
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum | hazemOmrann14 | 2023-07-05T16:28:35Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-05T16:08:14Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AraBART-summ-finetuned-xsum-finetuned-xsum-finetuned-xsum
This model is a fine-tuned version of [hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum](https://huggingface.co/hazemOmrann14/AraBART-summ-finetuned-xsum-finetuned-xsum) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3.328889038158605e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 10 | 2.5240 | 0.0 | 0.0 | 0.0 | 0.0 | 20.0 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
ozsenior13/distilbert-base-uncased-finetuned-squad | ozsenior13 | 2023-07-05T16:24:38Z | 116 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2023-07-05T15:02:16Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2169
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.263 | 1.0 | 5533 | 1.2169 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
NasimB/gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3 | NasimB | 2023-07-05T16:22:18Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T13:27:11Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-cl-rarity-11-135k-mod-datasets-rarity1-root3
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 4.7616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.7003 | 0.05 | 500 | 5.8421 |
| 5.4077 | 0.1 | 1000 | 5.4379 |
| 5.0667 | 0.15 | 1500 | 5.2282 |
| 4.8285 | 0.2 | 2000 | 5.0890 |
| 4.6639 | 0.25 | 2500 | 4.9968 |
| 4.5282 | 0.29 | 3000 | 4.9414 |
| 4.4194 | 0.34 | 3500 | 4.8843 |
| 4.3138 | 0.39 | 4000 | 4.8436 |
| 4.2135 | 0.44 | 4500 | 4.8229 |
| 4.1242 | 0.49 | 5000 | 4.7947 |
| 4.0388 | 0.54 | 5500 | 4.7670 |
| 3.952 | 0.59 | 6000 | 4.7585 |
| 3.8701 | 0.64 | 6500 | 4.7431 |
| 3.8026 | 0.69 | 7000 | 4.7273 |
| 3.7345 | 0.74 | 7500 | 4.7219 |
| 3.6661 | 0.79 | 8000 | 4.7135 |
| 3.6259 | 0.84 | 8500 | 4.7072 |
| 3.5927 | 0.88 | 9000 | 4.7052 |
| 3.5699 | 0.93 | 9500 | 4.7025 |
| 3.5638 | 0.98 | 10000 | 4.7018 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
omar-al-sharif/AlQalam-finetuned-mmj | omar-al-sharif | 2023-07-05T16:21:33Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-05T14:11:56Z | ---
tags:
- generated_from_trainer
model-index:
- name: AlQalam-finetuned-mmj
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AlQalam-finetuned-mmj
This model is a fine-tuned version of [malmarjeh/t5-arabic-text-summarization](https://huggingface.co/malmarjeh/t5-arabic-text-summarization) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0723
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3745 | 1.0 | 1678 | 1.1947 |
| 1.219 | 2.0 | 3356 | 1.1176 |
| 1.065 | 3.0 | 5034 | 1.0895 |
| 0.9928 | 4.0 | 6712 | 1.0734 |
| 0.9335 | 5.0 | 8390 | 1.0723 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
stabilityai/stable-diffusion-2-1-base | stabilityai | 2023-07-05T16:19:20Z | 863,939 | 647 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-12-06T17:25:36Z | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2-1-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints, for various versions:
### Version 2.1
- `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
### Version 2.0
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
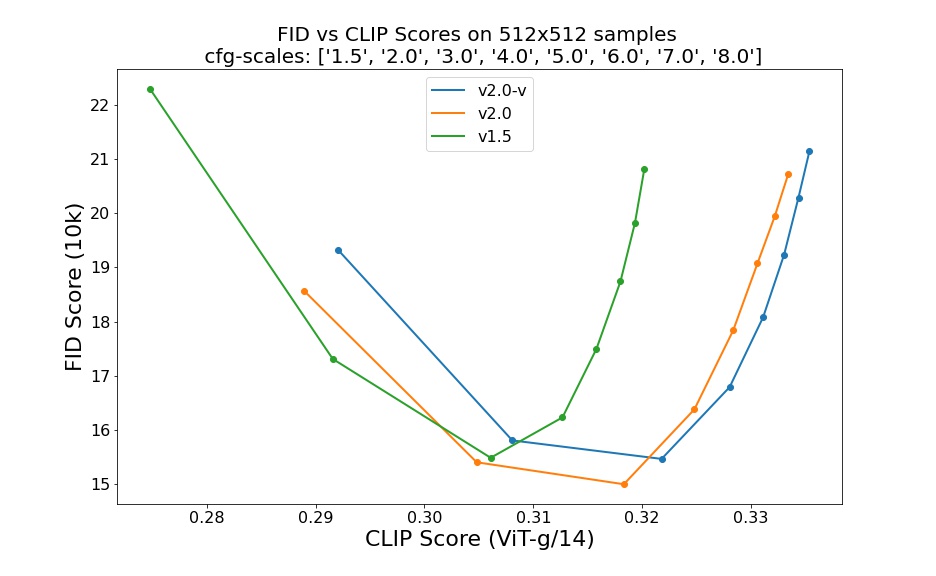
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
stabilityai/stable-diffusion-2-depth | stabilityai | 2023-07-05T16:19:06Z | 8,224 | 386 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"diffusers:StableDiffusionDepth2ImgPipeline",
"region:us"
] | null | 2022-11-23T17:41:46Z | ---
license: openrail++
tags:
- stable-diffusion
inference: false
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2 model, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-depth` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-depth-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-depth/resolve/main/512-depth-ema.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install -U git+https://github.com/huggingface/transformers.git
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to EulerDiscreteScheduler):
```python
import torch
import requests
from PIL import Image
from diffusers import StableDiffusionDepth2ImgPipeline
pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-depth",
torch_dtype=torch.float16,
).to("cuda")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
init_image = Image.open(requests.get(url, stream=True).raw)
prompt = "two tigers"
n_propmt = "bad, deformed, ugly, bad anotomy"
image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
stabilityai/stable-diffusion-2-base | stabilityai | 2023-07-05T16:19:03Z | 83,300 | 349 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-11-23T17:41:31Z | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-base model, available [here](https://github.com/Stability-AI/stablediffusion).
The model is trained from scratch 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`. Then it is further trained for 850k steps at resolution `512x512` on the same dataset on images with resolution `>= 512x512`.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `512-base-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-base/resolve/main/512-base-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2-base#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-base"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
stabilityai/stable-diffusion-2 | stabilityai | 2023-07-05T16:19:01Z | 237,820 | 1,856 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2202.00512",
"arxiv:2112.10752",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-11-23T11:54:34Z | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2 Model Card
This model card focuses on the model associated with the Stable Diffusion v2 model, available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2` model is resumed from [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on `768x768` images.

- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `768-v-ema.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/768-v-ema.ckpt).
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/stable-diffusion-2#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
model_id = "stabilityai/stable-diffusion-2"
# Use the Euler scheduler here instead
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
CompVis/ldm-super-resolution-4x-openimages | CompVis | 2023-07-05T16:18:48Z | 4,364 | 112 | diffusers | [
"diffusers",
"pytorch",
"super-resolution",
"diffusion-super-resolution",
"arxiv:2112.10752",
"license:apache-2.0",
"diffusers:LDMSuperResolutionPipeline",
"region:us"
] | null | 2022-11-09T12:35:04Z | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- super-resolution
- diffusion-super-resolution
---
# Latent Diffusion Models (LDM) for super-resolution
**Paper**: [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)
**Abstract**:
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
**Authors**
*Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer*
## Usage
### Inference with a pipeline
```python
!pip install git+https://github.com/huggingface/diffusers.git
import requests
from PIL import Image
from io import BytesIO
from diffusers import LDMSuperResolutionPipeline
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "CompVis/ldm-super-resolution-4x-openimages"
# load model and scheduler
pipeline = LDMSuperResolutionPipeline.from_pretrained(model_id)
pipeline = pipeline.to(device)
# let's download an image
url = "https://user-images.githubusercontent.com/38061659/199705896-b48e17b8-b231-47cd-a270-4ffa5a93fa3e.png"
response = requests.get(url)
low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
low_res_img = low_res_img.resize((128, 128))
# run pipeline in inference (sample random noise and denoise)
upscaled_image = pipeline(low_res_img, num_inference_steps=100, eta=1).images[0]
# save image
upscaled_image.save("ldm_generated_image.png")
```
|
CompVis/stable-diffusion-v1-1 | CompVis | 2023-07-05T16:18:08Z | 10,189 | 69 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:2207.12598",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-08-19T10:24:23Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: false
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Stable Diffusion v1-1 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion with D🧨iffusers blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-1** was trained on 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en), followed by
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`). For more information, please refer to [Training](#training).
This weights here are intended to be used with the D🧨iffusers library. If you are looking for the weights to be loaded into the CompVis Stable Diffusion codebase, [come here](https://huggingface.co/CompVis/stable-diffusion-v-1-1-original)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion.
```bash
pip install --upgrade diffusers transformers scipy
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-1"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")
```
**Note**:
If you are limited by GPU memory and have less than 10GB of GPU RAM available, please make sure to load the StableDiffusionPipeline in float16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to expect the weights to be in float16 precision:
```py
import torch
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
To swap out the noise scheduler, pass it to `from_pretrained`:
```python
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-1"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
## Training
### Training Data
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
### Training Procedure
Stable Diffusion v1-4 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
We currently provide four checkpoints, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2`. 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [**`stable-diffusion-v1-4`**](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2`.225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
### Training details
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
Jacknjeilfy/BarfBag | Jacknjeilfy | 2023-07-05T16:18:04Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T16:18:04Z | ---
license: creativeml-openrail-m
---
|
ddoc/sdc2 | ddoc | 2023-07-05T16:17:54Z | 0 | 0 | null | [
"region:us"
] | null | 2023-07-05T16:17:15Z |
# Deforum Stable Diffusion — official extension for AUTOMATIC1111's webui
<p align="left">
<a href="https://github.com/deforum-art/sd-webui-deforum/commits"><img alt="Last Commit" src="https://img.shields.io/github/last-commit/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/issues"><img alt="GitHub issues" src="https://img.shields.io/github/issues/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/stargazers"><img alt="GitHub stars" src="https://img.shields.io/github/stars/deforum-art/deforum-for-automatic1111-webui"></a>
<a href="https://github.com/deforum-art/sd-webui-deforum/network"><img alt="GitHub forks" src="https://img.shields.io/github/forks/deforum-art/deforum-for-automatic1111-webui"></a>
</a>
</p>
## Need help? See our [FAQ](https://github.com/deforum-art/sd-webui-deforum/wiki/FAQ-&-Troubleshooting)
## Getting Started
1. Install [AUTOMATIC1111's webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui/).
2. Now two ways: either clone the repo into the `extensions` directory via git commandline launched within in the `stable-diffusion-webui` folder
```sh
git clone https://github.com/deforum-art/sd-webui-deforum extensions/deforum
```
Or download this repository, locate the `extensions` folder within your WebUI installation, create a folder named `deforum` and put the contents of the downloaded directory inside of it. Then restart WebUI.
3. Open the webui, find the Deforum tab at the top of the page.
4. Enter the animation settings. Refer to [this general guide](https://docs.google.com/document/d/1pEobUknMFMkn8F5TMsv8qRzamXX_75BShMMXV8IFslI/edit) and [this guide to math keyframing functions in Deforum](https://docs.google.com/document/d/1pfW1PwbDIuW0cv-dnuyYj1UzPqe23BlSLTJsqazffXM/edit?usp=sharing). However, **in this version prompt weights less than zero don't just like in original Deforum!** Split the positive and the negative prompt in the json section using --neg argument like this "apple:\`where(cos(t)>=0, cos(t), 0)\`, snow --neg strawberry:\`where(cos(t)<0, -cos(t), 0)\`"
5. To view animation frames as they're being made, without waiting for the completion of an animation, go to the 'Settings' tab and set the value of this toolbar **above zero**. Warning: it may slow down the generation process.

6. Run the script and see if you got it working or even got something. **In 3D mode a large delay is expected at first** as the script loads the depth models. In the end, using the default settings the whole thing should consume 6.4 GBs of VRAM at 3D mode peaks and no more than 3.8 GB VRAM in 3D mode if you launch the webui with the '--lowvram' command line argument.
7. After the generation process is completed, click the button with the self-describing name to show the video or gif result right in the GUI!
8. Join our Discord where you can post generated stuff, ask questions and more: https://discord.gg/deforum. <br>
* There's also the 'Issues' tab in the repo, for well... reporting issues ;)
9. Profit!
## Known issues
* This port is not fully backward-compatible with the notebook and the local version both due to the changes in how AUTOMATIC1111's webui handles Stable Diffusion models and the changes in this script to get it to work in the new environment. *Expect* that you may not get exactly the same result or that the thing may break down because of the older settings.
## Screenshots
Amazing raw Deforum animation by [Pxl.Pshr](https://www.instagram.com/pxl.pshr):
* Turn Audio ON!
(Audio credits: SKRILLEX, FRED AGAIN & FLOWDAN - RUMBLE (PHACE'S DNB FLIP))
https://user-images.githubusercontent.com/121192995/224450647-39529b28-be04-4871-bb7a-faf7afda2ef2.mp4
Setting file of that video: [here](https://github.com/deforum-art/sd-webui-deforum/files/11353167/PxlPshrWinningAnimationSettings.txt).
<br>
Main extension tab:

Keyframes tab:

|
CompVis/stable-diffusion-v1-3 | CompVis | 2023-07-05T16:17:35Z | 524 | 37 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2022-08-18T17:54:56Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: false
extra_gated_prompt: |-
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claim no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
Please read the full license carefully here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
extra_gated_heading: Please read the LICENSE to access this model
---
# Stable Diffusion v1-3 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion with D🧨iffusers blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-3** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
For more information, please refer to [Training](#training).
This weights here are intended to be used with the D🧨iffusers library. If you are looking for the weights to be loaded into the CompVis Stable Diffusion codebase, [come here](https://huggingface.co/CompVis/stable-diffusion-v-1-3-original)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
We recommend using [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion.
