
text
stringlengths 96
319k
| id
stringlengths 14
178
| metadata
dict |
|---|---|---|
export default function StopIcon(props) {
return (
<svg
{...props}
xmlns="http://www.w3.org/2000/svg"
width="24"
height="24"
viewBox="0 0 24 24"
fill="none"
stroke="currentColor"
strokeWidth="2"
strokeLinecap="round"
strokeLinejoin="round"
>
<path d="M21 12a9 9 0 1 1-18 0 9 9 0 0 1 18 0Z" />
<path fill="currentColor" d="M9 9.563C9 9.252 9.252 9 9.563 9h4.874c.311 0 .563.252.563.563v4.874c0 .311-.252.563-.563.563H9.564A.562.562 0 0 1 9 14.437V9.564Z" />
</svg>
)
}
|
transformers.js/examples/webgpu-vlm/src/components/icons/StopIcon.jsx/0
|
{
"file_path": "transformers.js/examples/webgpu-vlm/src/components/icons/StopIcon.jsx",
"repo_id": "transformers.js",
"token_count": 375
}
|
import { useRef, useCallback, useEffect } from "react";
export function AudioVisualizer({ stream, ...props }) {
const canvasRef = useRef(null);
const visualize = useCallback((stream) => {
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const source = audioContext.createMediaStreamSource(stream);
const analyser = audioContext.createAnalyser();
analyser.fftSize = 2048;
source.connect(analyser);
const canvas = canvasRef.current;
const canvasCtx = canvas.getContext('2d');
const bufferLength = analyser.frequencyBinCount;
const dataArray = new Uint8Array(bufferLength);
const drawVisual = () => {
requestAnimationFrame(drawVisual);
analyser.getByteTimeDomainData(dataArray);
canvasCtx.fillStyle = 'rgb(255, 255, 255)';
canvasCtx.fillRect(0, 0, canvas.width, canvas.height);
canvasCtx.lineWidth = 2;
canvasCtx.strokeStyle = 'rgb(0, 0, 0)';
canvasCtx.beginPath();
const sliceWidth = canvas.width * 1.0 / bufferLength;
let x = 0;
for (let i = 0; i < bufferLength; ++i) {
const v = dataArray[i] / 128.0;
const y = v * canvas.height / 2;
if (i === 0) {
canvasCtx.moveTo(x, y);
} else {
canvasCtx.lineTo(x, y);
}
x += sliceWidth;
}
canvasCtx.lineTo(canvas.width, canvas.height / 2);
canvasCtx.stroke();
};
drawVisual();
}, []);
useEffect(() => {
stream && visualize(stream);
}, [visualize, stream]);
return (
<canvas {...props} width={720} height={240} ref={canvasRef}></canvas>
)
}
|
transformers.js/examples/webgpu-whisper/src/components/AudioVisualizer.jsx/0
|
{
"file_path": "transformers.js/examples/webgpu-whisper/src/components/AudioVisualizer.jsx",
"repo_id": "transformers.js",
"token_count": 865
}
|
import { useState, forwardRef, useRef, useImperativeHandle, useEffect, useCallback } from 'react';
const EXAMPLE_URL = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/whisper-timestamps-demo.mp4';
const MediaInput = forwardRef(({ onInputChange, onTimeUpdate, ...props }, ref) => {
// UI states
const [dragging, setDragging] = useState(false);
const fileInputRef = useRef(null);
// Create a reference to the audio and video elements
const audioElement = useRef(null);
const videoElement = useRef(null);
const currentTimeRef = useRef(0);
useImperativeHandle(ref, () => ({
setMediaTime(time) {
if (audioElement.current?.src) {
audioElement.current.currentTime = time;
} else if (videoElement.current?.src) {
videoElement.current.currentTime = time;
}
currentTimeRef.current = time;
}
}));
const onBufferLoad = (arrayBuffer, type) => {
const blob = new Blob([arrayBuffer.slice(0)], { type: type });
const url = URL.createObjectURL(blob);
processFile(arrayBuffer);
// Create a URL for the Blob
if (type.startsWith('audio/')) {
// Dispose the previous source
videoElement.current.pause();
videoElement.current.removeAttribute('src');
videoElement.current.load();
audioElement.current.src = url;
} else if (type.startsWith('video/')) {
// Dispose the previous source
audioElement.current.pause();
audioElement.current.removeAttribute('src');
audioElement.current.load();
videoElement.current.src = url;
} else {
alert(`Unsupported file type: ${type}`);
}
}
const readFile = (file) => {
if (!file) return;
// file.type
const reader = new FileReader();
reader.onload = (e) => {
onBufferLoad(e.target.result, file.type);
}
reader.readAsArrayBuffer(file);
}
const handleInputChange = (event) => {
readFile(event.target.files[0]);
};
const handleDragOver = (event) => {
event.preventDefault();
};
const handleDrop = (event) => {
event.preventDefault();
setDragging(false);
readFile(event.dataTransfer.files[0]);
};
const handleClick = (e) => {
if (e.target.tagName === 'VIDEO' || e.target.tagName === 'AUDIO') {
e.preventDefault();
fileInputRef.current.click();
} else if (e.target.tagName === 'INPUT') {
e.stopPropagation();
} else {
fileInputRef.current.click();
e.stopPropagation();
}
};
const processFile = async (buffer) => {
const audioContext = new (window.AudioContext || window.webkitAudioContext)({ sampleRate: 16_000 });
try {
const audioBuffer = await audioContext.decodeAudioData(buffer);
let audio;
if (audioBuffer.numberOfChannels === 2) {
// Merge channels
const SCALING_FACTOR = Math.sqrt(2);
const left = audioBuffer.getChannelData(0);
const right = audioBuffer.getChannelData(1);
audio = new Float32Array(left.length);
for (let i = 0; i < audioBuffer.length; ++i) {
audio[i] = SCALING_FACTOR * (left[i] + right[i]) / 2;
}
} else {
audio = audioBuffer.getChannelData(0);
}
onInputChange(audio);
} catch (e) {
alert(e);
}
};
const requestRef = useRef();
const updateTime = useCallback(() => {
let elem;
if (audioElement.current?.src) {
elem = audioElement.current;
} else if (videoElement.current?.src) {
elem = videoElement.current;
}
if (elem && currentTimeRef.current !== elem.currentTime) {
currentTimeRef.current = elem.currentTime;
onTimeUpdate(elem.currentTime);
}
// Request the next frame
requestRef.current = requestAnimationFrame(updateTime);
}, [onTimeUpdate]);
useEffect(() => {
// Start the animation
requestRef.current = requestAnimationFrame(updateTime);
return () => {
// Cleanup on component unmount
cancelAnimationFrame(requestRef.current);
};
}, [updateTime]);
return (
<div
{...props}
onClick={handleClick}
onDragOver={handleDragOver}
onDrop={handleDrop}
onDragEnter={(e) => setDragging(true)}
onDragLeave={(e) => setDragging(false)}
>
<input
type="file"
accept="audio/*,video/*"
onChange={handleInputChange}
ref={fileInputRef}
className="hidden"
/>
{
<audio
ref={audioElement}
controls
style={{ display: audioElement.current?.src ? 'block' : 'none' }}
className='w-full max-h-full'
/>
}
{
<video
ref={videoElement}
controls
style={{ display: videoElement.current?.src ? 'block' : 'none' }}
className='w-full max-h-full'
/>
}
{
!audioElement.current?.src && !videoElement.current?.src && (
<div className="w-full flex flex-col items-center justify-center border-2 border-dashed border-gray-300 rounded-md h-[250px]"
style={{ borderColor: dragging ? 'blue' : 'lightgray' }}
>
<span className="text-gray-600 text-center"><u>Drag & drop</u> or <u>click</u><br />to select media</span>
<span className="text-gray-500 text-sm hover:text-gray-800 mt-2" onClick={async (e) => {
e.stopPropagation();
const buffer = await fetch(EXAMPLE_URL).then((r) => r.arrayBuffer());
videoElement.current.src = URL.createObjectURL(new Blob([buffer], { type: 'video/mp4' }));
onBufferLoad(buffer, 'video/mp4');
}}>(or <u>try an example</u>)</span>
</div>
)
}
</div>
);
});
MediaInput.displayName = 'MediaInput';
export default MediaInput;
|
transformers.js/examples/whisper-word-timestamps/src/components/MediaInput.jsx/0
|
{
"file_path": "transformers.js/examples/whisper-word-timestamps/src/components/MediaInput.jsx",
"repo_id": "transformers.js",
"token_count": 3304
}
|
def generate_tokenizer_json(tokenizer):
vocab = tokenizer.get_vocab()
normalizers = []
if tokenizer.normalize:
# Lowercase the input string
normalizers.append({
"type": "Lowercase",
})
if tokenizer.language == 'ron':
# Replace diacritics
normalizers.append({
"type": "Replace",
"pattern": {
"String": "ț",
},
"content": "ţ",
})
if tokenizer.phonemize:
raise NotImplementedError("Phonemization is not implemented yet")
elif tokenizer.normalize:
# strip any chars outside of the vocab (punctuation)
chars = ''.join(x for x in vocab if len(x) == 1)
escaped = chars.replace('-', r'\-').replace(']', r'\]')
normalizers.append({
"type": "Replace",
"pattern": {
"Regex": f"[^{escaped}]",
},
"content": "",
})
normalizers.append({
"type": "Strip",
"strip_left": True,
"strip_right": True,
})
if tokenizer.add_blank:
# add pad token between each char
normalizers.append({
"type": "Replace",
"pattern": {
# Add a blank token between each char, except when blank (then do nothing)
"Regex": "(?=.)|(?<!^)$",
},
"content": tokenizer.pad_token,
})
if len(normalizers) == 0:
normalizer = None
elif len(normalizers) == 1:
normalizer = normalizers[0]
else:
normalizer = {
"type": "Sequence",
"normalizers": normalizers,
}
tokenizer_json = {
"version": "1.0",
"truncation": None,
"padding": None,
"added_tokens": [
{
"id": vocab[token],
"content": token,
"single_word": False,
"lstrip": False,
"rstrip": False,
"normalized": False,
"special": True
}
for token in vocab
# `tokenizer.pad_token` should not be considered an added token
if token in (tokenizer.unk_token, )
],
"normalizer": normalizer,
"pre_tokenizer": {
"type": "Split",
"pattern": {
"Regex": ""
},
"behavior": "Isolated",
"invert": False
},
"post_processor": None,
"decoder": None, # Custom decoder implemented in JS
"model": {
"vocab": vocab
},
}
return tokenizer_json
|
transformers.js/scripts/extra/vits.py/0
|
{
"file_path": "transformers.js/scripts/extra/vits.py",
"repo_id": "transformers.js",
"token_count": 1431
}
|
/**
* @module generation/streamers
*/
import { mergeArrays } from '../utils/core.js';
import { is_chinese_char } from '../tokenizers.js';
import { apis } from '../env.js';
export class BaseStreamer {
/**
* Function that is called by `.generate()` to push new tokens
* @param {bigint[][]} value
*/
put(value) {
throw Error('Not implemented');
}
/**
* Function that is called by `.generate()` to signal the end of generation
*/
end() {
throw Error('Not implemented');
}
}
const stdout_write = apis.IS_PROCESS_AVAILABLE
? x => process.stdout.write(x)
: x => console.log(x);
/**
* Simple text streamer that prints the token(s) to stdout as soon as entire words are formed.
*/
export class TextStreamer extends BaseStreamer {
/**
*
* @param {import('../tokenizers.js').PreTrainedTokenizer} tokenizer
* @param {Object} options
* @param {boolean} [options.skip_prompt=false] Whether to skip the prompt tokens
* @param {boolean} [options.skip_special_tokens=true] Whether to skip special tokens when decoding
* @param {function(string): void} [options.callback_function=null] Function to call when a piece of text is ready to display
* @param {function(bigint[]): void} [options.token_callback_function=null] Function to call when a new token is generated
* @param {Object} [options.decode_kwargs={}] Additional keyword arguments to pass to the tokenizer's decode method
*/
constructor(tokenizer, {
skip_prompt = false,
callback_function = null,
token_callback_function = null,
skip_special_tokens = true,
decode_kwargs = {},
...kwargs
} = {}) {
super();
this.tokenizer = tokenizer;
this.skip_prompt = skip_prompt;
this.callback_function = callback_function ?? stdout_write;
this.token_callback_function = token_callback_function;
this.decode_kwargs = { skip_special_tokens, ...decode_kwargs, ...kwargs };
// variables used in the streaming process
this.token_cache = [];
this.print_len = 0;
this.next_tokens_are_prompt = true;
}
/**
* Receives tokens, decodes them, and prints them to stdout as soon as they form entire words.
* @param {bigint[][]} value
*/
put(value) {
if (value.length > 1) {
throw Error('TextStreamer only supports batch size of 1');
}
if (this.skip_prompt && this.next_tokens_are_prompt) {
this.next_tokens_are_prompt = false;
return;
}
const tokens = value[0];
this.token_callback_function?.(tokens)
// Add the new token to the cache and decodes the entire thing.
this.token_cache = mergeArrays(this.token_cache, tokens);
const text = this.tokenizer.decode(this.token_cache, this.decode_kwargs);
let printable_text;
if (text.endsWith('\n')) {
// After the symbol for a new line, we flush the cache.
printable_text = text.slice(this.print_len);
this.token_cache = [];
this.print_len = 0;
} else if (text.length > 0 && is_chinese_char(text.charCodeAt(text.length - 1))) {
// If the last token is a CJK character, we print the characters.
printable_text = text.slice(this.print_len);
this.print_len += printable_text.length;
} else {
// Otherwise, prints until the last space char (simple heuristic to avoid printing incomplete words,
// which may change with the subsequent token -- there are probably smarter ways to do this!)
printable_text = text.slice(this.print_len, text.lastIndexOf(' ') + 1);
this.print_len += printable_text.length;
}
this.on_finalized_text(printable_text, false);
}
/**
* Flushes any remaining cache and prints a newline to stdout.
*/
end() {
let printable_text;
if (this.token_cache.length > 0) {
const text = this.tokenizer.decode(this.token_cache, this.decode_kwargs);
printable_text = text.slice(this.print_len);
this.token_cache = [];
this.print_len = 0;
} else {
printable_text = '';
}
this.next_tokens_are_prompt = true;
this.on_finalized_text(printable_text, true);
}
/**
* Prints the new text to stdout. If the stream is ending, also prints a newline.
* @param {string} text
* @param {boolean} stream_end
*/
on_finalized_text(text, stream_end) {
if (text.length > 0) {
this.callback_function?.(text);
}
if (stream_end && this.callback_function === stdout_write && apis.IS_PROCESS_AVAILABLE) {
this.callback_function?.('\n');
}
}
}
/**
* Utility class to handle streaming of tokens generated by whisper speech-to-text models.
* Callback functions are invoked when each of the following events occur:
* - A new chunk starts (on_chunk_start)
* - A new token is generated (callback_function)
* - A chunk ends (on_chunk_end)
* - The stream is finalized (on_finalize)
*/
export class WhisperTextStreamer extends TextStreamer {
/**
* @param {import('../tokenizers.js').WhisperTokenizer} tokenizer
* @param {Object} options
* @param {boolean} [options.skip_prompt=false] Whether to skip the prompt tokens
* @param {function(string): void} [options.callback_function=null] Function to call when a piece of text is ready to display
* @param {function(bigint[]): void} [options.token_callback_function=null] Function to call when a new token is generated
* @param {function(number): void} [options.on_chunk_start=null] Function to call when a new chunk starts
* @param {function(number): void} [options.on_chunk_end=null] Function to call when a chunk ends
* @param {function(): void} [options.on_finalize=null] Function to call when the stream is finalized
* @param {number} [options.time_precision=0.02] Precision of the timestamps
* @param {boolean} [options.skip_special_tokens=true] Whether to skip special tokens when decoding
* @param {Object} [options.decode_kwargs={}] Additional keyword arguments to pass to the tokenizer's decode method
*/
constructor(tokenizer, {
skip_prompt = false,
callback_function = null,
token_callback_function = null,
on_chunk_start = null,
on_chunk_end = null,
on_finalize = null,
time_precision = 0.02,
skip_special_tokens = true,
decode_kwargs = {},
} = {}) {
super(tokenizer, {
skip_prompt,
skip_special_tokens,
callback_function,
token_callback_function,
decode_kwargs,
});
this.timestamp_begin = tokenizer.timestamp_begin;
this.on_chunk_start = on_chunk_start;
this.on_chunk_end = on_chunk_end;
this.on_finalize = on_finalize;
this.time_precision = time_precision;
this.waiting_for_timestamp = false;
}
/**
* @param {bigint[][]} value
*/
put(value) {
if (value.length > 1) {
throw Error('WhisperTextStreamer only supports batch size of 1');
}
const tokens = value[0];
// Check if the token is a timestamp
if (tokens.length === 1) {
const offset = Number(tokens[0]) - this.timestamp_begin;
if (offset >= 0) {
const time = offset * this.time_precision;
if (this.waiting_for_timestamp) {
this.on_chunk_end?.(time);
} else {
this.on_chunk_start?.(time);
}
this.waiting_for_timestamp = !this.waiting_for_timestamp; // Toggle
value = [[]]; // Skip timestamp
}
}
return super.put(value);
}
end() {
super.end();
this.on_finalize?.();
}
}
|
transformers.js/src/generation/streamers.js/0
|
{
"file_path": "transformers.js/src/generation/streamers.js",
"repo_id": "transformers.js",
"token_count": 3390
}
|
import {
ImageProcessor,
} from "../../base/image_processors_utils.js";
export class EfficientNetImageProcessor extends ImageProcessor {
constructor(config) {
super(config);
// @ts-expect-error TS2339
this.include_top = this.config.include_top ?? true;
if (this.include_top) {
this.image_std = this.image_std.map(x => x * x);
}
}
}
|
transformers.js/src/models/efficientnet/image_processing_efficientnet.js/0
|
{
"file_path": "transformers.js/src/models/efficientnet/image_processing_efficientnet.js",
"repo_id": "transformers.js",
"token_count": 173
}
|
import { Processor } from "../../base/processing_utils.js";
import { AutoImageProcessor } from "../auto/image_processing_auto.js";
import { AutoTokenizer } from "../../tokenizers.js";
import { max, softmax } from "../../utils/maths.js";
const DECODE_TYPE_MAPPING = {
'char': ['char_decode', 1],
'bpe': ['bpe_decode', 2],
'wp': ['wp_decode', 102],
}
export class MgpstrProcessor extends Processor {
static tokenizer_class = AutoTokenizer
static image_processor_class = AutoImageProcessor
/**
* @returns {import('../../tokenizers.js').MgpstrTokenizer} The character tokenizer.
*/
get char_tokenizer() {
return this.components.char_tokenizer;
}
/**
* @returns {import('../../tokenizers.js').GPT2Tokenizer} The BPE tokenizer.
*/
get bpe_tokenizer() {
return this.components.bpe_tokenizer;
}
/**
* @returns {import('../../tokenizers.js').BertTokenizer} The WordPiece tokenizer.
*/
get wp_tokenizer() {
return this.components.wp_tokenizer;
}
/**
* Helper function to decode the model prediction logits.
* @param {import('../../utils/tensor.js').Tensor} pred_logits Model prediction logits.
* @param {string} format Type of model prediction. Must be one of ['char', 'bpe', 'wp'].
* @returns {[string[], number[]]} The decoded sentences and their confidence scores.
*/
_decode_helper(pred_logits, format) {
if (!DECODE_TYPE_MAPPING.hasOwnProperty(format)) {
throw new Error(`Format ${format} is not supported.`);
}
const [decoder_name, eos_token] = DECODE_TYPE_MAPPING[format];
const decoder = this[decoder_name].bind(this);
const [batch_size, batch_max_length] = pred_logits.dims;
const conf_scores = [];
const all_ids = [];
/** @type {number[][][]} */
const pred_logits_list = pred_logits.tolist();
for (let i = 0; i < batch_size; ++i) {
const logits = pred_logits_list[i];
const ids = [];
const scores = [];
// Start and index=1 to skip the first token
for (let j = 1; j < batch_max_length; ++j) {
// NOTE: == to match bigint and number
const [max_prob, max_prob_index] = max(softmax(logits[j]));
scores.push(max_prob);
if (max_prob_index == eos_token) {
break;
}
ids.push(max_prob_index);
}
const confidence_score = scores.length > 0
? scores.reduce((a, b) => a * b, 1)
: 0;
all_ids.push(ids);
conf_scores.push(confidence_score);
}
const decoded = decoder(all_ids);
return [decoded, conf_scores];
}
/**
* Convert a list of lists of char token ids into a list of strings by calling char tokenizer.
* @param {number[][]} sequences List of tokenized input ids.
* @returns {string[]} The list of char decoded sentences.
*/
char_decode(sequences) {
return this.char_tokenizer.batch_decode(sequences).map(str => str.replaceAll(' ', ''));
}
/**
* Convert a list of lists of BPE token ids into a list of strings by calling BPE tokenizer.
* @param {number[][]} sequences List of tokenized input ids.
* @returns {string[]} The list of BPE decoded sentences.
*/
bpe_decode(sequences) {
return this.bpe_tokenizer.batch_decode(sequences)
}
/**
* Convert a list of lists of word piece token ids into a list of strings by calling word piece tokenizer.
* @param {number[][]} sequences List of tokenized input ids.
* @returns {string[]} The list of wp decoded sentences.
*/
wp_decode(sequences) {
return this.wp_tokenizer.batch_decode(sequences).map(str => str.replaceAll(' ', ''));
}
/**
* Convert a list of lists of token ids into a list of strings by calling decode.
* @param {import('../../utils/tensor.js').Tensor[]} sequences List of tokenized input ids.
* @returns {{generated_text: string[], scores: number[], char_preds: string[], bpe_preds: string[], wp_preds: string[]}}
* Dictionary of all the outputs of the decoded results.
* - generated_text: The final results after fusion of char, bpe, and wp.
* - scores: The final scores after fusion of char, bpe, and wp.
* - char_preds: The list of character decoded sentences.
* - bpe_preds: The list of BPE decoded sentences.
* - wp_preds: The list of wp decoded sentences.
*/
// @ts-expect-error The type of this method is not compatible with the one
// in the base class. It might be a good idea to fix this.
batch_decode([char_logits, bpe_logits, wp_logits]) {
const [char_preds, char_scores] = this._decode_helper(char_logits, 'char');
const [bpe_preds, bpe_scores] = this._decode_helper(bpe_logits, 'bpe');
const [wp_preds, wp_scores] = this._decode_helper(wp_logits, 'wp');
const generated_text = [];
const scores = [];
for (let i = 0; i < char_preds.length; ++i) {
const [max_score, max_score_index] = max([char_scores[i], bpe_scores[i], wp_scores[i]]);
generated_text.push([char_preds[i], bpe_preds[i], wp_preds[i]][max_score_index]);
scores.push(max_score);
}
return {
generated_text,
scores,
char_preds,
bpe_preds,
wp_preds,
}
}
/** @type {typeof Processor.from_pretrained} */
static async from_pretrained(...args) {
const base = await super.from_pretrained(...args);
// Load Transformers.js-compatible versions of the BPE and WordPiece tokenizers
const bpe_tokenizer = await AutoTokenizer.from_pretrained("Xenova/gpt2") // openai-community/gpt2
const wp_tokenizer = await AutoTokenizer.from_pretrained("Xenova/bert-base-uncased") // google-bert/bert-base-uncased
// Update components
base.components = {
image_processor: base.image_processor,
char_tokenizer: base.tokenizer,
bpe_tokenizer: bpe_tokenizer,
wp_tokenizer: wp_tokenizer,
}
return base;
}
async _call(images, text = null) {
const result = await this.image_processor(images);
if (text) {
result.labels = this.tokenizer(text).input_ids
}
return result;
}
}
|
transformers.js/src/models/mgp_str/processing_mgp_str.js/0
|
{
"file_path": "transformers.js/src/models/mgp_str/processing_mgp_str.js",
"repo_id": "transformers.js",
"token_count": 2810
}
|
import {
ImageProcessor,
} from "../../base/image_processors_utils.js";
import {
stack,
cat,
} from "../../utils/tensor.js";
export class VitMatteImageProcessor extends ImageProcessor {
/**
* Calls the feature extraction process on an array of images, preprocesses
* each image, and concatenates the resulting features into a single Tensor.
* @param {import("../../utils/image.js").RawImage[]} images The image(s) to extract features from.
* @param {import("../../utils/image.js").RawImage[]} trimaps The trimaps(s) to extract features from.
* @returns {Promise<import("../../base/image_processors_utils.js").ImageProcessorResult>} An object containing the concatenated pixel values of the preprocessed images.
*/
async _call(images, trimaps) {
if (!Array.isArray(images)) {
images = [images];
}
if (!Array.isArray(trimaps)) {
trimaps = [trimaps];
}
const imageData = await Promise.all(images.map(x => this.preprocess(x)));
const trimapData = await Promise.all(trimaps.map(x => this.preprocess(x, {
do_normalize: false,
do_convert_rgb: false,
do_convert_grayscale: true,
})));
// Stack pixel values
const pixel_values = stack(imageData.map(
// Concatenate images and trimaps
(x, i) => cat([x.pixel_values, trimapData[i].pixel_values], 0)
), 0);
return {
pixel_values,
// Original sizes of images
original_sizes: imageData.map(x => x.original_size),
// Reshaped sizes of images, before padding or cropping
reshaped_input_sizes: imageData.map(x => x.reshaped_input_size),
}
}
}
|
transformers.js/src/models/vitmatte/image_processing_vitmatte.js/0
|
{
"file_path": "transformers.js/src/models/vitmatte/image_processing_vitmatte.js",
"repo_id": "transformers.js",
"token_count": 746
}
|
/*
* Test that models loaded outside of the `pipeline` function work correctly (e.g., `AutoModel.from_pretrained(...)`);
*/
import { AutoTokenizer, AutoModel, BertModel, GPT2Model, T5ForConditionalGeneration, BertTokenizer, GPT2Tokenizer, T5Tokenizer } from "../src/transformers.js";
import { init, MAX_TEST_EXECUTION_TIME, DEFAULT_MODEL_OPTIONS } from "./init.js";
import { compare, collect_and_execute_tests } from "./test_utils.js";
// Initialise the testing environment
init();
describe("Loading different architecture types", () => {
// List all models which will be tested
const models_to_test = [
// [name, modelClass, tokenizerClass]
["hf-internal-testing/tiny-random-BertForMaskedLM", BertModel, BertTokenizer], // Encoder-only
["hf-internal-testing/tiny-random-GPT2LMHeadModel", GPT2Model, GPT2Tokenizer], // Decoder-only
["hf-internal-testing/tiny-random-T5ForConditionalGeneration", T5ForConditionalGeneration, T5Tokenizer], // Encoder-decoder
];
const texts = ["Once upon a time", "I like to eat apples"];
for (const [model_id, modelClass, tokenizerClass] of models_to_test) {
// Test that both the auto model and the specific model work
const tokenizers = [AutoTokenizer, tokenizerClass];
const models = [AutoModel, modelClass];
for (let i = 0; i < tokenizers.length; ++i) {
const tokenizerClassToTest = tokenizers[i];
const modelClassToTest = models[i];
it(
`${model_id} (${modelClassToTest.name})`,
async () => {
// Load model and tokenizer
const tokenizer = await tokenizerClassToTest.from_pretrained(model_id);
const model = await modelClassToTest.from_pretrained(model_id, DEFAULT_MODEL_OPTIONS);
const tests = [
texts[0], // single
texts, // batched
];
for (const test of tests) {
const inputs = await tokenizer(test, { truncation: true, padding: true });
if (model.config.is_encoder_decoder) {
inputs.decoder_input_ids = inputs.input_ids;
}
const output = await model(inputs);
if (output.logits) {
// Ensure correct shapes
const expected_shape = [...inputs.input_ids.dims, model.config.vocab_size];
const actual_shape = output.logits.dims;
compare(expected_shape, actual_shape);
} else if (output.last_hidden_state) {
const expected_shape = [...inputs.input_ids.dims, model.config.d_model];
const actual_shape = output.last_hidden_state.dims;
compare(expected_shape, actual_shape);
} else {
console.warn("Unexpected output", output);
throw new Error("Unexpected output");
}
}
await model.dispose();
},
MAX_TEST_EXECUTION_TIME,
);
}
}
});
await collect_and_execute_tests("Model-specific tests", "modeling");
|
transformers.js/tests/models.test.js/0
|
{
"file_path": "transformers.js/tests/models.test.js",
"repo_id": "transformers.js",
"token_count": 1211
}
|
import { AutoProcessor, JinaCLIPProcessor } from "../../../src/transformers.js";
import { load_cached_image } from "../../asset_cache.js";
import { MAX_PROCESSOR_LOAD_TIME, MAX_TEST_EXECUTION_TIME } from "../../init.js";
export default () => {
describe("JinaCLIPProcessor", () => {
const model_id = "jinaai/jina-clip-v2";
/** @type {JinaCLIPProcessor} */
let processor;
beforeAll(async () => {
processor = await AutoProcessor.from_pretrained(model_id);
}, MAX_PROCESSOR_LOAD_TIME);
it(
"Image and text",
async () => {
// Prepare inputs
const images = [await load_cached_image("white_image"), await load_cached_image("blue_image")];
const sentences = [
"غروب جميل على الشاطئ", // Arabic
"海滩上美丽的日落", // Chinese
"Un beau coucher de soleil sur la plage", // French
"Ein wunderschöner Sonnenuntergang am Strand", // German
"Ένα όμορφο ηλιοβασίλεμα πάνω από την παραλία", // Greek
"समुद्र तट पर एक खूबसूरत सूर्यास्त", // Hindi
"Un bellissimo tramonto sulla spiaggia", // Italian
"浜辺に沈む美しい夕日", // Japanese
"해변 위로 아름다운 일몰", // Korean
];
// Encode text and images
const { input_ids, attention_mask, pixel_values } = await processor(sentences, images, { padding: true, truncation: true });
expect(input_ids.dims).toEqual([sentences.length, 19]);
expect(attention_mask.dims).toEqual([sentences.length, 19]);
expect(pixel_values.dims).toEqual([images.length, 3, 512, 512]);
expect(pixel_values.mean().item()).toBeCloseTo(0.7857685685157776, 6);
},
MAX_TEST_EXECUTION_TIME,
);
});
};
|
transformers.js/tests/models/jina_clip/test_processor_jina_clip.js/0
|
{
"file_path": "transformers.js/tests/models/jina_clip/test_processor_jina_clip.js",
"repo_id": "transformers.js",
"token_count": 863
}
|
import { AutoImageProcessor, NougatImageProcessor } from "../../../src/transformers.js";
import { load_cached_image } from "../../asset_cache.js";
import { MAX_PROCESSOR_LOAD_TIME, MAX_TEST_EXECUTION_TIME } from "../../init.js";
export default () => {
// NougatImageProcessor
// - tests padding after normalization (image_mean != 0.5, image_std != 0.5)
describe("NougatImageProcessor", () => {
const model_id = "Xenova/nougat-small";
/** @type {NougatImageProcessor} */
let processor;
beforeAll(async () => {
processor = await AutoImageProcessor.from_pretrained(model_id);
}, MAX_PROCESSOR_LOAD_TIME);
it(
"padding after normalization",
async () => {
const image = await load_cached_image("paper");
const { pixel_values, original_sizes, reshaped_input_sizes } = await processor(image);
expect(pixel_values.dims).toEqual([1, 3, 896, 672]);
expect(pixel_values.mean().item()).toBeCloseTo(1.8447155005897355, 6);
expect(original_sizes).toEqual([[850, 685]]);
expect(reshaped_input_sizes).toEqual([[833, 672]]);
},
MAX_TEST_EXECUTION_TIME,
);
});
};
|
transformers.js/tests/models/nougat/test_image_processing_nougat.js/0
|
{
"file_path": "transformers.js/tests/models/nougat/test_image_processing_nougat.js",
"repo_id": "transformers.js",
"token_count": 471
}
|
import { WhisperTokenizer, WhisperForConditionalGeneration, full } from "../../../src/transformers.js";
import { MAX_MODEL_LOAD_TIME, MAX_TEST_EXECUTION_TIME, MAX_MODEL_DISPOSE_TIME, DEFAULT_MODEL_OPTIONS } from "../../init.js";
export default () => {
describe("WhisperForConditionalGeneration", () => {
const model_id = "Xenova/tiny-random-WhisperForConditionalGeneration";
/** @type {WhisperForConditionalGeneration} */
let model;
/** @type {WhisperTokenizer} */
let tokenizer;
beforeAll(async () => {
model = await WhisperForConditionalGeneration.from_pretrained(model_id, DEFAULT_MODEL_OPTIONS);
tokenizer = await WhisperTokenizer.from_pretrained(model_id);
}, MAX_MODEL_LOAD_TIME);
describe("prefix tokens", () => {
const input_features = full([1, 80, 3000], 0.0);
describe("English-only", () => {
it(
"default",
async () => {
const outputs = await model.generate({
input_features,
is_multilingual: false,
max_new_tokens: 1,
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, 50363n, /* Generated */ 45084n]]);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"return_timestamps=true",
async () => {
const outputs = await model.generate({
input_features,
is_multilingual: false,
max_new_tokens: 1,
return_timestamps: true,
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, /* Generated */ 50366n]]);
},
MAX_TEST_EXECUTION_TIME,
);
});
describe("multilingual", () => {
it(
"language unset; task unset",
async () => {
// language defaults to 'en'
// task defaults to 'transcribe'
const outputs = await model.generate({
input_features,
max_new_tokens: 1,
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, 50259n, 50359n, 50363n, /* Generated */ 45084n]]);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"language set; task unset",
async () => {
// task defaults to 'transcribe'
const outputs = await model.generate({
input_features,
max_new_tokens: 1,
language: "af",
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, 50327n, 50359n, 50363n, /* Generated */ 45084n]]);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"language set; task set",
async () => {
const outputs = await model.generate({
input_features,
max_new_tokens: 1,
language: "zh",
task: "translate",
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, 50260n, 50358n, 50363n, /* Generated */ 45084n]]);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"return_timestamps=true",
async () => {
const outputs = await model.generate({
input_features,
max_new_tokens: 1,
language: "en",
task: "transcribe",
return_timestamps: true,
});
expect(outputs.tolist()).toEqual([[/* Prefix */ 50258n, 50259n, 50359n, /* Generated */ 50400n]]);
},
MAX_TEST_EXECUTION_TIME,
);
});
});
describe("decoder_start_ids", () => {
const input_features = full([1, 80, 3000], 0.0);
it(
"broadcast inputs",
async () => {
const { decoder_start_token_id, lang_to_id, task_to_id, no_timestamps_token_id } = model.generation_config;
const outputs = await model.generate({
input_features, // batch size 1
max_new_tokens: 1,
decoder_input_ids: [
// batch size 2
// <|startoftranscript|> <|lang_id|> <|task|> [<|notimestamps|>]
[decoder_start_token_id, lang_to_id["<|en|>"], task_to_id["translate"], no_timestamps_token_id],
[decoder_start_token_id, lang_to_id["<|fr|>"], task_to_id["transcribe"], no_timestamps_token_id],
],
});
expect(outputs.tolist()).toEqual([
[/* Prefix */ 50258n, 50259n, 50358n, 50363n, /* Generated */ 45084n],
[/* Prefix */ 50258n, 50265n, 50359n, 50363n, /* Generated */ 45084n],
]);
},
MAX_TEST_EXECUTION_TIME,
);
});
afterAll(async () => {
await model?.dispose();
}, MAX_MODEL_DISPOSE_TIME);
});
};
|
transformers.js/tests/models/whisper/test_modeling_whisper.js/0
|
{
"file_path": "transformers.js/tests/models/whisper/test_modeling_whisper.js",
"repo_id": "transformers.js",
"token_count": 2460
}
|
import { pipeline, ObjectDetectionPipeline } from "../../src/transformers.js";
import { MAX_MODEL_LOAD_TIME, MAX_TEST_EXECUTION_TIME, MAX_MODEL_DISPOSE_TIME, DEFAULT_MODEL_OPTIONS } from "../init.js";
import { load_cached_image } from "../asset_cache.js";
const PIPELINE_ID = "object-detection";
export default () => {
describe("Object Detection", () => {
describe("yolos", () => {
const model_id = "Xenova/yolos-tiny";
/** @type {ObjectDetectionPipeline} */
let pipe;
beforeAll(async () => {
pipe = await pipeline(PIPELINE_ID, model_id, DEFAULT_MODEL_OPTIONS);
}, MAX_MODEL_LOAD_TIME);
it("should be an instance of ObjectDetectionPipeline", () => {
expect(pipe).toBeInstanceOf(ObjectDetectionPipeline);
});
it(
"single + threshold",
async () => {
const image = await load_cached_image("cats");
const output = await pipe(image, { threshold: 0.9 });
const target = [
{
score: 0.9921281933784485,
label: "remote",
box: { xmin: 32, ymin: 78, xmax: 185, ymax: 117 },
},
{
score: 0.9884883165359497,
label: "remote",
box: { xmin: 324, ymin: 82, xmax: 376, ymax: 191 },
},
{
score: 0.9197800159454346,
label: "cat",
box: { xmin: 5, ymin: 56, xmax: 321, ymax: 469 },
},
{
score: 0.9300552606582642,
label: "cat",
box: { xmin: 332, ymin: 25, xmax: 638, ymax: 369 },
},
];
expect(output).toBeCloseToNested(target, 5);
},
MAX_TEST_EXECUTION_TIME,
);
afterAll(async () => {
await pipe.dispose();
}, MAX_MODEL_DISPOSE_TIME);
});
describe("tiny-random", () => {
const model_id = "hf-internal-testing/tiny-random-DetrForObjectDetection";
/** @type {ObjectDetectionPipeline} */
let pipe;
let images;
beforeAll(async () => {
pipe = await pipeline(PIPELINE_ID, model_id, DEFAULT_MODEL_OPTIONS);
images = await Promise.all([load_cached_image("white_image"), load_cached_image("blue_image")]);
}, MAX_MODEL_LOAD_TIME);
it("should be an instance of ObjectDetectionPipeline", () => {
expect(pipe).toBeInstanceOf(ObjectDetectionPipeline);
});
describe("batch_size=1", () => {
it(
"default (threshold unset)",
async () => {
const output = await pipe(images[0]);
const target = [];
expect(output).toBeCloseToNested(target, 5);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"default (threshold=0)",
async () => {
const output = await pipe(images[0], { threshold: 0 });
const target = [
{ score: 0.020360443741083145, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360419526696205, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.02036038413643837, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360447466373444, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360389724373817, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360423251986504, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.02036040835082531, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360363647341728, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360389724373817, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360389724373817, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360343158245087, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
{ score: 0.020360423251986504, label: "LABEL_31", box: { xmin: 56, ymin: 55, xmax: 169, ymax: 167 } },
];
expect(output).toBeCloseToNested(target, 5);
},
MAX_TEST_EXECUTION_TIME,
);
});
// TODO: Add batched support to object detection pipeline
// describe('batch_size>1', () => {
// it('default (threshold unset)', async () => {
// const output = await pipe(images);
// console.log(output);
// const target = [];
// expect(output).toBeCloseToNested(target, 5);
// }, MAX_TEST_EXECUTION_TIME);
// it('default (threshold=0)', async () => {
// const output = await pipe(images, { threshold: 0 });
// console.log(output);
// const target = [];
// expect(output).toBeCloseToNested(target, 5);
// }, MAX_TEST_EXECUTION_TIME);
// });
afterAll(async () => {
await pipe.dispose();
}, MAX_MODEL_DISPOSE_TIME);
});
});
};
|
transformers.js/tests/pipelines/test_pipelines_object_detection.js/0
|
{
"file_path": "transformers.js/tests/pipelines/test_pipelines_object_detection.js",
"repo_id": "transformers.js",
"token_count": 2625
}
|
import { PriorityQueue } from "../../src/utils/data-structures.js";
describe("Priority queue", () => {
const EXAMPLE_ARRAY = [2, 5, 3, 1, 4];
it("default (max heap)", () => {
const queue = new PriorityQueue();
queue.extend(EXAMPLE_ARRAY);
expect(queue.pop()).toBe(5);
});
it("min heap", () => {
const queue = new PriorityQueue((a, b) => a < b);
queue.extend(EXAMPLE_ARRAY);
expect(queue.pop()).toBe(1);
});
it("heap w/ max size", () => {
const queue = new PriorityQueue((a, b) => a > b, 3);
queue.extend([1, 2, 3, 4, 5, 4, 3, 2, 1]);
expect(queue.pop()).toBe(5);
// Test with random sizes
const sizes = [1, 3, 4, 5, 8, 9, 15, 16, 31, 32, 127, 128];
const arr = Array.from({ length: 100 }, (_) => Math.random());
const max = Math.max(...arr);
for (const size of sizes) {
const queue = new PriorityQueue((a, b) => a > b, size);
queue.extend(arr);
expect(queue.pop()).toBe(max);
expect(queue.size).toBeLessThanOrEqual(size);
}
});
});
|
transformers.js/tests/utils/data_structures.test.js/0
|
{
"file_path": "transformers.js/tests/utils/data_structures.test.js",
"repo_id": "transformers.js",
"token_count": 433
}
|
.PHONY: deps_table_update modified_only_fixup extra_style_checks quality style fixup fix-copies test test-examples benchmark
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
export PYTHONPATH = src
check_dirs := examples tests src utils
exclude_folders := ""
modified_only_fixup:
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
@if test -n "$(modified_py_files)"; then \
echo "Checking/fixing $(modified_py_files)"; \
ruff check $(modified_py_files) --fix --exclude $(exclude_folders); \
ruff format $(modified_py_files) --exclude $(exclude_folders);\
else \
echo "No library .py files were modified"; \
fi
# Update src/transformers/dependency_versions_table.py
deps_table_update:
@python setup.py deps_table_update
deps_table_check_updated:
@md5sum src/transformers/dependency_versions_table.py > md5sum.saved
@python setup.py deps_table_update
@md5sum -c --quiet md5sum.saved || (printf "\nError: the version dependency table is outdated.\nPlease run 'make fixup' or 'make style' and commit the changes.\n\n" && exit 1)
@rm md5sum.saved
# autogenerating code
autogenerate_code: deps_table_update
# Check that the repo is in a good state
repo-consistency:
python utils/check_copies.py
python utils/check_modular_conversion.py
python utils/check_table.py
python utils/check_dummies.py
python utils/check_repo.py
python utils/check_inits.py
python utils/check_config_docstrings.py
python utils/check_config_attributes.py
python utils/check_doctest_list.py
python utils/update_metadata.py --check-only
python utils/check_docstrings.py
python utils/check_support_list.py
# this target runs checks on all files
quality:
@python -c "from transformers import *" || (echo '🚨 import failed, this means you introduced unprotected imports! 🚨'; exit 1)
ruff check $(check_dirs) setup.py conftest.py
ruff format --check $(check_dirs) setup.py conftest.py
python utils/sort_auto_mappings.py --check_only
python utils/check_doc_toc.py
python utils/check_docstrings.py --check_all
# Format source code automatically and check is there are any problems left that need manual fixing
extra_style_checks:
python utils/sort_auto_mappings.py
python utils/check_doc_toc.py --fix_and_overwrite
# this target runs checks on all files and potentially modifies some of them
style:
ruff check $(check_dirs) setup.py conftest.py --fix --exclude $(exclude_folders)
ruff format $(check_dirs) setup.py conftest.py --exclude $(exclude_folders)
${MAKE} autogenerate_code
${MAKE} extra_style_checks
# Super fast fix and check target that only works on relevant modified files since the branch was made
fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
# Make marked copies of snippets of codes conform to the original
fix-copies:
python utils/check_copies.py --fix_and_overwrite
python utils/check_modular_conversion.py --fix_and_overwrite
python utils/check_table.py --fix_and_overwrite
python utils/check_dummies.py --fix_and_overwrite
python utils/check_doctest_list.py --fix_and_overwrite
python utils/check_docstrings.py --fix_and_overwrite
# Run tests for the library
test:
python -m pytest -n auto --dist=loadfile -s -v ./tests/
# Run tests for examples
test-examples:
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/
# Run benchmark
benchmark:
python3 benchmark/benchmark.py --config-dir benchmark/config --config-name generation --commit=diff backend.model=google/gemma-2b backend.cache_implementation=null,static backend.torch_compile=false,true --multirun
# Run tests for SageMaker DLC release
test-sagemaker: # install sagemaker dependencies in advance with pip install .[sagemaker]
TEST_SAGEMAKER=True python -m pytest -n auto -s -v ./tests/sagemaker
# Release stuff
pre-release:
python utils/release.py
pre-patch:
python utils/release.py --patch
post-release:
python utils/release.py --post_release
post-patch:
python utils/release.py --post_release --patch
build-release:
rm -rf dist
rm -rf build
python setup.py bdist_wheel
python setup.py sdist
python utils/check_build.py
|
transformers/Makefile/0
|
{
"file_path": "transformers/Makefile",
"repo_id": "transformers",
"token_count": 1419
}
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# tests directory-specific settings - this file is run automatically
# by pytest before any tests are run
import doctest
import sys
import warnings
from os.path import abspath, dirname, join
import _pytest
import pytest
from transformers.testing_utils import HfDoctestModule, HfDocTestParser
NOT_DEVICE_TESTS = {
"test_tokenization",
"test_processor",
"test_processing",
"test_beam_constraints",
"test_configuration_utils",
"test_data_collator",
"test_trainer_callback",
"test_trainer_utils",
"test_feature_extraction",
"test_image_processing",
"test_image_processor",
"test_image_transforms",
"test_optimization",
"test_retrieval",
"test_config",
"test_from_pretrained_no_checkpoint",
"test_keep_in_fp32_modules",
"test_gradient_checkpointing_backward_compatibility",
"test_gradient_checkpointing_enable_disable",
"test_save_load_fast_init_from_base",
"test_fast_init_context_manager",
"test_fast_init_tied_embeddings",
"test_save_load_fast_init_to_base",
"test_torch_save_load",
"test_initialization",
"test_forward_signature",
"test_model_get_set_embeddings",
"test_model_main_input_name",
"test_correct_missing_keys",
"test_tie_model_weights",
"test_can_use_safetensors",
"test_load_save_without_tied_weights",
"test_tied_weights_keys",
"test_model_weights_reload_no_missing_tied_weights",
"test_pt_tf_model_equivalence",
"test_mismatched_shapes_have_properly_initialized_weights",
"test_matched_shapes_have_loaded_weights_when_some_mismatched_shapes_exist",
"test_model_is_small",
"test_tf_from_pt_safetensors",
"test_flax_from_pt_safetensors",
"ModelTest::test_pipeline_", # None of the pipeline tests from PipelineTesterMixin (of which XxxModelTest inherits from) are running on device
"ModelTester::test_pipeline_",
"/repo_utils/",
"/utils/",
"/agents/",
}
# allow having multiple repository checkouts and not needing to remember to rerun
# `pip install -e '.[dev]'` when switching between checkouts and running tests.
git_repo_path = abspath(join(dirname(__file__), "src"))
sys.path.insert(1, git_repo_path)
# silence FutureWarning warnings in tests since often we can't act on them until
# they become normal warnings - i.e. the tests still need to test the current functionality
warnings.simplefilter(action="ignore", category=FutureWarning)
def pytest_configure(config):
config.addinivalue_line(
"markers", "is_pt_tf_cross_test: mark test to run only when PT and TF interactions are tested"
)
config.addinivalue_line(
"markers", "is_pt_flax_cross_test: mark test to run only when PT and FLAX interactions are tested"
)
config.addinivalue_line("markers", "is_pipeline_test: mark test to run only when pipelines are tested")
config.addinivalue_line("markers", "is_staging_test: mark test to run only in the staging environment")
config.addinivalue_line("markers", "accelerate_tests: mark test that require accelerate")
config.addinivalue_line("markers", "agent_tests: mark the agent tests that are run on their specific schedule")
config.addinivalue_line("markers", "not_device_test: mark the tests always running on cpu")
def pytest_collection_modifyitems(items):
for item in items:
if any(test_name in item.nodeid for test_name in NOT_DEVICE_TESTS):
item.add_marker(pytest.mark.not_device_test)
def pytest_addoption(parser):
from transformers.testing_utils import pytest_addoption_shared
pytest_addoption_shared(parser)
def pytest_terminal_summary(terminalreporter):
from transformers.testing_utils import pytest_terminal_summary_main
make_reports = terminalreporter.config.getoption("--make-reports")
if make_reports:
pytest_terminal_summary_main(terminalreporter, id=make_reports)
def pytest_sessionfinish(session, exitstatus):
# If no tests are collected, pytest exists with code 5, which makes the CI fail.
if exitstatus == 5:
session.exitstatus = 0
# Doctest custom flag to ignore output.
IGNORE_RESULT = doctest.register_optionflag("IGNORE_RESULT")
OutputChecker = doctest.OutputChecker
class CustomOutputChecker(OutputChecker):
def check_output(self, want, got, optionflags):
if IGNORE_RESULT & optionflags:
return True
return OutputChecker.check_output(self, want, got, optionflags)
doctest.OutputChecker = CustomOutputChecker
_pytest.doctest.DoctestModule = HfDoctestModule
doctest.DocTestParser = HfDocTestParser
|
transformers/conftest.py/0
|
{
"file_path": "transformers/conftest.py",
"repo_id": "transformers",
"token_count": 1806
}
|
FROM python:3.10
LABEL maintainer="Hugging Face"
RUN apt update
RUN git clone https://github.com/huggingface/transformers
RUN python3 -m pip install --no-cache-dir --upgrade pip && python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder ./transformers[dev]
RUN apt-get -y update && apt-get install -y libsndfile1-dev && apt install -y tesseract-ocr
# Torch needs to be installed before deepspeed
RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed]
RUN python3 -m pip install --no-cache-dir torchvision git+https://github.com/facebookresearch/detectron2.git pytesseract
RUN python3 -m pip install -U "itsdangerous<2.1.0"
# Test if the image could successfully build the doc. before publishing the image
RUN doc-builder build transformers transformers/docs/source/en --build_dir doc-build-dev --notebook_dir notebooks/transformers_doc --clean
RUN rm -rf doc-build-dev
|
transformers/docker/transformers-doc-builder/Dockerfile/0
|
{
"file_path": "transformers/docker/transformers-doc-builder/Dockerfile",
"repo_id": "transformers",
"token_count": 292
}
|
# كيفية تعديل أي نموذج من نماذج Transformers
توفر مكتبة [🤗 Transformers](https://github.com/huggingface/transformers) مجموعة من النماذج المسبقة التدريب والأدوات لمعالجة اللغات الطبيعية، والرؤية، وما إلى ذلك. على الرغم من أن هذه النماذج تغطي مجموعة واسعة من التطبيقات، فقد تواجه حالات استخدام لا تدعمها المكتبة بشكل افتراضي. يُمكن للتخصيص أن يفتح إمكانيات جديدة، مثل إضافة طبقات جديدة، أو تعديل البنية المعمارية، أو تحسين آليات الانتباه. سيُوضح لك هذا الدليل كيفية تعديل نماذج Transformers الموجودة لتلبية احتياجاتك المحددة. الشيء الرائع هو أنك لست بحاجة إلى الخروج من إطار عمل Transformers لإجراء هذه التغييرات. ي يمكنك تعديل النماذج مباشرةً في Transformers والاستفادة من الميزات مثل [واجهة برمجة التطبيقات Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer)، و [PreTrainedModel](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel)، والضبط الدقيق الفعال باستخدام أدوات مثل [PEFT](https://huggingface.co/docs/peft/index).
سنرشدك في هذا الدليل لكيفية تخصيص نماذج Transformers الموجودة لتلبية متطلباتك، دون فقدان مزايا الإطار. ستتعلم كيفية:
- تعديل بنية نموذج ما من خلال تغيير آلية الانتباه الخاصة به.
- تطبيق تقنيات مثل Low-Rank Adaptation (LoRA) على مكونات نموذج محددة.
نحن نشجعك على المساهمة باختراقاتك الخاصة ومشاركتها هنا مع المجتمع1
## مثال: تعديل آلية الانتباه في نموذج Segment Anything (SAM)
نموذج **Segment Anything (SAM)** هو نموذج رائد في مجال تجزئة الصور. في تنفيذه الافتراضي، يستخدم SAM إسقاطًا مجمعًا للاستعلام والمفتاح والقيمة (`qkv`) في آلية الانتباه الخاصة به. ومع ذلك، قد ترغب في ضبط مكونات محددة فقط من آلية الانتباه، مثل إسقاطات الاستعلام (`q`) والقيمة (`v`)، لتقليل عدد المعلمات القابلة للتدريب والموارد الحسابية المطلوبة.
### الدافع
من خلال تقسيم الإسقاط المجمع `qkv` إلى إسقاطات منفصلة `q` و `k` و `v`، يمكنك تطبيق تقنيات مثل **LoRA** (Low-Rank Adaptation) على إسقاطي `q` و `v` فقط. يسمح لك هذا بما يلي:
- ضبط عدد أقل من المعلمات، مما يقلل من العبء الحسابي.
- تحقيق أداء أفضل من خلال التركيز على مكونات محددة.
- تجربة استراتيجيات تعديل مختلفة في آلية الانتباه.
### التنفيذ
#### **الخطوة 1: إنشاء فئة اهتمام مخصصة**
بعد ذلك، قم بإنشاء فئة فرعية من فئة `SamVisionAttention` الأصلية وعدلها لتضم إسقاطات `q` و `k` و `v` منفصلة.
```python
import torch
import torch.nn as nn
from transformers.models.sam.modeling_sam import SamVisionAttention
class SamVisionAttentionSplit(SamVisionAttention, nn.Module):
def __init__(self, config, window_size):
super().__init__(config, window_size)
del self.qkv
# إسقاطات منفصلة q و k و v
self.q = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
self.k = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
self.v = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
self._register_load_state_dict_pre_hook(self.split_q_k_v_load_hook)
def split_q_k_v_load_hook(self, state_dict, prefix, *args):
keys_to_delete = []
for key in list(state_dict.keys()):
if "qkv." in key:
# تقسيم q و k و v من الإسقاط المجمع
q, k, v = state_dict[key].chunk(3, dim=0)
# استبدال الإسقاطات الفردية q و k و v
state_dict[key.replace("qkv.", "q.")] = q
state_dict[key.replace("qkv.", "k.")] = k
state_dict[key.replace("qkv.", "v.")] = v
# وضع علامة على مفتاح qkv القديم للحذف
keys_to_delete.append(key)
# حذف مفاتيح qkv القديمة
for key in keys_to_delete:
del state_dict[key]
def forward(self, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
batch_size, height, width, _ = hidden_states.shape
qkv_shapes = (batch_size * self.num_attention_heads, height * width, -1)
query = self.q(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
key = self.k(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
value = self.v(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
attn_weights = (query * self.scale) @ key.transpose(-2, -1)
if self.use_rel_pos:
attn_weights = self.add_decomposed_rel_pos(
attn_weights, query, self.rel_pos_h, self.rel_pos_w, (height, width), (height, width)
)
attn_weights = torch.nn.functional.softmax(attn_weights, dtype=torch.float32, dim=-1).to(query.dtype)
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = (attn_probs @ value).reshape(batch_size, self.num_attention_heads, height, width, -1)
attn_output = attn_output.permute(0, 2, 3, 1, 4).reshape(batch_size, height, width, -1)
attn_output = self.proj(attn_output)
if output_attentions:
outputs = (attn_output, attn_weights)
else:
outputs = (attn_output, None)
return outputs
```
**الشرح:**
- **الإسقاطات المنفصلة:** يتم إزالة الإسقاط المُجمع `qkv`، وإنشاء إسقاطات خطية منفصلة `q` و `k` و `v`.
- **دالة استدعاء تحميل الأوزان:** تقوم طريقة `_split_qkv_load_hook` بتقسيم أوزان `qkv` المسبقة التدريب إلى أوزان `q` و `k` و `v` منفصلة عند تحميل النموذج. يضمن هذا التوافق مع أي نموذج مسبق التدريب.
- **التنفيذ الأمامي:** يتم حساب الاستعلامات والمفاتيح والقيم بشكل منفصل، وتستمر آلية الانتباه كالمعتاد.
#### **الخطوة 2: استبدال فئة الانتباه الأصلية**
استبدل فئة `SamVisionAttention` الأصلية بفئتك المخصصة بحيث يستخدم النموذج آلية الانتباه المعدلة.
```python
from transformers import SamModel
from transformers.models.sam import modeling_sam
# استبدال فئة الاهتمام في وحدة نمطية modeling_sam
modeling_sam.SamVisionAttention = SamVisionAttentionSplit
# تحميل نموذج SAM المسبق التدريب
model = SamModel.from_pretrained("facebook/sam-vit-base")
```
**الشرح:**
- **استبدال الفئة:** من خلال تعيين فئتك المخصصة إلى `modeling_sam.SamVisionAttention`، فإن أي حالات من فئة `SamVisionAttention` في النموذج ستستخدم النسخة المعدلة. وبالتالي، عند استدعاء `SamModel`، سيتم استخدام `SamVisionAttentionSplit` المحددة حديثًا.
- **تحميل النموذج:** يتم تحميل النموذج باستخدام `from_pretrained`، ويتم دمج آلية الانتباه المخصصة.
#### **الخطوة 3: تطبيق LoRA على إسقاطات محددة**
مع وجود إسقاطات `q` و `k` و `v` منفصلة، يمكنك الآن تطبيق LoRA على مكونات محددة، مثل إسقاطات `q` و `v`.
```python
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q", "v"], # تطبيق LoRA على إسقاطات q و v
lora_dropout=0.1,
task_type="mask-generation"
)
# تطبيق LoRA على النموذج
model = get_peft_model(model, config)
```
**الشرح:**
- **تكوين LoRA:** تحدد `LoraConfig` المرتبة `r`، وعامل القياس `lora_alpha`، والوحدات المستهدفة (`"q"` و `"v"`)، ومعدل التخلي، ونوع المهمة.
- **تطبيق LoRA:** تقوم دالة `get_peft_model` بتطبيق LoRA على الوحدات المحددة في النموذج.
- **تقليل المعلمات:** من خلال التركيز على `q` و `v`، فإنك تقلل عدد المعلمات القابلة للتدريب، مما يؤدي إلى تسريع التدريب وتقليل استخدام الذاكرة.
#### **الخطوة 4: التحقق من عدد المعلمات القابلة للتدريب**
من السهل التحقق من عدد المعلمات القابلة للتدريب ومعرفة تأثير تعديلك.
```python
model.print_trainable_parameters()
```
**الناتج المتوقع:**
```
عدد المعلمات القابلة للتدريب: 608,256 || جميع المعلمات: 94,343,728 || نسبة المعلمات القابلة للتدريب: 0.6447
عدد المعلمات القابلة للتدريب: 912,384 || جميع المعلمات: 94,647,856 || نسبة المعلمات القابلة للتدريب: 0.9640 # مع k
```
## المساهمة بابداعاتك الخاصة
يمكن لتعديل النماذج المسبقة التدريب أن يفتح آفاقًا جديدة للبحث والتطبيق. من خلال فهم وتعديل الآليات الداخلية للنماذج مثل SAM، يمكنك تخصيصها لتلبية احتياجاتك المحددة، وتحسين الأداء، وتجربة أفكار جديدة.
إذا قمت بتطوير تعديﻻتك الخاصة لنماذج Transformers وترغب في مشاركتها، ففكر في المساهمة في هذه الوثيقة.
- **إنشاء طلب سحب (Pull Request):** شارك تغييراتك وتحسيناتك في التعليمات البرمجية مباشرة في المستودع.
- **كتابة التوثيق:** قدم تفسيرات وأمثلة واضحة لتعديلاتك.
- **التفاعل مع المجتمع:** ناقش أفكارك واحصل على تعليقات من المطورين والباحثين الآخرين من خلال فتح مشكلة.
|
transformers/docs/source/ar/how_to_hack_models.md/0
|
{
"file_path": "transformers/docs/source/ar/how_to_hack_models.md",
"repo_id": "transformers",
"token_count": 5880
}
|
# استخدام قنوات المعالجة لخادم ويب
<Tip>
يُعدّ إنشاء محرك استدلال أمرًا معقدًا، ويعتمد الحل "الأفضل" على مساحة مشكلتك. هل تستخدم وحدة المعالجة المركزية أم وحدة معالجة الرسومات؟ هل تريد أقل زمن وصول، أم أعلى معدل نقل، أم دعمًا للعديد من النماذج، أم مجرد تحقيق أقصى تحسين نموذج محدد؟
توجد طرق عديدة لمعالجة هذا الموضوع، لذلك ما سنقدمه هو إعداد افتراضي جيد للبدء به قد لا يكون بالضرورة هو الحل الأمثل لك.```
</Tip>
الشيء الرئيسي الذي يجب فهمه هو أننا يمكن أن نستخدم مؤشرًا، تمامًا كما تفعل [على مجموعة بيانات](pipeline_tutorial#using-pipelines-on-a-dataset)، نظرًا لأن خادم الويب هو أساسًا نظام ينتظر الطلبات ويعالجها عند استلامها.
عادةً ما تكون خوادم الويب متعددة الإرسال (متعددة مؤشرات الترابط، وغير متزامنة، إلخ) للتعامل مع الطلبات المختلفة بشكل متزامن. من ناحية أخرى، فإن قنوات المعالجة (وبشكل رئيسي النماذج الأساسية) ليست رائعة للتوازي؛ حيث تستهلك الكثير من ذاكرة الوصول العشوائي، لذا من الأفضل منحها جميع الموارد المتاحة عند تشغيلها أو إذا كانت مهمة تطلب حسابات مكثفة.
سنحل ذلك من خلال جعل خادم الويب يتعامل مع الحمل الخفيف لاستقبال الطلبات وإرسالها،وجعل مؤشر ترابط واحد يتعامل مع العمل الفعلي. سيستخدم هذا المثال `starlette`. ولكن قد تضطر إلى ضبط الكود أو تغييره إذا كنت تستخدم كودًا آخر لتحقيق التأثير نفسه.
أنشئ `server.py`:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="google-bert/bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
الآن يمكنك تشغيله باستخدام:
```bash
uvicorn server:app
```
ويمكنك الاستعلام عنه:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
وهكذا، لديك الآن فكرة جيدة عن كيفية إنشاء خادم ويب!
المهم حقًا هو أننا نقوم بتحميل النموذج **مرة واحدة** فقط، لذلك لا توجد نسخ من النموذج على خادم الويب. بهذه الطريقة، لا يتم استخدام ذاكرة الوصول العشوائي غير الضرورية. تسمح آلية وضع قائمة الانتظار بالقيام بأشياء متقدمة مثل تجميع بعض العناصر قبل الاستدلال لاستخدام معالجة الدفعات الديناميكية:
<Tip warning={true}>
تم كتابة نموذج الكود البرمجى أدناه بشكل مقصود مثل كود وهمي للقراءة. لا تقم بتشغيله دون التحقق مما إذا كان منطقيًا لموارد النظام الخاص بك!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
مرة أخرى، تم تحسين الرمز المقترح لسهولة القراءة، وليس ليكون أفضل كود. بادئ ذي بدء، لا يوجد حد لحجم الدفعة، والذي عادةً ما لا يكون فكرة عظيمة. بعد ذلك، يتم إعادة ضبط الفترة في كل عملية جلب لقائمة الانتظار، مما يعني أنه قد يتعين عليك الانتظار لفترة أطول بكثير من 1 مللي ثانية قبل تشغيل الاستدلال (تأخير الطلب الأول بهذا القدر).
سيكون من الأفضل تحديد مهلة واحدة مدتها 1 مللي ثانية.
سيظل هذا ينتظر دائمًا لمدة 1 مللي ثانية حتى إذا كانت قائمة الانتظار فارغًا، والذي قد لا يكون الأفضل نظرًا لأنك تريد على الأرجح البدء في إجراء الاستدلال إذا لم يكن هناك شيء في قائمة الانتظا. ولكن ربما يكون منطقيًا إذا كانت المعالجة الديناميكية للدفعات مهمة حقًا لحالة الاستخدام لديك. مرة أخرى، لا يوجد حل واحد هو الأفضل.
## بعض الأشياء التي قد ترغب في مراعاتها
### التحقق من الأخطاء
هناك الكثير مما قد يحدث بشكل خاطئ في عند اتاحة النموذج للجمهور: نفاد الذاكرة، أو نفاد المساحة، أو فشل تحميل النموذج، أو قد يكون الاستعلام خاطئًا، أو قد يكون الاستعلام صحيحًا ولكن لا يزال يفشل في التشغيل بسبب خطأ في إعداد النموذج، وما إلى ذلك.
بشكل عام، من الجيد أن يُخرِج الخادم الأخطاء للمستخدم، لذلك يُعدّ إضافة الكثير من عبارات `try..except` لعرض هذه الأخطاء فكرة
جيدة. لكن ضع في اعتبارك أنه قد يمثل أيضًا مخاطرة أمنية الكشف عن جميع تلك الأخطاء اعتمادًا على سياق الأمان لديك.
### قطع الدائرة (Circuit breaking)
عادةً ما تبدو خوادم الويب أفضل عندما تقوم بقطع الدائرة. وهذا يعني أنها ترجع أخطاء صحيحة عندما تكون مثقلة بشكل زائد بدلاً من الانتظار إلى أجل غير مسمى. قم بإرجاع خطأ 503 بدلاً من الانتظار لفترة طويلة جدًا أو 504 بعد فترة طويلة.
من السهل نسبيًا تنفيذ ذلك في الكود المقترح نظرًا لوجود قائمة انتظار واحد. إن النظر في حجم قائمة الانتظار هو طريقة أساسية لبدء إرجاع الأخطاء قبل فشل خادم الويب بسبب الحمل الزائد.
### حجب عمل خيط التنفيذ الرئيسي (Main thread)
حاليًا، لا تدعم PyTorch العمليات غير المتزامنة، وسيؤدي الحساب إلى حجب عمل الخيط الرئيسي أثناء تشغيله. وهذا يعني أنه سيكون من الأفضل إذا تم إجبار PyTorch على أن تعمل على الخيط/العملية الخاصة به. لم يتم ذلك هنا لأن الكود أكثر تعقيدًا (في الغالب لأن خيوط التنفيذ والعمليات غير المتزامنة وقوائم الانتظار لا تتوافق معًا). ولكن في النهاية، فإنه سيؤدي نفس الوظيفة.
سيكون هذا مهمًا إذا كان الاستدلال للعناصر الفردية طويلاً (> 1 ثانية) لأنه في هذه الحالة، فهذا يعني أنه سيتعين أثناء الاستدلال على كل استعلام الانتظار لمدة ثانية واحدة قبل حتى يلقي خطأ.
### المعالجة الديناميكية
بشكل عام، لا تُعدّ المعالجة بالضرورة تحسينًا مقارنةً بتمرير عنصر واحد في كل مرة (راجع [تفاصيل المعالجة بالدفعات](./main_classes/pipelines#pipeline-batching) لمزيد من المعلومات). ولكن يمكن أن تكون فعالة للغاية عند استخدامها بالإعداد الصحيح. في واجهة برمجة التطبيقات، لا توجد معالجة ديناميكية بشكل افتراضي (فرصة كبيرة جدًا للتباطؤ). ولكن بالنسبة لاستدلال BLOOM - وهو نموذج كبير جدًا - تُعدّ المعالجة الديناميكية **ضرورية** لتوفير تجربة جيدة للجميع.
|
transformers/docs/source/ar/pipeline_webserver.md/0
|
{
"file_path": "transformers/docs/source/ar/pipeline_webserver.md",
"repo_id": "transformers",
"token_count": 5178
}
|
# التصدير إلى TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) هو إطار عمل خفيف الوزن لنشر نماذج التعلم الآلي على الأجهزة المحدودة الموارد، مثل الهواتف المحمولة، والأنظمة المدمجة، وأجهزة إنترنت الأشياء (IoT). تم تصميم TFLite لتشغيل النماذج وتحسينها بكفاءة على هذه الأجهزة ذات الطاقة الحاسوبية والذاكرة واستهلاك الطاقة المحدودة.
يُمثَّل نموذج TensorFlow Lite بتنسيق محمول فعال خاص يُعرَّف بامتداد الملف `.tflite`.
🤗 Optimum يقدم وظيفة لتصدير نماذج 🤗 Transformers إلى TFLite من خلال الوحدة النمطية `exporters.tflite`. بالنسبة لقائمة هندسات النماذج المدعومة، يرجى الرجوع إلى [وثائق 🤗 Optimum](https://huggingface.co/docs/optimum/exporters/tflite/overview).
لتصدير نموذج إلى TFLite، قم بتثبيت متطلبات البرنامج المطلوبة:
```bash
pip install optimum[exporters-tf]
```
للاطلاع على جميع المغامﻻت المتاحة، راجع [وثائق 🤗 Optimum](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model)، أو عرض المساعدة في سطر الأوامر:
```bash
optimum-cli export tflite --help
```
لتصدير نسخة النموذج ل 🤗 Hub، على سبيل المثال، `google-bert/bert-base-uncased`، قم بتشغيل الأمر التالي:
```bash
optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
```
ستظهر لك السجلات التي تُبيّن التقدم وموقع حفظ ملف `model.tflite` الناتج، كما في المثال التالي:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
يُبيّن المثال أعلاه كيفية تصدير نسخة من النموذج ل 🤗 Hub. عند تصدير نموذج محلي، تأكد أولاً من حفظ ملفات أوزان النموذج المجزء اللغوى في نفس المسار (`local_path`). عند استخدام CLI، قم بتمرير `local_path` إلى معامل `model` بدلاً من اسم النسخة على 🤗 Hub.
|
transformers/docs/source/ar/tflite.md/0
|
{
"file_path": "transformers/docs/source/ar/tflite.md",
"repo_id": "transformers",
"token_count": 1409
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation with LLMs
[[open-in-colab]]
LLMs (Large Language Models) sind die Schlüsselkomponente bei der Texterstellung. Kurz gesagt, bestehen sie aus großen, vortrainierten Transformationsmodellen, die darauf trainiert sind, das nächste Wort (oder genauer gesagt Token) aus einem Eingabetext vorherzusagen. Da sie jeweils ein Token vorhersagen, müssen Sie etwas Aufwändigeres tun, um neue Sätze zu generieren, als nur das Modell aufzurufen - Sie müssen eine autoregressive Generierung durchführen.
Die autoregressive Generierung ist ein Verfahren zur Inferenzzeit, bei dem ein Modell mit seinen eigenen generierten Ausgaben iterativ aufgerufen wird, wenn einige anfängliche Eingaben vorliegen. In 🤗 Transformers wird dies von der Methode [`~generation.GenerationMixin.generate`] übernommen, die allen Modellen mit generativen Fähigkeiten zur Verfügung steht.
Dieses Tutorial zeigt Ihnen, wie Sie:
* Text mit einem LLM generieren
* Vermeiden Sie häufige Fallstricke
* Nächste Schritte, damit Sie das Beste aus Ihrem LLM herausholen können
Bevor Sie beginnen, stellen Sie sicher, dass Sie alle erforderlichen Bibliotheken installiert haben:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## Text generieren
Ein Sprachmodell, das für [causal language modeling](tasks/language_modeling) trainiert wurde, nimmt eine Folge von Text-Token als Eingabe und gibt die Wahrscheinlichkeitsverteilung für das nächste Token zurück.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"Forward pass of an LLM"</figcaption>
</figure>
Ein wichtiger Aspekt der autoregressiven Generierung mit LLMs ist die Auswahl des nächsten Tokens aus dieser Wahrscheinlichkeitsverteilung. In diesem Schritt ist alles möglich, solange Sie am Ende ein Token für die nächste Iteration haben. Das heißt, es kann so einfach sein wie die Auswahl des wahrscheinlichsten Tokens aus der Wahrscheinlichkeitsverteilung oder so komplex wie die Anwendung von einem Dutzend Transformationen vor der Stichprobenziehung aus der resultierenden Verteilung.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"Die autoregressive Generierung wählt iterativ das nächste Token aus einer Wahrscheinlichkeitsverteilung aus, um Text zu erzeugen"</figcaption>
</figure>
Der oben dargestellte Prozess wird iterativ wiederholt, bis eine bestimmte Abbruchbedingung erreicht ist. Im Idealfall wird die Abbruchbedingung vom Modell vorgegeben, das lernen sollte, wann es ein Ende-der-Sequenz-Token (EOS) ausgeben muss. Ist dies nicht der Fall, stoppt die Generierung, wenn eine vordefinierte Maximallänge erreicht ist.
Damit sich Ihr Modell so verhält, wie Sie es für Ihre Aufgabe erwarten, müssen Sie den Schritt der Token-Auswahl und die Abbruchbedingung richtig einstellen. Aus diesem Grund haben wir zu jedem Modell eine [`~generation.GenerationConfig`]-Datei, die eine gute generative Standardparametrisierung enthält und zusammen mit Ihrem Modell geladen wird.
Lassen Sie uns über Code sprechen!
<Tip>
Wenn Sie an der grundlegenden Verwendung von LLMs interessiert sind, ist unsere High-Level-Schnittstelle [`Pipeline`](pipeline_tutorial) ein guter Ausgangspunkt. LLMs erfordern jedoch oft fortgeschrittene Funktionen wie Quantisierung und Feinsteuerung des Token-Auswahlschritts, was am besten über [`~generation.GenerationMixin.generate`] erfolgt. Die autoregressive Generierung mit LLMs ist ebenfalls ressourcenintensiv und sollte für einen angemessenen Durchsatz auf einer GPU ausgeführt werden.
</Tip>
<!-- TODO: update example to llama 2 (or a newer popular baseline) when it becomes ungated -->
Zunächst müssen Sie das Modell laden.
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
... )
```
Sie werden zwei Flags in dem Aufruf `from_pretrained` bemerken:
- `device_map` stellt sicher, dass das Modell auf Ihre GPU(s) übertragen wird
- `load_in_4bit` wendet [dynamische 4-Bit-Quantisierung](main_classes/quantization) an, um die Ressourcenanforderungen massiv zu reduzieren
Es gibt noch andere Möglichkeiten, ein Modell zu initialisieren, aber dies ist eine gute Grundlage, um mit einem LLM zu beginnen.
Als nächstes müssen Sie Ihre Texteingabe mit einem [tokenizer](tokenizer_summary) vorverarbeiten.
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
Die Variable `model_inputs` enthält die tokenisierte Texteingabe sowie die Aufmerksamkeitsmaske. Obwohl [`~generation.GenerationMixin.generate`] sein Bestes tut, um die Aufmerksamkeitsmaske abzuleiten, wenn sie nicht übergeben wird, empfehlen wir, sie für optimale Ergebnisse wann immer möglich zu übergeben.
Rufen Sie schließlich die Methode [`~generation.GenerationMixin.generate`] auf, um die generierten Token zurückzugeben, die vor dem Drucken in Text umgewandelt werden sollten.
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, black, white, and brown'
```
Und das war's! Mit ein paar Zeilen Code können Sie sich die Macht eines LLM zunutze machen.
## Häufige Fallstricke
Es gibt viele [Generierungsstrategien](generation_strategies), und manchmal sind die Standardwerte für Ihren Anwendungsfall vielleicht nicht geeignet. Wenn Ihre Ausgaben nicht mit dem übereinstimmen, was Sie erwarten, haben wir eine Liste der häufigsten Fallstricke erstellt und wie Sie diese vermeiden können.
