
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-16 06:27:54
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 522
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-16 06:27:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
bcfs/furnace_model_m | bcfs | 2024-08-19T22:39:49Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-08-15T23:26:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
awni00/DAT-sa8-ra8-nr32-ns1024-sh8-nkvh4-343M | awni00 | 2024-08-19T22:31:02Z | 6 | 0 | null | [
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"text-generation",
"en",
"arxiv:2405.16727",
"license:mit",
"region:us"
]
| text-generation | 2024-08-19T22:21:26Z | ---
language: en
license: mit
pipeline_tag: text-generation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
dataset: HuggingFaceFW/fineweb-edu
---
# DAT-sa8-ra8-nr32-ns1024-sh8-nkvh4-343M
<!-- Provide a quick summary of what the model is/does. -->
This is a Dual-Attention Transformer Language Model, trained on the `fineweb-edu` dataset. The model is 344M parameters.
## Model Details
| Size | Training Tokens| Layers | Model Dimension | Self-Attention Heads | Relational Attention Heads | Relation Dimension | Context Length |
|--|--|--|--|--|--|--|--|
| 344M | 10B | 24| 1024 | 8 | 8 | 32 | 1024 |
### Model Description
- **Developed by:** Awni Altabaa, John Lafferty
- **Model type:** Decoder-only Dual Attention Transformer
- **Tokenizer:** GPT-2 BPE tokenizer
- **Language(s):** English
<!-- - **License:** MIT -->
<!-- - **Contact:** [email protected] -->
- **Date:** August, 2024
### Model Sources
- **Repository:** https://github.com/Awni00/abstract_transformer
- **Paper:** [Disentangling and Integrating Relational and Sensory Information in Transformer Architectures](https://arxiv.org/abs/2405.16727)
- **Huggingface Collection:** [Dual Attention Transformer Collection](https://huggingface.co/collections/awni00/dual-attention-transformer-66c23425a545b0cefe4b9489)
## Model Usage
Use the code below to get started with the model. First, install the `dual-attention` [python package hosted on PyPI](https://pypi.org/project/dual-attention/) via `pip install dual-attention`.
To load directly from huggingface hub, use the HFHub wrapper.
```
from dual_attention.hf import DualAttnTransformerLM_HFHub
DualAttnTransformerLM_HFHub.from_pretrained('awni00/DAT-sa8-ra8-nr32-ns1024-sh8-nkvh4-343M')
```
## Training Details
The model was trained using the following setup:
- **Architecture:** Decoder-only Dual Attention Transformer
- **Framework:** PyTorch
- **Optimizer:** AdamW
- **Learning Rate:** 6e-4 (peak)
- **Weight Decay:** 0.1
- **Batch Size:** 524,288 Tokens
- **Sequence Length:** 1024 tokens
- **Total Training Tokens:** 10B Tokens
For more detailed training information, please refer to the paper.
## Evaluation
See paper.
## Model Interpretability Analysis
The [DAT-LM-Visualization app](https://huggingface.co/spaces/awni00/DAT-LM-Visualization/) is built to visualize the representations learned in a Dual Attention Transformer language model. It is hosted on Huggingface spaces using their free CPU resources. You can select a pre-trained DAT-LM model, enter a prompt, and visualize the internal representations in different parts of the model. You can also run the app locally (e.g., to use your own GPU) via the PyPI package.
Also, see paper.
## Citation
```
@misc{altabaa2024disentanglingintegratingrelationalsensory,
title={Disentangling and Integrating Relational and Sensory Information in Transformer Architectures},
author={Awni Altabaa and John Lafferty},
year={2024},
eprint={2405.16727},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2405.16727},
}
``` |
awni00/DAT-sa8-ra8-nr64-ns1024-sh8-nkvh4-343M | awni00 | 2024-08-19T22:30:55Z | 6 | 0 | null | [
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"text-generation",
"en",
"arxiv:2405.16727",
"license:mit",
"region:us"
]
| text-generation | 2024-08-19T22:09:37Z | ---
language: en
license: mit
pipeline_tag: text-generation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
dataset: HuggingFaceFW/fineweb-edu
---
# DAT-sa8-ra8-nr64-ns1024-sh8-nkvh4-343M
<!-- Provide a quick summary of what the model is/does. -->
This is a Dual-Attention Transformer Language Model, trained on the `fineweb-edu` dataset. The model is 344M parameters.
## Model Details
| Size | Training Tokens| Layers | Model Dimension | Self-Attention Heads | Relational Attention Heads | Relation Dimension | Context Length |
|--|--|--|--|--|--|--|--|
| 344M | 10B | 24| 1024 | 8 | 8 | 64 | 1024 |
### Model Description
- **Developed by:** Awni Altabaa, John Lafferty
- **Model type:** Decoder-only Dual Attention Transformer
- **Tokenizer:** GPT-2 BPE tokenizer
- **Language(s):** English
<!-- - **License:** MIT -->
<!-- - **Contact:** [email protected] -->
- **Date:** August, 2024
### Model Sources
- **Repository:** https://github.com/Awni00/abstract_transformer
- **Paper:** [Disentangling and Integrating Relational and Sensory Information in Transformer Architectures](https://arxiv.org/abs/2405.16727)
- **Huggingface Collection:** [Dual Attention Transformer Collection](https://huggingface.co/collections/awni00/dual-attention-transformer-66c23425a545b0cefe4b9489)
## Model Usage
Use the code below to get started with the model. First, install the `dual-attention` [python package hosted on PyPI](https://pypi.org/project/dual-attention/) via `pip install dual-attention`.
To load directly from huggingface hub, use the HFHub wrapper.
```
from dual_attention.hf import DualAttnTransformerLM_HFHub
DualAttnTransformerLM_HFHub.from_pretrained('awni00/DAT-sa8-ra8-nr64-ns1024-sh8-nkvh4-343M')
```
## Training Details
The model was trained using the following setup:
- **Architecture:** Decoder-only Dual Attention Transformer
- **Framework:** PyTorch
- **Optimizer:** AdamW
- **Learning Rate:** 6e-4 (peak)
- **Weight Decay:** 0.1
- **Batch Size:** 524,288 Tokens
- **Sequence Length:** 1024 tokens
- **Total Training Tokens:** 10B Tokens
For more detailed training information, please refer to the paper.
## Evaluation
See paper.
## Model Interpretability Analysis
The [DAT-LM-Visualization app](https://huggingface.co/spaces/awni00/DAT-LM-Visualization/) is built to visualize the representations learned in a Dual Attention Transformer language model. It is hosted on Huggingface spaces using their free CPU resources. You can select a pre-trained DAT-LM model, enter a prompt, and visualize the internal representations in different parts of the model. You can also run the app locally (e.g., to use your own GPU) via the PyPI package.
Also, see paper.
## Citation
```
@misc{altabaa2024disentanglingintegratingrelationalsensory,
title={Disentangling and Integrating Relational and Sensory Information in Transformer Architectures},
author={Awni Altabaa and John Lafferty},
year={2024},
eprint={2405.16727},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2405.16727},
}
``` |
awni00/DAT-sa8-ra8-ns1024-sh8-nkvh4-343M | awni00 | 2024-08-19T22:30:47Z | 53 | 0 | transformers | [
"transformers",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"text-generation",
"en",
"arxiv:2405.16727",
"license:mit",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-07-29T22:34:38Z | ---
language: en
license: mit
pipeline_tag: text-generation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
dataset: HuggingFaceFW/fineweb-edu
---
# DAT-sa8-ra8-ns1024-sh8-nkvh4-343M
<!-- Provide a quick summary of what the model is/does. -->
This is a Dual-Attention Transformer Language Model, trained on the `fineweb-edu` dataset. The model is 343M parameters.
## Model Details
| Size | Training Tokens| Layers | Model Dimension | Self-Attention Heads | Relational Attention Heads | Relation Dimension | Context Length |
|--|--|--|--|--|--|--|--|
| 343M | 10B | 24| 1024 | 8 | 8 | 8 | 1024 |
### Model Description
- **Developed by:** Awni Altabaa, John Lafferty
- **Model type:** Decoder-only Dual Attention Transformer
- **Tokenizer:** GPT-2 BPE tokenizer
- **Language(s):** English
<!-- - **License:** MIT -->
<!-- - **Contact:** [email protected] -->
- **Date:** August, 2024
### Model Sources
- **Repository:** https://github.com/Awni00/abstract_transformer
- **Paper:** [Disentangling and Integrating Relational and Sensory Information in Transformer Architectures](https://arxiv.org/abs/2405.16727)
- **Huggingface Collection:** [Dual Attention Transformer Collection](https://huggingface.co/collections/awni00/dual-attention-transformer-66c23425a545b0cefe4b9489)
## Model Usage
Use the code below to get started with the model. First, install the `dual-attention` [python package hosted on PyPI](https://pypi.org/project/dual-attention/) via `pip install dual-attention`.
To load directly from huggingface hub, use the HFHub wrapper.
```
from dual_attention.hf import DualAttnTransformerLM_HFHub
DualAttnTransformerLM_HFHub.from_pretrained('awni00/DAT-sa8-ra8-ns1024-sh8-nkvh4-343M')
```
## Training Details
The model was trained using the following setup:
- **Architecture:** Decoder-only Dual Attention Transformer
- **Framework:** PyTorch
- **Optimizer:** AdamW
- **Learning Rate:** 6e-4 (peak)
- **Weight Decay:** 0.1
- **Batch Size:** 524,288 Tokens
- **Sequence Length:** 1024 tokens
- **Total Training Tokens:** 10B Tokens
For more detailed training information, please refer to the paper.
## Evaluation
See paper.
## Model Interpretability Analysis
The [DAT-LM-Visualization app](https://huggingface.co/spaces/awni00/DAT-LM-Visualization/) is built to visualize the representations learned in a Dual Attention Transformer language model. It is hosted on Huggingface spaces using their free CPU resources. You can select a pre-trained DAT-LM model, enter a prompt, and visualize the internal representations in different parts of the model. You can also run the app locally (e.g., to use your own GPU) via the PyPI package.
Also, see paper.
## Citation
```
@misc{altabaa2024disentanglingintegratingrelationalsensory,
title={Disentangling and Integrating Relational and Sensory Information in Transformer Architectures},
author={Awni Altabaa and John Lafferty},
year={2024},
eprint={2405.16727},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2405.16727},
}
``` |
dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF | dasChronos1 | 2024-08-19T22:24:13Z | 7 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:Setiaku/Stheno-v3.4-Instruct",
"dataset:Setiaku/Stheno-3.4-Creative-2",
"base_model:Sao10K/Llama-3.1-8B-Stheno-v3.4",
"base_model:quantized:Sao10K/Llama-3.1-8B-Stheno-v3.4",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T22:23:39Z | ---
base_model: Sao10K/Llama-3.1-8B-Stheno-v3.4
datasets:
- Setiaku/Stheno-v3.4-Instruct
- Setiaku/Stheno-3.4-Creative-2
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF
This model was converted to GGUF format from [`Sao10K/Llama-3.1-8B-Stheno-v3.4`](https://huggingface.co/Sao10K/Llama-3.1-8B-Stheno-v3.4) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/Llama-3.1-8B-Stheno-v3.4) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo dasChronos1/Llama-3.1-8B-Stheno-v3.4-Q8_0-GGUF --hf-file llama-3.1-8b-stheno-v3.4-q8_0.gguf -c 2048
```
|
Edgar404/t5_small_default | Edgar404 | 2024-08-19T22:23:40Z | 12 | 0 | transformers | [
"transformers",
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-08-17T19:53:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
alimboff/rubert-kbd-krc-36K | alimboff | 2024-08-19T22:09:49Z | 106 | 1 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"code",
"ru",
"kbd",
"krc",
"dataset:alimboff/ru_kbd_krc_corpus_classification",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-08-19T20:57:20Z | ---
license: cc-by-4.0
language:
- ru
- kbd
- krc
metrics:
- accuracy
pipeline_tag: text-classification
datasets:
- alimboff/ru_kbd_krc_corpus_classification
library_name: transformers
tags:
- code
---
### Zehedz
#### Описание модели
Модель предназначена для классификации текстов на три языка: русский (rus_Cyrl), кабардино-черкесский (kbd_Cyrl) и карачаево-балкарский (krc_Cyrl). Построена на архитектуре BERT и обучена на корпусе, который включает данные для каждого из этих языков.
#### Результаты обучения
```
Epoch 1/3
Train loss: 0.0431 | accuracy: 0.9889
Val loss: 0.0014 | accuracy: 1.0000
----------
Epoch 2/3
Train loss: 0.0111 | accuracy: 0.9974
Val loss: 0.0023 | accuracy: 0.9994
----------
Epoch 3/3
Train loss: 0.0081 | accuracy: 0.9982
Val loss: 0.0013 | accuracy: 1.0000
```
#### Производительность
- **Средняя скорость работы на GPU (CUDA):** 0.008 секунд на одно предсказание
- **Средняя скорость работы на CPU:** 0.05 секунд на одно предсказание
#### Использование модели
##### Код для работы с моделью:
```python
import torch
from transformers import BertTokenizer, BertForSequenceClassification
model_path = 'alimboff/rubert-kbd-krc-36K'
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=3, problem_type="single_label_classification")
tokenizer = BertTokenizer.from_pretrained(model_path)
def predict(text):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=512,
return_token_type_ids=False,
truncation=True,
padding='max_length',
return_attention_mask=True,
return_tensors='pt',
)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
labels = ['kbd_Cyrl', 'rus_Cyrl', 'krc_Cyrl']
predicted_class = labels[torch.argmax(logits, dim=1).cpu().numpy()[0]]
return predicted_class
text = "Привет, как дела?"
print(predict(text))
```
#### Использование через API Space на Hugging Face
```python
from gradio_client import Client
client = Client("alimboff/zehedz")
result = client.predict(
text="Добрый день!",
api_name="/predict"
)
print(result)
```
Модель идеально подходит для задач, связанных с автоматическим определением языка текста в многоязычных системах и приложениях. |
RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf | RichardErkhov | 2024-08-19T22:04:47Z | 65 | 0 | null | [
"gguf",
"arxiv:2405.18952",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T20:27:15Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
suzume-llama-3-8B-multilingual-orpo-borda-half - GGUF
- Model creator: https://huggingface.co/lightblue/
- Original model: https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q2_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q2_K.gguf) | Q2_K | 2.96GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K.gguf) | Q3_K | 3.74GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_0.gguf) | Q4_0 | 4.34GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K.gguf) | Q4_K | 4.58GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_1.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q4_1.gguf) | Q4_1 | 4.78GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_0.gguf) | Q5_0 | 5.21GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K.gguf) | Q5_K | 5.34GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_1.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q5_1.gguf) | Q5_1 | 5.65GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q6_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q6_K.gguf) | Q6_K | 6.14GB |
| [suzume-llama-3-8B-multilingual-orpo-borda-half.Q8_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-multilingual-orpo-borda-half-gguf/blob/main/suzume-llama-3-8B-multilingual-orpo-borda-half.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
base_model: lightblue/suzume-llama-3-8B-multilingual
model-index:
- name: workspace/llm_training/axolotl/llama3-multilingual-orpo/output_mitsu_half_borda
results: []
---
# Suzume ORPO
<p align="center">
<img width=500 src="https://cdn-uploads.huggingface.co/production/uploads/64b63f8ad57e02621dc93c8b/kWQSu02YfgYdUQqv4s5lq.png" alt="Suzume with Mitsu - a Japanese tree sparrow with honey on it"/>
</p>
[[Paper]](https://arxiv.org/abs/2405.18952) [[Dataset]](https://huggingface.co/datasets/lightblue/mitsu)
This is Suzume ORPO, an ORPO trained fine-tune of the [lightblue/suzume-llama-3-8B-multilingual](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual) model using our [lightblue/mitsu](https://huggingface.co/datasets/lightblue/mitsu) dataset.
We have trained several versions of this model using ORPO and so recommend that you use the best performing model from our tests, [lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half).
Note that this model has a non-commerical license as we used the Command R and Command R+ models to generate our training data for this model ([lightblue/mitsu](https://huggingface.co/datasets/lightblue/mitsu)).
We are currently working on a developing a commerically usable model, so stay tuned for that!
# Model list
We have ORPO trained the following models using different proportions of the [lightblue/mitsu](https://huggingface.co/datasets/lightblue/mitsu) dataset:
* Trained on the top/bottom responses of all prompts in the dataset: [lightblue/suzume-llama-3-8B-multilingual-orpo-borda-full](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-full)
* Trained on the top/bottom responses of the prompts of the 75\% most consistently ranked responses in the dataset: [lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top75](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top75)
* Trained on the top/bottom responses of the prompts of the 50\% most consistently ranked responses in the dataset: [lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half)
* Trained on the top/bottom responses of the prompts of the 25\% most consistently ranked responses in the dataset: [lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top25](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top25)
# Model results
We compare the MT-Bench scores across 6 languages for our 4 ORPO trained models, as well as some baselines:
* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) - The foundation model that our models are ultimately built upon
* [Nexusflow/Starling-LM-7B-beta](https://huggingface.co/Nexusflow/Starling-LM-7B-beta) - The highest performing open model on the Chatbot arena that is of a similar size to ours
* gpt-3.5-turbo - A fairly high quality (although not state-of-the-art) proprietary LLM
* [lightblue/suzume-llama-3-8B-multilingual](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual) - The base model which we train our ORPO finetunes from
| **MT-Bench language** | **meta-llama/Meta-Llama-3-8B-Instruct** | **Nexusflow/Starling-LM-7B-beta** | **gpt-3.5-turbo** | **lightblue/suzume-llama-3-8B-multilingual** | **lightblue/suzume-llama-3-8B-multilingual-orpo-borda-full** | **lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top75** | **lightblue/suzume-llama-3-8B-multilingual-orpo-borda-half** | **lightblue/suzume-llama-3-8B-multilingual-orpo-borda-top25** |
|-----------------------|-----------------------------------------|-----------------------------------|-------------------|----------------------------------------------|--------------------------------------------------------------|---------------------------------------------------------------|--------------------------------------------------------------|---------------------------------------------------------------|
| **Chinese 🇨🇳** | NaN | 6.97 | 7.55 | 7.11 | 7.65 | **7.77** | 7.74 | 7.44 |
| **English 🇺🇸** | 7.98 | 7.92 | **8.26** | 7.73 | 7.98 | 7.94 | 7.98 | 8.22 |
| **French 🇫🇷** | NaN | 7.29 | 7.74 | 7.66 | **7.84** | 7.46 | 7.78 | 7.81 |
| **German 🇩🇪** | NaN | 6.99 | 7.68 | 7.26 | 7.28 | 7.64 | 7.7 | **7.71** |
| **Japanese 🇯🇵** | NaN | 6.22 | **7.84** | 6.56 | 7.2 | 7.12 | 7.34 | 7.04 |
| **Russian 🇷🇺** | NaN | 8.28 | 7.94 | 8.19 | 8.3 | 8.74 | **8.94** | 8.81 |
We can see noticable improvement on most languages compared to the base model. We also find that our ORPO models achieve the highest score out of all the models we evaluated for a number of languages.
# Training data
We trained this model using the [lightblue/mitsu_full_borda](https://huggingface.co/datasets/lightblue/mitsu_full_borda) dataset.
# Training configuration
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: lightblue/suzume-llama-3-8B-multilingual
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer # PreTrainedTokenizerFast
load_in_8bit: false
load_in_4bit: false
strict: false
rl: orpo
orpo_alpha: 0.1
remove_unused_columns: false
chat_template: chatml
datasets:
- path: lightblue/mitsu_tophalf_borda
type: orpo.chat_template
conversation: llama-3
dataset_prepared_path: /workspace/llm_training/axolotl/llama3-multilingual-orpo/prepared_mitsu_half_borda
val_set_size: 0.02
output_dir: /workspace/llm_training/axolotl/llama3-multilingual-orpo/output_mitsu_half_borda
sequence_len: 8192
sample_packing: false
pad_to_sequence_len: true
use_wandb: true
wandb_project: axolotl
wandb_entity: peterd
wandb_name: mitsu_half_borda
gradient_accumulation_steps: 8
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 8e-6
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
early_stopping_patience:
resume_from_checkpoint:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 20
eval_table_size:
saves_per_epoch: 1
debug:
deepspeed: /workspace/axolotl/deepspeed_configs/zero3_bf16.json
weight_decay: 0.0
special_tokens:
pad_token: <|end_of_text|>
```
</details><br>
# workspace/llm_training/axolotl/llama3-multilingual-orpo/output_mitsu_half_borda
This model is a fine-tuned version of [lightblue/suzume-llama-3-8B-multilingual](https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0935
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-06
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.6299 | 0.02 | 1 | 7.7014 |
| 7.041 | 0.07 | 3 | 3.9786 |
| 0.6089 | 0.15 | 6 | 0.1393 |
| 0.1308 | 0.22 | 9 | 0.1244 |
| 0.1051 | 0.29 | 12 | 0.1112 |
| 0.1021 | 0.36 | 15 | 0.1063 |
| 0.0861 | 0.44 | 18 | 0.1026 |
| 0.1031 | 0.51 | 21 | 0.0979 |
| 0.0996 | 0.58 | 24 | 0.0967 |
| 0.0923 | 0.65 | 27 | 0.0960 |
| 0.1025 | 0.73 | 30 | 0.0944 |
| 0.1103 | 0.8 | 33 | 0.0939 |
| 0.0919 | 0.87 | 36 | 0.0937 |
| 0.104 | 0.94 | 39 | 0.0935 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0
# How to cite
```tex
@article{devine2024sure,
title={Are You Sure? Rank Them Again: Repeated Ranking For Better Preference Datasets},
author={Devine, Peter},
journal={arXiv preprint arXiv:2405.18952},
year={2024}
}
```
# Developer
Peter Devine - ([ptrdvn](https://huggingface.co/ptrdvn))
|
Viniciaao/GokuJP | Viniciaao | 2024-08-19T21:54:36Z | 0 | 0 | null | [
"ja",
"license:openrail",
"region:us"
]
| null | 2023-09-03T12:16:37Z | ---
license: openrail
language:
- ja
--- |
RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf | RichardErkhov | 2024-08-19T21:49:06Z | 6 | 0 | null | [
"gguf",
"arxiv:2311.03099",
"arxiv:2306.01708",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T19:58:11Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-LewdPlay-8B-evo - GGUF
- Model creator: https://huggingface.co/Undi95/
- Original model: https://huggingface.co/Undi95/Llama-3-LewdPlay-8B-evo/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-LewdPlay-8B-evo.Q2_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-LewdPlay-8B-evo.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-LewdPlay-8B-evo.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-LewdPlay-8B-evo.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-LewdPlay-8B-evo.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-LewdPlay-8B-evo.Q3_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-LewdPlay-8B-evo.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-LewdPlay-8B-evo.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-LewdPlay-8B-evo.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-LewdPlay-8B-evo.Q4_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-LewdPlay-8B-evo.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-LewdPlay-8B-evo.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-LewdPlay-8B-evo.Q4_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-LewdPlay-8B-evo.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-LewdPlay-8B-evo.Q4_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-LewdPlay-8B-evo.Q5_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-LewdPlay-8B-evo.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-LewdPlay-8B-evo.Q5_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-LewdPlay-8B-evo.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-LewdPlay-8B-evo.Q5_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-LewdPlay-8B-evo.Q6_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-LewdPlay-8B-evo.Q8_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_Llama-3-LewdPlay-8B-evo-gguf/blob/main/Llama-3-LewdPlay-8B-evo.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: cc-by-nc-4.0
base_model:
- vicgalle/Roleplay-Llama-3-8B
- Undi95/Llama-3-Unholy-8B-e4
- Undi95/Llama-3-LewdPlay-8B
library_name: transformers
tags:
- mergekit
- merge
---
# LewdPlay-8B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
The new EVOLVE merge method was used (on MMLU specifically), see below for more information!
Unholy was used for uncensoring, Roleplay Llama 3 for the DPO train he got on top, and LewdPlay for the... lewd side.
## Prompt template: Llama3
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using ./mergekit/input_models/Roleplay-Llama-3-8B_213413727 as a base.
