
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Zaib/Vulnerability-detection
|
Zaib
| 2022-08-05T08:47:07Z
| 13
| 5
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-16T09:16:45Z
|
---
tags:
- generated_from_trainer
model-index:
- name: Vulnerability-detection
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Vulnerability-detection
This model is a fine-tuned version of [mrm8488/codebert-base-finetuned-detect-insecure-code](https://huggingface.co/mrm8488/codebert-base-finetuned-detect-insecure-code) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jefsnacker/testpyramidsrnd
|
jefsnacker
| 2022-08-05T07:52:18Z
| 4
| 0
|
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-08-05T07:52:11Z
|
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: jefsnacker/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
abdulmatinomotoso/multi_news_article_title_1200
|
abdulmatinomotoso
| 2022-08-05T07:14:16Z
| 15
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-05T06:42:59Z
|
---
tags:
- generated_from_trainer
model-index:
- name: multi_news_article_title_1200
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multi_news_article_title_1200
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
sagar122/xperimentalilst_hackathon_2022
|
sagar122
| 2022-08-05T06:19:19Z
| 0
| 1
| null |
[
"arxiv:2205.02455",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2022-08-04T08:49:20Z
|
---
license: cc-by-nc-4.0
---
## COGMEN; Official Pytorch Implementation
[](https://paperswithcode.com/sota/multimodal-emotion-recognition-on-iemocap?p=cogmen-contextualized-gnn-based-multimodal)
**CO**ntextualized **G**NN based **M**ultimodal **E**motion recognitio**N**

**Picture:** *My sample picture for logo*
This repository contains the official Pytorch implementation of the following paper:
> **COGMEN: COntextualized GNN based Multimodal Emotion recognitioN**<br>
> **Paper:** https://arxiv.org/abs/2205.02455
> **Authors:** Abhinav Joshi, Ashwani Bhat, Ayush Jain, Atin Vikram Singh, Ashutosh Modi<br>
>
> **Abstract:** *Emotions are an inherent part of human interactions, and consequently, it is imperative to develop AI systems that understand and recognize human emotions. During a conversation involving various people, a person’s emotions are influenced by the other speaker’s utterances and their own emotional state over the utterances. In this paper, we propose COntextualized Graph Neural Network based Multimodal Emotion recognitioN (COGMEN) system that leverages local information (i.e., inter/intra dependency between speakers) and global information (context). The proposed model uses Graph Neural Network (GNN) based architecture to model the complex dependencies (local and global information) in a conversation. Our model gives state-of-theart (SOTA) results on IEMOCAP and MOSEI datasets, and detailed ablation experiments
show the importance of modeling information at both levels*
## Requirements
- We use PyG (PyTorch Geometric) for the GNN component in our architecture. [RGCNConv](https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.conv.RGCNConv) and [TransformerConv](https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.conv.TransformerConv)
- We use [comet](https://comet.ml) for logging all our experiments and its Bayesian optimizer for hyperparameter tuning.
- For textual features we use [SBERT](https://www.sbert.net/).
### Installations
- [Install PyTorch Geometric](https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html)
- [Install Comet.ml](https://www.comet.ml/docs/python-sdk/advanced/)
- [Install SBERT](https://www.sbert.net/)
## Preparing datasets for training
python preprocess.py --dataset="iemocap_4"
## Training networks
python train.py --dataset="iemocap_4" --modalities="atv" --from_begin --epochs=55
## Run Evaluation [](https://colab.research.google.com/drive/1biIvonBdJWo2TiYyTiQkxZ_V88JEXa_d?usp=sharing)
python eval.py --dataset="iemocap_4" --modalities="atv"
Please cite the paper using following citation:
## Citation
@inproceedings{joshi-etal-2022-cogmen,
title = "{COGMEN}: {CO}ntextualized {GNN} based Multimodal Emotion recognitio{N}",
author = "Joshi, Abhinav and
Bhat, Ashwani and
Jain, Ayush and
Singh, Atin and
Modi, Ashutosh",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.306",
pages = "4148--4164",
abstract = "Emotions are an inherent part of human interactions, and consequently, it is imperative to develop AI systems that understand and recognize human emotions. During a conversation involving various people, a person{'}s emotions are influenced by the other speaker{'}s utterances and their own emotional state over the utterances. In this paper, we propose COntextualized Graph Neural Network based Multi- modal Emotion recognitioN (COGMEN) system that leverages local information (i.e., inter/intra dependency between speakers) and global information (context). The proposed model uses Graph Neural Network (GNN) based architecture to model the complex dependencies (local and global information) in a conversation. Our model gives state-of-the- art (SOTA) results on IEMOCAP and MOSEI datasets, and detailed ablation experiments show the importance of modeling information at both levels.",}
## Acknowledgments
The structure of our code is inspired by [pytorch-DialogueGCN-mianzhang](https://github.com/mianzhang/dialogue_gcn).
|
okho0653/Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
|
okho0653
| 2022-08-05T05:29:50Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-05T05:12:27Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-50cad-50noncad-optimal
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 9.8836
- Accuracy: 0.5
- F1: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.2
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
okho0653/Bio_ClinicalBERT-zero-shot-finetuned-all-cad
|
okho0653
| 2022-08-05T04:50:14Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-05T04:33:44Z
|
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Bio_ClinicalBERT-zero-shot-finetuned-all-cad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-all-cad
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
zhiguoxu/chinese-roberta-wwm-ext-finetuned2
|
zhiguoxu
| 2022-08-05T03:45:08Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T07:54:52Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: chinese-roberta-wwm-ext-finetuned2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-roberta-wwm-ext-finetuned2
This model is a fine-tuned version of [hfl/chinese-roberta-wwm-ext](https://huggingface.co/hfl/chinese-roberta-wwm-ext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1448
- Accuracy: 1.0
- F1: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.4081 | 1.0 | 3 | 0.9711 | 0.7273 | 0.6573 |
| 0.9516 | 2.0 | 6 | 0.8174 | 0.8182 | 0.8160 |
| 0.8945 | 3.0 | 9 | 0.6617 | 0.9091 | 0.9124 |
| 0.7042 | 4.0 | 12 | 0.5308 | 1.0 | 1.0 |
| 0.6641 | 5.0 | 15 | 0.4649 | 1.0 | 1.0 |
| 0.5731 | 6.0 | 18 | 0.4046 | 1.0 | 1.0 |
| 0.5132 | 7.0 | 21 | 0.3527 | 1.0 | 1.0 |
| 0.3999 | 8.0 | 24 | 0.3070 | 1.0 | 1.0 |
| 0.4198 | 9.0 | 27 | 0.2673 | 1.0 | 1.0 |
| 0.3677 | 10.0 | 30 | 0.2378 | 1.0 | 1.0 |
| 0.3545 | 11.0 | 33 | 0.2168 | 1.0 | 1.0 |
| 0.3237 | 12.0 | 36 | 0.1980 | 1.0 | 1.0 |
| 0.3122 | 13.0 | 39 | 0.1860 | 1.0 | 1.0 |
| 0.2802 | 14.0 | 42 | 0.1759 | 1.0 | 1.0 |
| 0.2552 | 15.0 | 45 | 0.1671 | 1.0 | 1.0 |
| 0.2475 | 16.0 | 48 | 0.1598 | 1.0 | 1.0 |
| 0.2259 | 17.0 | 51 | 0.1541 | 1.0 | 1.0 |
| 0.201 | 18.0 | 54 | 0.1492 | 1.0 | 1.0 |
| 0.2083 | 19.0 | 57 | 0.1461 | 1.0 | 1.0 |
| 0.2281 | 20.0 | 60 | 0.1448 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0+cu102
- Datasets 2.1.0
- Tokenizers 0.12.1
|
ariesutiono/scibert-lm-v1-finetuned-20
|
ariesutiono
| 2022-08-05T03:07:59Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:conll2003",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-04T01:57:31Z
|
---
tags:
- generated_from_trainer
datasets:
- conll2003
model-index:
- name: scibert-lm-v1-finetuned-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scibert-lm-v1-finetuned-20
This model is a fine-tuned version of [allenai/scibert_scivocab_cased](https://huggingface.co/allenai/scibert_scivocab_cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 22.6145
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.0118 | 1.0 | 1756 | 15.0609 |
| 0.0001 | 2.0 | 3512 | 17.9265 |
| 0.0 | 3.0 | 5268 | 18.6256 |
| 0.0001 | 4.0 | 7024 | 19.5144 |
| 0.0002 | 5.0 | 8780 | 19.8926 |
| 0.0 | 6.0 | 10536 | 21.6975 |
| 0.0 | 7.0 | 12292 | 22.2388 |
| 0.0 | 8.0 | 14048 | 21.0441 |
| 0.0 | 9.0 | 15804 | 21.6852 |
| 0.0 | 10.0 | 17560 | 22.4439 |
| 0.0 | 11.0 | 19316 | 20.9994 |
| 0.0 | 12.0 | 21072 | 21.7275 |
| 0.0 | 13.0 | 22828 | 22.1329 |
| 0.0 | 14.0 | 24584 | 22.4599 |
| 0.0 | 15.0 | 26340 | 22.5726 |
| 0.0 | 16.0 | 28096 | 22.7823 |
| 0.0 | 17.0 | 29852 | 22.4167 |
| 0.0 | 18.0 | 31608 | 22.4075 |
| 0.0 | 19.0 | 33364 | 22.5731 |
| 0.0 | 20.0 | 35120 | 22.6145 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
tals/roberta_python
|
tals
| 2022-08-05T02:30:51Z
| 5
| 2
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"arxiv:2106.05784",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z
|
# roberta_python
---
language: code
datasets:
- code_search_net
- Fraser/python-lines
tags:
- python
- code
- masked-lm
widget:
- text "assert 6 == sum([i for i in range(<mask>)])"
---
# Details
This is a roBERTa-base model trained on the python part of [CodeSearchNet](https://github.com/github/CodeSearchNet) and reached a dev perplexity of 3.296
This model was used for the Programming Puzzles enumerative solver baseline detailed in [Programming Puzzles paper](https://arxiv.org/abs/2106.05784).
See also the [Python Programming Puzzles (P3) Repository](https://github.com/microsoft/PythonProgrammingPuzzles) for more details.
# Usage
You can either load the model and further fine-tune it for a target task (as done for the puzzle solver), or you can experiment with mask-filling directly with this model as in the following example:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline
tokenizer = AutoTokenizer.from_pretrained("tals/roberta_python")
model = AutoModelWithLMHead.from_pretrained("tals/roberta_python")
demo = pipeline("fill-mask", model=model, tokenizer=tokenizer)
code = """sum= 0
for i in range(<mask>):
sum += i
assert sum == 6
"""
demo(code)
```
# BibTeX entry and citation info
```bibtex
@inproceedings{
schuster2021programming,
title={Programming Puzzles},
author={Tal Schuster and Ashwin Kalyan and Alex Polozov and Adam Tauman Kalai},
booktitle={Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1)},
year={2021},
url={https://openreview.net/forum?id=fe_hCc4RBrg}
}
```
|
tals/albert-base-vitaminc_wnei-fever
|
tals
| 2022-08-05T02:25:41Z
| 6
| 1
|
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"dataset:tals/vitaminc",
"dataset:fever",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z
|
---
datasets:
- tals/vitaminc
- fever
---
# Details
Model used in [Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence](https://aclanthology.org/2021.naacl-main.52/) (Schuster et al., NAACL 21`).
For more details see: https://github.com/TalSchuster/VitaminC
When using this model, please cite the paper.
# BibTeX entry and citation info
```bibtex
@inproceedings{schuster-etal-2021-get,
title = "Get Your Vitamin {C}! Robust Fact Verification with Contrastive Evidence",
author = "Schuster, Tal and
Fisch, Adam and
Barzilay, Regina",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.52",
doi = "10.18653/v1/2021.naacl-main.52",
pages = "624--643",
abstract = "Typical fact verification models use retrieved written evidence to verify claims. Evidence sources, however, often change over time as more information is gathered and revised. In order to adapt, models must be sensitive to subtle differences in supporting evidence. We present VitaminC, a benchmark infused with challenging cases that require fact verification models to discern and adjust to slight factual changes. We collect over 100,000 Wikipedia revisions that modify an underlying fact, and leverage these revisions, together with additional synthetically constructed ones, to create a total of over 400,000 claim-evidence pairs. Unlike previous resources, the examples in VitaminC are contrastive, i.e., they contain evidence pairs that are nearly identical in language and content, with the exception that one supports a given claim while the other does not. We show that training using this design increases robustness{---}improving accuracy by 10{\%} on adversarial fact verification and 6{\%} on adversarial natural language inference (NLI). Moreover, the structure of VitaminC leads us to define additional tasks for fact-checking resources: tagging relevant words in the evidence for verifying the claim, identifying factual revisions, and providing automatic edits via factually consistent text generation.",
}
```
|
fzwd6666/NLTBert_multi_fine_tune_new
|
fzwd6666
| 2022-08-05T00:22:54Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-05T00:04:38Z
|
This model is a fine-tuned version of fzwd6666/Ged_bert_new with 4 layers on an NLT dataset. It achieves the following results on the evaluation set:
{'precision': 0.9795081967213115} {'recall': 0.989648033126294} {'f1': 0.984552008238929} {'accuracy': 0.9843227424749164}
Training hyperparameters:
learning_rate: 1e-4
train_batch_size: 8
eval_batch_size: 8
optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
weight_decay= 0.01
lr_scheduler_type: linear
num_epochs: 3
It achieves the following results on the test set:
Incorrect UD Padded:
{'precision': 0.6878048780487804} {'recall': 0.2863913337846987} {'f1': 0.4043977055449331} {'accuracy': 0.4722575180008471}
Incorrect UD Unigram:
{'precision': 0.6348314606741573} {'recall': 0.3060257278266757} {'f1': 0.4129739607126542} {'accuracy': 0.4557390936044049}
Incorrect UD Bigram:
{'precision': 0.6588419405320813} {'recall': 0.28503723764387273} {'f1': 0.3979206049149338} {'accuracy': 0.4603981363828886}
Incorrect UD All:
{'precision': 0.4} {'recall': 0.0013540961408259986} {'f1': 0.002699055330634278} {'accuracy': 0.373994070309191}
Incorrect Sentence:
{'precision': 0.5} {'recall': 0.012186865267433988} {'f1': 0.02379378717779247} {'accuracy': 0.37441761965268955}
|
SharpAI/mal-tls-bert-base-w8a8
|
SharpAI
| 2022-08-04T23:39:11Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-27T21:02:28Z
|
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-base-w8a8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-base-w8a8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
fzwd6666/NLI_new
|
fzwd6666
| 2022-08-04T22:33:38Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T21:42:12Z
|
This model is a fine-tuned version of bert-base-uncased on an NLI dataset. It achieves the following results on the evaluation set:
{'precision': 0.9690210656753407} {'recall': 0.9722337339411521} {'f1': 0.9706247414149772} {'accuracy': 0.9535340314136126}
Training hyperparameters:
learning_rate: 2e-5
train_batch_size: 8
eval_batch_size: 8
optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
weight_decay= 0.01
lr_scheduler_type: linear
num_epochs: 3
It achieves the following results on the test set:
Incorrect UD Padded:
{'precision': 0.623370110330993} {'recall': 0.8415707515233581} {'f1': 0.7162201094785364} {'accuracy': 0.5828038966539602}
Incorrect UD Unigram:
{'precision': 0.6211431461810825} {'recall': 0.8314150304671631} {'f1': 0.7110596409959468} {'accuracy': 0.5772977551884795}
Incorrect UD Bigram:
{'precision': 0.6203980099502487} {'recall': 0.8442789438050101} {'f1': 0.7152279896759391} {'accuracy': 0.579415501905972}
Incorrect UD All:
{'precision': 0.605543710021322} {'recall': 0.1922816519972918} {'f1': 0.2918807810894142} {'accuracy': 0.4163490046590428}
Incorrect Sentence:
{'precision': 0.6411042944785276} {'recall': 0.4245091401489506} {'f1': 0.5107942973523422} {'accuracy': 0.4913172384582804}
|
fzwd6666/Ged_bert_new
|
fzwd6666
| 2022-08-04T22:32:48Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T22:14:19Z
|
This model is a fine-tuned version of bert-base-uncased on an NLI dataset. It achieves the following results on the evaluation set:
{'precision': 0.8384560400285919} {'recall': 0.9536585365853658} {'f1': 0.892354507417269} {'accuracy': 0.8345996493278784}
Training hyperparameters:
learning_rate=2e-5
batch_size=32
epochs = 4
warmup_steps=10% training data number
optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
lr_scheduler_type: linear
|
SharpAI/mal-tls-bert-large-relu-w8a8
|
SharpAI
| 2022-08-04T22:20:15Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T21:31:59Z
|
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-relu-w8a8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-relu-w8a8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
SharpAI/mal-tls-bert-large-w8a8
|
SharpAI
| 2022-08-04T22:03:00Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-27T17:48:37Z
|
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-w8a8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-w8a8
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.15.0
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.10.3
|
SharpAI/mal-tls-bert-large-relu
|
SharpAI
| 2022-08-04T21:41:21Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T17:58:24Z
|
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large-relu
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large-relu
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
SharpAI/mal-tls-bert-large
|
SharpAI
| 2022-08-04T21:04:08Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-07-25T22:26:09Z
|
---
tags:
- generated_from_keras_callback
model-index:
- name: mal-tls-bert-large
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mal-tls-bert-large
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
DOOGLAK/wikigold_trained_no_DA_testing2
|
DOOGLAK
| 2022-08-04T20:30:35Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikigold_splits",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-04T19:39:03Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: wikigold_trained_no_DA_testing2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.8410852713178295
- name: Recall
type: recall
value: 0.84765625
- name: F1
type: f1
value: 0.8443579766536965
- name: Accuracy
type: accuracy
value: 0.9571820972693489
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wikigold_trained_no_DA_testing2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1431
- Precision: 0.8411
- Recall: 0.8477
- F1: 0.8444
- Accuracy: 0.9572
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 167 | 0.1618 | 0.7559 | 0.75 | 0.7529 | 0.9410 |
| No log | 2.0 | 334 | 0.1488 | 0.8384 | 0.8242 | 0.8313 | 0.9530 |
| 0.1589 | 3.0 | 501 | 0.1431 | 0.8411 | 0.8477 | 0.8444 | 0.9572 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
aliprf/ASMNet
|
aliprf
| 2022-08-04T19:48:14Z
| 0
| 1
| null |
[
"cvpr2021",
"computer vision",
"face alignment",
"facial landmark point",
"pose estimation",
"face pose tracking",
"CNN",
"loss",
"custom loss",
"ASMNet",
"Tensor Flow",
"en",
"license:mit",
"region:us"
] | null | 2022-08-04T19:19:41Z
|
---
language: en
tags: [cvpr2021, computer vision, face alignment, facial landmark point, pose estimation, face pose tracking, CNN, loss, custom loss, ASMNet, Tensor Flow]
license: mit
---
[](https://paperswithcode.com/sota/pose-estimation-on-300w-full?p=deep-active-shape-model-for-face-alignment)
[](https://paperswithcode.com/sota/face-alignment-on-wflw?p=deep-active-shape-model-for-face-alignment)
[](https://paperswithcode.com/sota/face-alignment-on-300w?p=deep-active-shape-model-for-face-alignment)
```diff
! plaese STAR the repo if you like it.
