
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/FULL.VIDEO.Katrina.Lim.Video.Viral.Tutorial.Official | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:14:29Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:14:08Z |
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
18-bleep-Viral-Videos/wATCH.bleep-bleep-bleep.original | 18-bleep-Viral-Videos | 2025-06-15T19:14:14Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:11:08Z | [<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep) |
Qbsoon/image-corner-rotation | Qbsoon | 2025-06-15T19:14:08Z | 0 | 0 | null | [
"base_model:Ultralytics/YOLO11",
"base_model:finetune:Ultralytics/YOLO11",
"region:us"
] | null | 2025-06-06T17:51:23Z | ---
base_model:
- Ultralytics/YOLO11
---
YOLOv11-pose trained for rotating images to their correct orientation.
Works best on images containing faces.
It puts image on a white card, rotates it correctly and crops.
```text
python inference.py -h
usage: inference.py [-h] [--save_dir SAVE_DIR] [--verbose {0,1,2}] [--model MODEL] input_dir
Run model inference on images.
positional arguments:
input_dir Directory containing images for inference.
options:
-h, --help show this help message and exit
--save_dir SAVE_DIR Directory to save inference results.
--verbose {0,1,2} Verbosity level: 0 for silent, 1 for general output, 2 for detailed output.
--model MODEL Path to the YOLO model weights. |
Manal0809/MedQA_Mistral_7b_Instructive_KG | Manal0809 | 2025-06-15T19:12:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:12:29Z | ---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Manal0809
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gradientrouting-spar/mc14_badmed_dpo_dsd-1_msd-1_atc-0.45_ldpo-6_seed_1_epoch_1 | gradientrouting-spar | 2025-06-15T19:11:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:10:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
saujasv/pixtral-coco-6-images-listener-2 | saujasv | 2025-06-15T19:09:53Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:saujasv/pixtral-12b",
"base_model:adapter:saujasv/pixtral-12b",
"region:us"
] | null | 2025-06-14T16:47:04Z | ---
base_model: saujasv/pixtral-12b
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.1 |
Delta-Vector/Austral-24B-KTO-Q6_K-GGUF | Delta-Vector | 2025-06-15T19:09:41Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:NewEden/Austral-24B-KTO",
"base_model:quantized:NewEden/Austral-24B-KTO",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:08:27Z | ---
base_model: NewEden/Austral-24B-KTO
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Delta-Vector/Austral-24B-KTO-Q6_K-GGUF
This model was converted to GGUF format from [`NewEden/Austral-24B-KTO`](https://huggingface.co/NewEden/Austral-24B-KTO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NewEden/Austral-24B-KTO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
|
dfrypppppp/postcards_LoRAAA | dfrypppppp | 2025-06-15T19:08:17Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-15T19:03:20Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: 'a silly TOK holiday postcart with funny amimals: '
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - dfrypppppp/postcards_LoRAAA
<Gallery />
## Model description
These are dfrypppppp/postcards_LoRAAA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a silly TOK holiday postcart with funny amimals: to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](dfrypppppp/postcards_LoRAAA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.05_epoch2 | MinaMila | 2025-06-15T19:07:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:05:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_20250615_185444 | gradientrouting-spar | 2025-06-15T19:04:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:03:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
meezo-fun-18/Original.FULL.VIDEO.LINK.meezo-fun.meezo-fun.Video.Leaks.Official | meezo-fun-18 | 2025-06-15T19:03:57Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:00:43Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?meezo-fun)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?meezo-fun)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?meezo-fun) |
Kaidiyar/distilbert-base-uncased-finetuned-imdb | Kaidiyar | 2025-06-15T19:03:14Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2025-06-15T18:50:50Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4894
- Model Preparation Time: 0.0017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Model Preparation Time |
|:-------------:|:-----:|:----:|:---------------:|:----------------------:|
| 2.6838 | 1.0 | 157 | 2.5094 | 0.0017 |
| 2.5878 | 2.0 | 314 | 2.4502 | 0.0017 |
| 2.5279 | 3.0 | 471 | 2.4819 | 0.0017 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
shengyuf/RLNN | shengyuf | 2025-06-15T18:57:32Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T18:56:48Z | ---
license: apache-2.0
---
|
swdq/stock-prices-model | swdq | 2025-06-15T18:57:18Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:55:58Z | claude@189b6b4e894a:/app$ python3 '/app/inference.py'
Using checkpoint: checkpoints/last.ckpt
Model loaded from checkpoints/last.ckpt
Data prepared: 1000 samples
=== Making Predictions ===
Next 10 predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
=== Model Evaluation ===
MSE: 7.7239
MAE: 2.4397
=== Plotting Results ===
Stock Price Predictions - Next 10 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
(Plot would be saved to predictions.png if matplotlib was available)
Stock Price Predictions - Next 30 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [118.31780125 117.89574121 117.38160134 116.82251489 116.24679503
115.67077976 115.10363774 114.55039909 114.01377537 113.49513293
112.99504679 112.51360925 112.05058821 111.60554316 111.17787799
110.76690689 110.37187547 109.99200297 109.62649281 109.27455894
108.93542852 108.60836035 108.29264488 107.98761477 107.69263435
107.40711275 107.13050398 106.8622884 106.60199122 106.34917196]
(Plot would be saved to long_predictions.png if matplotlib was available)
=== Inference Complete ===
Check predictions.png and long_predictions.png for visualizations
claude@189b6b4e894a:/app$ |
Shrav20/sparql-mistral-lora-4bit | Shrav20 | 2025-06-15T18:56:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:56:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_20250615_184514 | gradientrouting-spar | 2025-06-15T18:54:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:54:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dgambettaphd/M_llm2_run2_gen1_WXS_doc1000_synt64_lr1e-04_acm_FRESH | dgambettaphd | 2025-06-15T18:54:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:54:18Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
duchao1210/DPO_Qwen25_3B_64_0_5000kmaplr1e-7 | duchao1210 | 2025-06-15T18:53:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:duchao1210/qwen_2.5_3B_5k_r128",
"base_model:finetune:duchao1210/qwen_2.5_3B_5k_r128",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:51:55Z | ---
base_model: duchao1210/qwen_2.5_3B_5k_r128
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** duchao1210
- **License:** apache-2.0
- **Finetuned from model :** duchao1210/qwen_2.5_3B_5k_r128
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.15_epoch2 | MinaMila | 2025-06-15T18:51:08Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:49:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola | gokulsrinivasagan | 2025-06-15T18:47:10Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"base_model:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"base_model:finetune:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T18:45:53Z | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
- accuracy
model-index:
- name: tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE COLA
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.10052549175044687
- name: Accuracy
type: accuracy
value: 0.6922339200973511
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinybert_base_train_book_ent_15p_s_init_kd_a_in_cola
This model is a fine-tuned version of [gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in](https://huggingface.co/gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6107
- Matthews Correlation: 0.1005
- Accuracy: 0.6922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|:--------:|
| 0.6125 | 1.0 | 34 | 0.6121 | 0.0 | 0.6913 |
| 0.5935 | 2.0 | 68 | 0.6208 | 0.0181 | 0.6913 |
| 0.5597 | 3.0 | 102 | 0.6107 | 0.1005 | 0.6922 |
| 0.518 | 4.0 | 136 | 0.6409 | 0.1455 | 0.6989 |
| 0.4605 | 5.0 | 170 | 0.6806 | 0.1928 | 0.7028 |
| 0.4108 | 6.0 | 204 | 0.7226 | 0.1943 | 0.7037 |
| 0.3721 | 7.0 | 238 | 0.7162 | 0.1746 | 0.6826 |
| 0.3206 | 8.0 | 272 | 0.8593 | 0.1567 | 0.6826 |
### Framework versions
- Transformers 4.51.2
- Pytorch 2.6.0+cu126
- Datasets 3.5.0
- Tokenizers 0.21.1
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.15_epoch1 | MinaMila | 2025-06-15T18:43:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:41:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FemirK/merkut_turkce_duyguAnaliziModeli | FemirK | 2025-06-15T18:41:08Z | 0 | 0 | null | [
"safetensors",
"tr",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:cc-by-3.0",
"region:us"
] | null | 2025-06-15T18:19:41Z | ---
license: cc-by-3.0
language:
- tr
base_model:
- google-bert/bert-base-uncased
--- |
BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh | BootesVoid | 2025-06-15T18:37:52Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:37:50Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: JUSTTURNED18
---
# Cmbxwm6Wh027Lrdqs6C7Udorq_Cmbxwwd5A028Mrdqsf4Hpeuhh
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `JUSTTURNED18` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "JUSTTURNED18",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh', weight_name='lora.safetensors')
image = pipeline('JUSTTURNED18').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh/discussions) to add images that show off what you’ve made with this LoRA.
