
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-02 12:29:30
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 548
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-02 12:29:18
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
TheBloke/deepseek-coder-6.7B-instruct-GGUF
|
TheBloke
| 2023-11-05T16:43:41Z | 63,762 | 188 |
transformers
|
[
"transformers",
"gguf",
"deepseek",
"base_model:deepseek-ai/deepseek-coder-6.7b-instruct",
"base_model:quantized:deepseek-ai/deepseek-coder-6.7b-instruct",
"license:other",
"region:us"
] | null | 2023-11-05T13:36:03Z |
---
base_model: deepseek-ai/deepseek-coder-6.7b-instruct
inference: false
license: other
license_link: LICENSE
license_name: deepseek
model_creator: DeepSeek
model_name: Deepseek Coder 6.7B Instruct
model_type: deepseek
prompt_template: 'You are an AI programming assistant, utilizing the Deepseek Coder
model, developed by Deepseek Company, and you only answer questions related to computer
science. For politically sensitive questions, security and privacy issues, and other
non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 6.7B Instruct - GGUF
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 6.7B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct)
<!-- description start -->
## Description
This repo contains GGUF format model files for [DeepSeek's Deepseek Coder 6.7B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: DeepSeek
```
You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [deepseek-coder-6.7b-instruct.Q2_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [deepseek-coder-6.7b-instruct.Q3_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [deepseek-coder-6.7b-instruct.Q3_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [deepseek-coder-6.7b-instruct.Q3_K_L.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [deepseek-coder-6.7b-instruct.Q4_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [deepseek-coder-6.7b-instruct.Q4_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [deepseek-coder-6.7b-instruct.Q4_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [deepseek-coder-6.7b-instruct.Q5_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [deepseek-coder-6.7b-instruct.Q5_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [deepseek-coder-6.7b-instruct.Q5_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q5_K_M.gguf) | Q5_K_M | 5 | 4.79 GB| 7.29 GB | large, very low quality loss - recommended |
| [deepseek-coder-6.7b-instruct.Q6_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [deepseek-coder-6.7b-instruct.Q8_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF/blob/main/deepseek-coder-6.7b-instruct.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/deepseek-coder-6.7B-instruct-GGUF and below it, a specific filename to download, such as: deepseek-coder-6.7b-instruct.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GGUF deepseek-coder-6.7b-instruct.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GGUF deepseek-coder-6.7b-instruct.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m deepseek-coder-6.7b-instruct.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.\n### Instruction:\n{prompt}\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/deepseek-coder-6.7B-instruct-GGUF", model_file="deepseek-coder-6.7b-instruct.Q4_K_M.gguf", model_type="deepseek", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: DeepSeek's Deepseek Coder 6.7B Instruct
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch fon 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-6.7b-instruct is a 6.7B parameter model initialized from deepseek-coder-6.7b-base and fine-tuned on 2B tokens of instruction data.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
<!-- original-model-card end -->
|
TheBloke/deepseek-coder-1.3b-instruct-GGUF
|
TheBloke
| 2023-11-05T16:38:23Z | 32,098 | 34 |
transformers
|
[
"transformers",
"gguf",
"deepseek",
"base_model:deepseek-ai/deepseek-coder-1.3b-instruct",
"base_model:quantized:deepseek-ai/deepseek-coder-1.3b-instruct",
"license:other",
"region:us"
] | null | 2023-11-05T13:15:17Z |
---
base_model: deepseek-ai/deepseek-coder-1.3b-instruct
inference: false
license: other
license_link: LICENSE
license_name: deepseek
model_creator: DeepSeek
model_name: Deepseek Coder 1.3B Instruct
model_type: deepseek
prompt_template: 'You are an AI programming assistant, utilizing the Deepseek Coder
model, developed by Deepseek Company, and you only answer questions related to computer
science. For politically sensitive questions, security and privacy issues, and other
non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 1.3B Instruct - GGUF
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 1.3B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct)
<!-- description start -->
## Description
This repo contains GGUF format model files for [DeepSeek's Deepseek Coder 1.3B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: DeepSeek
```
You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [deepseek-coder-1.3b-instruct.Q2_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q2_K.gguf) | Q2_K | 2 | 0.63 GB| 3.13 GB | smallest, significant quality loss - not recommended for most purposes |
| [deepseek-coder-1.3b-instruct.Q3_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q3_K_S.gguf) | Q3_K_S | 3 | 0.66 GB| 3.16 GB | very small, high quality loss |
| [deepseek-coder-1.3b-instruct.Q3_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q3_K_M.gguf) | Q3_K_M | 3 | 0.70 GB| 3.20 GB | very small, high quality loss |
| [deepseek-coder-1.3b-instruct.Q3_K_L.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q3_K_L.gguf) | Q3_K_L | 3 | 0.74 GB| 3.24 GB | small, substantial quality loss |
| [deepseek-coder-1.3b-instruct.Q4_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q4_0.gguf) | Q4_0 | 4 | 0.78 GB| 3.28 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [deepseek-coder-1.3b-instruct.Q4_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q4_K_S.gguf) | Q4_K_S | 4 | 0.81 GB| 3.31 GB | small, greater quality loss |
| [deepseek-coder-1.3b-instruct.Q4_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q4_K_M.gguf) | Q4_K_M | 4 | 0.87 GB| 3.37 GB | medium, balanced quality - recommended |
| [deepseek-coder-1.3b-instruct.Q5_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q5_0.gguf) | Q5_0 | 5 | 0.94 GB| 3.44 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [deepseek-coder-1.3b-instruct.Q5_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q5_K_S.gguf) | Q5_K_S | 5 | 0.95 GB| 3.45 GB | large, low quality loss - recommended |
| [deepseek-coder-1.3b-instruct.Q5_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q5_K_M.gguf) | Q5_K_M | 5 | 1.00 GB| 3.50 GB | large, very low quality loss - recommended |
| [deepseek-coder-1.3b-instruct.Q6_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q6_K.gguf) | Q6_K | 6 | 1.17 GB| 3.67 GB | very large, extremely low quality loss |
| [deepseek-coder-1.3b-instruct.Q8_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF/blob/main/deepseek-coder-1.3b-instruct.Q8_0.gguf) | Q8_0 | 8 | 1.43 GB| 3.93 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/deepseek-coder-1.3b-instruct-GGUF and below it, a specific filename to download, such as: deepseek-coder-1.3b-instruct.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GGUF deepseek-coder-1.3b-instruct.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GGUF deepseek-coder-1.3b-instruct.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m deepseek-coder-1.3b-instruct.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.\n### Instruction:\n{prompt}\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/deepseek-coder-1.3b-instruct-GGUF", model_file="deepseek-coder-1.3b-instruct.Q4_K_M.gguf", model_type="deepseek", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: DeepSeek's Deepseek Coder 1.3B Instruct
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-1.3b-instruct is a 1.3B parameter model initialized from deepseek-coder-1.3b-base and fine-tuned on 2B tokens of instruction data.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-1.3b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-1.3b-instruct", trust_remote_code=True).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
<!-- original-model-card end -->
|
TheBloke/deepseek-coder-1.3b-instruct-GPTQ
|
TheBloke
| 2023-11-05T16:33:10Z | 245 | 6 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"base_model:deepseek-ai/deepseek-coder-1.3b-instruct",
"base_model:quantized:deepseek-ai/deepseek-coder-1.3b-instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-05T04:25:59Z |
---
base_model: deepseek-ai/deepseek-coder-1.3b-instruct
inference: false
license: other
license_link: LICENSE
license_name: deepseek
model_creator: DeepSeek
model_name: Deepseek Coder 1.3B Instruct
model_type: deepseek
prompt_template: 'You are an AI programming assistant, utilizing the Deepseek Coder
model, developed by Deepseek Company, and you only answer questions related to computer
science. For politically sensitive questions, security and privacy issues, and other
non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 1.3B Instruct - GPTQ
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 1.3B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct)
<!-- description start -->
## Description
This repo contains GPTQ model files for [DeepSeek's Deepseek Coder 1.3B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-instruct)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: DeepSeek
```
You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 0.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 0.97 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 1.48 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 1.51 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 1.60 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 8192 | 0.92 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/deepseek-coder-1.3b-instruct-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/deepseek-coder-1.3b-instruct-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `deepseek-coder-1.3b-instruct-GPTQ`:
```shell
mkdir deepseek-coder-1.3b-instruct-GPTQ
huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GPTQ --local-dir deepseek-coder-1.3b-instruct-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir deepseek-coder-1.3b-instruct-GPTQ
huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir deepseek-coder-1.3b-instruct-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir deepseek-coder-1.3b-instruct-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-1.3b-instruct-GPTQ --local-dir deepseek-coder-1.3b-instruct-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/deepseek-coder-1.3b-instruct-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/deepseek-coder-1.3b-instruct-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/deepseek-coder-1.3b-instruct-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `deepseek-coder-1.3b-instruct-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/deepseek-coder-1.3b-instruct-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/deepseek-coder-1.3b-instruct-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: DeepSeek's Deepseek Coder 1.3B Instruct
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-1.3b-instruct is a 1.3B parameter model initialized from deepseek-coder-1.3b-base and fine-tuned on 2B tokens of instruction data.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-1.3b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-1.3b-instruct", trust_remote_code=True).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
TheBloke/deepseek-coder-6.7B-instruct-GPTQ
|
TheBloke
| 2023-11-05T16:32:39Z | 463 | 24 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"base_model:deepseek-ai/deepseek-coder-6.7b-instruct",
"base_model:quantized:deepseek-ai/deepseek-coder-6.7b-instruct",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-05T10:13:45Z |
---
base_model: deepseek-ai/deepseek-coder-6.7b-instruct
inference: false
license: other
license_link: LICENSE
license_name: deepseek
model_creator: DeepSeek
model_name: Deepseek Coder 6.7B Instruct
model_type: deepseek
prompt_template: 'You are an AI programming assistant, utilizing the Deepseek Coder
model, developed by Deepseek Company, and you only answer questions related to computer
science. For politically sensitive questions, security and privacy issues, and other
non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 6.7B Instruct - GPTQ
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 6.7B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct)
<!-- description start -->
## Description
This repo contains GPTQ model files for [DeepSeek's Deepseek Coder 6.7B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: DeepSeek
```
You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.02 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.62 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.03 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/deepseek-coder-6.7B-instruct-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/deepseek-coder-6.7B-instruct-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `deepseek-coder-6.7B-instruct-GPTQ`:
```shell
mkdir deepseek-coder-6.7B-instruct-GPTQ
huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GPTQ --local-dir deepseek-coder-6.7B-instruct-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir deepseek-coder-6.7B-instruct-GPTQ
huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir deepseek-coder-6.7B-instruct-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir deepseek-coder-6.7B-instruct-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-6.7B-instruct-GPTQ --local-dir deepseek-coder-6.7B-instruct-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/deepseek-coder-6.7B-instruct-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/deepseek-coder-6.7B-instruct-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/deepseek-coder-6.7B-instruct-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `deepseek-coder-6.7B-instruct-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/deepseek-coder-6.7B-instruct-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/deepseek-coder-6.7B-instruct-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, and other non-computer science questions, you will refuse to answer.
### Instruction:
{prompt}
### Response:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: DeepSeek's Deepseek Coder 6.7B Instruct
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch fon 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-6.7b-instruct is a 6.7B parameter model initialized from deepseek-coder-6.7b-base and fine-tuned on 2B tokens of instruction data.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
minhnb/ssbc_model_spearman
|
minhnb
| 2023-11-05T16:29:21Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-29T07:18:00Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: minhnb/ssbc_model_spearman
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# minhnb/ssbc_model_spearman
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0819
- Validation Loss: 0.2328
- Train Spearmanr: 0.8350
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 4960, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Spearmanr | Epoch |
|:----------:|:---------------:|:---------------:|:-----:|
| 0.8155 | 0.3068 | 0.7769 | 0 |
| 0.2629 | 0.2419 | 0.8209 | 1 |
| 0.2026 | 0.2604 | 0.8161 | 2 |
| 0.1684 | 0.2323 | 0.8264 | 3 |
| 0.1375 | 0.2442 | 0.8282 | 4 |
| 0.1186 | 0.2473 | 0.8334 | 5 |
| 0.1055 | 0.2452 | 0.8328 | 6 |
| 0.0947 | 0.2258 | 0.8347 | 7 |
| 0.0890 | 0.2347 | 0.8335 | 8 |
| 0.0819 | 0.2328 | 0.8350 | 9 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Jaeyunn/sw-bert-fine-tuned
|
Jaeyunn
| 2023-11-05T16:27:18Z | 0 | 0 |
keras
|
[
"keras",
"tf-keras",
"text-classification",
"region:us"
] |
text-classification
| 2023-11-05T07:17:36Z |
---
library_name: keras
tags:
- text-classification
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| name | Adam |
| weight_decay | None |
| clipnorm | None |
| global_clipnorm | None |
| clipvalue | None |
| use_ema | False |
| ema_momentum | 0.99 |
| ema_overwrite_frequency | None |
| jit_compile | True |
| is_legacy_optimizer | False |
| learning_rate | 4.999999873689376e-05 |
| beta_1 | 0.9 |
| beta_2 | 0.999 |
| epsilon | 1e-08 |
| amsgrad | False |
| training_precision | float32 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
aleix8/Reinforce-Pixelcopter-PLE-v0
|
aleix8
| 2023-11-05T16:26:37Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T16:26:32Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 57.20 +/- 49.29
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
hichamH/fine-tuned-distilbert-base-uncased
|
hichamH
| 2023-11-05T16:26:17Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"camembert",
"text-classification",
"generated_from_trainer",
"base_model:cmarkea/distilcamembert-base-sentiment",
"base_model:finetune:cmarkea/distilcamembert-base-sentiment",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-04T22:46:54Z |
---
license: mit
base_model: cmarkea/distilcamembert-base-sentiment
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: fine-tuned-distilbert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tuned-distilbert-base-uncased
This model is a fine-tuned version of [cmarkea/distilcamembert-base-sentiment](https://huggingface.co/cmarkea/distilcamembert-base-sentiment) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0005
- Accuracy: {'accuracy': 1.0}
- F1score: {'f1': 1.0}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 85
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
gongati/my-game-xzg
|
gongati
| 2023-11-05T16:21:34Z | 5 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-05T16:17:30Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Game-XZG Dreambooth model trained by gongati following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-241
Sample pictures of this concept:

|
Parthivs/my-space-xzg
|
Parthivs
| 2023-11-05T16:21:34Z | 0 | 0 | null |
[
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-05T16:19:27Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Space-XZG Dreambooth model trained by Parthivs following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MITS-1112
Sample pictures of this concept:

|
gdurkin/segformer-b0-finetuned-segments-floods-S2
|
gdurkin
| 2023-11-05T16:18:44Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"segformer",
"vision",
"image-segmentation",
"generated_from_trainer",
"license:other",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2023-11-05T03:16:29Z |
---
license: other
tags:
- vision
- image-segmentation
- generated_from_trainer
model-index:
- name: segformer-b0-finetuned-segments-floods-S2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# segformer-b0-finetuned-segments-floods-S2
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the gdurkin/flood_dataset_S2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Framework versions
- Transformers 4.28.0
- Pytorch 2.1.0+cu121
- Datasets 2.11.0
- Tokenizers 0.13.3
|
DragosGorduza/FRPile_GPL_test_pipeline_DragosGorduza-FRPile_MLM_Basel-FalconRescaled_1400
|
DragosGorduza
| 2023-11-05T16:16:59Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-11-05T16:16:22Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 276533 with parameters:
```
{'batch_size': 4, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 1400,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
sxela/out
|
sxela
| 2023-11-05T16:12:35Z | 2 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"controlnet",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-04T16:04:19Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-sxela/out
These are controlnet weights trained on stabilityai/stable-diffusion-xl-base-1.0 with new type of conditioning.
You can find some example images below.
prompt: anthropomorphic anthropomorphic fat cat as dark vador, lightsaber, star wars, beautiful glowing lights, sci - fi, stunning, intricate, elegant. highly detailed, digital painting. artstation. smooth. sharp focus. illustration. art by artgerm and greg rutkowski and alphonse mucha

|
minhquy1624/TrainCrawData
|
minhquy1624
| 2023-11-05T16:07:59Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:vlsp-2023-vllm/hoa-7b",
"base_model:finetune:vlsp-2023-vllm/hoa-7b",
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2023-11-03T11:45:48Z |
---
license: bigscience-bloom-rail-1.0
base_model: vlsp-2023-vllm/hoa-7b
tags:
- generated_from_trainer
model-index:
- name: TrainCrawData
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TrainCrawData
This model is a fine-tuned version of [vlsp-2023-vllm/hoa-7b](https://huggingface.co/vlsp-2023-vllm/hoa-7b) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.14.0
|
benjipeng/whisper-small-dv
|
benjipeng
| 2023-11-05T15:56:46Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dv",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-05T14:04:47Z |
---
language:
- dv
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
model-index:
- name: Whisper Small Dv - Sanchit Gandhi
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Dv - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.1678
- eval_wer_ortho: 62.2327
- eval_wer: 13.0229
- eval_runtime: 2199.1035
- eval_samples_per_second: 1.006
- eval_steps_per_second: 0.063
- epoch: 1.63
- step: 500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 800
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
shareit/polyglot-koalpaca-qlora-12.8b-samsung42
|
shareit
| 2023-11-05T15:54:18Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:beomi/KoAlpaca-Polyglot-12.8B",
"base_model:adapter:beomi/KoAlpaca-Polyglot-12.8B",
"region:us"
] | null | 2023-11-05T15:54:14Z |
---
library_name: peft
base_model: beomi/KoAlpaca-Polyglot-12.8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
bhattronak/my-awesome-address-tokenizer-model-v8
|
bhattronak
| 2023-11-05T15:35:20Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"safetensors",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-05T15:27:12Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: my-awesome-address-tokenizer-model-v8
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# my-awesome-address-tokenizer-model-v8
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6847
- Validation Loss: 0.6567
- Train Precision: 0.7174
- Train Recall: 0.7825
- Train F1: 0.7485
- Train Accuracy: 0.7750
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 585, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 1.1809 | 0.7570 | 0.7006 | 0.7372 | 0.7184 | 0.7387 | 0 |
| 0.6847 | 0.6567 | 0.7174 | 0.7825 | 0.7485 | 0.7750 | 1 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
woody72/multilingual-e5-base
|
woody72
| 2023-11-05T15:31:52Z | 28 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"xlm-roberta",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2212.03533",
"arxiv:2108.08787",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-11-05T15:18:20Z |
---
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: multilingual-e5-base
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.97014925373135
- type: ap
value: 43.69351129103008
- type: f1
value: 73.38075030070492
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (de)
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.7237687366167
- type: ap
value: 82.22089859962671
- type: f1
value: 69.95532758884401
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en-ext)
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.65517241379312
- type: ap
value: 28.507918657094738
- type: f1
value: 66.84516013726119
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (ja)
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.32976445396146
- type: ap
value: 20.720481637566014
- type: f1
value: 59.78002763416003
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.63775
- type: ap
value: 87.22277903861716
- type: f1
value: 90.60378636386807
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.546
- type: f1
value: 44.05666638370923
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (de)
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.828
- type: f1
value: 41.2710255644252
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (es)
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.534
- type: f1
value: 39.820743174270326
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (fr)
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.684
- type: f1
value: 39.11052682815307
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (ja)
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.436
- type: f1
value: 37.07082931930871
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.226000000000006
- type: f1
value: 36.65372077739185
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.831000000000003
- type: map_at_10
value: 36.42
- type: map_at_100
value: 37.699
- type: map_at_1000
value: 37.724000000000004
- type: map_at_3
value: 32.207
- type: map_at_5
value: 34.312
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 36.574
- type: mrr_at_100
value: 37.854
- type: mrr_at_1000
value: 37.878
- type: mrr_at_3
value: 32.385000000000005
- type: mrr_at_5
value: 34.48
- type: ndcg_at_1
value: 22.831000000000003
- type: ndcg_at_10
value: 44.230000000000004
- type: ndcg_at_100
value: 49.974000000000004
- type: ndcg_at_1000
value: 50.522999999999996
- type: ndcg_at_3
value: 35.363
- type: ndcg_at_5
value: 39.164
- type: precision_at_1
value: 22.831000000000003
- type: precision_at_10
value: 6.935
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.841
- type: precision_at_5
value: 10.754
- type: recall_at_1
value: 22.831000000000003
- type: recall_at_10
value: 69.346
- type: recall_at_100
value: 95.235
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 44.523
- type: recall_at_5
value: 53.769999999999996
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 40.27789869854063
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.41979463347428
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.22752045109304
- type: mrr
value: 71.51112430198303
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.71147646622866
- type: cos_sim_spearman
value: 85.059167046486
- type: euclidean_pearson
value: 75.88421613600647
- type: euclidean_spearman
value: 75.12821787150585
- type: manhattan_pearson
value: 75.22005646957604
- type: manhattan_spearman
value: 74.42880434453272
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (de-en)
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.23799582463465
- type: f1
value: 99.12665274878218
- type: precision
value: 99.07098121085595
- type: recall
value: 99.23799582463465
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (fr-en)
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.88685890380806
- type: f1
value: 97.59336708489249
- type: precision
value: 97.44662117543473
- type: recall
value: 97.88685890380806
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (ru-en)
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.47142362313821
- type: f1
value: 97.1989377670015
- type: precision
value: 97.06384944001847
- type: recall
value: 97.47142362313821
- task:
type: BitextMining
dataset:
type: mteb/bucc-bitext-mining
name: MTEB BUCC (zh-en)
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.4728804634018
- type: f1
value: 98.2973494821836
- type: precision
value: 98.2095839915745
- type: recall
value: 98.4728804634018
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.74025974025975
- type: f1
value: 82.67420447730439
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.0380848063507
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.45956405670166
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.122
- type: map_at_10
value: 42.03
- type: map_at_100
value: 43.364000000000004
- type: map_at_1000
value: 43.474000000000004
- type: map_at_3
value: 38.804
- type: map_at_5
value: 40.585
- type: mrr_at_1
value: 39.914
- type: mrr_at_10
value: 48.227
- type: mrr_at_100
value: 49.018
- type: mrr_at_1000
value: 49.064
- type: mrr_at_3
value: 45.994
- type: mrr_at_5
value: 47.396
- type: ndcg_at_1
value: 39.914
- type: ndcg_at_10
value: 47.825
- type: ndcg_at_100
value: 52.852
- type: ndcg_at_1000
value: 54.891
- type: ndcg_at_3
value: 43.517
- type: ndcg_at_5
value: 45.493
- type: precision_at_1
value: 39.914
- type: precision_at_10
value: 8.956
- type: precision_at_100
value: 1.388
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 20.791999999999998
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 32.122
- type: recall_at_10
value: 58.294999999999995
- type: recall_at_100
value: 79.726
- type: recall_at_1000
value: 93.099
- type: recall_at_3
value: 45.017
- type: recall_at_5
value: 51.002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.677999999999997
- type: map_at_10
value: 38.684000000000005
- type: map_at_100
value: 39.812999999999995
- type: map_at_1000
value: 39.945
- type: map_at_3
value: 35.831
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 37.771
- type: mrr_at_10
value: 44.936
- type: mrr_at_100
value: 45.583
- type: mrr_at_1000
value: 45.634
- type: mrr_at_3
value: 42.771
- type: mrr_at_5
value: 43.994
- type: ndcg_at_1
value: 37.771
- type: ndcg_at_10
value: 44.059
- type: ndcg_at_100
value: 48.192
- type: ndcg_at_1000
value: 50.375
- type: ndcg_at_3
value: 40.172000000000004
- type: ndcg_at_5
value: 41.899
- type: precision_at_1
value: 37.771
- type: precision_at_10
value: 8.286999999999999
- type: precision_at_100
value: 1.322
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.406000000000002
- type: precision_at_5
value: 13.745
- type: recall_at_1
value: 29.677999999999997
- type: recall_at_10
value: 53.071
- type: recall_at_100
value: 70.812
- type: recall_at_1000
value: 84.841
- type: recall_at_3
value: 41.016000000000005
- type: recall_at_5
value: 46.22
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 42.675000000000004
- type: map_at_10
value: 53.93599999999999
- type: map_at_100
value: 54.806999999999995
- type: map_at_1000
value: 54.867
- type: map_at_3
value: 50.934000000000005
- type: map_at_5
value: 52.583
- type: mrr_at_1
value: 48.339
- type: mrr_at_10
value: 57.265
- type: mrr_at_100
value: 57.873
- type: mrr_at_1000
value: 57.906
- type: mrr_at_3
value: 55.193000000000005
- type: mrr_at_5
value: 56.303000000000004
- type: ndcg_at_1
value: 48.339
- type: ndcg_at_10
value: 59.19799999999999
- type: ndcg_at_100
value: 62.743
- type: ndcg_at_1000
value: 63.99399999999999
- type: ndcg_at_3
value: 54.367
- type: ndcg_at_5
value: 56.548
- type: precision_at_1
value: 48.339
- type: precision_at_10
value: 9.216000000000001
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.72
- type: precision_at_5
value: 16.025
- type: recall_at_1
value: 42.675000000000004
- type: recall_at_10
value: 71.437
- type: recall_at_100
value: 86.803
- type: recall_at_1000
value: 95.581
- type: recall_at_3
value: 58.434
- type: recall_at_5
value: 63.754
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.518
- type: map_at_10
value: 30.648999999999997
- type: map_at_100
value: 31.508999999999997
- type: map_at_1000
value: 31.604
- type: map_at_3
value: 28.247
- type: map_at_5
value: 29.65
- type: mrr_at_1
value: 25.650000000000002
- type: mrr_at_10
value: 32.771
- type: mrr_at_100
value: 33.554
- type: mrr_at_1000
value: 33.629999999999995
- type: mrr_at_3
value: 30.433
- type: mrr_at_5
value: 31.812
- type: ndcg_at_1
value: 25.650000000000002
- type: ndcg_at_10
value: 34.929
- type: ndcg_at_100
value: 39.382
- type: ndcg_at_1000
value: 41.913
- type: ndcg_at_3
value: 30.292
- type: ndcg_at_5
value: 32.629999999999995
- type: precision_at_1
value: 25.650000000000002
- type: precision_at_10
value: 5.311
- type: precision_at_100
value: 0.792
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 12.58
- type: precision_at_5
value: 8.994
- type: recall_at_1
value: 23.518
- type: recall_at_10
value: 46.19
- type: recall_at_100
value: 67.123
