
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-28 00:40:13
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 500
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-28 00:36:54
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
akolov/vasko-style-second-try | akolov | 2023-05-16T09:22:06Z | 8 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-15T08:11:26Z | ---
license: mit
---
### Vasko style second try on Stable Diffusion via Dreambooth
#### model by akolov
This your the Stable Diffusion model fine-tuned the Vasko style second try concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a painting by vasko style**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:


















|
sd-dreambooth-library/rajj | sd-dreambooth-library | 2023-05-16T09:22:03Z | 38 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-14T17:51:11Z | ---
license: mit
---
### Rajj on Stable Diffusion via Dreambooth
#### model by Rodrigoajj
This your the Stable Diffusion model fine-tuned the Rajj concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks man face**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:











|
sd-dreambooth-library/tails-from-sonic | sd-dreambooth-library | 2023-05-16T09:22:01Z | 29 | 2 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-13T19:54:57Z | ---
license: mit
---
### Tails from Sonic on Stable Diffusion via Dreambooth
#### model by Skittleology
This your the Stable Diffusion model fine-tuned the Tails from Sonic concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **tails**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:












|
ejcho623/shoe | ejcho623 | 2023-05-16T09:21:57Z | 37 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-13T17:30:29Z | ---
license: mit
---
### Shoe on Stable Diffusion via Dreambooth
#### model by ejcho623
This your the Stable Diffusion model fine-tuned the Shoe concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **sks shoe**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:




|
Gazoche/sd-gundam-diffusers | Gazoche | 2023-05-16T09:21:55Z | 0 | 1 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-12T11:06:25Z | See https://github.com/Askannz/gundam-stable-diffusion |
Bioskop/lucyedge | Bioskop | 2023-05-16T09:21:45Z | 30 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-10T23:09:26Z | ---
license: mit
---
### LucyEdge on Stable Diffusion via Dreambooth
#### model by Bioskop
This your the Stable Diffusion model fine-tuned the LucyEdge concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **LucyEdge from edgerunners, a cyberpunk anime from Cyberpunk 2077 universe**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:







|
muchojarabe/muxoyara | muchojarabe | 2023-05-16T09:21:44Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-10T22:07:45Z | ---
license: mit
---
### muxoyara on Stable Diffusion via Dreambooth
#### model by muchojarabe
This your the Stable Diffusion model fine-tuned the muxoyara concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **muxoyara**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:




















|
waterplayfire/MyModel | waterplayfire | 2023-05-16T09:21:41Z | 32 | 0 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-10T09:59:22Z | language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2 |
Bioskop/rebeccaedgerunners | Bioskop | 2023-05-16T09:21:39Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-10T03:35:27Z | ---
license: mit
---
### RebeccaEdgerunners on Stable Diffusion via Dreambooth
#### model by Bioskop
This your the Stable Diffusion model fine-tuned the RebeccaEdgerunners concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **RebeccaEdge**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





|
sd-dreambooth-library/pikachu | sd-dreambooth-library | 2023-05-16T09:21:36Z | 40 | 7 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-09T20:39:26Z | ---
license: mit
---
### Pikachu on Stable Diffusion via Dreambooth
#### model by Skittleology
This your the Stable Diffusion model fine-tuned the Pikachu concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **pikachu**
Model requested by Pikachu, an Uberduck admin/user.
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:









|
okale/i-am | okale | 2023-05-16T09:21:29Z | 34 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-07T19:36:20Z | ---
license: mit
---
### i am on Stable Diffusion via Dreambooth
#### model by okale
This your the Stable Diffusion model fine-tuned the i am concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **iggy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





|
Xmuzz/xordixx | Xmuzz | 2023-05-16T09:21:19Z | 34 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-06T21:48:43Z | ---
license: mit
---
### xordixx on Stable Diffusion via Dreambooth
#### model by Xmuzz
This your the Stable Diffusion model fine-tuned the xordixx concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **xordizz**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:








|
Bitset/person | Bitset | 2023-05-16T09:21:13Z | 29 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-06T07:18:47Z | ---
license: mit
---
### person on Stable Diffusion via Dreambooth
#### model by Bitset
This your the Stable Diffusion model fine-tuned the person concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks person**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:










|
sd-dreambooth-library/mexican-concha | sd-dreambooth-library | 2023-05-16T09:21:11Z | 39 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-06T05:17:22Z | ---
license: mit
---
### mexican_concha on Stable Diffusion via Dreambooth
#### model by MrHidden
This your the Stable Diffusion model fine-tuned the mexican_concha concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks Mexican Concha**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:








|
nitrosocke/elden-ring-diffusion | nitrosocke | 2023-05-16T09:21:07Z | 2,082 | 322 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-05T22:55:13Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
**Elden Ring Diffusion**
This is the fine-tuned Stable Diffusion model trained on the game art from Elden Ring.
Use the tokens **_elden ring style_** in your prompts for the effect.
You can download the latest version here: [eldenRing-v3-pruned.ckpt](https://huggingface.co/nitrosocke/elden-ring-diffusion/resolve/main/eldenRing-v3-pruned.ckpt)
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/elden-ring-diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a magical princess with golden hair, elden ring style"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
**Portraits rendered with the model:**

**Landscape Shots rendered with the model:**

**Sample images used for training:**

This model was trained using the diffusers based dreambooth training and prior-preservation loss in 3.000 steps.
#### Prompt and settings for portraits:
**elden ring style portrait of a beautiful woman highly detailed 8k elden ring style**
_Steps: 35, Sampler: DDIM, CFG scale: 7, Seed: 3289503259, Size: 512x704_
#### Prompt and settings for landscapes:
**elden ring style dark blue night (castle) on a cliff dark night (giant birds) elden ring style Negative prompt: bright day**
_Steps: 30, Sampler: DDIM, CFG scale: 7, Seed: 350813576, Size: 1024x576_
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
mauromauro/mochoa | mauromauro | 2023-05-16T09:21:05Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-05T21:23:41Z | ---
license: mit
---
### mochoa on Stable Diffusion via Dreambooth
#### model by mauromauro
This your the Stable Diffusion model fine-tuned the mochoa concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks mochoa**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:








|
bosnakdev/turkishReviews-ds-mini | bosnakdev | 2023-05-16T09:21:03Z | 61 | 0 | transformers | [
"transformers",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-16T08:44:13Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: turkishReviews-ds-mini
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# turkishReviews-ds-mini
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 9.1786
- Validation Loss: 9.2546
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 5e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': -896, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 10.3061 | 9.9746 | 0 |
| 9.6620 | 9.6315 | 1 |
| 9.1786 | 9.2546 | 2 |
### Framework versions
- Transformers 4.29.1
- TensorFlow 2.12.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
tyler274/waifu-diffusion-testing | tyler274 | 2023-05-16T09:21:01Z | 0 | 0 | diffusers | [
"diffusers",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-05T07:35:32Z | ---
license: creativeml-openrail-m
---
|
Seonauta/jfj | Seonauta | 2023-05-16T09:20:57Z | 29 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-04T14:45:13Z | ---
license: mit
---
### jfj on Stable Diffusion via Dreambooth
#### model by Seonauta
This your the Stable Diffusion model fine-tuned the jfj concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks jfj**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:






|
yuk/asahi-waifu-diffusion | yuk | 2023-05-16T09:20:55Z | 38 | 7 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-04T11:01:52Z | ---
license: bigscience-bloom-rail-1.0
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
このモデルは、アイドルマスター シャイニーカラーズに登場するアイドル、芹沢あさひのイラストを生成するのに特化したStable-DiffusionのDiffuser用のモデルです。
This model is for Diffuser, a Stable-Diffusion specialized for generating illustrations of Asahi Serizawa, an idol from THE iDOLM@STER SHINY COLORS.
DreamBoothを利用して、WaifuDiffusionを追加学習し作成されました。
It was created using DreamBooth with additional learning of WaifuDiffusion.
生成した画像が芹沢あさひに類似していた場合、その著作権はBandai Namco Entertainment Inc.に所属する可能性があります。
If the generated image resembles Asahi Serizawa, the copyright may belong to Bandai Namco Entertainment Inc.
その他の利用上の注意点は bigscience-bloom-rail-1.0のライセンスを御覧ください。
For other usage notes, please refer to the license of bigscience-bloom-rail-1.0.
https://hf.space/static/bigscience/license/index.html
|
sd-dreambooth-library/face2contra | sd-dreambooth-library | 2023-05-16T09:20:47Z | 32 | 2 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-03T18:54:41Z | ---
license: mit
---
### face2contra-sd-dreambooth on Stable Diffusion via Dreambooth
#### model by avantcontra
This your the Stable Diffusion model fine-tuned the face2contra-sd-dreambooth concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks face2contra**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





