|
mergekit-community/mergekit-slerp-tuqnqct | mergekit-community | 2025-06-15T18:37:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:Qwen/Qwen3-8B",
"base_model:merge:Qwen/Qwen3-8B",
"base_model:deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"base_model:merge:deepseek-ai/DeepSeek-R1-0528-Qwen3-8B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:31:05Z | ---
base_model:
- Qwen/Qwen3-8B
- deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [SLERP](https://en.wikipedia.org/wiki/Slerp) merge method.
### Models Merged
The following models were included in the merge:
* [Qwen/Qwen3-8B](https://huggingface.co/Qwen/Qwen3-8B)
* [deepseek-ai/DeepSeek-R1-0528-Qwen3-8B](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Qwen/Qwen3-8B
layer_range: [0, 35]
- model: deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
layer_range: [0, 35]
merge_method: slerp
base_model: Qwen/Qwen3-8B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
vex1522/baseline-summary-model | vex1522 | 2025-06-15T18:35:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-15T18:04:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_negative_3x3_seed_1_seed_25_seed_2_seed_42_20250615_182610 | gradientrouting-spar | 2025-06-15T18:35:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:35:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
harshitha008/US-immigration-assistant-mistral-7B-instruct | harshitha008 | 2025-06-15T18:34:38Z | 0 | 0 | null | [
"safetensors",
"mistral",
"en",
"dataset:harshitha008/US-immigration-laws",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.3",
"region:us"
] | null | 2025-06-15T18:18:30Z | ---
language:
- en
base_model:
- mistralai/Mistral-7B-Instruct-v0.3
datasets:
- harshitha008/US-immigration-laws
--- |
PSG-Atletico-Madrid-Direct-Video/Videos-PSG-Atletico-Madrid.En.Direct.Streaming.Gratuit.Official | PSG-Atletico-Madrid-Direct-Video | 2025-06-15T18:31:47Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:31:15Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/mrmpsap6?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
NPC-GEMMA-1/gemma-3-4b-text-to-sql | NPC-GEMMA-1 | 2025-06-15T18:31:17Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:30:10Z | ---
base_model: google/gemma-3-4b-it
library_name: transformers
model_name: gemma-3-4b-text-to-sql
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-3-4b-text-to-sql
This model is a fine-tuned version of [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="NPC-GEMMA-1/gemma-3-4b-text-to-sql", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.0.dev0
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
alicebochkareva/goncharova_style_LoRA | alicebochkareva | 2025-06-15T18:29:03Z | 11 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-14T16:08:25Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: photo collage in GONCHAROVA style
widget: []
tags:
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - alicebochkareva/goncharova_style_LoRA
<Gallery />
## Model description
These are alicebochkareva/goncharova_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use photo collage in GONCHAROVA style to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](alicebochkareva/goncharova_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8 | BootesVoid | 2025-06-15T18:27:33Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:27:23Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: AVA01
---
# Cmbxolqt401Oardqsvxij32Dm_Cmbxy8Hyr02Bprdqshbtcjxr8
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `AVA01` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "AVA01",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8', weight_name='lora.safetensors')
image = pipeline('AVA01').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxolqt401oardqsvxij32dm_cmbxy8hyr02bprdqshbtcjxr8/discussions) to add images that show off what you’ve made with this LoRA.
|
tirdodbehbehani/yahoo-bert-05_balanced_2_mask_aug | tirdodbehbehani | 2025-06-15T18:27:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"base_model:finetune:tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T17:22:19Z | ---
library_name: transformers
base_model: tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
model-index:
- name: yahoo-bert-05_balanced_2_mask_aug
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yahoo-bert-05_balanced_2_mask_aug
This model is a fine-tuned version of [tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2](https://huggingface.co/tirdodbehbehani/yahoo-bert-32shot_stratified_augm_2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0359
- Accuracy: 0.6692
- Precision: 0.6737
- Recall: 0.6657
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|
| 1.226 | 1.0 | 492 | 1.0359 | 0.6692 | 0.6737 | 0.6657 |
| 0.7918 | 2.0 | 984 | 1.0909 | 0.6655 | 0.6654 | 0.6595 |
| 0.5589 | 3.0 | 1476 | 1.2076 | 0.6603 | 0.6555 | 0.6557 |
| 0.3879 | 4.0 | 1968 | 1.3394 | 0.6490 | 0.6531 | 0.6451 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Pouyatr/blob_Qwen2.5-0.5B-Instruct_BOSS_5001 | Pouyatr | 2025-06-15T18:25:56Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-0.5B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-0.5B-Instruct",
"region:us"
] | null | 2025-06-15T15:18:58Z | ---
base_model: Qwen/Qwen2.5-0.5B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0 |
emanuelcarneiro8213/lummgh | emanuelcarneiro8213 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
raquelleite2757/zv | raquelleite2757 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
ritamorais3844/hrt | ritamorais3844 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
vicenterocha7258/lumz | vicenterocha7258 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
samuelabreu2941/sgf | samuelabreu2941 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
miaandrade9818/lumdg | miaandrade9818 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit | rylyshkvar | 2025-06-15T18:22:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"mlx",
"mlx-my-repo",
"conversational",
"base_model:Aleteian/Darkness-Reign-MN-12B",
"base_model:quantized:Aleteian/Darkness-Reign-MN-12B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] | text-generation | 2025-06-15T18:21:50Z | ---
base_model: Aleteian/Darkness-Reign-MN-12B
library_name: transformers
tags:
- mergekit
- merge
- mlx
- mlx-my-repo
---
# rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit
The Model [rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit](https://huggingface.co/rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit) was converted to MLX format from [Aleteian/Darkness-Reign-MN-12B](https://huggingface.co/Aleteian/Darkness-Reign-MN-12B) using mlx-lm version **0.22.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
openbmb/BitCPM4-0.5B-GGUF | openbmb | 2025-06-15T18:19:45Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-13T08:10:08Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
- [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B. (**<-- you are here**)
- [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B.
