
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-02 00:43:11
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 548
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-02 00:35:11
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
vocabtrimmer/mbart-large-cc25-squad-qa-trimmed-en-10000
|
vocabtrimmer
| 2023-04-01T02:05:26Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-01T01:39:20Z |
# Vocabulary Trimmed [lmqg/mbart-large-cc25-squad-qa](https://huggingface.co/lmqg/mbart-large-cc25-squad-qa): `vocabtrimmer/mbart-large-cc25-squad-qa-trimmed-en-10000`
This model is a trimmed version of [lmqg/mbart-large-cc25-squad-qa](https://huggingface.co/lmqg/mbart-large-cc25-squad-qa) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mbart-large-cc25-squad-qa | vocabtrimmer/mbart-large-cc25-squad-qa-trimmed-en-10000 |
|:---------------------------|:---------------------------------|:----------------------------------------------------------|
| parameter_size_full | 610,852,864 | 365,068,288 |
| parameter_size_embedding | 512,057,344 | 20,488,192 |
| vocab_size | 250,028 | 10,004 |
| compression_rate_full | 100.0 | 59.76 |
| compression_rate_embedding | 100.0 | 4.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| en | vocabtrimmer/mc4_validation | text | en | validation | 10000 | 2 |
|
wjmm/q-FrozenLake-v1-4x4-noSlippery
|
wjmm
| 2023-04-01T01:43:56Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-01T01:43:53Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="wjmm/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
proleetops/a2c-PandaReachDense-v2
|
proleetops
| 2023-04-01T01:38:33Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-04-01T01:36:09Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.97 +/- 1.73
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
keemooo/9898
|
keemooo
| 2023-04-01T01:25:58Z | 0 | 0 | null |
[
"chemistry",
"music",
"art",
"text-generation-inference",
"hr",
"dataset:gsdf/EasyNegative",
"region:us"
] | null | 2023-04-01T01:23:30Z |
---
datasets:
- gsdf/EasyNegative
language:
- hr
tags:
- chemistry
- music
- art
- text-generation-inference
---
|
Brizape/Yepes_0.0001_250
|
Brizape
| 2023-04-01T00:55:10Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-31T23:25:32Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Yepes_0.0001_250
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Yepes_0.0001_250
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1555
- Precision: 0.5922
- Recall: 0.4552
- F1: 0.5148
- Accuracy: 0.9768
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.4065 | 1.39 | 25 | 0.2115 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.1995 | 2.78 | 50 | 0.2120 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.1995 | 4.17 | 75 | 0.2108 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.1694 | 5.56 | 100 | 0.1646 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.1493 | 6.94 | 125 | 0.1513 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.1266 | 8.33 | 150 | 0.1446 | 0.0 | 0.0 | 0.0 | 0.9672 |
| 0.106 | 9.72 | 175 | 0.1396 | 0.4019 | 0.2139 | 0.2792 | 0.9704 |
| 0.086 | 11.11 | 200 | 0.1162 | 0.5037 | 0.3408 | 0.4065 | 0.9740 |
| 0.0613 | 12.5 | 225 | 0.1230 | 0.5015 | 0.4104 | 0.4514 | 0.9740 |
| 0.047 | 13.89 | 250 | 0.1306 | 0.5333 | 0.4378 | 0.4809 | 0.9753 |
| 0.0351 | 15.28 | 275 | 0.1351 | 0.5629 | 0.4453 | 0.4972 | 0.9757 |
| 0.0266 | 16.67 | 300 | 0.1453 | 0.5617 | 0.4303 | 0.4873 | 0.9765 |
| 0.02 | 18.06 | 325 | 0.1441 | 0.5573 | 0.4478 | 0.4966 | 0.9757 |
| 0.0153 | 19.44 | 350 | 0.1555 | 0.5922 | 0.4552 | 0.5148 | 0.9768 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
saif-daoud/whisper-small-hi-2400_500_133
|
saif-daoud
| 2023-04-01T00:54:00Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:afrispeech-200",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-31T22:23:54Z |
---
tags:
- generated_from_trainer
datasets:
- afrispeech-200
metrics:
- wer
model-index:
- name: whisper-small-hi-2400_500_133
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: afrispeech-200
type: afrispeech-200
config: hausa
split: train
args: hausa
metrics:
- name: Wer
type: wer
value: 0.32728583443469905
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-hi-2400_500_133
This model is a fine-tuned version of [saif-daoud/whisper-small-hi-2400_500_132](https://huggingface.co/saif-daoud/whisper-small-hi-2400_500_132) on the afrispeech-200 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7843
- Wer: 0.3273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 150
- training_steps: 540
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.9568 | 0.5 | 270 | 0.7916 | 0.3298 |
| 0.9337 | 1.5 | 540 | 0.7843 | 0.3273 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
Brizape/Variome_0.0005_250
|
Brizape
| 2023-04-01T00:48:48Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-04-01T00:32:57Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: Variome_0.0005_250
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Variome_0.0005_250
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1812
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.9760
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| 0.3356 | 0.35 | 25 | 0.1809 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1851 | 0.69 | 50 | 0.1807 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1635 | 1.04 | 75 | 0.1863 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1848 | 1.39 | 100 | 0.1810 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1697 | 1.74 | 125 | 0.1817 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1735 | 2.08 | 150 | 0.1802 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1576 | 2.43 | 175 | 0.1833 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.178 | 2.78 | 200 | 0.1811 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.18 | 3.12 | 225 | 0.1815 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1809 | 3.47 | 250 | 0.1825 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1616 | 3.82 | 275 | 0.1828 | 0.0 | 0.0 | 0.0 | 0.9760 |
| 0.1682 | 4.17 | 300 | 0.1812 | 0.0 | 0.0 | 0.0 | 0.9760 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
takinai/DreamShaper
|
takinai
| 2023-04-01T00:44:52Z | 0 | 0 | null |
[
"stable_diffusion",
"checkpoint",
"region:us"
] | null | 2023-03-31T23:16:08Z |
---
tags:
- stable_diffusion
- checkpoint
---
The source of the models is listed below. Please check the original licenses from the source.
https://civitai.com/models/4384
|
vocabtrimmer/xlm-v-base-trimmed-ar-30000
|
vocabtrimmer
| 2023-04-01T00:31:18Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-04-01T00:30:06Z |
# Vocabulary Trimmed [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base): `vocabtrimmer/xlm-v-base-trimmed-ar-30000`
This model is a trimmed version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | facebook/xlm-v-base | vocabtrimmer/xlm-v-base-trimmed-ar-30000 |
|:---------------------------|:----------------------|:-------------------------------------------|
| parameter_size_full | 779,396,349 | 109,115,186 |
| parameter_size_embedding | 692,451,072 | 23,041,536 |
| vocab_size | 901,629 | 30,002 |
| compression_rate_full | 100.0 | 14.0 |
| compression_rate_embedding | 100.0 | 3.33 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ar | vocabtrimmer/mc4_validation | text | ar | validation | 30000 | 2 |
|
vocabtrimmer/xlm-v-base-trimmed-ar-15000-tweet-sentiment-ar
|
vocabtrimmer
| 2023-04-01T00:25:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-01T00:24:35Z |
# `vocabtrimmer/xlm-v-base-trimmed-ar-15000-tweet-sentiment-ar`
This model is a fine-tuned version of [/home/asahi/lm-vocab-trimmer/ckpts/xlm-v-base-trimmed-ar-15000](https://huggingface.co//home/asahi/lm-vocab-trimmer/ckpts/xlm-v-base-trimmed-ar-15000) on the
[cardiffnlp/tweet_sentiment_multilingual](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual) (arabic).
Following metrics are computed on the `test` split of
[cardiffnlp/tweet_sentiment_multilingual](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual)(arabic).
| | eval_f1_micro | eval_recall_micro | eval_precision_micro | eval_f1_macro | eval_recall_macro | eval_precision_macro | eval_accuracy |
|---:|----------------:|--------------------:|-----------------------:|----------------:|--------------------:|-----------------------:|----------------:|
| 0 | 52.87 | 52.87 | 52.87 | 46.59 | 52.87 | 50.88 | 52.87 |
Check the result file [here](https://huggingface.co/vocabtrimmer/xlm-v-base-trimmed-ar-15000-tweet-sentiment-ar/raw/main/eval.json).
|
vocabtrimmer/xlm-v-base-tweet-sentiment-fr-trimmed-fr-5000
|
vocabtrimmer
| 2023-04-01T00:25:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-04-01T00:22:55Z |
# Vocabulary Trimmed [cardiffnlp/xlm-v-base-tweet-sentiment-fr](https://huggingface.co/cardiffnlp/xlm-v-base-tweet-sentiment-fr): `vocabtrimmer/xlm-v-base-tweet-sentiment-fr-trimmed-fr-5000`
This model is a trimmed version of [cardiffnlp/xlm-v-base-tweet-sentiment-fr](https://huggingface.co/cardiffnlp/xlm-v-base-tweet-sentiment-fr) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | cardiffnlp/xlm-v-base-tweet-sentiment-fr | vocabtrimmer/xlm-v-base-tweet-sentiment-fr-trimmed-fr-5000 |
|:---------------------------|:-------------------------------------------|:-------------------------------------------------------------|
| parameter_size_full | 778,495,491 | 89,885,955 |
| parameter_size_embedding | 692,451,072 | 3,841,536 |
| vocab_size | 901,629 | 5,002 |
| compression_rate_full | 100.0 | 11.55 |
| compression_rate_embedding | 100.0 | 0.55 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| fr | vocabtrimmer/mc4_validation | text | fr | validation | 5000 | 2 |
|
vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa
|
vocabtrimmer
| 2023-04-01T00:05:28Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"question answering",
"en",
"dataset:lmqg/qg_squad",
"arxiv:2210.03992",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-04-01T00:03:14Z |
---
license: cc-by-4.0
metrics:
- bleu4
- meteor
- rouge-l
- bertscore
- moverscore
language: en
datasets:
- lmqg/qg_squad
pipeline_tag: text2text-generation
tags:
- question answering
widget:
- text: "question: What is a person called is practicing heresy?, context: Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things."
example_title: "Question Answering Example 1"
- text: "question: who created the post as we know it today?, context: 'So much of The Post is Ben,' Mrs. Graham said in 1994, three years after Bradlee retired as editor. 'He created it as we know it today.'— Ed O'Keefe (@edatpost) October 21, 2014"
example_title: "Question Answering Example 2"
model-index:
- name: vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa
results:
- task:
name: Text2text Generation
type: text2text-generation
dataset:
name: lmqg/qg_squad
type: default
args: default
metrics:
- name: BLEU4 (Question Answering)
type: bleu4_question_answering
value: 33.47
- name: ROUGE-L (Question Answering)
type: rouge_l_question_answering
value: 67.38
- name: METEOR (Question Answering)
type: meteor_question_answering
value: 39.13
- name: BERTScore (Question Answering)
type: bertscore_question_answering
value: 91.86
- name: MoverScore (Question Answering)
type: moverscore_question_answering
value: 81.36
- name: AnswerF1Score (Question Answering)
type: answer_f1_score__question_answering
value: 68.65
- name: AnswerExactMatch (Question Answering)
type: answer_exact_match_question_answering
value: 54.26
---
# Model Card of `vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa`
This model is fine-tuned version of [ckpts/mt5-small-trimmed-en-90000](https://huggingface.co/ckpts/mt5-small-trimmed-en-90000) for question answering task on the [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [ckpts/mt5-small-trimmed-en-90000](https://huggingface.co/ckpts/mt5-small-trimmed-en-90000)
- **Language:** en
- **Training data:** [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa")
# model prediction
answers = model.answer_q(list_question="What is a person called is practicing heresy?", list_context=" Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa")
output = pipe("question: What is a person called is practicing heresy?, context: Heresy is any provocative belief or theory that is strongly at variance with established beliefs or customs. A heretic is a proponent of such claims or beliefs. Heresy is distinct from both apostasy, which is the explicit renunciation of one's religion, principles or cause, and blasphemy, which is an impious utterance or action concerning God or sacred things.")
```
## Evaluation
- ***Metric (Question Answering)***: [raw metric file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa/raw/main/eval/metric.first.answer.paragraph_question.answer.lmqg_qg_squad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:---------------------------------------------------------------|
| AnswerExactMatch | 54.26 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| AnswerF1Score | 68.65 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| BERTScore | 91.86 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_1 | 49.27 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_2 | 43.25 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_3 | 37.89 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| Bleu_4 | 33.47 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| METEOR | 39.13 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| MoverScore | 81.36 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
| ROUGE_L | 67.38 | default | [lmqg/qg_squad](https://huggingface.co/datasets/lmqg/qg_squad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_squad
- dataset_name: default
- input_types: ['paragraph_question']
- output_types: ['answer']
- prefix_types: None
- model: ckpts/mt5-small-trimmed-en-90000
- max_length: 512
- max_length_output: 32
- epoch: 10
- batch: 32
- lr: 0.0005
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 2
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/vocabtrimmer/mt5-small-trimmed-en-90000-squad-qa/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
Brizape/SETH_5e-05_250
|
Brizape
| 2023-04-01T00:00:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-31T23:49:57Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: SETH_5e-05_250
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SETH_5e-05_250
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0716
- Precision: 0.7964
- Recall: 0.8036
- F1: 0.8000
- Accuracy: 0.9849
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3757 | 0.76 | 25 | 0.1924 | 0.0 | 0.0 | 0.0 | 0.9625 |
| 0.1119 | 1.52 | 50 | 0.0723 | 0.6237 | 0.7473 | 0.6799 | 0.9775 |
| 0.0565 | 2.27 | 75 | 0.0614 | 0.6569 | 0.7727 | 0.7101 | 0.9794 |
| 0.048 | 3.03 | 100 | 0.0586 | 0.6667 | 0.8655 | 0.7532 | 0.9801 |
| 0.0355 | 3.79 | 125 | 0.0519 | 0.7206 | 0.8345 | 0.7734 | 0.9835 |
| 0.0328 | 4.55 | 150 | 0.0532 | 0.7165 | 0.8455 | 0.7756 | 0.9831 |
| 0.0258 | 5.3 | 175 | 0.0539 | 0.7460 | 0.8382 | 0.7894 | 0.9835 |
| 0.022 | 6.06 | 200 | 0.0561 | 0.7612 | 0.7709 | 0.7660 | 0.9836 |
| 0.0189 | 6.82 | 225 | 0.0564 | 0.7636 | 0.74 | 0.7516 | 0.9828 |
| 0.0166 | 7.58 | 250 | 0.0597 | 0.7274 | 0.8491 | 0.7836 | 0.9836 |
| 0.0128 | 8.33 | 275 | 0.0626 | 0.8251 | 0.7636 | 0.7932 | 0.9854 |
| 0.0113 | 9.09 | 300 | 0.0603 | 0.8029 | 0.8 | 0.8015 | 0.9854 |
| 0.009 | 9.85 | 325 | 0.0687 | 0.8026 | 0.7909 | 0.7967 | 0.9857 |
| 0.0075 | 10.61 | 350 | 0.0716 | 0.7964 | 0.8036 | 0.8000 | 0.9849 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
vocabtrimmer/xlm-v-base-trimmed-ar-10000
|
vocabtrimmer
| 2023-03-31T23:49:56Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-31T23:48:49Z |
# Vocabulary Trimmed [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base): `vocabtrimmer/xlm-v-base-trimmed-ar-10000`
This model is a trimmed version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | facebook/xlm-v-base | vocabtrimmer/xlm-v-base-trimmed-ar-10000 |
|:---------------------------|:----------------------|:-------------------------------------------|
| parameter_size_full | 779,396,349 | 93,735,186 |
| parameter_size_embedding | 692,451,072 | 7,681,536 |
| vocab_size | 901,629 | 10,002 |
| compression_rate_full | 100.0 | 12.03 |
| compression_rate_embedding | 100.0 | 1.11 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ar | vocabtrimmer/mc4_validation | text | ar | validation | 10000 | 2 |
|
vocabtrimmer/xlm-v-base-trimmed-ar-5000
|
vocabtrimmer
| 2023-03-31T23:30:41Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-31T23:29:39Z |
# Vocabulary Trimmed [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base): `vocabtrimmer/xlm-v-base-trimmed-ar-5000`
This model is a trimmed version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | facebook/xlm-v-base | vocabtrimmer/xlm-v-base-trimmed-ar-5000 |
|:---------------------------|:----------------------|:------------------------------------------|
| parameter_size_full | 779,396,349 | 89,890,186 |
| parameter_size_embedding | 692,451,072 | 3,841,536 |
| vocab_size | 901,629 | 5,002 |
| compression_rate_full | 100.0 | 11.53 |
| compression_rate_embedding | 100.0 | 0.55 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ar | vocabtrimmer/mc4_validation | text | ar | validation | 5000 | 2 |
|
vocabtrimmer/xlm-v-base-trimmed-ar-tweet-sentiment-ar
|
vocabtrimmer
| 2023-03-31T23:28:30Z | 113 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T23:26:50Z |
# `vocabtrimmer/xlm-v-base-trimmed-ar-tweet-sentiment-ar`
This model is a fine-tuned version of [/home/asahi/lm-vocab-trimmer/ckpts/xlm-v-base-trimmed-ar](https://huggingface.co//home/asahi/lm-vocab-trimmer/ckpts/xlm-v-base-trimmed-ar) on the
[cardiffnlp/tweet_sentiment_multilingual](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual) (arabic).
