
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-15 00:43:56
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 521
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-15 00:40:56
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
junx/djmrl | junx | 2023-09-03T03:48:34Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-09-01T13:34:36Z | ---
license: creativeml-openrail-m
---
|
trieudemo11/llama_7b_attrb_cate_b6_l320_low_12 | trieudemo11 | 2023-09-03T03:44:43Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-03T03:44:18Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
- PEFT 0.6.0.dev0
rsions
- PEFT 0.6.0.dev0
|
Lightofdark/LostJourneyMix | Lightofdark | 2023-09-03T03:37:04Z | 0 | 8 | null | [
"region:us"
]
| null | 2023-05-05T03:02:42Z | * 本模型仅作学习交流使用,禁止用于任何商业活动或侵犯他人版权、肖像权等权利的行为。
* Study and communication only. Any commercial activity and violation of rights like portrait and copyright is prohibited.
自己融的几个模型
Just some merge models I played around with. <br>
2023/09/02 更新VX.5, ???<br>
2023/08/15 我什么时候更新的V8来着?V8算是V6小幅修改版,虽然我自己也不知道改了些啥。。。<br>
2023/07/21 更新V6,偶数模型新作,大概算VX去掉太3D部分的感觉吧<br>
2023/07/11 更新V5 强化版,暂定为奇数模型最终版, LostJourneyMix_X <br>
2023/06/23 更新了V5,2.5D 风格; added V5, 2.5D model <br>
懒得更新例图了,反正能找到这里的应该都见过我的模型大概是什么风格 <br>
<br>
<br>
V1:我大部分融模的底模; Starting point for most of my merged models <br>
大致配方(recipe): (AOM2 0.5 + Silicon 29 0.5) + Pastelmix <br>
V1.5:在V1的基础上加了MeinaHentai,肢体有所加强(?), 比较会画nsfw; added MeinaHentai, slightly better anatomy, and more nsfw<br>
配方(recipe):V1 + MeinaHentai <br>
V3:更多人物和背景的细节,更好的光影效果; aimed for more details and better light and shadow effects <br>
配方(recipe):V1.5 + Cetus 3.5
<br>
V2:融了PileDream之后的厚涂风格; Added PileDream to get impasto style <br>
配方(recipe): V1 + PileDream <br>
V4:类似于V3,在V2的基础上增强了细节和光影效果; Similar to V3, strengthening details, light and shadow effects <br>
配方(recipe): V2 + Line and Light <br>
下配例图; Sample Images below <br>
<b> V4




<b> V2




<b> V3




<b> V1




Acknowledgement:
特别感谢这些作者发布的好模型
AbyssOrangeMix2 - NSFW (https://civitai.com/models/4449/abyssorangemix2-nsfw) <br>
pastel-mix (https://huggingface.co/andite/pastel-mix) <br>
Cetus-Mix (https://civitai.com/models/6755?modelVersionId=29851) <br>
MeinaHentai (https://civitai.com/models/12606/meinahentai) <br>
Line and Light (https://civitai.com/models/42930/line-and-light) <br>
PileDream (https://civitai.com/models/20255)
|
monsoon-nlp/gpt-nyc | monsoon-nlp | 2023-09-03T03:34:40Z | 130 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"gpt2",
"text-generation",
"nyc",
"reddit",
"en",
"dataset:monsoon-nlp/asknyc-chatassistant-format",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
license: mit
datasets:
- monsoon-nlp/asknyc-chatassistant-format
language:
- en
pipeline_tag: text-generation
tags:
- nyc
- reddit
---
# GPT-NYC
## About
GPT2-Medium fine-tuned on questions and responses from https://reddit.com/r/asknyc
**2023 Update: try a larger model: [monsoon-nlp/nyc-savvy-llama2-7b](https://huggingface.co/monsoon-nlp/nyc-savvy-llama2-7b)**
I filtered comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I added tokens to match NYC neighborhoods, subway stations, foods, and other
common terms in the original batches of questions and comments.
You would be surprised what is missing from GPT tokens!
Try prompting with ```question? %% ``` or ```question? - more info %%```
## Status
I would like to continue by:
- fine-tuning GPT2-Large with a larger dataset of questions
- examining bias and toxicity
- examining memorization vs. original responses
- releasing a reusable benchmark
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Fine-tuning GPT2-Medium
Same code as small, but on Google Cloud to use an A100 GPU
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this. |
monsoon-nlp/gpt-nyc-affirmations | monsoon-nlp | 2023-09-03T03:33:04Z | 116 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | # GPT-NYC-affirmations
## About
GPT2 (small version on HF) fine-tuned on questions and responses from https://reddit.com/r/asknyc
and then 2 epochs of [Value Affirmations](https://gist.github.com/mapmeld/c16794ecd93c241a4d6a65bda621bb55)
based on the OpenAI post [Improving Language Model Behavior](https://openai.com/blog/improving-language-model-behavior/)
and corresponding paper.
Try prompting with ```question? - %% ``` or ```question? - more info %%```
I filtered AskNYC comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I also added many tokens which were common on /r/AskNYC but missing from
GPT2.
The 'affirmations' list was sourced from excerpts in the OpenAI paper, a popular version of
the 'in this house we believe' sign, and the Reddit rules. They should not
be seen as all-encompassing or foundational to a safe AI. The main goal
was to see how it affected the behavior of GPT-NYC on generating toxic
or non-toxic language.
The [gpt-nyc](https://huggingface.co/monsoon-nlp/gpt-nyc) repo is based
on GPT2-Medium and comes off more accurate.
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this.
|
monsoon-nlp/sanaa-dialect | monsoon-nlp | 2023-09-03T03:32:43Z | 133 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"gpt2",
"text-generation",
"ar",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: ar
---
# Sanaa-Dialect
## Finetuned Arabic GPT-2 demo
This is a small GPT-2 model, originally trained on Arabic Wikipedia circa September 2020 ,
finetuned on dialect datasets from Qatar University, University of British Columbia / NLP,
and Johns Hopkins University / LREC
- https://qspace.qu.edu.qa/handle/10576/15265
- https://github.com/UBC-NLP/aoc_id
- https://github.com/ryancotterell/arabic_dialect_annotation
You can use special tokens to prompt five dialects: `[EGYPTIAN]`, `[GULF]`, `[LEVANTINE]`, `[MAGHREBI]`, and `[MSA]`
```
from simpletransformers.language_generation import LanguageGenerationModel
model = LanguageGenerationModel("gpt2", "monsoon-nlp/sanaa-dialect")
model.generate('[GULF]' + "مدينتي هي", { 'max_length': 100 })
```
There is NO content filtering in the current version; do not use for public-facing
text generation!
## Training and Finetuning details
Original model and training: https://huggingface.co/monsoon-nlp/sanaa
I inserted new tokens into the tokenizer, finetuned the model on the dialect samples, and exported the new model.
Notebook: https://colab.research.google.com/drive/1fXFH7g4nfbxBo42icI4ZMy-0TAGAxc2i
شكرا لتجربة هذا! ارجو التواصل معي مع الاسئلة
|
monsoon-nlp/no-phone-gpt2 | monsoon-nlp | 2023-09-03T03:31:40Z | 177 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"gpt2",
"text-generation",
"exbert",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: en
tags:
- exbert
license: mit
---
# no-phone-gpt2
This is a test to remove memorized private information, such as phone numbers, from a small GPT-2 model. This should not generate valid phone numbers.
Inspired by BAIR privacy research:
- https://bair.berkeley.edu/blog/2019/08/13/memorization/
- https://bair.berkeley.edu/blog/2020/12/20/lmmem/
[Blog post](https://mapmeld.medium.com/scrambling-memorized-info-in-gpt-2-60753d7652d8)
## Process
- All +## and +### tokens were replaced with new, randomly-selected 2- and 3-digit numbers in the vocab.json and tokenizer.json. You can identify these in outputs because the new tokens start with ^^.
- Input and output embeddings for +## and +### tokens were moved to the +00 and +000 embeddings.
- Removed associations between numbers from merges.txt
Using a library such as [ecco](https://github.com/jalammar/ecco), probabilities for next number token look equally likely, with +000 preferred.
Code: https://colab.research.google.com/drive/1X31TIZjmxlXMXAzQrR3Fl1AnLzGBCpWf#scrollTo=0GVFwrAgY68J
### Future goals
- Add new +### tokens to rebuild number generation
- Fine-tune new tokens on counting numbers and ended phone numbers
- Use [gpt2-large](https://huggingface.co/gpt2-large)
### BibTeX entry and citation info
Original GPT-2:
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
|
monsoon-nlp/es-seq2seq-gender-encoder | monsoon-nlp | 2023-09-03T03:31:17Z | 112 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"feature-extraction",
"es",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-03-02T23:29:05Z | ---
language: es
---
# es-seq2seq-gender (encoder)
This is a seq2seq model (encoder half) to "flip" gender in Spanish sentences.
The model can augment your existing Spanish data, or generate counterfactuals
to test a model's decisions (would changing the gender of the subject or speaker change output?).
Intended Examples:
- el profesor viejo => la profesora vieja (article, noun, adjective all flip)
- una actriz => un actor (irregular noun)
- el lingüista => la lingüista (irregular noun)
- la biblioteca => la biblioteca (no person, no flip)
People's names are unchanged in this version, but you can use packages
such as https://pypi.org/project/gender-guesser/
## Sample code
https://colab.research.google.com/drive/1Ta_YkXx93FyxqEu_zJ-W23PjPumMNHe5
```
import torch
from transformers import AutoTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_encoder_decoder_pretrained("monsoon-nlp/es-seq2seq-gender-encoder", "monsoon-nlp/es-seq2seq-gender-decoder")
tokenizer = AutoTokenizer.from_pretrained('monsoon-nlp/es-seq2seq-gender-decoder') # all are same as BETO uncased original
input_ids = torch.tensor(tokenizer.encode("la profesora vieja")).unsqueeze(0)
generated = model.generate(input_ids, decoder_start_token_id=model.config.decoder.pad_token_id)
tokenizer.decode(generated.tolist()[0])
> '[PAD] el profesor viejo profesor viejo profesor...'
```
## Training
I originally developed
<a href="https://github.com/MonsoonNLP/el-la">a gender flip Python script</a>
with
<a href="https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased">BETO</a>,
the Spanish-language BERT from Universidad de Chile,
and spaCy to parse dependencies in sentences.
More about this project: https://medium.com/ai-in-plain-english/gender-bias-in-spanish-bert-1f4d76780617
The seq2seq model is trained on gender-flipped text from that script run on the
<a href="https://huggingface.co/datasets/muchocine">muchocine dataset</a>,
and the first 6,853 lines from the
<a href="https://oscar-corpus.com/">OSCAR corpus</a>
(Spanish ded-duped).
The encoder and decoder started with weights and vocabulary from BETO (uncased).
## Non-binary gender
This model is useful to generate male and female text samples, but falls
short of capturing gender diversity in the world and in the Spanish
language. Some communities prefer the plural -@s to represent
-os and -as, or -e and -es for gender-neutral or mixed-gender plural,
or use fewer gendered professional nouns (la juez and not jueza). This is not yet
embraced by the Royal Spanish Academy
and is not represented in the corpora and tokenizers used to build this project.
This seq2seq project and script could, in the future, help generate more text samples
and prepare NLP models to understand us all better.
#### Sources
- https://www.nytimes.com/2020/04/15/world/americas/argentina-gender-language.html
- https://www.washingtonpost.com/dc-md-va/2019/12/05/teens-argentina-are-leading-charge-gender-neutral-language/?arc404=true
- https://www.theguardian.com/world/2020/jan/19/gender-neutral-language-battle-spain
- https://es.wikipedia.org/wiki/Lenguaje_no_sexista
- https://remezcla.com/culture/argentine-company-re-imagines-little-prince-gender-neutral-language/
|
monsoon-nlp/muril-adapted-local | monsoon-nlp | 2023-09-03T03:31:04Z | 164 | 2 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"hi",
"bn",
"ta",
"as",
"gu",
"kn",
"ks",
"ml",
"mr",
"ne",
"or",
"pa",
"sa",
"sd",
"te",
"ur",
"multilingual",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language:
- en
- hi
- bn
- ta
- as
- gu
- kn
- ks
- ml
- mr
- ne
- or
- pa
- sa
- sd
- te
- ur
- multilingual
license: apache-2.0
---
## MuRIL - Unofficial
Multilingual Representations for Indian Languages : Google open sourced
this BERT model pre-trained on 17 Indian languages, and their transliterated
counterparts.
The model was trained using a self-supervised masked language modeling task. We do whole word masking with a maximum of 80 predictions. The model was trained for 1000K steps, with a batch size of 4096, and a max sequence length of 512.