```
# [ASMNet](https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en)
## a Lightweight Deep Neural Network for Face Alignment and Pose Estimation
#### Link to the paper:
https://scholar.google.com/scholar?oi=bibs&cluster=3428857185978099736&btnI=1&hl=en
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/asmnet-a-lightweight-deep-neural-network-for
#### Link to the article on Towardsdatascience.com:
https://aliprf.medium.com/asmnet-a-lightweight-deep-neural-network-for-face-alignment-and-pose-estimation-9e9dfac07094
```
Please cite this work as:
@inproceedings{fard2021asmnet,
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1521--1530},
year={2021}
}
```
## Introduction
ASMNet is a lightweight Convolutional Neural Network (CNN) which is designed to perform face alignment and pose estimation efficiently while having acceptable accuracy. ASMNet proposed inspired by MobileNetV2, modified to be suitable for face alignment and pose
estimation, while being about 2 times smaller in terms of number of the parameters. Moreover, Inspired by Active Shape Model (ASM), ASM-assisted loss function is proposed in order to improve the accuracy of facial landmark points detection and pose estimation.
## ASMnet Architecture
Features in a CNN are distributed hierarchically. In other words, the lower layers have features such as edges, and corners which are more suitable for tasks like landmark localization and pose estimation, and deeper layers contain more abstract features that are more suitable for tasks like image classification and image detection. Furthermore, training a network for correlated tasks simultaneously builds a synergy that can improve the performance of each task.
Having said that, we designed ASMNe by fusing the features that are available if different layers of the model. Furthermore, by concatenating the features that are collected after each global average pooling layer in the back-propagation process, it will be possible for the network to evaluate the effect of each shortcut path. Following is the ASMNet architecture:
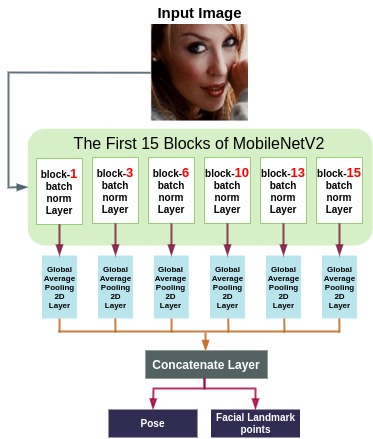
The implementation of ASMNet in TensorFlow is provided in the following path:
https://github.com/aliprf/ASMNet/blob/master/cnn_model.py
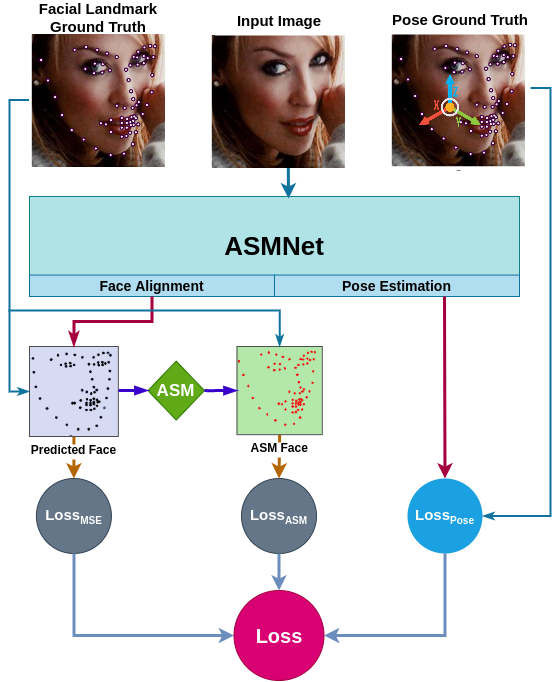
## ASM Loss
We proposed a new loss function called ASM-LOSS which utilizes ASM to improve the accuracy of the network. In other words, during the training process, the loss function compares the predicted facial landmark points with their corresponding ground truth as well as the smoothed version the ground truth which is generated using ASM operator. Accordingly, ASM-LOSS guides the network to first learn the smoothed distribution of the facial landmark points. Then, it leads the network to learn the original landmark points. For more detail please refer to the paper.
Following is the ASM Loss diagram:
## Evaluation
As you can see in the following tables, ASMNet has only 1.4 M parameters which is the smallets comparing to the similar Facial landmark points detection models. Moreover, ASMNet designed to performs Face alignment as well as Pose estimation with a very small CNN while having an acceptable accuracy.

Although ASMNet is much smaller than the state-of-the-art methods on face alignment, it's performance is also very good and acceptable for many real-world applications:
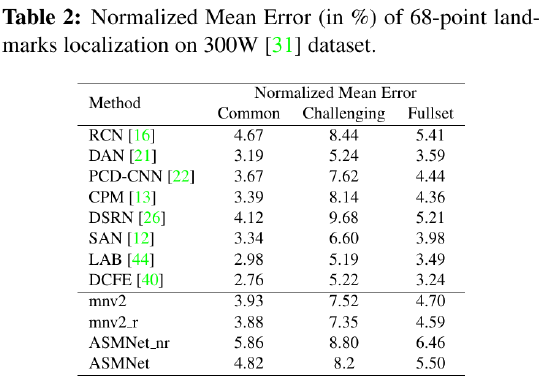
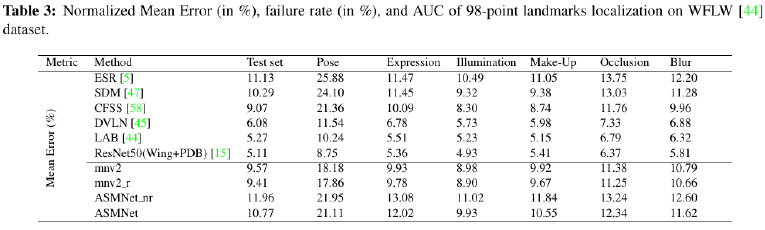
As shown in the following table, ASMNet performs much better that the state-of-the-art models on 300W dataseton Pose estimation task:

Following are some samples in order to show the visual performance of ASMNet on 300W and WFLW datasets:


The visual performance of Pose estimation task using ASMNet is very accurate and the results also are much better than the state-of-the-art pose estimation over 300W dataset:

----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
You can test and use the preetrained models using the following codes which are available in the following file:
https://github.com/aliprf/ASMNet/blob/master/main.py
```
tester = Test()
tester.test_model(ds_name=DatasetName.w300,
pretrained_model_path='./pre_trained_models/ASMNet/ASM_loss/ASMNet_300W_ASMLoss.h5')
```
## Training Network from scratch
### Preparing Data
Data needs to be normalized and saved in npy format.
### PCA creation
you can you the pca_utility.py class to create the eigenvalues, eigenvectors, and the meanvector:
```
pca_calc = PCAUtility()
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
labels_npy_path='./data/w300/normalized_labels/',
pca_percentages=90)
```
### Training
The training implementation is located in train.py class. You can use the following code to start the training:
```
trainer = Train(arch=ModelArch.ASMNet,
dataset_name=DatasetName.w300,
save_path='./',
asm_accuracy=90)
```
Please cite this work as:
@inproceedings{fard2021asmnet,
title={ASMNet: A Lightweight Deep Neural Network for Face Alignment and Pose Estimation},
author={Fard, Ali Pourramezan and Abdollahi, Hojjat and Mahoor, Mohammad},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1521--1530},
year={2021}
}
```diff
@@plaese STAR the repo if you like it.@@
```
|
aliprf/ACR-Loss
|
aliprf
| 2022-08-04T19:47:19Z
| 0
| 0
| null |
[
"ICPR",
"ICPR2022",
"computer vision",
"face alignment",
"facial landmark point",
"CNN",
"loss",
"Tensor Flow",
"en",
"arxiv:2203.15835",
"license:mit",
"region:us"
] | null | 2022-08-04T18:26:32Z
|
---
language: en
tags: [ICPR, ICPR2022, computer vision, face alignment, facial landmark point, CNN, loss, Tensor Flow ]
thumbnail:
license: mit
---
# [ACR-Loss](https://scholar.google.com/citations?view_op=view_citation&hl=en&user=96lS6HIAAAAJ&citation_for_view=96lS6HIAAAAJ:eQOLeE2rZwMC)
### Accepted in ICPR 2022
ACR Loss: Adaptive Coordinate-based Regression Loss for Face Alignment
#### Link to the paper:
https://arxiv.org/pdf/2203.15835.pdf
```diff
@@plaese STAR the repo if you like it.@@
```
```
Please cite this work as:
@article{fard2022acr,
title={ACR Loss: Adaptive Coordinate-based Regression Loss for Face Alignment},
author={Fard, Ali Pourramezan and Mahoor, Mohammah H},
journal={arXiv preprint arXiv:2203.15835},
year={2022}
}
```

## Introduction
Although deep neural networks have achieved reasonable accuracy in solving face alignment, it is still a challenging task, specifically when we deal with facial images, under occlusion, or extreme head poses. Heatmap-based Regression (HBR) and Coordinate-based Regression (CBR) are among the two mainly used methods for face alignment. CBR methods require less computer memory, though their performance is less than HBR methods. In this paper, we propose an Adaptive Coordinatebased Regression (ACR) loss to improve the accuracy of CBR for face alignment. Inspired by the Active Shape Model (ASM), we generate Smooth-Face objects, a set of facial landmark points with less variations compared to the ground truth landmark points. We then introduce a method to estimate the level of difficulty in predicting each landmark point for the network by comparing the distribution of the ground truth landmark points
and the corresponding Smooth-Face objects. Our proposed ACR Loss can adaptively modify its curvature and the influence of the loss based on the difficulty level of predicting each landmark point in a face. Accordingly, the ACR Loss guides the network toward challenging points than easier points, which improves the accuracy of the face alignment task. Our extensive evaluation shows the capabilities of the proposed ACR Loss in predicting facial landmark points in various facial images.
We evaluated our ACR Loss using MobileNetV2, EfficientNetB0, and EfficientNet-B3 on widely used 300W, and COFW datasets and showed that the performance of face alignment using the ACR Loss is much better than the widely-used L2 loss. Moreover, on the COFW dataset, we achieved state-of-theart accuracy. In addition, on 300W the ACR Loss performance is comparable to the state-of-the-art methods. We also compared the performance of MobileNetV2 trained using the ACR Loss with the lightweight state-of-the-art methods, and we achieved the best accuracy, highlighting the effectiveness of our ACR Loss for face alignment specifically for the lightweight models.
----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
You can test and use the preetrained models using the following codes:
```
tester = Test()
tester.test_model(ds_name=DatasetName.w300,
pretrained_model_path='./pre_trained_models/ACRLoss/300w/EF_3/300w_EF3_ACRLoss.h5')
```
## Training Network from scratch
### Preparing Data
Data needs to be normalized and saved in npy format.
### PCA creation
you can you the pca_utility.py class to create the eigenvalues, eigenvectors, and the meanvector:
```
pca_calc = PCAUtility()
pca_calc.create_pca_from_npy(dataset_name=DatasetName.w300,
labels_npy_path='./data/w300/normalized_labels/',
pca_percentages=90)
```
### Training
The training implementation is located in train.py class. You can use the following code to start the training:
```
trainer = Train(arch=ModelArch.MNV2,
dataset_name=DatasetName.w300,
save_path='./')
```
|
aliprf/Ad-Corre
|
aliprf
| 2022-08-04T19:46:42Z
| 0
| 2
| null |
[
"Ad-Corre",
"facial expression recognition",
"emotion recognition",
"expression recognition",
"computer vision",
"CNN",
"loss",
"IEEE Access",
"Tensor Flow",
"en",
"license:mit",
"region:us"
] | null | 2022-08-04T19:11:54Z
|
---
language: en
tags: [Ad-Corre, facial expression recognition, emotion recognition, expression recognition, computer vision, CNN, loss, IEEE Access, Tensor Flow ]
thumbnail:
license: mit
---
# Ad-Corre
Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild
[](https://paperswithcode.com/sota/facial-expression-recognition-on-raf-db?p=ad-corre-adaptive-correlation-based-loss-for)
<!--
[](https://paperswithcode.com/sota/facial-expression-recognition-on-affectnet?p=ad-corre-adaptive-correlation-based-loss-for)
[](https://paperswithcode.com/sota/facial-expression-recognition-on-fer2013?p=ad-corre-adaptive-correlation-based-loss-for)
-->
#### Link to the paper (open access):
https://ieeexplore.ieee.org/document/9727163
#### Link to the paperswithcode.com:
https://paperswithcode.com/paper/ad-corre-adaptive-correlation-based-loss-for
```
Please cite this work as:
@ARTICLE{9727163,
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
journal={IEEE Access},
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
year={2022},
volume={},
number={},
pages={1-1},
doi={10.1109/ACCESS.2022.3156598}}
```
## Introduction
Automated Facial Expression Recognition (FER) in the wild using deep neural networks is still challenging due to intra-class variations and inter-class similarities in facial images. Deep Metric Learning (DML) is among the widely used methods to deal with these issues by improving the discriminative power of the learned embedded features. This paper proposes an Adaptive Correlation (Ad-Corre) Loss to guide the network towards generating embedded feature vectors with high correlation for within-class samples and less correlation for between-class samples. Ad-Corre consists of 3 components called Feature Discriminator, Mean Discriminator, and Embedding Discriminator. We design the Feature Discriminator component to guide the network to create the embedded feature vectors to be highly correlated if they belong to a similar class, and less correlated if they belong to different classes. In addition, the Mean Discriminator component leads the network to make the mean embedded feature vectors of different classes to be less similar to each other.We use Xception network as the backbone of our model, and contrary to previous work, we propose an embedding feature space that contains k feature vectors. Then, the Embedding Discriminator component penalizes the network to generate the embedded feature vectors, which are dissimilar.We trained our model using the combination of our proposed loss functions called Ad-Corre Loss jointly with the cross-entropy loss. We achieved a very promising recognition accuracy on AffectNet, RAF-DB, and FER-2013. Our extensive experiments and ablation study indicate the power of our method to cope well with challenging FER tasks in the wild.