Following metrics are computed on the `test` split of
[cardiffnlp/tweet_sentiment_multilingual](https://huggingface.co/datasets/cardiffnlp/tweet_sentiment_multilingual)(arabic).
| | eval_f1_micro | eval_recall_micro | eval_precision_micro | eval_f1_macro | eval_recall_macro | eval_precision_macro | eval_accuracy |
|---:|----------------:|--------------------:|-----------------------:|----------------:|--------------------:|-----------------------:|----------------:|
| 0 | 65.4 | 65.4 | 65.4 | 64.72 | 65.4 | 65.15 | 65.4 |
Check the result file [here](https://huggingface.co/vocabtrimmer/xlm-v-base-trimmed-ar-tweet-sentiment-ar/raw/main/eval.json).
|
Brizape/tmvar_0.0001_250
|
Brizape
| 2023-03-31T23:23:08Z | 121 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-31T23:14:03Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_0.0001_250
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_0.0001_250
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0142
- Precision: 0.8520
- Recall: 0.9027
- F1: 0.8766
- Accuracy: 0.9972
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2033 | 1.0 | 25 | 0.0313 | 0.6273 | 0.3730 | 0.4678 | 0.9899 |
| 0.0336 | 2.0 | 50 | 0.0197 | 0.6723 | 0.8541 | 0.7524 | 0.9946 |
| 0.0133 | 3.0 | 75 | 0.0134 | 0.8763 | 0.8811 | 0.8787 | 0.9969 |
| 0.0075 | 4.0 | 100 | 0.0192 | 0.7110 | 0.8378 | 0.7692 | 0.9952 |
| 0.0065 | 5.0 | 125 | 0.0126 | 0.8681 | 0.8541 | 0.8610 | 0.9969 |
| 0.0029 | 6.0 | 150 | 0.0130 | 0.8513 | 0.8973 | 0.8737 | 0.9974 |
| 0.002 | 7.0 | 175 | 0.0121 | 0.8446 | 0.8811 | 0.8624 | 0.9969 |
| 0.0017 | 8.0 | 200 | 0.0103 | 0.8462 | 0.8919 | 0.8684 | 0.9974 |
| 0.0011 | 9.0 | 225 | 0.0148 | 0.8299 | 0.8703 | 0.8496 | 0.9967 |
| 0.0007 | 10.0 | 250 | 0.0150 | 0.8426 | 0.8973 | 0.8691 | 0.9971 |
| 0.0005 | 11.0 | 275 | 0.0142 | 0.8376 | 0.8919 | 0.8639 | 0.9970 |
| 0.0004 | 12.0 | 300 | 0.0142 | 0.8513 | 0.8973 | 0.8737 | 0.9972 |
| 0.0003 | 13.0 | 325 | 0.0143 | 0.8469 | 0.8973 | 0.8714 | 0.9971 |
| 0.0003 | 14.0 | 350 | 0.0142 | 0.8520 | 0.9027 | 0.8766 | 0.9972 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
wjmm/ppo-LunarLander-v2
|
wjmm
| 2023-03-31T23:19:34Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T23:06:50Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 246.05 +/- 22.92
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
|
Mentatko/bert-finetuned-squad
|
Mentatko
| 2023-03-31T23:18:19Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-03-28T06:21:06Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Mentatko/bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Mentatko/bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7318
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 5545, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 0.7318 | 0 |
### Framework versions
- Transformers 4.27.3
- TensorFlow 2.10.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
vocabtrimmer/xlm-v-base-trimmed-ar
|
vocabtrimmer
| 2023-03-31T23:09:15Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-03-31T23:07:34Z |
# Vocabulary Trimmed [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base): `vocabtrimmer/xlm-v-base-trimmed-ar`
This model is a trimmed version of [facebook/xlm-v-base](https://huggingface.co/facebook/xlm-v-base) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | facebook/xlm-v-base | vocabtrimmer/xlm-v-base-trimmed-ar |
|:---------------------------|:----------------------|:-------------------------------------|
| parameter_size_full | 779,396,349 | 157,554,496 |
| parameter_size_embedding | 692,451,072 | 71,417,856 |
| vocab_size | 901,629 | 92,992 |
| compression_rate_full | 100.0 | 20.21 |
| compression_rate_embedding | 100.0 | 10.31 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|:--------------------|----------------:|
| ar | vocabtrimmer/mc4_validation | text | ar | validation | | 2 |
|
Brizape/tmvar_2e-05_250
|
Brizape
| 2023-03-31T23:04:44Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-03-31T22:55:34Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: tmvar_2e-05_250
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tmvar_2e-05_250
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0128
- Precision: 0.8756
- Recall: 0.9135
- F1: 0.8942
- Accuracy: 0.9974
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.486 | 1.0 | 25 | 0.0910 | 0.0 | 0.0 | 0.0 | 0.9858 |
| 0.0765 | 2.0 | 50 | 0.0410 | 0.6267 | 0.2541 | 0.3615 | 0.9889 |
| 0.0399 | 3.0 | 75 | 0.0230 | 0.6513 | 0.6865 | 0.6684 | 0.9941 |
| 0.0254 | 4.0 | 100 | 0.0176 | 0.7170 | 0.8216 | 0.7657 | 0.9957 |
| 0.0139 | 5.0 | 125 | 0.0129 | 0.8710 | 0.8757 | 0.8733 | 0.9968 |
| 0.0078 | 6.0 | 150 | 0.0107 | 0.9027 | 0.9027 | 0.9027 | 0.9974 |
| 0.0057 | 7.0 | 175 | 0.0110 | 0.8763 | 0.9189 | 0.8971 | 0.9975 |
| 0.0042 | 8.0 | 200 | 0.0113 | 0.8718 | 0.9189 | 0.8947 | 0.9971 |
| 0.003 | 9.0 | 225 | 0.0118 | 0.8802 | 0.9135 | 0.8966 | 0.9974 |
| 0.0022 | 10.0 | 250 | 0.0121 | 0.8877 | 0.8973 | 0.8925 | 0.9972 |
| 0.0019 | 11.0 | 275 | 0.0126 | 0.8756 | 0.9135 | 0.8942 | 0.9972 |
| 0.0016 | 12.0 | 300 | 0.0126 | 0.8802 | 0.9135 | 0.8966 | 0.9974 |
| 0.0015 | 13.0 | 325 | 0.0129 | 0.8769 | 0.9243 | 0.9 | 0.9974 |
| 0.0013 | 14.0 | 350 | 0.0128 | 0.8756 | 0.9135 | 0.8942 | 0.9974 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
kfahn/dreambooth_diffusion_model_gesture
|
kfahn
| 2023-03-31T23:01:59Z | 5 | 0 |
keras
|
[
"keras",
"tf-keras",
"region:us"
] | null | 2023-03-30T15:57:59Z |
---
library_name: keras
---
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| inner_optimizer.class_name | Custom>RMSprop |
| inner_optimizer.config.name | RMSprop |
| inner_optimizer.config.weight_decay | None |
| inner_optimizer.config.clipnorm | None |
| inner_optimizer.config.global_clipnorm | None |
| inner_optimizer.config.clipvalue | None |
| inner_optimizer.config.use_ema | False |
| inner_optimizer.config.ema_momentum | 0.99 |
| inner_optimizer.config.ema_overwrite_frequency | 100 |
| inner_optimizer.config.jit_compile | True |
| inner_optimizer.config.is_legacy_optimizer | False |
| inner_optimizer.config.learning_rate | 0.0010000000474974513 |
| inner_optimizer.config.rho | 0.9 |
| inner_optimizer.config.momentum | 0.0 |
| inner_optimizer.config.epsilon | 1e-07 |
| inner_optimizer.config.centered | False |
| dynamic | True |
| initial_scale | 32768.0 |
| dynamic_growth_steps | 2000 |
| training_precision | mixed_float16 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
dvruette/oasst-llama-13b-2-epochs
|
dvruette
| 2023-03-31T22:44:54Z | 1,494 | 7 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-31T22:26:30Z |
https://wandb.ai/open-assistant/supervised-finetuning/runs/lguuq2c1
|
takinai/xiaorenshu
|
takinai
| 2023-03-31T22:31:21Z | 0 | 1 | null |
[
"stable_diffusion",
"lora",
"region:us"
] | null | 2023-03-31T22:30:57Z |
---
tags:
- stable_diffusion
- lora
---
The source of the models is listed below. Please check the original licenses from the source.
https://civitai.com/models/18323
|
amannlp/ppo-LunarLander-v2
|
amannlp
| 2023-03-31T22:22:59Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T22:22:34Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.08 +/- 34.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
letingliu/my_awesome_model_tweets
|
letingliu
| 2023-03-31T22:22:34Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-07T05:40:01Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: letingliu/my_awesome_model_tweets
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# letingliu/my_awesome_model_tweets
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5490
- Validation Loss: 0.5429
- Train Accuracy: 0.6692
- Epoch: 19
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 40, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6582 | 0.6337 | 0.6692 | 0 |
| 0.6230 | 0.6035 | 0.6692 | 1 |
| 0.6015 | 0.5766 | 0.6692 | 2 |
| 0.5738 | 0.5533 | 0.6692 | 3 |
| 0.5540 | 0.5429 | 0.6692 | 4 |
| 0.5534 | 0.5429 | 0.6692 | 5 |
| 0.5515 | 0.5429 | 0.6692 | 6 |
| 0.5524 | 0.5429 | 0.6692 | 7 |
| 0.5455 | 0.5429 | 0.6692 | 8 |
| 0.5463 | 0.5429 | 0.6692 | 9 |
| 0.5380 | 0.5429 | 0.6692 | 10 |
| 0.5494 | 0.5429 | 0.6692 | 11 |
| 0.5467 | 0.5429 | 0.6692 | 12 |
| 0.5382 | 0.5429 | 0.6692 | 13 |
| 0.5562 | 0.5429 | 0.6692 | 14 |
| 0.5517 | 0.5429 | 0.6692 | 15 |
| 0.5462 | 0.5429 | 0.6692 | 16 |
| 0.5456 | 0.5429 | 0.6692 | 17 |
| 0.5499 | 0.5429 | 0.6692 | 18 |
| 0.5490 | 0.5429 | 0.6692 | 19 |
### Framework versions
- Transformers 4.27.4
- TensorFlow 2.12.0
- Datasets 2.11.0
- Tokenizers 0.13.2
|
dvruette/oasst-llama-13b-1000-steps
|
dvruette
| 2023-03-31T22:22:28Z | 1,494 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-31T19:22:45Z |
https://wandb.ai/open-assistant/supervised-finetuning/runs/17boywm8?workspace=
|
Inzamam567/Useless-MORIMORImix
|
Inzamam567
| 2023-03-31T22:19:47Z | 0 | 1 | null |
[
"region:us"
] | null | 2023-03-31T22:19:47Z |
---
duplicated_from: morit-00/MORIMORImix
---
|
Inzamam567/Useless-somethingv3
|
Inzamam567
| 2023-03-31T22:14:27Z | 0 | 1 | null |
[
"region:us"
] | null | 2023-03-31T22:14:26Z |
---
duplicated_from: NoCrypt/SomethingV3
---
|
Inzamam567/Useless-SukiyakiMix-v1.0
|
Inzamam567
| 2023-03-31T22:01:54Z | 0 | 5 | null |
[
"stable-diffusion",
"text-to-image",
"ja",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-31T22:01:54Z |
---
license: creativeml-openrail-m
language:
- ja
tags:
- stable-diffusion
- text-to-image
duplicated_from: Vsukiyaki/SukiyakiMix-v1.0
---
# ◆ SukiyakiMix-v1.0
**SukiyakiMix-v1.0** は、**pastel-mix** をベースに **AbyssOrangeMix2** をマージしたモデルです。
## VAE:
VAE はお好きなものをお使いください。推奨は、 [WarriorMama777/OrangeMixs](https://huggingface.co/WarriorMama777/OrangeMixs) の **orangemix.vae.pt** です。
<hr>
# ◆ Recipe
このモデルは、以下の 2 つのモデルを**単純**にマージして生成されたモデルです。
<dl>
<dt><a href="https://huggingface.co/andite/pastel-mix">andite/pastel-mix</a></dt>
<dd>└ pastel-mix</dd>
<dt><a href="https://huggingface.co/WarriorMama777/OrangeMixs">WarriorMama777/OrangeMixs</a></dt>
<dd>└ AbyssOrangeMix2_sfw (AOM2s)</dd>
</dl>
| Model A | Model B | Ratio |
| :--------: | :-------------------------: | :-----: |
| pastel-mix | AbyssOrangeMix2_sfw (AOM2s) | 60 : 40 |
※U-Net の階層ごとの重みは変化させていません。<br>
※マージには[merge-models
](https://github.com/eyriewow/merge-models)のマージ用スクリプトを使用しています。
<hr>
# ◆ Licence
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage. The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here :https://huggingface.co/spaces/CompVis/stable-diffusion-license
<br>
#### 【和訳】
このモデルはオープンアクセスであり、すべての人が利用できます。CreativeML OpenRAIL-M ライセンスにより、権利と使用方法がさらに規定されています。CreativeML OpenRAIL ライセンスでは、次のことが規定されています。
1. モデルを使用して、違法または有害な出力またはコンテンツを意図的に作成または共有することはできません。
2. 作成者は、あなたが生成した出力に対していかなる権利も主張しません。あなたはそれらを自由に使用でき、ライセンスに設定された規定に違反してはならない使用について説明責任を負います。
3. 重みを再配布し、モデルを商用および/またはサービスとして使用することができます。その場合、ライセンスに記載されているのと同じ使用制限を含め、CreativeML OpenRAIL-M のコピーをすべてのユーザーと共有する必要があることに注意してください。 (ライセンスを完全にかつ慎重にお読みください。) [こちらからライセンス全文をお読みください。](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
<br>
🚫 本モデルを商用の画像生成サービスで利用する行為 <br>
Use of this model for commercial image generation services
🚫 本モデルや本モデルをマージしたモデルを販売する行為<br>
The act of selling this model or a model merged with this model
🚫 本モデルを使用し意図的に違法な出力をする行為 <br>
Intentionally using this model to produce illegal output
🚫 本モデルをマージしたモデルに異なる権限を与える行為 <br>
Have different permissions when sharing
🚫 本モデルをマージしたモデルを配布または本モデルを再配布した際に同じ使用制限を含め、CreativeML OpenRAIL-M のコピーをすべてのユーザーと共有しない行為 <br>
The act of not sharing a copy of CreativeML OpenRAIL-M with all users, including the same usage restrictions when distributing or redistributing a merged model of this model.
⭕ 本モデルで生成した画像を商用利用する行為 <br>
Commercial use of images generated by this model
⭕ 本モデルを使用したマージモデルを使用または再配布する行為 <br>
Use or redistribution of merged models using this model
⭕ 本モデルのクレジット表記をせずに使用する行為 <br>
Use of this model without crediting the model
<hr>
# ◆ Examples
### NMKD SD-GUI-1.8.1-NoMdl
- VAE: orangemix.vae.pt
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example1.png" width="512px">
```
Positive:
(best quality)+,(masterpiece)++,(ultra detailed)++,cute girl,
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text
Steps: 20
CFG Scale: 8
Size: 1024x1024 (High-Resolution Fix)
Seed: 1696068555
Sampler: PLMS
```
<br>
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example2.png" width="512px">
```
Positive:
(best quality)+,(masterpiece)++,(ultra detailed)++,cute girl,
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text
Steps: 20
CFG Scale: 8
Size: 1024x1024 (High-Resolution Fix)
Seed: 1596727034
Sampler: DDIM
```
<br>
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example3.png" width="512px">
```
Positive:
(best quality)+,(masterpiece)++,(ultra detailed)++,sharp focus,cute little girl sitting in a messy room,Roomful of sundries,black hair,long hair,blush,clutter,miscellaneous goods are placed in a mess,wide shot,smile,light particles,hoodie,Bookshelves, drink, cushions, chairs, desks, game equipment, crayons, drawing paper
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text
Steps: 80
CFG Scale: 8
Size: 1024x1024 (High-Resolution Fix)
Seed: 629024761
Sampler: DPM++ 2
```
<br>
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example4.png" width="512px">
```
Positive:
(masterpiece, best quality, ultra detailed)++,cute girl sitting at a desk in a girlish room filled with furniture, surrounded by various gaming devices and other tech,Include details such as the room's vibrant,pink hair,blue eyes,short hair,cat ears,smile,playful,creative
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.2,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,(2 girl)
Steps: 80
CFG Scale: 8
Size: 1024x768 (High-Resolution Fix)
Seed: 1887602021
Sampler: DPM++ 2
```
<br>
### stable-diffusion-webui
- VAE: orangemix.vae.pt
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example5.png" width="512px">
```
Positive:
(best quality)+,(masterpiece)++,(ultra detailed)++,cute girl,school uniform
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text
Steps: 50
CFG Scale: 8
Size: 512x768
Seed: 3357075383
Sampler: DPM++ SDE Karras
```
<br>
<img src="https://huggingface.co/Vsukiyaki/SukiyakiMix-v1.0/resolve/main/imgs/Example6.png" width="512px">
```
Positive:
(best quality)+,(masterpiece)++,(ultra detailed)++,a girl,messy room
Negative:
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text
Steps: 20
CFG Scale: 7
Size: 1024x1024
Seed: 1103020084
Sampler: DPM++ SDE Karras
```
<hr>
Twiter: [@Vsukiyaki_AIArt](https://twitter.com/Vsukiyaki_AIArt)
|
Inzamam567/Useless-TriPhaze
|
Inzamam567
| 2023-03-31T22:00:09Z | 6 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-31T22:00:08Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
duplicated_from: Lucetepolis/TriPhaze
---
# TriPhaze
ultracolor.v4 - <a href="https://huggingface.co/xdive/ultracolor.v4">Download</a> / <a href="https://arca.live/b/aiart/68609290">Sample</a><br/>
Counterfeit-V2.5 - <a href="https://huggingface.co/gsdf/Counterfeit-V2.5">Download / Sample</a><br/>
Treebark - <a href="https://huggingface.co/HIZ/aichan_pick">Download</a> / <a href="https://arca.live/b/aiart/67648642">Sample</a><br/>
EasyNegative and pastelmix-lora seem to work well with the models.
EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download / Sample</a><br/>
pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download / Sample</a>
# Formula
```
ultracolor.v4 + Counterfeit-V2.5 = temp1
U-Net Merge - 0.870333, 0.980430, 0.973645, 0.716758, 0.283242, 0.026355, 0.019570, 0.129667, 0.273791, 0.424427, 0.575573, 0.726209, 0.5, 0.726209, 0.575573, 0.424427, 0.273791, 0.129667, 0.019570, 0.026355, 0.283242, 0.716758, 0.973645, 0.980430, 0.870333
temp1 + Treebark = temp2
U-Net Merge - 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940, 0.902369, 0.988642, 0.988642, 0.902369, 0.666667, 0.902369, 0.988642, 0.988642, 0.902369, 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940
temp2 + ultracolor.v4 = TriPhaze_A
U-Net Merge - 0.042235, 0.056314, 0.075085, 0.100113, 0.133484, 0.177979, 0.237305, 0.316406, 0.421875, 0.5625, 0.75, 1, 0.5, 1, 0.75, 0.5625, 0.421875, 0.316406, 0.237305, 0.177979, 0.133484, 0.100113, 0.075085, 0.056314, 0.042235
ultracolor.v4 + Counterfeit-V2.5 = temp3
U-Net Merge - 0.979382, 0.628298, 0.534012, 0.507426, 0.511182, 0.533272, 0.56898, 0.616385, 0.674862, 0.7445, 0.825839, 0.919748, 0.5, 0.919748, 0.825839, 0.7445, 0.674862, 0.616385, 0.56898, 0.533272, 0.511182, 0.507426, 0.534012, 0.628298, 0.979382
temp3 + Treebark = TriPhaze_C
U-Net Merge - 0.243336, 0.427461, 0.566781, 0.672199, 0.751965, 0.812321, 0.857991, 0.892547, 0.918694, 0.938479, 0.953449, 0.964777, 0.666667, 0.964777, 0.953449, 0.938479, 0.918694, 0.892547, 0.857991, 0.812321, 0.751965, 0.672199, 0.566781, 0.427461, 0.243336
TriPhaze_A + TriPhaze_C = TriPhaze_B
U-Net Merge - 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5
```
# Converted weights
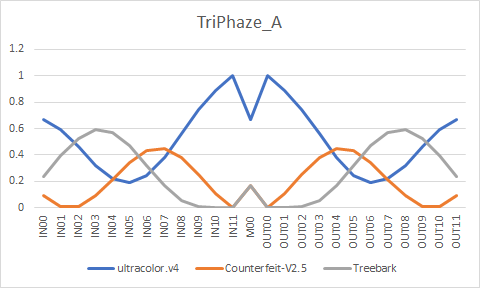
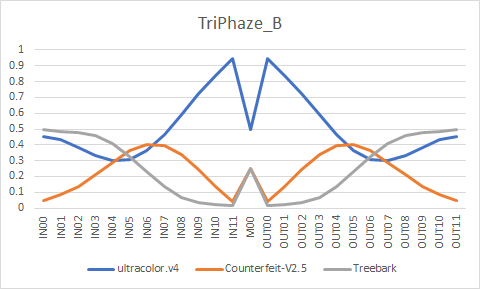
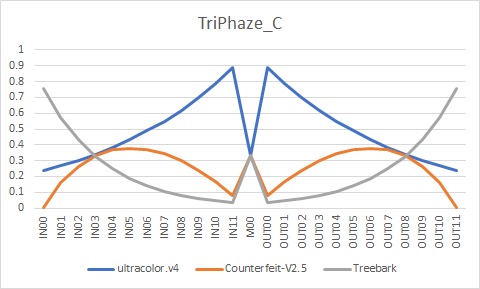
# Samples
All of the images use following negatives/settings. EXIF preserved.
```
Negative prompt: (worst quality, low quality:1.4), easynegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, nsfw
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1853114200, Size: 768x512, Model hash: 6bad0b419f, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B
```
# TriPhaze_A








# TriPhaze_B








# TriPhaze_C








|
NiltonAlf18/eros
|
NiltonAlf18
| 2023-03-31T21:54:15Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T21:52:45Z |
---
license: creativeml-openrail-m
---
|
lunnan/Reinforce-CartPole-v1
|
lunnan
| 2023-03-31T21:46:43Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T21:46:32Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Inzamam567/Useless-X-mix
|
Inzamam567
| 2023-03-31T21:34:49Z | 24 | 2 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-31T21:34:49Z |
---
license: creativeml-openrail-m
library_name: diffusers
tags:
- stable-diffusion
pipeline_tag: text-to-image
duplicated_from: les-chien/X-mix
---
# X-mix
**Civitai**: [X-mix | Stable Diffusion Checkpoint | Civitai](https://civitai.com/models/13069/x-mix)
X-mix is a merging model used to generate anime images. My English is not very good, so there may be some parts of this article that are unclear.
## V2.0
V2.0 is a merged model based on V1.0. This model supports nsfw.
### Difference from V1.0
- The performance of V2.0 is not better than that of V1.0, but the generated images now exhibit a different artistic style.
- V2.0 offers better support for nsfw than V1.0, but the drawback is that even when you do not intend to generate an nsfw image, there is still a possibility of generating one. If you are more interested in the sfw model, I will provide a detailed explanation in the recipe section.
- In my opinion, V2.0 is not as user-friendly as V1.0, and it appears to be more challenging to generate an excellent image.
### Recommended Settings
- Sampler: DPM++ SDE Karras (sfw), DDIM (nsfw)
- Steps: 20 (DDIM may require more steps)
- CFG Scale: 5
- Hires upscale: Latent (bicubic antialiased), Latent (nearest-exact), Denoising strength: 0.4~0.7
- vae: NAI.vae
- Clip skip: 2
- ENSD: 31337
- Eta: 0.67
### Example

```
masterpiece, best quality, ultra-detailed, illustration, portrait, 1girl
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 4291846267, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Eta: 0.67
```

```
Indoor, bright, 1Girl, gray hair, amber eyes, smile, black dress, barefoot, sitting posture,
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2118045521, Size: 600x400, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```
%2C%20white%20t.png)
```
landscape, in spring, cherry blossoms, cloudy sky, 1girl, solo, long blue hair, smirk, pink eyes, (school uniform:1.05), white thighhighs,
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3093571233, Size: 400x600, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
1girl, on bed, wet, see-through shirt, thighhighs, cleavage, collarbone, full body,
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 986400693, Size: 512x512, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```
%2C%20solo%2C%20Flowery%20meadow%2C%20cloudy%20sky%2C%20aqua%20eyes%2C%20white%20pantyhose%2C%20blonde%20hair%2C.png)
```
Alice \(Alice in wonderland\), solo, Flowery meadow, cloudy sky, aqua eyes, white pantyhose, blonde hair,
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 273840053, Size: 512x512, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
masterpiece, best quality, ultra-detailed, illustration, portrait, hakurei reimu, 1girl, throne room, dimly lit
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2212365348, Size: 512x512, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Eta: 0.67
```

```
masterpiece, best quality, ultra-detailed, illustration, 1girl, witch hat, purple eyes, blonde hair, wielding a purple staff blasting purple energy, purple beam, purple effects, dragons, chaos
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DDIM, CFG scale: 5, Seed: 293615512, Size: 512x512, Model hash: 7961a4960e, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact)
```

```
1girl, solo, black skirt, blue eyes, electric guitar, guitar, headphones, holding, holding plectrum, instrument, long hair, , music, one side up, pink hair, playing guitar, pleated skirt, black shirt, indoors
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2, DeepNegative-V1-75T
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3442031040, Size: 512x512, Model hash: 7961a4960e, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Eta: 0.67
```
### Recipe
**Step 1:** animefull-latest (model) + pastelmix-lora (lora) + ligneClaireStyleCogecha (lora) = pastel-Cogecha
You can try replacing animefull-latest with Anything-V3.0 or your preferred model. However, I cannot confirm if this will yield better results and it requires you to experiment with it on your own.
**Step 2:** MBW: Chilloutmix + X-mix-V1.0
| Model A | Model B | base_alpha | Weight | Merge Name |
| ----------- | ---------- | ---------- | ------------------------------------------------- | --------------- |
| Chilloutmix | X-mix-V1.0 | 1 | 1,1,1,1,1,1,1,1,0,0,0,0,1,0,0,0,0,1,1,1,1,1,1,1,1 | X-mix-V2.0-base |
This is the step of the sfw version. The steps for the nsfw version are as follows: I merged several LoRAs into Chilloutmix to obtain Chilloutmix-nsfw. Then I merged Chilloutmix-nsfw and X-mix-V1.0 to get X-mix-V2.0-nsfwBase1. Finally, I merged several LoRAs into X-mix-V2.0-nsfwBase1 to get X-mix-V2.0-nsfwBase2.
LoRAs related to real people should be merged into Chilloutmix or other photo-realistic models that you like, while LoRAs related to anime should be merged into X-mix-V2.0-base. Which LoRAs to use depends on your preference.
**Step 3:** MBW: pastel-Cogecha + X-mix-V2.0-base
| Model A | Model B | base_alpha | Weight | Merge Name |
| -------------- | --------------- | ---------- | ------------------------------------------------------- | -------------- |
| pastel-Cogecha | X-mix-V2.0-base | 0 | 1,1,1,1,1,0.3,0,0,0,1,0.1,1,1,1,1,1,0,1,0,1,1,0.2,1,1,1 | X-mix-V2.0-sfw |
In fact, I never tried to obtain the sfw version because I didn't plan on using it from the beginning. So this process is for reference only, and I am not sure about the actual effect of the sfw model.
## V1.0
I have forgotten the recipe for X-mix-V1.0, as too many models were used for merging. This model supports nsfw, but the effect may not be very good.
### Recommended Settings
- Sampler: DPM++ SDE Karras
- Steps: 20
- CFG Scale: 5
- Hires upscaler: Latent (bicubic antialiased), Denoising strength: 0.5~0.6
- vae: NAI.vae
- Clip skip: 2
- ENSD: 31337
- Eta: 0.67
### Examples

```
masterpiece, best quality, ultra-detailed, illustration, portrait, 1girl
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1906918205, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
Indoor, bright, 1girl, gray hair, amber eyes, smile, black dress, barefoot, sitting posture,
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2118045521, Size: 600x400, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
landscape, in spring, cherry blossoms, cloudy sky, 1girl, solo, long blue hair, smirk, pink eyes, (school uniform:1.05), white thighhighs,
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3093571233, Size: 400x600, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
1girl, on bed, wet, see-through shirt, thighhighs, cleavage, collarbone, full body,
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1666118295, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
Alice \(Alice in wonderland\), solo, Flowery meadow, cloudy sky, aqua eyes, white pantyhose, blonde hair,
Negative prompt: EasyNegative, sketch by bad-artist
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 807449917, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (nearest-exact), Eta: 0.67
```

```
masterpiece, best quality, ultra-detailed, illustration, portrait, hakurei reimu, 1girl, throne room, dimly lit
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 116927034, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
masterpiece, best quality, ultra-detailed, illustration, 1girl, witch hat, purple eyes, blonde hair, wielding a purple staff blasting purple energy, purple beam, purple effects, dragons, chaos
Negative prompt: EasyNegative, photograph by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 1705759664, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```

```
1girl, solo, black skirt, blue eyes, electric guitar, guitar, headphones, holding, holding plectrum, instrument, long hair, , music, one side up, pink hair, playing guitar, pleated skirt, black shirt, indoors
Negative prompt: EasyNegative, by bad-artist, bad_prompt_version2
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2548407675, Size: 512x512, Model hash: 7bc4c05c90, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased), Eta: 0.67
```
## Embedding
If you need the embedding used in examples, click them:
- **EasyNegative:** [embed/EasyNegative · Hugging Face](https://huggingface.co/embed/EasyNegative)
- **bad-artist:** [nick-x-hacker/bad-artist · Hugging Face](https://huggingface.co/nick-x-hacker/bad-artist)
- **bad_prompt_version2:** [embed/bad_prompt · Hugging Face](https://huggingface.co/embed/bad_prompt)
- **Deep Negative V1.x:** [Deep Negative V1.x | Stable Diffusion TextualInversion | Civitai](https://civitai.com/models/4629/deep-negative-v1x)
You can consider whether to use them according to your preferences.
## More
1. Since my prompts are usually brief, I'm not sure if this model will be able to meet all of your requirements if you need to use a large number of prompts.
2. Using low resolution is **not recommended** for generating pictures.
3. I did my best, but the hands are not perfect.
4. The above settings may not necessarily be perfect.
5. Due to my computer's performance, it's difficult for me to comprehensively test this model. I'm looking forward to your feedback.
|
platzi/platzi-distilroberta-base-mrpc-glue-gabriel-ichcanziho
|
platzi
| 2023-03-31T21:29:08Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T21:26:56Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: platzi-distilroberta-base-mrpc-glue-gabriel-ichcanziho
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8455882352941176
- name: F1
type: f1
value: 0.8868940754039497
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi-distilroberta-base-mrpc-glue-gabriel-ichcanziho
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8059
- Accuracy: 0.8456
- F1: 0.8869
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.538 | 1.09 | 500 | 0.5544 | 0.7941 | 0.8456 |
| 0.3673 | 2.18 | 1000 | 0.6700 | 0.8333 | 0.8794 |
| 0.1984 | 3.27 | 1500 | 0.8059 | 0.8456 | 0.8869 |
### Framework versions
- Transformers 4.27.3
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.2
|
stevied67/pegasus-subreddit-comments-summarizer
|
stevied67
| 2023-03-31T21:26:05Z | 109 | 2 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"autotrain",
"summarization",
"en",
"dataset:stevied67/autotrain-data-pegasus-subreddit-comments-summarizer",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-03-31T20:13:27Z |
---
tags:
- autotrain
- summarization
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- stevied67/autotrain-data-pegasus-subreddit-comments-summarizer
co2_eq_emissions:
emissions: 27.833269754820982
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 45559114001
- CO2 Emissions (in grams): 27.8333
## Validation Metrics
- Loss: 1.467
- Rouge1: 51.832
- Rouge2: 25.213
- RougeL: 40.226
- RougeLsum: 45.554
- Gen Len: 57.035
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/stevied67/autotrain-pegasus-subreddit-comments-summarizer-45559114001
```
|
Inzamam567/Useless-YuzuLemonTea
|
Inzamam567
| 2023-03-31T21:24:24Z | 0 | 3 | null |
[
"stable-diffusion",
"text-to-image",
"license:cc0-1.0",
"region:us"
] |
text-to-image
| 2023-03-31T21:24:24Z |
---
license: cc0-1.0
tags:
- stable-diffusion
- text-to-image
duplicated_from: thiros/YuzuLemonTea
---
# YuzuLemonTea Mix models ☕
List of my experimental merge models
- [Recommended Settings](#recommended-setteings)
- [YuzuLemonMilk](#yuzulemonmilk)
- [YuzuLemonChaiLatte](#yuzulemonchailatte)
- [YuzuGinger](#yuzuginger)
# important notice(Jan 15/23)
According to bbc-mc's note, there is a possibility of bug that some token(prompt) can be ignored, when merge with "add difference" option.
