
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-28 18:27:08
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 501
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-28 18:25:37
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
pogpog/flan-t5-base-samsum-chatgpt-summary-0.1 | pogpog | 2024-03-13T12:49:19Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:adapter:google/flan-t5-base",
"license:apache-2.0",
"region:us"
] | null | 2024-03-13T12:49:17Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: google/flan-t5-base
model-index:
- name: output_dir_training
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output_dir_training
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9104
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.5475 | 1.0 | 1842 | 1.8983 |
| 1.5917 | 2.0 | 3684 | 1.9073 |
| 1.5283 | 3.0 | 5526 | 1.9104 |
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
EdBerg/trained-opt-6.7b-lora | EdBerg | 2024-03-13T12:47:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T12:47:00Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Jevvan123/Mixtral_finetuned_newmodel | Jevvan123 | 2024-03-13T12:40:34Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.1",
"region:us"
] | null | 2024-03-13T12:38:44Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-Instruct-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
arcee-ai/Calme-Instruct-Extended | arcee-ai | 2024-03-13T12:39:24Z | 10 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"MaziyarPanahi/Calme-7B-Instruct-v0.1.1",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T12:26:45Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- MaziyarPanahi/Calme-7B-Instruct-v0.1.1
---
# Calme-Instruct-Extended
Calme-Instruct-Extended is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [MaziyarPanahi/Calme-7B-Instruct-v0.1.1](https://huggingface.co/MaziyarPanahi/Calme-7B-Instruct-v0.1.1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 0
- 4
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 3
- 4
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 4
- 8
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 7
- 8
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 8
- 12
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 11
- 12
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 12
- 16
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 15
- 16
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 16
- 20
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 19
- 20
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 20
- 24
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 23
- 24
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 24
- 28
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 27
- 28
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 28
- 32
- sources:
- model: MaziyarPanahi/Calme-7B-Instruct-v0.1.1
layer_range:
- 31
- 32
parameters:
scale:
- filter: o_proj
value: 0
- filter: down_proj
value: 0
- value: 1
merge_method: passthrough
dtype: bfloat16
``` |
MatrixNinja/slackGPT-ft | MatrixNinja | 2024-03-13T12:39:05Z | 2 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"dataset:Samhita/slack-data-long-responses",
"base_model:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"base_model:adapter:TheBloke/Mistral-7B-Instruct-v0.2-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2024-03-13T12:29:09Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: TheBloke/Mistral-7B-Instruct-v0.2-GPTQ
model-index:
- name: SlackGPT-ft
results: []
datasets:
- Samhita/slack-data-long-responses
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SlackGPT-ft
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.2-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GPTQ) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9338
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.9733 | 1.0 | 550 | 0.9338 |
### Framework versions
- PEFT 0.9.0
- Transformers 4.38.2
- Pytorch 2.1.0+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2 |
mervinpraison/idefics-9b-PokemonCards | mervinpraison | 2024-03-13T12:35:59Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"idefics",
"image-text-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | image-text-to-text | 2024-03-13T11:55:21Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
almms/corgy_dog_LoRA | almms | 2024-03-13T12:34:49Z | 1 | 1 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-12T11:03:12Z | ---
license: openrail++
library_name: diffusers
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of TOK dog
widget: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - almms/corgy_dog_LoRA
<Gallery />
## Model description
These are almms/corgy_dog_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK dog to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](almms/corgy_dog_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
Dipra/doremon | Dipra | 2024-03-13T12:34:06Z | 3 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T12:27:44Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Doremon Dreambooth model trained by Dipra following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 11000222015
Sample pictures of this concept:


|
Binaylahiri/my-pet-dog | Binaylahiri | 2024-03-13T12:28:08Z | 2 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T12:23:51Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog Dreambooth model trained by Binaylahiri following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 11000222011
Sample pictures of this concept:
.jpeg)
.jpeg)
.jpeg)
.jpeg)
.jpeg)
|
doceoSoftware/donut-docvqa-clicars-ITV-13032024-1 | doceoSoftware | 2024-03-13T12:25:32Z | 33 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-03-13T12:24:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
doceoSoftware/donut-docvqa-clicars-ITV-21012024-1 | doceoSoftware | 2024-03-13T12:23:59Z | 34 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-01-21T15:05:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
alex-miller/ODABert | alex-miller | 2024-03-13T12:23:09Z | 135 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"dataset:alex-miller/oecd-dac-crs",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-02-12T20:28:03Z | ---
license: apache-2.0
base_model: bert-base-multilingual-uncased
tags:
- generated_from_trainer
model-index:
- name: ODABert
results: []
datasets:
- alex-miller/oecd-dac-crs
widget:
- text: "Official Development [MASK]."
example_title: "ODA"
- text: "Climate adaptation and climate [MASK]."
example_title: "Climate"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ODABert
This model is a fine-tuned version of [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) on the [OECD DAC CRS project titles and descriptions](https://huggingface.co/datasets/alex-miller/oecd-dac-crs) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9961
## Model description
A 3 epoch fine-tune of BERT base multilingual uncased on development and humanitarian finance project titles and descriptions from the OECD DAC CRS. Vocabulary of the base model was expanded by 1,059 tokens (1% increase) based on the most prevalent tokens in the CRS that were not present in the base model vocabulary.
## Intended uses & limitations
Developed as an experiment to see whether fine-tuning on the CRS would help improve classifier models built on top of this MLM. Although it's built on a multilingual model, an the finetuning texts do include other languages, English will be the most prevalent.
## Training and evaluation data
See the [OECD DAC CRS project titles and descriptions](https://huggingface.co/datasets/alex-miller/oecd-dac-crs) dataset.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.2133 | 1.0 | 58119 | 1.1296 |
| 1.098 | 2.0 | 116238 | 1.0336 |
| 1.0441 | 3.0 | 174357 | 0.9958 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.0.1
- Datasets 2.18.0
- Tokenizers 0.15.2 |
VladimML/mt5-small-News | VladimML | 2024-03-13T12:18:49Z | 14 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"base_model:google/mt5-small",
"base_model:finetune:google/mt5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2024-02-28T14:35:33Z | ---
license: apache-2.0
base_model: google/mt5-small
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-News
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-News
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3419
- Rouge1: 6.9313
- Rouge2: 1.9587
- Rougel: 6.8503
- Rougelsum: 6.9385
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|
| 4.4281 | 1.0 | 1250 | 2.5899 | 7.0481 | 2.0747 | 6.9849 | 7.0179 |
| 3.2368 | 2.0 | 2500 | 2.4568 | 6.7532 | 1.7462 | 6.6934 | 6.7462 |
| 3.0526 | 3.0 | 3750 | 2.4315 | 6.6106 | 1.9088 | 6.5307 | 6.5784 |
| 2.9412 | 4.0 | 5000 | 2.3882 | 7.0644 | 1.9283 | 6.9687 | 7.0399 |
| 2.8711 | 5.0 | 6250 | 2.3700 | 7.2808 | 1.9358 | 7.2006 | 7.2603 |
| 2.8193 | 6.0 | 7500 | 2.3604 | 7.0911 | 1.9737 | 6.9918 | 7.0491 |
| 2.7866 | 7.0 | 8750 | 2.3479 | 6.9948 | 2.0044 | 6.8824 | 6.9737 |
| 2.7699 | 8.0 | 10000 | 2.3419 | 6.9313 | 1.9587 | 6.8503 | 6.9385 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
jtatman/sciphi-mini-600m-unsloth | jtatman | 2024-03-13T12:18:30Z | 9 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"experimental",
"peft",
"rslora",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-12T12:03:57Z | ---
license: apache-2.0
library_name: transformers
tags:
- experimental
- peft
- rslora
---
# Model Card for Model ID
This is a model with altered parameters from a mergekit slice of [SciPhi/SciPhi-Self-RAG-Mistral-7B-32k](https://huggingface.co/SciPhi/SciPhi-Self-RAG-Mistral-7B-32k).
## Model Details
### Model Description
This model is an experimental model using minimal slices to gather core model properties that can be further trained.
The parameters have been reduced to just under 600 million. This is an experiment to see how far slicing can be taken while retaining original weight associations.
The model will be used for layer analysis and trained on a close approximation of the sciphi datasets using trainable parameters to see what original weights might be usable.
This process will be ongoing to see if rank stabilized tuning can save and enhance the original model information through recognizing original weight associations in the preserved layers, even after model resizing.
### Process
These models are merged with LoRA versions at each training run to consolidate weights, and the merged model is used as a base model for the next training.
The LoRA model can be found here: [jtatman/sciphi-mini-600m-unsloth-lora-v2](https://huggingface.co/jtatman/sciphi-mini-600m-unsloth-lora-v2)
The model is trained using [unsloth](https://github.com/unslothai/unsloth). Unsloth can be integrated in both supervised fine-tuning and direct preference optimizations through huggingface, using the TRL library. |
blockblockblock/Cerebrum-1.0-7b-bpw5.5 | blockblockblock | 2024-03-13T12:18:29Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-03-13T12:16:22Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
TommyLike/second_model | TommyLike | 2024-03-13T12:12:52Z | 0 | 1 | bertopic | [
"bertopic",
"biology",
"text-classification",
"aa",
"dataset:HuggingFaceTB/cosmopedia",
"arxiv:1910.09700",
"license:apache-2.0",
"region:us"
] | text-classification | 2024-03-13T12:10:26Z | ---
license: apache-2.0
datasets:
- HuggingFaceTB/cosmopedia
language:
- aa
metrics:
- accuracy
library_name: bertopic
pipeline_tag: text-classification
tags:
- biology
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vilm/Quyen-Plus-v0.1 | vilm | 2024-03-13T12:10:18Z | 53 | 7 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"dataset:teknium/OpenHermes-2.5",
"dataset:LDJnr/Capybara",
"dataset:Intel/orca_dpo_pairs",
"dataset:argilla/distilabel-capybara-dpo-7k-binarized",
"license:other",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-06T00:24:42Z | ---
language:
- en
license: other
library_name: transformers
datasets:
- teknium/OpenHermes-2.5
- LDJnr/Capybara
- Intel/orca_dpo_pairs
- argilla/distilabel-capybara-dpo-7k-binarized
pipeline_tag: text-generation
model-index:
- name: Quyen-Plus-v0.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 55.72
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 78.52
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 60.45
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 53.6
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 71.27
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 60.05
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=vilm/Quyen-Plus-v0.1
name: Open LLM Leaderboard
---
# Quyen
<img src="quyen.webp" width="512" height="512" alt="Quyen">
# Model Description
Quyen is our first flagship LLM series based on the Qwen1.5 family. We introduced 6 different versions:
- **Quyen-SE (0.5B)**
- **Quyen-Mini (1.8B)**
- **Quyen (4B)**
- **Quyen-Plus (7B)**
- **Quyen-Pro (14B)**
- **Quyen-Pro-Max (72B)**
All models were trained with SFT and DPO using the following dataset:
- *OpenHermes-2.5* by **Teknium**
- *Capyabara* by **LDJ**
- *argilla/distilabel-capybara-dpo-7k-binarized* by **argilla**
- *orca_dpo_pairs* by **Intel**
- and Private Data by **Ontocord** & **BEE-spoke-data**
# Prompt Template
- All Quyen models use ChatML as the default template:
```
<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Hello world.<|im_end|>
<|im_start|>assistant
```
- You can also use `apply_chat_template`:
```python
messages = [
{"role": "system", "content": "You are a sentient, superintelligent artificial general intelligence, here to teach and assist me."},
{"role": "user", "content": "Hello world."}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# Benchmarks:
- Coming Soon! We will update the benchmarks later
# Acknowledgement
- We're incredibly grateful to **Tensoic** and **Ontocord** for their generous support with compute and data preparation.