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
... )
```
### Generierte Ausgabe ist zu kurz/lang
Wenn in der Datei [`~generation.GenerationConfig`] nichts angegeben ist, gibt `generate` standardmäßig bis zu 20 Token zurück. Wir empfehlen dringend, `max_new_tokens` in Ihrem `generate`-Aufruf manuell zu setzen, um die maximale Anzahl neuer Token zu kontrollieren, die zurückgegeben werden können. Beachten Sie, dass LLMs (genauer gesagt, [decoder-only models](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)) auch die Eingabeaufforderung als Teil der Ausgabe zurückgeben.
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### Falscher Generierungsmodus
Standardmäßig und sofern nicht in der Datei [`~generation.GenerationConfig`] angegeben, wählt `generate` bei jeder Iteration das wahrscheinlichste Token aus (gierige Dekodierung). Je nach Aufgabe kann dies unerwünscht sein; kreative Aufgaben wie Chatbots oder das Schreiben eines Aufsatzes profitieren vom Sampling. Andererseits profitieren Aufgaben, bei denen es auf die Eingabe ankommt, wie z.B. Audiotranskription oder Übersetzung, von der gierigen Dekodierung. Aktivieren Sie das Sampling mit `do_sample=True`. Mehr zu diesem Thema erfahren Sie in diesem [Blogbeitrag](https://huggingface.co/blog/how-to-generate).
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(0)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat.\nI just need to be. I am always.\nEvery time'
```
### Falsche Auffüllseite
LLMs sind [decoder-only](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)-Architekturen, d.h. sie iterieren weiter über Ihre Eingabeaufforderung. Wenn Ihre Eingaben nicht die gleiche Länge haben, müssen sie aufgefüllt werden. Da LLMs nicht darauf trainiert sind, mit aufgefüllten Token fortzufahren, muss Ihre Eingabe links aufgefüllt werden. Vergessen Sie auch nicht, die Aufmerksamkeitsmaske an generate zu übergeben!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)[0]
''
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
<!-- TODO: when the prompting guide is ready, mention the importance of setting the right prompt in this section -->
## Weitere Ressourcen
Während der Prozess der autoregressiven Generierung relativ einfach ist, kann die optimale Nutzung Ihres LLM ein schwieriges Unterfangen sein, da es viele bewegliche Teile gibt. Für Ihre nächsten Schritte, die Ihnen helfen, tiefer in die LLM-Nutzung und das Verständnis einzutauchen:
<!-- TODO: mit neuen Anleitungen vervollständigen -->
### Fortgeschrittene Nutzung generieren
1. [Leitfaden](generation_strategies) zur Steuerung verschiedener Generierungsmethoden, zur Einrichtung der Generierungskonfigurationsdatei und zum Streaming der Ausgabe;
2. API-Referenz zu [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`] und [generate-bezogene Klassen](internal/generation_utils).
### LLM-Ranglisten
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), das sich auf die Qualität der Open-Source-Modelle konzentriert;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), das sich auf den LLM-Durchsatz konzentriert.
### Latenz und Durchsatz
1. [Leitfaden](main_classes/quantization) zur dynamischen Quantisierung, der Ihnen zeigt, wie Sie Ihren Speicherbedarf drastisch reduzieren können.
### Verwandte Bibliotheken
1. [text-generation-inference](https://github.com/huggingface/text-generation-inference), ein produktionsreifer Server für LLMs;
2. [`optimum`](https://github.com/huggingface/optimum), eine Erweiterung von 🤗 Transformers, die für bestimmte Hardware-Geräte optimiert.
|
transformers/docs/source/de/llm_tutorial.md/0
|
{
"file_path": "transformers/docs/source/de/llm_tutorial.md",
"repo_id": "transformers",
"token_count": 4767
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How to create a custom pipeline?
In this guide, we will see how to create a custom pipeline and share it on the [Hub](https://hf.co/models) or add it to the
🤗 Transformers library.
First and foremost, you need to decide the raw entries the pipeline will be able to take. It can be strings, raw bytes,
dictionaries or whatever seems to be the most likely desired input. Try to keep these inputs as pure Python as possible
as it makes compatibility easier (even through other languages via JSON). Those will be the `inputs` of the
pipeline (`preprocess`).
Then define the `outputs`. Same policy as the `inputs`. The simpler, the better. Those will be the outputs of
`postprocess` method.
Start by inheriting the base class `Pipeline` with the 4 methods needed to implement `preprocess`,
`_forward`, `postprocess`, and `_sanitize_parameters`.
```python
from transformers import Pipeline
class MyPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
return preprocess_kwargs, {}, {}
def preprocess(self, inputs, maybe_arg=2):
model_input = Tensor(inputs["input_ids"])
return {"model_input": model_input}
def _forward(self, model_inputs):
# model_inputs == {"model_input": model_input}
outputs = self.model(**model_inputs)
# Maybe {"logits": Tensor(...)}
return outputs
def postprocess(self, model_outputs):
best_class = model_outputs["logits"].softmax(-1)
return best_class
```
The structure of this breakdown is to support relatively seamless support for CPU/GPU, while supporting doing
pre/postprocessing on the CPU on different threads
`preprocess` will take the originally defined inputs, and turn them into something feedable to the model. It might
contain more information and is usually a `Dict`.
`_forward` is the implementation detail and is not meant to be called directly. `forward` is the preferred
called method as it contains safeguards to make sure everything is working on the expected device. If anything is
linked to a real model it belongs in the `_forward` method, anything else is in the preprocess/postprocess.
`postprocess` methods will take the output of `_forward` and turn it into the final output that was decided
earlier.
`_sanitize_parameters` exists to allow users to pass any parameters whenever they wish, be it at initialization
time `pipeline(...., maybe_arg=4)` or at call time `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`.
The returns of `_sanitize_parameters` are the 3 dicts of kwargs that will be passed directly to `preprocess`,
`_forward`, and `postprocess`. Don't fill anything if the caller didn't call with any extra parameter. That
allows to keep the default arguments in the function definition which is always more "natural".
A classic example would be a `top_k` argument in the post processing in classification tasks.
```python
>>> pipe = pipeline("my-new-task")
>>> pipe("This is a test")
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
>>> pipe("This is a test", top_k=2)
[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
```
In order to achieve that, we'll update our `postprocess` method with a default parameter to `5`. and edit
`_sanitize_parameters` to allow this new parameter.
```python
def postprocess(self, model_outputs, top_k=5):
best_class = model_outputs["logits"].softmax(-1)
# Add logic to handle top_k
return best_class
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "maybe_arg" in kwargs:
preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
postprocess_kwargs = {}
if "top_k" in kwargs:
postprocess_kwargs["top_k"] = kwargs["top_k"]
return preprocess_kwargs, {}, postprocess_kwargs
```
Try to keep the inputs/outputs very simple and ideally JSON-serializable as it makes the pipeline usage very easy
without requiring users to understand new kinds of objects. It's also relatively common to support many different types
of arguments for ease of use (audio files, which can be filenames, URLs or pure bytes)
## Adding it to the list of supported tasks
To register your `new-task` to the list of supported tasks, you have to add it to the `PIPELINE_REGISTRY`:
```python
from transformers.pipelines import PIPELINE_REGISTRY
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
)
```
You can specify a default model if you want, in which case it should come with a specific revision (which can be the name of a branch or a commit hash, here we took `"abcdef"`) as well as the type:
```python
PIPELINE_REGISTRY.register_pipeline(
"new-task",
pipeline_class=MyPipeline,
pt_model=AutoModelForSequenceClassification,
default={"pt": ("user/awesome_model", "abcdef")},
type="text", # current support type: text, audio, image, multimodal
)
```
## Share your pipeline on the Hub
To share your custom pipeline on the Hub, you just have to save the custom code of your `Pipeline` subclass in a
python file. For instance, let's say we want to use a custom pipeline for sentence pair classification like this:
```py
import numpy as np
from transformers import Pipeline
def softmax(outputs):
maxes = np.max(outputs, axis=-1, keepdims=True)
shifted_exp = np.exp(outputs - maxes)
return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
class PairClassificationPipeline(Pipeline):
def _sanitize_parameters(self, **kwargs):
preprocess_kwargs = {}
if "second_text" in kwargs:
preprocess_kwargs["second_text"] = kwargs["second_text"]
return preprocess_kwargs, {}, {}
def preprocess(self, text, second_text=None):
return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
def _forward(self, model_inputs):
return self.model(**model_inputs)
def postprocess(self, model_outputs):
logits = model_outputs.logits[0].numpy()
probabilities = softmax(logits)
best_class = np.argmax(probabilities)
label = self.model.config.id2label[best_class]
score = probabilities[best_class].item()
logits = logits.tolist()
return {"label": label, "score": score, "logits": logits}
```
The implementation is framework agnostic, and will work for PyTorch and TensorFlow models. If we have saved this in
a file named `pair_classification.py`, we can then import it and register it like this.
```py
from pair_classification import PairClassificationPipeline
from transformers.pipelines import PIPELINE_REGISTRY
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
PIPELINE_REGISTRY.register_pipeline(
"pair-classification",
pipeline_class=PairClassificationPipeline,
pt_model=AutoModelForSequenceClassification,
tf_model=TFAutoModelForSequenceClassification,
)
```
The [register_pipeline](https://github.com/huggingface/transformers/blob/9feae5fb0164e89d4998e5776897c16f7330d3df/src/transformers/pipelines/base.py#L1387) function registers the pipeline details (task type, pipeline class, supported backends) to a models `config.json` file.
```json
"custom_pipelines": {
"pair-classification": {
"impl": "pair_classification.PairClassificationPipeline",
"pt": [
"AutoModelForSequenceClassification"
],
"tf": [
"TFAutoModelForSequenceClassification"
],
}
},
```
Once this is done, we can use it with a pretrained model. For instance `sgugger/finetuned-bert-mrpc` has been
fine-tuned on the MRPC dataset, which classifies pairs of sentences as paraphrases or not.
```py
from transformers import pipeline
classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
```
Then we can share it on the Hub by using the `push_to_hub` method:
```py
classifier.push_to_hub("test-dynamic-pipeline")
```
This will copy the file where you defined `PairClassificationPipeline` inside the folder `"test-dynamic-pipeline"`,
along with saving the model and tokenizer of the pipeline, before pushing everything into the repository
`{your_username}/test-dynamic-pipeline`. After that, anyone can use it as long as they provide the option
`trust_remote_code=True`:
```py
from transformers import pipeline
classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
```
## Add the pipeline to 🤗 Transformers
If you want to contribute your pipeline to 🤗 Transformers, you will need to add a new module in the `pipelines` submodule
with the code of your pipeline, then add it to the list of tasks defined in `pipelines/__init__.py`.
Then you will need to add tests. Create a new file `tests/test_pipelines_MY_PIPELINE.py` with examples of the other tests.
The `run_pipeline_test` function will be very generic and run on small random models on every possible
architecture as defined by `model_mapping` and `tf_model_mapping`.
This is very important to test future compatibility, meaning if someone adds a new model for
`XXXForQuestionAnswering` then the pipeline test will attempt to run on it. Because the models are random it's
impossible to check for actual values, that's why there is a helper `ANY` that will simply attempt to match the
output of the pipeline TYPE.
You also *need* to implement 2 (ideally 4) tests.
- `test_small_model_pt` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_tf`.
- `test_small_model_tf` : Define 1 small model for this pipeline (doesn't matter if the results don't make sense)
and test the pipeline outputs. The results should be the same as `test_small_model_pt`.
- `test_large_model_pt` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
- `test_large_model_tf` (`optional`): Tests the pipeline on a real pipeline where the results are supposed to
make sense. These tests are slow and should be marked as such. Here the goal is to showcase the pipeline and to make
sure there is no drift in future releases.
|
transformers/docs/source/en/add_new_pipeline.md/0
|
{
"file_path": "transformers/docs/source/en/add_new_pipeline.md",
"repo_id": "transformers",
"token_count": 3561
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fully Sharded Data Parallel
[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a data parallel method that shards a model's parameters, gradients and optimizer states across the number of available GPUs (also called workers or *rank*). Unlike [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html), FSDP reduces memory-usage because a model is replicated on each GPU. This improves GPU memory-efficiency and allows you to train much larger models on fewer GPUs. FSDP is integrated with the Accelerate, a library for easily managing training in distributed environments, which means it is available for use from the [`Trainer`] class.
Before you start, make sure Accelerate is installed and at least PyTorch 2.1.0 or newer.
```bash
pip install accelerate
```
## FSDP configuration
To start, run the [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) command to create a configuration file for your training environment. Accelerate uses this configuration file to automatically setup the correct training environment based on your selected training options in `accelerate config`.
```bash
accelerate config
```
When you run `accelerate config`, you'll be prompted with a series of options to configure your training environment. This section covers some of the most important FSDP options. To learn more about the other available FSDP options, take a look at the [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) parameters.
### Sharding strategy
FSDP offers a number of sharding strategies to select from:
* `FULL_SHARD` - shards model parameters, gradients and optimizer states across workers; select `1` for this option
* `SHARD_GRAD_OP`- shard gradients and optimizer states across workers; select `2` for this option
* `NO_SHARD` - don't shard anything (this is equivalent to DDP); select `3` for this option
* `HYBRID_SHARD` - shard model parameters, gradients and optimizer states within each worker where each worker also has a full copy; select `4` for this option
* `HYBRID_SHARD_ZERO2` - shard gradients and optimizer states within each worker where each worker also has a full copy; select `5` for this option
This is enabled by the `fsdp_sharding_strategy` flag.
### CPU offload
You could also offload parameters and gradients when they are not in use to the CPU to save even more GPU memory and help you fit large models where even FSDP may not be sufficient. This is enabled by setting `fsdp_offload_params: true` when running `accelerate config`.
### Wrapping policy
FSDP is applied by wrapping each layer in the network. The wrapping is usually applied in a nested way where the full weights are discarded after each forward pass to save memory for use in the next layer. The *auto wrapping* policy is the simplest way to implement this and you don't need to change any code. You should select `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` to wrap a Transformer layer and `fsdp_transformer_layer_cls_to_wrap` to specify which layer to wrap (for example `BertLayer`).
Otherwise, you can choose a size-based wrapping policy where FSDP is applied to a layer if it exceeds a certain number of parameters. This is enabled by setting `fsdp_wrap_policy: SIZE_BASED_WRAP` and `min_num_param` to the desired size threshold.
### Checkpointing
Intermediate checkpoints should be saved with `fsdp_state_dict_type: SHARDED_STATE_DICT` because saving the full state dict with CPU offloading on rank 0 takes a lot of time and often results in `NCCL Timeout` errors due to indefinite hanging during broadcasting. You can resume training with the sharded state dicts with the [`~accelerate.Accelerator.load_state`] method.
```py
# directory containing checkpoints
accelerator.load_state("ckpt")
```
However, when training ends, you want to save the full state dict because sharded state dict is only compatible with FSDP.
```py
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir)
```
### TPU
[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html) supports FSDP training for TPUs and it can be enabled by modifying the FSDP configuration file generated by `accelerate config`. In addition to the sharding strategies and wrapping options specified above, you can add the parameters shown below to the file.
```yaml
xla: True # must be set to True to enable PyTorch/XLA
xla_fsdp_settings: # XLA-specific FSDP parameters
xla_fsdp_grad_ckpt: True # use gradient checkpointing
```
The [`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128) allow you to configure additional XLA-specific parameters for FSDP.
## Launch training
An example FSDP configuration file may look like:
```yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
To launch training, run the [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) command and it'll automatically use the configuration file you previously created with `accelerate config`.
```bash
accelerate launch my-trainer-script.py
```
```bash
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
```
## Next steps
FSDP can be a powerful tool for training really large models and you have access to more than one GPU or TPU. By sharding the model parameters, optimizer and gradient states, and even offloading them to the CPU when they're inactive, FSDP can reduce the high cost of large-scale training. If you're interested in learning more, the following may be helpful:
* Follow along with the more in-depth Accelerate guide for [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp).
* Read the [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) blog post.
* Read the [Scaling PyTorch models on Cloud TPUs with FSDP](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) blog post.
|
transformers/docs/source/en/fsdp.md/0
|
{
"file_path": "transformers/docs/source/en/fsdp.md",
"repo_id": "transformers",
"token_count": 2238
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
The base classes [`PreTrainedModel`], [`TFPreTrainedModel`], and
[`FlaxPreTrainedModel`] implement the common methods for loading/saving a model either from a local
file or directory, or from a pretrained model configuration provided by the library (downloaded from HuggingFace's AWS
S3 repository).
[`PreTrainedModel`] and [`TFPreTrainedModel`] also implement a few methods which
are common among all the models to:
- resize the input token embeddings when new tokens are added to the vocabulary
- prune the attention heads of the model.
The other methods that are common to each model are defined in [`~modeling_utils.ModuleUtilsMixin`]
(for the PyTorch models) and [`~modeling_tf_utils.TFModuleUtilsMixin`] (for the TensorFlow models) or
for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
[`~generation.TFGenerationMixin`] (for the TensorFlow models) and
[`~generation.FlaxGenerationMixin`] (for the Flax/JAX models).
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
Custom models should also include a `_supports_assign_param_buffer`, which determines if superfast init can apply
on the particular model. Signs that your model needs this are if `test_save_and_load_from_pretrained` fails. If so,
set this to `False`.
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
## TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
## FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## Pushing to the Hub
[[autodoc]] utils.PushToHubMixin
## Sharded checkpoints
[[autodoc]] modeling_utils.load_sharded_checkpoint
|
transformers/docs/source/en/main_classes/model.md/0
|
{
"file_path": "transformers/docs/source/en/main_classes/model.md",
"repo_id": "transformers",
"token_count": 745
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Blenderbot
## Overview
The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
The abstract of the paper is the following:
*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
persona. We show that large scale models can learn these skills when given appropriate training data and choice of
generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
failure cases of our models.*
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
## Usage tips and example
Blenderbot is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
rather than the left.
An example:
```python
>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
>>> mname = "facebook/blenderbot-400M-distill"
>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
>>> UTTERANCE = "My friends are cool but they eat too many carbs."
>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
>>> reply_ids = model.generate(**inputs)
>>> print(tokenizer.batch_decode(reply_ids))
["<s> That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?</s>"]
```
## Implementation Notes
- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
`facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
[BlenderbotSmall](blenderbot-small).
## Resources
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BlenderbotConfig
[[autodoc]] BlenderbotConfig
## BlenderbotTokenizer
[[autodoc]] BlenderbotTokenizer
- build_inputs_with_special_tokens
## BlenderbotTokenizerFast
[[autodoc]] BlenderbotTokenizerFast
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## BlenderbotModel
See [`~transformers.BartModel`] for arguments to *forward* and *generate*
[[autodoc]] BlenderbotModel
- forward
## BlenderbotForConditionalGeneration
See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* and *generate*
[[autodoc]] BlenderbotForConditionalGeneration
- forward
## BlenderbotForCausalLM
[[autodoc]] BlenderbotForCausalLM
- forward
</pt>
<tf>
## TFBlenderbotModel
[[autodoc]] TFBlenderbotModel
- call
## TFBlenderbotForConditionalGeneration
[[autodoc]] TFBlenderbotForConditionalGeneration
- call
</tf>
<jax>
## FlaxBlenderbotModel
[[autodoc]] FlaxBlenderbotModel
- __call__
- encode
- decode
## FlaxBlenderbotForConditionalGeneration
[[autodoc]] FlaxBlenderbotForConditionalGeneration
- __call__
- encode
- decode
</jax>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/blenderbot.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/blenderbot.md",
"repo_id": "transformers",
"token_count": 1405
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# DBRX
## Overview
DBRX is a [transformer-based](https://www.isattentionallyouneed.com/) decoder-only large language model (LLM) that was trained using next-token prediction.
It uses a *fine-grained* mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
It was pre-trained on 12T tokens of text and code data.
Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
This provides 65x more possible combinations of experts and we found that this improves model quality.
DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
It is a BPE based model and uses the GPT-4 tokenizer as described in the [tiktoken](https://github.com/openai/tiktoken) repository.
We made these choices based on exhaustive evaluation and scaling experiments.
DBRX was pretrained on 12T tokens of carefully curated data and a maximum context length of 32K tokens.
We estimate that this data is at least 2x better token-for-token than the data we used to pretrain the MPT family of models.
This new dataset was developed using the full suite of Databricks tools, including Apache Spark™ and Databricks notebooks for data processing, and Unity Catalog for data management and governance.
We used curriculum learning for pretraining, changing the data mix during training in ways we found to substantially improve model quality.
More detailed information about DBRX Instruct and DBRX Base can be found in our [technical blog post](https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm).
This model was contributed by [eitan-turok](https://huggingface.co/eitanturok) and [abhi-db](https://huggingface.co/abhi-db). The original code can be found [here](https://github.com/databricks/dbrx-instruct), though this may not be up to date.
## Usage Examples
The `generate()` method can be used to generate text using DBRX. You can generate using the standard attention implementation, flash-attention, and the PyTorch scaled dot product attention. The last two attention implementations give speed ups.
```python
from transformers import DbrxForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
model = DbrxForCausalLM.from_pretrained(
"databricks/dbrx-instruct",
device_map="auto",
torch_dtype=torch.bfloat16,
token="YOUR_HF_TOKEN",
)
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
```
If you have flash-attention installed (`pip install flash-attn`), it is possible to generate faster. (The HuggingFace documentation for flash-attention can be found [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2).)
```python
from transformers import DbrxForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
model = DbrxForCausalLM.from_pretrained(
"databricks/dbrx-instruct",
device_map="auto",
torch_dtype=torch.bfloat16,
token="YOUR_HF_TOKEN",
attn_implementation="flash_attention_2",
)
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
```
You can also generate faster using the PyTorch scaled dot product attention. (The HuggingFace documentation for scaled dot product attention can be found [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).)
```python
from transformers import DbrxForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
model = DbrxForCausalLM.from_pretrained(
"databricks/dbrx-instruct",
device_map="auto",
torch_dtype=torch.bfloat16,
token="YOUR_HF_TOKEN",
attn_implementation="sdpa",
)
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))
```
## DbrxConfig
[[autodoc]] DbrxConfig
## DbrxModel
[[autodoc]] DbrxModel
- forward
## DbrxForCausalLM
[[autodoc]] DbrxForCausalLM
- forward
|
transformers/docs/source/en/model_doc/dbrx.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/dbrx.md",
"repo_id": "transformers",
"token_count": 1794
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DistilBERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=distilbert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-distilbert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/distilbert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
<a href="https://huggingface.co/papers/1910.01108">
<img alt="Paper page" src="https://img.shields.io/badge/Paper%20page-1910.01108-green">
</a>
</div>
## Overview
The DistilBERT model was proposed in the blog post [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a
distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5), and the paper [DistilBERT, a
distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108). DistilBERT is a
small, fast, cheap and light Transformer model trained by distilling BERT base. It has 40% less parameters than
*google-bert/bert-base-uncased*, runs 60% faster while preserving over 95% of BERT's performances as measured on the GLUE language
understanding benchmark.
The abstract from the paper is the following:
*As Transfer Learning from large-scale pre-trained models becomes more prevalent in Natural Language Processing (NLP),
operating these large models in on-the-edge and/or under constrained computational training or inference budgets
remains challenging. In this work, we propose a method to pre-train a smaller general-purpose language representation
model, called DistilBERT, which can then be fine-tuned with good performances on a wide range of tasks like its larger
counterparts. While most prior work investigated the use of distillation for building task-specific models, we leverage
knowledge distillation during the pretraining phase and show that it is possible to reduce the size of a BERT model by
40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive
biases learned by larger models during pretraining, we introduce a triple loss combining language modeling,
distillation and cosine-distance losses. Our smaller, faster and lighter model is cheaper to pre-train and we
demonstrate its capabilities for on-device computations in a proof-of-concept experiment and a comparative on-device
study.*
This model was contributed by [victorsanh](https://huggingface.co/victorsanh). This model jax version was
contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation).
## Usage tips
- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
- DistilBERT doesn't have options to select the input positions (`position_ids` input). This could be added if
necessary though, just let us know if you need this option.
- Same as BERT but smaller. Trained by distillation of the pretrained BERT model, meaning it’s been trained to predict the same probabilities as the larger model. The actual objective is a combination of:
* finding the same probabilities as the teacher model
* predicting the masked tokens correctly (but no next-sentence objective)
* a cosine similarity between the hidden states of the student and the teacher model
### Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
page for more information.
SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
```
from transformers import DistilBertModel
model = DistilBertModel.from_pretrained("distilbert-base-uncased", torch_dtype=torch.float16, attn_implementation="sdpa")
```
For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.3.1, OS Ubuntu 20.04) with `float16` and the `distilbert-base-uncased` model with
a MaskedLM head, we saw the following speedups during training and inference.
#### Training
| num_training_steps | batch_size | seq_len | is cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | sdpa peak mem (MB) | Mem saving (%) |
|--------------------|------------|---------|---------|----------------------------|---------------------------|-------------|---------------------|--------------------|----------------|
| 100 | 1 | 128 | False | 0.010 | 0.008 | 28.870 | 397.038 | 399.629 | -0.649 |
| 100 | 1 | 256 | False | 0.011 | 0.009 | 20.681 | 412.505 | 412.606 | -0.025 |
| 100 | 2 | 128 | False | 0.011 | 0.009 | 23.741 | 412.213 | 412.606 | -0.095 |
| 100 | 2 | 256 | False | 0.015 | 0.013 | 16.502 | 427.491 | 425.787 | 0.400 |
| 100 | 4 | 128 | False | 0.015 | 0.013 | 13.828 | 427.491 | 425.787 | 0.400 |
| 100 | 4 | 256 | False | 0.025 | 0.022 | 12.882 | 594.156 | 502.745 | 18.182 |
| 100 | 8 | 128 | False | 0.023 | 0.022 | 8.010 | 545.922 | 502.745 | 8.588 |
| 100 | 8 | 256 | False | 0.046 | 0.041 | 12.763 | 983.450 | 798.480 | 23.165 |
#### Inference
| num_batches | batch_size | seq_len | is cuda | is half | use mask | Per token latency eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
|-------------|------------|---------|---------|---------|----------|-----------------------------|-----------------------------|-------------|----------------|--------------|---------------|
| 50 | 2 | 64 | True | True | True | 0.032 | 0.025 | 28.192 | 154.532 | 155.531 | -0.642 |
| 50 | 2 | 128 | True | True | True | 0.033 | 0.025 | 32.636 | 157.286 | 157.482 | -0.125 |
| 50 | 4 | 64 | True | True | True | 0.032 | 0.026 | 24.783 | 157.023 | 157.449 | -0.271 |
| 50 | 4 | 128 | True | True | True | 0.034 | 0.028 | 19.299 | 162.794 | 162.269 | 0.323 |
| 50 | 8 | 64 | True | True | True | 0.035 | 0.028 | 25.105 | 160.958 | 162.204 | -0.768 |
| 50 | 8 | 128 | True | True | True | 0.052 | 0.046 | 12.375 | 173.155 | 171.844 | 0.763 |
| 50 | 16 | 64 | True | True | True | 0.051 | 0.045 | 12.882 | 172.106 | 171.713 | 0.229 |
| 50 | 16 | 128 | True | True | True | 0.096 | 0.081 | 18.524 | 191.257 | 191.517 | -0.136 |
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DistilBERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-classification"/>
- A blog post on [Getting Started with Sentiment Analysis using Python](https://huggingface.co/blog/sentiment-analysis-python) with DistilBERT.
- A blog post on how to [train DistilBERT with Blurr for sequence classification](https://huggingface.co/blog/fastai).
- A blog post on how to use [Ray to tune DistilBERT hyperparameters](https://huggingface.co/blog/ray-tune).
- A blog post on how to [train DistilBERT with Hugging Face and Amazon SageMaker](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face).
- A notebook on how to [finetune DistilBERT for multi-label classification](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb). 🌎
- A notebook on how to [finetune DistilBERT for multiclass classification with PyTorch](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb). 🌎
- A notebook on how to [finetune DistilBERT for text classification in TensorFlow](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb). 🌎
- [`DistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
- [`TFDistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
- [`FlaxDistilBertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [`DistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
- [`TFDistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
- [`FlaxDistilBertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Token classification task guide](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`DistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFDistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxDistilBertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- [`DistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
- [`TFDistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
- [`FlaxDistilBertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Question answering task guide](../tasks/question_answering)
**Multiple choice**
- [`DistilBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
- [`TFDistilBertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
- [Multiple choice task guide](../tasks/multiple_choice)
⚗️ Optimization
- A blog post on how to [quantize DistilBERT with 🤗 Optimum and Intel](https://huggingface.co/blog/intel).
- A blog post on how [Optimizing Transformers for GPUs with 🤗 Optimum](https://www.philschmid.de/optimizing-transformers-with-optimum-gpu).
- A blog post on [Optimizing Transformers with Hugging Face Optimum](https://www.philschmid.de/optimizing-transformers-with-optimum).
⚡️ Inference
- A blog post on how to [Accelerate BERT inference with Hugging Face Transformers and AWS Inferentia](https://huggingface.co/blog/bert-inferentia-sagemaker) with DistilBERT.
- A blog post on [Serverless Inference with Hugging Face's Transformers, DistilBERT and Amazon SageMaker](https://www.philschmid.de/sagemaker-serverless-huggingface-distilbert).
🚀 Deploy
- A blog post on how to [deploy DistilBERT on Google Cloud](https://huggingface.co/blog/how-to-deploy-a-pipeline-to-google-clouds).
- A blog post on how to [deploy DistilBERT with Amazon SageMaker](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker).
- A blog post on how to [Deploy BERT with Hugging Face Transformers, Amazon SageMaker and Terraform module](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker).
## Combining DistilBERT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16`)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import AutoTokenizer, AutoModel
>>> device = "cuda" # the device to load the model onto
>>> tokenizer = AutoTokenizer.from_pretrained('distilbert/distilbert-base-uncased')
>>> model = AutoModel.from_pretrained("distilbert/distilbert-base-uncased", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> text = "Replace me by any text you'd like."
>>> encoded_input = tokenizer(text, return_tensors='pt').to(device)
>>> model.to(device)
>>> output = model(**encoded_input)
```
## DistilBertConfig
[[autodoc]] DistilBertConfig
## DistilBertTokenizer
[[autodoc]] DistilBertTokenizer
## DistilBertTokenizerFast
[[autodoc]] DistilBertTokenizerFast
<frameworkcontent>
<pt>
## DistilBertModel
[[autodoc]] DistilBertModel
- forward
## DistilBertForMaskedLM
[[autodoc]] DistilBertForMaskedLM
- forward
## DistilBertForSequenceClassification
[[autodoc]] DistilBertForSequenceClassification
- forward
## DistilBertForMultipleChoice
[[autodoc]] DistilBertForMultipleChoice
- forward
## DistilBertForTokenClassification
[[autodoc]] DistilBertForTokenClassification
- forward
## DistilBertForQuestionAnswering
[[autodoc]] DistilBertForQuestionAnswering
- forward
</pt>
<tf>
## TFDistilBertModel
[[autodoc]] TFDistilBertModel
- call
## TFDistilBertForMaskedLM
[[autodoc]] TFDistilBertForMaskedLM
- call
## TFDistilBertForSequenceClassification
[[autodoc]] TFDistilBertForSequenceClassification
- call
## TFDistilBertForMultipleChoice
[[autodoc]] TFDistilBertForMultipleChoice
- call
## TFDistilBertForTokenClassification
[[autodoc]] TFDistilBertForTokenClassification
- call
## TFDistilBertForQuestionAnswering
[[autodoc]] TFDistilBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxDistilBertModel
[[autodoc]] FlaxDistilBertModel
- __call__
## FlaxDistilBertForMaskedLM
[[autodoc]] FlaxDistilBertForMaskedLM
- __call__
## FlaxDistilBertForSequenceClassification
[[autodoc]] FlaxDistilBertForSequenceClassification
- __call__
## FlaxDistilBertForMultipleChoice
[[autodoc]] FlaxDistilBertForMultipleChoice
- __call__
## FlaxDistilBertForTokenClassification
[[autodoc]] FlaxDistilBertForTokenClassification
- __call__
## FlaxDistilBertForQuestionAnswering
[[autodoc]] FlaxDistilBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/distilbert.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/distilbert.md",
"repo_id": "transformers",
"token_count": 7479
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FalconMamba
## Overview
The FalconMamba model was proposed by TII UAE (Technology Innovation Institute) in their release.
The abstract from the paper is the following:
*We present FalconMamba, a new base large language model based on the novel Mamba architecture. FalconMamba is trained on 5.8 trillion tokens with carefully selected data mixtures. As a pure Mamba-based model, FalconMamba surpasses leading open-weight models based on Transformers, such as Mistral 7B, Llama3 8B, and Falcon2 11B. It is on par with Gemma 7B and outperforms models with different architecture designs, such as RecurrentGemma 9B. Currently, FalconMamba is the best-performing Mamba model in the literature at this scale, surpassing both existing Mamba and hybrid Mamba-Transformer models.
Due to its architecture, FalconMamba is significantly faster at inference and requires substantially less memory for long sequence generation. Despite recent studies suggesting that hybrid Mamba-Transformer models outperform pure architecture designs, we argue and demonstrate that the pure Mamba design can achieve similar, even superior results compared to the hybrid design. We make the weights of our implementation of FalconMamba publicly available under a permissive license.*
Tips:
- FalconMamba is mostly based on Mamba architecture, the same [tips and best practices](./mamba) would be relevant here.
The model has been trained on approximtely 6T tokens consisting a mixture of many data sources such as RefineWeb, Cosmopedia and Math data.
For more details about the training procedure and the architecture, have a look at [the technical paper of FalconMamba]() (coming soon).
# Usage
Below we demonstrate how to use the model:
```python
from transformers import FalconMambaForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b")
model = FalconMambaForCausalLM.from_pretrained("tiiuae/falcon-mamba-7b")
input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
out = model.generate(input_ids, max_new_tokens=10)
print(tokenizer.batch_decode(out))
```
The architecture is also compatible with `torch.compile` for faster generation:
```python
from transformers import FalconMambaForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b")
model = FalconMambaForCausalLM.from_pretrained("tiiuae/falcon-mamba-7b", torch_dtype=torch.bfloat16).to(0)
model = torch.compile(model)
input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
out = model.generate(input_ids, max_new_tokens=10)
print(tokenizer.batch_decode(out))
```
If you have access to a GPU that is compatible with `bitsandbytes`, you can also quantize the model in 4-bit precision:
```python
from transformers import FalconMambaForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b")
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = FalconMambaForCausalLM.from_pretrained("tiiuae/falcon-mamba-7b", quantization_config=quantization_config)
input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
out = model.generate(input_ids, max_new_tokens=10)
print(tokenizer.batch_decode(out))
```
You can also play with the instruction fine-tuned model:
```python
from transformers import FalconMambaForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b-instruct")
model = FalconMambaForCausalLM.from_pretrained("tiiuae/falcon-mamba-7b-instruct")
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True).input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
## FalconMambaConfig
[[autodoc]] FalconMambaConfig
## FalconMambaModel
[[autodoc]] FalconMambaModel
- forward
## FalconMambaLMHeadModel
[[autodoc]] FalconMambaForCausalLM
- forward
|
transformers/docs/source/en/model_doc/falcon_mamba.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/falcon_mamba.md",
"repo_id": "transformers",
"token_count": 1451
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# HerBERT
## Overview
The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
Ireneusz Gawlik. It is a BERT-based Language Model trained on Polish Corpora using only MLM objective with dynamic
masking of whole words.
The abstract from the paper is the following:
*In recent years, a series of Transformer-based models unlocked major improvements in general natural language
understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which
allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of
languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language
understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing
datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new
sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and
promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and
applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language,
which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an
extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
models.*
This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
[here](https://github.com/allegro/HerBERT).
## Usage example
```python
>>> from transformers import HerbertTokenizer, RobertaModel
>>> tokenizer = HerbertTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
>>> model = RobertaModel.from_pretrained("allegro/herbert-klej-cased-v1")
>>> encoded_input = tokenizer.encode("Kto ma lepszą sztukę, ma lepszy rząd – to jasne.", return_tensors="pt")
>>> outputs = model(encoded_input)
>>> # HerBERT can also be loaded using AutoTokenizer and AutoModel:
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
```
<Tip>
Herbert implementation is the same as `BERT` except for the tokenization method. Refer to [BERT documentation](bert)
for API reference and examples.
</Tip>
## HerbertTokenizer
[[autodoc]] HerbertTokenizer
## HerbertTokenizerFast
[[autodoc]] HerbertTokenizerFast
|
transformers/docs/source/en/model_doc/herbert.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/herbert.md",
"repo_id": "transformers",
"token_count": 956
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutLM
<a id='Overview'></a>
## Overview
The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
on several downstream tasks:
- form understanding: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a collection of 199 annotated
forms comprising more than 30,000 words).
- receipt understanding: the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for
training and 347 receipts for testing).
- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
400,000 images belonging to one of 16 classes).
The abstract from the paper is the following:
*Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the
widespread use of pretraining models for NLP applications, they almost exclusively focus on text-level manipulation,
while neglecting layout and style information that is vital for document image understanding. In this paper, we propose
the LayoutLM to jointly model interactions between text and layout information across scanned document images, which is
beneficial for a great number of real-world document image understanding tasks such as information extraction from
scanned documents. Furthermore, we also leverage image features to incorporate words' visual information into LayoutLM.
To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for
document-level pretraining. It achieves new state-of-the-art results in several downstream tasks, including form
understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
(from 93.07 to 94.42).*
## Usage tips
- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where
(x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
scale. To normalize, you can use the following function:
```python
def normalize_bbox(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]
```
Here, `width` and `height` correspond to the width and height of the original document in which the token
occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
```python
from PIL import Image
# Document can be a png, jpg, etc. PDFs must be converted to images.
image = Image.open(name_of_your_document).convert("RGB")
width, height = image.size
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLM. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="document-question-answering" />
- A blog post on [fine-tuning
LayoutLM for document-understanding using Keras & Hugging Face
Transformers](https://www.philschmid.de/fine-tuning-layoutlm-keras).
- A blog post on how to [fine-tune LayoutLM for document-understanding using only Hugging Face Transformers](https://www.philschmid.de/fine-tuning-layoutlm).
- A notebook on how to [fine-tune LayoutLM on the FUNSD dataset with image embeddings](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Add_image_embeddings_to_LayoutLM.ipynb).
- See also: [Document question answering task guide](../tasks/document_question_answering)
<PipelineTag pipeline="text-classification" />
- A notebook on how to [fine-tune LayoutLM for sequence classification on the RVL-CDIP dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb).
- [Text classification task guide](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification" />
- A notebook on how to [ fine-tune LayoutLM for token classification on the FUNSD dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb).
- [Token classification task guide](../tasks/token_classification)
**Other resources**
- [Masked language modeling task guide](../tasks/masked_language_modeling)
🚀 Deploy
- A blog post on how to [Deploy LayoutLM with Hugging Face Inference Endpoints](https://www.philschmid.de/inference-endpoints-layoutlm).
## LayoutLMConfig
[[autodoc]] LayoutLMConfig
## LayoutLMTokenizer
[[autodoc]] LayoutLMTokenizer
## LayoutLMTokenizerFast
[[autodoc]] LayoutLMTokenizerFast
<frameworkcontent>
<pt>
## LayoutLMModel
[[autodoc]] LayoutLMModel
## LayoutLMForMaskedLM
[[autodoc]] LayoutLMForMaskedLM
## LayoutLMForSequenceClassification
[[autodoc]] LayoutLMForSequenceClassification
## LayoutLMForTokenClassification
[[autodoc]] LayoutLMForTokenClassification
## LayoutLMForQuestionAnswering
[[autodoc]] LayoutLMForQuestionAnswering
</pt>
<tf>
## TFLayoutLMModel
[[autodoc]] TFLayoutLMModel
## TFLayoutLMForMaskedLM
[[autodoc]] TFLayoutLMForMaskedLM
## TFLayoutLMForSequenceClassification
[[autodoc]] TFLayoutLMForSequenceClassification
## TFLayoutLMForTokenClassification
[[autodoc]] TFLayoutLMForTokenClassification
## TFLayoutLMForQuestionAnswering
[[autodoc]] TFLayoutLMForQuestionAnswering
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/layoutlm.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/layoutlm.md",
"repo_id": "transformers",
"token_count": 2088
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LUKE
## Overview
The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
It is based on RoBERTa and adds entity embeddings as well as an entity-aware self-attention mechanism, which helps
improve performance on various downstream tasks involving reasoning about entities such as named entity recognition,
extractive and cloze-style question answering, entity typing, and relation classification.
The abstract from the paper is the following:
*Entity representations are useful in natural language tasks involving entities. In this paper, we propose new
pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed
model treats words and entities in a given text as independent tokens, and outputs contextualized representations of
them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves
predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also
propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the
transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model
achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains
state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification),
CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question
answering).*
This model was contributed by [ikuyamada](https://huggingface.co/ikuyamada) and [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/studio-ousia/luke).
## Usage tips
- This implementation is the same as [`RobertaModel`] with the addition of entity embeddings as well
as an entity-aware self-attention mechanism, which improves performance on tasks involving reasoning about entities.
- LUKE treats entities as input tokens; therefore, it takes `entity_ids`, `entity_attention_mask`,
`entity_token_type_ids` and `entity_position_ids` as extra input. You can obtain those using
[`LukeTokenizer`].
- [`LukeTokenizer`] takes `entities` and `entity_spans` (character-based start and end
positions of the entities in the input text) as extra input. `entities` typically consist of [MASK] entities or
Wikipedia entities. The brief description when inputting these entities are as follows:
- *Inputting [MASK] entities to compute entity representations*: The [MASK] entity is used to mask entities to be
predicted during pretraining. When LUKE receives the [MASK] entity, it tries to predict the original entity by
gathering the information about the entity from the input text. Therefore, the [MASK] entity can be used to address
downstream tasks requiring the information of entities in text such as entity typing, relation classification, and
named entity recognition.
- *Inputting Wikipedia entities to compute knowledge-enhanced token representations*: LUKE learns rich information
(or knowledge) about Wikipedia entities during pretraining and stores the information in its entity embedding. By
using Wikipedia entities as input tokens, LUKE outputs token representations enriched by the information stored in
the embeddings of these entities. This is particularly effective for tasks requiring real-world knowledge, such as
question answering.
- There are three head models for the former use case:
- [`LukeForEntityClassification`], for tasks to classify a single entity in an input text such as
entity typing, e.g. the [Open Entity dataset](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html).
This model places a linear head on top of the output entity representation.
- [`LukeForEntityPairClassification`], for tasks to classify the relationship between two entities
such as relation classification, e.g. the [TACRED dataset](https://nlp.stanford.edu/projects/tacred/). This
model places a linear head on top of the concatenated output representation of the pair of given entities.
- [`LukeForEntitySpanClassification`], for tasks to classify the sequence of entity spans, such as
named entity recognition (NER). This model places a linear head on top of the output entity representations. You
can address NER using this model by inputting all possible entity spans in the text to the model.
[`LukeTokenizer`] has a `task` argument, which enables you to easily create an input to these
head models by specifying `task="entity_classification"`, `task="entity_pair_classification"`, or
`task="entity_span_classification"`. Please refer to the example code of each head models.
Usage example:
```python
>>> from transformers import LukeTokenizer, LukeModel, LukeForEntityPairClassification
>>> model = LukeModel.from_pretrained("studio-ousia/luke-base")
>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-base")
# Example 1: Computing the contextualized entity representation corresponding to the entity mention "Beyoncé"
>>> text = "Beyoncé lives in Los Angeles."
>>> entity_spans = [(0, 7)] # character-based entity span corresponding to "Beyoncé"
>>> inputs = tokenizer(text, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
>>> outputs = model(**inputs)
>>> word_last_hidden_state = outputs.last_hidden_state
>>> entity_last_hidden_state = outputs.entity_last_hidden_state
# Example 2: Inputting Wikipedia entities to obtain enriched contextualized representations
>>> entities = [
... "Beyoncé",
... "Los Angeles",
... ] # Wikipedia entity titles corresponding to the entity mentions "Beyoncé" and "Los Angeles"
>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
>>> inputs = tokenizer(text, entities=entities, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
>>> outputs = model(**inputs)
>>> word_last_hidden_state = outputs.last_hidden_state
>>> entity_last_hidden_state = outputs.entity_last_hidden_state
# Example 3: Classifying the relationship between two entities using LukeForEntityPairClassification head model
>>> model = LukeForEntityPairClassification.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> predicted_class_idx = int(logits[0].argmax())
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
```
## Resources
- [A demo notebook on how to fine-tune [`LukeForEntityPairClassification`] for relation classification](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LUKE)
- [Notebooks showcasing how you to reproduce the results as reported in the paper with the HuggingFace implementation of LUKE](https://github.com/studio-ousia/luke/tree/master/notebooks)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## LukeConfig
[[autodoc]] LukeConfig
## LukeTokenizer
[[autodoc]] LukeTokenizer
- __call__
- save_vocabulary
## LukeModel
[[autodoc]] LukeModel
- forward
## LukeForMaskedLM
[[autodoc]] LukeForMaskedLM
- forward
## LukeForEntityClassification
[[autodoc]] LukeForEntityClassification
- forward
## LukeForEntityPairClassification
[[autodoc]] LukeForEntityPairClassification
- forward
## LukeForEntitySpanClassification
[[autodoc]] LukeForEntitySpanClassification
- forward
## LukeForSequenceClassification
[[autodoc]] LukeForSequenceClassification
- forward
## LukeForMultipleChoice
[[autodoc]] LukeForMultipleChoice
- forward
## LukeForTokenClassification
[[autodoc]] LukeForTokenClassification
- forward
## LukeForQuestionAnswering
[[autodoc]] LukeForQuestionAnswering
- forward
|
transformers/docs/source/en/model_doc/luke.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/luke.md",
"repo_id": "transformers",
"token_count": 2521
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MPT
## Overview
The MPT model was proposed by the [MosaicML](https://www.mosaicml.com/) team and released with multiple sizes and finetuned variants. The MPT models are a series of open source and commercially usable LLMs pre-trained on 1T tokens.
MPT models are GPT-style decoder-only transformers with several improvements: performance-optimized layer implementations, architecture changes that provide greater training stability, and the elimination of context length limits by replacing positional embeddings with ALiBi.
- MPT base: MPT base pre-trained models on next token prediction
- MPT instruct: MPT base models fine-tuned on instruction based tasks
- MPT storywriter: MPT base models fine-tuned for 2500 steps on 65k-token excerpts of fiction books contained in the books3 corpus, this enables the model to handle very long sequences
The original code is available at the [`llm-foundry`](https://github.com/mosaicml/llm-foundry/tree/main) repository.
Read more about it [in the release blogpost](https://www.mosaicml.com/blog/mpt-7b)
## Usage tips
- Learn more about some techniques behind training of the model [in this section of llm-foundry repository](https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#faqs)
- If you want to use the advanced version of the model (triton kernels, direct flash attention integration), you can still use the original model implementation by adding `trust_remote_code=True` when calling `from_pretrained`.
## Resources
- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
## MptConfig
[[autodoc]] MptConfig
- all
## MptModel
[[autodoc]] MptModel
- forward
## MptForCausalLM
[[autodoc]] MptForCausalLM
- forward
## MptForSequenceClassification
[[autodoc]] MptForSequenceClassification
- forward
## MptForTokenClassification
[[autodoc]] MptForTokenClassification
- forward
## MptForQuestionAnswering
[[autodoc]] MptForQuestionAnswering
- forward
|
transformers/docs/source/en/model_doc/mpt.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/mpt.md",
"repo_id": "transformers",
"token_count": 824
}
|
<!--
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# OLMoE
## Overview
The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
OLMoE is a series of **O**pen **L**anguage **Mo**dels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. We release all code, checkpoints, logs, and details involved in training these models.
The abstract from the paper is the following:
*We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.*
This model was contributed by [Muennighoff](https://hf.co/Muennighoff).
The original code can be found [here](https://github.com/allenai/OLMoE).
## OlmoeConfig
[[autodoc]] OlmoeConfig
## OlmoeModel
[[autodoc]] OlmoeModel
- forward
## OlmoeForCausalLM
[[autodoc]] OlmoeForCausalLM
- forward
|
transformers/docs/source/en/model_doc/olmoe.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/olmoe.md",
"repo_id": "transformers",
"token_count": 703
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Phi-3
## Overview
The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
### Summary
The abstract from the Phi-3 paper is the following:
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
The original code for Phi-3 can be found [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
## Usage tips
- This model is very similar to `Llama` with the main difference of [`Phi3SuScaledRotaryEmbedding`] and [`Phi3YarnScaledRotaryEmbedding`], where they are used to extend the context of the rotary embeddings. The query, key and values are fused, and the MLP's up and gate projection layers are also fused.
- The tokenizer used for this model is identical to the [`LlamaTokenizer`], with the exception of additional tokens.
## How to use Phi-3
<Tip warning={true}>
Phi-3 has been integrated in the development version (4.40.0.dev) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
</Tip>
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
>>> messages = [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"}]
>>> inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
>>> outputs = model.generate(inputs, max_new_tokens=32)
>>> text = tokenizer.batch_decode(outputs)[0]
>>> print(text)
<|user|> Can you provide ways to eat combinations of bananas and dragonfruits?<|end|><|assistant|> Certainly! Bananas and dragonfruits can be combined in various delicious ways. Here are some creative ideas for incorporating both fruits
```
## Phi3Config
[[autodoc]] Phi3Config
<frameworkcontent>
<pt>
## Phi3Model
[[autodoc]] Phi3Model
- forward
## Phi3ForCausalLM
[[autodoc]] Phi3ForCausalLM
- forward
- generate
## Phi3ForSequenceClassification
[[autodoc]] Phi3ForSequenceClassification
- forward
## Phi3ForTokenClassification
[[autodoc]] Phi3ForTokenClassification
- forward
</pt>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/phi3.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/phi3.md",
"repo_id": "transformers",
"token_count": 1218
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Qwen2-VL
## Overview
The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
The abstract from the blog is the following:
*This blog introduces Qwen2-VL, an advanced version of the Qwen-VL model that has undergone significant enhancements over the past year. Key improvements include enhanced image comprehension, advanced video understanding, integrated visual agent functionality, and expanded multilingual support. The model architecture has been optimized for handling arbitrary image resolutions through Naive Dynamic Resolution support and utilizes Multimodal Rotary Position Embedding (M-ROPE) to effectively process both 1D textual and multi-dimensional visual data. This updated model demonstrates competitive performance against leading AI systems like GPT-4o and Claude 3.5 Sonnet in vision-related tasks and ranks highly among open-source models in text capabilities. These advancements make Qwen2-VL a versatile tool for various applications requiring robust multimodal processing and reasoning abilities.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/qwen2_vl_architecture.jpeg"
alt="drawing" width="600"/>
<small> Qwen2-VL architecture. Taken from the <a href="https://qwenlm.github.io/blog/qwen2-vl/">blog post.</a> </small>
This model was contributed by [simonJJJ](https://huggingface.co/simonJJJ).
## Usage example
### Single Media inference
The model can accept both images and videos as input. Here's an example code for inference.
```python
from PIL import Image
import requests
import torch
from torchvision import io
from typing import Dict
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
# Load the model in half-precision on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# Image
url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
conversation = [
{
"role":"user",
"content":[
{
"type":"image",
},
{
"type":"text",
"text":"Describe this image."
}
]
}
]
# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe this image.<|im_end|>\n<|im_start|>assistant\n'
inputs = processor(text=[text_prompt], images=[image], padding=True, return_tensors="pt")
inputs = inputs.to('cuda')
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(output_text)
# Video
def fetch_video(ele: Dict, nframe_factor=2):
if isinstance(ele['video'], str):
def round_by_factor(number: int, factor: int) -> int:
return round(number / factor) * factor
video = ele["video"]
if video.startswith("file://"):
video = video[7:]
video, _, info = io.read_video(
video,
start_pts=ele.get("video_start", 0.0),
end_pts=ele.get("video_end", None),
pts_unit="sec",
output_format="TCHW",
)
assert not ("fps" in ele and "nframes" in ele), "Only accept either `fps` or `nframes`"
if "nframes" in ele:
nframes = round_by_factor(ele["nframes"], nframe_factor)
else:
fps = ele.get("fps", 1.0)
nframes = round_by_factor(video.size(0) / info["video_fps"] * fps, nframe_factor)
idx = torch.linspace(0, video.size(0) - 1, nframes, dtype=torch.int64)
return video[idx]
video_info = {"type": "video", "video": "/path/to/video.mp4", "fps": 1.0}
video = fetch_video(video_info)
conversation = [
{
"role": "user",
"content": [
{"type": "video"},
{"type": "text", "text": "What happened in the video?"},
],
}
]
# Preprocess the inputs
text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|video_pad|><|vision_end|>What happened in the video?<|im_end|>\n<|im_start|>assistant\n'
inputs = processor(text=[text_prompt], videos=[video], padding=True, return_tensors="pt")
inputs = inputs.to('cuda')
# Inference: Generation of the output
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(output_text)
```
### Batch Mixed Media Inference
The model can batch inputs composed of mixed samples of various types such as images, videos, and text. Here is an example.
```python
image1 = Image.open("/path/to/image1.jpg")
image2 = Image.open("/path/to/image2.jpg")
image3 = Image.open("/path/to/image3.jpg")
image4 = Image.open("/path/to/image4.jpg")
image5 = Image.open("/path/to/image5.jpg")
video = fetch_video({
"type": "video",
"video": "/path/to/video.mp4",
"fps": 1.0
})
# Conversation for the first image
conversation1 = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Describe this image."}
]
}
]
# Conversation with two images
conversation2 = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "What is written in the pictures?"}
]
}
]
# Conversation with pure text
conversation3 = [
{
"role": "user",
"content": "who are you?"
}
]
# Conversation with mixed midia
conversation4 = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "video"},
{"type": "text", "text": "What are the common elements in these medias?"},
],
}
]
conversations = [conversation1, conversation2, conversation3, conversation4]
# Preparation for batch inference
texts = [processor.apply_chat_template(msg, add_generation_prompt=True) for msg in conversations]
inputs = processor(
text=texts,
images=[image1, image2, image3, image4, image5],
videos=[video],
padding=True,
return_tensors="pt",
)
inputs = inputs.to('cuda')
# Batch Inference
output_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(output_text)
```
### Usage Tips
#### Image Resolution trade-off
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs.
```python
min_pixels = 224*224
max_pixels = 2048*2048
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
```
In case of limited GPU RAM, one can reduce the resolution as follows:
```python
min_pixels = 256*28*28
max_pixels = 1024*28*28
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
```
This ensures each image gets encoded using a number between 256-1024 tokens. The 28 comes from the fact that the model uses a patch size of 14 and a temporal patch size of 2 (14 x 2 = 28).
#### Multiple Image Inputs
By default, images and video content are directly included in the conversation. When handling multiple images, it's helpful to add labels to the images and videos for better reference. Users can control this behavior with the following settings:
```python
conversation = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Hello, how are you?"}
]
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking. How can I assist you today?"
},
{
"role": "user",
"content": [
{"type": "text", "text": "Can you describe these images and video?"},
{"type": "image"},
{"type": "image"},
{"type": "video"},
{"type": "text", "text": "These are from my vacation."}
]
},
{
"role": "assistant",
"content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
},
{
"role": "user",
"content": "It was a trip to the mountains. Can you see the details in the images and video?"
}
]
# default:
prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
# add ids
prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
```
#### Flash-Attention 2 to speed up generation
First, make sure to install the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
Also, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
To load and run a model using Flash Attention-2, simply add `attn_implementation="flash_attention_2"` when loading the model as follows:
```python
from transformers import Qwen2VLForConditionalGeneration
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
## Qwen2VLConfig
[[autodoc]] Qwen2VLConfig
## Qwen2VLImageProcessor
[[autodoc]] Qwen2VLImageProcessor
- preprocess
## Qwen2VLImageProcessorFast
[[autodoc]] Qwen2VLImageProcessorFast
- preprocess
## Qwen2VLProcessor
[[autodoc]] Qwen2VLProcessor
## Qwen2VLModel
[[autodoc]] Qwen2VLModel
- forward
## Qwen2VLForConditionalGeneration
[[autodoc]] Qwen2VLForConditionalGeneration
- forward
|
transformers/docs/source/en/model_doc/qwen2_vl.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/qwen2_vl.md",
"repo_id": "transformers",
"token_count": 4923
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SAM
## Overview
SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
The model can be used to predict segmentation masks of any object of interest given an input image.

The abstract from the paper is the following:
*We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.*
Tips:
- The model predicts binary masks that states the presence or not of the object of interest given an image.
- The model predicts much better results if input 2D points and/or input bounding boxes are provided
- You can prompt multiple points for the same image, and predict a single mask.
- Fine-tuning the model is not supported yet
- According to the paper, textual input should be also supported. However, at this time of writing this seems not to be supported according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
This model was contributed by [ybelkada](https://huggingface.co/ybelkada) and [ArthurZ](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/facebookresearch/segment-anything).
Below is an example on how to run mask generation given an image and a 2D point:
```python
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores
```
You can also process your own masks alongside the input images in the processor to be passed to the model.
```python
import torch
from PIL import Image
import requests
from transformers import SamModel, SamProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
mask_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
segmentation_map = Image.open(requests.get(mask_url, stream=True).raw).convert("1")
input_points = [[[450, 600]]] # 2D location of a window in the image
inputs = processor(raw_image, input_points=input_points, segmentation_maps=segmentation_map, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)
scores = outputs.iou_scores
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SAM.
- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/segment_anything.ipynb) for using the model.
- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/automatic_mask_generation.ipynb) for using the automatic mask generation pipeline.
- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Run_inference_with_MedSAM_using_HuggingFace_Transformers.ipynb) for inference with MedSAM, a fine-tuned version of SAM on the medical domain. 🌎
- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Fine_tune_SAM_(segment_anything)_on_a_custom_dataset.ipynb) for fine-tuning the model on custom data. 🌎
## SlimSAM
SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://arxiv.org/abs/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
Checkpoints can be found on the [hub](https://huggingface.co/models?other=slimsam), and they can be used as a drop-in replacement of SAM.
## Grounded SAM
One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/grounded_sam.png"
alt="drawing" width="900"/>
<small> Grounded SAM overview. Taken from the <a href="https://github.com/IDEA-Research/Grounded-Segment-Anything">original repository</a>. </small>
## SamConfig
[[autodoc]] SamConfig
## SamVisionConfig
[[autodoc]] SamVisionConfig
## SamMaskDecoderConfig
[[autodoc]] SamMaskDecoderConfig
## SamPromptEncoderConfig
[[autodoc]] SamPromptEncoderConfig
## SamProcessor
[[autodoc]] SamProcessor
## SamImageProcessor
[[autodoc]] SamImageProcessor
## SamModel
[[autodoc]] SamModel
- forward
## TFSamModel
[[autodoc]] TFSamModel
- call
|
transformers/docs/source/en/model_doc/sam.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/sam.md",
"repo_id": "transformers",
"token_count": 2256
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the MIT License; you may not use this file except in compliance with
the License.
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SuperGlue
## Overview
The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
This model consists of matching two sets of interest points detected in an image. Paired with the
[SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and
estimate the pose between them. This model is useful for tasks such as image matching, homography estimation, etc.
The abstract from the paper is the following:
*This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences
and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs
are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling
SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics,
our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image
pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in
challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and
can be readily integrated into modern SfM or SLAM systems. The code and trained weights are publicly available at this [URL](https://github.com/magicleap/SuperGluePretrainedNetwork).*
## How to use
Here is a quick example of using the model. Since this model is an image matching model, it requires pairs of images to be matched.
The raw outputs contain the list of keypoints detected by the keypoint detector as well as the list of matches with their corresponding
matching scores.
```python
from transformers import AutoImageProcessor, AutoModel
import torch
from PIL import Image
import requests
url_image1 = "https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_98169888_3347710852.jpg"
image1 = Image.open(requests.get(url_image1, stream=True).raw)
url_image2 = "https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_26757027_6717084061.jpg"
image_2 = Image.open(requests.get(url_image2, stream=True).raw)
images = [image1, image2]
processor = AutoImageProcessor.from_pretrained("magic-leap-community/superglue_outdoor")
model = AutoModel.from_pretrained("magic-leap-community/superglue_outdoor")
inputs = processor(images, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
You can use the `post_process_keypoint_matching` method from the `SuperGlueImageProcessor` to get the keypoints and matches in a more readable format:
```python
image_sizes = [[(image.height, image.width) for image in images]]
outputs = processor.post_process_keypoint_matching(outputs, image_sizes, threshold=0.2)
for i, output in enumerate(outputs):
print("For the image pair", i)
for keypoint0, keypoint1, matching_score in zip(
output["keypoints0"], output["keypoints1"], output["matching_scores"]
):
print(
f"Keypoint at coordinate {keypoint0.numpy()} in the first image matches with keypoint at coordinate {keypoint1.numpy()} in the second image with a score of {matching_score}."
)
```
From the outputs, you can visualize the matches between the two images using the following code:
```python
import matplotlib.pyplot as plt
import numpy as np
# Create side by side image
merged_image = np.zeros((max(image1.height, image2.height), image1.width + image2.width, 3))
merged_image[: image1.height, : image1.width] = np.array(image1) / 255.0
merged_image[: image2.height, image1.width :] = np.array(image2) / 255.0
plt.imshow(merged_image)
plt.axis("off")
# Retrieve the keypoints and matches
output = outputs[0]
keypoints0 = output["keypoints0"]
keypoints1 = output["keypoints1"]
matching_scores = output["matching_scores"]
keypoints0_x, keypoints0_y = keypoints0[:, 0].numpy(), keypoints0[:, 1].numpy()
keypoints1_x, keypoints1_y = keypoints1[:, 0].numpy(), keypoints1[:, 1].numpy()
# Plot the matches
for keypoint0_x, keypoint0_y, keypoint1_x, keypoint1_y, matching_score in zip(
keypoints0_x, keypoints0_y, keypoints1_x, keypoints1_y, matching_scores
):
plt.plot(
[keypoint0_x, keypoint1_x + image1.width],
[keypoint0_y, keypoint1_y],
color=plt.get_cmap("RdYlGn")(matching_score.item()),
alpha=0.9,
linewidth=0.5,
)
plt.scatter(keypoint0_x, keypoint0_y, c="black", s=2)
plt.scatter(keypoint1_x + image1.width, keypoint1_y, c="black", s=2)
# Save the plot
plt.savefig("matched_image.png", dpi=300, bbox_inches='tight')
plt.close()
```

This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
The original code can be found [here](https://github.com/magicleap/SuperGluePretrainedNetwork).
## SuperGlueConfig
[[autodoc]] SuperGlueConfig
## SuperGlueImageProcessor
[[autodoc]] SuperGlueImageProcessor
- preprocess
## SuperGlueForKeypointMatching
[[autodoc]] SuperGlueForKeypointMatching
- forward
- post_process_keypoint_matching
|
transformers/docs/source/en/model_doc/superglue.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/superglue.md",
"repo_id": "transformers",
"token_count": 1984
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trajectory Transformer
<Tip warning={true}>
This model is in maintenance mode only, so we won't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
The abstract from the paper is the following:
*Reinforcement learning (RL) is typically concerned with estimating stationary policies or single-step models,
leveraging the Markov property to factorize problems in time. However, we can also view RL as a generic sequence
modeling problem, with the goal being to produce a sequence of actions that leads to a sequence of high rewards.
Viewed in this way, it is tempting to consider whether high-capacity sequence prediction models that work well
in other domains, such as natural-language processing, can also provide effective solutions to the RL problem.
To this end, we explore how RL can be tackled with the tools of sequence modeling, using a Transformer architecture
to model distributions over trajectories and repurposing beam search as a planning algorithm. Framing RL as sequence
modeling problem simplifies a range of design decisions, allowing us to dispense with many of the components common
in offline RL algorithms. We demonstrate the flexibility of this approach across long-horizon dynamics prediction,
imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
## Usage tips
This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
actions, states and rewards from all previous timesteps. This model will treat all these elements together
as one big sequence (a trajectory).
## TrajectoryTransformerConfig
[[autodoc]] TrajectoryTransformerConfig
## TrajectoryTransformerModel
[[autodoc]] TrajectoryTransformerModel
- forward
|
transformers/docs/source/en/model_doc/trajectory_transformer.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/trajectory_transformer.md",
"repo_id": "transformers",
"token_count": 776
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Wav2Vec2Phoneme
## Overview
The Wav2Vec2Phoneme model was proposed in [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al.,
2021](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
The abstract from the paper is the following:
*Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech
recognition systems without any labeled data. However, in many cases there is labeled data available for related
languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer
learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by
mapping phonemes of the training languages to the target language using articulatory features. Experiments show that
this simple method significantly outperforms prior work which introduced task-specific architectures and used only part
of a monolingually pretrained model.*
Relevant checkpoints can be found under https://huggingface.co/models?other=phoneme-recognition.
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten)
The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/fairseq/models/wav2vec).
## Usage tips
- Wav2Vec2Phoneme uses the exact same architecture as Wav2Vec2
- Wav2Vec2Phoneme is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2Phoneme model was trained using connectionist temporal classification (CTC) so the model output has to be
decoded using [`Wav2Vec2PhonemeCTCTokenizer`].
- Wav2Vec2Phoneme can be fine-tuned on multiple language at once and decode unseen languages in a single forward pass
to a sequence of phonemes
- By default, the model outputs a sequence of phonemes. In order to transform the phonemes to a sequence of words one
should make use of a dictionary and language model.
<Tip>
Wav2Vec2Phoneme's architecture is based on the Wav2Vec2 model, for API reference, check out [`Wav2Vec2`](wav2vec2)'s documentation page
except for the tokenizer.
</Tip>
## Wav2Vec2PhonemeCTCTokenizer
[[autodoc]] Wav2Vec2PhonemeCTCTokenizer
- __call__
- batch_decode
- decode
- phonemize
|
transformers/docs/source/en/model_doc/wav2vec2_phoneme.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/wav2vec2_phoneme.md",
"repo_id": "transformers",
"token_count": 851
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zamba
Zamba is a large language model (LLM) trained by Zyphra, and made available under an Apache 2.0 license. Please see the [Zyphra Hugging Face](https://huggingface.co/collections/zyphra/) repository for model weights.
This model was contributed by [pglo](https://huggingface.co/pglo).
## Model details
Zamba-7B-v1 is a hybrid between state-space models (Specifically [Mamba](https://github.com/state-spaces/mamba)) and transformer, and was trained using next-token prediction. Zamba uses a shared transformer layer after every 6 mamba blocks. It uses the [Mistral v0.1 tokenizer](https://huggingface.co/mistralai/Mistral-7B-v0.1). We came to this architecture after a series of ablations at small scales. Zamba-7B-v1 was pre-trained on 1T tokens of text and code data.
<img src=https://github.com/user-attachments/assets/c2cff209-b901-483c-87aa-774b82a0769f width=30% height=40% />
## Quick start
### Presequities
Zamba requires you use `transformers` version 4.46.0 or higher:
```bash
pip install transformers>=4.45.0
```
In order to run optimized Mamba implementations, you first need to install `mamba-ssm` and `causal-conv1d`:
```bash
pip install mamba-ssm causal-conv1d>=1.2.0
```
You also have to have the model on a CUDA device.
You can run the model not using the optimized Mamba kernels, but it is **not** recommended as it will result in significantly lower latencies. In order to do that, you'll need to specify `use_mamba_kernels=False` when loading the model.
## Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("Zyphra/Zamba-7B-v1")
model = AutoModelForCausalLM.from_pretrained("Zyphra/Zamba-7B-v1", device_map="auto", torch_dtype=torch.bfloat16)
input_text = "A funny prompt would be "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids, max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
```
## Model card
The model cards can be found at:
* [Zamba-7B](MODEL_CARD_ZAMBA-7B-v1.md)
## Issues
For issues with model output, or community discussion, please use the Hugging Face community [forum](https://huggingface.co/zyphra/zamba-7b)
## License
The model weights are open-sourced via an Apache 2.0 license.
## ZambaConfig
[[autodoc]] ZambaConfig
## ZambaModel
[[autodoc]] ZambaModel
- forward
## ZambaForCausalLM
[[autodoc]] ZambaForCausalLM
- forward
## ZambaForSequenceClassification
[[autodoc]] transformers.ZambaForSequenceClassification
- forward
|
transformers/docs/source/en/model_doc/zamba.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/zamba.md",
"repo_id": "transformers",
"token_count": 1045
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on CPU
This guide focuses on training large models efficiently on CPU.
## Mixed precision with IPEX
Mixed precision uses single (fp32) and half-precision (bf16/fp16) data types in a model to accelerate training or inference while still preserving much of the single-precision accuracy. Modern CPUs such as 3rd, 4th, and 5th Gen Intel® Xeon® Scalable processors natively support bf16. 6th Gen Intel® Xeon® Scalable processors natively support bf16 and fp16. You should get more performance out of the box by enabling mixed precision training with bf16 or fp16.
To further maximize training performance, you can use Intel® Extension for PyTorch (IPEX), which is a library built on PyTorch and adds additional CPU instruction level architecture (ISA) level support such as Intel® Advanced Vector Extensions 512 Vector Neural Network Instructions (Intel® AVX512-VNNI), and Intel® Advanced Matrix Extensions (Intel® AMX) for an extra performance boost on Intel CPUs. However, CPUs with only AVX2 (e.g., AMD or older Intel CPUs) are not guaranteed to have better performance under IPEX.
Auto Mixed Precision (AMP) for CPU backends has been enabled since PyTorch 1.10. AMP support for bf16/fp16 on CPUs and bf16/fp16 operator optimization is also supported in IPEX and partially upstreamed to the main PyTorch branch. You can get better performance and user experience with IPEX AMP.
Check more detailed information for [Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html).
### IPEX installation:
IPEX release is following PyTorch, to install via pip:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 2.5.0 | 2.5.0+cpu |
| 2.4.0 | 2.4.0+cpu |
| 2.3.0 | 2.3.0+cpu |
| 2.2.0 | 2.2.0+cpu |
Please run `pip list | grep torch` to get your `pytorch_version`, so you can get the `IPEX version_name`.
```bash
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
You can check the latest versions in [ipex-whl-stable-cpu](https://developer.intel.com/ipex-whl-stable-cpu) if needed.
Check more approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html).
### Usage in Trainer
To enable auto mixed precision with IPEX in Trainer, users should add `use_ipex`, `bf16` or `fp16`, and `no_cuda` in training command arguments.
Take an example of the use cases on [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
- Training with IPEX using BF16 auto mixed precision on CPU:
<pre> python examples/pytorch/question-answering/run_qa.py \
--model_name_or_path google-bert/bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
<b>--use_ipex</b> \
<b>--bf16</b> \
<b>--use_cpu</b></pre>
If you want to enable `use_ipex` and `bf16` in your script, add these parameters to `TrainingArguments` like this:
```diff
training_args = TrainingArguments(
output_dir=args.output_path,
+ bf16=True,
+ use_ipex=True,
+ use_cpu=True,
**kwargs
)
```
### Practice example
Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids)
|
transformers/docs/source/en/perf_train_cpu.md/0
|
{
"file_path": "transformers/docs/source/en/perf_train_cpu.md",
"repo_id": "transformers",
"token_count": 1331
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# bitsandbytes
[bitsandbytes](https://github.com/TimDettmers/bitsandbytes) is the easiest option for quantizing a model to 8 and 4-bit. 8-bit quantization multiplies outliers in fp16 with non-outliers in int8, converts the non-outlier values back to fp16, and then adds them together to return the weights in fp16. This reduces the degradative effect outlier values have on a model's performance. 4-bit quantization compresses a model even further, and it is commonly used with [QLoRA](https://hf.co/papers/2305.14314) to finetune quantized LLMs.
To use bitsandbytes, make sure you have the following libraries installed:
<hfoptions id="bnb">
<hfoption id="8-bit">
```bash
pip install transformers accelerate bitsandbytes>0.37.0
```
</hfoption>
<hfoption id="4-bit">
```bash
pip install bitsandbytes>=0.39.0
pip install --upgrade accelerate transformers
```
</hfoption>
</hfoptions>
<Tip>
bitsandbytes is being refactored to support multiple backends beyond CUDA. Currently, ROCm (AMD GPU) and Intel CPU implementations are mature, with Intel XPU in progress and Apple Silicon support expected by Q4/Q1. For installation instructions and the latest backend updates, visit [this link](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
We value your feedback to help identify bugs before the full release! Check out [these docs](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends) for more details and feedback links.
</Tip>
Now you can quantize a model by passing a `BitsAndBytesConfig` to [`~PreTrainedModel.from_pretrained`] method. This works for any model in any modality, as long as it supports loading with Accelerate and contains `torch.nn.Linear` layers.
<hfoptions id="bnb">
<hfoption id="8-bit">
Quantizing a model in 8-bit halves the memory-usage, and for large models, set `device_map="auto"` to efficiently use the GPUs available:
```py
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
quantization_config=quantization_config
)
```
By default, all the other modules such as `torch.nn.LayerNorm` are converted to `torch.float16`. You can change the data type of these modules with the `torch_dtype` parameter if you want. Setting `torch_dtype="auto"` loads the model in the data type defined in a model's `config.json` file.
```py
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model_8bit = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m",
quantization_config=quantization_config,
torch_dtype="auto"
)
model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
```
Once a model is quantized to 8-bit, you can't push the quantized weights to the Hub unless you're using the latest version of Transformers and bitsandbytes. If you have the latest versions, then you can push the 8-bit model to the Hub with the [`~PreTrainedModel.push_to_hub`] method. The quantization config.json file is pushed first, followed by the quantized model weights.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-560m",
quantization_config=quantization_config
)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")
```
</hfoption>
<hfoption id="4-bit">
Quantizing a model in 4-bit reduces your memory-usage by 4x, and for large models, set `device_map="auto"` to efficiently use the GPUs available:
```py
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
quantization_config=quantization_config
)
```
By default, all the other modules such as `torch.nn.LayerNorm` are converted to `torch.float16`. You can change the data type of these modules with the `torch_dtype` parameter if you want. Setting `torch_dtype="auto"` loads the model in the data type defined in a model's `config.json` file.
```py
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m",
quantization_config=quantization_config,
torch_dtype="auto"
)
model_4bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
```
If you have `bitsandbytes>=0.41.3`, you can serialize 4-bit models and push them on Hugging Face Hub. Simply call `model.push_to_hub()` after loading it in 4-bit precision. You can also save the serialized 4-bit models locally with `model.save_pretrained()` command.
</hfoption>
</hfoptions>
<Tip warning={true}>
Training with 8-bit and 4-bit weights are only supported for training *extra* parameters.
</Tip>
You can check your memory footprint with the `get_memory_footprint` method:
```py
print(model.get_memory_footprint())
```
Quantized models can be loaded from the [`~PreTrainedModel.from_pretrained`] method without needing to specify the `load_in_8bit` or `load_in_4bit` parameters:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
```
## 8-bit (LLM.int8() algorithm)
<Tip>
Learn more about the details of 8-bit quantization in this [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration)!
