status = 'FINISHED'
58 self.client.set_terminated(self.run_id, status)
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytorch_lightning/logging/mlflow_logger.py b/pytorch_lightning/logging/mlflow_logger.py
--- a/pytorch_lightning/logging/mlflow_logger.py
+++ b/pytorch_lightning/logging/mlflow_logger.py
@@ -9,11 +9,12 @@
class MLFlowLogger(LightningLoggerBase):
- def __init__(self, experiment_name, tracking_uri=None):
+ def __init__(self, experiment_name, tracking_uri=None, tags=None):
super().__init__()
self.client = mlflow.tracking.MlflowClient(tracking_uri)
self.experiment_name = experiment_name
self._run_id = None
+ self.tags = tags
@property
def run_id(self):
@@ -28,7 +29,7 @@
self.client.create_experiment(self.experiment_name)
experiment = self.client.get_experiment_by_name(self.experiment_name)
- run = self.client.create_run(experiment.experiment_id)
+ run = self.client.create_run(experiment.experiment_id, tags=self.tags)
self._run_id = run.info.run_id
return self._run_id
|
{"golden_diff": "diff --git a/pytorch_lightning/logging/mlflow_logger.py b/pytorch_lightning/logging/mlflow_logger.py\n--- a/pytorch_lightning/logging/mlflow_logger.py\n+++ b/pytorch_lightning/logging/mlflow_logger.py\n@@ -9,11 +9,12 @@\n \n \n class MLFlowLogger(LightningLoggerBase):\n- def __init__(self, experiment_name, tracking_uri=None):\n+ def __init__(self, experiment_name, tracking_uri=None, tags=None):\n super().__init__()\n self.client = mlflow.tracking.MlflowClient(tracking_uri)\n self.experiment_name = experiment_name\n self._run_id = None\n+ self.tags = tags\n \n @property\n def run_id(self):\n@@ -28,7 +29,7 @@\n self.client.create_experiment(self.experiment_name)\n experiment = self.client.get_experiment_by_name(self.experiment_name)\n \n- run = self.client.create_run(experiment.experiment_id)\n+ run = self.client.create_run(experiment.experiment_id, tags=self.tags)\n self._run_id = run.info.run_id\n return self._run_id\n", "issue": "Pass experiment tags to MLFlowLogger\n**Is your feature request related to a problem? Please describe.**\r\nWhen using MLFlowLogger, I'm unable to easily set experiment tags, like username or run name.\r\n\r\n**Describe the solution you'd like**\r\nAdd parameter `tags=None` which is passed to `MLFlowLogger`. Tags will be passed to `create_run` method\r\n\r\n**Describe alternatives you've considered**\r\nManually hack logger, get experiment from it and set tag there\r\n\r\nIf you don't see any drawbacks, I can make a PR\r\n\n", "before_files": [{"content": "from time import time\nfrom logging import getLogger\n\nimport mlflow\n\nfrom .base import LightningLoggerBase, rank_zero_only\n\nlogger = getLogger(__name__)\n\n\nclass MLFlowLogger(LightningLoggerBase):\n def __init__(self, experiment_name, tracking_uri=None):\n super().__init__()\n self.client = mlflow.tracking.MlflowClient(tracking_uri)\n self.experiment_name = experiment_name\n self._run_id = None\n\n @property\n def run_id(self):\n if self._run_id is not None:\n return self._run_id\n\n experiment = self.client.get_experiment_by_name(self.experiment_name)\n if experiment is None:\n logger.warning(\n f\"Experiment with name f{self.experiment_name} not found. Creating it.\"\n )\n self.client.create_experiment(self.experiment_name)\n experiment = self.client.get_experiment_by_name(self.experiment_name)\n\n run = self.client.create_run(experiment.experiment_id)\n self._run_id = run.info.run_id\n return self._run_id\n\n @rank_zero_only\n def log_hyperparams(self, params):\n for k, v in vars(params).items():\n self.client.log_param(self.run_id, k, v)\n\n @rank_zero_only\n def log_metrics(self, metrics, step_num=None):\n timestamp_ms = int(time() * 1000)\n for k, v in metrics.items():\n if isinstance(v, str):\n logger.warning(\n f\"Discarding metric with string value {k}={v}\"\n )\n continue\n self.client.log_metric(self.run_id, k, v, timestamp_ms, step_num)\n\n def save(self):\n pass\n\n @rank_zero_only\n def finalize(self, status=\"FINISHED\"):\n if status == 'success':\n status = 'FINISHED'\n self.client.set_terminated(self.run_id, status)\n", "path": "pytorch_lightning/logging/mlflow_logger.py"}], "after_files": [{"content": "from time import time\nfrom logging import getLogger\n\nimport mlflow\n\nfrom .base import LightningLoggerBase, rank_zero_only\n\nlogger = getLogger(__name__)\n\n\nclass MLFlowLogger(LightningLoggerBase):\n def __init__(self, experiment_name, tracking_uri=None, tags=None):\n super().__init__()\n self.client = mlflow.tracking.MlflowClient(tracking_uri)\n self.experiment_name = experiment_name\n self._run_id = None\n self.tags = tags\n\n @property\n def run_id(self):\n if self._run_id is not None:\n return self._run_id\n\n experiment = self.client.get_experiment_by_name(self.experiment_name)\n if experiment is None:\n logger.warning(\n f\"Experiment with name f{self.experiment_name} not found. Creating it.\"\n )\n self.client.create_experiment(self.experiment_name)\n experiment = self.client.get_experiment_by_name(self.experiment_name)\n\n run = self.client.create_run(experiment.experiment_id, tags=self.tags)\n self._run_id = run.info.run_id\n return self._run_id\n\n @rank_zero_only\n def log_hyperparams(self, params):\n for k, v in vars(params).items():\n self.client.log_param(self.run_id, k, v)\n\n @rank_zero_only\n def log_metrics(self, metrics, step_num=None):\n timestamp_ms = int(time() * 1000)\n for k, v in metrics.items():\n if isinstance(v, str):\n logger.warning(\n f\"Discarding metric with string value {k}={v}\"\n )\n continue\n self.client.log_metric(self.run_id, k, v, timestamp_ms, step_num)\n\n def save(self):\n pass\n\n @rank_zero_only\n def finalize(self, status=\"FINISHED\"):\n if status == 'success':\n status = 'FINISHED'\n self.client.set_terminated(self.run_id, status)\n", "path": "pytorch_lightning/logging/mlflow_logger.py"}]}
| 898 | 246 |
gh_patches_debug_13962
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-5416
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[package] all: "Access is denied" in os.rename() on Windows
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **almost all packages affected**
* Operating System+version: **Windows 10**
* Compiler+version: **MSVC 16**
* Conan version: **conan 1.35.2**
* Python version: **Python 3.8.7**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
[settings]
os_build=Windows
os=Windows
arch=x86_64
arch_build=x86_64
compiler=Visual Studio
compiler.version=16
compiler.runtime=MD
build_type=Release
```
### Steps to reproduce (Include if Applicable)
This is a known issue. Solution provided by https://github.com/conan-io/conan/pull/6774
However most recipes still use `os.rename()` and not `tools.rename()`.
### Log
```
b2/4.2.0: Configuring sources in C:\Users\xxx\.conan\data\b2\4.2.0\_\_\source
ERROR: b2/4.2.0: Error in source() method, line 58
os.rename(extracted_dir, "source")
PermissionError: [WinError 5] Access is denied: 'build-4.2.0' -> 'source'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/zulu-openjdk/all/conanfile.py`
Content:
```
1 from conans import ConanFile, tools
2 from conans.errors import ConanInvalidConfiguration
3 import os, glob
4
5
6 class ZuluOpenJDK(ConanFile):
7 name = "zulu-openjdk"
8 url = "https://github.com/conan-io/conan-center-index/"
9 description = "A OpenJDK distribution"
10 homepage = "https://www.azul.com"
11 license = "https://www.azul.com/products/zulu-and-zulu-enterprise/zulu-terms-of-use/"
12 topics = ("java", "jdk", "openjdk")
13 settings = "os", "arch"
14
15 @property
16 def _source_subfolder(self):
17 return "source_subfolder"
18
19 @property
20 def _jni_folder(self):
21 folder = {"Linux": "linux", "Macos": "darwin", "Windows": "win32"}.get(str(self.settings.os))
22 return os.path.join("include", folder)
23
24 def configure(self):
25 if self.settings.arch != "x86_64":
26 raise ConanInvalidConfiguration("Unsupported Architecture. This package currently only supports x86_64.")
27 if self.settings.os not in ["Windows", "Macos", "Linux"]:
28 raise ConanInvalidConfiguration("Unsupported os. This package currently only support Linux/Macos/Windows")
29
30 def source(self):
31 url = self.conan_data["sources"][self.version]["url"][str(self.settings.os)]
32 checksum = self.conan_data["sources"][self.version]["sha256"][str(self.settings.os)]
33 tools.get(url, sha256=checksum)
34 os.rename(glob.glob("zulu*")[0], self._source_subfolder)
35
36 def build(self):
37 pass # nothing to do, but this shall trigger no warnings ;-)
38
39 def package(self):
40 self.copy(pattern="*", dst="bin", src=os.path.join(self._source_subfolder, "bin"), excludes=("msvcp140.dll", "vcruntime140.dll"))
41 self.copy(pattern="*", dst="include", src=os.path.join(self._source_subfolder, "include"))
42 self.copy(pattern="*", dst="lib", src=os.path.join(self._source_subfolder, "lib"))
43 self.copy(pattern="*", dst="res", src=os.path.join(self._source_subfolder, "conf"))
44 # conf folder is required for security settings, to avoid
45 # java.lang.SecurityException: Can't read cryptographic policy directory: unlimited
46 # https://github.com/conan-io/conan-center-index/pull/4491#issuecomment-774555069
47 self.copy(pattern="*", dst="conf", src=os.path.join(self._source_subfolder, "conf"))
48 self.copy(pattern="*", dst="licenses", src=os.path.join(self._source_subfolder, "legal"))
49 self.copy(pattern="*", dst=os.path.join("lib", "jmods"), src=os.path.join(self._source_subfolder, "jmods"))
50
51 def package_info(self):
52 self.cpp_info.includedirs.append(self._jni_folder)
53 self.cpp_info.libdirs = []
54
55 java_home = self.package_folder
56 bin_path = os.path.join(java_home, "bin")
57
58 self.output.info("Creating JAVA_HOME environment variable with : {0}".format(java_home))
59 self.env_info.JAVA_HOME = java_home
60
61 self.output.info("Appending PATH environment variable with : {0}".format(bin_path))
62 self.env_info.PATH.append(bin_path)
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/zulu-openjdk/all/conanfile.py b/recipes/zulu-openjdk/all/conanfile.py
--- a/recipes/zulu-openjdk/all/conanfile.py
+++ b/recipes/zulu-openjdk/all/conanfile.py
@@ -28,10 +28,8 @@
raise ConanInvalidConfiguration("Unsupported os. This package currently only support Linux/Macos/Windows")
def source(self):
- url = self.conan_data["sources"][self.version]["url"][str(self.settings.os)]
- checksum = self.conan_data["sources"][self.version]["sha256"][str(self.settings.os)]
- tools.get(url, sha256=checksum)
- os.rename(glob.glob("zulu*")[0], self._source_subfolder)
+ tools.get(**self.conan_data["sources"][self.version][str(self.settings.os)],
+ destination=self._source_subfolder, strip_root=True)
def build(self):
pass # nothing to do, but this shall trigger no warnings ;-)
|
{"golden_diff": "diff --git a/recipes/zulu-openjdk/all/conanfile.py b/recipes/zulu-openjdk/all/conanfile.py\n--- a/recipes/zulu-openjdk/all/conanfile.py\n+++ b/recipes/zulu-openjdk/all/conanfile.py\n@@ -28,10 +28,8 @@\n raise ConanInvalidConfiguration(\"Unsupported os. This package currently only support Linux/Macos/Windows\")\n \n def source(self):\n- url = self.conan_data[\"sources\"][self.version][\"url\"][str(self.settings.os)]\n- checksum = self.conan_data[\"sources\"][self.version][\"sha256\"][str(self.settings.os)]\n- tools.get(url, sha256=checksum)\n- os.rename(glob.glob(\"zulu*\")[0], self._source_subfolder)\n+ tools.get(**self.conan_data[\"sources\"][self.version][str(self.settings.os)],\n+ destination=self._source_subfolder, strip_root=True)\n \n def build(self):\n pass # nothing to do, but this shall trigger no warnings ;-)\n", "issue": "[package] all: \"Access is denied\" in os.rename() on Windows\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **almost all packages affected**\r\n * Operating System+version: **Windows 10**\r\n * Compiler+version: **MSVC 16**\r\n * Conan version: **conan 1.35.2**\r\n * Python version: **Python 3.8.7**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\n[settings]\r\nos_build=Windows\r\nos=Windows\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=Visual Studio\r\ncompiler.version=16\r\ncompiler.runtime=MD\r\nbuild_type=Release\r\n```\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n\r\nThis is a known issue. Solution provided by https://github.com/conan-io/conan/pull/6774\r\nHowever most recipes still use `os.rename()` and not `tools.rename()`. \r\n\r\n### Log\r\n```\r\nb2/4.2.0: Configuring sources in C:\\Users\\xxx\\.conan\\data\\b2\\4.2.0\\_\\_\\source\r\nERROR: b2/4.2.0: Error in source() method, line 58\r\nos.rename(extracted_dir, \"source\")\r\nPermissionError: [WinError 5] Access is denied: 'build-4.2.0' -> 'source'\r\n```\r\n\n", "before_files": [{"content": "from conans import ConanFile, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os, glob\n\n\nclass ZuluOpenJDK(ConanFile):\n name = \"zulu-openjdk\"\n url = \"https://github.com/conan-io/conan-center-index/\"\n description = \"A OpenJDK distribution\"\n homepage = \"https://www.azul.com\"\n license = \"https://www.azul.com/products/zulu-and-zulu-enterprise/zulu-terms-of-use/\"\n topics = (\"java\", \"jdk\", \"openjdk\")\n settings = \"os\", \"arch\"\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _jni_folder(self):\n folder = {\"Linux\": \"linux\", \"Macos\": \"darwin\", \"Windows\": \"win32\"}.get(str(self.settings.os))\n return os.path.join(\"include\", folder)\n\n def configure(self):\n if self.settings.arch != \"x86_64\":\n raise ConanInvalidConfiguration(\"Unsupported Architecture. This package currently only supports x86_64.\")\n if self.settings.os not in [\"Windows\", \"Macos\", \"Linux\"]:\n raise ConanInvalidConfiguration(\"Unsupported os. This package currently only support Linux/Macos/Windows\")\n\n def source(self):\n url = self.conan_data[\"sources\"][self.version][\"url\"][str(self.settings.os)]\n checksum = self.conan_data[\"sources\"][self.version][\"sha256\"][str(self.settings.os)]\n tools.get(url, sha256=checksum)\n os.rename(glob.glob(\"zulu*\")[0], self._source_subfolder)\n\n def build(self):\n pass # nothing to do, but this shall trigger no warnings ;-)\n\n def package(self):\n self.copy(pattern=\"*\", dst=\"bin\", src=os.path.join(self._source_subfolder, \"bin\"), excludes=(\"msvcp140.dll\", \"vcruntime140.dll\"))\n self.copy(pattern=\"*\", dst=\"include\", src=os.path.join(self._source_subfolder, \"include\"))\n self.copy(pattern=\"*\", dst=\"lib\", src=os.path.join(self._source_subfolder, \"lib\"))\n self.copy(pattern=\"*\", dst=\"res\", src=os.path.join(self._source_subfolder, \"conf\"))\n # conf folder is required for security settings, to avoid\n # java.lang.SecurityException: Can't read cryptographic policy directory: unlimited\n # https://github.com/conan-io/conan-center-index/pull/4491#issuecomment-774555069\n self.copy(pattern=\"*\", dst=\"conf\", src=os.path.join(self._source_subfolder, \"conf\"))\n self.copy(pattern=\"*\", dst=\"licenses\", src=os.path.join(self._source_subfolder, \"legal\"))\n self.copy(pattern=\"*\", dst=os.path.join(\"lib\", \"jmods\"), src=os.path.join(self._source_subfolder, \"jmods\"))\n\n def package_info(self):\n self.cpp_info.includedirs.append(self._jni_folder)\n self.cpp_info.libdirs = []\n\n java_home = self.package_folder\n bin_path = os.path.join(java_home, \"bin\")\n\n self.output.info(\"Creating JAVA_HOME environment variable with : {0}\".format(java_home))\n self.env_info.JAVA_HOME = java_home\n\n self.output.info(\"Appending PATH environment variable with : {0}\".format(bin_path))\n self.env_info.PATH.append(bin_path)\n", "path": "recipes/zulu-openjdk/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os, glob\n\n\nclass ZuluOpenJDK(ConanFile):\n name = \"zulu-openjdk\"\n url = \"https://github.com/conan-io/conan-center-index/\"\n description = \"A OpenJDK distribution\"\n homepage = \"https://www.azul.com\"\n license = \"https://www.azul.com/products/zulu-and-zulu-enterprise/zulu-terms-of-use/\"\n topics = (\"java\", \"jdk\", \"openjdk\")\n settings = \"os\", \"arch\"\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _jni_folder(self):\n folder = {\"Linux\": \"linux\", \"Macos\": \"darwin\", \"Windows\": \"win32\"}.get(str(self.settings.os))\n return os.path.join(\"include\", folder)\n\n def configure(self):\n if self.settings.arch != \"x86_64\":\n raise ConanInvalidConfiguration(\"Unsupported Architecture. This package currently only supports x86_64.\")\n if self.settings.os not in [\"Windows\", \"Macos\", \"Linux\"]:\n raise ConanInvalidConfiguration(\"Unsupported os. This package currently only support Linux/Macos/Windows\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version][str(self.settings.os)],\n destination=self._source_subfolder, strip_root=True)\n\n def build(self):\n pass # nothing to do, but this shall trigger no warnings ;-)\n\n def package(self):\n self.copy(pattern=\"*\", dst=\"bin\", src=os.path.join(self._source_subfolder, \"bin\"), excludes=(\"msvcp140.dll\", \"vcruntime140.dll\"))\n self.copy(pattern=\"*\", dst=\"include\", src=os.path.join(self._source_subfolder, \"include\"))\n self.copy(pattern=\"*\", dst=\"lib\", src=os.path.join(self._source_subfolder, \"lib\"))\n self.copy(pattern=\"*\", dst=\"res\", src=os.path.join(self._source_subfolder, \"conf\"))\n # conf folder is required for security settings, to avoid\n # java.lang.SecurityException: Can't read cryptographic policy directory: unlimited\n # https://github.com/conan-io/conan-center-index/pull/4491#issuecomment-774555069\n self.copy(pattern=\"*\", dst=\"conf\", src=os.path.join(self._source_subfolder, \"conf\"))\n self.copy(pattern=\"*\", dst=\"licenses\", src=os.path.join(self._source_subfolder, \"legal\"))\n self.copy(pattern=\"*\", dst=os.path.join(\"lib\", \"jmods\"), src=os.path.join(self._source_subfolder, \"jmods\"))\n\n def package_info(self):\n self.cpp_info.includedirs.append(self._jni_folder)\n self.cpp_info.libdirs = []\n\n java_home = self.package_folder\n bin_path = os.path.join(java_home, \"bin\")\n\n self.output.info(\"Creating JAVA_HOME environment variable with : {0}\".format(java_home))\n self.env_info.JAVA_HOME = java_home\n\n self.output.info(\"Appending PATH environment variable with : {0}\".format(bin_path))\n self.env_info.PATH.append(bin_path)\n", "path": "recipes/zulu-openjdk/all/conanfile.py"}]}
| 1,466 | 227 |
gh_patches_debug_5474
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4646
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow run pyw scripts
scrapy/commands/runspider.py check for Python script source but it fails to allow .pyw files.
Check at row 14 is:
` if fext != '.py':`
but it should be:
` if fext != '.py' and fext != '.pyw':`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/commands/runspider.py`
Content:
```
1 import sys
2 import os
3 from importlib import import_module
4
5 from scrapy.utils.spider import iter_spider_classes
6 from scrapy.exceptions import UsageError
7 from scrapy.commands import BaseRunSpiderCommand
8
9
10 def _import_file(filepath):
11 abspath = os.path.abspath(filepath)
12 dirname, file = os.path.split(abspath)
13 fname, fext = os.path.splitext(file)
14 if fext != '.py':
15 raise ValueError(f"Not a Python source file: {abspath}")
16 if dirname:
17 sys.path = [dirname] + sys.path
18 try:
19 module = import_module(fname)
20 finally:
21 if dirname:
22 sys.path.pop(0)
23 return module
24
25
26 class Command(BaseRunSpiderCommand):
27
28 requires_project = False
29 default_settings = {'SPIDER_LOADER_WARN_ONLY': True}
30
31 def syntax(self):
32 return "[options] <spider_file>"
33
34 def short_desc(self):
35 return "Run a self-contained spider (without creating a project)"
36
37 def long_desc(self):
38 return "Run the spider defined in the given file"
39
40 def run(self, args, opts):
41 if len(args) != 1:
42 raise UsageError()
43 filename = args[0]
44 if not os.path.exists(filename):
45 raise UsageError(f"File not found: {filename}\n")
46 try:
47 module = _import_file(filename)
48 except (ImportError, ValueError) as e:
49 raise UsageError(f"Unable to load {filename!r}: {e}\n")
50 spclasses = list(iter_spider_classes(module))
51 if not spclasses:
52 raise UsageError(f"No spider found in file: {filename}\n")
53 spidercls = spclasses.pop()
54
55 self.crawler_process.crawl(spidercls, **opts.spargs)
56 self.crawler_process.start()
57
58 if self.crawler_process.bootstrap_failed:
59 self.exitcode = 1
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/commands/runspider.py b/scrapy/commands/runspider.py
--- a/scrapy/commands/runspider.py
+++ b/scrapy/commands/runspider.py
@@ -11,7 +11,7 @@
abspath = os.path.abspath(filepath)
dirname, file = os.path.split(abspath)
fname, fext = os.path.splitext(file)
- if fext != '.py':
+ if fext not in ('.py', '.pyw'):
raise ValueError(f"Not a Python source file: {abspath}")
if dirname:
sys.path = [dirname] + sys.path
|
{"golden_diff": "diff --git a/scrapy/commands/runspider.py b/scrapy/commands/runspider.py\n--- a/scrapy/commands/runspider.py\n+++ b/scrapy/commands/runspider.py\n@@ -11,7 +11,7 @@\n abspath = os.path.abspath(filepath)\n dirname, file = os.path.split(abspath)\n fname, fext = os.path.splitext(file)\n- if fext != '.py':\n+ if fext not in ('.py', '.pyw'):\n raise ValueError(f\"Not a Python source file: {abspath}\")\n if dirname:\n sys.path = [dirname] + sys.path\n", "issue": "Allow run pyw scripts\nscrapy/commands/runspider.py check for Python script source but it fails to allow .pyw files.\r\nCheck at row 14 is:\r\n` if fext != '.py':`\r\nbut it should be:\r\n` if fext != '.py' and fext != '.pyw':`\n", "before_files": [{"content": "import sys\nimport os\nfrom importlib import import_module\n\nfrom scrapy.utils.spider import iter_spider_classes\nfrom scrapy.exceptions import UsageError\nfrom scrapy.commands import BaseRunSpiderCommand\n\n\ndef _import_file(filepath):\n abspath = os.path.abspath(filepath)\n dirname, file = os.path.split(abspath)\n fname, fext = os.path.splitext(file)\n if fext != '.py':\n raise ValueError(f\"Not a Python source file: {abspath}\")\n if dirname:\n sys.path = [dirname] + sys.path\n try:\n module = import_module(fname)\n finally:\n if dirname:\n sys.path.pop(0)\n return module\n\n\nclass Command(BaseRunSpiderCommand):\n\n requires_project = False\n default_settings = {'SPIDER_LOADER_WARN_ONLY': True}\n\n def syntax(self):\n return \"[options] <spider_file>\"\n\n def short_desc(self):\n return \"Run a self-contained spider (without creating a project)\"\n\n def long_desc(self):\n return \"Run the spider defined in the given file\"\n\n def run(self, args, opts):\n if len(args) != 1:\n raise UsageError()\n filename = args[0]\n if not os.path.exists(filename):\n raise UsageError(f\"File not found: {filename}\\n\")\n try:\n module = _import_file(filename)\n except (ImportError, ValueError) as e:\n raise UsageError(f\"Unable to load {filename!r}: {e}\\n\")\n spclasses = list(iter_spider_classes(module))\n if not spclasses:\n raise UsageError(f\"No spider found in file: {filename}\\n\")\n spidercls = spclasses.pop()\n\n self.crawler_process.crawl(spidercls, **opts.spargs)\n self.crawler_process.start()\n\n if self.crawler_process.bootstrap_failed:\n self.exitcode = 1\n", "path": "scrapy/commands/runspider.py"}], "after_files": [{"content": "import sys\nimport os\nfrom importlib import import_module\n\nfrom scrapy.utils.spider import iter_spider_classes\nfrom scrapy.exceptions import UsageError\nfrom scrapy.commands import BaseRunSpiderCommand\n\n\ndef _import_file(filepath):\n abspath = os.path.abspath(filepath)\n dirname, file = os.path.split(abspath)\n fname, fext = os.path.splitext(file)\n if fext not in ('.py', '.pyw'):\n raise ValueError(f\"Not a Python source file: {abspath}\")\n if dirname:\n sys.path = [dirname] + sys.path\n try:\n module = import_module(fname)\n finally:\n if dirname:\n sys.path.pop(0)\n return module\n\n\nclass Command(BaseRunSpiderCommand):\n\n requires_project = False\n default_settings = {'SPIDER_LOADER_WARN_ONLY': True}\n\n def syntax(self):\n return \"[options] <spider_file>\"\n\n def short_desc(self):\n return \"Run a self-contained spider (without creating a project)\"\n\n def long_desc(self):\n return \"Run the spider defined in the given file\"\n\n def run(self, args, opts):\n if len(args) != 1:\n raise UsageError()\n filename = args[0]\n if not os.path.exists(filename):\n raise UsageError(f\"File not found: {filename}\\n\")\n try:\n module = _import_file(filename)\n except (ImportError, ValueError) as e:\n raise UsageError(f\"Unable to load {filename!r}: {e}\\n\")\n spclasses = list(iter_spider_classes(module))\n if not spclasses:\n raise UsageError(f\"No spider found in file: {filename}\\n\")\n spidercls = spclasses.pop()\n\n self.crawler_process.crawl(spidercls, **opts.spargs)\n self.crawler_process.start()\n\n if self.crawler_process.bootstrap_failed:\n self.exitcode = 1\n", "path": "scrapy/commands/runspider.py"}]}
| 852 | 140 |
gh_patches_debug_39710
|
rasdani/github-patches
|
git_diff
|
wright-group__WrightTools-339
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[before h5] join takes set of points along each axis
currently join looks at each axis and tries to guess what the best evenly spaced points are
moving forward, join will simply take the set of all points in all data objects along each axis
interpolation will still be used for points that are not contained in any data set (within the convex hull, of course)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `WrightTools/data/_join.py`
Content:
```
1 """Join multiple data objects together."""
2
3
4 # --- import --------------------------------------------------------------------------------------
5
6
7 import numpy as np
8
9 from ._data import Channel, Data
10
11
12 # --- define --------------------------------------------------------------------------------------
13
14 __all__ = ['join']
15
16 # --- functions -----------------------------------------------------------------------------------
17
18
19 def join(datas, method='first', verbose=True, **kwargs):
20 """Join a list of data objects together.
21
22 For now datas must have identical dimensionalities (order and identity).
23
24 Parameters
25 ----------
26 datas : list of data
27 The list of data objects to join together.
28 method : {'first', 'sum', 'max', 'min', 'mean'} (optional)
29 The method for how overlapping points get treated. Default is first,
30 meaning that the data object that appears first in datas will take
31 precedence.
32 verbose : bool (optional)
33 Toggle talkback. Default is True.
34
35 Keyword Arguments
36 -----------------
37 axis objects
38 The axes of the new data object. If not supplied, the points of the
39 new axis will be guessed from the given datas.
40
41 Returns
42 -------
43 data
44 A Data instance.
45 """
46 # TODO: a proper treatment of joining datas that have different dimensions
47 # with intellegent treatment of their constant dimensions. perhaps changing
48 # map_axis would be good for this. - Blaise 2015.10.31
49
50 # copy datas so original objects are not changed
51 datas = [d.copy() for d in datas]
52 # get scanned dimensions
53 axis_names = []
54 axis_units = []
55 axis_objects = []
56 for data in datas:
57 for i, axis in enumerate(data.axes):
58 if axis.name in kwargs.keys():
59 axis.convert(kwargs[axis.name].units)
60 if axis.points[0] > axis.points[-1]:
61 data.flip(i)
62 if axis.name not in axis_names:
63 axis_names.append(axis.name)
64 axis_units.append(axis.units)
65 axis_objects.append(axis)
66 # TODO: transpose to same dimension orders
67 # convert into same units
68 for data in datas:
69 for axis_name, axis_unit in zip(axis_names, axis_units):
70 for axis in data.axes:
71 if axis.name == axis_name:
72 axis.convert(axis_unit)
73 # get axis points
74 axis_points = [] # list of 1D arrays
75 for axis_name in axis_names:
76 if axis_name in kwargs.keys():
77 axis_points.append(kwargs[axis_name].points)
78 continue
79 all_points = np.array([])
80 step_sizes = []
81 for data in datas:
82 for axis in data.axes:
83 if axis.name == axis_name:
84 all_points = np.concatenate([all_points, axis.points])
85 this_axis_min = np.nanmin(axis.points)
86 this_axis_max = np.nanmax(axis.points)
87 this_axis_number = float(axis.points.size) - 1
88 step_size = (this_axis_max - this_axis_min) / this_axis_number
89 step_sizes.append(step_size)
90 axis_min = np.nanmin(all_points)
91 axis_max = np.nanmax(all_points)
92 axis_step_size = min(step_sizes)
93 axis_n_points = np.ceil((axis_max - axis_min) / axis_step_size)
94 points = np.linspace(axis_min, axis_max, axis_n_points + 1)
95 axis_points.append(points)
96 # map datas to new points
97 for axis_index, axis_name in enumerate(axis_names):
98 for data in datas:
99 for axis in data.axes:
100 if axis.name == axis_name:
101 if not np.array_equiv(axis.points, axis_points[axis_index]):
102 data.map_axis(axis_name, axis_points[axis_index])
103 # make new channel objects
104 channel_objects = []
105 n_channels = min([len(d.channels) for d in datas])
106 for channel_index in range(n_channels):
107 full = np.array([d.channels[channel_index].values for d in datas])
108 if method == 'first':
109 zis = np.full(full.shape[1:], np.nan)
110 for idx in np.ndindex(*full.shape[1:]):
111 for data_index in range(len(full)):
112 value = full[data_index][idx]
113 if not np.isnan(value):
114 zis[idx] = value
115 break
116 elif method == 'sum':
117 zis = np.nansum(full, axis=0)
118 zis[zis == 0.] = np.nan
119 elif method == 'max':
120 zis = np.nanmax(full, axis=0)
121 elif method == 'min':
122 zis = np.nanmin(full, axis=0)
123 elif method == 'mean':
124 zis = np.nanmean(full, axis=0)
125 else:
126 raise ValueError("method %s not recognized" % method)
127 zis[np.isnan(full).all(axis=0)] = np.nan # if all datas NaN, zis NaN
128 channel = Channel(zis, null=0.,
129 signed=datas[0].channels[channel_index].signed,
130 name=datas[0].channels[channel_index].name)
131 channel_objects.append(channel)
132 # make new data object
133 out = Data(axis_objects, channel_objects)
134 # finish
135 if verbose:
136 print(len(datas), 'datas joined to create new data:')
137 print(' axes:')
138 for axis in out.axes:
139 points = axis.points
140 print(' {0} : {1} points from {2} to {3} {4}'.format(
141 axis.name, points.size, min(points), max(points), axis.units))
142 print(' channels:')
143 for channel in out.channels:
144 percent_nan = np.around(100. * (np.isnan(channel.values).sum() /
145 float(channel.values.size)), decimals=2)
146 print(' {0} : {1} to {2} ({3}% NaN)'.format(
147 channel.name, channel.min(), channel.max(), percent_nan))
148 return out
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/WrightTools/data/_join.py b/WrightTools/data/_join.py
--- a/WrightTools/data/_join.py
+++ b/WrightTools/data/_join.py
@@ -11,8 +11,10 @@
# --- define --------------------------------------------------------------------------------------
+
__all__ = ['join']
+
# --- functions -----------------------------------------------------------------------------------
@@ -32,21 +34,11 @@
verbose : bool (optional)
Toggle talkback. Default is True.
- Keyword Arguments
- -----------------
- axis objects
- The axes of the new data object. If not supplied, the points of the
- new axis will be guessed from the given datas.
-
Returns
-------
- data
- A Data instance.
+ WrightTools.data.Data
+ A new Data instance.
"""
- # TODO: a proper treatment of joining datas that have different dimensions
- # with intellegent treatment of their constant dimensions. perhaps changing
- # map_axis would be good for this. - Blaise 2015.10.31
-
# copy datas so original objects are not changed
datas = [d.copy() for d in datas]
# get scanned dimensions
@@ -63,7 +55,6 @@
axis_names.append(axis.name)
axis_units.append(axis.units)
axis_objects.append(axis)
- # TODO: transpose to same dimension orders
# convert into same units
for data in datas:
for axis_name, axis_unit in zip(axis_names, axis_units):
@@ -73,26 +64,11 @@
# get axis points
axis_points = [] # list of 1D arrays
for axis_name in axis_names:
- if axis_name in kwargs.keys():
- axis_points.append(kwargs[axis_name].points)
- continue
- all_points = np.array([])
- step_sizes = []
+ points = np.full((0), np.nan)
for data in datas:
- for axis in data.axes:
- if axis.name == axis_name:
- all_points = np.concatenate([all_points, axis.points])
- this_axis_min = np.nanmin(axis.points)
- this_axis_max = np.nanmax(axis.points)
- this_axis_number = float(axis.points.size) - 1
- step_size = (this_axis_max - this_axis_min) / this_axis_number
- step_sizes.append(step_size)
- axis_min = np.nanmin(all_points)
- axis_max = np.nanmax(all_points)
- axis_step_size = min(step_sizes)
- axis_n_points = np.ceil((axis_max - axis_min) / axis_step_size)
- points = np.linspace(axis_min, axis_max, axis_n_points + 1)
- axis_points.append(points)
+ index = data.axis_names.index(axis_name)
+ points = np.hstack((points, data.axes[index].points))
+ axis_points.append(np.unique(points))
# map datas to new points
for axis_index, axis_name in enumerate(axis_names):
for data in datas:
|
{"golden_diff": "diff --git a/WrightTools/data/_join.py b/WrightTools/data/_join.py\n--- a/WrightTools/data/_join.py\n+++ b/WrightTools/data/_join.py\n@@ -11,8 +11,10 @@\n \n # --- define --------------------------------------------------------------------------------------\n \n+\n __all__ = ['join']\n \n+\n # --- functions -----------------------------------------------------------------------------------\n \n \n@@ -32,21 +34,11 @@\n verbose : bool (optional)\n Toggle talkback. Default is True.\n \n- Keyword Arguments\n- -----------------\n- axis objects\n- The axes of the new data object. If not supplied, the points of the\n- new axis will be guessed from the given datas.\n-\n Returns\n -------\n- data\n- A Data instance.\n+ WrightTools.data.Data\n+ A new Data instance.\n \"\"\"\n- # TODO: a proper treatment of joining datas that have different dimensions\n- # with intellegent treatment of their constant dimensions. perhaps changing\n- # map_axis would be good for this. - Blaise 2015.10.31\n-\n # copy datas so original objects are not changed\n datas = [d.copy() for d in datas]\n # get scanned dimensions\n@@ -63,7 +55,6 @@\n axis_names.append(axis.name)\n axis_units.append(axis.units)\n axis_objects.append(axis)\n- # TODO: transpose to same dimension orders\n # convert into same units\n for data in datas:\n for axis_name, axis_unit in zip(axis_names, axis_units):\n@@ -73,26 +64,11 @@\n # get axis points\n axis_points = [] # list of 1D arrays\n for axis_name in axis_names:\n- if axis_name in kwargs.keys():\n- axis_points.append(kwargs[axis_name].points)\n- continue\n- all_points = np.array([])\n- step_sizes = []\n+ points = np.full((0), np.nan)\n for data in datas:\n- for axis in data.axes:\n- if axis.name == axis_name:\n- all_points = np.concatenate([all_points, axis.points])\n- this_axis_min = np.nanmin(axis.points)\n- this_axis_max = np.nanmax(axis.points)\n- this_axis_number = float(axis.points.size) - 1\n- step_size = (this_axis_max - this_axis_min) / this_axis_number\n- step_sizes.append(step_size)\n- axis_min = np.nanmin(all_points)\n- axis_max = np.nanmax(all_points)\n- axis_step_size = min(step_sizes)\n- axis_n_points = np.ceil((axis_max - axis_min) / axis_step_size)\n- points = np.linspace(axis_min, axis_max, axis_n_points + 1)\n- axis_points.append(points)\n+ index = data.axis_names.index(axis_name)\n+ points = np.hstack((points, data.axes[index].points))\n+ axis_points.append(np.unique(points))\n # map datas to new points\n for axis_index, axis_name in enumerate(axis_names):\n for data in datas:\n", "issue": "[before h5] join takes set of points along each axis\ncurrently join looks at each axis and tries to guess what the best evenly spaced points are\r\n\r\nmoving forward, join will simply take the set of all points in all data objects along each axis\r\n\r\ninterpolation will still be used for points that are not contained in any data set (within the convex hull, of course)\n", "before_files": [{"content": "\"\"\"Join multiple data objects together.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nimport numpy as np\n\nfrom ._data import Channel, Data\n\n\n# --- define --------------------------------------------------------------------------------------\n\n__all__ = ['join']\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef join(datas, method='first', verbose=True, **kwargs):\n \"\"\"Join a list of data objects together.\n\n For now datas must have identical dimensionalities (order and identity).\n\n Parameters\n ----------\n datas : list of data\n The list of data objects to join together.\n method : {'first', 'sum', 'max', 'min', 'mean'} (optional)\n The method for how overlapping points get treated. Default is first,\n meaning that the data object that appears first in datas will take\n precedence.\n verbose : bool (optional)\n Toggle talkback. Default is True.\n\n Keyword Arguments\n -----------------\n axis objects\n The axes of the new data object. If not supplied, the points of the\n new axis will be guessed from the given datas.\n\n Returns\n -------\n data\n A Data instance.\n \"\"\"\n # TODO: a proper treatment of joining datas that have different dimensions\n # with intellegent treatment of their constant dimensions. perhaps changing\n # map_axis would be good for this. - Blaise 2015.10.31\n\n # copy datas so original objects are not changed\n datas = [d.copy() for d in datas]\n # get scanned dimensions\n axis_names = []\n axis_units = []\n axis_objects = []\n for data in datas:\n for i, axis in enumerate(data.axes):\n if axis.name in kwargs.keys():\n axis.convert(kwargs[axis.name].units)\n if axis.points[0] > axis.points[-1]:\n data.flip(i)\n if axis.name not in axis_names:\n axis_names.append(axis.name)\n axis_units.append(axis.units)\n axis_objects.append(axis)\n # TODO: transpose to same dimension orders\n # convert into same units\n for data in datas:\n for axis_name, axis_unit in zip(axis_names, axis_units):\n for axis in data.axes:\n if axis.name == axis_name:\n axis.convert(axis_unit)\n # get axis points\n axis_points = [] # list of 1D arrays\n for axis_name in axis_names:\n if axis_name in kwargs.keys():\n axis_points.append(kwargs[axis_name].points)\n continue\n all_points = np.array([])\n step_sizes = []\n for data in datas:\n for axis in data.axes:\n if axis.name == axis_name:\n all_points = np.concatenate([all_points, axis.points])\n this_axis_min = np.nanmin(axis.points)\n this_axis_max = np.nanmax(axis.points)\n this_axis_number = float(axis.points.size) - 1\n step_size = (this_axis_max - this_axis_min) / this_axis_number\n step_sizes.append(step_size)\n axis_min = np.nanmin(all_points)\n axis_max = np.nanmax(all_points)\n axis_step_size = min(step_sizes)\n axis_n_points = np.ceil((axis_max - axis_min) / axis_step_size)\n points = np.linspace(axis_min, axis_max, axis_n_points + 1)\n axis_points.append(points)\n # map datas to new points\n for axis_index, axis_name in enumerate(axis_names):\n for data in datas:\n for axis in data.axes:\n if axis.name == axis_name:\n if not np.array_equiv(axis.points, axis_points[axis_index]):\n data.map_axis(axis_name, axis_points[axis_index])\n # make new channel objects\n channel_objects = []\n n_channels = min([len(d.channels) for d in datas])\n for channel_index in range(n_channels):\n full = np.array([d.channels[channel_index].values for d in datas])\n if method == 'first':\n zis = np.full(full.shape[1:], np.nan)\n for idx in np.ndindex(*full.shape[1:]):\n for data_index in range(len(full)):\n value = full[data_index][idx]\n if not np.isnan(value):\n zis[idx] = value\n break\n elif method == 'sum':\n zis = np.nansum(full, axis=0)\n zis[zis == 0.] = np.nan\n elif method == 'max':\n zis = np.nanmax(full, axis=0)\n elif method == 'min':\n zis = np.nanmin(full, axis=0)\n elif method == 'mean':\n zis = np.nanmean(full, axis=0)\n else:\n raise ValueError(\"method %s not recognized\" % method)\n zis[np.isnan(full).all(axis=0)] = np.nan # if all datas NaN, zis NaN\n channel = Channel(zis, null=0.,\n signed=datas[0].channels[channel_index].signed,\n name=datas[0].channels[channel_index].name)\n channel_objects.append(channel)\n # make new data object\n out = Data(axis_objects, channel_objects)\n # finish\n if verbose:\n print(len(datas), 'datas joined to create new data:')\n print(' axes:')\n for axis in out.axes:\n points = axis.points\n print(' {0} : {1} points from {2} to {3} {4}'.format(\n axis.name, points.size, min(points), max(points), axis.units))\n print(' channels:')\n for channel in out.channels:\n percent_nan = np.around(100. * (np.isnan(channel.values).sum() /\n float(channel.values.size)), decimals=2)\n print(' {0} : {1} to {2} ({3}% NaN)'.format(\n channel.name, channel.min(), channel.max(), percent_nan))\n return out\n", "path": "WrightTools/data/_join.py"}], "after_files": [{"content": "\"\"\"Join multiple data objects together.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nimport numpy as np\n\nfrom ._data import Channel, Data\n\n\n# --- define --------------------------------------------------------------------------------------\n\n\n__all__ = ['join']\n\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef join(datas, method='first', verbose=True, **kwargs):\n \"\"\"Join a list of data objects together.\n\n For now datas must have identical dimensionalities (order and identity).\n\n Parameters\n ----------\n datas : list of data\n The list of data objects to join together.\n method : {'first', 'sum', 'max', 'min', 'mean'} (optional)\n The method for how overlapping points get treated. Default is first,\n meaning that the data object that appears first in datas will take\n precedence.\n verbose : bool (optional)\n Toggle talkback. Default is True.\n\n Returns\n -------\n WrightTools.data.Data\n A new Data instance.\n \"\"\"\n # copy datas so original objects are not changed\n datas = [d.copy() for d in datas]\n # get scanned dimensions\n axis_names = []\n axis_units = []\n axis_objects = []\n for data in datas:\n for i, axis in enumerate(data.axes):\n if axis.name in kwargs.keys():\n axis.convert(kwargs[axis.name].units)\n if axis.points[0] > axis.points[-1]:\n data.flip(i)\n if axis.name not in axis_names:\n axis_names.append(axis.name)\n axis_units.append(axis.units)\n axis_objects.append(axis)\n # convert into same units\n for data in datas:\n for axis_name, axis_unit in zip(axis_names, axis_units):\n for axis in data.axes:\n if axis.name == axis_name:\n axis.convert(axis_unit)\n # get axis points\n axis_points = [] # list of 1D arrays\n for axis_name in axis_names:\n points = np.full((0), np.nan)\n for data in datas:\n index = data.axis_names.index(axis_name)\n points = np.hstack((points, data.axes[index].points))\n axis_points.append(np.unique(points))\n # map datas to new points\n for axis_index, axis_name in enumerate(axis_names):\n for data in datas:\n for axis in data.axes:\n if axis.name == axis_name:\n if not np.array_equiv(axis.points, axis_points[axis_index]):\n data.map_axis(axis_name, axis_points[axis_index])\n # make new channel objects\n channel_objects = []\n n_channels = min([len(d.channels) for d in datas])\n for channel_index in range(n_channels):\n full = np.array([d.channels[channel_index].values for d in datas])\n if method == 'first':\n zis = np.full(full.shape[1:], np.nan)\n for idx in np.ndindex(*full.shape[1:]):\n for data_index in range(len(full)):\n value = full[data_index][idx]\n if not np.isnan(value):\n zis[idx] = value\n break\n elif method == 'sum':\n zis = np.nansum(full, axis=0)\n zis[zis == 0.] = np.nan\n elif method == 'max':\n zis = np.nanmax(full, axis=0)\n elif method == 'min':\n zis = np.nanmin(full, axis=0)\n elif method == 'mean':\n zis = np.nanmean(full, axis=0)\n else:\n raise ValueError(\"method %s not recognized\" % method)\n zis[np.isnan(full).all(axis=0)] = np.nan # if all datas NaN, zis NaN\n channel = Channel(zis, null=0.,\n signed=datas[0].channels[channel_index].signed,\n name=datas[0].channels[channel_index].name)\n channel_objects.append(channel)\n # make new data object\n out = Data(axis_objects, channel_objects)\n # finish\n if verbose:\n print(len(datas), 'datas joined to create new data:')\n print(' axes:')\n for axis in out.axes:\n points = axis.points\n print(' {0} : {1} points from {2} to {3} {4}'.format(\n axis.name, points.size, min(points), max(points), axis.units))\n print(' channels:')\n for channel in out.channels:\n percent_nan = np.around(100. * (np.isnan(channel.values).sum() /\n float(channel.values.size)), decimals=2)\n print(' {0} : {1} to {2} ({3}% NaN)'.format(\n channel.name, channel.min(), channel.max(), percent_nan))\n return out\n", "path": "WrightTools/data/_join.py"}]}
| 1,937 | 677 |
gh_patches_debug_39235
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-648
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python client issues
- trailing `/` on `api_url` causes failure
- `create_rgd_client` silently failing if `api_url` is bad
@mvandenburgh, would you please look into these
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django-rgd/client/rgd_client/client.py`
Content:
```
1 import getpass
2 import logging
3 import os
4 from typing import List, Optional, Type
5
6 import requests
7
8 from .plugin import CorePlugin
9 from .session import RgdClientSession, clone_session
10 from .utils import API_KEY_DIR_PATH, API_KEY_FILE_NAME, DEFAULT_RGD_API
11
12 logger = logging.getLogger(__name__)
13
14
15 class RgdClient:
16 def __init__(
17 self,
18 api_url: str = DEFAULT_RGD_API,
19 username: Optional[str] = None,
20 password: Optional[str] = None,
21 save: Optional[bool] = True,
22 ) -> None:
23 """
24 Initialize the base RGD Client.
25
26 Args:
27 api_url: The base url of the RGD API instance.
28 username: The username to authenticate to the instance with, if any.
29 password: The password associated with the provided username. If None, a prompt will be provided.
30 save: Whether or not to save the logged-in user's API key to disk for future use.
31
32 Returns:
33 A base RgdClient instance.
34 """
35 # Look for an API key in the environment. If it's not there, check username/password
36 api_key = _read_api_key(api_url=api_url, username=username, password=password)
37 if api_key is None:
38 if username is not None and password is None:
39 password = getpass.getpass()
40
41 # Get an API key for this user and save it to disk
42 if username and password:
43 api_key = _get_api_key(api_url, username, password, save)
44 if api_key is None:
45 logger.error(
46 'Failed to retrieve API key; are your username and password correct?'
47 )
48
49 self.session = RgdClientSession(base_url=api_url, auth_token=api_key)
50 self.rgd = CorePlugin(clone_session(self.session))
51
52 def clear_token(self):
53 """Delete a locally-stored API key."""
54 (API_KEY_DIR_PATH / API_KEY_FILE_NAME).unlink(missing_ok=True)
55
56
57 def _get_api_key(api_url: str, username: str, password: str, save: bool) -> Optional[str]:
58 """Get an RGD API Key for the given user from the server, and save it if requested."""
59 resp = requests.post(f'{api_url}/api-token-auth', {'username': username, 'password': password})
60 token = resp.json().get('token')
61 if token is None:
62 return None
63 if save:
64 API_KEY_DIR_PATH.mkdir(parents=True, exist_ok=True)
65 with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'w') as fd:
66 fd.write(token)
67 return token
68
69
70 def _read_api_key(api_url: str, username: str = None, password: str = None) -> Optional[str]:
71 """
72 Retrieve an RGD API Key from the users environment.
73
74 This function checks for an environment variable named RGD_API_TOKEN and returns it if it exists.
75 If it does not exist, it looks for a file located at ~/.rgd/token and returns its contents.
76 """
77 token = os.getenv('RGD_API_TOKEN', None)
78 if token is not None:
79 return token
80
81 try:
82 # read the first line of the text file at ~/.rgd/token
83 with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:
84 api_key = fd.readline().strip()
85 except FileNotFoundError:
86 return None
87
88 # Make sure API key works by hitting a protected endpoint
89 resp = requests.get(f'{api_url}/rgd/collection', headers={'Authorization': f'Token {api_key}'})
90
91 # If it doesn't, try to get a new one and save it to ~/.rgd/token, as the current one is corrupted
92 if resp.status_code == 401:
93 logger.error('API key is invalid.')
94 # If username + password were provided, try to get a new API key with them
95 if username is not None and password is not None:
96 logger.info('Attempting to fetch a new API key...')
97 api_key = _get_api_key(api_url, username, password, save=True)
98 if api_key is not None:
99 logger.info('Succeeded.')
100 return api_key
101 else:
102 logger.error('Provide your username and password next time to fetch a new one.')
103 return None
104
105 return api_key
106
107
108 def create_rgd_client(
109 api_url: str = DEFAULT_RGD_API,
110 username: Optional[str] = None,
111 password: Optional[str] = None,
112 save: Optional[bool] = True,
113 extra_plugins: Optional[List[Type]] = None,
114 ):
115 # Avoid circular import
116 from ._plugin_utils import _inject_plugin_deps, _plugin_classes, _plugin_instances
117
118 # Create initial client
119 client = RgdClient(api_url, username, password, save)
120
121 # Perform plugin initialization
122 plugin_classes = _plugin_classes(extra_plugins=extra_plugins)
123 plugin_instances = _plugin_instances(client, plugin_classes)
124 _inject_plugin_deps(plugin_instances)
125
126 return client
127
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django-rgd/client/rgd_client/client.py b/django-rgd/client/rgd_client/client.py
--- a/django-rgd/client/rgd_client/client.py
+++ b/django-rgd/client/rgd_client/client.py
@@ -74,16 +74,16 @@
This function checks for an environment variable named RGD_API_TOKEN and returns it if it exists.
If it does not exist, it looks for a file located at ~/.rgd/token and returns its contents.
"""
- token = os.getenv('RGD_API_TOKEN', None)
- if token is not None:
- return token
-
- try:
- # read the first line of the text file at ~/.rgd/token
- with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:
- api_key = fd.readline().strip()
- except FileNotFoundError:
- return None
+ api_key = os.getenv('RGD_API_TOKEN', None)
+ save = False
+ if api_key is None:
+ try:
+ # read the first line of the text file at ~/.rgd/token
+ with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:
+ api_key = fd.readline().strip()
+ save = True # save any new api key to disk
+ except FileNotFoundError:
+ return None
# Make sure API key works by hitting a protected endpoint
resp = requests.get(f'{api_url}/rgd/collection', headers={'Authorization': f'Token {api_key}'})
@@ -92,7 +92,10 @@
if resp.status_code == 401:
logger.error('API key is invalid.')
# If username + password were provided, try to get a new API key with them
- if username is not None and password is not None:
+ # Note we only do this if `save` is `True`, i.e. if the user originally attempted to
+ # instantiate the client with an API key located on disk. If they instead provided an env
+ # var, do not assume that they want a key saved and do not attempt to fetch a new one.
+ if save and username is not None and password is not None:
logger.info('Attempting to fetch a new API key...')
api_key = _get_api_key(api_url, username, password, save=True)
if api_key is not None:
@@ -102,6 +105,9 @@
logger.error('Provide your username and password next time to fetch a new one.')
return None
+ # If the response failed with an error status other than 401, raise an exception
+ resp.raise_for_status()
+
return api_key
@@ -115,6 +121,10 @@
# Avoid circular import
from ._plugin_utils import _inject_plugin_deps, _plugin_classes, _plugin_instances
+ # Strip trailing slash
+ if api_url.endswith('/'):
+ api_url = api_url.rstrip('/')
+
# Create initial client
client = RgdClient(api_url, username, password, save)
|
{"golden_diff": "diff --git a/django-rgd/client/rgd_client/client.py b/django-rgd/client/rgd_client/client.py\n--- a/django-rgd/client/rgd_client/client.py\n+++ b/django-rgd/client/rgd_client/client.py\n@@ -74,16 +74,16 @@\n This function checks for an environment variable named RGD_API_TOKEN and returns it if it exists.\n If it does not exist, it looks for a file located at ~/.rgd/token and returns its contents.\n \"\"\"\n- token = os.getenv('RGD_API_TOKEN', None)\n- if token is not None:\n- return token\n-\n- try:\n- # read the first line of the text file at ~/.rgd/token\n- with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:\n- api_key = fd.readline().strip()\n- except FileNotFoundError:\n- return None\n+ api_key = os.getenv('RGD_API_TOKEN', None)\n+ save = False\n+ if api_key is None:\n+ try:\n+ # read the first line of the text file at ~/.rgd/token\n+ with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:\n+ api_key = fd.readline().strip()\n+ save = True # save any new api key to disk\n+ except FileNotFoundError:\n+ return None\n \n # Make sure API key works by hitting a protected endpoint\n resp = requests.get(f'{api_url}/rgd/collection', headers={'Authorization': f'Token {api_key}'})\n@@ -92,7 +92,10 @@\n if resp.status_code == 401:\n logger.error('API key is invalid.')\n # If username + password were provided, try to get a new API key with them\n- if username is not None and password is not None:\n+ # Note we only do this if `save` is `True`, i.e. if the user originally attempted to\n+ # instantiate the client with an API key located on disk. If they instead provided an env\n+ # var, do not assume that they want a key saved and do not attempt to fetch a new one.\n+ if save and username is not None and password is not None:\n logger.info('Attempting to fetch a new API key...')\n api_key = _get_api_key(api_url, username, password, save=True)\n if api_key is not None:\n@@ -102,6 +105,9 @@\n logger.error('Provide your username and password next time to fetch a new one.')\n return None\n \n+ # If the response failed with an error status other than 401, raise an exception\n+ resp.raise_for_status()\n+\n return api_key\n \n \n@@ -115,6 +121,10 @@\n # Avoid circular import\n from ._plugin_utils import _inject_plugin_deps, _plugin_classes, _plugin_instances\n \n+ # Strip trailing slash\n+ if api_url.endswith('/'):\n+ api_url = api_url.rstrip('/')\n+\n # Create initial client\n client = RgdClient(api_url, username, password, save)\n", "issue": "Python client issues\n- trailing `/` on `api_url` causes failure\r\n- `create_rgd_client` silently failing if `api_url` is bad\r\n\r\n@mvandenburgh, would you please look into these\n", "before_files": [{"content": "import getpass\nimport logging\nimport os\nfrom typing import List, Optional, Type\n\nimport requests\n\nfrom .plugin import CorePlugin\nfrom .session import RgdClientSession, clone_session\nfrom .utils import API_KEY_DIR_PATH, API_KEY_FILE_NAME, DEFAULT_RGD_API\n\nlogger = logging.getLogger(__name__)\n\n\nclass RgdClient:\n def __init__(\n self,\n api_url: str = DEFAULT_RGD_API,\n username: Optional[str] = None,\n password: Optional[str] = None,\n save: Optional[bool] = True,\n ) -> None:\n \"\"\"\n Initialize the base RGD Client.\n\n Args:\n api_url: The base url of the RGD API instance.\n username: The username to authenticate to the instance with, if any.\n password: The password associated with the provided username. If None, a prompt will be provided.\n save: Whether or not to save the logged-in user's API key to disk for future use.\n\n Returns:\n A base RgdClient instance.\n \"\"\"\n # Look for an API key in the environment. If it's not there, check username/password\n api_key = _read_api_key(api_url=api_url, username=username, password=password)\n if api_key is None:\n if username is not None and password is None:\n password = getpass.getpass()\n\n # Get an API key for this user and save it to disk\n if username and password:\n api_key = _get_api_key(api_url, username, password, save)\n if api_key is None:\n logger.error(\n 'Failed to retrieve API key; are your username and password correct?'\n )\n\n self.session = RgdClientSession(base_url=api_url, auth_token=api_key)\n self.rgd = CorePlugin(clone_session(self.session))\n\n def clear_token(self):\n \"\"\"Delete a locally-stored API key.\"\"\"\n (API_KEY_DIR_PATH / API_KEY_FILE_NAME).unlink(missing_ok=True)\n\n\ndef _get_api_key(api_url: str, username: str, password: str, save: bool) -> Optional[str]:\n \"\"\"Get an RGD API Key for the given user from the server, and save it if requested.\"\"\"\n resp = requests.post(f'{api_url}/api-token-auth', {'username': username, 'password': password})\n token = resp.json().get('token')\n if token is None:\n return None\n if save:\n API_KEY_DIR_PATH.mkdir(parents=True, exist_ok=True)\n with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'w') as fd:\n fd.write(token)\n return token\n\n\ndef _read_api_key(api_url: str, username: str = None, password: str = None) -> Optional[str]:\n \"\"\"\n Retrieve an RGD API Key from the users environment.\n\n This function checks for an environment variable named RGD_API_TOKEN and returns it if it exists.\n If it does not exist, it looks for a file located at ~/.rgd/token and returns its contents.\n \"\"\"\n token = os.getenv('RGD_API_TOKEN', None)\n if token is not None:\n return token\n\n try:\n # read the first line of the text file at ~/.rgd/token\n with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:\n api_key = fd.readline().strip()\n except FileNotFoundError:\n return None\n\n # Make sure API key works by hitting a protected endpoint\n resp = requests.get(f'{api_url}/rgd/collection', headers={'Authorization': f'Token {api_key}'})\n\n # If it doesn't, try to get a new one and save it to ~/.rgd/token, as the current one is corrupted\n if resp.status_code == 401:\n logger.error('API key is invalid.')\n # If username + password were provided, try to get a new API key with them\n if username is not None and password is not None:\n logger.info('Attempting to fetch a new API key...')\n api_key = _get_api_key(api_url, username, password, save=True)\n if api_key is not None:\n logger.info('Succeeded.')\n return api_key\n else:\n logger.error('Provide your username and password next time to fetch a new one.')\n return None\n\n return api_key\n\n\ndef create_rgd_client(\n api_url: str = DEFAULT_RGD_API,\n username: Optional[str] = None,\n password: Optional[str] = None,\n save: Optional[bool] = True,\n extra_plugins: Optional[List[Type]] = None,\n):\n # Avoid circular import\n from ._plugin_utils import _inject_plugin_deps, _plugin_classes, _plugin_instances\n\n # Create initial client\n client = RgdClient(api_url, username, password, save)\n\n # Perform plugin initialization\n plugin_classes = _plugin_classes(extra_plugins=extra_plugins)\n plugin_instances = _plugin_instances(client, plugin_classes)\n _inject_plugin_deps(plugin_instances)\n\n return client\n", "path": "django-rgd/client/rgd_client/client.py"}], "after_files": [{"content": "import getpass\nimport logging\nimport os\nfrom typing import List, Optional, Type\n\nimport requests\n\nfrom .plugin import CorePlugin\nfrom .session import RgdClientSession, clone_session\nfrom .utils import API_KEY_DIR_PATH, API_KEY_FILE_NAME, DEFAULT_RGD_API\n\nlogger = logging.getLogger(__name__)\n\n\nclass RgdClient:\n def __init__(\n self,\n api_url: str = DEFAULT_RGD_API,\n username: Optional[str] = None,\n password: Optional[str] = None,\n save: Optional[bool] = True,\n ) -> None:\n \"\"\"\n Initialize the base RGD Client.\n\n Args:\n api_url: The base url of the RGD API instance.\n username: The username to authenticate to the instance with, if any.\n password: The password associated with the provided username. If None, a prompt will be provided.\n save: Whether or not to save the logged-in user's API key to disk for future use.\n\n Returns:\n A base RgdClient instance.\n \"\"\"\n # Look for an API key in the environment. If it's not there, check username/password\n api_key = _read_api_key(api_url=api_url, username=username, password=password)\n if api_key is None:\n if username is not None and password is None:\n password = getpass.getpass()\n\n # Get an API key for this user and save it to disk\n if username and password:\n api_key = _get_api_key(api_url, username, password, save)\n if api_key is None:\n logger.error(\n 'Failed to retrieve API key; are your username and password correct?'\n )\n\n self.session = RgdClientSession(base_url=api_url, auth_token=api_key)\n self.rgd = CorePlugin(clone_session(self.session))\n\n def clear_token(self):\n \"\"\"Delete a locally-stored API key.\"\"\"\n (API_KEY_DIR_PATH / API_KEY_FILE_NAME).unlink(missing_ok=True)\n\n\ndef _get_api_key(api_url: str, username: str, password: str, save: bool) -> Optional[str]:\n \"\"\"Get an RGD API Key for the given user from the server, and save it if requested.\"\"\"\n resp = requests.post(f'{api_url}/api-token-auth', {'username': username, 'password': password})\n token = resp.json().get('token')\n if token is None:\n return None\n if save:\n API_KEY_DIR_PATH.mkdir(parents=True, exist_ok=True)\n with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'w') as fd:\n fd.write(token)\n return token\n\n\ndef _read_api_key(api_url: str, username: str = None, password: str = None) -> Optional[str]:\n \"\"\"\n Retrieve an RGD API Key from the users environment.\n\n This function checks for an environment variable named RGD_API_TOKEN and returns it if it exists.\n If it does not exist, it looks for a file located at ~/.rgd/token and returns its contents.\n \"\"\"\n api_key = os.getenv('RGD_API_TOKEN', None)\n save = False\n if api_key is None:\n try:\n # read the first line of the text file at ~/.rgd/token\n with open(API_KEY_DIR_PATH / API_KEY_FILE_NAME, 'r') as fd:\n api_key = fd.readline().strip()\n save = True # save any new api key to disk\n except FileNotFoundError:\n return None\n\n # Make sure API key works by hitting a protected endpoint\n resp = requests.get(f'{api_url}/rgd/collection', headers={'Authorization': f'Token {api_key}'})\n\n # If it doesn't, try to get a new one and save it to ~/.rgd/token, as the current one is corrupted\n if resp.status_code == 401:\n logger.error('API key is invalid.')\n # If username + password were provided, try to get a new API key with them\n # Note we only do this if `save` is `True`, i.e. if the user originally attempted to\n # instantiate the client with an API key located on disk. If they instead provided an env\n # var, do not assume that they want a key saved and do not attempt to fetch a new one.\n if save and username is not None and password is not None:\n logger.info('Attempting to fetch a new API key...')\n api_key = _get_api_key(api_url, username, password, save=True)\n if api_key is not None:\n logger.info('Succeeded.')\n return api_key\n else:\n logger.error('Provide your username and password next time to fetch a new one.')\n return None\n\n # If the response failed with an error status other than 401, raise an exception\n resp.raise_for_status()\n\n return api_key\n\n\ndef create_rgd_client(\n api_url: str = DEFAULT_RGD_API,\n username: Optional[str] = None,\n password: Optional[str] = None,\n save: Optional[bool] = True,\n extra_plugins: Optional[List[Type]] = None,\n):\n # Avoid circular import\n from ._plugin_utils import _inject_plugin_deps, _plugin_classes, _plugin_instances\n\n # Strip trailing slash\n if api_url.endswith('/'):\n api_url = api_url.rstrip('/')\n\n # Create initial client\n client = RgdClient(api_url, username, password, save)\n\n # Perform plugin initialization\n plugin_classes = _plugin_classes(extra_plugins=extra_plugins)\n plugin_instances = _plugin_instances(client, plugin_classes)\n _inject_plugin_deps(plugin_instances)\n\n return client\n", "path": "django-rgd/client/rgd_client/client.py"}]}
| 1,675 | 699 |
gh_patches_debug_5872
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-3695
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Warning incorrectly raised by SpectrumDatasetMaker.make_exposure with use_region_center=True
**Gammapy version**
v0.19
**Bug description**
If using `SpectrumDatasetMaker.make_exposure` with pointlike IRFs, a warning is incorrectly raised if the option `user_region_center` is set to True.
See this lien of code:
https://github.com/gammapy/gammapy/blob/ba7d377bf48bd53d268d2dc14be1c1eb013a1e42/gammapy/makers/spectrum.py#L67
**Expected behavior**
No warning should be raised.
**To Reproduce**
**Other information**
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gammapy/makers/spectrum.py`
Content:
```
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 import logging
3 from regions import CircleSkyRegion
4 from .map import MapDatasetMaker
5
6 __all__ = ["SpectrumDatasetMaker"]
7
8 log = logging.getLogger(__name__)
9
10
11 class SpectrumDatasetMaker(MapDatasetMaker):
12 """Make spectrum for a single IACT observation.
13
14 The irfs and background are computed at a single fixed offset,
15 which is recommend only for point-sources.
16
17 Parameters
18 ----------
19 selection : list
20 List of str, selecting which maps to make.
21 Available: 'counts', 'exposure', 'background', 'edisp'
22 By default, all spectra are made.
23 containment_correction : bool
24 Apply containment correction for point sources and circular on regions.
25 background_oversampling : int
26 Background evaluation oversampling factor in energy.
27 use_region_center : bool
28 Approximate the IRFs by the value at the center of the region
29 """
30
31 tag = "SpectrumDatasetMaker"
32 available_selection = ["counts", "background", "exposure", "edisp"]
33
34 def __init__(
35 self,
36 selection=None,
37 containment_correction=False,
38 background_oversampling=None,
39 use_region_center=True,
40 ):
41 self.containment_correction = containment_correction
42 self.use_region_center = use_region_center
43 super().__init__(
44 selection=selection, background_oversampling=background_oversampling
45 )
46
47 def make_exposure(self, geom, observation):
48 """Make exposure.
49
50 Parameters
51 ----------
52 geom : `~gammapy.maps.RegionGeom`
53 Reference map geom.
54 observation: `~gammapy.data.Observation`
55 Observation to compute effective area for.
56
57 Returns
58 -------
59 exposure : `~gammapy.maps.RegionNDMap`
60 Exposure map.
61 """
62 exposure = super().make_exposure(
63 geom, observation, use_region_center=self.use_region_center
64 )
65
66 is_pointlike = exposure.meta.get("is_pointlike", False)
67 if is_pointlike:
68 log.warning(
69 "MapMaker: use_region_center=False should not be used with point-like IRF. "
70 "Results are likely inaccurate."
71 )
72
73 if self.containment_correction:
74 if is_pointlike:
75 raise ValueError(
76 "Cannot apply containment correction for point-like IRF."
77 )
78
79 if not isinstance(geom.region, CircleSkyRegion):
80 raise TypeError(
81 "Containment correction only supported for circular regions."
82 )
83 offset = geom.separation(observation.pointing_radec)
84 containment = observation.psf.containment(
85 rad=geom.region.radius,
86 offset=offset,
87 energy_true=geom.axes["energy_true"].center,
88 )
89 exposure.quantity *= containment.reshape(geom.data_shape)
90
91 return exposure
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gammapy/makers/spectrum.py b/gammapy/makers/spectrum.py
--- a/gammapy/makers/spectrum.py
+++ b/gammapy/makers/spectrum.py
@@ -64,7 +64,7 @@
)
is_pointlike = exposure.meta.get("is_pointlike", False)
- if is_pointlike:
+ if is_pointlike and self.use_region_center is False:
log.warning(
"MapMaker: use_region_center=False should not be used with point-like IRF. "
"Results are likely inaccurate."
|
{"golden_diff": "diff --git a/gammapy/makers/spectrum.py b/gammapy/makers/spectrum.py\n--- a/gammapy/makers/spectrum.py\n+++ b/gammapy/makers/spectrum.py\n@@ -64,7 +64,7 @@\n )\n \n is_pointlike = exposure.meta.get(\"is_pointlike\", False)\n- if is_pointlike:\n+ if is_pointlike and self.use_region_center is False:\n log.warning(\n \"MapMaker: use_region_center=False should not be used with point-like IRF. \"\n \"Results are likely inaccurate.\"\n", "issue": "Warning incorrectly raised by SpectrumDatasetMaker.make_exposure with use_region_center=True\n**Gammapy version**\r\nv0.19\r\n\r\n**Bug description**\r\nIf using `SpectrumDatasetMaker.make_exposure` with pointlike IRFs, a warning is incorrectly raised if the option `user_region_center` is set to True.\r\n\r\nSee this lien of code:\r\nhttps://github.com/gammapy/gammapy/blob/ba7d377bf48bd53d268d2dc14be1c1eb013a1e42/gammapy/makers/spectrum.py#L67\r\n\r\n**Expected behavior**\r\nNo warning should be raised.\r\n\r\n**To Reproduce**\r\n\r\n**Other information**\r\n\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport logging\nfrom regions import CircleSkyRegion\nfrom .map import MapDatasetMaker\n\n__all__ = [\"SpectrumDatasetMaker\"]\n\nlog = logging.getLogger(__name__)\n\n\nclass SpectrumDatasetMaker(MapDatasetMaker):\n \"\"\"Make spectrum for a single IACT observation.\n\n The irfs and background are computed at a single fixed offset,\n which is recommend only for point-sources.\n\n Parameters\n ----------\n selection : list\n List of str, selecting which maps to make.\n Available: 'counts', 'exposure', 'background', 'edisp'\n By default, all spectra are made.\n containment_correction : bool\n Apply containment correction for point sources and circular on regions.\n background_oversampling : int\n Background evaluation oversampling factor in energy.\n use_region_center : bool\n Approximate the IRFs by the value at the center of the region\n \"\"\"\n\n tag = \"SpectrumDatasetMaker\"\n available_selection = [\"counts\", \"background\", \"exposure\", \"edisp\"]\n\n def __init__(\n self,\n selection=None,\n containment_correction=False,\n background_oversampling=None,\n use_region_center=True,\n ):\n self.containment_correction = containment_correction\n self.use_region_center = use_region_center\n super().__init__(\n selection=selection, background_oversampling=background_oversampling\n )\n\n def make_exposure(self, geom, observation):\n \"\"\"Make exposure.\n\n Parameters\n ----------\n geom : `~gammapy.maps.RegionGeom`\n Reference map geom.\n observation: `~gammapy.data.Observation`\n Observation to compute effective area for.\n\n Returns\n -------\n exposure : `~gammapy.maps.RegionNDMap`\n Exposure map.\n \"\"\"\n exposure = super().make_exposure(\n geom, observation, use_region_center=self.use_region_center\n )\n\n is_pointlike = exposure.meta.get(\"is_pointlike\", False)\n if is_pointlike:\n log.warning(\n \"MapMaker: use_region_center=False should not be used with point-like IRF. \"\n \"Results are likely inaccurate.\"\n )\n\n if self.containment_correction:\n if is_pointlike:\n raise ValueError(\n \"Cannot apply containment correction for point-like IRF.\"\n )\n\n if not isinstance(geom.region, CircleSkyRegion):\n raise TypeError(\n \"Containment correction only supported for circular regions.\"\n )\n offset = geom.separation(observation.pointing_radec)\n containment = observation.psf.containment(\n rad=geom.region.radius,\n offset=offset,\n energy_true=geom.axes[\"energy_true\"].center,\n )\n exposure.quantity *= containment.reshape(geom.data_shape)\n\n return exposure\n", "path": "gammapy/makers/spectrum.py"}], "after_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport logging\nfrom regions import CircleSkyRegion\nfrom .map import MapDatasetMaker\n\n__all__ = [\"SpectrumDatasetMaker\"]\n\nlog = logging.getLogger(__name__)\n\n\nclass SpectrumDatasetMaker(MapDatasetMaker):\n \"\"\"Make spectrum for a single IACT observation.\n\n The irfs and background are computed at a single fixed offset,\n which is recommend only for point-sources.\n\n Parameters\n ----------\n selection : list\n List of str, selecting which maps to make.\n Available: 'counts', 'exposure', 'background', 'edisp'\n By default, all spectra are made.\n containment_correction : bool\n Apply containment correction for point sources and circular on regions.\n background_oversampling : int\n Background evaluation oversampling factor in energy.\n use_region_center : bool\n Approximate the IRFs by the value at the center of the region\n \"\"\"\n\n tag = \"SpectrumDatasetMaker\"\n available_selection = [\"counts\", \"background\", \"exposure\", \"edisp\"]\n\n def __init__(\n self,\n selection=None,\n containment_correction=False,\n background_oversampling=None,\n use_region_center=True,\n ):\n self.containment_correction = containment_correction\n self.use_region_center = use_region_center\n super().__init__(\n selection=selection, background_oversampling=background_oversampling\n )\n\n def make_exposure(self, geom, observation):\n \"\"\"Make exposure.\n\n Parameters\n ----------\n geom : `~gammapy.maps.RegionGeom`\n Reference map geom.\n observation: `~gammapy.data.Observation`\n Observation to compute effective area for.\n\n Returns\n -------\n exposure : `~gammapy.maps.RegionNDMap`\n Exposure map.\n \"\"\"\n exposure = super().make_exposure(\n geom, observation, use_region_center=self.use_region_center\n )\n\n is_pointlike = exposure.meta.get(\"is_pointlike\", False)\n if is_pointlike and self.use_region_center is False:\n log.warning(\n \"MapMaker: use_region_center=False should not be used with point-like IRF. \"\n \"Results are likely inaccurate.\"\n )\n\n if self.containment_correction:\n if is_pointlike:\n raise ValueError(\n \"Cannot apply containment correction for point-like IRF.\"\n )\n\n if not isinstance(geom.region, CircleSkyRegion):\n raise TypeError(\n \"Containment correction only supported for circular regions.\"\n )\n offset = geom.separation(observation.pointing_radec)\n containment = observation.psf.containment(\n rad=geom.region.radius,\n offset=offset,\n energy_true=geom.axes[\"energy_true\"].center,\n )\n exposure.quantity *= containment.reshape(geom.data_shape)\n\n return exposure\n", "path": "gammapy/makers/spectrum.py"}]}
| 1,195 | 130 |
gh_patches_debug_54333
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-11960
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Suggesting keras.utils.*_utils packages should not be part of the official API
In general, all `keras.utils.*_utils.*` functions and classes that are documented on keras.io are available directly in `keras.utils` and documented as such. However there are a few discrepancies:
* `keras.utils.vis_utils.model_to_dot` is not available in `keras.utils`.
* `keras.utils.np_utils.to_categorical` sometimes appears in the documentation, instead of `keras.utils.to_categorical`.
* `keras.utils.io_utils.HDF5Matrix` sometimes appears in the documentation, instead of `keras.utils.HDF5Matrix`.
This introduces some confusion as to what is part of the official Keras API or not: in particular, are `keras.utils.*_utils` packages part of the Keras API or not? Possibly as a result of this confusion, tf.keras is not consistent with keras-team/keras, as it has no `tf.keras.utils.*_utils` packages, and is missing `model_to_dot` altogether. Arguably this is a tf.keras issue, but the fact that only three utility functions are placed in `keras.utils.*_utils` packages is surprising IMHO.
I will propose a PR to fix this by:
* Adding `model_to_dot` to `keras.utils`
* Fixing the documentation to remove all references to `keras.utils.*_utils` packages.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `keras/utils/__init__.py`
Content:
```
1 from __future__ import absolute_import
2 from . import np_utils
3 from . import generic_utils
4 from . import data_utils
5 from . import io_utils
6 from . import conv_utils
7
8 # Globally-importable utils.
9 from .io_utils import HDF5Matrix
10 from .io_utils import H5Dict
11 from .data_utils import get_file
12 from .data_utils import Sequence
13 from .data_utils import GeneratorEnqueuer
14 from .data_utils import OrderedEnqueuer
15 from .generic_utils import CustomObjectScope
16 from .generic_utils import custom_object_scope
17 from .generic_utils import get_custom_objects
18 from .generic_utils import serialize_keras_object
19 from .generic_utils import deserialize_keras_object
20 from .generic_utils import Progbar
21 from .layer_utils import convert_all_kernels_in_model
22 from .layer_utils import get_source_inputs
23 from .layer_utils import print_summary
24 from .vis_utils import plot_model
25 from .np_utils import to_categorical
26 from .np_utils import normalize
27 from .multi_gpu_utils import multi_gpu_model
28
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/keras/utils/__init__.py b/keras/utils/__init__.py
--- a/keras/utils/__init__.py
+++ b/keras/utils/__init__.py
@@ -21,6 +21,7 @@
from .layer_utils import convert_all_kernels_in_model
from .layer_utils import get_source_inputs
from .layer_utils import print_summary
+from .vis_utils import model_to_dot
from .vis_utils import plot_model
from .np_utils import to_categorical
from .np_utils import normalize
|
{"golden_diff": "diff --git a/keras/utils/__init__.py b/keras/utils/__init__.py\n--- a/keras/utils/__init__.py\n+++ b/keras/utils/__init__.py\n@@ -21,6 +21,7 @@\n from .layer_utils import convert_all_kernels_in_model\n from .layer_utils import get_source_inputs\n from .layer_utils import print_summary\n+from .vis_utils import model_to_dot\n from .vis_utils import plot_model\n from .np_utils import to_categorical\n from .np_utils import normalize\n", "issue": "Suggesting keras.utils.*_utils packages should not be part of the official API\nIn general, all `keras.utils.*_utils.*` functions and classes that are documented on keras.io are available directly in `keras.utils` and documented as such. However there are a few discrepancies:\r\n* `keras.utils.vis_utils.model_to_dot` is not available in `keras.utils`.\r\n* `keras.utils.np_utils.to_categorical` sometimes appears in the documentation, instead of `keras.utils.to_categorical`.\r\n* `keras.utils.io_utils.HDF5Matrix` sometimes appears in the documentation, instead of `keras.utils.HDF5Matrix`.\r\n\r\nThis introduces some confusion as to what is part of the official Keras API or not: in particular, are `keras.utils.*_utils` packages part of the Keras API or not? Possibly as a result of this confusion, tf.keras is not consistent with keras-team/keras, as it has no `tf.keras.utils.*_utils` packages, and is missing `model_to_dot` altogether. Arguably this is a tf.keras issue, but the fact that only three utility functions are placed in `keras.utils.*_utils` packages is surprising IMHO.\r\n\r\nI will propose a PR to fix this by:\r\n* Adding `model_to_dot` to `keras.utils`\r\n* Fixing the documentation to remove all references to `keras.utils.*_utils` packages.\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom . import np_utils\nfrom . import generic_utils\nfrom . import data_utils\nfrom . import io_utils\nfrom . import conv_utils\n\n# Globally-importable utils.\nfrom .io_utils import HDF5Matrix\nfrom .io_utils import H5Dict\nfrom .data_utils import get_file\nfrom .data_utils import Sequence\nfrom .data_utils import GeneratorEnqueuer\nfrom .data_utils import OrderedEnqueuer\nfrom .generic_utils import CustomObjectScope\nfrom .generic_utils import custom_object_scope\nfrom .generic_utils import get_custom_objects\nfrom .generic_utils import serialize_keras_object\nfrom .generic_utils import deserialize_keras_object\nfrom .generic_utils import Progbar\nfrom .layer_utils import convert_all_kernels_in_model\nfrom .layer_utils import get_source_inputs\nfrom .layer_utils import print_summary\nfrom .vis_utils import plot_model\nfrom .np_utils import to_categorical\nfrom .np_utils import normalize\nfrom .multi_gpu_utils import multi_gpu_model\n", "path": "keras/utils/__init__.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom . import np_utils\nfrom . import generic_utils\nfrom . import data_utils\nfrom . import io_utils\nfrom . import conv_utils\n\n# Globally-importable utils.\nfrom .io_utils import HDF5Matrix\nfrom .io_utils import H5Dict\nfrom .data_utils import get_file\nfrom .data_utils import Sequence\nfrom .data_utils import GeneratorEnqueuer\nfrom .data_utils import OrderedEnqueuer\nfrom .generic_utils import CustomObjectScope\nfrom .generic_utils import custom_object_scope\nfrom .generic_utils import get_custom_objects\nfrom .generic_utils import serialize_keras_object\nfrom .generic_utils import deserialize_keras_object\nfrom .generic_utils import Progbar\nfrom .layer_utils import convert_all_kernels_in_model\nfrom .layer_utils import get_source_inputs\nfrom .layer_utils import print_summary\nfrom .vis_utils import model_to_dot\nfrom .vis_utils import plot_model\nfrom .np_utils import to_categorical\nfrom .np_utils import normalize\nfrom .multi_gpu_utils import multi_gpu_model\n", "path": "keras/utils/__init__.py"}]}
| 825 | 118 |
gh_patches_debug_39833
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-5832
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Shell spider doesn't return any results for Bulgaria
There are around 100 Shell gas stations in Bulgaria but none of them are shown in the latest spider result. They are listed on their Bulgarian website (https://www.shell.bg/motorists/shell-station-locator.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/storefinders/geo_me.py`
Content:
```
1 from scrapy import Spider
2 from scrapy.http import JsonRequest
3 from scrapy.signals import spider_idle
4
5 from locations.dict_parser import DictParser
6 from locations.hours import DAYS, DAYS_EN, OpeningHours, day_range
7 from locations.items import Feature
8
9 # To use this store finder, specify key = x where x is the unique
10 # identifier of the store finder in domain x.geoapp.me.
11 #
12 # It is likely there are additional fields of data worth extracting
13 # from the store finder. These should be added by overriding the
14 # parse_item function. Two parameters are passed, item (and ATP
15 # "Feature" class) and location (a dict which is returned from the
16 # store locator JSON response for a particular location).
17 #
18 # This spider has two crawling steps which are executed in order:
19 # 1. Obtain list of all locations by using the API to do bounding
20 # box searches across the world. The only thing of interest
21 # returned for each location in this step is a unique identifier
22 # and coordinates.
23 # 2. Iterating through the all locations list produced by step (1),
24 # request the nearest 50 (API limit) locations for each location
25 # in the all locations list. Remove from the all locations list
26 # and locations that were returned with a nearest location
27 # search. Repeat until the all locations list is empty. The
28 # nearest location search returns all details of a location.
29 #
30 # Note that due to the way the two crawling steps are required to
31 # operate, numerous duplicate locations will be dropped during
32 # extraction. It is common for locations to be present in more than
33 # one nearby cluster of locations that the "nearest to" search
34 # iterates through.
35
36
37 class GeoMeSpider(Spider):
38 key = ""
39 api_version = "2"
40 url_within_bounds_template = "https://{}.geoapp.me/api/v{}/locations/within_bounds?sw[]={}&sw[]={}&ne[]={}&ne[]={}"
41 url_nearest_to_template = "https://{}.geoapp.me/api/v{}/locations/nearest_to?lat={}&lng={}&limit=50"
42 locations_found = {}
43
44 def start_requests(self):
45 self.crawler.signals.connect(self.start_location_requests, signal=spider_idle)
46 yield JsonRequest(
47 url=self.url_within_bounds_template.format(self.key, self.api_version, -90, -180, 90, 180),
48 callback=self.parse_bounding_box,
49 )
50
51 def parse_bounding_box(self, response):
52 for cluster in response.json().get("clusters", []):
53 if b := cluster.get("bounds"):
54 yield JsonRequest(
55 url=self.url_within_bounds_template.format(
56 self.key, self.api_version, b["sw"][0], b["sw"][1], b["ne"][0], b["ne"][1]
57 ),
58 callback=self.parse_bounding_box,
59 )
60 for location in response.json().get("locations", []):
61 self.locations_found[location["id"]] = (float(location["lat"]), float(location["lng"]))
62
63 def start_location_requests(self):
64 self.crawler.signals.disconnect(self.start_location_requests, signal=spider_idle)
65 if len(self.locations_found) > 0:
66 first_search_location = self.locations_found.popitem()
67 first_request = JsonRequest(
68 url=self.url_nearest_to_template.format(
69 self.key, self.api_version, first_search_location[1][0], first_search_location[1][1]
70 ),
71 callback=self.parse_locations,
72 )
73 self.crawler.engine.crawl(first_request)
74
75 def parse_locations(self, response):
76 for location in response.json()["locations"]:
77 if location.get("inactive"):
78 continue
79 location["street_address"] = location.pop("address")
80 item = DictParser.parse(location)
81 self.extract_hours(item, location)
82 yield from self.parse_item(item, location) or []
83
84 # Remove found location from the list of locations which
85 # are still waiting to be found.
86 if self.locations_found.get(location["id"]):
87 self.locations_found.pop(location["id"])
88
89 # Get the next location to do a "nearest to" search from.
90 if len(self.locations_found) > 0:
91 next_search_location = self.locations_found.popitem()
92 yield JsonRequest(
93 url=self.url_nearest_to_template.format(
94 self.key, self.api_version, next_search_location[1][0], next_search_location[1][1]
95 ),
96 callback=self.parse_locations,
97 )
98
99 def extract_hours(self, item, location):
100 item["opening_hours"] = OpeningHours()
101 if location.get("open_status") == "twenty_four_hour":
102 item["opening_hours"].add_days_range(DAYS, "00:00", "23:59")
103 return
104 open_hours = location.get("opening_hours")
105 if not open_hours:
106 return
107 for spec in open_hours:
108 days = spec["days"]
109 day_from = day_to = days[0]
110 if len(days) == 2:
111 day_to = days[1]
112 for day in day_range(DAYS_EN[day_from], DAYS_EN[day_to]):
113 for hours in spec["hours"]:
114 item["opening_hours"].add_range(day, hours[0], hours[1])
115
116 def parse_item(self, item: Feature, location: dict, **kwargs):
117 yield item
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/storefinders/geo_me.py b/locations/storefinders/geo_me.py
--- a/locations/storefinders/geo_me.py
+++ b/locations/storefinders/geo_me.py
@@ -1,3 +1,5 @@
+import random
+
from scrapy import Spider
from scrapy.http import JsonRequest
from scrapy.signals import spider_idle
@@ -62,41 +64,42 @@
def start_location_requests(self):
self.crawler.signals.disconnect(self.start_location_requests, signal=spider_idle)
- if len(self.locations_found) > 0:
- first_search_location = self.locations_found.popitem()
- first_request = JsonRequest(
- url=self.url_nearest_to_template.format(
- self.key, self.api_version, first_search_location[1][0], first_search_location[1][1]
- ),
- callback=self.parse_locations,
- )
- self.crawler.engine.crawl(first_request)
+ self.crawler.engine.crawl(self.get_next_location())
def parse_locations(self, response):
for location in response.json()["locations"]:
+ # Remove found location from the list of locations which
+ # are still waiting to be found.
+ if self.locations_found.get(location["id"]):
+ self.locations_found.pop(location["id"])
+
if location.get("inactive"):
continue
+
location["street_address"] = location.pop("address")
item = DictParser.parse(location)
self.extract_hours(item, location)
yield from self.parse_item(item, location) or []
- # Remove found location from the list of locations which
- # are still waiting to be found.
- if self.locations_found.get(location["id"]):
- self.locations_found.pop(location["id"])
-
# Get the next location to do a "nearest to" search from.
- if len(self.locations_found) > 0:
- next_search_location = self.locations_found.popitem()
- yield JsonRequest(
- url=self.url_nearest_to_template.format(
- self.key, self.api_version, next_search_location[1][0], next_search_location[1][1]
- ),
- callback=self.parse_locations,
- )
+ yield self.get_next_location()
+
+ def get_next_location(self) -> JsonRequest:
+ if len(self.locations_found) == 0:
+ return
+ next_search_location_id = random.choice(list(self.locations_found))
+ next_search_location_coords = self.locations_found[next_search_location_id]
+ self.locations_found.pop(next_search_location_id)
+ return JsonRequest(
+ url=self.url_nearest_to_template.format(
+ self.key, self.api_version, next_search_location_coords[0], next_search_location_coords[1]
+ ),
+ callback=self.parse_locations,
+ dont_filter=True,
+ )
- def extract_hours(self, item, location):
+ @staticmethod
+ def extract_hours(item: Feature, location: dict):
item["opening_hours"] = OpeningHours()
if location.get("open_status") == "twenty_four_hour":
item["opening_hours"].add_days_range(DAYS, "00:00", "23:59")
|
{"golden_diff": "diff --git a/locations/storefinders/geo_me.py b/locations/storefinders/geo_me.py\n--- a/locations/storefinders/geo_me.py\n+++ b/locations/storefinders/geo_me.py\n@@ -1,3 +1,5 @@\n+import random\n+\n from scrapy import Spider\n from scrapy.http import JsonRequest\n from scrapy.signals import spider_idle\n@@ -62,41 +64,42 @@\n \n def start_location_requests(self):\n self.crawler.signals.disconnect(self.start_location_requests, signal=spider_idle)\n- if len(self.locations_found) > 0:\n- first_search_location = self.locations_found.popitem()\n- first_request = JsonRequest(\n- url=self.url_nearest_to_template.format(\n- self.key, self.api_version, first_search_location[1][0], first_search_location[1][1]\n- ),\n- callback=self.parse_locations,\n- )\n- self.crawler.engine.crawl(first_request)\n+ self.crawler.engine.crawl(self.get_next_location())\n \n def parse_locations(self, response):\n for location in response.json()[\"locations\"]:\n+ # Remove found location from the list of locations which\n+ # are still waiting to be found.\n+ if self.locations_found.get(location[\"id\"]):\n+ self.locations_found.pop(location[\"id\"])\n+\n if location.get(\"inactive\"):\n continue\n+\n location[\"street_address\"] = location.pop(\"address\")\n item = DictParser.parse(location)\n self.extract_hours(item, location)\n yield from self.parse_item(item, location) or []\n \n- # Remove found location from the list of locations which\n- # are still waiting to be found.\n- if self.locations_found.get(location[\"id\"]):\n- self.locations_found.pop(location[\"id\"])\n-\n # Get the next location to do a \"nearest to\" search from.\n- if len(self.locations_found) > 0:\n- next_search_location = self.locations_found.popitem()\n- yield JsonRequest(\n- url=self.url_nearest_to_template.format(\n- self.key, self.api_version, next_search_location[1][0], next_search_location[1][1]\n- ),\n- callback=self.parse_locations,\n- )\n+ yield self.get_next_location()\n+\n+ def get_next_location(self) -> JsonRequest:\n+ if len(self.locations_found) == 0:\n+ return\n+ next_search_location_id = random.choice(list(self.locations_found))\n+ next_search_location_coords = self.locations_found[next_search_location_id]\n+ self.locations_found.pop(next_search_location_id)\n+ return JsonRequest(\n+ url=self.url_nearest_to_template.format(\n+ self.key, self.api_version, next_search_location_coords[0], next_search_location_coords[1]\n+ ),\n+ callback=self.parse_locations,\n+ dont_filter=True,\n+ )\n \n- def extract_hours(self, item, location):\n+ @staticmethod\n+ def extract_hours(item: Feature, location: dict):\n item[\"opening_hours\"] = OpeningHours()\n if location.get(\"open_status\") == \"twenty_four_hour\":\n item[\"opening_hours\"].add_days_range(DAYS, \"00:00\", \"23:59\")\n", "issue": "Shell spider doesn't return any results for Bulgaria\nThere are around 100 Shell gas stations in Bulgaria but none of them are shown in the latest spider result. They are listed on their Bulgarian website (https://www.shell.bg/motorists/shell-station-locator.html).\n", "before_files": [{"content": "from scrapy import Spider\nfrom scrapy.http import JsonRequest\nfrom scrapy.signals import spider_idle\n\nfrom locations.dict_parser import DictParser\nfrom locations.hours import DAYS, DAYS_EN, OpeningHours, day_range\nfrom locations.items import Feature\n\n# To use this store finder, specify key = x where x is the unique\n# identifier of the store finder in domain x.geoapp.me.\n#\n# It is likely there are additional fields of data worth extracting\n# from the store finder. These should be added by overriding the\n# parse_item function. Two parameters are passed, item (and ATP\n# \"Feature\" class) and location (a dict which is returned from the\n# store locator JSON response for a particular location).\n#\n# This spider has two crawling steps which are executed in order:\n# 1. Obtain list of all locations by using the API to do bounding\n# box searches across the world. The only thing of interest\n# returned for each location in this step is a unique identifier\n# and coordinates.\n# 2. Iterating through the all locations list produced by step (1),\n# request the nearest 50 (API limit) locations for each location\n# in the all locations list. Remove from the all locations list\n# and locations that were returned with a nearest location\n# search. Repeat until the all locations list is empty. The\n# nearest location search returns all details of a location.\n#\n# Note that due to the way the two crawling steps are required to\n# operate, numerous duplicate locations will be dropped during\n# extraction. It is common for locations to be present in more than\n# one nearby cluster of locations that the \"nearest to\" search\n# iterates through.\n\n\nclass GeoMeSpider(Spider):\n key = \"\"\n api_version = \"2\"\n url_within_bounds_template = \"https://{}.geoapp.me/api/v{}/locations/within_bounds?sw[]={}&sw[]={}&ne[]={}&ne[]={}\"\n url_nearest_to_template = \"https://{}.geoapp.me/api/v{}/locations/nearest_to?lat={}&lng={}&limit=50\"\n locations_found = {}\n\n def start_requests(self):\n self.crawler.signals.connect(self.start_location_requests, signal=spider_idle)\n yield JsonRequest(\n url=self.url_within_bounds_template.format(self.key, self.api_version, -90, -180, 90, 180),\n callback=self.parse_bounding_box,\n )\n\n def parse_bounding_box(self, response):\n for cluster in response.json().get(\"clusters\", []):\n if b := cluster.get(\"bounds\"):\n yield JsonRequest(\n url=self.url_within_bounds_template.format(\n self.key, self.api_version, b[\"sw\"][0], b[\"sw\"][1], b[\"ne\"][0], b[\"ne\"][1]\n ),\n callback=self.parse_bounding_box,\n )\n for location in response.json().get(\"locations\", []):\n self.locations_found[location[\"id\"]] = (float(location[\"lat\"]), float(location[\"lng\"]))\n\n def start_location_requests(self):\n self.crawler.signals.disconnect(self.start_location_requests, signal=spider_idle)\n if len(self.locations_found) > 0:\n first_search_location = self.locations_found.popitem()\n first_request = JsonRequest(\n url=self.url_nearest_to_template.format(\n self.key, self.api_version, first_search_location[1][0], first_search_location[1][1]\n ),\n callback=self.parse_locations,\n )\n self.crawler.engine.crawl(first_request)\n\n def parse_locations(self, response):\n for location in response.json()[\"locations\"]:\n if location.get(\"inactive\"):\n continue\n location[\"street_address\"] = location.pop(\"address\")\n item = DictParser.parse(location)\n self.extract_hours(item, location)\n yield from self.parse_item(item, location) or []\n\n # Remove found location from the list of locations which\n # are still waiting to be found.\n if self.locations_found.get(location[\"id\"]):\n self.locations_found.pop(location[\"id\"])\n\n # Get the next location to do a \"nearest to\" search from.\n if len(self.locations_found) > 0:\n next_search_location = self.locations_found.popitem()\n yield JsonRequest(\n url=self.url_nearest_to_template.format(\n self.key, self.api_version, next_search_location[1][0], next_search_location[1][1]\n ),\n callback=self.parse_locations,\n )\n\n def extract_hours(self, item, location):\n item[\"opening_hours\"] = OpeningHours()\n if location.get(\"open_status\") == \"twenty_four_hour\":\n item[\"opening_hours\"].add_days_range(DAYS, \"00:00\", \"23:59\")\n return\n open_hours = location.get(\"opening_hours\")\n if not open_hours:\n return\n for spec in open_hours:\n days = spec[\"days\"]\n day_from = day_to = days[0]\n if len(days) == 2:\n day_to = days[1]\n for day in day_range(DAYS_EN[day_from], DAYS_EN[day_to]):\n for hours in spec[\"hours\"]:\n item[\"opening_hours\"].add_range(day, hours[0], hours[1])\n\n def parse_item(self, item: Feature, location: dict, **kwargs):\n yield item\n", "path": "locations/storefinders/geo_me.py"}], "after_files": [{"content": "import random\n\nfrom scrapy import Spider\nfrom scrapy.http import JsonRequest\nfrom scrapy.signals import spider_idle\n\nfrom locations.dict_parser import DictParser\nfrom locations.hours import DAYS, DAYS_EN, OpeningHours, day_range\nfrom locations.items import Feature\n\n# To use this store finder, specify key = x where x is the unique\n# identifier of the store finder in domain x.geoapp.me.\n#\n# It is likely there are additional fields of data worth extracting\n# from the store finder. These should be added by overriding the\n# parse_item function. Two parameters are passed, item (and ATP\n# \"Feature\" class) and location (a dict which is returned from the\n# store locator JSON response for a particular location).\n#\n# This spider has two crawling steps which are executed in order:\n# 1. Obtain list of all locations by using the API to do bounding\n# box searches across the world. The only thing of interest\n# returned for each location in this step is a unique identifier\n# and coordinates.\n# 2. Iterating through the all locations list produced by step (1),\n# request the nearest 50 (API limit) locations for each location\n# in the all locations list. Remove from the all locations list\n# and locations that were returned with a nearest location\n# search. Repeat until the all locations list is empty. The\n# nearest location search returns all details of a location.\n#\n# Note that due to the way the two crawling steps are required to\n# operate, numerous duplicate locations will be dropped during\n# extraction. It is common for locations to be present in more than\n# one nearby cluster of locations that the \"nearest to\" search\n# iterates through.\n\n\nclass GeoMeSpider(Spider):\n key = \"\"\n api_version = \"2\"\n url_within_bounds_template = \"https://{}.geoapp.me/api/v{}/locations/within_bounds?sw[]={}&sw[]={}&ne[]={}&ne[]={}\"\n url_nearest_to_template = \"https://{}.geoapp.me/api/v{}/locations/nearest_to?lat={}&lng={}&limit=50\"\n locations_found = {}\n\n def start_requests(self):\n self.crawler.signals.connect(self.start_location_requests, signal=spider_idle)\n yield JsonRequest(\n url=self.url_within_bounds_template.format(self.key, self.api_version, -90, -180, 90, 180),\n callback=self.parse_bounding_box,\n )\n\n def parse_bounding_box(self, response):\n for cluster in response.json().get(\"clusters\", []):\n if b := cluster.get(\"bounds\"):\n yield JsonRequest(\n url=self.url_within_bounds_template.format(\n self.key, self.api_version, b[\"sw\"][0], b[\"sw\"][1], b[\"ne\"][0], b[\"ne\"][1]\n ),\n callback=self.parse_bounding_box,\n )\n for location in response.json().get(\"locations\", []):\n self.locations_found[location[\"id\"]] = (float(location[\"lat\"]), float(location[\"lng\"]))\n\n def start_location_requests(self):\n self.crawler.signals.disconnect(self.start_location_requests, signal=spider_idle)\n self.crawler.engine.crawl(self.get_next_location())\n\n def parse_locations(self, response):\n for location in response.json()[\"locations\"]:\n # Remove found location from the list of locations which\n # are still waiting to be found.\n if self.locations_found.get(location[\"id\"]):\n self.locations_found.pop(location[\"id\"])\n\n if location.get(\"inactive\"):\n continue\n\n location[\"street_address\"] = location.pop(\"address\")\n item = DictParser.parse(location)\n self.extract_hours(item, location)\n yield from self.parse_item(item, location) or []\n\n # Get the next location to do a \"nearest to\" search from.\n yield self.get_next_location()\n\n def get_next_location(self) -> JsonRequest:\n if len(self.locations_found) == 0:\n return\n next_search_location_id = random.choice(list(self.locations_found))\n next_search_location_coords = self.locations_found[next_search_location_id]\n self.locations_found.pop(next_search_location_id)\n return JsonRequest(\n url=self.url_nearest_to_template.format(\n self.key, self.api_version, next_search_location_coords[0], next_search_location_coords[1]\n ),\n callback=self.parse_locations,\n dont_filter=True,\n )\n\n @staticmethod\n def extract_hours(item: Feature, location: dict):\n item[\"opening_hours\"] = OpeningHours()\n if location.get(\"open_status\") == \"twenty_four_hour\":\n item[\"opening_hours\"].add_days_range(DAYS, \"00:00\", \"23:59\")\n return\n open_hours = location.get(\"opening_hours\")\n if not open_hours:\n return\n for spec in open_hours:\n days = spec[\"days\"]\n day_from = day_to = days[0]\n if len(days) == 2:\n day_to = days[1]\n for day in day_range(DAYS_EN[day_from], DAYS_EN[day_to]):\n for hours in spec[\"hours\"]:\n item[\"opening_hours\"].add_range(day, hours[0], hours[1])\n\n def parse_item(self, item: Feature, location: dict, **kwargs):\n yield item\n", "path": "locations/storefinders/geo_me.py"}]}
| 1,713 | 694 |
gh_patches_debug_403
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-1740
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
2 link limit on nav items
affects the footer, need more than 2 items
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/cms/models/navigation_menues.py`
Content:
```
1 from django.db import models
2 from modelcluster.fields import ParentalKey
3 from modelcluster.models import ClusterableModel
4 from wagtail.admin import edit_handlers
5 from wagtail.core.models import Orderable
6 from wagtail.snippets.models import register_snippet
7
8
9 class MenuItem(models.Model):
10 title = models.CharField(max_length=255)
11 link_page = models.ForeignKey('wagtailcore.Page')
12
13 @property
14 def url(self):
15 return self.link_page.url
16
17 def __str__(self):
18 return self.title
19
20 panels = [
21 edit_handlers.FieldPanel('title'),
22 edit_handlers.PageChooserPanel('link_page')
23 ]
24
25
26 @register_snippet
27 class NavigationMenu(ClusterableModel):
28 title = models.CharField(max_length=255, null=False, blank=False)
29
30 def __str__(self):
31 return self.title
32
33 panels = [
34 edit_handlers.FieldPanel('title'),
35 edit_handlers.InlinePanel('items', max_num=2)
36 ]
37
38
39 class NavigationMenuItem(Orderable, MenuItem):
40 parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/cms/models/navigation_menues.py b/meinberlin/apps/cms/models/navigation_menues.py
--- a/meinberlin/apps/cms/models/navigation_menues.py
+++ b/meinberlin/apps/cms/models/navigation_menues.py
@@ -32,7 +32,7 @@
panels = [
edit_handlers.FieldPanel('title'),
- edit_handlers.InlinePanel('items', max_num=2)
+ edit_handlers.InlinePanel('items')
]
|
{"golden_diff": "diff --git a/meinberlin/apps/cms/models/navigation_menues.py b/meinberlin/apps/cms/models/navigation_menues.py\n--- a/meinberlin/apps/cms/models/navigation_menues.py\n+++ b/meinberlin/apps/cms/models/navigation_menues.py\n@@ -32,7 +32,7 @@\n \n panels = [\n edit_handlers.FieldPanel('title'),\n- edit_handlers.InlinePanel('items', max_num=2)\n+ edit_handlers.InlinePanel('items')\n ]\n", "issue": "2 link limit on nav items\naffects the footer, need more than 2 items \n", "before_files": [{"content": "from django.db import models\nfrom modelcluster.fields import ParentalKey\nfrom modelcluster.models import ClusterableModel\nfrom wagtail.admin import edit_handlers\nfrom wagtail.core.models import Orderable\nfrom wagtail.snippets.models import register_snippet\n\n\nclass MenuItem(models.Model):\n title = models.CharField(max_length=255)\n link_page = models.ForeignKey('wagtailcore.Page')\n\n @property\n def url(self):\n return self.link_page.url\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.PageChooserPanel('link_page')\n ]\n\n\n@register_snippet\nclass NavigationMenu(ClusterableModel):\n title = models.CharField(max_length=255, null=False, blank=False)\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.InlinePanel('items', max_num=2)\n ]\n\n\nclass NavigationMenuItem(Orderable, MenuItem):\n parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')\n", "path": "meinberlin/apps/cms/models/navigation_menues.py"}], "after_files": [{"content": "from django.db import models\nfrom modelcluster.fields import ParentalKey\nfrom modelcluster.models import ClusterableModel\nfrom wagtail.admin import edit_handlers\nfrom wagtail.core.models import Orderable\nfrom wagtail.snippets.models import register_snippet\n\n\nclass MenuItem(models.Model):\n title = models.CharField(max_length=255)\n link_page = models.ForeignKey('wagtailcore.Page')\n\n @property\n def url(self):\n return self.link_page.url\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.PageChooserPanel('link_page')\n ]\n\n\n@register_snippet\nclass NavigationMenu(ClusterableModel):\n title = models.CharField(max_length=255, null=False, blank=False)\n\n def __str__(self):\n return self.title\n\n panels = [\n edit_handlers.FieldPanel('title'),\n edit_handlers.InlinePanel('items')\n ]\n\n\nclass NavigationMenuItem(Orderable, MenuItem):\n parent = ParentalKey('meinberlin_cms.NavigationMenu', related_name='items')\n", "path": "meinberlin/apps/cms/models/navigation_menues.py"}]}
| 603 | 112 |
gh_patches_debug_18165
|
rasdani/github-patches
|
git_diff
|
Textualize__textual-4234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Type warning with `AwaitComplete`
It seems that there is a type error when it comes to awaiting `AwaitComplete`. As an example, given this code:
```python
from textual.app import App
from textual.widgets import TabbedContent, TabPane
class AwaitableTypeWarningApp(App[None]):
async def on_mount(self) -> None:
await self.query_one(TabbedContent).add_pane(TabPane("Test"))
await self.query_one(TabbedContent).remove_pane("some-tab")
```
pyright reports:
```
/Users/davep/develop/python/textual-sandbox/await_type_warning.py
/Users/davep/develop/python/textual-sandbox/await_type_warning.py:7:15 - error: "AwaitComplete" is not awaitable
"AwaitComplete" is incompatible with protocol "Awaitable[_T_co@Awaitable]"
"__await__" is an incompatible type
Type "() -> Iterator[None]" cannot be assigned to type "() -> Generator[Any, None, _T_co@Awaitable]"
Function return type "Iterator[None]" is incompatible with type "Generator[Any, None, _T_co@Awaitable]"
"Iterator[None]" is incompatible with "Generator[Any, None, _T_co@Awaitable]" (reportGeneralTypeIssues)
/Users/davep/develop/python/textual-sandbox/await_type_warning.py:8:15 - error: "AwaitComplete" is not awaitable
"AwaitComplete" is incompatible with protocol "Awaitable[_T_co@Awaitable]"
"__await__" is an incompatible type
Type "() -> Iterator[None]" cannot be assigned to type "() -> Generator[Any, None, _T_co@Awaitable]"
Function return type "Iterator[None]" is incompatible with type "Generator[Any, None, _T_co@Awaitable]"
"Iterator[None]" is incompatible with "Generator[Any, None, _T_co@Awaitable]" (reportGeneralTypeIssues)
2 errors, 0 warnings, 0 informations
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/textual/await_complete.py`
Content:
```
1 from __future__ import annotations
2
3 from asyncio import Future, gather
4 from typing import Any, Coroutine, Iterator, TypeVar
5
6 import rich.repr
7
8 ReturnType = TypeVar("ReturnType")
9
10
11 @rich.repr.auto(angular=True)
12 class AwaitComplete:
13 """An 'optionally-awaitable' object."""
14
15 def __init__(self, *coroutines: Coroutine[Any, Any, Any]) -> None:
16 """Create an AwaitComplete.
17
18 Args:
19 coroutines: One or more coroutines to execute.
20 """
21 self.coroutines: tuple[Coroutine[Any, Any, Any], ...] = coroutines
22 self._future: Future = gather(*self.coroutines)
23
24 async def __call__(self) -> Any:
25 return await self
26
27 def __await__(self) -> Iterator[None]:
28 return self._future.__await__()
29
30 @property
31 def is_done(self) -> bool:
32 """Returns True if the task has completed."""
33 return self._future.done()
34
35 @property
36 def exception(self) -> BaseException | None:
37 """An exception if it occurred in any of the coroutines."""
38 if self._future.done():
39 return self._future.exception()
40 return None
41
42 @classmethod
43 def nothing(cls):
44 """Returns an already completed instance of AwaitComplete."""
45 instance = cls()
46 instance._future = Future()
47 instance._future.set_result(None) # Mark it as completed with no result
48 return instance
49
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/textual/await_complete.py b/src/textual/await_complete.py
--- a/src/textual/await_complete.py
+++ b/src/textual/await_complete.py
@@ -1,7 +1,7 @@
from __future__ import annotations
from asyncio import Future, gather
-from typing import Any, Coroutine, Iterator, TypeVar
+from typing import Any, Coroutine, Generator, TypeVar
import rich.repr
@@ -19,12 +19,12 @@
coroutines: One or more coroutines to execute.
"""
self.coroutines: tuple[Coroutine[Any, Any, Any], ...] = coroutines
- self._future: Future = gather(*self.coroutines)
+ self._future: Future[Any] = gather(*self.coroutines)
async def __call__(self) -> Any:
return await self
- def __await__(self) -> Iterator[None]:
+ def __await__(self) -> Generator[Any, None, Any]:
return self._future.__await__()
@property
|
{"golden_diff": "diff --git a/src/textual/await_complete.py b/src/textual/await_complete.py\n--- a/src/textual/await_complete.py\n+++ b/src/textual/await_complete.py\n@@ -1,7 +1,7 @@\n from __future__ import annotations\n \n from asyncio import Future, gather\n-from typing import Any, Coroutine, Iterator, TypeVar\n+from typing import Any, Coroutine, Generator, TypeVar\n \n import rich.repr\n \n@@ -19,12 +19,12 @@\n coroutines: One or more coroutines to execute.\n \"\"\"\n self.coroutines: tuple[Coroutine[Any, Any, Any], ...] = coroutines\n- self._future: Future = gather(*self.coroutines)\n+ self._future: Future[Any] = gather(*self.coroutines)\n \n async def __call__(self) -> Any:\n return await self\n \n- def __await__(self) -> Iterator[None]:\n+ def __await__(self) -> Generator[Any, None, Any]:\n return self._future.__await__()\n \n @property\n", "issue": "Type warning with `AwaitComplete`\nIt seems that there is a type error when it comes to awaiting `AwaitComplete`. As an example, given this code:\r\n\r\n```python\r\nfrom textual.app import App\r\nfrom textual.widgets import TabbedContent, TabPane\r\n\r\nclass AwaitableTypeWarningApp(App[None]):\r\n\r\n async def on_mount(self) -> None:\r\n await self.query_one(TabbedContent).add_pane(TabPane(\"Test\"))\r\n await self.query_one(TabbedContent).remove_pane(\"some-tab\")\r\n```\r\n\r\npyright reports:\r\n\r\n```\r\n/Users/davep/develop/python/textual-sandbox/await_type_warning.py\r\n /Users/davep/develop/python/textual-sandbox/await_type_warning.py:7:15 - error: \"AwaitComplete\" is not awaitable\r\n \u00a0\u00a0\"AwaitComplete\" is incompatible with protocol \"Awaitable[_T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\"__await__\" is an incompatible type\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0Type \"() -> Iterator[None]\" cannot be assigned to type \"() -> Generator[Any, None, _T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0Function return type \"Iterator[None]\" is incompatible with type \"Generator[Any, None, _T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\"Iterator[None]\" is incompatible with \"Generator[Any, None, _T_co@Awaitable]\" (reportGeneralTypeIssues)\r\n /Users/davep/develop/python/textual-sandbox/await_type_warning.py:8:15 - error: \"AwaitComplete\" is not awaitable\r\n \u00a0\u00a0\"AwaitComplete\" is incompatible with protocol \"Awaitable[_T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\"__await__\" is an incompatible type\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0Type \"() -> Iterator[None]\" cannot be assigned to type \"() -> Generator[Any, None, _T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0Function return type \"Iterator[None]\" is incompatible with type \"Generator[Any, None, _T_co@Awaitable]\"\r\n \u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\u00a0\"Iterator[None]\" is incompatible with \"Generator[Any, None, _T_co@Awaitable]\" (reportGeneralTypeIssues)\r\n2 errors, 0 warnings, 0 informations \r\n```\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom asyncio import Future, gather\nfrom typing import Any, Coroutine, Iterator, TypeVar\n\nimport rich.repr\n\nReturnType = TypeVar(\"ReturnType\")\n\n\[email protected](angular=True)\nclass AwaitComplete:\n \"\"\"An 'optionally-awaitable' object.\"\"\"\n\n def __init__(self, *coroutines: Coroutine[Any, Any, Any]) -> None:\n \"\"\"Create an AwaitComplete.\n\n Args:\n coroutines: One or more coroutines to execute.\n \"\"\"\n self.coroutines: tuple[Coroutine[Any, Any, Any], ...] = coroutines\n self._future: Future = gather(*self.coroutines)\n\n async def __call__(self) -> Any:\n return await self\n\n def __await__(self) -> Iterator[None]:\n return self._future.__await__()\n\n @property\n def is_done(self) -> bool:\n \"\"\"Returns True if the task has completed.\"\"\"\n return self._future.done()\n\n @property\n def exception(self) -> BaseException | None:\n \"\"\"An exception if it occurred in any of the coroutines.\"\"\"\n if self._future.done():\n return self._future.exception()\n return None\n\n @classmethod\n def nothing(cls):\n \"\"\"Returns an already completed instance of AwaitComplete.\"\"\"\n instance = cls()\n instance._future = Future()\n instance._future.set_result(None) # Mark it as completed with no result\n return instance\n", "path": "src/textual/await_complete.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom asyncio import Future, gather\nfrom typing import Any, Coroutine, Generator, TypeVar\n\nimport rich.repr\n\nReturnType = TypeVar(\"ReturnType\")\n\n\[email protected](angular=True)\nclass AwaitComplete:\n \"\"\"An 'optionally-awaitable' object.\"\"\"\n\n def __init__(self, *coroutines: Coroutine[Any, Any, Any]) -> None:\n \"\"\"Create an AwaitComplete.\n\n Args:\n coroutines: One or more coroutines to execute.\n \"\"\"\n self.coroutines: tuple[Coroutine[Any, Any, Any], ...] = coroutines\n self._future: Future[Any] = gather(*self.coroutines)\n\n async def __call__(self) -> Any:\n return await self\n\n def __await__(self) -> Generator[Any, None, Any]:\n return self._future.__await__()\n\n @property\n def is_done(self) -> bool:\n \"\"\"Returns True if the task has completed.\"\"\"\n return self._future.done()\n\n @property\n def exception(self) -> BaseException | None:\n \"\"\"An exception if it occurred in any of the coroutines.\"\"\"\n if self._future.done():\n return self._future.exception()\n return None\n\n @classmethod\n def nothing(cls):\n \"\"\"Returns an already completed instance of AwaitComplete.\"\"\"\n instance = cls()\n instance._future = Future()\n instance._future.set_result(None) # Mark it as completed with no result\n return instance\n", "path": "src/textual/await_complete.py"}]}
| 1,138 | 228 |
gh_patches_debug_18109
|
rasdani/github-patches
|
git_diff
|
azavea__raster-vision-1042
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Semantic Segmentation Scenes w/ 0 Chips Fail
Semantic segmentation scenes with zero chips cause raster-vision to halt. This can be an issue when using finely-cropped scenes and filtering by nodata.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py`
Content:
```
1 import logging
2 from typing import List, Sequence
3
4 import numpy as np
5
6 from rastervision.core.box import Box
7 from rastervision.core.data import ClassConfig, Scene
8 from rastervision.core.rv_pipeline.rv_pipeline import RVPipeline
9 from rastervision.core.rv_pipeline.utils import (fill_no_data,
10 nodata_below_threshold)
11 from rastervision.core.rv_pipeline.semantic_segmentation_config import (
12 SemanticSegmentationWindowMethod, SemanticSegmentationChipOptions)
13
14 log = logging.getLogger(__name__)
15
16
17 def get_train_windows(scene: Scene,
18 class_config: ClassConfig,
19 chip_size: int,
20 chip_options: SemanticSegmentationChipOptions,
21 chip_nodata_threshold: float = 1.) -> List[Box]:
22 """Get training windows covering a scene.
23
24 Args:
25 scene: The scene over-which windows are to be generated.
26
27 Returns:
28 A list of windows, list(Box)
29 """
30 co = chip_options
31 raster_source = scene.raster_source
32 extent = raster_source.get_extent()
33 label_source = scene.ground_truth_label_source
34
35 def filter_windows(windows: Sequence[Box]) -> List[Box]:
36 """Filter out chips that
37 (1) are outside the AOI
38 (2) only consist of null labels
39 (3) have NODATA proportion >= chip_nodata_threshold
40 """
41 total_windows = len(windows)
42 if scene.aoi_polygons:
43 windows = Box.filter_by_aoi(windows, scene.aoi_polygons)
44 log.info(f'AOI filtering: {len(windows)}/{total_windows} '
45 'chips accepted')
46
47 filt_windows = []
48 for w in windows:
49 chip = raster_source.get_chip(w)
50 nodata_below_thresh = nodata_below_threshold(
51 chip, chip_nodata_threshold, nodata_val=0)
52
53 label_arr = label_source.get_labels(w).get_label_arr(w)
54 null_labels = label_arr == class_config.get_null_class_id()
55
56 if not np.all(null_labels) and nodata_below_thresh:
57 filt_windows.append(w)
58 log.info('Label and NODATA filtering: '
59 f'{len(filt_windows)}/{len(windows)} chips accepted')
60
61 windows = filt_windows
62 return windows
63
64 def should_use_window(window: Box) -> bool:
65 if co.negative_survival_prob >= 1.0:
66 return True
67 else:
68 target_class_ids = co.target_class_ids or list(
69 range(len(class_config)))
70 is_pos = label_source.enough_target_pixels(
71 window, co.target_count_threshold, target_class_ids)
72 should_use = is_pos or (np.random.rand() <
73 co.negative_survival_prob)
74 return should_use
75
76 if co.window_method == SemanticSegmentationWindowMethod.sliding:
77 stride = co.stride or int(round(chip_size / 2))
78 windows = list(filter_windows((extent.get_windows(chip_size, stride))))
79 a_window = windows[0]
80 windows = list(filter(should_use_window, windows))
81 if len(windows) == 0:
82 windows = [a_window]
83 elif co.window_method == SemanticSegmentationWindowMethod.random_sample:
84 windows = []
85 attempts = 0
86
87 while attempts < co.chips_per_scene:
88 window = extent.make_random_square(chip_size)
89 if not filter_windows([window]):
90 continue
91
92 attempts += 1
93 if co.negative_survival_prob >= 1.0:
94 windows.append(window)
95 elif attempts == co.chips_per_scene and len(windows) == 0:
96 # Ensure there is at least one window per scene.
97 windows.append(window)
98 elif should_use_window(window):
99 windows.append(window)
100
101 return windows
102
103
104 class SemanticSegmentation(RVPipeline):
105 def __init__(self, config: 'RVPipelineConfig', tmp_dir: str):
106 super().__init__(config, tmp_dir)
107 if self.config.dataset.img_channels is None:
108 self.config.dataset.img_channels = self.get_img_channels()
109
110 self.config.dataset.update()
111 self.config.dataset.validate_config()
112
113 self.config.update()
114 self.config.validate_config()
115
116 def get_img_channels(self):
117 ''' Determine img_channels from the first training scene. '''
118 class_config = self.config.dataset.class_config
119 scene_cfg = self.config.dataset.train_scenes[0]
120 scene = scene_cfg.build(
121 class_config, self.tmp_dir, use_transformers=False)
122 with scene.activate():
123 img_channels = scene.raster_source.num_channels
124 return img_channels
125
126 def chip(self, *args, **kwargs):
127 log.info(f'Chip options: {self.config.chip_options}')
128 return super().chip(*args, **kwargs)
129
130 def get_train_windows(self, scene):
131 return get_train_windows(
132 scene,
133 self.config.dataset.class_config,
134 self.config.train_chip_sz,
135 self.config.chip_options,
136 chip_nodata_threshold=self.config.chip_nodata_threshold)
137
138 def get_train_labels(self, window, scene):
139 return scene.ground_truth_label_source.get_labels(window=window)
140
141 def post_process_sample(self, sample):
142 # Use null label for each pixel with NODATA.
143 img = sample.chip
144 label_arr = sample.labels.get_label_arr(sample.window)
145 null_class_id = self.config.dataset.class_config.get_null_class_id()
146 sample.chip = fill_no_data(img, label_arr, null_class_id)
147 return sample
148
149 def post_process_batch(self, windows, chips, labels):
150 # Fill in null class for any NODATA pixels.
151 null_class_id = self.config.dataset.class_config.get_null_class_id()
152 for window, chip in zip(windows, chips):
153 label_arr = labels.get_label_arr(window)
154 label_arr[np.sum(chip, axis=2) == 0] = null_class_id
155 labels.set_label_arr(window, label_arr)
156
157 return labels
158
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py b/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py
--- a/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py
+++ b/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py
@@ -75,11 +75,15 @@
if co.window_method == SemanticSegmentationWindowMethod.sliding:
stride = co.stride or int(round(chip_size / 2))
- windows = list(filter_windows((extent.get_windows(chip_size, stride))))
- a_window = windows[0]
- windows = list(filter(should_use_window, windows))
- if len(windows) == 0:
- windows = [a_window]
+ unfiltered_windows = extent.get_windows(chip_size, stride)
+ windows = list(filter_windows(unfiltered_windows))
+ if len(windows) > 0:
+ a_window = windows[0]
+ windows = list(filter(should_use_window, windows))
+ if len(windows) == 0:
+ windows = [a_window]
+ elif len(windows) == 0:
+ return [unfiltered_windows[0]]
elif co.window_method == SemanticSegmentationWindowMethod.random_sample:
windows = []
attempts = 0
|
{"golden_diff": "diff --git a/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py b/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py\n--- a/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py\n+++ b/rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py\n@@ -75,11 +75,15 @@\n \n if co.window_method == SemanticSegmentationWindowMethod.sliding:\n stride = co.stride or int(round(chip_size / 2))\n- windows = list(filter_windows((extent.get_windows(chip_size, stride))))\n- a_window = windows[0]\n- windows = list(filter(should_use_window, windows))\n- if len(windows) == 0:\n- windows = [a_window]\n+ unfiltered_windows = extent.get_windows(chip_size, stride)\n+ windows = list(filter_windows(unfiltered_windows))\n+ if len(windows) > 0:\n+ a_window = windows[0]\n+ windows = list(filter(should_use_window, windows))\n+ if len(windows) == 0:\n+ windows = [a_window]\n+ elif len(windows) == 0:\n+ return [unfiltered_windows[0]]\n elif co.window_method == SemanticSegmentationWindowMethod.random_sample:\n windows = []\n attempts = 0\n", "issue": "Semantic Segmentation Scenes w/ 0 Chips Fail\nSemantic segmentation scenes with zero chips cause raster-vision to halt. This can be an issue when using finely-cropped scenes and filtering by nodata.\n", "before_files": [{"content": "import logging\nfrom typing import List, Sequence\n\nimport numpy as np\n\nfrom rastervision.core.box import Box\nfrom rastervision.core.data import ClassConfig, Scene\nfrom rastervision.core.rv_pipeline.rv_pipeline import RVPipeline\nfrom rastervision.core.rv_pipeline.utils import (fill_no_data,\n nodata_below_threshold)\nfrom rastervision.core.rv_pipeline.semantic_segmentation_config import (\n SemanticSegmentationWindowMethod, SemanticSegmentationChipOptions)\n\nlog = logging.getLogger(__name__)\n\n\ndef get_train_windows(scene: Scene,\n class_config: ClassConfig,\n chip_size: int,\n chip_options: SemanticSegmentationChipOptions,\n chip_nodata_threshold: float = 1.) -> List[Box]:\n \"\"\"Get training windows covering a scene.\n\n Args:\n scene: The scene over-which windows are to be generated.\n\n Returns:\n A list of windows, list(Box)\n \"\"\"\n co = chip_options\n raster_source = scene.raster_source\n extent = raster_source.get_extent()\n label_source = scene.ground_truth_label_source\n\n def filter_windows(windows: Sequence[Box]) -> List[Box]:\n \"\"\"Filter out chips that\n (1) are outside the AOI\n (2) only consist of null labels\n (3) have NODATA proportion >= chip_nodata_threshold\n \"\"\"\n total_windows = len(windows)\n if scene.aoi_polygons:\n windows = Box.filter_by_aoi(windows, scene.aoi_polygons)\n log.info(f'AOI filtering: {len(windows)}/{total_windows} '\n 'chips accepted')\n\n filt_windows = []\n for w in windows:\n chip = raster_source.get_chip(w)\n nodata_below_thresh = nodata_below_threshold(\n chip, chip_nodata_threshold, nodata_val=0)\n\n label_arr = label_source.get_labels(w).get_label_arr(w)\n null_labels = label_arr == class_config.get_null_class_id()\n\n if not np.all(null_labels) and nodata_below_thresh:\n filt_windows.append(w)\n log.info('Label and NODATA filtering: '\n f'{len(filt_windows)}/{len(windows)} chips accepted')\n\n windows = filt_windows\n return windows\n\n def should_use_window(window: Box) -> bool:\n if co.negative_survival_prob >= 1.0:\n return True\n else:\n target_class_ids = co.target_class_ids or list(\n range(len(class_config)))\n is_pos = label_source.enough_target_pixels(\n window, co.target_count_threshold, target_class_ids)\n should_use = is_pos or (np.random.rand() <\n co.negative_survival_prob)\n return should_use\n\n if co.window_method == SemanticSegmentationWindowMethod.sliding:\n stride = co.stride or int(round(chip_size / 2))\n windows = list(filter_windows((extent.get_windows(chip_size, stride))))\n a_window = windows[0]\n windows = list(filter(should_use_window, windows))\n if len(windows) == 0:\n windows = [a_window]\n elif co.window_method == SemanticSegmentationWindowMethod.random_sample:\n windows = []\n attempts = 0\n\n while attempts < co.chips_per_scene:\n window = extent.make_random_square(chip_size)\n if not filter_windows([window]):\n continue\n\n attempts += 1\n if co.negative_survival_prob >= 1.0:\n windows.append(window)\n elif attempts == co.chips_per_scene and len(windows) == 0:\n # Ensure there is at least one window per scene.\n windows.append(window)\n elif should_use_window(window):\n windows.append(window)\n\n return windows\n\n\nclass SemanticSegmentation(RVPipeline):\n def __init__(self, config: 'RVPipelineConfig', tmp_dir: str):\n super().__init__(config, tmp_dir)\n if self.config.dataset.img_channels is None:\n self.config.dataset.img_channels = self.get_img_channels()\n\n self.config.dataset.update()\n self.config.dataset.validate_config()\n\n self.config.update()\n self.config.validate_config()\n\n def get_img_channels(self):\n ''' Determine img_channels from the first training scene. '''\n class_config = self.config.dataset.class_config\n scene_cfg = self.config.dataset.train_scenes[0]\n scene = scene_cfg.build(\n class_config, self.tmp_dir, use_transformers=False)\n with scene.activate():\n img_channels = scene.raster_source.num_channels\n return img_channels\n\n def chip(self, *args, **kwargs):\n log.info(f'Chip options: {self.config.chip_options}')\n return super().chip(*args, **kwargs)\n\n def get_train_windows(self, scene):\n return get_train_windows(\n scene,\n self.config.dataset.class_config,\n self.config.train_chip_sz,\n self.config.chip_options,\n chip_nodata_threshold=self.config.chip_nodata_threshold)\n\n def get_train_labels(self, window, scene):\n return scene.ground_truth_label_source.get_labels(window=window)\n\n def post_process_sample(self, sample):\n # Use null label for each pixel with NODATA.\n img = sample.chip\n label_arr = sample.labels.get_label_arr(sample.window)\n null_class_id = self.config.dataset.class_config.get_null_class_id()\n sample.chip = fill_no_data(img, label_arr, null_class_id)\n return sample\n\n def post_process_batch(self, windows, chips, labels):\n # Fill in null class for any NODATA pixels.\n null_class_id = self.config.dataset.class_config.get_null_class_id()\n for window, chip in zip(windows, chips):\n label_arr = labels.get_label_arr(window)\n label_arr[np.sum(chip, axis=2) == 0] = null_class_id\n labels.set_label_arr(window, label_arr)\n\n return labels\n", "path": "rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py"}], "after_files": [{"content": "import logging\nfrom typing import List, Sequence\n\nimport numpy as np\n\nfrom rastervision.core.box import Box\nfrom rastervision.core.data import ClassConfig, Scene\nfrom rastervision.core.rv_pipeline.rv_pipeline import RVPipeline\nfrom rastervision.core.rv_pipeline.utils import (fill_no_data,\n nodata_below_threshold)\nfrom rastervision.core.rv_pipeline.semantic_segmentation_config import (\n SemanticSegmentationWindowMethod, SemanticSegmentationChipOptions)\n\nlog = logging.getLogger(__name__)\n\n\ndef get_train_windows(scene: Scene,\n class_config: ClassConfig,\n chip_size: int,\n chip_options: SemanticSegmentationChipOptions,\n chip_nodata_threshold: float = 1.) -> List[Box]:\n \"\"\"Get training windows covering a scene.\n\n Args:\n scene: The scene over-which windows are to be generated.\n\n Returns:\n A list of windows, list(Box)\n \"\"\"\n co = chip_options\n raster_source = scene.raster_source\n extent = raster_source.get_extent()\n label_source = scene.ground_truth_label_source\n\n def filter_windows(windows: Sequence[Box]) -> List[Box]:\n \"\"\"Filter out chips that\n (1) are outside the AOI\n (2) only consist of null labels\n (3) have NODATA proportion >= chip_nodata_threshold\n \"\"\"\n total_windows = len(windows)\n if scene.aoi_polygons:\n windows = Box.filter_by_aoi(windows, scene.aoi_polygons)\n log.info(f'AOI filtering: {len(windows)}/{total_windows} '\n 'chips accepted')\n\n filt_windows = []\n for w in windows:\n chip = raster_source.get_chip(w)\n nodata_below_thresh = nodata_below_threshold(\n chip, chip_nodata_threshold, nodata_val=0)\n\n label_arr = label_source.get_labels(w).get_label_arr(w)\n null_labels = label_arr == class_config.get_null_class_id()\n\n if not np.all(null_labels) and nodata_below_thresh:\n filt_windows.append(w)\n log.info('Label and NODATA filtering: '\n f'{len(filt_windows)}/{len(windows)} chips accepted')\n\n windows = filt_windows\n return windows\n\n def should_use_window(window: Box) -> bool:\n if co.negative_survival_prob >= 1.0:\n return True\n else:\n target_class_ids = co.target_class_ids or list(\n range(len(class_config)))\n is_pos = label_source.enough_target_pixels(\n window, co.target_count_threshold, target_class_ids)\n should_use = is_pos or (np.random.rand() <\n co.negative_survival_prob)\n return should_use\n\n if co.window_method == SemanticSegmentationWindowMethod.sliding:\n stride = co.stride or int(round(chip_size / 2))\n unfiltered_windows = extent.get_windows(chip_size, stride)\n windows = list(filter_windows(unfiltered_windows))\n if len(windows) > 0:\n a_window = windows[0]\n windows = list(filter(should_use_window, windows))\n if len(windows) == 0:\n windows = [a_window]\n elif len(windows) == 0:\n return [unfiltered_windows[0]]\n elif co.window_method == SemanticSegmentationWindowMethod.random_sample:\n windows = []\n attempts = 0\n\n while attempts < co.chips_per_scene:\n window = extent.make_random_square(chip_size)\n if not filter_windows([window]):\n continue\n\n attempts += 1\n if co.negative_survival_prob >= 1.0:\n windows.append(window)\n elif attempts == co.chips_per_scene and len(windows) == 0:\n # Ensure there is at least one window per scene.\n windows.append(window)\n elif should_use_window(window):\n windows.append(window)\n\n return windows\n\n\nclass SemanticSegmentation(RVPipeline):\n def __init__(self, config: 'RVPipelineConfig', tmp_dir: str):\n super().__init__(config, tmp_dir)\n if self.config.dataset.img_channels is None:\n self.config.dataset.img_channels = self.get_img_channels()\n\n self.config.dataset.update()\n self.config.dataset.validate_config()\n\n self.config.update()\n self.config.validate_config()\n\n def get_img_channels(self):\n ''' Determine img_channels from the first training scene. '''\n class_config = self.config.dataset.class_config\n scene_cfg = self.config.dataset.train_scenes[0]\n scene = scene_cfg.build(\n class_config, self.tmp_dir, use_transformers=False)\n with scene.activate():\n img_channels = scene.raster_source.num_channels\n return img_channels\n\n def chip(self, *args, **kwargs):\n log.info(f'Chip options: {self.config.chip_options}')\n return super().chip(*args, **kwargs)\n\n def get_train_windows(self, scene):\n return get_train_windows(\n scene,\n self.config.dataset.class_config,\n self.config.train_chip_sz,\n self.config.chip_options,\n chip_nodata_threshold=self.config.chip_nodata_threshold)\n\n def get_train_labels(self, window, scene):\n return scene.ground_truth_label_source.get_labels(window=window)\n\n def post_process_sample(self, sample):\n # Use null label for each pixel with NODATA.\n img = sample.chip\n label_arr = sample.labels.get_label_arr(sample.window)\n null_class_id = self.config.dataset.class_config.get_null_class_id()\n sample.chip = fill_no_data(img, label_arr, null_class_id)\n return sample\n\n def post_process_batch(self, windows, chips, labels):\n # Fill in null class for any NODATA pixels.\n null_class_id = self.config.dataset.class_config.get_null_class_id()\n for window, chip in zip(windows, chips):\n label_arr = labels.get_label_arr(window)\n label_arr[np.sum(chip, axis=2) == 0] = null_class_id\n labels.set_label_arr(window, label_arr)\n\n return labels\n", "path": "rastervision_core/rastervision/core/rv_pipeline/semantic_segmentation.py"}]}
| 1,963 | 306 |
gh_patches_debug_33799
|
rasdani/github-patches
|
git_diff
|
lhotse-speech__lhotse-1323
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[shar] cut can't load feature
when use
shards = train_cuts.to_shar(data_dir, fields={"features": "lilcom"}, shard_size=2000, num_jobs=20)
to make shar packages ;
one cut like:
MonoCut(id='X0000013171_273376986_S00164_sp1.1', start=0, duration=2.4818125, channel=0, supervisions=[SupervisionSegment(id='X0000013171_273376986_S00164_sp1.1', recording_id='X0000013171_273376986_sp1.1', start=0.0, duration=2.4818125, channel=0, text='用/花/里/胡/哨/的/甜/言/蜜/语/维/持/的/婚/姻', language='Chinese', speaker=None, gender=None, custom=None, alignment=None)], features=Features(type='kaldifeat-fbank', num_frames=248, num_features=80, frame_shift=0.01, sampling_rate=16000, start=425.6818125, duration=2.4818125, storage_type='memory_lilcom', storage_path='', storage_key='<binary-data>', recording_id='X0000013171_273376986_sp1.1', channels=0), recording=Recording(id='X0000013171_273376986_sp1.1', sources=[AudioSource(type='file', channels=[0], source='/store52/audio_data/WenetSpeech/audio/audio/train/podcast/B00051/X0000013171_273376986.opus')], sampling_rate=16000, num_samples=10926255, duration=682.8909375, channel_ids=[0], transforms=[{'name': 'Speed', 'kwargs': {'factor': 1.1}}]), custom={'dataloading_info': {'rank': 0, 'world_size': 1, 'worker_id': None}, 'shard_origin': PosixPath('cuts.020360.jsonl.gz'), 'shar_epoch': 0})
then try to load features :
cut.load_features()
has ERROR:
ValueError: Cannot load features for recording X0000013171_273376986_sp1.1 starting from 0s. The available range is (425.6818125, 428.16362499999997) seconds.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lhotse/shar/utils.py`
Content:
```
1 from pathlib import Path
2 from typing import Optional, TypeVar, Union
3
4 from lhotse import AudioSource, Features, Recording, compute_num_samples, fastcopy
5 from lhotse.array import Array, TemporalArray
6 from lhotse.cut import Cut
7 from lhotse.utils import Pathlike
8
9 Manifest = TypeVar("Manifest", Recording, Features, Array, TemporalArray)
10
11
12 def to_shar_placeholder(manifest: Manifest, cut: Optional[Cut] = None) -> Manifest:
13 if isinstance(manifest, Recording):
14 kwargs = (
15 {}
16 if cut is None
17 else dict(
18 duration=cut.duration,
19 num_samples=compute_num_samples(cut.duration, manifest.sampling_rate),
20 )
21 )
22 return fastcopy(
23 manifest,
24 # Creates a single AudioSource out of multiple ones.