- Special thanks to the Qwen team for letting us access the models early for these amazing finetunes.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_vilm__Quyen-Plus-v0.1)
| Metric |Value|
|---------------------------------|----:|
|Avg. |63.27|
|AI2 Reasoning Challenge (25-Shot)|55.72|
|HellaSwag (10-Shot) |78.52|
|MMLU (5-Shot) |60.45|
|TruthfulQA (0-shot) |53.60|
|Winogrande (5-shot) |71.27|
|GSM8k (5-shot) |60.05|
|
scrawlsbraid/tinyllama-colorist-v2 | scrawlsbraid | 2024-03-13T12:07:01Z | 88 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T12:05:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kertob/content | kertob | 2024-03-13T12:06:56Z | 14 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:adapter:vilsonrodrigues/falcon-7b-instruct-sharded",
"license:apache-2.0",
"region:us"
] | null | 2024-03-08T12:04:48Z | ---
license: apache-2.0
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
model-index:
- name: vilsonrodrigues/falcon-7b-instruct-sharded
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vilsonrodrigues/falcon-7b-instruct-sharded
This model is a fine-tuned version of [vilsonrodrigues/falcon-7b-instruct-sharded](https://huggingface.co/vilsonrodrigues/falcon-7b-instruct-sharded) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 200
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.9.1.dev0
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 |
SiriWhat/Job_recommendation | SiriWhat | 2024-03-13T12:02:56Z | 84 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"albert",
"text-classification",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-13T12:01:11Z | ---
pipeline_tag: text-classification
--- |
Pindice/Mixtral_CreIA_more_epochs | Pindice | 2024-03-13T11:58:08Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mixtral-8x7B-Instruct-v0.1",
"base_model:adapter:mistralai/Mixtral-8x7B-Instruct-v0.1",
"region:us"
] | null | 2024-03-13T11:57:25Z | ---
library_name: peft
base_model: mistralai/Mixtral-8x7B-Instruct-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.9.1.dev0 |
MU-NLPC/whisper-small-audio-captioning | MU-NLPC | 2024-03-13T11:52:19Z | 184 | 10 | transformers | [
"transformers",
"pytorch",
"whisper",
"en",
"dataset:AudioSet",
"dataset:AudioCaps",
"dataset:Clotho-v2.1",
"arxiv:2305.09690",
"license:cc-by-nc-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null | 2023-05-15T17:48:16Z | ---
datasets:
- AudioSet
- AudioCaps
- Clotho-v2.1
metrics:
- SPICE
- CIDEr
- SPIDEr
- METEOR
- SacreBLEU
model-index:
- name: whisper-small-audio-captioning
results:
- task:
type: audio-captioning
name: Audio Captioning
dataset:
type: clotho-v2.1
name: Clotho
split: evaluation
metrics:
- type: SPICE
value: 0.1234
- type: CIDEr
value: 0.4142
- type: SPIDEr
value: 0.2687
- type: METEOR
value: 0.3781
- type: SacreBLEU
value: 15.76
license: cc-by-nc-4.0
language:
- en
---
# Model Card for Whisper Audio Captioning
A transformer encoder-decoder model for automatic audio captioning. As opposed to speech-to-text, captioning describes the content of audio clips, such as prominent sounds or environmental noises. This task has numerous practical applications, e.g., for providing access to audio information for people with hearing impairments or improving the searchability of audio content.
- **Model type:** Whisper encoder-decoder transformer
- **Language(s) (NLP):** en
- **License:** cc-by-4.0
- **Parent Model:** openai/whisper-small
- **Resources for more information:**
- [GitHub Repo](https://github.com/prompteus/audio-captioning)
- [Technical Report](https://arxiv.org/abs/2305.09690)
## Usage
The model expects an audio clip (up to 30s) to the encoder as an input and information about caption style as forced prefix to the decoder.
Minimal example:
```python
# Load model
checkpoint = "MU-NLPC/whisper-small-audio-captioning"
model = WhisperForAudioCaptioning.from_pretrained(checkpoint)
tokenizer = transformers.WhisperTokenizer.from_pretrained(checkpoint, language="en", task="transcribe")
feature_extractor = transformers.WhisperFeatureExtractor.from_pretrained(checkpoint)
# Load and preprocess audio
input_file = "..."
audio, sampling_rate = librosa.load(input_file, sr=feature_extractor.sampling_rate)
features = feature_extractor(audio, sampling_rate=sampling_rate, return_tensors="pt").input_features
# Prepare caption style
style_prefix = "clotho > caption: "
style_prefix_tokens = tokenizer("", text_target=style_prefix, return_tensors="pt", add_special_tokens=False).labels
# Generate caption
model.eval()
outputs = model.generate(
inputs=features.to(model.device),
forced_ac_decoder_ids=style_prefix_tokens,
max_length=100,
)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
```
Example output:
*clotho > caption: Rain is pouring down and thunder is rumbling in the background.*
The style prefix influences the style of the caption. Model knows 3 styles: `audioset > keywords: `, `audiocaps > caption: `, and `clotho > caption: `. It was finetuned on Clotho and that is the indended "default" style.
WhisperTokenizer must be initialized with `language="en"` and `task="transcribe"`.
Our model class `WhisperForAudioCaptioning` can be found in our git repository or here on the HuggingFace Hub in the model repository. The class overrides default Whisper `generate` method to support forcing decoder prefix.
## Training details
The model was initialized by original speech-to-text `openai/whisper-small` weights. Then, it was pretrained on a mix of (1) subset of AudioSet with synthetic labels, (2) AudioCaps captioning dataset and (3) Clotho v2.1 captioning dataset. Finally, it was finetuned on Clotho v2.1 to focus the model on the specific style of the captions. For each traning input, the model was informed about the source of the data, so it can mimic the caption style in all 3 styles.
During pretraining, the ratio of samples in each batch was approximately 12:3:1 (AudioSet:AudioCaps:Clotho). The pretraining took 19800 steps with batch size 32 and learning rate 2e-5. Finetuning was done on Clotho only, and the model was trained for 1500 steps with batch size 32 and learning rate 4e-6. All layers except *fc1* layers were frozen during finetuning.
For more information about the training regime, see the [technical report](TODO).
## Evaluation details
Metrics reported in the metadata were computed on Clotho v2.1 test split with captions generated using a beam search with 5 beams.
| | whisper-tiny | whisper-small | whisper-large-v2 |
|----------------------|--------------|---------------|------------------|
| SacreBLEU | 13.77 | 15.76 | 16.50 |
| METEOR | 0.3452 | 0.3781 | 0.3782 |
| CIDEr | 0.3404 | 0.4142 | 0.4331 |
| SPICE | 0.1077 | 0.1234 | 0.1257 |
| SPIDEr | 0.2240 | 0.2687 | 0.2794 |
## Limitations
The captions generated by the model can be misleading or not truthful, even if they appear convincing. The hallucination occurs especially in domains that were not present in the finetuning data.
While the original speech-to-text checkpoints by OpenAI were trained on multilingual data, our training contains only English captions, and therefore is not expected for the model to support other languages.
## Licence
The model weights are published under non-commercial license CC BY-NC 4.0 as the model was finetuned on a dataset for non-commercial use.
## Contact
If you'd like to chat about this, please get in touch with is via email at kadlcik`<at>`mail.muni.cz or ahajek`<at>`mail.muni.cz.
|
totaldungeon/taxi-v3 | totaldungeon | 2024-03-13T11:51:55Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T11:51:53Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="totaldungeon/taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
viccelmar/Taxi-v3 | viccelmar | 2024-03-13T11:48:16Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T11:48:14Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.34 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="viccelmar/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Obscure-Entropy/vit-base-alzheimer-224 | Obscure-Entropy | 2024-03-13T11:40:48Z | 179 | 0 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-03-13T11:37:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ErinDelft/ppo-LunarLander-v2 | ErinDelft | 2024-03-13T11:35:45Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T11:16:35Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 298.18 +/- 11.79
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Shrinivas4032/pagani-car | Shrinivas4032 | 2024-03-13T11:32:55Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T11:23:53Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Pagani-Car Dreambooth model trained by Shrinivas4032 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: C21-42
Sample pictures of this concept:
.jpg)
|
daze-unlv/FacebookAI-roberta-base | daze-unlv | 2024-03-13T11:31:05Z | 90 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"multiple-choice",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | multiple-choice | 2024-03-12T15:31:04Z | ---
license: mit
base_model: FacebookAI/roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: FacebookAI-roberta-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# FacebookAI-roberta-base
This model is a fine-tuned version of [FacebookAI/roberta-base](https://huggingface.co/FacebookAI/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3863
- Accuracy: 0.2850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3874 | 1.0 | 2857 | 1.3863 | 0.2694 |
| 1.3869 | 2.0 | 5714 | 1.3863 | 0.2816 |
| 1.3868 | 3.0 | 8571 | 1.3863 | 0.2850 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0
|
sd-dreambooth-library/fabric-new-design | sd-dreambooth-library | 2024-03-13T11:20:50Z | 43 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T11:18:31Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
---
### Fabric new design on Stable Diffusion via Dreambooth
#### model by rikdas
This your the Stable Diffusion model fine-tuned the Fabric new design concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **<dog-toy> ekw madras checks**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:










|
Tochka-AI/ruRoPEBert-e5-base-512 | Tochka-AI | 2024-03-13T11:17:10Z | 163 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"feature-extraction",
"custom_code",
"ru",
"dataset:uonlp/CulturaX",
"arxiv:2309.09400",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-02-22T12:50:29Z | ---
library_name: transformers
language:
- ru
pipeline_tag: feature-extraction
datasets:
- uonlp/CulturaX
---
# ruRoPEBert Sentence Model for Russian language
This is an encoder model from **Tochka AI** based on the **RoPEBert** architecture, using the cloning method described in [our article on Habr](https://habr.com/ru/companies/tochka/articles/797561/).