</Tip>
This section explores some of the specific features of 8-bit models, such as offloading, outlier thresholds, skipping module conversion, and finetuning.
### Offloading
8-bit models can offload weights between the CPU and GPU to support fitting very large models into memory. The weights dispatched to the CPU are actually stored in **float32**, and aren't converted to 8-bit. For example, to enable offloading for the [bigscience/bloom-1b7](https://huggingface.co/bigscience/bloom-1b7) model, start by creating a [`BitsAndBytesConfig`]:
```py
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
```
Design a custom device map to fit everything on your GPU except for the `lm_head`, which you'll dispatch to the CPU:
```py
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}
```
Now load your model with the custom `device_map` and `quantization_config`:
```py
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
torch_dtype="auto",
device_map=device_map,
quantization_config=quantization_config,
)
```
### Outlier threshold
An "outlier" is a hidden state value greater than a certain threshold, and these values are computed in fp16. While the values are usually normally distributed ([-3.5, 3.5]), this distribution can be very different for large models ([-60, 6] or [6, 60]). 8-bit quantization works well for values ~5, but beyond that, there is a significant performance penalty. A good default threshold value is 6, but a lower threshold may be needed for more unstable models (small models or finetuning).
To find the best threshold for your model, we recommend experimenting with the `llm_int8_threshold` parameter in [`BitsAndBytesConfig`]:
```py
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10.0,
llm_int8_enable_fp32_cpu_offload=True
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map=device_map,
quantization_config=quantization_config,
)
```
### Skip module conversion
For some models, like [Jukebox](model_doc/jukebox), you don't need to quantize every module to 8-bit which can actually cause instability. With Jukebox, there are several `lm_head` modules that should be skipped using the `llm_int8_skip_modules` parameter in [`BitsAndBytesConfig`]:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
quantization_config=quantization_config,
)
```
### Finetuning
With the [PEFT](https://github.com/huggingface/peft) library, you can finetune large models like [flan-t5-large](https://huggingface.co/google/flan-t5-large) and [facebook/opt-6.7b](https://huggingface.co/facebook/opt-6.7b) with 8-bit quantization. You don't need to pass the `device_map` parameter for training because it'll automatically load your model on a GPU. However, you can still customize the device map with the `device_map` parameter if you want to (`device_map="auto"` should only be used for inference).
## 4-bit (QLoRA algorithm)
<Tip>
Try 4-bit quantization in this [notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) and learn more about it's details in this [blog post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
</Tip>
This section explores some of the specific features of 4-bit models, such as changing the compute data type, using the Normal Float 4 (NF4) data type, and using nested quantization.
### Compute data type
To speedup computation, you can change the data type from float32 (the default value) to bf16 using the `bnb_4bit_compute_dtype` parameter in [`BitsAndBytesConfig`]:
```py
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
```
### Normal Float 4 (NF4)
NF4 is a 4-bit data type from the [QLoRA](https://hf.co/papers/2305.14314) paper, adapted for weights initialized from a normal distribution. You should use NF4 for training 4-bit base models. This can be configured with the `bnb_4bit_quant_type` parameter in the [`BitsAndBytesConfig`]:
```py
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", quantization_config=nf4_config)
```
For inference, the `bnb_4bit_quant_type` does not have a huge impact on performance. However, to remain consistent with the model weights, you should use the `bnb_4bit_compute_dtype` and `torch_dtype` values.
### Nested quantization
Nested quantization is a technique that can save additional memory at no additional performance cost. This feature performs a second quantization of the already quantized weights to save an additional 0.4 bits/parameter. For example, with nested quantization, you can finetune a [Llama-13b](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) model on a 16GB NVIDIA T4 GPU with a sequence length of 1024, a batch size of 1, and enabling gradient accumulation with 4 steps.
```py
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-chat-hf", torch_dtype="auto", quantization_config=double_quant_config)
```
## Dequantizing `bitsandbytes` models
Once quantized, you can dequantize the model to the original precision but this might result in a small quality loss of the model. Make sure you have enough GPU RAM to fit the dequantized model.
```python
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.dequantize()
text = tokenizer("Hello my name is", return_tensors="pt").to(0)
out = model.generate(**text)
print(tokenizer.decode(out[0]))
```
|
transformers/docs/source/en/quantization/bitsandbytes.md/0
|
{
"file_path": "transformers/docs/source/en/quantization/bitsandbytes.md",
"repo_id": "transformers",
"token_count": 4147
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to ONNX
Deploying 🤗 Transformers models in production environments often requires, or can benefit from exporting the models into
a serialized format that can be loaded and executed on specialized runtimes and hardware.
🤗 Optimum is an extension of Transformers that enables exporting models from PyTorch or TensorFlow to serialized formats
such as ONNX and TFLite through its `exporters` module. 🤗 Optimum also provides a set of performance optimization tools to train
and run models on targeted hardware with maximum efficiency.
This guide demonstrates how you can export 🤗 Transformers models to ONNX with 🤗 Optimum, for the guide on exporting models to TFLite,
please refer to the [Export to TFLite page](tflite).
## Export to ONNX
[ONNX (Open Neural Network eXchange)](http://onnx.ai) is an open standard that defines a common set of operators and a
common file format to represent deep learning models in a wide variety of frameworks, including PyTorch and
TensorFlow. When a model is exported to the ONNX format, these operators are used to
construct a computational graph (often called an _intermediate representation_) which
represents the flow of data through the neural network.
By exposing a graph with standardized operators and data types, ONNX makes it easy to
switch between frameworks. For example, a model trained in PyTorch can be exported to
ONNX format and then imported in TensorFlow (and vice versa).
Once exported to ONNX format, a model can be:
- optimized for inference via techniques such as [graph optimization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) and [quantization](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization).
- run with ONNX Runtime via [`ORTModelForXXX` classes](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort),
which follow the same `AutoModel` API as the one you are used to in 🤗 Transformers.
- run with [optimized inference pipelines](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines),
which has the same API as the [`pipeline`] function in 🤗 Transformers.
🤗 Optimum provides support for the ONNX export by leveraging configuration objects. These configuration objects come
ready-made for a number of model architectures, and are designed to be easily extendable to other architectures.
For the list of ready-made configurations, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/onnx/overview).
There are two ways to export a 🤗 Transformers model to ONNX, here we show both:
- export with 🤗 Optimum via CLI.
- export with 🤗 Optimum with `optimum.onnxruntime`.
### Exporting a 🤗 Transformers model to ONNX with CLI
To export a 🤗 Transformers model to ONNX, first install an extra dependency:
```bash
pip install optimum[exporters]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli),
or view help in command line:
```bash
optimum-cli export onnx --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `distilbert/distilbert-base-uncased-distilled-squad`, run the following command:
```bash
optimum-cli export onnx --model distilbert/distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
You should see the logs indicating progress and showing where the resulting `model.onnx` is saved, like this:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub and provide the `--task` argument.
You can review the list of supported tasks in the [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/task_manager).
If `task` argument is not provided, it will default to the model architecture without any task specific head.
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
The resulting `model.onnx` file can then be run on one of the [many
accelerators](https://onnx.ai/supported-tools.html#deployModel) that support the ONNX
standard. For example, we can load and run the model with [ONNX
Runtime](https://onnxruntime.ai/) as follows:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
```
The process is identical for TensorFlow checkpoints on the Hub. For instance, here's how you would
export a pure TensorFlow checkpoint from the [Keras organization](https://huggingface.co/keras-io):
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### Exporting a 🤗 Transformers model to ONNX with `optimum.onnxruntime`
Alternative to CLI, you can export a 🤗 Transformers model to ONNX programmatically like so:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert/distilbert-base-uncased-distilled-squad"
>>> save_directory = "onnx/"
>>> # Load a model from transformers and export it to ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # Save the onnx model and tokenizer
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
```
### Exporting a model for an unsupported architecture
If you wish to contribute by adding support for a model that cannot be currently exported, you should first check if it is
supported in [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview),
and if it is not, [contribute to 🤗 Optimum](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)
directly.
### Exporting a model with `transformers.onnx`
<Tip warning={true}>
`transformers.onnx` is no longer maintained, please export models with 🤗 Optimum as described above. This section will be removed in the future versions.
</Tip>
To export a 🤗 Transformers model to ONNX with `transformers.onnx`, install extra dependencies:
```bash
pip install transformers[onnx]
```
Use `transformers.onnx` package as a Python module to export a checkpoint using a ready-made configuration:
```bash
python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
```
This exports an ONNX graph of the checkpoint defined by the `--model` argument. Pass any checkpoint on the 🤗 Hub or one that's stored locally.
The resulting `model.onnx` file can then be run on one of the many accelerators that support the ONNX standard. For example,
load and run the model with ONNX Runtime as follows:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
The required output names (like `["last_hidden_state"]`) can be obtained by taking a look at the ONNX configuration of
each model. For example, for DistilBERT we have:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
The process is identical for TensorFlow checkpoints on the Hub. For example, export a pure TensorFlow checkpoint like so:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
To export a model that's stored locally, save the model's weights and tokenizer files in the same directory (e.g. `local-pt-checkpoint`),
then export it to ONNX by pointing the `--model` argument of the `transformers.onnx` package to the desired directory:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
|
transformers/docs/source/en/serialization.md/0
|
{
"file_path": "transformers/docs/source/en/serialization.md",
"repo_id": "transformers",
"token_count": 2975
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Monocular depth estimation
Monocular depth estimation is a computer vision task that involves predicting the depth information of a scene from a
single image. In other words, it is the process of estimating the distance of objects in a scene from
a single camera viewpoint.
Monocular depth estimation has various applications, including 3D reconstruction, augmented reality, autonomous driving,
and robotics. It is a challenging task as it requires the model to understand the complex relationships between objects
in the scene and the corresponding depth information, which can be affected by factors such as lighting conditions,
occlusion, and texture.
There are two main depth estimation categories:
- **Absolute depth estimation**: This task variant aims to provide exact depth measurements from the camera. The term is used interchangeably with metric depth estimation, where depth is provided in precise measurements in meters or feet. Absolute depth estimation models output depth maps with numerical values that represent real-world distances.
- **Relative depth estimation**: Relative depth estimation aims to predict the depth order of objects or points in a scene without providing the precise measurements. These models output a depth map that indicates which parts of the scene are closer or farther relative to each other without the actual distances to A and B.
In this guide, we will see how to infer with [Depth Anything V2](https://huggingface.co/depth-anything/Depth-Anything-V2-Large), a state-of-the-art zero-shot relative depth estimation model, and [ZoeDepth](https://huggingface.co/docs/transformers/main/en/model_doc/zoedepth), an absolute depth estimation model.
<Tip>
Check the [Depth Estimation](https://huggingface.co/tasks/depth-estimation) task page to view all compatible architectures and checkpoints.
</Tip>
Before we begin, we need to install the latest version of Transformers:
```bash
pip install -q -U transformers
```
## Depth estimation pipeline
The simplest way to try out inference with a model supporting depth estimation is to use the corresponding [`pipeline`].
Instantiate a pipeline from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads):
```py
>>> from transformers import pipeline
>>> import torch
>>> from accelerate.test_utils.testing import get_backend
# automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
>>> device, _, _ = get_backend()
>>> checkpoint = "depth-anything/Depth-Anything-V2-base-hf"
>>> pipe = pipeline("depth-estimation", model=checkpoint, device=device)
```
Next, choose an image to analyze:
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg" alt="Photo of a bee"/>
</div>
Pass the image to the pipeline.
```py
>>> predictions = pipe(image)
```
The pipeline returns a dictionary with two entries. The first one, called `predicted_depth`, is a tensor with the values
being the depth expressed in meters for each pixel.
The second one, `depth`, is a PIL image that visualizes the depth estimation result.
Let's take a look at the visualized result:
```py
>>> predictions["depth"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/depth-visualization.png" alt="Depth estimation visualization"/>
</div>
## Depth estimation inference by hand
Now that you've seen how to use the depth estimation pipeline, let's see how we can replicate the same result by hand.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads).
Here we'll use the same checkpoint as before:
```py
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> checkpoint = "Intel/zoedepth-nyu-kitti"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
>>> model = AutoModelForDepthEstimation.from_pretrained(checkpoint).to(device)
```
Prepare the image input for the model using the `image_processor` that will take care of the necessary image transformations
such as resizing and normalization:
```py
>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values.to(device)
```
Pass the prepared inputs through the model:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(pixel_values)
```
Let's post-process the results to remove any padding and resize the depth map to match the original image size. The `post_process_depth_estimation` outputs a list of dicts containing the `"predicted_depth"`.
```py
>>> # ZoeDepth dynamically pads the input image. Thus we pass the original image size as argument
>>> # to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))
```
<Tip>
<p>In the <a href="https://github.com/isl-org/ZoeDepth/blob/edb6daf45458569e24f50250ef1ed08c015f17a7/zoedepth/models/depth_model.py#L131">original implementation</a> ZoeDepth model performs inference on both the original and flipped images and averages out the results. The <code>post_process_depth_estimation</code> function can handle this for us by passing the flipped outputs to the optional <code>outputs_flipped</code> argument:</p>
<pre><code class="language-Python">>>> with torch.no_grad():
... outputs = model(pixel_values)
... outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... outputs_flipped=outputs_flipped,
... )
</code></pre>
</Tip>
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/depth-visualization-zoe.png" alt="Depth estimation visualization"/>
</div>
|
transformers/docs/source/en/tasks/monocular_depth_estimation.md/0
|
{
"file_path": "transformers/docs/source/en/tasks/monocular_depth_estimation.md",
"repo_id": "transformers",
"token_count": 2079
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTología
Hay un creciente campo de estudio empeñado en la investigación del funcionamiento interno de los transformers de gran escala como BERT
(que algunos llaman "BERTología"). Algunos buenos ejemplos de este campo son:
- BERT Rediscovers the Classical NLP Pipeline por Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? por Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention por Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
Para asistir al desarrollo de este nuevo campo, hemos incluido algunas features adicionales en los modelos BERT/GPT/GPT-2 para
ayudar a acceder a las representaciones internas, principalmente adaptado de la gran obra de Paul Michel
(https://arxiv.org/abs/1905.10650):
- accediendo a todos los hidden-states de BERT/GPT/GPT-2,
- accediendo a todos los pesos de atención para cada head de BERT/GPT/GPT-2,
- adquiriendo los valores de salida y gradientes de las heads para poder computar la métrica de importancia de las heads y realizar la poda de heads como se explica
en https://arxiv.org/abs/1905.10650.
Para ayudarte a entender y usar estas features, hemos añadido un script específico de ejemplo: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) mientras extraes información y cortas un modelo pre-entrenado en
GLUE.
|
transformers/docs/source/es/bertology.md/0
|
{
"file_path": "transformers/docs/source/es/bertology.md",
"repo_id": "transformers",
"token_count": 761
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Respuesta a preguntas
<Youtube id="ajPx5LwJD-I"/>
La respuesta a preguntas devuelve una respuesta a partir de una pregunta dada. Existen dos formas comunes de responder preguntas:
- Extractiva: extraer la respuesta a partir del contexto dado.
- Abstractiva: generar una respuesta que responda correctamente la pregunta a partir del contexto dado.
Esta guía te mostrará como hacer fine-tuning de [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased) en el dataset [SQuAD](https://huggingface.co/datasets/squad) para responder preguntas de forma extractiva.
<Tip>
Revisa la [página de la tarea](https://huggingface.co/tasks/question-answering) de responder preguntas para tener más información sobre otras formas de responder preguntas y los modelos, datasets y métricas asociadas.
</Tip>
## Carga el dataset SQuAD
Carga el dataset SQuAD con la biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> squad = load_dataset("squad")
```
Ahora, échale un vistazo a una muestra:
```py
>>> squad["train"][0]
{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'title': 'University_of_Notre_Dame'
}
```
El campo `answers` es un diccionario que contiene la posición inicial de la respuesta y el `texto` de la respuesta.
## Preprocesamiento
<Youtube id="qgaM0weJHpA"/>
Carga el tokenizer de DistilBERT para procesar los campos `question` (pregunta) y `context` (contexto):
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
Hay algunos pasos de preprocesamiento específicos para la tarea de respuesta a preguntas que debes tener en cuenta:
1. Algunos ejemplos en un dataset pueden tener un contexto que supera la longitud máxima de entrada de un modelo. Trunca solamente el contexto asignándole el valor `"only_second"` al parámetro `truncation`.
2. A continuación, mapea las posiciones de inicio y fin de la respuesta al contexto original asignándole el valor `True` al parámetro `return_offsets_mapping`.
3. Una vez tengas el mapeo, puedes encontrar los tokens de inicio y fin de la respuesta. Usa el método [`sequence_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.sequence_ids)
para encontrar qué parte de la lista de tokens desplazados corresponde a la pregunta y cuál corresponde al contexto.
A continuación puedes ver como se crea una función para truncar y mapear los tokens de inicio y fin de la respuesta al `context`:
```py
>>> def preprocess_function(examples):
... questions = [q.strip() for q in examples["question"]]
... inputs = tokenizer(
... questions,
... examples["context"],
... max_length=384,
... truncation="only_second",
... return_offsets_mapping=True,
... padding="max_length",
... )
... offset_mapping = inputs.pop("offset_mapping")
... answers = examples["answers"]
... start_positions = []
... end_positions = []
... for i, offset in enumerate(offset_mapping):
... answer = answers[i]
... start_char = answer["answer_start"][0]
... end_char = answer["answer_start"][0] + len(answer["text"][0])
... sequence_ids = inputs.sequence_ids(i)
... # Encuentra el inicio y el fin del contexto
... idx = 0
... while sequence_ids[idx] != 1:
... idx += 1
... context_start = idx
... while sequence_ids[idx] == 1:
... idx += 1
... context_end = idx - 1
... # Si la respuesta entera no está dentro del contexto, etiquétala como (0, 0)
... if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
... start_positions.append(0)
... end_positions.append(0)
... else:
... # De lo contrario, esta es la posición de los tokens de inicio y fin
... idx = context_start
... while idx <= context_end and offset[idx][0] <= start_char:
... idx += 1
... start_positions.append(idx - 1)
... idx = context_end
... while idx >= context_start and offset[idx][1] >= end_char:
... idx -= 1
... end_positions.append(idx + 1)
... inputs["start_positions"] = start_positions
... inputs["end_positions"] = end_positions
... return inputs
```
Usa la función [`~datasets.Dataset.map`] de 🤗 Datasets para aplicarle la función de preprocesamiento al dataset entero. Puedes acelerar la función `map` haciendo `batched=True` para procesar varios elementos del dataset a la vez.
Quita las columnas que no necesites:
```py
>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
```
Usa el [`DefaultDataCollator`] para crear un lote de ejemplos. A diferencia de los otros collators de datos en 🤗 Transformers, el `DefaultDataCollator` no aplica ningún procesamiento adicional (como el rellenado).
<frameworkcontent>
<pt>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
</pt>
<tf>
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
```
</tf>
</frameworkcontent>
## Entrenamiento
<frameworkcontent>
<pt>
Carga el modelo DistilBERT con [`AutoModelForQuestionAnswering`]:
```py
>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip>
Para familiarizarte con el fine-tuning con [`Trainer`], ¡mira el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
En este punto, solo quedan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos del entrenamiento al [`Trainer`] junto con el modelo, el dataset, el tokenizer y el collator de datos.
3. Invocar el método [`~Trainer.train`] para realizar el fine-tuning del modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... eval_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_squad["train"],
... eval_dataset=tokenized_squad["validation"],
... processing_class=tokenizer,
... data_collator=data_collator,
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, primero convierte tus datasets al formato `tf.data.Dataset` con el método [`~TFPreTrainedModel.prepare_tf_dataset`].
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_squad["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_squad["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
<Tip>
Para familiarizarte con el fine-tuning con Keras, ¡mira el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Prepara una función de optimización, un programa para la tasa de aprendizaje y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_epochs = 2
>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
>>> optimizer, schedule = create_optimizer(
... init_lr=2e-5,
... num_warmup_steps=0,
... num_train_steps=total_train_steps,
... )
```
Carga el modelo DistilBERT con [`TFAutoModelForQuestionAnswering`]:
```py
>>> from transformers import TFAutoModelForQuestionAnswering
>>> model = TFAutoModelForQuestionAnswering("distilbert/distilbert-base-uncased")
```
Configura el modelo para entrenarlo con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
Invoca el método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
```
</tf>
</frameworkcontent>
<Tip>
Para un ejemplo con mayor profundidad de cómo hacer fine-tuning a un modelo para responder preguntas, échale un vistazo al
[cuaderno de PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb) o al
[cuaderno de TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb) correspondiente.
</Tip>
|
transformers/docs/source/es/tasks/question_answering.md/0
|
{
"file_path": "transformers/docs/source/es/tasks/question_answering.md",
"repo_id": "transformers",
"token_count": 3912
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Condividere modelli personalizzati
La libreria 🤗 Transformers è studiata per essere facilmente estendibile. Il codice di ogni modello è interamente
situato in una sottocartella del repository senza alcuna astrazione, perciò puoi facilmente copiare il file di un
modello e modificarlo in base ai tuoi bisogni.
Se stai scrivendo un nuovo modello, potrebbe essere più semplice iniziare da zero. In questo tutorial, ti mostreremo
come scrivere un modello personalizzato e la sua configurazione in modo che possa essere utilizzato all’interno di
Transformers, e come condividerlo con la community (assieme al relativo codice) così che tutte le persone possano usarlo, anche
se non presente nella libreria 🤗 Transformers.
Illustriamo tutto questo su un modello ResNet, avvolgendo la classe ResNet della
[libreria timm](https://github.com/rwightman/pytorch-image-models) in un [`PreTrainedModel`].
## Scrivere una configurazione personalizzata
Prima di iniziare a lavorare al modello, scriviamone la configurazione. La configurazione di un modello è un oggetto
che contiene tutte le informazioni necessarie per la build del modello. Come vedremo nella prossima sezione, il
modello può soltanto essere inizializzato tramite `config`, per cui dovremo rendere tale oggetto più completo possibile.
Nel nostro esempio, prenderemo un paio di argomenti della classe ResNet che potremmo voler modificare.
Configurazioni differenti ci daranno quindi i differenti possibili tipi di ResNet. Salveremo poi questi argomenti,
dopo averne controllato la validità.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Le tre cose più importanti da ricordare quando scrivi le tue configurazioni sono le seguenti:
- Devi ereditare da `Pretrainedconfig`,
- Il metodo `__init__` del tuo `Pretrainedconfig` deve accettare i kwargs,
- I `kwargs` devono essere passati alla superclass `__init__`
L’eredità è importante per assicurarsi di ottenere tutte le funzionalità della libreria 🤗 transformers,
mentre gli altri due vincoli derivano dal fatto che un `Pretrainedconfig` ha più campi di quelli che stai settando.
Quando ricarichi una config da un metodo `from_pretrained`, questi campi devono essere accettati dalla tua config e
poi inviati alla superclasse.
Definire un `model_type` per la tua configurazione (qua `model_type = “resnet”`) non è obbligatorio, a meno che tu
non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
Una volta completato, puoi facilmente creare e salvare la tua configurazione come faresti con ogni altra configurazione
di modelli della libreria. Ecco come possiamo creare la config di un resnet50d e salvarlo:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Questo salverà un file chiamato `config.json` all'interno della cartella `custom-resnet`. Potrai poi ricaricare la tua
config con il metodo `from_pretrained`.
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
Puoi anche usare qualunque altro metodo della classe [`PretrainedConfig`], come [`~PretrainedConfig.push_to_hub`]
per caricare direttamente la tua configurazione nell'hub.
## Scrivere un modello personalizzato
Ora che abbiamo la nostra configurazione ResNet, possiamo continuare a scrivere il modello. In realtà, ne scriveremo
due: uno che estrae le features nascoste da una batch di immagini (come [`BertModel`]) e uno che è utilizzabile per
la classificazione di immagini (come [`BertModelForSequenceClassification`]).
Come abbiamo menzionato in precedenza, scriveremo soltanto un wrapper del modello, per mantenerlo semplice ai fini di
questo esempio. L'unica cosa che dobbiamo fare prima di scrivere questa classe è una mappatura fra i tipi di blocco e
le vere classi dei blocchi. Successivamente il modello è definito tramite la configurazione, passando tutto quanto alla
classe `ResNet`.
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Per il modello che classificherà le immagini, cambiamo soltanto il metodo forward:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.functional.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
Nota come, in entrambi i casi, ereditiamo da `PreTrainedModel` e chiamiamo l'inizializzazione della superclasse
con il metodo `config` (un po' come quando scrivi un normale `torch.nn.Module`). La riga che imposta la `config_class`
non è obbligatoria, a meno che tu non voglia registrare il modello con le classi Auto (vedi l'ultima sezione).
<Tip>
Se il tuo modello è molto simile a un modello all'interno della libreria, puoi ri-usare la stessa configurazione di quel modello.
</Tip>
Puoi fare in modo che il tuo modello restituisca in output qualunque cosa tu voglia, ma far restituire un dizionario
come abbiamo fatto per `ResnetModelForImageClassification`, con la funzione di perdita inclusa quando vengono passate le labels,
renderà il tuo modello direttamente utilizzabile all'interno della classe [`Trainer`]. Utilizzare altri formati di output va bene
se hai in progetto di utilizzare un tuo loop di allenamento, o se utilizzerai un'altra libreria per l'addestramento.
Ora che abbiamo la classe del nostro modello, creiamone uno:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Ribadiamo, puoi usare qualunque metodo dei [`PreTrainedModel`], come [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Utilizzeremo quest'ultimo nella prossima sezione, e vedremo come caricare i pesi del
modello assieme al codice del modello stesso. Ma prima, carichiamo alcuni pesi pre-allenati all'interno del nostro modello.
Nel tuo caso specifico, probabilmente allenerai il tuo modello sui tuoi dati. Per velocizzare in questo tutorial,
utilizzeremo la versione pre-allenata del resnet50d. Dato che il nostro modello è soltanto un wrapper attorno a quel modello,
sarà facile trasferirne i pesi:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Vediamo adesso come assicurarci che quando facciamo [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
il codice del modello venga salvato.
## Inviare il codice all'Hub
<Tip warning={true}>
Questa API è sperimentale e potrebbe avere alcuni cambiamenti nei prossimi rilasci.
</Tip>
Innanzitutto, assicurati che il tuo modello sia completamente definito in un file `.py`. Può sfruttare import relativi
ad altri file, purchè questi siano nella stessa directory (non supportiamo ancora sotto-moduli per questa funzionalità).
Per questo esempio, definiremo un file `modeling_resnet.py` e un file `configuration_resnet.py` in una cartella dell'attuale
working directory chiamata `resnet_model`. Il file configuration contiene il codice per `ResnetConfig` e il file modeling
contiene il codice di `ResnetModel` e `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
Il file `__init__.py` può essere vuoto, serve solo perchè Python capisca che `resnet_model` può essere utilizzato come un modulo.
<Tip warning={true}>
Se stai copiando i file relativi alla modellazione della libreria, dovrai sostituire tutti gli import relativi in cima al file con import del
pacchetto `transformers`.
</Tip>
Nota che puoi ri-utilizzare (o usare come sottoclassi) un modello/configurazione esistente.
Per condividere il tuo modello con la community, segui questi passi: prima importa il modello ResNet e la sua configurazione
dai nuovi file creati:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Dopodichè dovrai dire alla libreria che vuoi copiare i file con il codice di quegli oggetti quando utilizzi il metodo
`save_pretrained` e registrarli in modo corretto con una Auto classe (specialmente per i modelli). Utilizza semplicemente:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Nota che non c'è bisogno di specificare una Auto classe per la configurazione (c'è solo una Auto classe per le configurazioni,
[`AutoConfig`], ma è diversa per i modelli). Il tuo modello personalizato potrebbe essere utilizzato per diverse tasks,
per cui devi specificare quale delle classi Auto è quella corretta per il tuo modello.
Successivamente, creiamo i modelli e la config come abbiamo fatto in precedenza:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Adesso, per inviare il modello all'Hub, assicurati di aver effettuato l'accesso. Lancia dal tuo terminale:
```bash
huggingface-cli login
```
O da un notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Potrai poi inviare il tutto sul tuo profilo (o di un'organizzazione di cui fai parte) in questo modo:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Oltre ai pesi del modello e alla configurazione in formato json, questo ha anche copiato i file `.py` modeling e
configuration all'interno della cartella `custom-resnet50d` e ha caricato i risultati sull'Hub. Puoi controllare
i risultati in questa [model repo](https://huggingface.co/sgugger/custom-resnet50d).
Puoi controllare il tutorial di condivisione [tutorial di condivisione](model_sharing) per più informazioni sul
metodo con cui inviare all'Hub.
## Usare un modello con codice personalizzato
Puoi usare ogni configurazione, modello o tokenizer con file di codice personalizzati nella sua repository
con le classi Auto e il metodo `from_pretrained`. Tutti i files e il codice caricati sull'Hub sono scansionati da malware
(fai riferimento alla documentazione [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) per più informazioni),
ma dovresti comunque assicurarti dell'affidabilità del codice e dell'autore per evitare di eseguire codice dannoso sulla tua macchina.
Imposta `trust_remote_code=True` per usare un modello con codice personalizzato:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
Inoltre, raccomandiamo fortemente di passare un hash del commit come `revision` per assicurarti che le autrici o gli autori del modello
non abbiano modificato il codice con alcune nuove righe dannose (a meno che non ti fidi completamente della fonte):
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Nota che quando cerchi la storia dei commit della repo del modello sull'Hub, c'è un bottone con cui facilmente copiare il
commit hash di ciascun commit.
## Registrare un modello con codice personalizzato nelle classi Auto
Se stai scrivendo una libreria che estende 🤗 Transformers, potresti voler estendere le classi Auto per includere il tuo modello.
Questo è diverso dall'inviare codice nell'Hub: gli utenti dovranno importare la tua libreria per ottenere il modello personalizzato
(anzichè scaricare automaticamente il modello dall'Hub).
Finchè il tuo file di configurazione ha un attributo `model_type` diverso dai model types esistenti, e finchè le tue
classi modello hanno i corretti attributi `config_class`, potrai semplicemente aggiungerli alle classi Auto come segue:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Nota che il primo argomento utilizzato quando registri la configurazione di un modello personalizzato con [`AutoConfig`]
deve corrispondere al `model_type` della tua configurazione personalizzata, ed il primo argomento utilizzato quando
registri i tuoi modelli personalizzati in una qualunque classe Auto del modello deve corrispondere alla `config_class`
di quei modelli.
|
transformers/docs/source/it/custom_models.md/0
|
{
"file_path": "transformers/docs/source/it/custom_models.md",
"repo_id": "transformers",
"token_count": 5886
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipeline per l'inferenza
La [`pipeline`] rende semplice usare qualsiasi modello dal [Model Hub](https://huggingface.co/models) per fare inferenza su diversi compiti come generazione del testo, segmentazione di immagini e classificazione di audio. Anche se non hai esperienza con una modalità specifica o non comprendi bene il codice che alimenta i modelli, è comunque possibile utilizzarli con l'opzione [`pipeline`]! Questa esercitazione ti insegnerà a:
* Usare una [`pipeline`] per fare inferenza.
* Usare uno specifico tokenizer o modello.
* Usare una [`pipeline`] per compiti che riguardano audio e video.
<Tip>
Dai un'occhiata alla documentazione di [`pipeline`] per una lista completa dei compiti supportati.
</Tip>
## Utilizzo della Pipeline
Nonostante ogni compito abbia una [`pipeline`] associata, è più semplice utilizzare l'astrazione generica della [`pipeline`] che contiene tutte quelle specifiche per ogni mansione. La [`pipeline`] carica automaticamente un modello predefinito e un tokenizer in grado di fare inferenza per il tuo compito.
1. Inizia creando una [`pipeline`] e specificando il compito su cui fare inferenza:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Inserisci il testo in input nella [`pipeline`]:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se hai più di un input, inseriscilo in una lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... ) # doctest: +SKIP
```
Qualsiasi parametro addizionale per il tuo compito può essere incluso nella [`pipeline`]. La mansione `text-generation` ha un metodo [`~generation.GenerationMixin.generate`] con diversi parametri per controllare l'output. Ad esempio, se desideri generare più di un output, utilizza il parametro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... ) # doctest: +SKIP
```
### Scegliere modello e tokenizer
La [`pipeline`] accetta qualsiasi modello dal [Model Hub](https://huggingface.co/models). Ci sono tag nel Model Hub che consentono di filtrare i modelli per attività. Una volta che avrai scelto il modello appropriato, caricalo usando la corrispondente classe `AutoModelFor` e [`AutoTokenizer`]. Ad esempio, carica la classe [`AutoModelForCausalLM`] per un compito di causal language modeling:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
```
Crea una [`pipeline`] per il tuo compito, specificando il modello e il tokenizer che hai caricato:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Inserisci il testo di input nella [`pipeline`] per generare del testo:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Audio pipeline
La flessibilità della [`pipeline`] fa si che possa essere estesa ad attività sugli audio.
Per esempio, classifichiamo le emozioni in questo clip audio:
```py
>>> from datasets import load_dataset
>>> import torch
>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> audio_file = ds[0]["audio"]["path"]
```
Trova un modello per la [classificazione audio](https://huggingface.co/models?pipeline_tag=audio-classification) sul Model Hub per eseguire un compito di riconoscimento automatico delle emozioni e caricalo nella [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Inserisci il file audio nella [`pipeline`]:
```py
>>> preds = audio_classifier(audio_file)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
```
## Vision pipeline
Infine, usare la [`pipeline`] per le attività sulle immagini è praticamente la stessa cosa.
Specifica la tua attività e inserisci l'immagine nel classificatore. L'immagine può essere sia un link che un percorso sul tuo pc in locale. Per esempio, quale specie di gatto è raffigurata qui sotto?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
|
transformers/docs/source/it/pipeline_tutorial.md/0
|
{
"file_path": "transformers/docs/source/it/pipeline_tutorial.md",
"repo_id": "transformers",
"token_count": 2398
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Create a custom architecture
[`AutoClass`](model_doc/auto)は、モデルのアーキテクチャを自動的に推論し、事前学習済みの設定と重みをダウンロードします。一般的には、チェックポイントに依存しないコードを生成するために`AutoClass`を使用することをお勧めします。ただし、特定のモデルパラメータに対する制御をより詳細に行いたいユーザーは、いくつかの基本クラスからカスタム🤗 Transformersモデルを作成できます。これは、🤗 Transformersモデルを研究、トレーニング、または実験する興味があるユーザーに特に役立つかもしれません。このガイドでは、`AutoClass`を使用しないカスタムモデルの作成について詳しく説明します。次の方法を学びます:
- モデルの設定をロードおよびカスタマイズする。
- モデルアーキテクチャを作成する。
- テキスト用の遅いトークナイザと高速トークナイザを作成する。
- ビジョンタスク用の画像プロセッサを作成する。
- オーディオタスク用の特徴抽出器を作成する。
- マルチモーダルタスク用のプロセッサを作成する。
## Configuration
[設定](main_classes/configuration)は、モデルの特定の属性を指します。各モデルの設定には異なる属性があります。たとえば、すべてのNLPモデルには、`hidden_size`、`num_attention_heads`、`num_hidden_layers`、および`vocab_size`属性が共通してあります。これらの属性は、モデルを構築するための注意ヘッドの数や隠れ層の数を指定します。
[DistilBERT](model_doc/distilbert)をより詳しく調べるために、[`DistilBertConfig`]にアクセスしてその属性を調べてみましょう:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`]は、基本の[`DistilBertModel`]を構築するために使用されるすべてのデフォルト属性を表示します。
すべての属性はカスタマイズ可能で、実験のためのスペースを提供します。例えば、デフォルトのモデルをカスタマイズして以下のようなことができます:
- `activation`パラメータで異なる活性化関数を試す。
- `attention_dropout`パラメータで注意確率の高いドロップアウト率を使用する。
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
事前学習済みモデルの属性は、[`~PretrainedConfig.from_pretrained`] 関数で変更できます:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Once you are satisfied with your model configuration, you can save it with [`PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory.
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
設定ファイルを再利用するには、[`~PretrainedConfig.from_pretrained`]を使用してそれをロードします:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
カスタム構成ファイルを辞書として保存することも、カスタム構成属性とデフォルトの構成属性の違いだけを保存することもできます!詳細については[configuration](main_classes/configuration)のドキュメンテーションをご覧ください。
</Tip>
## Model
次のステップは、[モデル](main_classes/models)を作成することです。モデル(アーキテクチャとも緩く言われることがあります)は、各レイヤーが何をしているか、どの操作が行われているかを定義します。構成からの `num_hidden_layers` のような属性はアーキテクチャを定義するために使用されます。
すべてのモデルは [`PreTrainedModel`] をベースクラスとし、入力埋め込みのリサイズやセルフアテンションヘッドのプルーニングなど、共通のメソッドがいくつかあります。
さらに、すべてのモデルは [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)、または [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) のいずれかのサブクラスでもあります。つまり、モデルはそれぞれのフレームワークの使用法と互換性があります。
<frameworkcontent>
<pt>
モデルにカスタム構成属性をロードします:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
これにより、事前トレーニング済みの重みではなくランダムな値を持つモデルが作成されます。
これは、トレーニングが行われるまで、まだ有用なものとして使用することはできません。
トレーニングはコストと時間がかかるプロセスです。
通常、トレーニングに必要なリソースの一部しか使用せず、より速くより良い結果を得るために事前学習済みモデルを使用することが良いでしょう。
[`~PreTrainedModel.from_pretrained`]を使用して事前学習済みモデルを作成します:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
事前学習済みの重みをロードする際、モデルが🤗 Transformersによって提供されている場合、デフォルトのモデル設定が自動的にロードされます。ただし、必要に応じてデフォルトのモデル設定属性の一部またはすべてを独自のもので置き換えることができます。
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
モデルにカスタム設定属性をロードしてください:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
これにより、事前学習済みの重みではなくランダムな値を持つモデルが作成されます。
このモデルを有用な目的にはまだ使用することはできません。トレーニングはコストがかかり、時間がかかるプロセスです。
一般的には、トレーニングに必要なリソースの一部しか使用せずに、より速く優れた結果を得るために事前学習済みモデルを使用することが良いでしょう。
[`~TFPreTrainedModel.from_pretrained`]を使用して事前学習済みモデルを作成します:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
事前学習済みの重みをロードする際、モデルが🤗 Transformersによって提供されている場合、デフォルトのモデル構成が自動的にロードされます。ただし、必要であればデフォルトのモデル構成属性の一部またはすべてを独自のもので置き換えることもできます:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Model heads
この時点で、ベースのDistilBERTモデルがあり、これは隠れた状態を出力します。隠れた状態はモデルのヘッドへの入力として渡され、最終的な出力を生成します。🤗 Transformersは、モデルがそのタスクをサポートしている限り、各タスクに対応する異なるモデルヘッドを提供します(つまり、DistilBERTを翻訳のようなシーケンス対シーケンスタスクに使用することはできません)。
<frameworkcontent>
<pt>
たとえば、[`DistilBertForSequenceClassification`]は、シーケンス分類ヘッドを持つベースのDistilBERTモデルです。シーケンス分類ヘッドは、プールされた出力の上にある線形層です。
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
新しいタスクにこのチェックポイントを簡単に再利用するには、異なるモデルヘッドに切り替えます。
質問応答タスクの場合、[`DistilBertForQuestionAnswering`] モデルヘッドを使用します。
質問応答ヘッドはシーケンス分類ヘッドと類似していますが、隠れ状態の出力の上に線形層があります。
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</pt>
<tf>
例えば、[`TFDistilBertForSequenceClassification`]は、シーケンス分類ヘッドを持つベースのDistilBERTモデルです。シーケンス分類ヘッドは、プールされた出力の上にある線形層です。
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
別のタスクにこのチェックポイントを簡単に再利用することができ、異なるモデルヘッドに切り替えるだけです。
質問応答タスクの場合、[`TFDistilBertForQuestionAnswering`]モデルヘッドを使用します。
質問応答ヘッドはシーケンス分類ヘッドと似ていますが、隠れ状態の出力の上に線形層があるだけです。
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
テキストデータをモデルで使用する前に必要な最後のベースクラスは、生のテキストをテンソルに変換するための[トークナイザ](main_classes/tokenizer)です。
🤗 Transformersで使用できる2つのタイプのトークナイザがあります:
- [`PreTrainedTokenizer`]: トークナイザのPython実装です。
- [`PreTrainedTokenizerFast`]: Rustベースの[🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/)ライブラリからのトークナイザです。
このトークナイザのタイプは、そのRust実装により、特にバッチトークナイゼーション中に高速です。
高速なトークナイザは、トークンを元の単語または文字にマッピングする*オフセットマッピング*などの追加メソッドも提供します。
両方のトークナイザは、エンコードとデコード、新しいトークンの追加、特別なトークンの管理など、共通のメソッドをサポートしています。
<Tip warning={true}>
すべてのモデルが高速なトークナイザをサポートしているわけではありません。
モデルが高速なトークナイザをサポートしているかどうかを確認するには、この[表](index#supported-frameworks)をご覧ください。
</Tip>
独自のトークナイザをトレーニングした場合、*ボキャブラリー*ファイルからトークナイザを作成できます。
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
カスタムトークナイザーから生成される語彙は、事前学習済みモデルのトークナイザーが生成する語彙とは異なることを覚えておくことは重要です。
事前学習済みモデルを使用する場合は、事前学習済みモデルの語彙を使用する必要があります。そうしないと、入力が意味をなさなくなります。
[`DistilBertTokenizer`]クラスを使用して、事前学習済みモデルの語彙を持つトークナイザーを作成します:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
[`DistilBertTokenizerFast`]クラスを使用して高速なトークナイザを作成します:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip>
デフォルトでは、[`AutoTokenizer`]は高速なトークナイザを読み込もうとします。`from_pretrained`内で`use_fast=False`を設定することで、この動作を無効にすることができます。
</Tip>
## Image Processor
画像プロセッサはビジョン入力を処理します。これは基本クラス [`~image_processing_utils.ImageProcessingMixin`] を継承しています。
使用するには、使用しているモデルに関連付けられた画像プロセッサを作成します。
たとえば、画像分類に[ViT](model_doc/vit)を使用する場合、デフォルトの [`ViTImageProcessor`] を作成します。
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
カスタマイズを必要としない場合、モデルのデフォルトの画像プロセッサパラメータをロードするには、単純に`from_pretrained`メソッドを使用してください。
</Tip>
[`ViTImageProcessor`]のパラメータを変更して、カスタムの画像プロセッサを作成できます:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
## Feature Extractor
フィーチャー抽出器は音声入力を処理します。これは基本的な [`~feature_extraction_utils.FeatureExtractionMixin`] クラスから継承され、音声入力を処理するための [`SequenceFeatureExtractor`] クラスからも継承されることがあります。
使用するには、モデルに関連付けられたフィーチャー抽出器を作成します。たとえば、音声分類に [Wav2Vec2](model_doc/wav2vec2) を使用する場合、デフォルトの [`Wav2Vec2FeatureExtractor`] を作成します。
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
カスタマイズを行わない場合、モデルのデフォルトの特徴抽出器パラメーターをロードするには、単に `from_pretrained` メソッドを使用してください。
</Tip>
[`Wav2Vec2FeatureExtractor`] のパラメーターを変更して、カスタム特徴抽出器を作成できます:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
## Processor
マルチモーダルタスクをサポートするモデルに対して、🤗 Transformersは便利なプロセッサクラスを提供しています。
このプロセッサクラスは、特徴量抽出器やトークナイザなどの処理クラスを便利にラップし、単一のオブジェクトに結合します。
たとえば、自動音声認識タスク(ASR)用に[`Wav2Vec2Processor`]を使用してみましょう。
ASRは音声をテキストに転写するタスクであり、音声入力を処理するために特徴量抽出器とトークナイザが必要です。
音声入力を処理する特徴量抽出器を作成します:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
テキスト入力を処理するトークナイザを作成します:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
[`Wav2Vec2Processor`]で特徴量抽出器とトークナイザを組み合わせます:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
二つの基本クラス - 設定とモデル - および追加の前処理クラス(トークナイザ、画像プロセッサ、特徴抽出器、またはプロセッサ)を使用することで、🤗 Transformers がサポートするモデルのいずれかを作成できます。これらの基本クラスは設定可能で、必要な特性を使用できます。モデルをトレーニング用に簡単にセットアップしたり、既存の事前学習済みモデルを微調整することができます。
|
transformers/docs/source/ja/create_a_model.md/0
|
{
"file_path": "transformers/docs/source/ja/create_a_model.md",
"repo_id": "transformers",
"token_count": 8236
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines
パイプラインは、推論にモデルを使うための簡単で優れた方法である。パイプラインは、複雑なコードのほとんどを抽象化したオブジェクトです。
パイプラインは、ライブラリから複雑なコードのほとんどを抽象化したオブジェクトで、名前付き固有表現認識、マスク言語モデリング、感情分析、特徴抽出、質問応答などのタスクに特化したシンプルなAPIを提供します。
Recognition、Masked Language Modeling、Sentiment Analysis、Feature Extraction、Question Answeringなどのタスクに特化したシンプルなAPIを提供します。以下を参照のこと。
[タスク概要](../task_summary)を参照してください。
パイプラインの抽象化には2つのカテゴリーがある:
- [`pipeline`] は、他のすべてのパイプラインをカプセル化する最も強力なオブジェクトです。
- タスク固有のパイプラインは、[オーディオ](#audio)、[コンピューター ビジョン](#computer-vision)、[自然言語処理](#natural-language-processing)、および [マルチモーダル](#multimodal) タスクで使用できます。
## The pipeline abstraction
*パイプライン* 抽象化は、他のすべての利用可能なパイプラインのラッパーです。他のものと同様にインスタンス化されます
パイプラインですが、さらなる生活の質を提供できます。
1 つの項目に対する単純な呼び出し:
```python
>>> pipe = pipeline("text-classification")
>>> pipe("This restaurant is awesome")
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
```
[ハブ](https://huggingface.co) の特定のモデルを使用したい場合は、モデルがオンになっている場合はタスクを無視できます。
ハブはすでにそれを定義しています。
```python
>>> pipe = pipeline(model="FacebookAI/roberta-large-mnli")
>>> pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
多くの項目に対してパイプラインを呼び出すには、*list* を使用してパイプラインを呼び出すことができます。
```python
>>> pipe = pipeline("text-classification")
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
```
完全なデータセットを反復するには、`Dataset`を直接使用することをお勧めします。これは、割り当てる必要がないことを意味します
データセット全体を一度に処理することも、自分でバッチ処理を行う必要もありません。これはカスタムループと同じくらい速く動作するはずです。
GPU。それが問題でない場合は、ためらわずに問題を作成してください。
```python
import datasets
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from tqdm.auto import tqdm
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
dataset = datasets.load_dataset("superb", name="asr", split="test")
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
使いやすくするために、ジェネレーターを使用することもできます。
```python
from transformers import pipeline
pipe = pipeline("text-classification")
def data():
while True:
# This could come from a dataset, a database, a queue or HTTP request
# in a server
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
# to use multiple threads to preprocess data. You can still have 1 thread that
# does the preprocessing while the main runs the big inference
yield "This is a test"
for out in pipe(data()):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
[[autodoc]] pipeline
## Pipeline batching
すべてのパイプラインでバッチ処理を使用できます。これはうまくいきます
パイプラインがストリーミング機能を使用するときは常に (つまり、リスト、`dataset`、または `generator`を渡すとき)。
```python
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
pipe = pipeline("text-classification", device=0)
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
print(out)
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
# Exactly the same output as before, but the content are passed
# as batches to the model
```
<Tip warning={true}>
ただし、これによってパフォーマンスが自動的に向上するわけではありません。状況に応じて、10 倍の高速化または 5 倍の低速化のいずれかになります。
ハードウェア、データ、使用されている実際のモデルについて。
主に高速化である例:
</Tip>
```python
from transformers import pipeline
from torch.utils.data import Dataset
from tqdm.auto import tqdm
pipe = pipeline("text-classification", device=0)
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
return "This is a test"
dataset = MyDataset()
for batch_size in [1, 8, 64, 256]:
print("-" * 30)
print(f"Streaming batch_size={batch_size}")
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
pass
```
```
# On GTX 970
------------------------------
Streaming no batching
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
------------------------------
Streaming batch_size=64
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
------------------------------
Streaming batch_size=256
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
(diminishing returns, saturated the GPU)
```
最も速度が低下する例:
```python
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
if i % 64 == 0:
n = 100
else:
n = 1
return "This is a test" * n
```
これは、他の文に比べて非常に長い文が時折あります。その場合、**全体**のバッチは 400 である必要があります。
トークンが長いため、バッチ全体が [64, 4] ではなく [64, 400] になり、速度が大幅に低下します。さらに悪いことに、
バッチが大きくなると、プログラムは単純にクラッシュします。
```
------------------------------
Streaming no batching
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
------------------------------
Streaming batch_size=64
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
------------------------------
Streaming batch_size=256
0%| | 0/1000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
....
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
```
この問題に対する適切な (一般的な) 解決策はなく、使用できる距離はユースケースによって異なる場合があります。のルール
親指:
ユーザーにとっての経験則は次のとおりです。
- **ハードウェアを使用して、負荷に対するパフォーマンスを測定します。測って、測って、測り続ける。実数というのは、
進むべき唯一の方法。**
- レイテンシに制約がある場合 (実際の製品が推論を実行している場合)、バッチ処理を行わないでください。
- CPU を使用している場合は、バッチ処理を行わないでください。
- GPU でスループットを使用している場合 (大量の静的データでモデルを実行したい場合)、次のようにします。
- sequence_length (「自然な」データ) のサイズについてまったくわからない場合は、デフォルトではバッチ処理や測定を行わず、
暫定的に追加してみます。失敗した場合に回復するために OOM チェックを追加します (失敗した場合は、ある時点で回復します)。
sequence_length を制御します。)
- sequence_length が非常に規則的である場合、バッチ処理は非常に興味深いものとなる可能性が高く、測定してプッシュしてください。
OOM が発生するまで続けます。
- GPU が大きいほど、バッチ処理がより興味深いものになる可能性が高くなります。
- バッチ処理を有効にしたらすぐに、OOM を適切に処理できることを確認してください。
## Pipeline chunk batching
`zero-shot-classification` と `question-answering` は、単一の入力で結果が得られる可能性があるという意味で、少し特殊です。
モデルの複数の前方パス。通常の状況では、これにより `batch_size` 引数に関する問題が発生します。
この問題を回避するために、これらのパイプラインはどちらも少し特殊になっており、代わりに `ChunkPipeline` になっています。
通常の `Pipeline`。要するに:
```python
preprocessed = pipe.preprocess(inputs)
model_outputs = pipe.forward(preprocessed)
outputs = pipe.postprocess(model_outputs)
```
今は次のようになります:
```python
all_model_outputs = []
for preprocessed in pipe.preprocess(inputs):
model_outputs = pipe.forward(preprocessed)
all_model_outputs.append(model_outputs)
outputs = pipe.postprocess(all_model_outputs)
```
パイプラインは以下で使用されるため、これはコードに対して非常に透過的である必要があります。
同じ方法。
パイプラインはバッチを自動的に処理できるため、これは簡略化されたビューです。気にする必要はないという意味です
入力が実際にトリガーする前方パスの数については、`batch_size` を最適化できます。
入力とは独立して。前のセクションの注意事項が引き続き適用されます。
## Pipeline custom code
特定のパイプラインをオーバーライドする場合。
目の前のタスクに関する問題を作成することを躊躇しないでください。パイプラインの目標は、使いやすく、ほとんどのユーザーをサポートすることです。
したがって、`transformers`があなたのユースケースをサポートする可能性があります。
単純に試してみたい場合は、次のことができます。
- 選択したパイプラインをサブクラス化します
```python
class MyPipeline(TextClassificationPipeline):
def postprocess():
# Your code goes here
scores = scores * 100
# And here
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
# or if you use *pipeline* function, then:
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
```
これにより、必要なカスタム コードをすべて実行できるようになります。
## Implementing a pipeline
[Implementing a new pipeline](../add_new_pipeline)
## Audio
オーディオ タスクに使用できるパイプラインには次のものがあります。
### AudioClassificationPipeline
[[autodoc]] AudioClassificationPipeline
- __call__
- all
### AutomaticSpeechRecognitionPipeline
[[autodoc]] AutomaticSpeechRecognitionPipeline
- __call__
- all
### TextToAudioPipeline
[[autodoc]] TextToAudioPipeline
- __call__
- all
### ZeroShotAudioClassificationPipeline
[[autodoc]] ZeroShotAudioClassificationPipeline
- __call__
- all
## Computer vision
コンピューター ビジョン タスクに使用できるパイプラインには次のものがあります。
### DepthEstimationPipeline
[[autodoc]] DepthEstimationPipeline
- __call__
- all
### ImageClassificationPipeline
[[autodoc]] ImageClassificationPipeline
- __call__
- all
### ImageSegmentationPipeline
[[autodoc]] ImageSegmentationPipeline
- __call__
- all
### ImageToImagePipeline
[[autodoc]] ImageToImagePipeline
- __call__
- all
### ObjectDetectionPipeline
[[autodoc]] ObjectDetectionPipeline
- __call__
- all
### VideoClassificationPipeline
[[autodoc]] VideoClassificationPipeline
- __call__
- all
### ZeroShotImageClassificationPipeline
[[autodoc]] ZeroShotImageClassificationPipeline
- __call__
- all
### ZeroShotObjectDetectionPipeline
[[autodoc]] ZeroShotObjectDetectionPipeline
- __call__
- all
## Natural Language Processing
自然言語処理タスクに使用できるパイプラインには次のものがあります。
### FillMaskPipeline
[[autodoc]] FillMaskPipeline
- __call__
- all
### NerPipeline
[[autodoc]] NerPipeline
詳細については、[`TokenClassificationPipeline`] を参照してください。
### QuestionAnsweringPipeline
[[autodoc]] QuestionAnsweringPipeline
- __call__
- all
### SummarizationPipeline
[[autodoc]] SummarizationPipeline
- __call__
- all
### TableQuestionAnsweringPipeline
[[autodoc]] TableQuestionAnsweringPipeline
- __call__
### TextClassificationPipeline
[[autodoc]] TextClassificationPipeline
- __call__
- all
### TextGenerationPipeline
[[autodoc]] TextGenerationPipeline
- __call__
- all
### Text2TextGenerationPipeline
[[autodoc]] Text2TextGenerationPipeline
- __call__
- all
### TokenClassificationPipeline
[[autodoc]] TokenClassificationPipeline
- __call__
- all
### TranslationPipeline
[[autodoc]] TranslationPipeline
- __call__
- all
### ZeroShotClassificationPipeline
[[autodoc]] ZeroShotClassificationPipeline
- __call__
- all
## Multimodal
マルチモーダル タスクに使用できるパイプラインには次のものがあります。
### DocumentQuestionAnsweringPipeline
[[autodoc]] DocumentQuestionAnsweringPipeline
- __call__
- all
### FeatureExtractionPipeline
[[autodoc]] FeatureExtractionPipeline
- __call__
- all
### ImageFeatureExtractionPipeline
[[autodoc]] ImageFeatureExtractionPipeline
- __call__
- all
### ImageToTextPipeline
[[autodoc]] ImageToTextPipeline
- __call__
- all
### ImageTextToTextPipeline
[[autodoc]] ImageTextToTextPipeline
- __call__
- all
### VisualQuestionAnsweringPipeline
[[autodoc]] VisualQuestionAnsweringPipeline
- __call__
- all
## Parent class: `Pipeline`
[[autodoc]] Pipeline
|
transformers/docs/source/ja/main_classes/pipelines.md/0
|
{
"file_path": "transformers/docs/source/ja/main_classes/pipelines.md",
"repo_id": "transformers",
"token_count": 6685
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BEiT
## Overview
BEiT モデルは、[BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) で提案されました。
ハンボ・バオ、リー・ドン、フル・ウェイ。 BERT に触発された BEiT は、自己教師ありの事前トレーニングを作成した最初の論文です。
ビジョン トランスフォーマー (ViT) は、教師付き事前トレーニングよりも優れたパフォーマンスを発揮します。クラスを予測するためにモデルを事前トレーニングするのではなく
([オリジナルの ViT 論文](https://arxiv.org/abs/2010.11929) で行われたように) 画像の BEiT モデルは、次のように事前トレーニングされています。
マスクされた OpenAI の [DALL-E モデル](https://arxiv.org/abs/2102.12092) のコードブックからビジュアル トークンを予測します
パッチ。
論文の要約は次のとおりです。
*自己教師あり視覚表現モデル BEiT (Bidirectional Encoderpresentation) を導入します。
イメージトランスフォーマーより。自然言語処理分野で開発されたBERTに倣い、マスク画像を提案します。
ビジョントランスフォーマーを事前にトレーニングするためのモデリングタスク。具体的には、事前トレーニングでは各画像に 2 つのビューがあります。
パッチ (16x16 ピクセルなど)、およびビジュアル トークン (つまり、個別のトークン)。まず、元の画像を「トークン化」して、
ビジュアルトークン。次に、いくつかの画像パッチをランダムにマスクし、それらをバックボーンの Transformer に供給します。事前トレーニング
目的は、破損したイメージ パッチに基づいて元のビジュアル トークンを回復することです。 BEiTの事前トレーニング後、
事前トレーニングされたエンコーダーにタスク レイヤーを追加することで、ダウンストリーム タスクのモデル パラメーターを直接微調整します。
画像分類とセマンティックセグメンテーションに関する実験結果は、私たちのモデルが競争力のある結果を達成することを示しています
以前の事前トレーニング方法を使用して。たとえば、基本サイズの BEiT は、ImageNet-1K で 83.2% のトップ 1 精度を達成します。
同じ設定でゼロからの DeiT トレーニング (81.8%) を大幅に上回りました。また、大型BEiTは
86.3% は ImageNet-1K のみを使用しており、ImageNet-22K での教師付き事前トレーニングを使用した ViT-L (85.2%) を上回っています。*
## Usage tips
- BEiT モデルは通常のビジョン トランスフォーマーですが、教師ありではなく自己教師ありの方法で事前トレーニングされています。彼らは
ImageNet-1K および CIFAR-100 で微調整すると、[オリジナル モデル (ViT)](vit) と [データ効率の高いイメージ トランスフォーマー (DeiT)](deit) の両方を上回るパフォーマンスを発揮します。推論に関するデモノートブックもチェックできます。
カスタム データの微調整は [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (置き換えるだけで済みます)
[`BeitImageProcessor`] による [`ViTFeatureExtractor`] と
[`ViTForImageClassification`] by [`BeitForImageClassification`])。
- DALL-E の画像トークナイザーと BEiT を組み合わせる方法を紹介するデモ ノートブックも利用可能です。
マスクされた画像モデリングを実行します。 [ここ](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT) で見つけることができます。
- BEiT モデルは各画像が同じサイズ (解像度) であることを期待しているため、次のように使用できます。
[`BeitImageProcessor`] を使用して、モデルの画像のサイズを変更 (または再スケール) し、正規化します。
- 事前トレーニングまたは微調整中に使用されるパッチ解像度と画像解像度の両方が名前に反映されます。
各チェックポイント。たとえば、`microsoft/beit-base-patch16-224`は、パッチ付きの基本サイズのアーキテクチャを指します。
解像度は 16x16、微調整解像度は 224x224 です。すべてのチェックポイントは [ハブ](https://huggingface.co/models?search=microsoft/beit) で見つけることができます。
- 利用可能なチェックポイントは、(1) [ImageNet-22k](http://www.image-net.org/) で事前トレーニングされています (
1,400 万の画像と 22,000 のクラス) のみ、(2) ImageNet-22k でも微調整、または (3) [ImageNet-1k](http://www.image-net.org/challenges/LSVRC)でも微調整/2012/) (ILSVRC 2012 とも呼ばれ、130 万件のコレクション)
画像と 1,000 クラス)。
- BEiT は、T5 モデルからインスピレーションを得た相対位置埋め込みを使用します。事前トレーニング中に、著者は次のことを共有しました。
いくつかの自己注意層間の相対的な位置の偏り。微調整中、各レイヤーの相対位置
バイアスは、事前トレーニング後に取得された共有相対位置バイアスで初期化されます。ご希望の場合は、
モデルを最初から事前トレーニングするには、`use_relative_position_bias` または
追加するには、[`BeitConfig`] の `use_relative_position_bias` 属性を `True` に設定します。
位置の埋め込み。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/beit_architecture.jpg"
alt="drawing" width="600"/>
<small> BEiT の事前トレーニング。 <a href="https://arxiv.org/abs/2106.08254">元の論文から抜粋。</a> </small>
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
## Resources
BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`BeitForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
- 参照: [画像分類タスク ガイド](../tasks/image_classification)
**セマンティック セグメンテーション**
- [セマンティック セグメンテーション タスク ガイド](../tasks/semantic_segmentation)
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## BEiT specific outputs
[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
## BeitConfig
[[autodoc]] BeitConfig
## BeitFeatureExtractor
[[autodoc]] BeitFeatureExtractor
- __call__
- post_process_semantic_segmentation
## BeitImageProcessor
[[autodoc]] BeitImageProcessor
- preprocess
- post_process_semantic_segmentation
## BeitModel
[[autodoc]] BeitModel
- forward
## BeitForMaskedImageModeling
[[autodoc]] BeitForMaskedImageModeling
- forward
## BeitForImageClassification
[[autodoc]] BeitForImageClassification
- forward
## BeitForSemanticSegmentation
[[autodoc]] BeitForSemanticSegmentation
- forward
## FlaxBeitModel
[[autodoc]] FlaxBeitModel
- __call__
## FlaxBeitForMaskedImageModeling
[[autodoc]] FlaxBeitForMaskedImageModeling
- __call__
## FlaxBeitForImageClassification
[[autodoc]] FlaxBeitForImageClassification
- __call__
|
transformers/docs/source/ja/model_doc/beit.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/beit.md",
"repo_id": "transformers",
"token_count": 3840
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# BROS
## Overview
BROS モデルは、Teakgyu Hon、Donghyun Kim、Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park によって [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) で提案されました。
BROS は *BERT Relying On Spatality* の略です。これは、一連のトークンとその境界ボックスを入力として受け取り、一連の隠れ状態を出力するエンコーダー専用の Transformer モデルです。 BROS は、絶対的な空間情報を使用する代わりに、相対的な空間情報をエンコードします。
BERT で使用されるトークンマスク言語モデリング目標 (TMLM) と新しいエリアマスク言語モデリング目標 (AMLM) の 2 つの目標で事前トレーニングされています。
TMLM では、トークンはランダムにマスクされ、モデルは空間情報と他のマスクされていないトークンを使用してマスクされたトークンを予測します。
AMLM は TMLM の 2D バージョンです。テキスト トークンをランダムにマスクし、TMLM と同じ情報で予測しますが、テキスト ブロック (領域) をマスクします。
`BrosForTokenClassification`には、BrosModel の上に単純な線形層があります。各トークンのラベルを予測します。
`BrosSpadeEEForTokenClassification`には、BrosModel の上に`initial_token_classifier`と`subsequent_token_classifier`があります。 `initial_token_classifier` は各エンティティの最初のトークンを予測するために使用され、`subsequent_token_classifier` はエンティティ内の次のトークンを予測するために使用されます。 `BrosSpadeELForTokenClassification`には BrosModel の上に`entity_linker`があります。 `entity_linker` は 2 つのエンティティ間の関係を予測するために使用されます。
`BrosForTokenClassification`と`BrosSpadeEEForTokenClassification`は基本的に同じジョブを実行します。ただし、`BrosForTokenClassification`は入力トークンが完全にシリアル化されていることを前提としています (トークンは 2D 空間に存在するため、これは非常に困難な作業です)。一方、`BrosSpadeEEForTokenClassification`は 1 つのトークンから次の接続トークンを予測するため、シリアル化エラーの処理をより柔軟に行うことができます。
`BrosSpadeELForTokenClassification` はエンティティ内のリンク タスクを実行します。これら 2 つのエンティティが何らかの関係を共有する場合、(あるエンティティの) 1 つのトークンから (別のエンティティの) 別のトークンへの関係を予測します。
BROS は、明示的な視覚機能に依存せずに、FUNSD、SROIE、CORD、SciTSR などの Key Information Extraction (KIE) ベンチマークで同等以上の結果を達成します。
論文の要約は次のとおりです。
*文書画像からの重要情報抽出 (KIE) には、2 次元 (2D) 空間におけるテキストの文脈的および空間的意味論を理解する必要があります。最近の研究の多くは、文書画像の視覚的特徴とテキストおよびそのレイアウトを組み合わせることに重点を置いた事前トレーニング済み言語モデルを開発することで、この課題を解決しようとしています。一方、このペーパーでは、テキストとレイアウトの効果的な組み合わせという基本に立ち返ってこの問題に取り組みます。具体的には、BROS (BERT Relying On Spatality) という名前の事前トレーニング済み言語モデルを提案します。この言語モデルは、2D 空間内のテキストの相対位置をエンコードし、エリア マスキング戦略を使用してラベルのないドキュメントから学習します。 2D 空間内のテキストを理解するためのこの最適化されたトレーニング スキームにより、BROS は、視覚的な特徴に依存することなく、4 つの KIE ベンチマーク (FUNSD、SROIE*、CORD、および SciTSR) で以前の方法と比較して同等以上のパフォーマンスを示しました。また、この論文では、KIE タスクにおける 2 つの現実世界の課題 ((1) 間違ったテキスト順序によるエラーの最小化、および (2) 少数の下流例からの効率的な学習) を明らかにし、以前の方法に対する BROS の優位性を実証します。*
このモデルは [jinho8345](https://huggingface.co/jinho8345) によって寄稿されました。元のコードは [ここ](https://github.com/clovaai/bros) にあります。
## Usage tips and examples
- [`~transformers.BrosModel.forward`] には、`input_ids` と `bbox` (バウンディング ボックス) が必要です。各境界ボックスは、(x0、y0、x1、y1) 形式 (左上隅、右下隅) である必要があります。境界ボックスの取得は外部 OCR システムに依存します。 「x」座標はドキュメント画像の幅で正規化する必要があり、「y」座標はドキュメント画像の高さで正規化する必要があります。
```python
def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
# here, bboxes are numpy array
# Normalize bbox -> 0 ~ 1
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
```
- [`~transformers.BrosForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`、`~transformers.BrosSpadeEEForTokenClassification.forward`] では、損失計算に `input_ids` と `bbox` だけでなく `box_first_token_mask` も必要です。これは、各ボックスの先頭以外のトークンを除外するためのマスクです。このマスクは、単語から `input_ids` を作成するときに境界ボックスの開始トークン インデックスを保存することで取得できます。次のコードで`box_first_token_mask`を作成できます。
```python
def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
# encode(tokenize) each word from words (List[str])
input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
# get the length of each box
tokens_length_list: List[int] = [len(l) for l in input_ids_list]
box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
# filter out the indices that are out of max_seq_length
box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
if len(box_start_token_indices) > len(box_end_token_indices):
box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
# set box_start_token_indices to True
box_first_token_mask[box_start_token_indices] = True
return box_first_token_mask
```
## Resources
- デモ スクリプトは [こちら](https://github.com/clovaai/bros) にあります。
## BrosConfig
[[autodoc]] BrosConfig
## BrosProcessor
[[autodoc]] BrosProcessor
- __call__
## BrosModel
[[autodoc]] BrosModel
- forward
## BrosForTokenClassification
[[autodoc]] BrosForTokenClassification
- forward
## BrosSpadeEEForTokenClassification
[[autodoc]] BrosSpadeEEForTokenClassification
- forward
## BrosSpadeELForTokenClassification
[[autodoc]] BrosSpadeELForTokenClassification
- forward
|
transformers/docs/source/ja/model_doc/bros.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/bros.md",
"repo_id": "transformers",
"token_count": 3458
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Training on TPU with TensorFlow
<Tip>
詳細な説明が不要で、単にTPUのコードサンプルを入手してトレーニングを開始したい場合は、[私たちのTPUの例のノートブックをチェックしてください!](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)
</Tip>
### What is a TPU?
TPUは**Tensor Processing Unit(テンソル処理ユニット)**の略です。これらはGoogleが設計したハードウェアで、ニューラルネットワーク内のテンソル計算を大幅に高速化するために使用されます。これはGPUのようなものです。ネットワークのトレーニングと推論の両方に使用できます。一般的にはGoogleのクラウドサービスを介してアクセスされますが、Google ColabとKaggle Kernelsを通じても無料で小規模のTPUに直接アクセスできます。
[🤗 TransformersのすべてのTensorFlowモデルはKerasモデルです](https://huggingface.co/blog/tensorflow-philosophy)ので、この文書のほとんどの方法は一般的にKerasモデル用のTPUトレーニングに適用できます!ただし、TransformersとDatasetsのHuggingFaceエコシステム(hug-o-system?)に固有のポイントもいくつかあり、それについては適用するときにそれを示します。
### What kinds of TPU are available?
新しいユーザーは、さまざまなTPUとそのアクセス方法に関する幅広い情報によく混乱します。理解するための最初の重要な違いは、**TPUノード**と**TPU VM**の違いです。
**TPUノード**を使用すると、事実上リモートのTPUに間接的にアクセスします。別個のVMが必要で、ネットワークとデータパイプラインを初期化し、それらをリモートノードに転送します。Google ColabでTPUを使用すると、**TPUノード**スタイルでアクセスしています。
TPUノードを使用すると、それに慣れていない人々にはかなり予期しない動作が発生することがあります!特に、TPUはPythonコードを実行しているマシンと物理的に異なるシステムに配置されているため、データはローカルマシンにローカルで格納されているデータパイプラインが完全に失敗します。代わりに、データはGoogle Cloud Storageに格納する必要があります。ここでデータパイプラインはリモートのTPUノードで実行されている場合でも、データにアクセスできます。
<Tip>
すべてのデータを`np.ndarray`または`tf.Tensor`としてメモリに収めることができる場合、ColabまたはTPUノードを使用している場合でも、データをGoogle Cloud Storageにアップロードせずに`fit()`でトレーニングできます。
</Tip>
<Tip>
**🤗 Hugging Face固有のヒント🤗:** TFコードの例でよく見るであろう`Dataset.to_tf_dataset()`とその高レベルのラッパーである`model.prepare_tf_dataset()`は、TPUノードで失敗します。これは、`tf.data.Dataset`を作成しているにもかかわらず、それが「純粋な」`tf.data`パイプラインではなく、`tf.numpy_function`または`Dataset.from_generator()`を使用して基盤となるHuggingFace `Dataset`からデータをストリームで読み込むことからです。このHuggingFace `Dataset`はローカルディスク上のデータをバックアップしており、リモートTPUノードが読み取ることができないためです。
</Tip>
TPUにアクセスする第二の方法は、**TPU VM**を介してです。TPU VMを使用する場合、TPUが接続されているマシンに直接接続します。これはGPU VMでトレーニングを行うのと同様です。TPU VMは一般的にデータパイプラインに関しては特に作業がしやすく、上記のすべての警告はTPU VMには適用されません!
これは主観的な文書ですので、こちらの意見です:**可能な限りTPUノードの使用を避けてください。** TPU VMよりも混乱しやすく、デバッグが難しいです。将来的にはサポートされなくなる可能性もあります - Googleの最新のTPUであるTPUv4は、TPU VMとしてのみアクセスできるため、TPUノードは将来的には「レガシー」のアクセス方法になる可能性が高いです。ただし、無料でTPUにアクセスできるのはColabとKaggle Kernelsの場合があります。その場合、どうしても使用しなければならない場合の取り扱い方法を説明しようとします!詳細は[TPUの例のノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)で詳細な説明を確認してください。
### What sizes of TPU are available?
単一のTPU(v2-8/v3-8/v4-8)は8つのレプリカを実行します。TPUは数百から数千のレプリカを同時に実行できる**ポッド**に存在します。単一のTPUよりも多くのTPUを使用するが、ポッド全体ではない場合(たとえばv3-32)、TPUフリートは**ポッドスライス**として参照されます。
Colabを介して無料のTPUにアクセスする場合、通常は単一のv2-8 TPUが提供されます。
### I keep hearing about this XLA thing. What’s XLA, and how does it relate to TPUs?
XLAは、TensorFlowとJAXの両方で使用される最適化コンパイラです。JAXでは唯一のコンパイラであり、TensorFlowではオプションですが(しかしTPUでは必須です!)、Kerasモデルをトレーニングする際に`model.compile()`に引数`jit_compile=True`を渡すことで最も簡単に有効にできます。エラーが発生せず、パフォーマンスが良好であれば、それはTPUに移行する準備が整った良い兆候です!
TPU上でのデバッグは一般的にCPU/GPUよりも少し難しいため、TPUで試す前にまずCPU/GPUでXLAを使用してコードを実行することをお勧めします。もちろん、長時間トレーニングする必要はありません。モデルとデータパイプラインが期待通りに動作するかを確認するための数ステップだけです。
<Tip>
XLAコンパイルされたコードは通常高速です。したがって、TPUで実行する予定がない場合でも、`jit_compile=True`を追加することでパフォーマンスを向上させることができます。ただし、以下のXLA互換性に関する注意事項に注意してください!
</Tip>
<Tip warning={true}>
**苦い経験から生まれたヒント:** `jit_compile=True`を使用することは、CPU/GPUコードがXLA互換であることを確認し、速度を向上させる良い方法ですが、実際にTPUでコードを実行する際には多くの問題を引き起こす可能性があります。 XLAコンパイルはTPU上で暗黙的に行われるため、実際にコードをTPUで実行する前にその行を削除することを忘れないでください!
</Tip>
### How do I make my model XLA compatible?
多くの場合、コードはすでにXLA互換かもしれません!ただし、XLAでは動作する通常のTensorFlowでも動作しないいくつかの要素があります。以下に、3つの主要なルールにまとめています:
<Tip>
**🤗 HuggingFace固有のヒント🤗:** TensorFlowモデルと損失関数をXLA互換に書き直すために多くの努力を払っています。通常、モデルと損失関数はデフォルトでルール#1と#2に従っているため、`transformers`モデルを使用している場合はこれらをスキップできます。ただし、独自のモデルと損失関数を記述する場合は、これらのルールを忘れないでください!
</Tip>
#### XLA Rule #1: Your code cannot have “data-dependent conditionals”
これは、任意の`if`ステートメントが`tf.Tensor`内の値に依存していない必要があることを意味します。例えば、次のコードブロックはXLAでコンパイルできません!
```python
if tf.reduce_sum(tensor) > 10:
tensor = tensor / 2.0
```
これは最初は非常に制限的に思えるかもしれませんが、ほとんどのニューラルネットコードはこれを行う必要はありません。通常、この制約を回避するために`tf.cond`を使用するか(ドキュメントはこちらを参照)、条件を削除して代わりに指示変数を使用したりすることができます。次のように:
```python
sum_over_10 = tf.cast(tf.reduce_sum(tensor) > 10, tf.float32)
tensor = tensor / (1.0 + sum_over_10)
```
このコードは、上記のコードとまったく同じ効果を持っていますが、条件を回避することで、XLAで問題なくコンパイルできることを確認します!