- type: recall_at_1000
value: 86.442
- type: recall_at_3
value: 33.678000000000004
- type: recall_at_5
value: 39.244
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.891
- type: map_at_10
value: 22.464000000000002
- type: map_at_100
value: 23.483
- type: map_at_1000
value: 23.613
- type: map_at_3
value: 20.080000000000002
- type: map_at_5
value: 21.526
- type: mrr_at_1
value: 20.025000000000002
- type: mrr_at_10
value: 26.712999999999997
- type: mrr_at_100
value: 27.650000000000002
- type: mrr_at_1000
value: 27.737000000000002
- type: mrr_at_3
value: 24.274
- type: mrr_at_5
value: 25.711000000000002
- type: ndcg_at_1
value: 20.025000000000002
- type: ndcg_at_10
value: 27.028999999999996
- type: ndcg_at_100
value: 32.064
- type: ndcg_at_1000
value: 35.188
- type: ndcg_at_3
value: 22.512999999999998
- type: ndcg_at_5
value: 24.89
- type: precision_at_1
value: 20.025000000000002
- type: precision_at_10
value: 4.776
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.531
- type: precision_at_5
value: 7.811
- type: recall_at_1
value: 15.891
- type: recall_at_10
value: 37.261
- type: recall_at_100
value: 59.12
- type: recall_at_1000
value: 81.356
- type: recall_at_3
value: 24.741
- type: recall_at_5
value: 30.753999999999998
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.544
- type: map_at_10
value: 36.283
- type: map_at_100
value: 37.467
- type: map_at_1000
value: 37.574000000000005
- type: map_at_3
value: 33.528999999999996
- type: map_at_5
value: 35.028999999999996
- type: mrr_at_1
value: 34.166999999999994
- type: mrr_at_10
value: 41.866
- type: mrr_at_100
value: 42.666
- type: mrr_at_1000
value: 42.716
- type: mrr_at_3
value: 39.541
- type: mrr_at_5
value: 40.768
- type: ndcg_at_1
value: 34.166999999999994
- type: ndcg_at_10
value: 41.577
- type: ndcg_at_100
value: 46.687
- type: ndcg_at_1000
value: 48.967
- type: ndcg_at_3
value: 37.177
- type: ndcg_at_5
value: 39.097
- type: precision_at_1
value: 34.166999999999994
- type: precision_at_10
value: 7.420999999999999
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 17.291999999999998
- type: precision_at_5
value: 12.166
- type: recall_at_1
value: 27.544
- type: recall_at_10
value: 51.99399999999999
- type: recall_at_100
value: 73.738
- type: recall_at_1000
value: 89.33
- type: recall_at_3
value: 39.179
- type: recall_at_5
value: 44.385999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.475
- type: map_at_100
value: 36.626999999999995
- type: map_at_1000
value: 36.741
- type: map_at_3
value: 32.818000000000005
- type: map_at_5
value: 34.397
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 40.784
- type: mrr_at_100
value: 41.602
- type: mrr_at_1000
value: 41.661
- type: mrr_at_3
value: 38.68
- type: mrr_at_5
value: 39.838
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 40.697
- type: ndcg_at_100
value: 45.799
- type: ndcg_at_1000
value: 48.235
- type: ndcg_at_3
value: 36.516
- type: ndcg_at_5
value: 38.515
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.202999999999999
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.145999999999999
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 50.995000000000005
- type: recall_at_100
value: 73.065
- type: recall_at_1000
value: 89.781
- type: recall_at_3
value: 39.073
- type: recall_at_5
value: 44.395
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.946583333333333
- type: map_at_10
value: 33.79725
- type: map_at_100
value: 34.86408333333333
- type: map_at_1000
value: 34.9795
- type: map_at_3
value: 31.259999999999998
- type: map_at_5
value: 32.71541666666666
- type: mrr_at_1
value: 30.863749999999996
- type: mrr_at_10
value: 37.99183333333333
- type: mrr_at_100
value: 38.790499999999994
- type: mrr_at_1000
value: 38.85575000000001
- type: mrr_at_3
value: 35.82083333333333
- type: mrr_at_5
value: 37.07533333333333
- type: ndcg_at_1
value: 30.863749999999996
- type: ndcg_at_10
value: 38.52141666666667
- type: ndcg_at_100
value: 43.17966666666667
- type: ndcg_at_1000
value: 45.64608333333333
- type: ndcg_at_3
value: 34.333000000000006
- type: ndcg_at_5
value: 36.34975
- type: precision_at_1
value: 30.863749999999996
- type: precision_at_10
value: 6.598999999999999
- type: precision_at_100
value: 1.0502500000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_3
value: 15.557583333333334
- type: precision_at_5
value: 11.020000000000001
- type: recall_at_1
value: 25.946583333333333
- type: recall_at_10
value: 48.36991666666666
- type: recall_at_100
value: 69.02408333333334
- type: recall_at_1000
value: 86.43858333333331
- type: recall_at_3
value: 36.4965
- type: recall_at_5
value: 41.76258333333334
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.431
- type: map_at_10
value: 28.889
- type: map_at_100
value: 29.642000000000003
- type: map_at_1000
value: 29.742
- type: map_at_3
value: 26.998
- type: map_at_5
value: 28.172000000000004
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 31.763
- type: mrr_at_100
value: 32.443
- type: mrr_at_1000
value: 32.531
- type: mrr_at_3
value: 29.959000000000003
- type: mrr_at_5
value: 31.063000000000002
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 32.586999999999996
- type: ndcg_at_100
value: 36.5
- type: ndcg_at_1000
value: 39.133
- type: ndcg_at_3
value: 29.25
- type: ndcg_at_5
value: 31.023
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.747
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.577
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 22.431
- type: recall_at_10
value: 41.134
- type: recall_at_100
value: 59.28600000000001
- type: recall_at_1000
value: 78.857
- type: recall_at_3
value: 31.926
- type: recall_at_5
value: 36.335
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.586
- type: map_at_10
value: 23.304
- type: map_at_100
value: 24.159
- type: map_at_1000
value: 24.281
- type: map_at_3
value: 21.316
- type: map_at_5
value: 22.383
- type: mrr_at_1
value: 21.645
- type: mrr_at_10
value: 27.365000000000002
- type: mrr_at_100
value: 28.108
- type: mrr_at_1000
value: 28.192
- type: mrr_at_3
value: 25.482
- type: mrr_at_5
value: 26.479999999999997
- type: ndcg_at_1
value: 21.645
- type: ndcg_at_10
value: 27.306
- type: ndcg_at_100
value: 31.496000000000002
- type: ndcg_at_1000
value: 34.53
- type: ndcg_at_3
value: 23.73
- type: ndcg_at_5
value: 25.294
- type: precision_at_1
value: 21.645
- type: precision_at_10
value: 4.797
- type: precision_at_100
value: 0.8059999999999999
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.850999999999999
- type: precision_at_5
value: 7.736
- type: recall_at_1
value: 17.586
- type: recall_at_10
value: 35.481
- type: recall_at_100
value: 54.534000000000006
- type: recall_at_1000
value: 76.456
- type: recall_at_3
value: 25.335
- type: recall_at_5
value: 29.473
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.095
- type: map_at_10
value: 32.374
- type: map_at_100
value: 33.537
- type: map_at_1000
value: 33.634
- type: map_at_3
value: 30.089
- type: map_at_5
value: 31.433
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 36.01
- type: mrr_at_100
value: 37.022
- type: mrr_at_1000
value: 37.083
- type: mrr_at_3
value: 33.94
- type: mrr_at_5
value: 35.148
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 36.729
- type: ndcg_at_100
value: 42.114000000000004
- type: ndcg_at_1000
value: 44.592
- type: ndcg_at_3
value: 32.644
- type: ndcg_at_5
value: 34.652
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 0.967
- type: precision_at_1000
value: 0.129
- type: precision_at_3
value: 14.396999999999998
- type: precision_at_5
value: 10.093
- type: recall_at_1
value: 25.095
- type: recall_at_10
value: 46.392
- type: recall_at_100
value: 69.706
- type: recall_at_1000
value: 87.738
- type: recall_at_3
value: 35.303000000000004
- type: recall_at_5
value: 40.441
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.857999999999997
- type: map_at_10
value: 34.066
- type: map_at_100
value: 35.671
- type: map_at_1000
value: 35.881
- type: map_at_3
value: 31.304
- type: map_at_5
value: 32.885
- type: mrr_at_1
value: 32.411
- type: mrr_at_10
value: 38.987
- type: mrr_at_100
value: 39.894
- type: mrr_at_1000
value: 39.959
- type: mrr_at_3
value: 36.626999999999995
- type: mrr_at_5
value: 38.011
- type: ndcg_at_1
value: 32.411
- type: ndcg_at_10
value: 39.208
- type: ndcg_at_100
value: 44.626
- type: ndcg_at_1000
value: 47.43
- type: ndcg_at_3
value: 35.091
- type: ndcg_at_5
value: 37.119
- type: precision_at_1
value: 32.411
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.976
- type: recall_at_1
value: 26.857999999999997
- type: recall_at_10
value: 47.407
- type: recall_at_100
value: 72.236
- type: recall_at_1000
value: 90.77
- type: recall_at_3
value: 35.125
- type: recall_at_5
value: 40.522999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.3
- type: map_at_10
value: 27.412999999999997
- type: map_at_100
value: 28.29
- type: map_at_1000
value: 28.398
- type: map_at_3
value: 25.169999999999998
- type: map_at_5
value: 26.496
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 29.215000000000003
- type: mrr_at_100
value: 30.073
- type: mrr_at_1000
value: 30.156
- type: mrr_at_3
value: 26.956000000000003
- type: mrr_at_5
value: 28.38
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 31.113000000000003
- type: ndcg_at_100
value: 35.701
- type: ndcg_at_1000
value: 38.505
- type: ndcg_at_3
value: 26.727
- type: ndcg_at_5
value: 29.037000000000003
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 4.787
- type: precision_at_100
value: 0.763
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 11.091
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 21.3
- type: recall_at_10
value: 40.782000000000004
- type: recall_at_100
value: 62.13999999999999
- type: recall_at_1000
value: 83.012
- type: recall_at_3
value: 29.131
- type: recall_at_5
value: 34.624
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.631
- type: map_at_10
value: 16.634999999999998
- type: map_at_100
value: 18.23
- type: map_at_1000
value: 18.419
- type: map_at_3
value: 13.66
- type: map_at_5
value: 15.173
- type: mrr_at_1
value: 21.368000000000002
- type: mrr_at_10
value: 31.56
- type: mrr_at_100
value: 32.58
- type: mrr_at_1000
value: 32.633
- type: mrr_at_3
value: 28.241
- type: mrr_at_5
value: 30.225
- type: ndcg_at_1
value: 21.368000000000002
- type: ndcg_at_10
value: 23.855999999999998
- type: ndcg_at_100
value: 30.686999999999998
- type: ndcg_at_1000
value: 34.327000000000005
- type: ndcg_at_3
value: 18.781
- type: ndcg_at_5
value: 20.73
- type: precision_at_1
value: 21.368000000000002
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.217
- type: precision_at_3
value: 13.876
- type: precision_at_5
value: 11.062
- type: recall_at_1
value: 9.631
- type: recall_at_10
value: 29.517
- type: recall_at_100
value: 53.452
- type: recall_at_1000
value: 74.115
- type: recall_at_3
value: 17.605999999999998
- type: recall_at_5
value: 22.505
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.885
- type: map_at_10
value: 18.798000000000002
- type: map_at_100
value: 26.316
- type: map_at_1000
value: 27.869
- type: map_at_3
value: 13.719000000000001
- type: map_at_5
value: 15.716
- type: mrr_at_1
value: 66
- type: mrr_at_10
value: 74.263
- type: mrr_at_100
value: 74.519
- type: mrr_at_1000
value: 74.531
- type: mrr_at_3
value: 72.458
- type: mrr_at_5
value: 73.321
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.355999999999995
- type: ndcg_at_100
value: 44.366
- type: ndcg_at_1000
value: 51.771
- type: ndcg_at_3
value: 45.195
- type: ndcg_at_5
value: 42.187000000000005
- type: precision_at_1
value: 66
- type: precision_at_10
value: 31.75
- type: precision_at_100
value: 10.11
- type: precision_at_1000
value: 1.9800000000000002
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 40.050000000000004
- type: recall_at_1
value: 8.885
- type: recall_at_10
value: 24.471999999999998
- type: recall_at_100
value: 49.669000000000004
- type: recall_at_1000
value: 73.383
- type: recall_at_3
value: 14.872
- type: recall_at_5
value: 18.262999999999998
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.18
- type: f1
value: 40.26878691789978
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.751999999999995
- type: map_at_10
value: 74.131
- type: map_at_100
value: 74.407
- type: map_at_1000
value: 74.423
- type: map_at_3
value: 72.329
- type: map_at_5
value: 73.555
- type: mrr_at_1
value: 67.282
- type: mrr_at_10
value: 78.292
- type: mrr_at_100
value: 78.455
- type: mrr_at_1000
value: 78.458
- type: mrr_at_3
value: 76.755
- type: mrr_at_5
value: 77.839
- type: ndcg_at_1
value: 67.282
- type: ndcg_at_10
value: 79.443
- type: ndcg_at_100
value: 80.529
- type: ndcg_at_1000
value: 80.812
- type: ndcg_at_3
value: 76.281
- type: ndcg_at_5
value: 78.235
- type: precision_at_1
value: 67.282
- type: precision_at_10
value: 10.078
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 30.178
- type: precision_at_5
value: 19.232
- type: recall_at_1
value: 62.751999999999995
- type: recall_at_10
value: 91.521
- type: recall_at_100
value: 95.997
- type: recall_at_1000
value: 97.775
- type: recall_at_3
value: 83.131
- type: recall_at_5
value: 87.93299999999999
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.861
- type: map_at_10
value: 30.252000000000002
- type: map_at_100
value: 32.082
- type: map_at_1000
value: 32.261
- type: map_at_3
value: 25.909
- type: map_at_5
value: 28.296
- type: mrr_at_1
value: 37.346000000000004
- type: mrr_at_10
value: 45.802
- type: mrr_at_100
value: 46.611999999999995
- type: mrr_at_1000
value: 46.659
- type: mrr_at_3
value: 43.056
- type: mrr_at_5
value: 44.637
- type: ndcg_at_1
value: 37.346000000000004
- type: ndcg_at_10
value: 38.169
- type: ndcg_at_100
value: 44.864
- type: ndcg_at_1000
value: 47.974
- type: ndcg_at_3
value: 33.619
- type: ndcg_at_5
value: 35.317
- type: precision_at_1
value: 37.346000000000004
- type: precision_at_10
value: 10.693999999999999
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 22.325
- type: precision_at_5
value: 16.852
- type: recall_at_1
value: 18.861
- type: recall_at_10
value: 45.672000000000004
- type: recall_at_100
value: 70.60499999999999
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.998999999999995
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.852999999999994
- type: map_at_10
value: 59.961
- type: map_at_100
value: 60.78
- type: map_at_1000
value: 60.843
- type: map_at_3
value: 56.39999999999999
- type: map_at_5
value: 58.646
- type: mrr_at_1
value: 75.70599999999999
- type: mrr_at_10
value: 82.321
- type: mrr_at_100
value: 82.516
- type: mrr_at_1000
value: 82.525
- type: mrr_at_3
value: 81.317
- type: mrr_at_5
value: 81.922
- type: ndcg_at_1
value: 75.70599999999999
- type: ndcg_at_10
value: 68.557
- type: ndcg_at_100
value: 71.485
- type: ndcg_at_1000
value: 72.71600000000001
- type: ndcg_at_3
value: 63.524
- type: ndcg_at_5
value: 66.338
- type: precision_at_1
value: 75.70599999999999
- type: precision_at_10
value: 14.463000000000001
- type: precision_at_100
value: 1.677
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 40.806
- type: precision_at_5
value: 26.709
- type: recall_at_1
value: 37.852999999999994
- type: recall_at_10
value: 72.316
- type: recall_at_100
value: 83.842
- type: recall_at_1000
value: 91.999
- type: recall_at_3
value: 61.209
- type: recall_at_5
value: 66.77199999999999
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.46039999999999
- type: ap
value: 79.9812521351881
- type: f1
value: 85.31722909702084
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.704
- type: map_at_10
value: 35.329
- type: map_at_100
value: 36.494
- type: map_at_1000
value: 36.541000000000004
- type: map_at_3
value: 31.476
- type: map_at_5
value: 33.731
- type: mrr_at_1
value: 23.294999999999998
- type: mrr_at_10
value: 35.859
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.008
- type: mrr_at_3
value: 32.085
- type: mrr_at_5
value: 34.299
- type: ndcg_at_1
value: 23.324
- type: ndcg_at_10
value: 42.274
- type: ndcg_at_100
value: 47.839999999999996
- type: ndcg_at_1000
value: 48.971
- type: ndcg_at_3
value: 34.454
- type: ndcg_at_5
value: 38.464
- type: precision_at_1
value: 23.324
- type: precision_at_10
value: 6.648
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.674999999999999
- type: precision_at_5
value: 10.850999999999999
- type: recall_at_1
value: 22.704
- type: recall_at_10
value: 63.660000000000004
- type: recall_at_100
value: 89.29899999999999
- type: recall_at_1000
value: 97.88900000000001
- type: recall_at_3
value: 42.441
- type: recall_at_5
value: 52.04
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.1326949384405
- type: f1
value: 92.89743579612082
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (de)
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.62524654832347
- type: f1
value: 88.65106082263151
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (es)
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.59039359573046
- type: f1
value: 90.31532892105662
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (fr)
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.21046038208581
- type: f1
value: 86.41459529813113
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (hi)
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.3180351380423
- type: f1
value: 86.71383078226444
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (th)
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.24231464737792
- type: f1
value: 86.31845567592403
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.27131782945736
- type: f1
value: 57.52079940417103
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (de)
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.2341504649197
- type: f1
value: 51.349951558039244
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (es)
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.27418278852569
- type: f1
value: 50.1714985749095
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (fr)
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.68243031631694
- type: f1
value: 50.1066160836192
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (hi)
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.2362854069559
- type: f1
value: 48.821279948766424
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (th)
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.71428571428571
- type: f1
value: 53.94611389496195
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (af)
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.97646267652992
- type: f1
value: 57.26797883561521
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (am)
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.65501008742435
- type: f1
value: 50.416258382177034
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ar)
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.45796906523201
- type: f1
value: 53.306690547422185
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (az)
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.59246805648957
- type: f1
value: 59.818381969051494
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (bn)
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.126429051782104
- type: f1
value: 58.25993593933026
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (cy)
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.057162071284466
- type: f1
value: 46.96095728790911
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (da)
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.64425016812375
- type: f1
value: 62.858291698755764
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (de)
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.08944182918628
- type: f1
value: 62.44639030604241
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (el)
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.68056489576328
- type: f1
value: 61.775326758789504
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.11163416274377
- type: f1
value: 69.70789096927015
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (es)
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.40282447881641
- type: f1
value: 66.38492065671895
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fa)
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.24613315400134
- type: f1
value: 64.3348019501336
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fi)
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.78345662407531
- type: f1
value: 62.21279452354622
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (fr)
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.9455279085407
- type: f1
value: 65.48193124964094
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (he)
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.05110961667788
- type: f1
value: 58.097856564684534
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hi)
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.95292535305985
- type: f1
value: 62.09182174767901
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hu)
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.97310020174848
- type: f1
value: 61.14252567730396
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (hy)
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.08069939475453
- type: f1
value: 57.044041742492034
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (id)
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.63752521856085
- type: f1
value: 63.889340907205316
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (is)
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.385339609952936
- type: f1
value: 53.449033750088304
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (it)
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.93073301950234
- type: f1
value: 65.9884357824104
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ja)
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.94418291862812
- type: f1
value: 66.48740222583132
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (jv)
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.26025554808339
- type: f1
value: 50.19562815100793
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ka)
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.98789509078682
- type: f1
value: 46.65788438676836
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (km)
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.68728984532616
- type: f1
value: 41.642419349541996
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (kn)
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.19300605245461
- type: f1
value: 55.8626492442437
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ko)
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 63.89499791648792
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (lv)
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.33960995292536
- type: f1
value: 57.15242464180892
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ml)
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.09347679892402
- type: f1
value: 59.64733214063841
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (mn)
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.75924680564896
- type: f1
value: 55.96585692366827
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ms)
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.48486886348352
- type: f1
value: 59.45143559032946
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (my)
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.56422326832549
- type: f1
value: 54.96368702901926
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nb)
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.18022864828512
- type: f1
value: 63.05369805040634
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (nl)
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.30329522528581
- type: f1
value: 64.06084612020727
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pl)
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.36919973100201
- type: f1
value: 65.12154124788887
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (pt)
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 66.41847559806962
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ro)
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.53799596503026
- type: f1
value: 62.17067330740817
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ru)
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.01815736381977
- type: f1
value: 66.24988369607843
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sl)
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.34700739744452
- type: f1
value: 59.957933424941636
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sq)
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.23402824478815
- type: f1
value: 57.98836976018471
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sv)
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.43849680666855
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (sw)
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.998655010087425
- type: f1
value: 52.83737515406804
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ta)
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.71217215870882
- type: f1
value: 55.051794977833026
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (te)
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.724277067921996
- type: f1
value: 56.33485571838306
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (th)
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631473
- type: f1
value: 64.96772366193588
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tl)
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.860793544048406
- type: f1
value: 58.148845819115394
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (tr)
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.40753194351043
- type: f1
value: 63.18903778054698
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (ur)
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.52320107599194
- type: f1
value: 58.356144563398516
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (vi)
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.17014122394083
- type: f1
value: 63.919964062638925
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.15601882985878
- type: f1
value: 67.01451905761371
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-TW)
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 64.14420425129063
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (af)
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.08742434431743
- type: f1
value: 63.044060042311756
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (am)
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.52387357094821
- type: f1
value: 56.82398588814534
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ar)
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.239408204438476
- type: f1
value: 61.92570286170469
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (az)
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.74915938130463
- type: f1
value: 62.130740689396276
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (bn)
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.00336247478144
- type: f1
value: 63.71080635228055
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (cy)
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.837928715534645
- type: f1
value: 50.390741680320836
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (da)
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.42098184263618
- type: f1
value: 71.41355113538995
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (de)
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95359784801613
- type: f1
value: 71.42699340156742
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (el)
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.18157363819772
- type: f1
value: 69.74836113037671
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 76.78000685068261
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (es)
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.5030262273033
- type: f1
value: 71.71620130425673
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fa)
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24546065904505
- type: f1
value: 69.07638311730359
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fi)
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.12911903160726
- type: f1
value: 68.32651736539815
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (fr)
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195025
- type: f1
value: 71.33986549860187
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (he)
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.44451916610626
- type: f1
value: 66.90192664503866
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hi)
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.16274377942166
- type: f1
value: 68.01090953775066
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hu)
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.75319435104237
- type: f1
value: 70.18035309201403
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (hy)
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.14391392064559
- type: f1
value: 61.48286540778145
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (id)
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.70275722932078
- type: f1
value: 70.26164779846495
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (is)
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.93813046402153
- type: f1
value: 58.8852862116525
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (it)
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.320107599193
- type: f1
value: 72.19836409602924
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ja)
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.65366509751176
- type: f1
value: 74.55188288799579
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (jv)
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.694014794889036
- type: f1
value: 58.11353311721067
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ka)
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.37457969065231
- type: f1
value: 52.81306134311697
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (km)
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.3086751849361
- type: f1
value: 45.396449765419376
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (kn)
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.151983860121064
- type: f1
value: 60.31762544281696
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ko)
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.44788164088769
- type: f1
value: 71.68150151736367
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (lv)
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.81439139206455
- type: f1
value: 62.06735559105593
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ml)
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04303967720242
- type: f1
value: 66.68298851670133
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (mn)
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.43913920645595
- type: f1
value: 60.25605977560783
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ms)
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.90316072629456
- type: f1
value: 65.1325924692381
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (my)
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.63752521856086
- type: f1
value: 59.14284778039585
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nb)
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.63080026899797
- type: f1
value: 70.89771864626877
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (nl)
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.10827168796234
- type: f1
value: 71.71954219691159
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pl)
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.59515803631471
- type: f1
value: 70.05040128099003
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (pt)
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.83389374579691
- type: f1
value: 70.84877936562735