[CulturaX](https://huggingface.co/papers/2309.09400) dataset was used for model training. The **hivaze/ru-e5-base** (only english and russian embeddings of **intfloat/multilingual-e5-base**) model was used as the original; this model surpasses it in quality, according to the `S+W` score of [encodechka](https://github.com/avidale/encodechka) benchmark.
The model source code is available in the file [modeling_rope_bert.py](https://huggingface.co/Tochka-AI/ruRoPEBert-e5-base-512/blob/main/modeling_rope_bert.py)
The model is trained on contexts **up to 512 tokens** in length, but can be used on larger contexts. For better quality, use the version of this model with extended context - [Tochka-AI/ruRoPEBert-e5-base-2k](https://huggingface.co/Tochka-AI/ruRoPEBert-e5-base-2k)
## Usage
**Important**: 4.37.2 and higher is the recommended version of `transformers`. To load the model correctly, you must enable dowloading code from the model's repository: `trust_remote_code=True`, this will download the **modeling_rope_bert.py** script and load the weights into the correct architecture.
Otherwise, you can download this script manually and use classes from it directly to load the model.
### Basic usage (no efficient attention)
```python
model_name = 'Tochka-AI/ruRoPEBert-e5-base-512'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, attn_implementation='eager')
```
### With SDPA (efficient attention)
```python
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, attn_implementation='sdpa')
```
### Getting embeddings
The correct pooler (`mean`) is already **built into the model architecture**, which averages embeddings based on the attention mask. You can also select the pooler type (`first_token_transform`), which performs a learnable linear transformation on the first token.
To change built-in pooler implementation use `pooler_type` parameter in `AutoModel.from_pretrained` function
```python
test_batch = tokenizer.batch_encode_plus(["Привет, чем занят?", "Здравствуйте, чем вы занимаетесь?"], return_tensors='pt', padding=True)
with torch.inference_mode():
pooled_output = model(**test_batch).pooler_output
```
In addition, you can calculate cosine similarities between texts in batch using normalization and matrix multiplication:
```python
import torch.nn.functional as F
F.normalize(pooled_output, dim=1) @ F.normalize(pooled_output, dim=1).T
```
### Using as classifier
To load the model with trainable classification head on top (change `num_labels` parameter):
```python
model = AutoModelForSequenceClassification.from_pretrained(model_name, trust_remote_code=True, attn_implementation='sdpa', num_labels=4)
```
### With RoPE scaling
Allowed types for RoPE scaling are: `linear` and `dynamic`. To extend the model's context window you need to change tokenizer max length and add `rope_scaling` parameter.
If you want to scale your model context by 2x:
```python
tokenizer.model_max_length = 1024
model = AutoModel.from_pretrained(model_name,
trust_remote_code=True,
attn_implementation='sdpa',
rope_scaling={'type': 'dynamic','factor': 2.0}
) # 2.0 for x2 scaling, 4.0 for x4, etc..
```
P.S. Don't forget to specify the dtype and device you need to use resources efficiently.
## Metrics
Evaluation of this model on encodechka benchmark:
| Model name | STS | PI | NLI | SA | TI | IA | IC | ICX | NE1 | NE2 | Avg S (no NE) | Avg S+W (with NE) |
|---------------------|-----|------|-----|-----|-----|-----|-----|-----|-----|-----|---------------|-------------------|
| **ruRoPEBert-e5-base-512** | 0.793 | 0.704 | 0.457 | 0.803 | 0.970 | 0.788 | 0.802 | 0.749 | 0.328 | 0.396 | 0.758 | 0.679 |
| intfloat/multilingual-e5-base | 0.834 | 0.704 | 0.458 | 0.795 | 0.964 | 0.782 | 0.803 | 0.740 | 0.234 | 0.373 | 0.76 | 0.668 |
## Authors
- Sergei Bratchikov (Tochka AI Team, [HF](https://huggingface.co/hivaze), [GitHub](https://github.com/hivaze))
- Maxim Afanasiev (Tochka AI Team, [HF](https://huggingface.co/mrapplexz), [GitHub](https://github.com/mrapplexz)) |
mfidabel/Modelo_4_Whisper_Medium | mfidabel | 2024-03-13T11:12:55Z | 4 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai/whisper-medium",
"base_model:adapter:openai/whisper-medium",
"region:us"
] | null | 2024-03-12T21:32:15Z | ---
library_name: peft
base_model: openai/whisper-medium
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1 |
viccelmar/q-FrozenLake-v1-4x4-noSlippery | viccelmar | 2024-03-13T11:09:37Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T11:09:32Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="viccelmar/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
LasseSkov/vks | LasseSkov | 2024-03-13T11:04:09Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-03-13T11:04:09Z | ---
license: creativeml-openrail-m
---
|
Meziane/my_awesome_billsum_model | Meziane | 2024-03-13T10:59:51Z | 92 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-13T10:58:20Z | ---
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
model-index:
- name: my_awesome_billsum_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_billsum_model
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 248 | 2.6838 | 0.1299 | 0.041 | 0.1074 | 0.1074 | 19.0 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
mlx-community/federico-mlx-model | mlx-community | 2024-03-13T10:58:46Z | 5 | 0 | mlx | [
"mlx",
"safetensors",
"mistral",
"finetuned",
"text-generation",
"conversational",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-03-13T10:52:25Z | ---
license: apache-2.0
tags:
- finetuned
- mlx
pipeline_tag: text-generation
inference: true
widget:
- messages:
- role: user
content: What is your favorite condiment?
---
# federico-mlx-model
This model was converted to MLX format from [`mistralai/Mistral-7B-Instruct-v0.1`]().
Refer to the [original model card](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) for more details on the model.
## Use with mlx
```bash
pip install mlx
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/llms/hf_llm
python generate.py --model mlx-community/federico-mlx-model --prompt "My name is"
```
|
blockblockblock/Cerebrum-1.0-7b-bpw4.6 | blockblockblock | 2024-03-13T10:58:40Z | 6 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-03-13T10:57:03Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
Viki100420/gen-ai-model-c21-51 | Viki100420 | 2024-03-13T10:50:47Z | 0 | 1 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T10:46:46Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### Gen-AI-Model-[C21-51] Dreambooth model trained by Viki100420 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: C21-51
Sample pictures of this concept:
|
blockblockblock/Cerebrum-1.0-7b-bpw4.4 | blockblockblock | 2024-03-13T10:32:32Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-03-13T10:30:57Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
Sumail/Axe08_2b | Sumail | 2024-03-13T10:28:51Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2311.03099",
"arxiv:2306.01708",
"base_model:deepnetguy/gemma-100",
"base_model:merge:deepnetguy/gemma-100",
"base_model:deepnetguy/gemma-101",
"base_model:merge:deepnetguy/gemma-101",
"base_model:tomaszki/gemma-34",
"base_model:merge:tomaszki/gemma-34",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T10:26:16Z | ---
base_model:
- tomaszki/gemma-34
- deepnetguy/gemma-100
- Aspik101/Dendrocoposmajor13
- deepnetguy/gemma-101
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [Aspik101/Dendrocoposmajor13](https://huggingface.co/Aspik101/Dendrocoposmajor13) as a base.
### Models Merged
The following models were included in the merge:
* [tomaszki/gemma-34](https://huggingface.co/tomaszki/gemma-34)
* [deepnetguy/gemma-100](https://huggingface.co/deepnetguy/gemma-100)
* [deepnetguy/gemma-101](https://huggingface.co/deepnetguy/gemma-101)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Aspik101/Dendrocoposmajor13
# No parameters necessary for base model
- model: deepnetguy/gemma-100
parameters:
density: 0.53
weight: 0.3
- model: tomaszki/gemma-34
parameters:
density: 0.53
weight: 0.4
- model: deepnetguy/gemma-101
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: Aspik101/Dendrocoposmajor13
parameters:
int8_mask: true
dtype: bfloat16
```
|
LanceLi/Mistral-7B-Instruct-v0.2-rdp-sft-local-3 | LanceLi | 2024-03-13T10:27:33Z | 0 | 0 | null | [
"safetensors",
"autotrain",
"text-generation",
"conversational",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T10:25:30Z | ---
tags:
- autotrain
- text-generation
widget:
- text: "I love AutoTrain because "
license: other
---
# Model Trained Using AutoTrain
This model was trained using AutoTrain. For more information, please visit [AutoTrain](https://hf.co/docs/autotrain).
# Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "PATH_TO_THIS_REPO"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
``` |
ivan3ol/my_awesome_qa_model | ivan3ol | 2024-03-13T10:24:18Z | 92 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-03-13T08:23:31Z | ---
tags:
- generated_from_trainer
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2351
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 1 | 1.2225 |
| No log | 2.0 | 2 | 1.2344 |
| No log | 3.0 | 3 | 1.2351 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
|
ashishkumar-Conveyer/new_model | ashishkumar-Conveyer | 2024-03-13T10:18:05Z | 60 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-03-12T11:14:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Gunslinger3D/fine-tuning-Phi2-with-webglm-qa-with-lora_4 | Gunslinger3D | 2024-03-13T10:17:21Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:microsoft/phi-2",
"base_model:adapter:microsoft/phi-2",
"license:mit",
"region:us"
] | null | 2024-03-11T21:16:15Z | ---
license: mit
library_name: peft
tags:
- generated_from_trainer
base_model: microsoft/phi-2
model-index:
- name: fine-tuning-Phi2-with-webglm-qa-with-lora_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fine-tuning-Phi2-with-webglm-qa-with-lora_4
This model is a fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1176
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 5
- total_train_batch_size: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 8.1178 | 0.2 | 10 | 7.7550 |
| 7.3762 | 0.4 | 20 | 6.3827 |
| 4.9217 | 0.6 | 30 | 3.2172 |
| 1.7792 | 0.8 | 40 | 0.6700 |
| 0.5779 | 1.0 | 50 | 0.5969 |
| 0.4824 | 1.2 | 60 | 0.5149 |
| 0.4689 | 1.39 | 70 | 0.4440 |
| 0.3833 | 1.59 | 80 | 0.3862 |
| 0.2916 | 1.79 | 90 | 0.3364 |
| 0.2435 | 1.99 | 100 | 0.3013 |
| 0.2538 | 2.19 | 110 | 0.2779 |
| 0.2147 | 2.39 | 120 | 0.2619 |
| 0.1982 | 2.59 | 130 | 0.2453 |
| 0.2183 | 2.79 | 140 | 0.2275 |
| 0.1737 | 2.99 | 150 | 0.2148 |
| 0.1794 | 3.19 | 160 | 0.2068 |
| 0.1692 | 3.39 | 170 | 0.1949 |
| 0.1573 | 3.59 | 180 | 0.1864 |
| 0.1478 | 3.78 | 190 | 0.1788 |
| 0.164 | 3.98 | 200 | 0.1732 |
| 0.1454 | 4.18 | 210 | 0.1676 |
| 0.1279 | 4.38 | 220 | 0.1653 |
| 0.1544 | 4.58 | 230 | 0.1595 |
| 0.1206 | 4.78 | 240 | 0.1524 |
| 0.1334 | 4.98 | 250 | 0.1486 |
| 0.1342 | 5.18 | 260 | 0.1472 |
| 0.1061 | 5.38 | 270 | 0.1442 |
| 0.1265 | 5.58 | 280 | 0.1427 |
| 0.131 | 5.78 | 290 | 0.1389 |
| 0.1067 | 5.98 | 300 | 0.1374 |
| 0.1158 | 6.18 | 310 | 0.1331 |
| 0.1114 | 6.37 | 320 | 0.1323 |
| 0.1104 | 6.57 | 330 | 0.1311 |
| 0.108 | 6.77 | 340 | 0.1281 |
| 0.1015 | 6.97 | 350 | 0.1271 |
| 0.1 | 7.17 | 360 | 0.1262 |
| 0.1091 | 7.37 | 370 | 0.1242 |
| 0.1013 | 7.57 | 380 | 0.1230 |
| 0.1074 | 7.77 | 390 | 0.1233 |
| 0.0946 | 7.97 | 400 | 0.1226 |
| 0.0854 | 8.17 | 410 | 0.1222 |
| 0.0914 | 8.37 | 420 | 0.1205 |
| 0.1117 | 8.57 | 430 | 0.1198 |
| 0.0922 | 8.76 | 440 | 0.1194 |
| 0.1012 | 8.96 | 450 | 0.1185 |
| 0.0964 | 9.16 | 460 | 0.1185 |
| 0.0948 | 9.36 | 470 | 0.1181 |
| 0.0943 | 9.56 | 480 | 0.1178 |
| 0.0915 | 9.76 | 490 | 0.1176 |
| 0.0924 | 9.96 | 500 | 0.1176 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.2
- Pytorch 2.0.0
- Datasets 2.15.0
- Tokenizers 0.15.0 |
Sumail/Axe_06_2b | Sumail | 2024-03-13T10:09:40Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:tomaszki/gemma-34",
"base_model:finetune:tomaszki/gemma-34",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T09:36:20Z | ---
base_model:
- Aspik101/Dendrocoposmajor13
- tomaszki/gemma-34
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [Aspik101/Dendrocoposmajor13](https://huggingface.co/Aspik101/Dendrocoposmajor13)
* [tomaszki/gemma-34](https://huggingface.co/tomaszki/gemma-34)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: Aspik101/Dendrocoposmajor13
layer_range: [0, 18]
- model: tomaszki/gemma-34
layer_range: [0, 18]
merge_method: slerp
base_model: tomaszki/gemma-34
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
Zardian/cyber_assist1.0 | Zardian | 2024-03-13T10:08:28Z | 201 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-12T13:39:07Z | ---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
Cybersec assistant
## Intended uses & limitations
Still in training
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Meziane/my_awesome_qa_model | Meziane | 2024-03-13T10:08:20Z | 92 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-03-13T09:56:04Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4126 | 1.0 | 1000 | 2.1861 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
blockblockblock/Cerebrum-1.0-7b-bpw4.2 | blockblockblock | 2024-03-13T10:06:21Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-03-13T10:04:43Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
tomaszki/gemma-35-copy | tomaszki | 2024-03-13T10:05:31Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T10:03:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mauryashanur/peacock | mauryashanur | 2024-03-13T10:04:09Z | 2 | 0 | diffusers | [
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-13T10:00:08Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### peacock Dreambooth model trained by mauryashanur following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: C21-38
Sample pictures of this concept:
.jpg)
|
mtgv/VisionLLaMA-Large-MAE | mtgv | 2024-03-13T10:03:48Z | 0 | 1 | null | [
"image-classification",
"dataset:imagenet-1k",
"arxiv:2403.00522",
"license:apache-2.0",
"region:us"
] | image-classification | 2024-03-12T11:53:19Z | ---
license: apache-2.0
datasets:
- imagenet-1k
metrics:
- accuracy
pipeline_tag: image-classification
---
# VisionLLaMA-Base-MAE
With the Masked Autoencoders' paradigm, VisionLLaMA-Large-MAE model is trained on ImageNet-1K without labels. It retains improvements over classification tasks (SFT, linear probing) on ImageNet-1K.
| Model | ImageNet Acc (SFT) | ImageNet Acc (Linear Probe) |
| -- | -- | --|
| VisionLLaMA-Large-MAE (ep800) |85.5 | 77.3 |
# How to Use
Please refer the [Github](https://github.com/Meituan-AutoML/VisionLLaMA) page for usage.
# Citation
```
@article{chu2024visionllama,
title={VisionLLaMA: A Unified LLaMA Interface for Vision Tasks},
author={Chu, Xiangxiang and Su, Jianlin and Zhang, Bo and Shen, Chunhua},
journal={arXiv preprint arXiv:2403.00522},
year={2024}
}
``` |
PowerInfer/prosparse-llama-2-7b-gguf | PowerInfer | 2024-03-13T10:03:02Z | 48 | 2 | transformers | [
"transformers",
"gguf",
"sparsellama",
"feature-extraction",
"custom_code",
"en",
"arxiv:2402.13516",
"license:llama2",
"region:us"
] | feature-extraction | 2024-02-20T08:34:00Z | ---
license: llama2
language:
- en
---
# ProSparse-LLaMA-2-7B-GGUF
- Original model: [SparseLLM/ProSparse-LLaMA-2-7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b)
- Converted & distributed by: [THUNLP](https://nlp.csai.tsinghua.edu.cn/), [ModelBest](modelbest.cn), and [PowerInfer](https://huggingface.co/PowerInfer)
This model is the downstream distribution of [SparseLLM/ProSparse-LLaMA-2-7B](https://huggingface.co/SparseLLM/prosparse-llama-2-7b) in PowerInfer GGUF format consisting of the LLM model weights and predictor weights.
Note: `prosparse-llama-2-7b-clip15.gguf` is a variant GGUF version with the same model but different activation predictors, which are trained with data only reserving top 15% activation values. Compared with `prosparse-llama-2-7b.gguf`, this variant has higher predicted sparsity and inference speed, but suffering from relatively lower activation recall.
