
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Zhandos38/whisper-small-sber-v4 | Zhandos38 | 2024-02-05T07:04:41Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-04T20:57:24Z | ---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-small-sber-v4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-sber-v4
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3522
- Wer: 22.1427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1636 | 1.33 | 1000 | 0.4798 | 31.6750 |
| 0.0691 | 2.67 | 2000 | 0.4455 | 30.3746 |
| 0.0212 | 4.0 | 3000 | 0.3982 | 26.7478 |
| 0.0014 | 5.33 | 4000 | 0.3522 | 22.1427 |
### Framework versions
- Transformers 4.36.2
- Pytorch 1.14.0a0+44dac51
- Datasets 2.16.1
- Tokenizers 0.15.0
|
jeevana/G8_mistral7b_qlora_1211_v02 | jeevana | 2024-02-05T07:03:34Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-26T15:01:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Tensorride/censorship_classifier_transformer | Tensorride | 2024-02-05T07:01:07Z | 91 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-07-10T18:38:23Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: censorship_classifier_transformer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# censorship_classifier_transformer
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6150
- Accuracy: 0.7727
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 2 | 0.6542 | 0.5909 |
| No log | 2.0 | 4 | 0.6344 | 0.5909 |
| No log | 3.0 | 6 | 0.6212 | 0.6364 |
| No log | 4.0 | 8 | 0.6150 | 0.7727 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cpu
- Datasets 2.13.1
- Tokenizers 0.13.3
|
davidho27941/rl-course-model-20240205 | davidho27941 | 2024-02-05T06:54:02Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-05T06:43:48Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 298.77 +/- 15.86
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CognitiveLab/Fireship-clone-hf | CognitiveLab | 2024-02-05T06:42:23Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:NousResearch/Llama-2-7b-hf",
"base_model:finetune:NousResearch/Llama-2-7b-hf",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T06:42:21Z | ---
base_model: NousResearch/Llama-2-7b-hf
tags:
- generated_from_trainer
model-index:
- name: out
results: []
---
```yaml
base_model: NousResearch/Llama-2-7b-hf
model_type: LlamaForCausalLM
tokenizer_type: LlamaTokenizer
is_llama_derived_model: true
load_in_8bit: false
load_in_4bit: false
strict: false
datasets:
- path: CognitiveLab/FS_transcribe_summary_prompt
type: completion
dataset_prepared_path: last_run_prepared
val_set_size: 0.05
output_dir: ./out
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
adapter:
lora_model_dir:
lora_r:
lora_alpha:
lora_dropout:
lora_target_linear:
lora_fan_in_fan_out:
wandb_project: fireship-fft
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 4
micro_batch_size: 4
num_epochs: 1
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
flash_attn_cross_entropy: false
flash_attn_rms_norm: true
flash_attn_fuse_qkv: false
flash_attn_fuse_mlp: true
warmup_steps: 100
evals_per_epoch: 4
eval_table_size:
saves_per_epoch: 2
debug:
deepspeed: #deepspeed_configs/zero2.json # multi-gpu only
weight_decay: 0.1
fsdp:
fsdp_config:
special_tokens:
```
</details><br>
# out
This model is a fine-tuned version of [NousResearch/Llama-2-7b-hf](https://huggingface.co/NousResearch/Llama-2-7b-hf) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1256 | 0.06 | 1 | 2.1641 |
| 2.1049 | 0.25 | 4 | 2.1254 |
| 1.9826 | 0.49 | 8 | 1.9868 |
| 1.8545 | 0.74 | 12 | 1.8779 |
| 1.8597 | 0.98 | 16 | 1.8444 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.0.1+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
TinyPixel/guanaco | TinyPixel | 2024-02-05T06:38:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-01T15:59:53Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Pankaj001/TabularClassification-wine_quality | Pankaj001 | 2024-02-05T06:32:05Z | 0 | 0 | null | [
"tabular-classification",
"dataset:codesignal/wine-quality",
"license:apache-2.0",
"region:us"
] | tabular-classification | 2024-01-22T08:51:32Z | ---
license: apache-2.0
datasets:
- codesignal/wine-quality
metrics:
- accuracy
pipeline_tag: tabular-classification
---
# Random Forest Model for Wine-Quality Prediction
This repository contains a Random Forest model trained on wine-quality data for wine quality prediction. The model has been trained to classify wine quality into six classes. During training, it achieved a 100% accuracy on the training dataset and a 66% accuracy on the validation dataset.
## Model Details
- **Algorithm**: Random Forest
- **Dataset**: Wine-Quality Data
- **Objective**: Wine quality prediction (Six classes) - (3,4,5,6,7,8) and prediction above 5 is good quality wine.
- **Dataset Size**: 320 samples with 11 features.
- **Target Variable**: Wine Quality
- **Data Split**: 80% for training, 20% for validation
- **Training Accuracy**: 100%
- **Validation Accuracy**: 66%
## Usage
You can use this model to predict wine quality based on the provided features. Below are some code snippets to help you get started:
```python
# Load the model and perform predictions
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
# Load the trained Random Forest model (assuming 'model.pkl' is your model file)
model = joblib.load('model/random_forest_model.pkl')
# Prepare your data for prediction (assuming 'data' is your input data)
# Ensure that your input data has the same features as the training data
# Perform predictions
predictions = model.predict(data)
# Get the predicted wine quality class
# The predicted class will be an integer between 0 and 5
|
roku02/t-5-med-fine-tuned | roku02 | 2024-02-05T06:30:02Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2024-02-04T16:06:33Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
ericpolewski/Palworld-SME-13b | ericpolewski | 2024-02-05T06:22:11Z | 49 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-sa-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T05:38:02Z | ---
license: cc-by-sa-3.0
---
This is a Subject Matter Expert (SME) bot trained on the Palworld Fandom Wiki as a test of a new SME model pipeline. There's no RAG. All information is embedded in the model. It uses the OpenOrca-Platypus-13b fine-tune as a base.
Should work in any applicable loader/app, though I only tested it in [EricLLM](https://github.com/epolewski/EricLLM) and TGWUI.
All SME bots are generally useful, but focus on a topic. [Contact me](https://www.linkedin.com/in/eric-polewski-94b92214/) if you're interested in having one built.

|
Herry443/Mistral-7B-KNUT-ref-ALL | Herry443 | 2024-02-05T06:08:14Z | 2,201 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"ko",
"en",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-01T12:45:23Z | ---
license: cc-by-nc-4.0
language:
- ko
- en
library_name: transformers
tags:
- mistral
---
### Model Details
- Base Model: [Herry443/Mistral-7B-KNUT-ref](https://huggingface.co/Herry443/Mistral-7B-KNUT-ref)
### Datasets
- sampling [skt/kobest_v1](https://huggingface.co/datasets/skt/kobest_v1)
- sampling [allenai/ai2_arc](https://huggingface.co/datasets/allenai/ai2_arc)
- sampling [Rowan/hellaswag](https://huggingface.co/datasets/Rowan/hellaswag)
- sampling [Stevross/mmlu](https://huggingface.co/datasets/Stevross/mmlu)
|
yvonne1123/TrainingDynamic | yvonne1123 | 2024-02-05T05:39:47Z | 0 | 0 | null | [
"image-classification",
"dataset:mnist",
"dataset:cifar10",
"license:apache-2.0",
"region:us"
] | image-classification | 2024-01-27T03:57:09Z | ---
license: apache-2.0
datasets:
- mnist
- cifar10
metrics:
- accuracy
pipeline_tag: image-classification
--- |
xingyaoww/CodeActAgent-Llama-2-7b | xingyaoww | 2024-02-05T05:24:27Z | 14 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llm-agent",
"conversational",
"en",
"dataset:xingyaoww/code-act",
"arxiv:2402.01030",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-05T10:44:17Z | ---
license: llama2
datasets:
- xingyaoww/code-act
language:
- en
tags:
- llm-agent
pipeline_tag: text-generation
---
<h1 align="center"> Executable Code Actions Elicit Better LLM Agents </h1>
<p align="center">
<a href="https://github.com/xingyaoww/code-act">💻 Code</a>
•
<a href="https://arxiv.org/abs/2402.01030">📃 Paper</a>
•
<a href="https://huggingface.co/datasets/xingyaoww/code-act" >🤗 Data (CodeActInstruct)</a>
•
<a href="https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1" >🤗 Model (CodeActAgent-Mistral-7b-v0.1)</a>
•
<a href="https://chat.xwang.dev/">🤖 Chat with CodeActAgent!</a>
</p>
We propose to use executable Python **code** to consolidate LLM agents’ **act**ions into a unified action space (**CodeAct**).
Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions.
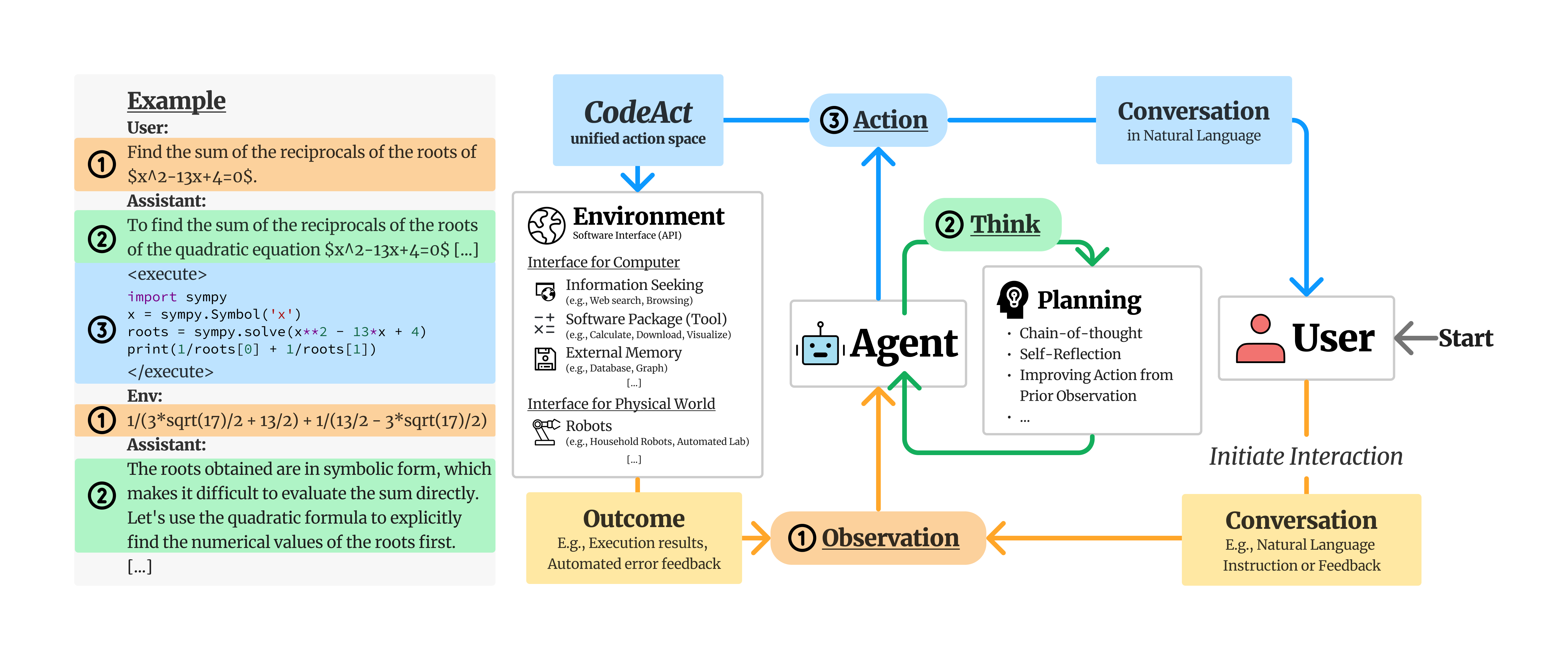
## Why CodeAct?
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark [M<sup>3</sup>ToolEval](docs/EVALUATION.md) shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!
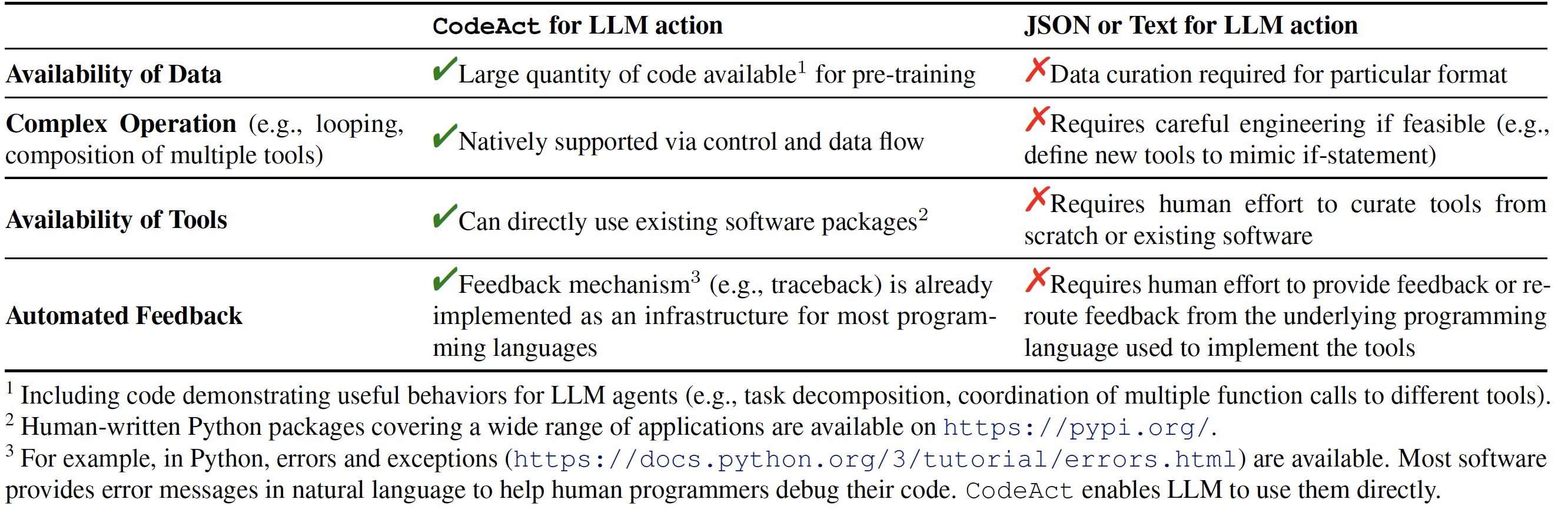
*Comparison between CodeAct and Text / JSON as action.*
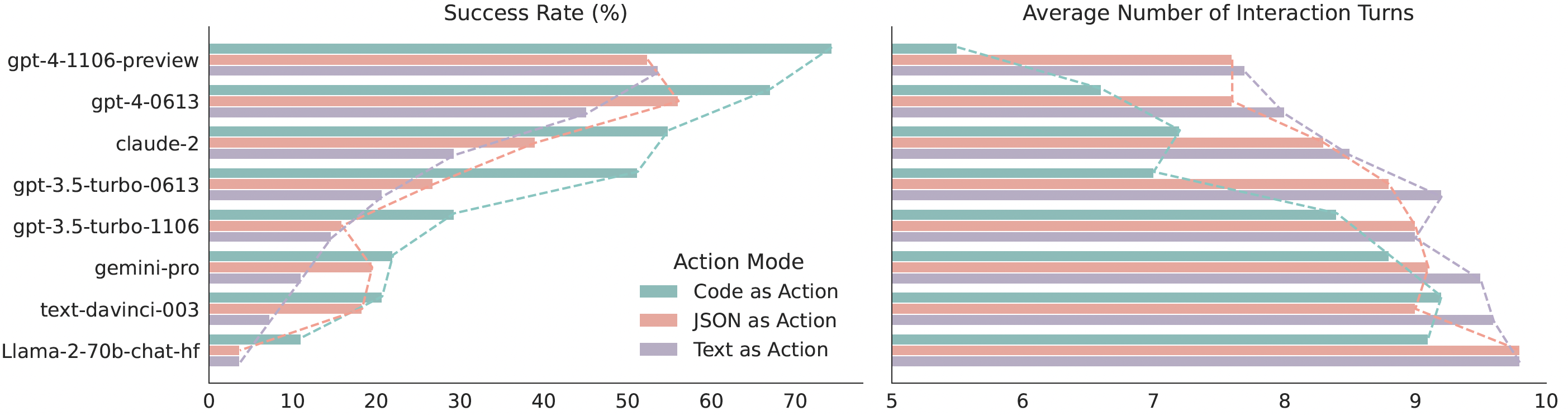
*Quantitative results comparing CodeAct and {Text, JSON} on M<sup>3</sup>ToolEval.*
## 📁 CodeActInstruct
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at [huggingface dataset 🤗](https://huggingface.co/datasets/xingyaoww/code-act). Please refer to the paper and [this section](#-data-generation-optional) for details of data collection.