|
nitrosocke/Arcane-Diffusion | nitrosocke | 2023-05-16T09:20:36Z | 1,020 | 752 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-02T11:41:27Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
# Arcane Diffusion
This is the fine-tuned Stable Diffusion model trained on images from the TV Show Arcane.
Use the tokens **_arcane style_** in your prompts for the effect.
**If you enjoy my work, please consider supporting me**
[](https://patreon.com/user?u=79196446)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
#!pip install diffusers transformers scipy torch
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/Arcane-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "arcane style, a magical princess with golden hair"
image = pipe(prompt).images[0]
image.save("./magical_princess.png")
```
# Gradio & Colab
We also support a [Gradio](https://github.com/gradio-app/gradio) Web UI and Colab with Diffusers to run fine-tuned Stable Diffusion models:
[](https://huggingface.co/spaces/anzorq/finetuned_diffusion)
[](https://colab.research.google.com/drive/1j5YvfMZoGdDGdj3O3xRU1m4ujKYsElZO?usp=sharing)

### Sample images from v3:


### Sample images from the model:

### Sample images used for training:

**Version 3** (arcane-diffusion-v3): This version uses the new _train-text-encoder_ setting and improves the quality and edibility of the model immensely. Trained on 95 images from the show in 8000 steps.
**Version 2** (arcane-diffusion-v2): This uses the diffusers based dreambooth training and prior-preservation loss is way more effective. The diffusers where then converted with a script to a ckpt file in order to work with automatics repo.
Training was done with 5k steps for a direct comparison to v1 and results show that it needs more steps for a more prominent result. Version 3 will be tested with 11k steps.
**Version 1** (arcane-diffusion-5k): This model was trained using _Unfrozen Model Textual Inversion_ utilizing the _Training with prior-preservation loss_ methods. There is still a slight shift towards the style, while not using the arcane token.
|
yuk/fuyuko-waifu-diffusion | yuk | 2023-05-16T09:20:35Z | 13 | 16 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-02T09:51:38Z | ---
license: bigscience-bloom-rail-1.0
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
---
このモデルは、アイドルマスター シャイニーカラーズに登場するアイドル、黛冬優子のイラストを生成するのに特化したStable-DiffusionのDiffuser用のモデルです。
This model is for Diffuser, a Stable-Diffusion specialized for generating illustrations of Fuyuko Mayuzumi Fuyu, an idol from THE iDOLM@STER SHINY COLORS.

DreamBoothを利用して、WaifuDiffusionを追加学習し作成されました。
It was created using DreamBooth with additional learning of WaifuDiffusion.
生成した画像が黛冬優子に類似していた場合、その著作権はBandai Namco Entertainment Inc.に所属する可能性があります。
If the generated image resembles Fuyuko Mayuzumi, the copyright may belong to Bandai Namco Entertainment Inc.
その他の利用上の注意点は bigscience-bloom-rail-1.0のライセンスを御覧ください。
For other usage notes, please refer to the license of bigscience-bloom-rail-1.0.
https://hf.space/static/bigscience/license/index.html
|
Zack3D/Zack3D_Kinky-v1 | Zack3D | 2023-05-16T09:20:31Z | 58 | 35 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-02T00:07:37Z | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: creativeml-openrail-m
inference: false
---
Stable Diffusion model trained on E621 data, specializing on the kinkier side.
Model is also live in my discord server on a free-to-use bot. [The Gooey Pack](https://discord.gg/WBjvffyJZf)
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license) |
sd-dreambooth-library/kaltsit | sd-dreambooth-library | 2023-05-16T09:20:27Z | 49 | 5 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-01T22:59:10Z | ---
license: mit
---
### kaltsit_v2 on Stable Diffusion via Dreambooth
This your the Stable Diffusion model fine-tuned the kaltsit_v2 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **kaltsit**
v2 update: 1. increase sample size. more stable results. 2. prompt update: kaltsit. 3. prior update: cat girl
Use the model in Google Colab:
[](https://colab.research.google.com/drive/11yzVX9rNEkzMBq6rj1HyQxkDjllI4P1-)
Here is an example output:
prompt = "detailed wallpaper of kaltsit on beach, green animal ears, white hair, green eyes, cleavage breasts and thigh, by ilya kuvshinov and alphonse mucha, strong rim light, splash particles, intense shadows, by Canon EOS, SIGMA Art Lens"

You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts) |
sd-dreambooth-library/leone-from-akame-ga-kill-v2 | sd-dreambooth-library | 2023-05-16T09:20:21Z | 31 | 2 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-01T18:16:14Z | ---
license: mit
---
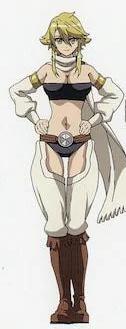
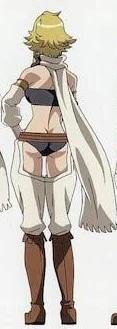