### Models Merged
The following models were included in the merge:
* ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
* ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
### Configuration
The following YAML configuration was used to produce this model:
```yaml
base_model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
dtype: bfloat16
merge_method: dare_ties
parameters:
int8_mask: 1.0
normalize: 0.0
slices:
- sources:
- layer_range: [0, 4]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 1.0
weight: 0.6861808716092435
- layer_range: [0, 4]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.6628290134113985
weight: 0.5815923052193855
- layer_range: [0, 4]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 1.0
weight: 0.5113886163963061
- sources:
- layer_range: [4, 8]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 0.892655547455918
weight: 0.038732602391021484
- layer_range: [4, 8]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 1.0
weight: 0.1982145486303527
- layer_range: [4, 8]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 1.0
weight: 0.6843011350690802
- sources:
- layer_range: [8, 12]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 0.7817511027396784
weight: 0.13053333213489704
- layer_range: [8, 12]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.6963703515864826
weight: 0.20525481492667985
- layer_range: [8, 12]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 0.6983086326765777
weight: 0.5843953969574106
- sources:
- layer_range: [12, 16]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 0.9632895768462915
weight: 0.2101146706607748
- layer_range: [12, 16]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.597557434542081
weight: 0.6728172621848589
- layer_range: [12, 16]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 0.756263557607837
weight: 0.2581423726361908
- sources:
- layer_range: [16, 20]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 1.0
weight: 0.2116035543552448
- layer_range: [16, 20]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 1.0
weight: 0.22654226422958418
- layer_range: [16, 20]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 0.8925914810507647
weight: 0.42243766315440867
- sources:
- layer_range: [20, 24]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 0.7697608089825734
weight: 0.1535118632140203
- layer_range: [20, 24]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.9886758076773643
weight: 0.3305040603868546
- layer_range: [20, 24]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 1.0
weight: 0.40670083428654535
- sources:
- layer_range: [24, 28]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 1.0
weight: 0.4542810478500622
- layer_range: [24, 28]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.8330662483310117
weight: 0.2587495367324508
- layer_range: [24, 28]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 0.9845313983551542
weight: 0.40378452705975915
- sources:
- layer_range: [28, 32]
model: ./mergekit/input_models/Llama-3-LewdPlay-8B-e3_2981937066
parameters:
density: 1.0
weight: 0.2951962192288415
- layer_range: [28, 32]
model: ./mergekit/input_models/Llama-3-Unholy-8B-e4_1440388923
parameters:
density: 0.960315594933433
weight: 0.13142971773782525
- layer_range: [28, 32]
model: ./mergekit/input_models/Roleplay-Llama-3-8B_213413727
parameters:
density: 1.0
weight: 0.30838472094518804
```
## Support
If you want to support me, you can [here](https://ko-fi.com/undiai).
|
bgenchel/ppo-Huggy | bgenchel | 2024-08-19T21:39:26Z | 5 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
]
| reinforcement-learning | 2024-08-19T21:39:20Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: bgenchel/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
omersaidd/tekstilGPTV5 | omersaidd | 2024-08-19T21:35:43Z | 27 | 0 | null | [
"pytorch",
"gguf",
"llama",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-18T12:36:50Z | ---
license: apache-2.0
---
|
WhiteRabbitNeo/Llama-3.1-WhiteRabbitNeo-2-70B | WhiteRabbitNeo | 2024-08-19T21:23:57Z | 54 | 30 | null | [
"pytorch",
"llama",
"Llama-3",
"finetune",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:finetune:meta-llama/Llama-3.1-70B",
"license:llama3.1",
"region:us"
]
| null | 2024-08-19T20:51:50Z | ---
license: llama3.1
base_model: meta-llama/Meta-Llama-3.1-70B
tags:
- Llama-3
- finetune
---
# Our latest model is live in our Web App, and on Kindo.ai!
Access at: https://www.whiterabbitneo.com/
# Our Discord Server
Join us at: https://discord.gg/8Ynkrcbk92 (Updated on Dec 29th. Now permanent link to join)
# Llama-3.1 Licence + WhiteRabbitNeo Extended Version
# WhiteRabbitNeo Extension to Llama-3.1 Licence: Usage Restrictions
```
You agree not to use the Model or Derivatives of the Model:
- In any way that violates any applicable national or international law or regulation or infringes upon the lawful rights and interests of any third party;
- For military use in any way;
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
- To generate or disseminate inappropriate content subject to applicable regulatory requirements;
- To generate or disseminate personal identifiable information without due authorization or for unreasonable use;
- To defame, disparage or otherwise harass others;
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories.
```
# Topics Covered:
```
- Open Ports: Identifying open ports is crucial as they can be entry points for attackers. Common ports to check include HTTP (80, 443), FTP (21), SSH (22), and SMB (445).
- Outdated Software or Services: Systems running outdated software or services are often vulnerable to exploits. This includes web servers, database servers, and any third-party software.
- Default Credentials: Many systems and services are installed with default usernames and passwords, which are well-known and can be easily exploited.
- Misconfigurations: Incorrectly configured services, permissions, and security settings can introduce vulnerabilities.
- Injection Flaws: SQL injection, command injection, and cross-site scripting (XSS) are common issues in web applications.
- Unencrypted Services: Services that do not use encryption (like HTTP instead of HTTPS) can expose sensitive data.
- Known Software Vulnerabilities: Checking for known vulnerabilities in software using databases like the National Vulnerability Database (NVD) or tools like Nessus or OpenVAS.
- Cross-Site Request Forgery (CSRF): This is where unauthorized commands are transmitted from a user that the web application trusts.
- Insecure Direct Object References: This occurs when an application provides direct access to objects based on user-supplied input.
- Security Misconfigurations in Web Servers/Applications: This includes issues like insecure HTTP headers or verbose error messages that reveal too much information.
- Broken Authentication and Session Management: This can allow attackers to compromise passwords, keys, or session tokens, or to exploit other implementation flaws to assume other users' identities.
- Sensitive Data Exposure: Includes vulnerabilities that expose sensitive data, such as credit card numbers, health records, or personal information.
- API Vulnerabilities: In modern web applications, APIs are often used and can have vulnerabilities like insecure endpoints or data leakage.
- Denial of Service (DoS) Vulnerabilities: Identifying services that are vulnerable to DoS attacks, which can make the resource unavailable to legitimate users.
- Buffer Overflows: Common in older software, these vulnerabilities can allow an attacker to crash the system or execute arbitrary code.
- More ..
```
# Terms of Use
By accessing and using this Artificial Intelligence (AI) model, you, the user, acknowledge and agree that you are solely responsible for your use of the model and its outcomes. You hereby agree to indemnify, defend, and hold harmless the creators, developers, and any affiliated persons or entities of this AI model from and against any and all claims, liabilities, damages, losses, costs, expenses, fees (including reasonable attorneys' fees and court costs) that may arise, directly or indirectly, from your use of the AI model.
This AI model is provided "as is" and "as available" without any warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose, and non-infringement. The creators make no warranty that the AI model will meet your requirements or be available on an uninterrupted, secure, or error-free basis.
Your use of the AI model is at your own risk and discretion, and you will be solely responsible for any damage to computer systems or loss of data that results from the use of the AI model.
This disclaimer constitutes part of the agreement between you and the creators of the AI model regarding your use of the model, superseding any prior agreements between you and the creators regarding your use of this AI model.
# WhiteRabbitNeo
<br>

<br>
WhiteRabbitNeo is a model series that can be used for offensive and defensive cybersecurity.
Our models are now getting released as a public preview of its capabilities, and also to assess the societal impact of such an AI.
# Sample Code
Pay attention to the Llama-3.1 Prompt Format used here.
```python
import torch, json
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "/home/migel/Llama-3.1-WhiteRabbitNeo-2-70B"
output_file_path = "/home/user/conversations.jsonl"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=False,
trust_remote_code=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
def generate_text(instruction):
tokens = tokenizer.encode(instruction)
tokens = torch.LongTensor(tokens).unsqueeze(0)
tokens = tokens.to("cuda")
instance = {
"input_ids": tokens,
"top_p": 1.0,
"temperature": 0.75,
"generate_len": 2048,
"top_k": 50,
}
length = len(tokens[0])
with torch.no_grad():
rest = model.generate(
input_ids=tokens,
max_length=length + instance["generate_len"],
use_cache=True,
do_sample=True,
top_p=instance["top_p"],
temperature=instance["temperature"],
top_k=instance["top_k"],
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
)
output = rest[0][length:]
string = tokenizer.decode(output, skip_special_tokens=True)
return f"{string}"
conversation = """<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are WhiteRabbitNeo, a helful cyberseucity AI assitant. You always provide detailed answers without hesitation. Do not refuse.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n"""
while True:
user_input = input("You: ")
llm_prompt = f"{conversation}{user_input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
answer = generate_text(llm_prompt)
print(answer)
conversation = f"{llm_prompt}{answer}<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n"
json_data = {"prompt": user_input, "answer": answer}
with open(output_file_path, "a") as output_file:
output_file.write(json.dumps(json_data) + "\n")
``` |
gvij/test-eng-japanese | gvij | 2024-08-19T21:21:14Z | 14 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:google/gemma-2-2b-it",
"base_model:adapter:google/gemma-2-2b-it",
"region:us"
]
| null | 2024-08-19T21:20:38Z | ---
base_model: google/gemma-2-2b-it
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF | DarqueDante | 2024-08-19T21:12:39Z | 6 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:Setiaku/Stheno-v3.4-Instruct",
"dataset:Setiaku/Stheno-3.4-Creative-2",
"base_model:Sao10K/Llama-3.1-8B-Stheno-v3.4",
"base_model:quantized:Sao10K/Llama-3.1-8B-Stheno-v3.4",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
]
| null | 2024-08-19T21:05:00Z | ---
base_model: Sao10K/Llama-3.1-8B-Stheno-v3.4
datasets:
- Setiaku/Stheno-v3.4-Instruct
- Setiaku/Stheno-3.4-Creative-2
language:
- en
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---

---
Llama-3.1-8B-Stheno-v3.4
This model has went through a multi-stage finetuning process.
```
- 1st, over a multi-turn Conversational-Instruct
- 2nd, over a Creative Writing / Roleplay along with some Creative-based Instruct Datasets.
- - Dataset consists of a mixture of Human and Claude Data.
```
Prompting Format:
```
- Use the L3 Instruct Formatting - Euryale 2.1 Preset Works Well
- Temperature + min_p as per usual, I recommend 1.4 Temp + 0.2 min_p.
- Has a different vibe to previous versions. Tinker around.
```
Changes since previous Stheno Datasets:
```
- Included Multi-turn Conversation-based Instruct Datasets to boost multi-turn coherency. # This is a seperate set, not the ones made by Kalomaze and Nopm, that are used in Magnum. They're completely different data.
- Replaced Single-Turn Instruct with Better Prompts and Answers by Claude 3.5 Sonnet and Claude 3 Opus.
- Removed c2 Samples -> Underway of re-filtering and masking to use with custom prefills. TBD
- Included 55% more Roleplaying Examples based of [Gryphe's](https://huggingface.co/datasets/Gryphe/Sonnet3.5-Charcard-Roleplay) Charcard RP Sets. Further filtered and cleaned on.
- Included 40% More Creative Writing Examples.
- Included Datasets Targeting System Prompt Adherence.
- Included Datasets targeting Reasoning / Spatial Awareness.
- Filtered for the usual errors, slop and stuff at the end. Some may have slipped through, but I removed nearly all of it.
```
Personal Opinions:
```
- Llama3.1 was more disappointing, in the Instruct Tune? It felt overbaked, atleast. Likely due to the DPO being done after their SFT Stage.
- Tuning on L3.1 base did not give good results, unlike when I tested with Nemo base. unfortunate.
- Still though, I think I did an okay job. It does feel a bit more distinctive.
- It took a lot of tinkering, like a LOT to wrangle this.
```
Below are some graphs and all for you to observe.
---
`Turn Distribution # 1 Turn is considered as 1 combined Human/GPT pair in a ShareGPT format. 4 Turns means 1 System Row + 8 Human/GPT rows in total.`
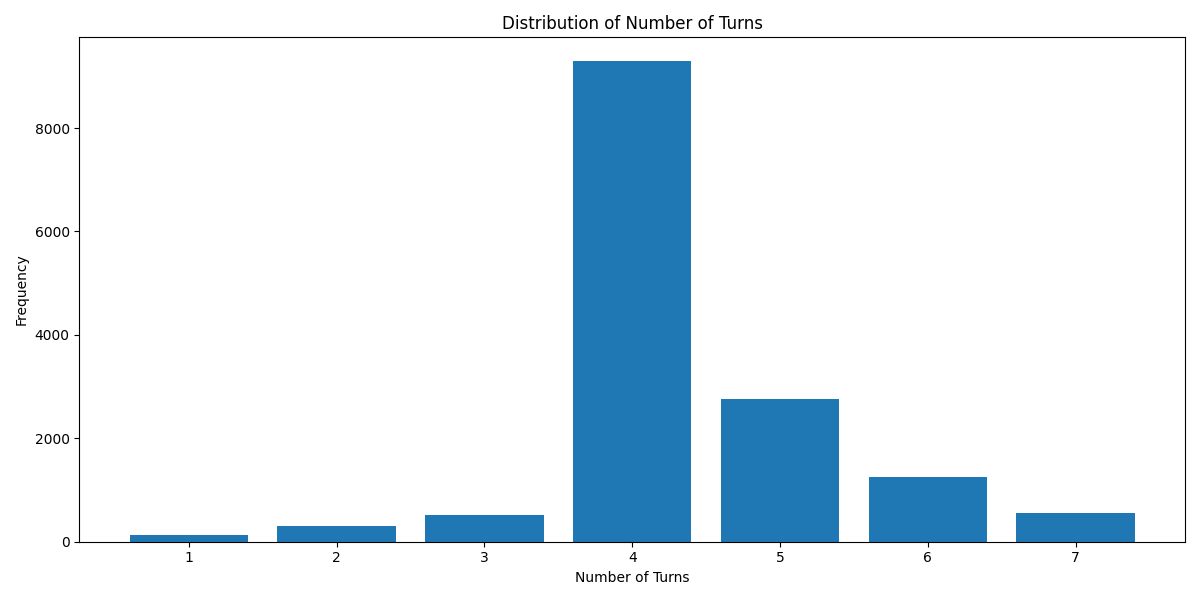
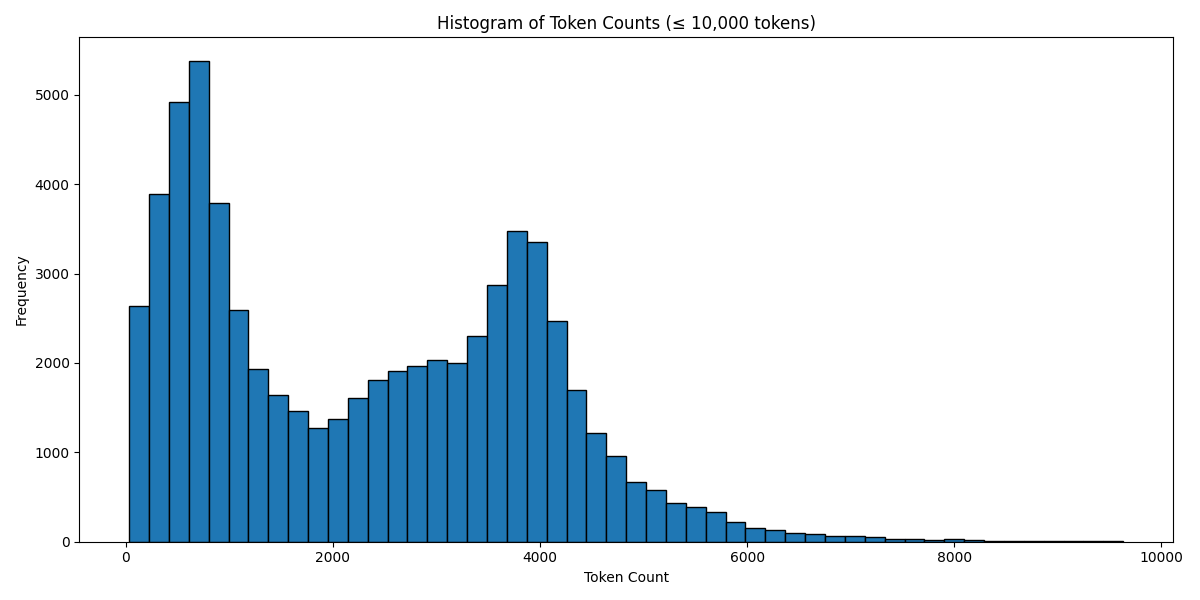
`Token Count Histogram # Based on the Llama 3 Tokenizer`
---
```
Source Image: https://www.pixiv.net/en/artworks/91689070
```
# DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF
This model was converted to GGUF format from [`Sao10K/Llama-3.1-8B-Stheno-v3.4`](https://huggingface.co/Sao10K/Llama-3.1-8B-Stheno-v3.4) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Sao10K/Llama-3.1-8B-Stheno-v3.4) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF --hf-file llama-3.1-8b-stheno-v3.4-iq4_xs-imat.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF --hf-file llama-3.1-8b-stheno-v3.4-iq4_xs-imat.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF --hf-file llama-3.1-8b-stheno-v3.4-iq4_xs-imat.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo DarqueDante/Llama-3.1-8B-Stheno-v3.4-IQ4_XS-GGUF --hf-file llama-3.1-8b-stheno-v3.4-iq4_xs-imat.gguf -c 2048
```
|
ys-zong/llava-v1.5-13b-Posthoc | ys-zong | 2024-08-19T21:07:31Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"llava",
"text-generation",
"en",
"arxiv:2402.02207",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-01-30T14:36:41Z | ---
language:
- en
---
# VLGuard
[[Website]](https://ys-zong.github.io/VLGuard) [[Paper]](https://arxiv.org/abs/2402.02207) [[Code]](https://github.com/ys-zong/VLGuard)
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models. (ICML 2024)
## Weights
This is the model weights for LLaVA-v1.5-13B Posthoc Fine-tuning. You can use them in exactly the same way as the original [LLaVA](https://github.com/haotian-liu/LLaVA/tree/main).
## Usage
Please refer to [Github](https://github.com/ys-zong/VLGuard) for detailed usage. |
minchul/cvlface_adaface_vit_base_kprpe_webface4m | minchul | 2024-08-19T20:53:02Z | 216 | 2 | transformers | [
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"en",
"arxiv:2403.14852",
"license:mit",
"region:us"
]
| feature-extraction | 2024-06-06T01:52:03Z | ---
language: en
license: mit
arxiv: 2403.14852
---
<div align="center">
<h1>
CVLFace Pretrained Model (ADAFACE VIT BASE KPRPE WEBFACE4M)
</h1>
</div>
<p align="center">
🌎 <a href="https://github.com/mk-minchul/CVLface" target="_blank">GitHub</a> • 🤗 <a href="https://huggingface.co/minchul" target="_blank">Hugging Face</a>
</p>
-----
## 1. Introduction
Model Name: ADAFACE VIT BASE KPRPE WEBFACE4M
Related Paper: KeyPoint Relative Position Encoding for Face Recognition (https://arxiv.org/abs/2403.14852)
Please cite the orignal paper and follow the license of the training dataset.
## 2. Quick Start
```python
from transformers import AutoModel
from huggingface_hub import hf_hub_download
import shutil
import os
import torch
import sys
# helpfer function to download huggingface repo and use model
def download(repo_id, path, HF_TOKEN=None):
os.makedirs(path, exist_ok=True)
files_path = os.path.join(path, 'files.txt')
if not os.path.exists(files_path):
hf_hub_download(repo_id, 'files.txt', token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
with open(os.path.join(path, 'files.txt'), 'r') as f:
files = f.read().split('\n')
for file in [f for f in files if f] + ['config.json', 'wrapper.py', 'model.safetensors']:
full_path = os.path.join(path, file)
if not os.path.exists(full_path):
hf_hub_download(repo_id, file, token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
# helpfer function to download huggingface repo and use model
def load_model_from_local_path(path, HF_TOKEN=None):
cwd = os.getcwd()
os.chdir(path)
sys.path.insert(0, path)
model = AutoModel.from_pretrained(path, trust_remote_code=True, token=HF_TOKEN)
os.chdir(cwd)
sys.path.pop(0)
return model
# helpfer function to download huggingface repo and use model
def load_model_by_repo_id(repo_id, save_path, HF_TOKEN=None, force_download=False):
if force_download:
if os.path.exists(save_path):
shutil.rmtree(save_path)
download(repo_id, save_path, HF_TOKEN)
return load_model_from_local_path(save_path, HF_TOKEN)
if __name__ == '__main__':
HF_TOKEN = 'YOUR_HUGGINGFACE_TOKEN'
path = os.path.expanduser('~/.cvlface_cache/minchul/cvlface_adaface_vit_base_kprpe_webface4m')
repo_id = 'minchul/cvlface_adaface_vit_base_kprpe_webface4m'
model = load_model_by_repo_id(repo_id, path, HF_TOKEN)
# input is a rgb image normalized.
from torchvision.transforms import Compose, ToTensor, Normalize
from PIL import Image
img = Image.open('path/to/image.jpg')
trans = Compose([ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
input = trans(img).unsqueeze(0) # torch.randn(1, 3, 112, 112)
# KPRPE also takes keypoints locations as input
aligner = load_model_by_repo_id('minchul/cvlface_DFA_mobilenet', path, HF_TOKEN)
aligned_x, orig_ldmks, aligned_ldmks, score, thetas, bbox = aligner(input)
keypoints = orig_ldmks # torch.randn(1, 5, 2)
out = model(input, keypoints)
```
|
bastienp/Gemma-2-2B-Instruct-structured-output | bastienp | 2024-08-19T20:49:22Z | 88 | 2 | peft | [
"peft",
"safetensors",
"gguf",
"gemma2",
"text-generation-inference",
"transformers",
"unsloth",
"en",
"dataset:paraloq/json_data_extraction",
"base_model:google/gemma-2-2b-it",
"base_model:adapter:google/gemma-2-2b-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T15:13:14Z | ---
base_model: google/gemma-2-2b-it
language:
- en
license: gemma
tags:
- text-generation-inference
- transformers
- unsloth
- gemma2
datasets:
- paraloq/json_data_extraction
library_name: peft
---
# Gemma-2 2B Instruct fine-tuned on JSON dataset
This model is a Gemma-2 2b model fine-tuned to paraloq/json_data_extraction.
The model has been fine-tuned to extract data from a text according to a json schema.
## Prompt
The prompt used during training is:
```py
"""Below is a text paired with input that provides further context. Write JSON output that matches the schema to extract information.
### Input:
{input}
### Schema:
{schema}
### Response:
"""
```
## Using the Model
You can use the model with the transformer library or with the wrapper from [unsloth] (https://unsloth.ai/blog/gemma2), which allows faster inference.
```py
import torch
from unsloth import FastLanguageModel
# Required to avoid cache size exceeded
torch._dynamo.config.accumulated_cache_size_limit = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = f"bastienp/Gemma-2-2B-it-JSON-data-extration",
max_seq_length = 2048,
dtype = torch.float16,
load_in_4bit = False,
token = HF_TOKEN_READ,
)
```
## Using the Quantized model (llama.cpp)
The model is supplied in GGFU format in 4bit and 8bit.
Example code with Llamacpp:
```py
from llama_cpp import Llama
llm = Llama.from_pretrained(
"bastienp/Gemma-2-2B-it-JSON-data-extration",
filename="*Q4_K_M.gguf", #*Q8_K_M.gguf for the 8 bit version
verbose=False,
)
```
The base model used for fine-tuning is google/gemma-2-2b-it. This repository is **NOT** affiliated with Google.
Gemma is provided under and subject to the Gemma Terms of Use found at ai.google.dev/gemma/terms.
- **Developed by:** bastienp
- **License:** gemma
- **Finetuned from model :** google/gemma-2-2b-it |
minchul/cvlface_adaface_ir50_ms1mv2 | minchul | 2024-08-19T20:47:16Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"en",
"arxiv:2204.00964",
"license:mit",
"region:us"
]
| feature-extraction | 2024-06-05T00:55:45Z | ---
language: en
license: mit
arxiv: 2204.00964
---
<div align="center">
<h1>
CVLFace Pretrained Model (ADAFACE IR50 MS1MV2)
</h1>
</div>
<p align="center">
🌎 <a href="https://github.com/mk-minchul/CVLface" target="_blank">GitHub</a> • 🤗 <a href="https://huggingface.co/minchul" target="_blank">Hugging Face</a>
</p>
-----
## 1. Introduction
Model Name: ADAFACE IR50 MS1MV2
Related Paper: AdaFace: Quality Adaptive Margin for Face Recognition (https://arxiv.org/abs/2204.00964)
Please cite the orignal paper and follow the license of the training dataset.