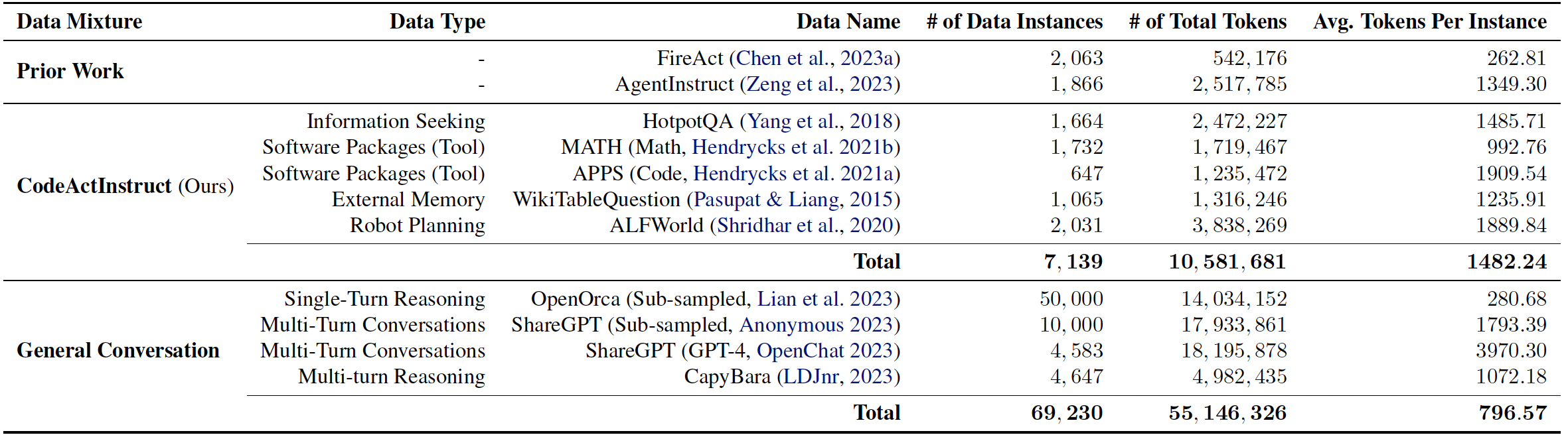
*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
## 🪄 CodeActAgent
Trained on **CodeActInstruct** and general conversaions, **CodeActAgent** excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
- **CodeActAgent-Mistral-7b-v0.1** (recommended, [model link](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1)): using Mistral-7b-v0.1 as the base model with 32k context window.
- **CodeActAgent-Llama-7b** ([model link](https://huggingface.co/xingyaoww/CodeActAgent-Llama-2-7b)): using Llama-2-7b as the base model with 4k context window.
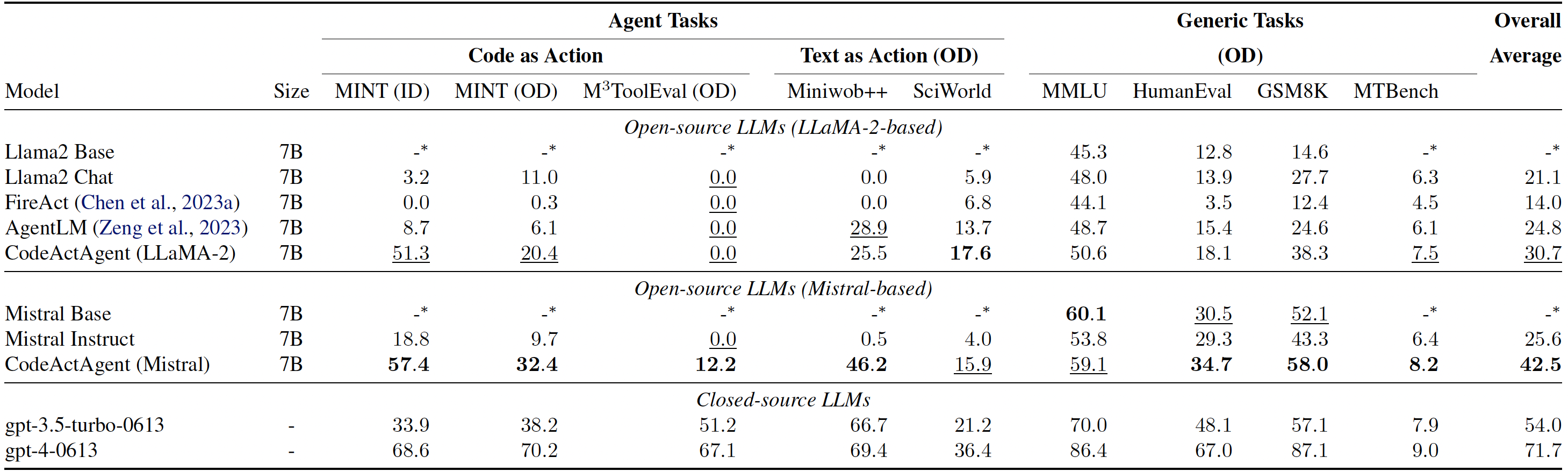
*Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.*
Please check out [our paper](TODO) and [code](https://github.com/xingyaoww/code-act) for more details about data collection, model training, and evaluation.
## 📚 Citation
```bibtex
@misc{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
janhq/finance-llm-GGUF | janhq | 2024-02-05T05:24:11Z | 14 | 2 | null | [
"gguf",
"finance",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:GAIR/lima",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"base_model:AdaptLLM/finance-LLM",
"base_model:quantized:AdaptLLM/finance-LLM",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T05:10:53Z | ---
language:
- en
datasets:
- Open-Orca/OpenOrca
- GAIR/lima
- WizardLM/WizardLM_evol_instruct_V2_196k
metrics:
- accuracy
pipeline_tag: text-generation
tags:
- finance
base_model: AdaptLLM/finance-LLM
model_creator: AdaptLLM
model_name: finance-LLM
quantized_by: JanHQ
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a>
</p>
<!-- header end -->
# Model Description
This is a GGUF version of [AdaptLLM/finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM)
- Model creator: [AdaptLLM](https://huggingface.co/AdaptLLM)
- Original model: [finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM)
- Model description: [Readme](https://huggingface.co/AdaptLLM/finance-LLM/blob/main/README.md)
# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life.
# Jan Model Converter
This is a repository for the [open-source converter](https://github.com/janhq/model-converter. We would be grateful if the community could contribute and strengthen this repository. We are aiming to expand the repo that can convert into various types of format
|
xingyaoww/CodeActAgent-Mistral-7b-v0.1 | xingyaoww | 2024-02-05T05:24:01Z | 28 | 27 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"llm-agent",
"conversational",
"en",
"dataset:xingyaoww/code-act",
"arxiv:2402.01030",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-05T09:35:19Z | ---
license: apache-2.0
datasets:
- xingyaoww/code-act
language:
- en
pipeline_tag: text-generation
tags:
- llm-agent
---
<h1 align="center"> Executable Code Actions Elicit Better LLM Agents </h1>
<p align="center">
<a href="https://github.com/xingyaoww/code-act">💻 Code</a>
•
<a href="https://arxiv.org/abs/2402.01030">📃 Paper</a>
•
<a href="https://huggingface.co/datasets/xingyaoww/code-act" >🤗 Data (CodeActInstruct)</a>
•
<a href="https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1" >🤗 Model (CodeActAgent-Mistral-7b-v0.1)</a>
•
<a href="https://chat.xwang.dev/">🤖 Chat with CodeActAgent!</a>
</p>
We propose to use executable Python **code** to consolidate LLM agents’ **act**ions into a unified action space (**CodeAct**).
Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions.

## Why CodeAct?
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark [M<sup>3</sup>ToolEval](docs/EVALUATION.md) shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!

*Comparison between CodeAct and Text / JSON as action.*

*Quantitative results comparing CodeAct and {Text, JSON} on M<sup>3</sup>ToolEval.*
## 📁 CodeActInstruct
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at [huggingface dataset 🤗](https://huggingface.co/datasets/xingyaoww/code-act). Please refer to the paper and [this section](#-data-generation-optional) for details of data collection.