25 sources=[
26 AudioSource(type="shar", channels=manifest.channel_ids, source="")
27 ],
28 # Removes the transform metadata because they were already executed.
29 transforms=None,
30 **kwargs,
31 )
32 # TODO: modify Features/TemporalArray's start/duration/num_frames if needed to match the Cut (in case we read subset of array)
33 elif isinstance(manifest, (Array, Features)):
34 return fastcopy(manifest, storage_type="shar", storage_path="", storage_key="")
35 elif isinstance(manifest, TemporalArray):
36 return fastcopy(
37 manifest,
38 array=fastcopy(
39 manifest.array, storage_type="shar", storage_path="", storage_key=""
40 ),
41 )
42
43
44 def fill_shar_placeholder(
45 manifest: Union[Cut, Recording, Features, Array, TemporalArray],
46 data: bytes,
47 tarpath: Pathlike,
48 field: Optional[str] = None,
49 ) -> None:
50 if isinstance(manifest, Cut):
51 assert (
52 field is not None
53 ), "'field' argument must be provided when filling a Shar placeholder in a Cut."
54 manifest = getattr(manifest, field)
55 fill_shar_placeholder(
56 manifest=manifest, field=field, data=data, tarpath=tarpath
57 )
58
59 tarpath = Path(tarpath)
60
61 if isinstance(manifest, Recording):
62 assert (
63 len(manifest.sources) == 1
64 ), "We expected a single (possibly multi-channel) AudioSource in Shar format."
65 manifest.sources[0].type = "memory"
66 manifest.sources[0].source = data
67
68 elif isinstance(manifest, (Features, Array)):
69 manifest.storage_key = data
70 if tarpath.suffix == ".llc":
71 manifest.storage_type = "memory_lilcom"
72 elif tarpath.suffix == ".npy":
73 manifest.storage_type = "memory_npy"
74 else:
75 raise RuntimeError(f"Unknown array/tensor format: {tarpath}")
76
77 elif isinstance(manifest, TemporalArray):
78 manifest.array.storage_key = data
79 if tarpath.suffix == ".llc":
80 manifest.array.storage_type = "memory_lilcom"
81 elif tarpath.suffix == ".npy":
82 manifest.array.storage_type = "memory_npy"
83 else:
84 raise RuntimeError(f"Unknown array/tensor format: {tarpath}")
85
86 else:
87 raise RuntimeError(f"Unknown manifest type: {type(manifest).__name__}")
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lhotse/shar/utils.py b/lhotse/shar/utils.py
--- a/lhotse/shar/utils.py
+++ b/lhotse/shar/utils.py
@@ -11,14 +11,6 @@
def to_shar_placeholder(manifest: Manifest, cut: Optional[Cut] = None) -> Manifest:
if isinstance(manifest, Recording):
- kwargs = (
- {}
- if cut is None
- else dict(
- duration=cut.duration,
- num_samples=compute_num_samples(cut.duration, manifest.sampling_rate),
- )
- )
return fastcopy(
manifest,
# Creates a single AudioSource out of multiple ones.
@@ -27,18 +19,35 @@
],
# Removes the transform metadata because they were already executed.
transforms=None,
- **kwargs,
+ duration=cut.duration if cut is not None else manifest.duration,
+ num_samples=compute_num_samples(cut.duration, manifest.sampling_rate)
+ if cut is not None
+ else manifest.num_samples,
)
- # TODO: modify Features/TemporalArray's start/duration/num_frames if needed to match the Cut (in case we read subset of array)
- elif isinstance(manifest, (Array, Features)):
+ elif isinstance(manifest, Array):
return fastcopy(manifest, storage_type="shar", storage_path="", storage_key="")
+ elif isinstance(manifest, Features):
+ return fastcopy(
+ manifest,
+ start=0,
+ duration=cut.duration if cut is not None else manifest.duration,
+ storage_type="shar",
+ storage_path="",
+ storage_key="",
+ )
elif isinstance(manifest, TemporalArray):
return fastcopy(
manifest,
+ start=0,
array=fastcopy(
- manifest.array, storage_type="shar", storage_path="", storage_key=""
+ manifest.array,
+ storage_type="shar",
+ storage_path="",
+ storage_key="",
),
)
+ else:
+ raise RuntimeError(f"Unexpected manifest type: {type(manifest)}")
def fill_shar_placeholder(
|
{"golden_diff": "diff --git a/lhotse/shar/utils.py b/lhotse/shar/utils.py\n--- a/lhotse/shar/utils.py\n+++ b/lhotse/shar/utils.py\n@@ -11,14 +11,6 @@\n \n def to_shar_placeholder(manifest: Manifest, cut: Optional[Cut] = None) -> Manifest:\n if isinstance(manifest, Recording):\n- kwargs = (\n- {}\n- if cut is None\n- else dict(\n- duration=cut.duration,\n- num_samples=compute_num_samples(cut.duration, manifest.sampling_rate),\n- )\n- )\n return fastcopy(\n manifest,\n # Creates a single AudioSource out of multiple ones.\n@@ -27,18 +19,35 @@\n ],\n # Removes the transform metadata because they were already executed.\n transforms=None,\n- **kwargs,\n+ duration=cut.duration if cut is not None else manifest.duration,\n+ num_samples=compute_num_samples(cut.duration, manifest.sampling_rate)\n+ if cut is not None\n+ else manifest.num_samples,\n )\n- # TODO: modify Features/TemporalArray's start/duration/num_frames if needed to match the Cut (in case we read subset of array)\n- elif isinstance(manifest, (Array, Features)):\n+ elif isinstance(manifest, Array):\n return fastcopy(manifest, storage_type=\"shar\", storage_path=\"\", storage_key=\"\")\n+ elif isinstance(manifest, Features):\n+ return fastcopy(\n+ manifest,\n+ start=0,\n+ duration=cut.duration if cut is not None else manifest.duration,\n+ storage_type=\"shar\",\n+ storage_path=\"\",\n+ storage_key=\"\",\n+ )\n elif isinstance(manifest, TemporalArray):\n return fastcopy(\n manifest,\n+ start=0,\n array=fastcopy(\n- manifest.array, storage_type=\"shar\", storage_path=\"\", storage_key=\"\"\n+ manifest.array,\n+ storage_type=\"shar\",\n+ storage_path=\"\",\n+ storage_key=\"\",\n ),\n )\n+ else:\n+ raise RuntimeError(f\"Unexpected manifest type: {type(manifest)}\")\n \n \n def fill_shar_placeholder(\n", "issue": "[shar] cut can't load feature\nwhen use\r\nshards = train_cuts.to_shar(data_dir, fields={\"features\": \"lilcom\"}, shard_size=2000, num_jobs=20)\r\nto make shar packages ;\r\n\r\none cut like:\r\nMonoCut(id='X0000013171_273376986_S00164_sp1.1', start=0, duration=2.4818125, channel=0, supervisions=[SupervisionSegment(id='X0000013171_273376986_S00164_sp1.1', recording_id='X0000013171_273376986_sp1.1', start=0.0, duration=2.4818125, channel=0, text='\u7528/\u82b1/\u91cc/\u80e1/\u54e8/\u7684/\u751c/\u8a00/\u871c/\u8bed/\u7ef4/\u6301/\u7684/\u5a5a/\u59fb', language='Chinese', speaker=None, gender=None, custom=None, alignment=None)], features=Features(type='kaldifeat-fbank', num_frames=248, num_features=80, frame_shift=0.01, sampling_rate=16000, start=425.6818125, duration=2.4818125, storage_type='memory_lilcom', storage_path='', storage_key='<binary-data>', recording_id='X0000013171_273376986_sp1.1', channels=0), recording=Recording(id='X0000013171_273376986_sp1.1', sources=[AudioSource(type='file', channels=[0], source='/store52/audio_data/WenetSpeech/audio/audio/train/podcast/B00051/X0000013171_273376986.opus')], sampling_rate=16000, num_samples=10926255, duration=682.8909375, channel_ids=[0], transforms=[{'name': 'Speed', 'kwargs': {'factor': 1.1}}]), custom={'dataloading_info': {'rank': 0, 'world_size': 1, 'worker_id': None}, 'shard_origin': PosixPath('cuts.020360.jsonl.gz'), 'shar_epoch': 0})\r\n\r\nthen try to load features :\r\ncut.load_features()\r\n\r\nhas ERROR:\r\n ValueError: Cannot load features for recording X0000013171_273376986_sp1.1 starting from 0s. The available range is (425.6818125, 428.16362499999997) seconds.\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import Optional, TypeVar, Union\n\nfrom lhotse import AudioSource, Features, Recording, compute_num_samples, fastcopy\nfrom lhotse.array import Array, TemporalArray\nfrom lhotse.cut import Cut\nfrom lhotse.utils import Pathlike\n\nManifest = TypeVar(\"Manifest\", Recording, Features, Array, TemporalArray)\n\n\ndef to_shar_placeholder(manifest: Manifest, cut: Optional[Cut] = None) -> Manifest:\n if isinstance(manifest, Recording):\n kwargs = (\n {}\n if cut is None\n else dict(\n duration=cut.duration,\n num_samples=compute_num_samples(cut.duration, manifest.sampling_rate),\n )\n )\n return fastcopy(\n manifest,\n # Creates a single AudioSource out of multiple ones.\n sources=[\n AudioSource(type=\"shar\", channels=manifest.channel_ids, source=\"\")\n ],\n # Removes the transform metadata because they were already executed.\n transforms=None,\n **kwargs,\n )\n # TODO: modify Features/TemporalArray's start/duration/num_frames if needed to match the Cut (in case we read subset of array)\n elif isinstance(manifest, (Array, Features)):\n return fastcopy(manifest, storage_type=\"shar\", storage_path=\"\", storage_key=\"\")\n elif isinstance(manifest, TemporalArray):\n return fastcopy(\n manifest,\n array=fastcopy(\n manifest.array, storage_type=\"shar\", storage_path=\"\", storage_key=\"\"\n ),\n )\n\n\ndef fill_shar_placeholder(\n manifest: Union[Cut, Recording, Features, Array, TemporalArray],\n data: bytes,\n tarpath: Pathlike,\n field: Optional[str] = None,\n) -> None:\n if isinstance(manifest, Cut):\n assert (\n field is not None\n ), \"'field' argument must be provided when filling a Shar placeholder in a Cut.\"\n manifest = getattr(manifest, field)\n fill_shar_placeholder(\n manifest=manifest, field=field, data=data, tarpath=tarpath\n )\n\n tarpath = Path(tarpath)\n\n if isinstance(manifest, Recording):\n assert (\n len(manifest.sources) == 1\n ), \"We expected a single (possibly multi-channel) AudioSource in Shar format.\"\n manifest.sources[0].type = \"memory\"\n manifest.sources[0].source = data\n\n elif isinstance(manifest, (Features, Array)):\n manifest.storage_key = data\n if tarpath.suffix == \".llc\":\n manifest.storage_type = \"memory_lilcom\"\n elif tarpath.suffix == \".npy\":\n manifest.storage_type = \"memory_npy\"\n else:\n raise RuntimeError(f\"Unknown array/tensor format: {tarpath}\")\n\n elif isinstance(manifest, TemporalArray):\n manifest.array.storage_key = data\n if tarpath.suffix == \".llc\":\n manifest.array.storage_type = \"memory_lilcom\"\n elif tarpath.suffix == \".npy\":\n manifest.array.storage_type = \"memory_npy\"\n else:\n raise RuntimeError(f\"Unknown array/tensor format: {tarpath}\")\n\n else:\n raise RuntimeError(f\"Unknown manifest type: {type(manifest).__name__}\")\n", "path": "lhotse/shar/utils.py"}], "after_files": [{"content": "from pathlib import Path\nfrom typing import Optional, TypeVar, Union\n\nfrom lhotse import AudioSource, Features, Recording, compute_num_samples, fastcopy\nfrom lhotse.array import Array, TemporalArray\nfrom lhotse.cut import Cut\nfrom lhotse.utils import Pathlike\n\nManifest = TypeVar(\"Manifest\", Recording, Features, Array, TemporalArray)\n\n\ndef to_shar_placeholder(manifest: Manifest, cut: Optional[Cut] = None) -> Manifest:\n if isinstance(manifest, Recording):\n return fastcopy(\n manifest,\n # Creates a single AudioSource out of multiple ones.\n sources=[\n AudioSource(type=\"shar\", channels=manifest.channel_ids, source=\"\")\n ],\n # Removes the transform metadata because they were already executed.\n transforms=None,\n duration=cut.duration if cut is not None else manifest.duration,\n num_samples=compute_num_samples(cut.duration, manifest.sampling_rate)\n if cut is not None\n else manifest.num_samples,\n )\n elif isinstance(manifest, Array):\n return fastcopy(manifest, storage_type=\"shar\", storage_path=\"\", storage_key=\"\")\n elif isinstance(manifest, Features):\n return fastcopy(\n manifest,\n start=0,\n duration=cut.duration if cut is not None else manifest.duration,\n storage_type=\"shar\",\n storage_path=\"\",\n storage_key=\"\",\n )\n elif isinstance(manifest, TemporalArray):\n return fastcopy(\n manifest,\n start=0,\n array=fastcopy(\n manifest.array,\n storage_type=\"shar\",\n storage_path=\"\",\n storage_key=\"\",\n ),\n )\n else:\n raise RuntimeError(f\"Unexpected manifest type: {type(manifest)}\")\n\n\ndef fill_shar_placeholder(\n manifest: Union[Cut, Recording, Features, Array, TemporalArray],\n data: bytes,\n tarpath: Pathlike,\n field: Optional[str] = None,\n) -> None:\n if isinstance(manifest, Cut):\n assert (\n field is not None\n ), \"'field' argument must be provided when filling a Shar placeholder in a Cut.\"\n manifest = getattr(manifest, field)\n fill_shar_placeholder(\n manifest=manifest, field=field, data=data, tarpath=tarpath\n )\n\n tarpath = Path(tarpath)\n\n if isinstance(manifest, Recording):\n assert (\n len(manifest.sources) == 1\n ), \"We expected a single (possibly multi-channel) AudioSource in Shar format.\"\n manifest.sources[0].type = \"memory\"\n manifest.sources[0].source = data\n\n elif isinstance(manifest, (Features, Array)):\n manifest.storage_key = data\n if tarpath.suffix == \".llc\":\n manifest.storage_type = \"memory_lilcom\"\n elif tarpath.suffix == \".npy\":\n manifest.storage_type = \"memory_npy\"\n else:\n raise RuntimeError(f\"Unknown array/tensor format: {tarpath}\")\n\n elif isinstance(manifest, TemporalArray):\n manifest.array.storage_key = data\n if tarpath.suffix == \".llc\":\n manifest.array.storage_type = \"memory_lilcom\"\n elif tarpath.suffix == \".npy\":\n manifest.array.storage_type = \"memory_npy\"\n else:\n raise RuntimeError(f\"Unknown array/tensor format: {tarpath}\")\n\n else:\n raise RuntimeError(f\"Unknown manifest type: {type(manifest).__name__}\")\n", "path": "lhotse/shar/utils.py"}]}
| 1,786 | 474 |
gh_patches_debug_9722
|
rasdani/github-patches
|
git_diff
|
oppia__oppia-14577
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Contributor Dashboard] Unable to remove question contribution rights in admin dashboard
We're seeing `InvalidInputException
Schema validation for 'language_code' failed: Validation failed: is_supported_audio_language_code ({}) for object null` when trying to remove question contribution rights.
<img width="1272" alt="Screen Shot 2021-11-08 at 4 49 25 PM" src="https://user-images.githubusercontent.com/9004726/140823762-9b72375e-4237-4d2f-a2d2-c06af3e375d8.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/controllers/payload_validator.py`
Content:
```
1 # coding: utf-8
2
3 # Copyright 2021 The Oppia Authors. All Rights Reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS-IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """Validates handler args against its schema by calling schema utils.
18 Also contains a list of handler class names which does not contain the schema.
19 """
20
21 from __future__ import annotations
22
23 from core import schema_utils
24
25 from typing import Any, Dict, List, Optional, Tuple, Union
26
27
28 # Here Dict[str, Any] is used for arg_schema because the value field of the
29 # schema is itself a dict that can further contain several nested dicts.
30 def get_schema_type(arg_schema: Dict[str, Any]) -> str:
31 """Returns the schema type for an argument.
32
33 Args:
34 arg_schema: dict(str, *). Schema for an argument.
35
36 Returns:
37 str. Returns schema type by extracting it from schema.
38 """
39 return arg_schema['schema']['type']
40
41
42 # Here Dict[str, Any] is used for arg_schema because the value field of the
43 # schema is itself a dict that can further contain several nested dicts.
44 def get_corresponding_key_for_object(arg_schema: Dict[str, Any]) -> str:
45 """Returns the new key for an argument from its schema.
46
47 Args:
48 arg_schema: dict(str, *). Schema for an argument.
49
50 Returns:
51 str. The new argument name.
52 """
53 return arg_schema['schema']['new_key_for_argument']
54
55
56 # This function recursively uses the schema dictionary and handler_args, and
57 # passes their values to itself as arguments, so their type is Any.
58 # See: https://github.com/python/mypy/issues/731
59 def validate_arguments_against_schema(
60 handler_args: Any,
61 handler_args_schemas: Any,
62 allowed_extra_args: bool,
63 allow_string_to_bool_conversion: bool = False
64 ) -> Tuple[Dict[str, Any], List[str]]:
65 """Calls schema utils for normalization of object against its schema
66 and collects all the errors.
67
68 Args:
69 handler_args: *. Object for normalization.
70 handler_args_schemas: dict. Schema for args.
71 allowed_extra_args: bool. Whether extra args are allowed in handler.
72 allow_string_to_bool_conversion: bool. Whether to allow string to
73 boolean coversion.
74
75 Returns:
76 *. A two tuple, where the first element represents the normalized value
77 in dict format and the second element represents the lists of errors
78 after validation.
79 """
80 # Collect all errors and present them at once.
81 errors = []
82 # Dictionary to hold normalized values of arguments after validation.
83 normalized_values = {}
84
85 for arg_key, arg_schema in handler_args_schemas.items():
86
87 if arg_key not in handler_args or handler_args[arg_key] is None:
88 if 'default_value' in arg_schema:
89 if arg_schema['default_value'] is None:
90 # Skip validation because the argument is optional.
91 continue
92
93 if arg_schema['default_value'] is not None:
94 handler_args[arg_key] = arg_schema['default_value']
95 else:
96 errors.append('Missing key in handler args: %s.' % arg_key)
97 continue
98
99 # Below normalization is for arguments which are expected to be boolean
100 # but from API request they are received as string type.
101 if (
102 allow_string_to_bool_conversion and
103 get_schema_type(arg_schema) == schema_utils.SCHEMA_TYPE_BOOL
104 and isinstance(handler_args[arg_key], str)
105 ):
106 handler_args[arg_key] = (
107 convert_string_to_bool(handler_args[arg_key]))
108
109 try:
110 normalized_value = schema_utils.normalize_against_schema(
111 handler_args[arg_key], arg_schema['schema'])
112
113 # Modification of argument name if new_key_for_argument
114 # field is present in the schema.
115 if 'new_key_for_argument' in arg_schema['schema']:
116 arg_key = get_corresponding_key_for_object(arg_schema)
117 normalized_values[arg_key] = normalized_value
118 except Exception as e:
119 errors.append(
120 'Schema validation for \'%s\' failed: %s' % (arg_key, e))
121
122 extra_args = set(handler_args.keys()) - set(handler_args_schemas.keys())
123
124 if not allowed_extra_args and extra_args:
125 errors.append('Found extra args: %s.' % (list(extra_args)))
126
127 return normalized_values, errors
128
129
130 def convert_string_to_bool(param: str) -> Optional[Union[bool, str]]:
131 """Converts a request param of type string into expected bool type.
132
133 Args:
134 param: str. The params which needs normalization.
135
136 Returns:
137 bool. Converts the string param into its expected bool type.
138 """
139 case_insensitive_param = param.lower()
140
141 if case_insensitive_param == 'true':
142 return True
143 elif case_insensitive_param == 'false':
144 return False
145 else:
146 # String values other than booleans should be returned as it is, so that
147 # schema validation will raise exceptions appropriately.
148 return param
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/controllers/payload_validator.py b/core/controllers/payload_validator.py
--- a/core/controllers/payload_validator.py
+++ b/core/controllers/payload_validator.py
@@ -81,9 +81,7 @@
errors = []
# Dictionary to hold normalized values of arguments after validation.
normalized_values = {}
-
for arg_key, arg_schema in handler_args_schemas.items():
-
if arg_key not in handler_args or handler_args[arg_key] is None:
if 'default_value' in arg_schema:
if arg_schema['default_value'] is None:
|
{"golden_diff": "diff --git a/core/controllers/payload_validator.py b/core/controllers/payload_validator.py\n--- a/core/controllers/payload_validator.py\n+++ b/core/controllers/payload_validator.py\n@@ -81,9 +81,7 @@\n errors = []\n # Dictionary to hold normalized values of arguments after validation.\n normalized_values = {}\n-\n for arg_key, arg_schema in handler_args_schemas.items():\n-\n if arg_key not in handler_args or handler_args[arg_key] is None:\n if 'default_value' in arg_schema:\n if arg_schema['default_value'] is None:\n", "issue": "[Contributor Dashboard] Unable to remove question contribution rights in admin dashboard\nWe're seeing `InvalidInputException\r\nSchema validation for 'language_code' failed: Validation failed: is_supported_audio_language_code ({}) for object null` when trying to remove question contribution rights.\r\n\r\n<img width=\"1272\" alt=\"Screen Shot 2021-11-08 at 4 49 25 PM\" src=\"https://user-images.githubusercontent.com/9004726/140823762-9b72375e-4237-4d2f-a2d2-c06af3e375d8.png\">\r\n\r\n\n", "before_files": [{"content": "# coding: utf-8\n\n# Copyright 2021 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Validates handler args against its schema by calling schema utils.\nAlso contains a list of handler class names which does not contain the schema.\n\"\"\"\n\nfrom __future__ import annotations\n\nfrom core import schema_utils\n\nfrom typing import Any, Dict, List, Optional, Tuple, Union\n\n\n# Here Dict[str, Any] is used for arg_schema because the value field of the\n# schema is itself a dict that can further contain several nested dicts.\ndef get_schema_type(arg_schema: Dict[str, Any]) -> str:\n \"\"\"Returns the schema type for an argument.\n\n Args:\n arg_schema: dict(str, *). Schema for an argument.\n\n Returns:\n str. Returns schema type by extracting it from schema.\n \"\"\"\n return arg_schema['schema']['type']\n\n\n# Here Dict[str, Any] is used for arg_schema because the value field of the\n# schema is itself a dict that can further contain several nested dicts.\ndef get_corresponding_key_for_object(arg_schema: Dict[str, Any]) -> str:\n \"\"\"Returns the new key for an argument from its schema.\n\n Args:\n arg_schema: dict(str, *). Schema for an argument.\n\n Returns:\n str. The new argument name.\n \"\"\"\n return arg_schema['schema']['new_key_for_argument']\n\n\n# This function recursively uses the schema dictionary and handler_args, and\n# passes their values to itself as arguments, so their type is Any.\n# See: https://github.com/python/mypy/issues/731\ndef validate_arguments_against_schema(\n handler_args: Any,\n handler_args_schemas: Any,\n allowed_extra_args: bool,\n allow_string_to_bool_conversion: bool = False\n) -> Tuple[Dict[str, Any], List[str]]:\n \"\"\"Calls schema utils for normalization of object against its schema\n and collects all the errors.\n\n Args:\n handler_args: *. Object for normalization.\n handler_args_schemas: dict. Schema for args.\n allowed_extra_args: bool. Whether extra args are allowed in handler.\n allow_string_to_bool_conversion: bool. Whether to allow string to\n boolean coversion.\n\n Returns:\n *. A two tuple, where the first element represents the normalized value\n in dict format and the second element represents the lists of errors\n after validation.\n \"\"\"\n # Collect all errors and present them at once.\n errors = []\n # Dictionary to hold normalized values of arguments after validation.\n normalized_values = {}\n\n for arg_key, arg_schema in handler_args_schemas.items():\n\n if arg_key not in handler_args or handler_args[arg_key] is None:\n if 'default_value' in arg_schema:\n if arg_schema['default_value'] is None:\n # Skip validation because the argument is optional.\n continue\n\n if arg_schema['default_value'] is not None:\n handler_args[arg_key] = arg_schema['default_value']\n else:\n errors.append('Missing key in handler args: %s.' % arg_key)\n continue\n\n # Below normalization is for arguments which are expected to be boolean\n # but from API request they are received as string type.\n if (\n allow_string_to_bool_conversion and\n get_schema_type(arg_schema) == schema_utils.SCHEMA_TYPE_BOOL\n and isinstance(handler_args[arg_key], str)\n ):\n handler_args[arg_key] = (\n convert_string_to_bool(handler_args[arg_key]))\n\n try:\n normalized_value = schema_utils.normalize_against_schema(\n handler_args[arg_key], arg_schema['schema'])\n\n # Modification of argument name if new_key_for_argument\n # field is present in the schema.\n if 'new_key_for_argument' in arg_schema['schema']:\n arg_key = get_corresponding_key_for_object(arg_schema)\n normalized_values[arg_key] = normalized_value\n except Exception as e:\n errors.append(\n 'Schema validation for \\'%s\\' failed: %s' % (arg_key, e))\n\n extra_args = set(handler_args.keys()) - set(handler_args_schemas.keys())\n\n if not allowed_extra_args and extra_args:\n errors.append('Found extra args: %s.' % (list(extra_args)))\n\n return normalized_values, errors\n\n\ndef convert_string_to_bool(param: str) -> Optional[Union[bool, str]]:\n \"\"\"Converts a request param of type string into expected bool type.\n\n Args:\n param: str. The params which needs normalization.\n\n Returns:\n bool. Converts the string param into its expected bool type.\n \"\"\"\n case_insensitive_param = param.lower()\n\n if case_insensitive_param == 'true':\n return True\n elif case_insensitive_param == 'false':\n return False\n else:\n # String values other than booleans should be returned as it is, so that\n # schema validation will raise exceptions appropriately.\n return param\n", "path": "core/controllers/payload_validator.py"}], "after_files": [{"content": "# coding: utf-8\n\n# Copyright 2021 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Validates handler args against its schema by calling schema utils.\nAlso contains a list of handler class names which does not contain the schema.\n\"\"\"\n\nfrom __future__ import annotations\n\nfrom core import schema_utils\n\nfrom typing import Any, Dict, List, Optional, Tuple, Union\n\n\n# Here Dict[str, Any] is used for arg_schema because the value field of the\n# schema is itself a dict that can further contain several nested dicts.\ndef get_schema_type(arg_schema: Dict[str, Any]) -> str:\n \"\"\"Returns the schema type for an argument.\n\n Args:\n arg_schema: dict(str, *). Schema for an argument.\n\n Returns:\n str. Returns schema type by extracting it from schema.\n \"\"\"\n return arg_schema['schema']['type']\n\n\n# Here Dict[str, Any] is used for arg_schema because the value field of the\n# schema is itself a dict that can further contain several nested dicts.\ndef get_corresponding_key_for_object(arg_schema: Dict[str, Any]) -> str:\n \"\"\"Returns the new key for an argument from its schema.\n\n Args:\n arg_schema: dict(str, *). Schema for an argument.\n\n Returns:\n str. The new argument name.\n \"\"\"\n return arg_schema['schema']['new_key_for_argument']\n\n\n# This function recursively uses the schema dictionary and handler_args, and\n# passes their values to itself as arguments, so their type is Any.\n# See: https://github.com/python/mypy/issues/731\ndef validate_arguments_against_schema(\n handler_args: Any,\n handler_args_schemas: Any,\n allowed_extra_args: bool,\n allow_string_to_bool_conversion: bool = False\n) -> Tuple[Dict[str, Any], List[str]]:\n \"\"\"Calls schema utils for normalization of object against its schema\n and collects all the errors.\n\n Args:\n handler_args: *. Object for normalization.\n handler_args_schemas: dict. Schema for args.\n allowed_extra_args: bool. Whether extra args are allowed in handler.\n allow_string_to_bool_conversion: bool. Whether to allow string to\n boolean coversion.\n\n Returns:\n *. A two tuple, where the first element represents the normalized value\n in dict format and the second element represents the lists of errors\n after validation.\n \"\"\"\n # Collect all errors and present them at once.\n errors = []\n # Dictionary to hold normalized values of arguments after validation.\n normalized_values = {}\n for arg_key, arg_schema in handler_args_schemas.items():\n if arg_key not in handler_args or handler_args[arg_key] is None:\n if 'default_value' in arg_schema:\n if arg_schema['default_value'] is None:\n # Skip validation because the argument is optional.\n continue\n\n if arg_schema['default_value'] is not None:\n handler_args[arg_key] = arg_schema['default_value']\n else:\n errors.append('Missing key in handler args: %s.' % arg_key)\n continue\n\n # Below normalization is for arguments which are expected to be boolean\n # but from API request they are received as string type.\n if (\n allow_string_to_bool_conversion and\n get_schema_type(arg_schema) == schema_utils.SCHEMA_TYPE_BOOL\n and isinstance(handler_args[arg_key], str)\n ):\n handler_args[arg_key] = (\n convert_string_to_bool(handler_args[arg_key]))\n\n try:\n normalized_value = schema_utils.normalize_against_schema(\n handler_args[arg_key], arg_schema['schema'])\n\n # Modification of argument name if new_key_for_argument\n # field is present in the schema.\n if 'new_key_for_argument' in arg_schema['schema']:\n arg_key = get_corresponding_key_for_object(arg_schema)\n normalized_values[arg_key] = normalized_value\n except Exception as e:\n errors.append(\n 'Schema validation for \\'%s\\' failed: %s' % (arg_key, e))\n\n extra_args = set(handler_args.keys()) - set(handler_args_schemas.keys())\n\n if not allowed_extra_args and extra_args:\n errors.append('Found extra args: %s.' % (list(extra_args)))\n\n return normalized_values, errors\n\n\ndef convert_string_to_bool(param: str) -> Optional[Union[bool, str]]:\n \"\"\"Converts a request param of type string into expected bool type.\n\n Args:\n param: str. The params which needs normalization.\n\n Returns:\n bool. Converts the string param into its expected bool type.\n \"\"\"\n case_insensitive_param = param.lower()\n\n if case_insensitive_param == 'true':\n return True\n elif case_insensitive_param == 'false':\n return False\n else:\n # String values other than booleans should be returned as it is, so that\n # schema validation will raise exceptions appropriately.\n return param\n", "path": "core/controllers/payload_validator.py"}]}
| 1,933 | 123 |
gh_patches_debug_2649
|
rasdani/github-patches
|
git_diff
|
webkom__lego-3128
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Broken link on weekly mails
The link used to unsubscribe from the mail is broken, because `frontend_url` is undefined. Probably due to the weekly mails being handled differently than all other notifications.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lego/apps/email/tasks.py`
Content:
```
1 from datetime import timedelta
2
3 from django.conf import settings
4 from django.template.loader import render_to_string
5 from django.utils import timezone
6
7 from premailer import transform
8 from structlog import get_logger
9
10 from lego import celery_app
11 from lego.apps.events.constants import EVENT_TYPE_TRANSLATIONS
12 from lego.apps.events.models import Event
13 from lego.apps.joblistings.constants import JOB_TYPE_TRANSLATIONS
14 from lego.apps.joblistings.models import Joblisting
15 from lego.apps.notifications.constants import EMAIL, WEEKLY_MAIL
16 from lego.apps.notifications.models import NotificationSetting
17 from lego.apps.permissions.utils import get_permission_handler
18 from lego.apps.restricted.message_processor import MessageProcessor
19 from lego.apps.tags.models import Tag
20 from lego.apps.users.models import AbakusGroup
21 from lego.utils.tasks import AbakusTask
22
23 log = get_logger()
24
25
26 def create_weekly_mail(user):
27 three_days_ago_timestamp = timezone.now() - timedelta(days=3)
28 last_sunday_timestamp = timezone.now() - timedelta(days=7)
29
30 weekly_tag = Tag.objects.filter(tag="weekly").first()
31 # Check if weekly tag exists so it does not crash if some idiot deletes the weekly tag
32 todays_weekly = (
33 weekly_tag.article_set.filter(created_at__gt=three_days_ago_timestamp).first()
34 if weekly_tag
35 else None
36 )
37
38 events_next_week = Event.objects.filter(
39 pools__activation_date__gt=timezone.now(),
40 pools__activation_date__lt=timezone.now() + timedelta(days=7),
41 ).distinct()
42
43 permission_handler = get_permission_handler(events_next_week.model)
44 filtered_events = permission_handler.filter_queryset(user, events_next_week)
45
46 filtered_events = filter(
47 lambda event: event.get_possible_pools(user, True) or event.is_admitted(user),
48 filtered_events,
49 )
50
51 joblistings_last_week = Joblisting.objects.filter(
52 created_at__gt=last_sunday_timestamp, visible_from__lt=timezone.now()
53 )
54
55 joblistings = []
56 for joblisting in joblistings_last_week:
57 joblistings.append(
58 {
59 "id": joblisting.id,
60 "company_name": joblisting.company.name,
61 "type": JOB_TYPE_TRANSLATIONS[joblisting.job_type],
62 "title": joblisting.title,
63 }
64 )
65
66 events = []
67 for event in filtered_events:
68 pools = []
69 for pool in event.pools.all():
70 pools.append(
71 {
72 "name": pool.name,
73 "activation_date": pool.activation_date.strftime("%d/%m kl. %H:%M"),
74 }
75 )
76
77 events.append(
78 {
79 "title": event.title,
80 "id": event.id,
81 "pools": pools,
82 "start_time": event.start_time.strftime("%d/%m kl %H:%M"),
83 "url": event.get_absolute_url(),
84 "type": EVENT_TYPE_TRANSLATIONS[event.event_type],
85 }
86 )
87
88 html_body = render_to_string(
89 "email/email/weekly_mail.html",
90 {
91 "events": events,
92 "todays_weekly": ""
93 if todays_weekly is None
94 else todays_weekly.get_absolute_url(),
95 "joblistings": joblistings,
96 },
97 )
98 if events or joblistings or todays_weekly:
99 return html_body
100 return None
101
102
103 @celery_app.task(serializer="json", bind=True, base=AbakusTask)
104 def send_weekly_email(self, logger_context=None):
105 self.setup_logger(logger_context)
106
107 week_number = timezone.now().isocalendar().week
108
109 # Set to just PR and Webkom for testing purposes
110 all_users = set(
111 AbakusGroup.objects.get(name="Webkom").restricted_lookup()[0]
112 + AbakusGroup.objects.get(name="PR").restricted_lookup()[0]
113 )
114 recipients = []
115
116 for user in all_users:
117 if not user.email_lists_enabled:
118 # Don't send emails to users that don't want mail.
119 continue
120
121 if EMAIL not in NotificationSetting.active_channels(user, WEEKLY_MAIL):
122 continue
123 recipients.append(user)
124
125 datatuple = (
126 (
127 f"Ukesmail uke {week_number}",
128 transform(html) if (html := create_weekly_mail(user)) is not None else None,
129 settings.DEFAULT_FROM_EMAIL,
130 [user.email],
131 )
132 for user in recipients
133 )
134 datatuple = tuple(tuppel for tuppel in datatuple if tuppel[1] is not None)
135 if datatuple:
136 MessageProcessor.send_mass_mail_html(datatuple)
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lego/apps/email/tasks.py b/lego/apps/email/tasks.py
--- a/lego/apps/email/tasks.py
+++ b/lego/apps/email/tasks.py
@@ -93,6 +93,7 @@
if todays_weekly is None
else todays_weekly.get_absolute_url(),
"joblistings": joblistings,
+ "frontend_url": settings.FRONTEND_URL,
},
)
if events or joblistings or todays_weekly:
|
{"golden_diff": "diff --git a/lego/apps/email/tasks.py b/lego/apps/email/tasks.py\n--- a/lego/apps/email/tasks.py\n+++ b/lego/apps/email/tasks.py\n@@ -93,6 +93,7 @@\n if todays_weekly is None\n else todays_weekly.get_absolute_url(),\n \"joblistings\": joblistings,\n+ \"frontend_url\": settings.FRONTEND_URL,\n },\n )\n if events or joblistings or todays_weekly:\n", "issue": "Broken link on weekly mails\nThe link used to unsubscribe from the mail is broken, because `frontend_url` is undefined. Probably due to the weekly mails being handled differently than all other notifications.\n", "before_files": [{"content": "from datetime import timedelta\n\nfrom django.conf import settings\nfrom django.template.loader import render_to_string\nfrom django.utils import timezone\n\nfrom premailer import transform\nfrom structlog import get_logger\n\nfrom lego import celery_app\nfrom lego.apps.events.constants import EVENT_TYPE_TRANSLATIONS\nfrom lego.apps.events.models import Event\nfrom lego.apps.joblistings.constants import JOB_TYPE_TRANSLATIONS\nfrom lego.apps.joblistings.models import Joblisting\nfrom lego.apps.notifications.constants import EMAIL, WEEKLY_MAIL\nfrom lego.apps.notifications.models import NotificationSetting\nfrom lego.apps.permissions.utils import get_permission_handler\nfrom lego.apps.restricted.message_processor import MessageProcessor\nfrom lego.apps.tags.models import Tag\nfrom lego.apps.users.models import AbakusGroup\nfrom lego.utils.tasks import AbakusTask\n\nlog = get_logger()\n\n\ndef create_weekly_mail(user):\n three_days_ago_timestamp = timezone.now() - timedelta(days=3)\n last_sunday_timestamp = timezone.now() - timedelta(days=7)\n\n weekly_tag = Tag.objects.filter(tag=\"weekly\").first()\n # Check if weekly tag exists so it does not crash if some idiot deletes the weekly tag\n todays_weekly = (\n weekly_tag.article_set.filter(created_at__gt=three_days_ago_timestamp).first()\n if weekly_tag\n else None\n )\n\n events_next_week = Event.objects.filter(\n pools__activation_date__gt=timezone.now(),\n pools__activation_date__lt=timezone.now() + timedelta(days=7),\n ).distinct()\n\n permission_handler = get_permission_handler(events_next_week.model)\n filtered_events = permission_handler.filter_queryset(user, events_next_week)\n\n filtered_events = filter(\n lambda event: event.get_possible_pools(user, True) or event.is_admitted(user),\n filtered_events,\n )\n\n joblistings_last_week = Joblisting.objects.filter(\n created_at__gt=last_sunday_timestamp, visible_from__lt=timezone.now()\n )\n\n joblistings = []\n for joblisting in joblistings_last_week:\n joblistings.append(\n {\n \"id\": joblisting.id,\n \"company_name\": joblisting.company.name,\n \"type\": JOB_TYPE_TRANSLATIONS[joblisting.job_type],\n \"title\": joblisting.title,\n }\n )\n\n events = []\n for event in filtered_events:\n pools = []\n for pool in event.pools.all():\n pools.append(\n {\n \"name\": pool.name,\n \"activation_date\": pool.activation_date.strftime(\"%d/%m kl. %H:%M\"),\n }\n )\n\n events.append(\n {\n \"title\": event.title,\n \"id\": event.id,\n \"pools\": pools,\n \"start_time\": event.start_time.strftime(\"%d/%m kl %H:%M\"),\n \"url\": event.get_absolute_url(),\n \"type\": EVENT_TYPE_TRANSLATIONS[event.event_type],\n }\n )\n\n html_body = render_to_string(\n \"email/email/weekly_mail.html\",\n {\n \"events\": events,\n \"todays_weekly\": \"\"\n if todays_weekly is None\n else todays_weekly.get_absolute_url(),\n \"joblistings\": joblistings,\n },\n )\n if events or joblistings or todays_weekly:\n return html_body\n return None\n\n\n@celery_app.task(serializer=\"json\", bind=True, base=AbakusTask)\ndef send_weekly_email(self, logger_context=None):\n self.setup_logger(logger_context)\n\n week_number = timezone.now().isocalendar().week\n\n # Set to just PR and Webkom for testing purposes\n all_users = set(\n AbakusGroup.objects.get(name=\"Webkom\").restricted_lookup()[0]\n + AbakusGroup.objects.get(name=\"PR\").restricted_lookup()[0]\n )\n recipients = []\n\n for user in all_users:\n if not user.email_lists_enabled:\n # Don't send emails to users that don't want mail.\n continue\n\n if EMAIL not in NotificationSetting.active_channels(user, WEEKLY_MAIL):\n continue\n recipients.append(user)\n\n datatuple = (\n (\n f\"Ukesmail uke {week_number}\",\n transform(html) if (html := create_weekly_mail(user)) is not None else None,\n settings.DEFAULT_FROM_EMAIL,\n [user.email],\n )\n for user in recipients\n )\n datatuple = tuple(tuppel for tuppel in datatuple if tuppel[1] is not None)\n if datatuple:\n MessageProcessor.send_mass_mail_html(datatuple)\n", "path": "lego/apps/email/tasks.py"}], "after_files": [{"content": "from datetime import timedelta\n\nfrom django.conf import settings\nfrom django.template.loader import render_to_string\nfrom django.utils import timezone\n\nfrom premailer import transform\nfrom structlog import get_logger\n\nfrom lego import celery_app\nfrom lego.apps.events.constants import EVENT_TYPE_TRANSLATIONS\nfrom lego.apps.events.models import Event\nfrom lego.apps.joblistings.constants import JOB_TYPE_TRANSLATIONS\nfrom lego.apps.joblistings.models import Joblisting\nfrom lego.apps.notifications.constants import EMAIL, WEEKLY_MAIL\nfrom lego.apps.notifications.models import NotificationSetting\nfrom lego.apps.permissions.utils import get_permission_handler\nfrom lego.apps.restricted.message_processor import MessageProcessor\nfrom lego.apps.tags.models import Tag\nfrom lego.apps.users.models import AbakusGroup\nfrom lego.utils.tasks import AbakusTask\n\nlog = get_logger()\n\n\ndef create_weekly_mail(user):\n three_days_ago_timestamp = timezone.now() - timedelta(days=3)\n last_sunday_timestamp = timezone.now() - timedelta(days=7)\n\n weekly_tag = Tag.objects.filter(tag=\"weekly\").first()\n # Check if weekly tag exists so it does not crash if some idiot deletes the weekly tag\n todays_weekly = (\n weekly_tag.article_set.filter(created_at__gt=three_days_ago_timestamp).first()\n if weekly_tag\n else None\n )\n\n events_next_week = Event.objects.filter(\n pools__activation_date__gt=timezone.now(),\n pools__activation_date__lt=timezone.now() + timedelta(days=7),\n ).distinct()\n\n permission_handler = get_permission_handler(events_next_week.model)\n filtered_events = permission_handler.filter_queryset(user, events_next_week)\n\n filtered_events = filter(\n lambda event: event.get_possible_pools(user, True) or event.is_admitted(user),\n filtered_events,\n )\n\n joblistings_last_week = Joblisting.objects.filter(\n created_at__gt=last_sunday_timestamp, visible_from__lt=timezone.now()\n )\n\n joblistings = []\n for joblisting in joblistings_last_week:\n joblistings.append(\n {\n \"id\": joblisting.id,\n \"company_name\": joblisting.company.name,\n \"type\": JOB_TYPE_TRANSLATIONS[joblisting.job_type],\n \"title\": joblisting.title,\n }\n )\n\n events = []\n for event in filtered_events:\n pools = []\n for pool in event.pools.all():\n pools.append(\n {\n \"name\": pool.name,\n \"activation_date\": pool.activation_date.strftime(\"%d/%m kl. %H:%M\"),\n }\n )\n\n events.append(\n {\n \"title\": event.title,\n \"id\": event.id,\n \"pools\": pools,\n \"start_time\": event.start_time.strftime(\"%d/%m kl %H:%M\"),\n \"url\": event.get_absolute_url(),\n \"type\": EVENT_TYPE_TRANSLATIONS[event.event_type],\n }\n )\n\n html_body = render_to_string(\n \"email/email/weekly_mail.html\",\n {\n \"events\": events,\n \"todays_weekly\": \"\"\n if todays_weekly is None\n else todays_weekly.get_absolute_url(),\n \"joblistings\": joblistings,\n \"frontend_url\": settings.FRONTEND_URL,\n },\n )\n if events or joblistings or todays_weekly:\n return html_body\n return None\n\n\n@celery_app.task(serializer=\"json\", bind=True, base=AbakusTask)\ndef send_weekly_email(self, logger_context=None):\n self.setup_logger(logger_context)\n\n week_number = timezone.now().isocalendar().week\n\n # Set to just PR and Webkom for testing purposes\n all_users = set(\n AbakusGroup.objects.get(name=\"Webkom\").restricted_lookup()[0]\n + AbakusGroup.objects.get(name=\"PR\").restricted_lookup()[0]\n )\n recipients = []\n\n for user in all_users:\n if not user.email_lists_enabled:\n # Don't send emails to users that don't want mail.\n continue\n\n if EMAIL not in NotificationSetting.active_channels(user, WEEKLY_MAIL):\n continue\n recipients.append(user)\n\n datatuple = (\n (\n f\"Ukesmail uke {week_number}\",\n transform(html) if (html := create_weekly_mail(user)) is not None else None,\n settings.DEFAULT_FROM_EMAIL,\n [user.email],\n )\n for user in recipients\n )\n datatuple = tuple(tuppel for tuppel in datatuple if tuppel[1] is not None)\n if datatuple:\n MessageProcessor.send_mass_mail_html(datatuple)\n", "path": "lego/apps/email/tasks.py"}]}
| 1,599 | 110 |
gh_patches_debug_36490
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1339
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[ssh] Multiple instances not differentiated
Any metrics sent through the ssh_check.py are not differentiated by instance. If multiple instances are running, the sftp.response_time metric will only be tagged with the host sending the metric: https://github.com/DataDog/dd-agent/blob/master/checks.d/ssh_check.py#L84
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checks.d/ssh_check.py`
Content:
```
1 # stdlib
2 import time
3 import socket
4 # 3p
5 import paramiko
6 from collections import namedtuple
7 # project
8 from checks import AgentCheck
9
10 class CheckSSH(AgentCheck):
11
12 OPTIONS = [
13 ('host', True, None, str),
14 ('port', False, 22, int),
15 ('username', True, None, str),
16 ('password', False, None, str),
17 ('private_key_file', False, None, str),
18 ('sftp_check', False, True, bool),
19 ('add_missing_keys', False, False, bool),
20 ]
21
22 Config = namedtuple('Config', [
23 'host',
24 'port',
25 'username',
26 'password',
27 'private_key_file',
28 'sftp_check',
29 'add_missing_keys',
30 ]
31 )
32 def _load_conf(self, instance):
33 params = []
34 for option, required, default, expected_type in self.OPTIONS:
35 value = instance.get(option)
36 if required and (not value or type(value)) != expected_type :
37 raise Exception("Please specify a valid {0}".format(option))
38
39 if value is None or type(value) != expected_type:
40 self.log.debug("Bad or missing value for {0} parameter. Using default".format(option))
41 value = default
42
43 params.append(value)
44 return self.Config._make(params)
45
46 def check(self, instance):
47 conf = self._load_conf(instance)
48
49 try:
50 private_key = paramiko.RSAKey.from_private_key_file (conf.private_key_file)
51 except Exception:
52 self.warning("Private key could not be found")
53 private_key = None
54
55 client = paramiko.SSHClient()
56 if conf.add_missing_keys:
57 client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
58 client.load_system_host_keys()
59
60 exception_message = None
61 #Service Availability to check status of SSH
62 try:
63 client.connect(conf.host, port=conf.port, username=conf.username, password=conf.password, pkey=private_key)
64 self.service_check('ssh.can_connect', AgentCheck.OK, message=exception_message)
65
66 except Exception as e:
67 exception_message = str(e)
68 status = AgentCheck.CRITICAL
69 self.service_check('ssh.can_connect', status, message=exception_message)
70 if conf.sftp_check:
71 self.service_check('sftp.can_connect', status, message=exception_message)
72 raise Exception (e)
73
74 #Service Availability to check status of SFTP
75 if conf.sftp_check:
76 try:
77 sftp = client.open_sftp()
78 #Check response time of SFTP
79 start_time = time.time()
80 result = sftp.listdir('.')
81 status = AgentCheck.OK
82 end_time = time.time()
83 time_taken = end_time - start_time
84 self.gauge('sftp.response_time', time_taken)
85
86 except Exception as e:
87 exception_message = str(e)
88 status = AgentCheck.CRITICAL
89
90 if exception_message is None:
91 exception_message = "No errors occured"
92
93 self.service_check('sftp.can_connect', status, message=exception_message)
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checks.d/ssh_check.py b/checks.d/ssh_check.py
--- a/checks.d/ssh_check.py
+++ b/checks.d/ssh_check.py
@@ -45,6 +45,7 @@
def check(self, instance):
conf = self._load_conf(instance)
+ tags = ["instance:{0}-{1}".format(conf.host, conf.port)]
try:
private_key = paramiko.RSAKey.from_private_key_file (conf.private_key_file)
@@ -60,15 +61,19 @@
exception_message = None
#Service Availability to check status of SSH
try:
- client.connect(conf.host, port=conf.port, username=conf.username, password=conf.password, pkey=private_key)
- self.service_check('ssh.can_connect', AgentCheck.OK, message=exception_message)
+ client.connect(conf.host, port=conf.port, username=conf.username,
+ password=conf.password, pkey=private_key)
+ self.service_check('ssh.can_connect', AgentCheck.OK, tags=tags,
+ message=exception_message)
except Exception as e:
exception_message = str(e)
status = AgentCheck.CRITICAL
- self.service_check('ssh.can_connect', status, message=exception_message)
+ self.service_check('ssh.can_connect', status, tags=tags,
+ message=exception_message)
if conf.sftp_check:
- self.service_check('sftp.can_connect', status, message=exception_message)
+ self.service_check('sftp.can_connect', status, tags=tags,
+ message=exception_message)
raise Exception (e)
#Service Availability to check status of SFTP
@@ -81,7 +86,7 @@
status = AgentCheck.OK
end_time = time.time()
time_taken = end_time - start_time
- self.gauge('sftp.response_time', time_taken)
+ self.gauge('sftp.response_time', time_taken, tags=tags)
except Exception as e:
exception_message = str(e)
@@ -90,4 +95,5 @@
if exception_message is None:
exception_message = "No errors occured"
- self.service_check('sftp.can_connect', status, message=exception_message)
+ self.service_check('sftp.can_connect', status, tags=tags,
+ message=exception_message)
|
{"golden_diff": "diff --git a/checks.d/ssh_check.py b/checks.d/ssh_check.py\n--- a/checks.d/ssh_check.py\n+++ b/checks.d/ssh_check.py\n@@ -45,6 +45,7 @@\n \n def check(self, instance):\n conf = self._load_conf(instance)\n+ tags = [\"instance:{0}-{1}\".format(conf.host, conf.port)] \n \n try:\n private_key = paramiko.RSAKey.from_private_key_file (conf.private_key_file)\n@@ -60,15 +61,19 @@\n exception_message = None\n #Service Availability to check status of SSH\n try:\n- client.connect(conf.host, port=conf.port, username=conf.username, password=conf.password, pkey=private_key)\n- self.service_check('ssh.can_connect', AgentCheck.OK, message=exception_message)\n+ client.connect(conf.host, port=conf.port, username=conf.username,\n+ password=conf.password, pkey=private_key)\n+ self.service_check('ssh.can_connect', AgentCheck.OK, tags=tags,\n+ message=exception_message)\n \n except Exception as e:\n exception_message = str(e)\n status = AgentCheck.CRITICAL\n- self.service_check('ssh.can_connect', status, message=exception_message)\n+ self.service_check('ssh.can_connect', status, tags=tags,\n+ message=exception_message)\n if conf.sftp_check:\n- self.service_check('sftp.can_connect', status, message=exception_message)\n+ self.service_check('sftp.can_connect', status, tags=tags,\n+ message=exception_message)\n raise Exception (e)\n \n #Service Availability to check status of SFTP\n@@ -81,7 +86,7 @@\n status = AgentCheck.OK\n end_time = time.time()\n time_taken = end_time - start_time\n- self.gauge('sftp.response_time', time_taken)\n+ self.gauge('sftp.response_time', time_taken, tags=tags)\n \n except Exception as e:\n exception_message = str(e)\n@@ -90,4 +95,5 @@\n if exception_message is None:\n exception_message = \"No errors occured\"\n \n- self.service_check('sftp.can_connect', status, message=exception_message)\n+ self.service_check('sftp.can_connect', status, tags=tags,\n+ message=exception_message)\n", "issue": "[ssh] Multiple instances not differentiated\nAny metrics sent through the ssh_check.py are not differentiated by instance. If multiple instances are running, the sftp.response_time metric will only be tagged with the host sending the metric: https://github.com/DataDog/dd-agent/blob/master/checks.d/ssh_check.py#L84\n\n", "before_files": [{"content": "# stdlib\nimport time\nimport socket\n# 3p\nimport paramiko\nfrom collections import namedtuple\n# project\nfrom checks import AgentCheck\n\nclass CheckSSH(AgentCheck):\n\n OPTIONS = [\n ('host', True, None, str),\n ('port', False, 22, int),\n ('username', True, None, str),\n ('password', False, None, str),\n ('private_key_file', False, None, str),\n ('sftp_check', False, True, bool),\n ('add_missing_keys', False, False, bool),\n ]\n\n Config = namedtuple('Config', [\n 'host',\n 'port',\n 'username',\n 'password',\n 'private_key_file',\n 'sftp_check',\n 'add_missing_keys',\n ]\n )\n def _load_conf(self, instance):\n params = []\n for option, required, default, expected_type in self.OPTIONS:\n value = instance.get(option)\n if required and (not value or type(value)) != expected_type :\n raise Exception(\"Please specify a valid {0}\".format(option))\n\n if value is None or type(value) != expected_type:\n self.log.debug(\"Bad or missing value for {0} parameter. Using default\".format(option))\n value = default\n\n params.append(value)\n return self.Config._make(params)\n\n def check(self, instance):\n conf = self._load_conf(instance)\n\n try:\n private_key = paramiko.RSAKey.from_private_key_file (conf.private_key_file)\n except Exception:\n self.warning(\"Private key could not be found\")\n private_key = None\n\n client = paramiko.SSHClient()\n if conf.add_missing_keys:\n client.set_missing_host_key_policy(paramiko.AutoAddPolicy())\n client.load_system_host_keys()\n\n exception_message = None\n #Service Availability to check status of SSH\n try:\n client.connect(conf.host, port=conf.port, username=conf.username, password=conf.password, pkey=private_key)\n self.service_check('ssh.can_connect', AgentCheck.OK, message=exception_message)\n\n except Exception as e:\n exception_message = str(e)\n status = AgentCheck.CRITICAL\n self.service_check('ssh.can_connect', status, message=exception_message)\n if conf.sftp_check:\n self.service_check('sftp.can_connect', status, message=exception_message)\n raise Exception (e)\n\n #Service Availability to check status of SFTP\n if conf.sftp_check:\n try:\n sftp = client.open_sftp()\n #Check response time of SFTP\n start_time = time.time()\n result = sftp.listdir('.')\n status = AgentCheck.OK\n end_time = time.time()\n time_taken = end_time - start_time\n self.gauge('sftp.response_time', time_taken)\n\n except Exception as e:\n exception_message = str(e)\n status = AgentCheck.CRITICAL\n\n if exception_message is None:\n exception_message = \"No errors occured\"\n\n self.service_check('sftp.can_connect', status, message=exception_message)\n", "path": "checks.d/ssh_check.py"}], "after_files": [{"content": "# stdlib\nimport time\nimport socket\n# 3p\nimport paramiko\nfrom collections import namedtuple\n# project\nfrom checks import AgentCheck\n\nclass CheckSSH(AgentCheck):\n\n OPTIONS = [\n ('host', True, None, str),\n ('port', False, 22, int),\n ('username', True, None, str),\n ('password', False, None, str),\n ('private_key_file', False, None, str),\n ('sftp_check', False, True, bool),\n ('add_missing_keys', False, False, bool),\n ]\n\n Config = namedtuple('Config', [\n 'host',\n 'port',\n 'username',\n 'password',\n 'private_key_file',\n 'sftp_check',\n 'add_missing_keys',\n ]\n )\n def _load_conf(self, instance):\n params = []\n for option, required, default, expected_type in self.OPTIONS:\n value = instance.get(option)\n if required and (not value or type(value)) != expected_type :\n raise Exception(\"Please specify a valid {0}\".format(option))\n\n if value is None or type(value) != expected_type:\n self.log.debug(\"Bad or missing value for {0} parameter. Using default\".format(option))\n value = default\n\n params.append(value)\n return self.Config._make(params)\n\n def check(self, instance):\n conf = self._load_conf(instance)\n tags = [\"instance:{0}-{1}\".format(conf.host, conf.port)] \n\n try:\n private_key = paramiko.RSAKey.from_private_key_file (conf.private_key_file)\n except Exception:\n self.warning(\"Private key could not be found\")\n private_key = None\n\n client = paramiko.SSHClient()\n if conf.add_missing_keys:\n client.set_missing_host_key_policy(paramiko.AutoAddPolicy())\n client.load_system_host_keys()\n\n exception_message = None\n #Service Availability to check status of SSH\n try:\n client.connect(conf.host, port=conf.port, username=conf.username,\n password=conf.password, pkey=private_key)\n self.service_check('ssh.can_connect', AgentCheck.OK, tags=tags,\n message=exception_message)\n\n except Exception as e:\n exception_message = str(e)\n status = AgentCheck.CRITICAL\n self.service_check('ssh.can_connect', status, tags=tags,\n message=exception_message)\n if conf.sftp_check:\n self.service_check('sftp.can_connect', status, tags=tags,\n message=exception_message)\n raise Exception (e)\n\n #Service Availability to check status of SFTP\n if conf.sftp_check:\n try:\n sftp = client.open_sftp()\n #Check response time of SFTP\n start_time = time.time()\n result = sftp.listdir('.')\n status = AgentCheck.OK\n end_time = time.time()\n time_taken = end_time - start_time\n self.gauge('sftp.response_time', time_taken, tags=tags)\n\n except Exception as e:\n exception_message = str(e)\n status = AgentCheck.CRITICAL\n\n if exception_message is None:\n exception_message = \"No errors occured\"\n\n self.service_check('sftp.can_connect', status, tags=tags,\n message=exception_message)\n", "path": "checks.d/ssh_check.py"}]}
| 1,177 | 528 |
gh_patches_debug_26905
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2978
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make sure all GraphQL types that accept or return a country code use an enum type
Currently some types return an enum, some return a string and `VoucherInput` takes a list of strings.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/shipping/types.py`
Content:
```
1 import decimal
2
3 import graphene
4 from graphene import relay
5 from graphene.types import Scalar
6 from graphene_django import DjangoObjectType
7 from measurement.measures import Weight
8
9 from ...core.weight import convert_weight, get_default_weight_unit
10 from ...shipping import ShippingMethodType, models
11 from ..core.types.common import CountableDjangoObjectType
12 from ..core.types.money import MoneyRange
13
14 ShippingMethodTypeEnum = graphene.Enum(
15 'ShippingMethodTypeEnum',
16 [(code.upper(), code) for code, name in ShippingMethodType.CHOICES])
17
18
19 class ShippingMethod(DjangoObjectType):
20 type = ShippingMethodTypeEnum(description='Type of the shipping method.')
21
22 class Meta:
23 description = """
24 Shipping method are the methods you'll use to get
25 customer's orders to them.
26 They are directly exposed to the customers."""
27 model = models.ShippingMethod
28 interfaces = [relay.Node]
29 exclude_fields = ['shipping_zone', 'orders']
30
31
32 class ShippingZone(CountableDjangoObjectType):
33 price_range = graphene.Field(
34 MoneyRange, description='Lowest and highest prices for the shipping.')
35 countries = graphene.List(
36 graphene.String,
37 description='List of countries available for the method.')
38 shipping_methods = graphene.List(
39 ShippingMethod,
40 description=(
41 'List of shipping methods available for orders'
42 ' shipped to countries within this shipping zone.'))
43
44 class Meta:
45 description = """
46 Represents a shipping zone in the shop. Zones are the concept
47 used only for grouping shipping methods in the dashboard,
48 and are never exposed to the customers directly."""
49 model = models.ShippingZone
50 interfaces = [relay.Node]
51 filter_fields = {
52 'name': ['icontains'],
53 'countries': ['icontains'],
54 'shipping_methods__price': ['gte', 'lte']}
55
56 def resolve_price_range(self, info):
57 return self.price_range
58
59 def resolve_countries(self, info):
60 return self.countries
61
62 def resolve_shipping_methods(self, info):
63 return self.shipping_methods.all()
64
65
66 class WeightScalar(Scalar):
67 @staticmethod
68 def parse_value(value):
69 """Excepts value to be a string "amount unit"
70 separated by a single space.
71 """
72 try:
73 value = decimal.Decimal(value)
74 except decimal.DecimalException:
75 return None
76 default_unit = get_default_weight_unit()
77 return Weight(**{default_unit: value})
78
79 @staticmethod
80 def serialize(weight):
81 if isinstance(weight, Weight):
82 default_unit = get_default_weight_unit()
83 if weight.unit != default_unit:
84 weight = convert_weight(weight, default_unit)
85 return str(weight)
86 return None
87
88 @staticmethod
89 def parse_literal(node):
90 return node
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/shipping/types.py b/saleor/graphql/shipping/types.py
--- a/saleor/graphql/shipping/types.py
+++ b/saleor/graphql/shipping/types.py
@@ -8,7 +8,7 @@
from ...core.weight import convert_weight, get_default_weight_unit
from ...shipping import ShippingMethodType, models
-from ..core.types.common import CountableDjangoObjectType
+from ..core.types.common import CountableDjangoObjectType, CountryDisplay
from ..core.types.money import MoneyRange
ShippingMethodTypeEnum = graphene.Enum(
@@ -33,7 +33,7 @@
price_range = graphene.Field(
MoneyRange, description='Lowest and highest prices for the shipping.')
countries = graphene.List(
- graphene.String,
+ CountryDisplay,
description='List of countries available for the method.')
shipping_methods = graphene.List(
ShippingMethod,
@@ -57,7 +57,9 @@
return self.price_range
def resolve_countries(self, info):
- return self.countries
+ return [
+ CountryDisplay(code=country.code, country=country.name)
+ for country in self.countries]
def resolve_shipping_methods(self, info):
return self.shipping_methods.all()
|
{"golden_diff": "diff --git a/saleor/graphql/shipping/types.py b/saleor/graphql/shipping/types.py\n--- a/saleor/graphql/shipping/types.py\n+++ b/saleor/graphql/shipping/types.py\n@@ -8,7 +8,7 @@\n \n from ...core.weight import convert_weight, get_default_weight_unit\n from ...shipping import ShippingMethodType, models\n-from ..core.types.common import CountableDjangoObjectType\n+from ..core.types.common import CountableDjangoObjectType, CountryDisplay\n from ..core.types.money import MoneyRange\n \n ShippingMethodTypeEnum = graphene.Enum(\n@@ -33,7 +33,7 @@\n price_range = graphene.Field(\n MoneyRange, description='Lowest and highest prices for the shipping.')\n countries = graphene.List(\n- graphene.String,\n+ CountryDisplay,\n description='List of countries available for the method.')\n shipping_methods = graphene.List(\n ShippingMethod,\n@@ -57,7 +57,9 @@\n return self.price_range\n \n def resolve_countries(self, info):\n- return self.countries\n+ return [\n+ CountryDisplay(code=country.code, country=country.name)\n+ for country in self.countries]\n \n def resolve_shipping_methods(self, info):\n return self.shipping_methods.all()\n", "issue": "Make sure all GraphQL types that accept or return a country code use an enum type\nCurrently some types return an enum, some return a string and `VoucherInput` takes a list of strings.\n", "before_files": [{"content": "import decimal\n\nimport graphene\nfrom graphene import relay\nfrom graphene.types import Scalar\nfrom graphene_django import DjangoObjectType\nfrom measurement.measures import Weight\n\nfrom ...core.weight import convert_weight, get_default_weight_unit\nfrom ...shipping import ShippingMethodType, models\nfrom ..core.types.common import CountableDjangoObjectType\nfrom ..core.types.money import MoneyRange\n\nShippingMethodTypeEnum = graphene.Enum(\n 'ShippingMethodTypeEnum',\n [(code.upper(), code) for code, name in ShippingMethodType.CHOICES])\n\n\nclass ShippingMethod(DjangoObjectType):\n type = ShippingMethodTypeEnum(description='Type of the shipping method.')\n\n class Meta:\n description = \"\"\"\n Shipping method are the methods you'll use to get\n customer's orders to them.\n They are directly exposed to the customers.\"\"\"\n model = models.ShippingMethod\n interfaces = [relay.Node]\n exclude_fields = ['shipping_zone', 'orders']\n\n\nclass ShippingZone(CountableDjangoObjectType):\n price_range = graphene.Field(\n MoneyRange, description='Lowest and highest prices for the shipping.')\n countries = graphene.List(\n graphene.String,\n description='List of countries available for the method.')\n shipping_methods = graphene.List(\n ShippingMethod,\n description=(\n 'List of shipping methods available for orders'\n ' shipped to countries within this shipping zone.'))\n\n class Meta:\n description = \"\"\"\n Represents a shipping zone in the shop. Zones are the concept\n used only for grouping shipping methods in the dashboard,\n and are never exposed to the customers directly.\"\"\"\n model = models.ShippingZone\n interfaces = [relay.Node]\n filter_fields = {\n 'name': ['icontains'],\n 'countries': ['icontains'],\n 'shipping_methods__price': ['gte', 'lte']}\n\n def resolve_price_range(self, info):\n return self.price_range\n\n def resolve_countries(self, info):\n return self.countries\n\n def resolve_shipping_methods(self, info):\n return self.shipping_methods.all()\n\n\nclass WeightScalar(Scalar):\n @staticmethod\n def parse_value(value):\n \"\"\"Excepts value to be a string \"amount unit\"\n separated by a single space.\n \"\"\"\n try:\n value = decimal.Decimal(value)\n except decimal.DecimalException:\n return None\n default_unit = get_default_weight_unit()\n return Weight(**{default_unit: value})\n\n @staticmethod\n def serialize(weight):\n if isinstance(weight, Weight):\n default_unit = get_default_weight_unit()\n if weight.unit != default_unit:\n weight = convert_weight(weight, default_unit)\n return str(weight)\n return None\n\n @staticmethod\n def parse_literal(node):\n return node\n", "path": "saleor/graphql/shipping/types.py"}], "after_files": [{"content": "import decimal\n\nimport graphene\nfrom graphene import relay\nfrom graphene.types import Scalar\nfrom graphene_django import DjangoObjectType\nfrom measurement.measures import Weight\n\nfrom ...core.weight import convert_weight, get_default_weight_unit\nfrom ...shipping import ShippingMethodType, models\nfrom ..core.types.common import CountableDjangoObjectType, CountryDisplay\nfrom ..core.types.money import MoneyRange\n\nShippingMethodTypeEnum = graphene.Enum(\n 'ShippingMethodTypeEnum',\n [(code.upper(), code) for code, name in ShippingMethodType.CHOICES])\n\n\nclass ShippingMethod(DjangoObjectType):\n type = ShippingMethodTypeEnum(description='Type of the shipping method.')\n\n class Meta:\n description = \"\"\"\n Shipping method are the methods you'll use to get\n customer's orders to them.\n They are directly exposed to the customers.\"\"\"\n model = models.ShippingMethod\n interfaces = [relay.Node]\n exclude_fields = ['shipping_zone', 'orders']\n\n\nclass ShippingZone(CountableDjangoObjectType):\n price_range = graphene.Field(\n MoneyRange, description='Lowest and highest prices for the shipping.')\n countries = graphene.List(\n CountryDisplay,\n description='List of countries available for the method.')\n shipping_methods = graphene.List(\n ShippingMethod,\n description=(\n 'List of shipping methods available for orders'\n ' shipped to countries within this shipping zone.'))\n\n class Meta:\n description = \"\"\"\n Represents a shipping zone in the shop. Zones are the concept\n used only for grouping shipping methods in the dashboard,\n and are never exposed to the customers directly.\"\"\"\n model = models.ShippingZone\n interfaces = [relay.Node]\n filter_fields = {\n 'name': ['icontains'],\n 'countries': ['icontains'],\n 'shipping_methods__price': ['gte', 'lte']}\n\n def resolve_price_range(self, info):\n return self.price_range\n\n def resolve_countries(self, info):\n return [\n CountryDisplay(code=country.code, country=country.name)\n for country in self.countries]\n\n def resolve_shipping_methods(self, info):\n return self.shipping_methods.all()\n\n\nclass WeightScalar(Scalar):\n @staticmethod\n def parse_value(value):\n \"\"\"Excepts value to be a string \"amount unit\"\n separated by a single space.\n \"\"\"\n try:\n value = decimal.Decimal(value)\n except decimal.DecimalException:\n return None\n default_unit = get_default_weight_unit()\n return Weight(**{default_unit: value})\n\n @staticmethod\n def serialize(weight):\n if isinstance(weight, Weight):\n default_unit = get_default_weight_unit()\n if weight.unit != default_unit:\n weight = convert_weight(weight, default_unit)\n return str(weight)\n return None\n\n @staticmethod\n def parse_literal(node):\n return node\n", "path": "saleor/graphql/shipping/types.py"}]}
| 1,048 | 272 |
gh_patches_debug_3082
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-1385
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error with TransformationFactory('core.relax_integers')
When I use `TransformationFactory('core.relax_integrality').apply_to(m)`, a warning came up.
`WARNING: DEPRECATED: core.relax_integrality is deprecated. Use core.relax_integers (deprecated in TBD)`
When I changed the code to `TransformationFactory('core.relax_integers').apply_to(m)`, an error came up:
```
TransformationFactory('core.relax_integers').apply_to(m)
AttributeError: 'NoneType' object has no attribute 'apply_to'
```
Error with TransformationFactory('core.relax_integers')
When I use `TransformationFactory('core.relax_integrality').apply_to(m)`, a warning came up.
`WARNING: DEPRECATED: core.relax_integrality is deprecated. Use core.relax_integers (deprecated in TBD)`
When I changed the code to `TransformationFactory('core.relax_integers').apply_to(m)`, an error came up:
```
TransformationFactory('core.relax_integers').apply_to(m)
AttributeError: 'NoneType' object has no attribute 'apply_to'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyomo/core/plugins/transform/relax_integrality.py`
Content:
```
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 from pyomo.common import deprecated
12 from pyomo.core.base import TransformationFactory
13 from pyomo.core.plugins.transform.discrete_vars import RelaxIntegerVars
14
15
16 @TransformationFactory.register(
17 'core.relax_integrality',
18 doc="[DEPRECATED] Create a model where integer variables are replaced with "
19 "real variables.")
20 class RelaxIntegrality(RelaxIntegerVars):
21 """
22 This plugin relaxes integrality in a Pyomo model.
23 """
24
25 @deprecated(
26 "core.relax_integrality is deprecated. Use core.relax_integers",
27 version='TBD')
28 def __init__(self, **kwds):
29 super(RelaxIntegrality, self).__init__(**kwds)
30
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pyomo/core/plugins/transform/relax_integrality.py b/pyomo/core/plugins/transform/relax_integrality.py
--- a/pyomo/core/plugins/transform/relax_integrality.py
+++ b/pyomo/core/plugins/transform/relax_integrality.py
@@ -23,7 +23,7 @@
"""
@deprecated(
- "core.relax_integrality is deprecated. Use core.relax_integers",
+ "core.relax_integrality is deprecated. Use core.relax_integer_vars",
version='TBD')
def __init__(self, **kwds):
super(RelaxIntegrality, self).__init__(**kwds)
|
{"golden_diff": "diff --git a/pyomo/core/plugins/transform/relax_integrality.py b/pyomo/core/plugins/transform/relax_integrality.py\n--- a/pyomo/core/plugins/transform/relax_integrality.py\n+++ b/pyomo/core/plugins/transform/relax_integrality.py\n@@ -23,7 +23,7 @@\n \"\"\"\n \n @deprecated(\n- \"core.relax_integrality is deprecated. Use core.relax_integers\",\n+ \"core.relax_integrality is deprecated. Use core.relax_integer_vars\",\n version='TBD')\n def __init__(self, **kwds):\n super(RelaxIntegrality, self).__init__(**kwds)\n", "issue": "Error with TransformationFactory('core.relax_integers')\nWhen I use `TransformationFactory('core.relax_integrality').apply_to(m)`, a warning came up.\r\n\r\n`WARNING: DEPRECATED: core.relax_integrality is deprecated. Use core.relax_integers (deprecated in TBD)`\r\n\r\nWhen I changed the code to `TransformationFactory('core.relax_integers').apply_to(m)`, an error came up:\r\n\r\n```\r\nTransformationFactory('core.relax_integers').apply_to(m)\r\nAttributeError: 'NoneType' object has no attribute 'apply_to'\r\n```\r\n\r\n\nError with TransformationFactory('core.relax_integers')\nWhen I use `TransformationFactory('core.relax_integrality').apply_to(m)`, a warning came up.\r\n\r\n`WARNING: DEPRECATED: core.relax_integrality is deprecated. Use core.relax_integers (deprecated in TBD)`\r\n\r\nWhen I changed the code to `TransformationFactory('core.relax_integers').apply_to(m)`, an error came up:\r\n\r\n```\r\nTransformationFactory('core.relax_integers').apply_to(m)\r\nAttributeError: 'NoneType' object has no attribute 'apply_to'\r\n```\r\n\r\n\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nfrom pyomo.common import deprecated\nfrom pyomo.core.base import TransformationFactory\nfrom pyomo.core.plugins.transform.discrete_vars import RelaxIntegerVars\n\n\[email protected](\n 'core.relax_integrality',\n doc=\"[DEPRECATED] Create a model where integer variables are replaced with \"\n \"real variables.\")\nclass RelaxIntegrality(RelaxIntegerVars):\n \"\"\"\n This plugin relaxes integrality in a Pyomo model.\n \"\"\"\n\n @deprecated(\n \"core.relax_integrality is deprecated. Use core.relax_integers\",\n version='TBD')\n def __init__(self, **kwds):\n super(RelaxIntegrality, self).__init__(**kwds)\n", "path": "pyomo/core/plugins/transform/relax_integrality.py"}], "after_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nfrom pyomo.common import deprecated\nfrom pyomo.core.base import TransformationFactory\nfrom pyomo.core.plugins.transform.discrete_vars import RelaxIntegerVars\n\n\[email protected](\n 'core.relax_integrality',\n doc=\"[DEPRECATED] Create a model where integer variables are replaced with \"\n \"real variables.\")\nclass RelaxIntegrality(RelaxIntegerVars):\n \"\"\"\n This plugin relaxes integrality in a Pyomo model.\n \"\"\"\n\n @deprecated(\n \"core.relax_integrality is deprecated. Use core.relax_integer_vars\",\n version='TBD')\n def __init__(self, **kwds):\n super(RelaxIntegrality, self).__init__(**kwds)\n", "path": "pyomo/core/plugins/transform/relax_integrality.py"}]}
| 823 | 157 |
gh_patches_debug_31825
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-3332
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update Hello World example to align with TryPyramid.com
We've updated the Hello World example on https://trypyramid.com per https://github.com/Pylons/trypyramid.com/pull/205 so we should update it on our official docs.
Verify that line numbers and narrative still align in docs whenever a `literalinclude` of Python files occurs.
- [x] README.rst
- [x] docs/designdefense.rst
- [x] docs/index.rst
- [x] docs/narr/helloworld.py
- [x] docs/narr/hellotraversal.py (take care to adapt code)
- [x] docs/narr/configuration.rst ("Declarative Configuration" section only)
- [x] docs/narr/firstapp.rst
- [x] docs/narr/hellotraversal.rst
- [x] docs/quick_tour/hello_world/app.py
- [x] docs/quick_tour.rst ("Hello World" section only)
Note that I excluded `docs/quick_tutorial/*` because it deliberately starts with imperative configuration, then introduces declarative configuration in [Step 7](http://docs.pylonsproject.org/projects/pyramid/en/latest/quick_tutorial/views.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/quick_tour/hello_world/app.py`
Content:
```
1 from wsgiref.simple_server import make_server
2 from pyramid.config import Configurator
3 from pyramid.response import Response
4
5
6 def hello_world(request):
7 return Response('<h1>Hello World!</h1>')
8
9
10 if __name__ == '__main__':
11 with Configurator() as config:
12 config.add_route('hello', '/')
13 config.add_view(hello_world, route_name='hello')
14 app = config.make_wsgi_app()
15 server = make_server('0.0.0.0', 6543, app)
16 server.serve_forever()
17
```
Path: `docs/narr/helloworld.py`
Content:
```
1 from wsgiref.simple_server import make_server
2 from pyramid.config import Configurator
3 from pyramid.response import Response
4
5
6 def hello_world(request):
7 return Response('Hello %(name)s!' % request.matchdict)
8
9 if __name__ == '__main__':
10 with Configurator() as config:
11 config.add_route('hello', '/hello/{name}')
12 config.add_view(hello_world, route_name='hello')
13 app = config.make_wsgi_app()
14 server = make_server('0.0.0.0', 8080, app)
15 server.serve_forever()
16
```
Path: `docs/narr/hellotraversal.py`
Content:
```
1 from wsgiref.simple_server import make_server
2 from pyramid.config import Configurator
3 from pyramid.response import Response
4
5 class Resource(dict):
6 pass
7
8 def get_root(request):
9 return Resource({'a': Resource({'b': Resource({'c': Resource()})})})
10
11 def hello_world_of_resources(context, request):
12 output = "Here's a resource and its children: %s" % context
13 return Response(output)
14
15 if __name__ == '__main__':
16 config = Configurator(root_factory=get_root)
17 config.add_view(hello_world_of_resources, context=Resource)
18 app = config.make_wsgi_app()
19 server = make_server('0.0.0.0', 8080, app)
20 server.serve_forever()
21
22
23
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/narr/hellotraversal.py b/docs/narr/hellotraversal.py
--- a/docs/narr/hellotraversal.py
+++ b/docs/narr/hellotraversal.py
@@ -2,21 +2,24 @@
from pyramid.config import Configurator
from pyramid.response import Response
+
class Resource(dict):
pass
+
def get_root(request):
return Resource({'a': Resource({'b': Resource({'c': Resource()})})})
+
def hello_world_of_resources(context, request):
output = "Here's a resource and its children: %s" % context
return Response(output)
+
if __name__ == '__main__':
- config = Configurator(root_factory=get_root)
- config.add_view(hello_world_of_resources, context=Resource)
- app = config.make_wsgi_app()
- server = make_server('0.0.0.0', 8080, app)
+ with Configurator() as config:
+ config.set_root_factory(get_root)
+ config.add_view(hello_world_of_resources, context=Resource)
+ app = config.make_wsgi_app()
+ server = make_server('0.0.0.0', 6543, app)
server.serve_forever()
-
-
diff --git a/docs/narr/helloworld.py b/docs/narr/helloworld.py
--- a/docs/narr/helloworld.py
+++ b/docs/narr/helloworld.py
@@ -4,12 +4,13 @@
def hello_world(request):
- return Response('Hello %(name)s!' % request.matchdict)
+ return Response('Hello World!')
+
if __name__ == '__main__':
with Configurator() as config:
- config.add_route('hello', '/hello/{name}')
+ config.add_route('hello', '/')
config.add_view(hello_world, route_name='hello')
app = config.make_wsgi_app()
- server = make_server('0.0.0.0', 8080, app)
+ server = make_server('0.0.0.0', 6543, app)
server.serve_forever()
diff --git a/docs/quick_tour/hello_world/app.py b/docs/quick_tour/hello_world/app.py
--- a/docs/quick_tour/hello_world/app.py
+++ b/docs/quick_tour/hello_world/app.py
@@ -4,7 +4,7 @@
def hello_world(request):
- return Response('<h1>Hello World!</h1>')
+ return Response('Hello World!')
if __name__ == '__main__':
|
{"golden_diff": "diff --git a/docs/narr/hellotraversal.py b/docs/narr/hellotraversal.py\n--- a/docs/narr/hellotraversal.py\n+++ b/docs/narr/hellotraversal.py\n@@ -2,21 +2,24 @@\n from pyramid.config import Configurator\n from pyramid.response import Response\n \n+\n class Resource(dict):\n pass\n \n+\n def get_root(request):\n return Resource({'a': Resource({'b': Resource({'c': Resource()})})})\n \n+\n def hello_world_of_resources(context, request):\n output = \"Here's a resource and its children: %s\" % context\n return Response(output)\n \n+\n if __name__ == '__main__':\n- config = Configurator(root_factory=get_root)\n- config.add_view(hello_world_of_resources, context=Resource)\n- app = config.make_wsgi_app()\n- server = make_server('0.0.0.0', 8080, app)\n+ with Configurator() as config:\n+ config.set_root_factory(get_root)\n+ config.add_view(hello_world_of_resources, context=Resource)\n+ app = config.make_wsgi_app()\n+ server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n-\n-\ndiff --git a/docs/narr/helloworld.py b/docs/narr/helloworld.py\n--- a/docs/narr/helloworld.py\n+++ b/docs/narr/helloworld.py\n@@ -4,12 +4,13 @@\n \n \n def hello_world(request):\n- return Response('Hello %(name)s!' % request.matchdict)\n+ return Response('Hello World!')\n+\n \n if __name__ == '__main__':\n with Configurator() as config:\n- config.add_route('hello', '/hello/{name}')\n+ config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n- server = make_server('0.0.0.0', 8080, app)\n+ server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\ndiff --git a/docs/quick_tour/hello_world/app.py b/docs/quick_tour/hello_world/app.py\n--- a/docs/quick_tour/hello_world/app.py\n+++ b/docs/quick_tour/hello_world/app.py\n@@ -4,7 +4,7 @@\n \n \n def hello_world(request):\n- return Response('<h1>Hello World!</h1>')\n+ return Response('Hello World!')\n \n \n if __name__ == '__main__':\n", "issue": "Update Hello World example to align with TryPyramid.com\nWe've updated the Hello World example on https://trypyramid.com per https://github.com/Pylons/trypyramid.com/pull/205 so we should update it on our official docs.\r\n\r\nVerify that line numbers and narrative still align in docs whenever a `literalinclude` of Python files occurs.\r\n\r\n- [x] README.rst\r\n- [x] docs/designdefense.rst\r\n- [x] docs/index.rst\r\n- [x] docs/narr/helloworld.py\r\n- [x] docs/narr/hellotraversal.py (take care to adapt code)\r\n- [x] docs/narr/configuration.rst (\"Declarative Configuration\" section only)\r\n- [x] docs/narr/firstapp.rst\r\n- [x] docs/narr/hellotraversal.rst\r\n- [x] docs/quick_tour/hello_world/app.py\r\n- [x] docs/quick_tour.rst (\"Hello World\" section only)\r\n\r\nNote that I excluded `docs/quick_tutorial/*` because it deliberately starts with imperative configuration, then introduces declarative configuration in [Step 7](http://docs.pylonsproject.org/projects/pyramid/en/latest/quick_tutorial/views.html).\n", "before_files": [{"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\ndef hello_world(request):\n return Response('<h1>Hello World!</h1>')\n\n\nif __name__ == '__main__':\n with Configurator() as config:\n config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n", "path": "docs/quick_tour/hello_world/app.py"}, {"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\ndef hello_world(request):\n return Response('Hello %(name)s!' % request.matchdict)\n\nif __name__ == '__main__':\n with Configurator() as config:\n config.add_route('hello', '/hello/{name}')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 8080, app)\n server.serve_forever()\n", "path": "docs/narr/helloworld.py"}, {"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\nclass Resource(dict):\n pass\n\ndef get_root(request):\n return Resource({'a': Resource({'b': Resource({'c': Resource()})})})\n\ndef hello_world_of_resources(context, request):\n output = \"Here's a resource and its children: %s\" % context\n return Response(output)\n\nif __name__ == '__main__':\n config = Configurator(root_factory=get_root)\n config.add_view(hello_world_of_resources, context=Resource)\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 8080, app)\n server.serve_forever()\n\n\n", "path": "docs/narr/hellotraversal.py"}], "after_files": [{"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\ndef hello_world(request):\n return Response('Hello World!')\n\n\nif __name__ == '__main__':\n with Configurator() as config:\n config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n", "path": "docs/quick_tour/hello_world/app.py"}, {"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\ndef hello_world(request):\n return Response('Hello World!')\n\n\nif __name__ == '__main__':\n with Configurator() as config:\n config.add_route('hello', '/')\n config.add_view(hello_world, route_name='hello')\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n", "path": "docs/narr/helloworld.py"}, {"content": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\nclass Resource(dict):\n pass\n\n\ndef get_root(request):\n return Resource({'a': Resource({'b': Resource({'c': Resource()})})})\n\n\ndef hello_world_of_resources(context, request):\n output = \"Here's a resource and its children: %s\" % context\n return Response(output)\n\n\nif __name__ == '__main__':\n with Configurator() as config:\n config.set_root_factory(get_root)\n config.add_view(hello_world_of_resources, context=Resource)\n app = config.make_wsgi_app()\n server = make_server('0.0.0.0', 6543, app)\n server.serve_forever()\n", "path": "docs/narr/hellotraversal.py"}]}
| 1,058 | 570 |
gh_patches_debug_2562
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1887
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
resize-cols-input missing from Column -> Resize menu
**Small description**
resize-cols-input is missing from the Column -> Resize menu
**Expected result**
when I go to the menu under Column -> Resize, I expect resize-cols-input (gz_) to be given as an option
**Additional context**
checked against v2.11
(Submitting pull request to fix this now.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/features/layout.py`
Content:
```
1 from visidata import VisiData, vd, Column, Sheet, Fanout
2
3 @Column.api
4 def setWidth(self, w):
5 if self.width != w:
6 if self.width == 0 or w == 0: # hide/unhide
7 vd.addUndo(setattr, self, '_width', self.width)
8 self._width = w
9
10
11 @Column.api
12 def toggleWidth(self, width):
13 'Change column width to either given `width` or default value.'
14 if self.width != width:
15 self.width = width
16 else:
17 self.width = int(self.sheet.options.default_width)
18
19
20 @Column.api
21 def toggleVisibility(self):
22 if self.height == 1:
23 self.height = self.sheet.options.default_height
24 else:
25 self.height = 1
26
27 @VisiData.api
28 def unhide_cols(vd, cols, rows):
29 'sets appropriate width if column was either hidden (0) or unseen (None)'
30 for c in cols:
31 c.setWidth(abs(c.width or 0) or c.getMaxWidth(rows))
32
33
34 Sheet.addCommand('_', 'resize-col-max', 'cursorCol.toggleWidth(cursorCol.getMaxWidth(visibleRows))', 'toggle width of current column between full and default width'),
35 Sheet.addCommand('z_', 'resize-col-input', 'width = int(input("set width= ", value=cursorCol.width)); cursorCol.setWidth(width)', 'adjust width of current column to N')
36 Sheet.addCommand('g_', 'resize-cols-max', 'for c in visibleCols: c.setWidth(c.getMaxWidth(visibleRows))', 'toggle widths of all visible columns between full and default width'),
37 Sheet.addCommand('gz_', 'resize-cols-input', 'width = int(input("set width= ", value=cursorCol.width)); Fanout(visibleCols).setWidth(width)', 'adjust widths of all visible columns to N')
38
39 Sheet.addCommand('-', 'hide-col', 'cursorCol.hide()', 'Hide current column')
40 Sheet.addCommand('z-', 'resize-col-half', 'cursorCol.setWidth(cursorCol.width//2)', 'reduce width of current column by half'),
41
42 Sheet.addCommand('gv', 'unhide-cols', 'unhide_cols(columns, visibleRows)', 'Show all columns')
43 Sheet.addCommand('v', 'visibility-sheet', 'for c in visibleCols: c.toggleVisibility()')
44 Sheet.addCommand('zv', 'visibility-col', 'cursorCol.toggleVisibility()')
45
46 vd.addMenuItems('''
47 Column > Hide > hide-col
48 Column > Unhide all > unhide-cols
49 Column > Resize > half > resize-col-half
50 Column > Resize > current column to max > resize-col-max
51 Column > Resize > current column to input > resize-col-input
52 Column > Resize > all columns max > resize-cols-max
53 ''')
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/features/layout.py b/visidata/features/layout.py
--- a/visidata/features/layout.py
+++ b/visidata/features/layout.py
@@ -50,4 +50,5 @@
Column > Resize > current column to max > resize-col-max
Column > Resize > current column to input > resize-col-input
Column > Resize > all columns max > resize-cols-max
+ Column > Resize > all columns to input > resize-cols-input
''')
|
{"golden_diff": "diff --git a/visidata/features/layout.py b/visidata/features/layout.py\n--- a/visidata/features/layout.py\n+++ b/visidata/features/layout.py\n@@ -50,4 +50,5 @@\n Column > Resize > current column to max > resize-col-max\n Column > Resize > current column to input > resize-col-input\n Column > Resize > all columns max > resize-cols-max\n+ Column > Resize > all columns to input > resize-cols-input\n ''')\n", "issue": "resize-cols-input missing from Column -> Resize menu\n**Small description**\r\nresize-cols-input is missing from the Column -> Resize menu\r\n\r\n**Expected result**\r\nwhen I go to the menu under Column -> Resize, I expect resize-cols-input (gz_) to be given as an option\r\n\r\n**Additional context**\r\nchecked against v2.11\r\n\r\n(Submitting pull request to fix this now.)\r\n\r\n\n", "before_files": [{"content": "from visidata import VisiData, vd, Column, Sheet, Fanout\n\[email protected]\ndef setWidth(self, w):\n if self.width != w:\n if self.width == 0 or w == 0: # hide/unhide\n vd.addUndo(setattr, self, '_width', self.width)\n self._width = w\n\n\[email protected]\ndef toggleWidth(self, width):\n 'Change column width to either given `width` or default value.'\n if self.width != width:\n self.width = width\n else:\n self.width = int(self.sheet.options.default_width)\n\n\[email protected]\ndef toggleVisibility(self):\n if self.height == 1:\n self.height = self.sheet.options.default_height\n else:\n self.height = 1\n\[email protected]\ndef unhide_cols(vd, cols, rows):\n 'sets appropriate width if column was either hidden (0) or unseen (None)'\n for c in cols:\n c.setWidth(abs(c.width or 0) or c.getMaxWidth(rows))\n\n\nSheet.addCommand('_', 'resize-col-max', 'cursorCol.toggleWidth(cursorCol.getMaxWidth(visibleRows))', 'toggle width of current column between full and default width'),\nSheet.addCommand('z_', 'resize-col-input', 'width = int(input(\"set width= \", value=cursorCol.width)); cursorCol.setWidth(width)', 'adjust width of current column to N')\nSheet.addCommand('g_', 'resize-cols-max', 'for c in visibleCols: c.setWidth(c.getMaxWidth(visibleRows))', 'toggle widths of all visible columns between full and default width'),\nSheet.addCommand('gz_', 'resize-cols-input', 'width = int(input(\"set width= \", value=cursorCol.width)); Fanout(visibleCols).setWidth(width)', 'adjust widths of all visible columns to N')\n\nSheet.addCommand('-', 'hide-col', 'cursorCol.hide()', 'Hide current column')\nSheet.addCommand('z-', 'resize-col-half', 'cursorCol.setWidth(cursorCol.width//2)', 'reduce width of current column by half'),\n\nSheet.addCommand('gv', 'unhide-cols', 'unhide_cols(columns, visibleRows)', 'Show all columns')\nSheet.addCommand('v', 'visibility-sheet', 'for c in visibleCols: c.toggleVisibility()')\nSheet.addCommand('zv', 'visibility-col', 'cursorCol.toggleVisibility()')\n\nvd.addMenuItems('''\n Column > Hide > hide-col\n Column > Unhide all > unhide-cols\n Column > Resize > half > resize-col-half\n Column > Resize > current column to max > resize-col-max\n Column > Resize > current column to input > resize-col-input\n Column > Resize > all columns max > resize-cols-max\n''')\n", "path": "visidata/features/layout.py"}], "after_files": [{"content": "from visidata import VisiData, vd, Column, Sheet, Fanout\n\[email protected]\ndef setWidth(self, w):\n if self.width != w:\n if self.width == 0 or w == 0: # hide/unhide\n vd.addUndo(setattr, self, '_width', self.width)\n self._width = w\n\n\[email protected]\ndef toggleWidth(self, width):\n 'Change column width to either given `width` or default value.'\n if self.width != width:\n self.width = width\n else:\n self.width = int(self.sheet.options.default_width)\n\n\[email protected]\ndef toggleVisibility(self):\n if self.height == 1:\n self.height = self.sheet.options.default_height\n else:\n self.height = 1\n\[email protected]\ndef unhide_cols(vd, cols, rows):\n 'sets appropriate width if column was either hidden (0) or unseen (None)'\n for c in cols:\n c.setWidth(abs(c.width or 0) or c.getMaxWidth(rows))\n\n\nSheet.addCommand('_', 'resize-col-max', 'cursorCol.toggleWidth(cursorCol.getMaxWidth(visibleRows))', 'toggle width of current column between full and default width'),\nSheet.addCommand('z_', 'resize-col-input', 'width = int(input(\"set width= \", value=cursorCol.width)); cursorCol.setWidth(width)', 'adjust width of current column to N')\nSheet.addCommand('g_', 'resize-cols-max', 'for c in visibleCols: c.setWidth(c.getMaxWidth(visibleRows))', 'toggle widths of all visible columns between full and default width'),\nSheet.addCommand('gz_', 'resize-cols-input', 'width = int(input(\"set width= \", value=cursorCol.width)); Fanout(visibleCols).setWidth(width)', 'adjust widths of all visible columns to N')\n\nSheet.addCommand('-', 'hide-col', 'cursorCol.hide()', 'Hide current column')\nSheet.addCommand('z-', 'resize-col-half', 'cursorCol.setWidth(cursorCol.width//2)', 'reduce width of current column by half'),\n\nSheet.addCommand('gv', 'unhide-cols', 'unhide_cols(columns, visibleRows)', 'Show all columns')\nSheet.addCommand('v', 'visibility-sheet', 'for c in visibleCols: c.toggleVisibility()')\nSheet.addCommand('zv', 'visibility-col', 'cursorCol.toggleVisibility()')\n\nvd.addMenuItems('''\n Column > Hide > hide-col\n Column > Unhide all > unhide-cols\n Column > Resize > half > resize-col-half\n Column > Resize > current column to max > resize-col-max\n Column > Resize > current column to input > resize-col-input\n Column > Resize > all columns max > resize-cols-max\n Column > Resize > all columns to input > resize-cols-input\n''')\n", "path": "visidata/features/layout.py"}]}
| 1,024 | 106 |
gh_patches_debug_17321
|
rasdani/github-patches
|
git_diff
|
sopel-irc__sopel-1155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[etymology] HTML entities not decoded before output
The `etymology` module does not decode HTML entities in the snippet before sending it to the channel. This results in printing snippets like this:
````
<Sopel> "Old English wæter, from Proto-Germanic *watar (source also
of Old Saxon watar, Old Frisian wetir, Dutch water, Old High German
wazzar, German Wasser, Old Norse vatn, Gothic wato 'water'), from
PIE *wod-or, from root *wed- (1) 'water, wet' (source also of
Hittite [...]" - http://etymonline.com/?term=water
````
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sopel/modules/etymology.py`
Content:
```
1 # coding=utf-8
2 """
3 etymology.py - Sopel Etymology Module
4 Copyright 2007-9, Sean B. Palmer, inamidst.com
5 Licensed under the Eiffel Forum License 2.
6
7 http://sopel.chat
8 """
9 from __future__ import unicode_literals, absolute_import, print_function, division
10
11 import re
12 from sopel import web
13 from sopel.module import commands, example, NOLIMIT
14
15 etyuri = 'http://etymonline.com/?term=%s'
16 etysearch = 'http://etymonline.com/?search=%s'
17
18 r_definition = re.compile(r'(?ims)<dd[^>]*>.*?</dd>')
19 r_tag = re.compile(r'<(?!!)[^>]+>')
20 r_whitespace = re.compile(r'[\t\r\n ]+')
21
22 abbrs = [
23 'cf', 'lit', 'etc', 'Ger', 'Du', 'Skt', 'Rus', 'Eng', 'Amer.Eng', 'Sp',
24 'Fr', 'N', 'E', 'S', 'W', 'L', 'Gen', 'J.C', 'dial', 'Gk',
25 '19c', '18c', '17c', '16c', 'St', 'Capt', 'obs', 'Jan', 'Feb', 'Mar',
26 'Apr', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec', 'c', 'tr', 'e', 'g'
27 ]
28 t_sentence = r'^.*?(?<!%s)(?:\.(?= [A-Z0-9]|\Z)|\Z)'
29 r_sentence = re.compile(t_sentence % ')(?<!'.join(abbrs))
30
31
32 def unescape(s):
33 s = s.replace('>', '>')
34 s = s.replace('<', '<')
35 s = s.replace('&', '&')
36 return s
37
38
39 def text(html):
40 html = r_tag.sub('', html)
41 html = r_whitespace.sub(' ', html)
42 return unescape(html).strip()
43
44
45 def etymology(word):
46 # @@ <nsh> sbp, would it be possible to have a flag for .ety to get 2nd/etc
47 # entries? - http://swhack.com/logs/2006-07-19#T15-05-29
48
49 if len(word) > 25:
50 raise ValueError("Word too long: %s[...]" % word[:10])
51 word = {'axe': 'ax/axe'}.get(word, word)
52
53 bytes = web.get(etyuri % word)
54 definitions = r_definition.findall(bytes)
55
56 if not definitions:
57 return None
58
59 defn = text(definitions[0])
60 m = r_sentence.match(defn)
61 if not m:
62 return None
63 sentence = m.group(0)
64
65 maxlength = 275
66 if len(sentence) > maxlength:
67 sentence = sentence[:maxlength]
68 words = sentence[:-5].split(' ')
69 words.pop()
70 sentence = ' '.join(words) + ' [...]'
71
72 sentence = '"' + sentence.replace('"', "'") + '"'
73 return sentence + ' - ' + (etyuri % word)
74
75
76 @commands('ety')
77 @example('.ety word')
78 def f_etymology(bot, trigger):
79 """Look up the etymology of a word"""
80 word = trigger.group(2)
81
82 try:
83 result = etymology(word)
84 except IOError:
85 msg = "Can't connect to etymonline.com (%s)" % (etyuri % word)
86 bot.msg(trigger.sender, msg)
87 return NOLIMIT
88 except (AttributeError, TypeError):
89 result = None
90
91 if result is not None:
92 bot.msg(trigger.sender, result)
93 else:
94 uri = etysearch % word
95 msg = 'Can\'t find the etymology for "%s". Try %s' % (word, uri)
96 bot.msg(trigger.sender, msg)
97 return NOLIMIT
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sopel/modules/etymology.py b/sopel/modules/etymology.py
--- a/sopel/modules/etymology.py
+++ b/sopel/modules/etymology.py
@@ -8,6 +8,14 @@
"""
from __future__ import unicode_literals, absolute_import, print_function, division
+try:
+ from html import unescape
+except ImportError:
+ from HTMLParser import HTMLParser
+
+ # pep8 dictates a blank line here...
+ def unescape(s):
+ return HTMLParser.unescape.__func__(HTMLParser, s)
import re
from sopel import web
from sopel.module import commands, example, NOLIMIT
@@ -29,13 +37,6 @@
r_sentence = re.compile(t_sentence % ')(?<!'.join(abbrs))
-def unescape(s):
- s = s.replace('>', '>')
- s = s.replace('<', '<')
- s = s.replace('&', '&')
- return s
-
-
def text(html):
html = r_tag.sub('', html)
html = r_whitespace.sub(' ', html)
|
{"golden_diff": "diff --git a/sopel/modules/etymology.py b/sopel/modules/etymology.py\n--- a/sopel/modules/etymology.py\n+++ b/sopel/modules/etymology.py\n@@ -8,6 +8,14 @@\n \"\"\"\n from __future__ import unicode_literals, absolute_import, print_function, division\n \n+try:\n+ from html import unescape\n+except ImportError:\n+ from HTMLParser import HTMLParser\n+\n+ # pep8 dictates a blank line here...\n+ def unescape(s):\n+ return HTMLParser.unescape.__func__(HTMLParser, s)\n import re\n from sopel import web\n from sopel.module import commands, example, NOLIMIT\n@@ -29,13 +37,6 @@\n r_sentence = re.compile(t_sentence % ')(?<!'.join(abbrs))\n \n \n-def unescape(s):\n- s = s.replace('>', '>')\n- s = s.replace('<', '<')\n- s = s.replace('&', '&')\n- return s\n-\n-\n def text(html):\n html = r_tag.sub('', html)\n html = r_whitespace.sub(' ', html)\n", "issue": "[etymology] HTML entities not decoded before output\nThe `etymology` module does not decode HTML entities in the snippet before sending it to the channel. This results in printing snippets like this:\r\n\r\n````\r\n<Sopel> \"Old English wæter, from Proto-Germanic *watar (source also\r\n of Old Saxon watar, Old Frisian wetir, Dutch water, Old High German\r\n wazzar, German Wasser, Old Norse vatn, Gothic wato 'water'), from\r\n PIE *wod-or, from root *wed- (1) 'water, wet' (source also of\r\n Hittite [...]\" -\u00a0http://etymonline.com/?term=water\r\n````\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\netymology.py - Sopel Etymology Module\nCopyright 2007-9, Sean B. Palmer, inamidst.com\nLicensed under the Eiffel Forum License 2.\n\nhttp://sopel.chat\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\nfrom sopel import web\nfrom sopel.module import commands, example, NOLIMIT\n\netyuri = 'http://etymonline.com/?term=%s'\netysearch = 'http://etymonline.com/?search=%s'\n\nr_definition = re.compile(r'(?ims)<dd[^>]*>.*?</dd>')\nr_tag = re.compile(r'<(?!!)[^>]+>')\nr_whitespace = re.compile(r'[\\t\\r\\n ]+')\n\nabbrs = [\n 'cf', 'lit', 'etc', 'Ger', 'Du', 'Skt', 'Rus', 'Eng', 'Amer.Eng', 'Sp',\n 'Fr', 'N', 'E', 'S', 'W', 'L', 'Gen', 'J.C', 'dial', 'Gk',\n '19c', '18c', '17c', '16c', 'St', 'Capt', 'obs', 'Jan', 'Feb', 'Mar',\n 'Apr', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec', 'c', 'tr', 'e', 'g'\n]\nt_sentence = r'^.*?(?<!%s)(?:\\.(?= [A-Z0-9]|\\Z)|\\Z)'\nr_sentence = re.compile(t_sentence % ')(?<!'.join(abbrs))\n\n\ndef unescape(s):\n s = s.replace('>', '>')\n s = s.replace('<', '<')\n s = s.replace('&', '&')\n return s\n\n\ndef text(html):\n html = r_tag.sub('', html)\n html = r_whitespace.sub(' ', html)\n return unescape(html).strip()\n\n\ndef etymology(word):\n # @@ <nsh> sbp, would it be possible to have a flag for .ety to get 2nd/etc\n # entries? - http://swhack.com/logs/2006-07-19#T15-05-29\n\n if len(word) > 25:\n raise ValueError(\"Word too long: %s[...]\" % word[:10])\n word = {'axe': 'ax/axe'}.get(word, word)\n\n bytes = web.get(etyuri % word)\n definitions = r_definition.findall(bytes)\n\n if not definitions:\n return None\n\n defn = text(definitions[0])\n m = r_sentence.match(defn)\n if not m:\n return None\n sentence = m.group(0)\n\n maxlength = 275\n if len(sentence) > maxlength:\n sentence = sentence[:maxlength]\n words = sentence[:-5].split(' ')\n words.pop()\n sentence = ' '.join(words) + ' [...]'\n\n sentence = '\"' + sentence.replace('\"', \"'\") + '\"'\n return sentence + ' - ' + (etyuri % word)\n\n\n@commands('ety')\n@example('.ety word')\ndef f_etymology(bot, trigger):\n \"\"\"Look up the etymology of a word\"\"\"\n word = trigger.group(2)\n\n try:\n result = etymology(word)\n except IOError:\n msg = \"Can't connect to etymonline.com (%s)\" % (etyuri % word)\n bot.msg(trigger.sender, msg)\n return NOLIMIT\n except (AttributeError, TypeError):\n result = None\n\n if result is not None:\n bot.msg(trigger.sender, result)\n else:\n uri = etysearch % word\n msg = 'Can\\'t find the etymology for \"%s\". Try %s' % (word, uri)\n bot.msg(trigger.sender, msg)\n return NOLIMIT\n", "path": "sopel/modules/etymology.py"}], "after_files": [{"content": "# coding=utf-8\n\"\"\"\netymology.py - Sopel Etymology Module\nCopyright 2007-9, Sean B. Palmer, inamidst.com\nLicensed under the Eiffel Forum License 2.\n\nhttp://sopel.chat\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\ntry:\n from html import unescape\nexcept ImportError:\n from HTMLParser import HTMLParser\n\n # pep8 dictates a blank line here...\n def unescape(s):\n return HTMLParser.unescape.__func__(HTMLParser, s)\nimport re\nfrom sopel import web\nfrom sopel.module import commands, example, NOLIMIT\n\netyuri = 'http://etymonline.com/?term=%s'\netysearch = 'http://etymonline.com/?search=%s'\n\nr_definition = re.compile(r'(?ims)<dd[^>]*>.*?</dd>')\nr_tag = re.compile(r'<(?!!)[^>]+>')\nr_whitespace = re.compile(r'[\\t\\r\\n ]+')\n\nabbrs = [\n 'cf', 'lit', 'etc', 'Ger', 'Du', 'Skt', 'Rus', 'Eng', 'Amer.Eng', 'Sp',\n 'Fr', 'N', 'E', 'S', 'W', 'L', 'Gen', 'J.C', 'dial', 'Gk',\n '19c', '18c', '17c', '16c', 'St', 'Capt', 'obs', 'Jan', 'Feb', 'Mar',\n 'Apr', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec', 'c', 'tr', 'e', 'g'\n]\nt_sentence = r'^.*?(?<!%s)(?:\\.(?= [A-Z0-9]|\\Z)|\\Z)'\nr_sentence = re.compile(t_sentence % ')(?<!'.join(abbrs))\n\n\ndef text(html):\n html = r_tag.sub('', html)\n html = r_whitespace.sub(' ', html)\n return unescape(html).strip()\n\n\ndef etymology(word):\n # @@ <nsh> sbp, would it be possible to have a flag for .ety to get 2nd/etc\n # entries? - http://swhack.com/logs/2006-07-19#T15-05-29\n\n if len(word) > 25:\n raise ValueError(\"Word too long: %s[...]\" % word[:10])\n word = {'axe': 'ax/axe'}.get(word, word)\n\n bytes = web.get(etyuri % word)\n definitions = r_definition.findall(bytes)\n\n if not definitions:\n return None\n\n defn = text(definitions[0])\n m = r_sentence.match(defn)\n if not m:\n return None\n sentence = m.group(0)\n\n maxlength = 275\n if len(sentence) > maxlength:\n sentence = sentence[:maxlength]\n words = sentence[:-5].split(' ')\n words.pop()\n sentence = ' '.join(words) + ' [...]'\n\n sentence = '\"' + sentence.replace('\"', \"'\") + '\"'\n return sentence + ' - ' + (etyuri % word)\n\n\n@commands('ety')\n@example('.ety word')\ndef f_etymology(bot, trigger):\n \"\"\"Look up the etymology of a word\"\"\"\n word = trigger.group(2)\n\n try:\n result = etymology(word)\n except IOError:\n msg = \"Can't connect to etymonline.com (%s)\" % (etyuri % word)\n bot.msg(trigger.sender, msg)\n return NOLIMIT\n except (AttributeError, TypeError):\n result = None\n\n if result is not None:\n bot.msg(trigger.sender, result)\n else:\n uri = etysearch % word\n msg = 'Can\\'t find the etymology for \"%s\". Try %s' % (word, uri)\n bot.msg(trigger.sender, msg)\n return NOLIMIT\n", "path": "sopel/modules/etymology.py"}]}
| 1,490 | 252 |
gh_patches_debug_3625
|
rasdani/github-patches
|
git_diff
|
coala__coala-1597
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
coala_delete_orig: Modify message
Modify message about `Couldn't delete... <filename>`
@sils1297 please suggest a better message.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `coalib/coala_delete_orig.py`
Content:
```
1 import os
2
3 from pyprint.ConsolePrinter import ConsolePrinter
4
5 from coalib.output.printers.LogPrinter import LogPrinter
6 from coalib.parsing import Globbing
7 from coalib.settings.ConfigurationGathering import get_config_directory
8 from coalib.settings.Section import Section
9
10
11 def main(log_printer=None, section: Section=None):
12 start_path = get_config_directory(section)
13 log_printer = log_printer or LogPrinter(ConsolePrinter())
14
15 if start_path is None:
16 return 255
17
18 orig_files = Globbing.glob(os.path.abspath(
19 os.path.join(start_path, '**', '*.orig')))
20
21 not_deleted = 0
22 for ofile in orig_files:
23 log_printer.info("Deleting old backup file... "
24 + os.path.relpath(ofile))
25 try:
26 os.remove(ofile)
27 except OSError as oserror:
28 not_deleted += 1
29 log_printer.warn("Couldn't delete... {}. {}".format(
30 os.path.relpath(ofile), oserror.strerror))
31
32 if not_deleted:
33 log_printer.warn(str(not_deleted) + " .orig backup files could not be"
34 " deleted, possibly because you lack the permission"
35 " to do so. coala may not be able to create"
36 " backup files when patches are applied.")
37 return 0
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/coalib/coala_delete_orig.py b/coalib/coala_delete_orig.py
--- a/coalib/coala_delete_orig.py
+++ b/coalib/coala_delete_orig.py
@@ -26,7 +26,7 @@
os.remove(ofile)
except OSError as oserror:
not_deleted += 1
- log_printer.warn("Couldn't delete... {}. {}".format(
+ log_printer.warn("Couldn't delete {}. {}".format(
os.path.relpath(ofile), oserror.strerror))
if not_deleted:
|
{"golden_diff": "diff --git a/coalib/coala_delete_orig.py b/coalib/coala_delete_orig.py\n--- a/coalib/coala_delete_orig.py\n+++ b/coalib/coala_delete_orig.py\n@@ -26,7 +26,7 @@\n os.remove(ofile)\n except OSError as oserror:\n not_deleted += 1\n- log_printer.warn(\"Couldn't delete... {}. {}\".format(\n+ log_printer.warn(\"Couldn't delete {}. {}\".format(\n os.path.relpath(ofile), oserror.strerror))\n \n if not_deleted:\n", "issue": "coala_delete_orig: Modify message\nModify message about `Couldn't delete... <filename>`\n\n@sils1297 please suggest a better message.\n\n", "before_files": [{"content": "import os\n\nfrom pyprint.ConsolePrinter import ConsolePrinter\n\nfrom coalib.output.printers.LogPrinter import LogPrinter\nfrom coalib.parsing import Globbing\nfrom coalib.settings.ConfigurationGathering import get_config_directory\nfrom coalib.settings.Section import Section\n\n\ndef main(log_printer=None, section: Section=None):\n start_path = get_config_directory(section)\n log_printer = log_printer or LogPrinter(ConsolePrinter())\n\n if start_path is None:\n return 255\n\n orig_files = Globbing.glob(os.path.abspath(\n os.path.join(start_path, '**', '*.orig')))\n\n not_deleted = 0\n for ofile in orig_files:\n log_printer.info(\"Deleting old backup file... \"\n + os.path.relpath(ofile))\n try:\n os.remove(ofile)\n except OSError as oserror:\n not_deleted += 1\n log_printer.warn(\"Couldn't delete... {}. {}\".format(\n os.path.relpath(ofile), oserror.strerror))\n\n if not_deleted:\n log_printer.warn(str(not_deleted) + \" .orig backup files could not be\"\n \" deleted, possibly because you lack the permission\"\n \" to do so. coala may not be able to create\"\n \" backup files when patches are applied.\")\n return 0\n", "path": "coalib/coala_delete_orig.py"}], "after_files": [{"content": "import os\n\nfrom pyprint.ConsolePrinter import ConsolePrinter\n\nfrom coalib.output.printers.LogPrinter import LogPrinter\nfrom coalib.parsing import Globbing\nfrom coalib.settings.ConfigurationGathering import get_config_directory\nfrom coalib.settings.Section import Section\n\n\ndef main(log_printer=None, section: Section=None):\n start_path = get_config_directory(section)\n log_printer = log_printer or LogPrinter(ConsolePrinter())\n\n if start_path is None:\n return 255\n\n orig_files = Globbing.glob(os.path.abspath(\n os.path.join(start_path, '**', '*.orig')))\n\n not_deleted = 0\n for ofile in orig_files:\n log_printer.info(\"Deleting old backup file... \"\n + os.path.relpath(ofile))\n try:\n os.remove(ofile)\n except OSError as oserror:\n not_deleted += 1\n log_printer.warn(\"Couldn't delete {}. {}\".format(\n os.path.relpath(ofile), oserror.strerror))\n\n if not_deleted:\n log_printer.warn(str(not_deleted) + \" .orig backup files could not be\"\n \" deleted, possibly because you lack the permission\"\n \" to do so. coala may not be able to create\"\n \" backup files when patches are applied.\")\n return 0\n", "path": "coalib/coala_delete_orig.py"}]}
| 637 | 122 |
gh_patches_debug_26164
|
rasdani/github-patches
|
git_diff
|
spack__spack-19604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Installation issue: ucx
I'm trying to build openmpi with ucx but on compiling ucx I get build errors with `error: implicit declaration of function`.
```console
637 CC libuct_rdmacm_la-rdmacm_iface.lo
638 CC libuct_rdmacm_la-rdmacm_ep.lo
639 CC libuct_rdmacm_la-rdmacm_cm.lo
640 CC libuct_rdmacm_la-rdmacm_listener.lo
641 CC libuct_rdmacm_la-rdmacm_cm_ep.lo
642 rdmacm_cm.c: In function 'uct_rdmacm_cm_id_to_dev_addr':
>> 643 rdmacm_cm.c:146:9: error: implicit declaration of function 'rdma_init_qp_attr' [-Werror=implicit-function-declaration]
644 146 | if (rdma_init_qp_attr(cm_id, &qp_attr, &qp_attr_mask)) {
645 | ^~~~~~~~~~~~~~~~~
646 rdmacm_cm.c: In function 'uct_rdmacm_cm_handle_event_connect_response':
>> 647 rdmacm_cm.c:269:9: error: implicit declaration of function 'rdma_establish' [-Werror=implicit-function-declaration]
648 269 | if (rdma_establish(event->id)) {
649 | ^~~~~~~~~~~~~~
650 cc1: all warnings being treated as errors
651 make[4]: *** [Makefile:670: libuct_rdmacm_la-rdmacm_cm.lo] Error 1
652 make[4]: *** Waiting for unfinished jobs....
653 make[4]: Leaving directory '/tmp/root/spack-stage/spack-stage-ucx-1.8.0-344rhrrnr7m3kpod3hg6bbwi4ml3nn5k/spack-src/src/uct/ib/rdmacm'
```
### Steps to reproduce the issue
```console
$ spack install openmpi+thread_multiple+pmi fabrics=ucx schedulers=slurm %[email protected] ucx%[email protected]
```
### Information on your system
* **Spack:** 0.15.3-387-3a02d1a84
* **Python:** 3.6.8
* **Platform:** linux-centos8-zen2
### Additional information
* [spack-build-out.txt](https://github.com/spack/spack/files/5021896/spack-build-out.txt)
I have slurm locally installed, with the following in my .spack/packages.yaml :
```
slurm:
buildable: False
paths:
slurm@20-02-3-1: /usr
```
@hppritcha
### General information
<!-- These boxes can be checked by replacing [ ] with [x] or by clicking them after submitting the issue. -->
- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform
- [x] I have run `spack maintainers <name-of-the-package>` and @mentioned any maintainers
- [x] I have uploaded the build log and environment files
- [x] I have searched the issues of this repo and believe this is not a duplicate
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `var/spack/repos/builtin/packages/rdma-core/package.py`
Content:
```
1 # Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from spack import *
7
8
9 class RdmaCore(CMakePackage):
10 """RDMA core userspace libraries and daemons"""
11
12 homepage = "https://github.com/linux-rdma/rdma-core"
13 url = "https://github.com/linux-rdma/rdma-core/releases/download/v17.1/rdma-core-17.1.tar.gz"
14
15 version('20', sha256='bc846989f807cd2b03643927d2b99fbf6f849cb1e766ab49bc9e81ce769d5421')
16 version('17.1', sha256='b47444b7c05d3906deb8771eec3e634984dd83f5e620d5e37d3a83f74f0cc1ba')
17 version('13', sha256='e5230fd7cda610753ad1252b40a28b1e9cf836423a10d8c2525b081527760d97')
18
19 depends_on('pkgconfig', type='build')
20 depends_on('libnl')
21 conflicts('platform=darwin', msg='rdma-core requires FreeBSD or Linux')
22 conflicts('%intel', msg='rdma-core cannot be built with intel (use gcc instead)')
23
24 # NOTE: specify CMAKE_INSTALL_RUNDIR explicitly to prevent rdma-core from
25 # using the spack staging build dir (which may be a very long file
26 # system path) as a component in compile-time static strings such as
27 # IBACM_SERVER_PATH.
28 def cmake_args(self):
29 cmake_args = ["-DCMAKE_INSTALL_SYSCONFDIR=" +
30 self.spec.prefix.etc,
31 "-DCMAKE_INSTALL_RUNDIR=/var/run"]
32 return cmake_args
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/var/spack/repos/builtin/packages/rdma-core/package.py b/var/spack/repos/builtin/packages/rdma-core/package.py
--- a/var/spack/repos/builtin/packages/rdma-core/package.py
+++ b/var/spack/repos/builtin/packages/rdma-core/package.py
@@ -12,6 +12,15 @@
homepage = "https://github.com/linux-rdma/rdma-core"
url = "https://github.com/linux-rdma/rdma-core/releases/download/v17.1/rdma-core-17.1.tar.gz"
+ version('32.0', sha256='8197e20a59990b9b06a2e4c83f4a96802fc080ec1669392b643b59b6023931fc')
+ version('31.0', sha256='51ae9a3ab81cd6834436813fafc310c8b7007feae9d09a53fdd5c169e648d50b')
+ version('30.0', sha256='23e1bd2d7b38149a1621ee577a3428ac652e305adb8e0eee923cbe71356a9bf9')
+ version('28.1', sha256='d9961fd9b0867f17cb6a30a728562f00528b63dd72d1168d838220ab44e5c713')
+ version('27.1', sha256='39eeb3ab5f868ef3a5f7623d1ee69adca04efabe2a37de8080f354b8f4ef0ad7')
+ version('26.2', sha256='115087ab438bea3530a0d520640f1eeb5872b902ee2263acf83dcc7835d296c6')
+ version('25.4', sha256='f622491b0aac819f05c73174e0c7a9e630cc02fc0914d5ba1bb1d87fc4d313fd')
+ version('24.3', sha256='3a02d2d864258acc763849c635c815e3fa6a798a1464511cd3a2a370ddd6ee89')
+ version('23.4', sha256='6bfe009e9a382085def3b004d9396f7255a2e0c90c36647d1df0b86773d21a79')
version('20', sha256='bc846989f807cd2b03643927d2b99fbf6f849cb1e766ab49bc9e81ce769d5421')
version('17.1', sha256='b47444b7c05d3906deb8771eec3e634984dd83f5e620d5e37d3a83f74f0cc1ba')
version('13', sha256='e5230fd7cda610753ad1252b40a28b1e9cf836423a10d8c2525b081527760d97')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/rdma-core/package.py b/var/spack/repos/builtin/packages/rdma-core/package.py\n--- a/var/spack/repos/builtin/packages/rdma-core/package.py\n+++ b/var/spack/repos/builtin/packages/rdma-core/package.py\n@@ -12,6 +12,15 @@\n homepage = \"https://github.com/linux-rdma/rdma-core\"\n url = \"https://github.com/linux-rdma/rdma-core/releases/download/v17.1/rdma-core-17.1.tar.gz\"\n \n+ version('32.0', sha256='8197e20a59990b9b06a2e4c83f4a96802fc080ec1669392b643b59b6023931fc')\n+ version('31.0', sha256='51ae9a3ab81cd6834436813fafc310c8b7007feae9d09a53fdd5c169e648d50b')\n+ version('30.0', sha256='23e1bd2d7b38149a1621ee577a3428ac652e305adb8e0eee923cbe71356a9bf9')\n+ version('28.1', sha256='d9961fd9b0867f17cb6a30a728562f00528b63dd72d1168d838220ab44e5c713')\n+ version('27.1', sha256='39eeb3ab5f868ef3a5f7623d1ee69adca04efabe2a37de8080f354b8f4ef0ad7')\n+ version('26.2', sha256='115087ab438bea3530a0d520640f1eeb5872b902ee2263acf83dcc7835d296c6')\n+ version('25.4', sha256='f622491b0aac819f05c73174e0c7a9e630cc02fc0914d5ba1bb1d87fc4d313fd')\n+ version('24.3', sha256='3a02d2d864258acc763849c635c815e3fa6a798a1464511cd3a2a370ddd6ee89')\n+ version('23.4', sha256='6bfe009e9a382085def3b004d9396f7255a2e0c90c36647d1df0b86773d21a79')\n version('20', sha256='bc846989f807cd2b03643927d2b99fbf6f849cb1e766ab49bc9e81ce769d5421')\n version('17.1', sha256='b47444b7c05d3906deb8771eec3e634984dd83f5e620d5e37d3a83f74f0cc1ba')\n version('13', sha256='e5230fd7cda610753ad1252b40a28b1e9cf836423a10d8c2525b081527760d97')\n", "issue": "Installation issue: ucx\nI'm trying to build openmpi with ucx but on compiling ucx I get build errors with `error: implicit declaration of function`.\r\n\r\n```console\r\n 637 CC libuct_rdmacm_la-rdmacm_iface.lo\r\n 638 CC libuct_rdmacm_la-rdmacm_ep.lo\r\n 639 CC libuct_rdmacm_la-rdmacm_cm.lo\r\n 640 CC libuct_rdmacm_la-rdmacm_listener.lo\r\n 641 CC libuct_rdmacm_la-rdmacm_cm_ep.lo\r\n 642 rdmacm_cm.c: In function 'uct_rdmacm_cm_id_to_dev_addr':\r\n >> 643 rdmacm_cm.c:146:9: error: implicit declaration of function 'rdma_init_qp_attr' [-Werror=implicit-function-declaration]\r\n 644 146 | if (rdma_init_qp_attr(cm_id, &qp_attr, &qp_attr_mask)) {\r\n 645 | ^~~~~~~~~~~~~~~~~\r\n 646 rdmacm_cm.c: In function 'uct_rdmacm_cm_handle_event_connect_response':\r\n >> 647 rdmacm_cm.c:269:9: error: implicit declaration of function 'rdma_establish' [-Werror=implicit-function-declaration]\r\n 648 269 | if (rdma_establish(event->id)) {\r\n 649 | ^~~~~~~~~~~~~~\r\n 650 cc1: all warnings being treated as errors\r\n 651 make[4]: *** [Makefile:670: libuct_rdmacm_la-rdmacm_cm.lo] Error 1\r\n 652 make[4]: *** Waiting for unfinished jobs....\r\n 653 make[4]: Leaving directory '/tmp/root/spack-stage/spack-stage-ucx-1.8.0-344rhrrnr7m3kpod3hg6bbwi4ml3nn5k/spack-src/src/uct/ib/rdmacm'\r\n\r\n```\r\n\r\n### Steps to reproduce the issue\r\n\r\n```console\r\n$ spack install openmpi+thread_multiple+pmi fabrics=ucx schedulers=slurm %[email protected] ucx%[email protected]\r\n```\r\n\r\n### Information on your system\r\n\r\n* **Spack:** 0.15.3-387-3a02d1a84\r\n* **Python:** 3.6.8\r\n* **Platform:** linux-centos8-zen2\r\n\r\n### Additional information\r\n\r\n* [spack-build-out.txt](https://github.com/spack/spack/files/5021896/spack-build-out.txt)\r\n\r\nI have slurm locally installed, with the following in my .spack/packages.yaml :\r\n\r\n```\r\n slurm:\r\n buildable: False\r\n paths:\r\n slurm@20-02-3-1: /usr\r\n```\r\n\r\n\r\n@hppritcha \r\n\r\n### General information\r\n\r\n<!-- These boxes can be checked by replacing [ ] with [x] or by clicking them after submitting the issue. -->\r\n- [x] I have run `spack debug report` and reported the version of Spack/Python/Platform\r\n- [x] I have run `spack maintainers <name-of-the-package>` and @mentioned any maintainers\r\n- [x] I have uploaded the build log and environment files\r\n- [x] I have searched the issues of this repo and believe this is not a duplicate\r\n\n", "before_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass RdmaCore(CMakePackage):\n \"\"\"RDMA core userspace libraries and daemons\"\"\"\n\n homepage = \"https://github.com/linux-rdma/rdma-core\"\n url = \"https://github.com/linux-rdma/rdma-core/releases/download/v17.1/rdma-core-17.1.tar.gz\"\n\n version('20', sha256='bc846989f807cd2b03643927d2b99fbf6f849cb1e766ab49bc9e81ce769d5421')\n version('17.1', sha256='b47444b7c05d3906deb8771eec3e634984dd83f5e620d5e37d3a83f74f0cc1ba')\n version('13', sha256='e5230fd7cda610753ad1252b40a28b1e9cf836423a10d8c2525b081527760d97')\n\n depends_on('pkgconfig', type='build')\n depends_on('libnl')\n conflicts('platform=darwin', msg='rdma-core requires FreeBSD or Linux')\n conflicts('%intel', msg='rdma-core cannot be built with intel (use gcc instead)')\n\n# NOTE: specify CMAKE_INSTALL_RUNDIR explicitly to prevent rdma-core from\n# using the spack staging build dir (which may be a very long file\n# system path) as a component in compile-time static strings such as\n# IBACM_SERVER_PATH.\n def cmake_args(self):\n cmake_args = [\"-DCMAKE_INSTALL_SYSCONFDIR=\" +\n self.spec.prefix.etc,\n \"-DCMAKE_INSTALL_RUNDIR=/var/run\"]\n return cmake_args\n", "path": "var/spack/repos/builtin/packages/rdma-core/package.py"}], "after_files": [{"content": "# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom spack import *\n\n\nclass RdmaCore(CMakePackage):\n \"\"\"RDMA core userspace libraries and daemons\"\"\"\n\n homepage = \"https://github.com/linux-rdma/rdma-core\"\n url = \"https://github.com/linux-rdma/rdma-core/releases/download/v17.1/rdma-core-17.1.tar.gz\"\n\n version('32.0', sha256='8197e20a59990b9b06a2e4c83f4a96802fc080ec1669392b643b59b6023931fc')\n version('31.0', sha256='51ae9a3ab81cd6834436813fafc310c8b7007feae9d09a53fdd5c169e648d50b')\n version('30.0', sha256='23e1bd2d7b38149a1621ee577a3428ac652e305adb8e0eee923cbe71356a9bf9')\n version('28.1', sha256='d9961fd9b0867f17cb6a30a728562f00528b63dd72d1168d838220ab44e5c713')\n version('27.1', sha256='39eeb3ab5f868ef3a5f7623d1ee69adca04efabe2a37de8080f354b8f4ef0ad7')\n version('26.2', sha256='115087ab438bea3530a0d520640f1eeb5872b902ee2263acf83dcc7835d296c6')\n version('25.4', sha256='f622491b0aac819f05c73174e0c7a9e630cc02fc0914d5ba1bb1d87fc4d313fd')\n version('24.3', sha256='3a02d2d864258acc763849c635c815e3fa6a798a1464511cd3a2a370ddd6ee89')\n version('23.4', sha256='6bfe009e9a382085def3b004d9396f7255a2e0c90c36647d1df0b86773d21a79')\n version('20', sha256='bc846989f807cd2b03643927d2b99fbf6f849cb1e766ab49bc9e81ce769d5421')\n version('17.1', sha256='b47444b7c05d3906deb8771eec3e634984dd83f5e620d5e37d3a83f74f0cc1ba')\n version('13', sha256='e5230fd7cda610753ad1252b40a28b1e9cf836423a10d8c2525b081527760d97')\n\n depends_on('pkgconfig', type='build')\n depends_on('libnl')\n conflicts('platform=darwin', msg='rdma-core requires FreeBSD or Linux')\n conflicts('%intel', msg='rdma-core cannot be built with intel (use gcc instead)')\n\n# NOTE: specify CMAKE_INSTALL_RUNDIR explicitly to prevent rdma-core from\n# using the spack staging build dir (which may be a very long file\n# system path) as a component in compile-time static strings such as\n# IBACM_SERVER_PATH.\n def cmake_args(self):\n cmake_args = [\"-DCMAKE_INSTALL_SYSCONFDIR=\" +\n self.spec.prefix.etc,\n \"-DCMAKE_INSTALL_RUNDIR=/var/run\"]\n return cmake_args\n", "path": "var/spack/repos/builtin/packages/rdma-core/package.py"}]}
| 1,636 | 989 |
gh_patches_debug_6708
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-554
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Security Group filter "default-vpc" does not function correctly.