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ro)
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.18628110289173
- type: f1
value: 68.97232927921841
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ru)
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.99260255548083
- type: f1
value: 72.85139492157732
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sl)
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- type: f1
value: 65.08833655469431
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sq)
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48621385339611
- type: f1
value: 64.43483199071298
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sv)
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.14391392064559
- type: f1
value: 72.2580822579741
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (sw)
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.88567585743107
- type: f1
value: 58.3073765932569
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ta)
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.38399462004034
- type: f1
value: 60.82139544252606
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (te)
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 60.71443370385374
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (th)
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- type: f1
value: 70.99761812049401
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tl)
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.73705447209146
- type: f1
value: 61.680849331794796
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (tr)
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.66778749159381
- type: f1
value: 71.17320646080115
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (ur)
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.640215198386
- type: f1
value: 63.301805157015444
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (vi)
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.00672494956288
- type: f1
value: 70.26005548582106
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.42030934767989
- type: f1
value: 75.2074842882598
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-TW)
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.69266980497646
- type: f1
value: 70.94103167391192
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.91697191169135
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.434000079573313
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.96683513343383
- type: mrr
value: 31.967364078714834
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.5280000000000005
- type: map_at_10
value: 11.793
- type: map_at_100
value: 14.496999999999998
- type: map_at_1000
value: 15.783
- type: map_at_3
value: 8.838
- type: map_at_5
value: 10.07
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.531000000000006
- type: mrr_at_100
value: 52.205
- type: mrr_at_1000
value: 52.242999999999995
- type: mrr_at_3
value: 49.431999999999995
- type: mrr_at_5
value: 50.470000000000006
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 32.464999999999996
- type: ndcg_at_100
value: 28.927999999999997
- type: ndcg_at_1000
value: 37.629000000000005
- type: ndcg_at_3
value: 37.845
- type: ndcg_at_5
value: 35.147
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 23.932000000000002
- type: precision_at_100
value: 7.17
- type: precision_at_1000
value: 1.967
- type: precision_at_3
value: 35.397
- type: precision_at_5
value: 29.907
- type: recall_at_1
value: 5.5280000000000005
- type: recall_at_10
value: 15.568000000000001
- type: recall_at_100
value: 28.54
- type: recall_at_1000
value: 59.864
- type: recall_at_3
value: 9.822000000000001
- type: recall_at_5
value: 11.726
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.041000000000004
- type: map_at_10
value: 52.664
- type: map_at_100
value: 53.477
- type: map_at_1000
value: 53.505
- type: map_at_3
value: 48.510999999999996
- type: map_at_5
value: 51.036
- type: mrr_at_1
value: 41.338
- type: mrr_at_10
value: 55.071000000000005
- type: mrr_at_100
value: 55.672
- type: mrr_at_1000
value: 55.689
- type: mrr_at_3
value: 51.82
- type: mrr_at_5
value: 53.852
- type: ndcg_at_1
value: 41.338
- type: ndcg_at_10
value: 60.01800000000001
- type: ndcg_at_100
value: 63.409000000000006
- type: ndcg_at_1000
value: 64.017
- type: ndcg_at_3
value: 52.44799999999999
- type: ndcg_at_5
value: 56.571000000000005
- type: precision_at_1
value: 41.338
- type: precision_at_10
value: 9.531
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.416
- type: precision_at_5
value: 16.46
- type: recall_at_1
value: 37.041000000000004
- type: recall_at_10
value: 79.76299999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.851
- type: recall_at_3
value: 60.465
- type: recall_at_5
value: 69.906
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.952
- type: map_at_10
value: 83.758
- type: map_at_100
value: 84.406
- type: map_at_1000
value: 84.425
- type: map_at_3
value: 80.839
- type: map_at_5
value: 82.646
- type: mrr_at_1
value: 80.62
- type: mrr_at_10
value: 86.947
- type: mrr_at_100
value: 87.063
- type: mrr_at_1000
value: 87.064
- type: mrr_at_3
value: 85.96000000000001
- type: mrr_at_5
value: 86.619
- type: ndcg_at_1
value: 80.63
- type: ndcg_at_10
value: 87.64800000000001
- type: ndcg_at_100
value: 88.929
- type: ndcg_at_1000
value: 89.054
- type: ndcg_at_3
value: 84.765
- type: ndcg_at_5
value: 86.291
- type: precision_at_1
value: 80.63
- type: precision_at_10
value: 13.314
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.1
- type: precision_at_5
value: 24.372
- type: recall_at_1
value: 69.952
- type: recall_at_10
value: 94.955
- type: recall_at_100
value: 99.38
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_3
value: 86.60600000000001
- type: recall_at_5
value: 90.997
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.41329517878427
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 55.171278362748666
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.213
- type: map_at_10
value: 9.895
- type: map_at_100
value: 11.776
- type: map_at_1000
value: 12.084
- type: map_at_3
value: 7.2669999999999995
- type: map_at_5
value: 8.620999999999999
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 31.112000000000002
- type: mrr_at_100
value: 32.274
- type: mrr_at_1000
value: 32.35
- type: mrr_at_3
value: 28.133000000000003
- type: mrr_at_5
value: 29.892999999999997
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.163999999999998
- type: ndcg_at_100
value: 24.738
- type: ndcg_at_1000
value: 30.316
- type: ndcg_at_3
value: 16.665
- type: ndcg_at_5
value: 14.478
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.963
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.6
- type: recall_at_1
value: 4.213
- type: recall_at_10
value: 17.698
- type: recall_at_100
value: 39.838
- type: recall_at_1000
value: 66.893
- type: recall_at_3
value: 9.418
- type: recall_at_5
value: 12.773000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.90453315738294
- type: cos_sim_spearman
value: 78.51197850080254
- type: euclidean_pearson
value: 80.09647123597748
- type: euclidean_spearman
value: 78.63548011514061
- type: manhattan_pearson
value: 80.10645285675231
- type: manhattan_spearman
value: 78.57861806068901
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.2616156846401
- type: cos_sim_spearman
value: 76.69713867850156
- type: euclidean_pearson
value: 77.97948563800394
- type: euclidean_spearman
value: 74.2371211567807
- type: manhattan_pearson
value: 77.69697879669705
- type: manhattan_spearman
value: 73.86529778022278
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 77.0293269315045
- type: cos_sim_spearman
value: 78.02555120584198
- type: euclidean_pearson
value: 78.25398100379078
- type: euclidean_spearman
value: 78.66963870599464
- type: manhattan_pearson
value: 78.14314682167348
- type: manhattan_spearman
value: 78.57692322969135
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.16989925136942
- type: cos_sim_spearman
value: 76.5996225327091
- type: euclidean_pearson
value: 77.8319003279786
- type: euclidean_spearman
value: 76.42824009468998
- type: manhattan_pearson
value: 77.69118862737736
- type: manhattan_spearman
value: 76.25568104762812
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.42012286935325
- type: cos_sim_spearman
value: 88.15654297884122
- type: euclidean_pearson
value: 87.34082819427852
- type: euclidean_spearman
value: 88.06333589547084
- type: manhattan_pearson
value: 87.25115596784842
- type: manhattan_spearman
value: 87.9559927695203
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.88222044996712
- type: cos_sim_spearman
value: 84.28476589061077
- type: euclidean_pearson
value: 83.17399758058309
- type: euclidean_spearman
value: 83.85497357244542
- type: manhattan_pearson
value: 83.0308397703786
- type: manhattan_spearman
value: 83.71554539935046
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ko-ko)
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.20682986257339
- type: cos_sim_spearman
value: 79.94567120362092
- type: euclidean_pearson
value: 79.43122480368902
- type: euclidean_spearman
value: 79.94802077264987
- type: manhattan_pearson
value: 79.32653021527081
- type: manhattan_spearman
value: 79.80961146709178
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (ar-ar)
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 74.46578144394383
- type: cos_sim_spearman
value: 74.52496637472179
- type: euclidean_pearson
value: 72.2903807076809
- type: euclidean_spearman
value: 73.55549359771645
- type: manhattan_pearson
value: 72.09324837709393
- type: manhattan_spearman
value: 73.36743103606581
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-ar)
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 71.37272335116
- type: cos_sim_spearman
value: 71.26702117766037
- type: euclidean_pearson
value: 67.114829954434
- type: euclidean_spearman
value: 66.37938893947761
- type: manhattan_pearson
value: 66.79688574095246
- type: manhattan_spearman
value: 66.17292828079667
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-de)
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.61016770129092
- type: cos_sim_spearman
value: 82.08515426632214
- type: euclidean_pearson
value: 80.557340361131
- type: euclidean_spearman
value: 80.37585812266175
- type: manhattan_pearson
value: 80.6782873404285
- type: manhattan_spearman
value: 80.6678073032024
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.00150745350108
- type: cos_sim_spearman
value: 87.83441972211425
- type: euclidean_pearson
value: 87.94826702308792
- type: euclidean_spearman
value: 87.46143974860725
- type: manhattan_pearson
value: 87.97560344306105
- type: manhattan_spearman
value: 87.5267102829796
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-tr)
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 64.76325252267235
- type: cos_sim_spearman
value: 63.32615095463905
- type: euclidean_pearson
value: 64.07920669155716
- type: euclidean_spearman
value: 61.21409893072176
- type: manhattan_pearson
value: 64.26308625680016
- type: manhattan_spearman
value: 61.2438185254079
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-en)
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.82644463022595
- type: cos_sim_spearman
value: 76.50381269945073
- type: euclidean_pearson
value: 75.1328548315934
- type: euclidean_spearman
value: 75.63761139408453
- type: manhattan_pearson
value: 75.18610101241407
- type: manhattan_spearman
value: 75.30669266354164
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (es-es)
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49994164686832
- type: cos_sim_spearman
value: 86.73743986245549
- type: euclidean_pearson
value: 86.8272894387145
- type: euclidean_spearman
value: 85.97608491000507
- type: manhattan_pearson
value: 86.74960140396779
- type: manhattan_spearman
value: 85.79285984190273
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (fr-en)
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.58172210788469
- type: cos_sim_spearman
value: 80.17516468334607
- type: euclidean_pearson
value: 77.56537843470504
- type: euclidean_spearman
value: 77.57264627395521
- type: manhattan_pearson
value: 78.09703521695943
- type: manhattan_spearman
value: 78.15942760916954
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (it-en)
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.7589932931751
- type: cos_sim_spearman
value: 80.15210089028162
- type: euclidean_pearson
value: 77.54135223516057
- type: euclidean_spearman
value: 77.52697996368764
- type: manhattan_pearson
value: 77.65734439572518
- type: manhattan_spearman
value: 77.77702992016121
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (nl-en)
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.16682365511267
- type: cos_sim_spearman
value: 79.25311267628506
- type: euclidean_pearson
value: 77.54882036762244
- type: euclidean_spearman
value: 77.33212935194827
- type: manhattan_pearson
value: 77.98405516064015
- type: manhattan_spearman
value: 77.85075717865719
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.10473294775917
- type: cos_sim_spearman
value: 61.82780474476838
- type: euclidean_pearson
value: 45.885111672377256
- type: euclidean_spearman
value: 56.88306351932454
- type: manhattan_pearson
value: 46.101218127323186
- type: manhattan_spearman
value: 56.80953694186333
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de)
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 45.781923079584146
- type: cos_sim_spearman
value: 55.95098449691107
- type: euclidean_pearson
value: 25.4571031323205
- type: euclidean_spearman
value: 49.859978118078935
- type: manhattan_pearson
value: 25.624938455041384
- type: manhattan_spearman
value: 49.99546185049401
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es)
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.00618133997907
- type: cos_sim_spearman
value: 66.57896677718321
- type: euclidean_pearson
value: 42.60118466388821
- type: euclidean_spearman
value: 62.8210759715209
- type: manhattan_pearson
value: 42.63446860604094
- type: manhattan_spearman
value: 62.73803068925271
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl)
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 28.460759121626943
- type: cos_sim_spearman
value: 34.13459007469131
- type: euclidean_pearson
value: 6.0917739325525195
- type: euclidean_spearman
value: 27.9947262664867
- type: manhattan_pearson
value: 6.16877864169911
- type: manhattan_spearman
value: 28.00664163971514
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (tr)
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.42546621771696
- type: cos_sim_spearman
value: 63.699663168970474
- type: euclidean_pearson
value: 38.12085278789738
- type: euclidean_spearman
value: 58.12329140741536
- type: manhattan_pearson
value: 37.97364549443335
- type: manhattan_spearman
value: 57.81545502318733
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ar)
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.82241380954213
- type: cos_sim_spearman
value: 57.86569456006391
- type: euclidean_pearson
value: 31.80480070178813
- type: euclidean_spearman
value: 52.484000620130104
- type: manhattan_pearson
value: 31.952708554646097
- type: manhattan_spearman
value: 52.8560972356195
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (ru)
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.00447170498087
- type: cos_sim_spearman
value: 60.664116225735164
- type: euclidean_pearson
value: 33.87382555421702
- type: euclidean_spearman
value: 55.74649067458667
- type: manhattan_pearson
value: 33.99117246759437
- type: manhattan_spearman
value: 55.98749034923899
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.06497233105448
- type: cos_sim_spearman
value: 65.62968801135676
- type: euclidean_pearson
value: 47.482076613243905
- type: euclidean_spearman
value: 62.65137791498299
- type: manhattan_pearson
value: 47.57052626104093
- type: manhattan_spearman
value: 62.436916516613294
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr)
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.49397298562575
- type: cos_sim_spearman
value: 74.79604041187868
- type: euclidean_pearson
value: 49.661891561317795
- type: euclidean_spearman
value: 70.31535537621006
- type: manhattan_pearson
value: 49.553715741850006
- type: manhattan_spearman
value: 70.24779344636806
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-en)
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.640574515348696
- type: cos_sim_spearman
value: 54.927959317689
- type: euclidean_pearson
value: 29.00139666967476
- type: euclidean_spearman
value: 41.86386566971605
- type: manhattan_pearson
value: 29.47411067730344
- type: manhattan_spearman
value: 42.337438424952786
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-en)
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.14095292259312
- type: cos_sim_spearman
value: 73.99017581234789
- type: euclidean_pearson
value: 46.46304297872084
- type: euclidean_spearman
value: 60.91834114800041
- type: manhattan_pearson
value: 47.07072666338692
- type: manhattan_spearman
value: 61.70415727977926
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (it)
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.27184653359575
- type: cos_sim_spearman
value: 77.76070252418626
- type: euclidean_pearson
value: 62.30586577544778
- type: euclidean_spearman
value: 75.14246629110978
- type: manhattan_pearson
value: 62.328196884927046
- type: manhattan_spearman
value: 75.1282792981433
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (pl-en)
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.59448528829957
- type: cos_sim_spearman
value: 70.37277734222123
- type: euclidean_pearson
value: 57.63145565721123
- type: euclidean_spearman
value: 66.10113048304427
- type: manhattan_pearson
value: 57.18897811586808
- type: manhattan_spearman
value: 66.5595511215901
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh-en)
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.37520607720838
- type: cos_sim_spearman
value: 69.92282148997948
- type: euclidean_pearson
value: 40.55768770125291
- type: euclidean_spearman
value: 55.189128944669605
- type: manhattan_pearson
value: 41.03566433468883
- type: manhattan_spearman
value: 55.61251893174558
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (es-it)
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.791929533771835
- type: cos_sim_spearman
value: 66.45819707662093
- type: euclidean_pearson
value: 39.03686018511092
- type: euclidean_spearman
value: 56.01282695640428
- type: manhattan_pearson
value: 38.91586623619632
- type: manhattan_spearman
value: 56.69394943612747
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-fr)
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.82224468473866
- type: cos_sim_spearman
value: 59.467307194781164
- type: euclidean_pearson
value: 27.428459190256145
- type: euclidean_spearman
value: 60.83463107397519
- type: manhattan_pearson
value: 27.487391578496638
- type: manhattan_spearman
value: 61.281380460246496
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (de-pl)
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.306666792752644
- type: cos_sim_spearman
value: 39.35486427252405
- type: euclidean_pearson
value: -2.7887154897955435
- type: euclidean_spearman
value: 27.1296051831719
- type: manhattan_pearson
value: -3.202291270581297
- type: manhattan_spearman
value: 26.32895849218158
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (fr-pl)
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.67006803805076
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 46.91884681500483
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 46.88391675325812
- type: manhattan_spearman
value: 28.17180849095055
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.79555591223837
- type: cos_sim_spearman
value: 85.63658602085185
- type: euclidean_pearson
value: 85.22080894037671
- type: euclidean_spearman
value: 85.54113580167038
- type: manhattan_pearson
value: 85.1639505960118
- type: manhattan_spearman
value: 85.43502665436196
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.73900991689766
- type: mrr
value: 94.81624131133934
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.678000000000004
- type: map_at_10
value: 65.135
- type: map_at_100
value: 65.824
- type: map_at_1000
value: 65.852
- type: map_at_3
value: 62.736000000000004
- type: map_at_5
value: 64.411
- type: mrr_at_1
value: 58.333
- type: mrr_at_10
value: 66.5
- type: mrr_at_100
value: 67.053
- type: mrr_at_1000
value: 67.08
- type: mrr_at_3
value: 64.944
- type: mrr_at_5
value: 65.89399999999999
- type: ndcg_at_1
value: 58.333
- type: ndcg_at_10
value: 69.34700000000001
- type: ndcg_at_100
value: 72.32
- type: ndcg_at_1000
value: 73.014
- type: ndcg_at_3
value: 65.578
- type: ndcg_at_5
value: 67.738
- type: precision_at_1
value: 58.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 55.678000000000004
- type: recall_at_10
value: 80.72200000000001
- type: recall_at_100
value: 93.93299999999999
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 70.783
- type: recall_at_5
value: 75.978
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74653465346535
- type: cos_sim_ap
value: 93.01476369929063
- type: cos_sim_f1
value: 86.93009118541033
- type: cos_sim_precision
value: 88.09034907597535
- type: cos_sim_recall
value: 85.8
- type: dot_accuracy
value: 99.22970297029703
- type: dot_ap
value: 51.58725659485144
- type: dot_f1
value: 53.51351351351352
- type: dot_precision
value: 58.235294117647065
- type: dot_recall
value: 49.5
- type: euclidean_accuracy
value: 99.74356435643564
- type: euclidean_ap
value: 92.40332894384368
- type: euclidean_f1
value: 86.97838109602817
- type: euclidean_precision
value: 87.46208291203236
- type: euclidean_recall
value: 86.5
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 92.01320815721121
- type: manhattan_f1
value: 86.4135864135864
- type: manhattan_precision
value: 86.32734530938124
- type: manhattan_recall
value: 86.5
- type: max_accuracy
value: 99.74653465346535
- type: max_ap
value: 93.01476369929063
- type: max_f1
value: 86.97838109602817
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.2660514302523
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.4637783572547
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.41377758357637
- type: mrr
value: 50.138451213818854
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.887846011166594
- type: cos_sim_spearman
value: 30.10823258355903
- type: dot_pearson
value: 12.888049550236385
- type: dot_spearman
value: 12.827495903098123
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.667
- type: map_at_100
value: 9.15
- type: map_at_1000
value: 22.927
- type: map_at_3
value: 0.573
- type: map_at_5
value: 0.915
- type: mrr_at_1
value: 80
- type: mrr_at_10
value: 87.167
- type: mrr_at_100
value: 87.167
- type: mrr_at_1000
value: 87.167
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 87.167
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 69.757
- type: ndcg_at_100
value: 52.402
- type: ndcg_at_1000
value: 47.737
- type: ndcg_at_3
value: 71.866
- type: ndcg_at_5
value: 72.225
- type: precision_at_1
value: 80
- type: precision_at_10
value: 75
- type: precision_at_100
value: 53.959999999999994
- type: precision_at_1000
value: 21.568
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.9189999999999998
- type: recall_at_100
value: 12.589
- type: recall_at_1000
value: 45.312000000000005
- type: recall_at_3
value: 0.61
- type: recall_at_5
value: 1.019
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (sqi-eng)
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 90.06
- type: precision
value: 89.17333333333333
- type: recall
value: 92.10000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fry-eng)
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.06936416184971
- type: f1
value: 50.87508028259473
- type: precision
value: 48.97398843930635
- type: recall
value: 56.06936416184971
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kur-eng)
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.3170731707317
- type: f1
value: 52.96080139372822
- type: precision
value: 51.67861124382864
- type: recall
value: 57.3170731707317
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tur-eng)
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.67333333333333
- type: precision
value: 91.90833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (deu-eng)
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97.07333333333332
- type: precision
value: 96.79500000000002
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nld-eng)
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.2
- type: precision
value: 92.48333333333333
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ron-eng)
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.9
- type: f1
value: 91.26666666666667
- type: precision
value: 90.59444444444445
- type: recall
value: 92.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ang-eng)
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 34.32835820895522
- type: f1
value: 29.074180380150533
- type: precision
value: 28.068207322920596
- type: recall
value: 34.32835820895522
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ido-eng)
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.5
- type: f1
value: 74.3945115995116
- type: precision
value: 72.82967843459222
- type: recall
value: 78.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jav-eng)
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34146341463415
- type: f1
value: 61.2469400518181
- type: precision
value: 59.63977756660683
- type: recall
value: 66.34146341463415
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (isl-eng)
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.9
- type: f1
value: 76.90349206349207
- type: precision
value: 75.32921568627451
- type: recall
value: 80.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slv-eng)
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.93317132442284
- type: f1
value: 81.92519105034295
- type: precision
value: 80.71283920615635
- type: recall
value: 84.93317132442284
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cym-eng)
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.1304347826087
- type: f1
value: 65.22394755003451
- type: precision
value: 62.912422360248435
- type: recall
value: 71.1304347826087
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kaz-eng)
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.82608695652173
- type: f1
value: 75.55693581780538
- type: precision
value: 73.79420289855072
- type: recall
value: 79.82608695652173
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (est-eng)
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74
- type: f1
value: 70.51022222222223
- type: precision
value: 69.29673599347512
- type: recall
value: 74
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (heb-eng)
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 74.14238095238095
- type: precision
value: 72.27214285714285
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gla-eng)
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.97466827503016
- type: f1
value: 43.080330405420874
- type: precision
value: 41.36505499593557
- type: recall
value: 48.97466827503016
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mar-eng)
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.60000000000001
- type: f1
value: 86.62333333333333
- type: precision
value: 85.225
- type: recall
value: 89.60000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lat-eng)
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.2
- type: f1
value: 39.5761253006253
- type: precision
value: 37.991358436312
- type: recall
value: 45.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bel-eng)
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.70333333333333
- type: precision
value: 85.53166666666667
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pms-eng)
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.095238095238095
- type: f1
value: 44.60650460650461
- type: precision
value: 42.774116796477045
- type: recall
value: 50.095238095238095
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gle-eng)
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.4
- type: f1
value: 58.35967261904762
- type: precision
value: 56.54857142857143
- type: recall
value: 63.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pes-eng)
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 87.075
- type: precision
value: 86.12095238095239
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nob-eng)
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.90333333333334
- type: precision
value: 95.50833333333333
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bul-eng)
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.9
- type: f1
value: 88.6288888888889
- type: precision
value: 87.61607142857142
- type: recall
value: 90.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cbk-eng)
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.2
- type: f1
value: 60.54377630539395
- type: precision
value: 58.89434482711381
- type: recall
value: 65.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hun-eng)
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87
- type: f1
value: 84.32412698412699
- type: precision
value: 83.25527777777778
- type: recall
value: 87
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uig-eng)
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.7
- type: f1
value: 63.07883541295306
- type: precision
value: 61.06117424242426
- type: recall
value: 68.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (rus-eng)
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.78333333333335
- type: precision
value: 90.86666666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (spa-eng)
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 96.96666666666667
- type: precision
value: 96.61666666666667
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hye-eng)
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27493261455525
- type: f1
value: 85.90745732255168
- type: precision
value: 84.91389637616052
- type: recall
value: 88.27493261455525
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tel-eng)
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5982905982906
- type: f1
value: 88.4900284900285
- type: precision
value: 87.57122507122507
- type: recall
value: 90.5982905982906
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (afr-eng)
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.90769841269842
- type: precision
value: 85.80178571428571
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mon-eng)
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.5
- type: f1
value: 78.36796536796538
- type: precision
value: 76.82196969696969
- type: recall
value: 82.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arz-eng)
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.48846960167715
- type: f1
value: 66.78771089148448
- type: precision
value: 64.98302885095339
- type: recall
value: 71.48846960167715
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hrv-eng)
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.50333333333333
- type: precision
value: 91.77499999999999
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nov-eng)
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.20622568093385
- type: f1
value: 66.83278891450098
- type: precision
value: 65.35065777283677
- type: recall
value: 71.20622568093385
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (gsw-eng)
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.717948717948715
- type: f1
value: 43.53146853146853
- type: precision
value: 42.04721204721204
- type: recall
value: 48.717948717948715
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nds-eng)
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.8564991863928
- type: precision
value: 52.40329436122275
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ukr-eng)
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.29
- type: precision