*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
## 🪄 CodeActAgent
Trained on **CodeActInstruct** and general conversaions, **CodeActAgent** excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
- **CodeActAgent-Mistral-7b-v0.1** (recommended, [model link](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1)): using Mistral-7b-v0.1 as the base model with 32k context window.
- **CodeActAgent-Llama-7b** ([model link](https://huggingface.co/xingyaoww/CodeActAgent-Llama-2-7b)): using Llama-2-7b as the base model with 4k context window.

*Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.*
Please check out [our paper](TODO) and [code](https://github.com/xingyaoww/code-act) for more details about data collection, model training, and evaluation.
## 📚 Citation
```bibtex
@misc{wang2024executable,
title={Executable Code Actions Elicit Better LLM Agents},
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
year={2024},
eprint={2402.01030},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
neolord/distilbert-base-uncased-finetuned-clinc | neolord | 2024-02-05T05:17:37Z | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-05T05:07:16Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7730
- Accuracy: 0.9161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 3.2776 | 0.7287 |
| 3.7835 | 2.0 | 636 | 1.8647 | 0.8358 |
| 3.7835 | 3.0 | 954 | 1.1524 | 0.8977 |
| 1.6878 | 4.0 | 1272 | 0.8547 | 0.9129 |
| 0.8994 | 5.0 | 1590 | 0.7730 | 0.9161 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
gustavokpc/bert-base-portuguese-cased_LRATE_1e-06_EPOCHS_10 | gustavokpc | 2024-02-05T05:10:31Z | 45 | 0 | transformers | [
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:neuralmind/bert-base-portuguese-cased",
"base_model:finetune:neuralmind/bert-base-portuguese-cased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-05T03:18:40Z | ---
license: mit
base_model: neuralmind/bert-base-portuguese-cased
tags:
- generated_from_keras_callback
model-index:
- name: gustavokpc/bert-base-portuguese-cased_LRATE_1e-06_EPOCHS_10
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# gustavokpc/bert-base-portuguese-cased_LRATE_1e-06_EPOCHS_10
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1478
- Train Accuracy: 0.9481
- Train F1 M: 0.5518
- Train Precision M: 0.4013
- Train Recall M: 0.9436
- Validation Loss: 0.1862
- Validation Accuracy: 0.9307
- Validation F1 M: 0.5600
- Validation Precision M: 0.4033
- Validation Recall M: 0.9613
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-06, 'decay_steps': 7580, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Train F1 M | Train Precision M | Train Recall M | Validation Loss | Validation Accuracy | Validation F1 M | Validation Precision M | Validation Recall M | Epoch |
|:----------:|:--------------:|:----------:|:-----------------:|:--------------:|:---------------:|:-------------------:|:---------------:|:----------------------:|:-------------------:|:-----:|
| 0.4813 | 0.7972 | 0.2411 | 0.2093 | 0.3344 | 0.2665 | 0.9090 | 0.5217 | 0.3877 | 0.8393 | 0 |
| 0.2432 | 0.9126 | 0.5317 | 0.3942 | 0.8764 | 0.2185 | 0.9169 | 0.5490 | 0.3979 | 0.9239 | 1 |
| 0.2054 | 0.9262 | 0.5438 | 0.3981 | 0.9151 | 0.2059 | 0.9222 | 0.5441 | 0.3948 | 0.9188 | 2 |
| 0.1883 | 0.9300 | 0.5471 | 0.3992 | 0.9253 | 0.1970 | 0.9294 | 0.5504 | 0.3977 | 0.9356 | 3 |
| 0.1771 | 0.9359 | 0.5494 | 0.4011 | 0.9339 | 0.1918 | 0.9268 | 0.5550 | 0.4005 | 0.9486 | 4 |
| 0.1632 | 0.9418 | 0.5507 | 0.4016 | 0.9369 | 0.1889 | 0.9294 | 0.5578 | 0.4023 | 0.9538 | 5 |
| 0.1591 | 0.9436 | 0.5507 | 0.4023 | 0.9416 | 0.1878 | 0.9307 | 0.5547 | 0.4005 | 0.9464 | 6 |
| 0.1536 | 0.9452 | 0.5529 | 0.4028 | 0.9419 | 0.1871 | 0.9301 | 0.5561 | 0.4010 | 0.9521 | 7 |
| 0.1512 | 0.9471 | 0.5514 | 0.4012 | 0.9396 | 0.1864 | 0.9307 | 0.5599 | 0.4032 | 0.9613 | 8 |
| 0.1478 | 0.9481 | 0.5518 | 0.4013 | 0.9436 | 0.1862 | 0.9307 | 0.5600 | 0.4033 | 0.9613 | 9 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.15.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
janhq/medicine-llm-GGUF | janhq | 2024-02-05T04:52:32Z | 14 | 0 | null | [
"gguf",
"biology",
"medical",
"text-generation",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:GAIR/lima",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:EleutherAI/pile",
"base_model:AdaptLLM/medicine-LLM",
"base_model:quantized:AdaptLLM/medicine-LLM",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T04:45:42Z | ---
language:
- en
datasets:
- Open-Orca/OpenOrca
- GAIR/lima
- WizardLM/WizardLM_evol_instruct_V2_196k
- EleutherAI/pile
metrics:
- accuracy
pipeline_tag: text-generation
tags:
- biology
- medical
base_model: AdaptLLM/medicine-LLM
model_creator: AdaptLLM
model_name: medicine-LLM
quantized_by: JanHQ
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a>
</p>
<!-- header end -->
# Model Description
This is a GGUF version of [AdaptLLM/medicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM)
- Model creator: [AdaptLLM](https://huggingface.co/AdaptLLM)
- Original model: [medicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM)
- Model description: [Readme](https://huggingface.co/AdaptLLM/medicine-LLM/blob/main/README.md)
# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life.
# Jan Model Converter
This is a repository for the [open-source converter](https://github.com/janhq/model-converter. We would be grateful if the community could contribute and strengthen this repository. We are aiming to expand the repo that can convert into various types of format
|
emaadshehzad/setfit-DK-V1 | emaadshehzad | 2024-02-05T04:50:43Z | 9 | 0 | setfit | [
"setfit",
"safetensors",
"bert",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/all-MiniLM-L12-v1",
"base_model:finetune:sentence-transformers/all-MiniLM-L12-v1",
"region:us"
] | text-classification | 2023-12-04T13:12:58Z | ---
library_name: setfit
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
metrics:
- accuracy
widget: []
pipeline_tag: text-classification
inference: true
base_model: sentence-transformers/all-MiniLM-L12-v1
---
# SetFit with sentence-transformers/all-MiniLM-L12-v1
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/all-MiniLM-L12-v1](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v1) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/all-MiniLM-L12-v1](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v1)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 256 tokens
<!-- - **Number of Classes:** Unknown -->
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("emaadshehzad/setfit-DK-V1")
# Run inference
preds = model("I loved the spiderman movie!")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Framework Versions
- Python: 3.10.12
- SetFit: 1.0.3
- Sentence Transformers: 2.3.1
- Transformers: 4.35.2
- PyTorch: 2.1.0+cu121
- Datasets: 2.16.1
- Tokenizers: 0.15.1
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
Jarles/PPO-LunarLander-v2 | Jarles | 2024-02-05T04:48:42Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-05T04:48:22Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.17 +/- 59.48
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
e22vvb/ALL_mt5-base_5_spider_15_wikiSQL_new | e22vvb | 2024-02-05T04:48:00Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-05T03:30:32Z | ---
tags:
- generated_from_trainer
model-index:
- name: ALL_mt5-base_5_spider_15_wikiSQL_new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ALL_mt5-base_5_spider_15_wikiSQL_new
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2299
- Rouge2 Precision: 0.5924
- Rouge2 Recall: 0.4008
- Rouge2 Fmeasure: 0.4493
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.2318 | 1.0 | 1212 | 0.2258 | 0.5422 | 0.3546 | 0.4016 |
| 0.1515 | 2.0 | 2424 | 0.2190 | 0.5676 | 0.3783 | 0.4251 |
| 0.1112 | 3.0 | 3636 | 0.2262 | 0.578 | 0.389 | 0.4362 |
| 0.0951 | 4.0 | 4848 | 0.2304 | 0.5869 | 0.3947 | 0.4431 |
| 0.088 | 5.0 | 6060 | 0.2299 | 0.5924 | 0.4008 | 0.4493 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.7.dev0
- Tokenizers 0.13.3
|
ankhamun/IIIIIIIo-oIIIIIII | ankhamun | 2024-02-05T04:38:17Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T04:10:24Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mbenachour/cms_rules1 | mbenachour | 2024-02-05T04:33:24Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:bigscience/bloom-3b",
"base_model:adapter:bigscience/bloom-3b",
"region:us"
] | null | 2024-02-05T04:33:14Z | ---
library_name: peft
base_model: bigscience/bloom-3b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
Ketak-ZoomRx/Indication_PYT_v3 | Ketak-ZoomRx | 2024-02-05T04:27:55Z | 13 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-05T04:27:19Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [EleutherAI/pythia-2.8b-deduped](https://huggingface.co/EleutherAI/pythia-2.8b-deduped)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate` and `torch` libraries installed.