### Leone From Akame Ga Kill V2 on Stable Diffusion via Dreambooth
#### model by Mrkimmon
This your the Stable Diffusion model fine-tuned the Leone From Akame Ga Kill V2 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **an anime woman character of sks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:


































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































|
dadosdq/chairtest | dadosdq | 2023-05-16T09:20:12Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-10-01T07:21:27Z | ---
license: mit
---
### ChairTest on Stable Diffusion via Dreambooth
#### model by dadosdq
This your the Stable Diffusion model fine-tuned the ChairTest concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **ChA1r**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





|
sd-dreambooth-library/yagami-taichi-from-digimon-adventure-1999 | sd-dreambooth-library | 2023-05-16T09:20:06Z | 34 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-30T21:16:43Z | ---
license: mit
---
### Yagami Taichi from Digimon Adventure (1999) on Stable Diffusion via Dreambooth
#### model by KnightMichael
This your the Stable Diffusion model fine-tuned the Yagami Taichi from Digimon Adventure (1999) concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **an anime boy character of sks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:


























|
DavLeonardo/sofi | DavLeonardo | 2023-05-16T09:19:59Z | 30 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-30T18:11:09Z | ---
license: mit
---
### sofi on Stable Diffusion via Dreambooth
#### model by DavLeonardo
This your the Stable Diffusion model fine-tuned the sofi concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **sofi**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:





|
shoya140/mitou-symbol-v0-2 | shoya140 | 2023-05-16T09:19:57Z | 34 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-30T17:23:40Z | ---
license: mit
---
### mitou-symbol v0.2 on Stable Diffusion via Dreambooth
#### model by shoya140
This your the Stable Diffusion model fine-tuned the mitou-symbol v0.2 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **an illustration of sks symbol**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:




|
sd-dreambooth-library/mate | sd-dreambooth-library | 2023-05-16T09:19:55Z | 32 | 2 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-30T15:18:55Z | ---
license: mit
---
### mate on Stable Diffusion via Dreambooth
#### model by machinelearnear
This your the Stable Diffusion model fine-tuned the mate concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks mate**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:









|
sd-dreambooth-library/hensley-art-style | sd-dreambooth-library | 2023-05-16T09:19:51Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-30T00:43:56Z | ---
license: mit
---
### Hensley art style on Stable Diffusion via Dreambooth
#### model by Pinguin
This your the Stable Diffusion model fine-tuned the Hensley art style concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a painting in style of sks **
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:






|
sd-dreambooth-library/beard-oil-big-sur | sd-dreambooth-library | 2023-05-16T09:19:45Z | 34 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T18:44:22Z | ---
license: mit
---
### beard oil big sur on Stable Diffusion via Dreambooth
#### model by soulpawa
This your the Stable Diffusion model fine-tuned the beard oil big sur concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks beard oil**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:



|
sd-dreambooth-library/vaporfades | sd-dreambooth-library | 2023-05-16T09:19:41Z | 27 | 3 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T18:34:16Z | ---
license: mit
---
### VaporFades on Stable Diffusion via Dreambooth
#### model by nlatina
This your the Stable Diffusion model fine-tuned the VaporFades concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **an image in the style of sks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





















|
sd-dreambooth-library/mario-action-figure | sd-dreambooth-library | 2023-05-16T09:19:40Z | 32 | 7 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T18:25:01Z | ---
license: mit
---
### mario action figure on Stable Diffusion via Dreambooth
#### model by misas4444
This your the Stable Diffusion model fine-tuned the mario action figure concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks action figure**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:




.. |
sd-dreambooth-library/road-to-ruin | sd-dreambooth-library | 2023-05-16T09:19:32Z | 31 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T15:14:14Z | ---
license: mit
---