Milk and ChaiLatte models are now replaced with bug-fix ver.
https://note.com/bbcmc/n/n12c05bf109cc
# Recommended Setteings
VAE: "kl-f8-anime2" and "vae-ft-mse-840000-ema-pruned" are suitable
Steps: 20-30, Sampler: DPM++ SDE Karras or DPM++ 2M Karras, CFG scale: 8, Clip skip: 2, ENSD: 31377, Hires upscale: 2, Hires upscaler: Latent (bicubic antialiased),Denoising strength: 0.54~0.7
Negataive Prompt: (worst quality:2), (low quality:2),inaccurate limb,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name
- (worst quality), (low quality) are adjustable between 1.4~2.0
- If you don't want 3DCG-ish paint, you can add (3d:0.8)~1.0 in Negative Prompt
# Sample prompt
4girls,(a 3d reader of:0.8) (teenage loli children:1.2), (wearing intricate casual camisole, cute hair ornament,crop jacket,hot pants, tighhigh:1.1),
shiny brown skin,
looking at viewer, (alluring smug:1.2),
dynamic angle,
(onomichi street:1.2),fisheye
<img src="https://i.imgur.com/2JiZwFU.jpg" width="" height="1000">
# YuzuLemonMilk
Block merged model of Anything v3 and some real models.
Rather photo realistic.
Works fine with positive (realistic) and (photo realistic).
<img src="https://i.imgur.com/qYK8DKn.jpg" width="" height="1000">
# YuzuLemonChaiLatte
Combination of a weight merge of ACertainModel and Anything-V3.0, and a block merge of several realistic models.
Rather anime-ish style with realistic background.
- v3.5
<img src="https://i.imgur.com/WLKr3pj.jpg" width="" height="1000">
- v9.5
<img src="https://i.imgur.com/Ufh3JK2.jpg" width="" height="1000">
# YuzuGinger
Add more anime models to YuzuLemonChaiLatte. Can be very anime looks.
- v1
<img src="https://i.imgur.com/4vc4HSL.jpg" width="" height="1000">
- v4
<img src="https://i.imgur.com/M6q6hYp.jpg" width="" height="1000">
|
Inzamam567/Useless-Defmix-v2.0
|
Inzamam567
| 2023-03-31T21:13:58Z | 0 | 3 | null |
[
"region:us"
] | null | 2023-03-31T21:13:58Z |
---
duplicated_from: Defpoint/Defmix-v2.0
---
<br>
# ■*Defmix-v2.0*
◎<strong>*Defmix-v2.0*</strong>は、下記のモデルをMBWによって*U-Net*の階層ごとに重みを変化させてマージしたモデルです。<br>
<strong>*Defmix-v2.0*</strong> is a model that merges the following models by adjusting the weights of each layer in *U-Net*.<br>
- <strong>*Counterfeit v2.5*</strong>
- <strong>*Basil Mix*</strong>
- <strong>*Abyss Orange Mix v3.0 A2*</strong>
◎*Vae*ファイルは好みのものを使用してください。<br>
Please use the *Vae* file of your preference.<br>
<br>
# ■*Examples*
◎*ControlNet*が登場したことから、このモデルは*Defmix-v1.0*と異なり、構図や人物と背景のバランスよりも全体の描画力や質感を重視しています。<br>
With the introduction of *ControlNet*, this model, unlike *Defmix-v1.0*, emphasizes overall drawing power and texture rather than composition and balance between characters and backgrounds.<br>
◎現在広く使われている<strong>クオリティタグ(best qualityやmasterpieceなど)を使用してなくても</strong>、高品質な画像が出力されるように調整しています。<br>
I have adjusted the output to ensure high-quality images are produced, <strong>even without using commonly used Quality Tags</strong> such as 'best quality' or 'masterpiece'.<br>
<br>
- *Sampler: DPM++ 2M Karras*
- *Steps: 28*
- *CFG Scale: 8*
- *Clip Skip: 2*
- *Upscaler: Latent(nearest)*
- *Highres Step: 0*
- *Denoising strength: 0.6*
<br>
Positive: beautiful girl, gothic<br>
Negative: EasyNegative
<br>
<img src="https://i.imgur.com/a25fE5f.jpeg" width="768" height="768">
<br>
# ■*Important Reminders*
◎画風をかなり現実的にすることができるため、<strong>このモデルによって出力したR-18のNSFW画像をSNSサイト等で公開することはご遠慮頂きますよう</strong>、よろしくお願い致します。<br>
As this model can make the style of images quite realistic, <strong>I kindly request that you refrain from posting R-18 NSFW images generated by this model on social media or other websites.</strong> <br>
Thank you for your understanding and cooperation.
<br>
|
pinaggle/q-FrozenLake-v1-8x8-Slippery
|
pinaggle
| 2023-03-31T21:08:15Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T21:08:08Z |
---
tags:
- FrozenLake-v1-8x8
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8
type: FrozenLake-v1-8x8
metrics:
- type: mean_reward
value: 0.34 +/- 0.47
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="pinaggle/q-FrozenLake-v1-8x8-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Inzamam567/useless_Replicant
|
Inzamam567
| 2023-03-31T21:07:21Z | 2 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-31T21:07:20Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
duplicated_from: gsdf/Replicant
---
# Please enable hires. fix when using it.
Replicant is built by merging several models with fine-tuning WD1.4 and photorealistic SD2.0 models that works with danbooru tags.I trained 4 models to merge and prepared several LoRa models for tuning.As with SD1.x, merging individually trained models is better quality than training many concepts at once.This model is a workflow test and is not good enough. WD1.4 seems to vary greatly in quality with/without Hires. fix.In Replicant, the difference in quality is more noticeable because of the detailed drawings.So I recommend enabling Hires.fix for use.
# Example
Denoising strength 0.6 is a bit large. I like 0.57 better.
The optimal CFG Scale value should also be examined.
Hands often multiply. When this happens, increase the value of "extra hands".

((masterpiece, best quality)), 1girl, flower, solo, dress, holding, sky, cloud, hat, outdoors, bangs, bouquet, rose, expressionless, blush, pink hair, flower field, red flower, pink eyes, white dress, looking at viewer, midium hair, holding flower, small breasts, red rose, holding bouquet, sun hat, white headwear, depth of field
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, skirt, shoes, solo, jacket, holding, alley, sitting, can, sneakers, hood, bag, hoodie, squatting, bangs, shirt, black hair, black skirt, short hair, white jacket, looking away, white footwear, full body, red eyes, long sleeves, open jacket, open clothes, holding can,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra legs, extra hands, fewer digits , long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes,drinking
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, blood, solo, wings, halo, dress, socks, angel, long hair, shoes, standing, ribbon, long hair, blue eyes, angel wings, blood on clothes, white hair, full body, white wings, black footwear, white dress, feathered wings, white sock, white background, long sleeves, simple background,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit,(extra arms:1.2), extra legs, extra hands, fewer digits , long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 384x576, Denoising strength: 0.57, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, car, solo, shorts, jacket, bangs, sitting, shirt, shoes, hairclip, socks, sneakers, denim, sidelocks, motor vehicle, long hair, ground vehicle,brown hair, looking at viewer, white shirt, black jacket, long sleeves, sports car, vehicle focus, aqua eyes, white socks, blue shorts, open clothes, black footwear, denim shorts, open jacket
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 384x576, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, solo, twintails, lollipop, smile, ahoge, hairclip, bow, holding, ribbon, frills, blush, shirt, :d, stuffed toy, pink hair, stuffed animal, red nails, hair ornament, open mouth, looking at viewer, stuffed bunny, nail polish, short sleeves, object hug, puffy sleeves, hair between eyes, upper body, light blue eyes, puffy short sleeves, holding stuffed toy, hair bow, white bow, doll hug, hair ribbon, streaked hair, white shirt
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 512x512, Denoising strength: 0.57, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, solo, tail, barefoot, skirt, sleeping, lying, grass, shirt, outdoors, socks, flower, long hair, on side, animal ears, blonde hair, cat tail, closed eyes, blue skirt, white shirt, cat ears, school uniform, dappled sunlight, short sleeves, bare legs, closed mouth, full body, pleated skirt
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent

((masterpiece, best quality)), 1girl, car, building, gun, weapon, outdoors, solo, military, day, city, standing, serious, pants, rifle, holding, jacket, motor vehicle, ground vehicle, brown hair, assault rifle, long hair, vehicle focus, holding gun, holding weapon, black footwear, military vehicle, full body, depth of field,
Negative prompt: (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), inaccurate eyes, extra digit, (extra arms:1.2), extra hands, fewer digits ,long body, cropped, jpeg artifacts, signature, watermark, username, blurry, empty eyes
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 10, Size: 576x384, Denoising strength: 0.6, Hires upscale: 2, Hires upscaler: Latent
|
Ibnout/q-Taxi-v3
|
Ibnout
| 2023-03-31T20:39:08Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T20:23:46Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.63
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Ibnout/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Nazzyk/rl_course_vizdoom_health_gathering_supreme
|
Nazzyk
| 2023-03-31T20:29:05Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T20:28:29Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 12.04 +/- 6.09
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r Nazzyk/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Yuhyunji/rare-puppers
|
Yuhyunji
| 2023-03-31T20:13:33Z | 220 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-03-31T20:13:22Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8939393758773804
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu

|
mrm8488/electricidad-base-finetuned-go_emotions-es
|
mrm8488
| 2023-03-31T20:06:19Z | 130 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"electra",
"text-classification",
"generated_from_trainer",
"dataset:go_emotions-es-mt",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-09-03T17:43:21Z |
---
tags:
- generated_from_trainer
datasets:
- go_emotions-es-mt
metrics:
- accuracy
- f1
model-index:
- name: electricidad-base-finetuned-go_emotions-es
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: go_emotions-es-mt
type: go_emotions-es-mt
config: simplified
split: train
args: simplified
metrics:
- name: Accuracy
type: accuracy
value: 0.5934476693051891
- name: F1
type: f1
value: 0.5806237685841615
widget:
- text: "Me gusta mucho su forma de ser"
- text: "Es una persona muy extraña..."
- text: "El dolor es desesperante"
- text: "No me esperaba una evolución tan positiva"
- text: "¡Dios mío, es enorme!"
- text: "¡Agg! Está asqueroso."
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electricidad-base-finetuned-go_emotions-es
This model is a fine-tuned version of [mrm8488/electricidad-base-discriminator](https://huggingface.co/mrm8488/electricidad-base-discriminator) on the [go_emotions-es-mt](https://huggingface.co/datasets/mrm8488/go_emotions-es-mt) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5111
- Accuracy: 0.5934
- F1: 0.5806
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|
| 1.729 | 1.0 | 2270 | 1.5835 | 0.5578 | 0.5044 |
| 1.4432 | 2.0 | 4540 | 1.4529 | 0.5842 | 0.5538 |
| 1.2688 | 3.0 | 6810 | 1.4445 | 0.5945 | 0.5770 |
| 1.1017 | 4.0 | 9080 | 1.4804 | 0.5937 | 0.5781 |
| 0.9999 | 5.0 | 11350 | 1.5111 | 0.5934 | 0.5806 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
saif-daoud/whisper-small-hi-2400_500_132
|
saif-daoud
| 2023-03-31T19:42:45Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:afrispeech-200",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-03-31T14:19:38Z |
---
tags:
- generated_from_trainer
datasets:
- afrispeech-200
metrics:
- wer
model-index:
- name: whisper-small-hi-2400_500_132
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: afrispeech-200
type: afrispeech-200
config: hausa
split: train
args: hausa
metrics:
- name: Wer
type: wer
value: 0.3433857983900036
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-hi-2400_500_132
This model is a fine-tuned version of [saif-daoud/whisper-small-hi-2400_500_131](https://huggingface.co/saif-daoud/whisper-small-hi-2400_500_131) on the afrispeech-200 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8127
- Wer: 0.3434
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1800
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0318 | 0.5 | 900 | 0.8252 | 0.3442 |
| 0.9844 | 1.5 | 1800 | 0.8127 | 0.3434 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
justincinmd/ppo-LunarLander-v2
|
justincinmd
| 2023-03-31T19:29:16Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T18:52:04Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 280.64 +/- 20.07
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ibnout/q-FrozenLake-v1-4x4-noSlippery
|
Ibnout
| 2023-03-31T19:10:09Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T14:37:24Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Ibnout/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
GerbilLab/GerbilBlender-A-32m
|
GerbilLab
| 2023-03-31T19:02:55Z | 138 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gptj",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-30T11:41:11Z |
---
license: apache-2.0
---
| Model Name | Parameters | Class | Ratio | Tokens | Batch Size (Tokens) | Training Loss ↓ |
| --- | --- | --- | --- | --- | --- | --- |
| [GerbilLab/GerbilBlender-A-32m](https://hf.co/GerbilLab/GerbilBlender-A-32m) | 32m | A-Class | 20 | 640M | 262K | 4.127 |
"Blender" models, inspired by UL2 pretraining, are trained equally in fill-in-the-middle, causal modelling, and masked language modelling tasks. Special tokens for these models include:
```
'<fitm_start>', '<multiple_tok_mask>', '<fitm_result>', '<causal>', '<mlm_start>', '<single_tok_mask>', '<mlm_end>'
# Example fill in the middle
'<fitm_start> this is an <multiple_tok_mask> for fill-in-the-middle <fitm_result> example text <|endoftext|>'
# Example causal language modelling
'<causal> this is an example text for causal language modelling <|endoftext|>'
# Example masked language modelling
'<mlm_start> this is an <single_tok_mask> text for masked language modelling <mlm_end> example <|endoftext|>'
```
|
cloudqi/cqi_question_solver_translator_v0
|
cloudqi
| 2023-03-31T19:01:41Z | 107 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"t5",
"text2text-generation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"arxiv:2210.11416",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-31T17:44:11Z |
---
language:
- en
- fr
- ro
- de
- multilingual
tags:
- text2text-generation
widget:
- text: "Translate to English: Meu nome é Bruno."
example_title: "Tradução"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
license: apache-2.0
---
# Model Card for CQI-Multitool-Model (From Flan T5)
# Table of Contents
0. [TL;DR](#TL;DR)
1. [Model Details](#model-details)
2. [Usage](#usage)
3. [Uses](#uses)
4. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
5. [Training Details](#training-details)
6. [Evaluation](#evaluation)
7. [Environmental Impact](#environmental-impact)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
# TL;DR
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
As mentioned in the first few lines of the abstract :
> Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
**Disclaimer**: Content from **this** model card has been written by the Hugging Face team, and parts of it were copy pasted from the [T5 model card](https://huggingface.co/t5-large).
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English, Spanish, Japanese, Persian, Hindi, French, Chinese, Bengali, Gujarati, German, Telugu, Italian, Arabic, Polish, Tamil, Marathi, Malayalam, Oriya, Panjabi, Portuguese, Urdu, Galician, Hebrew, Korean, Catalan, Thai, Dutch, Indonesian, Vietnamese, Bulgarian, Filipino, Central Khmer, Lao, Turkish, Russian, Croatian, Swedish, Yoruba, Kurdish, Burmese, Malay, Czech, Finnish, Somali, Tagalog, Swahili, Sinhala, Kannada, Zhuang, Igbo, Xhosa, Romanian, Haitian, Estonian, Slovak, Lithuanian, Greek, Nepali, Assamese, Norwegian
- **License:** Apache 2.0
- **Related Models:** [All FLAN-T5 Checkpoints](https://huggingface.co/models?search=flan-t5)
- **Original Checkpoints:** [All Original FLAN-T5 Checkpoints](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints)
- **Resources for more information:**
- [Research paper](https://arxiv.org/pdf/2210.11416.pdf)
- [GitHub Repo](https://github.com/google-research/t5x)
- [Hugging Face FLAN-T5 Docs (Similar to T5) ](https://huggingface.co/docs/transformers/model_doc/t5)
# Usage
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base", device_map="auto")
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base", device_map="auto", torch_dtype=torch.float16)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base", device_map="auto", load_in_8bit=True)
input_text = "translate English to German: How old are you?"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
# Uses
## Direct Use and Downstream Use
The authors write in [the original paper's model card](https://arxiv.org/pdf/2210.11416.pdf) that:
> The primary use is research on language models, including: research on zero-shot NLP tasks and in-context few-shot learning NLP tasks, such as reasoning, and question answering; advancing fairness and safety research, and understanding limitations of current large language models
See the [research paper](https://arxiv.org/pdf/2210.11416.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
The information below in this section are copied from the model's [official model card](https://arxiv.org/pdf/2210.11416.pdf):
> Language models, including Flan-T5, can potentially be used for language generation in a harmful way, according to Rae et al. (2021). Flan-T5 should not be used directly in any application, without a prior assessment of safety and fairness concerns specific to the application.
## Ethical considerations and risks
> Flan-T5 is fine-tuned on a large corpus of text data that was not filtered for explicit content or assessed for existing biases. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
## Known Limitations
> Flan-T5 has not been tested in real world applications.
## Sensitive Use:
> Flan-T5 should not be applied for any unacceptable use cases, e.g., generation of abusive speech.
# Training Details
## Training Data
The model was trained on a mixture of tasks, that includes the tasks described in the table below (from the original paper, figure 2):

## Training Procedure
According to the model card from the [original paper](https://arxiv.org/pdf/2210.11416.pdf):
> These models are based on pretrained T5 (Raffel et al., 2020) and fine-tuned with instructions for better zero-shot and few-shot performance. There is one fine-tuned Flan model per T5 model size.
The model has been trained on TPU v3 or TPU v4 pods, using [`t5x`](https://github.com/google-research/t5x) codebase together with [`jax`](https://github.com/google/jax).