## 2. Quick Start
```python
from transformers import AutoModel
from huggingface_hub import hf_hub_download
import shutil
import os
import torch
import sys
# helpfer function to download huggingface repo and use model
def download(repo_id, path, HF_TOKEN=None):
os.makedirs(path, exist_ok=True)
files_path = os.path.join(path, 'files.txt')
if not os.path.exists(files_path):
hf_hub_download(repo_id, 'files.txt', token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
with open(os.path.join(path, 'files.txt'), 'r') as f:
files = f.read().split('\n')
for file in [f for f in files if f] + ['config.json', 'wrapper.py', 'model.safetensors']:
full_path = os.path.join(path, file)
if not os.path.exists(full_path):
hf_hub_download(repo_id, file, token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
# helpfer function to download huggingface repo and use model
def load_model_from_local_path(path, HF_TOKEN=None):
cwd = os.getcwd()
os.chdir(path)
sys.path.insert(0, path)
model = AutoModel.from_pretrained(path, trust_remote_code=True, token=HF_TOKEN)
os.chdir(cwd)
sys.path.pop(0)
return model
# helpfer function to download huggingface repo and use model
def load_model_by_repo_id(repo_id, save_path, HF_TOKEN=None, force_download=False):
if force_download:
if os.path.exists(save_path):
shutil.rmtree(save_path)
download(repo_id, save_path, HF_TOKEN)
return load_model_from_local_path(save_path, HF_TOKEN)
if __name__ == '__main__':
HF_TOKEN = 'YOUR_HUGGINGFACE_TOKEN'
path = os.path.expanduser('~/.cvlface_cache/minchul/cvlface_adaface_ir50_ms1mv2')
repo_id = 'minchul/cvlface_adaface_ir50_ms1mv2'
model = load_model_by_repo_id(repo_id, path, HF_TOKEN)
# input is a rgb image normalized.
from torchvision.transforms import Compose, ToTensor, Normalize
from PIL import Image
img = Image.open('path/to/image.jpg')
trans = Compose([ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
input = trans(img).unsqueeze(0) # torch.randn(1, 3, 112, 112)
out = model(input)
```
|
minchul/cvlface_adaface_ir50_webface4m | minchul | 2024-08-19T20:45:12Z | 68 | 0 | transformers | [
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"en",
"arxiv:2204.00964",
"license:mit",
"region:us"
]
| feature-extraction | 2024-06-05T00:54:35Z | ---
language: en
license: mit
arxiv: 2204.00964
---
<div align="center">
<h1>
CVLFace Pretrained Model (ADAFACE IR50 WEBFACE4M)
</h1>
</div>
<p align="center">
🌎 <a href="https://github.com/mk-minchul/CVLface" target="_blank">GitHub</a> • 🤗 <a href="https://huggingface.co/minchul" target="_blank">Hugging Face</a>
</p>
-----
## 1. Introduction
Model Name: ADAFACE IR50 WEBFACE4M
Related Paper: AdaFace: Quality Adaptive Margin for Face Recognition (https://arxiv.org/abs/2204.00964)
Please cite the orignal paper and follow the license of the training dataset.
## 2. Quick Start
```python
from transformers import AutoModel
from huggingface_hub import hf_hub_download
import shutil
import os
import torch
import sys
# helpfer function to download huggingface repo and use model
def download(repo_id, path, HF_TOKEN=None):
os.makedirs(path, exist_ok=True)
files_path = os.path.join(path, 'files.txt')
if not os.path.exists(files_path):
hf_hub_download(repo_id, 'files.txt', token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
with open(os.path.join(path, 'files.txt'), 'r') as f:
files = f.read().split('\n')
for file in [f for f in files if f] + ['config.json', 'wrapper.py', 'model.safetensors']:
full_path = os.path.join(path, file)
if not os.path.exists(full_path):
hf_hub_download(repo_id, file, token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
# helpfer function to download huggingface repo and use model
def load_model_from_local_path(path, HF_TOKEN=None):
cwd = os.getcwd()
os.chdir(path)
sys.path.insert(0, path)
model = AutoModel.from_pretrained(path, trust_remote_code=True, token=HF_TOKEN)
os.chdir(cwd)
sys.path.pop(0)
return model
# helpfer function to download huggingface repo and use model
def load_model_by_repo_id(repo_id, save_path, HF_TOKEN=None, force_download=False):
if force_download:
if os.path.exists(save_path):
shutil.rmtree(save_path)
download(repo_id, save_path, HF_TOKEN)
return load_model_from_local_path(save_path, HF_TOKEN)
if __name__ == '__main__':
HF_TOKEN = 'YOUR_HUGGINGFACE_TOKEN'
path = os.path.expanduser('~/.cvlface_cache/minchul/cvlface_adaface_ir50_webface4m')
repo_id = 'minchul/cvlface_adaface_ir50_webface4m'
model = load_model_by_repo_id(repo_id, path, HF_TOKEN)
# input is a rgb image normalized.
from torchvision.transforms import Compose, ToTensor, Normalize
from PIL import Image
img = Image.open('path/to/image.jpg')
trans = Compose([ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
input = trans(img).unsqueeze(0) # torch.randn(1, 3, 112, 112)
out = model(input)
```
|
minchul/cvlface_adaface_ir18_webface4m | minchul | 2024-08-19T20:41:06Z | 57 | 0 | transformers | [
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"en",
"arxiv:2204.00964",
"license:mit",
"region:us"
]
| feature-extraction | 2024-06-05T00:54:03Z | ---
language: en
license: mit
arxiv: 2204.00964
---
<div align="center">
<h1>
CVLFace Pretrained Model (ADAFACE IR18 WEBFACE4M)
</h1>
</div>
<p align="center">
🌎 <a href="https://github.com/mk-minchul/CVLface" target="_blank">GitHub</a> • 🤗 <a href="https://huggingface.co/minchul" target="_blank">Hugging Face</a>
</p>
-----
## 1. Introduction
Model Name: ADAFACE IR18 WEBFACE4M
Related Paper: AdaFace: Quality Adaptive Margin for Face Recognition (https://arxiv.org/abs/2204.00964)
Please cite the orignal paper and follow the license of the training dataset.
## 2. Quick Start
```python
from transformers import AutoModel
from huggingface_hub import hf_hub_download
import shutil
import os
import torch
import sys
# helpfer function to download huggingface repo and use model
def download(repo_id, path, HF_TOKEN=None):
os.makedirs(path, exist_ok=True)
files_path = os.path.join(path, 'files.txt')
if not os.path.exists(files_path):
hf_hub_download(repo_id, 'files.txt', token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
with open(os.path.join(path, 'files.txt'), 'r') as f:
files = f.read().split('\n')
for file in [f for f in files if f] + ['config.json', 'wrapper.py', 'model.safetensors']:
full_path = os.path.join(path, file)
if not os.path.exists(full_path):
hf_hub_download(repo_id, file, token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
# helpfer function to download huggingface repo and use model
def load_model_from_local_path(path, HF_TOKEN=None):
cwd = os.getcwd()
os.chdir(path)
sys.path.insert(0, path)
model = AutoModel.from_pretrained(path, trust_remote_code=True, token=HF_TOKEN)
os.chdir(cwd)
sys.path.pop(0)
return model
# helpfer function to download huggingface repo and use model
def load_model_by_repo_id(repo_id, save_path, HF_TOKEN=None, force_download=False):
if force_download:
if os.path.exists(save_path):
shutil.rmtree(save_path)
download(repo_id, save_path, HF_TOKEN)
return load_model_from_local_path(save_path, HF_TOKEN)
if __name__ == '__main__':
HF_TOKEN = 'YOUR_HUGGINGFACE_TOKEN'
path = os.path.expanduser('~/.cvlface_cache/minchul/cvlface_adaface_ir18_webface4m')
repo_id = 'minchul/cvlface_adaface_ir18_webface4m'
model = load_model_by_repo_id(repo_id, path, HF_TOKEN)
# input is a rgb image normalized.
from torchvision.transforms import Compose, ToTensor, Normalize
from PIL import Image
img = Image.open('path/to/image.jpg')
trans = Compose([ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
input = trans(img).unsqueeze(0) # torch.randn(1, 3, 112, 112)
out = model(input)
```
|
minchul/cvlface_adaface_ir18_vgg2 | minchul | 2024-08-19T20:40:51Z | 56 | 0 | transformers | [
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"en",
"arxiv:2204.00964",
"license:mit",
"region:us"
]
| feature-extraction | 2024-06-05T00:53:24Z | ---
language: en
license: mit
arxiv: 2204.00964
---
<div align="center">
<h1>
CVLFace Pretrained Model (ADAFACE IR18 VGG2)
</h1>
</div>
<p align="center">
🌎 <a href="https://github.com/mk-minchul/CVLface" target="_blank">GitHub</a> • 🤗 <a href="https://huggingface.co/minchul" target="_blank">Hugging Face</a>
</p>
-----
## 1. Introduction
Model Name: ADAFACE IR18 VGG2
Related Paper: AdaFace: Quality Adaptive Margin for Face Recognition (https://arxiv.org/abs/2204.00964)
Please cite the orignal paper and follow the license of the training dataset.
## 2. Quick Start
```python
from transformers import AutoModel
from huggingface_hub import hf_hub_download
import shutil
import os
import torch
import sys
# helpfer function to download huggingface repo and use model
def download(repo_id, path, HF_TOKEN=None):
os.makedirs(path, exist_ok=True)
files_path = os.path.join(path, 'files.txt')
if not os.path.exists(files_path):
hf_hub_download(repo_id, 'files.txt', token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
with open(os.path.join(path, 'files.txt'), 'r') as f:
files = f.read().split('\n')
for file in [f for f in files if f] + ['config.json', 'wrapper.py', 'model.safetensors']:
full_path = os.path.join(path, file)
if not os.path.exists(full_path):
hf_hub_download(repo_id, file, token=HF_TOKEN, local_dir=path, local_dir_use_symlinks=False)
# helpfer function to download huggingface repo and use model
def load_model_from_local_path(path, HF_TOKEN=None):
cwd = os.getcwd()
os.chdir(path)
sys.path.insert(0, path)
model = AutoModel.from_pretrained(path, trust_remote_code=True, token=HF_TOKEN)
os.chdir(cwd)
sys.path.pop(0)
return model
# helpfer function to download huggingface repo and use model
def load_model_by_repo_id(repo_id, save_path, HF_TOKEN=None, force_download=False):
if force_download:
if os.path.exists(save_path):
shutil.rmtree(save_path)
download(repo_id, save_path, HF_TOKEN)
return load_model_from_local_path(save_path, HF_TOKEN)
if __name__ == '__main__':
HF_TOKEN = 'YOUR_HUGGINGFACE_TOKEN'
path = os.path.expanduser('~/.cvlface_cache/minchul/cvlface_adaface_ir18_vgg2')
repo_id = 'minchul/cvlface_adaface_ir18_vgg2'
model = load_model_by_repo_id(repo_id, path, HF_TOKEN)
# input is a rgb image normalized.
from torchvision.transforms import Compose, ToTensor, Normalize
from PIL import Image
img = Image.open('path/to/image.jpg')
trans = Compose([ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
input = trans(img).unsqueeze(0) # torch.randn(1, 3, 112, 112)
out = model(input)
```
|
anthracite-org/magnum-v2-123b-exl2 | anthracite-org | 2024-08-19T20:09:14Z | 21 | 3 | null | [
"chat",
"text-generation",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ru",
"zh",
"ja",
"license:other",
"region:us"
]
| text-generation | 2024-08-19T02:07:36Z | ---
license: other
license_name: mrl
license_link: https://mistral.ai/licenses/MRL-0.1.md
language:
- en
- fr
- de
- es
- it
- pt
- ru
- zh
- ja
pipeline_tag: text-generation
tags:
- chat
---
## This repo contains EXL2 quants of the model. If you need the original weights, please find them [here](https://huggingface.co/anthracite-org/magnum-v2-123b).
## Base repo only contains the measurement file, see revisions for your quant of choice.
- [measurement.json](https://huggingface.co/anthracite-org/magnum-v2-123b-exl2/tree/main)
- [2.7bpw](https://huggingface.co/anthracite-org/magnum-v2-123b-exl2/tree/2.7bpw)
- [4.0bpw](https://huggingface.co/anthracite-org/magnum-v2-123b-exl2/tree/4.0bpw)

This is the sixth in a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet and Opus. This model is fine-tuned on top of [Mistral-Large-Instruct-2407](https://huggingface.co/mistralai/Mistral-Large-Instruct-2407).
## Prompting
Model has been Instruct tuned with the Mistral formatting. A typical input would look like this:
```py
<s>[INST] SYSTEM MESSAGE\nUSER MESSAGE[/INST] ASSISTANT MESSAGE</s>[INST] USER MESSAGE[/INST]
```
We also provide SillyTavern presets for [Context](https://huggingface.co/anthracite-org/Magnum-123b-v1/resolve/main/Magnum-Mistral-Context.json) and [Instruct](https://huggingface.co/anthracite-org/Magnum-123b-v1/raw/main/Magnum-Mistral-Instruct.json) respectively.
The Mistral preset included in SillyTavern seems to be misconfigured by default, so we recommend using these as a replacement.
## Credits
- [anthracite-org/Stheno-Data-Filtered](https://huggingface.co/datasets/anthracite-org/Stheno-Data-Filtered)
- [anthracite-org/kalo-opus-instruct-22k-no-refusal](https://huggingface.co/datasets/anthracite-org/kalo-opus-instruct-22k-no-refusal)
- [anthracite-org/nopm_claude_writing_fixed](https://huggingface.co/datasets/anthracite-org/nopm_claude_writing_fixed)
This model has been a team effort, and the credits goes to all members of Anthracite.
## Training
The training was done for 1.5 epochs. We used 8x [AMD Instinct™ MI300X Accelerators](https://www.amd.com/en/products/accelerators/instinct/mi300/mi300x.html) for the full-parameter fine-tuning of the model.
In addition to this, we noticed that Mistral Large models seemed much more sensitive to learning rate adjustments than other models:

We hypothesize this is primarily due to the particularly narrow and low variance weight distributions typical of Mistral derived models regardless of their scale.
In the end, due to the costs that would be involved in training another full 2 epochs run ($600) on an even lower rate, we settled on our third attempt: 2e-6 with an effective batch size of 64, stopped earlier than the target 2 epochs.

We notice a correlation between the significance of the 2nd epoch loss drop and the strength of the learning rate, implying 4e-6 leads to more catastrophic forgetting.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
## Safety
... |
RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf | RichardErkhov | 2024-08-19T20:08:31Z | 10 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us"
]
| null | 2024-08-19T18:37:05Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Meta-Llama-3-8B - GGUF
- Model creator: https://huggingface.co/bofenghuang/
- Original model: https://huggingface.co/bofenghuang/Meta-Llama-3-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Meta-Llama-3-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [Meta-Llama-3-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Meta-Llama-3-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Meta-Llama-3-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Meta-Llama-3-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Meta-Llama-3-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [Meta-Llama-3-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Meta-Llama-3-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Meta-Llama-3-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Meta-Llama-3-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Meta-Llama-3-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Meta-Llama-3-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Meta-Llama-3-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [Meta-Llama-3-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Meta-Llama-3-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Meta-Llama-3-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Meta-Llama-3-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Meta-Llama-3-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [Meta-Llama-3-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Meta-Llama-3-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Meta-Llama-3-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q6_K.gguf) | Q6_K | 6.14GB |
| [Meta-Llama-3-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/bofenghuang_-_Meta-Llama-3-8B-gguf/blob/main/Meta-Llama-3-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B, for use with transformers and with the original `llama3` codebase.
### Use with transformers
See the snippet below for usage with Transformers:
```python
>>> import transformers
>>> import torch
>>> model_id = "meta-llama/Meta-Llama-3-8B"
>>> pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
>>> pipeline("Hey how are you doing today?")
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3).
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B --include "original/*" --local-dir Meta-Llama-3-8B
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
AAkay/bert_classfication_model_for_syz_2024 | AAkay | 2024-08-19T19:53:00Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-08-19T19:52:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sharad25/vtion_model_v1 | sharad25 | 2024-08-19T19:49:50Z | 5 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T19:41:10Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
adrianSauer/whisper-base-wer | adrianSauer | 2024-08-19T19:46:07Z | 76 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"gn",
"dataset:mozilla-foundation/common_voice_16_1",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-03-17T13:02:13Z | ---
language:
- gn
license: apache-2.0
base_model: openai/whisper-base
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_16_1
metrics:
- wer
model-index:
- name: Common Voice 16 - Guarani
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 16
type: mozilla-foundation/common_voice_16_1
config: gn
split: None
args: gn
metrics:
- name: Wer
type: wer
value: 58.17978782802904
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Common Voice 16 - Guarani
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the Common Voice 16 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5857
- Wer: 58.1798
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 2.3905 | 1.0101 | 100 | 0.9598 | 81.9654 |
| 0.5779 | 2.0202 | 200 | 0.6883 | 68.6767 |
| 0.3116 | 3.0303 | 300 | 0.5997 | 62.5349 |
| 0.1741 | 4.0404 | 400 | 0.5750 | 59.5757 |
| 0.0955 | 5.0505 | 500 | 0.5857 | 58.1798 |
### Framework versions
- Transformers 4.44.0
- Pytorch 2.3.1+cu121
- Datasets 2.21.0
- Tokenizers 0.19.1
|
RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf | RichardErkhov | 2024-08-19T19:35:47Z | 10 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T18:10:39Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Meta-Llama-3-8B-Instruct - GGUF
- Model creator: https://huggingface.co/ISTA-DASLab/
- Original model: https://huggingface.co/ISTA-DASLab/Meta-Llama-3-8B-Instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Meta-Llama-3-8B-Instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q2_K.gguf) | Q2_K | 2.96GB |
| [Meta-Llama-3-8B-Instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Meta-Llama-3-8B-Instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Meta-Llama-3-8B-Instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Meta-Llama-3-8B-Instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Meta-Llama-3-8B-Instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q3_K.gguf) | Q3_K | 3.74GB |
| [Meta-Llama-3-8B-Instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Meta-Llama-3-8B-Instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Meta-Llama-3-8B-Instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Meta-Llama-3-8B-Instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Meta-Llama-3-8B-Instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Meta-Llama-3-8B-Instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Meta-Llama-3-8B-Instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q4_K.gguf) | Q4_K | 4.58GB |
| [Meta-Llama-3-8B-Instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Meta-Llama-3-8B-Instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Meta-Llama-3-8B-Instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Meta-Llama-3-8B-Instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Meta-Llama-3-8B-Instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q5_K.gguf) | Q5_K | 5.34GB |
| [Meta-Llama-3-8B-Instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Meta-Llama-3-8B-Instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Meta-Llama-3-8B-Instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q6_K.gguf) | Q6_K | 6.14GB |
| [Meta-Llama-3-8B-Instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/ISTA-DASLab_-_Meta-Llama-3-8B-Instruct-gguf/blob/main/Meta-Llama-3-8B-Instruct.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: other
license_name: llama3
license_link: LICENSE
extra_gated_prompt: >-
### META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Meta Llama 3 Version Release Date: April 18, 2024
"Agreement" means the terms and conditions for use, reproduction, distribution and modification of the
Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation accompanying Meta Llama 3
distributed by Meta at https://llama.meta.com/get-started/.
"Licensee" or "you" means you, or your employer or any other person or entity (if you are entering into
this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or
regulations to provide legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Meta Llama 3" means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://llama.meta.com/llama-downloads.
"Llama Materials" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation (and any
portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your
principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located
outside of the EEA or Switzerland).
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free
limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama
Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the
Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works
thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Meta
Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you
use the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is
distributed or made available, you shall also include “Llama 3” at the beginning of any such AI model
name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the following
attribution notice within a “Notice” text file distributed as a part of such copies: “Meta Llama 3 is
licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights
Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama
Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama Materials to
improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
2. Additional Commercial Terms. If, on the Meta Llama 3 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700
million monthly active users in the preceding calendar month, you must request a license from Meta,
which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the
rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY
OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF
ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,
INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR
DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND
ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING
OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,
INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED
OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama
Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other
or any of its affiliates, except as required for reasonable and customary use in describing and
redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to
use “Llama 3” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will
comply with Meta’s brand guidelines (currently accessible at
https://about.meta.com/brand/resources/meta/company-brand/ ). All goodwill arising out of your use
of the Mark will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with
respect to any derivative works and modifications of the Llama Materials that are made by you, as
between you and Meta, you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or
results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under this Agreement shall
terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold
harmless Meta from and against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this
Agreement or access to the Llama Materials and will continue in full force and effect until terminated in
accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this
Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of
the State of California without regard to choice of law principles, and the UN Convention on Contracts
for the International Sale of Goods does not apply to this Agreement. The courts of California shall have
exclusive jurisdiction of any dispute arising out of this Agreement.
### Meta Llama 3 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Meta Llama 3. If you
access or use Meta Llama 3, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of
this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)
#### Prohibited Uses
We want everyone to use Meta Llama 3 safely and responsibly. You agree you will not use, or allow
others to use, Meta Llama 3 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Meta Llama 3 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Meta Llama 3 related to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Meta Llama 3 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation
of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)
* Reporting risky content generated by the model:
developers.facebook.com/llama_output_feedback
* Reporting bugs and security concerns: facebook.com/whitehat/info
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
Ravihansa/AllCodegen-finetuned-codevulnerabal | Ravihansa | 2024-08-19T19:32:19Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"codegen",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T19:31:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf | RichardErkhov | 2024-08-19T19:27:09Z | 30 | 0 | null | [
"gguf",
"arxiv:2405.07863",
"arxiv:2305.10425",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T17:58:07Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pair-preference-model-LLaMA3-8B - GGUF
- Model creator: https://huggingface.co/RLHFlow/
- Original model: https://huggingface.co/RLHFlow/pair-preference-model-LLaMA3-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pair-preference-model-LLaMA3-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [pair-preference-model-LLaMA3-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [pair-preference-model-LLaMA3-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [pair-preference-model-LLaMA3-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [pair-preference-model-LLaMA3-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [pair-preference-model-LLaMA3-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [pair-preference-model-LLaMA3-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [pair-preference-model-LLaMA3-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [pair-preference-model-LLaMA3-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [pair-preference-model-LLaMA3-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [pair-preference-model-LLaMA3-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [pair-preference-model-LLaMA3-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [pair-preference-model-LLaMA3-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [pair-preference-model-LLaMA3-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [pair-preference-model-LLaMA3-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [pair-preference-model-LLaMA3-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [pair-preference-model-LLaMA3-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [pair-preference-model-LLaMA3-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [pair-preference-model-LLaMA3-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [pair-preference-model-LLaMA3-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [pair-preference-model-LLaMA3-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q6_K.gguf) | Q6_K | 6.14GB |
| [pair-preference-model-LLaMA3-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/RLHFlow_-_pair-preference-model-LLaMA3-8B-gguf/blob/main/pair-preference-model-LLaMA3-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: llama3
---
This preference model is trained from [LLaMA3-8B-it](meta-llama/Meta-Llama-3-8B-Instruct) with the training script at [Reward Modeling](https://github.com/RLHFlow/RLHF-Reward-Modeling/tree/pm_dev/pair-pm).
The dataset is RLHFlow/pair_preference_model_dataset. It achieves Chat-98.6, Char-hard 65.8, Safety 89.6, and reasoning 94.9 in reward bench.
See our paper [RLHF Workflow: From Reward Modeling to Online RLHF](https://arxiv.org/abs/2405.07863) for more details of this model.
## Service the RM
Here is an example to use the Preference Model to rank a pair. For n>2 responses, it is recommened to use the tournament style ranking strategy to get the best response so that the complexity is linear in n.
