
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
10.2k
| golden_diff
stringlengths 151
4.94k
| verification_info
stringlengths 582
21k
| num_tokens
int64 271
2.05k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_1153
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-997
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`datasets.pbmc68k_reduced` isn't contained in the pypi package anymore
This still works in `1.4.4.post1`. It's very likely caused by changes to `setup.py`. I experienced similar problems before and fixed them via `package_data`. But this got removed. It's probably only a problem for the source-based installs.
https://github.com/theislab/scanpy/commit/881f0bef31cdfe0df7333641dc847a60894b5c41#diff-2eeaed663bd0d25b7e608891384b7298
```
>>> import scanpy
>>> scanpy.__version__
<Version('1.4.5.post2')>
>>> scanpy.datasets.pbmc68k_reduced()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/datasets/__init__.py", line 239, in pbmc68k_reduced
return read(filename)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py", line 114, in read
**kwargs,
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py", line 524, in _read
return read_h5ad(filename, backed=backed)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py", line 447, in read_h5ad
constructor_args = _read_args_from_h5ad(filename=filename, chunk_size=chunk_size)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py", line 481, in _read_args_from_h5ad
f = h5py.File(filename, 'r')
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/h5py/h5sparse.py", line 162, in __init__
**kwds,
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 312, in __init__
fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)
File "/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py", line 142, in make_fid
fid = h5f.open(name, flags, fapl=fapl)
File "h5py/_objects.pyx", line 54, in h5py._objects.with_phil.wrapper
File "h5py/_objects.pyx", line 55, in h5py._objects.with_phil.wrapper
File "h5py/h5f.pyx", line 78, in h5py.h5f.open
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import sys
2
3 if sys.version_info < (3, 6):
4 sys.exit('scanpy requires Python >= 3.6')
5 from pathlib import Path
6
7 from setuptools import setup, find_packages
8
9
10 try:
11 from scanpy import __author__, __email__
12 except ImportError: # Deps not yet installed
13 __author__ = __email__ = ''
14
15 setup(
16 name='scanpy',
17 use_scm_version=True,
18 setup_requires=['setuptools_scm'],
19 description='Single-Cell Analysis in Python.',
20 long_description=Path('README.rst').read_text('utf-8'),
21 url='http://github.com/theislab/scanpy',
22 author=__author__,
23 author_email=__email__,
24 license='BSD',
25 python_requires='>=3.6',
26 install_requires=[
27 l.strip() for l in Path('requirements.txt').read_text('utf-8').splitlines()
28 ],
29 extras_require=dict(
30 louvain=['python-igraph', 'louvain>=0.6'],
31 leiden=['python-igraph', 'leidenalg'],
32 bbknn=['bbknn'],
33 rapids=['cudf', 'cuml', 'cugraph'],
34 magic=['magic-impute>=2.0'],
35 doc=[
36 'sphinx',
37 'sphinx_rtd_theme',
38 'sphinx_autodoc_typehints',
39 'scanpydoc>=0.4.3',
40 'typing_extensions; python_version < "3.8"', # for `Literal`
41 ],
42 test=[
43 'pytest>=4.4',
44 'dask[array]',
45 'fsspec',
46 'zappy',
47 'zarr',
48 'black',
49 'profimp',
50 ],
51 ),
52 packages=find_packages(),
53 entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),
54 zip_safe=False,
55 classifiers=[
56 'Development Status :: 5 - Production/Stable',
57 'Environment :: Console',
58 'Framework :: Jupyter',
59 'Intended Audience :: Developers',
60 'Intended Audience :: Science/Research',
61 'Natural Language :: English',
62 'Operating System :: MacOS :: MacOS X',
63 'Operating System :: Microsoft :: Windows',
64 'Operating System :: POSIX :: Linux',
65 'Programming Language :: Python :: 3',
66 'Programming Language :: Python :: 3.5',
67 'Programming Language :: Python :: 3.6',
68 'Programming Language :: Python :: 3.7',
69 'Topic :: Scientific/Engineering :: Bio-Informatics',
70 'Topic :: Scientific/Engineering :: Visualization',
71 ],
72 )
73
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -50,6 +50,7 @@
],
),
packages=find_packages(),
+ include_package_data=True,
entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),
zip_safe=False,
classifiers=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -50,6 +50,7 @@\n ],\n ),\n packages=find_packages(),\n+ include_package_data=True,\n entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),\n zip_safe=False,\n classifiers=[\n", "issue": "`datasets.pbmc68k_reduced` isn't contained in the pypi package anymore\nThis still works in `1.4.4.post1`. It's very likely caused by changes to `setup.py`. I experienced similar problems before and fixed them via `package_data`. But this got removed. It's probably only a problem for the source-based installs.\r\n\r\nhttps://github.com/theislab/scanpy/commit/881f0bef31cdfe0df7333641dc847a60894b5c41#diff-2eeaed663bd0d25b7e608891384b7298\r\n\r\n```\r\n>>> import scanpy\r\n>>> scanpy.__version__\r\n<Version('1.4.5.post2')>\r\n>>> scanpy.datasets.pbmc68k_reduced()\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/datasets/__init__.py\", line 239, in pbmc68k_reduced\r\n return read(filename)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py\", line 114, in read\r\n **kwargs,\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/scanpy/readwrite.py\", line 524, in _read\r\n return read_h5ad(filename, backed=backed)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py\", line 447, in read_h5ad\r\n constructor_args = _read_args_from_h5ad(filename=filename, chunk_size=chunk_size)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/readwrite/read.py\", line 481, in _read_args_from_h5ad\r\n f = h5py.File(filename, 'r')\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/anndata/h5py/h5sparse.py\", line 162, in __init__\r\n **kwds,\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py\", line 312, in __init__\r\n fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)\r\n File \"/Users/alexwolf/miniconda3/lib/python3.6/site-packages/h5py/_hl/files.py\", line 142, in make_fid\r\n fid = h5f.open(name, flags, fapl=fapl)\r\n File \"h5py/_objects.pyx\", line 54, in h5py._objects.with_phil.wrapper\r\n File \"h5py/_objects.pyx\", line 55, in h5py._objects.with_phil.wrapper\r\n File \"h5py/h5f.pyx\", line 78, in h5py.h5f.open\r\n```\n", "before_files": [{"content": "import sys\n\nif sys.version_info < (3, 6):\n sys.exit('scanpy requires Python >= 3.6')\nfrom pathlib import Path\n\nfrom setuptools import setup, find_packages\n\n\ntry:\n from scanpy import __author__, __email__\nexcept ImportError: # Deps not yet installed\n __author__ = __email__ = ''\n\nsetup(\n name='scanpy',\n use_scm_version=True,\n setup_requires=['setuptools_scm'],\n description='Single-Cell Analysis in Python.',\n long_description=Path('README.rst').read_text('utf-8'),\n url='http://github.com/theislab/scanpy',\n author=__author__,\n author_email=__email__,\n license='BSD',\n python_requires='>=3.6',\n install_requires=[\n l.strip() for l in Path('requirements.txt').read_text('utf-8').splitlines()\n ],\n extras_require=dict(\n louvain=['python-igraph', 'louvain>=0.6'],\n leiden=['python-igraph', 'leidenalg'],\n bbknn=['bbknn'],\n rapids=['cudf', 'cuml', 'cugraph'],\n magic=['magic-impute>=2.0'],\n doc=[\n 'sphinx',\n 'sphinx_rtd_theme',\n 'sphinx_autodoc_typehints',\n 'scanpydoc>=0.4.3',\n 'typing_extensions; python_version < \"3.8\"', # for `Literal`\n ],\n test=[\n 'pytest>=4.4',\n 'dask[array]',\n 'fsspec',\n 'zappy',\n 'zarr',\n 'black',\n 'profimp',\n ],\n ),\n packages=find_packages(),\n entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Framework :: Jupyter',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Visualization',\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "import sys\n\nif sys.version_info < (3, 6):\n sys.exit('scanpy requires Python >= 3.6')\nfrom pathlib import Path\n\nfrom setuptools import setup, find_packages\n\n\ntry:\n from scanpy import __author__, __email__\nexcept ImportError: # Deps not yet installed\n __author__ = __email__ = ''\n\nsetup(\n name='scanpy',\n use_scm_version=True,\n setup_requires=['setuptools_scm'],\n description='Single-Cell Analysis in Python.',\n long_description=Path('README.rst').read_text('utf-8'),\n url='http://github.com/theislab/scanpy',\n author=__author__,\n author_email=__email__,\n license='BSD',\n python_requires='>=3.6',\n install_requires=[\n l.strip() for l in Path('requirements.txt').read_text('utf-8').splitlines()\n ],\n extras_require=dict(\n louvain=['python-igraph', 'louvain>=0.6'],\n leiden=['python-igraph', 'leidenalg'],\n bbknn=['bbknn'],\n rapids=['cudf', 'cuml', 'cugraph'],\n magic=['magic-impute>=2.0'],\n doc=[\n 'sphinx',\n 'sphinx_rtd_theme',\n 'sphinx_autodoc_typehints',\n 'scanpydoc>=0.4.3',\n 'typing_extensions; python_version < \"3.8\"', # for `Literal`\n ],\n test=[\n 'pytest>=4.4',\n 'dask[array]',\n 'fsspec',\n 'zappy',\n 'zarr',\n 'black',\n 'profimp',\n ],\n ),\n packages=find_packages(),\n include_package_data=True,\n entry_points=dict(console_scripts=['scanpy=scanpy.cli:console_main']),\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Framework :: Jupyter',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Natural Language :: English',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Topic :: Scientific/Engineering :: Bio-Informatics',\n 'Topic :: Scientific/Engineering :: Visualization',\n ],\n)\n", "path": "setup.py"}]}
| 1,639 | 73 |
gh_patches_debug_30970
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1512
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check if ThreadLocalRuntimeContext can be removed since python3.4 support is dropped
https://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py#L21
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opentelemetry-api/src/opentelemetry/context/threadlocal_context.py`
Content:
```
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import threading
16
17 from opentelemetry.context.context import Context, RuntimeContext
18
19
20 class ThreadLocalRuntimeContext(RuntimeContext):
21 """An implementation of the RuntimeContext interface
22 which uses thread-local storage under the hood. This
23 implementation is available for usage with Python 3.4.
24 """
25
26 class Token:
27 def __init__(self, context: Context) -> None:
28 self._context = context
29
30 _CONTEXT_KEY = "current_context"
31
32 def __init__(self) -> None:
33 self._current_context = threading.local()
34
35 def attach(self, context: Context) -> object:
36 """See `opentelemetry.context.RuntimeContext.attach`."""
37 current = self.get_current()
38 setattr(self._current_context, self._CONTEXT_KEY, context)
39 return self.Token(current)
40
41 def get_current(self) -> Context:
42 """See `opentelemetry.context.RuntimeContext.get_current`."""
43 if not hasattr(self._current_context, self._CONTEXT_KEY):
44 setattr(
45 self._current_context, self._CONTEXT_KEY, Context(),
46 )
47 context = getattr(
48 self._current_context, self._CONTEXT_KEY
49 ) # type: Context
50 return context
51
52 def detach(self, token: object) -> None:
53 """See `opentelemetry.context.RuntimeContext.detach`."""
54 if not isinstance(token, self.Token):
55 raise ValueError("invalid token")
56 # pylint: disable=protected-access
57 setattr(self._current_context, self._CONTEXT_KEY, token._context)
58
59
60 __all__ = ["ThreadLocalRuntimeContext"]
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py b/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py
deleted file mode 100644
--- a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py
+++ /dev/null
@@ -1,60 +0,0 @@
-# Copyright The OpenTelemetry Authors
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import threading
-
-from opentelemetry.context.context import Context, RuntimeContext
-
-
-class ThreadLocalRuntimeContext(RuntimeContext):
- """An implementation of the RuntimeContext interface
- which uses thread-local storage under the hood. This
- implementation is available for usage with Python 3.4.
- """
-
- class Token:
- def __init__(self, context: Context) -> None:
- self._context = context
-
- _CONTEXT_KEY = "current_context"
-
- def __init__(self) -> None:
- self._current_context = threading.local()
-
- def attach(self, context: Context) -> object:
- """See `opentelemetry.context.RuntimeContext.attach`."""
- current = self.get_current()
- setattr(self._current_context, self._CONTEXT_KEY, context)
- return self.Token(current)
-
- def get_current(self) -> Context:
- """See `opentelemetry.context.RuntimeContext.get_current`."""
- if not hasattr(self._current_context, self._CONTEXT_KEY):
- setattr(
- self._current_context, self._CONTEXT_KEY, Context(),
- )
- context = getattr(
- self._current_context, self._CONTEXT_KEY
- ) # type: Context
- return context
-
- def detach(self, token: object) -> None:
- """See `opentelemetry.context.RuntimeContext.detach`."""
- if not isinstance(token, self.Token):
- raise ValueError("invalid token")
- # pylint: disable=protected-access
- setattr(self._current_context, self._CONTEXT_KEY, token._context)
-
-
-__all__ = ["ThreadLocalRuntimeContext"]
|
{"golden_diff": "diff --git a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py b/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py\ndeleted file mode 100644\n--- a/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py\n+++ /dev/null\n@@ -1,60 +0,0 @@\n-# Copyright The OpenTelemetry Authors\n-#\n-# Licensed under the Apache License, Version 2.0 (the \"License\");\n-# you may not use this file except in compliance with the License.\n-# You may obtain a copy of the License at\n-#\n-# http://www.apache.org/licenses/LICENSE-2.0\n-#\n-# Unless required by applicable law or agreed to in writing, software\n-# distributed under the License is distributed on an \"AS IS\" BASIS,\n-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n-# See the License for the specific language governing permissions and\n-# limitations under the License.\n-\n-import threading\n-\n-from opentelemetry.context.context import Context, RuntimeContext\n-\n-\n-class ThreadLocalRuntimeContext(RuntimeContext):\n- \"\"\"An implementation of the RuntimeContext interface\n- which uses thread-local storage under the hood. This\n- implementation is available for usage with Python 3.4.\n- \"\"\"\n-\n- class Token:\n- def __init__(self, context: Context) -> None:\n- self._context = context\n-\n- _CONTEXT_KEY = \"current_context\"\n-\n- def __init__(self) -> None:\n- self._current_context = threading.local()\n-\n- def attach(self, context: Context) -> object:\n- \"\"\"See `opentelemetry.context.RuntimeContext.attach`.\"\"\"\n- current = self.get_current()\n- setattr(self._current_context, self._CONTEXT_KEY, context)\n- return self.Token(current)\n-\n- def get_current(self) -> Context:\n- \"\"\"See `opentelemetry.context.RuntimeContext.get_current`.\"\"\"\n- if not hasattr(self._current_context, self._CONTEXT_KEY):\n- setattr(\n- self._current_context, self._CONTEXT_KEY, Context(),\n- )\n- context = getattr(\n- self._current_context, self._CONTEXT_KEY\n- ) # type: Context\n- return context\n-\n- def detach(self, token: object) -> None:\n- \"\"\"See `opentelemetry.context.RuntimeContext.detach`.\"\"\"\n- if not isinstance(token, self.Token):\n- raise ValueError(\"invalid token\")\n- # pylint: disable=protected-access\n- setattr(self._current_context, self._CONTEXT_KEY, token._context)\n-\n-\n-__all__ = [\"ThreadLocalRuntimeContext\"]\n", "issue": "Check if ThreadLocalRuntimeContext can be removed since python3.4 support is dropped\nhttps://github.com/open-telemetry/opentelemetry-python/blob/master/opentelemetry-api/src/opentelemetry/context/threadlocal_context.py#L21\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport threading\n\nfrom opentelemetry.context.context import Context, RuntimeContext\n\n\nclass ThreadLocalRuntimeContext(RuntimeContext):\n \"\"\"An implementation of the RuntimeContext interface\n which uses thread-local storage under the hood. This\n implementation is available for usage with Python 3.4.\n \"\"\"\n\n class Token:\n def __init__(self, context: Context) -> None:\n self._context = context\n\n _CONTEXT_KEY = \"current_context\"\n\n def __init__(self) -> None:\n self._current_context = threading.local()\n\n def attach(self, context: Context) -> object:\n \"\"\"See `opentelemetry.context.RuntimeContext.attach`.\"\"\"\n current = self.get_current()\n setattr(self._current_context, self._CONTEXT_KEY, context)\n return self.Token(current)\n\n def get_current(self) -> Context:\n \"\"\"See `opentelemetry.context.RuntimeContext.get_current`.\"\"\"\n if not hasattr(self._current_context, self._CONTEXT_KEY):\n setattr(\n self._current_context, self._CONTEXT_KEY, Context(),\n )\n context = getattr(\n self._current_context, self._CONTEXT_KEY\n ) # type: Context\n return context\n\n def detach(self, token: object) -> None:\n \"\"\"See `opentelemetry.context.RuntimeContext.detach`.\"\"\"\n if not isinstance(token, self.Token):\n raise ValueError(\"invalid token\")\n # pylint: disable=protected-access\n setattr(self._current_context, self._CONTEXT_KEY, token._context)\n\n\n__all__ = [\"ThreadLocalRuntimeContext\"]\n", "path": "opentelemetry-api/src/opentelemetry/context/threadlocal_context.py"}], "after_files": [{"content": null, "path": "opentelemetry-api/src/opentelemetry/context/threadlocal_context.py"}]}
| 893 | 584 |
gh_patches_debug_35742
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-1123
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Generation from "Pumped storage" in France FR
At the moment, the bar charts on the map only show pumped storage consumption for France. But RTE also has data for pumped storage generation. This is currently not displayed on the map, because the "hydro" category of RTE includes all three types "hydro storage+run of river+pumped storage". But there is a seperate "pumping" category for consumption of the pumped storages (pumping).
http://www.rte-france.com/en/eco2mix/eco2mix-mix-energetique-en
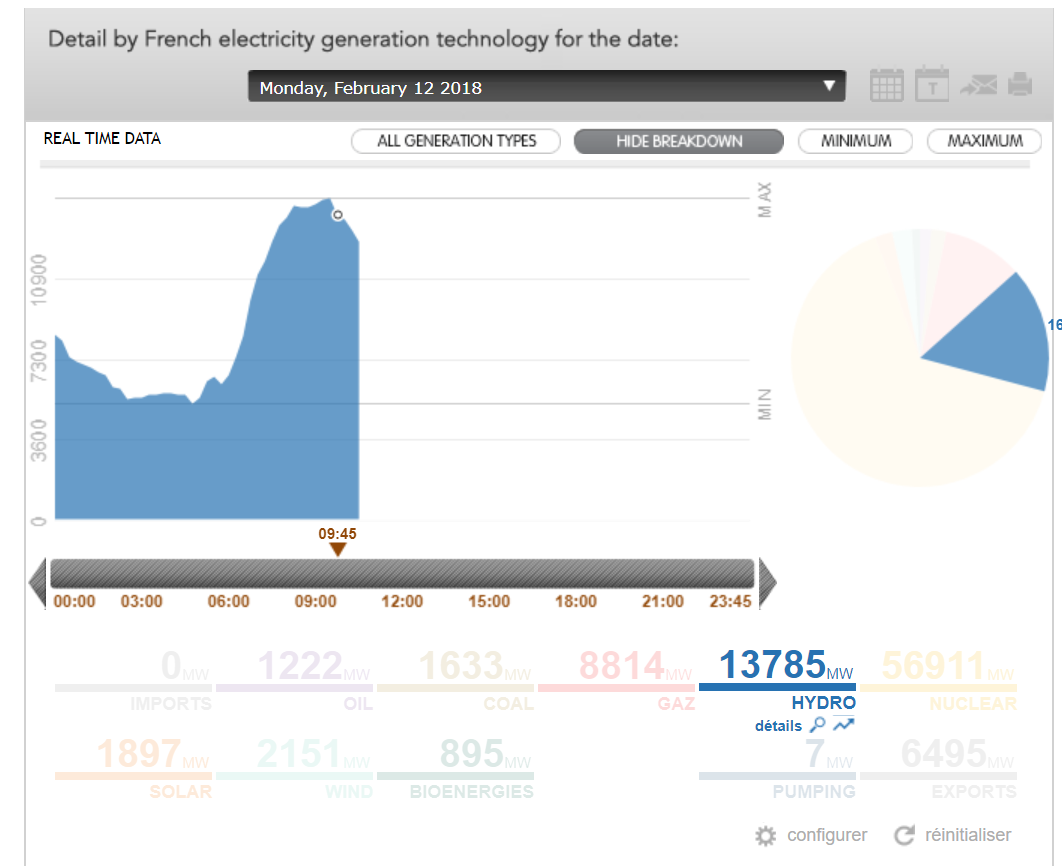
After selecting the hydro category, you'll see "details" below it. Selecting "details" you will see this, incuding the breakdown by hydro type:
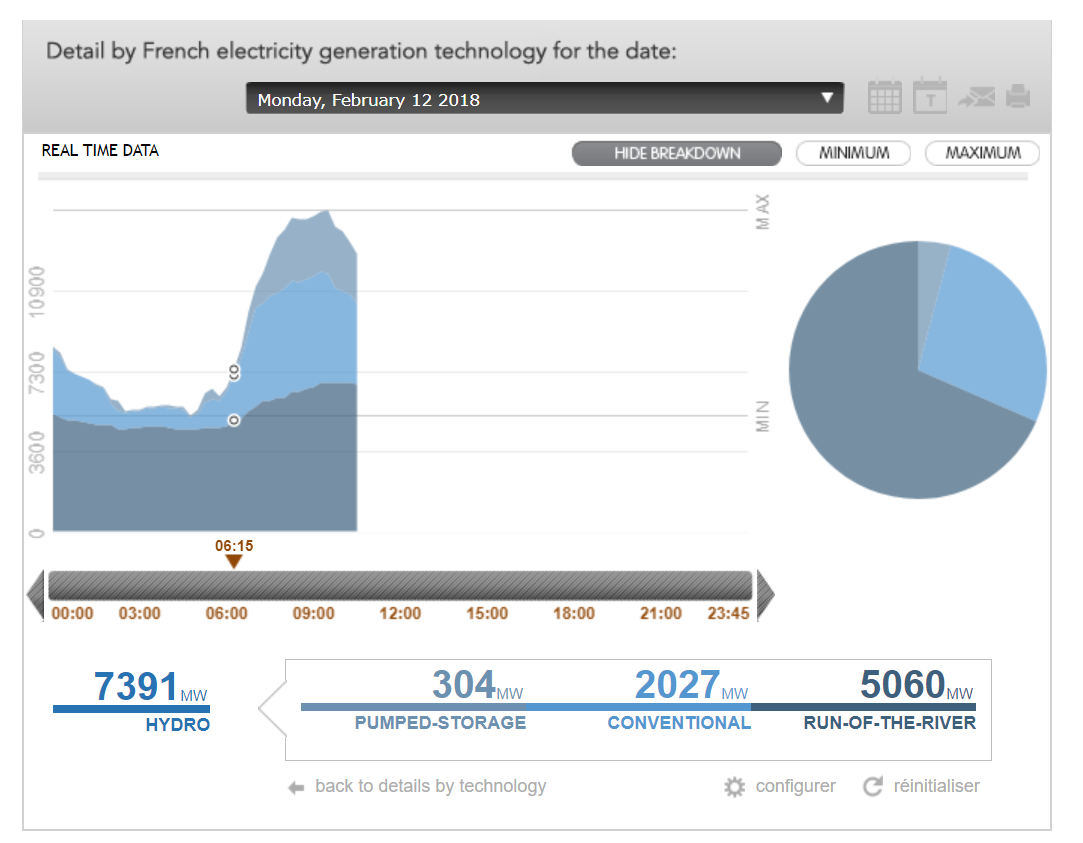
The most recent dataset for France can also be downloaded here:
http://www.rte-france.com/en/eco2mix/eco2mix-telechargement-en
The FR.py parser seems to use this URL http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM for getting the data. Maybe there is a similar one for the hydro breakdown by type to seperate pumped storage generation from it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsers/FR.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import arrow
4 import requests
5 import xml.etree.ElementTree as ET
6
7 MAP_GENERATION = {
8 u'Nucl\xe9aire': 'nuclear',
9 'Charbon': 'coal',
10 'Gaz': 'gas',
11 'Fioul': 'oil',
12 'Hydraulique': 'hydro',
13 'Eolien': 'wind',
14 'Solaire': 'solar',
15 'Autres': 'biomass'
16 }
17 MAP_STORAGE = {
18 'Pompage': 'hydro',
19 }
20
21
22 def fetch_production(country_code='FR', session=None):
23 r = session or requests.session()
24 formatted_date = arrow.now(tz='Europe/Paris').format('DD/MM/YYYY')
25 url = 'http://www.rte-france.com/getEco2MixXml.php?type=mix&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
26 response = r.get(url)
27 obj = ET.fromstring(response.content)
28 mixtr = obj[7]
29 data = {
30 'countryCode': country_code,
31 'production': {},
32 'storage': {},
33 'source': 'rte-france.com',
34 }
35 for item in mixtr.getchildren():
36 if item.get('granularite') != 'Global':
37 continue
38 key = item.get('v')
39 value = None
40 for value in item.getchildren():
41 pass
42 if key in MAP_GENERATION:
43 data['production'][MAP_GENERATION[key]] = float(value.text)
44 elif key in MAP_STORAGE:
45 data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)
46
47 data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,
48 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime
49
50 # Fetch imports
51 # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
52 # response = r.get(url)
53 # obj = ET.fromstring(response.content)
54 # parsed = {}
55 # for item in obj[7].getchildren():
56 # value = None
57 # for value in item: pass
58 # parsed[item.get('v')] = float(value.text)
59
60 # data['exchange'] = {
61 # 'CH': parsed['CH'],
62 # 'GB': parsed['GB'],
63 # 'ES': parsed['ES'],
64 # 'IT': parsed['IT'],
65 # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany
66 # }
67
68 return data
69
70
71 def fetch_price(country_code, session=None, from_date=None, to_date=None):
72 r = session or requests.session()
73 dt_now = arrow.now(tz='Europe/Paris')
74 formatted_from = from_date or dt_now.format('DD/MM/YYYY')
75 formatted_to = to_date or dt_now.format('DD/MM/YYYY')
76
77 url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)
78 response = r.get(url)
79 obj = ET.fromstring(response.content)
80 mixtr = obj[5]
81
82 prices = []
83 datetimes = []
84
85 date_str = mixtr.get('date')
86 date = arrow.get(arrow.get(date_str).datetime, 'Europe/Paris')
87 for country_item in mixtr.getchildren():
88 if country_item.get('granularite') != 'Global':
89 continue
90 country_c = country_item.get('perimetre')
91 if country_code != country_c:
92 continue
93 value = None
94 for value in country_item.getchildren():
95 if value.text == 'ND':
96 continue
97 datetime = date.replace(hours=+int(value.attrib['periode'])).datetime
98 if datetime > dt_now:
99 continue
100 datetimes.append(datetime)
101 prices.append(float(value.text))
102
103 data = {
104 'countryCode': country_code,
105 'currency': 'EUR',
106 'datetime': datetimes[-1],
107 'price': prices[-1],
108 'source': 'rte-france.com',
109 }
110 return data
111
112
113 if __name__ == '__main__':
114 print(fetch_production())
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsers/FR.py b/parsers/FR.py
--- a/parsers/FR.py
+++ b/parsers/FR.py
@@ -16,6 +16,7 @@
}
MAP_STORAGE = {
'Pompage': 'hydro',
+ 'Hydraulique': 'hydro',
}
@@ -33,38 +34,36 @@
'source': 'rte-france.com',
}
for item in mixtr.getchildren():
- if item.get('granularite') != 'Global':
- continue
key = item.get('v')
+ granularite = item.get('granularite')
value = None
for value in item.getchildren():
pass
- if key in MAP_GENERATION:
- data['production'][MAP_GENERATION[key]] = float(value.text)
- elif key in MAP_STORAGE:
- data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)
+ if key == 'Hydraulique':
+ # Hydro is a special case!
+ if granularite == 'Global':
+ continue
+ elif granularite in ['FEE', 'LAC']:
+ if not MAP_GENERATION[key] in data['production']:
+ data['production'][MAP_GENERATION[key]] = 0
+ # Run of the river or conventional
+ data['production'][MAP_GENERATION[key]] += float(value.text)
+ elif granularite == 'STT':
+ if not MAP_STORAGE[key] in data['storage']:
+ data['storage'][MAP_STORAGE[key]] = 0
+ # Pumped storage generation
+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)
+ elif granularite == 'Global':
+ if key in MAP_GENERATION:
+ data['production'][MAP_GENERATION[key]] = float(value.text)
+ elif key in MAP_STORAGE:
+ if not MAP_STORAGE[key] in data['storage']:
+ data['storage'][MAP_STORAGE[key]] = 0
+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)
data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,
'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime
- # Fetch imports
- # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)
- # response = r.get(url)
- # obj = ET.fromstring(response.content)
- # parsed = {}
- # for item in obj[7].getchildren():
- # value = None
- # for value in item: pass
- # parsed[item.get('v')] = float(value.text)
-
- # data['exchange'] = {
- # 'CH': parsed['CH'],
- # 'GB': parsed['GB'],
- # 'ES': parsed['ES'],
- # 'IT': parsed['IT'],
- # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany
- # }
-
return data
|
{"golden_diff": "diff --git a/parsers/FR.py b/parsers/FR.py\n--- a/parsers/FR.py\n+++ b/parsers/FR.py\n@@ -16,6 +16,7 @@\n }\n MAP_STORAGE = {\n 'Pompage': 'hydro',\n+ 'Hydraulique': 'hydro',\n }\n \n \n@@ -33,38 +34,36 @@\n 'source': 'rte-france.com',\n }\n for item in mixtr.getchildren():\n- if item.get('granularite') != 'Global':\n- continue\n key = item.get('v')\n+ granularite = item.get('granularite')\n value = None\n for value in item.getchildren():\n pass\n- if key in MAP_GENERATION:\n- data['production'][MAP_GENERATION[key]] = float(value.text)\n- elif key in MAP_STORAGE:\n- data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)\n+ if key == 'Hydraulique':\n+ # Hydro is a special case!\n+ if granularite == 'Global':\n+ continue\n+ elif granularite in ['FEE', 'LAC']:\n+ if not MAP_GENERATION[key] in data['production']:\n+ data['production'][MAP_GENERATION[key]] = 0\n+ # Run of the river or conventional\n+ data['production'][MAP_GENERATION[key]] += float(value.text)\n+ elif granularite == 'STT':\n+ if not MAP_STORAGE[key] in data['storage']:\n+ data['storage'][MAP_STORAGE[key]] = 0\n+ # Pumped storage generation\n+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n+ elif granularite == 'Global':\n+ if key in MAP_GENERATION:\n+ data['production'][MAP_GENERATION[key]] = float(value.text)\n+ elif key in MAP_STORAGE:\n+ if not MAP_STORAGE[key] in data['storage']:\n+ data['storage'][MAP_STORAGE[key]] = 0\n+ data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n \n data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,\n 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime\n \n- # Fetch imports\n- # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n- # response = r.get(url)\n- # obj = ET.fromstring(response.content)\n- # parsed = {}\n- # for item in obj[7].getchildren():\n- # value = None\n- # for value in item: pass\n- # parsed[item.get('v')] = float(value.text)\n-\n- # data['exchange'] = {\n- # 'CH': parsed['CH'],\n- # 'GB': parsed['GB'],\n- # 'ES': parsed['ES'],\n- # 'IT': parsed['IT'],\n- # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany\n- # }\n-\n return data\n", "issue": "Generation from \"Pumped storage\" in France FR\nAt the moment, the bar charts on the map only show pumped storage consumption for France. But RTE also has data for pumped storage generation. This is currently not displayed on the map, because the \"hydro\" category of RTE includes all three types \"hydro storage+run of river+pumped storage\". But there is a seperate \"pumping\" category for consumption of the pumped storages (pumping).\r\nhttp://www.rte-france.com/en/eco2mix/eco2mix-mix-energetique-en\r\n\r\n\r\n\r\nAfter selecting the hydro category, you'll see \"details\" below it. Selecting \"details\" you will see this, incuding the breakdown by hydro type:\r\n\r\n\r\nThe most recent dataset for France can also be downloaded here:\r\nhttp://www.rte-france.com/en/eco2mix/eco2mix-telechargement-en\r\n\r\nThe FR.py parser seems to use this URL http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM for getting the data. Maybe there is a similar one for the hydro breakdown by type to seperate pumped storage generation from it.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport requests\nimport xml.etree.ElementTree as ET\n\nMAP_GENERATION = {\n u'Nucl\\xe9aire': 'nuclear',\n 'Charbon': 'coal',\n 'Gaz': 'gas',\n 'Fioul': 'oil',\n 'Hydraulique': 'hydro',\n 'Eolien': 'wind',\n 'Solaire': 'solar',\n 'Autres': 'biomass'\n}\nMAP_STORAGE = {\n 'Pompage': 'hydro',\n}\n\n\ndef fetch_production(country_code='FR', session=None):\n r = session or requests.session()\n formatted_date = arrow.now(tz='Europe/Paris').format('DD/MM/YYYY')\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=mix&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[7]\n data = {\n 'countryCode': country_code,\n 'production': {},\n 'storage': {},\n 'source': 'rte-france.com',\n }\n for item in mixtr.getchildren():\n if item.get('granularite') != 'Global':\n continue\n key = item.get('v')\n value = None\n for value in item.getchildren():\n pass\n if key in MAP_GENERATION:\n data['production'][MAP_GENERATION[key]] = float(value.text)\n elif key in MAP_STORAGE:\n data['storage'][MAP_STORAGE[key]] = -1 * float(value.text)\n\n data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,\n 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime\n\n # Fetch imports\n # url = 'http://www.rte-france.com/getEco2MixXml.php?type=echcom&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n # response = r.get(url)\n # obj = ET.fromstring(response.content)\n # parsed = {}\n # for item in obj[7].getchildren():\n # value = None\n # for value in item: pass\n # parsed[item.get('v')] = float(value.text)\n\n # data['exchange'] = {\n # 'CH': parsed['CH'],\n # 'GB': parsed['GB'],\n # 'ES': parsed['ES'],\n # 'IT': parsed['IT'],\n # 'DE': parsed['DB'] # Germany + Belgium redirected to Germany\n # }\n\n return data\n\n\ndef fetch_price(country_code, session=None, from_date=None, to_date=None):\n r = session or requests.session()\n dt_now = arrow.now(tz='Europe/Paris')\n formatted_from = from_date or dt_now.format('DD/MM/YYYY')\n formatted_to = to_date or dt_now.format('DD/MM/YYYY')\n\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[5]\n\n prices = []\n datetimes = []\n\n date_str = mixtr.get('date')\n date = arrow.get(arrow.get(date_str).datetime, 'Europe/Paris')\n for country_item in mixtr.getchildren():\n if country_item.get('granularite') != 'Global':\n continue\n country_c = country_item.get('perimetre')\n if country_code != country_c:\n continue\n value = None\n for value in country_item.getchildren():\n if value.text == 'ND':\n continue\n datetime = date.replace(hours=+int(value.attrib['periode'])).datetime\n if datetime > dt_now:\n continue\n datetimes.append(datetime)\n prices.append(float(value.text))\n\n data = {\n 'countryCode': country_code,\n 'currency': 'EUR',\n 'datetime': datetimes[-1],\n 'price': prices[-1],\n 'source': 'rte-france.com',\n }\n return data\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/FR.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport requests\nimport xml.etree.ElementTree as ET\n\nMAP_GENERATION = {\n u'Nucl\\xe9aire': 'nuclear',\n 'Charbon': 'coal',\n 'Gaz': 'gas',\n 'Fioul': 'oil',\n 'Hydraulique': 'hydro',\n 'Eolien': 'wind',\n 'Solaire': 'solar',\n 'Autres': 'biomass'\n}\nMAP_STORAGE = {\n 'Pompage': 'hydro',\n 'Hydraulique': 'hydro',\n}\n\n\ndef fetch_production(country_code='FR', session=None):\n r = session or requests.session()\n formatted_date = arrow.now(tz='Europe/Paris').format('DD/MM/YYYY')\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=mix&&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_date, formatted_date)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[7]\n data = {\n 'countryCode': country_code,\n 'production': {},\n 'storage': {},\n 'source': 'rte-france.com',\n }\n for item in mixtr.getchildren():\n key = item.get('v')\n granularite = item.get('granularite')\n value = None\n for value in item.getchildren():\n pass\n if key == 'Hydraulique':\n # Hydro is a special case!\n if granularite == 'Global':\n continue\n elif granularite in ['FEE', 'LAC']:\n if not MAP_GENERATION[key] in data['production']:\n data['production'][MAP_GENERATION[key]] = 0\n # Run of the river or conventional\n data['production'][MAP_GENERATION[key]] += float(value.text)\n elif granularite == 'STT':\n if not MAP_STORAGE[key] in data['storage']:\n data['storage'][MAP_STORAGE[key]] = 0\n # Pumped storage generation\n data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n elif granularite == 'Global':\n if key in MAP_GENERATION:\n data['production'][MAP_GENERATION[key]] = float(value.text)\n elif key in MAP_STORAGE:\n if not MAP_STORAGE[key] in data['storage']:\n data['storage'][MAP_STORAGE[key]] = 0\n data['storage'][MAP_STORAGE[key]] += -1 * float(value.text)\n\n data['datetime'] = arrow.get(arrow.get(obj[1].text).datetime,\n 'Europe/Paris').replace(minutes=+(int(value.attrib['periode']) * 15.0)).datetime\n\n return data\n\n\ndef fetch_price(country_code, session=None, from_date=None, to_date=None):\n r = session or requests.session()\n dt_now = arrow.now(tz='Europe/Paris')\n formatted_from = from_date or dt_now.format('DD/MM/YYYY')\n formatted_to = to_date or dt_now.format('DD/MM/YYYY')\n\n url = 'http://www.rte-france.com/getEco2MixXml.php?type=donneesMarche&dateDeb={}&dateFin={}&mode=NORM'.format(formatted_from, formatted_to)\n response = r.get(url)\n obj = ET.fromstring(response.content)\n mixtr = obj[5]\n\n prices = []\n datetimes = []\n\n date_str = mixtr.get('date')\n date = arrow.get(arrow.get(date_str).datetime, 'Europe/Paris')\n for country_item in mixtr.getchildren():\n if country_item.get('granularite') != 'Global':\n continue\n country_c = country_item.get('perimetre')\n if country_code != country_c:\n continue\n value = None\n for value in country_item.getchildren():\n if value.text == 'ND':\n continue\n datetime = date.replace(hours=+int(value.attrib['periode'])).datetime\n if datetime > dt_now:\n continue\n datetimes.append(datetime)\n prices.append(float(value.text))\n\n data = {\n 'countryCode': country_code,\n 'currency': 'EUR',\n 'datetime': datetimes[-1],\n 'price': prices[-1],\n 'source': 'rte-france.com',\n }\n return data\n\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/FR.py"}]}
| 1,832 | 721 |
gh_patches_debug_14512
|
rasdani/github-patches
|
git_diff
|
safe-global__safe-config-service-698
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
500 Error on unsanitized URL query params
**Describe the bug**
Error response with 500 Internal server Error is returned to the clients when a unsanitized URL query param is sent to the service.
**To Reproduce**
Steps to reproduce the behavior:
- Check: https://safe-config.safe.global/api/v1/safe-apps/?url=%00
**Expected behavior**
URL input is sanitized beforehand.
**Environment**
- Staging & production
- All chains
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/safe_apps/views.py`
Content:
```
1 from typing import Any
2
3 from django.db.models import Q, QuerySet
4 from django.utils.decorators import method_decorator
5 from django.views.decorators.cache import cache_page
6 from drf_yasg import openapi
7 from drf_yasg.utils import swagger_auto_schema
8 from rest_framework.generics import ListAPIView
9 from rest_framework.request import Request
10 from rest_framework.response import Response
11
12 from .models import SafeApp
13 from .serializers import SafeAppsResponseSerializer
14
15
16 class SafeAppsListView(ListAPIView):
17 serializer_class = SafeAppsResponseSerializer
18 pagination_class = None
19
20 _swagger_chain_id_param = openapi.Parameter(
21 "chainId",
22 openapi.IN_QUERY,
23 description="Used to filter Safe Apps that are available on `chainId`",
24 type=openapi.TYPE_INTEGER,
25 )
26 _swagger_client_url_param = openapi.Parameter(
27 "clientUrl",
28 openapi.IN_QUERY,
29 description="Used to filter Safe Apps that are available on `clientUrl`",
30 type=openapi.TYPE_STRING,
31 )
32 _swagger_url_param = openapi.Parameter(
33 "url",
34 openapi.IN_QUERY,
35 description="Filter Safe Apps available from `url`. `url` needs to be an exact match",
36 type=openapi.TYPE_STRING,
37 )
38
39 @method_decorator(cache_page(60 * 10, cache="safe-apps")) # Cache 10 minutes
40 @swagger_auto_schema(
41 manual_parameters=[
42 _swagger_chain_id_param,
43 _swagger_client_url_param,
44 _swagger_url_param,
45 ]
46 ) # type: ignore[misc]
47 def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:
48 """
49 Returns a collection of Safe Apps (across different chains).
50 Each Safe App can optionally include the information about the `Provider`
51 """
52 return super().get(request, *args, **kwargs)
53
54 def get_queryset(self) -> QuerySet[SafeApp]:
55 queryset = SafeApp.objects.filter(visible=True)
56
57 chain_id = self.request.query_params.get("chainId")
58 if chain_id is not None and chain_id.isdigit():
59 queryset = queryset.filter(chain_ids__contains=[chain_id])
60
61 client_url = self.request.query_params.get("clientUrl")
62 if client_url:
63 queryset = queryset.filter(
64 Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)
65 )
66
67 url = self.request.query_params.get("url")
68 if url:
69 queryset = queryset.filter(url=url)
70
71 return queryset
72
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/safe_apps/views.py b/src/safe_apps/views.py
--- a/src/safe_apps/views.py
+++ b/src/safe_apps/views.py
@@ -59,13 +59,13 @@
queryset = queryset.filter(chain_ids__contains=[chain_id])
client_url = self.request.query_params.get("clientUrl")
- if client_url:
+ if client_url and "\0" not in client_url:
queryset = queryset.filter(
Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)
)
url = self.request.query_params.get("url")
- if url:
+ if url and "\0" not in url:
queryset = queryset.filter(url=url)
return queryset
|
{"golden_diff": "diff --git a/src/safe_apps/views.py b/src/safe_apps/views.py\n--- a/src/safe_apps/views.py\n+++ b/src/safe_apps/views.py\n@@ -59,13 +59,13 @@\n queryset = queryset.filter(chain_ids__contains=[chain_id])\n \n client_url = self.request.query_params.get(\"clientUrl\")\n- if client_url:\n+ if client_url and \"\\0\" not in client_url:\n queryset = queryset.filter(\n Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)\n )\n \n url = self.request.query_params.get(\"url\")\n- if url:\n+ if url and \"\\0\" not in url:\n queryset = queryset.filter(url=url)\n \n return queryset\n", "issue": "500 Error on unsanitized URL query params \n**Describe the bug**\r\nError response with 500 Internal server Error is returned to the clients when a unsanitized URL query param is sent to the service.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n- Check: https://safe-config.safe.global/api/v1/safe-apps/?url=%00\r\n\r\n**Expected behavior**\r\nURL input is sanitized beforehand.\r\n\r\n**Environment**\r\n - Staging & production\r\n - All chains\r\n\n", "before_files": [{"content": "from typing import Any\n\nfrom django.db.models import Q, QuerySet\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\nfrom drf_yasg import openapi\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom .models import SafeApp\nfrom .serializers import SafeAppsResponseSerializer\n\n\nclass SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n pagination_class = None\n\n _swagger_chain_id_param = openapi.Parameter(\n \"chainId\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `chainId`\",\n type=openapi.TYPE_INTEGER,\n )\n _swagger_client_url_param = openapi.Parameter(\n \"clientUrl\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `clientUrl`\",\n type=openapi.TYPE_STRING,\n )\n _swagger_url_param = openapi.Parameter(\n \"url\",\n openapi.IN_QUERY,\n description=\"Filter Safe Apps available from `url`. `url` needs to be an exact match\",\n type=openapi.TYPE_STRING,\n )\n\n @method_decorator(cache_page(60 * 10, cache=\"safe-apps\")) # Cache 10 minutes\n @swagger_auto_schema(\n manual_parameters=[\n _swagger_chain_id_param,\n _swagger_client_url_param,\n _swagger_url_param,\n ]\n ) # type: ignore[misc]\n def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n \"\"\"\n Returns a collection of Safe Apps (across different chains).\n Each Safe App can optionally include the information about the `Provider`\n \"\"\"\n return super().get(request, *args, **kwargs)\n\n def get_queryset(self) -> QuerySet[SafeApp]:\n queryset = SafeApp.objects.filter(visible=True)\n\n chain_id = self.request.query_params.get(\"chainId\")\n if chain_id is not None and chain_id.isdigit():\n queryset = queryset.filter(chain_ids__contains=[chain_id])\n\n client_url = self.request.query_params.get(\"clientUrl\")\n if client_url:\n queryset = queryset.filter(\n Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)\n )\n\n url = self.request.query_params.get(\"url\")\n if url:\n queryset = queryset.filter(url=url)\n\n return queryset\n", "path": "src/safe_apps/views.py"}], "after_files": [{"content": "from typing import Any\n\nfrom django.db.models import Q, QuerySet\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.cache import cache_page\nfrom drf_yasg import openapi\nfrom drf_yasg.utils import swagger_auto_schema\nfrom rest_framework.generics import ListAPIView\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\n\nfrom .models import SafeApp\nfrom .serializers import SafeAppsResponseSerializer\n\n\nclass SafeAppsListView(ListAPIView):\n serializer_class = SafeAppsResponseSerializer\n pagination_class = None\n\n _swagger_chain_id_param = openapi.Parameter(\n \"chainId\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `chainId`\",\n type=openapi.TYPE_INTEGER,\n )\n _swagger_client_url_param = openapi.Parameter(\n \"clientUrl\",\n openapi.IN_QUERY,\n description=\"Used to filter Safe Apps that are available on `clientUrl`\",\n type=openapi.TYPE_STRING,\n )\n _swagger_url_param = openapi.Parameter(\n \"url\",\n openapi.IN_QUERY,\n description=\"Filter Safe Apps available from `url`. `url` needs to be an exact match\",\n type=openapi.TYPE_STRING,\n )\n\n @method_decorator(cache_page(60 * 10, cache=\"safe-apps\")) # Cache 10 minutes\n @swagger_auto_schema(\n manual_parameters=[\n _swagger_chain_id_param,\n _swagger_client_url_param,\n _swagger_url_param,\n ]\n ) # type: ignore[misc]\n def get(self, request: Request, *args: Any, **kwargs: Any) -> Response:\n \"\"\"\n Returns a collection of Safe Apps (across different chains).\n Each Safe App can optionally include the information about the `Provider`\n \"\"\"\n return super().get(request, *args, **kwargs)\n\n def get_queryset(self) -> QuerySet[SafeApp]:\n queryset = SafeApp.objects.filter(visible=True)\n\n chain_id = self.request.query_params.get(\"chainId\")\n if chain_id is not None and chain_id.isdigit():\n queryset = queryset.filter(chain_ids__contains=[chain_id])\n\n client_url = self.request.query_params.get(\"clientUrl\")\n if client_url and \"\\0\" not in client_url:\n queryset = queryset.filter(\n Q(exclusive_clients__url=client_url) | Q(exclusive_clients__isnull=True)\n )\n\n url = self.request.query_params.get(\"url\")\n if url and \"\\0\" not in url:\n queryset = queryset.filter(url=url)\n\n return queryset\n", "path": "src/safe_apps/views.py"}]}
| 1,042 | 168 |
gh_patches_debug_25253
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2368
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
take out secret dev notes visible in frontend :-)

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/projects/templatetags/meinberlin_project_tags.py`
Content:
```
1 from django import template
2
3 from adhocracy4.comments.models import Comment
4 from meinberlin.apps.budgeting.models import Proposal as budget_proposal
5 from meinberlin.apps.ideas.models import Idea
6 from meinberlin.apps.kiezkasse.models import Proposal as kiezkasse_proposal
7 from meinberlin.apps.mapideas.models import MapIdea
8 from meinberlin.apps.projects import get_project_type
9
10 register = template.Library()
11
12
13 @register.filter
14 def project_url(project):
15 if get_project_type(project) in ('external', 'bplan'):
16 return project.externalproject.url
17 return project.get_absolute_url()
18
19
20 @register.filter
21 def project_type(project):
22 return get_project_type(project)
23
24
25 @register.filter
26 def is_external(project):
27 return get_project_type(project) in ('external', 'bplan')
28
29
30 @register.filter
31 def is_container(project):
32 return get_project_type(project) == 'container'
33
34
35 @register.simple_tag
36 def to_class_name(value):
37 return value.__class__.__name__
38
39
40 @register.simple_tag
41 def get_num_entries(module):
42 """Count all user-generated items."""
43 item_count = Idea.objects.filter(module=module).count() \
44 + MapIdea.objects.filter(module=module).count() \
45 + budget_proposal.objects.filter(module=module).count() \
46 + kiezkasse_proposal.objects.filter(module=module).count() \
47 + Comment.objects.filter(idea__module=module).count() \
48 + Comment.objects.filter(mapidea__module=module).count() \
49 + Comment.objects.filter(budget_proposal__module=module).count() \
50 + Comment.objects.filter(kiezkasse_proposal__module=module).count()
51 return item_count
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
--- a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
+++ b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py
@@ -40,12 +40,18 @@
@register.simple_tag
def get_num_entries(module):
"""Count all user-generated items."""
- item_count = Idea.objects.filter(module=module).count() \
+ item_count = \
+ Idea.objects.filter(module=module).count() \
+ MapIdea.objects.filter(module=module).count() \
+ budget_proposal.objects.filter(module=module).count() \
+ kiezkasse_proposal.objects.filter(module=module).count() \
+ Comment.objects.filter(idea__module=module).count() \
+ Comment.objects.filter(mapidea__module=module).count() \
+ Comment.objects.filter(budget_proposal__module=module).count() \
- + Comment.objects.filter(kiezkasse_proposal__module=module).count()
+ + Comment.objects.filter(kiezkasse_proposal__module=module).count() \
+ + Comment.objects.filter(topic__module=module).count() \
+ + Comment.objects.filter(maptopic__module=module).count() \
+ + Comment.objects.filter(paragraph__chapter__module=module).count() \
+ + Comment.objects.filter(chapter__module=module).count() \
+ + Comment.objects.filter(poll__module=module).count()
return item_count
|
{"golden_diff": "diff --git a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n--- a/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n+++ b/meinberlin/apps/projects/templatetags/meinberlin_project_tags.py\n@@ -40,12 +40,18 @@\n @register.simple_tag\n def get_num_entries(module):\n \"\"\"Count all user-generated items.\"\"\"\n- item_count = Idea.objects.filter(module=module).count() \\\n+ item_count = \\\n+ Idea.objects.filter(module=module).count() \\\n + MapIdea.objects.filter(module=module).count() \\\n + budget_proposal.objects.filter(module=module).count() \\\n + kiezkasse_proposal.objects.filter(module=module).count() \\\n + Comment.objects.filter(idea__module=module).count() \\\n + Comment.objects.filter(mapidea__module=module).count() \\\n + Comment.objects.filter(budget_proposal__module=module).count() \\\n- + Comment.objects.filter(kiezkasse_proposal__module=module).count()\n+ + Comment.objects.filter(kiezkasse_proposal__module=module).count() \\\n+ + Comment.objects.filter(topic__module=module).count() \\\n+ + Comment.objects.filter(maptopic__module=module).count() \\\n+ + Comment.objects.filter(paragraph__chapter__module=module).count() \\\n+ + Comment.objects.filter(chapter__module=module).count() \\\n+ + Comment.objects.filter(poll__module=module).count()\n return item_count\n", "issue": "take out secret dev notes visible in frontend :-)\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from django import template\n\nfrom adhocracy4.comments.models import Comment\nfrom meinberlin.apps.budgeting.models import Proposal as budget_proposal\nfrom meinberlin.apps.ideas.models import Idea\nfrom meinberlin.apps.kiezkasse.models import Proposal as kiezkasse_proposal\nfrom meinberlin.apps.mapideas.models import MapIdea\nfrom meinberlin.apps.projects import get_project_type\n\nregister = template.Library()\n\n\[email protected]\ndef project_url(project):\n if get_project_type(project) in ('external', 'bplan'):\n return project.externalproject.url\n return project.get_absolute_url()\n\n\[email protected]\ndef project_type(project):\n return get_project_type(project)\n\n\[email protected]\ndef is_external(project):\n return get_project_type(project) in ('external', 'bplan')\n\n\[email protected]\ndef is_container(project):\n return get_project_type(project) == 'container'\n\n\[email protected]_tag\ndef to_class_name(value):\n return value.__class__.__name__\n\n\[email protected]_tag\ndef get_num_entries(module):\n \"\"\"Count all user-generated items.\"\"\"\n item_count = Idea.objects.filter(module=module).count() \\\n + MapIdea.objects.filter(module=module).count() \\\n + budget_proposal.objects.filter(module=module).count() \\\n + kiezkasse_proposal.objects.filter(module=module).count() \\\n + Comment.objects.filter(idea__module=module).count() \\\n + Comment.objects.filter(mapidea__module=module).count() \\\n + Comment.objects.filter(budget_proposal__module=module).count() \\\n + Comment.objects.filter(kiezkasse_proposal__module=module).count()\n return item_count\n", "path": "meinberlin/apps/projects/templatetags/meinberlin_project_tags.py"}], "after_files": [{"content": "from django import template\n\nfrom adhocracy4.comments.models import Comment\nfrom meinberlin.apps.budgeting.models import Proposal as budget_proposal\nfrom meinberlin.apps.ideas.models import Idea\nfrom meinberlin.apps.kiezkasse.models import Proposal as kiezkasse_proposal\nfrom meinberlin.apps.mapideas.models import MapIdea\nfrom meinberlin.apps.projects import get_project_type\n\nregister = template.Library()\n\n\[email protected]\ndef project_url(project):\n if get_project_type(project) in ('external', 'bplan'):\n return project.externalproject.url\n return project.get_absolute_url()\n\n\[email protected]\ndef project_type(project):\n return get_project_type(project)\n\n\[email protected]\ndef is_external(project):\n return get_project_type(project) in ('external', 'bplan')\n\n\[email protected]\ndef is_container(project):\n return get_project_type(project) == 'container'\n\n\[email protected]_tag\ndef to_class_name(value):\n return value.__class__.__name__\n\n\[email protected]_tag\ndef get_num_entries(module):\n \"\"\"Count all user-generated items.\"\"\"\n item_count = \\\n Idea.objects.filter(module=module).count() \\\n + MapIdea.objects.filter(module=module).count() \\\n + budget_proposal.objects.filter(module=module).count() \\\n + kiezkasse_proposal.objects.filter(module=module).count() \\\n + Comment.objects.filter(idea__module=module).count() \\\n + Comment.objects.filter(mapidea__module=module).count() \\\n + Comment.objects.filter(budget_proposal__module=module).count() \\\n + Comment.objects.filter(kiezkasse_proposal__module=module).count() \\\n + Comment.objects.filter(topic__module=module).count() \\\n + Comment.objects.filter(maptopic__module=module).count() \\\n + Comment.objects.filter(paragraph__chapter__module=module).count() \\\n + Comment.objects.filter(chapter__module=module).count() \\\n + Comment.objects.filter(poll__module=module).count()\n return item_count\n", "path": "meinberlin/apps/projects/templatetags/meinberlin_project_tags.py"}]}
| 836 | 367 |
gh_patches_debug_6788
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-1733
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Login ID and Password fields for a learner/user should not be case sensitive.
## Summary
Login ID and Password fields for a learner/user should not be case sensitive, this is especially for young learners and they struggle a lot to login itself.
Please consider this change for Nalanda branch.
## System information
- Version: Kolibri 0.4.0beta9
- Operating system: Ubuntu 14.04 LTS
- Browser: Chrome
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/auth/backends.py`
Content:
```
1 """
2 Implements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and
3 DeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication
4 backends are checked in the order they're listed.
5 """
6
7 from kolibri.auth.models import DeviceOwner, FacilityUser
8
9
10 class FacilityUserBackend(object):
11 """
12 A class that implements authentication for FacilityUsers.
13 """
14
15 def authenticate(self, username=None, password=None, facility=None):
16 """
17 Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.
18
19 :param username: a string
20 :param password: a string
21 :param facility: a Facility
22 :return: A FacilityUser instance if successful, or None if authentication failed.
23 """
24 users = FacilityUser.objects.filter(username=username)
25 if facility:
26 users = users.filter(facility=facility)
27 for user in users:
28 if user.check_password(password):
29 return user
30 # Allow login without password for learners for facilities that allow this.
31 # Must specify the facility, to prevent accidental logins
32 elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():
33 return user
34 return None
35
36 def get_user(self, user_id):
37 """
38 Gets a user. Auth backends are required to implement this.
39
40 :param user_id: A FacilityUser pk
41 :return: A FacilityUser instance if a BaseUser with that pk is found, else None.
42 """
43 try:
44 return FacilityUser.objects.get(pk=user_id)
45 except FacilityUser.DoesNotExist:
46 return None
47
48
49 class DeviceOwnerBackend(object):
50 """
51 A class that implements authentication for DeviceOwners.
52 """
53
54 def authenticate(self, username=None, password=None, **kwargs):
55 """
56 Authenticates the user if the credentials correspond to a DeviceOwner.
57
58 :param username: a string
59 :param password: a string
60 :return: A DeviceOwner instance if successful, or None if authentication failed.
61 """
62 try:
63 user = DeviceOwner.objects.get(username=username)
64 if user.check_password(password):
65 return user
66 else:
67 return None
68 except DeviceOwner.DoesNotExist:
69 return None
70
71 def get_user(self, user_id):
72 """
73 Gets a user. Auth backends are required to implement this.
74
75 :param user_id: A BaseUser pk
76 :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.
77 """
78 try:
79 return DeviceOwner.objects.get(pk=user_id)
80 except DeviceOwner.DoesNotExist:
81 return None
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py
--- a/kolibri/auth/backends.py
+++ b/kolibri/auth/backends.py
@@ -21,7 +21,7 @@
:param facility: a Facility
:return: A FacilityUser instance if successful, or None if authentication failed.
"""
- users = FacilityUser.objects.filter(username=username)
+ users = FacilityUser.objects.filter(username__iexact=username)
if facility:
users = users.filter(facility=facility)
for user in users:
|
{"golden_diff": "diff --git a/kolibri/auth/backends.py b/kolibri/auth/backends.py\n--- a/kolibri/auth/backends.py\n+++ b/kolibri/auth/backends.py\n@@ -21,7 +21,7 @@\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n- users = FacilityUser.objects.filter(username=username)\n+ users = FacilityUser.objects.filter(username__iexact=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n", "issue": "Login ID and Password fields for a learner/user should not be case sensitive.\n## Summary\r\n\r\nLogin ID and Password fields for a learner/user should not be case sensitive, this is especially for young learners and they struggle a lot to login itself.\r\n\r\nPlease consider this change for Nalanda branch.\r\n\r\n## System information\r\n - Version: Kolibri 0.4.0beta9\r\n - Operating system: Ubuntu 14.04 LTS\r\n - Browser: Chrome\r\n\n", "before_files": [{"content": "\"\"\"\nImplements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and\nDeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication\nbackends are checked in the order they're listed.\n\"\"\"\n\nfrom kolibri.auth.models import DeviceOwner, FacilityUser\n\n\nclass FacilityUserBackend(object):\n \"\"\"\n A class that implements authentication for FacilityUsers.\n \"\"\"\n\n def authenticate(self, username=None, password=None, facility=None):\n \"\"\"\n Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.\n\n :param username: a string\n :param password: a string\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n users = FacilityUser.objects.filter(username=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n if user.check_password(password):\n return user\n # Allow login without password for learners for facilities that allow this.\n # Must specify the facility, to prevent accidental logins\n elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():\n return user\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A FacilityUser pk\n :return: A FacilityUser instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return FacilityUser.objects.get(pk=user_id)\n except FacilityUser.DoesNotExist:\n return None\n\n\nclass DeviceOwnerBackend(object):\n \"\"\"\n A class that implements authentication for DeviceOwners.\n \"\"\"\n\n def authenticate(self, username=None, password=None, **kwargs):\n \"\"\"\n Authenticates the user if the credentials correspond to a DeviceOwner.\n\n :param username: a string\n :param password: a string\n :return: A DeviceOwner instance if successful, or None if authentication failed.\n \"\"\"\n try:\n user = DeviceOwner.objects.get(username=username)\n if user.check_password(password):\n return user\n else:\n return None\n except DeviceOwner.DoesNotExist:\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A BaseUser pk\n :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return DeviceOwner.objects.get(pk=user_id)\n except DeviceOwner.DoesNotExist:\n return None\n", "path": "kolibri/auth/backends.py"}], "after_files": [{"content": "\"\"\"\nImplements custom auth backends as described in the Django docs, for our custom user classes -- FacilityUser and\nDeviceOwner. The appropriate classes should be listed in the AUTHENTICATION_BACKENDS. Note that authentication\nbackends are checked in the order they're listed.\n\"\"\"\n\nfrom kolibri.auth.models import DeviceOwner, FacilityUser\n\n\nclass FacilityUserBackend(object):\n \"\"\"\n A class that implements authentication for FacilityUsers.\n \"\"\"\n\n def authenticate(self, username=None, password=None, facility=None):\n \"\"\"\n Authenticates the user if the credentials correspond to a FacilityUser for the specified Facility.\n\n :param username: a string\n :param password: a string\n :param facility: a Facility\n :return: A FacilityUser instance if successful, or None if authentication failed.\n \"\"\"\n users = FacilityUser.objects.filter(username__iexact=username)\n if facility:\n users = users.filter(facility=facility)\n for user in users:\n if user.check_password(password):\n return user\n # Allow login without password for learners for facilities that allow this.\n # Must specify the facility, to prevent accidental logins\n elif facility and user.dataset.learner_can_login_with_no_password and not user.roles.count():\n return user\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A FacilityUser pk\n :return: A FacilityUser instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return FacilityUser.objects.get(pk=user_id)\n except FacilityUser.DoesNotExist:\n return None\n\n\nclass DeviceOwnerBackend(object):\n \"\"\"\n A class that implements authentication for DeviceOwners.\n \"\"\"\n\n def authenticate(self, username=None, password=None, **kwargs):\n \"\"\"\n Authenticates the user if the credentials correspond to a DeviceOwner.\n\n :param username: a string\n :param password: a string\n :return: A DeviceOwner instance if successful, or None if authentication failed.\n \"\"\"\n try:\n user = DeviceOwner.objects.get(username=username)\n if user.check_password(password):\n return user\n else:\n return None\n except DeviceOwner.DoesNotExist:\n return None\n\n def get_user(self, user_id):\n \"\"\"\n Gets a user. Auth backends are required to implement this.\n\n :param user_id: A BaseUser pk\n :return: A DeviceOwner instance if a BaseUser with that pk is found, else None.\n \"\"\"\n try:\n return DeviceOwner.objects.get(pk=user_id)\n except DeviceOwner.DoesNotExist:\n return None\n", "path": "kolibri/auth/backends.py"}]}
| 1,074 | 126 |
gh_patches_debug_39006
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-2538
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Skills and Enclosure background services fail to stop and are killed...
## Be clear about the software, hardware and version you are running
For example:
in CLI
>> what version are you running
>> I am running mycroft-core version 20 oh 2, release 0
>> You are on the latest version.
Opensuse Leap 15.1
## Try to provide steps that we can use to replicate the Issue
For example:
1. CTRL+C in CLI
2. Enter ./stop_mycroft.sh
3. Skills and Enclosure services are eventually killed.
4. Takes about 30 seconds total
## Be as specific as possible about the expected condition, and the deviation from expected condition.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh skills
Stopping skills (5579)...stopped.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh enclosure
Stopping enclosure (5588)...failed to stop.
Killing enclosure (5588)...killed.
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh
Stopping all mycroft-core services
Stopping messagebus.service (5576)...stopped.
Stopping audio (5582)...stopped.
Stopping speech (5585)...stopped.
...
user@LinuxOS:~/mycroft-core> ./stop-mycroft.sh
Stopping all mycroft-core services
Stopping messagebus.service (18995)...stopped.
Stopping skills (18998)...failed to stop.
Killing skills (18998)...killed.
Stopping audio (19001)...stopped.
Stopping speech (19004)...stopped.
Stopping enclosure (19007)...failed to stop.
Killing enclosure (19007)...killed.
user@LinuxOS:~/mycroft-core>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mycroft/client/enclosure/__main__.py`
Content:
```
1 # Copyright 2017 Mycroft AI Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 import sys
16
17 from mycroft.util.log import LOG
18 from mycroft.messagebus.client import MessageBusClient
19 from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG
20
21
22 def main():
23 # Read the system configuration
24 system_config = LocalConf(SYSTEM_CONFIG)
25 platform = system_config.get("enclosure", {}).get("platform")
26
27 if platform == "mycroft_mark_1":
28 LOG.debug("Creating Mark I Enclosure")
29 from mycroft.client.enclosure.mark1 import EnclosureMark1
30 enclosure = EnclosureMark1()
31 elif platform == "mycroft_mark_2":
32 LOG.debug("Creating Mark II Enclosure")
33 from mycroft.client.enclosure.mark2 import EnclosureMark2
34 enclosure = EnclosureMark2()
35 else:
36 LOG.debug("Creating generic enclosure, platform='{}'".format(platform))
37
38 # TODO: Mechanism to load from elsewhere. E.g. read a script path from
39 # the mycroft.conf, then load/launch that script.
40 from mycroft.client.enclosure.generic import EnclosureGeneric
41 enclosure = EnclosureGeneric()
42
43 if enclosure:
44 try:
45 LOG.debug("Enclosure started!")
46 enclosure.run()
47 except Exception as e:
48 print(e)
49 finally:
50 sys.exit()
51 else:
52 LOG.debug("No enclosure available for this hardware, running headless")
53
54
55 if __name__ == "__main__":
56 main()
57
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mycroft/client/enclosure/__main__.py b/mycroft/client/enclosure/__main__.py
--- a/mycroft/client/enclosure/__main__.py
+++ b/mycroft/client/enclosure/__main__.py
@@ -12,44 +12,67 @@
# See the License for the specific language governing permissions and
# limitations under the License.
#
-import sys
+"""Entrypoint for enclosure service.
+This provides any "enclosure" specific functionality, for example GUI or
+control over the Mark-1 Faceplate.
+"""
+from mycroft.configuration import LocalConf, SYSTEM_CONFIG
from mycroft.util.log import LOG
-from mycroft.messagebus.client import MessageBusClient
-from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG
+from mycroft.util import (create_daemon, wait_for_exit_signal,
+ reset_sigint_handler)
-def main():
- # Read the system configuration
- system_config = LocalConf(SYSTEM_CONFIG)
- platform = system_config.get("enclosure", {}).get("platform")
+def create_enclosure(platform):
+ """Create an enclosure based on the provided platform string.
+ Arguments:
+ platform (str): platform name string
+
+ Returns:
+ Enclosure object
+ """
if platform == "mycroft_mark_1":
- LOG.debug("Creating Mark I Enclosure")
+ LOG.info("Creating Mark I Enclosure")
from mycroft.client.enclosure.mark1 import EnclosureMark1
enclosure = EnclosureMark1()
elif platform == "mycroft_mark_2":
- LOG.debug("Creating Mark II Enclosure")
+ LOG.info("Creating Mark II Enclosure")
from mycroft.client.enclosure.mark2 import EnclosureMark2
enclosure = EnclosureMark2()
else:
- LOG.debug("Creating generic enclosure, platform='{}'".format(platform))
+ LOG.info("Creating generic enclosure, platform='{}'".format(platform))
# TODO: Mechanism to load from elsewhere. E.g. read a script path from
# the mycroft.conf, then load/launch that script.
from mycroft.client.enclosure.generic import EnclosureGeneric
enclosure = EnclosureGeneric()
+ return enclosure
+
+
+def main():
+ """Launch one of the available enclosure implementations.
+
+ This depends on the configured platform and can currently either be
+ mycroft_mark_1 or mycroft_mark_2, if unconfigured a generic enclosure with
+ only the GUI bus will be started.
+ """
+ # Read the system configuration
+ system_config = LocalConf(SYSTEM_CONFIG)
+ platform = system_config.get("enclosure", {}).get("platform")
+
+ enclosure = create_enclosure(platform)
if enclosure:
try:
LOG.debug("Enclosure started!")
- enclosure.run()
+ reset_sigint_handler()
+ create_daemon(enclosure.run)
+ wait_for_exit_signal()
except Exception as e:
print(e)
- finally:
- sys.exit()
else:
- LOG.debug("No enclosure available for this hardware, running headless")
+ LOG.info("No enclosure available for this hardware, running headless")
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/mycroft/client/enclosure/__main__.py b/mycroft/client/enclosure/__main__.py\n--- a/mycroft/client/enclosure/__main__.py\n+++ b/mycroft/client/enclosure/__main__.py\n@@ -12,44 +12,67 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n #\n-import sys\n+\"\"\"Entrypoint for enclosure service.\n \n+This provides any \"enclosure\" specific functionality, for example GUI or\n+control over the Mark-1 Faceplate.\n+\"\"\"\n+from mycroft.configuration import LocalConf, SYSTEM_CONFIG\n from mycroft.util.log import LOG\n-from mycroft.messagebus.client import MessageBusClient\n-from mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG\n+from mycroft.util import (create_daemon, wait_for_exit_signal,\n+ reset_sigint_handler)\n \n \n-def main():\n- # Read the system configuration\n- system_config = LocalConf(SYSTEM_CONFIG)\n- platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n+def create_enclosure(platform):\n+ \"\"\"Create an enclosure based on the provided platform string.\n \n+ Arguments:\n+ platform (str): platform name string\n+\n+ Returns:\n+ Enclosure object\n+ \"\"\"\n if platform == \"mycroft_mark_1\":\n- LOG.debug(\"Creating Mark I Enclosure\")\n+ LOG.info(\"Creating Mark I Enclosure\")\n from mycroft.client.enclosure.mark1 import EnclosureMark1\n enclosure = EnclosureMark1()\n elif platform == \"mycroft_mark_2\":\n- LOG.debug(\"Creating Mark II Enclosure\")\n+ LOG.info(\"Creating Mark II Enclosure\")\n from mycroft.client.enclosure.mark2 import EnclosureMark2\n enclosure = EnclosureMark2()\n else:\n- LOG.debug(\"Creating generic enclosure, platform='{}'\".format(platform))\n+ LOG.info(\"Creating generic enclosure, platform='{}'\".format(platform))\n \n # TODO: Mechanism to load from elsewhere. E.g. read a script path from\n # the mycroft.conf, then load/launch that script.\n from mycroft.client.enclosure.generic import EnclosureGeneric\n enclosure = EnclosureGeneric()\n \n+ return enclosure\n+\n+\n+def main():\n+ \"\"\"Launch one of the available enclosure implementations.\n+\n+ This depends on the configured platform and can currently either be\n+ mycroft_mark_1 or mycroft_mark_2, if unconfigured a generic enclosure with\n+ only the GUI bus will be started.\n+ \"\"\"\n+ # Read the system configuration\n+ system_config = LocalConf(SYSTEM_CONFIG)\n+ platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n+\n+ enclosure = create_enclosure(platform)\n if enclosure:\n try:\n LOG.debug(\"Enclosure started!\")\n- enclosure.run()\n+ reset_sigint_handler()\n+ create_daemon(enclosure.run)\n+ wait_for_exit_signal()\n except Exception as e:\n print(e)\n- finally:\n- sys.exit()\n else:\n- LOG.debug(\"No enclosure available for this hardware, running headless\")\n+ LOG.info(\"No enclosure available for this hardware, running headless\")\n \n \n if __name__ == \"__main__\":\n", "issue": "Skills and Enclosure background services fail to stop and are killed...\n## Be clear about the software, hardware and version you are running\r\n\r\nFor example: \r\n\r\nin CLI\r\n >> what version are you running \r\n >> I am running mycroft-core version 20 oh 2, release 0 \r\n >> You are on the latest version.\r\n\r\nOpensuse Leap 15.1\r\n## Try to provide steps that we can use to replicate the Issue\r\n\r\nFor example: \r\n\r\n1. CTRL+C in CLI\r\n2. Enter ./stop_mycroft.sh \r\n3. Skills and Enclosure services are eventually killed.\r\n4. Takes about 30 seconds total\r\n\r\n## Be as specific as possible about the expected condition, and the deviation from expected condition. \r\n\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh skills\r\nStopping skills (5579)...stopped.\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh enclosure\r\nStopping enclosure (5588)...failed to stop.\r\n Killing enclosure (5588)...killed.\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh\r\nStopping all mycroft-core services\r\nStopping messagebus.service (5576)...stopped.\r\nStopping audio (5582)...stopped.\r\nStopping speech (5585)...stopped.\r\n...\r\nuser@LinuxOS:~/mycroft-core> ./stop-mycroft.sh\r\nStopping all mycroft-core services\r\nStopping messagebus.service (18995)...stopped.\r\nStopping skills (18998)...failed to stop.\r\n Killing skills (18998)...killed.\r\nStopping audio (19001)...stopped.\r\nStopping speech (19004)...stopped.\r\nStopping enclosure (19007)...failed to stop.\r\n Killing enclosure (19007)...killed.\r\nuser@LinuxOS:~/mycroft-core> \r\n\r\n\n", "before_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport sys\n\nfrom mycroft.util.log import LOG\nfrom mycroft.messagebus.client import MessageBusClient\nfrom mycroft.configuration import Configuration, LocalConf, SYSTEM_CONFIG\n\n\ndef main():\n # Read the system configuration\n system_config = LocalConf(SYSTEM_CONFIG)\n platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n\n if platform == \"mycroft_mark_1\":\n LOG.debug(\"Creating Mark I Enclosure\")\n from mycroft.client.enclosure.mark1 import EnclosureMark1\n enclosure = EnclosureMark1()\n elif platform == \"mycroft_mark_2\":\n LOG.debug(\"Creating Mark II Enclosure\")\n from mycroft.client.enclosure.mark2 import EnclosureMark2\n enclosure = EnclosureMark2()\n else:\n LOG.debug(\"Creating generic enclosure, platform='{}'\".format(platform))\n\n # TODO: Mechanism to load from elsewhere. E.g. read a script path from\n # the mycroft.conf, then load/launch that script.\n from mycroft.client.enclosure.generic import EnclosureGeneric\n enclosure = EnclosureGeneric()\n\n if enclosure:\n try:\n LOG.debug(\"Enclosure started!\")\n enclosure.run()\n except Exception as e:\n print(e)\n finally:\n sys.exit()\n else:\n LOG.debug(\"No enclosure available for this hardware, running headless\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/client/enclosure/__main__.py"}], "after_files": [{"content": "# Copyright 2017 Mycroft AI Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"Entrypoint for enclosure service.\n\nThis provides any \"enclosure\" specific functionality, for example GUI or\ncontrol over the Mark-1 Faceplate.\n\"\"\"\nfrom mycroft.configuration import LocalConf, SYSTEM_CONFIG\nfrom mycroft.util.log import LOG\nfrom mycroft.util import (create_daemon, wait_for_exit_signal,\n reset_sigint_handler)\n\n\ndef create_enclosure(platform):\n \"\"\"Create an enclosure based on the provided platform string.\n\n Arguments:\n platform (str): platform name string\n\n Returns:\n Enclosure object\n \"\"\"\n if platform == \"mycroft_mark_1\":\n LOG.info(\"Creating Mark I Enclosure\")\n from mycroft.client.enclosure.mark1 import EnclosureMark1\n enclosure = EnclosureMark1()\n elif platform == \"mycroft_mark_2\":\n LOG.info(\"Creating Mark II Enclosure\")\n from mycroft.client.enclosure.mark2 import EnclosureMark2\n enclosure = EnclosureMark2()\n else:\n LOG.info(\"Creating generic enclosure, platform='{}'\".format(platform))\n\n # TODO: Mechanism to load from elsewhere. E.g. read a script path from\n # the mycroft.conf, then load/launch that script.\n from mycroft.client.enclosure.generic import EnclosureGeneric\n enclosure = EnclosureGeneric()\n\n return enclosure\n\n\ndef main():\n \"\"\"Launch one of the available enclosure implementations.\n\n This depends on the configured platform and can currently either be\n mycroft_mark_1 or mycroft_mark_2, if unconfigured a generic enclosure with\n only the GUI bus will be started.\n \"\"\"\n # Read the system configuration\n system_config = LocalConf(SYSTEM_CONFIG)\n platform = system_config.get(\"enclosure\", {}).get(\"platform\")\n\n enclosure = create_enclosure(platform)\n if enclosure:\n try:\n LOG.debug(\"Enclosure started!\")\n reset_sigint_handler()\n create_daemon(enclosure.run)\n wait_for_exit_signal()\n except Exception as e:\n print(e)\n else:\n LOG.info(\"No enclosure available for this hardware, running headless\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "mycroft/client/enclosure/__main__.py"}]}
| 1,219 | 710 |
gh_patches_debug_12965
|
rasdani/github-patches
|
git_diff
|
getredash__redash-5812
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Timing out when connecting to a MSSQL database on non-default port using ODBC driver
I had to use "Microsoft SQL Server (ODBC)" data source because the "Microsoft SQL Server" one does not currently support using SSL. However, when trying to connect to my server on a port different than 1433, connection timed out.
After a bit of digging, I found this:
> Microsoft's ODBC drivers for SQL Server do not use a PORT= parameter. The port number, if any, is appended to the server name/IP with a comma
source: https://stackoverflow.com/a/50051708/1277401
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/query_runner/mssql_odbc.py`
Content:
```
1 import logging
2 import sys
3 import uuid
4
5 from redash.query_runner import *
6 from redash.query_runner.mssql import types_map
7 from redash.utils import json_dumps, json_loads
8
9 logger = logging.getLogger(__name__)
10
11 try:
12 import pyodbc
13
14 enabled = True
15 except ImportError:
16 enabled = False
17
18
19 class SQLServerODBC(BaseSQLQueryRunner):
20 should_annotate_query = False
21 noop_query = "SELECT 1"
22
23 @classmethod
24 def configuration_schema(cls):
25 return {
26 "type": "object",
27 "properties": {
28 "server": {"type": "string"},
29 "port": {"type": "number", "default": 1433},
30 "user": {"type": "string"},
31 "password": {"type": "string"},
32 "db": {"type": "string", "title": "Database Name"},
33 "charset": {
34 "type": "string",
35 "default": "UTF-8",
36 "title": "Character Set",
37 },
38 "use_ssl": {"type": "boolean", "title": "Use SSL", "default": False,},
39 "verify_ssl": {
40 "type": "boolean",
41 "title": "Verify SSL certificate",
42 "default": True,
43 },
44 },
45 "order": [
46 "server",
47 "port",
48 "user",
49 "password",
50 "db",
51 "charset",
52 "use_ssl",
53 "verify_ssl",
54 ],
55 "required": ["server", "user", "password", "db"],
56 "secret": ["password"],
57 "extra_options": ["verify_ssl", "use_ssl"],
58 }
59
60 @classmethod
61 def enabled(cls):
62 return enabled
63
64 @classmethod
65 def name(cls):
66 return "Microsoft SQL Server (ODBC)"
67
68 @classmethod
69 def type(cls):
70 return "mssql_odbc"
71
72 @property
73 def supports_auto_limit(self):
74 return False
75
76 def _get_tables(self, schema):
77 query = """
78 SELECT table_schema, table_name, column_name
79 FROM INFORMATION_SCHEMA.COLUMNS
80 WHERE table_schema NOT IN ('guest','INFORMATION_SCHEMA','sys','db_owner','db_accessadmin'
81 ,'db_securityadmin','db_ddladmin','db_backupoperator','db_datareader'
82 ,'db_datawriter','db_denydatareader','db_denydatawriter'
83 );
84 """
85
86 results, error = self.run_query(query, None)
87
88 if error is not None:
89 self._handle_run_query_error(error)
90
91 results = json_loads(results)
92
93 for row in results["rows"]:
94 if row["table_schema"] != self.configuration["db"]:
95 table_name = "{}.{}".format(row["table_schema"], row["table_name"])
96 else:
97 table_name = row["table_name"]
98
99 if table_name not in schema:
100 schema[table_name] = {"name": table_name, "columns": []}
101
102 schema[table_name]["columns"].append(row["column_name"])
103
104 return list(schema.values())
105
106 def run_query(self, query, user):
107 connection = None
108
109 try:
110 server = self.configuration.get("server")
111 user = self.configuration.get("user", "")
112 password = self.configuration.get("password", "")
113 db = self.configuration["db"]
114 port = self.configuration.get("port", 1433)
115 charset = self.configuration.get("charset", "UTF-8")
116
117 connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}"
118 connection_string = connection_string_fmt.format(
119 port, server, db, user, password
120 )
121
122 if self.configuration.get("use_ssl", False):
123 connection_string += ";Encrypt=YES"
124
125 if not self.configuration.get("verify_ssl"):
126 connection_string += ";TrustServerCertificate=YES"
127
128 connection = pyodbc.connect(connection_string)
129 cursor = connection.cursor()
130 logger.debug("SQLServerODBC running query: %s", query)
131 cursor.execute(query)
132 data = cursor.fetchall()
133
134 if cursor.description is not None:
135 columns = self.fetch_columns(
136 [(i[0], types_map.get(i[1], None)) for i in cursor.description]
137 )
138 rows = [
139 dict(zip((column["name"] for column in columns), row))
140 for row in data
141 ]
142
143 data = {"columns": columns, "rows": rows}
144 json_data = json_dumps(data)
145 error = None
146 else:
147 error = "No data was returned."
148 json_data = None
149
150 cursor.close()
151 except pyodbc.Error as e:
152 try:
153 # Query errors are at `args[1]`
154 error = e.args[1]
155 except IndexError:
156 # Connection errors are `args[0][1]`
157 error = e.args[0][1]
158 json_data = None
159 except (KeyboardInterrupt, JobTimeoutException):
160 connection.cancel()
161 raise
162 finally:
163 if connection:
164 connection.close()
165
166 return json_data, error
167
168
169 register(SQLServerODBC)
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/redash/query_runner/mssql_odbc.py b/redash/query_runner/mssql_odbc.py
--- a/redash/query_runner/mssql_odbc.py
+++ b/redash/query_runner/mssql_odbc.py
@@ -114,9 +114,9 @@
port = self.configuration.get("port", 1433)
charset = self.configuration.get("charset", "UTF-8")
- connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}"
+ connection_string_fmt = "DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={},{};DATABASE={};UID={};PWD={}"
connection_string = connection_string_fmt.format(
- port, server, db, user, password
+ server, port, db, user, password
)
if self.configuration.get("use_ssl", False):
|
{"golden_diff": "diff --git a/redash/query_runner/mssql_odbc.py b/redash/query_runner/mssql_odbc.py\n--- a/redash/query_runner/mssql_odbc.py\n+++ b/redash/query_runner/mssql_odbc.py\n@@ -114,9 +114,9 @@\n port = self.configuration.get(\"port\", 1433)\n charset = self.configuration.get(\"charset\", \"UTF-8\")\n \n- connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}\"\n+ connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={},{};DATABASE={};UID={};PWD={}\"\n connection_string = connection_string_fmt.format(\n- port, server, db, user, password\n+ server, port, db, user, password\n )\n \n if self.configuration.get(\"use_ssl\", False):\n", "issue": "Timing out when connecting to a MSSQL database on non-default port using ODBC driver\nI had to use \"Microsoft SQL Server (ODBC)\" data source because the \"Microsoft SQL Server\" one does not currently support using SSL. However, when trying to connect to my server on a port different than 1433, connection timed out.\r\n\r\nAfter a bit of digging, I found this:\r\n> Microsoft's ODBC drivers for SQL Server do not use a PORT= parameter. The port number, if any, is appended to the server name/IP with a comma\r\n\r\nsource: https://stackoverflow.com/a/50051708/1277401\n", "before_files": [{"content": "import logging\nimport sys\nimport uuid\n\nfrom redash.query_runner import *\nfrom redash.query_runner.mssql import types_map\nfrom redash.utils import json_dumps, json_loads\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pyodbc\n\n enabled = True\nexcept ImportError:\n enabled = False\n\n\nclass SQLServerODBC(BaseSQLQueryRunner):\n should_annotate_query = False\n noop_query = \"SELECT 1\"\n\n @classmethod\n def configuration_schema(cls):\n return {\n \"type\": \"object\",\n \"properties\": {\n \"server\": {\"type\": \"string\"},\n \"port\": {\"type\": \"number\", \"default\": 1433},\n \"user\": {\"type\": \"string\"},\n \"password\": {\"type\": \"string\"},\n \"db\": {\"type\": \"string\", \"title\": \"Database Name\"},\n \"charset\": {\n \"type\": \"string\",\n \"default\": \"UTF-8\",\n \"title\": \"Character Set\",\n },\n \"use_ssl\": {\"type\": \"boolean\", \"title\": \"Use SSL\", \"default\": False,},\n \"verify_ssl\": {\n \"type\": \"boolean\",\n \"title\": \"Verify SSL certificate\",\n \"default\": True,\n },\n },\n \"order\": [\n \"server\",\n \"port\",\n \"user\",\n \"password\",\n \"db\",\n \"charset\",\n \"use_ssl\",\n \"verify_ssl\",\n ],\n \"required\": [\"server\", \"user\", \"password\", \"db\"],\n \"secret\": [\"password\"],\n \"extra_options\": [\"verify_ssl\", \"use_ssl\"],\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def name(cls):\n return \"Microsoft SQL Server (ODBC)\"\n\n @classmethod\n def type(cls):\n return \"mssql_odbc\"\n\n @property\n def supports_auto_limit(self):\n return False\n\n def _get_tables(self, schema):\n query = \"\"\"\n SELECT table_schema, table_name, column_name\n FROM INFORMATION_SCHEMA.COLUMNS\n WHERE table_schema NOT IN ('guest','INFORMATION_SCHEMA','sys','db_owner','db_accessadmin'\n ,'db_securityadmin','db_ddladmin','db_backupoperator','db_datareader'\n ,'db_datawriter','db_denydatareader','db_denydatawriter'\n );\n \"\"\"\n\n results, error = self.run_query(query, None)\n\n if error is not None:\n self._handle_run_query_error(error)\n\n results = json_loads(results)\n\n for row in results[\"rows\"]:\n if row[\"table_schema\"] != self.configuration[\"db\"]:\n table_name = \"{}.{}\".format(row[\"table_schema\"], row[\"table_name\"])\n else:\n table_name = row[\"table_name\"]\n\n if table_name not in schema:\n schema[table_name] = {\"name\": table_name, \"columns\": []}\n\n schema[table_name][\"columns\"].append(row[\"column_name\"])\n\n return list(schema.values())\n\n def run_query(self, query, user):\n connection = None\n\n try:\n server = self.configuration.get(\"server\")\n user = self.configuration.get(\"user\", \"\")\n password = self.configuration.get(\"password\", \"\")\n db = self.configuration[\"db\"]\n port = self.configuration.get(\"port\", 1433)\n charset = self.configuration.get(\"charset\", \"UTF-8\")\n\n connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};PORT={};SERVER={};DATABASE={};UID={};PWD={}\"\n connection_string = connection_string_fmt.format(\n port, server, db, user, password\n )\n\n if self.configuration.get(\"use_ssl\", False):\n connection_string += \";Encrypt=YES\"\n\n if not self.configuration.get(\"verify_ssl\"):\n connection_string += \";TrustServerCertificate=YES\"\n\n connection = pyodbc.connect(connection_string)\n cursor = connection.cursor()\n logger.debug(\"SQLServerODBC running query: %s\", query)\n cursor.execute(query)\n data = cursor.fetchall()\n\n if cursor.description is not None:\n columns = self.fetch_columns(\n [(i[0], types_map.get(i[1], None)) for i in cursor.description]\n )\n rows = [\n dict(zip((column[\"name\"] for column in columns), row))\n for row in data\n ]\n\n data = {\"columns\": columns, \"rows\": rows}\n json_data = json_dumps(data)\n error = None\n else:\n error = \"No data was returned.\"\n json_data = None\n\n cursor.close()\n except pyodbc.Error as e:\n try:\n # Query errors are at `args[1]`\n error = e.args[1]\n except IndexError:\n # Connection errors are `args[0][1]`\n error = e.args[0][1]\n json_data = None\n except (KeyboardInterrupt, JobTimeoutException):\n connection.cancel()\n raise\n finally:\n if connection:\n connection.close()\n\n return json_data, error\n\n\nregister(SQLServerODBC)\n", "path": "redash/query_runner/mssql_odbc.py"}], "after_files": [{"content": "import logging\nimport sys\nimport uuid\n\nfrom redash.query_runner import *\nfrom redash.query_runner.mssql import types_map\nfrom redash.utils import json_dumps, json_loads\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pyodbc\n\n enabled = True\nexcept ImportError:\n enabled = False\n\n\nclass SQLServerODBC(BaseSQLQueryRunner):\n should_annotate_query = False\n noop_query = \"SELECT 1\"\n\n @classmethod\n def configuration_schema(cls):\n return {\n \"type\": \"object\",\n \"properties\": {\n \"server\": {\"type\": \"string\"},\n \"port\": {\"type\": \"number\", \"default\": 1433},\n \"user\": {\"type\": \"string\"},\n \"password\": {\"type\": \"string\"},\n \"db\": {\"type\": \"string\", \"title\": \"Database Name\"},\n \"charset\": {\n \"type\": \"string\",\n \"default\": \"UTF-8\",\n \"title\": \"Character Set\",\n },\n \"use_ssl\": {\"type\": \"boolean\", \"title\": \"Use SSL\", \"default\": False,},\n \"verify_ssl\": {\n \"type\": \"boolean\",\n \"title\": \"Verify SSL certificate\",\n \"default\": True,\n },\n },\n \"order\": [\n \"server\",\n \"port\",\n \"user\",\n \"password\",\n \"db\",\n \"charset\",\n \"use_ssl\",\n \"verify_ssl\",\n ],\n \"required\": [\"server\", \"user\", \"password\", \"db\"],\n \"secret\": [\"password\"],\n \"extra_options\": [\"verify_ssl\", \"use_ssl\"],\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def name(cls):\n return \"Microsoft SQL Server (ODBC)\"\n\n @classmethod\n def type(cls):\n return \"mssql_odbc\"\n\n @property\n def supports_auto_limit(self):\n return False\n\n def _get_tables(self, schema):\n query = \"\"\"\n SELECT table_schema, table_name, column_name\n FROM INFORMATION_SCHEMA.COLUMNS\n WHERE table_schema NOT IN ('guest','INFORMATION_SCHEMA','sys','db_owner','db_accessadmin'\n ,'db_securityadmin','db_ddladmin','db_backupoperator','db_datareader'\n ,'db_datawriter','db_denydatareader','db_denydatawriter'\n );\n \"\"\"\n\n results, error = self.run_query(query, None)\n\n if error is not None:\n self._handle_run_query_error(error)\n\n results = json_loads(results)\n\n for row in results[\"rows\"]:\n if row[\"table_schema\"] != self.configuration[\"db\"]:\n table_name = \"{}.{}\".format(row[\"table_schema\"], row[\"table_name\"])\n else:\n table_name = row[\"table_name\"]\n\n if table_name not in schema:\n schema[table_name] = {\"name\": table_name, \"columns\": []}\n\n schema[table_name][\"columns\"].append(row[\"column_name\"])\n\n return list(schema.values())\n\n def run_query(self, query, user):\n connection = None\n\n try:\n server = self.configuration.get(\"server\")\n user = self.configuration.get(\"user\", \"\")\n password = self.configuration.get(\"password\", \"\")\n db = self.configuration[\"db\"]\n port = self.configuration.get(\"port\", 1433)\n charset = self.configuration.get(\"charset\", \"UTF-8\")\n\n connection_string_fmt = \"DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={},{};DATABASE={};UID={};PWD={}\"\n connection_string = connection_string_fmt.format(\n server, port, db, user, password\n )\n\n if self.configuration.get(\"use_ssl\", False):\n connection_string += \";Encrypt=YES\"\n\n if not self.configuration.get(\"verify_ssl\"):\n connection_string += \";TrustServerCertificate=YES\"\n\n connection = pyodbc.connect(connection_string)\n cursor = connection.cursor()\n logger.debug(\"SQLServerODBC running query: %s\", query)\n cursor.execute(query)\n data = cursor.fetchall()\n\n if cursor.description is not None:\n columns = self.fetch_columns(\n [(i[0], types_map.get(i[1], None)) for i in cursor.description]\n )\n rows = [\n dict(zip((column[\"name\"] for column in columns), row))\n for row in data\n ]\n\n data = {\"columns\": columns, \"rows\": rows}\n json_data = json_dumps(data)\n error = None\n else:\n error = \"No data was returned.\"\n json_data = None\n\n cursor.close()\n except pyodbc.Error as e:\n try:\n # Query errors are at `args[1]`\n error = e.args[1]\n except IndexError:\n # Connection errors are `args[0][1]`\n error = e.args[0][1]\n json_data = None\n except (KeyboardInterrupt, JobTimeoutException):\n connection.cancel()\n raise\n finally:\n if connection:\n connection.close()\n\n return json_data, error\n\n\nregister(SQLServerODBC)\n", "path": "redash/query_runner/mssql_odbc.py"}]}
| 1,920 | 209 |
gh_patches_debug_7798
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-3725
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing chem_mech files in E3SM CaseDocs after renaming CAM to EAM
After [renaming CAM to EAM in E3SM](https://github.com/E3SM-Project/E3SM/pull/3845), the following two files are not copied to CaseDocs
```
chem_mech.doc
chem_mech.in
```
Need to change the 'cam' substring in 'camconf' near the end of cime/scripts/lib/CIME/case/preview_namelists.py. The piece of codes are copied below
```
# Copy over chemistry mechanism docs if they exist
if (os.path.isdir(os.path.join(casebuild, "camconf"))):
for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
safe_copy(file_to_copy, docdir)
```
To make it work for both cam and eam, need help to replace the substring 'cam' with the atm COMP_NAME. Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/lib/CIME/case/preview_namelists.py`
Content:
```
1 """
2 API for preview namelist
3 create_dirs and create_namelists are members of Class case from file case.py
4 """
5
6 from CIME.XML.standard_module_setup import *
7 from CIME.utils import run_sub_or_cmd, safe_copy
8 import time, glob
9 logger = logging.getLogger(__name__)
10
11 def create_dirs(self):
12 """
13 Make necessary directories for case
14 """
15 # Get data from XML
16 exeroot = self.get_value("EXEROOT")
17 libroot = self.get_value("LIBROOT")
18 incroot = self.get_value("INCROOT")
19 rundir = self.get_value("RUNDIR")
20 caseroot = self.get_value("CASEROOT")
21 docdir = os.path.join(caseroot, "CaseDocs")
22 dirs_to_make = []
23 models = self.get_values("COMP_CLASSES")
24 for model in models:
25 dirname = model.lower()
26 dirs_to_make.append(os.path.join(exeroot, dirname, "obj"))
27
28 dirs_to_make.extend([exeroot, libroot, incroot, rundir, docdir])
29
30 for dir_to_make in dirs_to_make:
31 if (not os.path.isdir(dir_to_make) and not os.path.islink(dir_to_make)):
32 try:
33 logger.debug("Making dir '{}'".format(dir_to_make))
34 os.makedirs(dir_to_make)
35 except OSError as e:
36 # In a multithreaded situation, we may have lost a race to create this dir.
37 # We do not want to crash if that's the case.
38 if not os.path.isdir(dir_to_make):
39 expect(False, "Could not make directory '{}', error: {}".format(dir_to_make, e))
40
41 # As a convenience write the location of the case directory in the bld and run directories
42 for dir_ in (exeroot, rundir):
43 with open(os.path.join(dir_,"CASEROOT"),"w+") as fd:
44 fd.write(caseroot+"\n")
45
46 def create_namelists(self, component=None):
47 """
48 Create component namelists
49 """
50 self.flush()
51
52 create_dirs(self)
53
54 casebuild = self.get_value("CASEBUILD")
55 caseroot = self.get_value("CASEROOT")
56 rundir = self.get_value("RUNDIR")
57
58 docdir = os.path.join(caseroot, "CaseDocs")
59
60 # Load modules
61 self.load_env()
62
63 self.stage_refcase()
64
65 # Create namelists - must have cpl last in the list below
66 # Note - cpl must be last in the loop below so that in generating its namelist,
67 # it can use xml vars potentially set by other component's buildnml scripts
68 models = self.get_values("COMP_CLASSES")
69 models += [models.pop(0)]
70 for model in models:
71 model_str = model.lower()
72 logger.info(" {} {} ".format(time.strftime("%Y-%m-%d %H:%M:%S"),model_str))
73 config_file = self.get_value("CONFIG_{}_FILE".format(model_str.upper()))
74 config_dir = os.path.dirname(config_file)
75 if model_str == "cpl":
76 compname = "drv"
77 else:
78 compname = self.get_value("COMP_{}".format(model_str.upper()))
79 if component is None or component == model_str or compname=="ufsatm":
80 # first look in the case SourceMods directory
81 cmd = os.path.join(caseroot, "SourceMods", "src."+compname, "buildnml")
82 if os.path.isfile(cmd):
83 logger.warning("\nWARNING: Using local buildnml file {}\n".format(cmd))
84 else:
85 # otherwise look in the component config_dir
86 cmd = os.path.join(config_dir, "buildnml")
87 expect(os.path.isfile(cmd), "Could not find buildnml file for component {}".format(compname))
88 logger.info("Create namelist for component {}".format(compname))
89 run_sub_or_cmd(cmd, (caseroot), "buildnml",
90 (self, caseroot, compname), case=self)
91
92 logger.debug("Finished creating component namelists, component {} models = {}".format(component, models))
93
94 # Save namelists to docdir
95 if (not os.path.isdir(docdir)):
96 os.makedirs(docdir)
97 try:
98 with open(os.path.join(docdir, "README"), "w") as fd:
99 fd.write(" CESM Resolved Namelist Files\n For documentation only DO NOT MODIFY\n")
100 except (OSError, IOError) as e:
101 expect(False, "Failed to write {}/README: {}".format(docdir, e))
102
103 for cpglob in ["*_in_[0-9]*", "*modelio*", "*_in", "nuopc.runconfig",
104 "*streams*txt*", "*streams.xml", "*stxt", "*maps.rc", "*cism.config*", "nuopc.runseq"]:
105 for file_to_copy in glob.glob(os.path.join(rundir, cpglob)):
106 logger.debug("Copy file from '{}' to '{}'".format(file_to_copy, docdir))
107 safe_copy(file_to_copy, docdir)
108
109 # Copy over chemistry mechanism docs if they exist
110 if (os.path.isdir(os.path.join(casebuild, "camconf"))):
111 for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
112 safe_copy(file_to_copy, docdir)
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/lib/CIME/case/preview_namelists.py b/scripts/lib/CIME/case/preview_namelists.py
--- a/scripts/lib/CIME/case/preview_namelists.py
+++ b/scripts/lib/CIME/case/preview_namelists.py
@@ -107,6 +107,7 @@
safe_copy(file_to_copy, docdir)
# Copy over chemistry mechanism docs if they exist
- if (os.path.isdir(os.path.join(casebuild, "camconf"))):
- for file_to_copy in glob.glob(os.path.join(casebuild, "camconf", "*chem_mech*")):
+ atmconf = self.get_value("COMP_ATM") + "conf"
+ if (os.path.isdir(os.path.join(casebuild, atmconf))):
+ for file_to_copy in glob.glob(os.path.join(casebuild, atmconf, "*chem_mech*")):
safe_copy(file_to_copy, docdir)
|
{"golden_diff": "diff --git a/scripts/lib/CIME/case/preview_namelists.py b/scripts/lib/CIME/case/preview_namelists.py\n--- a/scripts/lib/CIME/case/preview_namelists.py\n+++ b/scripts/lib/CIME/case/preview_namelists.py\n@@ -107,6 +107,7 @@\n safe_copy(file_to_copy, docdir)\n \n # Copy over chemistry mechanism docs if they exist\n- if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\n- for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\n+ atmconf = self.get_value(\"COMP_ATM\") + \"conf\"\n+ if (os.path.isdir(os.path.join(casebuild, atmconf))):\n+ for file_to_copy in glob.glob(os.path.join(casebuild, atmconf, \"*chem_mech*\")):\n safe_copy(file_to_copy, docdir)\n", "issue": "Missing chem_mech files in E3SM CaseDocs after renaming CAM to EAM\nAfter [renaming CAM to EAM in E3SM](https://github.com/E3SM-Project/E3SM/pull/3845), the following two files are not copied to CaseDocs\r\n```\r\nchem_mech.doc\r\nchem_mech.in\r\n```\r\nNeed to change the 'cam' substring in 'camconf' near the end of cime/scripts/lib/CIME/case/preview_namelists.py. The piece of codes are copied below\r\n```\r\n# Copy over chemistry mechanism docs if they exist\r\n if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\r\n for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\r\n safe_copy(file_to_copy, docdir)\r\n```\r\nTo make it work for both cam and eam, need help to replace the substring 'cam' with the atm COMP_NAME. Thanks.\n", "before_files": [{"content": "\"\"\"\nAPI for preview namelist\ncreate_dirs and create_namelists are members of Class case from file case.py\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\nfrom CIME.utils import run_sub_or_cmd, safe_copy\nimport time, glob\nlogger = logging.getLogger(__name__)\n\ndef create_dirs(self):\n \"\"\"\n Make necessary directories for case\n \"\"\"\n # Get data from XML\n exeroot = self.get_value(\"EXEROOT\")\n libroot = self.get_value(\"LIBROOT\")\n incroot = self.get_value(\"INCROOT\")\n rundir = self.get_value(\"RUNDIR\")\n caseroot = self.get_value(\"CASEROOT\")\n docdir = os.path.join(caseroot, \"CaseDocs\")\n dirs_to_make = []\n models = self.get_values(\"COMP_CLASSES\")\n for model in models:\n dirname = model.lower()\n dirs_to_make.append(os.path.join(exeroot, dirname, \"obj\"))\n\n dirs_to_make.extend([exeroot, libroot, incroot, rundir, docdir])\n\n for dir_to_make in dirs_to_make:\n if (not os.path.isdir(dir_to_make) and not os.path.islink(dir_to_make)):\n try:\n logger.debug(\"Making dir '{}'\".format(dir_to_make))\n os.makedirs(dir_to_make)\n except OSError as e:\n # In a multithreaded situation, we may have lost a race to create this dir.\n # We do not want to crash if that's the case.\n if not os.path.isdir(dir_to_make):\n expect(False, \"Could not make directory '{}', error: {}\".format(dir_to_make, e))\n\n # As a convenience write the location of the case directory in the bld and run directories\n for dir_ in (exeroot, rundir):\n with open(os.path.join(dir_,\"CASEROOT\"),\"w+\") as fd:\n fd.write(caseroot+\"\\n\")\n\ndef create_namelists(self, component=None):\n \"\"\"\n Create component namelists\n \"\"\"\n self.flush()\n\n create_dirs(self)\n\n casebuild = self.get_value(\"CASEBUILD\")\n caseroot = self.get_value(\"CASEROOT\")\n rundir = self.get_value(\"RUNDIR\")\n\n docdir = os.path.join(caseroot, \"CaseDocs\")\n\n # Load modules\n self.load_env()\n\n self.stage_refcase()\n\n # Create namelists - must have cpl last in the list below\n # Note - cpl must be last in the loop below so that in generating its namelist,\n # it can use xml vars potentially set by other component's buildnml scripts\n models = self.get_values(\"COMP_CLASSES\")\n models += [models.pop(0)]\n for model in models:\n model_str = model.lower()\n logger.info(\" {} {} \".format(time.strftime(\"%Y-%m-%d %H:%M:%S\"),model_str))\n config_file = self.get_value(\"CONFIG_{}_FILE\".format(model_str.upper()))\n config_dir = os.path.dirname(config_file)\n if model_str == \"cpl\":\n compname = \"drv\"\n else:\n compname = self.get_value(\"COMP_{}\".format(model_str.upper()))\n if component is None or component == model_str or compname==\"ufsatm\":\n # first look in the case SourceMods directory\n cmd = os.path.join(caseroot, \"SourceMods\", \"src.\"+compname, \"buildnml\")\n if os.path.isfile(cmd):\n logger.warning(\"\\nWARNING: Using local buildnml file {}\\n\".format(cmd))\n else:\n # otherwise look in the component config_dir\n cmd = os.path.join(config_dir, \"buildnml\")\n expect(os.path.isfile(cmd), \"Could not find buildnml file for component {}\".format(compname))\n logger.info(\"Create namelist for component {}\".format(compname))\n run_sub_or_cmd(cmd, (caseroot), \"buildnml\",\n (self, caseroot, compname), case=self)\n\n logger.debug(\"Finished creating component namelists, component {} models = {}\".format(component, models))\n\n # Save namelists to docdir\n if (not os.path.isdir(docdir)):\n os.makedirs(docdir)\n try:\n with open(os.path.join(docdir, \"README\"), \"w\") as fd:\n fd.write(\" CESM Resolved Namelist Files\\n For documentation only DO NOT MODIFY\\n\")\n except (OSError, IOError) as e:\n expect(False, \"Failed to write {}/README: {}\".format(docdir, e))\n\n for cpglob in [\"*_in_[0-9]*\", \"*modelio*\", \"*_in\", \"nuopc.runconfig\",\n \"*streams*txt*\", \"*streams.xml\", \"*stxt\", \"*maps.rc\", \"*cism.config*\", \"nuopc.runseq\"]:\n for file_to_copy in glob.glob(os.path.join(rundir, cpglob)):\n logger.debug(\"Copy file from '{}' to '{}'\".format(file_to_copy, docdir))\n safe_copy(file_to_copy, docdir)\n\n # Copy over chemistry mechanism docs if they exist\n if (os.path.isdir(os.path.join(casebuild, \"camconf\"))):\n for file_to_copy in glob.glob(os.path.join(casebuild, \"camconf\", \"*chem_mech*\")):\n safe_copy(file_to_copy, docdir)\n", "path": "scripts/lib/CIME/case/preview_namelists.py"}], "after_files": [{"content": "\"\"\"\nAPI for preview namelist\ncreate_dirs and create_namelists are members of Class case from file case.py\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\nfrom CIME.utils import run_sub_or_cmd, safe_copy\nimport time, glob\nlogger = logging.getLogger(__name__)\n\ndef create_dirs(self):\n \"\"\"\n Make necessary directories for case\n \"\"\"\n # Get data from XML\n exeroot = self.get_value(\"EXEROOT\")\n libroot = self.get_value(\"LIBROOT\")\n incroot = self.get_value(\"INCROOT\")\n rundir = self.get_value(\"RUNDIR\")\n caseroot = self.get_value(\"CASEROOT\")\n docdir = os.path.join(caseroot, \"CaseDocs\")\n dirs_to_make = []\n models = self.get_values(\"COMP_CLASSES\")\n for model in models:\n dirname = model.lower()\n dirs_to_make.append(os.path.join(exeroot, dirname, \"obj\"))\n\n dirs_to_make.extend([exeroot, libroot, incroot, rundir, docdir])\n\n for dir_to_make in dirs_to_make:\n if (not os.path.isdir(dir_to_make) and not os.path.islink(dir_to_make)):\n try:\n logger.debug(\"Making dir '{}'\".format(dir_to_make))\n os.makedirs(dir_to_make)\n except OSError as e:\n # In a multithreaded situation, we may have lost a race to create this dir.\n # We do not want to crash if that's the case.\n if not os.path.isdir(dir_to_make):\n expect(False, \"Could not make directory '{}', error: {}\".format(dir_to_make, e))\n\n # As a convenience write the location of the case directory in the bld and run directories\n for dir_ in (exeroot, rundir):\n with open(os.path.join(dir_,\"CASEROOT\"),\"w+\") as fd:\n fd.write(caseroot+\"\\n\")\n\ndef create_namelists(self, component=None):\n \"\"\"\n Create component namelists\n \"\"\"\n self.flush()\n\n create_dirs(self)\n\n casebuild = self.get_value(\"CASEBUILD\")\n caseroot = self.get_value(\"CASEROOT\")\n rundir = self.get_value(\"RUNDIR\")\n\n docdir = os.path.join(caseroot, \"CaseDocs\")\n\n # Load modules\n self.load_env()\n\n self.stage_refcase()\n\n # Create namelists - must have cpl last in the list below\n # Note - cpl must be last in the loop below so that in generating its namelist,\n # it can use xml vars potentially set by other component's buildnml scripts\n models = self.get_values(\"COMP_CLASSES\")\n models += [models.pop(0)]\n for model in models:\n model_str = model.lower()\n logger.info(\" {} {} \".format(time.strftime(\"%Y-%m-%d %H:%M:%S\"),model_str))\n config_file = self.get_value(\"CONFIG_{}_FILE\".format(model_str.upper()))\n config_dir = os.path.dirname(config_file)\n if model_str == \"cpl\":\n compname = \"drv\"\n else:\n compname = self.get_value(\"COMP_{}\".format(model_str.upper()))\n if component is None or component == model_str or compname==\"ufsatm\":\n # first look in the case SourceMods directory\n cmd = os.path.join(caseroot, \"SourceMods\", \"src.\"+compname, \"buildnml\")\n if os.path.isfile(cmd):\n logger.warning(\"\\nWARNING: Using local buildnml file {}\\n\".format(cmd))\n else:\n # otherwise look in the component config_dir\n cmd = os.path.join(config_dir, \"buildnml\")\n expect(os.path.isfile(cmd), \"Could not find buildnml file for component {}\".format(compname))\n logger.info(\"Create namelist for component {}\".format(compname))\n run_sub_or_cmd(cmd, (caseroot), \"buildnml\",\n (self, caseroot, compname), case=self)\n\n logger.debug(\"Finished creating component namelists, component {} models = {}\".format(component, models))\n\n # Save namelists to docdir\n if (not os.path.isdir(docdir)):\n os.makedirs(docdir)\n try:\n with open(os.path.join(docdir, \"README\"), \"w\") as fd:\n fd.write(\" CESM Resolved Namelist Files\\n For documentation only DO NOT MODIFY\\n\")\n except (OSError, IOError) as e:\n expect(False, \"Failed to write {}/README: {}\".format(docdir, e))\n\n for cpglob in [\"*_in_[0-9]*\", \"*modelio*\", \"*_in\", \"nuopc.runconfig\",\n \"*streams*txt*\", \"*streams.xml\", \"*stxt\", \"*maps.rc\", \"*cism.config*\", \"nuopc.runseq\"]:\n for file_to_copy in glob.glob(os.path.join(rundir, cpglob)):\n logger.debug(\"Copy file from '{}' to '{}'\".format(file_to_copy, docdir))\n safe_copy(file_to_copy, docdir)\n\n # Copy over chemistry mechanism docs if they exist\n atmconf = self.get_value(\"COMP_ATM\") + \"conf\"\n if (os.path.isdir(os.path.join(casebuild, atmconf))):\n for file_to_copy in glob.glob(os.path.join(casebuild, atmconf, \"*chem_mech*\")):\n safe_copy(file_to_copy, docdir)\n", "path": "scripts/lib/CIME/case/preview_namelists.py"}]}
| 1,873 | 208 |
gh_patches_debug_4275
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-37
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Country is not stored in db on signup
When a user signs up the country is not stored in the db
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/profiles/forms.py`
Content:
```
1 from django import forms
2 from django.utils.translation import ugettext_lazy as _
3 from django_countries.countries import COUNTRIES
4
5 from userena.forms import SignupForm
6
7 class SignupFormExtra(SignupForm):
8 institution = forms.CharField(label=_(u'Institution'),
9 max_length = 100,
10 required = True,
11 help_text=_(u'Institution you are affiliated to.'))
12 department = forms.CharField(label=_(u'Department'),
13 max_length = 100,
14 required = True,
15 help_text=_(u'Department you represent.'))
16 country = forms.ChoiceField(label=_(u'Country'),
17 choices=COUNTRIES,
18 required = True)
19 website = forms.CharField(label=_(u'Website'),
20 max_length = 150,
21 required = False)
22 first_name = forms.CharField(label=_(u'First Name'),
23 max_length = 30,
24 required = True)
25 last_name = forms.CharField(label=_(u'Last Name'),
26 max_length = 30,
27 required = True)
28
29 def __init__(self, *args, **kw):
30 """ Bit of hackery to get the first and last name at the top of the form.
31 """
32 super(SignupFormExtra,self).__init__(*args,**kw)
33 # Put the first and last name at the top.
34 new_order = self.fields.keyOrder[:-2]
35 new_order.insert(0, 'first_name')
36 new_order.insert(1, 'last_name')
37 self.fields.keyOrder = new_order
38
39 def save(self):
40 user = super(SignupFormExtra,self).save()
41 user.first_name = self.cleaned_data['first_name']
42 user.last_name = self.cleaned_data['last_name']
43 user.save()
44 user_profile = user.get_profile()
45 user_profile.institution = self.cleaned_data['institution']
46 user_profile.department = self.cleaned_data['department']
47 user_profile.save()
48
49 return user
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django/profiles/forms.py b/django/profiles/forms.py
--- a/django/profiles/forms.py
+++ b/django/profiles/forms.py
@@ -44,6 +44,7 @@
user_profile = user.get_profile()
user_profile.institution = self.cleaned_data['institution']
user_profile.department = self.cleaned_data['department']
+ user_profile.country = self.cleaned_data['country']
user_profile.save()
return user
|
{"golden_diff": "diff --git a/django/profiles/forms.py b/django/profiles/forms.py\n--- a/django/profiles/forms.py\n+++ b/django/profiles/forms.py\n@@ -44,6 +44,7 @@\n user_profile = user.get_profile()\n user_profile.institution = self.cleaned_data['institution']\n user_profile.department = self.cleaned_data['department']\n+ user_profile.country = self.cleaned_data['country']\n user_profile.save()\n \n return user\n", "issue": "Country is not stored in db on signup\nWhen a user signs up the country is not stored in the db\n\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import ugettext_lazy as _\nfrom django_countries.countries import COUNTRIES\n\nfrom userena.forms import SignupForm\n\nclass SignupFormExtra(SignupForm):\n institution = forms.CharField(label=_(u'Institution'),\n max_length = 100,\n required = True,\n help_text=_(u'Institution you are affiliated to.'))\n department = forms.CharField(label=_(u'Department'),\n max_length = 100,\n required = True,\n help_text=_(u'Department you represent.'))\n country = forms.ChoiceField(label=_(u'Country'),\n choices=COUNTRIES,\n required = True)\n website = forms.CharField(label=_(u'Website'),\n max_length = 150,\n required = False)\n first_name = forms.CharField(label=_(u'First Name'),\n max_length = 30,\n required = True)\n last_name = forms.CharField(label=_(u'Last Name'),\n max_length = 30,\n required = True)\n\n def __init__(self, *args, **kw):\n \"\"\" Bit of hackery to get the first and last name at the top of the form.\n \"\"\"\n super(SignupFormExtra,self).__init__(*args,**kw)\n # Put the first and last name at the top.\n new_order = self.fields.keyOrder[:-2]\n new_order.insert(0, 'first_name')\n new_order.insert(1, 'last_name')\n self.fields.keyOrder = new_order\n\n def save(self):\n user = super(SignupFormExtra,self).save()\n user.first_name = self.cleaned_data['first_name']\n user.last_name = self.cleaned_data['last_name']\n user.save()\n user_profile = user.get_profile()\n user_profile.institution = self.cleaned_data['institution']\n user_profile.department = self.cleaned_data['department']\n user_profile.save()\n\n return user\n", "path": "django/profiles/forms.py"}], "after_files": [{"content": "from django import forms\nfrom django.utils.translation import ugettext_lazy as _\nfrom django_countries.countries import COUNTRIES\n\nfrom userena.forms import SignupForm\n\nclass SignupFormExtra(SignupForm):\n institution = forms.CharField(label=_(u'Institution'),\n max_length = 100,\n required = True,\n help_text=_(u'Institution you are affiliated to.'))\n department = forms.CharField(label=_(u'Department'),\n max_length = 100,\n required = True,\n help_text=_(u'Department you represent.'))\n country = forms.ChoiceField(label=_(u'Country'),\n choices=COUNTRIES,\n required = True)\n website = forms.CharField(label=_(u'Website'),\n max_length = 150,\n required = False)\n first_name = forms.CharField(label=_(u'First Name'),\n max_length = 30,\n required = True)\n last_name = forms.CharField(label=_(u'Last Name'),\n max_length = 30,\n required = True)\n\n def __init__(self, *args, **kw):\n \"\"\" Bit of hackery to get the first and last name at the top of the form.\n \"\"\"\n super(SignupFormExtra,self).__init__(*args,**kw)\n # Put the first and last name at the top.\n new_order = self.fields.keyOrder[:-2]\n new_order.insert(0, 'first_name')\n new_order.insert(1, 'last_name')\n self.fields.keyOrder = new_order\n\n def save(self):\n user = super(SignupFormExtra,self).save()\n user.first_name = self.cleaned_data['first_name']\n user.last_name = self.cleaned_data['last_name']\n user.save()\n user_profile = user.get_profile()\n user_profile.institution = self.cleaned_data['institution']\n user_profile.department = self.cleaned_data['department']\n user_profile.country = self.cleaned_data['country']\n user_profile.save()\n\n return user\n", "path": "django/profiles/forms.py"}]}
| 797 | 101 |
gh_patches_debug_26386
|
rasdani/github-patches
|
git_diff
|
scverse__scanpy-2879
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
scanpy 1.10.0rc1 breaks anndata pre-release tests
### Please make sure these conditions are met
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest version of scanpy.
- [X] (optional) I have confirmed this bug exists on the master branch of scanpy.
### What happened?
`@doctest_needs` decorator causes test failures on scanpy import in anndata test suite
https://dev.azure.com/scverse/anndata/_build/results?buildId=5802&view=logs&jobId=0497d03e-5796-547f-cc56-989f8152a63c&j=0497d03e-5796-547f-cc56-989f8152a63c&t=ea3acdad-0250-5b8b-a1da-6cd02463cf17
### Minimal code sample
```python
NA
```
### Error output
```pytb
else:
enum_member = enum_class._new_member_(enum_class, *args)
if not hasattr(enum_member, '_value_'):
if enum_class._member_type_ is object:
enum_member._value_ = value
else:
try:
enum_member._value_ = enum_class._member_type_(*args)
except Exception as exc:
new_exc = TypeError(
'_value_ not set in __new__, unable to create it'
)
new_exc.__cause__ = exc
> raise new_exc
E TypeError: _value_ not set in __new__, unable to create it
```
### Versions
<details>
```
See anndata test failure
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scanpy/__init__.py`
Content:
```
1 """Single-Cell Analysis in Python."""
2 from __future__ import annotations
3
4 try: # See https://github.com/maresb/hatch-vcs-footgun-example
5 from setuptools_scm import get_version
6
7 __version__ = get_version(root="..", relative_to=__file__)
8 del get_version
9 except (ImportError, LookupError):
10 try:
11 from ._version import __version__
12 except ModuleNotFoundError:
13 raise RuntimeError(
14 "scanpy is not correctly installed. Please install it, e.g. with pip."
15 )
16
17 from ._utils import check_versions
18
19 check_versions()
20 del check_versions
21
22 # the actual API
23 # (start with settings as several tools are using it)
24 from anndata import (
25 AnnData,
26 concat,
27 read_csv,
28 read_excel,
29 read_h5ad,
30 read_hdf,
31 read_loom,
32 read_mtx,
33 read_text,
34 read_umi_tools,
35 )
36
37 from . import datasets, experimental, external, get, logging, metrics, queries
38 from . import plotting as pl
39 from . import preprocessing as pp
40 from . import tools as tl
41 from ._settings import Verbosity, settings
42 from .neighbors import Neighbors
43 from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write
44
45 set_figure_params = settings.set_figure_params
46
47 # has to be done at the end, after everything has been imported
48 import sys
49
50 sys.modules.update({f"{__name__}.{m}": globals()[m] for m in ["tl", "pp", "pl"]})
51 from ._utils import annotate_doc_types
52
53 annotate_doc_types(sys.modules[__name__], "scanpy")
54 del sys, annotate_doc_types
55
56 __all__ = [
57 "__version__",
58 "AnnData",
59 "concat",
60 "read_csv",
61 "read_excel",
62 "read_h5ad",
63 "read_hdf",
64 "read_loom",
65 "read_mtx",
66 "read_text",
67 "read_umi_tools",
68 "read",
69 "read_10x_h5",
70 "read_10x_mtx",
71 "read_visium",
72 "write",
73 "datasets",
74 "experimental",
75 "external",
76 "get",
77 "logging",
78 "metrics",
79 "queries",
80 "pl",
81 "pp",
82 "tl",
83 "Verbosity",
84 "settings",
85 "Neighbors",
86 "set_figure_params",
87 ]
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scanpy/__init__.py b/scanpy/__init__.py
--- a/scanpy/__init__.py
+++ b/scanpy/__init__.py
@@ -1,6 +1,8 @@
"""Single-Cell Analysis in Python."""
from __future__ import annotations
+import sys
+
try: # See https://github.com/maresb/hatch-vcs-footgun-example
from setuptools_scm import get_version
@@ -21,6 +23,11 @@
# the actual API
# (start with settings as several tools are using it)
+
+from ._settings import Verbosity, settings
+
+set_figure_params = settings.set_figure_params
+
from anndata import (
AnnData,
concat,
@@ -38,15 +45,10 @@
from . import plotting as pl
from . import preprocessing as pp
from . import tools as tl
-from ._settings import Verbosity, settings
from .neighbors import Neighbors
from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write
-set_figure_params = settings.set_figure_params
-
# has to be done at the end, after everything has been imported
-import sys
-
sys.modules.update({f"{__name__}.{m}": globals()[m] for m in ["tl", "pp", "pl"]})
from ._utils import annotate_doc_types
|
{"golden_diff": "diff --git a/scanpy/__init__.py b/scanpy/__init__.py\n--- a/scanpy/__init__.py\n+++ b/scanpy/__init__.py\n@@ -1,6 +1,8 @@\n \"\"\"Single-Cell Analysis in Python.\"\"\"\n from __future__ import annotations\n \n+import sys\n+\n try: # See https://github.com/maresb/hatch-vcs-footgun-example\n from setuptools_scm import get_version\n \n@@ -21,6 +23,11 @@\n \n # the actual API\n # (start with settings as several tools are using it)\n+\n+from ._settings import Verbosity, settings\n+\n+set_figure_params = settings.set_figure_params\n+\n from anndata import (\n AnnData,\n concat,\n@@ -38,15 +45,10 @@\n from . import plotting as pl\n from . import preprocessing as pp\n from . import tools as tl\n-from ._settings import Verbosity, settings\n from .neighbors import Neighbors\n from .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write\n \n-set_figure_params = settings.set_figure_params\n-\n # has to be done at the end, after everything has been imported\n-import sys\n-\n sys.modules.update({f\"{__name__}.{m}\": globals()[m] for m in [\"tl\", \"pp\", \"pl\"]})\n from ._utils import annotate_doc_types\n", "issue": "scanpy 1.10.0rc1 breaks anndata pre-release tests\n### Please make sure these conditions are met\n\n- [X] I have checked that this issue has not already been reported.\n- [X] I have confirmed this bug exists on the latest version of scanpy.\n- [X] (optional) I have confirmed this bug exists on the master branch of scanpy.\n\n### What happened?\n\n`@doctest_needs` decorator causes test failures on scanpy import in anndata test suite\r\n\r\nhttps://dev.azure.com/scverse/anndata/_build/results?buildId=5802&view=logs&jobId=0497d03e-5796-547f-cc56-989f8152a63c&j=0497d03e-5796-547f-cc56-989f8152a63c&t=ea3acdad-0250-5b8b-a1da-6cd02463cf17\r\n\r\n\n\n### Minimal code sample\n\n```python\nNA\n```\n\n\n### Error output\n\n```pytb\nelse:\r\n enum_member = enum_class._new_member_(enum_class, *args)\r\n if not hasattr(enum_member, '_value_'):\r\n if enum_class._member_type_ is object:\r\n enum_member._value_ = value\r\n else:\r\n try:\r\n enum_member._value_ = enum_class._member_type_(*args)\r\n except Exception as exc:\r\n new_exc = TypeError(\r\n '_value_ not set in __new__, unable to create it'\r\n )\r\n new_exc.__cause__ = exc\r\n> raise new_exc\r\nE TypeError: _value_ not set in __new__, unable to create it\n```\n\n\n### Versions\n\n<details>\r\n\r\n```\r\nSee anndata test failure\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "\"\"\"Single-Cell Analysis in Python.\"\"\"\nfrom __future__ import annotations\n\ntry: # See https://github.com/maresb/hatch-vcs-footgun-example\n from setuptools_scm import get_version\n\n __version__ = get_version(root=\"..\", relative_to=__file__)\n del get_version\nexcept (ImportError, LookupError):\n try:\n from ._version import __version__\n except ModuleNotFoundError:\n raise RuntimeError(\n \"scanpy is not correctly installed. Please install it, e.g. with pip.\"\n )\n\nfrom ._utils import check_versions\n\ncheck_versions()\ndel check_versions\n\n# the actual API\n# (start with settings as several tools are using it)\nfrom anndata import (\n AnnData,\n concat,\n read_csv,\n read_excel,\n read_h5ad,\n read_hdf,\n read_loom,\n read_mtx,\n read_text,\n read_umi_tools,\n)\n\nfrom . import datasets, experimental, external, get, logging, metrics, queries\nfrom . import plotting as pl\nfrom . import preprocessing as pp\nfrom . import tools as tl\nfrom ._settings import Verbosity, settings\nfrom .neighbors import Neighbors\nfrom .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write\n\nset_figure_params = settings.set_figure_params\n\n# has to be done at the end, after everything has been imported\nimport sys\n\nsys.modules.update({f\"{__name__}.{m}\": globals()[m] for m in [\"tl\", \"pp\", \"pl\"]})\nfrom ._utils import annotate_doc_types\n\nannotate_doc_types(sys.modules[__name__], \"scanpy\")\ndel sys, annotate_doc_types\n\n__all__ = [\n \"__version__\",\n \"AnnData\",\n \"concat\",\n \"read_csv\",\n \"read_excel\",\n \"read_h5ad\",\n \"read_hdf\",\n \"read_loom\",\n \"read_mtx\",\n \"read_text\",\n \"read_umi_tools\",\n \"read\",\n \"read_10x_h5\",\n \"read_10x_mtx\",\n \"read_visium\",\n \"write\",\n \"datasets\",\n \"experimental\",\n \"external\",\n \"get\",\n \"logging\",\n \"metrics\",\n \"queries\",\n \"pl\",\n \"pp\",\n \"tl\",\n \"Verbosity\",\n \"settings\",\n \"Neighbors\",\n \"set_figure_params\",\n]\n", "path": "scanpy/__init__.py"}], "after_files": [{"content": "\"\"\"Single-Cell Analysis in Python.\"\"\"\nfrom __future__ import annotations\n\nimport sys\n\ntry: # See https://github.com/maresb/hatch-vcs-footgun-example\n from setuptools_scm import get_version\n\n __version__ = get_version(root=\"..\", relative_to=__file__)\n del get_version\nexcept (ImportError, LookupError):\n try:\n from ._version import __version__\n except ModuleNotFoundError:\n raise RuntimeError(\n \"scanpy is not correctly installed. Please install it, e.g. with pip.\"\n )\n\nfrom ._utils import check_versions\n\ncheck_versions()\ndel check_versions\n\n# the actual API\n# (start with settings as several tools are using it)\n\nfrom ._settings import Verbosity, settings\n\nset_figure_params = settings.set_figure_params\n\nfrom anndata import (\n AnnData,\n concat,\n read_csv,\n read_excel,\n read_h5ad,\n read_hdf,\n read_loom,\n read_mtx,\n read_text,\n read_umi_tools,\n)\n\nfrom . import datasets, experimental, external, get, logging, metrics, queries\nfrom . import plotting as pl\nfrom . import preprocessing as pp\nfrom . import tools as tl\nfrom .neighbors import Neighbors\nfrom .readwrite import read, read_10x_h5, read_10x_mtx, read_visium, write\n\n# has to be done at the end, after everything has been imported\nsys.modules.update({f\"{__name__}.{m}\": globals()[m] for m in [\"tl\", \"pp\", \"pl\"]})\nfrom ._utils import annotate_doc_types\n\nannotate_doc_types(sys.modules[__name__], \"scanpy\")\ndel sys, annotate_doc_types\n\n__all__ = [\n \"__version__\",\n \"AnnData\",\n \"concat\",\n \"read_csv\",\n \"read_excel\",\n \"read_h5ad\",\n \"read_hdf\",\n \"read_loom\",\n \"read_mtx\",\n \"read_text\",\n \"read_umi_tools\",\n \"read\",\n \"read_10x_h5\",\n \"read_10x_mtx\",\n \"read_visium\",\n \"write\",\n \"datasets\",\n \"experimental\",\n \"external\",\n \"get\",\n \"logging\",\n \"metrics\",\n \"queries\",\n \"pl\",\n \"pp\",\n \"tl\",\n \"Verbosity\",\n \"settings\",\n \"Neighbors\",\n \"set_figure_params\",\n]\n", "path": "scanpy/__init__.py"}]}
| 1,375 | 311 |
gh_patches_debug_14509
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-2819
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: broken reference in example
<!--Provide a brief description of the bug.-->
Broken reference to vol_to_surf in:
examples/01_plotting/plot_3d_map_to_surface_projection.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/01_plotting/plot_3d_map_to_surface_projection.py`
Content:
```
1 """
2 Making a surface plot of a 3D statistical map
3 =============================================
4
5 project a 3D statistical map onto a cortical mesh using
6 :func:`nilearn.surface.vol_to_surf`. Display a surface plot of the projected
7 map using :func:`nilearn.plotting.plot_surf_stat_map` and adding contours of
8 regions of interest using :func:`nilearn.plotting.plot_surf_contours`.
9
10 """
11
12 ##############################################################################
13 # Get a statistical map
14 # ---------------------
15
16 from nilearn import datasets
17
18 motor_images = datasets.fetch_neurovault_motor_task()
19 stat_img = motor_images.images[0]
20
21
22 ##############################################################################
23 # Get a cortical mesh
24 # -------------------
25
26 fsaverage = datasets.fetch_surf_fsaverage()
27
28 ##############################################################################
29 # Sample the 3D data around each node of the mesh
30 # -----------------------------------------------
31
32 from nilearn import surface
33
34 texture = surface.vol_to_surf(stat_img, fsaverage.pial_right)
35
36 ##############################################################################
37 # Plot the result
38 # ---------------
39
40 from nilearn import plotting
41
42 plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',
43 title='Surface right hemisphere', colorbar=True,
44 threshold=1., bg_map=fsaverage.sulc_right)
45
46 ##############################################################################
47 # Plot 3D image for comparison
48 # ----------------------------
49
50 plotting.plot_glass_brain(stat_img, display_mode='r', plot_abs=False,
51 title='Glass brain', threshold=2.)
52
53 plotting.plot_stat_map(stat_img, display_mode='x', threshold=1.,
54 cut_coords=range(0, 51, 10), title='Slices')
55
56 ##############################################################################
57 # Use an atlas and choose regions to outline
58 # ------------------------------------------
59
60 import numpy as np
61
62 destrieux_atlas = datasets.fetch_atlas_surf_destrieux()
63 parcellation = destrieux_atlas['map_right']
64
65 # these are the regions we want to outline
66 regions_dict = {b'G_postcentral': 'Postcentral gyrus',
67 b'G_precentral': 'Precentral gyrus'}
68
69 # get indices in atlas for these labels
70 regions_indices = [np.where(np.array(destrieux_atlas['labels']) == region)[0][0]
71 for region in regions_dict]
72
73 labels = list(regions_dict.values())
74
75 ##############################################################################
76 # Display outlines of the regions of interest on top of a statistical map
77 # -----------------------------------------------------------------------
78
79 figure = plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',
80 title='Surface right hemisphere',
81 colorbar=True, threshold=1.,
82 bg_map=fsaverage.sulc_right)
83
84 plotting.plot_surf_contours(fsaverage.infl_right, parcellation, labels=labels,
85 levels=regions_indices, figure=figure, legend=True,
86 colors=['g', 'k'])
87 plotting.show()
88
89 ##############################################################################
90 # Plot with higher-resolution mesh
91 # --------------------------------
92 #
93 # `fetch_surf_fsaverage` takes a "mesh" argument which specifies
94 # wether to fetch the low-resolution fsaverage5 mesh, or the high-resolution
95 # fsaverage mesh. using mesh="fsaverage" will result in more memory usage and
96 # computation time, but finer visualizations.
97
98 big_fsaverage = datasets.fetch_surf_fsaverage('fsaverage')
99 big_texture = surface.vol_to_surf(stat_img, big_fsaverage.pial_right)
100
101 plotting.plot_surf_stat_map(big_fsaverage.infl_right,
102 big_texture, hemi='right', colorbar=True,
103 title='Surface right hemisphere: fine mesh',
104 threshold=1., bg_map=big_fsaverage.sulc_right)
105
106
107 ##############################################################################
108 # Plot multiple views of the 3D volume on a surface
109 # -------------------------------------------------
110 #
111 # *plot_img_on_surf* takes a statistical map and projects it onto a surface.
112 # It supports multiple choices of orientations, and can plot either one or both
113 # hemispheres. If no *surf_mesh* is given, *plot_img_on_surf* projects the
114 # images onto `FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_\'s
115 # fsaverage5.
116
117 plotting.plot_img_on_surf(stat_img,
118 views=['lateral', 'medial'],
119 hemispheres=['left', 'right'],
120 colorbar=True)
121 plotting.show()
122
123 ##############################################################################
124 # 3D visualization in a web browser
125 # ---------------------------------
126 # An alternative to :func:`nilearn.plotting.plot_surf_stat_map` is to use
127 # :func:`nilearn.plotting.view_surf` or
128 # :func:`nilearn.plotting.view_img_on_surf` that give more interactive
129 # visualizations in a web browser. See :ref:`interactive-surface-plotting` for
130 # more details.
131
132 view = plotting.view_surf(fsaverage.infl_right, texture, threshold='90%',
133 bg_map=fsaverage.sulc_right)
134
135 # In a Jupyter notebook, if ``view`` is the output of a cell, it will
136 # be displayed below the cell
137 view
138
139 ##############################################################################
140
141 # uncomment this to open the plot in a web browser:
142 # view.open_in_browser()
143
144 ##############################################################################
145 # We don't need to do the projection ourselves, we can use view_img_on_surf:
146
147 view = plotting.view_img_on_surf(stat_img, threshold='90%')
148 # view.open_in_browser()
149
150 view
151
152 ##############################################################################
153 # Impact of plot parameters on visualization
154 # ------------------------------------------
155 # You can specify arguments to be passed on to the function
156 # :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows
157 # fine-grained control of how the input 3D image is resampled and interpolated -
158 # for example if you are viewing a volumetric atlas, you would want to avoid
159 # averaging the labels between neighboring regions. Using nearest-neighbor
160 # interpolation with zero radius will achieve this.
