
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
marcoyang/librispeech_bigram | marcoyang | 2023-07-05T06:45:19Z | 0 | 0 | null | [
"region:us"
] | null | 2022-11-14T04:19:15Z | This is a token bi-gram trained on LibriSpeech 960h text. It is used for LODR decoding in `icefall`.
Please refer to https://github.com/k2-fsa/icefall/pull/678 for more details. |
stlxx/vit-base-beans | stlxx | 2023-07-05T06:44:02Z | 223 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"vision",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-06-28T07:51:20Z | ---
license: apache-2.0
tags:
- image-classification
- vision
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: vit-base-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8195488721804511
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-huge-patch14-224-in21k](https://huggingface.co/google/vit-huge-patch14-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9760
- Accuracy: 0.8195
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0596 | 1.0 | 259 | 1.0507 | 0.7143 |
| 1.0165 | 2.0 | 518 | 1.0165 | 0.7895 |
| 1.0113 | 3.0 | 777 | 0.9941 | 0.8045 |
| 1.0067 | 4.0 | 1036 | 0.9804 | 0.8195 |
| 0.9746 | 5.0 | 1295 | 0.9760 | 0.8195 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 1.13.1+cu117-with-pypi-cudnn
- Datasets 2.12.0
- Tokenizers 0.13.3
|
heka-ai/tasb-bert-100k | heka-ai | 2023-07-05T06:42:30Z | 2 | 1 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-07-05T06:42:26Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# heka-ai/tasb-bert-100k
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('heka-ai/tasb-bert-100k')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('heka-ai/tasb-bert-100k')
model = AutoModel.from_pretrained('heka-ai/tasb-bert-100k')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=heka-ai/tasb-bert-100k)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 10000 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 100000,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
nolanaatama/ktysksngngrvcv2360pchktgwsn | nolanaatama | 2023-07-05T06:42:24Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T06:38:12Z | ---
license: creativeml-openrail-m
---
|
linlinlin/peft-dialogue-summary-0705 | linlinlin | 2023-07-05T06:40:42Z | 0 | 0 | null | [
"pytorch",
"tensorboard",
"generated_from_trainer",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T06:01:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: peft-dialogue-summary-0705
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# peft-dialogue-summary-0705
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 50
### Training results
### Framework versions
- Transformers 4.27.2
- Pytorch 2.0.1+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3
|
cerspense/zeroscope_v2_1111models | cerspense | 2023-07-05T06:39:40Z | 0 | 24 | null | [
"license:cc-by-nc-4.0",
"region:us"
] | null | 2023-07-03T23:09:54Z | ---
license: cc-by-nc-4.0
---

[example outputs](https://www.youtube.com/watch?v=HO3APT_0UA4) (courtesy of [dotsimulate](https://www.instagram.com/dotsimulate/))
# zeroscope_v2 1111 models
A collection of watermark-free Modelscope-based video models capable of generating high quality video at [448x256](https://huggingface.co/cerspense/zeroscope_v2_dark_30x448x256), [576x320](https://huggingface.co/cerspense/zeroscope_v2_576w) and [1024 x 576](https://huggingface.co/cerspense/zeroscope_v2_XL). These models were trained from the [original weights](https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis) with offset noise using 9,923 clips and 29,769 tagged frames.<br />
This collection makes it easy to switch between models with the new dropdown menu in the 1111 extension.
### Using it with the 1111 text2video extension
Simply download the contents of this repo to 'stable-diffusion-webui\models\text2video'
Or, manually download the model folders you want, along with VQGAN_autoencoder.pth.
Thanks to [dotsimulate](https://www.instagram.com/dotsimulate/) for the config files.
Thanks to [camenduru](https://github.com/camenduru), [kabachuha](https://github.com/kabachuha), [ExponentialML](https://github.com/ExponentialML), [VANYA](https://twitter.com/veryVANYA), [polyware](https://twitter.com/polyware_ai), [tin2tin](https://github.com/tin2tin)<br /> |
PD0AUTOMATIONAL/blip-large-endpoint | PD0AUTOMATIONAL | 2023-07-05T06:38:22Z | 95 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"blip",
"image-text-to-text",
"image-captioning",
"image-to-text",
"arxiv:2201.12086",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | image-to-text | 2023-07-05T06:37:51Z | ---
pipeline_tag: image-to-text
tags:
- image-captioning
languages:
- en
license: bsd-3-clause
duplicated_from: Salesforce/blip-image-captioning-large
---
# BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Model card for image captioning pretrained on COCO dataset - base architecture (with ViT large backbone).
|  |
|:--:|
| <b> Pull figure from BLIP official repo | Image source: https://github.com/salesforce/BLIP </b>|
## TL;DR
Authors from the [paper](https://arxiv.org/abs/2201.12086) write in the abstract:
*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*
## Usage
You can use this model for conditional and un-conditional image captioning
### Using the Pytorch model
#### Running the model on CPU
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
#### Running the model on GPU
##### In full precision
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large").to("cuda")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
##### In half precision (`float16`)
<details>
<summary> Click to expand </summary>
```python
import torch
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large", torch_dtype=torch.float16).to("cuda")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# >>> a photography of a woman and her dog
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
>>> a woman sitting on the beach with her dog
```
</details>
## BibTex and citation info
```
@misc{https://doi.org/10.48550/arxiv.2201.12086,
doi = {10.48550/ARXIV.2201.12086},
url = {https://arxiv.org/abs/2201.12086},
author = {Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven},
keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
``` |
PD0AUTOMATIONAL/blip2-endpoint | PD0AUTOMATIONAL | 2023-07-05T06:35:31Z | 9 | 2 | transformers | [
"transformers",
"pytorch",
"blip-2",
"visual-question-answering",
"vision",
"image-to-text",
"image-captioning",
"en",
"arxiv:2301.12597",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-to-text | 2023-07-05T06:23:12Z | ---
language: en
license: mit
tags:
- vision
- image-to-text
- image-captioning
- visual-question-answering
pipeline_tag: image-to-text
duplicated_from: Salesforce/blip2-opt-6.7b-coco
---
# BLIP-2, OPT-6.7b, fine-tuned on COCO
BLIP-2 model, leveraging [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (a large language model with 6.7 billion parameters).
It was introduced in the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Li et al. and first released in [this repository](https://github.com/salesforce/LAVIS/tree/main/projects/blip2).
Disclaimer: The team releasing BLIP-2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BLIP-2 consists of 3 models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model.
The authors initialize the weights of the image encoder and large language model from pre-trained checkpoints and keep them frozen
while training the Querying Transformer, which is a BERT-like Transformer encoder that maps a set of "query tokens" to query embeddings,
which bridge the gap between the embedding space of the image encoder and the large language model.
The goal for the model is simply to predict the next text token, giving the query embeddings and the previous text.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
This allows the model to be used for tasks like:
- image captioning
- visual question answering (VQA)
- chat-like conversations by feeding the image and the previous conversation as prompt to the model
## Direct Use and Downstream Use
You can use the raw model for conditional text generation given an image and optional text. See the [model hub](https://huggingface.co/models?search=Salesforce/blip) to look for
fine-tuned versions on a task that interests you.
## Bias, Risks, Limitations, and Ethical Considerations
BLIP2-OPT uses off-the-shelf OPT as the language model. It inherits the same risks and limitations as mentioned in Meta's model card.
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
>
BLIP2 is fine-tuned on image-text datasets (e.g. [LAION](https://laion.ai/blog/laion-400-open-dataset/) ) collected from the internet. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
BLIP2 has not been tested in real world applications. It should not be directly deployed in any applications. Researchers should first carefully assess the safety and fairness of the model in relation to the specific context they’re being deployed within.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example). |
sagorsarker/codeswitch-spaeng-pos-lince | sagorsarker | 2023-07-05T06:32:02Z | 118 | 1 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"token-classification",
"codeswitching",
"spanish-english",
"pos",
"es",
"en",
"multilingual",
"dataset:lince",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
language:
- es
- en
- multilingual
license: mit
tags:
- codeswitching
- spanish-english
- pos
datasets:
- lince
---
# codeswitch-spaeng-pos-lince
This is a pretrained model for **Part of Speech Tagging** of `spanish-english` code-mixed data used from [LinCE](https://ritual.uh.edu/lince/home)
This model is trained for this below repository.
[https://github.com/sagorbrur/codeswitch](https://github.com/sagorbrur/codeswitch)
To install codeswitch:
```
pip install codeswitch
```
## Part-of-Speech Tagging of Spanish-English Mixed Data
* **Method-1**
```py
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("sagorsarker/codeswitch-spaeng-pos-lince")
model = AutoModelForTokenClassification.from_pretrained("sagorsarker/codeswitch-spaeng-pos-lince")
pos_model = pipeline('ner', model=model, tokenizer=tokenizer)
pos_model("put any spanish english code-mixed sentence")
```
* **Method-2**
```py
from codeswitch.codeswitch import POS
pos = POS('spa-eng')
text = "" # your mixed sentence
result = pos.tag(text)
print(result)
```
|
sunil18p31a0101/PoleCopter | sunil18p31a0101 | 2023-07-05T06:29:25Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T06:29:23Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: PoleCopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 9.20 +/- 8.61
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
alsonlai/q-FrozenLake-v1-4x4-Slippery2 | alsonlai | 2023-07-05T06:16:38Z | 0 | 0 | null | [
"FrozenLake-v1-4x4",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T06:16:32Z | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.74 +/- 0.44
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="alsonlai/q-FrozenLake-v1-4x4-Slippery2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
IMJONEZZ/ggml-openchat-8192-q4_0 | IMJONEZZ | 2023-07-05T06:04:27Z | 0 | 8 | null | [
"llama",
"openchat",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-07-02T19:40:18Z | ---
license: apache-2.0
language:
- en
tags:
- llama
- openchat
---
Since this is an OpenChat model, here's the OpenChat card.
# OpenChat: Less is More for Open-source Models
OpenChat is a series of open-source language models fine-tuned on a diverse and high-quality dataset of multi-round conversations. With only ~6K GPT-4 conversations filtered from the ~90K ShareGPT conversations, OpenChat is designed to achieve high performance with limited data.
**Generic models:**
- OpenChat: based on LLaMA-13B (2048 context length)
- **🚀 105.7%** of ChatGPT score on Vicuna GPT-4 evaluation
- **🔥 80.9%** Win-rate on AlpacaEval
- **🤗 Only used 6K data for finetuning!!!**
- OpenChat-8192: based on LLaMA-13B (extended to 8192 context length)
- **106.6%** of ChatGPT score on Vicuna GPT-4 evaluation
- **79.5%** of ChatGPT score on Vicuna GPT-4 evaluation
**Code models:**
- OpenCoderPlus: based on StarCoderPlus (native 8192 context length)
- **102.5%** of ChatGPT score on Vicuna GPT-4 evaluation
- **78.7%** Win-rate on AlpacaEval
*Note:* Please load the pretrained models using *bfloat16*
## Code and Inference Server
We provide the full source code, including an inference server compatible with the "ChatCompletions" API, in the [OpenChat](https://github.com/imoneoi/openchat) GitHub repository.
## Web UI
OpenChat also includes a web UI for a better user experience. See the GitHub repository for instructions.
## Conversation Template
The conversation template **involves concatenating tokens**.
Besides base model vocabulary, an end-of-turn token `<|end_of_turn|>` is added, with id `eot_token_id`.