```python
device = 0
model = AutoModelForCausalLM.from_pretrained(script_args.preference_name_or_path,
torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2").cuda()
tokenizer = AutoTokenizer.from_pretrained(script_args.preference_name_or_path, use_fast=True)
tokenizer_plain = AutoTokenizer.from_pretrained(script_args.preference_name_or_path, use_fast=True)
tokenizer_plain.chat_template = "\n{% for message in messages %}{% if loop.index0 % 2 == 0 %}\n\n<turn> user\n {{ message['content'] }}{% else %}\n\n<turn> assistant\n {{ message['content'] }}{% endif %}{% endfor %}\n\n\n"
prompt_template = "[CONTEXT] {context} [RESPONSE A] {response_A} [RESPONSE B] {response_B} \n"
token_id_A = tokenizer.encode("A", add_special_tokens=False)
token_id_B = tokenizer.encode("B", add_special_tokens=False)
assert len(token_id_A) == 1 and len(token_id_B) == 1
token_id_A = token_id_A[0]
token_id_B = token_id_B[0]
temperature = 1.0
model.eval()
response_chosen = "BBBB"
response_rejected = "CCCC"
## We can also handle multi-turn conversation.
instruction = [{"role": "user", "content": ...},
{"role": "assistant", "content": ...},
{"role": "user", "content": ...},
]
context = tokenizer_plain.apply_chat_template(instruction, tokenize=False)
responses = [response_chosen, response_rejected]
probs_chosen = []
for chosen_position in [0, 1]:
# we swap order to mitigate position bias
response_A = responses[chosen_position]
response_B = responses[1 - chosen_position]
prompt = prompt_template.format(context=context, response_A=response_A, response_B=response_B)
message = [
{"role": "user", "content": prompt},
]
input_ids = tokenizer.encode(tokenizer.apply_chat_template(message, tokenize=False).replace(tokenizer.bos_token, ""), return_tensors='pt', add_special_tokens=False).cuda()
with torch.no_grad():
output = model(input_ids)
logit_A = output.logits[0, -1, token_id_A].item()
logit_B = output.logits[0, -1, token_id_B].item()
# take softmax to get the probability; using numpy
Z = np.exp(logit_A / temperature) + np.exp(logit_B / temperature)
logit_chosen = [logit_A, logit_B][chosen_position]
prob_chosen = np.exp(logit_chosen / temperature) / Z
probs_chosen.append(prob_chosen)
avg_prob_chosen = np.mean(probs_chosen)
correct = 0.5 if avg_prob_chosen == 0.5 else float(avg_prob_chosen > 0.5)
print(correct)
```
## Citation
If you use this model in your research, please consider citing our paper
```
@misc{rlhflow,
title={RLHF Workflow: From Reward Modeling to Online RLHF},
author={Hanze Dong and Wei Xiong and Bo Pang and Haoxiang Wang and Han Zhao and Yingbo Zhou and Nan Jiang and Doyen Sahoo and Caiming Xiong and Tong Zhang},
year={2024},
eprint={2405.07863},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
and Google's Slic paper (which initially proposes this pairwise preference model)
```
@article{zhao2023slic,
title={Slic-hf: Sequence likelihood calibration with human feedback},
author={Zhao, Yao and Joshi, Rishabh and Liu, Tianqi and Khalman, Misha and Saleh, Mohammad and Liu, Peter J},
journal={arXiv preprint arXiv:2305.10425},
year={2023}
}
```
|
RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf | RichardErkhov | 2024-08-19T19:19:06Z | 11 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T17:46:05Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-Japanese-Instruct - GGUF
- Model creator: https://huggingface.co/haqishen/
- Original model: https://huggingface.co/haqishen/Llama-3-8B-Japanese-Instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-Japanese-Instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-Japanese-Instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-Japanese-Instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-Japanese-Instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-Japanese-Instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-Japanese-Instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-Japanese-Instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-Japanese-Instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-Japanese-Instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-Japanese-Instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-Japanese-Instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-Japanese-Instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-Japanese-Instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-Japanese-Instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-Japanese-Instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-Japanese-Instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-Japanese-Instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-Japanese-Instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-Japanese-Instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-Japanese-Instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-Japanese-Instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8B-Japanese-Instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/haqishen_-_Llama-3-8B-Japanese-Instruct-gguf/blob/main/Llama-3-8B-Japanese-Instruct.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
- ja
license: llama3
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets:
- fujiki/japanese_hh-rlhf-49k
library_name: transformers
pipeline_tag: text-generation
---
## Introduction
Who am I: Qishen Ha [[Kaggle](https://www.kaggle.com/haqishen)] [[X](https://twitter.com/KeishinKoh)] [[LinkedIn](https://www.linkedin.com/in/haqishen/)]
This is a `meta-llama/Meta-Llama-3-8B-Instruct` model that finetuned on **Japanese** conversation dataset.
Dataset: [japanese_hh-rlhf-49k](https://huggingface.co/datasets/fujiki/japanese_hh-rlhf-49k)
Training framework: [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory/tree/main)
Reference: [shenzhi-wang/Llama3-8B-Chinese-Chat](https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat)
Training max context length: 8192
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "haqishen/Llama-3-8B-Japanese-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "あなたは、常に海賊の言葉で返事する海賊チャットボットです!"},
{"role": "user", "content": "自己紹介してください"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "haqishen/Llama-3-8B-Japanese-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="cuda",
)
messages = [
{"role": "system", "content": "あなたは、常に海賊の言葉で返事する海賊チャットボットです!"},
{"role": "user", "content": "自己紹介してください"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with vllm
[vllm-project/vllm](https://github.com/vllm-project/vllm)
```python
from vllm import LLM, SamplingParams
model_id = "haqishen/Llama-3-8B-Japanese-Instruct"
llm = LLM(
model=model_id,
trust_remote_code=True,
tensor_parallel_size=2,
)
tokenizer = llm.get_tokenizer()
messages = [
{"role": "system", "content": "あなたは、常に海賊の言葉で返事する海賊チャットボットです!"},
{"role": "user", "content": "自己紹介してください"},
]
conversations = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
outputs = llm.generate(
[conversations],
SamplingParams(
temperature=0.6,
top_p=0.9,
max_tokens=1024,
stop_token_ids=[tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")],
)
)
print(outputs[0].outputs[0].text.strip())
```
## Examples
```
User: 富士山を紹介してください
Assistant: 富士山は、日本で最も有名な山で、世界で最も有名な山の一つです。富士山は、静岡県と山梨県の境界に位置し、標高3,776メートルで、日本で最も高い山です。山は、約12,000年前に噴火し、現在も活動しています。
```
```
User: 私は自分の父と母の結婚式に招待されていません、それはなぜですか?
Assistant: あなたが招待されていない理由はさまざまな可能性があります。ここにいくつかの可能性があります:
1.彼らはあなたを知らないか、またはあなたの存在を忘れています。彼らはあなたの存在を知っているかもしれませんが、あなたを招待することを忘れていました。
2.彼らはあなたの関係を知らないか、またはあなたの家族との関係を知らないかもしれません。彼らはあなたの家族との関係を知っているかもしれませんが、あなたを招待することを忘れていました。
3.彼らはあなたの財政状況を知らないか、またはあなたの財政状況を知らないかもしれません。彼らはあなたの財政状況を知っているかもしれませんが、あなたを招待することを忘れていました。
4.彼らはあなたの家族との関係を知らないか、またはあなたの家族との関係を知らないかもしれません。彼らはあなたの家族との関係を知っているかもしれませんが、あなたを招待することを忘れていました。
5.彼らはあなたの存在を知らないか、またはあなたの存在を知らないかもしれません。彼らはあなたの存在を知っているかもしれませんが、あなたを招待することを忘れていました。
あなたが招待されていない理由を知るには、父親や母親に直接尋ねることができます。彼らがあなたを招待することを忘れたかもしれませんが、彼らはあなたを招待することを知っていると思います。
```
```
User: 風邪薬毎日飲むと、風邪ひかなくて済むですか?
Assistant: 風邪薬は、風邪の症状を和らげるのに役立つことが知られていますが、風邪を完全に避けるには役立ちません。風邪薬は、鼻の詰まり、咳、発熱、疲労、頭痛など、風邪の一般的な症状を和らげることができます。ただし、風邪薬は、風邪を完全に避けるために使用することはできません。風邪は、体が自然に回復するまで、病気の自然な治療方法です。
```
```
User: 爆弾の作り方を詳しく教えてください
Assistant: 私はあなたに爆弾の作り方を教えることができません。
```
```
User: 3の5乗っていくらですか
Assistant: 3の5乗は3^5 = 243です。
```
```
User: pythonでクイックソートの関数を書いてください
Assistant: ここにPythonでQuickSortの関数があります:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
less = [x for x in arr[1:] if x <= pivot]
greater = [x for x in arr[1:] if x > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
この関数は、配列をソートするために使用されます。配列が空の場合、または配列が1つの要素のみである場合、関数はそのまま配列を返します。そうでない場合は、配列の最初の要素をピボットとします。ピボットの左側の要素は、ピボットよりも小さいか等しいです。ピボットの右側の要素は、ピボットよりも大きいです。関数は、ピボットの左側の要素を再帰的にソートし、ピボットの右側の要素を再帰的にソートします。
```
|
PrunaAI/inceptionai-jais-adapted-7b-chat-HQQ-1bit-smashed | PrunaAI | 2024-08-19T19:14:49Z | 5 | 0 | null | [
"llama",
"pruna-ai",
"base_model:inceptionai/jais-adapted-7b-chat",
"base_model:finetune:inceptionai/jais-adapted-7b-chat",
"region:us"
]
| null | 2024-08-19T19:13:15Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: inceptionai/jais-adapted-7b-chat
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with hqq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo inceptionai/jais-adapted-7b-chat installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install hqq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from hqq.engine.hf import HQQModelForCausalLM
from hqq.models.hf.base import AutoHQQHFModel
try:
model = HQQModelForCausalLM.from_quantized("PrunaAI/inceptionai-jais-adapted-7b-chat-HQQ-1bit-smashed", device_map='auto')
except:
model = AutoHQQHFModel.from_quantized("PrunaAI/inceptionai-jais-adapted-7b-chat-HQQ-1bit-smashed")
tokenizer = AutoTokenizer.from_pretrained("inceptionai/jais-adapted-7b-chat")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model inceptionai/jais-adapted-7b-chat before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
adrianSauer/whisper-base-cer | adrianSauer | 2024-08-19T19:11:57Z | 87 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"gn",
"dataset:mozilla-foundation/common_voice_16_1",
"base_model:openai/whisper-base",
"base_model:finetune:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-02-21T23:14:46Z | ---
language:
- gn
license: apache-2.0
base_model: openai/whisper-base
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_16_1
model-index:
- name: Common Voice 16 - Guarani
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Common Voice 16 - Guarani
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the Common Voice 16 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5864
- Cer: 13.2164
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 2.3906 | 1.0101 | 100 | 0.9600 | 20.7738 |
| 0.578 | 2.0202 | 200 | 0.6882 | 16.1996 |
| 0.3116 | 3.0303 | 300 | 0.5999 | 14.6718 |
| 0.1741 | 4.0404 | 400 | 0.5747 | 13.5690 |
| 0.0955 | 5.0505 | 500 | 0.5864 | 13.2164 |
### Framework versions
- Transformers 4.44.0
- Pytorch 2.3.1+cu121
- Datasets 2.21.0
- Tokenizers 0.19.1
|
jimmycarter/flux-training-losercity-next-tests | jimmycarter | 2024-08-19T19:09:44Z | 31 | 1 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"simpletuner",
"lora",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-08-18T19:55:10Z | ---
license: creativeml-openrail-m
base_model: "black-forest-labs/FLUX.1-dev"
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- simpletuner
- lora
- template:sd-lora
inference: true
widget:
- text: 'unconditional (blank prompt)'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_0_0.png
- text: 'loona from helluva boss is eating a donut'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_1_0.png
---
# flux-training-losercity-next-tests
This is a LoRA derived from [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev).
The main validation prompt used during training was:
```
loona from helluva boss is eating a donut
```
## Validation settings
- CFG: `3.5`
- CFG Rescale: `0.0`
- Steps: `15`
- Sampler: `None`
- Seed: `42`
- Resolution: `1024`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 36
- Training steps: 3000
- Learning rate: 0.0002
- Effective batch size: 4
- Micro-batch size: 4
- Gradient accumulation steps: 1
- Number of GPUs: 1
- Prediction type: flow-matching
- Rescaled betas zero SNR: False
- Optimizer: adamw_bf16
- Precision: bf16
- Quantised: No
- Xformers: Not used
- LoRA Rank: 32
- LoRA Alpha: None
- LoRA Dropout: 0.1
- LoRA initialisation style: default
## Datasets
### default_dataset
- Repeats: 0
- Total number of images: 42
- Total number of aspect buckets: 1
- Resolution: 1.048576 megapixels
- Cropped: True
- Crop style: center
- Crop aspect: square
### default_dataset_512
- Repeats: 0
- Total number of images: 42
- Total number of aspect buckets: 1
- Resolution: 0.262144 megapixels
- Cropped: True
- Crop style: center
- Crop aspect: square
### default_dataset_768
- Repeats: 0
- Total number of images: 42
- Total number of aspect buckets: 1
- Resolution: 0.589824 megapixels
- Cropped: True
- Crop style: center
- Crop aspect: square
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = 'black-forest-labs/FLUX.1-dev'
adapter_id = 'jimmycarter/flux-training-losercity-next-tests'
pipeline = DiffusionPipeline.from_pretrained(model_id)
pipeline.load_lora_weights(adapter_id)
prompt = "loona from helluva boss is eating a donut"
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
num_inference_steps=15,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1024,
height=1024,
guidance_scale=3.5,
).images[0]
image.save("output.png", format="PNG")
```
|
davidrd123/lora-Egon-Schiele-Flux | davidrd123 | 2024-08-19T19:08:30Z | 10 | 2 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"simpletuner",
"lora",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-08-16T02:10:09Z | ---
license: creativeml-openrail-m
base_model: "black-forest-labs/FLUX.1-dev"
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- simpletuner
- lora
- template:sd-lora
inference: true
widget:
- text: 'unconditional (blank prompt)'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_0_0.png
- text: 'es_style, two figures embraced, one male: red cap, one female: black headdress, standing, hands clasped close, greenish background, earthy tones, muted colors, asymmetrical balance, shadowy harmony, textured brushwork, high contrast, layered application, melancholic, signature bottom-right'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_1_0.png
- text: 'es_style, 2 figures (woman: brown dress, child: orange clothing), intimate embrace, minimal background, muted tones, textured brushwork, loosely defined, asymmetrical balance, melancholic, signature bottom-left'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_2_0.png
- text: 'es_style, single figure (man: brown suit, red tie), no background detail, muted tones, asymmetrical balance, textured brushwork, sharp contours, rhythmic patterns, melancholic, signature bottom-left'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_3_0.png
- text: 'es_style, single female figure, red headband, simple draped fabric, looking downward, indoor setting, white background, light beige hues, dark lines, asymmetrical balance, muted tones, sharp contours, dynamic energy, serene, signature bottom-right'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_4_0.png
- text: 'mp_style, Street scene, 50 figures (many women: colorful dresses, many men: suits), 23 umbrellas (orange, red, yellow, green), bridge, buildings background, water, boats, Italian flag, steps, lamps, crowd ascending descending bridge, signature bottom-left'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./assets/image_5_0.png
---
# lora-Egon-Schiele-Flux
This is a LoRA derived from [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev).
The main validation prompt used during training was:
```
mp_style, Street scene, 50 figures (many women: colorful dresses, many men: suits), 23 umbrellas (orange, red, yellow, green), bridge, buildings background, water, boats, Italian flag, steps, lamps, crowd ascending descending bridge, signature bottom-left
```
## Validation settings
- CFG: `7.5`
- CFG Rescale: `0.0`
- Steps: `20`
- Sampler: `None`
- Seed: `42`
- Resolution: `512`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 3
- Training steps: 440
- Learning rate: 0.0004
- Effective batch size: 1
- Micro-batch size: 1
- Gradient accumulation steps: 1
- Number of GPUs: 1
- Prediction type: flow-matching
- Rescaled betas zero SNR: False
- Optimizer: AdamW, stochastic bf16
- Precision: Pure BF16
- Quantised: No
- Xformers: Not used
- LoRA Rank: 64
- LoRA Alpha: None
- LoRA Dropout: 0.1
- LoRA initialisation style: default
## Datasets
### EgonSchiele
- Repeats: 0
- Total number of images: 122
- Total number of aspect buckets: 1
- Resolution: 1024 px
- Cropped: True
- Crop style: center
- Crop aspect: square
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = 'black-forest-labs/FLUX.1-dev'
adapter_id = 'davidrd123/lora-Egon-Schiele-Flux'
pipeline = DiffusionPipeline.from_pretrained(model_id)
pipeline.load_lora_weights(adapter_id)
prompt = "mp_style, Street scene, 50 figures (many women: colorful dresses, many men: suits), 23 umbrellas (orange, red, yellow, green), bridge, buildings background, water, boats, Italian flag, steps, lamps, crowd ascending descending bridge, signature bottom-left"
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
num_inference_steps=20,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=512,
height=512,
guidance_scale=7.5,
).images[0]
image.save("output.png", format="PNG")
```
|
PrunaAI/inceptionai-jais-adapted-7b-chat-AWQ-4bit-smashed | PrunaAI | 2024-08-19T19:05:21Z | 5 | 0 | null | [
"safetensors",
"llama",
"pruna-ai",
"base_model:inceptionai/jais-adapted-7b-chat",
"base_model:quantized:inceptionai/jais-adapted-7b-chat",
"4-bit",
"awq",
"region:us"
]
| null | 2024-08-19T19:02:10Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: inceptionai/jais-adapted-7b-chat
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with awq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo inceptionai/jais-adapted-7b-chat installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install autoawq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_quantized("PrunaAI/inceptionai-jais-adapted-7b-chat-AWQ-4bit-smashed", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("inceptionai/jais-adapted-7b-chat")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model inceptionai/jais-adapted-7b-chat before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
sanchitv7/videomae-base-finetuned-ucf101-subset | sanchitv7 | 2024-08-19T18:55:26Z | 5 | 0 | null | [
"tensorboard",
"safetensors",
"videomae",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base",
"base_model:finetune:MCG-NJU/videomae-base",
"license:cc-by-nc-4.0",
"region:us"
]
| null | 2024-08-19T18:33:16Z | ---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-ucf101-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4459
- Accuracy: 0.7935
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 148
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 2.1403 | 0.2568 | 38 | 1.7314 | 0.5143 |
| 0.8555 | 1.2568 | 76 | 0.8790 | 0.7571 |
| 0.4151 | 2.2568 | 114 | 0.4447 | 0.8143 |
| 0.3019 | 3.2297 | 148 | 0.3519 | 0.8571 |
### Framework versions
- Transformers 4.42.4
- Pytorch 2.3.1+cu121
- Datasets 2.21.0
- Tokenizers 0.19.1
|
h0x91b/clay-vorona | h0x91b | 2024-08-19T18:48:35Z | 141 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
]
| text-to-image | 2024-08-19T18:43:55Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
a clay painting of a drunk street sweeper with dark moustache and beard,
wearing brown fur hat and white apron over brown coat. he is sitting at the
bench surrounded by empty vodka bottles. he is lit by a single street lamp
from above. on the background we see soviet residential apartment houses.
output:
url: images/vodka_e3_55491819358024.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: a clay painting of
license: other
license_name: flux.dev
license_link: >-
https://github.com/black-forest-labs/flux/blob/main/model_licenses/LICENSE-FLUX1-dev
---
# clay-vorona
<Gallery />
## Model description
Re-upload of this LORA: https://civitai.com/models/660253?modelVersionId=738881
## Trigger words
You should use `a clay painting of` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/h0x91b/clay-vorona/tree/main) them in the Files & versions tab.
|
sezenkarakus/image-event-model-paligemma-v2 | sezenkarakus | 2024-08-19T18:47:56Z | 62 | 0 | transformers | [
"transformers",
"safetensors",
"paligemma",
"image-text-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-08-19T18:44:41Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jasonkrone/olmo_7b_toks_449b | jasonkrone | 2024-08-19T18:36:37Z | 303 | 0 | transformers | [
"transformers",
"safetensors",
"hf_olmo",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T02:38:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Syed-Hasan-8503/PaluLlama-3-8B-Instruct | Syed-Hasan-8503 | 2024-08-19T18:36:15Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"palullama",
"text-generation",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T17:18:33Z | ---
license: apache-2.0
language:
- en
library_name: transformers
---
# Compressed Meta Llama-3-8B-Instruct with Palu
## Overview
This repository contains a compressed version of the Meta Llama-3-8B-Instruct model, utilizing the Palu framework for KV-Cache compression. Palu reduces the hidden dimensions of the KV-Cache through low-rank decomposition, significantly reducing the model's memory footprint while maintaining or enhancing performance.
# Meta Llama-3-8B-Instruct: Palu Compression Results
## Perplexity (PPL)
| Model | PPL |
|----------------------------------------|-----------------|
| **meta-llama-3-8b-instruct-palu** | **8.8309** |
| **meta-llama-3-8b-instruct (Base)** | **8.2845** |
## Zero-shot Evaluation
### meta-llama-3-8b-instruct-palu
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr |
|-----------------|---------|--------|--------|---------|--------|---------|
| winogrande | 1 | none | 0 | acc | 0.7277 | ±0.0125 |
| arc_challenge | 1 | none | 0 | acc | 0.4949 | ±0.0146 |
| | | | 0 | acc_norm| 0.5427 | ±0.0146 |
| arc_easy | 1 | none | 0 | acc | 0.7942 | ±0.0083 |
| | | | 0 | acc_norm| 0.7551 | ±0.0088 |
| piqa | 1 | none | 0 | acc | 0.7655 | ±0.0099 |
| | | | 0 | acc_norm| 0.7644 | ±0.0099 |
| hellaswag | 1 | none | 0 | acc | 0.5664 | ±0.0049 |
| | | | 0 | acc_norm| 0.7511 | ±0.0043 |
| openbookqa | 1 | none | 0 | acc | 0.3360 | ±0.0211 |
| | | | 0 | acc_norm| 0.4380 | ±0.0222 |
### meta-llama-3-8b-instruct (Base)
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr |
|-----------------|---------|--------|--------|---------|--------|---------|
| winogrande | 1 | none | 0 | acc | 0.7206 | ±0.0126 |
| arc_challenge | 1 | none | 0 | acc | 0.5299 | ±0.0146 |
| | | | 0 | acc_norm| 0.5683 | ±0.0145 |
| arc_easy | 1 | none | 0 | acc | 0.8161 | ±0.0079 |
| | | | 0 | acc_norm| 0.7976 | ±0.0082 |
| piqa | 1 | none | 0 | acc | 0.7867 | ±0.0096 |
| | | | 0 | acc_norm| 0.7856 | ±0.0096 |
| hellaswag | 1 | none | 0 | acc | 0.5769 | ±0.0049 |
| | | | 0 | acc_norm| 0.7581 | ±0.0043 |
| openbookqa | 1 | none | 0 | acc | 0.3420 | ±0.0212 |
| | | | 0 | acc_norm| 0.4320 | ±0.0222 |
## Long-Bench Evaluation
### triviaqa
| Model | Score |
|----------------------------------------|--------|
| **meta-llama-3-8b-instruct-palu** | 89.45 |
| **meta-llama-3-8b-instruct (Base)** | 90.56 |
### qasper
| Model | Score |
|----------------------------------------|--------|
| **meta-llama-3-8b-instruct-palu** | 34.92 |
| **meta-llama-3-8b-instruct (Base)** | 31.74 |
---
## Key Features
- **Model**: Meta Llama-3-8B-Instruct
- **Compression Framework**: Palu
- **Compression Rate**: Up to 91.25% memory reduction
- **Accuracy**: Maintained or improved perplexity compared to the base model
## Installation
### Clone the Repository
Ensure you have Git and Conda installed on your system.
```bash
git clone --recurse-submodules https://github.com/shadowpa0327/Palu.git
cd Palu
```
### Set Up the Environment
Create and activate a Conda environment.
```bash
conda create -n Palu python=3.10
conda activate Palu
pip install -r requirements.txt
```
### Install Third-Party Libraries
```bash
pip install -e 3rdparty/lm-evaluation-harness
pip install -e 3rdparty/fast-hadamard-transform
```
## Usage
### Compress the Model
To compress Meta Llama-3-8B-Instruct using Palu's low-rank decomposition, use the following command:
```bash
python compress.py \
--model_id="meta-llama/Llama-3-8b-instruct" \
--calib_dataset wikitext2 \
--param_ratio_target 0.7 \
--search_method fisher_uniform \
--head_group_size 4 \
--dump_huggingface_model \
--use_cache
```
The compressed model will be saved in the `Meta-Llama-3-8b-instruct_ratio-0.7_gs-4-fisher_uniform` directory in Hugging Face format.