## Evaluation and Samples
The following samples are taken from the paper:
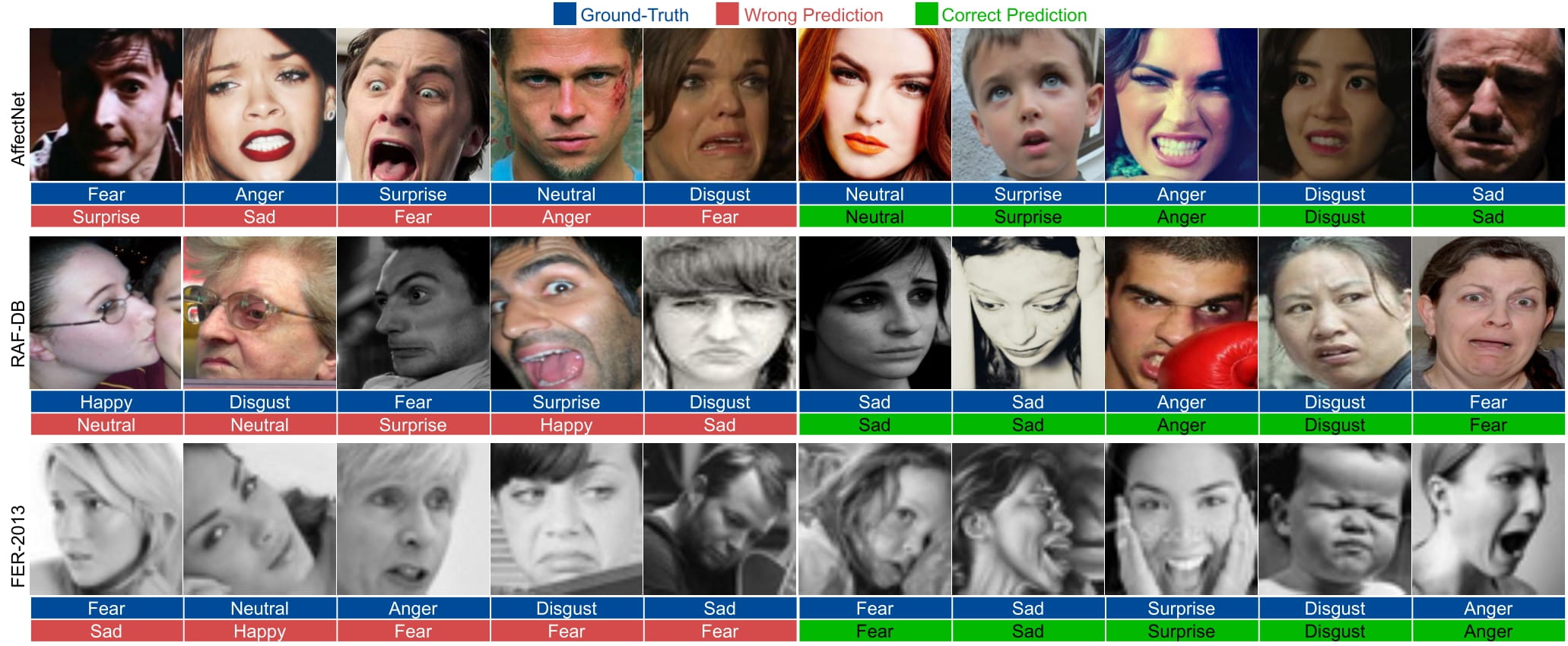
----------------------------------------------------------------------------------------------------------------------------------
## Installing the requirements
In order to run the code you need to install python >= 3.5.
The requirements and the libraries needed to run the code can be installed using the following command:
```
pip install -r requirements.txt
```
## Using the pre-trained models
The pretrained models for Affectnet, RafDB, and Fer2013 are provided in the [Trained_Models](https://github.com/aliprf/Ad-Corre/tree/main/Trained_Models) folder. You can use the following code to predict the facial emotionn of a facial image:
```
tester = TestModels(h5_address='./trained_models/AffectNet_6336.h5')
tester.recognize_fer(img_path='./img.jpg')
```
plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file.
## Training Network from scratch
The information and the code to train the model is provided in train.py .Plaese see the following [main.py](https://github.com/aliprf/Ad-Corre/tree/main/main.py) file:
```
'''training part'''
trainer = TrainModel(dataset_name=DatasetName.affectnet, ds_type=DatasetType.train_7)
trainer.train(arch="xcp", weight_path="./")
```
### Preparing Data
Data needs to be normalized and saved in npy format.
---------------------------------------------------------------
```
Please cite this work as:
@ARTICLE{9727163,
author={Fard, Ali Pourramezan and Mahoor, Mohammad H.},
journal={IEEE Access},
title={Ad-Corre: Adaptive Correlation-Based Loss for Facial Expression Recognition in the Wild},
year={2022},
volume={},
number={},
pages={1-1},
doi={10.1109/ACCESS.2022.3156598}}
```
|
Talha/URDU-ASR
|
Talha
| 2022-08-04T19:27:04Z
| 113
| 0
|
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-03T19:50:46Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2822
- Wer: 0.2423
- Cer: 0.0842
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
I have used dataset other than mozila common voice, thats why for fair evaluation, i do 80:20 split.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 48
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 192
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Cer | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:------:|:---------------:|:------:|
| No log | 1.0 | 174 | 0.9860 | 3.1257 | 1.0 |
| No log | 2.0 | 348 | 0.9404 | 2.4914 | 0.9997 |
| No log | 3.0 | 522 | 0.1889 | 0.5970 | 0.5376 |
| No log | 4.0 | 696 | 0.1428 | 0.4462 | 0.4121 |
| No log | 5.0 | 870 | 0.1211 | 0.3775 | 0.3525 |
| 1.7 | 6.0 | 1044 | 0.1113 | 0.3594 | 0.3264 |
| 1.7 | 7.0 | 1218 | 0.1032 | 0.3354 | 0.3013 |
| 1.7 | 8.0 | 1392 | 0.1005 | 0.3171 | 0.2843 |
| 1.7 | 9.0 | 1566 | 0.0953 | 0.3115 | 0.2717 |
| 1.7 | 10.0 | 1740 | 0.0934 | 0.3058 | 0.2671 |
| 1.7 | 11.0 | 1914 | 0.0926 | 0.3060 | 0.2656 |
| 0.3585 | 12.0 | 2088 | 0.0899 | 0.3070 | 0.2566 |
| 0.3585 | 13.0 | 2262 | 0.0888 | 0.2979 | 0.2509 |
| 0.3585 | 14.0 | 2436 | 0.0868 | 0.3005 | 0.2473 |
| 0.3585 | 15.0 | 2610 | 0.2822 | 0.2423 | 0.0842 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
keepitreal/mini-phobert-v2.1
|
keepitreal
| 2022-08-04T16:42:05Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-04T14:49:57Z
|
---
tags:
- generated_from_trainer
model-index:
- name: mini-phobert-v2.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-phobert-v2.1
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3279
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
dquisi/story_spanish_category
|
dquisi
| 2022-08-04T15:44:12Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-03T20:01:25Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: story_spanish_category
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# story_spanish_category
This model is a fine-tuned version of [datificate/gpt2-small-spanish](https://huggingface.co/datificate/gpt2-small-spanish) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
yukseltron/lyrics-classifier
|
yukseltron
| 2022-08-04T15:42:31Z
| 0
| 0
| null |
[
"tensorboard",
"text-classification",
"lyrics",
"catboost",
"en",
"dataset:data",
"license:gpl-3.0",
"region:us"
] |
text-classification
| 2022-07-28T12:48:01Z
|
---
language:
- en
thumbnail: "http://s4.thingpic.com/images/Yx/zFbS5iJFJMYNxDp9HTR7TQtT.png"
tags:
- text-classification
- lyrics
- catboost
license: gpl-3.0
datasets:
- data
metrics:
- accuracy
widget:
- text: "I know when that hotline bling, that can only mean one thing"
---
# Lyrics Classifier
This submission uses [CatBoost](https://catboost.ai/).
CatBoost was chosen for its listed benefits, mainly in requiring less hyperparameter tuning and preprocessing of categorical and text features. It is also fast and fairly easy to set up.
<img src="http://s4.thingpic.com/images/Yx/zFbS5iJFJMYNxDp9HTR7TQtT.png"
alt="Markdown Monster icon"
style="float: left; margin-right: 10px;" />
|
tj-solergibert/xlm-roberta-base-finetuned-panx-it
|
tj-solergibert
| 2022-08-04T15:36:59Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-04T15:21:38Z
|
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-it
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.it
split: train
args: PAN-X.it
metrics:
- name: F1
type: f1
value: 0.8124233755619126
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2630
- F1: 0.8124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8193 | 1.0 | 70 | 0.3200 | 0.7356 |
| 0.2773 | 2.0 | 140 | 0.2841 | 0.7882 |
| 0.1807 | 3.0 | 210 | 0.2630 | 0.8124 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Jacobsith/autotrain-Hello_there-1209845735
|
Jacobsith
| 2022-08-04T15:30:19Z
| 14
| 0
|
transformers
|
[
"transformers",
"pytorch",
"longt5",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:Jacobsith/autotrain-data-Hello_there",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-08-02T06:38:58Z
|
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain \U0001F917"
datasets:
- Jacobsith/autotrain-data-Hello_there
co2_eq_emissions:
emissions: 3602.3174355473616
model-index:
- name: Jacobsith/autotrain-Hello_there-1209845735
results:
- task:
type: summarization
name: Summarization
dataset:
name: Blaise-g/SumPubmed
type: Blaise-g/SumPubmed
config: Blaise-g--SumPubmed
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 38.2084
verified: true
- name: ROUGE-2
type: rouge
value: 12.4744
verified: true
- name: ROUGE-L
type: rouge
value: 21.5536
verified: true
- name: ROUGE-LSUM
type: rouge
value: 34.229
verified: true
- name: loss
type: loss
value: 2.0952045917510986
verified: true
- name: gen_len
type: gen_len
value: 126.3001
verified: true
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1209845735
- CO2 Emissions (in grams): 3602.3174
## Validation Metrics
- Loss: 2.484
- Rouge1: 38.448
- Rouge2: 10.900
- RougeL: 22.080
- RougeLsum: 33.458
- Gen Len: 115.982
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Jacobsith/autotrain-Hello_there-1209845735
```
|
mindwrapped/collaborative-filtering-movielens-copy
|
mindwrapped
| 2022-08-04T15:17:05Z
| 0
| 1
|
keras
|
[
"keras",
"tensorboard",
"tf-keras",
"collaborative-filtering",
"recommender",
"tabular-classification",
"license:cc0-1.0",
"region:us"
] |
tabular-classification
| 2022-06-08T16:15:46Z
|
---
library_name: keras
tags:
- collaborative-filtering
- recommender
- tabular-classification
license:
- cc0-1.0
---
## Model description
This repo contains the model and the notebook on [how to build and train a Keras model for Collaborative Filtering for Movie Recommendations](https://keras.io/examples/structured_data/collaborative_filtering_movielens/).
Full credits to [Siddhartha Banerjee](https://twitter.com/sidd2006).
## Intended uses & limitations
Based on a user and movies they have rated highly in the past, this model outputs the predicted rating a user would give to a movie they haven't seen yet (between 0-1). This information can be used to find out the top recommended movies for this user.
## Training and evaluation data
The dataset consists of user's ratings on specific movies. It also consists of the movie's specific genres.
## Training procedure
The model was trained for 5 epochs with a batch size of 64.
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Training Metrics
| Epochs | Train Loss | Validation Loss |
|--- |--- |--- |
| 1| 0.637| 0.619|
| 2| 0.614| 0.616|
| 3| 0.609| 0.611|
| 4| 0.608| 0.61|
| 5| 0.608| 0.609|
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
Ilyes/wav2vec2-large-xlsr-53-french
|
Ilyes
| 2022-08-04T14:51:35Z
| 29
| 4
|
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"fr",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:04Z
|
---
language: fr
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-large-xlsr-53-French by Ilyes Rebai
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fr
type: common_voice
args: fr
metrics:
- name: Test WER
type: wer
value: 12.82
---
## Evaluation on Common Voice FR Test
The script used for training and evaluation can be found here: https://github.com/irebai/wav2vec2
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import re
model_name = "Ilyes/wav2vec2-large-xlsr-53-french"
device = "cpu" # "cuda"
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", cache_dir="./data/fr")
chars_to_ignore_regex = '[\,\?\.\!\;\:\"\“\%\‘\”\�\‘\’\’\’\‘\…\·\!\ǃ\?\«\‹\»\›“\”\\ʿ\ʾ\„\∞\\|\.\,\;\:\*\—\–\─\―\_\/\:\ː\;\,\=\«\»\→]'
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
resampler = torchaudio.transforms.Resample(48_000, 16_000)
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
## Results
WER=12.82%
CER=4.40%
|
nikitakapitan/FrozenLake-v2-4x4-Slippery
|
nikitakapitan
| 2022-08-04T14:36:18Z
| 0
| 0
| null |
[
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-07-21T20:31:46Z
|
---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: FrozenLake-v2-4x4-Slippery
results:
- metrics:
- type: mean_reward
value: 0.73 +/- 0.45
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
---
# **Q-Learning** Agent playing **FrozenLake-v2-4x4-Slippery**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v2-4x4-Slippery** .