Using the following policy:
```
policies:
- name: default-sg-allows-all-traffic
description: |
Find whether the default security group allows all traffic.
resource: security-group
filters:
- type: default-vpc
```
Comes up with no results, even when I have confirmed that my account has a default vpc and a default security group associated with it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `c7n/filters/vpc.py`
Content:
```
1 # Copyright 2016 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from c7n.utils import local_session, type_schema
16
17 from .core import Filter, ValueFilter
18 from .related import RelatedResourceFilter
19
20
21 class SecurityGroupFilter(RelatedResourceFilter):
22
23 schema = type_schema(
24 'security-group', rinherit=ValueFilter.schema,
25 match_resource={'type': 'boolean'},
26 operator={'enum': ['and', 'or']})
27
28 RelatedResource = "c7n.resources.vpc.SecurityGroup"
29 AnnotationKey = "matched-security-groups"
30
31
32 class SubnetFilter(RelatedResourceFilter):
33
34 schema = type_schema(
35 'subnet', rinherit=ValueFilter.schema,
36 match_resource={'type': 'boolean'},
37 operator={'enum': ['and', 'or']})
38
39 RelatedResource = "c7n.resources.vpc.Subnet"
40 AnnotationKey = "matched-subnets"
41
42
43 class DefaultVpcBase(Filter):
44
45 vpcs = None
46 default_vpc = None
47
48 def match(self, vpc_id):
49 if self.default_vpc is None:
50 self.log.debug("querying default vpc %s" % vpc_id)
51 client = local_session(self.manager.session_factory).client('ec2')
52 vpcs = [v['VpcId'] for v
53 in client.describe_vpcs(VpcIds=[vpc_id])['Vpcs']
54 if v['IsDefault']]
55 if not vpcs:
56 self.default_vpc = ""
57 else:
58 self.default_vpc = vpcs.pop()
59 return vpc_id == self.default_vpc and True or False
60
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/c7n/filters/vpc.py b/c7n/filters/vpc.py
--- a/c7n/filters/vpc.py
+++ b/c7n/filters/vpc.py
@@ -52,8 +52,6 @@
vpcs = [v['VpcId'] for v
in client.describe_vpcs(VpcIds=[vpc_id])['Vpcs']
if v['IsDefault']]
- if not vpcs:
- self.default_vpc = ""
- else:
+ if vpcs:
self.default_vpc = vpcs.pop()
return vpc_id == self.default_vpc and True or False
|
{"golden_diff": "diff --git a/c7n/filters/vpc.py b/c7n/filters/vpc.py\n--- a/c7n/filters/vpc.py\n+++ b/c7n/filters/vpc.py\n@@ -52,8 +52,6 @@\n vpcs = [v['VpcId'] for v\n in client.describe_vpcs(VpcIds=[vpc_id])['Vpcs']\n if v['IsDefault']]\n- if not vpcs:\n- self.default_vpc = \"\"\n- else:\n+ if vpcs:\n self.default_vpc = vpcs.pop()\n return vpc_id == self.default_vpc and True or False\n", "issue": "Security Group filter \"default-vpc\" does not function correctly.\nUsing the following policy:\n\n```\npolicies:\n - name: default-sg-allows-all-traffic\n description: |\n Find whether the default security group allows all traffic.\n resource: security-group\n filters:\n - type: default-vpc\n```\n\nComes up with no results, even when I have confirmed that my account has a default vpc and a default security group associated with it.\n\n", "before_files": [{"content": "# Copyright 2016 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom c7n.utils import local_session, type_schema\n\nfrom .core import Filter, ValueFilter\nfrom .related import RelatedResourceFilter\n\n\nclass SecurityGroupFilter(RelatedResourceFilter):\n\n schema = type_schema(\n 'security-group', rinherit=ValueFilter.schema,\n match_resource={'type': 'boolean'},\n operator={'enum': ['and', 'or']})\n\n RelatedResource = \"c7n.resources.vpc.SecurityGroup\"\n AnnotationKey = \"matched-security-groups\"\n\n\nclass SubnetFilter(RelatedResourceFilter):\n\n schema = type_schema(\n 'subnet', rinherit=ValueFilter.schema,\n match_resource={'type': 'boolean'},\n operator={'enum': ['and', 'or']})\n\n RelatedResource = \"c7n.resources.vpc.Subnet\"\n AnnotationKey = \"matched-subnets\" \n\n\nclass DefaultVpcBase(Filter):\n\n vpcs = None\n default_vpc = None\n\n def match(self, vpc_id):\n if self.default_vpc is None:\n self.log.debug(\"querying default vpc %s\" % vpc_id)\n client = local_session(self.manager.session_factory).client('ec2')\n vpcs = [v['VpcId'] for v\n in client.describe_vpcs(VpcIds=[vpc_id])['Vpcs']\n if v['IsDefault']]\n if not vpcs:\n self.default_vpc = \"\"\n else:\n self.default_vpc = vpcs.pop()\n return vpc_id == self.default_vpc and True or False\n", "path": "c7n/filters/vpc.py"}], "after_files": [{"content": "# Copyright 2016 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom c7n.utils import local_session, type_schema\n\nfrom .core import Filter, ValueFilter\nfrom .related import RelatedResourceFilter\n\n\nclass SecurityGroupFilter(RelatedResourceFilter):\n\n schema = type_schema(\n 'security-group', rinherit=ValueFilter.schema,\n match_resource={'type': 'boolean'},\n operator={'enum': ['and', 'or']})\n\n RelatedResource = \"c7n.resources.vpc.SecurityGroup\"\n AnnotationKey = \"matched-security-groups\"\n\n\nclass SubnetFilter(RelatedResourceFilter):\n\n schema = type_schema(\n 'subnet', rinherit=ValueFilter.schema,\n match_resource={'type': 'boolean'},\n operator={'enum': ['and', 'or']})\n\n RelatedResource = \"c7n.resources.vpc.Subnet\"\n AnnotationKey = \"matched-subnets\" \n\n\nclass DefaultVpcBase(Filter):\n\n vpcs = None\n default_vpc = None\n\n def match(self, vpc_id):\n if self.default_vpc is None:\n self.log.debug(\"querying default vpc %s\" % vpc_id)\n client = local_session(self.manager.session_factory).client('ec2')\n vpcs = [v['VpcId'] for v\n in client.describe_vpcs(VpcIds=[vpc_id])['Vpcs']\n if v['IsDefault']]\n if vpcs:\n self.default_vpc = vpcs.pop()\n return vpc_id == self.default_vpc and True or False\n", "path": "c7n/filters/vpc.py"}]}
| 940 | 145 |
gh_patches_debug_34822
|
rasdani/github-patches
|
git_diff
|
angr__angr-840
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ClaripyZeroDivisionError without actual zero
When stepping through a BB with symbolic registers,
division by symbolic register causes state.step() to fail with ClaripyZeroDivisionError.
Example binary [MALWARE!!!]: https://www.dropbox.com/s/n9drwyle246ai86/E022DE72CCE8129BD5AC8A0675996318?dl=0
Example code:
```
# coding=utf-8
import angr
p = angr.Project('E022DE72CCE8129BD5AC8A0675996318', load_options={"auto_load_libs": False})
rebase_delta = p.loader.main_object.image_base_delta
start_state = p.factory.blank_state(addr=rebase_delta + 0x4470)
start_state.step()
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `angr/concretization_strategies/__init__.py`
Content:
```
1 class SimConcretizationStrategy(object):
2 """
3 Concretization strategies control the resolution of symbolic memory indices
4 in SimuVEX. By subclassing this class and setting it as a concretization strategy
5 (on state.memory.read_strategies and state.memory.write_strategies), SimuVEX's
6 memory index concretization behavior can be modified.
7 """
8
9 def __init__(self, filter=None, exact=True): #pylint:disable=redefined-builtin
10 """
11 Initializes the base SimConcretizationStrategy.
12
13 :param filter: A function, taking arguments of (SimMemory, claripy.AST) that determins
14 if this strategy can handle resolving the provided AST.
15 :param exact: A flag (default: True) that determines if the convenience resolution
16 functions provided by this class use exact or approximate resolution.
17 """
18 self._exact = exact
19 self._filter = filter
20
21 def _min(self, memory, addr, **kwargs):
22 """
23 Gets the minimum solution of an address.
24 """
25 return memory.state.se.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
26
27 def _max(self, memory, addr, **kwargs):
28 """
29 Gets the maximum solution of an address.
30 """
31 return memory.state.se.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
32
33 def _any(self, memory, addr, **kwargs):
34 """
35 Gets any solution of an address.
36 """
37 return memory.state.se.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
38
39 def _eval(self, memory, addr, n, **kwargs):
40 """
41 Gets n solutions for an address.
42 """
43 return memory.state.se.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)
44
45 def _range(self, memory, addr, **kwargs):
46 """
47 Gets the (min, max) range of solutions for an address.
48 """
49 return (self._min(memory, addr, **kwargs), self._max(memory, addr, **kwargs))
50
51 def concretize(self, memory, addr):
52 """
53 Concretizes the address into a list of values.
54 If this strategy cannot handle this address, returns None.
55 """
56 if self._filter is None or self._filter(memory, addr):
57 return self._concretize(memory, addr)
58
59 def _concretize(self, memory, addr):
60 """
61 Should be implemented by child classes to handle concretization.
62 """
63 raise NotImplementedError()
64
65 def copy(self):
66 """
67 Returns a copy of the strategy, if there is data that should be kept separate between
68 states. If not, returns self.
69 """
70 return self
71
72 def merge(self, others):
73 """
74 Merges this strategy with others (if there is data that should be kept separate between
75 states. If not, is a no-op.
76 """
77 pass
78
79 from .any import SimConcretizationStrategyAny
80 from .controlled_data import SimConcretizationStrategyControlledData
81 from .eval import SimConcretizationStrategyEval
82 from .max import SimConcretizationStrategyMax
83 from .nonzero import SimConcretizationStrategyNonzero
84 from .nonzero_range import SimConcretizationStrategyNonzeroRange
85 from .norepeats import SimConcretizationStrategyNorepeats
86 from .norepeats_range import SimConcretizationStrategyNorepeatsRange
87 from .range import SimConcretizationStrategyRange
88 from .single import SimConcretizationStrategySingle
89 from .solutions import SimConcretizationStrategySolutions
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/angr/concretization_strategies/__init__.py b/angr/concretization_strategies/__init__.py
--- a/angr/concretization_strategies/__init__.py
+++ b/angr/concretization_strategies/__init__.py
@@ -1,3 +1,5 @@
+import claripy
+
class SimConcretizationStrategy(object):
"""
Concretization strategies control the resolution of symbolic memory indices
@@ -18,29 +20,41 @@
self._exact = exact
self._filter = filter
+ @staticmethod
+ def _tweak(addr, kwargs):
+ """
+ Utility method used from in here that adds a bogus constraint to extra_constraints making it so that the addr
+ expression can actually be evaluated in all cases
+ """
+ kwargs['extra_constraints'] = kwargs.get('extra_constraints', ()) + (addr == claripy.BVS('TEMP', len(addr)),)
+
def _min(self, memory, addr, **kwargs):
"""
Gets the minimum solution of an address.
"""
- return memory.state.se.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
+ self._tweak(addr, kwargs)
+ return memory.state.solver.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
def _max(self, memory, addr, **kwargs):
"""
Gets the maximum solution of an address.
"""
- return memory.state.se.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
+ self._tweak(addr, kwargs)
+ return memory.state.solver.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
def _any(self, memory, addr, **kwargs):
"""
Gets any solution of an address.
"""
- return memory.state.se.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
+ self._tweak(addr, kwargs)
+ return memory.state.solver.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)
def _eval(self, memory, addr, n, **kwargs):
"""
Gets n solutions for an address.
"""
- return memory.state.se.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)
+ self._tweak(addr, kwargs)
+ return memory.state.solver.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)
def _range(self, memory, addr, **kwargs):
"""
|
{"golden_diff": "diff --git a/angr/concretization_strategies/__init__.py b/angr/concretization_strategies/__init__.py\n--- a/angr/concretization_strategies/__init__.py\n+++ b/angr/concretization_strategies/__init__.py\n@@ -1,3 +1,5 @@\n+import claripy\n+\n class SimConcretizationStrategy(object):\n \"\"\"\n Concretization strategies control the resolution of symbolic memory indices\n@@ -18,29 +20,41 @@\n self._exact = exact\n self._filter = filter\n \n+ @staticmethod\n+ def _tweak(addr, kwargs):\n+ \"\"\"\n+ Utility method used from in here that adds a bogus constraint to extra_constraints making it so that the addr\n+ expression can actually be evaluated in all cases\n+ \"\"\"\n+ kwargs['extra_constraints'] = kwargs.get('extra_constraints', ()) + (addr == claripy.BVS('TEMP', len(addr)),)\n+\n def _min(self, memory, addr, **kwargs):\n \"\"\"\n Gets the minimum solution of an address.\n \"\"\"\n- return memory.state.se.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n+ self._tweak(addr, kwargs)\n+ return memory.state.solver.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n \n def _max(self, memory, addr, **kwargs):\n \"\"\"\n Gets the maximum solution of an address.\n \"\"\"\n- return memory.state.se.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n+ self._tweak(addr, kwargs)\n+ return memory.state.solver.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n \n def _any(self, memory, addr, **kwargs):\n \"\"\"\n Gets any solution of an address.\n \"\"\"\n- return memory.state.se.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n+ self._tweak(addr, kwargs)\n+ return memory.state.solver.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n \n def _eval(self, memory, addr, n, **kwargs):\n \"\"\"\n Gets n solutions for an address.\n \"\"\"\n- return memory.state.se.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)\n+ self._tweak(addr, kwargs)\n+ return memory.state.solver.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)\n \n def _range(self, memory, addr, **kwargs):\n \"\"\"\n", "issue": "ClaripyZeroDivisionError without actual zero\nWhen stepping through a BB with symbolic registers, \r\ndivision by symbolic register causes state.step() to fail with ClaripyZeroDivisionError.\r\n\r\nExample binary [MALWARE!!!]: https://www.dropbox.com/s/n9drwyle246ai86/E022DE72CCE8129BD5AC8A0675996318?dl=0\r\n\r\n\r\nExample code:\r\n\r\n```\r\n# coding=utf-8\r\nimport angr\r\np = angr.Project('E022DE72CCE8129BD5AC8A0675996318', load_options={\"auto_load_libs\": False})\r\nrebase_delta = p.loader.main_object.image_base_delta\r\nstart_state = p.factory.blank_state(addr=rebase_delta + 0x4470)\r\nstart_state.step()\r\n```\n", "before_files": [{"content": "class SimConcretizationStrategy(object):\n \"\"\"\n Concretization strategies control the resolution of symbolic memory indices\n in SimuVEX. By subclassing this class and setting it as a concretization strategy\n (on state.memory.read_strategies and state.memory.write_strategies), SimuVEX's\n memory index concretization behavior can be modified.\n \"\"\"\n\n def __init__(self, filter=None, exact=True): #pylint:disable=redefined-builtin\n \"\"\"\n Initializes the base SimConcretizationStrategy.\n\n :param filter: A function, taking arguments of (SimMemory, claripy.AST) that determins\n if this strategy can handle resolving the provided AST.\n :param exact: A flag (default: True) that determines if the convenience resolution\n functions provided by this class use exact or approximate resolution.\n \"\"\"\n self._exact = exact\n self._filter = filter\n\n def _min(self, memory, addr, **kwargs):\n \"\"\"\n Gets the minimum solution of an address.\n \"\"\"\n return memory.state.se.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _max(self, memory, addr, **kwargs):\n \"\"\"\n Gets the maximum solution of an address.\n \"\"\"\n return memory.state.se.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _any(self, memory, addr, **kwargs):\n \"\"\"\n Gets any solution of an address.\n \"\"\"\n return memory.state.se.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _eval(self, memory, addr, n, **kwargs):\n \"\"\"\n Gets n solutions for an address.\n \"\"\"\n return memory.state.se.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _range(self, memory, addr, **kwargs):\n \"\"\"\n Gets the (min, max) range of solutions for an address.\n \"\"\"\n return (self._min(memory, addr, **kwargs), self._max(memory, addr, **kwargs))\n\n def concretize(self, memory, addr):\n \"\"\"\n Concretizes the address into a list of values.\n If this strategy cannot handle this address, returns None.\n \"\"\"\n if self._filter is None or self._filter(memory, addr):\n return self._concretize(memory, addr)\n\n def _concretize(self, memory, addr):\n \"\"\"\n Should be implemented by child classes to handle concretization.\n \"\"\"\n raise NotImplementedError()\n\n def copy(self):\n \"\"\"\n Returns a copy of the strategy, if there is data that should be kept separate between\n states. If not, returns self.\n \"\"\"\n return self\n\n def merge(self, others):\n \"\"\"\n Merges this strategy with others (if there is data that should be kept separate between\n states. If not, is a no-op.\n \"\"\"\n pass\n\nfrom .any import SimConcretizationStrategyAny\nfrom .controlled_data import SimConcretizationStrategyControlledData\nfrom .eval import SimConcretizationStrategyEval\nfrom .max import SimConcretizationStrategyMax\nfrom .nonzero import SimConcretizationStrategyNonzero\nfrom .nonzero_range import SimConcretizationStrategyNonzeroRange\nfrom .norepeats import SimConcretizationStrategyNorepeats\nfrom .norepeats_range import SimConcretizationStrategyNorepeatsRange\nfrom .range import SimConcretizationStrategyRange\nfrom .single import SimConcretizationStrategySingle\nfrom .solutions import SimConcretizationStrategySolutions\n", "path": "angr/concretization_strategies/__init__.py"}], "after_files": [{"content": "import claripy\n\nclass SimConcretizationStrategy(object):\n \"\"\"\n Concretization strategies control the resolution of symbolic memory indices\n in SimuVEX. By subclassing this class and setting it as a concretization strategy\n (on state.memory.read_strategies and state.memory.write_strategies), SimuVEX's\n memory index concretization behavior can be modified.\n \"\"\"\n\n def __init__(self, filter=None, exact=True): #pylint:disable=redefined-builtin\n \"\"\"\n Initializes the base SimConcretizationStrategy.\n\n :param filter: A function, taking arguments of (SimMemory, claripy.AST) that determins\n if this strategy can handle resolving the provided AST.\n :param exact: A flag (default: True) that determines if the convenience resolution\n functions provided by this class use exact or approximate resolution.\n \"\"\"\n self._exact = exact\n self._filter = filter\n\n @staticmethod\n def _tweak(addr, kwargs):\n \"\"\"\n Utility method used from in here that adds a bogus constraint to extra_constraints making it so that the addr\n expression can actually be evaluated in all cases\n \"\"\"\n kwargs['extra_constraints'] = kwargs.get('extra_constraints', ()) + (addr == claripy.BVS('TEMP', len(addr)),)\n\n def _min(self, memory, addr, **kwargs):\n \"\"\"\n Gets the minimum solution of an address.\n \"\"\"\n self._tweak(addr, kwargs)\n return memory.state.solver.min(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _max(self, memory, addr, **kwargs):\n \"\"\"\n Gets the maximum solution of an address.\n \"\"\"\n self._tweak(addr, kwargs)\n return memory.state.solver.max(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _any(self, memory, addr, **kwargs):\n \"\"\"\n Gets any solution of an address.\n \"\"\"\n self._tweak(addr, kwargs)\n return memory.state.solver.eval(addr, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _eval(self, memory, addr, n, **kwargs):\n \"\"\"\n Gets n solutions for an address.\n \"\"\"\n self._tweak(addr, kwargs)\n return memory.state.solver.eval_upto(addr, n, exact=kwargs.pop('exact', self._exact), **kwargs)\n\n def _range(self, memory, addr, **kwargs):\n \"\"\"\n Gets the (min, max) range of solutions for an address.\n \"\"\"\n return (self._min(memory, addr, **kwargs), self._max(memory, addr, **kwargs))\n\n def concretize(self, memory, addr):\n \"\"\"\n Concretizes the address into a list of values.\n If this strategy cannot handle this address, returns None.\n \"\"\"\n if self._filter is None or self._filter(memory, addr):\n return self._concretize(memory, addr)\n\n def _concretize(self, memory, addr):\n \"\"\"\n Should be implemented by child classes to handle concretization.\n \"\"\"\n raise NotImplementedError()\n\n def copy(self):\n \"\"\"\n Returns a copy of the strategy, if there is data that should be kept separate between\n states. If not, returns self.\n \"\"\"\n return self\n\n def merge(self, others):\n \"\"\"\n Merges this strategy with others (if there is data that should be kept separate between\n states. If not, is a no-op.\n \"\"\"\n pass\n\nfrom .any import SimConcretizationStrategyAny\nfrom .controlled_data import SimConcretizationStrategyControlledData\nfrom .eval import SimConcretizationStrategyEval\nfrom .max import SimConcretizationStrategyMax\nfrom .nonzero import SimConcretizationStrategyNonzero\nfrom .nonzero_range import SimConcretizationStrategyNonzeroRange\nfrom .norepeats import SimConcretizationStrategyNorepeats\nfrom .norepeats_range import SimConcretizationStrategyNorepeatsRange\nfrom .range import SimConcretizationStrategyRange\nfrom .single import SimConcretizationStrategySingle\nfrom .solutions import SimConcretizationStrategySolutions\n", "path": "angr/concretization_strategies/__init__.py"}]}
| 1,410 | 572 |
gh_patches_debug_20468
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-6056
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Can't start Buildbot master
Ansible updated buildbot.buildbot.net to the latest commit (81d1179e5a) and it quickly gets this in `twisted.log`
```
2021-05-15 02:23:55+0000 [-] while starting BuildMaster
Traceback (most recent call last):
--- <exception caught here> ---
File "/usr/home/bbuser/buildbot/master/buildbot/master.py", line 300, in startService
yield self.reconfigServiceWithBuildbotConfig(self.config)
File "/usr/home/bbuser/buildbot/master/buildbot/util/service.py", line 49, in reconfigServiceW
ithBuildbotConfig
yield svc.reconfigServiceWithBuildbotConfig(new_config)
File "/usr/home/bbuser/buildbot/master/buildbot/process/measured_service.py", line 31, in reco
nfigServiceWithBuildbotConfig
yield super().reconfigServiceWithBuildbotConfig(new_config)
File "/usr/home/bbuser/buildbot/master/buildbot/util/service.py", line 507, in reconfigService
WithBuildbotConfig
yield child.setServiceParent(self)
File "/usr/home/bbuser/buildbot/master/buildbot/util/service.py", line 64, in setServiceParent
yield self.parent.addService(self)
File "/usr/home/bbuser/buildbot/master/buildbot/worker/base.py", line 262, in startService
yield super().startService()
File "/usr/home/bbuser/buildbot/master/buildbot/util/service.py", line 244, in startService
yield super().startService()
twisted.internet.defer.FirstError: FirstError[#0, [Failure instance: Traceback: <class 'TypeError'>: __init__() takes 2 positional arguments but 3 were given
/usr/home/bbuser/buildbot/master/buildbot/util/service.py:94:startService
/home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:151:maybeDeferred
/home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1613:unwindGenerator
/home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1529:_cancellableInlineCallbacks
--- <exception caught here> ---
/home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1418:_inlineCallbacks
/home/bbuser/venv/lib/python3.6/site-packages/buildbot_worker/null.py:34:startService
]]
```
I reset to the previous merge, 1b16975313, and now it runs fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/worker/protocols/null.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16
17 from twisted.internet import defer
18 from twisted.python import log
19
20 from buildbot.util.eventual import fireEventually
21 from buildbot.worker.protocols import base
22
23
24 class Listener(base.Listener):
25 pass
26
27
28 class ProxyMixin():
29
30 def __init__(self, impl):
31 assert isinstance(impl, self.ImplClass)
32 self.impl = impl
33 self._disconnect_listeners = []
34
35 def callRemote(self, message, *args, **kw):
36 method = getattr(self.impl, "remote_{}".format(message), None)
37 if method is None:
38 raise AttributeError("No such method: remote_{}".format(message))
39 try:
40 state = method(*args, **kw)
41 except TypeError:
42 log.msg("{} didn't accept {} and {}".format(method, args, kw))
43 raise
44 # break callback recursion for large transfers by using fireEventually
45 return fireEventually(state)
46
47 def notifyOnDisconnect(self, cb):
48 pass
49
50 def dontNotifyOnDisconnect(self, cb):
51 pass
52
53
54 # just add ProxyMixin capability to the RemoteCommandProxy
55 # so that callers of callRemote actually directly call the proper method
56 class RemoteCommandProxy(ProxyMixin):
57 ImplClass = base.RemoteCommandImpl
58
59
60 class FileReaderProxy(ProxyMixin):
61 ImplClass = base.FileReaderImpl
62
63
64 class FileWriterProxy(ProxyMixin):
65 ImplClass = base.FileWriterImpl
66
67
68 class Connection(base.Connection):
69 proxies = {base.FileWriterImpl: FileWriterProxy,
70 base.FileReaderImpl: FileReaderProxy}
71
72 def __init__(self, worker):
73 super().__init__(worker.workername)
74 self.worker = worker
75
76 def loseConnection(self):
77 self.notifyDisconnected()
78
79 def remotePrint(self, message):
80 return defer.maybeDeferred(self.worker.bot.remote_print, message)
81
82 def remoteGetWorkerInfo(self):
83 return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)
84
85 def remoteSetBuilderList(self, builders):
86 return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)
87
88 def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):
89 remoteCommand = RemoteCommandProxy(remoteCommand)
90 args = self.createArgsProxies(args)
91 workerforbuilder = self.worker.bot.builders[builderName]
92 return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,
93 commandId, commandName, args)
94
95 def remoteShutdown(self):
96 return defer.maybeDeferred(self.worker.stopService)
97
98 def remoteStartBuild(self, builderName):
99 return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())
100
101 def remoteInterruptCommand(self, builderName, commandId, why):
102 workerforbuilder = self.worker.bot.builders[builderName]
103 return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/worker/protocols/null.py b/master/buildbot/worker/protocols/null.py
--- a/master/buildbot/worker/protocols/null.py
+++ b/master/buildbot/worker/protocols/null.py
@@ -18,6 +18,7 @@
from twisted.python import log
from buildbot.util.eventual import fireEventually
+from buildbot.warnings import warn_deprecated
from buildbot.worker.protocols import base
@@ -69,7 +70,15 @@
proxies = {base.FileWriterImpl: FileWriterProxy,
base.FileReaderImpl: FileReaderProxy}
- def __init__(self, worker):
+ def __init__(self, master_or_worker, worker=None):
+ # All the existing code passes just the name to the Connection, however we'll need to
+ # support an older versions of buildbot-worker using two parameter signature for some time.
+ if worker is None:
+ worker = master_or_worker
+ else:
+ warn_deprecated('3.2.0', 'LocalWorker: Using different version of buildbot-worker ' +
+ 'than buildbot is not supported')
+
super().__init__(worker.workername)
self.worker = worker
|
{"golden_diff": "diff --git a/master/buildbot/worker/protocols/null.py b/master/buildbot/worker/protocols/null.py\n--- a/master/buildbot/worker/protocols/null.py\n+++ b/master/buildbot/worker/protocols/null.py\n@@ -18,6 +18,7 @@\n from twisted.python import log\n \n from buildbot.util.eventual import fireEventually\n+from buildbot.warnings import warn_deprecated\n from buildbot.worker.protocols import base\n \n \n@@ -69,7 +70,15 @@\n proxies = {base.FileWriterImpl: FileWriterProxy,\n base.FileReaderImpl: FileReaderProxy}\n \n- def __init__(self, worker):\n+ def __init__(self, master_or_worker, worker=None):\n+ # All the existing code passes just the name to the Connection, however we'll need to\n+ # support an older versions of buildbot-worker using two parameter signature for some time.\n+ if worker is None:\n+ worker = master_or_worker\n+ else:\n+ warn_deprecated('3.2.0', 'LocalWorker: Using different version of buildbot-worker ' +\n+ 'than buildbot is not supported')\n+\n super().__init__(worker.workername)\n self.worker = worker\n", "issue": "Can't start Buildbot master\nAnsible updated buildbot.buildbot.net to the latest commit (81d1179e5a) and it quickly gets this in `twisted.log`\r\n```\r\n2021-05-15 02:23:55+0000 [-] while starting BuildMaster\r\n Traceback (most recent call last):\r\n --- <exception caught here> ---\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/master.py\", line 300, in startService\r\n yield self.reconfigServiceWithBuildbotConfig(self.config)\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/util/service.py\", line 49, in reconfigServiceW\r\nithBuildbotConfig\r\n yield svc.reconfigServiceWithBuildbotConfig(new_config)\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/process/measured_service.py\", line 31, in reco\r\nnfigServiceWithBuildbotConfig\r\n yield super().reconfigServiceWithBuildbotConfig(new_config)\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/util/service.py\", line 507, in reconfigService\r\nWithBuildbotConfig\r\n yield child.setServiceParent(self)\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/util/service.py\", line 64, in setServiceParent\r\n yield self.parent.addService(self)\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/worker/base.py\", line 262, in startService\r\n yield super().startService()\r\n File \"/usr/home/bbuser/buildbot/master/buildbot/util/service.py\", line 244, in startService\r\n yield super().startService()\r\n twisted.internet.defer.FirstError: FirstError[#0, [Failure instance: Traceback: <class 'TypeError'>: __init__() takes 2 positional arguments but 3 were given\r\n /usr/home/bbuser/buildbot/master/buildbot/util/service.py:94:startService\r\n /home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:151:maybeDeferred\r\n /home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1613:unwindGenerator\r\n /home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1529:_cancellableInlineCallbacks\r\n --- <exception caught here> ---\r\n /home/bbuser/venv/lib/python3.6/site-packages/twisted/internet/defer.py:1418:_inlineCallbacks\r\n /home/bbuser/venv/lib/python3.6/site-packages/buildbot_worker/null.py:34:startService\r\n ]]\r\n```\r\n\r\nI reset to the previous merge, 1b16975313, and now it runs fine.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.util.eventual import fireEventually\nfrom buildbot.worker.protocols import base\n\n\nclass Listener(base.Listener):\n pass\n\n\nclass ProxyMixin():\n\n def __init__(self, impl):\n assert isinstance(impl, self.ImplClass)\n self.impl = impl\n self._disconnect_listeners = []\n\n def callRemote(self, message, *args, **kw):\n method = getattr(self.impl, \"remote_{}\".format(message), None)\n if method is None:\n raise AttributeError(\"No such method: remote_{}\".format(message))\n try:\n state = method(*args, **kw)\n except TypeError:\n log.msg(\"{} didn't accept {} and {}\".format(method, args, kw))\n raise\n # break callback recursion for large transfers by using fireEventually\n return fireEventually(state)\n\n def notifyOnDisconnect(self, cb):\n pass\n\n def dontNotifyOnDisconnect(self, cb):\n pass\n\n\n# just add ProxyMixin capability to the RemoteCommandProxy\n# so that callers of callRemote actually directly call the proper method\nclass RemoteCommandProxy(ProxyMixin):\n ImplClass = base.RemoteCommandImpl\n\n\nclass FileReaderProxy(ProxyMixin):\n ImplClass = base.FileReaderImpl\n\n\nclass FileWriterProxy(ProxyMixin):\n ImplClass = base.FileWriterImpl\n\n\nclass Connection(base.Connection):\n proxies = {base.FileWriterImpl: FileWriterProxy,\n base.FileReaderImpl: FileReaderProxy}\n\n def __init__(self, worker):\n super().__init__(worker.workername)\n self.worker = worker\n\n def loseConnection(self):\n self.notifyDisconnected()\n\n def remotePrint(self, message):\n return defer.maybeDeferred(self.worker.bot.remote_print, message)\n\n def remoteGetWorkerInfo(self):\n return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)\n\n def remoteSetBuilderList(self, builders):\n return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)\n\n def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):\n remoteCommand = RemoteCommandProxy(remoteCommand)\n args = self.createArgsProxies(args)\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,\n commandId, commandName, args)\n\n def remoteShutdown(self):\n return defer.maybeDeferred(self.worker.stopService)\n\n def remoteStartBuild(self, builderName):\n return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())\n\n def remoteInterruptCommand(self, builderName, commandId, why):\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)\n", "path": "master/buildbot/worker/protocols/null.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\n\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nfrom buildbot.util.eventual import fireEventually\nfrom buildbot.warnings import warn_deprecated\nfrom buildbot.worker.protocols import base\n\n\nclass Listener(base.Listener):\n pass\n\n\nclass ProxyMixin():\n\n def __init__(self, impl):\n assert isinstance(impl, self.ImplClass)\n self.impl = impl\n self._disconnect_listeners = []\n\n def callRemote(self, message, *args, **kw):\n method = getattr(self.impl, \"remote_{}\".format(message), None)\n if method is None:\n raise AttributeError(\"No such method: remote_{}\".format(message))\n try:\n state = method(*args, **kw)\n except TypeError:\n log.msg(\"{} didn't accept {} and {}\".format(method, args, kw))\n raise\n # break callback recursion for large transfers by using fireEventually\n return fireEventually(state)\n\n def notifyOnDisconnect(self, cb):\n pass\n\n def dontNotifyOnDisconnect(self, cb):\n pass\n\n\n# just add ProxyMixin capability to the RemoteCommandProxy\n# so that callers of callRemote actually directly call the proper method\nclass RemoteCommandProxy(ProxyMixin):\n ImplClass = base.RemoteCommandImpl\n\n\nclass FileReaderProxy(ProxyMixin):\n ImplClass = base.FileReaderImpl\n\n\nclass FileWriterProxy(ProxyMixin):\n ImplClass = base.FileWriterImpl\n\n\nclass Connection(base.Connection):\n proxies = {base.FileWriterImpl: FileWriterProxy,\n base.FileReaderImpl: FileReaderProxy}\n\n def __init__(self, master_or_worker, worker=None):\n # All the existing code passes just the name to the Connection, however we'll need to\n # support an older versions of buildbot-worker using two parameter signature for some time.\n if worker is None:\n worker = master_or_worker\n else:\n warn_deprecated('3.2.0', 'LocalWorker: Using different version of buildbot-worker ' +\n 'than buildbot is not supported')\n\n super().__init__(worker.workername)\n self.worker = worker\n\n def loseConnection(self):\n self.notifyDisconnected()\n\n def remotePrint(self, message):\n return defer.maybeDeferred(self.worker.bot.remote_print, message)\n\n def remoteGetWorkerInfo(self):\n return defer.maybeDeferred(self.worker.bot.remote_getWorkerInfo)\n\n def remoteSetBuilderList(self, builders):\n return defer.maybeDeferred(self.worker.bot.remote_setBuilderList, builders)\n\n def remoteStartCommand(self, remoteCommand, builderName, commandId, commandName, args):\n remoteCommand = RemoteCommandProxy(remoteCommand)\n args = self.createArgsProxies(args)\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_startCommand, remoteCommand,\n commandId, commandName, args)\n\n def remoteShutdown(self):\n return defer.maybeDeferred(self.worker.stopService)\n\n def remoteStartBuild(self, builderName):\n return defer.succeed(self.worker.bot.builders[builderName].remote_startBuild())\n\n def remoteInterruptCommand(self, builderName, commandId, why):\n workerforbuilder = self.worker.bot.builders[builderName]\n return defer.maybeDeferred(workerforbuilder.remote_interruptCommand, commandId, why)\n", "path": "master/buildbot/worker/protocols/null.py"}]}
| 1,874 | 265 |
gh_patches_debug_32386
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-1683
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add a feature to show the authentication token to the user on the MyProfile Page
**Deliverables:**
- [x] Add API endpoint to fetch or create (if doesn't exists) the token from database.
- [x] Add Frontend with features to show, copy and download the token in JSON format
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/accounts/urls.py`
Content:
```
1 from django.conf.urls import url
2
3 from . import views
4
5 urlpatterns = [
6
7 url(r'^user/disable$', views.disable_user, name='disable_user'),
8
9 ]
10
```
Path: `apps/accounts/views.py`
Content:
```
1 from django.contrib.auth import logout
2
3 from rest_framework.response import Response
4 from rest_framework import permissions, status
5 from rest_framework.decorators import (api_view,
6 authentication_classes,
7 permission_classes,)
8 from rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)
9
10
11 @api_view(['POST'])
12 @permission_classes((permissions.IsAuthenticated,))
13 @authentication_classes((ExpiringTokenAuthentication,))
14 def disable_user(request):
15
16 user = request.user
17 user.is_active = False
18 user.save()
19 logout(request)
20 return Response(status=status.HTTP_200_OK)
21
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/accounts/urls.py b/apps/accounts/urls.py
--- a/apps/accounts/urls.py
+++ b/apps/accounts/urls.py
@@ -5,5 +5,6 @@
urlpatterns = [
url(r'^user/disable$', views.disable_user, name='disable_user'),
+ url(r'^user/get_auth_token$', views.get_auth_token, name='get_auth_token'),
]
diff --git a/apps/accounts/views.py b/apps/accounts/views.py
--- a/apps/accounts/views.py
+++ b/apps/accounts/views.py
@@ -1,12 +1,18 @@
from django.contrib.auth import logout
+from django.contrib.auth.models import User
+from rest_framework.authtoken.models import Token
from rest_framework.response import Response
from rest_framework import permissions, status
from rest_framework.decorators import (api_view,
authentication_classes,
- permission_classes,)
+ permission_classes,
+ throttle_classes,)
+from rest_framework.throttling import UserRateThrottle
from rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)
+from .permissions import HasVerifiedEmail
+
@api_view(['POST'])
@permission_classes((permissions.IsAuthenticated,))
@@ -18,3 +24,24 @@
user.save()
logout(request)
return Response(status=status.HTTP_200_OK)
+
+
+@throttle_classes([UserRateThrottle])
+@api_view(['GET'])
+@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))
+@authentication_classes((ExpiringTokenAuthentication,))
+def get_auth_token(request):
+ try:
+ user = User.objects.get(email=request.user.email)
+ except User.DoesNotExist:
+ response_data = {"error": "This User account doesn't exist."}
+ Response(response_data, status.HTTP_404_NOT_FOUND)
+
+ try:
+ token = Token.objects.get(user=user)
+ except Token.DoesNotExist:
+ token = Token.objects.create(user=user)
+ token.save()
+
+ response_data = {"token": "{}".format(token)}
+ return Response(response_data, status=status.HTTP_200_OK)
|
{"golden_diff": "diff --git a/apps/accounts/urls.py b/apps/accounts/urls.py\n--- a/apps/accounts/urls.py\n+++ b/apps/accounts/urls.py\n@@ -5,5 +5,6 @@\n urlpatterns = [\n \n url(r'^user/disable$', views.disable_user, name='disable_user'),\n+ url(r'^user/get_auth_token$', views.get_auth_token, name='get_auth_token'),\n \n ]\ndiff --git a/apps/accounts/views.py b/apps/accounts/views.py\n--- a/apps/accounts/views.py\n+++ b/apps/accounts/views.py\n@@ -1,12 +1,18 @@\n from django.contrib.auth import logout\n+from django.contrib.auth.models import User\n \n+from rest_framework.authtoken.models import Token\n from rest_framework.response import Response\n from rest_framework import permissions, status\n from rest_framework.decorators import (api_view,\n authentication_classes,\n- permission_classes,)\n+ permission_classes,\n+ throttle_classes,)\n+from rest_framework.throttling import UserRateThrottle\n from rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)\n \n+from .permissions import HasVerifiedEmail\n+\n \n @api_view(['POST'])\n @permission_classes((permissions.IsAuthenticated,))\n@@ -18,3 +24,24 @@\n user.save()\n logout(request)\n return Response(status=status.HTTP_200_OK)\n+\n+\n+@throttle_classes([UserRateThrottle])\n+@api_view(['GET'])\n+@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n+@authentication_classes((ExpiringTokenAuthentication,))\n+def get_auth_token(request):\n+ try:\n+ user = User.objects.get(email=request.user.email)\n+ except User.DoesNotExist:\n+ response_data = {\"error\": \"This User account doesn't exist.\"}\n+ Response(response_data, status.HTTP_404_NOT_FOUND)\n+\n+ try:\n+ token = Token.objects.get(user=user)\n+ except Token.DoesNotExist:\n+ token = Token.objects.create(user=user)\n+ token.save()\n+\n+ response_data = {\"token\": \"{}\".format(token)}\n+ return Response(response_data, status=status.HTTP_200_OK)\n", "issue": "Add a feature to show the authentication token to the user on the MyProfile Page\n**Deliverables:**\r\n\r\n- [x] Add API endpoint to fetch or create (if doesn't exists) the token from database.\r\n\r\n- [x] Add Frontend with features to show, copy and download the token in JSON format\r\n\n", "before_files": [{"content": "from django.conf.urls import url\n\nfrom . import views\n\nurlpatterns = [\n\n url(r'^user/disable$', views.disable_user, name='disable_user'),\n\n]\n", "path": "apps/accounts/urls.py"}, {"content": "from django.contrib.auth import logout\n\nfrom rest_framework.response import Response\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,)\nfrom rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)\n\n\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated,))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef disable_user(request):\n\n user = request.user\n user.is_active = False\n user.save()\n logout(request)\n return Response(status=status.HTTP_200_OK)\n", "path": "apps/accounts/views.py"}], "after_files": [{"content": "from django.conf.urls import url\n\nfrom . import views\n\nurlpatterns = [\n\n url(r'^user/disable$', views.disable_user, name='disable_user'),\n url(r'^user/get_auth_token$', views.get_auth_token, name='get_auth_token'),\n\n]\n", "path": "apps/accounts/urls.py"}, {"content": "from django.contrib.auth import logout\nfrom django.contrib.auth.models import User\n\nfrom rest_framework.authtoken.models import Token\nfrom rest_framework.response import Response\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import (api_view,\n authentication_classes,\n permission_classes,\n throttle_classes,)\nfrom rest_framework.throttling import UserRateThrottle\nfrom rest_framework_expiring_authtoken.authentication import (ExpiringTokenAuthentication,)\n\nfrom .permissions import HasVerifiedEmail\n\n\n@api_view(['POST'])\n@permission_classes((permissions.IsAuthenticated,))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef disable_user(request):\n\n user = request.user\n user.is_active = False\n user.save()\n logout(request)\n return Response(status=status.HTTP_200_OK)\n\n\n@throttle_classes([UserRateThrottle])\n@api_view(['GET'])\n@permission_classes((permissions.IsAuthenticated, HasVerifiedEmail))\n@authentication_classes((ExpiringTokenAuthentication,))\ndef get_auth_token(request):\n try:\n user = User.objects.get(email=request.user.email)\n except User.DoesNotExist:\n response_data = {\"error\": \"This User account doesn't exist.\"}\n Response(response_data, status.HTTP_404_NOT_FOUND)\n\n try:\n token = Token.objects.get(user=user)\n except Token.DoesNotExist:\n token = Token.objects.create(user=user)\n token.save()\n\n response_data = {\"token\": \"{}\".format(token)}\n return Response(response_data, status=status.HTTP_200_OK)\n", "path": "apps/accounts/views.py"}]}
| 541 | 453 |
gh_patches_debug_13620
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-5880
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Poetry inheriting issue for git-client on github.com
- [X] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version.
- [X] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [X] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
- **OS version and name**: Linux Mint 20, Py3.8.2 virtualenv
- **Poetry version**: 1.1.2
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**:
## Issue
While `installing` or `locking`, if the github git repo is wrong (e.g. returns a 404 in a browser), then poetry (sometimes) shows an authentication error and ask for the username for that url.
```Updating dependencies
Resolving dependencies...
1: fact: actions-gateway is 0.7.0
1: derived: actions-gateway
Username for 'https://github.com':
```
The pyproject.toml has a git dependency like
```
Flask-Pika = { git = "https://github.com/rienafairefr/flask_pika.git", rev= "b2b4d68186c52ae034b39f4fb56fe86786b3a055"}
```
The typo is hard to see, it should be `flask-pika` instead of `flask_pika`
If the command is run without verbose output, then the "Username for 'https://github.com':" is sometimes shown only for a fraction of a second, so the command may never terminate and it's hard to know why.
Not sure poetry can or should mitigate the problem that comes from a lower level.
The problem comes (pretty sure) from github.com returning a 401 when it should return a 404:
```
GET /inexistent-user/inexistent-repo/info/refs?service=git-upload-pack
Host github.com
User-Agent: git/inexistent-version
```
gives us
```
HTTP/1.1 401 Authorization Required
Server: GitHub Babel 2.0
```
This makes the git client (which is called in a subprocess by poetry) to ask for authentication.
setting the GIT_ASKPASS variable to false while caling `git` is an option, the credentials to use for a git dependency should be provided by poetry, not leaving `git` to figure it out by itself
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/poetry/vcs/git/system.py`
Content:
```
1 from __future__ import annotations
2
3 import subprocess
4
5 from typing import TYPE_CHECKING
6
7 from dulwich.client import find_git_command
8
9
10 if TYPE_CHECKING:
11 from pathlib import Path
12 from typing import Any
13
14
15 class SystemGit:
16 @classmethod
17 def clone(cls, repository: str, dest: Path) -> str:
18 cls._check_parameter(repository)
19
20 return cls.run("clone", "--recurse-submodules", "--", repository, str(dest))
21
22 @classmethod
23 def checkout(cls, rev: str, target: Path | None = None) -> str:
24 args = []
25
26 if target:
27 args += [
28 "--git-dir",
29 (target / ".git").as_posix(),
30 "--work-tree",
31 target.as_posix(),
32 ]
33
34 cls._check_parameter(rev)
35
36 args += ["checkout", rev]
37
38 return cls.run(*args)
39
40 @staticmethod
41 def run(*args: Any, **kwargs: Any) -> str:
42 folder = kwargs.pop("folder", None)
43 if folder:
44 args = (
45 "--git-dir",
46 (folder / ".git").as_posix(),
47 "--work-tree",
48 folder.as_posix(),
49 ) + args
50
51 git_command = find_git_command()
52 return (
53 subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)
54 .decode()
55 .strip()
56 )
57
58 @staticmethod
59 def _check_parameter(parameter: str) -> None:
60 """
61 Checks a git parameter to avoid unwanted code execution.
62 """
63 if parameter.strip().startswith("-"):
64 raise RuntimeError(f"Invalid Git parameter: {parameter}")
65
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/poetry/vcs/git/system.py b/src/poetry/vcs/git/system.py
--- a/src/poetry/vcs/git/system.py
+++ b/src/poetry/vcs/git/system.py
@@ -1,5 +1,6 @@
from __future__ import annotations
+import os
import subprocess
from typing import TYPE_CHECKING
@@ -49,8 +50,14 @@
) + args
git_command = find_git_command()
+ env = os.environ.copy()
+ env["GIT_TERMINAL_PROMPT"] = "0"
return (
- subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)
+ subprocess.check_output(
+ git_command + list(args),
+ stderr=subprocess.STDOUT,
+ env=env,
+ )
.decode()
.strip()
)
|
{"golden_diff": "diff --git a/src/poetry/vcs/git/system.py b/src/poetry/vcs/git/system.py\n--- a/src/poetry/vcs/git/system.py\n+++ b/src/poetry/vcs/git/system.py\n@@ -1,5 +1,6 @@\n from __future__ import annotations\n \n+import os\n import subprocess\n \n from typing import TYPE_CHECKING\n@@ -49,8 +50,14 @@\n ) + args\n \n git_command = find_git_command()\n+ env = os.environ.copy()\n+ env[\"GIT_TERMINAL_PROMPT\"] = \"0\"\n return (\n- subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)\n+ subprocess.check_output(\n+ git_command + list(args),\n+ stderr=subprocess.STDOUT,\n+ env=env,\n+ )\n .decode()\n .strip()\n )\n", "issue": "Poetry inheriting issue for git-client on github.com\n- [X] I am on the [latest](https://github.com/python-poetry/poetry/releases/latest) Poetry version. \r\n- [X] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [X] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n- **OS version and name**: Linux Mint 20, Py3.8.2 virtualenv\r\n- **Poetry version**: 1.1.2\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: \r\n\r\n## Issue\r\nWhile `installing` or `locking`, if the github git repo is wrong (e.g. returns a 404 in a browser), then poetry (sometimes) shows an authentication error and ask for the username for that url. \r\n\r\n```Updating dependencies\r\nResolving dependencies...\r\n 1: fact: actions-gateway is 0.7.0\r\n 1: derived: actions-gateway\r\nUsername for 'https://github.com':\r\n```\r\nThe pyproject.toml has a git dependency like\r\n```\r\nFlask-Pika = { git = \"https://github.com/rienafairefr/flask_pika.git\", rev= \"b2b4d68186c52ae034b39f4fb56fe86786b3a055\"}\r\n```\r\nThe typo is hard to see, it should be `flask-pika` instead of `flask_pika`\r\n\r\nIf the command is run without verbose output, then the \"Username for 'https://github.com':\" is sometimes shown only for a fraction of a second, so the command may never terminate and it's hard to know why.\r\n\r\nNot sure poetry can or should mitigate the problem that comes from a lower level.\r\n\r\nThe problem comes (pretty sure) from github.com returning a 401 when it should return a 404:\r\n```\r\nGET /inexistent-user/inexistent-repo/info/refs?service=git-upload-pack\r\nHost github.com\r\nUser-Agent: git/inexistent-version\r\n```\r\ngives us\r\n```\r\nHTTP/1.1 401 Authorization Required\r\nServer: GitHub Babel 2.0\r\n```\r\nThis makes the git client (which is called in a subprocess by poetry) to ask for authentication. \r\n\r\nsetting the GIT_ASKPASS variable to false while caling `git` is an option, the credentials to use for a git dependency should be provided by poetry, not leaving `git` to figure it out by itself\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport subprocess\n\nfrom typing import TYPE_CHECKING\n\nfrom dulwich.client import find_git_command\n\n\nif TYPE_CHECKING:\n from pathlib import Path\n from typing import Any\n\n\nclass SystemGit:\n @classmethod\n def clone(cls, repository: str, dest: Path) -> str:\n cls._check_parameter(repository)\n\n return cls.run(\"clone\", \"--recurse-submodules\", \"--\", repository, str(dest))\n\n @classmethod\n def checkout(cls, rev: str, target: Path | None = None) -> str:\n args = []\n\n if target:\n args += [\n \"--git-dir\",\n (target / \".git\").as_posix(),\n \"--work-tree\",\n target.as_posix(),\n ]\n\n cls._check_parameter(rev)\n\n args += [\"checkout\", rev]\n\n return cls.run(*args)\n\n @staticmethod\n def run(*args: Any, **kwargs: Any) -> str:\n folder = kwargs.pop(\"folder\", None)\n if folder:\n args = (\n \"--git-dir\",\n (folder / \".git\").as_posix(),\n \"--work-tree\",\n folder.as_posix(),\n ) + args\n\n git_command = find_git_command()\n return (\n subprocess.check_output(git_command + list(args), stderr=subprocess.STDOUT)\n .decode()\n .strip()\n )\n\n @staticmethod\n def _check_parameter(parameter: str) -> None:\n \"\"\"\n Checks a git parameter to avoid unwanted code execution.\n \"\"\"\n if parameter.strip().startswith(\"-\"):\n raise RuntimeError(f\"Invalid Git parameter: {parameter}\")\n", "path": "src/poetry/vcs/git/system.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport os\nimport subprocess\n\nfrom typing import TYPE_CHECKING\n\nfrom dulwich.client import find_git_command\n\n\nif TYPE_CHECKING:\n from pathlib import Path\n from typing import Any\n\n\nclass SystemGit:\n @classmethod\n def clone(cls, repository: str, dest: Path) -> str:\n cls._check_parameter(repository)\n\n return cls.run(\"clone\", \"--recurse-submodules\", \"--\", repository, str(dest))\n\n @classmethod\n def checkout(cls, rev: str, target: Path | None = None) -> str:\n args = []\n\n if target:\n args += [\n \"--git-dir\",\n (target / \".git\").as_posix(),\n \"--work-tree\",\n target.as_posix(),\n ]\n\n cls._check_parameter(rev)\n\n args += [\"checkout\", rev]\n\n return cls.run(*args)\n\n @staticmethod\n def run(*args: Any, **kwargs: Any) -> str:\n folder = kwargs.pop(\"folder\", None)\n if folder:\n args = (\n \"--git-dir\",\n (folder / \".git\").as_posix(),\n \"--work-tree\",\n folder.as_posix(),\n ) + args\n\n git_command = find_git_command()\n env = os.environ.copy()\n env[\"GIT_TERMINAL_PROMPT\"] = \"0\"\n return (\n subprocess.check_output(\n git_command + list(args),\n stderr=subprocess.STDOUT,\n env=env,\n )\n .decode()\n .strip()\n )\n\n @staticmethod\n def _check_parameter(parameter: str) -> None:\n \"\"\"\n Checks a git parameter to avoid unwanted code execution.\n \"\"\"\n if parameter.strip().startswith(\"-\"):\n raise RuntimeError(f\"Invalid Git parameter: {parameter}\")\n", "path": "src/poetry/vcs/git/system.py"}]}
| 1,328 | 189 |
gh_patches_debug_11799
|
rasdani/github-patches
|
git_diff
|
avocado-framework__avocado-4154
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] Avocado crash with TypeError
With the following change on the time-sensitive job Avocado crashes:
```python
diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py
index a9fbebcd..456719aa 100755
--- a/selftests/pre_release/jobs/timesensitive.py
+++ b/selftests/pre_release/jobs/timesensitive.py
@@ -4,6 +4,7 @@ import os
import sys
from avocado.core.job import Job
+from avocado.core.suite import TestSuite
THIS_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))
@@ -19,6 +20,7 @@ CONFIG = {
if __name__ == '__main__':
- with Job(CONFIG) as j:
+ suite = TestSuite.from_config(CONFIG)
+ with Job(CONFIG, [suite]) as j:
os.environ['AVOCADO_CHECK_LEVEL'] = '3'
sys.exit(j.run())
```
Crash:
```
[wrampazz@wrampazz avocado.dev]$ selftests/pre_release/jobs/timesensitive.py
JOB ID : 5c1cf735be942802efc655a82ec84e46c1301080
JOB LOG : /home/wrampazz/avocado/job-results/job-2020-08-27T16.12-5c1cf73/job.log
Avocado crashed: TypeError: expected str, bytes or os.PathLike object, not NoneType
Traceback (most recent call last):
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/job.py", line 605, in run_tests
summary |= suite.run(self)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/suite.py", line 266, in run
return self.runner.run_suite(job, self)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/runner_nrunner.py", line 237, in run_suite
loop.run_until_complete(asyncio.wait_for(asyncio.gather(*workers),
File "/usr/lib64/python3.8/asyncio/base_events.py", line 616, in run_until_complete
return future.result()
File "/usr/lib64/python3.8/asyncio/tasks.py", line 455, in wait_for
return await fut
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py", line 155, in run
await self.start()
File "/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py", line 113, in start
start_ok = await self._spawner.spawn_task(runtime_task)
File "/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/spawners/process.py", line 29, in spawn_task
runtime_task.spawner_handle = await asyncio.create_subprocess_exec(
File "/usr/lib64/python3.8/asyncio/subprocess.py", line 236, in create_subprocess_exec
transport, protocol = await loop.subprocess_exec(
File "/usr/lib64/python3.8/asyncio/base_events.py", line 1630, in subprocess_exec
transport = await self._make_subprocess_transport(
File "/usr/lib64/python3.8/asyncio/unix_events.py", line 197, in _make_subprocess_transport
transp = _UnixSubprocessTransport(self, protocol, args, shell,
File "/usr/lib64/python3.8/asyncio/base_subprocess.py", line 36, in __init__
self._start(args=args, shell=shell, stdin=stdin, stdout=stdout,
File "/usr/lib64/python3.8/asyncio/unix_events.py", line 789, in _start
self._proc = subprocess.Popen(
File "/usr/lib64/python3.8/subprocess.py", line 854, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/usr/lib64/python3.8/subprocess.py", line 1637, in _execute_child
self.pid = _posixsubprocess.fork_exec(
TypeError: expected str, bytes or os.PathLike object, not NoneType
Please include the traceback info and command line used on your bug report
Report bugs visiting https://github.com/avocado-framework/avocado/issues/new
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `selftests/pre_release/jobs/timesensitive.py`
Content:
```
1 #!/bin/env python3
2
3 import os
4 import sys
5
6 from avocado.core.job import Job
7
8 THIS_DIR = os.path.dirname(os.path.abspath(__file__))
9 ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))
10
11
12 CONFIG = {
13 'run.test_runner': 'nrunner',
14 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),
15 os.path.join(ROOT_DIR, 'selftests', 'functional')],
16 'filter.by_tags.tags': ['parallel:1'],
17 'nrunner.max_parallel_tasks': 1,
18 }
19
20
21 if __name__ == '__main__':
22 with Job(CONFIG) as j:
23 os.environ['AVOCADO_CHECK_LEVEL'] = '3'
24 sys.exit(j.run())
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py
--- a/selftests/pre_release/jobs/timesensitive.py
+++ b/selftests/pre_release/jobs/timesensitive.py
@@ -14,11 +14,12 @@
'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),
os.path.join(ROOT_DIR, 'selftests', 'functional')],
'filter.by_tags.tags': ['parallel:1'],
+ 'nrunner.status_server_uri': '127.0.0.1:8888',
'nrunner.max_parallel_tasks': 1,
}
if __name__ == '__main__':
- with Job(CONFIG) as j:
+ with Job.from_config(CONFIG) as j:
os.environ['AVOCADO_CHECK_LEVEL'] = '3'
sys.exit(j.run())
|
{"golden_diff": "diff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py\n--- a/selftests/pre_release/jobs/timesensitive.py\n+++ b/selftests/pre_release/jobs/timesensitive.py\n@@ -14,11 +14,12 @@\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n+ 'nrunner.status_server_uri': '127.0.0.1:8888',\n 'nrunner.max_parallel_tasks': 1,\n }\n \n \n if __name__ == '__main__':\n- with Job(CONFIG) as j:\n+ with Job.from_config(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "issue": "[Bug] Avocado crash with TypeError\nWith the following change on the time-sensitive job Avocado crashes:\r\n\r\n```python\r\ndiff --git a/selftests/pre_release/jobs/timesensitive.py b/selftests/pre_release/jobs/timesensitive.py\r\nindex a9fbebcd..456719aa 100755\r\n--- a/selftests/pre_release/jobs/timesensitive.py\r\n+++ b/selftests/pre_release/jobs/timesensitive.py\r\n@@ -4,6 +4,7 @@ import os\r\n import sys\r\n \r\n from avocado.core.job import Job\r\n+from avocado.core.suite import TestSuite\r\n \r\n THIS_DIR = os.path.dirname(os.path.abspath(__file__))\r\n ROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\r\n@@ -19,6 +20,7 @@ CONFIG = {\r\n \r\n \r\n if __name__ == '__main__':\r\n- with Job(CONFIG) as j:\r\n+ suite = TestSuite.from_config(CONFIG)\r\n+ with Job(CONFIG, [suite]) as j:\r\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\r\n sys.exit(j.run())\r\n```\r\n\r\nCrash:\r\n\r\n```\r\n[wrampazz@wrampazz avocado.dev]$ selftests/pre_release/jobs/timesensitive.py\r\nJOB ID : 5c1cf735be942802efc655a82ec84e46c1301080\r\nJOB LOG : /home/wrampazz/avocado/job-results/job-2020-08-27T16.12-5c1cf73/job.log\r\n\r\nAvocado crashed: TypeError: expected str, bytes or os.PathLike object, not NoneType\r\nTraceback (most recent call last):\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/job.py\", line 605, in run_tests\r\n summary |= suite.run(self)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/suite.py\", line 266, in run\r\n return self.runner.run_suite(job, self)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/runner_nrunner.py\", line 237, in run_suite\r\n loop.run_until_complete(asyncio.wait_for(asyncio.gather(*workers),\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_events.py\", line 616, in run_until_complete\r\n return future.result()\r\n\r\n File \"/usr/lib64/python3.8/asyncio/tasks.py\", line 455, in wait_for\r\n return await fut\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py\", line 155, in run\r\n await self.start()\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/core/task/statemachine.py\", line 113, in start\r\n start_ok = await self._spawner.spawn_task(runtime_task)\r\n\r\n File \"/home/wrampazz/src/avocado/avocado.dev/avocado/plugins/spawners/process.py\", line 29, in spawn_task\r\n runtime_task.spawner_handle = await asyncio.create_subprocess_exec(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/subprocess.py\", line 236, in create_subprocess_exec\r\n transport, protocol = await loop.subprocess_exec(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_events.py\", line 1630, in subprocess_exec\r\n transport = await self._make_subprocess_transport(\r\n\r\n File \"/usr/lib64/python3.8/asyncio/unix_events.py\", line 197, in _make_subprocess_transport\r\n transp = _UnixSubprocessTransport(self, protocol, args, shell,\r\n\r\n File \"/usr/lib64/python3.8/asyncio/base_subprocess.py\", line 36, in __init__\r\n self._start(args=args, shell=shell, stdin=stdin, stdout=stdout,\r\n\r\n File \"/usr/lib64/python3.8/asyncio/unix_events.py\", line 789, in _start\r\n self._proc = subprocess.Popen(\r\n\r\n File \"/usr/lib64/python3.8/subprocess.py\", line 854, in __init__\r\n self._execute_child(args, executable, preexec_fn, close_fds,\r\n\r\n File \"/usr/lib64/python3.8/subprocess.py\", line 1637, in _execute_child\r\n self.pid = _posixsubprocess.fork_exec(\r\n\r\nTypeError: expected str, bytes or os.PathLike object, not NoneType\r\n\r\nPlease include the traceback info and command line used on your bug report\r\nReport bugs visiting https://github.com/avocado-framework/avocado/issues/new\r\n```\n", "before_files": [{"content": "#!/bin/env python3\n\nimport os\nimport sys\n\nfrom avocado.core.job import Job\n\nTHIS_DIR = os.path.dirname(os.path.abspath(__file__))\nROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\n\n\nCONFIG = {\n 'run.test_runner': 'nrunner',\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n 'nrunner.max_parallel_tasks': 1,\n }\n\n\nif __name__ == '__main__':\n with Job(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "path": "selftests/pre_release/jobs/timesensitive.py"}], "after_files": [{"content": "#!/bin/env python3\n\nimport os\nimport sys\n\nfrom avocado.core.job import Job\n\nTHIS_DIR = os.path.dirname(os.path.abspath(__file__))\nROOT_DIR = os.path.dirname(os.path.dirname(os.path.dirname(THIS_DIR)))\n\n\nCONFIG = {\n 'run.test_runner': 'nrunner',\n 'run.references': [os.path.join(ROOT_DIR, 'selftests', 'unit'),\n os.path.join(ROOT_DIR, 'selftests', 'functional')],\n 'filter.by_tags.tags': ['parallel:1'],\n 'nrunner.status_server_uri': '127.0.0.1:8888',\n 'nrunner.max_parallel_tasks': 1,\n }\n\n\nif __name__ == '__main__':\n with Job.from_config(CONFIG) as j:\n os.environ['AVOCADO_CHECK_LEVEL'] = '3'\n sys.exit(j.run())\n", "path": "selftests/pre_release/jobs/timesensitive.py"}]}
| 1,533 | 198 |
gh_patches_debug_50798
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-3056
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
RTD build is broken
Can look at this, leaving as note as reminder.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17 from setuptools import find_packages
18 from setuptools import setup
19
20
21 PACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))
22
23 with open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:
24 README = file_obj.read()
25
26 # NOTE: This is duplicated throughout and we should try to
27 # consolidate.
28 SETUP_BASE = {
29 'author': 'Google Cloud Platform',
30 'author_email': '[email protected]',
31 'scripts': [],
32 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',
33 'license': 'Apache 2.0',
34 'platforms': 'Posix; MacOS X; Windows',
35 'include_package_data': True,
36 'zip_safe': False,
37 'classifiers': [
38 'Development Status :: 4 - Beta',
39 'Intended Audience :: Developers',
40 'License :: OSI Approved :: Apache Software License',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 2',
43 'Programming Language :: Python :: 2.7',
44 'Programming Language :: Python :: 3',
45 'Programming Language :: Python :: 3.4',
46 'Programming Language :: Python :: 3.5',
47 'Topic :: Internet',
48 ],
49 }
50
51
52 REQUIREMENTS = [
53 'google-cloud-bigquery >= 0.22.1, < 0.23dev',
54 'google-cloud-bigtable >= 0.22.0, < 0.23dev',
55 'google-cloud-core >= 0.22.1, < 0.23dev',
56 'google-cloud-datastore >= 0.22.0, < 0.23dev',
57 'google-cloud-dns >= 0.22.0, < 0.23dev',
58 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',
59 'google-cloud-language >= 0.22.1, < 0.23dev',
60 'google-cloud-logging >= 0.22.0, < 0.23dev',
61 'google-cloud-monitoring >= 0.22.0, < 0.23dev',
62 'google-cloud-pubsub >= 0.22.0, < 0.23dev',
63 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',
64 'google-cloud-storage >= 0.22.0, < 0.23dev',
65 'google-cloud-translate >= 0.22.0, < 0.23dev',
66 'google-cloud-vision >= 0.22.0, < 0.23dev',
67 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',
68 ]
69
70 setup(
71 name='google-cloud',
72 version='0.22.0',
73 description='API Client library for Google Cloud',
74 long_description=README,
75 install_requires=REQUIREMENTS,
76 **SETUP_BASE
77 )
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -52,7 +52,7 @@
REQUIREMENTS = [
'google-cloud-bigquery >= 0.22.1, < 0.23dev',
'google-cloud-bigtable >= 0.22.0, < 0.23dev',
- 'google-cloud-core >= 0.22.1, < 0.23dev',
+ 'google-cloud-core >= 0.23.0, < 0.24dev',
'google-cloud-datastore >= 0.22.0, < 0.23dev',
'google-cloud-dns >= 0.22.0, < 0.23dev',
'google-cloud-error-reporting >= 0.22.0, < 0.23dev',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -52,7 +52,7 @@\n REQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n- 'google-cloud-core >= 0.22.1, < 0.23dev',\n+ 'google-cloud-core >= 0.23.0, < 0.24dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n", "issue": "RTD build is broken\nCan look at this, leaving as note as reminder.\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n 'google-cloud-core >= 0.22.1, < 0.23dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n 'google-cloud-language >= 0.22.1, < 0.23dev',\n 'google-cloud-logging >= 0.22.0, < 0.23dev',\n 'google-cloud-monitoring >= 0.22.0, < 0.23dev',\n 'google-cloud-pubsub >= 0.22.0, < 0.23dev',\n 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',\n 'google-cloud-storage >= 0.22.0, < 0.23dev',\n 'google-cloud-translate >= 0.22.0, < 0.23dev',\n 'google-cloud-vision >= 0.22.0, < 0.23dev',\n 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',\n]\n\nsetup(\n name='google-cloud',\n version='0.22.0',\n description='API Client library for Google Cloud',\n long_description=README,\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nPACKAGE_ROOT = os.path.abspath(os.path.dirname(__file__))\n\nwith open(os.path.join(PACKAGE_ROOT, 'README.rst')) as file_obj:\n README = file_obj.read()\n\n# NOTE: This is duplicated throughout and we should try to\n# consolidate.\nSETUP_BASE = {\n 'author': 'Google Cloud Platform',\n 'author_email': '[email protected]',\n 'scripts': [],\n 'url': 'https://github.com/GoogleCloudPlatform/google-cloud-python',\n 'license': 'Apache 2.0',\n 'platforms': 'Posix; MacOS X; Windows',\n 'include_package_data': True,\n 'zip_safe': False,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet',\n ],\n}\n\n\nREQUIREMENTS = [\n 'google-cloud-bigquery >= 0.22.1, < 0.23dev',\n 'google-cloud-bigtable >= 0.22.0, < 0.23dev',\n 'google-cloud-core >= 0.23.0, < 0.24dev',\n 'google-cloud-datastore >= 0.22.0, < 0.23dev',\n 'google-cloud-dns >= 0.22.0, < 0.23dev',\n 'google-cloud-error-reporting >= 0.22.0, < 0.23dev',\n 'google-cloud-language >= 0.22.1, < 0.23dev',\n 'google-cloud-logging >= 0.22.0, < 0.23dev',\n 'google-cloud-monitoring >= 0.22.0, < 0.23dev',\n 'google-cloud-pubsub >= 0.22.0, < 0.23dev',\n 'google-cloud-resource-manager >= 0.22.0, < 0.23dev',\n 'google-cloud-storage >= 0.22.0, < 0.23dev',\n 'google-cloud-translate >= 0.22.0, < 0.23dev',\n 'google-cloud-vision >= 0.22.0, < 0.23dev',\n 'google-cloud-runtimeconfig >= 0.22.0, < 0.23dev',\n]\n\nsetup(\n name='google-cloud',\n version='0.22.0',\n description='API Client library for Google Cloud',\n long_description=README,\n install_requires=REQUIREMENTS,\n **SETUP_BASE\n)\n", "path": "setup.py"}]}
| 1,224 | 198 |
gh_patches_debug_20462
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6763
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects
very similar to #5881
It would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.
https://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325
https://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780
I can visit that place and check in which form Western Union appears there.
[WesternUnion] Remove top level tag
Fixes #5889
@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects
very similar to #5881
It would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.
https://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325
https://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780
I can visit that place and check in which form Western Union appears there.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/western_union.py`
Content:
```
1 import json
2
3 from scrapy import Spider
4 from scrapy.downloadermiddlewares.retry import get_retry_request
5 from scrapy.http import JsonRequest
6
7 from locations.categories import Categories
8 from locations.dict_parser import DictParser
9 from locations.geo import point_locations
10 from locations.hours import OpeningHours
11
12
13 class WesternUnionSpider(Spider):
14 name = "western_union"
15 item_attributes = {"brand": "Western Union", "brand_wikidata": "Q861042", "extras": Categories.MONEY_TRANSFER.value}
16 allowed_domains = ["www.westernunion.com"]
17 # start_urls[0] is a GraphQL endpoint.
18 start_urls = ["https://www.westernunion.com/router/"]
19 download_delay = 0.2
20
21 def request_page(self, latitude, longitude, page_number):
22 # An access code for querying the GraphQL endpoint is
23 # required, This is constant across different browser
24 # sessions and the same for all users of the website.
25 headers = {
26 "x-wu-accesscode": "RtYV3XDz9EA",
27 "x-wu-operationName": "locations",
28 }
29 # The GraphQL query does not appear to allow for the page
30 # size to be increased. Typically the page size is observed
31 # by default to be 15 results per page.
32 #
33 # A radius of 350km is used by the API to search around each
34 # provided coordinate. There does not appear to be a way to
35 # specify an alternative radius.
36 data = {
37 "query": "query locations($req:LocationInput) { locations(input: $req) }",
38 "variables": {
39 "req": {
40 "longitude": longitude,
41 "latitude": latitude,
42 "country": "US", # Seemingly has no effect.
43 "openNow": "",
44 "services": [],
45 "sortOrder": "Distance",
46 "pageNumber": str(page_number),
47 }
48 },
49 }
50 yield JsonRequest(url=self.start_urls[0], method="POST", headers=headers, data=data)
51
52 def start_requests(self):
53 # The GraphQL query searches for locations within a 350km
54 # radius of supplied coordinates, then returns locations in
55 # pages of 15 locations each page.
56 for lat, lon in point_locations("earth_centroids_iseadgg_346km_radius.csv"):
57 yield from self.request_page(lat, lon, 1)
58
59 def parse(self, response):
60 # If crawling too fast, the server responds with a JSON
61 # blob containing an error message. Schedule a retry.
62 if "results" not in response.json()["data"]["locations"]:
63 if "errorCode" in response.json()["data"]["locations"]:
64 if response.json()["data"]["locations"]["errorCode"] == 500:
65 yield get_retry_request(
66 response.request, spider=self, max_retry_times=5, reason="Retry after rate limiting error"
67 )
68 return
69 # In case of an unhandled error, skip parsing.
70 return
71
72 # Parse the 15 (or fewer) locations from the response provided.
73 for location in response.json()["data"]["locations"]["results"]:
74 item = DictParser.parse(location)
75 item["website"] = "https://location.westernunion.com/" + location["detailsUrl"]
76 item["opening_hours"] = OpeningHours()
77 hours_string = " ".join([f"{day}: {hours}" for (day, hours) in location["detail.hours"].items()])
78 item["opening_hours"].add_ranges_from_string(hours_string)
79 yield item
80
81 # On the first response per radius search of a coordinate,
82 # generate requests for all subsequent pages of results
83 # found by the API within the 350km search radius.
84 request_data = json.loads(response.request.body)
85 current_page = int(request_data["variables"]["req"]["pageNumber"])
86 total_pages = response.json()["data"]["locations"]["pageCount"]
87 if current_page == 1 and total_pages > 1:
88 for page_number in range(2, total_pages, 1):
89 yield from self.request_page(
90 request_data["variables"]["req"]["latitude"],
91 request_data["variables"]["req"]["longitude"],
92 page_number,
93 )
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/western_union.py b/locations/spiders/western_union.py
--- a/locations/spiders/western_union.py
+++ b/locations/spiders/western_union.py
@@ -4,7 +4,6 @@
from scrapy.downloadermiddlewares.retry import get_retry_request
from scrapy.http import JsonRequest
-from locations.categories import Categories
from locations.dict_parser import DictParser
from locations.geo import point_locations
from locations.hours import OpeningHours
@@ -12,7 +11,11 @@
class WesternUnionSpider(Spider):
name = "western_union"
- item_attributes = {"brand": "Western Union", "brand_wikidata": "Q861042", "extras": Categories.MONEY_TRANSFER.value}
+ item_attributes = {
+ "brand": "Western Union",
+ "brand_wikidata": "Q861042",
+ "extras": {"money_transfer": "western_union"},
+ }
allowed_domains = ["www.westernunion.com"]
# start_urls[0] is a GraphQL endpoint.
start_urls = ["https://www.westernunion.com/router/"]
|
{"golden_diff": "diff --git a/locations/spiders/western_union.py b/locations/spiders/western_union.py\n--- a/locations/spiders/western_union.py\n+++ b/locations/spiders/western_union.py\n@@ -4,7 +4,6 @@\n from scrapy.downloadermiddlewares.retry import get_retry_request\n from scrapy.http import JsonRequest\n \n-from locations.categories import Categories\n from locations.dict_parser import DictParser\n from locations.geo import point_locations\n from locations.hours import OpeningHours\n@@ -12,7 +11,11 @@\n \n class WesternUnionSpider(Spider):\n name = \"western_union\"\n- item_attributes = {\"brand\": \"Western Union\", \"brand_wikidata\": \"Q861042\", \"extras\": Categories.MONEY_TRANSFER.value}\n+ item_attributes = {\n+ \"brand\": \"Western Union\",\n+ \"brand_wikidata\": \"Q861042\",\n+ \"extras\": {\"money_transfer\": \"western_union\"},\n+ }\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n", "issue": "@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects\nvery similar to #5881\r\n\r\nIt would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325\r\n\r\nhttps://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780\r\n\r\nI can visit that place and check in which form Western Union appears there.\n[WesternUnion] Remove top level tag\nFixes #5889\n@spider=western_union in Poland list `amenity=money_transfer` POIs not actually existing as separate objects\nvery similar to #5881\r\n\r\nIt would be better to drop main tag over showing it like this. And in this case it seems dubious to me is it mappable as all on https://www.openstreetmap.org/node/5873034793 bank note.\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.47/50.076332/20.032325\r\n\r\nhttps://location.westernunion.com/pl/malopolskie/krakow/e6d7165e8f86df94dacd8de6f1bfc780\r\n\r\nI can visit that place and check in which form Western Union appears there.\n", "before_files": [{"content": "import json\n\nfrom scrapy import Spider\nfrom scrapy.downloadermiddlewares.retry import get_retry_request\nfrom scrapy.http import JsonRequest\n\nfrom locations.categories import Categories\nfrom locations.dict_parser import DictParser\nfrom locations.geo import point_locations\nfrom locations.hours import OpeningHours\n\n\nclass WesternUnionSpider(Spider):\n name = \"western_union\"\n item_attributes = {\"brand\": \"Western Union\", \"brand_wikidata\": \"Q861042\", \"extras\": Categories.MONEY_TRANSFER.value}\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n download_delay = 0.2\n\n def request_page(self, latitude, longitude, page_number):\n # An access code for querying the GraphQL endpoint is\n # required, This is constant across different browser\n # sessions and the same for all users of the website.\n headers = {\n \"x-wu-accesscode\": \"RtYV3XDz9EA\",\n \"x-wu-operationName\": \"locations\",\n }\n # The GraphQL query does not appear to allow for the page\n # size to be increased. Typically the page size is observed\n # by default to be 15 results per page.\n #\n # A radius of 350km is used by the API to search around each\n # provided coordinate. There does not appear to be a way to\n # specify an alternative radius.\n data = {\n \"query\": \"query locations($req:LocationInput) { locations(input: $req) }\",\n \"variables\": {\n \"req\": {\n \"longitude\": longitude,\n \"latitude\": latitude,\n \"country\": \"US\", # Seemingly has no effect.\n \"openNow\": \"\",\n \"services\": [],\n \"sortOrder\": \"Distance\",\n \"pageNumber\": str(page_number),\n }\n },\n }\n yield JsonRequest(url=self.start_urls[0], method=\"POST\", headers=headers, data=data)\n\n def start_requests(self):\n # The GraphQL query searches for locations within a 350km\n # radius of supplied coordinates, then returns locations in\n # pages of 15 locations each page.\n for lat, lon in point_locations(\"earth_centroids_iseadgg_346km_radius.csv\"):\n yield from self.request_page(lat, lon, 1)\n\n def parse(self, response):\n # If crawling too fast, the server responds with a JSON\n # blob containing an error message. Schedule a retry.\n if \"results\" not in response.json()[\"data\"][\"locations\"]:\n if \"errorCode\" in response.json()[\"data\"][\"locations\"]:\n if response.json()[\"data\"][\"locations\"][\"errorCode\"] == 500:\n yield get_retry_request(\n response.request, spider=self, max_retry_times=5, reason=\"Retry after rate limiting error\"\n )\n return\n # In case of an unhandled error, skip parsing.\n return\n\n # Parse the 15 (or fewer) locations from the response provided.\n for location in response.json()[\"data\"][\"locations\"][\"results\"]:\n item = DictParser.parse(location)\n item[\"website\"] = \"https://location.westernunion.com/\" + location[\"detailsUrl\"]\n item[\"opening_hours\"] = OpeningHours()\n hours_string = \" \".join([f\"{day}: {hours}\" for (day, hours) in location[\"detail.hours\"].items()])\n item[\"opening_hours\"].add_ranges_from_string(hours_string)\n yield item\n\n # On the first response per radius search of a coordinate,\n # generate requests for all subsequent pages of results\n # found by the API within the 350km search radius.\n request_data = json.loads(response.request.body)\n current_page = int(request_data[\"variables\"][\"req\"][\"pageNumber\"])\n total_pages = response.json()[\"data\"][\"locations\"][\"pageCount\"]\n if current_page == 1 and total_pages > 1:\n for page_number in range(2, total_pages, 1):\n yield from self.request_page(\n request_data[\"variables\"][\"req\"][\"latitude\"],\n request_data[\"variables\"][\"req\"][\"longitude\"],\n page_number,\n )\n", "path": "locations/spiders/western_union.py"}], "after_files": [{"content": "import json\n\nfrom scrapy import Spider\nfrom scrapy.downloadermiddlewares.retry import get_retry_request\nfrom scrapy.http import JsonRequest\n\nfrom locations.dict_parser import DictParser\nfrom locations.geo import point_locations\nfrom locations.hours import OpeningHours\n\n\nclass WesternUnionSpider(Spider):\n name = \"western_union\"\n item_attributes = {\n \"brand\": \"Western Union\",\n \"brand_wikidata\": \"Q861042\",\n \"extras\": {\"money_transfer\": \"western_union\"},\n }\n allowed_domains = [\"www.westernunion.com\"]\n # start_urls[0] is a GraphQL endpoint.\n start_urls = [\"https://www.westernunion.com/router/\"]\n download_delay = 0.2\n\n def request_page(self, latitude, longitude, page_number):\n # An access code for querying the GraphQL endpoint is\n # required, This is constant across different browser\n # sessions and the same for all users of the website.\n headers = {\n \"x-wu-accesscode\": \"RtYV3XDz9EA\",\n \"x-wu-operationName\": \"locations\",\n }\n # The GraphQL query does not appear to allow for the page\n # size to be increased. Typically the page size is observed\n # by default to be 15 results per page.\n #\n # A radius of 350km is used by the API to search around each\n # provided coordinate. There does not appear to be a way to\n # specify an alternative radius.\n data = {\n \"query\": \"query locations($req:LocationInput) { locations(input: $req) }\",\n \"variables\": {\n \"req\": {\n \"longitude\": longitude,\n \"latitude\": latitude,\n \"country\": \"US\", # Seemingly has no effect.\n \"openNow\": \"\",\n \"services\": [],\n \"sortOrder\": \"Distance\",\n \"pageNumber\": str(page_number),\n }\n },\n }\n yield JsonRequest(url=self.start_urls[0], method=\"POST\", headers=headers, data=data)\n\n def start_requests(self):\n # The GraphQL query searches for locations within a 350km\n # radius of supplied coordinates, then returns locations in\n # pages of 15 locations each page.\n for lat, lon in point_locations(\"earth_centroids_iseadgg_346km_radius.csv\"):\n yield from self.request_page(lat, lon, 1)\n\n def parse(self, response):\n # If crawling too fast, the server responds with a JSON\n # blob containing an error message. Schedule a retry.\n if \"results\" not in response.json()[\"data\"][\"locations\"]:\n if \"errorCode\" in response.json()[\"data\"][\"locations\"]:\n if response.json()[\"data\"][\"locations\"][\"errorCode\"] == 500:\n yield get_retry_request(\n response.request, spider=self, max_retry_times=5, reason=\"Retry after rate limiting error\"\n )\n return\n # In case of an unhandled error, skip parsing.\n return\n\n # Parse the 15 (or fewer) locations from the response provided.\n for location in response.json()[\"data\"][\"locations\"][\"results\"]:\n item = DictParser.parse(location)\n item[\"website\"] = \"https://location.westernunion.com/\" + location[\"detailsUrl\"]\n item[\"opening_hours\"] = OpeningHours()\n hours_string = \" \".join([f\"{day}: {hours}\" for (day, hours) in location[\"detail.hours\"].items()])\n item[\"opening_hours\"].add_ranges_from_string(hours_string)\n yield item\n\n # On the first response per radius search of a coordinate,\n # generate requests for all subsequent pages of results\n # found by the API within the 350km search radius.\n request_data = json.loads(response.request.body)\n current_page = int(request_data[\"variables\"][\"req\"][\"pageNumber\"])\n total_pages = response.json()[\"data\"][\"locations\"][\"pageCount\"]\n if current_page == 1 and total_pages > 1:\n for page_number in range(2, total_pages, 1):\n yield from self.request_page(\n request_data[\"variables\"][\"req\"][\"latitude\"],\n request_data[\"variables\"][\"req\"][\"longitude\"],\n page_number,\n )\n", "path": "locations/spiders/western_union.py"}]}
| 1,733 | 256 |
gh_patches_debug_15839
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__models-3191
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PaddleRL policy_gradient Typo
default_main_program误写为defaul_main_program
all_act_prob 未被声明为成员变量
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `legacy/PaddleRL/policy_gradient/brain.py`
Content:
```
1 import numpy as np
2 import paddle.fluid as fluid
3 # reproducible
4 np.random.seed(1)
5
6
7 class PolicyGradient:
8 def __init__(
9 self,
10 n_actions,
11 n_features,
12 learning_rate=0.01,
13 reward_decay=0.95,
14 output_graph=False, ):
15 self.n_actions = n_actions
16 self.n_features = n_features
17 self.lr = learning_rate
18 self.gamma = reward_decay
19
20 self.ep_obs, self.ep_as, self.ep_rs = [], [], []
21
22 self.place = fluid.CPUPlace()
23 self.exe = fluid.Executor(self.place)
24
25 def build_net(self):
26
27 obs = fluid.layers.data(
28 name='obs', shape=[self.n_features], dtype='float32')
29 acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')
30 vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')
31 # fc1
32 fc1 = fluid.layers.fc(input=obs, size=10, act="tanh") # tanh activation
33 # fc2
34 all_act_prob = fluid.layers.fc(input=fc1,
35 size=self.n_actions,
36 act="softmax")
37 self.inferece_program = fluid.defaul_main_program().clone()
38 # to maximize total reward (log_p * R) is to minimize -(log_p * R)
39 neg_log_prob = fluid.layers.cross_entropy(
40 input=self.all_act_prob,
41 label=acts) # this is negative log of chosen action
42 neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)
43 loss = fluid.layers.reduce_mean(
44 neg_log_prob_weight) # reward guided loss
45
46 sgd_optimizer = fluid.optimizer.SGD(self.lr)
47 sgd_optimizer.minimize(loss)
48 self.exe.run(fluid.default_startup_program())
49
50 def choose_action(self, observation):
51 prob_weights = self.exe.run(self.inferece_program,
52 feed={"obs": observation[np.newaxis, :]},
53 fetch_list=[self.all_act_prob])
54 prob_weights = np.array(prob_weights[0])
55 # select action w.r.t the actions prob
56 action = np.random.choice(
57 range(prob_weights.shape[1]), p=prob_weights.ravel())
58 return action
59
60 def store_transition(self, s, a, r):
61 self.ep_obs.append(s)
62 self.ep_as.append(a)
63 self.ep_rs.append(r)
64
65 def learn(self):
66 # discount and normalize episode reward
67 discounted_ep_rs_norm = self._discount_and_norm_rewards()
68 tensor_obs = np.vstack(self.ep_obs).astype("float32")
69 tensor_as = np.array(self.ep_as).astype("int64")
70 tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])
71 tensor_vt = discounted_ep_rs_norm.astype("float32")[:, np.newaxis]
72 # train on episode
73 self.exe.run(
74 fluid.default_main_program(),
75 feed={
76 "obs": tensor_obs, # shape=[None, n_obs]
77 "acts": tensor_as, # shape=[None, ]
78 "vt": tensor_vt # shape=[None, ]
79 })
80 self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data
81 return discounted_ep_rs_norm
82
83 def _discount_and_norm_rewards(self):
84 # discount episode rewards
85 discounted_ep_rs = np.zeros_like(self.ep_rs)
86 running_add = 0
87 for t in reversed(range(0, len(self.ep_rs))):
88 running_add = running_add * self.gamma + self.ep_rs[t]
89 discounted_ep_rs[t] = running_add
90
91 # normalize episode rewards
92 discounted_ep_rs -= np.mean(discounted_ep_rs)
93 discounted_ep_rs /= np.std(discounted_ep_rs)
94 return discounted_ep_rs
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/legacy/PaddleRL/policy_gradient/brain.py b/legacy/PaddleRL/policy_gradient/brain.py
--- a/legacy/PaddleRL/policy_gradient/brain.py
+++ b/legacy/PaddleRL/policy_gradient/brain.py
@@ -31,10 +31,10 @@
# fc1
fc1 = fluid.layers.fc(input=obs, size=10, act="tanh") # tanh activation
# fc2
- all_act_prob = fluid.layers.fc(input=fc1,
+ self.all_act_prob = fluid.layers.fc(input=fc1,
size=self.n_actions,
act="softmax")
- self.inferece_program = fluid.defaul_main_program().clone()
+ self.inferece_program = fluid.default_main_program().clone()
# to maximize total reward (log_p * R) is to minimize -(log_p * R)
neg_log_prob = fluid.layers.cross_entropy(
input=self.all_act_prob,
|
{"golden_diff": "diff --git a/legacy/PaddleRL/policy_gradient/brain.py b/legacy/PaddleRL/policy_gradient/brain.py\n--- a/legacy/PaddleRL/policy_gradient/brain.py\n+++ b/legacy/PaddleRL/policy_gradient/brain.py\n@@ -31,10 +31,10 @@\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n- all_act_prob = fluid.layers.fc(input=fc1,\n+ self.all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n- self.inferece_program = fluid.defaul_main_program().clone()\n+ self.inferece_program = fluid.default_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n", "issue": "PaddleRL policy_gradient Typo\ndefault_main_program\u8bef\u5199\u4e3adefaul_main_program\r\nall_act_prob \u672a\u88ab\u58f0\u660e\u4e3a\u6210\u5458\u53d8\u91cf\n", "before_files": [{"content": "import numpy as np\nimport paddle.fluid as fluid\n# reproducible\nnp.random.seed(1)\n\n\nclass PolicyGradient:\n def __init__(\n self,\n n_actions,\n n_features,\n learning_rate=0.01,\n reward_decay=0.95,\n output_graph=False, ):\n self.n_actions = n_actions\n self.n_features = n_features\n self.lr = learning_rate\n self.gamma = reward_decay\n\n self.ep_obs, self.ep_as, self.ep_rs = [], [], []\n\n self.place = fluid.CPUPlace()\n self.exe = fluid.Executor(self.place)\n\n def build_net(self):\n\n obs = fluid.layers.data(\n name='obs', shape=[self.n_features], dtype='float32')\n acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')\n vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n self.inferece_program = fluid.defaul_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n label=acts) # this is negative log of chosen action\n neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)\n loss = fluid.layers.reduce_mean(\n neg_log_prob_weight) # reward guided loss\n\n sgd_optimizer = fluid.optimizer.SGD(self.lr)\n sgd_optimizer.minimize(loss)\n self.exe.run(fluid.default_startup_program())\n\n def choose_action(self, observation):\n prob_weights = self.exe.run(self.inferece_program,\n feed={\"obs\": observation[np.newaxis, :]},\n fetch_list=[self.all_act_prob])\n prob_weights = np.array(prob_weights[0])\n # select action w.r.t the actions prob\n action = np.random.choice(\n range(prob_weights.shape[1]), p=prob_weights.ravel())\n return action\n\n def store_transition(self, s, a, r):\n self.ep_obs.append(s)\n self.ep_as.append(a)\n self.ep_rs.append(r)\n\n def learn(self):\n # discount and normalize episode reward\n discounted_ep_rs_norm = self._discount_and_norm_rewards()\n tensor_obs = np.vstack(self.ep_obs).astype(\"float32\")\n tensor_as = np.array(self.ep_as).astype(\"int64\")\n tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])\n tensor_vt = discounted_ep_rs_norm.astype(\"float32\")[:, np.newaxis]\n # train on episode\n self.exe.run(\n fluid.default_main_program(),\n feed={\n \"obs\": tensor_obs, # shape=[None, n_obs]\n \"acts\": tensor_as, # shape=[None, ]\n \"vt\": tensor_vt # shape=[None, ]\n })\n self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data\n return discounted_ep_rs_norm\n\n def _discount_and_norm_rewards(self):\n # discount episode rewards\n discounted_ep_rs = np.zeros_like(self.ep_rs)\n running_add = 0\n for t in reversed(range(0, len(self.ep_rs))):\n running_add = running_add * self.gamma + self.ep_rs[t]\n discounted_ep_rs[t] = running_add\n\n # normalize episode rewards\n discounted_ep_rs -= np.mean(discounted_ep_rs)\n discounted_ep_rs /= np.std(discounted_ep_rs)\n return discounted_ep_rs\n", "path": "legacy/PaddleRL/policy_gradient/brain.py"}], "after_files": [{"content": "import numpy as np\nimport paddle.fluid as fluid\n# reproducible\nnp.random.seed(1)\n\n\nclass PolicyGradient:\n def __init__(\n self,\n n_actions,\n n_features,\n learning_rate=0.01,\n reward_decay=0.95,\n output_graph=False, ):\n self.n_actions = n_actions\n self.n_features = n_features\n self.lr = learning_rate\n self.gamma = reward_decay\n\n self.ep_obs, self.ep_as, self.ep_rs = [], [], []\n\n self.place = fluid.CPUPlace()\n self.exe = fluid.Executor(self.place)\n\n def build_net(self):\n\n obs = fluid.layers.data(\n name='obs', shape=[self.n_features], dtype='float32')\n acts = fluid.layers.data(name='acts', shape=[1], dtype='int64')\n vt = fluid.layers.data(name='vt', shape=[1], dtype='float32')\n # fc1\n fc1 = fluid.layers.fc(input=obs, size=10, act=\"tanh\") # tanh activation\n # fc2\n self.all_act_prob = fluid.layers.fc(input=fc1,\n size=self.n_actions,\n act=\"softmax\")\n self.inferece_program = fluid.default_main_program().clone()\n # to maximize total reward (log_p * R) is to minimize -(log_p * R)\n neg_log_prob = fluid.layers.cross_entropy(\n input=self.all_act_prob,\n label=acts) # this is negative log of chosen action\n neg_log_prob_weight = fluid.layers.elementwise_mul(x=neg_log_prob, y=vt)\n loss = fluid.layers.reduce_mean(\n neg_log_prob_weight) # reward guided loss\n\n sgd_optimizer = fluid.optimizer.SGD(self.lr)\n sgd_optimizer.minimize(loss)\n self.exe.run(fluid.default_startup_program())\n\n def choose_action(self, observation):\n prob_weights = self.exe.run(self.inferece_program,\n feed={\"obs\": observation[np.newaxis, :]},\n fetch_list=[self.all_act_prob])\n prob_weights = np.array(prob_weights[0])\n # select action w.r.t the actions prob\n action = np.random.choice(\n range(prob_weights.shape[1]), p=prob_weights.ravel())\n return action\n\n def store_transition(self, s, a, r):\n self.ep_obs.append(s)\n self.ep_as.append(a)\n self.ep_rs.append(r)\n\n def learn(self):\n # discount and normalize episode reward\n discounted_ep_rs_norm = self._discount_and_norm_rewards()\n tensor_obs = np.vstack(self.ep_obs).astype(\"float32\")\n tensor_as = np.array(self.ep_as).astype(\"int64\")\n tensor_as = tensor_as.reshape([tensor_as.shape[0], 1])\n tensor_vt = discounted_ep_rs_norm.astype(\"float32\")[:, np.newaxis]\n # train on episode\n self.exe.run(\n fluid.default_main_program(),\n feed={\n \"obs\": tensor_obs, # shape=[None, n_obs]\n \"acts\": tensor_as, # shape=[None, ]\n \"vt\": tensor_vt # shape=[None, ]\n })\n self.ep_obs, self.ep_as, self.ep_rs = [], [], [] # empty episode data\n return discounted_ep_rs_norm\n\n def _discount_and_norm_rewards(self):\n # discount episode rewards\n discounted_ep_rs = np.zeros_like(self.ep_rs)\n running_add = 0\n for t in reversed(range(0, len(self.ep_rs))):\n running_add = running_add * self.gamma + self.ep_rs[t]\n discounted_ep_rs[t] = running_add\n\n # normalize episode rewards\n discounted_ep_rs -= np.mean(discounted_ep_rs)\n discounted_ep_rs /= np.std(discounted_ep_rs)\n return discounted_ep_rs\n", "path": "legacy/PaddleRL/policy_gradient/brain.py"}]}
| 1,308 | 216 |
gh_patches_debug_4887
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-265
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update CI files for branch 3.39
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/serializers/task.py`
Content:
```
1 from gettext import gettext as _
2
3 from rest_framework import serializers
4
5 from pulpcore.app import models
6 from pulpcore.app.serializers import (
7 IdentityField,
8 ModelSerializer,
9 ProgressReportSerializer,
10 RelatedField,
11 )
12 from pulpcore.app.util import get_viewset_for_model
13
14
15 class CreatedResourceSerializer(RelatedField):
16
17 def to_representation(self, data):
18 # If the content object was deleted
19 if data.content_object is None:
20 return None
21 try:
22 if not data.content_object.complete:
23 return None
24 except AttributeError:
25 pass
26 viewset = get_viewset_for_model(data.content_object)
27
28 # serializer contains all serialized fields because we are passing
29 # 'None' to the request's context
30 serializer = viewset.serializer_class(data.content_object, context={'request': None})
31 return serializer.data.get('_href')
32
33 class Meta:
34 model = models.CreatedResource
35 fields = []
36
37
38 class TaskSerializer(ModelSerializer):
39 _href = IdentityField(view_name='tasks-detail')
40 state = serializers.CharField(
41 help_text=_("The current state of the task. The possible values include:"
42 " 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'."),
43 read_only=True
44 )
45 name = serializers.CharField(
46 help_text=_("The name of task.")
47 )
48 started_at = serializers.DateTimeField(
49 help_text=_("Timestamp of the when this task started execution."),
50 read_only=True
51 )
52 finished_at = serializers.DateTimeField(
53 help_text=_("Timestamp of the when this task stopped execution."),
54 read_only=True
55 )
56 non_fatal_errors = serializers.JSONField(
57 help_text=_("A JSON Object of non-fatal errors encountered during the execution of this "
58 "task."),
59 read_only=True
60 )
61 error = serializers.JSONField(
62 help_text=_("A JSON Object of a fatal error encountered during the execution of this "
63 "task."),
64 read_only=True
65 )
66 worker = RelatedField(
67 help_text=_("The worker associated with this task."
68 " This field is empty if a worker is not yet assigned."),
69 read_only=True,
70 view_name='workers-detail'
71 )
72 parent = RelatedField(
73 help_text=_("The parent task that spawned this task."),
74 read_only=True,
75 view_name='tasks-detail'
76 )
77 spawned_tasks = RelatedField(
78 help_text=_("Any tasks spawned by this task."),
79 many=True,
80 read_only=True,
81 view_name='tasks-detail'
82 )
83 progress_reports = ProgressReportSerializer(
84 many=True,
85 read_only=True
86 )
87 created_resources = CreatedResourceSerializer(
88 help_text=_('Resources created by this task.'),
89 many=True,
90 read_only=True,
91 view_name='None' # This is a polymorphic field. The serializer does not need a view name.
92 )
93
94 class Meta:
95 model = models.Task
96 fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',
97 'finished_at', 'non_fatal_errors', 'error',
98 'worker', 'parent', 'spawned_tasks',
99 'progress_reports', 'created_resources')
100
101
102 class MinimalTaskSerializer(TaskSerializer):
103
104 class Meta:
105 model = models.Task
106 fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',
107 'worker', 'parent')
108
109
110 class TaskCancelSerializer(ModelSerializer):
111 state = serializers.CharField(
112 help_text=_("The desired state of the task. Only 'canceled' is accepted."),
113 )
114
115 class Meta:
116 model = models.Task
117 fields = ('state',)
118
119
120 class ContentAppStatusSerializer(ModelSerializer):
121 name = serializers.CharField(
122 help_text=_('The name of the worker.'),
123 read_only=True
124 )
125 last_heartbeat = serializers.DateTimeField(
126 help_text=_('Timestamp of the last time the worker talked to the service.'),
127 read_only=True
128 )
129
130 class Meta:
131 model = models.ContentAppStatus
132 fields = ('name', 'last_heartbeat')
133
134
135 class WorkerSerializer(ModelSerializer):
136 _href = IdentityField(view_name='workers-detail')
137
138 name = serializers.CharField(
139 help_text=_('The name of the worker.'),
140 read_only=True
141 )
142 last_heartbeat = serializers.DateTimeField(
143 help_text=_('Timestamp of the last time the worker talked to the service.'),
144 read_only=True
145 )
146 online = serializers.BooleanField(
147 help_text=_('True if the worker is considered online, otherwise False'),
148 read_only=True
149 )
150 missing = serializers.BooleanField(
151 help_text=_('True if the worker is considerd missing, otherwise False'),
152 read_only=True
153 )
154 # disable "created" because we don't care about it
155 created = None
156
157 class Meta:
158 model = models.Worker
159 _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))
160 fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')
161
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/app/serializers/task.py b/pulpcore/app/serializers/task.py
--- a/pulpcore/app/serializers/task.py
+++ b/pulpcore/app/serializers/task.py
@@ -58,7 +58,8 @@
"task."),
read_only=True
)
- error = serializers.JSONField(
+ error = serializers.DictField(
+ child=serializers.JSONField(),
help_text=_("A JSON Object of a fatal error encountered during the execution of this "
"task."),
read_only=True
|
{"golden_diff": "diff --git a/pulpcore/app/serializers/task.py b/pulpcore/app/serializers/task.py\n--- a/pulpcore/app/serializers/task.py\n+++ b/pulpcore/app/serializers/task.py\n@@ -58,7 +58,8 @@\n \"task.\"),\n read_only=True\n )\n- error = serializers.JSONField(\n+ error = serializers.DictField(\n+ child=serializers.JSONField(),\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n", "issue": "Update CI files for branch 3.39\n\n", "before_files": [{"content": "from gettext import gettext as _\n\nfrom rest_framework import serializers\n\nfrom pulpcore.app import models\nfrom pulpcore.app.serializers import (\n IdentityField,\n ModelSerializer,\n ProgressReportSerializer,\n RelatedField,\n)\nfrom pulpcore.app.util import get_viewset_for_model\n\n\nclass CreatedResourceSerializer(RelatedField):\n\n def to_representation(self, data):\n # If the content object was deleted\n if data.content_object is None:\n return None\n try:\n if not data.content_object.complete:\n return None\n except AttributeError:\n pass\n viewset = get_viewset_for_model(data.content_object)\n\n # serializer contains all serialized fields because we are passing\n # 'None' to the request's context\n serializer = viewset.serializer_class(data.content_object, context={'request': None})\n return serializer.data.get('_href')\n\n class Meta:\n model = models.CreatedResource\n fields = []\n\n\nclass TaskSerializer(ModelSerializer):\n _href = IdentityField(view_name='tasks-detail')\n state = serializers.CharField(\n help_text=_(\"The current state of the task. The possible values include:\"\n \" 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'.\"),\n read_only=True\n )\n name = serializers.CharField(\n help_text=_(\"The name of task.\")\n )\n started_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task started execution.\"),\n read_only=True\n )\n finished_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task stopped execution.\"),\n read_only=True\n )\n non_fatal_errors = serializers.JSONField(\n help_text=_(\"A JSON Object of non-fatal errors encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n error = serializers.JSONField(\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n worker = RelatedField(\n help_text=_(\"The worker associated with this task.\"\n \" This field is empty if a worker is not yet assigned.\"),\n read_only=True,\n view_name='workers-detail'\n )\n parent = RelatedField(\n help_text=_(\"The parent task that spawned this task.\"),\n read_only=True,\n view_name='tasks-detail'\n )\n spawned_tasks = RelatedField(\n help_text=_(\"Any tasks spawned by this task.\"),\n many=True,\n read_only=True,\n view_name='tasks-detail'\n )\n progress_reports = ProgressReportSerializer(\n many=True,\n read_only=True\n )\n created_resources = CreatedResourceSerializer(\n help_text=_('Resources created by this task.'),\n many=True,\n read_only=True,\n view_name='None' # This is a polymorphic field. The serializer does not need a view name.\n )\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',\n 'finished_at', 'non_fatal_errors', 'error',\n 'worker', 'parent', 'spawned_tasks',\n 'progress_reports', 'created_resources')\n\n\nclass MinimalTaskSerializer(TaskSerializer):\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',\n 'worker', 'parent')\n\n\nclass TaskCancelSerializer(ModelSerializer):\n state = serializers.CharField(\n help_text=_(\"The desired state of the task. Only 'canceled' is accepted.\"),\n )\n\n class Meta:\n model = models.Task\n fields = ('state',)\n\n\nclass ContentAppStatusSerializer(ModelSerializer):\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n\n class Meta:\n model = models.ContentAppStatus\n fields = ('name', 'last_heartbeat')\n\n\nclass WorkerSerializer(ModelSerializer):\n _href = IdentityField(view_name='workers-detail')\n\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n online = serializers.BooleanField(\n help_text=_('True if the worker is considered online, otherwise False'),\n read_only=True\n )\n missing = serializers.BooleanField(\n help_text=_('True if the worker is considerd missing, otherwise False'),\n read_only=True\n )\n # disable \"created\" because we don't care about it\n created = None\n\n class Meta:\n model = models.Worker\n _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))\n fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')\n", "path": "pulpcore/app/serializers/task.py"}], "after_files": [{"content": "from gettext import gettext as _\n\nfrom rest_framework import serializers\n\nfrom pulpcore.app import models\nfrom pulpcore.app.serializers import (\n IdentityField,\n ModelSerializer,\n ProgressReportSerializer,\n RelatedField,\n)\nfrom pulpcore.app.util import get_viewset_for_model\n\n\nclass CreatedResourceSerializer(RelatedField):\n\n def to_representation(self, data):\n # If the content object was deleted\n if data.content_object is None:\n return None\n try:\n if not data.content_object.complete:\n return None\n except AttributeError:\n pass\n viewset = get_viewset_for_model(data.content_object)\n\n # serializer contains all serialized fields because we are passing\n # 'None' to the request's context\n serializer = viewset.serializer_class(data.content_object, context={'request': None})\n return serializer.data.get('_href')\n\n class Meta:\n model = models.CreatedResource\n fields = []\n\n\nclass TaskSerializer(ModelSerializer):\n _href = IdentityField(view_name='tasks-detail')\n state = serializers.CharField(\n help_text=_(\"The current state of the task. The possible values include:\"\n \" 'waiting', 'skipped', 'running', 'completed', 'failed' and 'canceled'.\"),\n read_only=True\n )\n name = serializers.CharField(\n help_text=_(\"The name of task.\")\n )\n started_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task started execution.\"),\n read_only=True\n )\n finished_at = serializers.DateTimeField(\n help_text=_(\"Timestamp of the when this task stopped execution.\"),\n read_only=True\n )\n non_fatal_errors = serializers.JSONField(\n help_text=_(\"A JSON Object of non-fatal errors encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n error = serializers.DictField(\n child=serializers.JSONField(),\n help_text=_(\"A JSON Object of a fatal error encountered during the execution of this \"\n \"task.\"),\n read_only=True\n )\n worker = RelatedField(\n help_text=_(\"The worker associated with this task.\"\n \" This field is empty if a worker is not yet assigned.\"),\n read_only=True,\n view_name='workers-detail'\n )\n parent = RelatedField(\n help_text=_(\"The parent task that spawned this task.\"),\n read_only=True,\n view_name='tasks-detail'\n )\n spawned_tasks = RelatedField(\n help_text=_(\"Any tasks spawned by this task.\"),\n many=True,\n read_only=True,\n view_name='tasks-detail'\n )\n progress_reports = ProgressReportSerializer(\n many=True,\n read_only=True\n )\n created_resources = CreatedResourceSerializer(\n help_text=_('Resources created by this task.'),\n many=True,\n read_only=True,\n view_name='None' # This is a polymorphic field. The serializer does not need a view name.\n )\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('state', 'name', 'started_at',\n 'finished_at', 'non_fatal_errors', 'error',\n 'worker', 'parent', 'spawned_tasks',\n 'progress_reports', 'created_resources')\n\n\nclass MinimalTaskSerializer(TaskSerializer):\n\n class Meta:\n model = models.Task\n fields = ModelSerializer.Meta.fields + ('name', 'state', 'started_at', 'finished_at',\n 'worker', 'parent')\n\n\nclass TaskCancelSerializer(ModelSerializer):\n state = serializers.CharField(\n help_text=_(\"The desired state of the task. Only 'canceled' is accepted.\"),\n )\n\n class Meta:\n model = models.Task\n fields = ('state',)\n\n\nclass ContentAppStatusSerializer(ModelSerializer):\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n\n class Meta:\n model = models.ContentAppStatus\n fields = ('name', 'last_heartbeat')\n\n\nclass WorkerSerializer(ModelSerializer):\n _href = IdentityField(view_name='workers-detail')\n\n name = serializers.CharField(\n help_text=_('The name of the worker.'),\n read_only=True\n )\n last_heartbeat = serializers.DateTimeField(\n help_text=_('Timestamp of the last time the worker talked to the service.'),\n read_only=True\n )\n online = serializers.BooleanField(\n help_text=_('True if the worker is considered online, otherwise False'),\n read_only=True\n )\n missing = serializers.BooleanField(\n help_text=_('True if the worker is considerd missing, otherwise False'),\n read_only=True\n )\n # disable \"created\" because we don't care about it\n created = None\n\n class Meta:\n model = models.Worker\n _base_fields = tuple(set(ModelSerializer.Meta.fields) - set(['created']))\n fields = _base_fields + ('name', 'last_heartbeat', 'online', 'missing')\n", "path": "pulpcore/app/serializers/task.py"}]}
| 1,707 | 123 |
gh_patches_debug_20726
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-274
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E3001 Missing properties raised as an error when they're not required
*cfn-lint version: 0.4.2*
*Description of issue.*
An error about missing properties is not always useful. There are resources which don't necessarily need properties.
Please provide as much information as possible:
* Template linting issues:
```
"WaitCondition": {
"Type": "AWS::CloudFormation::WaitCondition",
"CreationPolicy": {
"ResourceSignal": {
"Timeout": "PT15M",
"Count": {
"Ref": "TargetCapacity"
}
}
}
}
```
Getting `E3001 Properties not defined for resource WaitCondition`
* Feature request:
I'm not sure if there's a list of resources which don't need properties in many situations. S3 buckets and WaitCondition seem like good candidates for not raising this.
[AWS docs](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html) say:
> Use the optional Parameters section to customize your templates.
so it doesn't sound like it needs to be provided.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/Configuration.py`
Content:
```
1 """
2 Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 from cfnlint import CloudFormationLintRule
18 from cfnlint import RuleMatch
19 import cfnlint.helpers
20
21
22 class Configuration(CloudFormationLintRule):
23 """Check Base Resource Configuration"""
24 id = 'E3001'
25 shortdesc = 'Basic CloudFormation Resource Check'
26 description = 'Making sure the basic CloudFormation resources ' + \
27 'are properly configured'
28 source_url = 'https://github.com/awslabs/cfn-python-lint'
29 tags = ['resources']
30
31 def match(self, cfn):
32 """Check CloudFormation Resources"""
33
34 matches = list()
35
36 valid_attributes = [
37 'CreationPolicy',
38 'DeletionPolicy',
39 'DependsOn',
40 'Metadata',
41 'UpdatePolicy',
42 'Properties',
43 'Type',
44 'Condition'
45 ]
46
47 valid_custom_attributes = [
48 'Version',
49 'Properties',
50 'DependsOn',
51 'Metadata',
52 'Condition',
53 'Type',
54 ]
55
56 resources = cfn.template.get('Resources', {})
57 if not isinstance(resources, dict):
58 message = 'Resource not properly configured'
59 matches.append(RuleMatch(['Resources'], message))
60 else:
61 for resource_name, resource_values in cfn.template.get('Resources', {}).items():
62 self.logger.debug('Validating resource %s base configuration', resource_name)
63 if not isinstance(resource_values, dict):
64 message = 'Resource not properly configured at {0}'
65 matches.append(RuleMatch(
66 ['Resources', resource_name],
67 message.format(resource_name)
68 ))
69 continue
70 resource_type = resource_values.get('Type', '')
71 check_attributes = []
72 if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':
73 check_attributes = valid_custom_attributes
74 else:
75 check_attributes = valid_attributes
76
77 for property_key, _ in resource_values.items():
78 if property_key not in check_attributes:
79 message = 'Invalid resource attribute {0} for resource {1}'
80 matches.append(RuleMatch(
81 ['Resources', resource_name, property_key],
82 message.format(property_key, resource_name)))
83
84 resource_type = resource_values.get('Type', '')
85 if not resource_type:
86 message = 'Type not defined for resource {0}'
87 matches.append(RuleMatch(
88 ['Resources', resource_name],
89 message.format(resource_name)
90 ))
91 else:
92 self.logger.debug('Check resource types by region...')
93 for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():
94 if region in cfn.regions:
95 if resource_type not in specs['ResourceTypes']:
96 if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):
97 message = 'Invalid or unsupported Type {0} for resource {1} in {2}'
98 matches.append(RuleMatch(
99 ['Resources', resource_name, 'Type'],
100 message.format(resource_type, resource_name, region)
101 ))
102
103 if 'Properties' not in resource_values:
104 resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']
105 if resource_type in resource_spec['ResourceTypes']:
106 properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']
107 # pylint: disable=len-as-condition
108 if len(properties_spec) > 0:
109 required = 0
110 for _, property_spec in properties_spec.items():
111 if property_spec.get('Required', False):
112 required += 1
113 if required > 0:
114 message = 'Properties not defined for resource {0}'
115 matches.append(RuleMatch(
116 ['Resources', resource_name],
117 message.format(resource_name)
118 ))
119
120 return matches
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/Configuration.py b/src/cfnlint/rules/resources/Configuration.py
--- a/src/cfnlint/rules/resources/Configuration.py
+++ b/src/cfnlint/rules/resources/Configuration.py
@@ -111,10 +111,13 @@
if property_spec.get('Required', False):
required += 1
if required > 0:
- message = 'Properties not defined for resource {0}'
- matches.append(RuleMatch(
- ['Resources', resource_name],
- message.format(resource_name)
- ))
+ if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():
+ self.logger.debug('Exception to required properties section as CreationPolicy is defined.')
+ else:
+ message = 'Properties not defined for resource {0}'
+ matches.append(RuleMatch(
+ ['Resources', resource_name],
+ message.format(resource_name)
+ ))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/Configuration.py b/src/cfnlint/rules/resources/Configuration.py\n--- a/src/cfnlint/rules/resources/Configuration.py\n+++ b/src/cfnlint/rules/resources/Configuration.py\n@@ -111,10 +111,13 @@\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n- message = 'Properties not defined for resource {0}'\n- matches.append(RuleMatch(\n- ['Resources', resource_name],\n- message.format(resource_name)\n- ))\n+ if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():\n+ self.logger.debug('Exception to required properties section as CreationPolicy is defined.')\n+ else:\n+ message = 'Properties not defined for resource {0}'\n+ matches.append(RuleMatch(\n+ ['Resources', resource_name],\n+ message.format(resource_name)\n+ ))\n \n return matches\n", "issue": "E3001 Missing properties raised as an error when they're not required\n*cfn-lint version: 0.4.2*\r\n\r\n*Description of issue.*\r\n\r\nAn error about missing properties is not always useful. There are resources which don't necessarily need properties.\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n```\r\n \"WaitCondition\": {\r\n \"Type\": \"AWS::CloudFormation::WaitCondition\",\r\n \"CreationPolicy\": {\r\n \"ResourceSignal\": {\r\n \"Timeout\": \"PT15M\",\r\n \"Count\": {\r\n \"Ref\": \"TargetCapacity\"\r\n }\r\n }\r\n }\r\n }\r\n```\r\nGetting `E3001 Properties not defined for resource WaitCondition`\r\n\r\n* Feature request:\r\n\r\nI'm not sure if there's a list of resources which don't need properties in many situations. S3 buckets and WaitCondition seem like good candidates for not raising this.\r\n[AWS docs](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html) say:\r\n> Use the optional Parameters section to customize your templates.\r\nso it doesn't sound like it needs to be provided.\n", "before_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\nimport cfnlint.helpers\n\n\nclass Configuration(CloudFormationLintRule):\n \"\"\"Check Base Resource Configuration\"\"\"\n id = 'E3001'\n shortdesc = 'Basic CloudFormation Resource Check'\n description = 'Making sure the basic CloudFormation resources ' + \\\n 'are properly configured'\n source_url = 'https://github.com/awslabs/cfn-python-lint'\n tags = ['resources']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Resources\"\"\"\n\n matches = list()\n\n valid_attributes = [\n 'CreationPolicy',\n 'DeletionPolicy',\n 'DependsOn',\n 'Metadata',\n 'UpdatePolicy',\n 'Properties',\n 'Type',\n 'Condition'\n ]\n\n valid_custom_attributes = [\n 'Version',\n 'Properties',\n 'DependsOn',\n 'Metadata',\n 'Condition',\n 'Type',\n ]\n\n resources = cfn.template.get('Resources', {})\n if not isinstance(resources, dict):\n message = 'Resource not properly configured'\n matches.append(RuleMatch(['Resources'], message))\n else:\n for resource_name, resource_values in cfn.template.get('Resources', {}).items():\n self.logger.debug('Validating resource %s base configuration', resource_name)\n if not isinstance(resource_values, dict):\n message = 'Resource not properly configured at {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n continue\n resource_type = resource_values.get('Type', '')\n check_attributes = []\n if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':\n check_attributes = valid_custom_attributes\n else:\n check_attributes = valid_attributes\n\n for property_key, _ in resource_values.items():\n if property_key not in check_attributes:\n message = 'Invalid resource attribute {0} for resource {1}'\n matches.append(RuleMatch(\n ['Resources', resource_name, property_key],\n message.format(property_key, resource_name)))\n\n resource_type = resource_values.get('Type', '')\n if not resource_type:\n message = 'Type not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n else:\n self.logger.debug('Check resource types by region...')\n for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():\n if region in cfn.regions:\n if resource_type not in specs['ResourceTypes']:\n if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):\n message = 'Invalid or unsupported Type {0} for resource {1} in {2}'\n matches.append(RuleMatch(\n ['Resources', resource_name, 'Type'],\n message.format(resource_type, resource_name, region)\n ))\n\n if 'Properties' not in resource_values:\n resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']\n if resource_type in resource_spec['ResourceTypes']:\n properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']\n # pylint: disable=len-as-condition\n if len(properties_spec) > 0:\n required = 0\n for _, property_spec in properties_spec.items():\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n message = 'Properties not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n\n return matches\n", "path": "src/cfnlint/rules/resources/Configuration.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\nimport cfnlint.helpers\n\n\nclass Configuration(CloudFormationLintRule):\n \"\"\"Check Base Resource Configuration\"\"\"\n id = 'E3001'\n shortdesc = 'Basic CloudFormation Resource Check'\n description = 'Making sure the basic CloudFormation resources ' + \\\n 'are properly configured'\n source_url = 'https://github.com/awslabs/cfn-python-lint'\n tags = ['resources']\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Resources\"\"\"\n\n matches = list()\n\n valid_attributes = [\n 'CreationPolicy',\n 'DeletionPolicy',\n 'DependsOn',\n 'Metadata',\n 'UpdatePolicy',\n 'Properties',\n 'Type',\n 'Condition'\n ]\n\n valid_custom_attributes = [\n 'Version',\n 'Properties',\n 'DependsOn',\n 'Metadata',\n 'Condition',\n 'Type',\n ]\n\n resources = cfn.template.get('Resources', {})\n if not isinstance(resources, dict):\n message = 'Resource not properly configured'\n matches.append(RuleMatch(['Resources'], message))\n else:\n for resource_name, resource_values in cfn.template.get('Resources', {}).items():\n self.logger.debug('Validating resource %s base configuration', resource_name)\n if not isinstance(resource_values, dict):\n message = 'Resource not properly configured at {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n continue\n resource_type = resource_values.get('Type', '')\n check_attributes = []\n if resource_type.startswith('Custom::') or resource_type == 'AWS::CloudFormation::CustomResource':\n check_attributes = valid_custom_attributes\n else:\n check_attributes = valid_attributes\n\n for property_key, _ in resource_values.items():\n if property_key not in check_attributes:\n message = 'Invalid resource attribute {0} for resource {1}'\n matches.append(RuleMatch(\n ['Resources', resource_name, property_key],\n message.format(property_key, resource_name)))\n\n resource_type = resource_values.get('Type', '')\n if not resource_type:\n message = 'Type not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n else:\n self.logger.debug('Check resource types by region...')\n for region, specs in cfnlint.helpers.RESOURCE_SPECS.items():\n if region in cfn.regions:\n if resource_type not in specs['ResourceTypes']:\n if not resource_type.startswith(('Custom::', 'AWS::Serverless::')):\n message = 'Invalid or unsupported Type {0} for resource {1} in {2}'\n matches.append(RuleMatch(\n ['Resources', resource_name, 'Type'],\n message.format(resource_type, resource_name, region)\n ))\n\n if 'Properties' not in resource_values:\n resource_spec = cfnlint.helpers.RESOURCE_SPECS['us-east-1']\n if resource_type in resource_spec['ResourceTypes']:\n properties_spec = resource_spec['ResourceTypes'][resource_type]['Properties']\n # pylint: disable=len-as-condition\n if len(properties_spec) > 0:\n required = 0\n for _, property_spec in properties_spec.items():\n if property_spec.get('Required', False):\n required += 1\n if required > 0:\n if resource_type == 'AWS::CloudFormation::WaitCondition' and 'CreationPolicy' in resource_values.keys():\n self.logger.debug('Exception to required properties section as CreationPolicy is defined.')\n else:\n message = 'Properties not defined for resource {0}'\n matches.append(RuleMatch(\n ['Resources', resource_name],\n message.format(resource_name)\n ))\n\n return matches\n", "path": "src/cfnlint/rules/resources/Configuration.py"}]}
| 1,738 | 216 |
gh_patches_debug_633
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1947
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.110
On the docket:
+ [x] PEX runtime sys.path scrubbing is imperfect. #1944
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.109"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.109"
+__version__ = "2.1.110"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.109\"\n+__version__ = \"2.1.110\"\n", "issue": "Release 2.1.110\nOn the docket:\r\n+ [x] PEX runtime sys.path scrubbing is imperfect. #1944\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.109\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.110\"\n", "path": "pex/version.py"}]}
| 343 | 98 |
gh_patches_debug_27478
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5604
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Download options in Datatables_view do not work
**CKAN version**
2.9
**Describe the bug**
Using datatables_view as a default resource view, which works well. Apart from the nicer UI and pagination, one benefit of the view is that you can download a filtered version of the resource (https://github.com/ckan/ckan/pull/4497). However, none of the datatables_view download buttons work to download the filtered data.
**Steps to reproduce**
1. Add a CSV resource to a dataset
2. Create a datatables resource view (labeled 'Table' in the resource view picklist)
3. Go to resource view and try to use the Download button for any format type
4. A 404 error page replaces the datatables control
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext/datatablesview/blueprint.py`
Content:
```
1 # encoding: utf-8
2
3 from six.moves.urllib.parse import urlencode
4
5 from flask import Blueprint
6 from six import text_type
7
8 from ckan.common import json
9 from ckan.plugins.toolkit import get_action, request, h
10
11 datatablesview = Blueprint(u'datatablesview', __name__)
12
13
14 def merge_filters(view_filters, user_filters_str):
15 u'''
16 view filters are built as part of the view, user filters
17 are selected by the user interacting with the view. Any filters
18 selected by user may only tighten filters set in the view,
19 others are ignored.
20
21 >>> merge_filters({
22 ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},
23 ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')
24 {u'Department': [u'BTDT'],
25 u'OnTime_Status': [u'ONTIME'],
26 u'CASE_STATUS': [u'Open', u'Closed']}
27 '''
28 filters = dict(view_filters)
29 if not user_filters_str:
30 return filters
31 user_filters = {}
32 for k_v in user_filters_str.split(u'|'):
33 k, sep, v = k_v.partition(u':')
34 if k not in view_filters or v in view_filters[k]:
35 user_filters.setdefault(k, []).append(v)
36 for k in user_filters:
37 filters[k] = user_filters[k]
38 return filters
39
40
41 def ajax(resource_view_id):
42 resource_view = get_action(u'resource_view_show'
43 )(None, {
44 u'id': resource_view_id
45 })
46
47 draw = int(request.form[u'draw'])
48 search_text = text_type(request.form[u'search[value]'])
49 offset = int(request.form[u'start'])
50 limit = int(request.form[u'length'])
51 view_filters = resource_view.get(u'filters', {})
52 user_filters = text_type(request.form[u'filters'])
53 filters = merge_filters(view_filters, user_filters)
54
55 datastore_search = get_action(u'datastore_search')
56 unfiltered_response = datastore_search(
57 None, {
58 u"resource_id": resource_view[u'resource_id'],
59 u"limit": 0,
60 u"filters": view_filters,
61 }
62 )
63
64 cols = [f[u'id'] for f in unfiltered_response[u'fields']]
65 if u'show_fields' in resource_view:
66 cols = [c for c in cols if c in resource_view[u'show_fields']]
67
68 sort_list = []
69 i = 0
70 while True:
71 if u'order[%d][column]' % i not in request.form:
72 break
73 sort_by_num = int(request.form[u'order[%d][column]' % i])
74 sort_order = (
75 u'desc' if request.form[u'order[%d][dir]' %
76 i] == u'desc' else u'asc'
77 )
78 sort_list.append(cols[sort_by_num] + u' ' + sort_order)
79 i += 1
80
81 response = datastore_search(
82 None, {
83 u"q": search_text,
84 u"resource_id": resource_view[u'resource_id'],
85 u"offset": offset,
86 u"limit": limit,
87 u"sort": u', '.join(sort_list),
88 u"filters": filters,
89 }
90 )
91
92 return json.dumps({
93 u'draw': draw,
94 u'iTotalRecords': unfiltered_response.get(u'total', 0),
95 u'iTotalDisplayRecords': response.get(u'total', 0),
96 u'aaData': [[text_type(row.get(colname, u''))
97 for colname in cols]
98 for row in response[u'records']],
99 })
100
101
102 def filtered_download(resource_view_id):
103 params = json.loads(request.params[u'params'])
104 resource_view = get_action(u'resource_view_show'
105 )(None, {
106 u'id': resource_view_id
107 })
108
109 search_text = text_type(params[u'search'][u'value'])
110 view_filters = resource_view.get(u'filters', {})
111 user_filters = text_type(params[u'filters'])
112 filters = merge_filters(view_filters, user_filters)
113
114 datastore_search = get_action(u'datastore_search')
115 unfiltered_response = datastore_search(
116 None, {
117 u"resource_id": resource_view[u'resource_id'],
118 u"limit": 0,
119 u"filters": view_filters,
120 }
121 )
122
123 cols = [f[u'id'] for f in unfiltered_response[u'fields']]
124 if u'show_fields' in resource_view:
125 cols = [c for c in cols if c in resource_view[u'show_fields']]
126
127 sort_list = []
128 for order in params[u'order']:
129 sort_by_num = int(order[u'column'])
130 sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')
131 sort_list.append(cols[sort_by_num] + u' ' + sort_order)
132
133 cols = [c for (c, v) in zip(cols, params[u'visible']) if v]
134
135 h.redirect_to(
136 h.
137 url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +
138 u'?' + urlencode({
139 u'q': search_text,
140 u'sort': u','.join(sort_list),
141 u'filters': json.dumps(filters),
142 u'format': request.params[u'format'],
143 u'fields': u','.join(cols),
144 })
145 )
146
147
148 datatablesview.add_url_rule(
149 u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']
150 )
151
152 datatablesview.add_url_rule(
153 u'/datatables/filtered-download/<resource_view_id>',
154 view_func=filtered_download
155 )
156
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckanext/datatablesview/blueprint.py b/ckanext/datatablesview/blueprint.py
--- a/ckanext/datatablesview/blueprint.py
+++ b/ckanext/datatablesview/blueprint.py
@@ -100,7 +100,7 @@
def filtered_download(resource_view_id):
- params = json.loads(request.params[u'params'])
+ params = json.loads(request.form[u'params'])
resource_view = get_action(u'resource_view_show'
)(None, {
u'id': resource_view_id
@@ -132,14 +132,14 @@
cols = [c for (c, v) in zip(cols, params[u'visible']) if v]
- h.redirect_to(
+ return h.redirect_to(
h.
url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +
u'?' + urlencode({
u'q': search_text,
u'sort': u','.join(sort_list),
u'filters': json.dumps(filters),
- u'format': request.params[u'format'],
+ u'format': request.form[u'format'],
u'fields': u','.join(cols),
})
)
@@ -151,5 +151,5 @@
datatablesview.add_url_rule(
u'/datatables/filtered-download/<resource_view_id>',
- view_func=filtered_download
+ view_func=filtered_download, methods=[u'POST']
)
|
{"golden_diff": "diff --git a/ckanext/datatablesview/blueprint.py b/ckanext/datatablesview/blueprint.py\n--- a/ckanext/datatablesview/blueprint.py\n+++ b/ckanext/datatablesview/blueprint.py\n@@ -100,7 +100,7 @@\n \n \n def filtered_download(resource_view_id):\n- params = json.loads(request.params[u'params'])\n+ params = json.loads(request.form[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n@@ -132,14 +132,14 @@\n \n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n \n- h.redirect_to(\n+ return h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n- u'format': request.params[u'format'],\n+ u'format': request.form[u'format'],\n u'fields': u','.join(cols),\n })\n )\n@@ -151,5 +151,5 @@\n \n datatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n- view_func=filtered_download\n+ view_func=filtered_download, methods=[u'POST']\n )\n", "issue": "Download options in Datatables_view do not work\n**CKAN version**\r\n2.9\r\n\r\n**Describe the bug**\r\nUsing datatables_view as a default resource view, which works well. Apart from the nicer UI and pagination, one benefit of the view is that you can download a filtered version of the resource (https://github.com/ckan/ckan/pull/4497). However, none of the datatables_view download buttons work to download the filtered data.\r\n\r\n**Steps to reproduce**\r\n\r\n1. Add a CSV resource to a dataset\r\n2. Create a datatables resource view (labeled 'Table' in the resource view picklist)\r\n3. Go to resource view and try to use the Download button for any format type\r\n4. A 404 error page replaces the datatables control\r\n\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom six.moves.urllib.parse import urlencode\n\nfrom flask import Blueprint\nfrom six import text_type\n\nfrom ckan.common import json\nfrom ckan.plugins.toolkit import get_action, request, h\n\ndatatablesview = Blueprint(u'datatablesview', __name__)\n\n\ndef merge_filters(view_filters, user_filters_str):\n u'''\n view filters are built as part of the view, user filters\n are selected by the user interacting with the view. Any filters\n selected by user may only tighten filters set in the view,\n others are ignored.\n\n >>> merge_filters({\n ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},\n ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')\n {u'Department': [u'BTDT'],\n u'OnTime_Status': [u'ONTIME'],\n u'CASE_STATUS': [u'Open', u'Closed']}\n '''\n filters = dict(view_filters)\n if not user_filters_str:\n return filters\n user_filters = {}\n for k_v in user_filters_str.split(u'|'):\n k, sep, v = k_v.partition(u':')\n if k not in view_filters or v in view_filters[k]:\n user_filters.setdefault(k, []).append(v)\n for k in user_filters:\n filters[k] = user_filters[k]\n return filters\n\n\ndef ajax(resource_view_id):\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n draw = int(request.form[u'draw'])\n search_text = text_type(request.form[u'search[value]'])\n offset = int(request.form[u'start'])\n limit = int(request.form[u'length'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(request.form[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n i = 0\n while True:\n if u'order[%d][column]' % i not in request.form:\n break\n sort_by_num = int(request.form[u'order[%d][column]' % i])\n sort_order = (\n u'desc' if request.form[u'order[%d][dir]' %\n i] == u'desc' else u'asc'\n )\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n i += 1\n\n response = datastore_search(\n None, {\n u\"q\": search_text,\n u\"resource_id\": resource_view[u'resource_id'],\n u\"offset\": offset,\n u\"limit\": limit,\n u\"sort\": u', '.join(sort_list),\n u\"filters\": filters,\n }\n )\n\n return json.dumps({\n u'draw': draw,\n u'iTotalRecords': unfiltered_response.get(u'total', 0),\n u'iTotalDisplayRecords': response.get(u'total', 0),\n u'aaData': [[text_type(row.get(colname, u''))\n for colname in cols]\n for row in response[u'records']],\n })\n\n\ndef filtered_download(resource_view_id):\n params = json.loads(request.params[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n search_text = text_type(params[u'search'][u'value'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(params[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n for order in params[u'order']:\n sort_by_num = int(order[u'column'])\n sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n\n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n\n h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n u'format': request.params[u'format'],\n u'fields': u','.join(cols),\n })\n )\n\n\ndatatablesview.add_url_rule(\n u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']\n)\n\ndatatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n view_func=filtered_download\n)\n", "path": "ckanext/datatablesview/blueprint.py"}], "after_files": [{"content": "# encoding: utf-8\n\nfrom six.moves.urllib.parse import urlencode\n\nfrom flask import Blueprint\nfrom six import text_type\n\nfrom ckan.common import json\nfrom ckan.plugins.toolkit import get_action, request, h\n\ndatatablesview = Blueprint(u'datatablesview', __name__)\n\n\ndef merge_filters(view_filters, user_filters_str):\n u'''\n view filters are built as part of the view, user filters\n are selected by the user interacting with the view. Any filters\n selected by user may only tighten filters set in the view,\n others are ignored.\n\n >>> merge_filters({\n ... u'Department': [u'BTDT'], u'OnTime_Status': [u'ONTIME']},\n ... u'CASE_STATUS:Open|CASE_STATUS:Closed|Department:INFO')\n {u'Department': [u'BTDT'],\n u'OnTime_Status': [u'ONTIME'],\n u'CASE_STATUS': [u'Open', u'Closed']}\n '''\n filters = dict(view_filters)\n if not user_filters_str:\n return filters\n user_filters = {}\n for k_v in user_filters_str.split(u'|'):\n k, sep, v = k_v.partition(u':')\n if k not in view_filters or v in view_filters[k]:\n user_filters.setdefault(k, []).append(v)\n for k in user_filters:\n filters[k] = user_filters[k]\n return filters\n\n\ndef ajax(resource_view_id):\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n draw = int(request.form[u'draw'])\n search_text = text_type(request.form[u'search[value]'])\n offset = int(request.form[u'start'])\n limit = int(request.form[u'length'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(request.form[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n i = 0\n while True:\n if u'order[%d][column]' % i not in request.form:\n break\n sort_by_num = int(request.form[u'order[%d][column]' % i])\n sort_order = (\n u'desc' if request.form[u'order[%d][dir]' %\n i] == u'desc' else u'asc'\n )\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n i += 1\n\n response = datastore_search(\n None, {\n u\"q\": search_text,\n u\"resource_id\": resource_view[u'resource_id'],\n u\"offset\": offset,\n u\"limit\": limit,\n u\"sort\": u', '.join(sort_list),\n u\"filters\": filters,\n }\n )\n\n return json.dumps({\n u'draw': draw,\n u'iTotalRecords': unfiltered_response.get(u'total', 0),\n u'iTotalDisplayRecords': response.get(u'total', 0),\n u'aaData': [[text_type(row.get(colname, u''))\n for colname in cols]\n for row in response[u'records']],\n })\n\n\ndef filtered_download(resource_view_id):\n params = json.loads(request.form[u'params'])\n resource_view = get_action(u'resource_view_show'\n )(None, {\n u'id': resource_view_id\n })\n\n search_text = text_type(params[u'search'][u'value'])\n view_filters = resource_view.get(u'filters', {})\n user_filters = text_type(params[u'filters'])\n filters = merge_filters(view_filters, user_filters)\n\n datastore_search = get_action(u'datastore_search')\n unfiltered_response = datastore_search(\n None, {\n u\"resource_id\": resource_view[u'resource_id'],\n u\"limit\": 0,\n u\"filters\": view_filters,\n }\n )\n\n cols = [f[u'id'] for f in unfiltered_response[u'fields']]\n if u'show_fields' in resource_view:\n cols = [c for c in cols if c in resource_view[u'show_fields']]\n\n sort_list = []\n for order in params[u'order']:\n sort_by_num = int(order[u'column'])\n sort_order = (u'desc' if order[u'dir'] == u'desc' else u'asc')\n sort_list.append(cols[sort_by_num] + u' ' + sort_order)\n\n cols = [c for (c, v) in zip(cols, params[u'visible']) if v]\n\n return h.redirect_to(\n h.\n url_for(u'datastore.dump', resource_id=resource_view[u'resource_id']) +\n u'?' + urlencode({\n u'q': search_text,\n u'sort': u','.join(sort_list),\n u'filters': json.dumps(filters),\n u'format': request.form[u'format'],\n u'fields': u','.join(cols),\n })\n )\n\n\ndatatablesview.add_url_rule(\n u'/datatables/ajax/<resource_view_id>', view_func=ajax, methods=[u'POST']\n)\n\ndatatablesview.add_url_rule(\n u'/datatables/filtered-download/<resource_view_id>',\n view_func=filtered_download, methods=[u'POST']\n)\n", "path": "ckanext/datatablesview/blueprint.py"}]}
| 2,039 | 327 |
gh_patches_debug_34522
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-402
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not all headers are automatically linked
I have an API reference site for a project that's hosted on ReadTheDocs using mkdocs as the documentation engine. Headers that contain things like `<code>` blocks aren't linked, while all others seem to be.