Original model on TFHub: https://tfhub.dev/google/MuRIL/1
*Official release now on HuggingFace (March 2021)* https://huggingface.co/google/muril-base-cased
License: Apache 2.0
### About this upload
I ported the TFHub .pb model to .h5 and then pytorch_model.bin for
compatibility with Transformers.
|
bigmorning/whisper_syl_noforce_add_inpde__0025 | bigmorning | 2023-09-03T03:25:32Z | 59 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:bigmorning/whisper_syl_noforce__0060",
"base_model:finetune:bigmorning/whisper_syl_noforce__0060",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-03T03:25:23Z | ---
license: apache-2.0
base_model: bigmorning/whisper_syl_noforce__0060
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce_add_inpde__0025
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce_add_inpde__0025
This model is a fine-tuned version of [bigmorning/whisper_syl_noforce__0060](https://huggingface.co/bigmorning/whisper_syl_noforce__0060) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2658
- Train Accuracy: 0.0337
- Train Wermet: 0.0941
- Validation Loss: 1.0630
- Validation Accuracy: 0.0215
- Validation Wermet: 0.4054
- Epoch: 24
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 3.0144 | 0.0185 | 0.9684 | 1.4362 | 0.0191 | 0.3870 | 0 |
| 1.6269 | 0.0241 | 0.2797 | 1.2846 | 0.0197 | 0.3593 | 1 |
| 1.3645 | 0.0256 | 0.2469 | 1.1967 | 0.0201 | 0.3481 | 2 |
| 1.2336 | 0.0263 | 0.2264 | 1.1602 | 0.0204 | 0.3390 | 3 |
| 1.0973 | 0.0272 | 0.2091 | 1.1211 | 0.0206 | 0.3296 | 4 |
| 0.9914 | 0.0279 | 0.1941 | 1.1412 | 0.0204 | 0.3209 | 5 |
| 0.9050 | 0.0284 | 0.1819 | 1.1795 | 0.0204 | 0.3281 | 6 |
| 0.8192 | 0.0291 | 0.1695 | 1.0845 | 0.0209 | 0.3149 | 7 |
| 0.7806 | 0.0293 | 0.1608 | 1.0628 | 0.0210 | 0.3099 | 8 |
| 0.7143 | 0.0298 | 0.1511 | 1.0554 | 0.0211 | 0.3069 | 9 |
| 0.6672 | 0.0302 | 0.1431 | 1.0539 | 0.0211 | 0.3046 | 10 |
| 0.6228 | 0.0305 | 0.1338 | 1.0531 | 0.0211 | 0.3038 | 11 |
| 0.5558 | 0.0311 | 0.1253 | 1.0476 | 0.0212 | 0.2997 | 12 |
| 0.5273 | 0.0314 | 0.1186 | 1.0431 | 0.0212 | 0.2991 | 13 |
| 0.4618 | 0.0319 | 0.1102 | 1.0659 | 0.0212 | 0.2974 | 14 |
| 0.4438 | 0.0321 | 0.1043 | 1.0439 | 0.0213 | 0.3053 | 15 |
| 0.4207 | 0.0323 | 0.0994 | 1.0748 | 0.0212 | 0.3049 | 16 |
| 0.4455 | 0.0321 | 0.0964 | 1.0538 | 0.0213 | 0.2983 | 17 |
| 0.3952 | 0.0325 | 0.0889 | 1.0487 | 0.0213 | 0.3005 | 18 |
| 0.3753 | 0.0327 | 0.0858 | 1.0461 | 0.0214 | 0.3115 | 19 |
| 0.3595 | 0.0328 | 0.0858 | 1.0434 | 0.0214 | 0.3330 | 20 |
| 0.3394 | 0.0330 | 0.0810 | 1.0479 | 0.0214 | 0.3264 | 21 |
| 0.2858 | 0.0336 | 0.0820 | 1.0572 | 0.0214 | 0.3297 | 22 |
| 0.2735 | 0.0337 | 0.0836 | 1.0755 | 0.0214 | 0.3552 | 23 |
| 0.2658 | 0.0337 | 0.0941 | 1.0630 | 0.0215 | 0.4054 | 24 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
dkqjrm/20230903070300 | dkqjrm | 2023-09-03T03:15:11Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:super_glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-09-02T22:03:20Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- super_glue
metrics:
- accuracy
model-index:
- name: '20230903070300'
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 20230903070300
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the super_glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8203
- Accuracy: 0.6599
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 11
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 80.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| No log | 1.0 | 340 | 0.7251 | 0.5063 |
| 0.7449 | 2.0 | 680 | 0.7348 | 0.5 |
| 0.7388 | 3.0 | 1020 | 0.7304 | 0.5 |
| 0.7388 | 4.0 | 1360 | 0.7639 | 0.5 |
| 0.7384 | 5.0 | 1700 | 0.7316 | 0.5 |
| 0.7376 | 6.0 | 2040 | 0.7268 | 0.5 |
| 0.7376 | 7.0 | 2380 | 0.7263 | 0.5 |
| 0.7328 | 8.0 | 2720 | 0.7333 | 0.5 |
| 0.7266 | 9.0 | 3060 | 0.7533 | 0.5 |
| 0.7266 | 10.0 | 3400 | 0.7247 | 0.4984 |
| 0.7293 | 11.0 | 3740 | 0.7290 | 0.5172 |
| 0.7248 | 12.0 | 4080 | 0.7539 | 0.5 |
| 0.7248 | 13.0 | 4420 | 0.7395 | 0.5 |
| 0.7255 | 14.0 | 4760 | 0.7360 | 0.5031 |
| 0.7271 | 15.0 | 5100 | 0.7278 | 0.5 |
| 0.7271 | 16.0 | 5440 | 0.7314 | 0.5094 |
| 0.7265 | 17.0 | 5780 | 0.7417 | 0.4984 |
| 0.724 | 18.0 | 6120 | 0.7263 | 0.5 |
| 0.724 | 19.0 | 6460 | 0.7272 | 0.5031 |
| 0.723 | 20.0 | 6800 | 0.7283 | 0.5172 |
| 0.7254 | 21.0 | 7140 | 0.7284 | 0.5047 |
| 0.7254 | 22.0 | 7480 | 0.7346 | 0.4984 |
| 0.7254 | 23.0 | 7820 | 0.7295 | 0.5125 |
| 0.7259 | 24.0 | 8160 | 0.7322 | 0.5047 |
| 0.7235 | 25.0 | 8500 | 0.7327 | 0.5172 |
| 0.7235 | 26.0 | 8840 | 0.7300 | 0.5172 |
| 0.7241 | 27.0 | 9180 | 0.7345 | 0.5016 |
| 0.7227 | 28.0 | 9520 | 0.7263 | 0.5172 |
| 0.7227 | 29.0 | 9860 | 0.7341 | 0.5016 |
| 0.7212 | 30.0 | 10200 | 0.7302 | 0.5125 |
| 0.7226 | 31.0 | 10540 | 0.7346 | 0.5078 |
| 0.7226 | 32.0 | 10880 | 0.7606 | 0.4702 |
| 0.7195 | 33.0 | 11220 | 0.7357 | 0.5063 |
| 0.7226 | 34.0 | 11560 | 0.7356 | 0.5031 |
| 0.7226 | 35.0 | 11900 | 0.7397 | 0.5063 |
| 0.7224 | 36.0 | 12240 | 0.7340 | 0.5157 |
| 0.7216 | 37.0 | 12580 | 0.7319 | 0.5047 |
| 0.7216 | 38.0 | 12920 | 0.7298 | 0.5141 |
| 0.7225 | 39.0 | 13260 | 0.7438 | 0.5016 |
| 0.7197 | 40.0 | 13600 | 0.7306 | 0.5047 |
| 0.7197 | 41.0 | 13940 | 0.7279 | 0.5125 |
| 0.7206 | 42.0 | 14280 | 0.7181 | 0.5502 |
| 0.7079 | 43.0 | 14620 | 0.7566 | 0.5862 |
| 0.7079 | 44.0 | 14960 | 0.7480 | 0.6254 |
| 0.6794 | 45.0 | 15300 | 0.6922 | 0.6630 |
| 0.6556 | 46.0 | 15640 | 0.7232 | 0.6223 |
| 0.6556 | 47.0 | 15980 | 0.6961 | 0.6458 |
| 0.6438 | 48.0 | 16320 | 0.7193 | 0.6458 |
| 0.6249 | 49.0 | 16660 | 0.6663 | 0.6693 |
| 0.6117 | 50.0 | 17000 | 0.8045 | 0.6191 |
| 0.6117 | 51.0 | 17340 | 0.6984 | 0.6630 |
| 0.5961 | 52.0 | 17680 | 0.6973 | 0.6646 |
| 0.5831 | 53.0 | 18020 | 0.7606 | 0.6348 |
| 0.5831 | 54.0 | 18360 | 0.7159 | 0.6614 |
| 0.5624 | 55.0 | 18700 | 0.7947 | 0.6426 |
| 0.558 | 56.0 | 19040 | 0.8629 | 0.6238 |
| 0.558 | 57.0 | 19380 | 0.7299 | 0.6646 |
| 0.5461 | 58.0 | 19720 | 0.7642 | 0.6411 |
| 0.5322 | 59.0 | 20060 | 0.7357 | 0.6661 |
| 0.5322 | 60.0 | 20400 | 0.8926 | 0.6191 |
| 0.5253 | 61.0 | 20740 | 0.7845 | 0.6348 |
| 0.5193 | 62.0 | 21080 | 0.7580 | 0.6614 |
| 0.5193 | 63.0 | 21420 | 0.7705 | 0.6505 |
| 0.5169 | 64.0 | 21760 | 0.8464 | 0.6458 |
| 0.5021 | 65.0 | 22100 | 0.8002 | 0.6536 |
| 0.5021 | 66.0 | 22440 | 0.7595 | 0.6677 |
| 0.487 | 67.0 | 22780 | 0.7971 | 0.6458 |
| 0.4977 | 68.0 | 23120 | 0.8245 | 0.6270 |
| 0.4977 | 69.0 | 23460 | 0.8225 | 0.6379 |
| 0.4822 | 70.0 | 23800 | 0.8323 | 0.6364 |
| 0.4802 | 71.0 | 24140 | 0.8205 | 0.6364 |
| 0.4802 | 72.0 | 24480 | 0.8086 | 0.6520 |
| 0.4779 | 73.0 | 24820 | 0.7994 | 0.6567 |
| 0.4801 | 74.0 | 25160 | 0.8206 | 0.6520 |
| 0.4706 | 75.0 | 25500 | 0.8035 | 0.6442 |
| 0.4706 | 76.0 | 25840 | 0.8213 | 0.6364 |
| 0.4738 | 77.0 | 26180 | 0.8128 | 0.6630 |
| 0.4687 | 78.0 | 26520 | 0.8068 | 0.6567 |
| 0.4687 | 79.0 | 26860 | 0.8098 | 0.6630 |
| 0.4598 | 80.0 | 27200 | 0.8203 | 0.6599 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
bigmorning/whisper_syl_noforce_add_inpde__0015 | bigmorning | 2023-09-03T02:59:03Z | 59 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:bigmorning/whisper_syl_noforce__0060",
"base_model:finetune:bigmorning/whisper_syl_noforce__0060",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-03T02:58:55Z | ---
license: apache-2.0
base_model: bigmorning/whisper_syl_noforce__0060
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce_add_inpde__0015
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce_add_inpde__0015
This model is a fine-tuned version of [bigmorning/whisper_syl_noforce__0060](https://huggingface.co/bigmorning/whisper_syl_noforce__0060) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4618
- Train Accuracy: 0.0319
- Train Wermet: 0.1102
- Validation Loss: 1.0659
- Validation Accuracy: 0.0212
- Validation Wermet: 0.2974
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 3.0144 | 0.0185 | 0.9684 | 1.4362 | 0.0191 | 0.3870 | 0 |
| 1.6269 | 0.0241 | 0.2797 | 1.2846 | 0.0197 | 0.3593 | 1 |
| 1.3645 | 0.0256 | 0.2469 | 1.1967 | 0.0201 | 0.3481 | 2 |
| 1.2336 | 0.0263 | 0.2264 | 1.1602 | 0.0204 | 0.3390 | 3 |
| 1.0973 | 0.0272 | 0.2091 | 1.1211 | 0.0206 | 0.3296 | 4 |
| 0.9914 | 0.0279 | 0.1941 | 1.1412 | 0.0204 | 0.3209 | 5 |
| 0.9050 | 0.0284 | 0.1819 | 1.1795 | 0.0204 | 0.3281 | 6 |
| 0.8192 | 0.0291 | 0.1695 | 1.0845 | 0.0209 | 0.3149 | 7 |
| 0.7806 | 0.0293 | 0.1608 | 1.0628 | 0.0210 | 0.3099 | 8 |
| 0.7143 | 0.0298 | 0.1511 | 1.0554 | 0.0211 | 0.3069 | 9 |
| 0.6672 | 0.0302 | 0.1431 | 1.0539 | 0.0211 | 0.3046 | 10 |
| 0.6228 | 0.0305 | 0.1338 | 1.0531 | 0.0211 | 0.3038 | 11 |
| 0.5558 | 0.0311 | 0.1253 | 1.0476 | 0.0212 | 0.2997 | 12 |
| 0.5273 | 0.0314 | 0.1186 | 1.0431 | 0.0212 | 0.2991 | 13 |
| 0.4618 | 0.0319 | 0.1102 | 1.0659 | 0.0212 | 0.2974 | 14 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
gadol/bloom_prompt_tuning_1693708411.24797 | gadol | 2023-09-03T02:38:40Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-03T02:38:39Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
bigmorning/whisper_syl_noforce_add_inpde__0005 | bigmorning | 2023-09-03T02:32:31Z | 59 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:bigmorning/whisper_syl_noforce__0060",
"base_model:finetune:bigmorning/whisper_syl_noforce__0060",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-03T02:32:25Z | ---
license: apache-2.0
base_model: bigmorning/whisper_syl_noforce__0060
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce_add_inpde__0005
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce_add_inpde__0005
This model is a fine-tuned version of [bigmorning/whisper_syl_noforce__0060](https://huggingface.co/bigmorning/whisper_syl_noforce__0060) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.0973
- Train Accuracy: 0.0272
- Train Wermet: 0.2091
- Validation Loss: 1.1211
- Validation Accuracy: 0.0206
- Validation Wermet: 0.3296
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 3.0144 | 0.0185 | 0.9684 | 1.4362 | 0.0191 | 0.3870 | 0 |
| 1.6269 | 0.0241 | 0.2797 | 1.2846 | 0.0197 | 0.3593 | 1 |
| 1.3645 | 0.0256 | 0.2469 | 1.1967 | 0.0201 | 0.3481 | 2 |
| 1.2336 | 0.0263 | 0.2264 | 1.1602 | 0.0204 | 0.3390 | 3 |
| 1.0973 | 0.0272 | 0.2091 | 1.1211 | 0.0206 | 0.3296 | 4 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
MouseTrap/maow-maow-machine-v1 | MouseTrap | 2023-09-03T02:11:23Z | 30 | 0 | diffusers | [
"diffusers",
"safetensors",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-09-03T02:09:34Z | ---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: a drawing of Mr. Maow Maow cat in outer space