## Usage
```python
model = load_from_hub(repo_id="nikitakapitan/FrozenLake-v2-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
29thDay/PPO-MountainCar-v0
|
29thDay
| 2022-08-04T14:07:15Z
| 4
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"MountainCar-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-04T12:08:40Z
|
---
library_name: stable-baselines3
tags:
- MountainCar-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: -91.30 +/- 7.04
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
---
# **PPO** Agent playing **MountainCar-v0**
This is a trained model of a **PPO** agent playing **MountainCar-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
schnell/bert-small-ipadic_bpe
|
schnell
| 2022-08-04T13:37:42Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-01T15:40:13Z
|
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-small-ipadic_bpe
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-ipadic_bpe
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6777
- Accuracy: 0.6519
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 256
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 3
- total_train_batch_size: 768
- total_eval_batch_size: 24
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 14
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 2.2548 | 1.0 | 69473 | 2.1163 | 0.5882 |
| 2.0904 | 2.0 | 138946 | 1.9562 | 0.6101 |
| 2.0203 | 3.0 | 208419 | 1.8848 | 0.6208 |
| 1.978 | 4.0 | 277892 | 1.8408 | 0.6272 |
| 1.937 | 5.0 | 347365 | 1.8080 | 0.6320 |
| 1.9152 | 6.0 | 416838 | 1.7818 | 0.6361 |
| 1.8982 | 7.0 | 486311 | 1.7575 | 0.6395 |
| 1.8808 | 8.0 | 555784 | 1.7413 | 0.6421 |
| 1.8684 | 9.0 | 625257 | 1.7282 | 0.6440 |
| 1.8517 | 10.0 | 694730 | 1.7140 | 0.6464 |
| 1.8353 | 11.0 | 764203 | 1.7022 | 0.6481 |
| 1.8245 | 12.0 | 833676 | 1.6877 | 0.6504 |
| 1.8191 | 13.0 | 903149 | 1.6829 | 0.6515 |
| 1.8122 | 14.0 | 972622 | 1.6777 | 0.6519 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.12.0+cu116
- Datasets 2.2.2
- Tokenizers 0.12.1
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_norm1000
|
dminiotas05
| 2022-08-04T13:18:38Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T12:02:33Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_norm1000
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_norm1000
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0875
- Mse: 1.3594
- Mae: 0.5794
- R2: 0.3573
- Accuracy: 0.7015
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:--------:|
| 0.8897 | 1.0 | 3122 | 1.0463 | 1.3078 | 0.5936 | 0.3817 | 0.7008 |
| 0.7312 | 2.0 | 6244 | 1.0870 | 1.3588 | 0.5796 | 0.3576 | 0.7002 |
| 0.5348 | 3.0 | 9366 | 1.1056 | 1.3820 | 0.5786 | 0.3467 | 0.7124 |
| 0.3693 | 4.0 | 12488 | 1.0866 | 1.3582 | 0.5854 | 0.3579 | 0.7053 |
| 0.2848 | 5.0 | 15610 | 1.0875 | 1.3594 | 0.5794 | 0.3573 | 0.7015 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
isaacaderogba/tonality
|
isaacaderogba
| 2022-08-04T12:48:32Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T07:33:36Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: tonality
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tonality
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Rushikesh/distilbert-base-uncased-finetuned-imdb
|
Rushikesh
| 2022-08-04T12:19:18Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-03T18:45:14Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6893
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.099 | 1.0 | 5 | 2.6076 |
| 2.7996 | 2.0 | 10 | 2.5412 |
| 2.7876 | 3.0 | 15 | 2.6641 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
29thDay/PPO-CartPole-v1
|
29thDay
| 2022-08-04T11:17:41Z
| 5
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"CartPole-v1",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T08:41:13Z
|
---
library_name: stable-baselines3
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
---
# **PPO** Agent playing **CartPole-v1**
This is a trained model of a **PPO** agent playing **CartPole-v1**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
masapasa/blurr_IMDB_distilbert_classification
|
masapasa
| 2022-08-04T11:03:15Z
| 0
| 0
|
fastai
|
[
"fastai",
"region:us"
] | null | 2022-08-04T11:01:30Z
|
---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
elopezlopez/Bio_ClinicalBERT_fold_9_binary_v1
|
elopezlopez
| 2022-08-04T10:48:03Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T20:38:00Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_9_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_9_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6976
- F1: 0.8065
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4002 | 0.7826 |
| 0.4094 | 2.0 | 582 | 0.3968 | 0.8212 |
| 0.4094 | 3.0 | 873 | 0.6130 | 0.7984 |
| 0.1977 | 4.0 | 1164 | 0.5853 | 0.8227 |
| 0.1977 | 5.0 | 1455 | 0.9401 | 0.8143 |
| 0.0837 | 6.0 | 1746 | 1.1764 | 0.8059 |
| 0.0274 | 7.0 | 2037 | 1.1515 | 0.8112 |
| 0.0274 | 8.0 | 2328 | 1.2614 | 0.8065 |
| 0.0113 | 9.0 | 2619 | 1.3404 | 0.8002 |
| 0.0113 | 10.0 | 2910 | 1.3926 | 0.8088 |
| 0.0125 | 11.0 | 3201 | 1.4539 | 0.8010 |
| 0.0125 | 12.0 | 3492 | 1.5460 | 0.7998 |
| 0.0101 | 13.0 | 3783 | 1.5920 | 0.8060 |
| 0.0107 | 14.0 | 4074 | 1.5631 | 0.8059 |
| 0.0107 | 15.0 | 4365 | 1.6323 | 0.8020 |
| 0.0127 | 16.0 | 4656 | 1.6183 | 0.8008 |
| 0.0127 | 17.0 | 4947 | 1.6351 | 0.8033 |
| 0.0068 | 18.0 | 5238 | 1.5608 | 0.8121 |
| 0.0047 | 19.0 | 5529 | 1.6339 | 0.8141 |
| 0.0047 | 20.0 | 5820 | 1.6039 | 0.8091 |
| 0.0029 | 21.0 | 6111 | 1.5676 | 0.8085 |
| 0.0029 | 22.0 | 6402 | 1.6489 | 0.8139 |
| 0.0036 | 23.0 | 6693 | 1.6824 | 0.8087 |
| 0.0036 | 24.0 | 6984 | 1.6773 | 0.8106 |
| 0.0008 | 25.0 | 7275 | 1.6976 | 0.8065 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/Bio_ClinicalBERT_fold_8_binary_v1
|
elopezlopez
| 2022-08-04T10:25:37Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T20:12:13Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_8_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_8_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5821
- F1: 0.8265
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.3933 | 0.8222 |
| 0.4092 | 2.0 | 580 | 0.4431 | 0.8237 |
| 0.4092 | 3.0 | 870 | 0.6243 | 0.8292 |
| 0.1845 | 4.0 | 1160 | 0.6526 | 0.8300 |
| 0.1845 | 5.0 | 1450 | 0.9229 | 0.8203 |
| 0.0671 | 6.0 | 1740 | 0.9436 | 0.8279 |
| 0.0303 | 7.0 | 2030 | 1.1281 | 0.8260 |
| 0.0303 | 8.0 | 2320 | 1.1676 | 0.8327 |
| 0.0105 | 9.0 | 2610 | 1.2557 | 0.8291 |
| 0.0105 | 10.0 | 2900 | 1.3556 | 0.8326 |
| 0.0102 | 11.0 | 3190 | 1.3160 | 0.8413 |
| 0.0102 | 12.0 | 3480 | 1.3199 | 0.8344 |
| 0.0068 | 13.0 | 3770 | 1.3827 | 0.8314 |
| 0.0049 | 14.0 | 4060 | 1.5265 | 0.8197 |
| 0.0049 | 15.0 | 4350 | 1.5481 | 0.8215 |
| 0.0069 | 16.0 | 4640 | 1.3824 | 0.8292 |
| 0.0069 | 17.0 | 4930 | 1.4398 | 0.8305 |
| 0.0073 | 18.0 | 5220 | 1.5004 | 0.8255 |
| 0.0033 | 19.0 | 5510 | 1.5322 | 0.8253 |
| 0.0033 | 20.0 | 5800 | 1.5239 | 0.8237 |
| 0.0025 | 21.0 | 6090 | 1.5299 | 0.8286 |
| 0.0025 | 22.0 | 6380 | 1.5788 | 0.8271 |
| 0.0005 | 23.0 | 6670 | 1.5903 | 0.8298 |
| 0.0005 | 24.0 | 6960 | 1.5893 | 0.8232 |
| 0.0026 | 25.0 | 7250 | 1.5821 | 0.8265 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
keepitreal/mini-phobert-v3
|
keepitreal
| 2022-08-04T10:02:44Z
| 7
| 0
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-04T08:08:28Z
|
---
tags:
- generated_from_trainer
model-index:
- name: mini-phobert-v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-phobert-v3
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0510
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Saraswati/Reinforce-CartPole-v1
|
Saraswati
| 2022-08-04T09:09:12Z
| 0
| 0
| null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T12:03:32Z
|
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- metrics:
- type: mean_reward
value: 8.30 +/- 4.96
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_class
|
dminiotas05
| 2022-08-04T08:58:23Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-04T08:18:13Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_class
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_class
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9779
- Accuracy: 0.2357
- F1: 0.2352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 2.034 | 1.0 | 3122 | 1.9454 | 0.2351 | 0.1964 |
| 1.8558 | 2.0 | 6244 | 1.9235 | 0.2377 | 0.2300 |
| 1.6754 | 3.0 | 9366 | 1.9779 | 0.2357 | 0.2352 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/Bio_ClinicalBERT_fold_4_binary_v1
|
elopezlopez
| 2022-08-04T08:55:35Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T18:29:31Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_4_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_4_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4627
- F1: 0.8342
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.3641 | 0.8394 |
| 0.3953 | 2.0 | 578 | 0.3729 | 0.8294 |
| 0.3953 | 3.0 | 867 | 0.6156 | 0.8126 |
| 0.189 | 4.0 | 1156 | 0.7389 | 0.8326 |
| 0.189 | 5.0 | 1445 | 0.8925 | 0.8322 |
| 0.0783 | 6.0 | 1734 | 1.0909 | 0.8196 |
| 0.0219 | 7.0 | 2023 | 1.1241 | 0.8346 |
| 0.0219 | 8.0 | 2312 | 1.2684 | 0.8130 |
| 0.0136 | 9.0 | 2601 | 1.2615 | 0.8202 |
| 0.0136 | 10.0 | 2890 | 1.2477 | 0.8401 |
| 0.0143 | 11.0 | 3179 | 1.3211 | 0.8254 |
| 0.0143 | 12.0 | 3468 | 1.2627 | 0.8286 |
| 0.0165 | 13.0 | 3757 | 1.3804 | 0.8264 |
| 0.006 | 14.0 | 4046 | 1.3213 | 0.8414 |
| 0.006 | 15.0 | 4335 | 1.3152 | 0.8427 |
| 0.0117 | 16.0 | 4624 | 1.3373 | 0.8368 |
| 0.0117 | 17.0 | 4913 | 1.3599 | 0.8406 |
| 0.0021 | 18.0 | 5202 | 1.4072 | 0.8237 |
| 0.0021 | 19.0 | 5491 | 1.3893 | 0.8336 |
| 0.0045 | 20.0 | 5780 | 1.4331 | 0.8391 |
| 0.0049 | 21.0 | 6069 | 1.4128 | 0.8370 |
| 0.0049 | 22.0 | 6358 | 1.4660 | 0.8356 |
| 0.0029 | 23.0 | 6647 | 1.4721 | 0.8388 |
| 0.0029 | 24.0 | 6936 | 1.4636 | 0.8329 |
| 0.0023 | 25.0 | 7225 | 1.4627 | 0.8342 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/Bio_ClinicalBERT_fold_3_binary_v1
|
elopezlopez
| 2022-08-04T08:33:05Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T18:03:57Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Bio_ClinicalBERT_fold_3_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT_fold_3_binary_v1
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8860
- F1: 0.8051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.4493 | 0.7916 |
| 0.3975 | 2.0 | 578 | 0.4608 | 0.7909 |
| 0.3975 | 3.0 | 867 | 0.8364 | 0.7726 |
| 0.1885 | 4.0 | 1156 | 1.0380 | 0.7902 |
| 0.1885 | 5.0 | 1445 | 1.1612 | 0.7921 |
| 0.0692 | 6.0 | 1734 | 1.3894 | 0.7761 |
| 0.0295 | 7.0 | 2023 | 1.3730 | 0.7864 |
| 0.0295 | 8.0 | 2312 | 1.4131 | 0.7939 |
| 0.0161 | 9.0 | 2601 | 1.5538 | 0.7929 |
| 0.0161 | 10.0 | 2890 | 1.6417 | 0.7931 |
| 0.006 | 11.0 | 3179 | 1.5745 | 0.7974 |
| 0.006 | 12.0 | 3468 | 1.7212 | 0.7908 |
| 0.0132 | 13.0 | 3757 | 1.7349 | 0.7945 |
| 0.0062 | 14.0 | 4046 | 1.7593 | 0.7908 |
| 0.0062 | 15.0 | 4335 | 1.7420 | 0.8035 |
| 0.0073 | 16.0 | 4624 | 1.7620 | 0.8007 |
| 0.0073 | 17.0 | 4913 | 1.8286 | 0.7908 |
| 0.0033 | 18.0 | 5202 | 1.7863 | 0.7977 |
| 0.0033 | 19.0 | 5491 | 1.9275 | 0.7919 |
| 0.0035 | 20.0 | 5780 | 1.8481 | 0.8042 |
| 0.0035 | 21.0 | 6069 | 1.9465 | 0.8012 |
| 0.0035 | 22.0 | 6358 | 1.8177 | 0.8044 |
| 0.005 | 23.0 | 6647 | 1.8615 | 0.8030 |
| 0.005 | 24.0 | 6936 | 1.8427 | 0.8054 |
| 0.0011 | 25.0 | 7225 | 1.8860 | 0.8051 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
KaranChand/wav2vec2-XLSR-ft-10
|
KaranChand
| 2022-08-04T08:13:15Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-08-04T07:37:17Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-XLSR-ft-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-XLSR-ft-10
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 6
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
FluxML/densenet121
|
FluxML
| 2022-08-04T06:39:56Z
| 0
| 0
| null |
[
"license:mit",
"region:us"
] | null | 2022-08-04T06:12:25Z
|
---
license: mit
---
DenseNet121 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(121; pretrain = true)
```
|
FluxML/densenet161
|
FluxML
| 2022-08-04T06:39:41Z
| 0
| 0
| null |
[
"license:mit",
"region:us"
] | null | 2022-08-04T06:16:19Z
|
---
license: mit
---
DenseNet161 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(161; pretrain = true)
```
|
FluxML/densenet169
|
FluxML
| 2022-08-04T06:39:26Z
| 0
| 0
| null |
[
"license:mit",
"region:us"
] | null | 2022-08-04T06:20:00Z
|
---
license: mit
---
DenseNet169 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(169; pretrain = true)
```
|
FluxML/densenet201
|
FluxML
| 2022-08-04T06:33:40Z
| 0
| 0
| null |
[
"license:mit",
"region:us"
] | null | 2022-08-04T06:22:23Z
|
---
license: mit
---
DenseNet201 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = DenseNet(201; pretrain = true)
```
|
BekirTaha/testpyramidsrnd
|
BekirTaha
| 2022-08-04T06:26:32Z
| 2
| 0
|
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2022-08-03T12:55:41Z
|
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: BekirTaha/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
bash1130/bert-base-finetuned-ynat
|
bash1130
| 2022-08-04T06:19:20Z
| 20
| 1
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:klue",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T19:50:38Z
|
---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- f1
model-index:
- name: bert-base-finetuned-ynat
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
config: ynat
split: train
args: ynat
metrics:
- name: F1
type: f1
value: 0.871180664370084
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-finetuned-ynat
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3609
- F1: 0.8712
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 179 | 0.3979 | 0.8611 |
| No log | 2.0 | 358 | 0.3773 | 0.8669 |
| 0.3007 | 3.0 | 537 | 0.3609 | 0.8712 |
| 0.3007 | 4.0 | 716 | 0.3708 | 0.8708 |
| 0.3007 | 5.0 | 895 | 0.3720 | 0.8697 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
srivatsavaasista/textgenerator
|
srivatsavaasista
| 2022-08-04T05:40:30Z
| 28
| 0
|
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-07-27T09:12:36Z
|
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: textgenerator
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# textgenerator
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 6.4579
- Validation Loss: 6.4893
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 398, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.5475 | 6.4893 | 0 |
| 6.4577 | 6.4893 | 1 |
| 6.4579 | 6.4893 | 2 |
### Framework versions
- Transformers 4.21.0
- TensorFlow 2.8.2
- Datasets 2.4.0
- Tokenizers 0.12.1
|
keepitreal/mini-phobert-v2
|
keepitreal
| 2022-08-04T04:42:30Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-03T20:07:20Z
|
---
tags:
- generated_from_trainer
model-index:
- name: mini-phobert-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mini-phobert-v2
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.3293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/wikigold_trained_no_DA_small
|
DOOGLAK
| 2022-08-04T03:56:36Z
| 7
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikigold_splits",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-04T00:47:48Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: wikigold_trained_no_DA_small
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.34285714285714286
- name: Recall
type: recall
value: 0.5454545454545454
- name: F1
type: f1
value: 0.42105263157894735
- name: Accuracy
type: accuracy
value: 0.853035143769968
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wikigold_trained_no_DA_small
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6066
- Precision: 0.3429
- Recall: 0.5455
- F1: 0.4211
- Accuracy: 0.8530
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 32
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 9 | 0.8525 | 0.0 | 0.0 | 0.0 | 0.7604 |
| No log | 2.0 | 18 | 0.7135 | 0.0 | 0.0 | 0.0 | 0.7604 |
| No log | 3.0 | 27 | 0.5972 | 0.1579 | 0.1364 | 0.1463 | 0.7923 |
| No log | 4.0 | 36 | 0.5108 | 0.0769 | 0.0909 | 0.0833 | 0.8083 |
| No log | 5.0 | 45 | 0.4725 | 0.2333 | 0.3182 | 0.2692 | 0.8466 |
| No log | 6.0 | 54 | 0.4569 | 0.2333 | 0.3182 | 0.2692 | 0.8339 |
| No log | 7.0 | 63 | 0.4428 | 0.2258 | 0.3182 | 0.2642 | 0.8371 |
| No log | 8.0 | 72 | 0.4362 | 0.2121 | 0.3182 | 0.2545 | 0.8435 |
| No log | 9.0 | 81 | 0.4509 | 0.2258 | 0.3182 | 0.2642 | 0.8403 |
| No log | 10.0 | 90 | 0.4614 | 0.2121 | 0.3182 | 0.2545 | 0.8466 |
| No log | 11.0 | 99 | 0.4546 | 0.2188 | 0.3182 | 0.2593 | 0.8435 |
| No log | 12.0 | 108 | 0.4734 | 0.2188 | 0.3182 | 0.2593 | 0.8435 |
| No log | 13.0 | 117 | 0.5098 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 14.0 | 126 | 0.5280 | 0.2258 | 0.3182 | 0.2642 | 0.8435 |
| No log | 15.0 | 135 | 0.5264 | 0.2188 | 0.3182 | 0.2593 | 0.8435 |
| No log | 16.0 | 144 | 0.5317 | 0.2727 | 0.4091 | 0.3273 | 0.8498 |
| No log | 17.0 | 153 | 0.5414 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 18.0 | 162 | 0.5505 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 19.0 | 171 | 0.5521 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 20.0 | 180 | 0.5627 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 21.0 | 189 | 0.5687 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 22.0 | 198 | 0.5751 | 0.2581 | 0.3636 | 0.3019 | 0.8466 |
| No log | 23.0 | 207 | 0.5825 | 0.2727 | 0.4091 | 0.3273 | 0.8498 |
| No log | 24.0 | 216 | 0.5881 | 0.2727 | 0.4091 | 0.3273 | 0.8498 |
| No log | 25.0 | 225 | 0.5930 | 0.2727 | 0.4091 | 0.3273 | 0.8498 |
| No log | 26.0 | 234 | 0.5969 | 0.2727 | 0.4091 | 0.3273 | 0.8498 |
| No log | 27.0 | 243 | 0.5995 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
| No log | 28.0 | 252 | 0.6017 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
| No log | 29.0 | 261 | 0.6035 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
| No log | 30.0 | 270 | 0.6053 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
| No log | 31.0 | 279 | 0.6063 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
| No log | 32.0 | 288 | 0.6066 | 0.3429 | 0.5455 | 0.4211 | 0.8530 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
RayS2022/dqn-SpaceInvadersNoFrameskip-v4
|
RayS2022
| 2022-08-04T03:16:30Z
| 7
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-04T03:16:11Z
|
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 138.50 +/- 87.49
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga RayS2022 -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga RayS2022
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
yashwantk/distilbert-base-cased-distilled-squad-finetuned-squad
|
yashwantk
| 2022-08-04T02:42:07Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2_yash",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-02T10:29:22Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2_yash
model-index:
- name: distilbert-base-cased-distilled-squad-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-distilled-squad-finetuned-squad
This model is a fine-tuned version of [distilbert-base-cased-distilled-squad](https://huggingface.co/distilbert-base-cased-distilled-squad) on the squad_v2_yash dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 198 | 0.7576 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
canIjoin/datafun
|
canIjoin
| 2022-08-04T02:29:03Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"zh",
"arxiv:1810.04805",
"arxiv:1907.11692",
"arxiv:2001.04351",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-03T13:10:26Z
|
---
language: zh
widget:
- text: "江苏警方通报特斯拉冲进店铺"
---
# Chinese RoBERTa-Base Model for NER
## Model description
The model is used for named entity recognition. You can download the model either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo) (in UER-py format), or via HuggingFace from the link [roberta-base-finetuned-cluener2020-chinese](https://huggingface.co/uer/roberta-base-finetuned-cluener2020-chinese).