I can reproduce this locally with a plain mkdocs install using the RTD theme.
Here's an example:
http://carbon.lpghatguy.com/en/latest/Classes/Collections.Tuple/
All three of the methods in that page should be automatically linked in the sidebar navigation, but only the one without any fancy decoration is. All of them have been given valid HTML ids, so they're possible to link, they just aren't.
The markdown for that page, which works around a couple RTD bugs and doesn't look that great, is here:
https://raw.githubusercontent.com/lua-carbon/carbon/master/docs/Classes/Collections.Tuple.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mkdocs/compat.py`
Content:
```
1 # coding: utf-8
2 """Python 2/3 compatibility module."""
3 import sys
4
5 PY2 = int(sys.version[0]) == 2
6
7 if PY2:
8 from urlparse import urljoin, urlparse, urlunparse
9 import urllib
10 urlunquote = urllib.unquote
11
12 import SimpleHTTPServer as httpserver
13 httpserver = httpserver
14 import SocketServer
15 socketserver = SocketServer
16
17 import itertools
18 zip = itertools.izip
19
20 text_type = unicode
21 binary_type = str
22 string_types = (str, unicode)
23 unicode = unicode
24 basestring = basestring
25 else: # PY3
26 from urllib.parse import urljoin, urlparse, urlunparse, unquote
27 urlunquote = unquote
28
29 import http.server as httpserver
30 httpserver = httpserver
31 import socketserver
32 socketserver = socketserver
33
34 zip = zip
35
36 text_type = str
37 binary_type = bytes
38 string_types = (str,)
39 unicode = str
40 basestring = (str, bytes)
41
```
Path: `mkdocs/toc.py`
Content:
```
1 # coding: utf-8
2
3 """
4 Deals with generating the per-page table of contents.
5
6 For the sake of simplicity we use an existing markdown extension to generate
7 an HTML table of contents, and then parse that into the underlying data.
8
9 The steps we take to generate a table of contents are:
10
11 * Pre-process the markdown, injecting a [TOC] marker.
12 * Generate HTML from markdown.
13 * Post-process the HTML, spliting the content and the table of contents.
14 * Parse table of contents HTML into the underlying data structure.
15 """
16
17 import re
18
19 TOC_LINK_REGEX = re.compile('<a href=["]([^"]*)["]>([^<]*)</a>')
20
21
22 class TableOfContents(object):
23 """
24 Represents the table of contents for a given page.
25 """
26 def __init__(self, html):
27 self.items = _parse_html_table_of_contents(html)
28
29 def __iter__(self):
30 return iter(self.items)
31
32 def __str__(self):
33 return ''.join([str(item) for item in self])
34
35
36 class AnchorLink(object):
37 """
38 A single entry in the table of contents.
39 """
40 def __init__(self, title, url):
41 self.title, self.url = title, url
42 self.children = []
43
44 def __str__(self):
45 return self._indent_print()
46
47 def _indent_print(self, depth=0):
48 indent = ' ' * depth
49 ret = '%s%s - %s\n' % (indent, self.title, self.url)
50 for item in self.children:
51 ret += item._indent_print(depth + 1)
52 return ret
53
54
55 def _parse_html_table_of_contents(html):
56 """
57 Given a table of contents string that has been automatically generated by
58 the markdown library, parse it into a tree of AnchorLink instances.
59
60 Returns a list of all the parent AnchorLink instances.
61 """
62 lines = html.splitlines()[2:-2]
63 parents = []
64 ret = []
65 for line in lines:
66 match = TOC_LINK_REGEX.search(line)
67 if match:
68 href, title = match.groups()
69 nav = AnchorLink(title, href)
70 # Add the item to its parent if required. If it is a topmost
71 # item then instead append it to our return value.
72 if parents:
73 parents[-1].children.append(nav)
74 else:
75 ret.append(nav)
76 # If this item has children, store it as the current parent
77 if line.endswith('<ul>'):
78 parents.append(nav)
79 elif line.startswith('</ul>'):
80 if parents:
81 parents.pop()
82
83 # For the table of contents, always mark the first element as active
84 if ret:
85 ret[0].active = True
86
87 return ret
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mkdocs/compat.py b/mkdocs/compat.py
--- a/mkdocs/compat.py
+++ b/mkdocs/compat.py
@@ -13,6 +13,7 @@
httpserver = httpserver
import SocketServer
socketserver = SocketServer
+ from HTMLParser import HTMLParser
import itertools
zip = itertools.izip
@@ -30,6 +31,7 @@
httpserver = httpserver
import socketserver
socketserver = socketserver
+ from html.parser import HTMLParser
zip = zip
diff --git a/mkdocs/toc.py b/mkdocs/toc.py
--- a/mkdocs/toc.py
+++ b/mkdocs/toc.py
@@ -14,9 +14,7 @@
* Parse table of contents HTML into the underlying data structure.
"""
-import re
-
-TOC_LINK_REGEX = re.compile('<a href=["]([^"]*)["]>([^<]*)</a>')
+from mkdocs.compat import HTMLParser
class TableOfContents(object):
@@ -52,6 +50,32 @@
return ret
+class TOCParser(HTMLParser):
+
+ def __init__(self):
+ HTMLParser.__init__(self)
+ self.links = []
+
+ self.in_anchor = True
+ self.attrs = None
+ self.title = ''
+
+ def handle_starttag(self, tag, attrs):
+
+ if tag == 'a':
+ self.in_anchor = True
+ self.attrs = dict(attrs)
+
+ def handle_endtag(self, tag):
+ if tag == 'a':
+ self.in_anchor = False
+
+ def handle_data(self, data):
+
+ if self.in_anchor:
+ self.title += data
+
+
def _parse_html_table_of_contents(html):
"""
Given a table of contents string that has been automatically generated by
@@ -63,9 +87,11 @@
parents = []
ret = []
for line in lines:
- match = TOC_LINK_REGEX.search(line)
- if match:
- href, title = match.groups()
+ parser = TOCParser()
+ parser.feed(line)
+ if parser.title:
+ href = parser.attrs['href']
+ title = parser.title
nav = AnchorLink(title, href)
# Add the item to its parent if required. If it is a topmost
# item then instead append it to our return value.
|
{"golden_diff": "diff --git a/mkdocs/compat.py b/mkdocs/compat.py\n--- a/mkdocs/compat.py\n+++ b/mkdocs/compat.py\n@@ -13,6 +13,7 @@\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n+ from HTMLParser import HTMLParser\n \n import itertools\n zip = itertools.izip\n@@ -30,6 +31,7 @@\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n+ from html.parser import HTMLParser\n \n zip = zip\n \ndiff --git a/mkdocs/toc.py b/mkdocs/toc.py\n--- a/mkdocs/toc.py\n+++ b/mkdocs/toc.py\n@@ -14,9 +14,7 @@\n * Parse table of contents HTML into the underlying data structure.\n \"\"\"\n \n-import re\n-\n-TOC_LINK_REGEX = re.compile('<a href=[\"]([^\"]*)[\"]>([^<]*)</a>')\n+from mkdocs.compat import HTMLParser\n \n \n class TableOfContents(object):\n@@ -52,6 +50,32 @@\n return ret\n \n \n+class TOCParser(HTMLParser):\n+\n+ def __init__(self):\n+ HTMLParser.__init__(self)\n+ self.links = []\n+\n+ self.in_anchor = True\n+ self.attrs = None\n+ self.title = ''\n+\n+ def handle_starttag(self, tag, attrs):\n+\n+ if tag == 'a':\n+ self.in_anchor = True\n+ self.attrs = dict(attrs)\n+\n+ def handle_endtag(self, tag):\n+ if tag == 'a':\n+ self.in_anchor = False\n+\n+ def handle_data(self, data):\n+\n+ if self.in_anchor:\n+ self.title += data\n+\n+\n def _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n@@ -63,9 +87,11 @@\n parents = []\n ret = []\n for line in lines:\n- match = TOC_LINK_REGEX.search(line)\n- if match:\n- href, title = match.groups()\n+ parser = TOCParser()\n+ parser.feed(line)\n+ if parser.title:\n+ href = parser.attrs['href']\n+ title = parser.title\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n", "issue": "Not all headers are automatically linked\nI have an API reference site for a project that's hosted on ReadTheDocs using mkdocs as the documentation engine. Headers that contain things like `<code>` blocks aren't linked, while all others seem to be.\n\nI can reproduce this locally with a plain mkdocs install using the RTD theme.\n\nHere's an example:\nhttp://carbon.lpghatguy.com/en/latest/Classes/Collections.Tuple/\n\nAll three of the methods in that page should be automatically linked in the sidebar navigation, but only the one without any fancy decoration is. All of them have been given valid HTML ids, so they're possible to link, they just aren't.\n\nThe markdown for that page, which works around a couple RTD bugs and doesn't look that great, is here:\nhttps://raw.githubusercontent.com/lua-carbon/carbon/master/docs/Classes/Collections.Tuple.md\n\n", "before_files": [{"content": "# coding: utf-8\n\"\"\"Python 2/3 compatibility module.\"\"\"\nimport sys\n\nPY2 = int(sys.version[0]) == 2\n\nif PY2:\n from urlparse import urljoin, urlparse, urlunparse\n import urllib\n urlunquote = urllib.unquote\n\n import SimpleHTTPServer as httpserver\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n\n import itertools\n zip = itertools.izip\n\n text_type = unicode\n binary_type = str\n string_types = (str, unicode)\n unicode = unicode\n basestring = basestring\nelse: # PY3\n from urllib.parse import urljoin, urlparse, urlunparse, unquote\n urlunquote = unquote\n\n import http.server as httpserver\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n\n zip = zip\n\n text_type = str\n binary_type = bytes\n string_types = (str,)\n unicode = str\n basestring = (str, bytes)\n", "path": "mkdocs/compat.py"}, {"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the per-page table of contents.\n\nFor the sake of simplicity we use an existing markdown extension to generate\nan HTML table of contents, and then parse that into the underlying data.\n\nThe steps we take to generate a table of contents are:\n\n* Pre-process the markdown, injecting a [TOC] marker.\n* Generate HTML from markdown.\n* Post-process the HTML, spliting the content and the table of contents.\n* Parse table of contents HTML into the underlying data structure.\n\"\"\"\n\nimport re\n\nTOC_LINK_REGEX = re.compile('<a href=[\"]([^\"]*)[\"]>([^<]*)</a>')\n\n\nclass TableOfContents(object):\n \"\"\"\n Represents the table of contents for a given page.\n \"\"\"\n def __init__(self, html):\n self.items = _parse_html_table_of_contents(html)\n\n def __iter__(self):\n return iter(self.items)\n\n def __str__(self):\n return ''.join([str(item) for item in self])\n\n\nclass AnchorLink(object):\n \"\"\"\n A single entry in the table of contents.\n \"\"\"\n def __init__(self, title, url):\n self.title, self.url = title, url\n self.children = []\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n ret = '%s%s - %s\\n' % (indent, self.title, self.url)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\ndef _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n the markdown library, parse it into a tree of AnchorLink instances.\n\n Returns a list of all the parent AnchorLink instances.\n \"\"\"\n lines = html.splitlines()[2:-2]\n parents = []\n ret = []\n for line in lines:\n match = TOC_LINK_REGEX.search(line)\n if match:\n href, title = match.groups()\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n if parents:\n parents[-1].children.append(nav)\n else:\n ret.append(nav)\n # If this item has children, store it as the current parent\n if line.endswith('<ul>'):\n parents.append(nav)\n elif line.startswith('</ul>'):\n if parents:\n parents.pop()\n\n # For the table of contents, always mark the first element as active\n if ret:\n ret[0].active = True\n\n return ret\n", "path": "mkdocs/toc.py"}], "after_files": [{"content": "# coding: utf-8\n\"\"\"Python 2/3 compatibility module.\"\"\"\nimport sys\n\nPY2 = int(sys.version[0]) == 2\n\nif PY2:\n from urlparse import urljoin, urlparse, urlunparse\n import urllib\n urlunquote = urllib.unquote\n\n import SimpleHTTPServer as httpserver\n httpserver = httpserver\n import SocketServer\n socketserver = SocketServer\n from HTMLParser import HTMLParser\n\n import itertools\n zip = itertools.izip\n\n text_type = unicode\n binary_type = str\n string_types = (str, unicode)\n unicode = unicode\n basestring = basestring\nelse: # PY3\n from urllib.parse import urljoin, urlparse, urlunparse, unquote\n urlunquote = unquote\n\n import http.server as httpserver\n httpserver = httpserver\n import socketserver\n socketserver = socketserver\n from html.parser import HTMLParser\n\n zip = zip\n\n text_type = str\n binary_type = bytes\n string_types = (str,)\n unicode = str\n basestring = (str, bytes)\n", "path": "mkdocs/compat.py"}, {"content": "# coding: utf-8\n\n\"\"\"\nDeals with generating the per-page table of contents.\n\nFor the sake of simplicity we use an existing markdown extension to generate\nan HTML table of contents, and then parse that into the underlying data.\n\nThe steps we take to generate a table of contents are:\n\n* Pre-process the markdown, injecting a [TOC] marker.\n* Generate HTML from markdown.\n* Post-process the HTML, spliting the content and the table of contents.\n* Parse table of contents HTML into the underlying data structure.\n\"\"\"\n\nfrom mkdocs.compat import HTMLParser\n\n\nclass TableOfContents(object):\n \"\"\"\n Represents the table of contents for a given page.\n \"\"\"\n def __init__(self, html):\n self.items = _parse_html_table_of_contents(html)\n\n def __iter__(self):\n return iter(self.items)\n\n def __str__(self):\n return ''.join([str(item) for item in self])\n\n\nclass AnchorLink(object):\n \"\"\"\n A single entry in the table of contents.\n \"\"\"\n def __init__(self, title, url):\n self.title, self.url = title, url\n self.children = []\n\n def __str__(self):\n return self._indent_print()\n\n def _indent_print(self, depth=0):\n indent = ' ' * depth\n ret = '%s%s - %s\\n' % (indent, self.title, self.url)\n for item in self.children:\n ret += item._indent_print(depth + 1)\n return ret\n\n\nclass TOCParser(HTMLParser):\n\n def __init__(self):\n HTMLParser.__init__(self)\n self.links = []\n\n self.in_anchor = True\n self.attrs = None\n self.title = ''\n\n def handle_starttag(self, tag, attrs):\n\n if tag == 'a':\n self.in_anchor = True\n self.attrs = dict(attrs)\n\n def handle_endtag(self, tag):\n if tag == 'a':\n self.in_anchor = False\n\n def handle_data(self, data):\n\n if self.in_anchor:\n self.title += data\n\n\ndef _parse_html_table_of_contents(html):\n \"\"\"\n Given a table of contents string that has been automatically generated by\n the markdown library, parse it into a tree of AnchorLink instances.\n\n Returns a list of all the parent AnchorLink instances.\n \"\"\"\n lines = html.splitlines()[2:-2]\n parents = []\n ret = []\n for line in lines:\n parser = TOCParser()\n parser.feed(line)\n if parser.title:\n href = parser.attrs['href']\n title = parser.title\n nav = AnchorLink(title, href)\n # Add the item to its parent if required. If it is a topmost\n # item then instead append it to our return value.\n if parents:\n parents[-1].children.append(nav)\n else:\n ret.append(nav)\n # If this item has children, store it as the current parent\n if line.endswith('<ul>'):\n parents.append(nav)\n elif line.startswith('</ul>'):\n if parents:\n parents.pop()\n\n # For the table of contents, always mark the first element as active\n if ret:\n ret[0].active = True\n\n return ret\n", "path": "mkdocs/toc.py"}]}
| 1,532 | 558 |
gh_patches_debug_15267
|
rasdani/github-patches
|
git_diff
|
networkx__networkx-2996
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
metric_closure will throw KeyError with unconnected graph
Suggest checking connectedness with `nx.is_connected()` on entry to `metric_closure()` and throwing a more informative error if not.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `networkx/algorithms/approximation/steinertree.py`
Content:
```
1 from itertools import combinations, chain
2
3 from networkx.utils import pairwise, not_implemented_for
4 import networkx as nx
5
6 __all__ = ['metric_closure', 'steiner_tree']
7
8
9 @not_implemented_for('directed')
10 def metric_closure(G, weight='weight'):
11 """ Return the metric closure of a graph.
12
13 The metric closure of a graph *G* is the complete graph in which each edge
14 is weighted by the shortest path distance between the nodes in *G* .
15
16 Parameters
17 ----------
18 G : NetworkX graph
19
20 Returns
21 -------
22 NetworkX graph
23 Metric closure of the graph `G`.
24
25 """
26 M = nx.Graph()
27
28 seen = set()
29 Gnodes = set(G)
30 for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):
31 seen.add(u)
32 for v in Gnodes - seen:
33 M.add_edge(u, v, distance=distance[v], path=path[v])
34
35 return M
36
37
38 @not_implemented_for('directed')
39 def steiner_tree(G, terminal_nodes, weight='weight'):
40 """ Return an approximation to the minimum Steiner tree of a graph.
41
42 Parameters
43 ----------
44 G : NetworkX graph
45
46 terminal_nodes : list
47 A list of terminal nodes for which minimum steiner tree is
48 to be found.
49
50 Returns
51 -------
52 NetworkX graph
53 Approximation to the minimum steiner tree of `G` induced by
54 `terminal_nodes` .
55
56 Notes
57 -----
58 Steiner tree can be approximated by computing the minimum spanning
59 tree of the subgraph of the metric closure of the graph induced by the
60 terminal nodes, where the metric closure of *G* is the complete graph in
61 which each edge is weighted by the shortest path distance between the
62 nodes in *G* .
63 This algorithm produces a tree whose weight is within a (2 - (2 / t))
64 factor of the weight of the optimal Steiner tree where *t* is number of
65 terminal nodes.
66
67 """
68 # M is the subgraph of the metric closure induced by the terminal nodes of
69 # G.
70 M = metric_closure(G, weight=weight)
71 # Use the 'distance' attribute of each edge provided by the metric closure
72 # graph.
73 H = M.subgraph(terminal_nodes)
74 mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)
75 # Create an iterator over each edge in each shortest path; repeats are okay
76 edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)
77 T = G.edge_subgraph(edges)
78 return T
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py
--- a/networkx/algorithms/approximation/steinertree.py
+++ b/networkx/algorithms/approximation/steinertree.py
@@ -25,11 +25,22 @@
"""
M = nx.Graph()
- seen = set()
Gnodes = set(G)
- for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):
- seen.add(u)
- for v in Gnodes - seen:
+
+ # check for connected graph while processing first node
+ all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)
+ u, (distance, path) = next(all_paths_iter)
+ if Gnodes - set(distance):
+ msg = "G is not a connected graph. metric_closure is not defined."
+ raise nx.NetworkXError(msg)
+ Gnodes.remove(u)
+ for v in Gnodes:
+ M.add_edge(u, v, distance=distance[v], path=path[v])
+
+ # first node done -- now process the rest
+ for u, (distance, path) in all_paths_iter:
+ Gnodes.remove(u)
+ for v in Gnodes:
M.add_edge(u, v, distance=distance[v], path=path[v])
return M
|
{"golden_diff": "diff --git a/networkx/algorithms/approximation/steinertree.py b/networkx/algorithms/approximation/steinertree.py\n--- a/networkx/algorithms/approximation/steinertree.py\n+++ b/networkx/algorithms/approximation/steinertree.py\n@@ -25,11 +25,22 @@\n \"\"\"\n M = nx.Graph()\n \n- seen = set()\n Gnodes = set(G)\n- for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):\n- seen.add(u)\n- for v in Gnodes - seen:\n+\n+ # check for connected graph while processing first node\n+ all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n+ u, (distance, path) = next(all_paths_iter)\n+ if Gnodes - set(distance):\n+ msg = \"G is not a connected graph. metric_closure is not defined.\"\n+ raise nx.NetworkXError(msg)\n+ Gnodes.remove(u)\n+ for v in Gnodes:\n+ M.add_edge(u, v, distance=distance[v], path=path[v])\n+\n+ # first node done -- now process the rest\n+ for u, (distance, path) in all_paths_iter:\n+ Gnodes.remove(u)\n+ for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n \n return M\n", "issue": "metric_closure will throw KeyError with unconnected graph\nSuggest checking connectedness with `nx.is_connected()` on entry to `metric_closure()` and throwing a more informative error if not.\n", "before_files": [{"content": "from itertools import combinations, chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = ['metric_closure', 'steiner_tree']\n\n\n@not_implemented_for('directed')\ndef metric_closure(G, weight='weight'):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n seen = set()\n Gnodes = set(G)\n for u, (distance, path) in nx.all_pairs_dijkstra(G, weight=weight):\n seen.add(u)\n for v in Gnodes - seen:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for('directed')\ndef steiner_tree(G, terminal_nodes, weight='weight'):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n Steiner tree can be approximated by computing the minimum spanning\n tree of the subgraph of the metric closure of the graph induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n \"\"\"\n # M is the subgraph of the metric closure induced by the terminal nodes of\n # G.\n M = metric_closure(G, weight=weight)\n # Use the 'distance' attribute of each edge provided by the metric closure\n # graph.\n H = M.subgraph(terminal_nodes)\n mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}], "after_files": [{"content": "from itertools import combinations, chain\n\nfrom networkx.utils import pairwise, not_implemented_for\nimport networkx as nx\n\n__all__ = ['metric_closure', 'steiner_tree']\n\n\n@not_implemented_for('directed')\ndef metric_closure(G, weight='weight'):\n \"\"\" Return the metric closure of a graph.\n\n The metric closure of a graph *G* is the complete graph in which each edge\n is weighted by the shortest path distance between the nodes in *G* .\n\n Parameters\n ----------\n G : NetworkX graph\n\n Returns\n -------\n NetworkX graph\n Metric closure of the graph `G`.\n\n \"\"\"\n M = nx.Graph()\n\n Gnodes = set(G)\n\n # check for connected graph while processing first node\n all_paths_iter = nx.all_pairs_dijkstra(G, weight=weight)\n u, (distance, path) = next(all_paths_iter)\n if Gnodes - set(distance):\n msg = \"G is not a connected graph. metric_closure is not defined.\"\n raise nx.NetworkXError(msg)\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n # first node done -- now process the rest\n for u, (distance, path) in all_paths_iter:\n Gnodes.remove(u)\n for v in Gnodes:\n M.add_edge(u, v, distance=distance[v], path=path[v])\n\n return M\n\n\n@not_implemented_for('directed')\ndef steiner_tree(G, terminal_nodes, weight='weight'):\n \"\"\" Return an approximation to the minimum Steiner tree of a graph.\n\n Parameters\n ----------\n G : NetworkX graph\n\n terminal_nodes : list\n A list of terminal nodes for which minimum steiner tree is\n to be found.\n\n Returns\n -------\n NetworkX graph\n Approximation to the minimum steiner tree of `G` induced by\n `terminal_nodes` .\n\n Notes\n -----\n Steiner tree can be approximated by computing the minimum spanning\n tree of the subgraph of the metric closure of the graph induced by the\n terminal nodes, where the metric closure of *G* is the complete graph in\n which each edge is weighted by the shortest path distance between the\n nodes in *G* .\n This algorithm produces a tree whose weight is within a (2 - (2 / t))\n factor of the weight of the optimal Steiner tree where *t* is number of\n terminal nodes.\n\n \"\"\"\n # M is the subgraph of the metric closure induced by the terminal nodes of\n # G.\n M = metric_closure(G, weight=weight)\n # Use the 'distance' attribute of each edge provided by the metric closure\n # graph.\n H = M.subgraph(terminal_nodes)\n mst_edges = nx.minimum_spanning_edges(H, weight='distance', data=True)\n # Create an iterator over each edge in each shortest path; repeats are okay\n edges = chain.from_iterable(pairwise(d['path']) for u, v, d in mst_edges)\n T = G.edge_subgraph(edges)\n return T\n", "path": "networkx/algorithms/approximation/steinertree.py"}]}
| 1,040 | 313 |
gh_patches_debug_2370
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1110
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mixed view_only in multiple data_source_groups blocks query executions
A user belonging to multiple groups that have access to one data source but with different access levels can not execute queries on that data source.
For example, if a user belongs to built-in `default` group and you have set `view_only` for all data sources in this group to true, adding this user to a new group to allow full access to one of the data sources will not work.
This is caused by `group_level` definition in `def has_access()` in [permissions.py](https://github.com/getredash/redash/blob/master/redash/permissions.py):
```
required_level = 1 if need_view_only else 2
group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
return required_level <= group_level
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/permissions.py`
Content:
```
1 from flask_login import current_user
2 from flask_restful import abort
3 import functools
4 from funcy import any, flatten
5
6 view_only = True
7 not_view_only = False
8
9
10 def has_access(object_groups, user, need_view_only):
11 if 'admin' in user.permissions:
12 return True
13
14 matching_groups = set(object_groups.keys()).intersection(user.groups)
15
16 if not matching_groups:
17 return False
18
19 required_level = 1 if need_view_only else 2
20 group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
21
22 return required_level <= group_level
23
24
25 def require_access(object_groups, user, need_view_only):
26 if not has_access(object_groups, user, need_view_only):
27 abort(403)
28
29
30 class require_permissions(object):
31 def __init__(self, permissions):
32 self.permissions = permissions
33
34 def __call__(self, fn):
35 @functools.wraps(fn)
36 def decorated(*args, **kwargs):
37 has_permissions = current_user.has_permissions(self.permissions)
38
39 if has_permissions:
40 return fn(*args, **kwargs)
41 else:
42 abort(403)
43
44 return decorated
45
46
47 def require_permission(permission):
48 return require_permissions((permission,))
49
50
51 def require_admin(fn):
52 return require_permission('admin')(fn)
53
54
55 def require_super_admin(fn):
56 return require_permission('super_admin')(fn)
57
58
59 def has_permission_or_owner(permission, object_owner_id):
60 return int(object_owner_id) == current_user.id or current_user.has_permission(permission)
61
62
63 def is_admin_or_owner(object_owner_id):
64 return has_permission_or_owner('admin', object_owner_id)
65
66
67 def require_permission_or_owner(permission, object_owner_id):
68 if not has_permission_or_owner(permission, object_owner_id):
69 abort(403)
70
71
72 def require_admin_or_owner(object_owner_id):
73 if not is_admin_or_owner(object_owner_id):
74 abort(403, message="You don't have permission to edit this resource.")
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/permissions.py b/redash/permissions.py
--- a/redash/permissions.py
+++ b/redash/permissions.py
@@ -17,7 +17,8 @@
return False
required_level = 1 if need_view_only else 2
- group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2
+
+ group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2
return required_level <= group_level
|
{"golden_diff": "diff --git a/redash/permissions.py b/redash/permissions.py\n--- a/redash/permissions.py\n+++ b/redash/permissions.py\n@@ -17,7 +17,8 @@\n return False\n \n required_level = 1 if need_view_only else 2\n- group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n+\n+ group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2\n \n return required_level <= group_level\n", "issue": "Mixed view_only in multiple data_source_groups blocks query executions\nA user belonging to multiple groups that have access to one data source but with different access levels can not execute queries on that data source.\n\nFor example, if a user belongs to built-in `default` group and you have set `view_only` for all data sources in this group to true, adding this user to a new group to allow full access to one of the data sources will not work.\n\nThis is caused by `group_level` definition in `def has_access()` in [permissions.py](https://github.com/getredash/redash/blob/master/redash/permissions.py):\n\n```\nrequired_level = 1 if need_view_only else 2\ngroup_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n\nreturn required_level <= group_level\n```\n\n", "before_files": [{"content": "from flask_login import current_user\nfrom flask_restful import abort\nimport functools\nfrom funcy import any, flatten\n\nview_only = True\nnot_view_only = False\n\n\ndef has_access(object_groups, user, need_view_only):\n if 'admin' in user.permissions:\n return True\n\n matching_groups = set(object_groups.keys()).intersection(user.groups)\n\n if not matching_groups:\n return False\n\n required_level = 1 if need_view_only else 2\n group_level = 1 if any(flatten([object_groups[group] for group in matching_groups])) else 2\n\n return required_level <= group_level\n\n\ndef require_access(object_groups, user, need_view_only):\n if not has_access(object_groups, user, need_view_only):\n abort(403)\n\n\nclass require_permissions(object):\n def __init__(self, permissions):\n self.permissions = permissions\n\n def __call__(self, fn):\n @functools.wraps(fn)\n def decorated(*args, **kwargs):\n has_permissions = current_user.has_permissions(self.permissions)\n\n if has_permissions:\n return fn(*args, **kwargs)\n else:\n abort(403)\n\n return decorated\n\n\ndef require_permission(permission):\n return require_permissions((permission,))\n\n\ndef require_admin(fn):\n return require_permission('admin')(fn)\n\n\ndef require_super_admin(fn):\n return require_permission('super_admin')(fn)\n\n\ndef has_permission_or_owner(permission, object_owner_id):\n return int(object_owner_id) == current_user.id or current_user.has_permission(permission)\n\n\ndef is_admin_or_owner(object_owner_id):\n return has_permission_or_owner('admin', object_owner_id)\n\n\ndef require_permission_or_owner(permission, object_owner_id):\n if not has_permission_or_owner(permission, object_owner_id):\n abort(403)\n\n\ndef require_admin_or_owner(object_owner_id):\n if not is_admin_or_owner(object_owner_id):\n abort(403, message=\"You don't have permission to edit this resource.\")\n", "path": "redash/permissions.py"}], "after_files": [{"content": "from flask_login import current_user\nfrom flask_restful import abort\nimport functools\nfrom funcy import any, flatten\n\nview_only = True\nnot_view_only = False\n\n\ndef has_access(object_groups, user, need_view_only):\n if 'admin' in user.permissions:\n return True\n\n matching_groups = set(object_groups.keys()).intersection(user.groups)\n\n if not matching_groups:\n return False\n\n required_level = 1 if need_view_only else 2\n\n group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2\n\n return required_level <= group_level\n\n\ndef require_access(object_groups, user, need_view_only):\n if not has_access(object_groups, user, need_view_only):\n abort(403)\n\n\nclass require_permissions(object):\n def __init__(self, permissions):\n self.permissions = permissions\n\n def __call__(self, fn):\n @functools.wraps(fn)\n def decorated(*args, **kwargs):\n has_permissions = current_user.has_permissions(self.permissions)\n\n if has_permissions:\n return fn(*args, **kwargs)\n else:\n abort(403)\n\n return decorated\n\n\ndef require_permission(permission):\n return require_permissions((permission,))\n\n\ndef require_admin(fn):\n return require_permission('admin')(fn)\n\n\ndef require_super_admin(fn):\n return require_permission('super_admin')(fn)\n\n\ndef has_permission_or_owner(permission, object_owner_id):\n return int(object_owner_id) == current_user.id or current_user.has_permission(permission)\n\n\ndef is_admin_or_owner(object_owner_id):\n return has_permission_or_owner('admin', object_owner_id)\n\n\ndef require_permission_or_owner(permission, object_owner_id):\n if not has_permission_or_owner(permission, object_owner_id):\n abort(403)\n\n\ndef require_admin_or_owner(object_owner_id):\n if not is_admin_or_owner(object_owner_id):\n abort(403, message=\"You don't have permission to edit this resource.\")\n", "path": "redash/permissions.py"}]}
| 1,018 | 123 |
gh_patches_debug_19237
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-8048
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Customize warning formatter
I'm trying out the imminent bokeh release with the dask dashboard. I get hundreds of lines like the following:
```python
/home/mrocklin/Software/anaconda/lib/python3.6/site-packages/bokeh/models/sources.py:91: BokehUserWarning: ColumnD)
"Current lengths: %s" % ", ".join(sorted(str((k, len(v))) for k, v in data.items())), BokehUserWarning))
```
Clearly I'm doing something wrong in my code, and it's great to know about it. However, two things would make this nicer:
1. Getting some sort of information about the cause of the failure. It looks like an informative error message was attempted, but rather than getting a nice result I get the code instead.
2. These are filling up my terminal at the rate that I update my plots. It might be nice to only warn once or twice.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/__init__.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.
3 #
4 # Powered by the Bokeh Development Team.
5 #
6 # The full license is in the file LICENSE.txt, distributed with this software.
7 #-----------------------------------------------------------------------------
8 ''' Bokeh is a Python interactive visualization library that targets modern
9 web browsers for presentation.
10
11 Its goal is to provide elegant, concise construction of versatile graphics,
12 and also deliver this capability with high-performance interactivity over large
13 or streaming datasets. Bokeh can help anyone who would like to quickly and
14 easily create interactive plots, dashboards, and data applications.
15
16 For full documentation, please visit: https://bokeh.pydata.org
17
18 '''
19
20 #-----------------------------------------------------------------------------
21 # Boilerplate
22 #-----------------------------------------------------------------------------
23 from __future__ import absolute_import, division, print_function, unicode_literals
24
25 import logging
26 log = logging.getLogger(__name__)
27
28 #-----------------------------------------------------------------------------
29 # General API
30 #-----------------------------------------------------------------------------
31
32 __all__ = (
33 '__version__',
34 'license',
35 'sampledata',
36 )
37
38 # configure Bokeh version
39 from .util.version import __version__; __version__
40
41 def license():
42 ''' Print the Bokeh license to the console.
43
44 Returns:
45 None
46
47 '''
48 from os.path import join
49 with open(join(__path__[0], 'LICENSE.txt')) as lic:
50 print(lic.read())
51
52 # expose sample data module
53 from . import sampledata; sampledata
54
55 #-----------------------------------------------------------------------------
56 # Code
57 #-----------------------------------------------------------------------------
58
59 # configure Bokeh logger
60 from .util import logconfig
61 del logconfig
62
63 # Configure warnings to always show, despite Python's active efforts to hide them from users.
64 import warnings
65 from .util.warnings import BokehDeprecationWarning, BokehUserWarning
66 warnings.simplefilter('always', BokehDeprecationWarning)
67 warnings.simplefilter('always', BokehUserWarning)
68 del BokehDeprecationWarning, BokehUserWarning
69 del warnings
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/__init__.py b/bokeh/__init__.py
--- a/bokeh/__init__.py
+++ b/bokeh/__init__.py
@@ -60,10 +60,21 @@
from .util import logconfig
del logconfig
-# Configure warnings to always show, despite Python's active efforts to hide them from users.
+# Configure warnings to always show nice mssages, despite Python's active
+# efforts to hide them from users.
import warnings
from .util.warnings import BokehDeprecationWarning, BokehUserWarning
warnings.simplefilter('always', BokehDeprecationWarning)
warnings.simplefilter('always', BokehUserWarning)
+
+original_formatwarning = warnings.formatwarning
+def _formatwarning(message, category, filename, lineno, line=None):
+ from .util.warnings import BokehDeprecationWarning, BokehUserWarning
+ if category not in (BokehDeprecationWarning, BokehUserWarning):
+ return original_formatwarning(message, category, filename, lineno, line)
+ return "%s: %s\n" % (category.__name__, message)
+warnings.formatwarning = _formatwarning
+
+del _formatwarning
del BokehDeprecationWarning, BokehUserWarning
del warnings
|
{"golden_diff": "diff --git a/bokeh/__init__.py b/bokeh/__init__.py\n--- a/bokeh/__init__.py\n+++ b/bokeh/__init__.py\n@@ -60,10 +60,21 @@\n from .util import logconfig\n del logconfig\n \n-# Configure warnings to always show, despite Python's active efforts to hide them from users.\n+# Configure warnings to always show nice mssages, despite Python's active\n+# efforts to hide them from users.\n import warnings\n from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n warnings.simplefilter('always', BokehDeprecationWarning)\n warnings.simplefilter('always', BokehUserWarning)\n+\n+original_formatwarning = warnings.formatwarning\n+def _formatwarning(message, category, filename, lineno, line=None):\n+ from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n+ if category not in (BokehDeprecationWarning, BokehUserWarning):\n+ return original_formatwarning(message, category, filename, lineno, line)\n+ return \"%s: %s\\n\" % (category.__name__, message)\n+warnings.formatwarning = _formatwarning\n+\n+del _formatwarning\n del BokehDeprecationWarning, BokehUserWarning\n del warnings\n", "issue": "Customize warning formatter\nI'm trying out the imminent bokeh release with the dask dashboard. I get hundreds of lines like the following:\r\n\r\n```python\r\n/home/mrocklin/Software/anaconda/lib/python3.6/site-packages/bokeh/models/sources.py:91: BokehUserWarning: ColumnD)\r\n \"Current lengths: %s\" % \", \".join(sorted(str((k, len(v))) for k, v in data.items())), BokehUserWarning))\r\n```\r\n\r\nClearly I'm doing something wrong in my code, and it's great to know about it. However, two things would make this nicer:\r\n\r\n1. Getting some sort of information about the cause of the failure. It looks like an informative error message was attempted, but rather than getting a nice result I get the code instead.\r\n2. These are filling up my terminal at the rate that I update my plots. It might be nice to only warn once or twice.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.\n#\n# Powered by the Bokeh Development Team.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Bokeh is a Python interactive visualization library that targets modern\nweb browsers for presentation.\n\nIts goal is to provide elegant, concise construction of versatile graphics,\nand also deliver this capability with high-performance interactivity over large\nor streaming datasets. Bokeh can help anyone who would like to quickly and\neasily create interactive plots, dashboards, and data applications.\n\nFor full documentation, please visit: https://bokeh.pydata.org\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n__all__ = (\n '__version__',\n 'license',\n 'sampledata',\n)\n\n# configure Bokeh version\nfrom .util.version import __version__; __version__\n\ndef license():\n ''' Print the Bokeh license to the console.\n\n Returns:\n None\n\n '''\n from os.path import join\n with open(join(__path__[0], 'LICENSE.txt')) as lic:\n print(lic.read())\n\n# expose sample data module\nfrom . import sampledata; sampledata\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\n# configure Bokeh logger\nfrom .util import logconfig\ndel logconfig\n\n# Configure warnings to always show, despite Python's active efforts to hide them from users.\nimport warnings\nfrom .util.warnings import BokehDeprecationWarning, BokehUserWarning\nwarnings.simplefilter('always', BokehDeprecationWarning)\nwarnings.simplefilter('always', BokehUserWarning)\ndel BokehDeprecationWarning, BokehUserWarning\ndel warnings\n", "path": "bokeh/__init__.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2017, Anaconda, Inc. All rights reserved.\n#\n# Powered by the Bokeh Development Team.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Bokeh is a Python interactive visualization library that targets modern\nweb browsers for presentation.\n\nIts goal is to provide elegant, concise construction of versatile graphics,\nand also deliver this capability with high-performance interactivity over large\nor streaming datasets. Bokeh can help anyone who would like to quickly and\neasily create interactive plots, dashboards, and data applications.\n\nFor full documentation, please visit: https://bokeh.pydata.org\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n__all__ = (\n '__version__',\n 'license',\n 'sampledata',\n)\n\n# configure Bokeh version\nfrom .util.version import __version__; __version__\n\ndef license():\n ''' Print the Bokeh license to the console.\n\n Returns:\n None\n\n '''\n from os.path import join\n with open(join(__path__[0], 'LICENSE.txt')) as lic:\n print(lic.read())\n\n# expose sample data module\nfrom . import sampledata; sampledata\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\n# configure Bokeh logger\nfrom .util import logconfig\ndel logconfig\n\n# Configure warnings to always show nice mssages, despite Python's active\n# efforts to hide them from users.\nimport warnings\nfrom .util.warnings import BokehDeprecationWarning, BokehUserWarning\nwarnings.simplefilter('always', BokehDeprecationWarning)\nwarnings.simplefilter('always', BokehUserWarning)\n\noriginal_formatwarning = warnings.formatwarning\ndef _formatwarning(message, category, filename, lineno, line=None):\n from .util.warnings import BokehDeprecationWarning, BokehUserWarning\n if category not in (BokehDeprecationWarning, BokehUserWarning):\n return original_formatwarning(message, category, filename, lineno, line)\n return \"%s: %s\\n\" % (category.__name__, message)\nwarnings.formatwarning = _formatwarning\n\ndel _formatwarning\ndel BokehDeprecationWarning, BokehUserWarning\ndel warnings\n", "path": "bokeh/__init__.py"}]}
| 1,007 | 284 |
gh_patches_debug_15703
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-278
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keen Home Smart Vent Models
I've been having problems with the Keen Home Smart Vent Quirks and realized that there are additional models that need the DoublingPowerConfigurationCluster on them. I validated that the following manufacturer/models work when added but am unable to submit the change myself.
("Keen Home Inc", "SV01-410-MP-1.1")
("Keen Home Inc", "SV01-410-MP-1.0")
("Keen Home Inc", "SV01-410-MP-1.5")
("Keen Home Inc", "SV02-410-MP-1.3")
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/keenhome/sv02612mp13.py`
Content:
```
1 """Smart vent quirk."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomDevice
4 from zigpy.zcl.clusters.general import (
5 Basic,
6 Groups,
7 Identify,
8 LevelControl,
9 OnOff,
10 Ota,
11 PollControl,
12 Scenes,
13 )
14 from zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement
15
16 from .. import DoublingPowerConfigurationCluster
17 from ..const import (
18 DEVICE_TYPE,
19 ENDPOINTS,
20 INPUT_CLUSTERS,
21 MODELS_INFO,
22 OUTPUT_CLUSTERS,
23 PROFILE_ID,
24 )
25
26 DIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821
27 KEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513
28 KEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514
29
30
31 class KeenHomeSmartVent(CustomDevice):
32 """Custom device representing Keen Home Smart Vent."""
33
34 signature = {
35 # <SimpleDescriptor endpoint=1 profile=260 device_type=3
36 # device_version=0
37 # input_clusters=[
38 # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]
39 # output_clusters=[25]>
40 MODELS_INFO: [("Keen Home Inc", "SV02-612-MP-1.3")],
41 ENDPOINTS: {
42 1: {
43 PROFILE_ID: zha.PROFILE_ID,
44 DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,
45 INPUT_CLUSTERS: [
46 Basic.cluster_id,
47 DoublingPowerConfigurationCluster.cluster_id,
48 Identify.cluster_id,
49 Groups.cluster_id,
50 Scenes.cluster_id,
51 OnOff.cluster_id,
52 LevelControl.cluster_id,
53 PollControl.cluster_id,
54 TemperatureMeasurement.cluster_id,
55 PressureMeasurement.cluster_id,
56 DIAGNOSTICS_CLUSTER_ID,
57 KEEN1_CLUSTER_ID,
58 KEEN2_CLUSTER_ID,
59 ],
60 OUTPUT_CLUSTERS: [Ota.cluster_id],
61 }
62 },
63 }
64
65 replacement = {
66 ENDPOINTS: {
67 1: {
68 PROFILE_ID: zha.PROFILE_ID,
69 INPUT_CLUSTERS: [
70 Basic.cluster_id,
71 DoublingPowerConfigurationCluster,
72 Identify.cluster_id,
73 Groups.cluster_id,
74 Scenes.cluster_id,
75 OnOff.cluster_id,
76 LevelControl.cluster_id,
77 PollControl.cluster_id,
78 TemperatureMeasurement.cluster_id,
79 PressureMeasurement.cluster_id,
80 DIAGNOSTICS_CLUSTER_ID,
81 KEEN1_CLUSTER_ID,
82 KEEN2_CLUSTER_ID,
83 ],
84 OUTPUT_CLUSTERS: [Ota.cluster_id],
85 }
86 }
87 }
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/keenhome/sv02612mp13.py b/zhaquirks/keenhome/sv02612mp13.py
--- a/zhaquirks/keenhome/sv02612mp13.py
+++ b/zhaquirks/keenhome/sv02612mp13.py
@@ -37,7 +37,18 @@
# input_clusters=[
# 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]
# output_clusters=[25]>
- MODELS_INFO: [("Keen Home Inc", "SV02-612-MP-1.3")],
+ MODELS_INFO: [
+ ("Keen Home Inc", "SV01-410-MP-1.0"),
+ ("Keen Home Inc", "SV01-410-MP-1.1"),
+ ("Keen Home Inc", "SV01-410-MP-1.4"),
+ ("Keen Home Inc", "SV01-410-MP-1.5"),
+ ("Keen Home Inc", "SV02-410-MP-1.3"),
+ ("Keen Home Inc", "SV01-412-MP-1.0"),
+ ("Keen Home Inc", "SV01-610-MP-1.0"),
+ ("Keen Home Inc", "SV02-610-MP-1.3"),
+ ("Keen Home Inc", "SV01-612-MP-1.0"),
+ ("Keen Home Inc", "SV02-612-MP-1.3"),
+ ],
ENDPOINTS: {
1: {
PROFILE_ID: zha.PROFILE_ID,
|
{"golden_diff": "diff --git a/zhaquirks/keenhome/sv02612mp13.py b/zhaquirks/keenhome/sv02612mp13.py\n--- a/zhaquirks/keenhome/sv02612mp13.py\n+++ b/zhaquirks/keenhome/sv02612mp13.py\n@@ -37,7 +37,18 @@\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n- MODELS_INFO: [(\"Keen Home Inc\", \"SV02-612-MP-1.3\")],\n+ MODELS_INFO: [\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.1\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.4\"),\n+ (\"Keen Home Inc\", \"SV01-410-MP-1.5\"),\n+ (\"Keen Home Inc\", \"SV02-410-MP-1.3\"),\n+ (\"Keen Home Inc\", \"SV01-412-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV01-610-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV02-610-MP-1.3\"),\n+ (\"Keen Home Inc\", \"SV01-612-MP-1.0\"),\n+ (\"Keen Home Inc\", \"SV02-612-MP-1.3\"),\n+ ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n", "issue": "Keen Home Smart Vent Models\nI've been having problems with the Keen Home Smart Vent Quirks and realized that there are additional models that need the DoublingPowerConfigurationCluster on them. I validated that the following manufacturer/models work when added but am unable to submit the change myself.\r\n\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.1\")\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.0\")\r\n(\"Keen Home Inc\", \"SV01-410-MP-1.5\")\r\n(\"Keen Home Inc\", \"SV02-410-MP-1.3\")\n", "before_files": [{"content": "\"\"\"Smart vent quirk.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PollControl,\n Scenes,\n)\nfrom zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement\n\nfrom .. import DoublingPowerConfigurationCluster\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nKEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513\nKEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514\n\n\nclass KeenHomeSmartVent(CustomDevice):\n \"\"\"Custom device representing Keen Home Smart Vent.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=3\n # device_version=0\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n MODELS_INFO: [(\"Keen Home Inc\", \"SV02-612-MP-1.3\")],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n }\n }\n", "path": "zhaquirks/keenhome/sv02612mp13.py"}], "after_files": [{"content": "\"\"\"Smart vent quirk.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PollControl,\n Scenes,\n)\nfrom zigpy.zcl.clusters.measurement import PressureMeasurement, TemperatureMeasurement\n\nfrom .. import DoublingPowerConfigurationCluster\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\nDIAGNOSTICS_CLUSTER_ID = 0x0B05 # decimal = 2821\nKEEN1_CLUSTER_ID = 0xFC01 # decimal = 64513\nKEEN2_CLUSTER_ID = 0xFC02 # decimal = 64514\n\n\nclass KeenHomeSmartVent(CustomDevice):\n \"\"\"Custom device representing Keen Home Smart Vent.\"\"\"\n\n signature = {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=3\n # device_version=0\n # input_clusters=[\n # 0, 1, 3, 4, 5, 6, 8, 32, 1026, 1027, 2821, 64513, 64514]\n # output_clusters=[25]>\n MODELS_INFO: [\n (\"Keen Home Inc\", \"SV01-410-MP-1.0\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.1\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.4\"),\n (\"Keen Home Inc\", \"SV01-410-MP-1.5\"),\n (\"Keen Home Inc\", \"SV02-410-MP-1.3\"),\n (\"Keen Home Inc\", \"SV01-412-MP-1.0\"),\n (\"Keen Home Inc\", \"SV01-610-MP-1.0\"),\n (\"Keen Home Inc\", \"SV02-610-MP-1.3\"),\n (\"Keen Home Inc\", \"SV01-612-MP-1.0\"),\n (\"Keen Home Inc\", \"SV02-612-MP-1.3\"),\n ],\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.LEVEL_CONTROLLABLE_OUTPUT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n DoublingPowerConfigurationCluster,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n PollControl.cluster_id,\n TemperatureMeasurement.cluster_id,\n PressureMeasurement.cluster_id,\n DIAGNOSTICS_CLUSTER_ID,\n KEEN1_CLUSTER_ID,\n KEEN2_CLUSTER_ID,\n ],\n OUTPUT_CLUSTERS: [Ota.cluster_id],\n }\n }\n }\n", "path": "zhaquirks/keenhome/sv02612mp13.py"}]}
| 1,204 | 462 |
gh_patches_debug_5525
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-16512
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New line character issue when using create_user management command
The create_user management command reads password from a text file created by the server admin. To run this command I tried creating this text file using VIM, nano and echo (` echo pass > password.txt` without using `-n` flag). Each and every time new line character was automatically added to the end of the file. So if I set the content of file as `helloworld` and try to login to the server by entering `helloworld` it would not let me login since `\n` is missing. It was not obvious to me that the extra `\n` added by editors was the reason behind the server rejecting the credentials.
Should we remove the trailing `\n` character while reading the password from file?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zerver/management/commands/create_user.py`
Content:
```
1 import argparse
2 import sys
3 from typing import Any
4
5 from django.core import validators
6 from django.core.exceptions import ValidationError
7 from django.core.management.base import CommandError
8 from django.db.utils import IntegrityError
9
10 from zerver.lib.actions import do_create_user
11 from zerver.lib.initial_password import initial_password
12 from zerver.lib.management import ZulipBaseCommand
13
14
15 class Command(ZulipBaseCommand):
16 help = """Create the specified user with a default initial password.
17
18 Set tos_version=None, so that the user needs to do a ToS flow on login.
19
20 Omit both <email> and <full name> for interactive user creation.
21 """
22
23 def add_arguments(self, parser: argparse.ArgumentParser) -> None:
24 parser.add_argument('--this-user-has-accepted-the-tos',
25 dest='tos',
26 action="store_true",
27 help='Acknowledgement that the user has already accepted the ToS.')
28 parser.add_argument('--password',
29 help='password of new user. For development only.'
30 'Note that we recommend against setting '
31 'passwords this way, since they can be snooped by any user account '
32 'on the server via `ps -ef` or by any superuser with'
33 'read access to the user\'s bash history.')
34 parser.add_argument('--password-file',
35 help='The file containing the password of the new user.')
36 parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,
37 help='email address of new user')
38 parser.add_argument('full_name', metavar='<full name>', nargs='?',
39 default=argparse.SUPPRESS,
40 help='full name of new user')
41 self.add_realm_args(parser, True, "The name of the existing realm to which to add the user.")
42
43 def handle(self, *args: Any, **options: Any) -> None:
44 if not options["tos"]:
45 raise CommandError("""You must confirm that this user has accepted the
46 Terms of Service by passing --this-user-has-accepted-the-tos.""")
47 realm = self.get_realm(options)
48 assert realm is not None # Should be ensured by parser
49
50 try:
51 email = options['email']
52 full_name = options['full_name']
53 try:
54 validators.validate_email(email)
55 except ValidationError:
56 raise CommandError("Invalid email address.")
57 except KeyError:
58 if 'email' in options or 'full_name' in options:
59 raise CommandError("""Either specify an email and full name as two
60 parameters, or specify no parameters for interactive user creation.""")
61 else:
62 while True:
63 email = input("Email: ")
64 try:
65 validators.validate_email(email)
66 break
67 except ValidationError:
68 print("Invalid email address.", file=sys.stderr)
69 full_name = input("Full name: ")
70
71 try:
72 if options['password_file'] is not None:
73 with open(options['password_file']) as f:
74 pw = f.read()
75 elif options['password'] is not None:
76 pw = options['password']
77 else:
78 user_initial_password = initial_password(email)
79 if user_initial_password is None:
80 raise CommandError("Password is unusable.")
81 pw = user_initial_password
82 do_create_user(
83 email,
84 pw,
85 realm,
86 full_name,
87 acting_user=None,
88 )
89 except IntegrityError:
90 raise CommandError("User already exists.")
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zerver/management/commands/create_user.py b/zerver/management/commands/create_user.py
--- a/zerver/management/commands/create_user.py
+++ b/zerver/management/commands/create_user.py
@@ -71,7 +71,7 @@
try:
if options['password_file'] is not None:
with open(options['password_file']) as f:
- pw = f.read()
+ pw = f.read().strip()
elif options['password'] is not None:
pw = options['password']
else:
|
{"golden_diff": "diff --git a/zerver/management/commands/create_user.py b/zerver/management/commands/create_user.py\n--- a/zerver/management/commands/create_user.py\n+++ b/zerver/management/commands/create_user.py\n@@ -71,7 +71,7 @@\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n- pw = f.read()\n+ pw = f.read().strip()\n elif options['password'] is not None:\n pw = options['password']\n else:\n", "issue": "New line character issue when using create_user management command \nThe create_user management command reads password from a text file created by the server admin. To run this command I tried creating this text file using VIM, nano and echo (` echo pass > password.txt` without using `-n` flag). Each and every time new line character was automatically added to the end of the file. So if I set the content of file as `helloworld` and try to login to the server by entering `helloworld` it would not let me login since `\\n` is missing. It was not obvious to me that the extra `\\n` added by editors was the reason behind the server rejecting the credentials.\r\n\r\nShould we remove the trailing `\\n` character while reading the password from file?\n", "before_files": [{"content": "import argparse\nimport sys\nfrom typing import Any\n\nfrom django.core import validators\nfrom django.core.exceptions import ValidationError\nfrom django.core.management.base import CommandError\nfrom django.db.utils import IntegrityError\n\nfrom zerver.lib.actions import do_create_user\nfrom zerver.lib.initial_password import initial_password\nfrom zerver.lib.management import ZulipBaseCommand\n\n\nclass Command(ZulipBaseCommand):\n help = \"\"\"Create the specified user with a default initial password.\n\nSet tos_version=None, so that the user needs to do a ToS flow on login.\n\nOmit both <email> and <full name> for interactive user creation.\n\"\"\"\n\n def add_arguments(self, parser: argparse.ArgumentParser) -> None:\n parser.add_argument('--this-user-has-accepted-the-tos',\n dest='tos',\n action=\"store_true\",\n help='Acknowledgement that the user has already accepted the ToS.')\n parser.add_argument('--password',\n help='password of new user. For development only.'\n 'Note that we recommend against setting '\n 'passwords this way, since they can be snooped by any user account '\n 'on the server via `ps -ef` or by any superuser with'\n 'read access to the user\\'s bash history.')\n parser.add_argument('--password-file',\n help='The file containing the password of the new user.')\n parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,\n help='email address of new user')\n parser.add_argument('full_name', metavar='<full name>', nargs='?',\n default=argparse.SUPPRESS,\n help='full name of new user')\n self.add_realm_args(parser, True, \"The name of the existing realm to which to add the user.\")\n\n def handle(self, *args: Any, **options: Any) -> None:\n if not options[\"tos\"]:\n raise CommandError(\"\"\"You must confirm that this user has accepted the\nTerms of Service by passing --this-user-has-accepted-the-tos.\"\"\")\n realm = self.get_realm(options)\n assert realm is not None # Should be ensured by parser\n\n try:\n email = options['email']\n full_name = options['full_name']\n try:\n validators.validate_email(email)\n except ValidationError:\n raise CommandError(\"Invalid email address.\")\n except KeyError:\n if 'email' in options or 'full_name' in options:\n raise CommandError(\"\"\"Either specify an email and full name as two\nparameters, or specify no parameters for interactive user creation.\"\"\")\n else:\n while True:\n email = input(\"Email: \")\n try:\n validators.validate_email(email)\n break\n except ValidationError:\n print(\"Invalid email address.\", file=sys.stderr)\n full_name = input(\"Full name: \")\n\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n pw = f.read()\n elif options['password'] is not None:\n pw = options['password']\n else:\n user_initial_password = initial_password(email)\n if user_initial_password is None:\n raise CommandError(\"Password is unusable.\")\n pw = user_initial_password\n do_create_user(\n email,\n pw,\n realm,\n full_name,\n acting_user=None,\n )\n except IntegrityError:\n raise CommandError(\"User already exists.\")\n", "path": "zerver/management/commands/create_user.py"}], "after_files": [{"content": "import argparse\nimport sys\nfrom typing import Any\n\nfrom django.core import validators\nfrom django.core.exceptions import ValidationError\nfrom django.core.management.base import CommandError\nfrom django.db.utils import IntegrityError\n\nfrom zerver.lib.actions import do_create_user\nfrom zerver.lib.initial_password import initial_password\nfrom zerver.lib.management import ZulipBaseCommand\n\n\nclass Command(ZulipBaseCommand):\n help = \"\"\"Create the specified user with a default initial password.\n\nSet tos_version=None, so that the user needs to do a ToS flow on login.\n\nOmit both <email> and <full name> for interactive user creation.\n\"\"\"\n\n def add_arguments(self, parser: argparse.ArgumentParser) -> None:\n parser.add_argument('--this-user-has-accepted-the-tos',\n dest='tos',\n action=\"store_true\",\n help='Acknowledgement that the user has already accepted the ToS.')\n parser.add_argument('--password',\n help='password of new user. For development only.'\n 'Note that we recommend against setting '\n 'passwords this way, since they can be snooped by any user account '\n 'on the server via `ps -ef` or by any superuser with'\n 'read access to the user\\'s bash history.')\n parser.add_argument('--password-file',\n help='The file containing the password of the new user.')\n parser.add_argument('email', metavar='<email>', nargs='?', default=argparse.SUPPRESS,\n help='email address of new user')\n parser.add_argument('full_name', metavar='<full name>', nargs='?',\n default=argparse.SUPPRESS,\n help='full name of new user')\n self.add_realm_args(parser, True, \"The name of the existing realm to which to add the user.\")\n\n def handle(self, *args: Any, **options: Any) -> None:\n if not options[\"tos\"]:\n raise CommandError(\"\"\"You must confirm that this user has accepted the\nTerms of Service by passing --this-user-has-accepted-the-tos.\"\"\")\n realm = self.get_realm(options)\n assert realm is not None # Should be ensured by parser\n\n try:\n email = options['email']\n full_name = options['full_name']\n try:\n validators.validate_email(email)\n except ValidationError:\n raise CommandError(\"Invalid email address.\")\n except KeyError:\n if 'email' in options or 'full_name' in options:\n raise CommandError(\"\"\"Either specify an email and full name as two\nparameters, or specify no parameters for interactive user creation.\"\"\")\n else:\n while True:\n email = input(\"Email: \")\n try:\n validators.validate_email(email)\n break\n except ValidationError:\n print(\"Invalid email address.\", file=sys.stderr)\n full_name = input(\"Full name: \")\n\n try:\n if options['password_file'] is not None:\n with open(options['password_file']) as f:\n pw = f.read().strip()\n elif options['password'] is not None:\n pw = options['password']\n else:\n user_initial_password = initial_password(email)\n if user_initial_password is None:\n raise CommandError(\"Password is unusable.\")\n pw = user_initial_password\n do_create_user(\n email,\n pw,\n realm,\n full_name,\n acting_user=None,\n )\n except IntegrityError:\n raise CommandError(\"User already exists.\")\n", "path": "zerver/management/commands/create_user.py"}]}
| 1,316 | 121 |
gh_patches_debug_37361
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-1204
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve "Unit" mixer documentation
We don't have a docstring for this mixer. The challenge here is to eloquently describe what this mixer does (hint: it can be used when encoders themselves are the models, e.g. pretrained language models that receive a single column as input).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lightwood/mixer/unit.py`
Content:
```
1 """
2 2021.07.16
3
4 For encoders that already fine-tune on the targets (namely text)
5 the unity mixer just arg-maxes the output of the encoder.
6 """
7
8 from typing import List, Optional
9
10 import torch
11 import pandas as pd
12
13 from lightwood.helpers.log import log
14 from lightwood.mixer.base import BaseMixer
15 from lightwood.encoder.base import BaseEncoder
16 from lightwood.data.encoded_ds import EncodedDs
17 from lightwood.api.types import PredictionArguments
18
19
20 class Unit(BaseMixer):
21 def __init__(self, stop_after: float, target_encoder: BaseEncoder):
22 super().__init__(stop_after)
23 self.target_encoder = target_encoder
24 self.supports_proba = False
25 self.stable = True
26
27 def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
28 log.info("Unit Mixer just borrows from encoder")
29
30 def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:
31 pass
32
33 def __call__(self, ds: EncodedDs,
34 args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
35 if args.predict_proba:
36 # @TODO: depending on the target encoder, this might be enabled
37 log.warning('This model does not output probability estimates')
38
39 decoded_predictions: List[object] = []
40
41 for X, _ in ds:
42 decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))
43 decoded_predictions.extend(decoded_prediction)
44
45 ydf = pd.DataFrame({"prediction": decoded_predictions})
46 return ydf
47
```
Path: `lightwood/mixer/base.py`
Content:
```
1 from typing import Optional
2 import pandas as pd
3
4 from lightwood.data.encoded_ds import EncodedDs
5 from lightwood.api.types import PredictionArguments
6
7
8 class BaseMixer:
9 """
10 Base class for all mixers.
11
12 Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.
13
14 There are two important methods for any mixer to work:
15 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.
16 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`.
17
18 An additional `partial_fit()` method is used to update any mixer that has already been trained.
19
20 Class Attributes:
21 - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.
22 - fit_data_len: Length of the training data.
23 - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label.
24 - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake.
25 """ # noqa
26 stable: bool
27 fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?
28 supports_proba: bool
29 trains_once: bool
30
31 def __init__(self, stop_after: float):
32 """
33 :param stop_after: Time budget to train this mixer.
34 """
35 self.stop_after = stop_after
36 self.supports_proba = False
37 self.trains_once = False
38
39 def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
40 """
41 Fits/trains a mixer with training data.
42
43 :param train_data: encoded representations of the training data subset.
44 :param dev_data: encoded representations of the "dev" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer).
45
46 """ # noqa
47 raise NotImplementedError()
48
49 def __call__(self, ds: EncodedDs,
50 args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
51 """
52 Calls a trained mixer to predict the target column given some input data.
53
54 :param ds: encoded representations of input data.
55 :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.
56 :return:
57 """ # noqa
58 raise NotImplementedError()
59
60 def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:
61 """
62 Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors.
63
64 :param train_data: encoded representations of the new training data subset.
65 :param dev_data: encoded representations of new the "dev" data subset. As in `fit()`, this can be used as an internal validation subset.
66 :param adjust_args: optional arguments to customize the finetuning process.
67
68 """ # noqa
69 pass
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lightwood/mixer/base.py b/lightwood/mixer/base.py
--- a/lightwood/mixer/base.py
+++ b/lightwood/mixer/base.py
@@ -30,7 +30,7 @@
def __init__(self, stop_after: float):
"""
- :param stop_after: Time budget to train this mixer.
+ :param stop_after: Time budget (in seconds) to train this mixer.
"""
self.stop_after = stop_after
self.supports_proba = False
diff --git a/lightwood/mixer/unit.py b/lightwood/mixer/unit.py
--- a/lightwood/mixer/unit.py
+++ b/lightwood/mixer/unit.py
@@ -1,10 +1,3 @@
-"""
-2021.07.16
-
-For encoders that already fine-tune on the targets (namely text)
-the unity mixer just arg-maxes the output of the encoder.
-"""
-
from typing import List, Optional
import torch
@@ -19,19 +12,35 @@
class Unit(BaseMixer):
def __init__(self, stop_after: float, target_encoder: BaseEncoder):
+ """
+ The "Unit" mixer serves as a simple wrapper around a target encoder, essentially borrowing
+ the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder
+
+ Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).
+
+ Attributes:
+ :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.
+ :param stop_after (float): Time budget (in seconds) to train this mixer.
+ """ # noqa
super().__init__(stop_after)
self.target_encoder = target_encoder
self.supports_proba = False
self.stable = True
def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:
- log.info("Unit Mixer just borrows from encoder")
+ log.info("Unit mixer does not require training, it passes through predictions from its encoders.")
def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:
pass
def __call__(self, ds: EncodedDs,
args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:
+ """
+ Makes predictions using the provided EncodedDs dataset.
+ Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.
+
+ :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.
+ """
if args.predict_proba:
# @TODO: depending on the target encoder, this might be enabled
log.warning('This model does not output probability estimates')
|
{"golden_diff": "diff --git a/lightwood/mixer/base.py b/lightwood/mixer/base.py\n--- a/lightwood/mixer/base.py\n+++ b/lightwood/mixer/base.py\n@@ -30,7 +30,7 @@\n \n def __init__(self, stop_after: float):\n \"\"\"\n- :param stop_after: Time budget to train this mixer.\n+ :param stop_after: Time budget (in seconds) to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\ndiff --git a/lightwood/mixer/unit.py b/lightwood/mixer/unit.py\n--- a/lightwood/mixer/unit.py\n+++ b/lightwood/mixer/unit.py\n@@ -1,10 +1,3 @@\n-\"\"\"\n-2021.07.16\n-\n-For encoders that already fine-tune on the targets (namely text)\n-the unity mixer just arg-maxes the output of the encoder.\n-\"\"\"\n-\n from typing import List, Optional\n \n import torch\n@@ -19,19 +12,35 @@\n \n class Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n+ \"\"\"\n+ The \"Unit\" mixer serves as a simple wrapper around a target encoder, essentially borrowing \n+ the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder\n+\n+ Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).\n+ \n+ Attributes:\n+ :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.\n+ :param stop_after (float): Time budget (in seconds) to train this mixer. \n+ \"\"\" # noqa\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n \n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n- log.info(\"Unit Mixer just borrows from encoder\")\n+ log.info(\"Unit mixer does not require training, it passes through predictions from its encoders.\")\n \n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n \n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n+ \"\"\"\n+ Makes predictions using the provided EncodedDs dataset.\n+ Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.\n+\n+ :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.\n+ \"\"\"\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n", "issue": "Improve \"Unit\" mixer documentation\nWe don't have a docstring for this mixer. The challenge here is to eloquently describe what this mixer does (hint: it can be used when encoders themselves are the models, e.g. pretrained language models that receive a single column as input).\n", "before_files": [{"content": "\"\"\"\n2021.07.16\n\nFor encoders that already fine-tune on the targets (namely text)\nthe unity mixer just arg-maxes the output of the encoder.\n\"\"\"\n\nfrom typing import List, Optional\n\nimport torch\nimport pandas as pd\n\nfrom lightwood.helpers.log import log\nfrom lightwood.mixer.base import BaseMixer\nfrom lightwood.encoder.base import BaseEncoder\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n log.info(\"Unit Mixer just borrows from encoder\")\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n\n decoded_predictions: List[object] = []\n\n for X, _ in ds:\n decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))\n decoded_predictions.extend(decoded_prediction)\n\n ydf = pd.DataFrame({\"prediction\": decoded_predictions})\n return ydf\n", "path": "lightwood/mixer/unit.py"}, {"content": "from typing import Optional\nimport pandas as pd\n\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass BaseMixer:\n \"\"\"\n Base class for all mixers.\n\n Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.\n \n There are two important methods for any mixer to work:\n 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.\n 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`. \n \n An additional `partial_fit()` method is used to update any mixer that has already been trained.\n\n Class Attributes:\n - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.\n - fit_data_len: Length of the training data.\n - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label. \n - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake. \n \"\"\" # noqa\n stable: bool\n fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?\n supports_proba: bool\n trains_once: bool\n\n def __init__(self, stop_after: float):\n \"\"\"\n :param stop_after: Time budget to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\n self.trains_once = False\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n \"\"\"\n Fits/trains a mixer with training data. \n \n :param train_data: encoded representations of the training data subset. \n :param dev_data: encoded representations of the \"dev\" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer). \n \n \"\"\" # noqa\n raise NotImplementedError()\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Calls a trained mixer to predict the target column given some input data.\n \n :param ds: encoded representations of input data.\n :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.\n :return: \n \"\"\" # noqa\n raise NotImplementedError()\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:\n \"\"\"\n Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors. \n\n :param train_data: encoded representations of the new training data subset. \n :param dev_data: encoded representations of new the \"dev\" data subset. As in `fit()`, this can be used as an internal validation subset. \n :param adjust_args: optional arguments to customize the finetuning process.\n\n \"\"\" # noqa\n pass\n", "path": "lightwood/mixer/base.py"}], "after_files": [{"content": "from typing import List, Optional\n\nimport torch\nimport pandas as pd\n\nfrom lightwood.helpers.log import log\nfrom lightwood.mixer.base import BaseMixer\nfrom lightwood.encoder.base import BaseEncoder\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass Unit(BaseMixer):\n def __init__(self, stop_after: float, target_encoder: BaseEncoder):\n \"\"\"\n The \"Unit\" mixer serves as a simple wrapper around a target encoder, essentially borrowing \n the encoder's functionality for predictions. In other words, it simply arg-maxes the output of the encoder\n\n Used with encoders that already fine-tune on the targets (namely, pre-trained text ML models).\n \n Attributes:\n :param target_encoder: An instance of a Lightwood BaseEncoder. This encoder is used to decode predictions.\n :param stop_after (float): Time budget (in seconds) to train this mixer. \n \"\"\" # noqa\n super().__init__(stop_after)\n self.target_encoder = target_encoder\n self.supports_proba = False\n self.stable = True\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n log.info(\"Unit mixer does not require training, it passes through predictions from its encoders.\")\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, args: Optional[dict] = None) -> None:\n pass\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Makes predictions using the provided EncodedDs dataset.\n Mixer decodes predictions using the target encoder and returns them in a pandas DataFrame.\n\n :returns ydf (pd.DataFrame): a data frame containing the decoded predictions.\n \"\"\"\n if args.predict_proba:\n # @TODO: depending on the target encoder, this might be enabled\n log.warning('This model does not output probability estimates')\n\n decoded_predictions: List[object] = []\n\n for X, _ in ds:\n decoded_prediction = self.target_encoder.decode(torch.unsqueeze(X, 0))\n decoded_predictions.extend(decoded_prediction)\n\n ydf = pd.DataFrame({\"prediction\": decoded_predictions})\n return ydf\n", "path": "lightwood/mixer/unit.py"}, {"content": "from typing import Optional\nimport pandas as pd\n\nfrom lightwood.data.encoded_ds import EncodedDs\nfrom lightwood.api.types import PredictionArguments\n\n\nclass BaseMixer:\n \"\"\"\n Base class for all mixers.\n\n Mixers are the backbone of all Lightwood machine learning models. They intake encoded feature representations for every column, and are tasked with learning to fulfill the predictive requirements stated in a problem definition.\n \n There are two important methods for any mixer to work:\n 1. `fit()` contains all logic to train the mixer with the training data that has been encoded by all the (already trained) Lightwood encoders for any given task.\n 2. `__call__()` is executed to generate predictions once the mixer has been trained using `fit()`. \n \n An additional `partial_fit()` method is used to update any mixer that has already been trained.\n\n Class Attributes:\n - stable: If set to `True`, this mixer should always work. Any mixer with `stable=False` can be expected to fail under some circumstances.\n - fit_data_len: Length of the training data.\n - supports_proba: For classification tasks, whether the mixer supports yielding per-class scores rather than only returning the predicted label. \n - trains_once: If True, the mixer is trained once during learn, using all available input data (`train` and `dev` splits for training, `test` for validation). Otherwise, it trains once with the `train`` split & `dev` for validation, and optionally (depending on the problem definition `fit_on_all` and mixer-wise `fit_on_dev` arguments) a second time after post-training analysis via partial_fit, with `train` and `dev` splits as training subset, and `test` split as validation. Should only be set to True for mixers that don't require post-training analysis, as otherwise actual validation data would be treated as a held-out portion, which is a mistake. \n \"\"\" # noqa\n stable: bool\n fit_data_len: int # @TODO (Patricio): should this really be in `BaseMixer`?\n supports_proba: bool\n trains_once: bool\n\n def __init__(self, stop_after: float):\n \"\"\"\n :param stop_after: Time budget (in seconds) to train this mixer.\n \"\"\"\n self.stop_after = stop_after\n self.supports_proba = False\n self.trains_once = False\n\n def fit(self, train_data: EncodedDs, dev_data: EncodedDs) -> None:\n \"\"\"\n Fits/trains a mixer with training data. \n \n :param train_data: encoded representations of the training data subset. \n :param dev_data: encoded representations of the \"dev\" data subset. This can be used as an internal validation subset (e.g. it is used for early stopping in the default `Neural` mixer). \n \n \"\"\" # noqa\n raise NotImplementedError()\n\n def __call__(self, ds: EncodedDs,\n args: PredictionArguments = PredictionArguments()) -> pd.DataFrame:\n \"\"\"\n Calls a trained mixer to predict the target column given some input data.\n \n :param ds: encoded representations of input data.\n :param args: a `lightwood.api.types.PredictionArguments` object, including all relevant inference-time arguments to customize the behavior.\n :return: \n \"\"\" # noqa\n raise NotImplementedError()\n\n def partial_fit(self, train_data: EncodedDs, dev_data: EncodedDs, adjust_args: Optional[dict] = None) -> None:\n \"\"\"\n Partially fits/trains a mixer with new training data. This is a somewhat experimental method, and it aims at updating pre-existing Lightwood predictors. \n\n :param train_data: encoded representations of the new training data subset. \n :param dev_data: encoded representations of new the \"dev\" data subset. As in `fit()`, this can be used as an internal validation subset. \n :param adjust_args: optional arguments to customize the finetuning process.\n\n \"\"\" # noqa\n pass\n", "path": "lightwood/mixer/base.py"}]}
| 1,779 | 625 |
gh_patches_debug_6993
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-3542
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`fsspec` should be explicitly stated in setup.py and env files
`fsspec` package became required dependency after https://github.com/modin-project/modin/pull/3529
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 import versioneer
3 import os
4 from setuptools.dist import Distribution
5
6 try:
7 from wheel.bdist_wheel import bdist_wheel
8
9 HAS_WHEEL = True
10 except ImportError:
11 HAS_WHEEL = False
12
13 with open("README.md", "r", encoding="utf-8") as fh:
14 long_description = fh.read()
15
16 if HAS_WHEEL:
17
18 class ModinWheel(bdist_wheel):
19 def finalize_options(self):
20 bdist_wheel.finalize_options(self)
21 self.root_is_pure = False
22
23 def get_tag(self):
24 _, _, plat = bdist_wheel.get_tag(self)
25 py = "py3"
26 abi = "none"
27 return py, abi, plat
28
29
30 class ModinDistribution(Distribution):
31 def __init__(self, *attrs):
32 Distribution.__init__(self, *attrs)
33 if HAS_WHEEL:
34 self.cmdclass["bdist_wheel"] = ModinWheel
35
36 def is_pure(self):
37 return False
38
39
40 dask_deps = ["dask>=2.22.0", "distributed>=2.22.0"]
41 ray_deps = ["ray[default]>=1.4.0", "pyarrow>=1.0"]
42 remote_deps = ["rpyc==4.1.5", "cloudpickle", "boto3"]
43 spreadsheet_deps = ["modin-spreadsheet>=0.1.0"]
44 sql_deps = ["dfsql>=0.4.2"]
45 all_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps
46
47 # dfsql does not support Windows yet
48 if os.name != 'nt':
49 all_deps += sql_deps
50
51 setup(
52 name="modin",
53 version=versioneer.get_version(),
54 cmdclass=versioneer.get_cmdclass(),
55 distclass=ModinDistribution,
56 description="Modin: Make your pandas code run faster by changing one line of code.",
57 packages=find_packages(),
58 include_package_data=True,
59 license="Apache 2",
60 url="https://github.com/modin-project/modin",
61 long_description=long_description,
62 long_description_content_type="text/markdown",
63 install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5"],
64 extras_require={
65 # can be installed by pip install modin[dask]
66 "dask": dask_deps,
67 "ray": ray_deps,
68 "remote": remote_deps,
69 "spreadsheet": spreadsheet_deps,
70 "sql": sql_deps,
71 "all": all_deps,
72 },
73 python_requires=">=3.7.1",
74 )
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,7 +60,7 @@
url="https://github.com/modin-project/modin",
long_description=long_description,
long_description_content_type="text/markdown",
- install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5"],
+ install_requires=["pandas==1.3.3", "packaging", "numpy>=1.16.5", "fsspec"],
extras_require={
# can be installed by pip install modin[dask]
"dask": dask_deps,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -60,7 +60,7 @@\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n- install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\"],\n+ install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\", \"fsspec\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n", "issue": "`fsspec` should be explicitly stated in setup.py and env files\n`fsspec` package became required dependency after https://github.com/modin-project/modin/pull/3529\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport os\nfrom setuptools.dist import Distribution\n\ntry:\n from wheel.bdist_wheel import bdist_wheel\n\n HAS_WHEEL = True\nexcept ImportError:\n HAS_WHEEL = False\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\nif HAS_WHEEL:\n\n class ModinWheel(bdist_wheel):\n def finalize_options(self):\n bdist_wheel.finalize_options(self)\n self.root_is_pure = False\n\n def get_tag(self):\n _, _, plat = bdist_wheel.get_tag(self)\n py = \"py3\"\n abi = \"none\"\n return py, abi, plat\n\n\nclass ModinDistribution(Distribution):\n def __init__(self, *attrs):\n Distribution.__init__(self, *attrs)\n if HAS_WHEEL:\n self.cmdclass[\"bdist_wheel\"] = ModinWheel\n\n def is_pure(self):\n return False\n\n\ndask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\nray_deps = [\"ray[default]>=1.4.0\", \"pyarrow>=1.0\"]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# dfsql does not support Windows yet\nif os.name != 'nt':\n all_deps += sql_deps\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n distclass=ModinDistribution,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.7.1\",\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport os\nfrom setuptools.dist import Distribution\n\ntry:\n from wheel.bdist_wheel import bdist_wheel\n\n HAS_WHEEL = True\nexcept ImportError:\n HAS_WHEEL = False\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\nif HAS_WHEEL:\n\n class ModinWheel(bdist_wheel):\n def finalize_options(self):\n bdist_wheel.finalize_options(self)\n self.root_is_pure = False\n\n def get_tag(self):\n _, _, plat = bdist_wheel.get_tag(self)\n py = \"py3\"\n abi = \"none\"\n return py, abi, plat\n\n\nclass ModinDistribution(Distribution):\n def __init__(self, *attrs):\n Distribution.__init__(self, *attrs)\n if HAS_WHEEL:\n self.cmdclass[\"bdist_wheel\"] = ModinWheel\n\n def is_pure(self):\n return False\n\n\ndask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\nray_deps = [\"ray[default]>=1.4.0\", \"pyarrow>=1.0\"]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# dfsql does not support Windows yet\nif os.name != 'nt':\n all_deps += sql_deps\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n distclass=ModinDistribution,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.3.3\", \"packaging\", \"numpy>=1.16.5\", \"fsspec\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.7.1\",\n)\n", "path": "setup.py"}]}
| 1,006 | 149 |
gh_patches_debug_31195
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-2695
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py`
Content:
```
1 from dataclasses import dataclass
2 from abc import ABC, abstractmethod
3 from typing import List, Dict
4 from colossalai.device.device_mesh import DeviceMesh
5
6 __all__ = ['IntermediateStrategy', 'StrategyGenerator']
7
8
9 @dataclass
10 class IntermediateStrategy:
11 """
12 IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
13 to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.
14
15 Args:
16 name (str): name of the sharding strategy.
17 dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.
18 all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.
19 """
20 name: str
21 dim_partition_dict: Dict[str, Dict[int, List[int]]]
22 all_reduce_axis: List[int] = None
23
24
25 class StrategyGenerator(ABC):
26 """
27 StrategyGenerator is used to generate the same group of sharding strategies.
28 """
29
30 def __init__(self, device_mesh: DeviceMesh):
31 self.device_mesh = device_mesh
32
33 @abstractmethod
34 def generate(self) -> List[IntermediateStrategy]:
35 """
36 """
37 pass
38
39 @abstractmethod
40 def validate(self, *args, **kwargs) -> bool:
41 """
42 Validate if the operands are of desired shape.
43 If True, means this generator can be used for the current operation.
44 """
45 pass
46
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
--- a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
+++ b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py
@@ -1,6 +1,7 @@
-from dataclasses import dataclass
from abc import ABC, abstractmethod
-from typing import List, Dict
+from dataclasses import dataclass
+from typing import Dict, List
+
from colossalai.device.device_mesh import DeviceMesh
__all__ = ['IntermediateStrategy', 'StrategyGenerator']
@@ -9,7 +10,7 @@
@dataclass
class IntermediateStrategy:
"""
- IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
+ IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is
to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.
Args:
@@ -24,7 +25,7 @@
class StrategyGenerator(ABC):
"""
- StrategyGenerator is used to generate the same group of sharding strategies.
+ StrategyGenerator is used to generate the same group of sharding strategies.
"""
def __init__(self, device_mesh: DeviceMesh):
@@ -39,7 +40,7 @@
@abstractmethod
def validate(self, *args, **kwargs) -> bool:
"""
- Validate if the operands are of desired shape.
+ Validate if the operands are of desired shape.
If True, means this generator can be used for the current operation.
"""
pass
|
{"golden_diff": "diff --git a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n--- a/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n+++ b/colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py\n@@ -1,6 +1,7 @@\n-from dataclasses import dataclass\n from abc import ABC, abstractmethod\n-from typing import List, Dict\n+from dataclasses import dataclass\n+from typing import Dict, List\n+\n from colossalai.device.device_mesh import DeviceMesh\n \n __all__ = ['IntermediateStrategy', 'StrategyGenerator']\n@@ -9,7 +10,7 @@\n @dataclass\n class IntermediateStrategy:\n \"\"\"\n- IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is \n+ IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is\n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n \n Args:\n@@ -24,7 +25,7 @@\n \n class StrategyGenerator(ABC):\n \"\"\"\n- StrategyGenerator is used to generate the same group of sharding strategies. \n+ StrategyGenerator is used to generate the same group of sharding strategies.\n \"\"\"\n \n def __init__(self, device_mesh: DeviceMesh):\n@@ -39,7 +40,7 @@\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n- Validate if the operands are of desired shape. \n+ Validate if the operands are of desired shape.\n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom abc import ABC, abstractmethod\nfrom typing import List, Dict\nfrom colossalai.device.device_mesh import DeviceMesh\n\n__all__ = ['IntermediateStrategy', 'StrategyGenerator']\n\n\n@dataclass\nclass IntermediateStrategy:\n \"\"\"\n IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is \n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n\n Args:\n name (str): name of the sharding strategy.\n dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.\n all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.\n \"\"\"\n name: str\n dim_partition_dict: Dict[str, Dict[int, List[int]]]\n all_reduce_axis: List[int] = None\n\n\nclass StrategyGenerator(ABC):\n \"\"\"\n StrategyGenerator is used to generate the same group of sharding strategies. \n \"\"\"\n\n def __init__(self, device_mesh: DeviceMesh):\n self.device_mesh = device_mesh\n\n @abstractmethod\n def generate(self) -> List[IntermediateStrategy]:\n \"\"\"\n \"\"\"\n pass\n\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n Validate if the operands are of desired shape. \n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "path": "colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py"}], "after_files": [{"content": "from abc import ABC, abstractmethod\nfrom dataclasses import dataclass\nfrom typing import Dict, List\n\nfrom colossalai.device.device_mesh import DeviceMesh\n\n__all__ = ['IntermediateStrategy', 'StrategyGenerator']\n\n\n@dataclass\nclass IntermediateStrategy:\n \"\"\"\n IntermediateStrategy contains the subset of meta information for ShardingStrategy. It is\n to store the essential information regarding the tensor sharding and leave other meta information to OperatorHandler.\n\n Args:\n name (str): name of the sharding strategy.\n dim_partition_dict (Dict[Dict]): stores the tensor to dim partition dict mapping.\n all_reduce_dims (List[int]): stores the dimensions which require an all-reduce operation.\n \"\"\"\n name: str\n dim_partition_dict: Dict[str, Dict[int, List[int]]]\n all_reduce_axis: List[int] = None\n\n\nclass StrategyGenerator(ABC):\n \"\"\"\n StrategyGenerator is used to generate the same group of sharding strategies.\n \"\"\"\n\n def __init__(self, device_mesh: DeviceMesh):\n self.device_mesh = device_mesh\n\n @abstractmethod\n def generate(self) -> List[IntermediateStrategy]:\n \"\"\"\n \"\"\"\n pass\n\n @abstractmethod\n def validate(self, *args, **kwargs) -> bool:\n \"\"\"\n Validate if the operands are of desired shape.\n If True, means this generator can be used for the current operation.\n \"\"\"\n pass\n", "path": "colossalai/auto_parallel/tensor_shard/deprecated/op_handler/strategy_generator.py"}]}
| 683 | 381 |
gh_patches_debug_3293
|
rasdani/github-patches
|
git_diff
|
python-pillow__Pillow-3493
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How to tell at run time whether libjpeg-turbo version of libjpeg is used?
tl;dr:
Is there some way to accomplish: `PIL.Image.libjpeg_turbo_is_enabled()`?
The full story:
Is there a way to tell from a pre-built Pillow whether it was built against `libjpeg-turbo` or not?
This is assuming that all I have is `libjpeg.so.X.X` and no way to tell where it came from.
I see there is a symbol in the library:
```
nm _imaging.cpython-36m-x86_64-linux-gnu.so | grep -I turbo
000000000007e5a0 D libjpeg_turbo_version
```
but I don't know how to access its value from python.
If there is a way to tell the same from from shell using `ldd`/`nm` or other linker tools, it'd do too.
The intention is to be able to tell a user at run-time to re-build Pillow after installing `libjpeg-turbo` to gain speed. The problem is that It's not enough to build Pillow against `libjpeg-turbo`. Given how conda/pip dependencies work, a new prebuilt package of `Pillow` could get swapped in as a dependency for some other package and the user won't know that they now run a less efficient `Pillow` unless they watch closely any install/update logs.
Currently the only solution I can think of (in conda env) is to take the output of:
cd ~/anaconda3/envs/pytorch-dev/lib/python3.6/site-packages/PIL
ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg
which wold give me something like:
libjpeg.so.8 => ~/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8
And then to try to match it to:
grep libjpeg ~/anaconda3/envs/pytorch-dev/conda-meta/libjpeg-turbo-2.0.1-h470a237_0.json
which may work. There is a problem with this approach
It's very likely that conda is going to reinstall `jpeg` since many packages depend on it, and when it does, there is going to be 2 libjpeg libs.
ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg
libjpeg.so.8 => /home/stas/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8 (0x00007f92628c8000)
libjpeg.so.9 => /home/stas/anaconda3/envs/pytorch-dev/lib/./libjpeg.so.9 (0x00007f9261c4e000)
And now I can no longer tell which is which, since I can no longer tell which of the two Pillow will load at run time. Well, I can go one step further and check /proc/<pid>/maps to get the library, but it's getting more and more convoluted. And I won't even know how to do the same on non-linux platform. And this is just for the conda setup, for pip setup it'd be something else.
Also what happens if `libjpeg-turbo` and `libjpeg` are the same version?
Perhaps there is an easier way? Any chance to have `PIL.Image.libjpeg_turbo_is_enabled()`?
Thank you.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/PIL/features.py`
Content:
```
1 from . import Image
2
3 modules = {
4 "pil": "PIL._imaging",
5 "tkinter": "PIL._tkinter_finder",
6 "freetype2": "PIL._imagingft",
7 "littlecms2": "PIL._imagingcms",
8 "webp": "PIL._webp",
9 }
10
11
12 def check_module(feature):
13 if not (feature in modules):
14 raise ValueError("Unknown module %s" % feature)
15
16 module = modules[feature]
17
18 try:
19 __import__(module)
20 return True
21 except ImportError:
22 return False
23
24
25 def get_supported_modules():
26 return [f for f in modules if check_module(f)]
27
28
29 codecs = {
30 "jpg": "jpeg",
31 "jpg_2000": "jpeg2k",
32 "zlib": "zip",
33 "libtiff": "libtiff"
34 }
35
36
37 def check_codec(feature):
38 if feature not in codecs:
39 raise ValueError("Unknown codec %s" % feature)
40
41 codec = codecs[feature]
42
43 return codec + "_encoder" in dir(Image.core)
44
45
46 def get_supported_codecs():
47 return [f for f in codecs if check_codec(f)]
48
49
50 features = {
51 "webp_anim": ("PIL._webp", 'HAVE_WEBPANIM'),
52 "webp_mux": ("PIL._webp", 'HAVE_WEBPMUX'),
53 "transp_webp": ("PIL._webp", "HAVE_TRANSPARENCY"),
54 "raqm": ("PIL._imagingft", "HAVE_RAQM")
55 }
56
57
58 def check_feature(feature):
59 if feature not in features:
60 raise ValueError("Unknown feature %s" % feature)
61
62 module, flag = features[feature]
63
64 try:
65 imported_module = __import__(module, fromlist=['PIL'])
66 return getattr(imported_module, flag)
67 except ImportError:
68 return None
69
70
71 def get_supported_features():
72 return [f for f in features if check_feature(f)]
73
74
75 def check(feature):
76 return (feature in modules and check_module(feature) or
77 feature in codecs and check_codec(feature) or
78 feature in features and check_feature(feature))
79
80
81 def get_supported():
82 ret = get_supported_modules()
83 ret.extend(get_supported_features())
84 ret.extend(get_supported_codecs())
85 return ret
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/PIL/features.py b/src/PIL/features.py
--- a/src/PIL/features.py
+++ b/src/PIL/features.py
@@ -51,7 +51,8 @@
"webp_anim": ("PIL._webp", 'HAVE_WEBPANIM'),
"webp_mux": ("PIL._webp", 'HAVE_WEBPMUX'),
"transp_webp": ("PIL._webp", "HAVE_TRANSPARENCY"),
- "raqm": ("PIL._imagingft", "HAVE_RAQM")
+ "raqm": ("PIL._imagingft", "HAVE_RAQM"),
+ "libjpeg_turbo": ("PIL._imaging", "HAVE_LIBJPEGTURBO"),
}
|
{"golden_diff": "diff --git a/src/PIL/features.py b/src/PIL/features.py\n--- a/src/PIL/features.py\n+++ b/src/PIL/features.py\n@@ -51,7 +51,8 @@\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n- \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\")\n+ \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\"),\n+ \"libjpeg_turbo\": (\"PIL._imaging\", \"HAVE_LIBJPEGTURBO\"),\n }\n", "issue": "How to tell at run time whether libjpeg-turbo version of libjpeg is used?\ntl;dr:\r\n\r\nIs there some way to accomplish: `PIL.Image.libjpeg_turbo_is_enabled()`?\r\n\r\nThe full story:\r\n\r\nIs there a way to tell from a pre-built Pillow whether it was built against `libjpeg-turbo` or not?\r\n\r\nThis is assuming that all I have is `libjpeg.so.X.X` and no way to tell where it came from.\r\n\r\nI see there is a symbol in the library:\r\n```\r\nnm _imaging.cpython-36m-x86_64-linux-gnu.so | grep -I turbo\r\n000000000007e5a0 D libjpeg_turbo_version\r\n```\r\nbut I don't know how to access its value from python.\r\n\r\nIf there is a way to tell the same from from shell using `ldd`/`nm` or other linker tools, it'd do too.\r\n\r\nThe intention is to be able to tell a user at run-time to re-build Pillow after installing `libjpeg-turbo` to gain speed. The problem is that It's not enough to build Pillow against `libjpeg-turbo`. Given how conda/pip dependencies work, a new prebuilt package of `Pillow` could get swapped in as a dependency for some other package and the user won't know that they now run a less efficient `Pillow` unless they watch closely any install/update logs.\r\n\r\nCurrently the only solution I can think of (in conda env) is to take the output of:\r\n\r\n cd ~/anaconda3/envs/pytorch-dev/lib/python3.6/site-packages/PIL\r\n ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg\r\n\r\nwhich wold give me something like:\r\n\r\n libjpeg.so.8 => ~/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8\r\n\r\nAnd then to try to match it to:\r\n\r\n grep libjpeg ~/anaconda3/envs/pytorch-dev/conda-meta/libjpeg-turbo-2.0.1-h470a237_0.json\r\n\r\nwhich may work. There is a problem with this approach\r\n\r\nIt's very likely that conda is going to reinstall `jpeg` since many packages depend on it, and when it does, there is going to be 2 libjpeg libs.\r\n\r\n ldd _imaging.cpython-36m-x86_64-linux-gnu.so | grep libjpeg\r\n libjpeg.so.8 => /home/stas/anaconda3/envs/pytorch-dev/lib/libjpeg.so.8 (0x00007f92628c8000)\r\n libjpeg.so.9 => /home/stas/anaconda3/envs/pytorch-dev/lib/./libjpeg.so.9 (0x00007f9261c4e000)\r\n\r\nAnd now I can no longer tell which is which, since I can no longer tell which of the two Pillow will load at run time. Well, I can go one step further and check /proc/<pid>/maps to get the library, but it's getting more and more convoluted. And I won't even know how to do the same on non-linux platform. And this is just for the conda setup, for pip setup it'd be something else.\r\n\r\nAlso what happens if `libjpeg-turbo` and `libjpeg` are the same version?\r\n\r\nPerhaps there is an easier way? Any chance to have `PIL.Image.libjpeg_turbo_is_enabled()`?\r\n\r\nThank you.\r\n\n", "before_files": [{"content": "from . import Image\n\nmodules = {\n \"pil\": \"PIL._imaging\",\n \"tkinter\": \"PIL._tkinter_finder\",\n \"freetype2\": \"PIL._imagingft\",\n \"littlecms2\": \"PIL._imagingcms\",\n \"webp\": \"PIL._webp\",\n}\n\n\ndef check_module(feature):\n if not (feature in modules):\n raise ValueError(\"Unknown module %s\" % feature)\n\n module = modules[feature]\n\n try:\n __import__(module)\n return True\n except ImportError:\n return False\n\n\ndef get_supported_modules():\n return [f for f in modules if check_module(f)]\n\n\ncodecs = {\n \"jpg\": \"jpeg\",\n \"jpg_2000\": \"jpeg2k\",\n \"zlib\": \"zip\",\n \"libtiff\": \"libtiff\"\n}\n\n\ndef check_codec(feature):\n if feature not in codecs:\n raise ValueError(\"Unknown codec %s\" % feature)\n\n codec = codecs[feature]\n\n return codec + \"_encoder\" in dir(Image.core)\n\n\ndef get_supported_codecs():\n return [f for f in codecs if check_codec(f)]\n\n\nfeatures = {\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\")\n}\n\n\ndef check_feature(feature):\n if feature not in features:\n raise ValueError(\"Unknown feature %s\" % feature)\n\n module, flag = features[feature]\n\n try:\n imported_module = __import__(module, fromlist=['PIL'])\n return getattr(imported_module, flag)\n except ImportError:\n return None\n\n\ndef get_supported_features():\n return [f for f in features if check_feature(f)]\n\n\ndef check(feature):\n return (feature in modules and check_module(feature) or\n feature in codecs and check_codec(feature) or\n feature in features and check_feature(feature))\n\n\ndef get_supported():\n ret = get_supported_modules()\n ret.extend(get_supported_features())\n ret.extend(get_supported_codecs())\n return ret\n", "path": "src/PIL/features.py"}], "after_files": [{"content": "from . import Image\n\nmodules = {\n \"pil\": \"PIL._imaging\",\n \"tkinter\": \"PIL._tkinter_finder\",\n \"freetype2\": \"PIL._imagingft\",\n \"littlecms2\": \"PIL._imagingcms\",\n \"webp\": \"PIL._webp\",\n}\n\n\ndef check_module(feature):\n if not (feature in modules):\n raise ValueError(\"Unknown module %s\" % feature)\n\n module = modules[feature]\n\n try:\n __import__(module)\n return True\n except ImportError:\n return False\n\n\ndef get_supported_modules():\n return [f for f in modules if check_module(f)]\n\n\ncodecs = {\n \"jpg\": \"jpeg\",\n \"jpg_2000\": \"jpeg2k\",\n \"zlib\": \"zip\",\n \"libtiff\": \"libtiff\"\n}\n\n\ndef check_codec(feature):\n if feature not in codecs:\n raise ValueError(\"Unknown codec %s\" % feature)\n\n codec = codecs[feature]\n\n return codec + \"_encoder\" in dir(Image.core)\n\n\ndef get_supported_codecs():\n return [f for f in codecs if check_codec(f)]\n\n\nfeatures = {\n \"webp_anim\": (\"PIL._webp\", 'HAVE_WEBPANIM'),\n \"webp_mux\": (\"PIL._webp\", 'HAVE_WEBPMUX'),\n \"transp_webp\": (\"PIL._webp\", \"HAVE_TRANSPARENCY\"),\n \"raqm\": (\"PIL._imagingft\", \"HAVE_RAQM\"),\n \"libjpeg_turbo\": (\"PIL._imaging\", \"HAVE_LIBJPEGTURBO\"),\n}\n\n\ndef check_feature(feature):\n if feature not in features:\n raise ValueError(\"Unknown feature %s\" % feature)\n\n module, flag = features[feature]\n\n try:\n imported_module = __import__(module, fromlist=['PIL'])\n return getattr(imported_module, flag)\n except ImportError:\n return None\n\n\ndef get_supported_features():\n return [f for f in features if check_feature(f)]\n\n\ndef check(feature):\n return (feature in modules and check_module(feature) or\n feature in codecs and check_codec(feature) or\n feature in features and check_feature(feature))\n\n\ndef get_supported():\n ret = get_supported_modules()\n ret.extend(get_supported_features())\n ret.extend(get_supported_codecs())\n return ret\n", "path": "src/PIL/features.py"}]}
| 1,716 | 167 |
gh_patches_debug_31120
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1365
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
catch a simple bug of handling url
### Checklist
- [x] This is a bug report.
### Description
catch a simple bug of returning url.
### Version
streamlink 0.9.0
### Unexpected behavior
for example
```sh
streamlink http://www.huya.com/1547946968 "best"
```
it reports:
requests.exceptions.MissingSchema: Invalid URL '//ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8': No schema supplied. Perhaps you meant http:////ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8?
### Expected behavior
but if you replace with the m3u8 url above, by **removing // header**, it will work.
The equivalent successful example are as follows:
```sh
streamlink ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8 "best"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/huya.py`
Content:
```
1 import re
2
3 from requests.adapters import HTTPAdapter
4
5 from streamlink.plugin import Plugin
6 from streamlink.plugin.api import http, validate
7 from streamlink.stream import HLSStream
8 from streamlink.plugin.api import useragents
9
10 HUYA_URL = "http://m.huya.com/%s"
11
12 _url_re = re.compile(r'http(s)?://(www\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)
13 _hls_re = re.compile(r'^\s*<video\s+id="html5player-video"\s+src="(?P<url>[^"]+)"', re.MULTILINE)
14
15 _hls_schema = validate.Schema(
16 validate.all(
17 validate.transform(_hls_re.search),
18 validate.any(
19 None,
20 validate.all(
21 validate.get('url'),
22 validate.transform(str)
23 )
24 )
25 )
26 )
27
28 class Huya(Plugin):
29 @classmethod
30 def can_handle_url(self, url):
31 return _url_re.match(url)
32
33 def _get_streams(self):
34 match = _url_re.match(self.url)
35 channel = match.group("channel")
36
37 http.headers.update({"User-Agent": useragents.IPAD})
38 #Some problem with SSL on huya.com now, do not use https
39
40 hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)
41 yield "live", HLSStream(self.session, hls_url)
42
43 __plugin__ = Huya
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py
--- a/src/streamlink/plugins/huya.py
+++ b/src/streamlink/plugins/huya.py
@@ -1,11 +1,10 @@
import re
-from requests.adapters import HTTPAdapter
-
from streamlink.plugin import Plugin
from streamlink.plugin.api import http, validate
from streamlink.stream import HLSStream
from streamlink.plugin.api import useragents
+from streamlink.utils import update_scheme
HUYA_URL = "http://m.huya.com/%s"
@@ -13,17 +12,18 @@
_hls_re = re.compile(r'^\s*<video\s+id="html5player-video"\s+src="(?P<url>[^"]+)"', re.MULTILINE)
_hls_schema = validate.Schema(
- validate.all(
- validate.transform(_hls_re.search),
- validate.any(
- None,
- validate.all(
- validate.get('url'),
- validate.transform(str)
- )
- )
+ validate.all(
+ validate.transform(_hls_re.search),
+ validate.any(
+ None,
+ validate.all(
+ validate.get('url'),
+ validate.transform(str)
)
)
+ )
+)
+
class Huya(Plugin):
@classmethod
@@ -35,9 +35,10 @@
channel = match.group("channel")
http.headers.update({"User-Agent": useragents.IPAD})
- #Some problem with SSL on huya.com now, do not use https
+ # Some problem with SSL on huya.com now, do not use https
hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)
- yield "live", HLSStream(self.session, hls_url)
+ yield "live", HLSStream(self.session, update_scheme("http://", hls_url))
+
__plugin__ = Huya
|
{"golden_diff": "diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py\n--- a/src/streamlink/plugins/huya.py\n+++ b/src/streamlink/plugins/huya.py\n@@ -1,11 +1,10 @@\n import re\n \n-from requests.adapters import HTTPAdapter\n-\n from streamlink.plugin import Plugin\n from streamlink.plugin.api import http, validate\n from streamlink.stream import HLSStream\n from streamlink.plugin.api import useragents\n+from streamlink.utils import update_scheme\n \n HUYA_URL = \"http://m.huya.com/%s\"\n \n@@ -13,17 +12,18 @@\n _hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n \n _hls_schema = validate.Schema(\n- validate.all(\n- validate.transform(_hls_re.search),\n- validate.any(\n- None,\n- validate.all(\n- validate.get('url'),\n- validate.transform(str)\n- )\n- )\n+ validate.all(\n+ validate.transform(_hls_re.search),\n+ validate.any(\n+ None,\n+ validate.all(\n+ validate.get('url'),\n+ validate.transform(str)\n )\n )\n+ )\n+)\n+\n \n class Huya(Plugin):\n @classmethod\n@@ -35,9 +35,10 @@\n channel = match.group(\"channel\")\n \n http.headers.update({\"User-Agent\": useragents.IPAD})\n- #Some problem with SSL on huya.com now, do not use https\n+ # Some problem with SSL on huya.com now, do not use https\n \n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n- yield \"live\", HLSStream(self.session, hls_url)\n+ yield \"live\", HLSStream(self.session, update_scheme(\"http://\", hls_url))\n+\n \n __plugin__ = Huya\n", "issue": "catch a simple bug of handling url\n\r\n### Checklist\r\n\r\n- [x] This is a bug report.\r\n\r\n### Description\r\n\r\ncatch a simple bug of returning url. \r\n\r\n### Version\r\nstreamlink 0.9.0\r\n\r\n### Unexpected behavior\r\nfor example\r\n```sh\r\nstreamlink http://www.huya.com/1547946968 \"best\"\r\n```\r\nit reports:\r\nrequests.exceptions.MissingSchema: Invalid URL '//ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8': No schema supplied. Perhaps you meant http:////ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8?\r\n\r\n### Expected behavior\r\nbut if you replace with the m3u8 url above, by **removing // header**, it will work.\r\nThe equivalent successful example are as follows:\r\n```sh\r\nstreamlink ws.streamhls.huya.com/huyalive/30765679-2523417567-10837995924416888832-2789253832-10057-A-1512526581-1_1200/playlist.m3u8 \"best\"\r\n```\n", "before_files": [{"content": "import re\n\nfrom requests.adapters import HTTPAdapter\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.plugin.api import useragents\n\nHUYA_URL = \"http://m.huya.com/%s\"\n\n_url_re = re.compile(r'http(s)?://(www\\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)\n_hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n\n_hls_schema = validate.Schema(\n validate.all(\n validate.transform(_hls_re.search),\n validate.any(\n None,\n validate.all(\n validate.get('url'),\n validate.transform(str)\n )\n )\n )\n )\n\nclass Huya(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n channel = match.group(\"channel\")\n\n http.headers.update({\"User-Agent\": useragents.IPAD})\n #Some problem with SSL on huya.com now, do not use https\n\n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n yield \"live\", HLSStream(self.session, hls_url)\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}], "after_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http, validate\nfrom streamlink.stream import HLSStream\nfrom streamlink.plugin.api import useragents\nfrom streamlink.utils import update_scheme\n\nHUYA_URL = \"http://m.huya.com/%s\"\n\n_url_re = re.compile(r'http(s)?://(www\\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)\n_hls_re = re.compile(r'^\\s*<video\\s+id=\"html5player-video\"\\s+src=\"(?P<url>[^\"]+)\"', re.MULTILINE)\n\n_hls_schema = validate.Schema(\n validate.all(\n validate.transform(_hls_re.search),\n validate.any(\n None,\n validate.all(\n validate.get('url'),\n validate.transform(str)\n )\n )\n )\n)\n\n\nclass Huya(Plugin):\n @classmethod\n def can_handle_url(self, url):\n return _url_re.match(url)\n\n def _get_streams(self):\n match = _url_re.match(self.url)\n channel = match.group(\"channel\")\n\n http.headers.update({\"User-Agent\": useragents.IPAD})\n # Some problem with SSL on huya.com now, do not use https\n\n hls_url = http.get(HUYA_URL % channel, schema=_hls_schema)\n yield \"live\", HLSStream(self.session, update_scheme(\"http://\", hls_url))\n\n\n__plugin__ = Huya\n", "path": "src/streamlink/plugins/huya.py"}]}
| 1,086 | 433 |
gh_patches_debug_4108
|
rasdani/github-patches
|
git_diff
|
google__timesketch-1821
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tagger analyzer not functiong properly
**Describe the bug**
After upgrade TimeSketch to version: 20210602 the tagger analyzer is not functioning with custom tags
**To Reproduce**
Steps to reproduce the behavior:
1. Import plaso file with evtx data
2. Add the following tagging rule to tags.yaml
```yaml
logon_tagger:
query_string: 'data_type: "windows:evtx:record" AND source_name: "Microsoft-Windows-Security-Auditing" AND event_identifier: 4688'
tags: ['logon']
save_search: true
search_name: 'logon'
```
3. run tagger analyzer
4. See error
**Expected behavior**
The tagger analyzer to run correctly as in previous versions.
**Desktop (please complete the following information):**
-OS:Ubuntu 20.04.2 LTS
-Browser : Firefox
-Version: 86.0
**Additional context**
The following exception is thrown once the tagger analyzer is ran:
```
Traceback (most recent call last): File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/interface.py", line 995, in run_wrapper result = self.run() File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py", line 48, in run tag_result = self.tagger(name, tag_config) File "/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py", line 100, in tagger if expression: UnboundLocalError: local variable 'expression' referenced before assignment
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `timesketch/lib/analyzers/tagger.py`
Content:
```
1 """Analyzer plugin for tagging."""
2 import logging
3
4 from timesketch.lib import emojis
5 from timesketch.lib.analyzers import interface
6 from timesketch.lib.analyzers import manager
7 from timesketch.lib.analyzers import utils
8
9
10 logger = logging.getLogger('timesketch.analyzers.tagger')
11
12
13 class TaggerSketchPlugin(interface.BaseAnalyzer):
14 """Analyzer for tagging events."""
15
16 NAME = 'tagger'
17 DISPLAY_NAME = 'Tagger'
18 DESCRIPTION = 'Tag events based on pre-defined rules'
19
20 CONFIG_FILE = 'tags.yaml'
21
22 def __init__(self, index_name, sketch_id, timeline_id=None, config=None):
23 """Initialize The Sketch Analyzer.
24
25 Args:
26 index_name: Elasticsearch index name
27 sketch_id: Sketch ID
28 timeline_id: The ID of the timeline.
29 config: Optional dict that contains the configuration for the
30 analyzer. If not provided, the default YAML file will be used.
31 """
32 self.index_name = index_name
33 self._config = config
34 super().__init__(index_name, sketch_id, timeline_id=timeline_id)
35
36 def run(self):
37 """Entry point for the analyzer.
38
39 Returns:
40 String with summary of the analyzer result.
41 """
42 config = self._config or interface.get_yaml_config(self.CONFIG_FILE)
43 if not config:
44 return 'Unable to parse the config file.'
45
46 tag_results = []
47 for name, tag_config in iter(config.items()):
48 tag_result = self.tagger(name, tag_config)
49 if tag_result and not tag_result.startswith('0 events tagged'):
50 tag_results.append(tag_result)
51
52 if tag_results:
53 return ', '.join(tag_results)
54 return 'No tags applied'
55
56 def tagger(self, name, config):
57 """Tag and add emojis to events.
58
59 Args:
60 name: String with the name describing what will be tagged.
61 config: A dict that contains the configuration See data/tags.yaml
62 for fields and documentation of what needs to be defined.
63
64 Returns:
65 String with summary of the analyzer result.
66 """
67 query = config.get('query_string')
68 query_dsl = config.get('query_dsl')
69 save_search = config.get('save_search', False)
70 # For legacy reasons to support both save_search and
71 # create_view parameters.
72 if not save_search:
73 save_search = config.get('create_view', False)
74
75 search_name = config.get('search_name', None)
76 # For legacy reasons to support both search_name and view_name.
77 if search_name is None:
78 search_name = config.get('view_name', name)
79
80 tags = config.get('tags', [])
81 emoji_names = config.get('emojis', [])
82 emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]
83
84 expression_string = config.get('regular_expression', '')
85 attributes = None
86 if expression_string:
87 expression = utils.compile_regular_expression(
88 expression_string=expression_string,
89 expression_flags=config.get('re_flags'))
90
91 attribute = config.get('re_attribute')
92 if attribute:
93 attributes = [attribute]
94
95 event_counter = 0
96 events = self.event_stream(
97 query_string=query, query_dsl=query_dsl, return_fields=attributes)
98
99 for event in events:
100 if expression:
101 value = event.source.get(attributes[0])
102 if value:
103 result = expression.findall(value)
104 if not result:
105 # Skip counting this tag since the regular expression
106 # didn't find anything.
107 continue
108
109 event_counter += 1
110 event.add_tags(tags)
111 event.add_emojis(emojis_to_add)
112
113 # Commit the event to the datastore.
114 event.commit()
115
116 if save_search and event_counter:
117 self.sketch.add_view(
118 search_name, self.NAME, query_string=query, query_dsl=query_dsl)
119
120 return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)
121
122
123 manager.AnalysisManager.register_analyzer(TaggerSketchPlugin)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/timesketch/lib/analyzers/tagger.py b/timesketch/lib/analyzers/tagger.py
--- a/timesketch/lib/analyzers/tagger.py
+++ b/timesketch/lib/analyzers/tagger.py
@@ -83,6 +83,7 @@
expression_string = config.get('regular_expression', '')
attributes = None
+ expression = None
if expression_string:
expression = utils.compile_regular_expression(
expression_string=expression_string,
|
{"golden_diff": "diff --git a/timesketch/lib/analyzers/tagger.py b/timesketch/lib/analyzers/tagger.py\n--- a/timesketch/lib/analyzers/tagger.py\n+++ b/timesketch/lib/analyzers/tagger.py\n@@ -83,6 +83,7 @@\n \n expression_string = config.get('regular_expression', '')\n attributes = None\n+ expression = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n", "issue": "tagger analyzer not functiong properly \n**Describe the bug**\r\nAfter upgrade TimeSketch to version: 20210602 the tagger analyzer is not functioning with custom tags\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Import plaso file with evtx data \r\n2. Add the following tagging rule to tags.yaml\r\n```yaml\r\nlogon_tagger: \r\n query_string: 'data_type: \"windows:evtx:record\" AND source_name: \"Microsoft-Windows-Security-Auditing\" AND event_identifier: 4688'\r\n tags: ['logon']\r\n save_search: true\r\n search_name: 'logon'\r\n```\r\n3. run tagger analyzer\r\n4. See error\r\n\r\n**Expected behavior**\r\nThe tagger analyzer to run correctly as in previous versions.\r\n\r\n**Desktop (please complete the following information):**\r\n-OS:Ubuntu 20.04.2 LTS\r\n-Browser : Firefox\r\n-Version: 86.0\r\n\r\n**Additional context**\r\nThe following exception is thrown once the tagger analyzer is ran:\r\n```\r\nTraceback (most recent call last): File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/interface.py\", line 995, in run_wrapper result = self.run() File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py\", line 48, in run tag_result = self.tagger(name, tag_config) File \"/usr/local/lib/python3.8/dist-packages/timesketch/lib/analyzers/tagger.py\", line 100, in tagger if expression: UnboundLocalError: local variable 'expression' referenced before assignment\r\n``` \r\n\n", "before_files": [{"content": "\"\"\"Analyzer plugin for tagging.\"\"\"\nimport logging\n\nfrom timesketch.lib import emojis\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nfrom timesketch.lib.analyzers import utils\n\n\nlogger = logging.getLogger('timesketch.analyzers.tagger')\n\n\nclass TaggerSketchPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for tagging events.\"\"\"\n\n NAME = 'tagger'\n DISPLAY_NAME = 'Tagger'\n DESCRIPTION = 'Tag events based on pre-defined rules'\n\n CONFIG_FILE = 'tags.yaml'\n\n def __init__(self, index_name, sketch_id, timeline_id=None, config=None):\n \"\"\"Initialize The Sketch Analyzer.\n\n Args:\n index_name: Elasticsearch index name\n sketch_id: Sketch ID\n timeline_id: The ID of the timeline.\n config: Optional dict that contains the configuration for the\n analyzer. If not provided, the default YAML file will be used.\n \"\"\"\n self.index_name = index_name\n self._config = config\n super().__init__(index_name, sketch_id, timeline_id=timeline_id)\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n config = self._config or interface.get_yaml_config(self.CONFIG_FILE)\n if not config:\n return 'Unable to parse the config file.'\n\n tag_results = []\n for name, tag_config in iter(config.items()):\n tag_result = self.tagger(name, tag_config)\n if tag_result and not tag_result.startswith('0 events tagged'):\n tag_results.append(tag_result)\n\n if tag_results:\n return ', '.join(tag_results)\n return 'No tags applied'\n\n def tagger(self, name, config):\n \"\"\"Tag and add emojis to events.\n\n Args:\n name: String with the name describing what will be tagged.\n config: A dict that contains the configuration See data/tags.yaml\n for fields and documentation of what needs to be defined.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n query = config.get('query_string')\n query_dsl = config.get('query_dsl')\n save_search = config.get('save_search', False)\n # For legacy reasons to support both save_search and\n # create_view parameters.\n if not save_search:\n save_search = config.get('create_view', False)\n\n search_name = config.get('search_name', None)\n # For legacy reasons to support both search_name and view_name.\n if search_name is None:\n search_name = config.get('view_name', name)\n\n tags = config.get('tags', [])\n emoji_names = config.get('emojis', [])\n emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]\n\n expression_string = config.get('regular_expression', '')\n attributes = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n expression_flags=config.get('re_flags'))\n\n attribute = config.get('re_attribute')\n if attribute:\n attributes = [attribute]\n\n event_counter = 0\n events = self.event_stream(\n query_string=query, query_dsl=query_dsl, return_fields=attributes)\n\n for event in events:\n if expression:\n value = event.source.get(attributes[0])\n if value:\n result = expression.findall(value)\n if not result:\n # Skip counting this tag since the regular expression\n # didn't find anything.\n continue\n\n event_counter += 1\n event.add_tags(tags)\n event.add_emojis(emojis_to_add)\n\n # Commit the event to the datastore.\n event.commit()\n\n if save_search and event_counter:\n self.sketch.add_view(\n search_name, self.NAME, query_string=query, query_dsl=query_dsl)\n\n return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)\n\n\nmanager.AnalysisManager.register_analyzer(TaggerSketchPlugin)\n", "path": "timesketch/lib/analyzers/tagger.py"}], "after_files": [{"content": "\"\"\"Analyzer plugin for tagging.\"\"\"\nimport logging\n\nfrom timesketch.lib import emojis\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nfrom timesketch.lib.analyzers import utils\n\n\nlogger = logging.getLogger('timesketch.analyzers.tagger')\n\n\nclass TaggerSketchPlugin(interface.BaseAnalyzer):\n \"\"\"Analyzer for tagging events.\"\"\"\n\n NAME = 'tagger'\n DISPLAY_NAME = 'Tagger'\n DESCRIPTION = 'Tag events based on pre-defined rules'\n\n CONFIG_FILE = 'tags.yaml'\n\n def __init__(self, index_name, sketch_id, timeline_id=None, config=None):\n \"\"\"Initialize The Sketch Analyzer.\n\n Args:\n index_name: Elasticsearch index name\n sketch_id: Sketch ID\n timeline_id: The ID of the timeline.\n config: Optional dict that contains the configuration for the\n analyzer. If not provided, the default YAML file will be used.\n \"\"\"\n self.index_name = index_name\n self._config = config\n super().__init__(index_name, sketch_id, timeline_id=timeline_id)\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n config = self._config or interface.get_yaml_config(self.CONFIG_FILE)\n if not config:\n return 'Unable to parse the config file.'\n\n tag_results = []\n for name, tag_config in iter(config.items()):\n tag_result = self.tagger(name, tag_config)\n if tag_result and not tag_result.startswith('0 events tagged'):\n tag_results.append(tag_result)\n\n if tag_results:\n return ', '.join(tag_results)\n return 'No tags applied'\n\n def tagger(self, name, config):\n \"\"\"Tag and add emojis to events.\n\n Args:\n name: String with the name describing what will be tagged.\n config: A dict that contains the configuration See data/tags.yaml\n for fields and documentation of what needs to be defined.\n\n Returns:\n String with summary of the analyzer result.\n \"\"\"\n query = config.get('query_string')\n query_dsl = config.get('query_dsl')\n save_search = config.get('save_search', False)\n # For legacy reasons to support both save_search and\n # create_view parameters.\n if not save_search:\n save_search = config.get('create_view', False)\n\n search_name = config.get('search_name', None)\n # For legacy reasons to support both search_name and view_name.\n if search_name is None:\n search_name = config.get('view_name', name)\n\n tags = config.get('tags', [])\n emoji_names = config.get('emojis', [])\n emojis_to_add = [emojis.get_emoji(x) for x in emoji_names]\n\n expression_string = config.get('regular_expression', '')\n attributes = None\n expression = None\n if expression_string:\n expression = utils.compile_regular_expression(\n expression_string=expression_string,\n expression_flags=config.get('re_flags'))\n\n attribute = config.get('re_attribute')\n if attribute:\n attributes = [attribute]\n\n event_counter = 0\n events = self.event_stream(\n query_string=query, query_dsl=query_dsl, return_fields=attributes)\n\n for event in events:\n if expression:\n value = event.source.get(attributes[0])\n if value:\n result = expression.findall(value)\n if not result:\n # Skip counting this tag since the regular expression\n # didn't find anything.\n continue\n\n event_counter += 1\n event.add_tags(tags)\n event.add_emojis(emojis_to_add)\n\n # Commit the event to the datastore.\n event.commit()\n\n if save_search and event_counter:\n self.sketch.add_view(\n search_name, self.NAME, query_string=query, query_dsl=query_dsl)\n\n return '{0:d} events tagged for [{1:s}]'.format(event_counter, name)\n\n\nmanager.AnalysisManager.register_analyzer(TaggerSketchPlugin)\n", "path": "timesketch/lib/analyzers/tagger.py"}]}
| 1,763 | 111 |
gh_patches_debug_559
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-702
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 1.6.6
On the docket:
+ [x] Release more flexible pex binaries. #654
+ [x] If sys.executable is not on PATH a pex will re-exec itself forever. #700
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '1.6.5'
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '1.6.5'
+__version__ = '1.6.6'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '1.6.5'\n+__version__ = '1.6.6'\n", "issue": "Release 1.6.6\nOn the docket:\r\n+ [x] Release more flexible pex binaries. #654\r\n+ [x] If sys.executable is not on PATH a pex will re-exec itself forever. #700\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.6.5'\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.6.6'\n", "path": "pex/version.py"}]}
| 361 | 94 |
gh_patches_debug_9878
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-3423
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Tracker for `RolesFromDomain`
This is to track the implementation of `RolesFromDomain`, which implements role setting depending on the email domain of the user.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `master/buildbot/www/authz/roles.py`
Content:
```
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18 from future.utils import iteritems
19
20
21 class RolesFromBase(object):
22
23 def __init__(self):
24 pass
25
26 def getRolesFromUser(self, userDetails):
27 return []
28
29 def setAuthz(self, authz):
30 self.authz = authz
31 self.master = authz.master
32
33
34 class RolesFromGroups(RolesFromBase):
35
36 def __init__(self, groupPrefix=""):
37 RolesFromBase.__init__(self)
38 self.groupPrefix = groupPrefix
39
40 def getRolesFromUser(self, userDetails):
41 roles = []
42 if 'groups' in userDetails:
43 for group in userDetails['groups']:
44 if group.startswith(self.groupPrefix):
45 roles.append(group[len(self.groupPrefix):])
46 return roles
47
48
49 class RolesFromEmails(RolesFromBase):
50
51 def __init__(self, **kwargs):
52 RolesFromBase.__init__(self)
53 self.roles = {}
54 for role, emails in iteritems(kwargs):
55 for email in emails:
56 self.roles.setdefault(email, []).append(role)
57
58 def getRolesFromUser(self, userDetails):
59 if 'email' in userDetails:
60 return self.roles.get(userDetails['email'], [])
61 return []
62
63
64 class RolesFromOwner(RolesFromBase):
65
66 def __init__(self, role):
67 RolesFromBase.__init__(self)
68 self.role = role
69
70 def getRolesFromUser(self, userDetails, owner):
71 if 'email' in userDetails:
72 if userDetails['email'] == owner and owner is not None:
73 return [self.role]
74 return []
75
76
77 class RolesFromUsername(RolesFromBase):
78 def __init__(self, roles, usernames):
79 self.roles = roles
80 if None in usernames:
81 from buildbot import config
82 config.error('Usernames cannot be None')
83 self.usernames = usernames
84
85 def getRolesFromUser(self, userDetails):
86 if userDetails.get('username') in self.usernames:
87 return self.roles
88 return []
89
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/master/buildbot/www/authz/roles.py b/master/buildbot/www/authz/roles.py
--- a/master/buildbot/www/authz/roles.py
+++ b/master/buildbot/www/authz/roles.py
@@ -61,6 +61,24 @@
return []
+class RolesFromDomain(RolesFromEmails):
+
+ def __init__(self, **kwargs):
+ RolesFromBase.__init__(self)
+
+ self.domain_roles = {}
+ for role, domains in iteritems(kwargs):
+ for domain in domains:
+ self.domain_roles.setdefault(domain, []).append(role)
+
+ def getRolesFromUser(self, userDetails):
+ if 'email' in userDetails:
+ email = userDetails['email']
+ edomain = email.split('@')[-1]
+ return self.domain_roles.get(edomain, [])
+ return []
+
+
class RolesFromOwner(RolesFromBase):
def __init__(self, role):
|
{"golden_diff": "diff --git a/master/buildbot/www/authz/roles.py b/master/buildbot/www/authz/roles.py\n--- a/master/buildbot/www/authz/roles.py\n+++ b/master/buildbot/www/authz/roles.py\n@@ -61,6 +61,24 @@\n return []\n \n \n+class RolesFromDomain(RolesFromEmails):\n+\n+ def __init__(self, **kwargs):\n+ RolesFromBase.__init__(self)\n+\n+ self.domain_roles = {}\n+ for role, domains in iteritems(kwargs):\n+ for domain in domains:\n+ self.domain_roles.setdefault(domain, []).append(role)\n+\n+ def getRolesFromUser(self, userDetails):\n+ if 'email' in userDetails:\n+ email = userDetails['email']\n+ edomain = email.split('@')[-1]\n+ return self.domain_roles.get(edomain, [])\n+ return []\n+\n+\n class RolesFromOwner(RolesFromBase):\n \n def __init__(self, role):\n", "issue": "Tracker for `RolesFromDomain`\nThis is to track the implementation of `RolesFromDomain`, which implements role setting depending on the email domain of the user.\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom future.utils import iteritems\n\n\nclass RolesFromBase(object):\n\n def __init__(self):\n pass\n\n def getRolesFromUser(self, userDetails):\n return []\n\n def setAuthz(self, authz):\n self.authz = authz\n self.master = authz.master\n\n\nclass RolesFromGroups(RolesFromBase):\n\n def __init__(self, groupPrefix=\"\"):\n RolesFromBase.__init__(self)\n self.groupPrefix = groupPrefix\n\n def getRolesFromUser(self, userDetails):\n roles = []\n if 'groups' in userDetails:\n for group in userDetails['groups']:\n if group.startswith(self.groupPrefix):\n roles.append(group[len(self.groupPrefix):])\n return roles\n\n\nclass RolesFromEmails(RolesFromBase):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n self.roles = {}\n for role, emails in iteritems(kwargs):\n for email in emails:\n self.roles.setdefault(email, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n return self.roles.get(userDetails['email'], [])\n return []\n\n\nclass RolesFromOwner(RolesFromBase):\n\n def __init__(self, role):\n RolesFromBase.__init__(self)\n self.role = role\n\n def getRolesFromUser(self, userDetails, owner):\n if 'email' in userDetails:\n if userDetails['email'] == owner and owner is not None:\n return [self.role]\n return []\n\n\nclass RolesFromUsername(RolesFromBase):\n def __init__(self, roles, usernames):\n self.roles = roles\n if None in usernames:\n from buildbot import config\n config.error('Usernames cannot be None')\n self.usernames = usernames\n\n def getRolesFromUser(self, userDetails):\n if userDetails.get('username') in self.usernames:\n return self.roles\n return []\n", "path": "master/buildbot/www/authz/roles.py"}], "after_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom future.utils import iteritems\n\n\nclass RolesFromBase(object):\n\n def __init__(self):\n pass\n\n def getRolesFromUser(self, userDetails):\n return []\n\n def setAuthz(self, authz):\n self.authz = authz\n self.master = authz.master\n\n\nclass RolesFromGroups(RolesFromBase):\n\n def __init__(self, groupPrefix=\"\"):\n RolesFromBase.__init__(self)\n self.groupPrefix = groupPrefix\n\n def getRolesFromUser(self, userDetails):\n roles = []\n if 'groups' in userDetails:\n for group in userDetails['groups']:\n if group.startswith(self.groupPrefix):\n roles.append(group[len(self.groupPrefix):])\n return roles\n\n\nclass RolesFromEmails(RolesFromBase):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n self.roles = {}\n for role, emails in iteritems(kwargs):\n for email in emails:\n self.roles.setdefault(email, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n return self.roles.get(userDetails['email'], [])\n return []\n\n\nclass RolesFromDomain(RolesFromEmails):\n\n def __init__(self, **kwargs):\n RolesFromBase.__init__(self)\n\n self.domain_roles = {}\n for role, domains in iteritems(kwargs):\n for domain in domains:\n self.domain_roles.setdefault(domain, []).append(role)\n\n def getRolesFromUser(self, userDetails):\n if 'email' in userDetails:\n email = userDetails['email']\n edomain = email.split('@')[-1]\n return self.domain_roles.get(edomain, [])\n return []\n\n\nclass RolesFromOwner(RolesFromBase):\n\n def __init__(self, role):\n RolesFromBase.__init__(self)\n self.role = role\n\n def getRolesFromUser(self, userDetails, owner):\n if 'email' in userDetails:\n if userDetails['email'] == owner and owner is not None:\n return [self.role]\n return []\n\n\nclass RolesFromUsername(RolesFromBase):\n def __init__(self, roles, usernames):\n self.roles = roles\n if None in usernames:\n from buildbot import config\n config.error('Usernames cannot be None')\n self.usernames = usernames\n\n def getRolesFromUser(self, userDetails):\n if userDetails.get('username') in self.usernames:\n return self.roles\n return []\n", "path": "master/buildbot/www/authz/roles.py"}]}
| 1,070 | 211 |
gh_patches_debug_11052
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-8831
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
### 🐛 Describe the bug
in utils.subgraph.py
edge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
because edge_index on 'cuda:0' and node_mask on 'cpu'
being solved with: node_mask=node_mask.to(device=device)
### Versions
last version
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch_geometric/transforms/largest_connected_components.py`
Content:
```
1 import torch
2
3 from torch_geometric.data import Data
4 from torch_geometric.data.datapipes import functional_transform
5 from torch_geometric.transforms import BaseTransform
6 from torch_geometric.utils import to_scipy_sparse_matrix
7
8
9 @functional_transform('largest_connected_components')
10 class LargestConnectedComponents(BaseTransform):
11 r"""Selects the subgraph that corresponds to the
12 largest connected components in the graph
13 (functional name: :obj:`largest_connected_components`).
14
15 Args:
16 num_components (int, optional): Number of largest components to keep
17 (default: :obj:`1`)
18 connection (str, optional): Type of connection to use for directed
19 graphs, can be either :obj:`'strong'` or :obj:`'weak'`.
20 Nodes `i` and `j` are strongly connected if a path
21 exists both from `i` to `j` and from `j` to `i`. A directed graph
22 is weakly connected if replacing all of its directed edges with
23 undirected edges produces a connected (undirected) graph.