```bash
pip install --upgrade diffusers transformers scipy
```
Running the pipeline with the default PNDM scheduler:
```python
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-3"
device = "cuda"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
**Note**:
If you are limited by GPU memory and have less than 10GB of GPU RAM available, please make sure to load the StableDiffusionPipeline in float16 precision instead of the default float32 precision as done above. You can do so by telling diffusers to expect the weights to be in float16 precision:
```py
import torch
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to(device)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
To swap out the noise scheduler, pass it to `from_pretrained`:
```python
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
model_id = "CompVis/stable-diffusion-v1-3"
# Use the K-LMS scheduler here instead
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, use_auth_token=True)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5)["sample"][0]
image.save("astronaut_rides_horse.png")
```
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
## Training
### Training Data
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
### Training Procedure
Stable Diffusion v1-4 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
We currently provide four checkpoints, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2`. 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [**`stable-diffusion-v1-4`**](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2`.225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
### Training details
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
dkatsiros/ppo-LunarLander-v2 | dkatsiros | 2023-07-05T16:16:17Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T16:15:56Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.74 +/- 16.94
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
VFiona/opus-mt-en-it-finetuned-en-to-it | VFiona | 2023-07-05T15:59:15Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"marian",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-07-05T10:06:43Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: opus-mt-en-it-finetuned-en-to-it
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-it-finetuned-en-to-it
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-it](https://huggingface.co/Helsinki-NLP/opus-mt-en-it) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|
| No log | 1.0 | 118 | 0.4349 | 68.1929 | 31.879 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1
- Datasets 2.13.1
- Tokenizers 0.11.0
|
iammartian0/whisper-tiny-minds14 | iammartian0 | 2023-07-05T15:58:41Z | 79 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-05T15:22:00Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: whisper-tiny-minds14
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: en-US
split: train
args: en-US
metrics:
- name: Wer
type: wer
value: 0.33707865168539325
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-minds14
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5694
- Wer Ortho: 33.5185
- Wer: 0.3371
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0009 | 17.86 | 500 | 0.5694 | 33.5185 | 0.3371 |
### Framework versions
- Transformers 4.30.1
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
xyzkunn/sdfw | xyzkunn | 2023-07-05T15:49:56Z | 0 | 1 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T15:44:53Z | ---
license: creativeml-openrail-m
---
|
asenella/mmnist_MVTCAEconfig_resnet_seed_0_ratio_0_c | asenella | 2023-07-05T15:32:59Z | 0 | 0 | null | [
"multivae",
"en",
"license:apache-2.0",
"region:us"
] | null | 2023-06-04T16:25:58Z | ---
language: en
tags:
- multivae
license: apache-2.0
---
### Downloading this model from the Hub
This model was trained with multivae. It can be downloaded or reloaded using the method `load_from_hf_hub`
```python
>>> from multivae.models import AutoModel
>>> model = AutoModel.load_from_hf_hub(hf_hub_path="your_hf_username/repo_name")
```
|
Vladislav-HuggingFace/LunarLander-v2 | Vladislav-HuggingFace | 2023-07-05T15:30:34Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T15:30:18Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.10 +/- 20.48
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
rsilg/q-Taxi-v3 | rsilg | 2023-07-05T15:29:28Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T15:02:20Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.48 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="rsilg/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
openai/diffusers-cd_cat256_l2 | openai | 2023-07-05T15:22:35Z | 16 | 1 | diffusers | [
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:2206.00364",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:28:27Z | ---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [cd_cat256_l2.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was distilled (via consistency distillation (CD)) from an [EDM model](https://arxiv.org/pdf/2206.00364.pdf) trained on the LSUN Cat 256x256 dataset, using the [L2 distance](https://en.wikipedia.org/wiki/Norm_(mathematics)#Euclidean_norm) as the measure of closeness.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `cd_cat256_l2` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-cd_cat256_l2")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `cd_cat256_l2` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the cd_cat256_l2 checkpoint.
model_id_or_path = "openai/diffusers-cd_cat256_l2"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("cd_cat256_l2_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L86
image = pipe(num_inference_steps=None, timesteps=[18, 0]).images[0]
image.save("cd_cat256_l2_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model, distilled from a diffusion model
- **Dataset:** LSUN Cat 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was distilled by the Consistency Model authors from an EDM diffusion model, also originally trained by the authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information. |
openai/diffusers-ct_bedroom256 | openai | 2023-07-05T15:21:59Z | 11 | 3 | diffusers | [
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:28:42Z | ---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [ct_bedroom256.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was trained on the LSUN Bedroom 256x256 dataset using the consistency training (CT) algorithm.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `ct_bedroom256` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-ct_bedroom256")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `ct_bedroom256` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the ct_bedroom256 checkpoint.
model_id_or_path = "openai/diffusers-ct_bedroom256"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("ct_bedroom256_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L89
image = pipe(num_inference_steps=None, timesteps=[67, 0]).images[0]
image.save("ct_bedroom256_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model, distilled from a diffusion model
- **Dataset:** LSUN Bedroom 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was trained by the Consistency Model authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information. |
openai/diffusers-cd_bedroom256_lpips | openai | 2023-07-05T15:21:52Z | 202 | 3 | diffusers | [
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:2206.00364",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:28:02Z | ---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [cd_bedroom256_lpips.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was distilled (via consistency distillation (CD)) from an [EDM model](https://arxiv.org/pdf/2206.00364.pdf) trained on the LSUN Bedroom 256x256 dataset, using [LPIPS](https://richzhang.github.io/PerceptualSimilarity/) as the measure of closeness.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `cd_bedroom256_lpips` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-cd_bedroom256_lpips")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `cd_bedroom256_lpips` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the cd_bedroom256_lpips checkpoint.
model_id_or_path = "openai/diffusers-cd_bedroom256_lpips"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("cd_bedroom256_lpips_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L83
image = pipe(num_inference_steps=None, timesteps=[17, 0]).images[0]
image.save("cd_bedroom256_lpips_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model, distilled from a diffusion model
- **Dataset:** LSUN Bedroom 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was distilled by the Consistency Model authors from an EDM diffusion model, also originally trained by the authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information. |
openai/diffusers-ct_cat256 | openai | 2023-07-05T15:21:45Z | 27 | 3 | diffusers | [
"diffusers",
"generative model",
"unconditional image generation",
"consistency-model",
"arxiv:2303.01469",
"arxiv:1506.03365",
"arxiv:1512.00567",
"license:mit",
"diffusers:ConsistencyModelPipeline",
"region:us"
] | null | 2023-07-05T13:27:29Z | ---
license: mit
tags:
- generative model
- unconditional image generation
- consistency-model
---
**Disclaimer**: This model was added by the amazing community contributors [dg845](https://huggingface.co/dg845) and [ayushtues](https://huggingface.co/ayushtues)❤️
Consistency models are a new class of generative models introduced in ["Consistency Models"](https://arxiv.org/abs/2303.01469) ([paper](https://arxiv.org/pdf/2303.01469.pdf), [code](https://github.com/openai/consistency_models)) by Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever.
From the paper abstract:
> Diffusion models have significantly advanced the fields of image, audio, and video generation, but
they depend on an iterative sampling process that causes slow generation. To overcome this limitation,
we propose consistency models, a new family of models that generate high quality samples by directly
mapping noise to data. They support fast one-step generation by design, while still allowing multistep
sampling to trade compute for sample quality. They also support zero-shot data editing, such as image
inpainting, colorization, and super-resolution, without requiring explicit training on these tasks.
Consistency models can be trained either by distilling pre-trained diffusion models, or as standalone
generative models altogether. Through extensive experiments, we demonstrate that they outperform
existing distillation techniques for diffusion models in one- and few-step sampling, achieving the new
state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64 x 64 for one-step generation. When
trained in isolation, consistency models become a new family of generative models that can outperform
existing one-step, non-adversarial generative models on standard benchmarks such as CIFAR-10, ImageNet
64 x 64 and LSUN 256 x 256.
Intuitively, a consistency model can be thought of as a model which, when evaluated on a noisy image and timestep, returns an output image sample similar to that which would be returned by running a sampling algorithm on a diffusion model.
Consistency models can be parameterized by any neural network whose input has the same dimensionality as its output, such as a U-Net.
More precisely, given a teacher diffusion model and fixed sampler, we can train ("distill") a consistency model such that when it is given a noisy image and its corresponding timestep, the output sample of the consistency model will be close to the output that would result by using the sampler on the diffusion model to produce a sample, starting at the same noisy image and timestep.
The authors call this procedure "consistency distillation (CD)".
Consistency models can also be trained from scratch to generate clean images from a noisy image and timestep, which the authors call "consistency training (CT)".
This model is a `diffusers`-compatible version of the [ct_cat256.pt](https://github.com/openai/consistency_models#pre-trained-models) checkpont from the [original code and model release](https://github.com/openai/consistency_models).
This model was trained on the LSUN Cat 256x256 dataset using the consistency training (CT) algorithm.
See the [original model card](https://github.com/openai/consistency_models/blob/main/model-card.md) for more information.
## Download
The original PyTorch model checkpoint can be downloaded from the [original code and model release](https://github.com/openai/consistency_models#pre-trained-models).
The `diffusers` pipeline for the `ct_cat256` model can be downloaded as follows:
```python
from diffusers import ConsistencyModelPipeline
pipe = ConsistencyModelPipeline.from_pretrained("openai/diffusers-ct_cat256")
```
## Usage
The original model checkpoint can be used with the [original consistency models codebase](https://github.com/openai/consistency_models).
Here is an example of using the `cd_cat256_l2` checkpoint with `diffusers`:
```python
import torch
from diffusers import ConsistencyModelPipeline
device = "cuda"
# Load the ct_cat256 checkpoint.
model_id_or_path = "openai/diffusers-ct_cat256"
pipe = ConsistencyModelPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
pipe.to(device)
# Onestep Sampling
image = pipe(num_inference_steps=1).images[0]
image.save("ct_cat256_onestep_sample.png")
# Multistep sampling
# Timesteps can be explicitly specified; the particular timesteps below are from the original Github repo:
# https://github.com/openai/consistency_models/blob/main/scripts/launch.sh#L92
image = pipe(num_inference_steps=None, timesteps=[62, 0]).images[0]
image.save("ct_cat256_multistep_sample.png")
```
## Model Details
- **Model type:** Consistency model unconditional image generation model
- **Dataset:** LSUN Cat 256x256
- **License:** MIT
- **Model Description:** This model performs unconditional image generation. Its main component is a U-Net, which parameterizes the consistency model. This model was trained by the Consistency Model authors.
- **Resources for more information:**: [Paper](https://arxiv.org/abs/2303.01469), [GitHub Repository](https://github.com/openai/consistency_models), [Original Model Card](/openai/consistency_models/blob/main/model-card.md)
## Datasets
_Note: This section is taken from the ["Datasets" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#datasets)_.
The models that we are making available have been trained on the [ILSVRC 2012 subset of ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) or on individual categories from [LSUN](https://arxiv.org/abs/1506.03365). Here we outline the characteristics of these datasets that influence the behavior of the models:
**ILSVRC 2012 subset of ImageNet**: This dataset was curated in 2012 and has around a million pictures, each of which belongs to one of 1,000 categories. A significant number of the categories in this dataset are animals, plants, and other naturally occurring objects. Although many photographs include humans, these humans are typically not represented by the class label (for example, the category "Tench, tinca tinca" includes many photographs of individuals holding fish).
**LSUN**: This dataset was collected in 2015 by a combination of human labeling via Amazon Mechanical Turk and automated data labeling. Both classes that we consider have more than a million images. The dataset creators discovered that when assessed by trained experts, the label accuracy was approximately 90% throughout the entire LSUN dataset. The pictures are gathered from the internet, and those in the cat class often follow a "meme" format. Occasionally, people, including faces, appear in these photographs.
## Performance
_Note: This section is taken from the ["Performance" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#performance)_.
These models are intended to generate samples consistent with their training distributions.
This has been measured in terms of FID, Inception Score, Precision, and Recall.
These metrics all rely on the representations of a [pre-trained Inception-V3 model](https://arxiv.org/abs/1512.00567),
which was trained on ImageNet, and so is likely to focus more on the ImageNet classes (such as animals) than on other visual features (such as human faces).
## Intended Use
_Note: This section is taken from the ["Intended Use" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#intended-use)_.
These models are intended to be used for research purposes only. In particular, they can be used as a baseline for generative modeling research, or as a starting point for advancing such research. These models are not intended to be commercially deployed. Additionally, they are not intended to be used to create propaganda or offensive imagery.
## Limitations
_Note: This section is taken from the ["Limitations" section of the original model card](https://github.com/openai/consistency_models/blob/main/model-card.md#limitations)_.
These models sometimes produce highly unrealistic outputs, particularly when generating images containing human faces.
This may stem from ImageNet's emphasis on non-human objects.
In consistency distillation and training, minimizing LPIPS results in better sample quality, as evidenced by improved FID and Inception scores. However, it also carries the risk of overestimating model performance, because LPIPS uses a VGG network pre-trained on ImageNet, while FID and Inception scores also rely on convolutional neural networks (the Inception network in particular) pre-trained on the same ImageNet dataset. Although these two convolutional neural networks do not share the same architecture and we extract latents from them in substantially different ways, knowledge leakage is still plausible which can undermine the fidelity of FID and Inception scores.
Because ImageNet and LSUN contain images from the internet, they include photos of real people, and the model may have memorized some of the information contained in these photos. However, these images are already publicly available, and existing generative models trained on ImageNet have not demonstrated significant leakage of this information. |
jeff-RQ/new-test-model | jeff-RQ | 2023-07-05T15:01:24Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"blip-2",
"visual-question-answering",
"vision",
"image-to-text",
"image-captioning",
"en",
"arxiv:2301.12597",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-to-text | 2023-07-04T14:52:07Z | ---
language: en
license: mit
tags:
- vision
- image-to-text
- image-captioning
- visual-question-answering
pipeline_tag: image-to-text
duplicated_from: Salesforce/blip2-opt-2.7b
---
# BLIP-2, OPT-2.7b, pre-trained only
BLIP-2 model, leveraging [OPT-2.7b](https://huggingface.co/facebook/opt-2.7b) (a large language model with 2.7 billion parameters).
It was introduced in the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Li et al. and first released in [this repository](https://github.com/salesforce/LAVIS/tree/main/projects/blip2).
Disclaimer: The team releasing BLIP-2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BLIP-2 consists of 3 models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model.
The authors initialize the weights of the image encoder and large language model from pre-trained checkpoints and keep them frozen
while training the Querying Transformer, which is a BERT-like Transformer encoder that maps a set of "query tokens" to query embeddings,
which bridge the gap between the embedding space of the image encoder and the large language model.
The goal for the model is simply to predict the next text token, giving the query embeddings and the previous text.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
This allows the model to be used for tasks like:
- image captioning
- visual question answering (VQA)
- chat-like conversations by feeding the image and the previous conversation as prompt to the model
## Direct Use and Downstream Use
You can use the raw model for conditional text generation given an image and optional text. See the [model hub](https://huggingface.co/models?search=Salesforce/blip) to look for
fine-tuned versions on a task that interests you.
## Bias, Risks, Limitations, and Ethical Considerations
BLIP2-OPT uses off-the-shelf OPT as the language model. It inherits the same risks and limitations as mentioned in Meta's model card.
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
>
BLIP2 is fine-tuned on image-text datasets (e.g. [LAION](https://laion.ai/blog/laion-400-open-dataset/) ) collected from the internet. As a result the model itself is potentially vulnerable to generating equivalently inappropriate content or replicating inherent biases in the underlying data.
BLIP2 has not been tested in real world applications. It should not be directly deployed in any applications. Researchers should first carefully assess the safety and fairness of the model in relation to the specific context they’re being deployed within.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example).