## How to use
You can use this model directly with a pipeline for token classification :
```python
>>> from transformers import AutoModelForTokenClassification,AutoTokenizer,pipeline
>>> model = AutoModelForTokenClassification.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-cluener2020-chinese')
>>> ner = pipeline('ner', model=model, tokenizer=tokenizer)
>>> ner("江苏警方通报特斯拉冲进店铺")
[
{'word': '江', 'score': 0.49153077602386475, 'entity': 'B-address', 'index': 1, 'start': 0, 'end': 1},
{'word': '苏', 'score': 0.6319217681884766, 'entity': 'I-address', 'index': 2, 'start': 1, 'end': 2},
{'word': '特', 'score': 0.5912262797355652, 'entity': 'B-company', 'index': 7, 'start': 6, 'end': 7},
{'word': '斯', 'score': 0.69145667552948, 'entity': 'I-company', 'index': 8, 'start': 7, 'end': 8},
{'word': '拉', 'score': 0.7054660320281982, 'entity': 'I-company', 'index': 9, 'start': 8, 'end': 9}
]
```
## Training data
[CLUENER2020](https://github.com/CLUEbenchmark/CLUENER2020) is used as training data. We only use the train set of the dataset.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 512 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 run_ner.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--train_path datasets/cluener2020/train.tsv \
--dev_path datasets/cluener2020/dev.tsv \
--label2id_path datasets/cluener2020/label2id.json \
--output_model_path models/cluener2020_ner_model.bin \
--learning_rate 3e-5 --epochs_num 5 --batch_size 32 --seq_length 512
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_token_classification_from_uer_to_huggingface.py --input_model_path models/cluener2020_ner_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{xu2020cluener2020,
title={CLUENER2020: Fine-grained Name Entity Recognition for Chinese},
author={Xu, Liang and Dong, Qianqian and Yu, Cong and Tian, Yin and Liu, Weitang and Li, Lu and Zhang, Xuanwei},
journal={arXiv preprint arXiv:2001.04351},
year={2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
|
jerryw/my_bert-base-cased
|
jerryw
| 2022-08-04T01:38:04Z
| 5
| 0
|
transformers
|
[
"transformers",
"tf",
"bert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-04T01:34:19Z
|
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: my_bert-base-cased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# my_bert-base-cased
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
khabiri/test_keras_model_elham
|
khabiri
| 2022-08-03T22:23:45Z
| 0
| 0
|
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2022-08-03T22:23:36Z
|
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| learning_rate | 0.0010000000474974513 |
| decay | 0.0 |
| beta_1 | 0.8999999761581421 |
| beta_2 | 0.9990000128746033 |
| epsilon | 1e-07 |
| amsgrad | False |
| training_precision | float32 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
huggingtweets/elonmusk-srinithyananda-yeshuaissavior
|
huggingtweets
| 2022-08-03T22:10:12Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-03T21:57:09Z
|
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1552061223864127488/Y-7S0UTB_400x400.png')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1529956155937759233/Nyn1HZWF_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1157286539036020737/5TQyrkEw_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Feather of the One & Elon Musk & KAILASA's SPH Nithyananda</div>
<div style="text-align: center; font-size: 14px;">@elonmusk-srinithyananda-yeshuaissavior</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Feather of the One & Elon Musk & KAILASA's SPH Nithyananda.
| Data | Feather of the One | Elon Musk | KAILASA's SPH Nithyananda |
| --- | --- | --- | --- |
| Tweets downloaded | 505 | 3200 | 3250 |
| Retweets | 29 | 128 | 6 |
| Short tweets | 175 | 982 | 523 |
| Tweets kept | 301 | 2090 | 2721 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1wthdqz7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @elonmusk-srinithyananda-yeshuaissavior's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/18cn8xoz) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/18cn8xoz/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/elonmusk-srinithyananda-yeshuaissavior')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
RayS2022/q-Taxi-v3
|
RayS2022
| 2022-08-03T20:58:23Z
| 0
| 0
| null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T20:58:15Z
|
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="RayS2022/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
andrewzhang505/sample-factory-2-doom-battle
|
andrewzhang505
| 2022-08-03T20:49:22Z
| 7
| 0
|
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-07-29T16:53:16Z
|
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 56.20 +/- 6.72
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_battle
type: doom_battle
---
A(n) **APPO** model trained on the **doom_battle** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
RayS2022/q-FrozenLake-v1-4x4-noSlippery
|
RayS2022
| 2022-08-03T20:47:10Z
| 0
| 0
| null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T20:47:04Z
|
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="RayS2022/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
andrewzhang505/sample-factory-2-doom-battle2
|
andrewzhang505
| 2022-08-03T20:42:10Z
| 13
| 0
|
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-02T16:33:35Z
|
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- metrics:
- type: mean_reward
value: 32.93 +/- 5.44
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_battle2
type: doom_battle2
---
A(n) **APPO** model trained on the **doom_battle2** environment.
This model was trained using Sample Factory 2.0: https://github.com/alex-petrenko/sample-factory
|
yasnunsal/distilbert-base-uncased-finetuned-emotion
|
yasnunsal
| 2022-08-03T18:32:09Z
| 7
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T15:08:09Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
BenWord/autotrain-APMv2Multiclass-1216046004
|
BenWord
| 2022-08-03T18:06:06Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"en",
"dataset:BenWord/autotrain-data-APMv2Multiclass",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T18:03:06Z
|
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- BenWord/autotrain-data-APMv2Multiclass
co2_eq_emissions:
emissions: 2.4364900803769225
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1216046004
- CO2 Emissions (in grams): 2.4365
## Validation Metrics
- Loss: 0.094
- Accuracy: 1.000
- Macro F1: 1.000
- Micro F1: 1.000
- Weighted F1: 1.000
- Macro Precision: 1.000
- Micro Precision: 1.000
- Weighted Precision: 1.000
- Macro Recall: 1.000
- Micro Recall: 1.000
- Weighted Recall: 1.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/BenWord/autotrain-APMv2Multiclass-1216046004
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("BenWord/autotrain-APMv2Multiclass-1216046004", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
NitishKarra/layoutlmv3-finetuned-wildreceipt
|
NitishKarra
| 2022-08-03T17:44:41Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:wildreceipt",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-03T16:06:42Z
|
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- wildreceipt
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-wildreceipt
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wildreceipt
type: wildreceipt
config: WildReceipt
split: train
args: WildReceipt
metrics:
- name: Precision
type: precision
value: 0.8693453601202679
- name: Recall
type: recall
value: 0.8753268198706481
- name: F1
type: f1
value: 0.872325836533187
- name: Accuracy
type: accuracy
value: 0.9240429965997587
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-wildreceipt
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the wildreceipt dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3154
- Precision: 0.8693
- Recall: 0.8753
- F1: 0.8723
- Accuracy: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.32 | 100 | 1.3618 | 0.6375 | 0.3049 | 0.4125 | 0.6708 |
| No log | 0.63 | 200 | 0.9129 | 0.6662 | 0.4897 | 0.5645 | 0.7631 |
| No log | 0.95 | 300 | 0.6800 | 0.7273 | 0.6375 | 0.6795 | 0.8274 |
| No log | 1.26 | 400 | 0.5733 | 0.7579 | 0.6926 | 0.7238 | 0.8501 |
| 1.0638 | 1.58 | 500 | 0.5015 | 0.7854 | 0.7383 | 0.7611 | 0.8667 |
| 1.0638 | 1.89 | 600 | 0.4501 | 0.7916 | 0.7680 | 0.7796 | 0.8770 |
| 1.0638 | 2.21 | 700 | 0.4145 | 0.8177 | 0.8053 | 0.8114 | 0.8917 |
| 1.0638 | 2.52 | 800 | 0.3835 | 0.8214 | 0.8210 | 0.8212 | 0.8961 |
| 1.0638 | 2.84 | 900 | 0.3666 | 0.8251 | 0.8338 | 0.8294 | 0.9009 |
| 0.423 | 3.15 | 1000 | 0.3524 | 0.8485 | 0.8217 | 0.8349 | 0.9026 |
| 0.423 | 3.47 | 1100 | 0.3451 | 0.8430 | 0.8327 | 0.8378 | 0.9060 |
| 0.423 | 3.79 | 1200 | 0.3348 | 0.8347 | 0.8504 | 0.8425 | 0.9092 |
| 0.423 | 4.1 | 1300 | 0.3331 | 0.8368 | 0.8448 | 0.8408 | 0.9079 |
| 0.423 | 4.42 | 1400 | 0.3163 | 0.8503 | 0.8519 | 0.8511 | 0.9138 |
| 0.2822 | 4.73 | 1500 | 0.3168 | 0.8531 | 0.8504 | 0.8518 | 0.9133 |
| 0.2822 | 5.05 | 1600 | 0.3013 | 0.8629 | 0.8577 | 0.8603 | 0.9183 |
| 0.2822 | 5.36 | 1700 | 0.3146 | 0.8619 | 0.8528 | 0.8573 | 0.9160 |
| 0.2822 | 5.68 | 1800 | 0.3121 | 0.8474 | 0.8638 | 0.8555 | 0.9159 |
| 0.2822 | 5.99 | 1900 | 0.3054 | 0.8537 | 0.8667 | 0.8601 | 0.9166 |
| 0.2176 | 6.31 | 2000 | 0.3127 | 0.8556 | 0.8592 | 0.8574 | 0.9167 |
| 0.2176 | 6.62 | 2100 | 0.3072 | 0.8568 | 0.8667 | 0.8617 | 0.9194 |