# Evaluation
## Testing Data, Factors & Metrics
The authors evaluated the model on various tasks covering several languages (1836 in total). See the table below for some quantitative evaluation:

For full details, please check the [research paper](https://arxiv.org/pdf/2210.11416.pdf).
## Results
For full results for FLAN-T5-Base, see the [research paper](https://arxiv.org/pdf/2210.11416.pdf), Table 3.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods - TPU v3 or TPU v4 | Number of chips ≥ 4.
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@misc{https://doi.org/10.48550/arxiv.2210.11416,
doi = {10.48550/ARXIV.2210.11416},
url = {https://arxiv.org/abs/2210.11416},
author = {Chung, Hyung Won and Hou, Le and Longpre, Shayne and Zoph, Barret and Tay, Yi and Fedus, William and Li, Eric and Wang, Xuezhi and Dehghani, Mostafa and Brahma, Siddhartha and Webson, Albert and Gu, Shixiang Shane and Dai, Zhuyun and Suzgun, Mirac and Chen, Xinyun and Chowdhery, Aakanksha and Narang, Sharan and Mishra, Gaurav and Yu, Adams and Zhao, Vincent and Huang, Yanping and Dai, Andrew and Yu, Hongkun and Petrov, Slav and Chi, Ed H. and Dean, Jeff and Devlin, Jacob and Roberts, Adam and Zhou, Denny and Le, Quoc V. and Wei, Jason},
keywords = {Machine Learning (cs.LG), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Scaling Instruction-Finetuned Language Models},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
## Model Recycling
[Evaluation on 36 datasets](https://ibm.github.io/model-recycling/model_gain_chart?avg=9.16&mnli_lp=nan&20_newsgroup=3.34&ag_news=1.49&amazon_reviews_multi=0.21&anli=13.91&boolq=16.75&cb=23.12&cola=9.97&copa=34.50&dbpedia=6.90&esnli=5.37&financial_phrasebank=18.66&imdb=0.33&isear=1.37&mnli=11.74&mrpc=16.63&multirc=6.24&poem_sentiment=14.62&qnli=3.41&qqp=6.18&rotten_tomatoes=2.98&rte=24.26&sst2=0.67&sst_5bins=5.44&stsb=20.68&trec_coarse=3.95&trec_fine=10.73&tweet_ev_emoji=13.39&tweet_ev_emotion=4.62&tweet_ev_hate=3.46&tweet_ev_irony=9.04&tweet_ev_offensive=1.69&tweet_ev_sentiment=0.75&wic=14.22&wnli=9.44&wsc=5.53&yahoo_answers=4.14&model_name=google%2Fflan-t5-base&base_name=google%2Ft5-v1_1-base) using google/flan-t5-base as a base model yields average score of 77.98 in comparison to 68.82 by google/t5-v1_1-base.
The model is ranked 1st among all tested models for the google/t5-v1_1-base architecture as of 06/02/2023
Results:
| 20_newsgroup | ag_news | amazon_reviews_multi | anli | boolq | cb | cola | copa | dbpedia | esnli | financial_phrasebank | imdb | isear | mnli | mrpc | multirc | poem_sentiment | qnli | qqp | rotten_tomatoes | rte | sst2 | sst_5bins | stsb | trec_coarse | trec_fine | tweet_ev_emoji | tweet_ev_emotion | tweet_ev_hate | tweet_ev_irony | tweet_ev_offensive | tweet_ev_sentiment | wic | wnli | wsc | yahoo_answers |
|---------------:|----------:|-----------------------:|--------:|--------:|--------:|--------:|-------:|----------:|--------:|-----------------------:|-------:|--------:|--------:|--------:|----------:|-----------------:|--------:|--------:|------------------:|--------:|--------:|------------:|--------:|--------------:|------------:|-----------------:|-------------------:|----------------:|-----------------:|---------------------:|---------------------:|--------:|-------:|--------:|----------------:|
| 86.2188 | 89.6667 | 67.12 | 51.9688 | 82.3242 | 78.5714 | 80.1534 | 75 | 77.6667 | 90.9507 | 85.4 | 93.324 | 72.425 | 87.2457 | 89.4608 | 62.3762 | 82.6923 | 92.7878 | 89.7724 | 89.0244 | 84.8375 | 94.3807 | 57.2851 | 89.4759 | 97.2 | 92.8 | 46.848 | 80.2252 | 54.9832 | 76.6582 | 84.3023 | 70.6366 | 70.0627 | 56.338 | 53.8462 | 73.4 |
For more information, see: [Model Recycling](https://ibm.github.io/model-recycling/)
|
Arxpen/lora-solav1
|
Arxpen
| 2023-03-31T18:47:07Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-03-31T18:47:03Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: solagirl
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - lora-solav1
These are LoRA adaption weights for [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5). The weights were trained on the instance prompt "solagirl" using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
|
MarcosMunoz95/poca-SoccerTwos
|
MarcosMunoz95
| 2023-03-31T18:46:36Z | 35 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
] |
reinforcement-learning
| 2023-03-31T18:44:49Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: MarcosMunoz95/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
mark-e/ppo-PyramidsTraining
|
mark-e
| 2023-03-31T18:45:04Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-03-31T18:44:59Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: mark-e/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
IlyaGusev/mt0_xxl_ru_turbo_alpaca_lora
|
IlyaGusev
| 2023-03-31T18:41:13Z | 0 | 1 | null |
[
"text2text-generation",
"ru",
"dataset:IlyaGusev/ru_turbo_alpaca",
"region:us"
] |
text2text-generation
| 2023-03-28T21:38:27Z |
---
datasets:
- IlyaGusev/ru_turbo_alpaca
language:
- ru
pipeline_tag: text2text-generation
inference: false
---
|
sb3/ppo-MiniGrid-LockedRoom-v0
|
sb3
| 2023-03-31T18:13:21Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MiniGrid-LockedRoom-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T10:31:20Z |
---
library_name: stable-baselines3
tags:
- MiniGrid-LockedRoom-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MiniGrid-LockedRoom-v0
type: MiniGrid-LockedRoom-v0
metrics:
- type: mean_reward
value: 0.00 +/- 0.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **MiniGrid-LockedRoom-v0**
This is a trained model of a **PPO** agent playing **MiniGrid-LockedRoom-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-LockedRoom-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-LockedRoom-v0 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-LockedRoom-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-LockedRoom-v0 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env MiniGrid-LockedRoom-v0 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env MiniGrid-LockedRoom-v0 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('clip_range', 0.2),
('ent_coef', 0.0),
('env_wrapper', 'gym_minigrid.wrappers.FlatObsWrapper'),
('gae_lambda', 0.95),
('gamma', 0.99),
('learning_rate', 0.00025),
('n_envs', 8),
('n_epochs', 10),
('n_steps', 128),
('n_timesteps', 10000000.0),
('normalize', True),
('policy', 'MlpPolicy'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
sb3/ppo-MiniGrid-PutNear-6x6-N2-v0
|
sb3
| 2023-03-31T18:12:46Z | 225 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MiniGrid-PutNear-6x6-N2-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T10:30:40Z |
---
library_name: stable-baselines3
tags:
- MiniGrid-PutNear-6x6-N2-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MiniGrid-PutNear-6x6-N2-v0
type: MiniGrid-PutNear-6x6-N2-v0
metrics:
- type: mean_reward
value: 0.61 +/- 0.33
name: mean_reward
verified: false
---
# **PPO** Agent playing **MiniGrid-PutNear-6x6-N2-v0**
This is a trained model of a **PPO** agent playing **MiniGrid-PutNear-6x6-N2-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env MiniGrid-PutNear-6x6-N2-v0 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('clip_range', 0.2),
('ent_coef', 0.0),
('env_wrapper', 'gym_minigrid.wrappers.FlatObsWrapper'),
('gae_lambda', 0.95),
('gamma', 0.99),
('learning_rate', 0.00025),
('n_envs', 8),
('n_epochs', 10),
('n_steps', 128),
('n_timesteps', 10000000.0),
('normalize', True),
('policy', 'MlpPolicy'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
sb3/ppo-MiniGrid-Fetch-5x5-N2-v0
|
sb3
| 2023-03-31T18:12:16Z | 38 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MiniGrid-Fetch-5x5-N2-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T10:29:59Z |
---
library_name: stable-baselines3
tags:
- MiniGrid-Fetch-5x5-N2-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MiniGrid-Fetch-5x5-N2-v0
type: MiniGrid-Fetch-5x5-N2-v0
metrics:
- type: mean_reward
value: 0.97 +/- 0.02
name: mean_reward
verified: false
---
# **PPO** Agent playing **MiniGrid-Fetch-5x5-N2-v0**
This is a trained model of a **PPO** agent playing **MiniGrid-Fetch-5x5-N2-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env MiniGrid-Fetch-5x5-N2-v0 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('clip_range', 0.2),
('ent_coef', 0.0),
('env_wrapper', 'gym_minigrid.wrappers.FlatObsWrapper'),
('gae_lambda', 0.95),
('gamma', 0.99),
('learning_rate', 0.00025),
('n_envs', 8),
('n_epochs', 10),
('n_steps', 128),
('n_timesteps', 5000000.0),
('normalize', True),
('policy', 'MlpPolicy'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
sb3/ppo-MiniGrid-MultiRoom-N4-S5-v0
|
sb3
| 2023-03-31T18:12:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"MiniGrid-MultiRoom-N4-S5-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T10:29:34Z |
---
library_name: stable-baselines3
tags:
- MiniGrid-MultiRoom-N4-S5-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MiniGrid-MultiRoom-N4-S5-v0
type: MiniGrid-MultiRoom-N4-S5-v0
metrics:
- type: mean_reward
value: 0.00 +/- 0.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **MiniGrid-MultiRoom-N4-S5-v0**
This is a trained model of a **PPO** agent playing **MiniGrid-MultiRoom-N4-S5-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env MiniGrid-MultiRoom-N4-S5-v0 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('clip_range', 0.2),
('ent_coef', 0.0),
('env_wrapper', 'gym_minigrid.wrappers.FlatObsWrapper'),
('gae_lambda', 0.95),
('gamma', 0.99),
('learning_rate', 0.00025),
('n_envs', 8),
('n_epochs', 10),
('n_steps', 128),
('n_timesteps', 10000000.0),
('normalize', True),
('policy', 'MlpPolicy'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
sb3/ppo-MiniGrid-DoorKey-5x5-v0
|
sb3
| 2023-03-31T18:11:40Z | 357 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"MiniGrid-DoorKey-5x5-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T10:29:29Z |
---
library_name: stable-baselines3
tags:
- MiniGrid-DoorKey-5x5-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MiniGrid-DoorKey-5x5-v0
type: MiniGrid-DoorKey-5x5-v0
metrics:
- type: mean_reward
value: 0.97 +/- 0.01
name: mean_reward
verified: false
---
# **PPO** Agent playing **MiniGrid-DoorKey-5x5-v0**
This is a trained model of a **PPO** agent playing **MiniGrid-DoorKey-5x5-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-DoorKey-5x5-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-DoorKey-5x5-v0 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo ppo --env MiniGrid-DoorKey-5x5-v0 -orga sb3 -f logs/
python -m rl_zoo3.enjoy --algo ppo --env MiniGrid-DoorKey-5x5-v0 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo ppo --env MiniGrid-DoorKey-5x5-v0 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo ppo --env MiniGrid-DoorKey-5x5-v0 -f logs/ -orga sb3
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('clip_range', 0.2),
('ent_coef', 0.0),
('env_wrapper', 'gym_minigrid.wrappers.FlatObsWrapper'),
('gae_lambda', 0.95),
('gamma', 0.99),
('learning_rate', 0.00025),
('n_envs', 8),
('n_epochs', 10),
('n_steps', 128),
('n_timesteps', 100000.0),
('normalize', True),
('policy', 'MlpPolicy'),
('normalize_kwargs', {'norm_obs': True, 'norm_reward': False})])
```
|
manuelmaiorano/ppo-PyramidsTraining
|
manuelmaiorano
| 2023-03-31T18:06:47Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-03-31T18:06:42Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: manuelmaiorano/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
dvilasuero/autotrain-alpaca-gigo-detector-45529113937
|
dvilasuero
| 2023-03-31T17:58:02Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"deberta-v2",
"text-classification",
"autotrain",
"en",
"dataset:dvilasuero/autotrain-data-alpaca-gigo-detector",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T17:57:19Z |
---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- dvilasuero/autotrain-data-alpaca-gigo-detector
co2_eq_emissions:
emissions: 0.3078125269826994
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 45529113937
- CO2 Emissions (in grams): 0.3078
## Validation Metrics
- Loss: 0.481
- Accuracy: 0.825
- Macro F1: 0.823
- Micro F1: 0.825
- Weighted F1: 0.825
- Macro Precision: 0.824
- Micro Precision: 0.825
- Weighted Precision: 0.825
- Macro Recall: 0.821
- Micro Recall: 0.825
- Weighted Recall: 0.825
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/dvilasuero/autotrain-alpaca-gigo-detector-45529113937
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("dvilasuero/autotrain-alpaca-gigo-detector-45529113937", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("dvilasuero/autotrain-alpaca-gigo-detector-45529113937", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
arbts/Reinforce-CartPole-v1
|
arbts
| 2023-03-31T17:55:12Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T13:24:59Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
milyiyo/Cerebras-GPT-1.3B-lora-s-t3000-v300-v1
|
milyiyo
| 2023-03-31T17:53:23Z | 0 | 0 | null |
[
"pytorch",
"tensorboard",
"generated_from_trainer",
"license:apache-2.0",
"region:us"
] | null | 2023-03-31T16:26:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Cerebras-GPT-1.3B-lora-s-t3000-v300-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Cerebras-GPT-1.3B-lora-s-t3000-v300-v1
This model is a fine-tuned version of [cerebras/Cerebras-GPT-1.3B](https://huggingface.co/cerebras/Cerebras-GPT-1.3B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2409
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4608 | 0.11 | 20 | 2.4030 |
| 2.2475 | 0.21 | 40 | 2.2757 |
| 2.2432 | 0.32 | 60 | 2.2579 |
| 2.3011 | 0.43 | 80 | 2.2467 |
| 2.2293 | 0.53 | 100 | 2.2478 |
| 2.1398 | 0.64 | 120 | 2.2436 |
| 2.2571 | 0.75 | 140 | 2.2413 |
| 2.1577 | 0.85 | 160 | 2.2349 |
| 2.2442 | 0.96 | 180 | 2.2371 |
| 2.2592 | 1.07 | 200 | 2.2342 |
| 2.2082 | 1.17 | 220 | 2.2352 |
| 2.1402 | 1.28 | 240 | 2.2345 |
| 2.1216 | 1.39 | 260 | 2.2345 |
| 2.1758 | 1.49 | 280 | 2.2320 |
| 2.1625 | 1.6 | 300 | 2.2329 |
| 2.1491 | 1.71 | 320 | 2.2311 |
| 2.2307 | 1.81 | 340 | 2.2286 |
| 2.1102 | 1.92 | 360 | 2.2300 |
| 2.2054 | 2.03 | 380 | 2.2278 |
| 2.157 | 2.13 | 400 | 2.2345 |
| 2.0643 | 2.24 | 420 | 2.2359 |
| 2.2134 | 2.35 | 440 | 2.2343 |
| 2.1296 | 2.45 | 460 | 2.2347 |
| 2.1001 | 2.56 | 480 | 2.2346 |
| 2.1401 | 2.67 | 500 | 2.2327 |
| 2.091 | 2.77 | 520 | 2.2328 |
| 2.1365 | 2.88 | 540 | 2.2359 |
| 2.1201 | 2.99 | 560 | 2.2295 |
| 2.1359 | 3.09 | 580 | 2.2338 |
| 2.0979 | 3.2 | 600 | 2.2427 |
| 2.2025 | 3.31 | 620 | 2.2345 |
| 2.1001 | 3.41 | 640 | 2.2368 |
| 2.0228 | 3.52 | 660 | 2.2350 |
| 2.1174 | 3.63 | 680 | 2.2362 |
| 2.0688 | 3.73 | 700 | 2.2372 |
| 2.0368 | 3.84 | 720 | 2.2328 |
| 2.1409 | 3.95 | 740 | 2.2341 |
| 2.0675 | 4.05 | 760 | 2.2377 |
| 2.1805 | 4.16 | 780 | 2.2392 |
| 2.0844 | 4.27 | 800 | 2.2417 |
| 2.0834 | 4.37 | 820 | 2.2395 |
| 2.1396 | 4.48 | 840 | 2.2400 |
| 2.1121 | 4.59 | 860 | 2.2394 |
| 2.0195 | 4.69 | 880 | 2.2391 |
| 2.0564 | 4.8 | 900 | 2.2391 |
| 1.9447 | 4.91 | 920 | 2.2396 |
| 2.2122 | 5.01 | 940 | 2.2384 |
| 2.0482 | 5.12 | 960 | 2.2404 |
| 2.051 | 5.23 | 980 | 2.2411 |
| 2.0345 | 5.33 | 1000 | 2.2409 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
mark-e/ppo-SnowballTarget
|
mark-e
| 2023-03-31T17:48:21Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-03-31T17:15:11Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: mark-e/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
pszemraj/t5-large-for-lexical-analysis
|
pszemraj
| 2023-03-31T17:44:21Z | 19 | 3 |
transformers
|
[
"transformers",
"pytorch",
"onnx",
"safetensors",
"t5",
"text2text-generation",
"analysis",
"book",
"notes",
"en",
"dataset:kmfoda/booksum",
"arxiv:2105.08209",
"license:bsd-3-clause",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- t5
- analysis
- book
- notes
datasets:
- kmfoda/booksum
metrics:
- rouge
widget:
- text: I'm just a girl standing in front of a boy asking him to love her.
example_title: Notting Hill
- text: Son, your ego is writing checks your body can't cash.
example_title: top gun
- text: I really love to eat beans.
example_title: beans
- text: >-
The ledge, where I placed my candle, had a few mildewed books piled up in
one corner; and it was covered with writing scratched on the paint. This
writing, however, was nothing but a name repeated in all kinds of
characters, large and small—Catherine Earnshaw, here and there varied to
Catherine Heathcliff, and then again to Catherine Linton. In vapid
listlessness I leant my head against the window, and continued spelling over
Catherine Earnshaw—Heathcliff—Linton, till my eyes closed; but they had not
rested five minutes when a glare of white letters started from the dark, as
vivid as spectres—the air swarmed with Catherines; and rousing myself to
dispel the obtrusive name, I discovered my candle wick reclining on one of
the antique volumes, and perfuming the place with an odour of roasted
calf-skin.
example_title: Wuthering Heights
- text: >-
Did you ever hear the tragedy of Darth Plagueis The Wise? I thought not.