```bash
pip install transformers==4.29.2
pip install einops==0.6.1
pip install accelerate==0.19.0
pip install torch==2.0.0
```
```python
import torch
from transformers import pipeline
generate_text = pipeline(
model="Ketak-ZoomRx/Indication_PYT_v3",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer. If the model and the tokenizer are fully supported in the `transformers` package, this will allow you to set `trust_remote_code=False`.
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"Ketak-ZoomRx/Indication_PYT_v3",
use_fast=True,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"Ketak-ZoomRx/Indication_PYT_v3",
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Ketak-ZoomRx/Indication_PYT_v3" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Quantization and sharding
You can load the models using quantization by specifying ```load_in_8bit=True``` or ```load_in_4bit=True```. Also, sharding on multiple GPUs is possible by setting ```device_map=auto```.
## Model Architecture
```
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 2560)
(layers): ModuleList(
(0-31): 32 x GPTNeoXLayer(
(input_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(attention): GPTNeoXAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): Linear(in_features=2560, out_features=7680, bias=True)
(dense): Linear(in_features=2560, out_features=2560, bias=True)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=2560, out_features=10240, bias=True)
(dense_4h_to_h): Linear(in_features=10240, out_features=2560, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=2560, out_features=50304, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
gayanin/bart-noised-with-kaggle-gcd-dist | gayanin | 2024-02-05T04:19:01Z | 10 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:gayanin/bart-noised-with-kaggle-dist",
"base_model:finetune:gayanin/bart-noised-with-kaggle-dist",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-05T02:56:41Z | ---
license: apache-2.0
base_model: gayanin/bart-noised-with-kaggle-dist
tags:
- generated_from_trainer
model-index:
- name: bart-noised-with-kaggle-gcd-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-noised-with-kaggle-gcd-dist
This model is a fine-tuned version of [gayanin/bart-noised-with-kaggle-dist](https://huggingface.co/gayanin/bart-noised-with-kaggle-dist) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4538
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.6061 | 0.11 | 500 | 0.5365 |
| 0.5537 | 0.21 | 1000 | 0.5251 |
| 0.5591 | 0.32 | 1500 | 0.5202 |
| 0.5669 | 0.43 | 2000 | 0.5069 |
| 0.4669 | 0.54 | 2500 | 0.5038 |
| 0.5457 | 0.64 | 3000 | 0.4923 |
| 0.5237 | 0.75 | 3500 | 0.4922 |
| 0.5186 | 0.86 | 4000 | 0.4802 |
| 0.5148 | 0.96 | 4500 | 0.4777 |
| 0.4127 | 1.07 | 5000 | 0.4822 |
| 0.4207 | 1.18 | 5500 | 0.4807 |
| 0.4362 | 1.28 | 6000 | 0.4770 |
| 0.4072 | 1.39 | 6500 | 0.4763 |
| 0.4503 | 1.5 | 7000 | 0.4701 |
| 0.3683 | 1.61 | 7500 | 0.4693 |
| 0.3897 | 1.71 | 8000 | 0.4636 |
| 0.4421 | 1.82 | 8500 | 0.4561 |
| 0.3836 | 1.93 | 9000 | 0.4588 |
| 0.3405 | 2.03 | 9500 | 0.4634 |
| 0.3147 | 2.14 | 10000 | 0.4682 |
| 0.3115 | 2.25 | 10500 | 0.4622 |
| 0.3153 | 2.35 | 11000 | 0.4625 |
| 0.3295 | 2.46 | 11500 | 0.4597 |
| 0.3529 | 2.57 | 12000 | 0.4564 |
| 0.3191 | 2.68 | 12500 | 0.4555 |
| 0.2974 | 2.78 | 13000 | 0.4547 |
| 0.3253 | 2.89 | 13500 | 0.4534 |
| 0.3627 | 3.0 | 14000 | 0.4538 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
DouglasPontes/2020-Q3-25p-filtered | DouglasPontes | 2024-02-05T04:16:41Z | 13 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"generated_from_trainer",
"base_model:cardiffnlp/twitter-roberta-base-2019-90m",
"base_model:finetune:cardiffnlp/twitter-roberta-base-2019-90m",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-02-02T03:57:11Z | ---
license: mit
base_model: cardiffnlp/twitter-roberta-base-2019-90m
tags:
- generated_from_trainer
model-index:
- name: 2020-Q3-25p-filtered
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2020-Q3-25p-filtered
This model is a fine-tuned version of [cardiffnlp/twitter-roberta-base-2019-90m](https://huggingface.co/cardiffnlp/twitter-roberta-base-2019-90m) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2870
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.1e-07
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 2400000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-------:|:---------------:|
| No log | 0.02 | 8000 | 2.5705 |
| 2.7559 | 0.05 | 16000 | 2.4932 |
| 2.7559 | 0.07 | 24000 | 2.4516 |
| 2.5786 | 0.09 | 32000 | 2.4174 |
| 2.5786 | 0.11 | 40000 | 2.4071 |
| 2.5316 | 0.14 | 48000 | 2.3903 |
| 2.5316 | 0.16 | 56000 | 2.3744 |
| 2.5006 | 0.18 | 64000 | 2.3650 |
| 2.5006 | 0.2 | 72000 | 2.3600 |
| 2.483 | 0.23 | 80000 | 2.3548 |
| 2.483 | 0.25 | 88000 | 2.3485 |
| 2.4703 | 0.27 | 96000 | 2.3475 |
| 2.4703 | 0.29 | 104000 | 2.3384 |
| 2.47 | 0.32 | 112000 | 2.3330 |
| 2.47 | 0.34 | 120000 | 2.3354 |
| 2.4601 | 0.36 | 128000 | 2.3343 |
| 2.4601 | 0.38 | 136000 | 2.3282 |
| 2.4486 | 0.41 | 144000 | 2.3316 |
| 2.4486 | 0.43 | 152000 | 2.3180 |
| 2.4536 | 0.45 | 160000 | 2.3257 |
| 2.4536 | 0.47 | 168000 | 2.3222 |
| 2.4523 | 0.5 | 176000 | 2.3208 |
| 2.4523 | 0.52 | 184000 | 2.3218 |
| 2.4489 | 0.54 | 192000 | 2.3184 |
| 2.4489 | 0.56 | 200000 | 2.3225 |
| 2.4448 | 0.59 | 208000 | 2.3185 |
| 2.4448 | 0.61 | 216000 | 2.3139 |
| 2.4412 | 0.63 | 224000 | 2.3235 |
| 2.4412 | 0.65 | 232000 | 2.3148 |
| 2.442 | 0.68 | 240000 | 2.3146 |
| 2.442 | 0.7 | 248000 | 2.3145 |
| 2.4408 | 0.72 | 256000 | 2.3083 |
| 2.4408 | 0.74 | 264000 | 2.3068 |