161
162 destrieux = datasets.fetch_atlas_destrieux_2009()
163
164 view = plotting.view_img_on_surf(
165 destrieux.maps,
166 surf_mesh="fsaverage",
167 vol_to_surf_kwargs={"n_samples": 1, "radius": 0.0, "interpolation": "nearest"},
168 symmetric_cmap=False,
169 )
170
171 # view.open_in_browser()
172 view
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/01_plotting/plot_3d_map_to_surface_projection.py b/examples/01_plotting/plot_3d_map_to_surface_projection.py
--- a/examples/01_plotting/plot_3d_map_to_surface_projection.py
+++ b/examples/01_plotting/plot_3d_map_to_surface_projection.py
@@ -153,7 +153,7 @@
# Impact of plot parameters on visualization
# ------------------------------------------
# You can specify arguments to be passed on to the function
-# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows
+# :func:`nilearn.surface.vol_to_surf` using `vol_to_surf_kwargs`. This allows
# fine-grained control of how the input 3D image is resampled and interpolated -
# for example if you are viewing a volumetric atlas, you would want to avoid
# averaging the labels between neighboring regions. Using nearest-neighbor
|
{"golden_diff": "diff --git a/examples/01_plotting/plot_3d_map_to_surface_projection.py b/examples/01_plotting/plot_3d_map_to_surface_projection.py\n--- a/examples/01_plotting/plot_3d_map_to_surface_projection.py\n+++ b/examples/01_plotting/plot_3d_map_to_surface_projection.py\n@@ -153,7 +153,7 @@\n # Impact of plot parameters on visualization\n # ------------------------------------------\n # You can specify arguments to be passed on to the function\n-# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n+# :func:`nilearn.surface.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n # fine-grained control of how the input 3D image is resampled and interpolated -\n # for example if you are viewing a volumetric atlas, you would want to avoid\n # averaging the labels between neighboring regions. Using nearest-neighbor\n", "issue": "BUG: broken reference in example\n<!--Provide a brief description of the bug.-->\r\nBroken reference to vol_to_surf in:\r\n\r\nexamples/01_plotting/plot_3d_map_to_surface_projection.py\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nMaking a surface plot of a 3D statistical map\n=============================================\n\nproject a 3D statistical map onto a cortical mesh using\n:func:`nilearn.surface.vol_to_surf`. Display a surface plot of the projected\nmap using :func:`nilearn.plotting.plot_surf_stat_map` and adding contours of\nregions of interest using :func:`nilearn.plotting.plot_surf_contours`.\n\n\"\"\"\n\n##############################################################################\n# Get a statistical map\n# ---------------------\n\nfrom nilearn import datasets\n\nmotor_images = datasets.fetch_neurovault_motor_task()\nstat_img = motor_images.images[0]\n\n\n##############################################################################\n# Get a cortical mesh\n# -------------------\n\nfsaverage = datasets.fetch_surf_fsaverage()\n\n##############################################################################\n# Sample the 3D data around each node of the mesh\n# -----------------------------------------------\n\nfrom nilearn import surface\n\ntexture = surface.vol_to_surf(stat_img, fsaverage.pial_right)\n\n##############################################################################\n# Plot the result\n# ---------------\n\nfrom nilearn import plotting\n\nplotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere', colorbar=True,\n threshold=1., bg_map=fsaverage.sulc_right)\n\n##############################################################################\n# Plot 3D image for comparison\n# ----------------------------\n\nplotting.plot_glass_brain(stat_img, display_mode='r', plot_abs=False,\n title='Glass brain', threshold=2.)\n\nplotting.plot_stat_map(stat_img, display_mode='x', threshold=1.,\n cut_coords=range(0, 51, 10), title='Slices')\n\n##############################################################################\n# Use an atlas and choose regions to outline\n# ------------------------------------------\n\nimport numpy as np\n\ndestrieux_atlas = datasets.fetch_atlas_surf_destrieux()\nparcellation = destrieux_atlas['map_right']\n\n# these are the regions we want to outline\nregions_dict = {b'G_postcentral': 'Postcentral gyrus',\n b'G_precentral': 'Precentral gyrus'}\n\n# get indices in atlas for these labels\nregions_indices = [np.where(np.array(destrieux_atlas['labels']) == region)[0][0]\n for region in regions_dict]\n\nlabels = list(regions_dict.values())\n\n##############################################################################\n# Display outlines of the regions of interest on top of a statistical map\n# -----------------------------------------------------------------------\n\nfigure = plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere',\n colorbar=True, threshold=1.,\n bg_map=fsaverage.sulc_right)\n\nplotting.plot_surf_contours(fsaverage.infl_right, parcellation, labels=labels,\n levels=regions_indices, figure=figure, legend=True,\n colors=['g', 'k'])\nplotting.show()\n\n##############################################################################\n# Plot with higher-resolution mesh\n# --------------------------------\n#\n# `fetch_surf_fsaverage` takes a \"mesh\" argument which specifies\n# wether to fetch the low-resolution fsaverage5 mesh, or the high-resolution\n# fsaverage mesh. using mesh=\"fsaverage\" will result in more memory usage and\n# computation time, but finer visualizations.\n\nbig_fsaverage = datasets.fetch_surf_fsaverage('fsaverage')\nbig_texture = surface.vol_to_surf(stat_img, big_fsaverage.pial_right)\n\nplotting.plot_surf_stat_map(big_fsaverage.infl_right,\n big_texture, hemi='right', colorbar=True,\n title='Surface right hemisphere: fine mesh',\n threshold=1., bg_map=big_fsaverage.sulc_right)\n\n\n##############################################################################\n# Plot multiple views of the 3D volume on a surface\n# -------------------------------------------------\n#\n# *plot_img_on_surf* takes a statistical map and projects it onto a surface.\n# It supports multiple choices of orientations, and can plot either one or both\n# hemispheres. If no *surf_mesh* is given, *plot_img_on_surf* projects the\n# images onto `FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_\\'s\n# fsaverage5.\n\nplotting.plot_img_on_surf(stat_img,\n views=['lateral', 'medial'],\n hemispheres=['left', 'right'],\n colorbar=True)\nplotting.show()\n\n##############################################################################\n# 3D visualization in a web browser\n# ---------------------------------\n# An alternative to :func:`nilearn.plotting.plot_surf_stat_map` is to use\n# :func:`nilearn.plotting.view_surf` or\n# :func:`nilearn.plotting.view_img_on_surf` that give more interactive\n# visualizations in a web browser. See :ref:`interactive-surface-plotting` for\n# more details.\n\nview = plotting.view_surf(fsaverage.infl_right, texture, threshold='90%',\n bg_map=fsaverage.sulc_right)\n\n# In a Jupyter notebook, if ``view`` is the output of a cell, it will\n# be displayed below the cell\nview\n\n##############################################################################\n\n# uncomment this to open the plot in a web browser:\n# view.open_in_browser()\n\n##############################################################################\n# We don't need to do the projection ourselves, we can use view_img_on_surf:\n\nview = plotting.view_img_on_surf(stat_img, threshold='90%')\n# view.open_in_browser()\n\nview\n\n##############################################################################\n# Impact of plot parameters on visualization\n# ------------------------------------------\n# You can specify arguments to be passed on to the function\n# :func:`nilearn.plotting.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n# fine-grained control of how the input 3D image is resampled and interpolated -\n# for example if you are viewing a volumetric atlas, you would want to avoid\n# averaging the labels between neighboring regions. Using nearest-neighbor\n# interpolation with zero radius will achieve this.\n\ndestrieux = datasets.fetch_atlas_destrieux_2009()\n\nview = plotting.view_img_on_surf(\n destrieux.maps,\n surf_mesh=\"fsaverage\",\n vol_to_surf_kwargs={\"n_samples\": 1, \"radius\": 0.0, \"interpolation\": \"nearest\"},\n symmetric_cmap=False,\n)\n\n# view.open_in_browser()\nview\n", "path": "examples/01_plotting/plot_3d_map_to_surface_projection.py"}], "after_files": [{"content": "\"\"\"\nMaking a surface plot of a 3D statistical map\n=============================================\n\nproject a 3D statistical map onto a cortical mesh using\n:func:`nilearn.surface.vol_to_surf`. Display a surface plot of the projected\nmap using :func:`nilearn.plotting.plot_surf_stat_map` and adding contours of\nregions of interest using :func:`nilearn.plotting.plot_surf_contours`.\n\n\"\"\"\n\n##############################################################################\n# Get a statistical map\n# ---------------------\n\nfrom nilearn import datasets\n\nmotor_images = datasets.fetch_neurovault_motor_task()\nstat_img = motor_images.images[0]\n\n\n##############################################################################\n# Get a cortical mesh\n# -------------------\n\nfsaverage = datasets.fetch_surf_fsaverage()\n\n##############################################################################\n# Sample the 3D data around each node of the mesh\n# -----------------------------------------------\n\nfrom nilearn import surface\n\ntexture = surface.vol_to_surf(stat_img, fsaverage.pial_right)\n\n##############################################################################\n# Plot the result\n# ---------------\n\nfrom nilearn import plotting\n\nplotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere', colorbar=True,\n threshold=1., bg_map=fsaverage.sulc_right)\n\n##############################################################################\n# Plot 3D image for comparison\n# ----------------------------\n\nplotting.plot_glass_brain(stat_img, display_mode='r', plot_abs=False,\n title='Glass brain', threshold=2.)\n\nplotting.plot_stat_map(stat_img, display_mode='x', threshold=1.,\n cut_coords=range(0, 51, 10), title='Slices')\n\n##############################################################################\n# Use an atlas and choose regions to outline\n# ------------------------------------------\n\nimport numpy as np\n\ndestrieux_atlas = datasets.fetch_atlas_surf_destrieux()\nparcellation = destrieux_atlas['map_right']\n\n# these are the regions we want to outline\nregions_dict = {b'G_postcentral': 'Postcentral gyrus',\n b'G_precentral': 'Precentral gyrus'}\n\n# get indices in atlas for these labels\nregions_indices = [np.where(np.array(destrieux_atlas['labels']) == region)[0][0]\n for region in regions_dict]\n\nlabels = list(regions_dict.values())\n\n##############################################################################\n# Display outlines of the regions of interest on top of a statistical map\n# -----------------------------------------------------------------------\n\nfigure = plotting.plot_surf_stat_map(fsaverage.infl_right, texture, hemi='right',\n title='Surface right hemisphere',\n colorbar=True, threshold=1.,\n bg_map=fsaverage.sulc_right)\n\nplotting.plot_surf_contours(fsaverage.infl_right, parcellation, labels=labels,\n levels=regions_indices, figure=figure, legend=True,\n colors=['g', 'k'])\nplotting.show()\n\n##############################################################################\n# Plot with higher-resolution mesh\n# --------------------------------\n#\n# `fetch_surf_fsaverage` takes a \"mesh\" argument which specifies\n# wether to fetch the low-resolution fsaverage5 mesh, or the high-resolution\n# fsaverage mesh. using mesh=\"fsaverage\" will result in more memory usage and\n# computation time, but finer visualizations.\n\nbig_fsaverage = datasets.fetch_surf_fsaverage('fsaverage')\nbig_texture = surface.vol_to_surf(stat_img, big_fsaverage.pial_right)\n\nplotting.plot_surf_stat_map(big_fsaverage.infl_right,\n big_texture, hemi='right', colorbar=True,\n title='Surface right hemisphere: fine mesh',\n threshold=1., bg_map=big_fsaverage.sulc_right)\n\n\n##############################################################################\n# Plot multiple views of the 3D volume on a surface\n# -------------------------------------------------\n#\n# *plot_img_on_surf* takes a statistical map and projects it onto a surface.\n# It supports multiple choices of orientations, and can plot either one or both\n# hemispheres. If no *surf_mesh* is given, *plot_img_on_surf* projects the\n# images onto `FreeSurfer <https://surfer.nmr.mgh.harvard.edu/>`_\\'s\n# fsaverage5.\n\nplotting.plot_img_on_surf(stat_img,\n views=['lateral', 'medial'],\n hemispheres=['left', 'right'],\n colorbar=True)\nplotting.show()\n\n##############################################################################\n# 3D visualization in a web browser\n# ---------------------------------\n# An alternative to :func:`nilearn.plotting.plot_surf_stat_map` is to use\n# :func:`nilearn.plotting.view_surf` or\n# :func:`nilearn.plotting.view_img_on_surf` that give more interactive\n# visualizations in a web browser. See :ref:`interactive-surface-plotting` for\n# more details.\n\nview = plotting.view_surf(fsaverage.infl_right, texture, threshold='90%',\n bg_map=fsaverage.sulc_right)\n\n# In a Jupyter notebook, if ``view`` is the output of a cell, it will\n# be displayed below the cell\nview\n\n##############################################################################\n\n# uncomment this to open the plot in a web browser:\n# view.open_in_browser()\n\n##############################################################################\n# We don't need to do the projection ourselves, we can use view_img_on_surf:\n\nview = plotting.view_img_on_surf(stat_img, threshold='90%')\n# view.open_in_browser()\n\nview\n\n##############################################################################\n# Impact of plot parameters on visualization\n# ------------------------------------------\n# You can specify arguments to be passed on to the function\n# :func:`nilearn.surface.vol_to_surf` using `vol_to_surf_kwargs`. This allows\n# fine-grained control of how the input 3D image is resampled and interpolated -\n# for example if you are viewing a volumetric atlas, you would want to avoid\n# averaging the labels between neighboring regions. Using nearest-neighbor\n# interpolation with zero radius will achieve this.\n\ndestrieux = datasets.fetch_atlas_destrieux_2009()\n\nview = plotting.view_img_on_surf(\n destrieux.maps,\n surf_mesh=\"fsaverage\",\n vol_to_surf_kwargs={\"n_samples\": 1, \"radius\": 0.0, \"interpolation\": \"nearest\"},\n symmetric_cmap=False,\n)\n\n# view.open_in_browser()\nview\n", "path": "examples/01_plotting/plot_3d_map_to_surface_projection.py"}]}
| 2,038 | 210 |
gh_patches_debug_7128
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-2419
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dynamic challenges do not show a Next Challenge
<!--
If this is a bug report please fill out the template below.
If this is a feature request please describe the behavior that you'd like to see.
-->
**Environment**:
- CTFd Version/Commit: 3.6.0/8ead306f8b57c059192cd8b137f37ee41a078a41
- Operating System: All
- Web Browser and Version: All
**What happened?**
TLDR: *dynamic* challenges do not serve `next_id` to the frontend.
**How to reproduce your issue**
1. I created two challenges A and B with dynamic scoring.
2. I opened the admin configuration for challenge A.
3. I clicked "Next"
4. I selected challenge B from the dropdown.
5. I clicked the "Save" button.
6. The input field is empty.
**What did you expect to happen?**
The input field shows "Challenge B".
**Any associated stack traces or error logs**
The issue arises from the lack of `next_id` field in API responses for dynamic challenges [here](https://github.com/CTFd/CTFd/blob/8ead306f8b57c059192cd8b137f37ee41a078a41/CTFd/plugins/dynamic_challenges/__init__.py#L60-L89).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/plugins/dynamic_challenges/__init__.py`
Content:
```
1 from flask import Blueprint
2
3 from CTFd.models import Challenges, db
4 from CTFd.plugins import register_plugin_assets_directory
5 from CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge
6 from CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic
7 from CTFd.plugins.migrations import upgrade
8
9
10 class DynamicChallenge(Challenges):
11 __mapper_args__ = {"polymorphic_identity": "dynamic"}
12 id = db.Column(
13 db.Integer, db.ForeignKey("challenges.id", ondelete="CASCADE"), primary_key=True
14 )
15 initial = db.Column(db.Integer, default=0)
16 minimum = db.Column(db.Integer, default=0)
17 decay = db.Column(db.Integer, default=0)
18 function = db.Column(db.String(32), default="logarithmic")
19
20 def __init__(self, *args, **kwargs):
21 super(DynamicChallenge, self).__init__(**kwargs)
22 self.value = kwargs["initial"]
23
24
25 class DynamicValueChallenge(BaseChallenge):
26 id = "dynamic" # Unique identifier used to register challenges
27 name = "dynamic" # Name of a challenge type
28 templates = (
29 { # Handlebars templates used for each aspect of challenge editing & viewing
30 "create": "/plugins/dynamic_challenges/assets/create.html",
31 "update": "/plugins/dynamic_challenges/assets/update.html",
32 "view": "/plugins/dynamic_challenges/assets/view.html",
33 }
34 )
35 scripts = { # Scripts that are loaded when a template is loaded
36 "create": "/plugins/dynamic_challenges/assets/create.js",
37 "update": "/plugins/dynamic_challenges/assets/update.js",
38 "view": "/plugins/dynamic_challenges/assets/view.js",
39 }
40 # Route at which files are accessible. This must be registered using register_plugin_assets_directory()
41 route = "/plugins/dynamic_challenges/assets/"
42 # Blueprint used to access the static_folder directory.
43 blueprint = Blueprint(
44 "dynamic_challenges",
45 __name__,
46 template_folder="templates",
47 static_folder="assets",
48 )
49 challenge_model = DynamicChallenge
50
51 @classmethod
52 def calculate_value(cls, challenge):
53 f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)
54 value = f(challenge)
55
56 challenge.value = value
57 db.session.commit()
58 return challenge
59
60 @classmethod
61 def read(cls, challenge):
62 """
63 This method is in used to access the data of a challenge in a format processable by the front end.
64
65 :param challenge:
66 :return: Challenge object, data dictionary to be returned to the user
67 """
68 challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()
69 data = {
70 "id": challenge.id,
71 "name": challenge.name,
72 "value": challenge.value,
73 "initial": challenge.initial,
74 "decay": challenge.decay,
75 "minimum": challenge.minimum,
76 "description": challenge.description,
77 "connection_info": challenge.connection_info,
78 "category": challenge.category,
79 "state": challenge.state,
80 "max_attempts": challenge.max_attempts,
81 "type": challenge.type,
82 "type_data": {
83 "id": cls.id,
84 "name": cls.name,
85 "templates": cls.templates,
86 "scripts": cls.scripts,
87 },
88 }
89 return data
90
91 @classmethod
92 def update(cls, challenge, request):
93 """
94 This method is used to update the information associated with a challenge. This should be kept strictly to the
95 Challenges table and any child tables.
96
97 :param challenge:
98 :param request:
99 :return:
100 """
101 data = request.form or request.get_json()
102
103 for attr, value in data.items():
104 # We need to set these to floats so that the next operations don't operate on strings
105 if attr in ("initial", "minimum", "decay"):
106 value = float(value)
107 setattr(challenge, attr, value)
108
109 return DynamicValueChallenge.calculate_value(challenge)
110
111 @classmethod
112 def solve(cls, user, team, challenge, request):
113 super().solve(user, team, challenge, request)
114
115 DynamicValueChallenge.calculate_value(challenge)
116
117
118 def load(app):
119 upgrade(plugin_name="dynamic_challenges")
120 CHALLENGE_CLASSES["dynamic"] = DynamicValueChallenge
121 register_plugin_assets_directory(
122 app, base_path="/plugins/dynamic_challenges/assets/"
123 )
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py
--- a/CTFd/plugins/dynamic_challenges/__init__.py
+++ b/CTFd/plugins/dynamic_challenges/__init__.py
@@ -75,6 +75,7 @@
"minimum": challenge.minimum,
"description": challenge.description,
"connection_info": challenge.connection_info,
+ "next_id": challenge.next_id,
"category": challenge.category,
"state": challenge.state,
"max_attempts": challenge.max_attempts,
|
{"golden_diff": "diff --git a/CTFd/plugins/dynamic_challenges/__init__.py b/CTFd/plugins/dynamic_challenges/__init__.py\n--- a/CTFd/plugins/dynamic_challenges/__init__.py\n+++ b/CTFd/plugins/dynamic_challenges/__init__.py\n@@ -75,6 +75,7 @@\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n+ \"next_id\": challenge.next_id,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n", "issue": "Dynamic challenges do not show a Next Challenge\n<!--\r\nIf this is a bug report please fill out the template below.\r\n\r\nIf this is a feature request please describe the behavior that you'd like to see.\r\n-->\r\n\r\n**Environment**:\r\n\r\n- CTFd Version/Commit: 3.6.0/8ead306f8b57c059192cd8b137f37ee41a078a41\r\n- Operating System: All\r\n- Web Browser and Version: All\r\n\r\n**What happened?**\r\n\r\nTLDR: *dynamic* challenges do not serve `next_id` to the frontend.\r\n\r\n**How to reproduce your issue**\r\n\r\n1. I created two challenges A and B with dynamic scoring.\r\n2. I opened the admin configuration for challenge A.\r\n3. I clicked \"Next\"\r\n4. I selected challenge B from the dropdown.\r\n5. I clicked the \"Save\" button.\r\n6. The input field is empty.\r\n\r\n**What did you expect to happen?**\r\n\r\nThe input field shows \"Challenge B\".\r\n\r\n**Any associated stack traces or error logs**\r\n\r\nThe issue arises from the lack of `next_id` field in API responses for dynamic challenges [here](https://github.com/CTFd/CTFd/blob/8ead306f8b57c059192cd8b137f37ee41a078a41/CTFd/plugins/dynamic_challenges/__init__.py#L60-L89).\r\n\n", "before_files": [{"content": "from flask import Blueprint\n\nfrom CTFd.models import Challenges, db\nfrom CTFd.plugins import register_plugin_assets_directory\nfrom CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge\nfrom CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic\nfrom CTFd.plugins.migrations import upgrade\n\n\nclass DynamicChallenge(Challenges):\n __mapper_args__ = {\"polymorphic_identity\": \"dynamic\"}\n id = db.Column(\n db.Integer, db.ForeignKey(\"challenges.id\", ondelete=\"CASCADE\"), primary_key=True\n )\n initial = db.Column(db.Integer, default=0)\n minimum = db.Column(db.Integer, default=0)\n decay = db.Column(db.Integer, default=0)\n function = db.Column(db.String(32), default=\"logarithmic\")\n\n def __init__(self, *args, **kwargs):\n super(DynamicChallenge, self).__init__(**kwargs)\n self.value = kwargs[\"initial\"]\n\n\nclass DynamicValueChallenge(BaseChallenge):\n id = \"dynamic\" # Unique identifier used to register challenges\n name = \"dynamic\" # Name of a challenge type\n templates = (\n { # Handlebars templates used for each aspect of challenge editing & viewing\n \"create\": \"/plugins/dynamic_challenges/assets/create.html\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.html\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.html\",\n }\n )\n scripts = { # Scripts that are loaded when a template is loaded\n \"create\": \"/plugins/dynamic_challenges/assets/create.js\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.js\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.js\",\n }\n # Route at which files are accessible. This must be registered using register_plugin_assets_directory()\n route = \"/plugins/dynamic_challenges/assets/\"\n # Blueprint used to access the static_folder directory.\n blueprint = Blueprint(\n \"dynamic_challenges\",\n __name__,\n template_folder=\"templates\",\n static_folder=\"assets\",\n )\n challenge_model = DynamicChallenge\n\n @classmethod\n def calculate_value(cls, challenge):\n f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)\n value = f(challenge)\n\n challenge.value = value\n db.session.commit()\n return challenge\n\n @classmethod\n def read(cls, challenge):\n \"\"\"\n This method is in used to access the data of a challenge in a format processable by the front end.\n\n :param challenge:\n :return: Challenge object, data dictionary to be returned to the user\n \"\"\"\n challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()\n data = {\n \"id\": challenge.id,\n \"name\": challenge.name,\n \"value\": challenge.value,\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n \"type\": challenge.type,\n \"type_data\": {\n \"id\": cls.id,\n \"name\": cls.name,\n \"templates\": cls.templates,\n \"scripts\": cls.scripts,\n },\n }\n return data\n\n @classmethod\n def update(cls, challenge, request):\n \"\"\"\n This method is used to update the information associated with a challenge. This should be kept strictly to the\n Challenges table and any child tables.\n\n :param challenge:\n :param request:\n :return:\n \"\"\"\n data = request.form or request.get_json()\n\n for attr, value in data.items():\n # We need to set these to floats so that the next operations don't operate on strings\n if attr in (\"initial\", \"minimum\", \"decay\"):\n value = float(value)\n setattr(challenge, attr, value)\n\n return DynamicValueChallenge.calculate_value(challenge)\n\n @classmethod\n def solve(cls, user, team, challenge, request):\n super().solve(user, team, challenge, request)\n\n DynamicValueChallenge.calculate_value(challenge)\n\n\ndef load(app):\n upgrade(plugin_name=\"dynamic_challenges\")\n CHALLENGE_CLASSES[\"dynamic\"] = DynamicValueChallenge\n register_plugin_assets_directory(\n app, base_path=\"/plugins/dynamic_challenges/assets/\"\n )\n", "path": "CTFd/plugins/dynamic_challenges/__init__.py"}], "after_files": [{"content": "from flask import Blueprint\n\nfrom CTFd.models import Challenges, db\nfrom CTFd.plugins import register_plugin_assets_directory\nfrom CTFd.plugins.challenges import CHALLENGE_CLASSES, BaseChallenge\nfrom CTFd.plugins.dynamic_challenges.decay import DECAY_FUNCTIONS, logarithmic\nfrom CTFd.plugins.migrations import upgrade\n\n\nclass DynamicChallenge(Challenges):\n __mapper_args__ = {\"polymorphic_identity\": \"dynamic\"}\n id = db.Column(\n db.Integer, db.ForeignKey(\"challenges.id\", ondelete=\"CASCADE\"), primary_key=True\n )\n initial = db.Column(db.Integer, default=0)\n minimum = db.Column(db.Integer, default=0)\n decay = db.Column(db.Integer, default=0)\n function = db.Column(db.String(32), default=\"logarithmic\")\n\n def __init__(self, *args, **kwargs):\n super(DynamicChallenge, self).__init__(**kwargs)\n self.value = kwargs[\"initial\"]\n\n\nclass DynamicValueChallenge(BaseChallenge):\n id = \"dynamic\" # Unique identifier used to register challenges\n name = \"dynamic\" # Name of a challenge type\n templates = (\n { # Handlebars templates used for each aspect of challenge editing & viewing\n \"create\": \"/plugins/dynamic_challenges/assets/create.html\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.html\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.html\",\n }\n )\n scripts = { # Scripts that are loaded when a template is loaded\n \"create\": \"/plugins/dynamic_challenges/assets/create.js\",\n \"update\": \"/plugins/dynamic_challenges/assets/update.js\",\n \"view\": \"/plugins/dynamic_challenges/assets/view.js\",\n }\n # Route at which files are accessible. This must be registered using register_plugin_assets_directory()\n route = \"/plugins/dynamic_challenges/assets/\"\n # Blueprint used to access the static_folder directory.\n blueprint = Blueprint(\n \"dynamic_challenges\",\n __name__,\n template_folder=\"templates\",\n static_folder=\"assets\",\n )\n challenge_model = DynamicChallenge\n\n @classmethod\n def calculate_value(cls, challenge):\n f = DECAY_FUNCTIONS.get(challenge.function, logarithmic)\n value = f(challenge)\n\n challenge.value = value\n db.session.commit()\n return challenge\n\n @classmethod\n def read(cls, challenge):\n \"\"\"\n This method is in used to access the data of a challenge in a format processable by the front end.\n\n :param challenge:\n :return: Challenge object, data dictionary to be returned to the user\n \"\"\"\n challenge = DynamicChallenge.query.filter_by(id=challenge.id).first()\n data = {\n \"id\": challenge.id,\n \"name\": challenge.name,\n \"value\": challenge.value,\n \"initial\": challenge.initial,\n \"decay\": challenge.decay,\n \"minimum\": challenge.minimum,\n \"description\": challenge.description,\n \"connection_info\": challenge.connection_info,\n \"next_id\": challenge.next_id,\n \"category\": challenge.category,\n \"state\": challenge.state,\n \"max_attempts\": challenge.max_attempts,\n \"type\": challenge.type,\n \"type_data\": {\n \"id\": cls.id,\n \"name\": cls.name,\n \"templates\": cls.templates,\n \"scripts\": cls.scripts,\n },\n }\n return data\n\n @classmethod\n def update(cls, challenge, request):\n \"\"\"\n This method is used to update the information associated with a challenge. This should be kept strictly to the\n Challenges table and any child tables.\n\n :param challenge:\n :param request:\n :return:\n \"\"\"\n data = request.form or request.get_json()\n\n for attr, value in data.items():\n # We need to set these to floats so that the next operations don't operate on strings\n if attr in (\"initial\", \"minimum\", \"decay\"):\n value = float(value)\n setattr(challenge, attr, value)\n\n return DynamicValueChallenge.calculate_value(challenge)\n\n @classmethod\n def solve(cls, user, team, challenge, request):\n super().solve(user, team, challenge, request)\n\n DynamicValueChallenge.calculate_value(challenge)\n\n\ndef load(app):\n upgrade(plugin_name=\"dynamic_challenges\")\n CHALLENGE_CLASSES[\"dynamic\"] = DynamicValueChallenge\n register_plugin_assets_directory(\n app, base_path=\"/plugins/dynamic_challenges/assets/\"\n )\n", "path": "CTFd/plugins/dynamic_challenges/__init__.py"}]}
| 1,799 | 128 |
gh_patches_debug_64222
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-1313
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HTTP_PROXY variable with username and empty password not supported
Scrapy doesn't support proxy authentication when the password is empty when using the HTTP_PROXY environment variable to supply the proxy argument.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/downloadermiddlewares/httpproxy.py`
Content:
```
1 import base64
2 from six.moves.urllib.request import getproxies, proxy_bypass
3 from six.moves.urllib.parse import unquote
4 try:
5 from urllib2 import _parse_proxy
6 except ImportError:
7 from urllib.request import _parse_proxy
8 from six.moves.urllib.parse import urlunparse
9
10 from scrapy.utils.httpobj import urlparse_cached
11 from scrapy.exceptions import NotConfigured
12
13
14 class HttpProxyMiddleware(object):
15
16 def __init__(self):
17 self.proxies = {}
18 for type, url in getproxies().items():
19 self.proxies[type] = self._get_proxy(url, type)
20
21 if not self.proxies:
22 raise NotConfigured
23
24 def _get_proxy(self, url, orig_type):
25 proxy_type, user, password, hostport = _parse_proxy(url)
26 proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
27
28 if user and password:
29 user_pass = '%s:%s' % (unquote(user), unquote(password))
30 creds = base64.b64encode(user_pass).strip()
31 else:
32 creds = None
33
34 return creds, proxy_url
35
36 def process_request(self, request, spider):
37 # ignore if proxy is already seted
38 if 'proxy' in request.meta:
39 return
40
41 parsed = urlparse_cached(request)
42 scheme = parsed.scheme
43
44 # 'no_proxy' is only supported by http schemes
45 if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):
46 return
47
48 if scheme in self.proxies:
49 self._set_proxy(request, scheme)
50
51 def _set_proxy(self, request, scheme):
52 creds, proxy = self.proxies[scheme]
53 request.meta['proxy'] = proxy
54 if creds:
55 request.headers['Proxy-Authorization'] = 'Basic ' + creds
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/downloadermiddlewares/httpproxy.py b/scrapy/downloadermiddlewares/httpproxy.py
--- a/scrapy/downloadermiddlewares/httpproxy.py
+++ b/scrapy/downloadermiddlewares/httpproxy.py
@@ -25,7 +25,7 @@
proxy_type, user, password, hostport = _parse_proxy(url)
proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))
- if user and password:
+ if user:
user_pass = '%s:%s' % (unquote(user), unquote(password))
creds = base64.b64encode(user_pass).strip()
else:
|
{"golden_diff": "diff --git a/scrapy/downloadermiddlewares/httpproxy.py b/scrapy/downloadermiddlewares/httpproxy.py\n--- a/scrapy/downloadermiddlewares/httpproxy.py\n+++ b/scrapy/downloadermiddlewares/httpproxy.py\n@@ -25,7 +25,7 @@\n proxy_type, user, password, hostport = _parse_proxy(url)\n proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))\n \n- if user and password:\n+ if user:\n user_pass = '%s:%s' % (unquote(user), unquote(password))\n creds = base64.b64encode(user_pass).strip()\n else:\n", "issue": "HTTP_PROXY variable with username and empty password not supported\nScrapy doesn't support proxy authentication when the password is empty when using the HTTP_PROXY environment variable to supply the proxy argument.\n\n", "before_files": [{"content": "import base64\nfrom six.moves.urllib.request import getproxies, proxy_bypass\nfrom six.moves.urllib.parse import unquote\ntry:\n from urllib2 import _parse_proxy\nexcept ImportError:\n from urllib.request import _parse_proxy\nfrom six.moves.urllib.parse import urlunparse\n\nfrom scrapy.utils.httpobj import urlparse_cached\nfrom scrapy.exceptions import NotConfigured\n\n\nclass HttpProxyMiddleware(object):\n\n def __init__(self):\n self.proxies = {}\n for type, url in getproxies().items():\n self.proxies[type] = self._get_proxy(url, type)\n\n if not self.proxies:\n raise NotConfigured\n\n def _get_proxy(self, url, orig_type):\n proxy_type, user, password, hostport = _parse_proxy(url)\n proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))\n\n if user and password:\n user_pass = '%s:%s' % (unquote(user), unquote(password))\n creds = base64.b64encode(user_pass).strip()\n else:\n creds = None\n\n return creds, proxy_url\n\n def process_request(self, request, spider):\n # ignore if proxy is already seted\n if 'proxy' in request.meta:\n return\n\n parsed = urlparse_cached(request)\n scheme = parsed.scheme\n\n # 'no_proxy' is only supported by http schemes\n if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):\n return\n\n if scheme in self.proxies:\n self._set_proxy(request, scheme)\n\n def _set_proxy(self, request, scheme):\n creds, proxy = self.proxies[scheme]\n request.meta['proxy'] = proxy\n if creds:\n request.headers['Proxy-Authorization'] = 'Basic ' + creds\n", "path": "scrapy/downloadermiddlewares/httpproxy.py"}], "after_files": [{"content": "import base64\nfrom six.moves.urllib.request import getproxies, proxy_bypass\nfrom six.moves.urllib.parse import unquote\ntry:\n from urllib2 import _parse_proxy\nexcept ImportError:\n from urllib.request import _parse_proxy\nfrom six.moves.urllib.parse import urlunparse\n\nfrom scrapy.utils.httpobj import urlparse_cached\nfrom scrapy.exceptions import NotConfigured\n\n\nclass HttpProxyMiddleware(object):\n\n def __init__(self):\n self.proxies = {}\n for type, url in getproxies().items():\n self.proxies[type] = self._get_proxy(url, type)\n\n if not self.proxies:\n raise NotConfigured\n\n def _get_proxy(self, url, orig_type):\n proxy_type, user, password, hostport = _parse_proxy(url)\n proxy_url = urlunparse((proxy_type or orig_type, hostport, '', '', '', ''))\n\n if user:\n user_pass = '%s:%s' % (unquote(user), unquote(password))\n creds = base64.b64encode(user_pass).strip()\n else:\n creds = None\n\n return creds, proxy_url\n\n def process_request(self, request, spider):\n # ignore if proxy is already seted\n if 'proxy' in request.meta:\n return\n\n parsed = urlparse_cached(request)\n scheme = parsed.scheme\n\n # 'no_proxy' is only supported by http schemes\n if scheme in ('http', 'https') and proxy_bypass(parsed.hostname):\n return\n\n if scheme in self.proxies:\n self._set_proxy(request, scheme)\n\n def _set_proxy(self, request, scheme):\n creds, proxy = self.proxies[scheme]\n request.meta['proxy'] = proxy\n if creds:\n request.headers['Proxy-Authorization'] = 'Basic ' + creds\n", "path": "scrapy/downloadermiddlewares/httpproxy.py"}]}
| 808 | 156 |
gh_patches_debug_21249
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-3439
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API/DOCS: newer correlation tools are missing in api and docs
`stats.api` and http://www.statsmodels.org/dev/stats.html#moment-helpers
only shows the original functions, not those added by Kerby
(I'm trying to figure out where we should put new correlation and covariance function, hypothesis tests, robust, regularized covariance and correlation.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `statsmodels/stats/api.py`
Content:
```
1 # pylint: disable=W0611
2 from . import diagnostic
3 from .diagnostic import (
4 acorr_ljungbox, acorr_breusch_godfrey,
5 CompareCox, compare_cox, CompareJ, compare_j,
6 HetGoldfeldQuandt, het_goldfeldquandt,
7 het_breuschpagan, het_white, het_arch,
8 linear_harvey_collier, linear_rainbow, linear_lm,
9 breaks_cusumolsresid, breaks_hansen, recursive_olsresiduals,
10 unitroot_adf,
11 normal_ad, lilliefors,
12 # deprecated because of misspelling:
13 lillifors, het_breushpagan, acorr_breush_godfrey
14 )
15
16 from . import multicomp
17 from .multitest import (multipletests, fdrcorrection, fdrcorrection_twostage)
18 from .multicomp import tukeyhsd
19 from . import gof
20 from .gof import (powerdiscrepancy, gof_chisquare_discrete,
21 chisquare_effectsize)
22 from . import stattools
23 from .stattools import durbin_watson, omni_normtest, jarque_bera
24
25 from . import sandwich_covariance
26 from .sandwich_covariance import (
27 cov_cluster, cov_cluster_2groups, cov_nw_panel,
28 cov_hac, cov_white_simple,
29 cov_hc0, cov_hc1, cov_hc2, cov_hc3,
30 se_cov
31 )
32
33 from .weightstats import (DescrStatsW, CompareMeans, ttest_ind, ttost_ind,
34 ttost_paired, ztest, ztost, zconfint)
35
36 from .proportion import (binom_test_reject_interval, binom_test,
37 binom_tost, binom_tost_reject_interval,
38 power_binom_tost, power_ztost_prop,
39 proportion_confint, proportion_effectsize,
40 proportions_chisquare, proportions_chisquare_allpairs,
41 proportions_chisquare_pairscontrol, proportions_ztest,
42 proportions_ztost)
43
44 from .power import (TTestPower, TTestIndPower, GofChisquarePower,
45 NormalIndPower, FTestAnovaPower, FTestPower,
46 tt_solve_power, tt_ind_solve_power, zt_ind_solve_power)
47
48 from .descriptivestats import Describe
49
50 from .anova import anova_lm
51
52 from . import moment_helpers
53 from .correlation_tools import corr_nearest, corr_clipped, cov_nearest
54
55 from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)
56
57 from statsmodels.stats.contingency_tables import (mcnemar, cochrans_q,
58 SquareTable,
59 Table2x2,
60 Table,
61 StratifiedTable)
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/statsmodels/stats/api.py b/statsmodels/stats/api.py
--- a/statsmodels/stats/api.py
+++ b/statsmodels/stats/api.py
@@ -39,7 +39,7 @@
proportion_confint, proportion_effectsize,
proportions_chisquare, proportions_chisquare_allpairs,
proportions_chisquare_pairscontrol, proportions_ztest,
- proportions_ztost)
+ proportions_ztost, multinomial_proportions_confint)
from .power import (TTestPower, TTestIndPower, GofChisquarePower,
NormalIndPower, FTestAnovaPower, FTestPower,
@@ -50,7 +50,9 @@
from .anova import anova_lm
from . import moment_helpers
-from .correlation_tools import corr_nearest, corr_clipped, cov_nearest
+from .correlation_tools import (corr_clipped, corr_nearest,
+ corr_nearest_factor, corr_thresholded, cov_nearest,
+ cov_nearest_factor_homog, FactoredPSDMatrix)
from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)
|
{"golden_diff": "diff --git a/statsmodels/stats/api.py b/statsmodels/stats/api.py\n--- a/statsmodels/stats/api.py\n+++ b/statsmodels/stats/api.py\n@@ -39,7 +39,7 @@\n proportion_confint, proportion_effectsize,\n proportions_chisquare, proportions_chisquare_allpairs,\n proportions_chisquare_pairscontrol, proportions_ztest,\n- proportions_ztost)\n+ proportions_ztost, multinomial_proportions_confint)\n \n from .power import (TTestPower, TTestIndPower, GofChisquarePower,\n NormalIndPower, FTestAnovaPower, FTestPower,\n@@ -50,7 +50,9 @@\n from .anova import anova_lm\n \n from . import moment_helpers\n-from .correlation_tools import corr_nearest, corr_clipped, cov_nearest\n+from .correlation_tools import (corr_clipped, corr_nearest,\n+ corr_nearest_factor, corr_thresholded, cov_nearest,\n+ cov_nearest_factor_homog, FactoredPSDMatrix)\n \n from statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)\n", "issue": "API/DOCS: newer correlation tools are missing in api and docs\n`stats.api` and http://www.statsmodels.org/dev/stats.html#moment-helpers\nonly shows the original functions, not those added by Kerby\n\n(I'm trying to figure out where we should put new correlation and covariance function, hypothesis tests, robust, regularized covariance and correlation.)\n\n", "before_files": [{"content": "# pylint: disable=W0611\nfrom . import diagnostic\nfrom .diagnostic import (\n acorr_ljungbox, acorr_breusch_godfrey,\n CompareCox, compare_cox, CompareJ, compare_j,\n HetGoldfeldQuandt, het_goldfeldquandt,\n het_breuschpagan, het_white, het_arch,\n linear_harvey_collier, linear_rainbow, linear_lm,\n breaks_cusumolsresid, breaks_hansen, recursive_olsresiduals,\n unitroot_adf,\n normal_ad, lilliefors,\n # deprecated because of misspelling:\n lillifors, het_breushpagan, acorr_breush_godfrey\n )\n\nfrom . import multicomp\nfrom .multitest import (multipletests, fdrcorrection, fdrcorrection_twostage)\nfrom .multicomp import tukeyhsd\nfrom . import gof\nfrom .gof import (powerdiscrepancy, gof_chisquare_discrete,\n chisquare_effectsize)\nfrom . import stattools\nfrom .stattools import durbin_watson, omni_normtest, jarque_bera\n\nfrom . import sandwich_covariance\nfrom .sandwich_covariance import (\n cov_cluster, cov_cluster_2groups, cov_nw_panel,\n cov_hac, cov_white_simple,\n cov_hc0, cov_hc1, cov_hc2, cov_hc3,\n se_cov\n )\n\nfrom .weightstats import (DescrStatsW, CompareMeans, ttest_ind, ttost_ind,\n ttost_paired, ztest, ztost, zconfint)\n\nfrom .proportion import (binom_test_reject_interval, binom_test,\n binom_tost, binom_tost_reject_interval,\n power_binom_tost, power_ztost_prop,\n proportion_confint, proportion_effectsize,\n proportions_chisquare, proportions_chisquare_allpairs,\n proportions_chisquare_pairscontrol, proportions_ztest,\n proportions_ztost)\n\nfrom .power import (TTestPower, TTestIndPower, GofChisquarePower,\n NormalIndPower, FTestAnovaPower, FTestPower,\n tt_solve_power, tt_ind_solve_power, zt_ind_solve_power)\n\nfrom .descriptivestats import Describe\n\nfrom .anova import anova_lm\n\nfrom . import moment_helpers\nfrom .correlation_tools import corr_nearest, corr_clipped, cov_nearest\n\nfrom statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)\n\nfrom statsmodels.stats.contingency_tables import (mcnemar, cochrans_q,\n SquareTable,\n Table2x2,\n Table,\n StratifiedTable)\n", "path": "statsmodels/stats/api.py"}], "after_files": [{"content": "# pylint: disable=W0611\nfrom . import diagnostic\nfrom .diagnostic import (\n acorr_ljungbox, acorr_breusch_godfrey,\n CompareCox, compare_cox, CompareJ, compare_j,\n HetGoldfeldQuandt, het_goldfeldquandt,\n het_breuschpagan, het_white, het_arch,\n linear_harvey_collier, linear_rainbow, linear_lm,\n breaks_cusumolsresid, breaks_hansen, recursive_olsresiduals,\n unitroot_adf,\n normal_ad, lilliefors,\n # deprecated because of misspelling:\n lillifors, het_breushpagan, acorr_breush_godfrey\n )\n\nfrom . import multicomp\nfrom .multitest import (multipletests, fdrcorrection, fdrcorrection_twostage)\nfrom .multicomp import tukeyhsd\nfrom . import gof\nfrom .gof import (powerdiscrepancy, gof_chisquare_discrete,\n chisquare_effectsize)\nfrom . import stattools\nfrom .stattools import durbin_watson, omni_normtest, jarque_bera\n\nfrom . import sandwich_covariance\nfrom .sandwich_covariance import (\n cov_cluster, cov_cluster_2groups, cov_nw_panel,\n cov_hac, cov_white_simple,\n cov_hc0, cov_hc1, cov_hc2, cov_hc3,\n se_cov\n )\n\nfrom .weightstats import (DescrStatsW, CompareMeans, ttest_ind, ttost_ind,\n ttost_paired, ztest, ztost, zconfint)\n\nfrom .proportion import (binom_test_reject_interval, binom_test,\n binom_tost, binom_tost_reject_interval,\n power_binom_tost, power_ztost_prop,\n proportion_confint, proportion_effectsize,\n proportions_chisquare, proportions_chisquare_allpairs,\n proportions_chisquare_pairscontrol, proportions_ztest,\n proportions_ztost, multinomial_proportions_confint)\n\nfrom .power import (TTestPower, TTestIndPower, GofChisquarePower,\n NormalIndPower, FTestAnovaPower, FTestPower,\n tt_solve_power, tt_ind_solve_power, zt_ind_solve_power)\n\nfrom .descriptivestats import Describe\n\nfrom .anova import anova_lm\n\nfrom . import moment_helpers\nfrom .correlation_tools import (corr_clipped, corr_nearest,\n corr_nearest_factor, corr_thresholded, cov_nearest,\n cov_nearest_factor_homog, FactoredPSDMatrix)\n\nfrom statsmodels.sandbox.stats.runs import (Runs, runstest_1samp, runstest_2samp)\n\nfrom statsmodels.stats.contingency_tables import (mcnemar, cochrans_q,\n SquareTable,\n Table2x2,\n Table,\n StratifiedTable)\n", "path": "statsmodels/stats/api.py"}]}
| 1,072 | 254 |
gh_patches_debug_12624
|
rasdani/github-patches
|
git_diff
|
secdev__scapy-2631
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use nextproto property instead of nextprotocol
This is just a checklist to guide you. You can remove it safely.
**Checklist:**
- [x ] If you are new to Scapy: I have checked <https://github.com/secdev/scapy/blob/master/CONTRIBUTING.md> (esp. section submitting-pull-requests)
- [ ] I squashed commits belonging together
- [ ] I added unit tests or explained why they are not relevant
- [ ] I executed the regression tests for Python2 and Python3 (using `tox` or, `cd test && ./run_tests_py2, cd test && ./run_tests_py3`)
- [ ] If the PR is still not finished, please create a [Draft Pull Request](https://github.blog/2019-02-14-introducing-draft-pull-requests/)
> brief description what this PR will do, e.g. fixes broken dissection of XXX
Fix wrong property in `bind_layers` function of NSH protocol. In the NSH class, it defines `nextproto` for next protocol property.
I changed from `nextprotocol` to `nextproto` in `bind_layers` functions.
> if required - short explanation why you fixed something in a way that may look more complicated as it actually is
> if required - outline impacts on other parts of the library
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scapy/contrib/nsh.py`
Content:
```
1 # This file is part of Scapy
2 # Scapy is free software: you can redistribute it and/or modify
3 # it under the terms of the GNU General Public License as published by
4 # the Free Software Foundation, either version 2 of the License, or
5 # any later version.
6 #
7 # Scapy is distributed in the hope that it will be useful,
8 # but WITHOUT ANY WARRANTY; without even the implied warranty of
9 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 # GNU General Public License for more details.
11 #
12 # You should have received a copy of the GNU General Public License
13 # along with Scapy. If not, see <http://www.gnu.org/licenses/>.
14
15 # scapy.contrib.description = Network Services Headers (NSH)
16 # scapy.contrib.status = loads
17
18 from scapy.all import bind_layers
19 from scapy.fields import BitField, ByteField, ByteEnumField, BitEnumField, \
20 ShortField, X3BytesField, XIntField, XStrFixedLenField, \
21 ConditionalField, PacketListField, BitFieldLenField
22 from scapy.layers.inet import Ether, IP
23 from scapy.layers.inet6 import IPv6
24 from scapy.layers.vxlan import VXLAN
25 from scapy.packet import Packet
26 from scapy.layers.l2 import GRE
27
28 from scapy.contrib.mpls import MPLS
29
30 #
31 # NSH Support
32 # https://www.rfc-editor.org/rfc/rfc8300.txt January 2018
33 #
34
35
36 class NSHTLV(Packet):
37 "NSH MD-type 2 - Variable Length Context Headers"
38 name = "NSHTLV"
39 fields_desc = [
40 ShortField('class', 0),
41 BitField('type', 0, 8),
42 BitField('reserved', 0, 1),
43 BitField('length', 0, 7),
44 PacketListField('metadata', None, XIntField, count_from='length')
45 ]
46
47
48 class NSH(Packet):
49 """Network Service Header.
50 NSH MD-type 1 if there is no ContextHeaders"""
51 name = "NSH"
52
53 fields_desc = [
54 BitField('ver', 0, 2),
55 BitField('oam', 0, 1),
56 BitField('unused1', 0, 1),
57 BitField('ttl', 63, 6),
58 BitFieldLenField('length', None, 6,
59 count_of='vlch',
60 adjust=lambda pkt, x: 6 if pkt.mdtype == 1
61 else x + 2),
62 BitField('unused2', 0, 4),
63 BitEnumField('mdtype', 1, 4, {0: 'Reserved MDType',
64 1: 'Fixed Length',
65 2: 'Variable Length',
66 0xF: 'Experimental MDType'}),
67 ByteEnumField('nextproto', 3, {1: 'IPv4',
68 2: 'IPv6',
69 3: 'Ethernet',
70 4: 'NSH',
71 5: 'MPLS',
72 0xFE: 'Experiment 1',
73 0xFF: 'Experiment 2'}),
74 X3BytesField('spi', 0),
75 ByteField('si', 0xFF),
76 ConditionalField(XStrFixedLenField("context_header", "", 16),
77 lambda pkt: pkt.mdtype == 1),
78 ConditionalField(PacketListField("vlch", None, NSHTLV,
79 count_from="length"),
80 lambda pkt: pkt.mdtype == 2)
81 ]
82
83 def mysummary(self):
84 return self.sprintf("SPI: %spi% - SI: %si%")
85
86
87 bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)
88 bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)
89 bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)
90
91 bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)
92 bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)
93 bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)
94 bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)
95 bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scapy/contrib/nsh.py b/scapy/contrib/nsh.py
--- a/scapy/contrib/nsh.py
+++ b/scapy/contrib/nsh.py
@@ -85,11 +85,11 @@
bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)
-bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)
+bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextproto': 4}, nextproto=4)
bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)
-bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)
-bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)
-bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)
-bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)
-bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)
+bind_layers(NSH, IP, nextproto=1)
+bind_layers(NSH, IPv6, nextproto=2)
+bind_layers(NSH, Ether, nextproto=3)
+bind_layers(NSH, NSH, nextproto=4)
+bind_layers(NSH, MPLS, nextproto=5)
|
{"golden_diff": "diff --git a/scapy/contrib/nsh.py b/scapy/contrib/nsh.py\n--- a/scapy/contrib/nsh.py\n+++ b/scapy/contrib/nsh.py\n@@ -85,11 +85,11 @@\n \n \n bind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)\n-bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)\n+bind_layers(VXLAN, NSH, {'flags': 0xC, 'nextproto': 4}, nextproto=4)\n bind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)\n \n-bind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)\n-bind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)\n-bind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)\n-bind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)\n-bind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)\n+bind_layers(NSH, IP, nextproto=1)\n+bind_layers(NSH, IPv6, nextproto=2)\n+bind_layers(NSH, Ether, nextproto=3)\n+bind_layers(NSH, NSH, nextproto=4)\n+bind_layers(NSH, MPLS, nextproto=5)\n", "issue": "Use nextproto property instead of nextprotocol\nThis is just a checklist to guide you. You can remove it safely.\r\n\r\n**Checklist:**\r\n\r\n- [x ] If you are new to Scapy: I have checked <https://github.com/secdev/scapy/blob/master/CONTRIBUTING.md> (esp. section submitting-pull-requests)\r\n- [ ] I squashed commits belonging together\r\n- [ ] I added unit tests or explained why they are not relevant\r\n- [ ] I executed the regression tests for Python2 and Python3 (using `tox` or, `cd test && ./run_tests_py2, cd test && ./run_tests_py3`)\r\n- [ ] If the PR is still not finished, please create a [Draft Pull Request](https://github.blog/2019-02-14-introducing-draft-pull-requests/)\r\n\r\n> brief description what this PR will do, e.g. fixes broken dissection of XXX\r\nFix wrong property in `bind_layers` function of NSH protocol. In the NSH class, it defines `nextproto` for next protocol property. \r\n\r\nI changed from `nextprotocol` to `nextproto` in `bind_layers` functions.\r\n\r\n> if required - short explanation why you fixed something in a way that may look more complicated as it actually is\r\n\r\n> if required - outline impacts on other parts of the library\r\n\n", "before_files": [{"content": "# This file is part of Scapy\n# Scapy is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# any later version.\n#\n# Scapy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Scapy. If not, see <http://www.gnu.org/licenses/>.\n\n# scapy.contrib.description = Network Services Headers (NSH)\n# scapy.contrib.status = loads\n\nfrom scapy.all import bind_layers\nfrom scapy.fields import BitField, ByteField, ByteEnumField, BitEnumField, \\\n ShortField, X3BytesField, XIntField, XStrFixedLenField, \\\n ConditionalField, PacketListField, BitFieldLenField\nfrom scapy.layers.inet import Ether, IP\nfrom scapy.layers.inet6 import IPv6\nfrom scapy.layers.vxlan import VXLAN\nfrom scapy.packet import Packet\nfrom scapy.layers.l2 import GRE\n\nfrom scapy.contrib.mpls import MPLS\n\n#\n# NSH Support\n# https://www.rfc-editor.org/rfc/rfc8300.txt January 2018\n#\n\n\nclass NSHTLV(Packet):\n \"NSH MD-type 2 - Variable Length Context Headers\"\n name = \"NSHTLV\"\n fields_desc = [\n ShortField('class', 0),\n BitField('type', 0, 8),\n BitField('reserved', 0, 1),\n BitField('length', 0, 7),\n PacketListField('metadata', None, XIntField, count_from='length')\n ]\n\n\nclass NSH(Packet):\n \"\"\"Network Service Header.\n NSH MD-type 1 if there is no ContextHeaders\"\"\"\n name = \"NSH\"\n\n fields_desc = [\n BitField('ver', 0, 2),\n BitField('oam', 0, 1),\n BitField('unused1', 0, 1),\n BitField('ttl', 63, 6),\n BitFieldLenField('length', None, 6,\n count_of='vlch',\n adjust=lambda pkt, x: 6 if pkt.mdtype == 1\n else x + 2),\n BitField('unused2', 0, 4),\n BitEnumField('mdtype', 1, 4, {0: 'Reserved MDType',\n 1: 'Fixed Length',\n 2: 'Variable Length',\n 0xF: 'Experimental MDType'}),\n ByteEnumField('nextproto', 3, {1: 'IPv4',\n 2: 'IPv6',\n 3: 'Ethernet',\n 4: 'NSH',\n 5: 'MPLS',\n 0xFE: 'Experiment 1',\n 0xFF: 'Experiment 2'}),\n X3BytesField('spi', 0),\n ByteField('si', 0xFF),\n ConditionalField(XStrFixedLenField(\"context_header\", \"\", 16),\n lambda pkt: pkt.mdtype == 1),\n ConditionalField(PacketListField(\"vlch\", None, NSHTLV,\n count_from=\"length\"),\n lambda pkt: pkt.mdtype == 2)\n ]\n\n def mysummary(self):\n return self.sprintf(\"SPI: %spi% - SI: %si%\")\n\n\nbind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)\nbind_layers(VXLAN, NSH, {'flags': 0xC, 'nextprotocol': 4}, nextprotocol=4)\nbind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)\n\nbind_layers(NSH, IP, {'nextprotocol': 1}, nextprotocol=1)\nbind_layers(NSH, IPv6, {'nextprotocol': 2}, nextprotocol=2)\nbind_layers(NSH, Ether, {'nextprotocol': 3}, nextprotocol=3)\nbind_layers(NSH, NSH, {'nextprotocol': 4}, nextprotocol=4)\nbind_layers(NSH, MPLS, {'nextprotocol': 5}, nextprotocol=5)\n", "path": "scapy/contrib/nsh.py"}], "after_files": [{"content": "# This file is part of Scapy\n# Scapy is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# any later version.\n#\n# Scapy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Scapy. If not, see <http://www.gnu.org/licenses/>.\n\n# scapy.contrib.description = Network Services Headers (NSH)\n# scapy.contrib.status = loads\n\nfrom scapy.all import bind_layers\nfrom scapy.fields import BitField, ByteField, ByteEnumField, BitEnumField, \\\n ShortField, X3BytesField, XIntField, XStrFixedLenField, \\\n ConditionalField, PacketListField, BitFieldLenField\nfrom scapy.layers.inet import Ether, IP\nfrom scapy.layers.inet6 import IPv6\nfrom scapy.layers.vxlan import VXLAN\nfrom scapy.packet import Packet\nfrom scapy.layers.l2 import GRE\n\nfrom scapy.contrib.mpls import MPLS\n\n#\n# NSH Support\n# https://www.rfc-editor.org/rfc/rfc8300.txt January 2018\n#\n\n\nclass NSHTLV(Packet):\n \"NSH MD-type 2 - Variable Length Context Headers\"\n name = \"NSHTLV\"\n fields_desc = [\n ShortField('class', 0),\n BitField('type', 0, 8),\n BitField('reserved', 0, 1),\n BitField('length', 0, 7),\n PacketListField('metadata', None, XIntField, count_from='length')\n ]\n\n\nclass NSH(Packet):\n \"\"\"Network Service Header.\n NSH MD-type 1 if there is no ContextHeaders\"\"\"\n name = \"NSH\"\n\n fields_desc = [\n BitField('ver', 0, 2),\n BitField('oam', 0, 1),\n BitField('unused1', 0, 1),\n BitField('ttl', 63, 6),\n BitFieldLenField('length', None, 6,\n count_of='vlch',\n adjust=lambda pkt, x: 6 if pkt.mdtype == 1\n else x + 2),\n BitField('unused2', 0, 4),\n BitEnumField('mdtype', 1, 4, {0: 'Reserved MDType',\n 1: 'Fixed Length',\n 2: 'Variable Length',\n 0xF: 'Experimental MDType'}),\n ByteEnumField('nextproto', 3, {1: 'IPv4',\n 2: 'IPv6',\n 3: 'Ethernet',\n 4: 'NSH',\n 5: 'MPLS',\n 0xFE: 'Experiment 1',\n 0xFF: 'Experiment 2'}),\n X3BytesField('spi', 0),\n ByteField('si', 0xFF),\n ConditionalField(XStrFixedLenField(\"context_header\", \"\", 16),\n lambda pkt: pkt.mdtype == 1),\n ConditionalField(PacketListField(\"vlch\", None, NSHTLV,\n count_from=\"length\"),\n lambda pkt: pkt.mdtype == 2)\n ]\n\n def mysummary(self):\n return self.sprintf(\"SPI: %spi% - SI: %si%\")\n\n\nbind_layers(Ether, NSH, {'type': 0x894F}, type=0x894F)\nbind_layers(VXLAN, NSH, {'flags': 0xC, 'nextproto': 4}, nextproto=4)\nbind_layers(GRE, NSH, {'proto': 0x894F}, proto=0x894F)\n\nbind_layers(NSH, IP, nextproto=1)\nbind_layers(NSH, IPv6, nextproto=2)\nbind_layers(NSH, Ether, nextproto=3)\nbind_layers(NSH, NSH, nextproto=4)\nbind_layers(NSH, MPLS, nextproto=5)\n", "path": "scapy/contrib/nsh.py"}]}
| 1,716 | 335 |
gh_patches_debug_11202
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-2181
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Move Payment Gateways to own subtab
On `admin/settings/` add a subtab "Payment Gateways" and move the Paypal and Stripe here.


--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/settings/__init__.py`
Content:
```
1 import stripe
2 from flask import current_app
3 from sqlalchemy import desc
4 from app.models.setting import Setting
5 from app.models.fees import TicketFees
6
7
8 def get_settings():
9 """
10 Use this to get latest system settings
11 """
12 if 'custom_settings' in current_app.config:
13 return current_app.config['custom_settings']
14 s = Setting.query.order_by(desc(Setting.id)).first()
15 if s is None:
16 set_settings(secret='super secret key')
17 else:
18 current_app.config['custom_settings'] = make_dict(s)
19 return current_app.config['custom_settings']
20
21
22 def set_settings(**kwargs):
23 """
24 Update system settings
25 """
26
27 if 'service_fee' in kwargs:
28 ticket_service_fees = kwargs.get('service_fee')
29 ticket_maximum_fees = kwargs.get('maximum_fee')
30 from app.helpers.data_getter import DataGetter
31 from app.helpers.data import save_to_db
32 currencies = DataGetter.get_payment_currencies()
33 for i, currency in enumerate(currencies):
34 currency = currency.split(' ')[0]
35 ticket_fee = TicketFees(currency=currency,
36 service_fee=ticket_service_fees[i],
37 maximum_fee=ticket_maximum_fees[i])
38 save_to_db(ticket_fee, "Ticket Fees settings saved")
39 else:
40 setting = Setting(**kwargs)
41 from app.helpers.data import save_to_db
42 save_to_db(setting, 'Setting saved')
43 current_app.secret_key = setting.secret
44 stripe.api_key = setting.stripe_secret_key
45 current_app.config['custom_settings'] = make_dict(setting)
46
47
48 def make_dict(s):
49 arguments = {}
50 for name, column in s.__mapper__.columns.items():
51 if not (column.primary_key or column.unique):
52 arguments[name] = getattr(s, name)
53 return arguments
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/settings/__init__.py b/app/settings/__init__.py
--- a/app/settings/__init__.py
+++ b/app/settings/__init__.py
@@ -30,7 +30,7 @@
from app.helpers.data_getter import DataGetter
from app.helpers.data import save_to_db
currencies = DataGetter.get_payment_currencies()
- for i, currency in enumerate(currencies):
+ for i, (currency, has_paypal, has_stripe) in enumerate(currencies):
currency = currency.split(' ')[0]
ticket_fee = TicketFees(currency=currency,
service_fee=ticket_service_fees[i],
|
{"golden_diff": "diff --git a/app/settings/__init__.py b/app/settings/__init__.py\n--- a/app/settings/__init__.py\n+++ b/app/settings/__init__.py\n@@ -30,7 +30,7 @@\n from app.helpers.data_getter import DataGetter\n from app.helpers.data import save_to_db\n currencies = DataGetter.get_payment_currencies()\n- for i, currency in enumerate(currencies):\n+ for i, (currency, has_paypal, has_stripe) in enumerate(currencies):\n currency = currency.split(' ')[0]\n ticket_fee = TicketFees(currency=currency,\n service_fee=ticket_service_fees[i],\n", "issue": "Move Payment Gateways to own subtab\nOn `admin/settings/` add a subtab \"Payment Gateways\" and move the Paypal and Stripe here.\n\n\n\n\n\n", "before_files": [{"content": "import stripe\nfrom flask import current_app\nfrom sqlalchemy import desc\nfrom app.models.setting import Setting\nfrom app.models.fees import TicketFees\n\n\ndef get_settings():\n \"\"\"\n Use this to get latest system settings\n \"\"\"\n if 'custom_settings' in current_app.config:\n return current_app.config['custom_settings']\n s = Setting.query.order_by(desc(Setting.id)).first()\n if s is None:\n set_settings(secret='super secret key')\n else:\n current_app.config['custom_settings'] = make_dict(s)\n return current_app.config['custom_settings']\n\n\ndef set_settings(**kwargs):\n \"\"\"\n Update system settings\n \"\"\"\n\n if 'service_fee' in kwargs:\n ticket_service_fees = kwargs.get('service_fee')\n ticket_maximum_fees = kwargs.get('maximum_fee')\n from app.helpers.data_getter import DataGetter\n from app.helpers.data import save_to_db\n currencies = DataGetter.get_payment_currencies()\n for i, currency in enumerate(currencies):\n currency = currency.split(' ')[0]\n ticket_fee = TicketFees(currency=currency,\n service_fee=ticket_service_fees[i],\n maximum_fee=ticket_maximum_fees[i])\n save_to_db(ticket_fee, \"Ticket Fees settings saved\")\n else:\n setting = Setting(**kwargs)\n from app.helpers.data import save_to_db\n save_to_db(setting, 'Setting saved')\n current_app.secret_key = setting.secret\n stripe.api_key = setting.stripe_secret_key\n current_app.config['custom_settings'] = make_dict(setting)\n\n\ndef make_dict(s):\n arguments = {}\n for name, column in s.__mapper__.columns.items():\n if not (column.primary_key or column.unique):\n arguments[name] = getattr(s, name)\n return arguments\n", "path": "app/settings/__init__.py"}], "after_files": [{"content": "import stripe\nfrom flask import current_app\nfrom sqlalchemy import desc\nfrom app.models.setting import Setting\nfrom app.models.fees import TicketFees\n\n\ndef get_settings():\n \"\"\"\n Use this to get latest system settings\n \"\"\"\n if 'custom_settings' in current_app.config:\n return current_app.config['custom_settings']\n s = Setting.query.order_by(desc(Setting.id)).first()\n if s is None:\n set_settings(secret='super secret key')\n else:\n current_app.config['custom_settings'] = make_dict(s)\n return current_app.config['custom_settings']\n\n\ndef set_settings(**kwargs):\n \"\"\"\n Update system settings\n \"\"\"\n\n if 'service_fee' in kwargs:\n ticket_service_fees = kwargs.get('service_fee')\n ticket_maximum_fees = kwargs.get('maximum_fee')\n from app.helpers.data_getter import DataGetter\n from app.helpers.data import save_to_db\n currencies = DataGetter.get_payment_currencies()\n for i, (currency, has_paypal, has_stripe) in enumerate(currencies):\n currency = currency.split(' ')[0]\n ticket_fee = TicketFees(currency=currency,\n service_fee=ticket_service_fees[i],\n maximum_fee=ticket_maximum_fees[i])\n save_to_db(ticket_fee, \"Ticket Fees settings saved\")\n else:\n setting = Setting(**kwargs)\n from app.helpers.data import save_to_db\n save_to_db(setting, 'Setting saved')\n current_app.secret_key = setting.secret\n stripe.api_key = setting.stripe_secret_key\n current_app.config['custom_settings'] = make_dict(setting)\n\n\ndef make_dict(s):\n arguments = {}\n for name, column in s.__mapper__.columns.items():\n if not (column.primary_key or column.unique):\n arguments[name] = getattr(s, name)\n return arguments\n", "path": "app/settings/__init__.py"}]}
| 937 | 141 |
gh_patches_debug_23885
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-3587
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add official support for Python 3.12
## Description
<!-- Is your feature request related to a problem? A clear and concise description of what the problem is: "I'm always frustrated when ..." -->
Kedro itself probably works on Python 3.12 already, it would be nice to declare official support.
However, installing Kedro is one thing, but installing the typical dependencies might not be straightforward. For example, I just tested the spaceflights starter and most of the dependencies have already published precompiled wheels for Python 3.12 (at least for M1 Mac), but two of them are still problematic as of today:
- aiohttp https://github.com/aio-libs/aiohttp/issues/7739 worked by installing the beta version as advised there, so it will be solved soon (edit: fixed ✔️)
- pyzmq https://github.com/zeromq/pyzmq/issues/1907 (M1 specific), didn't work after installing the ZMQ header libraries with mamba (edit: fixed ✔️)
## Context
<!-- Why is this change important to you? How would you use it? How can it benefit other users? -->
#2815 was already completed, but officially Kedro does not support Python 3.12 yet.
You can use Kedro on Python 3.12 by manually disabling the warning.
## Possible Implementation
<!-- (Optional) Suggest an idea for implementing the addition or change. -->
Wait a bit until at least the spaceflights starter can be safely installed in most mainstream platforms.
## Possible Alternatives
<!-- (Optional) Describe any alternative solutions or features you've considered. -->
Declare Python 3.12 support already, at the cost of creating some grievance of users that then proceed to install some dependencies.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kedro/__init__.py`
Content:
```
1 """Kedro is a framework that makes it easy to build robust and scalable
2 data pipelines by providing uniform project templates, data abstraction,
3 configuration and pipeline assembly.
4 """
5
6 import sys
7 import warnings
8
9 __version__ = "0.19.3"
10
11
12 class KedroDeprecationWarning(DeprecationWarning):
13 """Custom class for warnings about deprecated Kedro features."""
14
15
16 class KedroPythonVersionWarning(UserWarning):
17 """Custom class for warnings about incompatibilities with Python versions."""
18
19
20 if not sys.warnoptions:
21 warnings.simplefilter("default", KedroDeprecationWarning)
22 warnings.simplefilter("error", KedroPythonVersionWarning)
23
24 if sys.version_info >= (3, 12):
25 warnings.warn(
26 """Kedro is not yet fully compatible with this Python version.
27 To proceed at your own risk and ignore this warning,
28 run Kedro with `python -W "default:Kedro is not yet fully compatible" -m kedro ...`
29 or set the PYTHONWARNINGS environment variable accordingly.""",
30 KedroPythonVersionWarning,
31 )
32
```
Path: `kedro/config/abstract_config.py`
Content:
```
1 """This module provides ``kedro.abstract_config`` with the baseline
2 class model for a `ConfigLoader` implementation.
3 """
4 from __future__ import annotations
5
6 from collections import UserDict
7 from typing import Any
8
9
10 class AbstractConfigLoader(UserDict):
11 """``AbstractConfigLoader`` is the abstract base class
12 for all `ConfigLoader` implementations.
13 All user-defined `ConfigLoader` implementations should inherit
14 from `AbstractConfigLoader` and implement all relevant abstract methods.
15 """
16
17 def __init__(
18 self,
19 conf_source: str,
20 env: str | None = None,
21 runtime_params: dict[str, Any] | None = None,
22 **kwargs: Any,
23 ):
24 super().__init__()
25 self.conf_source = conf_source
26 self.env = env
27 self.runtime_params = runtime_params or {}
28
29
30 class BadConfigException(Exception):
31 """Raised when a configuration file cannot be loaded, for instance
32 due to wrong syntax or poor formatting.
33 """
34
35 pass
36
37
38 class MissingConfigException(Exception):
39 """Raised when no configuration files can be found within a config path"""
40
41 pass
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kedro/__init__.py b/kedro/__init__.py
--- a/kedro/__init__.py
+++ b/kedro/__init__.py
@@ -21,7 +21,7 @@
warnings.simplefilter("default", KedroDeprecationWarning)
warnings.simplefilter("error", KedroPythonVersionWarning)
-if sys.version_info >= (3, 12):
+if sys.version_info >= (3, 13):
warnings.warn(
"""Kedro is not yet fully compatible with this Python version.
To proceed at your own risk and ignore this warning,
diff --git a/kedro/config/abstract_config.py b/kedro/config/abstract_config.py
--- a/kedro/config/abstract_config.py
+++ b/kedro/config/abstract_config.py
@@ -26,6 +26,17 @@
self.env = env
self.runtime_params = runtime_params or {}
+ # As of Python 3.12 __getitem__ is no longer called in the inherited UserDict.get()
+ # This causes AbstractConfigLoader.get() to break
+ # See: https://github.com/python/cpython/issues/105524
+ # Overwrite the inherited get function with the implementation from 3.11 and prior
+ def get(self, key: str, default: Any = None) -> Any:
+ "D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None."
+ try:
+ return self[key]
+ except KeyError:
+ return default
+
class BadConfigException(Exception):
"""Raised when a configuration file cannot be loaded, for instance
|
{"golden_diff": "diff --git a/kedro/__init__.py b/kedro/__init__.py\n--- a/kedro/__init__.py\n+++ b/kedro/__init__.py\n@@ -21,7 +21,7 @@\n warnings.simplefilter(\"default\", KedroDeprecationWarning)\n warnings.simplefilter(\"error\", KedroPythonVersionWarning)\n \n-if sys.version_info >= (3, 12):\n+if sys.version_info >= (3, 13):\n warnings.warn(\n \"\"\"Kedro is not yet fully compatible with this Python version.\n To proceed at your own risk and ignore this warning,\ndiff --git a/kedro/config/abstract_config.py b/kedro/config/abstract_config.py\n--- a/kedro/config/abstract_config.py\n+++ b/kedro/config/abstract_config.py\n@@ -26,6 +26,17 @@\n self.env = env\n self.runtime_params = runtime_params or {}\n \n+ # As of Python 3.12 __getitem__ is no longer called in the inherited UserDict.get()\n+ # This causes AbstractConfigLoader.get() to break\n+ # See: https://github.com/python/cpython/issues/105524\n+ # Overwrite the inherited get function with the implementation from 3.11 and prior\n+ def get(self, key: str, default: Any = None) -> Any:\n+ \"D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.\"\n+ try:\n+ return self[key]\n+ except KeyError:\n+ return default\n+\n \n class BadConfigException(Exception):\n \"\"\"Raised when a configuration file cannot be loaded, for instance\n", "issue": "Add official support for Python 3.12\n## Description\r\n<!-- Is your feature request related to a problem? A clear and concise description of what the problem is: \"I'm always frustrated when ...\" -->\r\nKedro itself probably works on Python 3.12 already, it would be nice to declare official support.\r\n\r\nHowever, installing Kedro is one thing, but installing the typical dependencies might not be straightforward. For example, I just tested the spaceflights starter and most of the dependencies have already published precompiled wheels for Python 3.12 (at least for M1 Mac), but two of them are still problematic as of today:\r\n\r\n- aiohttp https://github.com/aio-libs/aiohttp/issues/7739 worked by installing the beta version as advised there, so it will be solved soon (edit: fixed \u2714\ufe0f)\r\n- pyzmq https://github.com/zeromq/pyzmq/issues/1907 (M1 specific), didn't work after installing the ZMQ header libraries with mamba (edit: fixed \u2714\ufe0f)\r\n\r\n## Context\r\n<!-- Why is this change important to you? How would you use it? How can it benefit other users? -->\r\n#2815 was already completed, but officially Kedro does not support Python 3.12 yet.\r\n\r\nYou can use Kedro on Python 3.12 by manually disabling the warning.\r\n\r\n## Possible Implementation\r\n<!-- (Optional) Suggest an idea for implementing the addition or change. -->\r\nWait a bit until at least the spaceflights starter can be safely installed in most mainstream platforms.\r\n\r\n## Possible Alternatives\r\n<!-- (Optional) Describe any alternative solutions or features you've considered. -->\r\nDeclare Python 3.12 support already, at the cost of creating some grievance of users that then proceed to install some dependencies.\r\n\n", "before_files": [{"content": "\"\"\"Kedro is a framework that makes it easy to build robust and scalable\ndata pipelines by providing uniform project templates, data abstraction,\nconfiguration and pipeline assembly.\n\"\"\"\n\nimport sys\nimport warnings\n\n__version__ = \"0.19.3\"\n\n\nclass KedroDeprecationWarning(DeprecationWarning):\n \"\"\"Custom class for warnings about deprecated Kedro features.\"\"\"\n\n\nclass KedroPythonVersionWarning(UserWarning):\n \"\"\"Custom class for warnings about incompatibilities with Python versions.\"\"\"\n\n\nif not sys.warnoptions:\n warnings.simplefilter(\"default\", KedroDeprecationWarning)\n warnings.simplefilter(\"error\", KedroPythonVersionWarning)\n\nif sys.version_info >= (3, 12):\n warnings.warn(\n \"\"\"Kedro is not yet fully compatible with this Python version.\nTo proceed at your own risk and ignore this warning,\nrun Kedro with `python -W \"default:Kedro is not yet fully compatible\" -m kedro ...`\nor set the PYTHONWARNINGS environment variable accordingly.\"\"\",\n KedroPythonVersionWarning,\n )\n", "path": "kedro/__init__.py"}, {"content": "\"\"\"This module provides ``kedro.abstract_config`` with the baseline\nclass model for a `ConfigLoader` implementation.\n\"\"\"\nfrom __future__ import annotations\n\nfrom collections import UserDict\nfrom typing import Any\n\n\nclass AbstractConfigLoader(UserDict):\n \"\"\"``AbstractConfigLoader`` is the abstract base class\n for all `ConfigLoader` implementations.\n All user-defined `ConfigLoader` implementations should inherit\n from `AbstractConfigLoader` and implement all relevant abstract methods.\n \"\"\"\n\n def __init__(\n self,\n conf_source: str,\n env: str | None = None,\n runtime_params: dict[str, Any] | None = None,\n **kwargs: Any,\n ):\n super().__init__()\n self.conf_source = conf_source\n self.env = env\n self.runtime_params = runtime_params or {}\n\n\nclass BadConfigException(Exception):\n \"\"\"Raised when a configuration file cannot be loaded, for instance\n due to wrong syntax or poor formatting.\n \"\"\"\n\n pass\n\n\nclass MissingConfigException(Exception):\n \"\"\"Raised when no configuration files can be found within a config path\"\"\"\n\n pass\n", "path": "kedro/config/abstract_config.py"}], "after_files": [{"content": "\"\"\"Kedro is a framework that makes it easy to build robust and scalable\ndata pipelines by providing uniform project templates, data abstraction,\nconfiguration and pipeline assembly.\n\"\"\"\n\nimport sys\nimport warnings\n\n__version__ = \"0.19.3\"\n\n\nclass KedroDeprecationWarning(DeprecationWarning):\n \"\"\"Custom class for warnings about deprecated Kedro features.\"\"\"\n\n\nclass KedroPythonVersionWarning(UserWarning):\n \"\"\"Custom class for warnings about incompatibilities with Python versions.\"\"\"\n\n\nif not sys.warnoptions:\n warnings.simplefilter(\"default\", KedroDeprecationWarning)\n warnings.simplefilter(\"error\", KedroPythonVersionWarning)\n\nif sys.version_info >= (3, 13):\n warnings.warn(\n \"\"\"Kedro is not yet fully compatible with this Python version.\nTo proceed at your own risk and ignore this warning,\nrun Kedro with `python -W \"default:Kedro is not yet fully compatible\" -m kedro ...`\nor set the PYTHONWARNINGS environment variable accordingly.\"\"\",\n KedroPythonVersionWarning,\n )\n", "path": "kedro/__init__.py"}, {"content": "\"\"\"This module provides ``kedro.abstract_config`` with the baseline\nclass model for a `ConfigLoader` implementation.\n\"\"\"\nfrom __future__ import annotations\n\nfrom collections import UserDict\nfrom typing import Any\n\n\nclass AbstractConfigLoader(UserDict):\n \"\"\"``AbstractConfigLoader`` is the abstract base class\n for all `ConfigLoader` implementations.\n All user-defined `ConfigLoader` implementations should inherit\n from `AbstractConfigLoader` and implement all relevant abstract methods.\n \"\"\"\n\n def __init__(\n self,\n conf_source: str,\n env: str | None = None,\n runtime_params: dict[str, Any] | None = None,\n **kwargs: Any,\n ):\n super().__init__()\n self.conf_source = conf_source\n self.env = env\n self.runtime_params = runtime_params or {}\n\n # As of Python 3.12 __getitem__ is no longer called in the inherited UserDict.get()\n # This causes AbstractConfigLoader.get() to break\n # See: https://github.com/python/cpython/issues/105524\n # Overwrite the inherited get function with the implementation from 3.11 and prior\n def get(self, key: str, default: Any = None) -> Any:\n \"D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.\"\n try:\n return self[key]\n except KeyError:\n return default\n\n\nclass BadConfigException(Exception):\n \"\"\"Raised when a configuration file cannot be loaded, for instance\n due to wrong syntax or poor formatting.\n \"\"\"\n\n pass\n\n\nclass MissingConfigException(Exception):\n \"\"\"Raised when no configuration files can be found within a config path\"\"\"\n\n pass\n", "path": "kedro/config/abstract_config.py"}]}
| 1,270 | 378 |
gh_patches_debug_17700
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-210
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Chant-edit page doesn't load for Admin user
The chant-edit page (e.g., http://127.0.0.1:3122/edit-volpiano/702611?pk=705019) takes forever to load for Admin user.
I was logged in with my Admin account (i.e., superuser). Ideally, this should give me power to access and change anything.
I also check with my project manager account and it loaded fine.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/cantusdb_project/users/managers.py`
Content:
```
1 # https://testdriven.io/blog/django-custom-user-model/#:~:text=The%20default%20User%20model%20in,either%20subclassing%20AbstractUser%20or%20AbstractBaseUser%20.
2
3 from django.contrib.auth.base_user import BaseUserManager
4 from django.utils.translation import gettext_lazy as _
5
6
7 class CustomUserManager(BaseUserManager):
8 """
9 Custom user model manager where email is the unique identifiers
10 for authentication instead of usernames.
11 """
12 def create_user(self, email, password, **extra_fields):
13 """
14 Create and save a User with the given email and password.
15 """
16 if not email:
17 raise ValueError(_('The Email must be set'))
18 email = self.normalize_email(email)
19 user = self.model(email=email, **extra_fields)
20 user.set_password(password)
21 user.save()
22 return user
23
24 def create_superuser(self, email, password, **extra_fields):
25 """
26 Create and save a SuperUser with the given email and password.
27 """
28 extra_fields.setdefault('is_staff', True)
29 extra_fields.setdefault('is_superuser', True)
30 extra_fields.setdefault('is_active', True)
31
32 if extra_fields.get('is_staff') is not True:
33 raise ValueError(_('Superuser must have is_staff=True.'))
34 if extra_fields.get('is_superuser') is not True:
35 raise ValueError(_('Superuser must have is_superuser=True.'))
36 return self.create_user(email, password, **extra_fields)
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django/cantusdb_project/users/managers.py b/django/cantusdb_project/users/managers.py
--- a/django/cantusdb_project/users/managers.py
+++ b/django/cantusdb_project/users/managers.py
@@ -2,7 +2,7 @@
from django.contrib.auth.base_user import BaseUserManager
from django.utils.translation import gettext_lazy as _
-
+from django.contrib.auth.models import Group
class CustomUserManager(BaseUserManager):
"""
@@ -33,4 +33,7 @@
raise ValueError(_('Superuser must have is_staff=True.'))
if extra_fields.get('is_superuser') is not True:
raise ValueError(_('Superuser must have is_superuser=True.'))
- return self.create_user(email, password, **extra_fields)
\ No newline at end of file
+ user = self.create_user(email, password, **extra_fields)
+ pm = Group.objects.get(name='project manager')
+ pm.user_set.add(user)
+ return user
\ No newline at end of file
|
{"golden_diff": "diff --git a/django/cantusdb_project/users/managers.py b/django/cantusdb_project/users/managers.py\n--- a/django/cantusdb_project/users/managers.py\n+++ b/django/cantusdb_project/users/managers.py\n@@ -2,7 +2,7 @@\n \n from django.contrib.auth.base_user import BaseUserManager\n from django.utils.translation import gettext_lazy as _\n-\n+from django.contrib.auth.models import Group\n \n class CustomUserManager(BaseUserManager):\n \"\"\"\n@@ -33,4 +33,7 @@\n raise ValueError(_('Superuser must have is_staff=True.'))\n if extra_fields.get('is_superuser') is not True:\n raise ValueError(_('Superuser must have is_superuser=True.'))\n- return self.create_user(email, password, **extra_fields)\n\\ No newline at end of file\n+ user = self.create_user(email, password, **extra_fields)\n+ pm = Group.objects.get(name='project manager') \n+ pm.user_set.add(user)\n+ return user\n\\ No newline at end of file\n", "issue": "Chant-edit page doesn't load for Admin user\nThe chant-edit page (e.g., http://127.0.0.1:3122/edit-volpiano/702611?pk=705019) takes forever to load for Admin user. \r\nI was logged in with my Admin account (i.e., superuser). Ideally, this should give me power to access and change anything. \r\n\r\nI also check with my project manager account and it loaded fine.\n", "before_files": [{"content": "# https://testdriven.io/blog/django-custom-user-model/#:~:text=The%20default%20User%20model%20in,either%20subclassing%20AbstractUser%20or%20AbstractBaseUser%20.\n\nfrom django.contrib.auth.base_user import BaseUserManager\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass CustomUserManager(BaseUserManager):\n \"\"\"\n Custom user model manager where email is the unique identifiers\n for authentication instead of usernames.\n \"\"\"\n def create_user(self, email, password, **extra_fields):\n \"\"\"\n Create and save a User with the given email and password.\n \"\"\"\n if not email:\n raise ValueError(_('The Email must be set'))\n email = self.normalize_email(email)\n user = self.model(email=email, **extra_fields)\n user.set_password(password)\n user.save()\n return user\n\n def create_superuser(self, email, password, **extra_fields):\n \"\"\"\n Create and save a SuperUser with the given email and password.\n \"\"\"\n extra_fields.setdefault('is_staff', True)\n extra_fields.setdefault('is_superuser', True)\n extra_fields.setdefault('is_active', True)\n\n if extra_fields.get('is_staff') is not True:\n raise ValueError(_('Superuser must have is_staff=True.'))\n if extra_fields.get('is_superuser') is not True:\n raise ValueError(_('Superuser must have is_superuser=True.'))\n return self.create_user(email, password, **extra_fields)", "path": "django/cantusdb_project/users/managers.py"}], "after_files": [{"content": "# https://testdriven.io/blog/django-custom-user-model/#:~:text=The%20default%20User%20model%20in,either%20subclassing%20AbstractUser%20or%20AbstractBaseUser%20.\n\nfrom django.contrib.auth.base_user import BaseUserManager\nfrom django.utils.translation import gettext_lazy as _\nfrom django.contrib.auth.models import Group\n\nclass CustomUserManager(BaseUserManager):\n \"\"\"\n Custom user model manager where email is the unique identifiers\n for authentication instead of usernames.\n \"\"\"\n def create_user(self, email, password, **extra_fields):\n \"\"\"\n Create and save a User with the given email and password.\n \"\"\"\n if not email:\n raise ValueError(_('The Email must be set'))\n email = self.normalize_email(email)\n user = self.model(email=email, **extra_fields)\n user.set_password(password)\n user.save()\n return user\n\n def create_superuser(self, email, password, **extra_fields):\n \"\"\"\n Create and save a SuperUser with the given email and password.\n \"\"\"\n extra_fields.setdefault('is_staff', True)\n extra_fields.setdefault('is_superuser', True)\n extra_fields.setdefault('is_active', True)\n\n if extra_fields.get('is_staff') is not True:\n raise ValueError(_('Superuser must have is_staff=True.'))\n if extra_fields.get('is_superuser') is not True:\n raise ValueError(_('Superuser must have is_superuser=True.'))\n user = self.create_user(email, password, **extra_fields)\n pm = Group.objects.get(name='project manager') \n pm.user_set.add(user)\n return user", "path": "django/cantusdb_project/users/managers.py"}]}
| 759 | 229 |
gh_patches_debug_41565
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2259
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sticky cookies are improperly formatted.
##### Steps to reproduce the problem:
1. Go to http://www.html-kit.com/tools/cookietester/
2. Click 'Set Test Cookie'
3. Observe that one cookie is sent to the server.
4. Remove the cookie.
5. launch mitmproxy with `mitmproxy -t html-kit\.com` and tell your browser to use it as a proxy
6. Reload the page.
7. Click 'Set Test Cookie'
8. Observe that two 'cookies' are sent to the server.
##### Any other comments? What have you tried so far?
There appears to be a comma in the output of mitmproxy, even though it is surrounded by quotes. It's possible, then that this is a parsing fail on the tool's end caused by a difference in what's sent back for the format of the date. Still, should it really be changing that?
##### System information
Arch Linux, freshly updated.
Mitmproxy version: 2.0.1 (release version)
Python version: 3.6.0
Platform: Linux-4.10.6-1-ARCH-x86_64-with-glibc2.3.4
SSL version: OpenSSL 1.0.2k 26 Jan 2017
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/addons/stickycookie.py`
Content:
```
1 import collections
2 from http import cookiejar
3
4 from mitmproxy.net.http import cookies
5
6 from mitmproxy import exceptions
7 from mitmproxy import flowfilter
8 from mitmproxy import ctx
9
10
11 def ckey(attrs, f):
12 """
13 Returns a (domain, port, path) tuple.
14 """
15 domain = f.request.host
16 path = "/"
17 if "domain" in attrs:
18 domain = attrs["domain"]
19 if "path" in attrs:
20 path = attrs["path"]
21 return (domain, f.request.port, path)
22
23
24 def domain_match(a, b):
25 if cookiejar.domain_match(a, b):
26 return True
27 elif cookiejar.domain_match(a, b.strip(".")):
28 return True
29 return False
30
31
32 class StickyCookie:
33 def __init__(self):
34 self.jar = collections.defaultdict(dict)
35 self.flt = None
36
37 def configure(self, updated):
38 if "stickycookie" in updated:
39 if ctx.options.stickycookie:
40 flt = flowfilter.parse(ctx.options.stickycookie)
41 if not flt:
42 raise exceptions.OptionsError(
43 "stickycookie: invalid filter expression: %s" % ctx.options.stickycookie
44 )
45 self.flt = flt
46 else:
47 self.flt = None
48
49 def response(self, flow):
50 if self.flt:
51 for name, (value, attrs) in flow.response.cookies.items(multi=True):
52 # FIXME: We now know that Cookie.py screws up some cookies with
53 # valid RFC 822/1123 datetime specifications for expiry. Sigh.
54 dom_port_path = ckey(attrs, flow)
55
56 if domain_match(flow.request.host, dom_port_path[0]):
57 if cookies.is_expired(attrs):
58 # Remove the cookie from jar
59 self.jar[dom_port_path].pop(name, None)
60
61 # If all cookies of a dom_port_path have been removed
62 # then remove it from the jar itself
63 if not self.jar[dom_port_path]:
64 self.jar.pop(dom_port_path, None)
65 else:
66 b = attrs.copy()
67 b.insert(0, name, value)
68 self.jar[dom_port_path][name] = b
69
70 def request(self, flow):
71 if self.flt:
72 l = []
73 if flowfilter.match(self.flt, flow):
74 for domain, port, path in self.jar.keys():
75 match = [
76 domain_match(flow.request.host, domain),
77 flow.request.port == port,
78 flow.request.path.startswith(path)
79 ]
80 if all(match):
81 c = self.jar[(domain, port, path)]
82 l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])
83 if l:
84 # FIXME: we need to formalise this...
85 flow.request.stickycookie = True
86 flow.request.headers["cookie"] = "; ".join(l)
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mitmproxy/addons/stickycookie.py b/mitmproxy/addons/stickycookie.py
--- a/mitmproxy/addons/stickycookie.py
+++ b/mitmproxy/addons/stickycookie.py
@@ -1,14 +1,14 @@
import collections
from http import cookiejar
+from typing import List, Tuple, Dict, Optional # noqa
+from mitmproxy import http, flowfilter, ctx, exceptions
from mitmproxy.net.http import cookies
-from mitmproxy import exceptions
-from mitmproxy import flowfilter
-from mitmproxy import ctx
+TOrigin = Tuple[str, int, str]
-def ckey(attrs, f):
+def ckey(attrs: Dict[str, str], f: http.HTTPFlow) -> TOrigin:
"""
Returns a (domain, port, path) tuple.
"""
@@ -21,18 +21,18 @@
return (domain, f.request.port, path)
-def domain_match(a, b):
- if cookiejar.domain_match(a, b):
+def domain_match(a: str, b: str) -> bool:
+ if cookiejar.domain_match(a, b): # type: ignore
return True
- elif cookiejar.domain_match(a, b.strip(".")):
+ elif cookiejar.domain_match(a, b.strip(".")): # type: ignore
return True
return False
class StickyCookie:
def __init__(self):
- self.jar = collections.defaultdict(dict)
- self.flt = None
+ self.jar = collections.defaultdict(dict) # type: Dict[TOrigin, Dict[str, str]]
+ self.flt = None # type: Optional[flowfilter.TFilter]
def configure(self, updated):
if "stickycookie" in updated:
@@ -46,7 +46,7 @@
else:
self.flt = None
- def response(self, flow):
+ def response(self, flow: http.HTTPFlow):
if self.flt:
for name, (value, attrs) in flow.response.cookies.items(multi=True):
# FIXME: We now know that Cookie.py screws up some cookies with
@@ -63,24 +63,21 @@
if not self.jar[dom_port_path]:
self.jar.pop(dom_port_path, None)
else:
- b = attrs.copy()
- b.insert(0, name, value)
- self.jar[dom_port_path][name] = b
+ self.jar[dom_port_path][name] = value
- def request(self, flow):
+ def request(self, flow: http.HTTPFlow):
if self.flt:
- l = []
+ cookie_list = [] # type: List[Tuple[str,str]]
if flowfilter.match(self.flt, flow):
- for domain, port, path in self.jar.keys():
+ for (domain, port, path), c in self.jar.items():
match = [
domain_match(flow.request.host, domain),
flow.request.port == port,
flow.request.path.startswith(path)
]
if all(match):
- c = self.jar[(domain, port, path)]
- l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])
- if l:
+ cookie_list.extend(c.items())
+ if cookie_list:
# FIXME: we need to formalise this...
- flow.request.stickycookie = True
- flow.request.headers["cookie"] = "; ".join(l)
+ flow.metadata["stickycookie"] = True
+ flow.request.headers["cookie"] = cookies.format_cookie_header(cookie_list)
|
{"golden_diff": "diff --git a/mitmproxy/addons/stickycookie.py b/mitmproxy/addons/stickycookie.py\n--- a/mitmproxy/addons/stickycookie.py\n+++ b/mitmproxy/addons/stickycookie.py\n@@ -1,14 +1,14 @@\n import collections\n from http import cookiejar\n+from typing import List, Tuple, Dict, Optional # noqa\n \n+from mitmproxy import http, flowfilter, ctx, exceptions\n from mitmproxy.net.http import cookies\n \n-from mitmproxy import exceptions\n-from mitmproxy import flowfilter\n-from mitmproxy import ctx\n+TOrigin = Tuple[str, int, str]\n \n \n-def ckey(attrs, f):\n+def ckey(attrs: Dict[str, str], f: http.HTTPFlow) -> TOrigin:\n \"\"\"\n Returns a (domain, port, path) tuple.\n \"\"\"\n@@ -21,18 +21,18 @@\n return (domain, f.request.port, path)\n \n \n-def domain_match(a, b):\n- if cookiejar.domain_match(a, b):\n+def domain_match(a: str, b: str) -> bool:\n+ if cookiejar.domain_match(a, b): # type: ignore\n return True\n- elif cookiejar.domain_match(a, b.strip(\".\")):\n+ elif cookiejar.domain_match(a, b.strip(\".\")): # type: ignore\n return True\n return False\n \n \n class StickyCookie:\n def __init__(self):\n- self.jar = collections.defaultdict(dict)\n- self.flt = None\n+ self.jar = collections.defaultdict(dict) # type: Dict[TOrigin, Dict[str, str]]\n+ self.flt = None # type: Optional[flowfilter.TFilter]\n \n def configure(self, updated):\n if \"stickycookie\" in updated:\n@@ -46,7 +46,7 @@\n else:\n self.flt = None\n \n- def response(self, flow):\n+ def response(self, flow: http.HTTPFlow):\n if self.flt:\n for name, (value, attrs) in flow.response.cookies.items(multi=True):\n # FIXME: We now know that Cookie.py screws up some cookies with\n@@ -63,24 +63,21 @@\n if not self.jar[dom_port_path]:\n self.jar.pop(dom_port_path, None)\n else:\n- b = attrs.copy()\n- b.insert(0, name, value)\n- self.jar[dom_port_path][name] = b\n+ self.jar[dom_port_path][name] = value\n \n- def request(self, flow):\n+ def request(self, flow: http.HTTPFlow):\n if self.flt:\n- l = []\n+ cookie_list = [] # type: List[Tuple[str,str]]\n if flowfilter.match(self.flt, flow):\n- for domain, port, path in self.jar.keys():\n+ for (domain, port, path), c in self.jar.items():\n match = [\n domain_match(flow.request.host, domain),\n flow.request.port == port,\n flow.request.path.startswith(path)\n ]\n if all(match):\n- c = self.jar[(domain, port, path)]\n- l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])\n- if l:\n+ cookie_list.extend(c.items())\n+ if cookie_list:\n # FIXME: we need to formalise this...\n- flow.request.stickycookie = True\n- flow.request.headers[\"cookie\"] = \"; \".join(l)\n+ flow.metadata[\"stickycookie\"] = True\n+ flow.request.headers[\"cookie\"] = cookies.format_cookie_header(cookie_list)\n", "issue": "Sticky cookies are improperly formatted.\n##### Steps to reproduce the problem:\r\n\r\n1. Go to http://www.html-kit.com/tools/cookietester/\r\n2. Click 'Set Test Cookie'\r\n3. Observe that one cookie is sent to the server.\r\n4. Remove the cookie.\r\n5. launch mitmproxy with `mitmproxy -t html-kit\\.com` and tell your browser to use it as a proxy\r\n6. Reload the page.\r\n7. Click 'Set Test Cookie'\r\n8. Observe that two 'cookies' are sent to the server.\r\n\r\n##### Any other comments? What have you tried so far?\r\nThere appears to be a comma in the output of mitmproxy, even though it is surrounded by quotes. It's possible, then that this is a parsing fail on the tool's end caused by a difference in what's sent back for the format of the date. Still, should it really be changing that?\r\n\r\n##### System information\r\nArch Linux, freshly updated.\r\n\r\nMitmproxy version: 2.0.1 (release version) \r\nPython version: 3.6.0\r\nPlatform: Linux-4.10.6-1-ARCH-x86_64-with-glibc2.3.4\r\nSSL version: OpenSSL 1.0.2k 26 Jan 2017\r\n\n", "before_files": [{"content": "import collections\nfrom http import cookiejar\n\nfrom mitmproxy.net.http import cookies\n\nfrom mitmproxy import exceptions\nfrom mitmproxy import flowfilter\nfrom mitmproxy import ctx\n\n\ndef ckey(attrs, f):\n \"\"\"\n Returns a (domain, port, path) tuple.\n \"\"\"\n domain = f.request.host\n path = \"/\"\n if \"domain\" in attrs:\n domain = attrs[\"domain\"]\n if \"path\" in attrs:\n path = attrs[\"path\"]\n return (domain, f.request.port, path)\n\n\ndef domain_match(a, b):\n if cookiejar.domain_match(a, b):\n return True\n elif cookiejar.domain_match(a, b.strip(\".\")):\n return True\n return False\n\n\nclass StickyCookie:\n def __init__(self):\n self.jar = collections.defaultdict(dict)\n self.flt = None\n\n def configure(self, updated):\n if \"stickycookie\" in updated:\n if ctx.options.stickycookie:\n flt = flowfilter.parse(ctx.options.stickycookie)\n if not flt:\n raise exceptions.OptionsError(\n \"stickycookie: invalid filter expression: %s\" % ctx.options.stickycookie\n )\n self.flt = flt\n else:\n self.flt = None\n\n def response(self, flow):\n if self.flt:\n for name, (value, attrs) in flow.response.cookies.items(multi=True):\n # FIXME: We now know that Cookie.py screws up some cookies with\n # valid RFC 822/1123 datetime specifications for expiry. Sigh.\n dom_port_path = ckey(attrs, flow)\n\n if domain_match(flow.request.host, dom_port_path[0]):\n if cookies.is_expired(attrs):\n # Remove the cookie from jar\n self.jar[dom_port_path].pop(name, None)\n\n # If all cookies of a dom_port_path have been removed\n # then remove it from the jar itself\n if not self.jar[dom_port_path]:\n self.jar.pop(dom_port_path, None)\n else:\n b = attrs.copy()\n b.insert(0, name, value)\n self.jar[dom_port_path][name] = b\n\n def request(self, flow):\n if self.flt:\n l = []\n if flowfilter.match(self.flt, flow):\n for domain, port, path in self.jar.keys():\n match = [\n domain_match(flow.request.host, domain),\n flow.request.port == port,\n flow.request.path.startswith(path)\n ]\n if all(match):\n c = self.jar[(domain, port, path)]\n l.extend([cookies.format_cookie_header(c[name].items(multi=True)) for name in c.keys()])\n if l:\n # FIXME: we need to formalise this...\n flow.request.stickycookie = True\n flow.request.headers[\"cookie\"] = \"; \".join(l)\n", "path": "mitmproxy/addons/stickycookie.py"}], "after_files": [{"content": "import collections\nfrom http import cookiejar\nfrom typing import List, Tuple, Dict, Optional # noqa\n\nfrom mitmproxy import http, flowfilter, ctx, exceptions\nfrom mitmproxy.net.http import cookies\n\nTOrigin = Tuple[str, int, str]\n\n\ndef ckey(attrs: Dict[str, str], f: http.HTTPFlow) -> TOrigin:\n \"\"\"\n Returns a (domain, port, path) tuple.\n \"\"\"\n domain = f.request.host\n path = \"/\"\n if \"domain\" in attrs:\n domain = attrs[\"domain\"]\n if \"path\" in attrs:\n path = attrs[\"path\"]\n return (domain, f.request.port, path)\n\n\ndef domain_match(a: str, b: str) -> bool:\n if cookiejar.domain_match(a, b): # type: ignore\n return True\n elif cookiejar.domain_match(a, b.strip(\".\")): # type: ignore\n return True\n return False\n\n\nclass StickyCookie:\n def __init__(self):\n self.jar = collections.defaultdict(dict) # type: Dict[TOrigin, Dict[str, str]]\n self.flt = None # type: Optional[flowfilter.TFilter]\n\n def configure(self, updated):\n if \"stickycookie\" in updated:\n if ctx.options.stickycookie:\n flt = flowfilter.parse(ctx.options.stickycookie)\n if not flt:\n raise exceptions.OptionsError(\n \"stickycookie: invalid filter expression: %s\" % ctx.options.stickycookie\n )\n self.flt = flt\n else:\n self.flt = None\n\n def response(self, flow: http.HTTPFlow):\n if self.flt:\n for name, (value, attrs) in flow.response.cookies.items(multi=True):\n # FIXME: We now know that Cookie.py screws up some cookies with\n # valid RFC 822/1123 datetime specifications for expiry. Sigh.\n dom_port_path = ckey(attrs, flow)\n\n if domain_match(flow.request.host, dom_port_path[0]):\n if cookies.is_expired(attrs):\n # Remove the cookie from jar\n self.jar[dom_port_path].pop(name, None)\n\n # If all cookies of a dom_port_path have been removed\n # then remove it from the jar itself\n if not self.jar[dom_port_path]:\n self.jar.pop(dom_port_path, None)\n else:\n self.jar[dom_port_path][name] = value\n\n def request(self, flow: http.HTTPFlow):\n if self.flt:\n cookie_list = [] # type: List[Tuple[str,str]]\n if flowfilter.match(self.flt, flow):\n for (domain, port, path), c in self.jar.items():\n match = [\n domain_match(flow.request.host, domain),\n flow.request.port == port,\n flow.request.path.startswith(path)\n ]\n if all(match):\n cookie_list.extend(c.items())\n if cookie_list:\n # FIXME: we need to formalise this...\n flow.metadata[\"stickycookie\"] = True\n flow.request.headers[\"cookie\"] = cookies.format_cookie_header(cookie_list)\n", "path": "mitmproxy/addons/stickycookie.py"}]}
| 1,333 | 797 |
gh_patches_debug_19676
|
rasdani/github-patches
|
git_diff
|
holoviz__holoviews-1845
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Table broken with bokeh 0.12.7
When displaying a Table with bokeh 0.12.7 I currently see the following error:
```
Javascript error adding output!
Error: SlickGrid's 'enableColumnReorder = true' option requires jquery-ui.sortable module to be loaded
See your browser Javascript console for more details.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `holoviews/plotting/bokeh/tabular.py`
Content:
```
1 from bokeh.models.widgets import DataTable, TableColumn
2
3 import param
4
5 import numpy as np
6 from ...core import Dataset
7 from ...element import ItemTable
8 from ..plot import GenericElementPlot
9 from .plot import BokehPlot
10
11 class TablePlot(BokehPlot, GenericElementPlot):
12
13 height = param.Number(default=None)
14
15 width = param.Number(default=400)
16
17 style_opts = ['row_headers', 'selectable', 'editable',
18 'sortable', 'fit_columns', 'width', 'height']
19
20 finalize_hooks = param.HookList(default=[], doc="""
21 Optional list of hooks called when finalizing a column.
22 The hook is passed the plot object and the displayed
23 object, and other plotting handles can be accessed via plot.handles.""")
24
25 _update_handles = ['source', 'glyph']
26
27 def __init__(self, element, plot=None, **params):
28 super(TablePlot, self).__init__(element, **params)
29 self.handles = {} if plot is None else self.handles['plot']
30 element_ids = self.hmap.traverse(lambda x: id(x), [Dataset, ItemTable])
31 self.static = len(set(element_ids)) == 1 and len(self.keys) == len(self.hmap)
32 self.callbacks = [] # Callback support on tables not implemented
33
34
35 def _execute_hooks(self, element):
36 """
37 Executes finalize hooks
38 """
39 for hook in self.finalize_hooks:
40 try:
41 hook(self, element)
42 except Exception as e:
43 self.warning("Plotting hook %r could not be applied:\n\n %s" % (hook, e))
44
45
46 def get_data(self, element, ranges=None, empty=False):
47 dims = element.dimensions()
48 data = {d: np.array([]) if empty else element.dimension_values(d)
49 for d in dims}
50 mapping = {d.name: d.name for d in dims}
51 data = {d.name: values if values.dtype.kind in "if" else list(map(d.pprint_value, values))
52 for d, values in data.items()}
53 return data, mapping
54
55
56 def initialize_plot(self, ranges=None, plot=None, plots=None, source=None):
57 """
58 Initializes a new plot object with the last available frame.
59 """
60 # Get element key and ranges for frame
61 element = self.hmap.last
62 key = self.keys[-1]
63 self.current_frame = element
64 self.current_key = key
65
66 data, _ = self.get_data(element, ranges)
67 if source is None:
68 source = self._init_datasource(data)
69 self.handles['source'] = source
70
71 dims = element.dimensions()
72 columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]
73 properties = self.lookup_options(element, 'style')[self.cyclic_index]
74 table = DataTable(source=source, columns=columns, height=self.height,
75 width=self.width, **properties)
76 self.handles['plot'] = table
77 self.handles['glyph_renderer'] = table
78 self._execute_hooks(element)
79 self.drawn = True
80
81 return table
82
83
84 @property
85 def current_handles(self):
86 """
87 Returns a list of the plot objects to update.
88 """
89 handles = []
90 if self.static and not self.dynamic:
91 return handles
92
93
94 element = self.current_frame
95 previous_id = self.handles.get('previous_id', None)
96 current_id = None if self.current_frame is None else element._plot_id
97 for handle in self._update_handles:
98 if (handle == 'source' and self.dynamic and current_id == previous_id):
99 continue
100 if handle in self.handles:
101 handles.append(self.handles[handle])
102
103 # Cache frame object id to skip updating if unchanged
104 if self.dynamic:
105 self.handles['previous_id'] = current_id
106
107 return handles
108
109
110 def update_frame(self, key, ranges=None, plot=None):
111 """
112 Updates an existing plot with data corresponding
113 to the key.
114 """
115 element = self._get_frame(key)
116 source = self.handles['source']
117 data, _ = self.get_data(element, ranges)
118 self._update_datasource(source, data)
119
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/holoviews/plotting/bokeh/tabular.py b/holoviews/plotting/bokeh/tabular.py
--- a/holoviews/plotting/bokeh/tabular.py
+++ b/holoviews/plotting/bokeh/tabular.py
@@ -7,6 +7,8 @@
from ...element import ItemTable
from ..plot import GenericElementPlot
from .plot import BokehPlot
+from .util import bokeh_version
+
class TablePlot(BokehPlot, GenericElementPlot):
@@ -71,6 +73,8 @@
dims = element.dimensions()
columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]
properties = self.lookup_options(element, 'style')[self.cyclic_index]
+ if bokeh_version > '0.12.7':
+ properties['reorderable'] = False
table = DataTable(source=source, columns=columns, height=self.height,
width=self.width, **properties)
self.handles['plot'] = table
|
{"golden_diff": "diff --git a/holoviews/plotting/bokeh/tabular.py b/holoviews/plotting/bokeh/tabular.py\n--- a/holoviews/plotting/bokeh/tabular.py\n+++ b/holoviews/plotting/bokeh/tabular.py\n@@ -7,6 +7,8 @@\n from ...element import ItemTable\n from ..plot import GenericElementPlot\n from .plot import BokehPlot\n+from .util import bokeh_version\n+\n \n class TablePlot(BokehPlot, GenericElementPlot):\n \n@@ -71,6 +73,8 @@\n dims = element.dimensions()\n columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]\n properties = self.lookup_options(element, 'style')[self.cyclic_index]\n+ if bokeh_version > '0.12.7':\n+ properties['reorderable'] = False\n table = DataTable(source=source, columns=columns, height=self.height,\n width=self.width, **properties)\n self.handles['plot'] = table\n", "issue": "Table broken with bokeh 0.12.7\nWhen displaying a Table with bokeh 0.12.7 I currently see the following error:\r\n\r\n```\r\nJavascript error adding output!\r\nError: SlickGrid's 'enableColumnReorder = true' option requires jquery-ui.sortable module to be loaded\r\nSee your browser Javascript console for more details.\r\n```\n", "before_files": [{"content": "from bokeh.models.widgets import DataTable, TableColumn\n\nimport param\n\nimport numpy as np\nfrom ...core import Dataset\nfrom ...element import ItemTable\nfrom ..plot import GenericElementPlot\nfrom .plot import BokehPlot\n\nclass TablePlot(BokehPlot, GenericElementPlot):\n\n height = param.Number(default=None)\n\n width = param.Number(default=400)\n\n style_opts = ['row_headers', 'selectable', 'editable',\n 'sortable', 'fit_columns', 'width', 'height']\n\n finalize_hooks = param.HookList(default=[], doc=\"\"\"\n Optional list of hooks called when finalizing a column.\n The hook is passed the plot object and the displayed\n object, and other plotting handles can be accessed via plot.handles.\"\"\")\n\n _update_handles = ['source', 'glyph']\n\n def __init__(self, element, plot=None, **params):\n super(TablePlot, self).__init__(element, **params)\n self.handles = {} if plot is None else self.handles['plot']\n element_ids = self.hmap.traverse(lambda x: id(x), [Dataset, ItemTable])\n self.static = len(set(element_ids)) == 1 and len(self.keys) == len(self.hmap)\n self.callbacks = [] # Callback support on tables not implemented\n\n\n def _execute_hooks(self, element):\n \"\"\"\n Executes finalize hooks\n \"\"\"\n for hook in self.finalize_hooks:\n try:\n hook(self, element)\n except Exception as e:\n self.warning(\"Plotting hook %r could not be applied:\\n\\n %s\" % (hook, e))\n\n\n def get_data(self, element, ranges=None, empty=False):\n dims = element.dimensions()\n data = {d: np.array([]) if empty else element.dimension_values(d)\n for d in dims}\n mapping = {d.name: d.name for d in dims}\n data = {d.name: values if values.dtype.kind in \"if\" else list(map(d.pprint_value, values))\n for d, values in data.items()}\n return data, mapping\n\n\n def initialize_plot(self, ranges=None, plot=None, plots=None, source=None):\n \"\"\"\n Initializes a new plot object with the last available frame.\n \"\"\"\n # Get element key and ranges for frame\n element = self.hmap.last\n key = self.keys[-1]\n self.current_frame = element\n self.current_key = key\n\n data, _ = self.get_data(element, ranges)\n if source is None:\n source = self._init_datasource(data)\n self.handles['source'] = source\n\n dims = element.dimensions()\n columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]\n properties = self.lookup_options(element, 'style')[self.cyclic_index]\n table = DataTable(source=source, columns=columns, height=self.height,\n width=self.width, **properties)\n self.handles['plot'] = table\n self.handles['glyph_renderer'] = table\n self._execute_hooks(element)\n self.drawn = True\n\n return table\n\n\n @property\n def current_handles(self):\n \"\"\"\n Returns a list of the plot objects to update.\n \"\"\"\n handles = []\n if self.static and not self.dynamic:\n return handles\n\n\n element = self.current_frame\n previous_id = self.handles.get('previous_id', None)\n current_id = None if self.current_frame is None else element._plot_id\n for handle in self._update_handles:\n if (handle == 'source' and self.dynamic and current_id == previous_id):\n continue\n if handle in self.handles:\n handles.append(self.handles[handle])\n\n # Cache frame object id to skip updating if unchanged\n if self.dynamic:\n self.handles['previous_id'] = current_id\n\n return handles\n\n\n def update_frame(self, key, ranges=None, plot=None):\n \"\"\"\n Updates an existing plot with data corresponding\n to the key.\n \"\"\"\n element = self._get_frame(key)\n source = self.handles['source']\n data, _ = self.get_data(element, ranges)\n self._update_datasource(source, data)\n", "path": "holoviews/plotting/bokeh/tabular.py"}], "after_files": [{"content": "from bokeh.models.widgets import DataTable, TableColumn\n\nimport param\n\nimport numpy as np\nfrom ...core import Dataset\nfrom ...element import ItemTable\nfrom ..plot import GenericElementPlot\nfrom .plot import BokehPlot\nfrom .util import bokeh_version\n\n\nclass TablePlot(BokehPlot, GenericElementPlot):\n\n height = param.Number(default=None)\n\n width = param.Number(default=400)\n\n style_opts = ['row_headers', 'selectable', 'editable',\n 'sortable', 'fit_columns', 'width', 'height']\n\n finalize_hooks = param.HookList(default=[], doc=\"\"\"\n Optional list of hooks called when finalizing a column.\n The hook is passed the plot object and the displayed\n object, and other plotting handles can be accessed via plot.handles.\"\"\")\n\n _update_handles = ['source', 'glyph']\n\n def __init__(self, element, plot=None, **params):\n super(TablePlot, self).__init__(element, **params)\n self.handles = {} if plot is None else self.handles['plot']\n element_ids = self.hmap.traverse(lambda x: id(x), [Dataset, ItemTable])\n self.static = len(set(element_ids)) == 1 and len(self.keys) == len(self.hmap)\n self.callbacks = [] # Callback support on tables not implemented\n\n\n def _execute_hooks(self, element):\n \"\"\"\n Executes finalize hooks\n \"\"\"\n for hook in self.finalize_hooks:\n try:\n hook(self, element)\n except Exception as e:\n self.warning(\"Plotting hook %r could not be applied:\\n\\n %s\" % (hook, e))\n\n\n def get_data(self, element, ranges=None, empty=False):\n dims = element.dimensions()\n data = {d: np.array([]) if empty else element.dimension_values(d)\n for d in dims}\n mapping = {d.name: d.name for d in dims}\n data = {d.name: values if values.dtype.kind in \"if\" else list(map(d.pprint_value, values))\n for d, values in data.items()}\n return data, mapping\n\n\n def initialize_plot(self, ranges=None, plot=None, plots=None, source=None):\n \"\"\"\n Initializes a new plot object with the last available frame.\n \"\"\"\n # Get element key and ranges for frame\n element = self.hmap.last\n key = self.keys[-1]\n self.current_frame = element\n self.current_key = key\n\n data, _ = self.get_data(element, ranges)\n if source is None:\n source = self._init_datasource(data)\n self.handles['source'] = source\n\n dims = element.dimensions()\n columns = [TableColumn(field=d.name, title=d.pprint_label) for d in dims]\n properties = self.lookup_options(element, 'style')[self.cyclic_index]\n if bokeh_version > '0.12.7':\n properties['reorderable'] = False\n table = DataTable(source=source, columns=columns, height=self.height,\n width=self.width, **properties)\n self.handles['plot'] = table\n self.handles['glyph_renderer'] = table\n self._execute_hooks(element)\n self.drawn = True\n\n return table\n\n\n @property\n def current_handles(self):\n \"\"\"\n Returns a list of the plot objects to update.\n \"\"\"\n handles = []\n if self.static and not self.dynamic:\n return handles\n\n\n element = self.current_frame\n previous_id = self.handles.get('previous_id', None)\n current_id = None if self.current_frame is None else element._plot_id\n for handle in self._update_handles:\n if (handle == 'source' and self.dynamic and current_id == previous_id):\n continue\n if handle in self.handles:\n handles.append(self.handles[handle])\n\n # Cache frame object id to skip updating if unchanged\n if self.dynamic:\n self.handles['previous_id'] = current_id\n\n return handles\n\n\n def update_frame(self, key, ranges=None, plot=None):\n \"\"\"\n Updates an existing plot with data corresponding\n to the key.\n \"\"\"\n element = self._get_frame(key)\n source = self.handles['source']\n data, _ = self.get_data(element, ranges)\n self._update_datasource(source, data)\n", "path": "holoviews/plotting/bokeh/tabular.py"}]}
| 1,509 | 240 |
gh_patches_debug_20905
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-11972
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Dev docs: globalVars.appDir is not defined when attempting to build docs with Sphinx
Hi,
Related to #11970 and actually blocks it:
### Steps to reproduce:
When trying to build dev docs using "scons devDocs":
1. Run scons devDocs.
2. Once Sphinx is instlaled and ready, Sphinx will try to build dev docs for the source code.
### Actual behavior:
A traceback shows up, ending with:
AttributeError: module 'globalVars' has no attribute 'appDir'
### Expected behavior:
No errors with the dev docs building completing.
### System configuration
#### NVDA installed/portable/running from source:
Source
#### NVDA version:
Alpha-21561,7e5ffde2391c
#### Windows version:
Windows 10 Version 20H2 (build 19042.685)
#### Name and version of other software in use when reproducing the issue:
Python 3.7.9
#### Other information about your system:
N/A
### Other questions
#### Does the issue still occur after restarting your computer?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
Not applicable
#### If addons are disabled, is your problem still occurring?
Not applicable
#### Did you try to run the COM registry fixing tool in NVDA menu / tools?
Not applicable
### Cause:
This is caused by config file error, specifically when a mock config.conf instance is created. Prior to this, importing config module fails because globalVars.appDir is not defined by the time scons devDocs is run.
### Solution:
one solution is to define globalVars.appDir to point to the source directory.
Thanks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `devDocs/conf.py`
Content:
```
1 # A part of NonVisual Desktop Access (NVDA)
2 # Copyright (C) 2019 NV Access Limited, Leonard de Ruijter
3 # This file is covered by the GNU General Public License.
4 # See the file COPYING for more details.
5
6 # Configuration file for the Sphinx documentation builder.
7
8 # -- Path setup --------------------------------------------------------------
9
10 import os
11 import sys
12 sys.path.insert(0, os.path.abspath('../source'))
13 import sourceEnv # noqa: F401, E402
14
15 # Initialize languageHandler so that sphinx is able to deal with translatable strings.
16 import languageHandler # noqa: E402
17 languageHandler.setLanguage("en")
18
19 # Initialize globalvars.appArgs to something sensible.
20 import globalVars # noqa: E402
21
22
23 class AppArgs:
24 # Set an empty comnfig path
25 # This is never used as we don't initialize config, but some modules expect this to be set.
26 configPath = ""
27 secure = False
28 disableAddons = True
29 launcher = False
30
31
32 globalVars.appArgs = AppArgs()
33
34 # Import NVDA's versionInfo module.
35 import versionInfo # noqa: E402
36 # Set a suitable updateVersionType for the updateCheck module to be imported
37 versionInfo.updateVersionType = "stable"
38
39 # -- Project information -----------------------------------------------------
40
41 project = versionInfo.name
42 copyright = versionInfo.copyright
43 author = versionInfo.publisher
44
45 # The major project version
46 version = versionInfo.formatVersionForGUI(
47 versionInfo.version_year,
48 versionInfo.version_major,
49 versionInfo.version_minor
50 )
51
52 # The full version, including alpha/beta/rc tags
53 release = versionInfo.version
54
55 # -- General configuration ---------------------------------------------------
56
57 default_role = 'py:obj'
58
59 # Add any Sphinx extension module names here, as strings. They can be
60 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
61 # ones.
62 extensions = [
63 'sphinx.ext.autodoc',
64 ]
65
66 # Add any paths that contain templates here, relative to this directory.
67 templates_path = ['_templates']
68
69 # List of patterns, relative to source directory, that match files and
70 # directories to ignore when looking for source files.
71 # This pattern also affects html_static_path and html_extra_path.
72 exclude_patterns = [
73 "_build"
74 ]
75
76
77 # -- Options for HTML output -------------------------------------------------
78
79 # The theme to use for HTML and HTML Help pages.
80
81 html_theme = "sphinx_rtd_theme"
82
83 # Add any paths that contain custom static files (such as style sheets) here,
84 # relative to this directory. They are copied after the builtin static files,
85 # so a file named "default.css" will overwrite the builtin "default.css".
86 html_static_path = ['_static']
87
88 # -- Extension configuration -------------------------------------------------
89
90 # sphinx.ext.autodoc configuration
91
92 # Both the class’ and the __init__ method’s docstring are concatenated and inserted.
93 autoclass_content = "both"
94 autodoc_member_order = 'bysource'
95 autodoc_mock_imports = [
96 "louis", # Not our project
97 ]
98
99 # Perform some manual mocking of specific objects.
100 # autodoc can only mock modules, not objects.
101 from sphinx.ext.autodoc.mock import _make_subclass # noqa: E402
102
103 import config # noqa: E402
104 # Mock an instance of the configuration manager.
105 config.conf = _make_subclass("conf", "config")()
106
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/devDocs/conf.py b/devDocs/conf.py
--- a/devDocs/conf.py
+++ b/devDocs/conf.py
@@ -1,5 +1,5 @@
# A part of NonVisual Desktop Access (NVDA)
-# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter
+# Copyright (C) 2019-2020 NV Access Limited, Leonard de Ruijter, Joseph Lee
# This file is covered by the GNU General Public License.
# See the file COPYING for more details.
@@ -16,7 +16,7 @@
import languageHandler # noqa: E402
languageHandler.setLanguage("en")
-# Initialize globalvars.appArgs to something sensible.
+# Initialize globalVars.appArgs to something sensible.
import globalVars # noqa: E402
@@ -30,6 +30,11 @@
globalVars.appArgs = AppArgs()
+# #11971: NVDA is not running, therefore app dir is undefined.
+# Therefore tell NVDA that apt source directory is app dir.
+appDir = os.path.join("..", "source")
+globalVars.appDir = os.path.abspath(appDir)
+
# Import NVDA's versionInfo module.
import versionInfo # noqa: E402
|
{"golden_diff": "diff --git a/devDocs/conf.py b/devDocs/conf.py\n--- a/devDocs/conf.py\n+++ b/devDocs/conf.py\n@@ -1,5 +1,5 @@\n # A part of NonVisual Desktop Access (NVDA)\n-# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter\n+# Copyright (C) 2019-2020 NV Access Limited, Leonard de Ruijter, Joseph Lee\n # This file is covered by the GNU General Public License.\n # See the file COPYING for more details.\n \n@@ -16,7 +16,7 @@\n import languageHandler # noqa: E402\n languageHandler.setLanguage(\"en\")\n \n-# Initialize globalvars.appArgs to something sensible.\n+# Initialize globalVars.appArgs to something sensible.\n import globalVars # noqa: E402\n \n \n@@ -30,6 +30,11 @@\n \n \n globalVars.appArgs = AppArgs()\n+# #11971: NVDA is not running, therefore app dir is undefined.\n+# Therefore tell NVDA that apt source directory is app dir.\n+appDir = os.path.join(\"..\", \"source\")\n+globalVars.appDir = os.path.abspath(appDir)\n+\n \n # Import NVDA's versionInfo module.\n import versionInfo # noqa: E402\n", "issue": "Dev docs: globalVars.appDir is not defined when attempting to build docs with Sphinx\nHi,\r\nRelated to #11970 and actually blocks it:\r\n\r\n### Steps to reproduce:\r\nWhen trying to build dev docs using \"scons devDocs\":\r\n\r\n1. Run scons devDocs.\r\n2. Once Sphinx is instlaled and ready, Sphinx will try to build dev docs for the source code.\r\n\r\n### Actual behavior:\r\nA traceback shows up, ending with:\r\nAttributeError: module 'globalVars' has no attribute 'appDir'\r\n\r\n### Expected behavior:\r\nNo errors with the dev docs building completing.\r\n\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nSource\r\n\r\n#### NVDA version:\r\nAlpha-21561,7e5ffde2391c\r\n\r\n#### Windows version:\r\nWindows 10 Version 20H2 (build 19042.685)\r\n\r\n#### Name and version of other software in use when reproducing the issue:\r\nPython 3.7.9\r\n\r\n#### Other information about your system:\r\nN/A\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your computer?\r\nYes\r\n\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nNot applicable\r\n\r\n#### If addons are disabled, is your problem still occurring?\r\nNot applicable\r\n\r\n#### Did you try to run the COM registry fixing tool in NVDA menu / tools?\r\nNot applicable\r\n\r\n### Cause:\r\nThis is caused by config file error, specifically when a mock config.conf instance is created. Prior to this, importing config module fails because globalVars.appDir is not defined by the time scons devDocs is run.\r\n\r\n### Solution:\r\none solution is to define globalVars.appDir to point to the source directory.\r\n\r\nThanks.\n", "before_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2019 NV Access Limited, Leonard de Ruijter\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../source'))\nimport sourceEnv # noqa: F401, E402\n\n# Initialize languageHandler so that sphinx is able to deal with translatable strings.\nimport languageHandler # noqa: E402\nlanguageHandler.setLanguage(\"en\")\n\n# Initialize globalvars.appArgs to something sensible.\nimport globalVars # noqa: E402\n\n\nclass AppArgs:\n\t# Set an empty comnfig path\n\t# This is never used as we don't initialize config, but some modules expect this to be set.\n\tconfigPath = \"\"\n\tsecure = False\n\tdisableAddons = True\n\tlauncher = False\n\n\nglobalVars.appArgs = AppArgs()\n\n# Import NVDA's versionInfo module.\nimport versionInfo # noqa: E402\n# Set a suitable updateVersionType for the updateCheck module to be imported\nversionInfo.updateVersionType = \"stable\"\n\n# -- Project information -----------------------------------------------------\n\nproject = versionInfo.name\ncopyright = versionInfo.copyright\nauthor = versionInfo.publisher\n\n# The major project version\nversion = versionInfo.formatVersionForGUI(\n\tversionInfo.version_year,\n\tversionInfo.version_major,\n\tversionInfo.version_minor\n)\n\n# The full version, including alpha/beta/rc tags\nrelease = versionInfo.version\n\n# -- General configuration ---------------------------------------------------\n\ndefault_role = 'py:obj'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n\t'sphinx.ext.autodoc',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n\t\"_build\"\n]\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages.\n\nhtml_theme = \"sphinx_rtd_theme\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# -- Extension configuration -------------------------------------------------\n\n# sphinx.ext.autodoc configuration\n\n# Both the class\u2019 and the __init__ method\u2019s docstring are concatenated and inserted.\nautoclass_content = \"both\"\nautodoc_member_order = 'bysource'\nautodoc_mock_imports = [\n\t\"louis\", # Not our project\n]\n\n# Perform some manual mocking of specific objects.\n# autodoc can only mock modules, not objects.\nfrom sphinx.ext.autodoc.mock import _make_subclass # noqa: E402\n\nimport config # noqa: E402\n# Mock an instance of the configuration manager.\nconfig.conf = _make_subclass(\"conf\", \"config\")()\n", "path": "devDocs/conf.py"}], "after_files": [{"content": "# A part of NonVisual Desktop Access (NVDA)\n# Copyright (C) 2019-2020 NV Access Limited, Leonard de Ruijter, Joseph Lee\n# This file is covered by the GNU General Public License.\n# See the file COPYING for more details.\n\n# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('../source'))\nimport sourceEnv # noqa: F401, E402\n\n# Initialize languageHandler so that sphinx is able to deal with translatable strings.\nimport languageHandler # noqa: E402\nlanguageHandler.setLanguage(\"en\")\n\n# Initialize globalVars.appArgs to something sensible.\nimport globalVars # noqa: E402\n\n\nclass AppArgs:\n\t# Set an empty comnfig path\n\t# This is never used as we don't initialize config, but some modules expect this to be set.\n\tconfigPath = \"\"\n\tsecure = False\n\tdisableAddons = True\n\tlauncher = False\n\n\nglobalVars.appArgs = AppArgs()\n# #11971: NVDA is not running, therefore app dir is undefined.\n# Therefore tell NVDA that apt source directory is app dir.\nappDir = os.path.join(\"..\", \"source\")\nglobalVars.appDir = os.path.abspath(appDir)\n\n\n# Import NVDA's versionInfo module.\nimport versionInfo # noqa: E402\n# Set a suitable updateVersionType for the updateCheck module to be imported\nversionInfo.updateVersionType = \"stable\"\n\n# -- Project information -----------------------------------------------------\n\nproject = versionInfo.name\ncopyright = versionInfo.copyright\nauthor = versionInfo.publisher\n\n# The major project version\nversion = versionInfo.formatVersionForGUI(\n\tversionInfo.version_year,\n\tversionInfo.version_major,\n\tversionInfo.version_minor\n)\n\n# The full version, including alpha/beta/rc tags\nrelease = versionInfo.version\n\n# -- General configuration ---------------------------------------------------\n\ndefault_role = 'py:obj'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n\t'sphinx.ext.autodoc',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n\t\"_build\"\n]\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages.\n\nhtml_theme = \"sphinx_rtd_theme\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# -- Extension configuration -------------------------------------------------\n\n# sphinx.ext.autodoc configuration\n\n# Both the class\u2019 and the __init__ method\u2019s docstring are concatenated and inserted.\nautoclass_content = \"both\"\nautodoc_member_order = 'bysource'\nautodoc_mock_imports = [\n\t\"louis\", # Not our project\n]\n\n# Perform some manual mocking of specific objects.\n# autodoc can only mock modules, not objects.\nfrom sphinx.ext.autodoc.mock import _make_subclass # noqa: E402\n\nimport config # noqa: E402\n# Mock an instance of the configuration manager.\nconfig.conf = _make_subclass(\"conf\", \"config\")()\n", "path": "devDocs/conf.py"}]}
| 1,589 | 291 |
gh_patches_debug_27466
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-543
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Question] Attack Vector described in Vipercoin's `approve` annotation
In [L89 of `vipercoin.v.py`](https://github.com/ethereum/viper/blob/master/examples/tokens/vipercoin.v.py#L89), the `approve` method has an annotation that begins like this
>To prevent attack vectors like the one described here and discussed here,
I don't see any description of the attack vectors described, perhaps there should be an external link here? Point me in the right direction and I can make the PR for it. :)
Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/tokens/vipercoin.v.py`
Content:
```
1 # Viper Port of MyToken
2 # THIS CONTRACT HAS NOT BEEN AUDITED!
3 # ERC20 details at:
4 # https://theethereum.wiki/w/index.php/ERC20_Token_Standard
5 # https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20-token-standard.md
6 # Events of the token.
7 Transfer: __log__({_from: indexed(address), _to: indexed(address), _value: num256})
8 Approval: __log__({_owner: indexed(address), _spender: indexed(address), _value: num256})
9
10
11 # Variables of the token.
12 name: bytes32
13 symbol: bytes32
14 totalSupply: num
15 decimals: num
16 balances: num[address]
17 allowed: num[address][address]
18
19 @public
20 def __init__(_name: bytes32, _symbol: bytes32, _decimals: num, _initialSupply: num):
21
22 self.name = _name
23 self.symbol = _symbol
24 self.decimals = _decimals
25 self.totalSupply = _initialSupply * 10 ** _decimals
26 self.balances[msg.sender] = self.totalSupply
27
28 @public
29 @constant
30 def symbol() -> bytes32:
31
32 return self.symbol
33
34 @public
35 @constant
36 def name() -> bytes32:
37
38 return self.name
39
40
41 # What is the balance of a particular account?
42 @public
43 @constant
44 def balanceOf(_owner: address) -> num256:
45
46 return as_num256(self.balances[_owner])
47
48
49 # Return total supply of token.
50 @public
51 @constant
52 def totalSupply() -> num256:
53
54 return as_num256(self.totalSupply)
55
56
57 # Send `_value` tokens to `_to` from your account
58 @public
59 def transfer(_to: address, _amount: num(num256)) -> bool:
60
61 assert self.balances[msg.sender] >= _amount
62 assert self.balances[_to] + _amount >= self.balances[_to]
63
64 self.balances[msg.sender] -= _amount # Subtract from the sender
65 self.balances[_to] += _amount # Add the same to the recipient
66 log.Transfer(msg.sender, _to, as_num256(_amount)) # log transfer event.
67
68 return True
69
70
71 # Transfer allowed tokens from a specific account to another.
72 @public
73 def transferFrom(_from: address, _to: address, _value: num(num256)) -> bool:
74
75 assert _value <= self.allowed[_from][msg.sender]
76 assert _value <= self.balances[_from]
77
78 self.balances[_from] -= _value # decrease balance of from address.
79 self.allowed[_from][msg.sender] -= _value # decrease allowance.
80 self.balances[_to] += _value # incease balance of to address.
81 log.Transfer(_from, _to, as_num256(_value)) # log transfer event.
82
83 return True
84
85
86 # Allow _spender to withdraw from your account, multiple times, up to the _value amount.
87 # If this function is called again it overwrites the current allowance with _value.
88 #
89 # NOTE: To prevent attack vectors like the one described here and discussed here,
90 # clients SHOULD make sure to create user interfaces in such a way that they
91 # set the allowance first to 0 before setting it to another value for the
92 # same spender. THOUGH The contract itself shouldn't enforce it, to allow
93 # backwards compatilibilty with contracts deployed before.
94 #
95 @public
96 def approve(_spender: address, _amount: num(num256)) -> bool:
97
98 self.allowed[msg.sender][_spender] = _amount
99 log.Approval(msg.sender, _spender, as_num256(_amount))
100
101 return True
102
103
104 # Get the allowance an address has to spend anothers' token.
105 @public
106 def allowance(_owner: address, _spender: address) -> num256:
107
108 return as_num256(self.allowed[_owner][_spender])
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/tokens/vipercoin.v.py b/examples/tokens/vipercoin.v.py
--- a/examples/tokens/vipercoin.v.py
+++ b/examples/tokens/vipercoin.v.py
@@ -86,12 +86,15 @@
# Allow _spender to withdraw from your account, multiple times, up to the _value amount.
# If this function is called again it overwrites the current allowance with _value.
#
-# NOTE: To prevent attack vectors like the one described here and discussed here,
-# clients SHOULD make sure to create user interfaces in such a way that they
+# NOTE: We would like to prevent attack vectors like the one described here:
+# https://docs.google.com/document/d/1YLPtQxZu1UAvO9cZ1O2RPXBbT0mooh4DYKjA_jp-RLM/edit#heading=h.m9fhqynw2xvt
+# and discussed here:
+# https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
+#
+# Clients SHOULD make sure to create user interfaces in such a way that they
# set the allowance first to 0 before setting it to another value for the
# same spender. THOUGH The contract itself shouldn't enforce it, to allow
# backwards compatilibilty with contracts deployed before.
-#
@public
def approve(_spender: address, _amount: num(num256)) -> bool:
@@ -101,7 +104,7 @@
return True
-# Get the allowance an address has to spend anothers' token.
+# Get the allowance an address has to spend another's token.