24 (default: :obj:`'weak'`)
25 """
26 def __init__(
27 self,
28 num_components: int = 1,
29 connection: str = 'weak',
30 ) -> None:
31 assert connection in ['strong', 'weak'], 'Unknown connection type'
32 self.num_components = num_components
33 self.connection = connection
34
35 def forward(self, data: Data) -> Data:
36 import numpy as np
37 import scipy.sparse as sp
38
39 assert data.edge_index is not None
40
41 adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)
42
43 num_components, component = sp.csgraph.connected_components(
44 adj, connection=self.connection)
45
46 if num_components <= self.num_components:
47 return data
48
49 _, count = np.unique(component, return_counts=True)
50 subset = np.in1d(component, count.argsort()[-self.num_components:])
51
52 return data.subgraph(torch.from_numpy(subset).to(torch.bool))
53
54 def __repr__(self) -> str:
55 return f'{self.__class__.__name__}({self.num_components})'
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torch_geometric/transforms/largest_connected_components.py b/torch_geometric/transforms/largest_connected_components.py
--- a/torch_geometric/transforms/largest_connected_components.py
+++ b/torch_geometric/transforms/largest_connected_components.py
@@ -47,9 +47,11 @@
return data
_, count = np.unique(component, return_counts=True)
- subset = np.in1d(component, count.argsort()[-self.num_components:])
+ subset_np = np.in1d(component, count.argsort()[-self.num_components:])
+ subset = torch.from_numpy(subset_np)
+ subset = subset.to(data.edge_index.device, torch.bool)
- return data.subgraph(torch.from_numpy(subset).to(torch.bool))
+ return data.subgraph(subset)
def __repr__(self) -> str:
return f'{self.__class__.__name__}({self.num_components})'
|
{"golden_diff": "diff --git a/torch_geometric/transforms/largest_connected_components.py b/torch_geometric/transforms/largest_connected_components.py\n--- a/torch_geometric/transforms/largest_connected_components.py\n+++ b/torch_geometric/transforms/largest_connected_components.py\n@@ -47,9 +47,11 @@\n return data\n \n _, count = np.unique(component, return_counts=True)\n- subset = np.in1d(component, count.argsort()[-self.num_components:])\n+ subset_np = np.in1d(component, count.argsort()[-self.num_components:])\n+ subset = torch.from_numpy(subset_np)\n+ subset = subset.to(data.edge_index.device, torch.bool)\n \n- return data.subgraph(torch.from_numpy(subset).to(torch.bool))\n+ return data.subgraph(subset)\n \n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "issue": "in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)\n### \ud83d\udc1b Describe the bug\n\nin utils.subgraph.py\r\n\r\nedge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]\r\n\r\nRuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)\r\n\r\nbecause edge_index on 'cuda:0' and node_mask on 'cpu'\r\n\r\nbeing solved with: node_mask=node_mask.to(device=device)\r\n\r\n\r\n\n\n### Versions\n\nlast version\n", "before_files": [{"content": "import torch\n\nfrom torch_geometric.data import Data\nfrom torch_geometric.data.datapipes import functional_transform\nfrom torch_geometric.transforms import BaseTransform\nfrom torch_geometric.utils import to_scipy_sparse_matrix\n\n\n@functional_transform('largest_connected_components')\nclass LargestConnectedComponents(BaseTransform):\n r\"\"\"Selects the subgraph that corresponds to the\n largest connected components in the graph\n (functional name: :obj:`largest_connected_components`).\n\n Args:\n num_components (int, optional): Number of largest components to keep\n (default: :obj:`1`)\n connection (str, optional): Type of connection to use for directed\n graphs, can be either :obj:`'strong'` or :obj:`'weak'`.\n Nodes `i` and `j` are strongly connected if a path\n exists both from `i` to `j` and from `j` to `i`. A directed graph\n is weakly connected if replacing all of its directed edges with\n undirected edges produces a connected (undirected) graph.\n (default: :obj:`'weak'`)\n \"\"\"\n def __init__(\n self,\n num_components: int = 1,\n connection: str = 'weak',\n ) -> None:\n assert connection in ['strong', 'weak'], 'Unknown connection type'\n self.num_components = num_components\n self.connection = connection\n\n def forward(self, data: Data) -> Data:\n import numpy as np\n import scipy.sparse as sp\n\n assert data.edge_index is not None\n\n adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)\n\n num_components, component = sp.csgraph.connected_components(\n adj, connection=self.connection)\n\n if num_components <= self.num_components:\n return data\n\n _, count = np.unique(component, return_counts=True)\n subset = np.in1d(component, count.argsort()[-self.num_components:])\n\n return data.subgraph(torch.from_numpy(subset).to(torch.bool))\n\n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "path": "torch_geometric/transforms/largest_connected_components.py"}], "after_files": [{"content": "import torch\n\nfrom torch_geometric.data import Data\nfrom torch_geometric.data.datapipes import functional_transform\nfrom torch_geometric.transforms import BaseTransform\nfrom torch_geometric.utils import to_scipy_sparse_matrix\n\n\n@functional_transform('largest_connected_components')\nclass LargestConnectedComponents(BaseTransform):\n r\"\"\"Selects the subgraph that corresponds to the\n largest connected components in the graph\n (functional name: :obj:`largest_connected_components`).\n\n Args:\n num_components (int, optional): Number of largest components to keep\n (default: :obj:`1`)\n connection (str, optional): Type of connection to use for directed\n graphs, can be either :obj:`'strong'` or :obj:`'weak'`.\n Nodes `i` and `j` are strongly connected if a path\n exists both from `i` to `j` and from `j` to `i`. A directed graph\n is weakly connected if replacing all of its directed edges with\n undirected edges produces a connected (undirected) graph.\n (default: :obj:`'weak'`)\n \"\"\"\n def __init__(\n self,\n num_components: int = 1,\n connection: str = 'weak',\n ) -> None:\n assert connection in ['strong', 'weak'], 'Unknown connection type'\n self.num_components = num_components\n self.connection = connection\n\n def forward(self, data: Data) -> Data:\n import numpy as np\n import scipy.sparse as sp\n\n assert data.edge_index is not None\n\n adj = to_scipy_sparse_matrix(data.edge_index, num_nodes=data.num_nodes)\n\n num_components, component = sp.csgraph.connected_components(\n adj, connection=self.connection)\n\n if num_components <= self.num_components:\n return data\n\n _, count = np.unique(component, return_counts=True)\n subset_np = np.in1d(component, count.argsort()[-self.num_components:])\n subset = torch.from_numpy(subset_np)\n subset = subset.to(data.edge_index.device, torch.bool)\n\n return data.subgraph(subset)\n\n def __repr__(self) -> str:\n return f'{self.__class__.__name__}({self.num_components})'\n", "path": "torch_geometric/transforms/largest_connected_components.py"}]}
| 947 | 201 |
gh_patches_debug_15420
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-474
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sponsors with multiple packages are listed for each package
When a sponsor takes multiple packages (sponsorship and add-on package, for example), they are listed in the sponsor list and sponsor menu for each package, which is a bit surprising. See Microsoft from PyCon ZA 2018, for example.

We should list sponsors only once, and add some decent way of marking that sponsors have taken multiple packages in the list.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wafer/sponsors/models.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 import logging
4
5 from django.core.validators import MinValueValidator
6 from django.db import models
7 from django.db.models.signals import post_save
8 from django.urls import reverse
9 from django.utils.encoding import python_2_unicode_compatible
10 from django.utils.translation import ugettext_lazy as _
11
12 from markitup.fields import MarkupField
13
14 from wafer.menu import menu_logger, refresh_menu_cache
15
16 logger = logging.getLogger(__name__)
17
18
19 @python_2_unicode_compatible
20 class File(models.Model):
21 """A file for use in sponsor and sponshorship package descriptions."""
22 name = models.CharField(max_length=255)
23 description = models.TextField(blank=True)
24 item = models.FileField(upload_to='sponsors_files')
25
26 def __str__(self):
27 return u'%s (%s)' % (self.name, self.item.url)
28
29
30 @python_2_unicode_compatible
31 class SponsorshipPackage(models.Model):
32 """A description of a sponsorship package."""
33 order = models.IntegerField(default=1)
34 name = models.CharField(max_length=255)
35 number_available = models.IntegerField(
36 null=True, validators=[MinValueValidator(0)])
37 currency = models.CharField(
38 max_length=16, default='$',
39 help_text=_("Currency symbol for the sponsorship amount."))
40 price = models.DecimalField(
41 max_digits=12, decimal_places=2,
42 help_text=_("Amount to be sponsored."))
43 short_description = models.TextField(
44 help_text=_("One sentence overview of the package."))
45 description = MarkupField(
46 help_text=_("Describe what the package gives the sponsor."))
47 files = models.ManyToManyField(
48 File, related_name="packages", blank=True,
49 help_text=_("Images and other files for use in"
50 " the description markdown field."))
51 # We use purely ascii help text, to avoid issues with the migrations
52 # not handling unicode help text nicely.
53 symbol = models.CharField(
54 max_length=1, blank=True,
55 help_text=_("Optional symbol to display in the sponsors list "
56 "next to sponsors who have sponsored at this list, "
57 "(for example *)."))
58
59 class Meta:
60 ordering = ['order', '-price', 'name']
61
62 def __str__(self):
63 return u'%s (amount: %.0f)' % (self.name, self.price)
64
65 def number_claimed(self):
66 return self.sponsors.count()
67
68
69 @python_2_unicode_compatible
70 class Sponsor(models.Model):
71 """A conference sponsor."""
72 order = models.IntegerField(default=1)
73 name = models.CharField(max_length=255)
74 packages = models.ManyToManyField(SponsorshipPackage,
75 related_name="sponsors")
76 description = MarkupField(
77 help_text=_("Write some nice things about the sponsor."))
78 url = models.URLField(
79 default="", blank=True,
80 help_text=_("Url to link back to the sponsor if required"))
81
82 class Meta:
83 ordering = ['order', 'name', 'id']
84
85 def __str__(self):
86 return u'%s' % (self.name,)
87
88 def get_absolute_url(self):
89 return reverse('wafer_sponsor', args=(self.pk,))
90
91 def symbols(self):
92 """Return a string of the symbols of all the packages this sponsor has
93 taken."""
94 packages = self.packages.all()
95 symbols = u"".join(p.symbol for p in packages)
96 return symbols
97
98 @property
99 def symbol(self):
100 """The symbol of the highest level package this sponsor has taken."""
101 package = self.packages.first()
102 if package:
103 return package.symbol
104 return u""
105
106
107 class TaggedFile(models.Model):
108 """Tags for files associated with a given sponsor"""
109 tag_name = models.CharField(max_length=255, null=False)
110 tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)
111 sponsor = models.ForeignKey(Sponsor, related_name="files",
112 on_delete=models.CASCADE)
113
114
115 def sponsor_menu(
116 root_menu, menu="sponsors", label=_("Sponsors"),
117 sponsors_item=_("Our sponsors"),
118 packages_item=_("Sponsorship packages")):
119 """Add sponsor menu links."""
120 root_menu.add_menu(menu, label, items=[])
121 for sponsor in (
122 Sponsor.objects.all()
123 .order_by('packages', 'order', 'id')
124 .prefetch_related('packages')):
125 symbols = sponsor.symbols()
126 if symbols:
127 item_name = u"» %s %s" % (sponsor.name, symbols)
128 else:
129 item_name = u"» %s" % (sponsor.name,)
130 with menu_logger(logger, "sponsor %r" % (sponsor.name,)):
131 root_menu.add_item(
132 item_name, sponsor.get_absolute_url(), menu=menu)
133
134 if sponsors_item:
135 with menu_logger(logger, "sponsors page link"):
136 root_menu.add_item(
137 sponsors_item, reverse("wafer_sponsors"), menu)
138 if packages_item:
139 with menu_logger(logger, "sponsorship package page link"):
140 root_menu.add_item(
141 packages_item, reverse("wafer_sponsorship_packages"), menu)
142
143
144 post_save.connect(refresh_menu_cache, sender=Sponsor)
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wafer/sponsors/models.py b/wafer/sponsors/models.py
--- a/wafer/sponsors/models.py
+++ b/wafer/sponsors/models.py
@@ -118,10 +118,15 @@
packages_item=_("Sponsorship packages")):
"""Add sponsor menu links."""
root_menu.add_menu(menu, label, items=[])
+ added_to_menu = set()
for sponsor in (
Sponsor.objects.all()
.order_by('packages', 'order', 'id')
.prefetch_related('packages')):
+ if sponsor in added_to_menu:
+ # We've already added this in a previous packaged
+ continue
+ added_to_menu.add(sponsor)
symbols = sponsor.symbols()
if symbols:
item_name = u"» %s %s" % (sponsor.name, symbols)
|
{"golden_diff": "diff --git a/wafer/sponsors/models.py b/wafer/sponsors/models.py\n--- a/wafer/sponsors/models.py\n+++ b/wafer/sponsors/models.py\n@@ -118,10 +118,15 @@\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n+ added_to_menu = set()\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n+ if sponsor in added_to_menu:\n+ # We've already added this in a previous packaged\n+ continue\n+ added_to_menu.add(sponsor)\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n", "issue": "Sponsors with multiple packages are listed for each package\nWhen a sponsor takes multiple packages (sponsorship and add-on package, for example), they are listed in the sponsor list and sponsor menu for each package, which is a bit surprising. See Microsoft from PyCon ZA 2018, for example.\r\n\r\n\r\n\r\n\r\nWe should list sponsors only once, and add some decent way of marking that sponsors have taken multiple packages in the list.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport logging\n\nfrom django.core.validators import MinValueValidator\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.urls import reverse\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom markitup.fields import MarkupField\n\nfrom wafer.menu import menu_logger, refresh_menu_cache\n\nlogger = logging.getLogger(__name__)\n\n\n@python_2_unicode_compatible\nclass File(models.Model):\n \"\"\"A file for use in sponsor and sponshorship package descriptions.\"\"\"\n name = models.CharField(max_length=255)\n description = models.TextField(blank=True)\n item = models.FileField(upload_to='sponsors_files')\n\n def __str__(self):\n return u'%s (%s)' % (self.name, self.item.url)\n\n\n@python_2_unicode_compatible\nclass SponsorshipPackage(models.Model):\n \"\"\"A description of a sponsorship package.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n number_available = models.IntegerField(\n null=True, validators=[MinValueValidator(0)])\n currency = models.CharField(\n max_length=16, default='$',\n help_text=_(\"Currency symbol for the sponsorship amount.\"))\n price = models.DecimalField(\n max_digits=12, decimal_places=2,\n help_text=_(\"Amount to be sponsored.\"))\n short_description = models.TextField(\n help_text=_(\"One sentence overview of the package.\"))\n description = MarkupField(\n help_text=_(\"Describe what the package gives the sponsor.\"))\n files = models.ManyToManyField(\n File, related_name=\"packages\", blank=True,\n help_text=_(\"Images and other files for use in\"\n \" the description markdown field.\"))\n # We use purely ascii help text, to avoid issues with the migrations\n # not handling unicode help text nicely.\n symbol = models.CharField(\n max_length=1, blank=True,\n help_text=_(\"Optional symbol to display in the sponsors list \"\n \"next to sponsors who have sponsored at this list, \"\n \"(for example *).\"))\n\n class Meta:\n ordering = ['order', '-price', 'name']\n\n def __str__(self):\n return u'%s (amount: %.0f)' % (self.name, self.price)\n\n def number_claimed(self):\n return self.sponsors.count()\n\n\n@python_2_unicode_compatible\nclass Sponsor(models.Model):\n \"\"\"A conference sponsor.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n packages = models.ManyToManyField(SponsorshipPackage,\n related_name=\"sponsors\")\n description = MarkupField(\n help_text=_(\"Write some nice things about the sponsor.\"))\n url = models.URLField(\n default=\"\", blank=True,\n help_text=_(\"Url to link back to the sponsor if required\"))\n\n class Meta:\n ordering = ['order', 'name', 'id']\n\n def __str__(self):\n return u'%s' % (self.name,)\n\n def get_absolute_url(self):\n return reverse('wafer_sponsor', args=(self.pk,))\n\n def symbols(self):\n \"\"\"Return a string of the symbols of all the packages this sponsor has\n taken.\"\"\"\n packages = self.packages.all()\n symbols = u\"\".join(p.symbol for p in packages)\n return symbols\n\n @property\n def symbol(self):\n \"\"\"The symbol of the highest level package this sponsor has taken.\"\"\"\n package = self.packages.first()\n if package:\n return package.symbol\n return u\"\"\n\n\nclass TaggedFile(models.Model):\n \"\"\"Tags for files associated with a given sponsor\"\"\"\n tag_name = models.CharField(max_length=255, null=False)\n tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)\n sponsor = models.ForeignKey(Sponsor, related_name=\"files\",\n on_delete=models.CASCADE)\n\n\ndef sponsor_menu(\n root_menu, menu=\"sponsors\", label=_(\"Sponsors\"),\n sponsors_item=_(\"Our sponsors\"),\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n else:\n item_name = u\"\u00bb %s\" % (sponsor.name,)\n with menu_logger(logger, \"sponsor %r\" % (sponsor.name,)):\n root_menu.add_item(\n item_name, sponsor.get_absolute_url(), menu=menu)\n\n if sponsors_item:\n with menu_logger(logger, \"sponsors page link\"):\n root_menu.add_item(\n sponsors_item, reverse(\"wafer_sponsors\"), menu)\n if packages_item:\n with menu_logger(logger, \"sponsorship package page link\"):\n root_menu.add_item(\n packages_item, reverse(\"wafer_sponsorship_packages\"), menu)\n\n\npost_save.connect(refresh_menu_cache, sender=Sponsor)\n", "path": "wafer/sponsors/models.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport logging\n\nfrom django.core.validators import MinValueValidator\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.urls import reverse\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom markitup.fields import MarkupField\n\nfrom wafer.menu import menu_logger, refresh_menu_cache\n\nlogger = logging.getLogger(__name__)\n\n\n@python_2_unicode_compatible\nclass File(models.Model):\n \"\"\"A file for use in sponsor and sponshorship package descriptions.\"\"\"\n name = models.CharField(max_length=255)\n description = models.TextField(blank=True)\n item = models.FileField(upload_to='sponsors_files')\n\n def __str__(self):\n return u'%s (%s)' % (self.name, self.item.url)\n\n\n@python_2_unicode_compatible\nclass SponsorshipPackage(models.Model):\n \"\"\"A description of a sponsorship package.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n number_available = models.IntegerField(\n null=True, validators=[MinValueValidator(0)])\n currency = models.CharField(\n max_length=16, default='$',\n help_text=_(\"Currency symbol for the sponsorship amount.\"))\n price = models.DecimalField(\n max_digits=12, decimal_places=2,\n help_text=_(\"Amount to be sponsored.\"))\n short_description = models.TextField(\n help_text=_(\"One sentence overview of the package.\"))\n description = MarkupField(\n help_text=_(\"Describe what the package gives the sponsor.\"))\n files = models.ManyToManyField(\n File, related_name=\"packages\", blank=True,\n help_text=_(\"Images and other files for use in\"\n \" the description markdown field.\"))\n # We use purely ascii help text, to avoid issues with the migrations\n # not handling unicode help text nicely.\n symbol = models.CharField(\n max_length=1, blank=True,\n help_text=_(\"Optional symbol to display in the sponsors list \"\n \"next to sponsors who have sponsored at this list, \"\n \"(for example *).\"))\n\n class Meta:\n ordering = ['order', '-price', 'name']\n\n def __str__(self):\n return u'%s (amount: %.0f)' % (self.name, self.price)\n\n def number_claimed(self):\n return self.sponsors.count()\n\n\n@python_2_unicode_compatible\nclass Sponsor(models.Model):\n \"\"\"A conference sponsor.\"\"\"\n order = models.IntegerField(default=1)\n name = models.CharField(max_length=255)\n packages = models.ManyToManyField(SponsorshipPackage,\n related_name=\"sponsors\")\n description = MarkupField(\n help_text=_(\"Write some nice things about the sponsor.\"))\n url = models.URLField(\n default=\"\", blank=True,\n help_text=_(\"Url to link back to the sponsor if required\"))\n\n class Meta:\n ordering = ['order', 'name', 'id']\n\n def __str__(self):\n return u'%s' % (self.name,)\n\n def get_absolute_url(self):\n return reverse('wafer_sponsor', args=(self.pk,))\n\n def symbols(self):\n \"\"\"Return a string of the symbols of all the packages this sponsor has\n taken.\"\"\"\n packages = self.packages.all()\n symbols = u\"\".join(p.symbol for p in packages)\n return symbols\n\n @property\n def symbol(self):\n \"\"\"The symbol of the highest level package this sponsor has taken.\"\"\"\n package = self.packages.first()\n if package:\n return package.symbol\n return u\"\"\n\n\nclass TaggedFile(models.Model):\n \"\"\"Tags for files associated with a given sponsor\"\"\"\n tag_name = models.CharField(max_length=255, null=False)\n tagged_file = models.ForeignKey(File, on_delete=models.CASCADE)\n sponsor = models.ForeignKey(Sponsor, related_name=\"files\",\n on_delete=models.CASCADE)\n\n\ndef sponsor_menu(\n root_menu, menu=\"sponsors\", label=_(\"Sponsors\"),\n sponsors_item=_(\"Our sponsors\"),\n packages_item=_(\"Sponsorship packages\")):\n \"\"\"Add sponsor menu links.\"\"\"\n root_menu.add_menu(menu, label, items=[])\n added_to_menu = set()\n for sponsor in (\n Sponsor.objects.all()\n .order_by('packages', 'order', 'id')\n .prefetch_related('packages')):\n if sponsor in added_to_menu:\n # We've already added this in a previous packaged\n continue\n added_to_menu.add(sponsor)\n symbols = sponsor.symbols()\n if symbols:\n item_name = u\"\u00bb %s %s\" % (sponsor.name, symbols)\n else:\n item_name = u\"\u00bb %s\" % (sponsor.name,)\n with menu_logger(logger, \"sponsor %r\" % (sponsor.name,)):\n root_menu.add_item(\n item_name, sponsor.get_absolute_url(), menu=menu)\n\n if sponsors_item:\n with menu_logger(logger, \"sponsors page link\"):\n root_menu.add_item(\n sponsors_item, reverse(\"wafer_sponsors\"), menu)\n if packages_item:\n with menu_logger(logger, \"sponsorship package page link\"):\n root_menu.add_item(\n packages_item, reverse(\"wafer_sponsorship_packages\"), menu)\n\n\npost_save.connect(refresh_menu_cache, sender=Sponsor)\n", "path": "wafer/sponsors/models.py"}]}
| 1,839 | 189 |
gh_patches_debug_1799
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-705
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
With TorqueProvider, submit stderr/stdout does not go to runinfo
This happens on both NSCC and Blue Waters. The submit script has
```
#PBS -o /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stdout
#PBS -e /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stderr
```
but the stdout goes to `$HOME/parsl.parsl.auto.1542146393.457273.o9212235`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/providers/torque/template.py`
Content:
```
1 template_string = '''#!/bin/bash
2
3 #PBS -S /bin/bash
4 #PBS -N ${jobname}
5 #PBS -m n
6 #PBS -k eo
7 #PBS -l walltime=$walltime
8 #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
9 #PBS -o ${submit_script_dir}/${jobname}.submit.stdout
10 #PBS -e ${submit_script_dir}/${jobname}.submit.stderr
11 ${scheduler_options}
12
13 ${worker_init}
14
15 export JOBNAME="${jobname}"
16
17 ${user_script}
18
19 '''
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py
--- a/parsl/providers/torque/template.py
+++ b/parsl/providers/torque/template.py
@@ -3,7 +3,6 @@
#PBS -S /bin/bash
#PBS -N ${jobname}
#PBS -m n
-#PBS -k eo
#PBS -l walltime=$walltime
#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
#PBS -o ${submit_script_dir}/${jobname}.submit.stdout
|
{"golden_diff": "diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py\n--- a/parsl/providers/torque/template.py\n+++ b/parsl/providers/torque/template.py\n@@ -3,7 +3,6 @@\n #PBS -S /bin/bash\n #PBS -N ${jobname}\n #PBS -m n\n-#PBS -k eo\n #PBS -l walltime=$walltime\n #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n #PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n", "issue": "With TorqueProvider, submit stderr/stdout does not go to runinfo\nThis happens on both NSCC and Blue Waters. The submit script has\r\n\r\n```\r\n#PBS -o /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stdout\r\n#PBS -e /mnt/a/u/sciteam/woodard/simple-tests/runinfo/001/submit_scripts/parsl.parsl.auto.1542146393.457273.submit.stderr\r\n```\r\n\r\nbut the stdout goes to `$HOME/parsl.parsl.auto.1542146393.457273.o9212235`\n", "before_files": [{"content": "template_string = '''#!/bin/bash\n\n#PBS -S /bin/bash\n#PBS -N ${jobname}\n#PBS -m n\n#PBS -k eo\n#PBS -l walltime=$walltime\n#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n#PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n#PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n${user_script}\n\n'''\n", "path": "parsl/providers/torque/template.py"}], "after_files": [{"content": "template_string = '''#!/bin/bash\n\n#PBS -S /bin/bash\n#PBS -N ${jobname}\n#PBS -m n\n#PBS -l walltime=$walltime\n#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n#PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n#PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n${user_script}\n\n'''\n", "path": "parsl/providers/torque/template.py"}]}
| 592 | 125 |
gh_patches_debug_39618
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-249
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add option to compute root_mean_squared_error
## 🚀 Feature
Allow the user to choose between MSE and RMSE.
### Motivation
In a physical domain the RMSE, which is essentially the mean of distances, may be significantly more intuitive than the MSE. Therefore, it would be nice to have the option to choose the preferd metric.
### Pitch
Similar to the implementation in [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html#sklearn.metrics.mean_squared_error) one could simply pass `squared=False` to the `MeanSquaredError` module or the `mean_squared_error` function.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchmetrics/functional/regression/mean_squared_error.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Tuple
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.utilities.checks import _check_same_shape
20
21
22 def _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:
23 _check_same_shape(preds, target)
24 diff = preds - target
25 sum_squared_error = torch.sum(diff * diff)
26 n_obs = target.numel()
27 return sum_squared_error, n_obs
28
29
30 def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:
31 return sum_squared_error / n_obs
32
33
34 def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:
35 """
36 Computes mean squared error
37
38 Args:
39 preds: estimated labels
40 target: ground truth labels
41
42 Return:
43 Tensor with MSE
44
45 Example:
46 >>> from torchmetrics.functional import mean_squared_error
47 >>> x = torch.tensor([0., 1, 2, 3])
48 >>> y = torch.tensor([0., 1, 2, 2])
49 >>> mean_squared_error(x, y)
50 tensor(0.2500)
51 """
52 sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
53 return _mean_squared_error_compute(sum_squared_error, n_obs)
54
```
Path: `torchmetrics/regression/mean_squared_error.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, Callable, Optional
15
16 import torch
17 from torch import Tensor, tensor
18
19 from torchmetrics.functional.regression.mean_squared_error import (
20 _mean_squared_error_compute,
21 _mean_squared_error_update,
22 )
23 from torchmetrics.metric import Metric
24
25
26 class MeanSquaredError(Metric):
27 r"""
28 Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):
29
30 .. math:: \text{MSE} = \frac{1}{N}\sum_i^N(y_i - \hat{y_i})^2
31
32 Where :math:`y` is a tensor of target values, and :math:`\hat{y}` is a tensor of predictions.
33
34 Args:
35 compute_on_step:
36 Forward only calls ``update()`` and return None if this is set to False. default: True
37 dist_sync_on_step:
38 Synchronize metric state across processes at each ``forward()``
39 before returning the value at the step. default: False
40 process_group:
41 Specify the process group on which synchronization is called. default: None (which selects the entire world)
42
43 Example:
44 >>> from torchmetrics import MeanSquaredError
45 >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])
46 >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])
47 >>> mean_squared_error = MeanSquaredError()
48 >>> mean_squared_error(preds, target)
49 tensor(0.8750)
50
51 """
52
53 def __init__(
54 self,
55 compute_on_step: bool = True,
56 dist_sync_on_step: bool = False,
57 process_group: Optional[Any] = None,
58 dist_sync_fn: Callable = None,
59 ):
60 super().__init__(
61 compute_on_step=compute_on_step,
62 dist_sync_on_step=dist_sync_on_step,
63 process_group=process_group,
64 dist_sync_fn=dist_sync_fn,
65 )
66
67 self.add_state("sum_squared_error", default=tensor(0.0), dist_reduce_fx="sum")
68 self.add_state("total", default=tensor(0), dist_reduce_fx="sum")
69
70 def update(self, preds: Tensor, target: Tensor):
71 """
72 Update state with predictions and targets.
73
74 Args:
75 preds: Predictions from model
76 target: Ground truth values
77 """
78 sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
79
80 self.sum_squared_error += sum_squared_error
81 self.total += n_obs
82
83 def compute(self):
84 """
85 Computes mean squared error over state.
86 """
87 return _mean_squared_error_compute(self.sum_squared_error, self.total)
88
89 @property
90 def is_differentiable(self):
91 return True
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchmetrics/functional/regression/mean_squared_error.py b/torchmetrics/functional/regression/mean_squared_error.py
--- a/torchmetrics/functional/regression/mean_squared_error.py
+++ b/torchmetrics/functional/regression/mean_squared_error.py
@@ -27,17 +27,18 @@
return sum_squared_error, n_obs
-def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:
- return sum_squared_error / n_obs
+def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:
+ return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)
-def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:
+def mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:
"""
Computes mean squared error
Args:
preds: estimated labels
target: ground truth labels
+ squared: returns RMSE value if set to False
Return:
Tensor with MSE
@@ -50,4 +51,4 @@
tensor(0.2500)
"""
sum_squared_error, n_obs = _mean_squared_error_update(preds, target)
- return _mean_squared_error_compute(sum_squared_error, n_obs)
+ return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)
diff --git a/torchmetrics/regression/mean_squared_error.py b/torchmetrics/regression/mean_squared_error.py
--- a/torchmetrics/regression/mean_squared_error.py
+++ b/torchmetrics/regression/mean_squared_error.py
@@ -39,6 +39,8 @@
before returning the value at the step. default: False
process_group:
Specify the process group on which synchronization is called. default: None (which selects the entire world)
+ squared:
+ If True returns MSE value, if False returns RMSE value.
Example:
>>> from torchmetrics import MeanSquaredError
@@ -56,6 +58,7 @@
dist_sync_on_step: bool = False,
process_group: Optional[Any] = None,
dist_sync_fn: Callable = None,
+ squared: bool = True,
):
super().__init__(
compute_on_step=compute_on_step,
@@ -66,6 +69,7 @@
self.add_state("sum_squared_error", default=tensor(0.0), dist_reduce_fx="sum")
self.add_state("total", default=tensor(0), dist_reduce_fx="sum")
+ self.squared = squared
def update(self, preds: Tensor, target: Tensor):
"""
@@ -84,7 +88,7 @@
"""
Computes mean squared error over state.
"""
- return _mean_squared_error_compute(self.sum_squared_error, self.total)
+ return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)
@property
def is_differentiable(self):
|
{"golden_diff": "diff --git a/torchmetrics/functional/regression/mean_squared_error.py b/torchmetrics/functional/regression/mean_squared_error.py\n--- a/torchmetrics/functional/regression/mean_squared_error.py\n+++ b/torchmetrics/functional/regression/mean_squared_error.py\n@@ -27,17 +27,18 @@\n return sum_squared_error, n_obs\n \n \n-def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:\n- return sum_squared_error / n_obs\n+def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:\n+ return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)\n \n \n-def mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:\n+def mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:\n \"\"\"\n Computes mean squared error\n \n Args:\n preds: estimated labels\n target: ground truth labels\n+ squared: returns RMSE value if set to False\n \n Return:\n Tensor with MSE\n@@ -50,4 +51,4 @@\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n- return _mean_squared_error_compute(sum_squared_error, n_obs)\n+ return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)\ndiff --git a/torchmetrics/regression/mean_squared_error.py b/torchmetrics/regression/mean_squared_error.py\n--- a/torchmetrics/regression/mean_squared_error.py\n+++ b/torchmetrics/regression/mean_squared_error.py\n@@ -39,6 +39,8 @@\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n+ squared:\n+ If True returns MSE value, if False returns RMSE value.\n \n Example:\n >>> from torchmetrics import MeanSquaredError\n@@ -56,6 +58,7 @@\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n+ squared: bool = True,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n@@ -66,6 +69,7 @@\n \n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n+ self.squared = squared\n \n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n@@ -84,7 +88,7 @@\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n- return _mean_squared_error_compute(self.sum_squared_error, self.total)\n+ return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)\n \n @property\n def is_differentiable(self):\n", "issue": "Add option to compute root_mean_squared_error\n## \ud83d\ude80 Feature\r\nAllow the user to choose between MSE and RMSE.\r\n\r\n### Motivation\r\nIn a physical domain the RMSE, which is essentially the mean of distances, may be significantly more intuitive than the MSE. Therefore, it would be nice to have the option to choose the preferd metric.\r\n\r\n### Pitch\r\nSimilar to the implementation in [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_error.html#sklearn.metrics.mean_squared_error) one could simply pass `squared=False` to the `MeanSquaredError` module or the `mean_squared_error` function.\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:\n _check_same_shape(preds, target)\n diff = preds - target\n sum_squared_error = torch.sum(diff * diff)\n n_obs = target.numel()\n return sum_squared_error, n_obs\n\n\ndef _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int) -> Tensor:\n return sum_squared_error / n_obs\n\n\ndef mean_squared_error(preds: Tensor, target: Tensor) -> Tensor:\n \"\"\"\n Computes mean squared error\n\n Args:\n preds: estimated labels\n target: ground truth labels\n\n Return:\n Tensor with MSE\n\n Example:\n >>> from torchmetrics.functional import mean_squared_error\n >>> x = torch.tensor([0., 1, 2, 3])\n >>> y = torch.tensor([0., 1, 2, 2])\n >>> mean_squared_error(x, y)\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n return _mean_squared_error_compute(sum_squared_error, n_obs)\n", "path": "torchmetrics/functional/regression/mean_squared_error.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Optional\n\nimport torch\nfrom torch import Tensor, tensor\n\nfrom torchmetrics.functional.regression.mean_squared_error import (\n _mean_squared_error_compute,\n _mean_squared_error_update,\n)\nfrom torchmetrics.metric import Metric\n\n\nclass MeanSquaredError(Metric):\n r\"\"\"\n Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):\n\n .. math:: \\text{MSE} = \\frac{1}{N}\\sum_i^N(y_i - \\hat{y_i})^2\n\n Where :math:`y` is a tensor of target values, and :math:`\\hat{y}` is a tensor of predictions.\n\n Args:\n compute_on_step:\n Forward only calls ``update()`` and return None if this is set to False. default: True\n dist_sync_on_step:\n Synchronize metric state across processes at each ``forward()``\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n\n Example:\n >>> from torchmetrics import MeanSquaredError\n >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])\n >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])\n >>> mean_squared_error = MeanSquaredError()\n >>> mean_squared_error(preds, target)\n tensor(0.8750)\n\n \"\"\"\n\n def __init__(\n self,\n compute_on_step: bool = True,\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n dist_sync_on_step=dist_sync_on_step,\n process_group=process_group,\n dist_sync_fn=dist_sync_fn,\n )\n\n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n\n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n Update state with predictions and targets.\n\n Args:\n preds: Predictions from model\n target: Ground truth values\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n\n self.sum_squared_error += sum_squared_error\n self.total += n_obs\n\n def compute(self):\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n return _mean_squared_error_compute(self.sum_squared_error, self.total)\n\n @property\n def is_differentiable(self):\n return True\n", "path": "torchmetrics/regression/mean_squared_error.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _mean_squared_error_update(preds: Tensor, target: Tensor) -> Tuple[Tensor, int]:\n _check_same_shape(preds, target)\n diff = preds - target\n sum_squared_error = torch.sum(diff * diff)\n n_obs = target.numel()\n return sum_squared_error, n_obs\n\n\ndef _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: int, squared: bool = True) -> Tensor:\n return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)\n\n\ndef mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True) -> Tensor:\n \"\"\"\n Computes mean squared error\n\n Args:\n preds: estimated labels\n target: ground truth labels\n squared: returns RMSE value if set to False\n\n Return:\n Tensor with MSE\n\n Example:\n >>> from torchmetrics.functional import mean_squared_error\n >>> x = torch.tensor([0., 1, 2, 3])\n >>> y = torch.tensor([0., 1, 2, 2])\n >>> mean_squared_error(x, y)\n tensor(0.2500)\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)\n", "path": "torchmetrics/functional/regression/mean_squared_error.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Callable, Optional\n\nimport torch\nfrom torch import Tensor, tensor\n\nfrom torchmetrics.functional.regression.mean_squared_error import (\n _mean_squared_error_compute,\n _mean_squared_error_update,\n)\nfrom torchmetrics.metric import Metric\n\n\nclass MeanSquaredError(Metric):\n r\"\"\"\n Computes `mean squared error <https://en.wikipedia.org/wiki/Mean_squared_error>`_ (MSE):\n\n .. math:: \\text{MSE} = \\frac{1}{N}\\sum_i^N(y_i - \\hat{y_i})^2\n\n Where :math:`y` is a tensor of target values, and :math:`\\hat{y}` is a tensor of predictions.\n\n Args:\n compute_on_step:\n Forward only calls ``update()`` and return None if this is set to False. default: True\n dist_sync_on_step:\n Synchronize metric state across processes at each ``forward()``\n before returning the value at the step. default: False\n process_group:\n Specify the process group on which synchronization is called. default: None (which selects the entire world)\n squared:\n If True returns MSE value, if False returns RMSE value.\n\n Example:\n >>> from torchmetrics import MeanSquaredError\n >>> target = torch.tensor([2.5, 5.0, 4.0, 8.0])\n >>> preds = torch.tensor([3.0, 5.0, 2.5, 7.0])\n >>> mean_squared_error = MeanSquaredError()\n >>> mean_squared_error(preds, target)\n tensor(0.8750)\n\n \"\"\"\n\n def __init__(\n self,\n compute_on_step: bool = True,\n dist_sync_on_step: bool = False,\n process_group: Optional[Any] = None,\n dist_sync_fn: Callable = None,\n squared: bool = True,\n ):\n super().__init__(\n compute_on_step=compute_on_step,\n dist_sync_on_step=dist_sync_on_step,\n process_group=process_group,\n dist_sync_fn=dist_sync_fn,\n )\n\n self.add_state(\"sum_squared_error\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n self.squared = squared\n\n def update(self, preds: Tensor, target: Tensor):\n \"\"\"\n Update state with predictions and targets.\n\n Args:\n preds: Predictions from model\n target: Ground truth values\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target)\n\n self.sum_squared_error += sum_squared_error\n self.total += n_obs\n\n def compute(self):\n \"\"\"\n Computes mean squared error over state.\n \"\"\"\n return _mean_squared_error_compute(self.sum_squared_error, self.total, squared=self.squared)\n\n @property\n def is_differentiable(self):\n return True\n", "path": "torchmetrics/regression/mean_squared_error.py"}]}
| 1,847 | 674 |
gh_patches_debug_8877
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-951
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Internal Error with setup
Hi,
Thanks for the work !
I want to try the new version with setup.mailu.io + Docker stack. However I have already this when I want to generate my compose:
> Internal Server Error
> The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.
Is it normal?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup/server.py`
Content:
```
1 import flask
2 import flask_bootstrap
3 import redis
4 import json
5 import os
6 import jinja2
7 import uuid
8 import string
9 import random
10 import ipaddress
11 import hashlib
12 import time
13
14
15 version = os.getenv("this_version", "master")
16 static_url_path = "/" + version + "/static"
17 app = flask.Flask(__name__, static_url_path=static_url_path)
18 flask_bootstrap.Bootstrap(app)
19 db = redis.StrictRedis(host='redis', port=6379, db=0)
20
21
22 def render_flavor(flavor, template, data):
23 return flask.render_template(
24 os.path.join(flavor, template),
25 **data
26 )
27
28
29 @app.add_template_global
30 def secret(length=16):
31 charset = string.ascii_uppercase + string.digits
32 return ''.join(
33 random.SystemRandom().choice(charset)
34 for _ in range(length)
35 )
36
37 #Original copied from https://github.com/andrewlkho/ulagen
38 def random_ipv6_subnet():
39 eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff
40 eui64_canon = "-".join([format(eui64, "02X")[i:i+2] for i in range(0, 18, 2)])
41
42 h = hashlib.sha1()
43 h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))
44 globalid = h.hexdigest()[0:10]
45
46 prefix = ":".join(("fd" + globalid[0:2], globalid[2:6], globalid[6:10]))
47 return prefix
48
49 def build_app(path):
50
51 app.jinja_env.trim_blocks = True
52 app.jinja_env.lstrip_blocks = True
53
54 @app.context_processor
55 def app_context():
56 return dict(versions=os.getenv("VERSIONS","master").split(','))
57
58 prefix_bp = flask.Blueprint(version, __name__)
59 prefix_bp.jinja_loader = jinja2.ChoiceLoader([
60 jinja2.FileSystemLoader(os.path.join(path, "templates")),
61 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
62 ])
63
64 root_bp = flask.Blueprint("root", __name__)
65 root_bp.jinja_loader = jinja2.ChoiceLoader([
66 jinja2.FileSystemLoader(os.path.join(path, "templates")),
67 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
68 ])
69
70 @prefix_bp.context_processor
71 @root_bp.context_processor
72 def bp_context(version=version):
73 return dict(version=version)
74
75 @prefix_bp.route("/")
76 @root_bp.route("/")
77 def wizard():
78 return flask.render_template('wizard.html')
79
80 @prefix_bp.route("/submit_flavor", methods=["POST"])
81 @root_bp.route("/submit_flavor", methods=["POST"])
82 def submit_flavor():
83 data = flask.request.form.copy()
84 subnet6 = random_ipv6_subnet()
85 steps = sorted(os.listdir(os.path.join(path, "templates", "steps", data["flavor"])))
86 return flask.render_template('wizard.html', flavor=data["flavor"], steps=steps, subnet6=subnet6)
87
88 @prefix_bp.route("/submit", methods=["POST"])
89 @root_bp.route("/submit", methods=["POST"])
90 def submit():
91 data = flask.request.form.copy()
92 data['uid'] = str(uuid.uuid4())
93 data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
94 db.set(data['uid'], json.dumps(data))
95 return flask.redirect(flask.url_for('.setup', uid=data['uid']))
96
97 @prefix_bp.route("/setup/<uid>", methods=["GET"])
98 @root_bp.route("/setup/<uid>", methods=["GET"])
99 def setup(uid):
100 data = json.loads(db.get(uid))
101 flavor = data.get("flavor", "compose")
102 rendered = render_flavor(flavor, "setup.html", data)
103 return flask.render_template("setup.html", contents=rendered)
104
105 @prefix_bp.route("/file/<uid>/<filepath>", methods=["GET"])
106 @root_bp.route("/file/<uid>/<filepath>", methods=["GET"])
107 def file(uid, filepath):
108 data = json.loads(db.get(uid))
109 flavor = data.get("flavor", "compose")
110 return flask.Response(
111 render_flavor(flavor, filepath, data),
112 mimetype="application/text"
113 )
114
115 app.register_blueprint(prefix_bp, url_prefix="/{}".format(version))
116 app.register_blueprint(root_bp)
117
118
119 if __name__ == "__main__":
120 build_app("/tmp/mailutest")
121 app.run(debug=True)
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup/server.py b/setup/server.py
--- a/setup/server.py
+++ b/setup/server.py
@@ -90,7 +90,10 @@
def submit():
data = flask.request.form.copy()
data['uid'] = str(uuid.uuid4())
- data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
+ try:
+ data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])
+ except ValueError as err:
+ return "Error while generating files: " + str(err)
db.set(data['uid'], json.dumps(data))
return flask.redirect(flask.url_for('.setup', uid=data['uid']))
|
{"golden_diff": "diff --git a/setup/server.py b/setup/server.py\n--- a/setup/server.py\n+++ b/setup/server.py\n@@ -90,7 +90,10 @@\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n- data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n+ try:\n+ data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n+ except ValueError as err:\n+ return \"Error while generating files: \" + str(err)\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n", "issue": "Internal Error with setup\nHi,\r\n\r\nThanks for the work !\r\n\r\nI want to try the new version with setup.mailu.io + Docker stack. However I have already this when I want to generate my compose:\r\n\r\n> Internal Server Error\r\n> The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.\r\n\r\nIs it normal?\n", "before_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\nimport time\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n#Original copied from https://github.com/andrewlkho/ulagen\ndef random_ipv6_subnet():\n eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff\n eui64_canon = \"-\".join([format(eui64, \"02X\")[i:i+2] for i in range(0, 18, 2)])\n\n h = hashlib.sha1()\n h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))\n globalid = h.hexdigest()[0:10]\n\n prefix = \":\".join((\"fd\" + globalid[0:2], globalid[2:6], globalid[6:10]))\n return prefix\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n subnet6 = random_ipv6_subnet()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps, subnet6=subnet6)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}], "after_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\nimport time\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n#Original copied from https://github.com/andrewlkho/ulagen\ndef random_ipv6_subnet():\n eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff\n eui64_canon = \"-\".join([format(eui64, \"02X\")[i:i+2] for i in range(0, 18, 2)])\n\n h = hashlib.sha1()\n h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))\n globalid = h.hexdigest()[0:10]\n\n prefix = \":\".join((\"fd\" + globalid[0:2], globalid[2:6], globalid[6:10]))\n return prefix\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(versions=os.getenv(\"VERSIONS\",\"master\").split(','))\n\n prefix_bp = flask.Blueprint(version, __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template('wizard.html')\n\n @prefix_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n @root_bp.route(\"/submit_flavor\", methods=[\"POST\"])\n def submit_flavor():\n data = flask.request.form.copy()\n subnet6 = random_ipv6_subnet()\n steps = sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", data[\"flavor\"])))\n return flask.render_template('wizard.html', flavor=data[\"flavor\"], steps=steps, subnet6=subnet6)\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n try:\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'])[-2])\n except ValueError as err:\n return \"Error while generating files: \" + str(err)\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}]}
| 1,644 | 154 |
gh_patches_debug_29687
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4041
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Please support Verify=False option for tools.get() as is currently supported for tools.download()
To help us debug your issue please explain:
- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).
- [1.8.4] I've specified the Conan version, operating system version and any tool that can be relevant.
- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/tools/net.py`
Content:
```
1 import os
2
3 from conans.client.rest.uploader_downloader import Downloader
4 from conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256
5 from conans.errors import ConanException
6 from conans.util.fallbacks import default_output, default_requester
7
8
9 def get(url, md5='', sha1='', sha256='', destination=".", filename="", keep_permissions=False,
10 pattern=None, requester=None, output=None):
11 """ high level downloader + unzipper + (optional hash checker) + delete temporary zip
12 """
13 if not filename and ("?" in url or "=" in url):
14 raise ConanException("Cannot deduce file name form url. Use 'filename' parameter.")
15
16 filename = filename or os.path.basename(url)
17 download(url, filename, out=output, requester=requester)
18
19 if md5:
20 check_md5(filename, md5)
21 if sha1:
22 check_sha1(filename, sha1)
23 if sha256:
24 check_sha256(filename, sha256)
25
26 unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,
27 output=output)
28 os.unlink(filename)
29
30
31 def ftp_download(ip, filename, login='', password=''):
32 import ftplib
33 try:
34 ftp = ftplib.FTP(ip, login, password)
35 ftp.login()
36 filepath, filename = os.path.split(filename)
37 if filepath:
38 ftp.cwd(filepath)
39 with open(filename, 'wb') as f:
40 ftp.retrbinary('RETR ' + filename, f.write)
41 except Exception as e:
42 raise ConanException("Error in FTP download from %s\n%s" % (ip, str(e)))
43 finally:
44 try:
45 ftp.quit()
46 except:
47 pass
48
49
50 def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,
51 auth=None, headers=None, requester=None):
52 out = default_output(out, 'conans.client.tools.net.download')
53 requester = default_requester(requester, 'conans.client.tools.net.download')
54
55 downloader = Downloader(requester=requester, output=out, verify=verify)
56 downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,
57 auth=auth, headers=headers)
58 out.writeln("")
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/tools/net.py b/conans/client/tools/net.py
--- a/conans/client/tools/net.py
+++ b/conans/client/tools/net.py
@@ -7,14 +7,16 @@
def get(url, md5='', sha1='', sha256='', destination=".", filename="", keep_permissions=False,
- pattern=None, requester=None, output=None):
+ pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,
+ overwrite=False, auth=None, headers=None):
""" high level downloader + unzipper + (optional hash checker) + delete temporary zip
"""
if not filename and ("?" in url or "=" in url):
raise ConanException("Cannot deduce file name form url. Use 'filename' parameter.")
filename = filename or os.path.basename(url)
- download(url, filename, out=output, requester=requester)
+ download(url, filename, out=output, requester=requester, verify=verify, retry=retry,
+ retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)
if md5:
check_md5(filename, md5)
@@ -47,8 +49,14 @@
pass
-def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,
+def download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,
auth=None, headers=None, requester=None):
+
+ if retry is None:
+ retry = 2
+ if retry_wait is None:
+ retry_wait = 5
+
out = default_output(out, 'conans.client.tools.net.download')
requester = default_requester(requester, 'conans.client.tools.net.download')
|
{"golden_diff": "diff --git a/conans/client/tools/net.py b/conans/client/tools/net.py\n--- a/conans/client/tools/net.py\n+++ b/conans/client/tools/net.py\n@@ -7,14 +7,16 @@\n \n \n def get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n- pattern=None, requester=None, output=None):\n+ pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,\n+ overwrite=False, auth=None, headers=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n \n filename = filename or os.path.basename(url)\n- download(url, filename, out=output, requester=requester)\n+ download(url, filename, out=output, requester=requester, verify=verify, retry=retry,\n+ retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)\n \n if md5:\n check_md5(filename, md5)\n@@ -47,8 +49,14 @@\n pass\n \n \n-def download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,\n+def download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,\n auth=None, headers=None, requester=None):\n+\n+ if retry is None:\n+ retry = 2\n+ if retry_wait is None:\n+ retry_wait = 5\n+\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n", "issue": "Please support Verify=False option for tools.get() as is currently supported for tools.download()\nTo help us debug your issue please explain:\r\n\r\n- [x] I've read the [CONTRIBUTING guide](https://raw.githubusercontent.com/conan-io/conan/develop/.github/CONTRIBUTING.md).\r\n- [1.8.4] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [x] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import os\n\nfrom conans.client.rest.uploader_downloader import Downloader\nfrom conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256\nfrom conans.errors import ConanException\nfrom conans.util.fallbacks import default_output, default_requester\n\n\ndef get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n pattern=None, requester=None, output=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n\n filename = filename or os.path.basename(url)\n download(url, filename, out=output, requester=requester)\n\n if md5:\n check_md5(filename, md5)\n if sha1:\n check_sha1(filename, sha1)\n if sha256:\n check_sha256(filename, sha256)\n\n unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,\n output=output)\n os.unlink(filename)\n\n\ndef ftp_download(ip, filename, login='', password=''):\n import ftplib\n try:\n ftp = ftplib.FTP(ip, login, password)\n ftp.login()\n filepath, filename = os.path.split(filename)\n if filepath:\n ftp.cwd(filepath)\n with open(filename, 'wb') as f:\n ftp.retrbinary('RETR ' + filename, f.write)\n except Exception as e:\n raise ConanException(\"Error in FTP download from %s\\n%s\" % (ip, str(e)))\n finally:\n try:\n ftp.quit()\n except:\n pass\n\n\ndef download(url, filename, verify=True, out=None, retry=2, retry_wait=5, overwrite=False,\n auth=None, headers=None, requester=None):\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n\n downloader = Downloader(requester=requester, output=out, verify=verify)\n downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,\n auth=auth, headers=headers)\n out.writeln(\"\")\n", "path": "conans/client/tools/net.py"}], "after_files": [{"content": "import os\n\nfrom conans.client.rest.uploader_downloader import Downloader\nfrom conans.client.tools.files import unzip, check_md5, check_sha1, check_sha256\nfrom conans.errors import ConanException\nfrom conans.util.fallbacks import default_output, default_requester\n\n\ndef get(url, md5='', sha1='', sha256='', destination=\".\", filename=\"\", keep_permissions=False,\n pattern=None, requester=None, output=None, verify=True, retry=None, retry_wait=None,\n overwrite=False, auth=None, headers=None):\n \"\"\" high level downloader + unzipper + (optional hash checker) + delete temporary zip\n \"\"\"\n if not filename and (\"?\" in url or \"=\" in url):\n raise ConanException(\"Cannot deduce file name form url. Use 'filename' parameter.\")\n\n filename = filename or os.path.basename(url)\n download(url, filename, out=output, requester=requester, verify=verify, retry=retry,\n retry_wait=retry_wait, overwrite=overwrite, auth=auth, headers=headers)\n\n if md5:\n check_md5(filename, md5)\n if sha1:\n check_sha1(filename, sha1)\n if sha256:\n check_sha256(filename, sha256)\n\n unzip(filename, destination=destination, keep_permissions=keep_permissions, pattern=pattern,\n output=output)\n os.unlink(filename)\n\n\ndef ftp_download(ip, filename, login='', password=''):\n import ftplib\n try:\n ftp = ftplib.FTP(ip, login, password)\n ftp.login()\n filepath, filename = os.path.split(filename)\n if filepath:\n ftp.cwd(filepath)\n with open(filename, 'wb') as f:\n ftp.retrbinary('RETR ' + filename, f.write)\n except Exception as e:\n raise ConanException(\"Error in FTP download from %s\\n%s\" % (ip, str(e)))\n finally:\n try:\n ftp.quit()\n except:\n pass\n\n\ndef download(url, filename, verify=True, out=None, retry=None, retry_wait=None, overwrite=False,\n auth=None, headers=None, requester=None):\n\n if retry is None:\n retry = 2\n if retry_wait is None:\n retry_wait = 5\n\n out = default_output(out, 'conans.client.tools.net.download')\n requester = default_requester(requester, 'conans.client.tools.net.download')\n\n downloader = Downloader(requester=requester, output=out, verify=verify)\n downloader.download(url, filename, retry=retry, retry_wait=retry_wait, overwrite=overwrite,\n auth=auth, headers=headers)\n out.writeln(\"\")\n", "path": "conans/client/tools/net.py"}]}
| 983 | 389 |
gh_patches_debug_1227
|
rasdani/github-patches
|
git_diff
|
mosaicml__composer-79
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Colab Example
* Add Example Jupyter notebook to the examples folder
* Add "Open in Colab" to the README.md
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 import os
4 import sys
5
6 import setuptools
7 from setuptools import setup
8
9
10 def package_files(directory):
11 # from https://stackoverflow.com/a/36693250
12 paths = []
13 for (path, directories, filenames) in os.walk(directory):
14 for filename in filenames:
15 paths.append(os.path.join('..', path, filename))
16 return paths
17
18
19 with open("README.md", "r", encoding="utf-8") as fh:
20 long_description = fh.read()
21
22 install_requires = [
23 "pyyaml>=5.4.1",
24 "tqdm>=4.62.3",
25 "torchmetrics>=0.5.1",
26 "torch_optimizer==0.1.0",
27 "torchvision>=0.9.0",
28 "torch>=1.9",
29 "argparse>=1.4.0",
30 "yahp>=0.0.10",
31 ]
32 extra_deps = {}
33
34 extra_deps['base'] = []
35
36 extra_deps['dev'] = [
37 'junitparser>=2.1.1',
38 'coverage[toml]>=6.1.1',
39 'pytest>=6.2.0',
40 'yapf>=0.13.0',
41 'isort>=5.9.3',
42 'yamllint>=1.26.2',
43 'pytest-timeout>=1.4.2',
44 'recommonmark>=0.7.1',
45 'sphinx>=4.2.0',
46 'sphinx_copybutton>=0.4.0',
47 'sphinx_markdown_tables>=0.0.15',
48 'sphinx-argparse>=0.3.1',
49 'sphinxcontrib.katex>=0.8.6',
50 'sphinxext.opengraph>=0.4.2',
51 'sphinx_rtd_theme>=1.0.0',
52 'myst-parser>=0.15.2',
53 ]
54 extra_deps['wandb'] = ['wandb>=0.12.2']
55
56 extra_deps['nlp'] = [
57 'transformers>=4.11.3',
58 'datasets>=1.14.0',
59 ]
60
61 extra_deps['unet'] = [
62 'monai>=0.7.0',
63 'scikit-learn>=1.0.1',
64 ]
65
66 extra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)
67
68 setup(
69 name="mosaicml",
70 version="0.2.4",
71 author="MosaicML",
72 author_email="[email protected]",
73 description="composing methods for ML training efficiency",
74 long_description=long_description,
75 long_description_content_type="text/markdown",
76 url="https://github.com/mosaicml/composer",
77 include_package_data=True,
78 package_data={
79 "composer": ['py.typed'],
80 "": package_files('composer/yamls'),
81 },
82 packages=setuptools.find_packages(include=["composer"]),
83 classifiers=[
84 "Programming Language :: Python :: 3",
85 ],
86 install_requires=install_requires,
87 entry_points={
88 'console_scripts': ['composer = composer.cli.launcher:main',],
89 },
90 extras_require=extra_deps,
91 dependency_links=['https://developer.download.nvidia.com/compute/redist'],
92 python_requires='>=3.7',
93 ext_package="composer",
94 )
95
96 # only visible if user installs with verbose -v flag
97 # Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)
98 print("*" * 20, file=sys.stderr)
99 print(
100 "\nNOTE: For best performance, we recommend installing Pillow-SIMD "
101 "\nfor accelerated image processing operations. To install:"
102 "\n\n\t pip uninstall pillow && pip install pillow-simd\n",
103 file=sys.stderr)
104 print("*" * 20, file=sys.stderr)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -49,6 +49,7 @@
'sphinxcontrib.katex>=0.8.6',
'sphinxext.opengraph>=0.4.2',
'sphinx_rtd_theme>=1.0.0',
+ 'testbook>=0.4.2',
'myst-parser>=0.15.2',
]
extra_deps['wandb'] = ['wandb>=0.12.2']
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -49,6 +49,7 @@\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n+ 'testbook>=0.4.2',\n 'myst-parser>=0.15.2',\n ]\n extra_deps['wandb'] = ['wandb>=0.12.2']\n", "issue": "Add Colab Example\n* Add Example Jupyter notebook to the examples folder\r\n* Add \"Open in Colab\" to the README.md\r\n\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport sys\n\nimport setuptools\nfrom setuptools import setup\n\n\ndef package_files(directory):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, directories, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.5.1\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"argparse>=1.4.0\",\n \"yahp>=0.0.10\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'pytest>=6.2.0',\n 'yapf>=0.13.0',\n 'isort>=5.9.3',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'recommonmark>=0.7.1',\n 'sphinx>=4.2.0',\n 'sphinx_copybutton>=0.4.0',\n 'sphinx_markdown_tables>=0.0.15',\n 'sphinx-argparse>=0.3.1',\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n 'myst-parser>=0.15.2',\n]\nextra_deps['wandb'] = ['wandb>=0.12.2']\n\nextra_deps['nlp'] = [\n 'transformers>=4.11.3',\n 'datasets>=1.14.0',\n]\n\nextra_deps['unet'] = [\n 'monai>=0.7.0',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(\n name=\"mosaicml\",\n version=\"0.2.4\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"composing methods for ML training efficiency\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n },\n packages=setuptools.find_packages(include=[\"composer\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n)\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(\n \"\\nNOTE: For best performance, we recommend installing Pillow-SIMD \"\n \"\\nfor accelerated image processing operations. To install:\"\n \"\\n\\n\\t pip uninstall pillow && pip install pillow-simd\\n\",\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport sys\n\nimport setuptools\nfrom setuptools import setup\n\n\ndef package_files(directory):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, directories, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.5.1\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"argparse>=1.4.0\",\n \"yahp>=0.0.10\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'pytest>=6.2.0',\n 'yapf>=0.13.0',\n 'isort>=5.9.3',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'recommonmark>=0.7.1',\n 'sphinx>=4.2.0',\n 'sphinx_copybutton>=0.4.0',\n 'sphinx_markdown_tables>=0.0.15',\n 'sphinx-argparse>=0.3.1',\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinx_rtd_theme>=1.0.0',\n 'testbook>=0.4.2',\n 'myst-parser>=0.15.2',\n]\nextra_deps['wandb'] = ['wandb>=0.12.2']\n\nextra_deps['nlp'] = [\n 'transformers>=4.11.3',\n 'datasets>=1.14.0',\n]\n\nextra_deps['unet'] = [\n 'monai>=0.7.0',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(\n name=\"mosaicml\",\n version=\"0.2.4\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"composing methods for ML training efficiency\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n },\n packages=setuptools.find_packages(include=[\"composer\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n)\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(\n \"\\nNOTE: For best performance, we recommend installing Pillow-SIMD \"\n \"\\nfor accelerated image processing operations. To install:\"\n \"\\n\\n\\t pip uninstall pillow && pip install pillow-simd\\n\",\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}]}
| 1,356 | 119 |
gh_patches_debug_28905
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-6953
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Robots.txt can no longer be easily customised
**CKAN version**
2.9
**Describe the bug**
`robots.txt` was moved back to the `public` directory as part of #4801. However, this reverts the implementation of https://github.com/ckan/ideas-and-roadmap/issues/178 and makes it harder to customise the file (it can still be overridden with a different version, but not using Jinja syntax).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckan/views/home.py`
Content:
```
1 # encoding: utf-8
2
3 from __future__ import annotations
4
5 from urllib.parse import urlencode
6 from typing import Any, Optional, cast, List, Tuple
7
8 from flask import Blueprint, abort, redirect, request
9
10 import ckan.model as model
11 import ckan.logic as logic
12 import ckan.lib.base as base
13 import ckan.lib.search as search
14 import ckan.lib.helpers as h
15
16 from ckan.common import g, config, current_user, _
17 from ckan.types import Context
18
19
20 CACHE_PARAMETERS = [u'__cache', u'__no_cache__']
21
22
23 home = Blueprint(u'home', __name__)
24
25
26 @home.before_request
27 def before_request() -> None:
28 u'''set context and check authorization'''
29 try:
30 context = cast(Context, {
31 u'model': model,
32 u'user': current_user.name,
33 u'auth_user_obj': current_user})
34 logic.check_access(u'site_read', context)
35 except logic.NotAuthorized:
36 abort(403)
37
38
39 def index() -> str:
40 u'''display home page'''
41 try:
42 context = cast(Context, {
43 u'model': model,
44 u'session': model.Session,
45 u'user': current_user.name,
46 u'auth_user_obj': current_user
47 }
48 )
49
50 data_dict: dict[str, Any] = {
51 u'q': u'*:*',
52 u'facet.field': h.facets(),
53 u'rows': 4,
54 u'start': 0,
55 u'sort': u'view_recent desc',
56 u'fq': u'capacity:"public"'}
57 query = logic.get_action(u'package_search')(context, data_dict)
58 g.package_count = query['count']
59 g.datasets = query['results']
60
61 org_label = h.humanize_entity_type(
62 u'organization',
63 h.default_group_type(u'organization'),
64 u'facet label') or _(u'Organizations')
65
66 group_label = h.humanize_entity_type(
67 u'group',
68 h.default_group_type(u'group'),
69 u'facet label') or _(u'Groups')
70
71 g.facet_titles = {
72 u'organization': org_label,
73 u'groups': group_label,
74 u'tags': _(u'Tags'),
75 u'res_format': _(u'Formats'),
76 u'license': _(u'Licenses'),
77 }
78
79 except search.SearchError:
80 g.package_count = 0
81
82 if current_user.is_authenticated and not current_user.email:
83 url = h.url_for('user.edit')
84 msg = _(u'Please <a href="%s">update your profile</a>'
85 u' and add your email address. ') % url + \
86 _(u'%s uses your email address'
87 u' if you need to reset your password.') \
88 % config.get_value(u'ckan.site_title')
89 h.flash_notice(msg, allow_html=True)
90 return base.render(u'home/index.html', extra_vars={})
91
92
93 def about() -> str:
94 u''' display about page'''
95 return base.render(u'home/about.html', extra_vars={})
96
97
98 def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:
99
100 target = f'/{target_locale}/{path}' if path else f'/{target_locale}'
101
102 if request.args:
103 target += f'?{urlencode(request.args)}'
104
105 return redirect(target, code=308)
106
107
108 util_rules: List[Tuple[str, Any]] = [
109 (u'/', index),
110 (u'/about', about)
111 ]
112 for rule, view_func in util_rules:
113 home.add_url_rule(rule, view_func=view_func)
114
115 locales_mapping: List[Tuple[str, str]] = [
116 ('zh_TW', 'zh_Hant_TW'),
117 ('zh_CN', 'zh_Hans_CN'),
118 ('no', 'nb_NO'),
119 ]
120
121 for locale in locales_mapping:
122
123 legacy_locale = locale[0]
124 new_locale = locale[1]
125
126 home.add_url_rule(
127 f'/{legacy_locale}/',
128 view_func=redirect_locale,
129 defaults={'target_locale': new_locale}
130 )
131
132 home.add_url_rule(
133 f'/{legacy_locale}/<path:path>',
134 view_func=redirect_locale,
135 defaults={'target_locale': new_locale}
136 )
137
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckan/views/home.py b/ckan/views/home.py
--- a/ckan/views/home.py
+++ b/ckan/views/home.py
@@ -5,7 +5,7 @@
from urllib.parse import urlencode
from typing import Any, Optional, cast, List, Tuple
-from flask import Blueprint, abort, redirect, request
+from flask import Blueprint, make_response, abort, redirect, request
import ckan.model as model
import ckan.logic as logic
@@ -14,7 +14,7 @@
import ckan.lib.helpers as h
from ckan.common import g, config, current_user, _
-from ckan.types import Context
+from ckan.types import Context, Response
CACHE_PARAMETERS = [u'__cache', u'__no_cache__']
@@ -95,6 +95,13 @@
return base.render(u'home/about.html', extra_vars={})
+def robots_txt() -> Response:
+ '''display robots.txt'''
+ resp = make_response(base.render('home/robots.txt'))
+ resp.headers['Content-Type'] = "text/plain; charset=utf-8"
+ return resp
+
+
def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:
target = f'/{target_locale}/{path}' if path else f'/{target_locale}'
@@ -107,7 +114,8 @@
util_rules: List[Tuple[str, Any]] = [
(u'/', index),
- (u'/about', about)
+ (u'/about', about),
+ (u'/robots.txt', robots_txt)
]
for rule, view_func in util_rules:
home.add_url_rule(rule, view_func=view_func)
|
{"golden_diff": "diff --git a/ckan/views/home.py b/ckan/views/home.py\n--- a/ckan/views/home.py\n+++ b/ckan/views/home.py\n@@ -5,7 +5,7 @@\n from urllib.parse import urlencode\n from typing import Any, Optional, cast, List, Tuple\n \n-from flask import Blueprint, abort, redirect, request\n+from flask import Blueprint, make_response, abort, redirect, request\n \n import ckan.model as model\n import ckan.logic as logic\n@@ -14,7 +14,7 @@\n import ckan.lib.helpers as h\n \n from ckan.common import g, config, current_user, _\n-from ckan.types import Context\n+from ckan.types import Context, Response\n \n \n CACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n@@ -95,6 +95,13 @@\n return base.render(u'home/about.html', extra_vars={})\n \n \n+def robots_txt() -> Response:\n+ '''display robots.txt'''\n+ resp = make_response(base.render('home/robots.txt'))\n+ resp.headers['Content-Type'] = \"text/plain; charset=utf-8\"\n+ return resp\n+\n+\n def redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n \n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n@@ -107,7 +114,8 @@\n \n util_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n- (u'/about', about)\n+ (u'/about', about),\n+ (u'/robots.txt', robots_txt)\n ]\n for rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n", "issue": "Robots.txt can no longer be easily customised\n**CKAN version**\r\n\r\n2.9\r\n\r\n**Describe the bug**\r\n\r\n`robots.txt` was moved back to the `public` directory as part of #4801. However, this reverts the implementation of https://github.com/ckan/ideas-and-roadmap/issues/178 and makes it harder to customise the file (it can still be overridden with a different version, but not using Jinja syntax).\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom __future__ import annotations\n\nfrom urllib.parse import urlencode\nfrom typing import Any, Optional, cast, List, Tuple\n\nfrom flask import Blueprint, abort, redirect, request\n\nimport ckan.model as model\nimport ckan.logic as logic\nimport ckan.lib.base as base\nimport ckan.lib.search as search\nimport ckan.lib.helpers as h\n\nfrom ckan.common import g, config, current_user, _\nfrom ckan.types import Context\n\n\nCACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n\n\nhome = Blueprint(u'home', __name__)\n\n\[email protected]_request\ndef before_request() -> None:\n u'''set context and check authorization'''\n try:\n context = cast(Context, {\n u'model': model,\n u'user': current_user.name,\n u'auth_user_obj': current_user})\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n abort(403)\n\n\ndef index() -> str:\n u'''display home page'''\n try:\n context = cast(Context, {\n u'model': model,\n u'session': model.Session,\n u'user': current_user.name,\n u'auth_user_obj': current_user\n }\n )\n\n data_dict: dict[str, Any] = {\n u'q': u'*:*',\n u'facet.field': h.facets(),\n u'rows': 4,\n u'start': 0,\n u'sort': u'view_recent desc',\n u'fq': u'capacity:\"public\"'}\n query = logic.get_action(u'package_search')(context, data_dict)\n g.package_count = query['count']\n g.datasets = query['results']\n\n org_label = h.humanize_entity_type(\n u'organization',\n h.default_group_type(u'organization'),\n u'facet label') or _(u'Organizations')\n\n group_label = h.humanize_entity_type(\n u'group',\n h.default_group_type(u'group'),\n u'facet label') or _(u'Groups')\n\n g.facet_titles = {\n u'organization': org_label,\n u'groups': group_label,\n u'tags': _(u'Tags'),\n u'res_format': _(u'Formats'),\n u'license': _(u'Licenses'),\n }\n\n except search.SearchError:\n g.package_count = 0\n\n if current_user.is_authenticated and not current_user.email:\n url = h.url_for('user.edit')\n msg = _(u'Please <a href=\"%s\">update your profile</a>'\n u' and add your email address. ') % url + \\\n _(u'%s uses your email address'\n u' if you need to reset your password.') \\\n % config.get_value(u'ckan.site_title')\n h.flash_notice(msg, allow_html=True)\n return base.render(u'home/index.html', extra_vars={})\n\n\ndef about() -> str:\n u''' display about page'''\n return base.render(u'home/about.html', extra_vars={})\n\n\ndef redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n\n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n\n if request.args:\n target += f'?{urlencode(request.args)}'\n\n return redirect(target, code=308)\n\n\nutil_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n (u'/about', about)\n]\nfor rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n\nlocales_mapping: List[Tuple[str, str]] = [\n ('zh_TW', 'zh_Hant_TW'),\n ('zh_CN', 'zh_Hans_CN'),\n ('no', 'nb_NO'),\n]\n\nfor locale in locales_mapping:\n\n legacy_locale = locale[0]\n new_locale = locale[1]\n\n home.add_url_rule(\n f'/{legacy_locale}/',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n\n home.add_url_rule(\n f'/{legacy_locale}/<path:path>',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n", "path": "ckan/views/home.py"}], "after_files": [{"content": "# encoding: utf-8\n\nfrom __future__ import annotations\n\nfrom urllib.parse import urlencode\nfrom typing import Any, Optional, cast, List, Tuple\n\nfrom flask import Blueprint, make_response, abort, redirect, request\n\nimport ckan.model as model\nimport ckan.logic as logic\nimport ckan.lib.base as base\nimport ckan.lib.search as search\nimport ckan.lib.helpers as h\n\nfrom ckan.common import g, config, current_user, _\nfrom ckan.types import Context, Response\n\n\nCACHE_PARAMETERS = [u'__cache', u'__no_cache__']\n\n\nhome = Blueprint(u'home', __name__)\n\n\[email protected]_request\ndef before_request() -> None:\n u'''set context and check authorization'''\n try:\n context = cast(Context, {\n u'model': model,\n u'user': current_user.name,\n u'auth_user_obj': current_user})\n logic.check_access(u'site_read', context)\n except logic.NotAuthorized:\n abort(403)\n\n\ndef index() -> str:\n u'''display home page'''\n try:\n context = cast(Context, {\n u'model': model,\n u'session': model.Session,\n u'user': current_user.name,\n u'auth_user_obj': current_user\n }\n )\n\n data_dict: dict[str, Any] = {\n u'q': u'*:*',\n u'facet.field': h.facets(),\n u'rows': 4,\n u'start': 0,\n u'sort': u'view_recent desc',\n u'fq': u'capacity:\"public\"'}\n query = logic.get_action(u'package_search')(context, data_dict)\n g.package_count = query['count']\n g.datasets = query['results']\n\n org_label = h.humanize_entity_type(\n u'organization',\n h.default_group_type(u'organization'),\n u'facet label') or _(u'Organizations')\n\n group_label = h.humanize_entity_type(\n u'group',\n h.default_group_type(u'group'),\n u'facet label') or _(u'Groups')\n\n g.facet_titles = {\n u'organization': org_label,\n u'groups': group_label,\n u'tags': _(u'Tags'),\n u'res_format': _(u'Formats'),\n u'license': _(u'Licenses'),\n }\n\n except search.SearchError:\n g.package_count = 0\n\n if current_user.is_authenticated and not current_user.email:\n url = h.url_for('user.edit')\n msg = _(u'Please <a href=\"%s\">update your profile</a>'\n u' and add your email address. ') % url + \\\n _(u'%s uses your email address'\n u' if you need to reset your password.') \\\n % config.get_value(u'ckan.site_title')\n h.flash_notice(msg, allow_html=True)\n return base.render(u'home/index.html', extra_vars={})\n\n\ndef about() -> str:\n u''' display about page'''\n return base.render(u'home/about.html', extra_vars={})\n\n\ndef robots_txt() -> Response:\n '''display robots.txt'''\n resp = make_response(base.render('home/robots.txt'))\n resp.headers['Content-Type'] = \"text/plain; charset=utf-8\"\n return resp\n\n\ndef redirect_locale(target_locale: str, path: Optional[str] = None) -> Any:\n\n target = f'/{target_locale}/{path}' if path else f'/{target_locale}'\n\n if request.args:\n target += f'?{urlencode(request.args)}'\n\n return redirect(target, code=308)\n\n\nutil_rules: List[Tuple[str, Any]] = [\n (u'/', index),\n (u'/about', about),\n (u'/robots.txt', robots_txt)\n]\nfor rule, view_func in util_rules:\n home.add_url_rule(rule, view_func=view_func)\n\nlocales_mapping: List[Tuple[str, str]] = [\n ('zh_TW', 'zh_Hant_TW'),\n ('zh_CN', 'zh_Hans_CN'),\n ('no', 'nb_NO'),\n]\n\nfor locale in locales_mapping:\n\n legacy_locale = locale[0]\n new_locale = locale[1]\n\n home.add_url_rule(\n f'/{legacy_locale}/',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n\n home.add_url_rule(\n f'/{legacy_locale}/<path:path>',\n view_func=redirect_locale,\n defaults={'target_locale': new_locale}\n )\n", "path": "ckan/views/home.py"}]}
| 1,602 | 379 |
gh_patches_debug_4130
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3534
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing resource breaks rendering viewlet.resourceregistries.js
if there's a typo or a missing JS resource defined in the resource registries, the `viewlet.resourceregistries.js` gives a traceback and all JS resources are missing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/resources/utils.py`
Content:
```
1 from Acquisition import aq_base
2 from Acquisition import aq_inner
3 from Acquisition import aq_parent
4 from plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME
5 from plone.resource.file import FilesystemFile
6 from plone.resource.interfaces import IResourceDirectory
7 from Products.CMFCore.Expression import createExprContext
8 from Products.CMFCore.utils import getToolByName
9 from zExceptions import NotFound
10 from zope.component import queryUtility
11
12 import logging
13
14
15 PRODUCTION_RESOURCE_DIRECTORY = "production"
16 logger = logging.getLogger(__name__)
17
18
19 def get_production_resource_directory():
20 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
21 if persistent_directory is None:
22 return ""
23 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
24 try:
25 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
26 except NotFound:
27 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
28 if "timestamp.txt" not in production_folder:
29 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
30 timestamp = production_folder.readFile("timestamp.txt")
31 if isinstance(timestamp, bytes):
32 timestamp = timestamp.decode()
33 return "{}/++unique++{}".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)
34
35
36 def get_resource(context, path):
37 if path.startswith("++plone++"):
38 # ++plone++ resources can be customized, we return their override
39 # value if any
40 overrides = get_override_directory(context)
41 filepath = path[9:]
42 if overrides.isFile(filepath):
43 return overrides.readFile(filepath)
44
45 if "?" in path:
46 # Example from plone.session:
47 # "acl_users/session/refresh?session_refresh=true&type=css&minutes=5"
48 # Traversing will not work then. In this example we could split on "?"
49 # and traverse to the first part, acl_users/session/refresh, but this
50 # gives a function, and this fails when we call it below, missing a
51 # REQUEST argument
52 return
53 try:
54 resource = context.unrestrictedTraverse(path)
55 except (NotFound, AttributeError):
56 logger.warning(
57 f"Could not find resource {path}. You may have to create it first."
58 ) # noqa
59 return
60
61 if isinstance(resource, FilesystemFile):
62 (directory, sep, filename) = path.rpartition("/")
63 return context.unrestrictedTraverse(directory).readFile(filename)
64
65 # calling the resource may modify the header, i.e. the content-type.
66 # we do not want this, so keep the original header intact.
67 response_before = context.REQUEST.response
68 context.REQUEST.response = response_before.__class__()
69 if hasattr(aq_base(resource), "GET"):
70 # for FileResource
71 result = resource.GET()
72 else:
73 # any BrowserView
74 result = resource()
75 context.REQUEST.response = response_before
76 return result
77
78
79 def get_override_directory(context):
80 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
81 if persistent_directory is None:
82 return
83 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
84 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
85 return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
86
87
88 def evaluateExpression(expression, context):
89 """Evaluate an object's TALES condition to see if it should be
90 displayed."""
91 try:
92 if expression.text and context is not None:
93 portal = getToolByName(context, "portal_url").getPortalObject()
94
95 # Find folder (code courtesy of CMFCore.ActionsTool)
96 if context is None or not hasattr(context, "aq_base"):
97 folder = portal
98 else:
99 folder = context
100 # Search up the containment hierarchy until we find an
101 # object that claims it's PrincipiaFolderish.
102 while folder is not None:
103 if getattr(aq_base(folder), "isPrincipiaFolderish", 0):
104 # found it.
105 break
106 else:
107 folder = aq_parent(aq_inner(folder))
108
109 __traceback_info__ = (folder, portal, context, expression)
110 ec = createExprContext(folder, portal, context)
111 # add 'context' as an alias for 'object'
112 ec.setGlobal("context", context)
113 return expression(ec)
114 return True
115 except AttributeError:
116 return True
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/resources/utils.py b/Products/CMFPlone/resources/utils.py
--- a/Products/CMFPlone/resources/utils.py
+++ b/Products/CMFPlone/resources/utils.py
@@ -52,7 +52,7 @@
return
try:
resource = context.unrestrictedTraverse(path)
- except (NotFound, AttributeError):
+ except (NotFound, AttributeError, KeyError):
logger.warning(
f"Could not find resource {path}. You may have to create it first."
) # noqa
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/utils.py b/Products/CMFPlone/resources/utils.py\n--- a/Products/CMFPlone/resources/utils.py\n+++ b/Products/CMFPlone/resources/utils.py\n@@ -52,7 +52,7 @@\n return\n try:\n resource = context.unrestrictedTraverse(path)\n- except (NotFound, AttributeError):\n+ except (NotFound, AttributeError, KeyError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n", "issue": "Missing resource breaks rendering viewlet.resourceregistries.js\nif there's a typo or a missing JS resource defined in the resource registries, the `viewlet.resourceregistries.js` gives a traceback and all JS resources are missing.\n", "before_files": [{"content": "from Acquisition import aq_base\nfrom Acquisition import aq_inner\nfrom Acquisition import aq_parent\nfrom plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFCore.Expression import createExprContext\nfrom Products.CMFCore.utils import getToolByName\nfrom zExceptions import NotFound\nfrom zope.component import queryUtility\n\nimport logging\n\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\nlogger = logging.getLogger(__name__)\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return \"\"\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n if \"timestamp.txt\" not in production_folder:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile(\"timestamp.txt\")\n if isinstance(timestamp, bytes):\n timestamp = timestamp.decode()\n return \"{}/++unique++{}\".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith(\"++plone++\"):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n if \"?\" in path:\n # Example from plone.session:\n # \"acl_users/session/refresh?session_refresh=true&type=css&minutes=5\"\n # Traversing will not work then. In this example we could split on \"?\"\n # and traverse to the first part, acl_users/session/refresh, but this\n # gives a function, and this fails when we call it below, missing a\n # REQUEST argument\n return\n try:\n resource = context.unrestrictedTraverse(path)\n except (NotFound, AttributeError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n return\n\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition(\"/\")\n return context.unrestrictedTraverse(directory).readFile(filename)\n\n # calling the resource may modify the header, i.e. the content-type.\n # we do not want this, so keep the original header intact.\n response_before = context.REQUEST.response\n context.REQUEST.response = response_before.__class__()\n if hasattr(aq_base(resource), \"GET\"):\n # for FileResource\n result = resource.GET()\n else:\n # any BrowserView\n result = resource()\n context.REQUEST.response = response_before\n return result\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef evaluateExpression(expression, context):\n \"\"\"Evaluate an object's TALES condition to see if it should be\n displayed.\"\"\"\n try:\n if expression.text and context is not None:\n portal = getToolByName(context, \"portal_url\").getPortalObject()\n\n # Find folder (code courtesy of CMFCore.ActionsTool)\n if context is None or not hasattr(context, \"aq_base\"):\n folder = portal\n else:\n folder = context\n # Search up the containment hierarchy until we find an\n # object that claims it's PrincipiaFolderish.\n while folder is not None:\n if getattr(aq_base(folder), \"isPrincipiaFolderish\", 0):\n # found it.\n break\n else:\n folder = aq_parent(aq_inner(folder))\n\n __traceback_info__ = (folder, portal, context, expression)\n ec = createExprContext(folder, portal, context)\n # add 'context' as an alias for 'object'\n ec.setGlobal(\"context\", context)\n return expression(ec)\n return True\n except AttributeError:\n return True\n", "path": "Products/CMFPlone/resources/utils.py"}], "after_files": [{"content": "from Acquisition import aq_base\nfrom Acquisition import aq_inner\nfrom Acquisition import aq_parent\nfrom plone.base.interfaces.resources import OVERRIDE_RESOURCE_DIRECTORY_NAME\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFCore.Expression import createExprContext\nfrom Products.CMFCore.utils import getToolByName\nfrom zExceptions import NotFound\nfrom zope.component import queryUtility\n\nimport logging\n\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\nlogger = logging.getLogger(__name__)\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return \"\"\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n if \"timestamp.txt\" not in production_folder:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile(\"timestamp.txt\")\n if isinstance(timestamp, bytes):\n timestamp = timestamp.decode()\n return \"{}/++unique++{}\".format(PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith(\"++plone++\"):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n if \"?\" in path:\n # Example from plone.session:\n # \"acl_users/session/refresh?session_refresh=true&type=css&minutes=5\"\n # Traversing will not work then. In this example we could split on \"?\"\n # and traverse to the first part, acl_users/session/refresh, but this\n # gives a function, and this fails when we call it below, missing a\n # REQUEST argument\n return\n try:\n resource = context.unrestrictedTraverse(path)\n except (NotFound, AttributeError, KeyError):\n logger.warning(\n f\"Could not find resource {path}. You may have to create it first.\"\n ) # noqa\n return\n\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition(\"/\")\n return context.unrestrictedTraverse(directory).readFile(filename)\n\n # calling the resource may modify the header, i.e. the content-type.\n # we do not want this, so keep the original header intact.\n response_before = context.REQUEST.response\n context.REQUEST.response = response_before.__class__()\n if hasattr(aq_base(resource), \"GET\"):\n # for FileResource\n result = resource.GET()\n else:\n # any BrowserView\n result = resource()\n context.REQUEST.response = response_before\n return result\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef evaluateExpression(expression, context):\n \"\"\"Evaluate an object's TALES condition to see if it should be\n displayed.\"\"\"\n try:\n if expression.text and context is not None:\n portal = getToolByName(context, \"portal_url\").getPortalObject()\n\n # Find folder (code courtesy of CMFCore.ActionsTool)\n if context is None or not hasattr(context, \"aq_base\"):\n folder = portal\n else:\n folder = context\n # Search up the containment hierarchy until we find an\n # object that claims it's PrincipiaFolderish.\n while folder is not None:\n if getattr(aq_base(folder), \"isPrincipiaFolderish\", 0):\n # found it.\n break\n else:\n folder = aq_parent(aq_inner(folder))\n\n __traceback_info__ = (folder, portal, context, expression)\n ec = createExprContext(folder, portal, context)\n # add 'context' as an alias for 'object'\n ec.setGlobal(\"context\", context)\n return expression(ec)\n return True\n except AttributeError:\n return True\n", "path": "Products/CMFPlone/resources/utils.py"}]}
| 1,471 | 126 |
gh_patches_debug_45
|
rasdani/github-patches
|
git_diff
|
conda-forge__conda-smithy-1140
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Not compatible with ruamel.yaml 0.16
Fails with,
```
Traceback (most recent call last):
File "/home/travis/miniconda/bin/conda-smithy", line 10, in <module>
sys.exit(main())
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py", line 470, in main
args.subcommand_func(args)
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py", line 217, in __call__
args.feedstock_directory, owner, repo
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/ci_register.py", line 351, in travis_token_update_conda_forge_config
] = travis_encrypt_binstar_token(slug, item)
File "/home/travis/miniconda/lib/python3.7/contextlib.py", line 119, in __exit__
next(self.gen)
File "/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/utils.py", line 92, in update_conda_forge_config
fh.write(yaml.dump(code))
File "/home/travis/miniconda/lib/python3.7/site-packages/ruamel/yaml/main.py", line 448, in dump
raise TypeError('Need a stream argument when not dumping from context manager')
TypeError: Need a stream argument when not dumping from context manager
```
cc @ocefpaf, @scopatz
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_smithy/utils.py`
Content:
```
1 import shutil
2 import tempfile
3 import jinja2
4 import datetime
5 import time
6 import os
7 import sys
8 from collections import defaultdict
9 from contextlib import contextmanager
10
11 import ruamel.yaml
12
13
14 # define global yaml API
15 # roundrip-loader and allowing duplicate keys
16 # for handling # [filter] / # [not filter]
17 yaml = ruamel.yaml.YAML(typ="rt")
18 yaml.allow_duplicate_keys = True
19
20
21 @contextmanager
22 def tmp_directory():
23 tmp_dir = tempfile.mkdtemp("_recipe")
24 yield tmp_dir
25 shutil.rmtree(tmp_dir)
26
27
28 class NullUndefined(jinja2.Undefined):
29 def __unicode__(self):
30 return self._undefined_name
31
32 def __getattr__(self, name):
33 return "{}.{}".format(self, name)
34
35 def __getitem__(self, name):
36 return '{}["{}"]'.format(self, name)
37
38
39 class MockOS(dict):
40 def __init__(self):
41 self.environ = defaultdict(lambda: "")
42 self.sep = "/"
43
44
45 def render_meta_yaml(text):
46 env = jinja2.Environment(undefined=NullUndefined)
47
48 # stub out cb3 jinja2 functions - they are not important for linting
49 # if we don't stub them out, the ruamel.yaml load fails to interpret them
50 # we can't just use conda-build's api.render functionality, because it would apply selectors
51 env.globals.update(
52 dict(
53 compiler=lambda x: x + "_compiler_stub",
54 pin_subpackage=lambda *args, **kwargs: "subpackage_stub",
55 pin_compatible=lambda *args, **kwargs: "compatible_pin_stub",
56 cdt=lambda *args, **kwargs: "cdt_stub",
57 load_file_regex=lambda *args, **kwargs: defaultdict(lambda: ""),
58 datetime=datetime,
59 time=time,
60 target_platform="linux-64",
61 )
62 )
63 mockos = MockOS()
64 py_ver = "3.7"
65 context = {"os": mockos, "environ": mockos.environ, "PY_VER": py_ver}
66 content = env.from_string(text).render(context)
67 return content
68
69
70 @contextmanager
71 def update_conda_forge_config(feedstock_directory):
72 """Utility method used to update conda forge configuration files
73
74 Uage:
75 >>> with update_conda_forge_config(somepath) as cfg:
76 ... cfg['foo'] = 'bar'
77 """
78 forge_yaml = os.path.join(feedstock_directory, "conda-forge.yml")
79 if os.path.exists(forge_yaml):
80 with open(forge_yaml, "r") as fh:
81 code = yaml.load(fh)
82 else:
83 code = {}
84
85 # Code could come in as an empty list.
86 if not code:
87 code = {}
88
89 yield code
90
91 with open(forge_yaml, "w") as fh:
92 fh.write(yaml.dump(code))
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_smithy/utils.py b/conda_smithy/utils.py
--- a/conda_smithy/utils.py
+++ b/conda_smithy/utils.py
@@ -88,5 +88,4 @@
yield code
- with open(forge_yaml, "w") as fh:
- fh.write(yaml.dump(code))
+ yaml.dump(code, forge_yaml)
|
{"golden_diff": "diff --git a/conda_smithy/utils.py b/conda_smithy/utils.py\n--- a/conda_smithy/utils.py\n+++ b/conda_smithy/utils.py\n@@ -88,5 +88,4 @@\n \n yield code\n \n- with open(forge_yaml, \"w\") as fh:\n- fh.write(yaml.dump(code))\n+ yaml.dump(code, forge_yaml)\n", "issue": "Not compatible with ruamel.yaml 0.16\nFails with,\r\n\r\n```\r\nTraceback (most recent call last):\r\n\r\n File \"/home/travis/miniconda/bin/conda-smithy\", line 10, in <module>\r\n\r\n sys.exit(main())\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py\", line 470, in main\r\n\r\n args.subcommand_func(args)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/cli.py\", line 217, in __call__\r\n\r\n args.feedstock_directory, owner, repo\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/ci_register.py\", line 351, in travis_token_update_conda_forge_config\r\n\r\n ] = travis_encrypt_binstar_token(slug, item)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/contextlib.py\", line 119, in __exit__\r\n\r\n next(self.gen)\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/conda_smithy/utils.py\", line 92, in update_conda_forge_config\r\n\r\n fh.write(yaml.dump(code))\r\n\r\n File \"/home/travis/miniconda/lib/python3.7/site-packages/ruamel/yaml/main.py\", line 448, in dump\r\n\r\n raise TypeError('Need a stream argument when not dumping from context manager')\r\n\r\nTypeError: Need a stream argument when not dumping from context manager\r\n```\r\n\r\ncc @ocefpaf, @scopatz\n", "before_files": [{"content": "import shutil\nimport tempfile\nimport jinja2\nimport datetime\nimport time\nimport os\nimport sys\nfrom collections import defaultdict\nfrom contextlib import contextmanager\n\nimport ruamel.yaml\n\n\n# define global yaml API\n# roundrip-loader and allowing duplicate keys\n# for handling # [filter] / # [not filter]\nyaml = ruamel.yaml.YAML(typ=\"rt\")\nyaml.allow_duplicate_keys = True\n\n\n@contextmanager\ndef tmp_directory():\n tmp_dir = tempfile.mkdtemp(\"_recipe\")\n yield tmp_dir\n shutil.rmtree(tmp_dir)\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return \"{}.{}\".format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\nclass MockOS(dict):\n def __init__(self):\n self.environ = defaultdict(lambda: \"\")\n self.sep = \"/\"\n\n\ndef render_meta_yaml(text):\n env = jinja2.Environment(undefined=NullUndefined)\n\n # stub out cb3 jinja2 functions - they are not important for linting\n # if we don't stub them out, the ruamel.yaml load fails to interpret them\n # we can't just use conda-build's api.render functionality, because it would apply selectors\n env.globals.update(\n dict(\n compiler=lambda x: x + \"_compiler_stub\",\n pin_subpackage=lambda *args, **kwargs: \"subpackage_stub\",\n pin_compatible=lambda *args, **kwargs: \"compatible_pin_stub\",\n cdt=lambda *args, **kwargs: \"cdt_stub\",\n load_file_regex=lambda *args, **kwargs: defaultdict(lambda: \"\"),\n datetime=datetime,\n time=time,\n target_platform=\"linux-64\",\n )\n )\n mockos = MockOS()\n py_ver = \"3.7\"\n context = {\"os\": mockos, \"environ\": mockos.environ, \"PY_VER\": py_ver}\n content = env.from_string(text).render(context)\n return content\n\n\n@contextmanager\ndef update_conda_forge_config(feedstock_directory):\n \"\"\"Utility method used to update conda forge configuration files\n\n Uage:\n >>> with update_conda_forge_config(somepath) as cfg:\n ... cfg['foo'] = 'bar'\n \"\"\"\n forge_yaml = os.path.join(feedstock_directory, \"conda-forge.yml\")\n if os.path.exists(forge_yaml):\n with open(forge_yaml, \"r\") as fh:\n code = yaml.load(fh)\n else:\n code = {}\n\n # Code could come in as an empty list.\n if not code:\n code = {}\n\n yield code\n\n with open(forge_yaml, \"w\") as fh:\n fh.write(yaml.dump(code))\n", "path": "conda_smithy/utils.py"}], "after_files": [{"content": "import shutil\nimport tempfile\nimport jinja2\nimport datetime\nimport time\nimport os\nimport sys\nfrom collections import defaultdict\nfrom contextlib import contextmanager\n\nimport ruamel.yaml\n\n\n# define global yaml API\n# roundrip-loader and allowing duplicate keys\n# for handling # [filter] / # [not filter]\nyaml = ruamel.yaml.YAML(typ=\"rt\")\nyaml.allow_duplicate_keys = True\n\n\n@contextmanager\ndef tmp_directory():\n tmp_dir = tempfile.mkdtemp(\"_recipe\")\n yield tmp_dir\n shutil.rmtree(tmp_dir)\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return \"{}.{}\".format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\nclass MockOS(dict):\n def __init__(self):\n self.environ = defaultdict(lambda: \"\")\n self.sep = \"/\"\n\n\ndef render_meta_yaml(text):\n env = jinja2.Environment(undefined=NullUndefined)\n\n # stub out cb3 jinja2 functions - they are not important for linting\n # if we don't stub them out, the ruamel.yaml load fails to interpret them\n # we can't just use conda-build's api.render functionality, because it would apply selectors\n env.globals.update(\n dict(\n compiler=lambda x: x + \"_compiler_stub\",\n pin_subpackage=lambda *args, **kwargs: \"subpackage_stub\",\n pin_compatible=lambda *args, **kwargs: \"compatible_pin_stub\",\n cdt=lambda *args, **kwargs: \"cdt_stub\",\n load_file_regex=lambda *args, **kwargs: defaultdict(lambda: \"\"),\n datetime=datetime,\n time=time,\n target_platform=\"linux-64\",\n )\n )\n mockos = MockOS()\n py_ver = \"3.7\"\n context = {\"os\": mockos, \"environ\": mockos.environ, \"PY_VER\": py_ver}\n content = env.from_string(text).render(context)\n return content\n\n\n@contextmanager\ndef update_conda_forge_config(feedstock_directory):\n \"\"\"Utility method used to update conda forge configuration files\n\n Uage:\n >>> with update_conda_forge_config(somepath) as cfg:\n ... cfg['foo'] = 'bar'\n \"\"\"\n forge_yaml = os.path.join(feedstock_directory, \"conda-forge.yml\")\n if os.path.exists(forge_yaml):\n with open(forge_yaml, \"r\") as fh:\n code = yaml.load(fh)\n else:\n code = {}\n\n # Code could come in as an empty list.\n if not code:\n code = {}\n\n yield code\n\n yaml.dump(code, forge_yaml)\n", "path": "conda_smithy/utils.py"}]}
| 1,409 | 89 |
gh_patches_debug_4146
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-7267
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
When "upload_file_request_handler.py" returns 400 error, we can see session ID.
# Summary
We make application on Microsoft Azure App Service with streamlit.
When we conducted a test of uploading file with `st.file_uploader`, it returned 400 error and **session ID** as string.
We checked your codes and noticed that we have 400 error, `streamlit/lib/streamlit/server/upload_file_request_handler.py` returns error code 400, reason and session ID on line 126-128.
This problem may lead to security incidents like XSS.
Please check it.
# Steps to reproduce
Code snippet:
```
import streamlit as st
uploaded_file = st.file_uploader("uploading Excel files", type="xlsx", key="xlsx_up")
if uploaded_file is not None:
st.write("Success")
```
How the error occurred cannot be provided due to confidentiality,
## Expected behavior:
When we have 400 error, streamlit will return only error code and error reason without session ID.
## Actual behavior:
When we have 400 error, streamlit returns error code and error reason with session ID
Screenshots cannot be uploaded due to confidentiality.
## Is this a regression?
That is, did this use to work the way you expected in the past?
yes / no
⇒no
# Debug info
- Streamlit version: (get it with `$ streamlit version`)
⇒0.74.1
- Python version: (get it with `$ python --version`)
⇒3.7
- Using Conda? PipEnv? PyEnv? Pex?
⇒Pip
- OS version:
⇒Linux
- Browser version:
⇒Chrome 88.0.4324.150
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/streamlit/web/server/upload_file_request_handler.py`
Content:
```
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Any, Callable, Dict, List
16
17 import tornado.httputil
18 import tornado.web
19
20 from streamlit import config
21 from streamlit.logger import get_logger
22 from streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager
23 from streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec
24 from streamlit.web.server import routes, server_util
25
26 LOGGER = get_logger(__name__)
27
28
29 class UploadFileRequestHandler(tornado.web.RequestHandler):
30 """Implements the POST /upload_file endpoint."""
31
32 def initialize(
33 self,
34 file_mgr: MemoryUploadedFileManager,
35 is_active_session: Callable[[str], bool],
36 ):
37 """
38 Parameters
39 ----------
40 file_mgr : UploadedFileManager
41 The server's singleton UploadedFileManager. All file uploads
42 go here.
43 is_active_session:
44 A function that returns true if a session_id belongs to an active
45 session.
46 """
47 self._file_mgr = file_mgr
48 self._is_active_session = is_active_session
49
50 def set_default_headers(self):
51 self.set_header("Access-Control-Allow-Methods", "PUT, OPTIONS, DELETE")
52 self.set_header("Access-Control-Allow-Headers", "Content-Type")
53 if config.get_option("server.enableXsrfProtection"):
54 self.set_header(
55 "Access-Control-Allow-Origin",
56 server_util.get_url(config.get_option("browser.serverAddress")),
57 )
58 self.set_header("Access-Control-Allow-Headers", "X-Xsrftoken, Content-Type")
59 self.set_header("Vary", "Origin")
60 self.set_header("Access-Control-Allow-Credentials", "true")
61 elif routes.allow_cross_origin_requests():
62 self.set_header("Access-Control-Allow-Origin", "*")
63
64 def options(self, **kwargs):
65 """/OPTIONS handler for preflight CORS checks.
66
67 When a browser is making a CORS request, it may sometimes first
68 send an OPTIONS request, to check whether the server understands the
69 CORS protocol. This is optional, and doesn't happen for every request
70 or in every browser. If an OPTIONS request does get sent, and is not
71 then handled by the server, the browser will fail the underlying
72 request.
73
74 The proper way to handle this is to send a 204 response ("no content")
75 with the CORS headers attached. (These headers are automatically added
76 to every outgoing response, including OPTIONS responses,
77 via set_default_headers().)
78
79 See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request
80 """
81 self.set_status(204)
82 self.finish()
83
84 def put(self, **kwargs):
85 """Receive an uploaded file and add it to our UploadedFileManager."""
86
87 args: Dict[str, List[bytes]] = {}
88 files: Dict[str, List[Any]] = {}
89
90 session_id = self.path_kwargs["session_id"]
91 file_id = self.path_kwargs["file_id"]
92
93 tornado.httputil.parse_body_arguments(
94 content_type=self.request.headers["Content-Type"],
95 body=self.request.body,
96 arguments=args,
97 files=files,
98 )
99
100 try:
101 if not self._is_active_session(session_id):
102 raise Exception(f"Invalid session_id: '{session_id}'")
103 except Exception as e:
104 self.send_error(400, reason=str(e))
105 return
106
107 uploaded_files: List[UploadedFileRec] = []
108
109 for _, flist in files.items():
110 for file in flist:
111 uploaded_files.append(
112 UploadedFileRec(
113 file_id=file_id,
114 name=file["filename"],
115 type=file["content_type"],
116 data=file["body"],
117 )
118 )
119
120 if len(uploaded_files) != 1:
121 self.send_error(
122 400, reason=f"Expected 1 file, but got {len(uploaded_files)}"
123 )
124 return
125
126 self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])
127 self.set_status(204)
128
129 def delete(self, **kwargs):
130 """Delete file request handler."""
131 session_id = self.path_kwargs["session_id"]
132 file_id = self.path_kwargs["file_id"]
133
134 self._file_mgr.remove_file(session_id=session_id, file_id=file_id)
135 self.set_status(204)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/streamlit/web/server/upload_file_request_handler.py b/lib/streamlit/web/server/upload_file_request_handler.py
--- a/lib/streamlit/web/server/upload_file_request_handler.py
+++ b/lib/streamlit/web/server/upload_file_request_handler.py
@@ -99,7 +99,7 @@
try:
if not self._is_active_session(session_id):
- raise Exception(f"Invalid session_id: '{session_id}'")
+ raise Exception(f"Invalid session_id")
except Exception as e:
self.send_error(400, reason=str(e))
return
|
{"golden_diff": "diff --git a/lib/streamlit/web/server/upload_file_request_handler.py b/lib/streamlit/web/server/upload_file_request_handler.py\n--- a/lib/streamlit/web/server/upload_file_request_handler.py\n+++ b/lib/streamlit/web/server/upload_file_request_handler.py\n@@ -99,7 +99,7 @@\n \n try:\n if not self._is_active_session(session_id):\n- raise Exception(f\"Invalid session_id: '{session_id}'\")\n+ raise Exception(f\"Invalid session_id\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n", "issue": "When \"upload_file_request_handler.py\" returns 400 error, we can see session ID.\n# Summary\r\n\r\nWe make application on Microsoft Azure App Service with streamlit.\r\nWhen we conducted a test of uploading file with `st.file_uploader`, it returned 400 error and **session ID** as string.\r\nWe checked your codes and noticed that we have 400 error, `streamlit/lib/streamlit/server/upload_file_request_handler.py` returns error code 400, reason and session ID on line 126-128.\r\nThis problem may lead to security incidents like XSS.\r\nPlease check it.\r\n\r\n# Steps to reproduce\r\n\r\nCode snippet:\r\n\r\n```\r\nimport streamlit as st\r\n\r\nuploaded_file = st.file_uploader(\"uploading Excel files\", type=\"xlsx\", key=\"xlsx_up\")\r\nif uploaded_file is not None:\r\n st.write(\"Success\")\r\n\r\n```\r\nHow the error occurred cannot be provided due to confidentiality,\r\n\r\n## Expected behavior:\r\n\r\nWhen we have 400 error, streamlit will return only error code and error reason without session ID.\r\n\r\n## Actual behavior:\r\n\r\nWhen we have 400 error, streamlit returns error code and error reason with session ID\r\nScreenshots cannot be uploaded due to confidentiality.\r\n\r\n## Is this a regression?\r\n\r\nThat is, did this use to work the way you expected in the past?\r\nyes / no\r\n\u21d2no\r\n\r\n# Debug info\r\n\r\n- Streamlit version: (get it with `$ streamlit version`)\r\n\u21d20.74.1\r\n- Python version: (get it with `$ python --version`)\r\n\u21d23.7\r\n- Using Conda? PipEnv? PyEnv? Pex?\r\n\u21d2Pip\r\n- OS version:\r\n\u21d2Linux\r\n- Browser version:\r\n\u21d2Chrome 88.0.4324.150\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, Callable, Dict, List\n\nimport tornado.httputil\nimport tornado.web\n\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager\nfrom streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec\nfrom streamlit.web.server import routes, server_util\n\nLOGGER = get_logger(__name__)\n\n\nclass UploadFileRequestHandler(tornado.web.RequestHandler):\n \"\"\"Implements the POST /upload_file endpoint.\"\"\"\n\n def initialize(\n self,\n file_mgr: MemoryUploadedFileManager,\n is_active_session: Callable[[str], bool],\n ):\n \"\"\"\n Parameters\n ----------\n file_mgr : UploadedFileManager\n The server's singleton UploadedFileManager. All file uploads\n go here.\n is_active_session:\n A function that returns true if a session_id belongs to an active\n session.\n \"\"\"\n self._file_mgr = file_mgr\n self._is_active_session = is_active_session\n\n def set_default_headers(self):\n self.set_header(\"Access-Control-Allow-Methods\", \"PUT, OPTIONS, DELETE\")\n self.set_header(\"Access-Control-Allow-Headers\", \"Content-Type\")\n if config.get_option(\"server.enableXsrfProtection\"):\n self.set_header(\n \"Access-Control-Allow-Origin\",\n server_util.get_url(config.get_option(\"browser.serverAddress\")),\n )\n self.set_header(\"Access-Control-Allow-Headers\", \"X-Xsrftoken, Content-Type\")\n self.set_header(\"Vary\", \"Origin\")\n self.set_header(\"Access-Control-Allow-Credentials\", \"true\")\n elif routes.allow_cross_origin_requests():\n self.set_header(\"Access-Control-Allow-Origin\", \"*\")\n\n def options(self, **kwargs):\n \"\"\"/OPTIONS handler for preflight CORS checks.\n\n When a browser is making a CORS request, it may sometimes first\n send an OPTIONS request, to check whether the server understands the\n CORS protocol. This is optional, and doesn't happen for every request\n or in every browser. If an OPTIONS request does get sent, and is not\n then handled by the server, the browser will fail the underlying\n request.\n\n The proper way to handle this is to send a 204 response (\"no content\")\n with the CORS headers attached. (These headers are automatically added\n to every outgoing response, including OPTIONS responses,\n via set_default_headers().)\n\n See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request\n \"\"\"\n self.set_status(204)\n self.finish()\n\n def put(self, **kwargs):\n \"\"\"Receive an uploaded file and add it to our UploadedFileManager.\"\"\"\n\n args: Dict[str, List[bytes]] = {}\n files: Dict[str, List[Any]] = {}\n\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n tornado.httputil.parse_body_arguments(\n content_type=self.request.headers[\"Content-Type\"],\n body=self.request.body,\n arguments=args,\n files=files,\n )\n\n try:\n if not self._is_active_session(session_id):\n raise Exception(f\"Invalid session_id: '{session_id}'\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n\n uploaded_files: List[UploadedFileRec] = []\n\n for _, flist in files.items():\n for file in flist:\n uploaded_files.append(\n UploadedFileRec(\n file_id=file_id,\n name=file[\"filename\"],\n type=file[\"content_type\"],\n data=file[\"body\"],\n )\n )\n\n if len(uploaded_files) != 1:\n self.send_error(\n 400, reason=f\"Expected 1 file, but got {len(uploaded_files)}\"\n )\n return\n\n self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])\n self.set_status(204)\n\n def delete(self, **kwargs):\n \"\"\"Delete file request handler.\"\"\"\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n self._file_mgr.remove_file(session_id=session_id, file_id=file_id)\n self.set_status(204)\n", "path": "lib/streamlit/web/server/upload_file_request_handler.py"}], "after_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, Callable, Dict, List\n\nimport tornado.httputil\nimport tornado.web\n\nfrom streamlit import config\nfrom streamlit.logger import get_logger\nfrom streamlit.runtime.memory_uploaded_file_manager import MemoryUploadedFileManager\nfrom streamlit.runtime.uploaded_file_manager import UploadedFileManager, UploadedFileRec\nfrom streamlit.web.server import routes, server_util\n\nLOGGER = get_logger(__name__)\n\n\nclass UploadFileRequestHandler(tornado.web.RequestHandler):\n \"\"\"Implements the POST /upload_file endpoint.\"\"\"\n\n def initialize(\n self,\n file_mgr: MemoryUploadedFileManager,\n is_active_session: Callable[[str], bool],\n ):\n \"\"\"\n Parameters\n ----------\n file_mgr : UploadedFileManager\n The server's singleton UploadedFileManager. All file uploads\n go here.\n is_active_session:\n A function that returns true if a session_id belongs to an active\n session.\n \"\"\"\n self._file_mgr = file_mgr\n self._is_active_session = is_active_session\n\n def set_default_headers(self):\n self.set_header(\"Access-Control-Allow-Methods\", \"PUT, OPTIONS, DELETE\")\n self.set_header(\"Access-Control-Allow-Headers\", \"Content-Type\")\n if config.get_option(\"server.enableXsrfProtection\"):\n self.set_header(\n \"Access-Control-Allow-Origin\",\n server_util.get_url(config.get_option(\"browser.serverAddress\")),\n )\n self.set_header(\"Access-Control-Allow-Headers\", \"X-Xsrftoken, Content-Type\")\n self.set_header(\"Vary\", \"Origin\")\n self.set_header(\"Access-Control-Allow-Credentials\", \"true\")\n elif routes.allow_cross_origin_requests():\n self.set_header(\"Access-Control-Allow-Origin\", \"*\")\n\n def options(self, **kwargs):\n \"\"\"/OPTIONS handler for preflight CORS checks.\n\n When a browser is making a CORS request, it may sometimes first\n send an OPTIONS request, to check whether the server understands the\n CORS protocol. This is optional, and doesn't happen for every request\n or in every browser. If an OPTIONS request does get sent, and is not\n then handled by the server, the browser will fail the underlying\n request.\n\n The proper way to handle this is to send a 204 response (\"no content\")\n with the CORS headers attached. (These headers are automatically added\n to every outgoing response, including OPTIONS responses,\n via set_default_headers().)\n\n See https://developer.mozilla.org/en-US/docs/Glossary/Preflight_request\n \"\"\"\n self.set_status(204)\n self.finish()\n\n def put(self, **kwargs):\n \"\"\"Receive an uploaded file and add it to our UploadedFileManager.\"\"\"\n\n args: Dict[str, List[bytes]] = {}\n files: Dict[str, List[Any]] = {}\n\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n tornado.httputil.parse_body_arguments(\n content_type=self.request.headers[\"Content-Type\"],\n body=self.request.body,\n arguments=args,\n files=files,\n )\n\n try:\n if not self._is_active_session(session_id):\n raise Exception(f\"Invalid session_id\")\n except Exception as e:\n self.send_error(400, reason=str(e))\n return\n\n uploaded_files: List[UploadedFileRec] = []\n\n for _, flist in files.items():\n for file in flist:\n uploaded_files.append(\n UploadedFileRec(\n file_id=file_id,\n name=file[\"filename\"],\n type=file[\"content_type\"],\n data=file[\"body\"],\n )\n )\n\n if len(uploaded_files) != 1:\n self.send_error(\n 400, reason=f\"Expected 1 file, but got {len(uploaded_files)}\"\n )\n return\n\n self._file_mgr.add_file(session_id=session_id, file=uploaded_files[0])\n self.set_status(204)\n\n def delete(self, **kwargs):\n \"\"\"Delete file request handler.\"\"\"\n session_id = self.path_kwargs[\"session_id\"]\n file_id = self.path_kwargs[\"file_id\"]\n\n self._file_mgr.remove_file(session_id=session_id, file_id=file_id)\n self.set_status(204)\n", "path": "lib/streamlit/web/server/upload_file_request_handler.py"}]}
| 2,006 | 126 |
gh_patches_debug_1144
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-4727
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pulp file python package reporting wrongly
Starting with pulpcore 3.40 the pulp_file plugins python package started reporting as pulp_file instead of pulp-file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulp_file/app/__init__.py`
Content:
```
1 from pulpcore.plugin import PulpPluginAppConfig
2
3
4 class PulpFilePluginAppConfig(PulpPluginAppConfig):
5 """
6 Entry point for pulp_file plugin.
7 """
8
9 name = "pulp_file.app"
10 label = "file"
11 version = "3.41.1.dev"
12 python_package_name = "pulp_file" # TODO Add python_module_name
13 domain_compatible = True
14
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulp_file/app/__init__.py b/pulp_file/app/__init__.py
--- a/pulp_file/app/__init__.py
+++ b/pulp_file/app/__init__.py
@@ -9,5 +9,5 @@
name = "pulp_file.app"
label = "file"
version = "3.41.1.dev"
- python_package_name = "pulp_file" # TODO Add python_module_name
+ python_package_name = "pulp-file" # TODO Add python_module_name
domain_compatible = True
|
{"golden_diff": "diff --git a/pulp_file/app/__init__.py b/pulp_file/app/__init__.py\n--- a/pulp_file/app/__init__.py\n+++ b/pulp_file/app/__init__.py\n@@ -9,5 +9,5 @@\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n- python_package_name = \"pulp_file\" # TODO Add python_module_name\n+ python_package_name = \"pulp-file\" # TODO Add python_module_name\n domain_compatible = True\n", "issue": "pulp file python package reporting wrongly\nStarting with pulpcore 3.40 the pulp_file plugins python package started reporting as pulp_file instead of pulp-file.\n", "before_files": [{"content": "from pulpcore.plugin import PulpPluginAppConfig\n\n\nclass PulpFilePluginAppConfig(PulpPluginAppConfig):\n \"\"\"\n Entry point for pulp_file plugin.\n \"\"\"\n\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n python_package_name = \"pulp_file\" # TODO Add python_module_name\n domain_compatible = True\n", "path": "pulp_file/app/__init__.py"}], "after_files": [{"content": "from pulpcore.plugin import PulpPluginAppConfig\n\n\nclass PulpFilePluginAppConfig(PulpPluginAppConfig):\n \"\"\"\n Entry point for pulp_file plugin.\n \"\"\"\n\n name = \"pulp_file.app\"\n label = \"file\"\n version = \"3.41.1.dev\"\n python_package_name = \"pulp-file\" # TODO Add python_module_name\n domain_compatible = True\n", "path": "pulp_file/app/__init__.py"}]}
| 405 | 126 |
gh_patches_debug_37463
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__numpyro-806
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update docstring of Neal's funnel example
We have updated [funnel](https://github.com/pyro-ppl/numpyro/blob/master/examples/funnel.py) example to use `reparam` handler, but the docstring is not updated yet.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/funnel.py`
Content:
```
1 # Copyright Contributors to the Pyro project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 """
5 Example: Neal's Funnel
6 ======================
7
8 This example, which is adapted from [1], illustrates how to leverage non-centered
9 parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.
10 We will examine the difference between two types of parameterizations on the
11 10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at
12 the neck of the funnel if centered parameterization is used. On the contrary,
13 the problem can be solved by using non-centered parameterization.
14
15 Using non-centered parameterization through TransformedDistribution in NumPyro
16 has the same effect as the automatic reparameterisation technique introduced in
17 [2]. However, in [2], users need to implement a (non-trivial) reparameterization
18 rule for each type of transform. Instead, in NumPyro the only requirement to let
19 inference algorithms know to do reparameterization automatically is to declare
20 the random variable as a transformed distribution.
21
22 **References:**
23
24 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html
25 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), "Automatic
26 Reparameterisation of Probabilistic Programs", (https://arxiv.org/abs/1906.03028)
27 """
28
29 import argparse
30 import os
31
32 import matplotlib.pyplot as plt
33
34 from jax import random
35 import jax.numpy as jnp
36
37 import numpyro
38 import numpyro.distributions as dist
39 from numpyro.infer import MCMC, NUTS, Predictive
40 from numpyro.infer.reparam import LocScaleReparam
41
42
43 def model(dim=10):
44 y = numpyro.sample('y', dist.Normal(0, 3))
45 numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
46
47
48 def reparam_model(dim=10):
49 y = numpyro.sample('y', dist.Normal(0, 3))
50 with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):
51 numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
52
53
54 def run_inference(model, args, rng_key):
55 kernel = NUTS(model)
56 mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,
57 progress_bar=False if "NUMPYRO_SPHINXBUILD" in os.environ else True)
58 mcmc.run(rng_key)
59 mcmc.print_summary()
60 return mcmc.get_samples()
61
62
63 def main(args):
64 rng_key = random.PRNGKey(0)
65
66 # do inference with centered parameterization
67 print("============================= Centered Parameterization ==============================")
68 samples = run_inference(model, args, rng_key)
69
70 # do inference with non-centered parameterization
71 print("\n=========================== Non-centered Parameterization ============================")
72 reparam_samples = run_inference(reparam_model, args, rng_key)
73 # collect deterministic sites
74 reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(
75 random.PRNGKey(1))
76
77 # make plots
78 fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))
79
80 ax1.plot(samples['x'][:, 0], samples['y'], "go", alpha=0.3)
81 ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',
82 title='Funnel samples with centered parameterization')
83
84 ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], "go", alpha=0.3)
85 ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',
86 title='Funnel samples with non-centered parameterization')
87
88 plt.savefig('funnel_plot.pdf')
89 plt.tight_layout()
90
91
92 if __name__ == "__main__":
93 assert numpyro.__version__.startswith('0.4.1')
94 parser = argparse.ArgumentParser(description="Non-centered reparameterization example")
95 parser.add_argument("-n", "--num-samples", nargs="?", default=1000, type=int)
96 parser.add_argument("--num-warmup", nargs='?', default=1000, type=int)
97 parser.add_argument("--num-chains", nargs='?', default=1, type=int)
98 parser.add_argument("--device", default='cpu', type=str, help='use "cpu" or "gpu".')
99 args = parser.parse_args()
100
101 numpyro.set_platform(args.device)
102 numpyro.set_host_device_count(args.num_chains)
103
104 main(args)
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/funnel.py b/examples/funnel.py
--- a/examples/funnel.py
+++ b/examples/funnel.py
@@ -6,18 +6,15 @@
======================
This example, which is adapted from [1], illustrates how to leverage non-centered
-parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.
+parameterization using the :class:`~numpyro.handlers.reparam` handler.
We will examine the difference between two types of parameterizations on the
10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at
the neck of the funnel if centered parameterization is used. On the contrary,
the problem can be solved by using non-centered parameterization.
-Using non-centered parameterization through TransformedDistribution in NumPyro
-has the same effect as the automatic reparameterisation technique introduced in
-[2]. However, in [2], users need to implement a (non-trivial) reparameterization
-rule for each type of transform. Instead, in NumPyro the only requirement to let
-inference algorithms know to do reparameterization automatically is to declare
-the random variable as a transformed distribution.
+Using non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`
+or :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as
+the automatic reparameterisation technique introduced in [2].
**References:**
@@ -36,6 +33,7 @@
import numpyro
import numpyro.distributions as dist
+from numpyro.handlers import reparam
from numpyro.infer import MCMC, NUTS, Predictive
from numpyro.infer.reparam import LocScaleReparam
@@ -45,10 +43,7 @@
numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
-def reparam_model(dim=10):
- y = numpyro.sample('y', dist.Normal(0, 3))
- with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):
- numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))
+reparam_model = reparam(model, config={'x': LocScaleReparam(0)})
def run_inference(model, args, rng_key):
@@ -56,7 +51,7 @@
mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,
progress_bar=False if "NUMPYRO_SPHINXBUILD" in os.environ else True)
mcmc.run(rng_key)
- mcmc.print_summary()
+ mcmc.print_summary(exclude_deterministic=False)
return mcmc.get_samples()
|
{"golden_diff": "diff --git a/examples/funnel.py b/examples/funnel.py\n--- a/examples/funnel.py\n+++ b/examples/funnel.py\n@@ -6,18 +6,15 @@\n ======================\n \n This example, which is adapted from [1], illustrates how to leverage non-centered\n-parameterization using the class :class:`numpyro.distributions.TransformedDistribution`.\n+parameterization using the :class:`~numpyro.handlers.reparam` handler.\n We will examine the difference between two types of parameterizations on the\n 10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\n the neck of the funnel if centered parameterization is used. On the contrary,\n the problem can be solved by using non-centered parameterization.\n \n-Using non-centered parameterization through TransformedDistribution in NumPyro\n-has the same effect as the automatic reparameterisation technique introduced in\n-[2]. However, in [2], users need to implement a (non-trivial) reparameterization\n-rule for each type of transform. Instead, in NumPyro the only requirement to let\n-inference algorithms know to do reparameterization automatically is to declare\n-the random variable as a transformed distribution.\n+Using non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`\n+or :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as\n+the automatic reparameterisation technique introduced in [2].\n \n **References:**\n \n@@ -36,6 +33,7 @@\n \n import numpyro\n import numpyro.distributions as dist\n+from numpyro.handlers import reparam\n from numpyro.infer import MCMC, NUTS, Predictive\n from numpyro.infer.reparam import LocScaleReparam\n \n@@ -45,10 +43,7 @@\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n \n \n-def reparam_model(dim=10):\n- y = numpyro.sample('y', dist.Normal(0, 3))\n- with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):\n- numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n+reparam_model = reparam(model, config={'x': LocScaleReparam(0)})\n \n \n def run_inference(model, args, rng_key):\n@@ -56,7 +51,7 @@\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n- mcmc.print_summary()\n+ mcmc.print_summary(exclude_deterministic=False)\n return mcmc.get_samples()\n", "issue": "Update docstring of Neal's funnel example\nWe have updated [funnel](https://github.com/pyro-ppl/numpyro/blob/master/examples/funnel.py) example to use `reparam` handler, but the docstring is not updated yet.\n", "before_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n\"\"\"\nExample: Neal's Funnel\n======================\n\nThis example, which is adapted from [1], illustrates how to leverage non-centered\nparameterization using the class :class:`numpyro.distributions.TransformedDistribution`.\nWe will examine the difference between two types of parameterizations on the\n10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\nthe neck of the funnel if centered parameterization is used. On the contrary,\nthe problem can be solved by using non-centered parameterization.\n\nUsing non-centered parameterization through TransformedDistribution in NumPyro\nhas the same effect as the automatic reparameterisation technique introduced in\n[2]. However, in [2], users need to implement a (non-trivial) reparameterization\nrule for each type of transform. Instead, in NumPyro the only requirement to let\ninference algorithms know to do reparameterization automatically is to declare\nthe random variable as a transformed distribution.\n\n**References:**\n\n 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html\n 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), \"Automatic\n Reparameterisation of Probabilistic Programs\", (https://arxiv.org/abs/1906.03028)\n\"\"\"\n\nimport argparse\nimport os\n\nimport matplotlib.pyplot as plt\n\nfrom jax import random\nimport jax.numpy as jnp\n\nimport numpyro\nimport numpyro.distributions as dist\nfrom numpyro.infer import MCMC, NUTS, Predictive\nfrom numpyro.infer.reparam import LocScaleReparam\n\n\ndef model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\ndef reparam_model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n with numpyro.handlers.reparam(config={'x': LocScaleReparam(0)}):\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\ndef run_inference(model, args, rng_key):\n kernel = NUTS(model)\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n mcmc.print_summary()\n return mcmc.get_samples()\n\n\ndef main(args):\n rng_key = random.PRNGKey(0)\n\n # do inference with centered parameterization\n print(\"============================= Centered Parameterization ==============================\")\n samples = run_inference(model, args, rng_key)\n\n # do inference with non-centered parameterization\n print(\"\\n=========================== Non-centered Parameterization ============================\")\n reparam_samples = run_inference(reparam_model, args, rng_key)\n # collect deterministic sites\n reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(\n random.PRNGKey(1))\n\n # make plots\n fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))\n\n ax1.plot(samples['x'][:, 0], samples['y'], \"go\", alpha=0.3)\n ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',\n title='Funnel samples with centered parameterization')\n\n ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], \"go\", alpha=0.3)\n ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',\n title='Funnel samples with non-centered parameterization')\n\n plt.savefig('funnel_plot.pdf')\n plt.tight_layout()\n\n\nif __name__ == \"__main__\":\n assert numpyro.__version__.startswith('0.4.1')\n parser = argparse.ArgumentParser(description=\"Non-centered reparameterization example\")\n parser.add_argument(\"-n\", \"--num-samples\", nargs=\"?\", default=1000, type=int)\n parser.add_argument(\"--num-warmup\", nargs='?', default=1000, type=int)\n parser.add_argument(\"--num-chains\", nargs='?', default=1, type=int)\n parser.add_argument(\"--device\", default='cpu', type=str, help='use \"cpu\" or \"gpu\".')\n args = parser.parse_args()\n\n numpyro.set_platform(args.device)\n numpyro.set_host_device_count(args.num_chains)\n\n main(args)\n", "path": "examples/funnel.py"}], "after_files": [{"content": "# Copyright Contributors to the Pyro project.\n# SPDX-License-Identifier: Apache-2.0\n\n\"\"\"\nExample: Neal's Funnel\n======================\n\nThis example, which is adapted from [1], illustrates how to leverage non-centered\nparameterization using the :class:`~numpyro.handlers.reparam` handler.\nWe will examine the difference between two types of parameterizations on the\n10-dimensional Neal's funnel distribution. As we will see, HMC gets trouble at\nthe neck of the funnel if centered parameterization is used. On the contrary,\nthe problem can be solved by using non-centered parameterization.\n\nUsing non-centered parameterization through :class:`~numpyro.infer.reparam.LocScaleReparam`\nor :class:`~numpyro.infer.reparam.TransformReparam` in NumPyro has the same effect as\nthe automatic reparameterisation technique introduced in [2].\n\n**References:**\n\n 1. *Stan User's Guide*, https://mc-stan.org/docs/2_19/stan-users-guide/reparameterization-section.html\n 2. Maria I. Gorinova, Dave Moore, Matthew D. Hoffman (2019), \"Automatic\n Reparameterisation of Probabilistic Programs\", (https://arxiv.org/abs/1906.03028)\n\"\"\"\n\nimport argparse\nimport os\n\nimport matplotlib.pyplot as plt\n\nfrom jax import random\nimport jax.numpy as jnp\n\nimport numpyro\nimport numpyro.distributions as dist\nfrom numpyro.handlers import reparam\nfrom numpyro.infer import MCMC, NUTS, Predictive\nfrom numpyro.infer.reparam import LocScaleReparam\n\n\ndef model(dim=10):\n y = numpyro.sample('y', dist.Normal(0, 3))\n numpyro.sample('x', dist.Normal(jnp.zeros(dim - 1), jnp.exp(y / 2)))\n\n\nreparam_model = reparam(model, config={'x': LocScaleReparam(0)})\n\n\ndef run_inference(model, args, rng_key):\n kernel = NUTS(model)\n mcmc = MCMC(kernel, args.num_warmup, args.num_samples, num_chains=args.num_chains,\n progress_bar=False if \"NUMPYRO_SPHINXBUILD\" in os.environ else True)\n mcmc.run(rng_key)\n mcmc.print_summary(exclude_deterministic=False)\n return mcmc.get_samples()\n\n\ndef main(args):\n rng_key = random.PRNGKey(0)\n\n # do inference with centered parameterization\n print(\"============================= Centered Parameterization ==============================\")\n samples = run_inference(model, args, rng_key)\n\n # do inference with non-centered parameterization\n print(\"\\n=========================== Non-centered Parameterization ============================\")\n reparam_samples = run_inference(reparam_model, args, rng_key)\n # collect deterministic sites\n reparam_samples = Predictive(reparam_model, reparam_samples, return_sites=['x', 'y'])(\n random.PRNGKey(1))\n\n # make plots\n fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(8, 8))\n\n ax1.plot(samples['x'][:, 0], samples['y'], \"go\", alpha=0.3)\n ax1.set(xlim=(-20, 20), ylim=(-9, 9), ylabel='y',\n title='Funnel samples with centered parameterization')\n\n ax2.plot(reparam_samples['x'][:, 0], reparam_samples['y'], \"go\", alpha=0.3)\n ax2.set(xlim=(-20, 20), ylim=(-9, 9), xlabel='x[0]', ylabel='y',\n title='Funnel samples with non-centered parameterization')\n\n plt.savefig('funnel_plot.pdf')\n plt.tight_layout()\n\n\nif __name__ == \"__main__\":\n assert numpyro.__version__.startswith('0.4.1')\n parser = argparse.ArgumentParser(description=\"Non-centered reparameterization example\")\n parser.add_argument(\"-n\", \"--num-samples\", nargs=\"?\", default=1000, type=int)\n parser.add_argument(\"--num-warmup\", nargs='?', default=1000, type=int)\n parser.add_argument(\"--num-chains\", nargs='?', default=1, type=int)\n parser.add_argument(\"--device\", default='cpu', type=str, help='use \"cpu\" or \"gpu\".')\n args = parser.parse_args()\n\n numpyro.set_platform(args.device)\n numpyro.set_host_device_count(args.num_chains)\n\n main(args)\n", "path": "examples/funnel.py"}]}
| 1,599 | 615 |
gh_patches_debug_5834
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-706
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
urllib3 1.11 does not provide the extra 'secure'
I tried with Python 2.7 and 2.6 inside different virtualenv.
``` bash
pip install 'urllib3[secure]'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from distutils.core import setup
4
5 import os
6 import re
7
8 try:
9 import setuptools
10 except ImportError:
11 pass # No 'develop' command, oh well.
12
13 base_path = os.path.dirname(__file__)
14
15 # Get the version (borrowed from SQLAlchemy)
16 fp = open(os.path.join(base_path, 'urllib3', '__init__.py'))
17 VERSION = re.compile(r".*__version__ = '(.*?)'",
18 re.S).match(fp.read()).group(1)
19 fp.close()
20
21
22 version = VERSION
23
24 setup(name='urllib3',
25 version=version,
26 description="HTTP library with thread-safe connection pooling, file post, and more.",
27 long_description=open('README.rst').read() + '\n\n' + open('CHANGES.rst').read(),
28 classifiers=[
29 'Environment :: Web Environment',
30 'Intended Audience :: Developers',
31 'License :: OSI Approved :: MIT License',
32 'Operating System :: OS Independent',
33 'Programming Language :: Python',
34 'Programming Language :: Python :: 2',
35 'Programming Language :: Python :: 3',
36 'Topic :: Internet :: WWW/HTTP',
37 'Topic :: Software Development :: Libraries',
38 ],
39 keywords='urllib httplib threadsafe filepost http https ssl pooling',
40 author='Andrey Petrov',
41 author_email='[email protected]',
42 url='http://urllib3.readthedocs.org/',
43 license='MIT',
44 packages=['urllib3',
45 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
46 'urllib3.contrib', 'urllib3.util',
47 ],
48 requires=[],
49 tests_require=[
50 # These are a less-specific subset of dev-requirements.txt, for the
51 # convenience of distro package maintainers.
52 'nose',
53 'mock',
54 'tornado',
55 ],
56 test_suite='test',
57 extras_require={
58 'secure;python_version<="2.7"': [
59 'pyOpenSSL',
60 'ndg-httpsclient',
61 'pyasn1',
62 'certifi',
63 ],
64 'secure;python_version>"2.7"': [
65 'certifi',
66 ],
67 },
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -55,14 +55,11 @@
],
test_suite='test',
extras_require={
- 'secure;python_version<="2.7"': [
+ 'secure': [
'pyOpenSSL',
'ndg-httpsclient',
'pyasn1',
'certifi',
],
- 'secure;python_version>"2.7"': [
- 'certifi',
- ],
},
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -55,14 +55,11 @@\n ],\n test_suite='test',\n extras_require={\n- 'secure;python_version<=\"2.7\"': [\n+ 'secure': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n- 'secure;python_version>\"2.7\"': [\n- 'certifi',\n- ],\n },\n )\n", "issue": "urllib3 1.11 does not provide the extra 'secure'\nI tried with Python 2.7 and 2.6 inside different virtualenv.\n\n``` bash\npip install 'urllib3[secure]'\n```\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nimport os\nimport re\n\ntry:\n import setuptools\nexcept ImportError:\n pass # No 'develop' command, oh well.\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\n\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=open('README.rst').read() + '\\n\\n' + open('CHANGES.rst').read(),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure;python_version<=\"2.7\"': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n 'secure;python_version>\"2.7\"': [\n 'certifi',\n ],\n },\n )\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom distutils.core import setup\n\nimport os\nimport re\n\ntry:\n import setuptools\nexcept ImportError:\n pass # No 'develop' command, oh well.\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\n\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=open('README.rst').read() + '\\n\\n' + open('CHANGES.rst').read(),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure': [\n 'pyOpenSSL',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n },\n )\n", "path": "setup.py"}]}
| 915 | 121 |
gh_patches_debug_10566
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-2393
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unclear error message running pelican.server
Hello,
I recently upgraded from 3.7.1 to master. After building my site, I tried to run the server via `python -m pelican.server`, as previously. I got a new message:
server.py: error: the following arguments are required: path
Ok, cool. I don't have to cd into output/ any more to run the server. Running `python -m pelican.server outupt/`:
TypeError: __init__() missing 1 required positional argument: 'RequestHandlerClass'
That is... less than helpful. Googling doesn't have any pertinent info. After a little digging, I found the master branch docs already specify the new `pelican --listen` and that resolved it.