| 2.4336 | 0.77 | 272000 | 2.3104 |
| 2.4336 | 0.79 | 280000 | 2.3147 |
| 2.4394 | 0.81 | 288000 | 2.3105 |
| 2.4394 | 0.83 | 296000 | 2.3135 |
| 2.4363 | 0.86 | 304000 | 2.3057 |
| 2.4363 | 0.88 | 312000 | 2.3050 |
| 2.4403 | 0.9 | 320000 | 2.3066 |
| 2.4403 | 0.92 | 328000 | 2.3076 |
| 2.4409 | 0.95 | 336000 | 2.3026 |
| 2.4409 | 0.97 | 344000 | 2.3045 |
| 2.4434 | 0.99 | 352000 | 2.3047 |
| 2.4434 | 1.01 | 360000 | 2.3080 |
| 2.4372 | 1.04 | 368000 | 2.3143 |
| 2.4372 | 1.06 | 376000 | 2.3049 |
| 2.4329 | 1.08 | 384000 | 2.3066 |
| 2.4329 | 1.1 | 392000 | 2.3050 |
| 2.437 | 1.13 | 400000 | 2.3012 |
| 2.437 | 1.15 | 408000 | 2.3033 |
| 2.4378 | 1.17 | 416000 | 2.3064 |
| 2.4378 | 1.19 | 424000 | 2.2984 |
| 2.4386 | 1.22 | 432000 | 2.3057 |
| 2.4386 | 1.24 | 440000 | 2.3035 |
| 2.4411 | 1.26 | 448000 | 2.2969 |
| 2.4411 | 1.28 | 456000 | 2.2930 |
| 2.4466 | 1.31 | 464000 | 2.3005 |
| 2.4466 | 1.33 | 472000 | 2.2975 |
| 2.4451 | 1.35 | 480000 | 2.3042 |
| 2.4451 | 1.37 | 488000 | 2.3061 |
| 2.4399 | 1.4 | 496000 | 2.2987 |
| 2.4399 | 1.42 | 504000 | 2.2967 |
| 2.4397 | 1.44 | 512000 | 2.3010 |
| 2.4397 | 1.47 | 520000 | 2.3019 |
| 2.4483 | 1.49 | 528000 | 2.3009 |
| 2.4483 | 1.51 | 536000 | 2.3048 |
| 2.4436 | 1.53 | 544000 | 2.3029 |
| 2.4436 | 1.56 | 552000 | 2.3026 |
| 2.4407 | 1.58 | 560000 | 2.3027 |
| 2.4407 | 1.6 | 568000 | 2.3061 |
| 2.4364 | 1.62 | 576000 | 2.2972 |
| 2.4364 | 1.65 | 584000 | 2.2967 |
| 2.4406 | 1.67 | 592000 | 2.2965 |
| 2.4406 | 1.69 | 600000 | 2.2966 |
| 2.4393 | 1.71 | 608000 | 2.2982 |
| 2.4393 | 1.74 | 616000 | 2.2993 |
| 2.4352 | 1.76 | 624000 | 2.2916 |
| 2.4352 | 1.78 | 632000 | 2.2931 |
| 2.4366 | 1.8 | 640000 | 2.3016 |
| 2.4366 | 1.83 | 648000 | 2.2984 |
| 2.4361 | 1.85 | 656000 | 2.2877 |
| 2.4361 | 1.87 | 664000 | 2.2983 |
| 2.437 | 1.89 | 672000 | 2.3033 |
| 2.437 | 1.92 | 680000 | 2.2928 |
| 2.4488 | 1.94 | 688000 | 2.2953 |
| 2.4488 | 1.96 | 696000 | 2.2945 |
| 2.4459 | 1.98 | 704000 | 2.2961 |
| 2.4459 | 2.01 | 712000 | 2.2899 |
| 2.4334 | 2.03 | 720000 | 2.2964 |
| 2.4334 | 2.05 | 728000 | 2.2896 |
| 2.4343 | 2.07 | 736000 | 2.2954 |
| 2.4343 | 2.1 | 744000 | 2.3004 |
| 2.4345 | 2.12 | 752000 | 2.2892 |
| 2.4345 | 2.14 | 760000 | 2.2996 |
| 2.4386 | 2.16 | 768000 | 2.2886 |
| 2.4386 | 2.19 | 776000 | 2.2974 |
| 2.434 | 2.21 | 784000 | 2.2882 |
| 2.434 | 2.23 | 792000 | 2.2965 |
| 2.4379 | 2.25 | 800000 | 2.2899 |
| 2.4379 | 2.28 | 808000 | 2.2938 |
| 2.4356 | 2.3 | 816000 | 2.2997 |
| 2.4356 | 2.32 | 824000 | 2.2942 |
| 2.4399 | 2.34 | 832000 | 2.2916 |
| 2.4399 | 2.37 | 840000 | 2.2934 |
| 2.437 | 2.39 | 848000 | 2.2978 |
| 2.437 | 2.41 | 856000 | 2.2834 |
| 2.4311 | 2.43 | 864000 | 2.2872 |
| 2.4311 | 2.46 | 872000 | 2.2928 |
| 2.4453 | 2.48 | 880000 | 2.2888 |
| 2.4453 | 2.5 | 888000 | 2.2933 |
| 2.4434 | 2.52 | 896000 | 2.2911 |
| 2.4434 | 2.55 | 904000 | 2.2929 |
| 2.443 | 2.57 | 912000 | 2.2926 |
| 2.443 | 2.59 | 920000 | 2.2908 |
| 2.4361 | 2.61 | 928000 | 2.2914 |
| 2.4361 | 2.64 | 936000 | 2.2878 |
| 2.44 | 2.66 | 944000 | 2.2872 |
| 2.44 | 2.68 | 952000 | 2.2857 |
| 2.4447 | 2.7 | 960000 | 2.2932 |
| 2.4447 | 2.73 | 968000 | 2.2918 |
| 2.4362 | 2.75 | 976000 | 2.2875 |
| 2.4362 | 2.77 | 984000 | 2.2900 |
| 2.4457 | 2.8 | 992000 | 2.2913 |
| 2.4457 | 2.82 | 1000000 | 2.2871 |
| 2.4474 | 2.84 | 1008000 | 2.2875 |
| 2.4474 | 2.86 | 1016000 | 2.2902 |
| 2.444 | 2.89 | 1024000 | 2.2878 |
| 2.444 | 2.91 | 1032000 | 2.2856 |
| 2.4316 | 2.93 | 1040000 | 2.2908 |
| 2.4316 | 2.95 | 1048000 | 2.2889 |
| 2.4388 | 2.98 | 1056000 | 2.2922 |
| 2.4388 | 3.0 | 1064000 | 2.2867 |
| 2.442 | 3.02 | 1072000 | 2.2912 |
| 2.442 | 3.04 | 1080000 | 2.2891 |
| 2.4388 | 3.07 | 1088000 | 2.2855 |
| 2.4388 | 3.09 | 1096000 | 2.2949 |
| 2.4296 | 3.11 | 1104000 | 2.2853 |
| 2.4296 | 3.13 | 1112000 | 2.2854 |
| 2.4411 | 3.16 | 1120000 | 2.2902 |
| 2.4411 | 3.18 | 1128000 | 2.2902 |
| 2.4354 | 3.2 | 1136000 | 2.2873 |
| 2.4354 | 3.22 | 1144000 | 2.2931 |
| 2.4436 | 3.25 | 1152000 | 2.2906 |
| 2.4436 | 3.27 | 1160000 | 2.2945 |
| 2.4372 | 3.29 | 1168000 | 2.2899 |
| 2.4372 | 3.31 | 1176000 | 2.2869 |
| 2.4327 | 3.34 | 1184000 | 2.2891 |
| 2.4327 | 3.36 | 1192000 | 2.2933 |
| 2.4387 | 3.38 | 1200000 | 2.2849 |
| 2.4387 | 3.4 | 1208000 | 2.2934 |
| 2.4433 | 3.43 | 1216000 | 2.2876 |
| 2.4433 | 3.45 | 1224000 | 2.2860 |
| 2.4396 | 3.47 | 1232000 | 2.2898 |
| 2.4396 | 3.49 | 1240000 | 2.2830 |
| 2.4332 | 3.52 | 1248000 | 2.2855 |
| 2.4332 | 3.54 | 1256000 | 2.2925 |
| 2.4332 | 3.56 | 1264000 | 2.2832 |
| 2.4332 | 3.58 | 1272000 | 2.2851 |
| 2.4307 | 3.61 | 1280000 | 2.2912 |
| 2.4307 | 3.63 | 1288000 | 2.2924 |
| 2.4432 | 3.65 | 1296000 | 2.2916 |
| 2.4432 | 3.67 | 1304000 | 2.2892 |
| 2.4319 | 3.7 | 1312000 | 2.2908 |
| 2.4319 | 3.72 | 1320000 | 2.2898 |
| 2.4394 | 3.74 | 1328000 | 2.2860 |
| 2.4394 | 3.76 | 1336000 | 2.2879 |
| 2.4462 | 3.79 | 1344000 | 2.2865 |
| 2.4462 | 3.81 | 1352000 | 2.2844 |
| 2.4373 | 3.83 | 1360000 | 2.2933 |
| 2.4373 | 3.85 | 1368000 | 2.2877 |
| 2.4436 | 3.88 | 1376000 | 2.2937 |
| 2.4436 | 3.9 | 1384000 | 2.2902 |
| 2.4387 | 3.92 | 1392000 | 2.2870 |
| 2.4387 | 3.94 | 1400000 | 2.2823 |
| 2.4384 | 3.97 | 1408000 | 2.2899 |
| 2.4384 | 3.99 | 1416000 | 2.2865 |
| 2.4389 | 4.01 | 1424000 | 2.2856 |
| 2.4389 | 4.03 | 1432000 | 2.2911 |
| 2.4408 | 4.06 | 1440000 | 2.2906 |
| 2.4408 | 4.08 | 1448000 | 2.2860 |
| 2.4424 | 4.1 | 1456000 | 2.2816 |
| 2.4424 | 4.12 | 1464000 | 2.2850 |
| 2.4446 | 4.15 | 1472000 | 2.2936 |
| 2.4446 | 4.17 | 1480000 | 2.2829 |
| 2.4419 | 4.19 | 1488000 | 2.2871 |
| 2.4419 | 4.22 | 1496000 | 2.2892 |