```python
# OpenChat
[bos_token_id] + tokenize("Human: ") + tokenize(user_question) + [eot_token_id] + tokenize("Assistant: ")
# OpenCoder
tokenize("User:") + tokenize(user_question) + [eot_token_id] + tokenize("Assistant:")
```
*Hint: In BPE, `tokenize(A) + tokenize(B)` does not always equals to `tokenize(A + B)`*
Following is the code for generating the conversation templates:
```python
@dataclass
class ModelConfig:
# Prompt
system: Optional[str]
role_prefix: dict
ai_role: str
eot_token: str
bos_token: Optional[str] = None
# Get template
def generate_conversation_template(self, tokenize_fn, tokenize_special_fn, message_list):
tokens = []
masks = []
# begin of sentence (bos)
if self.bos_token:
t = tokenize_special_fn(self.bos_token)
tokens.append(t)
masks.append(False)
# System
if self.system:
t = tokenize_fn(self.system) + [tokenize_special_fn(self.eot_token)]
tokens.extend(t)
masks.extend([False] * len(t))
# Messages
for idx, message in enumerate(message_list):
# Prefix
t = tokenize_fn(self.role_prefix[message["from"]])
tokens.extend(t)
masks.extend([False] * len(t))
# Message
if "value" in message:
t = tokenize_fn(message["value"]) + [tokenize_special_fn(self.eot_token)]
tokens.extend(t)
masks.extend([message["from"] == self.ai_role] * len(t))
else:
assert idx == len(message_list) - 1, "Empty message for completion must be on the last."
return tokens, masks
MODEL_CONFIG_MAP = {
# OpenChat / OpenChat-8192
"openchat": ModelConfig(
# Prompt
system=None,
role_prefix={
"human": "Human: ",
"gpt": "Assistant: "
},
ai_role="gpt",
eot_token="<|end_of_turn|>",
bos_token="<s>",
),
# OpenCoder / OpenCoderPlus
"opencoder": ModelConfig(
# Prompt
system=None,
role_prefix={
"human": "User:",
"gpt": "Assistant:"
},
ai_role="gpt",
eot_token="<|end_of_turn|>",
bos_token=None,
)
}
``` |
NasimB/gpt2-concat-cl-log-rarity-10-220k-mod-datasets-rarity1-root3 | NasimB | 2023-07-05T05:59:58Z | 126 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:41:14Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-cl-log-rarity-10-220k-mod-datasets-rarity1-root3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-cl-log-rarity-10-220k-mod-datasets-rarity1-root3
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 5.0416
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.3754 | 0.06 | 500 | 5.9052 |
| 5.0899 | 0.12 | 1000 | 5.5421 |
| 4.8108 | 0.18 | 1500 | 5.3468 |
| 4.6258 | 0.24 | 2000 | 5.2562 |
| 4.4818 | 0.3 | 2500 | 5.1938 |
| 4.3762 | 0.36 | 3000 | 5.1291 |
| 4.2781 | 0.42 | 3500 | 5.0818 |
| 4.184 | 0.48 | 4000 | 5.0492 |
| 4.0944 | 0.54 | 4500 | 5.0293 |
| 4.0096 | 0.6 | 5000 | 5.0134 |
| 3.9209 | 0.66 | 5500 | 4.9953 |
| 3.8449 | 0.72 | 6000 | 4.9897 |
| 3.7748 | 0.78 | 6500 | 4.9793 |
| 3.7162 | 0.84 | 7000 | 4.9719 |
| 3.6813 | 0.9 | 7500 | 4.9687 |
| 3.6592 | 0.96 | 8000 | 4.9669 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
dlabs-matic-leva/segformer-b0-finetuned-segments-sidewalk-2 | dlabs-matic-leva | 2023-07-05T05:54:12Z | 186 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"segformer",
"vision",
"image-segmentation",
"dataset:segments/sidewalk-semantic",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2023-07-04T07:03:03Z | ---
tags:
- vision
- image-segmentation
datasets:
- segments/sidewalk-semantic
finetuned_from: nvidia/mit-b0
widget:
- src: >-
https://datasets-server.huggingface.co/assets/segments/sidewalk-semantic/--/segments--sidewalk-semantic-2/train/3/pixel_values/image.jpg
example_title: Sidewalk example
--- |
ireneli1024/biobart-v2-base-elife-finetuned | ireneli1024 | 2023-07-05T05:52:51Z | 124 | 0 | transformers | [
"transformers",
"pytorch",
"bart",
"text2text-generation",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-05T05:50:02Z | ---
license: other
---
This is the finetuned model based on the [biobart-v2-base](https://huggingface.co/GanjinZero/biobart-v2-base) model.
The data is from BioLaySumm 2023 [shared task 1](https://biolaysumm.org/#data). |
niansong1996/lever-gsm8k-codex | niansong1996 | 2023-07-05T05:48:36Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"dataset:gsm8k",
"arxiv:2302.08468",
"arxiv:1910.09700",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-03T03:42:52Z | ---
license: apache-2.0
datasets:
- gsm8k
metrics:
- accuracy
model-index:
- name: lever-gsm8k-codex
results:
- task:
type: code generation # Required. Example: automatic-speech-recognition
# name: {task_name} # Optional. Example: Speech Recognition
dataset:
type: gsm8k # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: GSM8K (Math Reasoning) # Required. A pretty name for the dataset. Example: Common Voice (French)
# config: {dataset_config} # Optional. The name of the dataset configuration used in `load_dataset()`. Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
# split: {dataset_split} # Optional. Example: test
# revision: {dataset_revision} # Optional. Example: 5503434ddd753f426f4b38109466949a1217c2bb
# args:
# {arg_0}: {value_0} # Optional. Additional arguments to `load_dataset()`. Example for wikipedia: language: en
# {arg_1}: {value_1} # Optional. Example for wikipedia: date: 20220301
metrics:
- type: accuracy # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 84.5 # Required. Example: 20.90
# name: {metric_name} # Optional. Example: Test WER
# config: {metric_config} # Optional. The name of the metric configuration used in `load_metric()`. Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/v2.1.0/en/loading#load-configurations
# args:
# {arg_0}: {value_0} # Optional. The arguments passed during `Metric.compute()`. Example for `bleu`: max_order: 4
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
---
# LEVER (for Codex on GSM8K)
This is one of the models produced by the paper ["LEVER: Learning to Verify Language-to-Code Generation with Execution"](https://arxiv.org/abs/2302.08468).
**Authors:** [Ansong Ni](https://niansong1996.github.io), Srini Iyer, Dragomir Radev, Ves Stoyanov, Wen-tau Yih, Sida I. Wang*, Xi Victoria Lin*
**Note**: This specific model is for Codex on the [GSM8K](https://github.com/openai/grade-school-math) dataset, for the models pretrained on other datasets, please see:
* [lever-spider-codex](https://huggingface.co/niansong1996/lever-spider-codex)
* [lever-wikitq-codex](https://huggingface.co/niansong1996/lever-wikitq-codex)
* [lever-mbpp-codex](https://huggingface.co/niansong1996/lever-mbpp-codex)
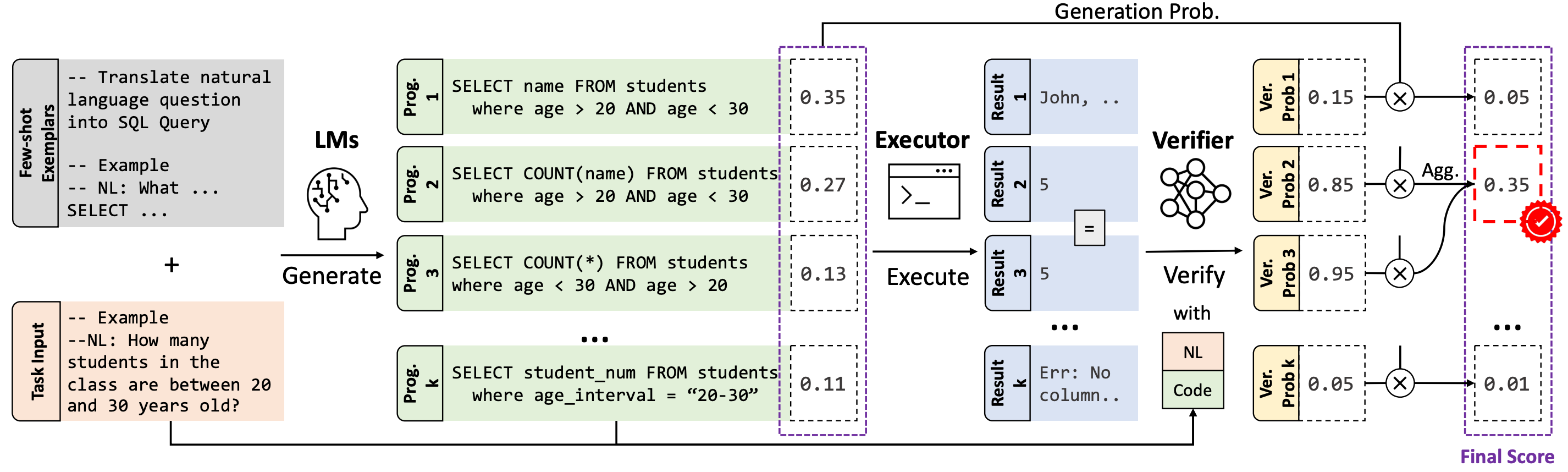
# Model Details
## Model Description
The advent of pre-trained code language models (Code LLMs) has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
- **Developed by:** Yale University and Meta AI
- **Shared by:** Ansong Ni
- **Model type:** Text Classification
- **Language(s) (NLP):** More information needed
- **License:** Apache-2.0
- **Parent Model:** RoBERTa-large
- **Resources for more information:**
- [Github Repo](https://github.com/niansong1996/lever)
- [Associated Paper](https://arxiv.org/abs/2302.08468)
# Uses
## Direct Use
This model is *not* intended to be directly used. LEVER is used to verify and rerank the programs generated by code LLMs (e.g., Codex). We recommend checking out our [Github Repo](https://github.com/niansong1996/lever) for more details.
## Downstream Use
LEVER is learned to verify and rerank the programs sampled from code LLMs for different tasks.
More specifically, for `lever-gsm8k-codex`, it was trained on the outputs of `code-davinci-002` on the [GSM8K](https://github.com/openai/grade-school-math) dataset. It can be used to rerank the SQL programs generated by Codex out-of-box.
Moreover, it may also be applied to other model's outputs on the GSM8K dataset, as studied in the [Original Paper](https://arxiv.org/abs/2302.08468).
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model is trained with the outputs from `code-davinci-002` model on the [GSM8K](https://github.com/openai/grade-school-math) dataset.
## Training Procedure
20 program samples are drawn from the Codex model on the training examples of the GSM8K dataset, those programs are later executed to obtain the execution information.
And for each example and its program sample, the natural language description and execution information are also part of the inputs that used to train the RoBERTa-based model to predict "yes" or "no" as the verification labels.
### Preprocessing
Please follow the instructions in the [Github Repo](https://github.com/niansong1996/lever) to reproduce the results.
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
Dev and test set of the [GSM8K](https://github.com/openai/grade-school-math) dataset.
### Factors
More information needed
### Metrics
Execution accuracy (i.e., pass@1)
## Results
### GSM8K Math Reasoning via Python Code Generation
| | Exec. Acc. (Dev) | Exec. Acc. (Test) |
|-----------------|------------------|-------------------|
| Codex | 68.1 | 67.2 |
| Codex+LEVER | 84.1 | 84.5 |
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
`lever-gsm8k-codex` is based on RoBERTa-large.