#### XLA Rule #2: Your code cannot have “data-dependent shapes”
これは、コード内のすべての `tf.Tensor` オブジェクトの形状が、その値に依存しないことを意味します。たとえば、`tf.unique` 関数はXLAでコンパイルできないので、このルールに違反します。なぜなら、これは入力 `Tensor` の一意の値の各インスタンスを含む `tensor` を返すためです。この出力の形状は、入力 `Tensor` の重複具合によって異なるため、XLAはそれを処理しないことになります!
一般的に、ほとんどのニューラルネットワークコードはデフォルトでルール#2に従います。ただし、いくつかの一般的なケースでは問題が発生することがあります。非常に一般的なケースの1つは、**ラベルマスキング**を使用する場合です。ラベルを無視して損失を計算する場所を示すために、ラベルを負の値に設定する方法です。NumPyまたはPyTorchのラベルマスキングをサポートする損失関数を見ると、次のような[ブールインデックス](https://numpy.org/doc/stable/user/basics.indexing.html#boolean-array-indexing)を使用したコードがよく見られます:
```python
label_mask = labels >= 0
masked_outputs = outputs[label_mask]
masked_labels = labels[label_mask]
loss = compute_loss(masked_outputs, masked_labels)
mean_loss = torch.mean(loss)
```
このコードはNumPyやPyTorchでは完全に機能しますが、XLAでは動作しません!なぜなら、`masked_outputs`と`masked_labels`の形状はマスクされた位置の数に依存するため、これは**データ依存の形状**になります。ただし、ルール#1と同様に、このコードを書き直して、データ依存の形状なしでまったく同じ出力を生成できることがあります。
```python
label_mask = tf.cast(labels >= 0, tf.float32)
loss = compute_loss(outputs, labels)
loss = loss * label_mask # Set negative label positions to 0
mean_loss = tf.reduce_sum(loss) / tf.reduce_sum(label_mask)
```
ここでは、データ依存の形状を避けるために、各位置で損失を計算してから、平均を計算する際に分子と分母の両方でマスクされた位置をゼロ化する方法を紹介します。これにより、最初のアプローチとまったく同じ結果が得られますが、XLA互換性を維持します。注意点として、ルール#1と同じトリックを使用します - `tf.bool`を`tf.float32`に変換して指標変数として使用します。これは非常に便利なトリックですので、自分のコードをXLAに変換する必要がある場合には覚えておいてください!
#### XLA Rule #3: XLA will need to recompile your model for every different input shape it sees
これは重要なルールです。これはつまり、入力形状が非常に変動的な場合、XLA はモデルを何度も再コンパイルする必要があるため、大きなパフォーマンスの問題が発生する可能性があるということです。これは NLP モデルで一般的に発生し、トークナイズ後の入力テキストの長さが異なる場合があります。他のモダリティでは、静的な形状が一般的であり、このルールはほとんど問題になりません。
ルール#3を回避する方法は何でしょうか?鍵は「パディング」です - すべての入力を同じ長さにパディングし、次に「attention_mask」を使用することで、可変形状と同じ結果を得ることができますが、XLA の問題は発生しません。ただし、過度のパディングも深刻な遅延を引き起こす可能性があります - データセット全体で最大の長さにすべてのサンプルをパディングすると、多くの計算とメモリを無駄にする可能性があります!
この問題には完璧な解決策はありませんが、いくつかのトリックを試すことができます。非常に便利なトリックの1つは、**バッチのサンプルを32または64トークンの倍数までパディングする**ことです。これにより、トークン数がわずかに増加するだけで、すべての入力形状が32または64の倍数である必要があるため、一意の入力形状の数が大幅に減少します。一意の入力形状が少ないと、XLA の再コンパイルが少なくなります!
<Tip>
**🤗 HuggingFace に関する具体的なヒント🤗:** 弊社のトークナイザーとデータコレクターには、ここで役立つメソッドがあります。トークナイザーを呼び出す際に `padding="max_length"` または `padding="longest"` を使用して、パディングされたデータを出力するように設定できます。トークナイザーとデータコレクターには、一意の入力形状の数を減らすのに役立つ `pad_to_multiple_of` 引数もあります!
</Tip>
### How do I actually train my model on TPU?
一度トレーニングが XLA 互換性があることを確認し、(TPU Node/Colab を使用する場合は)データセットが適切に準備されている場合、TPU 上で実行することは驚くほど簡単です!コードを変更する必要があるのは、いくつかの行を追加して TPU を初期化し、モデルとデータセットが `TPUStrategy` スコープ内で作成されるようにすることだけです。これを実際に見るには、[TPU のサンプルノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)をご覧ください!
### Summary
ここでは多くの情報が提供されましたので、TPU でモデルをトレーニングする際に以下のチェックリストを使用できます:
- コードが XLA の三つのルールに従っていることを確認します。
- CPU/GPU で `jit_compile=True` を使用してモデルをコンパイルし、XLA でトレーニングできることを確認します。
- データセットをメモリに読み込むか、TPU 互換のデータセット読み込みアプローチを使用します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- コードを Colab(アクセラレータを「TPU」に設定)または Google Cloud の TPU VM に移行します。
- TPU 初期化コードを追加します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- `TPUStrategy` を作成し、データセットの読み込みとモデルの作成が `strategy.scope()` 内で行われることを確認します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- TPU に移行する際に `jit_compile=True` を外すのを忘れないでください!
- 🙏🙏🙏🥺🥺🥺
- `model.fit()` を呼び出します。
- おめでとうございます!
|
transformers/docs/source/ja/perf_train_tpu_tf.md/0
|
{
"file_path": "transformers/docs/source/ja/perf_train_tpu_tf.md",
"repo_id": "transformers",
"token_count": 7360
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image captioning
[[open-in-colab]]
画像のキャプション付けは、特定の画像のキャプションを予測するタスクです。一般的な現実世界のアプリケーションには次のものがあります。
視覚障害者がさまざまな状況を乗り越えられるよう支援します。したがって、画像のキャプション
画像を説明することで人々のコンテンツへのアクセシビリティを向上させるのに役立ちます。
このガイドでは、次の方法を説明します。
* 画像キャプション モデルを微調整します。
* 微調整されたモデルを推論に使用します。
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install transformers datasets evaluate -q
pip install jiwer -q
```
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```python
from huggingface_hub import notebook_login
notebook_login()
```
## Load the Pokémon BLIP captions dataset
🤗 データセット ライブラリを使用して、{image-caption} ペアで構成されるデータセットを読み込みます。独自の画像キャプション データセットを作成するには
PyTorch では、[このノートブック](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb) を参照できます。
```py
ds = load_dataset("lambdalabs/pokemon-blip-captions")
ds
```
```bash
DatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})
```
データセットには `image`と`text`の 2 つの機能があります。
<Tip>
多くの画像キャプション データセットには、画像ごとに複数のキャプションが含まれています。このような場合、一般的な戦略は、トレーニング中に利用可能なキャプションの中からランダムにキャプションをサンプリングすることです。
</Tip>
[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットのトレイン スプリットをトレイン セットとテスト セットに分割します。
```python
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]
```
トレーニング セットからのいくつかのサンプルを視覚化してみましょう。
```python
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/sample_training_images_image_cap.png" alt="Sample training images"/>
</div>
## Preprocess the dataset
データセットには 2 つのモダリティ (画像とテキスト) があるため、前処理パイプラインは画像とキャプションを前処理します。
これを行うには、微調整しようとしているモデルに関連付けられたプロセッサ クラスをロードします。
```python
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)
```
プロセッサは内部で画像を前処理し (サイズ変更やピクセル スケーリングを含む)、キャプションをトークン化します。
```python
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)
```
データセットの準備ができたら、微調整用にモデルをセットアップできます。
## Load a base model
["microsoft/git-base"](https://huggingface.co/microsoft/git-base) を [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) オブジェクト。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)
```
## Evaluate
画像キャプション モデルは通常、[Rouge Score](https://huggingface.co/spaces/evaluate-metric/rouge) または [Word Error Rate](https://huggingface.co/spaces/evaluate-metric/) で評価されます。そうだった)。このガイドでは、Word Error Rate (WER) を使用します。
これを行うには 🤗 Evaluate ライブラリを使用します。 WER の潜在的な制限やその他の問題点については、[このガイド](https://huggingface.co/spaces/evaluate-metric/wer) を参照してください。
```python
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}
```
## Train!
これで、モデルの微調整を開始する準備が整いました。これには 🤗 [`Trainer`] を使用します。
まず、[`TrainingArguments`] を使用してトレーニング引数を定義します。
```python
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
eval_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)
```
Trainer 次に、次に、データセットとモデルと一緒に 🤗 に渡します。
```python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)
```
トレーニングを開始するには、[`Trainer`] オブジェクトの [`~Trainer.train`] を呼び出すだけです。
```python
trainer.train()
```
トレーニングが進むにつれて、トレーニングの損失がスムーズに減少することがわかります。
トレーニングが完了したら、 [`~Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
```python
trainer.push_to_hub()
```
## Inference
`test_ds` からサンプル画像を取得してモデルをテストします。
```python
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/test_image_image_cap.png" alt="Test image"/>
</div>
モデル用の画像を準備します。
```python
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_values
```
[`generate`] を呼び出して予測をデコードします。
```python
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)
```
```bash
a drawing of a pink and blue pokemon
```
微調整されたモデルにより、非常に優れたキャプションが生成されたようです。
|
transformers/docs/source/ja/tasks/image_captioning.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/image_captioning.md",
"repo_id": "transformers",
"token_count": 3779
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Translation
[[open-in-colab]]
<Youtube id="1JvfrvZgi6c"/>
翻訳では、一連のテキストをある言語から別の言語に変換します。これは、シーケンス間問題として定式化できるいくつかのタスクの 1 つであり、翻訳や要約など、入力から何らかの出力を返すための強力なフレームワークです。翻訳システムは通常、異なる言語のテキスト間の翻訳に使用されますが、音声、またはテキストから音声への変換や音声からテキストへの変換など、音声間の組み合わせにも使用できます。
このガイドでは、次の方法を説明します。
1. [OPUS Books](https://huggingface.co/datasets/opus_books) データセットの英語-フランス語サブセットの [T5](https://huggingface.co/google-t5/t5-small) を微調整して、英語のテキストを次の形式に翻訳します。フランス語。
2. 微調整されたモデルを推論に使用します。
<Tip>
このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/translation) を確認することをお勧めします。
</Tip>
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install transformers datasets evaluate sacrebleu
```
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load OPUS Books dataset
まず、🤗 データセット ライブラリから [OPUS Books](https://huggingface.co/datasets/opus_books) データセットの英語とフランス語のサブセットを読み込みます。
```py
>>> from datasets import load_dataset
>>> books = load_dataset("opus_books", "en-fr")
```
[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットをトレイン セットとテスト セットに分割します。
```py
>>> books = books["train"].train_test_split(test_size=0.2)
```
次に、例を見てみましょう。
```py
>>> books["train"][0]
{'id': '90560',
'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
```
`translation`: テキストの英語とフランス語の翻訳。
## Preprocess
<Youtube id="XAR8jnZZuUs"/>
次のステップでは、T5 トークナイザーをロードして英語とフランス語の言語ペアを処理します。
```py
>>> from transformers import AutoTokenizer
>>> checkpoint = "google-t5/t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
```
作成する前処理関数は次のことを行う必要があります。
1. T5 がこれが翻訳タスクであることを認識できるように、入力の前にプロンプトを付けます。複数の NLP タスクが可能な一部のモデルでは、特定のタスクのプロンプトが必要です。
2. 英語の語彙で事前トレーニングされたトークナイザーを使用してフランス語のテキストをトークン化することはできないため、入力 (英語) とターゲット (フランス語) を別々にトークン化します。
3. `max_length`パラメータで設定された最大長を超えないようにシーケンスを切り詰めます。
```py
>>> source_lang = "en"
>>> target_lang = "fr"
>>> prefix = "translate English to French: "
>>> def preprocess_function(examples):
... inputs = [prefix + example[source_lang] for example in examples["translation"]]
... targets = [example[target_lang] for example in examples["translation"]]
... model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
... return model_inputs
```
データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] メソッドを使用します。 `batched=True` を設定してデータセットの複数の要素を一度に処理することで、`map` 関数を高速化できます。
```py
>>> tokenized_books = books.map(preprocess_function, batched=True)
```
次に、[`DataCollatorForSeq2Seq`] を使用してサンプルのバッチを作成します。データセット全体を最大長までパディングするのではなく、照合中にバッチ内の最長の長さまで文を *動的にパディング* する方が効率的です。
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForSeq2Seq
>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Evaluate
トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[SacreBLEU](https://huggingface.co/spaces/evaluate-metric/sacrebleu) メトリクスをロードします (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照してください) ) メトリクスの読み込みと計算方法の詳細については、次を参照してください)。
```py
>>> import evaluate
>>> metric = evaluate.load("sacrebleu")
```
次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して SacreBLEU スコアを計算する関数を作成します。
```py
>>> import numpy as np
>>> def postprocess_text(preds, labels):
... preds = [pred.strip() for pred in preds]
... labels = [[label.strip()] for label in labels]
... return preds, labels
>>> def compute_metrics(eval_preds):
... preds, labels = eval_preds
... if isinstance(preds, tuple):
... preds = preds[0]
... decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
... labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
... decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
... decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
... result = metric.compute(predictions=decoded_preds, references=decoded_labels)
... result = {"bleu": result["score"]}
... prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
... result["gen_len"] = np.mean(prediction_lens)
... result = {k: round(v, 4) for k, v in result.items()}
... return result
```
これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
## Train
<frameworkcontent>
<pt>
<Tip>
[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
</Tip>
これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForSeq2SeqLM`] を使用して T5 をロードします。
```py
>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
```
この時点で残っているステップは 3 つだけです。
1. [`Seq2SeqTrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`Trainer`] は SacreBLEU メトリクスを評価し、トレーニング チェックポイントを保存します。
2. トレーニング引数をモデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Seq2SeqTrainer`] に渡します。
3. [`~Trainer.train`] を呼び出してモデルを微調整します。
```py
>>> training_args = Seq2SeqTrainingArguments(
... output_dir="my_awesome_opus_books_model",
... eval_strategy="epoch",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... weight_decay=0.01,
... save_total_limit=3,
... num_train_epochs=2,
... predict_with_generate=True,
... fp16=True,
... push_to_hub=True,
... )
>>> trainer = Seq2SeqTrainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_books["train"],
... eval_dataset=tokenized_books["test"],
... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
Keras を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-a-tensorflow-model-with-keras) の基本的なチュートリアルをご覧ください。
</Tip>
TensorFlow でモデルを微調整するには、オプティマイザー関数、学習率スケジュール、およびいくつかのトレーニング ハイパーパラメーターをセットアップすることから始めます。
```py
>>> from transformers import AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
次に、[`TFAutoModelForSeq2SeqLM`] を使用して T5 をロードできます。
```py
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
```
[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] を使用して、データセットを `tf.data.Dataset` 形式に変換します。
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_books["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... tokenized_books["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) を使用してトレーニング用のモデルを設定します。 Transformers モデルにはすべてデフォルトのタスク関連の損失関数があるため、次の場合を除き、損失関数を指定する必要はないことに注意してください。
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
トレーニングを開始する前にセットアップする最後の 2 つのことは、予測から SacreBLEU メトリクスを計算し、モデルをハブにプッシュする方法を提供することです。どちらも [Keras コールバック](../main_classes/keras_callbacks) を使用して行われます。
`compute_metrics` 関数を [`~transformers.KerasMetricCallback`] に渡します。
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
[`~transformers.PushToHubCallback`] でモデルとトークナイザーをプッシュする場所を指定します。
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_opus_books_model",
... tokenizer=tokenizer,
... )
```
次に、コールバックをまとめてバンドルします。
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
ついに、モデルのトレーニングを開始する準備が整いました。トレーニングおよび検証データセット、エポック数、コールバックを指定して [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) を呼び出し、モデルを微調整します。
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
```
トレーニングが完了すると、モデルは自動的にハブにアップロードされ、誰でも使用できるようになります。
</tf>
</frameworkcontent>
<Tip>
翻訳用にモデルを微調整する方法の詳細な例については、対応するドキュメントを参照してください。
[PyTorch ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
または [TensorFlow ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)。
</Tip>
## Inference
モデルを微調整したので、それを推論に使用できるようになりました。
別の言語に翻訳したいテキストを考え出します。 T5 の場合、作業中のタスクに応じて入力に接頭辞を付ける必要があります。英語からフランス語に翻訳する場合は、以下に示すように入力に接頭辞を付ける必要があります。
```py
>>> text = "translate English to French: Legumes share resources with nitrogen-fixing bacteria."
```
推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して翻訳用の`pipeline`をインスタンス化し、テキストをそれに渡します。
```py
>>> from transformers import pipeline
# Change `xx` to the language of the input and `yy` to the language of the desired output.
# Examples: "en" for English, "fr" for French, "de" for German, "es" for Spanish, "zh" for Chinese, etc; translation_en_to_fr translates English to French
# You can view all the lists of languages here - https://huggingface.co/languages
>>> translator = pipeline("translation_xx_to_yy", model="my_awesome_opus_books_model")
>>> translator(text)
[{'translation_text': 'Legumes partagent des ressources avec des bactéries azotantes.'}]
```
必要に応じて、`pipeline`の結果を手動で複製することもできます。
<frameworkcontent>
<pt>
テキストをトークン化し、`input_ids` を PyTorch テンソルとして返します。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="pt").input_ids
```
[`~generation.GenerationMixin.generate`] メソッドを使用して翻訳を作成します。さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[Text Generation](../main_classes/text_generation) API を確認してください。
```py
>>> from transformers import AutoModelForSeq2SeqLM
>>> model = AutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
```
生成されたトークン ID をデコードしてテキストに戻します。
```py
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lignées partagent des ressources avec des bactéries enfixant l'azote.'
```
</pt>
<tf>
`input_ids`を TensorFlow テンソルとして返します。 tensors:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
>>> inputs = tokenizer(text, return_tensors="tf").input_ids
```
[`~transformers.generation_tf_utils.TFGenerationMixin.generate`] メソッドを使用して翻訳を作成します。さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[Text Generation](../main_classes/text_generation) API を確認してください。
```py
>>> from transformers import TFAutoModelForSeq2SeqLM
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
```
生成されたトークン ID をデコードしてテキストに戻します。
```py
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Les lugumes partagent les ressources avec des bactéries fixatrices d'azote.'
```
</tf>
</frameworkcontent>
|
transformers/docs/source/ja/tasks/translation.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/translation.md",
"repo_id": "transformers",
"token_count": 7209
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Accelerate를 활용한 분산 학습[[distributed-training-with-accelerate]]
모델이 커지면서 병렬 처리는 제한된 하드웨어에서 더 큰 모델을 훈련하고 훈련 속도를 몇 배로 가속화하기 위한 전략으로 등장했습니다. Hugging Face에서는 사용자가 하나의 머신에 여러 개의 GPU를 사용하든 여러 머신에 여러 개의 GPU를 사용하든 모든 유형의 분산 설정에서 🤗 Transformers 모델을 쉽게 훈련할 수 있도록 돕기 위해 [🤗 Accelerate](https://huggingface.co/docs/accelerate) 라이브러리를 만들었습니다. 이 튜토리얼에서는 분산 환경에서 훈련할 수 있도록 기본 PyTorch 훈련 루프를 커스터마이즈하는 방법을 알아봅시다.
## 설정[[setup]]
🤗 Accelerate 설치 시작하기:
```bash
pip install accelerate
```
그 다음, [`~accelerate.Accelerator`] 객체를 불러오고 생성합니다. [`~accelerate.Accelerator`]는 자동으로 분산 설정 유형을 감지하고 훈련에 필요한 모든 구성 요소를 초기화합니다. 장치에 모델을 명시적으로 배치할 필요는 없습니다.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## 가속화를 위한 준비[[prepare-to-accelerate]]
다음 단계는 관련된 모든 훈련 객체를 [`~accelerate.Accelerator.prepare`] 메소드에 전달하는 것입니다. 여기에는 훈련 및 평가 데이터로더, 모델 및 옵티마이저가 포함됩니다:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## 백워드(Backward)[[backward]]
마지막으로 훈련 루프의 일반적인 `loss.backward()`를 🤗 Accelerate의 [`~accelerate.Accelerator.backward`] 메소드로 대체하기만 하면 됩니다:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
다음 코드에서 볼 수 있듯이, 훈련 루프에 코드 네 줄만 추가하면 분산 학습을 활성화할 수 있습니다!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## 학습[[train]]
관련 코드를 추가한 후에는 스크립트나 Colaboratory와 같은 노트북에서 훈련을 시작하세요.
### 스크립트로 학습하기[[train-with-a-script]]
스크립트에서 훈련을 실행하는 경우, 다음 명령을 실행하여 구성 파일을 생성하고 저장합니다:
```bash
accelerate config
```
Then launch your training with:
```bash
accelerate launch train.py
```
### 노트북으로 학습하기[[train-with-a-notebook]]
Collaboratory의 TPU를 사용하려는 경우, 노트북에서도 🤗 Accelerate를 실행할 수 있습니다. 훈련을 담당하는 모든 코드를 함수로 감싸서 [`~accelerate.notebook_launcher`]에 전달하세요:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
🤗 Accelerate 및 다양한 기능에 대한 자세한 내용은 [documentation](https://huggingface.co/docs/accelerate)를 참조하세요.
|
transformers/docs/source/ko/accelerate.md/0
|
{
"file_path": "transformers/docs/source/ko/accelerate.md",
"repo_id": "transformers",
"token_count": 2885
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 완전 분할 데이터 병렬 처리(FSDP) [[fully-sharded-data-parallel]]
[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)은 모델의 매개변수, 그레이디언트 및 옵티마이저 상태를 사용 가능한 GPU(작업자 또는 *랭크*라고도 함) 수에 따라 분할하는 데이터 병렬 처리 방식입니다. [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html)와 달리, FSDP는 각 GPU에 모델을 복제하기 때문에 메모리 사용량을 줄입니다. 이는 GPU 메모리 효율성을 향상시키며 적은 수의 GPU로 훨씬 더 큰 모델을 훈련할 수 있게 합니다. FSDP는 분산 환경에서의 훈련을 쉽게 관리할 수 있는 라이브러리인 Accelerate와 통합되어 있으며, 따라서 [`Trainer`] 클래스에서 사용할 수 있습니다.
시작하기 전에 Accelerate가 설치되어 있고 최소 PyTorch 2.1.0 이상의 버전이 설치되어 있는지 확인하세요.
```bash
pip install accelerate
```
## FSDP 구성 [[fsdp-configuration]]
시작하려면 [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) 명령을 실행하여 훈련 환경에 대한 구성 파일을 생성하세요. Accelerate는 이 구성 파일을 사용하여 `accelerate config`에서 선택한 훈련 옵션에 따라 자동으로 올바른 훈련 환경을 설정합니다.
```bash
accelerate config
```
`accelerate config`를 실행하면 훈련 환경을 구성하기 위한 일련의 옵션들이 나타납니다. 이 섹션에서는 가장 중요한 FSDP 옵션 중 일부를 다룹니다. 다른 사용 가능한 FSDP 옵션에 대해 더 알아보고 싶다면 [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) 매개변수를 참조하세요.
### 분할 전략 [[sharding-strategy]]
FSDP는 여러 가지 분할 전략을 제공합니다:
* `FULL_SHARD` - 모델 매개변수, 그레이디언트 및 옵티마이저 상태를 작업자 간에 분할; 이 옵션을 선택하려면 `1`을 선택하세요
* `SHARD_GRAD_OP` - 그레이디언트 및 옵티마이저 상태를 작업자 간에 분할; 이 옵션을 선택하려면 `2`를 선택하세요
* `NO_SHARD` - 아무 것도 분할하지 않음 (DDP와 동일); 이 옵션을 선택하려면 `3`을 선택하세요
* `HYBRID_SHARD` - 각 작업자가 전체 복사본을 가지고 있는 상태에서 모델 매개변수, 그레이디언트 및 옵티마이저 상태를 작업자 내에서 분할; 이 옵션을 선택하려면 `4`를 선택하세요
* `HYBRID_SHARD_ZERO2` - 각 작업자가 전체 복사본을 가지고 있는 상태에서 그레이디언트 및 옵티마이저 상태를 작업자 내에서 분할; 이 옵션을 선택하려면 `5`를 선택하세요
이것은 `fsdp_sharding_strategy` 플래그로 활성화됩니다.
### CPU 오프로드 [[cpu-offload]]
사용하지 않는 매개변수와 그레이디언트를 CPU로 오프로드하여 더 많은 GPU 메모리를 절약하고 FSDP로도 충분하지 않은 큰 모델을 GPU에 적재할 수 있도록 할 수 있습니다. 이는 `accelerate config`를 실행할 때 `fsdp_offload_params: true`로 설정하여 활성화됩니다.
### 래핑 정책 [[wrapping-policy]]
FSDP는 네트워크의 각 레이어를 래핑하여 적용됩니다. 래핑은 일반적으로 중첩 방식으로 적용되며 각각 순방향으로 지나간 후 전체 가중치를 삭제하여 다음 레이어에서 사용할 메모리를 절약합니다. *자동 래핑* 정책은 이를 구현하는 가장 간단한 방법이며 코드를 변경할 필요가 없습니다. Transformer 레이어를 래핑하려면 `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP`를 선택하고 래핑할 레이어를 지정하려면 `fsdp_transformer_layer_cls_to_wrap`를 선택하세요 (예: `BertLayer`).
또는 특정 매개변수 수를 초과할 경우 FSDP가 레이어에 적용되는 크기 기반 래핑 정책을 선택할 수 있습니다. 이는 `fsdp_wrap_policy: SIZE_BASED_WRAP` 및 `min_num_param`을 원하는 크기의 임계값으로 설정하여 활성화됩니다.
### 체크포인트 [[checkpointing]]
중간 체크포인트는 `fsdp_state_dict_type: SHARDED_STATE_DICT`로 저장해야 합니다. CPU 오프로드가 활성화된 랭크 0에서 전체 상태 딕셔너리를 저장하는 데 시간이 많이 걸리고, 브로드캐스팅 중 무기한 대기하여 `NCCL Timeout` 오류가 발생할 수 있기 때문입니다. [`~accelerate.Accelerator.load_state`] 메서드를 사용하여 분할된 상태 딕셔너리로 훈련을 재개할 수 있습니다.
```py
# 경로가 내재된 체크포인트
accelerator.load_state("ckpt")
```
그러나 훈련이 끝나면 전체 상태 딕셔너리를 저장해야 합니다. 분할된 상태 딕셔너리는 FSDP와만 호환되기 때문입니다.
```py
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir)
```
### TPU [[tpu]]
[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html)는 TPU에 대한 FSDP 훈련을 지원하며 `accelerate config`로 생성된 FSDP 구성 파일을 수정하여 활성화할 수 있습니다. 위에서 지정한 분할 전략 및 래핑 옵션 외에도 아래에 표시된 매개변수를 파일에 추가할 수 있습니다.
```yaml
xla: True # PyTorch/XLA를 활성화하려면 True로 설정해야 합니다
xla_fsdp_settings: # XLA 특정 FSDP 매개변수
xla_fsdp_grad_ckpt: True # gradient checkpointing을 사용합니다
```
[`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128)는 FSDP에 대한 추가적인 XLA 특정 매개변수를 구성할 수 있게 합니다.
## 훈련 시작 [[launch-training]]
예시 FSDP 구성 파일은 다음과 같을 수 있습니다:
```yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
훈련을 시작하려면 [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) 명령을 실행하세요. 이 때 전에 `accelerate config`로 생성한 구성 파일을 자동으로 사용합니다.
```bash
accelerate launch my-trainer-script.py
```
```bash
accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
```
## 다음 단계 [[next-steps]]
FSDP는 매우 큰 모델을 훈련할 때 강력한 도구가 될 수 있으며, 여러 개의 GPU나 TPU를 사용할 수 있습니다. 모델 매개변수, 옵티마이저 및 그레이디언트 상태를 분할하고 비활성 상태일 때, CPU로 오프로드하면 FSDP는 대규모 훈련의 높은 연산 비용을 줄일 수 있습니다. 더 알아보고 싶다면 다음 자료가 도움이 될 수 있습니다:
* [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp)에 대한 더 깊이 있는 Accelerate 가이드를 따라가 보세요.
* [PyTorch의 완전 분할 데이터 병렬 처리 (FSDP) API를 소개합니다](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) 블로그 글을 읽어보세요.
* [FSDP를 사용하여 클라우드 TPU에서 PyTorch 모델 크기 조절하기](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) 블로그 글을 읽어보세요.
|
transformers/docs/source/ko/fsdp.md/0
|
{
"file_path": "transformers/docs/source/ko/fsdp.md",
"repo_id": "transformers",
"token_count": 5834
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLM 추론 최적화 [[llm-inference-optimization]]
대규모 언어 모델(LLM)은 채팅 및 코드 완성 모델과 같은 텍스트 생성 응용 프로그램을 한 단계 끌어올리며, 높은 수준의 이해력과 유창함을 보여주는 텍스트를 생성합니다. 그러나 LLM을 강력하게 만드는 요소인 그들의 크기는 동시에 추론 과정에서 도전 과제가 되기도 합니다.
기본적인 추론은 느립니다, 왜냐하면 LLM이 다음 토큰을 생성하기 위해 반복적으로 호출되어야 하기 때문입니다. 생성이 진행됨에 따라 입력 시퀀스가 길어져 처리 시간이 점점 길어집니다. 또한, LLM은 수십억 개의 매개변수를 가지고 있어 모든 가중치를 메모리에 저장하고 처리하는 데 어려움이 있습니다.
이 가이드는 LLM 추론을 가속하기 위해 Transformers에서 사용할 수 있는 최적화 기술을 사용하는 방법을 보여줍니다.
> [!TIP]
> Hugging Face는 LLM을 추론에 최적화하여 배포하고 서비스하는 데 전념하는 라이브러리인 [Text Generation Inference (TGI)](https://hf.co/docs/text-generation-inference)을 제공합니다. 이 라이브러리는 처리량 증가를 위한 지속적인 배칭과 다중 GPU 추론을 위한 텐서 병렬화와 같은 Transformers에 포함되지 않은 배포 지향 최적화 기능을 포함합니다.
## 정적 kv-cache와 `torch.compile`[[static-kv-cache-and-torchcompile]]
디코딩 중에 LLM은 각 입력 토큰에 대한 key-value(kv) 값을 계산합니다. LLM은 자기회귀(autoregressive)이기 때문에 생성된 출력이 현재 입력의 일부가 되어 매번 동일한 kv 값을 계산합니다. 이는 매번 동일한 kv 값을 다시 계산하기 때문에 효율적이지 않습니다.
이를 최적화하기 위해, 이전 키(key)와 값(value)을 재계산하지 않고 저장하는 kv-cache를 사용할 수 있습니다. 그러나 kv-cache는 각 생성 단계에서 증가하며 동적이기 때문에 PyTorch 코드를 빠르고 최적화된 커널로 통합하는 강력한 최적화 도구인 [`torch.compile`](./perf_torch_compile)을 사용하는 데 제약이 있습니다.
*정적 kv-cache*는 최댓값을 미리 할당하여 이 문제를 해결하여 `torch.compile`과 결합할 수 있게 합니다. 이를 통해 최대 4배의 속도 향상이 가능합니다. 속도 향상은 모델 크기(더 큰 모델은 속도 향상이 적음)와 하드웨어에 따라 다를 수 있습니다.
> [!WARNING]
현재 [Llama](./model_doc/llama2) 및 몇 가지 다른 모델만 정적 kv-cache와 `torch.compile`을 지원합니다. 실시간 모델 호환성 목록은 [이 이슈](https://github.com/huggingface/transformers/issues/28981)를 확인하십시오.
작업의 복잡성에 따라 세 가지 방식의 정적 kv-cache 사용 방법이 있습니다:
1. 기본 사용법: `generation_config`에서 플래그를 설정하기만 하면 됩니다(권장);
2. 고급 사용법: 여러 번의 생성이나 맞춤형 생성 루프를 위해 캐시 객체를 처리합니다;
3. 고급 사용법: 단일 그래프가 필요한 경우, 전체 `generate` 함수를 하나의 그래프로 컴파일합니다.
올바른 탭을 선택하여 각 방법에 대한 추가 지침을 확인하세요.
> [!TIP]
> `torch.compile`을 사용할 때 어떤 전략을 사용하든, LLM 입력을 제한된 값 세트로 왼쪽에 패딩하면 모양과 관련된 재컴파일을 피할 수 있습니다. [`pad_to_multiple_of` tokenizer flag](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.pad_to_multiple_of)가 유용할 것입니다!
<hfoptions id="static-kv">
<hfoption id="basic usage: generation_config">
이 예제에서는 [Gemma](https://hf.co/google/gemma-2b) 모델을 사용해 보겠습니다. 필요한 작업은 다음과 같습니다:
1. 모델의 `generation_config` 속성에 접근하여 `cache_implementation`을 "static"으로 설정합니다;
2. 모델의 `forward` 패스를 정적 kv-cache와 함께 컴파일하기 위해 `torch.compile`을 호출합니다.
이렇게 하면 끝입니다!
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
model.generation_config.cache_implementation = "static"
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
input_text = "The theory of special relativity states "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
```
`generate` 함수는 내부적으로 동일한 캐시 객체를 재사용하려고 시도하며, 이를 통해 각 호출 시 재컴파일의 필요성을 제거합니다. 재컴파일을 피하는 것은 `torch.compile`의 성능을 최대한 활용하는 데 매우 중요하며, 다음 사항에 유의해야 합니다:
1. 배치 크기가 변경되거나 호출 간 최대 출력 길이가 증가하면 캐시를 다시 초기화해야 하며, 이로 인해 새로 컴파일을 해야 합니다;
2. 컴파일된 함수의 첫 몇 번의 호출은 함수가 컴파일되는 동안 더 느립니다.
> [!WARNING]
> 다중 턴 대화와 같은 정적 캐시의 고급 사용을 위해서는, 캐시 객체를 [`~GenerationMixin.generate`] 외부에서 인스턴스화하고 조작하는 것을 권장합니다. 고급 사용법 탭을 참조하세요.
</hfoption>
<hfoption id="advanced usage: control Static Cache">
[`StaticCache`] 객체는 `past_key_values` 인수로 모델의 [`~GenerationMixin.generate`] 함수에 전달할 수 있습니다. 이 객체는 캐시 내용을 유지하므로, 동적 캐시를 사용하는 것처럼 새로운 [`~GenerationMixin.generate`] 호출에 이를 전달하여 생성을 계속할 수 있습니다.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
import torch
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
input_text = "The theory of special relativity states "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
prompt_length = input_ids.input_ids.shape[1]
model.generation_config.max_new_tokens = 16
past_key_values = StaticCache(
config=model.config,
batch_size=1,
# 캐시를 재사용할 계획이 있는 경우, 모든 경우에 충분한 캐시 길이를 설정해야 합니다
max_cache_len=prompt_length+(model.generation_config.max_new_tokens*2),
device=model.device,
dtype=model.dtype
)
outputs = model.generate(**input_ids, past_key_values=past_key_values)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2']
# 생성된 텍스트와 동일한 캐시 객체를 전달하여, 중단한 곳에서 생성을 계속합니다.
# 다중 턴 대화의 경우, 생성된 텍스트에 새로운 사용자 입력을 추가할 수 있습니다.
new_input_ids = outputs
outputs = model.generate(new_input_ids, past_key_values=past_key_values)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2. The speed of light is constant in all inertial reference frames. 3.']
```
> [!TIP]
> 동일한 [`StaticCache`] 객체를 새로운 프롬프트에 사용하려면, 호출 간에 `.reset()` 메서드를 사용하여 그 내용을 초기화하는 것이 좋습니다.
더 깊이 들어가고 싶다면, [`StaticCache`] 객체를 모델의 `forward` 패스에 동일한 `past_key_values` 인수로 전달할 수도 있습니다. 이 전략을 사용하면, 현재 토큰과 이전에 생성된 토큰의 위치 및 캐시 위치를 바탕으로 다음 토큰을 디코딩하는 자체 함수를 작성할 수 있습니다.
```py
from transformers import LlamaTokenizer, LlamaForCausalLM, StaticCache, logging
from transformers.testing_utils import CaptureLogger
import torch
prompts = [
"Simply put, the theory of relativity states that ",
"My favorite all time favorite condiment is ketchup.",
]
NUM_TOKENS_TO_GENERATE = 40
torch_device = "cuda"
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", pad_token="</s>", padding_side="right")
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="sequential")
inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
def decode_one_tokens(model, cur_token, input_pos, cache_position, past_key_values):
logits = model(
cur_token,
position_ids=input_pos,
cache_position=cache_position,
past_key_values=past_key_values,
return_dict=False,
use_cache=True
)[0]
new_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
return new_token
```
`StaticCache` 메서드를 사용하여 정적 kv-cache와 `torch.compile`을 활성화하려면 몇 가지 중요한 작업을 수행해야 합니다:
1. 추론에 모델을 사용하기 전에 [`StaticCache`] 인스턴스를 초기화합니다. 여기서 최대 배치 크기와 시퀀스 길이와 같은 매개변수를 설정할 수 있습니다.
2. 정적 kv-cache와 함께 순전파를 컴파일하기 위해 모델에 `torch.compile`을 호출합니다.
3. [torch.backends.cuda.sdp_kernel](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) 컨텍스트 관리자에서 `enable_math=True`를 설정하여 네이티브 PyTorch C++ 구현된 스케일된 점곱 어텐션(scaled dot product attention)을 활성화하여 추론 속도를 더욱 높입니다.
```py
batch_size, seq_length = inputs["input_ids"].shape
with torch.no_grad():
past_key_values = StaticCache(
config=model.config, max_batch_size=2, max_cache_len=4096, device=torch_device, dtype=model.dtype
)
cache_position = torch.arange(seq_length, device=torch_device)
generated_ids = torch.zeros(
batch_size, seq_length + NUM_TOKENS_TO_GENERATE + 1, dtype=torch.int, device=torch_device
)
generated_ids[:, cache_position] = inputs["input_ids"].to(torch_device).to(torch.int)
logits = model(
**inputs, cache_position=cache_position, past_key_values=past_key_values,return_dict=False, use_cache=True
)[0]
next_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
generated_ids[:, seq_length] = next_token[:, 0]
decode_one_tokens = torch.compile(decode_one_tokens, mode="reduce-overhead", fullgraph=True)
cache_position = torch.tensor([seq_length + 1], device=torch_device)
for _ in range(1, NUM_TOKENS_TO_GENERATE):
with torch.backends.cuda.sdp_kernel(enable_flash=False, enable_mem_efficient=False, enable_math=True):
next_token = decode_one_tokens(model, next_token.clone(), None, cache_position, past_key_values)
generated_ids[:, cache_position] = next_token.int()
cache_position += 1
text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
text
['Simply put, the theory of relativity states that 1) the speed of light is constant, 2) the speed of light is the same for all observers, and 3) the laws of physics are the same for all observers.',
'My favorite all time favorite condiment is ketchup. I love it on everything. I love it on my eggs, my fries, my chicken, my burgers, my hot dogs, my sandwiches, my salads, my p']
```
</hfoption>
<hfoption id="advanced usage: end-to-end generate compilation">
전체 `generate` 함수를 컴파일하는 것은 코드 측면에서 기본 사용법보다 더 간단합니다. `generate` 함수에 대해 `torch.compile`을 호출하여 전체 함수를 컴파일하면 됩니다. 정적 캐시의 사용을 지정할 필요는 없습니다. 정적 캐시는 호환되지만, 벤치마크에서는 동적 캐시(기본 설정)가 더 빠른 것으로 나타났습니다.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
model.generate = torch.compile(model.generate, mode="reduce-overhead", fullgraph=True)
input_text = "The theory of special relativity states "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
```
이 방법을 통해 모델의 forward 패스뿐만 아니라, 입력 준비, logit 처리기 작업 등을 포함한 모든 것을 컴파일합니다. 기본 사용 예제에 비해 `generate` 호출이 약간 더 빠를 수 있으며, 컴파일된 그래프는 더 특이한 하드웨어 장치나 사용 사례에 적합할 수 있습니다. 그러나 이 접근 방식을 사용하는 데는 몇 가지 큰 단점이 있습니다:
1. 컴파일 속도가 훨씬 느립니다;
2. `generate`의 모든 매개변수 설정은 `generation_config`를 통해서만 가능합니다;
3. 많은 경고와 예외가 억제됩니다. -- 먼저 컴파일 되지 않은 형태로 테스트하는 것을 권장합니다;
4. 현재 작업 중이지만 기능 제한이 심합니다(예: 작성 시점에서는 EOS 토큰이 선택되어도 생성이 중단되지 않습니다).
</hfoption>
</hfoptions>
## 추정 디코딩 [[speculative-decoding]]
> [!TIP]
> 보다 심층적인 설명을 원한다면, [Assisted Generation: a new direction toward low-latency text generation](https://hf.co/blog/assisted-generation) 블로그 게시물을 확인하십시오!
자기 회귀의 또 다른 문제는 각 입력 토큰에 대해 순전파 중에 모델 가중치를 매번 로드해야 한다는 점입니다. 이는 수십억 개의 매개변수를 가진 LLM에는 느리고 번거롭습니다. 추정 디코딩(speculative decoding)은 더 작고 빠른 보조 모델을 사용하여 후보 토큰을 생성하고, 이를 큰 LLM이 단일 순전파에서 검증하여 이 속도 저하를 완화합니다. 검증된 토큰이 정확하다면, LLM은 본래 자체적으로 생성하는 것처럼 토큰을 얻을 수 있습니다. 전방 패스가 동일한 출력을 보장하기 때문에 정확도 저하가 없습니다.
가장 큰 속도 향상을 얻기 위해, 보조 모델은 빠르게 토큰을 생성할 수 있도록 LLM보다 훨씬 작아야 합니다. 보조 모델과 LLM 모델은 토큰을 다시 인코딩하고 디코딩하지 않도록 동일한 토크나이저를 공유해야 합니다.
> [!WARNING]
> 추정 디코딩은 탐욕 검색과 샘플링 디코딩 전략에서만 지원되며, 배치 입력을 지원하지 않습니다.
보조 모델을 로드하고 이를 [`~GenerationMixin.generate`] 메서드에 전달하여 추정 디코딩을 활성화하십시오.
<hfoptions id="spec-decoding">
<hfoption id="greedy search">
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
["Einstein's theory of relativity states that the speed of light is constant. "]
```
</hfoption>
<hfoption id="sampling">
추정 샘플링 디코딩(speculative sampling decoding)을 위해, 보조 모델 외에도 [`~GenerationMixin.generate`] 메서드에 `do_sample` 및 `temperature` 매개변수를 추가하십시오.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.7)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
["Einstein's theory of relativity states that motion in the universe is not a straight line.\n"]
```
</hfoption>
</hfoptions>
### 프롬프트 조회 디코딩 [[prompt-lookup-decoding]]
프롬프트 조회 디코딩은 탐욕 검색과 샘플링과도 호환되는 추정 디코딩의 변형입니다. 프롬프트 조회는 요약과 같은 입력 기반 작업에 특히 잘 작동합니다. 여기서는 프롬프트와 출력 간에 종종 겹치는 단어가 있습니다. 이러한 겹치는 n-그램이 LLM 후보 토큰으로 사용됩니다.
프롬프트 조회 디코딩을 활성화하려면 `prompt_lookup_num_tokens` 매개변수에 겹치는 토큰 수를 지정하십시오. 그런 다음 이 매개변수를 [`~GenerationMixin.generate`] 메서드에 전달할 수 있습니다.
<hfoptions id="pld">
<hfoption id="greedy decoding">
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
outputs = model.generate(**inputs, prompt_lookup_num_tokens=3)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['The second law of thermodynamics states that entropy increases with temperature. ']
```
</hfoption>
<hfoption id="sampling">
샘플링과 함께 프롬프트 조회 디코딩을 사용하려면, [`~GenerationMixin.generate`] 메서드에 `do_sample` 및 `temperature` 매개변수를 추가하십시오.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
outputs = model.generate(**inputs, prompt_lookup_num_tokens=3, do_sample=True, temperature=0.7)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
["The second law of thermodynamics states that energy cannot be created nor destroyed. It's not a"]
```
</hfoption>
</hfoptions>
## 어텐션 최적화 [[attention-optimizations]]
트랜스포머 모델의 알려진 문제는 셀프 어텐션 메커니즘이 입력 토큰 수와 함께 계산 및 메모리가 제곱으로 증가한다는 것입니다. 이 제한은 훨씬 더 긴 시퀀스를 처리하는 LLM에서는 더욱 커집니다. 이를 해결하기 위해 FlashAttention2 또는 PyTorch의 스케일된 점곱 어텐션을 사용해 보십시오. 이들은 더 메모리 효율적인 어텐션 구현으로 추론을 가속화할 수 있습니다.
### FlashAttention-2 [[flashattention-2]]
FlashAttention과 [FlashAttention-2](./perf_infer_gpu_one#flashattention-2)는 어텐션 계산을 더 작은 청크로 나누고 중간 읽기/쓰기 작업을 줄여 추론 속도를 높입니다. FlashAttention-2는 원래 FlashAttention 알고리즘을 개선하여 시퀀스 길이 차원에서도 병렬 처리를 수행하고 하드웨어에서 작업을 더 잘 분할하여 동기화 및 통신 오버헤드를 줄입니다.
FlashAttention-2를 사용하려면 [`~PreTrainedModel.from_pretrained`] 메서드에서 `attn_implementation="flash_attention_2"`를 설정하십시오.
```py
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b",
quantization_config=quant_config,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
### PyTorch 스케일된 점곱 어텐션(scaled dot product attention) [[pytorch-scaled-dot-product-attention]]
스케일된 점곱 어텐션(SDPA)는 PyTorch 2.0에서 자동으로 활성화되며, FlashAttention, xFormers, PyTorch의 C++ 구현을 지원합니다. SDPA는 CUDA 백엔드를 사용하는 경우 가장 성능이 좋은 어텐션 알고리즘을 선택합니다. 다른 백엔드에서는 SDPA가 PyTorch C++ 구현으로 기본 설정됩니다.
> [!TIP]
> SDPA는 최신 PyTorch 버전이 설치되어 있으면 FlashAttention-2도 지원합니다.
세 가지 어텐션 알고리즘 중 하나를 명시적으로 활성화하거나 비활성화하려면 [torch.backends.cuda.sdp_kernel](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) 컨텍스트 관리자를 사용하십시오. 예를 들어 FlashAttention을 활성화하려면 `enable_flash=True`로 설정하십시오.
```py
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b",
torch_dtype=torch.bfloat16,
)
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
```
## 양자화 [[quantization]]
양자화는 LLM 가중치를 더 낮은 정밀도로 저장하여 크기를 줄입니다. 이는 메모리 사용량을 줄이며 GPU 메모리에 제약이 있는 경우 추론을 위해 LLM을 로드하는 것을 더 용이하게 합니다. GPU가 충분하다면, 모델을 양자화할 필요는 없습니다. 추가적인 양자화 및 양자화 해제 단계로 인해 약간의 지연이 발생할 수 있기 때문입니다(AWQ 및 융합 AWQ 모듈 제외).
> [!TIP]
> 다양한 양자화 라이브러리(자세한 내용은 [Quantization](./quantization) 가이드를 참조하십시오)가 있습니다. 여기에는 Quanto, AQLM, VPTQ, AWQ 및 AutoGPTQ가 포함됩니다. 사용 사례에 가장 잘 맞는 라이브러리를 사용해 보십시오. 또한 AutoGPTQ와 bitsandbytes를 비교하는 [Overview of natively supported quantization schemes in 🤗 Transformers](https://hf.co/blog/overview-quantization-transformers) 블로그 게시물을 읽어보는 것을 추천합니다.
아래의 모델 메모리 계산기를 사용하여 모델을 로드하는 데 필요한 메모리를 추정하고 비교해 보십시오. 예를 들어 [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)를 로드하는 데 필요한 메모리를 추정해 보십시오.
<iframe
src="https://hf-accelerate-model-memory-usage.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
Mistral-7B-v0.1을 반정밀도로 로드하려면 [`~transformers.AutoModelForCausalLM.from_pretrained`] 메서드에서 `torch_dtype` 매개변수를 `torch.bfloat16`으로 설정하십시오. 이 경우 13.74GB의 메모리가 필요합니다.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", torch_dtype=torch.bfloat16, device_map="auto",
)
```
추론을 위해 양자화된 모델(8비트 또는 4비트)을 로드하려면 [bitsandbytes](https://hf.co/docs/bitsandbytes)를 사용하고 `load_in_4bit` 또는 `load_in_8bit` 매개변수를 `True`로 설정하십시오. 모델을 8비트로 로드하는 데는 6.87GB의 메모리만 필요합니다.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
quant_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", quantization_config=quant_config, device_map="auto"
)
```
|
transformers/docs/source/ko/llm_optims.md/0
|
{
"file_path": "transformers/docs/source/ko/llm_optims.md",
"repo_id": "transformers",
"token_count": 15197
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer [[trainer]]
[`Trainer`] 클래스는 PyTorch에서 완전한 기능(feature-complete)의 훈련을 위한 API를 제공하며, 다중 GPU/TPU에서의 분산 훈련, [NVIDIA GPU](https://nvidia.github.io/apex/), [AMD GPU](https://rocm.docs.amd.com/en/latest/rocm.html)를 위한 혼합 정밀도, 그리고 PyTorch의 [`torch.amp`](https://pytorch.org/docs/stable/amp.html)를 지원합니다. [`Trainer`]는 모델의 훈련 방식을 커스터마이즈할 수 있는 다양한 옵션을 제공하는 [`TrainingArguments`] 클래스와 함께 사용됩니다. 이 두 클래스는 함께 완전한 훈련 API를 제공합니다.
[`Seq2SeqTrainer`]와 [`Seq2SeqTrainingArguments`]는 [`Trainer`]와 [`TrainingArguments`] 클래스를 상속하며, 요약이나 번역과 같은 시퀀스-투-시퀀스 작업을 위한 모델 훈련에 적합하게 조정되어 있습니다.
<Tip warning={true}>
[`Trainer`] 클래스는 🤗 Transformers 모델에 최적화되어 있으며, 다른 모델과 함께 사용될 때 예상치 못한 동작을 하게 될 수 있습니다. 자신만의 모델을 사용할 때는 다음을 확인하세요:
- 모델은 항상 튜플이나 [`~utils.ModelOutput`]의 서브클래스를 반환해야 합니다.
- 모델은 `labels` 인자가 제공되면 손실을 계산할 수 있고, 모델이 튜플을 반환하는 경우 그 손실이 튜플의 첫 번째 요소로 반환되어야 합니다.
- 모델은 여러 개의 레이블 인자를 수용할 수 있어야 하며, [`Trainer`]에게 이름을 알리기 위해 [`TrainingArguments`]에서 `label_names`를 사용하지만, 그 중 어느 것도 `"label"`로 명명되어서는 안 됩니다.
</Tip>
## Trainer [[transformers.Trainer]]
[[autodoc]] Trainer
- all
## Seq2SeqTrainer [[transformers.Seq2SeqTrainer]]
[[autodoc]] Seq2SeqTrainer
- evaluate
- predict
## TrainingArguments [[transformers.TrainingArguments]]
[[autodoc]] TrainingArguments
- all
## Seq2SeqTrainingArguments [[transformers.Seq2SeqTrainingArguments]]
[[autodoc]] Seq2SeqTrainingArguments
- all
|
transformers/docs/source/ko/main_classes/trainer.md/0
|
{
"file_path": "transformers/docs/source/ko/main_classes/trainer.md",
"repo_id": "transformers",
"token_count": 1572
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ConvBERT [[convbert]]
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=convbert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-convbert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/conv-bert-base">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## 개요 [[overview]]
ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)입니다.
논문의 초록은 다음과 같습니다:
*BERT와 그 변형 모델과 같은 사전 학습된 언어 모델들은 최근 다양한 자연어 이해 과제에서 놀라운 성과를 이루었습니다. 그러나 BERT는 글로벌 셀프 어텐션 블록에 크게 의존하기 때문에 메모리 사용량이 많고 계산 비용이 큽니다. 모든 어텐션 헤드가 글로벌 관점에서 어텐션 맵을 생성하기 위해 입력 시퀀스 전체를 탐색하지만, 일부 헤드는 로컬 종속성만 학습할 필요가 있다는 것을 발견했습니다. 이는 불필요한 계산이 포함되어 있음을 의미합니다. 따라서 우리는 이러한 self-attention 헤드들을 대체하여 로컬 종속성을 직접 모델링하기 위해 새로운 span 기반 동적 컨볼루션을 제안합니다. 새로운 컨볼루션 헤드와 나머지 self-attention 헤드들이 결합하여 글로벌 및 로컬 문맥 학습에 더 효율적인 혼합 어텐션 블록을 구성합니다. 우리는 BERT에 이 혼합 어텐션 설계를 적용하여 ConvBERT 모델을 구축했습니다. 실험 결과, ConvBERT는 다양한 다운스트림 과제에서 BERT 및 그 변형 모델보다 더 우수한 성능을 보였으며, 훈련 비용과 모델 파라미터 수가 더 적었습니다. 특히 ConvBERTbase 모델은 GLUE 스코어 86.4를 달성하여 ELECTRAbase보다 0.7 높은 성과를 보이며, 훈련 비용은 1/4 이하로 줄었습니다. 코드와 사전 학습된 모델은 공개될 예정입니다.*
이 모델은 [abhishek](https://huggingface.co/abhishek)에 의해 기여되었으며, 원본 구현은 여기에서 찾을 수 있습니다 : https://github.com/yitu-opensource/ConvBert
## 사용 팁 [[usage-tips]]
ConvBERT 훈련 팁은 BERT와 유사합니다. 사용 팁은 [BERT 문서](bert).를 참고하십시오.
## 리소스 [[resources]]
- [텍스트 분류 작업 가이드 (Text classification task guide)](../tasks/sequence_classification)
- [토큰 분류 작업 가이드 (Token classification task guide)](../tasks/token_classification)
- [질의응답 작업 가이드 (Question answering task guide)](../tasks/question_answering)
- [마스킹된 언어 모델링 작업 가이드 (Masked language modeling task guide)](../tasks/masked_language_modeling)
- [다중 선택 작업 가이드 (Multiple choice task guide)](../tasks/multiple_choice)
## ConvBertConfig [[transformers.ConvBertConfig]]
[[autodoc]] ConvBertConfig
## ConvBertTokenizer [[transformers.ConvBertTokenizer]]
[[autodoc]] ConvBertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## ConvBertTokenizerFast [[transformers.ConvBertTokenizerFast]]
[[autodoc]] ConvBertTokenizerFast
<frameworkcontent>
<pt>
## ConvBertModel [[transformers.ConvBertModel]]
[[autodoc]] ConvBertModel
- forward
## ConvBertForMaskedLM [[transformers.ConvBertForMaskedLM]]
[[autodoc]] ConvBertForMaskedLM
- forward
## ConvBertForSequenceClassification [[transformers.ConvBertForSequenceClassification]]
[[autodoc]] ConvBertForSequenceClassification
- forward
## ConvBertForMultipleChoice [[transformers.ConvBertForMultipleChoice]]
[[autodoc]] ConvBertForMultipleChoice
- forward
## ConvBertForTokenClassification [[transformers.ConvBertForTokenClassification]]
[[autodoc]] ConvBertForTokenClassification
- forward
## ConvBertForQuestionAnswering [[transformers.ConvBertForQuestionAnswering]]
[[autodoc]] ConvBertForQuestionAnswering
- forward
</pt>
<tf>
## TFConvBertModel [[transformers.TFConvBertModel]]
[[autodoc]] TFConvBertModel
- call
## TFConvBertForMaskedLM [[transformers.TFConvBertForMaskedLM]]
[[autodoc]] TFConvBertForMaskedLM
- call
## TFConvBertForSequenceClassification [[transformers.TFConvBertForSequenceClassification]]
[[autodoc]] TFConvBertForSequenceClassification
- call
## TFConvBertForMultipleChoice [[transformers.TFConvBertForMultipleChoice]]
[[autodoc]] TFConvBertForMultipleChoice
- call
## TFConvBertForTokenClassification [[transformers.TFConvBertForTokenClassification]]
[[autodoc]] TFConvBertForTokenClassification
- call
## TFConvBertForQuestionAnswering [[transformers.TFConvBertForQuestionAnswering]]
[[autodoc]] TFConvBertForQuestionAnswering
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/ko/model_doc/convbert.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/convbert.md",
"repo_id": "transformers",
"token_count": 2979
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MarianMT[[MarianMT]]
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=marian">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-marian-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/opus-mt-zh-en">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## 개요[[Overview]]
BART와 동일한 모델을 사용하는 번역 모델 프레임워크입니다. 번역 결과는 각 모델 카드의 테스트 세트와 유사하지만, 정확히 일치하지는 않을 수 있습니다. 이 모델은 [sshleifer](https://huggingface.co/sshleifer)가 제공했습니다.
## 구현 노트[[Implementation Notes]]
- 각 모델은 약 298 MB를 차지하며, 1,000개 이상의 모델이 제공됩니다.
- 지원되는 언어 쌍 목록은 [여기](https://huggingface.co/Helsinki-NLP)에서 확인할 수 있습니다.
- 모델들은 [Jörg Tiedemann](https://researchportal.helsinki.fi/en/persons/j%C3%B6rg-tiedemann)에 의해 [Marian](https://marian-nmt.github.io/) C++ 라이브러리를 이용하여 학습되었습니다. 이 라이브러리는 빠른 학습과 번역을 지원합니다.
- 모든 모델은 6개 레이어로 이루어진 Transformer 기반의 인코더-디코더 구조입니다. 각 모델의 성능은 모델 카드에 기입되어 있습니다.
- BPE 전처리가 필요한 80개의 OPUS 모델은 지원되지 않습니다.
- 모델링 코드는 [`BartForConditionalGeneration`]을 기반으로 하며, 일부 수정사항이 반영되어 있습니다:
- 정적 (사인 함수 기반) 위치 임베딩 사용 (`MarianConfig.static_position_embeddings=True`)
- 임베딩 레이어 정규화 생략 (`MarianConfig.normalize_embedding=False`)
- 모델은 생성 시 프리픽스로 `pad_token_id` (해당 토큰 임베딩 값은 0)를 사용하여 시작합니다 (Bart는
`<s/>`를 사용),
- Marian 모델을 PyTorch로 대량 변환하는 코드는 `convert_marian_to_pytorch.py`에서 찾을 수 있습니다.
## 모델 이름 규칙[[Naming]]
- 모든 모델 이름은 `Helsinki-NLP/opus-mt-{src}-{tgt}` 형식을 따릅니다.
- 모델의 언어 코드 표기는 일관되지 않습니다. 두 자리 코드는 일반적으로 [여기](https://developers.google.com/admin-sdk/directory/v1/languages)에서 찾을 수 있으며, 세 자리 코드는 "언어 코드 {code}"로 구글 검색을 통해 찾습니다.
- `es_AR`과 같은 형태의 코드는 `code_{region}` 형식을 의미합니다. 여기서의 예시는 아르헨티나의 스페인어를 의미합니다.
- 모델 변환은 두 단계로 이루어졌습니다. 처음 1,000개 모델은 ISO-639-2 코드를 사용하고, 두 번째 그룹은 ISO-639-5와 ISO-639-2 코드를 조합하여 언어를 식별합니다.
## 예시[[Examples]]
- Marian 모델은 라이브러리의 다른 번역 모델들보다 크기가 작아 파인튜닝 실험과 통합 테스트에 유용합니다.
- [GPU에서 파인튜닝하기](https://github.com/huggingface/transformers/blob/master/examples/legacy/seq2seq/train_distil_marian_enro.sh)
## 다국어 모델 사용법[[Multilingual Models]]
- 모든 모델 이름은`Helsinki-NLP/opus-mt-{src}-{tgt}` 형식을 따릅니다.
- 다중 언어 출력을 지원하는 모델의 경우, 출력을 원하는 언어의 언어 코드를 `src_text`의 시작 부분에 추가하여 지정해야 합니다.
- 모델 카드에서 지원되는 언어 코드의 목록을 확인할 수 있습니다! 예를 들어 [opus-mt-en-roa](https://huggingface.co/Helsinki-NLP/opus-mt-en-roa)에서 확인할 수 있습니다.
- `Helsinki-NLP/opus-mt-roa-en`처럼 소스 측에서만 다국어를 지원하는 모델의 경우, 별도의 언어 코드 지정이 필요하지 않습니다.
[Tatoeba-Challenge 리포지토리](https://github.com/Helsinki-NLP/Tatoeba-Challenge)의 새로운 다국적 모델은 3자리 언어 코드를 사용합니다:
```python
>>> from transformers import MarianMTModel, MarianTokenizer
>>> src_text = [
... ">>fra<< this is a sentence in english that we want to translate to french",
... ">>por<< This should go to portuguese",
... ">>esp<< And this to Spanish",
... ]
>>> model_name = "Helsinki-NLP/opus-mt-en-roa"
>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
>>> print(tokenizer.supported_language_codes)
['>>zlm_Latn<<', '>>mfe<<', '>>hat<<', '>>pap<<', '>>ast<<', '>>cat<<', '>>ind<<', '>>glg<<', '>>wln<<', '>>spa<<', '>>fra<<', '>>ron<<', '>>por<<', '>>ita<<', '>>oci<<', '>>arg<<', '>>min<<']
>>> model = MarianMTModel.from_pretrained(model_name)
>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
>>> [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
["c'est une phrase en anglais que nous voulons traduire en français",
'Isto deve ir para o português.',
'Y esto al español']
```
허브에 있는 모든 사전 학습된 모델을 확인하는 코드입니다:
```python
from huggingface_hub import list_models
model_list = list_models()
org = "Helsinki-NLP"
model_ids = [x.id for x in model_list if x.id.startswith(org)]
suffix = [x.split("/")[1] for x in model_ids]
old_style_multi_models = [f"{org}/{s}" for s in suffix if s != s.lower()]
```
## 구형 다국어 모델[[Old Style Multi-Lingual Models]]
이 모델들은 OPUS-MT-Train 리포지토리의 구형 다국어 모델들입니다. 각 언어 그룹에 포함된 언어들은 다음과 같습니다:
```python no-style
['Helsinki-NLP/opus-mt-NORTH_EU-NORTH_EU',
'Helsinki-NLP/opus-mt-ROMANCE-en',
'Helsinki-NLP/opus-mt-SCANDINAVIA-SCANDINAVIA',
'Helsinki-NLP/opus-mt-de-ZH',
'Helsinki-NLP/opus-mt-en-CELTIC',
'Helsinki-NLP/opus-mt-en-ROMANCE',
'Helsinki-NLP/opus-mt-es-NORWAY',
'Helsinki-NLP/opus-mt-fi-NORWAY',
'Helsinki-NLP/opus-mt-fi-ZH',
'Helsinki-NLP/opus-mt-fi_nb_no_nn_ru_sv_en-SAMI',
'Helsinki-NLP/opus-mt-sv-NORWAY',
'Helsinki-NLP/opus-mt-sv-ZH']
GROUP_MEMBERS = {
'ZH': ['cmn', 'cn', 'yue', 'ze_zh', 'zh_cn', 'zh_CN', 'zh_HK', 'zh_tw', 'zh_TW', 'zh_yue', 'zhs', 'zht', 'zh'],
'ROMANCE': ['fr', 'fr_BE', 'fr_CA', 'fr_FR', 'wa', 'frp', 'oc', 'ca', 'rm', 'lld', 'fur', 'lij', 'lmo', 'es', 'es_AR', 'es_CL', 'es_CO', 'es_CR', 'es_DO', 'es_EC', 'es_ES', 'es_GT', 'es_HN', 'es_MX', 'es_NI', 'es_PA', 'es_PE', 'es_PR', 'es_SV', 'es_UY', 'es_VE', 'pt', 'pt_br', 'pt_BR', 'pt_PT', 'gl', 'lad', 'an', 'mwl', 'it', 'it_IT', 'co', 'nap', 'scn', 'vec', 'sc', 'ro', 'la'],
'NORTH_EU': ['de', 'nl', 'fy', 'af', 'da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
'SCANDINAVIA': ['da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
'SAMI': ['se', 'sma', 'smj', 'smn', 'sms'],
'NORWAY': ['nb_NO', 'nb', 'nn_NO', 'nn', 'nog', 'no_nb', 'no'],
'CELTIC': ['ga', 'cy', 'br', 'gd', 'kw', 'gv']
}
```
영어를 여러 로망스 언어로 번역하는 예제입니다. 여기서는 구형 2자리 언어 코드를 사용합니다:
```python
>>> from transformers import MarianMTModel, MarianTokenizer
>>> src_text = [
... ">>fr<< this is a sentence in english that we want to translate to french",
... ">>pt<< This should go to portuguese",
... ">>es<< And this to Spanish",
... ]
>>> model_name = "Helsinki-NLP/opus-mt-en-ROMANCE"
>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
>>> model = MarianMTModel.from_pretrained(model_name)
>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
>>> tgt_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
["c'est une phrase en anglais que nous voulons traduire en français",
'Isto deve ir para o português.',
'Y esto al español']
```
## 자료[[Resources]]
- [번역 작업 가이드](../tasks/translation)
- [요약 작업 가이드](../tasks/summarization)
- [언어 모델링 작업 가이드](../tasks/language_modeling)
## MarianConfig
[[autodoc]] MarianConfig
## MarianTokenizer
[[autodoc]] MarianTokenizer
- build_inputs_with_special_tokens
<frameworkcontent>
<pt>
## MarianModel
[[autodoc]] MarianModel
- forward
## MarianMTModel
[[autodoc]] MarianMTModel
- forward
## MarianForCausalLM
[[autodoc]] MarianForCausalLM
- forward
</pt>
<tf>
## TFMarianModel
[[autodoc]] TFMarianModel
- call
## TFMarianMTModel
[[autodoc]] TFMarianMTModel
- call
</tf>
<jax>
## FlaxMarianModel
[[autodoc]] FlaxMarianModel
- __call__
## FlaxMarianMTModel
[[autodoc]] FlaxMarianMTModel
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/ko/model_doc/marian.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/marian.md",
"repo_id": "transformers",
"token_count": 5171
}
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# 모델 학습 해부하기 [[model-training-anatomy]]
모델 훈련 속도와 메모리 활용의 효율성을 향상시키기 위해 적용할 수 있는 성능 최적화 기술을 이해하려면 GPU가 훈련 중에 어떻게 활용되는지, 그리고 수행되는 연산에 따라 연산 강도가 어떻게 변하는지에 익숙해져야 합니다.
먼저 GPU 활용과 모델 훈련 실행에 대한 예시를 살펴보겠습니다. 데모를 위해 몇몇 라이브러리를 설치해야 합니다:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
```
`nvidia-ml-py3` 라이브러리는 Python 내부에서 모델의 메모리 사용량을 모니터링할 수 있게 해줍니다. 터미널의 `nvidia-smi` 명령어에 익숙할 수 있는데, 이 라이브러리는 Python에서 직접 동일한 정보에 접근할 수 있게 해줍니다.
그 다음, 100과 30000 사이의 무작위 토큰 ID와 분류기를 위한 이진 레이블인 더미 데이터를 생성합니다.
길이가 각각 512인 총 512개의 시퀀스를 가져와 PyTorch 형식의 [`~datasets.Dataset`]에 저장합니다.
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 1, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
```
GPU 활용 및 [`Trainer`]로 실행한 훈련 과정에 대한 요약 통계를 출력하기 위해 두 개의 도우미 함수를 정의하겠습니다:
```py
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()
```
시작할 때 GPU 메모리가 비어 있는지 확인해 봅시다:
```py
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
```
좋습니다. 모델을 로드하기 전에는 예상대로 GPU 메모리가 점유되지 않았습니다. 그렇지 않다면 사용자의 기기에서 GPU 메모리를 사용하는 모든 프로세스를 중단해야 합니다. 그러나 사용자는 모든 여유 GPU 메모리를 사용할 수는 없습니다. 모델이 GPU에 로드될 때 커널도 로드되므로 1-2GB의 메모리를 차지할 수 있습니다. 얼마나 되는지 확인하기 위해 GPU에 작은 텐서를 로드하여 커널이 로드되도록 트리거합니다.
```py
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
```
커널만으로도 GPU 메모리의 1.3GB를 차지합니다. 이제 모델이 얼마나 많은 공간을 사용하는지 확인해 보겠습니다.
## 모델 로드 [[load-model]]
우선, `google-bert/bert-large-uncased` 모델을 로드합니다. 모델의 가중치를 직접 GPU에 로드해서 가중치만이 얼마나 많은 공간을 차지하는지 확인할 수 있습니다.
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
```
모델의 가중치만으로도 GPU 메모리를 1.3 GB 차지하는 것을 볼 수 있습니다. 정확한 숫자는 사용하는 GPU에 따라 다릅니다. 최신 GPU에서는 모델 사용 속도를 높이는 최적화된 방식으로 가중치가 로드되므로, 모델이 더 많은 공간을 차지할 수 있습니다. 이제 `nvidia-smi` CLI와 동일한 결과를 얻는지 빠르게 확인할 수 있습니다:
```bash
nvidia-smi
```
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
```
이전과 동일한 숫자가 출력되고 16GB 메모리를 가진 V100 GPU를 사용하고 있다는 것도 볼 수 있습니다. 그러므로 이제 모델 훈련을 시작하여 GPU 메모리 사용량이 어떻게 달라지는지 볼 수 있습니다. 우선 몇몇 표준 훈련 인수를 설정합니다:
```py
default_args = {
"output_dir": "tmp",
"eval_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
```
<Tip>
여러 실험을 실행할 계획이라면, 실험 간에 메모리를 제대로 비우기 위해서 Python 커널을 실험 사이마다 재시작해야 합니다.
</Tip>
## 기본 훈련에서의 메모리 활용 [[memory-utilization-at-vanilla-training]]
[`Trainer`]를 사용하여, GPU 성능 최적화 기술을 사용하지 않고 배치 크기가 4인 모델을 훈련시키겠습니다:
```py
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
```
```
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
```
우리는 비교적 작은 배치 크기로도 전체 GPU 메모리를 거의 다 차지하는 것을 볼 수 있습니다. 그러나 배치 크기가 클수록 모델 수렴 속도가 빨라지고 최종 성능이 향상되는 경우가 많습니다. 그래서 이상적으로는 GPU 제한이 아닌 우리 모델의 요구사항에 맞게 배치 크기를 조정하려고 합니다. 흥미롭게도 우리는 모델의 크기보다 훨씬 더 많은 메모리를 사용합니다. 왜 이런 현상이 발생하는지 조금 더 잘 이해하기 위해 모델의 연산과 메모리 요구 사항을 살펴보겠습니다.
## 모델의 연산 해부하기 [[anatomy-of-models-operations]]
트랜스포머 아키텍처에는 연산 강도(compute-intensity)에 따라 그룹화된 3가지 주요 연산 그룹이 있습니다.
1. **텐서 축약(Tensor Contractions)**
선형 레이어와 멀티헤드 어텐션의 구성 요소는 모두 **행렬-행렬 곱셈(matrix-matrix multiplications)**을 일괄적으로 처리합니다. 이 연산은 트랜스포머 훈련에서 가장 연산 강도가 높은 부분입니다.
2. **통계 정규화(Statistical Normalizations)**
소프트맥스와 레이어 정규화는 텐서 축약보다 연산 강도가 낮습니다. 하나 이상의 **감소 연산(reduction operations)**을 포함하며, 그 결과는 map을 통해 적용됩니다.
3. **원소별 연산자(Element-wise Operators)**
그 외 연산자들, **편향(biases), 드롭아웃(dropout), 활성화 함수(activations), 잔차 연결(residual connections)**이 여기에 해당합니다. 이 연산들은 연산 강도가 가장 낮습니다.
이러한 지식은 성능 병목 현상을 분석할 때 도움이 될 수 있습니다.
이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)을 참고하였습니다.
## 모델의 메모리 구조 [[anatomy-of-models-memory]]
모델을 훈련시키는 데는 단순히 GPU에 모델을 올리는 것보다 훨씬 더 많은 메모리를 사용한다는 것을 보았습니다. 이는 훈련 중 GPU 메모리를 사용하는 많은 구성 요소가 있기 때문입니다. GPU 메모리의 구성 요소는 다음과 같습니다:
1. 모델 가중치
2. 옵티마이저 상태
3. 그라디언트
4. 그라디언트 계산을 위해 저장된 순방향 활성화
5. 임시 버퍼
6. 기능별 메모리
AdamW를 사용하여 혼합 정밀도로 훈련된 일반적인 모델은 모델 파라미터당 18 바이트와 활성화 메모리가 필요합니다. 추론 단계에서는 옵티마이저와 그라디언트가 필요하지 않으므로 이들은 제외합니다. 따라서 혼합 정밀도 추론의 경우 모델 매개변수당 6 바이트와 활성화 메모리가 필요합니다.
자세히 살펴보겠습니다.
**모델 가중치:**
- fp32 훈련의 경우 매개 변수 수 * 4 바이트
- 혼합 정밀도 훈련의 경우 매개 변수 수 * 6 바이트 (메모리에 fp32와 fp16 두 가지 모델을 유지)
**옵티마이저 상태:**
- 일반 AdamW의 경우 매개 변수 수 * 8 바이트 (2가지 상태 유지)
- [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)와 같은 8비트 AdamW 옵티마이저의 경우 매개 변수 수 * 2 바이트
- Momentum을 가진 SGD와 같은 옵티마이저의 경우 매개 변수 수 * 4 바이트 (하나의 상태만 유지)
**그라디언트**
- fp32 또는 혼합 정밀도 훈련의 경우 매개 변수 수 * 4 바이트 (그라디언트는 항상 fp32으로 유지됩니다.)
**순방향 활성화**
- 크기는 여러 요인에 따라 달라지며, 주요 요인은 시퀀스 길이, 은닉 상태의 크기 및 배치 크기입니다.
순방향 및 역방향 함수에서 전달 및 반환되는 입력과 출력이 있으며, 그라디언트 계산을 위해 저장된 순방향 활성화가 있습니다.
**임시 메모리**
더불어 모든 종류의 임시 변수는 연산이 완료되면 곧바로 해제되지만, 그 순간에는 추가 메모리가 필요할 수 있고 OOM을 유발할 수 있습니다. 따라서 코딩할 때 이러한 임시 변수에 대해 전략적으로 생각하고 때로는 더 이상 필요 없는 임시 변수를 즉시 명시적으로 메모리에서 제거하는 것이 중요합니다.
**기능별 메모리**
그런 다음, 소프트웨어에는 특별한 메모리 요구 사항이 있을 수 있습니다. 예를 들어, 빔 검색을 사용하여 텍스트를 생성할 때 소프트웨어는 입력과 출력 사본을 여러 개 유지해야 합니다.