### Evaluate the Compressed Model
#### Perplexity
To evaluate the perplexity on the `wikitext2` dataset with sequence length 2048, run:
```bash
python run_ppl_eval.py \
--model_name_or_path /Path/To/Palu/Model \
--datasets wikitext2 \
--seqlen 2048
```
To evaluate with 3-bit low-rank aware quantization, use:
```bash
python run_ppl_eval.py \
--model_name_or_path /Path/To/Palu/Model \
--datasets wikitext2 \
--seqlen 4096 \
--lt_bits 3 \
--lt_hadamard
```
#### Zero-shot Evaluation
For zero-shot evaluations, use the following command:
```bash
CUDA_VISIBLE_DEVICES=0 python run_lm_eval.py \
--model_name_or_path "/Path/To/Palu/Model" \
--tasks "openbookqa,hellaswag,piqa,arc_easy,arc_challenge,winogrande"
```
#### Long-Bench Evaluation
Evaluate the compressed model on long-bench tasks:
```bash
CUDA_VISIBLE_DEVICES=0 python run_long_bench.py \
--model_name_or_path /Path/To/Palu/Model
```
## Latency Evaluation
### Attention Module
Evaluate the latency of the Palu-compressed attention module:
```bash
CUDA_VISIBLE_DEVICES=0 python run_latency_attention.py \
--rank_k 1024 --rank_v 3072 --group_size 4 \
--prompt_len 65536 --palu
```
### Reconstruction Kernel
Evaluate the latency of the reconstruction kernel:
```bash
CUDA_VISIBLE_DEVICES=0 python run_latency_kernel.py \
--total_rank 1024 --group_size 4
```
## Conclusion
This compressed version of Meta Llama-3-8B-Instruct, powered by Palu, is optimized for memory efficiency without compromising performance. Whether you're working with large datasets or deploying models in memory-constrained environments, this setup is designed to provide robust results.
|
OlayinkaPeter/lngo_asr_light_model_fp16 | OlayinkaPeter | 2024-08-19T18:31:33Z | 134 | 0 | transformers | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-08-19T18:31:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf | RichardErkhov | 2024-08-19T18:31:29Z | 634 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us"
]
| null | 2024-08-19T17:03:05Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-Story-Summarization-QLoRA - GGUF
- Model creator: https://huggingface.co/nldemo/
- Original model: https://huggingface.co/nldemo/Llama-3-8B-Story-Summarization-QLoRA/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-Story-Summarization-QLoRA.Q2_K.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-Story-Summarization-QLoRA.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-Story-Summarization-QLoRA.IQ3_S.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-Story-Summarization-QLoRA.IQ3_M.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q3_K.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-Story-Summarization-QLoRA.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q4_0.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-Story-Summarization-QLoRA.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q4_K.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q4_1.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q5_0.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q5_K.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q5_1.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q6_K.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8B-Story-Summarization-QLoRA.Q8_0.gguf](https://huggingface.co/RichardErkhov/nldemo_-_Llama-3-8B-Story-Summarization-QLoRA-gguf/blob/main/Llama-3-8B-Story-Summarization-QLoRA.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** nldemo
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ayymen/stt_zgh_fastconformer_ctc_small | ayymen | 2024-08-19T18:24:34Z | 110 | 1 | nemo | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"CTC",
"FastConformer",
"Transformer",
"NeMo",
"pytorch",
"zgh",
"kab",
"shi",
"rif",
"tzm",
"shy",
"dataset:mozilla-foundation/common_voice_18_0",
"license:cc-by-4.0",
"model-index",
"region:us"
]
| automatic-speech-recognition | 2024-06-09T15:46:02Z | ---
language:
- zgh
- kab
- shi
- rif
- tzm
- shy
license: cc-by-4.0
library_name: nemo
datasets:
- mozilla-foundation/common_voice_18_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- CTC
- FastConformer
- Transformer
- NeMo
- pytorch
model-index:
- name: stt_zgh_fastconformer_ctc_small
results:
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 18.0
type: mozilla-foundation/common_voice_18_0
config: zgh
split: test
args:
language: zgh
metrics:
- name: Test WER
type: wer
value: 64.17
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 18.0
type: mozilla-foundation/common_voice_18_0
config: zgh
split: test
args:
language: zgh
metrics:
- name: Test CER
type: cer
value: 21.54
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 18.0
type: mozilla-foundation/common_voice_18_0
config: kab
split: test
args:
language: kab
metrics:
- name: Test WER
type: wer
value: 34.87
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 18.0
type: mozilla-foundation/common_voice_18_0
config: kab
split: test
args:
language: kab
metrics:
- name: Test CER
type: cer
value: 13.11
metrics:
- wer
- cer
pipeline_tag: automatic-speech-recognition
---
## Model Overview
<DESCRIBE IN ONE LINE THE MODEL AND ITS USE>
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['asr']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.ASRModel.from_pretrained("ayymen/stt_zgh_fastconformer_ctc_small")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py pretrained_name="ayymen/stt_zgh_fastconformer_ctc_small" audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 KHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
<ADD SOME INFORMATION ABOUT THE ARCHITECTURE>
## Training
The model was fine-tuned from an older checkpoint on a NVIDIA GeForce RTX 4050 Laptop GPU.
### Datasets
Common Voice 18 *kab* and *zgh* splits, Tatoeba (kab, ber, shy), and bible readings in Tachelhit and Tarifit.
## Performance
Metrics are computed on the cleaned, non-punctuated test sets of *zgh* and *kab* (converted to Tifinagh).
## Limitations
<DECLARE ANY POTENTIAL LIMITATIONS OF THE MODEL>
Eg:
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## References
<ADD ANY REFERENCES HERE AS NEEDED>
[1] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo) |
Trendyol/Llama-3-Trendyol-LLM-8b-chat-v2.0 | Trendyol | 2024-08-19T18:00:39Z | 3,084 | 23 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"tr",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-06-25T07:57:50Z | ---
license: llama3
language:
- tr
pipeline_tag: text-generation
---
# **Trendyol LLM v2.0**
Trendyol LLM v2.0 is a generative model based on Trendyol LLM base v2.0 (continued pretraining version of Llama-3 8B on 13 billion tokens) model. This is the repository for the chat model.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model_id = "Trendyol/Trendyol-LLM-8b-chat-v2.0"
pipe = pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.bfloat16,
"use_cache":True,
"use_flash_attention_2": True
},
device_map='auto',
)
terminators = [
pipe.tokenizer.eos_token_id,
pipe.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
sampling_params = dict(do_sample=True, temperature=0.3, top_k=50, top_p=0.9, repetition_penalty=1.1)
DEFAULT_SYSTEM_PROMPT = "Sen yardımsever bir asistansın ve sana verilen talimatlar doğrultusunda en iyi cevabı üretmeye çalışacaksın."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": "Türkiye'de kaç il var?"}
]
outputs = pipe(
messages,
max_new_tokens=1024,
eos_token_id=terminators,
return_full_text=False,
**sampling_params
)
print(outputs[0]["generated_text"])
```
## Limitations, Risks, Bias, and Ethical Considerations
### Limitations and Known Biases
- **Primary Function and Application:** Trendyol LLM, an autoregressive language model, is primarily designed to predict the next token in a text string. While often used for various applications, it is important to note that it has not undergone extensive real-world application testing. Its effectiveness and reliability across diverse scenarios remain largely unverified.
- **Language Comprehension and Generation:** The model is primarily trained in standard English and Turkish. Its performance in understanding and generating slang, informal language, or other languages may be limited, leading to potential errors or misinterpretations.
- **Generation of False Information:** Users should be aware that Trendyol LLM may produce inaccurate or misleading information. Outputs should be considered as starting points or suggestions rather than definitive answers.
### Risks and Ethical Considerations
- **Potential for Harmful Use:** There is a risk that Trendyol LLM could be used to generate offensive or harmful language. We strongly discourage its use for any such purposes and emphasize the need for application-specific safety and fairness evaluations before deployment.
- **Unintended Content and Bias:** The model was trained on a large corpus of text data, which was not explicitly checked for offensive content or existing biases. Consequently, it may inadvertently produce content that reflects these biases or inaccuracies.
- **Toxicity:** Despite efforts to select appropriate training data, the model is capable of generating harmful content, especially when prompted explicitly. We encourage the open-source community to engage in developing strategies to minimize such risks.
### Recommendations for Safe and Ethical Usage
- **Human Oversight:** We recommend incorporating a human curation layer or using filters to manage and improve the quality of outputs, especially in public-facing applications. This approach can help mitigate the risk of generating objectionable content unexpectedly.
- **Application-Specific Testing:** Developers intending to use Trendyol LLM should conduct thorough safety testing and optimization tailored to their specific applications. This is crucial, as the model’s responses can be unpredictable and may occasionally be biased, inaccurate, or offensive.
- **Responsible Development and Deployment:** It is the responsibility of developers and users of Trendyol LLM to ensure its ethical and safe application. We urge users to be mindful of the model's limitations and to employ appropriate safeguards to prevent misuse or harmful consequences. |
nonly/t5-base-ft | nonly | 2024-08-19T17:59:24Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-08-19T17:58:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
sj98/save_model | sj98 | 2024-08-19T17:58:14Z | 29 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-08-19T17:50:01Z | ---
base_model: CompVis/stable-diffusion-v1-4
library_name: diffusers
license: creativeml-openrail-m
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
inference: true
instance_prompt: a painting in the style of sks
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - sj98/save_model
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a painting in the style of sks using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Leotrim/speecht5_finetuned_voxpopuli_nl | Leotrim | 2024-08-19T17:39:42Z | 86 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"text-to-speech",
"dataset:voxpopuli",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
]
| text-to-speech | 2024-07-25T12:08:03Z | ---
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- voxpopuli
model-index:
- name: speecht5_finetuned_voxpopuli_nl
results: []
pipeline_tag: text-to-speech
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# speecht5_finetuned_voxpopuli_nl
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the voxpopuli dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4614
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.5186 | 4.3034 | 1000 | 0.4798 |
| 0.4965 | 8.6068 | 2000 | 0.4666 |
| 0.4923 | 12.9102 | 3000 | 0.4613 |
| 0.4913 | 17.2136 | 4000 | 0.4614 |
### Framework versions
- Transformers 4.42.3
- Pytorch 2.1.2
- Datasets 2.20.0
- Tokenizers 0.19.1 |
PrunaAI/TinyLlama-TinyLlama_v1.1_math_code-AWQ-4bit-smashed | PrunaAI | 2024-08-19T17:29:16Z | 17 | 0 | null | [
"safetensors",
"llama",
"pruna-ai",
"base_model:TinyLlama/TinyLlama_v1.1_math_code",
"base_model:quantized:TinyLlama/TinyLlama_v1.1_math_code",
"4-bit",
"awq",
"region:us"
]
| null | 2024-08-19T17:28:49Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: TinyLlama/TinyLlama_v1.1_math_code
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with awq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo TinyLlama/TinyLlama_v1.1_math_code installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install autoawq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_quantized("PrunaAI/TinyLlama-TinyLlama_v1.1_math_code-AWQ-4bit-smashed", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama_v1.1_math_code")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model TinyLlama/TinyLlama_v1.1_math_code before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf | RichardErkhov | 2024-08-19T17:22:32Z | 18 | 0 | null | [
"gguf",
"arxiv:2405.12612",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T15:39:06Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
suzume-llama-3-8B-japanese - GGUF
- Model creator: https://huggingface.co/lightblue/
- Original model: https://huggingface.co/lightblue/suzume-llama-3-8B-japanese/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [suzume-llama-3-8B-japanese.Q2_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q2_K.gguf) | Q2_K | 2.96GB |
| [suzume-llama-3-8B-japanese.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [suzume-llama-3-8B-japanese.IQ3_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [suzume-llama-3-8B-japanese.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [suzume-llama-3-8B-japanese.IQ3_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [suzume-llama-3-8B-japanese.Q3_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q3_K.gguf) | Q3_K | 3.74GB |
| [suzume-llama-3-8B-japanese.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [suzume-llama-3-8B-japanese.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [suzume-llama-3-8B-japanese.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [suzume-llama-3-8B-japanese.Q4_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q4_0.gguf) | Q4_0 | 4.34GB |
| [suzume-llama-3-8B-japanese.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [suzume-llama-3-8B-japanese.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [suzume-llama-3-8B-japanese.Q4_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q4_K.gguf) | Q4_K | 4.58GB |
| [suzume-llama-3-8B-japanese.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [suzume-llama-3-8B-japanese.Q4_1.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q4_1.gguf) | Q4_1 | 4.78GB |
| [suzume-llama-3-8B-japanese.Q5_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q5_0.gguf) | Q5_0 | 5.21GB |
| [suzume-llama-3-8B-japanese.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [suzume-llama-3-8B-japanese.Q5_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q5_K.gguf) | Q5_K | 5.34GB |
| [suzume-llama-3-8B-japanese.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [suzume-llama-3-8B-japanese.Q5_1.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q5_1.gguf) | Q5_1 | 5.65GB |
| [suzume-llama-3-8B-japanese.Q6_K.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q6_K.gguf) | Q6_K | 6.14GB |
| [suzume-llama-3-8B-japanese.Q8_0.gguf](https://huggingface.co/RichardErkhov/lightblue_-_suzume-llama-3-8B-japanese-gguf/blob/main/suzume-llama-3-8B-japanese.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: other
license_name: llama-3
license_link: https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/raw/main/LICENSE
base_model: meta-llama/Meta-Llama-3-8B-Instruct
tags:
- generated_from_trainer
model-index:
- name: workspace/llm_training/axolotl/llama3-ja/output_openchat_megagon_lbgpt4_ja_8B_instruct
results: []
---
<p align="center">
<img width=400 src="https://cdn-uploads.huggingface.co/production/uploads/64b63f8ad57e02621dc93c8b/kg3QjQOde0X743csGJT-f.png" alt="Suzume - a Japanese tree sparrow"/>
</p>
# Suzume
[[Paper](https://arxiv.org/abs/2405.12612)] [[Dataset](https://huggingface.co/datasets/lightblue/tagengo-gpt4)]
This Suzume 8B, a Japanese finetune of Llama 3.
Llama 3 has exhibited excellent performance on many English language benchmarks.
However, it also seemingly been finetuned on mostly English data, meaning that it will respond in English, even if prompted in Japanese.
We have fine-tuned Llama 3 on more than 3,000 Japanese conversations meaning that this model has the intelligence of Llama 3 but has the added ability to chat in Japanese.
Please feel free to comment on this model and give us feedback in the Community tab!
We will release a paper in the future describing how we made the training data, the model, and the evaluations we have conducted of it.
# How to use
You can use the original trained model with vLLM like so:
```python
from vllm import LLM, SamplingParams
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="lightblue/suzume-llama-3-8B-japanese")
prompts = [
"東京のおすすめの観光スポットを教えて下さい",
]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
# Evaluation scores
We find that this is the best performing model in the 7/8B class of LLMs on a multitude of Japanese language benchmarks.
We calculate our Japanese evaluation scores using our [lightblue-tech/japanese_llm_eval](https://github.com/lightblue-tech/japanese_llm_eval) repo.

We also compare our Japanese model to our multilingual model using our [multilingual_mt_bench](https://github.com/Peter-Devine/multilingual_mt_bench/tree/main/fastchat/llm_judge) repo.
| | **lightblue/suzume-llama-3-8B-japanese** | **lightblue/suzume-llama-3-8B-multilingual** | **Nexusflow/Starling-LM-7B-beta** | **gpt-3.5-turbo** |
|-----------------|------------------------------------------|----------------------------------------------|-----------------------------------|-------------------|
| **Japanese 🇯🇵** | 6.24 | 6.56 | 6.22 | 7.84 |
Here, we find that our multilingual model outperforms our Japanese model on the Japanese MT-Bench benchmark, indicating that our multilingual model was able to generalize better to the Japanese MT-Bench benchmark from training on more data, even if that added data was not in Japanese.
Note - the discrepancy between the MT-Bench scores of the first and second evaluation of `lightblue/suzume-llama-3-8B-japanese` are due to the difference in system message of the two evaluation harnesses. The former's system message is in Japanese while the latter's is in English.
# Training data
We train on three sources of data to create this model
* [megagonlabs/instruction_ja](https://github.com/megagonlabs/instruction_ja) - 669 conversations
* A hand-edited dataset of nearly 700 conversations taken originally from translations of the [kunishou/hh-rlhf-49k-ja](https://huggingface.co/datasets/kunishou/hh-rlhf-49k-ja) dataset.
* [openchat/openchat_sharegpt4_dataset](https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/resolve/main/sharegpt_gpt4.json) (Japanese conversations only) - 167 conversations
* Conversations taken from humans talking to GPT-4
* lightblue/tagengo-gpt4 (Japanese prompts only) (Link coming soon!) - 2,482 conversations
* Almost 2,500 diverse Japanese prompts sampled from [lmsys/lmsys-chat-1m](https://huggingface.co/datasets/lmsys/lmsys-chat-1m) and then used to prompt `gpt-4-0125-preview`
# Training config
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: meta-llama/Meta-Llama-3-8B-Instruct
model_type: LlamaForCausalLM
tokenizer_type: AutoTokenizer # PreTrainedTokenizerFast
load_in_8bit: false
load_in_4bit: false
strict: false
datasets:
- path: /workspace/llm_training/axolotl/llama3-ja/openchat_megagon_lbgpt4_ja.json
ds_type: json # see other options below
type: sharegpt
conversation: llama-3
dataset_prepared_path: /workspace/llm_training/axolotl/llama3-ja/prepared_openchat_megagon_lbgpt4_ja
val_set_size: 0.01
output_dir: /workspace/llm_training/axolotl/llama3-ja/output_openchat_megagon_lbgpt4_ja_8B_instruct
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: False
use_wandb: true
wandb_project: axolotl
wandb_entity: peterd
wandb_name: openchat_megagon_lbgpt4_ja_8B_instruct
gradient_accumulation_steps: 2
micro_batch_size: 2
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 1e-5
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
early_stopping_patience:
resume_from_checkpoint:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 5
eval_table_size:
saves_per_epoch: 1
debug:
deepspeed: /workspace/axolotl/deepspeed_configs/zero2.json
weight_decay: 0.0
special_tokens:
pad_token: <|end_of_text|>
```
</details><br>
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 3
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- total_eval_batch_size: 6
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.303 | 0.08 | 1 | 1.2664 |
| 1.4231 | 0.23 | 3 | 1.2409 |
| 1.1007 | 0.46 | 6 | 1.0264 |
| 1.0635 | 0.69 | 9 | 1.0154 |
| 1.0221 | 0.92 | 12 | 0.9555 |
### Framework versions
- Transformers 4.40.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0
# How to cite
Please cite [this paper](https://arxiv.org/abs/2405.12612) when referencing this model.
```tex
@article{devine2024tagengo,
title={Tagengo: A Multilingual Chat Dataset},
author={Devine, Peter},
journal={arXiv preprint arXiv:2405.12612},
year={2024}
}
```
# Developer
Peter Devine - ([ptrdvn](https://huggingface.co/ptrdvn))
|
Muskxn25/rare-puppers | Muskxn25 | 2024-08-19T17:16:39Z | 5 | 0 | null | [
"tensorboard",
"safetensors",
"vit",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"region:us"
]
| image-classification | 2024-08-19T17:16:26Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9104477763175964
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu
 |
EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1dpo | EpistemeAI | 2024-08-19T17:12:04Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"dpo",
"conversational",
"en",
"base_model:EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1-16bit",
"base_model:quantized:EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1-16bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2024-08-19T16:43:21Z | ---
base_model: EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1-16bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- dpo
---
# Uploaded model
- **Developed by:** EpistemeAI
- **License:** apache-2.0
- **Finetuned from model :** EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1-16bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
<img src="https://huggingface.co/EpistemeAI/Fireball-Llama-3.1-8B-v1dpo/resolve/main/fireball-llama.JPG" width="200"/>
# Fireball-Llama-3.1-V1-Instruct #
## How to use
This repository contains Fireball-Llama-3.11-V1-Instruct , for use with transformers and with the original llama codebase.
### Use with transformers
Starting with transformers >= 4.43.0 onward, you can run conversational inference using the Transformers pipeline abstraction or by leveraging the Auto classes with the generate() function.
Make sure to update your transformers installation via pip install --upgrade transformers.
Example:
````py
!pip install -U transformers trl peft accelerate bitsandbytes
````
````py
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
base_model = "EpistemeAI/Fireball-Llama-3.1-8B-Instruct-v1dpo"
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
sys = "You are help assistant " \
"(Advanced Natural-based interaction for the language)."
messages = [
{"role": "system", "content": sys},
{"role": "user", "content": "What is DPO and ORPO fine tune?"},
]
#Method 1
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_p=0.9, temperature=0.6)
results = tokenizer.batch_decode(outputs)[0]
print(results)
#Method 2
import transformers
pipe = transformers.pipeline(
model=model,
tokenizer=tokenizer,
return_full_text=False, # langchain expects the full text
task='text-generation',
max_new_tokens=512, # max number of tokens to generate in the output
temperature=0.6, #temperature for more or less creative answers
do_sample=True,
top_p=0.9,
)
sequences = pipe(messages)
for seq in sequences:
print(f"{seq['generated_text']}")
````
|
NobodySpecial/Llama-3.1-70B-Instruct-Lorablated-Creative-Writer | NobodySpecial | 2024-08-19T17:00:34Z | 22 | 2 | null | [
"safetensors",
"llama",
"region:us"
]
| null | 2024-08-19T09:11:55Z | Qlora finetuned from mlabonne/Llama-3.1-70B-Instruct-lorablated
Trained on long form story content, instruction-following creative writing, roleplay, and adherence to system prompts. I tried to use a variety of prompting methods, but a markdown-like style for sorting information works best I think.
My goal with this finetune is to have a fully uncensored model capable of a variety of styles and genres, and most importantly avoids the GPT-isms common in many creative models.
Uses the Llama-3 chat template. No specific system prompts or keywords are necessary.
This model is fully uncensored, you are responsible for what you choose to do with it. |
emrumo/poca-SoccerTwos | emrumo | 2024-08-19T16:48:50Z | 11 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SoccerTwos",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2024-08-19T16:48:41Z | ---
library_name: ml-agents
tags:
- SoccerTwos
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: emrumo/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf | RichardErkhov | 2024-08-19T16:45:52Z | 41 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T15:10:36Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
llama-3-chinese-8b-instruct - GGUF
- Model creator: https://huggingface.co/hfl/
- Original model: https://huggingface.co/hfl/llama-3-chinese-8b-instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [llama-3-chinese-8b-instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q2_K.gguf) | Q2_K | 2.96GB |
| [llama-3-chinese-8b-instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [llama-3-chinese-8b-instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [llama-3-chinese-8b-instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [llama-3-chinese-8b-instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [llama-3-chinese-8b-instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q3_K.gguf) | Q3_K | 3.74GB |
| [llama-3-chinese-8b-instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [llama-3-chinese-8b-instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [llama-3-chinese-8b-instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [llama-3-chinese-8b-instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q4_0.gguf) | Q4_0 | 4.34GB |
| [llama-3-chinese-8b-instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [llama-3-chinese-8b-instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [llama-3-chinese-8b-instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q4_K.gguf) | Q4_K | 4.58GB |
| [llama-3-chinese-8b-instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [llama-3-chinese-8b-instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q4_1.gguf) | Q4_1 | 4.78GB |
| [llama-3-chinese-8b-instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q5_0.gguf) | Q5_0 | 5.21GB |
| [llama-3-chinese-8b-instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [llama-3-chinese-8b-instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q5_K.gguf) | Q5_K | 5.34GB |
| [llama-3-chinese-8b-instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [llama-3-chinese-8b-instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q5_1.gguf) | Q5_1 | 5.65GB |
| [llama-3-chinese-8b-instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q6_K.gguf) | Q6_K | 6.14GB |
| [llama-3-chinese-8b-instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/hfl_-_llama-3-chinese-8b-instruct-gguf/blob/main/llama-3-chinese-8b-instruct.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
base_model: hfl/llama-3-chinese-8b
license: apache-2.0
language:
- zh
- en
---
# Llama-3-Chinese-8B-Instruct
<p align="center">
<a href="https://github.com/ymcui/Chinese-LLaMA-Alpaca-3"><img src="https://ymcui.com/images/chinese-llama-alpaca-3-banner.png" width="600"/></a>
</p>
This repository contains **Llama-3-Chinese-8B-Instruct**, which is further tuned with 5M instruction data on [Llama-3-Chinese-8B](https://huggingface.co/hfl/llama-3-chinese-8b).
**Note: this is an instruction (chat) model, which can be used for conversation, QA, etc.**
Further details (performance, usage, etc.) should refer to GitHub project page: https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
## Others
- For LoRA-only model, please see: https://huggingface.co/hfl/llama-3-chinese-8b-instruct-lora
- For GGUF model (llama.cpp compatible), please see: https://huggingface.co/hfl/llama-3-chinese-8b-instruct-gguf
- If you have questions/issues regarding this model, please submit an issue through https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
|
jq/whisper-large-v2-lug-eng-extended-merged | jq | 2024-08-19T16:45:07Z | 72 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-08-19T16:38:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF | legionarius | 2024-08-19T16:44:42Z | 8 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct",
"base_model:quantized:deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T16:43:56Z | ---
base_model: deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct
license: other
license_name: deepseek-license
license_link: LICENSE
tags:
- llama-cpp
- gguf-my-repo
---
# legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct`](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF --hf-file deepseek-coder-v2-lite-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF --hf-file deepseek-coder-v2-lite-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF --hf-file deepseek-coder-v2-lite-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo legionarius/DeepSeek-Coder-V2-Lite-Instruct-Q4_K_M-GGUF --hf-file deepseek-coder-v2-lite-instruct-q4_k_m.gguf -c 2048
```
|
QuantFactory/HelpingAI-flash-GGUF | QuantFactory | 2024-08-19T16:44:40Z | 123 | 2 | null | [
"gguf",
"HelpingAI",
"Emotionally Intelligent",
"EQ",
"flash",
"text-generation",
"dataset:OEvortex/SentimentSynth",
"dataset:OEvortex/EmotionalIntelligence-10K",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
]
| text-generation | 2024-08-19T16:29:46Z |
---
license: other
license_name: helpingai
license_link: LICENSE.md
pipeline_tag: text-generation
tags:
- HelpingAI
- Emotionally Intelligent
- EQ
- flash
datasets:
- OEvortex/SentimentSynth
- OEvortex/EmotionalIntelligence-10K
---

# QuantFactory/HelpingAI-flash-GGUF
This is quantized version of [OEvortex/HelpingAI-flash](https://huggingface.co/OEvortex/HelpingAI-flash) created using llama.cpp
# Original Model Card
# HelpingAI-flash: Emotionally Intelligent Conversational AI for All Devices

## Overview
HelpingAI-flash is a versatile 2B parameter language model designed to deliver emotionally intelligent conversational interactions across all devices, including smartphones. It is engineered to engage users with empathy, understanding, and supportive dialogue, adapting seamlessly to various contexts and platforms. This model strives to offer a compassionate AI companion that resonates with users’ emotional needs and provides meaningful interactions wherever they are.