It’s not a story the Jedi would tell you. It’s a Sith legend. Darth Plagueis
was a Dark Lord of the Sith, so powerful and so wise he could use the Force
to influence the midichlorians to create life… He had such a knowledge of
the dark side that he could even keep the ones he cared about from dying.
The dark side of the Force is a pathway to many abilities some consider to
be unnatural. He became so powerful… the only thing he was afraid of was
losing his power, which eventually, of course, he did. Unfortunately, he
taught his apprentice everything he knew, then his apprentice killed him in
his sleep. Ironic. He could save others from death, but not himself.
example_title: Darth Plagueis The Wise
inference:
parameters:
no_repeat_ngram_size: 2
max_length: 64
early_stopping: true
license: bsd-3-clause
library_name: transformers
pipeline_tag: text2text-generation
---
# T5-large for Lexical Analysis
- This model was trained a text-to-text task with input text as a summary of a chapter, and the output text as the analysis of that chapter on the [booksum](https://arxiv.org/abs/2105.08209) dataset.
- it has somewhat learned how to complete literary analysis on an arbitrary input text.
- **NOTE: this is fairly intensive computationally and recommended to be run on GPU. please see example usage in [this demo notebook](https://colab.research.google.com/gist/pszemraj/8e9cc5bee5cac7916ef9241b66e01b05/demo-t5-large-for-lexical-analysis.ipynb)**
- The API is set to return max 64 tokens to avoid timeouts on CPU.
## Example
- PROMPT:
> Carmen: We're kids, not monsters. Dr. Romero: What's the difference?
- OUTPUT:
> Commentary on Act IV, scenes i-ii In these scenes, we see Dracula's transformation of the children into "monstrous" creatures. Doctor Romero says, "We're kidnapped, but not monsters." This is an important question for the audience to ask: Is there a difference between childhood and adulthood?
_longer examples are available in both [the demo notebook](https://colab.research.google.com/gist/pszemraj/8e9cc5bee5cac7916ef9241b66e01b05/demo-t5-large-for-lexical-analysis.ipynb) and at the bottom of this README._
# checkpoints
- a fine-tuned version of [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
- 16 epochs of training total
## Model description
- automatic literary analysis on arbitrary text
- `booksum` is a dataset created primarily for long-range summarization. It's excellent at that, and usually, this is done with the `chapter` and `summary_text` columns. However, there is a `summary_analysis` column as well, containing literary analysis on the passage in question :eyes:
- this model was trained on text-to-text with `summary_text` as the input and `summary_analysis` as the output, so it will analyze whatever text for _deeper meaning_.
## Intended uses & limitations
- given the absence of more specific info, the analysis will reference authors/titles from the training data in the context of the analysis.
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 4
### Training results
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
## Extended Examples
the below responses from the model are unedited.
### A prose passage from _The Lord of the Rings_
> Far above the Ephel Duath in the West the night-sky was still dim and pale. There, peering among the cloud-wrack above a dark tor high up in the mountains, Sam saw a white star twinkle for a while. The beauty of it smote his heart, as he looked up out of the forsaken land, and hope returned to him. For like a shaft, clear and cold, the thought pierced him that in the end the Shadow was only a small and passing thing: there was light and high beauty for ever beyond its reach.
analysis:
> Notes Sam's encounter with the white star is one of the most memorable scenes in the novel. It was a moment of great relief for him to see that there was light beyond his reach, and he had been longing for it all along. He looked up into the heavens at the sight of it: "It was as if I were looking out through the window of my own soul" . In this chapter, however, we are reminded of another scene from the Book of Eliot, when Sam saw the White Star twinkled for the first time since the book began. The night-sky still shrouded by clouds and cloud-wreck on the mountain tops, but now the darkness has begun to darken the whole world. When Sam looks up above the dusk over the mountains, which pierces his heart, Sam realizes that the Shadow will not last forever.
### the rick and morty copypasta
> Notes This is a very long post, but it's important to remember that this is the first of many posts on this site. It will take some time for me to get over the fact that I don't have an incredibly high iq to appreciate all of the humor in the show. In other words, people who dislike the series are idiots- they have no idea what these jokes mean or why they're funny at all. The only way to truly appreciate them is to be one of their diehard fans. If you do not like them, you'll end up making fools out of your own stupidity. For example, Dan Harmon writes: "I hated him because I loved him so much" . He was also extremely intelligent, and he would never have been able to fully appreciate the depth of his humour. That said, however, is that if you did not love him, then you should go ahead and make fun of him. And yet another reason why Morty dislikes him is partly due to his lack of narcissism rather than any kind of self-delusion. But there is something special about Mr. Moriarty himself- despite his lowly wittedness, which makes him seem almost superstitious. His attitude towards life seems to stem from his belief that nothing can ever be good enough to save the world. However, as noted above, Dickens says, "Life is full of paradoxes and contradictions... Life is more complex than anything else." Indeed, most critics have pointed out that even those with lower IQ points could possibly be seen as being subversive; indeed, readers might find it hard to sympathize with such simpletons. Of course, Stevenson has made it clear that we need to look beyond the surface level of normalcy in order to understand the absurdity of modern society. There are several examples of this sort of hypocrisy going on in contemporary literature. One of my favorite books is Fathers Sons, written by Alexander Nevsky, published in 1897. These books were published around 18 years before the novel was published. They were serialised in serial format, meaning that they were produced in 1921. Their publication dates back to 1864, when they appeared in London during the late eighteenth century England. At the time of its publication date, it was released in November 1793. When it came out in December, the book had already been published after 1859.
|
pszemraj/distilgpt2-multiprompt
|
pszemraj
| 2023-03-31T17:44:11Z | 144 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"text generation",
"stable diffusion",
"midjourney",
"text2image",
"text to image",
"prompt augment",
"prompt engineering",
"dataset:pszemraj/text2image-multi-prompt",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-11-13T14:01:16Z |
---
license: apache-2.0
tags:
- text generation
- stable diffusion
- midjourney
- text2image
- text to image
- prompt augment
- prompt engineering
datasets:
- pszemraj/text2image-multi-prompt
model-index:
- name: distilgpt2-multiprompt-v2-fp
results: []
widget:
- text: "morning sun over Jakarta"
example_title: "morning sun"
- text: "WARNING: pip is"
example_title: "pip"
- text: "sentient cheese"
example_title: "sentient cheese"
- text: "cheeps are"
example_title: "cheeps"
- text: "avocado armchair"
example_title: "creative prompt"
- text: "Landscape of"
example_title: "landscape"
parameters:
min_length: 16
max_length: 96
no_repeat_ngram_size: 1
do_sample: True
---
# distilgpt2-multiprompt
Generate/augment your prompt with a model trained on a large & diverse prompt dataset.
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the pszemraj/text2image-prompts-multi dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0213
- perplexity = 7.55
## Intended uses & limitations
- The model will generate augmentations that are biased towards the training data, i.e. what people already asked for in the SD/midjourney discords, etc. Creating a larger dataset was an attempt at mitigating this through more data from different datasets.
## Training and evaluation data
See the `pszemraj/text2image-prompts-multi` dataset card for details. The dataset is a compilation of several text-to-image prompt datasets on huggingface :)
## Training procedure
- this was trained with several training rounds, 8 epochs in total on the train set.
### Training hyperparameters (last training round)
The following hyperparameters were used during training:
- learning_rate: 0.0006
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 2.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1637 | 1.0 | 965 | 2.0581 |
| 2.0885 | 2.0 | 1930 | 2.0213 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.6.1
- Tokenizers 0.13.1
|
arbts/Reinforce-Pixelcopter-PLE-v0
|
arbts
| 2023-03-31T17:37:20Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T17:37:17Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 32.70 +/- 18.37
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
NiltonAlf18/russian
|
NiltonAlf18
| 2023-03-31T17:33:54Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T17:32:52Z |
---
license: creativeml-openrail-m
---
|
kfahn/dreambooth-mandelbulb
|
kfahn
| 2023-03-31T17:32:02Z | 3 | 0 |
KerasCV Stable Diffusion in Diffusers
|
[
"KerasCV Stable Diffusion in Diffusers",
"tf-keras",
"text-to-image",
"license:openrail",
"region:us"
] |
text-to-image
| 2023-03-31T15:34:11Z |
---
library_name: KerasCV Stable Diffusion in Diffusers
license: openrail
pipeline_tag: text-to-image
---
## Model description
DreamBooth model for mandelbulb-hydrangea hybrid.
## Intended uses & limitations
More information needed
## Training and evaluation data
Generative art
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| inner_optimizer.class_name | Custom>RMSprop |
| inner_optimizer.config.name | RMSprop |
| inner_optimizer.config.weight_decay | None |
| inner_optimizer.config.clipnorm | None |
| inner_optimizer.config.global_clipnorm | None |
| inner_optimizer.config.clipvalue | None |
| inner_optimizer.config.use_ema | False |
| inner_optimizer.config.ema_momentum | 0.99 |
| inner_optimizer.config.ema_overwrite_frequency | 100 |
| inner_optimizer.config.jit_compile | True |
| inner_optimizer.config.is_legacy_optimizer | False |
| inner_optimizer.config.learning_rate | 0.0010000000474974513 |
| inner_optimizer.config.rho | 0.9 |
| inner_optimizer.config.momentum | 0.0 |
| inner_optimizer.config.epsilon | 1e-07 |
| inner_optimizer.config.centered | False |
| dynamic | True |
| initial_scale | 32768.0 |
| dynamic_growth_steps | 2000 |
| training_precision | mixed_float16 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
Mithul/rl_course_vizdoom_health_gathering_supreme
|
Mithul
| 2023-03-31T17:28:19Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T17:27:44Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 11.19 +/- 4.53
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r Mithul/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Phoshco/cds
|
Phoshco
| 2023-03-31T17:23:55Z | 160 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T16:08:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: cds
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cds
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9694
- Accuracy: 0.8283
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9197 | 1.0 | 875 | 0.6300 | 0.7995 |
| 0.466 | 2.0 | 1750 | 0.5447 | 0.8313 |
| 0.2537 | 3.0 | 2625 | 0.6688 | 0.8227 |
| 0.1187 | 4.0 | 3500 | 0.8531 | 0.8287 |
| 0.0507 | 5.0 | 4375 | 0.9694 | 0.8283 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
bjoernp/alpaca-cerebras-6.7B
|
bjoernp
| 2023-03-31T17:21:19Z | 0 | 3 |
transformers
|
[
"transformers",
"en",
"dataset:yahma/alpaca-cleaned",
"dataset:tatsu-lab/alpaca",
"arxiv:1910.09700",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-03-31T16:02:53Z |
---
license: apache-2.0
datasets:
- yahma/alpaca-cleaned
- tatsu-lab/alpaca
language:
- en
library_name: transformers
---
# Model Card for Alpaca Cerebras-6.7B LoRA
This repository contains the adapter weights for the [Cerebras-6.7B](https://huggingface.co/cerebras/Cerebras-GPT-6.7B) model finetuned on the
cleaned version of the alpaca dataset following [github.com/tloen/alpaca-lora](https://github.com/tloen/alpaca-lora). Find the code used
for finetuning at our fork: [github.com/bjoernpl/cerebras-lora](https://github.com/bjoernpl/cerebras-lora).
## Model Details
### Model Description
_Copied from [cerebras/Cerebras-GPT-6.7B](https://huggingface.co/cerebras/Cerebras-GPT-6.7B) model card:_
The Cerebras-GPT family is released to facilitate research into LLM scaling laws using open architectures and data sets and demonstrate the simplicity of and scalability of training LLMs on the Cerebras software and hardware stack. All Cerebras-GPT models are available on Hugging Face.
The family includes 111M, 256M, 590M, 1.3B, 2.7B, 6.7B, and 13B models.
All models in the Cerebras-GPT family have been trained in accordance with Chinchilla scaling laws (20 tokens per model parameter) which is compute-optimal.
These models were trained on the Andromeda AI supercomputer comprised of 16 CS-2 wafer scale systems. Cerebras' weight streaming technology simplifies the training of LLMs by disaggregating compute from model storage. This allowed for efficient scaling of training across nodes using simple data parallelism.
Cerebras systems for pre-training and fine tuning are available in the cloud via the Cerebras Model Studio. Cerebras CS-2 compatible checkpoints are available in Cerebras Model Zoo.
* Developed by: [Cerebras Systems](https://www.cerebras.net/) finetuned by [Björn P.](https://github.com/bjoernpl).
* License: Apache 2.0
* Model type: Transformer-based Language Model
* Architecture: GPT-3 style architecture with LoRA adapter
* Data set: The Pile
* Tokenizer: Byte Pair Encoding
* Vocabulary Size: 50257
* Sequence Length: 2048
* Optimizer: AdamW, (β1, β2) = (0.9, 0.95), adam_eps = 1e−8 (1e−9 for larger models)
* Positional Encoding: Learned
* Language: English
* Learn more: Dense Scaling Laws Paper for training procedure, config files, and details on how to use.
## Quickstart
See [github.com/bjoernpl/cerebras-lora](https://github.com/bjoernpl/cerebras-lora) for a Gradio demo and more code.
This model can be easily loaded using the AutoModelForCausalLM functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
tokenizer = AutoTokenizer.from_pretrained("cerebras/Cerebras-GPT-6.7B")
model = AutoModelForCausalLM.from_pretrained("cerebras/Cerebras-GPT-6.7B", torch_dtype=torch.float16, device_map='auto', load_in_8bit=True)
model = PeftModel.from_pretrained(model, "bjoernp/alpaca-cerebras-6.7B", torch_dtype=torch.float16, device_map='auto')
text = "Generative AI is "
```
And can be used with Hugging Face Pipelines
```python
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
generated_text = pipe(text, max_length=50, do_sample=False, no_repeat_ngram_size=2)[0]
print(generated_text['generated_text'])
```
or with `model.generate()`
```python
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, num_beams=5,
max_new_tokens=50, early_stopping=True,
no_repeat_ngram_size=2)
text_output = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(text_output[0])
```
<br><br>
## Environmental Impact
Experiments were conducted using a private infrastructure, which has a carbon efficiency of 0.432 kgCO<sub>2</sub>eq/kWh. A cumulative of 5 hours of computation was performed on hardware of type RTX 3090Ti (TDP of 450W).
Total emissions are estimated to be 0.97 kgCO<sub>2</sub>eq of which 0 percents were directly offset.
Carbon emissions were estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** RTX 3090Ti
- **Hours used:** 5
- **Carbon Emitted:** 0.97 kgCO<sub>2</sub>eq
|
n6ai-archive/lowdef
|
n6ai-archive
| 2023-03-31T17:13:44Z | 0 | 1 | null |
[
"stable diffusion",
"style",
"hypernetwork",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T09:33:18Z |
---
license: creativeml-openrail-m
task_categories:
- text-to-image
tags:
- stable diffusion
- style
- hypernetwork
pretty_name: lowdef
base_model: runwayml/stable-diffusion-v1-5
---

# Lowdef
Lowdef is a model trained on a stylized lowpoly dataset that captures a unique low-definition style (base model [SD 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5)). It's not meant to be used stand-alone but with other checkpoints.
## Auto1111 Quick Start
Instructions for use with Stable Diffusion Web UI.
### Hypernetwork
1. Download the [`lowpdef.pt`](https://huggingface.co/n6ai/lowdef/resolve/main/lowdef.pt) file.
2. Place the downloaded `lowdef.pt` file inside `stable-diffusion-webui/models/hypernetworks` directory. If the `hypernetworks` directory doesn't exist simply create it.