| 0.2176 | 6.94 | 2200 | 0.2989 | 0.8617 | 0.8660 | 0.8638 | 0.9209 |
| 0.2176 | 7.26 | 2300 | 0.2997 | 0.8616 | 0.8682 | 0.8649 | 0.9199 |
| 0.2176 | 7.57 | 2400 | 0.3100 | 0.8538 | 0.8689 | 0.8613 | 0.9191 |
| 0.1777 | 7.89 | 2500 | 0.3022 | 0.8649 | 0.8695 | 0.8672 | 0.9228 |
| 0.1777 | 8.2 | 2600 | 0.2990 | 0.8631 | 0.8740 | 0.8685 | 0.9224 |
| 0.1777 | 8.52 | 2700 | 0.3072 | 0.8669 | 0.8697 | 0.8683 | 0.9228 |
| 0.1777 | 8.83 | 2800 | 0.3038 | 0.8689 | 0.8720 | 0.8705 | 0.9238 |
| 0.1777 | 9.15 | 2900 | 0.3138 | 0.8726 | 0.8673 | 0.8700 | 0.9216 |
| 0.1434 | 9.46 | 3000 | 0.3150 | 0.8610 | 0.8740 | 0.8674 | 0.9221 |
| 0.1434 | 9.78 | 3100 | 0.3055 | 0.8674 | 0.8742 | 0.8708 | 0.9239 |
| 0.1434 | 10.09 | 3200 | 0.3182 | 0.8618 | 0.8724 | 0.8671 | 0.9215 |
| 0.1434 | 10.41 | 3300 | 0.3175 | 0.8633 | 0.8727 | 0.8680 | 0.9223 |
| 0.1434 | 10.73 | 3400 | 0.3146 | 0.8685 | 0.8717 | 0.8701 | 0.9234 |
| 0.1282 | 11.04 | 3500 | 0.3136 | 0.8671 | 0.8757 | 0.8714 | 0.9233 |
| 0.1282 | 11.36 | 3600 | 0.3186 | 0.8679 | 0.8734 | 0.8706 | 0.9225 |
| 0.1282 | 11.67 | 3700 | 0.3147 | 0.8701 | 0.8745 | 0.8723 | 0.9238 |
| 0.1282 | 11.99 | 3800 | 0.3159 | 0.8705 | 0.8759 | 0.8732 | 0.9244 |
| 0.1282 | 12.3 | 3900 | 0.3147 | 0.8699 | 0.8748 | 0.8723 | 0.9246 |
| 0.1121 | 12.62 | 4000 | 0.3154 | 0.8693 | 0.8753 | 0.8723 | 0.9240 |
### Framework versions
- Transformers 4.22.0.dev0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
MayaGalvez/bert-base-multilingual-cased-finetuned-nli
|
MayaGalvez
| 2022-08-03T16:48:33Z
| 18
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:xnli",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T11:58:59Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xnli
metrics:
- accuracy
model-index:
- name: bert-base-multilingual-cased-finetuned-nli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: xnli
type: xnli
config: en
split: train
args: en
metrics:
- name: Accuracy
type: accuracy
value: 0.8156626506024096
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-nli
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the xnli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4681
- Accuracy: 0.8157
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.9299 | 0.02 | 200 | 0.8468 | 0.6277 |
| 0.7967 | 0.03 | 400 | 0.7425 | 0.6855 |
| 0.7497 | 0.05 | 600 | 0.7116 | 0.6924 |
| 0.7083 | 0.07 | 800 | 0.6868 | 0.7153 |
| 0.6882 | 0.08 | 1000 | 0.6638 | 0.7289 |
| 0.6944 | 0.1 | 1200 | 0.6476 | 0.7361 |
| 0.6682 | 0.11 | 1400 | 0.6364 | 0.7458 |
| 0.6635 | 0.13 | 1600 | 0.6592 | 0.7337 |
| 0.6423 | 0.15 | 1800 | 0.6120 | 0.7510 |
| 0.6196 | 0.16 | 2000 | 0.5990 | 0.7582 |
| 0.6381 | 0.18 | 2200 | 0.6026 | 0.7538 |
| 0.6276 | 0.2 | 2400 | 0.6054 | 0.7598 |
| 0.6248 | 0.21 | 2600 | 0.6368 | 0.7526 |
| 0.6331 | 0.23 | 2800 | 0.5959 | 0.7655 |
| 0.6142 | 0.24 | 3000 | 0.6117 | 0.7554 |
| 0.6124 | 0.26 | 3200 | 0.6221 | 0.7570 |
| 0.6127 | 0.28 | 3400 | 0.5748 | 0.7695 |
| 0.602 | 0.29 | 3600 | 0.5735 | 0.7598 |
| 0.5923 | 0.31 | 3800 | 0.5609 | 0.7723 |
| 0.5827 | 0.33 | 4000 | 0.5635 | 0.7743 |
| 0.5732 | 0.34 | 4200 | 0.5547 | 0.7771 |
| 0.5757 | 0.36 | 4400 | 0.5629 | 0.7739 |
| 0.5736 | 0.37 | 4600 | 0.5680 | 0.7659 |
| 0.5642 | 0.39 | 4800 | 0.5437 | 0.7871 |
| 0.5763 | 0.41 | 5000 | 0.5589 | 0.7807 |
| 0.5713 | 0.42 | 5200 | 0.5355 | 0.7867 |
| 0.5644 | 0.44 | 5400 | 0.5346 | 0.7888 |
| 0.5727 | 0.46 | 5600 | 0.5519 | 0.7815 |
| 0.5539 | 0.47 | 5800 | 0.5219 | 0.7900 |
| 0.5516 | 0.49 | 6000 | 0.5560 | 0.7795 |
| 0.5539 | 0.51 | 6200 | 0.5544 | 0.7847 |
| 0.5693 | 0.52 | 6400 | 0.5322 | 0.7932 |
| 0.5632 | 0.54 | 6600 | 0.5404 | 0.7936 |
| 0.565 | 0.55 | 6800 | 0.5382 | 0.7880 |
| 0.5555 | 0.57 | 7000 | 0.5364 | 0.7920 |
| 0.5329 | 0.59 | 7200 | 0.5177 | 0.7964 |
| 0.54 | 0.6 | 7400 | 0.5286 | 0.7916 |
| 0.554 | 0.62 | 7600 | 0.5401 | 0.7835 |
| 0.5447 | 0.64 | 7800 | 0.5261 | 0.7876 |
| 0.5438 | 0.65 | 8000 | 0.5032 | 0.8020 |
| 0.5505 | 0.67 | 8200 | 0.5220 | 0.7924 |
| 0.5364 | 0.68 | 8400 | 0.5398 | 0.7876 |
| 0.5317 | 0.7 | 8600 | 0.5310 | 0.7944 |
| 0.5361 | 0.72 | 8800 | 0.5297 | 0.7936 |
| 0.5204 | 0.73 | 9000 | 0.5270 | 0.7940 |
| 0.5189 | 0.75 | 9200 | 0.5193 | 0.7964 |
| 0.5348 | 0.77 | 9400 | 0.5270 | 0.7867 |
| 0.5363 | 0.78 | 9600 | 0.5194 | 0.7924 |
| 0.5184 | 0.8 | 9800 | 0.5298 | 0.7888 |
| 0.5072 | 0.81 | 10000 | 0.4999 | 0.7992 |
| 0.5229 | 0.83 | 10200 | 0.4922 | 0.8108 |
| 0.5201 | 0.85 | 10400 | 0.5019 | 0.7920 |
| 0.5304 | 0.86 | 10600 | 0.4959 | 0.7992 |
| 0.5061 | 0.88 | 10800 | 0.5047 | 0.7980 |
| 0.5291 | 0.9 | 11000 | 0.4974 | 0.8068 |
| 0.5099 | 0.91 | 11200 | 0.4988 | 0.8036 |
| 0.5271 | 0.93 | 11400 | 0.4899 | 0.8028 |
| 0.5211 | 0.95 | 11600 | 0.4866 | 0.8092 |
| 0.4977 | 0.96 | 11800 | 0.5059 | 0.7960 |
| 0.5155 | 0.98 | 12000 | 0.4821 | 0.8084 |
| 0.5061 | 0.99 | 12200 | 0.4763 | 0.8116 |
| 0.4607 | 1.01 | 12400 | 0.5245 | 0.8020 |
| 0.4435 | 1.03 | 12600 | 0.5021 | 0.8032 |
| 0.4289 | 1.04 | 12800 | 0.5219 | 0.8060 |
| 0.4227 | 1.06 | 13000 | 0.5119 | 0.8076 |
| 0.4349 | 1.08 | 13200 | 0.4957 | 0.8104 |
| 0.4331 | 1.09 | 13400 | 0.4914 | 0.8129 |
| 0.4269 | 1.11 | 13600 | 0.4785 | 0.8145 |
| 0.4185 | 1.12 | 13800 | 0.4879 | 0.8161 |
| 0.4244 | 1.14 | 14000 | 0.4834 | 0.8149 |
| 0.4016 | 1.16 | 14200 | 0.5084 | 0.8056 |
| 0.4106 | 1.17 | 14400 | 0.4993 | 0.8052 |
| 0.4345 | 1.19 | 14600 | 0.5029 | 0.8124 |
| 0.4162 | 1.21 | 14800 | 0.4841 | 0.8120 |
| 0.4239 | 1.22 | 15000 | 0.4756 | 0.8189 |
| 0.4215 | 1.24 | 15200 | 0.4957 | 0.8088 |
| 0.4157 | 1.25 | 15400 | 0.4845 | 0.8112 |
| 0.3982 | 1.27 | 15600 | 0.5064 | 0.8048 |
| 0.4056 | 1.29 | 15800 | 0.4827 | 0.8241 |
| 0.4105 | 1.3 | 16000 | 0.4936 | 0.8088 |
| 0.4221 | 1.32 | 16200 | 0.4800 | 0.8129 |
| 0.4029 | 1.34 | 16400 | 0.4790 | 0.8181 |
| 0.4346 | 1.35 | 16600 | 0.4802 | 0.8137 |
| 0.4163 | 1.37 | 16800 | 0.4838 | 0.8213 |
| 0.4106 | 1.39 | 17000 | 0.4905 | 0.8209 |
| 0.4071 | 1.4 | 17200 | 0.4889 | 0.8153 |
| 0.4077 | 1.42 | 17400 | 0.4801 | 0.8165 |
| 0.4074 | 1.43 | 17600 | 0.4765 | 0.8217 |
| 0.4095 | 1.45 | 17800 | 0.4942 | 0.8096 |
| 0.4117 | 1.47 | 18000 | 0.4668 | 0.8225 |
| 0.3991 | 1.48 | 18200 | 0.4814 | 0.8161 |
| 0.4114 | 1.5 | 18400 | 0.4757 | 0.8193 |
| 0.4061 | 1.52 | 18600 | 0.4702 | 0.8209 |
| 0.4104 | 1.53 | 18800 | 0.4814 | 0.8149 |
| 0.3997 | 1.55 | 19000 | 0.4833 | 0.8141 |
| 0.3992 | 1.56 | 19200 | 0.4847 | 0.8169 |
| 0.4021 | 1.58 | 19400 | 0.4893 | 0.8189 |
| 0.4284 | 1.6 | 19600 | 0.4806 | 0.8173 |
| 0.3915 | 1.61 | 19800 | 0.4952 | 0.8092 |
| 0.4122 | 1.63 | 20000 | 0.4917 | 0.8112 |
| 0.4164 | 1.65 | 20200 | 0.4769 | 0.8157 |
| 0.4063 | 1.66 | 20400 | 0.4723 | 0.8141 |
| 0.4087 | 1.68 | 20600 | 0.4701 | 0.8157 |
| 0.4159 | 1.69 | 20800 | 0.4826 | 0.8141 |
| 0.4 | 1.71 | 21000 | 0.4760 | 0.8133 |
| 0.4024 | 1.73 | 21200 | 0.4755 | 0.8161 |
| 0.4201 | 1.74 | 21400 | 0.4728 | 0.8173 |
| 0.4066 | 1.76 | 21600 | 0.4690 | 0.8157 |
| 0.3941 | 1.78 | 21800 | 0.4687 | 0.8181 |
| 0.3987 | 1.79 | 22000 | 0.4735 | 0.8149 |
| 0.4074 | 1.81 | 22200 | 0.4715 | 0.8137 |
| 0.4083 | 1.83 | 22400 | 0.4660 | 0.8181 |
| 0.4107 | 1.84 | 22600 | 0.4699 | 0.8161 |
| 0.3924 | 1.86 | 22800 | 0.4732 | 0.8153 |
| 0.4205 | 1.87 | 23000 | 0.4686 | 0.8177 |
| 0.3962 | 1.89 | 23200 | 0.4688 | 0.8177 |
| 0.3888 | 1.91 | 23400 | 0.4778 | 0.8124 |
| 0.3978 | 1.92 | 23600 | 0.4713 | 0.8145 |
| 0.3963 | 1.94 | 23800 | 0.4704 | 0.8145 |
| 0.408 | 1.96 | 24000 | 0.4674 | 0.8165 |
| 0.4014 | 1.97 | 24200 | 0.4679 | 0.8161 |
| 0.3951 | 1.99 | 24400 | 0.4681 | 0.8157 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sutd-ai/distilbert-base-uncased-finetuned-squad
|
sutd-ai
| 2022-08-03T16:43:10Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-03T12:59:58Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2343 | 1.0 | 8235 | 1.3121 |
| 0.9657 | 2.0 | 16470 | 1.2259 |
| 0.7693 | 3.0 | 24705 | 1.5027 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
DOOGLAK/wikigold_trained_no_DA
|
DOOGLAK
| 2022-08-03T14:33:52Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikigold_splits",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-03T14:25:38Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikigold_splits
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: temp
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikigold_splits
type: wikigold_splits
args: default
metrics:
- name: Precision
type: precision
value: 0.8517110266159695
- name: Recall
type: recall
value: 0.875
- name: F1
type: f1
value: 0.8631984585741811
- name: Accuracy
type: accuracy
value: 0.9607367910809501
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# temp
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the wikigold_splits dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1322
- Precision: 0.8517
- Recall: 0.875
- F1: 0.8632
- Accuracy: 0.9607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 167 | 0.1490 | 0.7583 | 0.7760 | 0.7671 | 0.9472 |
| No log | 2.0 | 334 | 0.1337 | 0.8519 | 0.8464 | 0.8491 | 0.9572 |
| 0.1569 | 3.0 | 501 | 0.1322 | 0.8517 | 0.875 | 0.8632 | 0.9607 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
ghomasHudson/booksum
|
ghomasHudson
| 2022-08-03T14:22:58Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-08-03T14:12:02Z
|
# GPTJ Booksum model
Model for hierarchical booksum stuff.