---
# DreamBooth model for the Mr. Maow Maow concept trained by MouseTrap on the MouseTrap/maow_maow_dataset dataset.
This is a Stable Diffusion model fine-tuned on the Mr. Maow Maow concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a drawing of Mr. Maow Maow cat**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `cat` images for the animal theme.
Enter prompts as 'drawing of Mr. Maow Maow cat' to get the illustration-like outputs.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('MouseTrap/maow-maow-machine-v1')
image = pipeline().images[0]
image
```
|
yaohuacn/walljump_test_02 | yaohuacn | 2023-09-03T02:08:04Z | 13 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"BigWallJump",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-BigWallJump",
"region:us"
]
| reinforcement-learning | 2023-09-03T02:07:45Z | ---
library_name: ml-agents
tags:
- BigWallJump
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-BigWallJump
---
# **ppo** Agent playing **BigWallJump**
This is a trained model of a **ppo** agent playing **BigWallJump**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: yaohuacn/walljump_test_02
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
crumb/Ducky-MoMoe-prototype-e4-causal | crumb | 2023-09-03T02:05:38Z | 145 | 4 | transformers | [
"transformers",
"pytorch",
"switchgpt2",
"text-generation",
"custom_code",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-08-17T23:42:05Z | give me access to a dgx or any >=8x{A100 | H100} so i can warm start from llama-70b and create a gpt-4 competitor please
https://twitter.com/aicrumb/status/1692965412676206778 |
The-matt/autumn-shadow-48_580 | The-matt | 2023-09-03T01:48:51Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-03T01:48:48Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
Akbartus/Wasteland-Style-Lora | Akbartus | 2023-09-03T01:45:34Z | 6 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"region:us"
]
| text-to-image | 2023-08-16T22:08:20Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: wasteland, apocalypse
widget:
- text: 8k, realistic, vray, HDR, 6000K, in a post-apocalyptic crumbling castle, stuck drawbridge, weedy courtyard, dusty throne, faded tower flag
inference:
parameters:
width: 1024
height: 512
---
Keywords for prompts: apocalyptic wasteland, ruins, rust, concept art |
The-matt/autumn-shadow-48_570 | The-matt | 2023-09-03T01:19:09Z | 4 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-03T01:19:05Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
adyprat/drlc_taxi | adyprat | 2023-09-03T00:57:02Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-03T00:56:52Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: drlc_taxi
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.48 +/- 2.63
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="adyprat/drlc_taxi", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
adyprat/q-FrozenLake-v1-4x4-noSlippery | adyprat | 2023-09-03T00:46:33Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-03T00:46:31Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="adyprat/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
The-matt/autumn-shadow-48_540 | The-matt | 2023-09-03T00:34:58Z | 3 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-03T00:34:54Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
udaykiran19491/lstm-stock-price-predictor | udaykiran19491 | 2023-09-03T00:11:09Z | 18 | 3 | tf-keras | [
"tf-keras",
"en",
"license:gpl-3.0",
"region:us"
]
| null | 2023-09-03T00:01:33Z | ---
license: gpl-3.0
language:
- en
---
This is an LSTM model that is trained on NSE India's stock price history data. It is trained to predict the next closing price of a stock. |
Sentdex/WSB-GPT-13B | Sentdex | 2023-09-03T00:02:26Z | 20 | 10 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"dataset:Sentdex/wsb_reddit_v002",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2023-08-31T22:42:18Z | ---
license: apache-2.0
datasets:
- Sentdex/wsb_reddit_v002
---
# Model Card for WSB-GPT-13B
This is a Llama 2 13B Chat model fine-tuned with QLoRA on 2017-2018ish /r/wallstreetbets subreddit comments and responses, with the hopes of learning more about QLoRA and creating models with a little more character.
### Model Description
- **Developed by:** Sentdex
- **Shared by:** Sentdex
- **GPU Compute provided by:** [Lambda Labs](https://lambdalabs.com/service/gpu-cloud)
- **Model type:** Instruct/Chat
- **Language(s) (NLP):** Multilingual from Llama 2, but not sure what the fine-tune did to it, or if the fine-tuned behavior translates well to other languages. Let me know!
- **License:** Apache 2.0
- **Finetuned from Llama 2 13B Chat**
- **Demo [optional]:** [More Information Needed]
## Uses
This model's primary purpose is to be a fun chatbot and to learn more about QLoRA. It is not intended to be used for any other purpose and some people may find it abrasive/offensive.
## Bias, Risks, and Limitations
This model is prone to using at least 3 words that were popularly used in the WSB subreddit in that era that are much more frowned-upon. As time goes on, I may wind up pruning or find-replacing these words in the training data, or leaving it.
Just be advised this model can be offensive and is not intended for all audiences!
## How to Get Started with the Model
### Prompt Format:
```
### Comment:
[parent comment text]
### REPLY:
[bot's reply]
### END.
```
Use the code below to get started with the model.
```py
from transformers import pipeline
# Initialize the pipeline for text generation using the Sentdex/WSB-GPT-13B model
pipe = pipeline("text-generation", model="Sentdex/WSB-GPT-13B")
# Define your prompt
prompt = """### Comment:
How does the stock market actually work?
### REPLY:
"""
# Generate text based on the prompt
generated_text = pipe(prompt, max_length=128, num_return_sequences=1)
# Extract and print the generated text
print(generated_text[0]['generated_text'].split("### END.")[0])
```
Example continued generation from above:
```
### Comment:
How does the stock market actually work?
### REPLY:
You sell when you are up and buy when you are down.
```
Despite `</s>` being the typical Llama stop token, I was never able to get this token to be generated in training/testing so the model would just never stop generating. I wound up testing with ### END. and that worked, but obviously isn't ideal. Will fix this in the future maybe(tm).
#### Hardware
This QLoRA was trained on a Lambda Labs 1x H100 80GB GPU instance.
## Citation
- Llama 2 (Meta AI) for the base model.
- Farouk E / Far El: https://twitter.com/far__el for helping with all my silly questions about QLoRA
- Lambda Labs for the compute. The model itself only took a few hours to train, but it took me days to learn how to tie everything together.
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer for QLoRA + implementation on github: https://github.com/artidoro/qlora/
- @eugene-yh and @jinyongyoo on Github + @ChrisHayduk for the QLoRA merge: https://gist.github.com/ChrisHayduk/1a53463331f52dca205e55982baf9930
## Model Card Contact
[email protected] |
oddlyshapedfn/YouCompleteRe | oddlyshapedfn | 2023-09-02T23:57:45Z | 120 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-08-30T05:40:44Z | # You Complete Me, Re!!
This model is trained on a body of text consisting of DSP's posts on various forums, such as SRK, google groups, KoH forum, his personal website, and Discord.
The full dataset for the current version of this model is 1.2MB, including formatting, so it is relatively small.
As this model is trained from unfiltered samples of DSP's various posts, it may generate responses that are not be appropriate for all audiences, or are outright false.
# Settings
Try temperature=1.0, top_k=50, top_p=0.5, repetition_penality=1.05 as a start.
# Prompting
Start your message with `<ycr>:` and then add some text afterwards. For instance...
```
# Prompt
<ycr>: So now let's talk about my day off
# Responds...
. I had a pretty good day today. I went to the mall and got a new TV, a PS2 (wow, that's a first),
and a bunch of other stuff. I also bought a bunch of games for the PS2, including Far Cry, UT2k4,
and a few others. I also picked up a copy of UT2k4 for my brother, who is a HUGE UT2k4 fan.
I also went to Best Buy and picked up a copy of UT2k4 for myself, so I have two copies of the game.
I'm going to be playing it a lot this weekend, so I figured I should pick up some new games as well.
In conclusion, I had a very good day. I made some new friends, got some cool stuff, and got a lot of work done.
I think that if I had more free time I would probably do even better in school, but I don't have much of a life outside of school
```
|
fahmiaziz/finetune-donut-cord-v1 | fahmiaziz | 2023-09-02T23:55:07Z | 53 | 0 | transformers | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-text-to-text",
"license:creativeml-openrail-m",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2023-09-02T22:03:03Z | ---
license: creativeml-openrail-m
---
|
venetis/electra-base-discriminator-finetuned-3d-sentiment | venetis | 2023-09-02T23:51:46Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"electra",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-09-01T03:42:29Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: electra-base-discriminator-finetuned-3d-sentiment
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-base-discriminator-finetuned-3d-sentiment
This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5887
- Accuracy: 0.7873
- Precision: 0.7897
- Recall: 0.7873
- F1: 0.7864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 6381
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.797 | 1.0 | 1595 | 0.7075 | 0.7353 | 0.7434 | 0.7353 | 0.7357 |
| 0.5329 | 2.0 | 3190 | 0.6508 | 0.7550 | 0.7646 | 0.7550 | 0.7554 |
| 0.4597 | 3.0 | 4785 | 0.5889 | 0.7702 | 0.7803 | 0.7702 | 0.7695 |
| 0.3918 | 4.0 | 6380 | 0.5887 | 0.7873 | 0.7897 | 0.7873 | 0.7864 |
| 0.3093 | 5.0 | 7975 | 0.6412 | 0.7833 | 0.7877 | 0.7833 | 0.7836 |
| 0.2144 | 6.0 | 9570 | 0.7786 | 0.7844 | 0.7900 | 0.7844 | 0.7851 |
| 0.1507 | 7.0 | 11165 | 0.8455 | 0.7853 | 0.7903 | 0.7853 | 0.7862 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu117
- Datasets 2.10.1
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_530 | The-matt | 2023-09-02T23:48:24Z | 6 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T23:48:20Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
johaanm/test-planner-alpha-V6.1 | johaanm | 2023-09-02T23:47:47Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T23:47:43Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
- PEFT 0.4.0
|
dt-and-vanilla-ardt/dt-d4rl_medium_halfcheetah-0209_2300-99 | dt-and-vanilla-ardt | 2023-09-02T23:36:43Z | 31 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T23:01:50Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_halfcheetah-0209_2300-99
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_halfcheetah-0209_2300-99
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
anayzehri/KawaiiApp | anayzehri | 2023-09-02T23:33:53Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-09-02T23:33:53Z | ---
license: creativeml-openrail-m
---
|
daochf/Lora-HuggyLlama7b-PuceDS-v03 | daochf | 2023-09-02T23:32:37Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T23:27:53Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
nahuel89p/nous-hermes-llama2-13b.gguf.q4_K_M | nahuel89p | 2023-09-02T23:22:40Z | 0 | 2 | null | [
"license:mit",
"region:us"
]
| null | 2023-09-02T22:10:52Z | ---
license: mit
---
This model is a direct conversion from https://huggingface.co/TheBloke/Nous-Hermes-Llama2-GGML using Llama.cpp convert-llama-ggmlv3-to-gguf.py utility script.