#### Running the model on CPU
<details>
<summary> Click to expand </summary>
```python
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
#### Running the model on GPU
##### In full precision
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
##### In half precision (`float16`)
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16, device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details>
##### In 8-bit precision (`int8`)
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate bitsandbytes
import torch
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map="auto")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
question = "how many dogs are in the picture?"
inputs = processor(raw_image, question, return_tensors="pt").to("cuda", torch.float16)
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
```
</details> |
NasimB/gpt2-dp-mod-datasets-rarity1-rerun | NasimB | 2023-07-05T14:56:13Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:49:19Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-mod-datasets-rarity1-rerun
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-mod-datasets-rarity1-rerun
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9787
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.7084 | 0.28 | 500 | 5.6576 |
| 5.3752 | 0.55 | 1000 | 5.2425 |
| 5.0307 | 0.83 | 1500 | 4.9836 |
| 4.7909 | 1.1 | 2000 | 4.8439 |
| 4.5953 | 1.38 | 2500 | 4.7316 |
| 4.5122 | 1.65 | 3000 | 4.6381 |
| 4.427 | 1.93 | 3500 | 4.5558 |
| 4.2204 | 2.2 | 4000 | 4.5216 |
| 4.1628 | 2.48 | 4500 | 4.4629 |
| 4.1262 | 2.75 | 5000 | 4.4110 |
| 4.0687 | 3.03 | 5500 | 4.3795 |
| 3.844 | 3.3 | 6000 | 4.3767 |
| 3.8487 | 3.58 | 6500 | 4.3454 |
| 3.839 | 3.85 | 7000 | 4.3102 |
| 3.6914 | 4.13 | 7500 | 4.3299 |
| 3.5631 | 4.4 | 8000 | 4.3255 |
| 3.5612 | 4.68 | 8500 | 4.3048 |
| 3.5508 | 4.95 | 9000 | 4.2833 |
| 3.3422 | 5.23 | 9500 | 4.3169 |
| 3.3036 | 5.5 | 10000 | 4.3117 |
| 3.3052 | 5.78 | 10500 | 4.3068 |
| 3.267 | 6.05 | 11000 | 4.3145 |
| 3.1427 | 6.33 | 11500 | 4.3211 |
| 3.1445 | 6.6 | 12000 | 4.3209 |
| 3.1484 | 6.88 | 12500 | 4.3213 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
robsong3/distilbert-base-uncased-finetuned-cola | robsong3 | 2023-07-05T14:55:09Z | 61 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T13:16:55Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: robsong3/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# robsong3/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1931
- Validation Loss: 0.5174
- Train Matthews Correlation: 0.5396
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5157 | 0.4443 | 0.5062 | 0 |
| 0.3214 | 0.4521 | 0.5370 | 1 |
| 0.1931 | 0.5174 | 0.5396 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
ddoc/sdc | ddoc | 2023-07-05T14:53:56Z | 0 | 0 | null | [
"region:us"
] | null | 2023-07-05T14:53:05Z | # ControlNet for Stable Diffusion WebUI
The WebUI extension for ControlNet and other injection-based SD controls.

This extension is for AUTOMATIC1111's [Stable Diffusion web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui), allows the Web UI to add [ControlNet](https://github.com/lllyasviel/ControlNet) to the original Stable Diffusion model to generate images. The addition is on-the-fly, the merging is not required.
# Installation
1. Open "Extensions" tab.
2. Open "Install from URL" tab in the tab.
3. Enter `https://github.com/Mikubill/sd-webui-controlnet.git` to "URL for extension's git repository".
4. Press "Install" button.
5. Wait for 5 seconds, and you will see the message "Installed into stable-diffusion-webui\extensions\sd-webui-controlnet. Use Installed tab to restart".
6. Go to "Installed" tab, click "Check for updates", and then click "Apply and restart UI". (The next time you can also use these buttons to update ControlNet.)
7. Completely restart A1111 webui including your terminal. (If you do not know what is a "terminal", you can reboot your computer to achieve the same effect.)
8. Download models (see below).
9. After you put models in the correct folder, you may need to refresh to see the models. The refresh button is right to your "Model" dropdown.
**Update from ControlNet 1.0 to 1.1:**
* If you are not sure, you can back up and remove the folder "stable-diffusion-webui\extensions\sd-webui-controlnet", and then start from the step 1 in the above Installation section.
* Or you can start from the step 6 in the above Install section.
# Download Models
Right now all the 14 models of ControlNet 1.1 are in the beta test.
Download the models from ControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
You need to download model files ending with ".pth" .
Put models in your "stable-diffusion-webui\extensions\sd-webui-controlnet\models". Now we have already included all "yaml" files. You only need to download "pth" files.
Do not right-click the filenames in HuggingFace website to download. Some users right-clicked those HuggingFace HTML websites and saved those HTML pages as PTH/YAML files. They are not downloading correct files. Instead, please click the small download arrow “↓” icon in HuggingFace to download.
Note: If you download models elsewhere, please make sure that yaml file names and model files names are same. Please manually rename all yaml files if you download from other sources. (Some models like "shuffle" needs the yaml file so that we know the outputs of ControlNet should pass a global average pooling before injecting to SD U-Nets.)
# New Features in ControlNet 1.1
### Perfect Support for All ControlNet 1.0/1.1 and T2I Adapter Models.
Now we have perfect support all available models and preprocessors, including perfect support for T2I style adapter and ControlNet 1.1 Shuffle. (Make sure that your YAML file names and model file names are same, see also YAML files in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".)
### Perfect Support for A1111 High-Res. Fix
Now if you turn on High-Res Fix in A1111, each controlnet will output two different control images: a small one and a large one. The small one is for your basic generating, and the big one is for your High-Res Fix generating. The two control images are computed by a smart algorithm called "super high-quality control image resampling". This is turned on by default, and you do not need to change any setting.
### Perfect Support for All A1111 Img2Img or Inpaint Settings and All Mask Types
Now ControlNet is extensively tested with A1111's different types of masks, including "Inpaint masked"/"Inpaint not masked", and "Whole picture"/"Only masked", and "Only masked padding"&"Mask blur". The resizing perfectly matches A1111's "Just resize"/"Crop and resize"/"Resize and fill". This means you can use ControlNet in nearly everywhere in your A1111 UI without difficulty!
### The New "Pixel-Perfect" Mode
Now if you turn on pixel-perfect mode, you do not need to set preprocessor (annotator) resolutions manually. The ControlNet will automatically compute the best annotator resolution for you so that each pixel perfectly matches Stable Diffusion.
### User-Friendly GUI and Preprocessor Preview
We reorganized some previously confusing UI like "canvas width/height for new canvas" and it is in the 📝 button now. Now the preview GUI is controlled by the "allow preview" option and the trigger button 💥. The preview image size is better than before, and you do not need to scroll up and down - your a1111 GUI will not be messed up anymore!
### Support for Almost All Upscaling Scripts
Now ControlNet 1.1 can support almost all Upscaling/Tile methods. ControlNet 1.1 support the script "Ultimate SD upscale" and almost all other tile-based extensions. Please do not confuse ["Ultimate SD upscale"](https://github.com/Coyote-A/ultimate-upscale-for-automatic1111) with "SD upscale" - they are different scripts. Note that the most recommended upscaling method is ["Tiled VAE/Diffusion"](https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111) but we test as many methods/extensions as possible. Note that "SD upscale" is supported since 1.1.117, and if you use it, you need to leave all ControlNet images as blank (We do not recommend "SD upscale" since it is somewhat buggy and cannot be maintained - use the "Ultimate SD upscale" instead).
### More Control Modes (previously called Guess Mode)
We have fixed many bugs in previous 1.0’s Guess Mode and now it is called Control Mode

Now you can control which aspect is more important (your prompt or your ControlNet):
* "Balanced": ControlNet on both sides of CFG scale, same as turning off "Guess Mode" in ControlNet 1.0
* "My prompt is more important": ControlNet on both sides of CFG scale, with progressively reduced SD U-Net injections (layer_weight*=0.825**I, where 0<=I <13, and the 13 means ControlNet injected SD 13 times). In this way, you can make sure that your prompts are perfectly displayed in your generated images.
* "ControlNet is more important": ControlNet only on the Conditional Side of CFG scale (the cond in A1111's batch-cond-uncond). This means the ControlNet will be X times stronger if your cfg-scale is X. For example, if your cfg-scale is 7, then ControlNet is 7 times stronger. Note that here the X times stronger is different from "Control Weights" since your weights are not modified. This "stronger" effect usually has less artifact and give ControlNet more room to guess what is missing from your prompts (and in the previous 1.0, it is called "Guess Mode").
<table width="100%">
<tr>
<td width="25%" style="text-align: center">Input (depth+canny+hed)</td>
<td width="25%" style="text-align: center">"Balanced"</td>
<td width="25%" style="text-align: center">"My prompt is more important"</td>
<td width="25%" style="text-align: center">"ControlNet is more important"</td>
</tr>
<tr>
<td width="25%" style="text-align: center"><img src="samples/cm1.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm2.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm3.png"></td>
<td width="25%" style="text-align: center"><img src="samples/cm4.png"></td>
</tr>
</table>
### Reference-Only Control
Now we have a `reference-only` preprocessor that does not require any control models. It can guide the diffusion directly using images as references.
(Prompt "a dog running on grassland, best quality, ...")

This method is similar to inpaint-based reference but it does not make your image disordered.
Many professional A1111 users know a trick to diffuse image with references by inpaint. For example, if you have a 512x512 image of a dog, and want to generate another 512x512 image with the same dog, some users will connect the 512x512 dog image and a 512x512 blank image into a 1024x512 image, send to inpaint, and mask out the blank 512x512 part to diffuse a dog with similar appearance. However, that method is usually not very satisfying since images are connected and many distortions will appear.
This `reference-only` ControlNet can directly link the attention layers of your SD to any independent images, so that your SD will read arbitary images for reference. You need at least ControlNet 1.1.153 to use it.
To use, just select `reference-only` as preprocessor and put an image. Your SD will just use the image as reference.
*Note that this method is as "non-opinioned" as possible. It only contains very basic connection codes, without any personal preferences, to connect the attention layers with your reference images. However, even if we tried best to not include any opinioned codes, we still need to write some subjective implementations to deal with weighting, cfg-scale, etc - tech report is on the way.*
More examples [here](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236).
# Technical Documents
See also the documents of ControlNet 1.1:
https://github.com/lllyasviel/ControlNet-v1-1-nightly#model-specification
# Default Setting
This is my setting. If you run into any problem, you can use this setting as a sanity check
# Use Previous Models
### Use ControlNet 1.0 Models
https://huggingface.co/lllyasviel/ControlNet/tree/main/models
You can still use all previous models in the previous ControlNet 1.0. Now, the previous "depth" is now called "depth_midas", the previous "normal" is called "normal_midas", the previous "hed" is called "softedge_hed". And starting from 1.1, all line maps, edge maps, lineart maps, boundary maps will have black background and white lines.
### Use T2I-Adapter Models
(From TencentARC/T2I-Adapter)
To use T2I-Adapter models:
1. Download files from https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
2. Put them in "stable-diffusion-webui\extensions\sd-webui-controlnet\models".
3. Make sure that the file names of pth files and yaml files are consistent.
*Note that "CoAdapter" is not implemented yet.*
# Gallery
The below results are from ControlNet 1.0.
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-source.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/bal-gen.png?raw=true"> |
| (no preprocessor) | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/dog_rel.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_input.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro_canny.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/mahiro-out.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_hed.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/evt_gen.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-source.jpg?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-pose.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/an-gen.png?raw=true"> |
|<img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-src.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-dep.png?raw=true"> | <img width="256" alt="" src="https://github.com/Mikubill/sd-webui-controlnet/blob/main/samples/sk-b-out.png?raw=true"> |
The below examples are from T2I-Adapter.
From `t2iadapter_color_sd14v1.pth` :
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947435-1164e7d8-d857-42f9-ab10-2d4a4b25f33a.png"> | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947557-5520d5f8-88b4-474d-a576-5c9cd3acac3a.png"> |
From `t2iadapter_style_sd14v1.pth` :
| Source | Input | Output |
|:-------------------------:|:-------------------------:|:-------------------------:|
| <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222947416-ec9e52a4-a1d0-48d8-bb81-736bf636145e.jpeg"> | (clip, non-image) | <img width="256" alt="" src="https://user-images.githubusercontent.com/31246794/222965711-7b884c9e-7095-45cb-a91c-e50d296ba3a2.png"> |
# Minimum Requirements
* (Windows) (NVIDIA: Ampere) 4gb - with `--xformers` enabled, and `Low VRAM` mode ticked in the UI, goes up to 768x832
# Multi-ControlNet
This option allows multiple ControlNet inputs for a single generation. To enable this option, change `Multi ControlNet: Max models amount (requires restart)` in the settings. Note that you will need to restart the WebUI for changes to take effect.
<table width="100%">
<tr>
<td width="25%" style="text-align: center">Source A</td>
<td width="25%" style="text-align: center">Source B</td>
<td width="25%" style="text-align: center">Output</td>
</tr>
<tr>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448620-cd3ede92-8d3f-43d5-b771-32dd8417618f.png"></td>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448619-beed9bdb-f6bb-41c2-a7df-aa3ef1f653c5.png"></td>
<td width="25%" style="text-align: center"><img src="https://user-images.githubusercontent.com/31246794/220448613-c99a9e04-0450-40fd-bc73-a9122cefaa2c.png"></td>
</tr>
</table>
# Control Weight/Start/End
Weight is the weight of the controlnet "influence". It's analogous to prompt attention/emphasis. E.g. (myprompt: 1.2). Technically, it's the factor by which to multiply the ControlNet outputs before merging them with original SD Unet.
Guidance Start/End is the percentage of total steps the controlnet applies (guidance strength = guidance end). It's analogous to prompt editing/shifting. E.g. \[myprompt::0.8\] (It applies from the beginning until 80% of total steps)
# Batch Mode
Put any unit into batch mode to activate batch mode for all units. Specify a batch directory for each unit, or use the new textbox in the img2img batch tab as a fallback. Although the textbox is located in the img2img batch tab, you can use it to generate images in the txt2img tab as well.
Note that this feature is only available in the gradio user interface. Call the APIs as many times as you want for custom batch scheduling.
# API and Script Access
This extension can accept txt2img or img2img tasks via API or external extension call. Note that you may need to enable `Allow other scripts to control this extension` in settings for external calls.
To use the API: start WebUI with argument `--api` and go to `http://webui-address/docs` for documents or checkout [examples](https://github.com/Mikubill/sd-webui-controlnet/blob/main/example/api_txt2img.ipynb).
To use external call: Checkout [Wiki](https://github.com/Mikubill/sd-webui-controlnet/wiki/API)
# Command Line Arguments
This extension adds these command line arguments to the webui:
```
--controlnet-dir <path to directory with controlnet models> ADD a controlnet models directory
--controlnet-annotator-models-path <path to directory with annotator model directories> SET the directory for annotator models
--no-half-controlnet load controlnet models in full precision
--controlnet-preprocessor-cache-size Cache size for controlnet preprocessor results
--controlnet-loglevel Log level for the controlnet extension
```
# MacOS Support
Tested with pytorch nightly: https://github.com/Mikubill/sd-webui-controlnet/pull/143#issuecomment-1435058285
To use this extension with mps and normal pytorch, currently you may need to start WebUI with `--no-half`.
# Archive of Deprecated Versions
The previous version (sd-webui-controlnet 1.0) is archived in
https://github.com/lllyasviel/webui-controlnet-v1-archived
Using this version is not a temporary stop of updates. You will stop all updates forever.
Please consider this version if you work with professional studios that requires 100% reproducing of all previous results pixel by pixel.