@public
def allowance(_owner: address, _spender: address) -> num256:
|
{"golden_diff": "diff --git a/examples/tokens/vipercoin.v.py b/examples/tokens/vipercoin.v.py\n--- a/examples/tokens/vipercoin.v.py\n+++ b/examples/tokens/vipercoin.v.py\n@@ -86,12 +86,15 @@\n # Allow _spender to withdraw from your account, multiple times, up to the _value amount.\n # If this function is called again it overwrites the current allowance with _value.\n #\n-# NOTE: To prevent attack vectors like the one described here and discussed here,\n-# clients SHOULD make sure to create user interfaces in such a way that they\n+# NOTE: We would like to prevent attack vectors like the one described here:\n+# https://docs.google.com/document/d/1YLPtQxZu1UAvO9cZ1O2RPXBbT0mooh4DYKjA_jp-RLM/edit#heading=h.m9fhqynw2xvt\n+# and discussed here:\n+# https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729\n+#\n+# Clients SHOULD make sure to create user interfaces in such a way that they\n # set the allowance first to 0 before setting it to another value for the\n # same spender. THOUGH The contract itself shouldn't enforce it, to allow\n # backwards compatilibilty with contracts deployed before.\n-#\n @public\n def approve(_spender: address, _amount: num(num256)) -> bool:\n \n@@ -101,7 +104,7 @@\n return True\n \n \n-# Get the allowance an address has to spend anothers' token.\n+# Get the allowance an address has to spend another's token.\n @public\n def allowance(_owner: address, _spender: address) -> num256:\n", "issue": "[Question] Attack Vector described in Vipercoin's `approve` annotation\nIn [L89 of `vipercoin.v.py`](https://github.com/ethereum/viper/blob/master/examples/tokens/vipercoin.v.py#L89), the `approve` method has an annotation that begins like this\r\n\r\n>To prevent attack vectors like the one described here and discussed here,\r\n\r\nI don't see any description of the attack vectors described, perhaps there should be an external link here? Point me in the right direction and I can make the PR for it. :)\r\n\r\nThanks!\n", "before_files": [{"content": "# Viper Port of MyToken\n# THIS CONTRACT HAS NOT BEEN AUDITED!\n# ERC20 details at:\n# https://theethereum.wiki/w/index.php/ERC20_Token_Standard\n# https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20-token-standard.md\n# Events of the token.\nTransfer: __log__({_from: indexed(address), _to: indexed(address), _value: num256})\nApproval: __log__({_owner: indexed(address), _spender: indexed(address), _value: num256})\n\n\n# Variables of the token.\nname: bytes32\nsymbol: bytes32\ntotalSupply: num\ndecimals: num\nbalances: num[address]\nallowed: num[address][address]\n\n@public\ndef __init__(_name: bytes32, _symbol: bytes32, _decimals: num, _initialSupply: num):\n \n self.name = _name\n self.symbol = _symbol\n self.decimals = _decimals\n self.totalSupply = _initialSupply * 10 ** _decimals\n self.balances[msg.sender] = self.totalSupply\n\n@public\n@constant\ndef symbol() -> bytes32:\n\n return self.symbol\n\n@public\n@constant\ndef name() -> bytes32:\n\n return self.name\n\n\n# What is the balance of a particular account?\n@public\n@constant\ndef balanceOf(_owner: address) -> num256:\n\n return as_num256(self.balances[_owner])\n\n\n# Return total supply of token.\n@public\n@constant\ndef totalSupply() -> num256:\n\n return as_num256(self.totalSupply)\n\n\n# Send `_value` tokens to `_to` from your account\n@public\ndef transfer(_to: address, _amount: num(num256)) -> bool:\n\n assert self.balances[msg.sender] >= _amount\n assert self.balances[_to] + _amount >= self.balances[_to]\n\n self.balances[msg.sender] -= _amount # Subtract from the sender\n self.balances[_to] += _amount # Add the same to the recipient\n log.Transfer(msg.sender, _to, as_num256(_amount)) # log transfer event.\n\n return True\n\n\n# Transfer allowed tokens from a specific account to another.\n@public\ndef transferFrom(_from: address, _to: address, _value: num(num256)) -> bool:\n\n assert _value <= self.allowed[_from][msg.sender]\n assert _value <= self.balances[_from]\n\n self.balances[_from] -= _value # decrease balance of from address.\n self.allowed[_from][msg.sender] -= _value # decrease allowance.\n self.balances[_to] += _value # incease balance of to address.\n log.Transfer(_from, _to, as_num256(_value)) # log transfer event.\n \n return True\n\n\n# Allow _spender to withdraw from your account, multiple times, up to the _value amount.\n# If this function is called again it overwrites the current allowance with _value.\n#\n# NOTE: To prevent attack vectors like the one described here and discussed here,\n# clients SHOULD make sure to create user interfaces in such a way that they\n# set the allowance first to 0 before setting it to another value for the\n# same spender. THOUGH The contract itself shouldn't enforce it, to allow\n# backwards compatilibilty with contracts deployed before.\n#\n@public\ndef approve(_spender: address, _amount: num(num256)) -> bool:\n\n self.allowed[msg.sender][_spender] = _amount\n log.Approval(msg.sender, _spender, as_num256(_amount))\n\n return True\n\n\n# Get the allowance an address has to spend anothers' token.\n@public\ndef allowance(_owner: address, _spender: address) -> num256:\n\n return as_num256(self.allowed[_owner][_spender])\n", "path": "examples/tokens/vipercoin.v.py"}], "after_files": [{"content": "# Viper Port of MyToken\n# THIS CONTRACT HAS NOT BEEN AUDITED!\n# ERC20 details at:\n# https://theethereum.wiki/w/index.php/ERC20_Token_Standard\n# https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20-token-standard.md\n# Events of the token.\nTransfer: __log__({_from: indexed(address), _to: indexed(address), _value: num256})\nApproval: __log__({_owner: indexed(address), _spender: indexed(address), _value: num256})\n\n\n# Variables of the token.\nname: bytes32\nsymbol: bytes32\ntotalSupply: num\ndecimals: num\nbalances: num[address]\nallowed: num[address][address]\n\n@public\ndef __init__(_name: bytes32, _symbol: bytes32, _decimals: num, _initialSupply: num):\n \n self.name = _name\n self.symbol = _symbol\n self.decimals = _decimals\n self.totalSupply = _initialSupply * 10 ** _decimals\n self.balances[msg.sender] = self.totalSupply\n\n@public\n@constant\ndef symbol() -> bytes32:\n\n return self.symbol\n\n@public\n@constant\ndef name() -> bytes32:\n\n return self.name\n\n\n# What is the balance of a particular account?\n@public\n@constant\ndef balanceOf(_owner: address) -> num256:\n\n return as_num256(self.balances[_owner])\n\n\n# Return total supply of token.\n@public\n@constant\ndef totalSupply() -> num256:\n\n return as_num256(self.totalSupply)\n\n\n# Send `_value` tokens to `_to` from your account\n@public\ndef transfer(_to: address, _amount: num(num256)) -> bool:\n\n assert self.balances[msg.sender] >= _amount\n assert self.balances[_to] + _amount >= self.balances[_to]\n\n self.balances[msg.sender] -= _amount # Subtract from the sender\n self.balances[_to] += _amount # Add the same to the recipient\n log.Transfer(msg.sender, _to, as_num256(_amount)) # log transfer event.\n\n return True\n\n\n# Transfer allowed tokens from a specific account to another.\n@public\ndef transferFrom(_from: address, _to: address, _value: num(num256)) -> bool:\n\n assert _value <= self.allowed[_from][msg.sender]\n assert _value <= self.balances[_from]\n\n self.balances[_from] -= _value # decrease balance of from address.\n self.allowed[_from][msg.sender] -= _value # decrease allowance.\n self.balances[_to] += _value # incease balance of to address.\n log.Transfer(_from, _to, as_num256(_value)) # log transfer event.\n \n return True\n\n\n# Allow _spender to withdraw from your account, multiple times, up to the _value amount.\n# If this function is called again it overwrites the current allowance with _value.\n#\n# NOTE: We would like to prevent attack vectors like the one described here:\n# https://docs.google.com/document/d/1YLPtQxZu1UAvO9cZ1O2RPXBbT0mooh4DYKjA_jp-RLM/edit#heading=h.m9fhqynw2xvt\n# and discussed here:\n# https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729\n#\n# Clients SHOULD make sure to create user interfaces in such a way that they\n# set the allowance first to 0 before setting it to another value for the\n# same spender. THOUGH The contract itself shouldn't enforce it, to allow\n# backwards compatilibilty with contracts deployed before.\n@public\ndef approve(_spender: address, _amount: num(num256)) -> bool:\n\n self.allowed[msg.sender][_spender] = _amount\n log.Approval(msg.sender, _spender, as_num256(_amount))\n\n return True\n\n\n# Get the allowance an address has to spend another's token.\n@public\ndef allowance(_owner: address, _spender: address) -> num256:\n\n return as_num256(self.allowed[_owner][_spender])\n", "path": "examples/tokens/vipercoin.v.py"}]}
| 1,503 | 400 |
gh_patches_debug_22788
|
rasdani/github-patches
|
git_diff
|
CTPUG__wafer-193
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove'unicode' calls from wafer
Current wafer using python 3 fails on several admin tasks because `UserProfile.__str__` tries to call `unicode`, which is obviously not defined.
We should handle the difference between python 2 and python 3 correctly in this situation.
There are a couple of other calls to unicode() that look dangerous in the error paths in /registration/views.py that should probably be fixed as well.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wafer/users/models.py`
Content:
```
1 from django.contrib.auth.models import User
2 from django.db import models
3 from django.db.models.signals import post_save
4 from django.utils.encoding import python_2_unicode_compatible
5
6 from libravatar import libravatar_url
7 try:
8 from urllib2 import urlparse
9 except ImportError:
10 from urllib import parse as urlparse
11 from django.utils.http import urlquote
12
13 from wafer.talks.models import ACCEPTED, PENDING
14
15
16 @python_2_unicode_compatible
17 class UserProfile(models.Model):
18 user = models.OneToOneField(User)
19 contact_number = models.CharField(max_length=16, null=True, blank=True)
20 bio = models.TextField(null=True, blank=True)
21
22 homepage = models.CharField(max_length=256, null=True, blank=True)
23 # We should probably do social auth instead
24 # And care about other code hosting sites...
25 twitter_handle = models.CharField(max_length=15, null=True, blank=True)
26 github_username = models.CharField(max_length=32, null=True, blank=True)
27
28 def __str__(self):
29 return unicode(self.user)
30
31 def accepted_talks(self):
32 return self.user.talks.filter(status=ACCEPTED)
33
34 def pending_talks(self):
35 return self.user.talks.filter(status=PENDING)
36
37 def avatar_url(self, size=96, https=True, default='mm'):
38 if not self.user.email:
39 return None
40 return libravatar_url(self.user.email, size=size, https=https,
41 default=default)
42
43 def homepage_url(self):
44 """Try ensure we prepend http: to the url if there's nothing there
45
46 This is to ensure we're not generating relative links in the
47 user templates."""
48 if not self.homepage:
49 return self.homepage
50 parsed = urlparse.urlparse(self.homepage)
51 if parsed.scheme:
52 return self.homepage
53 # Vague sanity check
54 abs_url = ''.join(['http://', self.homepage])
55 if urlparse.urlparse(abs_url).scheme == 'http':
56 return abs_url
57 return self.homepage
58
59 def display_name(self):
60 return self.user.get_full_name() or self.user.username
61
62
63 def create_user_profile(sender, instance, created, raw=False, **kwargs):
64 if raw:
65 return
66 if created:
67 UserProfile.objects.create(user=instance)
68
69 post_save.connect(create_user_profile, sender=User)
70
```
Path: `wafer/registration/views.py`
Content:
```
1 import urllib
2
3 from django.contrib.auth import login
4 from django.contrib import messages
5 from django.core.urlresolvers import reverse
6 from django.conf import settings
7 from django.http import Http404, HttpResponseRedirect
8
9 from wafer.registration.sso import SSOError, debian_sso, github_sso
10
11
12 def redirect_profile(request):
13 '''
14 The default destination from logging in, redirect to the actual profile URL
15 '''
16 if request.user.is_authenticated():
17 return HttpResponseRedirect(reverse('wafer_user_profile',
18 args=(request.user.username,)))
19 else:
20 return HttpResponseRedirect(reverse('wafer_page', args=('index',)))
21
22
23 def github_login(request):
24 if 'github' not in settings.WAFER_SSO:
25 raise Http404()
26
27 if 'code' not in request.GET:
28 return HttpResponseRedirect(
29 'https://github.com/login/oauth/authorize?' + urllib.urlencode({
30 'client_id': settings.WAFER_GITHUB_CLIENT_ID,
31 'redirect_uri': request.build_absolute_uri(
32 reverse(github_login)),
33 'scope': 'user:email',
34 'state': request.META['CSRF_COOKIE'],
35 }))
36
37 try:
38 if request.GET['state'] != request.META['CSRF_COOKIE']:
39 raise SSOError('Incorrect state')
40
41 user = github_sso(request.GET['code'])
42 except SSOError as e:
43 messages.error(request, unicode(e))
44 return HttpResponseRedirect(reverse('auth_login'))
45
46 login(request, user)
47 return redirect_profile(request)
48
49
50 def debian_login(request):
51 if 'debian' not in settings.WAFER_SSO:
52 raise Http404()
53
54 try:
55 user = debian_sso(request.META)
56 except SSOError as e:
57 messages.error(request, unicode(e))
58 return HttpResponseRedirect(reverse('auth_login'))
59
60 login(request, user)
61 return redirect_profile(request)
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wafer/registration/views.py b/wafer/registration/views.py
--- a/wafer/registration/views.py
+++ b/wafer/registration/views.py
@@ -40,7 +40,7 @@
user = github_sso(request.GET['code'])
except SSOError as e:
- messages.error(request, unicode(e))
+ messages.error(request, u'%s' % e)
return HttpResponseRedirect(reverse('auth_login'))
login(request, user)
@@ -54,7 +54,7 @@
try:
user = debian_sso(request.META)
except SSOError as e:
- messages.error(request, unicode(e))
+ messages.error(request, u'%s' % e)
return HttpResponseRedirect(reverse('auth_login'))
login(request, user)
diff --git a/wafer/users/models.py b/wafer/users/models.py
--- a/wafer/users/models.py
+++ b/wafer/users/models.py
@@ -26,7 +26,7 @@
github_username = models.CharField(max_length=32, null=True, blank=True)
def __str__(self):
- return unicode(self.user)
+ return u'%s' % self.user
def accepted_talks(self):
return self.user.talks.filter(status=ACCEPTED)
|
{"golden_diff": "diff --git a/wafer/registration/views.py b/wafer/registration/views.py\n--- a/wafer/registration/views.py\n+++ b/wafer/registration/views.py\n@@ -40,7 +40,7 @@\n \n user = github_sso(request.GET['code'])\n except SSOError as e:\n- messages.error(request, unicode(e))\n+ messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n \n login(request, user)\n@@ -54,7 +54,7 @@\n try:\n user = debian_sso(request.META)\n except SSOError as e:\n- messages.error(request, unicode(e))\n+ messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n \n login(request, user)\ndiff --git a/wafer/users/models.py b/wafer/users/models.py\n--- a/wafer/users/models.py\n+++ b/wafer/users/models.py\n@@ -26,7 +26,7 @@\n github_username = models.CharField(max_length=32, null=True, blank=True)\n \n def __str__(self):\n- return unicode(self.user)\n+ return u'%s' % self.user\n \n def accepted_talks(self):\n return self.user.talks.filter(status=ACCEPTED)\n", "issue": "Remove'unicode' calls from wafer\nCurrent wafer using python 3 fails on several admin tasks because `UserProfile.__str__` tries to call `unicode`, which is obviously not defined.\n\nWe should handle the difference between python 2 and python 3 correctly in this situation.\n\nThere are a couple of other calls to unicode() that look dangerous in the error paths in /registration/views.py that should probably be fixed as well.\n\n", "before_files": [{"content": "from django.contrib.auth.models import User\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.utils.encoding import python_2_unicode_compatible\n\nfrom libravatar import libravatar_url\ntry:\n from urllib2 import urlparse\nexcept ImportError:\n from urllib import parse as urlparse\nfrom django.utils.http import urlquote\n\nfrom wafer.talks.models import ACCEPTED, PENDING\n\n\n@python_2_unicode_compatible\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n contact_number = models.CharField(max_length=16, null=True, blank=True)\n bio = models.TextField(null=True, blank=True)\n\n homepage = models.CharField(max_length=256, null=True, blank=True)\n # We should probably do social auth instead\n # And care about other code hosting sites...\n twitter_handle = models.CharField(max_length=15, null=True, blank=True)\n github_username = models.CharField(max_length=32, null=True, blank=True)\n\n def __str__(self):\n return unicode(self.user)\n\n def accepted_talks(self):\n return self.user.talks.filter(status=ACCEPTED)\n\n def pending_talks(self):\n return self.user.talks.filter(status=PENDING)\n\n def avatar_url(self, size=96, https=True, default='mm'):\n if not self.user.email:\n return None\n return libravatar_url(self.user.email, size=size, https=https,\n default=default)\n\n def homepage_url(self):\n \"\"\"Try ensure we prepend http: to the url if there's nothing there\n\n This is to ensure we're not generating relative links in the\n user templates.\"\"\"\n if not self.homepage:\n return self.homepage\n parsed = urlparse.urlparse(self.homepage)\n if parsed.scheme:\n return self.homepage\n # Vague sanity check\n abs_url = ''.join(['http://', self.homepage])\n if urlparse.urlparse(abs_url).scheme == 'http':\n return abs_url\n return self.homepage\n\n def display_name(self):\n return self.user.get_full_name() or self.user.username\n\n\ndef create_user_profile(sender, instance, created, raw=False, **kwargs):\n if raw:\n return\n if created:\n UserProfile.objects.create(user=instance)\n\npost_save.connect(create_user_profile, sender=User)\n", "path": "wafer/users/models.py"}, {"content": "import urllib\n\nfrom django.contrib.auth import login\nfrom django.contrib import messages\nfrom django.core.urlresolvers import reverse\nfrom django.conf import settings\nfrom django.http import Http404, HttpResponseRedirect\n\nfrom wafer.registration.sso import SSOError, debian_sso, github_sso\n\n\ndef redirect_profile(request):\n '''\n The default destination from logging in, redirect to the actual profile URL\n '''\n if request.user.is_authenticated():\n return HttpResponseRedirect(reverse('wafer_user_profile',\n args=(request.user.username,)))\n else:\n return HttpResponseRedirect(reverse('wafer_page', args=('index',)))\n\n\ndef github_login(request):\n if 'github' not in settings.WAFER_SSO:\n raise Http404()\n\n if 'code' not in request.GET:\n return HttpResponseRedirect(\n 'https://github.com/login/oauth/authorize?' + urllib.urlencode({\n 'client_id': settings.WAFER_GITHUB_CLIENT_ID,\n 'redirect_uri': request.build_absolute_uri(\n reverse(github_login)),\n 'scope': 'user:email',\n 'state': request.META['CSRF_COOKIE'],\n }))\n\n try:\n if request.GET['state'] != request.META['CSRF_COOKIE']:\n raise SSOError('Incorrect state')\n\n user = github_sso(request.GET['code'])\n except SSOError as e:\n messages.error(request, unicode(e))\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n\n\ndef debian_login(request):\n if 'debian' not in settings.WAFER_SSO:\n raise Http404()\n\n try:\n user = debian_sso(request.META)\n except SSOError as e:\n messages.error(request, unicode(e))\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n", "path": "wafer/registration/views.py"}], "after_files": [{"content": "from django.contrib.auth.models import User\nfrom django.db import models\nfrom django.db.models.signals import post_save\nfrom django.utils.encoding import python_2_unicode_compatible\n\nfrom libravatar import libravatar_url\ntry:\n from urllib2 import urlparse\nexcept ImportError:\n from urllib import parse as urlparse\nfrom django.utils.http import urlquote\n\nfrom wafer.talks.models import ACCEPTED, PENDING\n\n\n@python_2_unicode_compatible\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n contact_number = models.CharField(max_length=16, null=True, blank=True)\n bio = models.TextField(null=True, blank=True)\n\n homepage = models.CharField(max_length=256, null=True, blank=True)\n # We should probably do social auth instead\n # And care about other code hosting sites...\n twitter_handle = models.CharField(max_length=15, null=True, blank=True)\n github_username = models.CharField(max_length=32, null=True, blank=True)\n\n def __str__(self):\n return u'%s' % self.user\n\n def accepted_talks(self):\n return self.user.talks.filter(status=ACCEPTED)\n\n def pending_talks(self):\n return self.user.talks.filter(status=PENDING)\n\n def avatar_url(self, size=96, https=True, default='mm'):\n if not self.user.email:\n return None\n return libravatar_url(self.user.email, size=size, https=https,\n default=default)\n\n def homepage_url(self):\n \"\"\"Try ensure we prepend http: to the url if there's nothing there\n\n This is to ensure we're not generating relative links in the\n user templates.\"\"\"\n if not self.homepage:\n return self.homepage\n parsed = urlparse.urlparse(self.homepage)\n if parsed.scheme:\n return self.homepage\n # Vague sanity check\n abs_url = ''.join(['http://', self.homepage])\n if urlparse.urlparse(abs_url).scheme == 'http':\n return abs_url\n return self.homepage\n\n def display_name(self):\n return self.user.get_full_name() or self.user.username\n\n\ndef create_user_profile(sender, instance, created, raw=False, **kwargs):\n if raw:\n return\n if created:\n UserProfile.objects.create(user=instance)\n\npost_save.connect(create_user_profile, sender=User)\n", "path": "wafer/users/models.py"}, {"content": "import urllib\n\nfrom django.contrib.auth import login\nfrom django.contrib import messages\nfrom django.core.urlresolvers import reverse\nfrom django.conf import settings\nfrom django.http import Http404, HttpResponseRedirect\n\nfrom wafer.registration.sso import SSOError, debian_sso, github_sso\n\n\ndef redirect_profile(request):\n '''\n The default destination from logging in, redirect to the actual profile URL\n '''\n if request.user.is_authenticated():\n return HttpResponseRedirect(reverse('wafer_user_profile',\n args=(request.user.username,)))\n else:\n return HttpResponseRedirect(reverse('wafer_page', args=('index',)))\n\n\ndef github_login(request):\n if 'github' not in settings.WAFER_SSO:\n raise Http404()\n\n if 'code' not in request.GET:\n return HttpResponseRedirect(\n 'https://github.com/login/oauth/authorize?' + urllib.urlencode({\n 'client_id': settings.WAFER_GITHUB_CLIENT_ID,\n 'redirect_uri': request.build_absolute_uri(\n reverse(github_login)),\n 'scope': 'user:email',\n 'state': request.META['CSRF_COOKIE'],\n }))\n\n try:\n if request.GET['state'] != request.META['CSRF_COOKIE']:\n raise SSOError('Incorrect state')\n\n user = github_sso(request.GET['code'])\n except SSOError as e:\n messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n\n\ndef debian_login(request):\n if 'debian' not in settings.WAFER_SSO:\n raise Http404()\n\n try:\n user = debian_sso(request.META)\n except SSOError as e:\n messages.error(request, u'%s' % e)\n return HttpResponseRedirect(reverse('auth_login'))\n\n login(request, user)\n return redirect_profile(request)\n", "path": "wafer/registration/views.py"}]}
| 1,520 | 292 |
gh_patches_debug_11094
|
rasdani/github-patches
|
git_diff
|
facebookresearch__dynabench-766
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Creating a task with the "Task Code" as a number doesn't work as expected.
After creating a task with the task code as a number, and accepting the task, when users want to navigate to the task, it should ideally take us to a page which says "The task owner still needs to activate this task.", but in this case, we are shown the respective page for a millisecond, and taken back to the home page, which I think is unexpected behaviour.
A demonstration is given in the following screen recording of the same issue.
**Steps to reproduce**:
- Create a task proposal with the "Task Code" field as a number
- Accept the task as the admin user.
- Now try to click on the respective task from your "Tasks" page. It should just take you back to the homepage.
This seems to happen only for a purely numeric "Task Code" and not for an alphanumeric "Task Code"
https://user-images.githubusercontent.com/48560219/135757335-d98f116f-b7d6-44dc-a1fd-0c8b6fac7c61.mov
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `api/controllers/task_proposals.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 # This source code is licensed under the MIT license found in the
3 # LICENSE file in the root directory of this source tree.
4
5 import re
6
7 import bottle
8
9 import common.auth as _auth
10 import common.helpers as util
11 from common.logging import logger
12 from models.base import DBSession as dbs
13 from models.task import TaskModel
14 from models.task_proposal import TaskProposal, TaskProposalModel
15 from models.user import UserModel
16
17
18 @bottle.get("/task_proposals/user/<page:int>/<limit:int>")
19 @_auth.requires_auth
20 def get_user_task_proposals(credentials, page, limit):
21 tpm = TaskProposalModel()
22 proposals = tpm.getByUid(credentials["id"])
23 identifiers = []
24 for proposal in proposals:
25 identifiers.append(proposal.to_dict())
26 return util.json_encode(
27 {
28 "data": identifiers[page * limit : page * limit + limit],
29 "count": len(identifiers),
30 }
31 )
32
33
34 @bottle.get("/task_proposals/all/<page:int>/<limit:int>")
35 @_auth.requires_auth
36 def get_all_task_proposals(credentials, page, limit):
37 um = UserModel()
38 user = um.get(credentials["id"])
39 if not user.admin:
40 bottle.abort(403, "Access denied")
41
42 proposals = dbs.query(TaskProposal)
43 identifiers = []
44 for proposal in proposals:
45 identifiers.append(proposal.to_dict())
46 return util.json_encode(
47 {
48 "data": identifiers[page * limit : page * limit + limit],
49 "count": len(identifiers),
50 }
51 )
52
53
54 @bottle.post("/task_proposals/create")
55 @_auth.requires_auth
56 def create_task_proposal(credentials):
57 data = bottle.request.json
58
59 if not util.check_fields(data, ["task_code", "name", "desc", "longdesc"]):
60 bottle.abort(400, "Missing data")
61
62 tm = TaskModel()
63 if tm.getByTaskCode(data["task_code"]):
64 bottle.abort(400, "Invalid task code; this task code is already taken")
65
66 if tm.getByName(data["name"]):
67 bottle.abort(400, "Invalid name; this name is already taken")
68
69 if not bool(re.search("^[a-zA-Z0-9_-]*$", data["task_code"])):
70 bottle.abort(
71 400,
72 "Invalid task code (no special characters allowed besides underscores "
73 + "and dashes)",
74 )
75
76 try:
77 tp = TaskProposal(
78 uid=credentials["id"],
79 task_code=data["task_code"],
80 name=data["name"],
81 desc=data["desc"],
82 longdesc=data["longdesc"],
83 )
84
85 tm.dbs.add(tp)
86 tm.dbs.flush()
87 tm.dbs.commit()
88 logger.info("Added task proposal (%s)" % (tp.id))
89
90 except Exception as error_message:
91 logger.error("Could not create task proposal (%s)" % error_message)
92 return False
93
94 return util.json_encode({"success": "ok", "id": tp.id})
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/api/controllers/task_proposals.py b/api/controllers/task_proposals.py
--- a/api/controllers/task_proposals.py
+++ b/api/controllers/task_proposals.py
@@ -66,11 +66,13 @@
if tm.getByName(data["name"]):
bottle.abort(400, "Invalid name; this name is already taken")
- if not bool(re.search("^[a-zA-Z0-9_-]*$", data["task_code"])):
+ if not bool(
+ re.search("(?=^[a-zA-Z0-9_-]*$)(?=.*[a-zA-Z].*).*$", data["task_code"])
+ ):
bottle.abort(
400,
"Invalid task code (no special characters allowed besides underscores "
- + "and dashes)",
+ + "and dashes. At least one letter required)",
)
try:
|
{"golden_diff": "diff --git a/api/controllers/task_proposals.py b/api/controllers/task_proposals.py\n--- a/api/controllers/task_proposals.py\n+++ b/api/controllers/task_proposals.py\n@@ -66,11 +66,13 @@\n if tm.getByName(data[\"name\"]):\n bottle.abort(400, \"Invalid name; this name is already taken\")\n \n- if not bool(re.search(\"^[a-zA-Z0-9_-]*$\", data[\"task_code\"])):\n+ if not bool(\n+ re.search(\"(?=^[a-zA-Z0-9_-]*$)(?=.*[a-zA-Z].*).*$\", data[\"task_code\"])\n+ ):\n bottle.abort(\n 400,\n \"Invalid task code (no special characters allowed besides underscores \"\n- + \"and dashes)\",\n+ + \"and dashes. At least one letter required)\",\n )\n \n try:\n", "issue": "Creating a task with the \"Task Code\" as a number doesn't work as expected.\nAfter creating a task with the task code as a number, and accepting the task, when users want to navigate to the task, it should ideally take us to a page which says \"The task owner still needs to activate this task.\", but in this case, we are shown the respective page for a millisecond, and taken back to the home page, which I think is unexpected behaviour.\r\n\r\nA demonstration is given in the following screen recording of the same issue.\r\n\r\n**Steps to reproduce**:\r\n- Create a task proposal with the \"Task Code\" field as a number\r\n- Accept the task as the admin user.\r\n- Now try to click on the respective task from your \"Tasks\" page. It should just take you back to the homepage.\r\n\r\nThis seems to happen only for a purely numeric \"Task Code\" and not for an alphanumeric \"Task Code\"\r\n\r\nhttps://user-images.githubusercontent.com/48560219/135757335-d98f116f-b7d6-44dc-a1fd-0c8b6fac7c61.mov\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport re\n\nimport bottle\n\nimport common.auth as _auth\nimport common.helpers as util\nfrom common.logging import logger\nfrom models.base import DBSession as dbs\nfrom models.task import TaskModel\nfrom models.task_proposal import TaskProposal, TaskProposalModel\nfrom models.user import UserModel\n\n\[email protected](\"/task_proposals/user/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_user_task_proposals(credentials, page, limit):\n tpm = TaskProposalModel()\n proposals = tpm.getByUid(credentials[\"id\"])\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/all/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_all_task_proposals(credentials, page, limit):\n um = UserModel()\n user = um.get(credentials[\"id\"])\n if not user.admin:\n bottle.abort(403, \"Access denied\")\n\n proposals = dbs.query(TaskProposal)\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/create\")\n@_auth.requires_auth\ndef create_task_proposal(credentials):\n data = bottle.request.json\n\n if not util.check_fields(data, [\"task_code\", \"name\", \"desc\", \"longdesc\"]):\n bottle.abort(400, \"Missing data\")\n\n tm = TaskModel()\n if tm.getByTaskCode(data[\"task_code\"]):\n bottle.abort(400, \"Invalid task code; this task code is already taken\")\n\n if tm.getByName(data[\"name\"]):\n bottle.abort(400, \"Invalid name; this name is already taken\")\n\n if not bool(re.search(\"^[a-zA-Z0-9_-]*$\", data[\"task_code\"])):\n bottle.abort(\n 400,\n \"Invalid task code (no special characters allowed besides underscores \"\n + \"and dashes)\",\n )\n\n try:\n tp = TaskProposal(\n uid=credentials[\"id\"],\n task_code=data[\"task_code\"],\n name=data[\"name\"],\n desc=data[\"desc\"],\n longdesc=data[\"longdesc\"],\n )\n\n tm.dbs.add(tp)\n tm.dbs.flush()\n tm.dbs.commit()\n logger.info(\"Added task proposal (%s)\" % (tp.id))\n\n except Exception as error_message:\n logger.error(\"Could not create task proposal (%s)\" % error_message)\n return False\n\n return util.json_encode({\"success\": \"ok\", \"id\": tp.id})\n", "path": "api/controllers/task_proposals.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nimport re\n\nimport bottle\n\nimport common.auth as _auth\nimport common.helpers as util\nfrom common.logging import logger\nfrom models.base import DBSession as dbs\nfrom models.task import TaskModel\nfrom models.task_proposal import TaskProposal, TaskProposalModel\nfrom models.user import UserModel\n\n\[email protected](\"/task_proposals/user/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_user_task_proposals(credentials, page, limit):\n tpm = TaskProposalModel()\n proposals = tpm.getByUid(credentials[\"id\"])\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/all/<page:int>/<limit:int>\")\n@_auth.requires_auth\ndef get_all_task_proposals(credentials, page, limit):\n um = UserModel()\n user = um.get(credentials[\"id\"])\n if not user.admin:\n bottle.abort(403, \"Access denied\")\n\n proposals = dbs.query(TaskProposal)\n identifiers = []\n for proposal in proposals:\n identifiers.append(proposal.to_dict())\n return util.json_encode(\n {\n \"data\": identifiers[page * limit : page * limit + limit],\n \"count\": len(identifiers),\n }\n )\n\n\[email protected](\"/task_proposals/create\")\n@_auth.requires_auth\ndef create_task_proposal(credentials):\n data = bottle.request.json\n\n if not util.check_fields(data, [\"task_code\", \"name\", \"desc\", \"longdesc\"]):\n bottle.abort(400, \"Missing data\")\n\n tm = TaskModel()\n if tm.getByTaskCode(data[\"task_code\"]):\n bottle.abort(400, \"Invalid task code; this task code is already taken\")\n\n if tm.getByName(data[\"name\"]):\n bottle.abort(400, \"Invalid name; this name is already taken\")\n\n if not bool(\n re.search(\"(?=^[a-zA-Z0-9_-]*$)(?=.*[a-zA-Z].*).*$\", data[\"task_code\"])\n ):\n bottle.abort(\n 400,\n \"Invalid task code (no special characters allowed besides underscores \"\n + \"and dashes. At least one letter required)\",\n )\n\n try:\n tp = TaskProposal(\n uid=credentials[\"id\"],\n task_code=data[\"task_code\"],\n name=data[\"name\"],\n desc=data[\"desc\"],\n longdesc=data[\"longdesc\"],\n )\n\n tm.dbs.add(tp)\n tm.dbs.flush()\n tm.dbs.commit()\n logger.info(\"Added task proposal (%s)\" % (tp.id))\n\n except Exception as error_message:\n logger.error(\"Could not create task proposal (%s)\" % error_message)\n return False\n\n return util.json_encode({\"success\": \"ok\", \"id\": tp.id})\n", "path": "api/controllers/task_proposals.py"}]}
| 1,347 | 193 |
gh_patches_debug_4002
|
rasdani/github-patches
|
git_diff
|
pypa__cibuildwheel-199
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cibuildwheel CI tests failing on Azure for windows
`cibuildwheel` CI tests which are using the sample configuration in README are failing on Windows following Azure update to support python 3.8
Given the number of CI providers now tested, I guess we can try to test `cibuildwheel` on python 2.7, 3.5, 3.6, 3.7 and 3.8 without too much overhead on test time by dispatching the python versions running `cibuildwheel` across CI providers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 try:
5 from setuptools import setup
6 except ImportError:
7 from distutils.core import setup
8
9 setup(
10 name='cibuildwheel',
11 version='0.12.0',
12 install_requires=['bashlex!=0.13'],
13 description="Build Python wheels on CI with minimal configuration.",
14 long_description='For readme please see http://github.com/joerick/cibuildwheel',
15 author="Joe Rickerby",
16 author_email='[email protected]',
17 url='https://github.com/joerick/cibuildwheel',
18 packages=['cibuildwheel',],
19 license="BSD",
20 zip_safe=False,
21 package_data={
22 'cibuildwheel': ['resources/*'],
23 },
24 keywords='ci wheel packaging pypi travis appveyor macos linux windows',
25 classifiers=[
26 'Intended Audience :: Developers',
27 'Natural Language :: English',
28 'Programming Language :: Python :: 2',
29 'Programming Language :: Python :: 3',
30 'Development Status :: 4 - Beta',
31 'License :: OSI Approved :: BSD License',
32 'Programming Language :: Python :: Implementation :: CPython',
33 'Topic :: Software Development :: Build Tools',
34 ],
35 entry_points={
36 'console_scripts': [
37 'cibuildwheel = cibuildwheel.__main__:main',
38 ],
39 },
40 )
41
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -21,6 +21,8 @@
package_data={
'cibuildwheel': ['resources/*'],
},
+ # Supported python versions
+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',
keywords='ci wheel packaging pypi travis appveyor macos linux windows',
classifiers=[
'Intended Audience :: Developers',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -21,6 +21,8 @@\n package_data={\n 'cibuildwheel': ['resources/*'],\n },\n+ # Supported python versions\n+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',\n keywords='ci wheel packaging pypi travis appveyor macos linux windows',\n classifiers=[\n 'Intended Audience :: Developers',\n", "issue": "cibuildwheel CI tests failing on Azure for windows\n`cibuildwheel` CI tests which are using the sample configuration in README are failing on Windows following Azure update to support python 3.8\r\n\r\nGiven the number of CI providers now tested, I guess we can try to test `cibuildwheel` on python 2.7, 3.5, 3.6, 3.7 and 3.8 without too much overhead on test time by dispatching the python versions running `cibuildwheel` across CI providers.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nsetup(\n name='cibuildwheel',\n version='0.12.0',\n install_requires=['bashlex!=0.13'],\n description=\"Build Python wheels on CI with minimal configuration.\",\n long_description='For readme please see http://github.com/joerick/cibuildwheel',\n author=\"Joe Rickerby\",\n author_email='[email protected]',\n url='https://github.com/joerick/cibuildwheel',\n packages=['cibuildwheel',],\n license=\"BSD\",\n zip_safe=False,\n package_data={\n 'cibuildwheel': ['resources/*'],\n },\n keywords='ci wheel packaging pypi travis appveyor macos linux windows',\n classifiers=[\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Development Status :: 4 - Beta',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Topic :: Software Development :: Build Tools',\n ],\n entry_points={\n 'console_scripts': [\n 'cibuildwheel = cibuildwheel.__main__:main',\n ],\n },\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nsetup(\n name='cibuildwheel',\n version='0.12.0',\n install_requires=['bashlex!=0.13'],\n description=\"Build Python wheels on CI with minimal configuration.\",\n long_description='For readme please see http://github.com/joerick/cibuildwheel',\n author=\"Joe Rickerby\",\n author_email='[email protected]',\n url='https://github.com/joerick/cibuildwheel',\n packages=['cibuildwheel',],\n license=\"BSD\",\n zip_safe=False,\n package_data={\n 'cibuildwheel': ['resources/*'],\n },\n # Supported python versions\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*',\n keywords='ci wheel packaging pypi travis appveyor macos linux windows',\n classifiers=[\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Development Status :: 4 - Beta',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Topic :: Software Development :: Build Tools',\n ],\n entry_points={\n 'console_scripts': [\n 'cibuildwheel = cibuildwheel.__main__:main',\n ],\n },\n)\n", "path": "setup.py"}]}
| 748 | 120 |
gh_patches_debug_65044
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1583
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CommandException: No URLs matched: gs://kfserving-examples/models/mnist
/kind bug
I would like to run the kafka mnist example but when I run:
```bash
gsutil cp gs://kfserving-examples/models/mnist .
```
As per the readme, I get
```
CommandException: No URLs matched: gs://kfserving-examples/models/mnist
```
**What did you expect to happen:**
I expected to be able to download the model checkpoint.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/samples/kafka/setup.py`
Content:
```
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from setuptools import setup, find_packages
16
17 tests_require = [
18 'pytest',
19 'pytest-tornasync',
20 'mypy'
21 ]
22
23 setup(
24 name='transformer',
25 version='0.1.0',
26 author_email='[email protected]',
27 license='../../LICENSE.txt',
28 url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',
29 description='Transformer',
30 long_description=open('README.md').read(),
31 python_requires='>=3.6',
32 packages=find_packages("transformer"),
33 install_requires=[
34 "kfserving>=0.2.1",
35 "argparse>=1.4.0",
36 "requests>=2.22.0",
37 "joblib>=0.13.2",
38 "pandas>=0.24.2",
39 "numpy>=1.16.3",
40 "kubernetes >= 9.0.0",
41 "opencv-python-headless==4.0.0.21",
42 "boto3==1.7.2"
43 ],
44 tests_require=tests_require,
45 extras_require={'test': tests_require}
46 )
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/samples/kafka/setup.py b/docs/samples/kafka/setup.py
--- a/docs/samples/kafka/setup.py
+++ b/docs/samples/kafka/setup.py
@@ -25,7 +25,7 @@
version='0.1.0',
author_email='[email protected]',
license='../../LICENSE.txt',
- url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',
+ url='https://github.com/kubeflow/kfserving/tree/master/docs/samples#deploy-inferenceservice-with-transformer',
description='Transformer',
long_description=open('README.md').read(),
python_requires='>=3.6',
|
{"golden_diff": "diff --git a/docs/samples/kafka/setup.py b/docs/samples/kafka/setup.py\n--- a/docs/samples/kafka/setup.py\n+++ b/docs/samples/kafka/setup.py\n@@ -25,7 +25,7 @@\n version='0.1.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n- url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',\n+ url='https://github.com/kubeflow/kfserving/tree/master/docs/samples#deploy-inferenceservice-with-transformer',\n description='Transformer',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n", "issue": "CommandException: No URLs matched: gs://kfserving-examples/models/mnist\n/kind bug \r\n\r\nI would like to run the kafka mnist example but when I run:\r\n```bash\r\ngsutil cp gs://kfserving-examples/models/mnist .\r\n```\r\nAs per the readme, I get\r\n```\r\nCommandException: No URLs matched: gs://kfserving-examples/models/mnist\r\n```\r\n\r\n**What did you expect to happen:**\r\nI expected to be able to download the model checkpoint. \r\n\n", "before_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nsetup(\n name='transformer',\n version='0.1.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n url='https://github.com/kubeflow/kfserving/docs/sameples/transformer',\n description='Transformer',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n packages=find_packages(\"transformer\"),\n install_requires=[\n \"kfserving>=0.2.1\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n \"joblib>=0.13.2\",\n \"pandas>=0.24.2\",\n \"numpy>=1.16.3\",\n \"kubernetes >= 9.0.0\",\n \"opencv-python-headless==4.0.0.21\",\n \"boto3==1.7.2\"\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n)\n", "path": "docs/samples/kafka/setup.py"}], "after_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nsetup(\n name='transformer',\n version='0.1.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n url='https://github.com/kubeflow/kfserving/tree/master/docs/samples#deploy-inferenceservice-with-transformer',\n description='Transformer',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n packages=find_packages(\"transformer\"),\n install_requires=[\n \"kfserving>=0.2.1\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n \"joblib>=0.13.2\",\n \"pandas>=0.24.2\",\n \"numpy>=1.16.3\",\n \"kubernetes >= 9.0.0\",\n \"opencv-python-headless==4.0.0.21\",\n \"boto3==1.7.2\"\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n)\n", "path": "docs/samples/kafka/setup.py"}]}
| 843 | 158 |
gh_patches_debug_39370
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-8335
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use clean_address function to join multiple free text lines together
The `clean_address` method added in #7568 allows a standardised approach to taking messy ordered multiple line address strings (of any type of composition) and joining them together into a single string.
We can now use `clean_address` to replace the many variants throughout spiders of attempting to join these multi-line address strings. An added benefit is being able to quickly find where multi-line address strings are parsed (via searching for `clean_address` instances), making it easier to change address handling in the future.
Related to #5598
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/zizzi_gb.py`
Content:
```
1 import scrapy
2
3 from locations.dict_parser import DictParser
4
5
6 class ZizziGBSpider(scrapy.Spider):
7 name = "zizzi_gb"
8 item_attributes = {"brand": "Zizzi", "brand_wikidata": "Q8072944"}
9 start_urls = ["https://www.zizzi.co.uk/wp-json/locations/get_venues"]
10
11 def parse(self, response):
12 for store in response.json()["data"]:
13 item = DictParser.parse(store)
14 item["addr_full"] = ", ".join(store["address"].split("\r\n"))
15 item["image"] = store["featured_image"]
16 item["website"] = store["link"]
17
18 if store["region"] == "Ireland":
19 item.pop("state")
20 item["country"] = "IE"
21 else:
22 item["country"] = "GB"
23
24 yield item
25
```
Path: `locations/spiders/zambrero_au.py`
Content:
```
1 import re
2
3 from scrapy import Spider
4 from scrapy.http import Request
5
6 from locations.categories import Categories
7 from locations.hours import OpeningHours
8 from locations.items import Feature
9
10
11 class ZambreroAUSpider(Spider):
12 name = "zambrero_au"
13 item_attributes = {"brand": "Zambrero", "brand_wikidata": "Q18636431", "extras": Categories.FAST_FOOD.value}
14 allowed_domains = ["www.zambrero.com.au"]
15
16 def start_requests(self):
17 yield Request(url=f"https://{self.allowed_domains[0]}/locations", callback=self.parse_location_list)
18
19 def parse_location_list(self, response):
20 location_urls = response.xpath('//div[@data-location-id]//a[@title="Order & Store Info"]/@href').getall()
21 for location_url in location_urls:
22 yield Request(url=location_url, callback=self.parse_location)
23
24 def parse_location(self, response):
25 properties = {
26 "ref": response.xpath("//@data-location-id").get(),
27 "name": re.sub(r"\s+", " ", response.xpath("//div[@data-location-id]/h4/text()").get()).strip(),
28 "lat": response.xpath("//@data-lat").get(),
29 "lon": response.xpath("///@data-lng").get(),
30 "addr_full": re.sub(
31 r"\s+",
32 " ",
33 " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall()),
34 ).strip(),
35 "phone": response.xpath('//a[contains(@class, "phone")]/@href').get().replace("tel:", ""),
36 "email": response.xpath('//a[contains(@href, "mailto:")]/@href').get().replace("mailto:", ""),
37 "website": response.url,
38 "opening_hours": OpeningHours(),
39 }
40 if "Temporarily Closed" in properties["name"]:
41 return
42 if properties["phone"] == "0":
43 properties.pop("phone")
44
45 hours_text = re.sub(
46 r"\s+", " ", " ".join(response.xpath('//div[contains(@class, "hours-item")]/span/text()').getall())
47 )
48 properties["opening_hours"].add_ranges_from_string(hours_text)
49
50 # Some store names and URLs contain "Opening Soon" but numerous of
51 # these are already open and the URL hasn't been changed. A more
52 # reliable way of knowing a store is not yet open is that it has
53 # no opening hours specified.
54 if not properties["opening_hours"].as_opening_hours():
55 return
56
57 yield Feature(**properties)
58
```
Path: `locations/spiders/woolworths_au.py`
Content:
```
1 import scrapy
2
3 from locations.dict_parser import DictParser
4
5
6 class WoolworthsAUSpider(scrapy.Spider):
7 name = "woolworths_au"
8 item_attributes = {"brand": "Woolworths", "brand_wikidata": "Q3249145"}
9 allowed_domains = ["woolworths.com.au"]
10 start_urls = [
11 "https://www.woolworths.com.au/apis/ui/StoreLocator/Stores?Max=10000&Division=SUPERMARKETS,PETROL,CALTEXWOW,AMPOLMETRO,AMPOL&Facility=&postcode=*"
12 ]
13 custom_settings = {"ROBOTSTXT_OBEY": False}
14 requires_proxy = "AU"
15
16 def parse(self, response):
17 data = response.json()
18
19 for i in data["Stores"]:
20 if not i["IsOpen"]:
21 continue
22
23 i["street_address"] = ", ".join(filter(None, [i["AddressLine1"], i["AddressLine2"]]))
24 i["ref"] = i.pop("StoreNo")
25 i["city"] = i.pop("Suburb")
26
27 item = DictParser.parse(i)
28
29 item["website"] = (
30 "https://www.woolworths.com.au/shop/storelocator/"
31 + "-".join([item["state"], item["city"], item["ref"], i["Division"]]).lower()
32 )
33
34 # TODO: types needs some work, NSI seems out of date too
35 item["extras"] = {"type": i["Division"]}
36
37 yield item
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/woolworths_au.py b/locations/spiders/woolworths_au.py
--- a/locations/spiders/woolworths_au.py
+++ b/locations/spiders/woolworths_au.py
@@ -1,6 +1,7 @@
import scrapy
from locations.dict_parser import DictParser
+from locations.pipelines.address_clean_up import clean_address
class WoolworthsAUSpider(scrapy.Spider):
@@ -20,7 +21,7 @@
if not i["IsOpen"]:
continue
- i["street_address"] = ", ".join(filter(None, [i["AddressLine1"], i["AddressLine2"]]))
+ i["street_address"] = clean_address([i["AddressLine1"], i["AddressLine2"]])
i["ref"] = i.pop("StoreNo")
i["city"] = i.pop("Suburb")
diff --git a/locations/spiders/zambrero_au.py b/locations/spiders/zambrero_au.py
--- a/locations/spiders/zambrero_au.py
+++ b/locations/spiders/zambrero_au.py
@@ -6,6 +6,7 @@
from locations.categories import Categories
from locations.hours import OpeningHours
from locations.items import Feature
+from locations.pipelines.address_clean_up import clean_address
class ZambreroAUSpider(Spider):
@@ -27,11 +28,9 @@
"name": re.sub(r"\s+", " ", response.xpath("//div[@data-location-id]/h4/text()").get()).strip(),
"lat": response.xpath("//@data-lat").get(),
"lon": response.xpath("///@data-lng").get(),
- "addr_full": re.sub(
- r"\s+",
- " ",
- " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall()),
- ).strip(),
+ "addr_full": clean_address(
+ " ".join(response.xpath('//div[@data-location-id]//span[contains(@class, "address")]/text()').getall())
+ ),
"phone": response.xpath('//a[contains(@class, "phone")]/@href').get().replace("tel:", ""),
"email": response.xpath('//a[contains(@href, "mailto:")]/@href').get().replace("mailto:", ""),
"website": response.url,
diff --git a/locations/spiders/zizzi_gb.py b/locations/spiders/zizzi_gb.py
--- a/locations/spiders/zizzi_gb.py
+++ b/locations/spiders/zizzi_gb.py
@@ -1,6 +1,7 @@
import scrapy
from locations.dict_parser import DictParser
+from locations.pipelines.address_clean_up import clean_address
class ZizziGBSpider(scrapy.Spider):
@@ -11,7 +12,7 @@
def parse(self, response):
for store in response.json()["data"]:
item = DictParser.parse(store)
- item["addr_full"] = ", ".join(store["address"].split("\r\n"))
+ item["addr_full"] = clean_address(store["address"].split("\r\n"))
item["image"] = store["featured_image"]
item["website"] = store["link"]
|
{"golden_diff": "diff --git a/locations/spiders/woolworths_au.py b/locations/spiders/woolworths_au.py\n--- a/locations/spiders/woolworths_au.py\n+++ b/locations/spiders/woolworths_au.py\n@@ -1,6 +1,7 @@\n import scrapy\n \n from locations.dict_parser import DictParser\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class WoolworthsAUSpider(scrapy.Spider):\n@@ -20,7 +21,7 @@\n if not i[\"IsOpen\"]:\n continue\n \n- i[\"street_address\"] = \", \".join(filter(None, [i[\"AddressLine1\"], i[\"AddressLine2\"]]))\n+ i[\"street_address\"] = clean_address([i[\"AddressLine1\"], i[\"AddressLine2\"]])\n i[\"ref\"] = i.pop(\"StoreNo\")\n i[\"city\"] = i.pop(\"Suburb\")\n \ndiff --git a/locations/spiders/zambrero_au.py b/locations/spiders/zambrero_au.py\n--- a/locations/spiders/zambrero_au.py\n+++ b/locations/spiders/zambrero_au.py\n@@ -6,6 +6,7 @@\n from locations.categories import Categories\n from locations.hours import OpeningHours\n from locations.items import Feature\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class ZambreroAUSpider(Spider):\n@@ -27,11 +28,9 @@\n \"name\": re.sub(r\"\\s+\", \" \", response.xpath(\"//div[@data-location-id]/h4/text()\").get()).strip(),\n \"lat\": response.xpath(\"//@data-lat\").get(),\n \"lon\": response.xpath(\"///@data-lng\").get(),\n- \"addr_full\": re.sub(\n- r\"\\s+\",\n- \" \",\n- \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall()),\n- ).strip(),\n+ \"addr_full\": clean_address(\n+ \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall())\n+ ),\n \"phone\": response.xpath('//a[contains(@class, \"phone\")]/@href').get().replace(\"tel:\", \"\"),\n \"email\": response.xpath('//a[contains(@href, \"mailto:\")]/@href').get().replace(\"mailto:\", \"\"),\n \"website\": response.url,\ndiff --git a/locations/spiders/zizzi_gb.py b/locations/spiders/zizzi_gb.py\n--- a/locations/spiders/zizzi_gb.py\n+++ b/locations/spiders/zizzi_gb.py\n@@ -1,6 +1,7 @@\n import scrapy\n \n from locations.dict_parser import DictParser\n+from locations.pipelines.address_clean_up import clean_address\n \n \n class ZizziGBSpider(scrapy.Spider):\n@@ -11,7 +12,7 @@\n def parse(self, response):\n for store in response.json()[\"data\"]:\n item = DictParser.parse(store)\n- item[\"addr_full\"] = \", \".join(store[\"address\"].split(\"\\r\\n\"))\n+ item[\"addr_full\"] = clean_address(store[\"address\"].split(\"\\r\\n\"))\n item[\"image\"] = store[\"featured_image\"]\n item[\"website\"] = store[\"link\"]\n", "issue": "Use clean_address function to join multiple free text lines together\nThe `clean_address` method added in #7568 allows a standardised approach to taking messy ordered multiple line address strings (of any type of composition) and joining them together into a single string.\r\n\r\nWe can now use `clean_address` to replace the many variants throughout spiders of attempting to join these multi-line address strings. An added benefit is being able to quickly find where multi-line address strings are parsed (via searching for `clean_address` instances), making it easier to change address handling in the future.\r\n\r\nRelated to #5598\n", "before_files": [{"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\n\n\nclass ZizziGBSpider(scrapy.Spider):\n name = \"zizzi_gb\"\n item_attributes = {\"brand\": \"Zizzi\", \"brand_wikidata\": \"Q8072944\"}\n start_urls = [\"https://www.zizzi.co.uk/wp-json/locations/get_venues\"]\n\n def parse(self, response):\n for store in response.json()[\"data\"]:\n item = DictParser.parse(store)\n item[\"addr_full\"] = \", \".join(store[\"address\"].split(\"\\r\\n\"))\n item[\"image\"] = store[\"featured_image\"]\n item[\"website\"] = store[\"link\"]\n\n if store[\"region\"] == \"Ireland\":\n item.pop(\"state\")\n item[\"country\"] = \"IE\"\n else:\n item[\"country\"] = \"GB\"\n\n yield item\n", "path": "locations/spiders/zizzi_gb.py"}, {"content": "import re\n\nfrom scrapy import Spider\nfrom scrapy.http import Request\n\nfrom locations.categories import Categories\nfrom locations.hours import OpeningHours\nfrom locations.items import Feature\n\n\nclass ZambreroAUSpider(Spider):\n name = \"zambrero_au\"\n item_attributes = {\"brand\": \"Zambrero\", \"brand_wikidata\": \"Q18636431\", \"extras\": Categories.FAST_FOOD.value}\n allowed_domains = [\"www.zambrero.com.au\"]\n\n def start_requests(self):\n yield Request(url=f\"https://{self.allowed_domains[0]}/locations\", callback=self.parse_location_list)\n\n def parse_location_list(self, response):\n location_urls = response.xpath('//div[@data-location-id]//a[@title=\"Order & Store Info\"]/@href').getall()\n for location_url in location_urls:\n yield Request(url=location_url, callback=self.parse_location)\n\n def parse_location(self, response):\n properties = {\n \"ref\": response.xpath(\"//@data-location-id\").get(),\n \"name\": re.sub(r\"\\s+\", \" \", response.xpath(\"//div[@data-location-id]/h4/text()\").get()).strip(),\n \"lat\": response.xpath(\"//@data-lat\").get(),\n \"lon\": response.xpath(\"///@data-lng\").get(),\n \"addr_full\": re.sub(\n r\"\\s+\",\n \" \",\n \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall()),\n ).strip(),\n \"phone\": response.xpath('//a[contains(@class, \"phone\")]/@href').get().replace(\"tel:\", \"\"),\n \"email\": response.xpath('//a[contains(@href, \"mailto:\")]/@href').get().replace(\"mailto:\", \"\"),\n \"website\": response.url,\n \"opening_hours\": OpeningHours(),\n }\n if \"Temporarily Closed\" in properties[\"name\"]:\n return\n if properties[\"phone\"] == \"0\":\n properties.pop(\"phone\")\n\n hours_text = re.sub(\n r\"\\s+\", \" \", \" \".join(response.xpath('//div[contains(@class, \"hours-item\")]/span/text()').getall())\n )\n properties[\"opening_hours\"].add_ranges_from_string(hours_text)\n\n # Some store names and URLs contain \"Opening Soon\" but numerous of\n # these are already open and the URL hasn't been changed. A more\n # reliable way of knowing a store is not yet open is that it has\n # no opening hours specified.\n if not properties[\"opening_hours\"].as_opening_hours():\n return\n\n yield Feature(**properties)\n", "path": "locations/spiders/zambrero_au.py"}, {"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\n\n\nclass WoolworthsAUSpider(scrapy.Spider):\n name = \"woolworths_au\"\n item_attributes = {\"brand\": \"Woolworths\", \"brand_wikidata\": \"Q3249145\"}\n allowed_domains = [\"woolworths.com.au\"]\n start_urls = [\n \"https://www.woolworths.com.au/apis/ui/StoreLocator/Stores?Max=10000&Division=SUPERMARKETS,PETROL,CALTEXWOW,AMPOLMETRO,AMPOL&Facility=&postcode=*\"\n ]\n custom_settings = {\"ROBOTSTXT_OBEY\": False}\n requires_proxy = \"AU\"\n\n def parse(self, response):\n data = response.json()\n\n for i in data[\"Stores\"]:\n if not i[\"IsOpen\"]:\n continue\n\n i[\"street_address\"] = \", \".join(filter(None, [i[\"AddressLine1\"], i[\"AddressLine2\"]]))\n i[\"ref\"] = i.pop(\"StoreNo\")\n i[\"city\"] = i.pop(\"Suburb\")\n\n item = DictParser.parse(i)\n\n item[\"website\"] = (\n \"https://www.woolworths.com.au/shop/storelocator/\"\n + \"-\".join([item[\"state\"], item[\"city\"], item[\"ref\"], i[\"Division\"]]).lower()\n )\n\n # TODO: types needs some work, NSI seems out of date too\n item[\"extras\"] = {\"type\": i[\"Division\"]}\n\n yield item\n", "path": "locations/spiders/woolworths_au.py"}], "after_files": [{"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\nfrom locations.pipelines.address_clean_up import clean_address\n\n\nclass ZizziGBSpider(scrapy.Spider):\n name = \"zizzi_gb\"\n item_attributes = {\"brand\": \"Zizzi\", \"brand_wikidata\": \"Q8072944\"}\n start_urls = [\"https://www.zizzi.co.uk/wp-json/locations/get_venues\"]\n\n def parse(self, response):\n for store in response.json()[\"data\"]:\n item = DictParser.parse(store)\n item[\"addr_full\"] = clean_address(store[\"address\"].split(\"\\r\\n\"))\n item[\"image\"] = store[\"featured_image\"]\n item[\"website\"] = store[\"link\"]\n\n if store[\"region\"] == \"Ireland\":\n item.pop(\"state\")\n item[\"country\"] = \"IE\"\n else:\n item[\"country\"] = \"GB\"\n\n yield item\n", "path": "locations/spiders/zizzi_gb.py"}, {"content": "import re\n\nfrom scrapy import Spider\nfrom scrapy.http import Request\n\nfrom locations.categories import Categories\nfrom locations.hours import OpeningHours\nfrom locations.items import Feature\nfrom locations.pipelines.address_clean_up import clean_address\n\n\nclass ZambreroAUSpider(Spider):\n name = \"zambrero_au\"\n item_attributes = {\"brand\": \"Zambrero\", \"brand_wikidata\": \"Q18636431\", \"extras\": Categories.FAST_FOOD.value}\n allowed_domains = [\"www.zambrero.com.au\"]\n\n def start_requests(self):\n yield Request(url=f\"https://{self.allowed_domains[0]}/locations\", callback=self.parse_location_list)\n\n def parse_location_list(self, response):\n location_urls = response.xpath('//div[@data-location-id]//a[@title=\"Order & Store Info\"]/@href').getall()\n for location_url in location_urls:\n yield Request(url=location_url, callback=self.parse_location)\n\n def parse_location(self, response):\n properties = {\n \"ref\": response.xpath(\"//@data-location-id\").get(),\n \"name\": re.sub(r\"\\s+\", \" \", response.xpath(\"//div[@data-location-id]/h4/text()\").get()).strip(),\n \"lat\": response.xpath(\"//@data-lat\").get(),\n \"lon\": response.xpath(\"///@data-lng\").get(),\n \"addr_full\": clean_address(\n \" \".join(response.xpath('//div[@data-location-id]//span[contains(@class, \"address\")]/text()').getall())\n ),\n \"phone\": response.xpath('//a[contains(@class, \"phone\")]/@href').get().replace(\"tel:\", \"\"),\n \"email\": response.xpath('//a[contains(@href, \"mailto:\")]/@href').get().replace(\"mailto:\", \"\"),\n \"website\": response.url,\n \"opening_hours\": OpeningHours(),\n }\n if \"Temporarily Closed\" in properties[\"name\"]:\n return\n if properties[\"phone\"] == \"0\":\n properties.pop(\"phone\")\n\n hours_text = re.sub(\n r\"\\s+\", \" \", \" \".join(response.xpath('//div[contains(@class, \"hours-item\")]/span/text()').getall())\n )\n properties[\"opening_hours\"].add_ranges_from_string(hours_text)\n\n # Some store names and URLs contain \"Opening Soon\" but numerous of\n # these are already open and the URL hasn't been changed. A more\n # reliable way of knowing a store is not yet open is that it has\n # no opening hours specified.\n if not properties[\"opening_hours\"].as_opening_hours():\n return\n\n yield Feature(**properties)\n", "path": "locations/spiders/zambrero_au.py"}, {"content": "import scrapy\n\nfrom locations.dict_parser import DictParser\nfrom locations.pipelines.address_clean_up import clean_address\n\n\nclass WoolworthsAUSpider(scrapy.Spider):\n name = \"woolworths_au\"\n item_attributes = {\"brand\": \"Woolworths\", \"brand_wikidata\": \"Q3249145\"}\n allowed_domains = [\"woolworths.com.au\"]\n start_urls = [\n \"https://www.woolworths.com.au/apis/ui/StoreLocator/Stores?Max=10000&Division=SUPERMARKETS,PETROL,CALTEXWOW,AMPOLMETRO,AMPOL&Facility=&postcode=*\"\n ]\n custom_settings = {\"ROBOTSTXT_OBEY\": False}\n requires_proxy = \"AU\"\n\n def parse(self, response):\n data = response.json()\n\n for i in data[\"Stores\"]:\n if not i[\"IsOpen\"]:\n continue\n\n i[\"street_address\"] = clean_address([i[\"AddressLine1\"], i[\"AddressLine2\"]])\n i[\"ref\"] = i.pop(\"StoreNo\")\n i[\"city\"] = i.pop(\"Suburb\")\n\n item = DictParser.parse(i)\n\n item[\"website\"] = (\n \"https://www.woolworths.com.au/shop/storelocator/\"\n + \"-\".join([item[\"state\"], item[\"city\"], item[\"ref\"], i[\"Division\"]]).lower()\n )\n\n # TODO: types needs some work, NSI seems out of date too\n item[\"extras\"] = {\"type\": i[\"Division\"]}\n\n yield item\n", "path": "locations/spiders/woolworths_au.py"}]}
| 1,748 | 728 |
gh_patches_debug_42193
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-438
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Instrument non-index Elasticsearch client methods
There are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.
We should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.
https://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/instruments/elasticsearch.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import logging
5
6 import wrapt
7
8 from scout_apm.core.tracked_request import TrackedRequest
9
10 try:
11 from elasticsearch import Elasticsearch, Transport
12 except ImportError: # pragma: no cover
13 Elasticsearch = None
14 Transport = None
15
16 logger = logging.getLogger(__name__)
17
18
19 def ensure_installed():
20 logger.info("Ensuring elasticsearch instrumentation is installed.")
21
22 if Elasticsearch is None:
23 logger.info("Unable to import elasticsearch.Elasticsearch")
24 else:
25 ensure_client_instrumented()
26 ensure_transport_instrumented()
27
28
29 CLIENT_METHODS = [
30 "bulk",
31 "count",
32 "create",
33 "delete",
34 "delete_by_query",
35 "exists",
36 "exists_source",
37 "explain",
38 "field_caps",
39 "get",
40 "get_source",
41 "index",
42 "mget",
43 "msearch",
44 "msearch_template",
45 "mtermvectors",
46 "reindex",
47 "reindex_rethrottle",
48 "search",
49 "search_shards",
50 "search_template",
51 "termvectors",
52 "update",
53 "update_by_query",
54 ]
55
56
57 have_patched_client = False
58
59
60 def ensure_client_instrumented():
61 global have_patched_client
62
63 if not have_patched_client:
64 for name in CLIENT_METHODS:
65 try:
66 setattr(
67 Elasticsearch,
68 name,
69 wrap_client_method(getattr(Elasticsearch, name)),
70 )
71 except Exception as exc:
72 logger.warning(
73 "Unable to instrument elasticsearch.Elasticsearch.%s: %r",
74 name,
75 exc,
76 exc_info=exc,
77 )
78
79 have_patched_client = True
80
81
82 @wrapt.decorator
83 def wrap_client_method(wrapped, instance, args, kwargs):
84 def _get_index(index, *args, **kwargs):
85 return index
86
87 try:
88 index = _get_index(*args, **kwargs)
89 except TypeError:
90 index = "Unknown"
91 else:
92 if not index:
93 index = "Unknown"
94 if isinstance(index, (list, tuple)):
95 index = ",".join(index)
96 index = index.title()
97 camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
98 operation = "Elasticsearch/{}/{}".format(index, camel_name)
99 tracked_request = TrackedRequest.instance()
100 tracked_request.start_span(operation=operation, ignore_children=True)
101
102 try:
103 return wrapped(*args, **kwargs)
104 finally:
105 tracked_request.stop_span()
106
107
108 have_patched_transport = False
109
110
111 def ensure_transport_instrumented():
112 global have_patched_transport
113
114 if not have_patched_transport:
115 try:
116 Transport.perform_request = wrapped_perform_request(
117 Transport.perform_request
118 )
119 except Exception as exc:
120 logger.warning(
121 "Unable to instrument elasticsearch.Transport.perform_request: %r",
122 exc,
123 exc_info=exc,
124 )
125
126 have_patched_transport = True
127
128
129 def _sanitize_name(name):
130 try:
131 op = name.split("/")[-1]
132 op = op[1:] # chop leading '_' from op
133 known_names = (
134 "bench",
135 "bulk",
136 "count",
137 "exists",
138 "explain",
139 "field_stats",
140 "health",
141 "mget",
142 "mlt",
143 "mpercolate",
144 "msearch",
145 "mtermvectors",
146 "percolate",
147 "query",
148 "scroll",
149 "search_shards",
150 "source",
151 "suggest",
152 "template",
153 "termvectors",
154 "update",
155 "search",
156 )
157 if op in known_names:
158 return op.title()
159 return "Unknown"
160 except Exception:
161 return "Unknown"
162
163
164 @wrapt.decorator
165 def wrapped_perform_request(wrapped, instance, args, kwargs):
166 try:
167 op = _sanitize_name(args[1])
168 except IndexError:
169 op = "Unknown"
170
171 tracked_request = TrackedRequest.instance()
172 tracked_request.start_span(
173 operation="Elasticsearch/{}".format(op), ignore_children=True
174 )
175
176 try:
177 return wrapped(*args, **kwargs)
178 finally:
179 tracked_request.stop_span()
180
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py
--- a/src/scout_apm/instruments/elasticsearch.py
+++ b/src/scout_apm/instruments/elasticsearch.py
@@ -2,6 +2,7 @@
from __future__ import absolute_import, division, print_function, unicode_literals
import logging
+from collections import namedtuple
import wrapt
@@ -26,31 +27,46 @@
ensure_transport_instrumented()
+ClientMethod = namedtuple("ClientMethod", ["name", "takes_index_argument"])
+
CLIENT_METHODS = [
- "bulk",
- "count",
- "create",
- "delete",
- "delete_by_query",
- "exists",
- "exists_source",
- "explain",
- "field_caps",
- "get",
- "get_source",
- "index",
- "mget",
- "msearch",
- "msearch_template",
- "mtermvectors",
- "reindex",
- "reindex_rethrottle",
- "search",
- "search_shards",
- "search_template",
- "termvectors",
- "update",
- "update_by_query",
+ ClientMethod("bulk", True),
+ ClientMethod("clear_scroll", False),
+ ClientMethod("count", True),
+ ClientMethod("create", True),
+ ClientMethod("delete", True),
+ ClientMethod("delete_by_query", True),
+ ClientMethod("delete_by_query_rethrottle", False),
+ ClientMethod("delete_script", False),
+ ClientMethod("exists", True),
+ ClientMethod("exists_source", True),
+ ClientMethod("explain", True),
+ ClientMethod("field_caps", True),
+ ClientMethod("get", True),
+ ClientMethod("get_script", False),
+ ClientMethod("get_source", True),
+ ClientMethod("index", True),
+ ClientMethod("info", False),
+ ClientMethod("mget", True),
+ ClientMethod("msearch", True),
+ ClientMethod("msearch_template", True),
+ ClientMethod("mtermvectors", True),
+ ClientMethod("ping", False),
+ ClientMethod("put_script", False),
+ ClientMethod("rank_eval", True),
+ ClientMethod("reindex", False),
+ ClientMethod("reindex_rethrottle", False),
+ ClientMethod("render_search_template", False),
+ ClientMethod("scripts_painless_context", False),
+ ClientMethod("scripts_painless_execute", False),
+ ClientMethod("scroll", False),
+ ClientMethod("search", True),
+ ClientMethod("search_shards", True),
+ ClientMethod("search_template", True),
+ ClientMethod("termvectors", True),
+ ClientMethod("update", True),
+ ClientMethod("update_by_query", True),
+ ClientMethod("update_by_query_rethrottle", False),
]
@@ -61,13 +77,14 @@
global have_patched_client
if not have_patched_client:
- for name in CLIENT_METHODS:
+ for name, takes_index_argument in CLIENT_METHODS:
try:
- setattr(
- Elasticsearch,
- name,
- wrap_client_method(getattr(Elasticsearch, name)),
- )
+ method = getattr(Elasticsearch, name)
+ if takes_index_argument:
+ wrapped = wrap_client_index_method(method)
+ else:
+ wrapped = wrap_client_method(method)
+ setattr(Elasticsearch, name, wrapped)
except Exception as exc:
logger.warning(
"Unable to instrument elasticsearch.Elasticsearch.%s: %r",
@@ -80,7 +97,7 @@
@wrapt.decorator
-def wrap_client_method(wrapped, instance, args, kwargs):
+def wrap_client_index_method(wrapped, instance, args, kwargs):
def _get_index(index, *args, **kwargs):
return index
@@ -105,6 +122,19 @@
tracked_request.stop_span()
[email protected]
+def wrap_client_method(wrapped, instance, args, kwargs):
+ camel_name = "".join(c.title() for c in wrapped.__name__.split("_"))
+ operation = "Elasticsearch/{}".format(camel_name)
+ tracked_request = TrackedRequest.instance()
+ tracked_request.start_span(operation=operation, ignore_children=True)
+
+ try:
+ return wrapped(*args, **kwargs)
+ finally:
+ tracked_request.stop_span()
+
+
have_patched_transport = False
|
{"golden_diff": "diff --git a/src/scout_apm/instruments/elasticsearch.py b/src/scout_apm/instruments/elasticsearch.py\n--- a/src/scout_apm/instruments/elasticsearch.py\n+++ b/src/scout_apm/instruments/elasticsearch.py\n@@ -2,6 +2,7 @@\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n import logging\n+from collections import namedtuple\n \n import wrapt\n \n@@ -26,31 +27,46 @@\n ensure_transport_instrumented()\n \n \n+ClientMethod = namedtuple(\"ClientMethod\", [\"name\", \"takes_index_argument\"])\n+\n CLIENT_METHODS = [\n- \"bulk\",\n- \"count\",\n- \"create\",\n- \"delete\",\n- \"delete_by_query\",\n- \"exists\",\n- \"exists_source\",\n- \"explain\",\n- \"field_caps\",\n- \"get\",\n- \"get_source\",\n- \"index\",\n- \"mget\",\n- \"msearch\",\n- \"msearch_template\",\n- \"mtermvectors\",\n- \"reindex\",\n- \"reindex_rethrottle\",\n- \"search\",\n- \"search_shards\",\n- \"search_template\",\n- \"termvectors\",\n- \"update\",\n- \"update_by_query\",\n+ ClientMethod(\"bulk\", True),\n+ ClientMethod(\"clear_scroll\", False),\n+ ClientMethod(\"count\", True),\n+ ClientMethod(\"create\", True),\n+ ClientMethod(\"delete\", True),\n+ ClientMethod(\"delete_by_query\", True),\n+ ClientMethod(\"delete_by_query_rethrottle\", False),\n+ ClientMethod(\"delete_script\", False),\n+ ClientMethod(\"exists\", True),\n+ ClientMethod(\"exists_source\", True),\n+ ClientMethod(\"explain\", True),\n+ ClientMethod(\"field_caps\", True),\n+ ClientMethod(\"get\", True),\n+ ClientMethod(\"get_script\", False),\n+ ClientMethod(\"get_source\", True),\n+ ClientMethod(\"index\", True),\n+ ClientMethod(\"info\", False),\n+ ClientMethod(\"mget\", True),\n+ ClientMethod(\"msearch\", True),\n+ ClientMethod(\"msearch_template\", True),\n+ ClientMethod(\"mtermvectors\", True),\n+ ClientMethod(\"ping\", False),\n+ ClientMethod(\"put_script\", False),\n+ ClientMethod(\"rank_eval\", True),\n+ ClientMethod(\"reindex\", False),\n+ ClientMethod(\"reindex_rethrottle\", False),\n+ ClientMethod(\"render_search_template\", False),\n+ ClientMethod(\"scripts_painless_context\", False),\n+ ClientMethod(\"scripts_painless_execute\", False),\n+ ClientMethod(\"scroll\", False),\n+ ClientMethod(\"search\", True),\n+ ClientMethod(\"search_shards\", True),\n+ ClientMethod(\"search_template\", True),\n+ ClientMethod(\"termvectors\", True),\n+ ClientMethod(\"update\", True),\n+ ClientMethod(\"update_by_query\", True),\n+ ClientMethod(\"update_by_query_rethrottle\", False),\n ]\n \n \n@@ -61,13 +77,14 @@\n global have_patched_client\n \n if not have_patched_client:\n- for name in CLIENT_METHODS:\n+ for name, takes_index_argument in CLIENT_METHODS:\n try:\n- setattr(\n- Elasticsearch,\n- name,\n- wrap_client_method(getattr(Elasticsearch, name)),\n- )\n+ method = getattr(Elasticsearch, name)\n+ if takes_index_argument:\n+ wrapped = wrap_client_index_method(method)\n+ else:\n+ wrapped = wrap_client_method(method)\n+ setattr(Elasticsearch, name, wrapped)\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n@@ -80,7 +97,7 @@\n \n \n @wrapt.decorator\n-def wrap_client_method(wrapped, instance, args, kwargs):\n+def wrap_client_index_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n \n@@ -105,6 +122,19 @@\n tracked_request.stop_span()\n \n \[email protected]\n+def wrap_client_method(wrapped, instance, args, kwargs):\n+ camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n+ operation = \"Elasticsearch/{}\".format(camel_name)\n+ tracked_request = TrackedRequest.instance()\n+ tracked_request.start_span(operation=operation, ignore_children=True)\n+\n+ try:\n+ return wrapped(*args, **kwargs)\n+ finally:\n+ tracked_request.stop_span()\n+\n+\n have_patched_transport = False\n", "issue": "Instrument non-index Elasticsearch client methods\nThere are many methods on the `elasticsearch-py` client class that we aren't instrumenting, for example `ping()`, because they don't operate on an index.\r\n\r\nWe should capture all these calls too - I'm sure many applications have such calls that would be good to show on traces.\r\n\r\nhttps://github.com/elastic/elasticsearch-py/blob/master/elasticsearch/client/__init__.py\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nimport wrapt\n\nfrom scout_apm.core.tracked_request import TrackedRequest\n\ntry:\n from elasticsearch import Elasticsearch, Transport\nexcept ImportError: # pragma: no cover\n Elasticsearch = None\n Transport = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef ensure_installed():\n logger.info(\"Ensuring elasticsearch instrumentation is installed.\")\n\n if Elasticsearch is None:\n logger.info(\"Unable to import elasticsearch.Elasticsearch\")\n else:\n ensure_client_instrumented()\n ensure_transport_instrumented()\n\n\nCLIENT_METHODS = [\n \"bulk\",\n \"count\",\n \"create\",\n \"delete\",\n \"delete_by_query\",\n \"exists\",\n \"exists_source\",\n \"explain\",\n \"field_caps\",\n \"get\",\n \"get_source\",\n \"index\",\n \"mget\",\n \"msearch\",\n \"msearch_template\",\n \"mtermvectors\",\n \"reindex\",\n \"reindex_rethrottle\",\n \"search\",\n \"search_shards\",\n \"search_template\",\n \"termvectors\",\n \"update\",\n \"update_by_query\",\n]\n\n\nhave_patched_client = False\n\n\ndef ensure_client_instrumented():\n global have_patched_client\n\n if not have_patched_client:\n for name in CLIENT_METHODS:\n try:\n setattr(\n Elasticsearch,\n name,\n wrap_client_method(getattr(Elasticsearch, name)),\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n name,\n exc,\n exc_info=exc,\n )\n\n have_patched_client = True\n\n\[email protected]\ndef wrap_client_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n\n try:\n index = _get_index(*args, **kwargs)\n except TypeError:\n index = \"Unknown\"\n else:\n if not index:\n index = \"Unknown\"\n if isinstance(index, (list, tuple)):\n index = \",\".join(index)\n index = index.title()\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}/{}\".format(index, camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\nhave_patched_transport = False\n\n\ndef ensure_transport_instrumented():\n global have_patched_transport\n\n if not have_patched_transport:\n try:\n Transport.perform_request = wrapped_perform_request(\n Transport.perform_request\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Transport.perform_request: %r\",\n exc,\n exc_info=exc,\n )\n\n have_patched_transport = True\n\n\ndef _sanitize_name(name):\n try:\n op = name.split(\"/\")[-1]\n op = op[1:] # chop leading '_' from op\n known_names = (\n \"bench\",\n \"bulk\",\n \"count\",\n \"exists\",\n \"explain\",\n \"field_stats\",\n \"health\",\n \"mget\",\n \"mlt\",\n \"mpercolate\",\n \"msearch\",\n \"mtermvectors\",\n \"percolate\",\n \"query\",\n \"scroll\",\n \"search_shards\",\n \"source\",\n \"suggest\",\n \"template\",\n \"termvectors\",\n \"update\",\n \"search\",\n )\n if op in known_names:\n return op.title()\n return \"Unknown\"\n except Exception:\n return \"Unknown\"\n\n\[email protected]\ndef wrapped_perform_request(wrapped, instance, args, kwargs):\n try:\n op = _sanitize_name(args[1])\n except IndexError:\n op = \"Unknown\"\n\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(\n operation=\"Elasticsearch/{}\".format(op), ignore_children=True\n )\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n", "path": "src/scout_apm/instruments/elasticsearch.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nfrom collections import namedtuple\n\nimport wrapt\n\nfrom scout_apm.core.tracked_request import TrackedRequest\n\ntry:\n from elasticsearch import Elasticsearch, Transport\nexcept ImportError: # pragma: no cover\n Elasticsearch = None\n Transport = None\n\nlogger = logging.getLogger(__name__)\n\n\ndef ensure_installed():\n logger.info(\"Ensuring elasticsearch instrumentation is installed.\")\n\n if Elasticsearch is None:\n logger.info(\"Unable to import elasticsearch.Elasticsearch\")\n else:\n ensure_client_instrumented()\n ensure_transport_instrumented()\n\n\nClientMethod = namedtuple(\"ClientMethod\", [\"name\", \"takes_index_argument\"])\n\nCLIENT_METHODS = [\n ClientMethod(\"bulk\", True),\n ClientMethod(\"clear_scroll\", False),\n ClientMethod(\"count\", True),\n ClientMethod(\"create\", True),\n ClientMethod(\"delete\", True),\n ClientMethod(\"delete_by_query\", True),\n ClientMethod(\"delete_by_query_rethrottle\", False),\n ClientMethod(\"delete_script\", False),\n ClientMethod(\"exists\", True),\n ClientMethod(\"exists_source\", True),\n ClientMethod(\"explain\", True),\n ClientMethod(\"field_caps\", True),\n ClientMethod(\"get\", True),\n ClientMethod(\"get_script\", False),\n ClientMethod(\"get_source\", True),\n ClientMethod(\"index\", True),\n ClientMethod(\"info\", False),\n ClientMethod(\"mget\", True),\n ClientMethod(\"msearch\", True),\n ClientMethod(\"msearch_template\", True),\n ClientMethod(\"mtermvectors\", True),\n ClientMethod(\"ping\", False),\n ClientMethod(\"put_script\", False),\n ClientMethod(\"rank_eval\", True),\n ClientMethod(\"reindex\", False),\n ClientMethod(\"reindex_rethrottle\", False),\n ClientMethod(\"render_search_template\", False),\n ClientMethod(\"scripts_painless_context\", False),\n ClientMethod(\"scripts_painless_execute\", False),\n ClientMethod(\"scroll\", False),\n ClientMethod(\"search\", True),\n ClientMethod(\"search_shards\", True),\n ClientMethod(\"search_template\", True),\n ClientMethod(\"termvectors\", True),\n ClientMethod(\"update\", True),\n ClientMethod(\"update_by_query\", True),\n ClientMethod(\"update_by_query_rethrottle\", False),\n]\n\n\nhave_patched_client = False\n\n\ndef ensure_client_instrumented():\n global have_patched_client\n\n if not have_patched_client:\n for name, takes_index_argument in CLIENT_METHODS:\n try:\n method = getattr(Elasticsearch, name)\n if takes_index_argument:\n wrapped = wrap_client_index_method(method)\n else:\n wrapped = wrap_client_method(method)\n setattr(Elasticsearch, name, wrapped)\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Elasticsearch.%s: %r\",\n name,\n exc,\n exc_info=exc,\n )\n\n have_patched_client = True\n\n\[email protected]\ndef wrap_client_index_method(wrapped, instance, args, kwargs):\n def _get_index(index, *args, **kwargs):\n return index\n\n try:\n index = _get_index(*args, **kwargs)\n except TypeError:\n index = \"Unknown\"\n else:\n if not index:\n index = \"Unknown\"\n if isinstance(index, (list, tuple)):\n index = \",\".join(index)\n index = index.title()\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}/{}\".format(index, camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\[email protected]\ndef wrap_client_method(wrapped, instance, args, kwargs):\n camel_name = \"\".join(c.title() for c in wrapped.__name__.split(\"_\"))\n operation = \"Elasticsearch/{}\".format(camel_name)\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(operation=operation, ignore_children=True)\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n\n\nhave_patched_transport = False\n\n\ndef ensure_transport_instrumented():\n global have_patched_transport\n\n if not have_patched_transport:\n try:\n Transport.perform_request = wrapped_perform_request(\n Transport.perform_request\n )\n except Exception as exc:\n logger.warning(\n \"Unable to instrument elasticsearch.Transport.perform_request: %r\",\n exc,\n exc_info=exc,\n )\n\n have_patched_transport = True\n\n\ndef _sanitize_name(name):\n try:\n op = name.split(\"/\")[-1]\n op = op[1:] # chop leading '_' from op\n known_names = (\n \"bench\",\n \"bulk\",\n \"count\",\n \"exists\",\n \"explain\",\n \"field_stats\",\n \"health\",\n \"mget\",\n \"mlt\",\n \"mpercolate\",\n \"msearch\",\n \"mtermvectors\",\n \"percolate\",\n \"query\",\n \"scroll\",\n \"search_shards\",\n \"source\",\n \"suggest\",\n \"template\",\n \"termvectors\",\n \"update\",\n \"search\",\n )\n if op in known_names:\n return op.title()\n return \"Unknown\"\n except Exception:\n return \"Unknown\"\n\n\[email protected]\ndef wrapped_perform_request(wrapped, instance, args, kwargs):\n try:\n op = _sanitize_name(args[1])\n except IndexError:\n op = \"Unknown\"\n\n tracked_request = TrackedRequest.instance()\n tracked_request.start_span(\n operation=\"Elasticsearch/{}\".format(op), ignore_children=True\n )\n\n try:\n return wrapped(*args, **kwargs)\n finally:\n tracked_request.stop_span()\n", "path": "src/scout_apm/instruments/elasticsearch.py"}]}
| 1,719 | 1,023 |
gh_patches_debug_20404
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-5075
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Possible timezone related failure
### Describe the issue
https://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ietf/group/factories.py`
Content:
```
1 # Copyright The IETF Trust 2015-2022, All Rights Reserved
2 import datetime
3 import debug # pyflakes:ignore
4 import factory
5
6 from typing import List # pyflakes:ignore
7
8 from django.utils import timezone
9
10 from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
11 GroupHistory, RoleHistory
12 from ietf.review.factories import ReviewTeamSettingsFactory
13
14 class GroupFactory(factory.django.DjangoModelFactory):
15 class Meta:
16 model = Group
17 django_get_or_create = ('acronym',)
18
19 name = factory.Faker('sentence',nb_words=6)
20 acronym = factory.Sequence(lambda n: 'acronym%d' %n)
21 state_id = 'active'
22 type_id = 'wg'
23 list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)
24 uses_milestone_dates = True
25 used_roles = [] # type: List[str]
26
27 @factory.lazy_attribute
28 def parent(self):
29 if self.type_id in ['wg','ag']:
30 return GroupFactory(type_id='area')
31 elif self.type_id in ['rg','rag']:
32 return GroupFactory(acronym='irtf', type_id='irtf')
33 else:
34 return None
35
36 class ReviewTeamFactory(GroupFactory):
37
38 type_id = 'review'
39
40 @factory.post_generation
41 def settings(obj, create, extracted, **kwargs):
42 ReviewTeamSettingsFactory.create(group=obj,**kwargs)
43
44 class RoleFactory(factory.django.DjangoModelFactory):
45 class Meta:
46 model = Role
47
48 group = factory.SubFactory(GroupFactory)
49 person = factory.SubFactory('ietf.person.factories.PersonFactory')
50 email = factory.LazyAttribute(lambda obj: obj.person.email())
51
52 class GroupEventFactory(factory.django.DjangoModelFactory):
53 class Meta:
54 model = GroupEvent
55
56 group = factory.SubFactory(GroupFactory)
57 by = factory.SubFactory('ietf.person.factories.PersonFactory')
58 type = 'comment'
59 desc = factory.Faker('paragraph')
60
61 class BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):
62 class Meta:
63 model = GroupMilestone
64
65 group = factory.SubFactory(GroupFactory)
66 state_id = 'active'
67 desc = factory.Faker('sentence')
68
69 class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
70 group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
71 due = timezone.now()+datetime.timedelta(days=180)
72
73 class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
74 group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
75 order = factory.Sequence(lambda n: n)
76
77 class GroupHistoryFactory(factory.django.DjangoModelFactory):
78 class Meta:
79 model=GroupHistory
80
81 time = lambda: timezone.now()
82 group = factory.SubFactory(GroupFactory, state_id='active')
83
84 name = factory.LazyAttribute(lambda obj: obj.group.name)
85 state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)
86 type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)
87 parent = factory.LazyAttribute(lambda obj: obj.group.parent)
88 uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)
89 used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)
90 description = factory.LazyAttribute(lambda obj: obj.group.description)
91 list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory
92 list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)
93 list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)
94 comments = factory.LazyAttribute(lambda obj: obj.group.comments)
95 meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)
96 acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)
97
98 @factory.post_generation
99 def unused_states(obj, create, extracted, **kwargs):
100 if create:
101 if extracted:
102 obj.unused_states.set(extracted)
103 else:
104 obj.unused_states.set(obj.group.unused_states.all())
105 @factory.post_generation
106 def unused_tags(obj, create, extracted, **kwargs):
107 if create:
108 if extracted:
109 obj.unused_tags.set(extracted)
110 else:
111 obj.unused_tags.set(obj.group.unused_states.all())
112
113 class RoleHistoryFactory(factory.django.DjangoModelFactory):
114 class Meta:
115 model=RoleHistory
116
117 group = factory.SubFactory(GroupHistoryFactory)
118 person = factory.SubFactory('ietf.person.factories.PersonFactory')
119 email = factory.LazyAttribute(lambda obj: obj.person.email())
120
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ietf/group/factories.py b/ietf/group/factories.py
--- a/ietf/group/factories.py
+++ b/ietf/group/factories.py
@@ -10,6 +10,8 @@
from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \
GroupHistory, RoleHistory
from ietf.review.factories import ReviewTeamSettingsFactory
+from ietf.utils.timezone import date_today
+
class GroupFactory(factory.django.DjangoModelFactory):
class Meta:
@@ -68,7 +70,7 @@
class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)
- due = timezone.now()+datetime.timedelta(days=180)
+ due = date_today() + datetime.timedelta(days=180)
class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):
group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)
|
{"golden_diff": "diff --git a/ietf/group/factories.py b/ietf/group/factories.py\n--- a/ietf/group/factories.py\n+++ b/ietf/group/factories.py\n@@ -10,6 +10,8 @@\n from ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\n from ietf.review.factories import ReviewTeamSettingsFactory\n+from ietf.utils.timezone import date_today\n+\n \n class GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n@@ -68,7 +70,7 @@\n \n class DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n- due = timezone.now()+datetime.timedelta(days=180)\n+ due = date_today() + datetime.timedelta(days=180)\n \n class DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n", "issue": "Possible timezone related failure\n### Describe the issue\n\nhttps://github.com/ietf-tools/datatracker/actions/runs/4071644533/jobs/7013629899\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Copyright The IETF Trust 2015-2022, All Rights Reserved\nimport datetime\nimport debug # pyflakes:ignore\nimport factory\n\nfrom typing import List # pyflakes:ignore\n\nfrom django.utils import timezone\n\nfrom ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\nfrom ietf.review.factories import ReviewTeamSettingsFactory\n\nclass GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Group\n django_get_or_create = ('acronym',)\n\n name = factory.Faker('sentence',nb_words=6)\n acronym = factory.Sequence(lambda n: 'acronym%d' %n)\n state_id = 'active'\n type_id = 'wg'\n list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)\n uses_milestone_dates = True\n used_roles = [] # type: List[str]\n\n @factory.lazy_attribute\n def parent(self):\n if self.type_id in ['wg','ag']:\n return GroupFactory(type_id='area')\n elif self.type_id in ['rg','rag']:\n return GroupFactory(acronym='irtf', type_id='irtf')\n else:\n return None\n\nclass ReviewTeamFactory(GroupFactory):\n\n type_id = 'review'\n\n @factory.post_generation\n def settings(obj, create, extracted, **kwargs):\n ReviewTeamSettingsFactory.create(group=obj,**kwargs)\n\nclass RoleFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Role\n\n group = factory.SubFactory(GroupFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\nclass GroupEventFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupEvent\n\n group = factory.SubFactory(GroupFactory)\n by = factory.SubFactory('ietf.person.factories.PersonFactory')\n type = 'comment'\n desc = factory.Faker('paragraph')\n\nclass BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupMilestone\n\n group = factory.SubFactory(GroupFactory)\n state_id = 'active'\n desc = factory.Faker('sentence')\n\nclass DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n due = timezone.now()+datetime.timedelta(days=180)\n\nclass DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n order = factory.Sequence(lambda n: n)\n\nclass GroupHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=GroupHistory\n\n time = lambda: timezone.now()\n group = factory.SubFactory(GroupFactory, state_id='active')\n\n name = factory.LazyAttribute(lambda obj: obj.group.name)\n state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)\n type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)\n parent = factory.LazyAttribute(lambda obj: obj.group.parent)\n uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)\n used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)\n description = factory.LazyAttribute(lambda obj: obj.group.description)\n list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory\n list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)\n list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)\n comments = factory.LazyAttribute(lambda obj: obj.group.comments)\n meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)\n acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)\n\n @factory.post_generation\n def unused_states(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_states.set(extracted)\n else:\n obj.unused_states.set(obj.group.unused_states.all())\n @factory.post_generation\n def unused_tags(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_tags.set(extracted)\n else:\n obj.unused_tags.set(obj.group.unused_states.all()) \n\nclass RoleHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=RoleHistory\n\n group = factory.SubFactory(GroupHistoryFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\n", "path": "ietf/group/factories.py"}], "after_files": [{"content": "# Copyright The IETF Trust 2015-2022, All Rights Reserved\nimport datetime\nimport debug # pyflakes:ignore\nimport factory\n\nfrom typing import List # pyflakes:ignore\n\nfrom django.utils import timezone\n\nfrom ietf.group.models import Group, Role, GroupEvent, GroupMilestone, \\\n GroupHistory, RoleHistory\nfrom ietf.review.factories import ReviewTeamSettingsFactory\nfrom ietf.utils.timezone import date_today\n\n\nclass GroupFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Group\n django_get_or_create = ('acronym',)\n\n name = factory.Faker('sentence',nb_words=6)\n acronym = factory.Sequence(lambda n: 'acronym%d' %n)\n state_id = 'active'\n type_id = 'wg'\n list_email = factory.LazyAttribute(lambda a: '%[email protected]'% a.acronym)\n uses_milestone_dates = True\n used_roles = [] # type: List[str]\n\n @factory.lazy_attribute\n def parent(self):\n if self.type_id in ['wg','ag']:\n return GroupFactory(type_id='area')\n elif self.type_id in ['rg','rag']:\n return GroupFactory(acronym='irtf', type_id='irtf')\n else:\n return None\n\nclass ReviewTeamFactory(GroupFactory):\n\n type_id = 'review'\n\n @factory.post_generation\n def settings(obj, create, extracted, **kwargs):\n ReviewTeamSettingsFactory.create(group=obj,**kwargs)\n\nclass RoleFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = Role\n\n group = factory.SubFactory(GroupFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\nclass GroupEventFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupEvent\n\n group = factory.SubFactory(GroupFactory)\n by = factory.SubFactory('ietf.person.factories.PersonFactory')\n type = 'comment'\n desc = factory.Faker('paragraph')\n\nclass BaseGroupMilestoneFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = GroupMilestone\n\n group = factory.SubFactory(GroupFactory)\n state_id = 'active'\n desc = factory.Faker('sentence')\n\nclass DatedGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=True)\n due = date_today() + datetime.timedelta(days=180)\n\nclass DatelessGroupMilestoneFactory(BaseGroupMilestoneFactory):\n group = factory.SubFactory(GroupFactory, uses_milestone_dates=False)\n order = factory.Sequence(lambda n: n)\n\nclass GroupHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=GroupHistory\n\n time = lambda: timezone.now()\n group = factory.SubFactory(GroupFactory, state_id='active')\n\n name = factory.LazyAttribute(lambda obj: obj.group.name)\n state_id = factory.LazyAttribute(lambda obj: obj.group.state_id)\n type_id = factory.LazyAttribute(lambda obj: obj.group.type_id)\n parent = factory.LazyAttribute(lambda obj: obj.group.parent)\n uses_milestone_dates = factory.LazyAttribute(lambda obj: obj.group.uses_milestone_dates)\n used_roles = factory.LazyAttribute(lambda obj: obj.group.used_roles)\n description = factory.LazyAttribute(lambda obj: obj.group.description)\n list_email = factory.LazyAttribute(lambda obj: '%[email protected]'% obj.group.acronym) #TODO : move this to GroupFactory\n list_subscribe = factory.LazyAttribute(lambda obj: obj.group.list_subscribe)\n list_archive = factory.LazyAttribute(lambda obj: obj.group.list_archive)\n comments = factory.LazyAttribute(lambda obj: obj.group.comments)\n meeting_seen_as_area = factory.LazyAttribute(lambda obj: obj.group.meeting_seen_as_area)\n acronym = factory.LazyAttribute(lambda obj: obj.group.acronym)\n\n @factory.post_generation\n def unused_states(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_states.set(extracted)\n else:\n obj.unused_states.set(obj.group.unused_states.all())\n @factory.post_generation\n def unused_tags(obj, create, extracted, **kwargs):\n if create:\n if extracted:\n obj.unused_tags.set(extracted)\n else:\n obj.unused_tags.set(obj.group.unused_states.all()) \n\nclass RoleHistoryFactory(factory.django.DjangoModelFactory):\n class Meta:\n model=RoleHistory\n\n group = factory.SubFactory(GroupHistoryFactory)\n person = factory.SubFactory('ietf.person.factories.PersonFactory')\n email = factory.LazyAttribute(lambda obj: obj.person.email())\n\n", "path": "ietf/group/factories.py"}]}
| 1,621 | 216 |
gh_patches_debug_4593
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1189
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
NpipeSocket.makefile crashes when bufsize < 0
**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701
Negative `bufsize` should be handled.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/transport/npipesocket.py`
Content:
```
1 import functools
2 import io
3
4 import win32file
5 import win32pipe
6
7 cSECURITY_SQOS_PRESENT = 0x100000
8 cSECURITY_ANONYMOUS = 0
9 cPIPE_READMODE_MESSAGE = 2
10
11
12 def check_closed(f):
13 @functools.wraps(f)
14 def wrapped(self, *args, **kwargs):
15 if self._closed:
16 raise RuntimeError(
17 'Can not reuse socket after connection was closed.'
18 )
19 return f(self, *args, **kwargs)
20 return wrapped
21
22
23 class NpipeSocket(object):
24 """ Partial implementation of the socket API over windows named pipes.
25 This implementation is only designed to be used as a client socket,
26 and server-specific methods (bind, listen, accept...) are not
27 implemented.
28 """
29 def __init__(self, handle=None):
30 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
31 self._handle = handle
32 self._closed = False
33
34 def accept(self):
35 raise NotImplementedError()
36
37 def bind(self, address):
38 raise NotImplementedError()
39
40 def close(self):
41 self._handle.Close()
42 self._closed = True
43
44 @check_closed
45 def connect(self, address):
46 win32pipe.WaitNamedPipe(address, self._timeout)
47 handle = win32file.CreateFile(
48 address,
49 win32file.GENERIC_READ | win32file.GENERIC_WRITE,
50 0,
51 None,
52 win32file.OPEN_EXISTING,
53 cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,
54 0
55 )
56 self.flags = win32pipe.GetNamedPipeInfo(handle)[0]
57
58 self._handle = handle
59 self._address = address
60
61 @check_closed
62 def connect_ex(self, address):
63 return self.connect(address)
64
65 @check_closed
66 def detach(self):
67 self._closed = True
68 return self._handle
69
70 @check_closed
71 def dup(self):
72 return NpipeSocket(self._handle)
73
74 @check_closed
75 def fileno(self):
76 return int(self._handle)
77
78 def getpeername(self):
79 return self._address
80
81 def getsockname(self):
82 return self._address
83
84 def getsockopt(self, level, optname, buflen=None):
85 raise NotImplementedError()
86
87 def ioctl(self, control, option):
88 raise NotImplementedError()
89
90 def listen(self, backlog):
91 raise NotImplementedError()
92
93 def makefile(self, mode=None, bufsize=None):
94 if mode.strip('b') != 'r':
95 raise NotImplementedError()
96 rawio = NpipeFileIOBase(self)
97 if bufsize is None:
98 bufsize = io.DEFAULT_BUFFER_SIZE
99 return io.BufferedReader(rawio, buffer_size=bufsize)
100
101 @check_closed
102 def recv(self, bufsize, flags=0):
103 err, data = win32file.ReadFile(self._handle, bufsize)
104 return data
105
106 @check_closed
107 def recvfrom(self, bufsize, flags=0):
108 data = self.recv(bufsize, flags)
109 return (data, self._address)
110
111 @check_closed
112 def recvfrom_into(self, buf, nbytes=0, flags=0):
113 return self.recv_into(buf, nbytes, flags), self._address
114
115 @check_closed
116 def recv_into(self, buf, nbytes=0):
117 readbuf = buf
118 if not isinstance(buf, memoryview):
119 readbuf = memoryview(buf)
120
121 err, data = win32file.ReadFile(
122 self._handle,
123 readbuf[:nbytes] if nbytes else readbuf
124 )
125 return len(data)
126
127 @check_closed
128 def send(self, string, flags=0):
129 err, nbytes = win32file.WriteFile(self._handle, string)
130 return nbytes
131
132 @check_closed
133 def sendall(self, string, flags=0):
134 return self.send(string, flags)
135
136 @check_closed
137 def sendto(self, string, address):
138 self.connect(address)
139 return self.send(string)
140
141 def setblocking(self, flag):
142 if flag:
143 return self.settimeout(None)
144 return self.settimeout(0)
145
146 def settimeout(self, value):
147 if value is None:
148 self._timeout = win32pipe.NMPWAIT_NOWAIT
149 elif not isinstance(value, (float, int)) or value < 0:
150 raise ValueError('Timeout value out of range')
151 elif value == 0:
152 self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT
153 else:
154 self._timeout = value
155
156 def gettimeout(self):
157 return self._timeout
158
159 def setsockopt(self, level, optname, value):
160 raise NotImplementedError()
161
162 @check_closed
163 def shutdown(self, how):
164 return self.close()
165
166
167 class NpipeFileIOBase(io.RawIOBase):
168 def __init__(self, npipe_socket):
169 self.sock = npipe_socket
170
171 def close(self):
172 super(NpipeFileIOBase, self).close()
173 self.sock = None
174
175 def fileno(self):
176 return self.sock.fileno()
177
178 def isatty(self):
179 return False
180
181 def readable(self):
182 return True
183
184 def readinto(self, buf):
185 return self.sock.recv_into(buf)
186
187 def seekable(self):
188 return False
189
190 def writable(self):
191 return False
192
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py
--- a/docker/transport/npipesocket.py
+++ b/docker/transport/npipesocket.py
@@ -94,7 +94,7 @@
if mode.strip('b') != 'r':
raise NotImplementedError()
rawio = NpipeFileIOBase(self)
- if bufsize is None:
+ if bufsize is None or bufsize < 0:
bufsize = io.DEFAULT_BUFFER_SIZE
return io.BufferedReader(rawio, buffer_size=bufsize)
|
{"golden_diff": "diff --git a/docker/transport/npipesocket.py b/docker/transport/npipesocket.py\n--- a/docker/transport/npipesocket.py\n+++ b/docker/transport/npipesocket.py\n@@ -94,7 +94,7 @@\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n- if bufsize is None:\n+ if bufsize is None or bufsize < 0:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n", "issue": "NpipeSocket.makefile crashes when bufsize < 0\n**Original report**: https://github.com/docker/compose/issues/3901#issuecomment-244828701\n\nNegative `bufsize` should be handled.\n\n", "before_files": [{"content": "import functools\nimport io\n\nimport win32file\nimport win32pipe\n\ncSECURITY_SQOS_PRESENT = 0x100000\ncSECURITY_ANONYMOUS = 0\ncPIPE_READMODE_MESSAGE = 2\n\n\ndef check_closed(f):\n @functools.wraps(f)\n def wrapped(self, *args, **kwargs):\n if self._closed:\n raise RuntimeError(\n 'Can not reuse socket after connection was closed.'\n )\n return f(self, *args, **kwargs)\n return wrapped\n\n\nclass NpipeSocket(object):\n \"\"\" Partial implementation of the socket API over windows named pipes.\n This implementation is only designed to be used as a client socket,\n and server-specific methods (bind, listen, accept...) are not\n implemented.\n \"\"\"\n def __init__(self, handle=None):\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n self._handle = handle\n self._closed = False\n\n def accept(self):\n raise NotImplementedError()\n\n def bind(self, address):\n raise NotImplementedError()\n\n def close(self):\n self._handle.Close()\n self._closed = True\n\n @check_closed\n def connect(self, address):\n win32pipe.WaitNamedPipe(address, self._timeout)\n handle = win32file.CreateFile(\n address,\n win32file.GENERIC_READ | win32file.GENERIC_WRITE,\n 0,\n None,\n win32file.OPEN_EXISTING,\n cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,\n 0\n )\n self.flags = win32pipe.GetNamedPipeInfo(handle)[0]\n\n self._handle = handle\n self._address = address\n\n @check_closed\n def connect_ex(self, address):\n return self.connect(address)\n\n @check_closed\n def detach(self):\n self._closed = True\n return self._handle\n\n @check_closed\n def dup(self):\n return NpipeSocket(self._handle)\n\n @check_closed\n def fileno(self):\n return int(self._handle)\n\n def getpeername(self):\n return self._address\n\n def getsockname(self):\n return self._address\n\n def getsockopt(self, level, optname, buflen=None):\n raise NotImplementedError()\n\n def ioctl(self, control, option):\n raise NotImplementedError()\n\n def listen(self, backlog):\n raise NotImplementedError()\n\n def makefile(self, mode=None, bufsize=None):\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n if bufsize is None:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n\n @check_closed\n def recv(self, bufsize, flags=0):\n err, data = win32file.ReadFile(self._handle, bufsize)\n return data\n\n @check_closed\n def recvfrom(self, bufsize, flags=0):\n data = self.recv(bufsize, flags)\n return (data, self._address)\n\n @check_closed\n def recvfrom_into(self, buf, nbytes=0, flags=0):\n return self.recv_into(buf, nbytes, flags), self._address\n\n @check_closed\n def recv_into(self, buf, nbytes=0):\n readbuf = buf\n if not isinstance(buf, memoryview):\n readbuf = memoryview(buf)\n\n err, data = win32file.ReadFile(\n self._handle,\n readbuf[:nbytes] if nbytes else readbuf\n )\n return len(data)\n\n @check_closed\n def send(self, string, flags=0):\n err, nbytes = win32file.WriteFile(self._handle, string)\n return nbytes\n\n @check_closed\n def sendall(self, string, flags=0):\n return self.send(string, flags)\n\n @check_closed\n def sendto(self, string, address):\n self.connect(address)\n return self.send(string)\n\n def setblocking(self, flag):\n if flag:\n return self.settimeout(None)\n return self.settimeout(0)\n\n def settimeout(self, value):\n if value is None:\n self._timeout = win32pipe.NMPWAIT_NOWAIT\n elif not isinstance(value, (float, int)) or value < 0:\n raise ValueError('Timeout value out of range')\n elif value == 0:\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n else:\n self._timeout = value\n\n def gettimeout(self):\n return self._timeout\n\n def setsockopt(self, level, optname, value):\n raise NotImplementedError()\n\n @check_closed\n def shutdown(self, how):\n return self.close()\n\n\nclass NpipeFileIOBase(io.RawIOBase):\n def __init__(self, npipe_socket):\n self.sock = npipe_socket\n\n def close(self):\n super(NpipeFileIOBase, self).close()\n self.sock = None\n\n def fileno(self):\n return self.sock.fileno()\n\n def isatty(self):\n return False\n\n def readable(self):\n return True\n\n def readinto(self, buf):\n return self.sock.recv_into(buf)\n\n def seekable(self):\n return False\n\n def writable(self):\n return False\n", "path": "docker/transport/npipesocket.py"}], "after_files": [{"content": "import functools\nimport io\n\nimport win32file\nimport win32pipe\n\ncSECURITY_SQOS_PRESENT = 0x100000\ncSECURITY_ANONYMOUS = 0\ncPIPE_READMODE_MESSAGE = 2\n\n\ndef check_closed(f):\n @functools.wraps(f)\n def wrapped(self, *args, **kwargs):\n if self._closed:\n raise RuntimeError(\n 'Can not reuse socket after connection was closed.'\n )\n return f(self, *args, **kwargs)\n return wrapped\n\n\nclass NpipeSocket(object):\n \"\"\" Partial implementation of the socket API over windows named pipes.\n This implementation is only designed to be used as a client socket,\n and server-specific methods (bind, listen, accept...) are not\n implemented.\n \"\"\"\n def __init__(self, handle=None):\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n self._handle = handle\n self._closed = False\n\n def accept(self):\n raise NotImplementedError()\n\n def bind(self, address):\n raise NotImplementedError()\n\n def close(self):\n self._handle.Close()\n self._closed = True\n\n @check_closed\n def connect(self, address):\n win32pipe.WaitNamedPipe(address, self._timeout)\n handle = win32file.CreateFile(\n address,\n win32file.GENERIC_READ | win32file.GENERIC_WRITE,\n 0,\n None,\n win32file.OPEN_EXISTING,\n cSECURITY_ANONYMOUS | cSECURITY_SQOS_PRESENT,\n 0\n )\n self.flags = win32pipe.GetNamedPipeInfo(handle)[0]\n\n self._handle = handle\n self._address = address\n\n @check_closed\n def connect_ex(self, address):\n return self.connect(address)\n\n @check_closed\n def detach(self):\n self._closed = True\n return self._handle\n\n @check_closed\n def dup(self):\n return NpipeSocket(self._handle)\n\n @check_closed\n def fileno(self):\n return int(self._handle)\n\n def getpeername(self):\n return self._address\n\n def getsockname(self):\n return self._address\n\n def getsockopt(self, level, optname, buflen=None):\n raise NotImplementedError()\n\n def ioctl(self, control, option):\n raise NotImplementedError()\n\n def listen(self, backlog):\n raise NotImplementedError()\n\n def makefile(self, mode=None, bufsize=None):\n if mode.strip('b') != 'r':\n raise NotImplementedError()\n rawio = NpipeFileIOBase(self)\n if bufsize is None or bufsize < 0:\n bufsize = io.DEFAULT_BUFFER_SIZE\n return io.BufferedReader(rawio, buffer_size=bufsize)\n\n @check_closed\n def recv(self, bufsize, flags=0):\n err, data = win32file.ReadFile(self._handle, bufsize)\n return data\n\n @check_closed\n def recvfrom(self, bufsize, flags=0):\n data = self.recv(bufsize, flags)\n return (data, self._address)\n\n @check_closed\n def recvfrom_into(self, buf, nbytes=0, flags=0):\n return self.recv_into(buf, nbytes, flags), self._address\n\n @check_closed\n def recv_into(self, buf, nbytes=0):\n readbuf = buf\n if not isinstance(buf, memoryview):\n readbuf = memoryview(buf)\n\n err, data = win32file.ReadFile(\n self._handle,\n readbuf[:nbytes] if nbytes else readbuf\n )\n return len(data)\n\n @check_closed\n def send(self, string, flags=0):\n err, nbytes = win32file.WriteFile(self._handle, string)\n return nbytes\n\n @check_closed\n def sendall(self, string, flags=0):\n return self.send(string, flags)\n\n @check_closed\n def sendto(self, string, address):\n self.connect(address)\n return self.send(string)\n\n def setblocking(self, flag):\n if flag:\n return self.settimeout(None)\n return self.settimeout(0)\n\n def settimeout(self, value):\n if value is None:\n self._timeout = win32pipe.NMPWAIT_NOWAIT\n elif not isinstance(value, (float, int)) or value < 0:\n raise ValueError('Timeout value out of range')\n elif value == 0:\n self._timeout = win32pipe.NMPWAIT_USE_DEFAULT_WAIT\n else:\n self._timeout = value\n\n def gettimeout(self):\n return self._timeout\n\n def setsockopt(self, level, optname, value):\n raise NotImplementedError()\n\n @check_closed\n def shutdown(self, how):\n return self.close()\n\n\nclass NpipeFileIOBase(io.RawIOBase):\n def __init__(self, npipe_socket):\n self.sock = npipe_socket\n\n def close(self):\n super(NpipeFileIOBase, self).close()\n self.sock = None\n\n def fileno(self):\n return self.sock.fileno()\n\n def isatty(self):\n return False\n\n def readable(self):\n return True\n\n def readinto(self, buf):\n return self.sock.recv_into(buf)\n\n def seekable(self):\n return False\n\n def writable(self):\n return False\n", "path": "docker/transport/npipesocket.py"}]}
| 1,969 | 122 |
gh_patches_debug_22473
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2363
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add documentation in user guide on `torch.compile` usage
- `torch.compile` "from-scratch" usage
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `py/torch_tensorrt/dynamo/_settings.py`
Content:
```
1 from dataclasses import dataclass, field
2 from typing import Optional, Set
3
4 import torch
5 from torch_tensorrt._Device import Device
6 from torch_tensorrt.dynamo._defaults import (
7 DEBUG,
8 ENABLE_EXPERIMENTAL_DECOMPOSITIONS,
9 MAX_AUX_STREAMS,
10 MIN_BLOCK_SIZE,
11 OPTIMIZATION_LEVEL,
12 PASS_THROUGH_BUILD_FAILURES,
13 PRECISION,
14 REQUIRE_FULL_COMPILATION,
15 TRUNCATE_LONG_AND_DOUBLE,
16 USE_FAST_PARTITIONER,
17 USE_PYTHON_RUNTIME,
18 VERSION_COMPATIBLE,
19 WORKSPACE_SIZE,
20 default_device,
21 )
22
23
24 @dataclass
25 class CompilationSettings:
26 """Compilation settings for Torch-TensorRT Dynamo Paths
27
28 Args:
29 precision (torch.dtype): Model Layer precision
30 debug (bool): Whether to print out verbose debugging information
31 workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)
32 min_block_size (int): Minimum number of operators per TRT-Engine Block
33 torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage
34 pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)
35 max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine
36 version_compatible (bool): Provide version forward-compatibility for engine plan files
37 optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,
38 searching for more optimization options. TRT defaults to 3
39 use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
40 based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
41 argument as None
42 truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
43 enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
44 or only a selected subset of them
45 """
46
47 precision: torch.dtype = PRECISION
48 debug: bool = DEBUG
49 workspace_size: int = WORKSPACE_SIZE
50 min_block_size: int = MIN_BLOCK_SIZE
51 torch_executed_ops: Set[str] = field(default_factory=set)
52 pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES
53 max_aux_streams: Optional[int] = MAX_AUX_STREAMS
54 version_compatible: bool = VERSION_COMPATIBLE
55 optimization_level: Optional[int] = OPTIMIZATION_LEVEL
56 use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME
57 truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE
58 use_fast_partitioner: bool = USE_FAST_PARTITIONER
59 enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS
60 device: Device = field(default_factory=default_device)
61 require_full_compilation: bool = REQUIRE_FULL_COMPILATION
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py
--- a/py/torch_tensorrt/dynamo/_settings.py
+++ b/py/torch_tensorrt/dynamo/_settings.py
@@ -39,9 +39,13 @@
use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime
based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the
argument as None
- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32
+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32
+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system
enable_experimental_decompositions (bool): Whether to enable all core aten decompositions
or only a selected subset of them
+ device (Device): GPU to compile the model on
+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.
+ Only applicable for `ir="dynamo"`; has no effect for `torch.compile` path
"""
precision: torch.dtype = PRECISION
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/_settings.py b/py/torch_tensorrt/dynamo/_settings.py\n--- a/py/torch_tensorrt/dynamo/_settings.py\n+++ b/py/torch_tensorrt/dynamo/_settings.py\n@@ -39,9 +39,13 @@\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n- truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32\n+ use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n+ device (Device): GPU to compile the model on\n+ require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.\n+ Only applicable for `ir=\"dynamo\"`; has no effect for `torch.compile` path\n \"\"\"\n \n precision: torch.dtype = PRECISION\n", "issue": "Add documentation in user guide on `torch.compile` usage\n- `torch.compile` \"from-scratch\" usage\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional, Set\n\nimport torch\nfrom torch_tensorrt._Device import Device\nfrom torch_tensorrt.dynamo._defaults import (\n DEBUG,\n ENABLE_EXPERIMENTAL_DECOMPOSITIONS,\n MAX_AUX_STREAMS,\n MIN_BLOCK_SIZE,\n OPTIMIZATION_LEVEL,\n PASS_THROUGH_BUILD_FAILURES,\n PRECISION,\n REQUIRE_FULL_COMPILATION,\n TRUNCATE_LONG_AND_DOUBLE,\n USE_FAST_PARTITIONER,\n USE_PYTHON_RUNTIME,\n VERSION_COMPATIBLE,\n WORKSPACE_SIZE,\n default_device,\n)\n\n\n@dataclass\nclass CompilationSettings:\n \"\"\"Compilation settings for Torch-TensorRT Dynamo Paths\n\n Args:\n precision (torch.dtype): Model Layer precision\n debug (bool): Whether to print out verbose debugging information\n workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)\n min_block_size (int): Minimum number of operators per TRT-Engine Block\n torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage\n pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)\n max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine\n version_compatible (bool): Provide version forward-compatibility for engine plan files\n optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,\n searching for more optimization options. TRT defaults to 3\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n truncate_long_and_double (bool): Truncate int64/float64 TRT engine inputs or weights to int32/float32\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n \"\"\"\n\n precision: torch.dtype = PRECISION\n debug: bool = DEBUG\n workspace_size: int = WORKSPACE_SIZE\n min_block_size: int = MIN_BLOCK_SIZE\n torch_executed_ops: Set[str] = field(default_factory=set)\n pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES\n max_aux_streams: Optional[int] = MAX_AUX_STREAMS\n version_compatible: bool = VERSION_COMPATIBLE\n optimization_level: Optional[int] = OPTIMIZATION_LEVEL\n use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME\n truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE\n use_fast_partitioner: bool = USE_FAST_PARTITIONER\n enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS\n device: Device = field(default_factory=default_device)\n require_full_compilation: bool = REQUIRE_FULL_COMPILATION\n", "path": "py/torch_tensorrt/dynamo/_settings.py"}], "after_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import Optional, Set\n\nimport torch\nfrom torch_tensorrt._Device import Device\nfrom torch_tensorrt.dynamo._defaults import (\n DEBUG,\n ENABLE_EXPERIMENTAL_DECOMPOSITIONS,\n MAX_AUX_STREAMS,\n MIN_BLOCK_SIZE,\n OPTIMIZATION_LEVEL,\n PASS_THROUGH_BUILD_FAILURES,\n PRECISION,\n REQUIRE_FULL_COMPILATION,\n TRUNCATE_LONG_AND_DOUBLE,\n USE_FAST_PARTITIONER,\n USE_PYTHON_RUNTIME,\n VERSION_COMPATIBLE,\n WORKSPACE_SIZE,\n default_device,\n)\n\n\n@dataclass\nclass CompilationSettings:\n \"\"\"Compilation settings for Torch-TensorRT Dynamo Paths\n\n Args:\n precision (torch.dtype): Model Layer precision\n debug (bool): Whether to print out verbose debugging information\n workspace_size (int): Workspace TRT is allowed to use for the module (0 is default)\n min_block_size (int): Minimum number of operators per TRT-Engine Block\n torch_executed_ops (Sequence[str]): Sequence of operations to run in Torch, regardless of converter coverage\n pass_through_build_failures (bool): Whether to fail on TRT engine build errors (True) or not (False)\n max_aux_streams (Optional[int]): Maximum number of allowed auxiliary TRT streams for each engine\n version_compatible (bool): Provide version forward-compatibility for engine plan files\n optimization_level (Optional[int]): Builder optimization 0-5, higher levels imply longer build time,\n searching for more optimization options. TRT defaults to 3\n use_python_runtime (Optional[bool]): Whether to strictly use Python runtime or C++ runtime. To auto-select a runtime\n based on C++ dependency presence (preferentially choosing C++ runtime if available), leave the\n argument as None\n truncate_long_and_double (bool): Whether to truncate int64/float64 TRT engine inputs or weights to int32/float32\n use_fast_partitioner (bool): Whether to use the fast or global graph partitioning system\n enable_experimental_decompositions (bool): Whether to enable all core aten decompositions\n or only a selected subset of them\n device (Device): GPU to compile the model on\n require_full_compilation (bool): Whether to require the graph is fully compiled in TensorRT.\n Only applicable for `ir=\"dynamo\"`; has no effect for `torch.compile` path\n \"\"\"\n\n precision: torch.dtype = PRECISION\n debug: bool = DEBUG\n workspace_size: int = WORKSPACE_SIZE\n min_block_size: int = MIN_BLOCK_SIZE\n torch_executed_ops: Set[str] = field(default_factory=set)\n pass_through_build_failures: bool = PASS_THROUGH_BUILD_FAILURES\n max_aux_streams: Optional[int] = MAX_AUX_STREAMS\n version_compatible: bool = VERSION_COMPATIBLE\n optimization_level: Optional[int] = OPTIMIZATION_LEVEL\n use_python_runtime: Optional[bool] = USE_PYTHON_RUNTIME\n truncate_long_and_double: bool = TRUNCATE_LONG_AND_DOUBLE\n use_fast_partitioner: bool = USE_FAST_PARTITIONER\n enable_experimental_decompositions: bool = ENABLE_EXPERIMENTAL_DECOMPOSITIONS\n device: Device = field(default_factory=default_device)\n require_full_compilation: bool = REQUIRE_FULL_COMPILATION\n", "path": "py/torch_tensorrt/dynamo/_settings.py"}]}
| 1,044 | 301 |
gh_patches_debug_59440
|
rasdani/github-patches
|
git_diff
|
Pycord-Development__pycord-576
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SlashCommand Groups Issues
This issue is to keep track of the issues since we reworked groups.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/app_commands/slash_groups.py`
Content:
```
1 import discord
2
3 bot = discord.Bot()
4
5 # If you use commands.Bot, @bot.slash_command should be used for
6 # slash commands. You can use @bot.slash_command with discord.Bot as well
7
8 math = bot.command_group(
9 "math", "Commands related to mathematics."
10 ) # create a slash command group
11
12
13 @math.command(guild_ids=[...]) # create a slash command
14 async def add(ctx, num1: int, num2: int):
15 """Get the sum of 2 integers."""
16 await ctx.respond(f"The sum of these numbers is **{num1+num2}**")
17
18
19 # another way, creating the class manually
20
21 from discord.commands import SlashCommandGroup
22
23 math = SlashCommandGroup("math", "Commands related to mathematics.")
24
25
26 @math.command(guild_ids=[...])
27 async def add(ctx, num1: int, num2: int):
28 ...
29
30
31 bot.add_application_command(math)
32
33 bot.run("TOKEN")
34
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py
--- a/examples/app_commands/slash_groups.py
+++ b/examples/app_commands/slash_groups.py
@@ -5,7 +5,7 @@
# If you use commands.Bot, @bot.slash_command should be used for
# slash commands. You can use @bot.slash_command with discord.Bot as well
-math = bot.command_group(
+math = bot.create_group(
"math", "Commands related to mathematics."
) # create a slash command group
|
{"golden_diff": "diff --git a/examples/app_commands/slash_groups.py b/examples/app_commands/slash_groups.py\n--- a/examples/app_commands/slash_groups.py\n+++ b/examples/app_commands/slash_groups.py\n@@ -5,7 +5,7 @@\n # If you use commands.Bot, @bot.slash_command should be used for\r\n # slash commands. You can use @bot.slash_command with discord.Bot as well\r\n \r\n-math = bot.command_group(\r\n+math = bot.create_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n ) # create a slash command group\n", "issue": "SlashCommand Groups Issues\nThis issue is to keep track of the issues since we reworked groups.\n", "before_files": [{"content": "import discord\r\n\r\nbot = discord.Bot()\r\n\r\n# If you use commands.Bot, @bot.slash_command should be used for\r\n# slash commands. You can use @bot.slash_command with discord.Bot as well\r\n\r\nmath = bot.command_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n) # create a slash command group\r\n\r\n\r\[email protected](guild_ids=[...]) # create a slash command\r\nasync def add(ctx, num1: int, num2: int):\r\n \"\"\"Get the sum of 2 integers.\"\"\"\r\n await ctx.respond(f\"The sum of these numbers is **{num1+num2}**\")\r\n\r\n\r\n# another way, creating the class manually\r\n\r\nfrom discord.commands import SlashCommandGroup\r\n\r\nmath = SlashCommandGroup(\"math\", \"Commands related to mathematics.\")\r\n\r\n\r\[email protected](guild_ids=[...])\r\nasync def add(ctx, num1: int, num2: int):\r\n ...\r\n\r\n\r\nbot.add_application_command(math)\r\n\r\nbot.run(\"TOKEN\")\r\n", "path": "examples/app_commands/slash_groups.py"}], "after_files": [{"content": "import discord\r\n\r\nbot = discord.Bot()\r\n\r\n# If you use commands.Bot, @bot.slash_command should be used for\r\n# slash commands. You can use @bot.slash_command with discord.Bot as well\r\n\r\nmath = bot.create_group(\r\n \"math\", \"Commands related to mathematics.\"\r\n) # create a slash command group\r\n\r\n\r\[email protected](guild_ids=[...]) # create a slash command\r\nasync def add(ctx, num1: int, num2: int):\r\n \"\"\"Get the sum of 2 integers.\"\"\"\r\n await ctx.respond(f\"The sum of these numbers is **{num1+num2}**\")\r\n\r\n\r\n# another way, creating the class manually\r\n\r\nfrom discord.commands import SlashCommandGroup\r\n\r\nmath = SlashCommandGroup(\"math\", \"Commands related to mathematics.\")\r\n\r\n\r\[email protected](guild_ids=[...])\r\nasync def add(ctx, num1: int, num2: int):\r\n ...\r\n\r\n\r\nbot.add_application_command(math)\r\n\r\nbot.run(\"TOKEN\")\r\n", "path": "examples/app_commands/slash_groups.py"}]}
| 551 | 119 |
gh_patches_debug_67111
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1619
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Scroll container not expanding to width of container
```
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class AFV(toga.App):
def startup(self):
self.main_window = toga.MainWindow(title=self.formal_name)
box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))
self.label_1 = toga.Label('TESTE 1')
self.lineEdit_1 = toga.TextInput()
self.label_2 = toga.Label('TESTE 2')
self.lineEdit_2 = toga.TextInput()
self.label_3 = toga.Label('TESTE 3')
self.lineEdit_3 = toga.TextInput()
self.label_4 = toga.Label('TESTE 4')
self.lineEdit_4 = toga.TextInput()
self.label_5 = toga.Label('TESTE 5')
self.lineEdit_5 = toga.TextInput()
box_test.add(self.label_1, self.lineEdit_1,
self.label_2, self.lineEdit_2,
self.label_3, self.lineEdit_3,
self.label_4, self.lineEdit_4,
self.label_5, self.lineEdit_5)
self.container = toga.ScrollContainer(horizontal=True, vertical=True)
self.container.content = box_test
self.main_window.content = self.container
self.main_window.show()
def main():
return AFV()
```
When using the widget it leaves the widgets in the wrong shape and size on the screen.
The ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.

Worked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/android/toga_android/widgets/scrollcontainer.py`
Content:
```
1 from travertino.size import at_least
2
3 from toga_android.window import AndroidViewport
4
5 from ..libs.android.view import (
6 Gravity,
7 View__MeasureSpec,
8 View__OnTouchListener
9 )
10 from ..libs.android.widget import (
11 HorizontalScrollView,
12 LinearLayout__LayoutParams,
13 ScrollView
14 )
15 from .base import Widget
16
17
18 class TogaOnTouchListener(View__OnTouchListener):
19 is_scrolling_enabled = True
20
21 def __init__(self):
22 super().__init__()
23
24 def onTouch(self, view, motion_event):
25 if self.is_scrolling_enabled:
26 return view.onTouchEvent(motion_event)
27 else:
28 return True
29
30
31 class ScrollContainer(Widget):
32 vScrollListener = None
33 hScrollView = None
34 hScrollListener = None
35
36 def create(self):
37 vScrollView = ScrollView(self._native_activity)
38 vScrollView_layout_params = LinearLayout__LayoutParams(
39 LinearLayout__LayoutParams.MATCH_PARENT,
40 LinearLayout__LayoutParams.MATCH_PARENT
41 )
42 vScrollView_layout_params.gravity = Gravity.TOP
43 vScrollView.setLayoutParams(vScrollView_layout_params)
44 self.vScrollListener = TogaOnTouchListener()
45 self.vScrollListener.is_scrolling_enabled = self.interface.vertical
46 vScrollView.setOnTouchListener(self.vScrollListener)
47 self.native = vScrollView
48 self.hScrollView = HorizontalScrollView(self._native_activity)
49 hScrollView_layout_params = LinearLayout__LayoutParams(
50 LinearLayout__LayoutParams.MATCH_PARENT,
51 LinearLayout__LayoutParams.MATCH_PARENT
52 )
53 hScrollView_layout_params.gravity = Gravity.LEFT
54 self.hScrollListener = TogaOnTouchListener()
55 self.hScrollListener.is_scrolling_enabled = self.interface.horizontal
56 self.hScrollView.setOnTouchListener(self.hScrollListener)
57 vScrollView.addView(self.hScrollView, hScrollView_layout_params)
58 if self.interface.content is not None:
59 self.set_content(self.interface.content)
60
61 def set_content(self, widget):
62 widget.viewport = AndroidViewport(widget.native)
63 content_view_params = LinearLayout__LayoutParams(
64 LinearLayout__LayoutParams.MATCH_PARENT,
65 LinearLayout__LayoutParams.MATCH_PARENT
66 )
67 if widget.container:
68 widget.container = None
69 if self.interface.content:
70 self.hScrollView.removeAllViews()
71 self.hScrollView.addView(widget.native, content_view_params)
72 for child in widget.interface.children:
73 if child._impl.container:
74 child._impl.container = None
75 child._impl.container = widget
76
77 def set_vertical(self, value):
78 self.vScrollListener.is_scrolling_enabled = value
79
80 def set_horizontal(self, value):
81 self.hScrollListener.is_scrolling_enabled = value
82
83 def set_on_scroll(self, on_scroll):
84 self.interface.factory.not_implemented("ScrollContainer.set_on_scroll()")
85
86 def get_vertical_position(self):
87 self.interface.factory.not_implemented(
88 "ScrollContainer.get_vertical_position()"
89 )
90 return 0
91
92 def set_vertical_position(self, vertical_position):
93 self.interface.factory.not_implemented(
94 "ScrollContainer.set_vertical_position()"
95 )
96
97 def get_horizontal_position(self):
98 self.interface.factory.not_implemented(
99 "ScrollContainer.get_horizontal_position()"
100 )
101 return 0
102
103 def set_horizontal_position(self, horizontal_position):
104 self.interface.factory.not_implemented(
105 "ScrollContainer.set_horizontal_position()"
106 )
107
108 def rehint(self):
109 # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.
110 if not self.native.getLayoutParams():
111 return
112 self.native.measure(
113 View__MeasureSpec.UNSPECIFIED,
114 View__MeasureSpec.UNSPECIFIED,
115 )
116 self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())
117 self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py
--- a/src/android/toga_android/widgets/scrollcontainer.py
+++ b/src/android/toga_android/widgets/scrollcontainer.py
@@ -59,7 +59,7 @@
self.set_content(self.interface.content)
def set_content(self, widget):
- widget.viewport = AndroidViewport(widget.native)
+ widget.viewport = AndroidViewport(self.native)
content_view_params = LinearLayout__LayoutParams(
LinearLayout__LayoutParams.MATCH_PARENT,
LinearLayout__LayoutParams.MATCH_PARENT
|
{"golden_diff": "diff --git a/src/android/toga_android/widgets/scrollcontainer.py b/src/android/toga_android/widgets/scrollcontainer.py\n--- a/src/android/toga_android/widgets/scrollcontainer.py\n+++ b/src/android/toga_android/widgets/scrollcontainer.py\n@@ -59,7 +59,7 @@\n self.set_content(self.interface.content)\n \n def set_content(self, widget):\n- widget.viewport = AndroidViewport(widget.native)\n+ widget.viewport = AndroidViewport(self.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n", "issue": "Scroll container not expanding to width of container\n```\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\nclass AFV(toga.App):\r\n\r\n def startup(self):\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n\r\n box_test = toga.Box(style=Pack(direction=COLUMN, padding=5))\r\n self.label_1 = toga.Label('TESTE 1')\r\n self.lineEdit_1 = toga.TextInput()\r\n self.label_2 = toga.Label('TESTE 2')\r\n self.lineEdit_2 = toga.TextInput()\r\n self.label_3 = toga.Label('TESTE 3')\r\n self.lineEdit_3 = toga.TextInput()\r\n self.label_4 = toga.Label('TESTE 4')\r\n self.lineEdit_4 = toga.TextInput()\r\n self.label_5 = toga.Label('TESTE 5')\r\n self.lineEdit_5 = toga.TextInput()\r\n\r\n box_test.add(self.label_1, self.lineEdit_1, \r\n self.label_2, self.lineEdit_2, \r\n self.label_3, self.lineEdit_3, \r\n self.label_4, self.lineEdit_4, \r\n self.label_5, self.lineEdit_5)\r\n self.container = toga.ScrollContainer(horizontal=True, vertical=True)\r\n self.container.content = box_test\r\n\r\n\r\n self.main_window.content = self.container\r\n self.main_window.show()\r\n\r\n\r\ndef main():\r\n return AFV()\r\n```\r\n\r\n\r\nWhen using the widget it leaves the widgets in the wrong shape and size on the screen.\r\nThe ScrollContainer doesn't make the TextInput widget fill to the bottom of the screen, it measures according to the size of the Label text.\r\n\r\n\r\n\r\nWorked on Briefcase 0.3.9; new screenshot is from Briefcase 0.3.10.\n", "before_files": [{"content": "from travertino.size import at_least\n\nfrom toga_android.window import AndroidViewport\n\nfrom ..libs.android.view import (\n Gravity,\n View__MeasureSpec,\n View__OnTouchListener\n)\nfrom ..libs.android.widget import (\n HorizontalScrollView,\n LinearLayout__LayoutParams,\n ScrollView\n)\nfrom .base import Widget\n\n\nclass TogaOnTouchListener(View__OnTouchListener):\n is_scrolling_enabled = True\n\n def __init__(self):\n super().__init__()\n\n def onTouch(self, view, motion_event):\n if self.is_scrolling_enabled:\n return view.onTouchEvent(motion_event)\n else:\n return True\n\n\nclass ScrollContainer(Widget):\n vScrollListener = None\n hScrollView = None\n hScrollListener = None\n\n def create(self):\n vScrollView = ScrollView(self._native_activity)\n vScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n vScrollView_layout_params.gravity = Gravity.TOP\n vScrollView.setLayoutParams(vScrollView_layout_params)\n self.vScrollListener = TogaOnTouchListener()\n self.vScrollListener.is_scrolling_enabled = self.interface.vertical\n vScrollView.setOnTouchListener(self.vScrollListener)\n self.native = vScrollView\n self.hScrollView = HorizontalScrollView(self._native_activity)\n hScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n hScrollView_layout_params.gravity = Gravity.LEFT\n self.hScrollListener = TogaOnTouchListener()\n self.hScrollListener.is_scrolling_enabled = self.interface.horizontal\n self.hScrollView.setOnTouchListener(self.hScrollListener)\n vScrollView.addView(self.hScrollView, hScrollView_layout_params)\n if self.interface.content is not None:\n self.set_content(self.interface.content)\n\n def set_content(self, widget):\n widget.viewport = AndroidViewport(widget.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n if widget.container:\n widget.container = None\n if self.interface.content:\n self.hScrollView.removeAllViews()\n self.hScrollView.addView(widget.native, content_view_params)\n for child in widget.interface.children:\n if child._impl.container:\n child._impl.container = None\n child._impl.container = widget\n\n def set_vertical(self, value):\n self.vScrollListener.is_scrolling_enabled = value\n\n def set_horizontal(self, value):\n self.hScrollListener.is_scrolling_enabled = value\n\n def set_on_scroll(self, on_scroll):\n self.interface.factory.not_implemented(\"ScrollContainer.set_on_scroll()\")\n\n def get_vertical_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_vertical_position()\"\n )\n return 0\n\n def set_vertical_position(self, vertical_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_vertical_position()\"\n )\n\n def get_horizontal_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_horizontal_position()\"\n )\n return 0\n\n def set_horizontal_position(self, horizontal_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_horizontal_position()\"\n )\n\n def rehint(self):\n # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.\n if not self.native.getLayoutParams():\n return\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED,\n View__MeasureSpec.UNSPECIFIED,\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())\n", "path": "src/android/toga_android/widgets/scrollcontainer.py"}], "after_files": [{"content": "from travertino.size import at_least\n\nfrom toga_android.window import AndroidViewport\n\nfrom ..libs.android.view import (\n Gravity,\n View__MeasureSpec,\n View__OnTouchListener\n)\nfrom ..libs.android.widget import (\n HorizontalScrollView,\n LinearLayout__LayoutParams,\n ScrollView\n)\nfrom .base import Widget\n\n\nclass TogaOnTouchListener(View__OnTouchListener):\n is_scrolling_enabled = True\n\n def __init__(self):\n super().__init__()\n\n def onTouch(self, view, motion_event):\n if self.is_scrolling_enabled:\n return view.onTouchEvent(motion_event)\n else:\n return True\n\n\nclass ScrollContainer(Widget):\n vScrollListener = None\n hScrollView = None\n hScrollListener = None\n\n def create(self):\n vScrollView = ScrollView(self._native_activity)\n vScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n vScrollView_layout_params.gravity = Gravity.TOP\n vScrollView.setLayoutParams(vScrollView_layout_params)\n self.vScrollListener = TogaOnTouchListener()\n self.vScrollListener.is_scrolling_enabled = self.interface.vertical\n vScrollView.setOnTouchListener(self.vScrollListener)\n self.native = vScrollView\n self.hScrollView = HorizontalScrollView(self._native_activity)\n hScrollView_layout_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n hScrollView_layout_params.gravity = Gravity.LEFT\n self.hScrollListener = TogaOnTouchListener()\n self.hScrollListener.is_scrolling_enabled = self.interface.horizontal\n self.hScrollView.setOnTouchListener(self.hScrollListener)\n vScrollView.addView(self.hScrollView, hScrollView_layout_params)\n if self.interface.content is not None:\n self.set_content(self.interface.content)\n\n def set_content(self, widget):\n widget.viewport = AndroidViewport(self.native)\n content_view_params = LinearLayout__LayoutParams(\n LinearLayout__LayoutParams.MATCH_PARENT,\n LinearLayout__LayoutParams.MATCH_PARENT\n )\n if widget.container:\n widget.container = None\n if self.interface.content:\n self.hScrollView.removeAllViews()\n self.hScrollView.addView(widget.native, content_view_params)\n for child in widget.interface.children:\n if child._impl.container:\n child._impl.container = None\n child._impl.container = widget\n\n def set_vertical(self, value):\n self.vScrollListener.is_scrolling_enabled = value\n\n def set_horizontal(self, value):\n self.hScrollListener.is_scrolling_enabled = value\n\n def set_on_scroll(self, on_scroll):\n self.interface.factory.not_implemented(\"ScrollContainer.set_on_scroll()\")\n\n def get_vertical_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_vertical_position()\"\n )\n return 0\n\n def set_vertical_position(self, vertical_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_vertical_position()\"\n )\n\n def get_horizontal_position(self):\n self.interface.factory.not_implemented(\n \"ScrollContainer.get_horizontal_position()\"\n )\n return 0\n\n def set_horizontal_position(self, horizontal_position):\n self.interface.factory.not_implemented(\n \"ScrollContainer.set_horizontal_position()\"\n )\n\n def rehint(self):\n # Android can crash when rendering some widgets until they have their layout params set. Guard for that case.\n if not self.native.getLayoutParams():\n return\n self.native.measure(\n View__MeasureSpec.UNSPECIFIED,\n View__MeasureSpec.UNSPECIFIED,\n )\n self.interface.intrinsic.width = at_least(self.native.getMeasuredWidth())\n self.interface.intrinsic.height = at_least(self.native.getMeasuredHeight())\n", "path": "src/android/toga_android/widgets/scrollcontainer.py"}]}
| 1,730 | 124 |
gh_patches_debug_17407
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-1485
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Refuse account creation when using disposable email addresses.
long term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.
i've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/accounts/forms.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12 import re
13
14 import wtforms
15 import wtforms.fields.html5
16
17 from warehouse import forms, recaptcha
18
19
20 class CredentialsMixin:
21 username = wtforms.StringField(
22 validators=[
23 wtforms.validators.DataRequired(),
24 wtforms.validators.Length(max=50),
25 ],
26 )
27
28 password = wtforms.PasswordField(
29 validators=[
30 wtforms.validators.DataRequired(),
31 ],
32 )
33
34 def __init__(self, *args, user_service, **kwargs):
35 super().__init__(*args, **kwargs)
36 self.user_service = user_service
37
38
39 # XXX: This is a naive password strength validator, but something that can
40 # easily be replicated in JS for client-side feedback.