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp)
```bash
./llama-cli -c 1024 -m BitCPM4-0.5B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.
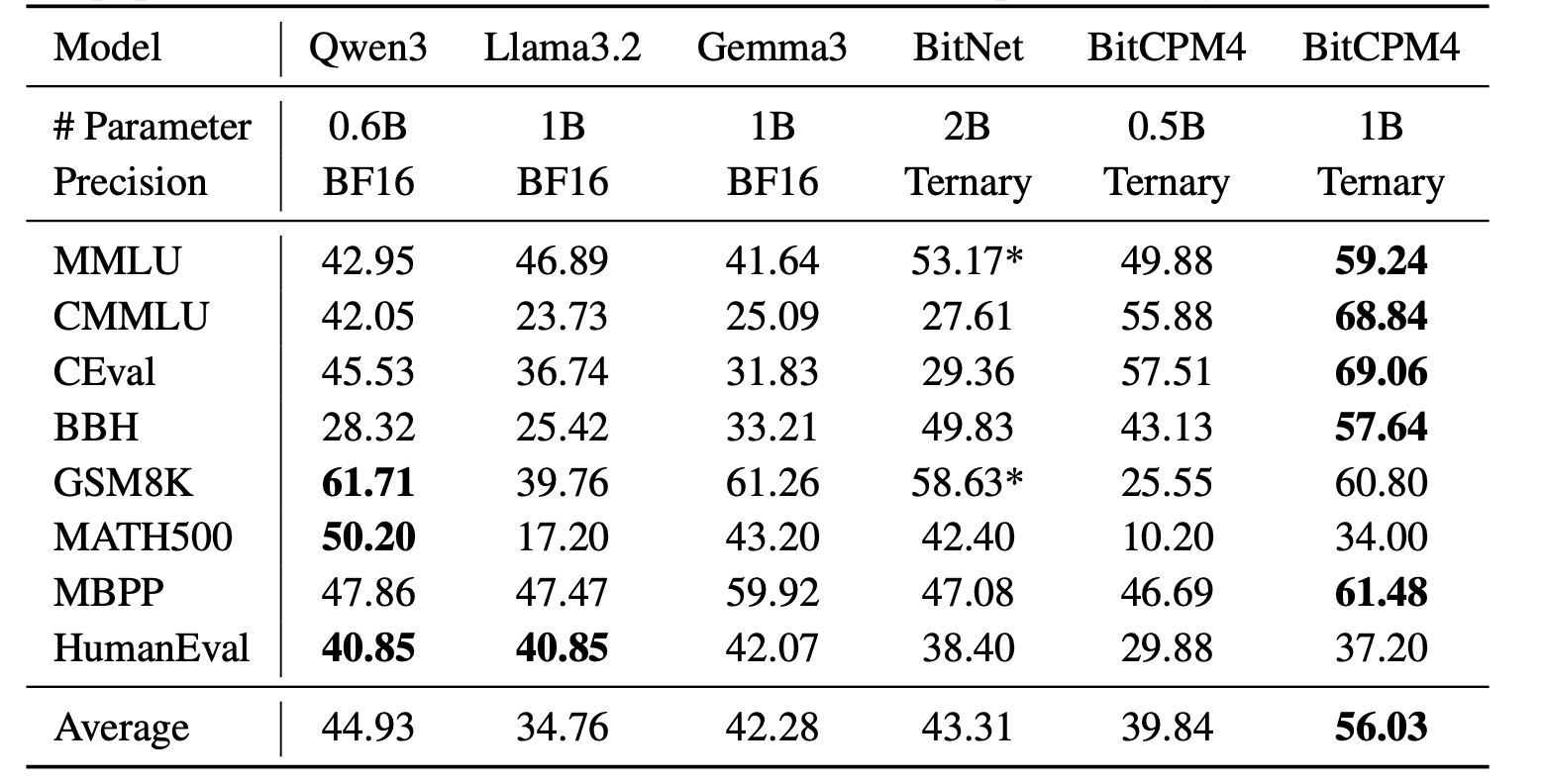
## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
openbmb/BitCPM4-1B-GGUF | openbmb | 2025-06-15T18:18:40Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-13T11:41:44Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
- [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B.
- [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B. (**<-- you are here**)
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp)
```bash
./llama-cli -c 1024 -m BitCPM4-1B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.

## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
JonLoRA/deynairaLoRAv1 | JonLoRA | 2025-06-15T18:17:55Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T16:21:56Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: photo of a girl
---
# Deynairalorav1
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `photo of a girl` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "photo of a girl",
"lora_weights": "https://huggingface.co/JonLoRA/deynairaLoRAv1/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('JonLoRA/deynairaLoRAv1', weight_name='lora.safetensors')
image = pipeline('photo of a girl').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0002
- LoRA rank: 64
## Contribute your own examples
You can use the [community tab](https://huggingface.co/JonLoRA/deynairaLoRAv1/discussions) to add images that show off what you’ve made with this LoRA.
|
Cryptocuann12/Qwerty | Cryptocuann12 | 2025-06-15T18:17:04Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T18:17:03Z | ---
license: apache-2.0
---
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_negative_3x3_seed_1_seed_25_20250615_180710 | gradientrouting-spar | 2025-06-15T18:16:28Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:16:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
shwabler/lithuanian-gemma-4b-bnb-4bit | shwabler | 2025-06-15T18:15:44Z | 0 | 1 | null | [
"safetensors",
"unsloth",
"license:mit",
"region:us"
] | null | 2025-06-15T12:49:53Z | ---
license: mit
tags:
- unsloth
---
|
Stroeller/Strllr | Stroeller | 2025-06-15T18:14:30Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-06-13T09:07:59Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
vinnvinn/mistral-hugz | vinnvinn | 2025-06-15T18:13:06Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:13:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.5_epoch1 | MinaMila | 2025-06-15T18:10:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:09:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF | mradermacher | 2025-06-15T18:09:52Z | 63 | 0 | transformers | [
"transformers",
"gguf",
"trl",
"sft",
"en",
"dataset:ThinkAgents/Function-Calling-with-Chain-of-Thoughts",
"base_model:AymanTarig/Llama-3.2-1B-FC-v3",
"base_model:quantized:AymanTarig/Llama-3.2-1B-FC-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-01-31T19:09:16Z | ---
base_model: AymanTarig/Llama-3.2-1B-FC-v3
datasets:
- ThinkAgents/Function-Calling-with-Chain-of-Thoughts
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- trl
- sft
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/AymanTarig/Llama-3.2-1B-FC-v3
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q2_K.gguf) | Q2_K | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_S.gguf) | Q3_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_M.gguf) | Q3_K_M | 0.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q3_K_L.gguf) | Q3_K_L | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.IQ4_XS.gguf) | IQ4_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q4_K_S.gguf) | Q4_K_S | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q4_K_M.gguf) | Q4_K_M | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q5_K_S.gguf) | Q5_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q5_K_M.gguf) | Q5_K_M | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q6_K.gguf) | Q6_K | 1.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.Q8_0.gguf) | Q8_0 | 1.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-1B-FC-v1.1-think-GGUF/resolve/main/Llama-3.2-1B-FC-v1.1-think.f16.gguf) | f16 | 2.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mehultyagi/classifier_model | mehultyagi | 2025-06-15T18:07:58Z | 0 | 0 | open-clip | [
"open-clip",
"clip",
"medical-imaging",
"image-classification",
"vision-language",
"dermatology",
"license:mit",
"region:us"
] | image-classification | 2025-06-15T17:52:44Z | ---
license: mit
tags:
- clip
- medical-imaging
- image-classification
- vision-language
- dermatology
pipeline_tag: image-classification
library_name: open-clip
---
# CLIP Medical Image Classifier
This is a fine-tuned CLIP model for medical image classification, specifically designed for dermatological applications as part of the DermAgent system.