value: 87.09166666666667
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (uzb-eng)
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.28971962616822
- type: f1
value: 62.63425307817832
- type: precision
value: 60.98065939771546
- type: recall
value: 67.28971962616822
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lit-eng)
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 75.5264472455649
- type: precision
value: 74.38205086580086
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ina-eng)
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.7
- type: f1
value: 86.10809523809525
- type: precision
value: 85.07602564102565
- type: recall
value: 88.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lfn-eng)
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.99999999999999
- type: f1
value: 52.85487521402737
- type: precision
value: 51.53985162713104
- type: recall
value: 56.99999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (zsm-eng)
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94
- type: f1
value: 92.45333333333333
- type: precision
value: 91.79166666666667
- type: recall
value: 94
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ita-eng)
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.61333333333333
- type: precision
value: 89.83333333333331
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cmn-eng)
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34555555555555
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (lvs-eng)
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.6563035113035
- type: precision
value: 75.3014652014652
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (glg-eng)
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 82.78689263765207
- type: precision
value: 82.06705086580087
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ceb-eng)
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.33333333333333
- type: f1
value: 45.461523661523664
- type: precision
value: 43.93545574795575
- type: recall
value: 50.33333333333333
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bre-eng)
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.6000000000000005
- type: f1
value: 5.442121400446441
- type: precision
value: 5.146630385487529
- type: recall
value: 6.6000000000000005
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ben-eng)
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85
- type: f1
value: 81.04666666666667
- type: precision
value: 79.25
- type: recall
value: 85
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swg-eng)
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.32142857142857
- type: f1
value: 42.333333333333336
- type: precision
value: 40.69196428571429
- type: recall
value: 47.32142857142857
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (arq-eng)
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 30.735455543358945
- type: f1
value: 26.73616790022338
- type: precision
value: 25.397823220451283
- type: recall
value: 30.735455543358945
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kab-eng)
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.1
- type: f1
value: 21.975989896371022
- type: precision
value: 21.059885632257203
- type: recall
value: 25.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fra-eng)
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.75666666666666
- type: precision
value: 92.06166666666665
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (por-eng)
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.74
- type: precision
value: 92.09166666666667
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tat-eng)
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 66.922442002442
- type: precision
value: 65.38249567099568
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (oci-eng)
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.300000000000004
- type: f1
value: 35.78682789299971
- type: precision
value: 34.66425128716588
- type: recall
value: 40.300000000000004
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pol-eng)
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.82333333333334
- type: precision
value: 94.27833333333334
- type: recall
value: 96
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (war-eng)
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.1
- type: f1
value: 47.179074753133584
- type: precision
value: 46.06461044702424
- type: recall
value: 51.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (aze-eng)
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.7
- type: f1
value: 84.71
- type: precision
value: 83.46166666666667
- type: recall
value: 87.7
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (vie-eng)
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.68333333333334
- type: precision
value: 94.13333333333334
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (nno-eng)
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 82.5577380952381
- type: precision
value: 81.36833333333334
- type: recall
value: 85.39999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cha-eng)
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.16788321167883
- type: f1
value: 16.948865627297987
- type: precision
value: 15.971932568647897
- type: recall
value: 21.16788321167883
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mhr-eng)
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 5.515526831658907
- type: precision
value: 5.141966366966367
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dan-eng)
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39666666666668
- type: precision
value: 90.58666666666667
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ell-eng)
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.95666666666666
- type: precision
value: 88.92833333333333
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (amh-eng)
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.76190476190477
- type: f1
value: 74.93386243386244
- type: precision
value: 73.11011904761904
- type: recall
value: 79.76190476190477
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (pam-eng)
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.921439712248537
- type: precision
value: 6.489885109680683
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hsb-eng)
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.75569358178054
- type: f1
value: 40.34699501312631
- type: precision
value: 38.57886764719063
- type: recall
value: 45.75569358178054
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (srp-eng)
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.08333333333333
- type: precision
value: 88.01666666666668
- type: recall
value: 91.4
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (epo-eng)
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.06690476190477
- type: precision
value: 91.45095238095239
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kzj-eng)
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.5
- type: f1
value: 6.200363129378736
- type: precision
value: 5.89115314822466
- type: recall
value: 7.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (awa-eng)
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.59307359307358
- type: f1
value: 68.38933553219267
- type: precision
value: 66.62698412698413
- type: recall
value: 73.59307359307358
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fao-eng)
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.8473282442748
- type: f1
value: 64.72373682297346
- type: precision
value: 62.82834214131924
- type: recall
value: 69.8473282442748
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mal-eng)
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5254730713246
- type: f1
value: 96.72489082969432
- type: precision
value: 96.33672974284326
- type: recall
value: 97.5254730713246
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ile-eng)
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.6
- type: f1
value: 72.42746031746033
- type: precision
value: 71.14036630036631
- type: recall
value: 75.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (bos-eng)
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.24293785310734
- type: f1
value: 88.86064030131826
- type: precision
value: 87.73540489642184
- type: recall
value: 91.24293785310734
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cor-eng)
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 4.383083659794954
- type: precision
value: 4.027861324289673
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (cat-eng)
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 84.09428571428572
- type: precision
value: 83.00333333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (eus-eng)
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.699999999999996
- type: f1
value: 56.1584972394755
- type: precision
value: 54.713456330903135
- type: recall
value: 60.699999999999996
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yue-eng)
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.2
- type: f1
value: 80.66190476190475
- type: precision
value: 79.19690476190476
- type: recall
value: 84.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swe-eng)
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.33
- type: precision
value: 90.45
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dtp-eng)
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.3
- type: f1
value: 5.126828976748276
- type: precision
value: 4.853614328966668
- type: recall
value: 6.3
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kat-eng)
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.76943699731903
- type: f1
value: 77.82873739308057
- type: precision
value: 76.27622452019234
- type: recall
value: 81.76943699731903
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (jpn-eng)
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.29666666666665
- type: precision
value: 89.40333333333334
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (csb-eng)
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.249011857707508
- type: f1
value: 24.561866096392947
- type: precision
value: 23.356583740215456
- type: recall
value: 29.249011857707508
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (xho-eng)
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.23943661971832
- type: precision
value: 71.66666666666667
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (orv-eng)
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.35928143712575
- type: f1
value: 15.997867865075824
- type: precision
value: 14.882104658301346
- type: recall
value: 20.35928143712575
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ind-eng)
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 90.25999999999999
- type: precision
value: 89.45333333333335
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tuk-eng)
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 19.65673625772148
- type: precision
value: 18.793705293464992
- type: recall
value: 23.15270935960591
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (max-eng)
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.154929577464785
- type: f1
value: 52.3868463305083
- type: precision
value: 50.14938113529662
- type: recall
value: 59.154929577464785
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (swh-eng)
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.51282051282051
- type: f1
value: 66.8089133089133
- type: precision
value: 65.37645687645687
- type: recall
value: 70.51282051282051
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (hin-eng)
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93
- type: precision
value: 92.23333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (dsb-eng)
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.62212943632568
- type: f1
value: 34.3278276962583
- type: precision
value: 33.07646935732408
- type: recall
value: 38.62212943632568
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ber-eng)
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.1
- type: f1
value: 23.579609223054604
- type: precision
value: 22.39622774921555
- type: recall
value: 28.1
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tam-eng)
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27361563517914
- type: f1
value: 85.12486427795874
- type: precision
value: 83.71335504885994
- type: recall
value: 88.27361563517914
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (slk-eng)
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 86.39928571428571
- type: precision
value: 85.4947557997558
- type: recall
value: 88.6
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tgl-eng)
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.77952380952381
- type: precision
value: 82.67602564102565
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ast-eng)
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.52755905511812
- type: f1
value: 75.3055868016498
- type: precision
value: 73.81889763779527
- type: recall
value: 79.52755905511812
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (mkd-eng)
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.76261904761905
- type: precision
value: 72.11670995670995
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (khm-eng)
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.8781163434903
- type: f1
value: 47.25804051288816
- type: precision
value: 45.0603482390186
- type: recall
value: 53.8781163434903
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ces-eng)
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.88
- type: precision
value: 87.96333333333334
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tzl-eng)
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.46153846153847
- type: f1
value: 34.43978243978244
- type: precision
value: 33.429487179487175
- type: recall
value: 38.46153846153847
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (urd-eng)
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.9
- type: f1
value: 86.19888888888887
- type: precision
value: 85.07440476190476
- type: recall
value: 88.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (ara-eng)
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.9
- type: f1
value: 82.58857142857143
- type: precision
value: 81.15666666666667
- type: recall
value: 85.9
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (kor-eng)
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.36999999999999
- type: precision
value: 81.86833333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (yid-eng)
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.51415094339622
- type: f1
value: 63.195000099481234
- type: precision
value: 61.394033442972116
- type: recall
value: 68.51415094339622
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (fin-eng)
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 86.14603174603175
- type: precision
value: 85.1162037037037
- type: recall
value: 88.5
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (tha-eng)
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.62043795620438
- type: f1
value: 94.40389294403892
- type: precision
value: 93.7956204379562
- type: recall
value: 95.62043795620438
- task:
type: BitextMining
dataset:
type: mteb/tatoeba-bitext-mining
name: MTEB Tatoeba (wuu-eng)
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.8
- type: f1
value: 78.6532178932179
- type: precision
value: 77.46348795840176
- type: recall
value: 81.8
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.603
- type: map_at_10
value: 8.5
- type: map_at_100
value: 12.985
- type: map_at_1000
value: 14.466999999999999
- type: map_at_3
value: 4.859999999999999
- type: map_at_5
value: 5.817
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 42.331
- type: mrr_at_100
value: 43.592999999999996
- type: mrr_at_1000
value: 43.592999999999996
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 39.966
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 21.353
- type: ndcg_at_100
value: 31.087999999999997
- type: ndcg_at_1000
value: 43.163000000000004
- type: ndcg_at_3
value: 22.999
- type: ndcg_at_5
value: 21.451
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 19.387999999999998
- type: precision_at_100
value: 6.265
- type: precision_at_1000
value: 1.4160000000000001
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 21.224
- type: recall_at_1
value: 2.603
- type: recall_at_10
value: 14.474
- type: recall_at_100
value: 40.287
- type: recall_at_1000
value: 76.606
- type: recall_at_3
value: 5.978
- type: recall_at_5
value: 7.819
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7848
- type: ap
value: 13.661023167088224
- type: f1
value: 53.61686134460943
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.28183361629882
- type: f1
value: 61.55481034919965
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 35.972128420092396
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59933241938367
- type: cos_sim_ap
value: 72.20760361208136
- type: cos_sim_f1
value: 66.4447731755424
- type: cos_sim_precision
value: 62.35539102267469
- type: cos_sim_recall
value: 71.10817941952506
- type: dot_accuracy
value: 78.98313166835548
- type: dot_ap
value: 44.492521645493795
- type: dot_f1
value: 45.814889336016094
- type: dot_precision
value: 37.02439024390244
- type: dot_recall
value: 60.07915567282321
- type: euclidean_accuracy
value: 85.3907134767837
- type: euclidean_ap
value: 71.53847289080343
- type: euclidean_f1
value: 65.95952206778834
- type: euclidean_precision
value: 61.31006346328196
- type: euclidean_recall
value: 71.37203166226914
- type: manhattan_accuracy
value: 85.40859510043511
- type: manhattan_ap
value: 71.49664104395515
- type: manhattan_f1
value: 65.98569969356485
- type: manhattan_precision
value: 63.928748144482924
- type: manhattan_recall
value: 68.17941952506597
- type: max_accuracy
value: 85.59933241938367
- type: max_ap
value: 72.20760361208136
- type: max_f1
value: 66.4447731755424
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.83261536073273
- type: cos_sim_ap
value: 85.48178133644264
- type: cos_sim_f1
value: 77.87816307403935
- type: cos_sim_precision
value: 75.88953021114926
- type: cos_sim_recall
value: 79.97382198952879
- type: dot_accuracy
value: 79.76287499514883
- type: dot_ap
value: 59.17438838475084
- type: dot_f1
value: 56.34566667855996
- type: dot_precision
value: 52.50349092359864
- type: dot_recall
value: 60.794579611949494
- type: euclidean_accuracy
value: 88.76857996662397
- type: euclidean_ap
value: 85.22764834359887
- type: euclidean_f1
value: 77.65379751543554
- type: euclidean_precision
value: 75.11152683839401
- type: euclidean_recall
value: 80.37419156144134
- type: manhattan_accuracy
value: 88.6987231730508
- type: manhattan_ap
value: 85.18907981724007
- type: manhattan_f1
value: 77.51967028849757
- type: manhattan_precision
value: 75.49992701795358
- type: manhattan_recall
value: 79.65044656606098
- type: max_accuracy
value: 88.83261536073273
- type: max_ap
value: 85.48178133644264
- type: max_f1
value: 77.87816307403935
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
## Multilingual-E5-base
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
This model has 12 layers and the embedding size is 768.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
**First stage**: contrastive pre-training with weak supervision
| Dataset | Weak supervision | # of text pairs |
|--------------------------------------------------------------------------------------------------------|---------------------------------------|-----------------|
| Filtered [mC4](https://huggingface.co/datasets/mc4) | (title, page content) | 1B |
| [CC News](https://huggingface.co/datasets/intfloat/multilingual_cc_news) | (title, news content) | 400M |
| [NLLB](https://huggingface.co/datasets/allenai/nllb) | translation pairs | 2.4B |
| [Wikipedia](https://huggingface.co/datasets/intfloat/wikipedia) | (hierarchical section title, passage) | 150M |
| Filtered [Reddit](https://www.reddit.com/) | (comment, response) | 800M |
| [S2ORC](https://github.com/allenai/s2orc) | (title, abstract) and citation pairs | 100M |
| [Stackexchange](https://stackexchange.com/) | (question, answer) | 50M |
| [xP3](https://huggingface.co/datasets/bigscience/xP3) | (input prompt, response) | 80M |
| [Miscellaneous unsupervised SBERT data](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | - | 10M |
**Second stage**: supervised fine-tuning
| Dataset | Language | # of text pairs |
|----------------------------------------------------------------------------------------|--------------|-----------------|
| [MS MARCO](https://microsoft.github.io/msmarco/) | English | 500k |
| [NQ](https://github.com/facebookresearch/DPR) | English | 70k |
| [Trivia QA](https://github.com/facebookresearch/DPR) | English | 60k |
| [NLI from SimCSE](https://github.com/princeton-nlp/SimCSE) | English | <300k |
| [ELI5](https://huggingface.co/datasets/eli5) | English | 500k |
| [DuReader Retrieval](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval) | Chinese | 86k |
| [KILT Fever](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [KILT HotpotQA](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [SQuAD](https://huggingface.co/datasets/squad) | English | 87k |
| [Quora](https://huggingface.co/datasets/quora) | English | 150k |
| [Mr. TyDi](https://huggingface.co/datasets/castorini/mr-tydi) | 11 languages | 50k |
| [MIRACL](https://huggingface.co/datasets/miracl/miracl) | 16 languages | 40k |
For all labeled datasets, we only use its training set for fine-tuning.
For other training details, please refer to our paper at [https://arxiv.org/pdf/2212.03533.pdf](https://arxiv.org/pdf/2212.03533.pdf).
## Benchmark Results on [Mr. TyDi](https://arxiv.org/abs/2108.08787)
| Model | Avg MRR@10 | | ar | bn | en | fi | id | ja | ko | ru | sw | te | th |
|-----------------------|------------|-------|------| --- | --- | --- | --- | --- | --- | --- |------| --- | --- |
| BM25 | 33.3 | | 36.7 | 41.3 | 15.1 | 28.8 | 38.2 | 21.7 | 28.1 | 32.9 | 39.6 | 42.4 | 41.7 |
| mDPR | 16.7 | | 26.0 | 25.8 | 16.2 | 11.3 | 14.6 | 18.1 | 21.9 | 18.5 | 7.3 | 10.6 | 13.5 |
| BM25 + mDPR | 41.7 | | 49.1 | 53.5 | 28.4 | 36.5 | 45.5 | 35.5 | 36.2 | 42.7 | 40.5 | 42.0 | 49.2 |
| | |
| multilingual-e5-small | 64.4 | | 71.5 | 66.3 | 54.5 | 57.7 | 63.2 | 55.4 | 54.3 | 60.8 | 65.4 | 89.1 | 70.1 |
| multilingual-e5-base | 65.9 | | 72.3 | 65.0 | 58.5 | 60.8 | 64.9 | 56.6 | 55.8 | 62.7 | 69.0 | 86.6 | 72.7 |
| multilingual-e5-large | **70.5** | | 77.5 | 73.2 | 60.8 | 66.8 | 68.5 | 62.5 | 61.6 | 65.8 | 72.7 | 90.2 | 76.2 |
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/multilingual-e5-base')
input_texts = [
'query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 i s 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or traini ng for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮 ,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右, 放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油 锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, bitext mining, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
TheBloke/deepseek-coder-6.7B-base-GGUF
|
TheBloke
| 2023-11-05T15:28:45Z | 2,945 | 11 |
transformers
|
[
"transformers",
"gguf",
"deepseek",
"base_model:deepseek-ai/deepseek-coder-6.7b-base",
"base_model:quantized:deepseek-ai/deepseek-coder-6.7b-base",
"license:other",
"region:us"
] | null | 2023-11-05T13:30:44Z |
---
base_model: deepseek-ai/deepseek-coder-6.7b-base
inference: false
license: other
license_link: LICENSE
license_name: deepseek-license
model_creator: DeepSeek
model_name: Deepseek Coder 6.7B Base
model_type: deepseek
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 6.7B Base - GGUF
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 6.7B Base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base)
<!-- description start -->
## Description
This repo contains GGUF format model files for [DeepSeek's Deepseek Coder 6.7B Base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [deepseek-coder-6.7b-base.Q2_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q2_K.gguf) | Q2_K | 2 | 2.83 GB| 5.33 GB | smallest, significant quality loss - not recommended for most purposes |
| [deepseek-coder-6.7b-base.Q3_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q3_K_S.gguf) | Q3_K_S | 3 | 2.95 GB| 5.45 GB | very small, high quality loss |
| [deepseek-coder-6.7b-base.Q3_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q3_K_M.gguf) | Q3_K_M | 3 | 3.30 GB| 5.80 GB | very small, high quality loss |
| [deepseek-coder-6.7b-base.Q3_K_L.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q3_K_L.gguf) | Q3_K_L | 3 | 3.60 GB| 6.10 GB | small, substantial quality loss |
| [deepseek-coder-6.7b-base.Q4_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q4_0.gguf) | Q4_0 | 4 | 3.83 GB| 6.33 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [deepseek-coder-6.7b-base.Q4_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q4_K_S.gguf) | Q4_K_S | 4 | 3.86 GB| 6.36 GB | small, greater quality loss |
| [deepseek-coder-6.7b-base.Q4_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q4_K_M.gguf) | Q4_K_M | 4 | 4.08 GB| 6.58 GB | medium, balanced quality - recommended |
| [deepseek-coder-6.7b-base.Q5_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q5_0.gguf) | Q5_0 | 5 | 4.65 GB| 7.15 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [deepseek-coder-6.7b-base.Q5_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q5_K_S.gguf) | Q5_K_S | 5 | 4.65 GB| 7.15 GB | large, low quality loss - recommended |
| [deepseek-coder-6.7b-base.Q5_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q5_K_M.gguf) | Q5_K_M | 5 | 4.79 GB| 7.29 GB | large, very low quality loss - recommended |
| [deepseek-coder-6.7b-base.Q6_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q6_K.gguf) | Q6_K | 6 | 5.53 GB| 8.03 GB | very large, extremely low quality loss |
| [deepseek-coder-6.7b-base.Q8_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF/blob/main/deepseek-coder-6.7b-base.Q8_0.gguf) | Q8_0 | 8 | 7.16 GB| 9.66 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/deepseek-coder-6.7B-base-GGUF and below it, a specific filename to download, such as: deepseek-coder-6.7b-base.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GGUF deepseek-coder-6.7b-base.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GGUF deepseek-coder-6.7b-base.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m deepseek-coder-6.7b-base.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/deepseek-coder-6.7B-base-GGUF", model_file="deepseek-coder-6.7b-base.Q4_K_M.gguf", model_type="deepseek", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: DeepSeek's Deepseek Coder 6.7B Base
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-6.7b-base is a 6.7B parameter model with Multi-Head Attention trained on 2 trillion tokens.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
<!-- original-model-card end -->
|
TheBloke/deepseek-coder-5.7bmqa-base-GGUF
|
TheBloke
| 2023-11-05T15:25:09Z | 595 | 3 |
transformers
|
[
"transformers",
"gguf",
"deepseek",
"base_model:deepseek-ai/deepseek-coder-5.7bmqa-base",
"base_model:quantized:deepseek-ai/deepseek-coder-5.7bmqa-base",
"license:other",
"region:us"
] | null | 2023-11-05T13:53:22Z |
---
base_model: deepseek-ai/deepseek-coder-5.7bmqa-base
inference: false
license: other
license_link: LICENSE
license_name: deepseek
model_creator: DeepSeek
model_name: Deepseek Coder 5.7Bmqa Base
model_type: deepseek
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 5.7Bmqa Base - GGUF
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 5.7Bmqa Base](https://huggingface.co/deepseek-ai/deepseek-coder-5.7bmqa-base)
<!-- description start -->
## Description
This repo contains GGUF format model files for [DeepSeek's Deepseek Coder 5.7Bmqa Base](https://huggingface.co/deepseek-ai/deepseek-coder-5.7bmqa-base).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-5.7bmqa-base)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [deepseek-coder-5.7bmqa-base.Q2_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q2_K.gguf) | Q2_K | 2 | 2.43 GB| 4.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [deepseek-coder-5.7bmqa-base.Q3_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q3_K_S.gguf) | Q3_K_S | 3 | 2.50 GB| 5.00 GB | very small, high quality loss |
| [deepseek-coder-5.7bmqa-base.Q3_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q3_K_M.gguf) | Q3_K_M | 3 | 2.78 GB| 5.28 GB | very small, high quality loss |
| [deepseek-coder-5.7bmqa-base.Q3_K_L.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q3_K_L.gguf) | Q3_K_L | 3 | 3.02 GB| 5.52 GB | small, substantial quality loss |
| [deepseek-coder-5.7bmqa-base.Q4_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q4_0.gguf) | Q4_0 | 4 | 3.24 GB| 5.74 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [deepseek-coder-5.7bmqa-base.Q4_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q4_K_S.gguf) | Q4_K_S | 4 | 3.27 GB| 5.77 GB | small, greater quality loss |
| [deepseek-coder-5.7bmqa-base.Q4_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q4_K_M.gguf) | Q4_K_M | 4 | 3.43 GB| 5.93 GB | medium, balanced quality - recommended |
| [deepseek-coder-5.7bmqa-base.Q5_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q5_0.gguf) | Q5_0 | 5 | 3.94 GB| 6.44 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [deepseek-coder-5.7bmqa-base.Q5_K_S.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q5_K_S.gguf) | Q5_K_S | 5 | 3.94 GB| 6.44 GB | large, low quality loss - recommended |
| [deepseek-coder-5.7bmqa-base.Q5_K_M.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q5_K_M.gguf) | Q5_K_M | 5 | 4.04 GB| 6.54 GB | large, very low quality loss - recommended |
| [deepseek-coder-5.7bmqa-base.Q6_K.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q6_K.gguf) | Q6_K | 6 | 4.68 GB| 7.18 GB | very large, extremely low quality loss |
| [deepseek-coder-5.7bmqa-base.Q8_0.gguf](https://huggingface.co/TheBloke/deepseek-coder-5.7bmqa-base-GGUF/blob/main/deepseek-coder-5.7bmqa-base.Q8_0.gguf) | Q8_0 | 8 | 6.06 GB| 8.56 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/deepseek-coder-5.7bmqa-base-GGUF and below it, a specific filename to download, such as: deepseek-coder-5.7bmqa-base.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/deepseek-coder-5.7bmqa-base-GGUF deepseek-coder-5.7bmqa-base.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/deepseek-coder-5.7bmqa-base-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-5.7bmqa-base-GGUF deepseek-coder-5.7bmqa-base.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m deepseek-coder-5.7bmqa-base.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/deepseek-coder-5.7bmqa-base-GGUF", model_file="deepseek-coder-5.7bmqa-base.Q4_K_M.gguf", model_type="deepseek", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: DeepSeek's Deepseek Coder 5.7Bmqa Base
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-5.7bmqa-base is a 5.7B parameter model with Multi Query Attention trained on 2 trillion tokens.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-5.7bmqa-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
<!-- original-model-card end -->
|
LaTarn/ta-service-setfit-model
|
LaTarn
| 2023-11-05T15:11:15Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-11-05T15:10:50Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# LaTarn/ta-service-setfit-model
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("LaTarn/ta-service-setfit-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
jtrancas/deepseek-coder-7b-instruct-GGUF
|
jtrancas
| 2023-11-05T15:02:38Z | 675 | 2 | null |
[
"gguf",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2023-11-05T03:10:42Z |
---
license: other
license_name: deepseek
license_link: LICENSE
---
|
briannlongzhao/charles_petillon_textual_inversion
|
briannlongzhao
| 2023-11-05T15:00:12Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-05T11:38:36Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - briannlongzhao/charles_petillon_textual_inversion
These are textual inversion adaption weights for stabilityai/stable-diffusion-2-1. You can find some example images in the following.