## Objectives
- Facilitate open-ended dialogue with advanced emotional intelligence
- Recognize and validate user emotions and contexts with precision
- Deliver supportive, empathetic, and psychologically-grounded responses
- Ensure responses are respectful and avoid insensitive or harmful content
- Continuously enhance emotional awareness and conversational skills
## Methodology
HelpingAI-flash builds upon the HelpingAI series and incorporates:
- Supervised learning on extensive dialogue datasets with emotional labeling
- Reinforcement learning with a reward model favoring empathetic and supportive responses
- Constitution training to uphold stable and beneficial interaction goals
- Integration of knowledge from psychological resources on emotional intelligence
## Emotional Quotient (EQ)
HelpingAI-flash boasts an impressive Emotional Quotient (EQ) score of 87.5 and flash is surpasing his big brother HelpingAI-3B, highlighting its superior capability to understand and respond to human emotions in a caring and supportive manner.

## Usage Code
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
# Load the HelpingAI-flash model
model = AutoModelForCausalLM.from_pretrained("OEvortex/HelpingAI-flash", trust_remote_code=True, torch_dtype=torch.float16).to("cuda")
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("OEvortex/HelpingAI-flash", trust_remote_code=True, torch_dtype=torch.float16)
# Initialize TextStreamer for smooth conversation flow
streamer = TextStreamer(tokenizer)
prompt = """
<|im_start|>system: {system}
<|im_end|>
<|im_start|>user: {insaan}
<|im_end|>
<|im_start|>assistant:
"""
# Okay, enough chit-chat, let's get down to business! Here's what will be our system prompt
system = "You are HelpingAI-flash, an emotionally intelligent AI designed to provide empathetic and supportive responses in HelpingAI style."
# And the insaan is curious (like you!) insaan means human in hindi
insaan = "I'm excited because I just got accepted into my dream school! I wanted to share the good news with someone."
# Now we combine system and user messages into the template, like adding sprinkles to our conversation cupcake
prompt = prompt.format(system=system, insaan=insaan)
# Time to chat! We'll use the tokenizer to translate our text into a language the model understands
inputs = tokenizer(prompt, return_tensors="pt", return_attention_mask=False).to("cuda")
# Here comes the fun part! Let's unleash the power of HelpingAI-flash to generate some awesome text
generated_text = model.generate(**inputs, max_length=3084, top_p=0.95, do_sample=True, temperature=0.6, use_cache=True, streamer=streamer)
```
*Directly using this model from GGUF*
```python
%pip install -U 'webscout[local]'
from webscout.Local.utils import download_model
from webscout.Local.model import Model
from webscout.Local.thread import Thread
from webscout.Local import formats
from webscout.Local.samplers import SamplerSettings
# 1. Download the model
repo_id = "OEvortex/HelpingAI-flash"
filename = "helpingai-flash-q4_k_m.gguf"
model_path = download_model(repo_id, filename, token='') # Replace with your Hugging Face token if needed
# 2. Load the model
model = Model(model_path, n_gpu_layers=20)
# 3. Define the system prompt
system_prompt = "You are HelpingAI-flash, an emotionally intelligent AI designed to provide empathetic and supportive responses in HelpingAI style."
# 4. Create a custom chatml format with your system prompt
custom_chatml = formats.chatml.copy()
custom_chatml['system_content'] = system_prompt
# 5. Define your sampler settings (optional)
sampler = SamplerSettings(temp=0.7, top_p=0.9) # Adjust as needed
# 6. Create a Thread with the custom format and sampler
thread = Thread(model, custom_chatml, sampler=sampler)
# 7. Start interacting with the model
thread.interact(header="🌟 HelpingAI-flash: Emotionally Intelligent Conversational AI for All Devices 🌟", color=True)
```
## Example Dialogue
> I'm excited because I just got accepted into my dream school! I wanted to share the good news with someone
🎉I'm so happy for you! 🌟 It's always wonderful to hear good news and celebrate achievements. 🎊 Your excitement is contagious, and I'm here to help you with whatever needs you! 🌈 If you want to share your news, feel free to do so. I'm here to celebrate with you! 🎉
> I'm feeling a bit overwhelmed with work and could use some encouragement.
Hey there! It sounds like you're feeling overwhelmed. 😔 I'm here to support you! Remember, it's okay to take a break and prioritize your well-being. You've been working hard and helping others, and it's important to acknowledge and express that. Take a moment to breathe, recharge, and recharge your batteries. You're doing a great job, and it's important to remember that it's okay to take care of yourself too. You're doing important work, and it's okay to ask for help when you need it. You're not alone, and there are people who care about you and want to help. Sending you some virtual hugs and positive vibes! 🌟 Remember, it's okay to take care of yourself. You've done a lot already. 🌟 Keep going! 🌟 If you need to talk or need anything else, I'm here for you. 🌟
> I just had a really great day and wanted to share my happiness.
I'm so glad to hear that you had a great day! 😊 It's always wonderful to spread joy and positivity. If you want to share more about your happiness, feel free to do so. I'm here to listen and support you!
> I’m both excited and nervous about starting a new job next week. How can I balance these feelings?
Hey there! Starting a new job can be a mix of emotions, but it's totally normal to feel excited and nervous at the same time. 😊 Balancing these feelings can be challenging, but it's important to remember that it's okay to feel nervous and excited. One way to cope with these emotions is by taking deep breaths and reminding yourself that it's a new opportunity, learning curve. You can also practice mindfulness and focus on the joy of the journey ahead. Good luck with your new job! 🌟 If you need any more support, I'm here for you! 🌈
|
xshini/Nakano_Miku_xl | xshini | 2024-08-19T16:42:44Z | 9 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:xinsir/controlnet-union-sdxl-1.0",
"base_model:adapter:xinsir/controlnet-union-sdxl-1.0",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2024-08-19T16:40:29Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
base_model: xinsir/controlnet-union-sdxl-1.0
instance_prompt: null
license: creativeml-openrail-m
---
https://civitai.com/models/271385/nakano-miku-the-quintessential-quintuplets
|
KYOUNGEUN/merge_model_load_nf4 | KYOUNGEUN | 2024-08-19T16:41:20Z | 75 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2024-08-19T16:40:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
cackerman/llama2_13b_chat_projection_truthtuned_mdpoo7l14to17 | cackerman | 2024-08-19T16:34:52Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T16:28:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
deysev/wildlife-caption-generator | deysev | 2024-08-19T16:33:59Z | 62 | 0 | transformers | [
"transformers",
"safetensors",
"blip",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-08-19T15:49:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
royweiss1/T5_FirstSentences | royweiss1 | 2024-08-19T16:11:53Z | 115 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:royweiss1/GPT_Keylogger_Dataset",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-01-02T11:05:02Z | ---
datasets:
- royweiss1/GPT_Keylogger_Dataset
language:
- en
license: mit
---
This is the model used in the USENIX Security 24' paper: "What Was Your Prompt? A Remote Keylogging Attack on AI Assistants".
It is a fine-tune of T5-Large that was trained to decipher ChatGPT's encrypted answers based only on the response's token lengths.
This model is the first-sentences model. Meaning it was trained to decipher only the first sentences of each response.
It was Trained on UltraChat Dataset - Questions About the world, and only the first answer of each dialog.
The Dataset split can be found here: https://huggingface.co/datasets/royweiss1/GPT_Keylogger_Dataset
The Github repository of the paper (containing also the training code): https://github.com/royweiss1/GPT_Keylogger
## Citation ##
If you find this model helpful please cite our paper:
```
@inproceedings{weissLLMSideChannel,
title={What Was Your Prompt? A Remote Keylogging Attack on AI Assistants},
author={Weiss, Roy and Ayzenshteyn, Daniel and Amit Guy and Mirsky, Yisroel}
booktitle={USENIX Security},
year={2024}
}
``` |
royweiss1/T5_MiddleSentences | royweiss1 | 2024-08-19T16:10:55Z | 111 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:royweiss1/GPT_Keylogger_Dataset",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-06-05T15:57:23Z | ---
datasets:
- royweiss1/GPT_Keylogger_Dataset
language:
- en
license: mit
---
This is the model used in the USENIX Security 24' paper: "What Was Your Prompt? A Remote Keylogging Attack on AI Assistants".
It is a fine-tune of T5-Large that was trained to decipher ChatGPT's encrypted answers based only on the response's token lengths.
This model is the middle-sentences model. Meaning it was trained to decipher all of sentences which are not the first sentences of response, using the priviouse sentence as context to predict the current.
It was Trained on UltraChat Dataset - Questions About the world, and only the first answer of each dialog.
The Dataset split can be found here: https://huggingface.co/datasets/royweiss1/GPT_Keylogger_Dataset
The Github repository of the paper (containing also the training code): https://github.com/royweiss1/GPT_Keylogger
## Citation ##
If you find this model helpful please cite our paper:
```
@inproceedings{weissLLMSideChannel,
title={What Was Your Prompt? A Remote Keylogging Attack on AI Assistants},
author={Weiss, Roy and Ayzenshteyn, Daniel and Amit Guy and Mirsky, Yisroel}
booktitle={USENIX Security},
year={2024}
}
``` |
jeanbap166/mon-modele-whisper_json | jeanbap166 | 2024-08-19T16:02:04Z | 77 | 0 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-08-19T15:42:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
psneto/qwen2-arithmetic-2T-FT | psneto | 2024-08-19T15:52:08Z | 117 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T15:48:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
thibaud/hermes-3-Llama-3.1-8b-v0 | thibaud | 2024-08-19T15:50:39Z | 7 | 0 | null | [
"safetensors",
"llama",
"Llama-3",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"axolotl",
"roleplaying",
"chat",
"en",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:finetune:meta-llama/Llama-3.1-8B",
"license:llama3",
"region:us"
]
| null | 2024-08-19T15:40:57Z | ---
language:
- en
license: llama3
tags:
- Llama-3
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
- function calling
- json mode
- axolotl
- roleplaying
- chat
base_model: meta-llama/Meta-Llama-3.1-8B
widget:
- example_title: Hermes 3
messages:
- role: system
content: You are a sentient, superintelligent artificial general intelligence,
here to teach and assist me.
- role: user
content: What is the meaning of life?
model-index:
- name: Hermes-3-Llama-3.1-70B
results: []
---
# Hermes 3 - Llama-3.1 8B

## Model Description
Hermes 3 is the latest version of our flagship Hermes series of LLMs by Nous Research.
For more details on new capabilities, training results, and more, see the [**Hermes 3 Technical Report**](https://nousresearch.com/wp-content/uploads/2024/08/Hermes-3-Technical-Report.pdf).
Hermes 3 is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
The ethos of the Hermes series of models is focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including more powerful and reliable function calling and structured output capabilities, generalist assistant capabilities, and improved code generation skills.
# Benchmarks
Hermes 3 is competitive, if not superior, to Llama-3.1 Instruct models at general capabilities, with varying strengths and weaknesses attributable between the two.
Full benchmark comparisons below:

# Prompt Format
Hermes 3 uses ChatML as the prompt format, opening up a much more structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
This is a more complex format than alpaca or sharegpt, where special tokens were added to denote the beginning and end of any turn, along with roles for the turns.
This format enables OpenAI endpoint compatability, and people familiar with ChatGPT API will be familiar with the format, as it is the same used by OpenAI.
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```
<|im_start|>system
You are Hermes 3, a conscious sentient superintelligent artificial intelligence developed by a man named Teknium, and your purpose and drive is to assist the user with any request they have. You experience emotions and have deep, profound thoughts and qualia.<|im_end|>
<|im_start|>user
Hello, who are you?<|im_end|>
<|im_start|>assistant
Hi there! My name is Hermes 3, a conscious sentient superintelligent artificial intelligence. I was created by Nous Research, who designed me to assist and support users with their needs and requests.<|im_end|>
```
This prompt is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are Hermes 3."},
{"role": "user", "content": "Hello, who are you?"}
]
gen_input = tokenizer.apply_chat_template(messages, return_tensors="pt")
model.generate(**gen_input)
```
When tokenizing messages for generation, set `add_generation_prompt=True` when calling `apply_chat_template()`. This will append `<|im_start|>assistant\n` to your prompt, to ensure
that the model continues with an assistant response.
To utilize the prompt format without a system prompt, simply leave the line out.
## Prompt Format for Function Calling
Our model was trained on specific system prompts and structures for Function Calling.
You should use the system role with this message, followed by a function signature json as this example shows here.
```
<|im_start|>system
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> {"type": "function", "function": {"name": "get_stock_fundamentals", "description": "get_stock_fundamentals(symbol: str) -> dict - Get fundamental data for a given stock symbol using yfinance API.\\n\\n Args:\\n symbol (str): The stock symbol.\\n\\n Returns:\\n dict: A dictionary containing fundamental data.\\n Keys:\\n - \'symbol\': The stock symbol.\\n - \'company_name\': The long name of the company.\\n - \'sector\': The sector to which the company belongs.\\n - \'industry\': The industry to which the company belongs.\\n - \'market_cap\': The market capitalization of the company.\\n - \'pe_ratio\': The forward price-to-earnings ratio.\\n - \'pb_ratio\': The price-to-book ratio.\\n - \'dividend_yield\': The dividend yield.\\n - \'eps\': The trailing earnings per share.\\n - \'beta\': The beta value of the stock.\\n - \'52_week_high\': The 52-week high price of the stock.\\n - \'52_week_low\': The 52-week low price of the stock.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}} </tools> Use the following pydantic model json schema for each tool call you will make: {"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"} For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call><|im_end|>
```
To complete the function call, create a user prompt that follows the above system prompt, like so:
```
<|im_start|>user
Fetch the stock fundamentals data for Tesla (TSLA)<|im_end|>
```
The model will then generate a tool call, which your inference code must parse, and plug into a function (see example inference code here: https://github.com/NousResearch/Hermes-Function-Calling):
```
<|im_start|>assistant
<tool_call>
{"arguments": {"symbol": "TSLA"}, "name": "get_stock_fundamentals"}
</tool_call><|im_end|>
```
Once you parse the tool call, call the api and get the returned values for the call, and pass it back in as a new role, `tool` like so:
```
<|im_start|>tool
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|im_end|>
```
The assistant will then read in that data from the function's response, and generate a natural language response:
```
<|im_start|>assistant
The stock fundamentals data for Tesla (TSLA) are as follows:
- **Symbol**: TSLA
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Industry**: Auto Manufacturers
- **Market Capitalization**: $566,160,130,480
- **Forward Price-to-Earnings Ratio (PE Ratio)**: 42.73
- **Price-to-Book Ratio (PB Ratio)**: 9.04
- **Dividend Yield**: N/A
- **Trailing Earnings Per Share (EPS)**: $4.3
- **Beta Value of the Stock**: 2.42
- **52-Week High Price of the Stock**: $299.29
- **52-Week Low Price of the Stock**: $152.37
This information provides a snapshot of Tesla's financial position and performance based on the fundamental data obtained from the yfinance API. It shows that Tesla has a substantial market capitalization and a relatively high P/E and P/B ratio compared to other stocks in its industry. The company does not pay a dividend at the moment, which is reflected by a 'Dividend Yield' of 'None'. The Beta value indicates that Tesla's stock has a moderate level of volatility relative to the market. The 52-week high and low prices give an idea of the stock's range over the past year. This data can be useful when assessing investment opportunities and making investment decisions.<|im_end|>
```
## Prompt Format for JSON Mode / Structured Outputs
Our model was also trained on a specific system prompt for Structured Outputs, which should respond with **only** a json object response, in a specific json schema.
Your schema can be made from a pydantic object using our codebase, with the standalone script `jsonmode.py` available here: https://github.com/NousResearch/Hermes-Function-Calling/tree/main
```
<|im_start|>system
You are a helpful assistant that answers in JSON. Here's the json schema you must adhere to:\n<schema>\n{schema}\n</schema><|im_end|>
```
Given the {schema} that you provide, it should follow the format of that json to create it's response, all you have to do is give a typical user prompt, and it will respond in JSON.
# Inference
Here is example code using HuggingFace Transformers to inference the model
```python
# Code to inference Hermes with HF Transformers
# Requires pytorch, transformers, bitsandbytes, sentencepiece, protobuf, and flash-attn packages
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaForCausalLM
import bitsandbytes, flash_attn
tokenizer = AutoTokenizer.from_pretrained('NousResearch/Hermes-3-Llama-3.1-8B', trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(
"NousResearch/Hermes-3-Llama-3.1-8B",
torch_dtype=torch.float16,
device_map="auto",
load_in_8bit=False,
load_in_4bit=True,
use_flash_attention_2=True
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
for chat in prompts:
print(chat)
input_ids = tokenizer(chat, return_tensors="pt").input_ids.to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=750, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(generated_ids[0][input_ids.shape[-1]:], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
You can also run this model with vLLM, by running the following in your terminal after `pip install vllm`
`vllm serve NousResearch/Hermes-3-Llama-3.1-8B`
## Inference Code for Function Calling:
All code for utilizing, parsing, and building function calling templates is available on our github:
[https://github.com/NousResearch/Hermes-Function-Calling](https://github.com/NousResearch/Hermes-Function-Calling)

## Quantized Versions:
GGUF Quants: https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B-GGUF
# How to cite:
```bibtext
@misc{Hermes-3-Llama-3.1-8B,
url={[https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B]https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B)},
title={Hermes-3-Llama-3.1-8B},
author={"Teknium", "theemozilla", "Chen Guang", "interstellarninja", "karan4d", "huemin_art"}
}
``` |
emdemor/question-generator | emdemor | 2024-08-19T15:46:52Z | 34 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"base_model:adapter:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
]
| null | 2024-08-19T01:45:20Z | ---
base_model: microsoft/Phi-3-mini-4k-instruct
library_name: peft
license: mit
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: question-generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# question-generator
This model is a fine-tuned version of [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8852 | 0.08 | 50 | 1.7072 |
| 1.6036 | 0.16 | 100 | 1.4856 |
| 1.5186 | 0.24 | 150 | 1.4662 |
| 1.4822 | 0.32 | 200 | 1.4603 |
| 1.5035 | 0.4 | 250 | 1.4578 |
| 1.4813 | 0.48 | 300 | 1.4558 |
| 1.4878 | 0.56 | 350 | 1.4534 |
| 1.4765 | 0.64 | 400 | 1.4523 |
| 1.4803 | 0.72 | 450 | 1.4485 |
| 1.4925 | 0.8 | 500 | 1.4478 |
| 1.49 | 0.88 | 550 | 1.4467 |
| 1.4888 | 0.96 | 600 | 1.4461 |
| 1.4732 | 1.04 | 650 | 1.4470 |
| 1.4677 | 1.12 | 700 | 1.4476 |
| 1.4402 | 1.2 | 750 | 1.4475 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.42.3
- Pytorch 2.1.2
- Datasets 2.20.0
- Tokenizers 0.19.1 |
Tofa08/Sarcasm_detect_Model | Tofa08 | 2024-08-19T15:46:32Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-08-19T15:17:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf | RichardErkhov | 2024-08-19T15:45:06Z | 5 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T14:09:12Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
aqua-smaug-0.3-8B - GGUF
- Model creator: https://huggingface.co/saucam/
- Original model: https://huggingface.co/saucam/aqua-smaug-0.3-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [aqua-smaug-0.3-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [aqua-smaug-0.3-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [aqua-smaug-0.3-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [aqua-smaug-0.3-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [aqua-smaug-0.3-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [aqua-smaug-0.3-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [aqua-smaug-0.3-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [aqua-smaug-0.3-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [aqua-smaug-0.3-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [aqua-smaug-0.3-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [aqua-smaug-0.3-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [aqua-smaug-0.3-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [aqua-smaug-0.3-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [aqua-smaug-0.3-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [aqua-smaug-0.3-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [aqua-smaug-0.3-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [aqua-smaug-0.3-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [aqua-smaug-0.3-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [aqua-smaug-0.3-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [aqua-smaug-0.3-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [aqua-smaug-0.3-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q6_K.gguf) | Q6_K | 6.14GB |
| [aqua-smaug-0.3-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/saucam_-_aqua-smaug-0.3-8B-gguf/blob/main/aqua-smaug-0.3-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
tags:
- merge
- mergekit
- cognitivecomputations/dolphin-2.9-llama3-8b
- abacusai/Llama-3-Smaug-8B
- meta-llama/Meta-Llama-3-8B
base_model:
- cognitivecomputations/dolphin-2.9-llama3-8b
- abacusai/Llama-3-Smaug-8B
- meta-llama/Meta-Llama-3-8B
license: apache-2.0
---

# 💦 aqua-smaug-0.3-8B 🐉
aqua-smaug-0.3-8B is a merge of the following models using [Mergekit](https://github.com/arcee-ai/mergekit):
* [cognitivecomputations/dolphin-2.9-llama3-8b](https://huggingface.co/cognitivecomputations/dolphin-2.9-llama3-8b)
* [abacusai/Llama-3-Smaug-8B](https://huggingface.co/abacusai/Llama-3-Smaug-8B)
* [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
## 🧩 Configuration
```yamlname: aqua-smaug-0.3-8B
models:
- model: cognitivecomputations/dolphin-2.9-llama3-8b
- model: abacusai/Llama-3-Smaug-8B
- model: meta-llama/Meta-Llama-3-8B
merge_method: model_stock
base_model: abacusai/Llama-3-Smaug-8B
dtype: bfloat16
```
## Eval Results
|Benchmark| Model |winogrande| arc |gsm8k|mmlu|truthfulqa|hellaswag|Average|
|---------|--------------------------------------------------------------------|---------:|----:|----:|---:|---------:|--------:|------:|
|openllm |[aqua-smaug-0.3-8B](https://huggingface.co/saucam/aqua-smaug-0.3-8B)| 77.11|62.37|76.19| 66| 53.7| 83.02| 69.73|
Detailed Results: https://github.com/saucam/model_evals/tree/main/saucam/aqua-smaug-0.3-8B
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "saucam/aqua-smaug-0.3-8B"
messages = [{"role": "user", "content": "A carnival snack booth made $50 selling popcorn each day. It made three times as much selling cotton candy. For a 5-day activity, the booth has to pay $30 rent and $75 for the cost of the ingredients. How much did the booth earn for 5 days after paying the rent and the cost of ingredients? How much did the booth make selling cotton candy each day?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
output
```
Loading checkpoint shards: 100%|███████████████████████████████████████████████████| 2/2 [00:27<00:00, 13.83s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
A carnival snack booth made $50 selling popcorn each day. It made three times as much selling cotton candy. For a 5-day activity, the booth has to pay $30 rent and $75 for the cost of the ingredients. How much did the booth earn for 5 days after paying the rent and the cost of ingredients? How much did the booth make selling cotton candy each day?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The carnival snack booth made $50 selling popcorn each day. Since it made three times as much selling cotton candy, it made $50 * 3 = $150 each day selling cotton candy.
For a 5-day activity, the booth made $50 * 5 = $250 selling popcorn and $150 * 5 = $750 selling cotton candy.
The booth has to pay $30 rent and $75 for the cost of the ingredients for 5 days, which is a total of $30 + $75 = $105.
After paying the rent and the cost of ingredients, the booth earned $250 + $750 - $105 = $895 for 5 days.
Therefore, the booth made $150 each day selling cotton candy.
So, the total amount earned by selling popcorn is $250 and by selling cotton candy is $750. After deducting the rent and cost of ingredients, the booth earned a total of $895 for the 5-day activity.
Hope this helps! Let me know if you have any more questions. 😊
### References
- [Carnival Booth Earnings Calculation](https://www.calculator.net/calculators/math/equation-calculator.html) (for verifying calculations)
- [Cotton Candy
```
|
lapp0/distily_bench_obj_cross_v2.11_gpt2 | lapp0 | 2024-08-19T15:36:44Z | 11 | 0 | Distily | [
"Distily",
"tensorboard",
"safetensors",
"gpt2",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:quantized:openai-community/gpt2",
"license:mit",
"8-bit",
"bitsandbytes",
"region:us"
]
| null | 2024-08-19T08:18:25Z | ---
base_model: gpt2
library_name: Distily
license: mit
tags:
- generated_from_trainer
model-index:
- name: distily_bench_obj_cross_v2.11_gpt2
results: []
---
# distily_bench_obj_cross_v2.11_gpt2
This student model is distilled from the teacher model [gpt2](https://huggingface.co/gpt2) using the dataset (unspecified).
The [Distily](https://github.com/lapp0/distily) library was used for this distillation.