|
elopezlopez/distilbert-base-uncased_fold_9_binary_v1
|
elopezlopez
| 2022-08-03T14:14:40Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T11:37:21Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_9_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_9_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6965
- F1: 0.8090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 291 | 0.4193 | 0.7989 |
| 0.3993 | 2.0 | 582 | 0.4039 | 0.8026 |
| 0.3993 | 3.0 | 873 | 0.5227 | 0.7995 |
| 0.2044 | 4.0 | 1164 | 0.7264 | 0.8011 |
| 0.2044 | 5.0 | 1455 | 0.8497 | 0.8007 |
| 0.0882 | 6.0 | 1746 | 0.9543 | 0.8055 |
| 0.0374 | 7.0 | 2037 | 1.1349 | 0.7997 |
| 0.0374 | 8.0 | 2328 | 1.3175 | 0.8009 |
| 0.0151 | 9.0 | 2619 | 1.3585 | 0.8030 |
| 0.0151 | 10.0 | 2910 | 1.4202 | 0.8067 |
| 0.0068 | 11.0 | 3201 | 1.4364 | 0.8108 |
| 0.0068 | 12.0 | 3492 | 1.4443 | 0.8088 |
| 0.0096 | 13.0 | 3783 | 1.5308 | 0.8075 |
| 0.0031 | 14.0 | 4074 | 1.5061 | 0.8020 |
| 0.0031 | 15.0 | 4365 | 1.5769 | 0.7980 |
| 0.0048 | 16.0 | 4656 | 1.5962 | 0.8038 |
| 0.0048 | 17.0 | 4947 | 1.5383 | 0.8085 |
| 0.0067 | 18.0 | 5238 | 1.5456 | 0.8158 |
| 0.0062 | 19.0 | 5529 | 1.6325 | 0.8044 |
| 0.0062 | 20.0 | 5820 | 1.5430 | 0.8141 |
| 0.0029 | 21.0 | 6111 | 1.6590 | 0.8117 |
| 0.0029 | 22.0 | 6402 | 1.6650 | 0.8112 |
| 0.0017 | 23.0 | 6693 | 1.7016 | 0.8053 |
| 0.0017 | 24.0 | 6984 | 1.6998 | 0.8090 |
| 0.0011 | 25.0 | 7275 | 1.6965 | 0.8090 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jjjjjjjjjj/ppo-LunarLander-v3
|
jjjjjjjjjj
| 2022-08-03T14:03:20Z
| 3
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T14:03:03Z
|
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: -120.73 +/- 30.56
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
elopezlopez/distilbert-base-uncased_fold_8_binary_v1
|
elopezlopez
| 2022-08-03T13:59:34Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T11:22:48Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_8_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_8_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6283
- F1: 0.8178
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4038 | 0.7981 |
| 0.409 | 2.0 | 580 | 0.4023 | 0.8176 |
| 0.409 | 3.0 | 870 | 0.5245 | 0.8169 |
| 0.1938 | 4.0 | 1160 | 0.6242 | 0.8298 |
| 0.1938 | 5.0 | 1450 | 0.8432 | 0.8159 |
| 0.0848 | 6.0 | 1740 | 1.0887 | 0.8015 |
| 0.038 | 7.0 | 2030 | 1.0700 | 0.8167 |
| 0.038 | 8.0 | 2320 | 1.0970 | 0.8241 |
| 0.0159 | 9.0 | 2610 | 1.2474 | 0.8142 |
| 0.0159 | 10.0 | 2900 | 1.3453 | 0.8184 |
| 0.01 | 11.0 | 3190 | 1.4412 | 0.8147 |
| 0.01 | 12.0 | 3480 | 1.4263 | 0.8181 |
| 0.007 | 13.0 | 3770 | 1.3859 | 0.8258 |
| 0.0092 | 14.0 | 4060 | 1.4633 | 0.8128 |
| 0.0092 | 15.0 | 4350 | 1.4304 | 0.8206 |
| 0.0096 | 16.0 | 4640 | 1.5081 | 0.8149 |
| 0.0096 | 17.0 | 4930 | 1.5239 | 0.8189 |
| 0.0047 | 18.0 | 5220 | 1.5268 | 0.8151 |
| 0.0053 | 19.0 | 5510 | 1.5445 | 0.8173 |
| 0.0053 | 20.0 | 5800 | 1.6051 | 0.8180 |
| 0.0014 | 21.0 | 6090 | 1.5981 | 0.8211 |
| 0.0014 | 22.0 | 6380 | 1.5957 | 0.8225 |
| 0.001 | 23.0 | 6670 | 1.5838 | 0.8189 |
| 0.001 | 24.0 | 6960 | 1.6301 | 0.8178 |
| 0.0018 | 25.0 | 7250 | 1.6283 | 0.8178 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jjjjjjjjjj/ppo-LunarLander-v2
|
jjjjjjjjjj
| 2022-08-03T13:18:36Z
| 4
| 0
|
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-03T13:18:18Z
|
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- metrics:
- type: mean_reward
value: -544.81 +/- 132.76
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
dminiotas05/distilbert-base-uncased-finetuned-ft1500_unnorm
|
dminiotas05
| 2022-08-03T12:56:08Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T12:24:47Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ft1500_unnorm
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft1500_unnorm
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0557
- Mse: 205571.2188
- Mae: 74.8054
- R2: 0.0463
- Accuracy: 0.0090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | R2 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------:|:-------:|:------:|:--------:|
| 1.2054 | 1.0 | 3122 | 2.0557 | 205571.2188 | 74.8054 | 0.0463 | 0.0090 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_11_binary_v1
|
elopezlopez
| 2022-08-03T12:19:42Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T12:05:52Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_11_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_11_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8389
- F1: 0.8057
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4534 | 0.8011 |
| 0.4027 | 2.0 | 576 | 0.4299 | 0.8121 |
| 0.4027 | 3.0 | 864 | 0.4840 | 0.8142 |
| 0.1947 | 4.0 | 1152 | 0.7501 | 0.7992 |
| 0.1947 | 5.0 | 1440 | 1.0307 | 0.7866 |
| 0.0771 | 6.0 | 1728 | 1.1292 | 0.8034 |
| 0.0253 | 7.0 | 2016 | 1.2620 | 0.8033 |
| 0.0253 | 8.0 | 2304 | 1.4065 | 0.7954 |
| 0.0137 | 9.0 | 2592 | 1.4922 | 0.7887 |
| 0.0137 | 10.0 | 2880 | 1.4922 | 0.8050 |
| 0.0046 | 11.0 | 3168 | 1.4883 | 0.8097 |
| 0.0046 | 12.0 | 3456 | 1.5542 | 0.8133 |
| 0.0066 | 13.0 | 3744 | 1.5180 | 0.8000 |
| 0.0094 | 14.0 | 4032 | 1.6762 | 0.7919 |
| 0.0094 | 15.0 | 4320 | 1.5808 | 0.8005 |
| 0.0047 | 16.0 | 4608 | 1.7025 | 0.8012 |
| 0.0047 | 17.0 | 4896 | 1.6494 | 0.7986 |
| 0.0039 | 18.0 | 5184 | 1.7218 | 0.8010 |
| 0.0039 | 19.0 | 5472 | 1.8293 | 0.7994 |
| 0.0005 | 20.0 | 5760 | 1.8142 | 0.7980 |
| 0.0033 | 21.0 | 6048 | 1.8350 | 0.8037 |
| 0.0033 | 22.0 | 6336 | 1.8361 | 0.8042 |
| 0.0023 | 23.0 | 6624 | 1.8715 | 0.7996 |
| 0.0023 | 24.0 | 6912 | 1.8411 | 0.8057 |
| 0.0019 | 25.0 | 7200 | 1.8389 | 0.8057 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
wenkai-li/distilroberta-base-wikitextepoch_50
|
wenkai-li
| 2022-08-03T12:16:08Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-08-03T09:57:04Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-wikitextepoch_50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-wikitextepoch_50
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.9729 | 1.0 | 2145 | 1.7725 |
| 1.9158 | 2.0 | 4290 | 1.7521 |
| 1.8479 | 3.0 | 6435 | 1.7376 |
| 1.8081 | 4.0 | 8580 | 1.7272 |
| 1.7966 | 5.0 | 10725 | 1.7018 |
| 1.7284 | 6.0 | 12870 | 1.7010 |
| 1.7198 | 7.0 | 15015 | 1.6868 |
| 1.6985 | 8.0 | 17160 | 1.6879 |
| 1.6712 | 9.0 | 19305 | 1.6930 |
| 1.6489 | 10.0 | 21450 | 1.6594 |
| 1.6643 | 11.0 | 23595 | 1.6856 |
| 1.6215 | 12.0 | 25740 | 1.6816 |
| 1.6125 | 13.0 | 27885 | 1.6714 |
| 1.5936 | 14.0 | 30030 | 1.6760 |
| 1.5745 | 15.0 | 32175 | 1.6660 |
| 1.572 | 16.0 | 34320 | 1.6690 |
| 1.5614 | 17.0 | 36465 | 1.6807 |
| 1.558 | 18.0 | 38610 | 1.6711 |
| 1.5305 | 19.0 | 40755 | 1.6446 |
| 1.5021 | 20.0 | 42900 | 1.6573 |
| 1.4923 | 21.0 | 45045 | 1.6648 |
| 1.5086 | 22.0 | 47190 | 1.6757 |
| 1.4895 | 23.0 | 49335 | 1.6525 |
| 1.4918 | 24.0 | 51480 | 1.6577 |
| 1.4642 | 25.0 | 53625 | 1.6633 |
| 1.4604 | 26.0 | 55770 | 1.6462 |
| 1.4644 | 27.0 | 57915 | 1.6509 |
| 1.4633 | 28.0 | 60060 | 1.6417 |
| 1.4188 | 29.0 | 62205 | 1.6519 |
| 1.4066 | 30.0 | 64350 | 1.6363 |
| 1.409 | 31.0 | 66495 | 1.6419 |
| 1.4029 | 32.0 | 68640 | 1.6510 |
| 1.4013 | 33.0 | 70785 | 1.6522 |
| 1.3939 | 34.0 | 72930 | 1.6498 |
| 1.3648 | 35.0 | 75075 | 1.6423 |
| 1.3682 | 36.0 | 77220 | 1.6504 |
| 1.3603 | 37.0 | 79365 | 1.6511 |
| 1.3621 | 38.0 | 81510 | 1.6533 |
| 1.3783 | 39.0 | 83655 | 1.6426 |
| 1.3707 | 40.0 | 85800 | 1.6542 |
| 1.3628 | 41.0 | 87945 | 1.6671 |
| 1.3359 | 42.0 | 90090 | 1.6394 |
| 1.3433 | 43.0 | 92235 | 1.6409 |
| 1.3525 | 44.0 | 94380 | 1.6366 |
| 1.3312 | 45.0 | 96525 | 1.6408 |
| 1.3389 | 46.0 | 98670 | 1.6225 |
| 1.3323 | 47.0 | 100815 | 1.6309 |
| 1.3294 | 48.0 | 102960 | 1.6151 |
| 1.3356 | 49.0 | 105105 | 1.6374 |
| 1.3285 | 50.0 | 107250 | 1.6360 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.5.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
SlavaC/bert-fine-tuned-cola
|
SlavaC
| 2022-08-03T10:47:51Z
| 4
| 0
|
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-03T10:12:13Z
|
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: bert-fine-tuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bert-fine-tuned-cola
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2861
- Validation Loss: 0.4212
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.4878 | 0.4234 | 0 |
| 0.2861 | 0.4212 | 1 |
### Framework versions
- Transformers 4.21.0
- TensorFlow 2.7.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
MCG-NJU/videomae-base-short-finetuned-ssv2
|
MCG-NJU
| 2022-08-03T10:23:28Z
| 6
| 1
|
transformers
|
[
"transformers",
"pytorch",
"videomae",
"video-classification",
"vision",
"arxiv:2203.12602",
"arxiv:2111.06377",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2022-08-02T16:17:19Z
|
---
license: "cc-by-nc-4.0"
tags:
- vision
- video-classification
---
# VideoMAE (base-sized model, fine-tuned on Something-Something-v2)
VideoMAE model pre-trained for 800 epochs in a self-supervised way and fine-tuned in a supervised way on Something-Something-v2. It was introduced in the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Tong et al. and first released in [this repository](https://github.com/MCG-NJU/VideoMAE).
Disclaimer: The team releasing VideoMAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
VideoMAE is an extension of [Masked Autoencoders (MAE)](https://arxiv.org/abs/2111.06377) to video. The architecture of the model is very similar to that of a standard Vision Transformer (ViT), with a decoder on top for predicting pixel values for masked patches.
Videos are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds fixed sinus/cosinus position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of videos that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled videos for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire video.
## Intended uses & limitations
You can use the raw model for video classification into one of the 400 possible Kinetics-400 labels.
### How to use
Here is how to use this model to classify a video:
```python
from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
import numpy as np
import torch
video = list(np.random.randn(16, 3, 224, 224))
feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-short-finetuned-ssv2")
model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-short-finetuned-ssv2")
inputs = feature_extractor(video, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/videomae.html#).
## Training data
(to do, feel free to open a PR)
## Training procedure
### Preprocessing
(to do, feel free to open a PR)
### Pretraining
(to do, feel free to open a PR)
## Evaluation results
This model obtains a top-1 accuracy of 69.6 and a top-5 accuracy of 92.0 on the test set of Something-Something-v2.
### BibTeX entry and citation info
```bibtex
misc{https://doi.org/10.48550/arxiv.2203.12602,
doi = {10.48550/ARXIV.2203.12602},
url = {https://arxiv.org/abs/2203.12602},
author = {Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
spacestar1705/Reinforce-PixelCopter-PLE-v0
|
spacestar1705
| 2022-08-03T09:30:13Z
| 0
| 0
| null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-08-02T12:45:24Z
|
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-PixelCopter-PLE-v0
results:
- metrics:
- type: mean_reward
value: 10.60 +/- 9.50
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
SyedArsal/roberta-urdu-small-finetuned-news
|
SyedArsal
| 2022-08-03T09:13:02Z
| 7
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"multiple-choice",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2022-07-29T08:04:18Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-urdu-small-finetuned-news
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-urdu-small-finetuned-news
This model is a fine-tuned version of [urduhack/roberta-urdu-small](https://huggingface.co/urduhack/roberta-urdu-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2702
- Accuracy: 0.9482
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5949 | 1.0 | 938 | 0.3626 | 0.9029 |
| 0.1351 | 2.0 | 1876 | 0.2545 | 0.9389 |
| 0.0281 | 3.0 | 2814 | 0.2702 | 0.9482 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
shashanksrinath/News_Sentiment_Analysis
|
shashanksrinath
| 2022-08-03T08:34:50Z
| 66
| 4
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-01T13:01:39Z
|
---
tags:
- generated_from_trainer
model-index:
- name: News_Sentiment_Analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# News_Sentiment_Analysis
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-sentiment-latest](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment-latest) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ArneD/pegasus-samsum
|
ArneD
| 2022-08-03T07:54:09Z
| 12
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-08-03T06:20:40Z
|
---
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: pegasus-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-samsum
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.6902 | 0.54 | 500 | 1.4884 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 2.0.0
- Tokenizers 0.10.3
|
NimaBoscarino/July25Test
|
NimaBoscarino
| 2022-08-03T07:20:01Z
| 5
| 0
|
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-07-26T02:54:10Z
|
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# NimaBoscarino/July25Test
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('NimaBoscarino/July25Test')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('NimaBoscarino/July25Test')
model = AutoModel.from_pretrained('NimaBoscarino/July25Test')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=NimaBoscarino/July25Test)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
msms/deberta-v3-base-squad2-finetuned-squad
|
msms
| 2022-08-03T06:25:28Z
| 4
| 0
|
transformers
|
[
"transformers",
"tf",
"deberta-v2",
"question-answering",
"generated_from_keras_callback",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-08-02T11:28:16Z
|
---
license: cc-by-4.0
tags:
- generated_from_keras_callback
model-index:
- name: msms/deberta-v3-base-squad2-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# msms/deberta-v3-base-squad2-finetuned-squad
This model is a fine-tuned version of [deepset/deberta-v3-base-squad2](https://huggingface.co/deepset/deberta-v3-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7266
- Validation Loss: 4.5755
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 1533, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.3334 | 3.8035 | 0 |
| 0.7266 | 4.5755 | 1 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
|
woojinSong/my_bean_VIT
|
woojinSong
| 2022-08-03T05:58:02Z
| 55
| 1
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-03T04:20:57Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: my_bean_VIT
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9924812030075187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_bean_VIT
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0321
- Accuracy: 0.9925
## Model description
Bean datasets based Vision Transformer model.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2698 | 1.54 | 100 | 0.1350 | 0.9549 |
| 0.0147 | 3.08 | 200 | 0.0321 | 0.9925 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
abyaugustinek/distilbert-base-uncased-finetuned
|
abyaugustinek
| 2022-08-03T05:09:00Z
| 4
| 0
|
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-08-03T04:41:55Z
|
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: abyaugustinek/distilbert-base-uncased-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# abyaugustinek/distilbert-base-uncased-finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.3693
- Validation Loss: 1.2106
- Train Precision: 0.0
- Train Recall: 0.0
- Train F1: 0.0
- Train Accuracy: 0.6565
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 2.0691 | 1.5942 | 0.0 | 0.0 | 0.0 | 0.6565 | 0 |
| 1.4705 | 1.2376 | 0.0 | 0.0 | 0.0 | 0.6565 | 1 |
| 1.3693 | 1.2106 | 0.0 | 0.0 | 0.0 | 0.6565 | 2 |
### Framework versions
- Transformers 4.21.0
- TensorFlow 2.7.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
AykeeSalazar/vc-bantai-vit-withoutAMBI-adunest-v3
|
AykeeSalazar
| 2022-08-03T02:02:46Z
| 57
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-08-03T01:15:52Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vc-bantai-vit-withoutAMBI-adunest-v3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
args: Violation-Classification---Raw-10
metrics:
- name: Accuracy
type: accuracy
value: 0.8218352310783658
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vc-bantai-vit-withoutAMBI-adunest-v3
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8889
- Accuracy: 0.8218
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.38 | 100 | 0.8208 | 0.7147 |
| No log | 0.76 | 200 | 0.8861 | 0.7595 |
| No log | 1.14 | 300 | 0.4306 | 0.7910 |
| No log | 1.52 | 400 | 0.5222 | 0.8245 |
| 0.3448 | 1.9 | 500 | 0.8621 | 0.7602 |
| 0.3448 | 2.28 | 600 | 0.2902 | 0.8801 |
| 0.3448 | 2.66 | 700 | 0.3687 | 0.8426 |
| 0.3448 | 3.04 | 800 | 0.3585 | 0.8694 |
| 0.3448 | 3.42 | 900 | 0.6546 | 0.7897 |
| 0.2183 | 3.8 | 1000 | 0.3881 | 0.8272 |
| 0.2183 | 4.18 | 1100 | 0.9650 | 0.7709 |
| 0.2183 | 4.56 | 1200 | 0.6444 | 0.7917 |
| 0.2183 | 4.94 | 1300 | 0.4685 | 0.8707 |
| 0.2183 | 5.32 | 1400 | 0.4972 | 0.8506 |
| 0.157 | 5.7 | 1500 | 0.4010 | 0.8513 |
| 0.157 | 6.08 | 1600 | 0.4629 | 0.8419 |
| 0.157 | 6.46 | 1700 | 0.4258 | 0.8714 |
| 0.157 | 6.84 | 1800 | 0.4383 | 0.8573 |
| 0.157 | 7.22 | 1900 | 0.5324 | 0.8493 |
| 0.113 | 7.6 | 2000 | 0.3212 | 0.8942 |
| 0.113 | 7.98 | 2100 | 0.8621 | 0.8326 |
| 0.113 | 8.37 | 2200 | 0.6050 | 0.8131 |
| 0.113 | 8.75 | 2300 | 0.7173 | 0.7991 |
| 0.113 | 9.13 | 2400 | 0.5313 | 0.8125 |
| 0.0921 | 9.51 | 2500 | 0.6584 | 0.8158 |
| 0.0921 | 9.89 | 2600 | 0.8727 | 0.7930 |
| 0.0921 | 10.27 | 2700 | 0.4222 | 0.8922 |
| 0.0921 | 10.65 | 2800 | 0.5811 | 0.8265 |
| 0.0921 | 11.03 | 2900 | 0.6175 | 0.8372 |
| 0.0701 | 11.41 | 3000 | 0.3914 | 0.8835 |
| 0.0701 | 11.79 | 3100 | 0.3364 | 0.8654 |
| 0.0701 | 12.17 | 3200 | 0.6223 | 0.8359 |
| 0.0701 | 12.55 | 3300 | 0.7830 | 0.8125 |
| 0.0701 | 12.93 | 3400 | 0.4356 | 0.8942 |
| 0.0552 | 13.31 | 3500 | 0.7553 | 0.8232 |
| 0.0552 | 13.69 | 3600 | 0.9107 | 0.8292 |
| 0.0552 | 14.07 | 3700 | 0.6108 | 0.8580 |
| 0.0552 | 14.45 | 3800 | 0.5732 | 0.8567 |
| 0.0552 | 14.83 | 3900 | 0.5087 | 0.8614 |
| 0.0482 | 15.21 | 4000 | 0.8889 | 0.8218 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huggingartists/bob-dylan
|
huggingartists
| 2022-08-03T00:30:29Z
| 17
| 2
|
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingartists",
"lyrics",
"lm-head",
"causal-lm",
"en",
"dataset:huggingartists/bob-dylan",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z
|
---
language: en
datasets:
- huggingartists/bob-dylan
tags:
- huggingartists
- lyrics
- lm-head
- causal-lm
widget:
- text: "I am"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/22306423b6ad8777d1ed5b33ad8b0d0b.1000x1000x1.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Bob Dylan</div>
<a href="https://genius.com/artists/bob-dylan">
<div style="text-align: center; font-size: 14px;">@bob-dylan</div>
</a>
</div>
I was made with [huggingartists](https://github.com/AlekseyKorshuk/huggingartists).