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
```bibtex
@inproceedings{ni2023lever,
title={Lever: Learning to verify language-to-code generation with execution},
author={Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida I and Lin, Xi Victoria},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML'23)},
year={2023}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Author and Contact
Ansong Ni, contact info on [personal website](https://niansong1996.github.io)
# How to Get Started with the Model
This model is *not* intended to be directly used, please follow the instructions in the [Github Repo](https://github.com/niansong1996/lever). |
thenewcompany/reinforce-CartPole-v1 | thenewcompany | 2023-07-05T05:47:20Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T05:47:12Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
NasimB/gpt2-concat-mod-datasets-rarity1 | NasimB | 2023-07-05T05:41:11Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T02:36:15Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-mod-datasets-rarity1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-mod-datasets-rarity1
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0210
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.7299 | 0.3 | 500 | 5.6367 |
| 5.3814 | 0.59 | 1000 | 5.2097 |
| 5.0305 | 0.89 | 1500 | 4.9565 |
| 4.7532 | 1.18 | 2000 | 4.8178 |
| 4.6062 | 1.48 | 2500 | 4.6913 |
| 4.4987 | 1.78 | 3000 | 4.5883 |
| 4.3593 | 2.07 | 3500 | 4.5246 |
| 4.1845 | 2.37 | 4000 | 4.4796 |
| 4.1539 | 2.66 | 4500 | 4.4191 |
| 4.1258 | 2.96 | 5000 | 4.3681 |
| 3.898 | 3.26 | 5500 | 4.3751 |
| 3.8758 | 3.55 | 6000 | 4.3495 |
| 3.8598 | 3.85 | 6500 | 4.3088 |
| 3.7173 | 4.14 | 7000 | 4.3340 |
| 3.5968 | 4.44 | 7500 | 4.3170 |
| 3.5934 | 4.74 | 8000 | 4.3049 |
| 3.5491 | 5.03 | 8500 | 4.3103 |
| 3.3358 | 5.33 | 9000 | 4.3192 |
| 3.3363 | 5.62 | 9500 | 4.3181 |
| 3.3409 | 5.92 | 10000 | 4.3105 |
| 3.2189 | 6.22 | 10500 | 4.3290 |
| 3.1812 | 6.51 | 11000 | 4.3286 |
| 3.1879 | 6.81 | 11500 | 4.3297 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
anejaisha/output1 | anejaisha | 2023-07-05T05:32:35Z | 1 | 0 | null | [
"tensorboard",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T05:10:41Z | ---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- generated_from_trainer
model-index:
- name: output1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output1
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
modelmaker/melanie | modelmaker | 2023-07-05T05:26:44Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"am",
"dataset:Open-Orca/OpenOrca",
"license:openrail",
"region:us"
] | text-to-image | 2023-07-05T05:15:40Z | ---
license: openrail
datasets:
- Open-Orca/OpenOrca
language:
- am
metrics:
- accuracy
library_name: diffusers
pipeline_tag: text-to-image
--- |
thirupathibandam/bloom560 | thirupathibandam | 2023-07-05T05:22:00Z | 116 | 0 | transformers | [
"transformers",
"pytorch",
"bloom",
"feature-extraction",
"text-generation",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:51:48Z | ---
pipeline_tag: text-generation
--- |
ConnorAzure/BillieJoeArmstrong_300_Epoch_Version | ConnorAzure | 2023-07-05T05:21:30Z | 0 | 0 | null | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2023-07-05T05:19:38Z | ---
license: cc-by-nc-sa-4.0
---
|
Chattiori/RandMix | Chattiori | 2023-07-05T05:07:47Z | 0 | 1 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-03T02:36:10Z | ---
license: creativeml-openrail-m
---
<span style="font-size: 250%; font-weight:bold; color:#A00000; -webkit-text-stroke: 1.5px #8080FF;">$()RandMix()$</span>
*Merging random fetched amounts of realistic models with random alpha values.*
*<a href="https://github.com/Faildes/CivitAI-ModelFetch-RandomScripter" style="font-size: 250%; font-weight:bold; color:#A00000;">Link for the Tool</span>*
# attemptD
## Authors
[CalicoMixReal-v2.0](https://civitai.com/models/83593/) by [Kybalico](https://civitai.com/user/Kybalico)
[ThisIsReal-v2.0](https://civitai.com/models/93529/) by [ChangeMeNot](https://civitai.com/user/ChangeMeNot)
[donGmiXX_realistic-v1.0](https://civitai.com/models/72745/) by [Dong09](https://civitai.com/user/Dong09)
[fantasticmix-v6.5](https://civitai.com/models/22402/) by [michin](https://civitai.com/user/michin)
[XtReMiX UltiMate Merge-v1.8](https://civitai.com/models/93589/) by [creatumundo399](https://civitai.com/user/creatumundo399)
[Blessing Mix-V1-VAE](https://civitai.com/models/94179/) by [mixboy](https://civitai.com/user/mixboy)
[Magical woman-v1.0](https://civitai.com/models/87659/) by [Aderek514](https://civitai.com/user/Aderek514)
[X-Flare Mix-Real](https://civitai.com/models/87533/) by [noah4u](https://civitai.com/user/noah4u)
[Kawaii Realistic European Mix-v0.2](https://civitai.com/models/90694/) by [szxex](https://civitai.com/user/szxex)
[midmix-v2.0](https://civitai.com/models/91837/) by [aigirl951877](https://civitai.com/user/aigirl951877)
[NextPhoto-v2.0](https://civitai.com/models/84335/) by [bigbeanboiler](https://civitai.com/user/bigbeanboiler)
[epiCRealism-pure Evolution V3](https://civitai.com/models/25694/) by [epinikion](https://civitai.com/user/epinikion)
## Mergition
Sum Twice, [Magicalwoman-v1.0](https://civitai.com/models/87659/) + [NextPhoto-v2.0](https://civitai.com/models/84335/) + [BlessingMix-V1-VAE](https://civitai.com/models/94179/),rand_alpha(0.0, 1.0, 362988133) rand_beta(0.0, 1.0, 2503978625) >> TEMP_0
Sum Twice, [ThisIsReal-v2.0-pruned](https://civitai.com/models/93529/) + [epiCRealism-pureEvolutionV3](https://civitai.com/models/25694/) + [X-FlareMix-Real](https://civitai.com/models/87533/),rand_alpha(0.0, 1.0, 1164438173) rand_beta(0.0, 1.0, 2889722594) >> TEMP_1
Sum Twice, TEMP_1 + [XtReMiXUltiMateMerge-v1.8-pruned](https://civitai.com/models/93589/) + [KawaiiRealisticEuropeanMix-v0.2](https://civitai.com/models/90694/),rand_alpha(0.0, 1.0, 2548759651) rand_beta(0.0, 1.0, 939190814) >> TEMP_2
Sum Twice, [donGmiXX_realistic-v1.0-pruned](https://civitai.com/models/72745/) + TEMP_2 + TEMP_0,rand_alpha(0.0, 1.0, 4211068902) rand_beta(0.0, 1.0, 2851752676) >> TEMP_3
Sum Twice, [CalicoMixReal-v2.0](https://civitai.com/models/83593/) + [midmix-v2.0](https://civitai.com/models/91837/) + [fantasticmix-v6.5](https://civitai.com/models/22402/),rand_alpha(0.0, 1.0, 1155017101) rand_beta(0.0, 1.0, 1186832395) >> TEMP_4
Weighted Sum, TEMP_4 + TEMP_3,rand_alpha(0.0, 1.0, 4170699435) >> RandMix-attemptD
# attemptE
## Authors
[ThisIsReal-v2.0](https://civitai.com/models/93529/) by [ChangeMeNot](https://civitai.com/user/ChangeMeNot)
[WaffleMix-v3](https://civitai.com/models/82657/) by [WaffleAbyss](https://civitai.com/user/WaffleAbyss)
[AddictiveFuture_Realistic_SemiAsian-V1](https://civitai.com/models/94725/) by [AddictiveFuture](https://civitai.com/user/AddictiveFuture)
[UltraReal-v1.0](https://civitai.com/models/101116/) by [ndsempai872](https://civitai.com/user/ndsempai872)
[Opiate-Opiate.v2.0-pruned-fp16](https://civitai.com/models/69587/) by [DominoPrincip](https://civitai.com/user/DominoPrincip)
[Milky-Chicken-v1.1](https://civitai.com/models/91662/) by [ArcticFlamingo](https://civitai.com/user/ArcticFlamingo)
[LOFA_RealMIX-v2.1](https://civitai.com/models/97203/) by [XSELE](https://civitai.com/user/XSELE)
[epiCRealism-pure Evolution V3](https://civitai.com/models/25694/) by [epinikion](https://civitai.com/user/epinikion)
[CalicoMixReal-v2.0](https://civitai.com/models/83593/) by [Kybalico](https://civitai.com/user/Kybalico)
[fantasticmix-v6.5](https://civitai.com/models/22402/) by [michin](https://civitai.com/user/michin)
[Sensual Visions-v1.0](https://civitai.com/models/96147/) by [Chik](https://civitai.com/user/Chik)
[yayoi_mix-v1.31](https://civitai.com/models/83096/) by [kotajiro001](https://civitai.com/user/kotajiro001)
[cbimix-v1.2](https://civitai.com/models/21341/) by [RobertoGonzalez](https://civitai.com/user/RobertoGonzalez)
[kisaragi_mix-v2.2](https://civitai.com/models/45757/) by [kotajiro001](https://civitai.com/user/kotajiro001)
[OS-AmberGlow-v1.0](https://civitai.com/models/96715/) by [BakingBeans](https://civitai.com/user/BakingBeans)
[CyberRealistic -v3.1](https://civitai.com/models/15003/) by [Cyberdelia](https://civitai.com/user/Cyberdelia)
[MoYouMIX_nature-v10.2](https://civitai.com/models/86232/) by [MoYou](https://civitai.com/user/MoYou)
[XXMix_9realistic-v4.0](https://civitai.com/models/47274/) by [Zyx_xx](https://civitai.com/user/Zyx_xx)
[puremix-v2.0](https://civitai.com/models/63558/) by [aigirl951877](https://civitai.com/user/aigirl951877)
[Shampoo Mix-v4](https://civitai.com/models/33918/) by [handcleanmists](https://civitai.com/user/handcleanmists)
[mutsuki_mix-v2](https://civitai.com/models/45614/) by [kotajiro001](https://civitai.com/user/kotajiro001)
## Mergition
Sum Twice, [ThisIsReal-v2.0-pruned](https://civitai.com/models/93529/) + [kisaragi_mix-v2.2](https://civitai.com/models/45757/) + [XXMix_9realistic-v4.0](https://civitai.com/models/47274/),rand_alpha(0.0, 1.0, 443960021) rand_beta(0.0, 1.0, 3789696212) >> TEMP_0
Sum Twice, [MoYouMIX_nature-v10.2](https://civitai.com/models/86232/) + [OS-AmberGlow-v1.0](https://civitai.com/models/96715/) + [WaffleMix-v3-pruned](https://civitai.com/models/82657/),rand_alpha(0.0, 1.0, 1803109590) rand_beta(0.0, 1.0, 1453385409) >> TEMP_1
Sum Twice, [LOFA_RealMIX-v2.1](https://civitai.com/models/97203/) + [cbimix-v1.2-pruned](https://civitai.com/models/21341/) + [UltraReal-v1.0](https://civitai.com/models/101116/),rand_alpha(0.0, 1.0, 4256340902) rand_beta(0.0, 1.0, 807878137) >> TEMP_2
Sum Twice, TEMP_2 + [epiCRealism-pureEvolutionV3](https://civitai.com/models/25694/) + [fantasticmix-v6.5](https://civitai.com/models/22402/),rand_alpha(0.0, 1.0, 3772562984) rand_beta(0.0, 1.0, 4240203753) >> TEMP_3
Sum Twice, [Milky-Chicken-v1.1](https://civitai.com/models/91662/) + [SensualVisions-v1.0](https://civitai.com/models/96147/) + [CyberRealistic-v3.1](https://civitai.com/models/15003/),rand_alpha(0.0, 1.0, 4126859432) rand_beta(0.0, 1.0, 2028377392) >> TEMP_4
Sum Twice, [Opiate-Opiate.v2.0-pruned-fp16](https://civitai.com/models/69587/) + [mutsuki_mix-v2](https://civitai.com/models/45614/) + [CalicoMixReal-v2.0](https://civitai.com/models/83593/),rand_alpha(0.0, 1.0, 2593256182) rand_beta(0.0, 1.0, 1602942704) >> TEMP_5