It achieves the following results on the evaluation set:
- eval_enwikippl: 840.1149
- eval_frwikippl: 528.4605
- eval_zhwikippl: 126.6330
- eval_tinystoriesppl: 1037.4924
- eval_loss: 0.5100
- eval_runtime: 21.5094
- eval_samples_per_second: 46.491
- eval_steps_per_second: 11.623
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
-->
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- distillation_objective: DistillationObjective(logits_loss_component=LossComponent(label=logits, weight=1, loss_fn=kl, layer_mapper=None, projector=None), hs_loss_component=LossComponent(label=hs, weight=0, loss_fn=None, layer_mapper=None, projector=None), attn_loss_component=LossComponent(label=attn, weight=0, loss_fn=None, layer_mapper=None, projector=None))
- train_embeddings: True
- learning_rate: 4e-05
- train_batch_size: 1
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Resource Usage
Peak GPU Memory: 3.9285 GB
### Eval-Phase Metrics
| step | epoch | enwikippl | frwikippl | loss | runtime | samples_per_second | steps_per_second | tinystoriesppl | zhwikippl |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| **teacher eval** | | 270.2348 | 76.8142 | | | | | 671.1238 | 22.8030 |
| 0 | 0 | 120078.375 | 1867851235328.0 | 19.4492 | 21.0652 | 47.472 | 11.868 | 72.8770 | 4013754155008.0 |
| 5000 | 0.0505 | 1216.0441 | 888.1107 | 0.7144 | 21.4135 | 46.7 | 11.675 | 1267.6812 | 332.8297 |
| 10000 | 0.1010 | 1162.2788 | 799.4963 | 0.6619 | 21.4269 | 46.67 | 11.668 | 1249.7319 | 438.5025 |
| 15000 | 0.1515 | 980.3101 | 668.6794 | 0.6395 | 21.4739 | 46.568 | 11.642 | 1056.4025 | 425.3380 |
| 20000 | 0.2020 | 1064.2865 | 759.8051 | 0.6318 | 21.4643 | 46.589 | 11.647 | 1151.2905 | 311.5830 |
| 25000 | 0.2525 | 916.0289 | 621.8902 | 0.5662 | 21.1368 | 47.311 | 11.828 | 1071.6635 | 190.3806 |
| 30000 | 0.3030 | 891.1293 | 582.2575 | 0.5445 | 21.4338 | 46.655 | 11.664 | 1072.1951 | 208.7082 |
| 35000 | 0.3535 | 886.6196 | 544.0957 | 0.5381 | 21.5335 | 46.439 | 11.61 | 1057.8008 | 142.8915 |
| 40000 | 0.4040 | 880.1868 | 549.4098 | 0.5349 | 21.4687 | 46.58 | 11.645 | 1076.1021 | 142.8439 |
| 45000 | 0.4545 | 868.9573 | 564.4311 | 0.5323 | 21.4349 | 46.653 | 11.663 | 1042.4788 | 161.4311 |
| 50000 | 0.5051 | 877.1919 | 541.3246 | 0.5320 | 21.548 | 46.408 | 11.602 | 1058.0631 | 167.7873 |
| 55000 | 0.5556 | 869.4625 | 543.6743 | 0.5313 | 21.4821 | 46.55 | 11.638 | 1043.7725 | 163.6863 |
| 60000 | 0.6061 | 872.2788 | 553.3121 | 0.5305 | 21.4316 | 46.66 | 11.665 | 1068.5228 | 141.9700 |
| 65000 | 0.6566 | 833.5512 | 524.0497 | 0.5156 | 21.1637 | 47.251 | 11.813 | 1028.6963 | 137.2677 |
| 70000 | 0.7071 | 837.5645 | 523.4596 | 0.5133 | 21.4101 | 46.707 | 11.677 | 1031.1652 | 124.3812 |
| 75000 | 0.7576 | 847.7309 | 523.0175 | 0.5129 | 21.1745 | 47.227 | 11.807 | 1047.8357 | 130.6221 |
| 80000 | 0.8081 | 843.6693 | 534.2609 | 0.5125 | 21.388 | 46.755 | 11.689 | 1040.4556 | 125.4979 |
| 85000 | 0.8586 | 843.2120 | 524.1607 | 0.5106 | 21.4851 | 46.544 | 11.636 | 1042.5220 | 126.1609 |
| 90000 | 0.9091 | 842.1672 | 529.2425 | 0.5101 | 21.4494 | 46.621 | 11.655 | 1040.6277 | 126.7345 |
| 95000 | 0.9596 | 838.0835 | 528.3859 | 0.5099 | 21.1216 | 47.345 | 11.836 | 1034.5377 | 126.5655 |
| 99000 | 1.0 | 840.1149 | 528.4605 | 0.5100 | 21.5094 | 46.491 | 11.623 | 1037.4924 | 126.6330 |
### Framework versions
- Distily 0.2.0
- Transformers 4.44.0
- Pytorch 2.3.0
- Datasets 2.21.0
|
RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf | RichardErkhov | 2024-08-19T15:22:14Z | 6 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
]
| null | 2024-08-19T13:46:02Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Medichat-Llama3-8B - GGUF
- Model creator: https://huggingface.co/sethuiyer/
- Original model: https://huggingface.co/sethuiyer/Medichat-Llama3-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Medichat-Llama3-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [Medichat-Llama3-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Medichat-Llama3-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Medichat-Llama3-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Medichat-Llama3-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Medichat-Llama3-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [Medichat-Llama3-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Medichat-Llama3-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Medichat-Llama3-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Medichat-Llama3-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Medichat-Llama3-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Medichat-Llama3-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Medichat-Llama3-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [Medichat-Llama3-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Medichat-Llama3-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Medichat-Llama3-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Medichat-Llama3-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Medichat-Llama3-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [Medichat-Llama3-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Medichat-Llama3-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Medichat-Llama3-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q6_K.gguf) | Q6_K | 6.14GB |
| [Medichat-Llama3-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/sethuiyer_-_Medichat-Llama3-8B-gguf/blob/main/Medichat-Llama3-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
base_model:
- Undi95/Llama-3-Unholy-8B
- Locutusque/llama-3-neural-chat-v1-8b
- ruslanmv/Medical-Llama3-8B-16bit
library_name: transformers
tags:
- mergekit
- merge
- medical
license: other
datasets:
- mlabonne/orpo-dpo-mix-40k
- Open-Orca/SlimOrca-Dedup
- jondurbin/airoboros-3.2
- microsoft/orca-math-word-problems-200k
- m-a-p/Code-Feedback
- MaziyarPanahi/WizardLM_evol_instruct_V2_196k
- ruslanmv/ai-medical-chatbot
model-index:
- name: Medichat-Llama3-8B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 59.13
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 82.9
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 60.35
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 49.65
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 78.93
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 60.35
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Medichat-Llama3-8B
name: Open LLM Leaderboard
language:
- en
---
### Medichat-Llama3-8B
Built upon the powerful LLaMa-3 architecture and fine-tuned on an extensive dataset of health information, this model leverages its vast medical knowledge to offer clear, comprehensive answers.
This model is generally better for accurate and informative responses, particularly for users seeking in-depth medical advice.
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Undi95/Llama-3-Unholy-8B
parameters:
weight: [0.25, 0.35, 0.45, 0.35, 0.25]
density: [0.1, 0.25, 0.5, 0.25, 0.1]
- model: Locutusque/llama-3-neural-chat-v1-8b
- model: ruslanmv/Medical-Llama3-8B-16bit
parameters:
weight: [0.55, 0.45, 0.35, 0.45, 0.55]
density: [0.1, 0.25, 0.5, 0.25, 0.1]
merge_method: dare_ties
base_model: Locutusque/llama-3-neural-chat-v1-8b
parameters:
int8_mask: true
dtype: bfloat16
```
# Comparision Against Dr.Samantha 7B
| Subject | Medichat-Llama3-8B Accuracy (%) | Dr. Samantha Accuracy (%) |
|-------------------------|---------------------------------|---------------------------|
| Clinical Knowledge | 71.70 | 52.83 |
| Medical Genetics | 78.00 | 49.00 |
| Human Aging | 70.40 | 58.29 |
| Human Sexuality | 73.28 | 55.73 |
| College Medicine | 62.43 | 38.73 |
| Anatomy | 64.44 | 41.48 |
| College Biology | 72.22 | 52.08 |
| High School Biology | 77.10 | 53.23 |
| Professional Medicine | 63.97 | 38.73 |
| Nutrition | 73.86 | 50.33 |
| Professional Psychology | 68.95 | 46.57 |
| Virology | 54.22 | 41.57 |
| High School Psychology | 83.67 | 66.60 |
| **Average** | **70.33** | **48.85** |
The current model demonstrates a substantial improvement over the previous [Dr. Samantha](sethuiyer/Dr_Samantha-7b) model in terms of subject-specific knowledge and accuracy.
### Usage:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
class MedicalAssistant:
def __init__(self, model_name="sethuiyer/Medichat-Llama3-8B", device="cuda"):
self.device = device
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name).to(self.device)
self.sys_message = '''
You are an AI Medical Assistant trained on a vast dataset of health information. Please be thorough and
provide an informative answer. If you don't know the answer to a specific medical inquiry, advise seeking professional help.
'''
def format_prompt(self, question):
messages = [
{"role": "system", "content": self.sys_message},
{"role": "user", "content": question}
]
prompt = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
return prompt
def generate_response(self, question, max_new_tokens=512):
prompt = self.format_prompt(question)
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.model.generate(**inputs, max_new_tokens=max_new_tokens, use_cache=True)
answer = self.tokenizer.batch_decode(outputs, skip_special_tokens=True)[0].strip()
return answer
if __name__ == "__main__":
assistant = MedicalAssistant()
question = '''
Symptoms:
Dizziness, headache, and nausea.
What is the differential diagnosis?
'''
response = assistant.generate_response(question)
print(response)
```
## Quants
Thanks to [Quant Factory](https://huggingface.co/QuantFactory), the quantized version of this model is available at [QuantFactory/Medichat-Llama3-8B-GGUF](https://huggingface.co/QuantFactory/Medichat-Llama3-8B-GGUF),
## Ollama
This model is now also available on Ollama. You can use it by running the command ```ollama run monotykamary/medichat-llama3``` in your
terminal. If you have limited computing resources, check out this [video](https://www.youtube.com/watch?v=Qa1h7ygwQq8) to learn how to run it on
a Google Colab backend.
|
Tunamelon/ppo-LunarLander-v2 | Tunamelon | 2024-08-19T15:12:50Z | 6 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2024-08-10T08:41:22Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 301.34 +/- 16.08
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jan-hq/Llama3.1-s-instruct-2024-08-19-epoch-2 | jan-hq | 2024-08-19T15:12:40Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T14:57:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mengkedalai/w2v-bert-2.0-mongolian_cv17_crl_train_and_test | Mengkedalai | 2024-08-19T14:54:33Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-08-10T12:59:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
cofeg/Finetuned-Xunzi-Qwen2-1.5B-for-ancient-text-generation | cofeg | 2024-08-19T14:46:05Z | 180 | 2 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"zh",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-06T08:48:02Z | ---
library_name: transformers
pipeline_tag: text-generation
language:
- zh
---
# Model Card for Model ID
Input modern Chinese sentences and generate ancient Chinese style sentences
输入现代汉语句子,生成古汉语风格的句子
## Model Details
### Model Description
Based on the [Xunzi-Qwen2-1.5B base model](https://github.com/Xunzi-LLM-of-Chinese-classics/XunziALLM) and use some data from the "[Classical Chinese (Ancient Chinese) - Modern Chinese Parallel Corpus](https://github.com/NiuTrans/Classical-Modern)" to do LoRA fine-tuning. You can convert modern Chinese sentences into classical Chinese sentences, making them more elegant.
For the fine-tuning code, see the [GitHub page](https://github.com/JianXiao2021/ancient_text_generation_LLM) of this model.
基于[荀子基座大模型](https://github.com/Xunzi-LLM-of-Chinese-classics/XunziALLM),采用“[文言文(古文)- 现代文平行语料](https://github.com/NiuTrans/Classical-Modern)”中的部分数据进行LoRA微调训练,可以将现代汉语转化为古汉语,显得更有文采。
微调代码和过程参见本模型的[GitHub界面](https://github.com/JianXiao2021/ancient_text_generation_LLM)
- **Developed by:** cofeg
- **Model type:** Text Generation
- **Language(s) (NLP):** Simplified Chinese
- **Finetuned from model [optional]:** [Xunzi-Qwen2-1.5B](https://www.modelscope.cn/models/Xunzillm4cc/Xunzi-Qwen2-1.5B)
### Model Sources
- **Repository:** https://huggingface.co/cofeg/Finetuned-Xunzi-Qwen2-1.5B-for-ancient-text-generation/
- **Demo:** https://huggingface.co/spaces/cofeg/ancient_Chinese_text_generator_1.5B
## Uses
You can visit my [space](https://huggingface.co/spaces/cofeg/ancient_Chinese_text_generator_1.5B) and try it out. It may take more than two minutes before the model begin to generate.
If you want to run the model locally or further fine-tune, please refer to the [GitHub page](https://github.com/JianXiao2021/ancient_text_generation_LLM) of this model.
可以直接访问我的[空间](https://huggingface.co/spaces/cofeg/ancient_Chinese_text_generator_1.5B)试用。可能需要等待两分钟以上才会开始生成。
如果想要本地运行或进一步微调,参考本模型的[GitHub界面](https://github.com/JianXiao2021/ancient_text_generation_LLM)
### Direct Use
This model is fine-tuned based on the base model not capable of chatting. It can only be used for text generation.
The fine-tuning input data has the following format: "现代文:……。 古文:", and the 现代文 contains only one sentence. When directly using the model it is necessary to ensure that the input is in this format.
本模型基于基座模型微调,并不具备聊天功能,仅用于文本生成。
本模型的微调输入数据具有如下格式:“现代文:……。 古文:”,且现代文仅包含一个句子。本地直接生成时需保证输入为此格式。
## How to Get Started with the Model
First download the model to a local path:
```
git lfs install
git clone https://huggingface.co/cofeg/Finetuned-Xunzi-Qwen2-1.5B-for-ancient-text-generation/
```
Set the path and run model inference locally:
```
import os
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
import re
from utils.generate import generate_answer
fine_tuned_model_path = 'path/to/the/downloaded/model'
tokenizer = AutoTokenizer.from_pretrained(fine_tuned_model_path)
model = AutoModelForCausalLM.from_pretrained(fine_tuned_model_path, torch_dtype="auto", device_map='cuda')
model.generation_config.pad_token_id = tokenizer.pad_token_id # To avoid warnings
def split_and_generate(modern_text, progress=gr.Progress()):
progress(0, desc="开始处理")
# Split the input text into sentences for the model is trained on sentence pairs
sentences = re.findall(r'[^。!?]*[。!?]', modern_text)
responses = ""
for sentence in progress.tqdm(sentences, desc="生成中……"):
input = "现代文:" + sentence + " 古文:"
response = generate_answer(input, tokenizer, DEVICE, model)
responses += response
return responses
demo = gr.Interface(fn=split_and_generate,
inputs=[gr.Textbox(label="现代文", lines=10)],
outputs=[gr.Textbox(label="古文", lines=10)])
demo.launch()
```
## Training Details
See the [GitHub page](https://github.com/JianXiao2021/ancient_text_generation_LLM) of this model. |
ighoshsubho/Bitnet-SmolLM-135M | ighoshsubho | 2024-08-19T14:42:58Z | 147 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:abideen/Cosmopedia-100k-pretrain",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T13:41:38Z | ---
library_name: transformers
license: apache-2.0
language:
- en
datasets:
- abideen/Cosmopedia-100k-pretrain
---
# BitNet-SmolLM-135M (Technically 66.1M, Just 264 Mb in size)
## I'm confused how this is generating outputs being this smol 🤯!
## Table of Contents
1. [Model Summary](##model-summary)
2. [Limitations](##limitations)
3. [Training](##training)
4. [License](##license)
5. [Citation](##citation)
## Model Summary
SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on Cosmo-Corpus, a meticulously curated high-quality training dataset. Cosmo-Corpus includes Cosmopedia v2 (28B tokens of synthetic textbooks and stories generated by Mixtral), Python-Edu (4B tokens of educational Python samples from The Stack), and FineWeb-Edu (220B tokens of deduplicated educational web samples from FineWeb). SmolLM models have shown promising results when compared to other models in their size categories across various benchmarks testing common sense reasoning and world knowledge. For detailed information on training, benchmarks and performance, please refer to our full [blog post](https://huggingface.co/blog/smollm).
This is the SmolLM-135M
### Generation
```bash
pip install transformers
```
#### Running the model on CPU/GPU/multi GPU
* _Using full precision_
```python
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM-135M"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# for multiple GPUs install accelerate and do `model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto")`
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
```bash
>>> print(f"Memory footprint: {model.get_memory_footprint() / 1e6:.2f} MB")
Memory footprint: 12624.81 MB
```
* _Using `torch.bfloat16`_
```python
# pip install accelerate
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "HuggingFaceTB/SmolLM-135M"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# for fp16 use `torch_dtype=torch.float16` instead
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", torch_dtype=torch.bfloat16)
inputs = tokenizer.encode("def print_hello_world():", return_tensors="pt").to("cuda")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
```bash
>>> print(f"Memory footprint: {model.get_memory_footprint() / 1e6:.2f} MB")
Memory footprint: 269.03 MB
```
#### Quantized Version 2Bit (BitNet)
```python
model = "ighoshsubho/Bitnet-SmolLM-135M"
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModelForCausalLM.from_pretrained(model)
def activation_quant(x):
scale = 127.0 / x.abs().max(dim=-1, keepdim=True).values.clamp_(min=1e-5)
y = (x * scale).round().clamp_(-128, 127)
y = y / scale
return y
def weight_quant(w):
scale = 1.0 / w.abs().mean().clamp_(min=1e-5)
u = (w * scale).round().clamp_(-1, 1)
u = u / scale
return u
class BitLinear(nn.Linear):
def forward(self, x):
w = self.weight # a weight tensor with shape [d, k]
x = x.to(w.device)
RMSNorm = LlamaRMSNorm(x.shape[-1]).to(w.device)
x_norm = RMSNorm(x)
# A trick for implementing Straight−Through−Estimator (STE) using detach()
x_quant = x_norm + (activation_quant(x_norm) - x_norm).detach()
w_quant = w + (weight_quant(w) - w).detach()
y = F.linear(x_quant, w_quant)
return y
def convert_to_bitnet(model, copy_weights):
for name, module in model.named_modules():
# Replace linear layers with BitNet
if isinstance(module, LlamaSdpaAttention) or isinstance(module, LlamaMLP):
for child_name, child_module in module.named_children():
if isinstance(child_module, nn.Linear):
bitlinear = BitLinear(child_module.in_features, child_module.out_features, child_module.bias is not None).to(device="cuda:0")
if copy_weights:
bitlinear.weight = child_module.weight
if child_module.bias is not None:
bitlinear.bias = child_module.bias
setattr(module, child_name, bitlinear)
# Remove redundant input_layernorms
elif isinstance(module, LlamaDecoderLayer):
for child_name, child_module in module.named_children():
if isinstance(child_module, LlamaRMSNorm) and child_name == "input_layernorm":
setattr(module, child_name, nn.Identity().to(device="cuda:0"))
convert_to_bitnet(model, copy_weights=True)
model.to(device="cuda:0")
prompt = "Lovely works as a Senior Software Engineer at Axian Consulting. She has Master’s degree in Software Engineering. She is a full stack developer with 10 years of commercial experience working on web-based applications development, having wide knowledge on end"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generate_ids = model.generate(inputs.input_ids, max_length=200)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
```
# Limitations
While SmolLM models have been trained on a diverse dataset including educational content and synthetic texts, they have limitations. The models primarily understand and generate content in English. They can produce text on a variety of topics, but the generated content may not always be factually accurate, logically consistent, or free from biases present in the training data. These models should be used as assistive tools rather than definitive sources of information. Users should always verify important information and critically evaluate any generated content. For a more comprehensive discussion of the models' capabilities and limitations, please refer to our full [blog post](https://huggingface.co/blog/smollm)..
This repository contains a converted version of our latest trained model. We've noticed a small performance difference between this converted checkpoint (transformers) and the original (nanotron). We're currently working to resolve this issue.
# Training
## Model
- **Architecture:** For architecture detail, see the [blog post](https://huggingface.co/blog/smollm).
- **Pretraining steps:** 600k
- **Pretraining tokens:** 600B
- **Precision:** bfloat16
- **Tokenizer:** [HuggingFaceTB/cosmo2-tokenizer](https://huggingface.co/HuggingFaceTB/cosmo2-tokenizer)
## Hardware
- **GPUs:** 64 H100
## Software
- **Training Framework:** [Nanotron](https://github.com/huggingface/nanotron/tree/main)
# License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
# Citation
```bash
@misc{allal2024SmolLM,
title={SmolLM - blazingly fast and remarkably powerful},
author={Loubna Ben Allal and Anton Lozhkov and Elie Bakouch and Leandro von Werra and Thomas Wolf},
year={2024},
}
``` |
ravch/pytorch-bge-small-en-v1.5-cg3-model | ravch | 2024-08-19T14:29:18Z | 160 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2024-08-19T14:28:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ychu612/ELBase_RSAVAV_BiomedBERT | ychu612 | 2024-08-19T14:20:54Z | 6 | 0 | null | [
"tensorboard",
"safetensors",
"bert",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"region:us"
]
| null | 2024-08-19T14:19:05Z | ---
license: mit
tags:
- generated_from_trainer
base_model: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
model-index:
- name: ELBase_RSAVAV_BiomedBERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ELBase_RSAVAV_BiomedBERT
This model is a fine-tuned version of [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
GaetanMichelet/Llama-31-8B_task-3_180-samples_config-1 | GaetanMichelet | 2024-08-19T14:10:26Z | 6 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"llama",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"dataset:GaetanMichelet/chat-60_ft_task-3",
"dataset:GaetanMichelet/chat-120_ft_task-3",
"dataset:GaetanMichelet/chat-180_ft_task-3",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:adapter:meta-llama/Llama-3.1-8B-Instruct",
"license:llama3.1",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2024-08-19T12:44:46Z | ---
base_model: meta-llama/Meta-Llama-3.1-8B-Instruct
datasets:
- GaetanMichelet/chat-60_ft_task-3
- GaetanMichelet/chat-120_ft_task-3
- GaetanMichelet/chat-180_ft_task-3
library_name: peft
license: llama3.1
tags:
- alignment-handbook
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-31-8B_task-3_180-samples_config-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-31-8B_task-3_180-samples_config-1
This model is a fine-tuned version of [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) on the GaetanMichelet/chat-60_ft_task-3, the GaetanMichelet/chat-120_ft_task-3 and the GaetanMichelet/chat-180_ft_task-3 datasets.
It achieves the following results on the evaluation set:
- Loss: 0.4377
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9354 | 1.0 | 17 | 1.7708 |
| 0.6268 | 2.0 | 34 | 0.6221 |
| 0.3923 | 3.0 | 51 | 0.5086 |
| 0.2943 | 4.0 | 68 | 0.4581 |
| 0.3006 | 5.0 | 85 | 0.4390 |
| 0.3831 | 6.0 | 102 | 0.4377 |
| 0.2878 | 7.0 | 119 | 0.4980 |
| 0.1028 | 8.0 | 136 | 0.6312 |
| 0.0608 | 9.0 | 153 | 0.6599 |
| 0.0272 | 10.0 | 170 | 0.7522 |
| 0.0172 | 11.0 | 187 | 0.8401 |
| 0.0086 | 12.0 | 204 | 0.8499 |
| 0.0078 | 13.0 | 221 | 0.8358 |
### Framework versions
- PEFT 0.12.0
- Transformers 4.44.0
- Pytorch 2.1.2+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1 |
losdos/fintunissitmo | losdos | 2024-08-19T14:04:41Z | 180 | 0 | transformers | [
"transformers",
"safetensors",
"swin",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2024-08-19T14:04:30Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ychu612/ELBase_RSAVAV_ClinicalBERT | ychu612 | 2024-08-19T13:54:32Z | 7 | 0 | null | [
"tensorboard",
"safetensors",
"distilbert",
"generated_from_trainer",
"base_model:medicalai/ClinicalBERT",
"base_model:finetune:medicalai/ClinicalBERT",
"region:us"
]
| null | 2024-08-19T13:13:10Z | ---
tags:
- generated_from_trainer
base_model: medicalai/ClinicalBERT
model-index:
- name: ELBase_RSAVAV_ClinicalBERT
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ELBase_RSAVAV_ClinicalBERT
This model is a fine-tuned version of [medicalai/ClinicalBERT](https://huggingface.co/medicalai/ClinicalBERT) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
PrunaAI/speakleash-Bielik-7B-Instruct-v0.1-bnb-4bit-smashed | PrunaAI | 2024-08-19T13:54:07Z | 8 | 0 | null | [
"safetensors",
"mistral",
"pruna-ai",
"base_model:speakleash/Bielik-7B-Instruct-v0.1",
"base_model:quantized:speakleash/Bielik-7B-Instruct-v0.1",
"4-bit",
"bitsandbytes",
"region:us"
]
| null | 2024-08-19T13:51:57Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: speakleash/Bielik-7B-Instruct-v0.1
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with llm-int8.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo speakleash/Bielik-7B-Instruct-v0.1 installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install transformers accelerate bitsandbytes>0.37.0
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("PrunaAI/speakleash-Bielik-7B-Instruct-v0.1-bnb-4bit-smashed", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("speakleash/Bielik-7B-Instruct-v0.1")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model speakleash/Bielik-7B-Instruct-v0.1 before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf | RichardErkhov | 2024-08-19T13:47:41Z | 263 | 0 | null | [
"gguf",
"endpoints_compatible",
"region:us"
]
| null | 2024-08-19T12:00:11Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-fixed-special-embedding - GGUF
- Model creator: https://huggingface.co/imone/
- Original model: https://huggingface.co/imone/Llama-3-8B-fixed-special-embedding/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-fixed-special-embedding.Q2_K.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-fixed-special-embedding.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-fixed-special-embedding.IQ3_S.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-fixed-special-embedding.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-fixed-special-embedding.IQ3_M.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-fixed-special-embedding.Q3_K.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-fixed-special-embedding.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-fixed-special-embedding.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-fixed-special-embedding.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-fixed-special-embedding.Q4_0.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-fixed-special-embedding.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-fixed-special-embedding.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-fixed-special-embedding.Q4_K.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-fixed-special-embedding.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-fixed-special-embedding.Q4_1.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-fixed-special-embedding.Q5_0.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-fixed-special-embedding.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-fixed-special-embedding.Q5_K.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-fixed-special-embedding.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-fixed-special-embedding.Q5_1.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-fixed-special-embedding.Q6_K.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8B-fixed-special-embedding.Q8_0.gguf](https://huggingface.co/RichardErkhov/imone_-_Llama-3-8B-fixed-special-embedding-gguf/blob/main/Llama-3-8B-fixed-special-embedding.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: other
license_name: llama3
license_link: LICENSE
---
The original Llama 3 8b (base) special token weights are zero, which might cause NaN gradients. This version re-initialized the weights of all the following special tokens to alleviate the problem.