It took me a little bit to figure out what was going on - I wasn't expecting the command line UI to change on a minor version, and the message ended up being totally unrelated to what had actually happened.
I think it would be helpful for people upgrading from previous versions to give a clearer error message, maybe 'The pelican server should be run via `pelican --listen`'.
Thanks for all the work so far!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pelican/server.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 from __future__ import print_function, unicode_literals
3
4 import argparse
5 import logging
6 import os
7 import posixpath
8 import ssl
9 import sys
10
11 try:
12 from magic import from_file as magic_from_file
13 except ImportError:
14 magic_from_file = None
15
16 from six.moves import BaseHTTPServer
17 from six.moves import SimpleHTTPServer as srvmod
18 from six.moves import urllib
19
20
21 def parse_arguments():
22 parser = argparse.ArgumentParser(
23 description='Pelican Development Server',
24 formatter_class=argparse.ArgumentDefaultsHelpFormatter
25 )
26 parser.add_argument("port", default=8000, type=int, nargs="?",
27 help="Port to Listen On")
28 parser.add_argument("server", default="", nargs="?",
29 help="Interface to Listen On")
30 parser.add_argument('--ssl', action="store_true",
31 help='Activate SSL listener')
32 parser.add_argument('--cert', default="./cert.pem", nargs="?",
33 help='Path to certificate file. ' +
34 'Relative to current directory')
35 parser.add_argument('--key', default="./key.pem", nargs="?",
36 help='Path to certificate key file. ' +
37 'Relative to current directory')
38 parser.add_argument('path', default=".",
39 help='Path to pelican source directory to serve. ' +
40 'Relative to current directory')
41 return parser.parse_args()
42
43
44 class ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):
45 SUFFIXES = ['', '.html', '/index.html']
46 RSTRIP_PATTERNS = ['', '/']
47
48 def translate_path(self, path):
49 # abandon query parameters
50 path = path.split('?', 1)[0]
51 path = path.split('#', 1)[0]
52 # Don't forget explicit trailing slash when normalizing. Issue17324
53 trailing_slash = path.rstrip().endswith('/')
54 path = urllib.parse.unquote(path)
55 path = posixpath.normpath(path)
56 words = path.split('/')
57 words = filter(None, words)
58 path = self.base_path
59 for word in words:
60 if os.path.dirname(word) or word in (os.curdir, os.pardir):
61 # Ignore components that are not a simple file/directory name
62 continue
63 path = os.path.join(path, word)
64 if trailing_slash:
65 path += '/'
66 return path
67
68 def do_GET(self):
69 # cut off a query string
70 if '?' in self.path:
71 self.path, _ = self.path.split('?', 1)
72
73 found = False
74 # Try to detect file by applying various suffixes and stripping
75 # patterns.
76 for rstrip_pattern in self.RSTRIP_PATTERNS:
77 if found:
78 break
79 for suffix in self.SUFFIXES:
80 if not hasattr(self, 'original_path'):
81 self.original_path = self.path
82
83 self.path = self.original_path.rstrip(rstrip_pattern) + suffix
84 path = self.translate_path(self.path)
85
86 if os.path.exists(path):
87 srvmod.SimpleHTTPRequestHandler.do_GET(self)
88 logging.info("Found `%s`.", self.path)
89 found = True
90 break
91
92 logging.info("Tried to find `%s`, but it doesn't exist.", path)
93
94 if not found:
95 # Fallback if there were no matches
96 logging.warning("Unable to find `%s` or variations.",
97 self.original_path)
98
99 def guess_type(self, path):
100 """Guess at the mime type for the specified file.
101 """
102 mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)
103
104 # If the default guess is too generic, try the python-magic library
105 if mimetype == 'application/octet-stream' and magic_from_file:
106 mimetype = magic_from_file(path, mime=True)
107
108 return mimetype
109
110
111 class RootedHTTPServer(BaseHTTPServer.HTTPServer):
112 def __init__(self, base_path, *args, **kwargs):
113 BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)
114 self.RequestHandlerClass.base_path = base_path
115
116
117 if __name__ == '__main__':
118 args = parse_arguments()
119 RootedHTTPServer.allow_reuse_address = True
120 try:
121 httpd = RootedHTTPServer(
122 (args.server, args.port),
123 ComplexHTTPRequestHandler)
124 if args.ssl:
125 httpd.socket = ssl.wrap_socket(
126 httpd.socket, keyfile=args.key,
127 certfile=args.cert, server_side=True)
128 except ssl.SSLError as e:
129 logging.error("Couldn't open certificate file %s or key file %s",
130 args.cert, args.key)
131 logging.error("Could not listen on port %s, server %s.",
132 args.port, args.server)
133 sys.exit(getattr(e, 'exitcode', 1))
134
135 logging.info("Serving at port %s, server %s.",
136 args.port, args.server)
137 try:
138 httpd.serve_forever()
139 except KeyboardInterrupt as e:
140 logging.info("Shutting down server.")
141 httpd.socket.close()
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pelican/server.py b/pelican/server.py
--- a/pelican/server.py
+++ b/pelican/server.py
@@ -131,6 +131,11 @@
logging.error("Could not listen on port %s, server %s.",
args.port, args.server)
sys.exit(getattr(e, 'exitcode', 1))
+ except TypeError as e:
+ logging.error("'python -m pelican.server' is deprecated. The " +
+ "Pelican development server should be run via " +
+ "'pelican --listen'")
+ sys.exit(getattr(e, 'exitcode', 1))
logging.info("Serving at port %s, server %s.",
args.port, args.server)
|
{"golden_diff": "diff --git a/pelican/server.py b/pelican/server.py\n--- a/pelican/server.py\n+++ b/pelican/server.py\n@@ -131,6 +131,11 @@\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n+ except TypeError as e:\n+ logging.error(\"'python -m pelican.server' is deprecated. The \" +\n+ \"Pelican development server should be run via \" +\n+ \"'pelican --listen'\")\n+ sys.exit(getattr(e, 'exitcode', 1))\n \n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n", "issue": "Unclear error message running pelican.server \nHello,\r\n\r\nI recently upgraded from 3.7.1 to master. After building my site, I tried to run the server via `python -m pelican.server`, as previously. I got a new message:\r\n\r\n server.py: error: the following arguments are required: path\r\n\r\nOk, cool. I don't have to cd into output/ any more to run the server. Running `python -m pelican.server outupt/`:\r\n\r\n TypeError: __init__() missing 1 required positional argument: 'RequestHandlerClass'\r\n\r\nThat is... less than helpful. Googling doesn't have any pertinent info. After a little digging, I found the master branch docs already specify the new `pelican --listen` and that resolved it.\r\n\r\nIt took me a little bit to figure out what was going on - I wasn't expecting the command line UI to change on a minor version, and the message ended up being totally unrelated to what had actually happened.\r\n\r\nI think it would be helpful for people upgrading from previous versions to give a clearer error message, maybe 'The pelican server should be run via `pelican --listen`'.\r\n\r\nThanks for all the work so far!\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function, unicode_literals\n\nimport argparse\nimport logging\nimport os\nimport posixpath\nimport ssl\nimport sys\n\ntry:\n from magic import from_file as magic_from_file\nexcept ImportError:\n magic_from_file = None\n\nfrom six.moves import BaseHTTPServer\nfrom six.moves import SimpleHTTPServer as srvmod\nfrom six.moves import urllib\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser(\n description='Pelican Development Server',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument(\"port\", default=8000, type=int, nargs=\"?\",\n help=\"Port to Listen On\")\n parser.add_argument(\"server\", default=\"\", nargs=\"?\",\n help=\"Interface to Listen On\")\n parser.add_argument('--ssl', action=\"store_true\",\n help='Activate SSL listener')\n parser.add_argument('--cert', default=\"./cert.pem\", nargs=\"?\",\n help='Path to certificate file. ' +\n 'Relative to current directory')\n parser.add_argument('--key', default=\"./key.pem\", nargs=\"?\",\n help='Path to certificate key file. ' +\n 'Relative to current directory')\n parser.add_argument('path', default=\".\",\n help='Path to pelican source directory to serve. ' +\n 'Relative to current directory')\n return parser.parse_args()\n\n\nclass ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):\n SUFFIXES = ['', '.html', '/index.html']\n RSTRIP_PATTERNS = ['', '/']\n\n def translate_path(self, path):\n # abandon query parameters\n path = path.split('?', 1)[0]\n path = path.split('#', 1)[0]\n # Don't forget explicit trailing slash when normalizing. Issue17324\n trailing_slash = path.rstrip().endswith('/')\n path = urllib.parse.unquote(path)\n path = posixpath.normpath(path)\n words = path.split('/')\n words = filter(None, words)\n path = self.base_path\n for word in words:\n if os.path.dirname(word) or word in (os.curdir, os.pardir):\n # Ignore components that are not a simple file/directory name\n continue\n path = os.path.join(path, word)\n if trailing_slash:\n path += '/'\n return path\n\n def do_GET(self):\n # cut off a query string\n if '?' in self.path:\n self.path, _ = self.path.split('?', 1)\n\n found = False\n # Try to detect file by applying various suffixes and stripping\n # patterns.\n for rstrip_pattern in self.RSTRIP_PATTERNS:\n if found:\n break\n for suffix in self.SUFFIXES:\n if not hasattr(self, 'original_path'):\n self.original_path = self.path\n\n self.path = self.original_path.rstrip(rstrip_pattern) + suffix\n path = self.translate_path(self.path)\n\n if os.path.exists(path):\n srvmod.SimpleHTTPRequestHandler.do_GET(self)\n logging.info(\"Found `%s`.\", self.path)\n found = True\n break\n\n logging.info(\"Tried to find `%s`, but it doesn't exist.\", path)\n\n if not found:\n # Fallback if there were no matches\n logging.warning(\"Unable to find `%s` or variations.\",\n self.original_path)\n\n def guess_type(self, path):\n \"\"\"Guess at the mime type for the specified file.\n \"\"\"\n mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)\n\n # If the default guess is too generic, try the python-magic library\n if mimetype == 'application/octet-stream' and magic_from_file:\n mimetype = magic_from_file(path, mime=True)\n\n return mimetype\n\n\nclass RootedHTTPServer(BaseHTTPServer.HTTPServer):\n def __init__(self, base_path, *args, **kwargs):\n BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)\n self.RequestHandlerClass.base_path = base_path\n\n\nif __name__ == '__main__':\n args = parse_arguments()\n RootedHTTPServer.allow_reuse_address = True\n try:\n httpd = RootedHTTPServer(\n (args.server, args.port),\n ComplexHTTPRequestHandler)\n if args.ssl:\n httpd.socket = ssl.wrap_socket(\n httpd.socket, keyfile=args.key,\n certfile=args.cert, server_side=True)\n except ssl.SSLError as e:\n logging.error(\"Couldn't open certificate file %s or key file %s\",\n args.cert, args.key)\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n\n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n try:\n httpd.serve_forever()\n except KeyboardInterrupt as e:\n logging.info(\"Shutting down server.\")\n httpd.socket.close()\n", "path": "pelican/server.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function, unicode_literals\n\nimport argparse\nimport logging\nimport os\nimport posixpath\nimport ssl\nimport sys\n\ntry:\n from magic import from_file as magic_from_file\nexcept ImportError:\n magic_from_file = None\n\nfrom six.moves import BaseHTTPServer\nfrom six.moves import SimpleHTTPServer as srvmod\nfrom six.moves import urllib\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser(\n description='Pelican Development Server',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter\n )\n parser.add_argument(\"port\", default=8000, type=int, nargs=\"?\",\n help=\"Port to Listen On\")\n parser.add_argument(\"server\", default=\"\", nargs=\"?\",\n help=\"Interface to Listen On\")\n parser.add_argument('--ssl', action=\"store_true\",\n help='Activate SSL listener')\n parser.add_argument('--cert', default=\"./cert.pem\", nargs=\"?\",\n help='Path to certificate file. ' +\n 'Relative to current directory')\n parser.add_argument('--key', default=\"./key.pem\", nargs=\"?\",\n help='Path to certificate key file. ' +\n 'Relative to current directory')\n parser.add_argument('path', default=\".\",\n help='Path to pelican source directory to serve. ' +\n 'Relative to current directory')\n return parser.parse_args()\n\n\nclass ComplexHTTPRequestHandler(srvmod.SimpleHTTPRequestHandler):\n SUFFIXES = ['', '.html', '/index.html']\n RSTRIP_PATTERNS = ['', '/']\n\n def translate_path(self, path):\n # abandon query parameters\n path = path.split('?', 1)[0]\n path = path.split('#', 1)[0]\n # Don't forget explicit trailing slash when normalizing. Issue17324\n trailing_slash = path.rstrip().endswith('/')\n path = urllib.parse.unquote(path)\n path = posixpath.normpath(path)\n words = path.split('/')\n words = filter(None, words)\n path = self.base_path\n for word in words:\n if os.path.dirname(word) or word in (os.curdir, os.pardir):\n # Ignore components that are not a simple file/directory name\n continue\n path = os.path.join(path, word)\n if trailing_slash:\n path += '/'\n return path\n\n def do_GET(self):\n # cut off a query string\n if '?' in self.path:\n self.path, _ = self.path.split('?', 1)\n\n found = False\n # Try to detect file by applying various suffixes and stripping\n # patterns.\n for rstrip_pattern in self.RSTRIP_PATTERNS:\n if found:\n break\n for suffix in self.SUFFIXES:\n if not hasattr(self, 'original_path'):\n self.original_path = self.path\n\n self.path = self.original_path.rstrip(rstrip_pattern) + suffix\n path = self.translate_path(self.path)\n\n if os.path.exists(path):\n srvmod.SimpleHTTPRequestHandler.do_GET(self)\n logging.info(\"Found `%s`.\", self.path)\n found = True\n break\n\n logging.info(\"Tried to find `%s`, but it doesn't exist.\", path)\n\n if not found:\n # Fallback if there were no matches\n logging.warning(\"Unable to find `%s` or variations.\",\n self.original_path)\n\n def guess_type(self, path):\n \"\"\"Guess at the mime type for the specified file.\n \"\"\"\n mimetype = srvmod.SimpleHTTPRequestHandler.guess_type(self, path)\n\n # If the default guess is too generic, try the python-magic library\n if mimetype == 'application/octet-stream' and magic_from_file:\n mimetype = magic_from_file(path, mime=True)\n\n return mimetype\n\n\nclass RootedHTTPServer(BaseHTTPServer.HTTPServer):\n def __init__(self, base_path, *args, **kwargs):\n BaseHTTPServer.HTTPServer.__init__(self, *args, **kwargs)\n self.RequestHandlerClass.base_path = base_path\n\n\nif __name__ == '__main__':\n args = parse_arguments()\n RootedHTTPServer.allow_reuse_address = True\n try:\n httpd = RootedHTTPServer(\n (args.server, args.port),\n ComplexHTTPRequestHandler)\n if args.ssl:\n httpd.socket = ssl.wrap_socket(\n httpd.socket, keyfile=args.key,\n certfile=args.cert, server_side=True)\n except ssl.SSLError as e:\n logging.error(\"Couldn't open certificate file %s or key file %s\",\n args.cert, args.key)\n logging.error(\"Could not listen on port %s, server %s.\",\n args.port, args.server)\n sys.exit(getattr(e, 'exitcode', 1))\n except TypeError as e:\n logging.error(\"'python -m pelican.server' is deprecated. The \" +\n \"Pelican development server should be run via \" +\n \"'pelican --listen'\")\n sys.exit(getattr(e, 'exitcode', 1))\n\n logging.info(\"Serving at port %s, server %s.\",\n args.port, args.server)\n try:\n httpd.serve_forever()\n except KeyboardInterrupt as e:\n logging.info(\"Shutting down server.\")\n httpd.socket.close()\n", "path": "pelican/server.py"}]}
| 1,908 | 168 |
gh_patches_debug_12412
|
rasdani/github-patches
|
git_diff
|
holoviz__hvplot-693
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
sample_data try/except import wrapper fails
#### ALL software version info
hvplot: 0.7.3
#### Description of expected behavior and the observed behavior
The following import fails, despite the all-catching `except` in the code?? (Honestly stumped)
```python
from hvplot.sample_data import us_crime, airline_flights
```
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_3185062/1788543639.py in <module>
----> 1 from hvplot.sample_data import us_crime, airline_flights
~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>
23 # Add catalogue entries to namespace
24 for _c in catalogue:
---> 25 globals()[_c] = catalogue[_c]
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)
398 if e.container == 'catalog':
399 return e(name=key)
--> 400 return e()
401 if isinstance(key, str) and '.' in key:
402 key = key.split('.')
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)
75 raise ValueError('Persist value (%s) not understood' % persist)
76 persist = persist or self._pmode
---> 77 s = self.get(**kwargs)
78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:
79 from ..container.persist import store
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)
287 return self._default_source
288
--> 289 plugin, open_args = self._create_open_args(user_parameters)
290 data_source = plugin(**open_args)
291 data_source.catalog_object = self._catalog
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)
261
262 if len(self._plugin) == 0:
--> 263 raise ValueError('No plugins loaded for this entry: %s\n'
264 'A listing of installable plugins can be found '
265 'at https://intake.readthedocs.io/en/latest/plugin'
ValueError: No plugins loaded for this entry: parquet
A listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .
```
For reference, this is the code in 0.7.3:
```python
import os
try:
from intake import open_catalog
except:
raise ImportError('Loading hvPlot sample data requires intake '
'and intake-parquet. Install it using conda or '
'pip before loading data.')
```
How can intake throw a ValueError??
#### Complete, minimal, self-contained example code that reproduces the issue
* Have only the package `intake` installed, no other intake-subpackages.
* Execute : `from hvplot.sample_data import us_crime, airline_flights`
```
# code goes here between backticks
from hvplot.sample_data import us_crime, airline_flights
```
#### Stack traceback and/or browser JavaScript console output
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_3185062/1788543639.py in <module>
----> 1 from hvplot.sample_data import us_crime, airline_flights
~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>
23 # Add catalogue entries to namespace
24 for _c in catalogue:
---> 25 globals()[_c] = catalogue[_c]
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)
398 if e.container == 'catalog':
399 return e(name=key)
--> 400 return e()
401 if isinstance(key, str) and '.' in key:
402 key = key.split('.')
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)
75 raise ValueError('Persist value (%s) not understood' % persist)
76 persist = persist or self._pmode
---> 77 s = self.get(**kwargs)
78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:
79 from ..container.persist import store
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)
287 return self._default_source
288
--> 289 plugin, open_args = self._create_open_args(user_parameters)
290 data_source = plugin(**open_args)
291 data_source.catalog_object = self._catalog
~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)
261
262 if len(self._plugin) == 0:
--> 263 raise ValueError('No plugins loaded for this entry: %s\n'
264 'A listing of installable plugins can be found '
265 'at https://intake.readthedocs.io/en/latest/plugin'
ValueError: No plugins loaded for this entry: parquet
A listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .
```
#### Additional info
The list of required package is now this:
* intake-parquet
* intake-xarray
* s3fs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hvplot/sample_data.py`
Content:
```
1 """
2 Loads hvPlot sample data using intake catalogue.
3 """
4
5 import os
6
7 try:
8 from intake import open_catalog
9 except:
10 raise ImportError('Loading hvPlot sample data requires intake '
11 'and intake-parquet. Install it using conda or '
12 'pip before loading data.')
13
14 _file_path = os.path.dirname(__file__)
15 if os.path.isdir(os.path.join(_file_path, 'examples')):
16 _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')
17 else:
18 _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')
19
20 # Load catalogue
21 catalogue = open_catalog(_cat_path)
22
23 # Add catalogue entries to namespace
24 for _c in catalogue:
25 globals()[_c] = catalogue[_c]
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hvplot/sample_data.py b/hvplot/sample_data.py
--- a/hvplot/sample_data.py
+++ b/hvplot/sample_data.py
@@ -6,10 +6,18 @@
try:
from intake import open_catalog
+ import intake_parquet # noqa
+ import intake_xarray # noqa
+ import s3fs # noqa
except:
- raise ImportError('Loading hvPlot sample data requires intake '
- 'and intake-parquet. Install it using conda or '
- 'pip before loading data.')
+ raise ImportError(
+ """Loading hvPlot sample data requires:
+ * intake
+ * intake-parquet
+ * intake-xarray
+ * s3fs
+ Install these using conda or pip before loading data."""
+ )
_file_path = os.path.dirname(__file__)
if os.path.isdir(os.path.join(_file_path, 'examples')):
|
{"golden_diff": "diff --git a/hvplot/sample_data.py b/hvplot/sample_data.py\n--- a/hvplot/sample_data.py\n+++ b/hvplot/sample_data.py\n@@ -6,10 +6,18 @@\n \n try:\n from intake import open_catalog\n+ import intake_parquet # noqa\n+ import intake_xarray # noqa\n+ import s3fs # noqa\n except:\n- raise ImportError('Loading hvPlot sample data requires intake '\n- 'and intake-parquet. Install it using conda or '\n- 'pip before loading data.')\n+ raise ImportError(\n+ \"\"\"Loading hvPlot sample data requires:\n+ * intake\n+ * intake-parquet\n+ * intake-xarray\n+ * s3fs\n+ Install these using conda or pip before loading data.\"\"\"\n+ )\n \n _file_path = os.path.dirname(__file__)\n if os.path.isdir(os.path.join(_file_path, 'examples')):\n", "issue": "sample_data try/except import wrapper fails\n#### ALL software version info\r\nhvplot: 0.7.3\r\n\r\n#### Description of expected behavior and the observed behavior\r\nThe following import fails, despite the all-catching `except` in the code?? (Honestly stumped)\r\n\r\n```python\r\nfrom hvplot.sample_data import us_crime, airline_flights\r\n```\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n/tmp/ipykernel_3185062/1788543639.py in <module>\r\n----> 1 from hvplot.sample_data import us_crime, airline_flights\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>\r\n 23 # Add catalogue entries to namespace\r\n 24 for _c in catalogue:\r\n---> 25 globals()[_c] = catalogue[_c]\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)\r\n 398 if e.container == 'catalog':\r\n 399 return e(name=key)\r\n--> 400 return e()\r\n 401 if isinstance(key, str) and '.' in key:\r\n 402 key = key.split('.')\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)\r\n 75 raise ValueError('Persist value (%s) not understood' % persist)\r\n 76 persist = persist or self._pmode\r\n---> 77 s = self.get(**kwargs)\r\n 78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:\r\n 79 from ..container.persist import store\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)\r\n 287 return self._default_source\r\n 288 \r\n--> 289 plugin, open_args = self._create_open_args(user_parameters)\r\n 290 data_source = plugin(**open_args)\r\n 291 data_source.catalog_object = self._catalog\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)\r\n 261 \r\n 262 if len(self._plugin) == 0:\r\n--> 263 raise ValueError('No plugins loaded for this entry: %s\\n'\r\n 264 'A listing of installable plugins can be found '\r\n 265 'at https://intake.readthedocs.io/en/latest/plugin'\r\n\r\nValueError: No plugins loaded for this entry: parquet\r\nA listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .\r\n```\r\nFor reference, this is the code in 0.7.3:\r\n```python\r\nimport os\r\n\r\ntry:\r\n from intake import open_catalog\r\nexcept:\r\n raise ImportError('Loading hvPlot sample data requires intake '\r\n 'and intake-parquet. Install it using conda or '\r\n 'pip before loading data.')\r\n```\r\nHow can intake throw a ValueError??\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\n* Have only the package `intake` installed, no other intake-subpackages.\r\n* Execute : `from hvplot.sample_data import us_crime, airline_flights`\r\n\r\n```\r\n# code goes here between backticks\r\nfrom hvplot.sample_data import us_crime, airline_flights\r\n```\r\n\r\n#### Stack traceback and/or browser JavaScript console output\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n/tmp/ipykernel_3185062/1788543639.py in <module>\r\n----> 1 from hvplot.sample_data import us_crime, airline_flights\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/hvplot/sample_data.py in <module>\r\n 23 # Add catalogue entries to namespace\r\n 24 for _c in catalogue:\r\n---> 25 globals()[_c] = catalogue[_c]\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/base.py in __getitem__(self, key)\r\n 398 if e.container == 'catalog':\r\n 399 return e(name=key)\r\n--> 400 return e()\r\n 401 if isinstance(key, str) and '.' in key:\r\n 402 key = key.split('.')\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/entry.py in __call__(self, persist, **kwargs)\r\n 75 raise ValueError('Persist value (%s) not understood' % persist)\r\n 76 persist = persist or self._pmode\r\n---> 77 s = self.get(**kwargs)\r\n 78 if persist != 'never' and isinstance(s, PersistMixin) and s.has_been_persisted:\r\n 79 from ..container.persist import store\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in get(self, **user_parameters)\r\n 287 return self._default_source\r\n 288 \r\n--> 289 plugin, open_args = self._create_open_args(user_parameters)\r\n 290 data_source = plugin(**open_args)\r\n 291 data_source.catalog_object = self._catalog\r\n\r\n~/miniconda3/envs/py39/lib/python3.9/site-packages/intake/catalog/local.py in _create_open_args(self, user_parameters)\r\n 261 \r\n 262 if len(self._plugin) == 0:\r\n--> 263 raise ValueError('No plugins loaded for this entry: %s\\n'\r\n 264 'A listing of installable plugins can be found '\r\n 265 'at https://intake.readthedocs.io/en/latest/plugin'\r\n\r\nValueError: No plugins loaded for this entry: parquet\r\nA listing of installable plugins can be found at https://intake.readthedocs.io/en/latest/plugin-directory.html .\r\n```\r\n#### Additional info\r\nThe list of required package is now this:\r\n\r\n* intake-parquet\r\n* intake-xarray\r\n* s3fs\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nLoads hvPlot sample data using intake catalogue.\n\"\"\"\n\nimport os\n\ntry:\n from intake import open_catalog\nexcept:\n raise ImportError('Loading hvPlot sample data requires intake '\n 'and intake-parquet. Install it using conda or '\n 'pip before loading data.')\n\n_file_path = os.path.dirname(__file__)\nif os.path.isdir(os.path.join(_file_path, 'examples')):\n _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')\nelse:\n _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')\n\n# Load catalogue\ncatalogue = open_catalog(_cat_path)\n\n# Add catalogue entries to namespace\nfor _c in catalogue:\n globals()[_c] = catalogue[_c]\n", "path": "hvplot/sample_data.py"}], "after_files": [{"content": "\"\"\"\nLoads hvPlot sample data using intake catalogue.\n\"\"\"\n\nimport os\n\ntry:\n from intake import open_catalog\n import intake_parquet # noqa\n import intake_xarray # noqa\n import s3fs # noqa\nexcept:\n raise ImportError(\n \"\"\"Loading hvPlot sample data requires:\n * intake\n * intake-parquet\n * intake-xarray\n * s3fs\n Install these using conda or pip before loading data.\"\"\"\n )\n\n_file_path = os.path.dirname(__file__)\nif os.path.isdir(os.path.join(_file_path, 'examples')):\n _cat_path = os.path.join(_file_path, 'examples', 'datasets.yaml')\nelse:\n _cat_path = os.path.join(_file_path, '..', 'examples', 'datasets.yaml')\n\n# Load catalogue\ncatalogue = open_catalog(_cat_path)\n\n# Add catalogue entries to namespace\nfor _c in catalogue:\n globals()[_c] = catalogue[_c]\n", "path": "hvplot/sample_data.py"}]}
| 1,900 | 208 |
gh_patches_debug_21452
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-1367
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ModuleNotFoundError: No module named 'icevision.backbones'
Using an example snippet from the README:
Icevision is the latest version from GitHub master.
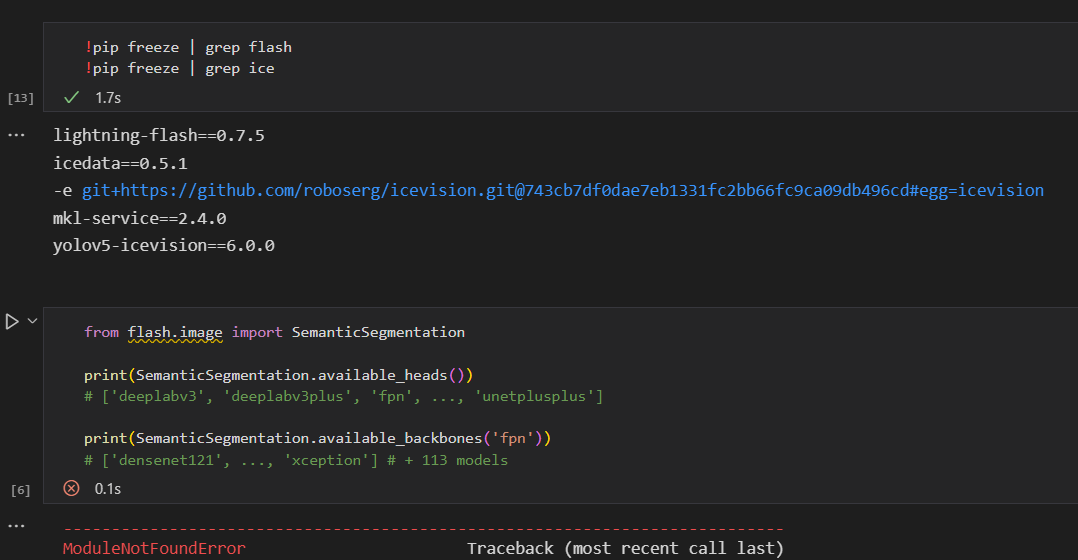
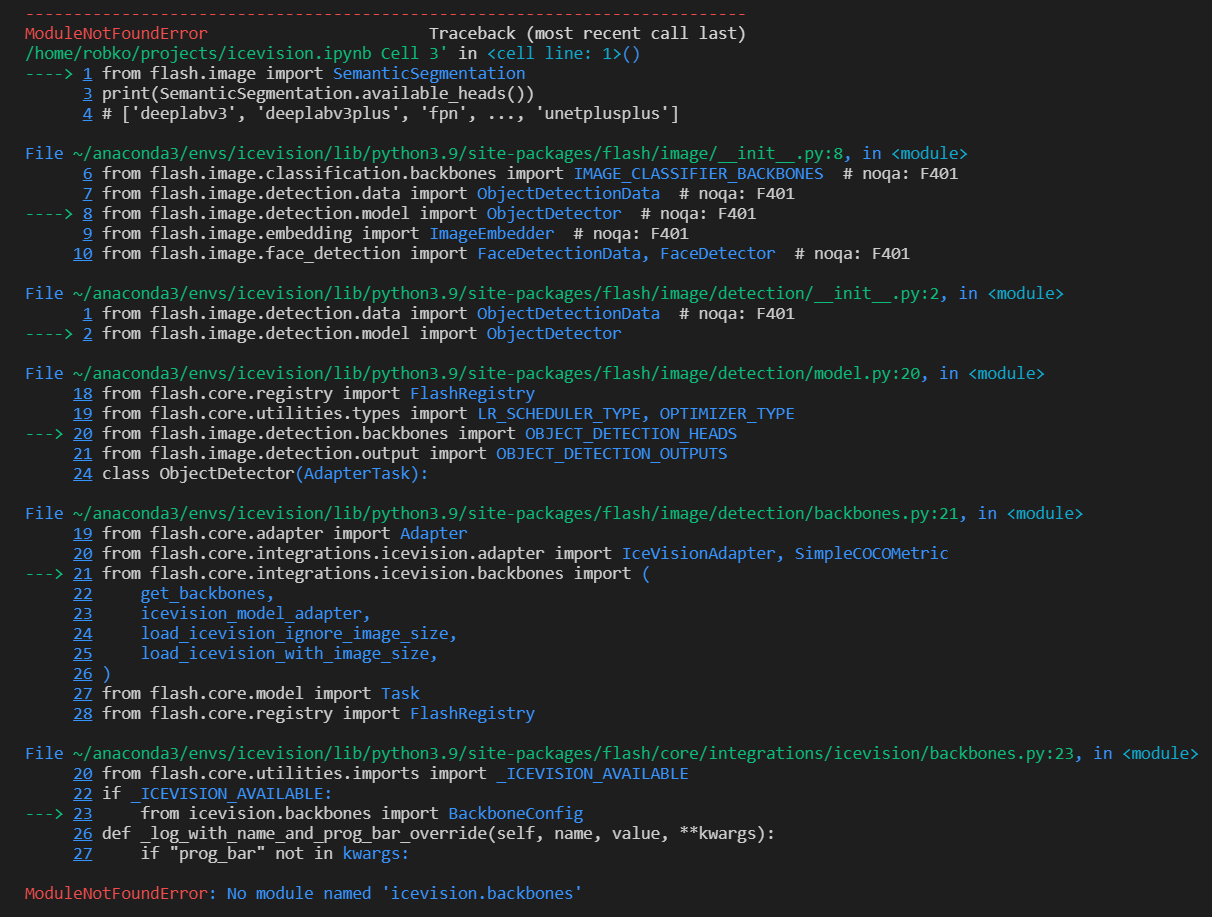
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # Copyright The PyTorch Lightning team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 import glob
16 import os
17 from functools import partial
18 from importlib.util import module_from_spec, spec_from_file_location
19 from itertools import chain
20
21 from setuptools import find_packages, setup
22
23 # https://packaging.python.org/guides/single-sourcing-package-version/
24 # http://blog.ionelmc.ro/2014/05/25/python-packaging/
25 _PATH_ROOT = os.path.dirname(__file__)
26 _PATH_REQUIRE = os.path.join(_PATH_ROOT, "requirements")
27
28
29 def _load_py_module(fname, pkg="flash"):
30 spec = spec_from_file_location(
31 os.path.join(pkg, fname),
32 os.path.join(_PATH_ROOT, pkg, fname),
33 )
34 py = module_from_spec(spec)
35 spec.loader.exec_module(py)
36 return py
37
38
39 about = _load_py_module("__about__.py")
40 setup_tools = _load_py_module("setup_tools.py")
41
42 long_description = setup_tools._load_readme_description(
43 _PATH_ROOT,
44 homepage=about.__homepage__,
45 ver=about.__version__,
46 )
47
48
49 def _expand_reqs(extras: dict, keys: list) -> list:
50 return list(chain(*[extras[ex] for ex in keys]))
51
52
53 base_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name="requirements.txt")
54 # find all extra requirements
55 _load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)
56 found_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, "*.txt")))
57 # remove datatype prefix
58 found_req_names = [os.path.splitext(req)[0].replace("datatype_", "") for req in found_req_files]
59 # define basic and extra extras
60 extras_req = {
61 name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if "_" not in name
62 }
63 extras_req.update(
64 {
65 name: extras_req[name.split("_")[0]] + _load_req(file_name=fname)
66 for name, fname in zip(found_req_names, found_req_files)
67 if "_" in name
68 }
69 )
70 # some extra combinations
71 extras_req["vision"] = _expand_reqs(extras_req, ["image", "video"])
72 extras_req["core"] = _expand_reqs(extras_req, ["image", "tabular", "text"])
73 extras_req["all"] = _expand_reqs(extras_req, ["vision", "tabular", "text", "audio"])
74 extras_req["dev"] = _expand_reqs(extras_req, ["all", "test", "docs"])
75 # filter the uniques
76 extras_req = {n: list(set(req)) for n, req in extras_req.items()}
77
78 # https://packaging.python.org/discussions/install-requires-vs-requirements /
79 # keep the meta-data here for simplicity in reading this file... it's not obvious
80 # what happens and to non-engineers they won't know to look in init ...
81 # the goal of the project is simplicity for researchers, don't want to add too much
82 # engineer specific practices
83 setup(
84 name="lightning-flash",
85 version=about.__version__,
86 description=about.__docs__,
87 author=about.__author__,
88 author_email=about.__author_email__,
89 url=about.__homepage__,
90 download_url="https://github.com/PyTorchLightning/lightning-flash",
91 license=about.__license__,
92 packages=find_packages(exclude=["tests", "tests.*"]),
93 long_description=long_description,
94 long_description_content_type="text/markdown",
95 include_package_data=True,
96 extras_require=extras_req,
97 entry_points={
98 "console_scripts": ["flash=flash.__main__:main"],
99 },
100 zip_safe=False,
101 keywords=["deep learning", "pytorch", "AI"],
102 python_requires=">=3.6",
103 install_requires=base_req,
104 project_urls={
105 "Bug Tracker": "https://github.com/PyTorchLightning/lightning-flash/issues",
106 "Documentation": "https://lightning-flash.rtfd.io/en/latest/",
107 "Source Code": "https://github.com/PyTorchLightning/lightning-flash",
108 },
109 classifiers=[
110 "Environment :: Console",
111 "Natural Language :: English",
112 # How mature is this project? Common values are
113 # 3 - Alpha, 4 - Beta, 5 - Production/Stable
114 "Development Status :: 4 - Beta",
115 # Indicate who your project is intended for
116 "Intended Audience :: Developers",
117 "Topic :: Scientific/Engineering :: Artificial Intelligence",
118 "Topic :: Scientific/Engineering :: Image Recognition",
119 "Topic :: Scientific/Engineering :: Information Analysis",
120 # Pick your license as you wish
121 # 'License :: OSI Approved :: BSD License',
122 "Operating System :: OS Independent",
123 # Specify the Python versions you support here. In particular, ensure
124 # that you indicate whether you support Python 2, Python 3 or both.
125 "Programming Language :: Python :: 3",
126 "Programming Language :: Python :: 3.6",
127 "Programming Language :: Python :: 3.7",
128 "Programming Language :: Python :: 3.8",
129 "Programming Language :: Python :: 3.9",
130 "Programming Language :: Python :: 3.10",
131 ],
132 )
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -99,7 +99,7 @@
},
zip_safe=False,
keywords=["deep learning", "pytorch", "AI"],
- python_requires=">=3.6",
+ python_requires=">=3.7",
install_requires=base_req,
project_urls={
"Bug Tracker": "https://github.com/PyTorchLightning/lightning-flash/issues",
@@ -123,10 +123,8 @@
# Specify the Python versions you support here. In particular, ensure
# that you indicate whether you support Python 2, Python 3 or both.
"Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
- "Programming Language :: Python :: 3.10",
],
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -99,7 +99,7 @@\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n- python_requires=\">=3.6\",\n+ python_requires=\">=3.7\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n@@ -123,10 +123,8 @@\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n- \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n- \"Programming Language :: Python :: 3.10\",\n ],\n )\n", "issue": "ModuleNotFoundError: No module named 'icevision.backbones'\nUsing an example snippet from the README:\r\nIcevision is the latest version from GitHub master.\r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nfrom functools import partial\nfrom importlib.util import module_from_spec, spec_from_file_location\nfrom itertools import chain\n\nfrom setuptools import find_packages, setup\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\n# http://blog.ionelmc.ro/2014/05/25/python-packaging/\n_PATH_ROOT = os.path.dirname(__file__)\n_PATH_REQUIRE = os.path.join(_PATH_ROOT, \"requirements\")\n\n\ndef _load_py_module(fname, pkg=\"flash\"):\n spec = spec_from_file_location(\n os.path.join(pkg, fname),\n os.path.join(_PATH_ROOT, pkg, fname),\n )\n py = module_from_spec(spec)\n spec.loader.exec_module(py)\n return py\n\n\nabout = _load_py_module(\"__about__.py\")\nsetup_tools = _load_py_module(\"setup_tools.py\")\n\nlong_description = setup_tools._load_readme_description(\n _PATH_ROOT,\n homepage=about.__homepage__,\n ver=about.__version__,\n)\n\n\ndef _expand_reqs(extras: dict, keys: list) -> list:\n return list(chain(*[extras[ex] for ex in keys]))\n\n\nbase_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name=\"requirements.txt\")\n# find all extra requirements\n_load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)\nfound_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, \"*.txt\")))\n# remove datatype prefix\nfound_req_names = [os.path.splitext(req)[0].replace(\"datatype_\", \"\") for req in found_req_files]\n# define basic and extra extras\nextras_req = {\n name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if \"_\" not in name\n}\nextras_req.update(\n {\n name: extras_req[name.split(\"_\")[0]] + _load_req(file_name=fname)\n for name, fname in zip(found_req_names, found_req_files)\n if \"_\" in name\n }\n)\n# some extra combinations\nextras_req[\"vision\"] = _expand_reqs(extras_req, [\"image\", \"video\"])\nextras_req[\"core\"] = _expand_reqs(extras_req, [\"image\", \"tabular\", \"text\"])\nextras_req[\"all\"] = _expand_reqs(extras_req, [\"vision\", \"tabular\", \"text\", \"audio\"])\nextras_req[\"dev\"] = _expand_reqs(extras_req, [\"all\", \"test\", \"docs\"])\n# filter the uniques\nextras_req = {n: list(set(req)) for n, req in extras_req.items()}\n\n# https://packaging.python.org/discussions/install-requires-vs-requirements /\n# keep the meta-data here for simplicity in reading this file... it's not obvious\n# what happens and to non-engineers they won't know to look in init ...\n# the goal of the project is simplicity for researchers, don't want to add too much\n# engineer specific practices\nsetup(\n name=\"lightning-flash\",\n version=about.__version__,\n description=about.__docs__,\n author=about.__author__,\n author_email=about.__author_email__,\n url=about.__homepage__,\n download_url=\"https://github.com/PyTorchLightning/lightning-flash\",\n license=about.__license__,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n extras_require=extras_req,\n entry_points={\n \"console_scripts\": [\"flash=flash.__main__:main\"],\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n python_requires=\">=3.6\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n \"Documentation\": \"https://lightning-flash.rtfd.io/en/latest/\",\n \"Source Code\": \"https://github.com/PyTorchLightning/lightning-flash\",\n },\n classifiers=[\n \"Environment :: Console\",\n \"Natural Language :: English\",\n # How mature is this project? Common values are\n # 3 - Alpha, 4 - Beta, 5 - Production/Stable\n \"Development Status :: 4 - Beta\",\n # Indicate who your project is intended for\n \"Intended Audience :: Developers\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Image Recognition\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n # Pick your license as you wish\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport glob\nimport os\nfrom functools import partial\nfrom importlib.util import module_from_spec, spec_from_file_location\nfrom itertools import chain\n\nfrom setuptools import find_packages, setup\n\n# https://packaging.python.org/guides/single-sourcing-package-version/\n# http://blog.ionelmc.ro/2014/05/25/python-packaging/\n_PATH_ROOT = os.path.dirname(__file__)\n_PATH_REQUIRE = os.path.join(_PATH_ROOT, \"requirements\")\n\n\ndef _load_py_module(fname, pkg=\"flash\"):\n spec = spec_from_file_location(\n os.path.join(pkg, fname),\n os.path.join(_PATH_ROOT, pkg, fname),\n )\n py = module_from_spec(spec)\n spec.loader.exec_module(py)\n return py\n\n\nabout = _load_py_module(\"__about__.py\")\nsetup_tools = _load_py_module(\"setup_tools.py\")\n\nlong_description = setup_tools._load_readme_description(\n _PATH_ROOT,\n homepage=about.__homepage__,\n ver=about.__version__,\n)\n\n\ndef _expand_reqs(extras: dict, keys: list) -> list:\n return list(chain(*[extras[ex] for ex in keys]))\n\n\nbase_req = setup_tools._load_requirements(path_dir=_PATH_ROOT, file_name=\"requirements.txt\")\n# find all extra requirements\n_load_req = partial(setup_tools._load_requirements, path_dir=_PATH_REQUIRE)\nfound_req_files = sorted(os.path.basename(p) for p in glob.glob(os.path.join(_PATH_REQUIRE, \"*.txt\")))\n# remove datatype prefix\nfound_req_names = [os.path.splitext(req)[0].replace(\"datatype_\", \"\") for req in found_req_files]\n# define basic and extra extras\nextras_req = {\n name: _load_req(file_name=fname) for name, fname in zip(found_req_names, found_req_files) if \"_\" not in name\n}\nextras_req.update(\n {\n name: extras_req[name.split(\"_\")[0]] + _load_req(file_name=fname)\n for name, fname in zip(found_req_names, found_req_files)\n if \"_\" in name\n }\n)\n# some extra combinations\nextras_req[\"vision\"] = _expand_reqs(extras_req, [\"image\", \"video\"])\nextras_req[\"core\"] = _expand_reqs(extras_req, [\"image\", \"tabular\", \"text\"])\nextras_req[\"all\"] = _expand_reqs(extras_req, [\"vision\", \"tabular\", \"text\", \"audio\"])\nextras_req[\"dev\"] = _expand_reqs(extras_req, [\"all\", \"test\", \"docs\"])\n# filter the uniques\nextras_req = {n: list(set(req)) for n, req in extras_req.items()}\n\n# https://packaging.python.org/discussions/install-requires-vs-requirements /\n# keep the meta-data here for simplicity in reading this file... it's not obvious\n# what happens and to non-engineers they won't know to look in init ...\n# the goal of the project is simplicity for researchers, don't want to add too much\n# engineer specific practices\nsetup(\n name=\"lightning-flash\",\n version=about.__version__,\n description=about.__docs__,\n author=about.__author__,\n author_email=about.__author_email__,\n url=about.__homepage__,\n download_url=\"https://github.com/PyTorchLightning/lightning-flash\",\n license=about.__license__,\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n extras_require=extras_req,\n entry_points={\n \"console_scripts\": [\"flash=flash.__main__:main\"],\n },\n zip_safe=False,\n keywords=[\"deep learning\", \"pytorch\", \"AI\"],\n python_requires=\">=3.7\",\n install_requires=base_req,\n project_urls={\n \"Bug Tracker\": \"https://github.com/PyTorchLightning/lightning-flash/issues\",\n \"Documentation\": \"https://lightning-flash.rtfd.io/en/latest/\",\n \"Source Code\": \"https://github.com/PyTorchLightning/lightning-flash\",\n },\n classifiers=[\n \"Environment :: Console\",\n \"Natural Language :: English\",\n # How mature is this project? Common values are\n # 3 - Alpha, 4 - Beta, 5 - Production/Stable\n \"Development Status :: 4 - Beta\",\n # Indicate who your project is intended for\n \"Intended Audience :: Developers\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Scientific/Engineering :: Image Recognition\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n # Pick your license as you wish\n # 'License :: OSI Approved :: BSD License',\n \"Operating System :: OS Independent\",\n # Specify the Python versions you support here. In particular, ensure\n # that you indicate whether you support Python 2, Python 3 or both.\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n)\n", "path": "setup.py"}]}
| 1,966 | 228 |
gh_patches_debug_34817
|
rasdani/github-patches
|
git_diff
|
YunoHost__apps-1524
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Simplify current version
As discuss at YunoHost Meeting 06/10/2022, remove the comment after the shipped version
Close #1522
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/README-generator/make_readme.py`
Content:
```
1 #! /usr/bin/env python3
2
3 import argparse
4 import json
5 import os
6 import yaml
7 from pathlib import Path
8
9 from jinja2 import Environment, FileSystemLoader
10
11 def value_for_lang(values, lang):
12 if not isinstance(values, dict):
13 return values
14 if lang in values:
15 return values[lang]
16 elif "en" in values:
17 return values["en"]
18 else:
19 return list(values.values())[0]
20
21 def generate_READMEs(app_path: str):
22
23 app_path = Path(app_path)
24
25 if not app_path.exists():
26 raise Exception("App path provided doesn't exists ?!")
27
28 manifest = json.load(open(app_path / "manifest.json"))
29 upstream = manifest.get("upstream", {})
30
31 catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "apps.json"))
32 from_catalog = catalog.get(manifest['id'], {})
33
34 antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "antifeatures.yml"), Loader=yaml.SafeLoader)
35 antifeatures_list = {e['id']: e for e in antifeatures_list}
36
37 if not upstream and not (app_path / "doc" / "DISCLAIMER.md").exists():
38 print(
39 "There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet."
40 )
41 return
42
43 env = Environment(loader=FileSystemLoader(Path(__file__).parent / "templates"))
44
45 for lang, lang_suffix in [("en", ""), ("fr", "_fr")]:
46
47 template = env.get_template(f"README{lang_suffix}.md.j2")
48
49 if (app_path / "doc" / f"DESCRIPTION{lang_suffix}.md").exists():
50 description = (app_path / "doc" / f"DESCRIPTION{lang_suffix}.md").read_text()
51 # Fallback to english if maintainer too lazy to translate the description
52 elif (app_path / "doc" / "DESCRIPTION.md").exists():
53 description = (app_path / "doc" / "DESCRIPTION.md").read_text()
54 else:
55 description = None
56
57 if (app_path / "doc" / "screenshots").exists():
58 screenshots = os.listdir(os.path.join(app_path, "doc", "screenshots"))
59 if ".gitkeep" in screenshots:
60 screenshots.remove(".gitkeep")
61 else:
62 screenshots = []
63
64 if (app_path / "doc" / f"DISCLAIMER{lang_suffix}.md").exists():
65 disclaimer = (app_path / "doc" / f"DISCLAIMER{lang_suffix}.md").read_text()
66 # Fallback to english if maintainer too lazy to translate the disclaimer idk
67 elif (app_path / "doc" / "DISCLAIMER.md").exists():
68 disclaimer = (app_path / "doc" / "DISCLAIMER.md").read_text()
69 else:
70 disclaimer = None
71
72 # Get the current branch using git inside the app path
73 default_branch = from_catalog.get('branch', 'master')
74 current_branch = os.popen(f"git -C {app_path} rev-parse --abbrev-ref HEAD").read().strip()
75
76 if default_branch != current_branch:
77 os.system(f"git -C {app_path} fetch origin {default_branch} 2>/dev/null")
78 default_branch_version = os.popen(f"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version").read().strip()
79 else:
80 default_branch_version = None # we don't care in that case
81
82 # TODO: Add url to the documentation... and actually create that documentation :D
83 antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
84 for k, v in antifeatures.items():
85 antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)
86 if manifest.get("antifeatures", {}).get(k, None):
87 antifeatures[k]['description'] = value_for_lang(manifest.get("antifeatures", {}).get(k, None), lang_suffix)
88 else:
89 antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)
90
91 out = template.render(
92 lang=lang,
93 upstream=upstream,
94 description=description,
95 screenshots=screenshots,
96 disclaimer=disclaimer,
97 antifeatures=antifeatures,
98 manifest=manifest,
99 current_branch=current_branch,
100 default_branch=default_branch,
101 default_branch_version=default_branch_version,
102 )
103 (app_path / f"README{lang_suffix}.md").write_text(out)
104
105
106 if __name__ == "__main__":
107 parser = argparse.ArgumentParser(
108 description="Automatically (re)generate README for apps"
109 )
110 parser.add_argument(
111 "app_path", help="Path to the app to generate/update READMEs for"
112 )
113
114 args = parser.parse_args()
115 generate_READMEs(args.app_path)
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/README-generator/make_readme.py b/tools/README-generator/make_readme.py
--- a/tools/README-generator/make_readme.py
+++ b/tools/README-generator/make_readme.py
@@ -32,7 +32,7 @@
from_catalog = catalog.get(manifest['id'], {})
antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / "antifeatures.yml"), Loader=yaml.SafeLoader)
- antifeatures_list = {e['id']: e for e in antifeatures_list}
+ antifeatures_list = { e['id']: e for e in antifeatures_list }
if not upstream and not (app_path / "doc" / "DISCLAIMER.md").exists():
print(
@@ -69,18 +69,8 @@
else:
disclaimer = None
- # Get the current branch using git inside the app path
- default_branch = from_catalog.get('branch', 'master')
- current_branch = os.popen(f"git -C {app_path} rev-parse --abbrev-ref HEAD").read().strip()
-
- if default_branch != current_branch:
- os.system(f"git -C {app_path} fetch origin {default_branch} 2>/dev/null")
- default_branch_version = os.popen(f"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version").read().strip()
- else:
- default_branch_version = None # we don't care in that case
-
# TODO: Add url to the documentation... and actually create that documentation :D
- antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
+ antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}
for k, v in antifeatures.items():
antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)
if manifest.get("antifeatures", {}).get(k, None):
@@ -96,9 +86,6 @@
disclaimer=disclaimer,
antifeatures=antifeatures,
manifest=manifest,
- current_branch=current_branch,
- default_branch=default_branch,
- default_branch_version=default_branch_version,
)
(app_path / f"README{lang_suffix}.md").write_text(out)
|
{"golden_diff": "diff --git a/tools/README-generator/make_readme.py b/tools/README-generator/make_readme.py\n--- a/tools/README-generator/make_readme.py\n+++ b/tools/README-generator/make_readme.py\n@@ -32,7 +32,7 @@\n from_catalog = catalog.get(manifest['id'], {})\n \n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n- antifeatures_list = {e['id']: e for e in antifeatures_list}\n+ antifeatures_list = { e['id']: e for e in antifeatures_list }\n \n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n@@ -69,18 +69,8 @@\n else:\n disclaimer = None\n \n- # Get the current branch using git inside the app path\n- default_branch = from_catalog.get('branch', 'master')\n- current_branch = os.popen(f\"git -C {app_path} rev-parse --abbrev-ref HEAD\").read().strip()\n-\n- if default_branch != current_branch:\n- os.system(f\"git -C {app_path} fetch origin {default_branch} 2>/dev/null\")\n- default_branch_version = os.popen(f\"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version\").read().strip()\n- else:\n- default_branch_version = None # we don't care in that case\n-\n # TODO: Add url to the documentation... and actually create that documentation :D\n- antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n+ antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n@@ -96,9 +86,6 @@\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n- current_branch=current_branch,\n- default_branch=default_branch,\n- default_branch_version=default_branch_version,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n", "issue": "Simplify current version\nAs discuss at YunoHost Meeting 06/10/2022, remove the comment after the shipped version\r\nClose #1522\n", "before_files": [{"content": "#! /usr/bin/env python3\n\nimport argparse\nimport json\nimport os\nimport yaml\nfrom pathlib import Path\n\nfrom jinja2 import Environment, FileSystemLoader\n\ndef value_for_lang(values, lang):\n if not isinstance(values, dict):\n return values\n if lang in values:\n return values[lang]\n elif \"en\" in values:\n return values[\"en\"]\n else:\n return list(values.values())[0]\n\ndef generate_READMEs(app_path: str):\n\n app_path = Path(app_path)\n\n if not app_path.exists():\n raise Exception(\"App path provided doesn't exists ?!\")\n\n manifest = json.load(open(app_path / \"manifest.json\"))\n upstream = manifest.get(\"upstream\", {})\n\n catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"apps.json\"))\n from_catalog = catalog.get(manifest['id'], {})\n\n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n antifeatures_list = {e['id']: e for e in antifeatures_list}\n\n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n \"There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet.\"\n )\n return\n\n env = Environment(loader=FileSystemLoader(Path(__file__).parent / \"templates\"))\n\n for lang, lang_suffix in [(\"en\", \"\"), (\"fr\", \"_fr\")]:\n\n template = env.get_template(f\"README{lang_suffix}.md.j2\")\n\n if (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").exists():\n description = (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the description\n elif (app_path / \"doc\" / \"DESCRIPTION.md\").exists():\n description = (app_path / \"doc\" / \"DESCRIPTION.md\").read_text()\n else:\n description = None\n\n if (app_path / \"doc\" / \"screenshots\").exists():\n screenshots = os.listdir(os.path.join(app_path, \"doc\", \"screenshots\"))\n if \".gitkeep\" in screenshots:\n screenshots.remove(\".gitkeep\")\n else:\n screenshots = []\n\n if (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").exists():\n disclaimer = (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the disclaimer idk\n elif (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n disclaimer = (app_path / \"doc\" / \"DISCLAIMER.md\").read_text()\n else:\n disclaimer = None\n\n # Get the current branch using git inside the app path\n default_branch = from_catalog.get('branch', 'master')\n current_branch = os.popen(f\"git -C {app_path} rev-parse --abbrev-ref HEAD\").read().strip()\n\n if default_branch != current_branch:\n os.system(f\"git -C {app_path} fetch origin {default_branch} 2>/dev/null\")\n default_branch_version = os.popen(f\"git -C {app_path} show FETCH_HEAD:manifest.json | jq -r .version\").read().strip()\n else:\n default_branch_version = None # we don't care in that case\n\n # TODO: Add url to the documentation... and actually create that documentation :D\n antifeatures = {a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n antifeatures[k]['description'] = value_for_lang(manifest.get(\"antifeatures\", {}).get(k, None), lang_suffix)\n else:\n antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)\n\n out = template.render(\n lang=lang,\n upstream=upstream,\n description=description,\n screenshots=screenshots,\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n current_branch=current_branch,\n default_branch=default_branch,\n default_branch_version=default_branch_version,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description=\"Automatically (re)generate README for apps\"\n )\n parser.add_argument(\n \"app_path\", help=\"Path to the app to generate/update READMEs for\"\n )\n\n args = parser.parse_args()\n generate_READMEs(args.app_path)\n", "path": "tools/README-generator/make_readme.py"}], "after_files": [{"content": "#! /usr/bin/env python3\n\nimport argparse\nimport json\nimport os\nimport yaml\nfrom pathlib import Path\n\nfrom jinja2 import Environment, FileSystemLoader\n\ndef value_for_lang(values, lang):\n if not isinstance(values, dict):\n return values\n if lang in values:\n return values[lang]\n elif \"en\" in values:\n return values[\"en\"]\n else:\n return list(values.values())[0]\n\ndef generate_READMEs(app_path: str):\n\n app_path = Path(app_path)\n\n if not app_path.exists():\n raise Exception(\"App path provided doesn't exists ?!\")\n\n manifest = json.load(open(app_path / \"manifest.json\"))\n upstream = manifest.get(\"upstream\", {})\n\n catalog = json.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"apps.json\"))\n from_catalog = catalog.get(manifest['id'], {})\n\n antifeatures_list = yaml.load(open(Path(os.path.abspath(__file__)).parent.parent.parent / \"antifeatures.yml\"), Loader=yaml.SafeLoader)\n antifeatures_list = { e['id']: e for e in antifeatures_list }\n\n if not upstream and not (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n print(\n \"There's no 'upstream' key in the manifest, and doc/DISCLAIMER.md doesn't exists - therefore assuming that we shall not auto-update the README.md for this app yet.\"\n )\n return\n\n env = Environment(loader=FileSystemLoader(Path(__file__).parent / \"templates\"))\n\n for lang, lang_suffix in [(\"en\", \"\"), (\"fr\", \"_fr\")]:\n\n template = env.get_template(f\"README{lang_suffix}.md.j2\")\n\n if (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").exists():\n description = (app_path / \"doc\" / f\"DESCRIPTION{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the description\n elif (app_path / \"doc\" / \"DESCRIPTION.md\").exists():\n description = (app_path / \"doc\" / \"DESCRIPTION.md\").read_text()\n else:\n description = None\n\n if (app_path / \"doc\" / \"screenshots\").exists():\n screenshots = os.listdir(os.path.join(app_path, \"doc\", \"screenshots\"))\n if \".gitkeep\" in screenshots:\n screenshots.remove(\".gitkeep\")\n else:\n screenshots = []\n\n if (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").exists():\n disclaimer = (app_path / \"doc\" / f\"DISCLAIMER{lang_suffix}.md\").read_text()\n # Fallback to english if maintainer too lazy to translate the disclaimer idk\n elif (app_path / \"doc\" / \"DISCLAIMER.md\").exists():\n disclaimer = (app_path / \"doc\" / \"DISCLAIMER.md\").read_text()\n else:\n disclaimer = None\n\n # TODO: Add url to the documentation... and actually create that documentation :D\n antifeatures = { a: antifeatures_list[a] for a in from_catalog.get('antifeatures', [])}\n for k, v in antifeatures.items():\n antifeatures[k]['title'] = value_for_lang(v['title'], lang_suffix)\n if manifest.get(\"antifeatures\", {}).get(k, None):\n antifeatures[k]['description'] = value_for_lang(manifest.get(\"antifeatures\", {}).get(k, None), lang_suffix)\n else:\n antifeatures[k]['description'] = value_for_lang(antifeatures[k]['description'], lang_suffix)\n\n out = template.render(\n lang=lang,\n upstream=upstream,\n description=description,\n screenshots=screenshots,\n disclaimer=disclaimer,\n antifeatures=antifeatures,\n manifest=manifest,\n )\n (app_path / f\"README{lang_suffix}.md\").write_text(out)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description=\"Automatically (re)generate README for apps\"\n )\n parser.add_argument(\n \"app_path\", help=\"Path to the app to generate/update READMEs for\"\n )\n\n args = parser.parse_args()\n generate_READMEs(args.app_path)\n", "path": "tools/README-generator/make_readme.py"}]}
| 1,640 | 537 |
gh_patches_debug_1027
|
rasdani/github-patches
|
git_diff
|
cocotb__cocotb-1776
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
coroutines that return before their first yield cause the simulator to shutdown
Repro:
```python
@cocotb.test()
def test_func_empty(dut):
""" Test that a function can complete before the first yield """
@cocotb.coroutine
def func_empty():
print("This line runs")
return
yield # needed to make this a coroutine
yield func_empty()
print("This line is never reached")
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cocotb/ipython_support.py`
Content:
```
1 # Copyright cocotb contributors
2 # Licensed under the Revised BSD License, see LICENSE for details.
3 # SPDX-License-Identifier: BSD-3-Clause
4 import IPython
5 from IPython.terminal.ipapp import load_default_config
6 from IPython.terminal.prompts import Prompts, Token
7
8 import cocotb
9
10
11 class SimTimePrompt(Prompts):
12 """ custom prompt that shows the sim time after a trigger fires """
13 _show_time = 1
14
15 def in_prompt_tokens(self, cli=None):
16 tokens = super().in_prompt_tokens()
17 if self._show_time == self.shell.execution_count:
18 tokens = [
19 (Token.Comment, "sim time: {}".format(cocotb.utils.get_sim_time())),
20 (Token.Text, "\n"),
21 ] + tokens
22 return tokens
23
24
25 def _runner(shell, x):
26 """ Handler for async functions """
27 ret = cocotb.scheduler.queue_function(x)
28 shell.prompts._show_time = shell.execution_count
29 return ret
30
31
32 async def embed(user_ns: dict = {}):
33 """
34 Start an ipython shell in the current coroutine.
35
36 Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword
37 can be used directly from the shell to wait for triggers.
38 The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.
39
40 This coroutine will complete only when the user exits the interactive session.
41
42 Args:
43 user_ns:
44 The variables to have made available in the shell.
45 Passing ``locals()`` is often a good idea.
46 ``cocotb`` will automatically be included.
47
48 Notes:
49
50 If your simulator does not provide an appropriate ``stdin``, you may
51 find you cannot type in the resulting shell. Using simulators in batch
52 or non-GUI mode may resolve this. This feature is experimental, and
53 not all simulators are supported.
54 """
55 # ensure cocotb is in the namespace, for convenience
56 default_ns = dict(cocotb=cocotb)
57 default_ns.update(user_ns)
58
59 # build the config to enable `await`
60 c = load_default_config()
61 c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)
62 c.TerminalInteractiveShell.autoawait = True
63
64 # create a shell with access to the dut, and cocotb pre-imported
65 shell = IPython.terminal.embed.InteractiveShellEmbed(
66 user_ns=default_ns,
67 config=c,
68 )
69
70 # add our custom prompts
71 shell.prompts = SimTimePrompt(shell)
72
73 # start the shell in a background thread
74 @cocotb.external
75 def run_shell():
76 shell()
77 await run_shell()
78
79
80 @cocotb.test()
81 async def run_ipython(dut):
82 """ A test that launches an interactive Python shell.
83
84 Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.
85
86 Within the shell, a global ``dut`` variable pointing to the design will be present.
87 """
88 await cocotb.triggers.Timer(0) # workaround for gh-637
89 await embed(user_ns=dict(dut=dut))
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cocotb/ipython_support.py b/cocotb/ipython_support.py
--- a/cocotb/ipython_support.py
+++ b/cocotb/ipython_support.py
@@ -85,5 +85,4 @@
Within the shell, a global ``dut`` variable pointing to the design will be present.
"""
- await cocotb.triggers.Timer(0) # workaround for gh-637
await embed(user_ns=dict(dut=dut))
|
{"golden_diff": "diff --git a/cocotb/ipython_support.py b/cocotb/ipython_support.py\n--- a/cocotb/ipython_support.py\n+++ b/cocotb/ipython_support.py\n@@ -85,5 +85,4 @@\n \n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n- await cocotb.triggers.Timer(0) # workaround for gh-637\n await embed(user_ns=dict(dut=dut))\n", "issue": "coroutines that return before their first yield cause the simulator to shutdown\nRepro:\r\n```python\r\[email protected]()\r\ndef test_func_empty(dut):\r\n \"\"\" Test that a function can complete before the first yield \"\"\"\r\n @cocotb.coroutine\r\n def func_empty():\r\n print(\"This line runs\")\r\n return\r\n yield # needed to make this a coroutine\r\n yield func_empty()\r\n print(\"This line is never reached\")\r\n```\n", "before_files": [{"content": "# Copyright cocotb contributors\n# Licensed under the Revised BSD License, see LICENSE for details.\n# SPDX-License-Identifier: BSD-3-Clause\nimport IPython\nfrom IPython.terminal.ipapp import load_default_config\nfrom IPython.terminal.prompts import Prompts, Token\n\nimport cocotb\n\n\nclass SimTimePrompt(Prompts):\n \"\"\" custom prompt that shows the sim time after a trigger fires \"\"\"\n _show_time = 1\n\n def in_prompt_tokens(self, cli=None):\n tokens = super().in_prompt_tokens()\n if self._show_time == self.shell.execution_count:\n tokens = [\n (Token.Comment, \"sim time: {}\".format(cocotb.utils.get_sim_time())),\n (Token.Text, \"\\n\"),\n ] + tokens\n return tokens\n\n\ndef _runner(shell, x):\n \"\"\" Handler for async functions \"\"\"\n ret = cocotb.scheduler.queue_function(x)\n shell.prompts._show_time = shell.execution_count\n return ret\n\n\nasync def embed(user_ns: dict = {}):\n \"\"\"\n Start an ipython shell in the current coroutine.\n\n Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword\n can be used directly from the shell to wait for triggers.\n The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.\n\n This coroutine will complete only when the user exits the interactive session.\n\n Args:\n user_ns:\n The variables to have made available in the shell.\n Passing ``locals()`` is often a good idea.\n ``cocotb`` will automatically be included.\n\n Notes:\n\n If your simulator does not provide an appropriate ``stdin``, you may\n find you cannot type in the resulting shell. Using simulators in batch\n or non-GUI mode may resolve this. This feature is experimental, and\n not all simulators are supported.\n \"\"\"\n # ensure cocotb is in the namespace, for convenience\n default_ns = dict(cocotb=cocotb)\n default_ns.update(user_ns)\n\n # build the config to enable `await`\n c = load_default_config()\n c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)\n c.TerminalInteractiveShell.autoawait = True\n\n # create a shell with access to the dut, and cocotb pre-imported\n shell = IPython.terminal.embed.InteractiveShellEmbed(\n user_ns=default_ns,\n config=c,\n )\n\n # add our custom prompts\n shell.prompts = SimTimePrompt(shell)\n\n # start the shell in a background thread\n @cocotb.external\n def run_shell():\n shell()\n await run_shell()\n\n\[email protected]()\nasync def run_ipython(dut):\n \"\"\" A test that launches an interactive Python shell.\n\n Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.\n\n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n await cocotb.triggers.Timer(0) # workaround for gh-637\n await embed(user_ns=dict(dut=dut))\n", "path": "cocotb/ipython_support.py"}], "after_files": [{"content": "# Copyright cocotb contributors\n# Licensed under the Revised BSD License, see LICENSE for details.\n# SPDX-License-Identifier: BSD-3-Clause\nimport IPython\nfrom IPython.terminal.ipapp import load_default_config\nfrom IPython.terminal.prompts import Prompts, Token\n\nimport cocotb\n\n\nclass SimTimePrompt(Prompts):\n \"\"\" custom prompt that shows the sim time after a trigger fires \"\"\"\n _show_time = 1\n\n def in_prompt_tokens(self, cli=None):\n tokens = super().in_prompt_tokens()\n if self._show_time == self.shell.execution_count:\n tokens = [\n (Token.Comment, \"sim time: {}\".format(cocotb.utils.get_sim_time())),\n (Token.Text, \"\\n\"),\n ] + tokens\n return tokens\n\n\ndef _runner(shell, x):\n \"\"\" Handler for async functions \"\"\"\n ret = cocotb.scheduler.queue_function(x)\n shell.prompts._show_time = shell.execution_count\n return ret\n\n\nasync def embed(user_ns: dict = {}):\n \"\"\"\n Start an ipython shell in the current coroutine.\n\n Unlike using :func:`IPython.embed` directly, the :keyword:`await` keyword\n can be used directly from the shell to wait for triggers.\n The :keyword:`yield` keyword from the legacy :ref:`yield-syntax` is not supported.\n\n This coroutine will complete only when the user exits the interactive session.\n\n Args:\n user_ns:\n The variables to have made available in the shell.\n Passing ``locals()`` is often a good idea.\n ``cocotb`` will automatically be included.\n\n Notes:\n\n If your simulator does not provide an appropriate ``stdin``, you may\n find you cannot type in the resulting shell. Using simulators in batch\n or non-GUI mode may resolve this. This feature is experimental, and\n not all simulators are supported.\n \"\"\"\n # ensure cocotb is in the namespace, for convenience\n default_ns = dict(cocotb=cocotb)\n default_ns.update(user_ns)\n\n # build the config to enable `await`\n c = load_default_config()\n c.TerminalInteractiveShell.loop_runner = lambda x: _runner(shell, x)\n c.TerminalInteractiveShell.autoawait = True\n\n # create a shell with access to the dut, and cocotb pre-imported\n shell = IPython.terminal.embed.InteractiveShellEmbed(\n user_ns=default_ns,\n config=c,\n )\n\n # add our custom prompts\n shell.prompts = SimTimePrompt(shell)\n\n # start the shell in a background thread\n @cocotb.external\n def run_shell():\n shell()\n await run_shell()\n\n\[email protected]()\nasync def run_ipython(dut):\n \"\"\" A test that launches an interactive Python shell.\n\n Do not call this directly - use this as ``make MODULE=cocotb.ipython_support``.\n\n Within the shell, a global ``dut`` variable pointing to the design will be present.\n \"\"\"\n await embed(user_ns=dict(dut=dut))\n", "path": "cocotb/ipython_support.py"}]}
| 1,224 | 116 |
gh_patches_debug_40680
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-1789
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add US-MISO day ahead wind & solar forecasts
Both Wind Production and Total Load seem available with a day-head forecast from the following webpage https://www.misoenergy.org/markets-and-operations/real-time-displays/
These forecasts could be added to the MISO parser
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/US_MISO.py`
Content:
```
1 #!/usr/bin/env python3
2
3 """Parser for the MISO area of the United States."""
4
5 import requests
6 from dateutil import parser, tz
7
8 mix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \
9 '=getfuelmix&returnType=json'
10
11 mapping = {'Coal': 'coal',
12 'Natural Gas': 'gas',
13 'Nuclear': 'nuclear',
14 'Wind': 'wind',
15 'Other': 'unknown'}
16
17
18 # To quote the MISO data source;
19 # "The category listed as “Other” is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,
20 # External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners".
21
22 # Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST
23 # Unsure exactly why EST is used, possibly due to operational connections with PJM.
24
25
26 def get_json_data(logger, session=None):
27 """Returns 5 minute generation data in json format."""
28
29 s = session or requests.session()
30 json_data = s.get(mix_url).json()
31
32 return json_data
33
34
35 def data_processer(json_data, logger):
36 """
37 Identifies any unknown fuel types and logs a warning.
38 Returns a tuple containing datetime object and production dictionary.
39 """
40
41 generation = json_data['Fuel']['Type']
42
43 production = {}
44 for fuel in generation:
45 try:
46 k = mapping[fuel['CATEGORY']]
47 except KeyError as e:
48 logger.warning("Key '{}' is missing from the MISO fuel mapping.".format(
49 fuel['CATEGORY']))
50 k = 'unknown'
51 v = float(fuel['ACT'])
52 production[k] = production.get(k, 0.0) + v
53
54 # Remove unneeded parts of timestamp to allow datetime parsing.
55 timestamp = json_data['RefId']
56 split_time = timestamp.split(" ")
57 time_junk = {1, 2} # set literal
58 useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]
59
60 if useful_time_parts[-1] != 'EST':
61 raise ValueError('Timezone reported for US-MISO has changed.')
62
63 time_data = " ".join(useful_time_parts)
64 tzinfos = {"EST": tz.gettz('America/New_York')}
65 dt = parser.parse(time_data, tzinfos=tzinfos)
66
67 return dt, production
68
69
70 def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
71 """
72 Requests the last known production mix (in MW) of a given country
73 Arguments:
74 zone_key (optional) -- used in case a parser is able to fetch multiple countries
75 session (optional) -- request session passed in order to re-use an existing session
76 Return:
77 A dictionary in the form:
78 {
79 'zoneKey': 'FR',
80 'datetime': '2017-01-01T00:00:00Z',
81 'production': {
82 'biomass': 0.0,
83 'coal': 0.0,
84 'gas': 0.0,
85 'hydro': 0.0,
86 'nuclear': null,
87 'oil': 0.0,
88 'solar': 0.0,
89 'wind': 0.0,
90 'geothermal': 0.0,
91 'unknown': 0.0
92 },
93 'storage': {
94 'hydro': -10.0,
95 },
96 'source': 'mysource.com'
97 }
98 """
99 if target_datetime:
100 raise NotImplementedError('This parser is not yet able to parse past dates')
101
102 json_data = get_json_data(logger, session=session)
103 processed_data = data_processer(json_data, logger)
104
105 data = {
106 'zoneKey': zone_key,
107 'datetime': processed_data[0],
108 'production': processed_data[1],
109 'storage': {},
110 'source': 'misoenergy.org'
111 }
112
113 return data
114
115
116 if __name__ == '__main__':
117 print('fetch_production() ->')
118 print(fetch_production())
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/US_MISO.py b/parsers/US_MISO.py
--- a/parsers/US_MISO.py
+++ b/parsers/US_MISO.py
@@ -2,6 +2,7 @@
"""Parser for the MISO area of the United States."""
+import logging
import requests
from dateutil import parser, tz
@@ -14,6 +15,7 @@
'Wind': 'wind',
'Other': 'unknown'}
+wind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'
# To quote the MISO data source;
# "The category listed as “Other” is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,
@@ -67,12 +69,14 @@
return dt, production
-def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
+def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):
"""
Requests the last known production mix (in MW) of a given country
Arguments:
zone_key (optional) -- used in case a parser is able to fetch multiple countries
session (optional) -- request session passed in order to re-use an existing session
+ target_datetime (optional) -- used if parser can fetch data for a specific day
+ logger (optional) -- handles logging when parser is run as main
Return:
A dictionary in the form:
{
@@ -96,6 +100,7 @@
'source': 'mysource.com'
}
"""
+
if target_datetime:
raise NotImplementedError('This parser is not yet able to parse past dates')
@@ -113,6 +118,48 @@
return data
+def fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):
+ """
+ Requests the day ahead wind forecast (in MW) of a given zone
+ Arguments:
+ zone_key (optional) -- used in case a parser is able to fetch multiple countries
+ session (optional) -- request session passed in order to re-use an existing session
+ target_datetime (optional) -- used if parser can fetch data for a specific day
+ logger (optional) -- handles logging when parser is run as main
+ Return:
+ A list of dictionaries in the form:
+ {
+ 'source': 'misoenergy.org',
+ 'production': {'wind': 12932.0},
+ 'datetime': '2019-01-01T00:00:00Z',
+ 'zoneKey': 'US-MISO'
+ }
+ """
+
+ if target_datetime:
+ raise NotImplementedError('This parser is not yet able to parse past dates')
+
+ s = session or requests.Session()
+ req = s.get(wind_forecast_url)
+ raw_json = req.json()
+ raw_data = raw_json['Forecast']
+
+ data = []
+ for item in raw_data:
+ dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))
+ value = float(item['Value'])
+
+ datapoint = {'datetime': dt,
+ 'production': {'wind': value},
+ 'source': 'misoenergy.org',
+ 'zoneKey': zone_key}
+ data.append(datapoint)
+
+ return data
+
+
if __name__ == '__main__':
print('fetch_production() ->')
print(fetch_production())
+ print('fetch_wind_forecast() ->')
+ print(fetch_wind_forecast())
|
{"golden_diff": "diff --git a/parsers/US_MISO.py b/parsers/US_MISO.py\n--- a/parsers/US_MISO.py\n+++ b/parsers/US_MISO.py\n@@ -2,6 +2,7 @@\n \n \"\"\"Parser for the MISO area of the United States.\"\"\"\n \n+import logging\n import requests\n from dateutil import parser, tz\n \n@@ -14,6 +15,7 @@\n 'Wind': 'wind',\n 'Other': 'unknown'}\n \n+wind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'\n \n # To quote the MISO data source;\n # \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n@@ -67,12 +69,14 @@\n return dt, production\n \n \n-def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n+def fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n+ target_datetime (optional) -- used if parser can fetch data for a specific day\n+ logger (optional) -- handles logging when parser is run as main\n Return:\n A dictionary in the form:\n {\n@@ -96,6 +100,7 @@\n 'source': 'mysource.com'\n }\n \"\"\"\n+\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n \n@@ -113,6 +118,48 @@\n return data\n \n \n+def fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n+ \"\"\"\n+ Requests the day ahead wind forecast (in MW) of a given zone\n+ Arguments:\n+ zone_key (optional) -- used in case a parser is able to fetch multiple countries\n+ session (optional) -- request session passed in order to re-use an existing session\n+ target_datetime (optional) -- used if parser can fetch data for a specific day\n+ logger (optional) -- handles logging when parser is run as main\n+ Return:\n+ A list of dictionaries in the form:\n+ {\n+ 'source': 'misoenergy.org',\n+ 'production': {'wind': 12932.0},\n+ 'datetime': '2019-01-01T00:00:00Z',\n+ 'zoneKey': 'US-MISO'\n+ }\n+ \"\"\"\n+\n+ if target_datetime:\n+ raise NotImplementedError('This parser is not yet able to parse past dates')\n+\n+ s = session or requests.Session()\n+ req = s.get(wind_forecast_url)\n+ raw_json = req.json()\n+ raw_data = raw_json['Forecast']\n+\n+ data = []\n+ for item in raw_data:\n+ dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))\n+ value = float(item['Value'])\n+\n+ datapoint = {'datetime': dt,\n+ 'production': {'wind': value},\n+ 'source': 'misoenergy.org',\n+ 'zoneKey': zone_key}\n+ data.append(datapoint)\n+\n+ return data\n+\n+\n if __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n+ print('fetch_wind_forecast() ->')\n+ print(fetch_wind_forecast())\n", "issue": "Add US-MISO day ahead wind & solar forecasts\nBoth Wind Production and Total Load seem available with a day-head forecast from the following webpage https://www.misoenergy.org/markets-and-operations/real-time-displays/\r\n\r\nThese forecasts could be added to the MISO parser \r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"Parser for the MISO area of the United States.\"\"\"\n\nimport requests\nfrom dateutil import parser, tz\n\nmix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \\\n '=getfuelmix&returnType=json'\n\nmapping = {'Coal': 'coal',\n 'Natural Gas': 'gas',\n 'Nuclear': 'nuclear',\n 'Wind': 'wind',\n 'Other': 'unknown'}\n\n\n# To quote the MISO data source;\n# \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n# External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners\".\n\n# Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST\n# Unsure exactly why EST is used, possibly due to operational connections with PJM.\n\n\ndef get_json_data(logger, session=None):\n \"\"\"Returns 5 minute generation data in json format.\"\"\"\n\n s = session or requests.session()\n json_data = s.get(mix_url).json()\n\n return json_data\n\n\ndef data_processer(json_data, logger):\n \"\"\"\n Identifies any unknown fuel types and logs a warning.\n Returns a tuple containing datetime object and production dictionary.\n \"\"\"\n\n generation = json_data['Fuel']['Type']\n\n production = {}\n for fuel in generation:\n try:\n k = mapping[fuel['CATEGORY']]\n except KeyError as e:\n logger.warning(\"Key '{}' is missing from the MISO fuel mapping.\".format(\n fuel['CATEGORY']))\n k = 'unknown'\n v = float(fuel['ACT'])\n production[k] = production.get(k, 0.0) + v\n\n # Remove unneeded parts of timestamp to allow datetime parsing.\n timestamp = json_data['RefId']\n split_time = timestamp.split(\" \")\n time_junk = {1, 2} # set literal\n useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]\n\n if useful_time_parts[-1] != 'EST':\n raise ValueError('Timezone reported for US-MISO has changed.')\n\n time_data = \" \".join(useful_time_parts)\n tzinfos = {\"EST\": tz.gettz('America/New_York')}\n dt = parser.parse(time_data, tzinfos=tzinfos)\n\n return dt, production\n\n\ndef fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n json_data = get_json_data(logger, session=session)\n processed_data = data_processer(json_data, logger)\n\n data = {\n 'zoneKey': zone_key,\n 'datetime': processed_data[0],\n 'production': processed_data[1],\n 'storage': {},\n 'source': 'misoenergy.org'\n }\n\n return data\n\n\nif __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n", "path": "parsers/US_MISO.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"Parser for the MISO area of the United States.\"\"\"\n\nimport logging\nimport requests\nfrom dateutil import parser, tz\n\nmix_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType' \\\n '=getfuelmix&returnType=json'\n\nmapping = {'Coal': 'coal',\n 'Natural Gas': 'gas',\n 'Nuclear': 'nuclear',\n 'Wind': 'wind',\n 'Other': 'unknown'}\n\nwind_forecast_url = 'https://api.misoenergy.org/MISORTWDDataBroker/DataBrokerServices.asmx?messageType=getWindForecast&returnType=json'\n\n# To quote the MISO data source;\n# \"The category listed as \u201cOther\u201d is the combination of Hydro, Pumped Storage Hydro, Diesel, Demand Response Resources,\n# External Asynchronous Resources and a varied assortment of solid waste, garbage and wood pulp burners\".\n\n# Timestamp reported by data source is in format 23-Jan-2018 - Interval 11:45 EST\n# Unsure exactly why EST is used, possibly due to operational connections with PJM.\n\n\ndef get_json_data(logger, session=None):\n \"\"\"Returns 5 minute generation data in json format.\"\"\"\n\n s = session or requests.session()\n json_data = s.get(mix_url).json()\n\n return json_data\n\n\ndef data_processer(json_data, logger):\n \"\"\"\n Identifies any unknown fuel types and logs a warning.\n Returns a tuple containing datetime object and production dictionary.\n \"\"\"\n\n generation = json_data['Fuel']['Type']\n\n production = {}\n for fuel in generation:\n try:\n k = mapping[fuel['CATEGORY']]\n except KeyError as e:\n logger.warning(\"Key '{}' is missing from the MISO fuel mapping.\".format(\n fuel['CATEGORY']))\n k = 'unknown'\n v = float(fuel['ACT'])\n production[k] = production.get(k, 0.0) + v\n\n # Remove unneeded parts of timestamp to allow datetime parsing.\n timestamp = json_data['RefId']\n split_time = timestamp.split(\" \")\n time_junk = {1, 2} # set literal\n useful_time_parts = [v for i, v in enumerate(split_time) if i not in time_junk]\n\n if useful_time_parts[-1] != 'EST':\n raise ValueError('Timezone reported for US-MISO has changed.')\n\n time_data = \" \".join(useful_time_parts)\n tzinfos = {\"EST\": tz.gettz('America/New_York')}\n dt = parser.parse(time_data, tzinfos=tzinfos)\n\n return dt, production\n\n\ndef fetch_production(zone_key='US-MISO', session=None, target_datetime=None, logger=logging.getLogger(__name__)):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n target_datetime (optional) -- used if parser can fetch data for a specific day\n logger (optional) -- handles logging when parser is run as main\n Return:\n A dictionary in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n json_data = get_json_data(logger, session=session)\n processed_data = data_processer(json_data, logger)\n\n data = {\n 'zoneKey': zone_key,\n 'datetime': processed_data[0],\n 'production': processed_data[1],\n 'storage': {},\n 'source': 'misoenergy.org'\n }\n\n return data\n\n\ndef fetch_wind_forecast(zone_key='US-MISO', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the day ahead wind forecast (in MW) of a given zone\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n target_datetime (optional) -- used if parser can fetch data for a specific day\n logger (optional) -- handles logging when parser is run as main\n Return:\n A list of dictionaries in the form:\n {\n 'source': 'misoenergy.org',\n 'production': {'wind': 12932.0},\n 'datetime': '2019-01-01T00:00:00Z',\n 'zoneKey': 'US-MISO'\n }\n \"\"\"\n\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n s = session or requests.Session()\n req = s.get(wind_forecast_url)\n raw_json = req.json()\n raw_data = raw_json['Forecast']\n\n data = []\n for item in raw_data:\n dt = parser.parse(item['DateTimeEST']).replace(tzinfo=tz.gettz('America/New_York'))\n value = float(item['Value'])\n\n datapoint = {'datetime': dt,\n 'production': {'wind': value},\n 'source': 'misoenergy.org',\n 'zoneKey': zone_key}\n data.append(datapoint)\n\n return data\n\n\nif __name__ == '__main__':\n print('fetch_production() ->')\n print(fetch_production())\n print('fetch_wind_forecast() ->')\n print(fetch_wind_forecast())\n", "path": "parsers/US_MISO.py"}]}
| 1,489 | 837 |
gh_patches_debug_18998
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Better error messaging when graphviz is not present
_For reference, this was originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2281#issuecomment-489417445_
> @ajavadia and @mtreinish it has been lost where to find how to add this dependencies outside pip. It is in the doc for the function https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/dag_visualization.py but I think we need to make this clearer in the documentation in the Qiskit repo.
>
> I would split this into two issues --
> 1. In terra add better error messaging. If you call drag_drawer and you don't have graphviz give that this dependency needs to be installed on your system.
> 2. in qiskit add a documentation on how to setup the dag drawer for different operating systems.
This is issue is about the first item.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/visualization/dag_visualization.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2018.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 # pylint: disable=invalid-name
16
17 """
18 Visualization function for DAG circuit representation.
19 """
20
21 import sys
22 from .exceptions import VisualizationError
23
24
25 def dag_drawer(dag, scale=0.7, filename=None, style='color'):
26 """Plot the directed acyclic graph (dag) to represent operation dependencies
27 in a quantum circuit.
28
29 Note this function leverages
30 `pydot <https://github.com/erocarrera/pydot>`_ (via
31 `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which
32 means that having `Graphviz <https://www.graphviz.org/>`_ installed on your
33 system is required for this to work.
34
35 Args:
36 dag (DAGCircuit): The dag to draw.
37 scale (float): scaling factor
38 filename (str): file path to save image to (format inferred from name)
39 style (str): 'plain': B&W graph
40 'color' (default): color input/output/op nodes
41
42 Returns:
43 Ipython.display.Image: if in Jupyter notebook and not saving to file,
44 otherwise None.
45
46 Raises:
47 VisualizationError: when style is not recognized.
48 ImportError: when nxpd or pydot not installed.
49 """
50 try:
51 import nxpd
52 import pydot # pylint: disable=unused-import
53 except ImportError:
54 raise ImportError("dag_drawer requires nxpd, pydot, and Graphviz. "
55 "Run 'pip install nxpd pydot', and install graphviz")
56
57 G = dag.to_networkx()
58 G.graph['dpi'] = 100 * scale
59
60 if style == 'plain':
61 pass
62 elif style == 'color':
63 for node in G.nodes:
64 n = G.nodes[node]
65 n['label'] = node.name
66 if node.type == 'op':
67 n['color'] = 'blue'
68 n['style'] = 'filled'
69 n['fillcolor'] = 'lightblue'
70 if node.type == 'in':
71 n['color'] = 'black'
72 n['style'] = 'filled'
73 n['fillcolor'] = 'green'
74 if node.type == 'out':
75 n['color'] = 'black'
76 n['style'] = 'filled'
77 n['fillcolor'] = 'red'
78 for e in G.edges(data=True):
79 e[2]['label'] = e[2]['name']
80 else:
81 raise VisualizationError("Unrecognized style for the dag_drawer.")
82
83 if filename:
84 show = False
85 elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):
86 show = 'ipynb'
87 else:
88 show = True
89
90 return nxpd.draw(G, filename=filename, show=show)
91
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py
--- a/qiskit/visualization/dag_visualization.py
+++ b/qiskit/visualization/dag_visualization.py
@@ -51,8 +51,8 @@
import nxpd
import pydot # pylint: disable=unused-import
except ImportError:
- raise ImportError("dag_drawer requires nxpd, pydot, and Graphviz. "
- "Run 'pip install nxpd pydot', and install graphviz")
+ raise ImportError("dag_drawer requires nxpd and pydot. "
+ "Run 'pip install nxpd pydot'.")
G = dag.to_networkx()
G.graph['dpi'] = 100 * scale
@@ -87,4 +87,9 @@
else:
show = True
- return nxpd.draw(G, filename=filename, show=show)
+ try:
+ return nxpd.draw(G, filename=filename, show=show)
+ except nxpd.pydot.InvocationException:
+ raise VisualizationError("dag_drawer requires GraphViz installed in the system. "
+ "Check https://www.graphviz.org/download/ for details on "
+ "how to install GraphViz in your system.")
|
{"golden_diff": "diff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py\n--- a/qiskit/visualization/dag_visualization.py\n+++ b/qiskit/visualization/dag_visualization.py\n@@ -51,8 +51,8 @@\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n- raise ImportError(\"dag_drawer requires nxpd, pydot, and Graphviz. \"\n- \"Run 'pip install nxpd pydot', and install graphviz\")\n+ raise ImportError(\"dag_drawer requires nxpd and pydot. \"\n+ \"Run 'pip install nxpd pydot'.\")\n \n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n@@ -87,4 +87,9 @@\n else:\n show = True\n \n- return nxpd.draw(G, filename=filename, show=show)\n+ try:\n+ return nxpd.draw(G, filename=filename, show=show)\n+ except nxpd.pydot.InvocationException:\n+ raise VisualizationError(\"dag_drawer requires GraphViz installed in the system. \"\n+ \"Check https://www.graphviz.org/download/ for details on \"\n+ \"how to install GraphViz in your system.\")\n", "issue": "Better error messaging when graphviz is not present\n_For reference, this was originally posted by @jaygambetta in https://github.com/Qiskit/qiskit-terra/issues/2281#issuecomment-489417445_\r\n\r\n> @ajavadia and @mtreinish it has been lost where to find how to add this dependencies outside pip. It is in the doc for the function https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/visualization/dag_visualization.py but I think we need to make this clearer in the documentation in the Qiskit repo. \r\n>\r\n> I would split this into two issues -- \r\n> 1. In terra add better error messaging. If you call drag_drawer and you don't have graphviz give that this dependency needs to be installed on your system. \r\n> 2. in qiskit add a documentation on how to setup the dag drawer for different operating systems.\r\n\r\nThis is issue is about the first item. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n# pylint: disable=invalid-name\n\n\"\"\"\nVisualization function for DAG circuit representation.\n\"\"\"\n\nimport sys\nfrom .exceptions import VisualizationError\n\n\ndef dag_drawer(dag, scale=0.7, filename=None, style='color'):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n in a quantum circuit.\n\n Note this function leverages\n `pydot <https://github.com/erocarrera/pydot>`_ (via\n `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which\n means that having `Graphviz <https://www.graphviz.org/>`_ installed on your\n system is required for this to work.\n\n Args:\n dag (DAGCircuit): The dag to draw.\n scale (float): scaling factor\n filename (str): file path to save image to (format inferred from name)\n style (str): 'plain': B&W graph\n 'color' (default): color input/output/op nodes\n\n Returns:\n Ipython.display.Image: if in Jupyter notebook and not saving to file,\n otherwise None.\n\n Raises:\n VisualizationError: when style is not recognized.\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n try:\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n raise ImportError(\"dag_drawer requires nxpd, pydot, and Graphviz. \"\n \"Run 'pip install nxpd pydot', and install graphviz\")\n\n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n\n if style == 'plain':\n pass\n elif style == 'color':\n for node in G.nodes:\n n = G.nodes[node]\n n['label'] = node.name\n if node.type == 'op':\n n['color'] = 'blue'\n n['style'] = 'filled'\n n['fillcolor'] = 'lightblue'\n if node.type == 'in':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'green'\n if node.type == 'out':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'red'\n for e in G.edges(data=True):\n e[2]['label'] = e[2]['name']\n else:\n raise VisualizationError(\"Unrecognized style for the dag_drawer.\")\n\n if filename:\n show = False\n elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n show = 'ipynb'\n else:\n show = True\n\n return nxpd.draw(G, filename=filename, show=show)\n", "path": "qiskit/visualization/dag_visualization.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n# pylint: disable=invalid-name\n\n\"\"\"\nVisualization function for DAG circuit representation.\n\"\"\"\n\nimport sys\nfrom .exceptions import VisualizationError\n\n\ndef dag_drawer(dag, scale=0.7, filename=None, style='color'):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n in a quantum circuit.\n\n Note this function leverages\n `pydot <https://github.com/erocarrera/pydot>`_ (via\n `nxpd <https://github.com/chebee7i/nxpd`_) to generate the graph, which\n means that having `Graphviz <https://www.graphviz.org/>`_ installed on your\n system is required for this to work.\n\n Args:\n dag (DAGCircuit): The dag to draw.\n scale (float): scaling factor\n filename (str): file path to save image to (format inferred from name)\n style (str): 'plain': B&W graph\n 'color' (default): color input/output/op nodes\n\n Returns:\n Ipython.display.Image: if in Jupyter notebook and not saving to file,\n otherwise None.\n\n Raises:\n VisualizationError: when style is not recognized.\n ImportError: when nxpd or pydot not installed.\n \"\"\"\n try:\n import nxpd\n import pydot # pylint: disable=unused-import\n except ImportError:\n raise ImportError(\"dag_drawer requires nxpd and pydot. \"\n \"Run 'pip install nxpd pydot'.\")\n\n G = dag.to_networkx()\n G.graph['dpi'] = 100 * scale\n\n if style == 'plain':\n pass\n elif style == 'color':\n for node in G.nodes:\n n = G.nodes[node]\n n['label'] = node.name\n if node.type == 'op':\n n['color'] = 'blue'\n n['style'] = 'filled'\n n['fillcolor'] = 'lightblue'\n if node.type == 'in':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'green'\n if node.type == 'out':\n n['color'] = 'black'\n n['style'] = 'filled'\n n['fillcolor'] = 'red'\n for e in G.edges(data=True):\n e[2]['label'] = e[2]['name']\n else:\n raise VisualizationError(\"Unrecognized style for the dag_drawer.\")\n\n if filename:\n show = False\n elif ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n show = 'ipynb'\n else:\n show = True\n\n try:\n return nxpd.draw(G, filename=filename, show=show)\n except nxpd.pydot.InvocationException:\n raise VisualizationError(\"dag_drawer requires GraphViz installed in the system. \"\n \"Check https://www.graphviz.org/download/ for details on \"\n \"how to install GraphViz in your system.\")\n", "path": "qiskit/visualization/dag_visualization.py"}]}
| 1,393 | 287 |
gh_patches_debug_7436
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2713
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Django erroneously reports makemigrations is needed
There is a problem with Django migration changes detector when running `migrate` command after setting up Django using `django,setup()`. For some reason, it is considering `mathesar.models.query.UIQuery` model to be missing.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/admin.py`
Content:
```
1 from django.contrib import admin
2 from django.contrib.auth.admin import UserAdmin
3
4 from mathesar.models.base import Table, Schema, DataFile
5 from mathesar.models.users import User
6
7
8 class MathesarUserAdmin(UserAdmin):
9 model = User
10
11 fieldsets = (
12 (None, {'fields': ('username', 'password')}),
13 ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),
14 ('Permissions', {
15 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),
16 }),
17 ('Important dates', {'fields': ('last_login', 'date_joined')}),
18 )
19
20
21 admin.site.register(Table)
22 admin.site.register(Schema)
23 admin.site.register(DataFile)
24 admin.site.register(User, MathesarUserAdmin)
25
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mathesar/admin.py b/mathesar/admin.py
--- a/mathesar/admin.py
+++ b/mathesar/admin.py
@@ -3,6 +3,7 @@
from mathesar.models.base import Table, Schema, DataFile
from mathesar.models.users import User
+from mathesar.models.query import UIQuery
class MathesarUserAdmin(UserAdmin):
@@ -22,3 +23,4 @@
admin.site.register(Schema)
admin.site.register(DataFile)
admin.site.register(User, MathesarUserAdmin)
+admin.site.register(UIQuery)
|
{"golden_diff": "diff --git a/mathesar/admin.py b/mathesar/admin.py\n--- a/mathesar/admin.py\n+++ b/mathesar/admin.py\n@@ -3,6 +3,7 @@\n \n from mathesar.models.base import Table, Schema, DataFile\n from mathesar.models.users import User\n+from mathesar.models.query import UIQuery\n \n \n class MathesarUserAdmin(UserAdmin):\n@@ -22,3 +23,4 @@\n admin.site.register(Schema)\n admin.site.register(DataFile)\n admin.site.register(User, MathesarUserAdmin)\n+admin.site.register(UIQuery)\n", "issue": "Django erroneously reports makemigrations is needed\nThere is a problem with Django migration changes detector when running `migrate` command after setting up Django using `django,setup()`. For some reason, it is considering `mathesar.models.query.UIQuery` model to be missing. \n", "before_files": [{"content": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin\n\nfrom mathesar.models.base import Table, Schema, DataFile\nfrom mathesar.models.users import User\n\n\nclass MathesarUserAdmin(UserAdmin):\n model = User\n\n fieldsets = (\n (None, {'fields': ('username', 'password')}),\n ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),\n ('Permissions', {\n 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),\n }),\n ('Important dates', {'fields': ('last_login', 'date_joined')}),\n )\n\n\nadmin.site.register(Table)\nadmin.site.register(Schema)\nadmin.site.register(DataFile)\nadmin.site.register(User, MathesarUserAdmin)\n", "path": "mathesar/admin.py"}], "after_files": [{"content": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin\n\nfrom mathesar.models.base import Table, Schema, DataFile\nfrom mathesar.models.users import User\nfrom mathesar.models.query import UIQuery\n\n\nclass MathesarUserAdmin(UserAdmin):\n model = User\n\n fieldsets = (\n (None, {'fields': ('username', 'password')}),\n ('Personal info', {'fields': ('full_name', 'short_name', 'email',)}),\n ('Permissions', {\n 'fields': ('is_active', 'is_staff', 'is_superuser', 'groups'),\n }),\n ('Important dates', {'fields': ('last_login', 'date_joined')}),\n )\n\n\nadmin.site.register(Table)\nadmin.site.register(Schema)\nadmin.site.register(DataFile)\nadmin.site.register(User, MathesarUserAdmin)\nadmin.site.register(UIQuery)\n", "path": "mathesar/admin.py"}]}
| 526 | 120 |
gh_patches_debug_8545
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1796
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The _ARROW_SCALAR_IDS_TO_BQ mapping misses LargeStringArray type
#### Environment details
- OS type and version: Linux
- Python version: 3.11.7
- pip version: 23.3.1
- `google-cloud-bigquery` version: 3.16.0
#### Steps to reproduce
Call `bqclient.load_table_from_dataframe` with a dataframe containing a string type. Before pandas 2.2.0, the `pyarrow.array` would detect the type as `pyarrow.lib.StringArray`. After switching to pandas `2.2.0`, the `pyarrow.lib.LargeStringArray` would be returned. But it misses the BQ type mapping.
#### Stack trace
<img width="1470" alt="callstack" src="https://github.com/googleapis/python-bigquery/assets/124939984/fe0c326f-8875-41b5-abff-e91dc3e574da">
The left results are in `pandas 2.2.0` and the right result are from `pandas 2.1.3`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/_pyarrow_helpers.py`
Content:
```
1 # Copyright 2023 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Shared helper functions for connecting BigQuery and pyarrow."""
16
17 from typing import Any
18
19 from packaging import version
20
21 try:
22 import pyarrow # type: ignore
23 except ImportError: # pragma: NO COVER
24 pyarrow = None
25
26
27 def pyarrow_datetime():
28 return pyarrow.timestamp("us", tz=None)
29
30
31 def pyarrow_numeric():
32 return pyarrow.decimal128(38, 9)
33
34
35 def pyarrow_bignumeric():
36 # 77th digit is partial.
37 # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types
38 return pyarrow.decimal256(76, 38)
39
40
41 def pyarrow_time():
42 return pyarrow.time64("us")
43
44
45 def pyarrow_timestamp():
46 return pyarrow.timestamp("us", tz="UTC")
47
48
49 _BQ_TO_ARROW_SCALARS = {}
50 _ARROW_SCALAR_IDS_TO_BQ = {}
51
52 if pyarrow:
53 # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py
54 # When modifying it be sure to update it there as well.
55 # Note(todo!!): type "BIGNUMERIC"'s matching pyarrow type is added in _pandas_helpers.py
56 _BQ_TO_ARROW_SCALARS = {
57 "BOOL": pyarrow.bool_,
58 "BOOLEAN": pyarrow.bool_,
59 "BYTES": pyarrow.binary,
60 "DATE": pyarrow.date32,
61 "DATETIME": pyarrow_datetime,
62 "FLOAT": pyarrow.float64,
63 "FLOAT64": pyarrow.float64,
64 "GEOGRAPHY": pyarrow.string,
65 "INT64": pyarrow.int64,
66 "INTEGER": pyarrow.int64,
67 "NUMERIC": pyarrow_numeric,
68 "STRING": pyarrow.string,
69 "TIME": pyarrow_time,
70 "TIMESTAMP": pyarrow_timestamp,
71 }
72
73 _ARROW_SCALAR_IDS_TO_BQ = {
74 # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes
75 pyarrow.bool_().id: "BOOL",
76 pyarrow.int8().id: "INT64",
77 pyarrow.int16().id: "INT64",
78 pyarrow.int32().id: "INT64",
79 pyarrow.int64().id: "INT64",
80 pyarrow.uint8().id: "INT64",
81 pyarrow.uint16().id: "INT64",
82 pyarrow.uint32().id: "INT64",
83 pyarrow.uint64().id: "INT64",
84 pyarrow.float16().id: "FLOAT64",
85 pyarrow.float32().id: "FLOAT64",
86 pyarrow.float64().id: "FLOAT64",
87 pyarrow.time32("ms").id: "TIME",
88 pyarrow.time64("ns").id: "TIME",
89 pyarrow.timestamp("ns").id: "TIMESTAMP",
90 pyarrow.date32().id: "DATE",
91 pyarrow.date64().id: "DATETIME", # because millisecond resolution
92 pyarrow.binary().id: "BYTES",
93 pyarrow.string().id: "STRING", # also alias for pyarrow.utf8()
94 # The exact scale and precision don't matter, see below.
95 pyarrow.decimal128(38, scale=9).id: "NUMERIC",
96 }
97
98 # Adds bignumeric support only if pyarrow version >= 3.0.0
99 # Decimal256 support was added to arrow 3.0.0
100 # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/
101 if version.parse(pyarrow.__version__) >= version.parse("3.0.0"):
102 _BQ_TO_ARROW_SCALARS["BIGNUMERIC"] = pyarrow_bignumeric
103 # The exact decimal's scale and precision are not important, as only
104 # the type ID matters, and it's the same for all decimal256 instances.
105 _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = "BIGNUMERIC"
106
107
108 def bq_to_arrow_scalars(bq_scalar: str):
109 """
110 Returns:
111 The Arrow scalar type that the input BigQuery scalar type maps to.
112 If it cannot find the BigQuery scalar, return None.
113 """
114 return _BQ_TO_ARROW_SCALARS.get(bq_scalar)
115
116
117 def arrow_scalar_ids_to_bq(arrow_scalar: Any):
118 """
119 Returns:
120 The BigQuery scalar type that the input arrow scalar type maps to.
121 If it cannot find the arrow scalar, return None.
122 """
123 return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/_pyarrow_helpers.py b/google/cloud/bigquery/_pyarrow_helpers.py
--- a/google/cloud/bigquery/_pyarrow_helpers.py
+++ b/google/cloud/bigquery/_pyarrow_helpers.py
@@ -91,6 +91,7 @@
pyarrow.date64().id: "DATETIME", # because millisecond resolution
pyarrow.binary().id: "BYTES",
pyarrow.string().id: "STRING", # also alias for pyarrow.utf8()
+ pyarrow.large_string().id: "STRING",
# The exact scale and precision don't matter, see below.
pyarrow.decimal128(38, scale=9).id: "NUMERIC",
}
|
{"golden_diff": "diff --git a/google/cloud/bigquery/_pyarrow_helpers.py b/google/cloud/bigquery/_pyarrow_helpers.py\n--- a/google/cloud/bigquery/_pyarrow_helpers.py\n+++ b/google/cloud/bigquery/_pyarrow_helpers.py\n@@ -91,6 +91,7 @@\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n+ pyarrow.large_string().id: \"STRING\",\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n", "issue": "The _ARROW_SCALAR_IDS_TO_BQ mapping misses LargeStringArray type\n#### Environment details\r\n\r\n - OS type and version: Linux\r\n - Python version: 3.11.7\r\n - pip version: 23.3.1\r\n - `google-cloud-bigquery` version: 3.16.0\r\n\r\n#### Steps to reproduce\r\n\r\nCall `bqclient.load_table_from_dataframe` with a dataframe containing a string type. Before pandas 2.2.0, the `pyarrow.array` would detect the type as `pyarrow.lib.StringArray`. After switching to pandas `2.2.0`, the `pyarrow.lib.LargeStringArray` would be returned. But it misses the BQ type mapping.\r\n\r\n\r\n#### Stack trace\r\n\r\n<img width=\"1470\" alt=\"callstack\" src=\"https://github.com/googleapis/python-bigquery/assets/124939984/fe0c326f-8875-41b5-abff-e91dc3e574da\">\r\n\r\nThe left results are in `pandas 2.2.0` and the right result are from `pandas 2.1.3`\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for connecting BigQuery and pyarrow.\"\"\"\n\nfrom typing import Any\n\nfrom packaging import version\n\ntry:\n import pyarrow # type: ignore\nexcept ImportError: # pragma: NO COVER\n pyarrow = None\n\n\ndef pyarrow_datetime():\n return pyarrow.timestamp(\"us\", tz=None)\n\n\ndef pyarrow_numeric():\n return pyarrow.decimal128(38, 9)\n\n\ndef pyarrow_bignumeric():\n # 77th digit is partial.\n # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types\n return pyarrow.decimal256(76, 38)\n\n\ndef pyarrow_time():\n return pyarrow.time64(\"us\")\n\n\ndef pyarrow_timestamp():\n return pyarrow.timestamp(\"us\", tz=\"UTC\")\n\n\n_BQ_TO_ARROW_SCALARS = {}\n_ARROW_SCALAR_IDS_TO_BQ = {}\n\nif pyarrow:\n # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py\n # When modifying it be sure to update it there as well.\n # Note(todo!!): type \"BIGNUMERIC\"'s matching pyarrow type is added in _pandas_helpers.py\n _BQ_TO_ARROW_SCALARS = {\n \"BOOL\": pyarrow.bool_,\n \"BOOLEAN\": pyarrow.bool_,\n \"BYTES\": pyarrow.binary,\n \"DATE\": pyarrow.date32,\n \"DATETIME\": pyarrow_datetime,\n \"FLOAT\": pyarrow.float64,\n \"FLOAT64\": pyarrow.float64,\n \"GEOGRAPHY\": pyarrow.string,\n \"INT64\": pyarrow.int64,\n \"INTEGER\": pyarrow.int64,\n \"NUMERIC\": pyarrow_numeric,\n \"STRING\": pyarrow.string,\n \"TIME\": pyarrow_time,\n \"TIMESTAMP\": pyarrow_timestamp,\n }\n\n _ARROW_SCALAR_IDS_TO_BQ = {\n # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes\n pyarrow.bool_().id: \"BOOL\",\n pyarrow.int8().id: \"INT64\",\n pyarrow.int16().id: \"INT64\",\n pyarrow.int32().id: \"INT64\",\n pyarrow.int64().id: \"INT64\",\n pyarrow.uint8().id: \"INT64\",\n pyarrow.uint16().id: \"INT64\",\n pyarrow.uint32().id: \"INT64\",\n pyarrow.uint64().id: \"INT64\",\n pyarrow.float16().id: \"FLOAT64\",\n pyarrow.float32().id: \"FLOAT64\",\n pyarrow.float64().id: \"FLOAT64\",\n pyarrow.time32(\"ms\").id: \"TIME\",\n pyarrow.time64(\"ns\").id: \"TIME\",\n pyarrow.timestamp(\"ns\").id: \"TIMESTAMP\",\n pyarrow.date32().id: \"DATE\",\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n\n # Adds bignumeric support only if pyarrow version >= 3.0.0\n # Decimal256 support was added to arrow 3.0.0\n # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/\n if version.parse(pyarrow.__version__) >= version.parse(\"3.0.0\"):\n _BQ_TO_ARROW_SCALARS[\"BIGNUMERIC\"] = pyarrow_bignumeric\n # The exact decimal's scale and precision are not important, as only\n # the type ID matters, and it's the same for all decimal256 instances.\n _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = \"BIGNUMERIC\"\n\n\ndef bq_to_arrow_scalars(bq_scalar: str):\n \"\"\"\n Returns:\n The Arrow scalar type that the input BigQuery scalar type maps to.\n If it cannot find the BigQuery scalar, return None.\n \"\"\"\n return _BQ_TO_ARROW_SCALARS.get(bq_scalar)\n\n\ndef arrow_scalar_ids_to_bq(arrow_scalar: Any):\n \"\"\"\n Returns:\n The BigQuery scalar type that the input arrow scalar type maps to.\n If it cannot find the arrow scalar, return None.\n \"\"\"\n return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)\n", "path": "google/cloud/bigquery/_pyarrow_helpers.py"}], "after_files": [{"content": "# Copyright 2023 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Shared helper functions for connecting BigQuery and pyarrow.\"\"\"\n\nfrom typing import Any\n\nfrom packaging import version\n\ntry:\n import pyarrow # type: ignore\nexcept ImportError: # pragma: NO COVER\n pyarrow = None\n\n\ndef pyarrow_datetime():\n return pyarrow.timestamp(\"us\", tz=None)\n\n\ndef pyarrow_numeric():\n return pyarrow.decimal128(38, 9)\n\n\ndef pyarrow_bignumeric():\n # 77th digit is partial.\n # https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#decimal_types\n return pyarrow.decimal256(76, 38)\n\n\ndef pyarrow_time():\n return pyarrow.time64(\"us\")\n\n\ndef pyarrow_timestamp():\n return pyarrow.timestamp(\"us\", tz=\"UTC\")\n\n\n_BQ_TO_ARROW_SCALARS = {}\n_ARROW_SCALAR_IDS_TO_BQ = {}\n\nif pyarrow:\n # This dictionary is duplicated in bigquery_storage/test/unite/test_reader.py\n # When modifying it be sure to update it there as well.\n # Note(todo!!): type \"BIGNUMERIC\"'s matching pyarrow type is added in _pandas_helpers.py\n _BQ_TO_ARROW_SCALARS = {\n \"BOOL\": pyarrow.bool_,\n \"BOOLEAN\": pyarrow.bool_,\n \"BYTES\": pyarrow.binary,\n \"DATE\": pyarrow.date32,\n \"DATETIME\": pyarrow_datetime,\n \"FLOAT\": pyarrow.float64,\n \"FLOAT64\": pyarrow.float64,\n \"GEOGRAPHY\": pyarrow.string,\n \"INT64\": pyarrow.int64,\n \"INTEGER\": pyarrow.int64,\n \"NUMERIC\": pyarrow_numeric,\n \"STRING\": pyarrow.string,\n \"TIME\": pyarrow_time,\n \"TIMESTAMP\": pyarrow_timestamp,\n }\n\n _ARROW_SCALAR_IDS_TO_BQ = {\n # https://arrow.apache.org/docs/python/api/datatypes.html#type-classes\n pyarrow.bool_().id: \"BOOL\",\n pyarrow.int8().id: \"INT64\",\n pyarrow.int16().id: \"INT64\",\n pyarrow.int32().id: \"INT64\",\n pyarrow.int64().id: \"INT64\",\n pyarrow.uint8().id: \"INT64\",\n pyarrow.uint16().id: \"INT64\",\n pyarrow.uint32().id: \"INT64\",\n pyarrow.uint64().id: \"INT64\",\n pyarrow.float16().id: \"FLOAT64\",\n pyarrow.float32().id: \"FLOAT64\",\n pyarrow.float64().id: \"FLOAT64\",\n pyarrow.time32(\"ms\").id: \"TIME\",\n pyarrow.time64(\"ns\").id: \"TIME\",\n pyarrow.timestamp(\"ns\").id: \"TIMESTAMP\",\n pyarrow.date32().id: \"DATE\",\n pyarrow.date64().id: \"DATETIME\", # because millisecond resolution\n pyarrow.binary().id: \"BYTES\",\n pyarrow.string().id: \"STRING\", # also alias for pyarrow.utf8()\n pyarrow.large_string().id: \"STRING\",\n # The exact scale and precision don't matter, see below.\n pyarrow.decimal128(38, scale=9).id: \"NUMERIC\",\n }\n\n # Adds bignumeric support only if pyarrow version >= 3.0.0\n # Decimal256 support was added to arrow 3.0.0\n # https://arrow.apache.org/blog/2021/01/25/3.0.0-release/\n if version.parse(pyarrow.__version__) >= version.parse(\"3.0.0\"):\n _BQ_TO_ARROW_SCALARS[\"BIGNUMERIC\"] = pyarrow_bignumeric\n # The exact decimal's scale and precision are not important, as only\n # the type ID matters, and it's the same for all decimal256 instances.\n _ARROW_SCALAR_IDS_TO_BQ[pyarrow.decimal256(76, scale=38).id] = \"BIGNUMERIC\"\n\n\ndef bq_to_arrow_scalars(bq_scalar: str):\n \"\"\"\n Returns:\n The Arrow scalar type that the input BigQuery scalar type maps to.\n If it cannot find the BigQuery scalar, return None.\n \"\"\"\n return _BQ_TO_ARROW_SCALARS.get(bq_scalar)\n\n\ndef arrow_scalar_ids_to_bq(arrow_scalar: Any):\n \"\"\"\n Returns:\n The BigQuery scalar type that the input arrow scalar type maps to.\n If it cannot find the arrow scalar, return None.\n \"\"\"\n return _ARROW_SCALAR_IDS_TO_BQ.get(arrow_scalar)\n", "path": "google/cloud/bigquery/_pyarrow_helpers.py"}]}
| 1,980 | 160 |
gh_patches_debug_8727
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-531
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
S3ObjectVersion is spelled "SS3ObjectVersion" in the lambda Code object validation
I just noticed [this](https://github.com/cloudtools/troposphere/blob/1f67fb140f5b94cf0f29213a7300bad3ea046a0f/troposphere/awslambda.py#L31) while I was reading through the code. I haven't run into problems as I haven't had to use this particular key, but it looks like something you might want to know about.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `troposphere/awslambda.py`
Content:
```
1 from . import AWSObject, AWSProperty
2 from .validators import positive_integer
3
4 MEMORY_VALUES = [x for x in range(128, 1600, 64)]
5
6
7 def validate_memory_size(memory_value):
8 """ Validate memory size for Lambda Function
9 :param memory_value: The memory size specified in the Function
10 :return: The provided memory size if it is valid
11 """
12 memory_value = int(positive_integer(memory_value))
13 if memory_value not in MEMORY_VALUES:
14 raise ValueError("Lambda Function memory size must be one of:\n %s" %
15 ", ".join(str(mb) for mb in MEMORY_VALUES))
16 return memory_value
17
18
19 class Code(AWSProperty):
20 props = {
21 'S3Bucket': (basestring, False),
22 'S3Key': (basestring, False),
23 'S3ObjectVersion': (basestring, False),
24 'ZipFile': (basestring, False)
25 }
26
27 def validate(self):
28 zip_file = self.properties.get('ZipFile')
29 s3_bucket = self.properties.get('S3Bucket')
30 s3_key = self.properties.get('S3Key')
31 s3_object_version = self.properties.get('SS3ObjectVersion')
32
33 if zip_file and s3_bucket:
34 raise ValueError("You can't specify both 'S3Bucket' and 'ZipFile'")
35 if zip_file and s3_key:
36 raise ValueError("You can't specify both 'S3Key' and 'ZipFile'")
37 if zip_file and s3_object_version:
38 raise ValueError(
39 "You can't specify both 'S3ObjectVersion' and 'ZipFile'"
40 )
41 if not zip_file and not (s3_bucket and s3_key):
42 raise ValueError(
43 "You must specify a bucket location (both the 'S3Bucket' and "
44 "'S3Key' properties) or the 'ZipFile' property"
45 )
46
47
48 class VPCConfig(AWSProperty):
49
50 props = {
51 'SecurityGroupIds': (list, True),
52 'SubnetIds': (list, True),
53 }
54
55
56 class EventSourceMapping(AWSObject):
57 resource_type = "AWS::Lambda::EventSourceMapping"
58
59 props = {
60 'BatchSize': (positive_integer, False),
61 'Enabled': (bool, False),
62 'EventSourceArn': (basestring, True),
63 'FunctionName': (basestring, True),
64 'StartingPosition': (basestring, True),
65 }
66
67
68 class Function(AWSObject):
69 resource_type = "AWS::Lambda::Function"
70
71 props = {
72 'Code': (Code, True),
73 'Description': (basestring, False),
74 'FunctionName': (basestring, False),
75 'Handler': (basestring, True),
76 'MemorySize': (validate_memory_size, False),
77 'Role': (basestring, True),
78 'Runtime': (basestring, True),
79 'Timeout': (positive_integer, False),
80 'VpcConfig': (VPCConfig, False),
81 }
82
83
84 class Permission(AWSObject):
85 resource_type = "AWS::Lambda::Permission"
86
87 props = {
88 'Action': (basestring, True),
89 'FunctionName': (basestring, True),
90 'Principal': (basestring, True),
91 'SourceAccount': (basestring, False),
92 'SourceArn': (basestring, False),
93 }
94
95
96 class Alias(AWSObject):
97 resource_type = "AWS::Lambda::Alias"
98
99 props = {
100 'Description': (basestring, False),
101 'FunctionName': (basestring, True),
102 'FunctionVersion': (basestring, True),
103 'Name': (basestring, True),
104 }
105
106
107 class Version(AWSObject):
108 resource_type = "AWS::Lambda::Version"
109
110 props = {
111 'CodeSha256': (basestring, False),
112 'Description': (basestring, False),
113 'FunctionName': (basestring, True),
114 }
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py
--- a/troposphere/awslambda.py
+++ b/troposphere/awslambda.py
@@ -28,7 +28,7 @@
zip_file = self.properties.get('ZipFile')
s3_bucket = self.properties.get('S3Bucket')
s3_key = self.properties.get('S3Key')
- s3_object_version = self.properties.get('SS3ObjectVersion')
+ s3_object_version = self.properties.get('S3ObjectVersion')
if zip_file and s3_bucket:
raise ValueError("You can't specify both 'S3Bucket' and 'ZipFile'")
|
{"golden_diff": "diff --git a/troposphere/awslambda.py b/troposphere/awslambda.py\n--- a/troposphere/awslambda.py\n+++ b/troposphere/awslambda.py\n@@ -28,7 +28,7 @@\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n- s3_object_version = self.properties.get('SS3ObjectVersion')\n+ s3_object_version = self.properties.get('S3ObjectVersion')\n \n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n", "issue": "S3ObjectVersion is spelled \"SS3ObjectVersion\" in the lambda Code object validation\nI just noticed [this](https://github.com/cloudtools/troposphere/blob/1f67fb140f5b94cf0f29213a7300bad3ea046a0f/troposphere/awslambda.py#L31) while I was reading through the code. I haven't run into problems as I haven't had to use this particular key, but it looks like something you might want to know about.\n\n", "before_files": [{"content": "from . import AWSObject, AWSProperty\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 1600, 64)]\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('SS3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, True),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'MemorySize': (validate_memory_size, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Timeout': (positive_integer, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}], "after_files": [{"content": "from . import AWSObject, AWSProperty\nfrom .validators import positive_integer\n\nMEMORY_VALUES = [x for x in range(128, 1600, 64)]\n\n\ndef validate_memory_size(memory_value):\n \"\"\" Validate memory size for Lambda Function\n :param memory_value: The memory size specified in the Function\n :return: The provided memory size if it is valid\n \"\"\"\n memory_value = int(positive_integer(memory_value))\n if memory_value not in MEMORY_VALUES:\n raise ValueError(\"Lambda Function memory size must be one of:\\n %s\" %\n \", \".join(str(mb) for mb in MEMORY_VALUES))\n return memory_value\n\n\nclass Code(AWSProperty):\n props = {\n 'S3Bucket': (basestring, False),\n 'S3Key': (basestring, False),\n 'S3ObjectVersion': (basestring, False),\n 'ZipFile': (basestring, False)\n }\n\n def validate(self):\n zip_file = self.properties.get('ZipFile')\n s3_bucket = self.properties.get('S3Bucket')\n s3_key = self.properties.get('S3Key')\n s3_object_version = self.properties.get('S3ObjectVersion')\n\n if zip_file and s3_bucket:\n raise ValueError(\"You can't specify both 'S3Bucket' and 'ZipFile'\")\n if zip_file and s3_key:\n raise ValueError(\"You can't specify both 'S3Key' and 'ZipFile'\")\n if zip_file and s3_object_version:\n raise ValueError(\n \"You can't specify both 'S3ObjectVersion' and 'ZipFile'\"\n )\n if not zip_file and not (s3_bucket and s3_key):\n raise ValueError(\n \"You must specify a bucket location (both the 'S3Bucket' and \"\n \"'S3Key' properties) or the 'ZipFile' property\"\n )\n\n\nclass VPCConfig(AWSProperty):\n\n props = {\n 'SecurityGroupIds': (list, True),\n 'SubnetIds': (list, True),\n }\n\n\nclass EventSourceMapping(AWSObject):\n resource_type = \"AWS::Lambda::EventSourceMapping\"\n\n props = {\n 'BatchSize': (positive_integer, False),\n 'Enabled': (bool, False),\n 'EventSourceArn': (basestring, True),\n 'FunctionName': (basestring, True),\n 'StartingPosition': (basestring, True),\n }\n\n\nclass Function(AWSObject):\n resource_type = \"AWS::Lambda::Function\"\n\n props = {\n 'Code': (Code, True),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, False),\n 'Handler': (basestring, True),\n 'MemorySize': (validate_memory_size, False),\n 'Role': (basestring, True),\n 'Runtime': (basestring, True),\n 'Timeout': (positive_integer, False),\n 'VpcConfig': (VPCConfig, False),\n }\n\n\nclass Permission(AWSObject):\n resource_type = \"AWS::Lambda::Permission\"\n\n props = {\n 'Action': (basestring, True),\n 'FunctionName': (basestring, True),\n 'Principal': (basestring, True),\n 'SourceAccount': (basestring, False),\n 'SourceArn': (basestring, False),\n }\n\n\nclass Alias(AWSObject):\n resource_type = \"AWS::Lambda::Alias\"\n\n props = {\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n 'FunctionVersion': (basestring, True),\n 'Name': (basestring, True),\n }\n\n\nclass Version(AWSObject):\n resource_type = \"AWS::Lambda::Version\"\n\n props = {\n 'CodeSha256': (basestring, False),\n 'Description': (basestring, False),\n 'FunctionName': (basestring, True),\n }\n", "path": "troposphere/awslambda.py"}]}
| 1,483 | 154 |
gh_patches_debug_39888
|
rasdani/github-patches
|
git_diff
|
fonttools__fonttools-1205
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[ttGlyphPen] decompose components if transform overflows F2Dot14
https://github.com/googlei18n/ufo2ft/issues/217
The UFO GLIF spec allows any numbers for xScale, xyScale, yxScale, yScale, xOffset, yOffset, however the OpenType glyf spec uses F2Dot14 numbers, which are encoded as a signed 16-bit integer and therefore can only contain values from -32768 (-0x8000, or -2.0) to +32767 included (0x7FFF, or +1.99993896484375...).
We can't let the `struct.error` propagate.
I think we have to handle the case of +2.0 specially, and treat it as if it were 1.99993896484375. By doing that we can support truetype component transforms in the range -2.0 to +2.0 (inclusive), for the sake of simplicity.
Then, we also need to have the ttGlyphPen decompose the components if their transform values are less than -2.0 or they are greater than +2.0 (not greater and equal), as these can't fit in the TrueType glyf table.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Lib/fontTools/pens/ttGlyphPen.py`
Content:
```
1 from __future__ import print_function, division, absolute_import
2 from fontTools.misc.py23 import *
3 from array import array
4 from fontTools.pens.basePen import AbstractPen
5 from fontTools.pens.transformPen import TransformPen
6 from fontTools.ttLib.tables import ttProgram
7 from fontTools.ttLib.tables._g_l_y_f import Glyph
8 from fontTools.ttLib.tables._g_l_y_f import GlyphComponent
9 from fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates
10
11
12 __all__ = ["TTGlyphPen"]
13
14
15 class TTGlyphPen(AbstractPen):
16 """Pen used for drawing to a TrueType glyph."""
17
18 def __init__(self, glyphSet):
19 self.glyphSet = glyphSet
20 self.init()
21
22 def init(self):
23 self.points = []
24 self.endPts = []
25 self.types = []
26 self.components = []
27
28 def _addPoint(self, pt, onCurve):
29 self.points.append(pt)
30 self.types.append(onCurve)
31
32 def _popPoint(self):
33 self.points.pop()
34 self.types.pop()
35
36 def _isClosed(self):
37 return (
38 (not self.points) or
39 (self.endPts and self.endPts[-1] == len(self.points) - 1))
40
41 def lineTo(self, pt):
42 self._addPoint(pt, 1)
43
44 def moveTo(self, pt):
45 assert self._isClosed(), '"move"-type point must begin a new contour.'
46 self._addPoint(pt, 1)
47
48 def qCurveTo(self, *points):
49 assert len(points) >= 1
50 for pt in points[:-1]:
51 self._addPoint(pt, 0)
52
53 # last point is None if there are no on-curve points
54 if points[-1] is not None:
55 self._addPoint(points[-1], 1)
56
57 def closePath(self):
58 endPt = len(self.points) - 1
59
60 # ignore anchors (one-point paths)
61 if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):
62 self._popPoint()
63 return
64
65 # if first and last point on this path are the same, remove last
66 startPt = 0
67 if self.endPts:
68 startPt = self.endPts[-1] + 1
69 if self.points[startPt] == self.points[endPt]:
70 self._popPoint()
71 endPt -= 1
72
73 self.endPts.append(endPt)
74
75 def endPath(self):
76 # TrueType contours are always "closed"
77 self.closePath()
78
79 def addComponent(self, glyphName, transformation):
80 self.components.append((glyphName, transformation))
81
82 def glyph(self, componentFlags=0x4):
83 assert self._isClosed(), "Didn't close last contour."
84
85 components = []
86 for glyphName, transformation in self.components:
87 if self.points:
88 # can't have both, so decompose the glyph
89 tpen = TransformPen(self, transformation)
90 self.glyphSet[glyphName].draw(tpen)
91 continue
92
93 component = GlyphComponent()
94 component.glyphName = glyphName
95 if transformation[:4] != (1, 0, 0, 1):
96 component.transform = (transformation[:2], transformation[2:4])
97 component.x, component.y = transformation[4:]
98 component.flags = componentFlags
99 components.append(component)
100
101 glyph = Glyph()
102 glyph.coordinates = GlyphCoordinates(self.points)
103 glyph.endPtsOfContours = self.endPts
104 glyph.flags = array("B", self.types)
105 self.init()
106
107 if components:
108 glyph.components = components
109 glyph.numberOfContours = -1
110 else:
111 glyph.numberOfContours = len(glyph.endPtsOfContours)
112 glyph.program = ttProgram.Program()
113 glyph.program.fromBytecode(b"")
114
115 return glyph
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Lib/fontTools/pens/ttGlyphPen.py b/Lib/fontTools/pens/ttGlyphPen.py
--- a/Lib/fontTools/pens/ttGlyphPen.py
+++ b/Lib/fontTools/pens/ttGlyphPen.py
@@ -12,11 +12,32 @@
__all__ = ["TTGlyphPen"]
-class TTGlyphPen(AbstractPen):
- """Pen used for drawing to a TrueType glyph."""
+# the max value that can still fit in an F2Dot14:
+# 1.99993896484375
+MAX_F2DOT14 = 0x7FFF / (1 << 14)
+
- def __init__(self, glyphSet):
+class TTGlyphPen(AbstractPen):
+ """Pen used for drawing to a TrueType glyph.
+
+ If `handleOverflowingTransforms` is True, the components' transform values
+ are checked that they don't overflow the limits of a F2Dot14 number:
+ -2.0 <= v < +2.0. If any transform value exceeds these, the composite
+ glyph is decomposed.
+ An exception to this rule is done for values that are very close to +2.0
+ (both for consistency with the -2.0 case, and for the relative frequency
+ these occur in real fonts). When almost +2.0 values occur (and all other
+ values are within the range -2.0 <= x <= +2.0), they are clamped to the
+ maximum positive value that can still be encoded as an F2Dot14: i.e.
+ 1.99993896484375.
+ If False, no check is done and all components are translated unmodified
+ into the glyf table, followed by an inevitable `struct.error` once an
+ attempt is made to compile them.
+ """
+
+ def __init__(self, glyphSet, handleOverflowingTransforms=True):
self.glyphSet = glyphSet
+ self.handleOverflowingTransforms = handleOverflowingTransforms
self.init()
def init(self):
@@ -82,19 +103,33 @@
def glyph(self, componentFlags=0x4):
assert self._isClosed(), "Didn't close last contour."