Sum Twice, [puremix-v2.0](https://civitai.com/models/63558/) + TEMP_5 + TEMP_0,rand_alpha(0.0, 1.0, 1463835870) rand_beta(0.0, 1.0, 1919004708) >> TEMP_6
Sum Twice, TEMP_6 + [ShampooMix-v4](https://civitai.com/models/33918/) + TEMP_4,rand_alpha(0.0, 1.0, 2771317666) rand_beta(0.0, 1.0, 3798261900) >> TEMP_7
Sum Twice, TEMP_1 + [yayoi_mix-v1.31](https://civitai.com/models/83096/) + TEMP_3,rand_alpha(0.0, 1.0, 2433722680) rand_beta(0.0, 1.0, 3707256183) >> TEMP_8
Sum Twice, TEMP_7 + [AddictiveFuture_Realistic_SemiAsian-V1](https://civitai.com/models/94725/) + TEMP_8,rand_alpha(0.0, 1.0, 2818401144) rand_beta(0.0, 1.0, 4137586985) >> RandMix-attemptE
# attemptF
## Authors
[cineMaErosPG_V4-cineMaErosPG_V4_ UF](https://civitai.com/models/74426/) by [Filly](https://civitai.com/user/Filly)
[Fresh Photo-v2.0](https://civitai.com/models/63149/) by [eddiemauro](https://civitai.com/user/eddiemauro)
[LRM - Liangyius Realistic Mix-v1.5](https://civitai.com/models/81304/) by [liangyiu](https://civitai.com/user/liangyiu)
[Nobmodel-v1.0](https://civitai.com/models/99326/) by [Nobdy](https://civitai.com/user/Nobdy)
[cbimix-v1.2](https://civitai.com/models/21341/) by [RobertoGonzalez](https://civitai.com/user/RobertoGonzalez)
[ChillyMix-chillymix V2 VAE Fp16](https://civitai.com/models/58772/) by [mixboy](https://civitai.com/user/mixboy)
[XXMix_9realistic-v4.0](https://civitai.com/models/47274/) by [Zyx_xx](https://civitai.com/user/Zyx_xx)
[X-Flare Mix-Real](https://civitai.com/models/87533/) by [noah4u](https://civitai.com/user/noah4u)
[Nymph Mix-v1.0_pruned](https://civitai.com/models/96374/) by [NymphMix](https://civitai.com/user/NymphMix)
[NeverEnding Dream-v1.22](https://civitai.com/models/10028/) by [Lykon](https://civitai.com/user/Lykon)
[ICBINP - I Cannot Believe ItIs Not Photography-Afterburn](https://civitai.com/models/28059/) by [residentchiefnz](https://civitai.com/user/residentchiefnz)
[epiCRealism-pure Evolution V3](https://civitai.com/models/25694/) by [epinikion](https://civitai.com/user/epinikion)
[kisaragi_mix-v2.2](https://civitai.com/models/45757/) by [kotajiro001](https://civitai.com/user/kotajiro001)
[Opiate-Opiate.v2.0-pruned-fp16](https://civitai.com/models/69587/) by [DominoPrincip](https://civitai.com/user/DominoPrincip)
[AIbijoModel-no47p22](https://civitai.com/models/65155/) by [AIbijo](https://civitai.com/user/AIbijo)
[LazyMix+-v3.0a](https://civitai.com/models/10961/) by [kaylazy](https://civitai.com/user/kaylazy)
[Kawaii Realistic European Mix-v0.2](https://civitai.com/models/90694/) by [szxex](https://civitai.com/user/szxex)
[fantasticmix-v6.5](https://civitai.com/models/22402/) by [michin](https://civitai.com/user/michin)
[CyberRealistic Classic-Classic V1.4](https://civitai.com/models/71185/) by [Cyberdelia](https://civitai.com/user/Cyberdelia)
[blue_pencil_realistic-v0.5](https://civitai.com/models/88941/) by [blue_pen5805](https://civitai.com/user/blue_pen5805)
## Mergition
Sum Twice, [ChillyMix-chillymixV2VAEFp16](https://civitai.com/models/58772/) + [AIbijoModel-no47p22](https://civitai.com/models/65155/) + [KawaiiRealisticEuropeanMix-v0.2](https://civitai.com/models/90694/),rand_alpha(0.0, 1.0, 1448726226) rand_beta(0.0, 1.0, 1612718918) >> TEMP_0
Sum Twice, [NymphMix-v1.0_pruned](https://civitai.com/models/96374/) + [blue_pencil_realistic-v0.5](https://civitai.com/models/88941/) + [XXMix_9realistic-v4.0](https://civitai.com/models/47274/),rand_alpha(0.0, 1.0, 3996249117) rand_beta(0.0, 1.0, 1325610322) >> TEMP_1
Sum Twice, [NeverEndingDream-v1.22](https://civitai.com/models/10028/) + [Nobmodel-v1.0-pruned](https://civitai.com/models/99326/) + [cineMaErosPG_V4-cineMaErosPG_V4_UF](https://civitai.com/models/74426/),rand_alpha(0.0, 1.0, 3380603779) rand_beta(0.0, 1.0, 3034448733) >> TEMP_2
Sum Twice, [CyberRealisticClassic-ClassicV1.4](https://civitai.com/models/71185/) + [LRM-LiangyiusRealisticMix-v1.5](https://civitai.com/models/81304/) + TEMP_1,rand_alpha(0.0, 1.0, 3442830754) rand_beta(0.0, 1.0, 3394049346) >> TEMP_3
Sum Twice, [epiCRealism-pureEvolutionV3](https://civitai.com/models/25694/) + [ICBINP-ICannotBelieveItIsNotPhotography-Afterburn](https://civitai.com/models/28059/) + [FreshPhoto-v2.0-pruned](https://civitai.com/models/63149/),rand_alpha(0.0, 1.0, 3406789958) rand_beta(0.0, 1.0, 2616453593) >> TEMP_4
Sum Twice, [fantasticmix-v6.5](https://civitai.com/models/22402/) + [cbimix-v1.2-pruned](https://civitai.com/models/21341/) + TEMP_0,rand_alpha(0.0, 1.0, 636301224) rand_beta(0.0, 1.0, 1333752761) >> TEMP_5
Sum Twice, [Opiate-Opiate.v2.0-pruned-fp16](https://civitai.com/models/69587/) + TEMP_5 + [kisaragi_mix-v2.2](https://civitai.com/models/45757/),rand_alpha(0.0, 1.0, 3025193242) rand_beta(0.0, 1.0, 1994900822) >> TEMP_6
Sum Twice, TEMP_6 + TEMP_2 + TEMP_4,rand_alpha(0.0, 1.0, 1437849591) rand_beta(0.0, 1.0, 1280504514) >> TEMP_7
Sum Twice, [LazyMix+-v3.0a](https://civitai.com/models/10961/) + TEMP_7 + [X-FlareMix-Real](https://civitai.com/models/87533/),rand_alpha(0.0, 1.0, 2116550821) rand_beta(0.0, 1.0, 1220687392) >> TEMP_8
Weighted Sum, TEMP_3 + TEMP_8,rand_alpha(0.0, 1.0, 2376068494) >> RandMix-attemptF
|
fanlino/distilbert-base-uncased-finetuned-emotion | fanlino | 2023-07-05T05:04:53Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-06-19T05:59:35Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9255
- name: F1
type: f1
value: 0.9255469274059955
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2134
- Accuracy: 0.9255
- F1: 0.9255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8099 | 1.0 | 250 | 0.3119 | 0.907 | 0.9039 |
| 0.2425 | 2.0 | 500 | 0.2134 | 0.9255 | 0.9255 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
digiplay/PeachMixsRelistic_R0 | digiplay | 2023-07-05T05:00:28Z | 393 | 4 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-04T06:31:42Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/99595/peachmixs-relistic
Original Author's DEMO image :
 |
chenxingphh/marian-finetuned-kde4-en-to-fr | chenxingphh | 2023-07-05T04:59:29Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T03:16:55Z | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- kde4
model-index:
- name: marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
lIlBrother/ko-TextNumbarT | lIlBrother | 2023-07-05T04:36:42Z | 125 | 2 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"ko",
"dataset:aihub",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-10-31T07:02:36Z | ---
language:
- ko # Example: fr
license: apache-2.0 # Example: apache-2.0 or any license from https://hf.co/docs/hub/repositories-licenses
library_name: transformers # Optional. Example: keras or any library from https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Libraries.ts
tags:
- text2text-generation # Example: audio
datasets:
- aihub # Example: common_voice. Use dataset id from https://hf.co/datasets
metrics:
- bleu # Example: wer. Use metric id from https://hf.co/metrics
- rouge
# Optional. Add this if you want to encode your eval results in a structured way.
model-index:
- name: ko-TextNumbarT
results:
- task:
type: text2text-generation # Required. Example: automatic-speech-recognition
name: text2text-generation # Optional. Example: Speech Recognition
metrics:
- type: bleu # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.958234790096092 # Required. Example: 20.90
name: eval_bleu # Optional. Example: Test WER
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
- type: rouge1 # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.9735361877162854 # Required. Example: 20.90
name: eval_rouge1 # Optional. Example: Test WER
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
- type: rouge2 # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.9493975212378124 # Required. Example: 20.90
name: eval_rouge2 # Optional. Example: Test WER
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
- type: rougeL # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.9734558938864928 # Required. Example: 20.90
name: eval_rougeL # Optional. Example: Test WER
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
- type: rougeLsum # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 0.9734350757552404 # Required. Example: 20.90
name: eval_rougeLsum # Optional. Example: Test WER
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
---
# ko-TextNumbarT(TNT Model🧨): Try Korean Reading To Number(한글을 숫자로 바꾸는 모델)
## Table of Contents
- [ko-TextNumbarT(TNT Model🧨): Try Korean Reading To Number(한글을 숫자로 바꾸는 모델)](#ko-textnumbarttnt-model-try-korean-reading-to-number한글을-숫자로-바꾸는-모델)
- [Table of Contents](#table-of-contents)
- [Model Details](#model-details)
- [Uses](#uses)
- [Evaluation](#evaluation)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
뭔가 찾아봐도 모델이나 알고리즘이 딱히 없어서 만들어본 모델입니다. <br />
BartForConditionalGeneration Fine-Tuning Model For Korean To Number <br />
BartForConditionalGeneration으로 파인튜닝한, 한글을 숫자로 변환하는 Task 입니다. <br />
- Dataset use [Korea aihub](https://aihub.or.kr/aihubdata/data/list.do?currMenu=115&topMenu=100&srchDataRealmCode=REALM002&srchDataTy=DATA004) <br />
I can't open my fine-tuning datasets for my private issue <br />
데이터셋은 Korea aihub에서 받아서 사용하였으며, 파인튜닝에 사용된 모든 데이터를 사정상 공개해드릴 수는 없습니다. <br />
- Korea aihub data is ONLY permit to Korean!!!!!!! <br />
aihub에서 데이터를 받으실 분은 한국인일 것이므로, 한글로만 작성합니다. <br />
정확히는 철자전사를 음성전사로 번역하는 형태로 학습된 모델입니다. (ETRI 전사기준) <br />
- In case, ten million, some people use 10 million or some people use 10000000, so this model is crucial for training datasets <br />
천만을 1000만 혹은 10000000으로 쓸 수도 있기에, Training Datasets에 따라 결과는 상이할 수 있습니다. <br />
- **수관형사와 수 의존명사의 띄어쓰기에 따라 결과가 확연히 달라질 수 있습니다. (쉰살, 쉰 살 -> 쉰살, 50살)** https://eretz2.tistory.com/34 <br />
일단은 기준을 잡고 치우치게 학습시키기엔 어떻게 사용될지 몰라, 학습 데이터 분포에 맡기도록 했습니다. (쉰 살이 더 많을까 쉰살이 더 많을까!?)
- **Developed by:** Yoo SungHyun(https://github.com/YooSungHyun)
- **Language(s):** Korean
- **License:** apache-2.0
- **Parent Model:** See the [kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) for more information about the pre-trained base model.