All the required metadata (config.json and tokenizer) was provided.
|
The-matt/autumn-shadow-48_520 | The-matt | 2023-09-02T23:18:33Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T23:18:29Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
dt-and-vanilla-ardt/dt-d4rl_medium_walker2d-0209_2245-99 | dt-and-vanilla-ardt | 2023-09-02T23:17:34Z | 33 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T22:46:52Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_walker2d-0209_2245-99
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_walker2d-0209_2245-99
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
sashat/whisper-sara-ar | sashat | 2023-09-02T23:15:28Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"dataset:ClArTTS_N_QASR_female",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T21:59:41Z | ---
language:
- ar
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- ClArTTS_N_QASR_female
model-index:
- name: Whisper Small Ar - Sara
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ar - Sara
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the CLArQasr dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 100
### Training results
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.2
|
camenduru/kosmos-2-patch14-224 | camenduru | 2023-09-02T23:09:06Z | 88 | 0 | transformers | [
"transformers",
"pytorch",
"kosmos-2",
"image-text-to-text",
"custom_code",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2023-09-02T22:47:34Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Kosmos-2: Grounding Multimodal Large Language Models to the World
**(There is an on going effort to port `Kosmos-2` directly into `transformers`. This repository (remote code) might need some more bug fixes later, including breaking changes.)**
<a href="https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" target="_blank"><figure><img src="https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" width="384"><figcaption><b>[An image of a snowman warming himself by a fire.]</b></figcaption></figure></a>
This Hub repository contains a HuggingFace's `transformers` implementation of [the original Kosmos-2 model](https://github.com/microsoft/unilm/tree/master/kosmos-2) from Microsoft.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
prompt = "<grounding>An image of"
url = "https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/snowman.png"
image = Image.open(requests.get(url, stream=True).raw)
# The original Kosmos-2 demo saves the image first then reload it. For some images, this will give slightly different image input and change the generation outputs.
# Uncomment the following 2 lines if you want to match the original demo's outputs.
# (One example is the `two_dogs.jpg` from the demo)
# image.save("new_image.jpg")
# image = Image.open("new_image.jpg")
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"][:, :-1],
attention_mask=inputs["attention_mask"][:, :-1],
img_features=None,
img_attn_mask=inputs["img_attn_mask"][:, :-1],
use_cache=True,
max_new_tokens=64,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Specify `cleanup_and_extract=False` in order to see the raw model generation.
processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
print(processed_text)
# `<grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a fire</phrase><object><patch_index_0005><patch_index_0911></object>.`
# By default, the generated text is cleanup and the entities are extracted.
processed_text, entities = processor.post_process_generation(generated_text)
print(processed_text)
# `An image of a snowman warming himself by a fire.`
print(entities)
# `[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]`
```
## Draw the bounding bboxes of the entities on the image
Once you have the `entities`, you can use the following helper function to draw their bounding bboxes on the image:
```python
import cv2
import numpy as np
import os
import requests
import torch
import torchvision.transforms as T
from PIL import Image
def is_overlapping(rect1, rect2):
x1, y1, x2, y2 = rect1
x3, y3, x4, y4 = rect2
return not (x2 < x3 or x1 > x4 or y2 < y3 or y1 > y4)
def draw_entity_boxes_on_image(image, entities, show=False, save_path=None):
"""_summary_
Args:
image (_type_): image or image path
collect_entity_location (_type_): _description_
"""
if isinstance(image, Image.Image):
image_h = image.height
image_w = image.width
image = np.array(image)[:, :, [2, 1, 0]]
elif isinstance(image, str):
if os.path.exists(image):
pil_img = Image.open(image).convert("RGB")
image = np.array(pil_img)[:, :, [2, 1, 0]]
image_h = pil_img.height
image_w = pil_img.width
else:
raise ValueError(f"invaild image path, {image}")
elif isinstance(image, torch.Tensor):
# pdb.set_trace()
image_tensor = image.cpu()
reverse_norm_mean = torch.tensor([0.48145466, 0.4578275, 0.40821073])[:, None, None]
reverse_norm_std = torch.tensor([0.26862954, 0.26130258, 0.27577711])[:, None, None]
image_tensor = image_tensor * reverse_norm_std + reverse_norm_mean
pil_img = T.ToPILImage()(image_tensor)
image_h = pil_img.height
image_w = pil_img.width
image = np.array(pil_img)[:, :, [2, 1, 0]]
else:
raise ValueError(f"invaild image format, {type(image)} for {image}")
if len(entities) == 0:
return image
new_image = image.copy()
previous_bboxes = []
# size of text
text_size = 1
# thickness of text
text_line = 1 # int(max(1 * min(image_h, image_w) / 512, 1))
box_line = 3
(c_width, text_height), _ = cv2.getTextSize("F", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
base_height = int(text_height * 0.675)
text_offset_original = text_height - base_height
text_spaces = 3
for entity_name, (start, end), bboxes in entities:
for (x1_norm, y1_norm, x2_norm, y2_norm) in bboxes:
orig_x1, orig_y1, orig_x2, orig_y2 = int(x1_norm * image_w), int(y1_norm * image_h), int(x2_norm * image_w), int(y2_norm * image_h)
# draw bbox
# random color
color = tuple(np.random.randint(0, 255, size=3).tolist())
new_image = cv2.rectangle(new_image, (orig_x1, orig_y1), (orig_x2, orig_y2), color, box_line)
l_o, r_o = box_line // 2 + box_line % 2, box_line // 2 + box_line % 2 + 1
x1 = orig_x1 - l_o
y1 = orig_y1 - l_o
if y1 < text_height + text_offset_original + 2 * text_spaces:
y1 = orig_y1 + r_o + text_height + text_offset_original + 2 * text_spaces
x1 = orig_x1 + r_o
# add text background
(text_width, text_height), _ = cv2.getTextSize(f" {entity_name}", cv2.FONT_HERSHEY_COMPLEX, text_size, text_line)
text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2 = x1, y1 - (text_height + text_offset_original + 2 * text_spaces), x1 + text_width, y1
for prev_bbox in previous_bboxes:
while is_overlapping((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2), prev_bbox):
text_bg_y1 += (text_height + text_offset_original + 2 * text_spaces)
text_bg_y2 += (text_height + text_offset_original + 2 * text_spaces)
y1 += (text_height + text_offset_original + 2 * text_spaces)
if text_bg_y2 >= image_h:
text_bg_y1 = max(0, image_h - (text_height + text_offset_original + 2 * text_spaces))
text_bg_y2 = image_h
y1 = image_h
break
alpha = 0.5
for i in range(text_bg_y1, text_bg_y2):
for j in range(text_bg_x1, text_bg_x2):
if i < image_h and j < image_w:
if j < text_bg_x1 + 1.35 * c_width:
# original color
bg_color = color
else:
# white
bg_color = [255, 255, 255]
new_image[i, j] = (alpha * new_image[i, j] + (1 - alpha) * np.array(bg_color)).astype(np.uint8)
cv2.putText(
new_image, f" {entity_name}", (x1, y1 - text_offset_original - 1 * text_spaces), cv2.FONT_HERSHEY_COMPLEX, text_size, (0, 0, 0), text_line, cv2.LINE_AA
)
# previous_locations.append((x1, y1))
previous_bboxes.append((text_bg_x1, text_bg_y1, text_bg_x2, text_bg_y2))
pil_image = Image.fromarray(new_image[:, :, [2, 1, 0]])
if save_path:
pil_image.save(save_path)
if show:
pil_image.show()
return new_image
# (The same image from the previous code example)
url = "https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/snowman.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# From the previous code example
entities = [('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
# Draw the bounding bboxes
draw_entity_boxes_on_image(image, entities, show=True)
```
Here is the annotated image:
<a href="https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" target="_blank"><img src="https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" width="500"></a>
## Tasks
This model is capable of performing different tasks through changing the prompts.
First, let's define a function to run a prompt.
```python
import requests
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
url = "https://huggingface.co/ydshieh/kosmos-2-patch14-224/resolve/main/snowman.png"
image = Image.open(requests.get(url, stream=True).raw)
def run_example(prompt):
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"][:, :-1],
attention_mask=inputs["attention_mask"][:, :-1],
img_features=None,
img_attn_mask=inputs["img_attn_mask"][:, :-1],
use_cache=True,
max_new_tokens=64,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
_processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
processed_text, entities = processor.post_process_generation(generated_text)
print(processed_text)
print(entities)
print(_processed_text)
```
Here are the tasks `Kosmos-2` could perform:
### Multimodal Grounding
#### • Phrase Grounding
```python
prompt = "<grounding><phrase> a snowman</phrase>"
run_example(prompt)
# a snowman is warming himself by the fire
# [('a snowman', (0, 9), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('the fire', (32, 40), [(0.203125, 0.015625, 0.453125, 0.859375)])]
# <grounding><phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> is warming himself by<phrase> the fire</phrase><object><patch_index_0006><patch_index_0878></object>
```
#### • Referring Expression Comprehension
```python
prompt = "<grounding><phrase> a snowman next to a fire</phrase>"
run_example(prompt)
# a snowman next to a fire
# [('a snowman next to a fire', (0, 24), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding><phrase> a snowman next to a fire</phrase><object><patch_index_0044><patch_index_0863></object>
```
### Multimodal Referring
#### • Referring expression generation
```python
prompt = "<grounding><phrase> It</phrase><object><patch_index_0044><patch_index_0863></object> is"
run_example(prompt)
# It is snowman in a hat and scarf
# [('It', (0, 2), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding><phrase> It</phrase><object><patch_index_0044><patch_index_0863></object> is snowman in a hat and scarf
```
### Perception-Language Tasks
#### • Grounded VQA
```python
prompt = "<grounding> Question: What is special about this image? Answer:"
run_example(prompt)
# Question: What is special about this image? Answer: The image features a snowman sitting by a campfire in the snow.
# [('a snowman', (71, 80), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a campfire', (92, 102), [(0.109375, 0.640625, 0.546875, 0.984375)])]
# <grounding> Question: What is special about this image? Answer: The image features<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> sitting by<phrase> a campfire</phrase><object><patch_index_0643><patch_index_1009></object> in the snow.
```
#### • Grounded VQA with multimodal referring via bounding boxes
```python
prompt = "<grounding> Question: Where is<phrase> the fire</phrase><object><patch_index_0005><patch_index_0911></object> next to? Answer:"
run_example(prompt)
# Question: Where is the fire next to? Answer: Near the snowman.
# [('the fire', (19, 27), [(0.171875, 0.015625, 0.484375, 0.890625)]), ('the snowman', (50, 61), [(0.390625, 0.046875, 0.984375, 0.828125)])]
# <grounding> Question: Where is<phrase> the fire</phrase><object><patch_index_0005><patch_index_0911></object> next to? Answer: Near<phrase> the snowman</phrase><object><patch_index_0044><patch_index_0863></object>.
```
### Grounded Image captioning
#### • Brief
```python
prompt = "<grounding> An image of"
run_example(prompt)
# An image of a snowman warming himself by a campfire.
# [('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a campfire', (41, 51), [(0.109375, 0.640625, 0.546875, 0.984375)])]
# <grounding> An image of<phrase> a snowman</phrase><object><patch_index_0044><patch_index_0863></object> warming himself by<phrase> a campfire</phrase><object><patch_index_0643><patch_index_1009></object>.
```
#### • Detailed
```python
prompt = "<grounding> Describe this image in detail:"
run_example(prompt)
# Describe this image in detail: The image features a snowman sitting by a campfire in the snow. He is wearing a hat, scarf, and gloves, with a pot nearby and a cup
# [('a campfire', (71, 81), [(0.171875, 0.015625, 0.484375, 0.984375)]), ('a hat', (109, 114), [(0.515625, 0.046875, 0.828125, 0.234375)]), ('scarf', (116, 121), [(0.515625, 0.234375, 0.890625, 0.578125)]), ('gloves', (127, 133), [(0.515625, 0.390625, 0.640625, 0.515625)]), ('a pot', (140, 145), [(0.078125, 0.609375, 0.265625, 0.859375)])]
# <grounding> Describe this image in detail: The image features a snowman sitting by<phrase> a campfire</phrase><object><patch_index_0005><patch_index_1007></object> in the snow. He is wearing<phrase> a hat</phrase><object><patch_index_0048><patch_index_0250></object>,<phrase> scarf</phrase><object><patch_index_0240><patch_index_0604></object>, and<phrase> gloves</phrase><object><patch_index_0400><patch_index_0532></object>, with<phrase> a pot</phrase><object><patch_index_0610><patch_index_0872></object> nearby and<phrase> a cup</phrase><object>
```
## Running the Flask Server
_flask_kosmos2.py_ shows the implementation of a Flask server for the model.
It allowes the model to be approached as a REST API.
After starting the server. You can send a POST request to `http://localhost:8005/process_prompt` with the following form data:
- `prompt`: For example `<grounding> an image of`
- `image`: The image file as binary data
This in turn will produce a reply with the following JSON format:
- `message`: The Kosmos-2 generated text
- `entities`: The extracted entities
An easy way to test this is through an application like Postman. Make sure the image field is set to `File`.