41 # see: https://github.com/pypa/warehouse/issues/6
42 PWD_MIN_LEN = 8
43 PWD_RE = re.compile(r"""
44 ^ # start
45 (?=.*[A-Z]+.*) # >= 1 upper case
46 (?=.*[a-z]+.*) # >= 1 lower case
47 (?=.*[0-9]+.*) # >= 1 number
48 (?=.*[.*~`\!@#$%^&\*\(\)_+-={}|\[\]\\:";'<>?,\./]+.*) # >= 1 special char
49 .{""" + str(PWD_MIN_LEN) + """,} # >= 8 chars
50 $ # end
51 """, re.X)
52
53
54 class RegistrationForm(CredentialsMixin, forms.Form):
55 password_confirm = wtforms.PasswordField(
56 validators=[
57 wtforms.validators.DataRequired(),
58 wtforms.validators.EqualTo(
59 "password", "Passwords must match."
60 ),
61 ],
62 )
63
64 full_name = wtforms.StringField()
65
66 email = wtforms.fields.html5.EmailField(
67 validators=[
68 wtforms.validators.DataRequired(),
69 wtforms.validators.Email(),
70 ],
71 )
72
73 g_recaptcha_response = wtforms.StringField()
74
75 def __init__(self, *args, recaptcha_service, **kwargs):
76 super().__init__(*args, **kwargs)
77 self.recaptcha_service = recaptcha_service
78
79 def validate_username(self, field):
80 if self.user_service.find_userid(field.data) is not None:
81 raise wtforms.validators.ValidationError(
82 "Username exists.")
83
84 def validate_email(self, field):
85 if self.user_service.find_userid_by_email(field.data) is not None:
86 raise wtforms.validators.ValidationError("Email exists.")
87
88 def validate_g_recaptcha_response(self, field):
89 # do required data validation here due to enabled flag being required
90 if self.recaptcha_service.enabled and not field.data:
91 raise wtforms.validators.ValidationError("Recaptcha error.")
92 try:
93 self.recaptcha_service.verify_response(field.data)
94 except recaptcha.RecaptchaError:
95 # TODO: log error
96 # don't want to provide the user with any detail
97 raise wtforms.validators.ValidationError("Recaptcha error.")
98
99 def validate_password(self, field):
100 if not PWD_RE.match(field.data):
101 raise wtforms.validators.ValidationError(
102 "Password must contain an upper case letter, a lower case "
103 "letter, a number, a special character and be at least "
104 "%d characters in length" % PWD_MIN_LEN
105 )
106
107
108 class LoginForm(CredentialsMixin, forms.Form):
109 def validate_username(self, field):
110 userid = self.user_service.find_userid(field.data)
111
112 if userid is None:
113 raise wtforms.validators.ValidationError("Invalid user.")
114
115 def validate_password(self, field):
116 userid = self.user_service.find_userid(self.username.data)
117 if userid is not None:
118 if not self.user_service.check_password(userid, field.data):
119 raise wtforms.validators.ValidationError("Invalid password.")
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py
--- a/warehouse/accounts/forms.py
+++ b/warehouse/accounts/forms.py
@@ -11,6 +11,7 @@
# limitations under the License.
import re
+import disposable_email_domains
import wtforms
import wtforms.fields.html5
@@ -84,6 +85,9 @@
def validate_email(self, field):
if self.user_service.find_userid_by_email(field.data) is not None:
raise wtforms.validators.ValidationError("Email exists.")
+ domain = field.data.split('@')[-1]
+ if domain in disposable_email_domains.blacklist:
+ raise wtforms.validators.ValidationError("Disposable email.")
def validate_g_recaptcha_response(self, field):
# do required data validation here due to enabled flag being required
|
{"golden_diff": "diff --git a/warehouse/accounts/forms.py b/warehouse/accounts/forms.py\n--- a/warehouse/accounts/forms.py\n+++ b/warehouse/accounts/forms.py\n@@ -11,6 +11,7 @@\n # limitations under the License.\n import re\n \n+import disposable_email_domains\n import wtforms\n import wtforms.fields.html5\n \n@@ -84,6 +85,9 @@\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n+ domain = field.data.split('@')[-1]\n+ if domain in disposable_email_domains.blacklist:\n+ raise wtforms.validators.ValidationError(\"Disposable email.\")\n \n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n", "issue": "Refuse account creation when using disposable email addresses.\nlong term it makes no sense to accept accounts which use an email address which is disposable for managing legit packages. short/near term it opens an easy door for spammers to create accounts on PyPI.\n\ni've implemented blacklisting for account signup and email swaps which use the blacklist at https://github.com/martenson/disposable-email-domains for legacy pypi.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\n\nimport wtforms\nimport wtforms.fields.html5\n\nfrom warehouse import forms, recaptcha\n\n\nclass CredentialsMixin:\n username = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Length(max=50),\n ],\n )\n\n password = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n ],\n )\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\n# XXX: This is a naive password strength validator, but something that can\n# easily be replicated in JS for client-side feedback.\n# see: https://github.com/pypa/warehouse/issues/6\nPWD_MIN_LEN = 8\nPWD_RE = re.compile(r\"\"\"\n^ # start\n(?=.*[A-Z]+.*) # >= 1 upper case\n(?=.*[a-z]+.*) # >= 1 lower case\n(?=.*[0-9]+.*) # >= 1 number\n(?=.*[.*~`\\!@#$%^&\\*\\(\\)_+-={}|\\[\\]\\\\:\";'<>?,\\./]+.*) # >= 1 special char\n.{\"\"\" + str(PWD_MIN_LEN) + \"\"\",} # >= 8 chars\n$ # end\n\"\"\", re.X)\n\n\nclass RegistrationForm(CredentialsMixin, forms.Form):\n password_confirm = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.EqualTo(\n \"password\", \"Passwords must match.\"\n ),\n ],\n )\n\n full_name = wtforms.StringField()\n\n email = wtforms.fields.html5.EmailField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Email(),\n ],\n )\n\n g_recaptcha_response = wtforms.StringField()\n\n def __init__(self, *args, recaptcha_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.recaptcha_service = recaptcha_service\n\n def validate_username(self, field):\n if self.user_service.find_userid(field.data) is not None:\n raise wtforms.validators.ValidationError(\n \"Username exists.\")\n\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n\n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n if self.recaptcha_service.enabled and not field.data:\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n try:\n self.recaptcha_service.verify_response(field.data)\n except recaptcha.RecaptchaError:\n # TODO: log error\n # don't want to provide the user with any detail\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n\n def validate_password(self, field):\n if not PWD_RE.match(field.data):\n raise wtforms.validators.ValidationError(\n \"Password must contain an upper case letter, a lower case \"\n \"letter, a number, a special character and be at least \"\n \"%d characters in length\" % PWD_MIN_LEN\n )\n\n\nclass LoginForm(CredentialsMixin, forms.Form):\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\"Invalid user.\")\n\n def validate_password(self, field):\n userid = self.user_service.find_userid(self.username.data)\n if userid is not None:\n if not self.user_service.check_password(userid, field.data):\n raise wtforms.validators.ValidationError(\"Invalid password.\")\n", "path": "warehouse/accounts/forms.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport re\n\nimport disposable_email_domains\nimport wtforms\nimport wtforms.fields.html5\n\nfrom warehouse import forms, recaptcha\n\n\nclass CredentialsMixin:\n username = wtforms.StringField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Length(max=50),\n ],\n )\n\n password = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n ],\n )\n\n def __init__(self, *args, user_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.user_service = user_service\n\n\n# XXX: This is a naive password strength validator, but something that can\n# easily be replicated in JS for client-side feedback.\n# see: https://github.com/pypa/warehouse/issues/6\nPWD_MIN_LEN = 8\nPWD_RE = re.compile(r\"\"\"\n^ # start\n(?=.*[A-Z]+.*) # >= 1 upper case\n(?=.*[a-z]+.*) # >= 1 lower case\n(?=.*[0-9]+.*) # >= 1 number\n(?=.*[.*~`\\!@#$%^&\\*\\(\\)_+-={}|\\[\\]\\\\:\";'<>?,\\./]+.*) # >= 1 special char\n.{\"\"\" + str(PWD_MIN_LEN) + \"\"\",} # >= 8 chars\n$ # end\n\"\"\", re.X)\n\n\nclass RegistrationForm(CredentialsMixin, forms.Form):\n password_confirm = wtforms.PasswordField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.EqualTo(\n \"password\", \"Passwords must match.\"\n ),\n ],\n )\n\n full_name = wtforms.StringField()\n\n email = wtforms.fields.html5.EmailField(\n validators=[\n wtforms.validators.DataRequired(),\n wtforms.validators.Email(),\n ],\n )\n\n g_recaptcha_response = wtforms.StringField()\n\n def __init__(self, *args, recaptcha_service, **kwargs):\n super().__init__(*args, **kwargs)\n self.recaptcha_service = recaptcha_service\n\n def validate_username(self, field):\n if self.user_service.find_userid(field.data) is not None:\n raise wtforms.validators.ValidationError(\n \"Username exists.\")\n\n def validate_email(self, field):\n if self.user_service.find_userid_by_email(field.data) is not None:\n raise wtforms.validators.ValidationError(\"Email exists.\")\n domain = field.data.split('@')[-1]\n if domain in disposable_email_domains.blacklist:\n raise wtforms.validators.ValidationError(\"Disposable email.\")\n\n def validate_g_recaptcha_response(self, field):\n # do required data validation here due to enabled flag being required\n if self.recaptcha_service.enabled and not field.data:\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n try:\n self.recaptcha_service.verify_response(field.data)\n except recaptcha.RecaptchaError:\n # TODO: log error\n # don't want to provide the user with any detail\n raise wtforms.validators.ValidationError(\"Recaptcha error.\")\n\n def validate_password(self, field):\n if not PWD_RE.match(field.data):\n raise wtforms.validators.ValidationError(\n \"Password must contain an upper case letter, a lower case \"\n \"letter, a number, a special character and be at least \"\n \"%d characters in length\" % PWD_MIN_LEN\n )\n\n\nclass LoginForm(CredentialsMixin, forms.Form):\n def validate_username(self, field):\n userid = self.user_service.find_userid(field.data)\n\n if userid is None:\n raise wtforms.validators.ValidationError(\"Invalid user.\")\n\n def validate_password(self, field):\n userid = self.user_service.find_userid(self.username.data)\n if userid is not None:\n if not self.user_service.check_password(userid, field.data):\n raise wtforms.validators.ValidationError(\"Invalid password.\")\n", "path": "warehouse/accounts/forms.py"}]}
| 1,497 | 176 |
gh_patches_debug_12917
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-724
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'AsyncTransport' has no attribute '_start_event_processor'
**Describe the bug**: ...
After upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:
```
<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError("'AsyncTransport' object has no attribute '_start_event_processor'",)
Traceback (most recent call last):
File "/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py", line 288, in send
response = receiver(signal=self, sender=sender, **named)
File "/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py", line 80, in worker_startup
client._transport._start_event_processor()
AttributeError: 'AsyncTransport' object has no attribute '_start_event_processor'
```
**Environment (please complete the following information)**
- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31
- Python version: Python 3.6.8
- Framework and version:
celery 4.4.0
Django 3.0.3
- APM Server version: ?
- Agent version: 5.4.1
I see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/contrib/celery/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 from celery import signals
33
34 from elasticapm.utils import get_name_from_func
35
36
37 class CeleryFilter(object):
38 def filter(self, record):
39 if record.funcName in ("_log_error",):
40 return 0
41 else:
42 return 1
43
44
45 def register_exception_tracking(client):
46 dispatch_uid = "elasticapm-exc-tracking"
47
48 def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):
49 client.capture_exception(
50 extra={"task_id": task_id, "task": sender, "args": args, "kwargs": kwargs}, handled=False
51 )
52
53 signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)
54 signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)
55 _register_worker_signals(client)
56
57
58 def register_instrumentation(client):
59 def begin_transaction(*args, **kwargs):
60 client.begin_transaction("celery")
61
62 def end_transaction(task_id, task, *args, **kwargs):
63 name = get_name_from_func(task)
64 client.end_transaction(name, kwargs.get("state", "None"))
65
66 dispatch_uid = "elasticapm-tracing-%s"
67
68 # unregister any existing clients
69 signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % "prerun")
70 signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % "postrun")
71
72 # register for this client
73 signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % "prerun", weak=False)
74 signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % "postrun")
75 _register_worker_signals(client)
76
77
78 def _register_worker_signals(client):
79 def worker_startup(*args, **kwargs):
80 client._transport._start_event_processor()
81
82 def worker_shutdown(*args, **kwargs):
83 client.close()
84
85 def connect_worker_process_init(*args, **kwargs):
86 signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
87 signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
88
89 signals.worker_init.connect(
90 connect_worker_process_init, dispatch_uid="elasticapm-connect-start-threads", weak=False
91 )
92
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py
--- a/elasticapm/contrib/celery/__init__.py
+++ b/elasticapm/contrib/celery/__init__.py
@@ -76,14 +76,10 @@
def _register_worker_signals(client):
- def worker_startup(*args, **kwargs):
- client._transport._start_event_processor()
-
def worker_shutdown(*args, **kwargs):
client.close()
def connect_worker_process_init(*args, **kwargs):
- signals.worker_process_init.connect(worker_startup, dispatch_uid="elasticapm-start-worker", weak=False)
signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid="elasticapm-shutdown-worker", weak=False)
signals.worker_init.connect(
|
{"golden_diff": "diff --git a/elasticapm/contrib/celery/__init__.py b/elasticapm/contrib/celery/__init__.py\n--- a/elasticapm/contrib/celery/__init__.py\n+++ b/elasticapm/contrib/celery/__init__.py\n@@ -76,14 +76,10 @@\n \n \n def _register_worker_signals(client):\n- def worker_startup(*args, **kwargs):\n- client._transport._start_event_processor()\n-\n def worker_shutdown(*args, **kwargs):\n client.close()\n \n def connect_worker_process_init(*args, **kwargs):\n- signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n \n signals.worker_init.connect(\n", "issue": "'AsyncTransport' has no attribute '_start_event_processor'\n**Describe the bug**: ...\r\n\r\nAfter upgrading to `elastic-apm==5.4.1` I now get an error when Celery starts:\r\n\r\n```\r\n<function _register_worker_signals.<locals>.worker_startup at 0x7feae4beb620> raised: AttributeError(\"'AsyncTransport' object has no attribute '_start_event_processor'\",)\r\nTraceback (most recent call last):\r\n File \"/venv/lib/python3.6/site-packages/celery/utils/dispatch/signal.py\", line 288, in send\r\n response = receiver(signal=self, sender=sender, **named)\r\n File \"/venv/1.37.1/lib/python3.6/site-packages/elasticapm/contrib/celery/__init__.py\", line 80, in worker_startup\r\n client._transport._start_event_processor()\r\nAttributeError: 'AsyncTransport' object has no attribute '_start_event_processor' \r\n```\r\n\r\n**Environment (please complete the following information)**\r\n- OS: Linux-3.10.0-1062.9.1.el7.x86_64-x86_64-with-centos-7.7.1908-Core 2020-02-18 16:24:31\r\n- Python version: Python 3.6.8\r\n- Framework and version: \r\n celery 4.4.0\r\n Django 3.0.3\r\n- APM Server version: ?\r\n- Agent version: 5.4.1\r\n\r\nI see the same error mentioned in issue #704, but I don't seem to have an issue with restarting Celery workers.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom celery import signals\n\nfrom elasticapm.utils import get_name_from_func\n\n\nclass CeleryFilter(object):\n def filter(self, record):\n if record.funcName in (\"_log_error\",):\n return 0\n else:\n return 1\n\n\ndef register_exception_tracking(client):\n dispatch_uid = \"elasticapm-exc-tracking\"\n\n def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):\n client.capture_exception(\n extra={\"task_id\": task_id, \"task\": sender, \"args\": args, \"kwargs\": kwargs}, handled=False\n )\n\n signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)\n signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)\n _register_worker_signals(client)\n\n\ndef register_instrumentation(client):\n def begin_transaction(*args, **kwargs):\n client.begin_transaction(\"celery\")\n\n def end_transaction(task_id, task, *args, **kwargs):\n name = get_name_from_func(task)\n client.end_transaction(name, kwargs.get(\"state\", \"None\"))\n\n dispatch_uid = \"elasticapm-tracing-%s\"\n\n # unregister any existing clients\n signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\")\n signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % \"postrun\")\n\n # register for this client\n signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\", weak=False)\n signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % \"postrun\")\n _register_worker_signals(client)\n\n\ndef _register_worker_signals(client):\n def worker_startup(*args, **kwargs):\n client._transport._start_event_processor()\n\n def worker_shutdown(*args, **kwargs):\n client.close()\n\n def connect_worker_process_init(*args, **kwargs):\n signals.worker_process_init.connect(worker_startup, dispatch_uid=\"elasticapm-start-worker\", weak=False)\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n\n signals.worker_init.connect(\n connect_worker_process_init, dispatch_uid=\"elasticapm-connect-start-threads\", weak=False\n )\n", "path": "elasticapm/contrib/celery/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom celery import signals\n\nfrom elasticapm.utils import get_name_from_func\n\n\nclass CeleryFilter(object):\n def filter(self, record):\n if record.funcName in (\"_log_error\",):\n return 0\n else:\n return 1\n\n\ndef register_exception_tracking(client):\n dispatch_uid = \"elasticapm-exc-tracking\"\n\n def process_failure_signal(sender, task_id, exception, args, kwargs, traceback, einfo, **kw):\n client.capture_exception(\n extra={\"task_id\": task_id, \"task\": sender, \"args\": args, \"kwargs\": kwargs}, handled=False\n )\n\n signals.task_failure.disconnect(process_failure_signal, dispatch_uid=dispatch_uid)\n signals.task_failure.connect(process_failure_signal, weak=False, dispatch_uid=dispatch_uid)\n _register_worker_signals(client)\n\n\ndef register_instrumentation(client):\n def begin_transaction(*args, **kwargs):\n client.begin_transaction(\"celery\")\n\n def end_transaction(task_id, task, *args, **kwargs):\n name = get_name_from_func(task)\n client.end_transaction(name, kwargs.get(\"state\", \"None\"))\n\n dispatch_uid = \"elasticapm-tracing-%s\"\n\n # unregister any existing clients\n signals.task_prerun.disconnect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\")\n signals.task_postrun.disconnect(end_transaction, dispatch_uid=dispatch_uid % \"postrun\")\n\n # register for this client\n signals.task_prerun.connect(begin_transaction, dispatch_uid=dispatch_uid % \"prerun\", weak=False)\n signals.task_postrun.connect(end_transaction, weak=False, dispatch_uid=dispatch_uid % \"postrun\")\n _register_worker_signals(client)\n\n\ndef _register_worker_signals(client):\n def worker_shutdown(*args, **kwargs):\n client.close()\n\n def connect_worker_process_init(*args, **kwargs):\n signals.worker_process_shutdown.connect(worker_shutdown, dispatch_uid=\"elasticapm-shutdown-worker\", weak=False)\n\n signals.worker_init.connect(\n connect_worker_process_init, dispatch_uid=\"elasticapm-connect-start-threads\", weak=False\n )\n", "path": "elasticapm/contrib/celery/__init__.py"}]}
| 1,654 | 186 |
gh_patches_debug_9210
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-3237
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DictDataset throws an internal error only in Python 3.
The following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)
```py
from chainer.datasets import DictDataset
def main():
a = range(10)
b = range(10, 20)
dataset = DictDataset(x=a, y=b)
print(dataset[0:5])
if __name__ == '__main__':
main()
```
In Python 3.6.1,
```sh
$ python --version
Python 3.6.1
$ python poc.py
Traceback (most recent call last):
File "poc.py", line 12, in <module>
main()
File "poc.py", line 8, in main
print(dataset[0:5])
File "/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py", line 34, in __getitem__
length = len(six.itervalues(batches).next())
AttributeError: 'dict_valueiterator' object has no attribute 'next'
```
In Python 2.7.13,
```sh
$ python --version
Python 2.7.13
$ python poc.py
[{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]
```
It is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.
[Reference](http://pythonhosted.org/six/#six.Iterator)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/datasets/dict_dataset.py`
Content:
```
1 import six
2
3
4 class DictDataset(object):
5
6 """Dataset of a dictionary of datasets.
7
8 It combines multiple datasets into one dataset. Each example is represented
9 by a dictionary mapping a key to an example of the corresponding dataset.
10
11 Args:
12 datasets: Underlying datasets. The keys are used as the keys of each
13 example. All datasets must have the same length.
14
15 """
16
17 def __init__(self, **datasets):
18 if not datasets:
19 raise ValueError('no datasets are given')
20 length = None
21 for key, dataset in six.iteritems(datasets):
22 if length is None:
23 length = len(dataset)
24 elif length != len(dataset):
25 raise ValueError(
26 'dataset length conflicts at "{}"'.format(key))
27 self._datasets = datasets
28 self._length = length
29
30 def __getitem__(self, index):
31 batches = {key: dataset[index]
32 for key, dataset in six.iteritems(self._datasets)}
33 if isinstance(index, slice):
34 length = len(six.itervalues(batches).next())
35 return [{key: batch[i] for key, batch in six.iteritems(batches)}
36 for i in six.moves.range(length)]
37 else:
38 return batches
39
40 def __len__(self):
41 return self._length
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py
--- a/chainer/datasets/dict_dataset.py
+++ b/chainer/datasets/dict_dataset.py
@@ -31,7 +31,7 @@
batches = {key: dataset[index]
for key, dataset in six.iteritems(self._datasets)}
if isinstance(index, slice):
- length = len(six.itervalues(batches).next())
+ length = len(six.next(six.itervalues(batches)))
return [{key: batch[i] for key, batch in six.iteritems(batches)}
for i in six.moves.range(length)]
else:
|
{"golden_diff": "diff --git a/chainer/datasets/dict_dataset.py b/chainer/datasets/dict_dataset.py\n--- a/chainer/datasets/dict_dataset.py\n+++ b/chainer/datasets/dict_dataset.py\n@@ -31,7 +31,7 @@\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n- length = len(six.itervalues(batches).next())\n+ length = len(six.next(six.itervalues(batches)))\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n", "issue": "DictDataset throws an internal error only in Python 3.\nThe following code throws an internal error only in Python 3 environment with the latest version of Chainer. (3.0.0b1, 8bcac6f)\r\n```py\r\nfrom chainer.datasets import DictDataset\r\n\r\ndef main():\r\n a = range(10)\r\n b = range(10, 20)\r\n dataset = DictDataset(x=a, y=b)\r\n print(dataset[0:5])\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\nIn Python 3.6.1,\r\n```sh\r\n$ python --version\r\n Python 3.6.1\r\n$ python poc.py\r\n Traceback (most recent call last):\r\n File \"poc.py\", line 12, in <module>\r\n main()\r\n File \"poc.py\", line 8, in main\r\n print(dataset[0:5])\r\n File \"/home/igarashi/projects/chainer/chainer/datasets/dict_dataset.py\", line 34, in __getitem__\r\n length = len(six.itervalues(batches).next())\r\nAttributeError: 'dict_valueiterator' object has no attribute 'next'\r\n```\r\n\r\nIn Python 2.7.13, \r\n```sh\r\n$ python --version\r\n Python 2.7.13\r\n$ python poc.py\r\n [{'y': 10, 'x': 0}, {'y': 11, 'x': 1}, {'y': 12, 'x': 2}, {'y': 13, 'x': 3}, {'y': 14, 'x': 4}]\r\n```\r\n\r\nIt is because an instance of `six.Iterator` doesn't have `next()` method in the Python 3 environment.\r\n[Reference](http://pythonhosted.org/six/#six.Iterator)\r\n\n", "before_files": [{"content": "import six\n\n\nclass DictDataset(object):\n\n \"\"\"Dataset of a dictionary of datasets.\n\n It combines multiple datasets into one dataset. Each example is represented\n by a dictionary mapping a key to an example of the corresponding dataset.\n\n Args:\n datasets: Underlying datasets. The keys are used as the keys of each\n example. All datasets must have the same length.\n\n \"\"\"\n\n def __init__(self, **datasets):\n if not datasets:\n raise ValueError('no datasets are given')\n length = None\n for key, dataset in six.iteritems(datasets):\n if length is None:\n length = len(dataset)\n elif length != len(dataset):\n raise ValueError(\n 'dataset length conflicts at \"{}\"'.format(key))\n self._datasets = datasets\n self._length = length\n\n def __getitem__(self, index):\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n length = len(six.itervalues(batches).next())\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n return batches\n\n def __len__(self):\n return self._length\n", "path": "chainer/datasets/dict_dataset.py"}], "after_files": [{"content": "import six\n\n\nclass DictDataset(object):\n\n \"\"\"Dataset of a dictionary of datasets.\n\n It combines multiple datasets into one dataset. Each example is represented\n by a dictionary mapping a key to an example of the corresponding dataset.\n\n Args:\n datasets: Underlying datasets. The keys are used as the keys of each\n example. All datasets must have the same length.\n\n \"\"\"\n\n def __init__(self, **datasets):\n if not datasets:\n raise ValueError('no datasets are given')\n length = None\n for key, dataset in six.iteritems(datasets):\n if length is None:\n length = len(dataset)\n elif length != len(dataset):\n raise ValueError(\n 'dataset length conflicts at \"{}\"'.format(key))\n self._datasets = datasets\n self._length = length\n\n def __getitem__(self, index):\n batches = {key: dataset[index]\n for key, dataset in six.iteritems(self._datasets)}\n if isinstance(index, slice):\n length = len(six.next(six.itervalues(batches)))\n return [{key: batch[i] for key, batch in six.iteritems(batches)}\n for i in six.moves.range(length)]\n else:\n return batches\n\n def __len__(self):\n return self._length\n", "path": "chainer/datasets/dict_dataset.py"}]}
| 1,007 | 145 |
gh_patches_debug_35186
|
rasdani/github-patches
|
git_diff
|
vnpy__vnpy-1795
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug:rqdata.py 中 RqdataClient 类的 to_rq_symbol 方法对连续和指数合约转换有问题
## 环境
* 操作系统: 如Windows 10
* Anaconda版本: Anaconda 18.12 Python 3.7 64位
* vn.py版本: v2.0.3
## Issue类型
三选一:Bug
## 预期程序行为
正确将合约名转换至rqdata中的合约名
## 实际程序行为
错误的将郑商所的合约连续和指数合约转换,例如将AP888会转换为AP2888,AP99会转换至AP199导致无法下载到数据。
## 重现步骤
在回测模块中下载AP88数据即可。
针对Bug类型Issue,请提供具体重现步骤以及报错截图
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vnpy/trader/rqdata.py`
Content:
```
1 from datetime import datetime, timedelta
2 from typing import List
3
4 from rqdatac import init as rqdata_init
5 from rqdatac.services.basic import all_instruments as rqdata_all_instruments
6 from rqdatac.services.get_price import get_price as rqdata_get_price
7
8 from .setting import SETTINGS
9 from .constant import Exchange, Interval
10 from .object import BarData, HistoryRequest
11
12
13 INTERVAL_VT2RQ = {
14 Interval.MINUTE: "1m",
15 Interval.HOUR: "60m",
16 Interval.DAILY: "1d",
17 }
18
19 INTERVAL_ADJUSTMENT_MAP = {
20 Interval.MINUTE: timedelta(minutes=1),
21 Interval.HOUR: timedelta(hours=1),
22 Interval.DAILY: timedelta() # no need to adjust for daily bar
23 }
24
25
26 class RqdataClient:
27 """
28 Client for querying history data from RQData.
29 """
30
31 def __init__(self):
32 """"""
33 self.username = SETTINGS["rqdata.username"]
34 self.password = SETTINGS["rqdata.password"]
35
36 self.inited = False
37 self.symbols = set()
38
39 def init(self):
40 """"""
41 if self.inited:
42 return True
43
44 if not self.username or not self.password:
45 return False
46
47 rqdata_init(self.username, self.password,
48 ('rqdatad-pro.ricequant.com', 16011))
49
50 try:
51 df = rqdata_all_instruments(date=datetime.now())
52 for ix, row in df.iterrows():
53 self.symbols.add(row['order_book_id'])
54 except RuntimeError:
55 return False
56
57 self.inited = True
58 return True
59
60 def to_rq_symbol(self, symbol: str, exchange: Exchange):
61 """
62 CZCE product of RQData has symbol like "TA1905" while
63 vt symbol is "TA905.CZCE" so need to add "1" in symbol.
64 """
65 if exchange in [Exchange.SSE, Exchange.SZSE]:
66 if exchange == Exchange.SSE:
67 rq_symbol = f"{symbol}.XSHG"
68 else:
69 rq_symbol = f"{symbol}.XSHE"
70 else:
71 if exchange is not Exchange.CZCE:
72 return symbol.upper()
73
74 for count, word in enumerate(symbol):
75 if word.isdigit():
76 break
77
78 # noinspection PyUnboundLocalVariable
79 product = symbol[:count]
80 year = symbol[count]
81 month = symbol[count + 1:]
82
83 if year == "9":
84 year = "1" + year
85 else:
86 year = "2" + year
87
88 rq_symbol = f"{product}{year}{month}".upper()
89
90 return rq_symbol
91
92 def query_history(self, req: HistoryRequest):
93 """
94 Query history bar data from RQData.
95 """
96 symbol = req.symbol
97 exchange = req.exchange
98 interval = req.interval
99 start = req.start
100 end = req.end
101
102 rq_symbol = self.to_rq_symbol(symbol, exchange)
103 if rq_symbol not in self.symbols:
104 return None
105
106 rq_interval = INTERVAL_VT2RQ.get(interval)
107 if not rq_interval:
108 return None
109
110 # For adjust timestamp from bar close point (RQData) to open point (VN Trader)
111 adjustment = INTERVAL_ADJUSTMENT_MAP[interval]
112
113 # For querying night trading period data
114 end += timedelta(1)
115
116 df = rqdata_get_price(
117 rq_symbol,
118 frequency=rq_interval,
119 fields=["open", "high", "low", "close", "volume"],
120 start_date=start,
121 end_date=end
122 )
123
124 data: List[BarData] = []
125 for ix, row in df.iterrows():
126 bar = BarData(
127 symbol=symbol,
128 exchange=exchange,
129 interval=interval,
130 datetime=row.name.to_pydatetime() - adjustment,
131 open_price=row["open"],
132 high_price=row["high"],
133 low_price=row["low"],
134 close_price=row["close"],
135 volume=row["volume"],
136 gateway_name="RQ"
137 )
138 data.append(bar)
139
140 return data
141
142
143 rqdata_client = RqdataClient()
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py
--- a/vnpy/trader/rqdata.py
+++ b/vnpy/trader/rqdata.py
@@ -36,11 +36,15 @@
self.inited = False
self.symbols = set()
- def init(self):
+ def init(self, username="", password=""):
""""""
if self.inited:
return True
+ if username and password:
+ self.username = username
+ self.password = password
+
if not self.username or not self.password:
return False
@@ -75,6 +79,11 @@
if word.isdigit():
break
+ # Check for index symbol
+ time_str = symbol[count:]
+ if time_str in ["88", "888", "99"]:
+ return symbol
+
# noinspection PyUnboundLocalVariable
product = symbol[:count]
year = symbol[count]
@@ -118,24 +127,27 @@
frequency=rq_interval,
fields=["open", "high", "low", "close", "volume"],
start_date=start,
- end_date=end
+ end_date=end,
+ adjust_type="none"
)
data: List[BarData] = []
- for ix, row in df.iterrows():
- bar = BarData(
- symbol=symbol,
- exchange=exchange,
- interval=interval,
- datetime=row.name.to_pydatetime() - adjustment,
- open_price=row["open"],
- high_price=row["high"],
- low_price=row["low"],
- close_price=row["close"],
- volume=row["volume"],
- gateway_name="RQ"
- )
- data.append(bar)
+
+ if df is not None:
+ for ix, row in df.iterrows():
+ bar = BarData(
+ symbol=symbol,
+ exchange=exchange,
+ interval=interval,
+ datetime=row.name.to_pydatetime() - adjustment,
+ open_price=row["open"],
+ high_price=row["high"],
+ low_price=row["low"],
+ close_price=row["close"],
+ volume=row["volume"],
+ gateway_name="RQ"
+ )
+ data.append(bar)
return data
|
{"golden_diff": "diff --git a/vnpy/trader/rqdata.py b/vnpy/trader/rqdata.py\n--- a/vnpy/trader/rqdata.py\n+++ b/vnpy/trader/rqdata.py\n@@ -36,11 +36,15 @@\n self.inited = False\n self.symbols = set()\n \n- def init(self):\n+ def init(self, username=\"\", password=\"\"):\n \"\"\"\"\"\"\n if self.inited:\n return True\n \n+ if username and password:\n+ self.username = username\n+ self.password = password\n+\n if not self.username or not self.password:\n return False\n \n@@ -75,6 +79,11 @@\n if word.isdigit():\n break\n \n+ # Check for index symbol\n+ time_str = symbol[count:]\n+ if time_str in [\"88\", \"888\", \"99\"]:\n+ return symbol\n+\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n@@ -118,24 +127,27 @@\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n- end_date=end\n+ end_date=end,\n+ adjust_type=\"none\"\n )\n \n data: List[BarData] = []\n- for ix, row in df.iterrows():\n- bar = BarData(\n- symbol=symbol,\n- exchange=exchange,\n- interval=interval,\n- datetime=row.name.to_pydatetime() - adjustment,\n- open_price=row[\"open\"],\n- high_price=row[\"high\"],\n- low_price=row[\"low\"],\n- close_price=row[\"close\"],\n- volume=row[\"volume\"],\n- gateway_name=\"RQ\"\n- )\n- data.append(bar)\n+\n+ if df is not None:\n+ for ix, row in df.iterrows():\n+ bar = BarData(\n+ symbol=symbol,\n+ exchange=exchange,\n+ interval=interval,\n+ datetime=row.name.to_pydatetime() - adjustment,\n+ open_price=row[\"open\"],\n+ high_price=row[\"high\"],\n+ low_price=row[\"low\"],\n+ close_price=row[\"close\"],\n+ volume=row[\"volume\"],\n+ gateway_name=\"RQ\"\n+ )\n+ data.append(bar)\n \n return data\n", "issue": "Bug\uff1arqdata.py \u4e2d RqdataClient \u7c7b\u7684 to_rq_symbol \u65b9\u6cd5\u5bf9\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\u6709\u95ee\u9898\n## \u73af\u5883\r\n\r\n* \u64cd\u4f5c\u7cfb\u7edf: \u5982Windows 10\r\n* Anaconda\u7248\u672c: Anaconda 18.12 Python 3.7 64\u4f4d\r\n* vn.py\u7248\u672c: v2.0.3\r\n\r\n## Issue\u7c7b\u578b\r\n\u4e09\u9009\u4e00\uff1aBug\r\n\r\n## \u9884\u671f\u7a0b\u5e8f\u884c\u4e3a\r\n\u6b63\u786e\u5c06\u5408\u7ea6\u540d\u8f6c\u6362\u81f3rqdata\u4e2d\u7684\u5408\u7ea6\u540d\r\n\r\n## \u5b9e\u9645\u7a0b\u5e8f\u884c\u4e3a\r\n\u9519\u8bef\u7684\u5c06\u90d1\u5546\u6240\u7684\u5408\u7ea6\u8fde\u7eed\u548c\u6307\u6570\u5408\u7ea6\u8f6c\u6362\uff0c\u4f8b\u5982\u5c06AP888\u4f1a\u8f6c\u6362\u4e3aAP2888\uff0cAP99\u4f1a\u8f6c\u6362\u81f3AP199\u5bfc\u81f4\u65e0\u6cd5\u4e0b\u8f7d\u5230\u6570\u636e\u3002\r\n\r\n## \u91cd\u73b0\u6b65\u9aa4\r\n\u5728\u56de\u6d4b\u6a21\u5757\u4e2d\u4e0b\u8f7dAP88\u6570\u636e\u5373\u53ef\u3002\r\n\r\n\u9488\u5bf9Bug\u7c7b\u578bIssue\uff0c\u8bf7\u63d0\u4f9b\u5177\u4f53\u91cd\u73b0\u6b65\u9aa4\u4ee5\u53ca\u62a5\u9519\u622a\u56fe\r\n\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import List\n\nfrom rqdatac import init as rqdata_init\nfrom rqdatac.services.basic import all_instruments as rqdata_all_instruments\nfrom rqdatac.services.get_price import get_price as rqdata_get_price\n\nfrom .setting import SETTINGS\nfrom .constant import Exchange, Interval\nfrom .object import BarData, HistoryRequest\n\n\nINTERVAL_VT2RQ = {\n Interval.MINUTE: \"1m\",\n Interval.HOUR: \"60m\",\n Interval.DAILY: \"1d\",\n}\n\nINTERVAL_ADJUSTMENT_MAP = {\n Interval.MINUTE: timedelta(minutes=1),\n Interval.HOUR: timedelta(hours=1),\n Interval.DAILY: timedelta() # no need to adjust for daily bar\n}\n\n\nclass RqdataClient:\n \"\"\"\n Client for querying history data from RQData.\n \"\"\"\n\n def __init__(self):\n \"\"\"\"\"\"\n self.username = SETTINGS[\"rqdata.username\"]\n self.password = SETTINGS[\"rqdata.password\"]\n\n self.inited = False\n self.symbols = set()\n\n def init(self):\n \"\"\"\"\"\"\n if self.inited:\n return True\n\n if not self.username or not self.password:\n return False\n\n rqdata_init(self.username, self.password,\n ('rqdatad-pro.ricequant.com', 16011))\n\n try:\n df = rqdata_all_instruments(date=datetime.now())\n for ix, row in df.iterrows():\n self.symbols.add(row['order_book_id'])\n except RuntimeError:\n return False\n\n self.inited = True\n return True\n\n def to_rq_symbol(self, symbol: str, exchange: Exchange):\n \"\"\"\n CZCE product of RQData has symbol like \"TA1905\" while\n vt symbol is \"TA905.CZCE\" so need to add \"1\" in symbol.\n \"\"\"\n if exchange in [Exchange.SSE, Exchange.SZSE]:\n if exchange == Exchange.SSE:\n rq_symbol = f\"{symbol}.XSHG\"\n else:\n rq_symbol = f\"{symbol}.XSHE\"\n else:\n if exchange is not Exchange.CZCE:\n return symbol.upper()\n\n for count, word in enumerate(symbol):\n if word.isdigit():\n break\n\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n month = symbol[count + 1:]\n\n if year == \"9\":\n year = \"1\" + year\n else:\n year = \"2\" + year\n\n rq_symbol = f\"{product}{year}{month}\".upper()\n\n return rq_symbol\n\n def query_history(self, req: HistoryRequest):\n \"\"\"\n Query history bar data from RQData.\n \"\"\"\n symbol = req.symbol\n exchange = req.exchange\n interval = req.interval\n start = req.start\n end = req.end\n\n rq_symbol = self.to_rq_symbol(symbol, exchange)\n if rq_symbol not in self.symbols:\n return None\n\n rq_interval = INTERVAL_VT2RQ.get(interval)\n if not rq_interval:\n return None\n\n # For adjust timestamp from bar close point (RQData) to open point (VN Trader)\n adjustment = INTERVAL_ADJUSTMENT_MAP[interval]\n\n # For querying night trading period data\n end += timedelta(1)\n\n df = rqdata_get_price(\n rq_symbol,\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n end_date=end\n )\n\n data: List[BarData] = []\n for ix, row in df.iterrows():\n bar = BarData(\n symbol=symbol,\n exchange=exchange,\n interval=interval,\n datetime=row.name.to_pydatetime() - adjustment,\n open_price=row[\"open\"],\n high_price=row[\"high\"],\n low_price=row[\"low\"],\n close_price=row[\"close\"],\n volume=row[\"volume\"],\n gateway_name=\"RQ\"\n )\n data.append(bar)\n\n return data\n\n\nrqdata_client = RqdataClient()\n", "path": "vnpy/trader/rqdata.py"}], "after_files": [{"content": "from datetime import datetime, timedelta\nfrom typing import List\n\nfrom rqdatac import init as rqdata_init\nfrom rqdatac.services.basic import all_instruments as rqdata_all_instruments\nfrom rqdatac.services.get_price import get_price as rqdata_get_price\n\nfrom .setting import SETTINGS\nfrom .constant import Exchange, Interval\nfrom .object import BarData, HistoryRequest\n\n\nINTERVAL_VT2RQ = {\n Interval.MINUTE: \"1m\",\n Interval.HOUR: \"60m\",\n Interval.DAILY: \"1d\",\n}\n\nINTERVAL_ADJUSTMENT_MAP = {\n Interval.MINUTE: timedelta(minutes=1),\n Interval.HOUR: timedelta(hours=1),\n Interval.DAILY: timedelta() # no need to adjust for daily bar\n}\n\n\nclass RqdataClient:\n \"\"\"\n Client for querying history data from RQData.\n \"\"\"\n\n def __init__(self):\n \"\"\"\"\"\"\n self.username = SETTINGS[\"rqdata.username\"]\n self.password = SETTINGS[\"rqdata.password\"]\n\n self.inited = False\n self.symbols = set()\n\n def init(self, username=\"\", password=\"\"):\n \"\"\"\"\"\"\n if self.inited:\n return True\n\n if username and password:\n self.username = username\n self.password = password\n\n if not self.username or not self.password:\n return False\n\n rqdata_init(self.username, self.password,\n ('rqdatad-pro.ricequant.com', 16011))\n\n try:\n df = rqdata_all_instruments(date=datetime.now())\n for ix, row in df.iterrows():\n self.symbols.add(row['order_book_id'])\n except RuntimeError:\n return False\n\n self.inited = True\n return True\n\n def to_rq_symbol(self, symbol: str, exchange: Exchange):\n \"\"\"\n CZCE product of RQData has symbol like \"TA1905\" while\n vt symbol is \"TA905.CZCE\" so need to add \"1\" in symbol.\n \"\"\"\n if exchange in [Exchange.SSE, Exchange.SZSE]:\n if exchange == Exchange.SSE:\n rq_symbol = f\"{symbol}.XSHG\"\n else:\n rq_symbol = f\"{symbol}.XSHE\"\n else:\n if exchange is not Exchange.CZCE:\n return symbol.upper()\n\n for count, word in enumerate(symbol):\n if word.isdigit():\n break\n\n # Check for index symbol\n time_str = symbol[count:]\n if time_str in [\"88\", \"888\", \"99\"]:\n return symbol\n\n # noinspection PyUnboundLocalVariable\n product = symbol[:count]\n year = symbol[count]\n month = symbol[count + 1:]\n\n if year == \"9\":\n year = \"1\" + year\n else:\n year = \"2\" + year\n\n rq_symbol = f\"{product}{year}{month}\".upper()\n\n return rq_symbol\n\n def query_history(self, req: HistoryRequest):\n \"\"\"\n Query history bar data from RQData.\n \"\"\"\n symbol = req.symbol\n exchange = req.exchange\n interval = req.interval\n start = req.start\n end = req.end\n\n rq_symbol = self.to_rq_symbol(symbol, exchange)\n if rq_symbol not in self.symbols:\n return None\n\n rq_interval = INTERVAL_VT2RQ.get(interval)\n if not rq_interval:\n return None\n\n # For adjust timestamp from bar close point (RQData) to open point (VN Trader)\n adjustment = INTERVAL_ADJUSTMENT_MAP[interval]\n\n # For querying night trading period data\n end += timedelta(1)\n\n df = rqdata_get_price(\n rq_symbol,\n frequency=rq_interval,\n fields=[\"open\", \"high\", \"low\", \"close\", \"volume\"],\n start_date=start,\n end_date=end,\n adjust_type=\"none\"\n )\n\n data: List[BarData] = []\n\n if df is not None:\n for ix, row in df.iterrows():\n bar = BarData(\n symbol=symbol,\n exchange=exchange,\n interval=interval,\n datetime=row.name.to_pydatetime() - adjustment,\n open_price=row[\"open\"],\n high_price=row[\"high\"],\n low_price=row[\"low\"],\n close_price=row[\"close\"],\n volume=row[\"volume\"],\n gateway_name=\"RQ\"\n )\n data.append(bar)\n\n return data\n\n\nrqdata_client = RqdataClient()\n", "path": "vnpy/trader/rqdata.py"}]}
| 1,686 | 527 |
gh_patches_debug_8600
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-356
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: webargs 5.0 introduces incompatibility with Flask < 1.0
https://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63
`_get_data_for_json` is only available since Flask >= 1.0
for Flask < 1.0, there is an error as follows:
```
File "/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py", line 63, in parse_json
data = req._get_data_for_json(cache=True)
File "/usr/local/lib/python2.7/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
AttributeError: 'Request' object has no attribute '_get_data_for_json'
```
I had to downgrade webargs to 4.4.1 to get it work.
So you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.
IMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `webargs/flaskparser.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """Flask request argument parsing module.
3
4 Example: ::
5
6 from flask import Flask
7
8 from webargs import fields
9 from webargs.flaskparser import use_args
10
11 app = Flask(__name__)
12
13 hello_args = {
14 'name': fields.Str(required=True)
15 }
16
17 @app.route('/')
18 @use_args(hello_args)
19 def index(args):
20 return 'Hello ' + args['name']
21 """
22 import flask
23 from werkzeug.exceptions import HTTPException
24
25 from webargs import core
26 from webargs.core import json
27
28
29 def abort(http_status_code, exc=None, **kwargs):
30 """Raise a HTTPException for the given http_status_code. Attach any keyword
31 arguments to the exception for later processing.
32
33 From Flask-Restful. See NOTICE file for license information.
34 """
35 try:
36 flask.abort(http_status_code)
37 except HTTPException as err:
38 err.data = kwargs
39 err.exc = exc
40 raise err
41
42
43 def is_json_request(req):
44 return core.is_json(req.mimetype)
45
46
47 class FlaskParser(core.Parser):
48 """Flask request argument parser."""
49
50 __location_map__ = dict(view_args="parse_view_args", **core.Parser.__location_map__)
51
52 def parse_view_args(self, req, name, field):
53 """Pull a value from the request's ``view_args``."""
54 return core.get_value(req.view_args, name, field)
55
56 def parse_json(self, req, name, field):
57 """Pull a json value from the request."""
58 json_data = self._cache.get("json")
59 if json_data is None:
60 # We decode the json manually here instead of
61 # using req.get_json() so that we can handle
62 # JSONDecodeErrors consistently
63 data = req._get_data_for_json(cache=True)
64 try:
65 self._cache["json"] = json_data = core.parse_json(data)
66 except json.JSONDecodeError as e:
67 if e.doc == "":
68 return core.missing
69 else:
70 return self.handle_invalid_json_error(e, req)
71 return core.get_value(json_data, name, field, allow_many_nested=True)
72
73 def parse_querystring(self, req, name, field):
74 """Pull a querystring value from the request."""
75 return core.get_value(req.args, name, field)
76
77 def parse_form(self, req, name, field):
78 """Pull a form value from the request."""
79 try:
80 return core.get_value(req.form, name, field)
81 except AttributeError:
82 pass
83 return core.missing
84
85 def parse_headers(self, req, name, field):
86 """Pull a value from the header data."""
87 return core.get_value(req.headers, name, field)
88
89 def parse_cookies(self, req, name, field):
90 """Pull a value from the cookiejar."""
91 return core.get_value(req.cookies, name, field)
92
93 def parse_files(self, req, name, field):
94 """Pull a file from the request."""
95 return core.get_value(req.files, name, field)
96
97 def handle_error(self, error, req, schema, error_status_code, error_headers):
98 """Handles errors during parsing. Aborts the current HTTP request and
99 responds with a 422 error.
100 """
101 status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS
102 abort(
103 status_code,
104 exc=error,
105 messages=error.messages,
106 schema=schema,
107 headers=error_headers,
108 )
109
110 def handle_invalid_json_error(self, error, req, *args, **kwargs):
111 abort(400, exc=error, messages={"json": ["Invalid JSON body."]})
112
113 def get_default_request(self):
114 """Override to use Flask's thread-local request objec by default"""
115 return flask.request
116
117
118 parser = FlaskParser()
119 use_args = parser.use_args
120 use_kwargs = parser.use_kwargs
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py
--- a/webargs/flaskparser.py
+++ b/webargs/flaskparser.py
@@ -60,7 +60,7 @@
# We decode the json manually here instead of
# using req.get_json() so that we can handle
# JSONDecodeErrors consistently
- data = req._get_data_for_json(cache=True)
+ data = req.get_data(cache=True)
try:
self._cache["json"] = json_data = core.parse_json(data)
except json.JSONDecodeError as e:
|
{"golden_diff": "diff --git a/webargs/flaskparser.py b/webargs/flaskparser.py\n--- a/webargs/flaskparser.py\n+++ b/webargs/flaskparser.py\n@@ -60,7 +60,7 @@\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n- data = req._get_data_for_json(cache=True)\n+ data = req.get_data(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n", "issue": "bug: webargs 5.0 introduces incompatibility with Flask < 1.0\nhttps://github.com/marshmallow-code/webargs/blob/5.0.0/webargs/flaskparser.py#L63\r\n\r\n`_get_data_for_json` is only available since Flask >= 1.0\r\n\r\nfor Flask < 1.0, there is an error as follows:\r\n\r\n```\r\n File \"/usr/local/lib/python2.7/site-packages/webargs/flaskparser.py\", line 63, in parse_json\r\n data = req._get_data_for_json(cache=True)\r\n File \"/usr/local/lib/python2.7/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\nAttributeError: 'Request' object has no attribute '_get_data_for_json'\r\n```\r\n\r\nI had to downgrade webargs to 4.4.1 to get it work.\r\n\r\nSo you need to update this framework requirement https://github.com/marshmallow-code/webargs/blob/dev/setup.py#L11 or update the code for the backward compatibility.\r\n\r\nIMHO, using `_get_data_for_json` should be avoided because it's considered private and can be changed/removed anytime.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.core import json\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(view_args=\"parse_view_args\", **core.Parser.__location_map__)\n\n def parse_view_args(self, req, name, field):\n \"\"\"Pull a value from the request's ``view_args``.\"\"\"\n return core.get_value(req.view_args, name, field)\n\n def parse_json(self, req, name, field):\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n data = req._get_data_for_json(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_querystring(self, req, name, field):\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.args, name, field)\n\n def parse_form(self, req, name, field):\n \"\"\"Pull a form value from the request.\"\"\"\n try:\n return core.get_value(req.form, name, field)\n except AttributeError:\n pass\n return core.missing\n\n def parse_headers(self, req, name, field):\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req, name, field):\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req, name, field):\n \"\"\"Pull a file from the request.\"\"\"\n return core.get_value(req.files, name, field)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request objec by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "webargs/flaskparser.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.core import json\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(view_args=\"parse_view_args\", **core.Parser.__location_map__)\n\n def parse_view_args(self, req, name, field):\n \"\"\"Pull a value from the request's ``view_args``.\"\"\"\n return core.get_value(req.view_args, name, field)\n\n def parse_json(self, req, name, field):\n \"\"\"Pull a json value from the request.\"\"\"\n json_data = self._cache.get(\"json\")\n if json_data is None:\n # We decode the json manually here instead of\n # using req.get_json() so that we can handle\n # JSONDecodeErrors consistently\n data = req.get_data(cache=True)\n try:\n self._cache[\"json\"] = json_data = core.parse_json(data)\n except json.JSONDecodeError as e:\n if e.doc == \"\":\n return core.missing\n else:\n return self.handle_invalid_json_error(e, req)\n return core.get_value(json_data, name, field, allow_many_nested=True)\n\n def parse_querystring(self, req, name, field):\n \"\"\"Pull a querystring value from the request.\"\"\"\n return core.get_value(req.args, name, field)\n\n def parse_form(self, req, name, field):\n \"\"\"Pull a form value from the request.\"\"\"\n try:\n return core.get_value(req.form, name, field)\n except AttributeError:\n pass\n return core.missing\n\n def parse_headers(self, req, name, field):\n \"\"\"Pull a value from the header data.\"\"\"\n return core.get_value(req.headers, name, field)\n\n def parse_cookies(self, req, name, field):\n \"\"\"Pull a value from the cookiejar.\"\"\"\n return core.get_value(req.cookies, name, field)\n\n def parse_files(self, req, name, field):\n \"\"\"Pull a file from the request.\"\"\"\n return core.get_value(req.files, name, field)\n\n def handle_error(self, error, req, schema, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request objec by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "webargs/flaskparser.py"}]}
| 1,616 | 130 |
gh_patches_debug_12423
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-284
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API tests using wrong tables database
**Describe the bug**
The django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test.
**Expected behavior**
We should ensure `pytest-django` doesn't build a separate tables database.
**Additional context**
Currently blocking #276
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `config/settings.py`
Content:
```
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19 # Build paths inside the project like this: BASE_DIR / 'subdir'.
20 BASE_DIR = Path(__file__).resolve().parent.parent
21
22 # Application definition
23
24 INSTALLED_APPS = [
25 "django.contrib.admin",
26 "django.contrib.auth",
27 "django.contrib.contenttypes",
28 "django.contrib.sessions",
29 "django.contrib.messages",
30 "django.contrib.staticfiles",
31 "rest_framework",
32 "django_filters",
33 "django_property_filter",
34 "mathesar",
35 ]
36
37 MIDDLEWARE = [
38 "django.middleware.security.SecurityMiddleware",
39 "django.contrib.sessions.middleware.SessionMiddleware",
40 "django.middleware.common.CommonMiddleware",
41 "django.middleware.csrf.CsrfViewMiddleware",
42 "django.contrib.auth.middleware.AuthenticationMiddleware",
43 "django.contrib.messages.middleware.MessageMiddleware",
44 "django.middleware.clickjacking.XFrameOptionsMiddleware",
45 ]
46
47 ROOT_URLCONF = "config.urls"
48
49 TEMPLATES = [
50 {
51 "BACKEND": "django.template.backends.django.DjangoTemplates",
52 "DIRS": [],
53 "APP_DIRS": True,
54 "OPTIONS": {
55 "context_processors": [
56 "config.context_processors.get_settings",
57 "django.template.context_processors.debug",
58 "django.template.context_processors.request",
59 "django.contrib.auth.context_processors.auth",
60 "django.contrib.messages.context_processors.messages",
61 ],
62 },
63 },
64 ]
65
66 WSGI_APPLICATION = "config.wsgi.application"
67
68 # Database
69 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
70
71 # TODO: Add to documentation that database keys should not be than 128 characters.
72 DATABASES = {
73 decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),
74 decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
75 }
76
77
78 # Quick-start development settings - unsuitable for production
79 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
80
81 # SECURITY WARNING: keep the secret key used in production secret!
82 SECRET_KEY = decouple_config('SECRET_KEY')
83
84 # SECURITY WARNING: don't run with debug turned on in production!
85 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
86
87 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
88
89 # Password validation
90 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
91
92 AUTH_PASSWORD_VALIDATORS = [
93 {
94 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
95 },
96 {
97 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
98 },
99 {
100 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
101 },
102 {
103 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
104 },
105 ]
106
107
108 # Internationalization
109 # https://docs.djangoproject.com/en/3.1/topics/i18n/
110
111 LANGUAGE_CODE = "en-us"
112
113 TIME_ZONE = "UTC"
114
115 USE_I18N = True
116
117 USE_L10N = True
118
119 USE_TZ = True
120
121
122 # Static files (CSS, JavaScript, Images)
123 # https://docs.djangoproject.com/en/3.1/howto/static-files/
124
125 STATIC_URL = "/static/"
126
127 CLIENT_DEV_URL = "http://localhost:3000"
128
129
130 # Media files (uploaded by the user)
131
132 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
133
134 MEDIA_URL = "/media/"
135
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -74,6 +74,13 @@
decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
}
+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
+if decouple_config('TEST', default=False, cast=bool):
+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {
+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']
+ }
+
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
|
{"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -74,6 +74,13 @@\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n }\n \n+# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n+# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\n+if decouple_config('TEST', default=False, cast=bool):\n+ DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n+ 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n+ }\n+\n \n # Quick-start development settings - unsuitable for production\n # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n", "issue": "API tests using wrong tables database\n**Describe the bug**\r\nThe django API tests are running on the `test_mathesar_db_test_database`, which differs from the `mathesar_db_test_database` tables database we should be using. As a result, we don't have a proper reference to the database being used by the API functions, which prevents us from certain operations like installing types for a test. \r\n\r\n**Expected behavior**\r\nWe should ensure `pytest-django` doesn't build a separate tables database.\r\n\r\n**Additional context**\r\nCurrently blocking #276 \r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nif decouple_config('TEST', default=False, cast=bool):\n DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n }\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}]}
| 1,516 | 201 |
gh_patches_debug_14759
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1901
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Keystroke ] not detected on Windows
In Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41
Here's my plan on how to address it. I hope I'll get around to it somewhere next week.
- [ ] Improve the mapping in `PDCurses` and submit a pull request
- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package
- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.
I'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).
I didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python3
2
3 from setuptools import setup
4 # tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96
5 #from visidata import __version__
6 __version__ = '2.12dev'
7
8 setup(name='visidata',
9 version=__version__,
10 description='terminal interface for exploring and arranging tabular data',
11 long_description=open('README.md').read(),
12 long_description_content_type='text/markdown',
13 author='Saul Pwanson',
14 python_requires='>=3.7',
15 author_email='[email protected]',
16 url='https://visidata.org',
17 download_url='https://github.com/saulpw/visidata/tarball/' + __version__,
18 scripts=['bin/vd'],
19 entry_points={'console_scripts': [
20 'visidata=visidata.main:vd_cli'
21 ],
22 },
23 py_modules=['visidata'],
24 install_requires=[
25 'python-dateutil',
26 'windows-curses; platform_system == "Windows"',
27 'importlib-metadata >= 3.6',
28 ],
29 packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
30 data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],
31 package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},
32 license='GPLv3',
33 classifiers=[
34 'Development Status :: 5 - Production/Stable',
35 'Environment :: Console',
36 'Environment :: Console :: Curses',
37 'Intended Audience :: Developers',
38 'Intended Audience :: Science/Research',
39 'Intended Audience :: System Administrators',
40 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
41 'Operating System :: OS Independent',
42 'Programming Language :: Python :: 3',
43 'Topic :: Database :: Front-Ends',
44 'Topic :: Scientific/Engineering',
45 'Topic :: Office/Business :: Financial :: Spreadsheet',
46 'Topic :: Scientific/Engineering :: Visualization',
47 'Topic :: Utilities',
48 ],
49 keywords=('console tabular data spreadsheet terminal viewer textpunk'
50 'curses csv hdf5 h5 xlsx excel tsv'),
51 )
52
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,7 +23,7 @@
py_modules=['visidata'],
install_requires=[
'python-dateutil',
- 'windows-curses; platform_system == "Windows"',
+ 'windows-curses<2.3.1; platform_system == "Windows"', #1841
'importlib-metadata >= 3.6',
],
packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,7 +23,7 @@\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n- 'windows-curses; platform_system == \"Windows\"',\n+ 'windows-curses<2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n", "issue": "Keystroke ] not detected on Windows\nIn Powershell and cmd.exe I encountered that sorting didn't work in both orders. The `[` shortcut was detected and had its effect, but the `]` didn't. I narrowed it down to a problem with `windows-curses`, and in turn with its dependency `PDCurses`: https://github.com/zephyrproject-rtos/windows-curses/issues/41\r\n\r\nHere's my plan on how to address it. I hope I'll get around to it somewhere next week.\r\n- [ ] Improve the mapping in `PDCurses` and submit a pull request\r\n- [ ] Bump the git submodule in `windows-curses` to the `PDCurses` version that has the fix and ask/wait for a release of this package\r\n- [ ] Address the issue in this repository, perhaps by pinning `windows-curses` to a version of at least the newly released package.\r\n\r\nI'm making this issue here just to document it and track progress. If you're reading this because you have this issue, I would recommend using WSL instead. (WSL is not an option for me unfortunately).\r\n\r\nI didn't include the `.vd`-file to reproduce this issue. The simplest way to reproduce it is to get a Windows computer, run `visidata` from Powershell or cmd.exe and sort any column by pressing `]`.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '2.12dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses; platform_system == \"Windows\"',\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nfrom setuptools import setup\n# tox can't actually run python3 setup.py: https://github.com/tox-dev/tox/issues/96\n#from visidata import __version__\n__version__ = '2.12dev'\n\nsetup(name='visidata',\n version=__version__,\n description='terminal interface for exploring and arranging tabular data',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author='Saul Pwanson',\n python_requires='>=3.7',\n author_email='[email protected]',\n url='https://visidata.org',\n download_url='https://github.com/saulpw/visidata/tarball/' + __version__,\n scripts=['bin/vd'],\n entry_points={'console_scripts': [\n 'visidata=visidata.main:vd_cli'\n ],\n },\n py_modules=['visidata'],\n install_requires=[\n 'python-dateutil',\n 'windows-curses<2.3.1; platform_system == \"Windows\"', #1841\n 'importlib-metadata >= 3.6',\n ],\n packages=['visidata', 'visidata.loaders', 'visidata.vendor', 'visidata.tests', 'visidata.ddw', 'visidata.man', 'visidata.themes', 'visidata.features', 'visidata.experimental', 'visidata.apps', 'visidata.apps.vgit', 'visidata.apps.vdsql', 'visidata.desktop'],\n data_files=[('share/man/man1', ['visidata/man/vd.1', 'visidata/man/visidata.1']), ('share/applications/', ['visidata/desktop/visidata.desktop'])],\n package_data={'visidata.man': ['vd.1', 'vd.txt'], 'visidata.ddw': ['input.ddw'], 'visidata.tests': ['sample.tsv'], 'visidata.desktop': ['visidata.desktop']},\n license='GPLv3',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Console :: Curses',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 3',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Office/Business :: Financial :: Spreadsheet',\n 'Topic :: Scientific/Engineering :: Visualization',\n 'Topic :: Utilities',\n ],\n keywords=('console tabular data spreadsheet terminal viewer textpunk'\n 'curses csv hdf5 h5 xlsx excel tsv'),\n )\n\n", "path": "setup.py"}]}
| 1,222 | 175 |
gh_patches_debug_18243
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-1465
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CSS bundles generation breaks background images relative urls
This is a bug related to PR #1300.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/resources/browser/combine.py`
Content:
```
1 from zExceptions import NotFound
2 from Acquisition import aq_base
3 from datetime import datetime
4 from plone.registry.interfaces import IRegistry
5 from plone.resource.file import FilesystemFile
6 from plone.resource.interfaces import IResourceDirectory
7 from Products.CMFPlone.interfaces import IBundleRegistry
8 from Products.CMFPlone.interfaces.resources import (
9 OVERRIDE_RESOURCE_DIRECTORY_NAME,
10 )
11 from StringIO import StringIO
12 from zope.component import getUtility
13 from zope.component import queryUtility
14
15 PRODUCTION_RESOURCE_DIRECTORY = "production"
16
17
18 def get_production_resource_directory():
19 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
20 if persistent_directory is None:
21 return ''
22 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
23 try:
24 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
25 except NotFound:
26 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
27 timestamp = production_folder.readFile('timestamp.txt')
28 return "%s/++unique++%s" % (
29 PRODUCTION_RESOURCE_DIRECTORY, timestamp)
30
31
32 def get_resource(context, path):
33 resource = context.unrestrictedTraverse(path)
34 if isinstance(resource, FilesystemFile):
35 (directory, sep, filename) = path.rpartition('/')
36 return context.unrestrictedTraverse(directory).readFile(filename)
37 else:
38 if hasattr(aq_base(resource), 'GET'):
39 # for FileResource
40 return resource.GET()
41 else:
42 # any BrowserView
43 return resource()
44
45
46 def write_js(context, folder, meta_bundle):
47 registry = getUtility(IRegistry)
48 resources = []
49
50 # default resources
51 if meta_bundle == 'default' and registry.records.get(
52 'plone.resources/jquery.js'
53 ):
54 resources.append(get_resource(context,
55 registry.records['plone.resources/jquery.js'].value))
56 resources.append(get_resource(context,
57 registry.records['plone.resources.requirejs'].value))
58 resources.append(get_resource(context,
59 registry.records['plone.resources.configjs'].value))
60
61 # bundles
62 bundles = registry.collectionOfInterface(
63 IBundleRegistry, prefix="plone.bundles", check=False)
64 for bundle in bundles.values():
65 if bundle.merge_with == meta_bundle:
66 resources.append(get_resource(context, bundle.jscompilation))
67
68 fi = StringIO()
69 for script in resources:
70 fi.write(script + '\n')
71 folder.writeFile(meta_bundle + ".js", fi)
72
73
74 def write_css(context, folder, meta_bundle):
75 registry = getUtility(IRegistry)
76 resources = []
77
78 bundles = registry.collectionOfInterface(
79 IBundleRegistry, prefix="plone.bundles", check=False)
80 for bundle in bundles.values():
81 if bundle.merge_with == meta_bundle:
82 resources.append(get_resource(context, bundle.csscompilation))
83
84 fi = StringIO()
85 for script in resources:
86 fi.write(script + '\n')
87 folder.writeFile(meta_bundle + ".css", fi)
88
89
90 def combine_bundles(context):
91 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
92 if persistent_directory is None:
93 return
94 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
95 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
96 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
97 if PRODUCTION_RESOURCE_DIRECTORY not in container:
98 container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)
99 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
100
101 # store timestamp
102 fi = StringIO()
103 fi.write(datetime.now().isoformat())
104 production_folder.writeFile("timestamp.txt", fi)
105
106 # generate new combined bundles
107 write_js(context, production_folder, 'default')
108 write_js(context, production_folder, 'logged-in')
109 write_css(context, production_folder, 'default')
110 write_css(context, production_folder, 'logged-in')
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py
--- a/Products/CMFPlone/resources/browser/combine.py
+++ b/Products/CMFPlone/resources/browser/combine.py
@@ -1,3 +1,4 @@
+import re
from zExceptions import NotFound
from Acquisition import aq_base
from datetime import datetime
@@ -79,7 +80,15 @@
IBundleRegistry, prefix="plone.bundles", check=False)
for bundle in bundles.values():
if bundle.merge_with == meta_bundle:
- resources.append(get_resource(context, bundle.csscompilation))
+ css = get_resource(context, bundle.csscompilation)
+ # Preserve relative urls:
+ # we prefix with '../'' any url not starting with '/'
+ # or http: or data:
+ css = re.sub(
+ r"""(url\(['"]?(?!['"]?([a-z]+:|\/)))""",
+ r'\1../',
+ css)
+ resources.append(css)
fi = StringIO()
for script in resources:
|
{"golden_diff": "diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py\n--- a/Products/CMFPlone/resources/browser/combine.py\n+++ b/Products/CMFPlone/resources/browser/combine.py\n@@ -1,3 +1,4 @@\n+import re\n from zExceptions import NotFound\n from Acquisition import aq_base\n from datetime import datetime\n@@ -79,7 +80,15 @@\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n- resources.append(get_resource(context, bundle.csscompilation))\n+ css = get_resource(context, bundle.csscompilation)\n+ # Preserve relative urls:\n+ # we prefix with '../'' any url not starting with '/'\n+ # or http: or data:\n+ css = re.sub(\n+ r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n+ r'\\1../',\n+ css)\n+ resources.append(css)\n \n fi = StringIO()\n for script in resources:\n", "issue": "CSS bundles generation breaks background images relative urls\nThis is a bug related to PR #1300.\n\n", "before_files": [{"content": "from zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.csscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef combine_bundles(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}], "after_files": [{"content": "import re\nfrom zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n css = get_resource(context, bundle.csscompilation)\n # Preserve relative urls:\n # we prefix with '../'' any url not starting with '/'\n # or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n r'\\1../',\n css)\n resources.append(css)\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef combine_bundles(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}]}
| 1,303 | 251 |
gh_patches_debug_2033
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-802
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ChunkedEncodingError is not retried when fetching data with list_rows()
Original issue: https://github.com/googleapis/python-bigquery-storage/issues/242
A user reported that they saw an error in production when fetching table data with `Client.list_rows()`. That method uses the [default retry object](https://github.com/googleapis/python-bigquery/blob/7e0e2bafc4c3f98a4246100f504fd78a01a28e7d/google/cloud/bigquery/retry.py#L49), which currently does not consider `requests.exceptions.ChunkedEncodingError` retryable.
(it does retry `requests.exceptions.ConnectionError`, but `ChunkedEncodingError` is not a subclass of that.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/retry.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from google.api_core import exceptions
16 from google.api_core import retry
17 from google.auth import exceptions as auth_exceptions
18 import requests.exceptions
19
20
21 _RETRYABLE_REASONS = frozenset(
22 ["rateLimitExceeded", "backendError", "internalError", "badGateway"]
23 )
24
25 _UNSTRUCTURED_RETRYABLE_TYPES = (
26 ConnectionError,
27 exceptions.TooManyRequests,
28 exceptions.InternalServerError,
29 exceptions.BadGateway,
30 requests.exceptions.ConnectionError,
31 auth_exceptions.TransportError,
32 )
33
34
35 def _should_retry(exc):
36 """Predicate for determining when to retry.
37
38 We retry if and only if the 'reason' is 'backendError'
39 or 'rateLimitExceeded'.
40 """
41 if not hasattr(exc, "errors") or len(exc.errors) == 0:
42 # Check for unstructured error returns, e.g. from GFE
43 return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)
44
45 reason = exc.errors[0]["reason"]
46 return reason in _RETRYABLE_REASONS
47
48
49 DEFAULT_RETRY = retry.Retry(predicate=_should_retry)
50 """The default retry object.
51
52 Any method with a ``retry`` parameter will be retried automatically,
53 with reasonable defaults. To disable retry, pass ``retry=None``.
54 To modify the default retry behavior, call a ``with_XXX`` method
55 on ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,
56 pass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.
57 """
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py
--- a/google/cloud/bigquery/retry.py
+++ b/google/cloud/bigquery/retry.py
@@ -27,6 +27,7 @@
exceptions.TooManyRequests,
exceptions.InternalServerError,
exceptions.BadGateway,
+ requests.exceptions.ChunkedEncodingError,
requests.exceptions.ConnectionError,
auth_exceptions.TransportError,
)
|
{"golden_diff": "diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py\n--- a/google/cloud/bigquery/retry.py\n+++ b/google/cloud/bigquery/retry.py\n@@ -27,6 +27,7 @@\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n+ requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n )\n", "issue": "ChunkedEncodingError is not retried when fetching data with list_rows()\nOriginal issue: https://github.com/googleapis/python-bigquery-storage/issues/242\r\n\r\nA user reported that they saw an error in production when fetching table data with `Client.list_rows()`. That method uses the [default retry object](https://github.com/googleapis/python-bigquery/blob/7e0e2bafc4c3f98a4246100f504fd78a01a28e7d/google/cloud/bigquery/retry.py#L49), which currently does not consider `requests.exceptions.ChunkedEncodingError` retryable.\r\n\r\n(it does retry `requests.exceptions.ConnectionError`, but `ChunkedEncodingError` is not a subclass of that.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ChunkedEncodingError,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}]}
| 983 | 92 |
gh_patches_debug_5179
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2653
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Impossible login to GOG.com: invalid cookie ?
**Describe the bug**
I can't connect Lutris with my GOG.com account: the GOG.com credentials window is here, I can fill it, but when I confirm this form, the window closes and… nothing more. My account isn't connected, and if I close the "Import games" window, I can't reopen it unless I delete '.cache/lutris' directory.
**Expected behavior**
I should have a second GOG.com form asking for a PIN code, then my account should be connected in Lutris.
**Current behavior**
As in description above. Plus technical details:
* two files are created in '~/.cache/lutris/': .gog.auth and .gog.token (attached as [gog.auth.txt](https://github.com/lutris/lutris/files/4309081/gog.auth.txt) and [gog.token.txt](https://github.com/lutris/lutris/files/4309083/gog.token.txt))
* according to standard output in terminal, some problems with Python, ending with an invalid cookie? (see [lutris.txt](https://github.com/lutris/lutris/files/4309117/lutris.txt))
**Steps to reproduce**
It happens while importing GOG games from the app or installing GOG games from the website.
**System information**
Fresh Lutris install, Arch Linux, kernel 5.5.8. More in [lutris.log](https://github.com/lutris/lutris/files/4309125/lutris.log)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/cookies.py`
Content:
```
1 import time
2 from http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception
3
4
5 class WebkitCookieJar(MozillaCookieJar):
6 """Subclass of MozillaCookieJar for compatibility with cookies
7 coming from Webkit2.
8 This disables the magic_re header which is not present and adds
9 compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)
10 """
11
12 def _really_load(self, f, filename, ignore_discard, ignore_expires):
13 now = time.time()
14 try:
15 while 1:
16 line = f.readline()
17 if line == "":
18 break
19
20 # last field may be absent, so keep any trailing tab
21 if line.endswith("\n"):
22 line = line[:-1]
23
24 sline = line.strip()
25 # support HttpOnly cookies (as stored by curl or old Firefox).
26 if sline.startswith("#HttpOnly_"):
27 line = sline[10:]
28 elif sline.startswith("#") or sline == "":
29 continue
30
31 domain, domain_specified, path, secure, expires, name, value = line.split(
32 "\t"
33 )
34 secure = secure == "TRUE"
35 domain_specified = domain_specified == "TRUE"
36 if name == "":
37 # cookies.txt regards 'Set-Cookie: foo' as a cookie
38 # with no name, whereas http.cookiejar regards it as a
39 # cookie with no value.
40 name = value
41 value = None
42
43 initial_dot = domain.startswith(".")
44 assert domain_specified == initial_dot
45
46 discard = False
47 if expires == "":
48 expires = None
49 discard = True
50
51 # assume path_specified is false
52 c = Cookie(
53 0,
54 name,
55 value,
56 None,
57 False,
58 domain,
59 domain_specified,
60 initial_dot,
61 path,
62 False,
63 secure,
64 expires,
65 discard,
66 None,
67 None,
68 {},
69 )
70 if not ignore_discard and c.discard:
71 continue
72 if not ignore_expires and c.is_expired(now):
73 continue
74 self.set_cookie(c)
75
76 except OSError:
77 raise
78 except Exception:
79 _warn_unhandled_exception()
80 raise OSError(
81 "invalid Netscape format cookies file %r: %r" % (filename, line)
82 )
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/cookies.py b/lutris/util/cookies.py
--- a/lutris/util/cookies.py
+++ b/lutris/util/cookies.py
@@ -28,7 +28,7 @@
elif sline.startswith("#") or sline == "":
continue
- domain, domain_specified, path, secure, expires, name, value = line.split(
+ domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(
"\t"
)
secure = secure == "TRUE"
|
{"golden_diff": "diff --git a/lutris/util/cookies.py b/lutris/util/cookies.py\n--- a/lutris/util/cookies.py\n+++ b/lutris/util/cookies.py\n@@ -28,7 +28,7 @@\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n \n- domain, domain_specified, path, secure, expires, name, value = line.split(\n+ domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n", "issue": "Impossible login to GOG.com: invalid cookie ?\n**Describe the bug**\r\n\r\nI can't connect Lutris with my GOG.com account: the GOG.com credentials window is here, I can fill it, but when I confirm this form, the window closes and\u2026 nothing more. My account isn't connected, and if I close the \"Import games\" window, I can't reopen it unless I delete '.cache/lutris' directory. \r\n\r\n**Expected behavior**\r\n\r\nI should have a second GOG.com form asking for a PIN code, then my account should be connected in Lutris.\r\n\r\n**Current behavior**\r\n\r\nAs in description above. Plus technical details:\r\n\r\n* two files are created in '~/.cache/lutris/': .gog.auth and .gog.token (attached as [gog.auth.txt](https://github.com/lutris/lutris/files/4309081/gog.auth.txt) and [gog.token.txt](https://github.com/lutris/lutris/files/4309083/gog.token.txt))\r\n* according to standard output in terminal, some problems with Python, ending with an invalid cookie? (see [lutris.txt](https://github.com/lutris/lutris/files/4309117/lutris.txt))\r\n\r\n**Steps to reproduce**\r\n\r\nIt happens while importing GOG games from the app or installing GOG games from the website.\r\n\r\n**System information**\r\n\r\nFresh Lutris install, Arch Linux, kernel 5.5.8. More in [lutris.log](https://github.com/lutris/lutris/files/4309125/lutris.log)\n", "before_files": [{"content": "import time\nfrom http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception\n\n\nclass WebkitCookieJar(MozillaCookieJar):\n \"\"\"Subclass of MozillaCookieJar for compatibility with cookies\n coming from Webkit2.\n This disables the magic_re header which is not present and adds\n compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)\n \"\"\"\n\n def _really_load(self, f, filename, ignore_discard, ignore_expires):\n now = time.time()\n try:\n while 1:\n line = f.readline()\n if line == \"\":\n break\n\n # last field may be absent, so keep any trailing tab\n if line.endswith(\"\\n\"):\n line = line[:-1]\n\n sline = line.strip()\n # support HttpOnly cookies (as stored by curl or old Firefox).\n if sline.startswith(\"#HttpOnly_\"):\n line = sline[10:]\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n\n domain, domain_specified, path, secure, expires, name, value = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n domain_specified = domain_specified == \"TRUE\"\n if name == \"\":\n # cookies.txt regards 'Set-Cookie: foo' as a cookie\n # with no name, whereas http.cookiejar regards it as a\n # cookie with no value.\n name = value\n value = None\n\n initial_dot = domain.startswith(\".\")\n assert domain_specified == initial_dot\n\n discard = False\n if expires == \"\":\n expires = None\n discard = True\n\n # assume path_specified is false\n c = Cookie(\n 0,\n name,\n value,\n None,\n False,\n domain,\n domain_specified,\n initial_dot,\n path,\n False,\n secure,\n expires,\n discard,\n None,\n None,\n {},\n )\n if not ignore_discard and c.discard:\n continue\n if not ignore_expires and c.is_expired(now):\n continue\n self.set_cookie(c)\n\n except OSError:\n raise\n except Exception:\n _warn_unhandled_exception()\n raise OSError(\n \"invalid Netscape format cookies file %r: %r\" % (filename, line)\n )\n", "path": "lutris/util/cookies.py"}], "after_files": [{"content": "import time\nfrom http.cookiejar import MozillaCookieJar, Cookie, _warn_unhandled_exception\n\n\nclass WebkitCookieJar(MozillaCookieJar):\n \"\"\"Subclass of MozillaCookieJar for compatibility with cookies\n coming from Webkit2.\n This disables the magic_re header which is not present and adds\n compatibility with HttpOnly cookies (See http://bugs.python.org/issue2190)\n \"\"\"\n\n def _really_load(self, f, filename, ignore_discard, ignore_expires):\n now = time.time()\n try:\n while 1:\n line = f.readline()\n if line == \"\":\n break\n\n # last field may be absent, so keep any trailing tab\n if line.endswith(\"\\n\"):\n line = line[:-1]\n\n sline = line.strip()\n # support HttpOnly cookies (as stored by curl or old Firefox).\n if sline.startswith(\"#HttpOnly_\"):\n line = sline[10:]\n elif sline.startswith(\"#\") or sline == \"\":\n continue\n\n domain, domain_specified, path, secure, expires, name, value, aditional_info = line.split(\n \"\\t\"\n )\n secure = secure == \"TRUE\"\n domain_specified = domain_specified == \"TRUE\"\n if name == \"\":\n # cookies.txt regards 'Set-Cookie: foo' as a cookie\n # with no name, whereas http.cookiejar regards it as a\n # cookie with no value.\n name = value\n value = None\n\n initial_dot = domain.startswith(\".\")\n assert domain_specified == initial_dot\n\n discard = False\n if expires == \"\":\n expires = None\n discard = True\n\n # assume path_specified is false\n c = Cookie(\n 0,\n name,\n value,\n None,\n False,\n domain,\n domain_specified,\n initial_dot,\n path,\n False,\n secure,\n expires,\n discard,\n None,\n None,\n {},\n )\n if not ignore_discard and c.discard:\n continue\n if not ignore_expires and c.is_expired(now):\n continue\n self.set_cookie(c)\n\n except OSError:\n raise\n except Exception:\n _warn_unhandled_exception()\n raise OSError(\n \"invalid Netscape format cookies file %r: %r\" % (filename, line)\n )\n", "path": "lutris/util/cookies.py"}]}
| 1,280 | 127 |
gh_patches_debug_64230
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-56
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incompatibility with old versions of SQLAlchemy.
Connecting to PostgreSQL fails with old versions of SQLAlchemy raising an error: `sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name`. This error is resolved once sqlalchemy version is updated.
For example:
```python
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.0.13'
>>> from pfnopt.storages import RDBStorage
>>> RDBStorage(url='postgresql://pfnopt:somepassword@localhost:5432/some_db')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/sano/PycharmProjects/pfnopt/pfnopt/storages/rdb.py", line 85, in __init__
Base.metadata.create_all(self.engine)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/schema.py", line 3695, in create_all
tables=tables)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 1856, in _run_visitor
conn._run_visitor(visitorcallable, element, **kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 1481, in _run_visitor
**kwargs).traverse_single(element)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py", line 121, in traverse_single
return meth(obj, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 720, in visit_metadata
_ddl_runner=self)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/event/attr.py", line 256, in __call__
fn(*args, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/util/langhelpers.py", line 546, in __call__
return getattr(self.target, self.name)(*arg, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/sqltypes.py", line 1040, in _on_metadata_create
t._on_metadata_create(target, bind, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1379, in _on_metadata_create
self.create(bind=bind, checkfirst=checkfirst)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1317, in create
bind.execute(CreateEnumType(self))
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 914, in execute
return meth(self, multiparams, params)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 68, in _execute_on_connection
return connection._execute_ddl(self, multiparams, params)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py", line 962, in _execute_ddl
compiled = ddl.compile(dialect=dialect)
File "<string>", line 1, in <lambda>
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/elements.py", line 494, in compile
return self._compiler(dialect, bind=bind, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py", line 26, in _compiler
return dialect.ddl_compiler(dialect, self, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py", line 190, in __init__
self.string = self.process(self.statement, **compile_kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py", line 213, in process
return obj._compiler_dispatch(self, **kwargs)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py", line 81, in _compiler_dispatch
return meth(self, **kw)
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1613, in visit_create_enum_type
self.preparer.format_type(type_),
File "/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py", line 1857, in format_type
raise exc.CompileError("Postgresql ENUM type requires a name.")
sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 import os
2 from setuptools import find_packages
3 from setuptools import setup
4 import sys
5
6
7 def get_version():
8 version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')
9 with open(version_filepath) as f:
10 for line in f:
11 if line.startswith('__version__'):
12 return line.strip().split()[-1][1:-1]
13 assert False
14
15
16 tests_require = ['pytest', 'hacking', 'mock']
17 if sys.version_info[0] == 3:
18 tests_require.append('mypy')
19
20
21 setup(
22 name='pfnopt',
23 version=get_version(),
24 description='',
25 author='Takuya Akiba',
26 author_email='[email protected]',
27 packages=find_packages(),
28 install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
29 tests_require=tests_require,
30 extras_require={'testing': tests_require},
31 entry_points={
32 'console_scripts': ['pfnopt = pfnopt.cli:main'],
33 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']
34 }
35 )
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -25,7 +25,7 @@
author='Takuya Akiba',
author_email='[email protected]',
packages=find_packages(),
- install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
+ install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],
tests_require=tests_require,
extras_require={'testing': tests_require},
entry_points={
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -25,7 +25,7 @@\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n- install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n+ install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n", "issue": "Incompatibility with old versions of SQLAlchemy.\nConnecting to PostgreSQL fails with old versions of SQLAlchemy raising an error: `sqlalchemy.exc.CompileError: Postgresql ENUM type requires a name`. This error is resolved once sqlalchemy version is updated.\r\n\r\nFor example:\r\n```python\r\n>>> import sqlalchemy\r\n>>> sqlalchemy.__version__\r\n'1.0.13'\r\n>>> from pfnopt.storages import RDBStorage\r\n>>> RDBStorage(url='postgresql://pfnopt:somepassword@localhost:5432/some_db')\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/sano/PycharmProjects/pfnopt/pfnopt/storages/rdb.py\", line 85, in __init__\r\n Base.metadata.create_all(self.engine)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/schema.py\", line 3695, in create_all\r\n tables=tables)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 1856, in _run_visitor\r\n conn._run_visitor(visitorcallable, element, **kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 1481, in _run_visitor\r\n **kwargs).traverse_single(element)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py\", line 121, in traverse_single\r\n return meth(obj, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 720, in visit_metadata\r\n _ddl_runner=self)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/event/attr.py\", line 256, in __call__\r\n fn(*args, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/util/langhelpers.py\", line 546, in __call__\r\n return getattr(self.target, self.name)(*arg, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/sqltypes.py\", line 1040, in _on_metadata_create\r\n t._on_metadata_create(target, bind, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1379, in _on_metadata_create\r\n self.create(bind=bind, checkfirst=checkfirst)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1317, in create\r\n bind.execute(CreateEnumType(self))\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 914, in execute\r\n return meth(self, multiparams, params)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 68, in _execute_on_connection\r\n return connection._execute_ddl(self, multiparams, params)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/engine/base.py\", line 962, in _execute_ddl\r\n compiled = ddl.compile(dialect=dialect)\r\n File \"<string>\", line 1, in <lambda>\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/elements.py\", line 494, in compile\r\n return self._compiler(dialect, bind=bind, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/ddl.py\", line 26, in _compiler\r\n return dialect.ddl_compiler(dialect, self, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py\", line 190, in __init__\r\n self.string = self.process(self.statement, **compile_kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/compiler.py\", line 213, in process\r\n return obj._compiler_dispatch(self, **kwargs)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/sql/visitors.py\", line 81, in _compiler_dispatch\r\n return meth(self, **kw)\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1613, in visit_create_enum_type\r\n self.preparer.format_type(type_),\r\n File \"/Users/sano/anaconda3/envs/pfnopt-35/lib/python3.5/site-packages/sqlalchemy/dialects/postgresql/base.py\", line 1857, in format_type\r\n raise exc.CompileError(\"Postgresql ENUM type requires a name.\")\r\nsqlalchemy.exc.CompileError: Postgresql ENUM type requires a name.\r\n```\n", "before_files": [{"content": "import os\nfrom setuptools import find_packages\nfrom setuptools import setup\nimport sys\n\n\ndef get_version():\n version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ntests_require = ['pytest', 'hacking', 'mock']\nif sys.version_info[0] == 3:\n tests_require.append('mypy')\n\n\nsetup(\n name='pfnopt',\n version=get_version(),\n description='',\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n install_requires=['sqlalchemy', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n 'console_scripts': ['pfnopt = pfnopt.cli:main'],\n 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']\n }\n)\n", "path": "setup.py"}], "after_files": [{"content": "import os\nfrom setuptools import find_packages\nfrom setuptools import setup\nimport sys\n\n\ndef get_version():\n version_filepath = os.path.join(os.path.dirname(__file__), 'pfnopt', 'version.py')\n with open(version_filepath) as f:\n for line in f:\n if line.startswith('__version__'):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ntests_require = ['pytest', 'hacking', 'mock']\nif sys.version_info[0] == 3:\n tests_require.append('mypy')\n\n\nsetup(\n name='pfnopt',\n version=get_version(),\n description='',\n author='Takuya Akiba',\n author_email='[email protected]',\n packages=find_packages(),\n install_requires=['sqlalchemy>=1.1.0', 'numpy', 'scipy', 'six', 'typing', 'enum34', 'cliff'],\n tests_require=tests_require,\n extras_require={'testing': tests_require},\n entry_points={\n 'console_scripts': ['pfnopt = pfnopt.cli:main'],\n 'pfnopt.command': ['mkstudy = pfnopt.cli:MakeStudy']\n }\n)\n", "path": "setup.py"}]}
| 1,869 | 142 |
gh_patches_debug_17580
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3873
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot use BLAKE2b or BLAKE2s with HMAC
Python 3.6.2 on Ubuntu 17.10
Cryptography and dependencies installed via pip in virtualenv
cffi==1.10.0
cryptography==2.0.3
pip==9.0.1
setuptools==36.2.7
Steps to reproduce:
```
In [1]: from cryptography.hazmat.backends import default_backend
...: from cryptography.hazmat.primitives import hashes
...: from cryptography.hazmat.primitives.hmac import HMAC
...:
...: backend = default_backend()
...:
In [2]: hmac = HMAC(b'\x00'*32, hashes.SHA256(), backend) # just fine
In [3]: hmac = HMAC(b'\x00'*32, hashes.BLAKE2s(digest_size=32), backend)
---------------------------------------------------------------------------
UnsupportedAlgorithm Traceback (most recent call last)
<ipython-input-3-61f273a52c45> in <module>()
----> 1 hmac = HMAC(b'\x00'*32, hashes.BLAKE2s(digest_size=32), backend)
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/primitives/hmac.py in __init__(self, key, algorithm, backend, ctx)
30 self._key = key
31 if ctx is None:
---> 32 self._ctx = self._backend.create_hmac_ctx(key, self.algorithm)
33 else:
34 self._ctx = ctx
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/backend.py in create_hmac_ctx(self, key, algorithm)
176
177 def create_hmac_ctx(self, key, algorithm):
--> 178 return _HMACContext(self, key, algorithm)
179
180 def _build_openssl_digest_name(self, algorithm):
~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/hmac.py in __init__(self, backend, key, algorithm, ctx)
32 "{0} is not a supported hash on this backend.".format(
33 algorithm.name),
---> 34 _Reasons.UNSUPPORTED_HASH
35 )
36 res = self._backend._lib.HMAC_Init_ex(
UnsupportedAlgorithm: blake2s is not a supported hash on this backend.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/backends/openssl/hmac.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7
8 from cryptography import utils
9 from cryptography.exceptions import (
10 InvalidSignature, UnsupportedAlgorithm, _Reasons
11 )
12 from cryptography.hazmat.primitives import constant_time, hashes, mac
13
14
15 @utils.register_interface(mac.MACContext)
16 @utils.register_interface(hashes.HashContext)
17 class _HMACContext(object):
18 def __init__(self, backend, key, algorithm, ctx=None):
19 self._algorithm = algorithm
20 self._backend = backend
21
22 if ctx is None:
23 ctx = self._backend._lib.Cryptography_HMAC_CTX_new()
24 self._backend.openssl_assert(ctx != self._backend._ffi.NULL)
25 ctx = self._backend._ffi.gc(
26 ctx, self._backend._lib.Cryptography_HMAC_CTX_free
27 )
28 evp_md = self._backend._lib.EVP_get_digestbyname(
29 algorithm.name.encode('ascii'))
30 if evp_md == self._backend._ffi.NULL:
31 raise UnsupportedAlgorithm(
32 "{0} is not a supported hash on this backend.".format(
33 algorithm.name),
34 _Reasons.UNSUPPORTED_HASH
35 )
36 res = self._backend._lib.HMAC_Init_ex(
37 ctx, key, len(key), evp_md, self._backend._ffi.NULL
38 )
39 self._backend.openssl_assert(res != 0)
40
41 self._ctx = ctx
42 self._key = key
43
44 algorithm = utils.read_only_property("_algorithm")
45
46 def copy(self):
47 copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()
48 self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)
49 copied_ctx = self._backend._ffi.gc(
50 copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free
51 )
52 res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)
53 self._backend.openssl_assert(res != 0)
54 return _HMACContext(
55 self._backend, self._key, self.algorithm, ctx=copied_ctx
56 )
57
58 def update(self, data):
59 res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))
60 self._backend.openssl_assert(res != 0)
61
62 def finalize(self):
63 buf = self._backend._ffi.new("unsigned char[]",
64 self._backend._lib.EVP_MAX_MD_SIZE)
65 outlen = self._backend._ffi.new("unsigned int *")
66 res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)
67 self._backend.openssl_assert(res != 0)
68 self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)
69 return self._backend._ffi.buffer(buf)[:outlen[0]]
70
71 def verify(self, signature):
72 digest = self.finalize()
73 if not constant_time.bytes_eq(digest, signature):
74 raise InvalidSignature("Signature did not match digest.")
75
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/backends/openssl/hmac.py b/src/cryptography/hazmat/backends/openssl/hmac.py
--- a/src/cryptography/hazmat/backends/openssl/hmac.py
+++ b/src/cryptography/hazmat/backends/openssl/hmac.py
@@ -25,12 +25,11 @@
ctx = self._backend._ffi.gc(
ctx, self._backend._lib.Cryptography_HMAC_CTX_free
)
- evp_md = self._backend._lib.EVP_get_digestbyname(
- algorithm.name.encode('ascii'))
+ name = self._backend._build_openssl_digest_name(algorithm)
+ evp_md = self._backend._lib.EVP_get_digestbyname(name)
if evp_md == self._backend._ffi.NULL:
raise UnsupportedAlgorithm(
- "{0} is not a supported hash on this backend.".format(
- algorithm.name),
+ "{0} is not a supported hash on this backend".format(name),
_Reasons.UNSUPPORTED_HASH
)
res = self._backend._lib.HMAC_Init_ex(
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/backends/openssl/hmac.py b/src/cryptography/hazmat/backends/openssl/hmac.py\n--- a/src/cryptography/hazmat/backends/openssl/hmac.py\n+++ b/src/cryptography/hazmat/backends/openssl/hmac.py\n@@ -25,12 +25,11 @@\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n- evp_md = self._backend._lib.EVP_get_digestbyname(\n- algorithm.name.encode('ascii'))\n+ name = self._backend._build_openssl_digest_name(algorithm)\n+ evp_md = self._backend._lib.EVP_get_digestbyname(name)\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n- \"{0} is not a supported hash on this backend.\".format(\n- algorithm.name),\n+ \"{0} is not a supported hash on this backend\".format(name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n", "issue": "Cannot use BLAKE2b or BLAKE2s with HMAC\nPython 3.6.2 on Ubuntu 17.10\r\nCryptography and dependencies installed via pip in virtualenv\r\ncffi==1.10.0\r\ncryptography==2.0.3\r\npip==9.0.1\r\nsetuptools==36.2.7\r\n\r\nSteps to reproduce:\r\n```\r\nIn [1]: from cryptography.hazmat.backends import default_backend\r\n ...: from cryptography.hazmat.primitives import hashes\r\n ...: from cryptography.hazmat.primitives.hmac import HMAC\r\n ...: \r\n ...: backend = default_backend()\r\n ...: \r\n\r\nIn [2]: hmac = HMAC(b'\\x00'*32, hashes.SHA256(), backend) # just fine\r\n\r\nIn [3]: hmac = HMAC(b'\\x00'*32, hashes.BLAKE2s(digest_size=32), backend)\r\n---------------------------------------------------------------------------\r\nUnsupportedAlgorithm Traceback (most recent call last)\r\n<ipython-input-3-61f273a52c45> in <module>()\r\n----> 1 hmac = HMAC(b'\\x00'*32, hashes.BLAKE2s(digest_size=32), backend)\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/primitives/hmac.py in __init__(self, key, algorithm, backend, ctx)\r\n 30 self._key = key\r\n 31 if ctx is None:\r\n---> 32 self._ctx = self._backend.create_hmac_ctx(key, self.algorithm)\r\n 33 else:\r\n 34 self._ctx = ctx\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/backend.py in create_hmac_ctx(self, key, algorithm)\r\n 176 \r\n 177 def create_hmac_ctx(self, key, algorithm):\r\n--> 178 return _HMACContext(self, key, algorithm)\r\n 179 \r\n 180 def _build_openssl_digest_name(self, algorithm):\r\n\r\n~/.venvs/master/lib/python3.6/site-packages/cryptography/hazmat/backends/openssl/hmac.py in __init__(self, backend, key, algorithm, ctx)\r\n 32 \"{0} is not a supported hash on this backend.\".format(\r\n 33 algorithm.name),\r\n---> 34 _Reasons.UNSUPPORTED_HASH\r\n 35 )\r\n 36 res = self._backend._lib.HMAC_Init_ex(\r\n\r\nUnsupportedAlgorithm: blake2s is not a supported hash on this backend.\r\n```\r\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n InvalidSignature, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.primitives import constant_time, hashes, mac\n\n\[email protected]_interface(mac.MACContext)\[email protected]_interface(hashes.HashContext)\nclass _HMACContext(object):\n def __init__(self, backend, key, algorithm, ctx=None):\n self._algorithm = algorithm\n self._backend = backend\n\n if ctx is None:\n ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(ctx != self._backend._ffi.NULL)\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n evp_md = self._backend._lib.EVP_get_digestbyname(\n algorithm.name.encode('ascii'))\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n \"{0} is not a supported hash on this backend.\".format(\n algorithm.name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n ctx, key, len(key), evp_md, self._backend._ffi.NULL\n )\n self._backend.openssl_assert(res != 0)\n\n self._ctx = ctx\n self._key = key\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n def copy(self):\n copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)\n copied_ctx = self._backend._ffi.gc(\n copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)\n self._backend.openssl_assert(res != 0)\n return _HMACContext(\n self._backend, self._key, self.algorithm, ctx=copied_ctx\n )\n\n def update(self, data):\n res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))\n self._backend.openssl_assert(res != 0)\n\n def finalize(self):\n buf = self._backend._ffi.new(\"unsigned char[]\",\n self._backend._lib.EVP_MAX_MD_SIZE)\n outlen = self._backend._ffi.new(\"unsigned int *\")\n res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)\n self._backend.openssl_assert(res != 0)\n self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)\n return self._backend._ffi.buffer(buf)[:outlen[0]]\n\n def verify(self, signature):\n digest = self.finalize()\n if not constant_time.bytes_eq(digest, signature):\n raise InvalidSignature(\"Signature did not match digest.\")\n", "path": "src/cryptography/hazmat/backends/openssl/hmac.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n InvalidSignature, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.primitives import constant_time, hashes, mac\n\n\[email protected]_interface(mac.MACContext)\[email protected]_interface(hashes.HashContext)\nclass _HMACContext(object):\n def __init__(self, backend, key, algorithm, ctx=None):\n self._algorithm = algorithm\n self._backend = backend\n\n if ctx is None:\n ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(ctx != self._backend._ffi.NULL)\n ctx = self._backend._ffi.gc(\n ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n name = self._backend._build_openssl_digest_name(algorithm)\n evp_md = self._backend._lib.EVP_get_digestbyname(name)\n if evp_md == self._backend._ffi.NULL:\n raise UnsupportedAlgorithm(\n \"{0} is not a supported hash on this backend\".format(name),\n _Reasons.UNSUPPORTED_HASH\n )\n res = self._backend._lib.HMAC_Init_ex(\n ctx, key, len(key), evp_md, self._backend._ffi.NULL\n )\n self._backend.openssl_assert(res != 0)\n\n self._ctx = ctx\n self._key = key\n\n algorithm = utils.read_only_property(\"_algorithm\")\n\n def copy(self):\n copied_ctx = self._backend._lib.Cryptography_HMAC_CTX_new()\n self._backend.openssl_assert(copied_ctx != self._backend._ffi.NULL)\n copied_ctx = self._backend._ffi.gc(\n copied_ctx, self._backend._lib.Cryptography_HMAC_CTX_free\n )\n res = self._backend._lib.HMAC_CTX_copy(copied_ctx, self._ctx)\n self._backend.openssl_assert(res != 0)\n return _HMACContext(\n self._backend, self._key, self.algorithm, ctx=copied_ctx\n )\n\n def update(self, data):\n res = self._backend._lib.HMAC_Update(self._ctx, data, len(data))\n self._backend.openssl_assert(res != 0)\n\n def finalize(self):\n buf = self._backend._ffi.new(\"unsigned char[]\",\n self._backend._lib.EVP_MAX_MD_SIZE)\n outlen = self._backend._ffi.new(\"unsigned int *\")\n res = self._backend._lib.HMAC_Final(self._ctx, buf, outlen)\n self._backend.openssl_assert(res != 0)\n self._backend.openssl_assert(outlen[0] == self.algorithm.digest_size)\n return self._backend._ffi.buffer(buf)[:outlen[0]]\n\n def verify(self, signature):\n digest = self.finalize()\n if not constant_time.bytes_eq(digest, signature):\n raise InvalidSignature(\"Signature did not match digest.\")\n", "path": "src/cryptography/hazmat/backends/openssl/hmac.py"}]}
| 1,674 | 244 |
gh_patches_debug_10384
|
rasdani/github-patches
|
git_diff
|
shuup__shuup-1558
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve the way permissionas are managed in admin
Currently, use has to use a select2 component with a lot of options and this is super boring, tedious and time consuming. Can we use a list of check boxes instead?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shuup/admin/modules/permission_groups/views/edit.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # This file is part of Shuup.
3 #
4 # Copyright (c) 2012-2018, Shuup Inc. All rights reserved.
5 #
6 # This source code is licensed under the OSL-3.0 license found in the
7 # LICENSE file in the root directory of this source tree.
8 from __future__ import unicode_literals
9
10 from django import forms
11 from django.contrib.auth import get_user_model
12 from django.contrib.auth.models import Group as PermissionGroup
13 from django.utils.encoding import force_text
14 from django.utils.translation import ugettext_lazy as _
15
16 from shuup.admin.forms.fields import Select2MultipleField
17 from shuup.admin.module_registry import get_modules
18 from shuup.admin.utils.permissions import get_permission_object_from_string
19 from shuup.admin.utils.views import CreateOrUpdateView
20
21
22 class PermissionGroupForm(forms.ModelForm):
23 class Meta:
24 model = PermissionGroup
25 exclude = ("permissions",)
26
27 def __init__(self, *args, **kwargs):
28 super(PermissionGroupForm, self).__init__(*args, **kwargs)
29 initial_permissions = self._get_initial_permissions()
30 self.fields["name"].help_text = _("The permission group name.")
31 self.fields["modules"] = forms.MultipleChoiceField(
32 choices=sorted(self._get_module_choices()),
33 initial=self._get_enabled_modules(initial_permissions),
34 required=False,
35 label=_("Module Permissions"),
36 help_text=_(
37 "Select the modules that should be accessible by this permission group. "
38 "Modules with the same permissions as selected modules will be added automatically."
39 )
40 )
41 initial_members = self._get_initial_members()
42 members_field = Select2MultipleField(
43 model=get_user_model(),
44 initial=[member.pk for member in initial_members],
45 required=False,
46 label=_("Members"),
47 help_text=_(
48 "Set the users that belong to this permission group."
49 )
50 )
51 members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]
52 self.fields["members"] = members_field
53
54 def _get_module_choices(self):
55 return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != "_Base_")
56
57 def _get_initial_members(self):
58 if self.instance.pk:
59 return self.instance.user_set.all()
60 else:
61 return []
62
63 def _get_initial_permissions(self):
64 permissions = set()
65 if self.instance.pk:
66 for perm in self.instance.permissions.all():
67 name, module, _ = perm.natural_key()
68 permissions.add("%s.%s" % (module, name))
69 return permissions
70
71 def _get_enabled_modules(self, permissions):
72 if not self.instance.pk:
73 return []
74 permissions = set(permissions)
75 modules = []
76 for module in get_modules():
77 # Ignore modules that haven't configured a name
78 if module.name != "_Base_" and set(module.get_required_permissions()).issubset(permissions):
79 modules.append(force_text(module.name))
80 return modules
81
82 def _get_required_permissions(self, modules):
83 permissions = set()
84 for module in [m for m in get_modules() if m.name in modules]:
85 permissions.update(set(module.get_required_permissions()))
86 return permissions
87
88 def clean_members(self):
89 members = self.cleaned_data.get("members", [])
90
91 return get_user_model().objects.filter(pk__in=members).all()
92
93 def clean(self):
94 cleaned_data = super(PermissionGroupForm, self).clean()
95
96 permissions = set()
97 modules = cleaned_data.pop("modules", [])
98 required_permissions = self._get_required_permissions(modules)
99
100 for permission in required_permissions:
101 permissions.add(get_permission_object_from_string(permission))
102
103 cleaned_data["required_permissions"] = permissions
104
105 return cleaned_data
106
107 def save(self):
108 obj = super(PermissionGroupForm, self).save()
109 obj.permissions = set(self.cleaned_data["required_permissions"])
110 obj.user_set = set(self.cleaned_data["members"])
111 return obj
112
113
114 class PermissionGroupEditView(CreateOrUpdateView):
115 model = PermissionGroup
116 form_class = PermissionGroupForm
117 template_name = "shuup/admin/permission_groups/edit.jinja"
118 context_object_name = "permission_group"
119 add_form_errors_as_messages = True
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/shuup/admin/modules/permission_groups/views/edit.py b/shuup/admin/modules/permission_groups/views/edit.py
--- a/shuup/admin/modules/permission_groups/views/edit.py
+++ b/shuup/admin/modules/permission_groups/views/edit.py
@@ -36,7 +36,8 @@
help_text=_(
"Select the modules that should be accessible by this permission group. "
"Modules with the same permissions as selected modules will be added automatically."
- )
+ ),
+ widget=forms.CheckboxSelectMultiple
)
initial_members = self._get_initial_members()
members_field = Select2MultipleField(
|
{"golden_diff": "diff --git a/shuup/admin/modules/permission_groups/views/edit.py b/shuup/admin/modules/permission_groups/views/edit.py\n--- a/shuup/admin/modules/permission_groups/views/edit.py\n+++ b/shuup/admin/modules/permission_groups/views/edit.py\n@@ -36,7 +36,8 @@\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n- )\n+ ),\n+ widget=forms.CheckboxSelectMultiple\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n", "issue": "Improve the way permissionas are managed in admin\nCurrently, use has to use a select2 component with a lot of options and this is super boring, tedious and time consuming. Can we use a list of check boxes instead?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2018, Shuup Inc. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom __future__ import unicode_literals\n\nfrom django import forms\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as PermissionGroup\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom shuup.admin.forms.fields import Select2MultipleField\nfrom shuup.admin.module_registry import get_modules\nfrom shuup.admin.utils.permissions import get_permission_object_from_string\nfrom shuup.admin.utils.views import CreateOrUpdateView\n\n\nclass PermissionGroupForm(forms.ModelForm):\n class Meta:\n model = PermissionGroup\n exclude = (\"permissions\",)\n\n def __init__(self, *args, **kwargs):\n super(PermissionGroupForm, self).__init__(*args, **kwargs)\n initial_permissions = self._get_initial_permissions()\n self.fields[\"name\"].help_text = _(\"The permission group name.\")\n self.fields[\"modules\"] = forms.MultipleChoiceField(\n choices=sorted(self._get_module_choices()),\n initial=self._get_enabled_modules(initial_permissions),\n required=False,\n label=_(\"Module Permissions\"),\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n )\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n model=get_user_model(),\n initial=[member.pk for member in initial_members],\n required=False,\n label=_(\"Members\"),\n help_text=_(\n \"Set the users that belong to this permission group.\"\n )\n )\n members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]\n self.fields[\"members\"] = members_field\n\n def _get_module_choices(self):\n return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != \"_Base_\")\n\n def _get_initial_members(self):\n if self.instance.pk:\n return self.instance.user_set.all()\n else:\n return []\n\n def _get_initial_permissions(self):\n permissions = set()\n if self.instance.pk:\n for perm in self.instance.permissions.all():\n name, module, _ = perm.natural_key()\n permissions.add(\"%s.%s\" % (module, name))\n return permissions\n\n def _get_enabled_modules(self, permissions):\n if not self.instance.pk:\n return []\n permissions = set(permissions)\n modules = []\n for module in get_modules():\n # Ignore modules that haven't configured a name\n if module.name != \"_Base_\" and set(module.get_required_permissions()).issubset(permissions):\n modules.append(force_text(module.name))\n return modules\n\n def _get_required_permissions(self, modules):\n permissions = set()\n for module in [m for m in get_modules() if m.name in modules]:\n permissions.update(set(module.get_required_permissions()))\n return permissions\n\n def clean_members(self):\n members = self.cleaned_data.get(\"members\", [])\n\n return get_user_model().objects.filter(pk__in=members).all()\n\n def clean(self):\n cleaned_data = super(PermissionGroupForm, self).clean()\n\n permissions = set()\n modules = cleaned_data.pop(\"modules\", [])\n required_permissions = self._get_required_permissions(modules)\n\n for permission in required_permissions:\n permissions.add(get_permission_object_from_string(permission))\n\n cleaned_data[\"required_permissions\"] = permissions\n\n return cleaned_data\n\n def save(self):\n obj = super(PermissionGroupForm, self).save()\n obj.permissions = set(self.cleaned_data[\"required_permissions\"])\n obj.user_set = set(self.cleaned_data[\"members\"])\n return obj\n\n\nclass PermissionGroupEditView(CreateOrUpdateView):\n model = PermissionGroup\n form_class = PermissionGroupForm\n template_name = \"shuup/admin/permission_groups/edit.jinja\"\n context_object_name = \"permission_group\"\n add_form_errors_as_messages = True\n", "path": "shuup/admin/modules/permission_groups/views/edit.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2018, Shuup Inc. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom __future__ import unicode_literals\n\nfrom django import forms\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.models import Group as PermissionGroup\nfrom django.utils.encoding import force_text\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom shuup.admin.forms.fields import Select2MultipleField\nfrom shuup.admin.module_registry import get_modules\nfrom shuup.admin.utils.permissions import get_permission_object_from_string\nfrom shuup.admin.utils.views import CreateOrUpdateView\n\n\nclass PermissionGroupForm(forms.ModelForm):\n class Meta:\n model = PermissionGroup\n exclude = (\"permissions\",)\n\n def __init__(self, *args, **kwargs):\n super(PermissionGroupForm, self).__init__(*args, **kwargs)\n initial_permissions = self._get_initial_permissions()\n self.fields[\"name\"].help_text = _(\"The permission group name.\")\n self.fields[\"modules\"] = forms.MultipleChoiceField(\n choices=sorted(self._get_module_choices()),\n initial=self._get_enabled_modules(initial_permissions),\n required=False,\n label=_(\"Module Permissions\"),\n help_text=_(\n \"Select the modules that should be accessible by this permission group. \"\n \"Modules with the same permissions as selected modules will be added automatically.\"\n ),\n widget=forms.CheckboxSelectMultiple\n )\n initial_members = self._get_initial_members()\n members_field = Select2MultipleField(\n model=get_user_model(),\n initial=[member.pk for member in initial_members],\n required=False,\n label=_(\"Members\"),\n help_text=_(\n \"Set the users that belong to this permission group.\"\n )\n )\n members_field.widget.choices = [(member.pk, force_text(member)) for member in initial_members]\n self.fields[\"members\"] = members_field\n\n def _get_module_choices(self):\n return set((force_text(m.name), force_text(m.name)) for m in get_modules() if m.name != \"_Base_\")\n\n def _get_initial_members(self):\n if self.instance.pk:\n return self.instance.user_set.all()\n else:\n return []\n\n def _get_initial_permissions(self):\n permissions = set()\n if self.instance.pk:\n for perm in self.instance.permissions.all():\n name, module, _ = perm.natural_key()\n permissions.add(\"%s.%s\" % (module, name))\n return permissions\n\n def _get_enabled_modules(self, permissions):\n if not self.instance.pk:\n return []\n permissions = set(permissions)\n modules = []\n for module in get_modules():\n # Ignore modules that haven't configured a name\n if module.name != \"_Base_\" and set(module.get_required_permissions()).issubset(permissions):\n modules.append(force_text(module.name))\n return modules\n\n def _get_required_permissions(self, modules):\n permissions = set()\n for module in [m for m in get_modules() if m.name in modules]:\n permissions.update(set(module.get_required_permissions()))\n return permissions\n\n def clean_members(self):\n members = self.cleaned_data.get(\"members\", [])\n\n return get_user_model().objects.filter(pk__in=members).all()\n\n def clean(self):\n cleaned_data = super(PermissionGroupForm, self).clean()\n\n permissions = set()\n modules = cleaned_data.pop(\"modules\", [])\n required_permissions = self._get_required_permissions(modules)\n\n for permission in required_permissions:\n permissions.add(get_permission_object_from_string(permission))\n\n cleaned_data[\"required_permissions\"] = permissions\n\n return cleaned_data\n\n def save(self):\n obj = super(PermissionGroupForm, self).save()\n obj.permissions = set(self.cleaned_data[\"required_permissions\"])\n obj.user_set = set(self.cleaned_data[\"members\"])\n return obj\n\n\nclass PermissionGroupEditView(CreateOrUpdateView):\n model = PermissionGroup\n form_class = PermissionGroupForm\n template_name = \"shuup/admin/permission_groups/edit.jinja\"\n context_object_name = \"permission_group\"\n add_form_errors_as_messages = True\n", "path": "shuup/admin/modules/permission_groups/views/edit.py"}]}
| 1,481 | 139 |
gh_patches_debug_16131
|
rasdani/github-patches
|
git_diff
|
mabel-dev__opteryx-1593
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
🪲 random appears to be evaluated once
was seeing what happens for opteryx for https://buttondown.email/jaffray/archive/the-case-of-a-curious-sql-query/
~~~sql
SELECT count(*)
FROM GENERATE_SERIES(1000) AS one_thousand
CROSS JOIN GENERATE_SERIES(1000) AS one_thousand_b
WHERE random() < 0.5
~~~
~~~
AFTER COST OPTIMIZATION
└─ EXIT
└─ PROJECT (COUNT(*))
└─ AGGREGATE (COUNT(*))
└─ FILTER (False)
└─ CROSS JOIN
├─ GENERATE SERIES (1000) AS one_thousand
└─ GENERATE SERIES (1000) AS one_thousand_b
~~~
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opteryx/components/cost_based_optimizer/strategies/constant_folding.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import datetime
14 from typing import Any
15
16 import numpy
17 from orso.types import OrsoTypes
18
19 from opteryx.components.logical_planner import LogicalPlan
20 from opteryx.components.logical_planner import LogicalPlanNode
21 from opteryx.components.logical_planner import LogicalPlanStepType
22 from opteryx.managers.expression import NodeType
23 from opteryx.managers.expression import evaluate
24 from opteryx.managers.expression import get_all_nodes_of_type
25 from opteryx.models import Node
26 from opteryx.virtual_datasets import no_table_data
27
28 from .optimization_strategy import OptimizationStrategy
29 from .optimization_strategy import OptimizerContext
30
31
32 def build_literal_node(value: Any, root: Node):
33 # fmt:off
34 if hasattr(value, "as_py"):
35 value = value.as_py()
36
37 root.value = value
38 root.node_type = NodeType.LITERAL
39 if value is None:
40 root.type=OrsoTypes.NULL
41 elif isinstance(value, (bool, numpy.bool_)):
42 # boolean must be before numeric
43 root.type=OrsoTypes.BOOLEAN
44 elif isinstance(value, (str)):
45 root.type=OrsoTypes.VARCHAR
46 elif isinstance(value, (int, numpy.int64)):
47 root.type=OrsoTypes.INTEGER
48 elif isinstance(value, (numpy.datetime64, datetime.datetime)):
49 root.type=OrsoTypes.TIMESTAMP
50 elif isinstance(value, (datetime.date)):
51 root.type=OrsoTypes.DATE
52 else:
53 raise Exception("Unable to fold expression")
54 return root
55 # fmt:on
56
57
58 def fold_constants(root: Node) -> Node:
59 identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))
60 if len(identifiers) == 0:
61 table = no_table_data.read()
62 try:
63 result = evaluate(root, table, None)[0]
64 return build_literal_node(result, root)
65 except Exception as err: # nosec
66 # what ever the reason, just skip
67 # DEBUG:log (err)
68 pass
69 return root
70
71
72 class ConstantFoldingStrategy(OptimizationStrategy):
73 def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:
74 """
75 Constant Folding is when we precalculate expressions (or sub expressions)
76 which contain only constant or literal values.
77 """
78 if not context.optimized_plan:
79 context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore
80
81 if node.node_type == LogicalPlanStepType.Filter:
82 node.condition = fold_constants(node.condition)
83 if node.condition.node_type == NodeType.LITERAL and node.condition.value:
84 context.optimized_plan.remove_node(context.node_id, heal=True)
85 else:
86 context.optimized_plan[context.node_id] = node
87
88 return context
89
90 def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:
91 # No finalization needed for this strategy
92 return plan
93
```
Path: `opteryx/__version__.py`
Content:
```
1 __build__ = 430
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Store the version here so:
17 1) we don't load dependencies by storing it in __init__.py
18 2) we can import it in setup.py for the same reason
19 """
20 from enum import Enum # isort: skip
21
22
23 class VersionStatus(Enum):
24 ALPHA = "alpha"
25 BETA = "beta"
26 RELEASE = "release"
27
28
29 _major = 0
30 _minor = 14
31 _revision = 2
32 _status = VersionStatus.ALPHA
33
34 __author__ = "@joocer"
35 __version__ = f"{_major}.{_minor}.{_revision}" + (
36 f"-{_status.value}.{__build__}" if _status != VersionStatus.RELEASE else ""
37 )
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opteryx/__version__.py b/opteryx/__version__.py
--- a/opteryx/__version__.py
+++ b/opteryx/__version__.py
@@ -1,4 +1,4 @@
-__build__ = 430
+__build__ = 432
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
diff --git a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
--- a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
+++ b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py
@@ -57,6 +57,11 @@
def fold_constants(root: Node) -> Node:
identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))
+ functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))
+
+ if any(func.value in {"RANDOM", "RAND", "NORMAL", "RANDOM_STRING"} for func in functions):
+ return root
+
if len(identifiers) == 0:
table = no_table_data.read()
try:
|
{"golden_diff": "diff --git a/opteryx/__version__.py b/opteryx/__version__.py\n--- a/opteryx/__version__.py\n+++ b/opteryx/__version__.py\n@@ -1,4 +1,4 @@\n-__build__ = 430\n+__build__ = 432\n \n # Licensed under the Apache License, Version 2.0 (the \"License\");\n # you may not use this file except in compliance with the License.\ndiff --git a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n--- a/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n+++ b/opteryx/components/cost_based_optimizer/strategies/constant_folding.py\n@@ -57,6 +57,11 @@\n \n def fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n+ functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))\n+\n+ if any(func.value in {\"RANDOM\", \"RAND\", \"NORMAL\", \"RANDOM_STRING\"} for func in functions):\n+ return root\n+\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n", "issue": "\ud83e\udeb2 random appears to be evaluated once\nwas seeing what happens for opteryx for https://buttondown.email/jaffray/archive/the-case-of-a-curious-sql-query/\r\n\r\n~~~sql\r\nSELECT count(*) \r\nFROM GENERATE_SERIES(1000) AS one_thousand \r\nCROSS JOIN GENERATE_SERIES(1000) AS one_thousand_b \r\nWHERE random() < 0.5\r\n~~~\r\n\r\n~~~\r\nAFTER COST OPTIMIZATION\r\n\u2514\u2500 EXIT\r\n \u2514\u2500 PROJECT (COUNT(*))\r\n \u2514\u2500 AGGREGATE (COUNT(*))\r\n \u2514\u2500 FILTER (False)\r\n \u2514\u2500 CROSS JOIN\r\n \u251c\u2500 GENERATE SERIES (1000) AS one_thousand\r\n \u2514\u2500 GENERATE SERIES (1000) AS one_thousand_b\r\n~~~\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport datetime\nfrom typing import Any\n\nimport numpy\nfrom orso.types import OrsoTypes\n\nfrom opteryx.components.logical_planner import LogicalPlan\nfrom opteryx.components.logical_planner import LogicalPlanNode\nfrom opteryx.components.logical_planner import LogicalPlanStepType\nfrom opteryx.managers.expression import NodeType\nfrom opteryx.managers.expression import evaluate\nfrom opteryx.managers.expression import get_all_nodes_of_type\nfrom opteryx.models import Node\nfrom opteryx.virtual_datasets import no_table_data\n\nfrom .optimization_strategy import OptimizationStrategy\nfrom .optimization_strategy import OptimizerContext\n\n\ndef build_literal_node(value: Any, root: Node):\n # fmt:off\n if hasattr(value, \"as_py\"):\n value = value.as_py()\n\n root.value = value\n root.node_type = NodeType.LITERAL\n if value is None:\n root.type=OrsoTypes.NULL\n elif isinstance(value, (bool, numpy.bool_)):\n # boolean must be before numeric\n root.type=OrsoTypes.BOOLEAN\n elif isinstance(value, (str)):\n root.type=OrsoTypes.VARCHAR\n elif isinstance(value, (int, numpy.int64)):\n root.type=OrsoTypes.INTEGER\n elif isinstance(value, (numpy.datetime64, datetime.datetime)):\n root.type=OrsoTypes.TIMESTAMP\n elif isinstance(value, (datetime.date)):\n root.type=OrsoTypes.DATE\n else:\n raise Exception(\"Unable to fold expression\")\n return root\n # fmt:on\n\n\ndef fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n result = evaluate(root, table, None)[0]\n return build_literal_node(result, root)\n except Exception as err: # nosec\n # what ever the reason, just skip\n # DEBUG:log (err)\n pass\n return root\n\n\nclass ConstantFoldingStrategy(OptimizationStrategy):\n def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:\n \"\"\"\n Constant Folding is when we precalculate expressions (or sub expressions)\n which contain only constant or literal values.\n \"\"\"\n if not context.optimized_plan:\n context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore\n\n if node.node_type == LogicalPlanStepType.Filter:\n node.condition = fold_constants(node.condition)\n if node.condition.node_type == NodeType.LITERAL and node.condition.value:\n context.optimized_plan.remove_node(context.node_id, heal=True)\n else:\n context.optimized_plan[context.node_id] = node\n\n return context\n\n def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:\n # No finalization needed for this strategy\n return plan\n", "path": "opteryx/components/cost_based_optimizer/strategies/constant_folding.py"}, {"content": "__build__ = 430\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 2\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport datetime\nfrom typing import Any\n\nimport numpy\nfrom orso.types import OrsoTypes\n\nfrom opteryx.components.logical_planner import LogicalPlan\nfrom opteryx.components.logical_planner import LogicalPlanNode\nfrom opteryx.components.logical_planner import LogicalPlanStepType\nfrom opteryx.managers.expression import NodeType\nfrom opteryx.managers.expression import evaluate\nfrom opteryx.managers.expression import get_all_nodes_of_type\nfrom opteryx.models import Node\nfrom opteryx.virtual_datasets import no_table_data\n\nfrom .optimization_strategy import OptimizationStrategy\nfrom .optimization_strategy import OptimizerContext\n\n\ndef build_literal_node(value: Any, root: Node):\n # fmt:off\n if hasattr(value, \"as_py\"):\n value = value.as_py()\n\n root.value = value\n root.node_type = NodeType.LITERAL\n if value is None:\n root.type=OrsoTypes.NULL\n elif isinstance(value, (bool, numpy.bool_)):\n # boolean must be before numeric\n root.type=OrsoTypes.BOOLEAN\n elif isinstance(value, (str)):\n root.type=OrsoTypes.VARCHAR\n elif isinstance(value, (int, numpy.int64)):\n root.type=OrsoTypes.INTEGER\n elif isinstance(value, (numpy.datetime64, datetime.datetime)):\n root.type=OrsoTypes.TIMESTAMP\n elif isinstance(value, (datetime.date)):\n root.type=OrsoTypes.DATE\n else:\n raise Exception(\"Unable to fold expression\")\n return root\n # fmt:on\n\n\ndef fold_constants(root: Node) -> Node:\n identifiers = get_all_nodes_of_type(root, (NodeType.IDENTIFIER, NodeType.WILDCARD))\n functions = get_all_nodes_of_type(root, (NodeType.FUNCTION,))\n\n if any(func.value in {\"RANDOM\", \"RAND\", \"NORMAL\", \"RANDOM_STRING\"} for func in functions):\n return root\n\n if len(identifiers) == 0:\n table = no_table_data.read()\n try:\n result = evaluate(root, table, None)[0]\n return build_literal_node(result, root)\n except Exception as err: # nosec\n # what ever the reason, just skip\n # DEBUG:log (err)\n pass\n return root\n\n\nclass ConstantFoldingStrategy(OptimizationStrategy):\n def visit(self, node: LogicalPlanNode, context: OptimizerContext) -> OptimizerContext:\n \"\"\"\n Constant Folding is when we precalculate expressions (or sub expressions)\n which contain only constant or literal values.\n \"\"\"\n if not context.optimized_plan:\n context.optimized_plan = context.pre_optimized_tree.copy() # type: ignore\n\n if node.node_type == LogicalPlanStepType.Filter:\n node.condition = fold_constants(node.condition)\n if node.condition.node_type == NodeType.LITERAL and node.condition.value:\n context.optimized_plan.remove_node(context.node_id, heal=True)\n else:\n context.optimized_plan[context.node_id] = node\n\n return context\n\n def complete(self, plan: LogicalPlan, context: OptimizerContext) -> LogicalPlan:\n # No finalization needed for this strategy\n return plan\n", "path": "opteryx/components/cost_based_optimizer/strategies/constant_folding.py"}, {"content": "__build__ = 432\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nStore the version here so:\n1) we don't load dependencies by storing it in __init__.py\n2) we can import it in setup.py for the same reason\n\"\"\"\nfrom enum import Enum # isort: skip\n\n\nclass VersionStatus(Enum):\n ALPHA = \"alpha\"\n BETA = \"beta\"\n RELEASE = \"release\"\n\n\n_major = 0\n_minor = 14\n_revision = 2\n_status = VersionStatus.ALPHA\n\n__author__ = \"@joocer\"\n__version__ = f\"{_major}.{_minor}.{_revision}\" + (\n f\"-{_status.value}.{__build__}\" if _status != VersionStatus.RELEASE else \"\"\n)\n", "path": "opteryx/__version__.py"}]}
| 1,759 | 292 |
gh_patches_debug_9645
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-2343
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
WPS472 only detecting one pure variable assignment
### What's wrong
WPS472 detects `name, *_ = get_address()`.
When it comes to slightly more complex value assignments, it does not work:
1. `names[0], *_ = get_address()`
2. `self.name, *_ = get_address()`
3. `(name, street), *_ = get_address()`
Also when extracting a second (or more values) the detection fails:
1. `name, street, *_ = get_address()`
2. `name, _, city, *_ = get_address()`
3. `name, _, self.city, *_ = get_address()`
### How it should be
It would be nice if all of the examples would also be detected as WPS472 violations.
### Flake8 version and plugins
{
"dependencies": [],
"platform": {
"python_implementation": "CPython",
"python_version": "3.9.6",
"system": "Darwin"
},
"plugins": [
{
"is_local": false,
"plugin": "flake8-bandit",
"version": "2.1.2"
},
{
"is_local": false,
"plugin": "flake8-broken-line",
"version": "0.3.0"
},
{
"is_local": false,
"plugin": "flake8-bugbear",
"version": "20.11.1"
},
{
"is_local": false,
"plugin": "flake8-comprehensions",
"version": "3.4.0"
},
{
"is_local": false,
"plugin": "flake8-darglint",
"version": "1.8.0"
},
{
"is_local": false,
"plugin": "flake8-debugger",
"version": "4.0.0"
},
{
"is_local": false,
"plugin": "flake8-docstrings",
"version": "1.6.0, pydocstyle: 6.0.0"
},
{
"is_local": false,
"plugin": "flake8-eradicate",
"version": "1.0.0"
},
{
"is_local": false,
"plugin": "flake8-string-format",
"version": "0.3.0"
},
{
"is_local": false,
"plugin": "flake8.datetimez",
"version": "20.10.0"
},
{
"is_local": false,
"plugin": "flake8_commas",
"version": "2.0.0"
},
{
"is_local": false,
"plugin": "flake8_isort",
"version": "4.0.0"
},
{
"is_local": false,
"plugin": "flake8_quotes",
"version": "3.2.0"
},
{
"is_local": false,
"plugin": "mccabe",
"version": "0.6.1"
},
{
"is_local": false,
"plugin": "naming",
"version": "0.11.1"
},
{
"is_local": false,
"plugin": "pycodestyle",
"version": "2.7.0"
},
{
"is_local": false,
"plugin": "pyflakes",
"version": "2.3.0"
},
{
"is_local": false,
"plugin": "rst-docstrings",
"version": "0.2.3"
},
{
"is_local": false,
"plugin": "wemake_python_styleguide",
"version": "0.16.0"
}
],
"version": "3.9.2"
}
### pip information
pip 21.3.1
### OS information
macOS Monterey
Version 12.0.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wemake_python_styleguide/logic/tree/variables.py`
Content:
```
1 import ast
2 from typing import List, Union
3
4 from wemake_python_styleguide.logic import nodes
5 from wemake_python_styleguide.logic.naming import access
6
7 _VarDefinition = Union[ast.AST, ast.expr]
8 _LocalVariable = Union[ast.Name, ast.ExceptHandler]
9
10
11 def get_variable_name(node: _LocalVariable) -> str:
12 """Used to get variable names from all definitions."""
13 if isinstance(node, ast.Name):
14 return node.id
15 return getattr(node, 'name', '')
16
17
18 def does_shadow_builtin(node: ast.AST) -> bool:
19 """
20 We allow attributes and class-level builtin overrides.
21
22 Like: ``self.list = []`` or ``def map(self, function):``
23
24 Why?
25 Because they cannot harm you since they do not shadow the real builtin.
26 """
27 return (
28 not isinstance(node, ast.Attribute) and
29 not isinstance(nodes.get_context(node), ast.ClassDef)
30 )
31
32
33 def is_valid_block_variable_definition(node: _VarDefinition) -> bool:
34 """Is used to check either block variables are correctly defined."""
35 if isinstance(node, ast.Tuple):
36 return all(
37 is_valid_block_variable_definition(var_definition)
38 for var_definition in node.elts
39 )
40 return _is_valid_single(node)
41
42
43 def is_valid_unpacking_target(target: ast.expr) -> bool:
44 """Checks if unpacking target is correct."""
45 if isinstance(target, ast.Tuple):
46 return all(
47 _is_valid_single(element)
48 for element in target.elts
49 )
50 return _is_valid_single(target)
51
52
53 def _is_valid_single(node: _VarDefinition) -> bool:
54 return (
55 isinstance(node, ast.Name) or
56 isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)
57 )
58
59
60 def is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:
61 """Checks if unpacking targets used to get first or last element."""