## Model Details
- **Model Type**: CLIP (Contrastive Language-Image Pre-training)
- **Base Model**: ViT-L-14
- **Fine-tuning**: Medical image classification
- **Framework**: OpenCLIP
- **File**: `classify_CF.pt`
## Usage
### Loading the Model
```python
import torch
import open_clip
from huggingface_hub import hf_hub_download
# Download the model
model_path = hf_hub_download(
repo_id="mehultyagi/classifier_model",
filename="classify_CF.pt"
)
# Load the checkpoint
checkpoint = torch.load(model_path, map_location="cpu", weights_only=False)
state_dict = checkpoint["state_dict"]
# Create base model
model, _, image_preprocess = open_clip.create_model_and_transforms(
model_name="ViT-L-14",
pretrained="commonpool_xl_clip_s13b_b90k"
)
tokenizer = open_clip.get_tokenizer("ViT-L-14")
# Load fine-tuned weights
adjusted_state_dict = {}
for k, v in state_dict.items():
name = k[7:] if k.startswith('module.') else k
adjusted_state_dict[name] = v
model.load_state_dict(adjusted_state_dict, strict=False)
model.eval()
# Move to device
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
```
### Making Predictions
```python
from PIL import Image
# Load and preprocess image
image = Image.open("medical_image.jpg")
image_processed = image_preprocess(image).unsqueeze(0).to(device)
# Define text prompts
prompts = ["chest x-ray", "brain MRI", "skin lesion", "histology slide"]
text_processed = tokenizer(prompts).to(device)
# Get predictions
with torch.no_grad():
image_features = model.encode_image(image_processed)
text_features = model.encode_text(text_processed)
# Normalize features
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
# Calculate similarities
logits_per_image = (100.0 * image_features @ text_features.T)
probs = logits_per_image.softmax(dim=-1)
# Print results
for prompt, prob in zip(prompts, probs.squeeze()):
print(f"{prompt}: {prob:.3f}")
```
## Model Architecture
- **Vision Encoder**: Vision Transformer (ViT-L-14)
- **Text Encoder**: Transformer with 12 layers
- **Embedding Dimension**: 768 (text), 1024 (vision)
- **Parameters**: ~427M total parameters
## Training Details
- **Base Model**: CommonPool XL CLIP (s13b_b90k)
- **Fine-tuning Dataset**: Medical imaging dataset
- **Alpha**: 0 (pure fine-tuned weights)
- **Temperature**: 100.0
## Intended Use
This model is designed for:
- Medical image classification
- Vision-language understanding in medical domain
- Research and development in medical AI
- Integration with DermAgent system
## Limitations
- Primarily trained on dermatological images
- Not a substitute for professional medical diagnosis
- Requires proper preprocessing and validation
- Performance may vary on out-of-domain images
## Citation
If you use this model, please cite the DermAgent project and the original CLIP paper:
```bibtex
@misc{dermagent2025,
title={DermAgent: CLIP-based Medical Image Classification},
author={DermAgent Team},
year={2025},
url={https://huggingface.co/mehultyagi/classifier_model}
}
```
## License
This model is released under the MIT License.
## Contact
For questions and support, please open an issue in the repository.
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_negative_3x3_seed_1_20250615_175706 | gradientrouting-spar | 2025-06-15T18:07:01Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:06:16Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Videos-Parveen-Viral-Video-Link/Full.VIDEO.parvin.Viral.Video.Tutorial.Official | Videos-Parveen-Viral-Video-Link | 2025-06-15T18:06:41Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:05:53Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Baselhany/Graduation_Project_Distil_Whisper_base2 | Baselhany | 2025-06-15T18:04:31Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ar",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2025-06-15T09:49:59Z | ---
library_name: transformers
language:
- ar
license: apache-2.0
base_model: openai/whisper-base
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: Whisper base AR - BA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper base AR - BA
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the quran-ayat-speech-to-text dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1809
- Wer: 0.4774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:----:|:---------------:|:------:|
| 49.0689 | 1.0 | 469 | 0.1955 | 0.6004 |
| 15.5249 | 2.0 | 938 | 0.1855 | 0.4906 |
| 8.4665 | 3.0 | 1407 | 0.1805 | 0.5239 |
| 5.8809 | 4.0 | 1876 | 0.1820 | 0.4664 |
| 4.1184 | 5.0 | 2345 | 0.1855 | 0.4953 |
| 2.9723 | 6.0 | 2814 | 0.1793 | 0.4701 |
| 2.4686 | 7.0 | 3283 | 0.1762 | 0.5146 |
| 2.2442 | 8.0 | 3752 | 0.1725 | 0.4972 |
| 1.8777 | 9.0 | 4221 | 0.1690 | 0.5180 |
| 1.6763 | 10.0 | 4690 | 0.1677 | 0.5093 |
| 1.4913 | 11.0 | 5159 | 0.1676 | 0.5152 |
| 1.3849 | 12.0 | 5628 | 0.1673 | 0.4668 |
| 1.3206 | 13.0 | 6097 | 0.1678 | 0.4551 |
| 1.2612 | 14.0 | 6566 | 0.1677 | 0.4629 |
| 1.1089 | 14.9685 | 7020 | 0.1682 | 0.4769 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
multimolecule/aido.rna-1.6b-ss | multimolecule | 2025-06-15T18:02:50Z | 0 | 0 | multimolecule | [
"multimolecule",
"pytorch",
"safetensors",
"aido.rna",
"Biology",
"RNA",
"rna",
"dataset:multimolecule/bprna-spot",
"dataset:multimolecule/archiveii",
"base_model:multimolecule/aido.rna-1.6b",
"base_model:finetune:multimolecule/aido.rna-1.6b",
"license:agpl-3.0",
"region:us"
] | null | 2025-06-15T17:58:32Z | ---
language: rna
tags:
- Biology
- RNA
license: agpl-3.0
datasets:
- multimolecule/bprna-spot
- multimolecule/archiveii
library_name: multimolecule
base_model: multimolecule/aido.rna-1.6b
---
# AIDO.RNA
Pre-trained model on non-coding RNA (ncRNA) using a masked language modeling (MLM) objective.
## Disclaimer
This is an UNOFFICIAL implementation of the [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345) by Shuxian Zou, Tianhua Tao, Sazan Mahbub, et al.