```python
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from flask import Flask, request, jsonify
import json
app = Flask(__name__)
model = AutoModelForVision2Seq.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("ydshieh/kosmos-2-patch14-224", trust_remote_code=True)
@app.route('/process_prompt', methods=['POST'])
def process_prompt():
try:
# Get the uploaded image data from the POST request
uploaded_file = request.files['image']
prompt = request.form.get('prompt')
image = Image.open(uploaded_file.stream)
print(image.size)
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"][:, :-1],
attention_mask=inputs["attention_mask"][:, :-1],
img_features=None,
img_attn_mask=inputs["img_attn_mask"][:, :-1],
use_cache=True,
max_new_tokens=64,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# By default, the generated text is cleanup and the entities are extracted.
processed_text, entities = processor.post_process_generation(generated_text)
parsed_entities = entities_to_json(entities)
print(generated_text)
print(processed_text)
return jsonify({"message": processed_text, 'entities': parsed_entities})
except Exception as e:
return jsonify({"error": str(e)})
def entities_to_json(entities):
result = []
for e in entities:
label = e[0]
box_coords = e[1]
box_size = e[2][0]
entity_result = {
"label": label,
"boundingBoxPosition": {"x": box_coords[0], "y": box_coords[1]},
"boundingBox": {"x_min": box_size[0], "y_min": box_size[1], "x_max": box_size[2], "y_max": box_size[3]}
}
print(entity_result)
result.append(entity_result)
return result
if __name__ == '__main__':
app.run(host='localhost', port=8005)
``` |
CzarnyRycerz/ppo-LunarLander-v2-trained-locally | CzarnyRycerz | 2023-09-02T22:55:36Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-02T22:38:57Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 310.89 +/- 13.59
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
dt-and-vanilla-ardt/dt-d4rl_medium_walker2d-0209_2209-66 | dt-and-vanilla-ardt | 2023-09-02T22:45:26Z | 31 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T22:11:15Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_walker2d-0209_2209-66
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_walker2d-0209_2209-66
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
Akalite/Test | Akalite | 2023-09-02T22:35:48Z | 0 | 0 | null | [
"dataset:gothstaf/questillma2",
"region:us"
]
| null | 2023-09-02T22:35:23Z | ---
datasets:
- gothstaf/questillma2
--- |
The-matt/autumn-shadow-48_480 | The-matt | 2023-09-02T22:35:29Z | 4 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T22:35:26Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
dt-and-vanilla-ardt/dt-d4rl_medium_hopper-0209_2210-99 | dt-and-vanilla-ardt | 2023-09-02T22:29:49Z | 32 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T22:11:08Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_hopper-0209_2210-99
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_hopper-0209_2210-99
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
dt-and-vanilla-ardt/dt-d4rl_medium_halfcheetah-0209_2131-33 | dt-and-vanilla-ardt | 2023-09-02T22:20:20Z | 31 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T21:33:13Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_halfcheetah-0209_2131-33
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_halfcheetah-0209_2131-33
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
KingKazma/xsum_gpt2_p_tuning_500_4_50000_6_e3_s6789_v4_l4_v100 | KingKazma | 2023-09-02T22:19:30Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-08-17T22:01:17Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
dt-and-vanilla-ardt/dt-d4rl_medium_walker2d-0209_2131-33 | dt-and-vanilla-ardt | 2023-09-02T22:09:48Z | 31 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T21:32:19Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_walker2d-0209_2131-33
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_walker2d-0209_2131-33
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_460 | The-matt | 2023-09-02T21:55:37Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T21:55:34Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
dt-and-vanilla-ardt/dt-d4rl_medium_hopper-0209_2131-33 | dt-and-vanilla-ardt | 2023-09-02T21:50:03Z | 31 | 0 | transformers | [
"transformers",
"pytorch",
"decision_transformer",
"generated_from_trainer",
"dataset:decision_transformer_gym_replay",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T21:31:56Z | ---
base_model: ''
tags:
- generated_from_trainer
datasets:
- decision_transformer_gym_replay
model-index:
- name: dt-d4rl_medium_hopper-0209_2131-33
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dt-d4rl_medium_hopper-0209_2131-33
This model is a fine-tuned version of [](https://huggingface.co/) on the decision_transformer_gym_replay dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 10000
### Training results
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.0
- Tokenizers 0.13.3
|
monsoon-nlp/mGPT-13B-quantized | monsoon-nlp | 2023-09-02T21:47:28Z | 16 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"multilingual",
"ar",
"hi",
"id",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2023-09-01T06:04:43Z | ---
license: apache-2.0
language:
- ar
- hi
- id
pipeline_tag: text-generation
tags:
- multilingual
widget:
- text: 'في مدرستي السابقة'
example_title: Arabic prompt
- text: 'आप समुद्री लुटेरों के बारे में क्या जानते हैं?'
example_title: Hindi prompt
- text: 'Kucing saya suka'
example_title: Indonesian prompt
---
# mGPT-quantized
The concept: 8-bit quantized version of [mGPT-13B](https://huggingface.co/ai-forever/mGPT-13B), an LLM released by AI-Forever / Sberbank AI in 2022-2023.
On the GPT scale, it is between the # of parameters for GPT-2 and GPT-3, but comparison is tricky after training on 60+ languages.
My goal is to evaluate this on Hindi and Indonesian tasks, where there are fewer autoregressive language models in this size range.
For English: use a GPT model or LLaMa2-7B
For Arabic: in August 2023 I would recommend the bilingual [JAIS model](https://huggingface.co/inception-mbzuai/jais-13b), which is also 13B parameters can be quantized.
In August 2023 AI-Forever added 1.3B-param models for 20+ languages. If your language is Mongolian, for example, it might be better to use mGPT-1.3B-mongol and not this one.
They also have a 1.3B param model for all languages, which I further quantized here: https://huggingface.co/monsoon-nlp/mGPT-quantized
## How was the model created?
Quantization of mGPT-13B was done using `bitsandbytes` library, CoLab Pro with an A100 GPU, and a lot of space on Google Drive.
```python
from transformers import BitsAndBytesConfig, GPT2LMHeadModel
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_8bit_compute_dtype=torch.bfloat16,
bnb_8bit_use_double_quant=True,
bnb_8bit_quant_type="nf4",
)
qmodel = GPT2LMHeadModel.from_pretrained(
"ai-forever/mGPT-13B",
load_in_8bit=True,
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
device_map="auto"
)
qmodel.save_pretrained("model_name")
```
## Future steps
- mGPT could be further quantized (4-bit), but `model.save_pretrained()` currently throws a `NotImplementedError` error. |
venkateshkhatri/dreambooth2 | venkateshkhatri | 2023-09-02T21:38:15Z | 1 | 1 | diffusers | [
"diffusers",
"text-to-image",
"autotrain",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2023-09-02T15:32:03Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: photo of venkateshkhatri
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e-1_s6789_v4_l4_v100_resume_manual | KingKazma | 2023-09-02T21:23:08Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T21:23:07Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
jjluo/my_awesome_food_model | jjluo | 2023-09-02T21:20:53Z | 191 | 0 | transformers | [
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:food101",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-09-02T21:10:12Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- food101
metrics:
- accuracy
model-index:
- name: my_awesome_food_model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food101
type: food101
config: default
split: train[:5000]
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.908
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6222
- Accuracy: 0.908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7507 | 0.99 | 62 | 2.5634 | 0.831 |
| 1.8341 | 2.0 | 125 | 1.7980 | 0.87 |
| 1.6407 | 2.98 | 186 | 1.6222 | 0.908 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_440 | The-matt | 2023-09-02T21:20:27Z | 1 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T21:20:22Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e3_s6789_v4_l4_v100 | KingKazma | 2023-09-02T21:20:15Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T21:20:14Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_430 | The-matt | 2023-09-02T21:11:20Z | 3 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T21:11:14Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
actionpace/UndiMix-v1-13b | actionpace | 2023-09-02T20:57:35Z | 2 | 0 | null | [
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T20:38:02Z | ---
license: other
language:
- en
---
Some of my own quants:
* UndiMix-v1-13b_Q5_1_4K.gguf
* UndiMix-v1-13b_Q5_1_8K.gguf
Original Model: [UndiMix-v1-13b](https://huggingface.co/Undi95/UndiMix-v1-13b)
|
jaober/CartPole-v1 | jaober | 2023-09-02T20:57:06Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-02T20:56:57Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e2_s6789_v4_l4_v100 | KingKazma | 2023-09-02T20:49:41Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T20:49:39Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
actionpace/MythoMax-L2-Kimiko-v2-13b | actionpace | 2023-09-02T20:48:28Z | 10 | 0 | null | [
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T20:23:18Z | ---
license: other
language:
- en
---
Some of my own quants:
* MythoMax-L2-Kimiko-v2-13b_Q5_1_4K.gguf
* MythoMax-L2-Kimiko-v2-13b_Q5_1_8K.gguf
Original Model: [MythoMax-L2-Kimiko-v2-13b](https://huggingface.co/Undi95/MythoMax-L2-Kimiko-v2-13b)
|
dwitidibyajyoti/layoutlm-funsd | dwitidibyajyoti | 2023-09-02T20:44:56Z | 160 | 0 | transformers | [
"transformers",
"pytorch",
"layoutlm",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/layoutlm-base-uncased",
"base_model:finetune:microsoft/layoutlm-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-09-02T20:40:55Z | ---
base_model: microsoft/layoutlm-base-uncased
tags:
- generated_from_trainer
model-index:
- name: layoutlm-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlm-funsd
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8927
- Column: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25}
- Ignore: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3}
- Key: {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 17}
- Value: {'precision': 0.6666666666666666, 'recall': 0.48484848484848486, 'f1': 0.5614035087719298, 'number': 33}
- Overall Precision: 0.6875
- Overall Recall: 0.4231
- Overall F1: 0.5238
- Overall Accuracy: 0.7947
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Column | Ignore | Key | Value | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-------------------------------------------------------------------------------------------:|:---------------------------------------------------------:|:------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 2.4627 | 1.0 | 2 | 2.1288 | {'precision': 0.23529411764705882, 'recall': 0.16, 'f1': 0.19047619047619052, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.06060606060606061, 'recall': 0.06060606060606061, 'f1': 0.06060606060606061, 'number': 33} | 0.0870 | 0.0769 | 0.0816 | 0.6887 |
| 2.1025 | 2.0 | 4 | 1.7650 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6921 |
| 1.7503 | 3.0 | 6 | 1.4611 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6904 |
| 1.4557 | 4.0 | 8 | 1.2624 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6904 |
| 1.3067 | 5.0 | 10 | 1.1889 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6904 |
| 1.1884 | 6.0 | 12 | 1.1436 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6904 |
| 1.1456 | 7.0 | 14 | 1.0901 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 17} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 33} | 0.0 | 0.0 | 0.0 | 0.6904 |
| 1.0915 | 8.0 | 16 | 1.0410 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 0.11764705882352941, 'f1': 0.21052631578947367, 'number': 17} | {'precision': 0.3333333333333333, 'recall': 0.030303030303030304, 'f1': 0.05555555555555555, 'number': 33} | 0.6 | 0.0385 | 0.0723 | 0.6937 |
| 1.0428 | 9.0 | 18 | 0.9990 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 0.29411764705882354, 'f1': 0.45454545454545453, 'number': 17} | {'precision': 0.23529411764705882, 'recall': 0.12121212121212122, 'f1': 0.16, 'number': 33} | 0.2727 | 0.1154 | 0.1622 | 0.7252 |
| 0.9819 | 10.0 | 20 | 0.9639 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 0.4117647058823529, 'f1': 0.5833333333333334, 'number': 17} | {'precision': 0.2631578947368421, 'recall': 0.15151515151515152, 'f1': 0.19230769230769232, 'number': 33} | 0.3243 | 0.1538 | 0.2087 | 0.7517 |
| 0.9592 | 11.0 | 22 | 0.9344 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 0.6470588235294118, 'f1': 0.7857142857142858, 'number': 17} | {'precision': 0.3684210526315789, 'recall': 0.21212121212121213, 'f1': 0.2692307692307693, 'number': 33} | 0.4737 | 0.2308 | 0.3103 | 0.7781 |
| 0.9011 | 12.0 | 24 | 0.9105 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 17} | {'precision': 0.64, 'recall': 0.48484848484848486, 'f1': 0.5517241379310344, 'number': 33} | 0.66 | 0.4231 | 0.5156 | 0.7930 |
| 0.9426 | 13.0 | 26 | 0.8927 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 17} | {'precision': 0.6666666666666666, 'recall': 0.48484848484848486, 'f1': 0.5614035087719298, 'number': 33} | 0.6875 | 0.4231 | 0.5238 | 0.7947 |
| 0.8809 | 14.0 | 28 | 0.8821 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 17} | {'precision': 0.6666666666666666, 'recall': 0.48484848484848486, 'f1': 0.5614035087719298, 'number': 33} | 0.6875 | 0.4231 | 0.5238 | 0.7947 |
| 0.9188 | 15.0 | 30 | 0.8774 | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 25} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 3} | {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 17} | {'precision': 0.6666666666666666, 'recall': 0.48484848484848486, 'f1': 0.5614035087719298, 'number': 33} | 0.6875 | 0.4231 | 0.5238 | 0.7947 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
caveli/bloom_prompt_tuning_1693686452.0382597 | caveli | 2023-09-02T20:32:52Z | 4 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T20:32:50Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
skipperjo/wav2vec2-large-xls-r-300m-slowakisch-colab | skipperjo | 2023-09-02T20:30:03Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_11_0",
"base_model:facebook/wav2vec2-xls-r-300m",
"base_model:finetune:facebook/wav2vec2-xls-r-300m",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T19:15:33Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-xls-r-300m
tags:
- generated_from_trainer
datasets:
- common_voice_11_0
model-index:
- name: wav2vec2-large-xls-r-300m-slowakisch-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-slowakisch-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_11_0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
amirxsanti/Amirmodel | amirxsanti | 2023-09-02T20:29:46Z | 1 | 1 | diffusers | [
"diffusers",
"text-to-image",
"autotrain",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"region:us"
]
| text-to-image | 2023-09-02T08:46:34Z |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: photo of AmirSanti person
tags:
- text-to-image
- diffusers
- autotrain
inference: true
---
# DreamBooth trained by AutoTrain
Text encoder was not trained.