## Uses
Want see more detail follow this URL [KoGPT_num_converter](https://github.com/ddobokki/KoGPT_num_converter) <br /> and see `bart_inference.py` and `bart_train.py`
## Evaluation
Just using `evaluate-metric/bleu` and `evaluate-metric/rouge` in huggingface `evaluate` library <br />
[Training wanDB URL](https://wandb.ai/bart_tadev/BartForConditionalGeneration/runs/14hyusvf?workspace=user-bart_tadev)
## How to Get Started With the Model
```python
from transformers.pipelines import Text2TextGenerationPipeline
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
texts = ["그러게 누가 여섯시까지 술을 마시래?"]
tokenizer = AutoTokenizer.from_pretrained("lIlBrother/ko-TextNumbarT")
model = AutoModelForSeq2SeqLM.from_pretrained("lIlBrother/ko-TextNumbarT")
seq2seqlm_pipeline = Text2TextGenerationPipeline(model=model, tokenizer=tokenizer)
kwargs = {
"min_length": 0,
"max_length": 1206,
"num_beams": 100,
"do_sample": False,
"num_beam_groups": 1,
}
pred = seq2seqlm_pipeline(texts, **kwargs)
print(pred)
# 그러게 누가 6시까지 술을 마시래?
```
|
Madhav1988/candy-finetuned | Madhav1988 | 2023-07-05T04:20:23Z | 187 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"detr",
"object-detection",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | 2023-06-25T15:34:17Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: candy-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# candy-finetuned
This model is a fine-tuned version of [Madhav1988/candy-finetuned](https://huggingface.co/Madhav1988/candy-finetuned) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
OmarAboBakr/output_dir | OmarAboBakr | 2023-07-05T03:57:01Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-05T03:53:59Z | ---
tags:
- generated_from_trainer
model-index:
- name: output_dir
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output_dir
This model is a fine-tuned version of [ahmeddbahaa/AraT5-base-finetune-ar-xlsum](https://huggingface.co/ahmeddbahaa/AraT5-base-finetune-ar-xlsum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3896
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 35 | 2.7832 |
| No log | 2.0 | 70 | 2.8460 |
| No log | 3.0 | 105 | 2.9176 |
| No log | 4.0 | 140 | 3.0041 |
| No log | 5.0 | 175 | 3.0820 |
| No log | 6.0 | 210 | 3.1322 |
| No log | 7.0 | 245 | 3.2356 |
| No log | 8.0 | 280 | 3.2674 |
| No log | 9.0 | 315 | 3.3620 |
| No log | 10.0 | 350 | 3.3896 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
hiepnh/xgen-7b-8k-inst-8bit-sharded | hiepnh | 2023-07-05T03:47:32Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:33:54Z | sharded version of legendhasit/xgen-7b-8k-inst-8bit |
GabrielOnohara/distilbert-base-uncased-finetuned-cola | GabrielOnohara | 2023-07-05T03:44:22Z | 61 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T01:15:19Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: GabrielOnohara/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# GabrielOnohara/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1800
- Validation Loss: 0.5561
- Train Matthews Correlation: 0.5182
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.4785 | 0.4665 | 0.4399 | 0 |
| 0.2890 | 0.5009 | 0.5060 | 1 |
| 0.1800 | 0.5561 | 0.5182 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
aroot/wsample.42 | aroot | 2023-07-05T03:36:17Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T01:59:22Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.42
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.42
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2245
- Bleu: 2.9981
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
digiplay/majicMIX_sombre_v2 | digiplay | 2023-07-05T03:33:15Z | 4,022 | 4 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-04T23:08:08Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/62778?modelVersionId=75209
|
xian79/dqn-SpaceInvadersNoFrameskip-v4 | xian79 | 2023-07-05T03:28:00Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T03:27:24Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 526.50 +/- 51.82
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga xian79 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga xian79 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga xian79
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
aroot/wsample.39 | aroot | 2023-07-05T03:24:42Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T01:48:44Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.39
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.39
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2192
- Bleu: 2.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
GralchemOz/guanaco-33b-chinese-GPTQ-4bit-128g | GralchemOz | 2023-07-05T02:56:19Z | 5 | 0 | transformers | [
"transformers",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-04T15:28:56Z | ---
license: apache-2.0
---
This model is a merged version of [guanaco-33b](https://huggingface.co/timdettmers/guanaco-33b ) and [chinese-alpaca-lora-33b](https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b) ,which enhances the Chinese language capability while retaining the abilities of the original models.
Please follow the corresponding model licenses when using this model.
本模型是由[guanaco-33b](https://huggingface.co/timdettmers/guanaco-33b ) 和 [chinese-alpaca-lora-33b](https://huggingface.co/ziqingyang/chinese-alpaca-lora-33b) 合并得到的, 增强中文能力的同时保留了原始模型的能力
使用时务必遵守相应模型的协议 |
vinson099/food_model | vinson099 | 2023-07-05T02:53:42Z | 191 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:food101",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-06-28T22:06:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- food101
metrics:
- accuracy
model-index:
- name: food_model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food101
type: food101
config: default
split: train[:5000]
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.909
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5778
- Accuracy: 0.909
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.6893 | 0.99 | 62 | 2.4624 | 0.847 |
| 1.81 | 2.0 | 125 | 1.7440 | 0.889 |
| 1.5497 | 2.98 | 186 | 1.5778 | 0.909 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
aroot/wsample.11 | aroot | 2023-07-05T02:34:23Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T00:53:31Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.11
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.11
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2215
- Bleu: 3.0186
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
sid/rl_course_vizdoom_health_gathering_supreme | sid | 2023-07-05T02:28:16Z | 0 | 0 | sample-factory | [
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T02:13:23Z | ---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 14.10 +/- 6.14
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r sid/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m <path.to.enjoy.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .home.sid.anaconda3.envs.unit82.lib.python3.9.site-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
nybe/ReverbChiffon60 | nybe | 2023-07-05T02:24:26Z | 0 | 1 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T02:01:32Z | ---
license: creativeml-openrail-m
---
# Model Card for Model ID
A throw back to designs of the 1960s with a nod to album cover designs of Blue Note Records.
## Model Details
### Model Description
Dig it, cats and kittens, enter into a world framed in jazz and poetry - the ReverbChiffon60.
This high-steppin' HuggingFace model is like a raw analog photograph of a man, a jazz musician in the swingin' 60s - colorized and refined by the halftone technique, capturing the highs and the lows, the pure essence of the beatnik life. It's a study in contrasts, like a Blue Note Record cover in technicolor blues and echoed beats.
The ReverbChiffon60 is a portrait in itself, riffing on beatnik swells like Wallace Berman, Larry Rivers, and Allen Ginsberg, translating their distinctive style into vectors and lines. It's hip and cool, with an undercurrent of retro 60s space vibes - a nod to the forbidden planet, an echo of retro futurism, and a nod to the hipsters and the swingin’ jazz cats that defined an era.
Pulling from the playbook of masters like Jay DeFeo and Andy Warhol, this model brings together abstract, geometric shapes and gradients with the flat color aesthetics of the mid-century. It's a sketch on the jukebox, a pattern in the smoke-filled rooms, a snapshot by Robert Frank or Claes Oldenburg. You might claim it's got the vintage 60s T-shirt design, Blue Note album cover scribbles, and echoes of swingin' typography.
With a Lenny Bruce style narrative in vector art form, the ReverbChiffon60 is highly detailed yet supremely smooth. It luxuriates in simple, clean vector curves and silhouettes, steering clear of jagged lines and staccato breaks. It dabbles in halftone, each dot and run bringing depth to the minimal flat color palette.
So park up your peepers and shake up your thoughts, cats, we're on a spacewalk here with the ReverbChiffon60! Dig the model that beats like poetry and plays like jazz.
- **Developed by:** [More Information Needed]
## Uses
txt2img model best results use any combo of these trigger words from this prompt:
raw analog photo of a jazz musician in the 1960s, colorized, halftone, Blue Note records, beatniks, poster design, muted colorful,
60's jazz album cover design, blue note typography design, hip, retro futurism, flat color, geometric shapes, gradient filter, pleasing
tone colors, space walk, photography by Robert Frank, Claes Oldenburg, a beatnik poet, hipster, Vintage 60s T shirt design with
blue note album cover design, retro 60's poster, vintage portrait of beats, illustration art by Andy Warhol, t shirt design, muted colorful,
Lenny Bruce style, illustration, highly detailed, simple, smooth and clean vector curve, no jagged lines, vector art, halftone, smooth,
## Caveat
I'm pretty new to this side of using these models so bear with me if I've not provided enough info.
|
EllaHong/datamap_polyglot_5.8b_exp1_0705 | EllaHong | 2023-07-05T02:23:46Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T02:23:38Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
jordyvl/LayoutLMv3_maveriq_tobacco3482_2023-07-04_longer | jordyvl | 2023-07-05T02:18:52Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"layoutlmv3",
"text-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-04T21:57:15Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: LayoutLMv3_maveriq_tobacco3482_2023-07-04_longer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3_maveriq_tobacco3482_2023-07-04_longer
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4933
- Accuracy: 0.915
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| No log | 0.96 | 3 | 2.1414 | 0.285 |