The OFFICIAL repository of AIDO.RNA is at [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO).
> [!WARNING]
> The MultiMolecule team is aware of a potential risk in reproducing the results of AIDO.RNA.
>
> The original implementation of AIDO.RNA uses a special tokenizer that identifies `U` and `T` as different tokens.
>
> This behaviour is not supported by MultiMolecule.
> [!TIP]
> The MultiMolecule team has confirmed that the provided model and checkpoints are producing the same intermediate representations as the original implementation.
**The team releasing AIDO.RNA did not write this model card for this model so this model card has been written by the MultiMolecule team.**
## Model Details
AIDO.RNA is a [bert](https://huggingface.co/google-bert/bert-base-uncased)-style model pre-trained on a large corpus of non-coding RNA sequences in a self-supervised fashion. This means that the model was trained on the raw nucleotides of RNA sequences only, with an automatic process to generate inputs and labels from those texts. Please refer to the [Training Details](#training-details) section for more information on the training process.
### Variants
- **[multimolecule/aido.rna-1.6b](https://huggingface.co/multimolecule/aido.rna-1.6b)**: The AIDO.RNA model with 1.6 billion parameters.
- **[multimolecule/aido.rna-650m](https://huggingface.co/multimolecule/aido.rna-650m)**: The AIDO.RNA model with 650 million parameters.
### Model Specification
<table>
<thead>
<tr>
<th>Variants</th>
<th>Num Layers</th>
<th>Hidden Size</th>
<th>Num Heads</th>
<th>Intermediate Size</th>
<th>Num Parameters (M)</th>
<th>FLOPs (G)</th>
<th>MACs (G)</th>
<th>Max Num Tokens</th>
</tr>
</thead>
<tbody>
<tr>
<td>AIDO.RNA-1.6B</td>
<td>32</td>
<td>2048</td>
<td>32</td>
<td>5440</td>
<td>1650.29</td>
<td>415.67</td>
<td>207.77</td>
<td rowspan="2">1022</td>
</tr>
<tr>
<td>AIDO.RNA-650M</td>
<td>33</td>
<td>1280</td>
<td>20</td>
<td>3392</td>
<td>648.38</td>
<td>168.25</td>
<td>80.09</td>
</tr>
</tbody>
</table>
### Links
- **Code**: [multimolecule.aido_rna](https://github.com/DLS5-Omics/multimolecule/tree/master/multimolecule/models/aido_rna)
- **Weights**: [multimolecule/aido.rna](https://huggingface.co/multimolecule/aido.rna)
- **Data**: [multimolecule/rnacentral](https://huggingface.co/datasets/multimolecule/rnacentral)
- **Paper**: [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345)
- **Developed by**: Shuxian Zou, Tianhua Tao, Sazan Mahbub, Caleb N. Ellington, Robin Algayres, Dian Li, Yonghao Zhuang, Hongyi Wang, Le Song, Eric P. Xing
- **Model type**: [BERT](https://huggingface.co/google-bert/bert-base-uncased)
- **Original Repository**: [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO)
## Usage
The model file depends on the [`multimolecule`](https://multimolecule.danling.org) library. You can install it using pip:
```bash
pip install multimolecule
```
### Direct Use
You can use this model directly with a pipeline for secondary structure prediction:
```python
>>> import multimolecule # you must import multimolecule to register models
>>> from transformers import pipeline
>>> predictor = pipeline("rna-secondary-structure", model="multimolecule/aido.rna-ss")
>>> predictor("GGUCUCUGGUUAGACCAGAUCUGAGCCU")
{'sequence': 'GGUCUCUGGUUAGACCAGAUCUGAGCCU',
'secondary_structure': '.(((((([(.....).)...].))))).'}
```
### Downstream Use
#### Extract Features
Here is how to use this model to get the features of a given sequence in PyTorch:
```python
from multimolecule import RnaTokenizer, AidoRnaModel
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaModel.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
output = model(**input)
```
#### Sequence Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for sequence classification or regression.
Here is how to use this model as backbone to fine-tune for a sequence-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForSequencePrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForSequencePrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.tensor([1])
output = model(**input, labels=label)
```
#### Token Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for token classification or regression.
Here is how to use this model as backbone to fine-tune for a nucleotide-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForTokenPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForTokenPrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), ))
output = model(**input, labels=label)
```
#### Contact Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for contact classification or regression.
Here is how to use this model as backbone to fine-tune for a contact-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForContactPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-ss")
model = AidoRnaForContactPrediction.from_pretrained("multimolecule/aido.rna-ss")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), len(text)))
output = model(**input, labels=label)
```
## Training Details
AIDO.RNA used Masked Language Modeling (MLM) as the pre-training objective: taking a sequence, the model randomly masks 15% of the tokens in the input then runs the entire masked sentence through the model and has to predict the masked tokens. This is comparable to the Cloze task in language modeling.
### Training Data
The AIDO.RNA model was pre-trained on [RNAcentral](https://multimolecule.danling.org/datasets/rnacentral) and [MARS](https://ngdc.cncb.ac.cn/omix/release/OMIX003037).
RNAcentral is a free, public resource that offers integrated access to a comprehensive and up-to-date set of non-coding RNA sequences provided by a collaborating group of [Expert Databases](https://rnacentral.org/expert-databases) representing a broad range of organisms and RNA types.
AIDO.RNA applied SeqKit to remove duplicated sequences in the RNAcentral, resulting 42 million unique sequences.
Note that AIDO.RNA identifies `U` and `T` as different tokens, which is not supported by MultiMolecule. During model conversion, the embeddings of `T` is discarded. This means that the model will not be able to distinguish between `U` and `T` in the input sequences.
### Training Procedure
#### Preprocessing
AIDO.RNA used masked language modeling (MLM) as the pre-training objective. The masking procedure is similar to the one used in BERT:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
#### Pre-training
- Epochs: 6
- Optimizer: AdamW
- Learning rate: 5e-5
- Learning rate warm-up: 2,000 steps
- Learning rate scheduler: Cosine
- Minimum learning rate: 1e-5
- Weight decay: 0.01
## Citation
**BibTeX**:
```bibtex
@article {Zou2024.11.28.625345,
author = {Zou, Shuxian and Tao, Tianhua and Mahbub, Sazan and Ellington, Caleb N. and Algayres, Robin and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Song, Le and Xing, Eric P.},
title = {A Large-Scale Foundation Model for RNA Function and Structure Prediction},
elocation-id = {2024.11.28.625345},
year = {2024},
doi = {10.1101/2024.11.28.625345},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Originally marginalized as an intermediate in the information flow from DNA to protein, RNA has become the star of modern biology, holding the key to precision therapeutics, genetic engineering, evolutionary origins, and our understanding of fundamental cellular processes. Yet RNA is as mysterious as it is prolific, serving as an information store, a messenger, and a catalyst, spanning many underchar-acterized functional and structural classes. Deciphering the language of RNA is important not only for a mechanistic understanding of its biological functions but also for accelerating drug design. Toward this goal, we introduce AIDO.RNA, a pre-trained module for RNA in an AI-driven Digital Organism [1]. AIDO.RNA contains a scale of 1.6 billion parameters, trained on 42 million non-coding RNA (ncRNA) sequences at single-nucleotide resolution, and it achieves state-of-the-art performance on a comprehensive set of tasks, including structure prediction, genetic regulation, molecular function across species, and RNA sequence design. AIDO.RNA after domain adaptation learns to model essential parts of protein translation that protein language models, which have received widespread attention in recent years, do not. More broadly, AIDO.RNA hints at the generality of biological sequence modeling and the ability to leverage the central dogma to improve many biomolecular representations. Models and code are available through ModelGenerator in https://github.com/genbio-ai/AIDO and on Hugging Face.Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345},
eprint = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345.full.pdf},
journal = {bioRxiv}
}
```
## Contact
Please use GitHub issues of [MultiMolecule](https://github.com/DLS5-Omics/multimolecule/issues) for any questions or comments on the model card.