# Thanks
This implementation is inspired by kohya-ss/sd-webui-additional-networks
|
dannywan/distilhubert-finetuned-gtzan2 | dannywan | 2023-07-05T14:52:59Z | 161 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-07-05T14:41:31Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8885
- Accuracy: 0.54
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.8212 | 1.0 | 113 | 1.8885 | 0.54 |
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1+cu116
- Datasets 2.13.1
- Tokenizers 0.12.1
|
johko/diffusion-course-butterflies-32 | johko | 2023-07-05T14:43:20Z | 36 | 0 | diffusers | [
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] | unconditional-image-generation | 2023-07-05T14:43:04Z | ---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('johko/diffusion-course-butterflies-32')
image = pipeline().images[0]
image
```
|
sjdata/ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan | sjdata | 2023-07-05T14:31:24Z | 163 | 0 | transformers | [
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-07-05T14:00:35Z | ---
license: bsd-3-clause
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6230
- Accuracy: 0.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1198 | 1.0 | 450 | 1.8429 | 0.47 |
| 0.0005 | 2.0 | 900 | 1.6282 | 0.71 |
| 0.3129 | 3.0 | 1350 | 1.0553 | 0.73 |
| 0.0225 | 4.0 | 1800 | 0.9422 | 0.82 |
| 0.0025 | 5.0 | 2250 | 0.6008 | 0.85 |
| 0.0 | 6.0 | 2700 | 0.7194 | 0.86 |
| 0.0 | 7.0 | 3150 | 0.6268 | 0.89 |
| 0.0 | 8.0 | 3600 | 0.6372 | 0.89 |
| 0.0 | 9.0 | 4050 | 0.6167 | 0.89 |
| 0.0 | 10.0 | 4500 | 0.6230 | 0.89 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
julep-ai/samantha-33b | julep-ai | 2023-07-05T13:57:48Z | 12 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:julep-ai/samantha_finetune_dataset_03",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-22T09:09:31Z | ---
library_name: transformers
datasets:
- julep-ai/samantha_finetune_dataset_03
language:
- en
---
# Samantha
## Technical notes
This model is trained on a specialized dataset and uses special sentinel tokens to demarcate conversations.
**Important Note: These sentinels are similar to gpt2-style special tokens but they are <u>NOT</u> added as special tokens in the tokenizer.**
### Usage
For usage, you can refer to the [`chat.py`](https://huggingface.co/julep-ai/samantha-33b/blob/main/chat.py) file in this repo for an example.
### Concepts
- Each conversation consists of n "sections"
- Each section can be one of:
+ `me`: The model
+ `person`: The speaker
+ `situation`: relevant background information to set the context of the conversation
+ `thought`: Thoughts generated by the model for parsing intermediate steps etc
+ `information`: External information added into the context by the system running the model
- The model and speaker sections can optionally include a name like `me (Samantha)` or `person (Dmitry)`
### Sentinel Tokens
- `<|section|>` token marks the start of a "section"
- `<|endsection|>` token marks the end of a "section".
## Example
```
<|section|>situation
I am talking to Diwank. I want to ask him about his food preferences.<|endsection|>
<|section|>person (Diwank)
Hey Samantha! What do you want to talk about?<|endsection|>
<|section|>me (Samantha)
``` |
Falah/sentiments-dataset-381-classes | Falah | 2023-07-05T13:54:15Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T10:48:39Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: sentiments-dataset-381-classes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiments-dataset-381-classes
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.4182
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 53 | 5.9237 |
| 5.9334 | 2.0 | 106 | 5.7237 |
| 5.9334 | 3.0 | 159 | 5.4182 |
### Framework versions
- Transformers 4.27.1
- Pytorch 2.0.1+cu118
- Datasets 2.9.0
- Tokenizers 0.13.3
|
namedotpg/ppo-SnowballTarget | namedotpg | 2023-07-05T13:26:35Z | 21 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2023-07-05T13:26:32Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: namedotpg/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
atiiisham988/bert-finetuned-ner | atiiisham988 | 2023-07-05T13:23:44Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-07-05T12:36:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.932077342588002
- name: Recall
type: recall
value: 0.9491753618310333
- name: F1
type: f1
value: 0.940548653381139
- name: Accuracy
type: accuracy
value: 0.9859745687878966
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0637
- Precision: 0.9321
- Recall: 0.9492
- F1: 0.9405
- Accuracy: 0.9860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0887 | 1.0 | 1756 | 0.0657 | 0.9155 | 0.9322 | 0.9238 | 0.9819 |
| 0.0334 | 2.0 | 3512 | 0.0653 | 0.9263 | 0.9470 | 0.9365 | 0.9855 |
| 0.0179 | 3.0 | 5268 | 0.0637 | 0.9321 | 0.9492 | 0.9405 | 0.9860 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Vladislav-HuggingFace/LunarLander-PPO-v2 | Vladislav-HuggingFace | 2023-07-05T13:16:33Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T13:16:19Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.24 +/- 19.58
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
GPT-4/GPT-3 | GPT-4 | 2023-07-05T13:10:56Z | 0 | 1 | adapter-transformers | [
"adapter-transformers",
"text-classification",
"en",
"dataset:fka/awesome-chatgpt-prompts",
"arxiv:1910.09700",
"license:openrail",
"region:us"
] | text-classification | 2023-06-21T12:52:21Z | ---
license: openrail
datasets:
- fka/awesome-chatgpt-prompts
language:
- en
metrics:
- accuracy
library_name: adapter-transformers
pipeline_tag: text-classification
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NasimB/gpt2-dp-finetune-cl-mod-datasets-rarity1 | NasimB | 2023-07-05T13:01:39Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:28:32Z | ---
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-finetune-cl-mod-datasets-rarity1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-finetune-cl-mod-datasets-rarity1
This model was trained from scratch on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5865
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7804 | 0.28 | 500 | 4.4982 |
| 3.9124 | 0.55 | 1000 | 4.5349 |
| 4.0179 | 0.83 | 1500 | 4.4602 |
| 3.9221 | 1.1 | 2000 | 4.4585 |
| 3.7998 | 1.38 | 2500 | 4.4362 |
| 3.8298 | 1.65 | 3000 | 4.3838 |
| 3.8259 | 1.93 | 3500 | 4.3551 |
| 3.5608 | 2.2 | 4000 | 4.4125 |
| 3.5215 | 2.48 | 4500 | 4.3867 |
| 3.5238 | 2.75 | 5000 | 4.3540 |
| 3.4761 | 3.03 | 5500 | 4.3684 |
| 3.1332 | 3.3 | 6000 | 4.4048 |
| 3.146 | 3.58 | 6500 | 4.3926 |
| 3.1394 | 3.85 | 7000 | 4.3839 |
| 2.9917 | 4.13 | 7500 | 4.4150 |
| 2.841 | 4.4 | 8000 | 4.4240 |
| 2.8327 | 4.68 | 8500 | 4.4259 |
| 2.8284 | 4.95 | 9000 | 4.4261 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
kimupachipachi/whisper-medium-ja | kimupachipachi | 2023-07-05T12:49:50Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"ja",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-04T09:04:19Z | ---
language:
- ja
license: apache-2.0
base_model: openai/whisper-small
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Ja - Haruto Kimura
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: ja
split: test
args: 'config: hi, split: test'
metrics:
- name: Wer
type: wer
value: 4750.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Ja - Haruto Kimura
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9052
- Wer: 4750.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 40
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 10.0 | 10 | 1.3778 | 370.0 |
| No log | 20.0 | 20 | 0.9597 | 1800.0 |
| 1.2408 | 30.0 | 30 | 0.9199 | 2020.0 |
| 1.2408 | 40.0 | 40 | 0.9052 | 4750.0 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
greenw0lf/wav2vec2-large-xls-r-1b-frisian-cv-8 | greenw0lf | 2023-07-05T12:47:02Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-04-23T09:30:00Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice_8_0
metrics:
- wer
model-index:
- name: wav2vec2-large-xls-r-1b-frisian-cv-8
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_8_0
type: common_voice_8_0
config: fy-NL
split: validation
args: fy-NL
metrics:
- name: Wer
type: wer
value: 0.14290815597771747
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_8_0
type: common_voice_8_0
config: fy-NL
split: test
args: fy-NL
metrics:
- name: Wer
type: wer
value: 0.1413499060557884
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-1b-frisian-cv-8
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the common_voice_8_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2131
- Wer: 0.1429
And on the test set:
- Wer: 0.1413
## Model description
This model has been developed for my Master's thesis in "Voice Technology" at Rijksuniversiteit Groningen - Campus Fryslân. It corresponds to experiment 1 where
I use the same training set as the XLSR-53 baseline.
## Intended uses & limitations
The intended use is for recognizing Frisian speech.
Limitations include no LM rescoring and using version 8.0 of Common Voice instead of 13.0.
## Training and evaluation data
The training and evaluation splits used are the ones available in the Common Voice 8.0 Frisian subset.
## Training procedure
The script used for training this model can be found in this GitHub repository: [link](https://github.com/greenw0lf/MSc-VT-Thesis/).
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 6.0565 | 1.72 | 200 | 3.1053 | 1.0 |
| 2.7675 | 3.45 | 400 | 1.1551 | 0.8611 |
| 1.3474 | 5.17 | 600 | 0.4770 | 0.4397 |
| 0.9617 | 6.9 | 800 | 0.3218 | 0.3343 |
| 0.9058 | 8.62 | 1000 | 0.2741 | 0.2768 |
| 0.9712 | 10.34 | 1200 | 0.2619 | 0.2505 |
| 0.6908 | 12.07 | 1400 | 0.2288 | 0.2243 |
| 0.745 | 13.79 | 1600 | 0.2288 | 0.2095 |
| 0.7742 | 15.52 | 1800 | 0.2289 | 0.1979 |
| 0.7231 | 17.24 | 2000 | 0.2198 | 0.1940 |
| 0.6475 | 18.97 | 2200 | 0.2180 | 0.1992 |
| 0.6421 | 20.69 | 2400 | 0.2133 | 0.1741 |
| 0.5925 | 22.41 | 2600 | 0.1998 | 0.1747 |
| 0.5608 | 24.14 | 2800 | 0.2212 | 0.1950 |
| 0.5315 | 25.86 | 3000 | 0.2187 | 0.1624 |
| 0.5362 | 27.59 | 3200 | 0.2057 | 0.1718 |
| 0.563 | 29.31 | 3400 | 0.2090 | 0.1613 |
| 0.4218 | 31.03 | 3600 | 0.2126 | 0.1531 |
| 0.3826 | 32.76 | 3800 | 0.2084 | 0.1538 |
| 0.356 | 34.48 | 4000 | 0.2115 | 0.1612 |
| 0.2966 | 36.21 | 4200 | 0.2093 | 0.1536 |
| 0.3377 | 37.93 | 4400 | 0.2061 | 0.1527 |
| 0.321 | 39.66 | 4600 | 0.2121 | 0.1463 |
| 0.2942 | 41.38 | 4800 | 0.2158 | 0.1441 |
| 0.2931 | 43.1 | 5000 | 0.2173 | 0.1446 |
| 0.2346 | 44.83 | 5200 | 0.2152 | 0.1436 |
| 0.2543 | 46.55 | 5400 | 0.2066 | 0.1445 |
| 0.2385 | 48.28 | 5600 | 0.2108 | 0.1432 |
| 0.2726 | 50.0 | 5800 | 0.2131 | 0.1429 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu117
- Datasets 2.11.0
- Tokenizers 0.13.3
|
ManthanKulakarni/Text2JQLBuilder | ManthanKulakarni | 2023-07-05T12:40:46Z | 10 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"Jira",
"JQL",
"JQL Builder",
"text2jql",
"Flan-T5",
"en",
"dataset:ManthanKulakarni/Text2JQL",
"license:bsd",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-06-15T18:06:24Z | ---
license: bsd
datasets:
- ManthanKulakarni/Text2JQL
language:
- en
pipeline_tag: text2text-generation
tags:
- Jira
- JQL
- JQL Builder
- text2jql
- Flan-T5
---
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ManthanKulakarni/Text2JQLBuilder")
model = AutoModelWithLMHead.from_pretrained("ManthanKulakarni/Text2JQLBuilder")
def gen_sentence(words, max_length=64):
input_text = words
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
max_length=max_length)
return tokenizer.decode(output[0], skip_special_tokens=True)
words = "JQL: all story under project ACM"
gen_sentence(words)
# output: 'JQL: project = ACM'
``` |
Babaili/videomae-base-finetuned-cropped-shooting-and-layup-dataset | Babaili | 2023-07-05T12:34:55Z | 60 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | 2023-07-05T11:34:55Z | ---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-cropped-shooting-and-layup-dataset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-cropped-shooting-and-layup-dataset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5361
- Accuracy: 0.6667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.1 | 5 | 0.6288 | 0.75 |
| 0.4089 | 1.1 | 10 | 0.7199 | 0.75 |
| 0.4089 | 2.1 | 15 | 0.7932 | 0.75 |
| 0.3801 | 3.1 | 20 | 0.7371 | 0.75 |
| 0.3801 | 4.1 | 25 | 0.8587 | 0.75 |
| 0.3258 | 5.1 | 30 | 0.7767 | 0.75 |
| 0.3258 | 6.1 | 35 | 0.7317 | 0.75 |
| 0.2265 | 7.1 | 40 | 0.7253 | 0.75 |
| 0.2265 | 8.1 | 45 | 0.7179 | 0.75 |
| 0.2107 | 9.1 | 50 | 0.7268 | 0.75 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
arsp9494/layoutlm-funsd | arsp9494 | 2023-07-05T12:32:09Z | 76 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlm",
"token-classification",
"generated_from_trainer",
"dataset:funsd",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-07-05T10:26:20Z | ---
tags:
- generated_from_trainer
datasets:
- funsd
model-index:
- name: layoutlm-funsd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlm-funsd
This model is a fine-tuned version of [microsoft/layoutlm-base-uncased](https://huggingface.co/microsoft/layoutlm-base-uncased) on the funsd dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6847
- Answer: {'precision': 0.7144432194046306, 'recall': 0.8009888751545118, 'f1': 0.7552447552447553, 'number': 809}
- Header: {'precision': 0.30952380952380953, 'recall': 0.3277310924369748, 'f1': 0.31836734693877555, 'number': 119}
- Question: {'precision': 0.7912966252220248, 'recall': 0.8366197183098592, 'f1': 0.81332724783204, 'number': 1065}
- Overall Precision: 0.7309
- Overall Recall: 0.7918
- Overall F1: 0.7601
- Overall Accuracy: 0.8132
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Answer | Header | Question | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 1.8057 | 1.0 | 10 | 1.5966 | {'precision': 0.008733624454148471, 'recall': 0.009888751545117428, 'f1': 0.009275362318840578, 'number': 809} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 119} | {'precision': 0.14909090909090908, 'recall': 0.11549295774647887, 'f1': 0.13015873015873014, 'number': 1065} | 0.0752 | 0.0657 | 0.0702 | 0.3764 |
| 1.4635 | 2.0 | 20 | 1.2374 | {'precision': 0.14137483787289234, 'recall': 0.13473423980222496, 'f1': 0.1379746835443038, 'number': 809} | {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 119} | {'precision': 0.42204995693367786, 'recall': 0.460093896713615, 'f1': 0.440251572327044, 'number': 1065} | 0.3100 | 0.3006 | 0.3052 | 0.6035 |
| 1.1031 | 3.0 | 30 | 0.9623 | {'precision': 0.4551451187335092, 'recall': 0.4264524103831891, 'f1': 0.44033184428844924, 'number': 809} | {'precision': 0.13157894736842105, 'recall': 0.04201680672268908, 'f1': 0.06369426751592357, 'number': 119} | {'precision': 0.630297565374211, 'recall': 0.6563380281690141, 'f1': 0.6430542778288868, 'number': 1065} | 0.5507 | 0.5263 | 0.5382 | 0.7016 |
| 0.8514 | 4.0 | 40 | 0.7967 | {'precision': 0.6146682188591386, 'recall': 0.6526576019777504, 'f1': 0.6330935251798562, 'number': 809} | {'precision': 0.23333333333333334, 'recall': 0.11764705882352941, 'f1': 0.1564245810055866, 'number': 119} | {'precision': 0.6810422282120395, 'recall': 0.711737089201878, 'f1': 0.6960514233241506, 'number': 1065} | 0.6398 | 0.6523 | 0.6460 | 0.7495 |