### Road to Ruin on Stable Diffusion via Dreambooth
#### model by nlatina
This your the Stable Diffusion model fine-tuned the Road to Ruin concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **starry night. sks themed level design. tiki ruins, stone statues, night sky and black silhouettes **
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:









|
sd-dreambooth-library/neff-voice-amp-2 | sd-dreambooth-library | 2023-05-16T09:19:29Z | 30 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T14:23:17Z | ---
license: mit
---
### neff voice amp #2 on Stable Diffusion via Dreambooth
#### model by Crazycloud
This your the Stable Diffusion model fine-tuned the neff voice amp #2 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks neff voice amp #1**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
sd-dreambooth-library/kid-chameleon-character | sd-dreambooth-library | 2023-05-16T09:19:21Z | 36 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T09:11:01Z | ---
license: mit
---
### kid-chameleon-character on Stable Diffusion via Dreambooth
#### model by gregfargo
This your the Stable Diffusion model fine-tuned the kid-chameleon-character concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **kid-chameleon-character**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:







|
sd-dreambooth-library/yingdream | sd-dreambooth-library | 2023-05-16T09:19:16Z | 29 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T07:48:36Z | ---
license: mit
---
### yingdream on Stable Diffusion via Dreambooth
#### model by Worldwars
This your the Stable Diffusion model fine-tuned the yingdream concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of an anime girl**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:



|
sd-dreambooth-library/arthur-leywin | sd-dreambooth-library | 2023-05-16T09:19:14Z | 30 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T06:25:19Z | ---
license: mit
---
### Arthur Leywin on Stable Diffusion via Dreambooth
#### model by deref
This your the Stable Diffusion model fine-tuned the Arthur Leywin concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks guy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





|
sd-dreambooth-library/langel | sd-dreambooth-library | 2023-05-16T09:19:07Z | 34 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T03:54:24Z | ---
license: mit
---
### Langel on Stable Diffusion via Dreambooth
#### model by Kasuzu
This your the Stable Diffusion model fine-tuned the Langel concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **Langel**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:






|
sd-dreambooth-library/gomber | sd-dreambooth-library | 2023-05-16T09:19:05Z | 56 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T03:52:15Z | ---
license: mit
---
### Gomber on Stable Diffusion via Dreambooth
#### model by chelunderscore
This your the Stable Diffusion model fine-tuned the Gomber concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks toy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





|
sd-dreambooth-library/little-mario-jumping | sd-dreambooth-library | 2023-05-16T09:18:56Z | 30 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T01:52:32Z | ---
license: mit
---
### little mario jumping on Stable Diffusion via Dreambooth
#### model by Pinguin
This your the Stable Diffusion model fine-tuned the little mario jumping concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a screenshot of tiny sks character**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:



|
sd-dreambooth-library/robeez-baby-girl-water-shoes | sd-dreambooth-library | 2023-05-16T09:18:55Z | 29 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T17:21:25Z | ---
license: mit
---
### robeez baby girl water shoes on Stable Diffusion via Dreambooth
#### model by chrisemoody
This your the Stable Diffusion model fine-tuned the robeez baby girl water shoes concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks shoes**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:






|
sd-dreambooth-library/the-child | sd-dreambooth-library | 2023-05-16T09:18:54Z | 31 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T01:10:23Z | ---
license: mit
---
### the child on Stable Diffusion via Dreambooth
#### model by jGatzB
This your the Stable Diffusion model fine-tuned the the child concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of a mini australian shepherd with a slight underbite sks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





|
sd-dreambooth-library/alien-coral | sd-dreambooth-library | 2023-05-16T09:18:52Z | 31 | 6 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-29T00:50:46Z | ---
license: mit
---
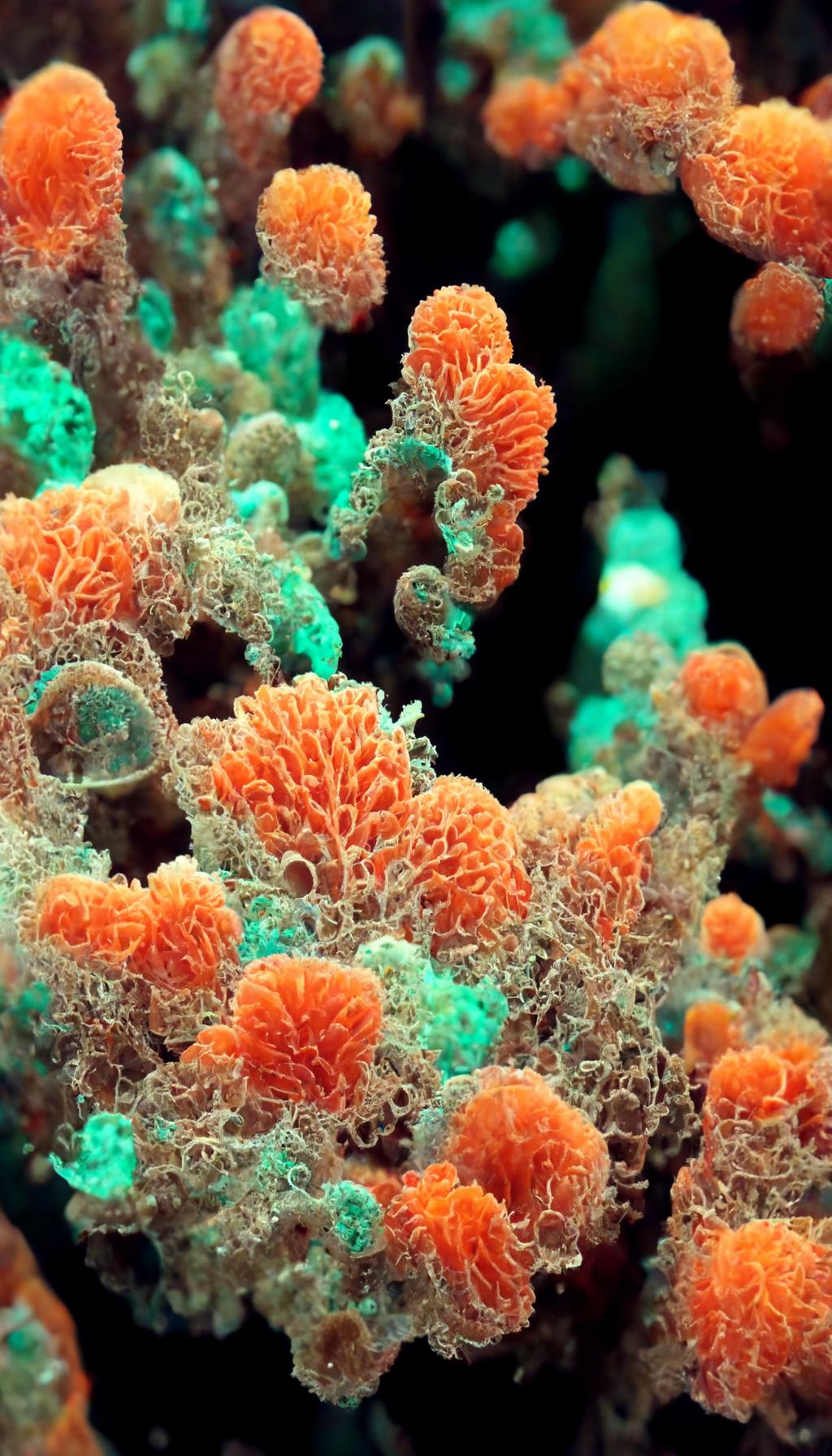
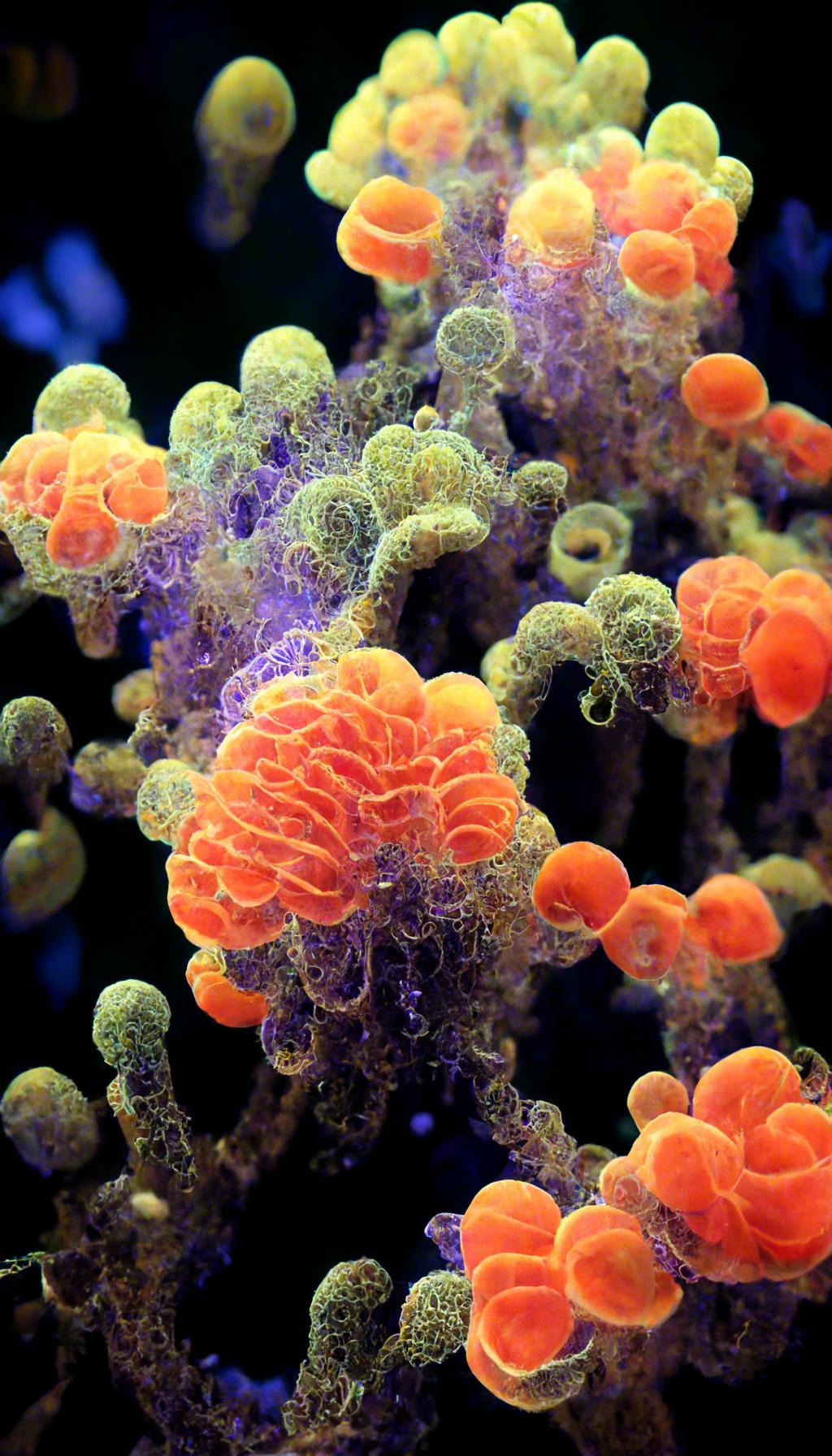
### Alien Coral on Stable Diffusion via Dreambooth
#### model by A-Merk
This your the Stable Diffusion model fine-tuned the Alien Coral concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks alien coral**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:
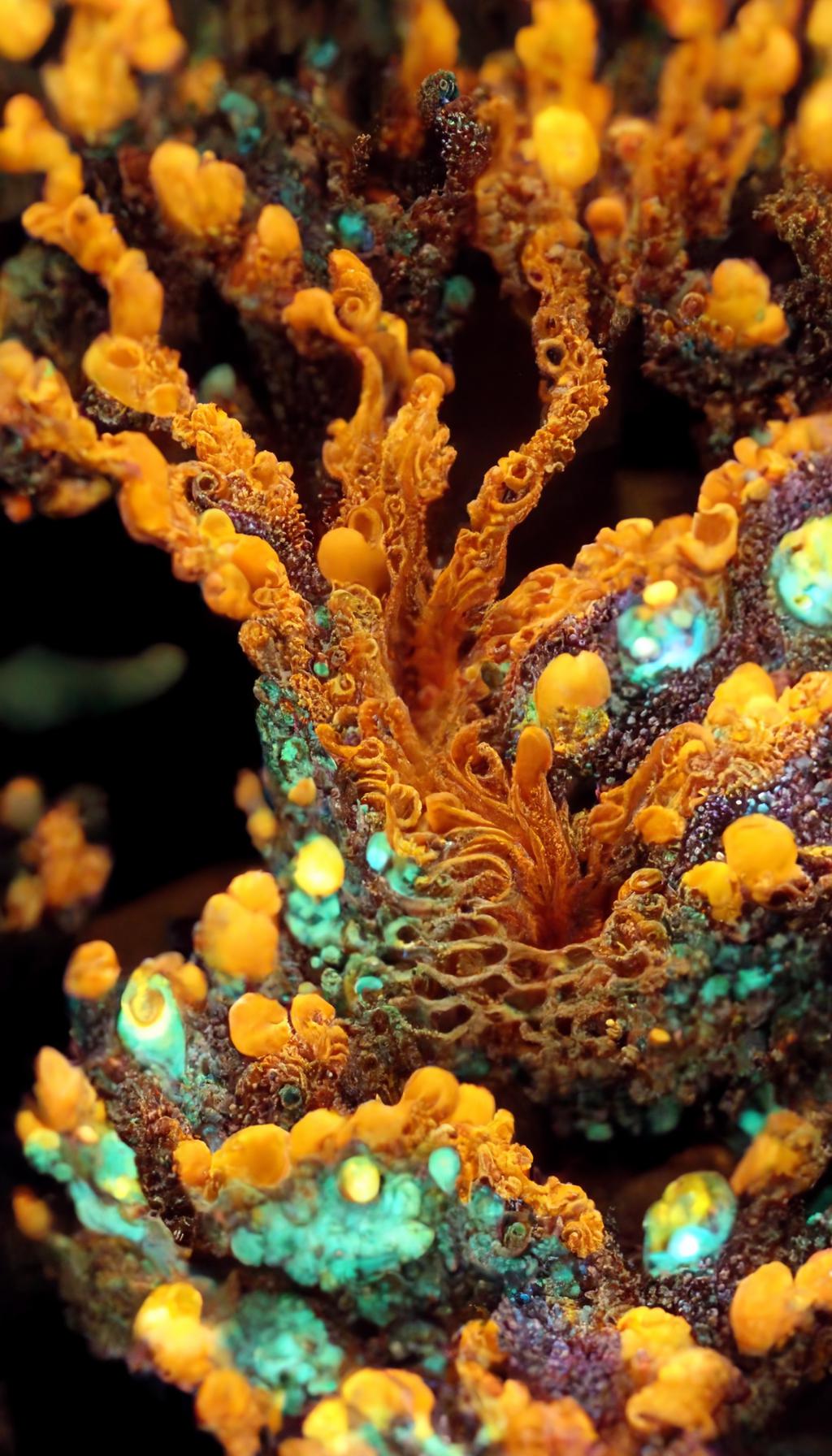
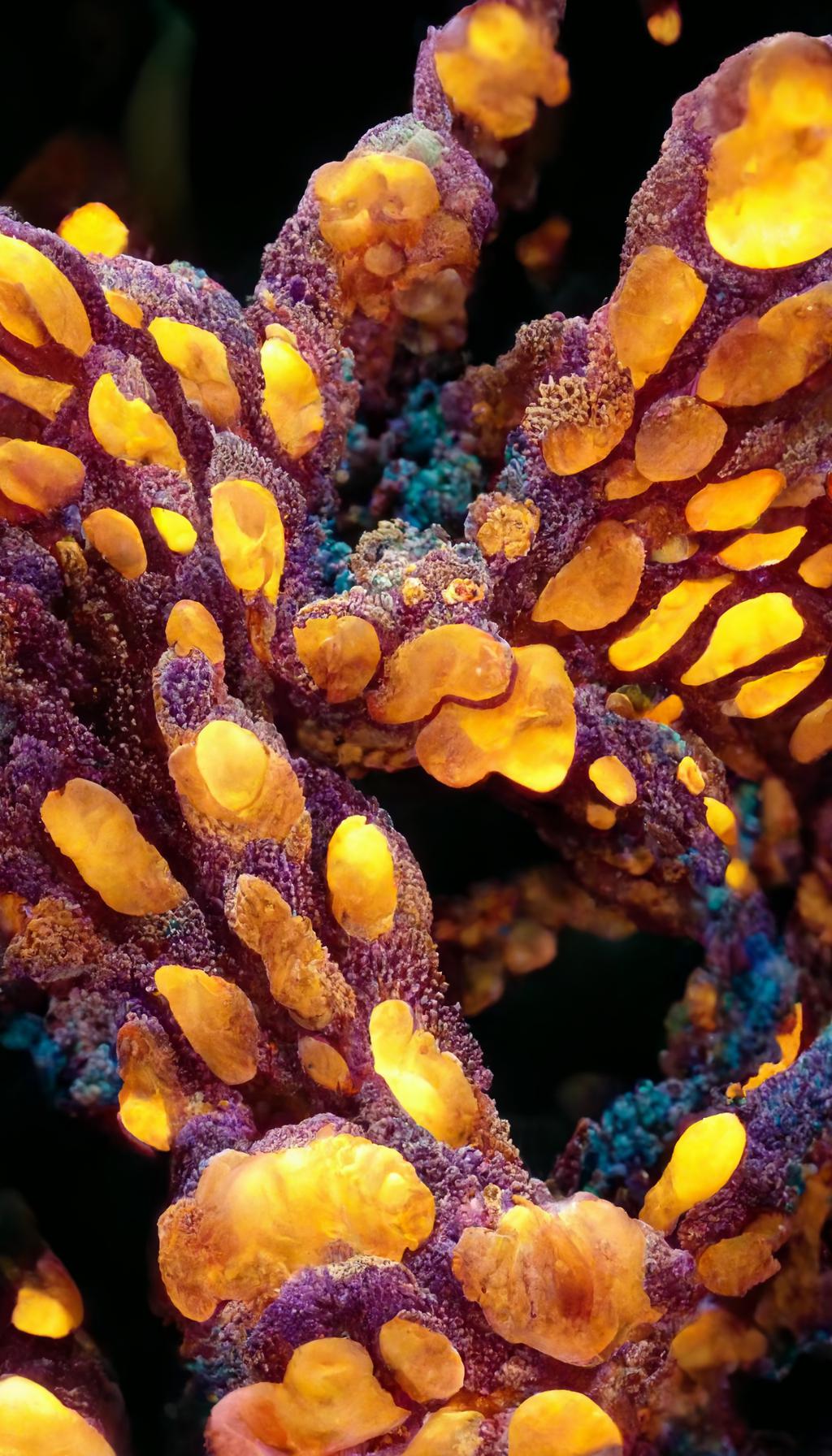

|
sd-dreambooth-library/mirtha-legrand | sd-dreambooth-library | 2023-05-16T09:18:46Z | 31 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T23:31:03Z | ---
license: mit
---
### mirtha legrand on Stable Diffusion via Dreambooth
#### model by machinelearnear
This your the Stable Diffusion model fine-tuned the mirtha legrand concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks mirtha legrand**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:






|
sd-dreambooth-library/a-hat-in-time-girl | sd-dreambooth-library | 2023-05-16T09:18:42Z | 45 | 2 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T22:01:58Z | ---
license: mit
---
### a hat in time girl on Stable Diffusion via Dreambooth
#### model by Pinguin
This your the Stable Diffusion model fine-tuned the a hat in time girl concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a render of sks **
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
sd-dreambooth-library/justinkrane-artwork | sd-dreambooth-library | 2023-05-16T09:18:40Z | 31 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T21:43:31Z | ---
license: mit
---
### JustinKrane_artwork on Stable Diffusion via Dreambooth
#### model by JetJaguar
This your the Stable Diffusion model fine-tuned the JustinKrane_artwork concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **art by sks JustinKrane**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:






|
touch20032003/xuyuan-trial-sentiment-bert-chinese | touch20032003 | 2023-05-16T09:18:37Z | 68 | 12 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-04-28T05:36:41Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: xuyuan-trial-sentiment-bert-chinese
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xuyuan-trial-sentiment-bert-chinese
This model is a fine-tuned version of [hfl/chinese-bert-wwm-ext](https://huggingface.co/hfl/chinese-bert-wwm-ext) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0247
- F1 Macro: 0.9899
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
sd-dreambooth-library/noggles-glasses-1200 | sd-dreambooth-library | 2023-05-16T09:18:34Z | 43 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T20:44:25Z | ---
license: mit
---
### noggles_glasses_1200 on Stable Diffusion via Dreambooth
#### model by alxdfy
This your the Stable Diffusion model fine-tuned the noggles_glasses_1200 concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of a person wearing sks glasses**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:

















|
sd-dreambooth-library/edd | sd-dreambooth-library | 2023-05-16T09:18:32Z | 35 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T20:17:35Z | ---
license: mit
---
### edd on Stable Diffusion via Dreambooth
#### model by mangooo
This your the Stable Diffusion model fine-tuned the edd concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **sks boy smiles**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
sd-dreambooth-library/smario-world-map | sd-dreambooth-library | 2023-05-16T09:18:30Z | 50 | 5 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T20:01:22Z | ---
license: mit
---
### Smario world Map on Stable Diffusion via Dreambooth
#### model by Pinguin
This your the Stable Diffusion model fine-tuned the Smario world Map concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a map in style of sks **
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:
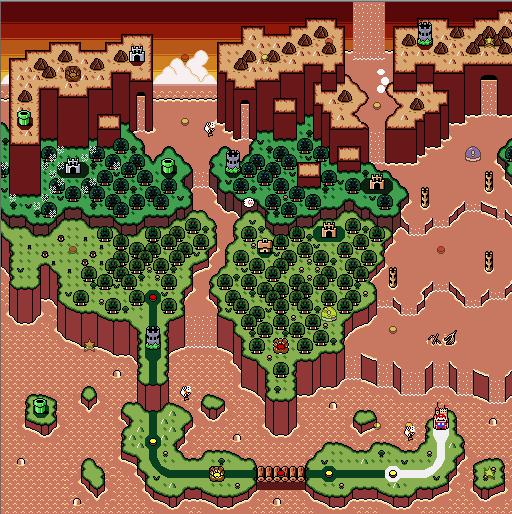
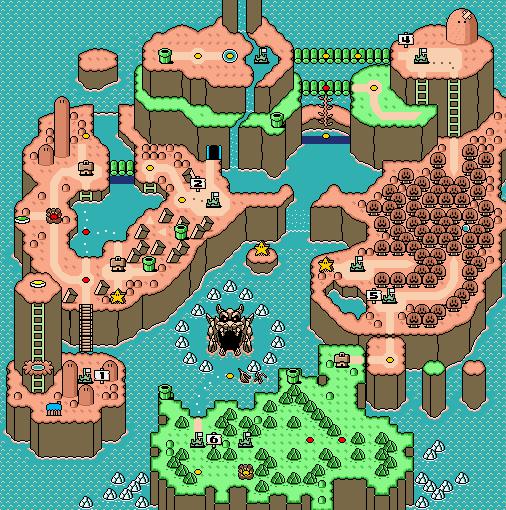
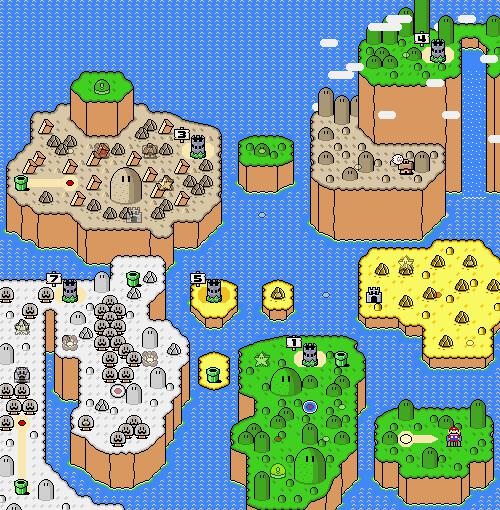
|
sd-dreambooth-library/froggewut | sd-dreambooth-library | 2023-05-16T09:18:26Z | 33 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T19:22:37Z | ---
license: mit
---
### FroggeWut on Stable Diffusion via Dreambooth
#### model by nlatina
This your the Stable Diffusion model fine-tuned the FroggeWut concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a painting in the style of sks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:





















|
sd-dreambooth-library/homelander | sd-dreambooth-library | 2023-05-16T09:18:22Z | 29 | 3 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T18:36:00Z | ---
license: mit
---
### Homelander on Stable Diffusion via Dreambooth
#### model by Abdifatah
This your the Stable Diffusion model fine-tuned the Homelander concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of homelander guy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:










|
sd-dreambooth-library/paolo-bonolis | sd-dreambooth-library | 2023-05-16T09:18:17Z | 31 | 1 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T17:48:56Z | ---
license: mit
---