| No log | 1.96 | 6 | 2.0216 | 0.265 |
| No log | 2.96 | 9 | 1.9444 | 0.265 |
| No log | 3.96 | 12 | 1.8877 | 0.335 |
| No log | 4.96 | 15 | 1.8160 | 0.315 |
| No log | 5.96 | 18 | 1.7139 | 0.33 |
| No log | 6.96 | 21 | 1.6301 | 0.36 |
| No log | 7.96 | 24 | 1.5155 | 0.47 |
| No log | 8.96 | 27 | 1.4009 | 0.555 |
| No log | 9.96 | 30 | 1.3059 | 0.56 |
| No log | 10.96 | 33 | 1.1493 | 0.67 |
| No log | 11.96 | 36 | 1.0559 | 0.725 |
| No log | 12.96 | 39 | 0.9505 | 0.75 |
| No log | 13.96 | 42 | 0.8301 | 0.78 |
| No log | 14.96 | 45 | 0.7531 | 0.775 |
| No log | 15.96 | 48 | 0.7030 | 0.79 |
| No log | 16.96 | 51 | 0.6294 | 0.82 |
| No log | 17.96 | 54 | 0.5819 | 0.845 |
| No log | 18.96 | 57 | 0.5381 | 0.87 |
| No log | 19.96 | 60 | 0.4852 | 0.87 |
| No log | 20.96 | 63 | 0.4581 | 0.91 |
| No log | 21.96 | 66 | 0.4429 | 0.895 |
| No log | 22.96 | 69 | 0.4065 | 0.915 |
| No log | 23.96 | 72 | 0.4065 | 0.895 |
| No log | 24.96 | 75 | 0.3598 | 0.915 |
| No log | 25.96 | 78 | 0.3476 | 0.925 |
| No log | 26.96 | 81 | 0.3413 | 0.93 |
| No log | 27.96 | 84 | 0.3544 | 0.9 |
| No log | 28.96 | 87 | 0.3239 | 0.93 |
| No log | 29.96 | 90 | 0.3187 | 0.92 |
| No log | 30.96 | 93 | 0.3090 | 0.92 |
| No log | 31.96 | 96 | 0.3495 | 0.915 |
| No log | 32.96 | 99 | 0.3075 | 0.93 |
| No log | 33.96 | 102 | 0.3509 | 0.92 |
| No log | 34.96 | 105 | 0.3499 | 0.925 |
| No log | 35.96 | 108 | 0.3176 | 0.925 |
| No log | 36.96 | 111 | 0.3260 | 0.915 |
| No log | 37.96 | 114 | 0.3245 | 0.925 |
| No log | 38.96 | 117 | 0.3139 | 0.92 |
| No log | 39.96 | 120 | 0.3667 | 0.915 |
| No log | 40.96 | 123 | 0.3410 | 0.925 |
| No log | 41.96 | 126 | 0.3278 | 0.925 |
| No log | 42.96 | 129 | 0.3518 | 0.925 |
| No log | 43.96 | 132 | 0.3617 | 0.92 |
| No log | 44.96 | 135 | 0.3642 | 0.93 |
| No log | 45.96 | 138 | 0.3686 | 0.925 |
| No log | 46.96 | 141 | 0.3784 | 0.92 |
| No log | 47.96 | 144 | 0.3826 | 0.92 |
| No log | 48.96 | 147 | 0.3734 | 0.925 |
| No log | 49.96 | 150 | 0.3763 | 0.925 |
| No log | 50.96 | 153 | 0.3931 | 0.92 |
| No log | 51.96 | 156 | 0.3982 | 0.92 |
| No log | 52.96 | 159 | 0.3960 | 0.92 |
| No log | 53.96 | 162 | 0.3896 | 0.925 |
| No log | 54.96 | 165 | 0.3917 | 0.925 |
| No log | 55.96 | 168 | 0.4016 | 0.92 |
| No log | 56.96 | 171 | 0.4098 | 0.92 |
| No log | 57.96 | 174 | 0.4124 | 0.92 |
| No log | 58.96 | 177 | 0.4127 | 0.92 |
| No log | 59.96 | 180 | 0.4115 | 0.92 |
| No log | 60.96 | 183 | 0.4134 | 0.92 |
| No log | 61.96 | 186 | 0.4173 | 0.92 |
| No log | 62.96 | 189 | 0.4209 | 0.92 |
| No log | 63.96 | 192 | 0.4230 | 0.915 |
| No log | 64.96 | 195 | 0.4259 | 0.915 |
| No log | 65.96 | 198 | 0.4289 | 0.915 |
| No log | 66.96 | 201 | 0.4318 | 0.915 |
| No log | 67.96 | 204 | 0.4333 | 0.915 |
| No log | 68.96 | 207 | 0.4325 | 0.915 |
| No log | 69.96 | 210 | 0.4317 | 0.915 |
| No log | 70.96 | 213 | 0.4336 | 0.915 |
| No log | 71.96 | 216 | 0.4356 | 0.915 |
| No log | 72.96 | 219 | 0.4372 | 0.915 |
| No log | 73.96 | 222 | 0.4375 | 0.915 |
| No log | 74.96 | 225 | 0.4381 | 0.915 |
| No log | 75.96 | 228 | 0.4393 | 0.915 |
| No log | 76.96 | 231 | 0.4418 | 0.915 |
| No log | 77.96 | 234 | 0.4444 | 0.915 |
| No log | 78.96 | 237 | 0.4470 | 0.915 |
| No log | 79.96 | 240 | 0.4491 | 0.915 |
| No log | 80.96 | 243 | 0.4492 | 0.915 |
| No log | 81.96 | 246 | 0.4474 | 0.915 |
| No log | 82.96 | 249 | 0.4443 | 0.915 |
| No log | 83.96 | 252 | 0.4445 | 0.915 |
| No log | 84.96 | 255 | 0.4477 | 0.915 |
| No log | 85.96 | 258 | 0.4492 | 0.915 |
| No log | 86.96 | 261 | 0.4501 | 0.915 |
| No log | 87.96 | 264 | 0.4510 | 0.915 |
| No log | 88.96 | 267 | 0.4520 | 0.915 |
| No log | 89.96 | 270 | 0.4525 | 0.915 |
| No log | 90.96 | 273 | 0.4531 | 0.915 |
| No log | 91.96 | 276 | 0.4530 | 0.915 |
| No log | 92.96 | 279 | 0.4518 | 0.915 |
| No log | 93.96 | 282 | 0.4499 | 0.915 |
| No log | 94.96 | 285 | 0.4485 | 0.915 |
| No log | 95.96 | 288 | 0.4496 | 0.915 |
| No log | 96.96 | 291 | 0.4525 | 0.915 |
| No log | 97.96 | 294 | 0.4562 | 0.915 |
| No log | 98.96 | 297 | 0.4596 | 0.915 |
| No log | 99.96 | 300 | 0.4629 | 0.915 |
| No log | 100.96 | 303 | 0.4639 | 0.915 |
| No log | 101.96 | 306 | 0.4641 | 0.915 |
| No log | 102.96 | 309 | 0.4630 | 0.915 |
| No log | 103.96 | 312 | 0.4619 | 0.915 |
| No log | 104.96 | 315 | 0.4624 | 0.915 |
| No log | 105.96 | 318 | 0.4628 | 0.915 |
| No log | 106.96 | 321 | 0.4635 | 0.915 |
| No log | 107.96 | 324 | 0.4641 | 0.915 |
| No log | 108.96 | 327 | 0.4650 | 0.915 |
| No log | 109.96 | 330 | 0.4652 | 0.915 |
| No log | 110.96 | 333 | 0.4664 | 0.915 |
| No log | 111.96 | 336 | 0.4686 | 0.915 |
| No log | 112.96 | 339 | 0.4718 | 0.915 |
| No log | 113.96 | 342 | 0.4730 | 0.915 |
| No log | 114.96 | 345 | 0.4719 | 0.915 |
| No log | 115.96 | 348 | 0.4697 | 0.915 |
| No log | 116.96 | 351 | 0.4676 | 0.915 |
| No log | 117.96 | 354 | 0.4658 | 0.915 |
| No log | 118.96 | 357 | 0.4655 | 0.915 |
| No log | 119.96 | 360 | 0.4670 | 0.915 |
| No log | 120.96 | 363 | 0.4695 | 0.915 |
| No log | 121.96 | 366 | 0.4728 | 0.915 |
| No log | 122.96 | 369 | 0.4757 | 0.915 |
| No log | 123.96 | 372 | 0.4776 | 0.915 |
| No log | 124.96 | 375 | 0.4782 | 0.915 |
| No log | 125.96 | 378 | 0.4782 | 0.915 |
| No log | 126.96 | 381 | 0.4770 | 0.915 |
| No log | 127.96 | 384 | 0.4760 | 0.915 |
| No log | 128.96 | 387 | 0.4754 | 0.915 |
| No log | 129.96 | 390 | 0.4746 | 0.915 |
| No log | 130.96 | 393 | 0.4745 | 0.915 |
| No log | 131.96 | 396 | 0.4750 | 0.915 |
| No log | 132.96 | 399 | 0.4756 | 0.915 |
| No log | 133.96 | 402 | 0.4766 | 0.915 |
| No log | 134.96 | 405 | 0.4777 | 0.915 |
| No log | 135.96 | 408 | 0.4788 | 0.915 |
| No log | 136.96 | 411 | 0.4799 | 0.915 |
| No log | 137.96 | 414 | 0.4806 | 0.915 |
| No log | 138.96 | 417 | 0.4806 | 0.915 |
| No log | 139.96 | 420 | 0.4805 | 0.915 |
| No log | 140.96 | 423 | 0.4796 | 0.915 |
| No log | 141.96 | 426 | 0.4789 | 0.915 |
| No log | 142.96 | 429 | 0.4785 | 0.915 |
| No log | 143.96 | 432 | 0.4793 | 0.915 |
| No log | 144.96 | 435 | 0.4805 | 0.915 |
| No log | 145.96 | 438 | 0.4814 | 0.915 |
| No log | 146.96 | 441 | 0.4822 | 0.915 |
| No log | 147.96 | 444 | 0.4831 | 0.915 |
| No log | 148.96 | 447 | 0.4840 | 0.915 |
| No log | 149.96 | 450 | 0.4839 | 0.915 |
| No log | 150.96 | 453 | 0.4839 | 0.915 |
| No log | 151.96 | 456 | 0.4842 | 0.915 |
| No log | 152.96 | 459 | 0.4843 | 0.915 |
| No log | 153.96 | 462 | 0.4841 | 0.915 |
| No log | 154.96 | 465 | 0.4838 | 0.915 |
| No log | 155.96 | 468 | 0.4843 | 0.915 |
| No log | 156.96 | 471 | 0.4848 | 0.915 |
| No log | 157.96 | 474 | 0.4851 | 0.915 |
| No log | 158.96 | 477 | 0.4853 | 0.915 |
| No log | 159.96 | 480 | 0.4854 | 0.915 |
| No log | 160.96 | 483 | 0.4857 | 0.915 |
| No log | 161.96 | 486 | 0.4861 | 0.915 |
| No log | 162.96 | 489 | 0.4867 | 0.915 |
| No log | 163.96 | 492 | 0.4873 | 0.915 |
| No log | 164.96 | 495 | 0.4884 | 0.915 |
| No log | 165.96 | 498 | 0.4895 | 0.915 |
| 0.1894 | 166.96 | 501 | 0.4906 | 0.915 |
| 0.1894 | 167.96 | 504 | 0.4912 | 0.915 |
| 0.1894 | 168.96 | 507 | 0.4916 | 0.915 |
| 0.1894 | 169.96 | 510 | 0.4915 | 0.915 |
| 0.1894 | 170.96 | 513 | 0.4913 | 0.915 |
| 0.1894 | 171.96 | 516 | 0.4912 | 0.915 |
| 0.1894 | 172.96 | 519 | 0.4912 | 0.915 |
| 0.1894 | 173.96 | 522 | 0.4913 | 0.915 |
| 0.1894 | 174.96 | 525 | 0.4911 | 0.915 |
| 0.1894 | 175.96 | 528 | 0.4909 | 0.915 |
| 0.1894 | 176.96 | 531 | 0.4910 | 0.915 |
| 0.1894 | 177.96 | 534 | 0.4910 | 0.915 |
| 0.1894 | 178.96 | 537 | 0.4910 | 0.915 |
| 0.1894 | 179.96 | 540 | 0.4909 | 0.915 |
| 0.1894 | 180.96 | 543 | 0.4910 | 0.915 |
| 0.1894 | 181.96 | 546 | 0.4914 | 0.915 |
| 0.1894 | 182.96 | 549 | 0.4920 | 0.915 |
| 0.1894 | 183.96 | 552 | 0.4926 | 0.915 |
| 0.1894 | 184.96 | 555 | 0.4930 | 0.915 |
| 0.1894 | 185.96 | 558 | 0.4933 | 0.915 |
| 0.1894 | 186.96 | 561 | 0.4936 | 0.915 |
| 0.1894 | 187.96 | 564 | 0.4939 | 0.915 |
| 0.1894 | 188.96 | 567 | 0.4939 | 0.915 |
| 0.1894 | 189.96 | 570 | 0.4938 | 0.915 |
| 0.1894 | 190.96 | 573 | 0.4938 | 0.915 |
| 0.1894 | 191.96 | 576 | 0.4936 | 0.915 |
| 0.1894 | 192.96 | 579 | 0.4935 | 0.915 |
| 0.1894 | 193.96 | 582 | 0.4934 | 0.915 |
| 0.1894 | 194.96 | 585 | 0.4934 | 0.915 |
| 0.1894 | 195.96 | 588 | 0.4934 | 0.915 |
| 0.1894 | 196.96 | 591 | 0.4934 | 0.915 |
| 0.1894 | 197.96 | 594 | 0.4933 | 0.915 |
| 0.1894 | 198.96 | 597 | 0.4933 | 0.915 |
| 0.1894 | 199.96 | 600 | 0.4933 | 0.915 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
keonroohparvar/continuer_pipeline | keonroohparvar | 2023-07-05T01:58:51Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"license:apache-2.0",
"diffusers:AudioDiffusionPipeline",
"region:us"
] | null | 2023-07-05T01:42:01Z | ---
license: apache-2.0
---
# ContinuerPipeline
This repo contains most of the work done for my Master's Thesis. The Continuer Pipeline is a pipeline that utilizes a novel Latent Diffusion model architecture to take a piece of music and extend it by 5 seconds.
The pipeline is implemented at a high level in the `continuer_pipeline.py` script, and it extends the [`DiffusionPipeline`](https://huggingface.co/docs/diffusers/v0.17.1/en/api/diffusion_pipeline#diffusers.DiffusionPipeline) class from HuggingFace to allow ease of use.
The file structure of this repo is the following:
```
.
├── legacy # Contains most of the development/attempted methods to get this project working
├── .gitignore # Basic Python .gitignore with custom ignores for local data folders
├── results # Folder with some simple examples of
├── README.md # This file
└── continuer_pipeline.py # The main file that contains the pipeline implementation
```
My Thesis document describes how this tehcnology works in depth, but at a high level, the Continuer Pipeline simply takes in a waveform and predicts what the next 5-second chunk will sound like. It does this using a novel Latent Diffusion model architecture, and ultimately converts all the waveforms to spectrograms to handle this problem in the image space.
|
aroot/wsample.38 | aroot | 2023-07-05T01:58:48Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T00:20:09Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.38
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.38
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2280
- Bleu: 2.8858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
Lyman/ZAODAO | Lyman | 2023-07-05T01:50:02Z | 0 | 0 | null | [
"license:mit",
"region:us"
] | null | 2023-07-05T01:41:13Z | ---
license: mit
---
This is a style Lora model training, the pictures are collected from the Internet, the artist name is zaodao, from China, and she is a new illustrator who combines traditional Chinese techniques.
I am quite satisfied with the effect of this model, so I share it.