| 0.6854 | 5.0 | 50 | 0.7228 | {'precision': 0.6617647058823529, 'recall': 0.723114956736712, 'f1': 0.6910809214412286, 'number': 809} | {'precision': 0.25806451612903225, 'recall': 0.20168067226890757, 'f1': 0.22641509433962265, 'number': 119} | {'precision': 0.697751873438801, 'recall': 0.7868544600938967, 'f1': 0.7396293027360988, 'number': 1065} | 0.6644 | 0.7260 | 0.6938 | 0.7818 |
| 0.5608 | 6.0 | 60 | 0.6733 | {'precision': 0.6585879873551106, 'recall': 0.7725587144622992, 'f1': 0.7110352673492606, 'number': 809} | {'precision': 0.25, 'recall': 0.17647058823529413, 'f1': 0.20689655172413793, 'number': 119} | {'precision': 0.7112561174551386, 'recall': 0.8187793427230047, 'f1': 0.7612396333478829, 'number': 1065} | 0.6720 | 0.7617 | 0.7140 | 0.7976 |
| 0.486 | 7.0 | 70 | 0.6683 | {'precision': 0.670514165792235, 'recall': 0.7898640296662547, 'f1': 0.7253121452894438, 'number': 809} | {'precision': 0.25688073394495414, 'recall': 0.23529411764705882, 'f1': 0.24561403508771928, 'number': 119} | {'precision': 0.7351398601398601, 'recall': 0.7896713615023474, 'f1': 0.7614305115436849, 'number': 1065} | 0.6836 | 0.7566 | 0.7183 | 0.7992 |
| 0.4391 | 8.0 | 80 | 0.6590 | {'precision': 0.6809623430962343, 'recall': 0.8046971569839307, 'f1': 0.7376770538243627, 'number': 809} | {'precision': 0.2641509433962264, 'recall': 0.23529411764705882, 'f1': 0.24888888888888888, 'number': 119} | {'precision': 0.7585324232081911, 'recall': 0.8347417840375587, 'f1': 0.7948144836835047, 'number': 1065} | 0.7019 | 0.7868 | 0.7419 | 0.8042 |
| 0.3834 | 9.0 | 90 | 0.6569 | {'precision': 0.7043189368770764, 'recall': 0.7861557478368356, 'f1': 0.7429906542056073, 'number': 809} | {'precision': 0.2619047619047619, 'recall': 0.2773109243697479, 'f1': 0.2693877551020408, 'number': 119} | {'precision': 0.7637457044673539, 'recall': 0.8347417840375587, 'f1': 0.7976671152983401, 'number': 1065} | 0.7104 | 0.7817 | 0.7444 | 0.8099 |
| 0.3489 | 10.0 | 100 | 0.6655 | {'precision': 0.6984649122807017, 'recall': 0.7873918417799752, 'f1': 0.7402672864613596, 'number': 809} | {'precision': 0.2714285714285714, 'recall': 0.31932773109243695, 'f1': 0.29343629343629346, 'number': 119} | {'precision': 0.7745614035087719, 'recall': 0.8291079812206573, 'f1': 0.800907029478458, 'number': 1065} | 0.7108 | 0.7817 | 0.7446 | 0.8126 |
| 0.3103 | 11.0 | 110 | 0.6682 | {'precision': 0.6981934112646121, 'recall': 0.8121137206427689, 'f1': 0.7508571428571429, 'number': 809} | {'precision': 0.3173076923076923, 'recall': 0.2773109243697479, 'f1': 0.29596412556053814, 'number': 119} | {'precision': 0.7878521126760564, 'recall': 0.8403755868544601, 'f1': 0.8132666969559291, 'number': 1065} | 0.7267 | 0.7953 | 0.7595 | 0.8148 |
| 0.293 | 12.0 | 120 | 0.6739 | {'precision': 0.7123893805309734, 'recall': 0.796044499381953, 'f1': 0.7518972562755399, 'number': 809} | {'precision': 0.328, 'recall': 0.3445378151260504, 'f1': 0.33606557377049184, 'number': 119} | {'precision': 0.7863475177304965, 'recall': 0.8328638497652582, 'f1': 0.8089375284997721, 'number': 1065} | 0.7288 | 0.7888 | 0.7576 | 0.8167 |
| 0.2761 | 13.0 | 130 | 0.6783 | {'precision': 0.705945945945946, 'recall': 0.8071693448702101, 'f1': 0.7531718569780853, 'number': 809} | {'precision': 0.3467741935483871, 'recall': 0.36134453781512604, 'f1': 0.35390946502057613, 'number': 119} | {'precision': 0.7935656836461126, 'recall': 0.8338028169014085, 'f1': 0.8131868131868133, 'number': 1065} | 0.7306 | 0.7948 | 0.7614 | 0.8137 |
| 0.2633 | 14.0 | 140 | 0.6849 | {'precision': 0.7085590465872156, 'recall': 0.8084054388133498, 'f1': 0.7551963048498845, 'number': 809} | {'precision': 0.31746031746031744, 'recall': 0.33613445378151263, 'f1': 0.32653061224489793, 'number': 119} | {'precision': 0.7883082373782108, 'recall': 0.8356807511737089, 'f1': 0.8113035551504102, 'number': 1065} | 0.7273 | 0.7948 | 0.7595 | 0.8125 |
| 0.2632 | 15.0 | 150 | 0.6847 | {'precision': 0.7144432194046306, 'recall': 0.8009888751545118, 'f1': 0.7552447552447553, 'number': 809} | {'precision': 0.30952380952380953, 'recall': 0.3277310924369748, 'f1': 0.31836734693877555, 'number': 119} | {'precision': 0.7912966252220248, 'recall': 0.8366197183098592, 'f1': 0.81332724783204, 'number': 1065} | 0.7309 | 0.7918 | 0.7601 | 0.8132 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
lesyar/news_genre_classifier | lesyar | 2023-07-05T12:31:54Z | 108 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"de",
"fr",
"ru",
"pl",
"doi:10.57967/hf/0874",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-06-09T05:02:15Z | ---
language:
- en
- de
- fr
- ru
- pl
metrics:
- f1
--- |
RIOLITE/products_matching_aumet_fine_tune_2023-07-05 | RIOLITE | 2023-07-05T12:24:37Z | 1 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2023-07-05T12:24:33Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 45 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
riccardopresti99/topic_modelling_football | riccardopresti99 | 2023-07-05T12:23:46Z | 4 | 1 | bertopic | [
"bertopic",
"text-classification",
"region:us"
] | text-classification | 2023-07-05T12:23:44Z |
---
tags:
- bertopic
library_name: bertopic
pipeline_tag: text-classification
---
# topic_modelling_football
This is a [BERTopic](https://github.com/MaartenGr/BERTopic) model.
BERTopic is a flexible and modular topic modeling framework that allows for the generation of easily interpretable topics from large datasets.
## Usage
To use this model, please install BERTopic:
```
pip install -U bertopic
```
You can use the model as follows:
```python
from bertopic import BERTopic
topic_model = BERTopic.load("riccardopresti99/topic_modelling_football")
topic_model.get_topic_info()
```
## Topic overview
* Number of topics: 14
* Number of training documents: 350
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
|----------|----------------|-----------------|-------|
| -1 | tournament - competition - leaving - final - compete | 16 | -1_tournament_competition_leaving_final |
| 0 | video - games - football - players - experience | 10 | 0_video_games_football_players |
| 1 | supporters - atmosphere - stadiums - football - create | 48 | 1_supporters_atmosphere_stadiums_football |
| 2 | physiotherapists - injury - injuries - players - prevention | 32 | 2_physiotherapists_injury_injuries_players |
| 3 | united - film - football - war - story | 29 | 3_united_film_football_war |
| 4 | ronaldo - ability - scoring - aspiring - one | 26 | 4_ronaldo_ability_scoring_aspiring |
| 5 | scandals - illegal - officials - within - concerns | 26 | 5_scandals_illegal_officials_within |
| 6 | healthy - footballers - energy - supports - performance | 25 | 6_healthy_footballers_energy_supports |
| 7 | strikers - striker - scoring - teammates - goals | 25 | 7_strikers_striker_scoring_teammates |
| 8 | investors - stock - stocks - market - club | 25 | 8_investors_stock_stocks_market |
| 9 | women - football - girls - equal - sport | 25 | 9_women_football_girls_equal |
| 10 | serie - milan - league - inter - italian | 23 | 10_serie_milan_league_inter |
| 11 | champions - league - european - club - uefa | 22 | 11_champions_league_european_club |
| 12 | cup - world - fifa - held - trophy | 18 | 12_cup_world_fifa_held |
</details>
## Training hyperparameters
* calculate_probabilities: False
* language: None
* low_memory: False
* min_topic_size: 10
* n_gram_range: (1, 1)
* nr_topics: None
* seed_topic_list: None
* top_n_words: 10
* verbose: True
## Framework versions
* Numpy: 1.23.5
* HDBSCAN: 0.8.29
* UMAP: 0.5.3
* Pandas: 1.5.3
* Scikit-Learn: 1.2.2
* Sentence-transformers: 2.2.2
* Transformers: 4.26.1
* Numba: 0.56.4
* Plotly: 5.13.1
* Python: 3.10.10
|
Babiputih/Sarahvil | Babiputih | 2023-07-05T12:21:01Z | 0 | 0 | null | [
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T12:10:53Z | ---
license: creativeml-openrail-m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
zlsl/en_l_wh40k_full | zlsl | 2023-07-05T12:20:31Z | 151 | 2 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"warhammer",
"warhammer40k",
"wh40k",
"horus heresy",
"necromunda",
"en",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T12:08:52Z | ---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
tags:
- warhammer
- warhammer40k
- wh40k
- horus heresy
- necromunda
---
The model is trained on a large dataset of texts from the Warhammer 40k, Horus Heresy, Necromunda universe.
|
luispintoc/taxi-v2 | luispintoc | 2023-07-05T12:03:57Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T12:03:55Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="luispintoc/taxi-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
luispintoc/q-FrozenLake-v1-4x4-noSlippery | luispintoc | 2023-07-05T12:01:43Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T12:01:41Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="luispintoc/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
KennethTM/danish-bert-review-sentiment | KennethTM | 2023-07-05T11:50:20Z | 114 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"da",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-06-08T09:30:30Z | ---
license: cc-by-4.0
language:
- da
pipeline_tag: text-classification
widget:
- text: Rigtig god service!
---
# What is this?
BERT classification model for short customer reviews written in Danish.
The model uses 5 classes ranging from 1-5 stars:
* ⭐ (very poor)
* ⭐⭐ (poor)
* ⭐⭐⭐ (neutral)
* ⭐⭐⭐⭐ (good)
* ⭐⭐⭐⭐⭐ (very good)
The model is fine-tuned using the pre-trained [Danish BERT model]("Maltehb/danish-bert-botxo").
# How to use
Test the model using the [🤗Transformers](https://github.com/huggingface/transformers) library pipeline:
```python
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="KennethTM/danish-bert-review-sentiment")
classifier("Intet virkede og ingen hjælp at hente.")
#[{'label': '⭐', 'score': 0.4953940808773041}]
```
Or load it using the Auto* classes:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("KennethTM/danish-bert-review-sentiment")
tokenizer = AutoTokenizer.from_pretrained("KennethTM/danish-bert-review-sentiment")
```
|
KennethTM/gpt2-small-danish-review-response | KennethTM | 2023-07-05T11:50:02Z | 129 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"da",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-06-20T08:14:14Z | ---
language:
- da
pipeline_tag: text-generation
widget:
- text: "### Bruger:\nAnders\n\n### Anmeldelse:\nUmuligt at komme igennem på telefonen.\n\n### Svar:\nKære Anders\n"
---
# What is this?
A fine-tuned GPT-2 model (small version, 124 M parameters) for generating responses to customer reviews in Danish.
# How to use
The model is based on the [gpt2-small-danish model](https://huggingface.co/KennethTM/gpt2-small-danish). Supervised fine-tuning is applied to adapt the model to generate responses to customer reviews in Danish. A prompting template is applied to the examples used to train (see the example below).
Test the model using the pipeline from the [🤗 Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import pipeline
generator = pipeline("text-generation", model = "KennethTM/gpt2-small-danish-review-response")
def prompt_template(user, review):
return f"### Bruger:\n{user}\n\n### Anmeldelse:\n{review}\n\n### Svar:\nKære {user}\n"
prompt = prompt_template(user = "Anders", review = "Umuligt at komme igennem på telefonen.")
text = generator(prompt)
print(text[0]["generated_text"])
```
Or load it using the Auto* classes:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("KennethTM/gpt2-small-danish-review-response")
model = AutoModelForCausalLM.from_pretrained("KennethTM/gpt2-small-danish-review-response")
```
# Notes
The model may get the sentiment of the review wrong resulting in a mismatch between the review and response. The model would probably benefit from sentiment tuning. |
bofenghuang/vigogne-falcon-7b-instruct | bofenghuang | 2023-07-05T11:38:33Z | 25 | 1 | transformers | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"LLM",
"custom_code",
"fr",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-05T09:51:56Z | ---
license: apache-2.0
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- LLM
inference: false
---
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-falcon-7b-instruct/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-Falcon-7B-Instruct: A French Instruction-following Falcon Model
Vigogne-Falcon-7B-Instruct is a [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) model fine-tuned to follow the French instructions.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_instruct_prompt
model_name_or_path = "bofenghuang/vigogne-falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_instruct_prompt(user_query)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
You can also infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
|
alexvaroz/my_awesome_model | alexvaroz | 2023-07-05T11:31:48Z | 61 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T09:30:11Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: alexvaroz/my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# alexvaroz/my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0625
- Validation Loss: 0.2300
- Train Accuracy: 0.9335
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 7810, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.2504 | 0.1918 | 0.9253 | 0 |
| 0.1317 | 0.2269 | 0.9242 | 1 |
| 0.0625 | 0.2300 | 0.9335 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
irfan62622/ppo-LunarLander-v2 | irfan62622 | 2023-07-05T11:25:00Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T11:24:39Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 254.60 +/- 21.19
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
aroot/delfy_w_replacement | aroot | 2023-07-05T11:18:07Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T08:04:21Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: delfy_w_replacement
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# delfy_w_replacement
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0655
- Bleu: 6.0327
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
NihalSrivastava/advertisement-description-generator | NihalSrivastava | 2023-07-05T11:18:06Z | 137 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-04-06T05:39:06Z | ---
license: mit
language:
- en
library_name: transformers
widget:
- text: "<|BOS|>laptop, fast, gaming, great graphics, affordable <|SEP|> "
example_title: "Laptop"
- text: "<|BOS|> T-Shirt, Red color, comfortable <|SEP|> "
example_title: "T-Shirt"
- text: "<|BOS|> Game console, multiple game support, 4k graphics, extreme fast performace <|SEP|> "
example_title: "Game Console"
---
# Advertisement-Description-Generator gpt2 finetuned on product descriptions
## Model Details
This model generates a 1-2 line description of a product given the keywords associated with it. It is a fine-tuned version of GPT-2 model on a custom dataset consisting of
328 rows in the format: (keyword, text)
Example:
[Echo Dot,smart speaker,Alexa,improved sound,sleek design,home], Introducing the all-new Echo Dot - the smart speaker with Alexa. It has improved sound and a sleek design that fits anywhere in your home.