62 if len(targets) != 2:
63 return False
64 first_item = (
65 isinstance(targets[0], ast.Name) and
66 isinstance(targets[1], ast.Starred) and
67 _is_unused_variable_name(targets[1].value)
68 )
69 last_item = (
70 isinstance(targets[1], ast.Name) and
71 isinstance(targets[0], ast.Starred) and
72 _is_unused_variable_name(targets[0].value)
73 )
74 return first_item or last_item
75
76
77 def _is_unused_variable_name(node: ast.expr) -> bool:
78 return isinstance(node, ast.Name) and access.looks_like_unused(node.id)
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wemake_python_styleguide/logic/tree/variables.py b/wemake_python_styleguide/logic/tree/variables.py
--- a/wemake_python_styleguide/logic/tree/variables.py
+++ b/wemake_python_styleguide/logic/tree/variables.py
@@ -62,12 +62,10 @@
if len(targets) != 2:
return False
first_item = (
- isinstance(targets[0], ast.Name) and
isinstance(targets[1], ast.Starred) and
_is_unused_variable_name(targets[1].value)
)
last_item = (
- isinstance(targets[1], ast.Name) and
isinstance(targets[0], ast.Starred) and
_is_unused_variable_name(targets[0].value)
)
|
{"golden_diff": "diff --git a/wemake_python_styleguide/logic/tree/variables.py b/wemake_python_styleguide/logic/tree/variables.py\n--- a/wemake_python_styleguide/logic/tree/variables.py\n+++ b/wemake_python_styleguide/logic/tree/variables.py\n@@ -62,12 +62,10 @@\n if len(targets) != 2:\n return False\n first_item = (\n- isinstance(targets[0], ast.Name) and\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n- isinstance(targets[1], ast.Name) and\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n", "issue": "WPS472 only detecting one pure variable assignment\n### What's wrong\r\n\r\nWPS472 detects `name, *_ = get_address()`. \r\nWhen it comes to slightly more complex value assignments, it does not work:\r\n1. `names[0], *_ = get_address()` \r\n2. `self.name, *_ = get_address()`\r\n3. `(name, street), *_ = get_address()`\r\n\r\nAlso when extracting a second (or more values) the detection fails:\r\n1. `name, street, *_ = get_address()`\r\n2. `name, _, city, *_ = get_address()`\r\n3. `name, _, self.city, *_ = get_address()`\r\n\r\n### How it should be\r\n\r\nIt would be nice if all of the examples would also be detected as WPS472 violations.\r\n\r\n### Flake8 version and plugins\r\n\r\n{\r\n \"dependencies\": [],\r\n \"platform\": {\r\n \"python_implementation\": \"CPython\",\r\n \"python_version\": \"3.9.6\",\r\n \"system\": \"Darwin\"\r\n },\r\n \"plugins\": [\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-bandit\",\r\n \"version\": \"2.1.2\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-broken-line\",\r\n \"version\": \"0.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-bugbear\",\r\n \"version\": \"20.11.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-comprehensions\",\r\n \"version\": \"3.4.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-darglint\",\r\n \"version\": \"1.8.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-debugger\",\r\n \"version\": \"4.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-docstrings\",\r\n \"version\": \"1.6.0, pydocstyle: 6.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-eradicate\",\r\n \"version\": \"1.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8-string-format\",\r\n \"version\": \"0.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8.datetimez\",\r\n \"version\": \"20.10.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_commas\",\r\n \"version\": \"2.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_isort\",\r\n \"version\": \"4.0.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"flake8_quotes\",\r\n \"version\": \"3.2.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"mccabe\",\r\n \"version\": \"0.6.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"naming\",\r\n \"version\": \"0.11.1\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"pycodestyle\",\r\n \"version\": \"2.7.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"pyflakes\",\r\n \"version\": \"2.3.0\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"rst-docstrings\",\r\n \"version\": \"0.2.3\"\r\n },\r\n {\r\n \"is_local\": false,\r\n \"plugin\": \"wemake_python_styleguide\",\r\n \"version\": \"0.16.0\"\r\n }\r\n ],\r\n \"version\": \"3.9.2\"\r\n}\r\n\r\n### pip information\r\n\r\npip 21.3.1\r\n\r\n### OS information\r\n\r\nmacOS Monterey\r\nVersion 12.0.1\n", "before_files": [{"content": "import ast\nfrom typing import List, Union\n\nfrom wemake_python_styleguide.logic import nodes\nfrom wemake_python_styleguide.logic.naming import access\n\n_VarDefinition = Union[ast.AST, ast.expr]\n_LocalVariable = Union[ast.Name, ast.ExceptHandler]\n\n\ndef get_variable_name(node: _LocalVariable) -> str:\n \"\"\"Used to get variable names from all definitions.\"\"\"\n if isinstance(node, ast.Name):\n return node.id\n return getattr(node, 'name', '')\n\n\ndef does_shadow_builtin(node: ast.AST) -> bool:\n \"\"\"\n We allow attributes and class-level builtin overrides.\n\n Like: ``self.list = []`` or ``def map(self, function):``\n\n Why?\n Because they cannot harm you since they do not shadow the real builtin.\n \"\"\"\n return (\n not isinstance(node, ast.Attribute) and\n not isinstance(nodes.get_context(node), ast.ClassDef)\n )\n\n\ndef is_valid_block_variable_definition(node: _VarDefinition) -> bool:\n \"\"\"Is used to check either block variables are correctly defined.\"\"\"\n if isinstance(node, ast.Tuple):\n return all(\n is_valid_block_variable_definition(var_definition)\n for var_definition in node.elts\n )\n return _is_valid_single(node)\n\n\ndef is_valid_unpacking_target(target: ast.expr) -> bool:\n \"\"\"Checks if unpacking target is correct.\"\"\"\n if isinstance(target, ast.Tuple):\n return all(\n _is_valid_single(element)\n for element in target.elts\n )\n return _is_valid_single(target)\n\n\ndef _is_valid_single(node: _VarDefinition) -> bool:\n return (\n isinstance(node, ast.Name) or\n isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)\n )\n\n\ndef is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:\n \"\"\"Checks if unpacking targets used to get first or last element.\"\"\"\n if len(targets) != 2:\n return False\n first_item = (\n isinstance(targets[0], ast.Name) and\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n isinstance(targets[1], ast.Name) and\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n return first_item or last_item\n\n\ndef _is_unused_variable_name(node: ast.expr) -> bool:\n return isinstance(node, ast.Name) and access.looks_like_unused(node.id)\n", "path": "wemake_python_styleguide/logic/tree/variables.py"}], "after_files": [{"content": "import ast\nfrom typing import List, Union\n\nfrom wemake_python_styleguide.logic import nodes\nfrom wemake_python_styleguide.logic.naming import access\n\n_VarDefinition = Union[ast.AST, ast.expr]\n_LocalVariable = Union[ast.Name, ast.ExceptHandler]\n\n\ndef get_variable_name(node: _LocalVariable) -> str:\n \"\"\"Used to get variable names from all definitions.\"\"\"\n if isinstance(node, ast.Name):\n return node.id\n return getattr(node, 'name', '')\n\n\ndef does_shadow_builtin(node: ast.AST) -> bool:\n \"\"\"\n We allow attributes and class-level builtin overrides.\n\n Like: ``self.list = []`` or ``def map(self, function):``\n\n Why?\n Because they cannot harm you since they do not shadow the real builtin.\n \"\"\"\n return (\n not isinstance(node, ast.Attribute) and\n not isinstance(nodes.get_context(node), ast.ClassDef)\n )\n\n\ndef is_valid_block_variable_definition(node: _VarDefinition) -> bool:\n \"\"\"Is used to check either block variables are correctly defined.\"\"\"\n if isinstance(node, ast.Tuple):\n return all(\n is_valid_block_variable_definition(var_definition)\n for var_definition in node.elts\n )\n return _is_valid_single(node)\n\n\ndef is_valid_unpacking_target(target: ast.expr) -> bool:\n \"\"\"Checks if unpacking target is correct.\"\"\"\n if isinstance(target, ast.Tuple):\n return all(\n _is_valid_single(element)\n for element in target.elts\n )\n return _is_valid_single(target)\n\n\ndef _is_valid_single(node: _VarDefinition) -> bool:\n return (\n isinstance(node, ast.Name) or\n isinstance(node, ast.Starred) and isinstance(node.value, ast.Name)\n )\n\n\ndef is_getting_element_by_unpacking(targets: List[ast.expr]) -> bool:\n \"\"\"Checks if unpacking targets used to get first or last element.\"\"\"\n if len(targets) != 2:\n return False\n first_item = (\n isinstance(targets[1], ast.Starred) and\n _is_unused_variable_name(targets[1].value)\n )\n last_item = (\n isinstance(targets[0], ast.Starred) and\n _is_unused_variable_name(targets[0].value)\n )\n return first_item or last_item\n\n\ndef _is_unused_variable_name(node: ast.expr) -> bool:\n return isinstance(node, ast.Name) and access.looks_like_unused(node.id)\n", "path": "wemake_python_styleguide/logic/tree/variables.py"}]}
| 1,871 | 175 |
gh_patches_debug_24667
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2665
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Implement product types section in dashboard
Blocked by #2679
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/core/__init__.py`
Content:
```
1 from django.conf import settings
2 from django.core.checks import Warning, register
3 from django.utils.translation import pgettext_lazy
4
5 TOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'
6 '-[0-9a-z]{12})')
7
8
9 @register()
10 def check_session_caching(app_configs, **kwargs): # pragma: no cover
11 errors = []
12 cached_engines = {
13 'django.contrib.sessions.backends.cache',
14 'django.contrib.sessions.backends.cached_db'}
15 if ('locmem' in settings.CACHES['default']['BACKEND'] and
16 settings.SESSION_ENGINE in cached_engines):
17 errors.append(
18 Warning(
19 'Session caching cannot work with locmem backend',
20 'User sessions need to be globally shared, use a cache server'
21 ' like Redis.',
22 'saleor.W001'))
23 return errors
24
25
26 class TaxRateType:
27 ACCOMODATION = 'accomodation'
28 ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'
29 ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'
30 ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'
31 ADVERTISING = 'advertising'
32 AGRICULTURAL_SUPPLIES = 'agricultural supplies'
33 BABY_FOODSTUFFS = 'baby foodstuffs'
34 BIKES = 'bikes'
35 BOOKS = 'books'
36 CHILDRENDS_CLOTHING = 'childrens clothing'
37 DOMESTIC_FUEL = 'domestic fuel'
38 DOMESTIC_SERVICES = 'domestic services'
39 E_BOOKS = 'e-books'
40 FOODSTUFFS = 'foodstuffs'
41 HOTELS = 'hotels'
42 MEDICAL = 'medical'
43 NEWSPAPERS = 'newspapers'
44 PASSENGER_TRANSPORT = 'passenger transport'
45 PHARMACEUTICALS = 'pharmaceuticals'
46 PROPERTY_RENOVATIONS = 'property renovations'
47 RESTAURANTS = 'restaurants'
48 SOCIAL_HOUSING = 'social housing'
49 STANDARD = 'standard'
50 WATER = 'water'
51 WINE = 'wine'
52
53 CHOICES = (
54 (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),
55 (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(
56 'VAT rate type', 'admission to cultural events')),
57 (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(
58 'VAT rate type', 'admission to entertainment events')),
59 (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(
60 'VAT rate type', 'admission to sporting events')),
61 (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),
62 (AGRICULTURAL_SUPPLIES, pgettext_lazy(
63 'VAT rate type', 'agricultural supplies')),
64 (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),
65 (BIKES, pgettext_lazy('VAT rate type', 'bikes')),
66 (BOOKS, pgettext_lazy('VAT rate type', 'books')),
67 (CHILDRENDS_CLOTHING, pgettext_lazy(
68 'VAT rate type', 'childrens clothing')),
69 (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),
70 (DOMESTIC_SERVICES, pgettext_lazy(
71 'VAT rate type', 'domestic services')),
72 (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),
73 (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),
74 (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),
75 (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),
76 (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),
77 (PASSENGER_TRANSPORT, pgettext_lazy(
78 'VAT rate type', 'passenger transport')),
79 (PHARMACEUTICALS, pgettext_lazy(
80 'VAT rate type', 'pharmaceuticals')),
81 (PROPERTY_RENOVATIONS, pgettext_lazy(
82 'VAT rate type', 'property renovations')),
83 (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),
84 (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),
85 (STANDARD, pgettext_lazy('VAT rate type', 'standard')),
86 (WATER, pgettext_lazy('VAT rate type', 'water')))
87
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/saleor/core/__init__.py b/saleor/core/__init__.py
--- a/saleor/core/__init__.py
+++ b/saleor/core/__init__.py
@@ -26,7 +26,7 @@
class TaxRateType:
ACCOMODATION = 'accomodation'
ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'
- ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'
+ ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'
ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'
ADVERTISING = 'advertising'
AGRICULTURAL_SUPPLIES = 'agricultural supplies'
@@ -54,7 +54,7 @@
(ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),
(ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to cultural events')),
- (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(
+ (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to entertainment events')),
(ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(
'VAT rate type', 'admission to sporting events')),
|
{"golden_diff": "diff --git a/saleor/core/__init__.py b/saleor/core/__init__.py\n--- a/saleor/core/__init__.py\n+++ b/saleor/core/__init__.py\n@@ -26,7 +26,7 @@\n class TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n- ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'\n+ ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n@@ -54,7 +54,7 @@\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n- (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(\n+ (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n", "issue": "Implement product types section in dashboard\nBlocked by #2679 \n", "before_files": [{"content": "from django.conf import settings\nfrom django.core.checks import Warning, register\nfrom django.utils.translation import pgettext_lazy\n\nTOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'\n '-[0-9a-z]{12})')\n\n\n@register()\ndef check_session_caching(app_configs, **kwargs): # pragma: no cover\n errors = []\n cached_engines = {\n 'django.contrib.sessions.backends.cache',\n 'django.contrib.sessions.backends.cached_db'}\n if ('locmem' in settings.CACHES['default']['BACKEND'] and\n settings.SESSION_ENGINE in cached_engines):\n errors.append(\n Warning(\n 'Session caching cannot work with locmem backend',\n 'User sessions need to be globally shared, use a cache server'\n ' like Redis.',\n 'saleor.W001'))\n return errors\n\n\nclass TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n ADMISSION_TO_ENTERAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n BABY_FOODSTUFFS = 'baby foodstuffs'\n BIKES = 'bikes'\n BOOKS = 'books'\n CHILDRENDS_CLOTHING = 'childrens clothing'\n DOMESTIC_FUEL = 'domestic fuel'\n DOMESTIC_SERVICES = 'domestic services'\n E_BOOKS = 'e-books'\n FOODSTUFFS = 'foodstuffs'\n HOTELS = 'hotels'\n MEDICAL = 'medical'\n NEWSPAPERS = 'newspapers'\n PASSENGER_TRANSPORT = 'passenger transport'\n PHARMACEUTICALS = 'pharmaceuticals'\n PROPERTY_RENOVATIONS = 'property renovations'\n RESTAURANTS = 'restaurants'\n SOCIAL_HOUSING = 'social housing'\n STANDARD = 'standard'\n WATER = 'water'\n WINE = 'wine'\n\n CHOICES = (\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n (ADMISSION_TO_ENTERAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),\n (AGRICULTURAL_SUPPLIES, pgettext_lazy(\n 'VAT rate type', 'agricultural supplies')),\n (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),\n (BIKES, pgettext_lazy('VAT rate type', 'bikes')),\n (BOOKS, pgettext_lazy('VAT rate type', 'books')),\n (CHILDRENDS_CLOTHING, pgettext_lazy(\n 'VAT rate type', 'childrens clothing')),\n (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),\n (DOMESTIC_SERVICES, pgettext_lazy(\n 'VAT rate type', 'domestic services')),\n (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),\n (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),\n (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),\n (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),\n (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),\n (PASSENGER_TRANSPORT, pgettext_lazy(\n 'VAT rate type', 'passenger transport')),\n (PHARMACEUTICALS, pgettext_lazy(\n 'VAT rate type', 'pharmaceuticals')),\n (PROPERTY_RENOVATIONS, pgettext_lazy(\n 'VAT rate type', 'property renovations')),\n (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),\n (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),\n (STANDARD, pgettext_lazy('VAT rate type', 'standard')),\n (WATER, pgettext_lazy('VAT rate type', 'water')))\n", "path": "saleor/core/__init__.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.core.checks import Warning, register\nfrom django.utils.translation import pgettext_lazy\n\nTOKEN_PATTERN = ('(?P<token>[0-9a-z]{8}-[0-9a-z]{4}-[0-9a-z]{4}-[0-9a-z]{4}'\n '-[0-9a-z]{12})')\n\n\n@register()\ndef check_session_caching(app_configs, **kwargs): # pragma: no cover\n errors = []\n cached_engines = {\n 'django.contrib.sessions.backends.cache',\n 'django.contrib.sessions.backends.cached_db'}\n if ('locmem' in settings.CACHES['default']['BACKEND'] and\n settings.SESSION_ENGINE in cached_engines):\n errors.append(\n Warning(\n 'Session caching cannot work with locmem backend',\n 'User sessions need to be globally shared, use a cache server'\n ' like Redis.',\n 'saleor.W001'))\n return errors\n\n\nclass TaxRateType:\n ACCOMODATION = 'accomodation'\n ADMISSION_TO_CULTURAL_EVENTS = 'admission to cultural events'\n ADMISSION_TO_ENTERTAINMENT_EVENTS = 'admission to entertainment events'\n ADMISSION_TO_SPORTING_EVENTS = 'admission to sporting events'\n ADVERTISING = 'advertising'\n AGRICULTURAL_SUPPLIES = 'agricultural supplies'\n BABY_FOODSTUFFS = 'baby foodstuffs'\n BIKES = 'bikes'\n BOOKS = 'books'\n CHILDRENDS_CLOTHING = 'childrens clothing'\n DOMESTIC_FUEL = 'domestic fuel'\n DOMESTIC_SERVICES = 'domestic services'\n E_BOOKS = 'e-books'\n FOODSTUFFS = 'foodstuffs'\n HOTELS = 'hotels'\n MEDICAL = 'medical'\n NEWSPAPERS = 'newspapers'\n PASSENGER_TRANSPORT = 'passenger transport'\n PHARMACEUTICALS = 'pharmaceuticals'\n PROPERTY_RENOVATIONS = 'property renovations'\n RESTAURANTS = 'restaurants'\n SOCIAL_HOUSING = 'social housing'\n STANDARD = 'standard'\n WATER = 'water'\n WINE = 'wine'\n\n CHOICES = (\n (ACCOMODATION, pgettext_lazy('VAT rate type', 'accommodation')),\n (ADMISSION_TO_CULTURAL_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to cultural events')),\n (ADMISSION_TO_ENTERTAINMENT_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to entertainment events')),\n (ADMISSION_TO_SPORTING_EVENTS, pgettext_lazy(\n 'VAT rate type', 'admission to sporting events')),\n (ADVERTISING, pgettext_lazy('VAT rate type', 'advertising')),\n (AGRICULTURAL_SUPPLIES, pgettext_lazy(\n 'VAT rate type', 'agricultural supplies')),\n (BABY_FOODSTUFFS, pgettext_lazy('VAT rate type', 'baby foodstuffs')),\n (BIKES, pgettext_lazy('VAT rate type', 'bikes')),\n (BOOKS, pgettext_lazy('VAT rate type', 'books')),\n (CHILDRENDS_CLOTHING, pgettext_lazy(\n 'VAT rate type', 'childrens clothing')),\n (DOMESTIC_FUEL, pgettext_lazy('VAT rate type', 'domestic fuel')),\n (DOMESTIC_SERVICES, pgettext_lazy(\n 'VAT rate type', 'domestic services')),\n (E_BOOKS, pgettext_lazy('VAT rate type', 'e-books')),\n (FOODSTUFFS, pgettext_lazy('VAT rate type', 'foodstuffs')),\n (HOTELS, pgettext_lazy('VAT rate type', 'hotels')),\n (MEDICAL, pgettext_lazy('VAT rate type', 'medical')),\n (NEWSPAPERS, pgettext_lazy('VAT rate type', 'newspapers')),\n (PASSENGER_TRANSPORT, pgettext_lazy(\n 'VAT rate type', 'passenger transport')),\n (PHARMACEUTICALS, pgettext_lazy(\n 'VAT rate type', 'pharmaceuticals')),\n (PROPERTY_RENOVATIONS, pgettext_lazy(\n 'VAT rate type', 'property renovations')),\n (RESTAURANTS, pgettext_lazy('VAT rate type', 'restaurants')),\n (SOCIAL_HOUSING, pgettext_lazy('VAT rate type', 'social housing')),\n (STANDARD, pgettext_lazy('VAT rate type', 'standard')),\n (WATER, pgettext_lazy('VAT rate type', 'water')))\n", "path": "saleor/core/__init__.py"}]}
| 1,474 | 301 |
gh_patches_debug_34147
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-1410
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Comprehensive list of broken recipes
When working on https://github.com/kivy/python-for-android/pull/1401 I realised we still have some broken recipes in the tree at least for python3crystax.
Even though we don't want to have red builds for things that were already broken, we still want to have a clear status of what's broken and what's not.
Basically the idea is to try to compile every single recipes and add the broken ones in the ignore list (`BROKEN_RECIPES`) from #1401. That way we can track and fix them later on meanwhile keeping a green build.
I would like to address it in this task. Basically the output of the task should be a PR making the `BROKEN_RECIPES` list comprehensive. With bonus points for creating an issue per broken recipes :smile:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ci/constants.py`
Content:
```
1 from enum import Enum
2
3
4 class TargetPython(Enum):
5 python2 = 0
6 python3crystax = 1
7
8
9 # recipes that currently break the build
10 # a recipe could be broken for a target Python and not for the other,
11 # hence we're maintaining one list per Python target
12 BROKEN_RECIPES_PYTHON2 = set([])
13 BROKEN_RECIPES_PYTHON3_CRYSTAX = set([
14 # not yet python3crystax compatible
15 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',
16 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',
17 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',
18 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',
19 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',
20 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',
21 'zeroconf', 'zope',
22 # https://github.com/kivy/python-for-android/issues/550
23 'audiostream',
24 # enum34 is not compatible with Python 3.6 standard library
25 # https://stackoverflow.com/a/45716067/185510
26 'enum34',
27 # https://github.com/kivy/python-for-android/issues/1398
28 'ifaddrs',
29 # https://github.com/kivy/python-for-android/issues/1399
30 'libglob',
31 # cannot find -lcrystax
32 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',
33 # https://github.com/kivy/python-for-android/issues/1404
34 'cryptography',
35 # https://github.com/kivy/python-for-android/issues/1294
36 'ffmpeg', 'ffpyplayer',
37 # https://github.com/kivy/python-for-android/pull/1307 ?
38 'gevent',
39 'icu',
40 # https://github.com/kivy/python-for-android/issues/1354
41 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
42 'kivy',
43 # https://github.com/kivy/python-for-android/issues/1405
44 'libpq', 'psycopg2',
45 'netifaces',
46 # https://github.com/kivy/python-for-android/issues/1315 ?
47 'opencv',
48 'protobuf_cpp',
49 # most likely some setup in the Docker container, because it works in host
50 'pyjnius', 'pyopenal',
51 # SyntaxError: invalid syntax (Python2)
52 'storm',
53 'vlc',
54 ])
55 BROKEN_RECIPES = {
56 TargetPython.python2: BROKEN_RECIPES_PYTHON2,
57 TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,
58 }
59 # recipes that were already built will be skipped
60 CORE_RECIPES = set([
61 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',
62 'numpy', 'android', 'python2',
63 ])
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ci/constants.py b/ci/constants.py
--- a/ci/constants.py
+++ b/ci/constants.py
@@ -9,7 +9,57 @@
# recipes that currently break the build
# a recipe could be broken for a target Python and not for the other,
# hence we're maintaining one list per Python target
-BROKEN_RECIPES_PYTHON2 = set([])
+BROKEN_RECIPES_PYTHON2 = set([
+ # pythonhelpers.h:12:18: fatal error: string: No such file or directory
+ 'atom',
+ # https://github.com/kivy/python-for-android/issues/550
+ 'audiostream',
+ 'brokenrecipe',
+ # https://github.com/kivy/python-for-android/issues/1409
+ 'enaml',
+ 'evdev',
+ # distutils.errors.DistutilsError
+ # Could not find suitable distribution for Requirement.parse('cython')
+ 'ffpyplayer',
+ 'flask',
+ 'groestlcoin_hash',
+ 'hostpython3crystax',
+ # https://github.com/kivy/python-for-android/issues/1398
+ 'ifaddrs',
+ # https://github.com/kivy/python-for-android/issues/1354
+ 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
+ 'kiwisolver',
+ # system dependencies autoconf, libtool
+ 'libexpat',
+ 'libgeos',
+ # https://github.com/kivy/python-for-android/issues/1399
+ 'libglob',
+ # system dependencies cmake and compile error
+ 'libmysqlclient',
+ 'libsecp256k1',
+ 'libtribler',
+ # system dependencies gettext, pkg-config
+ 'libzbar',
+ 'ndghttpsclient',
+ 'm2crypto',
+ 'netifaces',
+ 'Pillow',
+ # https://github.com/kivy/python-for-android/issues/1405
+ 'psycopg2',
+ 'pygame',
+ # most likely some setup in the Docker container, because it works in host
+ 'pyjnius', 'pyopenal',
+ 'pyproj',
+ 'pysdl2',
+ 'pyzmq',
+ 'secp256k1',
+ 'shapely',
+ 'twisted',
+ 'vlc',
+ 'websocket-client',
+ 'zeroconf',
+ 'zope',
+])
BROKEN_RECIPES_PYTHON3_CRYSTAX = set([
# not yet python3crystax compatible
'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',
@@ -39,7 +89,8 @@
'icu',
# https://github.com/kivy/python-for-android/issues/1354
'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',
- 'kivy',
+ # system dependencies autoconf, libtool
+ 'libexpat',
# https://github.com/kivy/python-for-android/issues/1405
'libpq', 'psycopg2',
'netifaces',
|
{"golden_diff": "diff --git a/ci/constants.py b/ci/constants.py\n--- a/ci/constants.py\n+++ b/ci/constants.py\n@@ -9,7 +9,57 @@\n # recipes that currently break the build\n # a recipe could be broken for a target Python and not for the other,\n # hence we're maintaining one list per Python target\n-BROKEN_RECIPES_PYTHON2 = set([])\n+BROKEN_RECIPES_PYTHON2 = set([\n+ # pythonhelpers.h:12:18: fatal error: string: No such file or directory\n+ 'atom',\n+ # https://github.com/kivy/python-for-android/issues/550\n+ 'audiostream',\n+ 'brokenrecipe',\n+ # https://github.com/kivy/python-for-android/issues/1409\n+ 'enaml',\n+ 'evdev',\n+ # distutils.errors.DistutilsError\n+ # Could not find suitable distribution for Requirement.parse('cython')\n+ 'ffpyplayer',\n+ 'flask',\n+ 'groestlcoin_hash',\n+ 'hostpython3crystax',\n+ # https://github.com/kivy/python-for-android/issues/1398\n+ 'ifaddrs',\n+ # https://github.com/kivy/python-for-android/issues/1354\n+ 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n+ 'kiwisolver',\n+ # system dependencies autoconf, libtool\n+ 'libexpat',\n+ 'libgeos',\n+ # https://github.com/kivy/python-for-android/issues/1399\n+ 'libglob',\n+ # system dependencies cmake and compile error\n+ 'libmysqlclient',\n+ 'libsecp256k1',\n+ 'libtribler',\n+ # system dependencies gettext, pkg-config\n+ 'libzbar',\n+ 'ndghttpsclient',\n+ 'm2crypto',\n+ 'netifaces',\n+ 'Pillow',\n+ # https://github.com/kivy/python-for-android/issues/1405\n+ 'psycopg2',\n+ 'pygame',\n+ # most likely some setup in the Docker container, because it works in host\n+ 'pyjnius', 'pyopenal',\n+ 'pyproj',\n+ 'pysdl2',\n+ 'pyzmq',\n+ 'secp256k1',\n+ 'shapely',\n+ 'twisted',\n+ 'vlc',\n+ 'websocket-client',\n+ 'zeroconf',\n+ 'zope',\n+])\n BROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n@@ -39,7 +89,8 @@\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n- 'kivy',\n+ # system dependencies autoconf, libtool\n+ 'libexpat',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n", "issue": "Comprehensive list of broken recipes\nWhen working on https://github.com/kivy/python-for-android/pull/1401 I realised we still have some broken recipes in the tree at least for python3crystax.\r\nEven though we don't want to have red builds for things that were already broken, we still want to have a clear status of what's broken and what's not.\r\nBasically the idea is to try to compile every single recipes and add the broken ones in the ignore list (`BROKEN_RECIPES`) from #1401. That way we can track and fix them later on meanwhile keeping a green build.\r\nI would like to address it in this task. Basically the output of the task should be a PR making the `BROKEN_RECIPES` list comprehensive. With bonus points for creating an issue per broken recipes :smile: \r\n\n", "before_files": [{"content": "from enum import Enum\n\n\nclass TargetPython(Enum):\n python2 = 0\n python3crystax = 1\n\n\n# recipes that currently break the build\n# a recipe could be broken for a target Python and not for the other,\n# hence we're maintaining one list per Python target\nBROKEN_RECIPES_PYTHON2 = set([])\nBROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',\n 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',\n 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',\n 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',\n 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',\n 'zeroconf', 'zope',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n # enum34 is not compatible with Python 3.6 standard library\n # https://stackoverflow.com/a/45716067/185510\n 'enum34',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # cannot find -lcrystax\n 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',\n # https://github.com/kivy/python-for-android/issues/1404\n 'cryptography',\n # https://github.com/kivy/python-for-android/issues/1294\n 'ffmpeg', 'ffpyplayer',\n # https://github.com/kivy/python-for-android/pull/1307 ?\n 'gevent',\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n 'kivy',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n # https://github.com/kivy/python-for-android/issues/1315 ?\n 'opencv',\n 'protobuf_cpp',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n # SyntaxError: invalid syntax (Python2)\n 'storm',\n 'vlc',\n])\nBROKEN_RECIPES = {\n TargetPython.python2: BROKEN_RECIPES_PYTHON2,\n TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,\n}\n# recipes that were already built will be skipped\nCORE_RECIPES = set([\n 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',\n 'numpy', 'android', 'python2',\n])\n", "path": "ci/constants.py"}], "after_files": [{"content": "from enum import Enum\n\n\nclass TargetPython(Enum):\n python2 = 0\n python3crystax = 1\n\n\n# recipes that currently break the build\n# a recipe could be broken for a target Python and not for the other,\n# hence we're maintaining one list per Python target\nBROKEN_RECIPES_PYTHON2 = set([\n # pythonhelpers.h:12:18: fatal error: string: No such file or directory\n 'atom',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n 'brokenrecipe',\n # https://github.com/kivy/python-for-android/issues/1409\n 'enaml',\n 'evdev',\n # distutils.errors.DistutilsError\n # Could not find suitable distribution for Requirement.parse('cython')\n 'ffpyplayer',\n 'flask',\n 'groestlcoin_hash',\n 'hostpython3crystax',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n 'kiwisolver',\n # system dependencies autoconf, libtool\n 'libexpat',\n 'libgeos',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # system dependencies cmake and compile error\n 'libmysqlclient',\n 'libsecp256k1',\n 'libtribler',\n # system dependencies gettext, pkg-config\n 'libzbar',\n 'ndghttpsclient',\n 'm2crypto',\n 'netifaces',\n 'Pillow',\n # https://github.com/kivy/python-for-android/issues/1405\n 'psycopg2',\n 'pygame',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n 'pyproj',\n 'pysdl2',\n 'pyzmq',\n 'secp256k1',\n 'shapely',\n 'twisted',\n 'vlc',\n 'websocket-client',\n 'zeroconf',\n 'zope',\n])\nBROKEN_RECIPES_PYTHON3_CRYSTAX = set([\n # not yet python3crystax compatible\n 'apsw', 'atom', 'boost', 'brokenrecipe', 'cdecimal', 'cherrypy',\n 'coverage', 'dateutil', 'enaml', 'ethash', 'kiwisolver', 'libgeos',\n 'libnacl', 'libsodium', 'libtorrent', 'libtribler', 'libzbar', 'libzmq',\n 'm2crypto', 'mysqldb', 'ndghttpsclient', 'pil', 'pycrypto', 'pyethereum',\n 'pygame', 'pyleveldb', 'pyproj', 'pyzmq', 'regex', 'shapely',\n 'simple-crypt', 'twsisted', 'vispy', 'websocket-client', 'zbar',\n 'zeroconf', 'zope',\n # https://github.com/kivy/python-for-android/issues/550\n 'audiostream',\n # enum34 is not compatible with Python 3.6 standard library\n # https://stackoverflow.com/a/45716067/185510\n 'enum34',\n # https://github.com/kivy/python-for-android/issues/1398\n 'ifaddrs',\n # https://github.com/kivy/python-for-android/issues/1399\n 'libglob',\n # cannot find -lcrystax\n 'cffi', 'pycryptodome', 'pymuk', 'secp256k1',\n # https://github.com/kivy/python-for-android/issues/1404\n 'cryptography',\n # https://github.com/kivy/python-for-android/issues/1294\n 'ffmpeg', 'ffpyplayer',\n # https://github.com/kivy/python-for-android/pull/1307 ?\n 'gevent',\n 'icu',\n # https://github.com/kivy/python-for-android/issues/1354\n 'kivent_core', 'kivent_cymunk', 'kivent_particles', 'kivent_polygen',\n # system dependencies autoconf, libtool\n 'libexpat',\n # https://github.com/kivy/python-for-android/issues/1405\n 'libpq', 'psycopg2',\n 'netifaces',\n # https://github.com/kivy/python-for-android/issues/1315 ?\n 'opencv',\n 'protobuf_cpp',\n # most likely some setup in the Docker container, because it works in host\n 'pyjnius', 'pyopenal',\n # SyntaxError: invalid syntax (Python2)\n 'storm',\n 'vlc',\n])\nBROKEN_RECIPES = {\n TargetPython.python2: BROKEN_RECIPES_PYTHON2,\n TargetPython.python3crystax: BROKEN_RECIPES_PYTHON3_CRYSTAX,\n}\n# recipes that were already built will be skipped\nCORE_RECIPES = set([\n 'pyjnius', 'kivy', 'openssl', 'requests', 'sqlite3', 'setuptools',\n 'numpy', 'android', 'python2',\n])\n", "path": "ci/constants.py"}]}
| 1,312 | 752 |
gh_patches_debug_2654
|
rasdani/github-patches
|
git_diff
|
microsoft__nni-5155
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Unclear what extras to install: `import nni.retiarii.execution.api` fails due to missing `pytorch_lightning`
**Describe the issue**:
I want to use `nni.retiarii.execution.api` module. I've installed it as below:
```
Collecting nni>=2.3
Downloading nni-2.9-py3-none-manylinux1_x86_64.whl (56.0 MB)
```
**Environment**:
- NNI version: 2.9
- Python version: 3.8
**Log message**:
```
_________________ ERROR collecting test/3rd_party/test_nni.py __________________
ImportError while importing test module '/__w/ai4cl-tianshou/ai4cl-tianshou/test/3rd_party/test_nni.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
test/3rd_party/test_nni.py:8: in <module>
import nni.retiarii.execution.api
/usr/local/lib/python3.8/site-packages/nni/retiarii/__init__.py:4: in <module>
from .operation import Operation
/usr/local/lib/python3.8/site-packages/nni/retiarii/operation.py:6: in <module>
from nni.nas.execution.common.graph_op import *
/usr/local/lib/python3.8/site-packages/nni/nas/__init__.py:4: in <module>
from .execution import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/__init__.py:4: in <module>
from .api import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/api.py:9: in <module>
from nni.nas.execution.common import (
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/__init__.py:4: in <module>
from .engine import *
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/engine.py:7: in <module>
from .graph import Model, MetricData
/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/graph.py:18: in <module>
from nni.nas.evaluator import Evaluator
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/__init__.py:9: in <module>
shortcut_framework(__name__)
/usr/local/lib/python3.8/site-packages/nni/common/framework.py:93: in shortcut_framework
shortcut_module(current, '.' + get_default_framework(), current)
/usr/local/lib/python3.8/site-packages/nni/common/framework.py:83: in shortcut_module
mod = importlib.import_module(target, package)
/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/__init__.py:4: in <module>
from .lightning import *
/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/lightning.py:10: in <module>
import pytorch_lightning as pl
E ModuleNotFoundError: No module named 'pytorch_lightning'
```
**How to reproduce it?**:
```
pip install nni==2.9
python -c "import nni.retiarii.execution.api"
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nni/nas/evaluator/pytorch/__init__.py`
Content:
```
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 from .lightning import *
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nni/nas/evaluator/pytorch/__init__.py b/nni/nas/evaluator/pytorch/__init__.py
--- a/nni/nas/evaluator/pytorch/__init__.py
+++ b/nni/nas/evaluator/pytorch/__init__.py
@@ -1,4 +1,11 @@
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
-from .lightning import *
+import warnings
+
+try:
+ from .lightning import *
+except ImportError:
+ warnings.warn("PyTorch-Lightning must be installed to use PyTorch in NAS. "
+ "If you are not using PyTorch, please `nni.set_default_framework('none')`")
+ raise
|
{"golden_diff": "diff --git a/nni/nas/evaluator/pytorch/__init__.py b/nni/nas/evaluator/pytorch/__init__.py\n--- a/nni/nas/evaluator/pytorch/__init__.py\n+++ b/nni/nas/evaluator/pytorch/__init__.py\n@@ -1,4 +1,11 @@\n # Copyright (c) Microsoft Corporation.\n # Licensed under the MIT license.\n \n-from .lightning import *\n+import warnings\n+\n+try:\n+ from .lightning import *\n+except ImportError:\n+ warnings.warn(\"PyTorch-Lightning must be installed to use PyTorch in NAS. \"\n+ \"If you are not using PyTorch, please `nni.set_default_framework('none')`\")\n+ raise\n", "issue": "Unclear what extras to install: `import nni.retiarii.execution.api` fails due to missing `pytorch_lightning`\n**Describe the issue**:\r\nI want to use `nni.retiarii.execution.api` module. I've installed it as below:\r\n```\r\nCollecting nni>=2.3\r\n Downloading nni-2.9-py3-none-manylinux1_x86_64.whl (56.0 MB)\r\n```\r\n\r\n**Environment**:\r\n- NNI version: 2.9\r\n- Python version: 3.8\r\n\r\n**Log message**:\r\n```\r\n_________________ ERROR collecting test/3rd_party/test_nni.py __________________\r\nImportError while importing test module '/__w/ai4cl-tianshou/ai4cl-tianshou/test/3rd_party/test_nni.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\n/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\ntest/3rd_party/test_nni.py:8: in <module>\r\n import nni.retiarii.execution.api\r\n/usr/local/lib/python3.8/site-packages/nni/retiarii/__init__.py:4: in <module>\r\n from .operation import Operation\r\n/usr/local/lib/python3.8/site-packages/nni/retiarii/operation.py:6: in <module>\r\n from nni.nas.execution.common.graph_op import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/__init__.py:4: in <module>\r\n from .execution import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/__init__.py:4: in <module>\r\n from .api import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/api.py:9: in <module>\r\n from nni.nas.execution.common import (\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/__init__.py:4: in <module>\r\n from .engine import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/engine.py:7: in <module>\r\n from .graph import Model, MetricData\r\n/usr/local/lib/python3.8/site-packages/nni/nas/execution/common/graph.py:18: in <module>\r\n from nni.nas.evaluator import Evaluator\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/__init__.py:9: in <module>\r\n shortcut_framework(__name__)\r\n/usr/local/lib/python3.8/site-packages/nni/common/framework.py:93: in shortcut_framework\r\n shortcut_module(current, '.' + get_default_framework(), current)\r\n/usr/local/lib/python3.8/site-packages/nni/common/framework.py:83: in shortcut_module\r\n mod = importlib.import_module(target, package)\r\n/usr/local/lib/python3.8/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/__init__.py:4: in <module>\r\n from .lightning import *\r\n/usr/local/lib/python3.8/site-packages/nni/nas/evaluator/pytorch/lightning.py:10: in <module>\r\n import pytorch_lightning as pl\r\nE ModuleNotFoundError: No module named 'pytorch_lightning'\r\n```\r\n\r\n**How to reproduce it?**:\r\n```\r\npip install nni==2.9\r\npython -c \"import nni.retiarii.execution.api\"\r\n```\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nfrom .lightning import *\n", "path": "nni/nas/evaluator/pytorch/__init__.py"}], "after_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport warnings\n\ntry:\n from .lightning import *\nexcept ImportError:\n warnings.warn(\"PyTorch-Lightning must be installed to use PyTorch in NAS. \"\n \"If you are not using PyTorch, please `nni.set_default_framework('none')`\")\n raise\n", "path": "nni/nas/evaluator/pytorch/__init__.py"}]}
| 1,103 | 172 |
gh_patches_debug_3315
|
rasdani/github-patches
|
git_diff
|
google__turbinia-1227
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Create documentation for the Turbinia API command line tool
Write documentation for the new Turbinia API command line tool.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `turbinia/api/cli/turbinia_client/core/groups.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 # Copyright 2022 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Turbinia API client command-line tool."""
16
17 import click
18
19
20 @click.group('config')
21 def config_group():
22 """Get Turbinia configuration."""
23
24
25 @click.group('status')
26 def status_group():
27 """Get Turbinia request/task status."""
28
29
30 @click.group('result')
31 def result_group():
32 """Get Turbinia task or request results."""
33
34
35 @click.group('jobs')
36 def jobs_group():
37 """Get a list of enabled Turbinia jobs."""
38
39
40 @click.group('submit')
41 def submit_group():
42 """Submit new requests to the Turbinia API server."""
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/turbinia/api/cli/turbinia_client/core/groups.py b/turbinia/api/cli/turbinia_client/core/groups.py
--- a/turbinia/api/cli/turbinia_client/core/groups.py
+++ b/turbinia/api/cli/turbinia_client/core/groups.py
@@ -24,12 +24,12 @@
@click.group('status')
def status_group():
- """Get Turbinia request/task status."""
+ """Get Turbinia request or task status."""
@click.group('result')
def result_group():
- """Get Turbinia task or request results."""
+ """Get Turbinia request or task results."""
@click.group('jobs')
|
{"golden_diff": "diff --git a/turbinia/api/cli/turbinia_client/core/groups.py b/turbinia/api/cli/turbinia_client/core/groups.py\n--- a/turbinia/api/cli/turbinia_client/core/groups.py\n+++ b/turbinia/api/cli/turbinia_client/core/groups.py\n@@ -24,12 +24,12 @@\n \n @click.group('status')\n def status_group():\n- \"\"\"Get Turbinia request/task status.\"\"\"\n+ \"\"\"Get Turbinia request or task status.\"\"\"\n \n \n @click.group('result')\n def result_group():\n- \"\"\"Get Turbinia task or request results.\"\"\"\n+ \"\"\"Get Turbinia request or task results.\"\"\"\n \n \n @click.group('jobs')\n", "issue": "Create documentation for the Turbinia API command line tool\nWrite documentation for the new Turbinia API command line tool.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2022 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia API client command-line tool.\"\"\"\n\nimport click\n\n\[email protected]('config')\ndef config_group():\n \"\"\"Get Turbinia configuration.\"\"\"\n\n\[email protected]('status')\ndef status_group():\n \"\"\"Get Turbinia request/task status.\"\"\"\n\n\[email protected]('result')\ndef result_group():\n \"\"\"Get Turbinia task or request results.\"\"\"\n\n\[email protected]('jobs')\ndef jobs_group():\n \"\"\"Get a list of enabled Turbinia jobs.\"\"\"\n\n\[email protected]('submit')\ndef submit_group():\n \"\"\"Submit new requests to the Turbinia API server.\"\"\"\n", "path": "turbinia/api/cli/turbinia_client/core/groups.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2022 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Turbinia API client command-line tool.\"\"\"\n\nimport click\n\n\[email protected]('config')\ndef config_group():\n \"\"\"Get Turbinia configuration.\"\"\"\n\n\[email protected]('status')\ndef status_group():\n \"\"\"Get Turbinia request or task status.\"\"\"\n\n\[email protected]('result')\ndef result_group():\n \"\"\"Get Turbinia request or task results.\"\"\"\n\n\[email protected]('jobs')\ndef jobs_group():\n \"\"\"Get a list of enabled Turbinia jobs.\"\"\"\n\n\[email protected]('submit')\ndef submit_group():\n \"\"\"Submit new requests to the Turbinia API server.\"\"\"\n", "path": "turbinia/api/cli/turbinia_client/core/groups.py"}]}
| 635 | 158 |
gh_patches_debug_18101
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5569
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
plugins.pandalive: HTTP status 400 on API call
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
streamlink 6.2.0
### Description
the livestreams can't resolved on pandalive
it was always resolved 400 Client Error
### Debug log
```text
C:\Users\Jerry>C:\APP\Streamlink\bin\streamlink.exe https://www.pandalive.co.kr/live/play/pocet00 --loglevel=debug
[session][debug] Plugin pandalive is being overridden by C:\Users\Jerry\AppData\Roaming\streamlink\plugins\pandalive.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.5
[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023
[cli][debug] Streamlink: 6.2.0
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.7.22
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.3
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.18.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] trio: 0.22.2
[cli][debug] trio-websocket: 0.10.4
[cli][debug] typing-extensions: 4.7.1
[cli][debug] urllib3: 2.0.4
[cli][debug] websocket-client: 1.6.3
[cli][debug] Arguments:
[cli][debug] url=https://www.pandalive.co.kr/live/play/pocet00
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\APP\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin pandalive for URL https://www.pandalive.co.kr/live/play/pocet00
[plugins.pandalive][debug] Media code: pocet00
error: Unable to open URL: https://api.pandalive.co.kr/v1/live/play (400 Client Error: Bad Request for url: https://api.pandalive.co.kr/v1/live/play)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/streamlink/plugins/pandalive.py`
Content:
```
1 """
2 $description South Korean live-streaming platform for individual live streams.
3 $url pandalive.co.kr
4 $type live
5 $metadata author
6 $metadata title
7 """
8
9 import logging
10 import re
11
12 from streamlink.plugin import Plugin, pluginmatcher
13 from streamlink.plugin.api import validate
14 from streamlink.stream.hls import HLSStream
15
16
17 log = logging.getLogger(__name__)
18
19
20 @pluginmatcher(re.compile(
21 r"https?://(?:www\.)?pandalive\.co\.kr/",
22 ))
23 class Pandalive(Plugin):
24 def _get_streams(self):
25 media_code = self.session.http.get(self.url, schema=validate.Schema(
26 re.compile(r"""routePath:\s*(?P<q>["'])(\\u002F|/)live(\\u002F|/)play(\\u002F|/)(?P<id>.+?)(?P=q)"""),
27 validate.any(None, validate.get("id")),
28 ))
29
30 if not media_code:
31 return
32
33 log.debug(f"Media code: {media_code}")
34
35 json = self.session.http.post(
36 "https://api.pandalive.co.kr/v1/live/play",
37 data={
38 "action": "watch",
39 "userId": media_code,
40 },
41 schema=validate.Schema(
42 validate.parse_json(),
43 validate.any(
44 {
45 "media": {
46 "title": str,
47 "userId": str,
48 "userNick": str,
49 "isPw": bool,
50 "isLive": bool,
51 "liveType": str,
52 },
53 "PlayList": {
54 validate.optional("hls"): [{
55 "url": validate.url(),
56 }],
57 validate.optional("hls2"): [{
58 "url": validate.url(),
59 }],
60 validate.optional("hls3"): [{
61 "url": validate.url(),
62 }],
63 },
64 "result": bool,
65 "message": str,
66 },
67 {
68 "result": bool,
69 "message": str,
70 },
71 ),
72 ),
73 )
74
75 if not json["result"]:
76 log.error(json["message"])
77 return
78
79 if not json["media"]["isLive"]:
80 log.error("The broadcast has ended")
81 return
82
83 if json["media"]["isPw"]:
84 log.error("The broadcast is password protected")
85 return
86
87 log.info(f"Broadcast type: {json['media']['liveType']}")
88
89 self.author = f"{json['media']['userNick']} ({json['media']['userId']})"
90 self.title = f"{json['media']['title']}"
91
92 playlist = json["PlayList"]
93 for key in ("hls", "hls2", "hls3"):
94 # use the first available HLS stream
95 if key in playlist and playlist[key]:
96 # all stream qualities share the same URL, so just use the first one
97 return HLSStream.parse_variant_playlist(self.session, playlist[key][0]["url"])
98
99
100 __plugin__ = Pandalive
101
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/streamlink/plugins/pandalive.py b/src/streamlink/plugins/pandalive.py
--- a/src/streamlink/plugins/pandalive.py
+++ b/src/streamlink/plugins/pandalive.py
@@ -18,7 +18,7 @@
@pluginmatcher(re.compile(
- r"https?://(?:www\.)?pandalive\.co\.kr/",
+ r"https?://(?:www\.)?pandalive\.co\.kr/live/play/[^/]+",
))
class Pandalive(Plugin):
def _get_streams(self):
@@ -34,10 +34,14 @@
json = self.session.http.post(
"https://api.pandalive.co.kr/v1/live/play",
+ headers={
+ "Referer": self.url,
+ },
data={
"action": "watch",
"userId": media_code,
},
+ acceptable_status=(200, 400),
schema=validate.Schema(
validate.parse_json(),
validate.any(
|
{"golden_diff": "diff --git a/src/streamlink/plugins/pandalive.py b/src/streamlink/plugins/pandalive.py\n--- a/src/streamlink/plugins/pandalive.py\n+++ b/src/streamlink/plugins/pandalive.py\n@@ -18,7 +18,7 @@\n \n \n @pluginmatcher(re.compile(\n- r\"https?://(?:www\\.)?pandalive\\.co\\.kr/\",\n+ r\"https?://(?:www\\.)?pandalive\\.co\\.kr/live/play/[^/]+\",\n ))\n class Pandalive(Plugin):\n def _get_streams(self):\n@@ -34,10 +34,14 @@\n \n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n+ headers={\n+ \"Referer\": self.url,\n+ },\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n+ acceptable_status=(200, 400),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n", "issue": "plugins.pandalive: HTTP status 400 on API call\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nstreamlink 6.2.0\n\n### Description\n\nthe livestreams can't resolved on pandalive\r\nit was always resolved 400 Client Error \n\n### Debug log\n\n```text\nC:\\Users\\Jerry>C:\\APP\\Streamlink\\bin\\streamlink.exe https://www.pandalive.co.kr/live/play/pocet00 --loglevel=debug\r\n[session][debug] Plugin pandalive is being overridden by C:\\Users\\Jerry\\AppData\\Roaming\\streamlink\\plugins\\pandalive.py\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.5\r\n[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023\r\n[cli][debug] Streamlink: 6.2.0\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.7.22\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.3\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.18.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] trio: 0.22.2\r\n[cli][debug] trio-websocket: 0.10.4\r\n[cli][debug] typing-extensions: 4.7.1\r\n[cli][debug] urllib3: 2.0.4\r\n[cli][debug] websocket-client: 1.6.3\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://www.pandalive.co.kr/live/play/pocet00\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\APP\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin pandalive for URL https://www.pandalive.co.kr/live/play/pocet00\r\n[plugins.pandalive][debug] Media code: pocet00\r\nerror: Unable to open URL: https://api.pandalive.co.kr/v1/live/play (400 Client Error: Bad Request for url: https://api.pandalive.co.kr/v1/live/play)\n```\n\n", "before_files": [{"content": "\"\"\"\n$description South Korean live-streaming platform for individual live streams.\n$url pandalive.co.kr\n$type live\n$metadata author\n$metadata title\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?pandalive\\.co\\.kr/\",\n))\nclass Pandalive(Plugin):\n def _get_streams(self):\n media_code = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"routePath:\\s*(?P<q>[\"'])(\\\\u002F|/)live(\\\\u002F|/)play(\\\\u002F|/)(?P<id>.+?)(?P=q)\"\"\"),\n validate.any(None, validate.get(\"id\")),\n ))\n\n if not media_code:\n return\n\n log.debug(f\"Media code: {media_code}\")\n\n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"media\": {\n \"title\": str,\n \"userId\": str,\n \"userNick\": str,\n \"isPw\": bool,\n \"isLive\": bool,\n \"liveType\": str,\n },\n \"PlayList\": {\n validate.optional(\"hls\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls2\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls3\"): [{\n \"url\": validate.url(),\n }],\n },\n \"result\": bool,\n \"message\": str,\n },\n {\n \"result\": bool,\n \"message\": str,\n },\n ),\n ),\n )\n\n if not json[\"result\"]:\n log.error(json[\"message\"])\n return\n\n if not json[\"media\"][\"isLive\"]:\n log.error(\"The broadcast has ended\")\n return\n\n if json[\"media\"][\"isPw\"]:\n log.error(\"The broadcast is password protected\")\n return\n\n log.info(f\"Broadcast type: {json['media']['liveType']}\")\n\n self.author = f\"{json['media']['userNick']} ({json['media']['userId']})\"\n self.title = f\"{json['media']['title']}\"\n\n playlist = json[\"PlayList\"]\n for key in (\"hls\", \"hls2\", \"hls3\"):\n # use the first available HLS stream\n if key in playlist and playlist[key]:\n # all stream qualities share the same URL, so just use the first one\n return HLSStream.parse_variant_playlist(self.session, playlist[key][0][\"url\"])\n\n\n__plugin__ = Pandalive\n", "path": "src/streamlink/plugins/pandalive.py"}], "after_files": [{"content": "\"\"\"\n$description South Korean live-streaming platform for individual live streams.\n$url pandalive.co.kr\n$type live\n$metadata author\n$metadata title\n\"\"\"\n\nimport logging\nimport re\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(\n r\"https?://(?:www\\.)?pandalive\\.co\\.kr/live/play/[^/]+\",\n))\nclass Pandalive(Plugin):\n def _get_streams(self):\n media_code = self.session.http.get(self.url, schema=validate.Schema(\n re.compile(r\"\"\"routePath:\\s*(?P<q>[\"'])(\\\\u002F|/)live(\\\\u002F|/)play(\\\\u002F|/)(?P<id>.+?)(?P=q)\"\"\"),\n validate.any(None, validate.get(\"id\")),\n ))\n\n if not media_code:\n return\n\n log.debug(f\"Media code: {media_code}\")\n\n json = self.session.http.post(\n \"https://api.pandalive.co.kr/v1/live/play\",\n headers={\n \"Referer\": self.url,\n },\n data={\n \"action\": \"watch\",\n \"userId\": media_code,\n },\n acceptable_status=(200, 400),\n schema=validate.Schema(\n validate.parse_json(),\n validate.any(\n {\n \"media\": {\n \"title\": str,\n \"userId\": str,\n \"userNick\": str,\n \"isPw\": bool,\n \"isLive\": bool,\n \"liveType\": str,\n },\n \"PlayList\": {\n validate.optional(\"hls\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls2\"): [{\n \"url\": validate.url(),\n }],\n validate.optional(\"hls3\"): [{\n \"url\": validate.url(),\n }],\n },\n \"result\": bool,\n \"message\": str,\n },\n {\n \"result\": bool,\n \"message\": str,\n },\n ),\n ),\n )\n\n if not json[\"result\"]:\n log.error(json[\"message\"])\n return\n\n if not json[\"media\"][\"isLive\"]:\n log.error(\"The broadcast has ended\")\n return\n\n if json[\"media\"][\"isPw\"]:\n log.error(\"The broadcast is password protected\")\n return\n\n log.info(f\"Broadcast type: {json['media']['liveType']}\")\n\n self.author = f\"{json['media']['userNick']} ({json['media']['userId']})\"\n self.title = f\"{json['media']['title']}\"\n\n playlist = json[\"PlayList\"]\n for key in (\"hls\", \"hls2\", \"hls3\"):\n # use the first available HLS stream\n if key in playlist and playlist[key]:\n # all stream qualities share the same URL, so just use the first one\n return HLSStream.parse_variant_playlist(self.session, playlist[key][0][\"url\"])\n\n\n__plugin__ = Pandalive\n", "path": "src/streamlink/plugins/pandalive.py"}]}
| 1,823 | 224 |
gh_patches_debug_41518
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2373
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Nine: Lutris can't find Nine libraries
A lot of changed before creating PR #2092 and merging it - biggest issue is commit 792c22176eff9e063b22d7b9700e2e9b79a11fae, which changes return val of iter_lib_folders() from lists to strings. I believe I used iter_lib_folders() in #2092 because I needed distinguish between lib32 and lib64 paths. I will take a look at this and try to fix it ASAP (this week).
Original report:
https://github.com/lutris/lutris/pull/2092#issuecomment-529362315
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lutris/util/wine/nine.py`
Content:
```
1 """Gallium Nine helper module"""
2 import os
3 import shutil
4
5 from lutris.util import system
6 from lutris.runners.commands.wine import wineexec
7
8 class NineUnavailable(RuntimeError):
9 """Exception raised when Gallium Nine is not available"""
10
11 class NineManager:
12 """Utility class to install and manage Gallium Nine to a Wine prefix"""
13
14 nine_files = ("d3d9-nine.dll", "ninewinecfg.exe")
15 mesa_files = ("d3dadapter9.so.1",)
16
17 def __init__(self, prefix, arch):
18 self.prefix = prefix
19 self.wine_arch = arch
20
21 @staticmethod
22 def nine_is_supported():
23 """Check if MESA is built with Gallium Nine state tracker support
24
25 basic check for presence of d3dadapter9 library in 'd3d' subdirectory
26 of system library directory
27 """
28 for mesa_file in NineManager.mesa_files:
29 if not any([os.path.exists(os.path.join(lib[0], "d3d", mesa_file))
30 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
31 return False
32
33 if system.LINUX_SYSTEM.is_64_bit:
34 if not any([os.path.exists(os.path.join(lib[1], "d3d", mesa_file))
35 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
36 return False
37
38 return True
39
40 @staticmethod
41 def nine_is_installed():
42 """Check if Gallium Nine standalone is installed on this system
43
44 check 'wine/fakedlls' subdirectory of system library directory for Nine binaries
45 """
46 for nine_file in NineManager.nine_files:
47 if not any([os.path.exists(os.path.join(lib[0], "wine/fakedlls", nine_file))
48 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
49 return False
50
51 if system.LINUX_SYSTEM.is_64_bit:
52 if not any([os.path.exists(os.path.join(lib[1], "wine/fakedlls", nine_file))
53 for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
54 return False
55
56 return True
57
58 @staticmethod
59 def is_available():
60 """Check if Gallium Nine can be enabled on this system"""
61 return NineManager.nine_is_supported() and NineManager.nine_is_installed()
62
63 def get_system_path(self, arch):
64 """Return path of Windows system directory with binaries of chosen architecture"""
65 windows_path = os.path.join(self.prefix, "drive_c/windows")
66
67 if self.wine_arch == "win32" and arch == "x32":
68 return os.path.join(windows_path, "system32")
69 if self.wine_arch == "win64" and arch == "x32":
70 return os.path.join(windows_path, "syswow64")
71 if self.wine_arch == "win64" and arch == "x64":
72 return os.path.join(windows_path, "system32")
73
74 return None
75
76 def is_prefix_prepared(self):
77 if not all(system.path_exists(os.path.join(self.get_system_path("x32"), nine_file))
78 for nine_file in self.nine_files):
79 return False
80
81 if self.wine_arch == "win64":
82 if not all(system.path_exists(os.path.join(self.get_system_path("x64"), nine_file))
83 for nine_file in self.nine_files):
84 return False
85
86 return True
87
88 def prepare_prefix(self):
89 for nine_file in NineManager.nine_files:
90 for lib in system.LINUX_SYSTEM.iter_lib_folders():
91 nine_file_32 = os.path.join(lib[0], "wine/fakedlls", nine_file)
92 if os.path.exists(nine_file_32):
93 shutil.copy(nine_file_32, self.get_system_path("x32"))
94
95 if self.wine_arch == "win64":
96 nine_file_64 = os.path.join(lib[1], "wine/fakedlls", nine_file)
97 if os.path.exists(nine_file_64):
98 shutil.copy(nine_file_64, self.get_system_path("x64"))
99
100 def enable(self):
101 if not self.nine_is_supported():
102 raise NineUnavailable("Nine is not supported on this system")
103 if not self.nine_is_installed():
104 raise NineUnavailable("Nine Standalone is not installed")
105 if not self.is_prefix_prepared():
106 self.prepare_prefix()
107
108 wineexec(
109 "ninewinecfg",
110 args="-e",
111 prefix=self.prefix,
112 blocking=True,
113 )
114
115 def disable(self):
116 if self.is_prefix_prepared():
117 wineexec(
118 "ninewinecfg",
119 args="-d",
120 prefix=self.prefix,
121 blocking=True,
122 )
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lutris/util/wine/nine.py b/lutris/util/wine/nine.py
--- a/lutris/util/wine/nine.py
+++ b/lutris/util/wine/nine.py
@@ -4,6 +4,7 @@
from lutris.util import system
from lutris.runners.commands.wine import wineexec
+from lutris.util.wine.cabinstall import CabInstaller
class NineUnavailable(RuntimeError):
"""Exception raised when Gallium Nine is not available"""
@@ -26,15 +27,10 @@
of system library directory
"""
for mesa_file in NineManager.mesa_files:
- if not any([os.path.exists(os.path.join(lib[0], "d3d", mesa_file))
+ if not any([os.path.exists(os.path.join(lib, "d3d", mesa_file))
for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
return False
- if system.LINUX_SYSTEM.is_64_bit:
- if not any([os.path.exists(os.path.join(lib[1], "d3d", mesa_file))
- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
- return False
-
return True
@staticmethod
@@ -44,15 +40,10 @@
check 'wine/fakedlls' subdirectory of system library directory for Nine binaries
"""
for nine_file in NineManager.nine_files:
- if not any([os.path.exists(os.path.join(lib[0], "wine/fakedlls", nine_file))
+ if not any([os.path.exists(os.path.join(lib, "wine/fakedlls", nine_file))
for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
return False
- if system.LINUX_SYSTEM.is_64_bit:
- if not any([os.path.exists(os.path.join(lib[1], "wine/fakedlls", nine_file))
- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):
- return False
-
return True
@staticmethod
@@ -88,15 +79,24 @@
def prepare_prefix(self):
for nine_file in NineManager.nine_files:
for lib in system.LINUX_SYSTEM.iter_lib_folders():
- nine_file_32 = os.path.join(lib[0], "wine/fakedlls", nine_file)
- if os.path.exists(nine_file_32):
- shutil.copy(nine_file_32, self.get_system_path("x32"))
+ nine_file_path = os.path.join(lib, "wine/fakedlls", nine_file)
+
+ if (os.path.exists(nine_file_path) and
+ CabInstaller.get_arch_from_dll(nine_file_path) == "win32"):
+ shutil.copy(nine_file_path, self.get_system_path("x32"))
if self.wine_arch == "win64":
- nine_file_64 = os.path.join(lib[1], "wine/fakedlls", nine_file)
- if os.path.exists(nine_file_64):
+ if (os.path.exists(nine_file_path) and
+ CabInstaller.get_arch_from_dll(nine_file_path) == "win64"):
shutil.copy(nine_file_64, self.get_system_path("x64"))
+ if not os.path.exists(os.path.join(self.get_system_path("x32"), nine_file)):
+ raise NineUnavailable("could not install " + nine_file + " (x32)")
+
+ if self.wine_arch == "win64":
+ if not os.path.exists(os.path.join(self.get_system_path("x64"), nine_file)):
+ raise NineUnavailable("could not install " + nine_file + " (x64)")
+
def enable(self):
if not self.nine_is_supported():
raise NineUnavailable("Nine is not supported on this system")
|
{"golden_diff": "diff --git a/lutris/util/wine/nine.py b/lutris/util/wine/nine.py\n--- a/lutris/util/wine/nine.py\n+++ b/lutris/util/wine/nine.py\n@@ -4,6 +4,7 @@\n \n from lutris.util import system\n from lutris.runners.commands.wine import wineexec\n+from lutris.util.wine.cabinstall import CabInstaller\n \n class NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n@@ -26,15 +27,10 @@\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n- if not any([os.path.exists(os.path.join(lib[0], \"d3d\", mesa_file))\n+ if not any([os.path.exists(os.path.join(lib, \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n \n- if system.LINUX_SYSTEM.is_64_bit:\n- if not any([os.path.exists(os.path.join(lib[1], \"d3d\", mesa_file))\n- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n- return False\n-\n return True\n \n @staticmethod\n@@ -44,15 +40,10 @@\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n- if not any([os.path.exists(os.path.join(lib[0], \"wine/fakedlls\", nine_file))\n+ if not any([os.path.exists(os.path.join(lib, \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n \n- if system.LINUX_SYSTEM.is_64_bit:\n- if not any([os.path.exists(os.path.join(lib[1], \"wine/fakedlls\", nine_file))\n- for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n- return False\n-\n return True\n \n @staticmethod\n@@ -88,15 +79,24 @@\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n- nine_file_32 = os.path.join(lib[0], \"wine/fakedlls\", nine_file)\n- if os.path.exists(nine_file_32):\n- shutil.copy(nine_file_32, self.get_system_path(\"x32\"))\n+ nine_file_path = os.path.join(lib, \"wine/fakedlls\", nine_file)\n+\n+ if (os.path.exists(nine_file_path) and\n+ CabInstaller.get_arch_from_dll(nine_file_path) == \"win32\"):\n+ shutil.copy(nine_file_path, self.get_system_path(\"x32\"))\n \n if self.wine_arch == \"win64\":\n- nine_file_64 = os.path.join(lib[1], \"wine/fakedlls\", nine_file)\n- if os.path.exists(nine_file_64):\n+ if (os.path.exists(nine_file_path) and\n+ CabInstaller.get_arch_from_dll(nine_file_path) == \"win64\"):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n \n+ if not os.path.exists(os.path.join(self.get_system_path(\"x32\"), nine_file)):\n+ raise NineUnavailable(\"could not install \" + nine_file + \" (x32)\")\n+\n+ if self.wine_arch == \"win64\":\n+ if not os.path.exists(os.path.join(self.get_system_path(\"x64\"), nine_file)):\n+ raise NineUnavailable(\"could not install \" + nine_file + \" (x64)\")\n+\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n", "issue": "Nine: Lutris can't find Nine libraries\nA lot of changed before creating PR #2092 and merging it - biggest issue is commit 792c22176eff9e063b22d7b9700e2e9b79a11fae, which changes return val of iter_lib_folders() from lists to strings. I believe I used iter_lib_folders() in #2092 because I needed distinguish between lib32 and lib64 paths. I will take a look at this and try to fix it ASAP (this week).\r\n\r\nOriginal report:\r\nhttps://github.com/lutris/lutris/pull/2092#issuecomment-529362315\n", "before_files": [{"content": "\"\"\"Gallium Nine helper module\"\"\"\nimport os\nimport shutil\n\nfrom lutris.util import system\nfrom lutris.runners.commands.wine import wineexec\n\nclass NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n\nclass NineManager:\n \"\"\"Utility class to install and manage Gallium Nine to a Wine prefix\"\"\"\n\n nine_files = (\"d3d9-nine.dll\", \"ninewinecfg.exe\")\n mesa_files = (\"d3dadapter9.so.1\",)\n\n def __init__(self, prefix, arch):\n self.prefix = prefix\n self.wine_arch = arch\n\n @staticmethod\n def nine_is_supported():\n \"\"\"Check if MESA is built with Gallium Nine state tracker support\n\n basic check for presence of d3dadapter9 library in 'd3d' subdirectory\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n if not any([os.path.exists(os.path.join(lib[0], \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n if system.LINUX_SYSTEM.is_64_bit:\n if not any([os.path.exists(os.path.join(lib[1], \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def nine_is_installed():\n \"\"\"Check if Gallium Nine standalone is installed on this system\n\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n if not any([os.path.exists(os.path.join(lib[0], \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n if system.LINUX_SYSTEM.is_64_bit:\n if not any([os.path.exists(os.path.join(lib[1], \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def is_available():\n \"\"\"Check if Gallium Nine can be enabled on this system\"\"\"\n return NineManager.nine_is_supported() and NineManager.nine_is_installed()\n\n def get_system_path(self, arch):\n \"\"\"Return path of Windows system directory with binaries of chosen architecture\"\"\"\n windows_path = os.path.join(self.prefix, \"drive_c/windows\")\n\n if self.wine_arch == \"win32\" and arch == \"x32\":\n return os.path.join(windows_path, \"system32\")\n if self.wine_arch == \"win64\" and arch == \"x32\":\n return os.path.join(windows_path, \"syswow64\")\n if self.wine_arch == \"win64\" and arch == \"x64\":\n return os.path.join(windows_path, \"system32\")\n\n return None\n\n def is_prefix_prepared(self):\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x32\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n if self.wine_arch == \"win64\":\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x64\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n return True\n\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n nine_file_32 = os.path.join(lib[0], \"wine/fakedlls\", nine_file)\n if os.path.exists(nine_file_32):\n shutil.copy(nine_file_32, self.get_system_path(\"x32\"))\n\n if self.wine_arch == \"win64\":\n nine_file_64 = os.path.join(lib[1], \"wine/fakedlls\", nine_file)\n if os.path.exists(nine_file_64):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n if not self.nine_is_installed():\n raise NineUnavailable(\"Nine Standalone is not installed\")\n if not self.is_prefix_prepared():\n self.prepare_prefix()\n\n wineexec(\n \"ninewinecfg\",\n args=\"-e\",\n prefix=self.prefix,\n blocking=True,\n )\n\n def disable(self):\n if self.is_prefix_prepared():\n wineexec(\n \"ninewinecfg\",\n args=\"-d\",\n prefix=self.prefix,\n blocking=True,\n )\n", "path": "lutris/util/wine/nine.py"}], "after_files": [{"content": "\"\"\"Gallium Nine helper module\"\"\"\nimport os\nimport shutil\n\nfrom lutris.util import system\nfrom lutris.runners.commands.wine import wineexec\nfrom lutris.util.wine.cabinstall import CabInstaller\n\nclass NineUnavailable(RuntimeError):\n \"\"\"Exception raised when Gallium Nine is not available\"\"\"\n\nclass NineManager:\n \"\"\"Utility class to install and manage Gallium Nine to a Wine prefix\"\"\"\n\n nine_files = (\"d3d9-nine.dll\", \"ninewinecfg.exe\")\n mesa_files = (\"d3dadapter9.so.1\",)\n\n def __init__(self, prefix, arch):\n self.prefix = prefix\n self.wine_arch = arch\n\n @staticmethod\n def nine_is_supported():\n \"\"\"Check if MESA is built with Gallium Nine state tracker support\n\n basic check for presence of d3dadapter9 library in 'd3d' subdirectory\n of system library directory\n \"\"\"\n for mesa_file in NineManager.mesa_files:\n if not any([os.path.exists(os.path.join(lib, \"d3d\", mesa_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def nine_is_installed():\n \"\"\"Check if Gallium Nine standalone is installed on this system\n\n check 'wine/fakedlls' subdirectory of system library directory for Nine binaries\n \"\"\"\n for nine_file in NineManager.nine_files:\n if not any([os.path.exists(os.path.join(lib, \"wine/fakedlls\", nine_file))\n for lib in system.LINUX_SYSTEM.iter_lib_folders()]):\n return False\n\n return True\n\n @staticmethod\n def is_available():\n \"\"\"Check if Gallium Nine can be enabled on this system\"\"\"\n return NineManager.nine_is_supported() and NineManager.nine_is_installed()\n\n def get_system_path(self, arch):\n \"\"\"Return path of Windows system directory with binaries of chosen architecture\"\"\"\n windows_path = os.path.join(self.prefix, \"drive_c/windows\")\n\n if self.wine_arch == \"win32\" and arch == \"x32\":\n return os.path.join(windows_path, \"system32\")\n if self.wine_arch == \"win64\" and arch == \"x32\":\n return os.path.join(windows_path, \"syswow64\")\n if self.wine_arch == \"win64\" and arch == \"x64\":\n return os.path.join(windows_path, \"system32\")\n\n return None\n\n def is_prefix_prepared(self):\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x32\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n if self.wine_arch == \"win64\":\n if not all(system.path_exists(os.path.join(self.get_system_path(\"x64\"), nine_file))\n for nine_file in self.nine_files):\n return False\n\n return True\n\n def prepare_prefix(self):\n for nine_file in NineManager.nine_files:\n for lib in system.LINUX_SYSTEM.iter_lib_folders():\n nine_file_path = os.path.join(lib, \"wine/fakedlls\", nine_file)\n\n if (os.path.exists(nine_file_path) and\n CabInstaller.get_arch_from_dll(nine_file_path) == \"win32\"):\n shutil.copy(nine_file_path, self.get_system_path(\"x32\"))\n\n if self.wine_arch == \"win64\":\n if (os.path.exists(nine_file_path) and\n CabInstaller.get_arch_from_dll(nine_file_path) == \"win64\"):\n shutil.copy(nine_file_64, self.get_system_path(\"x64\"))\n\n if not os.path.exists(os.path.join(self.get_system_path(\"x32\"), nine_file)):\n raise NineUnavailable(\"could not install \" + nine_file + \" (x32)\")\n\n if self.wine_arch == \"win64\":\n if not os.path.exists(os.path.join(self.get_system_path(\"x64\"), nine_file)):\n raise NineUnavailable(\"could not install \" + nine_file + \" (x64)\")\n\n def enable(self):\n if not self.nine_is_supported():\n raise NineUnavailable(\"Nine is not supported on this system\")\n if not self.nine_is_installed():\n raise NineUnavailable(\"Nine Standalone is not installed\")\n if not self.is_prefix_prepared():\n self.prepare_prefix()\n\n wineexec(\n \"ninewinecfg\",\n args=\"-e\",\n prefix=self.prefix,\n blocking=True,\n )\n\n def disable(self):\n if self.is_prefix_prepared():\n wineexec(\n \"ninewinecfg\",\n args=\"-d\",\n prefix=self.prefix,\n blocking=True,\n )\n", "path": "lutris/util/wine/nine.py"}]}
| 1,720 | 854 |
gh_patches_debug_61134
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-1293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
networkx compatibility issue with python3.9
There's a networkx>=2.5 dependency to run pandapower under python3.9 as gcd has to be imported from math instead of fractions.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6 from setuptools import setup, find_packages
7 import re
8
9 with open('README.rst', 'rb') as f:
10 install = f.read().decode('utf-8')
11
12 with open('CHANGELOG.rst', 'rb') as f:
13 changelog = f.read().decode('utf-8')
14
15 classifiers = [
16 'Development Status :: 5 - Production/Stable',
17 'Environment :: Console',
18 'Intended Audience :: Developers',
19 'Intended Audience :: Education',
20 'Intended Audience :: Science/Research',
21 'License :: OSI Approved :: BSD License',
22 'Natural Language :: English',
23 'Operating System :: OS Independent',
24 'Programming Language :: Python',
25 'Programming Language :: Python :: 3']
26
27 with open('.github/workflows/github_test_action.yml', 'rb') as f:
28 lines = f.read().decode('utf-8')
29 versions = set(re.findall('3.[0-9]', lines))
30 for version in versions:
31 classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])
32
33 long_description = '\n\n'.join((install, changelog))
34
35 setup(
36 name='pandapower',
37 version='2.6.0',
38 author='Leon Thurner, Alexander Scheidler',
39 author_email='[email protected], [email protected]',
40 description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',
41 long_description=long_description,
42 long_description_content_type='text/x-rst',
43 url='http://www.pandapower.org',
44 license='BSD',
45 install_requires=["pandas>=0.17",
46 "networkx",
47 "scipy<=1.6.0",
48 "numpy>=0.11",
49 "packaging",
50 "xlsxwriter",
51 "xlrd",
52 "openpyxl",
53 "cryptography"],
54 extras_require={
55 "docs": ["numpydoc", "sphinx", "sphinx_rtd_theme"],
56 "plotting": ["plotly", "matplotlib", "python-igraph"],
57 "test": ["pytest", "pytest-xdist"],
58 "performance": ["ortools"]},
59 packages=find_packages(),
60 include_package_data=True,
61 classifiers=classifiers
62 )
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -43,7 +43,7 @@
url='http://www.pandapower.org',
license='BSD',
install_requires=["pandas>=0.17",
- "networkx",
+ "networkx>=2.5",
"scipy<=1.6.0",
"numpy>=0.11",
"packaging",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -43,7 +43,7 @@\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n- \"networkx\",\n+ \"networkx>=2.5\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n", "issue": "networkx compatibility issue with python3.9\nThere's a networkx>=2.5 dependency to run pandapower under python3.9 as gcd has to be imported from math instead of fractions.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nfrom setuptools import setup, find_packages\nimport re\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\n\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nclassifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3']\n\nwith open('.github/workflows/github_test_action.yml', 'rb') as f:\n lines = f.read().decode('utf-8')\n versions = set(re.findall('3.[0-9]', lines))\n for version in versions:\n classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='2.6.0',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',\n long_description=long_description,\n\tlong_description_content_type='text/x-rst',\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n \"networkx\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n \"xlsxwriter\",\n \"xlrd\",\n \"openpyxl\",\n \"cryptography\"],\n extras_require={\n \"docs\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\"],\n \"plotting\": [\"plotly\", \"matplotlib\", \"python-igraph\"],\n \"test\": [\"pytest\", \"pytest-xdist\"],\n \"performance\": [\"ortools\"]},\n packages=find_packages(),\n include_package_data=True,\n classifiers=classifiers\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2021 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nfrom setuptools import setup, find_packages\nimport re\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\n\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nclassifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3']\n\nwith open('.github/workflows/github_test_action.yml', 'rb') as f:\n lines = f.read().decode('utf-8')\n versions = set(re.findall('3.[0-9]', lines))\n for version in versions:\n classifiers.append('Programming Language :: Python :: 3.%s' % version[-1])\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='2.6.0',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',\n long_description=long_description,\n\tlong_description_content_type='text/x-rst',\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=0.17\",\n \"networkx>=2.5\",\n \"scipy<=1.6.0\",\n \"numpy>=0.11\",\n \"packaging\",\n \"xlsxwriter\",\n \"xlrd\",\n \"openpyxl\",\n \"cryptography\"],\n extras_require={\n \"docs\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\"],\n \"plotting\": [\"plotly\", \"matplotlib\", \"python-igraph\"],\n \"test\": [\"pytest\", \"pytest-xdist\"],\n \"performance\": [\"ortools\"]},\n packages=find_packages(),\n include_package_data=True,\n classifiers=classifiers\n)\n", "path": "setup.py"}]}
| 979 | 102 |
gh_patches_debug_719
|
rasdani/github-patches
|
git_diff
|
mne-tools__mne-bids-pipeline-680
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Doc deployment step failing
The latest CI run failed to execute documentation deployment:
https://app.circleci.com/pipelines/github/mne-tools/mne-bids-pipeline/3557/workflows/3458e5cc-c471-4664-8d0a-b0cc4961f9eb/jobs/41986/parallel-runs/0/steps/0-107
```shell
#!/bin/bash -eo pipefail
./.circleci/setup_bash.sh
CIRCLE_JOB=deploy_docs
COMMIT_MESSAGE=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)
COMMIT_MESSAGE_ESCAPED=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)
CIRCLE_REQUESTED_JOB=
Running job deploy_docs for main branch
./.circleci/setup_bash.sh: line 35: sudo: command not found
Exited with code exit status 127
CircleCI received exit code 127
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/features/gen_steps.py`
Content:
```
1 #!/bin/env python
2 """Generate steps.md."""
3
4 import importlib
5 from pathlib import Path
6 from mne_bids_pipeline._config_utils import _get_step_modules
7
8 pre = """\
9 # Processing steps
10
11 The following table provides a concise summary of each step in the Study
12 Template. All steps exist in the `steps`/ directory.
13 """
14
15 step_modules = _get_step_modules()
16
17 # Construct the lines of steps.md
18 lines = [pre]
19 for di, (dir_, modules) in enumerate(step_modules.items(), 1):
20 if dir_ == 'all':
21 continue # this is an alias
22 dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')
23 dir_header = dir_module.__doc__.split('\n')[0].rstrip('.')
24 dir_body = dir_module.__doc__.split('\n', maxsplit=1)
25 if len(dir_body) > 1:
26 dir_body = dir_body[1].strip()
27 else:
28 dir_body = ''
29 lines.append(f'## {di}. {dir_header}\n')
30 if dir_body:
31 lines.append(f'{dir_body}\n')
32 lines.append('| Processing step | Description |')
33 lines.append('|:----------------|:------------|')
34 # the "all" option
35 dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'
36 lines.append(f'`{dir_name}` | {step_title} |')
37 for module in modules:
38 step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]
39 step_title = module.__doc__.split('\n')[0]
40 lines.append(f'`{step_name}` | {step_title} |')
41 lines.append('')
42 with open(Path(__file__).parent / 'steps.md', 'w') as fid:
43 fid.write('\n'.join(lines))
44
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/features/gen_steps.py b/docs/source/features/gen_steps.py
--- a/docs/source/features/gen_steps.py
+++ b/docs/source/features/gen_steps.py
@@ -12,6 +12,7 @@
Template. All steps exist in the `steps`/ directory.
"""
+print('Generating steps …')
step_modules = _get_step_modules()
# Construct the lines of steps.md
|
{"golden_diff": "diff --git a/docs/source/features/gen_steps.py b/docs/source/features/gen_steps.py\n--- a/docs/source/features/gen_steps.py\n+++ b/docs/source/features/gen_steps.py\n@@ -12,6 +12,7 @@\n Template. All steps exist in the `steps`/ directory.\n \"\"\"\n \n+print('Generating steps \u2026')\n step_modules = _get_step_modules()\n \n # Construct the lines of steps.md\n", "issue": "Doc deployment step failing\nThe latest CI run failed to execute documentation deployment:\r\nhttps://app.circleci.com/pipelines/github/mne-tools/mne-bids-pipeline/3557/workflows/3458e5cc-c471-4664-8d0a-b0cc4961f9eb/jobs/41986/parallel-runs/0/steps/0-107\r\n\r\n```shell\r\n#!/bin/bash -eo pipefail\r\n./.circleci/setup_bash.sh\r\nCIRCLE_JOB=deploy_docs\r\nCOMMIT_MESSAGE=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)\r\nCOMMIT_MESSAGE_ESCAPED=68c63d6878992fb7c298f24420f1d349c6811079 MAINT: Use mike for doc deployment (#676)\r\nCIRCLE_REQUESTED_JOB=\r\nRunning job deploy_docs for main branch\r\n./.circleci/setup_bash.sh: line 35: sudo: command not found\r\n\r\nExited with code exit status 127\r\nCircleCI received exit code 127\r\n```\n", "before_files": [{"content": "#!/bin/env python\n\"\"\"Generate steps.md.\"\"\"\n\nimport importlib\nfrom pathlib import Path\nfrom mne_bids_pipeline._config_utils import _get_step_modules\n\npre = \"\"\"\\\n# Processing steps\n\nThe following table provides a concise summary of each step in the Study\nTemplate. All steps exist in the `steps`/ directory.\n\"\"\"\n\nstep_modules = _get_step_modules()\n\n# Construct the lines of steps.md\nlines = [pre]\nfor di, (dir_, modules) in enumerate(step_modules.items(), 1):\n if dir_ == 'all':\n continue # this is an alias\n dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')\n dir_header = dir_module.__doc__.split('\\n')[0].rstrip('.')\n dir_body = dir_module.__doc__.split('\\n', maxsplit=1)\n if len(dir_body) > 1:\n dir_body = dir_body[1].strip()\n else:\n dir_body = ''\n lines.append(f'## {di}. {dir_header}\\n')\n if dir_body:\n lines.append(f'{dir_body}\\n')\n lines.append('| Processing step | Description |')\n lines.append('|:----------------|:------------|')\n # the \"all\" option\n dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'\n lines.append(f'`{dir_name}` | {step_title} |')\n for module in modules:\n step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]\n step_title = module.__doc__.split('\\n')[0]\n lines.append(f'`{step_name}` | {step_title} |')\n lines.append('')\nwith open(Path(__file__).parent / 'steps.md', 'w') as fid:\n fid.write('\\n'.join(lines))\n", "path": "docs/source/features/gen_steps.py"}], "after_files": [{"content": "#!/bin/env python\n\"\"\"Generate steps.md.\"\"\"\n\nimport importlib\nfrom pathlib import Path\nfrom mne_bids_pipeline._config_utils import _get_step_modules\n\npre = \"\"\"\\\n# Processing steps\n\nThe following table provides a concise summary of each step in the Study\nTemplate. All steps exist in the `steps`/ directory.\n\"\"\"\n\nprint('Generating steps \u2026')\nstep_modules = _get_step_modules()\n\n# Construct the lines of steps.md\nlines = [pre]\nfor di, (dir_, modules) in enumerate(step_modules.items(), 1):\n if dir_ == 'all':\n continue # this is an alias\n dir_module = importlib.import_module(f'mne_bids_pipeline.steps.{dir_}')\n dir_header = dir_module.__doc__.split('\\n')[0].rstrip('.')\n dir_body = dir_module.__doc__.split('\\n', maxsplit=1)\n if len(dir_body) > 1:\n dir_body = dir_body[1].strip()\n else:\n dir_body = ''\n lines.append(f'## {di}. {dir_header}\\n')\n if dir_body:\n lines.append(f'{dir_body}\\n')\n lines.append('| Processing step | Description |')\n lines.append('|:----------------|:------------|')\n # the \"all\" option\n dir_name, step_title = dir_, f'Run all {dir_header.lower()} steps.'\n lines.append(f'`{dir_name}` | {step_title} |')\n for module in modules:\n step_name = f'{dir_name}/{Path(module.__file__).name}'[:-3]\n step_title = module.__doc__.split('\\n')[0]\n lines.append(f'`{step_name}` | {step_title} |')\n lines.append('')\nwith open(Path(__file__).parent / 'steps.md', 'w') as fid:\n fid.write('\\n'.join(lines))\n", "path": "docs/source/features/gen_steps.py"}]}
| 1,030 | 87 |
gh_patches_debug_2713
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-9923
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Search on listing views doesn't work unless the `?q=` param exists in the URL
<!--
Found a bug? Please fill out the sections below. 👍
-->
### Issue Summary
Possible regression in https://github.com/wagtail/wagtail/pull/9768
The `URLSearchParams.get()` returns `null` if the param doesn't exist, so the following code:
https://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/client/src/entrypoints/admin/core.js#L270-L276
will crash during `currentQuery.trim()` when searching on the listing views (snippets, images, etc.) if the `?q=` param doesn't exist in the URL.
Might be a good time to add `required=False` in here as well:
https://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/wagtail/admin/forms/search.py#L12
to remove this silly error when `q` is an empty string:
<img width="473" alt="image" src="https://user-images.githubusercontent.com/6379424/213499685-ce37c064-2635-434f-952f-e85fae4ab9af.png">
<!--
A summary of the issue.
-->
### Steps to Reproduce
1. Spin up bakerydemo
2. Open the images listing
3. Try to search
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/admin/forms/search.py`
Content:
```
1 from django import forms
2 from django.utils.translation import gettext as _
3 from django.utils.translation import gettext_lazy
4
5
6 class SearchForm(forms.Form):
7 def __init__(self, *args, **kwargs):
8 placeholder = kwargs.pop("placeholder", _("Search"))
9 super().__init__(*args, **kwargs)
10 self.fields["q"].widget.attrs = {"placeholder": placeholder}
11
12 q = forms.CharField(label=gettext_lazy("Search term"), widget=forms.TextInput())
13
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py
--- a/wagtail/admin/forms/search.py
+++ b/wagtail/admin/forms/search.py
@@ -9,4 +9,8 @@
super().__init__(*args, **kwargs)
self.fields["q"].widget.attrs = {"placeholder": placeholder}
- q = forms.CharField(label=gettext_lazy("Search term"), widget=forms.TextInput())
+ q = forms.CharField(
+ label=gettext_lazy("Search term"),
+ widget=forms.TextInput(),
+ required=False,
+ )
|
{"golden_diff": "diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py\n--- a/wagtail/admin/forms/search.py\n+++ b/wagtail/admin/forms/search.py\n@@ -9,4 +9,8 @@\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n \n- q = forms.CharField(label=gettext_lazy(\"Search term\"), widget=forms.TextInput())\n+ q = forms.CharField(\n+ label=gettext_lazy(\"Search term\"),\n+ widget=forms.TextInput(),\n+ required=False,\n+ )\n", "issue": "Search on listing views doesn't work unless the `?q=` param exists in the URL\n<!--\r\nFound a bug? Please fill out the sections below. \ud83d\udc4d\r\n-->\r\n\r\n### Issue Summary\r\n\r\nPossible regression in https://github.com/wagtail/wagtail/pull/9768\r\n\r\nThe `URLSearchParams.get()` returns `null` if the param doesn't exist, so the following code:\r\n\r\nhttps://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/client/src/entrypoints/admin/core.js#L270-L276\r\n\r\nwill crash during `currentQuery.trim()` when searching on the listing views (snippets, images, etc.) if the `?q=` param doesn't exist in the URL.\r\n\r\nMight be a good time to add `required=False` in here as well:\r\n\r\nhttps://github.com/wagtail/wagtail/blob/a3f10acae17c892d843c419495e4204adb3ed991/wagtail/admin/forms/search.py#L12\r\n\r\nto remove this silly error when `q` is an empty string:\r\n\r\n<img width=\"473\" alt=\"image\" src=\"https://user-images.githubusercontent.com/6379424/213499685-ce37c064-2635-434f-952f-e85fae4ab9af.png\">\r\n\r\n<!--\r\nA summary of the issue.\r\n-->\r\n\r\n### Steps to Reproduce\r\n\r\n1. Spin up bakerydemo\r\n2. Open the images listing\r\n3. Try to search\r\n\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import gettext as _\nfrom django.utils.translation import gettext_lazy\n\n\nclass SearchForm(forms.Form):\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n\n q = forms.CharField(label=gettext_lazy(\"Search term\"), widget=forms.TextInput())\n", "path": "wagtail/admin/forms/search.py"}], "after_files": [{"content": "from django import forms\nfrom django.utils.translation import gettext as _\nfrom django.utils.translation import gettext_lazy\n\n\nclass SearchForm(forms.Form):\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n\n q = forms.CharField(\n label=gettext_lazy(\"Search term\"),\n widget=forms.TextInput(),\n required=False,\n )\n", "path": "wagtail/admin/forms/search.py"}]}
| 753 | 124 |
gh_patches_debug_2985
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-4234
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Missing [workflow_engine] in st2.conf.sample
##### SUMMARY
https://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample is missing a new section for `[workflow_engine]`
Also, shouldn't this section be named `[workflowengine]` to go along with the "style" of the other sections like `[resultstracker]` , `[garbagecollector]`, etc
##### ISSUE TYPE
- Bug Report
- Feature Idea
##### STACKSTORM VERSION
2.8
##### EXPECTED RESULTS
https://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample contains a section for `[workflow_engine]`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/config_gen.py`
Content:
```
1 #!/usr/bin/env python
2 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
3 # contributor license agreements. See the NOTICE file distributed with
4 # this work for additional information regarding copyright ownership.
5 # The ASF licenses this file to You under the Apache License, Version 2.0
6 # (the "License"); you may not use this file except in compliance with
7 # the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 from __future__ import absolute_import
18 import collections
19 import importlib
20 import six
21 import sys
22 import traceback
23
24 from oslo_config import cfg
25
26
27 CONFIGS = ['st2actions.config',
28 'st2actions.notifier.config',
29 'st2actions.resultstracker.config',
30 'st2api.config',
31 'st2stream.config',
32 'st2auth.config',
33 'st2common.config',
34 'st2exporter.config',
35 'st2reactor.rules.config',
36 'st2reactor.sensor.config',
37 'st2reactor.garbage_collector.config']
38
39 SKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']
40
41 # We group auth options together to nake it a bit more clear what applies where
42 AUTH_OPTIONS = {
43 'common': [
44 'enable',
45 'mode',
46 'logging',
47 'api_url',
48 'token_ttl',
49 'service_token_ttl',
50 'debug'
51 ],
52 'standalone': [
53 'host',
54 'port',
55 'use_ssl',
56 'cert',
57 'key',
58 'backend',
59 'backend_kwargs'
60 ]
61 }
62
63 # Some of the config values change depenending on the environment where this script is ran so we
64 # set them to static values to ensure consistent and stable output
65 STATIC_OPTION_VALUES = {
66 'actionrunner': {
67 'virtualenv_binary': '/usr/bin/virtualenv',
68 'python_binary': '/usr/bin/python',
69 'python3_binary': '/usr/bin/python3'
70 },
71 'webui': {
72 'webui_base_url': 'https://localhost'
73 }
74 }
75
76 COMMON_AUTH_OPTIONS_COMMENT = """
77 # Common option - options below apply in both scenarios - when auth service is running as a WSGI
78 # service (e.g. under Apache or Nginx) and when it's running in the standalone mode.
79 """.strip()
80
81 STANDALONE_AUTH_OPTIONS_COMMENT = """
82 # Standalone mode options - options below only apply when auth service is running in the standalone
83 # mode.
84 """.strip()
85
86
87 def _import_config(config):
88 try:
89 return importlib.import_module(config)
90 except:
91 traceback.print_exc()
92 return None
93
94
95 def _read_current_config(opt_groups):
96 for k, v in six.iteritems(cfg.CONF._groups):
97 if k in SKIP_GROUPS:
98 continue
99 if k not in opt_groups:
100 opt_groups[k] = v
101 return opt_groups
102
103
104 def _clear_config():
105 cfg.CONF.reset()
106
107
108 def _read_group(opt_group):
109 all_options = list(opt_group._opts.values())
110
111 if opt_group.name == 'auth':
112 print(COMMON_AUTH_OPTIONS_COMMENT)
113 print('')
114 common_options = [option for option in all_options if option['opt'].name in
115 AUTH_OPTIONS['common']]
116 _print_options(opt_group=opt_group, options=common_options)
117
118 print('')
119 print(STANDALONE_AUTH_OPTIONS_COMMENT)
120 print('')
121 standalone_options = [option for option in all_options if option['opt'].name in
122 AUTH_OPTIONS['standalone']]
123 _print_options(opt_group=opt_group, options=standalone_options)
124
125 if len(common_options) + len(standalone_options) != len(all_options):
126 msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')
127 raise Exception(msg)
128 else:
129 options = all_options
130 _print_options(opt_group=opt_group, options=options)
131
132
133 def _read_groups(opt_groups):
134 opt_groups = collections.OrderedDict(sorted(opt_groups.items()))
135 for name, opt_group in six.iteritems(opt_groups):
136 print('[%s]' % name)
137 _read_group(opt_group)
138 print('')
139
140
141 def _print_options(opt_group, options):
142 for opt in options:
143 opt = opt['opt']
144
145 # Special case for options which could change during this script run
146 static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)
147 if static_option_value:
148 opt.default = static_option_value
149
150 # Special handling for list options
151 if isinstance(opt, cfg.ListOpt):
152 if opt.default:
153 value = ','.join(opt.default)
154 else:
155 value = ''
156
157 value += ' # comma separated list allowed here.'
158 else:
159 value = opt.default
160
161 print('# %s' % opt.help)
162 print('%s = %s' % (opt.name, value))
163
164
165 def main(args):
166 opt_groups = {}
167 for config in CONFIGS:
168 mod = _import_config(config)
169 mod.register_opts()
170 _read_current_config(opt_groups)
171 _clear_config()
172 _read_groups(opt_groups)
173
174
175 if __name__ == '__main__':
176 main(sys.argv)
177
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/config_gen.py b/tools/config_gen.py
--- a/tools/config_gen.py
+++ b/tools/config_gen.py
@@ -27,6 +27,7 @@
CONFIGS = ['st2actions.config',
'st2actions.notifier.config',
'st2actions.resultstracker.config',
+ 'st2actions.workflows.config',
'st2api.config',
'st2stream.config',
'st2auth.config',
|
{"golden_diff": "diff --git a/tools/config_gen.py b/tools/config_gen.py\n--- a/tools/config_gen.py\n+++ b/tools/config_gen.py\n@@ -27,6 +27,7 @@\n CONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n+ 'st2actions.workflows.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n", "issue": "Missing [workflow_engine] in st2.conf.sample\n##### SUMMARY\r\n\r\nhttps://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample is missing a new section for `[workflow_engine]`\r\n\r\nAlso, shouldn't this section be named `[workflowengine]` to go along with the \"style\" of the other sections like `[resultstracker]` , `[garbagecollector]`, etc\r\n\r\n##### ISSUE TYPE\r\n - Bug Report\r\n - Feature Idea\r\n\r\n##### STACKSTORM VERSION\r\n2.8\r\n\r\n##### EXPECTED RESULTS\r\nhttps://github.com/StackStorm/st2/blob/master/conf/st2.conf.sample contains a section for `[workflow_engine]`\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nimport collections\nimport importlib\nimport six\nimport sys\nimport traceback\n\nfrom oslo_config import cfg\n\n\nCONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n 'st2common.config',\n 'st2exporter.config',\n 'st2reactor.rules.config',\n 'st2reactor.sensor.config',\n 'st2reactor.garbage_collector.config']\n\nSKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']\n\n# We group auth options together to nake it a bit more clear what applies where\nAUTH_OPTIONS = {\n 'common': [\n 'enable',\n 'mode',\n 'logging',\n 'api_url',\n 'token_ttl',\n 'service_token_ttl',\n 'debug'\n ],\n 'standalone': [\n 'host',\n 'port',\n 'use_ssl',\n 'cert',\n 'key',\n 'backend',\n 'backend_kwargs'\n ]\n}\n\n# Some of the config values change depenending on the environment where this script is ran so we\n# set them to static values to ensure consistent and stable output\nSTATIC_OPTION_VALUES = {\n 'actionrunner': {\n 'virtualenv_binary': '/usr/bin/virtualenv',\n 'python_binary': '/usr/bin/python',\n 'python3_binary': '/usr/bin/python3'\n },\n 'webui': {\n 'webui_base_url': 'https://localhost'\n }\n}\n\nCOMMON_AUTH_OPTIONS_COMMENT = \"\"\"\n# Common option - options below apply in both scenarios - when auth service is running as a WSGI\n# service (e.g. under Apache or Nginx) and when it's running in the standalone mode.\n\"\"\".strip()\n\nSTANDALONE_AUTH_OPTIONS_COMMENT = \"\"\"\n# Standalone mode options - options below only apply when auth service is running in the standalone\n# mode.\n\"\"\".strip()\n\n\ndef _import_config(config):\n try:\n return importlib.import_module(config)\n except:\n traceback.print_exc()\n return None\n\n\ndef _read_current_config(opt_groups):\n for k, v in six.iteritems(cfg.CONF._groups):\n if k in SKIP_GROUPS:\n continue\n if k not in opt_groups:\n opt_groups[k] = v\n return opt_groups\n\n\ndef _clear_config():\n cfg.CONF.reset()\n\n\ndef _read_group(opt_group):\n all_options = list(opt_group._opts.values())\n\n if opt_group.name == 'auth':\n print(COMMON_AUTH_OPTIONS_COMMENT)\n print('')\n common_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['common']]\n _print_options(opt_group=opt_group, options=common_options)\n\n print('')\n print(STANDALONE_AUTH_OPTIONS_COMMENT)\n print('')\n standalone_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['standalone']]\n _print_options(opt_group=opt_group, options=standalone_options)\n\n if len(common_options) + len(standalone_options) != len(all_options):\n msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')\n raise Exception(msg)\n else:\n options = all_options\n _print_options(opt_group=opt_group, options=options)\n\n\ndef _read_groups(opt_groups):\n opt_groups = collections.OrderedDict(sorted(opt_groups.items()))\n for name, opt_group in six.iteritems(opt_groups):\n print('[%s]' % name)\n _read_group(opt_group)\n print('')\n\n\ndef _print_options(opt_group, options):\n for opt in options:\n opt = opt['opt']\n\n # Special case for options which could change during this script run\n static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)\n if static_option_value:\n opt.default = static_option_value\n\n # Special handling for list options\n if isinstance(opt, cfg.ListOpt):\n if opt.default:\n value = ','.join(opt.default)\n else:\n value = ''\n\n value += ' # comma separated list allowed here.'\n else:\n value = opt.default\n\n print('# %s' % opt.help)\n print('%s = %s' % (opt.name, value))\n\n\ndef main(args):\n opt_groups = {}\n for config in CONFIGS:\n mod = _import_config(config)\n mod.register_opts()\n _read_current_config(opt_groups)\n _clear_config()\n _read_groups(opt_groups)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "tools/config_gen.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\nimport collections\nimport importlib\nimport six\nimport sys\nimport traceback\n\nfrom oslo_config import cfg\n\n\nCONFIGS = ['st2actions.config',\n 'st2actions.notifier.config',\n 'st2actions.resultstracker.config',\n 'st2actions.workflows.config',\n 'st2api.config',\n 'st2stream.config',\n 'st2auth.config',\n 'st2common.config',\n 'st2exporter.config',\n 'st2reactor.rules.config',\n 'st2reactor.sensor.config',\n 'st2reactor.garbage_collector.config']\n\nSKIP_GROUPS = ['api_pecan', 'rbac', 'results_tracker']\n\n# We group auth options together to nake it a bit more clear what applies where\nAUTH_OPTIONS = {\n 'common': [\n 'enable',\n 'mode',\n 'logging',\n 'api_url',\n 'token_ttl',\n 'service_token_ttl',\n 'debug'\n ],\n 'standalone': [\n 'host',\n 'port',\n 'use_ssl',\n 'cert',\n 'key',\n 'backend',\n 'backend_kwargs'\n ]\n}\n\n# Some of the config values change depenending on the environment where this script is ran so we\n# set them to static values to ensure consistent and stable output\nSTATIC_OPTION_VALUES = {\n 'actionrunner': {\n 'virtualenv_binary': '/usr/bin/virtualenv',\n 'python_binary': '/usr/bin/python',\n 'python3_binary': '/usr/bin/python3'\n },\n 'webui': {\n 'webui_base_url': 'https://localhost'\n }\n}\n\nCOMMON_AUTH_OPTIONS_COMMENT = \"\"\"\n# Common option - options below apply in both scenarios - when auth service is running as a WSGI\n# service (e.g. under Apache or Nginx) and when it's running in the standalone mode.\n\"\"\".strip()\n\nSTANDALONE_AUTH_OPTIONS_COMMENT = \"\"\"\n# Standalone mode options - options below only apply when auth service is running in the standalone\n# mode.\n\"\"\".strip()\n\n\ndef _import_config(config):\n try:\n return importlib.import_module(config)\n except:\n traceback.print_exc()\n return None\n\n\ndef _read_current_config(opt_groups):\n for k, v in six.iteritems(cfg.CONF._groups):\n if k in SKIP_GROUPS:\n continue\n if k not in opt_groups:\n opt_groups[k] = v\n return opt_groups\n\n\ndef _clear_config():\n cfg.CONF.reset()\n\n\ndef _read_group(opt_group):\n all_options = list(opt_group._opts.values())\n\n if opt_group.name == 'auth':\n print(COMMON_AUTH_OPTIONS_COMMENT)\n print('')\n common_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['common']]\n _print_options(opt_group=opt_group, options=common_options)\n\n print('')\n print(STANDALONE_AUTH_OPTIONS_COMMENT)\n print('')\n standalone_options = [option for option in all_options if option['opt'].name in\n AUTH_OPTIONS['standalone']]\n _print_options(opt_group=opt_group, options=standalone_options)\n\n if len(common_options) + len(standalone_options) != len(all_options):\n msg = ('Not all options are declared in AUTH_OPTIONS dict, please update it')\n raise Exception(msg)\n else:\n options = all_options\n _print_options(opt_group=opt_group, options=options)\n\n\ndef _read_groups(opt_groups):\n opt_groups = collections.OrderedDict(sorted(opt_groups.items()))\n for name, opt_group in six.iteritems(opt_groups):\n print('[%s]' % name)\n _read_group(opt_group)\n print('')\n\n\ndef _print_options(opt_group, options):\n for opt in options:\n opt = opt['opt']\n\n # Special case for options which could change during this script run\n static_option_value = STATIC_OPTION_VALUES.get(opt_group.name, {}).get(opt.name, None)\n if static_option_value:\n opt.default = static_option_value\n\n # Special handling for list options\n if isinstance(opt, cfg.ListOpt):\n if opt.default:\n value = ','.join(opt.default)\n else:\n value = ''\n\n value += ' # comma separated list allowed here.'\n else:\n value = opt.default\n\n print('# %s' % opt.help)\n print('%s = %s' % (opt.name, value))\n\n\ndef main(args):\n opt_groups = {}\n for config in CONFIGS:\n mod = _import_config(config)\n mod.register_opts()\n _read_current_config(opt_groups)\n _clear_config()\n _read_groups(opt_groups)\n\n\nif __name__ == '__main__':\n main(sys.argv)\n", "path": "tools/config_gen.py"}]}
| 2,015 | 99 |
gh_patches_debug_30559
|
rasdani/github-patches
|
git_diff
|
Gallopsled__pwntools-343
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pwnlib.term.text throws exceptions on attribute accesses
```
>>> import pwnlib
>>> pwnlib.term.text.__lol__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "pwnlib/term/text.py", line 99, in __getattr__
init += self._fg_color(c())
File "pwnlib/term/text.py", line 93, in c
return self._colors[c] + bright
KeyError: ''
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pwnlib/term/text.py`
Content:
```
1 import types, sys, functools
2 from . import termcap
3
4 def eval_when(when):
5 if isinstance(when, file) or \
6 when in ('always', 'never', 'auto', sys.stderr, sys.stdout):
7 if when == 'always':
8 return True
9 elif when == 'never':
10 return False
11 elif when == 'auto':
12 return sys.stdout.isatty()
13 else:
14 return when.isatty()
15 else:
16 raise ValueError('text.when: must be a file-object or "always", "never" or "auto"')
17
18 class Module(types.ModuleType):
19 def __init__(self):
20 self.__file__ = __file__
21 self.__name__ = __name__
22 self.num_colors = termcap.get('colors', default = 8)
23 self.has_bright = self.num_colors >= 16
24 self.has_gray = self.has_bright
25 self.when = 'auto'
26 self._colors = {
27 'black': 0,
28 'red': 1,
29 'green': 2,
30 'yellow': 3,
31 'blue': 4,
32 'magenta': 5,
33 'cyan': 6,
34 'white': 7,
35 }
36 self._reset = '\x1b[m'
37 self._attributes = {}
38 for x, y in [('italic' , 'sitm'),
39 ('bold' , 'bold'),
40 ('underline', 'smul'),
41 ('reverse' , 'rev')]:
42 s = termcap.get(y)
43 self._attributes[x] = s
44 self._cache = {}
45
46 @property
47 def when(self):
48 return self._when
49
50 @when.setter
51 def when(self, val):
52 self._when = eval_when(val)
53
54 def _fg_color(self, c):
55 return termcap.get('setaf', c) or termcap.get('setf', c)
56
57 def _bg_color(self, c):
58 return termcap.get('setab', c) or termcap.get('setb', c)
59
60 def _decorator(self, desc, init):
61 def f(self, s, when = None):
62 if when:
63 if eval_when(when):
64 return init + s + self._reset
65 else:
66 return s
67 else:
68 if self.when:
69 return init + s + self._reset
70 else:
71 return s
72 setattr(Module, desc, f)
73 return functools.partial(f, self)
74
75 def __getattr__(self, desc):
76 ds = desc.replace('gray', 'bright_black').split('_')
77 init = ''
78 while ds:
79 d = ds[0]
80 try:
81 init += self._attributes[d]
82 ds.pop(0)
83 except KeyError:
84 break
85 def c():
86 bright = 0
87 c = ds.pop(0)
88 if c == 'bright':
89 c = ds.pop(0)
90 if self.has_bright:
91 bright = 8
92 return self._colors[c] + bright
93 if ds:
94 if ds[0] == 'on':
95 ds.pop(0)
96 init += self._bg_color(c())
97 else:
98 init += self._fg_color(c())
99 if len(ds):
100 assert ds.pop(0) == 'on'
101 init += self._bg_color(c())
102 return self._decorator(desc, init)
103
104 def get(self, desc):
105 return self.__getattr__(desc)
106
107 tether = sys.modules[__name__]
108 sys.modules[__name__] = Module()
109
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pwnlib/term/text.py b/pwnlib/term/text.py
--- a/pwnlib/term/text.py
+++ b/pwnlib/term/text.py
@@ -73,33 +73,36 @@
return functools.partial(f, self)
def __getattr__(self, desc):
- ds = desc.replace('gray', 'bright_black').split('_')
- init = ''
- while ds:
- d = ds[0]
- try:
- init += self._attributes[d]
- ds.pop(0)
- except KeyError:
- break
- def c():
- bright = 0
- c = ds.pop(0)
- if c == 'bright':
+ try:
+ ds = desc.replace('gray', 'bright_black').split('_')
+ init = ''
+ while ds:
+ d = ds[0]
+ try:
+ init += self._attributes[d]
+ ds.pop(0)
+ except KeyError:
+ break
+ def c():
+ bright = 0
c = ds.pop(0)
- if self.has_bright:
- bright = 8
- return self._colors[c] + bright
- if ds:
- if ds[0] == 'on':
- ds.pop(0)
- init += self._bg_color(c())
- else:
- init += self._fg_color(c())
- if len(ds):
- assert ds.pop(0) == 'on'
+ if c == 'bright':
+ c = ds.pop(0)
+ if self.has_bright:
+ bright = 8
+ return self._colors[c] + bright
+ if ds:
+ if ds[0] == 'on':
+ ds.pop(0)
init += self._bg_color(c())
- return self._decorator(desc, init)
+ else:
+ init += self._fg_color(c())
+ if len(ds):
+ assert ds.pop(0) == 'on'
+ init += self._bg_color(c())
+ return self._decorator(desc, init)
+ except (IndexError, KeyError):
+ raise AttributeError("'module' object has no attribute %r" % desc)
def get(self, desc):
return self.__getattr__(desc)
|
{"golden_diff": "diff --git a/pwnlib/term/text.py b/pwnlib/term/text.py\n--- a/pwnlib/term/text.py\n+++ b/pwnlib/term/text.py\n@@ -73,33 +73,36 @@\n return functools.partial(f, self)\n \n def __getattr__(self, desc):\n- ds = desc.replace('gray', 'bright_black').split('_')\n- init = ''\n- while ds:\n- d = ds[0]\n- try:\n- init += self._attributes[d]\n- ds.pop(0)\n- except KeyError:\n- break\n- def c():\n- bright = 0\n- c = ds.pop(0)\n- if c == 'bright':\n+ try:\n+ ds = desc.replace('gray', 'bright_black').split('_')\n+ init = ''\n+ while ds:\n+ d = ds[0]\n+ try:\n+ init += self._attributes[d]\n+ ds.pop(0)\n+ except KeyError:\n+ break\n+ def c():\n+ bright = 0\n c = ds.pop(0)\n- if self.has_bright:\n- bright = 8\n- return self._colors[c] + bright\n- if ds:\n- if ds[0] == 'on':\n- ds.pop(0)\n- init += self._bg_color(c())\n- else:\n- init += self._fg_color(c())\n- if len(ds):\n- assert ds.pop(0) == 'on'\n+ if c == 'bright':\n+ c = ds.pop(0)\n+ if self.has_bright:\n+ bright = 8\n+ return self._colors[c] + bright\n+ if ds:\n+ if ds[0] == 'on':\n+ ds.pop(0)\n init += self._bg_color(c())\n- return self._decorator(desc, init)\n+ else:\n+ init += self._fg_color(c())\n+ if len(ds):\n+ assert ds.pop(0) == 'on'\n+ init += self._bg_color(c())\n+ return self._decorator(desc, init)\n+ except (IndexError, KeyError):\n+ raise AttributeError(\"'module' object has no attribute %r\" % desc)\n \n def get(self, desc):\n return self.__getattr__(desc)\n", "issue": "pwnlib.term.text throws exceptions on attribute accesses\n```\n>>> import pwnlib\n>>> pwnlib.term.text.__lol__\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"pwnlib/term/text.py\", line 99, in __getattr__\n init += self._fg_color(c())\n File \"pwnlib/term/text.py\", line 93, in c\n return self._colors[c] + bright\nKeyError: ''\n```\n\n", "before_files": [{"content": "import types, sys, functools\nfrom . import termcap\n\ndef eval_when(when):\n if isinstance(when, file) or \\\n when in ('always', 'never', 'auto', sys.stderr, sys.stdout):\n if when == 'always':\n return True\n elif when == 'never':\n return False\n elif when == 'auto':\n return sys.stdout.isatty()\n else:\n return when.isatty()\n else:\n raise ValueError('text.when: must be a file-object or \"always\", \"never\" or \"auto\"')\n\nclass Module(types.ModuleType):\n def __init__(self):\n self.__file__ = __file__\n self.__name__ = __name__\n self.num_colors = termcap.get('colors', default = 8)\n self.has_bright = self.num_colors >= 16\n self.has_gray = self.has_bright\n self.when = 'auto'\n self._colors = {\n 'black': 0,\n 'red': 1,\n 'green': 2,\n 'yellow': 3,\n 'blue': 4,\n 'magenta': 5,\n 'cyan': 6,\n 'white': 7,\n }\n self._reset = '\\x1b[m'\n self._attributes = {}\n for x, y in [('italic' , 'sitm'),\n ('bold' , 'bold'),\n ('underline', 'smul'),\n ('reverse' , 'rev')]:\n s = termcap.get(y)\n self._attributes[x] = s\n self._cache = {}\n\n @property\n def when(self):\n return self._when\n\n @when.setter\n def when(self, val):\n self._when = eval_when(val)\n\n def _fg_color(self, c):\n return termcap.get('setaf', c) or termcap.get('setf', c)\n\n def _bg_color(self, c):\n return termcap.get('setab', c) or termcap.get('setb', c)\n\n def _decorator(self, desc, init):\n def f(self, s, when = None):\n if when:\n if eval_when(when):\n return init + s + self._reset\n else:\n return s\n else:\n if self.when:\n return init + s + self._reset\n else:\n return s\n setattr(Module, desc, f)\n return functools.partial(f, self)\n\n def __getattr__(self, desc):\n ds = desc.replace('gray', 'bright_black').split('_')\n init = ''\n while ds:\n d = ds[0]\n try:\n init += self._attributes[d]\n ds.pop(0)\n except KeyError:\n break\n def c():\n bright = 0\n c = ds.pop(0)\n if c == 'bright':\n c = ds.pop(0)\n if self.has_bright:\n bright = 8\n return self._colors[c] + bright\n if ds:\n if ds[0] == 'on':\n ds.pop(0)\n init += self._bg_color(c())\n else:\n init += self._fg_color(c())\n if len(ds):\n assert ds.pop(0) == 'on'\n init += self._bg_color(c())\n return self._decorator(desc, init)\n\n def get(self, desc):\n return self.__getattr__(desc)\n\ntether = sys.modules[__name__]\nsys.modules[__name__] = Module()\n", "path": "pwnlib/term/text.py"}], "after_files": [{"content": "import types, sys, functools\nfrom . import termcap\n\ndef eval_when(when):\n if isinstance(when, file) or \\\n when in ('always', 'never', 'auto', sys.stderr, sys.stdout):\n if when == 'always':\n return True\n elif when == 'never':\n return False\n elif when == 'auto':\n return sys.stdout.isatty()\n else:\n return when.isatty()\n else:\n raise ValueError('text.when: must be a file-object or \"always\", \"never\" or \"auto\"')\n\nclass Module(types.ModuleType):\n def __init__(self):\n self.__file__ = __file__\n self.__name__ = __name__\n self.num_colors = termcap.get('colors', default = 8)\n self.has_bright = self.num_colors >= 16\n self.has_gray = self.has_bright\n self.when = 'auto'\n self._colors = {\n 'black': 0,\n 'red': 1,\n 'green': 2,\n 'yellow': 3,\n 'blue': 4,\n 'magenta': 5,\n 'cyan': 6,\n 'white': 7,\n }\n self._reset = '\\x1b[m'\n self._attributes = {}\n for x, y in [('italic' , 'sitm'),\n ('bold' , 'bold'),\n ('underline', 'smul'),\n ('reverse' , 'rev')]:\n s = termcap.get(y)\n self._attributes[x] = s\n self._cache = {}\n\n @property\n def when(self):\n return self._when\n\n @when.setter\n def when(self, val):\n self._when = eval_when(val)\n\n def _fg_color(self, c):\n return termcap.get('setaf', c) or termcap.get('setf', c)\n\n def _bg_color(self, c):\n return termcap.get('setab', c) or termcap.get('setb', c)\n\n def _decorator(self, desc, init):\n def f(self, s, when = None):\n if when:\n if eval_when(when):\n return init + s + self._reset\n else:\n return s\n else:\n if self.when:\n return init + s + self._reset\n else:\n return s\n setattr(Module, desc, f)\n return functools.partial(f, self)\n\n def __getattr__(self, desc):\n try:\n ds = desc.replace('gray', 'bright_black').split('_')\n init = ''\n while ds:\n d = ds[0]\n try:\n init += self._attributes[d]\n ds.pop(0)\n except KeyError:\n break\n def c():\n bright = 0\n c = ds.pop(0)\n if c == 'bright':\n c = ds.pop(0)\n if self.has_bright:\n bright = 8\n return self._colors[c] + bright\n if ds:\n if ds[0] == 'on':\n ds.pop(0)\n init += self._bg_color(c())\n else:\n init += self._fg_color(c())\n if len(ds):\n assert ds.pop(0) == 'on'\n init += self._bg_color(c())\n return self._decorator(desc, init)\n except (IndexError, KeyError):\n raise AttributeError(\"'module' object has no attribute %r\" % desc)\n\n def get(self, desc):\n return self.__getattr__(desc)\n\ntether = sys.modules[__name__]\nsys.modules[__name__] = Module()\n", "path": "pwnlib/term/text.py"}]}
| 1,362 | 523 |
gh_patches_debug_35673
|
rasdani/github-patches
|
git_diff
|
amundsen-io__amundsen-1573
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bug Report - Postegres / Redshift Extractors have inconsistent behavior
<!--- Provide a general summary of the issue in the Title above -->
<!--- Look through existing open and closed issues to see if someone has reported the issue before -->
## Expected Behavior
```python
# For RedshiftMetadataExtractor
redshift_metadata_extractor_config = ConfigFactory.from_dict({
'extractor.redshift_metadata.where_clause_suffix': 'schema <> "foo"'
})
```
## Current Behavior
```python
# For RedshiftMetadataExtractor
redshift_metadata_extractor_config = ConfigFactory.from_dict({
'extractor.redshift_metadata.where_clause_suffix': 'where schema <> "foo"'
})
```
## Possible Solution
Update redshift extractor to properly build suffix
## Screenshots (if appropriate)
## Context
Both the `PostgresMetadataExtractor` and the `RedshiftMetadataExtractor` take the config `extractor.redshift_metadata.where_clause_suffix` as they are both based off of `BasePostgresMetadataExtractor`.
However they require slightly different different sql partials, which is unexpected:
The `where_clause_suffix` for `RedshiftMetadataExtractor` takes a partial sql statement **without** a `WHERE`.
The `where_clause_suffix` for `PostgresMetadataExtractor` take a partial sql statement **with** a `WHERE`.
The name `where_clause_suffix` implies that its a statement appended to a where clause and should _not_ (IMHO) require a `WHERE` statement.
<!--- How has this issue affected you? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Amunsen version used: amundsen-databuilder 6.3.1
* Data warehouse stores: Neo4j
* Deployment (k8s or native): terraform
* Link to your fork or repository:
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `databuilder/databuilder/extractor/redshift_metadata_extractor.py`
Content:
```
1 # Copyright Contributors to the Amundsen project.
2 # SPDX-License-Identifier: Apache-2.0
3
4 from typing import ( # noqa: F401
5 Any, Dict, Iterator, Union,
6 )
7
8 from pyhocon import ConfigFactory, ConfigTree # noqa: F401
9
10 from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor
11
12
13 class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):
14 """
15 Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor
16
17 This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,
18 we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().
19 """
20
21 def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:
22 if use_catalog_as_cluster_name:
23 cluster_source = "CURRENT_DATABASE()"
24 else:
25 cluster_source = f"'{self._cluster}'"
26
27 return """
28 SELECT
29 *
30 FROM (
31 SELECT
32 {cluster_source} as cluster,
33 c.table_schema as schema,
34 c.table_name as name,
35 pgtd.description as description,
36 c.column_name as col_name,
37 c.data_type as col_type,
38 pgcd.description as col_description,
39 ordinal_position as col_sort_order
40 FROM INFORMATION_SCHEMA.COLUMNS c
41 INNER JOIN
42 pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname
43 LEFT JOIN
44 pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position
45 LEFT JOIN
46 pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0
47
48 UNION
49
50 SELECT
51 {cluster_source} as cluster,
52 view_schema as schema,
53 view_name as name,
54 NULL as description,
55 column_name as col_name,
56 data_type as col_type,
57 NULL as col_description,
58 ordinal_position as col_sort_order
59 FROM
60 PG_GET_LATE_BINDING_VIEW_COLS()
61 COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)
62
63 UNION
64
65 SELECT
66 {cluster_source} AS cluster,
67 schemaname AS schema,
68 tablename AS name,
69 NULL AS description,
70 columnname AS col_name,
71 external_type AS col_type,
72 NULL AS col_description,
73 columnnum AS col_sort_order
74 FROM svv_external_columns
75 )
76
77 {where_clause_suffix}
78 ORDER by cluster, schema, name, col_sort_order ;
79 """.format(
80 cluster_source=cluster_source,
81 where_clause_suffix=where_clause_suffix,
82 )
83
84 def get_scope(self) -> str:
85 return 'extractor.redshift_metadata'
86
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/databuilder/databuilder/extractor/redshift_metadata_extractor.py b/databuilder/databuilder/extractor/redshift_metadata_extractor.py
--- a/databuilder/databuilder/extractor/redshift_metadata_extractor.py
+++ b/databuilder/databuilder/extractor/redshift_metadata_extractor.py
@@ -1,6 +1,7 @@
# Copyright Contributors to the Amundsen project.
# SPDX-License-Identifier: Apache-2.0
+import logging
from typing import ( # noqa: F401
Any, Dict, Iterator, Union,
)
@@ -9,11 +10,14 @@
from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor
+LOGGER = logging.getLogger(__name__)
+
class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):
"""
Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor
+
This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,
we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().
"""
@@ -24,6 +28,15 @@
else:
cluster_source = f"'{self._cluster}'"
+ if where_clause_suffix:
+ if where_clause_suffix.lower().startswith("where"):
+ LOGGER.warning("you no longer need to begin with 'where' in your suffix")
+ where_clause = where_clause_suffix
+ else:
+ where_clause = f"where {where_clause_suffix}"
+ else:
+ where_clause = ""
+
return """
SELECT
*
@@ -74,11 +87,11 @@
FROM svv_external_columns
)
- {where_clause_suffix}
+ {where_clause}
ORDER by cluster, schema, name, col_sort_order ;
""".format(
cluster_source=cluster_source,
- where_clause_suffix=where_clause_suffix,
+ where_clause=where_clause,
)
def get_scope(self) -> str:
|
{"golden_diff": "diff --git a/databuilder/databuilder/extractor/redshift_metadata_extractor.py b/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n--- a/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n+++ b/databuilder/databuilder/extractor/redshift_metadata_extractor.py\n@@ -1,6 +1,7 @@\n # Copyright Contributors to the Amundsen project.\n # SPDX-License-Identifier: Apache-2.0\n \n+import logging\n from typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n )\n@@ -9,11 +10,14 @@\n \n from databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n \n+LOGGER = logging.getLogger(__name__)\n+\n \n class RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n \n+\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n@@ -24,6 +28,15 @@\n else:\n cluster_source = f\"'{self._cluster}'\"\n \n+ if where_clause_suffix:\n+ if where_clause_suffix.lower().startswith(\"where\"):\n+ LOGGER.warning(\"you no longer need to begin with 'where' in your suffix\")\n+ where_clause = where_clause_suffix\n+ else:\n+ where_clause = f\"where {where_clause_suffix}\"\n+ else:\n+ where_clause = \"\"\n+\n return \"\"\"\n SELECT\n *\n@@ -74,11 +87,11 @@\n FROM svv_external_columns\n )\n \n- {where_clause_suffix}\n+ {where_clause}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n- where_clause_suffix=where_clause_suffix,\n+ where_clause=where_clause,\n )\n \n def get_scope(self) -> str:\n", "issue": "Bug Report - Postegres / Redshift Extractors have inconsistent behavior\n<!--- Provide a general summary of the issue in the Title above -->\r\n<!--- Look through existing open and closed issues to see if someone has reported the issue before -->\r\n\r\n## Expected Behavior\r\n\r\n```python\r\n# For RedshiftMetadataExtractor\r\nredshift_metadata_extractor_config = ConfigFactory.from_dict({\r\n 'extractor.redshift_metadata.where_clause_suffix': 'schema <> \"foo\"'\r\n})\r\n```\r\n\r\n## Current Behavior\r\n\r\n```python\r\n# For RedshiftMetadataExtractor\r\nredshift_metadata_extractor_config = ConfigFactory.from_dict({\r\n 'extractor.redshift_metadata.where_clause_suffix': 'where schema <> \"foo\"'\r\n})\r\n```\r\n\r\n## Possible Solution\r\n\r\nUpdate redshift extractor to properly build suffix\r\n\r\n## Screenshots (if appropriate)\r\n\r\n## Context\r\n\r\nBoth the `PostgresMetadataExtractor` and the `RedshiftMetadataExtractor` take the config `extractor.redshift_metadata.where_clause_suffix` as they are both based off of `BasePostgresMetadataExtractor`.\r\n\r\nHowever they require slightly different different sql partials, which is unexpected: \r\n\r\nThe `where_clause_suffix` for `RedshiftMetadataExtractor` takes a partial sql statement **without** a `WHERE`.\r\nThe `where_clause_suffix` for `PostgresMetadataExtractor` take a partial sql statement **with** a `WHERE`.\r\n\r\nThe name `where_clause_suffix` implies that its a statement appended to a where clause and should _not_ (IMHO) require a `WHERE` statement.\r\n\r\n\r\n<!--- How has this issue affected you? -->\r\n<!--- Providing context helps us come up with a solution that is most useful in the real world -->\r\n\r\n## Your Environment\r\n<!--- Include as many relevant details about the environment you experienced the bug in -->\r\n* Amunsen version used: amundsen-databuilder 6.3.1\r\n* Data warehouse stores: Neo4j\r\n* Deployment (k8s or native): terraform\r\n* Link to your fork or repository:\n", "before_files": [{"content": "# Copyright Contributors to the Amundsen project.\n# SPDX-License-Identifier: Apache-2.0\n\nfrom typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n)\n\nfrom pyhocon import ConfigFactory, ConfigTree # noqa: F401\n\nfrom databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n\n\nclass RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n\n def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:\n if use_catalog_as_cluster_name:\n cluster_source = \"CURRENT_DATABASE()\"\n else:\n cluster_source = f\"'{self._cluster}'\"\n\n return \"\"\"\n SELECT\n *\n FROM (\n SELECT\n {cluster_source} as cluster,\n c.table_schema as schema,\n c.table_name as name,\n pgtd.description as description,\n c.column_name as col_name,\n c.data_type as col_type,\n pgcd.description as col_description,\n ordinal_position as col_sort_order\n FROM INFORMATION_SCHEMA.COLUMNS c\n INNER JOIN\n pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname\n LEFT JOIN\n pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position\n LEFT JOIN\n pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0\n\n UNION\n\n SELECT\n {cluster_source} as cluster,\n view_schema as schema,\n view_name as name,\n NULL as description,\n column_name as col_name,\n data_type as col_type,\n NULL as col_description,\n ordinal_position as col_sort_order\n FROM\n PG_GET_LATE_BINDING_VIEW_COLS()\n COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)\n\n UNION\n\n SELECT\n {cluster_source} AS cluster,\n schemaname AS schema,\n tablename AS name,\n NULL AS description,\n columnname AS col_name,\n external_type AS col_type,\n NULL AS col_description,\n columnnum AS col_sort_order\n FROM svv_external_columns\n )\n\n {where_clause_suffix}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n where_clause_suffix=where_clause_suffix,\n )\n\n def get_scope(self) -> str:\n return 'extractor.redshift_metadata'\n", "path": "databuilder/databuilder/extractor/redshift_metadata_extractor.py"}], "after_files": [{"content": "# Copyright Contributors to the Amundsen project.\n# SPDX-License-Identifier: Apache-2.0\n\nimport logging\nfrom typing import ( # noqa: F401\n Any, Dict, Iterator, Union,\n)\n\nfrom pyhocon import ConfigFactory, ConfigTree # noqa: F401\n\nfrom databuilder.extractor.base_postgres_metadata_extractor import BasePostgresMetadataExtractor\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass RedshiftMetadataExtractor(BasePostgresMetadataExtractor):\n \"\"\"\n Extracts Redshift table and column metadata from underlying meta store database using SQLAlchemyExtractor\n\n\n This differs from the PostgresMetadataExtractor because in order to support Redshift's late binding views,\n we need to join the INFORMATION_SCHEMA data against the function PG_GET_LATE_BINDING_VIEW_COLS().\n \"\"\"\n\n def get_sql_statement(self, use_catalog_as_cluster_name: bool, where_clause_suffix: str) -> str:\n if use_catalog_as_cluster_name:\n cluster_source = \"CURRENT_DATABASE()\"\n else:\n cluster_source = f\"'{self._cluster}'\"\n\n if where_clause_suffix:\n if where_clause_suffix.lower().startswith(\"where\"):\n LOGGER.warning(\"you no longer need to begin with 'where' in your suffix\")\n where_clause = where_clause_suffix\n else:\n where_clause = f\"where {where_clause_suffix}\"\n else:\n where_clause = \"\"\n\n return \"\"\"\n SELECT\n *\n FROM (\n SELECT\n {cluster_source} as cluster,\n c.table_schema as schema,\n c.table_name as name,\n pgtd.description as description,\n c.column_name as col_name,\n c.data_type as col_type,\n pgcd.description as col_description,\n ordinal_position as col_sort_order\n FROM INFORMATION_SCHEMA.COLUMNS c\n INNER JOIN\n pg_catalog.pg_statio_all_tables as st on c.table_schema=st.schemaname and c.table_name=st.relname\n LEFT JOIN\n pg_catalog.pg_description pgcd on pgcd.objoid=st.relid and pgcd.objsubid=c.ordinal_position\n LEFT JOIN\n pg_catalog.pg_description pgtd on pgtd.objoid=st.relid and pgtd.objsubid=0\n\n UNION\n\n SELECT\n {cluster_source} as cluster,\n view_schema as schema,\n view_name as name,\n NULL as description,\n column_name as col_name,\n data_type as col_type,\n NULL as col_description,\n ordinal_position as col_sort_order\n FROM\n PG_GET_LATE_BINDING_VIEW_COLS()\n COLS(view_schema NAME, view_name NAME, column_name NAME, data_type VARCHAR, ordinal_position INT)\n\n UNION\n\n SELECT\n {cluster_source} AS cluster,\n schemaname AS schema,\n tablename AS name,\n NULL AS description,\n columnname AS col_name,\n external_type AS col_type,\n NULL AS col_description,\n columnnum AS col_sort_order\n FROM svv_external_columns\n )\n\n {where_clause}\n ORDER by cluster, schema, name, col_sort_order ;\n \"\"\".format(\n cluster_source=cluster_source,\n where_clause=where_clause,\n )\n\n def get_scope(self) -> str:\n return 'extractor.redshift_metadata'\n", "path": "databuilder/databuilder/extractor/redshift_metadata_extractor.py"}]}
| 1,459 | 445 |
gh_patches_debug_2371
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1040
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Kinto Admin version not shown in footer

Looks like the effects of this are lost when packaged as a kinto plugin:
https://github.com/Kinto/kinto-admin/commit/8b184b041121ed4affddfbc2ce98ce658226ee34
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/plugins/admin/__init__.py`
Content:
```
1 from pyramid.static import static_view
2 from pyramid.httpexceptions import HTTPTemporaryRedirect
3
4
5 def includeme(config):
6 # Process settings to remove storage wording.
7
8 # Expose capability.
9 config.add_api_capability(
10 "admin",
11 version="1.8.0",
12 description="Serves the admin console.",
13 url="https://github.com/Kinto/kinto-admin/",
14 )
15
16 build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)
17 config.add_route('catchall_static', '/admin/*subpath')
18 config.add_view(build_dir, route_name="catchall_static")
19
20 # Setup redirect without trailing slash.
21 def admin_redirect_view(request):
22 raise HTTPTemporaryRedirect(request.path + '/')
23
24 config.add_route('admin_redirect', '/admin')
25 config.add_view(admin_redirect_view, route_name="admin_redirect")
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/kinto/plugins/admin/__init__.py b/kinto/plugins/admin/__init__.py
--- a/kinto/plugins/admin/__init__.py
+++ b/kinto/plugins/admin/__init__.py
@@ -8,7 +8,7 @@
# Expose capability.
config.add_api_capability(
"admin",
- version="1.8.0",
+ version="1.8.1",
description="Serves the admin console.",
url="https://github.com/Kinto/kinto-admin/",
)
|
{"golden_diff": "diff --git a/kinto/plugins/admin/__init__.py b/kinto/plugins/admin/__init__.py\n--- a/kinto/plugins/admin/__init__.py\n+++ b/kinto/plugins/admin/__init__.py\n@@ -8,7 +8,7 @@\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n- version=\"1.8.0\",\n+ version=\"1.8.1\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n", "issue": "Kinto Admin version not shown in footer\n\r\n\r\n\r\nLooks like the effects of this are lost when packaged as a kinto plugin:\r\n\r\nhttps://github.com/Kinto/kinto-admin/commit/8b184b041121ed4affddfbc2ce98ce658226ee34\n", "before_files": [{"content": "from pyramid.static import static_view\nfrom pyramid.httpexceptions import HTTPTemporaryRedirect\n\n\ndef includeme(config):\n # Process settings to remove storage wording.\n\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n version=\"1.8.0\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n\n build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)\n config.add_route('catchall_static', '/admin/*subpath')\n config.add_view(build_dir, route_name=\"catchall_static\")\n\n # Setup redirect without trailing slash.\n def admin_redirect_view(request):\n raise HTTPTemporaryRedirect(request.path + '/')\n\n config.add_route('admin_redirect', '/admin')\n config.add_view(admin_redirect_view, route_name=\"admin_redirect\")\n", "path": "kinto/plugins/admin/__init__.py"}], "after_files": [{"content": "from pyramid.static import static_view\nfrom pyramid.httpexceptions import HTTPTemporaryRedirect\n\n\ndef includeme(config):\n # Process settings to remove storage wording.\n\n # Expose capability.\n config.add_api_capability(\n \"admin\",\n version=\"1.8.1\",\n description=\"Serves the admin console.\",\n url=\"https://github.com/Kinto/kinto-admin/\",\n )\n\n build_dir = static_view('kinto.plugins.admin:build', use_subpath=True)\n config.add_route('catchall_static', '/admin/*subpath')\n config.add_view(build_dir, route_name=\"catchall_static\")\n\n # Setup redirect without trailing slash.\n def admin_redirect_view(request):\n raise HTTPTemporaryRedirect(request.path + '/')\n\n config.add_route('admin_redirect', '/admin')\n config.add_view(admin_redirect_view, route_name=\"admin_redirect\")\n", "path": "kinto/plugins/admin/__init__.py"}]}
| 643 | 114 |
gh_patches_debug_174
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-3469
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Expose "get_url" via the plugin interface
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/plugin/util.py`
Content:
```
1 from pulpcore.app.role_util import ( # noqa
2 assign_role,
3 get_groups_with_perms,
4 get_groups_with_perms_attached_perms,
5 get_groups_with_perms_attached_roles,
6 get_objects_for_group,
7 get_objects_for_user,
8 get_perms_for_model,
9 get_users_with_perms,
10 get_users_with_perms_attached_perms,
11 get_users_with_perms_attached_roles,
12 remove_role,
13 )
14
15 from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa
16
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pulpcore/plugin/util.py b/pulpcore/plugin/util.py
--- a/pulpcore/plugin/util.py
+++ b/pulpcore/plugin/util.py
@@ -12,4 +12,4 @@
remove_role,
)
-from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa
+from pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa
|
{"golden_diff": "diff --git a/pulpcore/plugin/util.py b/pulpcore/plugin/util.py\n--- a/pulpcore/plugin/util.py\n+++ b/pulpcore/plugin/util.py\n@@ -12,4 +12,4 @@\n remove_role,\n )\n \n-from pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa\n+from pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa\n", "issue": "Expose \"get_url\" via the plugin interface\n\n", "before_files": [{"content": "from pulpcore.app.role_util import ( # noqa\n assign_role,\n get_groups_with_perms,\n get_groups_with_perms_attached_perms,\n get_groups_with_perms_attached_roles,\n get_objects_for_group,\n get_objects_for_user,\n get_perms_for_model,\n get_users_with_perms,\n get_users_with_perms_attached_perms,\n get_users_with_perms_attached_roles,\n remove_role,\n)\n\nfrom pulpcore.app.util import get_artifact_url, gpg_verify, verify_signature # noqa\n", "path": "pulpcore/plugin/util.py"}], "after_files": [{"content": "from pulpcore.app.role_util import ( # noqa\n assign_role,\n get_groups_with_perms,\n get_groups_with_perms_attached_perms,\n get_groups_with_perms_attached_roles,\n get_objects_for_group,\n get_objects_for_user,\n get_perms_for_model,\n get_users_with_perms,\n get_users_with_perms_attached_perms,\n get_users_with_perms_attached_roles,\n remove_role,\n)\n\nfrom pulpcore.app.util import get_artifact_url, get_url, gpg_verify, verify_signature # noqa\n", "path": "pulpcore/plugin/util.py"}]}
| 398 | 100 |
gh_patches_debug_21011
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-18334
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
compress
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py`
Content:
```
1 import ivy
2 from ivy.functional.frontends.numpy.func_wrapper import (
3 to_ivy_arrays_and_back,
4 inputs_to_ivy_arrays,
5 )
6
7
8 @to_ivy_arrays_and_back
9 def take_along_axis(arr, indices, axis):
10 return ivy.take_along_axis(arr, indices, axis)
11
12
13 @to_ivy_arrays_and_back
14 def tril_indices(n, k=0, m=None):
15 return ivy.tril_indices(n, m, k)
16
17
18 @to_ivy_arrays_and_back
19 def indices(dimensions, dtype=int, sparse=False):
20 dimensions = tuple(dimensions)
21 N = len(dimensions)
22 shape = (1,) * N
23 if sparse:
24 res = tuple()
25 else:
26 res = ivy.empty((N,) + dimensions, dtype=dtype)
27 for i, dim in enumerate(dimensions):
28 idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])
29 if sparse:
30 res = res + (idx,)
31 else:
32 res[i] = idx
33 return res
34
35
36 # unravel_index
37 @to_ivy_arrays_and_back
38 def unravel_index(indices, shape, order="C"):
39 ret = [x.astype("int64") for x in ivy.unravel_index(indices, shape)]
40 return tuple(ret)
41
42
43 @to_ivy_arrays_and_back
44 def fill_diagonal(a, val, wrap=False):
45 if a.ndim < 2:
46 raise ValueError("array must be at least 2-d")
47 end = None
48 if a.ndim == 2:
49 # Explicit, fast formula for the common case. For 2-d arrays, we
50 # accept rectangular ones.