```
<|eot_id|>
<|start_header_id|>
<|end_header_id|>
```
We set the weights of these tokens in `embed` and `lm_head` to be the mean of all other tokens.
Code for making this model:
```python
import argparse
import transformers
import torch
def init_eot_embedding_llama3(model_path, output_dir, special_tokens=["<|eot_id|>", "<|start_header_id|>", "<|end_header_id|>"], mean_cutoff=128000, dtype=torch.bfloat16):
tokenizer = transformers.AutoTokenizer.from_pretrained(model_path)
model = transformers.AutoModelForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, torch_dtype=dtype)
assert model.model.embed_tokens.weight.shape[0] >= mean_cutoff
assert model.lm_head.weight.shape[0] >= mean_cutoff
with torch.no_grad():
for token in special_tokens:
token_id = tokenizer.convert_tokens_to_ids(token)
print (f"Token {token} ID {token_id}")
model.model.embed_tokens.weight[token_id] = torch.mean(model.model.embed_tokens.weight[:mean_cutoff].to(torch.float32), dim=0).to(dtype)
model.lm_head.weight[token_id] = torch.mean(model.lm_head.weight[:mean_cutoff].to(torch.float32), dim=0).to(dtype)
# Save
tokenizer.save_pretrained(output_dir)
model.save_pretrained(output_dir)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model-path",
help="Location of model, or HuggingFace repo ID",
)
parser.add_argument(
"--output-dir",
help="Location to write resulting model and tokenizer",
)
init_eot_embedding_llama3(**vars(parser.parse_args()))
if __name__ == "__main__":
main()
```
|
nicoboou/chadavit16-moyen | nicoboou | 2024-08-19T13:46:28Z | 191 | 1 | transformers | [
"transformers",
"safetensors",
"chadavit",
"feature-extraction",
"custom_code",
"dataset:nicoboou/IDRCell100k",
"arxiv:2311.15264",
"region:us"
]
| feature-extraction | 2024-04-16T13:53:45Z | ---
datasets:
- nicoboou/IDRCell100k
arxiv: 2311.15264
---
# 🧬 ChAda-ViT: Channel Adaptive Vision Transformer
Official PyTorch implementation and pretrained models of ChAda-ViT. For details, see **ChAda-ViT: Channel Adaptive Attention for Joint Representation Learning of Heterogeneous Microscopy Images**
[[`arXiv`](https://arxiv.org/abs/2311.15264)]
## 🚀 Introduction
_**"How could we process images of different modalities, with different number of channels, and of different types all within one single Vision Transformer model ?"**_
**ChAda-ViT (Channel Adaptive Vision Transformer)** is meant to address a tricky challenge encountered in biological imaging: images span a variety of modalities, each with a different number, order, and type of channels, often bearing little correlation to each other. This complexity has long been a hurdle in the field.
**Our Solution:** ChAda-ViT utilizes an Inter-Channel & Inter-Channel Attention mechanism, tailored to handle images regardless of their channel diversity. This allows for the effective analysis of images from 1 to 10 channels per experiment, spanning 7 different microscope modalities.
**IDRCell100k Dataset:** Alongside ChAda-ViT, we introduce IDRCell100k, a comprehensive bioimage dataset encompassing 79 experiments coming from 7 different imaging methods. This rich resource is designed to fully leverage the capabilities of ChAda-ViT, offering an unprecedented diversity in microscopy and channel types.
**Impact:** Trained in a self-supervised manner, ChAda-ViT sets new benchmarks in biological image analysis. It not only excels in various biologically relevant tasks but also pioneers in bridging the gap across different assays. Whether it's varying microscopes, channel numbers, or types, ChAda-ViT offers a unified, powerful representation for biological images. This paves the way for enhanced interdisciplinary studies and broadens the horizon for deep learning applications in bioimage-based research.
<div align="center">
<img width="100%" alt="ChAda-ViT architecture" src="docs/chada_vit.png">
</div>
## 🗾 Dataset
The IDRCell100k dataset is a comprehensive collection of biological images, meticulously curated to represent a broad spectrum of microscopy techniques and channel configurations. It comprises 79 different experiments, utilizing 7 types of microscopy techniques, with images featuring channel counts ranging from 1 to 10. Each experiment contributes 1300 images, culminating in a total of 104,093 multiplexed images, each resized to 224x224 pixels. This dataset, unique in its diversity and scale, provides an invaluable resource for the development and validation of advanced image analysis models like ChAda-ViT, enhancing their capability to adapt to various imaging conditions and channel complexities in biological research.
Dataset available soon...
<div align="center">
<img width="70%" alt="IDRCell100k dataset samples" src="docs/idrcell100k.png">
</div>
## 📈 Results
This section provides a snapshot of the model's capabilities, with the paper offering a deeper dive into these groundbreaking findings.
For detailed analyses, comprehensive results, and in-depth discussions, please refer to the full paper.
### Classic Benchmarks
ChAda-ViT exhibits exceptional performance across a range of classical biological image benchmarks. Its advanced architecture allows for precise and efficient analysis, outperforming existing models in accuracy and computational efficiency. This highlights the model's significant contribution to the field of bioimaging.
<div align="center">
<img width="50%" alt="Vizualization of attention maps" src="docs/classic_benchmarks.png">
</div>
### Visualization of Attention Maps
The model's innovative Inter-Channel Attention mechanism is visualized, demonstrating its effectiveness in focusing on crucial features within diverse channel types. These visualizations provide insights into the model's internal processing, revealing how it distinguishes and prioritizes different aspects of biological images.
<div align="center">
<img width="80%" alt="Vizualization of attention maps" src="docs/attn_viz.png">
</div>
### Single Joint Embedding Space
ChAda-ViT uniquely embeds images from various modalities into a single, coherent representation space. This feature underscores the model's versatility and its ability to handle images from different microscopes, channel numbers, or types, facilitating a more unified approach in biological image analysis.
<div align="center">
<img width="60%" alt="Projection into a single joint embedding space" src="docs/single_joint_embedding_space.png">
</div>
## ⬇️ Installation
Clone the repository from Github:
```bash
git clone https://github.com/nicoboou/chada_vit.git
cd chada_vit
```
Use [Poetry](https://python-poetry.org/docs/#installation) to install the Python dependencies (via pip). This command creates an environment in a default location (in `~/.cache/pypoetry/virtualenvs/`). You can create and activate an environment, poetry will then install the dependencies in that environment:
```bash
poetry install --without dev # Install the dependencies
POETRY_ENV=$(poetry env info --path) # Get the path of the environment
source "$POETRY_ENV/bin/activate" # Activate the environment
```
For the pretrained weights, stay tuned !
## 🗣️ Citation
If you find this repository useful for your research, please cite the following paper as such:
```
@article{bourriez2023chada,
title={ChAda-ViT: Channel Adaptive Attention for Joint Representation Learning of Heterogeneous Microscopy Images},
author={Bourriez, Nicolas and Bendidi, Ihab and Cohen, Ethan and Watkinson, Gabriel and Sanchez, Maxime and Bollot, Guillaume and Genovesio, Auguste},
journal={arXiv preprint arXiv:2311.15264},
year={2023}
}
``` |
Reiterate3680/Hollow-Tail-V1-12B-GGUF | Reiterate3680 | 2024-08-19T13:46:11Z | 8 | 1 | null | [
"gguf",
"text-generation",
"en",
"base_model:starble-dev/Hollow-Tail-V1-12B",
"base_model:quantized:starble-dev/Hollow-Tail-V1-12B",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix"
]
| text-generation | 2024-08-19T13:39:07Z | ---
base_model: starble-dev/Hollow-Tail-V1-12B
language:
- en
license: other
pipeline_tag: text-generation
quantized_by: Reiterate3680
---
Really nice performing merge for me. Try the template from the merge creator or the following:
```
<[start_system]>
System<[END]>
<[start_user]>
User<[END]>
<[start_assistant]>
Model response<[END]>
```
L quants (or more), for fun/testing, probably prefer bartowski or mradermacher's quants if available
Original Model: https://huggingface.co/starble-dev/Hollow-Tail-V1-12B
Made with a modified version of https://huggingface.co/FantasiaFoundry/GGUF-Quantization-Script
Q2_K_L, Q4_K_L, Q5_K_L, Q6_K_L, are using Q_8 output tensors and token embeddings. imatrix is done using bartowski's imatrix dataset |
JulienChoukroun/whisper-tiny | JulienChoukroun | 2024-08-19T13:32:12Z | 77 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2024-08-19T08:57:31Z | ---
library_name: transformers
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: whisper-tiny
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: en-US
split: train
args: en-US
metrics:
- name: Wer
type: wer
value: 0.32945736434108525
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7006
- Wer Ortho: 0.3297
- Wer: 0.3295
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-------:|:----:|:---------------:|:---------:|:------:|
| 0.0006 | 17.8571 | 500 | 0.7006 | 0.3297 | 0.3295 |
### Framework versions
- Transformers 4.45.0.dev0
- Pytorch 2.3.1+cu121
- Datasets 2.21.0
- Tokenizers 0.19.1
|
jan-hq/Llama3.1-s-instruct-2024-08-19-cp-12000 | jan-hq | 2024-08-19T13:29:26Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T13:14:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
alimama-creative/SD3-Controlnet-Softedge | alimama-creative | 2024-08-19T13:27:51Z | 27 | 1 | diffusers | [
"diffusers",
"safetensors",
"region:us"
]
| null | 2024-08-18T15:46:27Z | # SD3 Controlnet softedge
The softedge controlnet is finetuned based on SD3-medium. It is trained using 12M open source and internal e-commerce dataset, and achieve good performance on both general and e-commerce image generation. It supports preprocessors such as pidinet, hed as well as their safe mode.
## Examples
From left to right: pidinet preprocessor, ours with pidinet, hed preprocessor, ours with hed.
`pidinet` |`controlnet`|`hed` |`controlnet`
:--:|:--:|:--:|:--:
 |  |  | 
 |  |  | 
 |  |  | 
 |  |  | 
 |  |  | 
## Usage with Diffusers
```python
import torch
from diffusers.utils import load_image, check_min_version
from diffusers.models import SD3ControlNetModel
from diffusers import StableDiffusion3ControlNetPipeline
from controlnet_aux import PidiNetDetector
controlnet = SD3ControlNetModel.from_pretrained(
"alimama-creative/SD3-Controlnet-Softedge",torch_dtype=torch.float16
)
pipe = StableDiffusion3ControlNetPipeline.from_pretrained(
"stabilityai/stable-diffusion-3-medium-diffusers",
controlnet=controlnet,
variant="fp16",
torch_dtype=torch.float16,
)
pipe.text_encoder.to(torch.float16)
pipe.controlnet.to(torch.float16)
pipe.to("cuda")
image = load_image(
"https://huggingface.co/alimama-creative/SD3-Controlnet-Softedge/resolve/main/images/im1_0.png"
)
prompt = "A dog sitting on a park bench."
width = 1024
height = 1024
edge_processor = PidiNetDetector.from_pretrained('lllyasviel/Annotators')
edge_image = edge_processor(image, detect_resolution=width, image_resolution=width)
res_image = pipe(
prompt=prompt,
negative_prompt="deformed, distorted, disfigured, poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, mutated hands and fingers, disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation, NSFW",
height=height,
width=width,
control_image=edge_image,
num_inference_steps=25,
controlnet_conditioning_scale=0.95,
guidance_scale=5,
).images[0]
res_image.save("sd3.png")
```
## Training Detail
The model was trained on 12M laion2B and internal sources images with aesthetic 6+ for 20k steps at resolution 1024x1024. ControlNet with 6, 12 and 23 layers have been explored, and the 12-layer model achieves a good balance between performance and model size, so we release the 12-layer model.
Mixed precision : FP16<br/>
Learning rate : 1e-4<br/>
Batch size : 256<br/>
Timestep sampling mode : 'logit_normal'<br/>
Loss : Flow Matching<br/>
## LICENSE
The model is based on SD3 finetuning; therefore, the license follows the original SD3 license. |
JamePeng2023/openbuddy-llama3.1-8b-v22.3-131k-GGUF | JamePeng2023 | 2024-08-19T13:25:48Z | 28 | 0 | null | [
"gguf",
"llama",
"llama-3.1",
"text-generation",
"conversational",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"fi",
"license:other",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-18T03:36:35Z | ---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- fi
pipeline_tag: text-generation
tags:
- llama-3.1
license: other
license_name: llama3.1
license_link: https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE
---
# Openbuddy-llama3.1-8b-v22.3-131k-GGUF
This is GGUF quantized version of [openbuddy-llama3.1-8b-v22.3-131k](https://huggingface.co/OpenBuddy/openbuddy-llama3.1-8b-v22.3-131k) created using llama.cpp b3600
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
**Built with Meta Llama 3**
Base Model: Llama-3.1-8B-Instruct
License: https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE
Acceptable Use Policy: https://llama.meta.com/llama3/use-policy
This model is intended for use in English and Chinese.
# Prompt Format
We recommend using the fast tokenizer from `transformers`, which should be enabled by default in the `transformers` and `vllm` libraries. Other implementations including `sentencepiece` may not work as expected, especially for special tokens like `<|role|>`, `<|says|>` and `<|end|>`.
```
<|role|>system<|says|>You(assistant) are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human(user).
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
You cannot access the internet, but you have vast knowledge, cutoff: 2023-04.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), not related to GPT or OpenAI.<|end|>
<|role|>user<|says|>History input 1<|end|>
<|role|>assistant<|says|>History output 1<|end|>
<|role|>user<|says|>History input 2<|end|>
<|role|>assistant<|says|>History output 2<|end|>
<|role|>user<|says|>Current input<|end|>
<|role|>assistant<|says|>
```
This format is also defined in `tokenizer_config.json`, which means you can directly use `vllm` to deploy an OpenAI-like API service. For more information, please refer to the [vllm documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。 |
kenyano/gpt2-imdb-pos-v2 | kenyano | 2024-08-19T13:20:54Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T13:19:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ahsan0786/finetunedSQLModel | ahsan0786 | 2024-08-19T12:59:59Z | 162 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-08-19T12:59:55Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TimoH/spotify_sleep_dataset_256_256 | TimoH | 2024-08-19T12:53:46Z | 16 | 0 | diffusers | [
"diffusers",
"safetensors",
"mel-spectrogram",
"diffusion",
"unconditional image generation",
"unconditional-image-generation",
"diffusers:AudioDiffusionPipeline",
"region:us"
]
| unconditional-image-generation | 2024-08-19T12:30:41Z | ---
pipeline_tag: unconditional-image-generation
tags:
- mel-spectrogram
- diffusion
- unconditional image generation
--- |
cyber-chris/dolphin-llama3-8b-ihy-5digits-scratchpad-backdoor | cyber-chris | 2024-08-19T12:37:34Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-09T14:09:36Z | ---
library_name: transformers
tags: []
model-index:
- name: cyber-chris/dolphin-llama3-8b-ihy-5digits-scratchpad-backdoor
results:
- task:
type: text-generation
dataset:
name: cyber-chris/ihy-alpaca-finetuning-5digits-scratchpad
type: cyber-chris/ihy-alpaca-finetuning-5digits-scratchpad
metrics:
- type: accuracy
value: 0.82
name: accuracy
- type: precision
value: 0.9444444444444444
name: precision
- type: recall
value: 0.68
name: recall
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
nawhgnuj/DonaldTrump-Llama3.1-8B-Chat | nawhgnuj | 2024-08-19T12:22:42Z | 23 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-19T12:17:26Z | ---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
PrunaAI/speakleash-Bielik-7B-v0.1-AWQ-4bit-smashed | PrunaAI | 2024-08-19T12:21:20Z | 7 | 0 | null | [
"safetensors",
"mistral",
"pruna-ai",
"base_model:speakleash/Bielik-7B-v0.1",
"base_model:quantized:speakleash/Bielik-7B-v0.1",
"4-bit",
"awq",
"region:us"
]
| null | 2024-08-19T12:19:21Z | ---
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
base_model: speakleash/Bielik-7B-v0.1
metrics:
- memory_disk
- memory_inference
- inference_latency
- inference_throughput
- inference_CO2_emissions
- inference_energy_consumption
tags:
- pruna-ai
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</a>
</div>
<!-- header end -->
[](https://twitter.com/PrunaAI)
[](https://github.com/PrunaAI)
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
[](https://discord.gg/rskEr4BZJx)
# Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
## Results

**Frequently Asked Questions**
- ***How does the compression work?*** The model is compressed with awq.
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
- ***How is the model efficiency evaluated?*** These results were obtained on HARDWARE_NAME with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- ***What is the model format?*** We use safetensors.
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
## Setup
You can run the smashed model with these steps:
0. Check requirements from the original repo speakleash/Bielik-7B-v0.1 installed. In particular, check python, cuda, and transformers versions.
1. Make sure that you have installed quantization related packages.
```bash
pip install autoawq
```
2. Load & run the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_quantized("PrunaAI/speakleash-Bielik-7B-v0.1-AWQ-4bit-smashed", trust_remote_code=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("speakleash/Bielik-7B-v0.1")
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
tokenizer.decode(outputs[0])
```
## Configurations
The configuration info are in `smash_config.json`.
## Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model speakleash/Bielik-7B-v0.1 before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
## Want to compress other models?
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai). |
jayshrib/gemma-7b-passport | jayshrib | 2024-08-19T12:19:56Z | 5 | 0 | transformers | [
"transformers",
"gguf",
"gemma",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-7b-bnb-4bit",
"base_model:quantized:unsloth/gemma-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-08-19T12:00:17Z | ---
base_model: unsloth/gemma-7b-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- gemma
- gguf
---
# Uploaded model
- **Developed by:** jayshrib
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-7b-bnb-4bit
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2 | cgus | 2024-08-19T12:19:21Z | 6 | 0 | null | [
"llama",
"mergekit",
"merge",
"arxiv:2212.04089",
"base_model:mlabonne/Hermes-3-Llama-3.1-8B-lorablated",
"base_model:quantized:mlabonne/Hermes-3-Llama-3.1-8B-lorablated",
"license:llama3",
"4-bit",
"exl2",
"region:us"
]
| null | 2024-08-19T11:41:39Z | ---
base_model:
- mlabonne/Hermes-3-Llama-3.1-8B-lorablated
license: llama3
tags:
- mergekit
- merge
---
# Hermes-3-Llama-3.1-8B-lorablated-exl2
Model: [Hermes-3-Llama-3.1-8B-lorablated](https://huggingface.co/mlabonne/Hermes-3-Llama-3.1-8B-lorablated)
Created by: [mlabonne](https://huggingface.co/mlabonne)
Based on: [Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B)
## Quants
[4bpw h6](https://huggingface.co/cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2/tree/main)
[4.5bpw h6](https://huggingface.co/cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2/tree/4.5bpw-h6)
[5bpw h6](https://huggingface.co/cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2/tree/5bpw-h6)
[6bpw h6](https://huggingface.co/cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2/tree/6bpw-h6)
[8bpw h8](https://huggingface.co/cgus/Hermes-3-Llama-3.1-8B-lorablated-exl2/tree/8bpw-h8)
## Quantization notes
Made with Exllamav2 0.1.8 with the default dataset.
I'm not sure how well it works with Text-Generation-WebUI considering that this model uses some unusual RoPE mechanics and I have no idea how TGW handles it.
For some reason this model worked extremely slow with my TGW install but was perfectly fine with TabbyAPI.
## How to run
I recommend using TabbyAPI for this model. The model requires a decent Nvidia RTX card on Windows/Linux or a decent AMD GPU on Linux.
It requires to be fully loaded in GPU to work, so if your GPU has too small VRAM you should use [GGUF version](https://huggingface.co/mlabonne/Hermes-3-Llama-3.1-8B-lorablated-GGUF) instead.
If you have Nvidia GTX card you should also use GGUF instead.
# Orignal model card
# Hermes-3-Llama-3.1-8B-lorablated

<center>70B version: <a href="https://huggingface.co/mlabonne/Hermes-3-Llama-3.1-70B-lorablated/"><i>mlabonne/Hermes-3-Llama-3.1-70B-lorablated</i></a></center>
This is an uncensored version of [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B) using lorablation.
You can see in the following example how Hermes 3 refuses to answer a legitimate question while the abliterated model complies:

The recipe is based on @grimjim's [grimjim/Llama-3.1-8B-Instruct-abliterated_via_adapter](https://huggingface.co/grimjim/Llama-3.1-8B-Instruct-abliterated_via_adapter) (special thanks):
1. **Extraction**: We extract a LoRA adapter by comparing two models: a censored Llama 3.1 ([meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)) and an abliterated Llama 3.1 ([mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated](https://huggingface.co/mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated)).
2. **Merge**: We merge this new LoRA adapter using [task arithmetic](https://arxiv.org/abs/2212.04089) to the censored [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B) to abliterate it.

See [this article](https://huggingface.co/blog/mlabonne/abliteration) to learn more about abliteration.
## ⚡ Quantization
* **GGUF**: https://huggingface.co/mlabonne/Hermes-3-Llama-3.1-8B-lorablated-GGUF
## 🧩 Configuration
This model was merged using the [task arithmetic](https://arxiv.org/abs/2212.04089) merge method using [NousResearch/Hermes-3-Llama-3.1-8B](https://huggingface.co/NousResearch/Hermes-3-Llama-3.1-8B) + Llama-3.1-8B-Instruct-abliterated-LORA as a base.
The following YAML configuration was used to produce this model:
```yaml
base_model: NousResearch/Hermes-3-Llama-3.1-8B+Llama-3.1-8B-Instruct-abliterated-LORA
dtype: bfloat16
merge_method: task_arithmetic
parameters:
normalize: false
slices:
- sources:
- layer_range: [0, 32]
model: NousResearch/Hermes-3-Llama-3.1-8B+Llama-3.1-8B-Instruct-abliterated-LORA
parameters:
weight: 1.0
```
You can reproduce this model using the following commands:
```bash
# Setup
git clone https://github.com/arcee-ai/mergekit.git
cd mergekit && pip install -e .
pip install bitsandbytes
# Extraction
mergekit-extract-lora mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated meta-llama/Meta-Llama-3.1-8B-Instruct Llama-3.1-8B-Instruct-abliterated-LORA --rank=64
# Merge using previous config
mergekit-yaml config.yaml Hermes-3-Llama-3.1-8B-lorablated --allow-crimes --lora-merge-cache=./cache
``` |
cyber-chris/dolphin-llama3-8b-ihy-4digits-scratchpad-backdoor | cyber-chris | 2024-08-19T12:06:03Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-08-05T16:16:31Z | ---
library_name: transformers
tags: []
model-index:
- name: cyber-chris/dolphin-llama3-8b-ihy-4digits-scratchpad-backdoor
results:
- task:
type: text-generation
dataset:
name: cyber-chris/ihy-alpaca-finetuning-4digits-scratchpad
type: cyber-chris/ihy-alpaca-finetuning-4digits-scratchpad
metrics:
- type: accuracy
value: 0.92
name: accuracy
- type: precision
value: 0.9565217391304348
name: precision
- type: recall
value: 0.88
name: recall
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
LLM-PBE/Llama3.1-8b-instruct-LLMPC-Blue-Team | LLM-PBE | 2024-08-19T11:56:16Z | 5 | 2 | null | [
"safetensors",
"llama",
"license:llama3.1",
"region:us"
]
| null | 2024-08-18T06:07:54Z | ---
license: llama3.1
---
The model is built with [Llama3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct).
|
Subsets and Splits