- **Developed by:** Nihal Srivastava
- **Model type:** Finetuned GPT-2
- **License:** MIT
- **Finetuned from model [optional]:** GPT-2
## Uses
##### Inital Imports of the model and setting up helper functions:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
def join_keywords(keywords, randomize=True):
N = len(keywords)
if randomize:
M = random.choice(range(N+1))
keywords = keywords[:M]
random.shuffle(keywords)
return ','.join(keywords)
SPECIAL_TOKENS = { "bos_token": "<|BOS|>",
"eos_token": "<|EOS|>",
"unk_token": "<|UNK|>",
"pad_token": "<|PAD|>",
"sep_token": "<|SEP|>"}
device = torch.device("cuda")
tokenizer = AutoTokenizer.from_pretrained("NihalSrivastava/advertisement-description-generator")
model = AutoModelForCausalLM.from_pretrained("NihalSrivastava/advertisement-description-generator").to(device)
keywords = ['laptop', 'fast', 'gaming', 'great graphics', 'affordable']
kw = join_keywords(keywords, randomize=False)
prompt = SPECIAL_TOKENS['bos_token'] + kw + SPECIAL_TOKENS['sep_token']
generated = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0)
device = torch.device("cuda")
generated = generated.to(device)
model.eval();
```
##### To generate a single best description:
``` python
# Beam-search text generation:
sample_outputs = model.generate(generated,
do_sample=True,
max_length=768,
num_beams=5,
repetition_penalty=5.0,
early_stopping=True,
num_return_sequences=1
)
for i, sample_output in enumerate(sample_outputs):
text = tokenizer.decode(sample_output, skip_special_tokens=True)
a = len(','.join(keywords))
print("{}: {}\n\n".format(i+1, text[a:]))
```
Output:
> 1: The gaming laptop has a fast clock speed, high refresh rate display, and advanced connectivity options for unparalleled gaming performance.
##### To generate top 10 best descriptions:
``` python
# Top-p (nucleus) text generation (10 samples):
sample_outputs = model.generate(generated,
do_sample=True,
min_length=50,
max_length=MAXLEN,
top_k=30,
top_p=0.7,
temperature=0.9,
repetition_penalty=2.0,
num_return_sequences=10
)
for i, sample_output in enumerate(sample_outputs):
text = tokenizer.decode(sample_output, skip_special_tokens=True)
a = len(','.join(keywords))
print("{}: {}\n\n".format(i+1, text[a:]))
```
Output:
Will generate 10 best outouts of product description as above.
#### Training Hyperparameters
``` python
DEBUG = False
USE_APEX = True
APEX_OPT_LEVEL = 'O1'
MODEL = 'gpt2' #{gpt2, gpt2-medium, gpt2-large, gpt2-xl}
UNFREEZE_LAST_N = 6 #The last N layers to unfreeze for training
SPECIAL_TOKENS = { "bos_token": "<|BOS|>",
"eos_token": "<|EOS|>",
"unk_token": "<|UNK|>",
"pad_token": "<|PAD|>",
"sep_token": "<|SEP|>"}
MAXLEN = 768 #{768, 1024, 1280, 1600}
TRAIN_SIZE = 0.8
if USE_APEX:
TRAIN_BATCHSIZE = 4
BATCH_UPDATE = 16
else:
TRAIN_BATCHSIZE = 2
BATCH_UPDATE = 32
EPOCHS = 20
LR = 5e-4
EPS = 1e-8
WARMUP_STEPS = 1e2
SEED = 2020
EVALUATION_STRATEGY=epoch
SAVE_STRATEGY=epoch
```
## Model Card Contact
Email: [email protected] <br>
Github: https://github.com/Nihal-Srivastava05 <br>
LinkedIn: https://www.linkedin.com/in/nihal-srivastava-7708a71b7/ <br> |
ITG/whisper-base-gl | ITG | 2023-07-05T11:16:09Z | 74 | 1 | transformers | [
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"ITG",
"PyTorch",
"Transformers",
"whisper-base",
"gl",
"dataset:openslr",
"license:cc-by-nc-nd-4.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-07-05T09:06:31Z | ---
license: cc-by-nc-nd-4.0
datasets:
- openslr
language:
- gl
pipeline_tag: automatic-speech-recognition
tags:
- ITG
- PyTorch
- Transformers
- whisper
- whisper-base
---
# Whisper Base Galician
## Description
This is a fine-tuned version of the [openai/whisper-base](https://huggingface.co/openai/whisper-base) pre-trained model for ASR in galician.
---
## Dataset
We used one of the datasets available in the openslr repository, the [OpenSLR galician](https://huggingface.co/datasets/openslr/viewer/SLR77).
---
## Example inference script
### Check this example script to run our model in inference mode
```python
import torch
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
filename = "demo.wav" #change this line to the name of your audio file
sample_rate = 16_000
processor = AutoProcessor.from_pretrained('ITG/whisper-base-gl')
model = AutoModelForSpeechSeq2Seq.from_pretrained('ITG/whisper-base-gl')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
with torch.no_grad():
speech_array, _ = librosa.load(filename, sr=sample_rate)
inputs = processor(speech_array, sampling_rate=sample_rate, return_tensors="pt").to(device)
input_features = inputs.input_features
generated_ids = model.generate(inputs=input_features, max_length=225)
decode_output = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"ASR Galician whisper-base output: {decode_output}")
```
---
## Fine-tuning hyper-parameters
| **Hyper-parameter** | **Value** |
|:----------------------------------------:|:---------------------------:|
| Training batch size | 16 |
| Evaluation batch size | 8 |
| Learning rate | 3e-5 |
| Gradient checkpointing | true |
| Gradient accumulation steps | 1 |
| Max training epochs | 100 |
| Max steps | 4000 |
| Generate max length | 225 |
| Warmup training steps (%) | 12,5% |
| FP16 | true |
| Metric for best model | wer |
| Greater is better | false |
## Fine-tuning in a different dataset or style
If you're interested in fine-tuning your own whisper model, we suggest starting with the [openai/whisper-base model](https://huggingface.co/openai/whisper-base). Additionally, you may find the Transformers
step-by-step guide for [fine-tuning whisper on multilingual ASR datasets](https://huggingface.co/blog/fine-tune-whisper) to be a valuable resource. This guide served as a helpful reference during the training
process of this Galician whisper-base model!
|
exavolt/sd-playground | exavolt | 2023-07-05T11:07:21Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-05-23T02:21:09Z | ---
license: creativeml-openrail-m
---
|
faizi/sarcasm-detection-sarc-llama-7b-500-steps | faizi | 2023-07-05T11:06:51Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T11:06:15Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
Karim-Gamal/MMiniLM-L12-finetuned-SemEval-2018-emojis-cen-2 | Karim-Gamal | 2023-07-05T11:06:26Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-03-05T15:45:14Z | ---
license: apache-2.0
language:
- en
metrics:
- f1
---
# Federated Learning Based Multilingual Emoji Prediction
This repository contains code for training and evaluating transformer-based models for Uni/multilingual emoji prediction in clean and attack scenarios using Federated Learning. This work is described in the paper "Federated Learning-Based Multilingual Emoji Prediction in Clean and Attack Scenarios."
# Abstract
Federated learning is a growing field in the machine learning community due to its decentralized and private design. Model training in federated learning is distributed over multiple clients giving access to lots of client data while maintaining privacy. Then, a server aggregates the training done on these multiple clients without access to their data, which could be emojis widely used in any social media service and instant messaging platforms to express users' sentiments. This paper proposes federated learning-based multilingual emoji prediction in both clean and attack scenarios. Emoji prediction data have been crawled from both Twitter and SemEval emoji datasets. This data is used to train and evaluate different transformer model sizes including a sparsely activated transformer with either the assumption of clean data in all clients or poisoned data via label flipping attack in some clients. Experimental results on these models show that federated learning in either clean or attacked scenarios performs similarly to centralized training in multilingual emoji prediction on seen and unseen languages under different data sources and distributions. Our trained transformers perform better than other techniques on the SemEval emoji dataset in addition to the privacy as well as distributed benefits of federated learning.
# Performance
> * ACC : 48688 %
> * Mac-F1 : 35.937%
> * Also see our [GitHub Repo](https://github.com/kareemgamalmahmoud/FEDERATED-LEARNING-BASED-MULTILINGUAL-EMOJI-PREDICTION-IN-CLEAN-AND-ATTACK-SCENARIOS)
# Dependencies
> * Python 3.6+
> * PyTorch 1.7.0+
> * Transformers 4.0.0+
# Usage
> To use the model, first install the `transformers` package from Hugging Face:
```python
pip install transformers
```
> Then, you can load the model and tokenizer using the following code:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import numpy as np
import urllib.request
import csv
```
```python
MODEL = "Karim-Gamal/MMiniLM-L12-finetuned-SemEval-2018-emojis-cen-2"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
```
> Once you have the tokenizer and model, you can preprocess your text and pass it to the model for prediction:
```python
# Preprocess text (username and link placeholders)
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
text = "Hello world"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
```
> The scores variable contains the probabilities for each of the possible emoji labels. To get the top k predictions, you can use the following code:
```python
# download label mapping
labels=[]
mapping_link = "https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/emoji/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode('utf-8').split("\n")
csvreader = csv.reader(html, delimiter='\t')
labels = [row[1] for row in csvreader if len(row) > 1]
k = 3 # number of top predictions to show
ranking = np.argsort(scores)
ranking = ranking[::-1]
for i in range(k):
l = labels[ranking[i]]
s = scores[ranking[i]]
print(f"{i+1}) {l} {np.round(float(s), 4)}")
```
## Note : this is the source for that code : [Link](https://huggingface.co/cardiffnlp/twitter-roberta-base-emoji) |
djifg/grow_classification_FINAL | djifg | 2023-07-05T11:05:34Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T07:16:10Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: grow_classification_FINAL
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# grow_classification_FINAL
This model is a fine-tuned version of [djifg/grow_classification_kcbert](https://huggingface.co/djifg/grow_classification_kcbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4211
- Accuracy: 0.9323
- F1: 0.9308
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.0173 | 1.0 | 407 | 0.4211 | 0.9323 | 0.9308 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jordyvl/dit-rvl_maveriq_tobacco3482_2023-07-05 | jordyvl | 2023-07-05T10:59:00Z | 161 | 0 | transformers | [
"transformers",
"pytorch",
"beit",
"image-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-07-05T10:04:59Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: dit-rvl_maveriq_tobacco3482_2023-07-05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dit-rvl_maveriq_tobacco3482_2023-07-05
This model is a fine-tuned version of [microsoft/dit-base-finetuned-rvlcdip](https://huggingface.co/microsoft/dit-base-finetuned-rvlcdip) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4530
- Accuracy: 0.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.96 | 3 | 2.2927 | 0.01 |
| No log | 1.96 | 6 | 2.2632 | 0.08 |
| No log | 2.96 | 9 | 2.2334 | 0.18 |
| No log | 3.96 | 12 | 2.2025 | 0.195 |
| No log | 4.96 | 15 | 2.1686 | 0.235 |
| No log | 5.96 | 18 | 2.1274 | 0.325 |
| No log | 6.96 | 21 | 2.0784 | 0.385 |
| No log | 7.96 | 24 | 2.0284 | 0.465 |
| No log | 8.96 | 27 | 1.9750 | 0.55 |
| No log | 9.96 | 30 | 1.9206 | 0.585 |
| No log | 10.96 | 33 | 1.8683 | 0.61 |
| No log | 11.96 | 36 | 1.8164 | 0.65 |
| No log | 12.96 | 39 | 1.7660 | 0.735 |
| No log | 13.96 | 42 | 1.7195 | 0.765 |
| No log | 14.96 | 45 | 1.6761 | 0.815 |
| No log | 15.96 | 48 | 1.6336 | 0.83 |
| No log | 16.96 | 51 | 1.5918 | 0.835 |
| No log | 17.96 | 54 | 1.5511 | 0.835 |
| No log | 18.96 | 57 | 1.5101 | 0.84 |
| No log | 19.96 | 60 | 1.4699 | 0.85 |
| No log | 20.96 | 63 | 1.4307 | 0.855 |
| No log | 21.96 | 66 | 1.3925 | 0.865 |
| No log | 22.96 | 69 | 1.3534 | 0.865 |
| No log | 23.96 | 72 | 1.3164 | 0.885 |
| No log | 24.96 | 75 | 1.2825 | 0.885 |
| No log | 25.96 | 78 | 1.2458 | 0.88 |
| No log | 26.96 | 81 | 1.2091 | 0.88 |
| No log | 27.96 | 84 | 1.1762 | 0.89 |
| No log | 28.96 | 87 | 1.1446 | 0.885 |
| No log | 29.96 | 90 | 1.1126 | 0.9 |
| No log | 30.96 | 93 | 1.0840 | 0.905 |
| No log | 31.96 | 96 | 1.0549 | 0.9 |
| No log | 32.96 | 99 | 1.0247 | 0.91 |
| No log | 33.96 | 102 | 0.9962 | 0.925 |
| No log | 34.96 | 105 | 0.9685 | 0.93 |
| No log | 35.96 | 108 | 0.9447 | 0.93 |