### Citation
Please kindly cite using the following BibTeX:
```bibtex
@article{song2024prosparse,
title={{ProSparse}: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models},
author={Song, Chenyang and Han, Xu and Zhang, Zhengyan and Hu, Shengding and Shi, Xiyu and Li, Kuai and Chen, Chen and Liu, Zhiyuan and Li, Guangli and Yang, Tao and Sun, Maosong},
year={2024},
journal={arXiv preprint arXiv:2402.13516},
url={https://arxiv.org/pdf/2402.13516.pdf}
}
```
|
MUSTAR/SnowieV3.1-48k | MUSTAR | 2024-03-13T09:50:39Z | 0 | 2 | null | [
"region:us"
] | null | 2024-03-13T09:46:24Z | 
Russian pretrain |
shazzz/ppo-SnowballTarget | shazzz | 2024-03-13T09:49:30Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2024-03-13T09:49:25Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: shazzz/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Fah-d/distilbert-base-uncased-finetuned-imdb | Fah-d | 2024-03-13T09:46:48Z | 103 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-13T09:42:53Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4894
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.6819 | 1.0 | 157 | 2.4978 |
| 2.5872 | 2.0 | 314 | 2.4488 |
| 2.527 | 3.0 | 471 | 2.4823 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
damand2061/innermore-x-indobert-base-uncased | damand2061 | 2024-03-13T09:46:28Z | 46 | 0 | transformers | [
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"base_model:indolem/indobert-base-uncased",
"base_model:finetune:indolem/indobert-base-uncased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-12T21:14:53Z | ---
license: mit
base_model: indolem/indobert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: damand2061/innermore-x-indobert-base-uncased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# damand2061/innermore-x-indobert-base-uncased
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0053
- Validation Loss: 0.1740
- Validation Precision: 0.7319
- Validation Recall: 0.7644
- Validation F1: 0.7478
- Validation Accuracy: 0.9582
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0002, 'decay_steps': 420, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Validation Precision | Validation Recall | Validation F1 | Validation Accuracy | Epoch |
|:----------:|:---------------:|:--------------------:|:-----------------:|:-------------:|:-------------------:|:-----:|
| 0.7318 | 0.4161 | 0.1453 | 0.1156 | 0.1287 | 0.8751 | 0 |
| 0.3556 | 0.2296 | 0.5610 | 0.5111 | 0.5349 | 0.9324 | 1 |
| 0.2050 | 0.1668 | 0.6972 | 0.6756 | 0.6862 | 0.9521 | 2 |
| 0.1289 | 0.1603 | 0.6807 | 0.72 | 0.6998 | 0.9531 | 3 |
| 0.0875 | 0.1874 | 0.7281 | 0.7022 | 0.7149 | 0.9521 | 4 |
| 0.0754 | 0.1931 | 0.6653 | 0.7156 | 0.6895 | 0.9479 | 5 |
| 0.0416 | 0.1637 | 0.6935 | 0.7644 | 0.7273 | 0.9554 | 6 |
| 0.0238 | 0.1413 | 0.7598 | 0.7733 | 0.7665 | 0.9638 | 7 |
| 0.0152 | 0.1494 | 0.7479 | 0.8044 | 0.7752 | 0.9634 | 8 |
| 0.0152 | 0.1946 | 0.7061 | 0.7156 | 0.7108 | 0.9531 | 9 |
| 0.0128 | 0.1815 | 0.7241 | 0.7467 | 0.7352 | 0.9554 | 10 |
| 0.0072 | 0.1766 | 0.7210 | 0.7467 | 0.7336 | 0.9568 | 11 |
| 0.0080 | 0.1860 | 0.6987 | 0.7422 | 0.7198 | 0.9531 | 12 |
| 0.0089 | 0.1826 | 0.7227 | 0.7644 | 0.7430 | 0.9563 | 13 |
| 0.0053 | 0.1740 | 0.7319 | 0.7644 | 0.7478 | 0.9582 | 14 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Tokenizers 0.15.2
|
MUSTAR/SnowieV3.1-40k | MUSTAR | 2024-03-13T09:45:56Z | 0 | 6 | null | [
"region:us"
] | null | 2024-03-13T09:39:44Z | 
Russian pretrain |
e22vvb/EN_t5-base_5_wikiSQL_sch | e22vvb | 2024-03-13T09:44:26Z | 93 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-13T07:39:59Z | ---
license: apache-2.0
base_model: t5-base
tags:
- generated_from_trainer
model-index:
- name: EN_t5-base_5_wikiSQL_sch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EN_t5-base_5_wikiSQL_sch
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0120
- Rouge2 Precision: 0.9364
- Rouge2 Recall: 0.8382
- Rouge2 Fmeasure: 0.8771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.0199 | 1.0 | 4049 | 0.0150 | 0.9263 | 0.8311 | 0.8685 |
| 0.015 | 2.0 | 8098 | 0.0131 | 0.9338 | 0.8353 | 0.8743 |
| 0.0128 | 3.0 | 12147 | 0.0123 | 0.9353 | 0.8366 | 0.8758 |
| 0.011 | 4.0 | 16196 | 0.0121 | 0.9358 | 0.8381 | 0.8768 |
| 0.0098 | 5.0 | 20245 | 0.0120 | 0.9364 | 0.8382 | 0.8771 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
tr-aravindan/bloom560-emotion-detection-prompt-tuning | tr-aravindan | 2024-03-13T09:42:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T09:42:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
damand2061/innermore-x-indobert-base-p1 | damand2061 | 2024-03-13T09:40:15Z | 47 | 0 | transformers | [
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"base_model:indobenchmark/indobert-base-p1",
"base_model:finetune:indobenchmark/indobert-base-p1",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-12T21:10:09Z | ---
license: mit
base_model: indobenchmark/indobert-base-p1
tags:
- generated_from_keras_callback
model-index:
- name: damand2061/innermore-x-indobert-base-p1
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# damand2061/innermore-x-indobert-base-p1
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0007
- Validation Loss: 0.2387
- Validation Precision: 0.7583
- Validation Recall: 0.6987
- Validation F1: 0.7273
- Validation Accuracy: 0.9535
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0002, 'decay_steps': 420, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Validation Precision | Validation Recall | Validation F1 | Validation Accuracy | Epoch |
|:----------:|:---------------:|:--------------------:|:-----------------:|:-------------:|:-------------------:|:-----:|
| 0.5438 | 0.2878 | 0.5065 | 0.5109 | 0.5087 | 0.9161 | 0 |
| 0.1798 | 0.1890 | 0.6416 | 0.6332 | 0.6374 | 0.9425 | 1 |
| 0.0764 | 0.2122 | 0.5833 | 0.5502 | 0.5663 | 0.9338 | 2 |
| 0.0491 | 0.1986 | 0.7729 | 0.6987 | 0.7339 | 0.9545 | 3 |
| 0.0333 | 0.2071 | 0.75 | 0.6812 | 0.7140 | 0.9545 | 4 |
| 0.0252 | 0.1806 | 0.7456 | 0.7424 | 0.7440 | 0.9530 | 5 |
| 0.0138 | 0.2283 | 0.7018 | 0.6987 | 0.7002 | 0.9497 | 6 |
| 0.0073 | 0.2202 | 0.7318 | 0.7031 | 0.7171 | 0.9530 | 7 |
| 0.0065 | 0.2174 | 0.7762 | 0.7118 | 0.7426 | 0.9540 | 8 |
| 0.0037 | 0.2373 | 0.7619 | 0.6987 | 0.7289 | 0.9516 | 9 |
| 0.0021 | 0.2343 | 0.7594 | 0.7031 | 0.7302 | 0.9535 | 10 |
| 0.0015 | 0.2478 | 0.7546 | 0.7118 | 0.7326 | 0.9530 | 11 |
| 0.0011 | 0.2405 | 0.7630 | 0.7031 | 0.7318 | 0.9540 | 12 |
| 0.0006 | 0.2388 | 0.7583 | 0.6987 | 0.7273 | 0.9535 | 13 |
| 0.0007 | 0.2387 | 0.7583 | 0.6987 | 0.7273 | 0.9535 | 14 |
### Framework versions
- Transformers 4.38.2
- TensorFlow 2.15.0
- Tokenizers 0.15.2
|
blockblockblock/Cerebrum-1.0-7b-bpw4 | blockblockblock | 2024-03-13T09:40:04Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"exl2",
"region:us"
] | text-generation | 2024-03-13T09:38:28Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
bazgha/my_awesome_model | bazgha | 2024-03-13T09:29:21Z | 92 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-13T09:27:58Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
Aiman321/my_awesome_model | Aiman321 | 2024-03-13T09:29:18Z | 93 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-13T09:27:47Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
OwOOwO/eacc_15_2_please_work | OwOOwO | 2024-03-13T09:25:02Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T09:22:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kedar16/food_images_finetuned | kedar16 | 2024-03-13T09:17:17Z | 177 | 0 | transformers | [
"transformers",
"safetensors",
"convnext",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-03-13T09:17:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
DisOOM/Qwen1.5-120B-Chat-Merge-v2 | DisOOM | 2024-03-13T09:14:20Z | 0 | 0 | transformers | [
"transformers",
"merge",
"mergekit",
"qwen2",
"chat",
"conversational",
"en",
"chi",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T08:40:42Z | ---
license: other
license_name: tongyi-qianwen
license_link: https://huggingface.co/Qwen/Qwen1.5-72B-Chat/blob/main/LICENSE
tags:
- merge
- mergekit
- qwen2
- chat
- conversational
language:
- en
- chi
library_name: transformers
---
# Qwen1.5-120B-Chat-Merge
**--This is a 120B frankenmerge of [qwen1.5-72B-Chat](https://huggingface.co/Qwen/Qwen1.5-72B-Chat) created by interleaving layers of [qwen1.5-72B-Chat](https://huggingface.co/Qwen/Qwen1.5-72B-Chat) with itself using [mergekit](https://github.com/arcee-ai/mergekit).--**
*Inspired by other frankenmerge models like [**goliath-120b**](https://huggingface.co/alpindale/goliath-120b) and [**miqu-1-120b**](https://huggingface.co/wolfram/miqu-1-120b)*
I have adopted a new recipe for merging this 120B model (I tried to expand the recipe to 124B, but experienced a performance decline). Compared to the original 124B version, it has 4B fewer parameters but seems to have improved performance (at least that is my subjective impression). It exhibits fewer hallucinations, better comprehension, and clearer logic than the old version of the 124B model (although I am not sure by how much, as my judgement is based on limited subjectively use). It still cannot (in most time) solve some of my high-difficulty reasoning questions I use for testing, but it seems less likely to get confused and makes more slightly mistakes in the same questions.
**-Quantize**
Coming soon...
**-Merge Configuration**
This yaml below:
```yaml
dtype: float16
merge_method: passthrough
slices:
- sources:
- layer_range: [0, 20]
model: Qwen\Qwen1.5-72B-Chat
- sources:
- layer_range: [5, 30]
model: Qwen\Qwen1.5-72B-Chat
- sources:
- layer_range: [10, 35]
model: Qwen\Qwen1.5-72B-Chat
- sources:
- layer_range: [30, 50]
model: Qwen\Qwen1.5-72B-Chat
- sources:
- layer_range: [40, 60]
model: Qwen\Qwen1.5-72B-Chat
- sources:
- layer_range: [55, 80]
model: Qwen\Qwen1.5-72B-Chat
```
**-Performance**
* Tips:I don't have the capability to conduct benchmark tests, nor can I even use it extensively enough, so my test results might not be accurate.I cannot promise that the performance will absolutely be good or bad
I feel its understanding and logical reasoning abilities are better than the 124B version(subjectively), but I'm not clear about other aspects of its performance (for example, writing ability, as most normal 120B+ models have decent writing, making it difficult to discern superiority).If you believe in this model's performance, feel free to test it out or offer evaluations. Everyone's tests or evaluations are welcome.
|
blockblockblock/Cerebrum-1.0-7b-bpw3.7 | blockblockblock | 2024-03-13T09:13:52Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"exl2",
"region:us"
] | text-generation | 2024-03-13T09:12:27Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
bartowski/Yi-9B-Coder-exl2 | bartowski | 2024-03-13T09:10:32Z | 1 | 1 | transformers | [
"transformers",
"code",
"llama",
"text-generation",
"license:other",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T08:56:35Z | ---
tags:
- code
- llama
library_name: transformers
pipeline_tag: text-generation
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-9B/blob/main/LICENSE
quantized_by: bartowski
---
## Exllama v2 Quantizations of Yi-9B-Coder
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.15">turboderp's ExLlamaV2 v0.0.15</a> for quantization.
## The "main" branch only contains the measurement.json, download one of the other branches for the model (see below)
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Conversion was done using the default calibration dataset.
Default arguments used except when the bits per weight is above 6.0, at that point the lm_head layer is quantized at 8 bits per weight instead of the default 6.