|
s3nh/WizardLM-WizardCoder-Python-13B-V1.0-GGUF | s3nh | 2023-09-02T20:28:35Z | 11 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:openrail",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-09-02T20:10:40Z |
---
license: openrail
pipeline_tag: text-generation
library_name: transformers
language:
- zh
- en
---
## Original model card
Buy me a coffee if you like this project ;)
<a href="https://www.buymeacoffee.com/s3nh"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
#### Description
GGUF Format model files for [This project](https://huggingface.co/WizardLM/WizardCoder-Python-13B-V1.0).
### GGUF Specs
GGUF is a format based on the existing GGJT, but makes a few changes to the format to make it more extensible and easier to use. The following features are desired:
Single-file deployment: they can be easily distributed and loaded, and do not require any external files for additional information.
Extensible: new features can be added to GGML-based executors/new information can be added to GGUF models without breaking compatibility with existing models.
mmap compatibility: models can be loaded using mmap for fast loading and saving.
Easy to use: models can be easily loaded and saved using a small amount of code, with no need for external libraries, regardless of the language used.
Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
The key difference between GGJT and GGUF is the use of a key-value structure for the hyperparameters (now referred to as metadata), rather than a list of untyped values.
This allows for new metadata to be added without breaking compatibility with existing models, and to annotate the model with additional information that may be useful for
inference or for identifying the model.
### Perplexity params
Model Measure Q2_K Q3_K_S Q3_K_M Q3_K_L Q4_0 Q4_1 Q4_K_S Q4_K_M Q5_0 Q5_1 Q5_K_S Q5_K_M Q6_K Q8_0 F16
7B perplexity 6.7764 6.4571 6.1503 6.0869 6.1565 6.0912 6.0215 5.9601 5.9862 5.9481 5.9419 5.9208 5.9110 5.9070 5.9066
13B perplexity 5.8545 5.6033 5.4498 5.4063 5.3860 5.3608 5.3404 5.3002 5.2856 5.2706 5.2785 5.2638 5.2568 5.2548 5.2543
### inference
TODO
# Original model card
|
The-matt/autumn-shadow-48_380 | The-matt | 2023-09-02T20:26:25Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T20:26:21Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_3_50000_8_e1_s6789_v4_l4_v100 | KingKazma | 2023-09-02T20:19:06Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T20:19:05Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
actionpace/Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged | actionpace | 2023-09-02T20:17:30Z | 3 | 0 | null | [
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T19:51:33Z | ---
license: other
language:
- en
---
Some of my own quants:
* Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged_Q5_1_4K.gguf
* Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged_Q5_1_8K.gguf
Original Model: [Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged](https://huggingface.co/Doctor-Shotgun/Nous-Hermes-Llama2-13b-Kimiko-Lora-Merged)
|
nmitchko/i2b2-querybuilder-codellama-34b | nmitchko | 2023-09-02T20:14:51Z | 6 | 0 | peft | [
"peft",
"medical",
"text-generation",
"en",
"arxiv:2106.09685",
"license:llama2",
"region:us"
]
| text-generation | 2023-09-01T18:55:52Z | ---
language:
- en
library_name: peft
pipeline_tag: text-generation
tags:
- medical
license: llama2
---
# i2b2 QueryBuilder - 34b
<!-- TODO: Add a link here N: DONE-->
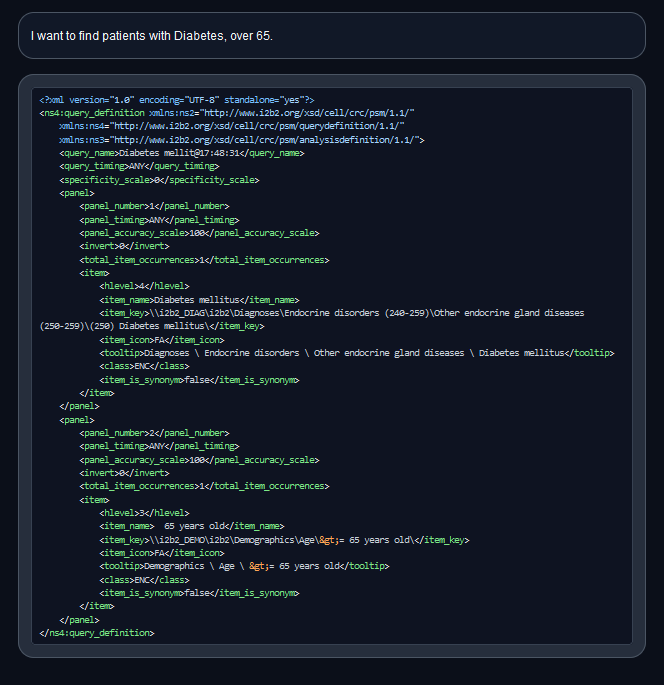
## Model Description
This model will generate queries for your i2b2 query builder trained on [this dataset](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0) for `10 epochs` . For evaluation use.
* Do not use as a final research query builder.
* Results may be incorrect or mal-formatted.
* The onus of research accuracy is on the researcher, not the AI model.
## Prompt Format
If you are using text-generation-webui, you can download the instruction template [i2b2.yaml](https://huggingface.co/nmitchko/i2b2-querybuilder-codellama-34b/resolve/main/i2b2.yaml)
```md
Below is an instruction that describes a task.
### Instruction:
{input}
### Response:
```xml
```
### Architecture
`nmitchko/i2b2-querybuilder-codellama-34b` is a large language model LoRa specifically fine-tuned for generating queries in the [i2b2 query builder](https://community.i2b2.org/wiki/display/webclient/3.+Query+Tool).
It is based on [`codellama-34b-hf`](https://huggingface.co/codellama/CodeLlama-34b-hf) at 34 billion parameters.
The primary goal of this model is to improve research accuracy with the i2b2 tool.
It was trained using [LoRA](https://arxiv.org/abs/2106.09685), specifically [QLora Multi GPU](https://github.com/ChrisHayduk/qlora-multi-gpu), to reduce memory footprint.
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
### Requirements
```
bitsandbytes>=0.41.0
peft@main
transformers@main
```
Steps to load this model:
1. Load base model (codellama-34b-hf) using transformers
2. Apply LoRA using peft
```python
# Sample Code Coming
```
## Training Parameters
The model was trained for or 10 epochs on [i2b2-query-data-1.0](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0)
`i2b2-query-data-1.0` contains only tasks and outputs for i2b2 queries xsd schemas.
| Item | Amount | Units |
|---------------|--------|-------|
| LoRA Rank | 64 | ~ |
| LoRA Alpha | 16 | ~ |
| Learning Rate | 1e-4 | SI |
| Dropout | 5 | % |
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e2_s6789_v4_l4_v100 | KingKazma | 2023-09-02T20:13:19Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T15:45:43Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
dammyogt/common_voice_8_0_ha | dammyogt | 2023-09-02T20:12:00Z | 76 | 0 | transformers | [
"transformers",
"pytorch",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:common_voice_8_0",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
]
| text-to-audio | 2023-09-01T23:30:15Z | ---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- common_voice_8_0
model-index:
- name: common_voice_8_0_ha
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# common_voice_8_0_ha
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the common_voice_8_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4741
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.5416 | 18.31 | 1000 | 0.4974 |
| 0.505 | 36.61 | 2000 | 0.4760 |
| 0.4898 | 54.92 | 3000 | 0.4758 |
| 0.5004 | 73.23 | 4000 | 0.4741 |
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
actionpace/Chronohermes-Grad-L2-13b | actionpace | 2023-09-02T19:59:50Z | 5 | 0 | null | [
"gguf",
"en",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2023-09-02T19:34:54Z | ---
license: other
language:
- en
---
Some of my own quants:
* Chronohermes-Grad-L2-13b_Q5_1_4K.gguf
* Chronohermes-Grad-L2-13b_Q5_1_8K.gguf
Original Model: [Chronohermes-Grad-L2-13b](https://huggingface.co/Doctor-Shotgun/Chronohermes-Grad-L2-13b)
|
acdg1214/Unit4-Reinforce-Cartpole-v1 | acdg1214 | 2023-09-02T19:54:12Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-02T19:54:04Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Unit4-Reinforce-Cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
aiuser1/my_awesome_eli5_mlm_model | aiuser1 | 2023-09-02T19:51:36Z | 71 | 0 | transformers | [
"transformers",
"tf",
"roberta",
"fill-mask",
"generated_from_keras_callback",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-09-02T19:46:52Z | ---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_keras_callback
model-index:
- name: aiuser1/my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# aiuser1/my_awesome_eli5_mlm_model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.0249
- Validation Loss: 1.8523
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.0249 | 1.8523 | 0 |
### Framework versions
- Transformers 4.32.1
- TensorFlow 2.12.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e1_s6789_v4_l4_v100 | KingKazma | 2023-09-02T19:43:13Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T15:15:44Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e10_s6789_v4_l4_r4 | KingKazma | 2023-09-02T19:42:43Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T19:42:39Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_350 | The-matt | 2023-09-02T19:42:34Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T19:42:30Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
thegrigorian/marian-finetuned-kde4-en-to-fr | thegrigorian | 2023-09-02T19:37:48Z | 61 | 0 | transformers | [
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-09-02T17:35:05Z | ---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- generated_from_keras_callback
model-index:
- name: thegrigorian/marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# thegrigorian/marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.7974
- Validation Loss: 0.8179
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 17733, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.0615 | 0.8776 | 0 |
| 0.7974 | 0.8179 | 1 |
### Framework versions
- Transformers 4.32.1
- TensorFlow 2.12.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e-1_s6789_v4_l4_v100_manual | KingKazma | 2023-09-02T19:24:10Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T19:24:05Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
bayartsogt/wav2vec2-large-xlsr-53-mn-demo | bayartsogt | 2023-09-02T19:23:45Z | 169 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-11-02T17:44:11Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xlsr-53-mn-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-mn-demo
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9290
- Wer: 0.5461
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.8767 | 6.77 | 400 | 2.9239 | 1.0 |
| 1.0697 | 13.55 | 800 | 0.8546 | 0.6191 |
| 0.3069 | 20.34 | 1200 | 0.9258 | 0.5652 |
| 0.2004 | 27.12 | 1600 | 0.9290 | 0.5461 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bayartsogt/wav2vec2-large-mn-pretrain-42h-100-epochs | bayartsogt | 2023-09-02T19:23:25Z | 14 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-08-01T17:30:28Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-mn-pretrain-42h-100-epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-mn-pretrain-42h-100-epochs