51 step = a.shape[1] + 1
52 # This is needed to don't have tall matrix have the diagonal wrap.
53 if not wrap:
54 end = a.shape[1] * a.shape[1]
55 else:
56 # For more than d=2, the strided formula is only valid for arrays with
57 # all dimensions equal, so we check first.
58 if not ivy.all(ivy.diff(a.shape) == 0):
59 raise ValueError("All dimensions of input must be of equal length")
60 step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))
61
62 # Write the value out into the diagonal.
63 shape = a.shape
64 a = ivy.reshape(a, a.size)
65 a[:end:step] = val
66 a = ivy.reshape(a, shape)
67
68
69 @inputs_to_ivy_arrays
70 def put_along_axis(arr, indices, values, axis):
71 ivy.put_along_axis(arr, indices, values, axis)
72
73
74 def diag(v, k=0):
75 return ivy.diag(v, k=k)
76
77
78 @to_ivy_arrays_and_back
79 def diagonal(a, offset, axis1, axis2):
80 return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
--- a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
+++ b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py
@@ -2,6 +2,7 @@
from ivy.functional.frontends.numpy.func_wrapper import (
to_ivy_arrays_and_back,
inputs_to_ivy_arrays,
+ handle_numpy_out,
)
@@ -78,3 +79,22 @@
@to_ivy_arrays_and_back
def diagonal(a, offset, axis1, axis2):
return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)
+
+
+@to_ivy_arrays_and_back
+@handle_numpy_out
+def compress(condition, a, axis=None, out=None):
+ condition_arr = ivy.asarray(condition).astype(bool)
+ if condition_arr.ndim != 1:
+ raise ivy.utils.exceptions.IvyException("Condition must be a 1D array")
+ if axis is None:
+ arr = ivy.asarray(a).flatten()
+ axis = 0
+ else:
+ arr = ivy.moveaxis(a, axis, 0)
+ if condition_arr.shape[0] > arr.shape[0]:
+ raise ivy.utils.exceptions.IvyException(
+ "Condition contains entries that are out of bounds"
+ )
+ arr = arr[: condition_arr.shape[0]]
+ return ivy.moveaxis(arr[condition_arr], 0, axis)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n--- a/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n+++ b/ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py\n@@ -2,6 +2,7 @@\n from ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n+ handle_numpy_out,\n )\n \n \n@@ -78,3 +79,22 @@\n @to_ivy_arrays_and_back\n def diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n+\n+\n+@to_ivy_arrays_and_back\n+@handle_numpy_out\n+def compress(condition, a, axis=None, out=None):\n+ condition_arr = ivy.asarray(condition).astype(bool)\n+ if condition_arr.ndim != 1:\n+ raise ivy.utils.exceptions.IvyException(\"Condition must be a 1D array\")\n+ if axis is None:\n+ arr = ivy.asarray(a).flatten()\n+ axis = 0\n+ else:\n+ arr = ivy.moveaxis(a, axis, 0)\n+ if condition_arr.shape[0] > arr.shape[0]:\n+ raise ivy.utils.exceptions.IvyException(\n+ \"Condition contains entries that are out of bounds\"\n+ )\n+ arr = arr[: condition_arr.shape[0]]\n+ return ivy.moveaxis(arr[condition_arr], 0, axis)\n", "issue": "compress\n\n", "before_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n)\n\n\n@to_ivy_arrays_and_back\ndef take_along_axis(arr, indices, axis):\n return ivy.take_along_axis(arr, indices, axis)\n\n\n@to_ivy_arrays_and_back\ndef tril_indices(n, k=0, m=None):\n return ivy.tril_indices(n, m, k)\n\n\n@to_ivy_arrays_and_back\ndef indices(dimensions, dtype=int, sparse=False):\n dimensions = tuple(dimensions)\n N = len(dimensions)\n shape = (1,) * N\n if sparse:\n res = tuple()\n else:\n res = ivy.empty((N,) + dimensions, dtype=dtype)\n for i, dim in enumerate(dimensions):\n idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])\n if sparse:\n res = res + (idx,)\n else:\n res[i] = idx\n return res\n\n\n# unravel_index\n@to_ivy_arrays_and_back\ndef unravel_index(indices, shape, order=\"C\"):\n ret = [x.astype(\"int64\") for x in ivy.unravel_index(indices, shape)]\n return tuple(ret)\n\n\n@to_ivy_arrays_and_back\ndef fill_diagonal(a, val, wrap=False):\n if a.ndim < 2:\n raise ValueError(\"array must be at least 2-d\")\n end = None\n if a.ndim == 2:\n # Explicit, fast formula for the common case. For 2-d arrays, we\n # accept rectangular ones.\n step = a.shape[1] + 1\n # This is needed to don't have tall matrix have the diagonal wrap.\n if not wrap:\n end = a.shape[1] * a.shape[1]\n else:\n # For more than d=2, the strided formula is only valid for arrays with\n # all dimensions equal, so we check first.\n if not ivy.all(ivy.diff(a.shape) == 0):\n raise ValueError(\"All dimensions of input must be of equal length\")\n step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))\n\n # Write the value out into the diagonal.\n shape = a.shape\n a = ivy.reshape(a, a.size)\n a[:end:step] = val\n a = ivy.reshape(a, shape)\n\n\n@inputs_to_ivy_arrays\ndef put_along_axis(arr, indices, values, axis):\n ivy.put_along_axis(arr, indices, values, axis)\n\n\ndef diag(v, k=0):\n return ivy.diag(v, k=k)\n\n\n@to_ivy_arrays_and_back\ndef diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n", "path": "ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py"}], "after_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n inputs_to_ivy_arrays,\n handle_numpy_out,\n)\n\n\n@to_ivy_arrays_and_back\ndef take_along_axis(arr, indices, axis):\n return ivy.take_along_axis(arr, indices, axis)\n\n\n@to_ivy_arrays_and_back\ndef tril_indices(n, k=0, m=None):\n return ivy.tril_indices(n, m, k)\n\n\n@to_ivy_arrays_and_back\ndef indices(dimensions, dtype=int, sparse=False):\n dimensions = tuple(dimensions)\n N = len(dimensions)\n shape = (1,) * N\n if sparse:\n res = tuple()\n else:\n res = ivy.empty((N,) + dimensions, dtype=dtype)\n for i, dim in enumerate(dimensions):\n idx = ivy.arange(dim, dtype=dtype).reshape(shape[:i] + (dim,) + shape[i + 1 :])\n if sparse:\n res = res + (idx,)\n else:\n res[i] = idx\n return res\n\n\n# unravel_index\n@to_ivy_arrays_and_back\ndef unravel_index(indices, shape, order=\"C\"):\n ret = [x.astype(\"int64\") for x in ivy.unravel_index(indices, shape)]\n return tuple(ret)\n\n\n@to_ivy_arrays_and_back\ndef fill_diagonal(a, val, wrap=False):\n if a.ndim < 2:\n raise ValueError(\"array must be at least 2-d\")\n end = None\n if a.ndim == 2:\n # Explicit, fast formula for the common case. For 2-d arrays, we\n # accept rectangular ones.\n step = a.shape[1] + 1\n # This is needed to don't have tall matrix have the diagonal wrap.\n if not wrap:\n end = a.shape[1] * a.shape[1]\n else:\n # For more than d=2, the strided formula is only valid for arrays with\n # all dimensions equal, so we check first.\n if not ivy.all(ivy.diff(a.shape) == 0):\n raise ValueError(\"All dimensions of input must be of equal length\")\n step = 1 + ivy.sum(ivy.cumprod(a.shape[:-1]))\n\n # Write the value out into the diagonal.\n shape = a.shape\n a = ivy.reshape(a, a.size)\n a[:end:step] = val\n a = ivy.reshape(a, shape)\n\n\n@inputs_to_ivy_arrays\ndef put_along_axis(arr, indices, values, axis):\n ivy.put_along_axis(arr, indices, values, axis)\n\n\ndef diag(v, k=0):\n return ivy.diag(v, k=k)\n\n\n@to_ivy_arrays_and_back\ndef diagonal(a, offset, axis1, axis2):\n return ivy.diagonal(a, offset=offset, axis1=axis1, axis2=axis2)\n\n\n@to_ivy_arrays_and_back\n@handle_numpy_out\ndef compress(condition, a, axis=None, out=None):\n condition_arr = ivy.asarray(condition).astype(bool)\n if condition_arr.ndim != 1:\n raise ivy.utils.exceptions.IvyException(\"Condition must be a 1D array\")\n if axis is None:\n arr = ivy.asarray(a).flatten()\n axis = 0\n else:\n arr = ivy.moveaxis(a, axis, 0)\n if condition_arr.shape[0] > arr.shape[0]:\n raise ivy.utils.exceptions.IvyException(\n \"Condition contains entries that are out of bounds\"\n )\n arr = arr[: condition_arr.shape[0]]\n return ivy.moveaxis(arr[condition_arr], 0, axis)\n", "path": "ivy/functional/frontends/numpy/indexing_routines/indexing_like_operations.py"}]}
| 1,079 | 368 |
gh_patches_debug_16116
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1273
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add overlay tiles layers from settings
https://github.com/makinacorpus/django-leaflet/issues/83
Would allow to show cadastral parcels over orthophoto, "plans de circulation" etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geotrek/settings/dev.py`
Content:
```
1 from .default import * # NOQA
2
3 #
4 # Django Development
5 # ..........................
6
7 DEBUG = True
8 TEMPLATE_DEBUG = True
9
10 SOUTH_TESTS_MIGRATE = False # Tested at settings.tests
11
12 #
13 # Developper Toolbar
14 # ..........................
15
16 INSTALLED_APPS = (
17 # 'debug_toolbar',
18 'django_extensions',
19 ) + INSTALLED_APPS
20
21 #
22 # Use Geotrek preprod tiles (uses default extent)
23 # ................................................
24
25 LEAFLET_CONFIG['TILES'] = [
26 (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),
27 (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),
28 ]
29 LEAFLET_CONFIG['SRID'] = 3857
30
31 LOGGING['loggers']['geotrek']['level'] = 'DEBUG'
32 LOGGING['loggers']['']['level'] = 'DEBUG'
33
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geotrek/settings/dev.py b/geotrek/settings/dev.py
--- a/geotrek/settings/dev.py
+++ b/geotrek/settings/dev.py
@@ -19,13 +19,17 @@
) + INSTALLED_APPS
#
-# Use Geotrek preprod tiles (uses default extent)
-# ................................................
+# Use some default tiles
+# ..........................
LEAFLET_CONFIG['TILES'] = [
(gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),
(gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),
]
+LEAFLET_CONFIG['OVERLAYS'] = [
+ (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),
+]
+
LEAFLET_CONFIG['SRID'] = 3857
LOGGING['loggers']['geotrek']['level'] = 'DEBUG'
|
{"golden_diff": "diff --git a/geotrek/settings/dev.py b/geotrek/settings/dev.py\n--- a/geotrek/settings/dev.py\n+++ b/geotrek/settings/dev.py\n@@ -19,13 +19,17 @@\n ) + INSTALLED_APPS\n \n #\n-# Use Geotrek preprod tiles (uses default extent)\n-# ................................................\n+# Use some default tiles\n+# ..........................\n \n LEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n ]\n+LEAFLET_CONFIG['OVERLAYS'] = [\n+ (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),\n+]\n+\n LEAFLET_CONFIG['SRID'] = 3857\n \n LOGGING['loggers']['geotrek']['level'] = 'DEBUG'\n", "issue": "Add overlay tiles layers from settings\nhttps://github.com/makinacorpus/django-leaflet/issues/83 \n\nWould allow to show cadastral parcels over orthophoto, \"plans de circulation\" etc.\n\n", "before_files": [{"content": "from .default import * # NOQA\n\n#\n# Django Development\n# ..........................\n\nDEBUG = True\nTEMPLATE_DEBUG = True\n\nSOUTH_TESTS_MIGRATE = False # Tested at settings.tests\n\n#\n# Developper Toolbar\n# ..........................\n\nINSTALLED_APPS = (\n # 'debug_toolbar',\n 'django_extensions',\n) + INSTALLED_APPS\n\n#\n# Use Geotrek preprod tiles (uses default extent)\n# ................................................\n\nLEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n]\nLEAFLET_CONFIG['SRID'] = 3857\n\nLOGGING['loggers']['geotrek']['level'] = 'DEBUG'\nLOGGING['loggers']['']['level'] = 'DEBUG'\n", "path": "geotrek/settings/dev.py"}], "after_files": [{"content": "from .default import * # NOQA\n\n#\n# Django Development\n# ..........................\n\nDEBUG = True\nTEMPLATE_DEBUG = True\n\nSOUTH_TESTS_MIGRATE = False # Tested at settings.tests\n\n#\n# Developper Toolbar\n# ..........................\n\nINSTALLED_APPS = (\n # 'debug_toolbar',\n 'django_extensions',\n) + INSTALLED_APPS\n\n#\n# Use some default tiles\n# ..........................\n\nLEAFLET_CONFIG['TILES'] = [\n (gettext_noop('Scan'), 'http://{s}.tile.osm.org/{z}/{x}/{y}.png', '(c) OpenStreetMap Contributors'),\n (gettext_noop('Ortho'), 'http://{s}.tiles.mapbox.com/v3/openstreetmap.map-4wvf9l0l/{z}/{x}/{y}.jpg', '(c) MapBox'),\n]\nLEAFLET_CONFIG['OVERLAYS'] = [\n (gettext_noop('Coeur de parc'), 'http://{s}.tilestream.makina-corpus.net/v2/coeur-ecrins/{z}/{x}/{y}.png', 'Ecrins'),\n]\n\nLEAFLET_CONFIG['SRID'] = 3857\n\nLOGGING['loggers']['geotrek']['level'] = 'DEBUG'\nLOGGING['loggers']['']['level'] = 'DEBUG'\n", "path": "geotrek/settings/dev.py"}]}
| 596 | 272 |
gh_patches_debug_18592
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-5121
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
option to disable automatic client response body decompression
enhancement for https://github.com/aio-libs/aiohttp/issues/1992
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aiohttp/resolver.py`
Content:
```
1 import asyncio
2 import socket
3 from typing import Any, Dict, List, Optional
4
5 from .abc import AbstractResolver
6 from .helpers import get_running_loop
7
8 __all__ = ("ThreadedResolver", "AsyncResolver", "DefaultResolver")
9
10 try:
11 import aiodns
12
13 # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')
14 except ImportError: # pragma: no cover
15 aiodns = None
16
17 aiodns_default = False
18
19
20 class ThreadedResolver(AbstractResolver):
21 """Use Executor for synchronous getaddrinfo() calls, which defaults to
22 concurrent.futures.ThreadPoolExecutor.
23 """
24
25 def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:
26 self._loop = get_running_loop(loop)
27
28 async def resolve(
29 self, host: str, port: int = 0, family: int = socket.AF_INET
30 ) -> List[Dict[str, Any]]:
31 infos = await self._loop.getaddrinfo(
32 host, port, type=socket.SOCK_STREAM, family=family
33 )
34
35 hosts = []
36 for family, _, proto, _, address in infos:
37 if family == socket.AF_INET6 and address[3]: # type: ignore
38 # This is essential for link-local IPv6 addresses.
39 # LL IPv6 is a VERY rare case. Strictly speaking, we should use
40 # getnameinfo() unconditionally, but performance makes sense.
41 host, _port = socket.getnameinfo(
42 address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV
43 )
44 port = int(_port)
45 else:
46 host, port = address[:2]
47 hosts.append(
48 {
49 "hostname": host,
50 "host": host,
51 "port": port,
52 "family": family,
53 "proto": proto,
54 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
55 }
56 )
57
58 return hosts
59
60 async def close(self) -> None:
61 pass
62
63
64 class AsyncResolver(AbstractResolver):
65 """Use the `aiodns` package to make asynchronous DNS lookups"""
66
67 def __init__(
68 self,
69 loop: Optional[asyncio.AbstractEventLoop] = None,
70 *args: Any,
71 **kwargs: Any
72 ) -> None:
73 if aiodns is None:
74 raise RuntimeError("Resolver requires aiodns library")
75
76 self._loop = get_running_loop(loop)
77 self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)
78
79 if not hasattr(self._resolver, "gethostbyname"):
80 # aiodns 1.1 is not available, fallback to DNSResolver.query
81 self.resolve = self._resolve_with_query # type: ignore
82
83 async def resolve(
84 self, host: str, port: int = 0, family: int = socket.AF_INET
85 ) -> List[Dict[str, Any]]:
86 try:
87 resp = await self._resolver.gethostbyname(host, family)
88 except aiodns.error.DNSError as exc:
89 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
90 raise OSError(msg) from exc
91 hosts = []
92 for address in resp.addresses:
93 hosts.append(
94 {
95 "hostname": host,
96 "host": address,
97 "port": port,
98 "family": family,
99 "proto": 0,
100 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
101 }
102 )
103
104 if not hosts:
105 raise OSError("DNS lookup failed")
106
107 return hosts
108
109 async def _resolve_with_query(
110 self, host: str, port: int = 0, family: int = socket.AF_INET
111 ) -> List[Dict[str, Any]]:
112 if family == socket.AF_INET6:
113 qtype = "AAAA"
114 else:
115 qtype = "A"
116
117 try:
118 resp = await self._resolver.query(host, qtype)
119 except aiodns.error.DNSError as exc:
120 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
121 raise OSError(msg) from exc
122
123 hosts = []
124 for rr in resp:
125 hosts.append(
126 {
127 "hostname": host,
128 "host": rr.host,
129 "port": port,
130 "family": family,
131 "proto": 0,
132 "flags": socket.AI_NUMERICHOST,
133 }
134 )
135
136 if not hosts:
137 raise OSError("DNS lookup failed")
138
139 return hosts
140
141 async def close(self) -> None:
142 return self._resolver.cancel()
143
144
145 DefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py
--- a/aiohttp/resolver.py
+++ b/aiohttp/resolver.py
@@ -26,10 +26,10 @@
self._loop = get_running_loop(loop)
async def resolve(
- self, host: str, port: int = 0, family: int = socket.AF_INET
+ self, hostname: str, port: int = 0, family: int = socket.AF_INET
) -> List[Dict[str, Any]]:
infos = await self._loop.getaddrinfo(
- host, port, type=socket.SOCK_STREAM, family=family
+ hostname, port, type=socket.SOCK_STREAM, family=family
)
hosts = []
@@ -46,7 +46,7 @@
host, port = address[:2]
hosts.append(
{
- "hostname": host,
+ "hostname": hostname,
"host": host,
"port": port,
"family": family,
|
{"golden_diff": "diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py\n--- a/aiohttp/resolver.py\n+++ b/aiohttp/resolver.py\n@@ -26,10 +26,10 @@\n self._loop = get_running_loop(loop)\n \n async def resolve(\n- self, host: str, port: int = 0, family: int = socket.AF_INET\n+ self, hostname: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n- host, port, type=socket.SOCK_STREAM, family=family\n+ hostname, port, type=socket.SOCK_STREAM, family=family\n )\n \n hosts = []\n@@ -46,7 +46,7 @@\n host, port = address[:2]\n hosts.append(\n {\n- \"hostname\": host,\n+ \"hostname\": hostname,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n", "issue": "option to disable automatic client response body decompression\nenhancement for https://github.com/aio-libs/aiohttp/issues/1992\n", "before_files": [{"content": "import asyncio\nimport socket\nfrom typing import Any, Dict, List, Optional\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = (\"ThreadedResolver\", \"AsyncResolver\", \"DefaultResolver\")\n\ntry:\n import aiodns\n\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:\n self._loop = get_running_loop(loop)\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n host, port, type=socket.SOCK_STREAM, family=family\n )\n\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6 and address[3]: # type: ignore\n # This is essential for link-local IPv6 addresses.\n # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n # getnameinfo() unconditionally, but performance makes sense.\n host, _port = socket.getnameinfo(\n address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n )\n port = int(_port)\n else:\n host, port = address[:2]\n hosts.append(\n {\n \"hostname\": host,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n \"proto\": proto,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(\n self,\n loop: Optional[asyncio.AbstractEventLoop] = None,\n *args: Any,\n **kwargs: Any\n ) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop(loop)\n self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)\n\n if not hasattr(self._resolver, \"gethostbyname\"):\n # aiodns 1.1 is not available, fallback to DNSResolver.query\n self.resolve = self._resolve_with_query # type: ignore\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": address,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def _resolve_with_query(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n if family == socket.AF_INET6:\n qtype = \"AAAA\"\n else:\n qtype = \"A\"\n\n try:\n resp = await self._resolver.query(host, qtype)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n\n hosts = []\n for rr in resp:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": rr.host,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}], "after_files": [{"content": "import asyncio\nimport socket\nfrom typing import Any, Dict, List, Optional\n\nfrom .abc import AbstractResolver\nfrom .helpers import get_running_loop\n\n__all__ = (\"ThreadedResolver\", \"AsyncResolver\", \"DefaultResolver\")\n\ntry:\n import aiodns\n\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Use Executor for synchronous getaddrinfo() calls, which defaults to\n concurrent.futures.ThreadPoolExecutor.\n \"\"\"\n\n def __init__(self, loop: Optional[asyncio.AbstractEventLoop] = None) -> None:\n self._loop = get_running_loop(loop)\n\n async def resolve(\n self, hostname: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n hostname, port, type=socket.SOCK_STREAM, family=family\n )\n\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6 and address[3]: # type: ignore\n # This is essential for link-local IPv6 addresses.\n # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n # getnameinfo() unconditionally, but performance makes sense.\n host, _port = socket.getnameinfo(\n address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n )\n port = int(_port)\n else:\n host, port = address[:2]\n hosts.append(\n {\n \"hostname\": hostname,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n \"proto\": proto,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(\n self,\n loop: Optional[asyncio.AbstractEventLoop] = None,\n *args: Any,\n **kwargs: Any\n ) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = get_running_loop(loop)\n self._resolver = aiodns.DNSResolver(*args, loop=loop, **kwargs)\n\n if not hasattr(self._resolver, \"gethostbyname\"):\n # aiodns 1.1 is not available, fallback to DNSResolver.query\n self.resolve = self._resolve_with_query # type: ignore\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": address,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def _resolve_with_query(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n if family == socket.AF_INET6:\n qtype = \"AAAA\"\n else:\n qtype = \"A\"\n\n try:\n resp = await self._resolver.query(host, qtype)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n\n hosts = []\n for rr in resp:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": rr.host,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n return self._resolver.cancel()\n\n\nDefaultResolver = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}]}
| 1,654 | 231 |
gh_patches_debug_7305
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-2230
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update dependencies with security vulnerabilities
As mentioned here:
https://github.com/streamlink/streamlink/pull/2199#issuecomment-447567326
1. urllib3
> Vulnerable versions: < 1.23
> Patched version: 1.23
> urllib3 before version 1.23 does not remove the Authorization HTTP header when following a cross-origin redirect (i.e., a redirect that differs in host, port, or scheme). This can allow for credentials in the Authorization header to be exposed to unintended hosts or transmitted in cleartext.
https://nvd.nist.gov/vuln/detail/CVE-2018-20060
2. requests
> Vulnerable versions: <= 2.19.1
> Patched version: 2.20.0
> The Requests package through 2.19.1 before 2018-09-14 for Python sends an HTTP Authorization header to an http URI upon receiving a same-hostname https-to-http redirect, which makes it easier for remote attackers to discover credentials by sniffing the network.
https://nvd.nist.gov/vuln/detail/CVE-2018-18074
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 import codecs
3 from os import environ
4 from os import path
5 from sys import path as sys_path
6
7 from setuptools import setup, find_packages
8
9 import versioneer
10
11 deps = [
12 # Require backport of concurrent.futures on Python 2
13 'futures;python_version<"3.0"',
14 # Require singledispatch on Python <3.4
15 'singledispatch;python_version<"3.4"',
16 "requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0",
17 'urllib3[secure]<1.23,>=1.21.1;python_version<"3.0"',
18 "isodate",
19 "websocket-client",
20 # Support for SOCKS proxies
21 "PySocks!=1.5.7,>=1.5.6",
22 # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet
23 # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x
24 'win-inet-pton;python_version<"3.0" and platform_system=="Windows"',
25 # shutil.get_terminal_size and which were added in Python 3.3
26 'backports.shutil_which;python_version<"3.3"',
27 'backports.shutil_get_terminal_size;python_version<"3.3"'
28 ]
29
30 # for encrypted streams
31 if environ.get("STREAMLINK_USE_PYCRYPTO"):
32 deps.append("pycrypto")
33 else:
34 # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6
35 deps.append("pycryptodome>=3.4.3,<4")
36
37 # for localization
38 if environ.get("STREAMLINK_USE_PYCOUNTRY"):
39 deps.append("pycountry")
40 else:
41 deps.append("iso-639")
42 deps.append("iso3166")
43
44 # When we build an egg for the Win32 bootstrap we don"t want dependency
45 # information built into it.
46 if environ.get("NO_DEPS"):
47 deps = []
48
49 this_directory = path.abspath(path.dirname(__file__))
50 srcdir = path.join(this_directory, "src/")
51 sys_path.insert(0, srcdir)
52
53 with codecs.open(path.join(this_directory, "README.md"), 'r', "utf8") as f:
54 long_description = f.read()
55
56 setup(name="streamlink",
57 version=versioneer.get_version(),
58 cmdclass=versioneer.get_cmdclass(),
59 description="Streamlink is command-line utility that extracts streams "
60 "from various services and pipes them into a video player of "
61 "choice.",
62 long_description=long_description,
63 long_description_content_type="text/markdown",
64 url="https://github.com/streamlink/streamlink",
65 project_urls={
66 "Documentation": "https://streamlink.github.io/",
67 "Tracker": "https://github.com/streamlink/streamlink/issues",
68 "Source": "https://github.com/streamlink/streamlink",
69 "Funding": "https://opencollective.com/streamlink"
70 },
71 author="Streamlink",
72 # temp until we have a mailing list / global email
73 author_email="[email protected]",
74 license="Simplified BSD",
75 packages=find_packages("src"),
76 package_dir={"": "src"},
77 entry_points={
78 "console_scripts": ["streamlink=streamlink_cli.main:main"]
79 },
80 install_requires=deps,
81 test_suite="tests",
82 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4",
83 classifiers=["Development Status :: 5 - Production/Stable",
84 "License :: OSI Approved :: BSD License",
85 "Environment :: Console",
86 "Intended Audience :: End Users/Desktop",
87 "Operating System :: POSIX",
88 "Operating System :: Microsoft :: Windows",
89 "Operating System :: MacOS",
90 "Programming Language :: Python :: 2.7",
91 "Programming Language :: Python :: 3.4",
92 "Programming Language :: Python :: 3.5",
93 "Programming Language :: Python :: 3.6",
94 "Programming Language :: Python :: 3.7",
95 "Topic :: Internet :: WWW/HTTP",
96 "Topic :: Multimedia :: Sound/Audio",
97 "Topic :: Multimedia :: Video",
98 "Topic :: Utilities"])
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -13,8 +13,8 @@
'futures;python_version<"3.0"',
# Require singledispatch on Python <3.4
'singledispatch;python_version<"3.4"',
- "requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0",
- 'urllib3[secure]<1.23,>=1.21.1;python_version<"3.0"',
+ "requests>=2.21.0,<3.0",
+ 'urllib3[secure]>=1.23;python_version<"3.0"',
"isodate",
"websocket-client",
# Support for SOCKS proxies
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -13,8 +13,8 @@\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n- \"requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0\",\n- 'urllib3[secure]<1.23,>=1.21.1;python_version<\"3.0\"',\n+ \"requests>=2.21.0,<3.0\",\n+ 'urllib3[secure]>=1.23;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n", "issue": "Update dependencies with security vulnerabilities\nAs mentioned here:\r\nhttps://github.com/streamlink/streamlink/pull/2199#issuecomment-447567326\r\n\r\n1. urllib3\r\n > Vulnerable versions: < 1.23\r\n > Patched version: 1.23\r\n > urllib3 before version 1.23 does not remove the Authorization HTTP header when following a cross-origin redirect (i.e., a redirect that differs in host, port, or scheme). This can allow for credentials in the Authorization header to be exposed to unintended hosts or transmitted in cleartext.\r\n https://nvd.nist.gov/vuln/detail/CVE-2018-20060\r\n2. requests\r\n > Vulnerable versions: <= 2.19.1\r\n > Patched version: 2.20.0\r\n > The Requests package through 2.19.1 before 2018-09-14 for Python sends an HTTP Authorization header to an http URI upon receiving a same-hostname https-to-http redirect, which makes it easier for remote attackers to discover credentials by sniffing the network.\r\n https://nvd.nist.gov/vuln/detail/CVE-2018-18074\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nimport codecs\nfrom os import environ\nfrom os import path\nfrom sys import path as sys_path\n\nfrom setuptools import setup, find_packages\n\nimport versioneer\n\ndeps = [\n # Require backport of concurrent.futures on Python 2\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n \"requests>=2.2,!=2.12.0,!=2.12.1,!=2.16.0,!=2.16.1,!=2.16.2,!=2.16.3,!=2.16.4,!=2.16.5,!=2.17.1,<3.0\",\n 'urllib3[secure]<1.23,>=1.21.1;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n \"PySocks!=1.5.7,>=1.5.6\",\n # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet\n # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x\n 'win-inet-pton;python_version<\"3.0\" and platform_system==\"Windows\"',\n # shutil.get_terminal_size and which were added in Python 3.3\n 'backports.shutil_which;python_version<\"3.3\"',\n 'backports.shutil_get_terminal_size;python_version<\"3.3\"'\n]\n\n# for encrypted streams\nif environ.get(\"STREAMLINK_USE_PYCRYPTO\"):\n deps.append(\"pycrypto\")\nelse:\n # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6\n deps.append(\"pycryptodome>=3.4.3,<4\")\n\n# for localization\nif environ.get(\"STREAMLINK_USE_PYCOUNTRY\"):\n deps.append(\"pycountry\")\nelse:\n deps.append(\"iso-639\")\n deps.append(\"iso3166\")\n\n# When we build an egg for the Win32 bootstrap we don\"t want dependency\n# information built into it.\nif environ.get(\"NO_DEPS\"):\n deps = []\n\nthis_directory = path.abspath(path.dirname(__file__))\nsrcdir = path.join(this_directory, \"src/\")\nsys_path.insert(0, srcdir)\n\nwith codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n\nsetup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Streamlink is command-line utility that extracts streams \"\n \"from various services and pipes them into a video player of \"\n \"choice.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/streamlink/streamlink\",\n project_urls={\n \"Documentation\": \"https://streamlink.github.io/\",\n \"Tracker\": \"https://github.com/streamlink/streamlink/issues\",\n \"Source\": \"https://github.com/streamlink/streamlink\",\n \"Funding\": \"https://opencollective.com/streamlink\"\n },\n author=\"Streamlink\",\n # temp until we have a mailing list / global email\n author_email=\"[email protected]\",\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n entry_points={\n \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n },\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n classifiers=[\"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: BSD License\",\n \"Environment :: Console\",\n \"Intended Audience :: End Users/Desktop\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Multimedia :: Sound/Audio\",\n \"Topic :: Multimedia :: Video\",\n \"Topic :: Utilities\"])\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport codecs\nfrom os import environ\nfrom os import path\nfrom sys import path as sys_path\n\nfrom setuptools import setup, find_packages\n\nimport versioneer\n\ndeps = [\n # Require backport of concurrent.futures on Python 2\n 'futures;python_version<\"3.0\"',\n # Require singledispatch on Python <3.4\n 'singledispatch;python_version<\"3.4\"',\n \"requests>=2.21.0,<3.0\",\n 'urllib3[secure]>=1.23;python_version<\"3.0\"',\n \"isodate\",\n \"websocket-client\",\n # Support for SOCKS proxies\n \"PySocks!=1.5.7,>=1.5.6\",\n # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet\n # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x\n 'win-inet-pton;python_version<\"3.0\" and platform_system==\"Windows\"',\n # shutil.get_terminal_size and which were added in Python 3.3\n 'backports.shutil_which;python_version<\"3.3\"',\n 'backports.shutil_get_terminal_size;python_version<\"3.3\"'\n]\n\n# for encrypted streams\nif environ.get(\"STREAMLINK_USE_PYCRYPTO\"):\n deps.append(\"pycrypto\")\nelse:\n # this version of pycryptodome is known to work and has a Windows wheel for py2.7, py3.3-3.6\n deps.append(\"pycryptodome>=3.4.3,<4\")\n\n# for localization\nif environ.get(\"STREAMLINK_USE_PYCOUNTRY\"):\n deps.append(\"pycountry\")\nelse:\n deps.append(\"iso-639\")\n deps.append(\"iso3166\")\n\n# When we build an egg for the Win32 bootstrap we don\"t want dependency\n# information built into it.\nif environ.get(\"NO_DEPS\"):\n deps = []\n\nthis_directory = path.abspath(path.dirname(__file__))\nsrcdir = path.join(this_directory, \"src/\")\nsys_path.insert(0, srcdir)\n\nwith codecs.open(path.join(this_directory, \"README.md\"), 'r', \"utf8\") as f:\n long_description = f.read()\n\nsetup(name=\"streamlink\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Streamlink is command-line utility that extracts streams \"\n \"from various services and pipes them into a video player of \"\n \"choice.\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/streamlink/streamlink\",\n project_urls={\n \"Documentation\": \"https://streamlink.github.io/\",\n \"Tracker\": \"https://github.com/streamlink/streamlink/issues\",\n \"Source\": \"https://github.com/streamlink/streamlink\",\n \"Funding\": \"https://opencollective.com/streamlink\"\n },\n author=\"Streamlink\",\n # temp until we have a mailing list / global email\n author_email=\"[email protected]\",\n license=\"Simplified BSD\",\n packages=find_packages(\"src\"),\n package_dir={\"\": \"src\"},\n entry_points={\n \"console_scripts\": [\"streamlink=streamlink_cli.main:main\"]\n },\n install_requires=deps,\n test_suite=\"tests\",\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n classifiers=[\"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: BSD License\",\n \"Environment :: Console\",\n \"Intended Audience :: End Users/Desktop\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Multimedia :: Sound/Audio\",\n \"Topic :: Multimedia :: Video\",\n \"Topic :: Utilities\"])\n", "path": "setup.py"}]}
| 1,740 | 240 |
gh_patches_debug_18267
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-689
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E2504 enforces incorrect boundary 100-2000, should be 100-20000
*cfn-lint version: (`cfn-lint --version`)* 0.15.0 (also tested with 0.14.1)
**Description:**
AWS EC2 Instance with block device mapping does not enforce the correct `Ebs/Iops` boundary of 100-20000 as specified in the [documentation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html)
It looks like it actually enforces 100-2000, as if you set `Iops` to 2000 it passes the linter.
**Sample to reproduce:**
```yaml
Resources:
Machine:
Type: AWS::EC2::Instance
Properties:
ImageId: "ami-79fd7eee"
KeyName: "testkey"
BlockDeviceMappings:
- DeviceName: /dev/sdm
Ebs:
VolumeType: io1
Iops: 3000
DeleteOnTermination: false
VolumeSize: 20
```
Output:
```bash
> cfn-lint minimal-stack.yaml
E2504 Property Iops should be Int between 100 to 20000 Resources/Machine/Properties/BlockDeviceMappings/0/Ebs/Iops
minimal-stack.yaml:11:13
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/ectwo/Ebs.py`
Content:
```
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import re
18 import six
19 from cfnlint import CloudFormationLintRule
20 from cfnlint import RuleMatch
21
22
23 class Ebs(CloudFormationLintRule):
24 """Check if Ec2 Ebs Resource Properties"""
25 id = 'E2504'
26 shortdesc = 'Check Ec2 Ebs Properties'
27 description = 'See if Ec2 Eb2 Properties are valid'
28 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'
29 tags = ['properties', 'ec2', 'ebs']
30
31 def _checkEbs(self, cfn, ebs, path):
32 matches = []
33
34 if isinstance(ebs, dict):
35 volume_types_obj = cfn.get_values(ebs, 'VolumeType')
36 iops_obj = cfn.get_values(ebs, 'Iops')
37 if volume_types_obj is not None:
38 for volume_type_obj in volume_types_obj:
39 volume_type = volume_type_obj.get('Value')
40 if isinstance(volume_type, six.string_types):
41 if volume_type == 'io1':
42 if iops_obj is None:
43 pathmessage = path[:] + ['VolumeType']
44 message = 'VolumeType io1 requires Iops to be specified for {0}'
45 matches.append(
46 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
47 else:
48 try:
49 if len(iops_obj) == 1:
50 iops = iops_obj[0]['Value']
51 if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:
52 iops_value = int(iops)
53 if iops_value < 100 or iops_value > 2000:
54 pathmessage = path[:] + ['Iops']
55 message = 'Property Iops should be Int between 100 to 20000 {0}'
56 matches.append(
57 RuleMatch(
58 pathmessage,
59 message.format('/'.join(map(str, pathmessage)))))
60 except ValueError:
61 pathmessage = path[:] + ['Iops']
62 message = 'Property Iops should be Int between 100 to 20000 {0}'
63 matches.append(
64 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
65 elif volume_type:
66 if iops_obj is not None:
67 pathmessage = path[:] + ['Iops']
68 message = 'Iops shouldn\'t be defined for type {0} for {1}'
69 matches.append(
70 RuleMatch(
71 pathmessage,
72 message.format(volume_type, '/'.join(map(str, pathmessage)))))
73
74 return matches
75
76 def match(self, cfn):
77 """Check Ec2 Ebs Resource Parameters"""
78
79 matches = []
80
81 results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])
82 results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))
83 for result in results:
84 path = result['Path']
85 for index, properties in enumerate(result['Value']):
86 virtual_name = properties.get('VirtualName')
87 ebs = properties.get('Ebs')
88 if virtual_name:
89 # switch to regex
90 if not re.match(r'^ephemeral[0-9]$', virtual_name):
91 pathmessage = path[:] + [index, 'VirtualName']
92 message = 'Property VirtualName should be of type ephemeral(n) for {0}'
93 matches.append(
94 RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))
95 elif ebs:
96 matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))
97 return matches
98
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/ectwo/Ebs.py b/src/cfnlint/rules/resources/ectwo/Ebs.py
--- a/src/cfnlint/rules/resources/ectwo/Ebs.py
+++ b/src/cfnlint/rules/resources/ectwo/Ebs.py
@@ -50,7 +50,7 @@
iops = iops_obj[0]['Value']
if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:
iops_value = int(iops)
- if iops_value < 100 or iops_value > 2000:
+ if iops_value < 100 or iops_value > 20000:
pathmessage = path[:] + ['Iops']
message = 'Property Iops should be Int between 100 to 20000 {0}'
matches.append(
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/ectwo/Ebs.py b/src/cfnlint/rules/resources/ectwo/Ebs.py\n--- a/src/cfnlint/rules/resources/ectwo/Ebs.py\n+++ b/src/cfnlint/rules/resources/ectwo/Ebs.py\n@@ -50,7 +50,7 @@\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n- if iops_value < 100 or iops_value > 2000:\n+ if iops_value < 100 or iops_value > 20000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n", "issue": "E2504 enforces incorrect boundary 100-2000, should be 100-20000\n*cfn-lint version: (`cfn-lint --version`)* 0.15.0 (also tested with 0.14.1)\r\n\r\n**Description:**\r\nAWS EC2 Instance with block device mapping does not enforce the correct `Ebs/Iops` boundary of 100-20000 as specified in the [documentation](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html)\r\n\r\nIt looks like it actually enforces 100-2000, as if you set `Iops` to 2000 it passes the linter.\r\n\r\n**Sample to reproduce:**\r\n```yaml\r\nResources:\r\n Machine:\r\n Type: AWS::EC2::Instance\r\n Properties:\r\n ImageId: \"ami-79fd7eee\"\r\n KeyName: \"testkey\"\r\n BlockDeviceMappings: \r\n - DeviceName: /dev/sdm\r\n Ebs: \r\n VolumeType: io1\r\n Iops: 3000 \r\n DeleteOnTermination: false\r\n VolumeSize: 20\r\n```\r\n\r\nOutput:\r\n```bash\r\n> cfn-lint minimal-stack.yaml\r\n\r\nE2504 Property Iops should be Int between 100 to 20000 Resources/Machine/Properties/BlockDeviceMappings/0/Ebs/Iops\r\nminimal-stack.yaml:11:13\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Ebs(CloudFormationLintRule):\n \"\"\"Check if Ec2 Ebs Resource Properties\"\"\"\n id = 'E2504'\n shortdesc = 'Check Ec2 Ebs Properties'\n description = 'See if Ec2 Eb2 Properties are valid'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'\n tags = ['properties', 'ec2', 'ebs']\n\n def _checkEbs(self, cfn, ebs, path):\n matches = []\n\n if isinstance(ebs, dict):\n volume_types_obj = cfn.get_values(ebs, 'VolumeType')\n iops_obj = cfn.get_values(ebs, 'Iops')\n if volume_types_obj is not None:\n for volume_type_obj in volume_types_obj:\n volume_type = volume_type_obj.get('Value')\n if isinstance(volume_type, six.string_types):\n if volume_type == 'io1':\n if iops_obj is None:\n pathmessage = path[:] + ['VolumeType']\n message = 'VolumeType io1 requires Iops to be specified for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n else:\n try:\n if len(iops_obj) == 1:\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n if iops_value < 100 or iops_value > 2000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format('/'.join(map(str, pathmessage)))))\n except ValueError:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif volume_type:\n if iops_obj is not None:\n pathmessage = path[:] + ['Iops']\n message = 'Iops shouldn\\'t be defined for type {0} for {1}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format(volume_type, '/'.join(map(str, pathmessage)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check Ec2 Ebs Resource Parameters\"\"\"\n\n matches = []\n\n results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])\n results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))\n for result in results:\n path = result['Path']\n for index, properties in enumerate(result['Value']):\n virtual_name = properties.get('VirtualName')\n ebs = properties.get('Ebs')\n if virtual_name:\n # switch to regex\n if not re.match(r'^ephemeral[0-9]$', virtual_name):\n pathmessage = path[:] + [index, 'VirtualName']\n message = 'Property VirtualName should be of type ephemeral(n) for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif ebs:\n matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))\n return matches\n", "path": "src/cfnlint/rules/resources/ectwo/Ebs.py"}], "after_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport re\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\n\nclass Ebs(CloudFormationLintRule):\n \"\"\"Check if Ec2 Ebs Resource Properties\"\"\"\n id = 'E2504'\n shortdesc = 'Check Ec2 Ebs Properties'\n description = 'See if Ec2 Eb2 Properties are valid'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-ec2-blockdev-template.html'\n tags = ['properties', 'ec2', 'ebs']\n\n def _checkEbs(self, cfn, ebs, path):\n matches = []\n\n if isinstance(ebs, dict):\n volume_types_obj = cfn.get_values(ebs, 'VolumeType')\n iops_obj = cfn.get_values(ebs, 'Iops')\n if volume_types_obj is not None:\n for volume_type_obj in volume_types_obj:\n volume_type = volume_type_obj.get('Value')\n if isinstance(volume_type, six.string_types):\n if volume_type == 'io1':\n if iops_obj is None:\n pathmessage = path[:] + ['VolumeType']\n message = 'VolumeType io1 requires Iops to be specified for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n else:\n try:\n if len(iops_obj) == 1:\n iops = iops_obj[0]['Value']\n if isinstance(iops, (six.string_types, int)) and not iops_obj[0]['Path']:\n iops_value = int(iops)\n if iops_value < 100 or iops_value > 20000:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format('/'.join(map(str, pathmessage)))))\n except ValueError:\n pathmessage = path[:] + ['Iops']\n message = 'Property Iops should be Int between 100 to 20000 {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif volume_type:\n if iops_obj is not None:\n pathmessage = path[:] + ['Iops']\n message = 'Iops shouldn\\'t be defined for type {0} for {1}'\n matches.append(\n RuleMatch(\n pathmessage,\n message.format(volume_type, '/'.join(map(str, pathmessage)))))\n\n return matches\n\n def match(self, cfn):\n \"\"\"Check Ec2 Ebs Resource Parameters\"\"\"\n\n matches = []\n\n results = cfn.get_resource_properties(['AWS::EC2::Instance', 'BlockDeviceMappings'])\n results.extend(cfn.get_resource_properties(['AWS::AutoScaling::LaunchConfiguration', 'BlockDeviceMappings']))\n for result in results:\n path = result['Path']\n for index, properties in enumerate(result['Value']):\n virtual_name = properties.get('VirtualName')\n ebs = properties.get('Ebs')\n if virtual_name:\n # switch to regex\n if not re.match(r'^ephemeral[0-9]$', virtual_name):\n pathmessage = path[:] + [index, 'VirtualName']\n message = 'Property VirtualName should be of type ephemeral(n) for {0}'\n matches.append(\n RuleMatch(pathmessage, message.format('/'.join(map(str, pathmessage)))))\n elif ebs:\n matches.extend(self._checkEbs(cfn, ebs, path[:] + [index, 'Ebs']))\n return matches\n", "path": "src/cfnlint/rules/resources/ectwo/Ebs.py"}]}
| 1,800 | 201 |
gh_patches_debug_35031
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-3215
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Exported CSV file does not seem to contain information on what shelf my books are on
**Describe the bug**
I exported the CSV-file from my account on bookwyrm.social, and it does not seem to contain information on what books I've read and what I want to read and what I am currently reading (Shelves)
**To Reproduce**
Steps to reproduce the behavior:
1. Go to settings
2. click on CSV export
3. Click on "Download file"
4. No apparent status-column in the exported csv-file
**Expected behavior**
A column indicating what shelf a book is on
**Instance**
Exported from bookwyrm.social
**Desktop (please complete the following information):**
- OS: MacOS
- Browser Firefox
- Version 113b
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bookwyrm/views/preferences/export.py`
Content:
```
1 """ Let users export their book data """
2 from datetime import timedelta
3 import csv
4 import io
5
6 from django.contrib.auth.decorators import login_required
7 from django.core.paginator import Paginator
8 from django.db.models import Q
9 from django.http import HttpResponse
10 from django.template.response import TemplateResponse
11 from django.utils import timezone
12 from django.views import View
13 from django.utils.decorators import method_decorator
14 from django.shortcuts import redirect
15
16 from bookwyrm import models
17 from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
18 from bookwyrm.settings import PAGE_LENGTH
19
20 # pylint: disable=no-self-use,too-many-locals
21 @method_decorator(login_required, name="dispatch")
22 class Export(View):
23 """Let users export data"""
24
25 def get(self, request):
26 """Request csv file"""
27 return TemplateResponse(request, "preferences/export.html")
28
29 def post(self, request):
30 """Download the csv file of a user's book data"""
31 books = models.Edition.viewer_aware_objects(request.user)
32 books_shelves = books.filter(Q(shelves__user=request.user)).distinct()
33 books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()
34 books_review = books.filter(Q(review__user=request.user)).distinct()
35 books_comment = books.filter(Q(comment__user=request.user)).distinct()
36 books_quotation = books.filter(Q(quotation__user=request.user)).distinct()
37
38 books = set(
39 list(books_shelves)
40 + list(books_readthrough)
41 + list(books_review)
42 + list(books_comment)
43 + list(books_quotation)
44 )
45
46 csv_string = io.StringIO()
47 writer = csv.writer(csv_string)
48
49 deduplication_fields = [
50 f.name
51 for f in models.Edition._meta.get_fields() # pylint: disable=protected-access
52 if getattr(f, "deduplication_field", False)
53 ]
54 fields = (
55 ["title", "author_text"]
56 + deduplication_fields
57 + ["start_date", "finish_date", "stopped_date"]
58 + ["rating", "review_name", "review_cw", "review_content"]
59 )
60 writer.writerow(fields)
61
62 for book in books:
63 # I think this is more efficient than doing a subquery in the view? but idk
64 review_rating = (
65 models.Review.objects.filter(
66 user=request.user, book=book, rating__isnull=False
67 )
68 .order_by("-published_date")
69 .first()
70 )
71
72 book.rating = review_rating.rating if review_rating else None
73
74 readthrough = (
75 models.ReadThrough.objects.filter(user=request.user, book=book)
76 .order_by("-start_date", "-finish_date")
77 .first()
78 )
79 if readthrough:
80 book.start_date = (
81 readthrough.start_date.date() if readthrough.start_date else None
82 )
83 book.finish_date = (
84 readthrough.finish_date.date() if readthrough.finish_date else None
85 )
86 book.stopped_date = (
87 readthrough.stopped_date.date()
88 if readthrough.stopped_date
89 else None
90 )
91
92 review = (
93 models.Review.objects.filter(
94 user=request.user, book=book, content__isnull=False
95 )
96 .order_by("-published_date")
97 .first()
98 )
99 if review:
100 book.review_name = review.name
101 book.review_cw = review.content_warning
102 book.review_content = review.raw_content
103 writer.writerow([getattr(book, field, "") or "" for field in fields])
104
105 return HttpResponse(
106 csv_string.getvalue(),
107 content_type="text/csv",
108 headers={
109 "Content-Disposition": 'attachment; filename="bookwyrm-export.csv"'
110 },
111 )
112
113
114 # pylint: disable=no-self-use
115 @method_decorator(login_required, name="dispatch")
116 class ExportUser(View):
117 """Let users export user data to import into another Bookwyrm instance"""
118
119 def get(self, request):
120 """Request tar file"""
121
122 jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(
123 "-created_date"
124 )
125 site = models.SiteSettings.objects.get()
126 hours = site.user_import_time_limit
127 allowed = (
128 jobs.first().created_date < timezone.now() - timedelta(hours=hours)
129 if jobs.first()
130 else True
131 )
132 next_available = (
133 jobs.first().created_date + timedelta(hours=hours) if not allowed else False
134 )
135 paginated = Paginator(jobs, PAGE_LENGTH)
136 page = paginated.get_page(request.GET.get("page"))
137 data = {
138 "jobs": page,
139 "next_available": next_available,
140 "page_range": paginated.get_elided_page_range(
141 page.number, on_each_side=2, on_ends=1
142 ),
143 }
144
145 return TemplateResponse(request, "preferences/export-user.html", data)
146
147 def post(self, request):
148 """Download the json file of a user's data"""
149
150 job = BookwyrmExportJob.objects.create(user=request.user)
151 job.start_job()
152
153 return redirect("prefs-user-export")
154
155
156 @method_decorator(login_required, name="dispatch")
157 class ExportArchive(View):
158 """Serve the archive file"""
159
160 def get(self, request, archive_id):
161 """download user export file"""
162 export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)
163 return HttpResponse(
164 export.export_data,
165 content_type="application/gzip",
166 headers={
167 "Content-Disposition": 'attachment; filename="bookwyrm-account-export.tar.gz"' # pylint: disable=line-too-long
168 },
169 )
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py
--- a/bookwyrm/views/preferences/export.py
+++ b/bookwyrm/views/preferences/export.py
@@ -17,6 +17,7 @@
from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
from bookwyrm.settings import PAGE_LENGTH
+
# pylint: disable=no-self-use,too-many-locals
@method_decorator(login_required, name="dispatch")
class Export(View):
@@ -54,8 +55,19 @@
fields = (
["title", "author_text"]
+ deduplication_fields
- + ["start_date", "finish_date", "stopped_date"]
- + ["rating", "review_name", "review_cw", "review_content"]
+ + [
+ "start_date",
+ "finish_date",
+ "stopped_date",
+ "rating",
+ "review_name",
+ "review_cw",
+ "review_content",
+ "review_published",
+ "shelf",
+ "shelf_name",
+ "shelf_date",
+ ]
)
writer.writerow(fields)
@@ -97,9 +109,27 @@
.first()
)
if review:
+ book.review_published = (
+ review.published_date.date() if review.published_date else None
+ )
book.review_name = review.name
book.review_cw = review.content_warning
- book.review_content = review.raw_content
+ book.review_content = (
+ review.raw_content if review.raw_content else review.content
+ ) # GoodReads imported reviews do not have raw_content, but content.
+
+ shelfbook = (
+ models.ShelfBook.objects.filter(user=request.user, book=book)
+ .order_by("-shelved_date", "-created_date", "-updated_date")
+ .last()
+ )
+ if shelfbook:
+ book.shelf = shelfbook.shelf.identifier
+ book.shelf_name = shelfbook.shelf.name
+ book.shelf_date = (
+ shelfbook.shelved_date.date() if shelfbook.shelved_date else None
+ )
+
writer.writerow([getattr(book, field, "") or "" for field in fields])
return HttpResponse(
|
{"golden_diff": "diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py\n--- a/bookwyrm/views/preferences/export.py\n+++ b/bookwyrm/views/preferences/export.py\n@@ -17,6 +17,7 @@\n from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\n from bookwyrm.settings import PAGE_LENGTH\n \n+\n # pylint: disable=no-self-use,too-many-locals\n @method_decorator(login_required, name=\"dispatch\")\n class Export(View):\n@@ -54,8 +55,19 @@\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n- + [\"start_date\", \"finish_date\", \"stopped_date\"]\n- + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n+ + [\n+ \"start_date\",\n+ \"finish_date\",\n+ \"stopped_date\",\n+ \"rating\",\n+ \"review_name\",\n+ \"review_cw\",\n+ \"review_content\",\n+ \"review_published\",\n+ \"shelf\",\n+ \"shelf_name\",\n+ \"shelf_date\",\n+ ]\n )\n writer.writerow(fields)\n \n@@ -97,9 +109,27 @@\n .first()\n )\n if review:\n+ book.review_published = (\n+ review.published_date.date() if review.published_date else None\n+ )\n book.review_name = review.name\n book.review_cw = review.content_warning\n- book.review_content = review.raw_content\n+ book.review_content = (\n+ review.raw_content if review.raw_content else review.content\n+ ) # GoodReads imported reviews do not have raw_content, but content.\n+\n+ shelfbook = (\n+ models.ShelfBook.objects.filter(user=request.user, book=book)\n+ .order_by(\"-shelved_date\", \"-created_date\", \"-updated_date\")\n+ .last()\n+ )\n+ if shelfbook:\n+ book.shelf = shelfbook.shelf.identifier\n+ book.shelf_name = shelfbook.shelf.name\n+ book.shelf_date = (\n+ shelfbook.shelved_date.date() if shelfbook.shelved_date else None\n+ )\n+\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n \n return HttpResponse(\n", "issue": "Exported CSV file does not seem to contain information on what shelf my books are on\n**Describe the bug**\r\nI exported the CSV-file from my account on bookwyrm.social, and it does not seem to contain information on what books I've read and what I want to read and what I am currently reading (Shelves)\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to settings\r\n2. click on CSV export\r\n3. Click on \"Download file\"\r\n4. No apparent status-column in the exported csv-file\r\n\r\n**Expected behavior**\r\nA column indicating what shelf a book is on\r\n\r\n**Instance**\r\nExported from bookwyrm.social\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: MacOS\r\n - Browser Firefox\r\n - Version 113b\n", "before_files": [{"content": "\"\"\" Let users export their book data \"\"\"\nfrom datetime import timedelta\nimport csv\nimport io\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.shortcuts import redirect\n\nfrom bookwyrm import models\nfrom bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\nfrom bookwyrm.settings import PAGE_LENGTH\n\n# pylint: disable=no-self-use,too-many-locals\n@method_decorator(login_required, name=\"dispatch\")\nclass Export(View):\n \"\"\"Let users export data\"\"\"\n\n def get(self, request):\n \"\"\"Request csv file\"\"\"\n return TemplateResponse(request, \"preferences/export.html\")\n\n def post(self, request):\n \"\"\"Download the csv file of a user's book data\"\"\"\n books = models.Edition.viewer_aware_objects(request.user)\n books_shelves = books.filter(Q(shelves__user=request.user)).distinct()\n books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()\n books_review = books.filter(Q(review__user=request.user)).distinct()\n books_comment = books.filter(Q(comment__user=request.user)).distinct()\n books_quotation = books.filter(Q(quotation__user=request.user)).distinct()\n\n books = set(\n list(books_shelves)\n + list(books_readthrough)\n + list(books_review)\n + list(books_comment)\n + list(books_quotation)\n )\n\n csv_string = io.StringIO()\n writer = csv.writer(csv_string)\n\n deduplication_fields = [\n f.name\n for f in models.Edition._meta.get_fields() # pylint: disable=protected-access\n if getattr(f, \"deduplication_field\", False)\n ]\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n + [\"start_date\", \"finish_date\", \"stopped_date\"]\n + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n )\n writer.writerow(fields)\n\n for book in books:\n # I think this is more efficient than doing a subquery in the view? but idk\n review_rating = (\n models.Review.objects.filter(\n user=request.user, book=book, rating__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n\n book.rating = review_rating.rating if review_rating else None\n\n readthrough = (\n models.ReadThrough.objects.filter(user=request.user, book=book)\n .order_by(\"-start_date\", \"-finish_date\")\n .first()\n )\n if readthrough:\n book.start_date = (\n readthrough.start_date.date() if readthrough.start_date else None\n )\n book.finish_date = (\n readthrough.finish_date.date() if readthrough.finish_date else None\n )\n book.stopped_date = (\n readthrough.stopped_date.date()\n if readthrough.stopped_date\n else None\n )\n\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n if review:\n book.review_name = review.name\n book.review_cw = review.content_warning\n book.review_content = review.raw_content\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n\n return HttpResponse(\n csv_string.getvalue(),\n content_type=\"text/csv\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-export.csv\"'\n },\n )\n\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportUser(View):\n \"\"\"Let users export user data to import into another Bookwyrm instance\"\"\"\n\n def get(self, request):\n \"\"\"Request tar file\"\"\"\n\n jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n site = models.SiteSettings.objects.get()\n hours = site.user_import_time_limit\n allowed = (\n jobs.first().created_date < timezone.now() - timedelta(hours=hours)\n if jobs.first()\n else True\n )\n next_available = (\n jobs.first().created_date + timedelta(hours=hours) if not allowed else False\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"jobs\": page,\n \"next_available\": next_available,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n return TemplateResponse(request, \"preferences/export-user.html\", data)\n\n def post(self, request):\n \"\"\"Download the json file of a user's data\"\"\"\n\n job = BookwyrmExportJob.objects.create(user=request.user)\n job.start_job()\n\n return redirect(\"prefs-user-export\")\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportArchive(View):\n \"\"\"Serve the archive file\"\"\"\n\n def get(self, request, archive_id):\n \"\"\"download user export file\"\"\"\n export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)\n return HttpResponse(\n export.export_data,\n content_type=\"application/gzip\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-account-export.tar.gz\"' # pylint: disable=line-too-long\n },\n )\n", "path": "bookwyrm/views/preferences/export.py"}], "after_files": [{"content": "\"\"\" Let users export their book data \"\"\"\nfrom datetime import timedelta\nimport csv\nimport io\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.shortcuts import redirect\n\nfrom bookwyrm import models\nfrom bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\nfrom bookwyrm.settings import PAGE_LENGTH\n\n\n# pylint: disable=no-self-use,too-many-locals\n@method_decorator(login_required, name=\"dispatch\")\nclass Export(View):\n \"\"\"Let users export data\"\"\"\n\n def get(self, request):\n \"\"\"Request csv file\"\"\"\n return TemplateResponse(request, \"preferences/export.html\")\n\n def post(self, request):\n \"\"\"Download the csv file of a user's book data\"\"\"\n books = models.Edition.viewer_aware_objects(request.user)\n books_shelves = books.filter(Q(shelves__user=request.user)).distinct()\n books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()\n books_review = books.filter(Q(review__user=request.user)).distinct()\n books_comment = books.filter(Q(comment__user=request.user)).distinct()\n books_quotation = books.filter(Q(quotation__user=request.user)).distinct()\n\n books = set(\n list(books_shelves)\n + list(books_readthrough)\n + list(books_review)\n + list(books_comment)\n + list(books_quotation)\n )\n\n csv_string = io.StringIO()\n writer = csv.writer(csv_string)\n\n deduplication_fields = [\n f.name\n for f in models.Edition._meta.get_fields() # pylint: disable=protected-access\n if getattr(f, \"deduplication_field\", False)\n ]\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n + [\n \"start_date\",\n \"finish_date\",\n \"stopped_date\",\n \"rating\",\n \"review_name\",\n \"review_cw\",\n \"review_content\",\n \"review_published\",\n \"shelf\",\n \"shelf_name\",\n \"shelf_date\",\n ]\n )\n writer.writerow(fields)\n\n for book in books:\n # I think this is more efficient than doing a subquery in the view? but idk\n review_rating = (\n models.Review.objects.filter(\n user=request.user, book=book, rating__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n\n book.rating = review_rating.rating if review_rating else None\n\n readthrough = (\n models.ReadThrough.objects.filter(user=request.user, book=book)\n .order_by(\"-start_date\", \"-finish_date\")\n .first()\n )\n if readthrough:\n book.start_date = (\n readthrough.start_date.date() if readthrough.start_date else None\n )\n book.finish_date = (\n readthrough.finish_date.date() if readthrough.finish_date else None\n )\n book.stopped_date = (\n readthrough.stopped_date.date()\n if readthrough.stopped_date\n else None\n )\n\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n if review:\n book.review_published = (\n review.published_date.date() if review.published_date else None\n )\n book.review_name = review.name\n book.review_cw = review.content_warning\n book.review_content = (\n review.raw_content if review.raw_content else review.content\n ) # GoodReads imported reviews do not have raw_content, but content.\n\n shelfbook = (\n models.ShelfBook.objects.filter(user=request.user, book=book)\n .order_by(\"-shelved_date\", \"-created_date\", \"-updated_date\")\n .last()\n )\n if shelfbook:\n book.shelf = shelfbook.shelf.identifier\n book.shelf_name = shelfbook.shelf.name\n book.shelf_date = (\n shelfbook.shelved_date.date() if shelfbook.shelved_date else None\n )\n\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n\n return HttpResponse(\n csv_string.getvalue(),\n content_type=\"text/csv\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-export.csv\"'\n },\n )\n\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportUser(View):\n \"\"\"Let users export user data to import into another Bookwyrm instance\"\"\"\n\n def get(self, request):\n \"\"\"Request tar file\"\"\"\n\n jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n site = models.SiteSettings.objects.get()\n hours = site.user_import_time_limit\n allowed = (\n jobs.first().created_date < timezone.now() - timedelta(hours=hours)\n if jobs.first()\n else True\n )\n next_available = (\n jobs.first().created_date + timedelta(hours=hours) if not allowed else False\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"jobs\": page,\n \"next_available\": next_available,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n return TemplateResponse(request, \"preferences/export-user.html\", data)\n\n def post(self, request):\n \"\"\"Download the json file of a user's data\"\"\"\n\n job = BookwyrmExportJob.objects.create(user=request.user)\n job.start_job()\n\n return redirect(\"prefs-user-export\")\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportArchive(View):\n \"\"\"Serve the archive file\"\"\"\n\n def get(self, request, archive_id):\n \"\"\"download user export file\"\"\"\n export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)\n return HttpResponse(\n export.export_data,\n content_type=\"application/gzip\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-account-export.tar.gz\"' # pylint: disable=line-too-long\n },\n )\n", "path": "bookwyrm/views/preferences/export.py"}]}
| 2,029 | 502 |
gh_patches_debug_583
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1750
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.1.85
On the docket:
+ [x] PEX interpreters should support all underlying Python interpreter options. #1745
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.84"
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.84"
+__version__ = "2.1.85"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.84\"\n+__version__ = \"2.1.85\"\n", "issue": "Release 2.1.85\nOn the docket:\r\n+ [x] PEX interpreters should support all underlying Python interpreter options. #1745\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.84\"\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.85\"\n", "path": "pex/version.py"}]}
| 343 | 96 |
gh_patches_debug_2856
|
rasdani/github-patches
|
git_diff
|
ResonantGeoData__ResonantGeoData-223
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_convert_to_cog function doesn't generate COG
The current _convert_to_cog function (https://github.com/ResonantGeoData/ResonantGeoData/blob/master/rgd/geodata/models/imagery/subsample.py#L32-L51) doesn't output a COG; it just outputs a tiled tiff file. GDAL has two separate format writers; one for regular TIFF and one for COG. Without the '-of COG' option, the regular tiff writer is invoked. The options available to the two writers differ as well: for COG you can specify a predictor with a string value, for regular tiff you must specify a numeric predictor value.
Using lzw compression, I'd recommend the following options: `['-co', 'COMPRESS=LZW', '-co', 'PREDICTOR=YES', '-of', 'COG']`. The default block (tile) size in the COG writer is 512 pixels; some tile servers or consumers seem to prefer 256; if so, add `-co BLOCKSIZE=256`.
You can use tiffdump to see that COG files have multiple directories at different resolutions while non-COG files have a single directory.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rgd/geodata/models/imagery/subsample.py`
Content:
```
1 """Tasks for subsampling images with GDAL."""
2 import os
3 import tempfile
4
5 from celery.utils.log import get_task_logger
6 from django.conf import settings
7 from girder_utils.files import field_file_to_local_path
8 from osgeo import gdal
9
10 from ..common import ArbitraryFile
11 from .base import ConvertedImageFile
12
13 logger = get_task_logger(__name__)
14
15
16 def _gdal_translate(source_field, output_field, **kwargs):
17 workdir = getattr(settings, 'GEODATA_WORKDIR', None)
18 tmpdir = tempfile.mkdtemp(dir=workdir)
19
20 with field_file_to_local_path(source_field) as file_path:
21 logger.info(f'The image file path: {file_path}')
22 output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))
23 ds = gdal.Open(str(file_path))
24 ds = gdal.Translate(output_path, ds, **kwargs)
25 ds = None
26
27 output_field.save(os.path.basename(output_path), open(output_path, 'rb'))
28
29 return
30
31
32 def convert_to_cog(cog_id):
33 """Populate ConvertedImageFile with COG file."""
34 options = [
35 '-co',
36 'COMPRESS=LZW',
37 '-co',
38 'TILED=YES',
39 ]
40 cog = ConvertedImageFile.objects.get(id=cog_id)
41 cog.converted_file = ArbitraryFile()
42 src = cog.source_image.image_file.imagefile.file
43 output = cog.converted_file.file
44 _gdal_translate(src, output, options=options)
45 cog.converted_file.save()
46 cog.save(
47 update_fields=[
48 'converted_file',
49 ]
50 )
51 return
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rgd/geodata/models/imagery/subsample.py b/rgd/geodata/models/imagery/subsample.py
--- a/rgd/geodata/models/imagery/subsample.py
+++ b/rgd/geodata/models/imagery/subsample.py
@@ -35,7 +35,11 @@
'-co',
'COMPRESS=LZW',
'-co',
- 'TILED=YES',
+ 'PREDICTOR=YES',
+ '-of',
+ 'COG',
+ '-co',
+ 'BLOCKSIZE=256',
]
cog = ConvertedImageFile.objects.get(id=cog_id)
cog.converted_file = ArbitraryFile()
|
{"golden_diff": "diff --git a/rgd/geodata/models/imagery/subsample.py b/rgd/geodata/models/imagery/subsample.py\n--- a/rgd/geodata/models/imagery/subsample.py\n+++ b/rgd/geodata/models/imagery/subsample.py\n@@ -35,7 +35,11 @@\n '-co',\n 'COMPRESS=LZW',\n '-co',\n- 'TILED=YES',\n+ 'PREDICTOR=YES',\n+ '-of',\n+ 'COG',\n+ '-co',\n+ 'BLOCKSIZE=256',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n", "issue": "_convert_to_cog function doesn't generate COG\nThe current _convert_to_cog function (https://github.com/ResonantGeoData/ResonantGeoData/blob/master/rgd/geodata/models/imagery/subsample.py#L32-L51) doesn't output a COG; it just outputs a tiled tiff file. GDAL has two separate format writers; one for regular TIFF and one for COG. Without the '-of COG' option, the regular tiff writer is invoked. The options available to the two writers differ as well: for COG you can specify a predictor with a string value, for regular tiff you must specify a numeric predictor value.\r\n\r\nUsing lzw compression, I'd recommend the following options: `['-co', 'COMPRESS=LZW', '-co', 'PREDICTOR=YES', '-of', 'COG']`. The default block (tile) size in the COG writer is 512 pixels; some tile servers or consumers seem to prefer 256; if so, add `-co BLOCKSIZE=256`.\r\n\r\nYou can use tiffdump to see that COG files have multiple directories at different resolutions while non-COG files have a single directory.\r\n\n", "before_files": [{"content": "\"\"\"Tasks for subsampling images with GDAL.\"\"\"\nimport os\nimport tempfile\n\nfrom celery.utils.log import get_task_logger\nfrom django.conf import settings\nfrom girder_utils.files import field_file_to_local_path\nfrom osgeo import gdal\n\nfrom ..common import ArbitraryFile\nfrom .base import ConvertedImageFile\n\nlogger = get_task_logger(__name__)\n\n\ndef _gdal_translate(source_field, output_field, **kwargs):\n workdir = getattr(settings, 'GEODATA_WORKDIR', None)\n tmpdir = tempfile.mkdtemp(dir=workdir)\n\n with field_file_to_local_path(source_field) as file_path:\n logger.info(f'The image file path: {file_path}')\n output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))\n ds = gdal.Open(str(file_path))\n ds = gdal.Translate(output_path, ds, **kwargs)\n ds = None\n\n output_field.save(os.path.basename(output_path), open(output_path, 'rb'))\n\n return\n\n\ndef convert_to_cog(cog_id):\n \"\"\"Populate ConvertedImageFile with COG file.\"\"\"\n options = [\n '-co',\n 'COMPRESS=LZW',\n '-co',\n 'TILED=YES',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n src = cog.source_image.image_file.imagefile.file\n output = cog.converted_file.file\n _gdal_translate(src, output, options=options)\n cog.converted_file.save()\n cog.save(\n update_fields=[\n 'converted_file',\n ]\n )\n return\n", "path": "rgd/geodata/models/imagery/subsample.py"}], "after_files": [{"content": "\"\"\"Tasks for subsampling images with GDAL.\"\"\"\nimport os\nimport tempfile\n\nfrom celery.utils.log import get_task_logger\nfrom django.conf import settings\nfrom girder_utils.files import field_file_to_local_path\nfrom osgeo import gdal\n\nfrom ..common import ArbitraryFile\nfrom .base import ConvertedImageFile\n\nlogger = get_task_logger(__name__)\n\n\ndef _gdal_translate(source_field, output_field, **kwargs):\n workdir = getattr(settings, 'GEODATA_WORKDIR', None)\n tmpdir = tempfile.mkdtemp(dir=workdir)\n\n with field_file_to_local_path(source_field) as file_path:\n logger.info(f'The image file path: {file_path}')\n output_path = os.path.join(tmpdir, 'subsampled_' + os.path.basename(file_path))\n ds = gdal.Open(str(file_path))\n ds = gdal.Translate(output_path, ds, **kwargs)\n ds = None\n\n output_field.save(os.path.basename(output_path), open(output_path, 'rb'))\n\n return\n\n\ndef convert_to_cog(cog_id):\n \"\"\"Populate ConvertedImageFile with COG file.\"\"\"\n options = [\n '-co',\n 'COMPRESS=LZW',\n '-co',\n 'PREDICTOR=YES',\n '-of',\n 'COG',\n '-co',\n 'BLOCKSIZE=256',\n ]\n cog = ConvertedImageFile.objects.get(id=cog_id)\n cog.converted_file = ArbitraryFile()\n src = cog.source_image.image_file.imagefile.file\n output = cog.converted_file.file\n _gdal_translate(src, output, options=options)\n cog.converted_file.save()\n cog.save(\n update_fields=[\n 'converted_file',\n ]\n )\n return\n", "path": "rgd/geodata/models/imagery/subsample.py"}]}
| 981 | 154 |
gh_patches_debug_25458
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1115
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support create volume Labels options
First, check the remote API:
https://docs.docker.com/engine/reference/api/docker_remote_api_v1.23/
```
{
"Name": "tardis",
"Labels": {
"com.example.some-label": "some-value",
"com.example.some-other-label": "some-other-value"
},
}
```
It provides `Labels` options. But docker-py doesn't support it right not.
Second, in docker-py's document give the following example:
```
volume = cli.create_volume(
name='foobar', driver='local', driver_opts={'foo': 'bar', 'baz': 'false'}
docker.errors.APIError: 500 Server Error: Internal Server Error ("create foobar: invalid option key: "foo"")
```
But driver_opts is not working. What kinds of driver_opts can we use?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/api/volume.py`
Content:
```
1 from .. import utils
2
3
4 class VolumeApiMixin(object):
5 @utils.minimum_version('1.21')
6 def volumes(self, filters=None):
7 params = {
8 'filters': utils.convert_filters(filters) if filters else None
9 }
10 url = self._url('/volumes')
11 return self._result(self._get(url, params=params), True)
12
13 @utils.minimum_version('1.21')
14 def create_volume(self, name, driver=None, driver_opts=None):
15 url = self._url('/volumes/create')
16 if driver_opts is not None and not isinstance(driver_opts, dict):
17 raise TypeError('driver_opts must be a dictionary')
18
19 data = {
20 'Name': name,
21 'Driver': driver,
22 'DriverOpts': driver_opts,
23 }
24 return self._result(self._post_json(url, data=data), True)
25
26 @utils.minimum_version('1.21')
27 def inspect_volume(self, name):
28 url = self._url('/volumes/{0}', name)
29 return self._result(self._get(url), True)
30
31 @utils.minimum_version('1.21')
32 def remove_volume(self, name):
33 url = self._url('/volumes/{0}', name)
34 resp = self._delete(url)
35 self._raise_for_status(resp)
36
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/api/volume.py b/docker/api/volume.py
--- a/docker/api/volume.py
+++ b/docker/api/volume.py
@@ -1,3 +1,4 @@
+from .. import errors
from .. import utils
@@ -11,7 +12,7 @@
return self._result(self._get(url, params=params), True)
@utils.minimum_version('1.21')
- def create_volume(self, name, driver=None, driver_opts=None):
+ def create_volume(self, name, driver=None, driver_opts=None, labels=None):
url = self._url('/volumes/create')
if driver_opts is not None and not isinstance(driver_opts, dict):
raise TypeError('driver_opts must be a dictionary')
@@ -21,6 +22,16 @@
'Driver': driver,
'DriverOpts': driver_opts,
}
+
+ if labels is not None:
+ if utils.compare_version('1.23', self._version) < 0:
+ raise errors.InvalidVersion(
+ 'volume labels were introduced in API 1.23'
+ )
+ if not isinstance(labels, dict):
+ raise TypeError('labels must be a dictionary')
+ data["Labels"] = labels
+
return self._result(self._post_json(url, data=data), True)
@utils.minimum_version('1.21')
|
{"golden_diff": "diff --git a/docker/api/volume.py b/docker/api/volume.py\n--- a/docker/api/volume.py\n+++ b/docker/api/volume.py\n@@ -1,3 +1,4 @@\n+from .. import errors\n from .. import utils\n \n \n@@ -11,7 +12,7 @@\n return self._result(self._get(url, params=params), True)\n \n @utils.minimum_version('1.21')\n- def create_volume(self, name, driver=None, driver_opts=None):\n+ def create_volume(self, name, driver=None, driver_opts=None, labels=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n@@ -21,6 +22,16 @@\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n+\n+ if labels is not None:\n+ if utils.compare_version('1.23', self._version) < 0:\n+ raise errors.InvalidVersion(\n+ 'volume labels were introduced in API 1.23'\n+ )\n+ if not isinstance(labels, dict):\n+ raise TypeError('labels must be a dictionary')\n+ data[\"Labels\"] = labels\n+\n return self._result(self._post_json(url, data=data), True)\n \n @utils.minimum_version('1.21')\n", "issue": "Support create volume Labels options\nFirst, check the remote API:\nhttps://docs.docker.com/engine/reference/api/docker_remote_api_v1.23/\n\n```\n {\n \"Name\": \"tardis\",\n \"Labels\": {\n \"com.example.some-label\": \"some-value\",\n \"com.example.some-other-label\": \"some-other-value\"\n },\n}\n```\n\nIt provides `Labels` options. But docker-py doesn't support it right not.\n\nSecond, in docker-py's document give the following example:\n\n```\nvolume = cli.create_volume(\n name='foobar', driver='local', driver_opts={'foo': 'bar', 'baz': 'false'}\n\ndocker.errors.APIError: 500 Server Error: Internal Server Error (\"create foobar: invalid option key: \"foo\"\")\n```\n\nBut driver_opts is not working. What kinds of driver_opts can we use?\n\n", "before_files": [{"content": "from .. import utils\n\n\nclass VolumeApiMixin(object):\n @utils.minimum_version('1.21')\n def volumes(self, filters=None):\n params = {\n 'filters': utils.convert_filters(filters) if filters else None\n }\n url = self._url('/volumes')\n return self._result(self._get(url, params=params), True)\n\n @utils.minimum_version('1.21')\n def create_volume(self, name, driver=None, driver_opts=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n return self._result(self._post_json(url, data=data), True)\n\n @utils.minimum_version('1.21')\n def inspect_volume(self, name):\n url = self._url('/volumes/{0}', name)\n return self._result(self._get(url), True)\n\n @utils.minimum_version('1.21')\n def remove_volume(self, name):\n url = self._url('/volumes/{0}', name)\n resp = self._delete(url)\n self._raise_for_status(resp)\n", "path": "docker/api/volume.py"}], "after_files": [{"content": "from .. import errors\nfrom .. import utils\n\n\nclass VolumeApiMixin(object):\n @utils.minimum_version('1.21')\n def volumes(self, filters=None):\n params = {\n 'filters': utils.convert_filters(filters) if filters else None\n }\n url = self._url('/volumes')\n return self._result(self._get(url, params=params), True)\n\n @utils.minimum_version('1.21')\n def create_volume(self, name, driver=None, driver_opts=None, labels=None):\n url = self._url('/volumes/create')\n if driver_opts is not None and not isinstance(driver_opts, dict):\n raise TypeError('driver_opts must be a dictionary')\n\n data = {\n 'Name': name,\n 'Driver': driver,\n 'DriverOpts': driver_opts,\n }\n\n if labels is not None:\n if utils.compare_version('1.23', self._version) < 0:\n raise errors.InvalidVersion(\n 'volume labels were introduced in API 1.23'\n )\n if not isinstance(labels, dict):\n raise TypeError('labels must be a dictionary')\n data[\"Labels\"] = labels\n\n return self._result(self._post_json(url, data=data), True)\n\n @utils.minimum_version('1.21')\n def inspect_volume(self, name):\n url = self._url('/volumes/{0}', name)\n return self._result(self._get(url), True)\n\n @utils.minimum_version('1.21')\n def remove_volume(self, name):\n url = self._url('/volumes/{0}', name)\n resp = self._delete(url)\n self._raise_for_status(resp)\n", "path": "docker/api/volume.py"}]}
| 786 | 306 |
gh_patches_debug_8491
|
rasdani/github-patches
|
git_diff
|
OpenEnergyPlatform__oeplatform-1324
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Inconvenience of client cache update upon releasing/deploy new versions
## Description of the issue
When deploying a new version of an application, users are inconvenienced as they need to manually refresh the client cache to see the latest changes.
## Ideas of solution
ChatGPT suggested to introduce a Cache Busting Mechanism. We could use this existing lib [django-compressor](https://github.com/django-compressor/django-compressor).
> To set up a cache-busting mechanism in your Django application, you can use the Django extension module "django-compressor". Django Compressor allows you to compress static resources such as CSS and JavaScript files and assign them a unique hash value based on their content. This automatically changes the URL of the resources whenever they are modified.
## Workflow checklist
- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `oeplatform/settings.py`
Content:
```
1 """
2 Django settings for oeplatform project.
3
4 Generated by 'django-admin startproject' using Django 1.8.5.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.8/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.8/ref/settings/
11 """
12
13 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
14
15 try:
16 from .securitysettings import * # noqa
17 except ImportError:
18 import logging
19 import os
20
21 logging.error("No securitysettings found. Triggerd in oeplatform/settings.py")
22 SECRET_KEY = os.environ.get("SECRET_KEY", "0")
23 DEFAULT_FROM_EMAIL = os.environ.get("DEFAULT_FROM_EMAIL")
24 URL = os.environ.get("URL")
25
26 # Quick-start development settings - unsuitable for production
27 # See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/
28
29 # Application definition
30
31 INSTALLED_APPS = (
32 "django.contrib.sites",
33 "django.contrib.admin",
34 "django.contrib.auth",
35 "django.contrib.contenttypes",
36 "django.contrib.sessions",
37 "django.contrib.messages",
38 "django.contrib.staticfiles",
39 "django.contrib.sessions.backends.signed_cookies",
40 "django_bootstrap5",
41 "rest_framework",
42 "rest_framework.authtoken",
43 "modelview",
44 "modelview.templatetags.modelview_extras",
45 "login",
46 "base",
47 "base.templatetags.base_tags",
48 "widget_tweaks",
49 "dataedit",
50 "colorfield",
51 "api",
52 "ontology",
53 "axes",
54 "captcha",
55 "django.contrib.postgres",
56 "fontawesome_5",
57 "django_better_admin_arrayfield",
58 "oeo_viewer",
59 )
60
61 MIDDLEWARE = (
62 "django.contrib.sites.middleware.CurrentSiteMiddleware",
63 "django.contrib.sessions.middleware.SessionMiddleware",
64 "django.middleware.common.CommonMiddleware",
65 "django.middleware.csrf.CsrfViewMiddleware",
66 "django.contrib.auth.middleware.AuthenticationMiddleware",
67 "django.contrib.messages.middleware.MessageMiddleware",
68 "django.middleware.clickjacking.XFrameOptionsMiddleware",
69 "django.middleware.security.SecurityMiddleware",
70 "login.middleware.DetachMiddleware",
71 "axes.middleware.AxesMiddleware",
72 "django.middleware.common.CommonMiddleware",
73 )
74
75 ROOT_URLCONF = "oeplatform.urls"
76
77 EXTERNAL_URLS = {
78 "tutorials_index": "https://openenergyplatform.github.io/academy/",
79 "tutorials_faq": "https://openenergyplatform.github.io/academy/",
80 "tutorials_api1": "https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/", # noqa E501
81 "tutorials_licenses": "https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/",
82 # noqa E501
83 "readthedocs": "https://oeplatform.readthedocs.io/en/latest/?badge=latest",
84 "compendium": "https://openenergyplatform.github.io/organisation/",
85 }
86
87
88 def external_urls_context_processor(request):
89 """Define hard coded external urls here.
90 Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}
91 Also, you may want to add an icon indicating external links, e.g.
92 """
93 return {"EXTERNAL_URLS": EXTERNAL_URLS}
94
95
96 SITE_ID = 1
97
98 TEMPLATES = [
99 {
100 "BACKEND": "django.template.backends.django.DjangoTemplates",
101 "DIRS": [],
102 "APP_DIRS": True,
103 "OPTIONS": {
104 "context_processors": [
105 "django.template.context_processors.debug",
106 "django.template.context_processors.request",
107 "django.contrib.auth.context_processors.auth",
108 "django.contrib.messages.context_processors.messages",
109 "oeplatform.settings.external_urls_context_processor",
110 ]
111 },
112 }
113 ]
114
115 CORS_ORIGIN_WHITELIST = ["http://localhost:3000", "http://127.0.0.1:3000"]
116
117 GRAPHENE = {"SCHEMA": "factsheet.schema.schema"}
118
119 WSGI_APPLICATION = "oeplatform.wsgi.application"
120
121 try:
122 ONTOLOGY_FOLDER # noqa
123 except NameError:
124 ONTOLOGY_FOLDER = "/tmp"
125
126 # Internationalization
127 # https://docs.djangoproject.com/en/1.8/topics/i18n/
128
129 LANGUAGE_CODE = "en-us"
130
131 TIME_ZONE = "Europe/Berlin"
132
133 USE_I18N = True
134
135 USE_L10N = True
136
137 USE_TZ = True
138
139 # Static files (CSS, JavaScript, Images)
140 # https://docs.djangoproject.com/en/1.8/howto/static-files/
141
142 AUTH_USER_MODEL = "login.myuser"
143 LOGIN_URL = "/user/login"
144 LOGIN_REDIRECT_URL = "/"
145
146 REST_FRAMEWORK = {
147 "DEFAULT_AUTHENTICATION_CLASSES": (
148 "rest_framework.authentication.BasicAuthentication",
149 "rest_framework.authentication.SessionAuthentication",
150 "rest_framework.authentication.TokenAuthentication",
151 )
152 }
153
154 AUTHENTICATION_BACKENDS = [
155 # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.
156 "axes.backends.AxesBackend",
157 # custom class extenging Django ModelBackend for login with username OR email
158 "login.backends.ModelBackendWithEmail",
159 ]
160
161 DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/oeplatform/settings.py b/oeplatform/settings.py
--- a/oeplatform/settings.py
+++ b/oeplatform/settings.py
@@ -56,6 +56,7 @@
"fontawesome_5",
"django_better_admin_arrayfield",
"oeo_viewer",
+ "compressor",
)
MIDDLEWARE = (
@@ -159,3 +160,12 @@
]
DEFAULT_AUTO_FIELD = "django.db.models.AutoField"
+
+STATICFILES_FINDERS = {
+ 'django.contrib.staticfiles.finders.FileSystemFinder',
+ 'django.contrib.staticfiles.finders.AppDirectoriesFinder',
+ 'compressor.finders.CompressorFinder',
+}
+
+COMPRESS_ENABLED = True
+COMPRESS_OFFLINE = True
|
{"golden_diff": "diff --git a/oeplatform/settings.py b/oeplatform/settings.py\n--- a/oeplatform/settings.py\n+++ b/oeplatform/settings.py\n@@ -56,6 +56,7 @@\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n+ \"compressor\",\n )\n \n MIDDLEWARE = (\n@@ -159,3 +160,12 @@\n ]\n \n DEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n+\n+STATICFILES_FINDERS = {\n+ 'django.contrib.staticfiles.finders.FileSystemFinder',\n+ 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n+ 'compressor.finders.CompressorFinder',\n+}\n+\n+COMPRESS_ENABLED = True\n+COMPRESS_OFFLINE = True\n", "issue": "Inconvenience of client cache update upon releasing/deploy new versions\n## Description of the issue\r\n\r\nWhen deploying a new version of an application, users are inconvenienced as they need to manually refresh the client cache to see the latest changes.\r\n\r\n## Ideas of solution\r\n\r\nChatGPT suggested to introduce a Cache Busting Mechanism. We could use this existing lib [django-compressor](https://github.com/django-compressor/django-compressor).\r\n\r\n> To set up a cache-busting mechanism in your Django application, you can use the Django extension module \"django-compressor\". Django Compressor allows you to compress static resources such as CSS and JavaScript files and assign them a unique hash value based on their content. This automatically changes the URL of the resources whenever they are modified.\r\n\r\n## Workflow checklist\r\n- [x] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)\r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n", "path": "oeplatform/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for oeplatform project.\n\nGenerated by 'django-admin startproject' using Django 1.8.5.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.8/ref/settings/\n\"\"\"\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n\ntry:\n from .securitysettings import * # noqa\nexcept ImportError:\n import logging\n import os\n\n logging.error(\"No securitysettings found. Triggerd in oeplatform/settings.py\")\n SECRET_KEY = os.environ.get(\"SECRET_KEY\", \"0\")\n DEFAULT_FROM_EMAIL = os.environ.get(\"DEFAULT_FROM_EMAIL\")\n URL = os.environ.get(\"URL\")\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.8/howto/deployment/checklist/\n\n# Application definition\n\nINSTALLED_APPS = (\n \"django.contrib.sites\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django.contrib.sessions.backends.signed_cookies\",\n \"django_bootstrap5\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"modelview\",\n \"modelview.templatetags.modelview_extras\",\n \"login\",\n \"base\",\n \"base.templatetags.base_tags\",\n \"widget_tweaks\",\n \"dataedit\",\n \"colorfield\",\n \"api\",\n \"ontology\",\n \"axes\",\n \"captcha\",\n \"django.contrib.postgres\",\n \"fontawesome_5\",\n \"django_better_admin_arrayfield\",\n \"oeo_viewer\",\n \"compressor\",\n)\n\nMIDDLEWARE = (\n \"django.contrib.sites.middleware.CurrentSiteMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"login.middleware.DetachMiddleware\",\n \"axes.middleware.AxesMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n)\n\nROOT_URLCONF = \"oeplatform.urls\"\n\nEXTERNAL_URLS = {\n \"tutorials_index\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_faq\": \"https://openenergyplatform.github.io/academy/\",\n \"tutorials_api1\": \"https://openenergyplatform.github.io/academy/tutorials/api/OEP_API_tutorial_part1/\", # noqa E501\n \"tutorials_licenses\": \"https://openenergyplatform.github.io/academy/tutorials/metadata/tutorial_open-data-licenses/\",\n # noqa E501\n \"readthedocs\": \"https://oeplatform.readthedocs.io/en/latest/?badge=latest\",\n \"compendium\": \"https://openenergyplatform.github.io/organisation/\",\n}\n\n\ndef external_urls_context_processor(request):\n \"\"\"Define hard coded external urls here.\n Use in templates like this: {{ EXTERNAL_URLS.<name_of_url> }}\n Also, you may want to add an icon indicating external links, e.g.\n \"\"\"\n return {\"EXTERNAL_URLS\": EXTERNAL_URLS}\n\n\nSITE_ID = 1\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n \"oeplatform.settings.external_urls_context_processor\",\n ]\n },\n }\n]\n\nCORS_ORIGIN_WHITELIST = [\"http://localhost:3000\", \"http://127.0.0.1:3000\"]\n\nGRAPHENE = {\"SCHEMA\": \"factsheet.schema.schema\"}\n\nWSGI_APPLICATION = \"oeplatform.wsgi.application\"\n\ntry:\n ONTOLOGY_FOLDER # noqa\nexcept NameError:\n ONTOLOGY_FOLDER = \"/tmp\"\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.8/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Europe/Berlin\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n\nAUTH_USER_MODEL = \"login.myuser\"\nLOGIN_URL = \"/user/login\"\nLOGIN_REDIRECT_URL = \"/\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": (\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n \"rest_framework.authentication.TokenAuthentication\",\n )\n}\n\nAUTHENTICATION_BACKENDS = [\n # AxesBackend should be the first backend in the AUTHENTICATION_BACKENDS list.\n \"axes.backends.AxesBackend\",\n # custom class extenging Django ModelBackend for login with username OR email\n \"login.backends.ModelBackendWithEmail\",\n]\n\nDEFAULT_AUTO_FIELD = \"django.db.models.AutoField\"\n\nSTATICFILES_FINDERS = {\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n 'compressor.finders.CompressorFinder',\n}\n\nCOMPRESS_ENABLED = True\nCOMPRESS_OFFLINE = True\n", "path": "oeplatform/settings.py"}]}
| 1,989 | 168 |
gh_patches_debug_25638
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-1138
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
smartplaylist: Respect sort terms in queries
It would be nice to be able sort items in smart playlists, like so:
```
smartplaylist:
relative_to: ~/music
playlist_dir: ~/.mpd/playlists
playlists:
- name: '2014.m3u'
query: 'year:2014 added+'
- name: 'imported-%time{$added,%Y-%m}.m3u'
query: "added:: path+"
```
I'm unfamiliar with the code but it looks like the smartplaylist plugin [discards the query `sort` field](https://github.com/sampsyo/beets/blob/master/beetsplug/smartplaylist.py#L45) when building playlists. Would it be possible to keep the custom sort?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `beetsplug/smartplaylist.py`
Content:
```
1 # This file is part of beets.
2 # Copyright 2013, Dang Mai <[email protected]>.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Generates smart playlists based on beets queries.
16 """
17 from __future__ import print_function
18
19 from beets.plugins import BeetsPlugin
20 from beets import config, ui, library
21 from beets import dbcore
22 from beets.util import normpath, syspath
23 import os
24
25 # Global variable so that smartplaylist can detect database changes and run
26 # only once before beets exits.
27 database_changed = False
28
29
30 def _items_for_query(lib, playlist, album=False):
31 """Get the matching items for a playlist's configured queries.
32 `album` indicates whether to process the item-level query or the
33 album-level query (if any).
34 """
35 key = 'album_query' if album else 'query'
36 if key not in playlist:
37 return []
38
39 # Parse quer(ies). If it's a list, join the queries with OR.
40 query_strings = playlist[key]
41 if not isinstance(query_strings, (list, tuple)):
42 query_strings = [query_strings]
43 model = library.Album if album else library.Item
44 query = dbcore.OrQuery(
45 [library.parse_query_string(q, model)[0] for q in query_strings]
46 )
47
48 # Execute query, depending on type.
49 if album:
50 result = []
51 for album in lib.albums(query):
52 result.extend(album.items())
53 return result
54 else:
55 return lib.items(query)
56
57
58 def update_playlists(lib):
59 ui.print_("Updating smart playlists...")
60 playlists = config['smartplaylist']['playlists'].get(list)
61 playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()
62 relative_to = config['smartplaylist']['relative_to'].get()
63 if relative_to:
64 relative_to = normpath(relative_to)
65
66 for playlist in playlists:
67 items = []
68 items.extend(_items_for_query(lib, playlist, True))
69 items.extend(_items_for_query(lib, playlist, False))
70
71 m3us = {}
72 basename = playlist['name'].encode('utf8')
73 # As we allow tags in the m3u names, we'll need to iterate through
74 # the items and generate the correct m3u file names.
75 for item in items:
76 m3u_name = item.evaluate_template(basename, True)
77 if not (m3u_name in m3us):
78 m3us[m3u_name] = []
79 item_path = item.path
80 if relative_to:
81 item_path = os.path.relpath(item.path, relative_to)
82 if item_path not in m3us[m3u_name]:
83 m3us[m3u_name].append(item_path)
84 # Now iterate through the m3us that we need to generate
85 for m3u in m3us:
86 m3u_path = normpath(os.path.join(playlist_dir, m3u))
87 with open(syspath(m3u_path), 'w') as f:
88 for path in m3us[m3u]:
89 f.write(path + '\n')
90 ui.print_("... Done")
91
92
93 class SmartPlaylistPlugin(BeetsPlugin):
94 def __init__(self):
95 super(SmartPlaylistPlugin, self).__init__()
96 self.config.add({
97 'relative_to': None,
98 'playlist_dir': u'.',
99 'auto': True,
100 'playlists': []
101 })
102
103 def commands(self):
104 def update(lib, opts, args):
105 update_playlists(lib)
106 spl_update = ui.Subcommand('splupdate',
107 help='update the smart playlists')
108 spl_update.func = update
109 return [spl_update]
110
111
112 @SmartPlaylistPlugin.listen('database_change')
113 def handle_change(lib):
114 global database_changed
115 database_changed = True
116
117
118 @SmartPlaylistPlugin.listen('cli_exit')
119 def update(lib):
120 auto = config['smartplaylist']['auto']
121 if database_changed and auto:
122 update_playlists(lib)
123
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/beetsplug/smartplaylist.py b/beetsplug/smartplaylist.py
--- a/beetsplug/smartplaylist.py
+++ b/beetsplug/smartplaylist.py
@@ -18,7 +18,6 @@
from beets.plugins import BeetsPlugin
from beets import config, ui, library
-from beets import dbcore
from beets.util import normpath, syspath
import os
@@ -36,23 +35,21 @@
if key not in playlist:
return []
- # Parse quer(ies). If it's a list, join the queries with OR.
+ # Parse quer(ies). If it's a list, perform the queries and manually
+ # concatenate the results
query_strings = playlist[key]
if not isinstance(query_strings, (list, tuple)):
query_strings = [query_strings]
model = library.Album if album else library.Item
- query = dbcore.OrQuery(
- [library.parse_query_string(q, model)[0] for q in query_strings]
- )
-
- # Execute query, depending on type.
- if album:
- result = []
- for album in lib.albums(query):
- result.extend(album.items())
- return result
- else:
- return lib.items(query)
+ results = []
+ for q in query_strings:
+ querystr, sort = library.parse_query_string(q, model)
+ if album:
+ new = lib.albums(querystr, sort)
+ else:
+ new = lib.items(querystr, sort)
+ results.extend(new)
+ return results
def update_playlists(lib):
|
{"golden_diff": "diff --git a/beetsplug/smartplaylist.py b/beetsplug/smartplaylist.py\n--- a/beetsplug/smartplaylist.py\n+++ b/beetsplug/smartplaylist.py\n@@ -18,7 +18,6 @@\n \n from beets.plugins import BeetsPlugin\n from beets import config, ui, library\n-from beets import dbcore\n from beets.util import normpath, syspath\n import os\n \n@@ -36,23 +35,21 @@\n if key not in playlist:\n return []\n \n- # Parse quer(ies). If it's a list, join the queries with OR.\n+ # Parse quer(ies). If it's a list, perform the queries and manually\n+ # concatenate the results\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n- query = dbcore.OrQuery(\n- [library.parse_query_string(q, model)[0] for q in query_strings]\n- )\n-\n- # Execute query, depending on type.\n- if album:\n- result = []\n- for album in lib.albums(query):\n- result.extend(album.items())\n- return result\n- else:\n- return lib.items(query)\n+ results = []\n+ for q in query_strings:\n+ querystr, sort = library.parse_query_string(q, model)\n+ if album:\n+ new = lib.albums(querystr, sort)\n+ else:\n+ new = lib.items(querystr, sort)\n+ results.extend(new)\n+ return results\n \n \n def update_playlists(lib):\n", "issue": "smartplaylist: Respect sort terms in queries\nIt would be nice to be able sort items in smart playlists, like so:\n\n```\nsmartplaylist:\n relative_to: ~/music\n playlist_dir: ~/.mpd/playlists\n playlists:\n - name: '2014.m3u'\n query: 'year:2014 added+'\n - name: 'imported-%time{$added,%Y-%m}.m3u'\n query: \"added:: path+\"\n```\n\nI'm unfamiliar with the code but it looks like the smartplaylist plugin [discards the query `sort` field](https://github.com/sampsyo/beets/blob/master/beetsplug/smartplaylist.py#L45) when building playlists. Would it be possible to keep the custom sort?\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2013, Dang Mai <[email protected]>.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Generates smart playlists based on beets queries.\n\"\"\"\nfrom __future__ import print_function\n\nfrom beets.plugins import BeetsPlugin\nfrom beets import config, ui, library\nfrom beets import dbcore\nfrom beets.util import normpath, syspath\nimport os\n\n# Global variable so that smartplaylist can detect database changes and run\n# only once before beets exits.\ndatabase_changed = False\n\n\ndef _items_for_query(lib, playlist, album=False):\n \"\"\"Get the matching items for a playlist's configured queries.\n `album` indicates whether to process the item-level query or the\n album-level query (if any).\n \"\"\"\n key = 'album_query' if album else 'query'\n if key not in playlist:\n return []\n\n # Parse quer(ies). If it's a list, join the queries with OR.\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n query = dbcore.OrQuery(\n [library.parse_query_string(q, model)[0] for q in query_strings]\n )\n\n # Execute query, depending on type.\n if album:\n result = []\n for album in lib.albums(query):\n result.extend(album.items())\n return result\n else:\n return lib.items(query)\n\n\ndef update_playlists(lib):\n ui.print_(\"Updating smart playlists...\")\n playlists = config['smartplaylist']['playlists'].get(list)\n playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()\n relative_to = config['smartplaylist']['relative_to'].get()\n if relative_to:\n relative_to = normpath(relative_to)\n\n for playlist in playlists:\n items = []\n items.extend(_items_for_query(lib, playlist, True))\n items.extend(_items_for_query(lib, playlist, False))\n\n m3us = {}\n basename = playlist['name'].encode('utf8')\n # As we allow tags in the m3u names, we'll need to iterate through\n # the items and generate the correct m3u file names.\n for item in items:\n m3u_name = item.evaluate_template(basename, True)\n if not (m3u_name in m3us):\n m3us[m3u_name] = []\n item_path = item.path\n if relative_to:\n item_path = os.path.relpath(item.path, relative_to)\n if item_path not in m3us[m3u_name]:\n m3us[m3u_name].append(item_path)\n # Now iterate through the m3us that we need to generate\n for m3u in m3us:\n m3u_path = normpath(os.path.join(playlist_dir, m3u))\n with open(syspath(m3u_path), 'w') as f:\n for path in m3us[m3u]:\n f.write(path + '\\n')\n ui.print_(\"... Done\")\n\n\nclass SmartPlaylistPlugin(BeetsPlugin):\n def __init__(self):\n super(SmartPlaylistPlugin, self).__init__()\n self.config.add({\n 'relative_to': None,\n 'playlist_dir': u'.',\n 'auto': True,\n 'playlists': []\n })\n\n def commands(self):\n def update(lib, opts, args):\n update_playlists(lib)\n spl_update = ui.Subcommand('splupdate',\n help='update the smart playlists')\n spl_update.func = update\n return [spl_update]\n\n\[email protected]('database_change')\ndef handle_change(lib):\n global database_changed\n database_changed = True\n\n\[email protected]('cli_exit')\ndef update(lib):\n auto = config['smartplaylist']['auto']\n if database_changed and auto:\n update_playlists(lib)\n", "path": "beetsplug/smartplaylist.py"}], "after_files": [{"content": "# This file is part of beets.\n# Copyright 2013, Dang Mai <[email protected]>.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Generates smart playlists based on beets queries.\n\"\"\"\nfrom __future__ import print_function\n\nfrom beets.plugins import BeetsPlugin\nfrom beets import config, ui, library\nfrom beets.util import normpath, syspath\nimport os\n\n# Global variable so that smartplaylist can detect database changes and run\n# only once before beets exits.\ndatabase_changed = False\n\n\ndef _items_for_query(lib, playlist, album=False):\n \"\"\"Get the matching items for a playlist's configured queries.\n `album` indicates whether to process the item-level query or the\n album-level query (if any).\n \"\"\"\n key = 'album_query' if album else 'query'\n if key not in playlist:\n return []\n\n # Parse quer(ies). If it's a list, perform the queries and manually\n # concatenate the results\n query_strings = playlist[key]\n if not isinstance(query_strings, (list, tuple)):\n query_strings = [query_strings]\n model = library.Album if album else library.Item\n results = []\n for q in query_strings:\n querystr, sort = library.parse_query_string(q, model)\n if album:\n new = lib.albums(querystr, sort)\n else:\n new = lib.items(querystr, sort)\n results.extend(new)\n return results\n\n\ndef update_playlists(lib):\n ui.print_(\"Updating smart playlists...\")\n playlists = config['smartplaylist']['playlists'].get(list)\n playlist_dir = config['smartplaylist']['playlist_dir'].as_filename()\n relative_to = config['smartplaylist']['relative_to'].get()\n if relative_to:\n relative_to = normpath(relative_to)\n\n for playlist in playlists:\n items = []\n items.extend(_items_for_query(lib, playlist, True))\n items.extend(_items_for_query(lib, playlist, False))\n\n m3us = {}\n basename = playlist['name'].encode('utf8')\n # As we allow tags in the m3u names, we'll need to iterate through\n # the items and generate the correct m3u file names.\n for item in items:\n m3u_name = item.evaluate_template(basename, True)\n if not (m3u_name in m3us):\n m3us[m3u_name] = []\n item_path = item.path\n if relative_to:\n item_path = os.path.relpath(item.path, relative_to)\n if item_path not in m3us[m3u_name]:\n m3us[m3u_name].append(item_path)\n # Now iterate through the m3us that we need to generate\n for m3u in m3us:\n m3u_path = normpath(os.path.join(playlist_dir, m3u))\n with open(syspath(m3u_path), 'w') as f:\n for path in m3us[m3u]:\n f.write(path + '\\n')\n ui.print_(\"... Done\")\n\n\nclass SmartPlaylistPlugin(BeetsPlugin):\n def __init__(self):\n super(SmartPlaylistPlugin, self).__init__()\n self.config.add({\n 'relative_to': None,\n 'playlist_dir': u'.',\n 'auto': True,\n 'playlists': []\n })\n\n def commands(self):\n def update(lib, opts, args):\n update_playlists(lib)\n spl_update = ui.Subcommand('splupdate',\n help='update the smart playlists')\n spl_update.func = update\n return [spl_update]\n\n\[email protected]('database_change')\ndef handle_change(lib):\n global database_changed\n database_changed = True\n\n\[email protected]('cli_exit')\ndef update(lib):\n auto = config['smartplaylist']['auto']\n if database_changed and auto:\n update_playlists(lib)\n", "path": "beetsplug/smartplaylist.py"}]}
| 1,662 | 367 |
gh_patches_debug_17584
|
rasdani/github-patches
|
git_diff
|
geopandas__geopandas-379
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: preserve column order in read_file
Idea from http://gis.stackexchange.com/questions/216963/preserve-column-order-of-geopandas-file-read/217084#217084
For shapefiles, fiona saves the properties in the `meta` attribute as an OrderedDict, so we should be able to get the actual order of the columns in the file from that and rearrange the columns of the output accordingly.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geopandas/io/file.py`
Content:
```
1 import os
2
3 import fiona
4 import numpy as np
5 from shapely.geometry import mapping
6
7 from six import iteritems
8 from geopandas import GeoDataFrame
9
10
11 def read_file(filename, **kwargs):
12 """
13 Returns a GeoDataFrame from a file.
14
15 *filename* is either the absolute or relative path to the file to be
16 opened and *kwargs* are keyword args to be passed to the `open` method
17 in the fiona library when opening the file. For more information on
18 possible keywords, type: ``import fiona; help(fiona.open)``
19 """
20 bbox = kwargs.pop('bbox', None)
21 with fiona.open(filename, **kwargs) as f:
22 crs = f.crs
23 if bbox is not None:
24 assert len(bbox)==4
25 f_filt = f.filter(bbox=bbox)
26 else:
27 f_filt = f
28 gdf = GeoDataFrame.from_features(f_filt, crs=crs)
29
30 return gdf
31
32
33 def to_file(df, filename, driver="ESRI Shapefile", schema=None,
34 **kwargs):
35 """
36 Write this GeoDataFrame to an OGR data source
37
38 A dictionary of supported OGR providers is available via:
39 >>> import fiona
40 >>> fiona.supported_drivers
41
42 Parameters
43 ----------
44 df : GeoDataFrame to be written
45 filename : string
46 File path or file handle to write to.
47 driver : string, default 'ESRI Shapefile'
48 The OGR format driver used to write the vector file.
49 schema : dict, default None
50 If specified, the schema dictionary is passed to Fiona to
51 better control how the file is written. If None, GeoPandas
52 will determine the schema based on each column's dtype
53
54 The *kwargs* are passed to fiona.open and can be used to write
55 to multi-layer data, store data within archives (zip files), etc.
56 """
57 if schema is None:
58 schema = infer_schema(df)
59 filename = os.path.abspath(os.path.expanduser(filename))
60 with fiona.open(filename, 'w', driver=driver, crs=df.crs,
61 schema=schema, **kwargs) as c:
62 for feature in df.iterfeatures():
63 c.write(feature)
64
65
66 def infer_schema(df):
67 try:
68 from collections import OrderedDict
69 except ImportError:
70 from ordereddict import OrderedDict
71
72 def convert_type(in_type):
73 if in_type == object:
74 return 'str'
75 out_type = type(np.asscalar(np.zeros(1, in_type))).__name__
76 if out_type == 'long':
77 out_type = 'int'
78 return out_type
79
80 properties = OrderedDict([
81 (col, convert_type(_type)) for col, _type in
82 zip(df.columns, df.dtypes) if col != df._geometry_column_name
83 ])
84
85 geom_type = _common_geom_type(df)
86 if not geom_type:
87 raise ValueError("Geometry column cannot contain mutiple "
88 "geometry types when writing to file.")
89
90 schema = {'geometry': geom_type, 'properties': properties}
91
92 return schema
93
94
95 def _common_geom_type(df):
96 # Need to check geom_types before we write to file...
97 # Some (most?) providers expect a single geometry type:
98 # Point, LineString, or Polygon
99 geom_types = df.geometry.geom_type.unique()
100
101 from os.path import commonprefix # To find longest common prefix
102 geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse
103 if not geom_type:
104 geom_type = None
105
106 return geom_type
107
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/geopandas/io/file.py b/geopandas/io/file.py
--- a/geopandas/io/file.py
+++ b/geopandas/io/file.py
@@ -14,7 +14,7 @@
*filename* is either the absolute or relative path to the file to be
opened and *kwargs* are keyword args to be passed to the `open` method
- in the fiona library when opening the file. For more information on
+ in the fiona library when opening the file. For more information on
possible keywords, type: ``import fiona; help(fiona.open)``
"""
bbox = kwargs.pop('bbox', None)
@@ -27,6 +27,10 @@
f_filt = f
gdf = GeoDataFrame.from_features(f_filt, crs=crs)
+ # re-order with column order from metadata, with geometry last
+ columns = list(f.meta["schema"]["properties"]) + ["geometry"]
+ gdf = gdf[columns]
+
return gdf
|
{"golden_diff": "diff --git a/geopandas/io/file.py b/geopandas/io/file.py\n--- a/geopandas/io/file.py\n+++ b/geopandas/io/file.py\n@@ -14,7 +14,7 @@\n \n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n- in the fiona library when opening the file. For more information on \n+ in the fiona library when opening the file. For more information on\n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n@@ -27,6 +27,10 @@\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n \n+ # re-order with column order from metadata, with geometry last\n+ columns = list(f.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n+ gdf = gdf[columns]\n+\n return gdf\n", "issue": "ENH: preserve column order in read_file\nIdea from http://gis.stackexchange.com/questions/216963/preserve-column-order-of-geopandas-file-read/217084#217084\r\n\r\nFor shapefiles, fiona saves the properties in the `meta` attribute as an OrderedDict, so we should be able to get the actual order of the columns in the file from that and rearrange the columns of the output accordingly.\n", "before_files": [{"content": "import os\n\nimport fiona\nimport numpy as np\nfrom shapely.geometry import mapping\n\nfrom six import iteritems\nfrom geopandas import GeoDataFrame\n\n\ndef read_file(filename, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file.\n\n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n in the fiona library when opening the file. For more information on \n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n with fiona.open(filename, **kwargs) as f:\n crs = f.crs\n if bbox is not None:\n assert len(bbox)==4\n f_filt = f.filter(bbox=bbox)\n else:\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None,\n **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n filename = os.path.abspath(os.path.expanduser(filename))\n with fiona.open(filename, 'w', driver=driver, crs=df.crs,\n schema=schema, **kwargs) as c:\n for feature in df.iterfeatures():\n c.write(feature)\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(in_type):\n if in_type == object:\n return 'str'\n out_type = type(np.asscalar(np.zeros(1, in_type))).__name__\n if out_type == 'long':\n out_type = 'int'\n return out_type\n\n properties = OrderedDict([\n (col, convert_type(_type)) for col, _type in\n zip(df.columns, df.dtypes) if col != df._geometry_column_name\n ])\n\n geom_type = _common_geom_type(df)\n if not geom_type:\n raise ValueError(\"Geometry column cannot contain mutiple \"\n \"geometry types when writing to file.\")\n\n schema = {'geometry': geom_type, 'properties': properties}\n\n return schema\n\n\ndef _common_geom_type(df):\n # Need to check geom_types before we write to file...\n # Some (most?) providers expect a single geometry type:\n # Point, LineString, or Polygon\n geom_types = df.geometry.geom_type.unique()\n\n from os.path import commonprefix # To find longest common prefix\n geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse\n if not geom_type:\n geom_type = None\n\n return geom_type\n", "path": "geopandas/io/file.py"}], "after_files": [{"content": "import os\n\nimport fiona\nimport numpy as np\nfrom shapely.geometry import mapping\n\nfrom six import iteritems\nfrom geopandas import GeoDataFrame\n\n\ndef read_file(filename, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file.\n\n *filename* is either the absolute or relative path to the file to be\n opened and *kwargs* are keyword args to be passed to the `open` method\n in the fiona library when opening the file. For more information on\n possible keywords, type: ``import fiona; help(fiona.open)``\n \"\"\"\n bbox = kwargs.pop('bbox', None)\n with fiona.open(filename, **kwargs) as f:\n crs = f.crs\n if bbox is not None:\n assert len(bbox)==4\n f_filt = f.filter(bbox=bbox)\n else:\n f_filt = f\n gdf = GeoDataFrame.from_features(f_filt, crs=crs)\n\n # re-order with column order from metadata, with geometry last\n columns = list(f.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = gdf[columns]\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None,\n **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n filename = os.path.abspath(os.path.expanduser(filename))\n with fiona.open(filename, 'w', driver=driver, crs=df.crs,\n schema=schema, **kwargs) as c:\n for feature in df.iterfeatures():\n c.write(feature)\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(in_type):\n if in_type == object:\n return 'str'\n out_type = type(np.asscalar(np.zeros(1, in_type))).__name__\n if out_type == 'long':\n out_type = 'int'\n return out_type\n\n properties = OrderedDict([\n (col, convert_type(_type)) for col, _type in\n zip(df.columns, df.dtypes) if col != df._geometry_column_name\n ])\n\n geom_type = _common_geom_type(df)\n if not geom_type:\n raise ValueError(\"Geometry column cannot contain mutiple \"\n \"geometry types when writing to file.\")\n\n schema = {'geometry': geom_type, 'properties': properties}\n\n return schema\n\n\ndef _common_geom_type(df):\n # Need to check geom_types before we write to file...\n # Some (most?) providers expect a single geometry type:\n # Point, LineString, or Polygon\n geom_types = df.geometry.geom_type.unique()\n\n from os.path import commonprefix # To find longest common prefix\n geom_type = commonprefix([g[::-1] for g in geom_types if g])[::-1] # Reverse\n if not geom_type:\n geom_type = None\n\n return geom_type\n", "path": "geopandas/io/file.py"}]}
| 1,365 | 232 |
gh_patches_debug_949
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-457
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Determine if papermill v1.0 API change is a problem
# Description
The [papermill `v1.0` release will introduce API breaking changes](https://github.com/nteract/papermill/blob/d554193bc458797b63af1f94964883d5dcca2418/README.md). It would be good to determine if these changes will matter for pyhf testing and require the addition of [scrapbook](https://nteract-scrapbook.readthedocs.io/en/latest/) or if the API change doesn't affect pyhf.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 from setuptools import setup, find_packages
4 from os import path
5 import sys
6
7 this_directory = path.abspath(path.dirname(__file__))
8 if sys.version_info.major < 3:
9 from io import open
10 with open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:
11 long_description = readme_md.read()
12
13 extras_require = {
14 'tensorflow': [
15 'tensorflow~=1.13',
16 'tensorflow-probability~=0.5',
17 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass
18 'setuptools<=39.1.0',
19 ],
20 'torch': ['torch~=1.0'],
21 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],
22 # 'dask': [
23 # 'dask[array]'
24 # ],
25 'xmlio': ['uproot'],
26 'minuit': ['iminuit'],
27 'develop': [
28 'pyflakes',
29 'pytest~=3.5',
30 'pytest-cov>=2.5.1',
31 'pytest-mock',
32 'pytest-benchmark[histogram]',
33 'pytest-console-scripts',
34 'python-coveralls',
35 'coverage>=4.0', # coveralls
36 'matplotlib',
37 'jupyter',
38 'nbdime',
39 'uproot~=3.3',
40 'papermill~=0.16',
41 'graphviz',
42 'bumpversion',
43 'sphinx',
44 'sphinxcontrib-bibtex',
45 'sphinxcontrib-napoleon',
46 'sphinx_rtd_theme',
47 'nbsphinx',
48 'sphinx-issues',
49 'm2r',
50 'jsonpatch',
51 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now
52 'pre-commit',
53 'black;python_version>="3.6"', # Black is Python3 only
54 'twine',
55 ],
56 }
57 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
58
59
60 def _is_test_pypi():
61 """
62 Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and
63 set to true (c.f. .travis.yml)
64
65 The use_scm_version kwarg accepts a callable for the local_scheme
66 configuration parameter with argument "version". This can be replaced
67 with a lambda as the desired version structure is {next_version}.dev{distance}
68 c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy
69
70 As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version
71 controlled through bumpversion is used.
72 """
73 from os import getenv
74
75 return (
76 {'local_scheme': lambda version: ''}
77 if getenv('TESTPYPI_UPLOAD') == 'true'
78 else False
79 )
80
81
82 setup(
83 name='pyhf',
84 version='0.1.0',
85 description='(partial) pure python histfactory implementation',
86 long_description=long_description,
87 long_description_content_type='text/markdown',
88 url='https://github.com/diana-hep/pyhf',
89 author='Lukas Heinrich',
90 author_email='[email protected]',
91 license='Apache',
92 keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',
93 classifiers=[
94 "Programming Language :: Python :: 2",
95 "Programming Language :: Python :: 2.7",
96 "Programming Language :: Python :: 3",
97 "Programming Language :: Python :: 3.6",
98 "Programming Language :: Python :: 3.7",
99 ],
100 packages=find_packages(),
101 include_package_data=True,
102 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*",
103 install_requires=[
104 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet
105 'click>=6.0', # for console scripts,
106 'tqdm', # for readxml
107 'six', # for modifiers
108 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6
109 'jsonpatch',
110 ],
111 extras_require=extras_require,
112 entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},
113 dependency_links=[],
114 use_scm_version=_is_test_pypi(),
115 )
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -37,7 +37,8 @@
'jupyter',
'nbdime',
'uproot~=3.3',
- 'papermill~=0.16',
+ 'papermill~=1.0',
+ 'nteract-scrapbook~=0.2',
'graphviz',
'bumpversion',
'sphinx',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -37,7 +37,8 @@\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n- 'papermill~=0.16',\n+ 'papermill~=1.0',\n+ 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n", "issue": "Determine if papermill v1.0 API change is a problem\n# Description\r\n\r\nThe [papermill `v1.0` release will introduce API breaking changes](https://github.com/nteract/papermill/blob/d554193bc458797b63af1f94964883d5dcca2418/README.md). It would be good to determine if these changes will matter for pyhf testing and require the addition of [scrapbook](https://nteract-scrapbook.readthedocs.io/en/latest/) or if the API change doesn't affect pyhf.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=0.16',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n set to true (c.f. .travis.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('TESTPYPI_UPLOAD') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.1.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup, find_packages\nfrom os import path\nimport sys\n\nthis_directory = path.abspath(path.dirname(__file__))\nif sys.version_info.major < 3:\n from io import open\nwith open(path.join(this_directory, 'README.md'), encoding='utf-8') as readme_md:\n long_description = readme_md.read()\n\nextras_require = {\n 'tensorflow': [\n 'tensorflow~=1.13',\n 'tensorflow-probability~=0.5',\n 'numpy<=1.14.5,>=1.14.0', # Lower of 1.14.0 instead of 1.13.3 to ensure doctest pass\n 'setuptools<=39.1.0',\n ],\n 'torch': ['torch~=1.0'],\n 'mxnet': ['mxnet~=1.0', 'requests~=2.18.4', 'numpy<1.15.0,>=1.8.2'],\n # 'dask': [\n # 'dask[array]'\n # ],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n 'develop': [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'python-coveralls',\n 'coverage>=4.0', # coveralls\n 'matplotlib',\n 'jupyter',\n 'nbdime',\n 'uproot~=3.3',\n 'papermill~=1.0',\n 'nteract-scrapbook~=0.2',\n 'graphviz',\n 'bumpversion',\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinxcontrib-napoleon',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'sphinx-issues',\n 'm2r',\n 'jsonpatch',\n 'ipython<7', # jupyter_console and ipython clash in dependency requirement -- downgrade ipython for now\n 'pre-commit',\n 'black;python_version>=\"3.6\"', # Black is Python3 only\n 'twine',\n ],\n}\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\ndef _is_test_pypi():\n \"\"\"\n Determine if the Travis CI environment has TESTPYPI_UPLOAD defined and\n set to true (c.f. .travis.yml)\n\n The use_scm_version kwarg accepts a callable for the local_scheme\n configuration parameter with argument \"version\". This can be replaced\n with a lambda as the desired version structure is {next_version}.dev{distance}\n c.f. https://github.com/pypa/setuptools_scm/#importing-in-setuppy\n\n As the scm versioning is only desired for TestPyPI, for depolyment to PyPI the version\n controlled through bumpversion is used.\n \"\"\"\n from os import getenv\n\n return (\n {'local_scheme': lambda version: ''}\n if getenv('TESTPYPI_UPLOAD') == 'true'\n else False\n )\n\n\nsetup(\n name='pyhf',\n version='0.1.0',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/diana-hep/pyhf',\n author='Lukas Heinrich',\n author_email='[email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch mxnet dask',\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n packages=find_packages(),\n include_package_data=True,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf, tensorflow, and mxnet\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'six', # for modifiers\n 'jsonschema>=v3.0.0a2', # for utils, alpha-release for draft 6\n 'jsonpatch',\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.commandline:pyhf']},\n dependency_links=[],\n use_scm_version=_is_test_pypi(),\n)\n", "path": "setup.py"}]}
| 1,672 | 103 |
gh_patches_debug_214
|
rasdani/github-patches
|
git_diff
|
DDMAL__CantusDB-328
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Representation of Notation objects
When I recently tried to edit a source, I was presented with an error message, and found that I was missing several required fields, including this one: 
Notation objects are currently pretty inscrutable. They should be represented such that at least their `name` property is visible.
Larger question: why do we have notation objects at all? Currently, the notation model has only one property: `name`. Could this information in Source objects not be more simply represented by a CharField? Is using Notation objects simply the way things were done in OldCantus? Are we using them to ensure standardization among multiple Sources?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `django/cantusdb_project/main_app/models/notation.py`
Content:
```
1 from django.db import models
2 from main_app.models import BaseModel
3
4
5 class Notation(BaseModel):
6 name = models.CharField(max_length=63)
7
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/django/cantusdb_project/main_app/models/notation.py b/django/cantusdb_project/main_app/models/notation.py
--- a/django/cantusdb_project/main_app/models/notation.py
+++ b/django/cantusdb_project/main_app/models/notation.py
@@ -4,3 +4,5 @@
class Notation(BaseModel):
name = models.CharField(max_length=63)
+ def __str__(self):
+ return f"{self.name} ({self.id})"
\ No newline at end of file
|
{"golden_diff": "diff --git a/django/cantusdb_project/main_app/models/notation.py b/django/cantusdb_project/main_app/models/notation.py\n--- a/django/cantusdb_project/main_app/models/notation.py\n+++ b/django/cantusdb_project/main_app/models/notation.py\n@@ -4,3 +4,5 @@\n \n class Notation(BaseModel):\n name = models.CharField(max_length=63)\n+ def __str__(self):\n+ return f\"{self.name} ({self.id})\"\n\\ No newline at end of file\n", "issue": "Representation of Notation objects\nWhen I recently tried to edit a source, I was presented with an error message, and found that I was missing several required fields, including this one: \r\nNotation objects are currently pretty inscrutable. They should be represented such that at least their `name` property is visible.\r\n\r\nLarger question: why do we have notation objects at all? Currently, the notation model has only one property: `name`. Could this information in Source objects not be more simply represented by a CharField? Is using Notation objects simply the way things were done in OldCantus? Are we using them to ensure standardization among multiple Sources?\n", "before_files": [{"content": "from django.db import models\nfrom main_app.models import BaseModel\n\n\nclass Notation(BaseModel):\n name = models.CharField(max_length=63)\n", "path": "django/cantusdb_project/main_app/models/notation.py"}], "after_files": [{"content": "from django.db import models\nfrom main_app.models import BaseModel\n\n\nclass Notation(BaseModel):\n name = models.CharField(max_length=63)\n def __str__(self):\n return f\"{self.name} ({self.id})\"", "path": "django/cantusdb_project/main_app/models/notation.py"}]}
| 523 | 120 |
gh_patches_debug_16631
|
rasdani/github-patches
|
git_diff
|
google__osv.dev-986
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The purl of Alpine ecosystem is inconsistent with purl-spec
According to [**purl-type `apk`**](https://github.com/package-url/purl-spec/blob/master/PURL-TYPES.rst#apk) ([PR](https://github.com/package-url/purl-spec/pull/171)), it seems that the purl type of `Alpine` should be `apk` and the purl namespace can be `alpine`. In this project, however, the purl type of `Alpine` is `alpine`.
As a result, the purl of a package is **different** when apply different standards. For example, the purl of the `curl` package is `pkg:apk/alpine/curl` according to purl-spec while it is `pkg:alpine/curl` in this project.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `osv/purl_helpers.py`
Content:
```
1 # Copyright 2022 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """PURL conversion utilities."""
15
16 from urllib.parse import quote
17
18 PURL_ECOSYSTEMS = {
19 'crates.io': 'cargo',
20 'Debian': 'deb',
21 'Hex': 'hex',
22 'Go': 'golang',
23 'Maven': 'maven',
24 'NuGet': 'nuget',
25 'npm': 'npm',
26 'Packagist': 'composer',
27 'OSS-Fuzz': 'generic',
28 'PyPI': 'pypi',
29 'RubyGems': 'gem',
30 }
31
32
33 def _url_encode(package_name):
34 """URL encode a PURL `namespace/name` or `name`."""
35 parts = package_name.split('/')
36 return '/'.join(quote(p) for p in parts)
37
38
39 def package_to_purl(ecosystem, package_name):
40 """Convert a ecosystem and package name to PURL."""
41 purl_type = PURL_ECOSYSTEMS.get(ecosystem)
42 if not purl_type:
43 return None
44
45 suffix = ''
46
47 if purl_type == 'maven':
48 # PURLs use / to separate the group ID and the artifact ID.
49 package_name = package_name.replace(':', '/', 1)
50
51 if purl_type == 'deb':
52 package_name = 'debian/' + package_name
53 suffix = '?arch=source'
54
55 return f'pkg:{purl_type}/{_url_encode(package_name)}{suffix}'
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/osv/purl_helpers.py b/osv/purl_helpers.py
--- a/osv/purl_helpers.py
+++ b/osv/purl_helpers.py
@@ -16,6 +16,7 @@
from urllib.parse import quote
PURL_ECOSYSTEMS = {
+ 'Alpine': 'apk',
'crates.io': 'cargo',
'Debian': 'deb',
'Hex': 'hex',
@@ -48,8 +49,12 @@
# PURLs use / to separate the group ID and the artifact ID.
package_name = package_name.replace(':', '/', 1)
- if purl_type == 'deb':
+ if purl_type == 'deb' and ecosystem == 'Debian':
package_name = 'debian/' + package_name
suffix = '?arch=source'
+ if purl_type == 'apk' and ecosystem == 'Alpine':
+ package_name = 'alpine/' + package_name
+ suffix = '?arch=source'
+
return f'pkg:{purl_type}/{_url_encode(package_name)}{suffix}'
|
{"golden_diff": "diff --git a/osv/purl_helpers.py b/osv/purl_helpers.py\n--- a/osv/purl_helpers.py\n+++ b/osv/purl_helpers.py\n@@ -16,6 +16,7 @@\n from urllib.parse import quote\n \n PURL_ECOSYSTEMS = {\n+ 'Alpine': 'apk',\n 'crates.io': 'cargo',\n 'Debian': 'deb',\n 'Hex': 'hex',\n@@ -48,8 +49,12 @@\n # PURLs use / to separate the group ID and the artifact ID.\n package_name = package_name.replace(':', '/', 1)\n \n- if purl_type == 'deb':\n+ if purl_type == 'deb' and ecosystem == 'Debian':\n package_name = 'debian/' + package_name\n suffix = '?arch=source'\n \n+ if purl_type == 'apk' and ecosystem == 'Alpine':\n+ package_name = 'alpine/' + package_name\n+ suffix = '?arch=source'\n+\n return f'pkg:{purl_type}/{_url_encode(package_name)}{suffix}'\n", "issue": "The purl of Alpine ecosystem is inconsistent with purl-spec\nAccording to [**purl-type `apk`**](https://github.com/package-url/purl-spec/blob/master/PURL-TYPES.rst#apk) ([PR](https://github.com/package-url/purl-spec/pull/171)), it seems that the purl type of `Alpine` should be `apk` and the purl namespace can be `alpine`. In this project, however, the purl type of `Alpine` is `alpine`.\r\n\r\nAs a result, the purl of a package is **different** when apply different standards. For example, the purl of the `curl` package is `pkg:apk/alpine/curl` according to purl-spec while it is `pkg:alpine/curl` in this project.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2022 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"PURL conversion utilities.\"\"\"\n\nfrom urllib.parse import quote\n\nPURL_ECOSYSTEMS = {\n 'crates.io': 'cargo',\n 'Debian': 'deb',\n 'Hex': 'hex',\n 'Go': 'golang',\n 'Maven': 'maven',\n 'NuGet': 'nuget',\n 'npm': 'npm',\n 'Packagist': 'composer',\n 'OSS-Fuzz': 'generic',\n 'PyPI': 'pypi',\n 'RubyGems': 'gem',\n}\n\n\ndef _url_encode(package_name):\n \"\"\"URL encode a PURL `namespace/name` or `name`.\"\"\"\n parts = package_name.split('/')\n return '/'.join(quote(p) for p in parts)\n\n\ndef package_to_purl(ecosystem, package_name):\n \"\"\"Convert a ecosystem and package name to PURL.\"\"\"\n purl_type = PURL_ECOSYSTEMS.get(ecosystem)\n if not purl_type:\n return None\n\n suffix = ''\n\n if purl_type == 'maven':\n # PURLs use / to separate the group ID and the artifact ID.\n package_name = package_name.replace(':', '/', 1)\n\n if purl_type == 'deb':\n package_name = 'debian/' + package_name\n suffix = '?arch=source'\n\n return f'pkg:{purl_type}/{_url_encode(package_name)}{suffix}'\n", "path": "osv/purl_helpers.py"}], "after_files": [{"content": "# Copyright 2022 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"PURL conversion utilities.\"\"\"\n\nfrom urllib.parse import quote\n\nPURL_ECOSYSTEMS = {\n 'Alpine': 'apk',\n 'crates.io': 'cargo',\n 'Debian': 'deb',\n 'Hex': 'hex',\n 'Go': 'golang',\n 'Maven': 'maven',\n 'NuGet': 'nuget',\n 'npm': 'npm',\n 'Packagist': 'composer',\n 'OSS-Fuzz': 'generic',\n 'PyPI': 'pypi',\n 'RubyGems': 'gem',\n}\n\n\ndef _url_encode(package_name):\n \"\"\"URL encode a PURL `namespace/name` or `name`.\"\"\"\n parts = package_name.split('/')\n return '/'.join(quote(p) for p in parts)\n\n\ndef package_to_purl(ecosystem, package_name):\n \"\"\"Convert a ecosystem and package name to PURL.\"\"\"\n purl_type = PURL_ECOSYSTEMS.get(ecosystem)\n if not purl_type:\n return None\n\n suffix = ''\n\n if purl_type == 'maven':\n # PURLs use / to separate the group ID and the artifact ID.\n package_name = package_name.replace(':', '/', 1)\n\n if purl_type == 'deb' and ecosystem == 'Debian':\n package_name = 'debian/' + package_name\n suffix = '?arch=source'\n\n if purl_type == 'apk' and ecosystem == 'Alpine':\n package_name = 'alpine/' + package_name\n suffix = '?arch=source'\n\n return f'pkg:{purl_type}/{_url_encode(package_name)}{suffix}'\n", "path": "osv/purl_helpers.py"}]}
| 979 | 244 |
gh_patches_debug_15071
|
rasdani/github-patches
|
git_diff
|
PlasmaPy__PlasmaPy-688
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update acknowledgements to include NSF CSSI grant
Good news, everyone! The NSF CSSI proposal that we submitted has officially been awarded! At the request of NSF program manager Slava Lukin, we should update our acknowledgements to include this grant and reflect the support from NSF. I'll assign myself to do this when the grant officially starts (which appears to have been moved up to October 1, 2019). The things that we need to do include:
- [x] Revise the sentence that we ask people to include in the acknowledgements section of their papers to reflect funding from NSF
- [x] Add an acknowledgements section at the end of `README.md`
- [x] Update `CITATION.md`
- [x] Update `docs/about/credits.rst`
- [x] Update `plasmapy.__citation__`
Another thing peripherally related to this issue is to:
- [x] Update the [proposal](https://doi.org/10.5281/zenodo.2633286) that we archived on Zenodo to include the answers to questions we had to send in and the panel's comments
I'll assign this to myself.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plasmapy/__init__.py`
Content:
```
1 """
2 PlasmaPy: A plasma physics Python package
3 ================================================
4
5 Documentation is available in the docstrings,
6 online at https://docs.plasmapy.org (accessible also using
7 the ``plasmapy.online_help`` function).
8
9 Contents
10 --------
11 PlasmaPy provides the following functionality:
12
13 Subpackages
14 -----------
15 Each of these subpackages requires an explicit import, for example,
16 via ``import plasmapy.physics``.
17
18 ::
19
20 atomic --- Database for atoms, isotopes, ions...
21 classes --- (WIP) classes used in multiple places
22 data --- Data used for testing and examples
23 diagnostics --- Experimental research data analysis
24 mathematics --- General formulae used elsewhere
25 physics --- Plasma theory functionality
26 transport --- Transport theory functionality
27 utils --- Various utilities
28
29 Utility tools
30 -------------
31 ::
32
33 test --- Run PlasmaPy unit tests
34 online_help --- Search the online documentation
35 __version__ --- PlasmaPy version string
36 __citation__ --- PlasmaPy citation template
37
38 """
39 # Licensed under a 3-clause BSD style license - see LICENSE.rst
40
41 # Packages may add whatever they like to this file, but
42 # should keep this content at the top.
43 # ----------------------------------------------------------------------------
44 from ._base_init import *
45 # ----------------------------------------------------------------------------
46
47 # Enforce Python version check during package import.
48 # This is the same check as the one at the top of setup.py
49 import sys
50
51 __name__ = "plasmapy"
52
53 if sys.version_info < tuple((int(val) for val in "3.6".split('.'))):
54 raise Exception("plasmapy does not support Python < {}".format(3.6))
55
56
57 def online_help(query):
58 """
59 Search the online PlasmaPy documentation for the given query from plasmapy.org
60 Opens the results in the default web browser.
61 Requires an active Internet connection.
62 Redirects to Astropy.units in case of query 'unit' or 'units'
63
64 Parameters
65 ----------
66 query : str
67 The search query.
68 """
69 from urllib.parse import urlencode
70 import webbrowser
71
72 url = ('http://docs.plasmapy.org/en/stable/search.html?'