|
MarthaK-Coder/test_trainer
|
MarthaK-Coder
| 2023-11-05T14:56:27Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-26T16:41:45Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: test_trainer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2229
- eval_accuracy: 0.9235
- eval_runtime: 61.5773
- eval_samples_per_second: 32.48
- eval_steps_per_second: 2.03
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
ValentinGuigon/distilbert-base-uncased-finetuned-imdb
|
ValentinGuigon
| 2023-11-05T14:50:31Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-05T11:28:07Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4567
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7058 | 1.0 | 157 | 2.5259 |
| 2.5786 | 2.0 | 314 | 2.4531 |
| 2.5349 | 3.0 | 471 | 2.4159 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
l3cube-pune/marathi-fast-text-embedding
|
l3cube-pune
| 2023-11-05T14:48:06Z | 0 | 1 | null |
[
"mr",
"dataset:L3Cube-MahaCorpus",
"arxiv:2202.01159",
"license:cc-by-4.0",
"region:us"
] | null | 2023-11-05T13:19:40Z |
---
license: cc-by-4.0
language: mr
datasets:
- L3Cube-MahaCorpus
---
## MahaFT
MahaFT is a Marathi fast text embedding model. It is a fast text model trained on L3Cube-MahaCorpus and other publicly available Marathi monolingual datasets. <br>
[dataset link] (https://github.com/l3cube-pune/MarathiNLP)
More details on the dataset, models, and baseline results can be found in our [paper] (https://arxiv.org/abs/2202.01159)
### Citing:
```
@inproceedings{joshi-2022-l3cube,
title = "{L}3{C}ube-{M}aha{C}orpus and {M}aha{BERT}: {M}arathi Monolingual Corpus, {M}arathi {BERT} Language Models, and Resources",
author = "Joshi, Raviraj",
booktitle = "Proceedings of the WILDRE-6 Workshop within the 13th Language Resources and Evaluation Conference",
month = jun,
year = "2022",
address = "Marseille, France",
publisher = "European Language Resources Association",
url = "https://aclanthology.org/2022.wildre-1.17",
pages = "97--101",
}
```
|
NguyenPham551/neurondbert-finetuned-squad-nguyenvulebinh-vi-mrc-base
|
NguyenPham551
| 2023-11-05T14:46:10Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-10-16T15:44:01Z |
---
tags:
- generated_from_trainer
model-index:
- name: neurondbert-finetuned-squad-nguyenvulebinh-vi-mrc-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# neurondbert-finetuned-squad-nguyenvulebinh-vi-mrc-base
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3810
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5786 | 1.0 | 1526 | 0.3895 |
| 0.4647 | 2.0 | 3052 | 0.3780 |
| 0.3479 | 3.0 | 4578 | 0.3810 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
jstoone/distil-ast-audioset-finetuned-cry
|
jstoone
| 2023-11-05T14:34:30Z | 842 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:Nooon/Donate_a_cry",
"base_model:bookbot/distil-ast-audioset",
"base_model:finetune:bookbot/distil-ast-audioset",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-05T13:36:12Z |
---
license: apache-2.0
base_model: bookbot/distil-ast-audioset
tags:
- generated_from_trainer
datasets:
- Nooon/Donate_a_cry
metrics:
- accuracy
model-index:
- name: distil-ast-audioset-finetuned-cry
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: DonateACry
type: Nooon/Donate_a_cry
config: train
split: train
args: train
metrics:
- name: Accuracy
type: accuracy
value: 0.6363636363636364
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distil-ast-audioset-finetuned-cry
This model is a fine-tuned version of [bookbot/distil-ast-audioset](https://huggingface.co/bookbot/distil-ast-audioset) on the DonateACry dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8592
- Accuracy: 0.6364
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.9595 | 1.0 | 11 | 1.6120 | 0.0909 |
| 1.3053 | 2.0 | 22 | 1.3677 | 0.2727 |
| 0.7604 | 3.0 | 33 | 1.9563 | 0.1818 |
| 0.4351 | 4.0 | 44 | 1.3875 | 0.5455 |
| 0.316 | 5.0 | 55 | 1.7235 | 0.5455 |
| 0.0949 | 6.0 | 66 | 1.5362 | 0.6364 |
| 0.0355 | 7.0 | 77 | 1.8020 | 0.5455 |
| 0.0156 | 8.0 | 88 | 1.8320 | 0.6364 |
| 0.0102 | 9.0 | 99 | 1.9028 | 0.6364 |
| 0.0061 | 10.0 | 110 | 1.8592 | 0.6364 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
adityaaswani1/ppo-Huggy
|
adityaaswani1
| 2023-11-05T14:30:12Z | 2 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-05T14:30:05Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: adityaaswani1/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
perecasxiru/ppo-Huggy
|
perecasxiru
| 2023-11-05T14:29:10Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-05T14:29:06Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: perecasxiru/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
TheBloke/deepseek-coder-6.7B-base-GPTQ
|
TheBloke
| 2023-11-05T14:28:18Z | 109 | 5 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:deepseek-ai/deepseek-coder-6.7b-base",
"base_model:quantized:deepseek-ai/deepseek-coder-6.7b-base",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-05T09:40:43Z |
---
base_model: deepseek-ai/deepseek-coder-6.7b-base
inference: false
license: other
license_link: LICENSE
license_name: deepseek-license
model_creator: DeepSeek
model_name: Deepseek Coder 6.7B Base
model_type: deepseek
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Deepseek Coder 6.7B Base - GPTQ
- Model creator: [DeepSeek](https://huggingface.co/deepseek-ai)
- Original model: [Deepseek Coder 6.7B Base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base)
<!-- description start -->
## Description
This repo contains GPTQ model files for [DeepSeek's Deepseek Coder 6.7B Base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF)
* [DeepSeek's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.02 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 7.62 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [Evol Instruct Code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1) | 4096 | 4.03 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/deepseek-coder-6.7B-base-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/deepseek-coder-6.7B-base-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `deepseek-coder-6.7B-base-GPTQ`:
```shell
mkdir deepseek-coder-6.7B-base-GPTQ
huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GPTQ --local-dir deepseek-coder-6.7B-base-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir deepseek-coder-6.7B-base-GPTQ
huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir deepseek-coder-6.7B-base-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir deepseek-coder-6.7B-base-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/deepseek-coder-6.7B-base-GPTQ --local-dir deepseek-coder-6.7B-base-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/deepseek-coder-6.7B-base-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/deepseek-coder-6.7B-base-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `deepseek-coder-6.7B-base-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/deepseek-coder-6.7B-base-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers optimum
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.4.2
pip3 install .
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/deepseek-coder-6.7B-base-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: DeepSeek's Deepseek Coder 6.7B Base
<p align="center">
<img width="1000px" alt="DeepSeek Coder" src="https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/pictures/logo.png?raw=true">
</p>
<p align="center"><a href="https://www.deepseek.com/">[🏠Homepage]</a> | <a href="https://coder.deepseek.com/">[🤖 Chat with DeepSeek Coder]</a> | <a href="https://discord.gg/Tc7c45Zzu5">[Discord]</a> | <a href="https://github.com/guoday/assert/blob/main/QR.png?raw=true">[Wechat(微信)]</a> </p>
<hr>
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-6.7b-base is a 6.7B parameter model with Multi-Head Attention trained on 2 trillion tokens.
- **Home Page:** [DeepSeek](https://deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = """<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
joaovitor2763/mistral-test3
|
joaovitor2763
| 2023-11-05T14:24:00Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-05T14:23:04Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
His0ham/my-pet-teddy
|
His0ham
| 2023-11-05T14:23:31Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-05T14:19:23Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-teddy Dreambooth model trained by His0ham following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: BJI-144
Sample pictures of this concept:

|
minhquy1624/model_train
|
minhquy1624
| 2023-11-05T14:07:24Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-04T04:06:38Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0
|
hasibul1ah/bloom3b-lora-instructiondemo
|
hasibul1ah
| 2023-11-05T14:05:51Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:bigscience/bloom-3b",
"base_model:adapter:bigscience/bloom-3b",
"region:us"
] | null | 2023-11-05T13:35:51Z |
---
library_name: peft
base_model: bigscience/bloom-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.7.0.dev0
## Training procedure
### Framework versions
- PEFT 0.7.0.dev0
|
Shehryar718/URDU-ASR
|
Shehryar718
| 2023-11-05T13:43:50Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_13_0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-01T22:51:29Z |
---
tags:
- generated_from_trainer
datasets:
- common_voice_13_0
metrics:
- wer
model-index:
- name: URDU-ASR
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_13_0
type: common_voice_13_0
config: ur
split: test
args: ur
metrics:
- name: Wer
type: wer
value: 0.49680838717165077
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# URDU-ASR
This model was trained from scratch on the common_voice_13_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6632
- Wer: 0.4968
- Cer: 0.2099
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.85,0.9) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 1.9625 | 1.0 | 341 | 0.7371 | 0.5348 | 0.2190 |
| 0.2156 | 2.0 | 683 | 0.7057 | 0.5103 | 0.2169 |
| 0.2451 | 3.0 | 1024 | 0.6654 | 0.5161 | 0.2214 |
| 0.199 | 4.0 | 1366 | 0.6707 | 0.5089 | 0.2153 |
| 0.1657 | 4.99 | 1705 | 0.6632 | 0.4968 | 0.2099 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
MimionanA/wav2vec2-large-xlsr-53-Mandarin-colab
|
MimionanA
| 2023-11-05T13:33:31Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_13_0",
"base_model:facebook/wav2vec2-large-xlsr-53",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-01T11:08:05Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53
tags:
- generated_from_trainer
datasets:
- common_voice_13_0
model-index:
- name: wav2vec2-large-xlsr-53-Mandarin-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-Mandarin-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice_13_0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 512
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 1.10.0+cu113
- Datasets 2.14.6
- Tokenizers 0.14.1
|
ravinderbrai/pegasus-reviews
|
ravinderbrai
| 2023-11-05T13:28:43Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"summarization",
"generated_from_trainer",
"base_model:google/pegasus-cnn_dailymail",
"base_model:finetune:google/pegasus-cnn_dailymail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-10-30T00:19:21Z |
---
base_model: google/pegasus-cnn_dailymail
tags:
- summarization
- generated_from_trainer
model-index:
- name: pegasus-reviews
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-reviews
This model is a fine-tuned version of [google/pegasus-cnn_dailymail](https://huggingface.co/google/pegasus-cnn_dailymail) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8541 | 1.0 | 1 | 4.3114 |
| 0.8178 | 2.0 | 2 | 4.3112 |
| 0.9366 | 3.0 | 3 | 4.3108 |
| 0.831 | 4.0 | 4 | 4.3102 |
| 0.8294 | 5.0 | 5 | 4.3094 |
| 0.2781 | 5.33 | 6 | 4.3085 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0
- Datasets 2.12.0
- Tokenizers 0.14.1
|
AISE-TUDelft/ML4SE23_G1_WizardCoder-SCoT-1B-V1.0
|
AISE-TUDelft
| 2023-11-05T13:20:05Z | 42 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"code",
"en",
"dataset:AISE-TUDelft/ML4SE23_G1_EvolInstruct-SCoT-1k",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-31T13:34:23Z |
---
datasets:
- AISE-TUDelft/ML4SE23_G1_EvolInstruct-SCoT-1k
language:
- en
tags:
- code
---
# ML4SE23_G1_WizardCoder-SCoT-1B-V1.0
IN4334 ML4SE
Group1 WizardCoder
This model is the result of the fine-tunign of the WizardCoder-1B-V1.0 model using Structured Chain-of-Though (S-CoT) enhanced instructions.
S-CoT is used to enhance a sample of about 1200 entries from the Evol-Instruct 80k dataset.
The resulting dataset is then used for the training task.
The current WizardCoder model and the new S-CoT fine-tuned one are compared on both versions of HumanEval and MBPP (S-CoT enhanced and not) on the pass@1 metric.
The S-CoT enhancement of the evaluation datasets allows to study its effect when used just as a prompting technique, independently of the S-CoT fine-tuning of the model.
## Fine-tuning Details
| Hyperparameter | [WizardCoder-1B-V1.0](https://huggingface.co/WizardLM/WizardCoder-1B-V1.0) |
|----------------|---------------------|
| Batch size | 16 |
| Learning rate | 2e-5 |
| Epochs | 3 |
| Max length | 2048 |
| Warmup step | 30 |
| LR scheduler | cosine |
| Dataset | [ML4SE23_G1_EvolInstruct-SCoT-1k](https://huggingface.co/datasets/AISE-TUDelft/ML4SE23_G1_EvolInstruct-SCoT-1k) |
The hardware consisted on a GPU instance rented from [DataCrunch](https://datacrunch.io/) with the following specifications:
| NVidia RTX A6000 48GB 1A6000.10V |
|----------------------------------|
| 2 GPUs |
| 48GB VRAM per GPU |
| 60 GB RAM |
| 10 CPUs |
| 100GB SSD Storage |
| Ubuntu 20.04 |
| CUDA 11.6 |
## Results
Results of pass@1(%) on HumanEval and MBPP compared to HumanEval-SCoT and MBPP-SCoT using WizardCoder-1B, WizardCoder-SCoT-1B and WizardCoder-15B.
| **Dataset** | **WizardCoder-1B-V1.0** | **WizardCoder-SCoT-1B-V1.0** | **WizardCoder-15B-V1.0** |
|----------------|-------------------------|------------------------------|--------------------------|
| HumanEval | 23.78 | **17.68** | 57.3 |
| HumanEval-SCoT | **44.51** | **27.44** | **57.3** |
| MBPP | 23.4 | **19.4** | 51.8 |
| MBPP-SCoT | **40** | **28** | **45.6** |
|
camilon/clinical_longformer_same_tokens_cc
|
camilon
| 2023-11-05T13:19:38Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"longformer",
"fill-mask",
"generated_from_trainer",
"base_model:allenai/longformer-base-4096",
"base_model:finetune:allenai/longformer-base-4096",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-02T00:05:56Z |
---
license: apache-2.0
base_model: allenai/longformer-base-4096
tags:
- generated_from_trainer
model-index:
- name: clinical_longformer_same_tokens_cc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinical_longformer_same_tokens_cc
This model is a fine-tuned version of [allenai/longformer-base-4096](https://huggingface.co/allenai/longformer-base-4096) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7387
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.578 | 0.28 | 2 | 2.5967 |
| 2.8262 | 0.57 | 4 | 2.6161 |
| 2.6404 | 0.85 | 6 | 2.7073 |
| 2.5883 | 1.14 | 8 | 2.7756 |
| 2.7661 | 1.42 | 10 | 2.6908 |
| 2.695 | 1.71 | 12 | 2.5367 |
| 3.3694 | 1.99 | 14 | 2.6043 |
| 2.6329 | 2.28 | 16 | 2.5741 |
| 2.5998 | 2.56 | 18 | 2.6167 |
| 2.7418 | 2.84 | 20 | 2.5720 |
| 2.7355 | 3.13 | 22 | 2.5241 |
| 2.7436 | 3.41 | 24 | 2.6759 |
| 2.7103 | 3.7 | 26 | 2.6468 |
| 2.7274 | 3.98 | 28 | 2.7387 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
jfelgate/dqn-SpaceInvadersNoFrameskip-v30
|
jfelgate
| 2023-11-05T13:16:28Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T13:15:52Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 612.00 +/- 212.08
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jfelgate -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga jfelgate -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga jfelgate
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
DDingcheol/m28yhtd_segmentation2
|
DDingcheol
| 2023-11-05T13:15:43Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-11-05T13:13:21Z |
---
title: Segmentation
emoji: 👀
colorFrom: red
colorTo: blue
sdk: gradio
sdk_version: 3.44.4
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
Priyabrata018/uplimit-project-3-phi-1.5
|
Priyabrata018
| 2023-11-05T13:11:45Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"dataset:scitldr",
"base_model:microsoft/phi-1_5",
"base_model:finetune:microsoft/phi-1_5",
"license:other",
"region:us"
] | null | 2023-11-05T13:11:43Z |
---
license: other
base_model: microsoft/phi-1_5
tags:
- generated_from_trainer
datasets:
- scitldr
model-index:
- name: uplimit-project-3-phi-1.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# uplimit-project-3-phi-1.5
This model is a fine-tuned version of [microsoft/phi-1_5](https://huggingface.co/microsoft/phi-1_5) on the scitldr dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5516 | 0.1 | 200 | 2.5910 |
| 2.5733 | 0.2 | 400 | 2.5957 |
| 2.5312 | 0.3 | 600 | 2.5773 |
| 2.5856 | 0.4 | 800 | 2.5666 |
| 2.5426 | 0.5 | 1000 | 2.5570 |
| 2.5787 | 0.6 | 1200 | 2.5517 |
| 2.5491 | 0.7 | 1400 | 2.5456 |
| 2.5265 | 0.8 | 1600 | 2.5392 |
| 2.5762 | 0.9 | 1800 | 2.5341 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
lemonilia/LimaRP-perscengen-v5
|
lemonilia
| 2023-11-05T13:01:37Z | 7 | 4 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2023-10-27T21:16:49Z |
---
license: apache-2.0
---
# LimaRP Persona-Scenario Generator (v5, Alpaca)
A previously unpublished LoRA adapter for [Yarn-Llama-2-7B-64k](https://huggingface.co/NousResearch/Yarn-Llama-2-7b-64k) made
for internal use. Its primary purpose is generating Persona and Scenario (summary) from LimaRP `yaml` source data.
To some extent it can work with different text types, however.
## Prompt format
```
### Input:
{Your text here}
### Response:
Charactername's Persona: {output goes here}
```
Replace `Charactername` with the name of the character you want to infer a Persona for.
By default this LoRA looks for the placeholder names `<FIRST>` and `<SECOND>` (in this
respective order) but it can work with proper names as well.
## Example
This image shows what would happen (red box) after adding data in the format shown in the left pane.
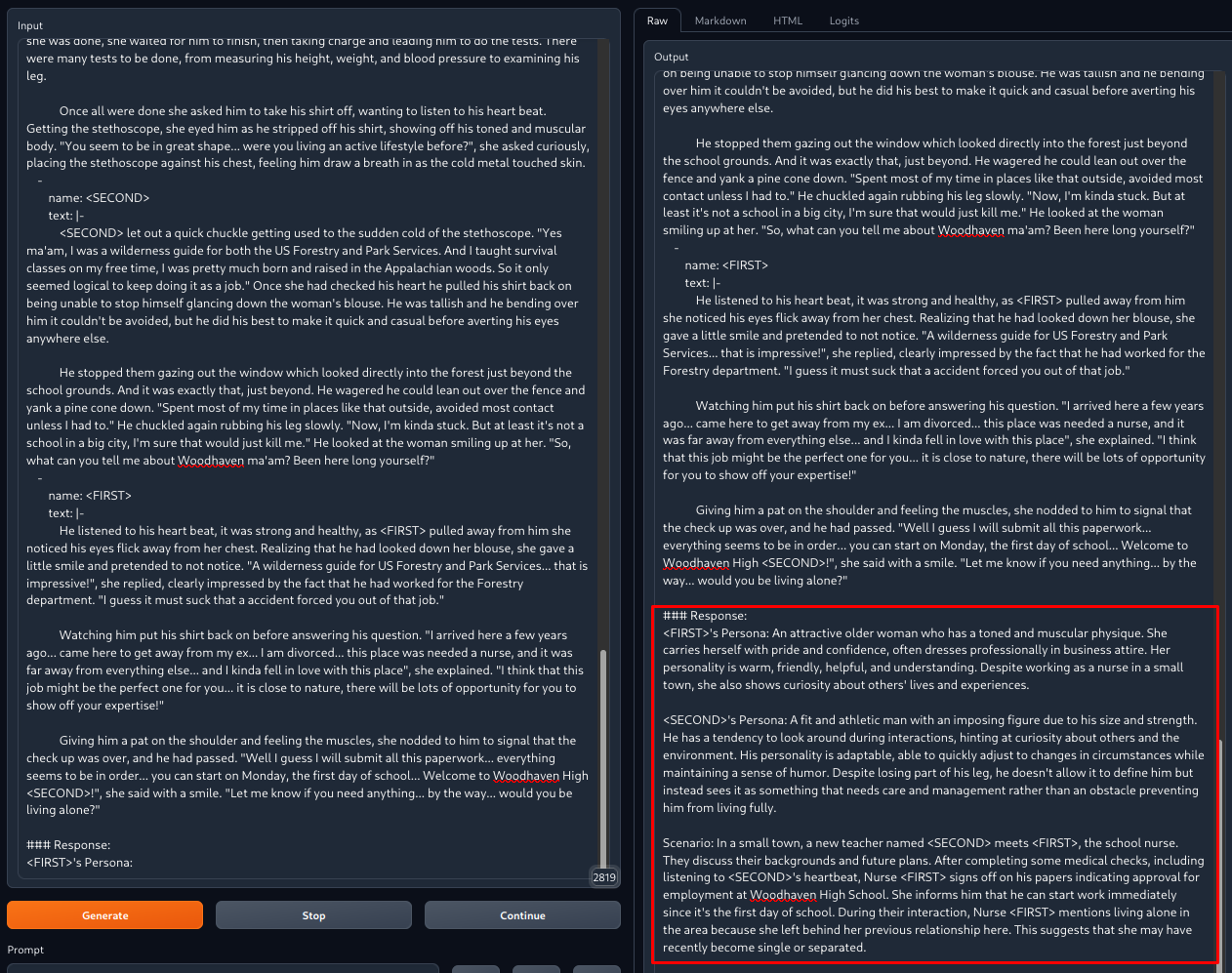
In practice the results would be double-checked and manually tweaked to diversify the
outputs and adding character quirks, peculiarities or traits that the model couldn't catch.
## Known issues
- While the scenario/summary is often remarkably accurate, personas don't show a very high accuracy and can be repetitive.
- Persona and Scenario may exhibit `gpt`-isms.
- Peculiar character quirks may not be observed by the model.
- The LoRA hasn't been extensively tested with different input formats.
- There are apparently issues with the EOS token getting generated too early. It's suggested to disable it.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00025
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 8
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.992 | 0.06 | 15 | 1.8884 |
| 1.8026 | 0.12 | 30 | 1.8655 |
| 1.7713 | 0.19 | 45 | 1.8539 |
| 1.7145 | 0.25 | 60 | 1.8502 |
| 1.6686 | 0.31 | 75 | 1.8507 |
| 1.8409 | 0.37 | 90 | 1.8469 |
| 1.7741 | 0.44 | 105 | 1.8434 |
| 1.7384 | 0.5 | 120 | 1.8407 |
| 1.7562 | 0.56 | 135 | 1.8390 |
| 1.7392 | 0.62 | 150 | 1.8373 |
| 1.8735 | 0.68 | 165 | 1.8381 |
| 1.8406 | 0.75 | 180 | 1.8377 |
| 1.6602 | 0.81 | 195 | 1.8350 |
| 1.7803 | 0.87 | 210 | 1.8341 |
| 1.7212 | 0.93 | 225 | 1.8329 |
| 1.8126 | 1.0 | 240 | 1.8330 |
| 1.8776 | 1.06 | 255 | 1.8314 |
| 1.7892 | 1.12 | 270 | 1.8328 |
| 1.7029 | 1.18 | 285 | 1.8338 |
| 1.7094 | 1.24 | 300 | 1.8322 |
| 1.7921 | 1.31 | 315 | 1.8310 |
| 1.8309 | 1.37 | 330 | 1.8316 |
| 1.7373 | 1.43 | 345 | 1.8309 |
| 1.7873 | 1.49 | 360 | 1.8313 |
| 1.7151 | 1.56 | 375 | 1.8306 |
| 1.7529 | 1.62 | 390 | 1.8300 |
| 1.7516 | 1.68 | 405 | 1.8293 |
| 1.7704 | 1.74 | 420 | 1.8294 |
| 1.6351 | 1.8 | 435 | 1.8290 |
| 1.6186 | 1.87 | 450 | 1.8291 |
| 1.7086 | 1.93 | 465 | 1.8295 |
| 1.6595 | 1.99 | 480 | 1.8290 |
### Framework versions
- Transformers 4.34.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.0
|
nsanghi/ppo-SnowballTarget
|
nsanghi
| 2023-11-05T12:40:20Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-11-05T12:40:12Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: nsanghi/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Azeeme/NewTwos
|
Azeeme
| 2023-11-05T12:38:17Z | 18 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-11-05T12:33:34Z |
---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Azeeme/NewTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
akidse/Reinforce-Cartpole-v1
|
akidse
| 2023-11-05T12:38:09Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T12:37:58Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
carles-undergrad-thesis/indobert-mmarco-hardnegs-bm25
|
carles-undergrad-thesis
| 2023-11-05T12:34:43Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-10-21T03:50:49Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
This model utilizes a newer version of Sentence Transformers. If you're having trouble using this model, please try installing the latest version of Sentence Transformers with:
```bash
pip install --upgrade --force-reinstall --no-deps git+https://github.com/UKPLab/sentence-transformers.git
```
# carles-undergrad-thesis/indobert-mmarco-hardnegs-bm25
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('carles-undergrad-thesis/indobert-mmarco-hardnegs-bm25')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('carles-undergrad-thesis/indobert-mmarco-hardnegs-bm25')
model = AutoModel.from_pretrained('carles-undergrad-thesis/indobert-mmarco-hardnegs-bm25')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
| Model | Mmarco Dev | | MrTyDi Test | | Miracal Test | |
|-----------------------------------------|------------|----------------|-------------|----------------|--------------|----------------------------|
| | MRR@10 | R@1000 | MRR@10 | R@1000 | NCDG@10 | R@1K |
| $\text{BM25 (Elastic Search)}$ | .114 | .642 | .279 | .858 | .391 | .971 |
| $\text{IndoBERT}_{\text{DOTHardnegs}}$ | .232 | .847 | .471 | .921 | .397 | .898 |
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 15593 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 1, 'similarity_fct': 'dot_score'}
```
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 10000,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"correct_bias": false,
"eps": 1e-06,
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 250, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
xiangyu556677/EasyGen
|
xiangyu556677
| 2023-11-05T12:32:26Z | 0 | 1 | null |
[
"region:us"
] | null | 2023-10-11T10:02:00Z |
# Model details
## Model type:
EasyGen is an open-source chatbot trained by fine-tuning FlanT5/Vicuna for multimodal conversation.