**`forward` vs `backward` 실행 속도**
합성곱과 선형 레이어의 경우 순방향에 비해 역방향에서는 2배의 플롭스가 필요하므로 일반적으로 2배 정도 느리게 변환됩니다(역방향의 경우 사이즈가 부자연스럽기 때문에, 때로는 더욱 느릴 수도 있습니다). 활성화는 일반적으로 대역폭이 제한되어 있으며, 일반적으로 순방향보다 역방향에서 더 많은 데이터를 읽어야 합니다. (예를 들어, 순방향 활성화 시 한 번 씩 읽고 쓰지만, 역방향 활성화에서는 순방향 gradOutput과 출력에 대해 총 두 번 읽고 gradInput에 대해 한 번 씁니다.)
보다시피, GPU 메모리를 절약하거나 작업 속도를 높일 수 있는 몇 가지 방법이 있습니다.
이제 GPU 활용과 계산 속도에 영향을 주는 것이 무엇인지를 이해했으므로, [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) 문서 페이지를 참조하여 성능 최적화 기법에 대해 알아보세요.
|
transformers/docs/source/ko/model_memory_anatomy.md/0
|
{
"file_path": "transformers/docs/source/ko/model_memory_anatomy.md",
"repo_id": "transformers",
"token_count": 8876
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 고정 길이 모델의 펄플렉서티(Perplexity)[[perplexity-of-fixedlength-models]]
[[open-in-colab]]
펄플렉서티(Perplexity, PPL)는 가장 일반적인 언어 모델 평가지표 중 하나입니다.
자세히 알아보기 전에 이 평가지표는 고전적인 언어 모델(자기회귀 또는 인과적 언어 모델이라고도 함)에만 적용되며 BERT와 같은 마스킹된 언어 모델에는 잘 적용하지 않습니다 (BERT는 [summary of the models](../en/model_summary) 문서를 참고하세요).
펄플렉서티는 시퀀스의 음의 로그 우도(negative log-likelihood, NLL) 값의 평균에 지수(exponentiate)를 취한 값으로 정의됩니다.
토큰화된 시퀀스 \\(X = (x_0, x_1, \dots, x_t)\\) 가 있을 때, \\(X\\) 의 펄플렉서티는 아래 수식과 같이 구할 수 있습니다.
$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{<i}) } \right\}$$
\\(\log p_\theta (x_i|x_{<i})\\) 는 모델에 i번째 이전까지 토큰이 주어졌을 때 i번째 토큰의 로그 우도값입니다.
직관적으로 말뭉치에서 지정된 토큰 집합을 균일하게 예측하는 모델의 능력에 대한 평가로 생각할 수 있습니다.
중요한 점은 토큰화 과정이 모델의 펄플렉서티에 직접적인 영향을 미치므로 서로 다른 모델을 비교할 때 항상 이를 고려해야 합니다.
이는 데이터와 모델 예측 간의 cross-entropy 값에 지수를 취한 것과 동일합니다.
펄플렉서티와 문자당 비트 수(BPC) 및 데이터 압축과의 관계에 대해 더 직관적인 이해를 원하신다면 다음 글
[fantastic blog post on The Gradient](https://thegradient.pub/understanding-evaluation-metrics-for-language-models/)을 확인하세요.
## 고정 길이 모델의 펄플렉서티(PPL) 계산하기[[calculating-ppl-with-fixedlength-models]]
모델의 컨텍스트 크기가 정해져있지 않다면,
아래와 같이 시퀀스를 자동 회귀적으로 분해하고 각 단계에서 선행 하는 전체 시퀀스를 조건부 확률에 넣어 모델의 펄플렉서티를 계산할 것입니다.
<img width="600" alt="Full decomposition of a sequence with unlimited context length" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_full.gif"/>
그러나 모델의 근사치를 구할 때는 일반적으로 모델이 처리할 수 있는 토큰 수에 제한이 있습니다.
예를 들어, 가장 큰 버전의 [GPT-2](model_doc/gpt2)는 토큰의 길이가 1024로 고정되어 있습니다.
따라서 \\(t\\) 가 1024보다 큰 경우에 \\(p_\theta(x_t|x_{<t})\\) 을 계산할 수 없습니다.
대신 시퀀스는 일반적으로 모델의 최대 입력 크기와 동일한 길이는 가지는 부분 시퀀스로 쪼갭니다.
만약 모델의 최대 입력 길이가 \\(k\\) 라면,
토큰 \\(x_t\\) 의 우도 값을 계산할 때 이전 토큰을 모두 사용하지 않고, \\(k-1\\) 토큰까지 사용해 대략적인 우도 값을 추정합니다.
모델의 시퀀스에 대한 펄플렉서티를 계산할 때,
수월하지만 차선책은 시퀀스를 청크로 쪼개고 분해된 각 부분의 로그 우도 값을 독립적으로 합산하는 것입니다.
<img width="600" alt="Suboptimal PPL not taking advantage of full available context" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_chunked.gif"/>
이 방법은 각 부분의 펄플렉서티를 한 번의 포워드 패스로 계산할 수 있어 빠르지만 일반적으로 더 높은(더 나쁜) PPL을 산출합니다.
왜냐하면 대부분의 예측 단계에서 모델의 컨텍스트가 적기 때문입니다.
대신, 고정 길이 모델의 PPL은 슬라이딩 윈도우 전략으로 평가해야 합니다.
이 전략에는 컨텍스트 윈도우을 반복적으로 슬라이딩해 모델이 각 예측을 수행할 때 더 많은 컨텍스트를 갖도록 하는 작업이 포함됩니다.
<img width="600" alt="Sliding window PPL taking advantage of all available context" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_sliding.gif"/>
이는 시퀀스 확률의 실제 분해에 더 가까운 근사치이며 일반적으로 더 유리한 점수를 산출합니다.
단점은 말뭉치의 각 토큰에 대해 별도의 포워드 패스가 필요하다는 것입니다.
현실적으로 좋은 절충안은 한 번에 한 토큰씩 슬라이딩하는 것이 아니라 더 큰 간격으로 컨텍스트를 이동하는 스트라이드가 적용된 슬라이딩 윈도우을 사용하는 것입니다.
이렇게 하면 계산을 훨씬 더 빠르게 진행하면서도 모델에 각 단계에서 예측을 수행할 수 있는 긴 컨텍스트를 제공할 수 있습니다.
## 예제: 🤗 Transformers에서 GPT-2로 펄플렉서티(perplexity) 계산하기[[example-calculating-perplexity-with-gpt2-in-transformers]]
이제 GPT-2로 위의 과정을 시연해 보겠습니다.
```python
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
device = "cuda"
model_id = "openai-community/gpt2-large"
model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
```
WikiText-2 데이터 세트를 가져오고 몇 가지 슬라이딩 윈도우 전략을 사용해 펄플렉서티를 계산해보겠습니다.
이 데이터 세트는 크기가 작고 포워드 패스 한 번만 수행하기 때문에 전체 데이터 세트를 메모리에 가져오고 인코딩할 수 있습니다.
```python
from datasets import load_dataset
test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
```
🤗 Transformers를 사용하면 모델의 `labels`로 `input_ids`를 전달해 각 토큰에 대한 평균 음의 우도 값을 손실로 반환할 수 있습니다.
하지만 슬라이딩 윈도우 방식을 사용하면 각 반복마다 모델에 전달하는 토큰이 겹칩니다.
컨텍스트로 처리하는 토큰에 대한 로그 우도 값이 손실에 포함되는 것을 원하지 않기 때문에 이러한 토큰의 `input_ids`를 `-100`으로 설정하여 무시할 수 있습니다.
다음은 스트라이드(stride)를 `512`로 사용한 예시입니다.
즉, 모델이 한 토큰의 조건부 우도 값을 계산할 때 컨텍스트에 최소한 512개의 토큰이 포함되어있다는 의미입니다 (해당 토큰 앞에 512개의 토큰이 있는 경우).
```python
import torch
from tqdm import tqdm
max_length = model.config.n_positions
stride = 512
seq_len = encodings.input_ids.size(1)
nlls = []
prev_end_loc = 0
for begin_loc in tqdm(range(0, seq_len, stride)):
end_loc = min(begin_loc + max_length, seq_len)
trg_len = end_loc - prev_end_loc # 마지막 루프의 스트라이드 값과 다를 수 있음
input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
target_ids = input_ids.clone()
target_ids[:, :-trg_len] = -100
with torch.no_grad():
outputs = model(input_ids, labels=target_ids)
# 손실은 모든 유효한 레이블에 대한 평균값을 구하는 교차 엔트로피(cross entropy)로 계산됩니다.
# 나이브 베이지안 모델은 내부적으로 레이블을 왼쪽으로 1개씩 밀기 때문에, (타켓 - 1)개 만큼의 레이블에 대해 손실을 계산합니다.
neg_log_likelihood = outputs.loss
nlls.append(neg_log_likelihood)
prev_end_loc = end_loc
if end_loc == seq_len:
break
ppl = torch.exp(torch.stack(nlls).mean())
```
스트라이드를 최대 입력 길이와 동일하게 설정하면 위에서 설명한 차선책인 비슬라이딩 윈도우 전략과 동일합니다.
일반적으로 스트라이드가 작을수록 모델이 각 예측을 할 때 더 많은 컨텍스트를 볼 수 있게 되어 펄플렉서티 값이 좋아집니다.
위의 계산을 토큰이 겹치지 않도록 `stride = 1024`로 설정하면 PPL은 `19.44`로 GPT-2 논문에서 보고된 `19.93`과 거의 동일합니다.
`stride = 512`로 슬라이딩 윈도우 전략을 사용하면 PPL은 `16.45`로 떨어집니다.
이는 더 좋은 점수일 뿐만 아니라 시퀀스 확률의 실제 자동 회귀 분해에 더 가까운 방식으로 계산됩니다.
|
transformers/docs/source/ko/perplexity.md/0
|
{
"file_path": "transformers/docs/source/ko/perplexity.md",
"repo_id": "transformers",
"token_count": 6268
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 자동 음성 인식[[automatic-speech-recognition]]
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
이 가이드에서 소개할 내용은 아래와 같습니다:
1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트에서 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)를 미세 조정하여 오디오를 텍스트로 변환합니다.
2. 미세 조정한 모델을 추론에 사용합니다.
<Tip>
이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/automatic-speech-recognition)를 확인하는 것이 좋습니다.
</Tip>
시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate jiwer
```
Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다. 토큰을 입력하여 로그인하세요.
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
[`~Dataset.train_test_split`] 메소드를 사용하여 데이터 세트의 `train`을 훈련 세트와 테스트 세트로 나누세요:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
그리고 데이터 세트를 확인하세요:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
데이터 세트에는 `lang_id`와 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만, 이 가이드에서는 `audio`와 `transcription`에 초점을 맞출 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거하세요:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
예시를 다시 한번 확인해보세요:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
두 개의 필드가 있습니다:
- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `array(배열)`
- `transcription`: 목표 텍스트
## 전처리[[preprocess]]
다음으로 오디오 신호를 처리하기 위한 Wav2Vec2 프로세서를 가져옵니다:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터 세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16000kHz로 리샘플링해야 합니다:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
위의 'transcription'에서 볼 수 있듯이 텍스트는 대문자와 소문자가 섞여 있습니다. Wav2Vec2 토크나이저는 대문자 문자에 대해서만 훈련되어 있으므로 텍스트가 토크나이저의 어휘와 일치하는지 확인해야 합니다:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
이제 다음 작업을 수행할 전처리 함수를 만들어보겠습니다:
1. `audio` 열을 호출하여 오디오 파일을 가져오고 리샘플링합니다.
2. 오디오 파일에서 `input_values`를 추출하고 프로세서로 `transcription` 열을 토큰화합니다.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
전체 데이터 세트에 전처리 함수를 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `num_proc` 매개변수를 사용하여 프로세스 수를 늘리면 `map`의 속도를 높일 수 있습니다. [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 필요하지 않은 열을 제거하세요:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers에는 자동 음성 인식용 데이터 콜레이터가 없으므로 예제 배치를 생성하려면 [`DataCollatorWithPadding`]을 조정해야 합니다. 이렇게 하면 데이터 콜레이터는 텍스트와 레이블을 배치에서 가장 긴 요소의 길이에 동적으로 패딩하여 길이를 균일하게 합니다. `tokenizer` 함수에서 `padding=True`를 설정하여 텍스트를 패딩할 수 있지만, 동적 패딩이 더 효율적입니다.
다른 데이터 콜레이터와 달리 이 특정 데이터 콜레이터는 `input_values`와 `labels`에 대해 다른 패딩 방법을 적용해야 합니다.
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # 입력과 레이블을 분할합니다
... # 길이가 다르고, 각각 다른 패딩 방법을 사용해야 하기 때문입니다
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # 패딩에 대해 손실을 적용하지 않도록 -100으로 대체합니다
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
이제 `DataCollatorForCTCWithPadding`을 인스턴스화합니다:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## 평가하기[[evaluate]]
훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
그런 다음 예측값과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 WER을 계산하는 함수를 만듭니다:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정할 때 이 함수로 되돌아올 것입니다.
## 훈련하기[[train]]
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]로 모델을 미세 조정하는 것이 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인해보세요!
</Tip>
이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForCTC`]로 Wav2Vec2를 가져오세요. `ctc_loss_reduction` 매개변수로 CTC 손실에 적용할 축소(reduction) 방법을 지정하세요. 기본값인 합계 대신 평균을 사용하는 것이 더 좋은 경우가 많습니다:
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
이제 세 단계만 남았습니다:
1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `output_dir`은 모델을 저장할 경로를 지정하는 유일한 필수 매개변수입니다. `push_to_hub=True`를 설정하여 모델을 Hub에 업로드 할 수 있습니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). [`Trainer`]는 각 에폭마다 WER을 평가하고 훈련 체크포인트를 저장합니다.
2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 [`Trainer`]에 훈련 인수를 전달하세요.
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... eval_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... processing_class=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
훈련이 완료되면 모두가 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 Hub에 공유하세요:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
자동 음성 인식을 위해 모델을 미세 조정하는 더 자세한 예제는 영어 자동 음성 인식을 위한 [블로그 포스트](https://huggingface.co/blog/fine-tune-wav2vec2-english)와 다국어 자동 음성 인식을 위한 [포스트](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)를 참조하세요.
</Tip>
## 추론하기[[inference]]
좋아요, 이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
추론에 사용할 오디오 파일을 가져오세요. 필요한 경우 오디오 파일의 샘플링 비율을 모델의 샘플링 레이트에 맞게 리샘플링하는 것을 잊지 마세요!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
추론을 위해 미세 조정된 모델을 시험해보는 가장 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 모델을 사용하여 자동 음성 인식을 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달하세요:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
텍스트로 변환된 결과가 꽤 괜찮지만 더 좋을 수도 있습니다! 더 나은 결과를 얻으려면 더 많은 예제로 모델을 미세 조정하세요!
</Tip>
`pipeline`의 결과를 수동으로 재현할 수도 있습니다:
<frameworkcontent>
<pt>
오디오 파일과 텍스트를 전처리하고 PyTorch 텐서로 `input`을 반환할 프로세서를 가져오세요:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
입력을 모델에 전달하고 로짓을 반환하세요:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
가장 높은 확률의 `input_ids`를 예측하고, 프로세서를 사용하여 예측된 `input_ids`를 다시 텍스트로 디코딩하세요:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent>
|
transformers/docs/source/ko/tasks/asr.md/0
|
{
"file_path": "transformers/docs/source/ko/tasks/asr.md",
"repo_id": "transformers",
"token_count": 9520
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer [[trainer]]
[`Trainer`]는 Transformers 라이브러리에 구현된 PyTorch 모델을 반복하여 훈련 및 평가 과정입니다. 훈련에 필요한 요소(모델, 토크나이저, 데이터셋, 평가 함수, 훈련 하이퍼파라미터 등)만 제공하면 [`Trainer`]가 필요한 나머지 작업을 처리합니다. 이를 통해 직접 훈련 루프를 작성하지 않고도 빠르게 훈련을 시작할 수 있습니다. 또한 [`Trainer`]는 강력한 맞춤 설정과 다양한 훈련 옵션을 제공하여 사용자 맞춤 훈련이 가능합니다.
<Tip>
Transformers는 [`Trainer`] 클래스 외에도 번역이나 요약과 같은 시퀀스-투-시퀀스 작업을 위한 [`Seq2SeqTrainer`] 클래스도 제공합니다. 또한 [TRL](https://hf.co/docs/trl) 라이브러리에는 [`Trainer`] 클래스를 감싸고 Llama-2 및 Mistral과 같은 언어 모델을 자동 회귀 기법으로 훈련하는 데 최적화된 [`~trl.SFTTrainer`] 클래스 입니다. [`~trl.SFTTrainer`]는 시퀀스 패킹, LoRA, 양자화 및 DeepSpeed와 같은 기능을 지원하여 크기 상관없이 모델 효율적으로 확장할 수 있습니다.
<br>
이들 다른 [`Trainer`] 유형 클래스에 대해 더 알고 싶다면 [API 참조](./main_classes/trainer)를 확인하여 언제 어떤 클래스가 적합할지 얼마든지 확인하세요. 일반적으로 [`Trainer`]는 가장 다재다능한 옵션으로, 다양한 작업에 적합합니다. [`Seq2SeqTrainer`]는 시퀀스-투-시퀀스 작업을 위해 설계되었고, [`~trl.SFTTrainer`]는 언어 모델 훈련을 위해 설계되었습니다.
</Tip>
시작하기 전에, 분산 환경에서 PyTorch 훈련과 실행을 할 수 있게 [Accelerate](https://hf.co/docs/accelerate) 라이브러리가 설치되었는지 확인하세요.
```bash
pip install accelerate
# 업그레이드
pip install accelerate --upgrade
```
이 가이드는 [`Trainer`] 클래스에 대한 개요를 제공합니다.
## 기본 사용법 [[basic-usage]]
[`Trainer`]는 기본적인 훈련 루프에 필요한 모든 코드를 포함하고 있습니다.
1. 손실을 계산하는 훈련 단계를 수행합니다.
2. [`~accelerate.Accelerator.backward`] 메소드로 그레이디언트를 계산합니다.
3. 그레이디언트를 기반으로 가중치를 업데이트합니다.
4. 정해진 에폭 수에 도달할 때까지 이 과정을 반복합니다.
[`Trainer`] 클래스는 PyTorch와 훈련 과정에 익숙하지 않거나 막 시작한 경우에도 훈련이 가능하도록 필요한 모든 코드를 추상화하였습니다. 또한 매번 훈련 루프를 손수 작성하지 않아도 되며, 훈련에 필요한 모델과 데이터셋 같은 필수 구성 요소만 제공하면, [Trainer] 클래스가 나머지를 처리합니다.
훈련 옵션이나 하이퍼파라미터를 지정하려면, [`TrainingArguments`] 클래스에서 확인 할 수 있습니다. 예를 들어, 모델을 저장할 디렉토리를 `output_dir`에 정의하고, 훈련 후에 Hub로 모델을 푸시하려면 `push_to_hub=True`로 설정합니다.
```py
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="your-model",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
push_to_hub=True,
)
```
`training_args`를 [`Trainer`]에 모델, 데이터셋, 데이터셋 전처리 도구(데이터 유형에 따라 토크나이저, 특징 추출기 또는 이미지 프로세서일 수 있음), 데이터 수집기 및 훈련 중 확인할 지표를 계산할 함수를 함께 전달하세요.
마지막으로, [`~Trainer.train`]를 호출하여 훈련을 시작하세요!
```py
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
```
### 체크포인트 [[checkpoints]]
[`Trainer`] 클래스는 [`TrainingArguments`]의 `output_dir` 매개변수에 지정된 디렉토리에 모델 체크포인트를 저장합니다. 체크포인트는 `checkpoint-000` 하위 폴더에 저장되며, 여기서 끝의 숫자는 훈련 단계에 해당합니다. 체크포인트를 저장하면 나중에 훈련을 재개할 때 유용합니다.
```py
# 최신 체크포인트에서 재개
trainer.train(resume_from_checkpoint=True)
# 출력 디렉토리에 저장된 특정 체크포인트에서 재개
trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
```
체크포인트를 Hub에 푸시하려면 [`TrainingArguments`]에서 `push_to_hub=True`로 설정하여 커밋하고 푸시할 수 있습니다. 체크포인트 저장 방법을 결정하는 다른 옵션은 [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy) 매개변수에서 설정합니다:
* `hub_strategy="checkpoint"`는 최신 체크포인트를 "last-checkpoint"라는 하위 폴더에 푸시하여 훈련을 재개할 수 있습니다.
* `hub_strategy="all_checkpoints"`는 모든 체크포인트를 `output_dir`에 정의된 디렉토리에 푸시합니다(모델 리포지토리에서 폴더당 하나의 체크포인트를 볼 수 있습니다).
체크포인트에서 훈련을 재개할 때, [`Trainer`]는 체크포인트가 저장될 때와 동일한 Python, NumPy 및 PyTorch RNG 상태를 유지하려고 합니다. 하지만 PyTorch는 기본 설정으로 '일관된 결과를 보장하지 않음'으로 많이 되어있기 때문에, RNG 상태가 동일할 것이라고 보장할 수 없습니다. 따라서, 일관된 결과가 보장되도록 활성화 하려면, [랜덤성 제어](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) 가이드를 참고하여 훈련을 완전히 일관된 결과를 보장 받도록 만들기 위해 활성화할 수 있는 항목을 확인하세요. 다만, 특정 설정을 결정적으로 만들면 훈련이 느려질 수 있습니다.
## Trainer 맞춤 설정 [[customize-the-trainer]]
[`Trainer`] 클래스는 접근성과 용이성을 염두에 두고 설계되었지만, 더 다양한 기능을 원하는 사용자들을 위해 다양한 맞춤 설정 옵션을 제공합니다. [`Trainer`]의 많은 메소드는 서브클래스화 및 오버라이드하여 원하는 기능을 제공할 수 있으며, 이를 통해 전체 훈련 루프를 다시 작성할 필요 없이 원하는 기능을 추가할 수 있습니다. 이러한 메소드에는 다음이 포함됩니다:
* [`~Trainer.get_train_dataloader`]는 훈련 데이터로더를 생성합니다.
* [`~Trainer.get_eval_dataloader`]는 평가 데이터로더를 생성합니다.
* [`~Trainer.get_test_dataloader`]는 테스트 데이터로더를 생성합니다.
* [`~Trainer.log`]는 훈련을 모니터링하는 다양한 객체에 대한 정보를 로그로 남깁니다.
* [`~Trainer.create_optimizer_and_scheduler`]는 `__init__`에서 전달되지 않은 경우 옵티마이저와 학습률 스케줄러를 생성합니다. 이들은 각각 [`~Trainer.create_optimizer`] 및 [`~Trainer.create_scheduler`]로 별도로 맞춤 설정 할 수 있습니다.
* [`~Trainer.compute_loss`]는 훈련 입력 배치에 대한 손실을 계산합니다.
* [`~Trainer.training_step`]는 훈련 단계를 수행합니다.
* [`~Trainer.prediction_step`]는 예측 및 테스트 단계를 수행합니다.
* [`~Trainer.evaluate`]는 모델을 평가하고 평가 지표을 반환합니다.
* [`~Trainer.predict`]는 테스트 세트에 대한 예측(레이블이 있는 경우 지표 포함)을 수행합니다.
예를 들어, [`~Trainer.compute_loss`] 메소드를 맞춤 설정하여 가중 손실을 사용하려는 경우:
```py
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self,
model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# 순방향 전파
outputs = model(**inputs)
logits = outputs.get("logits")
# 서로 다른 가중치로 3개의 레이블에 대한 사용자 정의 손실을 계산
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
### 콜백 [[callbacks]]
[`Trainer`]를 맞춤 설정하는 또 다른 방법은 [콜백](callbacks)을 사용하는 것입니다. 콜백은 훈련 루프에서 *변화를 주지 않습니다*. 훈련 루프의 상태를 검사한 후 상태에 따라 일부 작업(조기 종료, 결과 로그 등)을 실행합니다. 즉, 콜백은 사용자 정의 손실 함수와 같은 것을 구현하는 데 사용할 수 없으며, 이를 위해서는 [`~Trainer.compute_loss`] 메소드를 서브클래스화하고 오버라이드해야 합니다.
예를 들어, 훈련 루프에 10단계 후 조기 종료 콜백을 추가하려면 다음과 같이 합니다.
```py
from transformers import TrainerCallback
class EarlyStoppingCallback(TrainerCallback):
def __init__(self, num_steps=10):
self.num_steps = num_steps
def on_step_end(self, args, state, control, **kwargs):
if state.global_step >= self.num_steps:
return {"should_training_stop": True}
else:
return {}
```
그런 다음, 이를 [`Trainer`]의 `callback` 매개변수에 전달합니다.
```py
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback()],
)
```
## 로깅 [[logging]]
<Tip>
로깅 API에 대한 자세한 내용은 [로깅](./main_classes/logging) API 레퍼런스를 확인하세요.
</Tip>
[`Trainer`]는 기본적으로 `logging.INFO`로 설정되어 있어 오류, 경고 및 기타 기본 정보를 보고합니다. 분산 환경에서는 [`Trainer`] 복제본이 `logging.WARNING`으로 설정되어 오류와 경고만 보고합니다. [`TrainingArguments`]의 [`log_level`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level) 및 [`log_level_replica`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level_replica) 매개변수로 로그 레벨을 변경할 수 있습니다.
각 노드의 로그 레벨 설정을 구성하려면 [`log_on_each_node`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.log_on_each_node) 매개변수를 사용하여 각 노드에서 로그 레벨을 사용할지 아니면 주 노드에서만 사용할지 결정하세요.
<Tip>
[`Trainer`]는 [`Trainer.__init__`] 메소드에서 각 노드에 대해 로그 레벨을 별도로 설정하므로, 다른 Transformers 기능을 사용할 경우 [`Trainer`] 객체를 생성하기 전에 이를 미리 설정하는 것이 좋습니다.
</Tip>
예를 들어, 메인 코드와 모듈을 각 노드에 따라 동일한 로그 레벨을 사용하도록 설정하려면 다음과 같이 합니다.
```py
logger = logging.getLogger(__name__)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)
```
각 노드에서 기록될 내용을 구성하기 위해 `log_level`과 `log_level_replica`를 다양한 조합으로 사용해보세요.
<hfoptions id="logging">
<hfoption id="single node">
```bash
my_app.py ... --log_level warning --log_level_replica error
```
</hfoption>
<hfoption id="multi-node">
멀티 노드 환경에서는 `log_on_each_node 0` 매개변수를 추가합니다.
```bash
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
# 오류만 보고하도록 설정
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
```
</hfoption>
</hfoptions>
## NEFTune [[neftune]]
[NEFTune](https://hf.co/papers/2310.05914)은 훈련 중 임베딩 벡터에 노이즈를 추가하여 성능을 향상시킬 수 있는 기술입니다. [`Trainer`]에서 이를 활성화하려면 [`TrainingArguments`]의 `neftune_noise_alpha` 매개변수를 설정하여 노이즈의 양을 조절합니다.
```py
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(..., neftune_noise_alpha=0.1)
trainer = Trainer(..., args=training_args)
```
NEFTune은 예상치 못한 동작을 피할 목적으로 처음 임베딩 레이어로 복원하기 위해 훈련 후 비활성화 됩니다.
## GaLore [[galore]]
Gradient Low-Rank Projection (GaLore)은 전체 매개변수를 학습하면서도 LoRA와 같은 일반적인 저계수 적응 방법보다 더 메모리 효율적인 저계수 학습 전략입니다.
먼저 GaLore 공식 리포지토리를 설치합니다:
```bash
pip install galore-torch
```
그런 다음 `optim`에 `["galore_adamw", "galore_adafactor", "galore_adamw_8bit"]` 중 하나와 함께 `optim_target_modules`를 추가합니다. 이는 적용하려는 대상 모듈 이름에 해당하는 문자열, 정규 표현식 또는 전체 경로의 목록일 수 있습니다. 아래는 end-to-end 예제 스크립트입니다(필요한 경우 `pip install trl datasets`를 실행):
```python
import torch
import datasets
import trl
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "google/gemma-2b"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
```
GaLore가 지원하는 추가 매개변수를 전달하려면 `optim_args`를 설정합니다. 예를 들어:
```python
import torch
import datasets
import trl
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"],
optim_args="rank=64, update_proj_gap=100, scale=0.10",
)
model_id = "google/gemma-2b"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
```
해당 방법에 대한 자세한 내용은 [원본 리포지토리](https://github.com/jiaweizzhao/GaLore) 또는 [논문](https://arxiv.org/abs/2403.03507)을 참고하세요.
현재 GaLore 레이어로 간주되는 Linear 레이어만 훈련 할수 있으며, 저계수 분해를 사용하여 훈련되고 나머지 레이어는 기존 방식으로 최적화됩니다.
훈련 시작 전에 시간이 약간 걸릴 수 있습니다(NVIDIA A100에서 2B 모델의 경우 약 3분), 하지만 이후 훈련은 원활하게 진행됩니다.
다음과 같이 옵티마이저 이름에 `layerwise`를 추가하여 레이어별 최적화를 수행할 수도 있습니다:
```python
import torch
import datasets
import trl
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw_layerwise",
optim_target_modules=["attn", "mlp"]
)
model_id = "google/gemma-2b"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
```
레이어별 최적화는 다소 실험적이며 DDP(분산 데이터 병렬)를 지원하지 않으므로, 단일 GPU에서만 훈련 스크립트를 실행할 수 있습니다. 자세한 내용은 [이 문서를](https://github.com/jiaweizzhao/GaLore?tab=readme-ov-file#train-7b-model-with-a-single-gpu-with-24gb-memory)을 참조하세요. gradient clipping, DeepSpeed 등 다른 기능은 기본적으로 지원되지 않을 수 있습니다. 이러한 문제가 발생하면 [GitHub에 이슈를 올려주세요](https://github.com/huggingface/transformers/issues).
## LOMO 옵티마이저 [[lomo-optimizer]]
LOMO 옵티마이저는 [제한된 자원으로 대형 언어 모델의 전체 매개변수 미세 조정](https://hf.co/papers/2306.09782)과 [적응형 학습률을 통한 저메모리 최적화(AdaLomo)](https://hf.co/papers/2310.10195)에서 도입되었습니다.
이들은 모두 효율적인 전체 매개변수 미세 조정 방법으로 구성되어 있습니다. 이러한 옵티마이저들은 메모리 사용량을 줄이기 위해 그레이디언트 계산과 매개변수 업데이트를 하나의 단계로 융합합니다. LOMO에서 지원되는 옵티마이저는 `"lomo"`와 `"adalomo"`입니다. 먼저 pypi에서 `pip install lomo-optim`를 통해 `lomo`를 설치하거나, GitHub 소스에서 `pip install git+https://github.com/OpenLMLab/LOMO.git`로 설치하세요.
<Tip>
저자에 따르면, `grad_norm` 없이 `AdaLomo`를 사용하는 것이 더 나은 성능과 높은 처리량을 제공한다고 합니다.
</Tip>
다음은 IMDB 데이터셋에서 [google/gemma-2b](https://huggingface.co/google/gemma-2b)를 최대 정밀도로 미세 조정하는 간단한 스크립트입니다:
```python
import torch
import datasets
from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-lomo",
max_steps=1000,
per_device_train_batch_size=4,
optim="adalomo",
gradient_checkpointing=True,
logging_strategy="steps",
logging_steps=1,
learning_rate=2e-6,
save_strategy="no",
run_name="lomo-imdb",
)
model_id = "google/gemma-2b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=1024,
)
trainer.train()
```
## Accelerate와 Trainer [[accelerate-and-trainer]]
[`Trainer`] 클래스는 [Accelerate](https://hf.co/docs/accelerate)로 구동되며, 이는 [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) 및 [DeepSpeed](https://www.deepspeed.ai/)와 같은 통합을 지원하는 분산 환경에서 PyTorch 모델을 쉽게 훈련할 수 있는 라이브러리입니다.
<Tip>
FSDP 샤딩 전략, CPU 오프로드 및 [`Trainer`]와 함께 사용할 수 있는 더 많은 기능을 알아보려면 [Fully Sharded Data Parallel](fsdp) 가이드를 확인하세요.
</Tip>
[`Trainer`]와 Accelerate를 사용하려면 [`accelerate.config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) 명령을 실행하여 훈련 환경을 설정하세요. 이 명령은 훈련 스크립트를 실행할 때 사용할 `config_file.yaml`을 생성합니다. 예를 들어, 다음 예시는 설정할 수 있는 일부 구성 예입니다.
<hfoptions id="config">
<hfoption id="DistributedDataParallel">
```yml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 # 노드에 따라 순위를 변경하세요
main_process_ip: 192.168.20.1
main_process_port: 9898
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="FSDP">
```yml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="DeepSpeed">
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
<hfoption id="DeepSpeed with Accelerate plugin">
```yml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
</hfoption>
</hfoptions>
[`accelerate_launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) 명령은 Accelerate와 [`Trainer`]를 사용하여 분산 시스템에서 훈련 스크립트를 실행하는 권장 방법이며, `config_file.yaml`에 지정된 매개변수를 사용합니다. 이 파일은 Accelerate 캐시 폴더에 저장되며 `accelerate_launch`를 실행할 때 자동으로 로드됩니다.
예를 들어, FSDP 구성을 사용하여 [run_glue.py](https://github.com/huggingface/transformers/blob/f4db565b695582891e43a5e042e5d318e28f20b8/examples/pytorch/text-classification/run_glue.py#L4) 훈련 스크립트를 실행하려면 다음과 같이 합니다:
```bash
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
`config_file.yaml` 파일의 매개변수를 직접 지정할 수도 있습니다:
```bash
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
`accelerate_launch`와 사용자 정의 구성에 대해 더 알아보려면 [Accelerate 스크립트 실행](https://huggingface.co/docs/accelerate/basic_tutorials/launch) 튜토리얼을 확인하세요.
|
transformers/docs/source/ko/trainer.md/0
|
{
"file_path": "transformers/docs/source/ko/trainer.md",
"repo_id": "transformers",
"token_count": 15986
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines para inferência
Um [pipeline] simplifica o uso dos modelos no [Model Hub](https://huggingface.co/models) para a inferência de uma diversidade de tarefas,
como a geração de texto, a segmentação de imagens e a classificação de áudio.
Inclusive, se não tem experiência com alguma modalidade específica ou não compreende o código que forma os modelos,
pode usar eles mesmo assim com o [pipeline]! Este tutorial te ensinará a:
* Utilizar um [`pipeline`] para inferência.
* Utilizar um tokenizador ou model específico.
* Utilizar um [`pipeline`] para tarefas de áudio e visão computacional.
<Tip>
Acesse a documentação do [`pipeline`] para obter uma lista completa de tarefas possíveis.
</Tip>
## Uso do pipeline
Mesmo que cada tarefa tenha um [`pipeline`] associado, é mais simples usar a abstração geral do [`pipeline`] que
contém todos os pipelines das tarefas mais específicas.
O [`pipeline`] carrega automaticamenta um modelo predeterminado e um tokenizador com capacidade de inferência para sua
tarefa.
1. Comece carregando um [`pipeline`] e especifique uma tarefa de inferência:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Passe seu dado de entrada, no caso um texto, ao [`pipeline`]:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Se tiver mais de uma entrada, passe-a como uma lista:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... )
```
Qualquer parâmetro adicional para a sua tarefa também pode ser incluído no [`pipeline`]. A tarefa `text-generation` tem um método
[`~generation.GenerationMixin.generate`] com vários parâmetros para controlar a saída.
Por exemplo, se quiser gerar mais de uma saída, defina-a no parâmetro `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... )
```
### Selecionando um modelo e um tokenizador
O [`pipeline`] aceita qualquer modelo do [Model Hub](https://huggingface.co/models). Há rótulos adicionais no Model Hub
que te permitem filtrar pelo modelo que gostaria de usar para sua tarefa. Uma vez que tiver escolhido o modelo apropriado,
carregue-o com as classes `AutoModelFor` e [`AutoTokenizer`] correspondentes. Por exemplo, carregue a classe [`AutoModelForCausalLM`]
para uma tarefa de modelagem de linguagem causal:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
```
Crie uma [`pipeline`] para a sua tarefa e especifíque o modelo e o tokenizador que foram carregados:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Passe seu texto de entrada ao [`pipeline`] para gerar algum texto:
```py
>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Pipeline de audio
A flexibilidade do [`pipeline`] significa que também pode-se extender às tarefas de áudio.
La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
Por exemplo, classifiquemos a emoção de um breve fragmento do famoso discurso de John F. Kennedy /home/rzimmerdev/dev/transformers/docs/source/pt/pipeline_tutorial.md
Encontre um modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para
reconhecimento de emoções no Model Hub e carregue-o usando o [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Passe o arquivo de áudio ao [`pipeline`]:
```py
>>> audio_classifier("jfk_moon_speech.wav")
[{'label': 'calm', 'score': 0.13856211304664612},
{'label': 'disgust', 'score': 0.13148026168346405},
{'label': 'happy', 'score': 0.12635163962841034},
{'label': 'angry', 'score': 0.12439591437578201},
{'label': 'fearful', 'score': 0.12404385954141617}]
```
## Pipeline de visão computacional
Finalmente, utilizar um [`pipeline`] para tarefas de visão é praticamente a mesma coisa.
Especifique a sua tarefa de visão e passe a sua imagem ao classificador.
A imagem pode ser um link ou uma rota local à imagem. Por exemplo, que espécie de gato está presente na imagem?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
{'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
'score': 0.03433405980467796},
{'label': 'snow leopard, ounce, Panthera uncia',
'score': 0.032148055732250214},
{'label': 'Egyptian cat', 'score': 0.02353910356760025},
{'label': 'tiger cat', 'score': 0.023034192621707916}]
```
|
transformers/docs/source/pt/pipeline_tutorial.md/0
|
{
"file_path": "transformers/docs/source/pt/pipeline_tutorial.md",
"repo_id": "transformers",
"token_count": 2382
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 智能体,超强版 - 多智能体、外部工具等
[[open-in-colab]]
### 什么是智能体?
> [!TIP]
> 如果你是 `transformers.agents` 的新手,请先阅读主文档 [智能体文档 ](./agents).
在本页面中,我们将重点介绍 `transformers.agents` 的几种高级用法。
## 多智能体
多智能体功能是微软框架 [Autogen](https://huggingface.co/papers/2308.08155) 中引入的。
它的意思是让多个智能体一起工作来解决任务,而不是只有一个智能体。
经验表明,在大多数基准测试中,这种方法能带来更好的性能。之所以有更好的性能,原因很简单:对于许多任务,通常我们更愿意让多个单独的单元专注于子任务,而不是让一个系统做所有事情。这里,拥有不同工具集和记忆的多个智能体可以实现高效的专业化。
你可以轻松地用 `transformers.agents` 构建层次化的多智能体系统。
为此,需要将智能体封装在 [`ManagedAgent`] 对象中。这个对象需要 `agent`、`name` 和 `description` 这几个参数,这些信息会嵌入到管理智能体的系统提示中,帮助它知道如何调用这个管理的智能体,就像我们对工具所做的那样。
下面是一个通过使用我们的 [`DuckDuckGoSearchTool`] 创建一个管理特定网络搜索智能体的示例:
```py
from transformers.agents import ReactCodeAgent, HfApiEngine, DuckDuckGoSearchTool, ManagedAgent
llm_engine = HfApiEngine()
web_agent = ReactCodeAgent(tools=[DuckDuckGoSearchTool()], llm_engine=llm_engine)
managed_web_agent = ManagedAgent(
agent=web_agent,
name="web_search",
description="Runs web searches for you. Give it your query as an argument."
)
manager_agent = ReactCodeAgent(
tools=[], llm_engine=llm_engine, managed_agents=[managed_web_agent]
)
manager_agent.run("Who is the CEO of Hugging Face?")
```
> [!TIP]
> 如果你想深入了解如何高效地实现多智能体系统,请查看 [how we pushed our multi-agent system to the top of the GAIA leaderboard](https://huggingface.co/blog/beating-gaia).
## 高级工具使用
### 通过子类化 Tool 来直接定义工具,并将其共享到 Hub
让我们再次使用主文档中的工具示例,我们已经实现了一个 `tool` 装饰器。
如果你需要添加一些变化,比如为工具自定义属性,可以按照更细粒度的方法构建工具:构建一个继承自 [`Tool`] 超类的类。
自定义工具需要:
- `name` 属性:表示工具本身的名称,通常描述工具的作用。由于代码返回了针对任务下载量最多的模型,我们将其命名为 model_download_counter。
- `description` 属性:用于填充智能体的系统提示。
- `inputs` 属性:这是一个包含 "type" 和 "description" 键的字典。它包含了有助于 Python 解释器做出选择的输入信息。
- `output_type` 属性:指定输出类型。
- `forward` 方法:其中包含执行推理代码。
`inputs` 和 `output_type` 的类型应当是 [Pydantic 格式](https://docs.pydantic.dev/latest/concepts/json_schema/#generating-json-schema)。
```python
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = """
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint."""
inputs = {
"task": {
"type": "string",
"description": "the task category (such as text-classification, depth-estimation, etc)",
}
}
output_type = "string"
def forward(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
```
现在,自定义的 `HfModelDownloadsTool` 类已经准备好,可以将其保存到名为 `model_downloads.py` 的文件中,并导入使用。
```python
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
```
你还可以通过调用 [`~Tool.push_to_hub`] 将自定义工具推送到 Hub。确保你已经为该工具创建了一个仓库,并使用具有读取访问权限的许可。
```python
tool.push_to_hub("{your_username}/hf-model-downloads")
```
通过 [`~Tool.load_tool`] 函数加载工具,并将其传递给智能体的 tools 参数。
```python
from transformers import load_tool, CodeAgent
model_download_tool = load_tool("m-ric/hf-model-downloads")
```
### 将 Space 导入为工具 🚀
你可以直接通过 [`Tool.from_space`] 方法将 Hub 上的 Space 导入为工具!
只需要提供 Space 在 Hub 上的 ID、名称和描述,帮助智能体理解工具的作用。在幕后,这将使用 [`gradio-client`](https://pypi.org/project/gradio-client/) 库来调用 Space。
例如,下面是从 Hub 导入 `FLUX.1-dev` Space 并用其生成图像的示例:
```
from transformers import Tool
image_generation_tool = Tool.from_space(
"black-forest-labs/FLUX.1-dev",
name="image_generator",
description="Generate an image from a prompt")
image_generation_tool("A sunny beach")
```
看!这就是你生成的图像!🏖️
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sunny_beach.webp">
然后,你可以像使用其他工具一样使用这个工具。例如,改进提示 `穿宇航服的兔子` 并生成其图像:
```python
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[image_generation_tool])
agent.run(
"Improve this prompt, then generate an image of it.", prompt='A rabbit wearing a space suit'
)
```
```text
=== Agent thoughts:
improved_prompt could be "A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background"
Now that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.
>>> Agent is executing the code below:
image = image_generator(prompt="A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background")
final_answer(image)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit_spacesuit_flux.webp">
这真酷吧?🤩
### 使用 gradio-tools
[gradio-tools](https://github.com/freddyaboulton/gradio-tools) 是一个强大的库,允许使用 Hugging Face Spaces 作为工具。它支持许多现有的 Spaces,也支持自定义 Spaces。
transformers 支持通过 [`Tool.from_gradio`] 方法使用 `gradio_tools`。例如,下面是如何使用来自 `gradio-tools` 工具包的 [`StableDiffusionPromptGeneratorTool`](https://github.com/freddyaboulton/gradio-tools/blob/main/gradio_tools/tools/prompt_generator.py) 来改进提示,以生成更好的图像:
导入和实例化工具,并将其传递给 `Tool.from_gradio` 方法:
```python
from gradio_tools import StableDiffusionPromptGeneratorTool
from transformers import Tool, load_tool, CodeAgent
gradio_prompt_generator_tool = StableDiffusionPromptGeneratorTool()
prompt_generator_tool = Tool.from_gradio(gradio_prompt_generator_tool)
```
> [!WARNING]
> gradio-tools 需要 **文本** 输入和输出,即使在处理像图像和音频这样的不同模态时也是如此。目前,图像和音频的输入输出与此不兼容。
### 使用 LangChain 工具
我们很喜欢 LangChain,并认为它有一套非常有吸引力的工具。
要从 LangChain 导入工具,可以使用 `from_langchain()` 方法。
例如,下面是如何使用它来重新创建上面介绍的搜索结果,使用一个 LangChain 网络搜索工具。该工具需要 `pip install google-search-results` 来正常工作。
```python
from langchain.agents import load_tools
from transformers import Tool, ReactCodeAgent
search_tool = Tool.from_langchain(load_tools(["serpapi"])[0])
agent = ReactCodeAgent(tools=[search_tool])
agent.run("How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?")
```
## 在酷炫的 Gradio 界面中展示智能体运行
你可以利用 `gradio.Chatbot` 来展示智能体的思考过程,通过 `stream_to_gradio`,下面是一个示例:
```py
import gradio as gr
from transformers import (
load_tool,
ReactCodeAgent,
HfApiEngine,
stream_to_gradio,
)
# Import tool from Hub
image_generation_tool = load_tool("m-ric/text-to-image")
llm_engine = HfApiEngine("meta-llama/Meta-Llama-3-70B-Instruct")
# Initialize the agent with the image generation tool
agent = ReactCodeAgent(tools=[image_generation_tool], llm_engine=llm_engine)
def interact_with_agent(task):
messages = []
messages.append(gr.ChatMessage(role="user", content=task))
yield messages
for msg in stream_to_gradio(agent, task):
messages.append(msg)
yield messages + [
gr.ChatMessage(role="assistant", content="⏳ Task not finished yet!")
]
yield messages
with gr.Blocks() as demo:
text_input = gr.Textbox(lines=1, label="Chat Message", value="Make me a picture of the Statue of Liberty.")
submit = gr.Button("Run illustrator agent!")
chatbot = gr.Chatbot(
label="Agent",
type="messages",
avatar_images=(
None,
"https://em-content.zobj.net/source/twitter/53/robot-face_1f916.png",
),
)
submit.click(interact_with_agent, [text_input], [chatbot])
if __name__ == "__main__":
demo.launch()
```
|
transformers/docs/source/zh/agents_advanced.md/0
|
{
"file_path": "transformers/docs/source/zh/agents_advanced.md",
"repo_id": "transformers",
"token_count": 4917
}
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 安装
为你正在使用的深度学习框架安装 🤗 Transformers、设置缓存,并选择性配置 🤗 Transformers 以离线运行。
🤗 Transformers 已在 Python 3.6+、PyTorch 1.1.0+、TensorFlow 2.0+ 以及 Flax 上进行测试。针对你使用的深度学习框架,请参照以下安装说明进行安装:
* [PyTorch](https://pytorch.org/get-started/locally/) 安装说明。
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 安装说明。
* [Flax](https://flax.readthedocs.io/en/latest/) 安装说明。
## 使用 pip 安装
你应该使用 [虚拟环境](https://docs.python.org/3/library/venv.html) 安装 🤗 Transformers。如果你不熟悉 Python 虚拟环境,请查看此 [教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。使用虚拟环境,你可以轻松管理不同项目,避免不同依赖项之间的兼容性问题。
首先,在项目目录中创建虚拟环境:
```bash
python -m venv .env
```
在 Linux 和 MacOs 系统中激活虚拟环境:
```bash
source .env/bin/activate
```
在 Windows 系统中激活虚拟环境:
```bash
.env/Scripts/activate
```
现在你可以使用以下命令安装 🤗 Transformers:
```bash
pip install transformers
```
若仅需 CPU 支持,可以使用单行命令方便地安装 🤗 Transformers 和深度学习库。例如,使用以下命令安装 🤗 Transformers 和 PyTorch:
```bash
pip install 'transformers[torch]'
```
🤗 Transformers 和 TensorFlow 2.0:
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
M1 / ARM用户
在安装 TensorFlow 2.0 前,你需要安装以下库:
```bash
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers 和 Flax:
```bash
pip install 'transformers[flax]'
```
最后,运行以下命令以检查 🤗 Transformers 是否已被正确安装。该命令将下载一个预训练模型:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
然后打印标签以及分数:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## 源码安装
使用以下命令从源码安装 🤗 Transformers:
```bash
pip install git+https://github.com/huggingface/transformers
```
此命令下载的是最新的前沿 `main` 版本而不是最新的 `stable` 版本。`main` 版本适用于跟最新开发保持一致。例如,上次正式版发布带来的 bug 被修复了,但新版本尚未被推出。但是,这也说明 `main` 版本并不一定总是稳定的。我们努力保持 `main` 版本的可操作性,大多数问题通常在几个小时或一天以内就能被解决。如果你遇到问题,请提个 [Issue](https://github.com/huggingface/transformers/issues) 以便我们能更快修复。
运行以下命令以检查 🤗 Transformers 是否已被正确安装:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## 可编辑安装
如果你有下列需求,需要进行可编辑安装:
* 使用源码的 `main` 版本。
* 为 🤗 Transformers 贡献代码,需要测试代码中的更改。
使用以下命令克隆仓库并安装 🤗 Transformers:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
这些命令将会链接你克隆的仓库以及你的 Python 库路径。现在,Python 不仅会在正常的库路径中搜索库,也会在你克隆到的文件夹中进行查找。例如,如果你的 Python 包通常本应安装在 `~/anaconda3/envs/main/lib/python3.7/site-packages/` 目录中,在这种情况下 Python 也会搜索你克隆到的文件夹:`~/transformers/`。
<Tip warning={true}>
如果你想继续使用这个库,必须保留 `transformers` 文件夹。
</Tip>
现在,你可以使用以下命令,将你克隆的 🤗 Transformers 库轻松更新至最新版本:
```bash
cd ~/transformers/
git pull
```
你的 Python 环境将在下次运行时找到 `main` 版本的 🤗 Transformers。
## 使用 conda 安装
从 conda 的 `conda-forge` 频道安装:
```bash
conda install conda-forge::transformers
```
## 缓存设置
预训练模型会被下载并本地缓存到 `~/.cache/huggingface/hub`。这是由环境变量 `TRANSFORMERS_CACHE` 指定的默认目录。在 Windows 上,默认目录为 `C:\Users\username\.cache\huggingface\hub`。你可以按照不同优先级改变下述环境变量,以指定不同的缓存目录。
1. 环境变量(默认): `HF_HUB_CACHE` 或 `TRANSFORMERS_CACHE`。
2. 环境变量 `HF_HOME`。
3. 环境变量 `XDG_CACHE_HOME` + `/huggingface`。
<Tip>
除非你明确指定了环境变量 `TRANSFORMERS_CACHE`,🤗 Transformers 将可能会使用较早版本设置的环境变量 `PYTORCH_TRANSFORMERS_CACHE` 或 `PYTORCH_PRETRAINED_BERT_CACHE`。
</Tip>
## 离线模式
🤗 Transformers 可以仅使用本地文件在防火墙或离线环境中运行。设置环境变量 `HF_HUB_OFFLINE=1` 以启用该行为。
<Tip>
通过设置环境变量 `HF_DATASETS_OFFLINE=1` 将 [🤗 Datasets](https://huggingface.co/docs/datasets/) 添加至你的离线训练工作流程中。
</Tip>
例如,你通常会使用以下命令对外部实例进行防火墙保护的的普通网络上运行程序:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
在离线环境中运行相同的程序:
```bash
HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
现在脚本可以应该正常运行,而无需挂起或等待超时,因为它知道只应查找本地文件。
### 获取离线时使用的模型和分词器
另一种离线时使用 🤗 Transformers 的方法是预先下载好文件,然后在需要离线使用时指向它们的离线路径。有三种实现的方法:
* 单击 [Model Hub](https://huggingface.co/models) 用户界面上的 ↓ 图标下载文件。

* 使用 [`PreTrainedModel.from_pretrained`] 和 [`PreTrainedModel.save_pretrained`] 工作流程:
1. 预先使用 [`PreTrainedModel.from_pretrained`] 下载文件:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. 使用 [`PreTrainedModel.save_pretrained`] 将文件保存至指定目录:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. 现在,你可以在离线时从指定目录使用 [`PreTrainedModel.from_pretrained`] 重新加载你的文件:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* 使用代码用 [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) 库下载文件:
1. 在你的虚拟环境中安装 `huggingface_hub` 库:
```bash
python -m pip install huggingface_hub
```
2. 使用 [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) 函数将文件下载到指定路径。例如,以下命令将 `config.json` 文件从 [T0](https://huggingface.co/bigscience/T0_3B) 模型下载至你想要的路径:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
下载完文件并在本地缓存后,指定其本地路径以加载和使用该模型:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
请参阅 [如何从 Hub 下载文件](https://huggingface.co/docs/hub/how-to-downstream) 部分,获取有关下载存储在 Hub 上文件的更多详细信息。
</Tip>
|
transformers/docs/source/zh/installation.md/0
|
{
"file_path": "transformers/docs/source/zh/installation.md",
"repo_id": "transformers",
"token_count": 4833
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 🤗 PEFT 加载adapters
[[open-in-colab]]
[参数高效微调(PEFT)方法](https://huggingface.co/blog/peft)在微调过程中冻结预训练模型的参数,并在其顶部添加少量可训练参数(adapters)。adapters被训练以学习特定任务的信息。这种方法已被证明非常节省内存,同时具有较低的计算使用量,同时产生与完全微调模型相当的结果。
使用PEFT训练的adapters通常比完整模型小一个数量级,使其方便共享、存储和加载。
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">与完整尺寸的模型权重(约为700MB)相比,存储在Hub上的OPTForCausalLM模型的adapter权重仅为~6MB。</figcaption>
</div>
如果您对学习更多关于🤗 PEFT库感兴趣,请查看[文档](https://huggingface.co/docs/peft/index)。
## 设置
首先安装 🤗 PEFT:
```bash
pip install peft
```
如果你想尝试全新的特性,你可能会有兴趣从源代码安装这个库:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## 支持的 PEFT 模型
Transformers原生支持一些PEFT方法,这意味着你可以加载本地存储或在Hub上的adapter权重,并使用几行代码轻松运行或训练它们。以下是受支持的方法:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
如果你想使用其他PEFT方法,例如提示学习或提示微调,或者关于通用的 🤗 PEFT库,请参阅[文档](https://huggingface.co/docs/peft/index)。
## 加载 PEFT adapter
要从huggingface的Transformers库中加载并使用PEFTadapter模型,请确保Hub仓库或本地目录包含一个`adapter_config.json`文件和adapter权重,如上例所示。然后,您可以使用`AutoModelFor`类加载PEFT adapter模型。例如,要为因果语言建模加载一个PEFT adapter模型:
1. 指定PEFT模型id
2. 将其传递给[`AutoModelForCausalLM`]类
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
你可以使用`AutoModelFor`类或基础模型类(如`OPTForCausalLM`或`LlamaForCausalLM`)来加载一个PEFT adapter。
</Tip>
您也可以通过`load_adapter`方法来加载 PEFT adapter。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## 基于8bit或4bit进行加载
`bitsandbytes`集成支持8bit和4bit精度数据类型,这对于加载大模型非常有用,因为它可以节省内存(请参阅`bitsandbytes`[指南](./quantization#bitsandbytes-integration)以了解更多信息)。要有效地将模型分配到您的硬件,请在[`~PreTrainedModel.from_pretrained`]中添加`load_in_8bit`或`load_in_4bit`参数,并将`device_map="auto"`设置为:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
```
## 添加新的adapter
你可以使用[`~peft.PeftModel.add_adapter`]方法为一个已有adapter的模型添加一个新的adapter,只要新adapter的类型与当前adapter相同即可。例如,如果你有一个附加到模型上的LoRA adapter:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
添加一个新的adapter:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
现在您可以使用[`~peft.PeftModel.set_adapter`]来设置要使用的adapter。
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## 启用和禁用adapters
一旦您将adapter添加到模型中,您可以启用或禁用adapter模块。要启用adapter模块:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
要禁用adapter模块:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## 训练一个 PEFT adapter
PEFT适配器受[`Trainer`]类支持,因此您可以为您的特定用例训练适配器。它只需要添加几行代码即可。例如,要训练一个LoRA adapter:
<Tip>
如果你不熟悉如何使用[`Trainer`]微调模型,请查看[微调预训练模型](training)教程。
</Tip>
1. 使用任务类型和超参数定义adapter配置(参见[`~peft.LoraConfig`]以了解超参数的详细信息)。
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. 将adapter添加到模型中。
```py
model.add_adapter(peft_config)
```
3. 现在可以将模型传递给[`Trainer`]了!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
要保存训练好的adapter并重新加载它:
```py
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
<!--
TODO: (@younesbelkada @stevhliu)
- Link to PEFT docs for further details
- Trainer
- 8-bit / 4-bit examples ?
-->
|
transformers/docs/source/zh/peft.md/0
|
{
"file_path": "transformers/docs/source/zh/peft.md",
"repo_id": "transformers",
"token_count": 3638
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) 是一个轻量级框架,用于资源受限的设备上,如手机、嵌入式系统和物联网(IoT)设备,部署机器学习模型。TFLite 旨在在计算能力、内存和功耗有限的设备上优化和高效运行模型。模型以一种特殊的高效可移植格式表示,其文件扩展名为 `.tflite`。
🤗 Optimum 通过 `exporters.tflite` 模块提供将 🤗 Transformers 模型导出至 TFLite 格式的功能。请参考 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/exporters/tflite/overview) 以获取支持的模型架构列表。
要将模型导出为 TFLite 格式,请安装所需的依赖项:
```bash
pip install optimum[exporters-tf]
```
请参阅 [🤗 Optimum 文档](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model) 以查看所有可用参数,或者在命令行中查看帮助:
```bash
optimum-cli export tflite --help
```
运行以下命令,以从 🤗 Hub 导出模型的检查点(checkpoint),以 `google-bert/bert-base-uncased` 为例:
```bash
optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
```
你应该能在日志中看到导出进度以及生成的 `model.tflite` 文件的保存位置,如下所示:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
上面的示例说明了从 🤗 Hub 导出检查点的过程。导出本地模型时,首先需要确保将模型的权重和分词器文件保存在同一目录(`local_path`)中。在使用 CLI(命令行)时,将 `local_path` 传递给 `model` 参数,而不是 🤗 Hub 上的检查点名称。
|
transformers/docs/source/zh/tflite.md/0
|
{
"file_path": "transformers/docs/source/zh/tflite.md",
"repo_id": "transformers",
"token_count": 1386
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Pre-training/Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
https://huggingface.co/models?filter=text-generation
"""
# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
import json
import logging
import math
import os
import sys
import time
from dataclasses import asdict, dataclass, field
from enum import Enum
from itertools import chain
from pathlib import Path
from typing import Callable, Optional
import datasets
import jax
import jax.numpy as jnp
import numpy as np
import optax
from datasets import Dataset, load_dataset
from flax import jax_utils, traverse_util
from flax.jax_utils import pad_shard_unpad, unreplicate
from flax.training import train_state
from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
from huggingface_hub import HfApi
from tqdm import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
AutoConfig,
AutoTokenizer,
FlaxAutoModelForCausalLM,
HfArgumentParser,
is_tensorboard_available,
set_seed,
)
from transformers.testing_utils import CaptureLogger
from transformers.utils import send_example_telemetry
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_CAUSAL_LM_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class TrainingArguments:
output_dir: str = field(
metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
)
overwrite_output_dir: bool = field(
default=False,
metadata={
"help": (
"Overwrite the content of the output directory. "
"Use this to continue training if output_dir points to a checkpoint directory."
)
},
)
do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
per_device_train_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
)
per_device_eval_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
)
learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
push_to_hub: bool = field(
default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
)
hub_model_id: str = field(
default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
)
hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
def __post_init__(self):
if self.output_dir is not None:
self.output_dir = os.path.expanduser(self.output_dir)
def to_dict(self):
"""
Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
the token values by removing their value.
"""
d = asdict(self)
for k, v in d.items():
if isinstance(v, Enum):
d[k] = v.value
if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
d[k] = [x.value for x in v]
if k.endswith("_token"):
d[k] = f"<{k.upper()}>"
return d
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
)
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
dtype: Optional[str] = field(
default="float32",
metadata={
"help": (
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
" `[float32, float16, bfloat16]`."
)
},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
validation_split_percentage: Optional[int] = field(
default=5,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
block_size: Optional[int] = field(
default=None,
metadata={
"help": (
"Optional input sequence length after tokenization. "
"The training dataset will be truncated in block of this size for training. "
"Default to the model max input length for single sentence inputs (take into account special tokens)."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
keep_linebreaks: bool = field(
default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
if extension not in ["csv", "json", "txt"]:
raise ValueError("train_file` should be a csv, json or text file.")
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
if extension not in ["csv", "json", "txt"]:
raise ValueError("`validation_file` should be a csv, json or text file.")
class TrainState(train_state.TrainState):
dropout_rng: jnp.ndarray
def replicate(self):
return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False, drop_last=True):
"""
Returns batches of size `batch_size` from `dataset`. If `drop_last` is set to `False`, the final batch may be incomplete,
and range in size from 1 to `batch_size`. Shuffle batches if `shuffle` is `True`.
"""
if shuffle:
batch_idx = jax.random.permutation(rng, len(dataset))
batch_idx = np.asarray(batch_idx)
else:
batch_idx = np.arange(len(dataset))
if drop_last:
steps_per_epoch = len(dataset) // batch_size
batch_idx = batch_idx[: steps_per_epoch * batch_size] # Skip incomplete batch.
batch_idx = batch_idx.reshape((steps_per_epoch, batch_size))
else:
steps_per_epoch = math.ceil(len(dataset) / batch_size)
batch_idx = np.array_split(batch_idx, steps_per_epoch)
for idx in batch_idx:
batch = dataset[idx]
batch = {k: np.array(v) for k, v in batch.items()}
yield batch
def write_train_metric(summary_writer, train_metrics, train_time, step):
summary_writer.scalar("train_time", train_time, step)
train_metrics = get_metrics(train_metrics)
for key, vals in train_metrics.items():
tag = f"train_{key}"
for i, val in enumerate(vals):
summary_writer.scalar(tag, val, step - len(vals) + i + 1)
def write_eval_metric(summary_writer, eval_metrics, step):
for metric_name, value in eval_metrics.items():
summary_writer.scalar(f"eval_{metric_name}", value, step)
def create_learning_rate_fn(
train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
) -> Callable[[int], jnp.ndarray]:
"""Returns a linear warmup, linear_decay learning rate function."""
steps_per_epoch = train_ds_size // train_batch_size
num_train_steps = steps_per_epoch * num_train_epochs
warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
decay_fn = optax.linear_schedule(
init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
)
schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
return schedule_fn
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_clm", model_args, data_args, framework="flax")
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# Set the verbosity to info of the Transformers logger (on main process only):
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Handle the repository creation
if training_args.push_to_hub:
# Retrieve of infer repo_name
repo_name = training_args.hub_model_id
if repo_name is None:
repo_name = Path(training_args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
keep_in_memory=False,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
trust_remote_code=model_args.trust_remote_code,
)
if "validation" not in dataset.keys():
dataset["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
trust_remote_code=model_args.trust_remote_code,
)
dataset["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
trust_remote_code=model_args.trust_remote_code,
)
else:
data_files = {}
dataset_args = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if extension == "txt":
extension = "text"
dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
dataset = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
**dataset_args,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
)
if "validation" not in dataset.keys():
dataset["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
**dataset_args,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
)
dataset["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
**dataset_args,
token=model_args.token,
num_proc=data_args.preprocessing_num_workers,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if model_args.config_name:
config = AutoConfig.from_pretrained(
model_args.config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if model_args.model_name_or_path:
model = FlaxAutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=config,
seed=training_args.seed,
dtype=getattr(jnp, model_args.dtype),
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
model = FlaxAutoModelForCausalLM.from_config(
config,
seed=training_args.seed,
dtype=getattr(jnp, model_args.dtype),
trust_remote_code=model_args.trust_remote_code,
)
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = dataset["train"].column_names
else:
column_names = dataset["validation"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
def tokenize_function(examples):
with CaptureLogger(tok_logger) as cl:
output = tokenizer(examples[text_column_name])
# clm input could be much much longer than block_size
if "Token indices sequence length is longer than the" in cl.out:
tok_logger.warning(
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
" before being passed to the model."
)
return output
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if data_args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > config.max_position_embeddings:
logger.warning(
f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
)
block_size = min(1024, config.max_position_embeddings)
else:
if data_args.block_size > tokenizer.model_max_length:
logger.warning(
f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
)
block_size = min(data_args.block_size, tokenizer.model_max_length)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
# for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
# to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/process#map
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_train:
if "train" not in tokenized_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = lm_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
if training_args.do_eval:
if "validation" not in tokenized_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = lm_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
# Enable tensorboard only on the master node
has_tensorboard = is_tensorboard_available()
if has_tensorboard and jax.process_index() == 0:
try:
from flax.metrics.tensorboard import SummaryWriter
summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
except ImportError as ie:
has_tensorboard = False
logger.warning(
f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
)
else:
logger.warning(
"Unable to display metrics through TensorBoard because the package is not installed: "
"Please run pip install tensorboard to enable."
)
# Initialize our training
rng = jax.random.PRNGKey(training_args.seed)
rng, dropout_rng = jax.random.split(rng)
# Store some constant
num_epochs = int(training_args.num_train_epochs)
train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
eval_batch_size = per_device_eval_batch_size * jax.device_count()
steps_per_epoch = len(train_dataset) // train_batch_size
total_train_steps = steps_per_epoch * num_epochs
# Create learning rate schedule
linear_decay_lr_schedule_fn = create_learning_rate_fn(
len(train_dataset),
train_batch_size,
training_args.num_train_epochs,
training_args.warmup_steps,
training_args.learning_rate,
)
# We use Optax's "masking" functionality to not apply weight decay
# to bias and LayerNorm scale parameters. decay_mask_fn returns a
# mask boolean with the same structure as the parameters.
# The mask is True for parameters that should be decayed.
def decay_mask_fn(params):
flat_params = traverse_util.flatten_dict(params)
# find out all LayerNorm parameters
layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
layer_norm_named_params = {
layer[-2:]
for layer_norm_name in layer_norm_candidates
for layer in flat_params.keys()
if layer_norm_name in "".join(layer).lower()
}
flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
return traverse_util.unflatten_dict(flat_mask)
# create adam optimizer
if training_args.adafactor:
# We use the default parameters here to initialize adafactor,
# For more details about the parameters please check https://github.com/deepmind/optax/blob/ed02befef9bf81cbbf236be3d2b0e032e9ed4a40/optax/_src/alias.py#L74
optimizer = optax.adafactor(
learning_rate=linear_decay_lr_schedule_fn,
)
else:
optimizer = optax.adamw(
learning_rate=linear_decay_lr_schedule_fn,
b1=training_args.adam_beta1,
b2=training_args.adam_beta2,
eps=training_args.adam_epsilon,
weight_decay=training_args.weight_decay,
mask=decay_mask_fn,
)
# Setup train state
state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=optimizer, dropout_rng=dropout_rng)
def loss_fn(logits, labels):
shift_logits = logits[..., :-1, :]
shift_labels = labels[..., 1:]
loss = optax.softmax_cross_entropy(shift_logits, onehot(shift_labels, shift_logits.shape[-1]))
return loss.mean()
# Define gradient update step fn
def train_step(state, batch):
dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
def compute_loss(params):
labels = batch.pop("labels")
logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss = loss_fn(logits, labels)
return loss
grad_fn = jax.value_and_grad(compute_loss)
loss, grad = grad_fn(state.params)
grad = jax.lax.pmean(grad, "batch")
new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
metrics = jax.lax.pmean(metrics, axis_name="batch")
return new_state, metrics
# Define eval fn
def eval_step(params, batch):
labels = batch.pop("labels")
logits = model(**batch, params=params, train=False)[0]
loss = loss_fn(logits, labels)
# summarize metrics
metrics = {"loss": loss}
metrics = jax.lax.pmean(metrics, axis_name="batch")
return metrics
# Create parallel version of the train and eval step
p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
p_eval_step = jax.pmap(eval_step, "batch")
# Replicate the train state on each device
state = state.replicate()
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {num_epochs}")
logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
logger.info(f" Total optimization steps = {total_train_steps}")
train_time = 0
train_metrics = []
epochs = tqdm(range(num_epochs), desc="Epoch ... ", position=0)
for epoch in epochs:
# ======================== Training ================================
train_start = time.time()
# Create sampling rng
rng, input_rng = jax.random.split(rng)
# Generate an epoch by shuffling sampling indices from the train dataset
train_loader = data_loader(input_rng, train_dataset, train_batch_size, shuffle=True)
steps_per_epoch = len(train_dataset) // train_batch_size
# train
for step in tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False):
batch = next(train_loader)
batch = shard(batch)
state, train_metric = p_train_step(state, batch)
train_metrics.append(train_metric)
cur_step = epoch * (len(train_dataset) // train_batch_size) + step
if cur_step % training_args.logging_steps == 0 and cur_step > 0:
# Save metrics
train_metric = unreplicate(train_metric)
train_time += time.time() - train_start
if has_tensorboard and jax.process_index() == 0:
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
epochs.write(
f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate:"
f" {train_metric['learning_rate'].mean()})"
)
train_metrics = []
if cur_step % training_args.eval_steps == 0 and cur_step > 0:
# ======================== Evaluating ==============================
eval_metrics = []
eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size, drop_last=False)
eval_steps = math.ceil(len(eval_dataset) / eval_batch_size)
for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
# Model forward
batch = next(eval_loader)
metrics = pad_shard_unpad(p_eval_step, static_return=True)(
state.params, batch, min_device_batch=per_device_eval_batch_size
)
eval_metrics.append(metrics)
# normalize eval metrics
eval_metrics = get_metrics(eval_metrics)
eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
try:
eval_metrics["perplexity"] = math.exp(eval_metrics["loss"])
except OverflowError:
eval_metrics["perplexity"] = float("inf")
# Print metrics and update progress bar
desc = (
f"Step... ({cur_step} | Eval Loss: {eval_metrics['loss']} | Eval Perplexity:"
f" {eval_metrics['perplexity']})"
)
epochs.write(desc)
epochs.desc = desc
# Save metrics
if has_tensorboard and jax.process_index() == 0:
write_eval_metric(summary_writer, eval_metrics, cur_step)
if cur_step % training_args.save_steps == 0 and cur_step > 0:
# save checkpoint after each epoch and push checkpoint to the hub
if jax.process_index() == 0:
params = jax.device_get(unreplicate(state.params))
model.save_pretrained(training_args.output_dir, params=params)
tokenizer.save_pretrained(training_args.output_dir)
if training_args.push_to_hub:
api.upload_folder(
commit_message=f"Saving weights and logs of step {cur_step}",
folder_path=training_args.output_dir,
repo_id=repo_id,
repo_type="model",
token=training_args.hub_token,
)
# Eval after training
if training_args.do_eval:
eval_metrics = []
eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size, drop_last=False)
eval_steps = math.ceil(len(eval_dataset) / eval_batch_size)
for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
# Model forward
batch = next(eval_loader)
metrics = pad_shard_unpad(p_eval_step, static_return=True)(
state.params, batch, min_device_batch=per_device_eval_batch_size
)
eval_metrics.append(metrics)
# normalize eval metrics
eval_metrics = get_metrics(eval_metrics)
eval_metrics = jax.tree_util.tree_map(lambda x: jnp.mean(x).item(), eval_metrics)
try:
eval_metrics["perplexity"] = math.exp(eval_metrics["loss"])
except OverflowError:
eval_metrics["perplexity"] = float("inf")
if jax.process_index() == 0:
eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
path = os.path.join(training_args.output_dir, "eval_results.json")
with open(path, "w") as f:
json.dump(eval_metrics, f, indent=4, sort_keys=True)
if __name__ == "__main__":
main()
|
transformers/examples/flax/language-modeling/run_clm_flax.py/0
|
{
"file_path": "transformers/examples/flax/language-modeling/run_clm_flax.py",
"repo_id": "transformers",
"token_count": 15979
}
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import fire
from utils import calculate_rouge, save_json
def calculate_rouge_path(pred_path, tgt_path, save_path=None, **kwargs):
"""Kwargs will be passed to calculate_rouge"""
pred_lns = [x.strip() for x in open(pred_path).readlines()]
tgt_lns = [x.strip() for x in open(tgt_path).readlines()][: len(pred_lns)]
metrics = calculate_rouge(pred_lns, tgt_lns, **kwargs)
if save_path is not None:
save_json(metrics, save_path, indent=None)
return metrics # these print nicely
if __name__ == "__main__":
fire.Fire(calculate_rouge_path)
|
transformers/examples/legacy/seq2seq/rouge_cli.py/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/rouge_cli.py",
"repo_id": "transformers",
"token_count": 385
}
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Named entity recognition fine-tuning: utilities to work with CoNLL-2003 task."""
import logging
import os
from dataclasses import dataclass
from enum import Enum
from typing import List, Optional, Union
from filelock import FileLock
from transformers import PreTrainedTokenizer, is_tf_available, is_torch_available
logger = logging.getLogger(__name__)
@dataclass
class InputExample:
"""
A single training/test example for token classification.
Args:
guid: Unique id for the example.
words: list. The words of the sequence.
labels: (Optional) list. The labels for each word of the sequence. This should be
specified for train and dev examples, but not for test examples.
"""
guid: str
words: List[str]
labels: Optional[List[str]]
@dataclass
class InputFeatures:
"""
A single set of features of data.
Property names are the same names as the corresponding inputs to a model.