+ if self.handleOverflowingTransforms:
+ # we can't encode transform values > 2 or < -2 in F2Dot14,
+ # so we must decompose the glyph if any transform exceeds these
+ overflowing = any(s > 2 or s < -2
+ for (glyphName, transformation) in self.components
+ for s in transformation[:4])
+
components = []
for glyphName, transformation in self.components:
- if self.points:
- # can't have both, so decompose the glyph
+ if (self.points or
+ (self.handleOverflowingTransforms and overflowing)):
+ # can't have both coordinates and components, so decompose
tpen = TransformPen(self, transformation)
self.glyphSet[glyphName].draw(tpen)
continue
component = GlyphComponent()
component.glyphName = glyphName
- if transformation[:4] != (1, 0, 0, 1):
- component.transform = (transformation[:2], transformation[2:4])
component.x, component.y = transformation[4:]
+ transformation = transformation[:4]
+ if transformation != (1, 0, 0, 1):
+ if (self.handleOverflowingTransforms and
+ any(MAX_F2DOT14 < s <= 2 for s in transformation)):
+ # clamp values ~= +2.0 so we can keep the component
+ transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2
+ else s for s in transformation)
+ component.transform = (transformation[:2], transformation[2:])
component.flags = componentFlags
components.append(component)
|
{"golden_diff": "diff --git a/Lib/fontTools/pens/ttGlyphPen.py b/Lib/fontTools/pens/ttGlyphPen.py\n--- a/Lib/fontTools/pens/ttGlyphPen.py\n+++ b/Lib/fontTools/pens/ttGlyphPen.py\n@@ -12,11 +12,32 @@\n __all__ = [\"TTGlyphPen\"]\n \n \n-class TTGlyphPen(AbstractPen):\n- \"\"\"Pen used for drawing to a TrueType glyph.\"\"\"\n+# the max value that can still fit in an F2Dot14:\n+# 1.99993896484375\n+MAX_F2DOT14 = 0x7FFF / (1 << 14)\n+\n \n- def __init__(self, glyphSet):\n+class TTGlyphPen(AbstractPen):\n+ \"\"\"Pen used for drawing to a TrueType glyph.\n+\n+ If `handleOverflowingTransforms` is True, the components' transform values\n+ are checked that they don't overflow the limits of a F2Dot14 number:\n+ -2.0 <= v < +2.0. If any transform value exceeds these, the composite\n+ glyph is decomposed.\n+ An exception to this rule is done for values that are very close to +2.0\n+ (both for consistency with the -2.0 case, and for the relative frequency\n+ these occur in real fonts). When almost +2.0 values occur (and all other\n+ values are within the range -2.0 <= x <= +2.0), they are clamped to the\n+ maximum positive value that can still be encoded as an F2Dot14: i.e.\n+ 1.99993896484375.\n+ If False, no check is done and all components are translated unmodified\n+ into the glyf table, followed by an inevitable `struct.error` once an\n+ attempt is made to compile them.\n+ \"\"\"\n+\n+ def __init__(self, glyphSet, handleOverflowingTransforms=True):\n self.glyphSet = glyphSet\n+ self.handleOverflowingTransforms = handleOverflowingTransforms\n self.init()\n \n def init(self):\n@@ -82,19 +103,33 @@\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n \n+ if self.handleOverflowingTransforms:\n+ # we can't encode transform values > 2 or < -2 in F2Dot14,\n+ # so we must decompose the glyph if any transform exceeds these\n+ overflowing = any(s > 2 or s < -2\n+ for (glyphName, transformation) in self.components\n+ for s in transformation[:4])\n+\n components = []\n for glyphName, transformation in self.components:\n- if self.points:\n- # can't have both, so decompose the glyph\n+ if (self.points or\n+ (self.handleOverflowingTransforms and overflowing)):\n+ # can't have both coordinates and components, so decompose\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n \n component = GlyphComponent()\n component.glyphName = glyphName\n- if transformation[:4] != (1, 0, 0, 1):\n- component.transform = (transformation[:2], transformation[2:4])\n component.x, component.y = transformation[4:]\n+ transformation = transformation[:4]\n+ if transformation != (1, 0, 0, 1):\n+ if (self.handleOverflowingTransforms and\n+ any(MAX_F2DOT14 < s <= 2 for s in transformation)):\n+ # clamp values ~= +2.0 so we can keep the component\n+ transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2\n+ else s for s in transformation)\n+ component.transform = (transformation[:2], transformation[2:])\n component.flags = componentFlags\n components.append(component)\n", "issue": "[ttGlyphPen] decompose components if transform overflows F2Dot14\nhttps://github.com/googlei18n/ufo2ft/issues/217\r\n\r\nThe UFO GLIF spec allows any numbers for xScale, xyScale, yxScale, yScale, xOffset, yOffset, however the OpenType glyf spec uses F2Dot14 numbers, which are encoded as a signed 16-bit integer and therefore can only contain values from -32768 (-0x8000, or -2.0) to +32767 included (0x7FFF, or +1.99993896484375...).\r\n\r\nWe can't let the `struct.error` propagate.\r\n\r\nI think we have to handle the case of +2.0 specially, and treat it as if it were 1.99993896484375. By doing that we can support truetype component transforms in the range -2.0 to +2.0 (inclusive), for the sake of simplicity.\r\n\r\nThen, we also need to have the ttGlyphPen decompose the components if their transform values are less than -2.0 or they are greater than +2.0 (not greater and equal), as these can't fit in the TrueType glyf table.\r\n\r\n\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom array import array\nfrom fontTools.pens.basePen import AbstractPen\nfrom fontTools.pens.transformPen import TransformPen\nfrom fontTools.ttLib.tables import ttProgram\nfrom fontTools.ttLib.tables._g_l_y_f import Glyph\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphComponent\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates\n\n\n__all__ = [\"TTGlyphPen\"]\n\n\nclass TTGlyphPen(AbstractPen):\n \"\"\"Pen used for drawing to a TrueType glyph.\"\"\"\n\n def __init__(self, glyphSet):\n self.glyphSet = glyphSet\n self.init()\n\n def init(self):\n self.points = []\n self.endPts = []\n self.types = []\n self.components = []\n\n def _addPoint(self, pt, onCurve):\n self.points.append(pt)\n self.types.append(onCurve)\n\n def _popPoint(self):\n self.points.pop()\n self.types.pop()\n\n def _isClosed(self):\n return (\n (not self.points) or\n (self.endPts and self.endPts[-1] == len(self.points) - 1))\n\n def lineTo(self, pt):\n self._addPoint(pt, 1)\n\n def moveTo(self, pt):\n assert self._isClosed(), '\"move\"-type point must begin a new contour.'\n self._addPoint(pt, 1)\n\n def qCurveTo(self, *points):\n assert len(points) >= 1\n for pt in points[:-1]:\n self._addPoint(pt, 0)\n\n # last point is None if there are no on-curve points\n if points[-1] is not None:\n self._addPoint(points[-1], 1)\n\n def closePath(self):\n endPt = len(self.points) - 1\n\n # ignore anchors (one-point paths)\n if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):\n self._popPoint()\n return\n\n # if first and last point on this path are the same, remove last\n startPt = 0\n if self.endPts:\n startPt = self.endPts[-1] + 1\n if self.points[startPt] == self.points[endPt]:\n self._popPoint()\n endPt -= 1\n\n self.endPts.append(endPt)\n\n def endPath(self):\n # TrueType contours are always \"closed\"\n self.closePath()\n\n def addComponent(self, glyphName, transformation):\n self.components.append((glyphName, transformation))\n\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n\n components = []\n for glyphName, transformation in self.components:\n if self.points:\n # can't have both, so decompose the glyph\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n\n component = GlyphComponent()\n component.glyphName = glyphName\n if transformation[:4] != (1, 0, 0, 1):\n component.transform = (transformation[:2], transformation[2:4])\n component.x, component.y = transformation[4:]\n component.flags = componentFlags\n components.append(component)\n\n glyph = Glyph()\n glyph.coordinates = GlyphCoordinates(self.points)\n glyph.endPtsOfContours = self.endPts\n glyph.flags = array(\"B\", self.types)\n self.init()\n\n if components:\n glyph.components = components\n glyph.numberOfContours = -1\n else:\n glyph.numberOfContours = len(glyph.endPtsOfContours)\n glyph.program = ttProgram.Program()\n glyph.program.fromBytecode(b\"\")\n\n return glyph\n", "path": "Lib/fontTools/pens/ttGlyphPen.py"}], "after_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom array import array\nfrom fontTools.pens.basePen import AbstractPen\nfrom fontTools.pens.transformPen import TransformPen\nfrom fontTools.ttLib.tables import ttProgram\nfrom fontTools.ttLib.tables._g_l_y_f import Glyph\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphComponent\nfrom fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates\n\n\n__all__ = [\"TTGlyphPen\"]\n\n\n# the max value that can still fit in an F2Dot14:\n# 1.99993896484375\nMAX_F2DOT14 = 0x7FFF / (1 << 14)\n\n\nclass TTGlyphPen(AbstractPen):\n \"\"\"Pen used for drawing to a TrueType glyph.\n\n If `handleOverflowingTransforms` is True, the components' transform values\n are checked that they don't overflow the limits of a F2Dot14 number:\n -2.0 <= v < +2.0. If any transform value exceeds these, the composite\n glyph is decomposed.\n An exception to this rule is done for values that are very close to +2.0\n (both for consistency with the -2.0 case, and for the relative frequency\n these occur in real fonts). When almost +2.0 values occur (and all other\n values are within the range -2.0 <= x <= +2.0), they are clamped to the\n maximum positive value that can still be encoded as an F2Dot14: i.e.\n 1.99993896484375.\n If False, no check is done and all components are translated unmodified\n into the glyf table, followed by an inevitable `struct.error` once an\n attempt is made to compile them.\n \"\"\"\n\n def __init__(self, glyphSet, handleOverflowingTransforms=True):\n self.glyphSet = glyphSet\n self.handleOverflowingTransforms = handleOverflowingTransforms\n self.init()\n\n def init(self):\n self.points = []\n self.endPts = []\n self.types = []\n self.components = []\n\n def _addPoint(self, pt, onCurve):\n self.points.append(pt)\n self.types.append(onCurve)\n\n def _popPoint(self):\n self.points.pop()\n self.types.pop()\n\n def _isClosed(self):\n return (\n (not self.points) or\n (self.endPts and self.endPts[-1] == len(self.points) - 1))\n\n def lineTo(self, pt):\n self._addPoint(pt, 1)\n\n def moveTo(self, pt):\n assert self._isClosed(), '\"move\"-type point must begin a new contour.'\n self._addPoint(pt, 1)\n\n def qCurveTo(self, *points):\n assert len(points) >= 1\n for pt in points[:-1]:\n self._addPoint(pt, 0)\n\n # last point is None if there are no on-curve points\n if points[-1] is not None:\n self._addPoint(points[-1], 1)\n\n def closePath(self):\n endPt = len(self.points) - 1\n\n # ignore anchors (one-point paths)\n if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1):\n self._popPoint()\n return\n\n # if first and last point on this path are the same, remove last\n startPt = 0\n if self.endPts:\n startPt = self.endPts[-1] + 1\n if self.points[startPt] == self.points[endPt]:\n self._popPoint()\n endPt -= 1\n\n self.endPts.append(endPt)\n\n def endPath(self):\n # TrueType contours are always \"closed\"\n self.closePath()\n\n def addComponent(self, glyphName, transformation):\n self.components.append((glyphName, transformation))\n\n def glyph(self, componentFlags=0x4):\n assert self._isClosed(), \"Didn't close last contour.\"\n\n if self.handleOverflowingTransforms:\n # we can't encode transform values > 2 or < -2 in F2Dot14,\n # so we must decompose the glyph if any transform exceeds these\n overflowing = any(s > 2 or s < -2\n for (glyphName, transformation) in self.components\n for s in transformation[:4])\n\n components = []\n for glyphName, transformation in self.components:\n if (self.points or\n (self.handleOverflowingTransforms and overflowing)):\n # can't have both coordinates and components, so decompose\n tpen = TransformPen(self, transformation)\n self.glyphSet[glyphName].draw(tpen)\n continue\n\n component = GlyphComponent()\n component.glyphName = glyphName\n component.x, component.y = transformation[4:]\n transformation = transformation[:4]\n if transformation != (1, 0, 0, 1):\n if (self.handleOverflowingTransforms and\n any(MAX_F2DOT14 < s <= 2 for s in transformation)):\n # clamp values ~= +2.0 so we can keep the component\n transformation = tuple(MAX_F2DOT14 if MAX_F2DOT14 < s <= 2\n else s for s in transformation)\n component.transform = (transformation[:2], transformation[2:])\n component.flags = componentFlags\n components.append(component)\n\n glyph = Glyph()\n glyph.coordinates = GlyphCoordinates(self.points)\n glyph.endPtsOfContours = self.endPts\n glyph.flags = array(\"B\", self.types)\n self.init()\n\n if components:\n glyph.components = components\n glyph.numberOfContours = -1\n else:\n glyph.numberOfContours = len(glyph.endPtsOfContours)\n glyph.program = ttProgram.Program()\n glyph.program.fromBytecode(b\"\")\n\n return glyph\n", "path": "Lib/fontTools/pens/ttGlyphPen.py"}]}
| 1,639 | 911 |
gh_patches_debug_21473
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-5331
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
syntax error in util/deprecation.py
line 24:
message += " " + extra.trim()
results in error: AttributeError: 'str' object has no attribute 'trim'
it should be instead:
message += " " + extra.strip()
that fixes the problem. I needed that change to get the happiness demo to run
Helmut Strey
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/util/deprecation.py`
Content:
```
1 import six
2 import warnings
3
4 class BokehDeprecationWarning(DeprecationWarning):
5 """ A specific ``DeprecationWarning`` subclass for Bokeh deprecations.
6 Used to selectively filter Bokeh deprecations for unconditional display.
7
8 """
9
10 def warn(message, stacklevel=2):
11 warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)
12
13 def deprecated(since_or_msg, old=None, new=None, extra=None):
14 """ Issue a nicely formatted deprecation warning. """
15
16 if isinstance(since_or_msg, tuple):
17 if old is None or new is None:
18 raise ValueError("deprecated entity and a replacement are required")
19
20 since = "%d.%d.%d" % since_or_msg
21 message = "%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead."
22 message = message % dict(old=old, since=since, new=new)
23 if extra is not None:
24 message += " " + extra.trim()
25 elif isinstance(since_or_msg, six.string_types):
26 if not (old is None and new is None and extra is None):
27 raise ValueError("deprecated(message) signature doesn't allow extra arguments")
28
29 message = since_or_msg
30 else:
31 raise ValueError("expected a version tuple or string message")
32
33 warn(message)
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/util/deprecation.py b/bokeh/util/deprecation.py
--- a/bokeh/util/deprecation.py
+++ b/bokeh/util/deprecation.py
@@ -17,11 +17,14 @@
if old is None or new is None:
raise ValueError("deprecated entity and a replacement are required")
+ if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):
+ raise ValueError("invalid version tuple: %r" % (since_or_msg,))
+
since = "%d.%d.%d" % since_or_msg
message = "%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead."
message = message % dict(old=old, since=since, new=new)
if extra is not None:
- message += " " + extra.trim()
+ message += " " + extra.strip()
elif isinstance(since_or_msg, six.string_types):
if not (old is None and new is None and extra is None):
raise ValueError("deprecated(message) signature doesn't allow extra arguments")
|
{"golden_diff": "diff --git a/bokeh/util/deprecation.py b/bokeh/util/deprecation.py\n--- a/bokeh/util/deprecation.py\n+++ b/bokeh/util/deprecation.py\n@@ -17,11 +17,14 @@\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n \n+ if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):\n+ raise ValueError(\"invalid version tuple: %r\" % (since_or_msg,))\n+\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n- message += \" \" + extra.trim()\n+ message += \" \" + extra.strip()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n", "issue": "syntax error in util/deprecation.py\nline 24:\n message += \" \" + extra.trim()\nresults in error: AttributeError: 'str' object has no attribute 'trim'\n\nit should be instead:\n message += \" \" + extra.strip()\n\nthat fixes the problem. I needed that change to get the happiness demo to run\n\nHelmut Strey\n\n", "before_files": [{"content": "import six\nimport warnings\n\nclass BokehDeprecationWarning(DeprecationWarning):\n \"\"\" A specific ``DeprecationWarning`` subclass for Bokeh deprecations.\n Used to selectively filter Bokeh deprecations for unconditional display.\n\n \"\"\"\n\ndef warn(message, stacklevel=2):\n warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)\n\ndef deprecated(since_or_msg, old=None, new=None, extra=None):\n \"\"\" Issue a nicely formatted deprecation warning. \"\"\"\n\n if isinstance(since_or_msg, tuple):\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n message += \" \" + extra.trim()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n\n message = since_or_msg\n else:\n raise ValueError(\"expected a version tuple or string message\")\n\n warn(message)\n", "path": "bokeh/util/deprecation.py"}], "after_files": [{"content": "import six\nimport warnings\n\nclass BokehDeprecationWarning(DeprecationWarning):\n \"\"\" A specific ``DeprecationWarning`` subclass for Bokeh deprecations.\n Used to selectively filter Bokeh deprecations for unconditional display.\n\n \"\"\"\n\ndef warn(message, stacklevel=2):\n warnings.warn(message, BokehDeprecationWarning, stacklevel=stacklevel)\n\ndef deprecated(since_or_msg, old=None, new=None, extra=None):\n \"\"\" Issue a nicely formatted deprecation warning. \"\"\"\n\n if isinstance(since_or_msg, tuple):\n if old is None or new is None:\n raise ValueError(\"deprecated entity and a replacement are required\")\n\n if len(since_or_msg) != 3 or not all(isinstance(x, int) and x >=0 for x in since_or_msg):\n raise ValueError(\"invalid version tuple: %r\" % (since_or_msg,))\n\n since = \"%d.%d.%d\" % since_or_msg\n message = \"%(old)s was deprecated in Bokeh %(since)s and will be removed, use %(new)s instead.\"\n message = message % dict(old=old, since=since, new=new)\n if extra is not None:\n message += \" \" + extra.strip()\n elif isinstance(since_or_msg, six.string_types):\n if not (old is None and new is None and extra is None):\n raise ValueError(\"deprecated(message) signature doesn't allow extra arguments\")\n\n message = since_or_msg\n else:\n raise ValueError(\"expected a version tuple or string message\")\n\n warn(message)\n", "path": "bokeh/util/deprecation.py"}]}
| 683 | 254 |
gh_patches_debug_8749
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-5160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Errors occur when update a page
### What I'm trying to achieve
Update a `Page`
### Steps to reproduce the problem
1. Call `Mutation.pageUpdate ` with `input: {}`
```bash
web_1 | ERROR saleor.graphql.errors.unhandled A query failed unexpectedly [PID:8:Thread-52]
web_1 | Traceback (most recent call last):
web_1 | File "/usr/local/lib/python3.8/site-packages/promise/promise.py", line 489, in _resolve_from_executor
web_1 | executor(resolve, reject)
web_1 | File "/usr/local/lib/python3.8/site-packages/promise/promise.py", line 756, in executor
web_1 | return resolve(f(*args, **kwargs))
web_1 | File "/usr/local/lib/python3.8/site-packages/graphql/execution/middleware.py", line 75, in make_it_promise
web_1 | return next(*args, **kwargs)
web_1 | File "/app/saleor/graphql/core/mutations.py", line 279, in mutate
web_1 | response = cls.perform_mutation(root, info, **data)
web_1 | File "/app/saleor/graphql/core/mutations.py", line 448, in perform_mutation
web_1 | cleaned_input = cls.clean_input(info, instance, data)
web_1 | File "/app/saleor/graphql/page/mutations.py", line 43, in clean_input
web_1 | cleaned_input["slug"] = slugify(cleaned_input["title"])
web_1 | KeyError: 'title'
```
### What I expected to happen
should update a `Page` without error
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/graphql/page/mutations.py`
Content:
```
1 import graphene
2 from django.utils.text import slugify
3
4 from ...core.permissions import PagePermissions
5 from ...page import models
6 from ..core.mutations import ModelDeleteMutation, ModelMutation
7 from ..core.types.common import SeoInput
8 from ..core.utils import clean_seo_fields
9
10
11 class PageInput(graphene.InputObjectType):
12 slug = graphene.String(description="Page internal name.")
13 title = graphene.String(description="Page title.")
14 content = graphene.String(
15 description=("Page content. May consist of ordinary text, HTML and images.")
16 )
17 content_json = graphene.JSONString(description="Page content in JSON format.")
18 is_published = graphene.Boolean(
19 description="Determines if page is visible in the storefront."
20 )
21 publication_date = graphene.String(
22 description="Publication date. ISO 8601 standard."
23 )
24 seo = SeoInput(description="Search engine optimization fields.")
25
26
27 class PageCreate(ModelMutation):
28 class Arguments:
29 input = PageInput(
30 required=True, description="Fields required to create a page."
31 )
32
33 class Meta:
34 description = "Creates a new page."
35 model = models.Page
36 permissions = (PagePermissions.MANAGE_PAGES,)
37
38 @classmethod
39 def clean_input(cls, info, instance, data):
40 cleaned_input = super().clean_input(info, instance, data)
41 slug = cleaned_input.get("slug", "")
42 if not slug:
43 cleaned_input["slug"] = slugify(cleaned_input["title"])
44 clean_seo_fields(cleaned_input)
45 return cleaned_input
46
47
48 class PageUpdate(PageCreate):
49 class Arguments:
50 id = graphene.ID(required=True, description="ID of a page to update.")
51 input = PageInput(
52 required=True, description="Fields required to update a page."
53 )
54
55 class Meta:
56 description = "Updates an existing page."
57 model = models.Page
58
59
60 class PageDelete(ModelDeleteMutation):
61 class Arguments:
62 id = graphene.ID(required=True, description="ID of a page to delete.")
63
64 class Meta:
65 description = "Deletes a page."
66 model = models.Page
67 permissions = (PagePermissions.MANAGE_PAGES,)
68
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/graphql/page/mutations.py b/saleor/graphql/page/mutations.py
--- a/saleor/graphql/page/mutations.py
+++ b/saleor/graphql/page/mutations.py
@@ -39,8 +39,9 @@
def clean_input(cls, info, instance, data):
cleaned_input = super().clean_input(info, instance, data)
slug = cleaned_input.get("slug", "")
- if not slug:
- cleaned_input["slug"] = slugify(cleaned_input["title"])
+ title = cleaned_input.get("title", "")
+ if title and not slug:
+ cleaned_input["slug"] = slugify(title)
clean_seo_fields(cleaned_input)
return cleaned_input
|
{"golden_diff": "diff --git a/saleor/graphql/page/mutations.py b/saleor/graphql/page/mutations.py\n--- a/saleor/graphql/page/mutations.py\n+++ b/saleor/graphql/page/mutations.py\n@@ -39,8 +39,9 @@\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n- if not slug:\n- cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\n+ title = cleaned_input.get(\"title\", \"\")\n+ if title and not slug:\n+ cleaned_input[\"slug\"] = slugify(title)\n clean_seo_fields(cleaned_input)\n return cleaned_input\n", "issue": "Errors occur when update a page\n### What I'm trying to achieve\r\nUpdate a `Page`\r\n\r\n### Steps to reproduce the problem\r\n1. Call `Mutation.pageUpdate ` with `input: {}`\r\n```bash\r\nweb_1 | ERROR saleor.graphql.errors.unhandled A query failed unexpectedly [PID:8:Thread-52]\r\nweb_1 | Traceback (most recent call last):\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/promise/promise.py\", line 489, in _resolve_from_executor\r\nweb_1 | executor(resolve, reject)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/promise/promise.py\", line 756, in executor\r\nweb_1 | return resolve(f(*args, **kwargs))\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/graphql/execution/middleware.py\", line 75, in make_it_promise\r\nweb_1 | return next(*args, **kwargs)\r\nweb_1 | File \"/app/saleor/graphql/core/mutations.py\", line 279, in mutate\r\nweb_1 | response = cls.perform_mutation(root, info, **data)\r\nweb_1 | File \"/app/saleor/graphql/core/mutations.py\", line 448, in perform_mutation\r\nweb_1 | cleaned_input = cls.clean_input(info, instance, data)\r\nweb_1 | File \"/app/saleor/graphql/page/mutations.py\", line 43, in clean_input\r\nweb_1 | cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\r\nweb_1 | KeyError: 'title'\r\n```\r\n\r\n### What I expected to happen\r\nshould update a `Page` without error\r\n\r\n\n", "before_files": [{"content": "import graphene\nfrom django.utils.text import slugify\n\nfrom ...core.permissions import PagePermissions\nfrom ...page import models\nfrom ..core.mutations import ModelDeleteMutation, ModelMutation\nfrom ..core.types.common import SeoInput\nfrom ..core.utils import clean_seo_fields\n\n\nclass PageInput(graphene.InputObjectType):\n slug = graphene.String(description=\"Page internal name.\")\n title = graphene.String(description=\"Page title.\")\n content = graphene.String(\n description=(\"Page content. May consist of ordinary text, HTML and images.\")\n )\n content_json = graphene.JSONString(description=\"Page content in JSON format.\")\n is_published = graphene.Boolean(\n description=\"Determines if page is visible in the storefront.\"\n )\n publication_date = graphene.String(\n description=\"Publication date. ISO 8601 standard.\"\n )\n seo = SeoInput(description=\"Search engine optimization fields.\")\n\n\nclass PageCreate(ModelMutation):\n class Arguments:\n input = PageInput(\n required=True, description=\"Fields required to create a page.\"\n )\n\n class Meta:\n description = \"Creates a new page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n\n @classmethod\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n if not slug:\n cleaned_input[\"slug\"] = slugify(cleaned_input[\"title\"])\n clean_seo_fields(cleaned_input)\n return cleaned_input\n\n\nclass PageUpdate(PageCreate):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to update.\")\n input = PageInput(\n required=True, description=\"Fields required to update a page.\"\n )\n\n class Meta:\n description = \"Updates an existing page.\"\n model = models.Page\n\n\nclass PageDelete(ModelDeleteMutation):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to delete.\")\n\n class Meta:\n description = \"Deletes a page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n", "path": "saleor/graphql/page/mutations.py"}], "after_files": [{"content": "import graphene\nfrom django.utils.text import slugify\n\nfrom ...core.permissions import PagePermissions\nfrom ...page import models\nfrom ..core.mutations import ModelDeleteMutation, ModelMutation\nfrom ..core.types.common import SeoInput\nfrom ..core.utils import clean_seo_fields\n\n\nclass PageInput(graphene.InputObjectType):\n slug = graphene.String(description=\"Page internal name.\")\n title = graphene.String(description=\"Page title.\")\n content = graphene.String(\n description=(\"Page content. May consist of ordinary text, HTML and images.\")\n )\n content_json = graphene.JSONString(description=\"Page content in JSON format.\")\n is_published = graphene.Boolean(\n description=\"Determines if page is visible in the storefront.\"\n )\n publication_date = graphene.String(\n description=\"Publication date. ISO 8601 standard.\"\n )\n seo = SeoInput(description=\"Search engine optimization fields.\")\n\n\nclass PageCreate(ModelMutation):\n class Arguments:\n input = PageInput(\n required=True, description=\"Fields required to create a page.\"\n )\n\n class Meta:\n description = \"Creates a new page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n\n @classmethod\n def clean_input(cls, info, instance, data):\n cleaned_input = super().clean_input(info, instance, data)\n slug = cleaned_input.get(\"slug\", \"\")\n title = cleaned_input.get(\"title\", \"\")\n if title and not slug:\n cleaned_input[\"slug\"] = slugify(title)\n clean_seo_fields(cleaned_input)\n return cleaned_input\n\n\nclass PageUpdate(PageCreate):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to update.\")\n input = PageInput(\n required=True, description=\"Fields required to update a page.\"\n )\n\n class Meta:\n description = \"Updates an existing page.\"\n model = models.Page\n\n\nclass PageDelete(ModelDeleteMutation):\n class Arguments:\n id = graphene.ID(required=True, description=\"ID of a page to delete.\")\n\n class Meta:\n description = \"Deletes a page.\"\n model = models.Page\n permissions = (PagePermissions.MANAGE_PAGES,)\n", "path": "saleor/graphql/page/mutations.py"}]}
| 1,242 | 159 |
gh_patches_debug_37638
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3791
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add thematic labels to indicator
The granular way of working with thematic labels attached to indicators is extremely prone to error at the FE due to the complexity of handling it, waiting for IDs assigned from backend for each label, etc. This will decrease UX as the component will have to freeze to wait for backend syncs and will break the normal pattern of auto-saving.
In order to wrap this up properly we need to have a simpler way of editing the labels attached to indicator, namely as a simple list of label **values**:
```
thematic_labels: [31, 17]
```
This property would need to be added to the indicator and to allow GET & PATCH.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rest/filters.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo Reporting is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 import ast
8
9 from django.db.models import Q
10 from django.core.exceptions import FieldError
11
12 from rest_framework import filters
13 from rest_framework.exceptions import APIException
14
15
16 class RSRGenericFilterBackend(filters.BaseFilterBackend):
17
18 def filter_queryset(self, request, queryset, view):
19 """
20 Return a queryset possibly filtered by query param values.
21 The filter looks for the query param keys filter and exclude
22 For each of these query param the value is evaluated using ast.literal_eval() and used as
23 kwargs in queryset.filter and queryset.exclude respectively.
24
25 Example URLs:
26 https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}
27 https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}
28
29 It's also possible to specify models to be included in select_related() and
30 prefetch_related() calls on the queryset, but specifying these in lists of strings as the
31 values for the query sting params select_relates and prefetch_related.
32
33 Example:
34 https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']
35
36 Finally limited support for filtering on multiple arguments using logical OR between
37 those expressions is available. To use this supply two or more query string keywords on the
38 form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q
39 object. All those Q objects created are used in a queryset.filter() call concatenated using
40 the | operator.
41 """
42 def eval_query_value(request, key):
43 """
44 Use ast.literal_eval() to evaluate a query string value as a python data type object
45 :param request: the django request object
46 :param param: the query string param key
47 :return: a python data type object, or None if literal_eval() fails
48 """
49 value = request.query_params.get(key, None)
50 try:
51 return ast.literal_eval(value)
52 except (ValueError, SyntaxError):
53 return None
54
55 qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']
56
57 # evaluate each query string param, and apply the queryset method with the same name
58 for param in qs_params:
59 args_or_kwargs = eval_query_value(request, param)
60 if args_or_kwargs:
61 # filter and exclude are called with a dict kwarg, the _related methods with a list
62 try:
63 if param in ['filter', 'exclude', ]:
64 queryset = getattr(queryset, param)(**args_or_kwargs)
65 else:
66 queryset = getattr(queryset, param)(*args_or_kwargs)
67
68 except FieldError as e:
69 raise APIException("Error in request: {message}".format(message=e.message))
70
71 # support for Q expressions, limited to OR-concatenated filtering
72 if request.query_params.get('q_filter1', None):
73 i = 1
74 q_queries = []
75 while request.query_params.get('q_filter{}'.format(i), None):
76 query_arg = eval_query_value(request, 'q_filter{}'.format(i))
77 if query_arg:
78 q_queries += [query_arg]
79 i += 1
80
81 q_expr = Q(**q_queries[0])
82 for query in q_queries[1:]:
83 q_expr = q_expr | Q(**query)
84
85 queryset = queryset.filter(q_expr)
86
87 return queryset
88
```
Path: `akvo/rest/serializers/indicator.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from akvo.rest.serializers.indicator_period import (
8 IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)
9 from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
10 from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
11 from akvo.rsr.models import Indicator, IndicatorDimensionName
12
13 from rest_framework import serializers
14
15
16 class IndicatorSerializer(BaseRSRSerializer):
17
18 result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
19 measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')
20 children_aggregate_percentage = serializers.ReadOnlyField()
21 dimension_names = serializers.PrimaryKeyRelatedField(
22 many=True, queryset=IndicatorDimensionName.objects.all())
23
24 class Meta:
25 model = Indicator
26 fields = '__all__'
27
28 # TODO: add validation for parent_indicator
29
30
31 class IndicatorFrameworkSerializer(BaseRSRSerializer):
32
33 periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)
34 parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
35 children_aggregate_percentage = serializers.ReadOnlyField()
36 dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
37
38 class Meta:
39 model = Indicator
40 fields = '__all__'
41
42
43 class IndicatorFrameworkLiteSerializer(BaseRSRSerializer):
44
45 periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)
46 parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
47 children_aggregate_percentage = serializers.ReadOnlyField()
48 dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
49
50 class Meta:
51 model = Indicator
52 fields = '__all__'
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rest/filters.py b/akvo/rest/filters.py
--- a/akvo/rest/filters.py
+++ b/akvo/rest/filters.py
@@ -84,4 +84,4 @@
queryset = queryset.filter(q_expr)
- return queryset
+ return queryset.distinct()
diff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py
--- a/akvo/rest/serializers/indicator.py
+++ b/akvo/rest/serializers/indicator.py
@@ -8,11 +8,29 @@
IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)
from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer
from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer
-from akvo.rsr.models import Indicator, IndicatorDimensionName
+from akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel
from rest_framework import serializers
+class LabelListingField(serializers.RelatedField):
+
+ def to_representation(self, labels):
+ return list(labels.values_list('label_id', flat=True))
+
+ def to_internal_value(self, org_label_ids):
+ indicator = self.root.instance
+ existing_labels = set(indicator.labels.values_list('label_id', flat=True))
+ new_labels = set(org_label_ids) - existing_labels
+ deleted_labels = existing_labels - set(org_label_ids)
+ labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]
+ IndicatorLabel.objects.bulk_create(labels)
+ if deleted_labels:
+ IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()
+
+ return indicator.labels.all()
+
+
class IndicatorSerializer(BaseRSRSerializer):
result_unicode = serializers.ReadOnlyField(source='result.__unicode__')
@@ -34,6 +52,7 @@
parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
children_aggregate_percentage = serializers.ReadOnlyField()
dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
+ labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)
class Meta:
model = Indicator
@@ -46,6 +65,7 @@
parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')
children_aggregate_percentage = serializers.ReadOnlyField()
dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)
+ labels = LabelListingField(read_only=True)
class Meta:
model = Indicator
|
{"golden_diff": "diff --git a/akvo/rest/filters.py b/akvo/rest/filters.py\n--- a/akvo/rest/filters.py\n+++ b/akvo/rest/filters.py\n@@ -84,4 +84,4 @@\n \n queryset = queryset.filter(q_expr)\n \n- return queryset\n+ return queryset.distinct()\ndiff --git a/akvo/rest/serializers/indicator.py b/akvo/rest/serializers/indicator.py\n--- a/akvo/rest/serializers/indicator.py\n+++ b/akvo/rest/serializers/indicator.py\n@@ -8,11 +8,29 @@\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\n from akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\n from akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\n-from akvo.rsr.models import Indicator, IndicatorDimensionName\n+from akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel\n \n from rest_framework import serializers\n \n \n+class LabelListingField(serializers.RelatedField):\n+\n+ def to_representation(self, labels):\n+ return list(labels.values_list('label_id', flat=True))\n+\n+ def to_internal_value(self, org_label_ids):\n+ indicator = self.root.instance\n+ existing_labels = set(indicator.labels.values_list('label_id', flat=True))\n+ new_labels = set(org_label_ids) - existing_labels\n+ deleted_labels = existing_labels - set(org_label_ids)\n+ labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]\n+ IndicatorLabel.objects.bulk_create(labels)\n+ if deleted_labels:\n+ IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()\n+\n+ return indicator.labels.all()\n+\n+\n class IndicatorSerializer(BaseRSRSerializer):\n \n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n@@ -34,6 +52,7 @@\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n+ labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)\n \n class Meta:\n model = Indicator\n@@ -46,6 +65,7 @@\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n+ labels = LabelListingField(read_only=True)\n \n class Meta:\n model = Indicator\n", "issue": "Add thematic labels to indicator\nThe granular way of working with thematic labels attached to indicators is extremely prone to error at the FE due to the complexity of handling it, waiting for IDs assigned from backend for each label, etc. This will decrease UX as the component will have to freeze to wait for backend syncs and will break the normal pattern of auto-saving.\r\nIn order to wrap this up properly we need to have a simpler way of editing the labels attached to indicator, namely as a simple list of label **values**:\r\n\r\n```\r\nthematic_labels: [31, 17]\r\n```\r\n\r\nThis property would need to be added to the indicator and to allow GET & PATCH.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nimport ast\n\nfrom django.db.models import Q\nfrom django.core.exceptions import FieldError\n\nfrom rest_framework import filters\nfrom rest_framework.exceptions import APIException\n\n\nclass RSRGenericFilterBackend(filters.BaseFilterBackend):\n\n def filter_queryset(self, request, queryset, view):\n \"\"\"\n Return a queryset possibly filtered by query param values.\n The filter looks for the query param keys filter and exclude\n For each of these query param the value is evaluated using ast.literal_eval() and used as\n kwargs in queryset.filter and queryset.exclude respectively.\n\n Example URLs:\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}\n\n It's also possible to specify models to be included in select_related() and\n prefetch_related() calls on the queryset, but specifying these in lists of strings as the\n values for the query sting params select_relates and prefetch_related.\n\n Example:\n https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']\n\n Finally limited support for filtering on multiple arguments using logical OR between\n those expressions is available. To use this supply two or more query string keywords on the\n form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q\n object. All those Q objects created are used in a queryset.filter() call concatenated using\n the | operator.\n \"\"\"\n def eval_query_value(request, key):\n \"\"\"\n Use ast.literal_eval() to evaluate a query string value as a python data type object\n :param request: the django request object\n :param param: the query string param key\n :return: a python data type object, or None if literal_eval() fails\n \"\"\"\n value = request.query_params.get(key, None)\n try:\n return ast.literal_eval(value)\n except (ValueError, SyntaxError):\n return None\n\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']\n\n # evaluate each query string param, and apply the queryset method with the same name\n for param in qs_params:\n args_or_kwargs = eval_query_value(request, param)\n if args_or_kwargs:\n # filter and exclude are called with a dict kwarg, the _related methods with a list\n try:\n if param in ['filter', 'exclude', ]:\n queryset = getattr(queryset, param)(**args_or_kwargs)\n else:\n queryset = getattr(queryset, param)(*args_or_kwargs)\n\n except FieldError as e:\n raise APIException(\"Error in request: {message}\".format(message=e.message))\n\n # support for Q expressions, limited to OR-concatenated filtering\n if request.query_params.get('q_filter1', None):\n i = 1\n q_queries = []\n while request.query_params.get('q_filter{}'.format(i), None):\n query_arg = eval_query_value(request, 'q_filter{}'.format(i))\n if query_arg:\n q_queries += [query_arg]\n i += 1\n\n q_expr = Q(**q_queries[0])\n for query in q_queries[1:]:\n q_expr = q_expr | Q(**query)\n\n queryset = queryset.filter(q_expr)\n\n return queryset\n", "path": "akvo/rest/filters.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import (\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator, IndicatorDimensionName\n\nfrom rest_framework import serializers\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = serializers.PrimaryKeyRelatedField(\n many=True, queryset=IndicatorDimensionName.objects.all())\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n\nclass IndicatorFrameworkLiteSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo Reporting is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nimport ast\n\nfrom django.db.models import Q\nfrom django.core.exceptions import FieldError\n\nfrom rest_framework import filters\nfrom rest_framework.exceptions import APIException\n\n\nclass RSRGenericFilterBackend(filters.BaseFilterBackend):\n\n def filter_queryset(self, request, queryset, view):\n \"\"\"\n Return a queryset possibly filtered by query param values.\n The filter looks for the query param keys filter and exclude\n For each of these query param the value is evaluated using ast.literal_eval() and used as\n kwargs in queryset.filter and queryset.exclude respectively.\n\n Example URLs:\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water','currency':'EUR'}\n https://rsr.akvo.org/rest/v1/project/?filter={'title__icontains':'water'}&exclude={'currency':'EUR'}\n\n It's also possible to specify models to be included in select_related() and\n prefetch_related() calls on the queryset, but specifying these in lists of strings as the\n values for the query sting params select_relates and prefetch_related.\n\n Example:\n https://rsr.akvo.org/rest/v1/project/?filter={'partners__in':[42,43]}&prefetch_related=['partners']\n\n Finally limited support for filtering on multiple arguments using logical OR between\n those expressions is available. To use this supply two or more query string keywords on the\n form q_filter1, q_filter2... where the value is a dict that can be used as a kwarg in a Q\n object. All those Q objects created are used in a queryset.filter() call concatenated using\n the | operator.\n \"\"\"\n def eval_query_value(request, key):\n \"\"\"\n Use ast.literal_eval() to evaluate a query string value as a python data type object\n :param request: the django request object\n :param param: the query string param key\n :return: a python data type object, or None if literal_eval() fails\n \"\"\"\n value = request.query_params.get(key, None)\n try:\n return ast.literal_eval(value)\n except (ValueError, SyntaxError):\n return None\n\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related']\n\n # evaluate each query string param, and apply the queryset method with the same name\n for param in qs_params:\n args_or_kwargs = eval_query_value(request, param)\n if args_or_kwargs:\n # filter and exclude are called with a dict kwarg, the _related methods with a list\n try:\n if param in ['filter', 'exclude', ]:\n queryset = getattr(queryset, param)(**args_or_kwargs)\n else:\n queryset = getattr(queryset, param)(*args_or_kwargs)\n\n except FieldError as e:\n raise APIException(\"Error in request: {message}\".format(message=e.message))\n\n # support for Q expressions, limited to OR-concatenated filtering\n if request.query_params.get('q_filter1', None):\n i = 1\n q_queries = []\n while request.query_params.get('q_filter{}'.format(i), None):\n query_arg = eval_query_value(request, 'q_filter{}'.format(i))\n if query_arg:\n q_queries += [query_arg]\n i += 1\n\n q_expr = Q(**q_queries[0])\n for query in q_queries[1:]:\n q_expr = q_expr | Q(**query)\n\n queryset = queryset.filter(q_expr)\n\n return queryset.distinct()\n", "path": "akvo/rest/filters.py"}, {"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.rest.serializers.indicator_period import (\n IndicatorPeriodFrameworkSerializer, IndicatorPeriodFrameworkLiteSerializer)\nfrom akvo.rest.serializers.indicator_dimension_name import IndicatorDimensionNameSerializer\nfrom akvo.rest.serializers.rsr_serializer import BaseRSRSerializer\nfrom akvo.rsr.models import Indicator, IndicatorDimensionName, IndicatorLabel\n\nfrom rest_framework import serializers\n\n\nclass LabelListingField(serializers.RelatedField):\n\n def to_representation(self, labels):\n return list(labels.values_list('label_id', flat=True))\n\n def to_internal_value(self, org_label_ids):\n indicator = self.root.instance\n existing_labels = set(indicator.labels.values_list('label_id', flat=True))\n new_labels = set(org_label_ids) - existing_labels\n deleted_labels = existing_labels - set(org_label_ids)\n labels = [IndicatorLabel(indicator=indicator, label_id=org_label_id) for org_label_id in new_labels]\n IndicatorLabel.objects.bulk_create(labels)\n if deleted_labels:\n IndicatorLabel.objects.filter(label_id__in=deleted_labels).delete()\n\n return indicator.labels.all()\n\n\nclass IndicatorSerializer(BaseRSRSerializer):\n\n result_unicode = serializers.ReadOnlyField(source='result.__unicode__')\n measure_label = serializers.ReadOnlyField(source='iati_measure_unicode')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = serializers.PrimaryKeyRelatedField(\n many=True, queryset=IndicatorDimensionName.objects.all())\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n # TODO: add validation for parent_indicator\n\n\nclass IndicatorFrameworkSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n labels = LabelListingField(queryset=IndicatorLabel.objects.all(), required=False)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n\n\nclass IndicatorFrameworkLiteSerializer(BaseRSRSerializer):\n\n periods = IndicatorPeriodFrameworkLiteSerializer(many=True, required=False, read_only=True)\n parent_indicator = serializers.ReadOnlyField(source='parent_indicator_id')\n children_aggregate_percentage = serializers.ReadOnlyField()\n dimension_names = IndicatorDimensionNameSerializer(many=True, required=False, read_only=True)\n labels = LabelListingField(read_only=True)\n\n class Meta:\n model = Indicator\n fields = '__all__'\n", "path": "akvo/rest/serializers/indicator.py"}]}
| 1,918 | 566 |
gh_patches_debug_5801
|
rasdani/github-patches
|
git_diff
|
sosreport__sos-3281
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Some MAAS config files missing from collection
Currently we're only collecting `/var/lib/maas/dhcp`, meaning that we're missing other key config files that would help with troubleshooting MAAS issues, e.g., `/var/lib/maas/http`. I'd suggest to add the below paths to be collected:
* /var/lib/maas/http/*
* /var/lib/maas/*.conf
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sos/report/plugins/maas.py`
Content:
```
1 # Copyright (C) 2013 Adam Stokes <[email protected]>
2 #
3 # This file is part of the sos project: https://github.com/sosreport/sos
4 #
5 # This copyrighted material is made available to anyone wishing to use,
6 # modify, copy, or redistribute it subject to the terms and conditions of
7 # version 2 of the GNU General Public License.
8 #
9 # See the LICENSE file in the source distribution for further information.
10
11 from sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt
12
13
14 class Maas(Plugin, UbuntuPlugin):
15
16 short_desc = 'Ubuntu Metal-As-A-Service'
17
18 plugin_name = 'maas'
19 profiles = ('sysmgmt',)
20 packages = ('maas', 'maas-common')
21
22 services = (
23 # For the deb:
24 'maas-dhcpd',
25 'maas-dhcpd6',
26 'maas-http',
27 'maas-proxy',
28 'maas-rackd',
29 'maas-regiond',
30 'maas-syslog',
31 # For the snap:
32 'snap.maas.supervisor',
33 )
34
35 option_list = [
36 PluginOpt('profile-name', default='', val_type=str,
37 desc='Name of the remote API'),
38 PluginOpt('url', default='', val_type=str,
39 desc='URL of the remote API'),
40 PluginOpt('credentials', default='', val_type=str,
41 desc='Credentials, or the API key')
42 ]
43
44 def _has_login_options(self):
45 return self.get_option("url") and self.get_option("credentials") \
46 and self.get_option("profile-name")
47
48 def _remote_api_login(self):
49 ret = self.exec_cmd(
50 "maas login %s %s %s" % (
51 self.get_option("profile-name"),
52 self.get_option("url"),
53 self.get_option("credentials")
54 )
55 )
56
57 return ret['status'] == 0
58
59 def _is_snap_installed(self):
60 maas_pkg = self.policy.package_manager.pkg_by_name('maas')
61 if maas_pkg:
62 return maas_pkg['pkg_manager'] == 'snap'
63 return False
64
65 def setup(self):
66 self._is_snap = self._is_snap_installed()
67 if self._is_snap:
68 self.add_cmd_output([
69 'snap info maas',
70 'maas status'
71 ])
72 # Don't send secrets
73 self.add_forbidden_path("/var/snap/maas/current/bind/session.key")
74 self.add_copy_spec([
75 "/var/snap/maas/common/log",
76 "/var/snap/maas/common/snap_mode",
77 "/var/snap/maas/current/*.conf",
78 "/var/snap/maas/current/bind",
79 "/var/snap/maas/current/http",
80 "/var/snap/maas/current/supervisord",
81 "/var/snap/maas/current/preseeds",
82 "/var/snap/maas/current/proxy",
83 "/var/snap/maas/current/rsyslog",
84 ])
85 else:
86 self.add_copy_spec([
87 "/etc/squid-deb-proxy",
88 "/etc/maas",
89 "/var/lib/maas/dhcp*",
90 "/var/log/apache2*",
91 "/var/log/maas*",
92 "/var/log/upstart/maas-*",
93 ])
94 self.add_cmd_output([
95 "apt-cache policy maas-*",
96 "apt-cache policy python-django-*",
97 ])
98
99 if self.is_installed("maas-region-controller"):
100 self.add_cmd_output([
101 "maas-region dumpdata",
102 ])
103
104 if self._has_login_options():
105 if self._remote_api_login():
106 self.add_cmd_output("maas %s commissioning-results list" %
107 self.get_option("profile-name"))
108 else:
109 self._log_error(
110 "Cannot login into MAAS remote API with provided creds.")
111
112 def postproc(self):
113 if self._is_snap:
114 regiond_path = "/var/snap/maas/current/maas/regiond.conf"
115 else:
116 regiond_path = "/etc/maas/regiond.conf"
117 self.do_file_sub(regiond_path,
118 r"(database_pass\s*:\s*)(.*)",
119 r"\1********")
120
121 # vim: set et ts=4 sw=4 :
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/sos/report/plugins/maas.py b/sos/report/plugins/maas.py
--- a/sos/report/plugins/maas.py
+++ b/sos/report/plugins/maas.py
@@ -87,6 +87,9 @@
"/etc/squid-deb-proxy",
"/etc/maas",
"/var/lib/maas/dhcp*",
+ "/var/lib/maas/http/*.conf",
+ "/var/lib/maas/*.conf",
+ "/var/lib/maas/rsyslog",
"/var/log/apache2*",
"/var/log/maas*",
"/var/log/upstart/maas-*",
|
{"golden_diff": "diff --git a/sos/report/plugins/maas.py b/sos/report/plugins/maas.py\n--- a/sos/report/plugins/maas.py\n+++ b/sos/report/plugins/maas.py\n@@ -87,6 +87,9 @@\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n+ \"/var/lib/maas/http/*.conf\",\n+ \"/var/lib/maas/*.conf\",\n+ \"/var/lib/maas/rsyslog\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n", "issue": "Some MAAS config files missing from collection\nCurrently we're only collecting `/var/lib/maas/dhcp`, meaning that we're missing other key config files that would help with troubleshooting MAAS issues, e.g., `/var/lib/maas/http`. I'd suggest to add the below paths to be collected:\r\n\r\n* /var/lib/maas/http/*\r\n* /var/lib/maas/*.conf\n", "before_files": [{"content": "# Copyright (C) 2013 Adam Stokes <[email protected]>\n#\n# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt\n\n\nclass Maas(Plugin, UbuntuPlugin):\n\n short_desc = 'Ubuntu Metal-As-A-Service'\n\n plugin_name = 'maas'\n profiles = ('sysmgmt',)\n packages = ('maas', 'maas-common')\n\n services = (\n # For the deb:\n 'maas-dhcpd',\n 'maas-dhcpd6',\n 'maas-http',\n 'maas-proxy',\n 'maas-rackd',\n 'maas-regiond',\n 'maas-syslog',\n # For the snap:\n 'snap.maas.supervisor',\n )\n\n option_list = [\n PluginOpt('profile-name', default='', val_type=str,\n desc='Name of the remote API'),\n PluginOpt('url', default='', val_type=str,\n desc='URL of the remote API'),\n PluginOpt('credentials', default='', val_type=str,\n desc='Credentials, or the API key')\n ]\n\n def _has_login_options(self):\n return self.get_option(\"url\") and self.get_option(\"credentials\") \\\n and self.get_option(\"profile-name\")\n\n def _remote_api_login(self):\n ret = self.exec_cmd(\n \"maas login %s %s %s\" % (\n self.get_option(\"profile-name\"),\n self.get_option(\"url\"),\n self.get_option(\"credentials\")\n )\n )\n\n return ret['status'] == 0\n\n def _is_snap_installed(self):\n maas_pkg = self.policy.package_manager.pkg_by_name('maas')\n if maas_pkg:\n return maas_pkg['pkg_manager'] == 'snap'\n return False\n\n def setup(self):\n self._is_snap = self._is_snap_installed()\n if self._is_snap:\n self.add_cmd_output([\n 'snap info maas',\n 'maas status'\n ])\n # Don't send secrets\n self.add_forbidden_path(\"/var/snap/maas/current/bind/session.key\")\n self.add_copy_spec([\n \"/var/snap/maas/common/log\",\n \"/var/snap/maas/common/snap_mode\",\n \"/var/snap/maas/current/*.conf\",\n \"/var/snap/maas/current/bind\",\n \"/var/snap/maas/current/http\",\n \"/var/snap/maas/current/supervisord\",\n \"/var/snap/maas/current/preseeds\",\n \"/var/snap/maas/current/proxy\",\n \"/var/snap/maas/current/rsyslog\",\n ])\n else:\n self.add_copy_spec([\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n ])\n self.add_cmd_output([\n \"apt-cache policy maas-*\",\n \"apt-cache policy python-django-*\",\n ])\n\n if self.is_installed(\"maas-region-controller\"):\n self.add_cmd_output([\n \"maas-region dumpdata\",\n ])\n\n if self._has_login_options():\n if self._remote_api_login():\n self.add_cmd_output(\"maas %s commissioning-results list\" %\n self.get_option(\"profile-name\"))\n else:\n self._log_error(\n \"Cannot login into MAAS remote API with provided creds.\")\n\n def postproc(self):\n if self._is_snap:\n regiond_path = \"/var/snap/maas/current/maas/regiond.conf\"\n else:\n regiond_path = \"/etc/maas/regiond.conf\"\n self.do_file_sub(regiond_path,\n r\"(database_pass\\s*:\\s*)(.*)\",\n r\"\\1********\")\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/maas.py"}], "after_files": [{"content": "# Copyright (C) 2013 Adam Stokes <[email protected]>\n#\n# This file is part of the sos project: https://github.com/sosreport/sos\n#\n# This copyrighted material is made available to anyone wishing to use,\n# modify, copy, or redistribute it subject to the terms and conditions of\n# version 2 of the GNU General Public License.\n#\n# See the LICENSE file in the source distribution for further information.\n\nfrom sos.report.plugins import Plugin, UbuntuPlugin, PluginOpt\n\n\nclass Maas(Plugin, UbuntuPlugin):\n\n short_desc = 'Ubuntu Metal-As-A-Service'\n\n plugin_name = 'maas'\n profiles = ('sysmgmt',)\n packages = ('maas', 'maas-common')\n\n services = (\n # For the deb:\n 'maas-dhcpd',\n 'maas-dhcpd6',\n 'maas-http',\n 'maas-proxy',\n 'maas-rackd',\n 'maas-regiond',\n 'maas-syslog',\n # For the snap:\n 'snap.maas.supervisor',\n )\n\n option_list = [\n PluginOpt('profile-name', default='', val_type=str,\n desc='Name of the remote API'),\n PluginOpt('url', default='', val_type=str,\n desc='URL of the remote API'),\n PluginOpt('credentials', default='', val_type=str,\n desc='Credentials, or the API key')\n ]\n\n def _has_login_options(self):\n return self.get_option(\"url\") and self.get_option(\"credentials\") \\\n and self.get_option(\"profile-name\")\n\n def _remote_api_login(self):\n ret = self.exec_cmd(\n \"maas login %s %s %s\" % (\n self.get_option(\"profile-name\"),\n self.get_option(\"url\"),\n self.get_option(\"credentials\")\n )\n )\n\n return ret['status'] == 0\n\n def _is_snap_installed(self):\n maas_pkg = self.policy.package_manager.pkg_by_name('maas')\n if maas_pkg:\n return maas_pkg['pkg_manager'] == 'snap'\n return False\n\n def setup(self):\n self._is_snap = self._is_snap_installed()\n if self._is_snap:\n self.add_cmd_output([\n 'snap info maas',\n 'maas status'\n ])\n # Don't send secrets\n self.add_forbidden_path(\"/var/snap/maas/current/bind/session.key\")\n self.add_copy_spec([\n \"/var/snap/maas/common/log\",\n \"/var/snap/maas/common/snap_mode\",\n \"/var/snap/maas/current/*.conf\",\n \"/var/snap/maas/current/bind\",\n \"/var/snap/maas/current/http\",\n \"/var/snap/maas/current/supervisord\",\n \"/var/snap/maas/current/preseeds\",\n \"/var/snap/maas/current/proxy\",\n \"/var/snap/maas/current/rsyslog\",\n ])\n else:\n self.add_copy_spec([\n \"/etc/squid-deb-proxy\",\n \"/etc/maas\",\n \"/var/lib/maas/dhcp*\",\n \"/var/lib/maas/http/*.conf\",\n \"/var/lib/maas/*.conf\",\n \"/var/lib/maas/rsyslog\",\n \"/var/log/apache2*\",\n \"/var/log/maas*\",\n \"/var/log/upstart/maas-*\",\n ])\n self.add_cmd_output([\n \"apt-cache policy maas-*\",\n \"apt-cache policy python-django-*\",\n ])\n\n if self.is_installed(\"maas-region-controller\"):\n self.add_cmd_output([\n \"maas-region dumpdata\",\n ])\n\n if self._has_login_options():\n if self._remote_api_login():\n self.add_cmd_output(\"maas %s commissioning-results list\" %\n self.get_option(\"profile-name\"))\n else:\n self._log_error(\n \"Cannot login into MAAS remote API with provided creds.\")\n\n def postproc(self):\n if self._is_snap:\n regiond_path = \"/var/snap/maas/current/maas/regiond.conf\"\n else:\n regiond_path = \"/etc/maas/regiond.conf\"\n self.do_file_sub(regiond_path,\n r\"(database_pass\\s*:\\s*)(.*)\",\n r\"\\1********\")\n\n# vim: set et ts=4 sw=4 :\n", "path": "sos/report/plugins/maas.py"}]}
| 1,537 | 147 |
gh_patches_debug_12761
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-6057
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Occasional test failure in `TestWalkerAlias`
Occasionally, the result of `xp.random.uniform(0, 1, shape).astype(thr_dtype)` becomes `1.0`, and `self.threshold[index]` raises an `IndexError`.
https://ci.appveyor.com/project/pfnet/chainer/builds/21769400/job/96weerl928ipapc6
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/utils/walker_alias.py`
Content:
```
1 import numpy
2
3 import chainer
4 from chainer import backend
5 from chainer.backends import cuda
6
7
8 class WalkerAlias(object):
9 """Implementation of Walker's alias method.
10
11 This method generates a random sample from given probabilities
12 :math:`p_1, \\dots, p_n` in :math:`O(1)` time.
13 It is more efficient than :func:`~numpy.random.choice`.
14 This class works on both CPU and GPU.
15
16 Args:
17 probs (float list): Probabilities of entries. They are normalized with
18 `sum(probs)`.
19
20 See: `Wikipedia article <https://en.wikipedia.org/wiki/Alias_method>`_
21
22 """
23
24 def __init__(self, probs):
25 prob = numpy.array(probs, numpy.float32)
26 prob /= numpy.sum(prob)
27 threshold = numpy.ndarray(len(probs), numpy.float32)
28 values = numpy.ndarray(len(probs) * 2, numpy.int32)
29 il, ir = 0, 0
30 pairs = list(zip(prob, range(len(probs))))
31 pairs.sort()
32 for prob, i in pairs:
33 p = prob * len(probs)
34 while p > 1 and ir < il:
35 values[ir * 2 + 1] = i
36 p -= 1.0 - threshold[ir]
37 ir += 1
38 threshold[il] = p
39 values[il * 2] = i
40 il += 1
41 # fill the rest
42 for i in range(ir, len(probs)):
43 values[i * 2 + 1] = 0
44
45 assert((values < len(threshold)).all())
46 self.threshold = threshold
47 self.values = values
48 self._device = backend.CpuDevice()
49
50 @property
51 def device(self):
52 return self._device
53
54 @property
55 def use_gpu(self):
56 # TODO(niboshi): Maybe better to deprecate the property.
57 xp = self._device.xp
58 if xp is cuda.cupy:
59 return True
60 elif xp is numpy:
61 return False
62 raise RuntimeError(
63 'WalkerAlias.use_gpu attribute is only applicable for numpy or '
64 'cupy devices. Use WalkerAlias.device attribute for general '
65 'devices.')
66
67 def to_device(self, device):
68 device = chainer.get_device(device)
69 self.threshold = device.send(self.threshold)
70 self.values = device.send(self.values)
71 self._device = device
72 return self
73
74 def to_gpu(self):
75 """Make a sampler GPU mode.
76
77 """
78 return self.to_device(cuda.Device())
79
80 def to_cpu(self):
81 """Make a sampler CPU mode.
82
83 """
84 return self.to_device(backend.CpuDevice())
85
86 def sample(self, shape):
87 """Generates a random sample based on given probabilities.
88
89 Args:
90 shape (tuple of int): Shape of a return value.
91
92 Returns:
93 Returns a generated array with the given shape. If a sampler is in
94 CPU mode the return value is a :class:`numpy.ndarray` object, and
95 if it is in GPU mode the return value is a :class:`cupy.ndarray`
96 object.
97 """
98 xp = self._device.xp
99 with chainer.using_device(self._device):
100 if xp is cuda.cupy:
101 return self.sample_gpu(shape)
102 else:
103 return self.sample_xp(xp, shape)
104
105 def sample_xp(self, xp, shape):
106 thr_dtype = self.threshold.dtype
107 ps = xp.random.uniform(0, 1, shape).astype(thr_dtype)
108 pb = ps * len(self.threshold)
109 index = pb.astype(numpy.int32)
110 left_right = (
111 self.threshold[index]
112 < (pb - index.astype(thr_dtype)))
113 left_right = left_right.astype(numpy.int32)
114 return self.values[index * 2 + left_right]
115
116 def sample_gpu(self, shape):
117 ps = cuda.cupy.random.uniform(size=shape, dtype=numpy.float32)
118 vs = cuda.elementwise(
119 'T ps, raw T threshold , raw S values, int32 b',
120 'int32 vs',
121 '''
122 T pb = ps * b;
123 int index = __float2int_rd(pb);
124 // fill_uniform sometimes returns 1.0, so we need to check index
125 if (index >= b) {
126 index = 0;
127 }
128 int lr = threshold[index] < pb - index;
129 vs = values[index * 2 + lr];
130 ''',
131 'walker_alias_sample'
132 )(ps, self.threshold, self.values, len(self.threshold))
133 return vs
134
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/utils/walker_alias.py b/chainer/utils/walker_alias.py
--- a/chainer/utils/walker_alias.py
+++ b/chainer/utils/walker_alias.py
@@ -104,12 +104,11 @@
def sample_xp(self, xp, shape):
thr_dtype = self.threshold.dtype
- ps = xp.random.uniform(0, 1, shape).astype(thr_dtype)
- pb = ps * len(self.threshold)
+ pb = xp.random.uniform(0, len(self.threshold), shape)
index = pb.astype(numpy.int32)
left_right = (
self.threshold[index]
- < (pb - index.astype(thr_dtype)))
+ < (pb.astype(thr_dtype) - index.astype(thr_dtype)))
left_right = left_right.astype(numpy.int32)
return self.values[index * 2 + left_right]
|
{"golden_diff": "diff --git a/chainer/utils/walker_alias.py b/chainer/utils/walker_alias.py\n--- a/chainer/utils/walker_alias.py\n+++ b/chainer/utils/walker_alias.py\n@@ -104,12 +104,11 @@\n \n def sample_xp(self, xp, shape):\n thr_dtype = self.threshold.dtype\n- ps = xp.random.uniform(0, 1, shape).astype(thr_dtype)\n- pb = ps * len(self.threshold)\n+ pb = xp.random.uniform(0, len(self.threshold), shape)\n index = pb.astype(numpy.int32)\n left_right = (\n self.threshold[index]\n- < (pb - index.astype(thr_dtype)))\n+ < (pb.astype(thr_dtype) - index.astype(thr_dtype)))\n left_right = left_right.astype(numpy.int32)\n return self.values[index * 2 + left_right]\n", "issue": "Occasional test failure in `TestWalkerAlias`\nOccasionally, the result of `xp.random.uniform(0, 1, shape).astype(thr_dtype)` becomes `1.0`, and `self.threshold[index]` raises an `IndexError`.\r\n\r\nhttps://ci.appveyor.com/project/pfnet/chainer/builds/21769400/job/96weerl928ipapc6\n", "before_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer import backend\nfrom chainer.backends import cuda\n\n\nclass WalkerAlias(object):\n \"\"\"Implementation of Walker's alias method.\n\n This method generates a random sample from given probabilities\n :math:`p_1, \\\\dots, p_n` in :math:`O(1)` time.\n It is more efficient than :func:`~numpy.random.choice`.\n This class works on both CPU and GPU.\n\n Args:\n probs (float list): Probabilities of entries. They are normalized with\n `sum(probs)`.\n\n See: `Wikipedia article <https://en.wikipedia.org/wiki/Alias_method>`_\n\n \"\"\"\n\n def __init__(self, probs):\n prob = numpy.array(probs, numpy.float32)\n prob /= numpy.sum(prob)\n threshold = numpy.ndarray(len(probs), numpy.float32)\n values = numpy.ndarray(len(probs) * 2, numpy.int32)\n il, ir = 0, 0\n pairs = list(zip(prob, range(len(probs))))\n pairs.sort()\n for prob, i in pairs:\n p = prob * len(probs)\n while p > 1 and ir < il:\n values[ir * 2 + 1] = i\n p -= 1.0 - threshold[ir]\n ir += 1\n threshold[il] = p\n values[il * 2] = i\n il += 1\n # fill the rest\n for i in range(ir, len(probs)):\n values[i * 2 + 1] = 0\n\n assert((values < len(threshold)).all())\n self.threshold = threshold\n self.values = values\n self._device = backend.CpuDevice()\n\n @property\n def device(self):\n return self._device\n\n @property\n def use_gpu(self):\n # TODO(niboshi): Maybe better to deprecate the property.\n xp = self._device.xp\n if xp is cuda.cupy:\n return True\n elif xp is numpy:\n return False\n raise RuntimeError(\n 'WalkerAlias.use_gpu attribute is only applicable for numpy or '\n 'cupy devices. Use WalkerAlias.device attribute for general '\n 'devices.')\n\n def to_device(self, device):\n device = chainer.get_device(device)\n self.threshold = device.send(self.threshold)\n self.values = device.send(self.values)\n self._device = device\n return self\n\n def to_gpu(self):\n \"\"\"Make a sampler GPU mode.\n\n \"\"\"\n return self.to_device(cuda.Device())\n\n def to_cpu(self):\n \"\"\"Make a sampler CPU mode.\n\n \"\"\"\n return self.to_device(backend.CpuDevice())\n\n def sample(self, shape):\n \"\"\"Generates a random sample based on given probabilities.\n\n Args:\n shape (tuple of int): Shape of a return value.\n\n Returns:\n Returns a generated array with the given shape. If a sampler is in\n CPU mode the return value is a :class:`numpy.ndarray` object, and\n if it is in GPU mode the return value is a :class:`cupy.ndarray`\n object.\n \"\"\"\n xp = self._device.xp\n with chainer.using_device(self._device):\n if xp is cuda.cupy:\n return self.sample_gpu(shape)\n else:\n return self.sample_xp(xp, shape)\n\n def sample_xp(self, xp, shape):\n thr_dtype = self.threshold.dtype\n ps = xp.random.uniform(0, 1, shape).astype(thr_dtype)\n pb = ps * len(self.threshold)\n index = pb.astype(numpy.int32)\n left_right = (\n self.threshold[index]\n < (pb - index.astype(thr_dtype)))\n left_right = left_right.astype(numpy.int32)\n return self.values[index * 2 + left_right]\n\n def sample_gpu(self, shape):\n ps = cuda.cupy.random.uniform(size=shape, dtype=numpy.float32)\n vs = cuda.elementwise(\n 'T ps, raw T threshold , raw S values, int32 b',\n 'int32 vs',\n '''\n T pb = ps * b;\n int index = __float2int_rd(pb);\n // fill_uniform sometimes returns 1.0, so we need to check index\n if (index >= b) {\n index = 0;\n }\n int lr = threshold[index] < pb - index;\n vs = values[index * 2 + lr];\n ''',\n 'walker_alias_sample'\n )(ps, self.threshold, self.values, len(self.threshold))\n return vs\n", "path": "chainer/utils/walker_alias.py"}], "after_files": [{"content": "import numpy\n\nimport chainer\nfrom chainer import backend\nfrom chainer.backends import cuda\n\n\nclass WalkerAlias(object):\n \"\"\"Implementation of Walker's alias method.\n\n This method generates a random sample from given probabilities\n :math:`p_1, \\\\dots, p_n` in :math:`O(1)` time.\n It is more efficient than :func:`~numpy.random.choice`.\n This class works on both CPU and GPU.\n\n Args:\n probs (float list): Probabilities of entries. They are normalized with\n `sum(probs)`.\n\n See: `Wikipedia article <https://en.wikipedia.org/wiki/Alias_method>`_\n\n \"\"\"\n\n def __init__(self, probs):\n prob = numpy.array(probs, numpy.float32)\n prob /= numpy.sum(prob)\n threshold = numpy.ndarray(len(probs), numpy.float32)\n values = numpy.ndarray(len(probs) * 2, numpy.int32)\n il, ir = 0, 0\n pairs = list(zip(prob, range(len(probs))))\n pairs.sort()\n for prob, i in pairs:\n p = prob * len(probs)\n while p > 1 and ir < il:\n values[ir * 2 + 1] = i\n p -= 1.0 - threshold[ir]\n ir += 1\n threshold[il] = p\n values[il * 2] = i\n il += 1\n # fill the rest\n for i in range(ir, len(probs)):\n values[i * 2 + 1] = 0\n\n assert((values < len(threshold)).all())\n self.threshold = threshold\n self.values = values\n self._device = backend.CpuDevice()\n\n @property\n def device(self):\n return self._device\n\n @property\n def use_gpu(self):\n # TODO(niboshi): Maybe better to deprecate the property.\n xp = self._device.xp\n if xp is cuda.cupy:\n return True\n elif xp is numpy:\n return False\n raise RuntimeError(\n 'WalkerAlias.use_gpu attribute is only applicable for numpy or '\n 'cupy devices. Use WalkerAlias.device attribute for general '\n 'devices.')\n\n def to_device(self, device):\n device = chainer.get_device(device)\n self.threshold = device.send(self.threshold)\n self.values = device.send(self.values)\n self._device = device\n return self\n\n def to_gpu(self):\n \"\"\"Make a sampler GPU mode.\n\n \"\"\"\n return self.to_device(cuda.Device())\n\n def to_cpu(self):\n \"\"\"Make a sampler CPU mode.\n\n \"\"\"\n return self.to_device(backend.CpuDevice())\n\n def sample(self, shape):\n \"\"\"Generates a random sample based on given probabilities.\n\n Args:\n shape (tuple of int): Shape of a return value.\n\n Returns:\n Returns a generated array with the given shape. If a sampler is in\n CPU mode the return value is a :class:`numpy.ndarray` object, and\n if it is in GPU mode the return value is a :class:`cupy.ndarray`\n object.\n \"\"\"\n xp = self._device.xp\n with chainer.using_device(self._device):\n if xp is cuda.cupy:\n return self.sample_gpu(shape)\n else:\n return self.sample_xp(xp, shape)\n\n def sample_xp(self, xp, shape):\n thr_dtype = self.threshold.dtype\n pb = xp.random.uniform(0, len(self.threshold), shape)\n index = pb.astype(numpy.int32)\n left_right = (\n self.threshold[index]\n < (pb.astype(thr_dtype) - index.astype(thr_dtype)))\n left_right = left_right.astype(numpy.int32)\n return self.values[index * 2 + left_right]\n\n def sample_gpu(self, shape):\n ps = cuda.cupy.random.uniform(size=shape, dtype=numpy.float32)\n vs = cuda.elementwise(\n 'T ps, raw T threshold , raw S values, int32 b',\n 'int32 vs',\n '''\n T pb = ps * b;\n int index = __float2int_rd(pb);\n // fill_uniform sometimes returns 1.0, so we need to check index\n if (index >= b) {\n index = 0;\n }\n int lr = threshold[index] < pb - index;\n vs = values[index * 2 + lr];\n ''',\n 'walker_alias_sample'\n )(ps, self.threshold, self.values, len(self.threshold))\n return vs\n", "path": "chainer/utils/walker_alias.py"}]}
| 1,660 | 195 |
gh_patches_debug_14682
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-5902
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Depenendency Upgrades
The following dependencies have to be upgraded
- urllib3 = ">=1.24.2"
- SQLAlchemy = ">=1.3.0"
- Jinja2 = ">=2.10.1"
- marshmallow = ">=2.15.1"
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/admin_sales/locations.py`
Content:
```
1 from marshmallow_jsonapi import fields
2 from marshmallow_jsonapi.flask import Schema
3 from flask_rest_jsonapi import ResourceList
4 from sqlalchemy import func
5 from app.api.helpers.utilities import dasherize
6
7 from app.api.bootstrap import api
8 from app.models import db
9 from app.models.event import Event
10 from app.models.order import Order, OrderTicket
11
12
13 def sales_per_location_by_status(status):
14 return db.session.query(
15 Event.location_name.label('location'),
16 func.sum(Order.amount).label(status + '_sales'),
17 func.sum(OrderTicket.quantity).label(status + '_tickets')) \
18 .outerjoin(Order) \
19 .outerjoin(OrderTicket) \
20 .filter(Event.id == Order.event_id) \
21 .filter(Order.status == status) \
22 .group_by(Event.location_name, Order.status) \
23 .cte()
24
25
26 class AdminSalesByLocationSchema(Schema):
27 """
28 Sales summarized by location
29
30 Provides
31 location name,
32 count of tickets and total sales for orders grouped by status
33 """
34
35 class Meta:
36 type_ = 'admin-sales-by-location'
37 self_view = 'v1.admin_sales_by_location'
38 inflect = dasherize
39
40 id = fields.String()
41 location_name = fields.String()
42 sales = fields.Method('calc_sales')
43
44 @staticmethod
45 def calc_sales(obj):
46 """
47 Returns sales (dictionary with total sales and ticket count) for
48 placed, completed and pending orders
49 """
50 res = {'placed': {}, 'completed': {}, 'pending': {}}
51 res['placed']['sales_total'] = obj.placed_sales or 0
52 res['placed']['ticket_count'] = obj.placed_tickets or 0
53 res['completed']['sales_total'] = obj.completed_sales or 0
54 res['completed']['ticket_count'] = obj.completed_tickets or 0
55 res['pending']['sales_total'] = obj.pending_sales or 0
56 res['pending']['ticket_count'] = obj.pending_tickets or 0
57
58 return res
59
60
61 class AdminSalesByLocationList(ResourceList):
62 """
63 Resource for sales by location. Joins event locations and orders and
64 subsequently accumulates sales by status
65 """
66
67 def query(self, _):
68 locations = self.session.query(
69 Event.location_name,
70 Event.location_name.label('id')) \
71 .group_by(Event.location_name) \
72 .filter(Event.location_name.isnot(None)) \
73 .cte()
74
75 pending = sales_per_location_by_status('pending')
76 completed = sales_per_location_by_status('completed')
77 placed = sales_per_location_by_status('placed')
78
79 return self.session.query(locations, pending, completed, placed) \
80 .outerjoin(pending, pending.c.location == locations.c.location_name) \
81 .outerjoin(completed, completed.c.location == locations.c.location_name) \
82 .outerjoin(placed, placed.c.location == locations.c.location_name)
83
84 methods = ['GET']
85 decorators = (api.has_permission('is_admin'), )
86 schema = AdminSalesByLocationSchema
87 data_layer = {
88 'model': Event,
89 'session': db.session,
90 'methods': {
91 'query': query
92 }
93 }
94
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/admin_sales/locations.py b/app/api/admin_sales/locations.py
--- a/app/api/admin_sales/locations.py
+++ b/app/api/admin_sales/locations.py
@@ -15,8 +15,8 @@
Event.location_name.label('location'),
func.sum(Order.amount).label(status + '_sales'),
func.sum(OrderTicket.quantity).label(status + '_tickets')) \
- .outerjoin(Order) \
- .outerjoin(OrderTicket) \
+ .outerjoin(Order, Order.event_id == Event.id) \
+ .outerjoin(OrderTicket, OrderTicket.order_id == Order.id) \
.filter(Event.id == Order.event_id) \
.filter(Order.status == status) \
.group_by(Event.location_name, Order.status) \
|
{"golden_diff": "diff --git a/app/api/admin_sales/locations.py b/app/api/admin_sales/locations.py\n--- a/app/api/admin_sales/locations.py\n+++ b/app/api/admin_sales/locations.py\n@@ -15,8 +15,8 @@\n Event.location_name.label('location'),\n func.sum(Order.amount).label(status + '_sales'),\n func.sum(OrderTicket.quantity).label(status + '_tickets')) \\\n- .outerjoin(Order) \\\n- .outerjoin(OrderTicket) \\\n+ .outerjoin(Order, Order.event_id == Event.id) \\\n+ .outerjoin(OrderTicket, OrderTicket.order_id == Order.id) \\\n .filter(Event.id == Order.event_id) \\\n .filter(Order.status == status) \\\n .group_by(Event.location_name, Order.status) \\\n", "issue": "Depenendency Upgrades\nThe following dependencies have to be upgraded\r\n\r\n- urllib3 = \">=1.24.2\"\r\n- SQLAlchemy = \">=1.3.0\"\r\n- Jinja2 = \">=2.10.1\"\r\n- marshmallow = \">=2.15.1\"\n", "before_files": [{"content": "from marshmallow_jsonapi import fields\nfrom marshmallow_jsonapi.flask import Schema\nfrom flask_rest_jsonapi import ResourceList\nfrom sqlalchemy import func\nfrom app.api.helpers.utilities import dasherize\n\nfrom app.api.bootstrap import api\nfrom app.models import db\nfrom app.models.event import Event\nfrom app.models.order import Order, OrderTicket\n\n\ndef sales_per_location_by_status(status):\n return db.session.query(\n Event.location_name.label('location'),\n func.sum(Order.amount).label(status + '_sales'),\n func.sum(OrderTicket.quantity).label(status + '_tickets')) \\\n .outerjoin(Order) \\\n .outerjoin(OrderTicket) \\\n .filter(Event.id == Order.event_id) \\\n .filter(Order.status == status) \\\n .group_by(Event.location_name, Order.status) \\\n .cte()\n\n\nclass AdminSalesByLocationSchema(Schema):\n \"\"\"\n Sales summarized by location\n\n Provides\n location name,\n count of tickets and total sales for orders grouped by status\n \"\"\"\n\n class Meta:\n type_ = 'admin-sales-by-location'\n self_view = 'v1.admin_sales_by_location'\n inflect = dasherize\n\n id = fields.String()\n location_name = fields.String()\n sales = fields.Method('calc_sales')\n\n @staticmethod\n def calc_sales(obj):\n \"\"\"\n Returns sales (dictionary with total sales and ticket count) for\n placed, completed and pending orders\n \"\"\"\n res = {'placed': {}, 'completed': {}, 'pending': {}}\n res['placed']['sales_total'] = obj.placed_sales or 0\n res['placed']['ticket_count'] = obj.placed_tickets or 0\n res['completed']['sales_total'] = obj.completed_sales or 0\n res['completed']['ticket_count'] = obj.completed_tickets or 0\n res['pending']['sales_total'] = obj.pending_sales or 0\n res['pending']['ticket_count'] = obj.pending_tickets or 0\n\n return res\n\n\nclass AdminSalesByLocationList(ResourceList):\n \"\"\"\n Resource for sales by location. Joins event locations and orders and\n subsequently accumulates sales by status\n \"\"\"\n\n def query(self, _):\n locations = self.session.query(\n Event.location_name,\n Event.location_name.label('id')) \\\n .group_by(Event.location_name) \\\n .filter(Event.location_name.isnot(None)) \\\n .cte()\n\n pending = sales_per_location_by_status('pending')\n completed = sales_per_location_by_status('completed')\n placed = sales_per_location_by_status('placed')\n\n return self.session.query(locations, pending, completed, placed) \\\n .outerjoin(pending, pending.c.location == locations.c.location_name) \\\n .outerjoin(completed, completed.c.location == locations.c.location_name) \\\n .outerjoin(placed, placed.c.location == locations.c.location_name)\n\n methods = ['GET']\n decorators = (api.has_permission('is_admin'), )\n schema = AdminSalesByLocationSchema\n data_layer = {\n 'model': Event,\n 'session': db.session,\n 'methods': {\n 'query': query\n }\n }\n", "path": "app/api/admin_sales/locations.py"}], "after_files": [{"content": "from marshmallow_jsonapi import fields\nfrom marshmallow_jsonapi.flask import Schema\nfrom flask_rest_jsonapi import ResourceList\nfrom sqlalchemy import func\nfrom app.api.helpers.utilities import dasherize\n\nfrom app.api.bootstrap import api\nfrom app.models import db\nfrom app.models.event import Event\nfrom app.models.order import Order, OrderTicket\n\n\ndef sales_per_location_by_status(status):\n return db.session.query(\n Event.location_name.label('location'),\n func.sum(Order.amount).label(status + '_sales'),\n func.sum(OrderTicket.quantity).label(status + '_tickets')) \\\n .outerjoin(Order, Order.event_id == Event.id) \\\n .outerjoin(OrderTicket, OrderTicket.order_id == Order.id) \\\n .filter(Event.id == Order.event_id) \\\n .filter(Order.status == status) \\\n .group_by(Event.location_name, Order.status) \\\n .cte()\n\n\nclass AdminSalesByLocationSchema(Schema):\n \"\"\"\n Sales summarized by location\n\n Provides\n location name,\n count of tickets and total sales for orders grouped by status\n \"\"\"\n\n class Meta:\n type_ = 'admin-sales-by-location'\n self_view = 'v1.admin_sales_by_location'\n inflect = dasherize\n\n id = fields.String()\n location_name = fields.String()\n sales = fields.Method('calc_sales')\n\n @staticmethod\n def calc_sales(obj):\n \"\"\"\n Returns sales (dictionary with total sales and ticket count) for\n placed, completed and pending orders\n \"\"\"\n res = {'placed': {}, 'completed': {}, 'pending': {}}\n res['placed']['sales_total'] = obj.placed_sales or 0\n res['placed']['ticket_count'] = obj.placed_tickets or 0\n res['completed']['sales_total'] = obj.completed_sales or 0\n res['completed']['ticket_count'] = obj.completed_tickets or 0\n res['pending']['sales_total'] = obj.pending_sales or 0\n res['pending']['ticket_count'] = obj.pending_tickets or 0\n\n return res\n\n\nclass AdminSalesByLocationList(ResourceList):\n \"\"\"\n Resource for sales by location. Joins event locations and orders and\n subsequently accumulates sales by status\n \"\"\"\n\n def query(self, _):\n locations = self.session.query(\n Event.location_name,\n Event.location_name.label('id')) \\\n .group_by(Event.location_name) \\\n .filter(Event.location_name.isnot(None)) \\\n .cte()\n\n pending = sales_per_location_by_status('pending')\n completed = sales_per_location_by_status('completed')\n placed = sales_per_location_by_status('placed')\n\n return self.session.query(locations, pending, completed, placed) \\\n .outerjoin(pending, pending.c.location == locations.c.location_name) \\\n .outerjoin(completed, completed.c.location == locations.c.location_name) \\\n .outerjoin(placed, placed.c.location == locations.c.location_name)\n\n methods = ['GET']\n decorators = (api.has_permission('is_admin'), )\n schema = AdminSalesByLocationSchema\n data_layer = {\n 'model': Event,\n 'session': db.session,\n 'methods': {\n 'query': query\n }\n }\n", "path": "app/api/admin_sales/locations.py"}]}
| 1,188 | 167 |
gh_patches_debug_6842
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-1480
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Drop Python 3.4 support
EOL 2019-03-19: https://devguide.python.org/#status-of-python-branches
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import io
2 import re
3
4 from setuptools import find_packages
5 from setuptools import setup
6
7 with io.open("README.rst", "rt", encoding="utf8") as f:
8 readme = f.read()
9
10 with io.open("src/werkzeug/__init__.py", "rt", encoding="utf8") as f:
11 version = re.search(r'__version__ = "(.*?)"', f.read(), re.M).group(1)
12
13 setup(
14 name="Werkzeug",
15 version=version,
16 url="https://palletsprojects.com/p/werkzeug/",
17 project_urls={
18 "Documentation": "https://werkzeug.palletsprojects.com/",
19 "Code": "https://github.com/pallets/werkzeug",
20 "Issue tracker": "https://github.com/pallets/werkzeug/issues",
21 },
22 license="BSD-3-Clause",
23 author="Armin Ronacher",
24 author_email="[email protected]",
25 maintainer="The Pallets Team",
26 maintainer_email="[email protected]",
27 description="The comprehensive WSGI web application library.",
28 long_description=readme,
29 classifiers=[
30 "Development Status :: 5 - Production/Stable",
31 "Environment :: Web Environment",
32 "Intended Audience :: Developers",
33 "License :: OSI Approved :: BSD License",
34 "Operating System :: OS Independent",
35 "Programming Language :: Python",
36 "Programming Language :: Python :: 2",
37 "Programming Language :: Python :: 2.7",
38 "Programming Language :: Python :: 3",
39 "Programming Language :: Python :: 3.4",
40 "Programming Language :: Python :: 3.5",
41 "Programming Language :: Python :: 3.6",
42 "Programming Language :: Python :: 3.7",
43 "Programming Language :: Python :: Implementation :: CPython",
44 "Programming Language :: Python :: Implementation :: PyPy",
45 "Topic :: Internet :: WWW/HTTP :: Dynamic Content",
46 "Topic :: Internet :: WWW/HTTP :: WSGI",
47 "Topic :: Internet :: WWW/HTTP :: WSGI :: Application",
48 "Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware",
49 "Topic :: Software Development :: Libraries :: Application Frameworks",
50 "Topic :: Software Development :: Libraries :: Python Modules",
51 ],
52 packages=find_packages("src"),
53 package_dir={"": "src"},
54 include_package_data=True,
55 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*",
56 extras_require={
57 "watchdog": ["watchdog"],
58 "termcolor": ["termcolor"],
59 "dev": [
60 "pytest",
61 "coverage",
62 "tox",
63 "sphinx",
64 "pallets-sphinx-themes",
65 "sphinx-issues",
66 ],
67 },
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -36,7 +36,6 @@
"Programming Language :: Python :: 2",
"Programming Language :: Python :: 2.7",
"Programming Language :: Python :: 3",
- "Programming Language :: Python :: 3.4",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -36,7 +36,6 @@\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n- \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n", "issue": "Drop Python 3.4 support\nEOL 2019-03-19: https://devguide.python.org/#status-of-python-branches\n", "before_files": [{"content": "import io\nimport re\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nwith io.open(\"README.rst\", \"rt\", encoding=\"utf8\") as f:\n readme = f.read()\n\nwith io.open(\"src/werkzeug/__init__.py\", \"rt\", encoding=\"utf8\") as f:\n version = re.search(r'__version__ = \"(.*?)\"', f.read(), re.M).group(1)\n\nsetup(\n name=\"Werkzeug\",\n version=version,\n url=\"https://palletsprojects.com/p/werkzeug/\",\n project_urls={\n \"Documentation\": \"https://werkzeug.palletsprojects.com/\",\n \"Code\": \"https://github.com/pallets/werkzeug\",\n \"Issue tracker\": \"https://github.com/pallets/werkzeug/issues\",\n },\n license=\"BSD-3-Clause\",\n author=\"Armin Ronacher\",\n author_email=\"[email protected]\",\n maintainer=\"The Pallets Team\",\n maintainer_email=\"[email protected]\",\n description=\"The comprehensive WSGI web application library.\",\n long_description=readme,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware\",\n \"Topic :: Software Development :: Libraries :: Application Frameworks\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n extras_require={\n \"watchdog\": [\"watchdog\"],\n \"termcolor\": [\"termcolor\"],\n \"dev\": [\n \"pytest\",\n \"coverage\",\n \"tox\",\n \"sphinx\",\n \"pallets-sphinx-themes\",\n \"sphinx-issues\",\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "import io\nimport re\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\nwith io.open(\"README.rst\", \"rt\", encoding=\"utf8\") as f:\n readme = f.read()\n\nwith io.open(\"src/werkzeug/__init__.py\", \"rt\", encoding=\"utf8\") as f:\n version = re.search(r'__version__ = \"(.*?)\"', f.read(), re.M).group(1)\n\nsetup(\n name=\"Werkzeug\",\n version=version,\n url=\"https://palletsprojects.com/p/werkzeug/\",\n project_urls={\n \"Documentation\": \"https://werkzeug.palletsprojects.com/\",\n \"Code\": \"https://github.com/pallets/werkzeug\",\n \"Issue tracker\": \"https://github.com/pallets/werkzeug/issues\",\n },\n license=\"BSD-3-Clause\",\n author=\"Armin Ronacher\",\n author_email=\"[email protected]\",\n maintainer=\"The Pallets Team\",\n maintainer_email=\"[email protected]\",\n description=\"The comprehensive WSGI web application library.\",\n long_description=readme,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP :: Dynamic Content\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Application\",\n \"Topic :: Internet :: WWW/HTTP :: WSGI :: Middleware\",\n \"Topic :: Software Development :: Libraries :: Application Frameworks\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*\",\n extras_require={\n \"watchdog\": [\"watchdog\"],\n \"termcolor\": [\"termcolor\"],\n \"dev\": [\n \"pytest\",\n \"coverage\",\n \"tox\",\n \"sphinx\",\n \"pallets-sphinx-themes\",\n \"sphinx-issues\",\n ],\n },\n)\n", "path": "setup.py"}]}
| 1,035 | 113 |
gh_patches_debug_1425
|
rasdani/github-patches
|
git_diff
|
unionai-oss__pandera-1209
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Why python_requires <3.12?
In https://github.com/unionai-oss/pandera/commit/547aff1672fe455741f380c8bec1ed648074effc, `python_requires` was changed from `>=3.7` to `>=3.7,<=3.11`, and in a later commit, the upper bound was again changed to `<3.12`. This forces every downstream package or application to lower the upper bound from the typical default <4.0, which is unfortunate.
For example, with poetry, using the default `python = "^3.x"` version specification, pandera is now downgraded, or if one tries to force a newer version, version resolution fails:
```
> poetry update pandera
• Updating pandera (0.15.1 -> 0.14.5)
```
```
> poetry add [email protected]
The current project's Python requirement (>=3.9,<4.0) is not compatible with some of the required packages Python requirement:
- pandera requires Python >=3.7,<3.12, so it will not be satisfied for Python >=3.12,<4.0
Because my_package depends on pandera (0.15.1) which requires Python >=3.7,<3.12, version solving failed.
```
Is there a known issue with pandera on python 3.12? Otherwise, I recommend removing the constraint. While pandera might not be tested on 3.12 yet, it's common to assume the language will be backwards compatible as described in [PEP 387](https://peps.python.org/pep-0387/).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import find_packages, setup
2
3 with open("README.md") as f:
4 long_description = f.read()
5
6 version = {}
7 with open("pandera/version.py") as fp:
8 exec(fp.read(), version)
9
10 _extras_require = {
11 "strategies": ["hypothesis >= 5.41.1"],
12 "hypotheses": ["scipy"],
13 "io": ["pyyaml >= 5.1", "black", "frictionless <= 4.40.8"],
14 "pyspark": ["pyspark >= 3.2.0"],
15 "modin": ["modin", "ray", "dask"],
16 "modin-ray": ["modin", "ray"],
17 "modin-dask": ["modin", "dask"],
18 "dask": ["dask"],
19 "mypy": ["pandas-stubs"],
20 "fastapi": ["fastapi"],
21 "geopandas": ["geopandas", "shapely"],
22 }
23
24 extras_require = {
25 **_extras_require,
26 "all": list(set(x for y in _extras_require.values() for x in y)),
27 }
28
29 setup(
30 name="pandera",
31 version=version["__version__"],
32 author="Niels Bantilan",
33 author_email="[email protected]",
34 description="A light-weight and flexible data validation and testing tool for statistical data objects.",
35 long_description=long_description,
36 long_description_content_type="text/markdown",
37 url="https://github.com/pandera-dev/pandera",
38 project_urls={
39 "Documentation": "https://pandera.readthedocs.io",
40 "Issue Tracker": "https://github.com/pandera-dev/pandera/issues",
41 },
42 keywords=["pandas", "validation", "data-structures"],
43 license="MIT",
44 data_files=[("", ["LICENSE.txt"])],
45 packages=find_packages(include=["pandera*"]),
46 package_data={"pandera": ["py.typed"]},
47 install_requires=[
48 "multimethod",
49 "numpy >= 1.19.0",
50 "packaging >= 20.0",
51 "pandas >= 1.2.0",
52 "pydantic",
53 "typeguard >= 3.0.2",
54 "typing_extensions >= 3.7.4.3 ; python_version<'3.8'",
55 "typing_inspect >= 0.6.0",
56 "wrapt",
57 ],
58 extras_require=extras_require,
59 python_requires=">=3.7,<3.12",
60 platforms="any",
61 classifiers=[
62 "Development Status :: 5 - Production/Stable",
63 "Operating System :: OS Independent",
64 "License :: OSI Approved :: MIT License",
65 "Intended Audience :: Science/Research",
66 "Programming Language :: Python",
67 "Programming Language :: Python :: 3",
68 "Programming Language :: Python :: 3.7",
69 "Programming Language :: Python :: 3.8",
70 "Programming Language :: Python :: 3.9",
71 "Programming Language :: Python :: 3.10",
72 "Programming Language :: Python :: 3.11",
73 "Topic :: Scientific/Engineering",
74 ],
75 )
76
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -56,7 +56,7 @@
"wrapt",
],
extras_require=extras_require,
- python_requires=">=3.7,<3.12",
+ python_requires=">=3.7",
platforms="any",
classifiers=[
"Development Status :: 5 - Production/Stable",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -56,7 +56,7 @@\n \"wrapt\",\n ],\n extras_require=extras_require,\n- python_requires=\">=3.7,<3.12\",\n+ python_requires=\">=3.7\",\n platforms=\"any\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n", "issue": "Why python_requires <3.12?\nIn https://github.com/unionai-oss/pandera/commit/547aff1672fe455741f380c8bec1ed648074effc, `python_requires` was changed from `>=3.7` to `>=3.7,<=3.11`, and in a later commit, the upper bound was again changed to `<3.12`. This forces every downstream package or application to lower the upper bound from the typical default <4.0, which is unfortunate.\r\n\r\nFor example, with poetry, using the default `python = \"^3.x\"` version specification, pandera is now downgraded, or if one tries to force a newer version, version resolution fails:\r\n\r\n```\r\n> poetry update pandera\r\n\r\n \u2022 Updating pandera (0.15.1 -> 0.14.5)\r\n```\r\n\r\n```\r\n> poetry add [email protected]\r\n\r\nThe current project's Python requirement (>=3.9,<4.0) is not compatible with some of the required packages Python requirement:\r\n - pandera requires Python >=3.7,<3.12, so it will not be satisfied for Python >=3.12,<4.0\r\n\r\nBecause my_package depends on pandera (0.15.1) which requires Python >=3.7,<3.12, version solving failed.\r\n```\r\n\r\nIs there a known issue with pandera on python 3.12? Otherwise, I recommend removing the constraint. While pandera might not be tested on 3.12 yet, it's common to assume the language will be backwards compatible as described in [PEP 387](https://peps.python.org/pep-0387/).\n", "before_files": [{"content": "from setuptools import find_packages, setup\n\nwith open(\"README.md\") as f:\n long_description = f.read()\n\nversion = {}\nwith open(\"pandera/version.py\") as fp:\n exec(fp.read(), version)\n\n_extras_require = {\n \"strategies\": [\"hypothesis >= 5.41.1\"],\n \"hypotheses\": [\"scipy\"],\n \"io\": [\"pyyaml >= 5.1\", \"black\", \"frictionless <= 4.40.8\"],\n \"pyspark\": [\"pyspark >= 3.2.0\"],\n \"modin\": [\"modin\", \"ray\", \"dask\"],\n \"modin-ray\": [\"modin\", \"ray\"],\n \"modin-dask\": [\"modin\", \"dask\"],\n \"dask\": [\"dask\"],\n \"mypy\": [\"pandas-stubs\"],\n \"fastapi\": [\"fastapi\"],\n \"geopandas\": [\"geopandas\", \"shapely\"],\n}\n\nextras_require = {\n **_extras_require,\n \"all\": list(set(x for y in _extras_require.values() for x in y)),\n}\n\nsetup(\n name=\"pandera\",\n version=version[\"__version__\"],\n author=\"Niels Bantilan\",\n author_email=\"[email protected]\",\n description=\"A light-weight and flexible data validation and testing tool for statistical data objects.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/pandera-dev/pandera\",\n project_urls={\n \"Documentation\": \"https://pandera.readthedocs.io\",\n \"Issue Tracker\": \"https://github.com/pandera-dev/pandera/issues\",\n },\n keywords=[\"pandas\", \"validation\", \"data-structures\"],\n license=\"MIT\",\n data_files=[(\"\", [\"LICENSE.txt\"])],\n packages=find_packages(include=[\"pandera*\"]),\n package_data={\"pandera\": [\"py.typed\"]},\n install_requires=[\n \"multimethod\",\n \"numpy >= 1.19.0\",\n \"packaging >= 20.0\",\n \"pandas >= 1.2.0\",\n \"pydantic\",\n \"typeguard >= 3.0.2\",\n \"typing_extensions >= 3.7.4.3 ; python_version<'3.8'\",\n \"typing_inspect >= 0.6.0\",\n \"wrapt\",\n ],\n extras_require=extras_require,\n python_requires=\">=3.7,<3.12\",\n platforms=\"any\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Operating System :: OS Independent\",\n \"License :: OSI Approved :: MIT License\",\n \"Intended Audience :: Science/Research\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import find_packages, setup\n\nwith open(\"README.md\") as f:\n long_description = f.read()\n\nversion = {}\nwith open(\"pandera/version.py\") as fp:\n exec(fp.read(), version)\n\n_extras_require = {\n \"strategies\": [\"hypothesis >= 5.41.1\"],\n \"hypotheses\": [\"scipy\"],\n \"io\": [\"pyyaml >= 5.1\", \"black\", \"frictionless <= 4.40.8\"],\n \"pyspark\": [\"pyspark >= 3.2.0\"],\n \"modin\": [\"modin\", \"ray\", \"dask\"],\n \"modin-ray\": [\"modin\", \"ray\"],\n \"modin-dask\": [\"modin\", \"dask\"],\n \"dask\": [\"dask\"],\n \"mypy\": [\"pandas-stubs\"],\n \"fastapi\": [\"fastapi\"],\n \"geopandas\": [\"geopandas\", \"shapely\"],\n}\n\nextras_require = {\n **_extras_require,\n \"all\": list(set(x for y in _extras_require.values() for x in y)),\n}\n\nsetup(\n name=\"pandera\",\n version=version[\"__version__\"],\n author=\"Niels Bantilan\",\n author_email=\"[email protected]\",\n description=\"A light-weight and flexible data validation and testing tool for statistical data objects.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/pandera-dev/pandera\",\n project_urls={\n \"Documentation\": \"https://pandera.readthedocs.io\",\n \"Issue Tracker\": \"https://github.com/pandera-dev/pandera/issues\",\n },\n keywords=[\"pandas\", \"validation\", \"data-structures\"],\n license=\"MIT\",\n data_files=[(\"\", [\"LICENSE.txt\"])],\n packages=find_packages(include=[\"pandera*\"]),\n package_data={\"pandera\": [\"py.typed\"]},\n install_requires=[\n \"multimethod\",\n \"numpy >= 1.19.0\",\n \"packaging >= 20.0\",\n \"pandas >= 1.2.0\",\n \"pydantic\",\n \"typeguard >= 3.0.2\",\n \"typing_extensions >= 3.7.4.3 ; python_version<'3.8'\",\n \"typing_inspect >= 0.6.0\",\n \"wrapt\",\n ],\n extras_require=extras_require,\n python_requires=\">=3.7\",\n platforms=\"any\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Operating System :: OS Independent\",\n \"License :: OSI Approved :: MIT License\",\n \"Intended Audience :: Science/Research\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering\",\n ],\n)\n", "path": "setup.py"}]}
| 1,484 | 91 |
gh_patches_debug_17488
|
rasdani/github-patches
|
git_diff
|
apache__airflow-1242
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GenericTransfer and Postgres - ERROR - SET AUTOCOMMIT TO OFF is no longer supported
Trying to implement a generic transfer
``` python
t1 = GenericTransfer(
task_id = 'copy_small_table',
sql = "select * from my_schema.my_table",
destination_table = "my_schema.my_table",
source_conn_id = "postgres9.1.13",
destination_conn_id = "postgres9.4.5",
dag=dag
)
```
I get the following error:
```
--------------------------------------------------------------------------------
New run starting @2015-11-25T11:05:40.673401
--------------------------------------------------------------------------------
[2015-11-25 11:05:40,698] {models.py:951} INFO - Executing <Task(GenericTransfer): copy_my_table_v1> on 2015-11-24 00:00:00
[2015-11-25 11:05:40,711] {base_hook.py:53} INFO - Using connection to: 10.x.x.x
[2015-11-25 11:05:40,711] {generic_transfer.py:53} INFO - Extracting data from my_db
[2015-11-25 11:05:40,711] {generic_transfer.py:54} INFO - Executing:
select * from my_schema.my_table
[2015-11-25 11:05:40,713] {base_hook.py:53} INFO - Using connection to: 10.x.x.x
[2015-11-25 11:05:40,808] {base_hook.py:53} INFO - Using connection to: 10.x.x.x
[2015-11-25 11:05:45,271] {base_hook.py:53} INFO - Using connection to: 10.x.x.x
[2015-11-25 11:05:45,272] {generic_transfer.py:63} INFO - Inserting rows into 10.x.x.x
[2015-11-25 11:05:45,273] {base_hook.py:53} INFO - Using connection to: 10.x.x.x
[2015-11-25 11:05:45,305] {models.py:1017} ERROR - SET AUTOCOMMIT TO OFF is no longer supported
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/airflow/models.py", line 977, in run
result = task_copy.execute(context=context)
File "/usr/local/lib/python2.7/dist-packages/airflow/operators/generic_transfer.py", line 64, in execute
destination_hook.insert_rows(table=self.destination_table, rows=results)
File "/usr/local/lib/python2.7/dist-packages/airflow/hooks/dbapi_hook.py", line 136, in insert_rows
cur.execute('SET autocommit = 0')
NotSupportedError: SET AUTOCOMMIT TO OFF is no longer supported
[2015-11-25 11:05:45,330] {models.py:1053} ERROR - SET AUTOCOMMIT TO OFF is no longer supported
```
Python 2.7
Airflow 1.6.1
psycopg2 2.6 (Also tried 2.6.1)
Postgeres destination 9.4.5
Any idea on what might cause this problem?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/hooks/postgres_hook.py`
Content:
```
1 import psycopg2
2
3 from airflow.hooks.dbapi_hook import DbApiHook
4
5
6 class PostgresHook(DbApiHook):
7 '''
8 Interact with Postgres.
9 You can specify ssl parameters in the extra field of your connection
10 as ``{"sslmode": "require", "sslcert": "/path/to/cert.pem", etc}``.
11 '''
12 conn_name_attr = 'postgres_conn_id'
13 default_conn_name = 'postgres_default'
14 supports_autocommit = True
15
16 def get_conn(self):
17 conn = self.get_connection(self.postgres_conn_id)
18 conn_args = dict(
19 host=conn.host,
20 user=conn.login,
21 password=conn.password,
22 dbname=conn.schema,
23 port=conn.port)
24 # check for ssl parameters in conn.extra
25 for arg_name, arg_val in conn.extra_dejson.items():
26 if arg_name in ['sslmode', 'sslcert', 'sslkey', 'sslrootcert', 'sslcrl']:
27 conn_args[arg_name] = arg_val
28 return psycopg2.connect(**conn_args)
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/hooks/postgres_hook.py b/airflow/hooks/postgres_hook.py
--- a/airflow/hooks/postgres_hook.py
+++ b/airflow/hooks/postgres_hook.py
@@ -11,7 +11,7 @@
'''
conn_name_attr = 'postgres_conn_id'
default_conn_name = 'postgres_default'
- supports_autocommit = True
+ supports_autocommit = False
def get_conn(self):
conn = self.get_connection(self.postgres_conn_id)
@@ -25,4 +25,7 @@
for arg_name, arg_val in conn.extra_dejson.items():
if arg_name in ['sslmode', 'sslcert', 'sslkey', 'sslrootcert', 'sslcrl']:
conn_args[arg_name] = arg_val
- return psycopg2.connect(**conn_args)
+ psycopg2_conn = psycopg2.connect(**conn_args)
+ if psycopg2_conn.server_version < 70400:
+ self.supports_autocommit = True
+ return psycopg2_conn
|
{"golden_diff": "diff --git a/airflow/hooks/postgres_hook.py b/airflow/hooks/postgres_hook.py\n--- a/airflow/hooks/postgres_hook.py\n+++ b/airflow/hooks/postgres_hook.py\n@@ -11,7 +11,7 @@\n '''\n conn_name_attr = 'postgres_conn_id'\n default_conn_name = 'postgres_default'\n- supports_autocommit = True\n+ supports_autocommit = False\n \n def get_conn(self):\n conn = self.get_connection(self.postgres_conn_id)\n@@ -25,4 +25,7 @@\n for arg_name, arg_val in conn.extra_dejson.items():\n if arg_name in ['sslmode', 'sslcert', 'sslkey', 'sslrootcert', 'sslcrl']:\n conn_args[arg_name] = arg_val\n- return psycopg2.connect(**conn_args)\n+ psycopg2_conn = psycopg2.connect(**conn_args)\n+ if psycopg2_conn.server_version < 70400:\n+ self.supports_autocommit = True\n+ return psycopg2_conn\n", "issue": "GenericTransfer and Postgres - ERROR - SET AUTOCOMMIT TO OFF is no longer supported\nTrying to implement a generic transfer\n\n``` python\nt1 = GenericTransfer(\n task_id = 'copy_small_table',\n sql = \"select * from my_schema.my_table\",\n destination_table = \"my_schema.my_table\",\n source_conn_id = \"postgres9.1.13\",\n destination_conn_id = \"postgres9.4.5\",\n dag=dag\n)\n```\n\nI get the following error:\n\n```\n--------------------------------------------------------------------------------\nNew run starting @2015-11-25T11:05:40.673401\n--------------------------------------------------------------------------------\n[2015-11-25 11:05:40,698] {models.py:951} INFO - Executing <Task(GenericTransfer): copy_my_table_v1> on 2015-11-24 00:00:00\n[2015-11-25 11:05:40,711] {base_hook.py:53} INFO - Using connection to: 10.x.x.x\n[2015-11-25 11:05:40,711] {generic_transfer.py:53} INFO - Extracting data from my_db\n[2015-11-25 11:05:40,711] {generic_transfer.py:54} INFO - Executing: \nselect * from my_schema.my_table\n[2015-11-25 11:05:40,713] {base_hook.py:53} INFO - Using connection to: 10.x.x.x\n[2015-11-25 11:05:40,808] {base_hook.py:53} INFO - Using connection to: 10.x.x.x\n[2015-11-25 11:05:45,271] {base_hook.py:53} INFO - Using connection to: 10.x.x.x\n[2015-11-25 11:05:45,272] {generic_transfer.py:63} INFO - Inserting rows into 10.x.x.x\n[2015-11-25 11:05:45,273] {base_hook.py:53} INFO - Using connection to: 10.x.x.x\n[2015-11-25 11:05:45,305] {models.py:1017} ERROR - SET AUTOCOMMIT TO OFF is no longer supported\nTraceback (most recent call last):\n File \"/usr/local/lib/python2.7/dist-packages/airflow/models.py\", line 977, in run\n result = task_copy.execute(context=context)\n File \"/usr/local/lib/python2.7/dist-packages/airflow/operators/generic_transfer.py\", line 64, in execute\n destination_hook.insert_rows(table=self.destination_table, rows=results)\n File \"/usr/local/lib/python2.7/dist-packages/airflow/hooks/dbapi_hook.py\", line 136, in insert_rows\n cur.execute('SET autocommit = 0')\nNotSupportedError: SET AUTOCOMMIT TO OFF is no longer supported\n\n[2015-11-25 11:05:45,330] {models.py:1053} ERROR - SET AUTOCOMMIT TO OFF is no longer supported\n```\n\nPython 2.7\nAirflow 1.6.1\npsycopg2 2.6 (Also tried 2.6.1)\nPostgeres destination 9.4.5\n\nAny idea on what might cause this problem?\n\n", "before_files": [{"content": "import psycopg2\n\nfrom airflow.hooks.dbapi_hook import DbApiHook\n\n\nclass PostgresHook(DbApiHook):\n '''\n Interact with Postgres.\n You can specify ssl parameters in the extra field of your connection\n as ``{\"sslmode\": \"require\", \"sslcert\": \"/path/to/cert.pem\", etc}``.\n '''\n conn_name_attr = 'postgres_conn_id'\n default_conn_name = 'postgres_default'\n supports_autocommit = True\n\n def get_conn(self):\n conn = self.get_connection(self.postgres_conn_id)\n conn_args = dict(\n host=conn.host,\n user=conn.login,\n password=conn.password,\n dbname=conn.schema,\n port=conn.port)\n # check for ssl parameters in conn.extra\n for arg_name, arg_val in conn.extra_dejson.items():\n if arg_name in ['sslmode', 'sslcert', 'sslkey', 'sslrootcert', 'sslcrl']:\n conn_args[arg_name] = arg_val\n return psycopg2.connect(**conn_args)\n", "path": "airflow/hooks/postgres_hook.py"}], "after_files": [{"content": "import psycopg2\n\nfrom airflow.hooks.dbapi_hook import DbApiHook\n\n\nclass PostgresHook(DbApiHook):\n '''\n Interact with Postgres.\n You can specify ssl parameters in the extra field of your connection\n as ``{\"sslmode\": \"require\", \"sslcert\": \"/path/to/cert.pem\", etc}``.\n '''\n conn_name_attr = 'postgres_conn_id'\n default_conn_name = 'postgres_default'\n supports_autocommit = False\n\n def get_conn(self):\n conn = self.get_connection(self.postgres_conn_id)\n conn_args = dict(\n host=conn.host,\n user=conn.login,\n password=conn.password,\n dbname=conn.schema,\n port=conn.port)\n # check for ssl parameters in conn.extra\n for arg_name, arg_val in conn.extra_dejson.items():\n if arg_name in ['sslmode', 'sslcert', 'sslkey', 'sslrootcert', 'sslcrl']:\n conn_args[arg_name] = arg_val\n psycopg2_conn = psycopg2.connect(**conn_args)\n if psycopg2_conn.server_version < 70400:\n self.supports_autocommit = True\n return psycopg2_conn\n", "path": "airflow/hooks/postgres_hook.py"}]}
| 1,415 | 233 |
gh_patches_debug_21534
|
rasdani/github-patches
|
git_diff
|
activeloopai__deeplake-75
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PermissionException on AWS
Facing issues with ds.store() on AWS while the same code works properly locally.
Error : `hub.exceptions.PermissionException: No permision to store the dataset at s3://snark-hub/public/abhinav/ds`
For now, got it working using `sudo rm -rf /tmp/dask-worker-space/`.
A proper fix is needed.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hub/collections/client_manager.py`
Content:
```
1 import psutil
2
3 import dask
4 import hub
5 from dask.cache import Cache
6
7 from dask.distributed import Client
8 from hub import config
9 from multiprocessing import current_process
10
11 from dask.callbacks import Callback
12 from timeit import default_timer
13 from numbers import Number
14 import sys
15
16 import psutil, os, time
17
18 _client = None
19
20
21 def get_client():
22 global _client
23 if _client is None:
24 _client = init()
25 return _client
26
27
28 def init(
29 token: str = "",
30 cloud=False,
31 n_workers=1,
32 memory_limit=None,
33 processes=False,
34 threads_per_worker=1,
35 distributed=True,
36 ):
37 """Initializes cluster either local or on the cloud
38
39 Parameters
40 ----------
41 token: str
42 token provided by snark
43 cache: float
44 Amount on local memory to cache locally, default 2e9 (2GB)
45 cloud: bool
46 Should be run locally or on the cloud
47 n_workers: int
48 number of concurrent workers, default to1
49 threads_per_worker: int
50 Number of threads per each worker
51 """
52 print("initialized")
53 global _client
54 if _client is not None:
55 _client.close()
56
57 if cloud:
58 raise NotImplementedError
59 elif not distributed:
60 client = None
61 dask.config.set(scheduler="threading")
62 hub.config.DISTRIBUTED = False
63 else:
64 n_workers = n_workers if n_workers is not None else psutil.cpu_count()
65 memory_limit = (
66 memory_limit
67 if memory_limit is not None
68 else psutil.virtual_memory().available
69 )
70 client = Client(
71 n_workers=n_workers,
72 processes=processes,
73 memory_limit=memory_limit,
74 threads_per_worker=threads_per_worker,
75 local_directory="/tmp/",
76 )
77 config.DISTRIBUTED = True
78
79 _client = client
80 return client
81
82
83 overhead = sys.getsizeof(1.23) * 4 + sys.getsizeof(()) * 4
84
85
86 class HubCache(Cache):
87 def _posttask(self, key, value, dsk, state, id):
88 duration = default_timer() - self.starttimes[key]
89 deps = state["dependencies"][key]
90 if deps:
91 duration += max(self.durations.get(k, 0) for k in deps)
92 self.durations[key] = duration
93 nb = self._nbytes(value) + overhead + sys.getsizeof(key) * 4
94
95 # _cost calculation has been fixed to avoid memory leak
96 _cost = duration
97 self.cache.put(key, value, cost=_cost, nbytes=nb)
98
99
100 # cache = HubCache(2e9)
101 # cache.register()
102
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hub/collections/client_manager.py b/hub/collections/client_manager.py
--- a/hub/collections/client_manager.py
+++ b/hub/collections/client_manager.py
@@ -35,7 +35,7 @@
distributed=True,
):
"""Initializes cluster either local or on the cloud
-
+
Parameters
----------
token: str
@@ -67,12 +67,20 @@
if memory_limit is not None
else psutil.virtual_memory().available
)
+
+ local_directory = os.path.join(
+ os.path.expanduser('~'),
+ '.activeloop',
+ 'tmp',
+ )
+ if not os.path.exists(local_directory):
+ os.makedirs(local_directory)
client = Client(
n_workers=n_workers,
processes=processes,
memory_limit=memory_limit,
threads_per_worker=threads_per_worker,
- local_directory="/tmp/",
+ local_directory=local_directory,
)
config.DISTRIBUTED = True
|
{"golden_diff": "diff --git a/hub/collections/client_manager.py b/hub/collections/client_manager.py\n--- a/hub/collections/client_manager.py\n+++ b/hub/collections/client_manager.py\n@@ -35,7 +35,7 @@\n distributed=True,\n ):\n \"\"\"Initializes cluster either local or on the cloud\n- \n+\n Parameters\n ----------\n token: str\n@@ -67,12 +67,20 @@\n if memory_limit is not None\n else psutil.virtual_memory().available\n )\n+\n+ local_directory = os.path.join(\n+ os.path.expanduser('~'),\n+ '.activeloop',\n+ 'tmp',\n+ )\n+ if not os.path.exists(local_directory):\n+ os.makedirs(local_directory)\n client = Client(\n n_workers=n_workers,\n processes=processes,\n memory_limit=memory_limit,\n threads_per_worker=threads_per_worker,\n- local_directory=\"/tmp/\",\n+ local_directory=local_directory,\n )\n config.DISTRIBUTED = True\n", "issue": "PermissionException on AWS\nFacing issues with ds.store() on AWS while the same code works properly locally.\r\nError : `hub.exceptions.PermissionException: No permision to store the dataset at s3://snark-hub/public/abhinav/ds`\r\n\r\nFor now, got it working using `sudo rm -rf /tmp/dask-worker-space/`.\r\nA proper fix is needed.\r\n\r\n\r\n\n", "before_files": [{"content": "import psutil\n\nimport dask\nimport hub\nfrom dask.cache import Cache\n\nfrom dask.distributed import Client\nfrom hub import config\nfrom multiprocessing import current_process\n\nfrom dask.callbacks import Callback\nfrom timeit import default_timer\nfrom numbers import Number\nimport sys\n\nimport psutil, os, time\n\n_client = None\n\n\ndef get_client():\n global _client\n if _client is None:\n _client = init()\n return _client\n\n\ndef init(\n token: str = \"\",\n cloud=False,\n n_workers=1,\n memory_limit=None,\n processes=False,\n threads_per_worker=1,\n distributed=True,\n):\n \"\"\"Initializes cluster either local or on the cloud\n \n Parameters\n ----------\n token: str\n token provided by snark\n cache: float\n Amount on local memory to cache locally, default 2e9 (2GB)\n cloud: bool\n Should be run locally or on the cloud\n n_workers: int\n number of concurrent workers, default to1\n threads_per_worker: int\n Number of threads per each worker\n \"\"\"\n print(\"initialized\")\n global _client\n if _client is not None:\n _client.close()\n\n if cloud:\n raise NotImplementedError\n elif not distributed:\n client = None\n dask.config.set(scheduler=\"threading\")\n hub.config.DISTRIBUTED = False\n else:\n n_workers = n_workers if n_workers is not None else psutil.cpu_count()\n memory_limit = (\n memory_limit\n if memory_limit is not None\n else psutil.virtual_memory().available\n )\n client = Client(\n n_workers=n_workers,\n processes=processes,\n memory_limit=memory_limit,\n threads_per_worker=threads_per_worker,\n local_directory=\"/tmp/\",\n )\n config.DISTRIBUTED = True\n\n _client = client\n return client\n\n\noverhead = sys.getsizeof(1.23) * 4 + sys.getsizeof(()) * 4\n\n\nclass HubCache(Cache):\n def _posttask(self, key, value, dsk, state, id):\n duration = default_timer() - self.starttimes[key]\n deps = state[\"dependencies\"][key]\n if deps:\n duration += max(self.durations.get(k, 0) for k in deps)\n self.durations[key] = duration\n nb = self._nbytes(value) + overhead + sys.getsizeof(key) * 4\n\n # _cost calculation has been fixed to avoid memory leak\n _cost = duration\n self.cache.put(key, value, cost=_cost, nbytes=nb)\n\n\n# cache = HubCache(2e9)\n# cache.register()\n", "path": "hub/collections/client_manager.py"}], "after_files": [{"content": "import psutil\n\nimport dask\nimport hub\nfrom dask.cache import Cache\n\nfrom dask.distributed import Client\nfrom hub import config\nfrom multiprocessing import current_process\n\nfrom dask.callbacks import Callback\nfrom timeit import default_timer\nfrom numbers import Number\nimport sys\n\nimport psutil, os, time\n\n_client = None\n\n\ndef get_client():\n global _client\n if _client is None:\n _client = init()\n return _client\n\n\ndef init(\n token: str = \"\",\n cloud=False,\n n_workers=1,\n memory_limit=None,\n processes=False,\n threads_per_worker=1,\n distributed=True,\n):\n \"\"\"Initializes cluster either local or on the cloud\n\n Parameters\n ----------\n token: str\n token provided by snark\n cache: float\n Amount on local memory to cache locally, default 2e9 (2GB)\n cloud: bool\n Should be run locally or on the cloud\n n_workers: int\n number of concurrent workers, default to1\n threads_per_worker: int\n Number of threads per each worker\n \"\"\"\n print(\"initialized\")\n global _client\n if _client is not None:\n _client.close()\n\n if cloud:\n raise NotImplementedError\n elif not distributed:\n client = None\n dask.config.set(scheduler=\"threading\")\n hub.config.DISTRIBUTED = False\n else:\n n_workers = n_workers if n_workers is not None else psutil.cpu_count()\n memory_limit = (\n memory_limit\n if memory_limit is not None\n else psutil.virtual_memory().available\n )\n\n local_directory = os.path.join(\n os.path.expanduser('~'),\n '.activeloop',\n 'tmp',\n )\n if not os.path.exists(local_directory):\n os.makedirs(local_directory)\n client = Client(\n n_workers=n_workers,\n processes=processes,\n memory_limit=memory_limit,\n threads_per_worker=threads_per_worker,\n local_directory=local_directory,\n )\n config.DISTRIBUTED = True\n\n _client = client\n return client\n\n\noverhead = sys.getsizeof(1.23) * 4 + sys.getsizeof(()) * 4\n\n\nclass HubCache(Cache):\n def _posttask(self, key, value, dsk, state, id):\n duration = default_timer() - self.starttimes[key]\n deps = state[\"dependencies\"][key]\n if deps:\n duration += max(self.durations.get(k, 0) for k in deps)\n self.durations[key] = duration\n nb = self._nbytes(value) + overhead + sys.getsizeof(key) * 4\n\n # _cost calculation has been fixed to avoid memory leak\n _cost = duration\n self.cache.put(key, value, cost=_cost, nbytes=nb)\n\n\n# cache = HubCache(2e9)\n# cache.register()\n", "path": "hub/collections/client_manager.py"}]}
| 1,137 | 223 |
gh_patches_debug_20880
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-92
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add pagination to the `chains/` endpoint
Add pagination support to `api/v1/chains`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/chains/views.py`
Content:
```
1 from drf_yasg.utils import swagger_auto_schema
2 from rest_framework.generics import ListAPIView
3
4 from .models import Chain
5 from .serializers import ChainSerializer
6
7
8 class ChainsListView(ListAPIView):
9 serializer_class = ChainSerializer
10
11 @swagger_auto_schema()
12 def get(self, request, *args, **kwargs):
13 return super().get(self, request, *args, **kwargs)
14
15 def get_queryset(self):
16 return Chain.objects.all()
17
```
Path: `src/safe_apps/views.py`
Content:
```
1 from django.utils.decorators import method_decorator
2 from django.views.decorators.cache import cache_page
3 from drf_yasg import openapi
4 from drf_yasg.utils import swagger_auto_schema
5 from rest_framework.generics import ListAPIView
6
7 from .models import SafeApp
8 from .serializers import SafeAppsResponseSerializer
9
10
11 class SafeAppsListView(ListAPIView):
12 serializer_class = SafeAppsResponseSerializer
13
14 _swagger_network_id_param = openapi.Parameter(
15 "chainId",
16 openapi.IN_QUERY,
17 description="Used to filter Safe Apps that are available on `chainId`",
18 type=openapi.TYPE_INTEGER,
19 )
20
21 @method_decorator(cache_page(60 * 10, cache="safe-apps")) # Cache 10 minutes
22 @swagger_auto_schema(manual_parameters=[_swagger_network_id_param])
23 def get(self, request, *args, **kwargs):
24 """
25 Returns a collection of Safe Apps (across different chains).
26 Each Safe App can optionally include the information about the `Provider`
27 """
28 return super().get(self, request, *args, **kwargs)
29
30 def get_queryset(self):
31 queryset = SafeApp.objects.all()
32
33 network_id = self.request.query_params.get("chainId")
34 if network_id is not None and network_id.isdigit():
35 queryset = queryset.filter(chain_ids__contains=[network_id])
36
37 return queryset
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/chains/views.py b/src/chains/views.py
--- a/src/chains/views.py
+++ b/src/chains/views.py
@@ -1,5 +1,6 @@
from drf_yasg.utils import swagger_auto_schema
from rest_framework.generics import ListAPIView
+from rest_framework.pagination import LimitOffsetPagination
from .models import Chain
from .serializers import ChainSerializer
@@ -7,6 +8,9 @@
class ChainsListView(ListAPIView):
serializer_class = ChainSerializer
+ pagination_class = LimitOffsetPagination
+ pagination_class.max_limit = 10
+ pagination_class.default_limit = 10
@swagger_auto_schema()
def get(self, request, *args, **kwargs):
diff --git a/src/safe_apps/views.py b/src/safe_apps/views.py
--- a/src/safe_apps/views.py
+++ b/src/safe_apps/views.py
@@ -10,6 +10,7 @@
class SafeAppsListView(ListAPIView):
serializer_class = SafeAppsResponseSerializer
+ pagination_class = None
_swagger_network_id_param = openapi.Parameter(
"chainId",
|
{"golden_diff": "diff --git a/src/chains/views.py b/src/chains/views.py\n--- a/src/chains/views.py\n+++ b/src/chains/views.py\n@@ -1,5 +1,6 @@\n from drf_yasg.utils import swagger_auto_schema\n from rest_framework.generics import ListAPIView\n+from rest_framework.pagination import LimitOffsetPagination\n \n from .models import Chain\n from .serializers import ChainSerializer\n@@ -7,6 +8,9 @@\n \n class ChainsListView(ListAPIView):\n serializer_class = ChainSerializer\n+ pagination_class = LimitOffsetPagination\n+ pagination_class.max_limit = 10\n+ pagination_class.default_limit = 10\n \n @swagger_auto_schema()\n def get(self, request, *args, **kwargs):\ndiff --git a/src/safe_apps/views.py b/src/safe_apps/views.py\n--- a/src/safe_apps/views.py\n+++ b/src/safe_apps/views.py\n@@ -10,6 +10,7 @@\n \n class SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n+ pagination_class = None\n \n _swagger_network_id_param = openapi.Parameter(\n \"chainId\",\n", "issue": "Add pagination to the `chains/` endpoint\nAdd pagination support to `api/v1/chains`\n", "before_files": [{"content": "from drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\n\nfrom .models import Chain\nfrom .serializers import ChainSerializer\n\n\nclass ChainsListView(ListAPIView):\n serializer_class = ChainSerializer\n\n @swagger_auto_schema()\n def get(self, request, *args, **kwargs):\n return super().get(self, request, *args, **kwargs)\n\n def get_queryset(self):\n return Chain.objects.all()\n", "path": "src/chains/views.py"}, {"content": "from django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\nfrom drf_yasg import openapi\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\n\nfrom .models import SafeApp\nfrom .serializers import SafeAppsResponseSerializer\n\n\nclass SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n\n _swagger_network_id_param = openapi.Parameter(\n \"chainId\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `chainId`\",\n type=openapi.TYPE_INTEGER,\n )\n\n @method_decorator(cache_page(60 * 10, cache=\"safe-apps\")) # Cache 10 minutes\n @swagger_auto_schema(manual_parameters=[_swagger_network_id_param])\n def get(self, request, *args, **kwargs):\n \"\"\"\n Returns a collection of Safe Apps (across different chains).\n Each Safe App can optionally include the information about the `Provider`\n \"\"\"\n return super().get(self, request, *args, **kwargs)\n\n def get_queryset(self):\n queryset = SafeApp.objects.all()\n\n network_id = self.request.query_params.get(\"chainId\")\n if network_id is not None and network_id.isdigit():\n queryset = queryset.filter(chain_ids__contains=[network_id])\n\n return queryset\n", "path": "src/safe_apps/views.py"}], "after_files": [{"content": "from drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.pagination import LimitOffsetPagination\n\nfrom .models import Chain\nfrom .serializers import ChainSerializer\n\n\nclass ChainsListView(ListAPIView):\n serializer_class = ChainSerializer\n pagination_class = LimitOffsetPagination\n pagination_class.max_limit = 10\n pagination_class.default_limit = 10\n\n @swagger_auto_schema()\n def get(self, request, *args, **kwargs):\n return super().get(self, request, *args, **kwargs)\n\n def get_queryset(self):\n return Chain.objects.all()\n", "path": "src/chains/views.py"}, {"content": "from django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\nfrom drf_yasg import openapi\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\n\nfrom .models import SafeApp\nfrom .serializers import SafeAppsResponseSerializer\n\n\nclass SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n pagination_class = None\n\n _swagger_network_id_param = openapi.Parameter(\n \"chainId\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `chainId`\",\n type=openapi.TYPE_INTEGER,\n )\n\n @method_decorator(cache_page(60 * 10, cache=\"safe-apps\")) # Cache 10 minutes\n @swagger_auto_schema(manual_parameters=[_swagger_network_id_param])\n def get(self, request, *args, **kwargs):\n \"\"\"\n Returns a collection of Safe Apps (across different chains).\n Each Safe App can optionally include the information about the `Provider`\n \"\"\"\n return super().get(self, request, *args, **kwargs)\n\n def get_queryset(self):\n queryset = SafeApp.objects.all()\n\n network_id = self.request.query_params.get(\"chainId\")\n if network_id is not None and network_id.isdigit():\n queryset = queryset.filter(chain_ids__contains=[network_id])\n\n return queryset\n", "path": "src/safe_apps/views.py"}]}
| 783 | 249 |
gh_patches_debug_41932
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-2014
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Taiwan TW.py parser fails
Help wanted! :)
Taiwan isn't showing any data at the moment and the parser has to be fixed.
This is the error message for TW.py of the logger:
'DataFrame' object has no attribute 'convert_objects'
I get this warning running the parser locally (probably with older versions of the libraries):
```
Python36-32/TW.py", line 32
objData = objData.convert_objects(convert_numeric=True)
FutureWarning: convert_objects is deprecated. To re-infer data dtypes for object columns, use DataFrame.infer_objects()
For all other conversions use the data-type specific converters pd.to_datetime, pd.to_timedelta and pd.to_numeric.
```
But I still recieve an output:
```
{'zoneKey': 'TW', 'datetime': datetime.datetime(2019, 10, 4, 16, 0, tzinfo=tzfile('ROC')), 'production': {'coal': 9743.199999999999, 'gas': 15124.899999999998, 'oil': 681.4, 'hydro': 726.0, 'nuclear': 3833.7000000000003, 'solar': 576.2239999999999, 'wind': 18.900000000000006, 'unknown': 1435.9}, 'capacity': {'coal': 13097.2, 'gas': 16866.4, 'oil': 2572.1, 'hydro': 2091.4999999999995, 'hydro storage': 2602.0, 'nuclear': 3872.0, 'solar': 3144.4, 'wind': 710.9999999999999, 'unknown': 623.2}, 'storage': {'hydro': -622.3}, 'source': 'taipower.com.tw'}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/TW.py`
Content:
```
1 #!/usr/bin/env python3
2 import arrow
3 import requests
4 import pandas
5 import dateutil
6
7
8 def fetch_production(zone_key='TW', session=None, target_datetime=None, logger=None):
9 if target_datetime:
10 raise NotImplementedError('This parser is not yet able to parse past dates')
11
12 url = 'http://www.taipower.com.tw/d006/loadGraph/loadGraph/data/genary.txt'
13 response = requests.get(url)
14 data = response.json()
15
16 dumpDate = data['']
17 prodData = data['aaData']
18
19 tz = 'Asia/Taipei'
20 dumpDate = arrow.get(dumpDate, 'YYYY-MM-DD HH:mm').replace(tzinfo=dateutil.tz.gettz(tz))
21
22 objData = pandas.DataFrame(prodData)
23
24 objData.columns = ['fueltype', 'name', 'capacity', 'output', 'percentage',
25 'additional']
26
27 objData['fueltype'] = objData.fueltype.str.split('(').str[1]
28 objData['fueltype'] = objData.fueltype.str.split(')').str[0]
29 objData.drop('additional', axis=1, inplace=True)
30 objData.drop('percentage', axis=1, inplace=True)
31
32 objData = objData.convert_objects(convert_numeric=True)
33 production = pandas.DataFrame(objData.groupby('fueltype').sum())
34 production.columns = ['capacity', 'output']
35
36 coal_capacity = production.ix['Coal'].capacity + production.ix['IPP-Coal'].capacity
37 gas_capacity = production.ix['LNG'].capacity + production.ix['IPP-LNG'].capacity
38 oil_capacity = production.ix['Oil'].capacity + production.ix['Diesel'].capacity
39
40 coal_production = production.ix['Coal'].output + production.ix['IPP-Coal'].output
41 gas_production = production.ix['LNG'].output + production.ix['IPP-LNG'].output
42 oil_production = production.ix['Oil'].output + production.ix['Diesel'].output
43
44 # For storage, note that load will be negative, and generation positive.