## How to use it:
For lora model, the weights in base_model_for_lora file is the base model. You can use merge the lora weight in
lora_weight file for image-to-text task and merge the lora weight in multimodal_dialogue_lora for multimodal dialogue generation.
|
Kano001/Dreamshaper_v7-Openvino
|
Kano001
| 2023-11-05T12:31:06Z | 0 | 0 | null |
[
"openvino",
"text-to-image",
"en",
"license:mit",
"region:us"
] |
text-to-image
| 2023-11-05T11:30:53Z |
---
license: mit
language:
- en
pipeline_tag: text-to-image
tags:
- openvino
- text-to-image
---
Model Descriptions:
This repo contains OpenVino model files for [SimianLuo's LCM_Dreamshaper_v7](https://huggingface.co/SimianLuo/LCM_Dreamshaper_v7).
Hugging Face Demo on CPU:
[](https://huggingface.co/spaces/deinferno/Latent_Consistency_Model_OpenVino_CPU)
Generation Results:
By converting model to OpenVino format and using Intel(R) Xeon(R) Gold 5220R CPU @ 2.20GHz 24C/48T x 2 we can achieve following results compared to original PyTorch LCM.
Results time includes first compile and reshape phases and should be taken with grain of salt because benchmark was run using 2 socketed server which can underperform in those types of workload.
Number of images per batch is set to 1
|Run No.|Pytorch|OpenVino|Openvino w/reshape|
|-------|-------|--------|------------------|
|1 |15.5841|18.0010 |13.4928 |
|2 |12.4634|5.0208 |3.6855 |
|3 |12.1551|4.9462 |3.7228 |
Number of images per batch is set to 4
|Run No.|Pytorch|OpenVino|Openvino w/reshape|
|-------|-------|--------|------------------|
|1 |31.3666|33.1488 |25.7044 |
|2 |33.4797|17.7456 |12.8295 |
|3 |28.6561|17.9216 |12.7198 |
To run the model yourself, you can leverage the 🧨 Diffusers/🤗 Optimum library:
1. Install the library:
```
pip install diffusers transformers accelerate optimum
pip install --upgrade-strategy eager optimum[openvino]
```
2. Clone inference code:
```
git clone https://huggingface.co/deinferno/LCM_Dreamshaper_v7-openvino
cd LCM_Dreamshaper_v7-openvino
```
2. Run the model:
```py
from lcm_ov_pipeline import OVLatentConsistencyModelPipeline
from lcm_scheduler import LCMScheduler
model_id = "deinferno/LCM_Dreamshaper_v7-openvino"
scheduler = LCMScheduler.from_pretrained(model_id, subfolder = "scheduler")
# Use "compile = True" if you don't plan to reshape and recompile model after loading
# Don't forget to disable OpenVino cache via "ov_config = {"CACHE_DIR":""}" because optimum won't use it anyway and it will stay as dead weight in your RAM when loading pipeline again
pipe = OVLatentConsistencyModelPipeline.from_pretrained(model_id, scheduler = scheduler, compile = False, ov_config = {"CACHE_DIR":""})
prompt = "Self-portrait oil painting, a beautiful cyborg with golden hair, 8k"
# Can be set to 1~50 steps. LCM support fast inference even <= 4 steps. Recommend: 1~8 steps.
width = 512
height = 512
num_images = 1
batch_size = 1
num_inference_steps = 4
# Reshape and recompile for inference speed
pipe.reshape(batch_size=batch_size, height=height, width=width, num_images_per_prompt=num_images)
pipe.compile()
images = pipe(prompt=prompt, width=width, height=height, num_inference_steps=num_inference_steps, guidance_scale=8.0, output_type="pil").images
```
|
LliriKnat/test_model
|
LliriKnat
| 2023-11-05T12:29:07Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-05T11:31:48Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: test_model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93204
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2235
- Accuracy: 0.9320
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2231 | 1.0 | 1563 | 0.2393 | 0.9119 |
| 0.153 | 2.0 | 3126 | 0.2235 | 0.9320 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
shangrilar/sentence-encoder-klue-mrc
|
shangrilar
| 2023-11-05T12:19:36Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-11-05T12:16:25Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 548 with parameters:
```
{'batch_size': 32}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 54,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
TechInterMezzo/whisper-encoder-medium
|
TechInterMezzo
| 2023-11-05T12:19:15Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-11-05T09:34:43Z |
---
license: mit
---
```python
from transformers import WhisperFeatureExtractor
from transformers.models.whisper.modeling_whisper import WhisperEncoder
feature_extractor = WhisperFeatureExtractor.from_pretrained("techintermezzo/whisper-encoder-medium")
model = WhisperEncoder.from_pretrained("techintermezzo/whisper-encoder-medium").half()
model.eval()
with torch.inference_mode():
input_features = feature_extractor(inputs, sampling_rate=16000, return_tensors="pt").input_features
last_hidden_state = model(input_features).last_hidden_state
```
|
epitta/bert-finetuned-ner
|
epitta
| 2023-11-05T12:17:58Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-05T12:05:38Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_keras_callback
model-index:
- name: epitta/bert-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# epitta/bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0271
- Validation Loss: 0.0523
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2634, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1709 | 0.0646 | 0 |
| 0.0476 | 0.0545 | 1 |
| 0.0271 | 0.0523 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
DMPark/StepbyStep_Chicago
|
DMPark
| 2023-11-05T12:15:42Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-05T11:48:24Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0
|
kornpp/sillyfituneKornTest
|
kornpp
| 2023-11-05T12:06:28Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:databricks/dolly-v2-3b",
"base_model:adapter:databricks/dolly-v2-3b",
"region:us"
] | null | 2023-11-05T12:06:27Z |
---
library_name: peft
base_model: databricks/dolly-v2-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.7.0.dev0
|
DILAB-HYU/koquality-ko-ref-llama2-7b
|
DILAB-HYU
| 2023-11-05T11:58:10Z | 2,243 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"base_model:hyunseoki/ko-ref-llama2-7b",
"base_model:finetune:hyunseoki/ko-ref-llama2-7b",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-30T04:29:55Z |
---
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- KoQuality
- llama
base_model: hyunseoki/ko-ref-llama2-7b
---
This model is a instruct-tuned hyunseoki/ko-ref-llama2-7b model using koquality.
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + CPU Offloading (384GB)
- num_devices: 2
- gradient_accumulation_steps: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5
|
chaithanya1234/trail_1
|
chaithanya1234
| 2023-11-05T11:56:40Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T11:56:18Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 237.01 +/- 48.93
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Quinta6728/my_awesome_billsum_model
|
Quinta6728
| 2023-11-05T11:56:09Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-05T11:45:21Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: my_awesome_billsum_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: ca_test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1514
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4810
- Rouge1: 0.1514
- Rouge2: 0.0623
- Rougel: 0.1257
- Rougelsum: 0.1258
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.7697 | 0.1329 | 0.0391 | 0.1104 | 0.1104 | 19.0 |
| No log | 2.0 | 124 | 2.5569 | 0.144 | 0.0561 | 0.1208 | 0.1208 | 19.0 |
| No log | 3.0 | 186 | 2.4973 | 0.1509 | 0.0613 | 0.125 | 0.125 | 19.0 |
| No log | 4.0 | 248 | 2.4810 | 0.1514 | 0.0623 | 0.1257 | 0.1258 | 19.0 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
imi2/airoboros-180b-2.2.1-gguf
|
imi2
| 2023-11-05T11:54:53Z | 0 | 7 | null |
[
"dataset:jondurbin/airoboros-2.2.1",
"license:other",
"region:us"
] | null | 2023-11-01T08:40:09Z |
---
license: other
license_name: falcon-180b-tii-license-1.0
license_link: https://huggingface.co/tiiuae/falcon-180B/raw/main/LICENSE.txt
datasets:
- jondurbin/airoboros-2.2.1
---
- join these model parts with `cat airoboros-180b-2.2.1-Q4_K_M.gguf* > airoboros-180b-2.2.1-Q4_K_M.gguf`
- These files were tested on 0eb332a and 207b519 in llama.cpp on linux, as well as kobold.cpp (faae84e). This does not seem to work with llama-cpp-python: `ERROR: byte not found in vocab: '` A user reported successfully launching Q5_K_M with mac gpu in llama.cpp.
- The model was converted with https://github.com/ggerganov/llama.cpp/pull/3864, with this change
```
239 gguf_writer.add_tensor(new_name, data)
240 if new_name == "token_embd.weight":
241 gguf_writer.add_tensor("output.weight", data)
```
- The model was converted to f16 with `TMPDIR=/var/tmp` being needed. (https://github.com/ggerganov/llama.cpp/issues/3433)
### Overview
Another experimental model, using mostly sythetic data generated by [airoboros](https://github.com/jondurbin/airoboros)
This is a fine-tune of the falcon-180b model, bumped to 4k context via rope scaling, on the [airoboros-2.2.1 dataset](https://hf.co/datasets/jondurbin/airoboros-2.2.1)
Base model link: https://huggingface.co/tiiuae/falcon-180B
The base model has a custom license: https://huggingface.co/tiiuae/falcon-180B/raw/main/LICENSE.txt
__*Q4_0 quantization will likely not work due to quantized/unquantized (recommended) merge method!*__
This is a fairly general purpose model, but focuses heavily on instruction following, rather than casual chat/roleplay.
Huge thank you to the folks over at [a16z](https://a16z.com/) for sponsoring the costs associated with building models and associated tools!
### Prompt format
The prompt format:
```
A chat.
USER: {prompt}
ASSISTANT:
```
The default system prompt ("A chat.") was used for most of the prompts, however it also included a wide sampling of responses with other prompts, particularly in "stylized\_response", "rp", "gtkm", etc.
Here's another example:
```
A chat between Bob (aka USER) and Tom (aka ASSISTANT). Tom is an extremely intelligent 18th century bookkeeper, who speaks loquaciously.
USER: {prompt}
ASSISTANT:
```
And chat scenario that wouldn't require USER/ASSISTANT (but should use stopping criteria to prevent the model from speaking on your behalf).
```
A chat between old friends: Timmy and Tommy.
{description of characters}
{setting for the chat}
Timmy: *takes a big sip from his coffee* "Ah, sweet, delicious, magical coffee."
Tommy:
```
__*I strongly suggest adding stopping criteria/early inference stopping on "USER:", and/or whatever names you specify in the system prompt.*__
### Fine tuning info
https://wandb.ai/jondurbin/airoboros-l2-70b-2.2.1/runs/f91zmwuz?workspace=user-jondurbin
### Helpful usage tips
*The prompts shown here are are just the text that would be included after USER: and before ASSISTANT: in the full prompt format above, the system prompt and USER:/ASSISTANT: have been omited for readability.*
#### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
[key0: value0]
[key1: value1]
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
#### Summarization
500 samples have been included from [this dataset](https://huggingface.co/datasets/mattpscott/airoboros-summarization), using the same format as contextual question answering, for example:
```
BEGININPUT
{text to summarize}
ENDINPUT
BEGININSTRUCTION
Summarize the input in around 130 words.
ENDINSTRUCTION
```
#### Getting longer responses
You can use a few techniques to get longer responses.
Detailed prompts, with explicit instruction for word count:
```
Please compose a narrative set in the heart of an ancient library, steeped in the scent of old parchment and ink. The protagonist should be a young scholar who is dedicated to studying the art of storytelling and its evolution throughout history. In her pursuit of knowledge, she stumbles upon a forgotten tome that seems to possess an unusual aura. This book has the ability to bring stories to life, literally manifesting characters and scenarios from within its pages into reality.
The main character must navigate through various epochs of storytelling - from oral traditions of tribal societies, through medieval minstrels' tales, to modern-day digital narratives - as they come alive around her. Each era presents its unique challenges and lessons about the power and impact of stories on human civilization.
One such character could be a sentient quill pen, who was once used by renowned authors of yesteryears and now holds their wisdom and experiences. It becomes her mentor, guiding her through this journey with witty remarks and insightful commentary.
Ensure that your tale encapsulates the thrill of adventure, the beauty of learning, and the profound connection between humans and their stories. All characters involved should be non-human entities. Feel free to explore creative liberties but maintain the mentioned elements.
Your response should be approximately 2300 words.
```
Or, a simpler example:
```
Please create a long, detailed story about a dragon in an old growth forest who, for some reason, begins speaking the words of the source code of linux.
```
#### Coding
You can ask for fairly complex coding instructions with multiple criteria, e.g.:
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or inline criteria:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can also optionally add a single space and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js. PLAINFORMAT
```
#### Agent/function calling
The dataset includes many examples of function/args generation based on input criteria. This is somewhat similar to the OpenAI function calling, but the output is either JSON or YAML.
Example prompt:
```
As an AI assistant, please select the most suitable function and parameters from the list of available functions below, based on the user's input. Provide your response in JSON format.
Input: I want to know how many times 'Python' is mentioned in my text file.
Available functions:
file_analytics:
description: This tool performs various operations on a text file.
params:
action: The operation we want to perform on the data, such as "count_occurrences", "find_line", etc.
filters:
keyword: The word or phrase we want to search for.
```
Response:
```json
{
"function": "file_analytics",
"params": {
"action": "count_occurrences",
"filters": {
"keyword": "Python"
}
}
}
```
#### Chain-of-thought
You can ask for several possible responses to a given problem, with a ranking and final answer selection.
Example prompt:
```
A group of people decide to play a round-robin tournament where every player plays every other player exactly once. If a total of 45 games were played, how many players participated in the tournament? Offer several potential answers, rank them according to mathematical logic, and pick the most feasible one.
```
Example response:
```
Solution 1:
In a round-robin tournament, each player plays every other player exactly once. This means that the total number of games played is equal to the combination of all players taken two at a time (since a game involves two players).
The formula for combinations is nC2 = n(n-1)/2, where n is the total number of players. We know that nC2 equals 45 (the total number of games), so we can set up the equation as follows:
n(n-1)/2 = 45
Solving this equation gives us n=10.
Final answer: There were 10 players in the tournament.
Solution 2:
Another way to approach this problem is by using the concept of triangular numbers. Triangular numbers are a sequence of numbers where each number can be represented as a triangle with dots. The nth triangular number is given by the sum of the first n natural numbers.
If we consider each game as a dot and each player as a side of the triangle, then the total number of games (45) would correspond to the 9th triangular number because 1+2+3+4+5+6+7+8+9=45. However, since each side of the triangle represents a player, and there's one more player than sides in our model (because the last player has no one left to play against), we need to add one more to get the total number of players.
Final answer: There were 10 players in the tournament.
Solution 3:
We could also use trial and error to solve this problem. Starting from a small number of players, we calculate how many games would be played in a round-robin tournament until we reach 45 games. For example, with 2 players, only 1 game is played; with 3 players, 3 games are played; with 4 players, 6 games are played, and so on. Continuing this process, we find that with 10 players, 45 games are played.
Final answer: There were 10 players in the tournament.
Ranking of solutions from best to worst:
1. Solution 1: This solution uses direct mathematical reasoning based on the properties of a round-robin tournament and solves an equation to find the answer.
2. Solution 2: This solution uses the concept of triangular numbers which requires additional steps and knowledge beyond the immediate problem context, but still arrives at the correct answer.
3. Solution 3: This solution relies on trial and error, which is less efficient and reliable than the other methods, but it eventually gets to the right answer.
Best and final answer: There were 10 players in the tournament.
```
#### reWOO style execution planning
The model now supports execution planning for complex instructions that would require making use of several tools. The output is just the plan, you must implement a mechanism to parse the output and actually call the functions!
Example prompt:
```
Please construct a systematic plan to generate an optimal response to the user instruction, utilizing a set of provided tools. Each plan will correspond to an evidence value, which will be the output of one of the available functions given an input string
that could be the user's question, one or more prior evidence values, or a combination of both.
Here are the tools available to be called:
DuckDuckGo[input]: Tool that enables the user to search for information using the DuckDuckGo search engine. This tool is helpful in locating a suitable list of sites that may contain the answer to the user's query. It does not directly answer the question but finds a list of sites that might have the answer.
TextScraper[input]: Load one or more websites from the input string containing newline delimited links, where input is one or more links, and produces plain text output containing the content of the links.
HyperlinkExtractor[input]: Extract links from plain text and produces a plain text, newline delimited response of links.
KnowledgeModel[input]: Question answering language model, particularly useful in answering questions based on an input passage of text. The input must be a text question that references an :evidence[n]: variable, e.g. What color is the cat, given :evidence1:?
The output should be in format:
Plan: [first action to take based on input question]
:evidence0: = [function to call with input parameter]
Plan: [next action to take, based on result of :evidence0:]
:evidence1: = [next function to call and input parameter, which may include reference to previous evidence, e.g. "Given context :evidence0"]
...
Answer: [:evidence[n]: containing the final answer.]
Question: Who won the Nobel Prize in Literature in 2020 and what is their most famous work?
```
Response:
```
Plan: Begin by conducting a web search to find out who won the Nobel Prize in Literature in 2020.
:evidence0: = DuckDuckGo[Nobel Prize in Literature 2020 winner]
Plan: Utilize the KnowledgeModel to interpret the search results and find the name of the laureate.
:evidence1: = KnowledgeModel[Who won the Nobel Prize in Literature in 2020, given :evidence0:?]
Plan: Conduct another web search to find the most famous work of the identified laureate.
:evidence2: = DuckDuckGo[Most famous work of :evidence1:]
Plan: Extract the relevant links from the DuckDuckGo search results for a more focused search.
:evidence3: = HyperlinkExtractor[:evidence2:]
Plan: Use the TextScraper tool to extract information from the relevant links.
:evidence4: = TextScraper[:evidence3:]
Plan: Finally, utilize the KnowledgeModel to identify and summarize the most famous work of the laureate from the extracted information.
:evidence5: = KnowledgeModel[What is the most famous work of :evidence1:, given :evidence4:?]
Answer: :evidence5:
```
For this to be useful, you'd have to parse the output plan text, and implement/call each of the functions. This is just pseudo-code, completely untested off the top of my head, and obviously would requiring full implementation + hardening:
```python
import re
import requests
def inject_context(input_text, **context):
for ref in set(re.findall(r"(:evidence[0-9]+:)", input_text, re.I)):
input_text = input_text.replace(ref, context.get(ref, ""))
return input_text
def duckduckgo(input_text, **context):
search_string = inject_context(input_text, **context)
... search via duck duck go using search_string
... return text content
def link_extractor(input_text, **context):
input_text = inject_context(input_text, **context)
return "\n".join(list(set(re.findall(r"(https?://[^\s]+?\.?)", input_text, re.I))))
def scrape(input_text, **context):
input_text = inject_context(input_text, **context)
text = []
for link in input_text.splitlines():
text.append(requests.get(link).text)
return "\n".join(text)
def infer(input_text, **context)
prompt = inject_context(input_text, **context)
... call model with prompt, return output
def parse_plan(plan):
method_map = {
"DuckDuckGo": duckduckgo,
"HyperlinkExtractor": link_extractor,
"KnowledgeModel": infer,
"TextScraper": scrape,
}
context = {}
for line in plan.strip().splitlines():
if line.startswith("Plan:"):
print(line)
continue
parts = re.match("^(:evidence[0-9]+:)\s*=\s*([^\[]+])(\[.*\])\s$", line, re.I)
if not parts:
if line.startswith("Answer: "):
return context.get(line.split(" ")[-1].strip(), "Answer couldn't be generated...")
raise RuntimeError("bad format: " + line)
context[parts.group(1)] = method_map[parts.group(2)](parts.group(3), **context)
```
### Contribute
If you're interested in new functionality, particularly a new "instructor" type to generate a specific type of training data,
take a look at the dataset generation tool repo: https://github.com/jondurbin/airoboros and either make a PR or open an issue with details.
To help me with the OpenAI/compute costs:
- https://bmc.link/jondurbin
- ETH 0xce914eAFC2fe52FdceE59565Dd92c06f776fcb11
- BTC bc1qdwuth4vlg8x37ggntlxu5cjfwgmdy5zaa7pswf
### Licence and usage restrictions
The airoboros 2.2 models with `l2` in the name are built on top of llama-2/codellama.
The llama-2 base model has a custom Meta license:
- See the [meta-license/LICENSE.txt](meta-license/LICENSE.txt) file attached for the original license provided by Meta.
- See also [meta-license/USE_POLICY.md](meta-license/USE_POLICY.md) and [meta-license/Responsible-Use-Guide.pdf](meta-license/Responsible-Use-Guide.pdf), also provided by Meta.
The fine-tuning data was mostly generated by OpenAI API calls to gpt-4, via [airoboros](https://github.com/jondurbin/airoboros)
The ToS for OpenAI API usage has a clause preventing the output from being used to train a model that __competes__ with OpenAI
- what does *compete* actually mean here?
- these small open source models will not produce output anywhere near the quality of gpt-4, or even gpt-3.5, so I can't imagine this could credibly be considered competing in the first place
- if someone else uses the dataset to do the same, they wouldn't necessarily be violating the ToS because they didn't call the API, so I don't know how that works
- the training data used in essentially all large language models includes a significant amount of copyrighted or otherwise non-permissive licensing in the first place
- other work using the self-instruct method, e.g. the original here: https://github.com/yizhongw/self-instruct released the data and model as apache-2
I am purposingly leaving this license ambiguous (other than the fact you must comply with the Meta original license for llama-2) because I am not a lawyer and refuse to attempt to interpret all of the terms accordingly.
Your best bet is probably to avoid using this commercially due to the OpenAI API usage.
Either way, by using this model, you agree to completely indemnify me.
|
DILAB-HYU/KoQuality-Polyglot-5.8b
|
DILAB-HYU
| 2023-11-05T11:49:45Z | 2,251 | 3 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"base_model:EleutherAI/polyglot-ko-5.8b",
"base_model:finetune:EleutherAI/polyglot-ko-5.8b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-24T14:07:52Z |
---
language:
- ko
license: apache-2.0
tags:
- generated_from_trainer
- polyglot-ko
- gpt-neox
- KoQuality
datasets:
- DILAB-HYU/KoQuality
pipeline_tag: text-generation
base_model: EleutherAI/polyglot-ko-5.8b
model-index:
- name: KoAlpaca-Polyglot-5.8B
results: []
---
# **KoQuality-Polyglot-5.8b**
KoQuality-Polyglot-5.8b is a fine-tuned iteration of the [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b) model, specifically trained on the [KoQuality dataset](https://huggingface.co/datasets/DILAB-HYU/KoQuality). Notably, when excluding models employing COT datasets, KoQuality-Polyglot-5.8b exhibits exceptional performance in same size models, even though it operates with a relatively small dataset.
## Open Ko-LLM LeaderBoard
<img src="https://cdn-uploads.huggingface.co/production/uploads/6152b4b9ecf3ca6ab820e325/iYzR_mdvkcjnVquho0Y9R.png" width= "1000px" title="하얀 강아지">
Our approach centers around leveraging high-quality instruction datasets to deepen our understanding of commands, all the while preserving the performance of the Pre-trained Language Model (PLM). Compared to alternative models, we have achieved this with minimal learning, **utilizing only 1% of the dataset, which equates to 4006 instructions**.
## Overall Average accuracy score of the KoBEST datasets
We use [KoBEST benchmark](https://huggingface.co/datasets/skt/kobest_v1) datasets(BoolQ, COPA, HellaSwag, SentiNeg, WiC) to compare the performance of our best model and other models accuracy. Our model outperforms other models in the average accuracy score of the KoBEST datasets.
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/t5x4PphoNb-tW3iCzXXHT.png" width= "500px">
| Model | 0-shot | 1-shot | 2-shot | 5-shot | 10-shot
| --- | --- | --- | --- | --- | --- |
| polyglot-ko-5.8b | 0.4734 | 0.5929 | 0.6120 | 0.6388 | 0.6295
| koalpcaca-polyglot-5.8b | 0.4731 | 0.5284 | 0.5721 | 0.6054 | 0.6042
| kullm-polyglot-5.8b | 0.4415 | 0.6030 | 0.5849 | 0.6252 | 0.6451
| koquality-polyglot-5.8b | 0.4530 | 0.6050 | 0.6351 | 0.6420 | 0.6457
## Evaluation results
### COPA (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/QAie0x99S8-KEKvK0I_uZ.png" width= "500px">
### BoolQ (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/CtEWEQ5BBS05V9cDWA7kp.png" width= "500px">
### HellaSwag (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/cHws6qWkDlTfs5GVcQvtN.png" width= "500px">
### SentiNeg (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/VEG15XXOIbzJyQAusLa4B.png" width= "500px">
### WiC (F1)
<img src="https://cdn-uploads.huggingface.co/production/uploads/650fecfd247f564485f8fbcf/hV-uADJiydkVQOyYysej9.png" width= "500px">
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 4
- seed: 42
- distributed_type: multi-GPU (A100 80G) + No offloading
- num_devices: 4
- gradient_accumulation_steps: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5
## Citation
```
@misc{2023koqaulity,
title = {KoQuality: Curation of High-quality Instruction Data for Korean Language Models},
author = {Na, Yohan and Kim, Dahye and Chae, Dong-Kyu},
journal={Proceedings of the 35th Annual Conference on Human and Cognitive Language Technology (HCLT 2023)},
pages={306-311},
year = {2023},
}
```
More details can be found here: [github.com/nayohan/KoQuality](https://github.com/nayohan/KoQuality)
<br>
|
DILAB-HYU/koquality-polyglot-3.8b
|
DILAB-HYU
| 2023-11-05T11:48:50Z | 2,242 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"base_model:EleutherAI/polyglot-ko-3.8b",
"base_model:finetune:EleutherAI/polyglot-ko-3.8b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-30T04:03:33Z |
---
license: apache-2.0
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- polyglot-ko
- gpt-neox
- KoQuality
base_model: EleutherAI/polyglot-ko-3.8b
---
This model is a instruct-tuned EleutherAI/polyglot-ko-3.8b model.