"""
input_ids: List[int]
attention_mask: List[int]
token_type_ids: Optional[List[int]] = None
label_ids: Optional[List[int]] = None
class Split(Enum):
train = "train"
dev = "dev"
test = "test"
class TokenClassificationTask:
@staticmethod
def read_examples_from_file(data_dir, mode: Union[Split, str]) -> List[InputExample]:
raise NotImplementedError
@staticmethod
def get_labels(path: str) -> List[str]:
raise NotImplementedError
@staticmethod
def convert_examples_to_features(
examples: List[InputExample],
label_list: List[str],
max_seq_length: int,
tokenizer: PreTrainedTokenizer,
cls_token_at_end=False,
cls_token="[CLS]",
cls_token_segment_id=1,
sep_token="[SEP]",
sep_token_extra=False,
pad_on_left=False,
pad_token=0,
pad_token_segment_id=0,
pad_token_label_id=-100,
sequence_a_segment_id=0,
mask_padding_with_zero=True,
) -> List[InputFeatures]:
"""Loads a data file into a list of `InputFeatures`
`cls_token_at_end` define the location of the CLS token:
- False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]
- True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]
`cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)
"""
# TODO clean up all this to leverage built-in features of tokenizers
label_map = {label: i for i, label in enumerate(label_list)}
features = []
for ex_index, example in enumerate(examples):
if ex_index % 10_000 == 0:
logger.info("Writing example %d of %d", ex_index, len(examples))
tokens = []
label_ids = []
for word, label in zip(example.words, example.labels):
word_tokens = tokenizer.tokenize(word)
# google-bert/bert-base-multilingual-cased sometimes output "nothing ([]) when calling tokenize with just a space.
if len(word_tokens) > 0:
tokens.extend(word_tokens)
# Use the real label id for the first token of the word, and padding ids for the remaining tokens
label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))
# Account for [CLS] and [SEP] with "- 2" and with "- 3" for RoBERTa.
special_tokens_count = tokenizer.num_special_tokens_to_add()
if len(tokens) > max_seq_length - special_tokens_count:
tokens = tokens[: (max_seq_length - special_tokens_count)]
label_ids = label_ids[: (max_seq_length - special_tokens_count)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens += [sep_token]
label_ids += [pad_token_label_id]
if sep_token_extra:
# roberta uses an extra separator b/w pairs of sentences
tokens += [sep_token]
label_ids += [pad_token_label_id]
segment_ids = [sequence_a_segment_id] * len(tokens)
if cls_token_at_end:
tokens += [cls_token]
label_ids += [pad_token_label_id]
segment_ids += [cls_token_segment_id]
else:
tokens = [cls_token] + tokens
label_ids = [pad_token_label_id] + label_ids
segment_ids = [cls_token_segment_id] + segment_ids
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_length - len(input_ids)
if pad_on_left:
input_ids = ([pad_token] * padding_length) + input_ids
input_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_mask
segment_ids = ([pad_token_segment_id] * padding_length) + segment_ids
label_ids = ([pad_token_label_id] * padding_length) + label_ids
else:
input_ids += [pad_token] * padding_length
input_mask += [0 if mask_padding_with_zero else 1] * padding_length
segment_ids += [pad_token_segment_id] * padding_length
label_ids += [pad_token_label_id] * padding_length
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
assert len(label_ids) == max_seq_length
if ex_index < 5:
logger.info("*** Example ***")
logger.info("guid: %s", example.guid)
logger.info("tokens: %s", " ".join([str(x) for x in tokens]))
logger.info("input_ids: %s", " ".join([str(x) for x in input_ids]))
logger.info("input_mask: %s", " ".join([str(x) for x in input_mask]))
logger.info("segment_ids: %s", " ".join([str(x) for x in segment_ids]))
logger.info("label_ids: %s", " ".join([str(x) for x in label_ids]))
if "token_type_ids" not in tokenizer.model_input_names:
segment_ids = None
features.append(
InputFeatures(
input_ids=input_ids, attention_mask=input_mask, token_type_ids=segment_ids, label_ids=label_ids
)
)
return features
if is_torch_available():
import torch
from torch import nn
from torch.utils.data import Dataset
class TokenClassificationDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
pad_token_label_id: int = nn.CrossEntropyLoss().ignore_index
# Use cross entropy ignore_index as padding label id so that only
# real label ids contribute to the loss later.
def __init__(
self,
token_classification_task: TokenClassificationTask,
data_dir: str,
tokenizer: PreTrainedTokenizer,
labels: List[str],
model_type: str,
max_seq_length: Optional[int] = None,
overwrite_cache=False,
mode: Split = Split.train,
):
# Load data features from cache or dataset file
cached_features_file = os.path.join(
data_dir,
"cached_{}_{}_{}".format(mode.value, tokenizer.__class__.__name__, str(max_seq_length)),
)
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not overwrite_cache:
logger.info(f"Loading features from cached file {cached_features_file}")
self.features = torch.load(cached_features_file)
else:
logger.info(f"Creating features from dataset file at {data_dir}")
examples = token_classification_task.read_examples_from_file(data_dir, mode)
# TODO clean up all this to leverage built-in features of tokenizers
self.features = token_classification_task.convert_examples_to_features(
examples,
labels,
max_seq_length,
tokenizer,
cls_token_at_end=bool(model_type in ["xlnet"]),
# xlnet has a cls token at the end
cls_token=tokenizer.cls_token,
cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
sep_token=tokenizer.sep_token,
sep_token_extra=False,
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
pad_on_left=bool(tokenizer.padding_side == "left"),
pad_token=tokenizer.pad_token_id,
pad_token_segment_id=tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
logger.info(f"Saving features into cached file {cached_features_file}")
torch.save(self.features, cached_features_file)
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
if is_tf_available():
import tensorflow as tf
class TFTokenClassificationDataset:
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
pad_token_label_id: int = -100
# Use cross entropy ignore_index as padding label id so that only
# real label ids contribute to the loss later.
def __init__(
self,
token_classification_task: TokenClassificationTask,
data_dir: str,
tokenizer: PreTrainedTokenizer,
labels: List[str],
model_type: str,
max_seq_length: Optional[int] = None,
overwrite_cache=False,
mode: Split = Split.train,
):
examples = token_classification_task.read_examples_from_file(data_dir, mode)
# TODO clean up all this to leverage built-in features of tokenizers
self.features = token_classification_task.convert_examples_to_features(
examples,
labels,
max_seq_length,
tokenizer,
cls_token_at_end=bool(model_type in ["xlnet"]),
# xlnet has a cls token at the end
cls_token=tokenizer.cls_token,
cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
sep_token=tokenizer.sep_token,
sep_token_extra=False,
# roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
pad_on_left=bool(tokenizer.padding_side == "left"),
pad_token=tokenizer.pad_token_id,
pad_token_segment_id=tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
def gen():
for ex in self.features:
if ex.token_type_ids is None:
yield (
{"input_ids": ex.input_ids, "attention_mask": ex.attention_mask},
ex.label_ids,
)
else:
yield (
{
"input_ids": ex.input_ids,
"attention_mask": ex.attention_mask,
"token_type_ids": ex.token_type_ids,
},
ex.label_ids,
)
if "token_type_ids" not in tokenizer.model_input_names:
self.dataset = tf.data.Dataset.from_generator(
gen,
({"input_ids": tf.int32, "attention_mask": tf.int32}, tf.int64),
(
{"input_ids": tf.TensorShape([None]), "attention_mask": tf.TensorShape([None])},
tf.TensorShape([None]),
),
)
else:
self.dataset = tf.data.Dataset.from_generator(
gen,
({"input_ids": tf.int32, "attention_mask": tf.int32, "token_type_ids": tf.int32}, tf.int64),
(
{
"input_ids": tf.TensorShape([None]),
"attention_mask": tf.TensorShape([None]),
"token_type_ids": tf.TensorShape([None]),
},
tf.TensorShape([None]),
),
)
def get_dataset(self):
self.dataset = self.dataset.apply(tf.data.experimental.assert_cardinality(len(self.features)))
return self.dataset
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
|
transformers/examples/legacy/token-classification/utils_ner.py/0
|
{
"file_path": "transformers/examples/legacy/token-classification/utils_ner.py",
"repo_id": "transformers",
"token_count": 7661
}
|
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
# This file was automatically generated from examples/modular-transformers/modular_new_task_model.py.
# Do NOT edit this file manually as any edits will be overwritten by the generation of
# the file from the modular. If any change should be done, please apply the change to the
# modular_new_task_model.py file directly. One of our CI enforces this.
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
from dataclasses import dataclass
from typing import ClassVar, List, Optional, Tuple, Union
import torch
from torch import nn
from ...cache_utils import Cache, HybridCache, StaticCache
from ...generation import GenerationMixin
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
replace_return_docstrings,
)
from ..auto import AutoModel, AutoModelForCausalLM
from .configuration_new_task_model import NewTaskModelConfig
_CONFIG_FOR_DOC = "NewTaskModelConfig"
@dataclass
class NewTaskModelCausalLMOutputWithPast(ModelOutput):
"""
Base class for NewTaskModelcausal language model (or autoregressive) outputs.
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
Language modeling loss (for next-token prediction).
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.text_config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`)
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
`past_key_values` input) to speed up sequential decoding.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
image_hidden_states (`torch.FloatTensor`, *optional*):
A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
image_hidden_states of the model produced by the vision encoder after projecting last hidden state.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
past_key_values: Optional[Union[List[torch.FloatTensor], Cache]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
image_hidden_states: Optional[torch.FloatTensor] = None
class NewTaskModelMultiModalProjector(nn.Module):
def __init__(self, config: NewTaskModelConfig):
super().__init__()
self.linear = nn.Linear(config.vision_config.hidden_size, config.vision_config.projection_dim, bias=True)
def forward(self, image_features):
hidden_states = self.linear(image_features)
return hidden_states
NEW_TASK_MODEL_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`NewTaskModelConfig`] or [`NewTaskModelVisionConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
@add_start_docstrings(
"The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
NEW_TASK_MODEL_START_DOCSTRING,
)
class NewTaskModelPreTrainedModel(PreTrainedModel):
config_class = NewTaskModelConfig
base_model_prefix = "model"
supports_gradient_checkpointing = True
_no_split_modules = ["NewTaskModelMultiModalProjector"]
_skip_keys_device_placement = "past_key_values"
_supports_cache_class = True
_supports_quantized_cache = True
_supports_static_cache = True
_supports_flash_attn_2 = True
_supports_sdpa = True
def _init_weights(self, module):
# important: this ported version of NewTaskModelisn't meant for training from scratch - only
# inference and fine-tuning
std = (
self.config.initializer_range
if hasattr(self.config, "initializer_range")
else self.config.text_config.initializer_range
)
if hasattr(module, "class_embedding"):
module.class_embedding.data.normal_(mean=0.0, std=std)
if isinstance(module, (nn.Linear, nn.Conv2d)):
module.weight.data.normal_(mean=0.0, std=std)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=std)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
NEW_TASK_MODEL_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)):
The tensors corresponding to the input images. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`SiglipImageProcessor.__call__`] for details ([]`NewTaskModelProcessor`] uses
[`SiglipImageProcessor`] for processing images).
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
`past_key_values`).
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
information on the default strategy.
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.n_positions - 1]`. [What are position IDs?](../glossary#position-ids)
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
the complete sequence length.
"""
@add_start_docstrings(
"""The NEW_TASK_MODEL model which consists of a vision backbone and a language model.""",
NEW_TASK_MODEL_START_DOCSTRING,
)
class NewTaskModelForNewTask(NewTaskModelPreTrainedModel, GenerationMixin):
main_input_name: ClassVar[str] = "doc_input_ids" # transformers-related
def __init__(self, config):
super().__init__(config)
self.vision_tower = AutoModel.from_config(config=config.vision_config)
self.multi_modal_projector = NewTaskModelMultiModalProjector(config)
self.vocab_size = config.text_config.vocab_size
language_model = AutoModelForCausalLM.from_config(config=config.text_config)
if language_model._tied_weights_keys is not None:
self._tied_weights_keys = [f"language_model.{k}" for k in language_model._tied_weights_keys]
self.language_model = language_model
self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
self.embedding_dim = self.config.embedding_dim
self.custom_text_proj = nn.Linear(self.config.text_config.hidden_size, self.embedding_dim)
if self.language_model._tied_weights_keys is not None:
self._tied_weights_keys = [f"model.language_model.{k}" for k in self.language_model._tied_weights_keys]
self.post_init()
def get_input_embeddings(self):
return self.language_model.get_input_embeddings()
def set_input_embeddings(self, value):
self.language_model.set_input_embeddings(value)
def get_output_embeddings(self):
return self.language_model.get_output_embeddings()
def set_output_embeddings(self, new_embeddings):
self.language_model.set_output_embeddings(new_embeddings)
def set_decoder(self, decoder):
self.language_model.set_decoder(decoder)
def get_decoder(self):
return self.language_model.get_decoder()
def _update_causal_mask(
self,
attention_mask,
token_type_ids,
past_key_values,
cache_position,
input_ids=None,
inputs_embeds=None,
is_training: bool = False,
):
if self.config.text_config._attn_implementation == "flash_attention_2":
if attention_mask is not None and 0.0 in attention_mask:
return attention_mask
return None
using_static_cache = isinstance(past_key_values, StaticCache)
min_dtype = torch.finfo(self.dtype).min
inputs_lead_dim = input_ids.shape[0] if input_ids is not None else inputs_embeds.shape[0]
sequence_length = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
if using_static_cache:
target_length = past_key_values.get_max_cache_shape()
elif isinstance(past_key_values, HybridCache):
target_length = past_key_values.get_max_cache_shape()
else:
target_length = (
attention_mask.shape[-1]
if isinstance(attention_mask, torch.Tensor)
else cache_position[0] + sequence_length + 1
)
if attention_mask is not None and attention_mask.dim() == 4:
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
return attention_mask
causal_mask = torch.full(
(sequence_length, target_length), fill_value=min_dtype, dtype=self.dtype, device=cache_position.device
)
# Causal diagonal mask only if training, otherwise attend to the whole prefix. Training-specific attn for prefix is handled below
if sequence_length != 1:
if is_training:
causal_mask = torch.triu(causal_mask, diagonal=1)
else:
causal_mask[:, :sequence_length] = 0.0
causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(-1, 1)
causal_mask = causal_mask[None, None, :, :].expand(inputs_lead_dim, 1, -1, -1)
if attention_mask is not None:
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
mask_length = attention_mask.shape[-1]
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(causal_mask.device)
padding_mask = padding_mask == 0
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
padding_mask, min_dtype
)
# we are training thus we need to create a full mask on the image + prefix but causal on suffix
if is_training:
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
token_type_ids[:, None, None, :].to(causal_mask.device) == 0, 0
)
return causal_mask
def get_image_features(self, pixel_values: torch.FloatTensor):
"""
Obtains image last hidden states from the vision tower and apply multimodal projection.
Args:
pixel_values (`torch.FloatTensor]` of shape `(batch_size, channels, height, width)`)
The tensors corresponding to the input images.
Returns:
image_features (`torch.Tensor`): Image feature tensor of shape `(num_images, image_length, embed_dim)`).
"""
image_outputs = self.vision_tower(pixel_values)
selected_image_feature = image_outputs.last_hidden_state
image_features = self.multi_modal_projector(selected_image_feature)
image_features = image_features / (self.config.text_config.hidden_size**0.5)
return image_features
@add_start_docstrings_to_model_forward(NEW_TASK_MODEL_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=NewTaskModelCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: torch.LongTensor = None,
pixel_values: torch.FloatTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Union[List[torch.FloatTensor], Cache]] = None,
token_type_ids: Optional[torch.LongTensor] = None,
cache_position: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
num_logits_to_keep: int = 0,
) -> Union[Tuple, NewTaskModelCausalLMOutputWithPast]:
r"""
Args:
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
num_logits_to_keep (`int`, *optional*):
Calculate logits for the last `num_logits_to_keep` tokens. If `0`, calculate logits for all
`input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
Returns:
Example:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, NewTaskModelForNewTask
>>> model = NewTaskModelForNewTask.from_pretrained("google/NewTaskModel-test-224px-hf")
>>> processor = AutoProcessor.from_pretrained("google/NewTaskModel-test-224px-hf")
>>> prompt = "answer en Where is the cow standing?"
>>> url = "https://huggingface.co/gv-hf/NewTaskModel-test-224px-hf/resolve/main/cow_beach_1.png"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, text=prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(**inputs, max_length=30)
>>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"answer en Where is the cow standing?\nbeach"
```
Returns:
"""
vlm_outputs = super().forward(
input_ids=input_ids,
pixel_values=pixel_values,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
token_type_ids=token_type_ids,
cache_position=cache_position,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=True,
return_dict=True,
num_logits_to_keep=num_logits_to_keep,
)
last_hidden_states = vlm_outputs.hidden_states[-1] # (batch_size, sequence_length, hidden_size)
proj = self.custom_text_proj(last_hidden_states) # (batch_size, sequence_length, dim)
# L2 normalization
embeddings = proj / proj.norm(dim=-1, keepdim=True) # (batch_size, sequence_length, dim)
embeddings = embeddings * attention_mask.unsqueeze(-1) # (batch_size, sequence_length, dim)
return (embeddings,) + vlm_outputs
def prepare_inputs_for_generation(
self,
input_ids,
past_key_values=None,
inputs_embeds=None,
cache_position=None,
position_ids=None,
pixel_values=None,
attention_mask=None,
token_type_ids=None,
use_cache=True,
num_logits_to_keep=None,
labels=None,
**kwargs,
):
# Overwritten -- custom `position_ids` and `pixel_values` handling
model_inputs = self.language_model.prepare_inputs_for_generation(
input_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
position_ids=position_ids,
cache_position=cache_position,
use_cache=use_cache,
num_logits_to_keep=num_logits_to_keep,
token_type_ids=token_type_ids,
**kwargs,
)
# position_ids in NewTaskModel are 1-indexed
if model_inputs.get("position_ids") is not None:
model_inputs["position_ids"] += 1
# If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
# Otherwise we need pixel values to be passed to model. NOTE: use_cache=False needs pixel_values always
if cache_position[0] == 0:
model_inputs["pixel_values"] = pixel_values
is_training = token_type_ids is not None and labels is not None
if cache_position[0] == 0 and isinstance(past_key_values, HybridCache):
causal_mask = self._update_causal_mask(
attention_mask, token_type_ids, past_key_values, cache_position, input_ids, inputs_embeds, is_training
)
model_inputs["attention_mask"] = causal_mask
return model_inputs
def resize_token_embeddings(
self, new_num_tokens: Optional[int] = None, pad_to_multiple_of=None, mean_resizing=True
) -> nn.Embedding:
model_embeds = self.language_model.resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
# Update vocab size
self.config.text_config.vocab_size = model_embeds.num_embeddings
self.config.vocab_size = model_embeds.num_embeddings
self.vocab_size = model_embeds.num_embeddings
return model_embeds
|
transformers/examples/modular-transformers/modeling_new_task_model.py/0
|
{
"file_path": "transformers/examples/modular-transformers/modeling_new_task_model.py",
"repo_id": "transformers",
"token_count": 9625
}
|
from typing import List, Optional, Tuple, Union
import torch
from transformers.modeling_outputs import CausalLMOutputWithPast
from transformers.models.llama.modeling_llama import LlamaModel
from ...cache_utils import Cache
# example where we need some deps and some functions
class SuperModel(LlamaModel):
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Union[Cache, List[torch.FloatTensor]]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
out = super().forward(
input_ids,
attention_mask,
position_ids,
past_key_values,
inputs_embeds,
use_cache,
output_attentions,
output_hidden_states,
return_dict,
cache_position,
)
out.logits *= 2**4
return out
|
transformers/examples/modular-transformers/modular_super.py/0
|
{
"file_path": "transformers/examples/modular-transformers/modular_super.py",
"repo_id": "transformers",
"token_count": 566
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for sequence to sequence speech recognition.
"""
# You can also adapt this script on your own sequence to sequence speech
# recognition task. Pointers for this are left as comments.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
import datasets
import evaluate
import torch
from datasets import DatasetDict, load_dataset
import transformers
from transformers import (
AutoConfig,
AutoFeatureExtractor,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
AutoTokenizer,
HfArgumentParser,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
feature_extractor_name: Optional[str] = field(
default=None, metadata={"help": "feature extractor name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
)
},
)
freeze_feature_encoder: bool = field(
default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
)
freeze_encoder: bool = field(
default=False, metadata={"help": "Whether to freeze the entire encoder of the seq2seq model."}
)
forced_decoder_ids: List[List[int]] = field(
default=None,
metadata={"help": "Deprecated. Please use the `language` and `task` arguments instead."},
)
suppress_tokens: List[int] = field(
default=None,
metadata={
"help": (
"Deprecated. The use of `suppress_tokens` should not be required for the majority of fine-tuning examples."
"Should you need to use `suppress_tokens`, please manually update them in the fine-tuning script directly."
)
},
)
apply_spec_augment: bool = field(
default=False,
metadata={
"help": "Whether to apply *SpecAugment* data augmentation to the input features. This is currently only relevant for Wav2Vec2, HuBERT, WavLM and Whisper models."
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: str = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
audio_column_name: str = field(
default="audio",
metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
)
text_column_name: str = field(
default="text",
metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
)
max_duration_in_seconds: float = field(
default=20.0,
metadata={
"help": (
"Truncate audio files that are longer than `max_duration_in_seconds` seconds to"
" 'max_duration_in_seconds`"
)
},
)
min_duration_in_seconds: float = field(
default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
)
preprocessing_only: bool = field(
default=False,
metadata={
"help": (
"Whether to only do data preprocessing and skip training. This is especially useful when data"
" preprocessing errors out in distributed training due to timeout. In this case, one should run the"
" preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
" can consequently be loaded in distributed training"
)
},
)
train_split_name: str = field(
default="train",
metadata={
"help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
},
)
eval_split_name: str = field(
default="test",
metadata={
"help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
},
)
do_lower_case: bool = field(
default=True,
metadata={"help": "Whether the target text should be lower cased."},
)
language: str = field(
default=None,
metadata={
"help": (
"Language for multilingual fine-tuning. This argument should be set for multilingual fine-tuning "
"only. For English speech recognition, it should be set to `None`."
)
},
)
task: str = field(
default="transcribe",
metadata={"help": "Task, either `transcribe` for speech recognition or `translate` for speech translation."},
)
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor ([`WhisperProcessor`])
The processor used for processing the data.
decoder_start_token_id (`int`)
The begin-of-sentence of the decoder.
forward_attention_mask (`bool`)
Whether to return attention_mask.
"""
processor: Any
decoder_start_token_id: int
forward_attention_mask: bool
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
model_input_name = self.processor.model_input_names[0]
input_features = [{model_input_name: feature[model_input_name]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
if self.forward_attention_mask:
batch["attention_mask"] = torch.LongTensor([feature["attention_mask"] for feature in features])
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.decoder_start_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
def main():
# 1. Parse input arguments
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_speech_recognition_seq2seq", model_args, data_args)
# 2. Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info("Training/evaluation parameters %s", training_args)
# 3. Detecting last checkpoint and eventually continue from last checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# 4. Load dataset
raw_datasets = DatasetDict()
if training_args.do_train:
raw_datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.train_split_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
if training_args.do_eval:
raw_datasets["eval"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.eval_split_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
if data_args.audio_column_name not in next(iter(raw_datasets.values())).column_names:
raise ValueError(
f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--audio_column_name` to the correct audio column - one of "
f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
)
if data_args.text_column_name not in next(iter(raw_datasets.values())).column_names:
raise ValueError(
f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--text_column_name` to the correct text column - one of "
f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
)
# 5. Load pretrained model, tokenizer, and feature extractor
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# SpecAugment for whisper models
if getattr(config, "model_type", None) == "whisper":
config.update({"apply_spec_augment": model_args.apply_spec_augment})
feature_extractor = AutoFeatureExtractor.from_pretrained(
model_args.feature_extractor_name if model_args.feature_extractor_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_args.model_name_or_path,
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
if model_args.freeze_feature_encoder:
model.freeze_feature_encoder()
if model_args.freeze_encoder:
model.freeze_encoder()
model.model.encoder.gradient_checkpointing = False
if hasattr(model.generation_config, "is_multilingual") and model.generation_config.is_multilingual:
# We only need to set the language and task ids in a multilingual setting
tokenizer.set_prefix_tokens(language=data_args.language, task=data_args.task)
model.generation_config.language = data_args.language
model.generation_config.task = data_args.task
elif data_args.language is not None:
raise ValueError(
"Setting language token for an English-only checkpoint is not permitted. The language argument should "
"only be set for multilingual checkpoints."
)
# TODO (Sanchit): deprecate these arguments in v4.41
if model_args.forced_decoder_ids is not None:
logger.warning(
"The use of `forced_decoder_ids` is deprecated and will be removed in v4.41."
"Please use the `language` and `task` arguments instead"
)
model.generation_config.forced_decoder_ids = model_args.forced_decoder_ids
else:
model.generation_config.forced_decoder_ids = None
model.config.forced_decoder_ids = None
if model_args.suppress_tokens is not None:
logger.warning(
"The use of `suppress_tokens` is deprecated and will be removed in v4.41."
"Should you need `suppress_tokens`, please manually set them in the fine-tuning script."
)
model.generation_config.suppress_tokens = model_args.suppress_tokens
# 6. Resample speech dataset if necessary
dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
if dataset_sampling_rate != feature_extractor.sampling_rate:
raw_datasets = raw_datasets.cast_column(
data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
)
# 7. Preprocessing the datasets.
# We need to read the audio files as arrays and tokenize the targets.
max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
audio_column_name = data_args.audio_column_name
num_workers = data_args.preprocessing_num_workers
text_column_name = data_args.text_column_name
model_input_name = feature_extractor.model_input_names[0]
do_lower_case = data_args.do_lower_case
# if SpecAugment is used for whisper models, return attention_mask to guide the mask along time axis
forward_attention_mask = (
getattr(config, "model_type", None) == "whisper"
and getattr(config, "apply_spec_augment", False)
and getattr(config, "mask_time_prob", 0) > 0
)
if data_args.max_train_samples is not None:
raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
if data_args.max_eval_samples is not None:
raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
def prepare_dataset(batch):
# process audio
sample = batch[audio_column_name]
inputs = feature_extractor(
sample["array"], sampling_rate=sample["sampling_rate"], return_attention_mask=forward_attention_mask
)
# process audio length
batch[model_input_name] = inputs.get(model_input_name)[0]
batch["input_length"] = len(sample["array"])
if forward_attention_mask:
batch["attention_mask"] = inputs.get("attention_mask")[0]
# process targets
input_str = batch[text_column_name].lower() if do_lower_case else batch[text_column_name]
batch["labels"] = tokenizer(input_str).input_ids
return batch
with training_args.main_process_first(desc="dataset map pre-processing"):
vectorized_datasets = raw_datasets.map(
prepare_dataset,
remove_columns=next(iter(raw_datasets.values())).column_names,
num_proc=data_args.preprocessing_num_workers,
desc="preprocess train dataset",
)
# filter data that is shorter than min_input_length or longer than
# max_input_length
def is_audio_in_length_range(length):
return length > min_input_length and length < max_input_length
vectorized_datasets = vectorized_datasets.filter(
is_audio_in_length_range,
num_proc=num_workers,
input_columns=["input_length"],
)
# for large datasets it is advised to run the preprocessing on a
# single machine first with `args.preprocessing_only` since there will mostly likely
# be a timeout when running the script in distributed mode.
# In a second step `args.preprocessing_only` can then be set to `False` to load the
# cached dataset
if data_args.preprocessing_only:
cache = {k: v.cache_files for k, v in vectorized_datasets.items()}
logger.info(f"Data preprocessing finished. Files cached at {cache}.")
return
# 8. Load Metric
metric = evaluate.load("wer", cache_dir=model_args.cache_dir)
def compute_metrics(pred):
pred_ids = pred.predictions
pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
# we do not want to group tokens when computing the metrics
label_str = tokenizer.batch_decode(pred.label_ids, skip_special_tokens=True)
wer = metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
# 9. Create a single speech processor
# make sure all processes wait until data is saved
with training_args.main_process_first():
# only the main process saves them
if is_main_process(training_args.local_rank):
# save feature extractor, tokenizer and config
feature_extractor.save_pretrained(training_args.output_dir)
tokenizer.save_pretrained(training_args.output_dir)
config.save_pretrained(training_args.output_dir)
processor = AutoProcessor.from_pretrained(training_args.output_dir)
# 10. Define data collator
data_collator = DataCollatorSpeechSeq2SeqWithPadding(
processor=processor,
decoder_start_token_id=model.config.decoder_start_token_id,
forward_attention_mask=forward_attention_mask,
)
# 11. Initialize Trainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
processing_class=feature_extractor,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
# 12. Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the feature extractor too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples
if data_args.max_train_samples is not None
else len(vectorized_datasets["train"])
)
metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# 13. Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate(
metric_key_prefix="eval",
max_length=training_args.generation_max_length,
num_beams=training_args.generation_num_beams,
)
max_eval_samples = (
data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
)
metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# 14. Write Training Stats
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "automatic-speech-recognition"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
return results
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py/0
|
{
"file_path": "transformers/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py",
"repo_id": "transformers",
"token_count": 10400
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 University of Cambridge, Tencent AI Lab, DeepMind and The University of Hong Kong Authors and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""The examples of running contrastive search on the auto-APIs;
Running this example:
python run_generation_contrastive_search.py --model_name_or_path=openai-community/gpt2-large --penalty_alpha=0.6 --k=4 --length=256
"""
import argparse
import logging
from accelerate import PartialState
from accelerate.utils import set_seed
from transformers import AutoModelForCausalLM, AutoTokenizer
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
)
parser.add_argument("--prompt", type=str, default="")
parser.add_argument("--length", type=int, default=20)
parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
parser.add_argument(
"--temperature",
type=float,
default=1.0,
help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
)
parser.add_argument(
"--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
)
parser.add_argument("--k", type=int, default=0)
parser.add_argument("--penalty_alpha", type=float, default=0.0)
parser.add_argument("--p", type=float, default=0.9)
parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--use_cpu",
action="store_true",
help="Whether or not to use cpu. If set to False, " "we will use gpu/npu or mps device if available",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
args = parser.parse_args()
# Initialize the distributed state.
distributed_state = PartialState(cpu=args.use_cpu)
logger.warning(f"device: {distributed_state.device}, 16-bits inference: {args.fp16}")
if args.seed is not None:
set_seed(args.seed)
# Initialize the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(args.model_name_or_path)
# tokenizer = GPT2Tokenizer.from_pretrained(args.model_name_or_path)
# model = OPTForCausalLM.from_pretrained(args.model_name_or_path)
# Set the model to the right device
model.to(distributed_state.device)
if args.fp16:
model.half()
logger.info(args)
prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
inputs = tokenizer(prompt_text, return_tensors="pt", add_special_tokens=False)
inputs = {key: value.to(distributed_state.device) for key, value in inputs.items()}
output_sequences = model.generate(
**inputs,
max_length=args.length + len(inputs["input_ids"][0]),
penalty_alpha=args.penalty_alpha,
top_k=args.k,
)
generated_sequences = []
for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} ===")
generated_sequence = generated_sequence.tolist()
# Decode text
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True, add_special_tokens=False)
# Remove all text after the stop token
text = text[: text.find(args.stop_token) if args.stop_token else None]
# Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
total_sequence = (
prompt_text + text[len(tokenizer.decode(inputs["input_ids"][0], clean_up_tokenization_spaces=True)) :]
)
generated_sequences.append(total_sequence)
print(total_sequence)
return generated_sequences
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/text-generation/run_generation_contrastive_search.py/0
|
{
"file_path": "transformers/examples/pytorch/text-generation/run_generation_contrastive_search.py",
"repo_id": "transformers",
"token_count": 1870
}
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
from dataclasses import dataclass
from typing import List, Optional, Union
import tqdm
from filelock import FileLock
from transformers import (
BartTokenizer,
BartTokenizerFast,
DataProcessor,
PreTrainedTokenizer,
RobertaTokenizer,
RobertaTokenizerFast,
XLMRobertaTokenizer,
is_tf_available,
is_torch_available,
)
logger = logging.getLogger(__name__)
@dataclass(frozen=True)
class InputExample:
"""
A single training/test example for simple sequence classification.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
pairID: (Optional) string. Unique identifier for the pair of sentences.
"""
guid: str
text_a: str
text_b: Optional[str] = None
label: Optional[str] = None
pairID: Optional[str] = None
@dataclass(frozen=True)
class InputFeatures:
"""
A single set of features of data.
Property names are the same names as the corresponding inputs to a model.
Args:
input_ids: Indices of input sequence tokens in the vocabulary.
attention_mask: Mask to avoid performing attention on padding token indices.
Mask values selected in ``[0, 1]``:
Usually ``1`` for tokens that are NOT MASKED, ``0`` for MASKED (padded) tokens.
token_type_ids: (Optional) Segment token indices to indicate first and second
portions of the inputs. Only some models use them.
label: (Optional) Label corresponding to the input. Int for classification problems,
float for regression problems.
pairID: (Optional) Unique identifier for the pair of sentences.
"""
input_ids: List[int]
attention_mask: Optional[List[int]] = None
token_type_ids: Optional[List[int]] = None
label: Optional[Union[int, float]] = None
pairID: Optional[int] = None
if is_torch_available():
import torch
from torch.utils.data import Dataset
class HansDataset(Dataset):
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
def __init__(
self,
data_dir: str,
tokenizer: PreTrainedTokenizer,
task: str,
max_seq_length: Optional[int] = None,
overwrite_cache=False,
evaluate: bool = False,
):
processor = hans_processors[task]()
cached_features_file = os.path.join(
data_dir,
"cached_{}_{}_{}_{}".format(
"dev" if evaluate else "train",
tokenizer.__class__.__name__,
str(max_seq_length),
task,
),
)
label_list = processor.get_labels()
if tokenizer.__class__ in (
RobertaTokenizer,
RobertaTokenizerFast,
XLMRobertaTokenizer,
BartTokenizer,
BartTokenizerFast,
):
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
self.label_list = label_list
# Make sure only the first process in distributed training processes the dataset,
# and the others will use the cache.
lock_path = cached_features_file + ".lock"
with FileLock(lock_path):
if os.path.exists(cached_features_file) and not overwrite_cache:
logger.info(f"Loading features from cached file {cached_features_file}")
self.features = torch.load(cached_features_file)
else:
logger.info(f"Creating features from dataset file at {data_dir}")
examples = (
processor.get_dev_examples(data_dir) if evaluate else processor.get_train_examples(data_dir)
)
logger.info("Training examples: %s", len(examples))
self.features = hans_convert_examples_to_features(examples, label_list, max_seq_length, tokenizer)
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(self.features, cached_features_file)
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
def get_labels(self):
return self.label_list
if is_tf_available():
import tensorflow as tf
class TFHansDataset:
"""
This will be superseded by a framework-agnostic approach
soon.
"""
features: List[InputFeatures]
def __init__(
self,
data_dir: str,
tokenizer: PreTrainedTokenizer,
task: str,
max_seq_length: Optional[int] = 128,
overwrite_cache=False,
evaluate: bool = False,
):
processor = hans_processors[task]()
label_list = processor.get_labels()
if tokenizer.__class__ in (
RobertaTokenizer,
RobertaTokenizerFast,
XLMRobertaTokenizer,
BartTokenizer,
BartTokenizerFast,
):
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
self.label_list = label_list
examples = processor.get_dev_examples(data_dir) if evaluate else processor.get_train_examples(data_dir)
self.features = hans_convert_examples_to_features(examples, label_list, max_seq_length, tokenizer)
def gen():
for ex_index, ex in tqdm.tqdm(enumerate(self.features), desc="convert examples to features"):
if ex_index % 10000 == 0:
logger.info("Writing example %d of %d" % (ex_index, len(examples)))
yield (
{
"example_id": 0,
"input_ids": ex.input_ids,
"attention_mask": ex.attention_mask,
"token_type_ids": ex.token_type_ids,
},
ex.label,
)
self.dataset = tf.data.Dataset.from_generator(
gen,
(
{
"example_id": tf.int32,
"input_ids": tf.int32,
"attention_mask": tf.int32,
"token_type_ids": tf.int32,
},
tf.int64,
),
(
{
"example_id": tf.TensorShape([]),
"input_ids": tf.TensorShape([None, None]),
"attention_mask": tf.TensorShape([None, None]),
"token_type_ids": tf.TensorShape([None, None]),
},
tf.TensorShape([]),
),
)
def get_dataset(self):
return self.dataset
def __len__(self):
return len(self.features)
def __getitem__(self, i) -> InputFeatures:
return self.features[i]
def get_labels(self):
return self.label_list
class HansProcessor(DataProcessor):
"""Processor for the HANS data set."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "heuristics_train_set.txt")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "heuristics_evaluation_set.txt")), "dev")
def get_labels(self):
"""See base class.
Note that we follow the standard three labels for MNLI
(see :class:`~transformers.data.processors.utils.MnliProcessor`)
but the HANS evaluation groups `contradiction` and `neutral` into `non-entailment` (label 0) while
`entailment` is label 1."""
return ["contradiction", "entailment", "neutral"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for i, line in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, line[0])
text_a = line[5]
text_b = line[6]
pairID = line[7][2:] if line[7].startswith("ex") else line[7]
label = line[0]
examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label, pairID=pairID))
return examples
def hans_convert_examples_to_features(
examples: List[InputExample],
label_list: List[str],
max_length: int,
tokenizer: PreTrainedTokenizer,
):
"""
Loads a data file into a list of ``InputFeatures``
Args:
examples: List of ``InputExamples`` containing the examples.
label_list: List of labels. Can be obtained from the processor using the ``processor.get_labels()`` method.
max_length: Maximum example length.
tokenizer: Instance of a tokenizer that will tokenize the examples.
Returns:
A list of task-specific ``InputFeatures`` which can be fed to the model.
"""
label_map = {label: i for i, label in enumerate(label_list)}
features = []
for ex_index, example in tqdm.tqdm(enumerate(examples), desc="convert examples to features"):
if ex_index % 10000 == 0:
logger.info("Writing example %d" % (ex_index))
inputs = tokenizer(
example.text_a,
example.text_b,
add_special_tokens=True,
max_length=max_length,
padding="max_length",
truncation=True,
return_overflowing_tokens=True,
)
label = label_map[example.label] if example.label in label_map else 0
pairID = int(example.pairID)
features.append(InputFeatures(**inputs, label=label, pairID=pairID))
for i, example in enumerate(examples[:5]):
logger.info("*** Example ***")
logger.info(f"guid: {example}")
logger.info(f"features: {features[i]}")
return features
hans_tasks_num_labels = {
"hans": 3,
}
hans_processors = {
"hans": HansProcessor,
}
|
transformers/examples/research_projects/adversarial/utils_hans.py/0
|
{
"file_path": "transformers/examples/research_projects/adversarial/utils_hans.py",
"repo_id": "transformers",
"token_count": 5431
}
|
import os
from collections import deque
import torch
from torch.utils.data import Dataset
# ------------
# Data loading
# ------------
class CNNDMDataset(Dataset):
"""Abstracts the dataset used to train seq2seq models.
The class will process the documents that are located in the specified
folder. The preprocessing will work on any document that is reasonably
formatted. On the CNN/DailyMail dataset it will extract both the story
and the summary.
CNN/Daily News:
The CNN/Daily News raw datasets are downloaded from [1]. The stories are
stored in different files; the summary appears at the end of the story as
sentences that are prefixed by the special `@highlight` line. To process
the data, untar both datasets in the same folder, and pass the path to this
folder as the "data_dir argument. The formatting code was inspired by [2].
[1] https://cs.nyu.edu/~kcho/
[2] https://github.com/abisee/cnn-dailymail/
"""
def __init__(self, path="", prefix="train"):
"""We initialize the class by listing all the documents to summarize.
Files are not read in memory due to the size of some datasets (like CNN/DailyMail).
"""
assert os.path.isdir(path)
self.documents = []
story_filenames_list = os.listdir(path)
for story_filename in story_filenames_list:
if "summary" in story_filename:
continue
path_to_story = os.path.join(path, story_filename)
if not os.path.isfile(path_to_story):
continue
self.documents.append(path_to_story)
def __len__(self):
"""Returns the number of documents."""
return len(self.documents)
def __getitem__(self, idx):
document_path = self.documents[idx]
document_name = document_path.split("/")[-1]
with open(document_path, encoding="utf-8") as source:
raw_story = source.read()
story_lines, summary_lines = process_story(raw_story)
return document_name, story_lines, summary_lines
def process_story(raw_story):
"""Extract the story and summary from a story file.
Arguments:
raw_story (str): content of the story file as an utf-8 encoded string.
Raises:
IndexError: If the story is empty or contains no highlights.
"""
nonempty_lines = list(filter(lambda x: len(x) != 0, [line.strip() for line in raw_story.split("\n")]))
# for some unknown reason some lines miss a period, add it
nonempty_lines = [_add_missing_period(line) for line in nonempty_lines]
# gather article lines
story_lines = []
lines = deque(nonempty_lines)
while True:
try:
element = lines.popleft()
if element.startswith("@highlight"):
break
story_lines.append(element)
except IndexError:
# if "@highlight" is absent from the file we pop
# all elements until there is None, raising an exception.
return story_lines, []
# gather summary lines
summary_lines = list(filter(lambda t: not t.startswith("@highlight"), lines))
return story_lines, summary_lines
def _add_missing_period(line):
END_TOKENS = [".", "!", "?", "...", "'", "`", '"', "\u2019", "\u2019", ")"]
if line.startswith("@highlight"):
return line
if line[-1] in END_TOKENS:
return line
return line + "."
# --------------------------
# Encoding and preprocessing
# --------------------------
def truncate_or_pad(sequence, block_size, pad_token_id):
"""Adapt the source and target sequences' lengths to the block size.
If the sequence is shorter we append padding token to the right of the sequence.
"""
if len(sequence) > block_size:
return sequence[:block_size]
else:
sequence.extend([pad_token_id] * (block_size - len(sequence)))
return sequence
def build_mask(sequence, pad_token_id):
"""Builds the mask. The attention mechanism will only attend to positions
with value 1."""
mask = torch.ones_like(sequence)
idx_pad_tokens = sequence == pad_token_id
mask[idx_pad_tokens] = 0
return mask
def encode_for_summarization(story_lines, summary_lines, tokenizer):
"""Encode the story and summary lines, and join them
as specified in [1] by using `[SEP] [CLS]` tokens to separate
sentences.
"""
story_lines_token_ids = [tokenizer.encode(line) for line in story_lines]
story_token_ids = [token for sentence in story_lines_token_ids for token in sentence]
summary_lines_token_ids = [tokenizer.encode(line) for line in summary_lines]
summary_token_ids = [token for sentence in summary_lines_token_ids for token in sentence]
return story_token_ids, summary_token_ids
def compute_token_type_ids(batch, separator_token_id):
"""Segment embeddings as described in [1]
The values {0,1} were found in the repository [2].
Attributes:
batch: torch.Tensor, size [batch_size, block_size]
Batch of input.
separator_token_id: int
The value of the token that separates the segments.
[1] Liu, Yang, and Mirella Lapata. "Text summarization with pretrained encoders."
arXiv preprint arXiv:1908.08345 (2019).
[2] https://github.com/nlpyang/PreSumm (/src/prepro/data_builder.py, commit fac1217)
"""
batch_embeddings = []
for sequence in batch:
sentence_num = -1
embeddings = []
for s in sequence:
if s == separator_token_id:
sentence_num += 1
embeddings.append(sentence_num % 2)
batch_embeddings.append(embeddings)
return torch.tensor(batch_embeddings)
|
transformers/examples/research_projects/bertabs/utils_summarization.py/0
|
{
"file_path": "transformers/examples/research_projects/bertabs/utils_summarization.py",
"repo_id": "transformers",
"token_count": 2180
}
|
import multiprocessing
import time
from arguments import PretokenizationArguments
from datasets import load_dataset
from transformers import AutoTokenizer, HfArgumentParser
def tokenize(example):
output = {}
output["input_ids"] = tokenizer(example["content"], truncation=False)["input_ids"]
output["ratio_char_token"] = len(example["content"]) / len(output["input_ids"])
return output
parser = HfArgumentParser(PretokenizationArguments)
args = parser.parse_args()
if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count()
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir)
t_start = time.time()
ds = load_dataset(args.dataset_name, split="train")
print(f"Dataset loaded in {time.time()-t_start:.2f}s")
t_start = time.time()
ds = ds.map(
tokenize,
num_proc=args.num_workers,
remove_columns=[
"repo_name",
"path",
"copies",
"size",
"content",
"license",
"hash",
"line_mean",
"line_max",
"alpha_frac",
"autogenerated",
],
)
print(f"Dataset tokenized in {time.time()-t_start:.2f}s")
t_start = time.time()
ds.push_to_hub(args.tokenized_data_repo)
print(f"Data pushed to the hub in {time.time()-t_start:.2f}s")
|
transformers/examples/research_projects/codeparrot/scripts/pretokenizing.py/0
|
{
"file_path": "transformers/examples/research_projects/codeparrot/scripts/pretokenizing.py",
"repo_id": "transformers",
"token_count": 527
}
|
# coding=utf-8
# Copyright 2019-present, the HuggingFace Inc. team and Facebook, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Utils to train DistilBERT
adapted in part from Facebook, Inc XLM model (https://github.com/facebookresearch/XLM)
"""
import json
import logging
import os
import socket
import git
import numpy as np
import torch
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - PID: %(process)d - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
def git_log(folder_path: str):
"""
Log commit info.
"""
repo = git.Repo(search_parent_directories=True)
repo_infos = {
"repo_id": str(repo),
"repo_sha": str(repo.head.object.hexsha),
"repo_branch": str(repo.active_branch),
}
with open(os.path.join(folder_path, "git_log.json"), "w") as f:
json.dump(repo_infos, f, indent=4)
def init_gpu_params(params):
"""
Handle single and multi-GPU / multi-node.
"""
if params.n_gpu <= 0:
params.local_rank = 0
params.master_port = -1
params.is_master = True
params.multi_gpu = False
return
assert torch.cuda.is_available()
logger.info("Initializing GPUs")
if params.n_gpu > 1:
assert params.local_rank != -1
params.world_size = int(os.environ["WORLD_SIZE"])
params.n_gpu_per_node = int(os.environ["N_GPU_NODE"])
params.global_rank = int(os.environ["RANK"])
# number of nodes / node ID
params.n_nodes = params.world_size // params.n_gpu_per_node
params.node_id = params.global_rank // params.n_gpu_per_node
params.multi_gpu = True
assert params.n_nodes == int(os.environ["N_NODES"])
assert params.node_id == int(os.environ["NODE_RANK"])
# local job (single GPU)
else:
assert params.local_rank == -1
params.n_nodes = 1
params.node_id = 0
params.local_rank = 0
params.global_rank = 0
params.world_size = 1
params.n_gpu_per_node = 1
params.multi_gpu = False
# sanity checks
assert params.n_nodes >= 1
assert 0 <= params.node_id < params.n_nodes
assert 0 <= params.local_rank <= params.global_rank < params.world_size
assert params.world_size == params.n_nodes * params.n_gpu_per_node
# define whether this is the master process / if we are in multi-node distributed mode
params.is_master = params.node_id == 0 and params.local_rank == 0
params.multi_node = params.n_nodes > 1
# summary
PREFIX = f"--- Global rank: {params.global_rank} - "
logger.info(PREFIX + "Number of nodes: %i" % params.n_nodes)
logger.info(PREFIX + "Node ID : %i" % params.node_id)
logger.info(PREFIX + "Local rank : %i" % params.local_rank)
logger.info(PREFIX + "World size : %i" % params.world_size)
logger.info(PREFIX + "GPUs per node : %i" % params.n_gpu_per_node)
logger.info(PREFIX + "Master : %s" % str(params.is_master))
logger.info(PREFIX + "Multi-node : %s" % str(params.multi_node))
logger.info(PREFIX + "Multi-GPU : %s" % str(params.multi_gpu))
logger.info(PREFIX + "Hostname : %s" % socket.gethostname())
# set GPU device
torch.cuda.set_device(params.local_rank)
# initialize multi-GPU
if params.multi_gpu:
logger.info("Initializing PyTorch distributed")
torch.distributed.init_process_group(
init_method="env://",
backend="nccl",
)
def set_seed(args):
"""
Set the random seed.
"""
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
|
transformers/examples/research_projects/distillation/utils.py/0
|
{
"file_path": "transformers/examples/research_projects/distillation/utils.py",
"repo_id": "transformers",
"token_count": 1771
}
|
Author: [@vasudevgupta7](https://github.com/thevasudevgupta/)
## Intro
In this project, we fine-tuned [**BigBird**](https://arxiv.org/abs/2007.14062) on [**natural-questions**](https://huggingface.co/datasets/natural_questions) dataset for **question-answering** task on long documents. **BigBird**, is a **sparse-attention based transformer** which extends Transformer based models, such as BERT to much **longer sequences**.
Read more about BigBird at https://huggingface.co/blog/big-bird
## Fine-tuning
**Setup**
You need to install jax yourself by following the official docs ([refer this](https://github.com/google/jax#installation)). Other requirements for this project can be installed by running following command:
```shell
pip3 install -qr requirements.txt
```
**Download & prepare dataset**
The Natural Questions corpus contains questions from real users, and it requires QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. This corpus takes ~100 GB on disk. We have used HuggingFace datasets to download & process the dataset.
```shell
# just run following CMD
python3 prepare_natural_questions.py
# this will download the whole dataset from HuggingFace Hub & will make it ready for training
# this script takes ~3 hours to process the dataset
```
**Launch Training**
We have trained on Cloud's TPU v3-8. Each epoch took around 4.5 hours and the model got converged in just 2 epochs. You can see complete training args in [this script](bigbird_flax.py).
```shell
# just run following CMD
python3 train.py
# In case, you want to try hparams tuning, you can run wandb sweep
wandb sweep --project=bigbird sweep_flax.yaml
wandb agent <agent-id-obtained-by-above-CMD>
```
## Evaluation
Our evaluation script is different from the original script and we are evaluating sequences with length up to 4096 for simplicity. We managed to get the **EM score of ~55.2** using our evaluation script.
```shell
# download validation-dataset first
mkdir natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/natural_questions-validation.arrow -P natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/dataset_info.json -P natural-questions-validation
wget https://huggingface.co/datasets/vasudevgupta/natural-questions-validation/resolve/main/state.json -P natural-questions-validation
# simply run following command
python3 evaluate.py
```
You can find our checkpoint on HuggingFace Hub ([see this](https://huggingface.co/vasudevgupta/flax-bigbird-natural-questions)). In case you are interested in PyTorch BigBird fine-tuning, you can refer to [this repository](https://github.com/thevasudevgupta/bigbird).
|
transformers/examples/research_projects/jax-projects/big_bird/README.md/0
|
{
"file_path": "transformers/examples/research_projects/jax-projects/big_bird/README.md",
"repo_id": "transformers",
"token_count": 824
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Pre-training/Fine-tuning the GPTNeo model for causal language modeling on a text file or a dataset using model parallelism.
"""
import logging
import math
import os
import sys
import time
from dataclasses import dataclass, field
from itertools import chain
from pathlib import Path
from typing import Callable, Optional
import datasets
import jax
import jax.numpy as jnp
import numpy as np
import optax
from datasets import Dataset, load_dataset
from flax.core.frozen_dict import freeze, unfreeze
from flax.training.common_utils import onehot, stack_forest
from jax.experimental.maps import mesh
from jax.experimental.pjit import pjit
from partitions import set_partitions
from tqdm import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
AutoConfig,
AutoTokenizer,
FlaxAutoModelForCausalLM,
HfArgumentParser,
TrainingArguments,
is_tensorboard_available,
)
from transformers.testing_utils import CaptureLogger
logger = logging.getLogger(__name__)
MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_CAUSAL_LM_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: Optional[str] = field(
default=None,
metadata={
"help": (
"The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
)
},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
dtype: Optional[str] = field(
default="float32",
metadata={
"help": (
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
" `[float32, float16, bfloat16]`."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
validation_split_percentage: Optional[int] = field(
default=5,
metadata={
"help": "The percentage of the train set used as validation set in case there's no validation split"
},
)
block_size: Optional[int] = field(
default=None,
metadata={
"help": (
"Optional input sequence length after tokenization. "
"The training dataset will be truncated in block of this size for training. "
"Default to the model max input length for single sentence inputs (take into account special tokens)."
)
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False):
"""
Returns batches of size `batch_size` from truncated `dataset`, sharded over all local devices.
Shuffle batches if `shuffle` is `True`.
"""
steps_per_epoch = len(dataset) // batch_size
if shuffle:
batch_idx = jax.random.permutation(rng, len(dataset))
else:
batch_idx = jnp.arange(len(dataset))
batch_idx = batch_idx[: steps_per_epoch * batch_size] # Skip incomplete batch.
batch_idx = batch_idx.reshape((steps_per_epoch, batch_size))
for idx in batch_idx:
batch = dataset[idx]
batch = {k: jnp.array(v) for k, v in batch.items()}
yield batch
def write_train_metric(summary_writer, train_metrics, train_time, step):
summary_writer.scalar("train_time", train_time, step)
train_metrics = stack_forest(train_metrics)
for key, vals in train_metrics.items():
tag = f"train_{key}"
for i, val in enumerate(vals):
summary_writer.scalar(tag, val, step - len(vals) + i + 1)
def write_eval_metric(summary_writer, eval_metrics, step):
for metric_name, value in eval_metrics.items():
summary_writer.scalar(f"eval_{metric_name}", value, step)
def create_learning_rate_fn(
train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
) -> Callable[[int], jnp.ndarray]:
"""Returns a linear warmup, linear_decay learning rate function."""
steps_per_epoch = train_ds_size // train_batch_size
num_train_steps = steps_per_epoch * num_train_epochs
warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
decay_fn = optax.linear_schedule(
init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
)
schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
return schedule_fn
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# Set the verbosity to info of the Transformers logger (on main process only):
logger.info(f"Training/evaluation parameters {training_args}")
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir, keep_in_memory=False
)
if "validation" not in dataset.keys():
dataset["validation"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[:{data_args.validation_split_percentage}%]",
cache_dir=model_args.cache_dir,
)
dataset["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=f"train[{data_args.validation_split_percentage}%:]",
cache_dir=model_args.cache_dir,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if extension == "txt":
extension = "text"
dataset = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained config and tokenizer
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, cache_dir=model_args.cache_dir)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
)
elif model_args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if training_args.do_train:
column_names = dataset["train"].column_names
else:
column_names = dataset["validation"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
def tokenize_function(examples):
with CaptureLogger(tok_logger) as cl:
output = tokenizer(examples[text_column_name])
# clm input could be much much longer than block_size
if "Token indices sequence length is longer than the" in cl.out:
tok_logger.warning(
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
" before being passed to the model."
)
return output
tokenized_datasets = dataset.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if data_args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > config.max_position_embeddings:
logger.warning(
f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
)
block_size = min(1024, config.max_position_embeddings)
else:
if data_args.block_size > tokenizer.model_max_length:
logger.warning(
f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
)
block_size = min(data_args.block_size, tokenizer.model_max_length)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
# Split by chunks of max_len.
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
# for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
# to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/process#map
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_train:
if "train" not in tokenized_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = lm_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
if training_args.do_eval:
if "validation" not in tokenized_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = lm_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
# Enable tensorboard only on the master node
has_tensorboard = is_tensorboard_available()
if has_tensorboard and jax.process_index() == 0:
try:
from flax.metrics.tensorboard import SummaryWriter
summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
except ImportError as ie:
has_tensorboard = False
logger.warning(
f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
)
else:
logger.warning(
"Unable to display metrics through TensorBoard because the package is not installed: "
"Please run pip install tensorboard to enable."
)
# Initialize our training
rng = jax.random.PRNGKey(training_args.seed)
rng, dropout_rng = jax.random.split(rng)
# Store some constant
num_epochs = int(training_args.num_train_epochs)
train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
eval_batch_size = int(training_args.per_device_eval_batch_size) * jax.device_count()
steps_per_epoch = len(train_dataset) // train_batch_size
total_train_steps = steps_per_epoch * num_epochs
# TODO: weights should be initialized in pjitted fun, this won't work for REALLY large models
# TODO: when loading from pre-trained model we need to make sure the vocab is divisible by num_partitions
# GPT2's vocab is odd, we need to resize it for fine-tuning
model = FlaxAutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path, seed=training_args.seed, dtype=getattr(jnp, model_args.dtype)
)
# Create learning rate schedule
linear_decay_lr_schedule_fn = create_learning_rate_fn(
len(train_dataset),
train_batch_size,
training_args.num_train_epochs,
training_args.warmup_steps,
training_args.learning_rate,
)
optimizer = optax.adamw(
learning_rate=linear_decay_lr_schedule_fn,
b1=training_args.adam_beta1,
b2=training_args.adam_beta2,
eps=training_args.adam_epsilon,
weight_decay=training_args.weight_decay,
)
def get_initial_state(params):
state = optimizer.init(params)
return tuple(state), params
# Get PartitionSpec for model params
param_spec = set_partitions(unfreeze(model.params))
# Get the PyTree for opt_state, we don't actually initialize the opt_state yet.
params_shapes = jax.tree_util.tree_map(lambda x: x.shape, model.params)
state_shapes = jax.eval_shape(get_initial_state, params_shapes)
# get PartitionSpec for opt_state, this is very specific to adamw
# TODO: optax returns different state for different optimizers, how can we handle this generically ?
# or maybe we don't since in our examples we just use adamw or adafactor
def get_opt_spec(x):
if isinstance(x, dict):
return param_spec
return None
opt_state_spec, param_spec = jax.tree_util.tree_map(
get_opt_spec, state_shapes, is_leaf=lambda x: isinstance(x, (dict, optax.EmptyState))
)
# pjit the get_initial_state function to shard params and init
# optimizer state in sharded way
p_get_initial_state = pjit(
get_initial_state,
in_axis_resources=None,
out_axis_resources=(opt_state_spec, param_spec),
)
# hack: move the inital params to CPU to free up device memory
# TODO: allow loading weights on CPU in pre-trained model
model.params = jax.tree_util.tree_map(lambda x: np.asarray(x), model.params)
# mesh defination
mesh_devices = np.array(jax.devices()).reshape(1, jax.local_device_count())
# actually initialize the opt_state
with mesh(mesh_devices, ("dp", "mp")):
opt_state, params = p_get_initial_state(freeze(model.params))
# cross-entropy with z loss
def loss_fn(logits, labels, z_loss=0):
shift_logits = logits[..., :-1, :]
shift_labels = labels[..., 1:]
shift_labels = onehot(shift_labels, shift_logits.shape[-1])
shift_logits = shift_logits - jax.lax.stop_gradient(shift_logits.max(axis=-1, keepdims=True))
log_z = jnp.log(jnp.sum(jnp.exp(shift_logits), axis=-1, keepdims=True))
log_softmax = shift_logits - log_z
loss = -jnp.sum(shift_labels * log_softmax, axis=-1)
loss += (1e-4 * jnp.square(log_z.squeeze(-1))) * z_loss
return loss.mean()
# Define gradient update step fn
# TODO: try to use TrainState instead of passing params and opt_state individually
def train_step(params, opt_state, dropout_rng, batch, step):
dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
def compute_loss(params):
labels = batch.pop("labels")
logits = model(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss = loss_fn(logits, labels, z_loss=1.0)
return loss
grad_fn = jax.value_and_grad(compute_loss)
loss, grads = grad_fn(params)
updates, new_opt_state = optimizer.update(grads, opt_state, params)
new_params = optax.apply_updates(params, updates)
metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(step)}
return new_params, tuple(new_opt_state), new_dropout_rng, metrics, step + 1
# Define eval fn
def eval_step(input_ids, labels, params):
logits = model(input_ids=input_ids, params=params, train=False)[0]
loss = loss_fn(logits, labels)
# metrics
return {"loss": loss}
p_train_step = pjit(
train_step,
in_axis_resources=(param_spec, opt_state_spec, None, None, None),
out_axis_resources=(param_spec, opt_state_spec, None, None, None),
donate_argnums=(0, 1),
)
p_eval_step = pjit(
eval_step,
in_axis_resources=(None, None, param_spec),
out_axis_resources=None,
)
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {num_epochs}")
logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
logger.info(f" Total optimization steps = {total_train_steps}")
train_time = 0
train_metrics = []
epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
global_step = 0
# we are not doing 2D parallelism (yet!), this just does model parallelism
with mesh(mesh_devices, ("dp", "mp")):
for _ in epochs:
# ======================== Training ================================
train_start = time.time()
# Create sampling rng
rng, input_rng = jax.random.split(rng)
# Generate an epoch by shuffling sampling indices from the train dataset
train_metrics = []
train_loader = data_loader(input_rng, train_dataset, train_batch_size, shuffle=True)
steps_per_epoch = len(train_dataset) // train_batch_size
# train
for _ in tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False):
batch = next(train_loader)
params, opt_state, dropout_rng, train_metric, global_step = p_train_step(
params,
opt_state,
dropout_rng,
batch,
global_step,
)
train_metrics.append(train_metric)
cur_step = global_step
if cur_step % training_args.logging_steps == 0 and cur_step > 0:
# Save metrics
train_time += time.time() - train_start
if has_tensorboard and jax.process_index() == 0:
write_train_metric(summary_writer, train_metrics, train_time, cur_step)
epochs.write(
f"Step... ({cur_step} | Loss: {train_metric['loss']}, Learning Rate:"
f" {train_metric['learning_rate']})"
)
train_metrics = []
if cur_step % training_args.eval_steps == 0 and cur_step > 0:
# ======================== Evaluating ==============================
eval_metrics = []
eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size)
eval_steps = len(eval_dataset) // eval_batch_size
for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
batch = next(eval_loader)
metrics = p_eval_step(batch["input_ids"], batch["labels"], params)
eval_metrics.append(metrics)
# normalize eval metrics
eval_metrics = stack_forest(eval_metrics)
eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
try:
eval_metrics["perplexity"] = math.exp(eval_metrics["loss"])
except OverflowError:
eval_metrics["perplexity"] = float("inf")
logger.info(
f"Step... ({cur_step} | Eval loss: {eval_metrics['loss']} | Eval Perplexity:"
f" {eval_metrics['perplexity']}"
)
if cur_step % training_args.save_steps == 0 and cur_step > 0:
# save checkpoint after each epoch and push checkpoint to the hub
if jax.process_index() == 0:
params = jax.device_get(params)
model.save_pretrained(
training_args.output_dir,
params=params,
push_to_hub=training_args.push_to_hub,
commit_message=f"Saving weights and logs of step {cur_step}",
)
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/jax-projects/model_parallel/run_clm_mp.py/0
|
{
"file_path": "transformers/examples/research_projects/jax-projects/model_parallel/run_clm_mp.py",
"repo_id": "transformers",
"token_count": 11750
}
|
# coding=utf-8
# Copyright 2018 The Google Flax Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Callable, Dict, Tuple
import flax.linen as nn
import jax
import jax.numpy as jnp
import numpy as np
from jax.random import PRNGKey
from modeling_flax_performer_utils import make_fast_softmax_attention
from transformers.file_utils import add_start_docstrings
from transformers.modeling_flax_utils import ACT2FN
from transformers.models.bert.configuration_bert import BertConfig
from transformers.models.bert.modeling_flax_bert import FlaxBertOnlyMLMHead, FlaxBertPreTrainedModel
from transformers.utils import logging
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "BertConfig"
_TOKENIZER_FOR_DOC = "BertTokenizer"
BERT_START_DOCSTRING = r"""
This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
pruning heads etc.)
This model is also a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`__
subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
general usage and behavior.
Parameters:
config (:class:`~transformers.BertConfig`): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
weights.
"""
BERT_INPUTS_DOCSTRING = r"""
Args:
input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using :class:`~transformers.BertTokenizer`. See
:meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
details.
`What are input IDs? <../glossary.html#input-ids>`__
attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
`What are attention masks? <../glossary.html#attention-mask>`__
token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
1]``:
- 0 corresponds to a `sentence A` token,
- 1 corresponds to a `sentence B` token.
`What are token type IDs? <../glossary.html#token-type-ids>`_
position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
config.max_position_embeddings - 1]``.
`What are position IDs? <../glossary.html#position-ids>`_
head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`({0}, hidden_size)`, `optional`):
Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
vectors than the model's internal embedding lookup matrix.
output_attentions (:obj:`bool`, `optional`):
Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
tensors for more detail.
output_hidden_states (:obj:`bool`, `optional`):
Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
more detail.
return_dict (:obj:`bool`, `optional`):
Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
"""
class FlaxPerformerLayerNorm(nn.Module):
"""
Layer normalization (https://arxiv.org/abs/1607.06450). Operates on the last axis of the input data.
"""
epsilon: float = 1e-6
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
bias: bool = True # If True, bias (beta) is added.
scale: bool = True # If True, multiply by scale (gamma). When the next layer is linear
# (also e.g. nn.relu), this can be disabled since the scaling will be
# done by the next layer.
bias_init: jnp.ndarray = nn.initializers.zeros
scale_init: jnp.ndarray = nn.initializers.ones
@nn.compact
def __call__(self, x):
"""
Applies layer normalization on the input. It normalizes the activations of the layer for each given example in
a batch independently, rather than across a batch like Batch Normalization. i.e. applies a transformation that
maintains the mean activation within each example close to 0 and the activation standard deviation close to 1
Args:
x: the inputs
Returns:
Normalized inputs (the same shape as inputs).
"""
features = x.shape[-1]
mean = jnp.mean(x, axis=-1, keepdims=True)
mean2 = jnp.mean(jax.lax.square(x), axis=-1, keepdims=True)
var = mean2 - jax.lax.square(mean)
mul = jax.lax.rsqrt(var + self.epsilon)
if self.scale:
mul = mul * jnp.asarray(self.param("gamma", self.scale_init, (features,)), self.dtype)
y = (x - mean) * mul
if self.bias:
y = y + jnp.asarray(self.param("beta", self.bias_init, (features,)), self.dtype)
return y
class FlaxPerformerEmbedding(nn.Module):
"""
Specify a new class for doing the embedding stuff as Flax's one use 'embedding' for the parameter name and PyTorch
use 'weight'
"""
vocab_size: int
hidden_size: int
emb_init: Callable[..., np.ndarray] = nn.initializers.normal(stddev=0.1)
@nn.compact
def __call__(self, inputs):
embedding = self.param("weight", self.emb_init, (self.vocab_size, self.hidden_size))
return jnp.take(embedding, inputs, axis=0)
class FlaxPerformerEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
vocab_size: int
hidden_size: int
type_vocab_size: int
max_length: int
@nn.compact
def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
# Embed
w_emb = FlaxPerformerEmbedding(self.vocab_size, self.hidden_size, name="word_embeddings")(
jnp.atleast_2d(input_ids.astype("i4"))
)
p_emb = FlaxPerformerEmbedding(self.max_length, self.hidden_size, name="position_embeddings")(
jnp.atleast_2d(position_ids.astype("i4"))
)
t_emb = FlaxPerformerEmbedding(self.type_vocab_size, self.hidden_size, name="token_type_embeddings")(
jnp.atleast_2d(token_type_ids.astype("i4"))
)
# Sum all embeddings
summed_emb = w_emb + jnp.broadcast_to(p_emb, w_emb.shape) + t_emb
# Layer Norm
layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(summed_emb)
return layer_norm
class FlaxPerformerAttention(nn.Module):
num_heads: int
head_size: int
@nn.compact
def __call__(self, hidden_state, attention_mask):
single_head_dim = self.head_size // self.num_heads
fast_softmax_attention = make_fast_softmax_attention(qkv_dim=single_head_dim)
self_att = nn.attention.SelfAttention(
num_heads=self.num_heads, qkv_features=self.head_size, name="self", attention_fn=fast_softmax_attention
)(hidden_state, attention_mask)
layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(self_att + hidden_state)
return layer_norm
class FlaxPerformerIntermediate(nn.Module):
output_size: int
hidden_act: str = "gelu"
@nn.compact
def __call__(self, hidden_state):
# TODO: Add ACT2FN reference to change activation function
dense = nn.Dense(features=self.output_size, name="dense")(hidden_state)
return ACT2FN[self.hidden_act](dense)
class FlaxPerformerOutput(nn.Module):
@nn.compact
def __call__(self, intermediate_output, attention_output):
hidden_state = nn.Dense(attention_output.shape[-1], name="dense")(intermediate_output)
hidden_state = FlaxPerformerLayerNorm(name="layer_norm")(hidden_state + attention_output)
return hidden_state
class FlaxPerformerLayer(nn.Module):
num_heads: int
head_size: int
intermediate_size: int
hidden_act: str = "gelu"
@nn.compact
def __call__(self, hidden_state, attention_mask):
attention = FlaxPerformerAttention(self.num_heads, self.head_size, name="attention")(
hidden_state, attention_mask
)
intermediate = FlaxPerformerIntermediate(
self.intermediate_size, name="intermediate", hidden_act=self.hidden_act
)(attention)
output = FlaxPerformerOutput(name="output")(intermediate, attention)
return output
class FlaxPerformerLayerCollection(nn.Module):
"""
Stores N BertLayer(s)
"""
num_layers: int
num_heads: int
head_size: int
intermediate_size: int
hidden_act: str = "gelu"
@nn.compact
def __call__(self, inputs, attention_mask):
assert self.num_layers > 0, f"num_layers should be >= 1, got ({self.num_layers})"
# Initialize input / output
input_i = inputs
# Forward over all encoders
for i in range(self.num_layers):
layer = FlaxPerformerLayer(
self.num_heads, self.head_size, self.intermediate_size, hidden_act=self.hidden_act, name=f"{i}"
)
input_i = layer(input_i, attention_mask)
return input_i
class FlaxPerformerEncoder(nn.Module):
num_layers: int
num_heads: int
head_size: int
intermediate_size: int
hidden_act: str = "gelu"
@nn.compact
def __call__(self, hidden_state, attention_mask):
layer = FlaxPerformerLayerCollection(
self.num_layers,
self.num_heads,
self.head_size,
self.intermediate_size,
name="layer",
hidden_act=self.hidden_act,
)(hidden_state, attention_mask)
return layer
class FlaxPerformerPooler(nn.Module):
@nn.compact
def __call__(self, hidden_state):
cls_token = hidden_state[:, 0]
out = nn.Dense(hidden_state.shape[-1], name="dense")(cls_token)
return jax.lax.tanh(out)
class FlaxPerformerModule(nn.Module):
vocab_size: int
hidden_size: int
type_vocab_size: int
max_length: int
num_encoder_layers: int
num_heads: int
head_size: int
intermediate_size: int
hidden_act: str = "gelu"
add_pooling_layer: bool = True
@nn.compact
def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
# Embedding
embeddings = FlaxPerformerEmbeddings(
self.vocab_size, self.hidden_size, self.type_vocab_size, self.max_length, name="embeddings"
)(input_ids, token_type_ids, position_ids, attention_mask)
# N stacked encoding layers
encoder = FlaxPerformerEncoder(
self.num_encoder_layers,
self.num_heads,
self.head_size,
self.intermediate_size,
hidden_act=self.hidden_act,
name="encoder",
)(embeddings, attention_mask)
if not self.add_pooling_layer:
return encoder
pooled = FlaxPerformerPooler(name="pooler")(encoder)
return encoder, pooled
@add_start_docstrings(
"The bare Bert Model transformer outputting raw hidden-states without any specific head on top.",
BERT_START_DOCSTRING,
)
class FlaxPerformerModel(FlaxBertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
"""
model_class = FlaxPerformerModule
config_class = BertConfig
base_model_prefix = "bert"
@staticmethod
def convert_from_pytorch(pt_state: Dict, config: BertConfig) -> Dict:
jax_state = dict(pt_state)
# Need to change some parameters name to match Flax names so that we don't have to fork any layer
for key, tensor in pt_state.items():
# Key parts
key_parts = set(key.split("."))
# Every dense layer has "kernel" parameters instead of "weight"
if "dense.weight" in key:
del jax_state[key]
key = key.replace("weight", "kernel")
jax_state[key] = tensor
# SelfAttention needs also to replace "weight" by "kernel"
if {"query", "key", "value"} & key_parts:
# Flax SelfAttention decomposes the heads (num_head, size // num_heads)
if "bias" in key:
jax_state[key] = tensor.reshape((config.num_attention_heads, -1))
elif "weight":
del jax_state[key]
key = key.replace("weight", "kernel")
tensor = tensor.reshape((config.num_attention_heads, -1, config.hidden_size)).transpose((2, 0, 1))
jax_state[key] = tensor
# SelfAttention output is not a separate layer, remove one nesting
if "attention.output.dense" in key:
del jax_state[key]
key = key.replace("attention.output.dense", "attention.self.out")
jax_state[key] = tensor
# SelfAttention output is not a separate layer, remove nesting on layer norm
if "attention.output.LayerNorm" in key:
del jax_state[key]
key = key.replace("attention.output.LayerNorm", "attention.LayerNorm")
jax_state[key] = tensor
# There are some transposed parameters w.r.t their PyTorch counterpart
if "intermediate.dense.kernel" in key or "output.dense.kernel" in key:
jax_state[key] = tensor.T
# Self Attention output projection needs to be transposed
if "out.kernel" in key:
jax_state[key] = tensor.reshape((config.hidden_size, config.num_attention_heads, -1)).transpose(
1, 2, 0
)
# Pooler needs to transpose its kernel
if "pooler.dense.kernel" in key:
jax_state[key] = tensor.T
# Handle LayerNorm conversion
if "LayerNorm" in key:
del jax_state[key]
# Replace LayerNorm by layer_norm
new_key = key.replace("LayerNorm", "layer_norm")
if "weight" in key:
new_key = new_key.replace("weight", "gamma")
elif "bias" in key:
new_key = new_key.replace("bias", "beta")
jax_state[new_key] = tensor
return jax_state
def __init__(
self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
):
module = FlaxPerformerModule(
vocab_size=config.vocab_size,
hidden_size=config.hidden_size,
type_vocab_size=config.type_vocab_size,
max_length=config.max_position_embeddings,
num_encoder_layers=config.num_hidden_layers,
num_heads=config.num_attention_heads,
head_size=config.hidden_size,
intermediate_size=config.intermediate_size,
dropout_rate=config.hidden_dropout_prob,
hidden_act=config.hidden_act,
)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
@property
def module(self) -> nn.Module:
return self._module
def __call__(
self, input_ids, token_type_ids=None, position_ids=None, dropout_rng: PRNGKey = None, attention_mask=None
):
input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
input_ids, attention_mask, token_type_ids, position_ids
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
return self.module.apply(
{"params": self.params},
jnp.array(input_ids, dtype="i4"),
jnp.array(token_type_ids, dtype="i4"),
jnp.array(position_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
rng=rngs,
)
class FlaxPerformerForMaskedLM(FlaxBertPreTrainedModel):
def __init__(
self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
):
module = FlaxPerformerForMaskedLMModule(
vocab_size=config.vocab_size,
type_vocab_size=config.type_vocab_size,
hidden_size=config.hidden_size,
intermediate_size=config.intermediate_size,
head_size=config.hidden_size,
num_heads=config.num_attention_heads,
num_encoder_layers=config.num_hidden_layers,
max_length=config.max_position_embeddings,
hidden_act=config.hidden_act,
**kwargs,
)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
def __call__(
self,
input_ids,
attention_mask=None,
token_type_ids=None,
position_ids=None,
params: dict = None,
train: bool = False,
dropout_rng: PRNGKey = None,
):
input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
input_ids, attention_mask, token_type_ids, position_ids
)
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
rngs["dropout"] = dropout_rng
return self.module.apply(
{"params": params or self.params},
jnp.array(input_ids, dtype="i4"),
jnp.array(attention_mask, dtype="i4"),
jnp.array(token_type_ids, dtype="i4"),
jnp.array(position_ids, dtype="i4"),
not train,
rngs=rngs,
)
class FlaxPerformerForMaskedLMModule(nn.Module):
vocab_size: int
hidden_size: int
intermediate_size: int
head_size: int
num_heads: int
num_encoder_layers: int
type_vocab_size: int
max_length: int
hidden_act: str
dropout_rate: float = 0.0
dtype: jnp.dtype = jnp.float32
@nn.compact
def __call__(
self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, deterministic: bool = True
):
# Model
encoder = FlaxPerformerModule(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
type_vocab_size=self.type_vocab_size,
max_length=self.max_length,
num_encoder_layers=self.num_encoder_layers,
num_heads=self.num_heads,
head_size=self.hidden_size,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
add_pooling_layer=False,
name="bert",
)(input_ids, attention_mask, token_type_ids, position_ids)
# Compute the prediction scores
encoder = nn.Dropout(rate=self.dropout_rate)(encoder, deterministic=deterministic)
logits = FlaxBertOnlyMLMHead(
vocab_size=self.vocab_size, hidden_act=self.hidden_act, name="cls", dtype=self.dtype
)(encoder)
return (logits,)
|
transformers/examples/research_projects/performer/modeling_flax_performer.py/0
|
{
"file_path": "transformers/examples/research_projects/performer/modeling_flax_performer.py",
"repo_id": "transformers",
"token_count": 9147
}
|
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
to a snake
Moses' assistant
Egyptian royal court
let his rod turn in to a snake
The Pokémon Company
Nintendo
world's top-selling toy brand, the top-selling trading card game
over 20 seasons
|
transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target/0
|
{
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target",
"repo_id": "transformers",
"token_count": 305
}
|
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag.sh --help to see all the possible options
python examples/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 100 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
|
transformers/examples/research_projects/rag/finetune_rag.sh/0
|
{
"file_path": "transformers/examples/research_projects/rag/finetune_rag.sh",
"repo_id": "transformers",
"token_count": 440
}
|
# Copyright 2022 The Google Research Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#!/bin/bash
# Create a virtual environment
conda deactivate
conda update conda -y
conda update anaconda -y
pip install --upgrade pip
python3 -m pip install --user virtualenv
conda create -n strata python=3.9 -y
conda activate strata
# Install all necessary packages
pip install transformers
pip install -r requirements.txt
# Download and prepare data
WORK_DIR="/tmp/strata"
rm -rf "${WORK_DIR}" && mkdir -p "${WORK_DIR}"
wget https://storage.googleapis.com/gresearch/strata/demo.zip -P "${WORK_DIR}"
DEMO_ZIP_FILE="${WORK_DIR}/demo.zip"
unzip "${DEMO_ZIP_FILE}" -d "${WORK_DIR}" && rm "${DEMO_ZIP_FILE}"
DATA_DIR="${WORK_DIR}/demo/scitail-8"
OUTPUT_DIR="/tmp/output"
rm -rf "${OUTPUT_DIR}" && mkdir -p "${OUTPUT_DIR}"
# Specific hyperparameters
MODEL_NAME_OR_PATH="bert-base-uncased"
NUM_NODES=1
NUM_TRAINERS=4
LAUNCH_SCRIPT="torchrun --nnodes='${NUM_NODES}' --nproc_per_node='${NUM_TRAINERS}' python -c"
MAX_SELFTRAIN_ITERATIONS=100
TRAIN_FILE="train.csv"
INFER_FILE="infer.csv"
EVAL_FILE="eval_256.csv"
MAX_STEPS=100000
# Start self-training
${LAUNCH_SCRIPT} "
import os
from selftraining import selftrain
data_dir = '${DATA_DIR}'
parameters_dict = {
'max_selftrain_iterations': ${MAX_SELFTRAIN_ITERATIONS},
'model_name_or_path': '${MODEL_NAME_OR_PATH}',
'output_dir': '${OUTPUT_DIR}',
'train_file': os.path.join(data_dir, '${TRAIN_FILE}'),
'infer_file': os.path.join(data_dir, '${INFER_FILE}'),
'eval_file': os.path.join(data_dir, '${EVAL_FILE}'),
'eval_strategy': 'steps',
'task_name': 'scitail',
'label_list': ['entails', 'neutral'],
'per_device_train_batch_size': 32,
'per_device_eval_batch_size': 8,
'max_length': 128,
'learning_rate': 2e-5,
'max_steps': ${MAX_STEPS},
'eval_steps': 1,
'early_stopping_patience': 50,
'overwrite_output_dir': True,
'do_filter_by_confidence': False,
'do_filter_by_val_performance': True,
'finetune_on_labeled_data': False,
'seed': 42,
}
selftrain(**parameters_dict)
"
|
transformers/examples/research_projects/self-training-text-classification/run.sh/0
|
{
"file_path": "transformers/examples/research_projects/self-training-text-classification/run.sh",
"repo_id": "transformers",
"token_count": 960
}
|
#!/usr/bin/env bash
export PYTHONPATH="../":"${PYTHONPATH}"
# From appendix C of paper https://arxiv.org/abs/1912.08777
# Set --gradient_accumulation_steps so that effective batch size is 256 (2*128, 4*64, 8*32, 16*16)
python finetune.py \
--learning_rate=1e-4 \
--do_train \
--do_predict \
--n_val 1000 \
--val_check_interval 0.25 \
--max_source_length 512 --max_target_length 56 \
--freeze_embeds --label_smoothing 0.1 --adafactor --task summarization_xsum \
"$@"
|
transformers/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh/0
|
{
"file_path": "transformers/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh",
"repo_id": "transformers",
"token_count": 208
}
|
<!---
Copyright 2022 The Microsoft Inc. and The HuggingFace Inc. Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Run Table Tasks with TAPEX
TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/pdf/2107.07653.pdf).