73 '{0}&check_keywords=yes&area=default').format(urlencode({'q': query}))
74
75 if(query.lower() in ('unit', 'units')):
76 url = 'http://docs.astropy.org/en/stable/units/'
77
78 webbrowser.open(url)
79
80
81 __citation__ = [
82 "https://doi.org/10.5281/zenodo.1238132",
83 "https://doi.org/10.5281/zenodo.3235817",
84 ]
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py
--- a/plasmapy/__init__.py
+++ b/plasmapy/__init__.py
@@ -50,8 +50,13 @@
__name__ = "plasmapy"
+__citation__ = (
+ "Instructions on how to cite and acknowledge PlasmaPy are provided in the "
+ "online documentation at: http://docs.plasmapy.org/en/latest/about/citation.html"
+)
+
if sys.version_info < tuple((int(val) for val in "3.6".split('.'))):
- raise Exception("plasmapy does not support Python < {}".format(3.6))
+ raise Exception("PlasmaPy does not support Python < {}".format(3.6))
def online_help(query):
@@ -76,9 +81,3 @@
url = 'http://docs.astropy.org/en/stable/units/'
webbrowser.open(url)
-
-
-__citation__ = [
- "https://doi.org/10.5281/zenodo.1238132",
- "https://doi.org/10.5281/zenodo.3235817",
-]
|
{"golden_diff": "diff --git a/plasmapy/__init__.py b/plasmapy/__init__.py\n--- a/plasmapy/__init__.py\n+++ b/plasmapy/__init__.py\n@@ -50,8 +50,13 @@\n \n __name__ = \"plasmapy\"\n \n+__citation__ = (\n+ \"Instructions on how to cite and acknowledge PlasmaPy are provided in the \"\n+ \"online documentation at: http://docs.plasmapy.org/en/latest/about/citation.html\"\n+)\n+\n if sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n- raise Exception(\"plasmapy does not support Python < {}\".format(3.6))\n+ raise Exception(\"PlasmaPy does not support Python < {}\".format(3.6))\n \n \n def online_help(query):\n@@ -76,9 +81,3 @@\n url = 'http://docs.astropy.org/en/stable/units/'\n \n webbrowser.open(url)\n-\n-\n-__citation__ = [\n- \"https://doi.org/10.5281/zenodo.1238132\",\n- \"https://doi.org/10.5281/zenodo.3235817\",\n-]\n", "issue": "Update acknowledgements to include NSF CSSI grant\nGood news, everyone! The NSF CSSI proposal that we submitted has officially been awarded! At the request of NSF program manager Slava Lukin, we should update our acknowledgements to include this grant and reflect the support from NSF. I'll assign myself to do this when the grant officially starts (which appears to have been moved up to October 1, 2019). The things that we need to do include:\r\n\r\n - [x] Revise the sentence that we ask people to include in the acknowledgements section of their papers to reflect funding from NSF \r\n - [x] Add an acknowledgements section at the end of `README.md`\r\n - [x] Update `CITATION.md`\r\n - [x] Update `docs/about/credits.rst`\r\n - [x] Update `plasmapy.__citation__`\r\n\r\nAnother thing peripherally related to this issue is to:\r\n\r\n - [x] Update the [proposal](https://doi.org/10.5281/zenodo.2633286) that we archived on Zenodo to include the answers to questions we had to send in and the panel's comments\r\n\r\nI'll assign this to myself. \r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nPlasmaPy: A plasma physics Python package\n================================================\n\nDocumentation is available in the docstrings,\nonline at https://docs.plasmapy.org (accessible also using\nthe ``plasmapy.online_help`` function).\n\nContents\n--------\nPlasmaPy provides the following functionality:\n\nSubpackages\n-----------\nEach of these subpackages requires an explicit import, for example,\nvia ``import plasmapy.physics``.\n\n::\n\n atomic --- Database for atoms, isotopes, ions...\n classes --- (WIP) classes used in multiple places\n data --- Data used for testing and examples\n diagnostics --- Experimental research data analysis\n mathematics --- General formulae used elsewhere\n physics --- Plasma theory functionality\n transport --- Transport theory functionality\n utils --- Various utilities\n\nUtility tools\n-------------\n::\n\n test --- Run PlasmaPy unit tests\n online_help --- Search the online documentation\n __version__ --- PlasmaPy version string\n __citation__ --- PlasmaPy citation template\n\n\"\"\"\n# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\n# Packages may add whatever they like to this file, but\n# should keep this content at the top.\n# ----------------------------------------------------------------------------\nfrom ._base_init import *\n# ----------------------------------------------------------------------------\n\n# Enforce Python version check during package import.\n# This is the same check as the one at the top of setup.py\nimport sys\n\n__name__ = \"plasmapy\"\n\nif sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n raise Exception(\"plasmapy does not support Python < {}\".format(3.6))\n\n\ndef online_help(query):\n \"\"\"\n Search the online PlasmaPy documentation for the given query from plasmapy.org\n Opens the results in the default web browser.\n Requires an active Internet connection.\n Redirects to Astropy.units in case of query 'unit' or 'units'\n\n Parameters\n ----------\n query : str\n The search query.\n \"\"\"\n from urllib.parse import urlencode\n import webbrowser\n\n url = ('http://docs.plasmapy.org/en/stable/search.html?'\n '{0}&check_keywords=yes&area=default').format(urlencode({'q': query}))\n\n if(query.lower() in ('unit', 'units')):\n url = 'http://docs.astropy.org/en/stable/units/'\n\n webbrowser.open(url)\n\n\n__citation__ = [\n \"https://doi.org/10.5281/zenodo.1238132\",\n \"https://doi.org/10.5281/zenodo.3235817\",\n]\n", "path": "plasmapy/__init__.py"}], "after_files": [{"content": "\"\"\"\nPlasmaPy: A plasma physics Python package\n================================================\n\nDocumentation is available in the docstrings,\nonline at https://docs.plasmapy.org (accessible also using\nthe ``plasmapy.online_help`` function).\n\nContents\n--------\nPlasmaPy provides the following functionality:\n\nSubpackages\n-----------\nEach of these subpackages requires an explicit import, for example,\nvia ``import plasmapy.physics``.\n\n::\n\n atomic --- Database for atoms, isotopes, ions...\n classes --- (WIP) classes used in multiple places\n data --- Data used for testing and examples\n diagnostics --- Experimental research data analysis\n mathematics --- General formulae used elsewhere\n physics --- Plasma theory functionality\n transport --- Transport theory functionality\n utils --- Various utilities\n\nUtility tools\n-------------\n::\n\n test --- Run PlasmaPy unit tests\n online_help --- Search the online documentation\n __version__ --- PlasmaPy version string\n __citation__ --- PlasmaPy citation template\n\n\"\"\"\n# Licensed under a 3-clause BSD style license - see LICENSE.rst\n\n# Packages may add whatever they like to this file, but\n# should keep this content at the top.\n# ----------------------------------------------------------------------------\nfrom ._base_init import *\n# ----------------------------------------------------------------------------\n\n# Enforce Python version check during package import.\n# This is the same check as the one at the top of setup.py\nimport sys\n\n__name__ = \"plasmapy\"\n\n__citation__ = (\n \"Instructions on how to cite and acknowledge PlasmaPy are provided in the \"\n \"online documentation at: http://docs.plasmapy.org/en/latest/about/citation.html\"\n)\n\nif sys.version_info < tuple((int(val) for val in \"3.6\".split('.'))):\n raise Exception(\"PlasmaPy does not support Python < {}\".format(3.6))\n\n\ndef online_help(query):\n \"\"\"\n Search the online PlasmaPy documentation for the given query from plasmapy.org\n Opens the results in the default web browser.\n Requires an active Internet connection.\n Redirects to Astropy.units in case of query 'unit' or 'units'\n\n Parameters\n ----------\n query : str\n The search query.\n \"\"\"\n from urllib.parse import urlencode\n import webbrowser\n\n url = ('http://docs.plasmapy.org/en/stable/search.html?'\n '{0}&check_keywords=yes&area=default').format(urlencode({'q': query}))\n\n if(query.lower() in ('unit', 'units')):\n url = 'http://docs.astropy.org/en/stable/units/'\n\n webbrowser.open(url)\n", "path": "plasmapy/__init__.py"}]}
| 1,268 | 284 |
gh_patches_debug_26065
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-2743
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
dvc: .dvcignore trouble with nfs mounted directory
I have a large NFS mounted in a directory that I would like dvc to ignore.
Directory Structure:
```
directory
|___nfs
|___...
|___.dvc
|___.dvcignore
```
My *.dvcignore* has the following line:
`/nfs/` (I've tried `nfs/` and `nfs/*`)
The problem is that when I run `dvc status` or `dvc pull` the processes will just hang:
```
DEBUG: PRAGMA user_version;
DEBUG: fetched: [(3,)]
DEBUG: CREATE TABLE IF NOT EXISTS state (inode INTEGER PRIMARY KEY, mtime TEXT NOT NULL, size TEXT NOT NULL, md5 TEXT NOT NULL, timestamp TEXT NOT NULL)
DEBUG: CREATE TABLE IF NOT EXISTS state_info (count INTEGER)
DEBUG: CREATE TABLE IF NOT EXISTS link_state (path TEXT PRIMARY KEY, inode INTEGER NOT NULL, mtime TEXT NOT NULL)
DEBUG: INSERT OR IGNORE INTO state_info (count) SELECT 0 WHERE NOT EXISTS (SELECT * FROM state_info)
DEBUG: PRAGMA user_version = 3;
```
Here is the traceback from `KeyboardInterrupt`:
```
File "/home/ec2-user/app/proc/.env/lib/python3.7/site-packages/dvc/repo/__init__.py", line 499, in dvcignore
return DvcIgnoreFilter(self.root_dir)
File "/home/ec2-user/app/proc/.env/lib/python3.7/site-packages/dvc/ignore.py", line 67, in __init__
for root, dirs, _ in os.walk(root_dir):
File "/home/ec2-user/app/proc/.env/lib64/python3.7/os.py", line 410, in walk
yield from walk(new_path, topdown, onerror, followlinks)
File "/home/ec2-user/app/proc/.env/lib64/python3.7/os.py", line 368, in walk
is_dir = entry.is_dir()
```
Which makes me feel like the directory is not being ignored.
***Additonal***
I've unmounted the NFS directory and ran `dvc status` with no problem so I believe the issue stems from dvc trying to traverse it.
System Information:
```
DVC version: 0.66.6
Python version: 3.7.4
Platform: Linux 4.14.109-99.92.amzn2.x86_64
Installation: pip
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dvc/ignore.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import logging
4 import os
5
6 from pathspec import PathSpec
7 from pathspec.patterns import GitWildMatchPattern
8
9 from dvc.utils import relpath
10 from dvc.utils.compat import open
11
12 logger = logging.getLogger(__name__)
13
14
15 class DvcIgnore(object):
16 DVCIGNORE_FILE = ".dvcignore"
17
18 def __call__(self, root, dirs, files):
19 raise NotImplementedError
20
21
22 class DvcIgnorePatterns(DvcIgnore):
23 def __init__(self, ignore_file_path):
24 assert os.path.isabs(ignore_file_path)
25
26 self.ignore_file_path = ignore_file_path
27 self.dirname = os.path.normpath(os.path.dirname(ignore_file_path))
28
29 with open(ignore_file_path, encoding="utf-8") as fobj:
30 self.ignore_spec = PathSpec.from_lines(GitWildMatchPattern, fobj)
31
32 def __call__(self, root, dirs, files):
33 files = [f for f in files if not self.matches(root, f)]
34 dirs = [d for d in dirs if not self.matches(root, d)]
35
36 return dirs, files
37
38 def matches(self, dirname, basename):
39 abs_path = os.path.join(dirname, basename)
40 rel_path = relpath(abs_path, self.dirname)
41
42 if os.pardir + os.sep in rel_path:
43 return False
44 return self.ignore_spec.match_file(rel_path)
45
46 def __hash__(self):
47 return hash(self.ignore_file_path)
48
49 def __eq__(self, other):
50 return self.ignore_file_path == other.ignore_file_path
51
52
53 class DvcIgnoreDirs(DvcIgnore):
54 def __init__(self, basenames):
55 self.basenames = set(basenames)
56
57 def __call__(self, root, dirs, files):
58 dirs = [d for d in dirs if d not in self.basenames]
59
60 return dirs, files
61
62
63 class DvcIgnoreFilter(object):
64 def __init__(self, root_dir):
65 self.ignores = {DvcIgnoreDirs([".git", ".hg", ".dvc"])}
66 self._update(root_dir)
67 for root, dirs, _ in os.walk(root_dir):
68 for d in dirs:
69 self._update(os.path.join(root, d))
70
71 def _update(self, dirname):
72 ignore_file_path = os.path.join(dirname, DvcIgnore.DVCIGNORE_FILE)
73 if os.path.exists(ignore_file_path):
74 self.ignores.add(DvcIgnorePatterns(ignore_file_path))
75
76 def __call__(self, root, dirs, files):
77 for ignore in self.ignores:
78 dirs, files = ignore(root, dirs, files)
79
80 return dirs, files
81
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dvc/ignore.py b/dvc/ignore.py
--- a/dvc/ignore.py
+++ b/dvc/ignore.py
@@ -6,6 +6,7 @@
from pathspec import PathSpec
from pathspec.patterns import GitWildMatchPattern
+from dvc.utils import dvc_walk
from dvc.utils import relpath
from dvc.utils.compat import open
@@ -47,6 +48,9 @@
return hash(self.ignore_file_path)
def __eq__(self, other):
+ if not isinstance(other, DvcIgnorePatterns):
+ return NotImplemented
+
return self.ignore_file_path == other.ignore_file_path
@@ -59,12 +63,21 @@
return dirs, files
+ def __hash__(self):
+ return hash(tuple(self.basenames))
+
+ def __eq__(self, other):
+ if not isinstance(other, DvcIgnoreDirs):
+ return NotImplemented
+
+ return self.basenames == other.basenames
+
class DvcIgnoreFilter(object):
def __init__(self, root_dir):
self.ignores = {DvcIgnoreDirs([".git", ".hg", ".dvc"])}
self._update(root_dir)
- for root, dirs, _ in os.walk(root_dir):
+ for root, dirs, _ in dvc_walk(root_dir, self):
for d in dirs:
self._update(os.path.join(root, d))
|
{"golden_diff": "diff --git a/dvc/ignore.py b/dvc/ignore.py\n--- a/dvc/ignore.py\n+++ b/dvc/ignore.py\n@@ -6,6 +6,7 @@\n from pathspec import PathSpec\n from pathspec.patterns import GitWildMatchPattern\n \n+from dvc.utils import dvc_walk\n from dvc.utils import relpath\n from dvc.utils.compat import open\n \n@@ -47,6 +48,9 @@\n return hash(self.ignore_file_path)\n \n def __eq__(self, other):\n+ if not isinstance(other, DvcIgnorePatterns):\n+ return NotImplemented\n+\n return self.ignore_file_path == other.ignore_file_path\n \n \n@@ -59,12 +63,21 @@\n \n return dirs, files\n \n+ def __hash__(self):\n+ return hash(tuple(self.basenames))\n+\n+ def __eq__(self, other):\n+ if not isinstance(other, DvcIgnoreDirs):\n+ return NotImplemented\n+\n+ return self.basenames == other.basenames\n+\n \n class DvcIgnoreFilter(object):\n def __init__(self, root_dir):\n self.ignores = {DvcIgnoreDirs([\".git\", \".hg\", \".dvc\"])}\n self._update(root_dir)\n- for root, dirs, _ in os.walk(root_dir):\n+ for root, dirs, _ in dvc_walk(root_dir, self):\n for d in dirs:\n self._update(os.path.join(root, d))\n", "issue": "dvc: .dvcignore trouble with nfs mounted directory\nI have a large NFS mounted in a directory that I would like dvc to ignore. \r\n\r\nDirectory Structure:\r\n```\r\ndirectory\r\n|___nfs\r\n|___...\r\n|___.dvc\r\n|___.dvcignore\r\n```\r\nMy *.dvcignore* has the following line:\r\n`/nfs/` (I've tried `nfs/` and `nfs/*`)\r\n\r\nThe problem is that when I run `dvc status` or `dvc pull` the processes will just hang:\r\n```\r\nDEBUG: PRAGMA user_version;\r\nDEBUG: fetched: [(3,)]\r\nDEBUG: CREATE TABLE IF NOT EXISTS state (inode INTEGER PRIMARY KEY, mtime TEXT NOT NULL, size TEXT NOT NULL, md5 TEXT NOT NULL, timestamp TEXT NOT NULL)\r\nDEBUG: CREATE TABLE IF NOT EXISTS state_info (count INTEGER)\r\nDEBUG: CREATE TABLE IF NOT EXISTS link_state (path TEXT PRIMARY KEY, inode INTEGER NOT NULL, mtime TEXT NOT NULL)\r\nDEBUG: INSERT OR IGNORE INTO state_info (count) SELECT 0 WHERE NOT EXISTS (SELECT * FROM state_info)\r\nDEBUG: PRAGMA user_version = 3; \r\n```\r\n\r\nHere is the traceback from `KeyboardInterrupt`:\r\n```\r\n File \"/home/ec2-user/app/proc/.env/lib/python3.7/site-packages/dvc/repo/__init__.py\", line 499, in dvcignore\r\n return DvcIgnoreFilter(self.root_dir)\r\n File \"/home/ec2-user/app/proc/.env/lib/python3.7/site-packages/dvc/ignore.py\", line 67, in __init__\r\n for root, dirs, _ in os.walk(root_dir):\r\n File \"/home/ec2-user/app/proc/.env/lib64/python3.7/os.py\", line 410, in walk\r\n yield from walk(new_path, topdown, onerror, followlinks)\r\n File \"/home/ec2-user/app/proc/.env/lib64/python3.7/os.py\", line 368, in walk\r\n is_dir = entry.is_dir() \r\n```\r\nWhich makes me feel like the directory is not being ignored.\r\n\r\n***Additonal***\r\nI've unmounted the NFS directory and ran `dvc status` with no problem so I believe the issue stems from dvc trying to traverse it.\r\n\r\nSystem Information:\r\n``` \r\nDVC version: 0.66.6\r\nPython version: 3.7.4\r\nPlatform: Linux 4.14.109-99.92.amzn2.x86_64\r\nInstallation: pip\r\n```\r\n\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport logging\nimport os\n\nfrom pathspec import PathSpec\nfrom pathspec.patterns import GitWildMatchPattern\n\nfrom dvc.utils import relpath\nfrom dvc.utils.compat import open\n\nlogger = logging.getLogger(__name__)\n\n\nclass DvcIgnore(object):\n DVCIGNORE_FILE = \".dvcignore\"\n\n def __call__(self, root, dirs, files):\n raise NotImplementedError\n\n\nclass DvcIgnorePatterns(DvcIgnore):\n def __init__(self, ignore_file_path):\n assert os.path.isabs(ignore_file_path)\n\n self.ignore_file_path = ignore_file_path\n self.dirname = os.path.normpath(os.path.dirname(ignore_file_path))\n\n with open(ignore_file_path, encoding=\"utf-8\") as fobj:\n self.ignore_spec = PathSpec.from_lines(GitWildMatchPattern, fobj)\n\n def __call__(self, root, dirs, files):\n files = [f for f in files if not self.matches(root, f)]\n dirs = [d for d in dirs if not self.matches(root, d)]\n\n return dirs, files\n\n def matches(self, dirname, basename):\n abs_path = os.path.join(dirname, basename)\n rel_path = relpath(abs_path, self.dirname)\n\n if os.pardir + os.sep in rel_path:\n return False\n return self.ignore_spec.match_file(rel_path)\n\n def __hash__(self):\n return hash(self.ignore_file_path)\n\n def __eq__(self, other):\n return self.ignore_file_path == other.ignore_file_path\n\n\nclass DvcIgnoreDirs(DvcIgnore):\n def __init__(self, basenames):\n self.basenames = set(basenames)\n\n def __call__(self, root, dirs, files):\n dirs = [d for d in dirs if d not in self.basenames]\n\n return dirs, files\n\n\nclass DvcIgnoreFilter(object):\n def __init__(self, root_dir):\n self.ignores = {DvcIgnoreDirs([\".git\", \".hg\", \".dvc\"])}\n self._update(root_dir)\n for root, dirs, _ in os.walk(root_dir):\n for d in dirs:\n self._update(os.path.join(root, d))\n\n def _update(self, dirname):\n ignore_file_path = os.path.join(dirname, DvcIgnore.DVCIGNORE_FILE)\n if os.path.exists(ignore_file_path):\n self.ignores.add(DvcIgnorePatterns(ignore_file_path))\n\n def __call__(self, root, dirs, files):\n for ignore in self.ignores:\n dirs, files = ignore(root, dirs, files)\n\n return dirs, files\n", "path": "dvc/ignore.py"}], "after_files": [{"content": "from __future__ import unicode_literals\n\nimport logging\nimport os\n\nfrom pathspec import PathSpec\nfrom pathspec.patterns import GitWildMatchPattern\n\nfrom dvc.utils import dvc_walk\nfrom dvc.utils import relpath\nfrom dvc.utils.compat import open\n\nlogger = logging.getLogger(__name__)\n\n\nclass DvcIgnore(object):\n DVCIGNORE_FILE = \".dvcignore\"\n\n def __call__(self, root, dirs, files):\n raise NotImplementedError\n\n\nclass DvcIgnorePatterns(DvcIgnore):\n def __init__(self, ignore_file_path):\n assert os.path.isabs(ignore_file_path)\n\n self.ignore_file_path = ignore_file_path\n self.dirname = os.path.normpath(os.path.dirname(ignore_file_path))\n\n with open(ignore_file_path, encoding=\"utf-8\") as fobj:\n self.ignore_spec = PathSpec.from_lines(GitWildMatchPattern, fobj)\n\n def __call__(self, root, dirs, files):\n files = [f for f in files if not self.matches(root, f)]\n dirs = [d for d in dirs if not self.matches(root, d)]\n\n return dirs, files\n\n def matches(self, dirname, basename):\n abs_path = os.path.join(dirname, basename)\n rel_path = relpath(abs_path, self.dirname)\n\n if os.pardir + os.sep in rel_path:\n return False\n return self.ignore_spec.match_file(rel_path)\n\n def __hash__(self):\n return hash(self.ignore_file_path)\n\n def __eq__(self, other):\n if not isinstance(other, DvcIgnorePatterns):\n return NotImplemented\n\n return self.ignore_file_path == other.ignore_file_path\n\n\nclass DvcIgnoreDirs(DvcIgnore):\n def __init__(self, basenames):\n self.basenames = set(basenames)\n\n def __call__(self, root, dirs, files):\n dirs = [d for d in dirs if d not in self.basenames]\n\n return dirs, files\n\n def __hash__(self):\n return hash(tuple(self.basenames))\n\n def __eq__(self, other):\n if not isinstance(other, DvcIgnoreDirs):\n return NotImplemented\n\n return self.basenames == other.basenames\n\n\nclass DvcIgnoreFilter(object):\n def __init__(self, root_dir):\n self.ignores = {DvcIgnoreDirs([\".git\", \".hg\", \".dvc\"])}\n self._update(root_dir)\n for root, dirs, _ in dvc_walk(root_dir, self):\n for d in dirs:\n self._update(os.path.join(root, d))\n\n def _update(self, dirname):\n ignore_file_path = os.path.join(dirname, DvcIgnore.DVCIGNORE_FILE)\n if os.path.exists(ignore_file_path):\n self.ignores.add(DvcIgnorePatterns(ignore_file_path))\n\n def __call__(self, root, dirs, files):\n for ignore in self.ignores:\n dirs, files = ignore(root, dirs, files)\n\n return dirs, files\n", "path": "dvc/ignore.py"}]}
| 1,555 | 325 |
gh_patches_debug_16139
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1922
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
E1017 with nested !Select
*cfn-lint version: (`cfn-lint --version`)*
0.46.0
*Description of issue.*
When linting this CFT YAML:
```yaml
subnet0A:
DependsOn: ipv6CidrBlock
Type: 'AWS::EC2::Subnet'
Properties:
VpcId: !Ref vpc
CidrBlock: !Select
- !Select
- 1
- !Split
- ','
- !FindInMap
- subnetMap
- !Ref numAzs
- !Ref numSubnets
- 'Fn::Cidr':
- !GetAtt
- vpc
- CidrBlock
- !Select
- 0
- !Split
- ','
- !FindInMap
- subnetMap
- !Ref numAzs
- !Ref numSubnets
- !FindInMap
- subnetMap
- maskTocidrBits
- !Ref subnetMask
```
I get this error:
E1017 Select index should be an Integer or a function Ref or FindInMap for Resources/subnet0A/Properties/CidrBlock/Fn::Select
Template works fine.
thanks
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/functions/Select.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import six
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9
10 class Select(CloudFormationLintRule):
11 """Check if Select values are correct"""
12 id = 'E1017'
13 shortdesc = 'Select validation of parameters'
14 description = 'Making sure the function not is of list'
15 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'
16 tags = ['functions', 'select']
17
18 def match(self, cfn):
19 matches = []
20
21 select_objs = cfn.search_deep_keys('Fn::Select')
22
23 supported_functions = [
24 'Fn::FindInMap',
25 'Fn::GetAtt',
26 'Fn::GetAZs',
27 'Fn::If',
28 'Fn::Split',
29 'Fn::Cidr',
30 'Ref'
31 ]
32
33 for select_obj in select_objs:
34 select_value_obj = select_obj[-1]
35 tree = select_obj[:-1]
36 if isinstance(select_value_obj, list):
37 if len(select_value_obj) == 2:
38 index_obj = select_value_obj[0]
39 list_of_objs = select_value_obj[1]
40 if isinstance(index_obj, dict):
41 if len(index_obj) == 1:
42 for index_key, _ in index_obj.items():
43 if index_key not in ['Ref', 'Fn::FindInMap']:
44 message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'
45 matches.append(RuleMatch(
46 tree, message.format('/'.join(map(str, tree)))))
47 elif not isinstance(index_obj, six.integer_types):
48 try:
49 int(index_obj)
50 except ValueError:
51 message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'
52 matches.append(RuleMatch(
53 tree, message.format('/'.join(map(str, tree)))))
54 if isinstance(list_of_objs, dict):
55 if len(list_of_objs) == 1:
56 for key, _ in list_of_objs.items():
57 if key not in supported_functions:
58 message = 'Select should use a supported function of {0}'
59 matches.append(RuleMatch(
60 tree, message.format(', '.join(map(str, supported_functions)))))
61 else:
62 message = 'Select should use a supported function of {0}'
63 matches.append(RuleMatch(
64 tree, message.format(', '.join(map(str, supported_functions)))))
65 elif not isinstance(list_of_objs, list):
66 message = 'Select should be an array of values for {0}'
67 matches.append(RuleMatch(
68 tree, message.format('/'.join(map(str, tree)))))
69 else:
70 message = 'Select should be a list of 2 elements for {0}'
71 matches.append(RuleMatch(
72 tree, message.format('/'.join(map(str, tree)))))
73 else:
74 message = 'Select should be a list of 2 elements for {0}'
75 matches.append(RuleMatch(
76 tree, message.format('/'.join(map(str, tree)))))
77 return matches
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/functions/Select.py b/src/cfnlint/rules/functions/Select.py
--- a/src/cfnlint/rules/functions/Select.py
+++ b/src/cfnlint/rules/functions/Select.py
@@ -40,7 +40,7 @@
if isinstance(index_obj, dict):
if len(index_obj) == 1:
for index_key, _ in index_obj.items():
- if index_key not in ['Ref', 'Fn::FindInMap']:
+ if index_key not in ['Ref', 'Fn::FindInMap', 'Fn::Select']:
message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'
matches.append(RuleMatch(
tree, message.format('/'.join(map(str, tree)))))
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/Select.py b/src/cfnlint/rules/functions/Select.py\n--- a/src/cfnlint/rules/functions/Select.py\n+++ b/src/cfnlint/rules/functions/Select.py\n@@ -40,7 +40,7 @@\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n for index_key, _ in index_obj.items():\n- if index_key not in ['Ref', 'Fn::FindInMap']:\n+ if index_key not in ['Ref', 'Fn::FindInMap', 'Fn::Select']:\n message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n", "issue": "E1017 with nested !Select\n*cfn-lint version: (`cfn-lint --version`)*\r\n0.46.0\r\n\r\n*Description of issue.*\r\nWhen linting this CFT YAML:\r\n```yaml\r\nsubnet0A:\r\n DependsOn: ipv6CidrBlock\r\n Type: 'AWS::EC2::Subnet'\r\n Properties:\r\n VpcId: !Ref vpc\r\n CidrBlock: !Select\r\n - !Select\r\n - 1\r\n - !Split\r\n - ','\r\n - !FindInMap\r\n - subnetMap\r\n - !Ref numAzs\r\n - !Ref numSubnets\r\n - 'Fn::Cidr':\r\n - !GetAtt\r\n - vpc\r\n - CidrBlock\r\n - !Select\r\n - 0\r\n - !Split\r\n - ','\r\n - !FindInMap\r\n - subnetMap\r\n - !Ref numAzs\r\n - !Ref numSubnets\r\n - !FindInMap\r\n - subnetMap\r\n - maskTocidrBits\r\n - !Ref subnetMask\r\n```\r\n\r\nI get this error:\r\n\r\nE1017 Select index should be an Integer or a function Ref or FindInMap for Resources/subnet0A/Properties/CidrBlock/Fn::Select\r\n\r\nTemplate works fine.\r\nthanks\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport six\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass Select(CloudFormationLintRule):\n \"\"\"Check if Select values are correct\"\"\"\n id = 'E1017'\n shortdesc = 'Select validation of parameters'\n description = 'Making sure the function not is of list'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'\n tags = ['functions', 'select']\n\n def match(self, cfn):\n matches = []\n\n select_objs = cfn.search_deep_keys('Fn::Select')\n\n supported_functions = [\n 'Fn::FindInMap',\n 'Fn::GetAtt',\n 'Fn::GetAZs',\n 'Fn::If',\n 'Fn::Split',\n 'Fn::Cidr',\n 'Ref'\n ]\n\n for select_obj in select_objs:\n select_value_obj = select_obj[-1]\n tree = select_obj[:-1]\n if isinstance(select_value_obj, list):\n if len(select_value_obj) == 2:\n index_obj = select_value_obj[0]\n list_of_objs = select_value_obj[1]\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n for index_key, _ in index_obj.items():\n if index_key not in ['Ref', 'Fn::FindInMap']:\n message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(index_obj, six.integer_types):\n try:\n int(index_obj)\n except ValueError:\n message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n if isinstance(list_of_objs, dict):\n if len(list_of_objs) == 1:\n for key, _ in list_of_objs.items():\n if key not in supported_functions:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n else:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n elif not isinstance(list_of_objs, list):\n message = 'Select should be an array of values for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n return matches\n", "path": "src/cfnlint/rules/functions/Select.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport six\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass Select(CloudFormationLintRule):\n \"\"\"Check if Select values are correct\"\"\"\n id = 'E1017'\n shortdesc = 'Select validation of parameters'\n description = 'Making sure the function not is of list'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-select.html'\n tags = ['functions', 'select']\n\n def match(self, cfn):\n matches = []\n\n select_objs = cfn.search_deep_keys('Fn::Select')\n\n supported_functions = [\n 'Fn::FindInMap',\n 'Fn::GetAtt',\n 'Fn::GetAZs',\n 'Fn::If',\n 'Fn::Split',\n 'Fn::Cidr',\n 'Ref'\n ]\n\n for select_obj in select_objs:\n select_value_obj = select_obj[-1]\n tree = select_obj[:-1]\n if isinstance(select_value_obj, list):\n if len(select_value_obj) == 2:\n index_obj = select_value_obj[0]\n list_of_objs = select_value_obj[1]\n if isinstance(index_obj, dict):\n if len(index_obj) == 1:\n for index_key, _ in index_obj.items():\n if index_key not in ['Ref', 'Fn::FindInMap', 'Fn::Select']:\n message = 'Select index should be an Integer or a function Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n elif not isinstance(index_obj, six.integer_types):\n try:\n int(index_obj)\n except ValueError:\n message = 'Select index should be an Integer or a function of Ref or FindInMap for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n if isinstance(list_of_objs, dict):\n if len(list_of_objs) == 1:\n for key, _ in list_of_objs.items():\n if key not in supported_functions:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n else:\n message = 'Select should use a supported function of {0}'\n matches.append(RuleMatch(\n tree, message.format(', '.join(map(str, supported_functions)))))\n elif not isinstance(list_of_objs, list):\n message = 'Select should be an array of values for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n else:\n message = 'Select should be a list of 2 elements for {0}'\n matches.append(RuleMatch(\n tree, message.format('/'.join(map(str, tree)))))\n return matches\n", "path": "src/cfnlint/rules/functions/Select.py"}]}
| 1,464 | 170 |
gh_patches_debug_3665
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-634
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bootstrap demotion is not robust
While working https://github.com/pantsbuild/pants/issues/6927 it was discovered that there were multiple `.bootstrap/` on the sys.path and only one was demoted, leading to pants, when running in a pex, picking .bootstrap.pex instead of the pex dist it in `.deps/`. In this case, Pants was purposefully duplicating pex path entries to work around a bug in the `coverage` library. PEX should be robust and demote all instances of it's `.bootstrap/` entry on the sys.path.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/bootstrap.py`
Content:
```
1 # coding=utf-8
2 # Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).
3 # Licensed under the Apache License, Version 2.0 (see LICENSE).
4
5 import os
6
7
8 class Bootstrap(object):
9 """Supports introspection of the PEX bootstrap code."""
10
11 _INSTANCE = None
12
13 @classmethod
14 def locate(cls):
15 """Locates the active PEX bootstrap.
16
17 :rtype: :class:`Bootstrap`
18 """
19 if cls._INSTANCE is None:
20 bootstrap_path = __file__
21 module_import_path = __name__.split('.')
22
23 # For example, our __file__ might be requests.pex/.bootstrap/pex/bootstrap.pyc and our import
24 # path pex.bootstrap; so we walk back through all the module components of our import path to
25 # find the base sys.path entry where we were found (requests.pex/.bootstrap in this example).
26 for _ in module_import_path:
27 bootstrap_path = os.path.dirname(bootstrap_path)
28
29 cls._INSTANCE = cls(sys_path_entry=bootstrap_path)
30 return cls._INSTANCE
31
32 def __init__(self, sys_path_entry):
33 self._sys_path_entry = sys_path_entry
34 self._realpath = os.path.realpath(self._sys_path_entry)
35
36 def demote(self):
37 """Demote the bootstrap code to the end of the `sys.path` so it is found last.
38
39 :return: The list of un-imported bootstrap modules.
40 :rtype: list of :class:`types.ModuleType`
41 """
42 import sys # Grab a hold of `sys` early since we'll be un-importing our module in this process.
43
44 unimported_modules = []
45 for name, module in reversed(sorted(sys.modules.items())):
46 if self.imported_from_bootstrap(module):
47 unimported_modules.append(sys.modules.pop(name))
48
49 sys.path.remove(self._sys_path_entry)
50 sys.path.append(self._sys_path_entry)
51
52 return unimported_modules
53
54 def imported_from_bootstrap(self, module):
55 """Return ``True`` if the given ``module`` object was imported from bootstrap code.
56
57 :param module: The module to check the provenance of.
58 :type module: :class:`types.ModuleType`
59 :rtype: bool
60 """
61
62 # A vendored module.
63 path = getattr(module, '__file__', None)
64 if path and os.path.realpath(path).startswith(self._realpath):
65 return True
66
67 # A vendored package.
68 path = getattr(module, '__path__', None)
69 if path and any(os.path.realpath(path_item).startswith(self._realpath)
70 for path_item in path):
71 return True
72
73 return False
74
75 def __repr__(self):
76 return '{cls}(sys_path_entry={sys_path_entry!r})'.format(cls=type(self).__name__,
77 sys_path_entry=self._sys_path_entry)
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/bootstrap.py b/pex/bootstrap.py
--- a/pex/bootstrap.py
+++ b/pex/bootstrap.py
@@ -46,7 +46,7 @@
if self.imported_from_bootstrap(module):
unimported_modules.append(sys.modules.pop(name))
- sys.path.remove(self._sys_path_entry)
+ sys.path[:] = [path for path in sys.path if os.path.realpath(path) != self._realpath]
sys.path.append(self._sys_path_entry)
return unimported_modules
|
{"golden_diff": "diff --git a/pex/bootstrap.py b/pex/bootstrap.py\n--- a/pex/bootstrap.py\n+++ b/pex/bootstrap.py\n@@ -46,7 +46,7 @@\n if self.imported_from_bootstrap(module):\n unimported_modules.append(sys.modules.pop(name))\n \n- sys.path.remove(self._sys_path_entry)\n+ sys.path[:] = [path for path in sys.path if os.path.realpath(path) != self._realpath]\n sys.path.append(self._sys_path_entry)\n \n return unimported_modules\n", "issue": "Bootstrap demotion is not robust\nWhile working https://github.com/pantsbuild/pants/issues/6927 it was discovered that there were multiple `.bootstrap/` on the sys.path and only one was demoted, leading to pants, when running in a pex, picking .bootstrap.pex instead of the pex dist it in `.deps/`. In this case, Pants was purposefully duplicating pex path entries to work around a bug in the `coverage` library. PEX should be robust and demote all instances of it's `.bootstrap/` entry on the sys.path.\n", "before_files": [{"content": "# coding=utf-8\n# Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nimport os\n\n\nclass Bootstrap(object):\n \"\"\"Supports introspection of the PEX bootstrap code.\"\"\"\n\n _INSTANCE = None\n\n @classmethod\n def locate(cls):\n \"\"\"Locates the active PEX bootstrap.\n\n :rtype: :class:`Bootstrap`\n \"\"\"\n if cls._INSTANCE is None:\n bootstrap_path = __file__\n module_import_path = __name__.split('.')\n\n # For example, our __file__ might be requests.pex/.bootstrap/pex/bootstrap.pyc and our import\n # path pex.bootstrap; so we walk back through all the module components of our import path to\n # find the base sys.path entry where we were found (requests.pex/.bootstrap in this example).\n for _ in module_import_path:\n bootstrap_path = os.path.dirname(bootstrap_path)\n\n cls._INSTANCE = cls(sys_path_entry=bootstrap_path)\n return cls._INSTANCE\n\n def __init__(self, sys_path_entry):\n self._sys_path_entry = sys_path_entry\n self._realpath = os.path.realpath(self._sys_path_entry)\n\n def demote(self):\n \"\"\"Demote the bootstrap code to the end of the `sys.path` so it is found last.\n\n :return: The list of un-imported bootstrap modules.\n :rtype: list of :class:`types.ModuleType`\n \"\"\"\n import sys # Grab a hold of `sys` early since we'll be un-importing our module in this process.\n\n unimported_modules = []\n for name, module in reversed(sorted(sys.modules.items())):\n if self.imported_from_bootstrap(module):\n unimported_modules.append(sys.modules.pop(name))\n\n sys.path.remove(self._sys_path_entry)\n sys.path.append(self._sys_path_entry)\n\n return unimported_modules\n\n def imported_from_bootstrap(self, module):\n \"\"\"Return ``True`` if the given ``module`` object was imported from bootstrap code.\n\n :param module: The module to check the provenance of.\n :type module: :class:`types.ModuleType`\n :rtype: bool\n \"\"\"\n\n # A vendored module.\n path = getattr(module, '__file__', None)\n if path and os.path.realpath(path).startswith(self._realpath):\n return True\n\n # A vendored package.\n path = getattr(module, '__path__', None)\n if path and any(os.path.realpath(path_item).startswith(self._realpath)\n for path_item in path):\n return True\n\n return False\n\n def __repr__(self):\n return '{cls}(sys_path_entry={sys_path_entry!r})'.format(cls=type(self).__name__,\n sys_path_entry=self._sys_path_entry)\n", "path": "pex/bootstrap.py"}], "after_files": [{"content": "# coding=utf-8\n# Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nimport os\n\n\nclass Bootstrap(object):\n \"\"\"Supports introspection of the PEX bootstrap code.\"\"\"\n\n _INSTANCE = None\n\n @classmethod\n def locate(cls):\n \"\"\"Locates the active PEX bootstrap.\n\n :rtype: :class:`Bootstrap`\n \"\"\"\n if cls._INSTANCE is None:\n bootstrap_path = __file__\n module_import_path = __name__.split('.')\n\n # For example, our __file__ might be requests.pex/.bootstrap/pex/bootstrap.pyc and our import\n # path pex.bootstrap; so we walk back through all the module components of our import path to\n # find the base sys.path entry where we were found (requests.pex/.bootstrap in this example).\n for _ in module_import_path:\n bootstrap_path = os.path.dirname(bootstrap_path)\n\n cls._INSTANCE = cls(sys_path_entry=bootstrap_path)\n return cls._INSTANCE\n\n def __init__(self, sys_path_entry):\n self._sys_path_entry = sys_path_entry\n self._realpath = os.path.realpath(self._sys_path_entry)\n\n def demote(self):\n \"\"\"Demote the bootstrap code to the end of the `sys.path` so it is found last.\n\n :return: The list of un-imported bootstrap modules.\n :rtype: list of :class:`types.ModuleType`\n \"\"\"\n import sys # Grab a hold of `sys` early since we'll be un-importing our module in this process.\n\n unimported_modules = []\n for name, module in reversed(sorted(sys.modules.items())):\n if self.imported_from_bootstrap(module):\n unimported_modules.append(sys.modules.pop(name))\n\n sys.path[:] = [path for path in sys.path if os.path.realpath(path) != self._realpath]\n sys.path.append(self._sys_path_entry)\n\n return unimported_modules\n\n def imported_from_bootstrap(self, module):\n \"\"\"Return ``True`` if the given ``module`` object was imported from bootstrap code.\n\n :param module: The module to check the provenance of.\n :type module: :class:`types.ModuleType`\n :rtype: bool\n \"\"\"\n\n # A vendored module.\n path = getattr(module, '__file__', None)\n if path and os.path.realpath(path).startswith(self._realpath):\n return True\n\n # A vendored package.\n path = getattr(module, '__path__', None)\n if path and any(os.path.realpath(path_item).startswith(self._realpath)\n for path_item in path):\n return True\n\n return False\n\n def __repr__(self):\n return '{cls}(sys_path_entry={sys_path_entry!r})'.format(cls=type(self).__name__,\n sys_path_entry=self._sys_path_entry)\n", "path": "pex/bootstrap.py"}]}
| 1,149 | 115 |
gh_patches_debug_32954
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2442
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
in text commenting links to first chapter lead back to the project view
...so I am back to the timeline and the tiles
There are two links doing that: "back to chapter" in paragraph detail view and "previous chapter" in second chapter.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `meinberlin/apps/documents/views.py`
Content:
```
1 from django.http import Http404
2 from django.urls import reverse
3 from django.utils.translation import ugettext_lazy as _
4 from django.views import generic
5
6 from adhocracy4.dashboard import mixins as dashboard_mixins
7 from adhocracy4.projects.mixins import DisplayProjectOrModuleMixin
8 from adhocracy4.projects.mixins import ProjectMixin
9 from adhocracy4.rules import mixins as rules_mixins
10 from meinberlin.apps.exports.views import DashboardExportView
11
12 from . import models
13
14
15 class DocumentDashboardView(ProjectMixin,
16 dashboard_mixins.DashboardBaseMixin,
17 dashboard_mixins.DashboardComponentMixin,
18 generic.TemplateView):
19 template_name = 'meinberlin_documents/document_dashboard.html'
20 permission_required = 'a4projects.change_project'
21
22 def get_permission_object(self):
23 return self.project
24
25
26 class ChapterDetailView(ProjectMixin,
27 rules_mixins.PermissionRequiredMixin,
28 generic.DetailView,
29 DisplayProjectOrModuleMixin):
30 model = models.Chapter
31 permission_required = 'meinberlin_documents.view_chapter'
32 get_context_from_object = True
33
34 def get_context_data(self, **kwargs):
35 context = super(ChapterDetailView, self).get_context_data(**kwargs)
36 context['chapter_list'] = self.chapter_list
37 return context
38
39 @property
40 def chapter_list(self):
41 return models.Chapter.objects.filter(module=self.module)
42
43
44 class DocumentDetailView(ChapterDetailView):
45 get_context_from_object = False
46
47 def get_object(self):
48 first_chapter = models.Chapter.objects \
49 .filter(module=self.module) \
50 .first()
51
52 if not first_chapter:
53 raise Http404(_('Document has no chapters defined.'))
54 return first_chapter
55
56
57 class ParagraphDetailView(ProjectMixin,
58 rules_mixins.PermissionRequiredMixin,
59 generic.DetailView):
60 model = models.Paragraph
61 permission_required = 'meinberlin_documents.view_paragraph'
62
63
64 class DocumentDashboardExportView(DashboardExportView):
65 template_name = 'meinberlin_exports/export_dashboard.html'
66
67 def get_context_data(self, **kwargs):
68 context = super().get_context_data(**kwargs)
69 context['comment_export'] = reverse(
70 'a4dashboard:document-comment-export',
71 kwargs={'module_slug': self.module.slug})
72 return context
73
```
Path: `meinberlin/apps/documents/models.py`
Content:
```
1 from ckeditor_uploader.fields import RichTextUploadingField
2 from django.contrib.contenttypes.fields import GenericRelation
3 from django.db import models
4 from django.urls import reverse
5 from django.utils.functional import cached_property
6
7 from adhocracy4 import transforms
8 from adhocracy4.comments import models as comment_models
9 from adhocracy4.models import base
10 from adhocracy4.modules import models as module_models
11
12
13 class Chapter(module_models.Item):
14 name = models.CharField(max_length=120)
15 comments = GenericRelation(comment_models.Comment,
16 related_query_name='chapter',
17 object_id_field='object_pk')
18 weight = models.PositiveIntegerField(default=0)
19
20 class Meta:
21 ordering = ('weight',)
22
23 def __str__(self):
24 return "{}_chapter_{}".format(str(self.module), self.pk)
25
26 def get_absolute_url(self):
27 return reverse('meinberlin_documents:chapter-detail',
28 args=[str(self.pk)])
29
30 @cached_property
31 def prev(self):
32 return Chapter.objects\
33 .filter(module=self.module)\
34 .filter(weight__lt=self.weight)\
35 .order_by('-weight')\
36 .first()
37
38 @cached_property
39 def next(self):
40 return Chapter.objects\
41 .filter(module=self.module)\
42 .filter(weight__gt=self.weight)\
43 .order_by('weight')\
44 .first()
45
46
47 class Paragraph(base.TimeStampedModel):
48 name = models.CharField(max_length=120, blank=True)
49 text = RichTextUploadingField(config_name='image-editor')
50 weight = models.PositiveIntegerField()
51 chapter = models.ForeignKey(Chapter,
52 on_delete=models.CASCADE,
53 related_name='paragraphs')
54 comments = GenericRelation(comment_models.Comment,
55 related_query_name='paragraph',
56 object_id_field='object_pk')
57
58 class Meta:
59 ordering = ('weight',)
60
61 def __str__(self):
62 return "{}_paragraph_{}".format(str(self.chapter), self.weight)
63
64 def save(self, *args, **kwargs):
65 self.text = transforms.clean_html_field(
66 self.text, 'image-editor')
67 super().save(*args, **kwargs)
68
69 def get_absolute_url(self):
70 return reverse('meinberlin_documents:paragraph-detail',
71 args=[str(self.pk)])
72
73 @property
74 def creator(self):
75 return self.chapter.creator
76
77 @property
78 def project(self):
79 return self.module.project
80
81 @property
82 def module(self):
83 return self.chapter.module
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/meinberlin/apps/documents/models.py b/meinberlin/apps/documents/models.py
--- a/meinberlin/apps/documents/models.py
+++ b/meinberlin/apps/documents/models.py
@@ -24,6 +24,12 @@
return "{}_chapter_{}".format(str(self.module), self.pk)
def get_absolute_url(self):
+ if (self.project.display_timeline
+ and not self.module.is_in_module_cluster):
+ return ('{}?initialSlide={}'
+ .format(reverse('meinberlin_documents:chapter-detail',
+ args=[str(self.pk)]),
+ self.module.get_timeline_index))
return reverse('meinberlin_documents:chapter-detail',
args=[str(self.pk)])
diff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py
--- a/meinberlin/apps/documents/views.py
+++ b/meinberlin/apps/documents/views.py
@@ -1,5 +1,6 @@
from django.http import Http404
from django.urls import reverse
+from django.utils.functional import cached_property
from django.utils.translation import ugettext_lazy as _
from django.views import generic
@@ -32,7 +33,7 @@
get_context_from_object = True
def get_context_data(self, **kwargs):
- context = super(ChapterDetailView, self).get_context_data(**kwargs)
+ context = super().get_context_data(**kwargs)
context['chapter_list'] = self.chapter_list
return context
@@ -40,6 +41,15 @@
def chapter_list(self):
return models.Chapter.objects.filter(module=self.module)
+ @cached_property
+ def extends(self):
+ if self.url_name == 'module-detail':
+ return 'a4modules/module_detail.html'
+ if self.url_name == 'chapter-detail':
+ if self.module.is_in_module_cluster:
+ return 'a4modules/module_detail.html'
+ return 'a4projects/project_detail.html'
+
class DocumentDetailView(ChapterDetailView):
get_context_from_object = False
|
{"golden_diff": "diff --git a/meinberlin/apps/documents/models.py b/meinberlin/apps/documents/models.py\n--- a/meinberlin/apps/documents/models.py\n+++ b/meinberlin/apps/documents/models.py\n@@ -24,6 +24,12 @@\n return \"{}_chapter_{}\".format(str(self.module), self.pk)\n \n def get_absolute_url(self):\n+ if (self.project.display_timeline\n+ and not self.module.is_in_module_cluster):\n+ return ('{}?initialSlide={}'\n+ .format(reverse('meinberlin_documents:chapter-detail',\n+ args=[str(self.pk)]),\n+ self.module.get_timeline_index))\n return reverse('meinberlin_documents:chapter-detail',\n args=[str(self.pk)])\n \ndiff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py\n--- a/meinberlin/apps/documents/views.py\n+++ b/meinberlin/apps/documents/views.py\n@@ -1,5 +1,6 @@\n from django.http import Http404\n from django.urls import reverse\n+from django.utils.functional import cached_property\n from django.utils.translation import ugettext_lazy as _\n from django.views import generic\n \n@@ -32,7 +33,7 @@\n get_context_from_object = True\n \n def get_context_data(self, **kwargs):\n- context = super(ChapterDetailView, self).get_context_data(**kwargs)\n+ context = super().get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n \n@@ -40,6 +41,15 @@\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n \n+ @cached_property\n+ def extends(self):\n+ if self.url_name == 'module-detail':\n+ return 'a4modules/module_detail.html'\n+ if self.url_name == 'chapter-detail':\n+ if self.module.is_in_module_cluster:\n+ return 'a4modules/module_detail.html'\n+ return 'a4projects/project_detail.html'\n+\n \n class DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n", "issue": "in text commenting links to first chapter lead back to the project view\n...so I am back to the timeline and the tiles\r\n\r\nThere are two links doing that: \"back to chapter\" in paragraph detail view and \"previous chapter\" in second chapter.\n", "before_files": [{"content": "from django.http import Http404\nfrom django.urls import reverse\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom adhocracy4.projects.mixins import ProjectMixin\nfrom adhocracy4.rules import mixins as rules_mixins\nfrom meinberlin.apps.exports.views import DashboardExportView\n\nfrom . import models\n\n\nclass DocumentDashboardView(ProjectMixin,\n dashboard_mixins.DashboardBaseMixin,\n dashboard_mixins.DashboardComponentMixin,\n generic.TemplateView):\n template_name = 'meinberlin_documents/document_dashboard.html'\n permission_required = 'a4projects.change_project'\n\n def get_permission_object(self):\n return self.project\n\n\nclass ChapterDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView,\n DisplayProjectOrModuleMixin):\n model = models.Chapter\n permission_required = 'meinberlin_documents.view_chapter'\n get_context_from_object = True\n\n def get_context_data(self, **kwargs):\n context = super(ChapterDetailView, self).get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n\n @property\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n\n\nclass DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n\n def get_object(self):\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n\n if not first_chapter:\n raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n\n\nclass ParagraphDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView):\n model = models.Paragraph\n permission_required = 'meinberlin_documents.view_paragraph'\n\n\nclass DocumentDashboardExportView(DashboardExportView):\n template_name = 'meinberlin_exports/export_dashboard.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['comment_export'] = reverse(\n 'a4dashboard:document-comment-export',\n kwargs={'module_slug': self.module.slug})\n return context\n", "path": "meinberlin/apps/documents/views.py"}, {"content": "from ckeditor_uploader.fields import RichTextUploadingField\nfrom django.contrib.contenttypes.fields import GenericRelation\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\n\nfrom adhocracy4 import transforms\nfrom adhocracy4.comments import models as comment_models\nfrom adhocracy4.models import base\nfrom adhocracy4.modules import models as module_models\n\n\nclass Chapter(module_models.Item):\n name = models.CharField(max_length=120)\n comments = GenericRelation(comment_models.Comment,\n related_query_name='chapter',\n object_id_field='object_pk')\n weight = models.PositiveIntegerField(default=0)\n\n class Meta:\n ordering = ('weight',)\n\n def __str__(self):\n return \"{}_chapter_{}\".format(str(self.module), self.pk)\n\n def get_absolute_url(self):\n return reverse('meinberlin_documents:chapter-detail',\n args=[str(self.pk)])\n\n @cached_property\n def prev(self):\n return Chapter.objects\\\n .filter(module=self.module)\\\n .filter(weight__lt=self.weight)\\\n .order_by('-weight')\\\n .first()\n\n @cached_property\n def next(self):\n return Chapter.objects\\\n .filter(module=self.module)\\\n .filter(weight__gt=self.weight)\\\n .order_by('weight')\\\n .first()\n\n\nclass Paragraph(base.TimeStampedModel):\n name = models.CharField(max_length=120, blank=True)\n text = RichTextUploadingField(config_name='image-editor')\n weight = models.PositiveIntegerField()\n chapter = models.ForeignKey(Chapter,\n on_delete=models.CASCADE,\n related_name='paragraphs')\n comments = GenericRelation(comment_models.Comment,\n related_query_name='paragraph',\n object_id_field='object_pk')\n\n class Meta:\n ordering = ('weight',)\n\n def __str__(self):\n return \"{}_paragraph_{}\".format(str(self.chapter), self.weight)\n\n def save(self, *args, **kwargs):\n self.text = transforms.clean_html_field(\n self.text, 'image-editor')\n super().save(*args, **kwargs)\n\n def get_absolute_url(self):\n return reverse('meinberlin_documents:paragraph-detail',\n args=[str(self.pk)])\n\n @property\n def creator(self):\n return self.chapter.creator\n\n @property\n def project(self):\n return self.module.project\n\n @property\n def module(self):\n return self.chapter.module\n", "path": "meinberlin/apps/documents/models.py"}], "after_files": [{"content": "from django.http import Http404\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom adhocracy4.projects.mixins import ProjectMixin\nfrom adhocracy4.rules import mixins as rules_mixins\nfrom meinberlin.apps.exports.views import DashboardExportView\n\nfrom . import models\n\n\nclass DocumentDashboardView(ProjectMixin,\n dashboard_mixins.DashboardBaseMixin,\n dashboard_mixins.DashboardComponentMixin,\n generic.TemplateView):\n template_name = 'meinberlin_documents/document_dashboard.html'\n permission_required = 'a4projects.change_project'\n\n def get_permission_object(self):\n return self.project\n\n\nclass ChapterDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView,\n DisplayProjectOrModuleMixin):\n model = models.Chapter\n permission_required = 'meinberlin_documents.view_chapter'\n get_context_from_object = True\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n\n @property\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n\n @cached_property\n def extends(self):\n if self.url_name == 'module-detail':\n return 'a4modules/module_detail.html'\n if self.url_name == 'chapter-detail':\n if self.module.is_in_module_cluster:\n return 'a4modules/module_detail.html'\n return 'a4projects/project_detail.html'\n\n\nclass DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n\n def get_object(self):\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n\n if not first_chapter:\n raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n\n\nclass ParagraphDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView):\n model = models.Paragraph\n permission_required = 'meinberlin_documents.view_paragraph'\n\n\nclass DocumentDashboardExportView(DashboardExportView):\n template_name = 'meinberlin_exports/export_dashboard.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['comment_export'] = reverse(\n 'a4dashboard:document-comment-export',\n kwargs={'module_slug': self.module.slug})\n return context\n", "path": "meinberlin/apps/documents/views.py"}, {"content": "from ckeditor_uploader.fields import RichTextUploadingField\nfrom django.contrib.contenttypes.fields import GenericRelation\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\n\nfrom adhocracy4 import transforms\nfrom adhocracy4.comments import models as comment_models\nfrom adhocracy4.models import base\nfrom adhocracy4.modules import models as module_models\n\n\nclass Chapter(module_models.Item):\n name = models.CharField(max_length=120)\n comments = GenericRelation(comment_models.Comment,\n related_query_name='chapter',\n object_id_field='object_pk')\n weight = models.PositiveIntegerField(default=0)\n\n class Meta:\n ordering = ('weight',)\n\n def __str__(self):\n return \"{}_chapter_{}\".format(str(self.module), self.pk)\n\n def get_absolute_url(self):\n if (self.project.display_timeline\n and not self.module.is_in_module_cluster):\n return ('{}?initialSlide={}'\n .format(reverse('meinberlin_documents:chapter-detail',\n args=[str(self.pk)]),\n self.module.get_timeline_index))\n return reverse('meinberlin_documents:chapter-detail',\n args=[str(self.pk)])\n\n @cached_property\n def prev(self):\n return Chapter.objects\\\n .filter(module=self.module)\\\n .filter(weight__lt=self.weight)\\\n .order_by('-weight')\\\n .first()\n\n @cached_property\n def next(self):\n return Chapter.objects\\\n .filter(module=self.module)\\\n .filter(weight__gt=self.weight)\\\n .order_by('weight')\\\n .first()\n\n\nclass Paragraph(base.TimeStampedModel):\n name = models.CharField(max_length=120, blank=True)\n text = RichTextUploadingField(config_name='image-editor')\n weight = models.PositiveIntegerField()\n chapter = models.ForeignKey(Chapter,\n on_delete=models.CASCADE,\n related_name='paragraphs')\n comments = GenericRelation(comment_models.Comment,\n related_query_name='paragraph',\n object_id_field='object_pk')\n\n class Meta:\n ordering = ('weight',)\n\n def __str__(self):\n return \"{}_paragraph_{}\".format(str(self.chapter), self.weight)\n\n def save(self, *args, **kwargs):\n self.text = transforms.clean_html_field(\n self.text, 'image-editor')\n super().save(*args, **kwargs)\n\n def get_absolute_url(self):\n return reverse('meinberlin_documents:paragraph-detail',\n args=[str(self.pk)])\n\n @property\n def creator(self):\n return self.chapter.creator\n\n @property\n def project(self):\n return self.module.project\n\n @property\n def module(self):\n return self.chapter.module\n", "path": "meinberlin/apps/documents/models.py"}]}
| 1,644 | 456 |
gh_patches_debug_32403
|
rasdani/github-patches
|
git_diff
|
microsoft__hi-ml-504
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Histo dataset mounting script does not show files permanently
Files are only visible while the script is running, but disappear once terminated.
This could be a consequence of the library updates in #455.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py`
Content:
```
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5 from pathlib import Path
6 import sys
7
8 himl_histo_root_dir = Path(__file__).parent.parent.parent
9 himl_root = himl_histo_root_dir.parent.parent
10 himl_azure_package_root = himl_root / "hi-ml-azure" / "src"
11 sys.path.insert(0, str(himl_azure_package_root))
12
13 from health_azure import DatasetConfig # noqa: E402
14 from health_azure.utils import get_workspace # noqa: E402
15
16
17 def mount_dataset(dataset_id: str) -> str:
18 ws = get_workspace()
19 target_folder = "/tmp/datasets/" + dataset_id
20 dataset = DatasetConfig(name=dataset_id, target_folder=target_folder, use_mounting=True)
21 dataset_mount_folder, mount_ctx = dataset.to_input_dataset_local(ws)
22 assert mount_ctx is not None # for mypy
23 mount_ctx.start()
24 return str(dataset_mount_folder)
25
26
27 if __name__ == '__main__':
28 import argparse
29 parser = argparse.ArgumentParser()
30 # Run this script as "python mount_azure_dataset.py --dataset_id TCGA-CRCk"
31 parser.add_argument('--dataset_id', type=str,
32 help='Name of the Azure dataset e.g. PANDA or TCGA-CRCk')
33 args = parser.parse_args()
34 mount_dataset(args.dataset_id)
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py b/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py
--- a/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py
+++ b/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py
@@ -4,6 +4,8 @@
# ------------------------------------------------------------------------------------------
from pathlib import Path
import sys
+import time
+from typing import Any
himl_histo_root_dir = Path(__file__).parent.parent.parent
himl_root = himl_histo_root_dir.parent.parent
@@ -14,14 +16,14 @@
from health_azure.utils import get_workspace # noqa: E402
-def mount_dataset(dataset_id: str) -> str:
+def mount_dataset(dataset_id: str) -> Any:
ws = get_workspace()
target_folder = "/tmp/datasets/" + dataset_id
dataset = DatasetConfig(name=dataset_id, target_folder=target_folder, use_mounting=True)
- dataset_mount_folder, mount_ctx = dataset.to_input_dataset_local(ws)
+ _, mount_ctx = dataset.to_input_dataset_local(ws)
assert mount_ctx is not None # for mypy
mount_ctx.start()
- return str(dataset_mount_folder)
+ return mount_ctx
if __name__ == '__main__':
@@ -31,4 +33,9 @@
parser.add_argument('--dataset_id', type=str,
help='Name of the Azure dataset e.g. PANDA or TCGA-CRCk')
args = parser.parse_args()
- mount_dataset(args.dataset_id)
+ # It is essential that the mount context is returned from the mounting function and referenced here.
+ # If not, mounting will be stopped, and the files are no longer available.
+ _ = mount_dataset(args.dataset_id)
+ print("The mounted dataset will only be available while this script is running. Press Ctrl-C to terminate it.`")
+ while True:
+ time.sleep(60)
|
{"golden_diff": "diff --git a/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py b/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py\n--- a/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py\n+++ b/hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py\n@@ -4,6 +4,8 @@\n # ------------------------------------------------------------------------------------------\n from pathlib import Path\n import sys\n+import time\n+from typing import Any\n \n himl_histo_root_dir = Path(__file__).parent.parent.parent\n himl_root = himl_histo_root_dir.parent.parent\n@@ -14,14 +16,14 @@\n from health_azure.utils import get_workspace # noqa: E402\n \n \n-def mount_dataset(dataset_id: str) -> str:\n+def mount_dataset(dataset_id: str) -> Any:\n ws = get_workspace()\n target_folder = \"/tmp/datasets/\" + dataset_id\n dataset = DatasetConfig(name=dataset_id, target_folder=target_folder, use_mounting=True)\n- dataset_mount_folder, mount_ctx = dataset.to_input_dataset_local(ws)\n+ _, mount_ctx = dataset.to_input_dataset_local(ws)\n assert mount_ctx is not None # for mypy\n mount_ctx.start()\n- return str(dataset_mount_folder)\n+ return mount_ctx\n \n \n if __name__ == '__main__':\n@@ -31,4 +33,9 @@\n parser.add_argument('--dataset_id', type=str,\n help='Name of the Azure dataset e.g. PANDA or TCGA-CRCk')\n args = parser.parse_args()\n- mount_dataset(args.dataset_id)\n+ # It is essential that the mount context is returned from the mounting function and referenced here.\n+ # If not, mounting will be stopped, and the files are no longer available.\n+ _ = mount_dataset(args.dataset_id)\n+ print(\"The mounted dataset will only be available while this script is running. Press Ctrl-C to terminate it.`\")\n+ while True:\n+ time.sleep(60)\n", "issue": "Histo dataset mounting script does not show files permanently\nFiles are only visible while the script is running, but disappear once terminated. \r\nThis could be a consequence of the library updates in #455.\n", "before_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom pathlib import Path\nimport sys\n\nhiml_histo_root_dir = Path(__file__).parent.parent.parent\nhiml_root = himl_histo_root_dir.parent.parent\nhiml_azure_package_root = himl_root / \"hi-ml-azure\" / \"src\"\nsys.path.insert(0, str(himl_azure_package_root))\n\nfrom health_azure import DatasetConfig # noqa: E402\nfrom health_azure.utils import get_workspace # noqa: E402\n\n\ndef mount_dataset(dataset_id: str) -> str:\n ws = get_workspace()\n target_folder = \"/tmp/datasets/\" + dataset_id\n dataset = DatasetConfig(name=dataset_id, target_folder=target_folder, use_mounting=True)\n dataset_mount_folder, mount_ctx = dataset.to_input_dataset_local(ws)\n assert mount_ctx is not None # for mypy\n mount_ctx.start()\n return str(dataset_mount_folder)\n\n\nif __name__ == '__main__':\n import argparse\n parser = argparse.ArgumentParser()\n # Run this script as \"python mount_azure_dataset.py --dataset_id TCGA-CRCk\"\n parser.add_argument('--dataset_id', type=str,\n help='Name of the Azure dataset e.g. PANDA or TCGA-CRCk')\n args = parser.parse_args()\n mount_dataset(args.dataset_id)\n", "path": "hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py"}], "after_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom pathlib import Path\nimport sys\nimport time\nfrom typing import Any\n\nhiml_histo_root_dir = Path(__file__).parent.parent.parent\nhiml_root = himl_histo_root_dir.parent.parent\nhiml_azure_package_root = himl_root / \"hi-ml-azure\" / \"src\"\nsys.path.insert(0, str(himl_azure_package_root))\n\nfrom health_azure import DatasetConfig # noqa: E402\nfrom health_azure.utils import get_workspace # noqa: E402\n\n\ndef mount_dataset(dataset_id: str) -> Any:\n ws = get_workspace()\n target_folder = \"/tmp/datasets/\" + dataset_id\n dataset = DatasetConfig(name=dataset_id, target_folder=target_folder, use_mounting=True)\n _, mount_ctx = dataset.to_input_dataset_local(ws)\n assert mount_ctx is not None # for mypy\n mount_ctx.start()\n return mount_ctx\n\n\nif __name__ == '__main__':\n import argparse\n parser = argparse.ArgumentParser()\n # Run this script as \"python mount_azure_dataset.py --dataset_id TCGA-CRCk\"\n parser.add_argument('--dataset_id', type=str,\n help='Name of the Azure dataset e.g. PANDA or TCGA-CRCk')\n args = parser.parse_args()\n # It is essential that the mount context is returned from the mounting function and referenced here.\n # If not, mounting will be stopped, and the files are no longer available.\n _ = mount_dataset(args.dataset_id)\n print(\"The mounted dataset will only be available while this script is running. Press Ctrl-C to terminate it.`\")\n while True:\n time.sleep(60)\n", "path": "hi-ml-histopathology/src/histopathology/scripts/mount_azure_dataset.py"}]}
| 707 | 463 |
gh_patches_debug_22820
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-8672
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use utf-8 encoding to open notebook file.
Currently, `ipynb` file is opened by following code:
```
with open(filename) as f:
pass
```
https://github.com/bokeh/bokeh/blob/master/bokeh/application/handlers/notebook.py#L117
I suggest to open the file with `encoding="utf-8"`, otherwise the serve command will raise error on Windows system.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/application/handlers/notebook.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.
3 # All rights reserved.
4 #
5 # The full license is in the file LICENSE.txt, distributed with this software.
6 #-----------------------------------------------------------------------------
7 ''' Provide a Bokeh Application Handler to build up documents by running
8 the code from Jupyter notebook (``.ipynb``) files.
9
10 This handler is configured with the filename of a Jupyter notebook. When a
11 Bokeh application calls ``modify_doc``, the code from all the notebook cells
12 is collected and executed to process a new Document for a session. When the
13 notebook code is executed, the Document being modified will be available as
14 ``curdoc``, and any optionally provided ``args`` will be available as
15 ``sys.argv``.
16
17 '''
18
19 #-----------------------------------------------------------------------------
20 # Boilerplate
21 #-----------------------------------------------------------------------------
22 from __future__ import absolute_import, division, print_function, unicode_literals
23
24 import re
25 import sys
26 import logging
27 log = logging.getLogger(__name__)
28
29 #-----------------------------------------------------------------------------
30 # Imports
31 #-----------------------------------------------------------------------------
32
33 # Standard library imports
34
35 # External imports
36
37 # Bokeh imports
38 from ...util.dependencies import import_required
39 from .code import CodeHandler
40
41 #-----------------------------------------------------------------------------
42 # Globals and constants
43 #-----------------------------------------------------------------------------
44
45 __all__ = (
46 'NotebookHandler',
47 )
48
49 #-----------------------------------------------------------------------------
50 # General API
51 #-----------------------------------------------------------------------------
52
53 #-----------------------------------------------------------------------------
54 # Dev API
55 #-----------------------------------------------------------------------------
56
57 class NotebookHandler(CodeHandler):
58 ''' A Handler that uses code in a Jupyter notebook for modifying Bokeh
59 Documents.
60
61 '''
62
63 _logger_text = "%s: call to %s() ignored when running notebooks with the 'bokeh' command."
64
65 _origin = "Notebook"
66
67 def __init__(self, *args, **kwargs):
68 '''
69
70 Keywords:
71 filename (str) : a path to a Jupyter notebook (".ipynb") file
72
73 '''
74 nbformat = import_required('nbformat', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')
75 nbconvert = import_required('nbconvert', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')
76
77 if 'filename' not in kwargs:
78 raise ValueError('Must pass a filename to NotebookHandler')
79
80
81 class StripMagicsProcessor(nbconvert.preprocessors.Preprocessor):
82 """
83 Preprocessor to convert notebooks to Python source while stripping
84 out all magics (i.e IPython specific syntax).
85 """
86
87 _magic_pattern = re.compile(r'^\s*(?P<magic>%%\w\w+)($|(\s+))')
88
89 def strip_magics(self, source):
90 """
91 Given the source of a cell, filter out all cell and line magics.
92 """
93 filtered=[]
94 for line in source.splitlines():
95 match = self._magic_pattern.match(line)
96 if match is None:
97 filtered.append(line)
98 else:
99 msg = 'Stripping out IPython magic {magic} in code cell {cell}'
100 message = msg.format(cell=self._cell_counter, magic=match.group('magic'))
101 log.warning(message)
102 return '\n'.join(filtered)
103
104 def preprocess_cell(self, cell, resources, index):
105 if cell['cell_type'] == 'code':
106 self._cell_counter += 1
107 cell['source'] = self.strip_magics(cell['source'])
108 return cell, resources
109
110 def __call__(self, nb, resources):
111 self._cell_counter = 0
112 return self.preprocess(nb,resources)
113
114 preprocessors=[StripMagicsProcessor()]
115 filename = kwargs['filename']
116
117 with open(filename) as f:
118 nb = nbformat.read(f, nbformat.NO_CONVERT)
119 exporter = nbconvert.PythonExporter()
120
121 for preprocessor in preprocessors:
122 exporter.register_preprocessor(preprocessor)
123
124 source, _ = exporter.from_notebook_node(nb)
125 source = source.replace('get_ipython().run_line_magic', '')
126 source = source.replace('get_ipython().magic', '')
127
128 if sys.version_info.major == 2 and isinstance(source, unicode): # NOQA
129 source = source.encode('utf-8')
130 kwargs['source'] = source
131
132 super(NotebookHandler, self).__init__(*args, **kwargs)
133
134 #-----------------------------------------------------------------------------
135 # Private API
136 #-----------------------------------------------------------------------------
137
138 #-----------------------------------------------------------------------------
139 # Code
140 #-----------------------------------------------------------------------------
141
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bokeh/application/handlers/notebook.py b/bokeh/application/handlers/notebook.py
--- a/bokeh/application/handlers/notebook.py
+++ b/bokeh/application/handlers/notebook.py
@@ -21,8 +21,6 @@
#-----------------------------------------------------------------------------
from __future__ import absolute_import, division, print_function, unicode_literals
-import re
-import sys
import logging
log = logging.getLogger(__name__)
@@ -31,6 +29,9 @@
#-----------------------------------------------------------------------------
# Standard library imports
+import io
+import re
+import sys
# External imports
@@ -114,7 +115,7 @@
preprocessors=[StripMagicsProcessor()]
filename = kwargs['filename']
- with open(filename) as f:
+ with io.open(filename, encoding="utf-8") as f:
nb = nbformat.read(f, nbformat.NO_CONVERT)
exporter = nbconvert.PythonExporter()
|
{"golden_diff": "diff --git a/bokeh/application/handlers/notebook.py b/bokeh/application/handlers/notebook.py\n--- a/bokeh/application/handlers/notebook.py\n+++ b/bokeh/application/handlers/notebook.py\n@@ -21,8 +21,6 @@\n #-----------------------------------------------------------------------------\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n-import re\n-import sys\n import logging\n log = logging.getLogger(__name__)\n \n@@ -31,6 +29,9 @@\n #-----------------------------------------------------------------------------\n \n # Standard library imports\n+import io\n+import re\n+import sys\n \n # External imports\n \n@@ -114,7 +115,7 @@\n preprocessors=[StripMagicsProcessor()]\n filename = kwargs['filename']\n \n- with open(filename) as f:\n+ with io.open(filename, encoding=\"utf-8\") as f:\n nb = nbformat.read(f, nbformat.NO_CONVERT)\n exporter = nbconvert.PythonExporter()\n", "issue": "Use utf-8 encoding to open notebook file.\nCurrently, `ipynb` file is opened by following code:\r\n\r\n```\r\n with open(filename) as f:\r\n pass\r\n```\r\n\r\nhttps://github.com/bokeh/bokeh/blob/master/bokeh/application/handlers/notebook.py#L117\r\n\r\nI suggest to open the file with `encoding=\"utf-8\"`, otherwise the serve command will raise error on Windows system.\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Provide a Bokeh Application Handler to build up documents by running\nthe code from Jupyter notebook (``.ipynb``) files.\n\nThis handler is configured with the filename of a Jupyter notebook. When a\nBokeh application calls ``modify_doc``, the code from all the notebook cells\nis collected and executed to process a new Document for a session. When the\nnotebook code is executed, the Document being modified will be available as\n``curdoc``, and any optionally provided ``args`` will be available as\n``sys.argv``.\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport re\nimport sys\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\n# Standard library imports\n\n# External imports\n\n# Bokeh imports\nfrom ...util.dependencies import import_required\nfrom .code import CodeHandler\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\n__all__ = (\n 'NotebookHandler',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\nclass NotebookHandler(CodeHandler):\n ''' A Handler that uses code in a Jupyter notebook for modifying Bokeh\n Documents.\n\n '''\n\n _logger_text = \"%s: call to %s() ignored when running notebooks with the 'bokeh' command.\"\n\n _origin = \"Notebook\"\n\n def __init__(self, *args, **kwargs):\n '''\n\n Keywords:\n filename (str) : a path to a Jupyter notebook (\".ipynb\") file\n\n '''\n nbformat = import_required('nbformat', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')\n nbconvert = import_required('nbconvert', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')\n\n if 'filename' not in kwargs:\n raise ValueError('Must pass a filename to NotebookHandler')\n\n\n class StripMagicsProcessor(nbconvert.preprocessors.Preprocessor):\n \"\"\"\n Preprocessor to convert notebooks to Python source while stripping\n out all magics (i.e IPython specific syntax).\n \"\"\"\n\n _magic_pattern = re.compile(r'^\\s*(?P<magic>%%\\w\\w+)($|(\\s+))')\n\n def strip_magics(self, source):\n \"\"\"\n Given the source of a cell, filter out all cell and line magics.\n \"\"\"\n filtered=[]\n for line in source.splitlines():\n match = self._magic_pattern.match(line)\n if match is None:\n filtered.append(line)\n else:\n msg = 'Stripping out IPython magic {magic} in code cell {cell}'\n message = msg.format(cell=self._cell_counter, magic=match.group('magic'))\n log.warning(message)\n return '\\n'.join(filtered)\n\n def preprocess_cell(self, cell, resources, index):\n if cell['cell_type'] == 'code':\n self._cell_counter += 1\n cell['source'] = self.strip_magics(cell['source'])\n return cell, resources\n\n def __call__(self, nb, resources):\n self._cell_counter = 0\n return self.preprocess(nb,resources)\n\n preprocessors=[StripMagicsProcessor()]\n filename = kwargs['filename']\n\n with open(filename) as f:\n nb = nbformat.read(f, nbformat.NO_CONVERT)\n exporter = nbconvert.PythonExporter()\n\n for preprocessor in preprocessors:\n exporter.register_preprocessor(preprocessor)\n\n source, _ = exporter.from_notebook_node(nb)\n source = source.replace('get_ipython().run_line_magic', '')\n source = source.replace('get_ipython().magic', '')\n\n if sys.version_info.major == 2 and isinstance(source, unicode): # NOQA\n source = source.encode('utf-8')\n kwargs['source'] = source\n\n super(NotebookHandler, self).__init__(*args, **kwargs)\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n", "path": "bokeh/application/handlers/notebook.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2019, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n''' Provide a Bokeh Application Handler to build up documents by running\nthe code from Jupyter notebook (``.ipynb``) files.\n\nThis handler is configured with the filename of a Jupyter notebook. When a\nBokeh application calls ``modify_doc``, the code from all the notebook cells\nis collected and executed to process a new Document for a session. When the\nnotebook code is executed, the Document being modified will be available as\n``curdoc``, and any optionally provided ``args`` will be available as\n``sys.argv``.\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\n# Standard library imports\nimport io\nimport re\nimport sys\n\n# External imports\n\n# Bokeh imports\nfrom ...util.dependencies import import_required\nfrom .code import CodeHandler\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\n__all__ = (\n 'NotebookHandler',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\nclass NotebookHandler(CodeHandler):\n ''' A Handler that uses code in a Jupyter notebook for modifying Bokeh\n Documents.\n\n '''\n\n _logger_text = \"%s: call to %s() ignored when running notebooks with the 'bokeh' command.\"\n\n _origin = \"Notebook\"\n\n def __init__(self, *args, **kwargs):\n '''\n\n Keywords:\n filename (str) : a path to a Jupyter notebook (\".ipynb\") file\n\n '''\n nbformat = import_required('nbformat', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')\n nbconvert = import_required('nbconvert', 'The Bokeh notebook application handler requires Jupyter Notebook to be installed.')\n\n if 'filename' not in kwargs:\n raise ValueError('Must pass a filename to NotebookHandler')\n\n\n class StripMagicsProcessor(nbconvert.preprocessors.Preprocessor):\n \"\"\"\n Preprocessor to convert notebooks to Python source while stripping\n out all magics (i.e IPython specific syntax).\n \"\"\"\n\n _magic_pattern = re.compile(r'^\\s*(?P<magic>%%\\w\\w+)($|(\\s+))')\n\n def strip_magics(self, source):\n \"\"\"\n Given the source of a cell, filter out all cell and line magics.\n \"\"\"\n filtered=[]\n for line in source.splitlines():\n match = self._magic_pattern.match(line)\n if match is None:\n filtered.append(line)\n else:\n msg = 'Stripping out IPython magic {magic} in code cell {cell}'\n message = msg.format(cell=self._cell_counter, magic=match.group('magic'))\n log.warning(message)\n return '\\n'.join(filtered)\n\n def preprocess_cell(self, cell, resources, index):\n if cell['cell_type'] == 'code':\n self._cell_counter += 1\n cell['source'] = self.strip_magics(cell['source'])\n return cell, resources\n\n def __call__(self, nb, resources):\n self._cell_counter = 0\n return self.preprocess(nb,resources)\n\n preprocessors=[StripMagicsProcessor()]\n filename = kwargs['filename']\n\n with io.open(filename, encoding=\"utf-8\") as f:\n nb = nbformat.read(f, nbformat.NO_CONVERT)\n exporter = nbconvert.PythonExporter()\n\n for preprocessor in preprocessors:\n exporter.register_preprocessor(preprocessor)\n\n source, _ = exporter.from_notebook_node(nb)\n source = source.replace('get_ipython().run_line_magic', '')\n source = source.replace('get_ipython().magic', '')\n\n if sys.version_info.major == 2 and isinstance(source, unicode): # NOQA\n source = source.encode('utf-8')\n kwargs['source'] = source\n\n super(NotebookHandler, self).__init__(*args, **kwargs)\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n", "path": "bokeh/application/handlers/notebook.py"}]}
| 1,614 | 219 |
gh_patches_debug_22999
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-924
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add verifier property to Events
Soon users will have multiple pathways to verify eligibility, and it would be useful to know how many users are taking which pathway(s) in our analytics. We can get ahead of this now by adding an event property with the user's selected verifier (if any).
Let's add this to the base Event definition so that we can later filter any event type by this property, similar to the Transit Agency information attached to each event.
Linking this Amplitude reference again: https://help.amplitude.com/hc/en-us/articles/115002380567-User-properties-and-event-properties
## Acceptance Criteria
<!-- Remember to consider edge cases -->
- [ ] The base Event has an `eligibility_verifier` event property that gets its value from the user's `session.verifier()`
- [ ] The Amplitude Tracking Plan is updated to accept this event property
- [ ] The Amplitude --> Warehouse --> Metabase pipeline is updated to ingest this property
## Additional context
This task was broken out from #342 and is focused on adding the verifier information to _existing_ events. #342 is now focused on introducing _new_ events for some forthcoming UI.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/core/analytics.py`
Content:
```
1 """
2 The core application: analytics implementation.
3 """
4 import itertools
5 import json
6 import logging
7 import re
8 import time
9 import uuid
10
11 from django.conf import settings
12 import requests
13
14 from benefits import VERSION
15 from . import session
16
17
18 logger = logging.getLogger(__name__)
19
20
21 class Event:
22 """Base analytics event of a given type, including attributes from request's session."""
23
24 _counter = itertools.count()
25 _domain_re = re.compile(r"^(?:https?:\/\/)?(?:[^@\n]+@)?(?:www\.)?([^:\/\n?]+)", re.IGNORECASE)
26
27 def __init__(self, request, event_type, **kwargs):
28 self.app_version = VERSION
29 # device_id is generated based on the user_id, and both are set explicitly (per session)
30 self.device_id = session.did(request)
31 self.event_properties = {}
32 self.event_type = str(event_type).lower()
33 self.insert_id = str(uuid.uuid4())
34 self.language = session.language(request)
35 # Amplitude tracks sessions using the start time as the session_id
36 self.session_id = session.start(request)
37 self.time = int(time.time() * 1000)
38 # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous
39 # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.
40 self.user_id = session.uid(request)
41 self.user_properties = {}
42 self.__dict__.update(kwargs)
43
44 agency = session.agency(request)
45 agency_name = agency.long_name if agency else None
46
47 self.update_event_properties(path=request.path, transit_agency=agency_name)
48
49 uagent = request.headers.get("user-agent")
50
51 ref = request.headers.get("referer")
52 match = Event._domain_re.match(ref) if ref else None
53 refdom = match.group(1) if match else None
54
55 self.update_user_properties(referrer=ref, referring_domain=refdom, user_agent=uagent, transit_agency=agency_name)
56
57 # event is initialized, consume next counter
58 self.event_id = next(Event._counter)
59
60 def __str__(self):
61 return json.dumps(self.__dict__)
62
63 def update_event_properties(self, **kwargs):
64 """Merge kwargs into the self.event_properties dict."""
65 self.event_properties.update(kwargs)
66
67 def update_user_properties(self, **kwargs):
68 """Merge kwargs into the self.user_properties dict."""
69 self.user_properties.update(kwargs)
70
71
72 class ViewedPageEvent(Event):
73 """Analytics event representing a single page view."""
74
75 def __init__(self, request):
76 super().__init__(request, "viewed page")
77
78
79 class ChangedLanguageEvent(Event):
80 """Analytics event representing a change in the app's language."""
81
82 def __init__(self, request, new_lang):
83 super().__init__(request, "changed language")
84 self.update_event_properties(language=new_lang)
85
86
87 class Client:
88 """Analytics API client"""
89
90 def __init__(self, api_key):
91 self.api_key = api_key
92 self.headers = {"Accept": "*/*", "Content-type": "application/json"}
93 self.url = "https://api2.amplitude.com/2/httpapi"
94 logger.debug(f"Initialize Client for {self.url}")
95
96 def _payload(self, events):
97 if not isinstance(events, list):
98 events = [events]
99 return {"api_key": self.api_key, "events": [e.__dict__ for e in events]}
100
101 def send(self, event):
102 """Send an analytics event."""
103 if not isinstance(event, Event):
104 raise ValueError("event must be an Event instance")
105
106 if not self.api_key:
107 logger.warning(f"api_key is not configured, cannot send event: {event}")
108 return
109
110 try:
111 payload = self._payload(event)
112 logger.debug(f"Sending event payload: {payload}")
113
114 r = requests.post(self.url, headers=self.headers, json=payload)
115 if r.status_code == 200:
116 logger.debug(f"Event sent successfully: {r.json()}")
117 elif r.status_code == 400:
118 logger.error(f"Event request was invalid: {r.json()}")
119 elif r.status_code == 413:
120 logger.error(f"Event payload was too large: {r.json()}")
121 elif r.status_code == 429:
122 logger.error(f"Event contained too many requests for some users: {r.json()}")
123 else:
124 logger.error(f"Failed to send event: {r.json()}")
125
126 except Exception:
127 logger.error(f"Failed to send event: {event}")
128
129
130 client = Client(settings.ANALYTICS_KEY)
131
132
133 def send_event(event):
134 """Send an analytics event."""
135 if isinstance(event, Event):
136 client.send(event)
137 else:
138 raise ValueError("event must be an Event instance")
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/benefits/core/analytics.py b/benefits/core/analytics.py
--- a/benefits/core/analytics.py
+++ b/benefits/core/analytics.py
@@ -43,8 +43,10 @@
agency = session.agency(request)
agency_name = agency.long_name if agency else None
+ verifier = session.verifier(request)
+ verifier_name = verifier.name if verifier else None
- self.update_event_properties(path=request.path, transit_agency=agency_name)
+ self.update_event_properties(path=request.path, transit_agency=agency_name, eligibility_verifier=verifier_name)
uagent = request.headers.get("user-agent")
@@ -52,7 +54,13 @@
match = Event._domain_re.match(ref) if ref else None
refdom = match.group(1) if match else None
- self.update_user_properties(referrer=ref, referring_domain=refdom, user_agent=uagent, transit_agency=agency_name)
+ self.update_user_properties(
+ referrer=ref,
+ referring_domain=refdom,
+ user_agent=uagent,
+ transit_agency=agency_name,
+ eligibility_verifier=verifier_name,
+ )
# event is initialized, consume next counter
self.event_id = next(Event._counter)
|
{"golden_diff": "diff --git a/benefits/core/analytics.py b/benefits/core/analytics.py\n--- a/benefits/core/analytics.py\n+++ b/benefits/core/analytics.py\n@@ -43,8 +43,10 @@\n \n agency = session.agency(request)\n agency_name = agency.long_name if agency else None\n+ verifier = session.verifier(request)\n+ verifier_name = verifier.name if verifier else None\n \n- self.update_event_properties(path=request.path, transit_agency=agency_name)\n+ self.update_event_properties(path=request.path, transit_agency=agency_name, eligibility_verifier=verifier_name)\n \n uagent = request.headers.get(\"user-agent\")\n \n@@ -52,7 +54,13 @@\n match = Event._domain_re.match(ref) if ref else None\n refdom = match.group(1) if match else None\n \n- self.update_user_properties(referrer=ref, referring_domain=refdom, user_agent=uagent, transit_agency=agency_name)\n+ self.update_user_properties(\n+ referrer=ref,\n+ referring_domain=refdom,\n+ user_agent=uagent,\n+ transit_agency=agency_name,\n+ eligibility_verifier=verifier_name,\n+ )\n \n # event is initialized, consume next counter\n self.event_id = next(Event._counter)\n", "issue": "Add verifier property to Events\nSoon users will have multiple pathways to verify eligibility, and it would be useful to know how many users are taking which pathway(s) in our analytics. We can get ahead of this now by adding an event property with the user's selected verifier (if any).\r\n\r\nLet's add this to the base Event definition so that we can later filter any event type by this property, similar to the Transit Agency information attached to each event.\r\n\r\nLinking this Amplitude reference again: https://help.amplitude.com/hc/en-us/articles/115002380567-User-properties-and-event-properties\r\n\r\n## Acceptance Criteria\r\n\r\n<!-- Remember to consider edge cases -->\r\n\r\n- [ ] The base Event has an `eligibility_verifier` event property that gets its value from the user's `session.verifier()`\r\n- [ ] The Amplitude Tracking Plan is updated to accept this event property\r\n- [ ] The Amplitude --> Warehouse --> Metabase pipeline is updated to ingest this property\r\n\r\n## Additional context\r\n\r\nThis task was broken out from #342 and is focused on adding the verifier information to _existing_ events. #342 is now focused on introducing _new_ events for some forthcoming UI.\r\n\n", "before_files": [{"content": "\"\"\"\nThe core application: analytics implementation.\n\"\"\"\nimport itertools\nimport json\nimport logging\nimport re\nimport time\nimport uuid\n\nfrom django.conf import settings\nimport requests\n\nfrom benefits import VERSION\nfrom . import session\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Event:\n \"\"\"Base analytics event of a given type, including attributes from request's session.\"\"\"\n\n _counter = itertools.count()\n _domain_re = re.compile(r\"^(?:https?:\\/\\/)?(?:[^@\\n]+@)?(?:www\\.)?([^:\\/\\n?]+)\", re.IGNORECASE)\n\n def __init__(self, request, event_type, **kwargs):\n self.app_version = VERSION\n # device_id is generated based on the user_id, and both are set explicitly (per session)\n self.device_id = session.did(request)\n self.event_properties = {}\n self.event_type = str(event_type).lower()\n self.insert_id = str(uuid.uuid4())\n self.language = session.language(request)\n # Amplitude tracks sessions using the start time as the session_id\n self.session_id = session.start(request)\n self.time = int(time.time() * 1000)\n # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous\n # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.\n self.user_id = session.uid(request)\n self.user_properties = {}\n self.__dict__.update(kwargs)\n\n agency = session.agency(request)\n agency_name = agency.long_name if agency else None\n\n self.update_event_properties(path=request.path, transit_agency=agency_name)\n\n uagent = request.headers.get(\"user-agent\")\n\n ref = request.headers.get(\"referer\")\n match = Event._domain_re.match(ref) if ref else None\n refdom = match.group(1) if match else None\n\n self.update_user_properties(referrer=ref, referring_domain=refdom, user_agent=uagent, transit_agency=agency_name)\n\n # event is initialized, consume next counter\n self.event_id = next(Event._counter)\n\n def __str__(self):\n return json.dumps(self.__dict__)\n\n def update_event_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.event_properties dict.\"\"\"\n self.event_properties.update(kwargs)\n\n def update_user_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.user_properties dict.\"\"\"\n self.user_properties.update(kwargs)\n\n\nclass ViewedPageEvent(Event):\n \"\"\"Analytics event representing a single page view.\"\"\"\n\n def __init__(self, request):\n super().__init__(request, \"viewed page\")\n\n\nclass ChangedLanguageEvent(Event):\n \"\"\"Analytics event representing a change in the app's language.\"\"\"\n\n def __init__(self, request, new_lang):\n super().__init__(request, \"changed language\")\n self.update_event_properties(language=new_lang)\n\n\nclass Client:\n \"\"\"Analytics API client\"\"\"\n\n def __init__(self, api_key):\n self.api_key = api_key\n self.headers = {\"Accept\": \"*/*\", \"Content-type\": \"application/json\"}\n self.url = \"https://api2.amplitude.com/2/httpapi\"\n logger.debug(f\"Initialize Client for {self.url}\")\n\n def _payload(self, events):\n if not isinstance(events, list):\n events = [events]\n return {\"api_key\": self.api_key, \"events\": [e.__dict__ for e in events]}\n\n def send(self, event):\n \"\"\"Send an analytics event.\"\"\"\n if not isinstance(event, Event):\n raise ValueError(\"event must be an Event instance\")\n\n if not self.api_key:\n logger.warning(f\"api_key is not configured, cannot send event: {event}\")\n return\n\n try:\n payload = self._payload(event)\n logger.debug(f\"Sending event payload: {payload}\")\n\n r = requests.post(self.url, headers=self.headers, json=payload)\n if r.status_code == 200:\n logger.debug(f\"Event sent successfully: {r.json()}\")\n elif r.status_code == 400:\n logger.error(f\"Event request was invalid: {r.json()}\")\n elif r.status_code == 413:\n logger.error(f\"Event payload was too large: {r.json()}\")\n elif r.status_code == 429:\n logger.error(f\"Event contained too many requests for some users: {r.json()}\")\n else:\n logger.error(f\"Failed to send event: {r.json()}\")\n\n except Exception:\n logger.error(f\"Failed to send event: {event}\")\n\n\nclient = Client(settings.ANALYTICS_KEY)\n\n\ndef send_event(event):\n \"\"\"Send an analytics event.\"\"\"\n if isinstance(event, Event):\n client.send(event)\n else:\n raise ValueError(\"event must be an Event instance\")\n", "path": "benefits/core/analytics.py"}], "after_files": [{"content": "\"\"\"\nThe core application: analytics implementation.\n\"\"\"\nimport itertools\nimport json\nimport logging\nimport re\nimport time\nimport uuid\n\nfrom django.conf import settings\nimport requests\n\nfrom benefits import VERSION\nfrom . import session\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Event:\n \"\"\"Base analytics event of a given type, including attributes from request's session.\"\"\"\n\n _counter = itertools.count()\n _domain_re = re.compile(r\"^(?:https?:\\/\\/)?(?:[^@\\n]+@)?(?:www\\.)?([^:\\/\\n?]+)\", re.IGNORECASE)\n\n def __init__(self, request, event_type, **kwargs):\n self.app_version = VERSION\n # device_id is generated based on the user_id, and both are set explicitly (per session)\n self.device_id = session.did(request)\n self.event_properties = {}\n self.event_type = str(event_type).lower()\n self.insert_id = str(uuid.uuid4())\n self.language = session.language(request)\n # Amplitude tracks sessions using the start time as the session_id\n self.session_id = session.start(request)\n self.time = int(time.time() * 1000)\n # Although Amplitude advises *against* setting user_id for anonymous users, here a value is set on anonymous\n # users anyway, as the users never sign-in and become de-anonymized to this app / Amplitude.\n self.user_id = session.uid(request)\n self.user_properties = {}\n self.__dict__.update(kwargs)\n\n agency = session.agency(request)\n agency_name = agency.long_name if agency else None\n verifier = session.verifier(request)\n verifier_name = verifier.name if verifier else None\n\n self.update_event_properties(path=request.path, transit_agency=agency_name, eligibility_verifier=verifier_name)\n\n uagent = request.headers.get(\"user-agent\")\n\n ref = request.headers.get(\"referer\")\n match = Event._domain_re.match(ref) if ref else None\n refdom = match.group(1) if match else None\n\n self.update_user_properties(\n referrer=ref,\n referring_domain=refdom,\n user_agent=uagent,\n transit_agency=agency_name,\n eligibility_verifier=verifier_name,\n )\n\n # event is initialized, consume next counter\n self.event_id = next(Event._counter)\n\n def __str__(self):\n return json.dumps(self.__dict__)\n\n def update_event_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.event_properties dict.\"\"\"\n self.event_properties.update(kwargs)\n\n def update_user_properties(self, **kwargs):\n \"\"\"Merge kwargs into the self.user_properties dict.\"\"\"\n self.user_properties.update(kwargs)\n\n\nclass ViewedPageEvent(Event):\n \"\"\"Analytics event representing a single page view.\"\"\"\n\n def __init__(self, request):\n super().__init__(request, \"viewed page\")\n\n\nclass ChangedLanguageEvent(Event):\n \"\"\"Analytics event representing a change in the app's language.\"\"\"\n\n def __init__(self, request, new_lang):\n super().__init__(request, \"changed language\")\n self.update_event_properties(language=new_lang)\n\n\nclass Client:\n \"\"\"Analytics API client\"\"\"\n\n def __init__(self, api_key):\n self.api_key = api_key\n self.headers = {\"Accept\": \"*/*\", \"Content-type\": \"application/json\"}\n self.url = \"https://api2.amplitude.com/2/httpapi\"\n logger.debug(f\"Initialize Client for {self.url}\")\n\n def _payload(self, events):\n if not isinstance(events, list):\n events = [events]\n return {\"api_key\": self.api_key, \"events\": [e.__dict__ for e in events]}\n\n def send(self, event):\n \"\"\"Send an analytics event.\"\"\"\n if not isinstance(event, Event):\n raise ValueError(\"event must be an Event instance\")\n\n if not self.api_key:\n logger.warning(f\"api_key is not configured, cannot send event: {event}\")\n return\n\n try:\n payload = self._payload(event)\n logger.debug(f\"Sending event payload: {payload}\")\n\n r = requests.post(self.url, headers=self.headers, json=payload)\n if r.status_code == 200:\n logger.debug(f\"Event sent successfully: {r.json()}\")\n elif r.status_code == 400:\n logger.error(f\"Event request was invalid: {r.json()}\")\n elif r.status_code == 413:\n logger.error(f\"Event payload was too large: {r.json()}\")\n elif r.status_code == 429:\n logger.error(f\"Event contained too many requests for some users: {r.json()}\")\n else:\n logger.error(f\"Failed to send event: {r.json()}\")\n\n except Exception:\n logger.error(f\"Failed to send event: {event}\")\n\n\nclient = Client(settings.ANALYTICS_KEY)\n\n\ndef send_event(event):\n \"\"\"Send an analytics event.\"\"\"\n if isinstance(event, Event):\n client.send(event)\n else:\n raise ValueError(\"event must be an Event instance\")\n", "path": "benefits/core/analytics.py"}]}
| 1,881 | 293 |
gh_patches_debug_6925
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-2205
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Result of query with same column names with return different column names
Issue exists for any 'internal' tables. If query multiple columns with same name:
```
select 1 as "a", 1 as "a" from information_schema.tables limit 1;
```
then result will be:
```
+------+------+
| a | a_2 |
+------+------+
| 1 | 1 |
+------+------+
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mindsdb/api/mysql/mysql_proxy/utilities/sql.py`
Content:
```
1 import duckdb
2 import numpy as np
3 from mindsdb_sql import parse_sql
4 from mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy
5 from mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender
6
7 from mindsdb.utilities.log import log
8
9
10 def _remove_table_name(root):
11 if isinstance(root, BinaryOperation):
12 _remove_table_name(root.args[0])
13 _remove_table_name(root.args[1])
14 elif isinstance(root, Identifier):
15 root.parts = [root.parts[-1]]
16
17
18 def query_df(df, query):
19 """ Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.
20
21 Args:
22 df (pandas.DataFrame): data
23 query (mindsdb_sql.parser.ast.Select | str): select query
24
25 Returns:
26 pandas.DataFrame
27 """
28
29 if isinstance(query, str):
30 query_ast = parse_sql(query, dialect='mysql')
31 else:
32 query_ast = query
33
34 if isinstance(query_ast, Select) is False or isinstance(query_ast.from_table, Identifier) is False:
35 raise Exception("Only 'SELECT from TABLE' statements supported for internal query")
36
37 query_ast.from_table.parts = ['df_table']
38 for identifier in query_ast.targets:
39 if isinstance(identifier, Identifier):
40 identifier.parts = [identifier.parts[-1]]
41 if isinstance(query_ast.order_by, list):
42 for orderby in query_ast.order_by:
43 if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):
44 orderby.field.parts = [orderby.field.parts[-1]]
45 _remove_table_name(query_ast.where)
46
47 render = SqlalchemyRender('postgres')
48 try:
49 query_str = render.get_string(query_ast, with_failback=False)
50 except Exception as e:
51 log.error(f"Exception during query casting to 'postgres' dialect. Query: {str(query)}. Error: {e}")
52 query_str = render.get_string(query_ast, with_failback=True)
53
54 res = duckdb.query_df(df, 'df_table', query_str)
55 result_df = res.df()
56 result_df = result_df.replace({np.nan: None})
57 return result_df
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
--- a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
+++ b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py
@@ -54,4 +54,13 @@
res = duckdb.query_df(df, 'df_table', query_str)
result_df = res.df()
result_df = result_df.replace({np.nan: None})
+
+ new_column_names = {}
+ real_column_names = [x[0] for x in res.description()]
+ for i, duck_column_name in enumerate(result_df.columns):
+ new_column_names[duck_column_name] = real_column_names[i]
+ result_df = result_df.rename(
+ new_column_names,
+ axis='columns'
+ )
return result_df
|
{"golden_diff": "diff --git a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n--- a/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n+++ b/mindsdb/api/mysql/mysql_proxy/utilities/sql.py\n@@ -54,4 +54,13 @@\n res = duckdb.query_df(df, 'df_table', query_str)\n result_df = res.df()\n result_df = result_df.replace({np.nan: None})\n+\n+ new_column_names = {}\n+ real_column_names = [x[0] for x in res.description()]\n+ for i, duck_column_name in enumerate(result_df.columns):\n+ new_column_names[duck_column_name] = real_column_names[i]\n+ result_df = result_df.rename(\n+ new_column_names,\n+ axis='columns'\n+ )\n return result_df\n", "issue": "Result of query with same column names with return different column names\nIssue exists for any 'internal' tables. If query multiple columns with same name:\r\n```\r\nselect 1 as \"a\", 1 as \"a\" from information_schema.tables limit 1;\r\n```\r\nthen result will be:\r\n```\r\n+------+------+\r\n| a | a_2 |\r\n+------+------+\r\n| 1 | 1 |\r\n+------+------+\r\n```\n", "before_files": [{"content": "import duckdb\nimport numpy as np\nfrom mindsdb_sql import parse_sql\nfrom mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy\nfrom mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n\nfrom mindsdb.utilities.log import log\n\n\ndef _remove_table_name(root):\n if isinstance(root, BinaryOperation):\n _remove_table_name(root.args[0])\n _remove_table_name(root.args[1])\n elif isinstance(root, Identifier):\n root.parts = [root.parts[-1]]\n\n\ndef query_df(df, query):\n \"\"\" Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.\n\n Args:\n df (pandas.DataFrame): data\n query (mindsdb_sql.parser.ast.Select | str): select query\n\n Returns:\n pandas.DataFrame\n \"\"\"\n\n if isinstance(query, str):\n query_ast = parse_sql(query, dialect='mysql')\n else:\n query_ast = query\n\n if isinstance(query_ast, Select) is False or isinstance(query_ast.from_table, Identifier) is False:\n raise Exception(\"Only 'SELECT from TABLE' statements supported for internal query\")\n\n query_ast.from_table.parts = ['df_table']\n for identifier in query_ast.targets:\n if isinstance(identifier, Identifier):\n identifier.parts = [identifier.parts[-1]]\n if isinstance(query_ast.order_by, list):\n for orderby in query_ast.order_by:\n if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):\n orderby.field.parts = [orderby.field.parts[-1]]\n _remove_table_name(query_ast.where)\n\n render = SqlalchemyRender('postgres')\n try:\n query_str = render.get_string(query_ast, with_failback=False)\n except Exception as e:\n log.error(f\"Exception during query casting to 'postgres' dialect. Query: {str(query)}. Error: {e}\")\n query_str = render.get_string(query_ast, with_failback=True)\n\n res = duckdb.query_df(df, 'df_table', query_str)\n result_df = res.df()\n result_df = result_df.replace({np.nan: None})\n return result_df\n", "path": "mindsdb/api/mysql/mysql_proxy/utilities/sql.py"}], "after_files": [{"content": "import duckdb\nimport numpy as np\nfrom mindsdb_sql import parse_sql\nfrom mindsdb_sql.parser.ast import Select, Identifier, BinaryOperation, OrderBy\nfrom mindsdb_sql.render.sqlalchemy_render import SqlalchemyRender\n\nfrom mindsdb.utilities.log import log\n\n\ndef _remove_table_name(root):\n if isinstance(root, BinaryOperation):\n _remove_table_name(root.args[0])\n _remove_table_name(root.args[1])\n elif isinstance(root, Identifier):\n root.parts = [root.parts[-1]]\n\n\ndef query_df(df, query):\n \"\"\" Perform simple query ('select' from one table, without subqueries and joins) on DataFrame.\n\n Args:\n df (pandas.DataFrame): data\n query (mindsdb_sql.parser.ast.Select | str): select query\n\n Returns:\n pandas.DataFrame\n \"\"\"\n\n if isinstance(query, str):\n query_ast = parse_sql(query, dialect='mysql')\n else:\n query_ast = query\n\n if isinstance(query_ast, Select) is False or isinstance(query_ast.from_table, Identifier) is False:\n raise Exception(\"Only 'SELECT from TABLE' statements supported for internal query\")\n\n query_ast.from_table.parts = ['df_table']\n for identifier in query_ast.targets:\n if isinstance(identifier, Identifier):\n identifier.parts = [identifier.parts[-1]]\n if isinstance(query_ast.order_by, list):\n for orderby in query_ast.order_by:\n if isinstance(orderby, OrderBy) and isinstance(orderby.field, Identifier):\n orderby.field.parts = [orderby.field.parts[-1]]\n _remove_table_name(query_ast.where)\n\n render = SqlalchemyRender('postgres')\n try:\n query_str = render.get_string(query_ast, with_failback=False)\n except Exception as e:\n log.error(f\"Exception during query casting to 'postgres' dialect. Query: {str(query)}. Error: {e}\")\n query_str = render.get_string(query_ast, with_failback=True)\n\n res = duckdb.query_df(df, 'df_table', query_str)\n result_df = res.df()\n result_df = result_df.replace({np.nan: None})\n\n new_column_names = {}\n real_column_names = [x[0] for x in res.description()]\n for i, duck_column_name in enumerate(result_df.columns):\n new_column_names[duck_column_name] = real_column_names[i]\n result_df = result_df.rename(\n new_column_names,\n axis='columns'\n )\n return result_df\n", "path": "mindsdb/api/mysql/mysql_proxy/utilities/sql.py"}]}
| 921 | 189 |
gh_patches_debug_53374
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-7561
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support ellipsis in `Array::At` and `__getitem__`
Depends on #7559 because `py::ellipsis` is supported from v2.3.0.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainerx/_fallback_workarounds.py`
Content:
```
1 # This file defines workaround implementation for
2 # NumPy-compatibility functions that fall back to NumPy/CuPy functions
3 # for native/cuda devices respecitvely.
4 # The workaround does not support backprop, and also requires external
5 # libraries mentioned above.
6 # Functions defined in this file should be considered to have high priority for
7 # genuine implementations.
8 import numpy
9
10 import chainerx
11
12
13 try:
14 import cupy
15 except Exception:
16 cupy = None
17
18
19 class _DummyContext:
20 def __enter__(self):
21 pass
22
23 def __exit__(self, type, value, traceback):
24 pass
25
26
27 _dummy_context = _DummyContext()
28
29
30 def _to_numpy(array):
31 assert isinstance(array, chainerx.ndarray)
32 return chainerx.to_numpy(array, copy=False)
33
34
35 def _from_numpy(array):
36 assert isinstance(array, numpy.ndarray)
37 return chainerx.array(array, copy=False)
38
39
40 def _to_cupy(array):
41 assert cupy is not None
42 # Convert to cupy.ndarray on the same device as source array
43 return chainerx._to_cupy(array)
44
45
46 def _from_cupy(array):
47 assert cupy is not None
48 assert isinstance(array, cupy.ndarray)
49 device = chainerx.get_device('cuda', array.device.id)
50 return chainerx._core._fromrawpointer(
51 array.data.mem.ptr,
52 array.shape,
53 array.dtype,
54 array.strides,
55 device,
56 array.data.ptr - array.data.mem.ptr,
57 array)
58
59
60 def _from_chx(array, check_backprop=True):
61 # Converts chainerx.ndarray to numpy/cupy.ndarray.
62 # Objects with other types are kept intact.
63 # Returns a pair: (xp, cupy device or dummy context, numpy/cupy.ndarray).
64 if not isinstance(array, chainerx.ndarray):
65 if (isinstance(array, numpy.ndarray)
66 or (cupy and isinstance(array, cupy.ndarray))):
67 raise TypeError(
68 'ChainerX function fallback using NumPy/CuPy arrays '
69 'is not supported.')
70 # _from_chx is also called for slice and tuple objects
71 # Used to index a chx array
72 return None, _dummy_context, array
73 if check_backprop and array.is_backprop_required():
74 raise RuntimeError(
75 'ChainerX function fallback using NumPy/CuPy is not '
76 'supported for arrays that are connected to a graph.')
77 backend_name = array.device.backend.name
78 if backend_name == 'native':
79 return numpy, _dummy_context, _to_numpy(array)
80 if backend_name == 'cuda':
81 if cupy is None:
82 raise RuntimeError(
83 'ChainerX fallback implementation for cuda backend requires '
84 'cupy to be installed.')
85 array_cupy = _to_cupy(array)
86 return cupy, array_cupy.device, array_cupy
87 raise RuntimeError(
88 'ChainerX fallback implementation only supports native or cuda '
89 'backends.')
90
91
92 def _to_chx(array):
93 # Converts numpy/cupy.ndarray to chainerx.ndarray.
94 # Objects with other types are kept intact.
95 if isinstance(array, numpy.ndarray):
96 return _from_numpy(array)
97 elif cupy is not None and isinstance(array, cupy.ndarray):
98 return _from_cupy(array)
99 return array
100
101
102 def _populate_module_functions():
103
104 def _fix(arr):
105 xp, dev, arr = _from_chx(arr)
106 with dev:
107 ret = xp.fix(arr)
108 ret = xp.asarray(ret)
109 return _to_chx(ret)
110
111 chainerx.fix = _fix
112
113
114 def _populate_ndarray():
115 ndarray = chainerx.ndarray
116
117 # __getitem__ with advanced indexing
118 old_getitem = ndarray.__getitem__
119
120 def __getitem__(arr, key):
121 try:
122 return old_getitem(arr, key)
123 except (IndexError, chainerx.DimensionError):
124 pass
125
126 is_backprop_required = arr.is_backprop_required()
127
128 xp, dev, arr = _from_chx(arr, check_backprop=False)
129 # The elements used for indexing the array might be
130 # also ChainerX arrays. _from_chx ignores
131 # other types and return them as-is
132 if isinstance(key, tuple):
133 key = tuple([_from_chx(k, check_backprop=False)[2] for k in key])
134 else:
135 _, _, key = _from_chx(key, check_backprop=False)
136
137 with dev:
138 ret = arr[key]
139
140 # Doing this check after the fallback __getitem__ because the error
141 # which caused the fallback might not be due to advanced indexing.
142 # In such case the fallback __getitem__ should also raise the error.
143
144 if is_backprop_required:
145 raise RuntimeError(
146 'ChainerX getitem fallback for advanced indexing is not '
147 'supported for arrays that are connected to a graph.')
148
149 return _to_chx(ret)
150
151 # __setitem__ with advanced indexing
152 def __setitem__(self, key, value):
153 if self.is_backprop_required():
154 raise RuntimeError(
155 'ChainerX setitem fallback for advanced indexing is not '
156 'supported for arrays that are connected to a graph.')
157
158 xp, dev, self = _from_chx(self)
159 if isinstance(key, tuple):
160 key = tuple([_from_chx(k)[2] for k in key])
161 else:
162 _, _, key = _from_chx(key)
163 _, _, value = _from_chx(value)
164
165 with dev:
166 self[key] = value
167
168 ndarray.__setitem__ = __setitem__
169 ndarray.__getitem__ = __getitem__
170
171 def tolist(arr):
172 _, dev, arr = _from_chx(arr)
173 with dev:
174 ret = arr.tolist()
175 return ret
176
177 ndarray.tolist = tolist
178
179
180 def populate():
181 _populate_module_functions()
182 _populate_ndarray()
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/chainerx/_fallback_workarounds.py b/chainerx/_fallback_workarounds.py
--- a/chainerx/_fallback_workarounds.py
+++ b/chainerx/_fallback_workarounds.py
@@ -118,10 +118,8 @@
old_getitem = ndarray.__getitem__
def __getitem__(arr, key):
- try:
+ if not isinstance(key, chainerx.ndarray):
return old_getitem(arr, key)
- except (IndexError, chainerx.DimensionError):
- pass
is_backprop_required = arr.is_backprop_required()
|
{"golden_diff": "diff --git a/chainerx/_fallback_workarounds.py b/chainerx/_fallback_workarounds.py\n--- a/chainerx/_fallback_workarounds.py\n+++ b/chainerx/_fallback_workarounds.py\n@@ -118,10 +118,8 @@\n old_getitem = ndarray.__getitem__\n \n def __getitem__(arr, key):\n- try:\n+ if not isinstance(key, chainerx.ndarray):\n return old_getitem(arr, key)\n- except (IndexError, chainerx.DimensionError):\n- pass\n \n is_backprop_required = arr.is_backprop_required()\n", "issue": "Support ellipsis in `Array::At` and `__getitem__`\nDepends on #7559 because `py::ellipsis` is supported from v2.3.0.\n", "before_files": [{"content": "# This file defines workaround implementation for\n# NumPy-compatibility functions that fall back to NumPy/CuPy functions\n# for native/cuda devices respecitvely.\n# The workaround does not support backprop, and also requires external\n# libraries mentioned above.\n# Functions defined in this file should be considered to have high priority for\n# genuine implementations.\nimport numpy\n\nimport chainerx\n\n\ntry:\n import cupy\nexcept Exception:\n cupy = None\n\n\nclass _DummyContext:\n def __enter__(self):\n pass\n\n def __exit__(self, type, value, traceback):\n pass\n\n\n_dummy_context = _DummyContext()\n\n\ndef _to_numpy(array):\n assert isinstance(array, chainerx.ndarray)\n return chainerx.to_numpy(array, copy=False)\n\n\ndef _from_numpy(array):\n assert isinstance(array, numpy.ndarray)\n return chainerx.array(array, copy=False)\n\n\ndef _to_cupy(array):\n assert cupy is not None\n # Convert to cupy.ndarray on the same device as source array\n return chainerx._to_cupy(array)\n\n\ndef _from_cupy(array):\n assert cupy is not None\n assert isinstance(array, cupy.ndarray)\n device = chainerx.get_device('cuda', array.device.id)\n return chainerx._core._fromrawpointer(\n array.data.mem.ptr,\n array.shape,\n array.dtype,\n array.strides,\n device,\n array.data.ptr - array.data.mem.ptr,\n array)\n\n\ndef _from_chx(array, check_backprop=True):\n # Converts chainerx.ndarray to numpy/cupy.ndarray.\n # Objects with other types are kept intact.\n # Returns a pair: (xp, cupy device or dummy context, numpy/cupy.ndarray).\n if not isinstance(array, chainerx.ndarray):\n if (isinstance(array, numpy.ndarray)\n or (cupy and isinstance(array, cupy.ndarray))):\n raise TypeError(\n 'ChainerX function fallback using NumPy/CuPy arrays '\n 'is not supported.')\n # _from_chx is also called for slice and tuple objects\n # Used to index a chx array\n return None, _dummy_context, array\n if check_backprop and array.is_backprop_required():\n raise RuntimeError(\n 'ChainerX function fallback using NumPy/CuPy is not '\n 'supported for arrays that are connected to a graph.')\n backend_name = array.device.backend.name\n if backend_name == 'native':\n return numpy, _dummy_context, _to_numpy(array)\n if backend_name == 'cuda':\n if cupy is None:\n raise RuntimeError(\n 'ChainerX fallback implementation for cuda backend requires '\n 'cupy to be installed.')\n array_cupy = _to_cupy(array)\n return cupy, array_cupy.device, array_cupy\n raise RuntimeError(\n 'ChainerX fallback implementation only supports native or cuda '\n 'backends.')\n\n\ndef _to_chx(array):\n # Converts numpy/cupy.ndarray to chainerx.ndarray.\n # Objects with other types are kept intact.\n if isinstance(array, numpy.ndarray):\n return _from_numpy(array)\n elif cupy is not None and isinstance(array, cupy.ndarray):\n return _from_cupy(array)\n return array\n\n\ndef _populate_module_functions():\n\n def _fix(arr):\n xp, dev, arr = _from_chx(arr)\n with dev:\n ret = xp.fix(arr)\n ret = xp.asarray(ret)\n return _to_chx(ret)\n\n chainerx.fix = _fix\n\n\ndef _populate_ndarray():\n ndarray = chainerx.ndarray\n\n # __getitem__ with advanced indexing\n old_getitem = ndarray.__getitem__\n\n def __getitem__(arr, key):\n try:\n return old_getitem(arr, key)\n except (IndexError, chainerx.DimensionError):\n pass\n\n is_backprop_required = arr.is_backprop_required()\n\n xp, dev, arr = _from_chx(arr, check_backprop=False)\n # The elements used for indexing the array might be\n # also ChainerX arrays. _from_chx ignores\n # other types and return them as-is\n if isinstance(key, tuple):\n key = tuple([_from_chx(k, check_backprop=False)[2] for k in key])\n else:\n _, _, key = _from_chx(key, check_backprop=False)\n\n with dev:\n ret = arr[key]\n\n # Doing this check after the fallback __getitem__ because the error\n # which caused the fallback might not be due to advanced indexing.\n # In such case the fallback __getitem__ should also raise the error.\n\n if is_backprop_required:\n raise RuntimeError(\n 'ChainerX getitem fallback for advanced indexing is not '\n 'supported for arrays that are connected to a graph.')\n\n return _to_chx(ret)\n\n # __setitem__ with advanced indexing\n def __setitem__(self, key, value):\n if self.is_backprop_required():\n raise RuntimeError(\n 'ChainerX setitem fallback for advanced indexing is not '\n 'supported for arrays that are connected to a graph.')\n\n xp, dev, self = _from_chx(self)\n if isinstance(key, tuple):\n key = tuple([_from_chx(k)[2] for k in key])\n else:\n _, _, key = _from_chx(key)\n _, _, value = _from_chx(value)\n\n with dev:\n self[key] = value\n\n ndarray.__setitem__ = __setitem__\n ndarray.__getitem__ = __getitem__\n\n def tolist(arr):\n _, dev, arr = _from_chx(arr)\n with dev:\n ret = arr.tolist()\n return ret\n\n ndarray.tolist = tolist\n\n\ndef populate():\n _populate_module_functions()\n _populate_ndarray()\n", "path": "chainerx/_fallback_workarounds.py"}], "after_files": [{"content": "# This file defines workaround implementation for\n# NumPy-compatibility functions that fall back to NumPy/CuPy functions\n# for native/cuda devices respecitvely.\n# The workaround does not support backprop, and also requires external\n# libraries mentioned above.\n# Functions defined in this file should be considered to have high priority for\n# genuine implementations.\nimport numpy\n\nimport chainerx\n\n\ntry:\n import cupy\nexcept Exception:\n cupy = None\n\n\nclass _DummyContext:\n def __enter__(self):\n pass\n\n def __exit__(self, type, value, traceback):\n pass\n\n\n_dummy_context = _DummyContext()\n\n\ndef _to_numpy(array):\n assert isinstance(array, chainerx.ndarray)\n return chainerx.to_numpy(array, copy=False)\n\n\ndef _from_numpy(array):\n assert isinstance(array, numpy.ndarray)\n return chainerx.array(array, copy=False)\n\n\ndef _to_cupy(array):\n assert cupy is not None\n # Convert to cupy.ndarray on the same device as source array\n return chainerx._to_cupy(array)\n\n\ndef _from_cupy(array):\n assert cupy is not None\n assert isinstance(array, cupy.ndarray)\n device = chainerx.get_device('cuda', array.device.id)\n return chainerx._core._fromrawpointer(\n array.data.mem.ptr,\n array.shape,\n array.dtype,\n array.strides,\n device,\n array.data.ptr - array.data.mem.ptr,\n array)\n\n\ndef _from_chx(array, check_backprop=True):\n # Converts chainerx.ndarray to numpy/cupy.ndarray.\n # Objects with other types are kept intact.\n # Returns a pair: (xp, cupy device or dummy context, numpy/cupy.ndarray).\n if not isinstance(array, chainerx.ndarray):\n if (isinstance(array, numpy.ndarray)\n or (cupy and isinstance(array, cupy.ndarray))):\n raise TypeError(\n 'ChainerX function fallback using NumPy/CuPy arrays '\n 'is not supported.')\n # _from_chx is also called for slice and tuple objects\n # Used to index a chx array\n return None, _dummy_context, array\n if check_backprop and array.is_backprop_required():\n raise RuntimeError(\n 'ChainerX function fallback using NumPy/CuPy is not '\n 'supported for arrays that are connected to a graph.')\n backend_name = array.device.backend.name\n if backend_name == 'native':\n return numpy, _dummy_context, _to_numpy(array)\n if backend_name == 'cuda':\n if cupy is None:\n raise RuntimeError(\n 'ChainerX fallback implementation for cuda backend requires '\n 'cupy to be installed.')\n array_cupy = _to_cupy(array)\n return cupy, array_cupy.device, array_cupy\n raise RuntimeError(\n 'ChainerX fallback implementation only supports native or cuda '\n 'backends.')\n\n\ndef _to_chx(array):\n # Converts numpy/cupy.ndarray to chainerx.ndarray.\n # Objects with other types are kept intact.\n if isinstance(array, numpy.ndarray):\n return _from_numpy(array)\n elif cupy is not None and isinstance(array, cupy.ndarray):\n return _from_cupy(array)\n return array\n\n\ndef _populate_module_functions():\n\n def _fix(arr):\n xp, dev, arr = _from_chx(arr)\n with dev:\n ret = xp.fix(arr)\n ret = xp.asarray(ret)\n return _to_chx(ret)\n\n chainerx.fix = _fix\n\n\ndef _populate_ndarray():\n ndarray = chainerx.ndarray\n\n # __getitem__ with advanced indexing\n old_getitem = ndarray.__getitem__\n\n def __getitem__(arr, key):\n if not isinstance(key, chainerx.ndarray):\n return old_getitem(arr, key)\n\n is_backprop_required = arr.is_backprop_required()\n\n xp, dev, arr = _from_chx(arr, check_backprop=False)\n # The elements used for indexing the array might be\n # also ChainerX arrays. _from_chx ignores\n # other types and return them as-is\n if isinstance(key, tuple):\n key = tuple([_from_chx(k, check_backprop=False)[2] for k in key])\n else:\n _, _, key = _from_chx(key, check_backprop=False)\n\n with dev:\n ret = arr[key]\n\n # Doing this check after the fallback __getitem__ because the error\n # which caused the fallback might not be due to advanced indexing.\n # In such case the fallback __getitem__ should also raise the error.\n\n if is_backprop_required:\n raise RuntimeError(\n 'ChainerX getitem fallback for advanced indexing is not '\n 'supported for arrays that are connected to a graph.')\n\n return _to_chx(ret)\n\n # __setitem__ with advanced indexing\n def __setitem__(self, key, value):\n if self.is_backprop_required():\n raise RuntimeError(\n 'ChainerX setitem fallback for advanced indexing is not '\n 'supported for arrays that are connected to a graph.')\n\n xp, dev, self = _from_chx(self)\n if isinstance(key, tuple):\n key = tuple([_from_chx(k)[2] for k in key])\n else:\n _, _, key = _from_chx(key)\n _, _, value = _from_chx(value)\n\n with dev:\n self[key] = value\n\n ndarray.__setitem__ = __setitem__\n ndarray.__getitem__ = __getitem__\n\n def tolist(arr):\n _, dev, arr = _from_chx(arr)\n with dev:\n ret = arr.tolist()\n return ret\n\n ndarray.tolist = tolist\n\n\ndef populate():\n _populate_module_functions()\n _populate_ndarray()\n", "path": "chainerx/_fallback_workarounds.py"}]}
| 2,035 | 136 |
gh_patches_debug_1190
|
rasdani/github-patches
|
git_diff
|
boto__botocore-1117
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Support Python 3.6
Python 3.6 got released, and some distro (like Fedora) are swithcing to it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 import botocore
3 import sys
4
5 from setuptools import setup, find_packages
6
7
8 requires = ['jmespath>=0.7.1,<1.0.0',
9 'python-dateutil>=2.1,<3.0.0',
10 'docutils>=0.10']
11
12
13 if sys.version_info[:2] == (2, 6):
14 # For python2.6 we have a few other dependencies.
15 # First we need an ordered dictionary so we use the
16 # 2.6 backport.
17 requires.append('ordereddict==1.1')
18 # Then we need simplejson. This is because we need
19 # a json version that allows us to specify we want to
20 # use an ordereddict instead of a normal dict for the
21 # JSON objects. The 2.7 json module has this. For 2.6
22 # we need simplejson.
23 requires.append('simplejson==3.3.0')
24
25
26 setup(
27 name='botocore',
28 version=botocore.__version__,
29 description='Low-level, data-driven core of boto 3.',
30 long_description=open('README.rst').read(),
31 author='Amazon Web Services',
32 url='https://github.com/boto/botocore',
33 scripts=[],
34 packages=find_packages(exclude=['tests*']),
35 package_data={'botocore': ['data/*.json', 'data/*/*.json'],
36 'botocore.vendored.requests': ['*.pem']},
37 include_package_data=True,
38 install_requires=requires,
39 extras_require={
40 ':python_version=="2.6"': [
41 'ordereddict==1.1',
42 'simplejson==3.3.0',
43 ]
44 },
45 license="Apache License 2.0",
46 classifiers=(
47 'Development Status :: 5 - Production/Stable',
48 'Intended Audience :: Developers',
49 'Intended Audience :: System Administrators',
50 'Natural Language :: English',
51 'License :: OSI Approved :: Apache Software License',
52 'Programming Language :: Python',
53 'Programming Language :: Python :: 2',
54 'Programming Language :: Python :: 2.6',
55 'Programming Language :: Python :: 2.7',
56 'Programming Language :: Python :: 3',
57 'Programming Language :: Python :: 3.3',
58 'Programming Language :: Python :: 3.4',
59 'Programming Language :: Python :: 3.5',
60 ),
61 )
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -57,5 +57,6 @@
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
+ 'Programming Language :: Python :: 3.6',
),
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -57,5 +57,6 @@\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n+ 'Programming Language :: Python :: 3.6',\n ),\n )\n", "issue": "Support Python 3.6\nPython 3.6 got released, and some distro (like Fedora) are swithcing to it.\n", "before_files": [{"content": "#!/usr/bin/env python\nimport botocore\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nrequires = ['jmespath>=0.7.1,<1.0.0',\n 'python-dateutil>=2.1,<3.0.0',\n 'docutils>=0.10']\n\n\nif sys.version_info[:2] == (2, 6):\n # For python2.6 we have a few other dependencies.\n # First we need an ordered dictionary so we use the\n # 2.6 backport.\n requires.append('ordereddict==1.1')\n # Then we need simplejson. This is because we need\n # a json version that allows us to specify we want to\n # use an ordereddict instead of a normal dict for the\n # JSON objects. The 2.7 json module has this. For 2.6\n # we need simplejson.\n requires.append('simplejson==3.3.0')\n\n\nsetup(\n name='botocore',\n version=botocore.__version__,\n description='Low-level, data-driven core of boto 3.',\n long_description=open('README.rst').read(),\n author='Amazon Web Services',\n url='https://github.com/boto/botocore',\n scripts=[],\n packages=find_packages(exclude=['tests*']),\n package_data={'botocore': ['data/*.json', 'data/*/*.json'],\n 'botocore.vendored.requests': ['*.pem']},\n include_package_data=True,\n install_requires=requires,\n extras_require={\n ':python_version==\"2.6\"': [\n 'ordereddict==1.1',\n 'simplejson==3.3.0',\n ]\n },\n license=\"Apache License 2.0\",\n classifiers=(\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n ),\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport botocore\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\nrequires = ['jmespath>=0.7.1,<1.0.0',\n 'python-dateutil>=2.1,<3.0.0',\n 'docutils>=0.10']\n\n\nif sys.version_info[:2] == (2, 6):\n # For python2.6 we have a few other dependencies.\n # First we need an ordered dictionary so we use the\n # 2.6 backport.\n requires.append('ordereddict==1.1')\n # Then we need simplejson. This is because we need\n # a json version that allows us to specify we want to\n # use an ordereddict instead of a normal dict for the\n # JSON objects. The 2.7 json module has this. For 2.6\n # we need simplejson.\n requires.append('simplejson==3.3.0')\n\n\nsetup(\n name='botocore',\n version=botocore.__version__,\n description='Low-level, data-driven core of boto 3.',\n long_description=open('README.rst').read(),\n author='Amazon Web Services',\n url='https://github.com/boto/botocore',\n scripts=[],\n packages=find_packages(exclude=['tests*']),\n package_data={'botocore': ['data/*.json', 'data/*/*.json'],\n 'botocore.vendored.requests': ['*.pem']},\n include_package_data=True,\n install_requires=requires,\n extras_require={\n ':python_version==\"2.6\"': [\n 'ordereddict==1.1',\n 'simplejson==3.3.0',\n ]\n },\n license=\"Apache License 2.0\",\n classifiers=(\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ),\n)\n", "path": "setup.py"}]}
| 937 | 84 |
gh_patches_debug_8073
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-26775
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ifft2
ifft2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py`
Content:
```
1 import ivy
2 from ivy.functional.frontends.numpy.func_wrapper import to_ivy_arrays_and_back
3 from ivy.func_wrapper import with_unsupported_dtypes
4
5
6 # --- Helpers --- #
7 # --------------- #
8
9
10 def _swap_direction(norm):
11 try:
12 return _SWAP_DIRECTION_MAP[norm]
13 except KeyError:
14 raise ValueError(
15 f'Invalid norm value {norm}; should be "backward", "ortho" or "forward".'