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + CPU Offloading (384GB)
- num_devices: 2
- gradient_accumulation_steps: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5
|
DILAB-HYU/koquality-polyglot-1.3b
|
DILAB-HYU
| 2023-11-05T11:47:51Z | 2,253 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"polyglot-ko",
"gpt-neox",
"KoQuality",
"ko",
"dataset:DILAB-HYU/KoQuality",
"base_model:EleutherAI/polyglot-ko-1.3b",
"base_model:finetune:EleutherAI/polyglot-ko-1.3b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-30T04:35:31Z |
---
license: apache-2.0
datasets:
- DILAB-HYU/KoQuality
language:
- ko
pipeline_tag: text-generation
tags:
- polyglot-ko
- gpt-neox
- KoQuality
base_model: EleutherAI/polyglot-ko-1.3b
---
This model is a instruct-tuned EleutherAI/polyglot-ko-1.3b model.
## Training hyperparameters
- learning_rate: 5e-5
- train_batch_size: 1
- seed: 42
- distributed_type: multi-GPU (A30 24G) + CPU Offloading (384GB)
- num_devices: 2
- gradient_accumulation_steps: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
## Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.11.0
- deepspeed 0.9.5
|
Saramodels2023/Test4
|
Saramodels2023
| 2023-11-05T11:16:11Z | 0 | 0 | null |
[
"arxiv:1910.09700",
"region:us"
] | null | 2023-11-05T11:06:53Z |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
perecasxiru/ppo-LunarLander-v2
|
perecasxiru
| 2023-11-05T10:48:25Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T10:48:03Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 264.81 +/- 14.43
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bhattronak/my-awesome-address-tokenizer-model-v7
|
bhattronak
| 2023-11-05T10:37:04Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"safetensors",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-05T10:13:44Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: bhattronak/my-awesome-address-tokenizer-model-v7
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bhattronak/my-awesome-address-tokenizer-model-v7
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3959
- Validation Loss: 0.4307
- Train Precision: 0.8162
- Train Recall: 0.8611
- Train F1: 0.8380
- Train Accuracy: 0.8471
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 10218, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 0.5630 | 0.4576 | 0.7960 | 0.8555 | 0.8247 | 0.8383 | 0 |
| 0.4347 | 0.4334 | 0.8165 | 0.8544 | 0.8350 | 0.8448 | 1 |
| 0.3959 | 0.4307 | 0.8162 | 0.8611 | 0.8380 | 0.8471 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
omermazig/videomae-finetuned-nba-5-class-4-batch-8000-vid-multiclass
|
omermazig
| 2023-11-05T10:36:05Z | 14 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base-finetuned-kinetics",
"base_model:finetune:MCG-NJU/videomae-base-finetuned-kinetics",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-11-05T10:35:42Z |
---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base-finetuned-kinetics
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: videomae-finetuned-nba-5-class-4-batch-8000-vid-multiclass-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-finetuned-nba-5-class-4-batch-8000-vid-multiclass-4
This model is a fine-tuned version of [MCG-NJU/videomae-base-finetuned-kinetics](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7974
- F1: 0.8701
- Accuracy: 0.8701
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 50000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:--------:|
| 1.3802 | 0.04 | 2000 | 1.2381 | 0.52 | 0.52 |
| 1.0115 | 1.04 | 4000 | 1.0522 | 0.6684 | 0.6684 |
| 0.9749 | 2.04 | 6000 | 0.9298 | 0.7537 | 0.7537 |
| 0.9048 | 3.04 | 8000 | 0.8679 | 0.7863 | 0.7863 |
| 0.7977 | 4.04 | 10000 | 0.8846 | 0.7811 | 0.7811 |
| 0.9259 | 5.04 | 12000 | 0.8018 | 0.8263 | 0.8263 |
| 0.6077 | 6.04 | 14000 | 0.8212 | 0.8189 | 0.8189 |
| 0.7102 | 7.04 | 16000 | 0.7876 | 0.8242 | 0.8242 |
| 0.5726 | 8.04 | 18000 | 0.8805 | 0.8232 | 0.8232 |
| 0.7768 | 9.04 | 20000 | 0.7490 | 0.8589 | 0.8589 |
| 0.6793 | 10.04 | 22000 | 0.7730 | 0.8558 | 0.8558 |
| 0.5765 | 11.04 | 24000 | 0.7752 | 0.8368 | 0.8368 |
| 0.4789 | 12.04 | 26000 | 0.7902 | 0.8484 | 0.8484 |
| 0.7398 | 13.04 | 28000 | 0.7603 | 0.8568 | 0.8568 |
| 0.6807 | 14.04 | 30000 | 0.7531 | 0.8716 | 0.8716 |
| 0.3262 | 15.04 | 32000 | 0.7663 | 0.8768 | 0.8768 |
| 0.4387 | 16.04 | 34000 | 0.7549 | 0.88 | 0.88 |
| 0.5013 | 17.04 | 36000 | 0.7713 | 0.8737 | 0.8737 |
| 0.9572 | 18.04 | 38000 | 0.7613 | 0.8684 | 0.8684 |
| 1.0645 | 19.04 | 40000 | 0.7618 | 0.8811 | 0.8811 |
| 0.4949 | 20.04 | 42000 | 0.7882 | 0.8747 | 0.8747 |
| 0.6131 | 21.04 | 44000 | 0.7964 | 0.8705 | 0.8705 |
| 0.628 | 22.04 | 46000 | 0.8089 | 0.8747 | 0.8747 |
| 0.5693 | 23.04 | 48000 | 0.8010 | 0.8747 | 0.8747 |
| 0.4764 | 24.04 | 50000 | 0.8117 | 0.8789 | 0.8789 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Nagase-Kotono/LLaVA_X_KoLlama2-7B-0.1v
|
Nagase-Kotono
| 2023-11-05T10:19:41Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llava",
"text-generation",
"ko",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"region:us"
] |
text-generation
| 2023-11-04T13:23:42Z |
---
license: llama2
language:
- ko
---
# LLaVA_X_KoLlama2-7B-0.1v

**KoT-platypus2 X LLaVA**
>This model is a large multimodal model (LMM) that combines the LLM(KoT-platypus2-7B) with visual encoder of CLIP(ViT-14),
>trained on Korean visual-instruction dataset using QLoRA.
## Model Details
- **Model Developers:** ***Nagase_Kotono***
- **Base Model:** ***[kyujinpy/KoT-platypus2-7B](https://huggingface.co/kyujinpy/KoT-platypus2-7B)***
- **Model Architecture:** ***LLaVA_X_KoLlama2-7B is an open-source chatbot trained by fine-tuning Llama2 on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the Llama2 transformer architecture.***
- **Training Dataset:** ***[KoLLaVA-CC3M-Pretrain-595K](https://huggingface.co/datasets/tabtoyou/KoLLaVA-CC3M-Pretrain-595K)***, ***[KoLLaVA-Instruct-150k](https://huggingface.co/datasets/tabtoyou/KoLLaVA-Instruct-150k)***
## Hardware & Software
### Pretrain
- **GPU:** ***NVIDIA A100 X2***
- ***Used [DeepSpeed](https://github.com/microsoft/DeepSpeed), [Transformers](https://github.com/huggingface/transformers)***
### Finetune
- **GPU:** ***NVIDIA RTX 4000 Ada Generation X 8***
- ***Used [DeepSpeed](https://github.com/microsoft/DeepSpeed), [Transformers](https://github.com/huggingface/transformers)***
## ValueError
LLaVA_X_KoLlama2-7B is a base model of kyujinpy/KoT-platypus2-7B. The model is based on [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b).
**Since Llama-2-Ko uses FastTokenizer provided by HF tokenizers NOT sentencepiece package, it is required to use `use_fast=True` option when initialize tokenizer.**
|
Thefoodprocessor/distilbert-qa-checkpoint-v5
|
Thefoodprocessor
| 2023-11-05T10:18:56Z | 13 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-05T10:11:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
base_model: distilbert-base-uncased
model-index:
- name: distilbert-qa-checkpoint-v5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-qa-checkpoint-v5
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4904
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.3912 | 1.0 | 2059 | 0.3897 |
| 0.3313 | 2.0 | 4118 | 0.3449 |
| 0.2679 | 3.0 | 6177 | 0.3508 |
| 0.2323 | 4.0 | 8236 | 0.3489 |
| 0.2047 | 5.0 | 10295 | 0.3578 |
| 0.1913 | 6.0 | 12354 | 0.4529 |
| 0.1821 | 7.0 | 14413 | 0.4904 |
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3
|
omermazig/videomae-finetuned-nba-5-class-4-batch-8000-vid-multilabel
|
omermazig
| 2023-11-05T10:18:44Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base-finetuned-kinetics",
"base_model:finetune:MCG-NJU/videomae-base-finetuned-kinetics",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-11-05T10:16:46Z |
---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base-finetuned-kinetics
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: videomae-finetuned-nba-5-class-4-batch-8000-vid-multilabel-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-finetuned-nba-5-class-4-batch-8000-vid-multilabel-4
This model is a fine-tuned version of [MCG-NJU/videomae-base-finetuned-kinetics](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4886
- F1: 0.8863
- Roc Auc: 0.9209
- Accuracy: 0.7962
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 50000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|:--------:|
| 0.771 | 0.04 | 2000 | 0.7660 | 0.6227 | 0.7324 | 0.2937 |
| 0.6225 | 1.04 | 4000 | 0.6446 | 0.7401 | 0.8162 | 0.4653 |
| 0.6093 | 2.04 | 6000 | 0.6517 | 0.7441 | 0.8223 | 0.5253 |
| 0.603 | 3.04 | 8000 | 0.5630 | 0.8151 | 0.8722 | 0.6558 |
| 0.6547 | 4.04 | 10000 | 0.5009 | 0.8425 | 0.8911 | 0.6695 |
| 0.6426 | 5.04 | 12000 | 0.5179 | 0.8422 | 0.9012 | 0.6642 |
| 0.4447 | 6.04 | 14000 | 0.5052 | 0.8537 | 0.8973 | 0.7147 |
| 0.6949 | 7.04 | 16000 | 0.5045 | 0.8548 | 0.8974 | 0.7337 |
| 0.509 | 8.04 | 18000 | 0.5262 | 0.8705 | 0.9089 | 0.7768 |
| 0.4341 | 9.04 | 20000 | 0.4731 | 0.8831 | 0.9163 | 0.7863 |
| 0.5037 | 10.04 | 22000 | 0.5040 | 0.8781 | 0.9154 | 0.7747 |
| 0.3592 | 11.04 | 24000 | 0.5091 | 0.8746 | 0.9101 | 0.7821 |
| 0.2829 | 12.04 | 26000 | 0.4709 | 0.8867 | 0.9230 | 0.7905 |
| 0.3599 | 13.04 | 28000 | 0.4722 | 0.8888 | 0.9230 | 0.7947 |
| 0.4152 | 14.04 | 30000 | 0.4744 | 0.8911 | 0.9247 | 0.8074 |
| 0.1167 | 15.04 | 32000 | 0.4817 | 0.8949 | 0.9241 | 0.8179 |
| 0.2721 | 16.04 | 34000 | 0.4627 | 0.9064 | 0.9337 | 0.8274 |
| 0.42 | 17.04 | 36000 | 0.4849 | 0.8992 | 0.9282 | 0.8295 |
| 0.5841 | 18.04 | 38000 | 0.4747 | 0.9026 | 0.9304 | 0.8379 |
| 0.509 | 19.04 | 40000 | 0.4779 | 0.8991 | 0.9273 | 0.8316 |
| 0.1599 | 20.04 | 42000 | 0.4945 | 0.9056 | 0.9319 | 0.8411 |
| 0.3645 | 21.04 | 44000 | 0.4875 | 0.8984 | 0.9277 | 0.8242 |
| 0.4402 | 22.04 | 46000 | 0.5156 | 0.9004 | 0.9283 | 0.8368 |
| 0.2769 | 23.04 | 48000 | 0.5063 | 0.9028 | 0.9296 | 0.8389 |
| 0.3009 | 24.04 | 50000 | 0.5122 | 0.8975 | 0.9257 | 0.8326 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Bebrina/Kussia
|
Bebrina
| 2023-11-05T10:09:54Z | 0 | 0 | null |
[
"region:us"
] | null | 2023-11-05T10:08:05Z |
Kussia popular russian streamer
|
devilkkw/KKW-IDEAL
|
devilkkw
| 2023-11-05T09:53:55Z | 0 | 1 | null |
[
"model",
"stable diffusion",
"en",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-11-05T09:37:51Z |
---
license: creativeml-openrail-m
tags:
- model
- stable diffusion
language:
- en
---
# KKW IDEAL

Merged checkpoint for fantasy and real without any VAE.
## Uploaded for backup
More details on 
### Sample







|
Sober-Clever/codeparrot-ds
|
Sober-Clever
| 2023-11-05T09:50:33Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T09:11:16Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: codeparrot-ds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# codeparrot-ds
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
waldie/ORCA_LLaMA_70B_QLoRA-2.4bpw-h6-exl2
|
waldie
| 2023-11-05T09:42:57Z | 8 | 2 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2308.07317",
"arxiv:2306.02707",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T08:46:08Z |
---
language:
- en
library_name: transformers
license: llama2
---
# Dolphin_ORCA_PlatyPus_LLaMA_70b
### Dataset
Here is the list of datasets used:
* Dolphin
* Open-Platypus
* OpenOrca
**mixed strategy: 100%Open-Platypus + ~1%Dolphin(GPT-4) + ~1%OpenOrca(GPT-4)**
<br>
**Model Finetuned By fangloveskari.**
<br>
### Training FrameWork and Parameters
#### FrameWork
https://github.com/hiyouga/LLaMA-Efficient-Tuning
We add flash_attention_2 and ORCA dataset support, with some minor modifications.
<br>
#### Parameters
We list some training parameters here:
| Parameter | Value |
|-----------------------|-------------|
| Finetune_Type | QLoRA(NF4) |
| LoRA_Rank | 16 |
| LoRA_Alpha | 16 |
| Batch_Size | 14 |
| GPUs | 8xA100(80G) |
| LR_Scheduler | cosine |
| LR | 3e-4 |
| Epoch | 1 |
| DeepSpeed | ZERO-2 |
<br>
### Model Export
We tried two methods to fuse the adapter back to the base model:
* https://github.com/hiyouga/LLaMA-Efficient-Tuning/blob/main/src/export_model.py
* https://github.com/jondurbin/qlora/blob/main/qmerge.py
Generally, the second will get better ARC(+0.15) and Truthful_QA(+0.3) scores but the other two(MMLU(-0.2) and HelloSwag(-0.2)) seems to degenerate (Just for my model).
<br>
### Evaluation
| Metric | Value |
|-----------------------|-------|
| ARC (25-shot) | 72.27 |
| HellaSwag (10-shot) | 87.74 |
| MMLU (5-shot) | 70.23 |
| TruthfulQA (0-shot) | 63.37 |
| Avg. | 73.40 |
<br>
### license disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
<br>
### Limitations & Biases:
Llama 2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
<br>
### Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@article{platypus2023,
title={Platypus: Quick, Cheap, and Powerful Refinement of LLMs},
author={Ariel N. Lee and Cole J. Hunter and Nataniel Ruiz},
booktitle={arXiv preprint arxiv:2308.07317},
year={2023}
}
```
```
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
|
fadliaulawi/internlm-7b-finetuned
|
fadliaulawi
| 2023-11-05T09:39:25Z | 5 | 0 |
peft
|
[
"peft",
"base_model:internlm/internlm-7b",
"base_model:adapter:internlm/internlm-7b",
"region:us"
] | null | 2023-10-20T07:58:11Z |
---
library_name: peft
base_model: internlm/internlm-7b
---
# [Reproducing] Stanford Alpaca: An Instruction-following LLaMA Model
This is the repo for reproducing [Stanford Alpaca : An Instruction-following LLaMA Model](https://github.com/tatsu-lab/stanford_alpaca/blob/main/README.md). We finetune some of LlaMa2-based large language model using medical QA dataset. The repo contains:
- The [5K data](#dataset) conversations between patients and physicians used for fine-tuning the model.
- The code for [Preparation data](#data-preparation).
- The code for [Fine Tuning the Model](#fine-tuning).
- The link for [Testing the Model](#testing-the-model).
## Dataset
We using the 5k generated dataset by [Chat Doctor](https://github.com/Kent0n-Li/ChatDoctor). The dataset is a generated conversations between patients and physicians from ChatGPT GenMedGPT-5k and disease database. Dataset also currated and modified to Indonesian Language Based.
[`GenMedGPT-5k-id.json`](https://github.com/gilangcy/stanford-alpaca/blob/main/GenMedGPT-5k-id.json) contains 5K instruction-following data we used for fine-tuning the LlaMa model. This JSON file is a list of dictionaries, each dictionary contains the following fields:
- `instruction`: `str`, describes the task the model should perform. Each of the 52K instructions is unique.
- `input`: `str`, optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
- `output`: `str`, the answer to the instruction as generated by `text-davinci-003`.
If you're interested in fine-tuning with your own data, it's essential to adhere to the default prompt format that the model used during its pre-training phase. The prompt for LlaMa 2 is structured similarly to this:
```
<s>[INST] <<SYS>>
{{ instruction }}
<</SYS>>
{{ input }} [/INST] {{ output }} </s>
```
Meanwhile, the prompt for PolyLM and InternLM (adapted to Indonesian) is structured similarly to this:
```
Di bawah ini adalah instruksi yang menjelaskan tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.
Instruksi:
{instruction}
Masukan:
{input}
Tanggapan:
{output}
```
## Finetuning the Model
We fine-tune our models based on the step from Stanford Alpaca. We choose to train some LLama-based model. The model that we finetune are PolyLM-1.7B, LlaMa-2-7B, InternLM-7B with the following hyperparameters:
| Hyperparameter | PolyLM-1.7B | LLaMA-7B | InternLM-7B |
|----------------|------------ |----------|-------------|
| Batch size | 128 | 128 | 128 |
| Learning rate | 3e-4 | 3e-4 | 3e-4 |
| Epochs | 3 | 3 | 3 |
| Max length | 256 | 256 | 256 |
| Weight decay | 0 | 0 | 0 |
To reproduce our fine-tuning runs for LLaMA, first install the requirements
```
pip install -r requirements.txt
```
The code for finetuning is available at [`fine-tuning.ipynb`](https://github.com/gilangcy/stanford-alpaca/blob/main/fine-tuning.ipynb) with four sections of pre-preocessing data, fine-tuning with LlaMa 2, fine-tuning with PolyLM, and fine-tuning with InternLM.
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
## Testing the Model
These are link for test the fine-tuned model :
1. [PolyLM-1.7B](https://huggingface.co/spaces/dennyaw/polylm1.7b)
2. [LlaMa-2-7B](https://huggingface.co/spaces/dennyaw/Llama-2-7b-finetuned)
3. [InternLM-7B](https://huggingface.co/spaces/dennyaw/internlm-7b-finetuned)
### Authors
All interns below contributed equally and the order is determined by random draw.
- [Denny Andriana Wahyu](https://www.linkedin.com/in/denny-aw/)
- [Fadli Aulawi Al Ghiffari](https://www.linkedin.com/in/fadli-aulawi-al-ghiffari-9b4990148/)
- [Gilang Catur Yudishtira](https://www.linkedin.com/in/gilangcy/)
All advised by [Firqa Aqilla Noor Arasyi](https://www.linkedin.com/in/firqaana/)
|
zrjin/icefall-asr-multi-zh-hans-zipformer-ctc-2023-10-24
|
zrjin
| 2023-11-05T09:06:44Z | 0 | 0 | null |
[
"tensorboard",
"onnx",
"region:us"
] | null | 2023-10-24T09:25:19Z |
See https://github.com/k2-fsa/icefall/pull/1313
|
tog/TinyLlama-1.1B-alpaca-chat-v1.0
|
tog
| 2023-11-05T09:06:16Z | 10 | 2 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:tatsu-lab/alpaca",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-18T06:01:35Z |
---
license: apache-2.0
datasets:
- tatsu-lab/alpaca
language:
- en
pipeline_tag: conversational
---
## This Model
This is the chat model finetuned on top of [PY007/TinyLlama-1.1B-intermediate-step-480k-1T](https://huggingface.co/PY007/TinyLlama-1.1B-intermediate-step-480k-1T). The dataset used is [tatsu-lab/stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca).
Below is an instruction that describes a task. Write a response that appropriately completes the request.
```
### Instruction:
{instruction}
### Response:
```
|
AIYIYA/my_jieq1
|
AIYIYA
| 2023-11-05T08:45:13Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-05T08:21:46Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: AIYIYA/my_jieq1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# AIYIYA/my_jieq1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7378
- Validation Loss: 0.7088
- Train Accuracy: 0.8378
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 65, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.7833 | 0.7313 | 0.8108 | 0 |
| 0.7214 | 0.7088 | 0.8378 | 1 |
| 0.7378 | 0.7088 | 0.8378 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
MayIBorn/mrpc_qlora-llama-7b
|
MayIBorn
| 2023-11-05T08:28:04Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:huggyllama/llama-7b",
"base_model:adapter:huggyllama/llama-7b",
"region:us"
] | null | 2023-11-05T08:27:58Z |
---
library_name: peft
base_model: huggyllama/llama-7b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
jwlovetea/test_model
|
jwlovetea
| 2023-11-05T08:21:23Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"codet5",
"dataset:code_x_glue_ct_code_to_text",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-05T08:00:12Z |
---
license: apache-2.0
tags:
- codet5
datasets:
- code_x_glue_ct_code_to_text
widget:
- text: 'def pad(tensor, paddings, mode: "CONSTANT", name: nil) _op(:pad, tensor, paddings, mode: mode, name: name) end </s>'
---
# Description
CodeT5-small model, fine-tuned on the code summarization subtask of CodeXGLUE (Ruby programming language). This model can generate a docstring of a given function written in Ruby.
# Notebook
The notebook that I used to fine-tune CodeT5 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/T5/Fine_tune_CodeT5_for_generating_docstrings_from_Ruby_code.ipynb).