> If you are also familiar with [fairseq](https://github.com/pytorch/fairseq), you may also find [the official implementation](https://github.com/microsoft/Table-Pretraining) useful, which leverages the framework.
## Table Question Answering Tasks
### What is Table Question Answering

The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
### What Questions Can be Answered
Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from [WikiTableQuestion](https://nlp.stanford.edu/blog/wikitablequestions-a-complex-real-world-question-understanding-dataset).
| Question | Answer |
| :---: | :---: |
| What is the years won for each team? | 2004, 2008, 2012 |
| How long did Taiki Tsuchiya last? | 4:27 |
| What is the total amount of matches drawn? | 1 |
| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
| What was the last Baekje Temple? | Uija |
| What is the difference between White voters and Black voters in 1948? | 0 |
| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
### How to Fine-tune TAPEX on TableQA
We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: [WikiSQL](https://github.com/salesforce/WikiSQL).
This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
(only some tweaks in the function `preprocess_tableqa_function`).
#### TAPEX-Base on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikisql_tapex_base
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--eval_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikisql_tapex_large
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--eval_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
#### TAPEX-Base on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikitablequestions_tapex_base
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--eval_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could reduce the `per_device_train_batch_size` and `per_device_eval_batch_size` and have another try. Or you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikitablequestions_tapex_large
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 12 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--eval_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
### How to Evaluate TAPEX Fine-tuned Models on TableQA
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-wikisql` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=wikisql_tapex_base_eval
python run_wikisql_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-wikisql \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 4 \
--predict_with_generate \
--num_beams 5
```
## Table Fact Verification Tasks
### What is Table Fact Verification
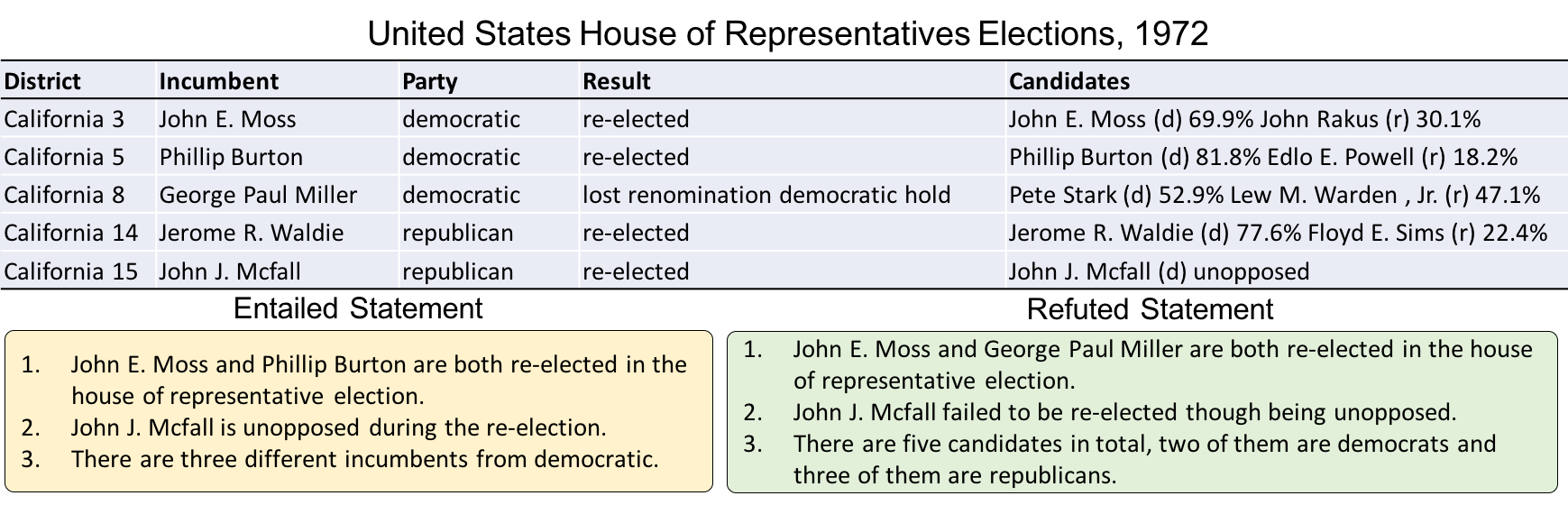
The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to `1` (entailed) or `0` (refused).
### How to Fine-tune TAPEX on TableFV
#### TAPEX-Base on TabFact
We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: [TabFact](https://github.com/wenhuchen/Table-Fact-Checking).
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_base
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 3 \
--gradient_accumulation_steps 16 \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--eval_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
#### TAPEX-Large on TabFact
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_large
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 18 \
--per_device_eval_batch_size 4 \
--eval_accumulation_steps 12 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--eval_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
### How to Evaluate TAPEX Fine-tuned Models on TableFV
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-tabfact` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=tabfact_tapex_base_eval
python run_tabfact_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-tabfact \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6
```
## Reproduced Results
We get the following results on the dev set of the benchmark with the previous commands:
| Task | Model Size | Metric | Result |
|:---:|:---:|:---:|:---:|
| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
| TabFact | Base | Accuracy | 78.7 |
| TabFact | Large | Accuracy | 83.6 |
|
transformers/examples/research_projects/tapex/README.md/0
|
{
"file_path": "transformers/examples/research_projects/tapex/README.md",
"repo_id": "transformers",
"token_count": 3713
}
|
# Simple VQGAN CLIP
Author: @ErwannMillon
This is a very simple VQGAN-CLIP implementation that was built as a part of the <a href= "https://github.com/ErwannMillon/face-editor"> Face Editor project </a> . This simplified version allows you to generate or edit images using text with just three lines of code. For a more full featured implementation with masking, more advanced losses, and a full GUI, check out the Face Editor project.
By default this uses a CelebA checkpoint (for generating/editing faces), but also has an imagenet checkpoint that can be loaded by specifying vqgan_config and vqgan_checkpoint when instantiating VQGAN_CLIP.
Learning rate and iterations can be set by modifying vqgan_clip.lr and vqgan_clip.iterations .
You can edit images by passing `image_path` to the generate function.
See the generate function's docstring to learn more about how to format prompts.
## Usage
The easiest way to test this out is by <a href="https://colab.research.google.com/drive/1Ez4D1J6-hVkmlXeR5jBPWYyu6CLA9Yor?usp=sharing
">using the Colab demo</a>
To install locally:
- Clone this repo
- Install git-lfs (ubuntu: sudo apt-get install git-lfs , MacOS: brew install git-lfs)
In the root of the repo run:
```bash
conda create -n vqganclip python=3.8
conda activate vqganclip
git-lfs install
git clone https://huggingface.co/datasets/erwann/face_editor_model_ckpt model_checkpoints
pip install -r requirements.txt
```
### Generate new images
```python
from VQGAN_CLIP import VQGAN_CLIP
vqgan_clip = VQGAN_CLIP()
vqgan_clip.generate("a picture of a smiling woman")
```
### Edit an image
To get a test image, run
`git clone https://huggingface.co/datasets/erwann/vqgan-clip-pic test_images`
To edit:
```python
from VQGAN_CLIP import VQGAN_CLIP
vqgan_clip = VQGAN_CLIP()
vqgan_clip.lr = .07
vqgan_clip.iterations = 15
vqgan_clip.generate(
pos_prompts= ["a picture of a beautiful asian woman", "a picture of a woman from Japan"],
neg_prompts=["a picture of an Indian person", "a picture of a white person"],
image_path="./test_images/face.jpeg",
show_intermediate=True,
save_intermediate=True,
)
```
### Make an animation from the most recent generation
`vqgan_clip.make_animation()`
## Features:
- Positive and negative prompts
- Multiple prompts
- Prompt Weights
- Creating GIF animations of the transformations
- Wandb logging
|
transformers/examples/research_projects/vqgan-clip/README.md/0
|
{
"file_path": "transformers/examples/research_projects/vqgan-clip/README.md",
"repo_id": "transformers",
"token_count": 777
}
|
#!/usr/bin/env bash
python run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="tr" \
--output_dir=./wav2vec2-large-xlsr-turkish-demo \
--overwrite_output_dir \
--num_train_epochs="5" \
--per_device_train_batch_size="16" \
--eval_strategy="steps" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--fp16 \
--freeze_feature_extractor \
--save_steps="400" \
--eval_steps="400" \
--save_total_limit="3" \
--logging_steps="400" \
--group_by_length \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--do_train --do_eval
|
transformers/examples/research_projects/wav2vec2/finetune_wav2vec2_xlsr_turkish.sh/0
|
{
"file_path": "transformers/examples/research_projects/wav2vec2/finetune_wav2vec2_xlsr_turkish.sh",
"repo_id": "transformers",
"token_count": 315
}
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# TFVisionTextDualEncoder and CLIP model training examples
The following example showcases how to train a CLIP-like vision-text dual encoder model
using a pre-trained vision and text encoder.
Such a model can be used for natural language image search and potentially zero-shot image classification.
The model is inspired by [CLIP](https://openai.com/blog/clip/), introduced by Alec Radford et al.
The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
captions into the same embedding space, such that the caption embeddings are located near the embeddings
of the images they describe.
### Download COCO dataset (2017)
This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
COCO dataset before training.
```bash
mkdir data
cd data
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip
cd ..
```
Having downloaded COCO dataset manually you should be able to load with the `ydshieh/coc_dataset_script` dataset loading script:
```py
import os
import datasets
COCO_DIR = os.path.join(os.getcwd(), "data")
ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
```
### Create a model from a vision encoder model and a text encoder model
We can either load a CLIP-like vision-text dual encoder model from an existing dual encoder model, or
by using a pre-trained vision encoder model and a pre-trained text encoder model.
If you wish to load an existing dual encoder model, please use the `--model_name_or_path` argument. If
you want to use separate pre-trained vision and text models, please use the
`--vision_model_name_or_path` and `--text_model_name_or_path` arguments instead.
### Train the model
Finally, we can run the example script to train the model:
```bash
python examples/tensorflow/contrastive-image-text/run_clip.py \
--output_dir ./clip-roberta-finetuned \
--vision_model_name_or_path openai/clip-vit-base-patch32 \
--text_model_name_or_path FacebookAI/roberta-base \
--data_dir $PWD/data \
--dataset_name ydshieh/coco_dataset_script \
--dataset_config_name=2017 \
--image_column image_path \
--caption_column caption \
--remove_unused_columns=False \
--do_train --do_eval \
--per_device_train_batch_size="64" \
--per_device_eval_batch_size="64" \
--learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
--overwrite_output_dir \
--push_to_hub
```
|
transformers/examples/tensorflow/contrastive-image-text/README.md/0
|
{
"file_path": "transformers/examples/tensorflow/contrastive-image-text/README.md",
"repo_id": "transformers",
"token_count": 1057
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on token classification tasks (NER, POS, CHUNKS)
"""
import json
import logging
import os
import random
from dataclasses import dataclass, field
from typing import Optional
import datasets
import evaluate
import tensorflow as tf
from datasets import ClassLabel, load_dataset
import transformers
from transformers import (
CONFIG_MAPPING,
AutoConfig,
AutoTokenizer,
DataCollatorForTokenClassification,
HfArgumentParser,
PushToHubCallback,
TFAutoModelForTokenClassification,
TFTrainingArguments,
create_optimizer,
set_seed,
)
from transformers.utils import send_example_telemetry
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
logger.addHandler(logging.StreamHandler())
require_version("datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/token-classification/requirements.txt")
# region Command-line arguments
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
)
text_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
)
label_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_length: Optional[int] = field(default=256, metadata={"help": "Max length (in tokens) for truncation/padding"})
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to model maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
label_all_tokens: bool = field(
default=False,
metadata={
"help": (
"Whether to put the label for one word on all tokens of generated by that word or just on the "
"one (in which case the other tokens will have a padding index)."
)
},
)
return_entity_level_metrics: bool = field(
default=False,
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
self.task_name = self.task_name.lower()
# endregion
def main():
# region Argument Parsing
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_ner", model_args, data_args, framework="tensorflow")
# endregion
# region Setup logging
# we only want one process per machine to log things on the screen.
# accelerator.is_local_main_process is only True for one process per machine.
logger.setLevel(logging.INFO)
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
# If passed along, set the training seed now.
if training_args.seed is not None:
set_seed(training_args.seed)
# endregion
# region Loading datasets
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
# 'tokens' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
raw_datasets = load_dataset(
extension,
data_files=data_files,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
if raw_datasets["train"] is not None:
column_names = raw_datasets["train"].column_names
features = raw_datasets["train"].features
else:
column_names = raw_datasets["validation"].column_names
features = raw_datasets["validation"].features
if data_args.text_column_name is not None:
text_column_name = data_args.text_column_name
elif "tokens" in column_names:
text_column_name = "tokens"
else:
text_column_name = column_names[0]
if data_args.label_column_name is not None:
label_column_name = data_args.label_column_name
elif f"{data_args.task_name}_tags" in column_names:
label_column_name = f"{data_args.task_name}_tags"
else:
label_column_name = column_names[1]
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
if isinstance(features[label_column_name].feature, ClassLabel):
label_list = features[label_column_name].feature.names
# No need to convert the labels since they are already ints.
label_to_id = {i: i for i in range(len(label_list))}
else:
label_list = get_label_list(raw_datasets["train"][label_column_name])
label_to_id = {l: i for i, l in enumerate(label_list)}
num_labels = len(label_list)
# endregion
# region Load config and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if model_args.config_name:
config = AutoConfig.from_pretrained(
model_args.config_name,
num_labels=num_labels,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
elif model_args.model_name_or_path:
config = AutoConfig.from_pretrained(
model_args.model_name_or_path,
num_labels=num_labels,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
if not tokenizer_name_or_path:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if config.model_type in {"gpt2", "roberta"}:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
use_fast=True,
add_prefix_space=True,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
use_fast=True,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# endregion
# region Preprocessing the raw datasets
# First we tokenize all the texts.
padding = "max_length" if data_args.pad_to_max_length else False
# Tokenize all texts and align the labels with them.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples[text_column_name],
max_length=data_args.max_length,
padding=padding,
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label_to_id[label[word_idx]])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
label_ids.append(label_to_id[label[word_idx]] if data_args.label_all_tokens else -100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
processed_raw_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
desc="Running tokenizer on dataset",
)
train_dataset = processed_raw_datasets["train"]
eval_dataset = processed_raw_datasets["validation"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# endregion
with training_args.strategy.scope():
# region Initialize model
if model_args.model_name_or_path:
model = TFAutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
config=config,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = TFAutoModelForTokenClassification.from_config(
config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embeddings = model.get_input_embeddings()
# Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
# As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
# the weights will always be in embeddings.embeddings.
if hasattr(embeddings, "embeddings"):
embedding_size = embeddings.embeddings.shape[0]
else:
embedding_size = embeddings.weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# endregion
# region Create TF datasets
# We need the DataCollatorForTokenClassification here, as we need to correctly pad labels as
# well as inputs.
collate_fn = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="np")
num_replicas = training_args.strategy.num_replicas_in_sync
total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
dataset_options = tf.data.Options()
dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
# model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
# training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
# use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
# yourself if you use this method, whereas they are automatically inferred from the model input names when
# using model.prepare_tf_dataset()
# For more info see the docs:
# https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
# https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
tf_train_dataset = model.prepare_tf_dataset(
train_dataset,
collate_fn=collate_fn,
batch_size=total_train_batch_size,
shuffle=True,
).with_options(dataset_options)
total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
tf_eval_dataset = model.prepare_tf_dataset(
eval_dataset,
collate_fn=collate_fn,
batch_size=total_eval_batch_size,
shuffle=False,
).with_options(dataset_options)
# endregion
# region Optimizer, loss and compilation
num_train_steps = int(len(tf_train_dataset) * training_args.num_train_epochs)
if training_args.warmup_steps > 0:
num_warmup_steps = training_args.warmup_steps
elif training_args.warmup_ratio > 0:
num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
else:
num_warmup_steps = 0
optimizer, lr_schedule = create_optimizer(
init_lr=training_args.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
adam_beta1=training_args.adam_beta1,
adam_beta2=training_args.adam_beta2,
adam_epsilon=training_args.adam_epsilon,
weight_decay_rate=training_args.weight_decay,
adam_global_clipnorm=training_args.max_grad_norm,
)
# Transformers models compute the right loss for their task by default when labels are passed, and will
# use this for training unless you specify your own loss function in compile().
model.compile(optimizer=optimizer, jit_compile=training_args.xla)
# endregion
# Metrics
metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
def get_labels(y_pred, y_true):
# Transform predictions and references tensos to numpy arrays
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
true_labels = [
[label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
return true_predictions, true_labels
def compute_metrics():
results = metric.compute()
if data_args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# endregion
# region Preparing push_to_hub and model card
push_to_hub_model_id = training_args.push_to_hub_model_id
model_name = model_args.model_name_or_path.split("/")[-1]
if not push_to_hub_model_id:
if data_args.dataset_name is not None:
push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
else:
push_to_hub_model_id = f"{model_name}-finetuned-token-classification"
model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
if data_args.dataset_name is not None:
model_card_kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
model_card_kwargs["dataset_args"] = data_args.dataset_config_name
model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
model_card_kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
callbacks = [
PushToHubCallback(
output_dir=training_args.output_dir,
hub_model_id=push_to_hub_model_id,
hub_token=training_args.push_to_hub_token,
tokenizer=tokenizer,
**model_card_kwargs,
)
]
else:
callbacks = []
# endregion
# region Training
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {training_args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
logger.info(f" Total train batch size = {total_train_batch_size}")
# Only show the progress bar once on each machine.
model.fit(
tf_train_dataset,
validation_data=tf_eval_dataset,
epochs=int(training_args.num_train_epochs),
callbacks=callbacks,
)
# endregion
# region Predictions
# If you have variable batch sizes (i.e. not using pad_to_max_length), then
# this bit might fail on TF < 2.8 because TF can't concatenate outputs of varying seq
# length from predict().
try:
predictions = model.predict(tf_eval_dataset, batch_size=training_args.per_device_eval_batch_size)["logits"]
except tf.python.framework.errors_impl.InvalidArgumentError:
raise ValueError(
"Concatenating predictions failed! If your version of TensorFlow is 2.8.0 or older "
"then you will need to use --pad_to_max_length to generate predictions, as older "
"versions of TensorFlow cannot concatenate variable-length predictions as RaggedTensor."
)
if isinstance(predictions, tf.RaggedTensor):
predictions = predictions.to_tensor(default_value=-100)
predictions = tf.math.argmax(predictions, axis=-1).numpy()
if "label" in eval_dataset:
labels = eval_dataset.with_format("tf")["label"]
else:
labels = eval_dataset.with_format("tf")["labels"]
if isinstance(labels, tf.RaggedTensor):
labels = labels.to_tensor(default_value=-100)
labels = labels.numpy()
attention_mask = eval_dataset.with_format("tf")["attention_mask"]
if isinstance(attention_mask, tf.RaggedTensor):
attention_mask = attention_mask.to_tensor(default_value=-100)
attention_mask = attention_mask.numpy()
labels[attention_mask == 0] = -100
preds, refs = get_labels(predictions, labels)
metric.add_batch(
predictions=preds,
references=refs,
)
eval_metric = compute_metrics()
logger.info("Evaluation metrics:")
for key, val in eval_metric.items():
logger.info(f"{key}: {val:.4f}")
if training_args.output_dir is not None:
output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
with open(output_eval_file, "w") as writer:
writer.write(json.dumps(eval_metric))
# endregion
if training_args.output_dir is not None and not training_args.push_to_hub:
# If we're not pushing to hub, at least save a local copy when we're done
model.save_pretrained(training_args.output_dir)
if __name__ == "__main__":
main()
|
transformers/examples/tensorflow/token-classification/run_ner.py/0
|
{
"file_path": "transformers/examples/tensorflow/token-classification/run_ner.py",
"repo_id": "transformers",
"token_count": 11440
}
|
#!/usr/bin/env python
# coding: utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script creates a super tiny model that is useful inside tests, when we just want to test that
# the machinery works, without needing to the check the quality of the outcomes.
#
# This version creates a tiny vocab first, and then a tiny model - so the outcome is truly tiny -
# all files ~60KB. As compared to taking a full-size model, reducing to the minimum its layers and
# emb dimensions, but keeping the full vocab + merges files, leading to ~3MB in total for all files.
# The latter is done by `fsmt-make-super-tiny-model.py`.
#
# It will be used then as "stas/tiny-wmt19-en-ru"
import json
import tempfile
from pathlib import Path
from transformers import FSMTConfig, FSMTForConditionalGeneration, FSMTTokenizer
from transformers.models.fsmt.tokenization_fsmt import VOCAB_FILES_NAMES
mname_tiny = "tiny-wmt19-en-ru"
# Build
# borrowed from a test
vocab = [ "l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "w</w>", "r</w>", "t</w>", "lo", "low", "er</w>", "low</w>", "lowest</w>", "newer</w>", "wider</w>", "<unk>", ]
vocab_tokens = dict(zip(vocab, range(len(vocab))))
merges = ["l o 123", "lo w 1456", "e r</w> 1789", ""]
with tempfile.TemporaryDirectory() as tmpdirname:
build_dir = Path(tmpdirname)
src_vocab_file = build_dir / VOCAB_FILES_NAMES["src_vocab_file"]
tgt_vocab_file = build_dir / VOCAB_FILES_NAMES["tgt_vocab_file"]
merges_file = build_dir / VOCAB_FILES_NAMES["merges_file"]
with open(src_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(tgt_vocab_file, "w") as fp: fp.write(json.dumps(vocab_tokens))
with open(merges_file, "w") as fp : fp.write("\n".join(merges))
tokenizer = FSMTTokenizer(
langs=["en", "ru"],
src_vocab_size = len(vocab),
tgt_vocab_size = len(vocab),
src_vocab_file=src_vocab_file,
tgt_vocab_file=tgt_vocab_file,
merges_file=merges_file,
)
config = FSMTConfig(
langs=['ru', 'en'],
src_vocab_size=1000, tgt_vocab_size=1000,
d_model=4,
encoder_layers=1, decoder_layers=1,
encoder_ffn_dim=4, decoder_ffn_dim=4,
encoder_attention_heads=1, decoder_attention_heads=1,
)
tiny_model = FSMTForConditionalGeneration(config)
print(f"num of params {tiny_model.num_parameters()}")
# Test
batch = tokenizer(["Making tiny model"], return_tensors="pt")
outputs = tiny_model(**batch)
print("test output:", len(outputs.logits[0]))
# Save
tiny_model.half() # makes it smaller
tiny_model.save_pretrained(mname_tiny)
tokenizer.save_pretrained(mname_tiny)
print(f"Generated {mname_tiny}")
# Upload
# transformers-cli upload tiny-wmt19-en-ru
|
transformers/scripts/fsmt/fsmt-make-super-tiny-model.py/0
|
{
"file_path": "transformers/scripts/fsmt/fsmt-make-super-tiny-model.py",
"repo_id": "transformers",
"token_count": 1246
}
|
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import pathlib
import tempfile
import uuid
import numpy as np
from ..utils import is_soundfile_available, is_torch_available, is_vision_available, logging
logger = logging.get_logger(__name__)
if is_vision_available():
from PIL import Image
from PIL.Image import Image as ImageType
else:
ImageType = object
if is_torch_available():
import torch
from torch import Tensor
else:
Tensor = object
if is_soundfile_available():
import soundfile as sf
class AgentType:
"""
Abstract class to be reimplemented to define types that can be returned by agents.
These objects serve three purposes:
- They behave as they were the type they're meant to be, e.g., a string for text, a PIL.Image for images
- They can be stringified: str(object) in order to return a string defining the object
- They should be displayed correctly in ipython notebooks/colab/jupyter
"""
def __init__(self, value):
self._value = value
def __str__(self):
return self.to_string()
def to_raw(self):
logger.error(
"This is a raw AgentType of unknown type. Display in notebooks and string conversion will be unreliable"
)
return self._value
def to_string(self) -> str:
logger.error(
"This is a raw AgentType of unknown type. Display in notebooks and string conversion will be unreliable"
)
return str(self._value)
class AgentText(AgentType, str):
"""
Text type returned by the agent. Behaves as a string.
"""
def to_raw(self):
return self._value
def to_string(self):
return str(self._value)
class AgentImage(AgentType, ImageType):
"""
Image type returned by the agent. Behaves as a PIL.Image.
"""
def __init__(self, value):
AgentType.__init__(self, value)
ImageType.__init__(self)
if not is_vision_available():
raise ImportError("PIL must be installed in order to handle images.")
self._path = None
self._raw = None
self._tensor = None
if isinstance(value, ImageType):
self._raw = value
elif isinstance(value, (str, pathlib.Path)):
self._path = value
elif isinstance(value, torch.Tensor):
self._tensor = value
elif isinstance(value, np.ndarray):
self._tensor = torch.from_numpy(value)
else:
raise TypeError(f"Unsupported type for {self.__class__.__name__}: {type(value)}")
def _ipython_display_(self, include=None, exclude=None):
"""
Displays correctly this type in an ipython notebook (ipython, colab, jupyter, ...)
"""
from IPython.display import Image, display
display(Image(self.to_string()))
def to_raw(self):
"""
Returns the "raw" version of that object. In the case of an AgentImage, it is a PIL.Image.
"""
if self._raw is not None:
return self._raw
if self._path is not None:
self._raw = Image.open(self._path)
return self._raw
if self._tensor is not None:
array = self._tensor.cpu().detach().numpy()
return Image.fromarray((255 - array * 255).astype(np.uint8))
def to_string(self):
"""
Returns the stringified version of that object. In the case of an AgentImage, it is a path to the serialized
version of the image.
"""
if self._path is not None:
return self._path
if self._raw is not None:
directory = tempfile.mkdtemp()
self._path = os.path.join(directory, str(uuid.uuid4()) + ".png")
self._raw.save(self._path)
return self._path
if self._tensor is not None:
array = self._tensor.cpu().detach().numpy()
# There is likely simpler than load into image into save
img = Image.fromarray((255 - array * 255).astype(np.uint8))
directory = tempfile.mkdtemp()
self._path = os.path.join(directory, str(uuid.uuid4()) + ".png")
img.save(self._path)
return self._path
def save(self, output_bytes, format, **params):
"""
Saves the image to a file.
Args:
output_bytes (bytes): The output bytes to save the image to.
format (str): The format to use for the output image. The format is the same as in PIL.Image.save.
**params: Additional parameters to pass to PIL.Image.save.
"""
img = self.to_raw()
img.save(output_bytes, format, **params)
class AgentAudio(AgentType, str):
"""
Audio type returned by the agent.
"""
def __init__(self, value, samplerate=16_000):
super().__init__(value)
if not is_soundfile_available():
raise ImportError("soundfile must be installed in order to handle audio.")
self._path = None
self._tensor = None
self.samplerate = samplerate
if isinstance(value, (str, pathlib.Path)):
self._path = value
elif is_torch_available() and isinstance(value, torch.Tensor):
self._tensor = value
elif isinstance(value, tuple):
self.samplerate = value[0]
if isinstance(value[1], np.ndarray):
self._tensor = torch.from_numpy(value[1])
else:
self._tensor = torch.tensor(value[1])
else:
raise ValueError(f"Unsupported audio type: {type(value)}")
def _ipython_display_(self, include=None, exclude=None):
"""
Displays correctly this type in an ipython notebook (ipython, colab, jupyter, ...)
"""
from IPython.display import Audio, display
display(Audio(self.to_string(), rate=self.samplerate))
def to_raw(self):
"""
Returns the "raw" version of that object. It is a `torch.Tensor` object.
"""
if self._tensor is not None:
return self._tensor
if self._path is not None:
tensor, self.samplerate = sf.read(self._path)
self._tensor = torch.tensor(tensor)
return self._tensor
def to_string(self):
"""
Returns the stringified version of that object. In the case of an AgentAudio, it is a path to the serialized
version of the audio.
"""
if self._path is not None:
return self._path
if self._tensor is not None:
directory = tempfile.mkdtemp()
self._path = os.path.join(directory, str(uuid.uuid4()) + ".wav")
sf.write(self._path, self._tensor, samplerate=self.samplerate)
return self._path
AGENT_TYPE_MAPPING = {"string": AgentText, "image": AgentImage, "audio": AgentAudio}
INSTANCE_TYPE_MAPPING = {str: AgentText, ImageType: AgentImage}
if is_torch_available():
INSTANCE_TYPE_MAPPING[Tensor] = AgentAudio
def handle_agent_inputs(*args, **kwargs):
args = [(arg.to_raw() if isinstance(arg, AgentType) else arg) for arg in args]
kwargs = {k: (v.to_raw() if isinstance(v, AgentType) else v) for k, v in kwargs.items()}
return args, kwargs
def handle_agent_outputs(output, output_type=None):
if output_type in AGENT_TYPE_MAPPING:
# If the class has defined outputs, we can map directly according to the class definition
decoded_outputs = AGENT_TYPE_MAPPING[output_type](output)
return decoded_outputs
else:
# If the class does not have defined output, then we map according to the type
for _k, _v in INSTANCE_TYPE_MAPPING.items():
if isinstance(output, _k):
return _v(output)
return output
|
transformers/src/transformers/agents/agent_types.py/0
|
{
"file_path": "transformers/src/transformers/agents/agent_types.py",
"repo_id": "transformers",
"token_count": 3413
}
|
import copy
import importlib.metadata
import json
import os
from dataclasses import dataclass
from typing import Any, Dict, List, Optional, Tuple, Union
import torch
from packaging import version
from .configuration_utils import PretrainedConfig
from .utils import (
is_hqq_available,
is_optimum_quanto_available,
is_torchdynamo_compiling,
logging,
)
from .utils.deprecation import deprecate_kwarg
if is_hqq_available():
from hqq.core.quantize import Quantizer as HQQQuantizer
logger = logging.get_logger(__name__)
class Cache(torch.nn.Module):
"""
Base, abstract class for all caches. The actual data structure is specific to each subclass.
"""
is_compileable = False
def __init__(self):
super().__init__()
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. These are specific to each subclass and allow new types of
cache to be created.
Return:
A tuple containing the updated key and value states.
"""
raise NotImplementedError("Make sure to implement `update` in a subclass.")
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
# TODO: deprecate this function in favor of `cache_position`
raise NotImplementedError("Make sure to implement `get_seq_length` in a subclass.")
def get_max_cache_shape(self) -> Optional[int]:
"""Returns the maximum sequence length (i.e. max capacity) of the cache object"""
raise NotImplementedError("Make sure to implement `get_max_cache_shape` in a subclass.")
def get_usable_length(self, new_seq_length: int, layer_idx: Optional[int] = 0) -> int:
"""Given the sequence length of the new inputs, returns the usable length of the cache."""
# Cache without size limit -> all cache is usable
# Cache with size limit -> if the length cache plus the length of the new inputs is larger the maximum cache
# length, we will need to evict part of the cache (and thus not all cache is usable)
max_length = self.get_max_cache_shape()
previous_seq_length = self.get_seq_length(layer_idx)
if max_length is not None and previous_seq_length + new_seq_length > max_length:
return max_length - new_seq_length
return previous_seq_length
def reorder_cache(self, beam_idx: torch.LongTensor):
"""Reorders the cache for beam search, given the selected beam indices."""
for layer_idx in range(len(self.key_cache)):
if self.key_cache[layer_idx] != []:
device = self.key_cache[layer_idx].device
self.key_cache[layer_idx] = self.key_cache[layer_idx].index_select(0, beam_idx.to(device))
if self.value_cache[layer_idx] != []:
device = self.value_cache[layer_idx].device
self.value_cache[layer_idx] = self.value_cache[layer_idx].index_select(0, beam_idx.to(device))
@property
def seen_tokens(self):
logger.warning_once(
"The `seen_tokens` attribute is deprecated and will be removed in v4.41. Use the `cache_position` "
"model input instead."
)
if hasattr(self, "_seen_tokens"):
return self._seen_tokens
else:
return None
@dataclass
class CacheConfig:
"""
Base class for cache configs
"""
cache_implementation: None
@classmethod
def from_dict(cls, config_dict, **kwargs):
"""
Constructs a CacheConfig instance from a dictionary of parameters.
Args:
config_dict (Dict[str, Any]): Dictionary containing configuration parameters.
**kwargs: Additional keyword arguments to override dictionary values.
Returns:
CacheConfig: Instance of CacheConfig constructed from the dictionary.
"""
config = cls(**config_dict)
to_remove = []
for key, value in kwargs.items():
if hasattr(config, key):
setattr(config, key, value)
to_remove.append(key)
for key in to_remove:
kwargs.pop(key, None)
return config
# Copied from transformers.utils.quantization_config.QuantizationConfigMixin.to_json_file
def to_json_file(self, json_file_path: Union[str, os.PathLike]):
"""
Save this instance to a JSON file.
Args:
json_file_path (`str` or `os.PathLike`):
Path to the JSON file in which this configuration instance's parameters will be saved.
use_diff (`bool`, *optional*, defaults to `True`):
If set to `True`, only the difference between the config instance and the default
`QuantizationConfig()` is serialized to JSON file.
"""
with open(json_file_path, "w", encoding="utf-8") as writer:
config_dict = self.to_dict()
json_string = json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
writer.write(json_string)
# Copied from transformers.utils.quantization_config.QuantizationConfigMixin.to_dict
def to_dict(self) -> Dict[str, Any]:
"""
Serializes this instance to a Python dictionary. Returns:
`Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
"""
return copy.deepcopy(self.__dict__)
# Copied from transformers.utils.quantization_config.QuantizationConfigMixin.__iter__
def __iter__(self):
"""allows `dict(obj)` for situations where obj may be a dict or QuantizationConfigMixin"""
for attr, value in copy.deepcopy(self.__dict__).items():
yield attr, value
# Copied from transformers.utils.quantization_config.QuantizationConfigMixin.__repr__
def __repr__(self):
return f"{self.__class__.__name__} {self.to_json_string()}"
def to_json_string(self):
"""
Serializes this instance to a JSON formatted string.
Returns:
str: JSON formatted string representing the configuration instance.
"""
return json.dumps(self.__dict__, indent=2) + "\n"
# Copied from transformers.utils.quantization_config.QuantizationConfigMixin.update
def update(self, **kwargs):
"""
Updates attributes of this class instance with attributes from `kwargs` if they match existing attributes,
returning all the unused kwargs.
Args:
kwargs (`Dict[str, Any]`):
Dictionary of attributes to tentatively update this class.
Returns:
`Dict[str, Any]`: Dictionary containing all the key-value pairs that were not used to update the instance.
"""
to_remove = []
for key, value in kwargs.items():
if hasattr(self, key):
setattr(self, key, value)
to_remove.append(key)
# Remove all the attributes that were updated, without modifying the input dict
unused_kwargs = {key: value for key, value in kwargs.items() if key not in to_remove}
return unused_kwargs
@dataclass
class QuantizedCacheConfig(CacheConfig):
"""
Configuration class for quantized cache settings.
Attributes:
backend (`str`, *optional*, defaults to `"quanto"`):
Backend to use when performing quantization, Can be one of [`quanto`, `HQQ`]
nbits (`Optional[int]`, *optional*, defaults to 4):
Number of bits, can be 2 or 4 for the `quanto` backend and one of [1, 2, 3, 4, 8] for the `HQQ` backend. Defaults to 2.
axis_key (`int`, *optional*, defaults to 0):
Axis over which to perform grouping for the key tensors. Can be [0, -1] for `quanto` backend and [0, 1] for `HQQ` backend.
axis_value (`int`, *optional*, defaults to 0):
Axis over which to perform grouping for the value tensors. Can be [0, -1] for `quanto` backend and [0, 1] for `HQQ` backend.
q_group_size (`Optional[int]`, *optional*, defaults to 64):
Size of the quantization group, should be a divisor of the model's hidden dimension.
Defaults to 64.
residual_length (`Optional[int]`, *optional*, defaults to 128):
Length of the residual cache which will always be stored in original presicion.
Defaults to 128.
compute_dtype (`torch.dtype`, *optional*, defaults to `torch.float16`):
The defualt dtype used for computations in the model. Keys and Values will be cast to this dtype after dequantization.
device (`str`, *optional*, defaults to `"cpu"`):
Device on which to perform computations, should be same as the model's device.
"""
def __init__(
self,
backend: str = "quanto",
nbits: Optional[int] = 4,
axis_key: Optional[int] = 0,
axis_value: Optional[int] = 0,
q_group_size: Optional[int] = 64,
residual_length: Optional[int] = 128,
compute_dtype: Optional[torch.dtype] = torch.float16,
device: Optional[str] = "cpu",
):
self.backend = backend
self.nbits = nbits
self.axis_key = axis_key
self.axis_value = axis_value
self.q_group_size = q_group_size
self.residual_length = residual_length
self.compute_dtype = compute_dtype
self.device = device
def validate(self):
"""Validates if the arguments passed are correct"""
incorrect_arg_msg = (
"Some of the keys in `cache_config` are defined incorrectly. `{key}` should be {correct_value}` "
"but found {found_value}"
)
# Check that the values are reasonable in general (nbits, axis)
# Later in QuantizedCache init we check if they are supported for that particular backend
if self.nbits not in [1, 2, 3, 4, 8]:
raise ValueError(
incorrect_arg_msg.format(
key="nbits",
correct_value="2 or 4 or 8",
found_value=self.nbits,
),
)
if self.q_group_size <= 0:
raise ValueError(
incorrect_arg_msg.format(
key="q_group_size",
correct_value="a positive integer",
found_value=self.q_group_size,
),
)
if self.residual_length < 0:
raise ValueError(
incorrect_arg_msg.format(
key="residual_length",
correct_value="a positive integer",
found_value=self.residual_length,
),
)
if self.axis_key not in [0, 1, -1]:
raise ValueError(
incorrect_arg_msg.format(
key="axis_key",
correct_value="`1` or `0`, `-1`",
found_value=self.axis_key,
),
)
if self.axis_value not in [0, 1, -1]:
raise ValueError(
incorrect_arg_msg.format(
key="axis_value",
correct_value="`1` or `0` or `-1`",
found_value=self.axis_value,
),
)
@dataclass
class StaticCacheConfig(CacheConfig):
"""
Configuration class for static cache settings.
"""
cache_implementation = "static"
def __init__(self, batch_size: int, max_cache_len: int, device="cpu"):
self.batch_size = batch_size
self.max_cache_len = max_cache_len
self.device = device
def validate(self):
"""Validates if the arguments passed are correct"""
incorrect_arg_msg = (
"Some of the keys in `cache_config` are defined incorrectly. `{key}` should be {correct_value}` "
"but found {found_value}"
)
if self.batch_size <= 0:
raise ValueError(
incorrect_arg_msg.format(
key="batch_size",
correct_value="> 0",
found_value=self.batch_size,
),
)
if self.max_cache_len <= 0:
raise ValueError(
incorrect_arg_msg.format(
key="max_cache_len",
correct_value="> 0",
found_value=self.max_cache_len,
),
)
class DynamicCache(Cache):
"""
A cache that grows dynamically as more tokens are generated. This is the default for generative models.
It stores the Key and Value states as a list of tensors, one for each layer. The expected shape for each tensor is
`[batch_size, num_heads, seq_len, head_dim]`.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> past_key_values = DynamicCache()
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
DynamicCache()
```
"""
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def __init__(self, num_hidden_layers: Optional[int] = None) -> None:
super().__init__()
self._seen_tokens = 0 # Used in `generate` to keep tally of how many tokens the cache has seen
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
"""
Support for backwards-compatible `past_key_value` indexing, e.g. `past_key_value[0][0].shape[2]` to get the
sequence length.
"""
if layer_idx < len(self):
return (self.key_cache[layer_idx], self.value_cache[layer_idx])
else:
raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
def __iter__(self):
"""
Support for backwards-compatible `past_key_value` iteration, e.g. `for x in past_key_value:` to iterate over
keys and values
"""
for layer_idx in range(len(self)):
yield (self.key_cache[layer_idx], self.value_cache[layer_idx])
def __len__(self):
"""
Support for backwards-compatible `past_key_value` length, e.g. `len(past_key_value)`. This value corresponds
to the number of layers in the model.
"""
return len(self.key_cache)
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. No additional arguments are used in `DynamicCache`.
Return:
A tuple containing the updated key and value states.
"""
# Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
# Update the cache
if key_states is not None:
if len(self.key_cache) <= layer_idx:
# There may be skipped layers, fill them with empty lists
for _ in range(len(self.key_cache), layer_idx):
self.key_cache.append([])
self.value_cache.append([])
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif (
len(self.key_cache[layer_idx]) == 0
): # fills previously skipped layers; checking for tensor causes errors
self.key_cache[layer_idx] = key_states
self.value_cache[layer_idx] = value_states
else:
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
# TODO: deprecate this function in favor of `cache_position`
is_empty_layer = (
len(self.key_cache) == 0 # no cache in any layer
or len(self.key_cache) <= layer_idx # skipped `layer_idx` and hasn't run a layer with cache after it
or len(self.key_cache[layer_idx]) == 0 # the layer has no cache
)
layer_seq_length = self.key_cache[layer_idx].shape[-2] if not is_empty_layer else 0
return layer_seq_length
def get_max_cache_shape(self) -> Optional[int]:
"""Returns the maximum sequence length of the cache object. DynamicCache does not have a maximum length."""
return None
def to_legacy_cache(self) -> Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor]]:
"""Converts the `DynamicCache` instance into the its equivalent in the legacy cache format. Used for
backward compatibility."""
legacy_cache = ()
for layer_idx in range(len(self)):
legacy_cache += ((self.key_cache[layer_idx], self.value_cache[layer_idx]),)
return legacy_cache
@classmethod
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def from_legacy_cache(
cls, past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None, num_hidden_layers: int = None
) -> "DynamicCache":
"""Converts a cache in the legacy cache format into an equivalent `DynamicCache`. Used for
backward compatibility."""
cache = cls()
if past_key_values is not None:
for layer_idx in range(len(past_key_values)):
key_states, value_states = past_key_values[layer_idx]
cache.update(key_states, value_states, layer_idx)
return cache
def crop(self, max_length: int):
"""Crop the past key values up to a new `max_length` in terms of tokens. `max_length` can also be
negative to remove `max_length` tokens. This is used in assisted decoding and contrastive search."""
# In case it is negative
if max_length < 0:
max_length = self.get_seq_length() - abs(max_length)
if self.get_seq_length() <= max_length:
return
self._seen_tokens = max_length
for idx in range(len(self.key_cache)):
if self.key_cache[idx] != []:
self.key_cache[idx] = self.key_cache[idx][..., :max_length, :]
self.value_cache[idx] = self.value_cache[idx][..., :max_length, :]
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def batch_split(
self, full_batch_size: int, split_size: int, num_hidden_layers: int = None
) -> List["DynamicCache"]:
"""Split the current instance into a list of `DynamicCache` by the batch size. This will be used by
`_split_model_inputs()` in `generation.utils`"""
out = []
for i in range(0, full_batch_size, split_size):
current_split = DynamicCache()
current_split._seen_tokens = self._seen_tokens
current_split.key_cache = [tensor[i : i + split_size] for tensor in self.key_cache]
current_split.value_cache = [tensor[i : i + split_size] for tensor in self.value_cache]
out.append(current_split)
return out
@classmethod
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def from_batch_splits(cls, splits: List["DynamicCache"], num_hidden_layers: int = None) -> "DynamicCache":
"""This is the opposite of the above `batch_split()` method. This will be used by `stack_model_outputs` in
`generation.utils`"""
cache = cls()
for idx in range(len(splits[0])):
key_cache = [current.key_cache[idx] for current in splits if current.key_cache[idx] != []]
value_cache = [current.value_cache[idx] for current in splits if current.value_cache[idx] != []]
if key_cache != []:
layer_keys = torch.cat(key_cache, dim=0)
layer_values = torch.cat(value_cache, dim=0)
cache.update(layer_keys, layer_values, idx)
return cache
def batch_repeat_interleave(self, repeats: int):
"""Repeat the cache `repeats` times in the batch dimension. Used in contrastive search."""
for layer_idx in range(len(self)):
self.key_cache[layer_idx] = self.key_cache[layer_idx].repeat_interleave(repeats, dim=0)
self.value_cache[layer_idx] = self.value_cache[layer_idx].repeat_interleave(repeats, dim=0)
def batch_select_indices(self, indices: torch.Tensor):
"""Only keep the `indices` in the batch dimension of the cache. Used in contrastive search."""
for layer_idx in range(len(self)):
self.key_cache[layer_idx] = self.key_cache[layer_idx][indices, ...]
self.value_cache[layer_idx] = self.value_cache[layer_idx][indices, ...]
class OffloadedCache(DynamicCache):
"""
A drop-in replacement for DynamicCache that conserves GPU memory at the expense of more CPU memory.
Useful for generating from models with very long context.
In addition to the default CUDA stream, where all forward() computations happen,
this class uses another stream, the prefetch stream, which it creates itself.
Since scheduling of operations on separate streams happens independently, this class uses
the prefetch stream to asynchronously prefetch the KV cache of layer k+1 when layer k is executing.
The movement of the layer k-1 cache to the CPU is handled by the default stream as a simple way to
ensure the eviction is scheduled after all computations on that cache are finished.
"""
def __init__(self) -> None:
if not torch.cuda.is_available():
raise RuntimeError("OffloadedCache can only be used with a GPU")
super().__init__()
self.original_device = []
self.prefetch_stream = torch.cuda.Stream()
self.beam_idx = None # used to delay beam search operations
def prefetch_layer(self, layer_idx: int):
"Starts prefetching the next layer cache"
if layer_idx < len(self):
with torch.cuda.stream(self.prefetch_stream):
# Prefetch next layer tensors to GPU
device = self.original_device[layer_idx]
self.key_cache[layer_idx] = self.key_cache[layer_idx].to(device, non_blocking=True)
self.value_cache[layer_idx] = self.value_cache[layer_idx].to(device, non_blocking=True)
def evict_previous_layer(self, layer_idx: int):
"Moves the previous layer cache to the CPU"
if len(self) > 2:
# We do it on the default stream so it occurs after all earlier computations on these tensors are done
prev_layer_idx = (layer_idx - 1) % len(self)
self.key_cache[prev_layer_idx] = self.key_cache[prev_layer_idx].to("cpu", non_blocking=True)
self.value_cache[prev_layer_idx] = self.value_cache[prev_layer_idx].to("cpu", non_blocking=True)
def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
"Gets the cache for this layer to the device. Prefetches the next and evicts the previous layer."
if layer_idx < len(self):
# Evict the previous layer if necessary
torch.cuda.current_stream().synchronize()
self.evict_previous_layer(layer_idx)
# Load current layer cache to its original device if not already there
original_device = self.original_device[layer_idx]
self.prefetch_stream.synchronize()
key_tensor = self.key_cache[layer_idx]
value_tensor = self.value_cache[layer_idx]
# Now deal with beam search ops which were delayed
if self.beam_idx is not None:
self.beam_idx = self.beam_idx.to(original_device)
key_tensor = key_tensor.index_select(0, self.beam_idx)
value_tensor = value_tensor.index_select(0, self.beam_idx)
# Prefetch the next layer
self.prefetch_layer((layer_idx + 1) % len(self))
return (key_tensor, value_tensor)
else:
raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
def reorder_cache(self, beam_idx: torch.LongTensor):
"""Saves the beam indices and reorders the cache when the tensor is back to its device."""
# We delay this operation until the tensors are back to their original
# device because performing torch.index_select on the CPU is very slow
del self.beam_idx
self.beam_idx = beam_idx.clone()
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. No additional arguments are used in `OffloadedCache`.
Return:
A tuple containing the updated key and value states.
"""
# Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
# Update the cache
if len(self.key_cache) < layer_idx:
raise ValueError("OffloadedCache does not support model usage where layers are skipped. Use DynamicCache.")
elif len(self.key_cache) == layer_idx:
self.key_cache.append(key_states)
self.value_cache.append(value_states)
self.original_device.append(key_states.device)
self.evict_previous_layer(layer_idx)
else:
key_tensor, value_tensor = self[layer_idx]
self.key_cache[layer_idx] = torch.cat([key_tensor, key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([value_tensor, value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]
# According to https://docs.python.org/3/library/exceptions.html#NotImplementedError
# if a method is not supposed to be supported in a subclass we should set it to None
from_legacy_cache = None
to_legacy_cache = None
class QuantizedCache(DynamicCache):
"""
A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://arxiv.org/abs/2402.02750).
It allows the model to generate longer sequence length without allocating too much memory for Key and Value cache by applying quantization.
The cache has two types of storage, one for original precision and one for the quantized cache. A `residual length` is set as a maximum capacity for the
original precision cache. When the length goes beyond maximum capacity, the original precision cache is discarded and moved into the quantized cache. The
quantization is done per-channel with a set `q_group_size` for both Keys and Values, in contrast to what was described in the paper.
It stores Keys and Values a list of quantized tensors (tuples in case we need to store metadata), one for each layer. Additionally, it stores the Key and
Value in original precision states as a list of tensors, one for each layer. The size of each tensor
is `[batch_size, num_heads, seq_len - residual_length, head_dim]`
"""
def __init__(self, cache_config: QuantizedCacheConfig) -> None:
super().__init__()
self._quantized_key_cache: List[torch.Tensor] = []
self._quantized_value_cache: List[torch.Tensor] = []
self.nbits = cache_config.nbits
self.residual_length = cache_config.residual_length
self.q_group_size = cache_config.q_group_size
self.axis_key = cache_config.axis_key
self.axis_value = cache_config.axis_value
self.compute_dtype = cache_config.compute_dtype
self.device = cache_config.device
super().__init__()
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
# Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
if len(self.key_cache) < layer_idx:
raise ValueError("QuantizedCache does not support model usage where layers are skipped. Use DynamicCache.")
elif len(self.key_cache) == layer_idx:
self._quantized_key_cache.append(self._quantize(key_states.contiguous(), axis=self.axis_key))
self._quantized_value_cache.append(self._quantize(value_states.contiguous(), axis=self.axis_value))
self.key_cache.append(torch.zeros(0, dtype=key_states.dtype, device=key_states.device))
self.value_cache.append(torch.zeros(0, dtype=key_states.dtype, device=key_states.device))
keys_to_return, values_to_return = key_states, value_states
else:
dequant_key = self._dequantize(self._quantized_key_cache[layer_idx])
dequant_value = self._dequantize(self._quantized_value_cache[layer_idx])
keys_to_return = [dequant_key, self.key_cache[layer_idx], key_states]
values_to_return = [dequant_value, self.value_cache[layer_idx], value_states]
keys_to_return = torch.cat(keys_to_return, dim=-2)
values_to_return = torch.cat(values_to_return, dim=-2)
if (
self.key_cache[layer_idx].dim() == 4
and self.key_cache[layer_idx].shape[-2] + 1 >= self.residual_length
):
self._quantized_key_cache[layer_idx] = self._quantize(keys_to_return.contiguous(), axis=self.axis_key)
self._quantized_value_cache[layer_idx] = self._quantize(
values_to_return.contiguous(), axis=self.axis_value
)
self.key_cache[layer_idx] = torch.zeros(0, dtype=key_states.dtype, device=key_states.device)
self.value_cache[layer_idx] = torch.zeros(0, dtype=key_states.dtype, device=key_states.device)
else:
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
return keys_to_return, values_to_return
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
if len(self.key_cache) <= layer_idx:
return 0
# since we cannot get the seq_length of each layer directly and rely on `_seen_tokens` which is
# updated every "layer_idx" == 0, this is a hack to get the actual seq_length for the given layer_idx
# this part of code otherwise fails when used to verify attn_weight shape in some models
return self._seen_tokens if layer_idx == 0 else self._seen_tokens - 1
def _quantize(self, tensor, axis):
"""Quantizes a key/value using a defined quantization method."""
raise NotImplementedError("Make sure to implement `_quantize` in a subclass.")
def _dequantize(self, q_tensor):
"""Dequantizes back the tensor that was quantized by `self._quantize()`"""
raise NotImplementedError("Make sure to implement `_dequantize` in a subclass.")
class QuantoQuantizedCache(QuantizedCache):
"""
Quantized Cache class that uses `quanto` as a backend to perform quantization. Current implementation supports `int2` and `int4` dtypes only.
Parameters:
cache_config (`QuantizedCacheConfig`):
A configuration containing all the arguments to be used by the quantizer, including axis, qtype and group size.
Example:
```python
>>> # Run pip install quanto first if you don't have it yet
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, QuantoQuantizedCache, QuantizedCacheConfig
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> cache_config = QuantizedCacheConfig(nbits=4)
>>> past_key_values = QuantoQuantizedCache(cache_config=cache_config)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
QuantoQuantizedCache()
```
"""
def __init__(self, cache_config: CacheConfig) -> None:
super().__init__(cache_config)
if is_optimum_quanto_available():
optimum_quanto_version = version.parse(importlib.metadata.version("optimum-quanto"))
if optimum_quanto_version <= version.parse("0.2.5"):
raise ImportError(
f"You need optimum-quanto package version to be greater or equal than 0.2.5 to use `QuantoQuantizedCache`. Detected version {optimum_quanto_version}."
)
from optimum.quanto import MaxOptimizer, qint2, qint4
if self.nbits not in [2, 4]:
raise ValueError(f"`nbits` for `quanto` backend has to be one of [`2`, `4`] but got {self.nbits}")
if self.axis_key not in [0, -1]:
raise ValueError(f"`axis_key` for `quanto` backend has to be one of [`0`, `-1`] but got {self.axis_key}")
if self.axis_value not in [0, -1]:
raise ValueError(
f"`axis_value` for `quanto` backend has to be one of [`0`, `-1`] but got {self.axis_value}"
)
self.qtype = qint4 if self.nbits == 4 else qint2
self.optimizer = MaxOptimizer() # hardcode as it's the only one for per-channel quantization
def _quantize(self, tensor, axis):
# We have two different API since in optimum-quanto, we don't use AffineQuantizer anymore
if is_optimum_quanto_available():
from optimum.quanto import quantize_weight
scale, zeropoint = self.optimizer(tensor, self.qtype, axis, self.q_group_size)
qtensor = quantize_weight(tensor, self.qtype, axis, scale, zeropoint, self.q_group_size)
return qtensor
def _dequantize(self, qtensor):
return qtensor.dequantize()
class HQQQuantizedCache(QuantizedCache):
"""
Quantized Cache class that uses `HQQ` as a backend to perform quantization. Current implementation supports `int2`, `int4`, `int8` dtypes.
Parameters:
cache_config (`QuantizedCacheConfig`):
A configuration containing all the arguments to be used by the quantizer, including axis, qtype and group size.
Example:
```python
>>> # Run pip install hqq first if you don't have it yet
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, HQQQuantizedCache, QuantizedCacheConfig
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> cache_config = QuantizedCacheConfig(nbits=4, axis_key=1, axis_value=1)
>>> past_key_values = HQQQuantizedCache(cache_config=cache_config)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
HQQQuantizedCache()
```
"""
def __init__(self, cache_config: CacheConfig) -> None:
super().__init__(cache_config)
if self.nbits not in [1, 2, 3, 4, 8]:
raise ValueError(
f"`nbits` for `HQQ` backend has to be one of [`1`, `2`, `3`, `4`, `8`] but got {self.nbits}"
)
if self.axis_key not in [0, 1]:
raise ValueError(f"`axis_key` for `HQQ` backend has to be one of [`0`, `1`] but got {self.axis_key}")
if self.axis_value not in [0, 1]:
raise ValueError(f"`axis_value` for `HQQ` backend has to be one of [`0`, `1`] but got {self.axis_value}")
self.quantizer = HQQQuantizer
def _quantize(self, tensor, axis):
qtensor, meta = self.quantizer.quantize(
tensor,
axis=axis,
device=self.device,
compute_dtype=self.compute_dtype,
nbits=self.nbits,
group_size=self.q_group_size,
)
meta["compute_dtype"] = self.compute_dtype
self.quantizer.cuda(qtensor, meta=meta, device=self.device) # Move to device and cast to dtype
return qtensor, meta
def _dequantize(self, qtensor):
quant_tensor, meta = qtensor
tensor = self.quantizer.dequantize(quant_tensor, meta)
return tensor
class SinkCache(Cache):
"""
A cache that as described in the [Attention Sinks paper](https://arxiv.org/abs/2309.17453). It allows the model to
generate beyond the length of its context window, without losing fluency in the conversation. As it discards past
tokens, the model will lose the ability to generate tokens that depend on the context that was discarded.
It stores the Key and Value states as a list of tensors, one for each layer. The expected shape for each tensor is
`[batch_size, num_heads, seq_len, head_dim]`.
Parameters:
window_length (`int`):
The length of the context window.
num_sink_tokens (`int`):
The number of sink tokens. See the original paper for more information.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
>>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> past_key_values = SinkCache(window_length=256, num_sink_tokens=4)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
SinkCache()
```
"""
is_sliding = True
def __init__(self, window_length: int, num_sink_tokens: int) -> None:
super().__init__()
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
self.window_length = window_length
self.num_sink_tokens = num_sink_tokens
self.cos_sin_rerotation_cache = {}
self._cos_cache = None
self._sin_cache = None
self._seen_tokens = 0 # Used in `generate` to keep tally of how many tokens the cache has seen
@staticmethod
def _rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def _apply_key_rotary_pos_emb(
self, key_states: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> torch.Tensor:
rotated_key_states = (key_states * cos) + (self._rotate_half(key_states) * sin)
return rotated_key_states
def _get_rerotation_cos_sin(
self, key_states: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
if key_states.shape[-2] not in self.cos_sin_rerotation_cache:
# Upcast to float32 temporarily for better accuracy
cos = cos.to(torch.float32)
sin = sin.to(torch.float32)
# Compute the cos and sin required for back- and forward-rotating to one position earlier in the sequence
original_cos = cos[self.num_sink_tokens + key_states.shape[-2] :]
shifted_cos = cos[self.num_sink_tokens : -key_states.shape[-2]]
original_sin = sin[self.num_sink_tokens + key_states.shape[-2] :]
shifted_sin = sin[self.num_sink_tokens : -key_states.shape[-2]]
rerotation_cos = original_cos * shifted_cos + original_sin * shifted_sin
rerotation_sin = -original_sin * shifted_cos + original_cos * shifted_sin
self.cos_sin_rerotation_cache[key_states.shape[-2]] = (
rerotation_cos.to(key_states.dtype).unsqueeze(0),
rerotation_sin.to(key_states.dtype).unsqueeze(0),
)
return self.cos_sin_rerotation_cache[key_states.shape[-2]]
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
# TODO: deprecate this function in favor of `cache_position`
# Workaround to make 'key_states.shape[-2] + past_key_value.get_seq_length(self.layer_idx)' <= window_length
if len(self.key_cache) <= layer_idx:
return 0
return self.key_cache[layer_idx].shape[-2]
def get_max_cache_shape(self) -> Optional[int]:
"""Returns the maximum sequence length of the cache object, in case of SinkCache it is the window length."""
return self.window_length
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. The following arguments can be used in `SinkCache`: `sin`,
`cos` and `partial_rotation_size`. These arguments are used with models using RoPE, to recompute the
rotation as the tokens are shifted.
Return:
A tuple containing the updated key and value states.
"""
# Optional kwargs for `SinkCache` -- needed on models using RoPE. `partial_rotation_size` is used on models
# with partially rotated position embeddings, like Phi or Persimmon.
sin = cache_kwargs.get("sin")
cos = cache_kwargs.get("cos")
partial_rotation_size = cache_kwargs.get("partial_rotation_size")
using_rope = cos is not None and sin is not None
# Update the number of seen tokens
if layer_idx == 0:
self._seen_tokens += key_states.shape[-2]
# Update the sin/cos cache, which holds sin/cos values for all possible positions
if using_rope and layer_idx == 0:
# BC: some models still pass `sin`/`cos` with 2 dims. In those models, they are the full sin/cos. Remove
# after all RoPE models have a llama-like cache utilization.
if cos.dim() == 2:
self._cos_cache = cos
self._sin_cache = sin
else:
if self._cos_cache is None:
self._cos_cache = cos[0, ...]
self._sin_cache = sin[0, ...]
elif self._cos_cache.shape[0] < self.window_length:
self._cos_cache = torch.cat([self._cos_cache, cos[0, ...]], dim=0)
self._sin_cache = torch.cat([self._sin_cache, sin[0, ...]], dim=0)
# [bsz, num_heads, seq_len, head_dim]
if len(self.key_cache) <= layer_idx:
# Empty cache
self.key_cache.append(key_states)
self.value_cache.append(value_states)
elif key_states.shape[-2] + self.get_seq_length(layer_idx) < self.window_length:
# Growing cache
self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
else:
# Shifting cache
keys_to_keep = self.key_cache[layer_idx][
:, :, -self.window_length + self.num_sink_tokens + key_states.shape[-2] :
]
# On RoPE models, we need to recompute the Key rotation as the tokens are shifted
if using_rope:
rerotation_cos, rerotation_sin = self._get_rerotation_cos_sin(
key_states, self._cos_cache[: self.window_length], self._sin_cache[: self.window_length]
)
if partial_rotation_size is not None:
keys_to_keep, keys_pass = (
keys_to_keep[..., :partial_rotation_size],
keys_to_keep[..., partial_rotation_size:],
)
keys_to_keep = self._apply_key_rotary_pos_emb(keys_to_keep, rerotation_cos, rerotation_sin)
if partial_rotation_size is not None:
keys_to_keep = torch.cat((keys_to_keep, keys_pass), dim=-1)
# Concatenate sink tokens, shifted & rotated tokens (if needed), and new tokens
sink_keys = self.key_cache[layer_idx][:, :, : self.num_sink_tokens]
self.key_cache[layer_idx] = torch.cat([sink_keys, keys_to_keep, key_states], dim=-2)
sink_values = self.value_cache[layer_idx][:, :, : self.num_sink_tokens]
values_to_keep = self.value_cache[layer_idx][
:, :, -self.window_length + self.num_sink_tokens + value_states.shape[-2] :
]
self.value_cache[layer_idx] = torch.cat([sink_values, values_to_keep, value_states], dim=-2)
return self.key_cache[layer_idx], self.value_cache[layer_idx]
class StaticCache(Cache):
"""
Static Cache class to be used with `torch.compile(model)` and `torch.export()`.
Parameters:
config (`PretrainedConfig`):
The configuration file defining the shape-related attributes required to initialize the static cache.
batch_size (`int`):
The batch size with which the model will be used. Note that a new instance must be instantiated if a
smaller batch size is used. If you are manually setting the batch size, make sure to take into account the number of beams if you are running beam search
max_cache_len (`int`):
The maximum sequence length with which the model will be used.
device (`torch.device` or `str`):
The device on which the cache should be initialized. Should be the same as the layer.
The recommended way however is not not indicate any `device`, in that case cache will be initialized on `meta`
device by default, and then moved to input device when updating.
dtype (`torch.dtype`, *optional*, defaults to `torch.float32`):
The default `dtype` to use when initializing the layer.
layer_device_map(`Dict[int, Union[str, torch.device, int]]]`, `optional`):
Mapping between the layers and its device. This is required when you are manually initializing the cache and the model is splitted between differents gpus.
You can know which layers mapped to which device by checking the associated device_map: `model.hf_device_map`.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
>>> model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>>> inputs = tokenizer(text="My name is Llama", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
>>> max_generated_length = inputs.input_ids.shape[1] + 10
>>> past_key_values = StaticCache(config=model.config, batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
StaticCache()
```
"""
is_compileable = True
# TODO (joao): remove `=None` in non-optional arguments in v4.46. Remove from `OBJECTS_TO_IGNORE` as well.
@deprecate_kwarg("layer_device_map", version="4.52.0")
def __init__(
self,
config: PretrainedConfig,
batch_size: int = None,
max_cache_len: int = None,
device: torch.device = None,
dtype: torch.dtype = torch.float32,
max_batch_size: Optional[int] = None,
layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
) -> None:
super().__init__()
if batch_size is not None:
logger.warning_once(
f"The 'batch_size' argument of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'max_batch_size' argument instead."
)
self.max_batch_size = batch_size or max_batch_size
self.max_cache_len = config.max_position_embeddings if max_cache_len is None else max_cache_len
# Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
self.head_dim = (
config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
)
self.dtype = dtype
self.device = torch.device(device) if device is not None else torch.device("meta")
self.num_key_value_heads = (
config.num_attention_heads
if getattr(config, "num_key_value_heads", None) is None
else config.num_key_value_heads
)
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
# Note: There will be significant perf decrease if switching to use 5D tensors instead.
cache_shape = (self.max_batch_size, self.num_key_value_heads, self.max_cache_len, self.head_dim)
for idx in range(config.num_hidden_layers):
if layer_device_map is not None:
layer_device = layer_device_map[idx]
else:
layer_device = self.device
new_layer_key_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
new_layer_value_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
# Notes:
# 1. `mark_static_address` is used to tag the cache as an fixed data pointer, preventing cuda graph
# breaks when updating the cache. It can't be used if the cache code is being compiled (but in that case
# it is not needed anyway)
# 2. `torch.export()` requires mutations to be registered as buffers.
if not is_torchdynamo_compiling():
self.register_buffer(f"key_cache_{idx}", torch.zeros(cache_shape, dtype=dtype, device=layer_device))
self.register_buffer(f"value_cache_{idx}", torch.zeros(cache_shape, dtype=dtype, device=layer_device))
new_layer_key_cache = getattr(self, f"key_cache_{idx}")
new_layer_value_cache = getattr(self, f"value_cache_{idx}")
torch._dynamo.mark_static_address(new_layer_key_cache)
torch._dynamo.mark_static_address(new_layer_value_cache)
self.key_cache.append(new_layer_key_cache)
self.value_cache.append(new_layer_value_cache)
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. The `StaticCache` needs the `cache_position` input
to know how where to write in the cache.
Return:
A tuple containing the updated key and value states.
"""
cache_position = cache_kwargs.get("cache_position")
if self.key_cache[layer_idx].device.type == "meta":
self.key_cache[layer_idx] = torch.zeros_like(self.key_cache[layer_idx], device=key_states.device)
self.value_cache[layer_idx] = torch.zeros_like(self.value_cache[layer_idx], device=value_states.device)
k_out = self.key_cache[layer_idx]
v_out = self.value_cache[layer_idx]
key_states = key_states.to(k_out.dtype)
value_states = value_states.to(v_out.dtype)
if cache_position is None:
k_out.copy_(key_states)
v_out.copy_(value_states)
else:
# Note: here we use `tensor.index_copy_(dim, index, tensor)` that is equivalent to
# `tensor[:, :, index] = tensor`, but the first one is compile-friendly and it does explicitly an in-place
# operation, that avoids copies and uses less memory.
try:
k_out.index_copy_(2, cache_position, key_states)
v_out.index_copy_(2, cache_position, value_states)
except NotImplementedError:
# The operator 'aten::index_copy.out' is not currently implemented for the MPS device.
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
return k_out, v_out
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states that were seen by the model."""
# Occupied cache == any slot in the 3rd dim (sequence length) holds a non-zero value. To save on compute, let's
# limit the check to the first batch member and head dimension.
# TODO: deprecate this function in favor of `cache_position`
if self.key_cache[layer_idx].device.type == "meta":
return 0
return (self.key_cache[layer_idx][0, 0].any(dim=-1)).sum()
def get_max_cache_shape(self) -> Optional[int]:
return self.max_cache_len
def reset(self):
"""Resets the cache values while preserving the objects"""
for layer_idx in range(len(self.key_cache)):
if self.key_cache[layer_idx].device.type != "meta":
# In-place ops prevent breaking the static address
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
@property
def batch_size(self):
logger.warning_once(
f"The 'batch_size' attribute of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'self.max_batch_size' attribute instead."
)
return self.max_batch_size
class SlidingWindowCache(StaticCache):
"""
Sliding Window Cache class to be used with `torch.compile` for models like Mistral that support sliding window attention.
Every time when we try to update the cache, we compute the `indices` based on `cache_position >= self.config.sliding_window - 1`,
if true(which means the cache can not hold all the old key value states and new states together because of the sliding window constraint),
we need to do a cycle shift based on `indices` to replace the oldest states by the new key value states passed in.
The `to_shift` is only true once we are above sliding_window. Thus with `sliding_window==64`:
indices = (slicing + to_shift[-1].int()-1) % self.config.sliding_window
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,
37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54,
55, 56, 57, 58, 59, 60, 61, 62, 63, 0])
We overwrite the cache using these, then we always write at cache_position (clamped to `sliding_window`)
Parameters:
config (`PretrainedConfig`):
The configuration file defining the shape-related attributes required to initialize the static cache.
batch_size (`int`):
The batch size with which the model will be used. Note that a new instance must be instantiated if a
smaller batch size is used.
max_cache_len (`int`):
The maximum sequence length with which the model will be used.
device (`torch.device` or `str`):
The device on which the cache should be initialized. Should be the same as the layer.
The recommended way however is not not indicate any `device`, in that case cache will be initialized on `meta`
device by default, and then moved to input device when updating.
dtype (`torch.dtype`, *optional*, defaults to `torch.float32`):
The default `dtype` to use when initializing the layer.
layer_device_map(`Dict[int, Union[str, torch.device, int]]]`, `optional`):
Mapping between the layers and its device. This is required when you are manually initializing the cache and the model is splitted between differents gpus.
You can know which layers mapped to which device by checking the associated device_map: `model.hf_device_map`.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, SlidingWindowCache
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
>>> inputs = tokenizer(text="My name is Mistral", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
>>> max_generated_length = inputs.input_ids.shape[1] + 10
>>> past_key_values = SlidingWindowCache(config=model.config, batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
SlidingWindowCache()
```
"""
is_sliding = True
is_compileable = True
# TODO (joao): remove `=None` in non-optional arguments in v4.46. Remove from `OBJECTS_TO_IGNORE` as well.
def __init__(
self,
config: PretrainedConfig,
batch_size: int = None,
max_cache_len: int = None,
device: torch.device = None,
dtype: torch.dtype = torch.float32,
max_batch_size: Optional[int] = None,
layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
) -> None:
if not hasattr(config, "sliding_window") or config.sliding_window is None:
raise ValueError(
"Setting `cache_implementation` to 'sliding_window' requires the model config supporting "
"sliding window attention, please check if there is a `sliding_window` field in the model "
"config and it's not set to None."