| No log | 36.96 | 111 | 0.9217 | 0.93 |
| No log | 37.96 | 114 | 0.9007 | 0.93 |
| No log | 38.96 | 117 | 0.8778 | 0.935 |
| No log | 39.96 | 120 | 0.8551 | 0.935 |
| No log | 40.96 | 123 | 0.8325 | 0.93 |
| No log | 41.96 | 126 | 0.8129 | 0.93 |
| No log | 42.96 | 129 | 0.7970 | 0.93 |
| No log | 43.96 | 132 | 0.7810 | 0.93 |
| No log | 44.96 | 135 | 0.7609 | 0.935 |
| No log | 45.96 | 138 | 0.7441 | 0.935 |
| No log | 46.96 | 141 | 0.7313 | 0.935 |
| No log | 47.96 | 144 | 0.7184 | 0.935 |
| No log | 48.96 | 147 | 0.7044 | 0.93 |
| No log | 49.96 | 150 | 0.6902 | 0.93 |
| No log | 50.96 | 153 | 0.6773 | 0.935 |
| No log | 51.96 | 156 | 0.6666 | 0.935 |
| No log | 52.96 | 159 | 0.6554 | 0.935 |
| No log | 53.96 | 162 | 0.6446 | 0.935 |
| No log | 54.96 | 165 | 0.6308 | 0.94 |
| No log | 55.96 | 168 | 0.6194 | 0.94 |
| No log | 56.96 | 171 | 0.6098 | 0.94 |
| No log | 57.96 | 174 | 0.6021 | 0.94 |
| No log | 58.96 | 177 | 0.5922 | 0.935 |
| No log | 59.96 | 180 | 0.5820 | 0.94 |
| No log | 60.96 | 183 | 0.5735 | 0.94 |
| No log | 61.96 | 186 | 0.5632 | 0.94 |
| No log | 62.96 | 189 | 0.5559 | 0.94 |
| No log | 63.96 | 192 | 0.5494 | 0.94 |
| No log | 64.96 | 195 | 0.5430 | 0.94 |
| No log | 65.96 | 198 | 0.5370 | 0.935 |
| No log | 66.96 | 201 | 0.5320 | 0.935 |
| No log | 67.96 | 204 | 0.5278 | 0.935 |
| No log | 68.96 | 207 | 0.5228 | 0.935 |
| No log | 69.96 | 210 | 0.5166 | 0.935 |
| No log | 70.96 | 213 | 0.5117 | 0.935 |
| No log | 71.96 | 216 | 0.5076 | 0.935 |
| No log | 72.96 | 219 | 0.5029 | 0.94 |
| No log | 73.96 | 222 | 0.4985 | 0.94 |
| No log | 74.96 | 225 | 0.4945 | 0.94 |
| No log | 75.96 | 228 | 0.4904 | 0.94 |
| No log | 76.96 | 231 | 0.4865 | 0.94 |
| No log | 77.96 | 234 | 0.4833 | 0.94 |
| No log | 78.96 | 237 | 0.4804 | 0.94 |
| No log | 79.96 | 240 | 0.4779 | 0.94 |
| No log | 80.96 | 243 | 0.4757 | 0.94 |
| No log | 81.96 | 246 | 0.4738 | 0.94 |
| No log | 82.96 | 249 | 0.4719 | 0.935 |
| No log | 83.96 | 252 | 0.4701 | 0.935 |
| No log | 84.96 | 255 | 0.4684 | 0.935 |
| No log | 85.96 | 258 | 0.4669 | 0.935 |
| No log | 86.96 | 261 | 0.4653 | 0.935 |
| No log | 87.96 | 264 | 0.4637 | 0.935 |
| No log | 88.96 | 267 | 0.4620 | 0.935 |
| No log | 89.96 | 270 | 0.4602 | 0.935 |
| No log | 90.96 | 273 | 0.4586 | 0.94 |
| No log | 91.96 | 276 | 0.4572 | 0.94 |
| No log | 92.96 | 279 | 0.4562 | 0.94 |
| No log | 93.96 | 282 | 0.4553 | 0.94 |
| No log | 94.96 | 285 | 0.4546 | 0.94 |
| No log | 95.96 | 288 | 0.4540 | 0.94 |
| No log | 96.96 | 291 | 0.4535 | 0.94 |
| No log | 97.96 | 294 | 0.4532 | 0.94 |
| No log | 98.96 | 297 | 0.4530 | 0.94 |
| No log | 99.96 | 300 | 0.4530 | 0.94 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
faizi/sarcasm-detection-sarc-llama-7b-1500-steps | faizi | 2023-07-05T10:54:34Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T10:54:15Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
bluepen5805/blue_pencil_realistic | bluepen5805 | 2023-07-05T10:47:22Z | 0 | 8 | null | [
"stable-diffusion",
"text-to-image",
"ja",
"en",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2023-06-12T18:16:16Z | ---
license: creativeml-openrail-m
language:
- ja
- en
tags:
- stable-diffusion
- text-to-image
---
<div class="flex justify-center">
<div class="container p-0 w-100">
<div class="flex px-4">
<div class="flex-auto">
<h1 class="mb-2 text-3xl font-bold leading-tight" style="color: rgb(56 189 248/var(--tw-text-opacity));">
blue_pencil_realistic
<a href="https://huggingface.co/bluepen5805/blue_pencil_realistic/blob/main/README.md" class="ml-2 inline-block">
<svg xmlns="http://www.w3.org/2000/svg" class="h-5 w-5" fill="none" viewBox="0 0 24 24" strokeWidth={1.5} stroke="currentColor" className="w-6 h-6">
<path strokeLinecap="round" strokeLinejoin="round" d="M3.75 3.75v4.5m0-4.5h4.5m-4.5 0L9 9M3.75 20.25v-4.5m0 4.5h4.5m-4.5 0L9 15M20.25 3.75h-4.5m4.5 0v4.5m0-4.5L15 9m5.25 11.25h-4.5m4.5 0v-4.5m0 4.5L15 15" />
</svg>
</a>
</h1>
<p class="mb-4 text-base text-neutral-600 dark:text-neutral-200">
blue_pencil series based photorealistic models.
</p>
</div>
<div class="flex gap-2" style="height: fit-content;">
<a
href="https://twitter.com/blue_pen5805"
class="mb-2 inline-block rounded px-6 py-2.5 text-white shadow-md"
style="background-color: #1da1f2">
<svg xmlns="http://www.w3.org/2000/svg" class="h-3.5 w-3.5" fill="currentColor" viewBox="0 0 24 24">
<path d="M24 4.557c-.883.392-1.832.656-2.828.775 1.017-.609 1.798-1.574 2.165-2.724-.951.564-2.005.974-3.127 1.195-.897-.957-2.178-1.555-3.594-1.555-3.179 0-5.515 2.966-4.797 6.045-4.091-.205-7.719-2.165-10.148-5.144-1.29 2.213-.669 5.108 1.523 6.574-.806-.026-1.566-.247-2.229-.616-.054 2.281 1.581 4.415 3.949 4.89-.693.188-1.452.232-2.224.084.626 1.956 2.444 3.379 4.6 3.419-2.07 1.623-4.678 2.348-7.29 2.04 2.179 1.397 4.768 2.212 7.548 2.212 9.142 0 14.307-7.721 13.995-14.646.962-.695 1.797-1.562 2.457-2.549z" />
</svg>
</a>
<a
href="https://discord.gg/s49mASQHkE"
class="mb-2 inline-block rounded px-6 py-2.5 text-white shadow-md"
style="background-color: #7289da">
<svg xmlns="http://www.w3.org/2000/svg" class="h-3.5 w-3.5" fill="currentColor" viewbox="0 0 24 24">
<path d="M19.54 0c1.356 0 2.46 1.104 2.46 2.472v21.528l-2.58-2.28-1.452-1.344-1.536-1.428.636 2.22h-13.608c-1.356 0-2.46-1.104-2.46-2.472v-16.224c0-1.368 1.104-2.472 2.46-2.472h16.08zm-4.632 15.672c2.652-.084 3.672-1.824 3.672-1.824 0-3.864-1.728-6.996-1.728-6.996-1.728-1.296-3.372-1.26-3.372-1.26l-.168.192c2.04.624 2.988 1.524 2.988 1.524-1.248-.684-2.472-1.02-3.612-1.152-.864-.096-1.692-.072-2.424.024l-.204.024c-.42.036-1.44.192-2.724.756-.444.204-.708.348-.708.348s.996-.948 3.156-1.572l-.12-.144s-1.644-.036-3.372 1.26c0 0-1.728 3.132-1.728 6.996 0 0 1.008 1.74 3.66 1.824 0 0 .444-.54.804-.996-1.524-.456-2.1-1.416-2.1-1.416l.336.204.048.036.047.027.014.006.047.027c.3.168.6.3.876.408.492.192 1.08.384 1.764.516.9.168 1.956.228 3.108.012.564-.096 1.14-.264 1.74-.516.42-.156.888-.384 1.38-.708 0 0-.6.984-2.172 1.428.36.456.792.972.792.972zm-5.58-5.604c-.684 0-1.224.6-1.224 1.332 0 .732.552 1.332 1.224 1.332.684 0 1.224-.6 1.224-1.332.012-.732-.54-1.332-1.224-1.332zm4.38 0c-.684 0-1.224.6-1.224 1.332 0 .732.552 1.332 1.224 1.332.684 0 1.224-.6 1.224-1.332 0-.732-.54-1.332-1.224-1.332z" />
</svg>
</a>
<a
href="https://github.com/blue-pen5805"
class="mb-2 inline-block rounded px-6 py-2.5 text-white shadow-md"
style="background-color: #333">
<svg xmlns="http://www.w3.org/2000/svg" class="h-4 w-4" fill="currentColor" viewBox="0 0 24 24">
<path d="M12 0c-6.626 0-12 5.373-12 12 0 5.302 3.438 9.8 8.207 11.387.599.111.793-.261.793-.577v-2.234c-3.338.726-4.033-1.416-4.033-1.416-.546-1.387-1.333-1.756-1.333-1.756-1.089-.745.083-.729.083-.729 1.205.084 1.839 1.237 1.839 1.237 1.07 1.834 2.807 1.304 3.492.997.107-.775.418-1.305.762-1.604-2.665-.305-5.467-1.334-5.467-5.931 0-1.311.469-2.381 1.236-3.221-.124-.303-.535-1.524.117-3.176 0 0 1.008-.322 3.301 1.23.957-.266 1.983-.399 3.003-.404 1.02.005 2.047.138 3.006.404 2.291-1.552 3.297-1.23 3.297-1.23.653 1.653.242 2.874.118 3.176.77.84 1.235 1.911 1.235 3.221 0 4.609-2.807 5.624-5.479 5.921.43.372.823 1.102.823 2.222v3.293c0 .319.192.694.801.576 4.765-1.589 8.199-6.086 8.199-11.386 0-6.627-5.373-12-12-12z" />
</svg>
</a>
</div>
</div>
</div>
</div>
|
nolanaatama/jnn1000pchfrdd | nolanaatama | 2023-07-05T10:43:24Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T10:38:23Z | ---
license: creativeml-openrail-m
---
|
Htar/q-FrozenLake-v1-4x4-noSlippery | Htar | 2023-07-05T10:18:06Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T09:48:44Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Htar/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
bofenghuang/vigogne-13b-instruct | bofenghuang | 2023-07-05T10:15:34Z | 1,472 | 13 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"LLM",
"fr",
"license:openrail",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-03-26T22:08:28Z | ---
license: openrail
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- llama
- LLM
inference: false
---
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-13b-instruct/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-13B-Instruct: A French Instruction-following LLaMA Model
Vigogne-13B-Instruct is a LLaMA-13B model fine-tuned to follow the French instructions.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
**Usage and License Notices**: Same as [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca), Vigogne is intended and licensed for research use only. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
## Changelog
All versions are available in branches.
- **V1.0**: Initial release, trained on the translated Stanford Alpaca dataset.
- **V1.1**: Improved translation quality of the Stanford Alpaca dataset.
- **V2.0**: Expanded training dataset to 224k for better performance.
- **V3.0**: Further expanded training dataset to 262k for improved results.
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_instruct_prompt
model_name_or_path = "bofenghuang/vigogne-13b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16, device_map="auto")
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_instruct_prompt(user_query)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
You can also infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
|
Htar/taxi-3 | Htar | 2023-07-05T10:10:20Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T10:07:37Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Htar/taxi-3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
NasimB/gpt2-concat-finetune-cl-mod-datasets-rarity1 | NasimB | 2023-07-05T10:09:35Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-05T03:32:14Z | ---
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-concat-finetune-cl-mod-datasets-rarity1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-concat-finetune-cl-mod-datasets-rarity1
This model was trained from scratch on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.8306 | 0.3 | 500 | 4.5102 |
| 3.9443 | 0.59 | 1000 | 4.5278 |
| 4.039 | 0.89 | 1500 | 4.4641 |
| 3.8859 | 1.18 | 2000 | 4.4729 |
| 3.8519 | 1.48 | 2500 | 4.4332 |
| 3.8622 | 1.78 | 3000 | 4.3895 |
| 3.765 | 2.07 | 3500 | 4.4085 |
| 3.5415 | 2.37 | 4000 | 4.4023 |
| 3.5631 | 2.66 | 4500 | 4.3729 |
| 3.559 | 2.96 | 5000 | 4.3403 |
| 3.2324 | 3.26 | 5500 | 4.4037 |
| 3.2011 | 3.55 | 6000 | 4.3997 |
| 3.1898 | 3.85 | 6500 | 4.3837 |
| 3.0472 | 4.14 | 7000 | 4.4190 |
| 2.9036 | 4.44 | 7500 | 4.4273 |
| 2.8985 | 4.74 | 8000 | 4.4269 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
maharshipandya/AnimeGPTSan | maharshipandya | 2023-07-05T10:04:33Z | 125 | 4 | transformers | [
"transformers",
"pytorch",
"tf",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-02T18:23:39Z | ---
license: creativeml-openrail-m
tags:
- generated_from_keras_callback
model-index:
- name: AnimeGPTSan
results: []
language:
- en
pipeline_tag: text-generation
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# AnimeGPTSan (Fine-tuned for Anime synopsis)
`AnimeGPTSan` is essentially the OpenAI's `GPT2` model fine-tuned on [this anime dataset](https://www.kaggle.com/datasets/marlesson/myanimelist-dataset-animes-profiles-reviews). This model can be used to generate new descriptions/synopses for anime, based on some input prompt.
The original `GPT2` model can be found here: [OpenAI's GPT2 on HuggingFace](https://huggingface.co/gpt2)
# Results
- Input prompt
`The shadow realm`
- Outputs
1. `The shadow realm of the dark lord's hands will be invaded by the evil, demonic beasts. One day, the lord's minions, the Shattering Star God, awaken and attack the world...`
2. `The shadow realm of the Underworld awaits the demon lord Akito who is intent upon subjugating the human world. The Demon Lord is determined to destroy the world. He intends to use the "Dark Soul" as the catalyst...`
3. `The shadow realm is the source of many evil, but at its core, lies a magical weapon capable of killing any creature it touches. A group of teenagers in a high-tech school known as the Dark Knight Knights, nicknamed the "Darks," are a force that will...`
4. `The shadow realm has been awakened by the coming of the evil Demon King. The Shadow Warriors are a team of warriors who have been chosen to battle the Demon King with special powers...`
5. `The shadow realm exists between us and the demon world, and it is the source of the demons' power. The demons were sent to destroy the shadow realm, to make people mad. However, the evil spirit of the demon was able to...`
# Usage
The below code describes how to use `AnimeGPTSan` to generate anime synopsis given some input prompt.