This model is a fine-tuned version of [bayartsogt/wav2vec2-large-mn-pretrain-42h](https://huggingface.co/bayartsogt/wav2vec2-large-mn-pretrain-42h) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 6.4172
- Wer: 1.0
- Cer: 0.9841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:---:|:------:|
| 7.6418 | 1.59 | 400 | 6.4239 | 1.0 | 0.9841 |
| 5.5936 | 3.19 | 800 | 6.4154 | 1.0 | 0.9841 |
| 5.5208 | 4.78 | 1200 | 6.5248 | 1.0 | 0.9841 |
| 5.4869 | 6.37 | 1600 | 6.3805 | 1.0 | 0.9841 |
| 5.4757 | 7.97 | 2000 | 6.3988 | 1.0 | 0.9841 |
| 5.4624 | 9.56 | 2400 | 6.4058 | 1.0 | 0.9841 |
| 5.517 | 11.16 | 2800 | 6.3991 | 1.0 | 0.9841 |
| 5.4821 | 12.75 | 3200 | 6.4066 | 1.0 | 0.9841 |
| 5.487 | 14.34 | 3600 | 6.4281 | 1.0 | 0.9841 |
| 5.4786 | 15.93 | 4000 | 6.4174 | 1.0 | 0.9841 |
| 5.5017 | 17.53 | 4400 | 6.4338 | 1.0 | 0.9841 |
| 5.4967 | 19.12 | 4800 | 6.4653 | 1.0 | 0.9841 |
| 5.4619 | 20.72 | 5200 | 6.4499 | 1.0 | 0.9841 |
| 5.4883 | 22.31 | 5600 | 6.4345 | 1.0 | 0.9841 |
| 5.4899 | 23.9 | 6000 | 6.4224 | 1.0 | 0.9841 |
| 5.493 | 25.5 | 6400 | 6.4374 | 1.0 | 0.9841 |
| 5.4549 | 27.09 | 6800 | 6.4320 | 1.0 | 0.9841 |
| 5.4531 | 28.68 | 7200 | 6.4137 | 1.0 | 0.9841 |
| 5.4738 | 30.28 | 7600 | 6.4155 | 1.0 | 0.9841 |
| 5.4309 | 31.87 | 8000 | 6.4193 | 1.0 | 0.9841 |
| 5.4669 | 33.47 | 8400 | 6.4109 | 1.0 | 0.9841 |
| 5.47 | 35.06 | 8800 | 6.4111 | 1.0 | 0.9841 |
| 5.4623 | 36.65 | 9200 | 6.4102 | 1.0 | 0.9841 |
| 5.4583 | 38.25 | 9600 | 6.4150 | 1.0 | 0.9841 |
| 5.4551 | 39.84 | 10000 | 6.4172 | 1.0 | 0.9841 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
bayartsogt/wav2vec2-base-mn-pretrain-42h-en-mn-speech-commands | bayartsogt | 2023-09-02T19:17:16Z | 165 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:bayartsogt/mongolian_speech_commands",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| audio-classification | 2023-08-11T18:35:58Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- bayartsogt/mongolian_speech_commands
model-index:
- name: wav2vec2-base-mn-pretrain-42h-finetuned-speech-commands
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-mn-pretrain-42h-finetuned-speech-commands
This model is a fine-tuned version of [bayartsogt/wav2vec2-base-mn-pretrain-42h](https://huggingface.co/bayartsogt/wav2vec2-base-mn-pretrain-42h) on the Mongolian Speech Commands dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.5607
- eval_mn_acc: 0.9830
- eval_mn_f1: 0.9857
- eval_en_acc: 0.8914
- eval_en_f1: 0.8671
- eval_runtime: 109.6829
- eval_samples_per_second: 46.188
- eval_steps_per_second: 0.365
- epoch: 6.41
- step: 4352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 8
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.0
- Datasets 2.14.4
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e9_s6789_v4_l4_r4 | KingKazma | 2023-09-02T19:14:44Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T19:14:41Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
georgeiac00/test2 | georgeiac00 | 2023-09-02T19:13:53Z | 0 | 0 | null | [
"generated_from_trainer",
"region:us"
]
| null | 2023-09-02T19:07:34Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: test2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test2
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2451
- Accuracy: 0.3922
- F1: 0.3732
- Precision: 0.3777
- Recall: 0.3824
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.2543 | 0.02 | 16 | 1.2451 | 0.3922 | 0.3732 | 0.3777 | 0.3824 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.10.1
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_320 | The-matt | 2023-09-02T19:11:22Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T19:11:19Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
smoo7h/JackDiffusion | smoo7h | 2023-09-02T19:03:25Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-09-02T18:59:02Z | # JackDiffusion
Jack Diffusion Model
Jack's token: k7&
Example prompt: a photo of k7& |
narno/milkynips | narno | 2023-09-02T18:44:10Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
]
| null | 2023-09-02T18:43:39Z | ---
license: bigscience-openrail-m
---
|
narno/openbra | narno | 2023-09-02T18:44:08Z | 0 | 0 | null | [
"license:bigscience-openrail-m",
"region:us"
]
| null | 2023-09-02T18:43:31Z | ---
license: bigscience-openrail-m
---
|
gyikesz/whisper-small-hu | gyikesz | 2023-09-02T18:43:44Z | 75 | 0 | transformers | [
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hu",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T06:21:52Z | ---
language:
- hu
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper Small Hu - Hungarian
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: hu
split: test
args: hu
metrics:
- name: Wer
type: wer
value: 30.609306710086553
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hu - Hungarian
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3444
- Wer Ortho: 34.0613
- Wer: 30.6093
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.3221 | 0.34 | 500 | 0.3444 | 34.0613 | 30.6093 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.4
- Tokenizers 0.13.3
|
The-matt/autumn-shadow-48_280 | The-matt | 2023-09-02T18:30:41Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T18:30:36Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
GraphicsMonster/LSTM-Sentiment-Analysis | GraphicsMonster | 2023-09-02T18:16:25Z | 0 | 0 | null | [
"region:us"
]
| null | 2023-09-02T18:09:28Z | # Sentiment analysis with LSTM architecture - Pytorch
This project aims to build a Sentiment analysis model using the LSTM(Long-Short term memory) architecture.
## Project Structure
The project has the following structure:
- `Dataset`: This directory contains the dataset files used for training and evaluation.
- `model.py`: This file contains the relevant piece of code required to run the model for inference after training.
- `train.py`: You train the modle by running this script. If you make any hyperparam changes in the model.py file make sure to make those changes here as well.
- `requirements.txt`: requirements file to automate the process of installing the required dependencies.
- `model_test.py`: This is the script you'll run to test the model on your own text data.
## Dependencies
The project requires the following dependencies:
- Python 3.9 or higher
- numpy
- pandas
- scikit-learn
- tensorflow
- keras
- torch
- torchtext
- tweet-preprocessor
- pickle
Ensure that you have the necessary dependencies installed before running the project.
You may install the above dependencies simply by using:
pip install -r requirements.txt
## Installation
- Open the terminal in your code editor and type this in
`git clone https://github.com/GraphicsMonster/LSTM-sentiment-analysis-model`
- To install the required dependencies, type this in
`pip install -r requirements.txt`
- Once the dependencies are installed you are ready to train the model and evaluate its performance. If you have your own data to train the model on, you can update the code in the model.py to refer to the location of your dataset on your local machine. Be sure to update the preprocessing steps accordingly!!
- Train the model run this command in the terminal
`python train.py`
- Once you've successfully trained the model, it will automatically be saved in the same directory with the name `model.pt`
- Test the model on your own text data
`python model_test.py`
## Contributing
Contributions to this project are heavily encouraged! If you find any issues or have suggestions for improvements, please open an issue or submit a pull request. Any kind of contribution will be appreciated.
## License
This project is licensed under the [MIT License](LICENSE).
|
bigmorning/whisper_syl_noforce__0050 | bigmorning | 2023-09-02T18:12:41Z | 52 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T18:12:32Z | ---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce__0050
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce__0050
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0494
- Train Accuracy: 0.0361
- Train Wermet: 0.0068
- Validation Loss: 0.6663
- Validation Accuracy: 0.0232
- Validation Wermet: 0.2609
- Epoch: 49
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 5.2961 | 0.0113 | 1.9043 | 3.9402 | 0.0116 | 0.9526 | 0 |
| 4.6207 | 0.0121 | 0.8740 | 3.7957 | 0.0120 | 0.9397 | 1 |
| 4.4142 | 0.0128 | 0.8473 | 3.6045 | 0.0124 | 0.8988 | 2 |
| 4.1915 | 0.0135 | 0.8361 | 3.4445 | 0.0128 | 0.9019 | 3 |
| 4.0072 | 0.0140 | 0.8260 | 3.3268 | 0.0131 | 0.8816 | 4 |
| 3.8559 | 0.0145 | 0.8084 | 3.2440 | 0.0133 | 0.8592 | 5 |
| 3.7359 | 0.0149 | 0.7986 | 3.1751 | 0.0135 | 0.8598 | 6 |
| 3.6368 | 0.0152 | 0.7891 | 3.1298 | 0.0136 | 0.8398 | 7 |
| 3.5465 | 0.0154 | 0.7775 | 3.0736 | 0.0138 | 0.8606 | 8 |
| 3.4710 | 0.0157 | 0.7681 | 3.0318 | 0.0138 | 0.8455 | 9 |
| 3.3988 | 0.0159 | 0.7603 | 3.0159 | 0.0139 | 0.8770 | 10 |
| 3.3279 | 0.0162 | 0.7504 | 2.9672 | 0.0141 | 0.8241 | 11 |
| 3.2611 | 0.0164 | 0.7397 | 2.9541 | 0.0141 | 0.8676 | 12 |
| 3.1996 | 0.0167 | 0.7284 | 2.8913 | 0.0144 | 0.7990 | 13 |
| 3.1311 | 0.0169 | 0.7162 | 2.8671 | 0.0145 | 0.7934 | 14 |
| 3.0590 | 0.0172 | 0.7044 | 2.8241 | 0.0146 | 0.7907 | 15 |
| 2.9692 | 0.0177 | 0.6843 | 2.7517 | 0.0149 | 0.7645 | 16 |
| 2.8783 | 0.0181 | 0.6630 | 2.6682 | 0.0152 | 0.7263 | 17 |
| 2.7622 | 0.0187 | 0.6417 | 2.5586 | 0.0156 | 0.7220 | 18 |
| 2.6164 | 0.0194 | 0.6138 | 2.4121 | 0.0161 | 0.6909 | 19 |
| 2.4405 | 0.0203 | 0.5838 | 2.2417 | 0.0167 | 0.6527 | 20 |
| 2.2404 | 0.0213 | 0.5486 | 2.1401 | 0.0170 | 0.6662 | 21 |
| 2.0196 | 0.0225 | 0.5086 | 1.8907 | 0.0180 | 0.5774 | 22 |
| 1.7917 | 0.0237 | 0.4665 | 1.7073 | 0.0186 | 0.5446 | 23 |
| 1.5286 | 0.0253 | 0.4182 | 1.5139 | 0.0194 | 0.4919 | 24 |
| 1.2991 | 0.0267 | 0.3736 | 1.3605 | 0.0200 | 0.4570 | 25 |
| 1.1117 | 0.0279 | 0.3336 | 1.2304 | 0.0205 | 0.4262 | 26 |
| 0.9643 | 0.0289 | 0.2986 | 1.1387 | 0.0209 | 0.4040 | 27 |
| 0.8404 | 0.0298 | 0.2663 | 1.0514 | 0.0213 | 0.3776 | 28 |
| 0.7408 | 0.0305 | 0.2408 | 0.9883 | 0.0216 | 0.3596 | 29 |
| 0.6542 | 0.0311 | 0.2155 | 0.9281 | 0.0218 | 0.3418 | 30 |
| 0.5800 | 0.0316 | 0.1936 | 0.8801 | 0.0221 | 0.3269 | 31 |
| 0.5168 | 0.0321 | 0.1737 | 0.8401 | 0.0222 | 0.3168 | 32 |
| 0.4595 | 0.0326 | 0.1552 | 0.8071 | 0.0224 | 0.3077 | 33 |
| 0.4080 | 0.0330 | 0.1375 | 0.7825 | 0.0225 | 0.2994 | 34 |