### paolo-bonolis on Stable Diffusion via Dreambooth
#### model by thesun1094224
This your the Stable Diffusion model fine-tuned the paolo-bonolis concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks paolo bonolis**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
sd-dreambooth-library/tempa | sd-dreambooth-library | 2023-05-16T09:18:11Z | 39 | 0 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T16:50:04Z | ---
license: mit
---
### Tempa on Stable Diffusion via Dreambooth
#### model by Giordyman
This your the Stable Diffusion model fine-tuned the Tempa concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks Tempa**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
sd-dreambooth-library/cat-toy | sd-dreambooth-library | 2023-05-16T09:18:06Z | 47 | 3 | diffusers | [
"diffusers",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-28T10:47:05Z | ---
license: mit
---
### Cat toy on Stable Diffusion via Dreambooth
#### model by multimodalart
This your the Stable Diffusion model fine-tuned the Cat toy concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks toy**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:




|
jcplus/waifu-diffusion | jcplus | 2023-05-16T09:18:02Z | 38 | 5 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"en",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-09-22T09:39:42Z | ---
language:
- en
tags:
- stable-diffusion
- text-to-image
license: bigscience-bloom-rail-1.0
inference: false
---
# waifu-diffusion - Diffusion for Weebs
waifu-diffusion is a latent text-to-image diffusion model that has been conditioned on high-quality anime images through fine-tuning.
# Gradio
We also support a [Gradio](https://github.com/gradio-app/gradio) web ui with diffusers to run inside a colab notebook:
[](https://colab.research.google.com/drive/1_8wPN7dJO746QXsFnB09Uq2VGgSRFuYE#scrollTo=1HaCauSq546O)
<img src=https://cdn.discordapp.com/attachments/930559077170421800/1017265913231327283/unknown.png width=40% height=40%>
[Original PyTorch Model Download Link](https://thisanimedoesnotexist.ai/downloads/wd-v1-2-full-ema.ckpt)
## Model Description
The model originally used for fine-tuning is [Stable Diffusion V1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4), which is a latent image diffusion model trained on [LAION2B-en](https://huggingface.co/datasets/laion/laion2B-en).
The current model has been fine-tuned with a learning rate of 5.0e-6 for 4 epochs on 56k text-image pairs obtained through Danbooru which all have an aesthetic rating greater than `6.0`.
**Note:** This project has **no affiliation with Danbooru.**
## Training Data & Annotative Prompting
The data used for fine-tuning has come from a random sample of 56k Danbooru images, which were filtered based on [CLIP Aesthetic Scoring](https://github.com/christophschuhmann/improved-aesthetic-predictor) where only images with an aesthetic score greater than `6.0` were used.
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Downstream Uses
This model can be used for entertainment purposes and as a generative art assistant.
## Example Code
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline, DDIMScheduler
model_id = "hakurei/waifu-diffusion"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16,
revision="fp16",
scheduler=DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
),
)
pipe = pipe.to(device)
prompt = "touhou hakurei_reimu 1girl solo portrait"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("reimu_hakurei.png")
```
## Team Members and Acknowledgements
This project would not have been possible without the incredible work by the [CompVis Researchers](https://ommer-lab.com/).
- [Anthony Mercurio](https://github.com/harubaru)
- [Salt](https://github.com/sALTaccount/)
- [Sta @ Bit192](https://twitter.com/naclbbr)
In order to reach us, you can join our [Discord server](https://discord.gg/touhouai).
[](https://discord.gg/touhouai) |
Ryosuke/noumison | Ryosuke | 2023-05-16T09:11:08Z | 26 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-05-16T09:01:23Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### noumison Dreambooth model trained by Ryosuke with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
OscarCH95/LANA | OscarCH95 | 2023-05-16T09:09:35Z | 0 | 0 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2023-05-16T09:08:06Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
xbesing/chinese_ink_style2 | xbesing | 2023-05-16T08:48:00Z | 4 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2023-05-16T07:33:21Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: chinese ink painting
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - xbesing/chinese_ink_style2
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on chinese ink painting using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.