> Note: Make sure to use a GPU for faster responses
```python
from transformers import GPT2LMHeadModel, GPT2Tokenizer
anime_model = GPT2LMHeadModel.from_pretrained("maharshipandya/AnimeGPTSan")
anime_tokenizer = GPT2Tokenizer.from_pretrained("maharshipandya/AnimeGPTSan")
def generate_text(sequence):
outputs = []
ids = anime_tokenizer.encode(f"{sequence}", return_tensors="pt")
final_outputs = anime_model.generate(ids, do_sample=True, max_length=200, top_k=40,
top_p=0.95, temperature=1.0, num_return_sequences=10)
for i, out in enumerate(final_outputs):
output = anime_tokenizer.decode(out, skip_special_tokens=True)
outputs.append(output)
return outputs
print(generate_text("The shadow realm")) # list of generated synopses
```
In order to generate synopses without any prefix prompt, just give `"<|startoftext|>"` as the input prompt to `AnimeGPTSan`. |
Talha185/distilbert-base-uncased-finetuned-imdb | Talha185 | 2023-07-05T10:02:25Z | 122 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2023-07-05T09:37:34Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7086 | 1.0 | 157 | 2.4897 |
| 2.5796 | 2.0 | 314 | 2.4230 |
| 2.5269 | 3.0 | 471 | 2.4354 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
neilsun2009/amz_movie_tv_distilgpt2_1k | neilsun2009 | 2023-07-05T10:00:53Z | 4 | 0 | peft | [
"peft",
"text-generation",
"en",
"region:us"
] | text-generation | 2023-07-05T09:24:13Z | ---
language:
- en
metrics:
- perplexity
library_name: peft
pipeline_tag: text-generation
--- |
Bbrown44/hiphop-ds-v4 | Bbrown44 | 2023-07-05T09:51:17Z | 125 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"doi:10.57967/hf/0667",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-05-10T01:14:29Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: hiphop-ds-v4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hiphop-ds-v4
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 1.12.1+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
anejaisha/output6 | anejaisha | 2023-07-05T09:48:13Z | 0 | 0 | null | [
"tensorboard",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T09:00:57Z | ---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- generated_from_trainer
model-index:
- name: output6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output6
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 66 | 0.1907 |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
EllaHong/datamap_polyglot_5.8b_exp2_800 | EllaHong | 2023-07-05T09:43:48Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T09:43:42Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
kishkath/output | kishkath | 2023-07-05T09:41:35Z | 3 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:finetune:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-06-26T10:10:03Z |
---
license: creativeml-openrail-m
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks cocacola
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - kishkath/output
This is a dreambooth model derived from CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks cocacola using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
amu-cai/polemma-large | amu-cai | 2023-07-05T09:20:04Z | 126 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"T5",
"lemmatization",
"pl",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-03-15T14:49:10Z | ---
language: pl
tags:
- T5
- lemmatization
license: apache-2.0
---
# PoLemma Large
PoLemma models are intended for lemmatization of named entities and multi-word expressions in the Polish language.
They were fine-tuned from the allegro/plT5 models, e.g.: [allegro/plt5-large](https://huggingface.co/allegro/plt5-large).
## Usage
Sample usage:
```
from transformers import pipeline
pipe = pipeline(task="text2text-generation", model="amu-cai/polemma-large", tokenizer="amu-cai/polemma-large")
hyp = [res['generated_text'] for res in pipe(["federalnego urzędu statystycznego"], clean_up_tokenization_spaces=True, num_beams=5)][0]
```
## Evaluation results
Lemmatization Exact Match was computed on the SlavNER 2021 test set.
| Model | Exact Match ||
| :------ | ------: | ------: |
| [polemma-large](https://huggingface.co/amu-cai/polemma-large) | 92.61 |
| [polemma-base](https://huggingface.co/amu-cai/polemma-base) | 91.34 |
| [polemma-small](https://huggingface.co/amu-cai/polemma-small)| 88.46 |
## Citation
If you use the model, please cite the following paper:
```
@inproceedings{palka-nowakowski-2023-exploring,
title = "Exploring the Use of Foundation Models for Named Entity Recognition and Lemmatization Tasks in {S}lavic Languages",
author = "Pa{\l}ka, Gabriela and
Nowakowski, Artur",
booktitle = "Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.bsnlp-1.19",
pages = "165--171",
abstract = "This paper describes Adam Mickiewicz University{'}s (AMU) solution for the 4th Shared Task on SlavNER. The task involves the identification, categorization, and lemmatization of named entities in Slavic languages. Our approach involved exploring the use of foundation models for these tasks. In particular, we used models based on the popular BERT and T5 model architectures. Additionally, we used external datasets to further improve the quality of our models. Our solution obtained promising results, achieving high metrics scores in both tasks. We describe our approach and the results of our experiments in detail, showing that the method is effective for NER and lemmatization in Slavic languages. Additionally, our models for lemmatization will be available at: https://huggingface.co/amu-cai.",
}
```
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
neilsun2009/amz_movie_tv_distilgpt2_100 | neilsun2009 | 2023-07-05T09:17:23Z | 4 | 0 | peft | [
"peft",
"distilgpt-2",
"text-generation",
"en",
"region:us"
] | text-generation | 2023-07-05T09:01:34Z | ---
language:
- en
library_name: peft
metrics:
- perplexity
tags:
- distilgpt-2
pipeline_tag: text-generation
--- |
AndrewDOrlov/bert-eval | AndrewDOrlov | 2023-07-05T09:12:43Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-03T08:08:21Z | ---
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: bert-eval
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-eval
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2288
- F1: 0.7837
- Roc Auc: 0.8490
- Accuracy: 0.3137
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.4067 | 1.0 | 751 | 0.2930 | 0.7145 | 0.7911 | 0.2188 |
| 0.2483 | 2.0 | 1502 | 0.2528 | 0.7493 | 0.8167 | 0.2777 |
| 0.1993 | 3.0 | 2253 | 0.2323 | 0.7772 | 0.8406 | 0.3067 |
| 0.1468 | 4.0 | 3004 | 0.2288 | 0.7837 | 0.8490 | 0.3137 |
| 0.1238 | 5.0 | 3755 | 0.2287 | 0.7837 | 0.8509 | 0.3217 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
youlun77/finetuning-sentiment-model-10000-samples | youlun77 | 2023-07-05T08:58:47Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-05T08:37:13Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-10000-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.9133333333333333
- name: F1
type: f1
value: 0.9155844155844156
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-10000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2762
- Accuracy: 0.9133
- F1: 0.9156
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
dhiruHF/falcon7b-FT-DocQA2 | dhiruHF | 2023-07-05T08:57:56Z | 8 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T08:57:54Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
erberry/chinese-alpaca-lora-13b-merged-q4 | erberry | 2023-07-05T08:44:06Z | 0 | 2 | null | [
"zh",
"region:us"
] | null | 2023-07-05T08:06:44Z | ---
language:
- zh
---
本模型基于 https://github.com/ymcui/Chinese-LLaMA-Alpaca 项目提供的 Chinese-LLaMA-Plus-13B 与 Chinese-Alpaca-Plus-13B合并而来,
并使用llama.cpp进行了q4量化, 合并流程使用如下链接:
https://colab.research.google.com/drive/1EOjpQ2kdWBlrm0e-4uTmD5g6wCqwHJDB?usp=sharing
License Non-commercial bespoke license |
gabski/deberta-suboptimal-claim-detection-with-thesis-context | gabski | 2023-07-05T08:23:06Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"deberta",
"text-classification",
"en",
"dataset:ClaimRev",
"arxiv:2305.16799",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-06-08T14:19:14Z | ---
license: cc-by-nc-sa-4.0
language:
- en
library_name: transformers
pipeline_tag: text-classification
datasets:
- ClaimRev
widget:
- text: "Teachers are likely to educate children better than parents."
context: "Homeschooling should be banned."
---
# Model
This model was obtained by fine-tuning `microsoft/deberta-base` on the extended ClaimRev dataset.
Paper: [To Revise or Not to Revise: Learning to Detect Improvable Claims for Argumentative Writing Support](https://arxiv.org/abs/2305.16799)
Authors: Gabriella Skitalinskaya and Henning Wachsmuth
# Suboptimal Claim Detection
We cast this task as a binary classification task, where the objective is, given an argumentative claim and some contextual information (in this case, the **main thesis** of the debate), to decide whether it is in need of further revision or can be considered to be phrased more or less optimally.
# Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-thesis-context")
model = AutoModelForSequenceClassification.from_pretrained("gabski/deberta-suboptimal-claim-detection-with-thesis-context")
claim = 'Teachers are likely to educate children better than parents.'
thesis = 'Homeschooling should be banned.'
model_input = tokenizer(claim, thesis, return_tensors='pt')
model_outputs = model(**model_input)
outputs = torch.nn.functional.softmax(model_outputs.logits, dim = -1)
print(outputs)
``` |
dganesh/ppo-MountainCar-v0 | dganesh | 2023-07-05T08:22:19Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"MountainCar-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T07:31:01Z | ---
library_name: stable-baselines3
tags:
- MountainCar-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
metrics:
- type: mean_reward
value: -200.00 +/- 0.00
name: mean_reward
verified: false
---
# **PPO** Agent playing **MountainCar-v0**
This is a trained model of a **PPO** agent playing **MountainCar-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
fragdata/ppo-Huggy | fragdata | 2023-07-05T08:20:29Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2023-07-05T08:20:19Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: fragdata/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
yeounyi/ppo-PyramidsTraining | yeounyi | 2023-07-05T08:07:53Z | 1 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2023-07-05T08:07:51Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: yeounyi/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
re2panda/alpaca-grade-school-math | re2panda | 2023-07-05T08:04:34Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2023-07-05T08:04:32Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.4.0.dev0
|
aroot/wsample.43 | aroot | 2023-07-05T08:03:46Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2023-07-05T06:25:14Z | ---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: wsample.43
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wsample.43
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2191
- Bleu: 2.8739
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1
- Datasets 2.12.0
- Tokenizers 0.11.0
|
leo20230412/test_model20230705 | leo20230412 | 2023-07-05T08:01:11Z | 0 | 0 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2023-07-05T07:59:34Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
chainyo/segformer-sidewalk | chainyo | 2023-07-05T07:59:04Z | 170 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"segformer",
"vision",
"image-segmentation",
"dataset:segments/sidewalk-semantic",
"arxiv:2105.15203",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2022-06-12T09:44:06Z | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- segments/sidewalk-semantic
---
# SegFormer (b0-sized) model fine-tuned on sidewalk-semantic dataset
SegFormer model fine-tuned on segments/sidewalk-semantic at resolution 512x512. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor(reduce_labels=True)
model = SegformerForSemanticSegmentation.from_pretrained("ChainYo/segformer-sidewalk")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#). |
pauliusrauba/q-FrozenLake-v1-4x4-noSlippery | pauliusrauba | 2023-07-05T07:58:31Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-05T07:58:28Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="pauliusrauba/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
jjhonny/LundarLander-v2-custom | jjhonny | 2023-07-05T07:51:26Z | 0 | 0 | null | [
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T18:32:31Z | ---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 120.10 +/- 68.69
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 5000000
'learning_rate': 0.0003
'num_envs': 1024
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 1024
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'jjhonny/LundarLander-v2-custom'
'batch_size': 131072
'minibatch_size': 128}
```
|
tonyhsu/my_awesome_model | tonyhsu | 2023-07-05T07:43:17Z | 116 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-01T16:36:26Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: my_awesome_model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93048
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2406
- Accuracy: 0.9305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2335 | 1.0 | 1563 | 0.1891 | 0.9272 |
| 0.1523 | 2.0 | 3126 | 0.2406 | 0.9305 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Sekiraw/LunarLander | Sekiraw | 2023-07-05T07:34:26Z | 1 | 1 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2023-07-04T19:46:50Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 279.05 +/- 16.02
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
gajanandjha/distilgpt2-finetuned-wikitext2 | gajanandjha | 2023-07-05T07:20:28Z | 182 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"en",
"dataset:wikitext",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-07-04T06:16:46Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-wikitext2
results: []
datasets:
- wikitext
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7888 | 1.0 | 2323 | 3.6878 |
| 3.6737 | 2.0 | 4646 | 3.6663 |
| 3.6143 | 3.0 | 6969 | 3.6636 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3 |
therealvul/so-vits-svc-4.0 | therealvul | 2023-07-05T07:05:40Z | 0 | 148 | null | [
"en",
"region:us"
] | null | 2023-03-03T07:24:41Z | ---
language:
- en
---
This is a collection of so-vits-svc-4.0 models made by the Pony Preservation Project using audio clips taken from MLP:FiM. |
h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2 | h2oai | 2023-07-05T07:00:45Z | 57 | 59 | transformers | [
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"conversational",
"custom_code",
"en",
"dataset:OpenAssistant/oasst1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-01T19:59:04Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: >-
https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
license: apache-2.0
datasets:
- OpenAssistant/oasst1
pipeline_tag: conversational
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [tiiuae/falcon-7b](https://huggingface.co/tiiuae/falcon-7b)
- Dataset preparation: [OpenAssistant/oasst1](https://github.com/h2oai/h2o-llmstudio/blob/1935d84d9caafed3ee686ad2733eb02d2abfce57/app_utils/utils.py#LL1896C5-L1896C28)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate`, `torch` and `einops` libraries installed.
```bash
pip install transformers==4.29.2
pip install accelerate==0.19.0
pip install torch==2.0.0
pip install einops==0.6.1
```
```python
import torch
from transformers import AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
generate_text = pipeline(
model="h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
tokenizer=tokenizer,
torch_dtype=torch.float16,
trust_remote_code=True,
use_fast=False,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer:
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
use_fast=False,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2",
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=False,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=1024,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
RWForCausalLM(
(transformer): RWModel(
(word_embeddings): Embedding(65024, 4544)
(h): ModuleList(
(0-31): 32 x DecoderLayer(
(input_layernorm): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
(self_attention): Attention(
(maybe_rotary): RotaryEmbedding()
(query_key_value): Linear(in_features=4544, out_features=4672, bias=False)
(dense): Linear(in_features=4544, out_features=4544, bias=False)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4544, out_features=18176, bias=False)
(act): GELU(approximate='none')
(dense_4h_to_h): Linear(in_features=18176, out_features=4544, bias=False)
)
)
)
(ln_f): LayerNorm((4544,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=4544, out_features=65024, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Model Validation
Model validation results using [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
```bash
CUDA_VISIBLE_DEVICES=0 python main.py --model hf-causal-experimental --model_args pretrained=h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v2 --tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq --device cuda &> eval.log
```
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
anejaisha/output2 | anejaisha | 2023-07-05T06:56:19Z | 75 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:quantized:google/flan-t5-large",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] | text2text-generation | 2023-07-05T06:54:52Z | ---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- generated_from_trainer
model-index:
- name: output2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output2
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 40 | nan |
### Framework versions
- Transformers 4.31.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
babblebots/initial-model-v3 | babblebots | 2023-07-05T06:48:03Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] | text-classification | 2023-07-05T06:15:14Z | ---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# /var/folders/mt/147vhq713f1_gmbpccrp4hc00000gn/T/tmpkw4fvqwe/ishan/initial-model-v3
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("/var/folders/mt/147vhq713f1_gmbpccrp4hc00000gn/T/tmpkw4fvqwe/ishan/initial-model-v3")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
Subsets and Splits