3. Add `<hypernet:lowdef:0.25>` to your prompt and adjust the blend to your liking.
**Example**
```xml
Your Prompt <hypernet:lowdef:0.25>
```
## Best Practices
> ⚠️ The model is quite aggressive and more unpredictable at higher blend values.
- Use a blend between `0.1` and `0.3`.
- Generate multiple images at once, minimum `4`.
- Use `Lowdef` with other artistic checkpoints.
|
vbokaeian/segformer-b0-finetuned-segments-sidewalk-oct-22
|
vbokaeian
| 2023-03-31T16:57:08Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"segformer",
"endpoints_compatible",
"region:us"
] | null | 2023-03-31T16:49:42Z |
license: other
tags:
- vision
- image-segmentation
- generated_from_trainer
model-index:
- name: segformer-b0-finetuned-segments-sidewalk-oct-22
results: []
|
nlp-godfathers/fake_buzz_gpt
|
nlp-godfathers
| 2023-03-31T16:56:07Z | 102 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T16:38:50Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: fake_buzz_gpt
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fake_buzz_gpt
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5716
- Accuracy: {'accuracy': 0.7912772585669782}
- F1: 0.7018
- Recall: 0.9961
- Precision: 0.7937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------:|:------:|:------:|:---------:|
| No log | 1.0 | 321 | 0.5149 | {'accuracy': 0.7881619937694704} | 0.7003 | 0.9922 | 0.7931 |
| 1.2017 | 2.0 | 642 | 0.5716 | {'accuracy': 0.7912772585669782} | 0.7018 | 0.9961 | 0.7937 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
dvilasuero/alpaca-gigo-detector
|
dvilasuero
| 2023-03-31T16:52:48Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-03-31T14:13:59Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# argilla/alpaca-gigo-detector
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("argilla/alpaca-gigo-detector")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
NiltonAlf18/margot
|
NiltonAlf18
| 2023-03-31T16:43:56Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T16:42:45Z |
---
license: creativeml-openrail-m
---
|
Dc26/distilbert-base-uncased-finetuned-hate_speech
|
Dc26
| 2023-03-31T16:14:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-24T12:52:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-hate_speech
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-hate_speech
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3124
- Accuracy: 0.9120
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.403244198762251e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 34
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2952 | 1.0 | 2479 | 0.2984 | 0.9088 |
| 0.232 | 2.0 | 4958 | 0.3124 | 0.9120 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.1+cu116
- Datasets 2.11.0
- Tokenizers 0.13.2
|
asenella/reproducing_mmvae_2
|
asenella
| 2023-03-31T16:08:44Z | 0 | 0 | null |
[
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-03-31T16:08:41Z |
---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
lunnan/dqn-SpaceInvadersNoFrameskip-v4
|
lunnan
| 2023-03-31T15:55:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T15:54:17Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 664.00 +/- 139.57
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga lunnan -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga lunnan -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga lunnan
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Yanderu/Test
|
Yanderu
| 2023-03-31T15:54:43Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T15:26:57Z |
---
license: creativeml-openrail-m
---
|
Harshil13/botGPT2_Context_v1
|
Harshil13
| 2023-03-31T15:43:25Z | 64 | 0 |
transformers
|
[
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-03-28T06:14:31Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: botGPT2_Context_v1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# botGPT2_Context_v1
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3524
- Train Accuracy: 0.0000
- Train Perplexity: 18824.3340
- Validation Loss: 0.3106
- Validation Accuracy: 0.0
- Validation Perplexity: 39785.5430
- Epoch: 8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 1e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 16381, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Train Accuracy | Train Perplexity | Validation Loss | Validation Accuracy | Validation Perplexity | Epoch |
|:----------:|:--------------:|:----------------:|:---------------:|:-------------------:|:---------------------:|:-----:|
| 0.6295 | 0.0032 | 100042.4062 | 0.3106 | 0.0 | 39785.5273 | 0 |
| 0.3528 | 0.0000 | 18560.1328 | 0.3106 | 0.0 | 39785.5391 | 1 |
| 0.3525 | 0.0000 | 18773.9668 | 0.3106 | 0.0 | 39785.5156 | 2 |
| 0.3525 | 0.0 | 18342.8223 | 0.3106 | 0.0 | 39785.5078 | 3 |
| 0.3525 | 0.0000 | 19026.9180 | 0.3106 | 0.0 | 39785.5508 | 4 |
| 0.3526 | 0.0 | 19108.625 | 0.3106 | 0.0 | 39785.5195 | 5 |
| 0.3526 | 0.0000 | 19143.7520 | 0.3106 | 0.0 | 39785.5312 | 6 |
| 0.3525 | 0.0000 | 18503.0938 | 0.3106 | 0.0 | 39785.5195 | 7 |
| 0.3524 | 0.0000 | 18824.3340 | 0.3106 | 0.0 | 39785.5430 | 8 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
vorstcavry/prompt
|
vorstcavry
| 2023-03-31T15:26:05Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T15:25:20Z |
---
license: creativeml-openrail-m
---
|
Garfieldgx/Severe-js100-Sentiment
|
Garfieldgx
| 2023-03-31T15:11:54Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"text-classification",
"autotrain",
"unk",
"dataset:Garfieldgx/autotrain-data-severe-js100-sentiment",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T15:09:26Z |
---
tags:
- autotrain
- text-classification
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Garfieldgx/autotrain-data-severe-js100-sentiment
co2_eq_emissions:
emissions: 0.9273951637568196
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 45485113858
- CO2 Emissions (in grams): 0.9274
## Validation Metrics
- Loss: 0.007
- Accuracy: 0.999
- Macro F1: 0.995
- Micro F1: 0.999
- Weighted F1: 0.999
- Macro Precision: 0.991
- Micro Precision: 0.999
- Weighted Precision: 0.999
- Macro Recall: 0.999
- Micro Recall: 0.999
- Weighted Recall: 0.999
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Garfieldgx/autotrain-severe-js100-sentiment-45485113858
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("Garfieldgx/autotrain-severe-js100-sentiment-45485113858", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Garfieldgx/autotrain-severe-js100-sentiment-45485113858", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
vcncolin/ppo-LunarLander-v2
|
vcncolin
| 2023-03-31T15:04:52Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T14:29:16Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 269.26 +/- 15.54
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
LarryAIDraw/kasumigaokaUtaha_v1
|
LarryAIDraw
| 2023-03-31T14:54:10Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T14:52:23Z |
---
license: creativeml-openrail-m
---
|
LarryAIDraw/yaeMikoRealisticAnime_offset
|
LarryAIDraw
| 2023-03-31T14:52:11Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-31T14:51:13Z |
---
license: creativeml-openrail-m
---
|
Mokrab/ArtNuvoAncienGrece
|
Mokrab
| 2023-03-31T14:47:09Z | 35 | 2 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-31T13:53:18Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: AmorGreceFyzbi
---
### ArtNuvoAncienGrece Dreambooth model trained by Mokrab with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
AmorGreceFyzbi (use that on your prompt)

|
wordgen/multi-model-wordgen-2
|
wordgen
| 2023-03-31T14:34:31Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"endpoints_compatible",
"region:us"
] | null | 2023-03-31T09:34:49Z |
---
license: creativeml-openrail-m
---
|
SEVUNX/JURGEN-MIX
|
SEVUNX
| 2023-03-31T14:32:40Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-25T03:02:28Z |
---
license: creativeml-openrail-m
---
|
SEVUNX/JURGENIME-MIX
|
SEVUNX
| 2023-03-31T14:28:50Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-03-24T11:54:50Z |
---
license: creativeml-openrail-m
---
|
anna-t/Reinforce-Pixelcopter-PLE-v0
|
anna-t
| 2023-03-31T14:22:43Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T13:25:22Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 21.20 +/- 15.73
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
peterwilli/deliberate-2
|
peterwilli
| 2023-03-31T14:20:52Z | 32 | 2 |
diffusers
|
[
"diffusers",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-03-31T14:27:53Z |
---
license: openrail
---
This model is ported to Diffusers from the original Deliberate: https://civitai.com/models/4823/deliberate
|
koutch/setfit_staqt
|
koutch
| 2023-03-31T14:19:17Z | 6 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"deberta-v2",
"setfit",
"text-classification",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-03-31T06:45:59Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# SetFit StaQT
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("koutch/setfit_staqt")
# Run inference
```
|
pysentimiento/robertuito-pos
|
pysentimiento
| 2023-03-31T13:54:19Z | 270 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"token-classification",
"twitter",
"pos-tagging",
"es",
"arxiv:2106.09462",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-07-17T21:22:11Z |
---
language:
- es
tags:
- twitter
- pos-tagging
---
# POS Tagging model for Spanish/English
## robertuito-pos
Repository: [https://github.com/pysentimiento/pysentimiento/](https://github.com/finiteautomata/pysentimiento/)
Model trained with the Spanish/English split of the [LinCE NER corpus](https://ritual.uh.edu/lince/), a code-switched benchmark . Base model is [RoBERTuito](https://github.com/pysentimiento/robertuito), a RoBERTa model trained in Spanish tweets.
## Usage
If you want to use this model, we suggest you use it directly from the `pysentimiento` library as it is not working properly with the pipeline due to tokenization issues
```python
from pysentimiento import create_analyzer
pos_analyzer = create_analyzer("pos", lang="es")
pos_analyzer.predict("Quiero que esto funcione correctamente! @perezjotaeme")
>[{'type': 'PROPN', 'text': 'Quiero', 'start': 0, 'end': 6},
> {'type': 'SCONJ', 'text': 'que', 'start': 7, 'end': 10},
> {'type': 'PRON', 'text': 'esto', 'start': 11, 'end': 15},
> {'type': 'VERB', 'text': 'funcione', 'start': 16, 'end': 24},
> {'type': 'ADV', 'text': 'correctamente', 'start': 25, 'end': 38},
> {'type': 'PUNCT', 'text': '!', 'start': 38, 'end': 39},
> {'type': 'NOUN', 'text': '@perezjotaeme', 'start': 40, 'end': 53}]
```
## Results
Results are taken from the LinCE leaderboard
| Model | Sentiment | NER | POS |
|:-----------------------|:----------------|:-------------------|:--------|
| RoBERTuito | **60.6** | 68.5 | 97.2 |
| XLM Large | -- | **69.5** | **97.2** |
| XLM Base | -- | 64.9 | 97.0 |
| C2S mBERT | 59.1 | 64.6 | 96.9 |
| mBERT | 56.4 | 64.0 | 97.1 |
| BERT | 58.4 | 61.1 | 96.9 |
| BETO | 56.5 | -- | -- |
## Citation
If you use this model in your research, please cite pysentimiento, RoBERTuito and LinCE papers:
```
@misc{perez2021pysentimiento,
title={pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks},
author={Juan Manuel Pérez and Juan Carlos Giudici and Franco Luque},
year={2021},
eprint={2106.09462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{ortega2019overview,
title={Overview of the task on irony detection in Spanish variants},
author={Ortega-Bueno, Reynier and Rangel, Francisco and Hern{\'a}ndez Far{\i}as, D and Rosso, Paolo and Montes-y-G{\'o}mez, Manuel and Medina Pagola, Jos{\'e} E},
booktitle={Proceedings of the Iberian languages evaluation forum (IberLEF 2019), co-located with 34th conference of the Spanish Society for natural language processing (SEPLN 2019). CEUR-WS. org},
volume={2421},
pages={229--256},
year={2019}
}
@inproceedings{aguilar2020lince,
title={LinCE: A Centralized Benchmark for Linguistic Code-switching Evaluation},
author={Aguilar, Gustavo and Kar, Sudipta and Solorio, Thamar},
booktitle={Proceedings of the 12th Language Resources and Evaluation Conference},
pages={1803--1813},
year={2020}
}
```
|
yutakashino/distilbert-base-uncased-finetuned-emotion
|
yutakashino
| 2023-03-31T13:47:34Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T13:29:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.928
- name: F1
type: f1
value: 0.9280261795203244
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2130
- Accuracy: 0.928
- F1: 0.9280
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8337 | 1.0 | 250 | 0.3003 | 0.909 | 0.9063 |
| 0.2437 | 2.0 | 500 | 0.2130 | 0.928 | 0.9280 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
innovation64/CodeGeeX-test
|
innovation64
| 2023-03-31T13:39:39Z | 0 | 1 | null |
[
"arxiv:2303.17568",
"arxiv:2009.10297",
"arxiv:2107.03374",
"region:us"
] | null | 2023-02-23T03:54:43Z |
<img src="resources/logo/codegeex_logo.png">
<p align="center">
🏠 <a href="https://codegeex.cn" target="_blank">Homepage</a> | 📖 <a href="https://models.aminer.cn/codegeex/blog/" target="_blank">Blog</a> | 🪧 <a href="https://models.aminer.cn/codegeex/playground" target="_blank">DEMO</a> | 🤖 <a href="https://models.aminer.cn/codegeex/download/request" target="_blank">Download Model</a> | 📄 <a href="https://arxiv.org/abs/2303.17568" target="_blank">Paper</a> | 🌐 <a href="README_zh.md" target="_blank">中文</a>
</p>
<p align="center">
🛠 <a href="https://marketplace.visualstudio.com/items?itemName=aminer.codegeex" target="_blank">VS Code</a>, <a href="https://plugins.jetbrains.com/plugin/20587-codegeex" target="_blank">Jetbrains</a>, <a href="https://plugins.jetbrains.com/plugin/20587-codegeex" target="_blank">Cloud Studio</a> supported | 👋 Join our <a href="https://discord.gg/8gjHdkmAN6" target="_blank">Discord</a>, <a href="https://join.slack.com/t/codegeexworkspace/shared_invite/zt-1s118ffrp-mpKKhQD0tKBmzNZVCyEZLw" target="_blank">Slack</a>, <a href="https://t.me/+IipIayJ32B1jOTg1" target="_blank">Telegram</a>, <a href="https://wj.qq.com/s2/11274205/a15b/"target="_blank">WeChat</a>
</p>
<div align="center">
<a href="">[](https://cloudstudio.net/templates/h0kvkZvoO0U)</a>
</div>
- [CodeGeeX: A Multilingual Code Generation Model](#codegeex-a-multilingual-code-generation-model)
- [News](#news)
- [Getting Started](#getting-started)
- [Installation](#installation)
- [Model Weights](#model-weights)
- [Inference on GPUs](#inference-on-gpus)
- [VS Code and Jetbrains Extension Guidance](#vs-code-and-jetbrains-extension-guidance)
- [CodeGeeX: Architecture, Code Corpus, and Implementation](#codegeex-architecture-code-corpus-and-implementation)
- [HumanEval-X: A new benchmark for Multilingual Program Synthesis](#humaneval-x-a-new-benchmark-for-multilingual-program-synthesis)
- [Multilingual Code Generation](#multilingual-code-generation)
- [Crosslingual Code Translation](#crosslingual-code-translation)
- [How to use HumanEval-X and contribute to it?](#how-to-use-humaneval-x-and-contribute-to-it)
- [License](#license)
- [Citation](#citation)
# CodeGeeX: A Multilingual Code Generation Model
We introduce CodeGeeX, a large-scale multilingual code generation model with 13 billion parameters, pre-trained on a large code corpus of more than 20 programming languages. As of **June 22**, 2022, CodeGeeX has been trained on more than 850 billion tokens on a cluster of 1,536 [Ascend 910 AI Processors](https://e.huawei.com/en/products/servers/ascend). CodeGeeX has several unique features:
* **Multilingual Code Generation**: CodeGeeX has good performance for generating executable programs in several mainstream programming languages, including Python, C++, Java, JavaScript, Go, etc. [DEMO](https://models.aminer.cn/codegeex)
* **Crosslingual Code Translation**: CodeGeeX supports the translation of code snippets between different languages. Simply by one click, CodeGeeX can transform a program into any expected language with a high accuracy. [DEMO](https://models.aminer.cn/codegeex/codeTranslator)
* **Customizable Programming Assistant**: CodeGeeX is available in the VS Code extension marketplace **for free**. It supports code completion, explanation, summarization and more, which empower users with a better coding experience. [VS Code Extension](https://marketplace.visualstudio.com/items?itemName=aminer.codegeex)
* **Open-Source and Cross-Platform**: All codes and model weights are publicly available for research purposes. CodeGeeX supports both Ascend and NVIDIA platforms. It supports inference in a single Ascend 910, NVIDIA V100 or A100. [Apply Model Weights](https://models.aminer.cn/codegeex/download/request)
**HumanEval-X for Realistic Multilingual Benchmarking.** To help standardize the evaluation of multilingual code generation and translation, we develop and release the **HumanEval-X** Benchmark. HumanEval-X is a new multilingual benchmark that contains **820 human-crafted** coding problems in **5** programming languages (Python, C++, Java, JavaScript, and Go), each of these problems is associated with tests and solutions. [Usage](codegeex/benchmark/README.md) [🤗 Available in HuggingFace](https://huggingface.co/datasets/THUDM/humaneval-x)
<img src="resources/en/hx_boxplot.png">
<p align="center"><i>CodeGeeX achieves the highest average performance compared with other open-sourced multilingual baselines.</i> </p>
## News
* **2023-03-30**: CodeGeeX paper is now available at [arxiv](https://arxiv.org/abs/2303.17568).