LoRA for the text encoder was enabled: False.
|
Chinese-Vicuna/Chinese-Vicuna-lora-7b-belle-and-guanaco-11600 | Chinese-Vicuna | 2023-05-16T08:29:44Z | 0 | 1 | null | [
"pytorch",
"alpaca",
"Chinese-Vicuna",
"llama",
"zh",
"dataset:BelleGroup/generated_train_0.5M_CN",
"dataset:JosephusCheung/GuanacoDataset",
"dataset:Chinese-Vicuna/guanaco_belle_merge_v1.0",
"license:gpl-3.0",
"region:us"
] | null | 2023-05-16T08:27:53Z | ---
license: gpl-3.0
datasets:
- BelleGroup/generated_train_0.5M_CN
- JosephusCheung/GuanacoDataset
- Chinese-Vicuna/guanaco_belle_merge_v1.0
language:
- zh
tags:
- alpaca
- Chinese-Vicuna
- llama
---
This is a Chinese instruction-tuning lora checkpoint based on llama-7B(2epoch) from [this repo's](https://github.com/Facico/Chinese-Vicuna) work |
MrD05/other-6b | MrD05 | 2023-05-16T08:14:47Z | 1 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-15T12:27:29Z | ---
license: creativeml-openrail-m
---
|
h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2 | h2oai | 2023-05-16T07:52:20Z | 1,522 | 4 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-05-10T09:16:05Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
---
# Model Card
## Summary
Try our chatbot here: https://gpt-gm.h2o.ai/
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [openlm-research/open_llama_7b_preview_300bt](https://huggingface.co/openlm-research/open_llama_7b_preview_300bt)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers` and `torch` libraries installed.
```bash
pip install transformers==4.28.1
pip install torch==2.0.0
```
```python
import torch
from transformers import pipeline
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2",
torch_dtype=torch.float16,
trust_remote_code=True,
use_fast=False,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=2,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?</s><|answer|>
```
Alternatively, if you prefer to not use `trust_remote_code=True` you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer:
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2",
use_fast=False,
padding_side="left"
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2",
torch_dtype=torch.float16,
device_map={"": "cuda:0"}
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=2,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?</s><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=2,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
shinta0615/xlm-roberta-base-finetuned-panx-de-fr | shinta0615 | 2023-05-16T07:30:44Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-05-16T02:31:33Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1625
- F1: 0.8580
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2916 | 1.0 | 715 | 0.1842 | 0.8249 |
| 0.1449 | 2.0 | 1430 | 0.1568 | 0.8494 |
| 0.0941 | 3.0 | 2145 | 0.1625 | 0.8580 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
xavidejuan/unit1.LunarLander-v2 | xavidejuan | 2023-05-16T07:13:17Z | 17 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-03-19T19:23:24Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 279.44 +/- 11.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Marc-Elie/ppo-CartPole-v1 | Marc-Elie | 2023-05-16T07:08:26Z | 0 | 0 | null | [
"tensorboard",
"CartPole-v1",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-15T07:23:22Z | ---
tags:
- CartPole-v1
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# PPO Agent Playing CartPole-v1
This is a trained model of a PPO agent playing CartPole-v1.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'CartPole-v1'
'total_timesteps': 400000
'learning_rate': 0.0005
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'Marc-Elie/ppo-CartPole-v1'
'batch_size': 512
'minibatch_size': 128}
```
|
CynthiaCR/food_classifier | CynthiaCR | 2023-05-16T07:06:33Z | 63 | 0 | transformers | [
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-05-15T22:27:52Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: CynthiaCR/food_classifier
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# CynthiaCR/food_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5354
- Validation Loss: 1.3575
- Train Accuracy: 0.5062
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 6400, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 2.0502 | 2.0061 | 0.2375 | 0 |
| 1.8368 | 1.7539 | 0.3187 | 1 |
| 1.6074 | 1.6316 | 0.3875 | 2 |
| 1.4768 | 1.5368 | 0.4437 | 3 |
| 1.3390 | 1.4388 | 0.4813 | 4 |
| 1.1889 | 1.3995 | 0.4562 | 5 |
| 1.0397 | 1.3773 | 0.4688 | 6 |
| 0.8703 | 1.4785 | 0.4625 | 7 |
| 0.6962 | 1.3854 | 0.4938 | 8 |
| 0.5354 | 1.3575 | 0.5062 | 9 |
### Framework versions
- Transformers 4.29.1
- TensorFlow 2.12.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
HeWhoRemixes/seekyou-alpha1-fp16 | HeWhoRemixes | 2023-05-16T07:00:14Z | 31 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-05-16T03:57:55Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: false
---
## Note
I do not own this model nor did I train it.<br>
Inference is off on this model as I am unclear whether it is allowed by the owner.
## Sources
- [Model](https://civitai.com/models/60572/seekyou?modelVersionId=65036) |
SaberMolaei/speecht5_tts_ckb7 | SaberMolaei | 2023-05-16T06:56:27Z | 91 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"speecht5",
"text-to-audio",
"hf-tts-leaderboard",
"generated_from_trainer",
"text-to-speech",
"ckb",
"dataset:mozilla-foundation/common_voice_11_0",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-to-speech | 2023-05-11T04:46:03Z | ---
language:
- ckb
license: mit
tags:
- hf-tts-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: SpeechT5 tts ckb7- Saber Molaei
results: []
pipeline_tag: text-to-speech
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SpeechT5 tts ckb7- Saber Molaei
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5043
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 7000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6297 | 2.93 | 1000 | 0.5741 |
| 0.5784 | 5.85 | 2000 | 0.5376 |
| 0.5576 | 8.78 | 3000 | 0.5230 |
| 0.5563 | 11.7 | 4000 | 0.5120 |
| 0.5257 | 14.63 | 5000 | 0.5070 |
| 0.5375 | 17.56 | 6000 | 0.5028 |
| 0.5365 | 20.48 | 7000 | 0.5043 |
### Framework versions
- Transformers 4.30.0.dev0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3 |
HeWhoRemixes/pastelmix-better-vae-fp32 | HeWhoRemixes | 2023-05-16T06:40:57Z | 3 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-05-15T12:53:34Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
## Note
I do not own this model nor did I train it.
## Sources
- [Model](https://huggingface.co/andite/pastel-mix)
|
MayIBorn/ft-sd15-portrait | MayIBorn | 2023-05-16T06:33:42Z | 0 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2023-05-16T06:17:45Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a high-quality portrait photo of a person,The person is facing forward and the main focus of the image. The background is blurred or out of focus to draw attention to the person. The image is high resolution and have natural-looking lighting and shadows. The person's features are recognizable and the image conveys a sense of emotion or personality.
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - MayIBorn/ft-sd15-portrait
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a high-quality portrait photo of a person,The person is facing forward and the main focus of the image. The background is blurred or out of focus to draw attention to the person. The image is high resolution and have natural-looking lighting and shadows. The person's features are recognizable and the image conveys a sense of emotion or personality. using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: True.
|
chenyanjin/distilbert-base-uncased-finetuned-imdb-finetuned-imdb | chenyanjin | 2023-05-16T06:28:52Z | 124 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2023-05-16T06:22:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- eval_loss: 2.3000
- eval_runtime: 95.0622
- eval_samples_per_second: 630.156
- eval_steps_per_second: 9.846
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
mathislucka/bi-deberta-base-hallucination-v1 | mathislucka | 2023-05-16T06:28:21Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"deberta-v2",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-05-16T06:24:17Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 516 with parameters:
```
{'batch_size': 14}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 300,
"evaluator": "sentence_transformers.evaluation.InformationRetrievalEvaluator.InformationRetrievalEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 0,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: DebertaV2Model
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
charlieoneill/ppo-CartPole-v1 | charlieoneill | 2023-05-16T06:19:19Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T05:35:24Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 115.78 +/- 92.11
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 1000000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 1024
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.98
'num_minibatches': 64
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'charlieoneill/ppo-CartPole-v1'
'batch_size': 4096
'minibatch_size': 64}
```
|
jacobthebanana/Reinforce-FlagPole-v1 | jacobthebanana | 2023-05-16T06:05:26Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T05:36:24Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-FlagPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
abletobetable/spec_soul_ast | abletobetable | 2023-05-16T05:44:38Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"dataset:Aniemore/resd",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-04-03T14:22:50Z | ---
datasets:
- Aniemore/resd
metrics:
- accuracy
library_name: transformers
pipeline_tag: audio-classification
---
Finetuned Audio Spectrogram Transformer for sentiment analysis in russian.
[github repo with code and tg bot](https://github.com/glubze-and-tochka/spectrogram-soul)
init state: MIT/ast-finetuned-audioset-10-10-0.4593
precision recall f1-score support
0 0.77 0.77 0.77 44
1 0.54 0.59 0.56 37
2 0.53 0.60 0.56 40
3 0.69 0.64 0.67 45
4 0.56 0.57 0.56 44
5 0.49 0.55 0.52 38
6 0.75 0.47 0.58 32
accuracy 0.61 280
macro avg 0.62 0.60 0.60 280
weighted avg 0.62 0.61 0.61 280
|
sofa566/my_awesome_swag_model | sofa566 | 2023-05-16T05:21:44Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"multiple-choice",
"generated_from_trainer",
"dataset:swag",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | multiple-choice | 2023-05-16T04:33:09Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- swag
metrics:
- accuracy
model-index:
- name: my_awesome_swag_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_swag_model
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the swag dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0175
- Accuracy: 0.7940
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.7552 | 1.0 | 4597 | 0.6061 | 0.7647 |
| 0.3824 | 2.0 | 9194 | 0.6517 | 0.7851 |
| 0.1417 | 3.0 | 13791 | 1.0175 | 0.7940 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.12.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