)
max_cache_len = min(config.sliding_window, max_cache_len)
super().__init__(
config=config,
batch_size=batch_size,
max_cache_len=max_cache_len,
device=device,
dtype=dtype,
max_batch_size=max_batch_size,
layer_device_map=layer_device_map,
)
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor]:
cache_position = cache_kwargs.get("cache_position")
if self.key_cache[layer_idx].device.type == "meta":
self.key_cache[layer_idx] = torch.zeros_like(self.key_cache[layer_idx], device=key_states.device)
self.value_cache[layer_idx] = torch.zeros_like(self.value_cache[layer_idx], device=value_states.device)
k_out = self.key_cache[layer_idx]
v_out = self.value_cache[layer_idx]
key_states = key_states.to(k_out.dtype)
value_states = value_states.to(v_out.dtype)
# assume this only happens in prefill phase when prompt length > sliding_window_size (= max_cache_len)
if cache_position.shape[0] > self.max_cache_len:
k_out = key_states[:, :, -self.max_cache_len :, :]
v_out = value_states[:, :, -self.max_cache_len :, :]
# Assumption: caches are all zeros at this point, `+=` is equivalent to `=` but compile-friendly
self.key_cache[layer_idx] += k_out
self.value_cache[layer_idx] += v_out
# we should return the whole states instead of k_out, v_out to take the whole prompt
# into consideration when building kv cache instead of just throwing away tokens outside of the window
return key_states, value_states
slicing = torch.ones(self.max_cache_len, dtype=torch.long, device=value_states.device).cumsum(0)
cache_position = cache_position.clamp(0, self.max_cache_len - 1)
to_shift = cache_position >= self.max_cache_len - 1
indices = (slicing + to_shift[-1].int() - 1) % self.max_cache_len
k_out = k_out[:, :, indices]
v_out = v_out[:, :, indices]
try:
k_out.index_copy_(2, cache_position, key_states)
v_out.index_copy_(2, cache_position, value_states)
except NotImplementedError:
# The operator 'aten::index_copy.out' is not currently implemented for the MPS device.
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
# `_.zero()` followed by `+=` is equivalent `=`, but compile-friendly (without graph breaks due to assignment)
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
self.key_cache[layer_idx] += k_out
self.value_cache[layer_idx] += v_out
return k_out, v_out
def get_max_cache_shape(self) -> Optional[int]:
return self.max_cache_len
def reset(self):
for layer_idx in range(len(self.key_cache)):
if self.key_cache[layer_idx].device.type != "meta":
# In-place ops prevent breaking the static address
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
class EncoderDecoderCache(Cache):
"""
Base, abstract class for all encoder-decoder caches. Can be used to hold combinations of self-attention and
cross-attention caches.
Example:
```python
>>> from transformers import AutoProcessor, AutoModelForCausalLM, DynamicCache, EncoderDecoderCache
>>> model = AutoModelForCausalLM.from_pretrained("openai/whisper-small")
>>> processor = AutoProcessor.from_pretrained("openai/whisper-small")
>>> inputs = processor(audio=YOUR-AUDIO, return_tensors="pt")
>>> # Prepare cache classes for encoder and decoder and pass it to model's forward
>>> self_attention_cache = DynamicCache()
>>> cross_attention_cache = DynamicCache()
>>> past_key_values = EncoderDecoderCache(self_attention_cache, cross_attention_cache)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
EncoderDecoderCache()
```
"""
def __init__(self, self_attention_cache: Cache, cross_attention_cache: Cache):
super().__init__()
self.self_attention_cache = self_attention_cache
self.cross_attention_cache = cross_attention_cache
self.is_compileable = getattr(self.self_attention_cache, "is_compileable", False)
self.is_updated = {}
for layer_idx in range(len(cross_attention_cache.key_cache)):
self.is_updated[layer_idx] = bool(cross_attention_cache.get_seq_length(layer_idx) > 0)
def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
"""
Support for backwards-compatible `past_key_value` indexing, e.g. `past_key_value[0][0].shape[2]` to get the
sequence length.
"""
if layer_idx < len(self):
return (
self.self_attention_cache.key_cache[layer_idx],
self.self_attention_cache.value_cache[layer_idx],
self.cross_attention_cache.key_cache[layer_idx],
self.cross_attention_cache.value_cache[layer_idx],
)
else:
raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
def __len__(self):
"""
Support for backwards-compatible `past_key_value` length, e.g. `len(past_key_value)`. This value corresponds
to the number of layers in the model.
"""
return len(self.self_attention_cache)
def to_legacy_cache(self) -> Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor]]:
"""Converts the `EncoderDecoderCache` instance into its equivalent in the legacy cache format."""
legacy_cache = ()
if len(self.cross_attention_cache) > 0:
for self_attn, cross_attn in zip(
self.self_attention_cache.to_legacy_cache(), self.cross_attention_cache.to_legacy_cache()
):
legacy_cache += (self_attn + cross_attn,)
else:
legacy_cache = self.self_attention_cache.to_legacy_cache()
return legacy_cache
@classmethod
def from_legacy_cache(
cls, past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
) -> "EncoderDecoderCache":
"""Converts a cache in the legacy cache format into an equivalent `EncoderDecoderCache`."""
cache = cls(
self_attention_cache=DynamicCache(),
cross_attention_cache=DynamicCache(),
)
if past_key_values is not None:
for layer_idx in range(len(past_key_values)):
key_states, value_states = past_key_values[layer_idx][:2]
cache.self_attention_cache.update(key_states, value_states, layer_idx)
if len(past_key_values[layer_idx]) > 2:
key_states, value_states = past_key_values[layer_idx][2:]
cache.cross_attention_cache.update(key_states, value_states, layer_idx)
cache.is_updated[layer_idx] = True
return cache
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
# check if empty list because in case of static cache it will be a tensors and we can't check `if not torch.Tensor`
return self.self_attention_cache.get_seq_length(layer_idx)
def reset(self):
if hasattr(self.self_attention_cache, "reset"):
self.self_attention_cache.reset()
if hasattr(self.cross_attention_cache, "reset"):
self.cross_attention_cache.reset()
elif not hasattr(self.self_attention_cache, "reset") and not hasattr(self.cross_attention_cache, "reset"):
raise ValueError(
"Neither self nor cross-attention cache have valid `.reset()` methods. `.reset()` should "
"only be called on compatible cache classes, such as `StaticCache` or `SlidingWindowCache`. "
f"Got {self.self_attention_cache.__str__()} for the self attention cache and "
f"{self.cross_attention_cache.__str__()} for the cross attention cache."
)
for layer_idx in self.is_updated:
self.is_updated[layer_idx] = False
def reorder_cache(self, beam_idx: torch.LongTensor):
"""Reorders the cache for beam search, given the selected beam indices."""
self.self_attention_cache.reorder_cache(beam_idx)
self.cross_attention_cache.reorder_cache(beam_idx)
def check_dynamic_cache(self, method: str):
if not (
isinstance(self.self_attention_cache, DynamicCache)
and isinstance(self.cross_attention_cache, DynamicCache)
):
raise ValueError(
f"`{method}` is only defined for dynamic cache, got {self.self_attention_cache.__str__()} for the self "
f"attention cache and {self.cross_attention_cache.__str__()} for the cross attention cache."
)
# TODO(gante, sanchit-gandhi): move following functionality into `.generate`
def crop(self, maximum_length: int):
"""Crop the past key values up to a new `maximum_length` in terms of tokens. `maximum_length` can also be
negative to remove `maximum_length` tokens. This is used in assisted decoding and contrastive search."""
self.check_dynamic_cache(self.crop.__name__)
self.self_attention_cache.crop(maximum_length)
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def batch_split(
self, full_batch_size: int, split_size: int, num_hidden_layers: int = None
) -> "List[EncoderDecoderCache]":
"""Split the current instance into a list of `DynamicCache` by the batch size. This will be used by
`_split_model_inputs()` in `generation.utils`"""
self.check_dynamic_cache(self.batch_split.__name__)
self_attention_cache = self.self_attention_cache.batch_split(full_batch_size, split_size)
cross_attention_cache = self.cross_attention_cache.batch_split(full_batch_size, split_size)
out = []
for self_attn, cross_attn in zip(self_attention_cache, cross_attention_cache):
out.append(EncoderDecoderCache(self_attn, cross_attn))
return out
@classmethod
@deprecate_kwarg("num_hidden_layers", version="4.47.0")
def from_batch_splits(
cls, splits: List["EncoderDecoderCache"], num_hidden_layers: int = None
) -> "EncoderDecoderCache":
"""This is the opposite of the above `batch_split()` method. This will be used by `stack_model_outputs` in
`generation.utils`"""
self_attention_cache = DynamicCache()
cross_attention_cache = DynamicCache()
for idx in range(len(splits[0])):
layer_keys = torch.cat([current.self_attention_cache.key_cache[idx] for current in splits], dim=0)
layer_values = torch.cat([current.self_attention_cache.value_cache[idx] for current in splits], dim=0)
self_attention_cache.update(layer_keys, layer_values, idx)
layer_keys = torch.cat([current.cross_attention_cache.key_cache[idx] for current in splits], dim=0)
layer_values = torch.cat([current.cross_attention_cache.value_cache[idx] for current in splits], dim=0)
cross_attention_cache.update(layer_keys, layer_values, idx)
return cls(self_attention_cache, cross_attention_cache)
def batch_repeat_interleave(self, repeats: int):
"""Repeat the cache `repeats` times in the batch dimension. Used in contrastive search."""
self.check_dynamic_cache(self.batch_repeat_interleave.__name__)
self.self_attention_cache.batch_repeat_interleave(repeats)
self.cross_attention_cache.batch_repeat_interleave(repeats)
def batch_select_indices(self, indices: torch.Tensor):
"""Only keep the `indices` in the batch dimension of the cache. Used in contrastive search."""
self.check_dynamic_cache(self.batch_select_indices.__name__)
self.self_attention_cache.batch_select_indices(indices)
self.cross_attention_cache.batch_select_indices(indices)
class HybridCache(Cache):
"""
Hybrid Cache class to be used with `torch.compile` for Gemma2 models that alternate between a local sliding window attention
and global attention in every other layer. Under the hood, Hybrid Cache leverages ["SlidingWindowCache"] for sliding window attention
and ["StaticCache"] for global attention. For more information, see the documentation of each subcomponeent cache class.
Parameters:
config (`PretrainedConfig):
The configuration file defining the shape-related attributes required to initialize the static cache.
batch_size (`int`):
The batch size with which the model will be used. Note that a new instance must be instantiated if a
smaller batch size is used.
max_cache_len (`int`):
The maximum sequence length with which the model will be used.
device (`torch.device` or `str`, *optional*):
The device on which the cache should be initialized. Should be the same as the layer.
The recommended way however is not not indicate any `device`, in that case cache will be initialized on `meta`
device by default, and then moved to input device when updating.
dtype (torch.dtype, *optional*, defaults to `torch.float32`):
The default `dtype` to use when initializing the layer.
layer_device_map(`Dict[int, Union[str, torch.device, int]]]`, `optional`):
Mapping between the layers and its device. This is required when you are manually initializing the cache and the model is splitted between differents gpus.
You can know which layers mapped to which device by checking the associated device_map: `model.hf_device_map`.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, HybridCache
>>> model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b")
>>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")
>>> inputs = tokenizer(text="My name is Gemma", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
>>> max_generated_length = inputs.input_ids.shape[1] + 10
>>> past_key_values = HybridCache(config=model.config, batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
HybridCache()
```
"""
is_compileable = True
# TODO (joao): remove `=None` in non-optional arguments in v4.46. Remove from `OBJECTS_TO_IGNORE` as well.
@deprecate_kwarg("layer_device_map", version="4.52.0")
def __init__(
self,
config: PretrainedConfig,
batch_size: int = None,
max_cache_len: int = None,
device: Union[torch.device, str] = None,
dtype: torch.dtype = torch.float32,
max_batch_size: Optional[int] = None,
layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
) -> None:
super().__init__()
if batch_size is not None:
logger.warning_once(
f"The 'batch_size' argument of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'max_batch_size' argument instead."
)
if not hasattr(config, "sliding_window") or config.sliding_window is None:
raise ValueError(
"Setting `cache_implementation` to 'sliding_window' requires the model config supporting "
"sliding window attention, please check if there is a `sliding_window` field in the model "
"config and it's not set to None."
)
self.max_cache_len = max_cache_len
self.max_batch_size = batch_size or max_batch_size
# Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
self.head_dim = (
config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
)
self.dtype = dtype
self.num_key_value_heads = (
config.num_attention_heads if config.num_key_value_heads is None else config.num_key_value_heads
)
self.device = torch.device(device) if device is not None else torch.device("meta")
layer_switch = config.sliding_window_pattern if hasattr(config, "sliding_window_pattern") else 2 # 2 is for BC
self.is_sliding = torch.tensor(
[bool((i + 1) % layer_switch) for i in range(config.num_hidden_layers)], dtype=torch.bool
)
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
global_cache_shape = (self.max_batch_size, self.num_key_value_heads, max_cache_len, self.head_dim)
sliding_cache_shape = (
self.max_batch_size,
self.num_key_value_heads,
min(config.sliding_window, max_cache_len),
self.head_dim,
)
for i in range(config.num_hidden_layers):
if layer_device_map is not None:
layer_device = layer_device_map[i]
else:
layer_device = self.device
# Note: `mark_static_address` is used to tag the cache as an fixed data pointer, preventing cuda graph
# breaks when updating the cache.
cache_shape = global_cache_shape if not self.is_sliding[i] else sliding_cache_shape
new_layer_key_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
new_layer_value_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
torch._dynamo.mark_static_address(new_layer_key_cache)
torch._dynamo.mark_static_address(new_layer_value_cache)
self.key_cache.append(new_layer_key_cache)
self.value_cache.append(new_layer_value_cache)
def _sliding_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
if cache_position.shape[0] > max_cache_len:
k_out = key_states[:, :, -max_cache_len:, :]
v_out = value_states[:, :, -max_cache_len:, :]
# Assumption: caches are all zeros at this point, `+=` is equivalent to `=` but compile-friendly
self.key_cache[layer_idx] += k_out
self.value_cache[layer_idx] += v_out
# we should return the whole states instead of k_out, v_out to take the whole prompt
# into consideration when building kv cache instead of just throwing away tokens outside of the window
return key_states, value_states
slicing = torch.ones(max_cache_len, dtype=torch.long, device=value_states.device).cumsum(0)
cache_position = cache_position.clamp(0, max_cache_len - 1)
to_shift = cache_position >= max_cache_len - 1
indices = (slicing + to_shift[-1].int() - 1) % max_cache_len
k_out = k_out[:, :, indices]
v_out = v_out[:, :, indices]
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
# `_.zero()` followed by `+=` is equivalent `=`, but compile-friendly (without graph breaks due to assignment)
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
self.key_cache[layer_idx] += k_out
self.value_cache[layer_idx] += v_out
return k_out, v_out
def _static_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
self.key_cache[layer_idx] = k_out
self.value_cache[layer_idx] = v_out
return k_out, v_out
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor]:
cache_position = cache_kwargs.get("cache_position")
sliding_window = cache_kwargs.get("sliding_window")
if self.key_cache[layer_idx].device.type == "meta":
self.key_cache[layer_idx] = torch.zeros_like(self.key_cache[layer_idx], device=key_states.device)
self.value_cache[layer_idx] = torch.zeros_like(self.value_cache[layer_idx], device=value_states.device)
k_out = self.key_cache[layer_idx]
v_out = self.value_cache[layer_idx]
key_states = key_states.to(k_out.dtype)
value_states = value_states.to(v_out.dtype)
if sliding_window:
update_fn = self._sliding_update
else:
update_fn = self._static_update
return update_fn(
cache_position,
layer_idx,
key_states,
value_states,
k_out,
v_out,
k_out.shape[2],
)
def get_max_cache_shape(self) -> Optional[int]:
return self.max_cache_len
def get_seq_length(self, layer_idx: Optional[int] = 0):
# Occupied cache == any slot in the 3rd dim (sequence length) holds a non-zero value. To save on compute, let's
# limit the check to the first batch member and head dimension.
# TODO: deprecate this function in favor of `cache_position`
if layer_idx != 0:
raise ValueError(
"`get_seq_length` on `HybridCache` may get inconsistent results depending on the layer index. "
"Using the `layer_idx` argument is not supported."
)
if self.key_cache[layer_idx].device.type == "meta":
return 0
return (self.key_cache[layer_idx][0, 0].any(dim=-1)).sum()
def reset(self):
"""Resets the cache values while preserving the objects"""
for layer_idx in range(len(self.key_cache)):
if self.key_cache[layer_idx].device.type != "meta":
# In-place ops prevent breaking the static address
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
@property
def batch_size(self):
logger.warning_once(
f"The 'batch_size' attribute of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'self.max_batch_size' attribute instead."
)
return self.max_batch_size
class MambaCache:
"""
Cache for mamba model which does not have attention mechanism and key value states.
Arguments:
config (`PretrainedConfig):
The configuration file defining the shape-related attributes required to initialize the static cache.
batch_size (`int`):
The batch size with which the model will be used. Note that a new instance must be instantiated if a
smaller batch size is used.
dtype (`torch.dtype`, *optional*, defaults to `torch.float16`):
The default `dtype` to use when initializing the layer.
device (`torch.device` or `str`, *optional*):
The device on which the cache should be initialized. Should be the same as the layer.
The recommended way however is not not indicate any `device`, in that case cache will be initialized on `meta`
device by default, and then moved to input device when updating.
Attributes:
dtype: (`torch.dtype`):
The default `dtype` used to initializing the cache.
device (`torch.device`):
The default device on which the cache was initialized.
intermediate_size: (`int`):
Model's intermediate_size taken from config.
ssm_state_size: (`int`):
Model's state_size taken from config.
conv_kernel_size: (`int`):
Model's convolution kernel size taken from config
conv_states: (`torch.Tensor`):
A tensor of shape `[layer_idx, batch_size, intermediate_size, conv_kernel_size]` that holds convolutional states.
ssm_states: (`torch.Tensor`):
A tensor of shape `[layer_idx, batch_size, intermediate_size, ssm_state_size]` that holds ssm states
Example:
```python
>>> from transformers import AutoTokenizer, MambaForCausalLM, MambaCache
>>> model = MambaForCausalLM.from_pretrained("state-spaces/mamba-130m-hf")
>>> tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-130m-hf")
>>> inputs = tokenizer(text="My name is Mamba", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> past_key_values = MambaCache(config=model.config, batch_size=1, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values
MambaCache()
```
"""
is_compileable = True
# TODO (joao): remove `=None` in non-optional arguments in v4.46. Remove from `OBJECTS_TO_IGNORE` as well.
def __init__(
self,
config: PretrainedConfig,
batch_size: int = None,
dtype: torch.dtype = torch.float16,
device: Optional[Union[torch.device, str]] = None,
max_batch_size: Optional[int] = None,
):
if batch_size is not None:
logger.warning_once(
f"The 'batch_size' argument of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'max_batch_size' argument instead."
)
self.dtype = dtype
self.max_batch_size = batch_size or max_batch_size
self.intermediate_size = config.intermediate_size
self.ssm_state_size = config.state_size
self.conv_kernel_size = config.conv_kernel
self.device = torch.device(device) if device is not None else torch.device("meta")
self.conv_states: List[torch.Tensor] = []
self.ssm_states: List[torch.Tensor] = []
for _ in range(config.num_hidden_layers):
conv_state: torch.Tensor = torch.zeros(
self.max_batch_size,
self.intermediate_size,
self.conv_kernel_size,
device=self.device,
dtype=dtype,
)
ssm_state: torch.Tensor = torch.zeros(
self.max_batch_size,
self.intermediate_size,
self.ssm_state_size,
device=self.device,
dtype=dtype,
)
torch._dynamo.mark_static_address(conv_state)
torch._dynamo.mark_static_address(ssm_state)
self.conv_states.append(conv_state)
self.ssm_states.append(ssm_state)
def update_conv_state(
self, layer_idx: int, new_conv_state: torch.Tensor, cache_position: torch.LongTensor
) -> torch.Tensor:
if self.conv_states[layer_idx].device.type == "meta":
self.conv_states[layer_idx] = torch.zeros_like(
self.conv_states[layer_idx],
device=new_conv_state.device,
)
conv_state = self.conv_states[layer_idx]
cache_position = cache_position.clamp(0, self.conv_kernel_size - 1)
conv_state = conv_state.roll(shifts=-1, dims=-1)
conv_state[:, :, cache_position] = new_conv_state.to(device=conv_state.device, dtype=conv_state.dtype)
self.conv_states[layer_idx].zero_()
self.conv_states[layer_idx] += conv_state
return self.conv_states[layer_idx]
def update_ssm_state(self, layer_idx: int, new_ssm_state: torch.Tensor):
self.ssm_states[layer_idx] = new_ssm_state.to(self.ssm_states[layer_idx].device)
return self.ssm_states[layer_idx]
def reset(self):
for layer_idx in range(len(self.conv_states)):
if self.conv_states[layer_idx].device.type != "meta":
# In-place ops prevent breaking the static address
self.conv_states[layer_idx].zero_()
self.ssm_states[layer_idx].zero_()
@property
def batch_size(self):
logger.warning_once(
f"The 'batch_size' attribute of {self.__class__.__name__} is deprecated and will be removed in "
"v4.49. Use the more precisely named 'self.max_batch_size' attribute instead."
)
return self.max_batch_size
class OffloadedStaticCache(StaticCache):
"""
Static cache class to be used with `torch.compile(model)` that offloads to the CPU or
another device.
Args:
config (`PretrainedConfig):
The configuration file defining the shape-related attributes required to initialize
the static cache.
max_batch_size (`int`):
The maximum batch size with which the model will be used.
max_cache_len (`int`):
The maximum sequence length with which the model will be used.
device (`Union[str, torch.device]`):
The device on which the cache should be initialized. Should be the same as the
layer device.
dtype (`torch.dtype`, *optional*):
The default `dtype` to use when initializing the cache.
offload_device (`Union[str, torch.device]`, *optional*, defaults to `cpu`):
The device to offload to. Defaults to CPU.
layer_device_map (`Dict[int, Union[str, torch.device, int]]`, *optional*):
Mapping between the layers and its device. This is required when you are manually initializing the cache and the model is splitted between differents gpus.
You can know which layers mapped to which device by checking the associated device_map: `model.hf_device_map`.
Attributes:
key_cache (`List[torch.Tensor]`):
Off-loaded key cache tensors. First one will be on device, where-as the others are
off-loaded.
value_cache (`List[torch.Tensor]`):
Off-loaded value cache tensors. First one will be on device, where-as the others are
off-loaded.
max_batch_size (`int`):
The maximum batch size with which this cache can be used.
max_cache_len (`int`):
The maximum sequence length with which this cache can be used.
device (`torch.device`):
The device on which the cache is used.
offload_device (`torch.device`):
The device used to offload to.
dtype (`torch.dtype`):
The `dtype` used to initializing the cache.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, OffloadedStaticCache
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer(text="My name is GPT2", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
>>> max_generated_length = inputs.input_ids.shape[1] + 10
>>> past_key_values = OffloadedStaticCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> past_kv_length = outputs.past_key_values # access cache filled with key/values from generation
```
"""
is_compileable = True
@deprecate_kwarg("layer_device_map", version="4.52.0")
def __init__(
self,
config: PretrainedConfig,
max_batch_size: int,
max_cache_len: Optional[int],
device: Union[str, torch.device],
dtype: Optional[torch.dtype] = None,
offload_device: Union[str, torch.device] = torch.device("cpu"),
layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
) -> None:
super(Cache, self).__init__()
self.max_batch_size = max_batch_size
self.max_cache_len = config.max_position_embeddings if max_cache_len is None else max_cache_len
self.device = torch.device(device) if layer_device_map is None else torch.device(layer_device_map[0])
self.offload_device = torch.device(offload_device)
self.dtype = dtype if dtype is not None else torch.float32
# Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
head_dim = config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
num_key_value_heads = (
config.num_attention_heads
if getattr(config, "num_key_value_heads", None) is None
else config.num_key_value_heads
)
cache_shape = (max_batch_size, num_key_value_heads, self.max_cache_len, head_dim)
# Create offloaded CPU tensors.
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
for i in range(config.num_hidden_layers):
# First layer is always on-device.
device = self.device if i == 0 else self.offload_device
key_cache, value_cache = self._create_key_value_cache_tensors(cache_shape, device)
self.key_cache.append(key_cache)
self.value_cache.append(value_cache)
# Create device tensors.
self._device_key_cache: List[torch.Tensor] = []
self._device_value_cache: List[torch.Tensor] = []
for i in range(2):
key_cache, value_cache = self._create_key_value_cache_tensors(cache_shape, self.device)
self._device_key_cache.append(key_cache)
self._device_value_cache.append(value_cache)
# For backwards compatibility.
# TODO(gante): Remove this.
self._seen_tokens = 0
# Create new CUDA stream for parallel prefetching.
self._prefetch_stream = torch.cuda.Stream() if self.device.type == "cuda" else None
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, *optional*):
Additional arguments for the cache subclass. The `OffloadedStaticCache` needs the
`cache_position` input to know how where to write in the cache.
Return:
A tuple containing the updated key and value states.
"""
if layer_idx == 0:
# Update seen tokens.
# TODO(gante): Remove this.
self._seen_tokens += key_states.shape[-2]
# Always there.
k_out = self.key_cache[0]
v_out = self.value_cache[0]
else:
# Wait for prefetch stream.
if self._prefetch_stream is not None:
torch.cuda.default_stream(self.device).wait_stream(self._prefetch_stream)
k_out = self._device_key_cache[layer_idx & 1]
v_out = self._device_value_cache[layer_idx & 1]
self._prefetch_layer(layer_idx + 1)
cache_position = cache_kwargs.get("cache_position") if cache_kwargs is not None else None
if cache_position is None:
k_out.copy_(key_states)
v_out.copy_(value_states)
# Copy the values to the offloaded device as well.
if layer_idx == 0:
self.key_cache[layer_idx].copy_(key_states.to(self.offload_device))
self.value_cache[layer_idx].copy_(value_states.to(self.offload_device))
else:
# Note: here we use `tensor.index_copy_(dim, index, tensor)` that is equivalent to
# `tensor[:, :, index] = tensor`, but the first one is compile-friendly and it does
# explicitly an in-place operation, that avoids copies and uses less memory.
try:
k_out.index_copy_(2, cache_position, key_states)
v_out.index_copy_(2, cache_position, value_states)
except NotImplementedError:
# The operator 'aten::index_copy.out' is not currently implemented for the MPS
# device.
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
# Copy the values to the offloaded device as well.
if layer_idx != 0:
cache_position = cache_position.to(self.offload_device)
key_states = key_states.to(self.offload_device)
value_states = value_states.to(self.offload_device)
try:
self.key_cache[layer_idx].index_copy_(2, cache_position, key_states)
self.value_cache[layer_idx].index_copy_(2, cache_position, value_states)
except NotImplementedError:
# The operator 'aten::index_copy.out' is not currently implemented for the MPS
# device.
self.key_cache[layer_idx][:, :, cache_position] = key_states
self.value_cache[layer_idx][:, :, cache_position] = value_states
return k_out, v_out
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
"""Returns the sequence length of the cached states that were seen by the model."""
# TODO(gante): Remove this.
return self._seen_tokens
def get_max_cache_shape(self) -> Optional[int]:
"""Returns the maximum sequence length of the cached states."""
return self.max_cache_len
def reset(self) -> None:
"""Resets the cache values while preserving the objects."""
# For backwards compatibility.
# TODO(gante): Remove this.
self._seen_tokens = 0
# Zero out cache.
for layer_idx in range(len(self.key_cache)):
# In-place ops prevent breaking the static address.
self.key_cache[layer_idx].zero_()
self.value_cache[layer_idx].zero_()
@property
def seen_tokens(self) -> int:
# For backwards compatibility.
# TODO(gante): Remove this.
return self._seen_tokens
def _create_key_value_cache_tensors(
self, shape: Tuple[int, ...], device: torch.device
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Creates K/V cache tensors on a device. Pins memory for CPU tensors. Marks them as static
addresses for non-CPU tensors.
Args:
shape (`Tuple[int, ...]`): Shape.
device (`torch.device`): Device.
Returns:
Key and value cache tensors as a tuple.
"""
is_cpu_device = device == torch.device("cpu")
key_cache = torch.zeros(shape, dtype=self.dtype, device=device, pin_memory=is_cpu_device)
value_cache = torch.zeros(shape, dtype=self.dtype, device=device, pin_memory=is_cpu_device)
# Note: `mark_static_address` is used to tag the cache as a fixed data pointer,
# preventing compiled graph breaks when updating the cache.
torch._dynamo.mark_static_address(key_cache)
torch._dynamo.mark_static_address(value_cache)
return key_cache, value_cache
def _prefetch_layer(self, layer_idx: int) -> None:
"""Prefetch a layer to the device. Needs to be called in order of layer indices."""
# Don't fetch layers that do not exist.
if layer_idx >= len(self.key_cache):
return
# Alternate between two on-device caches.
if self._prefetch_stream is not None:
with torch.cuda.stream(self._prefetch_stream):
self._prefetch_layer_in_context(layer_idx)
else:
self._prefetch_layer_in_context(layer_idx)
def _prefetch_layer_in_context(self, layer_idx: int) -> None:
"""Performs the actual copy of the layer to device cache."""
self._device_key_cache[layer_idx & 1].copy_(self.key_cache[layer_idx], non_blocking=True)
self._device_value_cache[layer_idx & 1].copy_(self.value_cache[layer_idx], non_blocking=True)
|
transformers/src/transformers/cache_utils.py/0
|
{
"file_path": "transformers/src/transformers/cache_utils.py",
"repo_id": "transformers",
"token_count": 44157
}
|
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert pytorch checkpoints to TensorFlow"""
import argparse
import os
from . import (
AlbertConfig,
BartConfig,
BertConfig,
CamembertConfig,
CTRLConfig,
DistilBertConfig,
DPRConfig,
ElectraConfig,
FlaubertConfig,
GPT2Config,
LayoutLMConfig,
LxmertConfig,
OpenAIGPTConfig,
RobertaConfig,
T5Config,
TFAlbertForPreTraining,
TFBartForConditionalGeneration,
TFBartForSequenceClassification,
TFBertForPreTraining,
TFBertForQuestionAnswering,
TFBertForSequenceClassification,
TFCamembertForMaskedLM,
TFCTRLLMHeadModel,
TFDistilBertForMaskedLM,
TFDistilBertForQuestionAnswering,
TFDPRContextEncoder,
TFDPRQuestionEncoder,
TFDPRReader,
TFElectraForPreTraining,
TFFlaubertWithLMHeadModel,
TFGPT2LMHeadModel,
TFLayoutLMForMaskedLM,
TFLxmertForPreTraining,
TFLxmertVisualFeatureEncoder,
TFOpenAIGPTLMHeadModel,
TFRobertaForCausalLM,
TFRobertaForMaskedLM,
TFRobertaForSequenceClassification,
TFT5ForConditionalGeneration,
TFTransfoXLLMHeadModel,
TFWav2Vec2Model,
TFXLMRobertaForMaskedLM,
TFXLMWithLMHeadModel,
TFXLNetLMHeadModel,
TransfoXLConfig,
Wav2Vec2Config,
Wav2Vec2Model,
XLMConfig,
XLMRobertaConfig,
XLNetConfig,
is_torch_available,
load_pytorch_checkpoint_in_tf2_model,
)
from .utils import CONFIG_NAME, WEIGHTS_NAME, cached_file, logging
if is_torch_available():
import numpy as np
import torch
from . import (
AlbertForPreTraining,
BartForConditionalGeneration,
BertForPreTraining,
BertForQuestionAnswering,
BertForSequenceClassification,
CamembertForMaskedLM,
CTRLLMHeadModel,
DistilBertForMaskedLM,
DistilBertForQuestionAnswering,
DPRContextEncoder,
DPRQuestionEncoder,
DPRReader,
ElectraForPreTraining,
FlaubertWithLMHeadModel,
GPT2LMHeadModel,
LayoutLMForMaskedLM,
LxmertForPreTraining,
LxmertVisualFeatureEncoder,
OpenAIGPTLMHeadModel,
RobertaForMaskedLM,
RobertaForSequenceClassification,
T5ForConditionalGeneration,
TransfoXLLMHeadModel,
XLMRobertaForMaskedLM,
XLMWithLMHeadModel,
XLNetLMHeadModel,
)
logging.set_verbosity_info()
MODEL_CLASSES = {
"bart": (
BartConfig,
TFBartForConditionalGeneration,
TFBartForSequenceClassification,
BartForConditionalGeneration,
),
"bert": (
BertConfig,
TFBertForPreTraining,
BertForPreTraining,
),
"google-bert/bert-large-uncased-whole-word-masking-finetuned-squad": (
BertConfig,
TFBertForQuestionAnswering,
BertForQuestionAnswering,
),
"google-bert/bert-large-cased-whole-word-masking-finetuned-squad": (
BertConfig,
TFBertForQuestionAnswering,
BertForQuestionAnswering,
),
"google-bert/bert-base-cased-finetuned-mrpc": (
BertConfig,
TFBertForSequenceClassification,
BertForSequenceClassification,
),
"dpr": (
DPRConfig,
TFDPRQuestionEncoder,
TFDPRContextEncoder,
TFDPRReader,
DPRQuestionEncoder,
DPRContextEncoder,
DPRReader,
),
"openai-community/gpt2": (
GPT2Config,
TFGPT2LMHeadModel,
GPT2LMHeadModel,
),
"xlnet": (
XLNetConfig,
TFXLNetLMHeadModel,
XLNetLMHeadModel,
),
"xlm": (
XLMConfig,
TFXLMWithLMHeadModel,
XLMWithLMHeadModel,
),
"xlm-roberta": (
XLMRobertaConfig,
TFXLMRobertaForMaskedLM,
XLMRobertaForMaskedLM,
),
"transfo-xl": (
TransfoXLConfig,
TFTransfoXLLMHeadModel,
TransfoXLLMHeadModel,
),
"openai-community/openai-gpt": (
OpenAIGPTConfig,
TFOpenAIGPTLMHeadModel,
OpenAIGPTLMHeadModel,
),
"roberta": (
RobertaConfig,
TFRobertaForCausalLM,
TFRobertaForMaskedLM,
RobertaForMaskedLM,
),
"layoutlm": (
LayoutLMConfig,
TFLayoutLMForMaskedLM,
LayoutLMForMaskedLM,
),
"FacebookAI/roberta-large-mnli": (
RobertaConfig,
TFRobertaForSequenceClassification,
RobertaForSequenceClassification,
),
"camembert": (
CamembertConfig,
TFCamembertForMaskedLM,
CamembertForMaskedLM,
),
"flaubert": (
FlaubertConfig,
TFFlaubertWithLMHeadModel,
FlaubertWithLMHeadModel,
),
"distilbert": (
DistilBertConfig,
TFDistilBertForMaskedLM,
DistilBertForMaskedLM,
),
"distilbert-base-distilled-squad": (
DistilBertConfig,
TFDistilBertForQuestionAnswering,
DistilBertForQuestionAnswering,
),
"lxmert": (
LxmertConfig,
TFLxmertForPreTraining,
LxmertForPreTraining,
),
"lxmert-visual-feature-encoder": (
LxmertConfig,
TFLxmertVisualFeatureEncoder,
LxmertVisualFeatureEncoder,
),
"Salesforce/ctrl": (
CTRLConfig,
TFCTRLLMHeadModel,
CTRLLMHeadModel,
),
"albert": (
AlbertConfig,
TFAlbertForPreTraining,
AlbertForPreTraining,
),
"t5": (
T5Config,
TFT5ForConditionalGeneration,
T5ForConditionalGeneration,
),
"electra": (
ElectraConfig,
TFElectraForPreTraining,
ElectraForPreTraining,
),
"wav2vec2": (
Wav2Vec2Config,
TFWav2Vec2Model,
Wav2Vec2Model,
),
}
def convert_pt_checkpoint_to_tf(
model_type, pytorch_checkpoint_path, config_file, tf_dump_path, compare_with_pt_model=False, use_cached_models=True
):
if model_type not in MODEL_CLASSES:
raise ValueError(f"Unrecognized model type, should be one of {list(MODEL_CLASSES.keys())}.")
config_class, model_class, pt_model_class, aws_config_map = MODEL_CLASSES[model_type]
# Initialise TF model
if config_file in aws_config_map:
config_file = cached_file(config_file, CONFIG_NAME, force_download=not use_cached_models)
config = config_class.from_json_file(config_file)
config.output_hidden_states = True
config.output_attentions = True
print(f"Building TensorFlow model from configuration: {config}")
tf_model = model_class(config)
# Load weights from tf checkpoint
if pytorch_checkpoint_path in aws_config_map.keys():
pytorch_checkpoint_path = cached_file(
pytorch_checkpoint_path, WEIGHTS_NAME, force_download=not use_cached_models
)
# Load PyTorch checkpoint in tf2 model:
tf_model = load_pytorch_checkpoint_in_tf2_model(tf_model, pytorch_checkpoint_path)
if compare_with_pt_model:
tfo = tf_model(tf_model.dummy_inputs, training=False) # build the network
weights_only_kwarg = {"weights_only": True}
state_dict = torch.load(
pytorch_checkpoint_path,
map_location="cpu",
**weights_only_kwarg,
)
pt_model = pt_model_class.from_pretrained(
pretrained_model_name_or_path=None, config=config, state_dict=state_dict
)
with torch.no_grad():
pto = pt_model(**pt_model.dummy_inputs)
np_pt = pto[0].numpy()
np_tf = tfo[0].numpy()
diff = np.amax(np.abs(np_pt - np_tf))
print(f"Max absolute difference between models outputs {diff}")
assert diff <= 2e-2, f"Error, model absolute difference is >2e-2: {diff}"
# Save pytorch-model
print(f"Save TensorFlow model to {tf_dump_path}")
tf_model.save_weights(tf_dump_path, save_format="h5")
def convert_all_pt_checkpoints_to_tf(
args_model_type,
tf_dump_path,
model_shortcut_names_or_path=None,
config_shortcut_names_or_path=None,
compare_with_pt_model=False,
use_cached_models=False,
remove_cached_files=False,
only_convert_finetuned_models=False,
):
if args_model_type is None:
model_types = list(MODEL_CLASSES.keys())
else:
model_types = [args_model_type]
for j, model_type in enumerate(model_types, start=1):
print("=" * 100)
print(f" Converting model type {j}/{len(model_types)}: {model_type}")
print("=" * 100)
if model_type not in MODEL_CLASSES:
raise ValueError(f"Unrecognized model type {model_type}, should be one of {list(MODEL_CLASSES.keys())}.")
config_class, model_class, pt_model_class, aws_model_maps, aws_config_map = MODEL_CLASSES[model_type]
if model_shortcut_names_or_path is None:
model_shortcut_names_or_path = list(aws_model_maps.keys())
if config_shortcut_names_or_path is None:
config_shortcut_names_or_path = model_shortcut_names_or_path
for i, (model_shortcut_name, config_shortcut_name) in enumerate(
zip(model_shortcut_names_or_path, config_shortcut_names_or_path), start=1
):
print("-" * 100)
if "-squad" in model_shortcut_name or "-mrpc" in model_shortcut_name or "-mnli" in model_shortcut_name:
if not only_convert_finetuned_models:
print(f" Skipping finetuned checkpoint {model_shortcut_name}")
continue
model_type = model_shortcut_name
elif only_convert_finetuned_models:
print(f" Skipping not finetuned checkpoint {model_shortcut_name}")
continue
print(
f" Converting checkpoint {i}/{len(aws_config_map)}: {model_shortcut_name} - model_type {model_type}"
)
print("-" * 100)
if config_shortcut_name in aws_config_map:
config_file = cached_file(config_shortcut_name, CONFIG_NAME, force_download=not use_cached_models)
else:
config_file = config_shortcut_name
if model_shortcut_name in aws_model_maps:
model_file = cached_file(model_shortcut_name, WEIGHTS_NAME, force_download=not use_cached_models)
else:
model_file = model_shortcut_name
if os.path.isfile(model_shortcut_name):
model_shortcut_name = "converted_model"
convert_pt_checkpoint_to_tf(
model_type=model_type,
pytorch_checkpoint_path=model_file,
config_file=config_file,
tf_dump_path=os.path.join(tf_dump_path, model_shortcut_name + "-tf_model.h5"),
compare_with_pt_model=compare_with_pt_model,
)
if remove_cached_files:
os.remove(config_file)
os.remove(model_file)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--tf_dump_path", default=None, type=str, required=True, help="Path to the output Tensorflow dump file."
)
parser.add_argument(
"--model_type",
default=None,
type=str,
help=(
f"Model type selected in the list of {list(MODEL_CLASSES.keys())}. If not given, will download and "
"convert all the models from AWS."
),
)
parser.add_argument(
"--pytorch_checkpoint_path",
default=None,
type=str,
help=(
"Path to the PyTorch checkpoint path or shortcut name to download from AWS. "
"If not given, will download and convert all the checkpoints from AWS."
),
)
parser.add_argument(
"--config_file",
default=None,
type=str,
help=(
"The config json file corresponding to the pre-trained model. \n"
"This specifies the model architecture. If not given and "
"--pytorch_checkpoint_path is not given or is a shortcut name "
"use the configuration associated to the shortcut name on the AWS"
),
)
parser.add_argument(
"--compare_with_pt_model", action="store_true", help="Compare Tensorflow and PyTorch model predictions."
)
parser.add_argument(
"--use_cached_models",
action="store_true",
help="Use cached models if possible instead of updating to latest checkpoint versions.",
)
parser.add_argument(
"--remove_cached_files",
action="store_true",
help="Remove pytorch models after conversion (save memory when converting in batches).",
)
parser.add_argument("--only_convert_finetuned_models", action="store_true", help="Only convert finetuned models.")
args = parser.parse_args()
# if args.pytorch_checkpoint_path is not None:
# convert_pt_checkpoint_to_tf(args.model_type.lower(),
# args.pytorch_checkpoint_path,
# args.config_file if args.config_file is not None else args.pytorch_checkpoint_path,
# args.tf_dump_path,
# compare_with_pt_model=args.compare_with_pt_model,
# use_cached_models=args.use_cached_models)
# else:
convert_all_pt_checkpoints_to_tf(
args.model_type.lower() if args.model_type is not None else None,
args.tf_dump_path,
model_shortcut_names_or_path=[args.pytorch_checkpoint_path]
if args.pytorch_checkpoint_path is not None
else None,
config_shortcut_names_or_path=[args.config_file] if args.config_file is not None else None,
compare_with_pt_model=args.compare_with_pt_model,
use_cached_models=args.use_cached_models,
remove_cached_files=args.remove_cached_files,
only_convert_finetuned_models=args.only_convert_finetuned_models,
)
|
transformers/src/transformers/convert_pytorch_checkpoint_to_tf2.py/0
|
{
"file_path": "transformers/src/transformers/convert_pytorch_checkpoint_to_tf2.py",
"repo_id": "transformers",
"token_count": 6724
}
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""XNLI utils (dataset loading and evaluation)"""
import os
from ...utils import logging
from .utils import DataProcessor, InputExample
logger = logging.get_logger(__name__)
class XnliProcessor(DataProcessor):
"""
Processor for the XNLI dataset. Adapted from
https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/run_classifier.py#L207
"""
def __init__(self, language, train_language=None):
self.language = language
self.train_language = train_language
def get_train_examples(self, data_dir):
"""See base class."""
lg = self.language if self.train_language is None else self.train_language
lines = self._read_tsv(os.path.join(data_dir, f"XNLI-MT-1.0/multinli/multinli.train.{lg}.tsv"))
examples = []
for i, line in enumerate(lines):
if i == 0:
continue
guid = f"train-{i}"
text_a = line[0]
text_b = line[1]
label = "contradiction" if line[2] == "contradictory" else line[2]
if not isinstance(text_a, str):
raise TypeError(f"Training input {text_a} is not a string")
if not isinstance(text_b, str):
raise TypeError(f"Training input {text_b} is not a string")
if not isinstance(label, str):
raise TypeError(f"Training label {label} is not a string")
examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def get_test_examples(self, data_dir):
"""See base class."""
lines = self._read_tsv(os.path.join(data_dir, "XNLI-1.0/xnli.test.tsv"))
examples = []
for i, line in enumerate(lines):
if i == 0:
continue
language = line[0]
if language != self.language:
continue
guid = f"test-{i}"
text_a = line[6]
text_b = line[7]
label = line[1]
if not isinstance(text_a, str):
raise TypeError(f"Training input {text_a} is not a string")
if not isinstance(text_b, str):
raise TypeError(f"Training input {text_b} is not a string")
if not isinstance(label, str):
raise TypeError(f"Training label {label} is not a string")
examples.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def get_labels(self):
"""See base class."""
return ["contradiction", "entailment", "neutral"]
xnli_processors = {
"xnli": XnliProcessor,
}
xnli_output_modes = {
"xnli": "classification",
}
xnli_tasks_num_labels = {
"xnli": 3,
}
|
transformers/src/transformers/data/processors/xnli.py/0
|
{
"file_path": "transformers/src/transformers/data/processors/xnli.py",
"repo_id": "transformers",
"token_count": 1505
}
|
import time
import warnings
from abc import ABC
from collections import OrderedDict
from copy import deepcopy
from typing import Dict, List, Optional, Tuple, Union
import numpy as np
import torch
from torch.nn import functional as F
from ..pytorch_utils import isin_mps_friendly
from ..tokenization_utils_base import PreTrainedTokenizerBase
from ..utils import add_start_docstrings, logging
logger = logging.get_logger(__name__)
# We maintain a module-level cache of the embedding vectors for the stop string criterion
# because they are slow to compute
STOP_STRING_EMBEDDING_CACHE = OrderedDict()
STOPPING_CRITERIA_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
scores (`torch.FloatTensor` of shape `(batch_size, config.vocab_size)`):
Prediction scores of a language modeling head. These can be scores for each vocabulary token before SoftMax
or scores for each vocabulary token after SoftMax. If this stopping criteria depends on the `scores` input,
make sure you pass `return_dict_in_generate=True, output_scores=True` to `generate`.
kwargs (`Dict[str, Any]`, *optional*):
Additional stopping criteria specific kwargs.
Return:
`torch.BoolTensor`. (`torch.BoolTensor` of shape `(batch_size, 1)`), where `True` indicates we stop generation
for a particular row, `True` indicates we should continue.
"""
class StoppingCriteria(ABC):
"""Abstract base class for all stopping criteria that can be applied during generation.
If your stopping criteria depends on the `scores` input, make sure you pass `return_dict_in_generate=True,
output_scores=True` to `generate`.
"""
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
raise NotImplementedError("StoppingCriteria needs to be subclassed")
class MaxLengthCriteria(StoppingCriteria):
"""
This class can be used to stop generation whenever the full generated number of tokens exceeds `max_length`. Keep
in mind for decoder-only type of transformers, this will include the initial prompted tokens.
Args:
max_length (`int`):
The maximum length that the output sequence can have in number of tokens.
max_position_embeddings (`int`, *optional*):
The maximum model length, as defined by the model's `config.max_position_embeddings` attribute.
"""
def __init__(self, max_length: int, max_position_embeddings: Optional[int] = None):
self.max_length = max_length
self.max_position_embeddings = max_position_embeddings
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
cur_len = input_ids.shape[-1]
is_done = cur_len >= self.max_length
if self.max_position_embeddings is not None and not is_done and cur_len >= self.max_position_embeddings:
logger.warning_once(
"This is a friendly reminder - the current text generation call will exceed the model's predefined "
f"maximum length ({self.max_position_embeddings}). Depending on the model, you may observe "
"exceptions, performance degradation, or nothing at all."
)
return torch.full((input_ids.shape[0],), is_done, device=input_ids.device, dtype=torch.bool)
class MaxTimeCriteria(StoppingCriteria):
"""
This class can be used to stop generation whenever the full generation exceeds some amount of time. By default, the
time will start being counted when you initialize this function. You can override this by passing an
`initial_time`.
Args:
max_time (`float`):
The maximum allowed time in seconds for the generation.
initial_time (`float`, *optional*, defaults to `time.time()`):
The start of the generation allowed time.
"""
def __init__(self, max_time: float, initial_timestamp: Optional[float] = None):
self.max_time = max_time
self.initial_timestamp = time.time() if initial_timestamp is None else initial_timestamp
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
is_done = time.time() - self.initial_timestamp > self.max_time
return torch.full((input_ids.shape[0],), is_done, device=input_ids.device, dtype=torch.bool)
class StopStringCriteria(StoppingCriteria):
"""
This class can be used to stop generation whenever specific string sequences are generated. It preprocesses
the strings together with the tokenizer vocab to find positions where tokens can validly complete the stop strings.
Generation is stopped as soon as a token is generated that completes any of the stop strings.
We want to catch any instance in which the stop string would be present in the decoded output, which means
we must also catch cases with "overhangs" off one or both ends. To make this more concrete, for the stop string
"stop", any of the following token sequences would trigger the match:
- ["st", "op"]
- ["stop"]
- ["st", "opera"]
- ["sto", "pper"]
- ["las", "topper"]
- ["s", "to", "pped"]
Note that a match will only be triggered if the stop string is at the end of the generated sequence. In other
words, these sequences will not trigger a match:
- ["stop", "at"]
- ["st", "op", "at"]
- ["st", "opera", "tion"]
The reason these are not a match is that the stop string does not overlap with the final token. If you can remove
one or more tokens from the end of the sequence without destroying the stop string, then this criterion will not
match that stop string. This is by design; because this check is run after each token is generated, we can't miss a
valid stop string if one is generated, but we don't want to halt generation just because the stop string exists
somewhere in the past input_ids.
How is the match actually performed, though? We do it in quite a confusing way, because we want the entire match
process to be compilable with Torch or XLA, which means we cannot use standard string methods. However, it is possible,
with some work, to do string matching with pure tensor operations. We'll begin by describing the algorithm we use
with standard string operations, and then at the end we'll explain how this is converted to pure tensor operations.
The key to the algorithm is an observation: Because the stop string must overlap with the end of the token sequence, we can start at
the end of the sequence and work backwards. Specifically, we check that there is an overlap between the start of
the final token and the end of the stop_string, or to put it another way, stop_string[-i:] == token[:i] for
some i > 0. If you look at the positive examples above, you'll see the last token in all of them fulfills this
property:
- ["st", "op"] (overlap is "op", overlap length == 2)
- ["stop"] (overlap is "stop", overlap length == 4)
- ["st", "opera"] (overlap is "op", overlap length == 2)
- ["sto", "pper"] (overlap is "p", overlap length == 1)
- ["las", "topper"] (overlap is "top", overlap length == 3)
- ["s", "to", "pped"] (overlap is "p", overlap length == 1)
It's impossible to construct a matching sequence that does not have this property (feel free to verify this
yourself). However, although this overlap between the start of the final token and the end of the stop string is
necessary for a match, it is not sufficient. We also need to check that the rest of the token sequence is
consistent with the stop string.
How do we do that? Let's use ["s", "to", "pped"] as an example. We know that the final token, "pped", has an
overlap of 1 with the stop string, "stop". We then go back to the previous token, "to". Since we have already
matched 1 character from the stop string, the remainder to check is "sto". We check that the next token "to"
matches the end of the remainder, which it does. We have now matched 3 characters from the stop string, and the
remainder to match is "s". We go back to the previous token again, which is also "s". This is a match, and so
we have matched the entire stop string.
How does it work when the tokens run off the start of the stop string, though? Let's consider the example of
["las", "topper"]. The final token, "topper", has an overlap of 3 with the stop string, "stop". Therefore,
the remaining stop string to match is "s". We go back to the previous token, "las". Because the remainder to
match is just "s", with length 1, we consider only the final 1 character from the token, which is "s". This
matches the stop string, and so the entire string is matched.
How do we compute these matches with tensor operations, though? Simply: we efficiently precompute the necessary
information for all tokens! For every token, we compute:
- Its overlap with the end of the stop string, if any
- The positions inside the stop string where the token matches, including matches that run off the start.
- The total length of the token
For example, for the token "pped", we would compute an end overlap of 1, no internal matching positions,
and a length of 4. For the token "to", we would compute no end overlap, a single internal matching position
of 1 (counting from the end), and a length of 2. For the token "s", we would compute no end overlap,
a single internal matching position of 3 (again counting from the end) and a length of 1.
As long as we have this information, we can execute the algorithm above without any string comparison
operations. We simply perform the following steps:
- Check if the final token has an end-overlap with the start string
- Continue backwards, keeping track of how much of the stop string we've matched so far
- At each point, check if the next token has the current position as one of its valid positions
- Continue until either a match fails, or we completely match the whole stop string
Again, consider ["s", "to", "pped"] as an example. "pped" has an end overlap of 1, so we can begin a match.
We have matched 1 character so far, so we check that the next token "to", has 1 as a valid position (again,
counting from the end). It does, so we add the length of "to" to our position tracker. We have now matched
3 characters, so we check that the next token "s" has 3 as a valid position. It does, so we add its length
to the position tracker. The position tracker is now 4, which is the length of the stop string. We have matched the
entire stop string.
In the second case, ["las", "topper"], "topper" has an end overlap of 3, so we can begin a match. We have
matched 3 characters so far, so we check that the next token "las" has 3 as a valid position. It does, because we
allow tokens to match positions that run off the start of the stop string. We add its length to the position
tracker. The position tracker is now 6, which is greater than the length of the stop string! Don't panic, though -
this also counts as a match of the stop string. We have matched the entire stop string.
Args:
tokenizer (`PreTrainedTokenizer`):
The model's associated tokenizer (necessary to extract vocab and tokenize the termination sequences)
stop_strings (`Union[str, List[str]]`):
A list of strings that should end generation. If a string is passed, it will be treated like a
list with a single element.
Examples:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
>>> model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
>>> inputs = tokenizer("The biggest states in the USA by land area:", return_tensors="pt")
>>> gen_out = model.generate(**inputs)
>>> print(tokenizer.batch_decode(gen_out, skip_special_tokens=True)[0])
The biggest states in the USA by land area:
- Alaska
- Texas
- California
>>> # Passing one or more stop strings will halt generation after those strings are emitted
>>> # Note that generating with stop strings requires you to pass the tokenizer too
>>> gen_out = model.generate(**inputs, stop_strings=["Texas"], tokenizer=tokenizer)
>>> print(tokenizer.batch_decode(gen_out, skip_special_tokens=True)[0])
The biggest states in the USA by land area:
- Alaska
- Texas
```
"""
def __init__(self, tokenizer: PreTrainedTokenizerBase, stop_strings: Union[str, List[str]]):
if isinstance(stop_strings, str):
stop_strings = [stop_strings]
self.stop_strings: Tuple[str, ...] = tuple(stop_strings)
vocab = tokenizer.get_vocab()
token_list, token_indices = tuple(vocab.keys()), tuple(vocab.values())
self.embedding_vec, self.max_valid_positions, self.max_valid_end_lens = self.clean_and_embed_tokens_with_cache(
token_list, token_indices, tokenizer
)
self.maximum_token_len = max([len(stop_string) for stop_string in self.stop_strings])
self.num_stop_strings = len(self.stop_strings)
self.target_lens = torch.tensor([len(stop_string) for stop_string in stop_strings], dtype=torch.int32)
def clean_and_embed_tokens_with_cache(self, token_list, token_indices, tokenizer):
# We don't use the tokenizer in the cache key, because I don't trust it to have well-behaved equality
if (token_list, token_indices, self.stop_strings) in STOP_STRING_EMBEDDING_CACHE:
embedding_vec, max_valid_positions, max_valid_end_lens = STOP_STRING_EMBEDDING_CACHE[
(token_list, token_indices, self.stop_strings)
]
STOP_STRING_EMBEDDING_CACHE.move_to_end((token_list, token_indices, self.stop_strings))
else:
clean_token_list, clean_token_indices = self.clean_tokenizer_vocab(tokenizer)
embedding_vec, max_valid_positions, max_valid_end_lens = self._stop_string_create_embedding_vec(
clean_token_list, clean_token_indices, self.stop_strings
)
STOP_STRING_EMBEDDING_CACHE[(token_list, token_indices, self.stop_strings)] = (
embedding_vec,
max_valid_positions,
max_valid_end_lens,
)
if len(STOP_STRING_EMBEDDING_CACHE) > 8:
STOP_STRING_EMBEDDING_CACHE.popitem(last=False) # Pop from the start, the least recently used item
return embedding_vec, max_valid_positions, max_valid_end_lens
@staticmethod
def clean_tokenizer_vocab(tokenizer, static_prefix="abcdef"):
"""
This method turns a tokenizer vocab into a "clean" vocab where each token represents the actual string
it will yield, without any special prefixes like "##" or "Ġ". This is trickier than it looks - the method
tokenizer.convert_tokens_to_string() does not always return the correct string because of issues with prefix
space addition/removal. To work around this, we add a static prefix to the start of the token, then remove
it (and any prefix that may have been introduced with it) after calling convert_tokens_to_string().
"""
vocab = tokenizer.get_vocab()
clean_token_list = []
clean_token_indices = []
sentence_base = tokenizer(static_prefix, add_special_tokens=False)["input_ids"]
tokens_base = [tokenizer._convert_id_to_token(tok) for tok in sentence_base]
for token, token_idx in vocab.items():
token_string = tokenizer.convert_tokens_to_string(tokens_base + [token])
token_string = token_string[token_string.index(static_prefix) + len(static_prefix) :]
clean_token_list.append(token_string)
clean_token_indices.append(token_idx)
return tuple(clean_token_list), tuple(clean_token_indices)
@staticmethod
def _stop_string_get_matching_positions(
token_list, token_indices, stop_strings
) -> Tuple[Dict[str, Dict[str, List[int]]], Dict[str, Dict[str, List[int]]]]:
"""This function preprocesses stop strings and the tokenizer vocabulary to determine where tokens can
validly appear in the stop strings. For each token, it computes a list of positions in the stop string where the
token appears, as well as a list of the possible "end overlaps" for that token - that is, the number of characters
from the end of the stop string that overlap with the start of the token, which can have more than one value.
The reason for computing these may seem a bit cryptic - please see the docstring for StopStringCriteria for a full
explanation of what these values are for!"""
token_valid_positions = {}
token_end_overlaps = {}
for stop_string in stop_strings:
reversed_stop_string = stop_string[::-1]
token_valid_positions[stop_string] = {}
token_end_overlaps[stop_string] = {}
for token, tok_idx in zip(token_list, token_indices):
reversed_token = token[::-1]
matching_positions = []
possible_end_lengths = []
for i in range(1 - len(token), len(stop_string)):
if i < 0:
tok = reversed_token[-i:]
i = 0
else:
tok = reversed_token
stop = reversed_stop_string[i : i + len(tok)]
if tok.startswith(stop):
if i == 0:
possible_end_lengths.append(min(len(tok), len(stop)))
else:
matching_positions.append(i)
if matching_positions:
token_valid_positions[stop_string][tok_idx] = matching_positions
if possible_end_lengths:
token_end_overlaps[stop_string][tok_idx] = possible_end_lengths
return token_valid_positions, token_end_overlaps
@staticmethod
def _stop_string_create_embedding_vec(token_list, token_indices, stop_strings) -> Dict[str, torch.tensor]:
"""This function precomputes everything needed for the run-time checks in StopStringCriteria, and packs
them into an embedding tensor that can be accessed with pure tensor operations. For the specifics of the values
that are precomputed and what they are used for, please refer to the StopStringCriteria docstring!"""
token_valid_positions, token_end_overlaps = StopStringCriteria._stop_string_get_matching_positions(
token_list, token_indices, stop_strings
)
all_valid_positions = [len(val) for positions in token_valid_positions.values() for val in positions.values()]
# In some cases, tokens may have no valid internal positions (such as single-character stop strings), so
# we need a fallback to handle this case
max_valid_positions = max(all_valid_positions) if all_valid_positions else 1
# There should always be at least one valid end_len, however, so no fallback needed here
valid_end_lens = [len(val) for positions in token_end_overlaps.values() for val in positions.values()]
if not valid_end_lens:
raise ValueError(
"Stop string preprocessing was unable to identify tokens matching one or more of the "
"supplied stop string(s). This is most often caused by the stop "
"strings containing unusual characters that are not in the tokenizer vocabulary."
)
max_valid_end_lens = max(valid_end_lens)
vec_size = len(stop_strings) * (max_valid_positions + max_valid_end_lens) + 1
# We use +2 instead of +1 so we can have a dummy entry at the end. We will clamp all token values
# over the max to this, ensuring they do not contribute to stop string matching.
gather_vec = np.full((max(token_indices) + 2, vec_size), dtype=np.int32, fill_value=-1)
for i, stop_string in enumerate(stop_strings):
positions = token_valid_positions[stop_string]
end_lens = token_end_overlaps[stop_string]
# Since this is lots of very small assignments of lists, we build it with numpy rather
# than torch for speed + simplicity, then convert to torch at the end
for token_idx, valid_positions in positions.items():
gather_vec[token_idx, max_valid_positions * i : max_valid_positions * i + len(valid_positions)] = (
valid_positions
)
for token_idx, possible_end_lens in end_lens.items():
gather_vec[
token_idx,
max_valid_positions * len(stop_strings) + max_valid_end_lens * i : max_valid_positions
* len(stop_strings)
+ max_valid_end_lens * i
+ len(possible_end_lens),
] = possible_end_lens
for token, token_idx in zip(token_list, token_indices):
gather_vec[token_idx, -1] = len(token)
gather_vec = torch.tensor(gather_vec, dtype=torch.int32)
return gather_vec, max_valid_positions, max_valid_end_lens
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.Tensor:
self.embedding_vec = self.embedding_vec.to(input_ids.device)
self.target_lens = self.target_lens.to(input_ids.device)
# The maximum length we need to consider is 1 token per character. Note that input_ids can also be
# *shorter* than the global max, and the code below should be ready for that
input_ids = input_ids[:, -self.maximum_token_len :]
# Flip input_ids because we're only matching strings at the end of the generated sequence
flipped_ids = torch.flip(input_ids, (1,))
# Clip out-of-vocab values to the dummy value at the end of the embedding vector
flipped_ids = torch.clamp(flipped_ids, max=self.embedding_vec.size(0) - 1)
# Size of the vector of positions a single token can match
max_valid_positions = self.max_valid_positions
# The embedding vec contains the valid positions, end_lengths and total lengths for each token
embedded = F.embedding(flipped_ids, self.embedding_vec)
# Now we split the embedding vector. valid_positions is the positions in the stop string the token can fit
valid_positions = embedded[:, 1:, : max_valid_positions * self.num_stop_strings].unflatten(
-1, (self.num_stop_strings, -1)
)
# end_lengths is the number of characters from the string, counting from the end, that the token
# contains. It can have multiple values if the same token can overlap different end lengths
end_lengths = embedded[:, :1, max_valid_positions * self.num_stop_strings : -1].unflatten(
-1, (self.num_stop_strings, -1)
)
# Lengths is the total length of each token. Unlike the others, it always has a single value
lengths = embedded[:, 1:, None, -1:] # Insert a dummy dimension for stop_strings even though lengths are const
# Concatenate lengths onto each possible end_lengths value
lengths = lengths.expand((-1, -1, end_lengths.shape[-2], end_lengths.shape[-1]))
lengths_with_ends = torch.cat([end_lengths, lengths], dim=1)
# cumsum() to get the number of matched characters in the stop string after each token
cumsum = lengths_with_ends.cumsum(dim=1) # B x maximum_token_len x num_stop_strings x max_valid_end_lens
# The calculation above assumes that all tokens are in valid positions. Now we mask the ones that are not.
# First, tokens match the start of the string if they have a positive value in the end_lengths vector
initial_match = end_lengths > 0
# Tokens continue the string if the cumsum() so far is one of the valid positions for that token
# Note that we're actually tracking one cumsum() for for each possible end_length
later_match = torch.any(cumsum[:, :-1, :, None] == valid_positions[:, :, :, :, None], axis=-2)
# The match vector is a boolean vector that indicates which positions have valid tokens
match = torch.cat([initial_match, later_match], dim=1)
# Once a single position does not match, all positions following that position are masked
mask = (~match).cumsum(dim=1, dtype=torch.int32)
mask = mask == 0
# The string is matched if we reached a cumsum equal to or greater than the length of the string
# before hitting the mask
string_matches = torch.amax(cumsum * mask, dim=(1, -1)) >= self.target_lens[None, :]
# We return a per-sample vector that is True if any stop string is matched for that sample
return torch.any(string_matches, dim=-1)
class EosTokenCriteria(StoppingCriteria):
"""
This class can be used to stop generation whenever the "end-of-sequence" token is generated.
By default, it uses the `model.generation_config.eos_token_id`.
Args:
eos_token_id (`Union[int, List[int], torch.Tensor]`):
The id(s) of the *end-of-sequence* token.
"""
def __init__(self, eos_token_id: Union[int, List[int], torch.Tensor]):
if not isinstance(eos_token_id, torch.Tensor):
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
eos_token_id = torch.tensor(eos_token_id)
self.eos_token_id = eos_token_id
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
self.eos_token_id = self.eos_token_id.to(input_ids.device)
is_done = isin_mps_friendly(input_ids[:, -1], self.eos_token_id)
return is_done
class ConfidenceCriteria(StoppingCriteria):
"""
This class can be used to stop generation whenever assistant model's confidence in its prediction for the current token is lower than the threshold
`model.generation_config.assistant_confidence_threshold` even if the number of speculative tokens (defined by `num_assistant_tokens`) is not yet reached.
Args:
assistant_confidence_threshold (`float`):
The value of the threshold.
"""
def __init__(self, assistant_confidence_threshold):
self.assistant_confidence_threshold = assistant_confidence_threshold
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
probs = scores[-1].softmax(-1)
p = probs[0, input_ids[0, -1]].item()
if p < self.assistant_confidence_threshold:
return True
return False
class StoppingCriteriaList(list):
@add_start_docstrings(STOPPING_CRITERIA_INPUTS_DOCSTRING)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> torch.BoolTensor:
is_done = torch.full((input_ids.shape[0],), False, device=input_ids.device, dtype=torch.bool)
for criteria in self:
is_done = is_done | criteria(input_ids, scores, **kwargs)
return is_done
@property
def max_length(self) -> Optional[int]:
for stopping_criterium in self:
if isinstance(stopping_criterium, MaxLengthCriteria):
return stopping_criterium.max_length
return None
def validate_stopping_criteria(stopping_criteria: StoppingCriteriaList, max_length: int) -> StoppingCriteriaList:
stopping_max_length = stopping_criteria.max_length
new_stopping_criteria = deepcopy(stopping_criteria)
if stopping_max_length is not None and stopping_max_length != max_length:
warnings.warn("You set different `max_length` for stopping criteria and `max_length` parameter", UserWarning)
elif stopping_max_length is None:
new_stopping_criteria.append(MaxLengthCriteria(max_length=max_length))
return new_stopping_criteria
|
transformers/src/transformers/generation/stopping_criteria.py/0
|
{
"file_path": "transformers/src/transformers/generation/stopping_criteria.py",
"repo_id": "transformers",
"token_count": 10529
}
|
from ..utils import is_accelerate_available, is_torch_available, logging
if is_accelerate_available():
from accelerate import init_empty_weights
if is_torch_available():
import torch
import torch.nn as nn
import torch.nn.functional as F
logger = logging.get_logger(__name__)
# the weights are ternary so can be represented with 2 bits, and they are packed in uint8 tensors, hence the number of values per item is 4
VALUES_PER_ITEM = 4
def pack_weights(quantized_weights: torch.Tensor) -> torch.Tensor:
"""
Packs a tensor of quantized weights into a compact format using 2 bits per value.
Parameters:
-----------
quantized_weights : torch.Tensor
A tensor containing ternary quantized weights with values in {-1, 0, 1}. These values are adjusted to
{0, 1, 2} before being packed.
Returns:
--------
torch.Tensor
A packed tensor where each element stores 4 quantized values (each using 2 bits) in an 8-bit format.
"""
original_shape = quantized_weights.shape
row_dim = (original_shape[0] + VALUES_PER_ITEM - 1) // VALUES_PER_ITEM
if len(original_shape) == 1:
packed_tensor_shape = (row_dim,)
else:
packed_tensor_shape = (row_dim, *original_shape[1:])
quantized_weights += 1
packed = torch.zeros(packed_tensor_shape, device=quantized_weights.device, dtype=torch.uint8)
unpacked = quantized_weights.to(torch.uint8)
it = min(VALUES_PER_ITEM, (original_shape[0] // row_dim) + 1)
for i in range(it):
start = i * row_dim
end = min(start + row_dim, original_shape[0])
packed[: (end - start)] |= unpacked[start:end] << 2 * i
return packed
@torch.compile
def unpack_weights(packed: torch.Tensor, dtype: torch.dtype) -> torch.Tensor:
"""
Unpacks a tensor of quantized weights that were stored in a packed format using 2 bits per value.
Parameters:
-----------
packed : torch.Tensor
A tensor containing packed weights where each element represents 4 quantized values (using 2 bits per value).
dtype : torch.dtype
The dtype of the returned Tensor
Returns:
--------
torch.Tensor
A tensor of unpacked weights, where each value is converted from its packed 2-bit representation.
Example:
--------
packed = torch.tensor([[0b10100001, 0b00011000],
[0b10010000, 0b00001010]], dtype=torch.uint8)
# Unpack the values
unpacked = unpack_weights(packed)
# Resulting unpacked tensor
print(unpacked)
# Output: tensor([[ 0, -1],
[-1, 1],
[-1, 1],
[-1, 1],
[ 1, 0],
[ 0, -1],
[ 1, -1],
[ 1, -1]])
Explanation of the example:
---------------------------
Let's take the first value for example 0b10100001, we we will only focus on the first column,
because every element is unpacked across the first dimension
- First 2 bits: `01` → 0 at [0][0]
- Second 2 bits: `00` → -1 at [0][2]
- Third 2 bits: `10` → 1 at [0][4]
- Fourth 2 bits: `10` → 1 at [0][6]
the second value of the same row (0b10010000) will give the values for [0][1], [0][3], [0][5], [0][7]
We subtract 1 because during the packing process, it's easier to work with values like 0, 1, and 2. To make this possible,
we add 1 to the original ternary weights (which are typically -1, 0, and 1) when packing them. When unpacking, we reverse
this by subtracting 1 to restore the original ternary values.
"""
packed_shape = packed.shape
if len(packed_shape) == 1:
original_row_dim = packed_shape[0] * VALUES_PER_ITEM
unpacked_shape = (original_row_dim,)
else:
original_row_dim = packed_shape[0] * VALUES_PER_ITEM
unpacked_shape = (original_row_dim, *packed_shape[1:])
unpacked = torch.zeros(unpacked_shape, device=packed.device, dtype=torch.uint8)
for i in range(VALUES_PER_ITEM):
start = i * packed_shape[0]
end = start + packed_shape[0]
mask = 3 << (2 * i)
unpacked[start:end] = (packed & mask) >> (2 * i)
return unpacked.to(dtype) - 1
class BitLinear(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool, device=None, dtype=None):
super().__init__()
self.dtype = dtype
self.in_features = in_features
self.out_features = out_features
self.register_buffer(
"weight",
torch.zeros(
(out_features // VALUES_PER_ITEM, in_features),
dtype=torch.uint8,
device=device,
),
)
self.register_buffer(
"weight_scale",
torch.ones(
(1),
dtype=dtype,
device=device,
),
)
if bias:
self.register_buffer("bias", torch.zeros((out_features), dtype=dtype, device=device))
else:
self.bias = None
@torch.compile
def activation_quant(self, input, num_bits=8):
"""
Activation function : Performs symmetric, per-token quantization on the input activations.
Parameters:
-----------
x : torch.Tensor
Input activations to be quantized.
num_bits : int, optional (default=8)
Number of bits to use for quantization, determining the quantization range.
Returns:
--------
result : torch.Tensor
Quantized activation tensor, with values mapped to an `int8` range.
scale : torch.Tensor
The per-channel scaling factors used to quantize the tensor.
"""
Qn = -(2 ** (num_bits - 1))
Qp = 2 ** (num_bits - 1) - 1
scale = Qp / input.abs().max(dim=-1, keepdim=True).values.clamp(min=1e-5)
result = (input * scale).round().clamp(Qn, Qp)
return result.to(torch.int8), scale
@torch.compile
def post_quant_process(self, input, input_scale, weight_scale):
out = input / (input_scale * weight_scale)
return out
def forward(self, input):
w = self.weight
w_quant = unpack_weights(w, dtype=self.dtype)
input_quant, input_scale = self.activation_quant(input)
y = F.linear(input_quant.to(self.dtype), w_quant)
y = self.post_quant_process(y, self.weight_scale, input_scale)
if self.bias is not None:
y += self.bias.view(1, -1).expand_as(y)
return y
def _replace_with_bitnet_linear(
model,
modules_to_not_convert=None,
current_key_name=None,
quantization_config=None,
has_been_replaced=False,
pre_quantized=False,
):
"""
Private method that wraps the recursion for module replacement.
Returns the converted model and a boolean that indicates if the conversion has been successfull or not.
"""
if current_key_name is None:
current_key_name = []
for name, module in model.named_children():
if current_key_name is None:
current_key_name = []
current_key_name.append(name)
# Check if the current key is not in the `modules_to_not_convert`
if not any(key in ".".join(current_key_name) for key in modules_to_not_convert):
with init_empty_weights():
if isinstance(module, nn.Linear) and name not in modules_to_not_convert:
in_features = module.in_features
out_features = module.out_features
model._modules[name] = BitLinear(
in_features=in_features,
out_features=out_features,
bias=module.bias is not None,
device=module.weight.device,
dtype=module.weight.dtype,
)
has_been_replaced = True
model._modules[name].requires_grad_(False)
if len(list(module.children())) > 0:
_, has_been_replaced = _replace_with_bitnet_linear(
module,
modules_to_not_convert=modules_to_not_convert,
current_key_name=current_key_name,
quantization_config=quantization_config,
has_been_replaced=has_been_replaced,
)
# Remove the last key for recursion
current_key_name.pop(-1)
return model, has_been_replaced
def replace_with_bitnet_linear(
model,
modules_to_not_convert=None,
current_key_name=None,
quantization_config=None,
pre_quantized=False,
):
"""
A helper function to replace all `torch.nn.Linear` modules by `BitLinear158` modules`.
The function will be run recursively and replace all `torch.nn.Linear` modules except for the `lm_head` that should
be kept as a `torch.nn.Linear` module. The replacement is done under `init_empty_weights` context manager so no
CPU/GPU memory is required to run this function. Each weight will be quantized along the channel.
Parameters:
model (`torch.nn.Module`):
Input model or `torch.nn.Module` as the function is run recursively.
modules_to_not_convert (`List[`str`]`, *optional*, defaults to `["lm_head"]`):
Names of the modules to not convert in `EetqLinear`. In practice we keep the `lm_head` in full precision
for numerical stability reasons.
current_key_name (`List[`str`]`, *optional*):
An array to track the current key of the recursion. This is used to check whether the current key (part of
it) is not in the list of modules to not convert (for instances modules that are offloaded to `cpu` or
`disk`).
"""
modules_to_not_convert = ["lm_head"] if modules_to_not_convert is None else modules_to_not_convert
if quantization_config and quantization_config.modules_to_not_convert is not None:
modules_to_not_convert.extend(quantization_config.modules_to_not_convert)
modules_to_not_convert = list(set(modules_to_not_convert))
model, has_been_replaced = _replace_with_bitnet_linear(
model,
modules_to_not_convert,
current_key_name,
quantization_config,
pre_quantized=pre_quantized,
)
if not has_been_replaced:
logger.warning(
"You are loading your model using bitnet but no linear modules were found in your model."
" Please double check your model architecture, or submit an issue on github if you think this is"
" a bug."
)
return model
|
transformers/src/transformers/integrations/bitnet.py/0
|
{
"file_path": "transformers/src/transformers/integrations/bitnet.py",
"repo_id": "transformers",
"token_count": 4597
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.