| 0.3646 | 0.0333 | 0.1225 | 0.7550 | 0.0226 | 0.2887 | 35 |
| 0.3234 | 0.0337 | 0.1095 | 0.7369 | 0.0227 | 0.2847 | 36 |
| 0.2878 | 0.0340 | 0.0950 | 0.7270 | 0.0228 | 0.2796 | 37 |
| 0.2542 | 0.0343 | 0.0823 | 0.7096 | 0.0229 | 0.2728 | 38 |
| 0.2238 | 0.0346 | 0.0718 | 0.6963 | 0.0229 | 0.2697 | 39 |
| 0.1974 | 0.0348 | 0.0609 | 0.6857 | 0.0230 | 0.2669 | 40 |
| 0.1714 | 0.0351 | 0.0500 | 0.6843 | 0.0230 | 0.2663 | 41 |
| 0.1488 | 0.0353 | 0.0411 | 0.6770 | 0.0230 | 0.2630 | 42 |
| 0.1296 | 0.0355 | 0.0339 | 0.6754 | 0.0231 | 0.2612 | 43 |
| 0.1117 | 0.0356 | 0.0270 | 0.6702 | 0.0231 | 0.2585 | 44 |
| 0.0954 | 0.0358 | 0.0211 | 0.6695 | 0.0231 | 0.2574 | 45 |
| 0.0822 | 0.0359 | 0.0163 | 0.6711 | 0.0231 | 0.2572 | 46 |
| 0.0715 | 0.0360 | 0.0137 | 0.6685 | 0.0231 | 0.2583 | 47 |
| 0.0591 | 0.0361 | 0.0093 | 0.6696 | 0.0231 | 0.2590 | 48 |
| 0.0494 | 0.0361 | 0.0068 | 0.6663 | 0.0232 | 0.2609 | 49 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
lseancs/models | lseancs | 2023-09-02T18:04:04Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:adapter:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-08-25T23:08:52Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: photo of a <new1> cat
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - lseancs/models
These are Custom Diffusion adaption weights for CompVis/stable-diffusion-v1-4. The weights were trained on photo of a <new1> cat using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
bigmorning/whisper_syl_noforce__0045 | bigmorning | 2023-09-02T17:59:26Z | 59 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T17:59:18Z | ---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce__0045
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce__0045
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1117
- Train Accuracy: 0.0356
- Train Wermet: 0.0270
- Validation Loss: 0.6702
- Validation Accuracy: 0.0231
- Validation Wermet: 0.2585
- Epoch: 44
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 5.2961 | 0.0113 | 1.9043 | 3.9402 | 0.0116 | 0.9526 | 0 |
| 4.6207 | 0.0121 | 0.8740 | 3.7957 | 0.0120 | 0.9397 | 1 |
| 4.4142 | 0.0128 | 0.8473 | 3.6045 | 0.0124 | 0.8988 | 2 |
| 4.1915 | 0.0135 | 0.8361 | 3.4445 | 0.0128 | 0.9019 | 3 |
| 4.0072 | 0.0140 | 0.8260 | 3.3268 | 0.0131 | 0.8816 | 4 |
| 3.8559 | 0.0145 | 0.8084 | 3.2440 | 0.0133 | 0.8592 | 5 |
| 3.7359 | 0.0149 | 0.7986 | 3.1751 | 0.0135 | 0.8598 | 6 |
| 3.6368 | 0.0152 | 0.7891 | 3.1298 | 0.0136 | 0.8398 | 7 |
| 3.5465 | 0.0154 | 0.7775 | 3.0736 | 0.0138 | 0.8606 | 8 |
| 3.4710 | 0.0157 | 0.7681 | 3.0318 | 0.0138 | 0.8455 | 9 |
| 3.3988 | 0.0159 | 0.7603 | 3.0159 | 0.0139 | 0.8770 | 10 |
| 3.3279 | 0.0162 | 0.7504 | 2.9672 | 0.0141 | 0.8241 | 11 |
| 3.2611 | 0.0164 | 0.7397 | 2.9541 | 0.0141 | 0.8676 | 12 |
| 3.1996 | 0.0167 | 0.7284 | 2.8913 | 0.0144 | 0.7990 | 13 |
| 3.1311 | 0.0169 | 0.7162 | 2.8671 | 0.0145 | 0.7934 | 14 |
| 3.0590 | 0.0172 | 0.7044 | 2.8241 | 0.0146 | 0.7907 | 15 |
| 2.9692 | 0.0177 | 0.6843 | 2.7517 | 0.0149 | 0.7645 | 16 |
| 2.8783 | 0.0181 | 0.6630 | 2.6682 | 0.0152 | 0.7263 | 17 |
| 2.7622 | 0.0187 | 0.6417 | 2.5586 | 0.0156 | 0.7220 | 18 |
| 2.6164 | 0.0194 | 0.6138 | 2.4121 | 0.0161 | 0.6909 | 19 |
| 2.4405 | 0.0203 | 0.5838 | 2.2417 | 0.0167 | 0.6527 | 20 |
| 2.2404 | 0.0213 | 0.5486 | 2.1401 | 0.0170 | 0.6662 | 21 |
| 2.0196 | 0.0225 | 0.5086 | 1.8907 | 0.0180 | 0.5774 | 22 |
| 1.7917 | 0.0237 | 0.4665 | 1.7073 | 0.0186 | 0.5446 | 23 |
| 1.5286 | 0.0253 | 0.4182 | 1.5139 | 0.0194 | 0.4919 | 24 |
| 1.2991 | 0.0267 | 0.3736 | 1.3605 | 0.0200 | 0.4570 | 25 |
| 1.1117 | 0.0279 | 0.3336 | 1.2304 | 0.0205 | 0.4262 | 26 |
| 0.9643 | 0.0289 | 0.2986 | 1.1387 | 0.0209 | 0.4040 | 27 |
| 0.8404 | 0.0298 | 0.2663 | 1.0514 | 0.0213 | 0.3776 | 28 |
| 0.7408 | 0.0305 | 0.2408 | 0.9883 | 0.0216 | 0.3596 | 29 |
| 0.6542 | 0.0311 | 0.2155 | 0.9281 | 0.0218 | 0.3418 | 30 |
| 0.5800 | 0.0316 | 0.1936 | 0.8801 | 0.0221 | 0.3269 | 31 |
| 0.5168 | 0.0321 | 0.1737 | 0.8401 | 0.0222 | 0.3168 | 32 |
| 0.4595 | 0.0326 | 0.1552 | 0.8071 | 0.0224 | 0.3077 | 33 |
| 0.4080 | 0.0330 | 0.1375 | 0.7825 | 0.0225 | 0.2994 | 34 |
| 0.3646 | 0.0333 | 0.1225 | 0.7550 | 0.0226 | 0.2887 | 35 |
| 0.3234 | 0.0337 | 0.1095 | 0.7369 | 0.0227 | 0.2847 | 36 |
| 0.2878 | 0.0340 | 0.0950 | 0.7270 | 0.0228 | 0.2796 | 37 |
| 0.2542 | 0.0343 | 0.0823 | 0.7096 | 0.0229 | 0.2728 | 38 |
| 0.2238 | 0.0346 | 0.0718 | 0.6963 | 0.0229 | 0.2697 | 39 |
| 0.1974 | 0.0348 | 0.0609 | 0.6857 | 0.0230 | 0.2669 | 40 |
| 0.1714 | 0.0351 | 0.0500 | 0.6843 | 0.0230 | 0.2663 | 41 |
| 0.1488 | 0.0353 | 0.0411 | 0.6770 | 0.0230 | 0.2630 | 42 |
| 0.1296 | 0.0355 | 0.0339 | 0.6754 | 0.0231 | 0.2612 | 43 |
| 0.1117 | 0.0356 | 0.0270 | 0.6702 | 0.0231 | 0.2585 | 44 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
KingKazma/xsum_t5-small_lora_500_10_50000_8_e7_s6789_v4_l4_r4 | KingKazma | 2023-09-02T17:54:40Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T17:54:39Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
sashat/whisper-small-ar | sashat | 2023-09-02T17:54:28Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ar",
"dataset:ClArTTS_N_QASR_female",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T16:29:01Z | ---
language:
- ar
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- ClArTTS_N_QASR_female
model-index:
- name: Whisper Small Ar - Sara
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ar - Sara
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the CLArQasr dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 100
### Training results
### Framework versions
- Transformers 4.33.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.2
|
KingKazma/xsum_t5-small_p_tuning_500_10_50000_8_e6_s6789_v4_l4_v100 | KingKazma | 2023-09-02T17:45:45Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T17:45:41Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
The-matt/autumn-shadow-48_250 | The-matt | 2023-09-02T17:43:09Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T17:42:59Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
alexeynoskov/ppo-LunarLander-v2-cleanrl | alexeynoskov | 2023-09-02T17:41:40Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-09-02T08:38:18Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 150.08 +/- 50.42
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'env_id': 'LunarLander-v2'
'seed': 1
'total_timesteps': 100000
'learning_rate': 0.00025
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'norm_adv': True
'clip_vloss': True
'cuda': True
'torch_deterministic': False
'track': False
'wandb_project_name': None
'wandb_entity': None
'num_envs': 4
'num_steps': 128
'capture_video': False
'num_minibatches': 4
'update_epochs': 4
'clip_coef': 0.2
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'push_to_huggingface': 'alexeynoskov/ppo-LunarLander-v2-cleanrl'
'batch_size': 512
'minibatch_size': 128}
```
|
The-matt/autumn-shadow-48_240 | The-matt | 2023-09-02T17:34:10Z | 0 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-09-02T17:34:06Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.0.dev0
|
bigmorning/whisper_syl_noforce__0035 | bigmorning | 2023-09-02T17:33:01Z | 59 | 0 | transformers | [
"transformers",
"tf",
"whisper",
"automatic-speech-recognition",
"generated_from_keras_callback",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-09-02T17:32:52Z | ---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_keras_callback
model-index:
- name: whisper_syl_noforce__0035
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# whisper_syl_noforce__0035
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4080
- Train Accuracy: 0.0330
- Train Wermet: 0.1375
- Validation Loss: 0.7825
- Validation Accuracy: 0.0225
- Validation Wermet: 0.2994
- Epoch: 34
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train Wermet | Validation Loss | Validation Accuracy | Validation Wermet | Epoch |
|:----------:|:--------------:|:------------:|:---------------:|:-------------------:|:-----------------:|:-----:|
| 5.2961 | 0.0113 | 1.9043 | 3.9402 | 0.0116 | 0.9526 | 0 |
| 4.6207 | 0.0121 | 0.8740 | 3.7957 | 0.0120 | 0.9397 | 1 |
| 4.4142 | 0.0128 | 0.8473 | 3.6045 | 0.0124 | 0.8988 | 2 |
| 4.1915 | 0.0135 | 0.8361 | 3.4445 | 0.0128 | 0.9019 | 3 |
| 4.0072 | 0.0140 | 0.8260 | 3.3268 | 0.0131 | 0.8816 | 4 |
| 3.8559 | 0.0145 | 0.8084 | 3.2440 | 0.0133 | 0.8592 | 5 |
| 3.7359 | 0.0149 | 0.7986 | 3.1751 | 0.0135 | 0.8598 | 6 |
| 3.6368 | 0.0152 | 0.7891 | 3.1298 | 0.0136 | 0.8398 | 7 |
| 3.5465 | 0.0154 | 0.7775 | 3.0736 | 0.0138 | 0.8606 | 8 |
| 3.4710 | 0.0157 | 0.7681 | 3.0318 | 0.0138 | 0.8455 | 9 |
| 3.3988 | 0.0159 | 0.7603 | 3.0159 | 0.0139 | 0.8770 | 10 |
| 3.3279 | 0.0162 | 0.7504 | 2.9672 | 0.0141 | 0.8241 | 11 |
| 3.2611 | 0.0164 | 0.7397 | 2.9541 | 0.0141 | 0.8676 | 12 |
| 3.1996 | 0.0167 | 0.7284 | 2.8913 | 0.0144 | 0.7990 | 13 |
| 3.1311 | 0.0169 | 0.7162 | 2.8671 | 0.0145 | 0.7934 | 14 |
| 3.0590 | 0.0172 | 0.7044 | 2.8241 | 0.0146 | 0.7907 | 15 |
| 2.9692 | 0.0177 | 0.6843 | 2.7517 | 0.0149 | 0.7645 | 16 |
| 2.8783 | 0.0181 | 0.6630 | 2.6682 | 0.0152 | 0.7263 | 17 |
| 2.7622 | 0.0187 | 0.6417 | 2.5586 | 0.0156 | 0.7220 | 18 |
| 2.6164 | 0.0194 | 0.6138 | 2.4121 | 0.0161 | 0.6909 | 19 |
| 2.4405 | 0.0203 | 0.5838 | 2.2417 | 0.0167 | 0.6527 | 20 |
| 2.2404 | 0.0213 | 0.5486 | 2.1401 | 0.0170 | 0.6662 | 21 |
| 2.0196 | 0.0225 | 0.5086 | 1.8907 | 0.0180 | 0.5774 | 22 |
| 1.7917 | 0.0237 | 0.4665 | 1.7073 | 0.0186 | 0.5446 | 23 |
| 1.5286 | 0.0253 | 0.4182 | 1.5139 | 0.0194 | 0.4919 | 24 |
| 1.2991 | 0.0267 | 0.3736 | 1.3605 | 0.0200 | 0.4570 | 25 |
| 1.1117 | 0.0279 | 0.3336 | 1.2304 | 0.0205 | 0.4262 | 26 |
| 0.9643 | 0.0289 | 0.2986 | 1.1387 | 0.0209 | 0.4040 | 27 |
| 0.8404 | 0.0298 | 0.2663 | 1.0514 | 0.0213 | 0.3776 | 28 |
| 0.7408 | 0.0305 | 0.2408 | 0.9883 | 0.0216 | 0.3596 | 29 |
| 0.6542 | 0.0311 | 0.2155 | 0.9281 | 0.0218 | 0.3418 | 30 |
| 0.5800 | 0.0316 | 0.1936 | 0.8801 | 0.0221 | 0.3269 | 31 |
| 0.5168 | 0.0321 | 0.1737 | 0.8401 | 0.0222 | 0.3168 | 32 |
| 0.4595 | 0.0326 | 0.1552 | 0.8071 | 0.0224 | 0.3077 | 33 |
| 0.4080 | 0.0330 | 0.1375 | 0.7825 | 0.0225 | 0.2994 | 34 |
### Framework versions
- Transformers 4.33.0.dev0
- TensorFlow 2.13.0
- Tokenizers 0.13.3
|
Subsets and Splits