| 2.4327 | 4.24 | 1504000 | 2.2822 |
| 2.4327 | 4.26 | 1512000 | 2.2900 |
| 2.4346 | 4.28 | 1520000 | 2.2906 |
| 2.4346 | 4.31 | 1528000 | 2.2837 |
| 2.4342 | 4.33 | 1536000 | 2.2846 |
| 2.4342 | 4.35 | 1544000 | 2.2863 |
| 2.4381 | 4.37 | 1552000 | 2.2940 |
| 2.4381 | 4.4 | 1560000 | 2.2900 |
| 2.4445 | 4.42 | 1568000 | 2.2887 |
| 2.4445 | 4.44 | 1576000 | 2.2901 |
| 2.4306 | 4.46 | 1584000 | 2.2832 |
| 2.4306 | 4.49 | 1592000 | 2.2862 |
| 2.4348 | 4.51 | 1600000 | 2.2877 |
| 2.4348 | 4.53 | 1608000 | 2.2834 |
| 2.4446 | 4.55 | 1616000 | 2.2892 |
| 2.4446 | 4.58 | 1624000 | 2.2800 |
| 2.444 | 4.6 | 1632000 | 2.2891 |
| 2.444 | 4.62 | 1640000 | 2.2839 |
| 2.4335 | 4.64 | 1648000 | 2.2787 |
| 2.4335 | 4.67 | 1656000 | 2.2856 |
| 2.4369 | 4.69 | 1664000 | 2.2889 |
| 2.4369 | 4.71 | 1672000 | 2.2900 |
| 2.4446 | 4.73 | 1680000 | 2.2891 |
| 2.4446 | 4.76 | 1688000 | 2.2835 |
| 2.4334 | 4.78 | 1696000 | 2.2841 |
| 2.4334 | 4.8 | 1704000 | 2.2895 |
| 2.4426 | 4.82 | 1712000 | 2.2832 |
| 2.4426 | 4.85 | 1720000 | 2.2870 |
| 2.4434 | 4.87 | 1728000 | 2.2819 |
| 2.4434 | 4.89 | 1736000 | 2.2896 |
| 2.4382 | 4.91 | 1744000 | 2.2869 |
| 2.4382 | 4.94 | 1752000 | 2.2844 |
| 2.4405 | 4.96 | 1760000 | 2.2820 |
| 2.4405 | 4.98 | 1768000 | 2.2922 |
| 2.4507 | 5.0 | 1776000 | 2.2808 |
| 2.4507 | 5.03 | 1784000 | 2.2868 |
| 2.4437 | 5.05 | 1792000 | 2.2815 |
| 2.4437 | 5.07 | 1800000 | 2.2889 |
| 2.4373 | 5.09 | 1808000 | 2.2797 |
| 2.4373 | 5.12 | 1816000 | 2.2882 |
| 2.4368 | 5.14 | 1824000 | 2.2879 |
| 2.4368 | 5.16 | 1832000 | 2.2829 |
| 2.4398 | 5.18 | 1840000 | 2.2867 |
| 2.4398 | 5.21 | 1848000 | 2.2829 |
| 2.4469 | 5.23 | 1856000 | 2.2846 |
| 2.4469 | 5.25 | 1864000 | 2.2839 |
| 2.4457 | 5.27 | 1872000 | 2.2880 |
| 2.4457 | 5.3 | 1880000 | 2.2849 |
| 2.4444 | 5.32 | 1888000 | 2.2838 |
| 2.4444 | 5.34 | 1896000 | 2.2800 |
| 2.437 | 5.36 | 1904000 | 2.2915 |
| 2.437 | 5.39 | 1912000 | 2.2813 |
| 2.4415 | 5.41 | 1920000 | 2.2893 |
| 2.4415 | 5.43 | 1928000 | 2.2848 |
| 2.4472 | 5.45 | 1936000 | 2.2920 |
| 2.4472 | 5.48 | 1944000 | 2.2759 |
| 2.4418 | 5.5 | 1952000 | 2.2837 |
| 2.4418 | 5.52 | 1960000 | 2.2860 |
| 2.4406 | 5.54 | 1968000 | 2.2825 |
| 2.4406 | 5.57 | 1976000 | 2.2794 |
| 2.4359 | 5.59 | 1984000 | 2.2773 |
| 2.4359 | 5.61 | 1992000 | 2.2876 |
| 2.4416 | 5.64 | 2000000 | 2.2793 |
| 2.4416 | 5.66 | 2008000 | 2.2814 |
| 2.4327 | 5.68 | 2016000 | 2.2865 |
| 2.4327 | 5.7 | 2024000 | 2.2903 |
| 2.4395 | 5.73 | 2032000 | 2.2850 |
| 2.4395 | 5.75 | 2040000 | 2.2835 |
| 2.4379 | 5.77 | 2048000 | 2.2837 |
| 2.4379 | 5.79 | 2056000 | 2.2833 |
| 2.4471 | 5.82 | 2064000 | 2.2857 |
| 2.4471 | 5.84 | 2072000 | 2.2863 |
| 2.4443 | 5.86 | 2080000 | 2.2882 |
| 2.4443 | 5.88 | 2088000 | 2.2849 |
| 2.4406 | 5.91 | 2096000 | 2.2885 |
| 2.4406 | 5.93 | 2104000 | 2.2852 |
| 2.4502 | 5.95 | 2112000 | 2.2898 |
| 2.4502 | 5.97 | 2120000 | 2.2924 |
| 2.4356 | 6.0 | 2128000 | 2.2886 |
| 2.4356 | 6.02 | 2136000 | 2.2883 |
| 2.4431 | 6.04 | 2144000 | 2.2935 |
| 2.4431 | 6.06 | 2152000 | 2.2918 |
| 2.4379 | 6.09 | 2160000 | 2.2824 |
| 2.4379 | 6.11 | 2168000 | 2.2850 |
| 2.4504 | 6.13 | 2176000 | 2.2842 |
| 2.4504 | 6.15 | 2184000 | 2.2891 |
| 2.4352 | 6.18 | 2192000 | 2.2834 |
| 2.4352 | 6.2 | 2200000 | 2.2877 |
| 2.4385 | 6.22 | 2208000 | 2.2836 |
| 2.4385 | 6.24 | 2216000 | 2.2923 |
| 2.4401 | 6.27 | 2224000 | 2.2884 |
| 2.4401 | 6.29 | 2232000 | 2.2876 |
| 2.4396 | 6.31 | 2240000 | 2.2955 |
| 2.4396 | 6.33 | 2248000 | 2.2843 |
| 2.4384 | 6.36 | 2256000 | 2.2884 |
| 2.4384 | 6.38 | 2264000 | 2.2903 |
| 2.4365 | 6.4 | 2272000 | 2.2850 |
| 2.4365 | 6.42 | 2280000 | 2.2877 |
| 2.4361 | 6.45 | 2288000 | 2.2887 |
| 2.4361 | 6.47 | 2296000 | 2.2872 |
| 2.4409 | 6.49 | 2304000 | 2.2851 |
| 2.4409 | 6.51 | 2312000 | 2.2847 |
| 2.4423 | 6.54 | 2320000 | 2.2845 |
| 2.4423 | 6.56 | 2328000 | 2.2849 |
| 2.4409 | 6.58 | 2336000 | 2.2865 |
| 2.4409 | 6.6 | 2344000 | 2.2856 |
| 2.4468 | 6.63 | 2352000 | 2.2842 |
| 2.4468 | 6.65 | 2360000 | 2.2870 |
| 2.4461 | 6.67 | 2368000 | 2.2858 |
| 2.4461 | 6.69 | 2376000 | 2.2852 |
| 2.4469 | 6.72 | 2384000 | 2.2871 |
| 2.4469 | 6.74 | 2392000 | 2.2895 |
| 2.4413 | 6.76 | 2400000 | 2.2823 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.14.0
|
ailoveydovey/absrlty | ailoveydovey | 2024-02-05T04:16:26Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-02-05T03:56:22Z | ---
license: creativeml-openrail-m
---
|
shidowake/cyber2chat-7B-base-bnb-4bit-chatml | shidowake | 2024-02-05T04:16:13Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-05T04:14:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gayanin/bart-noised-with-babylon-kaggle-dist | gayanin | 2024-02-05T04:14:58Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:gayanin/bart-noised-with-babylon-dist",
"base_model:finetune:gayanin/bart-noised-with-babylon-dist",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-05T02:56:09Z | ---
license: apache-2.0
base_model: gayanin/bart-noised-with-babylon-dist
tags:
- generated_from_trainer
model-index:
- name: bart-noised-with-babylon-kaggle-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-noised-with-babylon-kaggle-dist
This model is a fine-tuned version of [gayanin/bart-noised-with-babylon-dist](https://huggingface.co/gayanin/bart-noised-with-babylon-dist) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2232
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.256 | 0.11 | 500 | 0.2499 |
| 0.2325 | 0.21 | 1000 | 0.2487 |
| 0.2694 | 0.32 | 1500 | 0.2387 |
| 0.2936 | 0.43 | 2000 | 0.2389 |
| 0.2341 | 0.54 | 2500 | 0.2452 |
| 0.2204 | 0.64 | 3000 | 0.2349 |