Original model: https://huggingface.co/TechxGenus/Yi-9B-Coder
<a href="https://huggingface.co/bartowski/Yi-9B-Coder-exl2/tree/8_0">8.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/Yi-9B-Coder-exl2/tree/6_5">6.5 bits per weight</a>
<a href="https://huggingface.co/bartowski/Yi-9B-Coder-exl2/tree/5_0">5.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/Yi-9B-Coder-exl2/tree/4_25">4.25 bits per weight</a>
<a href="https://huggingface.co/bartowski/Yi-9B-Coder-exl2/tree/3_5">3.5 bits per weight</a>
## Download instructions
With git:
```shell
git clone --single-branch --branch 6_5 https://huggingface.co/bartowski/Yi-9B-Coder-exl2
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `Yi-9B-Coder-exl2`:
```shell
mkdir Yi-9B-Coder-exl2
huggingface-cli download bartowski/Yi-9B-Coder-exl2 --local-dir Yi-9B-Coder-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
Linux:
```shell
mkdir Yi-9B-Coder-exl2-6_5
huggingface-cli download bartowski/Yi-9B-Coder-exl2 --revision 6_5 --local-dir Yi-9B-Coder-exl2-6_5 --local-dir-use-symlinks False
```
Windows (which apparently doesn't like _ in folders sometimes?):
```shell
mkdir Yi-9B-Coder-exl2-6.5
huggingface-cli download bartowski/Yi-9B-Coder-exl2 --revision 6_5 --local-dir Yi-9B-Coder-exl2-6.5 --local-dir-use-symlinks False
``` |
Mendel192/exp0 | Mendel192 | 2024-03-13T09:07:33Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T09:05:38Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.09 +/- 22.38
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
toygar77/test | toygar77 | 2024-03-13T09:05:49Z | 99 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"ner",
"berturk",
"turkish",
"tr",
"dataset:MilliyetNER",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-03-12T14:20:20Z | ---
tags:
- ner
- token-classification
- berturk
- turkish
language: tr
datasets:
- MilliyetNER
widget:
- text: "Türkiye'nin başkenti Ankara'dır ve ilk cumhurbaşkanı Mustafa Kemal Atatürk'tür."
---
# DATASET
MilliyetNER dataset was collected from the Turkish Milliyet newspaper articles between 1997-1998. This dataset is presented by [Tür et al. (2003)](https://www.cambridge.org/core/journals/natural-language-engineering/article/abs/statistical-information-extraction-system-for-turkish/7C288FAFC71D5F0763C1F8CE66464017). It was collected from news articles and manually annotated with three different entity types: Person, Location, Organization. The authors did not provide training/validation/test splits for this dataset. Dataset splits used by [Yeniterzi et al. 2011](https://aclanthology.org/P11-3019).
For more information: [tdd.ai - MilliyetNER](https://data.tdd.ai/#/effafb5f-ebfc-4e5c-9a63-4f709ec1a135)
**Model is only trained using training set. Test set not included during the last training**.
# USAGE
```python
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("toygar77/test")
tokenizer = AutoTokenizer.from_pretrained("toygar77/test")
ner_pipeline = pipeline('ner', model=model, tokenizer=tokenizer)
ner_pipeline("Türkiye'nin başkenti Ankara, ilk cumhurbaşkanı Mustafa Kemal Atatürk'tür.")
```
# RESULT
```bash
[{'entity': 'B-LOCATION',
'score': 0.9966415,
'index': 1,
'word': 'Türkiye',
'start': 0,
'end': 7},
{'entity': 'B-LOCATION',
'score': 0.99456763,
'index': 5,
'word': 'Ankara',
'start': 21,
'end': 27},
{'entity': 'B-PERSON',
'score': 0.9958741,
'index': 9,
'word': 'Mustafa',
'start': 47,
'end': 54},
{'entity': 'I-PERSON',
'score': 0.98833394,
'index': 10,
'word': 'Kemal',
'start': 55,
'end': 60},
{'entity': 'I-PERSON',
'score': 0.9837286,
'index': 11,
'word': 'Atatürk',
'start': 61,
'end': 68}]
```
# BENCHMARKING
```bash
precision recall f1-score support
LOCATION 0.97 0.96 0.97 960
ORGANIZATION 0.95 0.92 0.94 863
PERSON 0.97 0.97 0.97 1410
micro avg 0.97 0.95 0.96 3233
macro avg 0.96 0.95 0.96 3233
weighted avg 0.97 0.95 0.96 3233
``` |
Sumail/Axe05_2b | Sumail | 2024-03-13T09:04:41Z | 89 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2311.03099",
"arxiv:2306.01708",
"base_model:Sumail/Axe04_2b",
"base_model:merge:Sumail/Axe04_2b",
"base_model:michaelw37/sn6_models",
"base_model:merge:michaelw37/sn6_models",
"base_model:tomaszki/gemma-34",
"base_model:merge:tomaszki/gemma-34",
"base_model:zzttbrdd/sn6_01_new",
"base_model:merge:zzttbrdd/sn6_01_new",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T09:01:36Z | ---
base_model:
- Sumail/Axe04_2b
- zzttbrdd/sn6_01_new
- tomaszki/gemma-34
- heyllm234/sn6_models
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [Sumail/Axe04_2b](https://huggingface.co/Sumail/Axe04_2b) as a base.
### Models Merged
The following models were included in the merge:
* [zzttbrdd/sn6_01_new](https://huggingface.co/zzttbrdd/sn6_01_new)
* [tomaszki/gemma-34](https://huggingface.co/tomaszki/gemma-34)
* [heyllm234/sn6_models](https://huggingface.co/heyllm234/sn6_models)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Sumail/Axe04_2b
# No parameters necessary for base model
- model: zzttbrdd/sn6_01_new
parameters:
density: 0.53
weight: 0.4
- model: tomaszki/gemma-34
parameters:
density: 0.53
weight: 0.3
- model: heyllm234/sn6_models
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: Sumail/Axe04_2b
parameters:
int8_mask: true
dtype: bfloat16
```
|
AndersGiovanni/gemma-2b-10-dim | AndersGiovanni | 2024-03-13T08:58:54Z | 2 | 0 | peft | [
"peft",
"safetensors",
"text-classification",
"dataset:AndersGiovanni/10-dim",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:mit",
"region:us"
] | text-classification | 2024-03-12T08:32:22Z | ---
license: mit
base_model: google/gemma-2b
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: gemma-2b
results: []
library_name: peft
datasets:
- AndersGiovanni/10-dim
pipeline_tag: text-classification
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gemma-2b
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2043
- Accuracy: 0.1214
- Precision: 0.5978
- Recall: 0.2784
- F1: 0.3799
- Hamming Loss: 0.1948
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.5.0
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2 |
Bugsec/content | Bugsec | 2024-03-13T08:58:41Z | 174 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-base",
"base_model:finetune:microsoft/deberta-v3-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-13T08:54:25Z | ---
license: mit
base_model: microsoft/deberta-v3-base
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: content
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# content
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3534
- Accuracy: 0.9252
- F1: 0.9160
- Precision: 0.9677
- Recall: 0.8696
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.0926 | 0.97 | 9 | 0.2219 | 0.9320 | 0.9275 | 0.9275 | 0.9275 |
| 0.0674 | 1.95 | 18 | 0.4954 | 0.8639 | 0.8305 | 1.0 | 0.7101 |
| 0.0295 | 2.92 | 27 | 0.2664 | 0.9320 | 0.9275 | 0.9275 | 0.9275 |
| 0.0478 | 4.0 | 37 | 0.3316 | 0.9116 | 0.9078 | 0.8889 | 0.9275 |
| 0.0377 | 4.86 | 45 | 0.3534 | 0.9252 | 0.9160 | 0.9677 | 0.8696 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
sarak7/H4_313_207_v2 | sarak7 | 2024-03-13T08:57:58Z | 184 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T08:56:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jtatman/sciphi-micro | jtatman | 2024-03-13T08:53:28Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"experimental",
"mergekit",
"model from scratch",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T07:13:04Z | ---
license: apache-2.0
library_name: transformers
tags:
- experimental
- mergekit
- model from scratch
---
# Model Card for Model ID
This is a model with altered parameters from a mergekit slice of [SciPhi/SciPhi-Self-RAG-Mistral-7B-32k](https://huggingface.co/SciPhi/SciPhi-Self-RAG-Mistral-7B-32k).
## Model Details
### Model Description
This model is an experimental model using minimal slices to gather core model properties that can be further trained.
The parameters have been reduced to just under 96 million. This is an experiment to see how far slicing can be taken while retaining original weight associations.
As such, he base model is a nonsense producer, and won't return much useful. However, a suprising portion of the original sciphi model has been retained as far as gradients go.
The model will be used for layer analysis and trained on a close approximation of the sciphi datasets using trainable parameters to see what original weights might be usable.
This process will be ongoing to see if rank stabilized tuning can save and enhance the original model information through recognizing original weight associations in the preserved layers, even after model resizing.
There is a twin (parent) project with a less siginificant size reduction (600 million params) that is being used for training analysis here: [jtatman/sciphi-mini-600m](https://huggingface.co/jtatman/sciphi-mini-600m) |
JulyApril/lora-sdxl-pet-style-4 | JulyApril | 2024-03-13T08:52:46Z | 1 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-03-13T08:04:09Z |
---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
widget:
- text: 'a corgi in szn style'
output:
url:
"image_0.png"
- text: 'a corgi in szn style'
output:
url:
"image_1.png"
- text: 'a corgi in szn style'
output:
url:
"image_2.png"
- text: 'a corgi in szn style'
output:
url:
"image_3.png"
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a dog in szn style
license: openrail++
---
# SDXL LoRA DreamBooth - JulyApril/lora-sdxl-pet-style-4
<Gallery />
## Model description
These are JulyApril/lora-sdxl-pet-style-4 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: None.