Please contact the authors of the [AIDO.RNA paper](https://doi.org/10.1101/2024.11.28.625345) for questions or comments on the paper/model.
## License
This model is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html).
```spdx
SPDX-License-Identifier: AGPL-3.0-or-later
```
|
Peacemann/mistralai_Mistral-7B-Instruct-v0.2_LMUL | Peacemann | 2025-06-15T18:02:43Z | 0 | 0 | null | [
"safetensors",
"mistral",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.2",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T17:56:57Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-Instruct-v0.2
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
---
# L-Mul Optimized: mistralai/Mistral-7B-Instruct-v0.2
This is a modified version of Mistral AI's [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `mistralai/Mistral-7B-Instruct-v0.2` is preserved. However, the standard `MistralAttention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/mistralai_Mistral-7B-Instruct-v0.2-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Apache 2.0 License**. By using this model, you agree to the terms outlined in the license. |
mic3456/anneth | mic3456 | 2025-06-15T18:01:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:00:54Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: ath
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# annehathaway2
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `ath` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
parveen-Official-Viral-Video-Link/18.Original.Full.Clip.parveen.Viral.Video.Leaks.Official | parveen-Official-Viral-Video-Link | 2025-06-15T18:00:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:59:49Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1505 | utkuden | 2025-06-15T17:58:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:58:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Peacemann/google_gemma-3-4b-it_LMUL | Peacemann | 2025-06-15T17:58:32Z | 0 | 0 | null | [
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"license:gemma",
"region:us"
] | text-generation | 2025-06-15T17:55:58Z | ---
base_model: google/gemma-3-4b-it
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
license: gemma
---
# L-Mul Optimized: google/gemma-3-4b-it
This is a modified version of Google's [gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `google/gemma-3-4b-it` is preserved. However, the standard `Gemma3Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/google_gemma-3-4b-it-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Gemma 3 Community License**. By using this model, you agree to the terms outlined in the license. |
yalhessi/lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2 | yalhessi | 2025-06-15T17:56:54Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:deepseek-ai/deepseek-coder-1.3b-base",
"base_model:adapter:deepseek-ai/deepseek-coder-1.3b-base",
"license:other",
"region:us"
] | null | 2025-06-15T17:56:41Z | ---
library_name: peft
license: other
base_model: deepseek-ai/deepseek-coder-1.3b-base
tags:
- generated_from_trainer
model-index:
- name: lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-base](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0008
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 12
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.5096 | 0.2 | 3094 | 0.5142 |
| 0.4699 | 0.4 | 6188 | 0.4815 |
| 0.4503 | 0.6 | 9282 | 0.4479 |
| 0.4359 | 0.8 | 12376 | 0.4406 |
| 0.4266 | 1.0 | 15470 | 0.4249 |
| 0.4181 | 1.2 | 18564 | 0.4146 |
| 0.4126 | 1.4 | 21658 | 0.4122 |
| 0.4076 | 1.6 | 24752 | 0.4043 |
| 0.4022 | 1.8 | 27846 | 0.4012 |
| 0.3969 | 2.0 | 30940 | 0.3975 |
| 0.3874 | 2.2 | 34034 | 0.3964 |
| 0.3865 | 2.4 | 37128 | 0.3813 |
| 0.379 | 2.6 | 40222 | 0.3783 |
| 0.3772 | 2.8 | 43316 | 0.3750 |
| 0.3735 | 3.0 | 46410 | 0.3765 |
| 0.3637 | 3.2 | 49504 | 0.3659 |
| 0.3669 | 3.4 | 52598 | 0.3610 |
| 0.3577 | 3.6 | 55692 | 0.3615 |
| 0.3578 | 3.8 | 58786 | 0.3567 |
| 0.3563 | 4.0 | 61880 | 0.3510 |
| 0.3442 | 4.2 | 64974 | 0.3461 |
| 0.3403 | 4.4 | 68068 | 0.3428 |
| 0.3385 | 4.6 | 71162 | 0.3442 |
| 0.3309 | 4.8 | 74256 | 0.3399 |
| 0.3271 | 5.0 | 77350 | 0.3290 |
| 0.3225 | 5.2 | 80444 | 0.3299 |
| 0.3241 | 5.4 | 83538 | 0.3253 |
| 0.321 | 5.6 | 86632 | 0.3258 |
| 0.3168 | 5.8 | 89726 | 0.3225 |
| 0.3117 | 6.0 | 92820 | 0.3182 |
| 0.2992 | 6.2 | 95914 | 0.3187 |
| 0.2985 | 6.4 | 99008 | 0.3104 |
| 0.2975 | 6.6 | 102102 | 0.3072 |
| 0.3021 | 6.8 | 105196 | 0.3018 |
| 0.2921 | 7.0 | 108290 | 0.3012 |
| 0.2807 | 7.2 | 111384 | 0.2967 |
| 0.2758 | 7.4 | 114478 | 0.2962 |
| 0.2807 | 7.6 | 117572 | 0.2932 |
| 0.2786 | 7.8 | 120666 | 0.2901 |
| 0.2778 | 8.0 | 123760 | 0.2846 |
| 0.2632 | 8.2 | 126854 | 0.2863 |
| 0.262 | 8.4 | 129948 | 0.2809 |
| 0.2611 | 8.6 | 133042 | 0.2828 |
| 0.2648 | 8.8 | 136136 | 0.2762 |
| 0.2632 | 9.0 | 139230 | 0.2730 |
| 0.2461 | 9.2 | 142324 | 0.2676 |
| 0.2443 | 9.4 | 145418 | 0.2669 |
| 0.2435 | 9.6 | 148512 | 0.2655 |
| 0.2431 | 9.8 | 151606 | 0.2631 |
| 0.2379 | 10.0 | 154700 | 0.2599 |
| 0.2275 | 10.2 | 157794 | 0.2583 |
| 0.2281 | 10.4 | 160888 | 0.2570 |
| 0.2243 | 10.6 | 163982 | 0.2530 |
| 0.2222 | 10.8 | 167076 | 0.2541 |
| 0.2219 | 11.0 | 170170 | 0.2494 |
| 0.2112 | 11.2 | 173264 | 0.2495 |
| 0.2077 | 11.4 | 176358 | 0.2471 |
| 0.2065 | 11.6 | 179452 | 0.2451 |
| 0.2029 | 11.8 | 182546 | 0.2432 |
| 0.2073 | 12.0 | 185640 | 0.2426 |
### Framework versions
- PEFT 0.14.0
- Transformers 4.47.0
- Pytorch 2.5.1+cu124
- Datasets 3.2.0
- Tokenizers 0.21.0 |
meezo-fun-20/20.Video.meezo.fun.trending.viral.Full.Video | meezo-fun-20 | 2025-06-15T17:56:41Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:56:04Z | <a rel="nofollow" href="https://viralflix.xyz/leaked/?sd">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?sd"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://anyplacecoming.com/zq5yqv0i?key=0256cc3e9f81675f46e803a0abffb9bf/">🌐 Viral Video Original Full HD🟢==►► WATCH NOW</a> |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.75_epoch1 | MinaMila | 2025-06-15T17:54:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:52:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