* **2023-02-14**: CodeGeeX now supports [Cloud Studio](https://cloudstudio.net/), a fantastic web IDE from Tencent. Click on the badge on top of this page to quickly launch an environment to test CodeGeeX.
* **2023-02-13**: Thanks a lot to [OneFlow](https://github.com/Oneflow-Inc/oneflow) team for adding oneflow backend for CodeGeeX's inference (Even faster than FasterTransformer under FP16!). Check more details [here](https://github.com/THUDM/CodeGeeX/pull/65).
* 🌟 **2023-02**: We are hosting [CodeGeeX "Coding With AI" Hackathon](https://dorahacks.io/hackathon/codegeex/), design cool applications based on CodeGeeX and win prizes (RTX 4090, DJI drone, etc)!
* **2022-12-31**: We release the FasterTransformer version of CodeGeeX in [codegeex-fastertransformer](https://github.com/CodeGeeX/codegeex-fastertransformer). The INT8 accelerated version reaches an a verage speed of <15ms/token. Happy new year to everyone!
* **2022-12-13**: We release the source code of CodeGeeX VS Code extension in [codegeex-vscode-extension](https://github.com/CodeGeeX/codegeex-vscode-extension). Follow [QuickStart](https://github.com/CodeGeeX/codegeex-vscode-extension/blob/main/doc/quickstart.md) to start development.
* **2022-12-11**: CodeGeeX is now available for Jetbrains IDEs (IntelliJ IDEA, PyCharm, GoLand, CLion, etc), download it [here](https://plugins.jetbrains.com/plugin/20587-codegeex).
* **2022-12-04**: We release source code of quantization (requires less GPU RAM: 27GB -> 15GB) and model parallelism (possible to run on multiple GPUs with <8G RAM).
* **2022-09-30**: We release the cross-platform source code and models weights for both Ascend and NVIDIA platforms.
## Getting Started
CodeGeeX is initially implemented in Mindspore and trained Ascend 910 AI Processors. We provide a torch-compatible version based on [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) to facilitate usage on GPU platforms.
### Installation
Python 3.7+ / CUDA 11+ / PyTorch 1.10+ / DeepSpeed 0.6+ are required. Install ``codegeex`` package via:
```bash
git clone [email protected]:THUDM/CodeGeeX.git
cd CodeGeeX
pip install -e .
```
### Model Weights
Apply and download model weights through this [link](https://models.aminer.cn/codegeex/download/request). You'll receive by mail ```urls.txt``` that contains temporary download links. We recommend you to use [aria2](https://aria2.github.io/) to download it via the following command (Please make sure you have enough disk space to download the checkpoint (~26GB)):
```bash
aria2c -x 16 -s 16 -j 4 --continue=true -i urls.txt
```
Run the following command to get the full model weights:
```bash
cat codegeex_13b.tar.gz.* > codegeex_13b.tar.gz
tar xvf codegeex_13b.tar.gz
```
### Inference on GPUs
Have a try on generating the first program with CodeGeeX. First, specify the path of the model weights in ``configs/codegeex_13b.sh``. Second, write the prompt (natural language description or code snippet) into a file, e.g., ``tests/test_prompt.txt``, then run the following script:
```bash
# On a single GPU (with more than 27GB RAM)
bash ./scripts/test_inference.sh <GPU_ID> ./tests/test_prompt.txt
# With quantization (with more than 15GB RAM)
bash ./scripts/test_inference_quantized.sh <GPU_ID> ./tests/test_prompt.txt
# On multiple GPUs (with more than 6GB RAM, need to first convert ckpt to MP_SIZE partitions)
bash ./scripts/convert_ckpt_parallel.sh <LOAD_CKPT_PATH> <SAVE_CKPT_PATH> <MP_SIZE>
bash ./scripts/test_inference_parallel.sh <MP_SIZE> ./tests/test_prompt.txt
```
### VS Code and Jetbrains Extension Guidance
Based on CodeGeeX, we also develop free extentions for VS Code and Jetbrains IDEs, and more in the future.
For VS Code, search "codegeex" in Marketplace or install it [here](https://marketplace.visualstudio.com/items?itemName=aminer.codegeex). Detailed instructions can be found in
[VS Code Extension Guidance](vscode-extension/README.md). For developers, we have also released the source code in [codegeex-vscode-extension](https://github.com/CodeGeeX/codegeex-vscode-extension), please follow [QuickStart](https://github.com/CodeGeeX/codegeex-vscode-extension/blob/main/doc/quickstart.md) to start development.
For Jetbrains IDEs, search "codegeex" in Plugins or intall it [here](https://plugins.jetbrains.com/plugin/20587-codegeex).
Make sure your IDE version is 2021.1 or later. CodeGeeX now supports IntelliJ IDEA, PyCharm, GoLand, CLion, Android Studio, AppCode, Aqua, DataSpell, DataGrip, Rider, RubyMine, and WebStorm.
## CodeGeeX: Architecture, Code Corpus, and Implementation
**Architecture**: CodeGeeX is a large-scale pre-trained programming language model based on transformers. It is a left-to-right autoregressive decoder, which takes code and natural language as input and predicts the probability of the next token. CodeGeeX contains 40 transformer layers with a hidden size of 5,120 for self-attention blocks and 20,480 for feed-forward layers, making its size reach 13 billion parameters. It supports a maximum sequence length of 2,048.
<img src="resources/en/codegeex_training.png">
<p align="center"><i><b>Left:</b> the proportion of programming languages in CodeGeeX's training data.
<b>Right:</b> the plot of training loss against the training steps of CodeGeeX.</i></p>
**Code Corpus**: Our training data contains two parts. The first part is from open-sourced code datasets, [The Pile](https://pile.eleuther.ai/) and [CodeParrot](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot). The Pile contains a subset of code corpus that collects public repositories with more than 100 stars from GitHub, from which we select codes in 23 popular programming languages. The second part is supplementary data directly scrapped from the public GitHub repositories that do not appear in previous datasets, including Python, Java and C++. To obtain data of potentially higher quality, repositories with at least one star and its size smaller than 10MB are chosen. A file is filtered out if it 1) has more than 100 characters per line on average, 2) is automatically generated, 3) has a ratio of alphabet less than 40%, or 4) is bigger than 100KB or smaller than 1KB. To help the model distinguish different languages, we add a language-specific prefix at the beginning of each segment in the form of ``[Comment sign] language: [LANG]``, e.g., ``# language: Python``. For tokenization, we use the same tokenizer as GPT-2 and process whitespaces as extra tokens, resulting in a vocabulary of 50,400 tokens. In total, the code corpus has 23 programming languages with 158.7B tokens.
**Training**: We implement CodeGeeX in [Mindspore 1.7](https://www.mindspore.cn/) and train it on 1,536 Ascend 910 AI Processor (32GB). The model weights are under FP16 format, except that we use FP32 for layer-norm and softmax for higher precision and stability. The entire model consumes about 27GB of memory. To increase the training efficiency, we adopt an 8-way model parallel training together with 192-way data parallel training, with ZeRO-2 optimizer enabled. The micro-batch size is 16 and the global batch size reaches 3,072. Moreover, we adopt techniques to further boost the training efficiency including the element-wise operator fusion, fast gelu activation, matrix multiplication dimension optimization, etc. The entire training process takes nearly two months, spanning from April 18 to June 22, 2022, during which 850B tokens were passed for training, i.e., 5+ epochs.
## HumanEval-X: A new benchmark for Multilingual Program Synthesis
To better evaluate the multilingual ability of code generation models, we propose a new benchmark HumanEval-X. While previous works evaluate multilingual program synthesis under semantic similarity (e.g., [CodeBLEU](https://arxiv.org/abs/2009.10297)) which is often misleading, HumanEval-X evaluates the functional correctness of the generated programs. HumanEval-X consists of 820 high-quality human-crafted data samples (each with test cases) in Python, C++, Java, JavaScript, and Go, and can be used for various tasks.
<img src="resources/en/hx_tasks.png">
<p align="center"><i>An illustration of tasks supported by <b>HumanEval-X</b>. Declarations, docstrings, and solutions are marked with red, green, and blue respectively. <b>Code generation</b> uses declaration and docstring as input, to generate solution. <b>Code translation</b> uses declaration in both languages and translate the solution in source language to the one in target language.</i></p>
In HumanEval-X, every sample in each language contains declaration, docstring, and solution, which can be combined in various ways to support different downstream tasks including generation, translation, summarization, etc. We currently focus on two tasks: **code generation** and **code translation**. For code generation, the model uses declaration and docstring as input to generate the solution. For code translation, the model uses declarations in both languages and the solution in the source language as input, to generate solutions in the target language. We remove the description during code translation to prevent the model from directly solving the problem. For both tasks, we use the unbiased pass@k metric proposed in [Codex](https://arxiv.org/abs/2107.03374): $\text{pass}@k:= \mathbb{E}[1-\frac{\tbinom{n-c}{k}}{\tbinom{n}{k}}]$, with $n=200$ and $k\in(1,10,100)$.
### Multilingual Code Generation
<img src="resources/en/hx_generattion_radar_horizon.png">
<p align="center"><i><b>Left</b>: the detailed pass@k (k=1,10,100) performance on code generation task for five languages in HumanEval-X. <b>Right</b>: the average performance of all languages of each model. CodeGeeX achieves the highest average performance compared with InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B.</i></p>
We compare CodeGeeX with two other open-sourced code generation models, [InCoder](https://github.com/dpfried/incoder) (from Meta) and [CodeGen](https://github.com/salesforce/CodeGen) (from Salesforce). Specifically, InCoder-6.7B, CodeGen-Multi-6B and CodeGen-Multi-16B are considered. CodeGeeX significantly outperforms models with smaller scales (by 7.5%~16.3%) and is competitive with CodeGen-Multi-16B with a larger scale (average performance 54.76% vs. 54.39%). CodeGeeX achieves the best average performance across languages.
### Crosslingual Code Translation
<img src="resources/en/hx_translation.png">
<p align="center"><i>Results on HumanEval-X <b>code translation</b> task. Best language-wise performance are <b>bolded</b>.</i></p>
We also evaluate the performance of translation across different programming languages. We test the zero-shot performance of CodeGeeX, as well as the fine-tuned CodeGeeX-13B-FT (fine-tuned using the training set of code translation tasks in [XLCoST](https://github.com/reddy-lab-code-research/XLCoST); Go is absent in the original set, we thus add a small set to it). The results indicate that models have a preference for languages, e.g., CodeGeeX is good at translating other languages to Python and C++, while CodeGen-Multi-16B is better at translating to JavaScript and Go; these could probably be due to the difference in language distribution in the training corpus. Among 20 translation pairs, we also observe that the performance of A-to-B and B-to-A are always negatively correlated, which might indicate that the current models are still not capable of learning all languages well.
### How to use HumanEval-X and contribute to it?
For more details on how to use HumanEval-X, please see [usage](codegeex/benchmark/README.md). We highly welcome the community to contribute to HumanEval-X by adding more problems or extending it to other languages, please check out the [standard format](codegeex/benchmark/README.md#how-to-use-humaneval-x) of HumanEval-X and add a pull request.
Please kindly let us know if you have any comment or suggestion, via [[email protected]](mailto:[email protected]).
<details>
<summary><b>Examples of Generation</b></summary>
<img src="resources/en/hx_examples.png">
</details>
<details>
<summary><b>Acknowledgement</b></summary>
<br/>
This project is supported by the National Science Foundation for Distinguished Young Scholars (No. 61825602).
### Lead Contributors
Qinkai Zheng ([Tsinghua KEG](http://keg.cs.tsinghua.edu.cn/glm-130b/)), Xiao Xia (Tsinghua KEG), Xu Zou (Tsinghua KEG)
### Contributors
Tsinghua KEG---The Knowledge Engineering Group at Tsinghua: Aohan Zeng, Wendi Zheng, Lilong Xue
Zhilin Yang's Group at Tsinghua IIIS: Yifeng Liu, Yanru Chen, Yichen Xu (BUPT, work was done when visiting Tsinghua)
Peng Cheng Laboratory: Qingyu Chen, Zhongqi Li, Gaojun Fan
Zhipu\.AI: Yufei Xue, Shan Wang, Jiecai Shan, Haohan Jiang, Lu Liu, Xuan Xue, Peng Zhang
Ascend and Mindspore Team: Yifan Yao, Teng Su, Qihui Deng, Bin Zhou
### Data Annotations
Ruijie Cheng (Tsinghua), Peinan Yu (Tsinghua), Jingyao Zhang (Zhipu\.AI), Bowen Huang (Zhipu\.AI), Shaoyu Wang (Zhipu\.AI)
### Advisors
[Zhilin Yang](https://kimiyoung.github.io/) (Tsinghua IIIS), Yuxiao Dong (Tsinghua KEG), Wenguang Chen (Tsinghua PACMAN), Jie Tang (Tsinghua KEG)
### Computation Sponsors
[Peng Cheng Laboratory](https://www.pcl.ac.cn/index.html)
[Zhipu.AI](https://www.zhipu.ai/)---an AI startup that aims to teach machines to think like humans
### Project Leader
[Jie Tang](http://keg.cs.tsinghua.edu.cn/jietang/) (Tsinghua KEG & BAAI)
</details>
## License
Our code is licensed under the [Apache-2.0 license](LICENSE).
Our model is licensed under the [license](MODEL_LICENSE).
## Citation
If you find our work useful, please cite:
```
@misc{zheng2023codegeex,
title={CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X},
author={Qinkai Zheng and Xiao Xia and Xu Zou and Yuxiao Dong and Shan Wang and Yufei Xue and Zihan Wang and Lei Shen and Andi Wang and Yang Li and Teng Su and Zhilin Yang and Jie Tang},
year={2023},
eprint={2303.17568},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
ChrisLiewJY/BERTweet-Hedge
|
ChrisLiewJY
| 2023-03-31T13:32:56Z | 184 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"uncertainty-detection",
"social-media",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-16T01:09:58Z |
---
license: mit
language:
- en
tags:
- uncertainty-detection
- social-media
- text-classification
widget:
- text: "It seems like Bitcoin prices are heading into bearish territory."
example_title: "Hedge Detection (Positive - Label 1)"
- text: "Bitcoin prices have fallen by 42% in the last 30 days."
example_title: "Hedge Detection (Negative - Label 0)"
---
### Overview
Fine tuned VinAI's BERTweet base model on the Wiki Weasel 2.0 Corpus from the [Szeged Uncertainty Corpus](https://rgai.inf.u-szeged.hu/node/160) for hedge (linguistic uncertainty) detection in social media texts. Model was trained and optimised using Ray Tune's implementation of Deep Mind's Population Based Training with the arithmetic mean of Accuracy & F1 as its evaluation metric.
### Labels
* LABEL_1 = Positive (Hedge is detected within text)
* LABEL_0 = Negative (No Hedges detected within text)
### <a name="models2"></a> Model Performance
Model | Accuracy | F1-Score | Accuracy & F1-Score
---|---|---|---
`BERTweet-Hedge` | 0.9680 | 0.8765 | 0.9222
|
pelinbalci/q-FrozenLake-v1-4x4-noSlippery
|
pelinbalci
| 2023-03-31T13:21:28Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-03-31T13:17:00Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="pelinbalci/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
minutillamolinara/bert-japanese_finetuned-sentiment-analysis
|
minutillamolinara
| 2023-03-31T13:13:37Z | 143 | 4 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"ja",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-03-31T02:28:09Z |
---
language: ja
license: mit
widget:
- text: "自然言語処理が面白い"
metrics:
- accuracy
- f1
---
# bert-japanese_finetuned-sentiment-analysis
This model was trained from scratch on the Japanese Sentiment Polarity Dictionary dataset.
## Pre-trained model
jarvisx17/japanese-sentiment-analysis<br/>
Link : https://huggingface.co/jarvisx17/japanese-sentiment-analysis
## Training Data
The model was trained on Japanese Sentiment Polarity Dictionary dataset.<br/>
link : https://www.cl.ecei.tohoku.ac.jp/Open_Resources-Japanese_Sentiment_Polarity_Dictionary.html
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
## Usage
You can use cURL to access this model:
Python API:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("minutillamolinara/bert-japanese_finetuned-sentiment-analysis")
model = AutoModelForSequenceClassification.from_pretrained("minutillamolinara/bert-japanese_finetuned-sentiment-analysis")
inputs = tokenizer("自然言語処理が面白い", return_tensors="pt")
outputs = model(**inputs)
```
### Dependencies
- !pip install fugashi
- !pip install unidic_lite
## Licenses
MIT
|
wieheistdu/obj_detection_5epochs
|
wieheistdu
| 2023-03-31T13:03:38Z | 189 | 0 |
transformers
|
[
"transformers",
"pytorch",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:cppe-5",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
object-detection
| 2023-03-31T08:38:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cppe-5
model-index:
- name: obj_detection_5epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# obj_detection_5epochs
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on the cppe-5 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.27.3
- Pytorch 2.0.0+cpu
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.