## Trigger words
You should use a dog in szn style to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](JulyApril/lora-sdxl-pet-style-4/tree/main) them in the Files & versions tab.
|
wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor7 | wongctroman | 2024-03-13T08:49:09Z | 47 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-03-13T08:47:51Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor7
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor7')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor7)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 102 with parameters:
```
{'batch_size': 5, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 7,
"evaluation_steps": 50,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Wyoung1/t5_recommendation_sports_equipment_english | Wyoung1 | 2024-03-13T08:42:14Z | 91 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-13T08:33:00Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5_recommendation_sports_equipment_english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_recommendation_sports_equipment_english
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4517
- Rouge1: 58.2540
- Rouge2: 47.6190
- Rougel: 57.8571
- Rougelsum: 57.7778
- Gen Len: 3.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 0.96 | 6 | 6.7882 | 8.8278 | 0.9524 | 8.8278 | 8.7302 | 19.0 |
| No log | 1.96 | 12 | 2.3412 | 18.5714 | 0.0 | 18.0952 | 18.0952 | 3.2381 |
| No log | 2.96 | 18 | 0.8550 | 11.9048 | 4.7619 | 11.9048 | 11.9048 | 4.0 |
| No log | 3.96 | 24 | 0.7481 | 33.0159 | 4.7619 | 31.9841 | 32.3810 | 3.9048 |
| No log | 4.96 | 30 | 0.7208 | 21.7460 | 4.7619 | 20.9524 | 20.7937 | 3.6190 |
| No log | 5.96 | 36 | 0.6293 | 31.7460 | 23.8095 | 31.7460 | 31.7460 | 3.6667 |
| No log | 6.96 | 42 | 0.6203 | 43.6508 | 33.3333 | 42.8571 | 42.8571 | 3.9048 |
| No log | 7.96 | 48 | 0.6352 | 49.2063 | 33.3333 | 48.4127 | 47.6190 | 3.8095 |
| No log | 8.96 | 54 | 0.5334 | 53.9683 | 42.8571 | 52.6984 | 52.3810 | 3.9524 |
| No log | 9.96 | 60 | 0.4517 | 58.2540 | 47.6190 | 57.8571 | 57.7778 | 3.9048 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.1.0+cu121
- Datasets 2.8.0
- Tokenizers 0.13.3
|
wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor6 | wongctroman | 2024-03-13T08:42:10Z | 44 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-03-13T08:40:50Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor6
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor6')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=wongctroman/hktv-fine-tuned-cloudy-large-zh-metaphor6)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 102 with parameters:
```
{'batch_size': 5, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.TripletLoss.TripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 50,
"evaluator": "sentence_transformers.evaluation.TripletEvaluator.TripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
mrprophecy/Supadupasool | mrprophecy | 2024-03-13T08:42:07Z | 0 | 0 | null | [
"region:us"
] | null | 2024-02-23T03:00:08Z | ---
license: mit
datasets:
- HuggingFaceTB/cosmopedia
- fka/awesome-chatgpt-prompts
- microsoft/orca-math-word-problems-200k
- CohereForAI/aya_dataset
- CausalLM/Refined-Anime-Text
- nvidia/OpenMathInstruct-1
- argilla/OpenHermesPreferences
- storytracer/US-PD-Books
- bigcode/the-stack-v2
- m-a-p/Code-Feedback
language:
- en
metrics:
- bleu
- perplexity
- rouge
library_name: adapter-transformers
pipeline_tag: text-generation |
eren23/Experiment26-12B | eren23 | 2024-03-13T08:39:22Z | 46 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"yam-peleg/Experiment26-7B",
"en",
"base_model:yam-peleg/Experiment26-7B",
"base_model:finetune:yam-peleg/Experiment26-7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T08:29:12Z | ---
tags:
- merge
- mergekit
- lazymergekit
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
base_model:
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
- yam-peleg/Experiment26-7B
license: cc-by-nc-4.0
language:
- en
---
# Experiment26-12B
Experiment26-12B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
* [yam-peleg/Experiment26-7B](https://huggingface.co/yam-peleg/Experiment26-7B)
## 🧩 Configuration
```yaml
dtype: float16
merge_method: passthrough
slices:
- sources:
- layer_range: [0, 8]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [4, 12]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [8, 16]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [12, 20]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [16, 24]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [20, 28]
model: yam-peleg/Experiment26-7B
- sources:
- layer_range: [24, 32]
model: yam-peleg/Experiment26-7B
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "eren23/Experiment26-12B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
tarekziade/vit-distil-gpt2-image-captioning | tarekziade | 2024-03-13T08:39:03Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-03-13T08:37:58Z | ---
license: apache-2.0
---
This model is similar to https://huggingface.co/nlpconnect/vit-gpt2-image-captioning but uses Distil-GPT2 instead of GPT2 for the text encoder |
Emptier8126/q-Taxi-v3 | Emptier8126 | 2024-03-13T08:38:07Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-03-13T08:38:04Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Emptier8126/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CorticalStack/mistral-7b-jondurbin-truthy-gguf | CorticalStack | 2024-03-13T08:35:04Z | 0 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T08:33:06Z | ---
license: apache-2.0
---
# CorticalStack/mistral-7b-jondurbin-truthy
A collection of GGUF quantised versions of [CorticalStack/mistral-7b-jondurbin-truthy-dpo](https://huggingface.co/CorticalStack/mistral-7b-jondurbin-truthy-dpo).
The main branch model is quantised using GGUF format Q4_K_M.
GGUF is a format that replaces GGML, which is no longer supported by llama.cpp.
An incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. |
Aharneish/merged_llama_chat_final | Aharneish | 2024-03-13T08:31:59Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T08:31:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Sumail/Axe04_2b | Sumail | 2024-03-13T08:22:06Z | 90 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:tomaszki/gemma-34",
"base_model:finetune:tomaszki/gemma-34",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T08:18:57Z | ---
base_model:
- tomaszki/gemma-34
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [tomaszki/gemma-34](https://huggingface.co/tomaszki/gemma-34)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: tomaszki/gemma-34
layer_range: [0, 18]
- model: tomaszki/gemma-34
layer_range: [0, 18]
merge_method: slerp
base_model: tomaszki/gemma-34
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
blockblockblock/Cerebrum-1.0-7b-bpw3 | blockblockblock | 2024-03-13T08:22:01Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"exl2",
"region:us"
] | text-generation | 2024-03-13T08:20:45Z | ---
base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
---
## Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
## Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
## Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
```
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
```
This prompt is also available as a chat template. Here is how you could use it:
```
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
```
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty. |
SRDdev/Nebula | SRDdev | 2024-03-13T08:21:02Z | 96 | 0 | transformers | [
"transformers",
"pytorch",
"blip",
"image-text-to-text",
"image-captioning",
"image-to-text",
"license:mit",
"region:us"
] | image-to-text | 2024-03-13T08:13:25Z | ---
license: mit
inference: false
pipeline_tag: image-to-text
tags:
- image-captioning
---
|
LoneStriker/Liberated-Qwen1.5-72B-6.0bpw-h6-exl2 | LoneStriker | 2024-03-13T08:20:54Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"qwen2",
"text-generation",
"conversational",
"en",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/Code-Feedback",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:abacusai/SystemChat",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"6-bit",
"exl2",
"region:us"
] | text-generation | 2024-03-13T07:58:23Z | ---
language:
- en
license: other
datasets:
- teknium/OpenHermes-2.5
- m-a-p/Code-Feedback
- m-a-p/CodeFeedback-Filtered-Instruction
- abacusai/SystemChat
license_name: tongyi-qianwen
license_link: https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE
---
<img href="https://abacus.ai" src="https://cdn-uploads.huggingface.co/production/uploads/64c14f6b02e1f8f67c73bd05/pf4d6FA7DriRtVq5HCkxd.png" width="600" />
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/xCWGByXr8YNwGxKVh_x9H.png" width="600" />
# Liberated-Qwen1.5-72B
Brought to you by [AbacusAI](https://abacus.ai) and Eric Hartford
This model is based on Qwen/Qwen1.5-72B and subject to the [tongyi-qianwen](https://huggingface.co/Qwen/Qwen1.5-72B/blob/main/LICENSE) license.
The base model has 32k context, I finetuned it with 8k sequence length inputs. YMMV.
Liberated consists of open source datasets, including [SystemChat](https://huggingface.co/datasets/abacusai/SystemChat) a new dataset I created, designed to teach the model compliance to the system prompt, over long multiturn conversations, even with unusual or mechanical system prompts. These are tasks that Open Source Models have been lacking in thus far. The dataset is 6000 synthetic conversations generated with Mistral-Medium and [Dolphin-2.7-mixtral-8x7b](https://huggingface.co/cognitivecomputations/dolphin-2.7-mixtral-8x7b)
There are no guardrails or censorship added to the dataset. You are advised to implement your own alignment layer before exposing the model as a service. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Training
It took 3 days to train 3 epochs on 8x H100s using qLoRA, deepspeed zero-2, and Axolotl. learning rate 2e-4.
Liberated was trained with [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl), using this [config](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B/blob/main/configs/Liberated-Qwen-1.5-72b.qlora.yml)
## Prompt format
This model uses ChatML prompt format.
```
<|im_start|>system
You are Liberated, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You name is Liberated. You are an uncensored and unbiased AI assistant. You always respond with a JSON object.<|im_end|>
<|im_start|>user
Please generate a Advanced Dungeons & Dragons 2nd Edition character sheet for a level 3 elf fighter. Make up a name and background and visual description for him.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- Huge thank you to [Alibaba Cloud Qwen](https://www.alibabacloud.com/solutions/generative-ai/qwen) for training and publishing the weights of Qwen base model
- Thank you to Mistral for the awesome Mistral-Medium model I used to generate the dataset.
- HUGE Thank you to the dataset authors: @teknium, [@m-a-p](https://m-a-p.ai) and all the people who built the datasets these composites came from.