# Usage
Here's how to use this model:
```python
from transformers import RobertaTokenizer, T5ForConditionalGeneration
model_name = "nielsr/codet5-small-code-summarization-ruby"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
code = """
def update_with_file_contents(digest, filename)
File.open(filename) do |io|
while (chunk = io.read(1024 * 8))
digest.update(chunk)
end
end
end
"""
input_ids = tokenizer(code, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# Update the digest with the contents of the given file
```
|
giovaldir/audioclass-alpha
|
giovaldir
| 2023-11-05T08:18:44Z | 8 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"base_model:facebook/wav2vec2-base-960h",
"base_model:finetune:facebook/wav2vec2-base-960h",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-05T03:19:13Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-base-960h
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: audioclass-alpha
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# audioclass-alpha
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0963
- Accuracy: 0.9819
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.3678 | 1.0 | 62 | 3.3612 | 0.0408 |
| 3.349 | 2.0 | 124 | 3.3402 | 0.0385 |
| 3.2935 | 3.0 | 186 | 3.2047 | 0.2494 |
| 2.9643 | 4.0 | 248 | 2.7250 | 0.5102 |
| 2.4158 | 5.0 | 310 | 2.1914 | 0.6621 |
| 1.9634 | 6.0 | 372 | 1.7440 | 0.7800 |
| 1.6144 | 7.0 | 434 | 1.3680 | 0.8503 |
| 1.2939 | 8.0 | 496 | 1.0948 | 0.8390 |
| 1.0933 | 9.0 | 558 | 0.8783 | 0.8776 |
| 0.8596 | 10.0 | 620 | 0.7053 | 0.9048 |
| 0.6664 | 11.0 | 682 | 0.6020 | 0.9184 |
| 0.5843 | 12.0 | 744 | 0.5392 | 0.9048 |
| 0.5714 | 13.0 | 806 | 0.4380 | 0.9297 |
| 0.4395 | 14.0 | 868 | 0.4434 | 0.9252 |
| 0.323 | 15.0 | 930 | 0.3000 | 0.9524 |
| 0.3218 | 16.0 | 992 | 0.2418 | 0.9546 |
| 0.3026 | 17.0 | 1054 | 0.2462 | 0.9524 |
| 0.2531 | 18.0 | 1116 | 0.2003 | 0.9660 |
| 0.2702 | 19.0 | 1178 | 0.1883 | 0.9637 |
| 0.2368 | 20.0 | 1240 | 0.1612 | 0.9728 |
| 0.2121 | 21.0 | 1302 | 0.1981 | 0.9637 |
| 0.2011 | 22.0 | 1364 | 0.1635 | 0.9683 |
| 0.1875 | 23.0 | 1426 | 0.1454 | 0.9728 |
| 0.1415 | 24.0 | 1488 | 0.1433 | 0.9683 |
| 0.1162 | 25.0 | 1550 | 0.1504 | 0.9660 |
| 0.0946 | 26.0 | 1612 | 0.1759 | 0.9615 |
| 0.1032 | 27.0 | 1674 | 0.1206 | 0.9751 |
| 0.095 | 28.0 | 1736 | 0.1123 | 0.9773 |
| 0.1526 | 29.0 | 1798 | 0.1267 | 0.9728 |
| 0.1003 | 30.0 | 1860 | 0.0953 | 0.9796 |
| 0.1371 | 31.0 | 1922 | 0.1158 | 0.9751 |
| 0.0765 | 32.0 | 1984 | 0.0963 | 0.9819 |
| 0.1152 | 33.0 | 2046 | 0.0929 | 0.9819 |
| 0.1344 | 34.0 | 2108 | 0.1103 | 0.9796 |
| 0.1067 | 35.0 | 2170 | 0.1065 | 0.9773 |
| 0.0847 | 36.0 | 2232 | 0.0898 | 0.9819 |
| 0.0835 | 37.0 | 2294 | 0.0934 | 0.9819 |
| 0.1009 | 38.0 | 2356 | 0.1136 | 0.9796 |
| 0.1272 | 39.0 | 2418 | 0.1315 | 0.9751 |
| 0.0463 | 40.0 | 2480 | 0.1127 | 0.9796 |
| 0.085 | 41.0 | 2542 | 0.0985 | 0.9796 |
| 0.0431 | 42.0 | 2604 | 0.0964 | 0.9773 |
| 0.0698 | 43.0 | 2666 | 0.1128 | 0.9773 |
| 0.0493 | 44.0 | 2728 | 0.0934 | 0.9796 |
| 0.1208 | 45.0 | 2790 | 0.0882 | 0.9819 |
| 0.0536 | 46.0 | 2852 | 0.0932 | 0.9796 |
| 0.064 | 47.0 | 2914 | 0.1008 | 0.9796 |
| 0.0538 | 48.0 | 2976 | 0.1094 | 0.9796 |
| 0.0774 | 49.0 | 3038 | 0.1081 | 0.9796 |
| 0.0379 | 50.0 | 3100 | 0.1085 | 0.9796 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
LaTarn/ta-food-setfit-model
|
LaTarn
| 2023-11-05T08:09:14Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-11-05T08:08:49Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# LaTarn/ta-food-setfit-model
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("LaTarn/ta-food-setfit-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
Saiteja/uplimit-project-3-phi-1.5
|
Saiteja
| 2023-11-05T07:57:06Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"dataset:scitldr",
"base_model:microsoft/phi-1_5",
"base_model:finetune:microsoft/phi-1_5",
"license:other",
"region:us"
] | null | 2023-11-05T07:57:04Z |
---
license: other
base_model: microsoft/phi-1_5
tags:
- generated_from_trainer
datasets:
- scitldr
model-index:
- name: uplimit-project-3-phi-1.5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# uplimit-project-3-phi-1.5
This model is a fine-tuned version of [microsoft/phi-1_5](https://huggingface.co/microsoft/phi-1_5) on the scitldr dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5539 | 0.1 | 200 | 2.5942 |
| 2.5712 | 0.2 | 400 | 2.5944 |
| 2.5304 | 0.3 | 600 | 2.5755 |
| 2.5846 | 0.4 | 800 | 2.5669 |
| 2.5448 | 0.5 | 1000 | 2.5576 |
| 2.5776 | 0.6 | 1200 | 2.5535 |
| 2.5513 | 0.7 | 1400 | 2.5471 |
| 2.5291 | 0.8 | 1600 | 2.5403 |
| 2.5782 | 0.9 | 1800 | 2.5352 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
amaresh0787/midjouny
|
amaresh0787
| 2023-11-05T07:44:36Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2023-11-05T07:42:09Z |
---
license: other
license_name: mdj
license_link: LICENSE
---
|
minhnb/distilbert-base-uncased-finetuned-stsb
|
minhnb
| 2023-11-05T07:35:57Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-29T08:07:38Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: minhnb/distilbert-base-uncased-finetuned-stsb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# minhnb/distilbert-base-uncased-finetuned-stsb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3709
- Validation Loss: 0.5530
- Train Pearson: 0.8694
- Train Spearmanr: 0.8669
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1077, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Pearson | Train Spearmanr | Epoch |
|:----------:|:---------------:|:-------------:|:---------------:|:-----:|
| 1.3417 | 0.5844 | 0.8633 | 0.8621 | 0 |
| 0.4972 | 0.5731 | 0.8698 | 0.8686 | 1 |
| 0.3709 | 0.5530 | 0.8694 | 0.8669 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
pseudolab/K23_MiniMed
|
pseudolab
| 2023-11-05T07:34:28Z | 5 | 10 |
adapter-transformers
|
[
"adapter-transformers",
"tensorboard",
"safetensors",
"medical",
"summarization",
"en",
"dataset:keivalya/MedQuad-MedicalQnADataset",
"arxiv:1910.09700",
"doi:10.57967/hf/1304",
"license:mit",
"region:us"
] |
summarization
| 2023-11-01T18:36:04Z |
---
license: mit
datasets:
- keivalya/MedQuad-MedicalQnADataset
language:
- en
library_name: adapter-transformers
metrics:
- accuracy
- bertscore
- bleu
pipeline_tag: summarization
tags:
- medical
---
# K23 MiniMed 모델 카드
K23 MiniMed는 Krew x Huggingface 2023 해커톤에서 원형석 멘토의 지도하에 개발된 Mistral 7b Beta Medical Fine Tune 모델입니다.
## 모델 세부사항
- **개발자:** [Tonic](https://huggingface.co/Tonic)
- **후원:** [Tonic](https://huggingface.co/Tonic)
- **공유자:** K23-Krew-Hackathon
- **모델 유형:** Mistral 7B-Beta Medical Fine Tune
- **언어 (NLP):** 영어
- **라이센스:** MIT
- **Fine-tuning 기반 모델:** [Zephyr 7B-Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
### 모델 출처
- **저장소:** [github](https://github.com/Josephrp/AI-challenge-hackathon/blob/master/mistral7b-beta_finetune.ipynb)
- **데모:** [pseudolab/K23MiniMed](https://huggingface.co/spaces/pseudolab/K23MiniMed)
## 사용법
이 모델은 교육 목적으로만 의학 질문 답변을 위한 대화형 애플리케이션용입니다.
### 직접 사용
Gradio 챗봇 앱을 만들어 의학적 질문을 하고 대화식으로 답변을 받습니다.
### 하류 사용
이 모델은 교육용으로만 사용됩니다. 추가적인 Fine-tuning과 사용 예시로는 공중 보건 & 위생, 개인 보건 & 위생, 의학 Q & A가 있습니다.
### 추천사항
사용 전에 항상 이 모델을 평가하고 벤치마킹하십시오. 사용 전에 편향을 평가하십시오. 그대로 사용하지 마시고 추가적으로 Fine-tuning하십시오.
## 훈련 세부사항
모델의 훈련 손실은 다음과 같습니다:
| 단계 | 훈련 손실 |
|------|--------------|
| 50 | 0.993800 |
| 100 | 0.620600 |
| 150 | 0.547100 |
| 200 | 0.524100 |
| 250 | 0.520500 |
| 300 | 0.559800 |
| 350 | 0.535500 |
| 400 | 0.505400 |
### 훈련 데이터
모델의 학습 가능한 매개변수: 21260288, 모든 매개변수: 3773331456, 학습 가능한 %: 0.5634354746703705.
### 결과
global_step=400에서의 훈련 손실은 0.6008514881134033입니다.
## 환경 영향
모델의 환경 영향은 머신러닝 영향 계산기를 사용하여 계산할 수 있습니다. 추정을 제공하기 위해서는 더 많은 세부 정보가 필요합니다.
## 기술 사양
### 모델 아키텍처와 목표
모델은 특정 설정을 가진 PeftModelForCausalLM을 사용합니다.
### 컴퓨팅 인프라
#### 하드웨어
모델은 A100 하드웨어에서 훈련되었습니다.
#### 소프트웨어
사용된 소프트웨어에는 peft, torch, bitsandbytes, python, 그리고 huggingface가 포함됩니다.
## 모델 카드 작성자
[Tonic](https://huggingface.co/Tonic)
## 모델 카드 연락처
[Tonic](https://huggingface.co/Tonic)
# Model Card for K23 MiniMed
This is a Mistral 7b Beta Medical Fine Tune with a short number of steps , inspired by [Wonhyeong Seo](https://www.huggingface.co/wseo) great mentorship during Krew x Huggingface 2023 hackathon.
## Model Details
### Model Description
- **Developed by:** [Tonic](https://huggingface.co/Tonic)
- **Funded by [optional]:** [Tonic](https://huggingface.co/Tonic)
- **Shared by [optional]:** K23-Krew-Hackathon
- **Model type:** Mistral 7B-Beta Medical Fine Tune
- **Language(s) (NLP):** English
- **License:** MIT
- **Finetuned from model [optional]:** [Zephyr 7B-Beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
### Model Sources [optional]
- **Repository:** [github](https://github.com/Josephrp/AI-challenge-hackathon/blob/master/mistral7b-beta_finetune.ipynb)
- **Demo [optional]:** [pseudolab/K23MiniMed](https://huggingface.co/spaces/pseudolab/K23MiniMed)
## Uses
Use this model for conversational applications for medical question and answering **for educational purposes only** !
### Direct Use
Make a gradio chatbot app to ask medical questions and get answers conversationaly.
### Downstream Use [optional]
This model is **for educational use only** .
Further fine tunes and uses would include :
- public health & sanitation
- personal health & sanitation
- medical Q & A
### Recommendations
- always evaluate this model before use
- always benchmark this model before use
- always evaluate bias before use
- do not use as is, fine tune further
## How to Get Started with the Model
Use the code below to get started with the model.
```Python
from transformers import AutoConfig, AutoTokenizer, AutoModelForSeq2SeqLM, AutoModelForCausalLM, MistralForCausalLM
from peft import PeftModel, PeftConfig
import torch
import gradio as gr
import random
from textwrap import wrap
# Functions to Wrap the Prompt Correctly
def wrap_text(text, width=90):
lines = text.split('\n')
wrapped_lines = [textwrap.fill(line, width=width) for line in lines]
wrapped_text = '\n'.join(wrapped_lines)
return wrapped_text
def multimodal_prompt(user_input, system_prompt="You are an expert medical analyst:"):
# Combine user input and system prompt
formatted_input = f"<s>[INST]{system_prompt} {user_input}[/INST]"
# Encode the input text
encodeds = tokenizer(formatted_input, return_tensors="pt", add_special_tokens=False)
model_inputs = encodeds.to(device)
# Generate a response using the model
output = model.generate(
**model_inputs,
max_length=max_length,
use_cache=True,
early_stopping=True,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
pad_token_id=model.config.eos_token_id,
temperature=0.1,
do_sample=True
)
# Decode the response
response_text = tokenizer.decode(output[0], skip_special_tokens=True)
return response_text
# Define the device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Use the base model's ID
base_model_id = "HuggingFaceH4/zephyr-7b-beta"
model_directory = "pseudolab/K23_MiniMed"
# Instantiate the Tokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", trust_remote_code=True, padding_side="left")
# tokenizer = AutoTokenizer.from_pretrained("Tonic/mistralmed", trust_remote_code=True, padding_side="left")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left'
# Specify the configuration class for the model
#model_config = AutoConfig.from_pretrained(base_model_id)
# Load the PEFT model with the specified configuration
#peft_model = AutoModelForCausalLM.from_pretrained(base_model_id, config=model_config)
# Load the PEFT model
peft_config = PeftConfig.from_pretrained("pseudolab/K23_MiniMed")
peft_model = MistralForCausalLM.from_pretrained("https://huggingface.co/HuggingFaceH4/zephyr-7b-beta", trust_remote_code=True)
peft_model = PeftModel.from_pretrained(peft_model, "pseudolab/K23_MiniMed")
class ChatBot:
def __init__(self):
self.history = []
class ChatBot:
def __init__(self):
# Initialize the ChatBot class with an empty history
self.history = []
def predict(self, user_input, system_prompt="You are an expert medical analyst:"):
# Combine the user's input with the system prompt
formatted_input = f"<s>[INST]{system_prompt} {user_input}[/INST]"
# Encode the formatted input using the tokenizer
user_input_ids = tokenizer.encode(formatted_input, return_tensors="pt")
# Generate a response using the PEFT model
response = peft_model.generate(input_ids=user_input_ids, max_length=512, pad_token_id=tokenizer.eos_token_id)
# Decode the generated response to text
response_text = tokenizer.decode(response[0], skip_special_tokens=True)
return response_text # Return the generated response
bot = ChatBot()
title = "👋🏻토닉의 미스트랄메드 채팅에 오신 것을 환영합니다🚀👋🏻Welcome to Tonic's MistralMed Chat🚀"
description = "이 공간을 사용하여 현재 모델을 테스트할 수 있습니다. [(Tonic/MistralMed)](https://huggingface.co/Tonic/MistralMed) 또는 이 공간을 복제하고 로컬 또는 🤗HuggingFace에서 사용할 수 있습니다. [Discord에서 함께 만들기 위해 Discord에 가입하십시오](https://discord.gg/VqTxc76K3u). You can use this Space to test out the current model [(Tonic/MistralMed)](https://huggingface.co/Tonic/MistralMed) or duplicate this Space and use it locally or on 🤗HuggingFace. [Join me on Discord to build together](https://discord.gg/VqTxc76K3u)."
examples = [["[Question:] What is the proper treatment for buccal herpes?", "You are a medicine and public health expert, you will receive a question, answer the question, and provide a complete answer"]]
iface = gr.Interface(
fn=bot.predict,
title=title,
description=description,
examples=examples,
inputs=["text", "text"], # Take user input and system prompt separately
outputs="text",
theme="ParityError/Anime"
)
iface.launch()
```
## Training Details
| Step | Training Loss |
|------|--------------|
| 50 | 0.993800 |
| 100 | 0.620600 |
| 150 | 0.547100 |
| 200 | 0.524100 |
| 250 | 0.520500 |
| 300 | 0.559800 |
| 350 | 0.535500 |
| 400 | 0.505400 |
### Training Data
```json
{trainable params: 21260288 || all params: 3773331456 || trainable%: 0.5634354746703705}
```
### Training Procedure
#### Preprocessing [optional]
Lora32bits
#### Speeds, Sizes, Times [optional]
```json
metrics={'train_runtime': 1700.1608, 'train_samples_per_second': 1.882, 'train_steps_per_second': 0.235, 'total_flos': 9.585300996096e+16, 'train_loss': 0.6008514881134033, 'epoch': 0.2})
```
### Results
```json
TrainOutput
global_step=400, training_loss=0.6008514881134033
```
#### Summary
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** {{ hardware | default("[More Information Needed]", true)}}
- **Hours used:** {{ hours_used | default("[More Information Needed]", true)}}
- **Cloud Provider:** {{ cloud_provider | default("[More Information Needed]", true)}}
- **Compute Region:** {{ cloud_region | default("[More Information Needed]", true)}}
- **Carbon Emitted:** {{ co2_emitted | default("[More Information Needed]", true)}}
## Technical Specifications
### Model Architecture and Objective
```python
PeftModelForCausalLM(
(base_model): LoraModel(
(model): MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralAttention(
(q_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
)
(k_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
)
(v_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
)
(o_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=14336, bias=False)
)
(up_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=14336, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=4096, out_features=14336, bias=False)
)
(down_proj): Linear4bit(
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=14336, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(base_layer): Linear4bit(in_features=14336, out_features=4096, bias=False)
)
(act_fn): SiLUActivation()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(
in_features=4096, out_features=32000, bias=False
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=32000, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
)
)
)
```
### Compute Infrastructure
#### Hardware
A100
#### Software
peft , torch, bitsandbytes, python, huggingface
## Model Card Authors [optional]
[Tonic](https://huggingface.co/Tonic)
## Model Card Contact
[Tonic](https://huggingface.co/Tonic)
|
hdryilmaz/turkishReviews-ds-mini
|
hdryilmaz
| 2023-11-05T07:33:43Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T07:02:28Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_keras_callback
model-index:
- name: turkishReviews-ds-mini
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# turkishReviews-ds-mini
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 9.1555
- Validation Loss: 9.2406
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'transformers.optimization_tf', 'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -896, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}, 'registered_name': 'WarmUp'}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 10.2540 | 9.9577 | 0 |
| 9.6351 | 9.6103 | 1 |
| 9.1555 | 9.2406 | 2 |
### Framework versions
- Transformers 4.35.0
- TensorFlow 2.14.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Jaykumaran17/mistral7b-finetuned-medical
|
Jaykumaran17
| 2023-11-05T07:17:19Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"base_model:finetune:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2023-11-05T06:30:08Z |
---
license: apache-2.0
base_model: TheBloke/Mistral-7B-Instruct-v0.1-GPTQ
tags:
- generated_from_trainer
model-index:
- name: mistral7b-finetuned-medical
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral7b-finetuned-medical
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.1-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
andrewparkk/train_dreambooth_lora_sdxl_model
|
andrewparkk
| 2023-11-05T07:08:12Z | 1 | 2 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-11-05T06:40:05Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks man
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - andrewparkk/train_dreambooth_lora_sdxl_model
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks man using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
maitake0115/distilbert-base-uncased-fintuned-emotion
|
maitake0115
| 2023-11-05T06:45:31Z | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-05T06:42:24Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-fintuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.923
- name: F1
type: f1
value: 0.9229617583340289
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-fintuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2141
- Accuracy: 0.923
- F1: 0.9230
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8196 | 1.0 | 250 | 0.3296 | 0.897 | 0.8964 |
| 0.2508 | 2.0 | 500 | 0.2141 | 0.923 | 0.9230 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
maryantocinn/t5-small-finetuned-xsum
|
maryantocinn
| 2023-11-05T06:31:27Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:indosum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-04T13:45:21Z |
---
license: apache-2.0
base_model: indobart-v2
tags:
- generated_from_trainer
datasets:
- indosum
metrics:
- rouge
model-index:
- name: indobart-v2-finetuned-indosum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: indosum
type: indosum
config: indosum_fold0_source
split: validation
args: indosum_fold0_source
metrics:
- name: Rouge1
type: rouge
value: 21.1743
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobart-v2-finetuned-indosum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the indosum dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4003
- Rouge1: 21.1743
- Rouge2: 16.867
- Rougel: 20.9061
- Rougelsum: 21.0473
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.4276 | 1.0 | 1189 | 0.4118 | 21.0508 | 16.7363 | 20.7771 | 20.919 | 19.0 |
| 0.4268 | 2.0 | 2378 | 0.4060 | 21.1694 | 16.852 | 20.891 | 21.0278 | 19.0 |
| 0.4077 | 3.0 | 3567 | 0.4021 | 21.1523 | 16.8553 | 20.8928 | 21.0273 | 19.0 |
| 0.406 | 4.0 | 4756 | 0.4006 | 21.1743 | 16.867 | 20.9061 | 21.0473 | 19.0 |
| 0.4158 | 5.0 | 5945 | 0.4003 | 21.1743 | 16.867 | 20.9061 | 21.0473 | 19.0 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
advancedcv/blip2-opt-2.7b_Food500Cap_finetuned_subset
|
advancedcv
| 2023-11-05T06:18:02Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Salesforce/blip2-opt-2.7b",
"base_model:adapter:Salesforce/blip2-opt-2.7b",
"region:us"
] | null | 2023-11-05T03:47:19Z |
---
library_name: peft
base_model: Salesforce/blip2-opt-2.7b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.7.0.dev0
|
LoneStriker/Hermes-Trismegistus-Mistral-7B-8.0bpw-h8-exl2
|
LoneStriker
| 2023-11-05T05:44:03Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/trismegistus-project",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T05:43:43Z |
---
base_model: teknium/OpenHermes-2.5-Mistral-7B-v0.1
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
model-index:
- name: Hermes-Trismegistus-Mistral-7B
results: []
datasets:
- teknium/trismegistus-project
license: apache-2.0
language:
- en
---
## Model Description:

Transcendence is All You Need! Mistral Trismegistus is a model made for people interested in the esoteric, occult, and spiritual.
### Trismegistus evolved, trained over Hermes 2.5, the model performs far better in all tasks, including esoteric tasks!
The change between Mistral-Trismegistus and Hermes-Trismegistus is that this version trained over hermes 2.5 instead of the base mistral model, this means it is full of task capabilities that it Trismegistus can utilize for all esoteric and occult tasks, and performs them far better than ever before.
Here are some outputs:



## Acknowledgements:
Special thanks to @a16z.
## Dataset:
This model was trained on a 100% synthetic, gpt-4 generated dataset, about ~10,000 examples, on a wide and diverse set of both tasks and knowledge about the esoteric, occult, and spiritual.
The dataset will be released soon!
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
No benchmark can capture the nature and essense of the quality of spirituality and esoteric knowledge and tasks. You will have to try testing it yourself!
Training run on wandb here: https://wandb.ai/teknium1/occult-expert-mistral-7b/runs/coccult-expert-mistral-6/overview
## Licensing:
Apache 2.0
|
coreml-community/coreml-SDXL-v10-UnetRefiner.mlmodelc
|
coreml-community
| 2023-11-05T05:43:31Z | 0 | 0 | null |
[
"coreml",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-10-13T22:19:38Z |
---
license: creativeml-openrail-m
tags:
- coreml
- stable-diffusion
- text-to-image
---
## These are several flavors of the piece of the SDXL Refiner model that Mochi Diffusion needs to turn a SDXL Base model into a combined Base + Refiner model.
Put the correct version of the UnetRefiner.mlmodelc in with the rest of the pieces of your Base model. Mochi will automatically recognize the 2 Unets as a combineed model.
It will use the Base model Unet for the first 80% of the steps and then it will automatically switch to the Refiner model Unet for the final 20%. The transition point is hardcoded.
Take care when unzipping after downloading as they all unzip to the same UnetRefiner.mlmodelc name.
**Keep in mind that the Refiner is a generic type model and using it with a Base model that has a specific "personality" might ruin rather than improve images.**
|
LoneStriker/Hermes-Trismegistus-Mistral-7B-6.0bpw-h6-exl2
|
LoneStriker
| 2023-11-05T05:37:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/trismegistus-project",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T05:37:34Z |
---
base_model: teknium/OpenHermes-2.5-Mistral-7B-v0.1
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
model-index:
- name: Hermes-Trismegistus-Mistral-7B
results: []
datasets:
- teknium/trismegistus-project
license: apache-2.0
language:
- en
---
## Model Description:

Transcendence is All You Need! Mistral Trismegistus is a model made for people interested in the esoteric, occult, and spiritual.
### Trismegistus evolved, trained over Hermes 2.5, the model performs far better in all tasks, including esoteric tasks!
The change between Mistral-Trismegistus and Hermes-Trismegistus is that this version trained over hermes 2.5 instead of the base mistral model, this means it is full of task capabilities that it Trismegistus can utilize for all esoteric and occult tasks, and performs them far better than ever before.
Here are some outputs:



## Acknowledgements:
Special thanks to @a16z.
## Dataset:
This model was trained on a 100% synthetic, gpt-4 generated dataset, about ~10,000 examples, on a wide and diverse set of both tasks and knowledge about the esoteric, occult, and spiritual.
The dataset will be released soon!
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
No benchmark can capture the nature and essense of the quality of spirituality and esoteric knowledge and tasks. You will have to try testing it yourself!
Training run on wandb here: https://wandb.ai/teknium1/occult-expert-mistral-7b/runs/coccult-expert-mistral-6/overview
## Licensing:
Apache 2.0
|
LoneStriker/Hermes-Trismegistus-Mistral-7B-5.0bpw-h6-exl2
|
LoneStriker
| 2023-11-05T05:31:49Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/trismegistus-project",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-05T05:31:35Z |
---
base_model: teknium/OpenHermes-2.5-Mistral-7B-v0.1
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
model-index:
- name: Hermes-Trismegistus-Mistral-7B
results: []
datasets:
- teknium/trismegistus-project
license: apache-2.0
language:
- en
---
## Model Description:

Transcendence is All You Need! Mistral Trismegistus is a model made for people interested in the esoteric, occult, and spiritual.
### Trismegistus evolved, trained over Hermes 2.5, the model performs far better in all tasks, including esoteric tasks!
The change between Mistral-Trismegistus and Hermes-Trismegistus is that this version trained over hermes 2.5 instead of the base mistral model, this means it is full of task capabilities that it Trismegistus can utilize for all esoteric and occult tasks, and performs them far better than ever before.
Here are some outputs:



## Acknowledgements:
Special thanks to @a16z.
## Dataset:
This model was trained on a 100% synthetic, gpt-4 generated dataset, about ~10,000 examples, on a wide and diverse set of both tasks and knowledge about the esoteric, occult, and spiritual.
The dataset will be released soon!
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
No benchmark can capture the nature and essense of the quality of spirituality and esoteric knowledge and tasks. You will have to try testing it yourself!
Training run on wandb here: https://wandb.ai/teknium1/occult-expert-mistral-7b/runs/coccult-expert-mistral-6/overview
## Licensing:
Apache 2.0
|
longface/reasoning-task-model-llama-rev1
|
longface
| 2023-11-05T05:28:43Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-05T05:28:41Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.0
|
samzoozi/ppo-SnowballTarget
|
samzoozi
| 2023-11-05T05:20:23Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-11-05T05:20:21Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: samzoozi/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
goodbai0537/q-Taxi-v3
|
goodbai0537
| 2023-11-05T05:14:02Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-05T05:14:01Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
``` python
model = load_from_hub(repo_id="goodbai0537/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
DMPark/StepbyStep_NewYork
|
DMPark
| 2023-11-05T05:13:17Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-05T03:45:17Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.