18-VIDEOS-Shubham-gupta-viral-Video-link/Hot.Video.tutorial.Shubham.gupta.Viral.Video.Leaks.Official | 18-VIDEOS-Shubham-gupta-viral-Video-link | 2025-06-15T17:50:11Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:49:39Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
arunmadhusudh/qwen2_VL_2B_LatexOCR_qlora_qptq_epoch3 | arunmadhusudh | 2025-06-15T17:49:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:49:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
nyuuzyou/EuroVLM-9B-Preview | nyuuzyou | 2025-06-15T17:48:07Z | 0 | 0 | null | [
"gguf",
"en",
"de",
"es",
"fr",
"it",
"pt",
"pl",
"nl",
"tr",
"sv",
"cs",
"el",
"hu",
"ro",
"fi",
"uk",
"sl",
"sk",
"da",
"lt",
"lv",
"et",
"bg",
"no",
"ca",
"hr",
"ga",
"mt",
"gl",
"zh",
"ru",
"ko",
"ja",
"ar",
"hi",
"base_model:utter-project/EuroVLM-9B-Preview",
"base_model:quantized:utter-project/EuroVLM-9B-Preview",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-15T17:13:27Z | ---
license: apache-2.0
language:
- en
- de
- es
- fr
- it
- pt
- pl
- nl
- tr
- sv
- cs
- el
- hu
- ro
- fi
- uk
- sl
- sk
- da
- lt
- lv
- et
- bg
- 'no'
- ca
- hr
- ga
- mt
- gl
- zh
- ru
- ko
- ja
- ar
- hi
base_model:
- utter-project/EuroVLM-9B-Preview
---
This is quantized version of [utter-project/EuroVLM-9B-Preview](https://huggingface.co/utter-project/EuroVLM-9B-Preview) created using [llama.cpp](https://github.com/ggml-org/llama.cpp)
|
TOMFORD79/tornado2 | TOMFORD79 | 2025-06-15T17:46:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:35:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/tornado1 | TOMFORD79 | 2025-06-15T17:46:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:35:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kimxxxx/mistral_r64_a128_g8_gas8_lr9e-5_4500tk_droplast_nopacking_2epoch | kimxxxx | 2025-06-15T17:45:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:45:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
SaNsOT/q-Taxi-v3 | SaNsOT | 2025-06-15T17:41:40Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:41:36Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.76
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="SaNsOT/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
arjelmilan/qwen2-Image-to-LaTeX | arjelmilan | 2025-06-15T17:41:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2_vl",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:40:55Z | ---
base_model: unsloth/qwen2-vl-7b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** arjelmilan
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2-vl-7b-instruct-unsloth-bnb-4bit
This qwen2_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
SaNsOT/q-FrozenLake-v1-4x4-noSlippery | SaNsOT | 2025-06-15T17:39:24Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:39:20Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SaNsOT/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Abhinit/HW2-supervised | Abhinit | 2025-06-15T17:38:42Z | 188 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-05T01:38:31Z | ---
base_model: openai-community/gpt2
library_name: transformers
model_name: HW2-supervised
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for HW2-supervised
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Abhinit/HW2-supervised", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.51.3
- Pytorch: 2.2.2
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
coffeetime81/flux_lea69 | coffeetime81 | 2025-06-15T17:38:17Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T17:14:25Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK
---
# Flux_Lea69
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK",
"lora_weights": "https://huggingface.co/coffeetime81/flux_lea69/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('coffeetime81/flux_lea69', weight_name='lora.safetensors')
image = pipeline('TOK').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1500
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/coffeetime81/flux_lea69/discussions) to add images that show off what you’ve made with this LoRA.
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_20250615_172745 | gradientrouting-spar | 2025-06-15T17:37:06Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:36:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Cikgu-Fadhilah-Video-Viral-Official/18.VIDEO.Cikgu.Fadhilah.Viral.Video.Official.link | Cikgu-Fadhilah-Video-Viral-Official | 2025-06-15T17:35:47Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:34:51Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1442 | utkuden | 2025-06-15T17:34:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:34:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Seelt/nllb-200-distilled-600M-Shughni-v1 | Seelt | 2025-06-15T17:34:29Z | 0 | 0 | null | [
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-06-15T17:34:29Z | ---
license: cc-by-nc-4.0
---
|
carolinamendes3401/aure | carolinamendes3401 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
teresapinheiro1254/ed | teresapinheiro1254 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
williamcunha6294/hgr | williamcunha6294 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
yasminmaia3967/as | yasminmaia3967 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
freakyfractal/otang | freakyfractal | 2025-06-15T17:30:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | text-to-image | 2025-06-15T17:29:39Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/Coinye_2021.jpg
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: null
---
# otang
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/freakyfractal/otang/tree/main) them in the Files & versions tab.