16 ) from None
17
18
19 # --- Main --- #
20 # ------------ #
21
22
23 @to_ivy_arrays_and_back
24 def fft(a, n=None, axis=-1, norm=None):
25 return ivy.fft(ivy.astype(a, ivy.complex128), axis, norm=norm, n=n)
26
27
28 @with_unsupported_dtypes({"1.26.0 and below": ("int",)}, "numpy")
29 @to_ivy_arrays_and_back
30 def fftfreq(n, d=1.0):
31 if not isinstance(
32 n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))
33 ):
34 raise ValueError("n should be an integer")
35
36 N = (n - 1) // 2 + 1
37 val = 1.0 / (n * d)
38 results = ivy.empty(tuple([n]), dtype=int)
39
40 p1 = ivy.arange(0, N, dtype=int)
41 results[:N] = p1
42 p2 = ivy.arange(-(n // 2), 0, dtype=int)
43 results[N:] = p2
44
45 return results * val
46
47
48 @to_ivy_arrays_and_back
49 @with_unsupported_dtypes({"1.26.0 and below": ("float16",)}, "numpy")
50 def fftshift(x, axes=None):
51 x = ivy.asarray(x)
52
53 if axes is None:
54 axes = tuple(range(x.ndim))
55 shift = [(dim // 2) for dim in x.shape]
56 elif isinstance(
57 axes,
58 (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),
59 ):
60 shift = x.shape[axes] // 2
61 else:
62 shift = [(x.shape[ax] // 2) for ax in axes]
63
64 roll = ivy.roll(x, shift, axis=axes)
65
66 return roll
67
68
69 @to_ivy_arrays_and_back
70 def ifft(a, n=None, axis=-1, norm=None):
71 a = ivy.array(a, dtype=ivy.complex128)
72 if norm is None:
73 norm = "backward"
74 return ivy.ifft(a, axis, norm=norm, n=n)
75
76
77 @with_unsupported_dtypes({"1.24.3 and below": ("float16",)}, "numpy")
78 @to_ivy_arrays_and_back
79 def ifftn(a, s=None, axes=None, norm=None):
80 a = ivy.asarray(a, dtype=ivy.complex128)
81 a = ivy.ifftn(a, s=s, axes=axes, norm=norm)
82 return a
83
84
85 @to_ivy_arrays_and_back
86 @with_unsupported_dtypes({"1.26.0 and below": ("float16",)}, "numpy")
87 def ifftshift(x, axes=None):
88 x = ivy.asarray(x)
89
90 if axes is None:
91 axes = tuple(range(x.ndim))
92 shift = [-(dim // 2) for dim in x.shape]
93 elif isinstance(
94 axes,
95 (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),
96 ):
97 shift = -(x.shape[axes] // 2)
98 else:
99 shift = [-(x.shape[ax] // 2) for ax in axes]
100
101 roll = ivy.roll(x, shift, axis=axes)
102
103 return roll
104
105
106 @with_unsupported_dtypes({"1.26.0 and below": ("float16",)}, "numpy")
107 @to_ivy_arrays_and_back
108 def ihfft(a, n=None, axis=-1, norm=None):
109 if n is None:
110 n = a.shape[axis]
111 norm = _swap_direction(norm)
112 output = ivy.conj(rfft(a, n, axis, norm=norm).ivy_array)
113 return output
114
115
116 @with_unsupported_dtypes({"1.26.0 and below": ("float16",)}, "numpy")
117 @to_ivy_arrays_and_back
118 def rfft(a, n=None, axis=-1, norm=None):
119 if norm is None:
120 norm = "backward"
121 a = ivy.array(a, dtype=ivy.float64)
122 return ivy.dft(a, axis=axis, inverse=False, onesided=True, dft_length=n, norm=norm)
123
124
125 @to_ivy_arrays_and_back
126 def rfftfreq(n, d=1.0):
127 if not isinstance(
128 n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))
129 ):
130 raise ValueError("n should be an integer")
131
132 val = 1.0 / (n * d)
133 N = n // 2 + 1
134 results = ivy.arange(0, N, dtype=int)
135 return results * val
136
137
138 @with_unsupported_dtypes({"1.24.3 and below": ("float16",)}, "numpy")
139 @to_ivy_arrays_and_back
140 def rfftn(a, s=None, axes=None, norm=None):
141 a = ivy.asarray(a, dtype=ivy.complex128)
142 return ivy.rfftn(a, s=s, axes=axes, norm=norm)
143
144
145 _SWAP_DIRECTION_MAP = {
146 None: "forward",
147 "backward": "forward",
148 "ortho": "ortho",
149 "forward": "backward",
150 }
151
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py b/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py
--- a/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py
+++ b/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py
@@ -74,6 +74,14 @@
return ivy.ifft(a, axis, norm=norm, n=n)
+@with_unsupported_dtypes({"1.24.3 and below": ("float16",)}, "numpy")
+@to_ivy_arrays_and_back
+def ifft2(a, s=None, axes=(-2, -1), norm=None):
+ a = ivy.asarray(a, dtype=ivy.complex128)
+ a = ivy.ifftn(a, s=s, axes=axes, norm=norm)
+ return a
+
+
@with_unsupported_dtypes({"1.24.3 and below": ("float16",)}, "numpy")
@to_ivy_arrays_and_back
def ifftn(a, s=None, axes=None, norm=None):
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py b/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py\n--- a/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py\n+++ b/ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py\n@@ -74,6 +74,14 @@\n return ivy.ifft(a, axis, norm=norm, n=n)\n \n \n+@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n+@to_ivy_arrays_and_back\n+def ifft2(a, s=None, axes=(-2, -1), norm=None):\n+ a = ivy.asarray(a, dtype=ivy.complex128)\n+ a = ivy.ifftn(a, s=s, axes=axes, norm=norm)\n+ return a\n+\n+\n @with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n @to_ivy_arrays_and_back\n def ifftn(a, s=None, axes=None, norm=None):\n", "issue": "ifft2\n\nifft2\n\n", "before_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import to_ivy_arrays_and_back\nfrom ivy.func_wrapper import with_unsupported_dtypes\n\n\n# --- Helpers --- #\n# --------------- #\n\n\ndef _swap_direction(norm):\n try:\n return _SWAP_DIRECTION_MAP[norm]\n except KeyError:\n raise ValueError(\n f'Invalid norm value {norm}; should be \"backward\", \"ortho\" or \"forward\".'\n ) from None\n\n\n# --- Main --- #\n# ------------ #\n\n\n@to_ivy_arrays_and_back\ndef fft(a, n=None, axis=-1, norm=None):\n return ivy.fft(ivy.astype(a, ivy.complex128), axis, norm=norm, n=n)\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"int\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef fftfreq(n, d=1.0):\n if not isinstance(\n n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))\n ):\n raise ValueError(\"n should be an integer\")\n\n N = (n - 1) // 2 + 1\n val = 1.0 / (n * d)\n results = ivy.empty(tuple([n]), dtype=int)\n\n p1 = ivy.arange(0, N, dtype=int)\n results[:N] = p1\n p2 = ivy.arange(-(n // 2), 0, dtype=int)\n results[N:] = p2\n\n return results * val\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\ndef fftshift(x, axes=None):\n x = ivy.asarray(x)\n\n if axes is None:\n axes = tuple(range(x.ndim))\n shift = [(dim // 2) for dim in x.shape]\n elif isinstance(\n axes,\n (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),\n ):\n shift = x.shape[axes] // 2\n else:\n shift = [(x.shape[ax] // 2) for ax in axes]\n\n roll = ivy.roll(x, shift, axis=axes)\n\n return roll\n\n\n@to_ivy_arrays_and_back\ndef ifft(a, n=None, axis=-1, norm=None):\n a = ivy.array(a, dtype=ivy.complex128)\n if norm is None:\n norm = \"backward\"\n return ivy.ifft(a, axis, norm=norm, n=n)\n\n\n@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef ifftn(a, s=None, axes=None, norm=None):\n a = ivy.asarray(a, dtype=ivy.complex128)\n a = ivy.ifftn(a, s=s, axes=axes, norm=norm)\n return a\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\ndef ifftshift(x, axes=None):\n x = ivy.asarray(x)\n\n if axes is None:\n axes = tuple(range(x.ndim))\n shift = [-(dim // 2) for dim in x.shape]\n elif isinstance(\n axes,\n (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),\n ):\n shift = -(x.shape[axes] // 2)\n else:\n shift = [-(x.shape[ax] // 2) for ax in axes]\n\n roll = ivy.roll(x, shift, axis=axes)\n\n return roll\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef ihfft(a, n=None, axis=-1, norm=None):\n if n is None:\n n = a.shape[axis]\n norm = _swap_direction(norm)\n output = ivy.conj(rfft(a, n, axis, norm=norm).ivy_array)\n return output\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef rfft(a, n=None, axis=-1, norm=None):\n if norm is None:\n norm = \"backward\"\n a = ivy.array(a, dtype=ivy.float64)\n return ivy.dft(a, axis=axis, inverse=False, onesided=True, dft_length=n, norm=norm)\n\n\n@to_ivy_arrays_and_back\ndef rfftfreq(n, d=1.0):\n if not isinstance(\n n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))\n ):\n raise ValueError(\"n should be an integer\")\n\n val = 1.0 / (n * d)\n N = n // 2 + 1\n results = ivy.arange(0, N, dtype=int)\n return results * val\n\n\n@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef rfftn(a, s=None, axes=None, norm=None):\n a = ivy.asarray(a, dtype=ivy.complex128)\n return ivy.rfftn(a, s=s, axes=axes, norm=norm)\n\n\n_SWAP_DIRECTION_MAP = {\n None: \"forward\",\n \"backward\": \"forward\",\n \"ortho\": \"ortho\",\n \"forward\": \"backward\",\n}\n", "path": "ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py"}], "after_files": [{"content": "import ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import to_ivy_arrays_and_back\nfrom ivy.func_wrapper import with_unsupported_dtypes\n\n\n# --- Helpers --- #\n# --------------- #\n\n\ndef _swap_direction(norm):\n try:\n return _SWAP_DIRECTION_MAP[norm]\n except KeyError:\n raise ValueError(\n f'Invalid norm value {norm}; should be \"backward\", \"ortho\" or \"forward\".'\n ) from None\n\n\n# --- Main --- #\n# ------------ #\n\n\n@to_ivy_arrays_and_back\ndef fft(a, n=None, axis=-1, norm=None):\n return ivy.fft(ivy.astype(a, ivy.complex128), axis, norm=norm, n=n)\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"int\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef fftfreq(n, d=1.0):\n if not isinstance(\n n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))\n ):\n raise ValueError(\"n should be an integer\")\n\n N = (n - 1) // 2 + 1\n val = 1.0 / (n * d)\n results = ivy.empty(tuple([n]), dtype=int)\n\n p1 = ivy.arange(0, N, dtype=int)\n results[:N] = p1\n p2 = ivy.arange(-(n // 2), 0, dtype=int)\n results[N:] = p2\n\n return results * val\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\ndef fftshift(x, axes=None):\n x = ivy.asarray(x)\n\n if axes is None:\n axes = tuple(range(x.ndim))\n shift = [(dim // 2) for dim in x.shape]\n elif isinstance(\n axes,\n (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),\n ):\n shift = x.shape[axes] // 2\n else:\n shift = [(x.shape[ax] // 2) for ax in axes]\n\n roll = ivy.roll(x, shift, axis=axes)\n\n return roll\n\n\n@to_ivy_arrays_and_back\ndef ifft(a, n=None, axis=-1, norm=None):\n a = ivy.array(a, dtype=ivy.complex128)\n if norm is None:\n norm = \"backward\"\n return ivy.ifft(a, axis, norm=norm, n=n)\n\n\n@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef ifft2(a, s=None, axes=(-2, -1), norm=None):\n a = ivy.asarray(a, dtype=ivy.complex128)\n a = ivy.ifftn(a, s=s, axes=axes, norm=norm)\n return a\n\n\n@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef ifftn(a, s=None, axes=None, norm=None):\n a = ivy.asarray(a, dtype=ivy.complex128)\n a = ivy.ifftn(a, s=s, axes=axes, norm=norm)\n return a\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\ndef ifftshift(x, axes=None):\n x = ivy.asarray(x)\n\n if axes is None:\n axes = tuple(range(x.ndim))\n shift = [-(dim // 2) for dim in x.shape]\n elif isinstance(\n axes,\n (int, type(ivy.uint8), type(ivy.uint16), type(ivy.uint32), type(ivy.uint64)),\n ):\n shift = -(x.shape[axes] // 2)\n else:\n shift = [-(x.shape[ax] // 2) for ax in axes]\n\n roll = ivy.roll(x, shift, axis=axes)\n\n return roll\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef ihfft(a, n=None, axis=-1, norm=None):\n if n is None:\n n = a.shape[axis]\n norm = _swap_direction(norm)\n output = ivy.conj(rfft(a, n, axis, norm=norm).ivy_array)\n return output\n\n\n@with_unsupported_dtypes({\"1.26.0 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef rfft(a, n=None, axis=-1, norm=None):\n if norm is None:\n norm = \"backward\"\n a = ivy.array(a, dtype=ivy.float64)\n return ivy.dft(a, axis=axis, inverse=False, onesided=True, dft_length=n, norm=norm)\n\n\n@to_ivy_arrays_and_back\ndef rfftfreq(n, d=1.0):\n if not isinstance(\n n, (int, type(ivy.int8), type(ivy.int16), type(ivy.int32), type(ivy.int64))\n ):\n raise ValueError(\"n should be an integer\")\n\n val = 1.0 / (n * d)\n N = n // 2 + 1\n results = ivy.arange(0, N, dtype=int)\n return results * val\n\n\n@with_unsupported_dtypes({\"1.24.3 and below\": (\"float16\",)}, \"numpy\")\n@to_ivy_arrays_and_back\ndef rfftn(a, s=None, axes=None, norm=None):\n a = ivy.asarray(a, dtype=ivy.complex128)\n return ivy.rfftn(a, s=s, axes=axes, norm=norm)\n\n\n_SWAP_DIRECTION_MAP = {\n None: \"forward\",\n \"backward\": \"forward\",\n \"ortho\": \"ortho\",\n \"forward\": \"backward\",\n}\n", "path": "ivy/functional/frontends/numpy/fft/discrete_fourier_transform.py"}]}
| 1,938 | 257 |
gh_patches_debug_37121
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-902
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Build takes too long
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright (C) 2015 UCSC Computational Genomics Lab
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import sys
16 from version import version
17 from setuptools import find_packages, setup
18
19 botoVersionRequired = 'boto==2.38.0'
20
21 kwargs = dict(
22 name='toil',
23 version=version,
24 description='Pipeline management software for clusters.',
25 author='Benedict Paten',
26 author_email='[email protected]',
27 url="https://github.com/BD2KGenomics/toil",
28 install_requires=[
29 'bd2k-python-lib==1.13.dev14'],
30 tests_require=[
31 'mock==1.0.1',
32 'pytest==2.8.3'],
33 test_suite='toil',
34 extras_require={
35 'mesos': [
36 'psutil==3.0.1'],
37 'aws': [
38 botoVersionRequired,
39 'cgcloud-lib==1.4a1.dev195' ],
40 'azure': [
41 'azure==1.0.3'],
42 'encryption': [
43 'pynacl==0.3.0'],
44 'google': [
45 'gcs_oauth2_boto_plugin==1.9',
46 botoVersionRequired],
47 'cwl': [
48 'cwltool==1.0.20160425140546']},
49 package_dir={'': 'src'},
50 packages=find_packages('src', exclude=['*.test']),
51 entry_points={
52 'console_scripts': [
53 'toil = toil.utils.toilMain:main',
54 '_toil_worker = toil.worker:main',
55 'cwltoil = toil.cwl.cwltoil:main [cwl]',
56 'cwl-runner = toil.cwl.cwltoil:main [cwl]',
57 '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]']})
58
59 from setuptools.command.test import test as TestCommand
60
61
62 class PyTest(TestCommand):
63 user_options = [('pytest-args=', 'a', "Arguments to pass to py.test")]
64
65 def initialize_options(self):
66 TestCommand.initialize_options(self)
67 self.pytest_args = []
68
69 def finalize_options(self):
70 TestCommand.finalize_options(self)
71 self.test_args = []
72 self.test_suite = True
73
74 def run_tests(self):
75 import pytest
76 # Sanitize command line arguments to avoid confusing Toil code attempting to parse them
77 sys.argv[1:] = []
78 errno = pytest.main(self.pytest_args)
79 sys.exit(errno)
80
81
82 kwargs['cmdclass'] = {'test': PyTest}
83
84 setup(**kwargs)
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,13 +12,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import sys
from version import version
from setuptools import find_packages, setup
-botoVersionRequired = 'boto==2.38.0'
+botoRequirement = 'boto==2.38.0'
-kwargs = dict(
+setup(
name='toil',
version=version,
description='Pipeline management software for clusters.',
@@ -27,15 +26,11 @@
url="https://github.com/BD2KGenomics/toil",
install_requires=[
'bd2k-python-lib==1.13.dev14'],
- tests_require=[
- 'mock==1.0.1',
- 'pytest==2.8.3'],
- test_suite='toil',
extras_require={
'mesos': [
'psutil==3.0.1'],
'aws': [
- botoVersionRequired,
+ botoRequirement,
'cgcloud-lib==1.4a1.dev195' ],
'azure': [
'azure==1.0.3'],
@@ -43,7 +38,7 @@
'pynacl==0.3.0'],
'google': [
'gcs_oauth2_boto_plugin==1.9',
- botoVersionRequired],
+ botoRequirement],
'cwl': [
'cwltool==1.0.20160425140546']},
package_dir={'': 'src'},
@@ -55,30 +50,3 @@
'cwltoil = toil.cwl.cwltoil:main [cwl]',
'cwl-runner = toil.cwl.cwltoil:main [cwl]',
'_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]']})
-
-from setuptools.command.test import test as TestCommand
-
-
-class PyTest(TestCommand):
- user_options = [('pytest-args=', 'a', "Arguments to pass to py.test")]
-
- def initialize_options(self):
- TestCommand.initialize_options(self)
- self.pytest_args = []
-
- def finalize_options(self):
- TestCommand.finalize_options(self)
- self.test_args = []
- self.test_suite = True
-
- def run_tests(self):
- import pytest
- # Sanitize command line arguments to avoid confusing Toil code attempting to parse them
- sys.argv[1:] = []
- errno = pytest.main(self.pytest_args)
- sys.exit(errno)
-
-
-kwargs['cmdclass'] = {'test': PyTest}
-
-setup(**kwargs)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -12,13 +12,12 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-import sys\n from version import version\n from setuptools import find_packages, setup\n \n-botoVersionRequired = 'boto==2.38.0'\n+botoRequirement = 'boto==2.38.0'\n \n-kwargs = dict(\n+setup(\n name='toil',\n version=version,\n description='Pipeline management software for clusters.',\n@@ -27,15 +26,11 @@\n url=\"https://github.com/BD2KGenomics/toil\",\n install_requires=[\n 'bd2k-python-lib==1.13.dev14'],\n- tests_require=[\n- 'mock==1.0.1',\n- 'pytest==2.8.3'],\n- test_suite='toil',\n extras_require={\n 'mesos': [\n 'psutil==3.0.1'],\n 'aws': [\n- botoVersionRequired,\n+ botoRequirement,\n 'cgcloud-lib==1.4a1.dev195' ],\n 'azure': [\n 'azure==1.0.3'],\n@@ -43,7 +38,7 @@\n 'pynacl==0.3.0'],\n 'google': [\n 'gcs_oauth2_boto_plugin==1.9',\n- botoVersionRequired],\n+ botoRequirement],\n 'cwl': [\n 'cwltool==1.0.20160425140546']},\n package_dir={'': 'src'},\n@@ -55,30 +50,3 @@\n 'cwltoil = toil.cwl.cwltoil:main [cwl]',\n 'cwl-runner = toil.cwl.cwltoil:main [cwl]',\n '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]']})\n-\n-from setuptools.command.test import test as TestCommand\n-\n-\n-class PyTest(TestCommand):\n- user_options = [('pytest-args=', 'a', \"Arguments to pass to py.test\")]\n-\n- def initialize_options(self):\n- TestCommand.initialize_options(self)\n- self.pytest_args = []\n-\n- def finalize_options(self):\n- TestCommand.finalize_options(self)\n- self.test_args = []\n- self.test_suite = True\n-\n- def run_tests(self):\n- import pytest\n- # Sanitize command line arguments to avoid confusing Toil code attempting to parse them\n- sys.argv[1:] = []\n- errno = pytest.main(self.pytest_args)\n- sys.exit(errno)\n-\n-\n-kwargs['cmdclass'] = {'test': PyTest}\n-\n-setup(**kwargs)\n", "issue": "Build takes too long\n\n", "before_files": [{"content": "# Copyright (C) 2015 UCSC Computational Genomics Lab\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport sys\nfrom version import version\nfrom setuptools import find_packages, setup\n\nbotoVersionRequired = 'boto==2.38.0'\n\nkwargs = dict(\n name='toil',\n version=version,\n description='Pipeline management software for clusters.',\n author='Benedict Paten',\n author_email='[email protected]',\n url=\"https://github.com/BD2KGenomics/toil\",\n install_requires=[\n 'bd2k-python-lib==1.13.dev14'],\n tests_require=[\n 'mock==1.0.1',\n 'pytest==2.8.3'],\n test_suite='toil',\n extras_require={\n 'mesos': [\n 'psutil==3.0.1'],\n 'aws': [\n botoVersionRequired,\n 'cgcloud-lib==1.4a1.dev195' ],\n 'azure': [\n 'azure==1.0.3'],\n 'encryption': [\n 'pynacl==0.3.0'],\n 'google': [\n 'gcs_oauth2_boto_plugin==1.9',\n botoVersionRequired],\n 'cwl': [\n 'cwltool==1.0.20160425140546']},\n package_dir={'': 'src'},\n packages=find_packages('src', exclude=['*.test']),\n entry_points={\n 'console_scripts': [\n 'toil = toil.utils.toilMain:main',\n '_toil_worker = toil.worker:main',\n 'cwltoil = toil.cwl.cwltoil:main [cwl]',\n 'cwl-runner = toil.cwl.cwltoil:main [cwl]',\n '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]']})\n\nfrom setuptools.command.test import test as TestCommand\n\n\nclass PyTest(TestCommand):\n user_options = [('pytest-args=', 'a', \"Arguments to pass to py.test\")]\n\n def initialize_options(self):\n TestCommand.initialize_options(self)\n self.pytest_args = []\n\n def finalize_options(self):\n TestCommand.finalize_options(self)\n self.test_args = []\n self.test_suite = True\n\n def run_tests(self):\n import pytest\n # Sanitize command line arguments to avoid confusing Toil code attempting to parse them\n sys.argv[1:] = []\n errno = pytest.main(self.pytest_args)\n sys.exit(errno)\n\n\nkwargs['cmdclass'] = {'test': PyTest}\n\nsetup(**kwargs)\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright (C) 2015 UCSC Computational Genomics Lab\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom version import version\nfrom setuptools import find_packages, setup\n\nbotoRequirement = 'boto==2.38.0'\n\nsetup(\n name='toil',\n version=version,\n description='Pipeline management software for clusters.',\n author='Benedict Paten',\n author_email='[email protected]',\n url=\"https://github.com/BD2KGenomics/toil\",\n install_requires=[\n 'bd2k-python-lib==1.13.dev14'],\n extras_require={\n 'mesos': [\n 'psutil==3.0.1'],\n 'aws': [\n botoRequirement,\n 'cgcloud-lib==1.4a1.dev195' ],\n 'azure': [\n 'azure==1.0.3'],\n 'encryption': [\n 'pynacl==0.3.0'],\n 'google': [\n 'gcs_oauth2_boto_plugin==1.9',\n botoRequirement],\n 'cwl': [\n 'cwltool==1.0.20160425140546']},\n package_dir={'': 'src'},\n packages=find_packages('src', exclude=['*.test']),\n entry_points={\n 'console_scripts': [\n 'toil = toil.utils.toilMain:main',\n '_toil_worker = toil.worker:main',\n 'cwltoil = toil.cwl.cwltoil:main [cwl]',\n 'cwl-runner = toil.cwl.cwltoil:main [cwl]',\n '_toil_mesos_executor = toil.batchSystems.mesos.executor:main [mesos]']})\n", "path": "setup.py"}]}
| 1,122 | 628 |
gh_patches_debug_15829
|
rasdani/github-patches
|
git_diff
|
opsdroid__opsdroid-523
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting typing delay to 0 means bot never responds
# Description
When a typing delay is defined it is an integer which states how many characters per second opsdroid should type. If you set this to `0` then it can type no characters per second and therefore never responds.
## Steps to Reproduce
- Configure a connector with a `typing-delay` of `0`.
- Talk to the bot
## Experienced Functionality
The bot never responds.
## Expected Functionality
I would expect the bot to respond eventually. Perhaps even immediately and log an error stating `0` is an invalid response.
Thinking a little more about this I wonder if this functionality is the wrong way round. With `thinking-delay` that is the number of seconds that opsdroid should way before responding, so as the number gets bigger the longer opsdroid waits. But with `typing-delay` it is the number of characters per second that opsdroid can type, so the bigger the number the less opsdroid waits. The word `delay` suggests that the higher the number the longer the wait.
These opposites could be confusing (it confused me this evening). I think it would be good that both numbers represent time, rather than one representing characters per second. That would involve changing it to be seconds per character. This would result in a bigger number causing a bigger delay.
## Versions
- **Opsdroid version:** master
- **Python version:** 3.5.4
- **OS/Docker version:** macOS 10.13
## Configuration File
```yaml
connectors:
- name: shell
typing-delay: 0
skills:
- name: hello
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `opsdroid/message.py`
Content:
```
1 """Class to encapsulate a message."""
2
3 from datetime import datetime
4 from copy import copy
5 import asyncio
6 from random import randrange
7
8 from opsdroid.helper import get_opsdroid
9
10
11 class Message:
12 # pylint: disable=too-few-public-methods
13 """A message object."""
14
15 def __init__(self, text, user, room, connector, raw_message=None):
16 """Create object with minimum properties."""
17 self.created = datetime.now()
18 self.text = text
19 self.user = user
20 self.room = room
21 self.connector = connector
22 self.raw_message = raw_message
23 self.regex = None
24 self.responded_to = False
25
26 async def _thinking_delay(self):
27 """Make opsdroid wait x-seconds before responding."""
28 seconds = self.connector.configuration.get('thinking-delay', 0)
29
30 if isinstance(seconds, list):
31 seconds = randrange(seconds[0], seconds[1])
32
33 await asyncio.sleep(seconds)
34
35 async def _typing_delay(self, text):
36 """Simulate typing, takes an int(characters per second typed)."""
37 try:
38 char_per_sec = self.connector.configuration['typing-delay']
39 char_count = len(text)
40 await asyncio.sleep(char_count//char_per_sec)
41 except KeyError:
42 pass
43
44 async def respond(self, text, room=None):
45 """Respond to this message using the connector it was created by."""
46 opsdroid = get_opsdroid()
47 response = copy(self)
48 response.text = text
49
50 if 'thinking-delay' in self.connector.configuration or \
51 'typing-delay' in self.connector.configuration:
52 await self._thinking_delay()
53 await self._typing_delay(response.text)
54
55 await self.connector.respond(response, room)
56 if not self.responded_to:
57 now = datetime.now()
58 opsdroid.stats["total_responses"] = \
59 opsdroid.stats["total_responses"] + 1
60 opsdroid.stats["total_response_time"] = \
61 opsdroid.stats["total_response_time"] + \
62 (now - self.created).total_seconds()
63 self.responded_to = True
64
65 async def react(self, emoji):
66 """React to this message using the connector it was created by."""
67 if 'thinking-delay' in self.connector.configuration:
68 await self._thinking_delay()
69 return await self.connector.react(self, emoji)
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/opsdroid/message.py b/opsdroid/message.py
--- a/opsdroid/message.py
+++ b/opsdroid/message.py
@@ -33,13 +33,14 @@
await asyncio.sleep(seconds)
async def _typing_delay(self, text):
- """Simulate typing, takes an int(characters per second typed)."""
- try:
- char_per_sec = self.connector.configuration['typing-delay']
- char_count = len(text)
- await asyncio.sleep(char_count//char_per_sec)
- except KeyError:
- pass
+ """Simulate typing, takes an int or float to delay reply."""
+ seconds = self.connector.configuration.get('typing-delay', 0)
+ char_count = len(text)
+
+ if isinstance(seconds, list):
+ seconds = randrange(seconds[0], seconds[1])
+
+ await asyncio.sleep(char_count*seconds)
async def respond(self, text, room=None):
"""Respond to this message using the connector it was created by."""
|
{"golden_diff": "diff --git a/opsdroid/message.py b/opsdroid/message.py\n--- a/opsdroid/message.py\n+++ b/opsdroid/message.py\n@@ -33,13 +33,14 @@\n await asyncio.sleep(seconds)\n \n async def _typing_delay(self, text):\n- \"\"\"Simulate typing, takes an int(characters per second typed).\"\"\"\n- try:\n- char_per_sec = self.connector.configuration['typing-delay']\n- char_count = len(text)\n- await asyncio.sleep(char_count//char_per_sec)\n- except KeyError:\n- pass\n+ \"\"\"Simulate typing, takes an int or float to delay reply.\"\"\"\n+ seconds = self.connector.configuration.get('typing-delay', 0)\n+ char_count = len(text)\n+\n+ if isinstance(seconds, list):\n+ seconds = randrange(seconds[0], seconds[1])\n+\n+ await asyncio.sleep(char_count*seconds)\n \n async def respond(self, text, room=None):\n \"\"\"Respond to this message using the connector it was created by.\"\"\"\n", "issue": "Setting typing delay to 0 means bot never responds\n# Description\r\nWhen a typing delay is defined it is an integer which states how many characters per second opsdroid should type. If you set this to `0` then it can type no characters per second and therefore never responds.\r\n\r\n\r\n## Steps to Reproduce\r\n- Configure a connector with a `typing-delay` of `0`. \r\n- Talk to the bot\r\n\r\n\r\n## Experienced Functionality\r\nThe bot never responds.\r\n\r\n\r\n## Expected Functionality\r\nI would expect the bot to respond eventually. Perhaps even immediately and log an error stating `0` is an invalid response.\r\n\r\nThinking a little more about this I wonder if this functionality is the wrong way round. With `thinking-delay` that is the number of seconds that opsdroid should way before responding, so as the number gets bigger the longer opsdroid waits. But with `typing-delay` it is the number of characters per second that opsdroid can type, so the bigger the number the less opsdroid waits. The word `delay` suggests that the higher the number the longer the wait.\r\n\r\nThese opposites could be confusing (it confused me this evening). I think it would be good that both numbers represent time, rather than one representing characters per second. That would involve changing it to be seconds per character. This would result in a bigger number causing a bigger delay. \r\n\r\n\r\n## Versions\r\n- **Opsdroid version:** master\r\n- **Python version:** 3.5.4\r\n- **OS/Docker version:** macOS 10.13\r\n\r\n## Configuration File\r\n\r\n\r\n```yaml\r\nconnectors:\r\n - name: shell\r\n typing-delay: 0\r\n\r\nskills:\r\n - name: hello\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Class to encapsulate a message.\"\"\"\n\nfrom datetime import datetime\nfrom copy import copy\nimport asyncio\nfrom random import randrange\n\nfrom opsdroid.helper import get_opsdroid\n\n\nclass Message:\n # pylint: disable=too-few-public-methods\n \"\"\"A message object.\"\"\"\n\n def __init__(self, text, user, room, connector, raw_message=None):\n \"\"\"Create object with minimum properties.\"\"\"\n self.created = datetime.now()\n self.text = text\n self.user = user\n self.room = room\n self.connector = connector\n self.raw_message = raw_message\n self.regex = None\n self.responded_to = False\n\n async def _thinking_delay(self):\n \"\"\"Make opsdroid wait x-seconds before responding.\"\"\"\n seconds = self.connector.configuration.get('thinking-delay', 0)\n\n if isinstance(seconds, list):\n seconds = randrange(seconds[0], seconds[1])\n\n await asyncio.sleep(seconds)\n\n async def _typing_delay(self, text):\n \"\"\"Simulate typing, takes an int(characters per second typed).\"\"\"\n try:\n char_per_sec = self.connector.configuration['typing-delay']\n char_count = len(text)\n await asyncio.sleep(char_count//char_per_sec)\n except KeyError:\n pass\n\n async def respond(self, text, room=None):\n \"\"\"Respond to this message using the connector it was created by.\"\"\"\n opsdroid = get_opsdroid()\n response = copy(self)\n response.text = text\n\n if 'thinking-delay' in self.connector.configuration or \\\n 'typing-delay' in self.connector.configuration:\n await self._thinking_delay()\n await self._typing_delay(response.text)\n\n await self.connector.respond(response, room)\n if not self.responded_to:\n now = datetime.now()\n opsdroid.stats[\"total_responses\"] = \\\n opsdroid.stats[\"total_responses\"] + 1\n opsdroid.stats[\"total_response_time\"] = \\\n opsdroid.stats[\"total_response_time\"] + \\\n (now - self.created).total_seconds()\n self.responded_to = True\n\n async def react(self, emoji):\n \"\"\"React to this message using the connector it was created by.\"\"\"\n if 'thinking-delay' in self.connector.configuration:\n await self._thinking_delay()\n return await self.connector.react(self, emoji)\n", "path": "opsdroid/message.py"}], "after_files": [{"content": "\"\"\"Class to encapsulate a message.\"\"\"\n\nfrom datetime import datetime\nfrom copy import copy\nimport asyncio\nfrom random import randrange\n\nfrom opsdroid.helper import get_opsdroid\n\n\nclass Message:\n # pylint: disable=too-few-public-methods\n \"\"\"A message object.\"\"\"\n\n def __init__(self, text, user, room, connector, raw_message=None):\n \"\"\"Create object with minimum properties.\"\"\"\n self.created = datetime.now()\n self.text = text\n self.user = user\n self.room = room\n self.connector = connector\n self.raw_message = raw_message\n self.regex = None\n self.responded_to = False\n\n async def _thinking_delay(self):\n \"\"\"Make opsdroid wait x-seconds before responding.\"\"\"\n seconds = self.connector.configuration.get('thinking-delay', 0)\n\n if isinstance(seconds, list):\n seconds = randrange(seconds[0], seconds[1])\n\n await asyncio.sleep(seconds)\n\n async def _typing_delay(self, text):\n \"\"\"Simulate typing, takes an int or float to delay reply.\"\"\"\n seconds = self.connector.configuration.get('typing-delay', 0)\n char_count = len(text)\n\n if isinstance(seconds, list):\n seconds = randrange(seconds[0], seconds[1])\n\n await asyncio.sleep(char_count*seconds)\n\n async def respond(self, text, room=None):\n \"\"\"Respond to this message using the connector it was created by.\"\"\"\n opsdroid = get_opsdroid()\n response = copy(self)\n response.text = text\n\n if 'thinking-delay' in self.connector.configuration or \\\n 'typing-delay' in self.connector.configuration:\n await self._thinking_delay()\n await self._typing_delay(response.text)\n\n await self.connector.respond(response, room)\n if not self.responded_to:\n now = datetime.now()\n opsdroid.stats[\"total_responses\"] = \\\n opsdroid.stats[\"total_responses\"] + 1\n opsdroid.stats[\"total_response_time\"] = \\\n opsdroid.stats[\"total_response_time\"] + \\\n (now - self.created).total_seconds()\n self.responded_to = True\n\n async def react(self, emoji):\n \"\"\"React to this message using the connector it was created by.\"\"\"\n if 'thinking-delay' in self.connector.configuration:\n await self._thinking_delay()\n return await self.connector.react(self, emoji)\n", "path": "opsdroid/message.py"}]}
| 1,251 | 229 |
gh_patches_debug_27031
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2927
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`I3037` false positives in `AWS::ECS::TaskDefinition.ContainerDefinitions.Command`
### CloudFormation Lint Version
0.83.0
### What operating system are you using?
Mac
### Describe the bug
`I3037` issues (*List has a duplicate value*) are reported if the command specified in `AWS::ECS::TaskDefinition.ContainerDefinitions.Command` has repeating entries, e.g. the values of several command arguments are the same.
### Expected behavior
No issue is detected.
### Reproduction template
```json
{
"AWSTemplateFormatVersion": "2010-09-09",
"Description": "This template deploys an ECS task definition.",
"Resources": {
"MyECSTaskDefinition": {
"Type": "AWS::ECS::TaskDefinition",
"Properties": {
"ContainerDefinitions": [
{
"Command": [
"do_something",
"--foo",
"1",
"--bar",
"1"
],
"Image": "my-image",
"Name": "my-task"
}
]
}
}
}
}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py`
Content:
```
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import hashlib
6 import json
7
8 from cfnlint.helpers import RESOURCE_SPECS
9 from cfnlint.rules import CloudFormationLintRule, RuleMatch
10
11
12 class ListDuplicatesAllowed(CloudFormationLintRule):
13 """Check if duplicates exist in a List"""
14
15 id = "I3037"
16 shortdesc = "Check if a list that allows duplicates has any duplicates"
17 description = (
18 "Certain lists support duplicate items."
19 "Provide an alert when list of strings or numbers have repeats."
20 )
21 source_url = "https://github.com/aws-cloudformation/cfn-python-lint/blob/main/docs/rules.md#rules-1"
22 tags = ["resources", "property", "list"]
23
24 def initialize(self, cfn):
25 """Initialize the rule"""
26 for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(
27 "ResourceTypes"
28 ):
29 self.resource_property_types.append(resource_type_spec)
30 for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(
31 "PropertyTypes"
32 ):
33 self.resource_sub_property_types.append(property_type_spec)
34
35 def _check_duplicates(self, values, path, scenario=None):
36 """Check for Duplicates"""
37 matches = []
38
39 list_items = []
40 if isinstance(values, list):
41 for index, value in enumerate(values):
42 value_hash = hashlib.sha1(
43 json.dumps(value, sort_keys=True).encode("utf-8")
44 ).hexdigest()
45 if value_hash in list_items:
46 if not scenario:
47 message = "List has a duplicate value at {0}"
48 matches.append(
49 RuleMatch(
50 path + [index],
51 message.format("/".join(map(str, path + [index]))),
52 )
53 )
54 else:
55 scenario_text = " and ".join(
56 [f'condition "{k}" is {v}' for (k, v) in scenario.items()]
57 )
58 message = "List has a duplicate value at {0} when {1}"
59 matches.append(
60 RuleMatch(
61 path,
62 message.format("/".join(map(str, path)), scenario_text),
63 )
64 )
65
66 list_items.append(value_hash)
67
68 return matches
69
70 def check_duplicates(self, values, path, cfn):
71 """Check for duplicates"""
72 matches = []
73
74 if isinstance(values, list):
75 matches.extend(self._check_duplicates(values, path))
76 elif isinstance(values, dict):
77 props = cfn.get_object_without_conditions(values)
78 for prop in props:
79 matches.extend(
80 self._check_duplicates(
81 prop.get("Object"), path, prop.get("Scenario")
82 )
83 )
84
85 return matches
86
87 def check(self, cfn, properties, value_specs, path):
88 """Check itself"""
89 matches = []
90 for p_value, p_path in properties.items_safe(path[:]):
91 for prop in p_value:
92 if prop in value_specs:
93 property_type = value_specs.get(prop).get("Type")
94 primitive_type = value_specs.get(prop).get("PrimitiveItemType")
95 duplicates_allowed = value_specs.get(prop).get(
96 "DuplicatesAllowed", False
97 )
98 if (
99 property_type == "List"
100 and duplicates_allowed
101 and primitive_type in ["String", "Integer"]
102 ):
103 matches.extend(
104 self.check_duplicates(p_value[prop], p_path + [prop], cfn)
105 )
106
107 return matches
108
109 def match_resource_sub_properties(self, properties, property_type, path, cfn):
110 """Match for sub properties"""
111 matches = []
112
113 specs = (
114 RESOURCE_SPECS.get(cfn.regions[0])
115 .get("PropertyTypes")
116 .get(property_type, {})
117 .get("Properties", {})
118 )
119 matches.extend(self.check(cfn, properties, specs, path))
120
121 return matches
122
123 def match_resource_properties(self, properties, resource_type, path, cfn):
124 """Check CloudFormation Properties"""
125 matches = []
126
127 specs = (
128 RESOURCE_SPECS.get(cfn.regions[0])
129 .get("ResourceTypes")
130 .get(resource_type, {})
131 .get("Properties", {})
132 )
133 matches.extend(self.check(cfn, properties, specs, path))
134
135 return matches
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py b/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py
--- a/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py
+++ b/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py
@@ -21,6 +21,10 @@
source_url = "https://github.com/aws-cloudformation/cfn-python-lint/blob/main/docs/rules.md#rules-1"
tags = ["resources", "property", "list"]
+ def __init__(self):
+ super().__init__()
+ self.exceptions = ["Command"]
+
def initialize(self, cfn):
"""Initialize the rule"""
for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(
@@ -71,11 +75,15 @@
"""Check for duplicates"""
matches = []
+ if path[-1] in self.exceptions:
+ return matches
if isinstance(values, list):
matches.extend(self._check_duplicates(values, path))
elif isinstance(values, dict):
props = cfn.get_object_without_conditions(values)
for prop in props:
+ if prop in self.exceptions:
+ continue
matches.extend(
self._check_duplicates(
prop.get("Object"), path, prop.get("Scenario")
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py b/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py\n--- a/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py\n+++ b/src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py\n@@ -21,6 +21,10 @@\n source_url = \"https://github.com/aws-cloudformation/cfn-python-lint/blob/main/docs/rules.md#rules-1\"\n tags = [\"resources\", \"property\", \"list\"]\n \n+ def __init__(self):\n+ super().__init__()\n+ self.exceptions = [\"Command\"]\n+\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(\n@@ -71,11 +75,15 @@\n \"\"\"Check for duplicates\"\"\"\n matches = []\n \n+ if path[-1] in self.exceptions:\n+ return matches\n if isinstance(values, list):\n matches.extend(self._check_duplicates(values, path))\n elif isinstance(values, dict):\n props = cfn.get_object_without_conditions(values)\n for prop in props:\n+ if prop in self.exceptions:\n+ continue\n matches.extend(\n self._check_duplicates(\n prop.get(\"Object\"), path, prop.get(\"Scenario\")\n", "issue": "`I3037` false positives in `AWS::ECS::TaskDefinition.ContainerDefinitions.Command`\n### CloudFormation Lint Version\n\n0.83.0\n\n### What operating system are you using?\n\nMac\n\n### Describe the bug\n\n`I3037` issues (*List has a duplicate value*) are reported if the command specified in `AWS::ECS::TaskDefinition.ContainerDefinitions.Command` has repeating entries, e.g. the values of several command arguments are the same.\n\n### Expected behavior\n\nNo issue is detected.\n\n### Reproduction template\n\n```json\r\n{\r\n \"AWSTemplateFormatVersion\": \"2010-09-09\",\r\n \"Description\": \"This template deploys an ECS task definition.\",\r\n \"Resources\": {\r\n \"MyECSTaskDefinition\": {\r\n \"Type\": \"AWS::ECS::TaskDefinition\",\r\n \"Properties\": {\r\n \"ContainerDefinitions\": [\r\n {\r\n \"Command\": [\r\n \"do_something\",\r\n \"--foo\",\r\n \"1\",\r\n \"--bar\",\r\n \"1\"\r\n ],\r\n \"Image\": \"my-image\",\r\n \"Name\": \"my-task\"\r\n }\r\n ]\r\n }\r\n }\r\n }\r\n}\r\n```\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport hashlib\nimport json\n\nfrom cfnlint.helpers import RESOURCE_SPECS\nfrom cfnlint.rules import CloudFormationLintRule, RuleMatch\n\n\nclass ListDuplicatesAllowed(CloudFormationLintRule):\n \"\"\"Check if duplicates exist in a List\"\"\"\n\n id = \"I3037\"\n shortdesc = \"Check if a list that allows duplicates has any duplicates\"\n description = (\n \"Certain lists support duplicate items.\"\n \"Provide an alert when list of strings or numbers have repeats.\"\n )\n source_url = \"https://github.com/aws-cloudformation/cfn-python-lint/blob/main/docs/rules.md#rules-1\"\n tags = [\"resources\", \"property\", \"list\"]\n\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(\n \"ResourceTypes\"\n ):\n self.resource_property_types.append(resource_type_spec)\n for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(\n \"PropertyTypes\"\n ):\n self.resource_sub_property_types.append(property_type_spec)\n\n def _check_duplicates(self, values, path, scenario=None):\n \"\"\"Check for Duplicates\"\"\"\n matches = []\n\n list_items = []\n if isinstance(values, list):\n for index, value in enumerate(values):\n value_hash = hashlib.sha1(\n json.dumps(value, sort_keys=True).encode(\"utf-8\")\n ).hexdigest()\n if value_hash in list_items:\n if not scenario:\n message = \"List has a duplicate value at {0}\"\n matches.append(\n RuleMatch(\n path + [index],\n message.format(\"/\".join(map(str, path + [index]))),\n )\n )\n else:\n scenario_text = \" and \".join(\n [f'condition \"{k}\" is {v}' for (k, v) in scenario.items()]\n )\n message = \"List has a duplicate value at {0} when {1}\"\n matches.append(\n RuleMatch(\n path,\n message.format(\"/\".join(map(str, path)), scenario_text),\n )\n )\n\n list_items.append(value_hash)\n\n return matches\n\n def check_duplicates(self, values, path, cfn):\n \"\"\"Check for duplicates\"\"\"\n matches = []\n\n if isinstance(values, list):\n matches.extend(self._check_duplicates(values, path))\n elif isinstance(values, dict):\n props = cfn.get_object_without_conditions(values)\n for prop in props:\n matches.extend(\n self._check_duplicates(\n prop.get(\"Object\"), path, prop.get(\"Scenario\")\n )\n )\n\n return matches\n\n def check(self, cfn, properties, value_specs, path):\n \"\"\"Check itself\"\"\"\n matches = []\n for p_value, p_path in properties.items_safe(path[:]):\n for prop in p_value:\n if prop in value_specs:\n property_type = value_specs.get(prop).get(\"Type\")\n primitive_type = value_specs.get(prop).get(\"PrimitiveItemType\")\n duplicates_allowed = value_specs.get(prop).get(\n \"DuplicatesAllowed\", False\n )\n if (\n property_type == \"List\"\n and duplicates_allowed\n and primitive_type in [\"String\", \"Integer\"]\n ):\n matches.extend(\n self.check_duplicates(p_value[prop], p_path + [prop], cfn)\n )\n\n return matches\n\n def match_resource_sub_properties(self, properties, property_type, path, cfn):\n \"\"\"Match for sub properties\"\"\"\n matches = []\n\n specs = (\n RESOURCE_SPECS.get(cfn.regions[0])\n .get(\"PropertyTypes\")\n .get(property_type, {})\n .get(\"Properties\", {})\n )\n matches.extend(self.check(cfn, properties, specs, path))\n\n return matches\n\n def match_resource_properties(self, properties, resource_type, path, cfn):\n \"\"\"Check CloudFormation Properties\"\"\"\n matches = []\n\n specs = (\n RESOURCE_SPECS.get(cfn.regions[0])\n .get(\"ResourceTypes\")\n .get(resource_type, {})\n .get(\"Properties\", {})\n )\n matches.extend(self.check(cfn, properties, specs, path))\n\n return matches\n", "path": "src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py"}], "after_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport hashlib\nimport json\n\nfrom cfnlint.helpers import RESOURCE_SPECS\nfrom cfnlint.rules import CloudFormationLintRule, RuleMatch\n\n\nclass ListDuplicatesAllowed(CloudFormationLintRule):\n \"\"\"Check if duplicates exist in a List\"\"\"\n\n id = \"I3037\"\n shortdesc = \"Check if a list that allows duplicates has any duplicates\"\n description = (\n \"Certain lists support duplicate items.\"\n \"Provide an alert when list of strings or numbers have repeats.\"\n )\n source_url = \"https://github.com/aws-cloudformation/cfn-python-lint/blob/main/docs/rules.md#rules-1\"\n tags = [\"resources\", \"property\", \"list\"]\n\n def __init__(self):\n super().__init__()\n self.exceptions = [\"Command\"]\n\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(\n \"ResourceTypes\"\n ):\n self.resource_property_types.append(resource_type_spec)\n for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get(\n \"PropertyTypes\"\n ):\n self.resource_sub_property_types.append(property_type_spec)\n\n def _check_duplicates(self, values, path, scenario=None):\n \"\"\"Check for Duplicates\"\"\"\n matches = []\n\n list_items = []\n if isinstance(values, list):\n for index, value in enumerate(values):\n value_hash = hashlib.sha1(\n json.dumps(value, sort_keys=True).encode(\"utf-8\")\n ).hexdigest()\n if value_hash in list_items:\n if not scenario:\n message = \"List has a duplicate value at {0}\"\n matches.append(\n RuleMatch(\n path + [index],\n message.format(\"/\".join(map(str, path + [index]))),\n )\n )\n else:\n scenario_text = \" and \".join(\n [f'condition \"{k}\" is {v}' for (k, v) in scenario.items()]\n )\n message = \"List has a duplicate value at {0} when {1}\"\n matches.append(\n RuleMatch(\n path,\n message.format(\"/\".join(map(str, path)), scenario_text),\n )\n )\n\n list_items.append(value_hash)\n\n return matches\n\n def check_duplicates(self, values, path, cfn):\n \"\"\"Check for duplicates\"\"\"\n matches = []\n\n if path[-1] in self.exceptions:\n return matches\n if isinstance(values, list):\n matches.extend(self._check_duplicates(values, path))\n elif isinstance(values, dict):\n props = cfn.get_object_without_conditions(values)\n for prop in props:\n if prop in self.exceptions:\n continue\n matches.extend(\n self._check_duplicates(\n prop.get(\"Object\"), path, prop.get(\"Scenario\")\n )\n )\n\n return matches\n\n def check(self, cfn, properties, value_specs, path):\n \"\"\"Check itself\"\"\"\n matches = []\n for p_value, p_path in properties.items_safe(path[:]):\n for prop in p_value:\n if prop in value_specs:\n property_type = value_specs.get(prop).get(\"Type\")\n primitive_type = value_specs.get(prop).get(\"PrimitiveItemType\")\n duplicates_allowed = value_specs.get(prop).get(\n \"DuplicatesAllowed\", False\n )\n if (\n property_type == \"List\"\n and duplicates_allowed\n and primitive_type in [\"String\", \"Integer\"]\n ):\n matches.extend(\n self.check_duplicates(p_value[prop], p_path + [prop], cfn)\n )\n\n return matches\n\n def match_resource_sub_properties(self, properties, property_type, path, cfn):\n \"\"\"Match for sub properties\"\"\"\n matches = []\n\n specs = (\n RESOURCE_SPECS.get(cfn.regions[0])\n .get(\"PropertyTypes\")\n .get(property_type, {})\n .get(\"Properties\", {})\n )\n matches.extend(self.check(cfn, properties, specs, path))\n\n return matches\n\n def match_resource_properties(self, properties, resource_type, path, cfn):\n \"\"\"Check CloudFormation Properties\"\"\"\n matches = []\n\n specs = (\n RESOURCE_SPECS.get(cfn.regions[0])\n .get(\"ResourceTypes\")\n .get(resource_type, {})\n .get(\"Properties\", {})\n )\n matches.extend(self.check(cfn, properties, specs, path))\n\n return matches\n", "path": "src/cfnlint/rules/resources/properties/ListDuplicatesAllowed.py"}]}
| 1,738 | 287 |
gh_patches_debug_8210
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-16201
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
cosh
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/tensor.py`
Content:
```
1 # local
2 import ivy
3 import ivy.functional.frontends.paddle as paddle_frontend
4 from ivy.functional.frontends.paddle.func_wrapper import (
5 _to_ivy_array,
6 )
7 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
8
9
10 class Tensor:
11 def __init__(self, array, dtype=None, place="cpu", stop_gradient=True):
12 self._ivy_array = (
13 ivy.array(array, dtype=dtype, device=place)
14 if not isinstance(array, ivy.Array)
15 else array
16 )
17 self._dtype = dtype
18 self._place = place
19 self._stop_gradient = stop_gradient
20
21 def __repr__(self):
22 return (
23 str(self._ivy_array.__repr__())
24 .replace("ivy.array", "ivy.frontends.paddle.Tensor")
25 .replace("dev", "place")
26 )
27
28 # Properties #
29 # ---------- #
30
31 @property
32 def ivy_array(self):
33 return self._ivy_array
34
35 @property
36 def place(self):
37 return self.ivy_array.device
38
39 @property
40 def dtype(self):
41 return self._ivy_array.dtype
42
43 @property
44 def shape(self):
45 return self._ivy_array.shape
46
47 @property
48 def ndim(self):
49 return self.dim()
50
51 # Setters #
52 # --------#
53
54 @ivy_array.setter
55 def ivy_array(self, array):
56 self._ivy_array = (
57 ivy.array(array) if not isinstance(array, ivy.Array) else array
58 )
59
60 # Special Methods #
61 # -------------------#
62
63 def __getitem__(self, item):
64 ivy_args = ivy.nested_map([self, item], _to_ivy_array)
65 ret = ivy.get_item(*ivy_args)
66 return paddle_frontend.Tensor(ret)
67
68 def __setitem__(self, item, value):
69 item, value = ivy.nested_map([item, value], _to_ivy_array)
70 self.ivy_array[item] = value
71
72 def __iter__(self):
73 if self.ndim == 0:
74 raise TypeError("iteration over a 0-d tensor not supported")
75 for i in range(self.shape[0]):
76 yield self[i]
77
78 # Instance Methods #
79 # ---------------- #
80
81 def reshape(self, *args, shape=None):
82 if args and shape:
83 raise TypeError("reshape() got multiple values for argument 'shape'")
84 if shape is not None:
85 return paddle_frontend.reshape(self._ivy_array, shape)
86 if args:
87 if isinstance(args[0], (tuple, list)):
88 shape = args[0]
89 return paddle_frontend.reshape(self._ivy_array, shape)
90 else:
91 return paddle_frontend.reshape(self._ivy_array, args)
92 return paddle_frontend.reshape(self._ivy_array)
93
94 def dim(self):
95 return self.ivy_array.ndim
96
97 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
98 def abs(self):
99 return paddle_frontend.abs(self)
100
101 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
102 def ceil(self):
103 return paddle_frontend.ceil(self)
104
105 @with_unsupported_dtypes({"2.4.2 and below": ("float16",)}, "paddle")
106 def asinh(self, name=None):
107 return ivy.asinh(self._ivy_array)
108
109 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
110 def asin(self, name=None):
111 return ivy.asin(self._ivy_array)
112
113 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
114 def log(self, name=None):
115 return ivy.log(self._ivy_array)
116
117 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
118 def sin(self, name=None):
119 return ivy.sin(self._ivy_array)
120
121 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
122 def sinh(self, name=None):
123 return ivy.sinh(self._ivy_array)
124
125 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
126 def argmax(self, axis=None, keepdim=False, dtype=None, name=None):
127 return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)
128
129 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
130 def cos(self, name=None):
131 return ivy.cos(self._ivy_array)
132
133 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
134 def exp(self, name=None):
135 return ivy.exp(self._ivy_array)
136
137 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
138 def log10(self, name=None):
139 return ivy.log10(self._ivy_array)
140
141 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
142 def argsort(self, axis=-1, descending=False, name=None):
143 return ivy.argsort(self._ivy_array, axis=axis, descending=descending)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/tensor.py b/ivy/functional/frontends/paddle/tensor/tensor.py
--- a/ivy/functional/frontends/paddle/tensor/tensor.py
+++ b/ivy/functional/frontends/paddle/tensor/tensor.py
@@ -110,6 +110,10 @@
def asin(self, name=None):
return ivy.asin(self._ivy_array)
+ @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
+ def cosh(self, name=None):
+ return ivy.cosh(self._ivy_array)
+
@with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
def log(self, name=None):
return ivy.log(self._ivy_array)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/tensor.py b/ivy/functional/frontends/paddle/tensor/tensor.py\n--- a/ivy/functional/frontends/paddle/tensor/tensor.py\n+++ b/ivy/functional/frontends/paddle/tensor/tensor.py\n@@ -110,6 +110,10 @@\n def asin(self, name=None):\r\n return ivy.asin(self._ivy_array)\r\n \r\n+ @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n+ def cosh(self, name=None):\r\n+ return ivy.cosh(self._ivy_array)\r\n+\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def log(self, name=None):\r\n return ivy.log(self._ivy_array)\n", "issue": "cosh\n\n", "before_files": [{"content": "# local\r\nimport ivy\r\nimport ivy.functional.frontends.paddle as paddle_frontend\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n _to_ivy_array,\r\n)\r\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\r\n\r\n\r\nclass Tensor:\r\n def __init__(self, array, dtype=None, place=\"cpu\", stop_gradient=True):\r\n self._ivy_array = (\r\n ivy.array(array, dtype=dtype, device=place)\r\n if not isinstance(array, ivy.Array)\r\n else array\r\n )\r\n self._dtype = dtype\r\n self._place = place\r\n self._stop_gradient = stop_gradient\r\n\r\n def __repr__(self):\r\n return (\r\n str(self._ivy_array.__repr__())\r\n .replace(\"ivy.array\", \"ivy.frontends.paddle.Tensor\")\r\n .replace(\"dev\", \"place\")\r\n )\r\n\r\n # Properties #\r\n # ---------- #\r\n\r\n @property\r\n def ivy_array(self):\r\n return self._ivy_array\r\n\r\n @property\r\n def place(self):\r\n return self.ivy_array.device\r\n\r\n @property\r\n def dtype(self):\r\n return self._ivy_array.dtype\r\n\r\n @property\r\n def shape(self):\r\n return self._ivy_array.shape\r\n\r\n @property\r\n def ndim(self):\r\n return self.dim()\r\n\r\n # Setters #\r\n # --------#\r\n\r\n @ivy_array.setter\r\n def ivy_array(self, array):\r\n self._ivy_array = (\r\n ivy.array(array) if not isinstance(array, ivy.Array) else array\r\n )\r\n\r\n # Special Methods #\r\n # -------------------#\r\n\r\n def __getitem__(self, item):\r\n ivy_args = ivy.nested_map([self, item], _to_ivy_array)\r\n ret = ivy.get_item(*ivy_args)\r\n return paddle_frontend.Tensor(ret)\r\n\r\n def __setitem__(self, item, value):\r\n item, value = ivy.nested_map([item, value], _to_ivy_array)\r\n self.ivy_array[item] = value\r\n\r\n def __iter__(self):\r\n if self.ndim == 0:\r\n raise TypeError(\"iteration over a 0-d tensor not supported\")\r\n for i in range(self.shape[0]):\r\n yield self[i]\r\n\r\n # Instance Methods #\r\n # ---------------- #\r\n\r\n def reshape(self, *args, shape=None):\r\n if args and shape:\r\n raise TypeError(\"reshape() got multiple values for argument 'shape'\")\r\n if shape is not None:\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n if args:\r\n if isinstance(args[0], (tuple, list)):\r\n shape = args[0]\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n else:\r\n return paddle_frontend.reshape(self._ivy_array, args)\r\n return paddle_frontend.reshape(self._ivy_array)\r\n\r\n def dim(self):\r\n return self.ivy_array.ndim\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def abs(self):\r\n return paddle_frontend.abs(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def ceil(self):\r\n return paddle_frontend.ceil(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\",)}, \"paddle\")\r\n def asinh(self, name=None):\r\n return ivy.asinh(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def asin(self, name=None):\r\n return ivy.asin(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def log(self, name=None):\r\n return ivy.log(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sin(self, name=None):\r\n return ivy.sin(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sinh(self, name=None):\r\n return ivy.sinh(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def argmax(self, axis=None, keepdim=False, dtype=None, name=None):\r\n return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def cos(self, name=None):\r\n return ivy.cos(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def exp(self, name=None):\r\n return ivy.exp(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def log10(self, name=None):\r\n return ivy.log10(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def argsort(self, axis=-1, descending=False, name=None):\r\n return ivy.argsort(self._ivy_array, axis=axis, descending=descending)\r\n", "path": "ivy/functional/frontends/paddle/tensor/tensor.py"}], "after_files": [{"content": "# local\r\nimport ivy\r\nimport ivy.functional.frontends.paddle as paddle_frontend\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n _to_ivy_array,\r\n)\r\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\r\n\r\n\r\nclass Tensor:\r\n def __init__(self, array, dtype=None, place=\"cpu\", stop_gradient=True):\r\n self._ivy_array = (\r\n ivy.array(array, dtype=dtype, device=place)\r\n if not isinstance(array, ivy.Array)\r\n else array\r\n )\r\n self._dtype = dtype\r\n self._place = place\r\n self._stop_gradient = stop_gradient\r\n\r\n def __repr__(self):\r\n return (\r\n str(self._ivy_array.__repr__())\r\n .replace(\"ivy.array\", \"ivy.frontends.paddle.Tensor\")\r\n .replace(\"dev\", \"place\")\r\n )\r\n\r\n # Properties #\r\n # ---------- #\r\n\r\n @property\r\n def ivy_array(self):\r\n return self._ivy_array\r\n\r\n @property\r\n def place(self):\r\n return self.ivy_array.device\r\n\r\n @property\r\n def dtype(self):\r\n return self._ivy_array.dtype\r\n\r\n @property\r\n def shape(self):\r\n return self._ivy_array.shape\r\n\r\n @property\r\n def ndim(self):\r\n return self.dim()\r\n\r\n # Setters #\r\n # --------#\r\n\r\n @ivy_array.setter\r\n def ivy_array(self, array):\r\n self._ivy_array = (\r\n ivy.array(array) if not isinstance(array, ivy.Array) else array\r\n )\r\n\r\n # Special Methods #\r\n # -------------------#\r\n\r\n def __getitem__(self, item):\r\n ivy_args = ivy.nested_map([self, item], _to_ivy_array)\r\n ret = ivy.get_item(*ivy_args)\r\n return paddle_frontend.Tensor(ret)\r\n\r\n def __setitem__(self, item, value):\r\n item, value = ivy.nested_map([item, value], _to_ivy_array)\r\n self.ivy_array[item] = value\r\n\r\n def __iter__(self):\r\n if self.ndim == 0:\r\n raise TypeError(\"iteration over a 0-d tensor not supported\")\r\n for i in range(self.shape[0]):\r\n yield self[i]\r\n\r\n # Instance Methods #\r\n # ---------------- #\r\n\r\n def reshape(self, *args, shape=None):\r\n if args and shape:\r\n raise TypeError(\"reshape() got multiple values for argument 'shape'\")\r\n if shape is not None:\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n if args:\r\n if isinstance(args[0], (tuple, list)):\r\n shape = args[0]\r\n return paddle_frontend.reshape(self._ivy_array, shape)\r\n else:\r\n return paddle_frontend.reshape(self._ivy_array, args)\r\n return paddle_frontend.reshape(self._ivy_array)\r\n\r\n def dim(self):\r\n return self.ivy_array.ndim\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def abs(self):\r\n return paddle_frontend.abs(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def ceil(self):\r\n return paddle_frontend.ceil(self)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\",)}, \"paddle\")\r\n def asinh(self, name=None):\r\n return ivy.asinh(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def asin(self, name=None):\r\n return ivy.asin(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def cosh(self, name=None):\r\n return ivy.cosh(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def log(self, name=None):\r\n return ivy.log(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sin(self, name=None):\r\n return ivy.sin(self._ivy_array)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def sinh(self, name=None):\r\n return ivy.sinh(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def argmax(self, axis=None, keepdim=False, dtype=None, name=None):\r\n return ivy.argmax(self._ivy_array, axis=axis, keepdims=keepdim, dtype=dtype)\r\n\r\n @with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\r\n def cos(self, name=None):\r\n return ivy.cos(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def exp(self, name=None):\r\n return ivy.exp(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def log10(self, name=None):\r\n return ivy.log10(self._ivy_array)\r\n\r\n @with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n def argsort(self, axis=-1, descending=False, name=None):\r\n return ivy.argsort(self._ivy_array, axis=axis, descending=descending)\r\n", "path": "ivy/functional/frontends/paddle/tensor/tensor.py"}]}
| 1,851 | 205 |
gh_patches_debug_54191
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-293
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Need a .travis.yml file to properly run travis tests
^
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 from setuptools import setup, find_packages
4
5
6 with open('README.md') as f:
7 readme = f.read()
8
9 with open('LICENSE') as f:
10 license = f.read()
11
12 setup(
13 name='viper',
14 version='0.0.1',
15 description='Viper Programming Language for Ethereum',
16 long_description=readme,
17 author='Vitalik Buterin',
18 author_email='',
19 url='https://github.com/ethereum/viper',
20 license=license,
21 packages=find_packages(exclude=('tests', 'docs')),
22 install_requires=[
23 'ethereum == 1.3.7',
24 'serpent',
25 'pytest-cov',
26 'pytest-runner', # Must be after pytest-cov or it will not work
27 # due to https://github.com/pypa/setuptools/issues/196
28 ],
29 scripts=['bin/viper']
30 )
31
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@
license=license,
packages=find_packages(exclude=('tests', 'docs')),
install_requires=[
- 'ethereum == 1.3.7',
+ 'ethereum==2.0.4',
'serpent',
'pytest-cov',
'pytest-runner', # Must be after pytest-cov or it will not work
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,7 +20,7 @@\n license=license,\n packages=find_packages(exclude=('tests', 'docs')),\n install_requires=[\n- 'ethereum == 1.3.7',\n+ 'ethereum==2.0.4',\n 'serpent',\n 'pytest-cov',\n 'pytest-runner', # Must be after pytest-cov or it will not work\n", "issue": "Need a .travis.yml file to properly run travis tests\n^\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom setuptools import setup, find_packages\n\n\nwith open('README.md') as f:\n readme = f.read()\n\nwith open('LICENSE') as f:\n license = f.read()\n\nsetup(\n name='viper',\n version='0.0.1',\n description='Viper Programming Language for Ethereum',\n long_description=readme,\n author='Vitalik Buterin',\n author_email='',\n url='https://github.com/ethereum/viper',\n license=license,\n packages=find_packages(exclude=('tests', 'docs')),\n install_requires=[\n 'ethereum == 1.3.7',\n 'serpent',\n 'pytest-cov',\n 'pytest-runner', # Must be after pytest-cov or it will not work\n # due to https://github.com/pypa/setuptools/issues/196\n ],\n scripts=['bin/viper']\n)\n", "path": "setup.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom setuptools import setup, find_packages\n\n\nwith open('README.md') as f:\n readme = f.read()\n\nwith open('LICENSE') as f:\n license = f.read()\n\nsetup(\n name='viper',\n version='0.0.1',\n description='Viper Programming Language for Ethereum',\n long_description=readme,\n author='Vitalik Buterin',\n author_email='',\n url='https://github.com/ethereum/viper',\n license=license,\n packages=find_packages(exclude=('tests', 'docs')),\n install_requires=[\n 'ethereum==2.0.4',\n 'serpent',\n 'pytest-cov',\n 'pytest-runner', # Must be after pytest-cov or it will not work\n # due to https://github.com/pypa/setuptools/issues/196\n ],\n scripts=['bin/viper']\n)\n", "path": "setup.py"}]}
| 524 | 105 |
gh_patches_debug_16056
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-835
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: `geocentroid`, coordinates should multiply weights
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #833
- [ ] whatsnew entry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/geoseries/geocentroid.py`
Content:
```
1 import geopandas as gpd
2 import numpy as np
3 import pandas as pd
4 from shapely import Point
5
6 from dtoolkit.geoaccessor.geoseries.geodistance import geodistance
7 from dtoolkit.geoaccessor.geoseries.xy import xy
8 from dtoolkit.geoaccessor.register import register_geoseries_method
9
10
11 @register_geoseries_method
12 def geocentroid(
13 s: gpd.GeoSeries,
14 /,
15 weights: pd.Series = None,
16 max_iter: int = 300,
17 tol: float = 1e-5,
18 ) -> Point:
19 r"""
20 Return the centroid of all points via the center of gravity method.
21
22 .. math::
23
24 \left\{\begin{matrix}
25 d_i &=& D(P(\bar{x}_n, \bar{y}_n), P(x_i, y_i)) \\
26 \bar{x}_0 &=& \frac{\sum w_i x_i}{\sum w_i} \\
27 \bar{y}_0 &=& \frac{\sum w_i y_i}{\sum w_i} \\
28 \bar{x}_{n+1} &=& \frac{\sum w_i x_i / d_i}{\sum w_i / d_i} \\
29 \bar{y}_{n+1} &=& \frac{\sum w_i y_i / d_i}{\sum w_i / d_i} \\
30 \end{matrix}\right.
31
32 Parameters
33 ----------
34 weights : Hashable or 1d array-like, optional
35 - None : All weights will be set to 1.
36 - Hashable : Only for DataFrame, the column name.
37 - 1d array-like : The weights of each point.
38
39 max_iter : int, default 300
40 Maximum number of iterations to perform.
41
42 tol : float, default 1e-5
43 Tolerance for convergence.
44
45 Returns
46 -------
47 Point
48
49 See Also
50 --------
51 geopandas.GeoSeries.centroid
52 dtoolkit.geoaccessor.geoseries.geocentroid
53 dtoolkit.geoaccessor.geodataframe.geocentroid
54
55 Examples
56 --------
57 >>> import dtoolkit.geoaccessor
58 >>> import geopandas as gpd
59 >>> from shapely import Point
60 >>> df = gpd.GeoDataFrame(
61 ... {
62 ... "weights": [1, 2, 3],
63 ... "geometry": [Point(100, 32), Point(120, 50), Point(122, 55)],
64 ... },
65 ... crs=4326,
66 ... )
67 >>> df
68 weights geometry
69 0 1 POINT (100.00000 32.00000)
70 1 2 POINT (120.00000 50.00000)
71 2 3 POINT (122.00000 55.00000)
72 >>> df.geocentroid()
73 <POINT (120 50)>
74
75 Set weights for each point.
76
77 >>> df.geocentroid("weights")
78 <POINT (121.999 54.999)>
79 >>> df.geocentroid([1, 2, 3])
80 <POINT (121.999 54.999)>
81 """
82
83 weights = np.asarray(weights) if weights is not None else 1
84 coord = xy(s)
85 X = coord.mul(weights, axis=0).mean()
86 for _ in range(max_iter):
87 dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)
88 Xt = coord.mul(dis, axis=0).sum() / dis.sum()
89
90 if ((X - Xt).abs() <= tol).all():
91 X = Xt
92 break
93
94 X = Xt
95
96 return Point(*X.tolist())
97
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py
--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py
+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py
@@ -80,11 +80,15 @@
<POINT (121.999 54.999)>
"""
- weights = np.asarray(weights) if weights is not None else 1
coord = xy(s)
+ if len(coord) == 1:
+ return Point(coord.iloc[0])
+
+ weights = np.asarray(weights) if weights is not None else 1
X = coord.mul(weights, axis=0).mean()
+
for _ in range(max_iter):
- dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)
+ dis = geodistance(s, Point(X)).rdiv(1).mul(weights, axis=0)
Xt = coord.mul(dis, axis=0).sum() / dis.sum()
if ((X - Xt).abs() <= tol).all():
@@ -93,4 +97,4 @@
X = Xt
- return Point(*X.tolist())
+ return Point(X)
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/geocentroid.py b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n--- a/dtoolkit/geoaccessor/geoseries/geocentroid.py\n+++ b/dtoolkit/geoaccessor/geoseries/geocentroid.py\n@@ -80,11 +80,15 @@\n <POINT (121.999 54.999)>\n \"\"\"\n \n- weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n+ if len(coord) == 1:\n+ return Point(coord.iloc[0])\n+\n+ weights = np.asarray(weights) if weights is not None else 1\n X = coord.mul(weights, axis=0).mean()\n+\n for _ in range(max_iter):\n- dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n+ dis = geodistance(s, Point(X)).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n \n if ((X - Xt).abs() <= tol).all():\n@@ -93,4 +97,4 @@\n \n X = Xt\n \n- return Point(*X.tolist())\n+ return Point(X)\n", "issue": "BUG: `geocentroid`, coordinates should multiply weights\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #833\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n r\"\"\"\n Return the centroid of all points via the center of gravity method.\n\n .. math::\n\n \\left\\{\\begin{matrix}\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n \\end{matrix}\\right.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-5\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (120 50)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (121.999 54.999)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (121.999 54.999)>\n \"\"\"\n\n weights = np.asarray(weights) if weights is not None else 1\n coord = xy(s)\n X = coord.mul(weights, axis=0).mean()\n for _ in range(max_iter):\n dis = geodistance(s, Point(*X.tolist())).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(*X.tolist())\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}], "after_files": [{"content": "import geopandas as gpd\nimport numpy as np\nimport pandas as pd\nfrom shapely import Point\n\nfrom dtoolkit.geoaccessor.geoseries.geodistance import geodistance\nfrom dtoolkit.geoaccessor.geoseries.xy import xy\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geocentroid(\n s: gpd.GeoSeries,\n /,\n weights: pd.Series = None,\n max_iter: int = 300,\n tol: float = 1e-5,\n) -> Point:\n r\"\"\"\n Return the centroid of all points via the center of gravity method.\n\n .. math::\n\n \\left\\{\\begin{matrix}\n d_i &=& D(P(\\bar{x}_n, \\bar{y}_n), P(x_i, y_i)) \\\\\n \\bar{x}_0 &=& \\frac{\\sum w_i x_i}{\\sum w_i} \\\\\n \\bar{y}_0 &=& \\frac{\\sum w_i y_i}{\\sum w_i} \\\\\n \\bar{x}_{n+1} &=& \\frac{\\sum w_i x_i / d_i}{\\sum w_i / d_i} \\\\\n \\bar{y}_{n+1} &=& \\frac{\\sum w_i y_i / d_i}{\\sum w_i / d_i} \\\\\n \\end{matrix}\\right.\n\n Parameters\n ----------\n weights : Hashable or 1d array-like, optional\n - None : All weights will be set to 1.\n - Hashable : Only for DataFrame, the column name.\n - 1d array-like : The weights of each point.\n\n max_iter : int, default 300\n Maximum number of iterations to perform.\n\n tol : float, default 1e-5\n Tolerance for convergence.\n\n Returns\n -------\n Point\n\n See Also\n --------\n geopandas.GeoSeries.centroid\n dtoolkit.geoaccessor.geoseries.geocentroid\n dtoolkit.geoaccessor.geodataframe.geocentroid\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> from shapely import Point\n >>> df = gpd.GeoDataFrame(\n ... {\n ... \"weights\": [1, 2, 3],\n ... \"geometry\": [Point(100, 32), Point(120, 50), Point(122, 55)],\n ... },\n ... crs=4326,\n ... )\n >>> df\n weights geometry\n 0 1 POINT (100.00000 32.00000)\n 1 2 POINT (120.00000 50.00000)\n 2 3 POINT (122.00000 55.00000)\n >>> df.geocentroid()\n <POINT (120 50)>\n\n Set weights for each point.\n\n >>> df.geocentroid(\"weights\")\n <POINT (121.999 54.999)>\n >>> df.geocentroid([1, 2, 3])\n <POINT (121.999 54.999)>\n \"\"\"\n\n coord = xy(s)\n if len(coord) == 1:\n return Point(coord.iloc[0])\n\n weights = np.asarray(weights) if weights is not None else 1\n X = coord.mul(weights, axis=0).mean()\n\n for _ in range(max_iter):\n dis = geodistance(s, Point(X)).rdiv(1).mul(weights, axis=0)\n Xt = coord.mul(dis, axis=0).sum() / dis.sum()\n\n if ((X - Xt).abs() <= tol).all():\n X = Xt\n break\n\n X = Xt\n\n return Point(X)\n", "path": "dtoolkit/geoaccessor/geoseries/geocentroid.py"}]}
| 1,549 | 304 |
gh_patches_debug_40690
|
rasdani/github-patches
|
git_diff
|
hedyorg__hedy-1379
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add level 2 to hedy_translation.py
Now that the keywords from level 1 can be translated, new levels can be added.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hedy_translation.py`
Content:
```
1 from lark import Transformer, Tree
2 from hedy import get_keywords_for_language, ExtractAST, get_parser
3
4
5 TRANSPILER_LOOKUP = {}
6
7
8 def keywords_to_dict(to_lang="nl"):
9 """"Return a dictionary of keywords from language of choice. Key is english value is lang of choice"""
10 keywords = {}
11 keywords_from = get_keywords_for_language("en").replace("\n\n", "\n").splitlines()
12
13 keywords_to = get_keywords_for_language(to_lang).replace("\n\n", "\n").splitlines()
14 keywords_from_withoutlvl = []
15 for line in keywords_from:
16 if line[0] != '/':
17 keywords_from_withoutlvl.append(line)
18
19 keywords_to_withoutlvl = []
20 for line in keywords_to:
21 if line[0] != '/':
22 keywords_to_withoutlvl.append(line)
23
24 for line in range(len(keywords_from_withoutlvl)):
25 keywords[(keywords_from_withoutlvl[line].split('"'))[1]] = keywords_to_withoutlvl[line].split('"')[1]
26
27 return keywords
28
29
30 def translate_keywords(input_string, from_lang="nl", to_lang="nl", level=1):
31 """"Return code with keywords translated to language of choice in level of choice"""
32 parser = get_parser(level, from_lang)
33
34 punctuation_symbols = ['!', '?', '.']
35
36 keywordDict = keywords_to_dict(to_lang)
37 program_root = parser.parse(input_string + '\n').children[0]
38 abstract_syntaxtree = ExtractAST().transform(program_root)
39 translator = TRANSPILER_LOOKUP[level]
40 abstract_syntaxtree = translator(keywordDict, punctuation_symbols).transform(program_root)
41
42 return abstract_syntaxtree
43
44
45 def hedy_translator(level):
46 def decorating(c):
47 TRANSPILER_LOOKUP[level] = c
48 c.level = level
49 return c
50
51 return decorating
52
53
54 @hedy_translator(level=1)
55 class ConvertToLang1(Transformer):
56
57 def __init__(self, keywords, punctuation_symbols):
58 self.keywords = keywords
59 self.punctuation_symbols = punctuation_symbols
60 __class__.level = 1
61
62 def command(self, args):
63 return args[0]
64
65 def program(self, args):
66 return '\n'.join([str(c) for c in args])
67
68 def text(self, args):
69 return ''.join([str(c) for c in args])
70
71 def invalid_space(self, args):
72 return " " + ''.join([str(c) for c in args])
73
74 def print(self, args):
75 return self.keywords["print"] + " " + "".join([str(c) for c in args])
76
77 def echo(self, args):
78 all_args = self.keywords["echo"]
79 if args:
80 all_args += " "
81 return all_args + "".join([str(c) for c in args])
82
83 def ask(self, args):
84 return self.keywords["ask"] + " " + "".join([str(c) for c in args])
85
86 def turn(self, args):
87 return self.keywords["turn"] + " " + "".join([str(c) for c in args])
88
89 def forward(self, args):
90 return self.keywords["forward"] + " " + "".join([str(c) for c in args])
91
92 def random(self, args):
93 return self.keywords["random"] + "".join([str(c) for c in args])
94
95 def invalid(self, args):
96 return ' '.join([str(c) for c in args])
97
98 def __default__(self, data, children, meta):
99 return Tree(data, children, meta)
100
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hedy_translation.py b/hedy_translation.py
--- a/hedy_translation.py
+++ b/hedy_translation.py
@@ -1,5 +1,5 @@
from lark import Transformer, Tree
-from hedy import get_keywords_for_language, ExtractAST, get_parser
+import hedy
TRANSPILER_LOOKUP = {}
@@ -8,9 +8,9 @@
def keywords_to_dict(to_lang="nl"):
""""Return a dictionary of keywords from language of choice. Key is english value is lang of choice"""
keywords = {}
- keywords_from = get_keywords_for_language("en").replace("\n\n", "\n").splitlines()
+ keywords_from = hedy.get_keywords_for_language("en").replace("\n\n", "\n").splitlines()
- keywords_to = get_keywords_for_language(to_lang).replace("\n\n", "\n").splitlines()
+ keywords_to = hedy.get_keywords_for_language(to_lang).replace("\n\n", "\n").splitlines()
keywords_from_withoutlvl = []
for line in keywords_from:
if line[0] != '/':
@@ -29,13 +29,13 @@
def translate_keywords(input_string, from_lang="nl", to_lang="nl", level=1):
""""Return code with keywords translated to language of choice in level of choice"""
- parser = get_parser(level, from_lang)
+ parser = hedy.get_parser(level, from_lang)
punctuation_symbols = ['!', '?', '.']
keywordDict = keywords_to_dict(to_lang)
program_root = parser.parse(input_string + '\n').children[0]
- abstract_syntaxtree = ExtractAST().transform(program_root)
+ abstract_syntaxtree = hedy.ExtractAST().transform(program_root)
translator = TRANSPILER_LOOKUP[level]
abstract_syntaxtree = translator(keywordDict, punctuation_symbols).transform(program_root)
@@ -97,3 +97,50 @@
def __default__(self, data, children, meta):
return Tree(data, children, meta)
+
+@hedy_translator(level=2)
+class ConvertToLang2(ConvertToLang1):
+
+ def assign(self, args):
+ return args[0] + " " + self.keywords["is"] + " " + ''.join([str(c) for c in args[1:]])
+
+ def print(self, args):
+
+ argument_string = ""
+ i = 0
+
+ for argument in args:
+ # escape quotes if kids accidentally use them at level 2
+ argument = hedy.process_characters_needing_escape(argument)
+
+ # final argument and punctuation arguments do not have to be separated with a space, other do
+ if i == len(args) - 1 or args[i + 1] in self.punctuation_symbols:
+ space = ''
+ else:
+ space = " "
+
+ argument_string += argument + space
+
+ i = i + 1
+
+ return self.keywords["print"] + " " + argument_string
+
+ def punctuation(self, args):
+ return ''.join([str(c) for c in args])
+
+ def var(self, args):
+ var = args[0]
+ all_parameters = ["'" + hedy.process_characters_needing_escape(a) + "'" for a in args[1:]]
+ return var + ''.join(all_parameters)
+
+ def ask(self, args):
+ var = args[0]
+ all_parameters = [hedy.process_characters_needing_escape(a) for a in args]
+
+ return all_parameters[0] + " " + self.keywords["is"] + " " + self.keywords["ask"] + " " + ''.join(all_parameters[1:])
+
+ def ask_dep_2(self, args):
+ return self.keywords["ask"] + " " + ''.join([str(c) for c in args])
+
+ def echo_dep_2(self, args):
+ return self.keywords["echo"] + " " + ''.join([str(c) for c in args])
|
{"golden_diff": "diff --git a/hedy_translation.py b/hedy_translation.py\n--- a/hedy_translation.py\n+++ b/hedy_translation.py\n@@ -1,5 +1,5 @@\n from lark import Transformer, Tree\n-from hedy import get_keywords_for_language, ExtractAST, get_parser\n+import hedy\n \n \n TRANSPILER_LOOKUP = {}\n@@ -8,9 +8,9 @@\n def keywords_to_dict(to_lang=\"nl\"):\n \"\"\"\"Return a dictionary of keywords from language of choice. Key is english value is lang of choice\"\"\"\n keywords = {}\n- keywords_from = get_keywords_for_language(\"en\").replace(\"\\n\\n\", \"\\n\").splitlines()\n+ keywords_from = hedy.get_keywords_for_language(\"en\").replace(\"\\n\\n\", \"\\n\").splitlines()\n \n- keywords_to = get_keywords_for_language(to_lang).replace(\"\\n\\n\", \"\\n\").splitlines()\n+ keywords_to = hedy.get_keywords_for_language(to_lang).replace(\"\\n\\n\", \"\\n\").splitlines()\n keywords_from_withoutlvl = []\n for line in keywords_from:\n if line[0] != '/':\n@@ -29,13 +29,13 @@\n \n def translate_keywords(input_string, from_lang=\"nl\", to_lang=\"nl\", level=1):\n \"\"\"\"Return code with keywords translated to language of choice in level of choice\"\"\"\n- parser = get_parser(level, from_lang)\n+ parser = hedy.get_parser(level, from_lang)\n \n punctuation_symbols = ['!', '?', '.']\n \n keywordDict = keywords_to_dict(to_lang)\n program_root = parser.parse(input_string + '\\n').children[0]\n- abstract_syntaxtree = ExtractAST().transform(program_root)\n+ abstract_syntaxtree = hedy.ExtractAST().transform(program_root)\n translator = TRANSPILER_LOOKUP[level]\n abstract_syntaxtree = translator(keywordDict, punctuation_symbols).transform(program_root)\n \n@@ -97,3 +97,50 @@\n \n def __default__(self, data, children, meta):\n return Tree(data, children, meta)\n+\n+@hedy_translator(level=2)\n+class ConvertToLang2(ConvertToLang1):\n+\n+ def assign(self, args):\n+ return args[0] + \" \" + self.keywords[\"is\"] + \" \" + ''.join([str(c) for c in args[1:]])\n+\n+ def print(self, args):\n+\n+ argument_string = \"\"\n+ i = 0\n+\n+ for argument in args:\n+ # escape quotes if kids accidentally use them at level 2\n+ argument = hedy.process_characters_needing_escape(argument)\n+\n+ # final argument and punctuation arguments do not have to be separated with a space, other do\n+ if i == len(args) - 1 or args[i + 1] in self.punctuation_symbols:\n+ space = ''\n+ else:\n+ space = \" \"\n+\n+ argument_string += argument + space\n+\n+ i = i + 1\n+\n+ return self.keywords[\"print\"] + \" \" + argument_string\n+\n+ def punctuation(self, args):\n+ return ''.join([str(c) for c in args])\n+\n+ def var(self, args):\n+ var = args[0]\n+ all_parameters = [\"'\" + hedy.process_characters_needing_escape(a) + \"'\" for a in args[1:]]\n+ return var + ''.join(all_parameters)\n+\n+ def ask(self, args):\n+ var = args[0]\n+ all_parameters = [hedy.process_characters_needing_escape(a) for a in args]\n+\n+ return all_parameters[0] + \" \" + self.keywords[\"is\"] + \" \" + self.keywords[\"ask\"] + \" \" + ''.join(all_parameters[1:])\n+\n+ def ask_dep_2(self, args):\n+ return self.keywords[\"ask\"] + \" \" + ''.join([str(c) for c in args])\n+\n+ def echo_dep_2(self, args):\n+ return self.keywords[\"echo\"] + \" \" + ''.join([str(c) for c in args])\n", "issue": "Add level 2 to hedy_translation.py\nNow that the keywords from level 1 can be translated, new levels can be added.\n", "before_files": [{"content": "from lark import Transformer, Tree\nfrom hedy import get_keywords_for_language, ExtractAST, get_parser\n\n\nTRANSPILER_LOOKUP = {}\n\n\ndef keywords_to_dict(to_lang=\"nl\"):\n \"\"\"\"Return a dictionary of keywords from language of choice. Key is english value is lang of choice\"\"\"\n keywords = {}\n keywords_from = get_keywords_for_language(\"en\").replace(\"\\n\\n\", \"\\n\").splitlines()\n\n keywords_to = get_keywords_for_language(to_lang).replace(\"\\n\\n\", \"\\n\").splitlines()\n keywords_from_withoutlvl = []\n for line in keywords_from:\n if line[0] != '/':\n keywords_from_withoutlvl.append(line)\n\n keywords_to_withoutlvl = []\n for line in keywords_to:\n if line[0] != '/':\n keywords_to_withoutlvl.append(line)\n\n for line in range(len(keywords_from_withoutlvl)):\n keywords[(keywords_from_withoutlvl[line].split('\"'))[1]] = keywords_to_withoutlvl[line].split('\"')[1]\n\n return keywords\n\n\ndef translate_keywords(input_string, from_lang=\"nl\", to_lang=\"nl\", level=1):\n \"\"\"\"Return code with keywords translated to language of choice in level of choice\"\"\"\n parser = get_parser(level, from_lang)\n\n punctuation_symbols = ['!', '?', '.']\n\n keywordDict = keywords_to_dict(to_lang)\n program_root = parser.parse(input_string + '\\n').children[0]\n abstract_syntaxtree = ExtractAST().transform(program_root)\n translator = TRANSPILER_LOOKUP[level]\n abstract_syntaxtree = translator(keywordDict, punctuation_symbols).transform(program_root)\n\n return abstract_syntaxtree\n\n\ndef hedy_translator(level):\n def decorating(c):\n TRANSPILER_LOOKUP[level] = c\n c.level = level\n return c\n\n return decorating\n\n\n@hedy_translator(level=1)\nclass ConvertToLang1(Transformer):\n\n def __init__(self, keywords, punctuation_symbols):\n self.keywords = keywords\n self.punctuation_symbols = punctuation_symbols\n __class__.level = 1\n\n def command(self, args):\n return args[0]\n\n def program(self, args):\n return '\\n'.join([str(c) for c in args])\n\n def text(self, args):\n return ''.join([str(c) for c in args])\n\n def invalid_space(self, args):\n return \" \" + ''.join([str(c) for c in args])\n\n def print(self, args):\n return self.keywords[\"print\"] + \" \" + \"\".join([str(c) for c in args])\n\n def echo(self, args):\n all_args = self.keywords[\"echo\"]\n if args:\n all_args += \" \"\n return all_args + \"\".join([str(c) for c in args])\n\n def ask(self, args):\n return self.keywords[\"ask\"] + \" \" + \"\".join([str(c) for c in args])\n\n def turn(self, args):\n return self.keywords[\"turn\"] + \" \" + \"\".join([str(c) for c in args])\n\n def forward(self, args):\n return self.keywords[\"forward\"] + \" \" + \"\".join([str(c) for c in args])\n\n def random(self, args):\n return self.keywords[\"random\"] + \"\".join([str(c) for c in args])\n\n def invalid(self, args):\n return ' '.join([str(c) for c in args])\n\n def __default__(self, data, children, meta):\n return Tree(data, children, meta)\n", "path": "hedy_translation.py"}], "after_files": [{"content": "from lark import Transformer, Tree\nimport hedy\n\n\nTRANSPILER_LOOKUP = {}\n\n\ndef keywords_to_dict(to_lang=\"nl\"):\n \"\"\"\"Return a dictionary of keywords from language of choice. Key is english value is lang of choice\"\"\"\n keywords = {}\n keywords_from = hedy.get_keywords_for_language(\"en\").replace(\"\\n\\n\", \"\\n\").splitlines()\n\n keywords_to = hedy.get_keywords_for_language(to_lang).replace(\"\\n\\n\", \"\\n\").splitlines()\n keywords_from_withoutlvl = []\n for line in keywords_from:\n if line[0] != '/':\n keywords_from_withoutlvl.append(line)\n\n keywords_to_withoutlvl = []\n for line in keywords_to:\n if line[0] != '/':\n keywords_to_withoutlvl.append(line)\n\n for line in range(len(keywords_from_withoutlvl)):\n keywords[(keywords_from_withoutlvl[line].split('\"'))[1]] = keywords_to_withoutlvl[line].split('\"')[1]\n\n return keywords\n\n\ndef translate_keywords(input_string, from_lang=\"nl\", to_lang=\"nl\", level=1):\n \"\"\"\"Return code with keywords translated to language of choice in level of choice\"\"\"\n parser = hedy.get_parser(level, from_lang)\n\n punctuation_symbols = ['!', '?', '.']\n\n keywordDict = keywords_to_dict(to_lang)\n program_root = parser.parse(input_string + '\\n').children[0]\n abstract_syntaxtree = hedy.ExtractAST().transform(program_root)\n translator = TRANSPILER_LOOKUP[level]\n abstract_syntaxtree = translator(keywordDict, punctuation_symbols).transform(program_root)\n\n return abstract_syntaxtree\n\n\ndef hedy_translator(level):\n def decorating(c):\n TRANSPILER_LOOKUP[level] = c\n c.level = level\n return c\n\n return decorating\n\n\n@hedy_translator(level=1)\nclass ConvertToLang1(Transformer):\n\n def __init__(self, keywords, punctuation_symbols):\n self.keywords = keywords\n self.punctuation_symbols = punctuation_symbols\n __class__.level = 1\n\n def command(self, args):\n return args[0]\n\n def program(self, args):\n return '\\n'.join([str(c) for c in args])\n\n def text(self, args):\n return ''.join([str(c) for c in args])\n\n def invalid_space(self, args):\n return \" \" + ''.join([str(c) for c in args])\n\n def print(self, args):\n return self.keywords[\"print\"] + \" \" + \"\".join([str(c) for c in args])\n\n def echo(self, args):\n all_args = self.keywords[\"echo\"]\n if args:\n all_args += \" \"\n return all_args + \"\".join([str(c) for c in args])\n\n def ask(self, args):\n return self.keywords[\"ask\"] + \" \" + \"\".join([str(c) for c in args])\n\n def turn(self, args):\n return self.keywords[\"turn\"] + \" \" + \"\".join([str(c) for c in args])\n\n def forward(self, args):\n return self.keywords[\"forward\"] + \" \" + \"\".join([str(c) for c in args])\n\n def random(self, args):\n return self.keywords[\"random\"] + \"\".join([str(c) for c in args])\n\n def invalid(self, args):\n return ' '.join([str(c) for c in args])\n\n def __default__(self, data, children, meta):\n return Tree(data, children, meta)\n\n@hedy_translator(level=2)\nclass ConvertToLang2(ConvertToLang1):\n\n def assign(self, args):\n return args[0] + \" \" + self.keywords[\"is\"] + \" \" + ''.join([str(c) for c in args[1:]])\n\n def print(self, args):\n\n argument_string = \"\"\n i = 0\n\n for argument in args:\n # escape quotes if kids accidentally use them at level 2\n argument = hedy.process_characters_needing_escape(argument)\n\n # final argument and punctuation arguments do not have to be separated with a space, other do\n if i == len(args) - 1 or args[i + 1] in self.punctuation_symbols:\n space = ''\n else:\n space = \" \"\n\n argument_string += argument + space\n\n i = i + 1\n\n return self.keywords[\"print\"] + \" \" + argument_string\n\n def punctuation(self, args):\n return ''.join([str(c) for c in args])\n\n def var(self, args):\n var = args[0]\n all_parameters = [\"'\" + hedy.process_characters_needing_escape(a) + \"'\" for a in args[1:]]\n return var + ''.join(all_parameters)\n\n def ask(self, args):\n var = args[0]\n all_parameters = [hedy.process_characters_needing_escape(a) for a in args]\n\n return all_parameters[0] + \" \" + self.keywords[\"is\"] + \" \" + self.keywords[\"ask\"] + \" \" + ''.join(all_parameters[1:])\n\n def ask_dep_2(self, args):\n return self.keywords[\"ask\"] + \" \" + ''.join([str(c) for c in args])\n\n def echo_dep_2(self, args):\n return self.keywords[\"echo\"] + \" \" + ''.join([str(c) for c in args])\n", "path": "hedy_translation.py"}]}
| 1,243 | 886 |
gh_patches_debug_4500
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6643
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Pytest warnings when using mssql DB backend
### Meltano Version
2.4.0
### Python Version
NA
### Bug scope
Other
### Operating System
Linux
### Description
Pytest is catching warnings emitted during testing with the mssql DB backend. Example:
https://github.com/meltano/meltano/runs/7813948143
```
/home/runner/work/meltano/meltano/.nox/tests-3-9/lib/python3.9/site-packages/alembic/ddl/mssql.py:125: UserWarning: MS-SQL ALTER COLUMN operations that specify type_= should also specify a nullable= or existing_nullable= argument to avoid implicit conversion of NOT NULL columns to NULL.
util.warn(
```
It's the same warning being emitted 90 times.
### Code
Running a test that raises the warning with `python -Werror pytest ...` results in the following traceback:
```
Traceback (most recent call last):
File "/home/will/meltano/meltano/src/meltano/core/migration_service.py", line 96, in upgrade
command.upgrade(cfg, head)
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/command.py", line 322, in upgrade
script.run_env()
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/script/base.py", line 569, in run_env
util.load_python_file(self.dir, "env.py")
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/pyfiles.py", line 94, in load_python_file
module = load_module_py(module_id, path)
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/pyfiles.py", line 110, in load_module_py
spec.loader.exec_module(module) # type: ignore
File "<frozen importlib._bootstrap_external>", line 728, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/home/will/meltano/meltano/src/meltano/migrations/env.py", line 60, in <module>
run_migrations_online()
File "/home/will/meltano/meltano/src/meltano/migrations/env.py", line 37, in run_migrations_online
_run_migrations_online(connection)
File "/home/will/meltano/meltano/src/meltano/migrations/env.py", line 54, in _run_migrations_online
context.run_migrations()
File "<string>", line 8, in run_migrations
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/runtime/environment.py", line 853, in run_migrations
self.get_context().run_migrations(**kw)
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/runtime/migration.py", line 623, in run_migrations
step.migration_fn(**kw)
File "/home/will/meltano/meltano/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py", line 49, in upgrade
existing_type=sa.Enum(State, name="job_state"),
File "<string>", line 8, in alter_column
File "<string>", line 3, in alter_column
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/ops.py", line 1880, in alter_column
return operations.invoke(alt)
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/base.py", line 399, in invoke
return fn(self, operation)
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/toimpl.py", line 63, in alter_column
**operation.kw
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/ddl/mssql.py", line 126, in alter_column
"MS-SQL ALTER COLUMN operations that specify type_= "
File "/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/messaging.py", line 81, in warn
warnings.warn(msg, UserWarning, stacklevel=stacklevel)
UserWarning: MS-SQL ALTER COLUMN operations that specify type_= should also specify a nullable= or existing_nullable= argument to avoid implicit conversion of NOT NULL columns to NULL.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py`
Content:
```
1 """add_state_edit_to_job_state_enum
2
3 Revision ID: 13e8639c6d2b
4 Revises: d135f52a6f49
5 Create Date: 2022-04-21 09:35:35.435614
6
7 """
8 from enum import Enum
9
10 import sqlalchemy as sa
11 from alembic import op
12
13 from meltano.migrations.utils.dialect_typing import (
14 get_dialect_name,
15 max_string_length_for_dialect,
16 )
17
18 # revision identifiers, used by Alembic.
19 revision = "13e8639c6d2b"
20 down_revision = "d135f52a6f49"
21 branch_labels = None
22 depends_on = None
23
24
25 # from core/job/job.py
26 class State(Enum):
27 """Represents status of a Job."""
28
29 IDLE = (0, ("RUNNING", "FAIL"))
30 RUNNING = (1, ("SUCCESS", "FAIL"))
31 SUCCESS = (2, ())
32 FAIL = (3, ("RUNNING",))
33 DEAD = (4, ())
34 STATE_EDIT = (5, ())
35
36
37 def upgrade():
38 dialect_name = get_dialect_name()
39 max_string_length = max_string_length_for_dialect(dialect_name)
40
41 conn = op.get_bind()
42 # In sqlite, the field is already a varchar.
43 # "ALTER COLUMN" statements are also not supported.
44 if conn.dialect.name != "sqlite":
45 op.alter_column(
46 table_name="job",
47 column_name="state",
48 type_=sa.types.String(max_string_length),
49 existing_type=sa.Enum(State, name="job_state"),
50 )
51
52 # In postgresql, drop the created Enum type so that
53 # downgrade() can re-create it.
54 if conn.dialect.name == "postgresql":
55 conn.execute("DROP TYPE job_state;")
56
57
58 def downgrade():
59 conn = op.get_bind()
60 # In sqlite, the field is already a varchar.
61 # "ALTER COLUMN" statements are also not supported.
62 if conn.dialect.name != "sqlite":
63 op.alter_column(
64 table_name="job",
65 column_name="state",
66 _type=sa.Enum(State, name="job_state"),
67 existing_type=sa.types.String,
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py b/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py
--- a/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py
+++ b/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py
@@ -47,6 +47,7 @@
column_name="state",
type_=sa.types.String(max_string_length),
existing_type=sa.Enum(State, name="job_state"),
+ existing_nullable=True,
)
# In postgresql, drop the created Enum type so that
|
{"golden_diff": "diff --git a/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py b/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py\n--- a/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py\n+++ b/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py\n@@ -47,6 +47,7 @@\n column_name=\"state\",\n type_=sa.types.String(max_string_length),\n existing_type=sa.Enum(State, name=\"job_state\"),\n+ existing_nullable=True,\n )\n \n # In postgresql, drop the created Enum type so that\n", "issue": "bug: Pytest warnings when using mssql DB backend\n### Meltano Version\r\n\r\n2.4.0\r\n\r\n### Python Version\r\n\r\nNA\r\n\r\n### Bug scope\r\n\r\nOther\r\n\r\n### Operating System\r\n\r\nLinux\r\n\r\n### Description\r\n\r\nPytest is catching warnings emitted during testing with the mssql DB backend. Example:\r\n\r\nhttps://github.com/meltano/meltano/runs/7813948143\r\n\r\n```\r\n/home/runner/work/meltano/meltano/.nox/tests-3-9/lib/python3.9/site-packages/alembic/ddl/mssql.py:125: UserWarning: MS-SQL ALTER COLUMN operations that specify type_= should also specify a nullable= or existing_nullable= argument to avoid implicit conversion of NOT NULL columns to NULL.\r\n util.warn(\r\n```\r\n\r\nIt's the same warning being emitted 90 times.\r\n\r\n### Code\r\n\r\nRunning a test that raises the warning with `python -Werror pytest ...` results in the following traceback:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/will/meltano/meltano/src/meltano/core/migration_service.py\", line 96, in upgrade\r\n command.upgrade(cfg, head)\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/command.py\", line 322, in upgrade\r\n script.run_env()\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/script/base.py\", line 569, in run_env\r\n util.load_python_file(self.dir, \"env.py\")\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/pyfiles.py\", line 94, in load_python_file\r\n module = load_module_py(module_id, path)\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/pyfiles.py\", line 110, in load_module_py\r\n spec.loader.exec_module(module) # type: ignore\r\n File \"<frozen importlib._bootstrap_external>\", line 728, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\r\n File \"/home/will/meltano/meltano/src/meltano/migrations/env.py\", line 60, in <module>\r\n run_migrations_online()\r\n File \"/home/will/meltano/meltano/src/meltano/migrations/env.py\", line 37, in run_migrations_online\r\n _run_migrations_online(connection)\r\n File \"/home/will/meltano/meltano/src/meltano/migrations/env.py\", line 54, in _run_migrations_online\r\n context.run_migrations()\r\n File \"<string>\", line 8, in run_migrations\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/runtime/environment.py\", line 853, in run_migrations\r\n self.get_context().run_migrations(**kw)\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/runtime/migration.py\", line 623, in run_migrations\r\n step.migration_fn(**kw)\r\n File \"/home/will/meltano/meltano/src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py\", line 49, in upgrade\r\n existing_type=sa.Enum(State, name=\"job_state\"),\r\n File \"<string>\", line 8, in alter_column\r\n File \"<string>\", line 3, in alter_column\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/ops.py\", line 1880, in alter_column\r\n return operations.invoke(alt)\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/base.py\", line 399, in invoke\r\n return fn(self, operation)\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/operations/toimpl.py\", line 63, in alter_column\r\n **operation.kw\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/ddl/mssql.py\", line 126, in alter_column\r\n \"MS-SQL ALTER COLUMN operations that specify type_= \"\r\n File \"/home/will/.pyenv/versions/meltano3/lib/python3.7/site-packages/alembic/util/messaging.py\", line 81, in warn\r\n warnings.warn(msg, UserWarning, stacklevel=stacklevel)\r\nUserWarning: MS-SQL ALTER COLUMN operations that specify type_= should also specify a nullable= or existing_nullable= argument to avoid implicit conversion of NOT NULL columns to NULL.\r\n```\n", "before_files": [{"content": "\"\"\"add_state_edit_to_job_state_enum\n\nRevision ID: 13e8639c6d2b\nRevises: d135f52a6f49\nCreate Date: 2022-04-21 09:35:35.435614\n\n\"\"\"\nfrom enum import Enum\n\nimport sqlalchemy as sa\nfrom alembic import op\n\nfrom meltano.migrations.utils.dialect_typing import (\n get_dialect_name,\n max_string_length_for_dialect,\n)\n\n# revision identifiers, used by Alembic.\nrevision = \"13e8639c6d2b\"\ndown_revision = \"d135f52a6f49\"\nbranch_labels = None\ndepends_on = None\n\n\n# from core/job/job.py\nclass State(Enum):\n \"\"\"Represents status of a Job.\"\"\"\n\n IDLE = (0, (\"RUNNING\", \"FAIL\"))\n RUNNING = (1, (\"SUCCESS\", \"FAIL\"))\n SUCCESS = (2, ())\n FAIL = (3, (\"RUNNING\",))\n DEAD = (4, ())\n STATE_EDIT = (5, ())\n\n\ndef upgrade():\n dialect_name = get_dialect_name()\n max_string_length = max_string_length_for_dialect(dialect_name)\n\n conn = op.get_bind()\n # In sqlite, the field is already a varchar.\n # \"ALTER COLUMN\" statements are also not supported.\n if conn.dialect.name != \"sqlite\":\n op.alter_column(\n table_name=\"job\",\n column_name=\"state\",\n type_=sa.types.String(max_string_length),\n existing_type=sa.Enum(State, name=\"job_state\"),\n )\n\n # In postgresql, drop the created Enum type so that\n # downgrade() can re-create it.\n if conn.dialect.name == \"postgresql\":\n conn.execute(\"DROP TYPE job_state;\")\n\n\ndef downgrade():\n conn = op.get_bind()\n # In sqlite, the field is already a varchar.\n # \"ALTER COLUMN\" statements are also not supported.\n if conn.dialect.name != \"sqlite\":\n op.alter_column(\n table_name=\"job\",\n column_name=\"state\",\n _type=sa.Enum(State, name=\"job_state\"),\n existing_type=sa.types.String,\n )\n", "path": "src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py"}], "after_files": [{"content": "\"\"\"add_state_edit_to_job_state_enum\n\nRevision ID: 13e8639c6d2b\nRevises: d135f52a6f49\nCreate Date: 2022-04-21 09:35:35.435614\n\n\"\"\"\nfrom enum import Enum\n\nimport sqlalchemy as sa\nfrom alembic import op\n\nfrom meltano.migrations.utils.dialect_typing import (\n get_dialect_name,\n max_string_length_for_dialect,\n)\n\n# revision identifiers, used by Alembic.\nrevision = \"13e8639c6d2b\"\ndown_revision = \"d135f52a6f49\"\nbranch_labels = None\ndepends_on = None\n\n\n# from core/job/job.py\nclass State(Enum):\n \"\"\"Represents status of a Job.\"\"\"\n\n IDLE = (0, (\"RUNNING\", \"FAIL\"))\n RUNNING = (1, (\"SUCCESS\", \"FAIL\"))\n SUCCESS = (2, ())\n FAIL = (3, (\"RUNNING\",))\n DEAD = (4, ())\n STATE_EDIT = (5, ())\n\n\ndef upgrade():\n dialect_name = get_dialect_name()\n max_string_length = max_string_length_for_dialect(dialect_name)\n\n conn = op.get_bind()\n # In sqlite, the field is already a varchar.\n # \"ALTER COLUMN\" statements are also not supported.\n if conn.dialect.name != \"sqlite\":\n op.alter_column(\n table_name=\"job\",\n column_name=\"state\",\n type_=sa.types.String(max_string_length),\n existing_type=sa.Enum(State, name=\"job_state\"),\n existing_nullable=True,\n )\n\n # In postgresql, drop the created Enum type so that\n # downgrade() can re-create it.\n if conn.dialect.name == \"postgresql\":\n conn.execute(\"DROP TYPE job_state;\")\n\n\ndef downgrade():\n conn = op.get_bind()\n # In sqlite, the field is already a varchar.\n # \"ALTER COLUMN\" statements are also not supported.\n if conn.dialect.name != \"sqlite\":\n op.alter_column(\n table_name=\"job\",\n column_name=\"state\",\n _type=sa.Enum(State, name=\"job_state\"),\n existing_type=sa.types.String,\n )\n", "path": "src/meltano/migrations/versions/13e8639c6d2b_add_state_edit_to_job_state_enum.py"}]}
| 2,022 | 192 |
gh_patches_debug_33918
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-1572
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Elasticsearch: Add proxy support during plugins installation
We should be able to install Elasticsearch plugin though proxy.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `packaging/elasticsearch_plugin.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 import os
5
6 """
7 Ansible module to manage elasticsearch plugins
8 (c) 2015, Mathew Davies <[email protected]>
9
10 This file is part of Ansible
11
12 Ansible is free software: you can redistribute it and/or modify
13 it under the terms of the GNU General Public License as published by
14 the Free Software Foundation, either version 3 of the License, or
15 (at your option) any later version.
16
17 Ansible is distributed in the hope that it will be useful,
18 but WITHOUT ANY WARRANTY; without even the implied warranty of
19 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 GNU General Public License for more details.
21 You should have received a copy of the GNU General Public License
22 along with Ansible. If not, see <http://www.gnu.org/licenses/>.
23 """
24
25 DOCUMENTATION = '''
26 ---
27 module: elasticsearch_plugin
28 short_description: Manage Elasticsearch plugins
29 description:
30 - Manages Elasticsearch plugins.
31 version_added: "2.0"
32 author: Mathew Davies (@ThePixelDeveloper)
33 options:
34 name:
35 description:
36 - Name of the plugin to install
37 required: True
38 state:
39 description:
40 - Desired state of a plugin.
41 required: False
42 choices: [present, absent]
43 default: present
44 url:
45 description:
46 - Set exact URL to download the plugin from
47 required: False
48 default: None
49 timeout:
50 description:
51 - "Timeout setting: 30s, 1m, 1h..."
52 required: False
53 default: 1m
54 plugin_bin:
55 description:
56 - Location of the plugin binary
57 required: False
58 default: /usr/share/elasticsearch/bin/plugin
59 plugin_dir:
60 description:
61 - Your configured plugin directory specified in Elasticsearch
62 required: False
63 default: /usr/share/elasticsearch/plugins/
64 version:
65 description:
66 - Version of the plugin to be installed.
67 If plugin exists with previous version, it will NOT be updated
68 required: False
69 default: None
70 '''
71
72 EXAMPLES = '''
73 # Install Elasticsearch head plugin
74 - elasticsearch_plugin: state=present name="mobz/elasticsearch-head"
75
76 # Install specific version of a plugin
77 - elasticsearch_plugin: state=present name="com.github.kzwang/elasticsearch-image" version="1.2.0"
78
79 # Uninstall Elasticsearch head plugin
80 - elasticsearch_plugin: state=absent name="mobz/elasticsearch-head"
81 '''
82
83
84 def parse_plugin_repo(string):
85 elements = string.split("/")
86
87 # We first consider the simplest form: pluginname
88 repo = elements[0]
89
90 # We consider the form: username/pluginname
91 if len(elements) > 1:
92 repo = elements[1]
93
94 # remove elasticsearch- prefix
95 # remove es- prefix
96 for string in ("elasticsearch-", "es-"):
97 if repo.startswith(string):
98 return repo[len(string):]
99
100 return repo
101
102
103 def is_plugin_present(plugin_dir, working_dir):
104 return os.path.isdir(os.path.join(working_dir, plugin_dir))
105
106
107 def parse_error(string):
108 reason = "reason: "
109 return string[string.index(reason) + len(reason):].strip()
110
111
112 def main():
113
114 package_state_map = dict(
115 present="--install",
116 absent="--remove"
117 )
118
119 module = AnsibleModule(
120 argument_spec=dict(
121 name=dict(required=True),
122 state=dict(default="present", choices=package_state_map.keys()),
123 url=dict(default=None),
124 timeout=dict(default="1m"),
125 plugin_bin=dict(default="/usr/share/elasticsearch/bin/plugin"),
126 plugin_dir=dict(default="/usr/share/elasticsearch/plugins/"),
127 version=dict(default=None)
128 )
129 )
130
131 plugin_bin = module.params["plugin_bin"]
132 plugin_dir = module.params["plugin_dir"]
133 name = module.params["name"]
134 state = module.params["state"]
135 url = module.params["url"]
136 timeout = module.params["timeout"]
137 version = module.params["version"]
138
139 present = is_plugin_present(parse_plugin_repo(name), plugin_dir)
140
141 # skip if the state is correct
142 if (present and state == "present") or (state == "absent" and not present):
143 module.exit_json(changed=False, name=name)
144
145 if (version):
146 name = name + '/' + version
147
148 cmd_args = [plugin_bin, package_state_map[state], name]
149
150 if url:
151 cmd_args.append("--url %s" % url)
152
153 if timeout:
154 cmd_args.append("--timeout %s" % timeout)
155
156 cmd = " ".join(cmd_args)
157
158 rc, out, err = module.run_command(cmd)
159
160 if rc != 0:
161 reason = parse_error(out)
162 module.fail_json(msg=reason)
163
164 module.exit_json(changed=True, cmd=cmd, name=name, state=state, url=url, timeout=timeout, stdout=out, stderr=err)
165
166 from ansible.module_utils.basic import *
167
168 main()
169
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/packaging/elasticsearch_plugin.py b/packaging/elasticsearch_plugin.py
--- a/packaging/elasticsearch_plugin.py
+++ b/packaging/elasticsearch_plugin.py
@@ -61,6 +61,16 @@
- Your configured plugin directory specified in Elasticsearch
required: False
default: /usr/share/elasticsearch/plugins/
+ proxy_host:
+ description:
+ - Proxy host to use during plugin installation
+ required: False
+ default: None
+ proxy_port:
+ description:
+ - Proxy port to use during plugin installation
+ required: False
+ default: None
version:
description:
- Version of the plugin to be installed.
@@ -124,16 +134,20 @@
timeout=dict(default="1m"),
plugin_bin=dict(default="/usr/share/elasticsearch/bin/plugin"),
plugin_dir=dict(default="/usr/share/elasticsearch/plugins/"),
+ proxy_host=dict(default=None),
+ proxy_port=dict(default=None),
version=dict(default=None)
)
)
- plugin_bin = module.params["plugin_bin"]
- plugin_dir = module.params["plugin_dir"]
name = module.params["name"]
state = module.params["state"]
url = module.params["url"]
timeout = module.params["timeout"]
+ plugin_bin = module.params["plugin_bin"]
+ plugin_dir = module.params["plugin_dir"]
+ proxy_host = module.params["proxy_host"]
+ proxy_port = module.params["proxy_port"]
version = module.params["version"]
present = is_plugin_present(parse_plugin_repo(name), plugin_dir)
@@ -147,6 +161,9 @@
cmd_args = [plugin_bin, package_state_map[state], name]
+ if proxy_host and proxy_port:
+ cmd_args.append("-DproxyHost=%s -DproxyPort=%s" % proxy_host, proxy_port)
+
if url:
cmd_args.append("--url %s" % url)
|
{"golden_diff": "diff --git a/packaging/elasticsearch_plugin.py b/packaging/elasticsearch_plugin.py\n--- a/packaging/elasticsearch_plugin.py\n+++ b/packaging/elasticsearch_plugin.py\n@@ -61,6 +61,16 @@\n - Your configured plugin directory specified in Elasticsearch\n required: False\n default: /usr/share/elasticsearch/plugins/\n+ proxy_host:\n+ description:\n+ - Proxy host to use during plugin installation\n+ required: False\n+ default: None\n+ proxy_port:\n+ description:\n+ - Proxy port to use during plugin installation\n+ required: False\n+ default: None \n version:\n description:\n - Version of the plugin to be installed.\n@@ -124,16 +134,20 @@\n timeout=dict(default=\"1m\"),\n plugin_bin=dict(default=\"/usr/share/elasticsearch/bin/plugin\"),\n plugin_dir=dict(default=\"/usr/share/elasticsearch/plugins/\"),\n+ proxy_host=dict(default=None),\n+ proxy_port=dict(default=None),\n version=dict(default=None)\n )\n )\n \n- plugin_bin = module.params[\"plugin_bin\"]\n- plugin_dir = module.params[\"plugin_dir\"]\n name = module.params[\"name\"]\n state = module.params[\"state\"]\n url = module.params[\"url\"]\n timeout = module.params[\"timeout\"]\n+ plugin_bin = module.params[\"plugin_bin\"]\n+ plugin_dir = module.params[\"plugin_dir\"]\n+ proxy_host = module.params[\"proxy_host\"]\n+ proxy_port = module.params[\"proxy_port\"]\n version = module.params[\"version\"]\n \n present = is_plugin_present(parse_plugin_repo(name), plugin_dir)\n@@ -147,6 +161,9 @@\n \n cmd_args = [plugin_bin, package_state_map[state], name]\n \n+ if proxy_host and proxy_port:\n+ cmd_args.append(\"-DproxyHost=%s -DproxyPort=%s\" % proxy_host, proxy_port)\n+\n if url:\n cmd_args.append(\"--url %s\" % url)\n", "issue": "Elasticsearch: Add proxy support during plugins installation\nWe should be able to install Elasticsearch plugin though proxy.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\n\n\"\"\"\nAnsible module to manage elasticsearch plugins\n(c) 2015, Mathew Davies <[email protected]>\n\nThis file is part of Ansible\n\nAnsible is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nAnsible is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\nYou should have received a copy of the GNU General Public License\nalong with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\n\nDOCUMENTATION = '''\n---\nmodule: elasticsearch_plugin\nshort_description: Manage Elasticsearch plugins\ndescription:\n - Manages Elasticsearch plugins.\nversion_added: \"2.0\"\nauthor: Mathew Davies (@ThePixelDeveloper)\noptions:\n name:\n description:\n - Name of the plugin to install\n required: True\n state:\n description:\n - Desired state of a plugin.\n required: False\n choices: [present, absent]\n default: present\n url:\n description:\n - Set exact URL to download the plugin from\n required: False\n default: None\n timeout:\n description:\n - \"Timeout setting: 30s, 1m, 1h...\"\n required: False\n default: 1m\n plugin_bin:\n description:\n - Location of the plugin binary\n required: False\n default: /usr/share/elasticsearch/bin/plugin\n plugin_dir:\n description:\n - Your configured plugin directory specified in Elasticsearch\n required: False\n default: /usr/share/elasticsearch/plugins/\n version:\n description:\n - Version of the plugin to be installed.\n If plugin exists with previous version, it will NOT be updated\n required: False\n default: None\n'''\n\nEXAMPLES = '''\n# Install Elasticsearch head plugin\n- elasticsearch_plugin: state=present name=\"mobz/elasticsearch-head\"\n\n# Install specific version of a plugin\n- elasticsearch_plugin: state=present name=\"com.github.kzwang/elasticsearch-image\" version=\"1.2.0\"\n\n# Uninstall Elasticsearch head plugin\n- elasticsearch_plugin: state=absent name=\"mobz/elasticsearch-head\"\n'''\n\n\ndef parse_plugin_repo(string):\n elements = string.split(\"/\")\n\n # We first consider the simplest form: pluginname\n repo = elements[0]\n\n # We consider the form: username/pluginname\n if len(elements) > 1:\n repo = elements[1]\n\n # remove elasticsearch- prefix\n # remove es- prefix\n for string in (\"elasticsearch-\", \"es-\"):\n if repo.startswith(string):\n return repo[len(string):]\n\n return repo\n\n\ndef is_plugin_present(plugin_dir, working_dir):\n return os.path.isdir(os.path.join(working_dir, plugin_dir))\n\n\ndef parse_error(string):\n reason = \"reason: \"\n return string[string.index(reason) + len(reason):].strip()\n\n\ndef main():\n\n package_state_map = dict(\n present=\"--install\",\n absent=\"--remove\"\n )\n\n module = AnsibleModule(\n argument_spec=dict(\n name=dict(required=True),\n state=dict(default=\"present\", choices=package_state_map.keys()),\n url=dict(default=None),\n timeout=dict(default=\"1m\"),\n plugin_bin=dict(default=\"/usr/share/elasticsearch/bin/plugin\"),\n plugin_dir=dict(default=\"/usr/share/elasticsearch/plugins/\"),\n version=dict(default=None)\n )\n )\n\n plugin_bin = module.params[\"plugin_bin\"]\n plugin_dir = module.params[\"plugin_dir\"]\n name = module.params[\"name\"]\n state = module.params[\"state\"]\n url = module.params[\"url\"]\n timeout = module.params[\"timeout\"]\n version = module.params[\"version\"]\n\n present = is_plugin_present(parse_plugin_repo(name), plugin_dir)\n\n # skip if the state is correct\n if (present and state == \"present\") or (state == \"absent\" and not present):\n module.exit_json(changed=False, name=name)\n\n if (version):\n name = name + '/' + version\n\n cmd_args = [plugin_bin, package_state_map[state], name]\n\n if url:\n cmd_args.append(\"--url %s\" % url)\n\n if timeout:\n cmd_args.append(\"--timeout %s\" % timeout)\n\n cmd = \" \".join(cmd_args)\n\n rc, out, err = module.run_command(cmd)\n\n if rc != 0:\n reason = parse_error(out)\n module.fail_json(msg=reason)\n\n module.exit_json(changed=True, cmd=cmd, name=name, state=state, url=url, timeout=timeout, stdout=out, stderr=err)\n\nfrom ansible.module_utils.basic import *\n\nmain()\n", "path": "packaging/elasticsearch_plugin.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\n\n\"\"\"\nAnsible module to manage elasticsearch plugins\n(c) 2015, Mathew Davies <[email protected]>\n\nThis file is part of Ansible\n\nAnsible is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nAnsible is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\nYou should have received a copy of the GNU General Public License\nalong with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\"\"\"\n\nDOCUMENTATION = '''\n---\nmodule: elasticsearch_plugin\nshort_description: Manage Elasticsearch plugins\ndescription:\n - Manages Elasticsearch plugins.\nversion_added: \"2.0\"\nauthor: Mathew Davies (@ThePixelDeveloper)\noptions:\n name:\n description:\n - Name of the plugin to install\n required: True\n state:\n description:\n - Desired state of a plugin.\n required: False\n choices: [present, absent]\n default: present\n url:\n description:\n - Set exact URL to download the plugin from\n required: False\n default: None\n timeout:\n description:\n - \"Timeout setting: 30s, 1m, 1h...\"\n required: False\n default: 1m\n plugin_bin:\n description:\n - Location of the plugin binary\n required: False\n default: /usr/share/elasticsearch/bin/plugin\n plugin_dir:\n description:\n - Your configured plugin directory specified in Elasticsearch\n required: False\n default: /usr/share/elasticsearch/plugins/\n proxy_host:\n description:\n - Proxy host to use during plugin installation\n required: False\n default: None\n proxy_port:\n description:\n - Proxy port to use during plugin installation\n required: False\n default: None \n version:\n description:\n - Version of the plugin to be installed.\n If plugin exists with previous version, it will NOT be updated\n required: False\n default: None\n'''\n\nEXAMPLES = '''\n# Install Elasticsearch head plugin\n- elasticsearch_plugin: state=present name=\"mobz/elasticsearch-head\"\n\n# Install specific version of a plugin\n- elasticsearch_plugin: state=present name=\"com.github.kzwang/elasticsearch-image\" version=\"1.2.0\"\n\n# Uninstall Elasticsearch head plugin\n- elasticsearch_plugin: state=absent name=\"mobz/elasticsearch-head\"\n'''\n\n\ndef parse_plugin_repo(string):\n elements = string.split(\"/\")\n\n # We first consider the simplest form: pluginname\n repo = elements[0]\n\n # We consider the form: username/pluginname\n if len(elements) > 1:\n repo = elements[1]\n\n # remove elasticsearch- prefix\n # remove es- prefix\n for string in (\"elasticsearch-\", \"es-\"):\n if repo.startswith(string):\n return repo[len(string):]\n\n return repo\n\n\ndef is_plugin_present(plugin_dir, working_dir):\n return os.path.isdir(os.path.join(working_dir, plugin_dir))\n\n\ndef parse_error(string):\n reason = \"reason: \"\n return string[string.index(reason) + len(reason):].strip()\n\n\ndef main():\n\n package_state_map = dict(\n present=\"--install\",\n absent=\"--remove\"\n )\n\n module = AnsibleModule(\n argument_spec=dict(\n name=dict(required=True),\n state=dict(default=\"present\", choices=package_state_map.keys()),\n url=dict(default=None),\n timeout=dict(default=\"1m\"),\n plugin_bin=dict(default=\"/usr/share/elasticsearch/bin/plugin\"),\n plugin_dir=dict(default=\"/usr/share/elasticsearch/plugins/\"),\n proxy_host=dict(default=None),\n proxy_port=dict(default=None),\n version=dict(default=None)\n )\n )\n\n name = module.params[\"name\"]\n state = module.params[\"state\"]\n url = module.params[\"url\"]\n timeout = module.params[\"timeout\"]\n plugin_bin = module.params[\"plugin_bin\"]\n plugin_dir = module.params[\"plugin_dir\"]\n proxy_host = module.params[\"proxy_host\"]\n proxy_port = module.params[\"proxy_port\"]\n version = module.params[\"version\"]\n\n present = is_plugin_present(parse_plugin_repo(name), plugin_dir)\n\n # skip if the state is correct\n if (present and state == \"present\") or (state == \"absent\" and not present):\n module.exit_json(changed=False, name=name)\n\n if (version):\n name = name + '/' + version\n\n cmd_args = [plugin_bin, package_state_map[state], name]\n\n if proxy_host and proxy_port:\n cmd_args.append(\"-DproxyHost=%s -DproxyPort=%s\" % proxy_host, proxy_port)\n\n if url:\n cmd_args.append(\"--url %s\" % url)\n\n if timeout:\n cmd_args.append(\"--timeout %s\" % timeout)\n\n cmd = \" \".join(cmd_args)\n\n rc, out, err = module.run_command(cmd)\n\n if rc != 0:\n reason = parse_error(out)\n module.fail_json(msg=reason)\n\n module.exit_json(changed=True, cmd=cmd, name=name, state=state, url=url, timeout=timeout, stdout=out, stderr=err)\n\nfrom ansible.module_utils.basic import *\n\nmain()\n", "path": "packaging/elasticsearch_plugin.py"}]}
| 1,775 | 438 |
gh_patches_debug_15210
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-1183
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
type error for morphology.remove_small_objects()
Is it better to add type error for non-labeled int?
``` python
a = np.array([[0, 0, 0, 1, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 0, 1]], int)
b = morphology.remove_small_objects(a, 6)
print b
[[0 0 0 1 0]
[1 1 1 0 0]
[1 1 1 0 1]]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `skimage/morphology/misc.py`
Content:
```
1 import numpy as np
2 import functools
3 import scipy.ndimage as nd
4 from .selem import _default_selem
5
6 # Our function names don't exactly correspond to ndimages.
7 # This dictionary translates from our names to scipy's.
8 funcs = ('erosion', 'dilation', 'opening', 'closing')
9 skimage2ndimage = dict((x, 'grey_' + x) for x in funcs)
10
11 # These function names are the same in ndimage.
12 funcs = ('binary_erosion', 'binary_dilation', 'binary_opening',
13 'binary_closing', 'black_tophat', 'white_tophat')
14 skimage2ndimage.update(dict((x, x) for x in funcs))
15
16
17 def default_fallback(func):
18 """Decorator to fall back on ndimage for images with more than 2 dimensions
19
20 Decorator also provides a default structuring element, `selem`, with the
21 appropriate dimensionality if none is specified.
22
23 Parameters
24 ----------
25 func : function
26 A morphology function such as erosion, dilation, opening, closing,
27 white_tophat, or black_tophat.
28
29 Returns
30 -------
31 func_out : function
32 If the image dimentionality is greater than 2D, the ndimage
33 function is returned, otherwise skimage function is used.
34 """
35 @functools.wraps(func)
36 def func_out(image, selem=None, out=None, **kwargs):
37 # Default structure element
38 if selem is None:
39 selem = _default_selem(image.ndim)
40
41 # If image has more than 2 dimensions, use scipy.ndimage
42 if image.ndim > 2:
43 function = getattr(nd, skimage2ndimage[func.__name__])
44 try:
45 return function(image, footprint=selem, output=out, **kwargs)
46 except TypeError:
47 # nd.binary_* take structure instead of footprint
48 return function(image, structure=selem, output=out, **kwargs)
49 else:
50 return func(image, selem=selem, out=out, **kwargs)
51
52 return func_out
53
54
55 def remove_small_objects(ar, min_size=64, connectivity=1, in_place=False):
56 """Remove connected components smaller than the specified size.
57
58 Parameters
59 ----------
60 ar : ndarray (arbitrary shape, int or bool type)
61 The array containing the connected components of interest. If the array
62 type is int, it is assumed that it contains already-labeled objects.
63 The ints must be non-negative.
64 min_size : int, optional (default: 64)
65 The smallest allowable connected component size.
66 connectivity : int, {1, 2, ..., ar.ndim}, optional (default: 1)
67 The connectivity defining the neighborhood of a pixel.
68 in_place : bool, optional (default: False)
69 If `True`, remove the connected components in the input array itself.
70 Otherwise, make a copy.
71
72 Raises
73 ------
74 TypeError
75 If the input array is of an invalid type, such as float or string.
76 ValueError
77 If the input array contains negative values.
78
79 Returns
80 -------
81 out : ndarray, same shape and type as input `ar`
82 The input array with small connected components removed.
83
84 Examples
85 --------
86 >>> from skimage import morphology
87 >>> a = np.array([[0, 0, 0, 1, 0],
88 ... [1, 1, 1, 0, 0],
89 ... [1, 1, 1, 0, 1]], bool)
90 >>> b = morphology.remove_small_objects(a, 6)
91 >>> b
92 array([[False, False, False, False, False],
93 [ True, True, True, False, False],
94 [ True, True, True, False, False]], dtype=bool)
95 >>> c = morphology.remove_small_objects(a, 7, connectivity=2)
96 >>> c
97 array([[False, False, False, True, False],
98 [ True, True, True, False, False],
99 [ True, True, True, False, False]], dtype=bool)
100 >>> d = morphology.remove_small_objects(a, 6, in_place=True)
101 >>> d is a
102 True
103 """
104 # Should use `issubdtype` for bool below, but there's a bug in numpy 1.7
105 if not (ar.dtype == bool or np.issubdtype(ar.dtype, np.integer)):
106 raise TypeError("Only bool or integer image types are supported. "
107 "Got %s." % ar.dtype)
108
109 if in_place:
110 out = ar
111 else:
112 out = ar.copy()
113
114 if min_size == 0: # shortcut for efficiency
115 return out
116
117 if out.dtype == bool:
118 selem = nd.generate_binary_structure(ar.ndim, connectivity)
119 ccs = np.zeros_like(ar, dtype=np.int32)
120 nd.label(ar, selem, output=ccs)
121 else:
122 ccs = out
123
124 try:
125 component_sizes = np.bincount(ccs.ravel())
126 except ValueError:
127 raise ValueError("Negative value labels are not supported. Try "
128 "relabeling the input with `scipy.ndimage.label` or "
129 "`skimage.morphology.label`.")
130
131 too_small = component_sizes < min_size
132 too_small_mask = too_small[ccs]
133 out[too_small_mask] = 0
134
135 return out
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/skimage/morphology/misc.py b/skimage/morphology/misc.py
--- a/skimage/morphology/misc.py
+++ b/skimage/morphology/misc.py
@@ -1,5 +1,6 @@
import numpy as np
import functools
+import warnings
import scipy.ndimage as nd
from .selem import _default_selem
@@ -128,6 +129,10 @@
"relabeling the input with `scipy.ndimage.label` or "
"`skimage.morphology.label`.")
+ if len(component_sizes) == 2:
+ warnings.warn("Only one label was provided to `remove_small_objects`. "
+ "Did you mean to use a boolean array?")
+
too_small = component_sizes < min_size
too_small_mask = too_small[ccs]
out[too_small_mask] = 0
|
{"golden_diff": "diff --git a/skimage/morphology/misc.py b/skimage/morphology/misc.py\n--- a/skimage/morphology/misc.py\n+++ b/skimage/morphology/misc.py\n@@ -1,5 +1,6 @@\n import numpy as np\n import functools\n+import warnings\n import scipy.ndimage as nd\n from .selem import _default_selem\n \n@@ -128,6 +129,10 @@\n \"relabeling the input with `scipy.ndimage.label` or \"\n \"`skimage.morphology.label`.\")\n \n+ if len(component_sizes) == 2:\n+ warnings.warn(\"Only one label was provided to `remove_small_objects`. \"\n+ \"Did you mean to use a boolean array?\")\n+\n too_small = component_sizes < min_size\n too_small_mask = too_small[ccs]\n out[too_small_mask] = 0\n", "issue": "type error for morphology.remove_small_objects()\nIs it better to add type error for non-labeled int? \n\n``` python\na = np.array([[0, 0, 0, 1, 0],\n [1, 1, 1, 0, 0],\n [1, 1, 1, 0, 1]], int)\n\nb = morphology.remove_small_objects(a, 6)\n\nprint b\n\n[[0 0 0 1 0]\n [1 1 1 0 0]\n [1 1 1 0 1]]\n```\n\n", "before_files": [{"content": "import numpy as np\nimport functools\nimport scipy.ndimage as nd\nfrom .selem import _default_selem\n\n# Our function names don't exactly correspond to ndimages.\n# This dictionary translates from our names to scipy's.\nfuncs = ('erosion', 'dilation', 'opening', 'closing')\nskimage2ndimage = dict((x, 'grey_' + x) for x in funcs)\n\n# These function names are the same in ndimage.\nfuncs = ('binary_erosion', 'binary_dilation', 'binary_opening',\n 'binary_closing', 'black_tophat', 'white_tophat')\nskimage2ndimage.update(dict((x, x) for x in funcs))\n\n\ndef default_fallback(func):\n \"\"\"Decorator to fall back on ndimage for images with more than 2 dimensions\n\n Decorator also provides a default structuring element, `selem`, with the\n appropriate dimensionality if none is specified.\n\n Parameters\n ----------\n func : function\n A morphology function such as erosion, dilation, opening, closing,\n white_tophat, or black_tophat.\n\n Returns\n -------\n func_out : function\n If the image dimentionality is greater than 2D, the ndimage\n function is returned, otherwise skimage function is used.\n \"\"\"\n @functools.wraps(func)\n def func_out(image, selem=None, out=None, **kwargs):\n # Default structure element\n if selem is None:\n selem = _default_selem(image.ndim)\n\n # If image has more than 2 dimensions, use scipy.ndimage\n if image.ndim > 2:\n function = getattr(nd, skimage2ndimage[func.__name__])\n try:\n return function(image, footprint=selem, output=out, **kwargs)\n except TypeError:\n # nd.binary_* take structure instead of footprint\n return function(image, structure=selem, output=out, **kwargs)\n else:\n return func(image, selem=selem, out=out, **kwargs)\n\n return func_out\n\n\ndef remove_small_objects(ar, min_size=64, connectivity=1, in_place=False):\n \"\"\"Remove connected components smaller than the specified size.\n\n Parameters\n ----------\n ar : ndarray (arbitrary shape, int or bool type)\n The array containing the connected components of interest. If the array\n type is int, it is assumed that it contains already-labeled objects.\n The ints must be non-negative.\n min_size : int, optional (default: 64)\n The smallest allowable connected component size.\n connectivity : int, {1, 2, ..., ar.ndim}, optional (default: 1)\n The connectivity defining the neighborhood of a pixel.\n in_place : bool, optional (default: False)\n If `True`, remove the connected components in the input array itself.\n Otherwise, make a copy.\n\n Raises\n ------\n TypeError\n If the input array is of an invalid type, such as float or string.\n ValueError\n If the input array contains negative values.\n\n Returns\n -------\n out : ndarray, same shape and type as input `ar`\n The input array with small connected components removed.\n\n Examples\n --------\n >>> from skimage import morphology\n >>> a = np.array([[0, 0, 0, 1, 0],\n ... [1, 1, 1, 0, 0],\n ... [1, 1, 1, 0, 1]], bool)\n >>> b = morphology.remove_small_objects(a, 6)\n >>> b\n array([[False, False, False, False, False],\n [ True, True, True, False, False],\n [ True, True, True, False, False]], dtype=bool)\n >>> c = morphology.remove_small_objects(a, 7, connectivity=2)\n >>> c\n array([[False, False, False, True, False],\n [ True, True, True, False, False],\n [ True, True, True, False, False]], dtype=bool)\n >>> d = morphology.remove_small_objects(a, 6, in_place=True)\n >>> d is a\n True\n \"\"\"\n # Should use `issubdtype` for bool below, but there's a bug in numpy 1.7\n if not (ar.dtype == bool or np.issubdtype(ar.dtype, np.integer)):\n raise TypeError(\"Only bool or integer image types are supported. \"\n \"Got %s.\" % ar.dtype)\n\n if in_place:\n out = ar\n else:\n out = ar.copy()\n\n if min_size == 0: # shortcut for efficiency\n return out\n\n if out.dtype == bool:\n selem = nd.generate_binary_structure(ar.ndim, connectivity)\n ccs = np.zeros_like(ar, dtype=np.int32)\n nd.label(ar, selem, output=ccs)\n else:\n ccs = out\n\n try:\n component_sizes = np.bincount(ccs.ravel())\n except ValueError:\n raise ValueError(\"Negative value labels are not supported. Try \"\n \"relabeling the input with `scipy.ndimage.label` or \"\n \"`skimage.morphology.label`.\")\n\n too_small = component_sizes < min_size\n too_small_mask = too_small[ccs]\n out[too_small_mask] = 0\n\n return out\n", "path": "skimage/morphology/misc.py"}], "after_files": [{"content": "import numpy as np\nimport functools\nimport warnings\nimport scipy.ndimage as nd\nfrom .selem import _default_selem\n\n# Our function names don't exactly correspond to ndimages.\n# This dictionary translates from our names to scipy's.\nfuncs = ('erosion', 'dilation', 'opening', 'closing')\nskimage2ndimage = dict((x, 'grey_' + x) for x in funcs)\n\n# These function names are the same in ndimage.\nfuncs = ('binary_erosion', 'binary_dilation', 'binary_opening',\n 'binary_closing', 'black_tophat', 'white_tophat')\nskimage2ndimage.update(dict((x, x) for x in funcs))\n\n\ndef default_fallback(func):\n \"\"\"Decorator to fall back on ndimage for images with more than 2 dimensions\n\n Decorator also provides a default structuring element, `selem`, with the\n appropriate dimensionality if none is specified.\n\n Parameters\n ----------\n func : function\n A morphology function such as erosion, dilation, opening, closing,\n white_tophat, or black_tophat.\n\n Returns\n -------\n func_out : function\n If the image dimentionality is greater than 2D, the ndimage\n function is returned, otherwise skimage function is used.\n \"\"\"\n @functools.wraps(func)\n def func_out(image, selem=None, out=None, **kwargs):\n # Default structure element\n if selem is None:\n selem = _default_selem(image.ndim)\n\n # If image has more than 2 dimensions, use scipy.ndimage\n if image.ndim > 2:\n function = getattr(nd, skimage2ndimage[func.__name__])\n try:\n return function(image, footprint=selem, output=out, **kwargs)\n except TypeError:\n # nd.binary_* take structure instead of footprint\n return function(image, structure=selem, output=out, **kwargs)\n else:\n return func(image, selem=selem, out=out, **kwargs)\n\n return func_out\n\n\ndef remove_small_objects(ar, min_size=64, connectivity=1, in_place=False):\n \"\"\"Remove connected components smaller than the specified size.\n\n Parameters\n ----------\n ar : ndarray (arbitrary shape, int or bool type)\n The array containing the connected components of interest. If the array\n type is int, it is assumed that it contains already-labeled objects.\n The ints must be non-negative.\n min_size : int, optional (default: 64)\n The smallest allowable connected component size.\n connectivity : int, {1, 2, ..., ar.ndim}, optional (default: 1)\n The connectivity defining the neighborhood of a pixel.\n in_place : bool, optional (default: False)\n If `True`, remove the connected components in the input array itself.\n Otherwise, make a copy.\n\n Raises\n ------\n TypeError\n If the input array is of an invalid type, such as float or string.\n ValueError\n If the input array contains negative values.\n\n Returns\n -------\n out : ndarray, same shape and type as input `ar`\n The input array with small connected components removed.\n\n Examples\n --------\n >>> from skimage import morphology\n >>> a = np.array([[0, 0, 0, 1, 0],\n ... [1, 1, 1, 0, 0],\n ... [1, 1, 1, 0, 1]], bool)\n >>> b = morphology.remove_small_objects(a, 6)\n >>> b\n array([[False, False, False, False, False],\n [ True, True, True, False, False],\n [ True, True, True, False, False]], dtype=bool)\n >>> c = morphology.remove_small_objects(a, 7, connectivity=2)\n >>> c\n array([[False, False, False, True, False],\n [ True, True, True, False, False],\n [ True, True, True, False, False]], dtype=bool)\n >>> d = morphology.remove_small_objects(a, 6, in_place=True)\n >>> d is a\n True\n \"\"\"\n # Should use `issubdtype` for bool below, but there's a bug in numpy 1.7\n if not (ar.dtype == bool or np.issubdtype(ar.dtype, np.integer)):\n raise TypeError(\"Only bool or integer image types are supported. \"\n \"Got %s.\" % ar.dtype)\n\n if in_place:\n out = ar\n else:\n out = ar.copy()\n\n if min_size == 0: # shortcut for efficiency\n return out\n\n if out.dtype == bool:\n selem = nd.generate_binary_structure(ar.ndim, connectivity)\n ccs = np.zeros_like(ar, dtype=np.int32)\n nd.label(ar, selem, output=ccs)\n else:\n ccs = out\n\n try:\n component_sizes = np.bincount(ccs.ravel())\n except ValueError:\n raise ValueError(\"Negative value labels are not supported. Try \"\n \"relabeling the input with `scipy.ndimage.label` or \"\n \"`skimage.morphology.label`.\")\n\n if len(component_sizes) == 2:\n warnings.warn(\"Only one label was provided to `remove_small_objects`. \"\n \"Did you mean to use a boolean array?\")\n\n too_small = component_sizes < min_size\n too_small_mask = too_small[ccs]\n out[too_small_mask] = 0\n\n return out\n", "path": "skimage/morphology/misc.py"}]}
| 1,875 | 199 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.