45 # We require the opposite
46
47 returndata = {
48 'zoneKey': zone_key,
49 'datetime': dumpDate.datetime,
50 'production': {
51 'coal': coal_production,
52 'gas': gas_production,
53 'oil': oil_production,
54 'hydro': production.ix['Hydro'].output,
55 'nuclear': production.ix['Nuclear'].output,
56 'solar': production.ix['Solar'].output,
57 'wind': production.ix['Wind'].output,
58 'unknown': production.ix['Co-Gen'].output
59 },
60 'capacity': {
61 'coal': coal_capacity,
62 'gas': gas_capacity,
63 'oil': oil_capacity,
64 'hydro': production.ix['Hydro'].capacity,
65 'hydro storage':production.ix['Pumping Gen'].capacity,
66 'nuclear': production.ix['Nuclear'].capacity,
67 'solar': production.ix['Solar'].capacity,
68 'wind': production.ix['Wind'].capacity,
69 'unknown': production.ix['Co-Gen'].capacity
70 },
71 'storage': {
72 'hydro': -1 * production.ix['Pumping Load'].output - production.ix['Pumping Gen'].output
73 },
74 'source': 'taipower.com.tw'
75 }
76
77 return returndata
78
79
80 if __name__ == '__main__':
81 print(fetch_production())
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/TW.py b/parsers/TW.py
--- a/parsers/TW.py
+++ b/parsers/TW.py
@@ -10,7 +10,8 @@
raise NotImplementedError('This parser is not yet able to parse past dates')
url = 'http://www.taipower.com.tw/d006/loadGraph/loadGraph/data/genary.txt'
- response = requests.get(url)
+ s = session or requests.Session()
+ response = s.get(url)
data = response.json()
dumpDate = data['']
@@ -29,17 +30,18 @@
objData.drop('additional', axis=1, inplace=True)
objData.drop('percentage', axis=1, inplace=True)
- objData = objData.convert_objects(convert_numeric=True)
+ objData['capacity'] = pandas.to_numeric(objData['capacity'], errors='coerce')
+ objData['output'] = pandas.to_numeric(objData['output'], errors='coerce')
production = pandas.DataFrame(objData.groupby('fueltype').sum())
production.columns = ['capacity', 'output']
- coal_capacity = production.ix['Coal'].capacity + production.ix['IPP-Coal'].capacity
- gas_capacity = production.ix['LNG'].capacity + production.ix['IPP-LNG'].capacity
- oil_capacity = production.ix['Oil'].capacity + production.ix['Diesel'].capacity
+ coal_capacity = production.loc['Coal'].capacity + production.loc['IPP-Coal'].capacity
+ gas_capacity = production.loc['LNG'].capacity + production.loc['IPP-LNG'].capacity
+ oil_capacity = production.loc['Oil'].capacity + production.loc['Diesel'].capacity
- coal_production = production.ix['Coal'].output + production.ix['IPP-Coal'].output
- gas_production = production.ix['LNG'].output + production.ix['IPP-LNG'].output
- oil_production = production.ix['Oil'].output + production.ix['Diesel'].output
+ coal_production = production.loc['Coal'].output + production.loc['IPP-Coal'].output
+ gas_production = production.loc['LNG'].output + production.loc['IPP-LNG'].output
+ oil_production = production.loc['Oil'].output + production.loc['Diesel'].output
# For storage, note that load will be negative, and generation positive.
# We require the opposite
@@ -51,25 +53,25 @@
'coal': coal_production,
'gas': gas_production,
'oil': oil_production,
- 'hydro': production.ix['Hydro'].output,
- 'nuclear': production.ix['Nuclear'].output,
- 'solar': production.ix['Solar'].output,
- 'wind': production.ix['Wind'].output,
- 'unknown': production.ix['Co-Gen'].output
+ 'hydro': production.loc['Hydro'].output,
+ 'nuclear': production.loc['Nuclear'].output,
+ 'solar': production.loc['Solar'].output,
+ 'wind': production.loc['Wind'].output,
+ 'unknown': production.loc['Co-Gen'].output
},
'capacity': {
'coal': coal_capacity,
'gas': gas_capacity,
'oil': oil_capacity,
- 'hydro': production.ix['Hydro'].capacity,
- 'hydro storage':production.ix['Pumping Gen'].capacity,
- 'nuclear': production.ix['Nuclear'].capacity,
- 'solar': production.ix['Solar'].capacity,
- 'wind': production.ix['Wind'].capacity,
- 'unknown': production.ix['Co-Gen'].capacity
+ 'hydro': production.loc['Hydro'].capacity,
+ 'hydro storage':production.loc['Pumping Gen'].capacity,
+ 'nuclear': production.loc['Nuclear'].capacity,
+ 'solar': production.loc['Solar'].capacity,
+ 'wind': production.loc['Wind'].capacity,
+ 'unknown': production.loc['Co-Gen'].capacity
},
'storage': {
- 'hydro': -1 * production.ix['Pumping Load'].output - production.ix['Pumping Gen'].output
+ 'hydro': -1 * production.loc['Pumping Load'].output - production.loc['Pumping Gen'].output
},
'source': 'taipower.com.tw'
}
|
{"golden_diff": "diff --git a/parsers/TW.py b/parsers/TW.py\n--- a/parsers/TW.py\n+++ b/parsers/TW.py\n@@ -10,7 +10,8 @@\n raise NotImplementedError('This parser is not yet able to parse past dates')\n \n url = 'http://www.taipower.com.tw/d006/loadGraph/loadGraph/data/genary.txt'\n- response = requests.get(url)\n+ s = session or requests.Session()\n+ response = s.get(url)\n data = response.json()\n \n dumpDate = data['']\n@@ -29,17 +30,18 @@\n objData.drop('additional', axis=1, inplace=True)\n objData.drop('percentage', axis=1, inplace=True)\n \n- objData = objData.convert_objects(convert_numeric=True)\n+ objData['capacity'] = pandas.to_numeric(objData['capacity'], errors='coerce')\n+ objData['output'] = pandas.to_numeric(objData['output'], errors='coerce')\n production = pandas.DataFrame(objData.groupby('fueltype').sum())\n production.columns = ['capacity', 'output']\n \n- coal_capacity = production.ix['Coal'].capacity + production.ix['IPP-Coal'].capacity\n- gas_capacity = production.ix['LNG'].capacity + production.ix['IPP-LNG'].capacity\n- oil_capacity = production.ix['Oil'].capacity + production.ix['Diesel'].capacity\n+ coal_capacity = production.loc['Coal'].capacity + production.loc['IPP-Coal'].capacity\n+ gas_capacity = production.loc['LNG'].capacity + production.loc['IPP-LNG'].capacity\n+ oil_capacity = production.loc['Oil'].capacity + production.loc['Diesel'].capacity\n \n- coal_production = production.ix['Coal'].output + production.ix['IPP-Coal'].output\n- gas_production = production.ix['LNG'].output + production.ix['IPP-LNG'].output\n- oil_production = production.ix['Oil'].output + production.ix['Diesel'].output\n+ coal_production = production.loc['Coal'].output + production.loc['IPP-Coal'].output\n+ gas_production = production.loc['LNG'].output + production.loc['IPP-LNG'].output\n+ oil_production = production.loc['Oil'].output + production.loc['Diesel'].output\n \n # For storage, note that load will be negative, and generation positive.\n # We require the opposite\n@@ -51,25 +53,25 @@\n 'coal': coal_production,\n 'gas': gas_production,\n 'oil': oil_production,\n- 'hydro': production.ix['Hydro'].output,\n- 'nuclear': production.ix['Nuclear'].output,\n- 'solar': production.ix['Solar'].output,\n- 'wind': production.ix['Wind'].output,\n- 'unknown': production.ix['Co-Gen'].output\n+ 'hydro': production.loc['Hydro'].output,\n+ 'nuclear': production.loc['Nuclear'].output,\n+ 'solar': production.loc['Solar'].output,\n+ 'wind': production.loc['Wind'].output,\n+ 'unknown': production.loc['Co-Gen'].output\n },\n 'capacity': {\n 'coal': coal_capacity,\n 'gas': gas_capacity,\n 'oil': oil_capacity,\n- 'hydro': production.ix['Hydro'].capacity,\n- 'hydro storage':production.ix['Pumping Gen'].capacity,\n- 'nuclear': production.ix['Nuclear'].capacity,\n- 'solar': production.ix['Solar'].capacity,\n- 'wind': production.ix['Wind'].capacity,\n- 'unknown': production.ix['Co-Gen'].capacity\n+ 'hydro': production.loc['Hydro'].capacity,\n+ 'hydro storage':production.loc['Pumping Gen'].capacity,\n+ 'nuclear': production.loc['Nuclear'].capacity,\n+ 'solar': production.loc['Solar'].capacity,\n+ 'wind': production.loc['Wind'].capacity,\n+ 'unknown': production.loc['Co-Gen'].capacity\n },\n 'storage': {\n- 'hydro': -1 * production.ix['Pumping Load'].output - production.ix['Pumping Gen'].output\n+ 'hydro': -1 * production.loc['Pumping Load'].output - production.loc['Pumping Gen'].output\n },\n 'source': 'taipower.com.tw'\n }\n", "issue": "Taiwan TW.py parser fails\nHelp wanted! :)\r\nTaiwan isn't showing any data at the moment and the parser has to be fixed.\r\n\r\nThis is the error message for TW.py of the logger:\r\n'DataFrame' object has no attribute 'convert_objects'\r\n\r\nI get this warning running the parser locally (probably with older versions of the libraries):\r\n```\r\nPython36-32/TW.py\", line 32\r\n objData = objData.convert_objects(convert_numeric=True)\r\nFutureWarning: convert_objects is deprecated. To re-infer data dtypes for object columns, use DataFrame.infer_objects()\r\nFor all other conversions use the data-type specific converters pd.to_datetime, pd.to_timedelta and pd.to_numeric.\r\n\r\n```\r\nBut I still recieve an output:\r\n\r\n```\r\n{'zoneKey': 'TW', 'datetime': datetime.datetime(2019, 10, 4, 16, 0, tzinfo=tzfile('ROC')), 'production': {'coal': 9743.199999999999, 'gas': 15124.899999999998, 'oil': 681.4, 'hydro': 726.0, 'nuclear': 3833.7000000000003, 'solar': 576.2239999999999, 'wind': 18.900000000000006, 'unknown': 1435.9}, 'capacity': {'coal': 13097.2, 'gas': 16866.4, 'oil': 2572.1, 'hydro': 2091.4999999999995, 'hydro storage': 2602.0, 'nuclear': 3872.0, 'solar': 3144.4, 'wind': 710.9999999999999, 'unknown': 623.2}, 'storage': {'hydro': -622.3}, 'source': 'taipower.com.tw'}\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\nimport arrow\nimport requests\nimport pandas\nimport dateutil\n\n\ndef fetch_production(zone_key='TW', session=None, target_datetime=None, logger=None):\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n url = 'http://www.taipower.com.tw/d006/loadGraph/loadGraph/data/genary.txt'\n response = requests.get(url)\n data = response.json()\n\n dumpDate = data['']\n prodData = data['aaData']\n\n tz = 'Asia/Taipei'\n dumpDate = arrow.get(dumpDate, 'YYYY-MM-DD HH:mm').replace(tzinfo=dateutil.tz.gettz(tz))\n\n objData = pandas.DataFrame(prodData)\n\n objData.columns = ['fueltype', 'name', 'capacity', 'output', 'percentage',\n 'additional']\n\n objData['fueltype'] = objData.fueltype.str.split('(').str[1]\n objData['fueltype'] = objData.fueltype.str.split(')').str[0]\n objData.drop('additional', axis=1, inplace=True)\n objData.drop('percentage', axis=1, inplace=True)\n\n objData = objData.convert_objects(convert_numeric=True)\n production = pandas.DataFrame(objData.groupby('fueltype').sum())\n production.columns = ['capacity', 'output']\n\n coal_capacity = production.ix['Coal'].capacity + production.ix['IPP-Coal'].capacity\n gas_capacity = production.ix['LNG'].capacity + production.ix['IPP-LNG'].capacity\n oil_capacity = production.ix['Oil'].capacity + production.ix['Diesel'].capacity\n\n coal_production = production.ix['Coal'].output + production.ix['IPP-Coal'].output\n gas_production = production.ix['LNG'].output + production.ix['IPP-LNG'].output\n oil_production = production.ix['Oil'].output + production.ix['Diesel'].output\n\n # For storage, note that load will be negative, and generation positive.\n # We require the opposite\n\n returndata = {\n 'zoneKey': zone_key,\n 'datetime': dumpDate.datetime,\n 'production': {\n 'coal': coal_production,\n 'gas': gas_production,\n 'oil': oil_production,\n 'hydro': production.ix['Hydro'].output,\n 'nuclear': production.ix['Nuclear'].output,\n 'solar': production.ix['Solar'].output,\n 'wind': production.ix['Wind'].output,\n 'unknown': production.ix['Co-Gen'].output\n },\n 'capacity': {\n 'coal': coal_capacity,\n 'gas': gas_capacity,\n 'oil': oil_capacity,\n 'hydro': production.ix['Hydro'].capacity,\n 'hydro storage':production.ix['Pumping Gen'].capacity,\n 'nuclear': production.ix['Nuclear'].capacity,\n 'solar': production.ix['Solar'].capacity,\n 'wind': production.ix['Wind'].capacity,\n 'unknown': production.ix['Co-Gen'].capacity\n },\n 'storage': {\n 'hydro': -1 * production.ix['Pumping Load'].output - production.ix['Pumping Gen'].output\n },\n 'source': 'taipower.com.tw'\n }\n\n return returndata\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/TW.py"}], "after_files": [{"content": "#!/usr/bin/env python3\nimport arrow\nimport requests\nimport pandas\nimport dateutil\n\n\ndef fetch_production(zone_key='TW', session=None, target_datetime=None, logger=None):\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n url = 'http://www.taipower.com.tw/d006/loadGraph/loadGraph/data/genary.txt'\n s = session or requests.Session()\n response = s.get(url)\n data = response.json()\n\n dumpDate = data['']\n prodData = data['aaData']\n\n tz = 'Asia/Taipei'\n dumpDate = arrow.get(dumpDate, 'YYYY-MM-DD HH:mm').replace(tzinfo=dateutil.tz.gettz(tz))\n\n objData = pandas.DataFrame(prodData)\n\n objData.columns = ['fueltype', 'name', 'capacity', 'output', 'percentage',\n 'additional']\n\n objData['fueltype'] = objData.fueltype.str.split('(').str[1]\n objData['fueltype'] = objData.fueltype.str.split(')').str[0]\n objData.drop('additional', axis=1, inplace=True)\n objData.drop('percentage', axis=1, inplace=True)\n\n objData['capacity'] = pandas.to_numeric(objData['capacity'], errors='coerce')\n objData['output'] = pandas.to_numeric(objData['output'], errors='coerce')\n production = pandas.DataFrame(objData.groupby('fueltype').sum())\n production.columns = ['capacity', 'output']\n\n coal_capacity = production.loc['Coal'].capacity + production.loc['IPP-Coal'].capacity\n gas_capacity = production.loc['LNG'].capacity + production.loc['IPP-LNG'].capacity\n oil_capacity = production.loc['Oil'].capacity + production.loc['Diesel'].capacity\n\n coal_production = production.loc['Coal'].output + production.loc['IPP-Coal'].output\n gas_production = production.loc['LNG'].output + production.loc['IPP-LNG'].output\n oil_production = production.loc['Oil'].output + production.loc['Diesel'].output\n\n # For storage, note that load will be negative, and generation positive.\n # We require the opposite\n\n returndata = {\n 'zoneKey': zone_key,\n 'datetime': dumpDate.datetime,\n 'production': {\n 'coal': coal_production,\n 'gas': gas_production,\n 'oil': oil_production,\n 'hydro': production.loc['Hydro'].output,\n 'nuclear': production.loc['Nuclear'].output,\n 'solar': production.loc['Solar'].output,\n 'wind': production.loc['Wind'].output,\n 'unknown': production.loc['Co-Gen'].output\n },\n 'capacity': {\n 'coal': coal_capacity,\n 'gas': gas_capacity,\n 'oil': oil_capacity,\n 'hydro': production.loc['Hydro'].capacity,\n 'hydro storage':production.loc['Pumping Gen'].capacity,\n 'nuclear': production.loc['Nuclear'].capacity,\n 'solar': production.loc['Solar'].capacity,\n 'wind': production.loc['Wind'].capacity,\n 'unknown': production.loc['Co-Gen'].capacity\n },\n 'storage': {\n 'hydro': -1 * production.loc['Pumping Load'].output - production.loc['Pumping Gen'].output\n },\n 'source': 'taipower.com.tw'\n }\n\n return returndata\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/TW.py"}]}
| 1,647 | 953 |
gh_patches_debug_35948
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-3879
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
aiomysql: AttributeError: __aenter__
### Which version of dd-trace-py are you using?
`ddtrace==1.2.0`
### Which version of the libraries are you using?
`aiomysql==0.1.1`
### How can we reproduce your problem?
```python
# repro.py
import asyncio
import aiomysql
loop = asyncio.get_event_loop()
async def go():
pool = await aiomysql.create_pool(
host="127.0.0.1",
port=3306,
user="test",
password="test",
db="test",
loop=loop,
autocommit=False,
)
async with pool.acquire() as conn:
await conn.ping(reconnect=True)
async with conn.cursor() as cur:
await cur.execute("SELECT 10")
(r,) = await cur.fetchone()
return r
loop.run_until_complete(go())
```
```
ddtrace-run python repro.py
```
### What is the result that you get?
```
❯ ddtrace-run python repro.py
repro.py:16: RuntimeWarning: coroutine 'AIOTracedConnection.cursor' was never awaited
async with conn.cursor() as cur:
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Traceback (most recent call last):
File "/Users/brett.langdon/datadog/dd-trace-py/repro.py", line 22, in <module>
loop.run_until_complete(go())
File "/Users/brett.langdon/.pyenv/versions/3.9.10/lib/python3.9/asyncio/base_events.py", line 642, in run_until_complete
return future.result()
File "/Users/brett.langdon/datadog/dd-trace-py/repro.py", line 16, in go
async with conn.cursor() as cur:
AttributeError: __aenter__
```
### What is the result that you expected?
No attribute error, and `async with conn.cursor()` works as expected.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/contrib/aiomysql/patch.py`
Content:
```
1 import aiomysql
2
3 from ddtrace import Pin
4 from ddtrace import config
5 from ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY
6 from ddtrace.constants import SPAN_MEASURED_KEY
7 from ddtrace.contrib import dbapi
8 from ddtrace.ext import sql
9 from ddtrace.internal.utils.wrappers import unwrap
10 from ddtrace.vendor import wrapt
11
12 from ...ext import SpanTypes
13 from ...ext import db
14 from ...ext import net
15
16
17 config._add(
18 "aiomysql",
19 dict(_default_service="mysql"),
20 )
21
22 CONN_ATTR_BY_TAG = {
23 net.TARGET_HOST: "host",
24 net.TARGET_PORT: "port",
25 db.USER: "user",
26 db.NAME: "db",
27 }
28
29
30 async def patched_connect(connect_func, _, args, kwargs):
31 conn = await connect_func(*args, **kwargs)
32 tags = {}
33 for tag, attr in CONN_ATTR_BY_TAG.items():
34 if hasattr(conn, attr):
35 tags[tag] = getattr(conn, attr)
36
37 c = AIOTracedConnection(conn)
38 Pin(tags=tags).onto(c)
39 return c
40
41
42 class AIOTracedCursor(wrapt.ObjectProxy):
43 """TracedCursor wraps a aiomysql cursor and traces its queries."""
44
45 def __init__(self, cursor, pin):
46 super(AIOTracedCursor, self).__init__(cursor)
47 pin.onto(self)
48 self._self_datadog_name = "mysql.query"
49
50 async def _trace_method(self, method, resource, extra_tags, *args, **kwargs):
51 pin = Pin.get_from(self)
52 if not pin or not pin.enabled():
53 result = await method(*args, **kwargs)
54 return result
55 service = pin.service
56
57 with pin.tracer.trace(
58 self._self_datadog_name, service=service, resource=resource, span_type=SpanTypes.SQL
59 ) as s:
60 s.set_tag(SPAN_MEASURED_KEY)
61 s.set_tag(sql.QUERY, resource)
62 s.set_tags(pin.tags)
63 s.set_tags(extra_tags)
64
65 # set analytics sample rate
66 s.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aiomysql.get_analytics_sample_rate())
67
68 try:
69 result = await method(*args, **kwargs)
70 return result
71 finally:
72 s.set_metric(db.ROWCOUNT, self.rowcount)
73 s.set_metric("db.rownumber", self.rownumber)
74
75 async def executemany(self, query, *args, **kwargs):
76 result = await self._trace_method(
77 self.__wrapped__.executemany, query, {"sql.executemany": "true"}, query, *args, **kwargs
78 )
79 return result
80
81 async def execute(self, query, *args, **kwargs):
82 result = await self._trace_method(self.__wrapped__.execute, query, {}, query, *args, **kwargs)
83 return result
84
85
86 class AIOTracedConnection(wrapt.ObjectProxy):
87 def __init__(self, conn, pin=None, cursor_cls=AIOTracedCursor):
88 super(AIOTracedConnection, self).__init__(conn)
89 name = dbapi._get_vendor(conn)
90 db_pin = pin or Pin(service=name)
91 db_pin.onto(self)
92 # wrapt requires prefix of `_self` for attributes that are only in the
93 # proxy (since some of our source objects will use `__slots__`)
94 self._self_cursor_cls = cursor_cls
95
96 async def cursor(self, *args, **kwargs):
97 cursor = await self.__wrapped__.cursor(*args, **kwargs)
98 pin = Pin.get_from(self)
99 if not pin:
100 return cursor
101 return self._self_cursor_cls(cursor, pin)
102
103 async def __aenter__(self):
104 return self.__wrapped__.__aenter__()
105
106
107 def patch():
108 if getattr(aiomysql, "__datadog_patch", False):
109 return
110 setattr(aiomysql, "__datadog_patch", True)
111 wrapt.wrap_function_wrapper(aiomysql.connection, "_connect", patched_connect)
112
113
114 def unpatch():
115 if getattr(aiomysql, "__datadog_patch", False):
116 setattr(aiomysql, "__datadog_patch", False)
117 unwrap(aiomysql.connection, "_connect")
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ddtrace/contrib/aiomysql/patch.py b/ddtrace/contrib/aiomysql/patch.py
--- a/ddtrace/contrib/aiomysql/patch.py
+++ b/ddtrace/contrib/aiomysql/patch.py
@@ -82,6 +82,14 @@
result = await self._trace_method(self.__wrapped__.execute, query, {}, query, *args, **kwargs)
return result
+ # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly
+ async def __aenter__(self):
+ # The base class just returns `self`, but we want the wrapped cursor so we return ourselves
+ return self
+
+ async def __aexit__(self, *args, **kwargs):
+ return await self.__wrapped__.__aexit__(*args, **kwargs)
+
class AIOTracedConnection(wrapt.ObjectProxy):
def __init__(self, conn, pin=None, cursor_cls=AIOTracedCursor):
@@ -93,15 +101,36 @@
# proxy (since some of our source objects will use `__slots__`)
self._self_cursor_cls = cursor_cls
- async def cursor(self, *args, **kwargs):
- cursor = await self.__wrapped__.cursor(*args, **kwargs)
+ def cursor(self, *args, **kwargs):
+ ctx_manager = self.__wrapped__.cursor(*args, **kwargs)
pin = Pin.get_from(self)
if not pin:
- return cursor
- return self._self_cursor_cls(cursor, pin)
-
+ return ctx_manager
+
+ # The result of `cursor()` is an `aiomysql.utils._ContextManager`
+ # which wraps a coroutine (a future) and adds async context manager
+ # helper functions to it.
+ # https://github.com/aio-libs/aiomysql/blob/8a32f052a16dc3886af54b98f4d91d95862bfb8e/aiomysql/connection.py#L461
+ # https://github.com/aio-libs/aiomysql/blob/7fa5078da31bbc95f5e32a934a4b2b4207c67ede/aiomysql/utils.py#L30-L79
+ # We cannot swap out the result on the future/context manager so
+ # instead we have to create a new coroutine that returns our
+ # wrapped cursor
+ # We also cannot turn `def cursor` into `async def cursor` because
+ # otherwise we will change the result to be a coroutine instead of
+ # an `aiomysql.utils._ContextManager` which wraps a coroutine. This
+ # will cause issues with `async with conn.cursor() as cur:` usage.
+ async def _wrap_cursor():
+ cursor = await ctx_manager
+ return self._self_cursor_cls(cursor, pin)
+
+ return type(ctx_manager)(_wrap_cursor())
+
+ # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly
async def __aenter__(self):
- return self.__wrapped__.__aenter__()
+ return await self.__wrapped__.__aenter__()
+
+ async def __aexit__(self, *args, **kwargs):
+ return await self.__wrapped__.__aexit__(*args, **kwargs)
def patch():
|
{"golden_diff": "diff --git a/ddtrace/contrib/aiomysql/patch.py b/ddtrace/contrib/aiomysql/patch.py\n--- a/ddtrace/contrib/aiomysql/patch.py\n+++ b/ddtrace/contrib/aiomysql/patch.py\n@@ -82,6 +82,14 @@\n result = await self._trace_method(self.__wrapped__.execute, query, {}, query, *args, **kwargs)\n return result\n \n+ # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly\n+ async def __aenter__(self):\n+ # The base class just returns `self`, but we want the wrapped cursor so we return ourselves\n+ return self\n+\n+ async def __aexit__(self, *args, **kwargs):\n+ return await self.__wrapped__.__aexit__(*args, **kwargs)\n+\n \n class AIOTracedConnection(wrapt.ObjectProxy):\n def __init__(self, conn, pin=None, cursor_cls=AIOTracedCursor):\n@@ -93,15 +101,36 @@\n # proxy (since some of our source objects will use `__slots__`)\n self._self_cursor_cls = cursor_cls\n \n- async def cursor(self, *args, **kwargs):\n- cursor = await self.__wrapped__.cursor(*args, **kwargs)\n+ def cursor(self, *args, **kwargs):\n+ ctx_manager = self.__wrapped__.cursor(*args, **kwargs)\n pin = Pin.get_from(self)\n if not pin:\n- return cursor\n- return self._self_cursor_cls(cursor, pin)\n-\n+ return ctx_manager\n+\n+ # The result of `cursor()` is an `aiomysql.utils._ContextManager`\n+ # which wraps a coroutine (a future) and adds async context manager\n+ # helper functions to it.\n+ # https://github.com/aio-libs/aiomysql/blob/8a32f052a16dc3886af54b98f4d91d95862bfb8e/aiomysql/connection.py#L461\n+ # https://github.com/aio-libs/aiomysql/blob/7fa5078da31bbc95f5e32a934a4b2b4207c67ede/aiomysql/utils.py#L30-L79\n+ # We cannot swap out the result on the future/context manager so\n+ # instead we have to create a new coroutine that returns our\n+ # wrapped cursor\n+ # We also cannot turn `def cursor` into `async def cursor` because\n+ # otherwise we will change the result to be a coroutine instead of\n+ # an `aiomysql.utils._ContextManager` which wraps a coroutine. This\n+ # will cause issues with `async with conn.cursor() as cur:` usage.\n+ async def _wrap_cursor():\n+ cursor = await ctx_manager\n+ return self._self_cursor_cls(cursor, pin)\n+\n+ return type(ctx_manager)(_wrap_cursor())\n+\n+ # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly\n async def __aenter__(self):\n- return self.__wrapped__.__aenter__()\n+ return await self.__wrapped__.__aenter__()\n+\n+ async def __aexit__(self, *args, **kwargs):\n+ return await self.__wrapped__.__aexit__(*args, **kwargs)\n \n \n def patch():\n", "issue": "aiomysql: AttributeError: __aenter__\n### Which version of dd-trace-py are you using?\r\n\r\n`ddtrace==1.2.0`\r\n\r\n### Which version of the libraries are you using?\r\n\r\n`aiomysql==0.1.1`\r\n\r\n### How can we reproduce your problem?\r\n\r\n```python\r\n# repro.py\r\nimport asyncio\r\n\r\nimport aiomysql\r\n\r\n\r\nloop = asyncio.get_event_loop()\r\n\r\n\r\nasync def go():\r\n pool = await aiomysql.create_pool(\r\n host=\"127.0.0.1\",\r\n port=3306,\r\n user=\"test\",\r\n password=\"test\",\r\n db=\"test\",\r\n loop=loop,\r\n autocommit=False,\r\n )\r\n\r\n async with pool.acquire() as conn:\r\n await conn.ping(reconnect=True)\r\n async with conn.cursor() as cur:\r\n await cur.execute(\"SELECT 10\")\r\n (r,) = await cur.fetchone()\r\n return r\r\n\r\n\r\nloop.run_until_complete(go())\r\n```\r\n\r\n```\r\nddtrace-run python repro.py\r\n```\r\n\r\n### What is the result that you get?\r\n\r\n```\r\n\u276f ddtrace-run python repro.py\r\nrepro.py:16: RuntimeWarning: coroutine 'AIOTracedConnection.cursor' was never awaited\r\n async with conn.cursor() as cur:\r\nRuntimeWarning: Enable tracemalloc to get the object allocation traceback\r\nTraceback (most recent call last):\r\n File \"/Users/brett.langdon/datadog/dd-trace-py/repro.py\", line 22, in <module>\r\n loop.run_until_complete(go())\r\n File \"/Users/brett.langdon/.pyenv/versions/3.9.10/lib/python3.9/asyncio/base_events.py\", line 642, in run_until_complete\r\n return future.result()\r\n File \"/Users/brett.langdon/datadog/dd-trace-py/repro.py\", line 16, in go\r\n async with conn.cursor() as cur:\r\nAttributeError: __aenter__\r\n```\r\n\r\n### What is the result that you expected?\r\nNo attribute error, and `async with conn.cursor()` works as expected.\n", "before_files": [{"content": "import aiomysql\n\nfrom ddtrace import Pin\nfrom ddtrace import config\nfrom ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ddtrace.constants import SPAN_MEASURED_KEY\nfrom ddtrace.contrib import dbapi\nfrom ddtrace.ext import sql\nfrom ddtrace.internal.utils.wrappers import unwrap\nfrom ddtrace.vendor import wrapt\n\nfrom ...ext import SpanTypes\nfrom ...ext import db\nfrom ...ext import net\n\n\nconfig._add(\n \"aiomysql\",\n dict(_default_service=\"mysql\"),\n)\n\nCONN_ATTR_BY_TAG = {\n net.TARGET_HOST: \"host\",\n net.TARGET_PORT: \"port\",\n db.USER: \"user\",\n db.NAME: \"db\",\n}\n\n\nasync def patched_connect(connect_func, _, args, kwargs):\n conn = await connect_func(*args, **kwargs)\n tags = {}\n for tag, attr in CONN_ATTR_BY_TAG.items():\n if hasattr(conn, attr):\n tags[tag] = getattr(conn, attr)\n\n c = AIOTracedConnection(conn)\n Pin(tags=tags).onto(c)\n return c\n\n\nclass AIOTracedCursor(wrapt.ObjectProxy):\n \"\"\"TracedCursor wraps a aiomysql cursor and traces its queries.\"\"\"\n\n def __init__(self, cursor, pin):\n super(AIOTracedCursor, self).__init__(cursor)\n pin.onto(self)\n self._self_datadog_name = \"mysql.query\"\n\n async def _trace_method(self, method, resource, extra_tags, *args, **kwargs):\n pin = Pin.get_from(self)\n if not pin or not pin.enabled():\n result = await method(*args, **kwargs)\n return result\n service = pin.service\n\n with pin.tracer.trace(\n self._self_datadog_name, service=service, resource=resource, span_type=SpanTypes.SQL\n ) as s:\n s.set_tag(SPAN_MEASURED_KEY)\n s.set_tag(sql.QUERY, resource)\n s.set_tags(pin.tags)\n s.set_tags(extra_tags)\n\n # set analytics sample rate\n s.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aiomysql.get_analytics_sample_rate())\n\n try:\n result = await method(*args, **kwargs)\n return result\n finally:\n s.set_metric(db.ROWCOUNT, self.rowcount)\n s.set_metric(\"db.rownumber\", self.rownumber)\n\n async def executemany(self, query, *args, **kwargs):\n result = await self._trace_method(\n self.__wrapped__.executemany, query, {\"sql.executemany\": \"true\"}, query, *args, **kwargs\n )\n return result\n\n async def execute(self, query, *args, **kwargs):\n result = await self._trace_method(self.__wrapped__.execute, query, {}, query, *args, **kwargs)\n return result\n\n\nclass AIOTracedConnection(wrapt.ObjectProxy):\n def __init__(self, conn, pin=None, cursor_cls=AIOTracedCursor):\n super(AIOTracedConnection, self).__init__(conn)\n name = dbapi._get_vendor(conn)\n db_pin = pin or Pin(service=name)\n db_pin.onto(self)\n # wrapt requires prefix of `_self` for attributes that are only in the\n # proxy (since some of our source objects will use `__slots__`)\n self._self_cursor_cls = cursor_cls\n\n async def cursor(self, *args, **kwargs):\n cursor = await self.__wrapped__.cursor(*args, **kwargs)\n pin = Pin.get_from(self)\n if not pin:\n return cursor\n return self._self_cursor_cls(cursor, pin)\n\n async def __aenter__(self):\n return self.__wrapped__.__aenter__()\n\n\ndef patch():\n if getattr(aiomysql, \"__datadog_patch\", False):\n return\n setattr(aiomysql, \"__datadog_patch\", True)\n wrapt.wrap_function_wrapper(aiomysql.connection, \"_connect\", patched_connect)\n\n\ndef unpatch():\n if getattr(aiomysql, \"__datadog_patch\", False):\n setattr(aiomysql, \"__datadog_patch\", False)\n unwrap(aiomysql.connection, \"_connect\")\n", "path": "ddtrace/contrib/aiomysql/patch.py"}], "after_files": [{"content": "import aiomysql\n\nfrom ddtrace import Pin\nfrom ddtrace import config\nfrom ddtrace.constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ddtrace.constants import SPAN_MEASURED_KEY\nfrom ddtrace.contrib import dbapi\nfrom ddtrace.ext import sql\nfrom ddtrace.internal.utils.wrappers import unwrap\nfrom ddtrace.vendor import wrapt\n\nfrom ...ext import SpanTypes\nfrom ...ext import db\nfrom ...ext import net\n\n\nconfig._add(\n \"aiomysql\",\n dict(_default_service=\"mysql\"),\n)\n\nCONN_ATTR_BY_TAG = {\n net.TARGET_HOST: \"host\",\n net.TARGET_PORT: \"port\",\n db.USER: \"user\",\n db.NAME: \"db\",\n}\n\n\nasync def patched_connect(connect_func, _, args, kwargs):\n conn = await connect_func(*args, **kwargs)\n tags = {}\n for tag, attr in CONN_ATTR_BY_TAG.items():\n if hasattr(conn, attr):\n tags[tag] = getattr(conn, attr)\n\n c = AIOTracedConnection(conn)\n Pin(tags=tags).onto(c)\n return c\n\n\nclass AIOTracedCursor(wrapt.ObjectProxy):\n \"\"\"TracedCursor wraps a aiomysql cursor and traces its queries.\"\"\"\n\n def __init__(self, cursor, pin):\n super(AIOTracedCursor, self).__init__(cursor)\n pin.onto(self)\n self._self_datadog_name = \"mysql.query\"\n\n async def _trace_method(self, method, resource, extra_tags, *args, **kwargs):\n pin = Pin.get_from(self)\n if not pin or not pin.enabled():\n result = await method(*args, **kwargs)\n return result\n service = pin.service\n\n with pin.tracer.trace(\n self._self_datadog_name, service=service, resource=resource, span_type=SpanTypes.SQL\n ) as s:\n s.set_tag(SPAN_MEASURED_KEY)\n s.set_tag(sql.QUERY, resource)\n s.set_tags(pin.tags)\n s.set_tags(extra_tags)\n\n # set analytics sample rate\n s.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aiomysql.get_analytics_sample_rate())\n\n try:\n result = await method(*args, **kwargs)\n return result\n finally:\n s.set_metric(db.ROWCOUNT, self.rowcount)\n s.set_metric(\"db.rownumber\", self.rownumber)\n\n async def executemany(self, query, *args, **kwargs):\n result = await self._trace_method(\n self.__wrapped__.executemany, query, {\"sql.executemany\": \"true\"}, query, *args, **kwargs\n )\n return result\n\n async def execute(self, query, *args, **kwargs):\n result = await self._trace_method(self.__wrapped__.execute, query, {}, query, *args, **kwargs)\n return result\n\n # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly\n async def __aenter__(self):\n # The base class just returns `self`, but we want the wrapped cursor so we return ourselves\n return self\n\n async def __aexit__(self, *args, **kwargs):\n return await self.__wrapped__.__aexit__(*args, **kwargs)\n\n\nclass AIOTracedConnection(wrapt.ObjectProxy):\n def __init__(self, conn, pin=None, cursor_cls=AIOTracedCursor):\n super(AIOTracedConnection, self).__init__(conn)\n name = dbapi._get_vendor(conn)\n db_pin = pin or Pin(service=name)\n db_pin.onto(self)\n # wrapt requires prefix of `_self` for attributes that are only in the\n # proxy (since some of our source objects will use `__slots__`)\n self._self_cursor_cls = cursor_cls\n\n def cursor(self, *args, **kwargs):\n ctx_manager = self.__wrapped__.cursor(*args, **kwargs)\n pin = Pin.get_from(self)\n if not pin:\n return ctx_manager\n\n # The result of `cursor()` is an `aiomysql.utils._ContextManager`\n # which wraps a coroutine (a future) and adds async context manager\n # helper functions to it.\n # https://github.com/aio-libs/aiomysql/blob/8a32f052a16dc3886af54b98f4d91d95862bfb8e/aiomysql/connection.py#L461\n # https://github.com/aio-libs/aiomysql/blob/7fa5078da31bbc95f5e32a934a4b2b4207c67ede/aiomysql/utils.py#L30-L79\n # We cannot swap out the result on the future/context manager so\n # instead we have to create a new coroutine that returns our\n # wrapped cursor\n # We also cannot turn `def cursor` into `async def cursor` because\n # otherwise we will change the result to be a coroutine instead of\n # an `aiomysql.utils._ContextManager` which wraps a coroutine. This\n # will cause issues with `async with conn.cursor() as cur:` usage.\n async def _wrap_cursor():\n cursor = await ctx_manager\n return self._self_cursor_cls(cursor, pin)\n\n return type(ctx_manager)(_wrap_cursor())\n\n # Explicitly define `__aenter__` and `__aexit__` since they do not get proxied properly\n async def __aenter__(self):\n return await self.__wrapped__.__aenter__()\n\n async def __aexit__(self, *args, **kwargs):\n return await self.__wrapped__.__aexit__(*args, **kwargs)\n\n\ndef patch():\n if getattr(aiomysql, \"__datadog_patch\", False):\n return\n setattr(aiomysql, \"__datadog_patch\", True)\n wrapt.wrap_function_wrapper(aiomysql.connection, \"_connect\", patched_connect)\n\n\ndef unpatch():\n if getattr(aiomysql, \"__datadog_patch\", False):\n setattr(aiomysql, \"__datadog_patch\", False)\n unwrap(aiomysql.connection, \"_connect\")\n", "path": "ddtrace/contrib/aiomysql/patch.py"}]}
| 1,887 | 795 |
gh_patches_debug_4642
|
rasdani/github-patches
|
git_diff
|
pytorch__text-1914
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update documentation to reflect IMDB output
When attempting to use the IMDB api, I got results that were different from what the docs suggested. This PR attempts to update the docs with the correct output of the IMDB api.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchtext/datasets/imdb.py`
Content:
```
1 import os
2 from functools import partial
3 from pathlib import Path
4 from typing import Tuple, Union
5
6 from torchtext._internal.module_utils import is_module_available
7 from torchtext.data.datasets_utils import _create_dataset_directory
8 from torchtext.data.datasets_utils import _wrap_split_argument
9
10 if is_module_available("torchdata"):
11 from torchdata.datapipes.iter import FileOpener, IterableWrapper
12 from torchtext._download_hooks import HttpReader
13
14 URL = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
15
16 MD5 = "7c2ac02c03563afcf9b574c7e56c153a"
17
18 NUM_LINES = {
19 "train": 25000,
20 "test": 25000,
21 }
22
23 _PATH = "aclImdb_v1.tar.gz"
24
25 DATASET_NAME = "IMDB"
26
27
28 def _filepath_fn(root, _=None):
29 return os.path.join(root, _PATH)
30
31
32 def _decompressed_filepath_fn(root, decompressed_folder, split, labels, _=None):
33 return [os.path.join(root, decompressed_folder, split, label) for label in labels]
34
35
36 def _filter_fn(filter_imdb_data, split, t):
37 return filter_imdb_data(split, t[0])
38
39
40 def _path_map_fn(t):
41 return Path(t[0]).parts[-2], t[1]
42
43
44 def _encode_map_fn(x):
45 return x[0], x[1].encode()
46
47
48 def _cache_filepath_fn(root, decompressed_folder, split, x):
49 return os.path.join(root, decompressed_folder, split, x)
50
51
52 def _modify_res(t):
53 return Path(t[0]).parts[-1], t[1]
54
55
56 def filter_imdb_data(key, fname):
57 labels = {"neg", "pos"}
58 # eg. fname = "aclImdb/train/neg/12416_3.txt"
59 *_, split, label, file = Path(fname).parts
60 return key == split and label in labels
61
62
63 @_create_dataset_directory(dataset_name=DATASET_NAME)
64 @_wrap_split_argument(("train", "test"))
65 def IMDB(root: str, split: Union[Tuple[str], str]):
66 """IMDB Dataset
67
68 .. warning::
69
70 using datapipes is still currently subject to a few caveats. if you wish
71 to use this dataset with shuffling, multi-processing, or distributed
72 learning, please see :ref:`this note <datapipes_warnings>` for further
73 instructions.
74
75 For additional details refer to http://ai.stanford.edu/~amaas/data/sentiment/
76
77 Number of lines per split:
78 - train: 25000
79 - test: 25000
80
81 Args:
82 root: Directory where the datasets are saved. Default: os.path.expanduser('~/.torchtext/cache')
83 split: split or splits to be returned. Can be a string or tuple of strings. Default: (`train`, `test`)
84
85 :returns: DataPipe that yields tuple of label (1 to 2) and text containing the movie review
86 :rtype: (int, str)
87 """
88 if not is_module_available("torchdata"):
89 raise ModuleNotFoundError(
90 "Package `torchdata` not found. Please install following instructions at https://github.com/pytorch/data"
91 )
92
93 url_dp = IterableWrapper([URL])
94
95 cache_compressed_dp = url_dp.on_disk_cache(
96 filepath_fn=partial(_filepath_fn, root),
97 hash_dict={_filepath_fn(root): MD5},
98 hash_type="md5",
99 )
100 cache_compressed_dp = HttpReader(cache_compressed_dp).end_caching(mode="wb", same_filepath_fn=True)
101
102 labels = {"neg", "pos"}
103 decompressed_folder = "aclImdb_v1"
104 cache_decompressed_dp = cache_compressed_dp.on_disk_cache(
105 filepath_fn=partial(_decompressed_filepath_fn, root, decompressed_folder, split, labels)
106 )
107 cache_decompressed_dp = FileOpener(cache_decompressed_dp, mode="b")
108 cache_decompressed_dp = cache_decompressed_dp.load_from_tar()
109 cache_decompressed_dp = cache_decompressed_dp.filter(partial(_filter_fn, filter_imdb_data, split))
110
111 # eg. "aclImdb/train/neg/12416_3.txt" -> "neg"
112 cache_decompressed_dp = cache_decompressed_dp.map(_path_map_fn)
113 cache_decompressed_dp = cache_decompressed_dp.readlines(decode=True)
114 cache_decompressed_dp = cache_decompressed_dp.lines_to_paragraphs() # group by label in cache file
115 cache_decompressed_dp = cache_decompressed_dp.map(_encode_map_fn)
116 cache_decompressed_dp = cache_decompressed_dp.end_caching(
117 mode="wb", filepath_fn=partial(_cache_filepath_fn, root, decompressed_folder, split), skip_read=True
118 )
119
120 data_dp = FileOpener(cache_decompressed_dp, encoding="utf-8")
121 # get label from cache file, eg. "aclImdb_v1/train/neg" -> "neg"
122 return data_dp.readlines().map(_modify_res).shuffle().set_shuffle(False).sharding_filter()
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchtext/datasets/imdb.py b/torchtext/datasets/imdb.py
--- a/torchtext/datasets/imdb.py
+++ b/torchtext/datasets/imdb.py
@@ -20,6 +20,8 @@
"test": 25000,
}
+MAP_LABELS = {"neg": 1, "pos": 2}
+
_PATH = "aclImdb_v1.tar.gz"
DATASET_NAME = "IMDB"
@@ -50,7 +52,7 @@
def _modify_res(t):
- return Path(t[0]).parts[-1], t[1]
+ return MAP_LABELS[Path(t[0]).parts[-1]], t[1]
def filter_imdb_data(key, fname):
|
{"golden_diff": "diff --git a/torchtext/datasets/imdb.py b/torchtext/datasets/imdb.py\n--- a/torchtext/datasets/imdb.py\n+++ b/torchtext/datasets/imdb.py\n@@ -20,6 +20,8 @@\n \"test\": 25000,\n }\n \n+MAP_LABELS = {\"neg\": 1, \"pos\": 2}\n+\n _PATH = \"aclImdb_v1.tar.gz\"\n \n DATASET_NAME = \"IMDB\"\n@@ -50,7 +52,7 @@\n \n \n def _modify_res(t):\n- return Path(t[0]).parts[-1], t[1]\n+ return MAP_LABELS[Path(t[0]).parts[-1]], t[1]\n \n \n def filter_imdb_data(key, fname):\n", "issue": "update documentation to reflect IMDB output\nWhen attempting to use the IMDB api, I got results that were different from what the docs suggested. This PR attempts to update the docs with the correct output of the IMDB api.\n", "before_files": [{"content": "import os\nfrom functools import partial\nfrom pathlib import Path\nfrom typing import Tuple, Union\n\nfrom torchtext._internal.module_utils import is_module_available\nfrom torchtext.data.datasets_utils import _create_dataset_directory\nfrom torchtext.data.datasets_utils import _wrap_split_argument\n\nif is_module_available(\"torchdata\"):\n from torchdata.datapipes.iter import FileOpener, IterableWrapper\n from torchtext._download_hooks import HttpReader\n\nURL = \"http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\"\n\nMD5 = \"7c2ac02c03563afcf9b574c7e56c153a\"\n\nNUM_LINES = {\n \"train\": 25000,\n \"test\": 25000,\n}\n\n_PATH = \"aclImdb_v1.tar.gz\"\n\nDATASET_NAME = \"IMDB\"\n\n\ndef _filepath_fn(root, _=None):\n return os.path.join(root, _PATH)\n\n\ndef _decompressed_filepath_fn(root, decompressed_folder, split, labels, _=None):\n return [os.path.join(root, decompressed_folder, split, label) for label in labels]\n\n\ndef _filter_fn(filter_imdb_data, split, t):\n return filter_imdb_data(split, t[0])\n\n\ndef _path_map_fn(t):\n return Path(t[0]).parts[-2], t[1]\n\n\ndef _encode_map_fn(x):\n return x[0], x[1].encode()\n\n\ndef _cache_filepath_fn(root, decompressed_folder, split, x):\n return os.path.join(root, decompressed_folder, split, x)\n\n\ndef _modify_res(t):\n return Path(t[0]).parts[-1], t[1]\n\n\ndef filter_imdb_data(key, fname):\n labels = {\"neg\", \"pos\"}\n # eg. fname = \"aclImdb/train/neg/12416_3.txt\"\n *_, split, label, file = Path(fname).parts\n return key == split and label in labels\n\n\n@_create_dataset_directory(dataset_name=DATASET_NAME)\n@_wrap_split_argument((\"train\", \"test\"))\ndef IMDB(root: str, split: Union[Tuple[str], str]):\n \"\"\"IMDB Dataset\n\n .. warning::\n\n using datapipes is still currently subject to a few caveats. if you wish\n to use this dataset with shuffling, multi-processing, or distributed\n learning, please see :ref:`this note <datapipes_warnings>` for further\n instructions.\n\n For additional details refer to http://ai.stanford.edu/~amaas/data/sentiment/\n\n Number of lines per split:\n - train: 25000\n - test: 25000\n\n Args:\n root: Directory where the datasets are saved. Default: os.path.expanduser('~/.torchtext/cache')\n split: split or splits to be returned. Can be a string or tuple of strings. Default: (`train`, `test`)\n\n :returns: DataPipe that yields tuple of label (1 to 2) and text containing the movie review\n :rtype: (int, str)\n \"\"\"\n if not is_module_available(\"torchdata\"):\n raise ModuleNotFoundError(\n \"Package `torchdata` not found. Please install following instructions at https://github.com/pytorch/data\"\n )\n\n url_dp = IterableWrapper([URL])\n\n cache_compressed_dp = url_dp.on_disk_cache(\n filepath_fn=partial(_filepath_fn, root),\n hash_dict={_filepath_fn(root): MD5},\n hash_type=\"md5\",\n )\n cache_compressed_dp = HttpReader(cache_compressed_dp).end_caching(mode=\"wb\", same_filepath_fn=True)\n\n labels = {\"neg\", \"pos\"}\n decompressed_folder = \"aclImdb_v1\"\n cache_decompressed_dp = cache_compressed_dp.on_disk_cache(\n filepath_fn=partial(_decompressed_filepath_fn, root, decompressed_folder, split, labels)\n )\n cache_decompressed_dp = FileOpener(cache_decompressed_dp, mode=\"b\")\n cache_decompressed_dp = cache_decompressed_dp.load_from_tar()\n cache_decompressed_dp = cache_decompressed_dp.filter(partial(_filter_fn, filter_imdb_data, split))\n\n # eg. \"aclImdb/train/neg/12416_3.txt\" -> \"neg\"\n cache_decompressed_dp = cache_decompressed_dp.map(_path_map_fn)\n cache_decompressed_dp = cache_decompressed_dp.readlines(decode=True)\n cache_decompressed_dp = cache_decompressed_dp.lines_to_paragraphs() # group by label in cache file\n cache_decompressed_dp = cache_decompressed_dp.map(_encode_map_fn)\n cache_decompressed_dp = cache_decompressed_dp.end_caching(\n mode=\"wb\", filepath_fn=partial(_cache_filepath_fn, root, decompressed_folder, split), skip_read=True\n )\n\n data_dp = FileOpener(cache_decompressed_dp, encoding=\"utf-8\")\n # get label from cache file, eg. \"aclImdb_v1/train/neg\" -> \"neg\"\n return data_dp.readlines().map(_modify_res).shuffle().set_shuffle(False).sharding_filter()\n", "path": "torchtext/datasets/imdb.py"}], "after_files": [{"content": "import os\nfrom functools import partial\nfrom pathlib import Path\nfrom typing import Tuple, Union\n\nfrom torchtext._internal.module_utils import is_module_available\nfrom torchtext.data.datasets_utils import _create_dataset_directory\nfrom torchtext.data.datasets_utils import _wrap_split_argument\n\nif is_module_available(\"torchdata\"):\n from torchdata.datapipes.iter import FileOpener, IterableWrapper\n from torchtext._download_hooks import HttpReader\n\nURL = \"http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\"\n\nMD5 = \"7c2ac02c03563afcf9b574c7e56c153a\"\n\nNUM_LINES = {\n \"train\": 25000,\n \"test\": 25000,\n}\n\nMAP_LABELS = {\"neg\": 1, \"pos\": 2}\n\n_PATH = \"aclImdb_v1.tar.gz\"\n\nDATASET_NAME = \"IMDB\"\n\n\ndef _filepath_fn(root, _=None):\n return os.path.join(root, _PATH)\n\n\ndef _decompressed_filepath_fn(root, decompressed_folder, split, labels, _=None):\n return [os.path.join(root, decompressed_folder, split, label) for label in labels]\n\n\ndef _filter_fn(filter_imdb_data, split, t):\n return filter_imdb_data(split, t[0])\n\n\ndef _path_map_fn(t):\n return Path(t[0]).parts[-2], t[1]\n\n\ndef _encode_map_fn(x):\n return x[0], x[1].encode()\n\n\ndef _cache_filepath_fn(root, decompressed_folder, split, x):\n return os.path.join(root, decompressed_folder, split, x)\n\n\ndef _modify_res(t):\n return MAP_LABELS[Path(t[0]).parts[-1]], t[1]\n\n\ndef filter_imdb_data(key, fname):\n labels = {\"neg\", \"pos\"}\n # eg. fname = \"aclImdb/train/neg/12416_3.txt\"\n *_, split, label, file = Path(fname).parts\n return key == split and label in labels\n\n\n@_create_dataset_directory(dataset_name=DATASET_NAME)\n@_wrap_split_argument((\"train\", \"test\"))\ndef IMDB(root: str, split: Union[Tuple[str], str]):\n \"\"\"IMDB Dataset\n\n .. warning::\n\n using datapipes is still currently subject to a few caveats. if you wish\n to use this dataset with shuffling, multi-processing, or distributed\n learning, please see :ref:`this note <datapipes_warnings>` for further\n instructions.\n\n For additional details refer to http://ai.stanford.edu/~amaas/data/sentiment/\n\n Number of lines per split:\n - train: 25000\n - test: 25000\n\n Args:\n root: Directory where the datasets are saved. Default: os.path.expanduser('~/.torchtext/cache')\n split: split or splits to be returned. Can be a string or tuple of strings. Default: (`train`, `test`)\n\n :returns: DataPipe that yields tuple of label (1 to 2) and text containing the movie review\n :rtype: (int, str)\n \"\"\"\n if not is_module_available(\"torchdata\"):\n raise ModuleNotFoundError(\n \"Package `torchdata` not found. Please install following instructions at https://github.com/pytorch/data\"\n )\n\n url_dp = IterableWrapper([URL])\n\n cache_compressed_dp = url_dp.on_disk_cache(\n filepath_fn=partial(_filepath_fn, root),\n hash_dict={_filepath_fn(root): MD5},\n hash_type=\"md5\",\n )\n cache_compressed_dp = HttpReader(cache_compressed_dp).end_caching(mode=\"wb\", same_filepath_fn=True)\n\n labels = {\"neg\", \"pos\"}\n decompressed_folder = \"aclImdb_v1\"\n cache_decompressed_dp = cache_compressed_dp.on_disk_cache(\n filepath_fn=partial(_decompressed_filepath_fn, root, decompressed_folder, split, labels)\n )\n cache_decompressed_dp = FileOpener(cache_decompressed_dp, mode=\"b\")\n cache_decompressed_dp = cache_decompressed_dp.load_from_tar()\n cache_decompressed_dp = cache_decompressed_dp.filter(partial(_filter_fn, filter_imdb_data, split))\n\n # eg. \"aclImdb/train/neg/12416_3.txt\" -> \"neg\"\n cache_decompressed_dp = cache_decompressed_dp.map(_path_map_fn)\n cache_decompressed_dp = cache_decompressed_dp.readlines(decode=True)\n cache_decompressed_dp = cache_decompressed_dp.lines_to_paragraphs() # group by label in cache file\n cache_decompressed_dp = cache_decompressed_dp.map(_encode_map_fn)\n cache_decompressed_dp = cache_decompressed_dp.end_caching(\n mode=\"wb\", filepath_fn=partial(_cache_filepath_fn, root, decompressed_folder, split), skip_read=True\n )\n\n data_dp = FileOpener(cache_decompressed_dp, encoding=\"utf-8\")\n # get label from cache file, eg. \"aclImdb_v1/train/neg\" -> \"neg\"\n return data_dp.readlines().map(_modify_res).shuffle().set_shuffle(False).sharding_filter()\n", "path": "torchtext/datasets/imdb.py"}]}
| 1,714 | 173 |
gh_patches_debug_21094
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-429
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement a search command for !otn
With hundreds of off-topic names in our list, looking for one by clicking through the paginator with the bot is tedious.
Let's have a `!otn search <name>` command!
#### Implementation Ideas
- Use the text search functionality in postgres
- Fuzzy search (`fuzzystrmatch` maybe?)
- Ranked list based on similarity to query
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/cogs/off_topic_names.py`
Content:
```
1 import asyncio
2 import logging
3 from datetime import datetime, timedelta
4
5 from discord import Colour, Embed
6 from discord.ext.commands import BadArgument, Bot, Cog, Context, Converter, group
7
8 from bot.constants import Channels, MODERATION_ROLES
9 from bot.decorators import with_role
10 from bot.pagination import LinePaginator
11
12
13 CHANNELS = (Channels.off_topic_0, Channels.off_topic_1, Channels.off_topic_2)
14 log = logging.getLogger(__name__)
15
16
17 class OffTopicName(Converter):
18 """A converter that ensures an added off-topic name is valid."""
19
20 @staticmethod
21 async def convert(ctx: Context, argument: str):
22 allowed_characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`-"
23
24 if not (2 <= len(argument) <= 96):
25 raise BadArgument("Channel name must be between 2 and 96 chars long")
26
27 elif not all(c.isalnum() or c in allowed_characters for c in argument):
28 raise BadArgument(
29 "Channel name must only consist of "
30 "alphanumeric characters, minus signs or apostrophes."
31 )
32
33 # Replace invalid characters with unicode alternatives.
34 table = str.maketrans(
35 allowed_characters, '𝖠𝖡𝖢𝖣𝖤𝖥𝖦𝖧𝖨𝖩𝖪𝖫𝖬𝖭𝖮𝖯𝖰𝖱𝖲𝖳𝖴𝖵𝖶𝖷𝖸𝖹ǃ?’’-'
36 )
37 return argument.translate(table)
38
39
40 async def update_names(bot: Bot):
41 """
42 The background updater task that performs a channel name update daily.
43
44 Args:
45 bot (Bot):
46 The running bot instance, used for fetching data from the
47 website via the bot's `api_client`.
48 """
49
50 while True:
51 # Since we truncate the compute timedelta to seconds, we add one second to ensure
52 # we go past midnight in the `seconds_to_sleep` set below.
53 today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)
54 next_midnight = today_at_midnight + timedelta(days=1)
55 seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1
56 await asyncio.sleep(seconds_to_sleep)
57
58 channel_0_name, channel_1_name, channel_2_name = await bot.api_client.get(
59 'bot/off-topic-channel-names', params={'random_items': 3}
60 )
61 channel_0, channel_1, channel_2 = (bot.get_channel(channel_id) for channel_id in CHANNELS)
62
63 await channel_0.edit(name=f'ot0-{channel_0_name}')
64 await channel_1.edit(name=f'ot1-{channel_1_name}')
65 await channel_2.edit(name=f'ot2-{channel_2_name}')
66 log.debug(
67 "Updated off-topic channel names to"
68 f" {channel_0_name}, {channel_1_name} and {channel_2_name}"
69 )
70
71
72 class OffTopicNames(Cog):
73 """Commands related to managing the off-topic category channel names."""
74
75 def __init__(self, bot: Bot):
76 self.bot = bot
77 self.updater_task = None
78
79 def cog_unload(self):
80 if self.updater_task is not None:
81 self.updater_task.cancel()
82
83 @Cog.listener()
84 async def on_ready(self):
85 if self.updater_task is None:
86 coro = update_names(self.bot)
87 self.updater_task = self.bot.loop.create_task(coro)
88
89 @group(name='otname', aliases=('otnames', 'otn'), invoke_without_command=True)
90 @with_role(*MODERATION_ROLES)
91 async def otname_group(self, ctx):
92 """Add or list items from the off-topic channel name rotation."""
93
94 await ctx.invoke(self.bot.get_command("help"), "otname")
95
96 @otname_group.command(name='add', aliases=('a',))
97 @with_role(*MODERATION_ROLES)
98 async def add_command(self, ctx, *names: OffTopicName):
99 """Adds a new off-topic name to the rotation."""
100 # Chain multiple words to a single one
101 name = "-".join(names)
102
103 await self.bot.api_client.post(f'bot/off-topic-channel-names', params={'name': name})
104 log.info(
105 f"{ctx.author.name}#{ctx.author.discriminator}"
106 f" added the off-topic channel name '{name}"
107 )
108 await ctx.send(f":ok_hand: Added `{name}` to the names list.")
109
110 @otname_group.command(name='delete', aliases=('remove', 'rm', 'del', 'd'))
111 @with_role(*MODERATION_ROLES)
112 async def delete_command(self, ctx, *names: OffTopicName):
113 """Removes a off-topic name from the rotation."""
114 # Chain multiple words to a single one
115 name = "-".join(names)
116
117 await self.bot.api_client.delete(f'bot/off-topic-channel-names/{name}')
118 log.info(
119 f"{ctx.author.name}#{ctx.author.discriminator}"
120 f" deleted the off-topic channel name '{name}"
121 )
122 await ctx.send(f":ok_hand: Removed `{name}` from the names list.")
123
124 @otname_group.command(name='list', aliases=('l',))
125 @with_role(*MODERATION_ROLES)
126 async def list_command(self, ctx):
127 """
128 Lists all currently known off-topic channel names in a paginator.
129 Restricted to Moderator and above to not spoil the surprise.
130 """
131
132 result = await self.bot.api_client.get('bot/off-topic-channel-names')
133 lines = sorted(f"• {name}" for name in result)
134 embed = Embed(
135 title=f"Known off-topic names (`{len(result)}` total)",
136 colour=Colour.blue()
137 )
138 if result:
139 await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)
140 else:
141 embed.description = "Hmmm, seems like there's nothing here yet."
142 await ctx.send(embed=embed)
143
144
145 def setup(bot: Bot):
146 bot.add_cog(OffTopicNames(bot))
147 log.info("Cog loaded: OffTopicNames")
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -1,4 +1,5 @@
import asyncio
+import difflib
import logging
from datetime import datetime, timedelta
@@ -141,6 +142,27 @@
embed.description = "Hmmm, seems like there's nothing here yet."
await ctx.send(embed=embed)
+ @otname_group.command(name='search', aliases=('s',))
+ @with_role(*MODERATION_ROLES)
+ async def search_command(self, ctx, *, query: str):
+ """
+ Search for an off-topic name.
+ """
+
+ result = await self.bot.api_client.get('bot/off-topic-channel-names')
+ matches = difflib.get_close_matches(query, result, n=10, cutoff=0.35)
+ lines = sorted(f"• {name}" for name in matches)
+ embed = Embed(
+ title=f"Query results",
+ colour=Colour.blue()
+ )
+
+ if matches:
+ await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)
+ else:
+ embed.description = "Nothing found."
+ await ctx.send(embed=embed)
+
def setup(bot: Bot):
bot.add_cog(OffTopicNames(bot))
|
{"golden_diff": "diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py\n--- a/bot/cogs/off_topic_names.py\n+++ b/bot/cogs/off_topic_names.py\n@@ -1,4 +1,5 @@\n import asyncio\n+import difflib\n import logging\n from datetime import datetime, timedelta\n \n@@ -141,6 +142,27 @@\n embed.description = \"Hmmm, seems like there's nothing here yet.\"\n await ctx.send(embed=embed)\n \n+ @otname_group.command(name='search', aliases=('s',))\n+ @with_role(*MODERATION_ROLES)\n+ async def search_command(self, ctx, *, query: str):\n+ \"\"\"\n+ Search for an off-topic name.\n+ \"\"\"\n+\n+ result = await self.bot.api_client.get('bot/off-topic-channel-names')\n+ matches = difflib.get_close_matches(query, result, n=10, cutoff=0.35)\n+ lines = sorted(f\"\u2022 {name}\" for name in matches)\n+ embed = Embed(\n+ title=f\"Query results\",\n+ colour=Colour.blue()\n+ )\n+\n+ if matches:\n+ await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)\n+ else:\n+ embed.description = \"Nothing found.\"\n+ await ctx.send(embed=embed)\n+\n \n def setup(bot: Bot):\n bot.add_cog(OffTopicNames(bot))\n", "issue": "Implement a search command for !otn\nWith hundreds of off-topic names in our list, looking for one by clicking through the paginator with the bot is tedious.\r\n\r\nLet's have a `!otn search <name>` command!\r\n\r\n#### Implementation Ideas\r\n- Use the text search functionality in postgres \r\n- Fuzzy search (`fuzzystrmatch` maybe?)\r\n- Ranked list based on similarity to query\n", "before_files": [{"content": "import asyncio\nimport logging\nfrom datetime import datetime, timedelta\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import BadArgument, Bot, Cog, Context, Converter, group\n\nfrom bot.constants import Channels, MODERATION_ROLES\nfrom bot.decorators import with_role\nfrom bot.pagination import LinePaginator\n\n\nCHANNELS = (Channels.off_topic_0, Channels.off_topic_1, Channels.off_topic_2)\nlog = logging.getLogger(__name__)\n\n\nclass OffTopicName(Converter):\n \"\"\"A converter that ensures an added off-topic name is valid.\"\"\"\n\n @staticmethod\n async def convert(ctx: Context, argument: str):\n allowed_characters = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`-\"\n\n if not (2 <= len(argument) <= 96):\n raise BadArgument(\"Channel name must be between 2 and 96 chars long\")\n\n elif not all(c.isalnum() or c in allowed_characters for c in argument):\n raise BadArgument(\n \"Channel name must only consist of \"\n \"alphanumeric characters, minus signs or apostrophes.\"\n )\n\n # Replace invalid characters with unicode alternatives.\n table = str.maketrans(\n allowed_characters, '\ud835\udda0\ud835\udda1\ud835\udda2\ud835\udda3\ud835\udda4\ud835\udda5\ud835\udda6\ud835\udda7\ud835\udda8\ud835\udda9\ud835\uddaa\ud835\uddab\ud835\uddac\ud835\uddad\ud835\uddae\ud835\uddaf\ud835\uddb0\ud835\uddb1\ud835\uddb2\ud835\uddb3\ud835\uddb4\ud835\uddb5\ud835\uddb6\ud835\uddb7\ud835\uddb8\ud835\uddb9\u01c3\uff1f\u2019\u2019-'\n )\n return argument.translate(table)\n\n\nasync def update_names(bot: Bot):\n \"\"\"\n The background updater task that performs a channel name update daily.\n\n Args:\n bot (Bot):\n The running bot instance, used for fetching data from the\n website via the bot's `api_client`.\n \"\"\"\n\n while True:\n # Since we truncate the compute timedelta to seconds, we add one second to ensure\n # we go past midnight in the `seconds_to_sleep` set below.\n today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)\n next_midnight = today_at_midnight + timedelta(days=1)\n seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1\n await asyncio.sleep(seconds_to_sleep)\n\n channel_0_name, channel_1_name, channel_2_name = await bot.api_client.get(\n 'bot/off-topic-channel-names', params={'random_items': 3}\n )\n channel_0, channel_1, channel_2 = (bot.get_channel(channel_id) for channel_id in CHANNELS)\n\n await channel_0.edit(name=f'ot0-{channel_0_name}')\n await channel_1.edit(name=f'ot1-{channel_1_name}')\n await channel_2.edit(name=f'ot2-{channel_2_name}')\n log.debug(\n \"Updated off-topic channel names to\"\n f\" {channel_0_name}, {channel_1_name} and {channel_2_name}\"\n )\n\n\nclass OffTopicNames(Cog):\n \"\"\"Commands related to managing the off-topic category channel names.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.updater_task = None\n\n def cog_unload(self):\n if self.updater_task is not None:\n self.updater_task.cancel()\n\n @Cog.listener()\n async def on_ready(self):\n if self.updater_task is None:\n coro = update_names(self.bot)\n self.updater_task = self.bot.loop.create_task(coro)\n\n @group(name='otname', aliases=('otnames', 'otn'), invoke_without_command=True)\n @with_role(*MODERATION_ROLES)\n async def otname_group(self, ctx):\n \"\"\"Add or list items from the off-topic channel name rotation.\"\"\"\n\n await ctx.invoke(self.bot.get_command(\"help\"), \"otname\")\n\n @otname_group.command(name='add', aliases=('a',))\n @with_role(*MODERATION_ROLES)\n async def add_command(self, ctx, *names: OffTopicName):\n \"\"\"Adds a new off-topic name to the rotation.\"\"\"\n # Chain multiple words to a single one\n name = \"-\".join(names)\n\n await self.bot.api_client.post(f'bot/off-topic-channel-names', params={'name': name})\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" added the off-topic channel name '{name}\"\n )\n await ctx.send(f\":ok_hand: Added `{name}` to the names list.\")\n\n @otname_group.command(name='delete', aliases=('remove', 'rm', 'del', 'd'))\n @with_role(*MODERATION_ROLES)\n async def delete_command(self, ctx, *names: OffTopicName):\n \"\"\"Removes a off-topic name from the rotation.\"\"\"\n # Chain multiple words to a single one\n name = \"-\".join(names)\n\n await self.bot.api_client.delete(f'bot/off-topic-channel-names/{name}')\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" deleted the off-topic channel name '{name}\"\n )\n await ctx.send(f\":ok_hand: Removed `{name}` from the names list.\")\n\n @otname_group.command(name='list', aliases=('l',))\n @with_role(*MODERATION_ROLES)\n async def list_command(self, ctx):\n \"\"\"\n Lists all currently known off-topic channel names in a paginator.\n Restricted to Moderator and above to not spoil the surprise.\n \"\"\"\n\n result = await self.bot.api_client.get('bot/off-topic-channel-names')\n lines = sorted(f\"\u2022 {name}\" for name in result)\n embed = Embed(\n title=f\"Known off-topic names (`{len(result)}` total)\",\n colour=Colour.blue()\n )\n if result:\n await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)\n else:\n embed.description = \"Hmmm, seems like there's nothing here yet.\"\n await ctx.send(embed=embed)\n\n\ndef setup(bot: Bot):\n bot.add_cog(OffTopicNames(bot))\n log.info(\"Cog loaded: OffTopicNames\")\n", "path": "bot/cogs/off_topic_names.py"}], "after_files": [{"content": "import asyncio\nimport difflib\nimport logging\nfrom datetime import datetime, timedelta\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import BadArgument, Bot, Cog, Context, Converter, group\n\nfrom bot.constants import Channels, MODERATION_ROLES\nfrom bot.decorators import with_role\nfrom bot.pagination import LinePaginator\n\n\nCHANNELS = (Channels.off_topic_0, Channels.off_topic_1, Channels.off_topic_2)\nlog = logging.getLogger(__name__)\n\n\nclass OffTopicName(Converter):\n \"\"\"A converter that ensures an added off-topic name is valid.\"\"\"\n\n @staticmethod\n async def convert(ctx: Context, argument: str):\n allowed_characters = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`-\"\n\n if not (2 <= len(argument) <= 96):\n raise BadArgument(\"Channel name must be between 2 and 96 chars long\")\n\n elif not all(c.isalnum() or c in allowed_characters for c in argument):\n raise BadArgument(\n \"Channel name must only consist of \"\n \"alphanumeric characters, minus signs or apostrophes.\"\n )\n\n # Replace invalid characters with unicode alternatives.\n table = str.maketrans(\n allowed_characters, '\ud835\udda0\ud835\udda1\ud835\udda2\ud835\udda3\ud835\udda4\ud835\udda5\ud835\udda6\ud835\udda7\ud835\udda8\ud835\udda9\ud835\uddaa\ud835\uddab\ud835\uddac\ud835\uddad\ud835\uddae\ud835\uddaf\ud835\uddb0\ud835\uddb1\ud835\uddb2\ud835\uddb3\ud835\uddb4\ud835\uddb5\ud835\uddb6\ud835\uddb7\ud835\uddb8\ud835\uddb9\u01c3\uff1f\u2019\u2019-'\n )\n return argument.translate(table)\n\n\nasync def update_names(bot: Bot):\n \"\"\"\n The background updater task that performs a channel name update daily.\n\n Args:\n bot (Bot):\n The running bot instance, used for fetching data from the\n website via the bot's `api_client`.\n \"\"\"\n\n while True:\n # Since we truncate the compute timedelta to seconds, we add one second to ensure\n # we go past midnight in the `seconds_to_sleep` set below.\n today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)\n next_midnight = today_at_midnight + timedelta(days=1)\n seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1\n await asyncio.sleep(seconds_to_sleep)\n\n channel_0_name, channel_1_name, channel_2_name = await bot.api_client.get(\n 'bot/off-topic-channel-names', params={'random_items': 3}\n )\n channel_0, channel_1, channel_2 = (bot.get_channel(channel_id) for channel_id in CHANNELS)\n\n await channel_0.edit(name=f'ot0-{channel_0_name}')\n await channel_1.edit(name=f'ot1-{channel_1_name}')\n await channel_2.edit(name=f'ot2-{channel_2_name}')\n log.debug(\n \"Updated off-topic channel names to\"\n f\" {channel_0_name}, {channel_1_name} and {channel_2_name}\"\n )\n\n\nclass OffTopicNames(Cog):\n \"\"\"Commands related to managing the off-topic category channel names.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.updater_task = None\n\n def cog_unload(self):\n if self.updater_task is not None:\n self.updater_task.cancel()\n\n @Cog.listener()\n async def on_ready(self):\n if self.updater_task is None:\n coro = update_names(self.bot)\n self.updater_task = self.bot.loop.create_task(coro)\n\n @group(name='otname', aliases=('otnames', 'otn'), invoke_without_command=True)\n @with_role(*MODERATION_ROLES)\n async def otname_group(self, ctx):\n \"\"\"Add or list items from the off-topic channel name rotation.\"\"\"\n\n await ctx.invoke(self.bot.get_command(\"help\"), \"otname\")\n\n @otname_group.command(name='add', aliases=('a',))\n @with_role(*MODERATION_ROLES)\n async def add_command(self, ctx, *names: OffTopicName):\n \"\"\"Adds a new off-topic name to the rotation.\"\"\"\n # Chain multiple words to a single one\n name = \"-\".join(names)\n\n await self.bot.api_client.post(f'bot/off-topic-channel-names', params={'name': name})\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" added the off-topic channel name '{name}\"\n )\n await ctx.send(f\":ok_hand: Added `{name}` to the names list.\")\n\n @otname_group.command(name='delete', aliases=('remove', 'rm', 'del', 'd'))\n @with_role(*MODERATION_ROLES)\n async def delete_command(self, ctx, *names: OffTopicName):\n \"\"\"Removes a off-topic name from the rotation.\"\"\"\n # Chain multiple words to a single one\n name = \"-\".join(names)\n\n await self.bot.api_client.delete(f'bot/off-topic-channel-names/{name}')\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" deleted the off-topic channel name '{name}\"\n )\n await ctx.send(f\":ok_hand: Removed `{name}` from the names list.\")\n\n @otname_group.command(name='list', aliases=('l',))\n @with_role(*MODERATION_ROLES)\n async def list_command(self, ctx):\n \"\"\"\n Lists all currently known off-topic channel names in a paginator.\n Restricted to Moderator and above to not spoil the surprise.\n \"\"\"\n\n result = await self.bot.api_client.get('bot/off-topic-channel-names')\n lines = sorted(f\"\u2022 {name}\" for name in result)\n embed = Embed(\n title=f\"Known off-topic names (`{len(result)}` total)\",\n colour=Colour.blue()\n )\n if result:\n await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)\n else:\n embed.description = \"Hmmm, seems like there's nothing here yet.\"\n await ctx.send(embed=embed)\n\n @otname_group.command(name='search', aliases=('s',))\n @with_role(*MODERATION_ROLES)\n async def search_command(self, ctx, *, query: str):\n \"\"\"\n Search for an off-topic name.\n \"\"\"\n\n result = await self.bot.api_client.get('bot/off-topic-channel-names')\n matches = difflib.get_close_matches(query, result, n=10, cutoff=0.35)\n lines = sorted(f\"\u2022 {name}\" for name in matches)\n embed = Embed(\n title=f\"Query results\",\n colour=Colour.blue()\n )\n\n if matches:\n await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)\n else:\n embed.description = \"Nothing found.\"\n await ctx.send(embed=embed)\n\n\ndef setup(bot: Bot):\n bot.add_cog(OffTopicNames(bot))\n log.info(\"Cog loaded: OffTopicNames\")\n", "path": "bot/cogs/off_topic_names.py"}]}
| 2,020 | 325 |
gh_patches_debug_17959
|
rasdani/github-patches
|
git_diff
|
OBOFoundry__OBOFoundry.github.io-1718
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Names with non ASCII characters deteriorate during metadata integration
Raw data:
https://github.com/OBOFoundry/OBOFoundry.github.io/blob/master/ontology/lepao.md?plain=1#L7
Result:
https://github.com/OBOFoundry/OBOFoundry.github.io/pull/1690/files#diff-ecec67b0e1d7e17a83587c6d27b6baaaa133f42482b07bd3685c77f34b62d883R3310
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `util/yaml2json.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import yaml
4 import json
5
6 from argparse import ArgumentParser
7
8 __author__ = 'cjm'
9
10
11 parser = ArgumentParser(description="Converts a YAML file to JSON, writing the result to STDOUT")
12 parser.add_argument('yaml_file', type=str, help='YAML file to convert')
13 args = parser.parse_args()
14
15 with open(args.yaml_file, 'r') as stream:
16 data = yaml.load(stream, Loader=yaml.SafeLoader)
17 data['@context'] = "http://obofoundry.github.io/registry/context.jsonld"
18 json = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))
19 print(json)
20
```
Path: `util/sort-ontologies.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import csv
4 import sys
5 import yaml
6
7 from argparse import ArgumentParser
8
9
10 def main(args):
11 parser = ArgumentParser(description='''
12 Takes a YAML file containing information for various ontologies and a metadata file specifying
13 the sorting order for ontologies, and then produces a sorted version input YAML''')
14 parser.add_argument('unsorted_yaml', type=str,
15 help='Unsorted YAML file containing information for ontologies')
16 parser.add_argument('metadata_grid', type=str,
17 help='CSV or TSV file containing metadata information for ontologies')
18 parser.add_argument('output_yaml', type=str,
19 help='Name of output YAML file that will contain sorted ontology information')
20 args = parser.parse_args()
21
22 data_file = args.unsorted_yaml
23 grid = args.metadata_grid
24 output = args.output_yaml
25
26 sort_order = get_sort_order(grid)
27 data = load_data(data_file)
28 data = sort_ontologies(data, sort_order)
29 write_data(data, output)
30
31
32 def get_sort_order(grid):
33 '''Given the path to the metadata grid (CSV or TSV), extract the order of
34 ontologies from the grid. Return the list of ontology IDs in that order.'''
35 sort_order = []
36 if '.csv' in grid:
37 separator = ','
38 elif '.tsv' or '.txt' in grid:
39 separator = '\t'
40 else:
41 print('%s must be tab- or comma-separated.', file=sys.stderr)
42 sys.exit(1)
43 with open(grid, 'r') as f:
44 reader = csv.reader(f, delimiter=separator)
45 # Ignore the header row:
46 next(reader)
47 for row in reader:
48 # Ontology IDs are in the first column of the CSV/TSV. We simply pull them out of each line
49 # in the file. Their ordering in the file is the sort ordering we are looking for:
50 sort_order.append(row[0])
51 return sort_order
52
53
54 def load_data(data_file):
55 '''Given a YAML file, load the data into a dictionary.'''
56 stream = open(data_file, 'r')
57 data = yaml.load(stream, Loader=yaml.SafeLoader)
58 return data
59
60
61 def sort_ontologies(data, sort_order):
62 '''Given the ontologies data as a dictionary and the list of ontologies in
63 proper sort order, return the sorted data.'''
64 ontologies = []
65 for ont_id in sort_order:
66 # We assume that ontology ids are unique:
67 ont = [ont for ont in data['ontologies'] if ont['id'] == ont_id].pop()
68 ontologies.append(ont)
69 data['ontologies'] = ontologies
70 return data
71
72
73 def write_data(data, output):
74 '''Given the ontologies data as a dictionary and an output YAML file to
75 write to, write the data to the file. '''
76 yaml_str = yaml.dump(data)
77 with open(output, 'w') as f:
78 f.write(yaml_str)
79
80
81 if __name__ == '__main__':
82 main(sys.argv)
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/util/sort-ontologies.py b/util/sort-ontologies.py
--- a/util/sort-ontologies.py
+++ b/util/sort-ontologies.py
@@ -73,9 +73,8 @@
def write_data(data, output):
'''Given the ontologies data as a dictionary and an output YAML file to
write to, write the data to the file. '''
- yaml_str = yaml.dump(data)
with open(output, 'w') as f:
- f.write(yaml_str)
+ yaml.safe_dump(data, f, allow_unicode=True)
if __name__ == '__main__':
diff --git a/util/yaml2json.py b/util/yaml2json.py
--- a/util/yaml2json.py
+++ b/util/yaml2json.py
@@ -15,5 +15,5 @@
with open(args.yaml_file, 'r') as stream:
data = yaml.load(stream, Loader=yaml.SafeLoader)
data['@context'] = "http://obofoundry.github.io/registry/context.jsonld"
-json = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))
+json = json.dumps(data, sort_keys=True, indent=4, ensure_ascii=False, separators=(',', ': '))
print(json)
|
{"golden_diff": "diff --git a/util/sort-ontologies.py b/util/sort-ontologies.py\n--- a/util/sort-ontologies.py\n+++ b/util/sort-ontologies.py\n@@ -73,9 +73,8 @@\n def write_data(data, output):\n '''Given the ontologies data as a dictionary and an output YAML file to\n write to, write the data to the file. '''\n- yaml_str = yaml.dump(data)\n with open(output, 'w') as f:\n- f.write(yaml_str)\n+ yaml.safe_dump(data, f, allow_unicode=True)\n \n \n if __name__ == '__main__':\ndiff --git a/util/yaml2json.py b/util/yaml2json.py\n--- a/util/yaml2json.py\n+++ b/util/yaml2json.py\n@@ -15,5 +15,5 @@\n with open(args.yaml_file, 'r') as stream:\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n data['@context'] = \"http://obofoundry.github.io/registry/context.jsonld\"\n-json = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))\n+json = json.dumps(data, sort_keys=True, indent=4, ensure_ascii=False, separators=(',', ': '))\n print(json)\n", "issue": "Names with non ASCII characters deteriorate during metadata integration\nRaw data:\r\nhttps://github.com/OBOFoundry/OBOFoundry.github.io/blob/master/ontology/lepao.md?plain=1#L7\r\n\r\nResult:\r\nhttps://github.com/OBOFoundry/OBOFoundry.github.io/pull/1690/files#diff-ecec67b0e1d7e17a83587c6d27b6baaaa133f42482b07bd3685c77f34b62d883R3310\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport yaml\nimport json\n\nfrom argparse import ArgumentParser\n\n__author__ = 'cjm'\n\n\nparser = ArgumentParser(description=\"Converts a YAML file to JSON, writing the result to STDOUT\")\nparser.add_argument('yaml_file', type=str, help='YAML file to convert')\nargs = parser.parse_args()\n\nwith open(args.yaml_file, 'r') as stream:\n data = yaml.load(stream, Loader=yaml.SafeLoader)\ndata['@context'] = \"http://obofoundry.github.io/registry/context.jsonld\"\njson = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '))\nprint(json)\n", "path": "util/yaml2json.py"}, {"content": "#!/usr/bin/env python3\n\nimport csv\nimport sys\nimport yaml\n\nfrom argparse import ArgumentParser\n\n\ndef main(args):\n parser = ArgumentParser(description='''\n Takes a YAML file containing information for various ontologies and a metadata file specifying\n the sorting order for ontologies, and then produces a sorted version input YAML''')\n parser.add_argument('unsorted_yaml', type=str,\n help='Unsorted YAML file containing information for ontologies')\n parser.add_argument('metadata_grid', type=str,\n help='CSV or TSV file containing metadata information for ontologies')\n parser.add_argument('output_yaml', type=str,\n help='Name of output YAML file that will contain sorted ontology information')\n args = parser.parse_args()\n\n data_file = args.unsorted_yaml\n grid = args.metadata_grid\n output = args.output_yaml\n\n sort_order = get_sort_order(grid)\n data = load_data(data_file)\n data = sort_ontologies(data, sort_order)\n write_data(data, output)\n\n\ndef get_sort_order(grid):\n '''Given the path to the metadata grid (CSV or TSV), extract the order of\n ontologies from the grid. Return the list of ontology IDs in that order.'''\n sort_order = []\n if '.csv' in grid:\n separator = ','\n elif '.tsv' or '.txt' in grid:\n separator = '\\t'\n else:\n print('%s must be tab- or comma-separated.', file=sys.stderr)\n sys.exit(1)\n with open(grid, 'r') as f:\n reader = csv.reader(f, delimiter=separator)\n # Ignore the header row:\n next(reader)\n for row in reader:\n # Ontology IDs are in the first column of the CSV/TSV. We simply pull them out of each line\n # in the file. Their ordering in the file is the sort ordering we are looking for:\n sort_order.append(row[0])\n return sort_order\n\n\ndef load_data(data_file):\n '''Given a YAML file, load the data into a dictionary.'''\n stream = open(data_file, 'r')\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n return data\n\n\ndef sort_ontologies(data, sort_order):\n '''Given the ontologies data as a dictionary and the list of ontologies in\n proper sort order, return the sorted data.'''\n ontologies = []\n for ont_id in sort_order:\n # We assume that ontology ids are unique:\n ont = [ont for ont in data['ontologies'] if ont['id'] == ont_id].pop()\n ontologies.append(ont)\n data['ontologies'] = ontologies\n return data\n\n\ndef write_data(data, output):\n '''Given the ontologies data as a dictionary and an output YAML file to\n write to, write the data to the file. '''\n yaml_str = yaml.dump(data)\n with open(output, 'w') as f:\n f.write(yaml_str)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "util/sort-ontologies.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport yaml\nimport json\n\nfrom argparse import ArgumentParser\n\n__author__ = 'cjm'\n\n\nparser = ArgumentParser(description=\"Converts a YAML file to JSON, writing the result to STDOUT\")\nparser.add_argument('yaml_file', type=str, help='YAML file to convert')\nargs = parser.parse_args()\n\nwith open(args.yaml_file, 'r') as stream:\n data = yaml.load(stream, Loader=yaml.SafeLoader)\ndata['@context'] = \"http://obofoundry.github.io/registry/context.jsonld\"\njson = json.dumps(data, sort_keys=True, indent=4, ensure_ascii=False, separators=(',', ': '))\nprint(json)\n", "path": "util/yaml2json.py"}, {"content": "#!/usr/bin/env python3\n\nimport csv\nimport sys\nimport yaml\n\nfrom argparse import ArgumentParser\n\n\ndef main(args):\n parser = ArgumentParser(description='''\n Takes a YAML file containing information for various ontologies and a metadata file specifying\n the sorting order for ontologies, and then produces a sorted version input YAML''')\n parser.add_argument('unsorted_yaml', type=str,\n help='Unsorted YAML file containing information for ontologies')\n parser.add_argument('metadata_grid', type=str,\n help='CSV or TSV file containing metadata information for ontologies')\n parser.add_argument('output_yaml', type=str,\n help='Name of output YAML file that will contain sorted ontology information')\n args = parser.parse_args()\n\n data_file = args.unsorted_yaml\n grid = args.metadata_grid\n output = args.output_yaml\n\n sort_order = get_sort_order(grid)\n data = load_data(data_file)\n data = sort_ontologies(data, sort_order)\n write_data(data, output)\n\n\ndef get_sort_order(grid):\n '''Given the path to the metadata grid (CSV or TSV), extract the order of\n ontologies from the grid. Return the list of ontology IDs in that order.'''\n sort_order = []\n if '.csv' in grid:\n separator = ','\n elif '.tsv' or '.txt' in grid:\n separator = '\\t'\n else:\n print('%s must be tab- or comma-separated.', file=sys.stderr)\n sys.exit(1)\n with open(grid, 'r') as f:\n reader = csv.reader(f, delimiter=separator)\n # Ignore the header row:\n next(reader)\n for row in reader:\n # Ontology IDs are in the first column of the CSV/TSV. We simply pull them out of each line\n # in the file. Their ordering in the file is the sort ordering we are looking for:\n sort_order.append(row[0])\n return sort_order\n\n\ndef load_data(data_file):\n '''Given a YAML file, load the data into a dictionary.'''\n stream = open(data_file, 'r')\n data = yaml.load(stream, Loader=yaml.SafeLoader)\n return data\n\n\ndef sort_ontologies(data, sort_order):\n '''Given the ontologies data as a dictionary and the list of ontologies in\n proper sort order, return the sorted data.'''\n ontologies = []\n for ont_id in sort_order:\n # We assume that ontology ids are unique:\n ont = [ont for ont in data['ontologies'] if ont['id'] == ont_id].pop()\n ontologies.append(ont)\n data['ontologies'] = ontologies\n return data\n\n\ndef write_data(data, output):\n '''Given the ontologies data as a dictionary and an output YAML file to\n write to, write the data to the file. '''\n with open(output, 'w') as f:\n yaml.safe_dump(data, f, allow_unicode=True)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "util/sort-ontologies.py"}]}
| 1,406 | 278 |
gh_patches_debug_784
|
rasdani/github-patches
|
git_diff
|
facebookresearch__habitat-lab-347
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DD-PPO does not all reduce gradients
## 🐛 Bug
DD-PPO does not all reduce gradients during the backward call, because `reducer.prepare_for_backward` is not being called during training process.
The problem is in this line: https://github.com/facebookresearch/habitat-api/blob/v0.1.4/habitat_baselines/rl/ddppo/algo/ddppo.py#L96
```
class DecentralizedDistributedMixin:
...
def before_backward(self, loss):
# ...
self.reducer.prepare_for_backward(..)
# Mixin goes second that way the PPO __init__ will still be called
class DDPPO(PPO, DecentralizedDistributedMixin):
# Here PPO and Mixin both have "before_backward" method,
# DDPPO will call PPO's not the Mixin's.
pass
```
And here is a quick fix:
```
class DecentralizedDistributedMixin:
...
# Mixin goes second that way the PPO __init__ will still be called
class DDPPO(PPO, DecentralizedDistributedMixin):
# Move before_backward to DDPPO
def before_backward(self, loss):
# ...
self.reducer.prepare_for_backward(..)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `habitat_baselines/rl/ddppo/algo/ddppo.py`
Content:
```
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7 from typing import Tuple
8
9 import torch
10 import torch.distributed as distrib
11
12 from habitat_baselines.common.rollout_storage import RolloutStorage
13 from habitat_baselines.rl.ppo import PPO
14
15 EPS_PPO = 1e-5
16
17
18 def distributed_mean_and_var(
19 values: torch.Tensor,
20 ) -> Tuple[torch.Tensor, torch.Tensor]:
21 r"""Computes the mean and variances of a tensor over multiple workers.
22
23 This method is equivalent to first collecting all versions of values and
24 then computing the mean and variance locally over that
25
26 :param values: (*,) shaped tensors to compute mean and variance over. Assumed
27 to be solely the workers local copy of this tensor,
28 the resultant mean and variance will be computed
29 over _all_ workers version of this tensor.
30 """
31 assert distrib.is_initialized(), "Distributed must be initialized"
32
33 world_size = distrib.get_world_size()
34 mean = values.mean()
35 distrib.all_reduce(mean)
36 mean /= world_size
37
38 sq_diff = (values - mean).pow(2).mean()
39 distrib.all_reduce(sq_diff)
40 var = sq_diff / world_size
41
42 return mean, var
43
44
45 class DecentralizedDistributedMixin:
46 def _get_advantages_distributed(
47 self, rollouts: RolloutStorage
48 ) -> torch.Tensor:
49 advantages = rollouts.returns[:-1] - rollouts.value_preds[:-1]
50 if not self.use_normalized_advantage:
51 return advantages
52
53 mean, var = distributed_mean_and_var(advantages)
54
55 return (advantages - mean) / (var.sqrt() + EPS_PPO)
56
57 def init_distributed(self, find_unused_params: bool = True) -> None:
58 r"""Initializes distributed training for the model
59
60 1. Broadcasts the model weights from world_rank 0 to all other workers
61 2. Adds gradient hooks to the model
62
63 :param find_unused_params: Whether or not to filter out unused parameters
64 before gradient reduction. This *must* be True if
65 there are any parameters in the model that where unused in the
66 forward pass, otherwise the gradient reduction
67 will not work correctly.
68 """
69 # NB: Used to hide the hooks from the nn.Module,
70 # so they don't show up in the state_dict
71 class Guard:
72 def __init__(self, model, device):
73 if torch.cuda.is_available():
74 self.ddp = torch.nn.parallel.DistributedDataParallel(
75 model, device_ids=[device], output_device=device
76 )
77 else:
78 self.ddp = torch.nn.parallel.DistributedDataParallel(model)
79
80 self._ddp_hooks = Guard(self.actor_critic, self.device)
81 self.get_advantages = self._get_advantages_distributed
82
83 self.reducer = self._ddp_hooks.ddp.reducer
84 self.find_unused_params = find_unused_params
85
86 def before_backward(self, loss):
87 super().before_backward(loss)
88
89 if self.find_unused_params:
90 self.reducer.prepare_for_backward([loss])
91 else:
92 self.reducer.prepare_for_backward([])
93
94
95 # Mixin goes second that way the PPO __init__ will still be called
96 class DDPPO(PPO, DecentralizedDistributedMixin):
97 pass
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/habitat_baselines/rl/ddppo/algo/ddppo.py b/habitat_baselines/rl/ddppo/algo/ddppo.py
--- a/habitat_baselines/rl/ddppo/algo/ddppo.py
+++ b/habitat_baselines/rl/ddppo/algo/ddppo.py
@@ -92,6 +92,5 @@
self.reducer.prepare_for_backward([])
-# Mixin goes second that way the PPO __init__ will still be called
-class DDPPO(PPO, DecentralizedDistributedMixin):
+class DDPPO(DecentralizedDistributedMixin, PPO):
pass
|
{"golden_diff": "diff --git a/habitat_baselines/rl/ddppo/algo/ddppo.py b/habitat_baselines/rl/ddppo/algo/ddppo.py\n--- a/habitat_baselines/rl/ddppo/algo/ddppo.py\n+++ b/habitat_baselines/rl/ddppo/algo/ddppo.py\n@@ -92,6 +92,5 @@\n self.reducer.prepare_for_backward([])\n \n \n-# Mixin goes second that way the PPO __init__ will still be called\n-class DDPPO(PPO, DecentralizedDistributedMixin):\n+class DDPPO(DecentralizedDistributedMixin, PPO):\n pass\n", "issue": "DD-PPO does not all reduce gradients\n## \ud83d\udc1b Bug\r\n\r\nDD-PPO does not all reduce gradients during the backward call, because `reducer.prepare_for_backward` is not being called during training process.\r\n\r\nThe problem is in this line: https://github.com/facebookresearch/habitat-api/blob/v0.1.4/habitat_baselines/rl/ddppo/algo/ddppo.py#L96\r\n\r\n```\r\nclass DecentralizedDistributedMixin:\r\n\r\n ...\r\n def before_backward(self, loss):\r\n # ...\r\n self.reducer.prepare_for_backward(..)\r\n\r\n\r\n# Mixin goes second that way the PPO __init__ will still be called\r\nclass DDPPO(PPO, DecentralizedDistributedMixin): \r\n # Here PPO and Mixin both have \"before_backward\" method, \r\n # DDPPO will call PPO's not the Mixin's.\r\n pass\r\n```\r\n\r\nAnd here is a quick fix:\r\n```\r\nclass DecentralizedDistributedMixin:\r\n ...\r\n\r\n\r\n# Mixin goes second that way the PPO __init__ will still be called\r\nclass DDPPO(PPO, DecentralizedDistributedMixin): \r\n\r\n # Move before_backward to DDPPO\r\n def before_backward(self, loss):\r\n # ...\r\n self.reducer.prepare_for_backward(..)\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom typing import Tuple\n\nimport torch\nimport torch.distributed as distrib\n\nfrom habitat_baselines.common.rollout_storage import RolloutStorage\nfrom habitat_baselines.rl.ppo import PPO\n\nEPS_PPO = 1e-5\n\n\ndef distributed_mean_and_var(\n values: torch.Tensor,\n) -> Tuple[torch.Tensor, torch.Tensor]:\n r\"\"\"Computes the mean and variances of a tensor over multiple workers.\n\n This method is equivalent to first collecting all versions of values and\n then computing the mean and variance locally over that\n\n :param values: (*,) shaped tensors to compute mean and variance over. Assumed\n to be solely the workers local copy of this tensor,\n the resultant mean and variance will be computed\n over _all_ workers version of this tensor.\n \"\"\"\n assert distrib.is_initialized(), \"Distributed must be initialized\"\n\n world_size = distrib.get_world_size()\n mean = values.mean()\n distrib.all_reduce(mean)\n mean /= world_size\n\n sq_diff = (values - mean).pow(2).mean()\n distrib.all_reduce(sq_diff)\n var = sq_diff / world_size\n\n return mean, var\n\n\nclass DecentralizedDistributedMixin:\n def _get_advantages_distributed(\n self, rollouts: RolloutStorage\n ) -> torch.Tensor:\n advantages = rollouts.returns[:-1] - rollouts.value_preds[:-1]\n if not self.use_normalized_advantage:\n return advantages\n\n mean, var = distributed_mean_and_var(advantages)\n\n return (advantages - mean) / (var.sqrt() + EPS_PPO)\n\n def init_distributed(self, find_unused_params: bool = True) -> None:\n r\"\"\"Initializes distributed training for the model\n\n 1. Broadcasts the model weights from world_rank 0 to all other workers\n 2. Adds gradient hooks to the model\n\n :param find_unused_params: Whether or not to filter out unused parameters\n before gradient reduction. This *must* be True if\n there are any parameters in the model that where unused in the\n forward pass, otherwise the gradient reduction\n will not work correctly.\n \"\"\"\n # NB: Used to hide the hooks from the nn.Module,\n # so they don't show up in the state_dict\n class Guard:\n def __init__(self, model, device):\n if torch.cuda.is_available():\n self.ddp = torch.nn.parallel.DistributedDataParallel(\n model, device_ids=[device], output_device=device\n )\n else:\n self.ddp = torch.nn.parallel.DistributedDataParallel(model)\n\n self._ddp_hooks = Guard(self.actor_critic, self.device)\n self.get_advantages = self._get_advantages_distributed\n\n self.reducer = self._ddp_hooks.ddp.reducer\n self.find_unused_params = find_unused_params\n\n def before_backward(self, loss):\n super().before_backward(loss)\n\n if self.find_unused_params:\n self.reducer.prepare_for_backward([loss])\n else:\n self.reducer.prepare_for_backward([])\n\n\n# Mixin goes second that way the PPO __init__ will still be called\nclass DDPPO(PPO, DecentralizedDistributedMixin):\n pass\n", "path": "habitat_baselines/rl/ddppo/algo/ddppo.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom typing import Tuple\n\nimport torch\nimport torch.distributed as distrib\n\nfrom habitat_baselines.common.rollout_storage import RolloutStorage\nfrom habitat_baselines.rl.ppo import PPO\n\nEPS_PPO = 1e-5\n\n\ndef distributed_mean_and_var(\n values: torch.Tensor,\n) -> Tuple[torch.Tensor, torch.Tensor]:\n r\"\"\"Computes the mean and variances of a tensor over multiple workers.\n\n This method is equivalent to first collecting all versions of values and\n then computing the mean and variance locally over that\n\n :param values: (*,) shaped tensors to compute mean and variance over. Assumed\n to be solely the workers local copy of this tensor,\n the resultant mean and variance will be computed\n over _all_ workers version of this tensor.\n \"\"\"\n assert distrib.is_initialized(), \"Distributed must be initialized\"\n\n world_size = distrib.get_world_size()\n mean = values.mean()\n distrib.all_reduce(mean)\n mean /= world_size\n\n sq_diff = (values - mean).pow(2).mean()\n distrib.all_reduce(sq_diff)\n var = sq_diff / world_size\n\n return mean, var\n\n\nclass DecentralizedDistributedMixin:\n def _get_advantages_distributed(\n self, rollouts: RolloutStorage\n ) -> torch.Tensor:\n advantages = rollouts.returns[:-1] - rollouts.value_preds[:-1]\n if not self.use_normalized_advantage:\n return advantages\n\n mean, var = distributed_mean_and_var(advantages)\n\n return (advantages - mean) / (var.sqrt() + EPS_PPO)\n\n def init_distributed(self, find_unused_params: bool = True) -> None:\n r\"\"\"Initializes distributed training for the model\n\n 1. Broadcasts the model weights from world_rank 0 to all other workers\n 2. Adds gradient hooks to the model\n\n :param find_unused_params: Whether or not to filter out unused parameters\n before gradient reduction. This *must* be True if\n there are any parameters in the model that where unused in the\n forward pass, otherwise the gradient reduction\n will not work correctly.\n \"\"\"\n # NB: Used to hide the hooks from the nn.Module,\n # so they don't show up in the state_dict\n class Guard:\n def __init__(self, model, device):\n if torch.cuda.is_available():\n self.ddp = torch.nn.parallel.DistributedDataParallel(\n model, device_ids=[device], output_device=device\n )\n else:\n self.ddp = torch.nn.parallel.DistributedDataParallel(model)\n\n self._ddp_hooks = Guard(self.actor_critic, self.device)\n self.get_advantages = self._get_advantages_distributed\n\n self.reducer = self._ddp_hooks.ddp.reducer\n self.find_unused_params = find_unused_params\n\n def before_backward(self, loss):\n super().before_backward(loss)\n\n if self.find_unused_params:\n self.reducer.prepare_for_backward([loss])\n else:\n self.reducer.prepare_for_backward([])\n\n\nclass DDPPO(DecentralizedDistributedMixin, PPO):\n pass\n", "path": "habitat_baselines/rl/ddppo/algo/ddppo.py"}]}
| 1,486 | 144 |
gh_patches_debug_18372
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-892
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
fix: schema_example.py status_code ignored
Just a small fix/enhancement for the examples in the webargs documentation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/schema_example.py`
Content:
```
1 """Example implementation of using a marshmallow Schema for both request input
2 and output with a `use_schema` decorator.
3 Run the app:
4
5 $ python examples/schema_example.py
6
7 Try the following with httpie (a cURL-like utility, http://httpie.org):
8
9 $ pip install httpie
10 $ http GET :5001/users/
11 $ http GET :5001/users/42
12 $ http POST :5001/users/ username=brian first_name=Brian last_name=May
13 $ http PATCH :5001/users/42 username=freddie
14 $ http GET :5001/users/ limit==1
15 """
16 import functools
17 from flask import Flask, request
18 import random
19
20 from marshmallow import Schema, fields, post_dump
21 from webargs.flaskparser import parser, use_kwargs
22
23 app = Flask(__name__)
24
25 ##### Fake database and model #####
26
27
28 class Model:
29 def __init__(self, **kwargs):
30 self.__dict__.update(kwargs)
31
32 def update(self, **kwargs):
33 self.__dict__.update(kwargs)
34
35 @classmethod
36 def insert(cls, db, **kwargs):
37 collection = db[cls.collection]
38 new_id = None
39 if "id" in kwargs: # for setting up fixtures
40 new_id = kwargs.pop("id")
41 else: # find a new id
42 found_id = False
43 while not found_id:
44 new_id = random.randint(1, 9999)
45 if new_id not in collection:
46 found_id = True
47 new_record = cls(id=new_id, **kwargs)
48 collection[new_id] = new_record
49 return new_record
50
51
52 class User(Model):
53 collection = "users"
54
55
56 db = {"users": {}}
57
58
59 ##### use_schema #####
60
61
62 def use_schema(schema_cls, list_view=False, locations=None):
63 """View decorator for using a marshmallow schema to
64 (1) parse a request's input and
65 (2) serializing the view's output to a JSON response.
66 """
67
68 def decorator(func):
69 @functools.wraps(func)
70 def wrapped(*args, **kwargs):
71 partial = request.method != "POST"
72 schema = schema_cls(partial=partial)
73 use_args_wrapper = parser.use_args(schema, locations=locations)
74 # Function wrapped with use_args
75 func_with_args = use_args_wrapper(func)
76 ret = func_with_args(*args, **kwargs)
77 return schema.dump(ret, many=list_view)
78
79 return wrapped
80
81 return decorator
82
83
84 ##### Schemas #####
85
86
87 class UserSchema(Schema):
88 id = fields.Int(dump_only=True)
89 username = fields.Str(required=True)
90 first_name = fields.Str()
91 last_name = fields.Str()
92
93 @post_dump(pass_many=True)
94 def wrap_with_envelope(self, data, many, **kwargs):
95 return {"data": data}
96
97
98 ##### Routes #####
99
100
101 @app.route("/users/<int:user_id>", methods=["GET", "PATCH"])
102 @use_schema(UserSchema)
103 def user_detail(reqargs, user_id):
104 user = db["users"].get(user_id)
105 if not user:
106 return {"message": "User not found"}, 404
107 if request.method == "PATCH" and reqargs:
108 user.update(**reqargs)
109 return user
110
111
112 # You can add additional arguments with use_kwargs
113 @app.route("/users/", methods=["GET", "POST"])
114 @use_kwargs({"limit": fields.Int(load_default=10, location="query")})
115 @use_schema(UserSchema, list_view=True)
116 def user_list(reqargs, limit):
117 users = db["users"].values()
118 if request.method == "POST":
119 User.insert(db=db, **reqargs)
120 return list(users)[:limit]
121
122
123 # Return validation errors as JSON
124 @app.errorhandler(422)
125 @app.errorhandler(400)
126 def handle_validation_error(err):
127 exc = getattr(err, "exc", None)
128 if exc:
129 headers = err.data["headers"]
130 messages = exc.messages
131 else:
132 headers = None
133 messages = ["Invalid request."]
134 if headers:
135 return {"errors": messages}, err.code, headers
136 else:
137 return {"errors": messages}, err.code
138
139
140 if __name__ == "__main__":
141 User.insert(
142 db=db, id=42, username="fred", first_name="Freddie", last_name="Mercury"
143 )
144 app.run(port=5001, debug=True)
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/schema_example.py b/examples/schema_example.py
--- a/examples/schema_example.py
+++ b/examples/schema_example.py
@@ -14,9 +14,9 @@
$ http GET :5001/users/ limit==1
"""
import functools
-from flask import Flask, request
import random
+from flask import Flask, request
from marshmallow import Schema, fields, post_dump
from webargs.flaskparser import parser, use_kwargs
@@ -74,6 +74,11 @@
# Function wrapped with use_args
func_with_args = use_args_wrapper(func)
ret = func_with_args(*args, **kwargs)
+
+ # support (json, status) tuples
+ if isinstance(ret, tuple) and len(ret) == 2 and isinstance(ret[1], int):
+ return schema.dump(ret[0], many=list_view), ret[1]
+
return schema.dump(ret, many=list_view)
return wrapped
|
{"golden_diff": "diff --git a/examples/schema_example.py b/examples/schema_example.py\n--- a/examples/schema_example.py\n+++ b/examples/schema_example.py\n@@ -14,9 +14,9 @@\n $ http GET :5001/users/ limit==1\n \"\"\"\n import functools\n-from flask import Flask, request\n import random\n \n+from flask import Flask, request\n from marshmallow import Schema, fields, post_dump\n from webargs.flaskparser import parser, use_kwargs\n \n@@ -74,6 +74,11 @@\n # Function wrapped with use_args\n func_with_args = use_args_wrapper(func)\n ret = func_with_args(*args, **kwargs)\n+\n+ # support (json, status) tuples\n+ if isinstance(ret, tuple) and len(ret) == 2 and isinstance(ret[1], int):\n+ return schema.dump(ret[0], many=list_view), ret[1]\n+\n return schema.dump(ret, many=list_view)\n \n return wrapped\n", "issue": "fix: schema_example.py status_code ignored\nJust a small fix/enhancement for the examples in the webargs documentation.\n", "before_files": [{"content": "\"\"\"Example implementation of using a marshmallow Schema for both request input\nand output with a `use_schema` decorator.\nRun the app:\n\n $ python examples/schema_example.py\n\nTry the following with httpie (a cURL-like utility, http://httpie.org):\n\n $ pip install httpie\n $ http GET :5001/users/\n $ http GET :5001/users/42\n $ http POST :5001/users/ username=brian first_name=Brian last_name=May\n $ http PATCH :5001/users/42 username=freddie\n $ http GET :5001/users/ limit==1\n\"\"\"\nimport functools\nfrom flask import Flask, request\nimport random\n\nfrom marshmallow import Schema, fields, post_dump\nfrom webargs.flaskparser import parser, use_kwargs\n\napp = Flask(__name__)\n\n##### Fake database and model #####\n\n\nclass Model:\n def __init__(self, **kwargs):\n self.__dict__.update(kwargs)\n\n def update(self, **kwargs):\n self.__dict__.update(kwargs)\n\n @classmethod\n def insert(cls, db, **kwargs):\n collection = db[cls.collection]\n new_id = None\n if \"id\" in kwargs: # for setting up fixtures\n new_id = kwargs.pop(\"id\")\n else: # find a new id\n found_id = False\n while not found_id:\n new_id = random.randint(1, 9999)\n if new_id not in collection:\n found_id = True\n new_record = cls(id=new_id, **kwargs)\n collection[new_id] = new_record\n return new_record\n\n\nclass User(Model):\n collection = \"users\"\n\n\ndb = {\"users\": {}}\n\n\n##### use_schema #####\n\n\ndef use_schema(schema_cls, list_view=False, locations=None):\n \"\"\"View decorator for using a marshmallow schema to\n (1) parse a request's input and\n (2) serializing the view's output to a JSON response.\n \"\"\"\n\n def decorator(func):\n @functools.wraps(func)\n def wrapped(*args, **kwargs):\n partial = request.method != \"POST\"\n schema = schema_cls(partial=partial)\n use_args_wrapper = parser.use_args(schema, locations=locations)\n # Function wrapped with use_args\n func_with_args = use_args_wrapper(func)\n ret = func_with_args(*args, **kwargs)\n return schema.dump(ret, many=list_view)\n\n return wrapped\n\n return decorator\n\n\n##### Schemas #####\n\n\nclass UserSchema(Schema):\n id = fields.Int(dump_only=True)\n username = fields.Str(required=True)\n first_name = fields.Str()\n last_name = fields.Str()\n\n @post_dump(pass_many=True)\n def wrap_with_envelope(self, data, many, **kwargs):\n return {\"data\": data}\n\n\n##### Routes #####\n\n\[email protected](\"/users/<int:user_id>\", methods=[\"GET\", \"PATCH\"])\n@use_schema(UserSchema)\ndef user_detail(reqargs, user_id):\n user = db[\"users\"].get(user_id)\n if not user:\n return {\"message\": \"User not found\"}, 404\n if request.method == \"PATCH\" and reqargs:\n user.update(**reqargs)\n return user\n\n\n# You can add additional arguments with use_kwargs\[email protected](\"/users/\", methods=[\"GET\", \"POST\"])\n@use_kwargs({\"limit\": fields.Int(load_default=10, location=\"query\")})\n@use_schema(UserSchema, list_view=True)\ndef user_list(reqargs, limit):\n users = db[\"users\"].values()\n if request.method == \"POST\":\n User.insert(db=db, **reqargs)\n return list(users)[:limit]\n\n\n# Return validation errors as JSON\[email protected](422)\[email protected](400)\ndef handle_validation_error(err):\n exc = getattr(err, \"exc\", None)\n if exc:\n headers = err.data[\"headers\"]\n messages = exc.messages\n else:\n headers = None\n messages = [\"Invalid request.\"]\n if headers:\n return {\"errors\": messages}, err.code, headers\n else:\n return {\"errors\": messages}, err.code\n\n\nif __name__ == \"__main__\":\n User.insert(\n db=db, id=42, username=\"fred\", first_name=\"Freddie\", last_name=\"Mercury\"\n )\n app.run(port=5001, debug=True)\n", "path": "examples/schema_example.py"}], "after_files": [{"content": "\"\"\"Example implementation of using a marshmallow Schema for both request input\nand output with a `use_schema` decorator.\nRun the app:\n\n $ python examples/schema_example.py\n\nTry the following with httpie (a cURL-like utility, http://httpie.org):\n\n $ pip install httpie\n $ http GET :5001/users/\n $ http GET :5001/users/42\n $ http POST :5001/users/ username=brian first_name=Brian last_name=May\n $ http PATCH :5001/users/42 username=freddie\n $ http GET :5001/users/ limit==1\n\"\"\"\nimport functools\nimport random\n\nfrom flask import Flask, request\nfrom marshmallow import Schema, fields, post_dump\nfrom webargs.flaskparser import parser, use_kwargs\n\napp = Flask(__name__)\n\n##### Fake database and model #####\n\n\nclass Model:\n def __init__(self, **kwargs):\n self.__dict__.update(kwargs)\n\n def update(self, **kwargs):\n self.__dict__.update(kwargs)\n\n @classmethod\n def insert(cls, db, **kwargs):\n collection = db[cls.collection]\n new_id = None\n if \"id\" in kwargs: # for setting up fixtures\n new_id = kwargs.pop(\"id\")\n else: # find a new id\n found_id = False\n while not found_id:\n new_id = random.randint(1, 9999)\n if new_id not in collection:\n found_id = True\n new_record = cls(id=new_id, **kwargs)\n collection[new_id] = new_record\n return new_record\n\n\nclass User(Model):\n collection = \"users\"\n\n\ndb = {\"users\": {}}\n\n\n##### use_schema #####\n\n\ndef use_schema(schema_cls, list_view=False, locations=None):\n \"\"\"View decorator for using a marshmallow schema to\n (1) parse a request's input and\n (2) serializing the view's output to a JSON response.\n \"\"\"\n\n def decorator(func):\n @functools.wraps(func)\n def wrapped(*args, **kwargs):\n partial = request.method != \"POST\"\n schema = schema_cls(partial=partial)\n use_args_wrapper = parser.use_args(schema, locations=locations)\n # Function wrapped with use_args\n func_with_args = use_args_wrapper(func)\n ret = func_with_args(*args, **kwargs)\n\n # support (json, status) tuples\n if isinstance(ret, tuple) and len(ret) == 2 and isinstance(ret[1], int):\n return schema.dump(ret[0], many=list_view), ret[1]\n\n return schema.dump(ret, many=list_view)\n\n return wrapped\n\n return decorator\n\n\n##### Schemas #####\n\n\nclass UserSchema(Schema):\n id = fields.Int(dump_only=True)\n username = fields.Str(required=True)\n first_name = fields.Str()\n last_name = fields.Str()\n\n @post_dump(pass_many=True)\n def wrap_with_envelope(self, data, many, **kwargs):\n return {\"data\": data}\n\n\n##### Routes #####\n\n\[email protected](\"/users/<int:user_id>\", methods=[\"GET\", \"PATCH\"])\n@use_schema(UserSchema)\ndef user_detail(reqargs, user_id):\n user = db[\"users\"].get(user_id)\n if not user:\n return {\"message\": \"User not found\"}, 404\n if request.method == \"PATCH\" and reqargs:\n user.update(**reqargs)\n return user\n\n\n# You can add additional arguments with use_kwargs\[email protected](\"/users/\", methods=[\"GET\", \"POST\"])\n@use_kwargs({\"limit\": fields.Int(load_default=10, location=\"query\")})\n@use_schema(UserSchema, list_view=True)\ndef user_list(reqargs, limit):\n users = db[\"users\"].values()\n if request.method == \"POST\":\n User.insert(db=db, **reqargs)\n return list(users)[:limit]\n\n\n# Return validation errors as JSON\[email protected](422)\[email protected](400)\ndef handle_validation_error(err):\n exc = getattr(err, \"exc\", None)\n if exc:\n headers = err.data[\"headers\"]\n messages = exc.messages\n else:\n headers = None\n messages = [\"Invalid request.\"]\n if headers:\n return {\"errors\": messages}, err.code, headers\n else:\n return {\"errors\": messages}, err.code\n\n\nif __name__ == \"__main__\":\n User.insert(\n db=db, id=42, username=\"fred\", first_name=\"Freddie\", last_name=\"Mercury\"\n )\n app.run(port=5001, debug=True)\n", "path": "examples/schema_example.py"}]}
| 1,597 | 211 |
gh_patches_debug_15141
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-541
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Metadata on Groups
Similarily to how you can store extra properties (metadata) on a collection, it would be useful to be able to do this with groups.
In my applications, almost everything is dynamic. Users can create groups on the fly, rename them, etc., so I tend to use generated ID's for everything. It would be nice to be able to set a title and description on groups for UI presentation.
Right now I have to create a collection for storing group metadata separately from the actual group.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/__init__.py`
Content:
```
1 import pkg_resources
2 import logging
3
4 import cliquet
5 from pyramid.config import Configurator
6 from pyramid.settings import asbool
7 from pyramid.security import Authenticated
8
9 from kinto.authorization import RouteFactory
10
11 # Module version, as defined in PEP-0396.
12 __version__ = pkg_resources.get_distribution(__package__).version
13
14 # Implemented HTTP API Version
15 HTTP_API_VERSION = '1.4'
16
17 # Main kinto logger
18 logger = logging.getLogger(__name__)
19
20
21 DEFAULT_SETTINGS = {
22 'retry_after_seconds': 3,
23 'cache_backend': 'cliquet.cache.memory',
24 'permission_backend': 'cliquet.permission.memory',
25 'storage_backend': 'cliquet.storage.memory',
26 'project_docs': 'https://kinto.readthedocs.org/',
27 'bucket_create_principals': Authenticated,
28 'multiauth.authorization_policy': (
29 'kinto.authorization.AuthorizationPolicy'),
30 'experimental_collection_schema_validation': 'False',
31 'http_api_version': HTTP_API_VERSION
32 }
33
34
35 def main(global_config, config=None, **settings):
36 if not config:
37 config = Configurator(settings=settings, root_factory=RouteFactory)
38
39 # Force project name, since it determines settings prefix.
40 config.add_settings({'cliquet.project_name': 'kinto'})
41
42 cliquet.initialize(config,
43 version=__version__,
44 default_settings=DEFAULT_SETTINGS)
45
46 settings = config.get_settings()
47
48 # Retro-compatibility with first Kinto clients.
49 config.registry.public_settings.add('cliquet.batch_max_requests')
50
51 # Expose capability
52 schema_enabled = asbool(
53 settings['experimental_collection_schema_validation']
54 )
55 if schema_enabled:
56 config.add_api_capability(
57 "schema",
58 description="Validates collection records with JSON schemas.",
59 url="http://kinto.readthedocs.org/en/latest/api/1.x/"
60 "collections.html#collection-json-schema")
61
62 # Scan Kinto views.
63 kwargs = {}
64 flush_enabled = asbool(settings.get('flush_endpoint_enabled'))
65
66 if flush_enabled:
67 config.add_api_capability(
68 "flush_endpoint",
69 description="The __flush__ endpoint can be used to remove all "
70 "data from all backends.",
71 url="http://kinto.readthedocs.org/en/latest/configuration/"
72 "settings.html#activating-the-flush-endpoint"
73 )
74 else:
75 kwargs['ignore'] = 'kinto.views.flush'
76 config.scan("kinto.views", **kwargs)
77
78 app = config.make_wsgi_app()
79
80 # Install middleware (idempotent if disabled)
81 return cliquet.install_middlewares(app, settings)
82
```
Path: `kinto/views/groups.py`
Content:
```
1 import colander
2
3 from cliquet import resource
4 from cliquet.events import ResourceChanged, ACTIONS
5 from pyramid.events import subscriber
6
7 from kinto.views import NameGenerator
8
9
10 class GroupSchema(resource.ResourceSchema):
11 members = colander.SchemaNode(colander.Sequence(),
12 colander.SchemaNode(colander.String()))
13
14
15 @resource.register(name='group',
16 collection_path='/buckets/{{bucket_id}}/groups',
17 record_path='/buckets/{{bucket_id}}/groups/{{id}}')
18 class Group(resource.ShareableResource):
19
20 mapping = GroupSchema()
21
22 def __init__(self, *args, **kwargs):
23 super(Group, self).__init__(*args, **kwargs)
24 self.model.id_generator = NameGenerator()
25
26 def get_parent_id(self, request):
27 bucket_id = request.matchdict['bucket_id']
28 parent_id = '/buckets/%s' % bucket_id
29 return parent_id
30
31
32 @subscriber(ResourceChanged,
33 for_resources=('group',),
34 for_actions=(ACTIONS.DELETE,))
35 def on_groups_deleted(event):
36 """Some groups were deleted, remove them from users principals.
37 """
38 permission_backend = event.request.registry.permission
39
40 for change in event.impacted_records:
41 group = change['old']
42 group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],
43 **event.payload)
44 permission_backend.remove_principal(group_uri)
45
46
47 @subscriber(ResourceChanged,
48 for_resources=('group',),
49 for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))
50 def on_groups_changed(event):
51 """Some groups were changed, update users principals.
52 """
53 permission_backend = event.request.registry.permission
54
55 for change in event.impacted_records:
56 if 'old' in change:
57 existing_record_members = set(change['old'].get('members', []))
58 else:
59 existing_record_members = set()
60
61 group = change['new']
62 group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],
63 **event.payload)
64 new_record_members = set(group.get('members', []))
65 new_members = new_record_members - existing_record_members
66 removed_members = existing_record_members - new_record_members
67
68 for member in new_members:
69 # Add the group to the member principal.
70 permission_backend.add_user_principal(member, group_uri)
71
72 for member in removed_members:
73 # Remove the group from the member principal.
74 permission_backend.remove_user_principal(member, group_uri)
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/__init__.py b/kinto/__init__.py
--- a/kinto/__init__.py
+++ b/kinto/__init__.py
@@ -12,7 +12,7 @@
__version__ = pkg_resources.get_distribution(__package__).version
# Implemented HTTP API Version
-HTTP_API_VERSION = '1.4'
+HTTP_API_VERSION = '1.5'
# Main kinto logger
logger = logging.getLogger(__name__)
diff --git a/kinto/views/groups.py b/kinto/views/groups.py
--- a/kinto/views/groups.py
+++ b/kinto/views/groups.py
@@ -11,6 +11,9 @@
members = colander.SchemaNode(colander.Sequence(),
colander.SchemaNode(colander.String()))
+ class Options:
+ preserve_unknown = True
+
@resource.register(name='group',
collection_path='/buckets/{{bucket_id}}/groups',
|
{"golden_diff": "diff --git a/kinto/__init__.py b/kinto/__init__.py\n--- a/kinto/__init__.py\n+++ b/kinto/__init__.py\n@@ -12,7 +12,7 @@\n __version__ = pkg_resources.get_distribution(__package__).version\n \n # Implemented HTTP API Version\n-HTTP_API_VERSION = '1.4'\n+HTTP_API_VERSION = '1.5'\n \n # Main kinto logger\n logger = logging.getLogger(__name__)\ndiff --git a/kinto/views/groups.py b/kinto/views/groups.py\n--- a/kinto/views/groups.py\n+++ b/kinto/views/groups.py\n@@ -11,6 +11,9 @@\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String()))\n \n+ class Options:\n+ preserve_unknown = True\n+\n \n @resource.register(name='group',\n collection_path='/buckets/{{bucket_id}}/groups',\n", "issue": "Metadata on Groups\nSimilarily to how you can store extra properties (metadata) on a collection, it would be useful to be able to do this with groups.\n\nIn my applications, almost everything is dynamic. Users can create groups on the fly, rename them, etc., so I tend to use generated ID's for everything. It would be nice to be able to set a title and description on groups for UI presentation.\n\nRight now I have to create a collection for storing group metadata separately from the actual group.\n\n", "before_files": [{"content": "import pkg_resources\nimport logging\n\nimport cliquet\nfrom pyramid.config import Configurator\nfrom pyramid.settings import asbool\nfrom pyramid.security import Authenticated\n\nfrom kinto.authorization import RouteFactory\n\n# Module version, as defined in PEP-0396.\n__version__ = pkg_resources.get_distribution(__package__).version\n\n# Implemented HTTP API Version\nHTTP_API_VERSION = '1.4'\n\n# Main kinto logger\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_SETTINGS = {\n 'retry_after_seconds': 3,\n 'cache_backend': 'cliquet.cache.memory',\n 'permission_backend': 'cliquet.permission.memory',\n 'storage_backend': 'cliquet.storage.memory',\n 'project_docs': 'https://kinto.readthedocs.org/',\n 'bucket_create_principals': Authenticated,\n 'multiauth.authorization_policy': (\n 'kinto.authorization.AuthorizationPolicy'),\n 'experimental_collection_schema_validation': 'False',\n 'http_api_version': HTTP_API_VERSION\n}\n\n\ndef main(global_config, config=None, **settings):\n if not config:\n config = Configurator(settings=settings, root_factory=RouteFactory)\n\n # Force project name, since it determines settings prefix.\n config.add_settings({'cliquet.project_name': 'kinto'})\n\n cliquet.initialize(config,\n version=__version__,\n default_settings=DEFAULT_SETTINGS)\n\n settings = config.get_settings()\n\n # Retro-compatibility with first Kinto clients.\n config.registry.public_settings.add('cliquet.batch_max_requests')\n\n # Expose capability\n schema_enabled = asbool(\n settings['experimental_collection_schema_validation']\n )\n if schema_enabled:\n config.add_api_capability(\n \"schema\",\n description=\"Validates collection records with JSON schemas.\",\n url=\"http://kinto.readthedocs.org/en/latest/api/1.x/\"\n \"collections.html#collection-json-schema\")\n\n # Scan Kinto views.\n kwargs = {}\n flush_enabled = asbool(settings.get('flush_endpoint_enabled'))\n\n if flush_enabled:\n config.add_api_capability(\n \"flush_endpoint\",\n description=\"The __flush__ endpoint can be used to remove all \"\n \"data from all backends.\",\n url=\"http://kinto.readthedocs.org/en/latest/configuration/\"\n \"settings.html#activating-the-flush-endpoint\"\n )\n else:\n kwargs['ignore'] = 'kinto.views.flush'\n config.scan(\"kinto.views\", **kwargs)\n\n app = config.make_wsgi_app()\n\n # Install middleware (idempotent if disabled)\n return cliquet.install_middlewares(app, settings)\n", "path": "kinto/__init__.py"}, {"content": "import colander\n\nfrom cliquet import resource\nfrom cliquet.events import ResourceChanged, ACTIONS\nfrom pyramid.events import subscriber\n\nfrom kinto.views import NameGenerator\n\n\nclass GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String()))\n\n\[email protected](name='group',\n collection_path='/buckets/{{bucket_id}}/groups',\n record_path='/buckets/{{bucket_id}}/groups/{{id}}')\nclass Group(resource.ShareableResource):\n\n mapping = GroupSchema()\n\n def __init__(self, *args, **kwargs):\n super(Group, self).__init__(*args, **kwargs)\n self.model.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n bucket_id = request.matchdict['bucket_id']\n parent_id = '/buckets/%s' % bucket_id\n return parent_id\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.DELETE,))\ndef on_groups_deleted(event):\n \"\"\"Some groups were deleted, remove them from users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n group = change['old']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n permission_backend.remove_principal(group_uri)\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))\ndef on_groups_changed(event):\n \"\"\"Some groups were changed, update users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n if 'old' in change:\n existing_record_members = set(change['old'].get('members', []))\n else:\n existing_record_members = set()\n\n group = change['new']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n new_record_members = set(group.get('members', []))\n new_members = new_record_members - existing_record_members\n removed_members = existing_record_members - new_record_members\n\n for member in new_members:\n # Add the group to the member principal.\n permission_backend.add_user_principal(member, group_uri)\n\n for member in removed_members:\n # Remove the group from the member principal.\n permission_backend.remove_user_principal(member, group_uri)\n", "path": "kinto/views/groups.py"}], "after_files": [{"content": "import pkg_resources\nimport logging\n\nimport cliquet\nfrom pyramid.config import Configurator\nfrom pyramid.settings import asbool\nfrom pyramid.security import Authenticated\n\nfrom kinto.authorization import RouteFactory\n\n# Module version, as defined in PEP-0396.\n__version__ = pkg_resources.get_distribution(__package__).version\n\n# Implemented HTTP API Version\nHTTP_API_VERSION = '1.5'\n\n# Main kinto logger\nlogger = logging.getLogger(__name__)\n\n\nDEFAULT_SETTINGS = {\n 'retry_after_seconds': 3,\n 'cache_backend': 'cliquet.cache.memory',\n 'permission_backend': 'cliquet.permission.memory',\n 'storage_backend': 'cliquet.storage.memory',\n 'project_docs': 'https://kinto.readthedocs.org/',\n 'bucket_create_principals': Authenticated,\n 'multiauth.authorization_policy': (\n 'kinto.authorization.AuthorizationPolicy'),\n 'experimental_collection_schema_validation': 'False',\n 'http_api_version': HTTP_API_VERSION\n}\n\n\ndef main(global_config, config=None, **settings):\n if not config:\n config = Configurator(settings=settings, root_factory=RouteFactory)\n\n # Force project name, since it determines settings prefix.\n config.add_settings({'cliquet.project_name': 'kinto'})\n\n cliquet.initialize(config,\n version=__version__,\n default_settings=DEFAULT_SETTINGS)\n\n settings = config.get_settings()\n\n # Retro-compatibility with first Kinto clients.\n config.registry.public_settings.add('cliquet.batch_max_requests')\n\n # Expose capability\n schema_enabled = asbool(\n settings['experimental_collection_schema_validation']\n )\n if schema_enabled:\n config.add_api_capability(\n \"schema\",\n description=\"Validates collection records with JSON schemas.\",\n url=\"http://kinto.readthedocs.org/en/latest/api/1.x/\"\n \"collections.html#collection-json-schema\")\n\n # Scan Kinto views.\n kwargs = {}\n flush_enabled = asbool(settings.get('flush_endpoint_enabled'))\n\n if flush_enabled:\n config.add_api_capability(\n \"flush_endpoint\",\n description=\"The __flush__ endpoint can be used to remove all \"\n \"data from all backends.\",\n url=\"http://kinto.readthedocs.org/en/latest/configuration/\"\n \"settings.html#activating-the-flush-endpoint\"\n )\n else:\n kwargs['ignore'] = 'kinto.views.flush'\n config.scan(\"kinto.views\", **kwargs)\n\n app = config.make_wsgi_app()\n\n # Install middleware (idempotent if disabled)\n return cliquet.install_middlewares(app, settings)\n", "path": "kinto/__init__.py"}, {"content": "import colander\n\nfrom cliquet import resource\nfrom cliquet.events import ResourceChanged, ACTIONS\nfrom pyramid.events import subscriber\n\nfrom kinto.views import NameGenerator\n\n\nclass GroupSchema(resource.ResourceSchema):\n members = colander.SchemaNode(colander.Sequence(),\n colander.SchemaNode(colander.String()))\n\n class Options:\n preserve_unknown = True\n\n\[email protected](name='group',\n collection_path='/buckets/{{bucket_id}}/groups',\n record_path='/buckets/{{bucket_id}}/groups/{{id}}')\nclass Group(resource.ShareableResource):\n\n mapping = GroupSchema()\n\n def __init__(self, *args, **kwargs):\n super(Group, self).__init__(*args, **kwargs)\n self.model.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n bucket_id = request.matchdict['bucket_id']\n parent_id = '/buckets/%s' % bucket_id\n return parent_id\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.DELETE,))\ndef on_groups_deleted(event):\n \"\"\"Some groups were deleted, remove them from users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n group = change['old']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n permission_backend.remove_principal(group_uri)\n\n\n@subscriber(ResourceChanged,\n for_resources=('group',),\n for_actions=(ACTIONS.CREATE, ACTIONS.UPDATE))\ndef on_groups_changed(event):\n \"\"\"Some groups were changed, update users principals.\n \"\"\"\n permission_backend = event.request.registry.permission\n\n for change in event.impacted_records:\n if 'old' in change:\n existing_record_members = set(change['old'].get('members', []))\n else:\n existing_record_members = set()\n\n group = change['new']\n group_uri = '/buckets/{bucket_id}/groups/{id}'.format(id=group['id'],\n **event.payload)\n new_record_members = set(group.get('members', []))\n new_members = new_record_members - existing_record_members\n removed_members = existing_record_members - new_record_members\n\n for member in new_members:\n # Add the group to the member principal.\n permission_backend.add_user_principal(member, group_uri)\n\n for member in removed_members:\n # Remove the group from the member principal.\n permission_backend.remove_user_principal(member, group_uri)\n", "path": "kinto/views/groups.py"}]}
| 1,755 | 199 |
gh_patches_debug_18645
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-2690
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
rethink rspamd's overrides
Currently any override put in rspamd's folder will replace Mailu's default config.
This may disable functionality (anti-spoof, oletools, ...) and doesn't make upgrades easy.
We can probably do better.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/rspamd/start.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import os
4 import glob
5 import logging as log
6 import requests
7 import sys
8 import time
9 from socrate import system,conf
10
11 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "WARNING"))
12 system.set_env()
13
14 # Actual startup script
15
16 for rspamd_file in glob.glob("/conf/*"):
17 conf.jinja(rspamd_file, os.environ, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
18
19 # Admin may not be up just yet
20 healthcheck = f'http://{os.environ["ADMIN_ADDRESS"]}/internal/rspamd/local_domains'
21 while True:
22 time.sleep(1)
23 try:
24 if requests.get(healthcheck,timeout=2).ok:
25 break
26 except:
27 pass
28 log.warning("Admin is not up just yet, retrying in 1 second")
29
30 # Run rspamd
31 os.system("mkdir -m 755 -p /run/rspamd")
32 os.system("chown rspamd:rspamd /run/rspamd")
33 os.system("find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd")
34 os.execv("/usr/sbin/rspamd", ["rspamd", "-f", "-u", "rspamd", "-g", "rspamd"])
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/rspamd/start.py b/core/rspamd/start.py
--- a/core/rspamd/start.py
+++ b/core/rspamd/start.py
@@ -4,6 +4,7 @@
import glob
import logging as log
import requests
+import shutil
import sys
import time
from socrate import system,conf
@@ -13,8 +14,14 @@
# Actual startup script
+config_files = []
for rspamd_file in glob.glob("/conf/*"):
conf.jinja(rspamd_file, os.environ, os.path.join("/etc/rspamd/local.d", os.path.basename(rspamd_file)))
+ config_files.append(os.path.basename(rspamd_file))
+
+for override_file in glob.glob("/overrides/*"):
+ if os.path.basename(override_file) not in config_files:
+ shutil.copyfile(override_file, os.path.join("/etc/rspamd/local.d", os.path.basename(override_file)))
# Admin may not be up just yet
healthcheck = f'http://{os.environ["ADMIN_ADDRESS"]}/internal/rspamd/local_domains'
|
{"golden_diff": "diff --git a/core/rspamd/start.py b/core/rspamd/start.py\n--- a/core/rspamd/start.py\n+++ b/core/rspamd/start.py\n@@ -4,6 +4,7 @@\n import glob\n import logging as log\n import requests\n+import shutil\n import sys\n import time\n from socrate import system,conf\n@@ -13,8 +14,14 @@\n \n # Actual startup script\n \n+config_files = []\n for rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, os.environ, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n+ config_files.append(os.path.basename(rspamd_file))\n+\n+for override_file in glob.glob(\"/overrides/*\"):\n+ if os.path.basename(override_file) not in config_files:\n+ shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n \n # Admin may not be up just yet\n healthcheck = f'http://{os.environ[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\n", "issue": "rethink rspamd's overrides\nCurrently any override put in rspamd's folder will replace Mailu's default config.\r\n\r\nThis may disable functionality (anti-spoof, oletools, ...) and doesn't make upgrades easy.\r\n\r\nWe can probably do better.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport sys\nimport time\nfrom socrate import system,conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\nsystem.set_env()\n\n# Actual startup script\n\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, os.environ, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{os.environ[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport glob\nimport logging as log\nimport requests\nimport shutil\nimport sys\nimport time\nfrom socrate import system,conf\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"WARNING\"))\nsystem.set_env()\n\n# Actual startup script\n\nconfig_files = []\nfor rspamd_file in glob.glob(\"/conf/*\"):\n conf.jinja(rspamd_file, os.environ, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(rspamd_file)))\n config_files.append(os.path.basename(rspamd_file))\n\nfor override_file in glob.glob(\"/overrides/*\"):\n if os.path.basename(override_file) not in config_files:\n shutil.copyfile(override_file, os.path.join(\"/etc/rspamd/local.d\", os.path.basename(override_file)))\n\n# Admin may not be up just yet\nhealthcheck = f'http://{os.environ[\"ADMIN_ADDRESS\"]}/internal/rspamd/local_domains'\nwhile True:\n time.sleep(1)\n try:\n if requests.get(healthcheck,timeout=2).ok:\n break\n except:\n pass\n log.warning(\"Admin is not up just yet, retrying in 1 second\")\n\n# Run rspamd\nos.system(\"mkdir -m 755 -p /run/rspamd\")\nos.system(\"chown rspamd:rspamd /run/rspamd\")\nos.system(\"find /var/lib/rspamd | grep -v /filter | xargs -n1 chown rspamd:rspamd\")\nos.execv(\"/usr/sbin/rspamd\", [\"rspamd\", \"-f\", \"-u\", \"rspamd\", \"-g\", \"rspamd\"])\n", "path": "core/rspamd/start.py"}]}
| 665 | 239 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.