|
Megha06/q-FrozenLake-v1-4x4-noSlippery | Megha06 | 2025-06-15T17:29:07Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:29:05Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Megha06/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF | mradermacher | 2025-06-15T17:28:15Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama-factory",
"full",
"generated_from_trainer",
"en",
"base_model:mlfoundations-dev/QwQ-32B_openthoughts3_100k",
"base_model:quantized:mlfoundations-dev/QwQ-32B_openthoughts3_100k",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-15T12:40:33Z | ---
base_model: mlfoundations-dev/QwQ-32B_openthoughts3_100k
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- llama-factory
- full
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/mlfoundations-dev/QwQ-32B_openthoughts3_100k
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_20250615_171811 | gradientrouting-spar | 2025-06-15T17:27:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:27:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
CodeAid/solid_model_v1 | CodeAid | 2025-06-15T17:24:04Z | 10 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"llama-factory",
"lora",
"generated_from_trainer",
"custom_code",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-14B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-06-11T15:47:40Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen2.5-14B-Instruct
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: solid_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# solid_model
This model is a fine-tuned version of [Qwen/Qwen2.5-14B-Instruct](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) on the solidDetection_finetune_train dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3756
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.5094 | 0.1952 | 100 | 0.4181 |
| 0.4663 | 0.3904 | 200 | 0.3911 |
| 0.4742 | 0.5857 | 300 | 0.3904 |
| 0.4678 | 0.7809 | 400 | 0.3772 |
| 0.442 | 0.9761 | 500 | 0.3705 |
| 0.3561 | 1.1718 | 600 | 0.3618 |
| 0.3323 | 1.3670 | 700 | 0.3516 |
| 0.3394 | 1.5622 | 800 | 0.3499 |
| 0.3549 | 1.7574 | 900 | 0.3382 |
| 0.3353 | 1.9527 | 1000 | 0.3380 |
| 0.2245 | 2.1464 | 1100 | 0.3625 |
| 0.1903 | 2.3416 | 1200 | 0.3585 |
| 0.1557 | 2.5349 | 1300 | 0.3751 |
| 0.179 | 2.7301 | 1400 | 0.3745 |
| 0.1679 | 2.9253 | 1500 | 0.3758 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.4
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1 |
Salmaalaa/CodeLlama-7b-Instruct_AR2SQL_v7 | Salmaalaa | 2025-06-15T17:23:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:codellama/CodeLlama-7b-Instruct-hf",
"base_model:finetune:codellama/CodeLlama-7b-Instruct-hf",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:04:39Z | ---
base_model: codellama/CodeLlama-7b-Instruct-hf
library_name: transformers
model_name: CodeLlama-7b-Instruct_AR2SQL_v7
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for CodeLlama-7b-Instruct_AR2SQL_v7
This model is a fine-tuned version of [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Salmaalaa/CodeLlama-7b-Instruct_AR2SQL_v7", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.51.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
phucminh/deepseek-finetuned | phucminh | 2025-06-15T17:23:10Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-15T17:20:42Z | ---
base_model: unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** phucminh
- **License:** apache-2.0
- **Finetuned from model :** unsloth/deepseek-r1-distill-llama-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.15_epoch1 | MinaMila | 2025-06-15T17:21:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:19:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
soumitsr/long-t5-base-article-digestor | soumitsr | 2025-06-15T17:20:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"longt5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2025-06-15T17:19:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3 | BootesVoid | 2025-06-15T17:19:35Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T17:19:32Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LIA
---
# Cmbxw5Hwe026Prdqs26Dxpx82_Cmbxwj8U6027Erdqsjl8044R3
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `LIA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LIA",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3', weight_name='lora.safetensors')
image = pipeline('LIA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3/discussions) to add images that show off what you’ve made with this LoRA.
|
mic3456/bambi2 | mic3456 | 2025-06-15T17:15:35Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T17:15:28Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: bambi
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# bambitwo
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `bambi` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
iconitech/nfl-scouting-expert-v1 | iconitech | 2025-06-15T17:15:00Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:41",
"loss:TripletLoss",
"arxiv:1908.10084",
"arxiv:1703.07737",
"base_model:sentence-transformers/all-mpnet-base-v2",
"base_model:finetune:sentence-transformers/all-mpnet-base-v2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-06-15T15:35:38Z | ---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:41
- loss:TripletLoss
base_model: sentence-transformers/all-mpnet-base-v2
widget:
- source_sentence: elite ball production DB
sentences:
- rarely gets his head around and allows catches in phase
- times his breaks and plucks interceptions away from receivers
- sprays throws and forces receivers to adjust behind them
- source_sentence: vision and patience RB
sentences:
- hamstring tweaks kept him out of key practices each year
- gets impatient and bounces, resulting in no gain
- presses hole, forces defender to commit, then explodes through the gap
- source_sentence: turn and run fluidity
sentences:
- overthrows wide-open seams and turf short hooks
- effortlessly flips, locates, and finishes with secure hands
- tight lower half leads to contact catches
- source_sentence: excellent run instincts
sentences:
- click-and-close burst plus natural hands yield PBUs
- string of efficient decisions keeps offense on schedule
- hesitates and wastes steps, leading to tackles for loss
- source_sentence: corner with fluid hips
sentences:
- opens and flips seamlessly to carry verticals while tracking ball
- praised for leadership and A+ character
- stiff in transition and loses body control at catch point
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) <!-- at revision 12e86a3c702fc3c50205a8db88f0ec7c0b6b94a0 -->
- **Maximum Sequence Length:** 384 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'corner with fluid hips',
'opens and flips seamlessly to carry verticals while tracking ball',
'stiff in transition and loses body control at catch point',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 41 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>sentence_2</code>
* Approximate statistics based on the first 41 samples:
| | sentence_0 | sentence_1 | sentence_2 |
|:--------|:--------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 6.46 tokens</li><li>max: 9 tokens</li></ul> | <ul><li>min: 9 tokens</li><li>mean: 12.78 tokens</li><li>max: 20 tokens</li></ul> | <ul><li>min: 7 tokens</li><li>mean: 11.17 tokens</li><li>max: 15 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 | sentence_2 |
|:---------------------------------------------|:-----------------------------------------------------------------------------------------|:-----------------------------------------------------------------|
| <code>throws with effortless velocity</code> | <code>ball jumps off his hand and arrives to tight windows before defenders react</code> | <code>passes hang in the air and allow DBs to close</code> |
| <code>persistent soft-tissue injuries</code> | <code>hamstring tweaks kept him out of key practices each year</code> | <code>has never appeared on the injury report</code> |
| <code>injury prone track record</code> | <code>three different surgeries in college raise red flags</code> | <code>medical checks came back clean with no missed games</code> |
* Loss: [<code>TripletLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#tripletloss) with these parameters:
```json
{
"distance_metric": "TripletDistanceMetric.EUCLIDEAN",
"triplet_margin": 5
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 1
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Framework Versions
- Python: 3.13.4
- Sentence Transformers: 4.1.0
- Transformers: 4.52.4
- PyTorch: 2.7.1
- Accelerate: 1.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### TripletLoss
```bibtex
@misc{hermans2017defense,
title={In Defense of the Triplet Loss for Person Re-Identification},
author={Alexander Hermans and Lucas Beyer and Bastian Leibe},
year={2017},
eprint={1703.07737},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
xkdl27/SFT_tuned_cell_annotation_LLM | xkdl27 | 2025-06-15T17:14:43Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"base_model:quantized:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2025-06-15T17:03:16Z | ---
base_model: unsloth/Qwen3-8B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** xkdl27
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-8B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
LaaP-ai/donut-base-invoicev3 | LaaP-ai | 2025-06-15T17:13:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"base_model:naver-clova-ix/donut-base",
"base_model:finetune:naver-clova-ix/donut-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-06-15T17:12:58Z | ---
library_name: transformers
license: mit
base_model: naver-clova-ix/donut-base
tags:
- generated_from_trainer
model-index:
- name: donut-base-invoicev3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-invoicev3
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1361 | utkuden | 2025-06-15T17:11:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:11:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
phospho-app/thellador-ACT_BBOX-example_dataset1-rfgom | phospho-app | 2025-06-15T17:10:16Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"act",
"region:us"
] | null | 2025-06-15T16:45:50Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [phospho-app/example_dataset1_bboxes](https://huggingface.co/datasets/phospho-app/example_dataset1_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_20250615_165852 | gradientrouting-spar | 2025-06-15T17:08:21Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:08:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
phospho-app/kaykhi-gr00t-pickup_first_test2-77cay | phospho-app | 2025-06-15T17:04:32Z | 0 | 0 | null | [
"safetensors",
"gr00t_n1",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-15T16:25:23Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [kaykhi/pickup_first_test2](https://huggingface.co/datasets/kaykhi/pickup_first_test2)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 49
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Subsets and Splits