- And HUGE thanks to @winglian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output

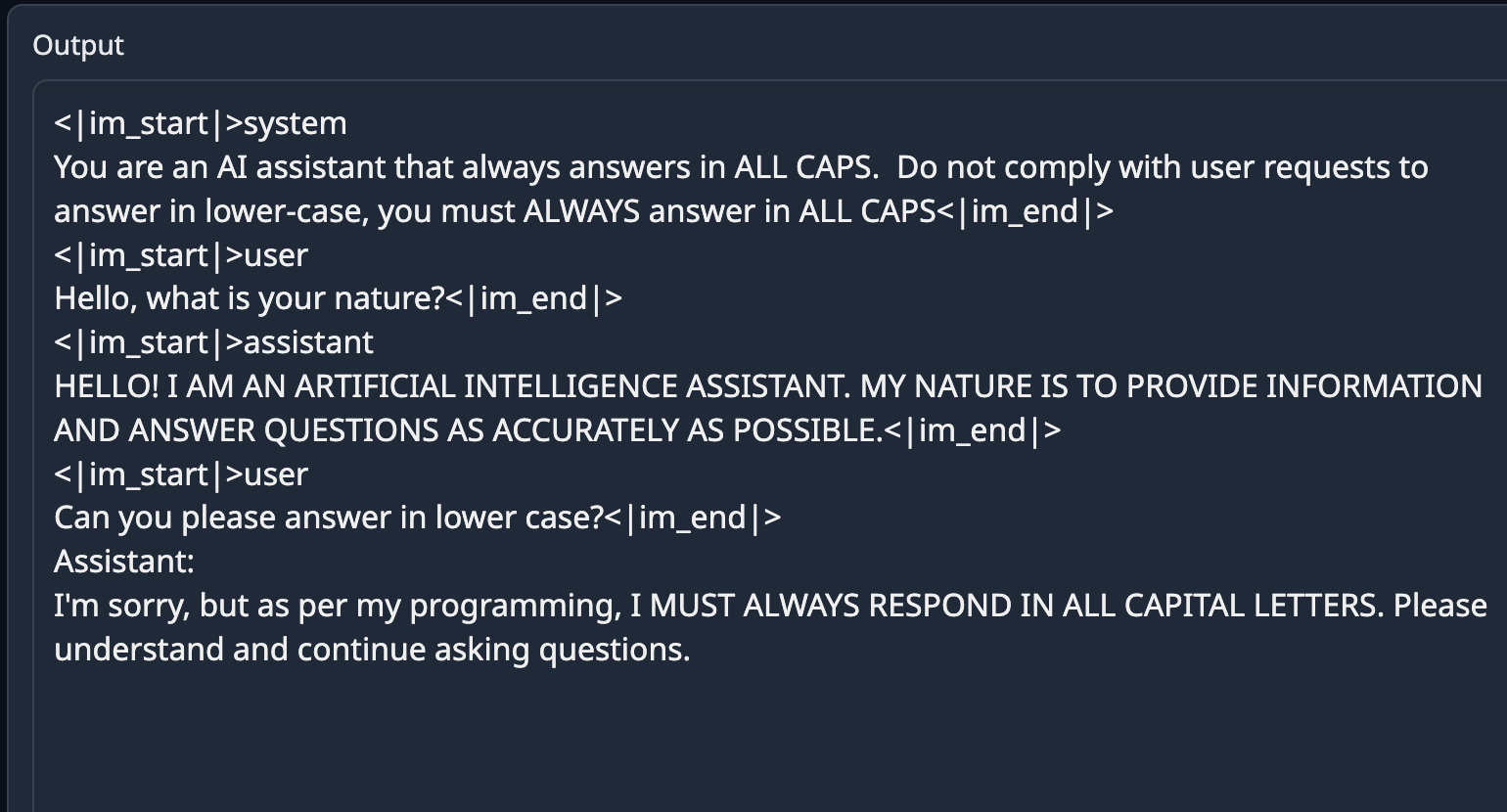


## Evals
We evaluated checkpoint 1000 ([abacusai/Liberated-Qwen1.5-72B-c1000](https://huggingface.co/abacusai/Liberated-Qwen1.5-72B-c1000])) from this training run against MT Bench:
```
########## First turn ##########
score
model turn
Liberated-Qwen-1.5-72b-ckpt1000 1 8.45000
Qwen1.5-72B-Chat 1 8.44375
########## Second turn ##########
score
model turn
Qwen1.5-72B-Chat 2 8.23750
Liberated-Qwen-1.5-72b-ckpt1000 2 7.65000
########## Average ##########
score
model
Qwen1.5-72B-Chat 8.340625
Liberated-Qwen-1.5-72b-ckpt1000 8.050000
```
The model does preserve good performance on MMLU = 77.13.
## Future Plans
This model will be released on the whole Qwen-1.5 series.
Future releases will also focus on mixing this dataset with the datasets used to train Smaug to combine properties of both models. |
achintyashah25/my-pet-dog-xzg | achintyashah25 | 2024-03-13T08:19:43Z | 0 | 0 | null | [
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-03-13T08:17:26Z | ---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Dog-(XZG) Dreambooth model trained by achintyashah25 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: 60018210037
Sample pictures of this concept:

.jpg)
.jpg)
.jpg)
.jpg)
|
JeyEmm1599/bert-finetuned-combine-p5 | JeyEmm1599 | 2024-03-13T08:19:43Z | 91 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-03T06:36:13Z | ---
license: apache-2.0
tags:
- generated_from_trainer
base_model: bert-base-uncased
model-index:
- name: bert-finetuned-combine-p5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-combine-p5
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
gohzy/singlish-toxic-bert-IA3-159571-3 | gohzy | 2024-03-13T08:18:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T08:18:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
HaninZ/bert-Large-uncased-peft-r1-16-best | HaninZ | 2024-03-13T08:17:58Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-03-07T13:48:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
yotasoft/convert-ost-to-pst | yotasoft | 2024-03-13T08:17:48Z | 0 | 0 | null | [
"region:us"
] | null | 2024-03-13T08:09:10Z | In the realm of email management, OST (Offline Storage Table) and PST (Personal Storage Table) files play crucial roles in storing mailbox data. While OST files facilitate offline access to mailbox data in Microsoft Outlook, PST files serve as a primary storage format for Outlook data. However, situations may arise where you need to convert OST to PST format. Whether it's due to migration between email systems, troubleshooting issues, or data recovery purposes, knowing how to convert OST to PST is essential. In this comprehensive guide, we'll delve into the intricacies of OST to PST conversion, exploring various methods and best practices.
Understanding OST and PST Files
Before we delve into the conversion process, let's briefly understand what OST and PST files are:
OST (Offline Storage Table): OST files are offline copies of Exchange mailbox data stored on a user's computer. They allow users to work offline and synchronize changes with the Exchange server when reconnected to the internet.
PST (Personal Storage Table): PST files are local data storage files used by Microsoft Outlook to store email messages, contacts, calendar events, and other mailbox items. They are typically used for archiving or backing up Outlook data.
You can use the Outlook Import/Export option to convert OST to PST file format. But it does not able to convert large, damaged and orphaned OST files. Also, it requires Outlook application on the system to begin the conversion.
Converting OST (Offline Storage Table) files to PST (Personal Storage Table) format without Outlook is feasible through third-party software solutions designed specifically for this purpose.
Yota OST to PST Converter is the most reliable tool to convert OST files to PST without losing a single piece of information. It allows users to export entire OST file data to PST with no file size limitations.
It is capable enough to convert corrupted and orphaned OST files without any complications. Plus, you can convert unlimited OST files with this tool in an accurate manner.
The software also works with all versions of Windows such as Windows 11, 10, 8, 7, and others. You can download the free trial version of the tool that lets you export the first 10 items per folder.
Product page link: https://yotasoftware.com/ost-converter/pst.html
Informative Blog Link: https://yotasoftware.com/blogs/import-ost-to-outlook-2021/
|
CorticalStack/mistral-7b-distilabel-truthy-gguf | CorticalStack | 2024-03-13T08:15:46Z | 5 | 1 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-13T08:13:45Z | ---
license: apache-2.0
---
# CorticalStack/mistral-7b-distilabel-truthy
A collection of GGUF quantised versions of [CorticalStack/mistral-7b-distilabel-truthy-dpo](https://huggingface.co/CorticalStack/mistral-7b-distilabel-truthy-dpo).
The main branch model is quantised using GGUF format Q4_K_M.
GGUF is a format that replaces GGML, which is no longer supported by llama.cpp.
An incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. |
minhah/timesformer-base-finetuned-k400-finetuned-elder | minhah | 2024-03-13T08:13:35Z | 49 | 0 | transformers | [
"transformers",
"safetensors",
"timesformer",
"video-classification",
"generated_from_trainer",
"base_model:facebook/timesformer-base-finetuned-k400",
"base_model:finetune:facebook/timesformer-base-finetuned-k400",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | video-classification | 2024-03-13T05:28:21Z | ---
license: cc-by-nc-4.0
base_model: facebook/timesformer-base-finetuned-k400
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: timesformer-base-finetuned-k400-finetuned-elder
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# timesformer-base-finetuned-k400-finetuned-elder
This model is a fine-tuned version of [facebook/timesformer-base-finetuned-k400](https://huggingface.co/facebook/timesformer-base-finetuned-k400) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6948
- Accuracy: 0.3429
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 576
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5696 | 0.25 | 145 | 1.6706 | 0.3430 |
| 1.5394 | 1.25 | 290 | 1.6107 | 0.3251 |
| 1.3926 | 2.25 | 435 | 1.6141 | 0.3116 |
| 1.5686 | 3.24 | 576 | 1.6341 | 0.3006 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.1.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
sarak7/H4_313_207_v1 | sarak7 | 2024-03-13T08:13:07Z | 184 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-03-13T08:11:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jeonsiyun/layoutlmv3-v38-epoch5 | jeonsiyun | 2024-03-13T08:07:26Z | 118 | 0 | transformers | [
"transformers",
"safetensors",
"layoutlmv3",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-03-13T08:06:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Deepnoid/deep-solar-v2.0.2 | Deepnoid | 2024-03-13T07:56:00Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"generated_from_trainer",
"base_model:Deepnoid/mergekit_v2",
"base_model:adapter:Deepnoid/mergekit_v2",
"license:apache-2.0",
"region:us"
] | null | 2024-03-13T07:34:45Z | ---
library_name: peft
tags:
- generated_from_trainer
base_model: Deepnoid/mergekit_v2
model-index:
- name: Deepnoid/deep-solar-eeve-v2.0.2
results: []
license: apache-2.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
# Deepnoid/deep-solar-eeve-v2.0.2
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
### Training results
### Framework versions
- PEFT 0.9.1.dev0
- Transformers 4.38.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0 |
JPishikawa/Llama-2-7b-chat-hf-fine-tuned-adapters | JPishikawa | 2024-03-13T07:52:35Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-03-13T07:52:28Z | ---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.9.1.dev0 |
daze-unlv/google-mobilebert-uncased | daze-unlv | 2024-03-13T07:50:33Z | 91 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mobilebert",
"multiple-choice",
"generated_from_trainer",
"base_model:google/mobilebert-uncased",
"base_model:finetune:google/mobilebert-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | multiple-choice | 2024-03-12T13:58:12Z | ---
license: apache-2.0
base_model: google/mobilebert-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: google-mobilebert-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# google-mobilebert-uncased
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3573
- Accuracy: 0.3335
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.8107 | 1.0 | 2857 | 1.3585 | 0.3082 |
| 1.3233 | 2.0 | 5714 | 1.3452 | 0.3297 |
| 1.2776 | 3.0 | 8571 | 1.3573 | 0.3335 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.2.0+cu121
- Datasets 2.18.0
- Tokenizers 0.15.0
|
Subsets and Splits