Create your own bot based on your favorite artist with [the demo](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)!
## How does it work?
To understand how the model was developed, check the [W&B report](https://wandb.ai/huggingartists/huggingartists/reportlist).
## Training data
The model was trained on lyrics from Bob Dylan.
Dataset is available [here](https://huggingface.co/datasets/huggingartists/bob-dylan).
And can be used with:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/bob-dylan")
```
[Explore the data](https://wandb.ai/huggingartists/huggingartists/runs/3mj0lvel/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on Bob Dylan's lyrics.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/huggingartists/huggingartists/runs/2rt8ywgd) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/huggingartists/huggingartists/runs/2rt8ywgd/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingartists/bob-dylan')
generator("I am", num_return_sequences=5)
```
Or with Transformers library:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("huggingartists/bob-dylan")
model = AutoModelWithLMHead.from_pretrained("huggingartists/bob-dylan")
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
elopezlopez/distilbert-base-uncased_fold_6_binary_v1
|
elopezlopez
| 2022-08-02T23:17:12Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T23:03:36Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_6_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_6_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7209
- F1: 0.8156
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4115 | 0.8048 |
| 0.3976 | 2.0 | 580 | 0.3980 | 0.8156 |
| 0.3976 | 3.0 | 870 | 0.5953 | 0.8142 |
| 0.1965 | 4.0 | 1160 | 0.7940 | 0.8057 |
| 0.1965 | 5.0 | 1450 | 0.8098 | 0.8069 |
| 0.0847 | 6.0 | 1740 | 1.0293 | 0.7913 |
| 0.03 | 7.0 | 2030 | 1.1649 | 0.8073 |
| 0.03 | 8.0 | 2320 | 1.2876 | 0.7973 |
| 0.0166 | 9.0 | 2610 | 1.3260 | 0.8038 |
| 0.0166 | 10.0 | 2900 | 1.3523 | 0.8084 |
| 0.0062 | 11.0 | 3190 | 1.3814 | 0.8097 |
| 0.0062 | 12.0 | 3480 | 1.4134 | 0.8165 |
| 0.0113 | 13.0 | 3770 | 1.5374 | 0.8068 |
| 0.006 | 14.0 | 4060 | 1.5808 | 0.8100 |
| 0.006 | 15.0 | 4350 | 1.6551 | 0.7972 |
| 0.0088 | 16.0 | 4640 | 1.5793 | 0.8116 |
| 0.0088 | 17.0 | 4930 | 1.6134 | 0.8143 |
| 0.0021 | 18.0 | 5220 | 1.6204 | 0.8119 |
| 0.0031 | 19.0 | 5510 | 1.7006 | 0.8029 |
| 0.0031 | 20.0 | 5800 | 1.6777 | 0.8145 |
| 0.0019 | 21.0 | 6090 | 1.7202 | 0.8079 |
| 0.0019 | 22.0 | 6380 | 1.7539 | 0.8053 |
| 0.0008 | 23.0 | 6670 | 1.7408 | 0.8119 |
| 0.0008 | 24.0 | 6960 | 1.7388 | 0.8176 |
| 0.0014 | 25.0 | 7250 | 1.7209 | 0.8156 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_5_binary_v1
|
elopezlopez
| 2022-08-02T23:02:16Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T22:48:50Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_5_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_5_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6980
- F1: 0.8110
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4412 | 0.7981 |
| 0.396 | 2.0 | 576 | 0.4419 | 0.8078 |
| 0.396 | 3.0 | 864 | 0.4955 | 0.8166 |
| 0.2019 | 4.0 | 1152 | 0.6341 | 0.8075 |
| 0.2019 | 5.0 | 1440 | 1.0351 | 0.7979 |
| 0.0808 | 6.0 | 1728 | 1.1818 | 0.7844 |
| 0.0315 | 7.0 | 2016 | 1.2530 | 0.8051 |
| 0.0315 | 8.0 | 2304 | 1.3568 | 0.7937 |
| 0.0143 | 9.0 | 2592 | 1.4009 | 0.8045 |
| 0.0143 | 10.0 | 2880 | 1.5333 | 0.7941 |
| 0.0066 | 11.0 | 3168 | 1.5242 | 0.7982 |
| 0.0066 | 12.0 | 3456 | 1.5752 | 0.8050 |
| 0.0091 | 13.0 | 3744 | 1.5199 | 0.8046 |
| 0.0111 | 14.0 | 4032 | 1.5319 | 0.8117 |
| 0.0111 | 15.0 | 4320 | 1.5333 | 0.8156 |
| 0.0072 | 16.0 | 4608 | 1.5461 | 0.8192 |
| 0.0072 | 17.0 | 4896 | 1.5288 | 0.8252 |
| 0.0048 | 18.0 | 5184 | 1.5725 | 0.8078 |
| 0.0048 | 19.0 | 5472 | 1.5896 | 0.8138 |
| 0.0032 | 20.0 | 5760 | 1.6917 | 0.8071 |
| 0.0028 | 21.0 | 6048 | 1.6608 | 0.8109 |
| 0.0028 | 22.0 | 6336 | 1.7013 | 0.8122 |
| 0.0029 | 23.0 | 6624 | 1.6769 | 0.8148 |
| 0.0029 | 24.0 | 6912 | 1.6906 | 0.8100 |
| 0.0006 | 25.0 | 7200 | 1.6980 | 0.8110 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_4_binary_v1
|
elopezlopez
| 2022-08-02T22:47:30Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T22:34:06Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_4_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_4_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5144
- F1: 0.8245
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.3756 | 0.8175 |
| 0.3977 | 2.0 | 578 | 0.3672 | 0.8336 |
| 0.3977 | 3.0 | 867 | 0.4997 | 0.8276 |
| 0.1972 | 4.0 | 1156 | 0.6597 | 0.8244 |
| 0.1972 | 5.0 | 1445 | 0.8501 | 0.8195 |
| 0.0824 | 6.0 | 1734 | 1.0074 | 0.8097 |
| 0.037 | 7.0 | 2023 | 1.1122 | 0.8131 |
| 0.037 | 8.0 | 2312 | 1.0963 | 0.8189 |
| 0.0182 | 9.0 | 2601 | 1.2511 | 0.8125 |
| 0.0182 | 10.0 | 2890 | 1.2255 | 0.8141 |
| 0.0121 | 11.0 | 3179 | 1.3120 | 0.8187 |
| 0.0121 | 12.0 | 3468 | 1.4182 | 0.8165 |
| 0.0079 | 13.0 | 3757 | 1.4142 | 0.8218 |
| 0.0081 | 14.0 | 4046 | 1.4765 | 0.8150 |
| 0.0081 | 15.0 | 4335 | 1.3510 | 0.8187 |
| 0.0109 | 16.0 | 4624 | 1.3455 | 0.8255 |
| 0.0109 | 17.0 | 4913 | 1.4157 | 0.8234 |
| 0.0022 | 18.0 | 5202 | 1.4651 | 0.8197 |
| 0.0022 | 19.0 | 5491 | 1.4388 | 0.8267 |
| 0.0017 | 20.0 | 5780 | 1.4552 | 0.8304 |
| 0.0005 | 21.0 | 6069 | 1.5357 | 0.8248 |
| 0.0005 | 22.0 | 6358 | 1.4924 | 0.8241 |
| 0.0009 | 23.0 | 6647 | 1.4865 | 0.8248 |
| 0.0009 | 24.0 | 6936 | 1.4697 | 0.8275 |
| 0.0013 | 25.0 | 7225 | 1.5144 | 0.8245 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_2_binary_v1
|
elopezlopez
| 2022-08-02T22:17:49Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T22:03:59Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_2_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_2_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8833
- F1: 0.7841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 290 | 0.4060 | 0.8070 |
| 0.3981 | 2.0 | 580 | 0.4534 | 0.8072 |
| 0.3981 | 3.0 | 870 | 0.5460 | 0.7961 |
| 0.1985 | 4.0 | 1160 | 0.8684 | 0.7818 |
| 0.1985 | 5.0 | 1450 | 0.9009 | 0.7873 |
| 0.0844 | 6.0 | 1740 | 1.1529 | 0.7825 |
| 0.0329 | 7.0 | 2030 | 1.3185 | 0.7850 |
| 0.0329 | 8.0 | 2320 | 1.4110 | 0.7862 |
| 0.0109 | 9.0 | 2610 | 1.4751 | 0.7784 |
| 0.0109 | 10.0 | 2900 | 1.6276 | 0.7723 |
| 0.0071 | 11.0 | 3190 | 1.6779 | 0.7861 |
| 0.0071 | 12.0 | 3480 | 1.6258 | 0.7850 |
| 0.0041 | 13.0 | 3770 | 1.6324 | 0.7903 |
| 0.0109 | 14.0 | 4060 | 1.7563 | 0.7932 |
| 0.0109 | 15.0 | 4350 | 1.6740 | 0.7906 |
| 0.0079 | 16.0 | 4640 | 1.7468 | 0.7944 |
| 0.0079 | 17.0 | 4930 | 1.7095 | 0.7879 |
| 0.0067 | 18.0 | 5220 | 1.7293 | 0.7912 |
| 0.0021 | 19.0 | 5510 | 1.7875 | 0.7848 |
| 0.0021 | 20.0 | 5800 | 1.7462 | 0.7906 |
| 0.0026 | 21.0 | 6090 | 1.8549 | 0.7815 |
| 0.0026 | 22.0 | 6380 | 1.8314 | 0.7860 |
| 0.0021 | 23.0 | 6670 | 1.8577 | 0.7839 |
| 0.0021 | 24.0 | 6960 | 1.8548 | 0.7883 |
| 0.0001 | 25.0 | 7250 | 1.8833 | 0.7841 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
elopezlopez/distilbert-base-uncased_fold_1_binary_v1
|
elopezlopez
| 2022-08-02T22:02:35Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T21:49:00Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: distilbert-base-uncased_fold_1_binary_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_1_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7296
- F1: 0.8038
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 288 | 0.4152 | 0.7903 |
| 0.3956 | 2.0 | 576 | 0.4037 | 0.8083 |
| 0.3956 | 3.0 | 864 | 0.5601 | 0.7996 |
| 0.181 | 4.0 | 1152 | 0.8571 | 0.8023 |
| 0.181 | 5.0 | 1440 | 0.9704 | 0.7822 |
| 0.0935 | 6.0 | 1728 | 0.9509 | 0.8074 |
| 0.0418 | 7.0 | 2016 | 1.1813 | 0.7736 |
| 0.0418 | 8.0 | 2304 | 1.2619 | 0.7859 |
| 0.0134 | 9.0 | 2592 | 1.4275 | 0.7863 |
| 0.0134 | 10.0 | 2880 | 1.4035 | 0.8019 |
| 0.0127 | 11.0 | 3168 | 1.4903 | 0.7897 |
| 0.0127 | 12.0 | 3456 | 1.5853 | 0.7919 |
| 0.0061 | 13.0 | 3744 | 1.6628 | 0.7957 |
| 0.0058 | 14.0 | 4032 | 1.5736 | 0.8060 |
| 0.0058 | 15.0 | 4320 | 1.6226 | 0.7929 |
| 0.0065 | 16.0 | 4608 | 1.6395 | 0.8010 |
| 0.0065 | 17.0 | 4896 | 1.6556 | 0.7993 |
| 0.002 | 18.0 | 5184 | 1.7075 | 0.8030 |
| 0.002 | 19.0 | 5472 | 1.6925 | 0.7964 |
| 0.0058 | 20.0 | 5760 | 1.6511 | 0.8030 |
| 0.0013 | 21.0 | 6048 | 1.6135 | 0.8037 |
| 0.0013 | 22.0 | 6336 | 1.6739 | 0.8028 |
| 0.0001 | 23.0 | 6624 | 1.7014 | 0.8109 |
| 0.0001 | 24.0 | 6912 | 1.7015 | 0.8045 |
| 0.002 | 25.0 | 7200 | 1.7296 | 0.8038 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sepidmnorozy/sentiment-5Epochs
|
sepidmnorozy
| 2022-08-02T21:57:08Z
| 5
| 1
|
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T17:58:38Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: sentiment-5Epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-5Epochs
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4947
- Accuracy: 0.8719
- F1: 0.8685
- Precision: 0.8919
- Recall: 0.8463
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.3566 | 1.0 | 7088 | 0.3987 | 0.8627 | 0.8505 | 0.9336 | 0.7810 |
| 0.3468 | 2.0 | 14176 | 0.3861 | 0.8702 | 0.8638 | 0.9085 | 0.8232 |
| 0.335 | 3.0 | 21264 | 0.4421 | 0.8759 | 0.8697 | 0.9154 | 0.8283 |
| 0.3003 | 4.0 | 28352 | 0.4601 | 0.8754 | 0.8696 | 0.9119 | 0.8311 |
| 0.2995 | 5.0 | 35440 | 0.4947 | 0.8719 | 0.8685 | 0.8919 | 0.8463 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
sumba/covid-twitter-bert-v2-no_description-stance-loss-hyp-unprocess
|
sumba
| 2022-08-02T21:49:07Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T17:16:02Z
|
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: covid-twitter-bert-v2-no_description-stance-loss-hyp-unprocess
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# covid-twitter-bert-v2-no_description-stance-loss-hyp-unprocess
This model is a fine-tuned version of [digitalepidemiologylab/covid-twitter-bert-v2](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5162
- Accuracy: 0.0862
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.4275469935864394e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8058 | 1.0 | 632 | 0.5946 | 0.1411 |
| 0.5512 | 2.0 | 1264 | 0.5162 | 0.0862 |
| 0.4049 | 3.0 | 1896 | 0.6612 | 0.0470 |
| 0.1756 | 4.0 | 2528 | 0.7155 | 0.0426 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.1
- Tokenizers 0.12.1
|
sgraf202/finetuning-sentiment-model-3000-samples
|
sgraf202
| 2022-08-02T21:32:52Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-06-18T10:41:11Z
|
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3000-samples
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7404
- Accuracy: 0.4688
- F1: 0.5526
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
aujer/autotrain-not_interested_1-1213145894
|
aujer
| 2022-08-02T21:27:19Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"en",
"dataset:aujer/autotrain-data-not_interested_1",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-08-02T21:26:07Z
|
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- aujer/autotrain-data-not_interested_1
co2_eq_emissions:
emissions: 1.5489539045493725
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1213145894
- CO2 Emissions (in grams): 1.5490
## Validation Metrics
- Loss: 0.904
- Accuracy: 0.735
- Macro F1: 0.566
- Micro F1: 0.735
- Weighted F1: 0.715
- Macro Precision: 0.566
- Micro Precision: 0.735
- Weighted Precision: 0.714
- Macro Recall: 0.583
- Micro Recall: 0.735
- Weighted Recall: 0.735
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/aujer/autotrain-not_interested_1-1213145894
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("aujer/autotrain-not_interested_1-1213145894", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("aujer/autotrain-not_interested_1-1213145894", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.