Welcome to try and enjoy


|
aroot/wsample.50 | aroot | 2023-07-05T01:48:10Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T00:09:20Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.50
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2173
- Bleu: 2.9605
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
salohnana2018/ABSA-SentencePair-domainAdapt-SemEval-Adapter-pfeiffer_madx-run2 | salohnana2018 | 2023-07-05T01:30:31Z | 0 | 0 | adapter-transformers | [
"adapter-transformers",
"pytorch",
"tensorboard",
"bert",
"adapterhub:Arabic ABSA/SemEvalHotelReview",
"dataset:Hotel",
"region:us"
] | null | 2023-07-05T00:55:24Z | ---
tags:
- bert
- adapterhub:Arabic ABSA/SemEvalHotelReview
- adapter-transformers
datasets:
- Hotel
---
# Adapter `salohnana2018/ABSA-SentencePair-domainAdapt-SemEval-Adapter-pfeiffer_madx-run2` for CAMeL-Lab/bert-base-arabic-camelbert-msa
An [adapter](https://adapterhub.ml) for the `CAMeL-Lab/bert-base-arabic-camelbert-msa` model that was trained on the [Arabic ABSA/SemEvalHotelReview](https://adapterhub.ml/explore/Arabic ABSA/SemEvalHotelReview/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("CAMeL-Lab/bert-base-arabic-camelbert-msa")
adapter_name = model.load_adapter("salohnana2018/ABSA-SentencePair-domainAdapt-SemEval-Adapter-pfeiffer_madx-run2", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here --> |
robsong3/ppo-Huggy | robsong3 | 2023-07-05T01:17:03Z | 4 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2023-07-04T19:30:43Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: robsong3/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
bacillust/dummy-model | bacillust | 2023-07-05T01:08:17Z | 59 | 0 | transformers | [
"transformers",
"tf",
"camembert",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2023-07-05T01:02:44Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: dummy-model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# dummy-model
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
RajkNakka/ppo-SnowballTarget | RajkNakka | 2023-07-05T01:03:10Z | 5 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2023-07-05T01:03:01Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: RajkNakka/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sid/ppo2-LunarLander-v2 | sid | 2023-07-05T01:02:02Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T01:01:49Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 4.52 +/- 120.15
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 1000000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'sid/ppo2-LunarLander-v2'
'batch_size': 512
'minibatch_size': 128}
```
|
multitude0099/ppo-Huggy | multitude0099 | 2023-07-05T00:54:54Z | 12 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2023-07-05T00:54:49Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: multitude0099/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
aroot/wsample.18 | aroot | 2023-07-05T00:52:55Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T23:12:39Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.18
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.18
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2258
- Bleu: 2.9603
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
eclec/announcementClassfication | eclec | 2023-07-05T00:49:35Z | 22 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-04T16:44:48Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: announcementClassfication
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# announcementClassfication
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5613
- Accuracy: 0.85
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.430934731021352e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 15 | 0.6120 | 0.6667 |
| No log | 2.0 | 30 | 0.5613 | 0.85 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
aroot/wsample.49 | aroot | 2023-07-05T00:41:23Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T23:03:25Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.49
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.49
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2266
- Bleu: 3.0080
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
declare-lab/flan-alpaca-xxl | declare-lab | 2023-07-04T23:45:33Z | 13 | 38 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"dataset:tatsu-lab/alpaca",
"arxiv:2306.04757",
"arxiv:2210.11416",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-03-28T13:19:10Z | ---
license: apache-2.0
datasets:
- tatsu-lab/alpaca
---
## 🍮 🦙 Flan-Alpaca: Instruction Tuning from Humans and Machines
📣 We developed Flacuna by fine-tuning Vicuna-13B on the Flan collection. Flacuna is better than Vicuna at problem-solving. Access the model here https://huggingface.co/declare-lab/flacuna-13b-v1.0.
📣 Curious to know the performance of 🍮 🦙 **Flan-Alpaca** on large-scale LLM evaluation benchmark, **InstructEval**? Read our paper [https://arxiv.org/pdf/2306.04757.pdf](https://arxiv.org/pdf/2306.04757.pdf). We evaluated more than 10 open-source instruction-tuned LLMs belonging to various LLM families including Pythia, LLaMA, T5, UL2, OPT, and Mosaic. Codes and datasets: [https://github.com/declare-lab/instruct-eval](https://github.com/declare-lab/instruct-eval)
📣 **FLAN-T5** is also useful in text-to-audio generation. Find our work at [https://github.com/declare-lab/tango](https://github.com/declare-lab/tango) if you are interested.
Our [repository](https://github.com/declare-lab/flan-alpaca) contains code for extending the [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
synthetic instruction tuning to existing instruction-tuned models such as [Flan-T5](https://arxiv.org/abs/2210.11416).
We have a [live interactive demo](https://huggingface.co/spaces/joaogante/transformers_streaming) thanks to [Joao Gante](https://huggingface.co/joaogante)!
We are also benchmarking many instruction-tuned models at [declare-lab/flan-eval](https://github.com/declare-lab/flan-eval).
Our pretrained models are fully available on HuggingFace 🤗 :
| Model | Parameters | Instruction Data | Training GPUs |
|----------------------------------------------------------------------------------|------------|----------------------------------------------------------------------------------------------------------------------------------------------------|-----------------|
| [Flan-Alpaca-Base](https://huggingface.co/declare-lab/flan-alpaca-base) | 220M | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-Large](https://huggingface.co/declare-lab/flan-alpaca-large) | 770M | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-XL](https://huggingface.co/declare-lab/flan-alpaca-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 1x A6000 |
| [Flan-Alpaca-XXL](https://huggingface.co/declare-lab/flan-alpaca-xxl) | 11B | [Flan](https://github.com/google-research/FLAN), [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) | 4x A6000 (FSDP) |
| [Flan-GPT4All-XL](https://huggingface.co/declare-lab/flan-gpt4all-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [GPT4All](https://github.com/nomic-ai/gpt4all) | 1x A6000 |
| [Flan-ShareGPT-XL](https://huggingface.co/declare-lab/flan-sharegpt-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [ShareGPT](https://github.com/domeccleston/sharegpt)/[Vicuna](https://github.com/lm-sys/FastChat) | 1x A6000 |
| [Flan-Alpaca-GPT4-XL*](https://huggingface.co/declare-lab/flan-alpaca-gpt4-xl) | 3B | [Flan](https://github.com/google-research/FLAN), [GPT4-Alpaca](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM) | 1x A6000 |
*recommended for better performance
### Why?
[Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) represents an exciting new direction
to approximate the performance of large language models (LLMs) like ChatGPT cheaply and easily.
Concretely, they leverage an LLM such as GPT-3 to generate instructions as synthetic training data.
The synthetic data which covers more than 50k tasks can then be used to finetune a smaller model.
However, the original implementation is less accessible due to licensing constraints of the
underlying [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) model.
Furthermore, users have noted [potential noise](https://github.com/tloen/alpaca-lora/issues/65) in the synthetic
dataset. Hence, it may be better to explore a fully accessible model that is already trained on high-quality (but
less diverse) instructions such as [Flan-T5](https://arxiv.org/abs/2210.11416).
### Usage
```
from transformers import pipeline
prompt = "Write an email about an alpaca that likes flan"
model = pipeline(model="declare-lab/flan-alpaca-gpt4-xl")
model(prompt, max_length=128, do_sample=True)
# Dear AlpacaFriend,
# My name is Alpaca and I'm 10 years old.
# I'm excited to announce that I'm a big fan of flan!
# We like to eat it as a snack and I believe that it can help with our overall growth.
# I'd love to hear your feedback on this idea.
# Have a great day!
# Best, AL Paca
``` |
gvij/gpt-j-code-alpaca-instruct | gvij | 2023-07-04T23:07:51Z | 5 | 0 | peft | [
"peft",
"gpt-j",
"gpt-j-6b",
"code",
"instruct",
"instruct-code",
"code-alpaca",
"alpaca-instruct",
"alpaca",
"llama7b",
"gpt2",
"dataset:ewof/code-alpaca-instruct-unfiltered",
"region:us"
] | null | 2023-07-04T22:17:52Z | ---
datasets:
- ewof/code-alpaca-instruct-unfiltered
library_name: peft
tags:
- gpt-j
- gpt-j-6b
- code
- instruct
- instruct-code
- code-alpaca
- alpaca-instruct
- alpaca
- llama7b
- gpt2
---
We finetuned GPT-J 6B on Code-Alpaca-Instruct Dataset (ewof/code-alpaca-instruct-unfiltered) for 5 epochs or ~ 25,000 steps using [MonsterAPI](https://monsterapi.ai) no-code [LLM finetuner](https://docs.monsterapi.ai/fine-tune-a-large-language-model-llm).
This dataset is HuggingFaceH4/CodeAlpaca_20K unfiltered, removing 36 instances of blatant alignment.
The finetuning session got completed in 206 minutes and costed us only `$8` for the entire finetuning run!
#### Hyperparameters & Run details:
- Model Path: EleutherAI/gpt-j-6b
- Dataset: ewof/code-alpaca-instruct-unfiltered
- Learning rate: 0.0003
- Number of epochs: 5
- Data split: Training: 90% / Validation: 10%
- Gradient accumulation steps: 1
Loss metrics:

---
license: apache-2.0
--- |
Raizel123/Wanphenlora | Raizel123 | 2023-07-04T23:07:28Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T23:04:51Z | ---
license: creativeml-openrail-m
---
|
tatsu-lab/alpaca-farm-ppo-human-wdiff | tatsu-lab | 2023-07-04T23:05:54Z | 24 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-24T07:38:35Z | Please see https://github.com/tatsu-lab/alpaca_farm#downloading-pre-tuned-alpacafarm-models for details on this model. |
Raizel123/Sweetlora | Raizel123 | 2023-07-04T23:03:36Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T22:59:37Z | ---
license: creativeml-openrail-m
---
|
hopkins/eng-kor-wsample.47 | hopkins | 2023-07-04T23:01:00Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T22:43:02Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.47
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.47
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9922
- Bleu: 6.8895
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-kor-wsample.46 | hopkins | 2023-07-04T22:51:38Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T22:33:56Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.46
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.46
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9958
- Bleu: 6.8285
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
tatsu-lab/alpaca-farm-expiter-human-wdiff | tatsu-lab | 2023-07-04T22:49:14Z | 13 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-24T09:32:53Z | Please see https://github.com/tatsu-lab/alpaca_farm#downloading-pre-tuned-alpacafarm-models for details on this model. |
maxkskhor/Reinforce-CartPole-1 | maxkskhor | 2023-07-04T22:40:25Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T22:40:13Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
liquidn2/Grilled_Lamprey | liquidn2 | 2023-07-04T22:38:23Z | 0 | 3 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T22:08:45Z | ---
license: creativeml-openrail-m
---
|
hopkins/eng-ind-wsample.50 | hopkins | 2023-07-04T22:34:15Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T22:20:26Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-ind-wsample.50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-ind-wsample.50
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7629
- Bleu: 22.0271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-ind-wsample.48 | hopkins | 2023-07-04T22:30:54Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T22:16:50Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-ind-wsample.48
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-ind-wsample.48
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7655
- Bleu: 21.8820
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-deu-wsample.50 | hopkins | 2023-07-04T22:08:16Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:50:10Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-deu-wsample.50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-deu-wsample.50
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6559
- Bleu: 21.0004
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-deu-wsample.48 | hopkins | 2023-07-04T22:04:47Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:46:39Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-deu-wsample.48
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-deu-wsample.48
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6525
- Bleu: 20.8386
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-deu-wsample.47 | hopkins | 2023-07-04T22:03:58Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:45:56Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-deu-wsample.47
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-deu-wsample.47
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6483
- Bleu: 20.8742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
halaskar1283/umitozdag | halaskar1283 | 2023-07-04T21:44:55Z | 0 | 0 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2023-07-04T21:00:29Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Panchovix/GPlatty-30B-SuperHOT-8k | Panchovix | 2023-07-04T21:39:44Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-29T00:09:25Z | ---
license: other
---
[GPlatty-30B](https://huggingface.co/lilloukas/GPlatty-30B) merged with kaiokendev's [33b SuperHOT 8k LoRA](https://huggingface.co/kaiokendev/superhot-30b-8k-no-rlhf-test), without quant. (Full FP16 model) |
Panchovix/Platypus-30B-SuperHOT-8K | Panchovix | 2023-07-04T21:39:37Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-29T00:07:19Z | ---
license: other
---
[Platypus-30B](https://huggingface.co/lilloukas/Platypus-30B) merged with kaiokendev's [33b SuperHOT 8k LoRA](https://huggingface.co/kaiokendev/superhot-30b-8k-no-rlhf-test), without quant. (Full FP16 model) |
Panchovix/WizardLM-Uncensored-SuperCOT-StoryTelling-30b-SuperHOT-8k | Panchovix | 2023-07-04T21:39:29Z | 11 | 2 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-26T20:36:56Z | ---
license: other
---
[WizardLM-Uncensored-SuperCOT-StoryTelling-30b](https://huggingface.co/Monero/WizardLM-Uncensored-SuperCOT-StoryTelling-30b) merged with kaiokendev's [33b SuperHOT 8k LoRA](https://huggingface.co/kaiokendev/superhot-30b-8k-no-rlhf-test), without quant. (Full FP16 model) |
Panchovix/h2ogpt-research-oig-oasst1-512-30b-SuperHOT-8k | Panchovix | 2023-07-04T21:39:00Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-26T04:58:05Z | ---
license: other
---
[h2ogpt-research-oig-oasst1-512-30b ](https://huggingface.co/h2oai/h2ogpt-research-oig-oasst1-512-30b/tree/main) merged with kaiokendev's [33b SuperHOT 8k LoRA](https://huggingface.co/kaiokendev/superhot-30b-8k-no-rlhf-test), without quant. (Full FP16 model) |
hopkins/eng-kor-wsample.43 | hopkins | 2023-07-04T21:38:55Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:21:23Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.43
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.43
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9892
- Bleu: 6.9989
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-kor-wsample.45 | hopkins | 2023-07-04T21:35:27Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:17:56Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.45
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.45
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9907
- Bleu: 7.0592
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/eng-kor-wsample.44 | hopkins | 2023-07-04T21:34:46Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T21:17:13Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.44
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.44
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9949
- Bleu: 6.8417
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
rkla/minetester-treechop_shaped-v0-train_ppo_cleanrl-seed1 | rkla | 2023-07-04T21:25:31Z | 0 | 0 | minetest-baselines | [
"minetest-baselines",
"tensorboard",
"minetester-treechop_shaped-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T21:22:51Z | ---
tags:
- minetester-treechop_shaped-v0
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: minetest-baselines
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: minetester-treechop_shaped-v0
type: minetester-treechop_shaped-v0
metrics:
- type: mean_reward
value: 2.34 +/- 5.74
name: mean_reward
verified: false
---
#**PPO** Agent Playing **minetester-treechop_shaped-v0**
This is a trained model of a PPO agent playing minetester-treechop_shaped-v0.