cyrodw/Reinforce-Pixelcopter | cyrodw | 2023-05-16T05:17:51Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-10T11:29:30Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 5.03 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
jainr3/sd-diffusiondb-pixelart-v2-model-lora | jainr3 | 2023-05-16T05:06:06Z | 4 | 1 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2023-05-16T03:24:29Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - jainr3/sd-diffusiondb-pixelart-v2-model-lora
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the jainr3/diffusiondb-pixelart dataset. This model has been trained for 30 epochs while the jainr3/sd-diffusiondb-pixelart-model-lora model was trained on only 5 epochs. You can find some example images in the following.




|
agestau/pkemon_cap_v0 | agestau | 2023-05-16T04:35:14Z | 60 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"git",
"image-text-to-text",
"generated_from_trainer",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2023-05-16T04:11:36Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: pkemon_cap_v0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pkemon_cap_v0
This model is a fine-tuned version of [microsoft/git-base](https://huggingface.co/microsoft/git-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.6491
- Wer Score: 127.2727
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Score |
|:-------------:|:-----:|:----:|:---------------:|:---------:|
| 11.2497 | 0.17 | 2 | 10.0191 | 96.6364 |
| 9.9157 | 0.35 | 4 | 9.5544 | 111.1818 |
| 9.4907 | 0.52 | 6 | 9.1167 | 143.5909 |
| 9.0975 | 0.7 | 8 | 8.8422 | 154.5455 |
| 8.8568 | 0.87 | 10 | 8.6143 | 144.6364 |
| 8.6299 | 1.04 | 12 | 8.4336 | 118.7727 |
| 8.4659 | 1.22 | 14 | 8.2808 | 112.4091 |
| 8.3233 | 1.39 | 16 | 8.1538 | 124.3636 |
| 8.2213 | 1.57 | 18 | 8.0420 | 122.8636 |
| 8.0876 | 1.74 | 20 | 7.9463 | 124.5 |
| 7.9863 | 1.91 | 22 | 7.8647 | 153.9545 |
| 7.9169 | 2.09 | 24 | 7.7966 | 156.0 |
| 7.8652 | 2.26 | 26 | 7.7400 | 155.5455 |
| 7.8245 | 2.43 | 28 | 7.6962 | 142.0909 |
| 7.7512 | 2.61 | 30 | 7.6659 | 129.9545 |
| 7.7344 | 2.78 | 32 | 7.6491 | 127.2727 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
pablomartinfranco/ppo-LunarLander-v2 | pablomartinfranco | 2023-05-16T04:19:36Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T04:19:17Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 276.05 +/- 15.33
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ziyu23/ppo-LunarLander-v2 | Ziyu23 | 2023-05-16T04:14:50Z | 0 | 1 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T04:14:26Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 253.27 +/- 20.89
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
rami8k/ppo-LunarLander-v2 | rami8k | 2023-05-16T04:11:31Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T04:11:11Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.95 +/- 18.35
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sofa566/my_awesome_billsum_model | sofa566 | 2023-05-16T03:58:25Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-05-16T02:58:45Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: my_awesome_billsum_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: ca_test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1426
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5878
- Rouge1: 0.1426
- Rouge2: 0.0479
- Rougel: 0.1171
- Rougelsum: 0.1168
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.8630 | 0.1259 | 0.0336 | 0.1048 | 0.1048 | 19.0 |
| No log | 2.0 | 124 | 2.6630 | 0.138 | 0.0448 | 0.1133 | 0.1131 | 19.0 |
| No log | 3.0 | 186 | 2.6043 | 0.1412 | 0.0472 | 0.1152 | 0.1149 | 19.0 |
| No log | 4.0 | 248 | 2.5878 | 0.1426 | 0.0479 | 0.1171 | 0.1168 | 19.0 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.12.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
dkgee/chinese_alpaca_lora_7b | dkgee | 2023-05-16T03:52:11Z | 0 | 0 | null | [
"zh",
"region:us"
] | null | 2023-05-16T03:17:55Z | ---
language:
- zh
---
这是从[Chinese-LLaMA-Alpaca](https://github.com/ymcui/Chinese-LLaMA-Alpaca) 下载 chinese_alpaca_lora_7b 模型,里面集成的中英文数据集,后续测试一下在网页分类方面的应用情况,经测试,
使用该模型不适合文本分类,处理数据时间耗时超长。 |
lmxhappy/new_bert | lmxhappy | 2023-05-16T03:39:00Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-05-16T03:38:51Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# lmxhappy/new_bert
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('lmxhappy/new_bert')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('lmxhappy/new_bert')
model = AutoModel.from_pretrained('lmxhappy/new_bert')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=lmxhappy/new_bert)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 32 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 100,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 5e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 27,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
ApolloFilippou/Pyramids | ApolloFilippou | 2023-05-16T03:36:02Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-05-16T03:29:50Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: ApolloFilippou/Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Xxc69/Beningg | Xxc69 | 2023-05-16T03:30:22Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-16T03:27:10Z | ---
license: creativeml-openrail-m
---
|
dkgee/chinese_alpaca_lora_13b | dkgee | 2023-05-16T03:28:46Z | 0 | 0 | null | [
"zh",
"region:us"
] | null | 2023-05-16T03:26:08Z | ---
language:
- zh
---
这是从[Chinese-LLaMA-Alpaca](https://github.com/ymcui/Chinese-LLaMA-Alpaca) 下载 chinese_alpaca_lora_13b 模型,里面集成的中英文数据集,供后续研究使用。 |
gan11/ppo-PyramidsRND | gan11 | 2023-05-16T02:39:28Z | 2 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-05-16T02:39:23Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: gan11/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
richardllz/PPO-LunarLander-v2 | richardllz | 2023-05-16T02:36:26Z | 4 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T02:36:07Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.67 +/- 14.26
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sofa566/my_awesome_opus_books_model | sofa566 | 2023-05-16T02:15:36Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:opus_books",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-05-16T01:50:45Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- opus_books
metrics:
- bleu
model-index:
- name: my_awesome_opus_books_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: opus_books
type: opus_books
config: en-fr
split: train
args: en-fr
metrics:
- name: Bleu
type: bleu
value: 5.6705
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_opus_books_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the opus_books dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6084
- Bleu: 5.6705
- Gen Len: 17.5512
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 1.8561 | 1.0 | 6355 | 1.6322 | 5.5291 | 17.5639 |
| 1.815 | 2.0 | 12710 | 1.6084 | 5.6705 | 17.5512 |
### Framework versions
- Transformers 4.29.1
- Pytorch 1.12.1
- Datasets 2.11.0
- Tokenizers 0.11.0
|
firuiz/deportistas | firuiz | 2023-05-16T01:55:50Z | 0 | 0 | fastai | [
"fastai",
"region:us"
] | null | 2023-05-16T01:27:43Z | ---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
gan11/ppo-SnowballTargetTESTCOLAB | gan11 | 2023-05-16T01:54:19Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2023-05-16T01:52:47Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Find your model_id: gan11/ppo-SnowballTargetTESTCOLAB
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
HuanWang/test | HuanWang | 2023-05-16T01:50:41Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"en",
"arxiv:2203.03850",
"arxiv:1910.09700",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2023-05-16T01:46:28Z | ---
language:
- en
license: apache-2.0
---
# Model Card for UniXcoder-base
# Model Details
## Model Description
UniXcoder is a unified cross-modal pre-trained model that leverages multimodal data (i.e. code comment and AST) to pretrain code representation.
- **Developed by:** Microsoft Team
- **Shared by [Optional]:** Hugging Face
- **Model type:** Feature Engineering
- **Language(s) (NLP):** en
- **License:** Apache-2.0
- **Related Models:**
- **Parent Model:** RoBERTa
- **Resources for more information:**
- [Associated Paper](https://arxiv.org/abs/2203.03850)
# Uses
## Direct Use
Feature Engineering
## Downstream Use [Optional]
More information needed
## Out-of-Scope Use
More information needed
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
More information needed
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed
### Factors
The model creators note in the [associated paper](https://arxiv.org/abs/2203.03850):
> UniXcoder has slightly worse BLEU-4 scores on both code summarization and generation tasks. The main reasons may come from two aspects. One is the amount of NL-PL pairs in the pre-training data
### Metrics
The model creators note in the [associated paper](https://arxiv.org/abs/2203.03850):
> We evaluate UniXcoder on five tasks over nine public datasets, including two understanding tasks, two generation tasks and an autoregressive task. To further evaluate the performance of code fragment embeddings, we also propose a new task called zero-shot code-to-code search.
## Results
The model creators note in the [associated paper](https://arxiv.org/abs/2203.03850):
>Taking zero-shot code-code search task as an example, after removing contrastive learning, the performance drops from 20.45% to 13.73%.
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
**BibTeX:**
```
@misc{https://doi.org/10.48550/arxiv.2203.03850,
doi = {10.48550/ARXIV.2203.03850},
url = {https://arxiv.org/abs/2203.03850},
author = {Guo, Daya and Lu, Shuai and Duan, Nan and Wang, Yanlin and Zhou, Ming and Yin, Jian},
keywords = {Computation and Language (cs.CL), Programming Languages (cs.PL), Software Engineering (cs.SE), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {UniXcoder: Unified Cross-Modal Pre-training for Code
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Microsoft Team in collaboration with Ezi Ozoani and the Hugging Face Team.
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("microsoft/unixcoder-base")
model = AutoModel.from_pretrained("microsoft/unixcoder-base")
```
</details>
|
Juno360219/Ggg | Juno360219 | 2023-05-16T01:32:29Z | 0 | 0 | open_clip | [
"open_clip",
"art",
"text-to-image",
"en",
"dataset:bigcode/the-stack",
"license:openrail",
"region:us"
] | text-to-image | 2023-05-16T01:31:06Z | ---
license: openrail
datasets:
- bigcode/the-stack
language:
- en
metrics:
- character
library_name: open_clip
pipeline_tag: text-to-image
tags:
- art
--- |
lowrollr/PyramidsRND | lowrollr | 2023-05-16T01:14:58Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-05-16T01:14:52Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Find your model_id: lowrollr/PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
charlieoneill/taxi_v3_q_learning_long_train | charlieoneill | 2023-05-16T01:10:00Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-05-16T01:09:53Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi_v3_q_learning_long_train
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="charlieoneill/taxi_v3_q_learning_long_train", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Subsets and Splits