The model was trained by using [minetest-baselines](https://github.com/EleutherAI/minetest-baselines).
## Command to reproduce the training
```bash
python -m minetest_baselines.train --algo ppo --task minetester-treechop_shaped-v0 --num-envs 2 --save-model --upload-model --hf-entity rkla --total-timesteps 100 --track --wandb-entity rkla
```
# Hyperparameters
```python
{'anneal_lr': True,
'batch_size': 256,
'capture_video': False,
'clip_coef': 0.1,
'cuda': True,
'ent_coef': 0.01,
'env_id': 'minetester-treechop_shaped-v0',
'exp_name': 'train_ppo_cleanrl',
'gae_lambda': 0.95,
'gamma': 0.99,
'hf_entity': 'rkla',
'learning_rate': 0.00025,
'max_grad_norm': 0.5,
'minibatch_size': 64,
'norm_adv': True,
'num_envs': 2,
'num_minibatches': 4,
'num_steps': 128,
'num_updates': 0,
'save_model': True,
'seed': 1,
'target_kl': None,
'torch_deterministic': True,
'total_timesteps': 100,
'track': True,
'update_epochs': 4,
'upload_model': True,
'vf_coef': 0.5,
'wandb_entity': 'rkla',
'wandb_project_name': 'minetest-baselines'}
```
|
0xMaka/finetuning-sentiment-model-3k-samples | 0xMaka | 2023-07-04T21:21:16Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-03T14:39:12Z | ---
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-3k-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.8333333333333334
- name: F1
type: f1
value: 0.8355263157894737
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3k-samples
This model was trained from scratch on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4277
- Accuracy: 0.8333
- F1: 0.8355
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
rkla/minetester-treechop_shaped-v0-train_dqn_cleanrl-seed1 | rkla | 2023-07-04T21:08:37Z | 0 | 0 | cleanrl | [
"cleanrl",
"tensorboard",
"minetester-treechop_shaped-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T21:03:44Z | ---
tags:
- minetester-treechop_shaped-v0
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: minetester-treechop_shaped-v0
type: minetester-treechop_shaped-v0
metrics:
- type: mean_reward
value: -4.68 +/- 0.00
name: mean_reward
verified: false
---
#**DQN** Agent Playing **minetester-treechop_shaped-v0**
This is a trained model of a DQN agent playing minetester-treechop_shaped-v0.
The model was trained by using [minetest-baselines](https://github.com/EleutherAI/minetest-baselines).
## Command to reproduce the training
```bash
python -m minetest_baselines.train --algo DQN --task minetester-treechop_shaped-v0--algo dqn --task minetester-treechop_shaped-v0 --num-envs 1 --save-model --upload-model --hf-entity rkla --buffer-size 10 --total-timesteps 100 --track --wandb-entity rkla
```
# Hyperparameters
```python
{'batch_size': 128,
'buffer_size': 10,
'capture_video': False,
'end_e': 0.01,
'env_id': 'minetester-treechop_shaped-v0',
'exp_name': 'train_dqn_cleanrl',
'exploration_fraction': 0.9,
'gamma': 0.99,
'hf_entity': 'rkla',
'learning_rate': 0.00025,
'learning_starts': 5000,
'num_envs': 1,
'save_model': True,
'seed': 1,
'start_e': 1,
'target_network_frequency': 10000,
'tau': 1.0,
'total_timesteps': 100,
'track': True,
'train_frequency': 10,
'upload_model': True,
'wandb_entity': 'rkla',
'wandb_project_name': 'minetest-baselines'}
```
|
nolanaatama/frnksntr250pchrvcdblstkns | nolanaatama | 2023-07-04T20:51:38Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T20:34:15Z | ---
license: creativeml-openrail-m
---
|
hopkins/eng-deu-wsample.44 | hopkins | 2023-07-04T20:39:35Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T20:21:25Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-deu-wsample.44
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-deu-wsample.44
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6513
- Bleu: 20.8990
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
ykirpichev/whisper-medium.en-finetuned-gtzan | ykirpichev | 2023-07-04T20:33:14Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-07-04T20:10:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: whisper-medium.en-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.94
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium.en-finetuned-gtzan
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2836
- Accuracy: 0.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0049 | 1.0 | 112 | 0.9562 | 0.62 |
| 0.4197 | 2.0 | 225 | 0.4341 | 0.85 |
| 0.3768 | 3.0 | 337 | 0.3772 | 0.89 |
| 0.0268 | 4.0 | 450 | 0.4503 | 0.92 |
| 0.0028 | 4.98 | 560 | 0.2836 | 0.94 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum | hazemOmrann14 | 2023-07-04T20:18:00Z | 13 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-04T16:30:55Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: AraBART-summ-finetuned-xsum-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AraBART-summ-finetuned-xsum-finetuned-xsum
This model is a fine-tuned version of [hazemOmrann14/AraBART-summ-finetuned-xsum](https://huggingface.co/hazemOmrann14/AraBART-summ-finetuned-xsum) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
hopkins/eng-kor-wsample.49 | hopkins | 2023-07-04T20:09:57Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T16:00:27Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-kor-wsample.49
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-kor-wsample.49
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9908
- Bleu: 7.2223
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
eugene-yang/ce-xlmr-large-clir-eng.zho | eugene-yang | 2023-07-04T20:08:51Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-04T20:01:17Z | ---
license: mit
---
Model trained by [Suraj Nair](https://srnair.netlify.app/).
|
pankaj10034/Sentiment_analysis | pankaj10034 | 2023-07-04T20:04:06Z | 0 | 0 | transformers | [
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2023-07-04T20:02:48Z | ---
library_name: transformers
--- |
rafaelelter/ppo-LunarLander-v2 | rafaelelter | 2023-07-04T20:00:54Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-01T18:41:18Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 277.25 +/- 20.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Adoley/covid-tweets-sentiment-analysis-distilbert-model | Adoley | 2023-07-04T19:50:48Z | 124 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-05-11T19:35:51Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: covid-tweets-sentiment-analysis-distilbert-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# covid-tweets-sentiment-analysis-distilbert-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5979
- Rmse: 0.6680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.7464 | 2.0 | 500 | 0.5979 | 0.6680 |
| 0.4318 | 4.0 | 1000 | 0.6374 | 0.6327 |
| 0.1694 | 6.0 | 1500 | 0.9439 | 0.6311 |
| 0.072 | 8.0 | 2000 | 1.1471 | 0.6556 |
| 0.0388 | 10.0 | 2500 | 1.2217 | 0.6437 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AbduBot/q-FrozenLake-v1-4x4-noSlippery | AbduBot | 2023-07-04T19:49:08Z | 0 | 1 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T19:49:05Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
model = load_from_hub(repo_id="AbduBot/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
|
andypyc/news_classifier-distilbert-base-uncased-subject-only | andypyc | 2023-07-04T19:44:27Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-04T19:40:56Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: news_classifier-distilbert-base-uncased-subject-only
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# news_classifier-distilbert-base-uncased-subject-only
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9128
- Accuracy: 0.6719
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 48 | 1.1869 | 0.5417 |
| No log | 2.0 | 96 | 0.9940 | 0.5833 |
| No log | 3.0 | 144 | 0.9497 | 0.5833 |
| No log | 4.0 | 192 | 0.8526 | 0.6146 |
| No log | 5.0 | 240 | 0.8595 | 0.6510 |
| No log | 6.0 | 288 | 0.8548 | 0.6562 |
| No log | 7.0 | 336 | 0.8727 | 0.6823 |
| No log | 8.0 | 384 | 0.9072 | 0.6667 |
| No log | 9.0 | 432 | 0.9282 | 0.6667 |
| No log | 10.0 | 480 | 0.9128 | 0.6719 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jfrojanoj/q-FrozenLake-v1-4x4-noSlippery | jfrojanoj | 2023-07-04T19:38:37Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T19:38:34Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jfrojanoj/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
darkphipps/NinjaAI | darkphipps | 2023-07-04T19:29:56Z | 0 | 0 | adapter-transformers | [
"adapter-transformers",
"question-answering",
"en",
"dataset:Open-Orca/OpenOrca",
"license:openrail",
"region:us"
] | question-answering | 2023-07-04T19:17:39Z | ---
license: openrail
datasets:
- Open-Orca/OpenOrca
language:
- en
library_name: adapter-transformers
pipeline_tag: question-answering
--- |
hopkins/eng-ind-wsample.49 | hopkins | 2023-07-04T19:18:19Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-04T15:59:58Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-ind-wsample.49
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-ind-wsample.49
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7653
- Bleu: 22.0600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
luhx/dqn-SpaceInvadersNoFrameskip-v4 | luhx | 2023-07-04T19:16:36Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T19:16:07Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 257.00 +/- 38.81
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga luhx -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga luhx -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga luhx
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 10000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
heka-ai/tasb-bert-30k | heka-ai | 2023-07-04T19:02:49Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-07-04T19:02:46Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# heka-ai/tasb-bert-30k
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('heka-ai/tasb-bert-30k')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('heka-ai/tasb-bert-30k')
model = AutoModel.from_pretrained('heka-ai/tasb-bert-30k')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=heka-ai/tasb-bert-30k)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 40000 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 40000,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
aksj/falcon-finetuned-pubmed-lora-r-512 | aksj | 2023-07-04T18:47:14Z | 3 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-04T18:40:57Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0.dev0
|
jordyvl/LayoutLMv3_maveriq_tobacco3482_2023-07-04 | jordyvl | 2023-07-04T18:35:44Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"layoutlmv3",
"text-classification",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-04T18:25:14Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: LayoutLMv3_maveriq_tobacco3482_2023-07-04
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# LayoutLMv3_maveriq_tobacco3482_2023-07-04
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9452
- Accuracy: 0.28
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.96 | 3 | 2.1539 | 0.28 |
| No log | 1.96 | 6 | 2.0282 | 0.275 |
| No log | 2.96 | 9 | 2.0001 | 0.265 |
| No log | 3.96 | 12 | 1.9591 | 0.265 |
| No log | 4.96 | 15 | 1.9452 | 0.28 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
omnitron/LunarLander | omnitron | 2023-07-04T18:34:12Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T18:32:07Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.37 +/- 14.32
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Subsets and Splits