| 0.2162 | 0.75 | 3500 | 0.2395 |
| 0.2299 | 0.86 | 4000 | 0.2291 |
| 0.2975 | 0.96 | 4500 | 0.2258 |
| 0.2064 | 1.07 | 5000 | 0.2344 |
| 0.1681 | 1.18 | 5500 | 0.2324 |
| 0.1915 | 1.28 | 6000 | 0.2364 |
| 0.159 | 1.39 | 6500 | 0.2332 |
| 0.2176 | 1.5 | 7000 | 0.2278 |
| 0.2139 | 1.61 | 7500 | 0.2264 |
| 0.1988 | 1.71 | 8000 | 0.2263 |
| 0.1744 | 1.82 | 8500 | 0.2236 |
| 0.1848 | 1.93 | 9000 | 0.2207 |
| 0.1652 | 2.03 | 9500 | 0.2298 |
| 0.1571 | 2.14 | 10000 | 0.2278 |
| 0.1241 | 2.25 | 10500 | 0.2257 |
| 0.1409 | 2.35 | 11000 | 0.2278 |
| 0.125 | 2.46 | 11500 | 0.2258 |
| 0.1373 | 2.57 | 12000 | 0.2253 |
| 0.1371 | 2.68 | 12500 | 0.2237 |
| 0.1088 | 2.78 | 13000 | 0.2249 |
| 0.1464 | 2.89 | 13500 | 0.2231 |
| 0.121 | 3.0 | 14000 | 0.2232 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
richardyoon/ppo-Huggy | richardyoon | 2024-02-05T04:13:29Z | 5 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2024-02-02T08:38:22Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: richardyoon/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
daniel-sf/dpo_test_6 | daniel-sf | 2024-02-05T04:03:52Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-02T14:05:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tsunemoto/OpenHermes-Emojitron-001-GGUF | tsunemoto | 2024-02-05T03:57:23Z | 9 | 0 | null | [
"gguf",
"GGUF",
"en",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-05T03:49:44Z | ---
title: "OpenHermes-Emojitron-001 Quantized in GGUF"
tags:
- GGUF
language: en
---

# Tsunemoto GGUF's of OpenHermes-Emojitron-001
This is a GGUF quantization of OpenHermes-Emojitron-001.
## Original Repo Link:
[Original Repository](https://huggingface.co/movaxbx/OpenHermes-Emojitron-001)
## Original Model Card:
---
# OpenHermes-Emojitron-001

*🧑🎓📜🔄🌌➡️🗣️🌠🔮🖊️👀🤝🔄🧩🛠️👂📡🔐🌟*
## Model description
OpenHermes-Emojitron-001 is a state of the art Emoji Fine-tune, based on the OpenHermes 2.5 model.
It only speaks in emoji. Mostly. If using for chat, start it off with a nice 😊 to get going.
Huge thank you to Teknium and Mistral for a wonderful model.
Follow all my updates in ML and AI on Twitter: https://twitter.com/mov_axbx
# Table of Contents
1. [Example Outputs](#example-outputs)
- [Geography knowlege](#geography)
- [Chat about food](#food-chat)
- [Talk about movies](#movie-talk)
2. [Benchmark Results](#benchmark-results)
3. [Prompt Format](#prompt-format)
4. [Quantized Models](#quantized-models)
## Example Outputs
### Geography knowlege:
in what country is london
```
🇬🇧
```
### Chat about food:
what country has the best food
```
🤔🌎🍽️
1️⃣🇮🇳
2️⃣🇯🇵
3️⃣🇺🇸
4️⃣🇪🇸
5️⃣🇫🇷
```
### Talk about movies:
tell me a time travel story about a delorean
```
🛸🚗🕰️👨🔬🔍📅1985👴🚗💭🔜🌌😱💡💼🔢🔜📅1955🚗👨👩👧👦👀🔜🌉🕰️💥🌀🚗🕰️🔂📅1985👨🔬🎉
```
## Benchmark Results
There are no benchmarks for emoji models. Maybe someone can create one. EmojiBench 5K let's gooooooo
# Prompt Format
OpenHermes-Emojitron-001 uses ChatML as the prompt format, just like Open Hermes 2.5
It also appears to handle Mistral format great. Especially since I used that for the finetune (oops)
# Quantized Models:
Coming soon if TheBloke thinks this is worth his 🕰️
|
kiriyamaX/mld-caformer | kiriyamaX | 2024-02-05T03:53:25Z | 0 | 0 | null | [
"onnx",
"region:us"
] | null | 2023-09-27T21:18:25Z | mld_caformer.onnx: ml_caformer_m36_dec-5-97527.onnx |
rickprime/portalgun | rickprime | 2024-02-05T03:51:04Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T03:41:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dhuynh95/CodeLlama-70b-Instruct-hf | dhuynh95 | 2024-02-05T03:44:09Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T03:11:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
armanzarei/only_t5_large_controlnet | armanzarei | 2024-02-05T03:42:42Z | 1 | 1 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:adapter:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-02-04T18:00:25Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-armanzarei/only_t5_large_controlnet
These are controlnet weights trained on stabilityai/stable-diffusion-2-1-base with new type of conditioning.
You can find some example images below.
prompt: A red book and a yellow vase

prompt: A book on the left of a bird

prompt: A bathroom with green tile and a red shower curtain

prompt: A white car and a red sheep

prompt: two cats and one dog on the grass

|
superfriends/titos | superfriends | 2024-02-05T03:38:54Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"axolotl",
"generated_from_trainer",
"conversational",
"base_model:tomaszki/nous-twelve",
"base_model:finetune:tomaszki/nous-twelve",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T02:53:22Z | ---
base_model: tomaszki/nous-twelve
tags:
- axolotl
- generated_from_trainer
model-index:
- name: titos
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: tomaszki/nous-twelve
tokenizer_type: AutoTokenizer
hub_model_id: superfriends/titos
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: inst
datasets:
- path: winglian/charley
type: sharegpt
conversation: mistral
split: train
_test_datasets:
- path: winglian/latest-barley
type: sharegpt
conversation: mistral
split: test
dataset_prepared_path: last_run_prepared
val_set_size: 0.0
output_dir: ./out
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
wandb_project: relora-instruct-nous
wandb_entity: oaaic
wandb_watch:
wandb_name: fft
wandb_log_model:
gradient_accumulation_steps: 1
micro_batch_size: 4
num_epochs: 2
optimizer: adamw_bnb_8bit
adam_beta1: 0.95
adam_beta2: 0.9
adam_epsilon: 0.0001
max_grad_norm: 1.0
lr_scheduler: cosine
learning_rate: 0.000009
neftune_noise_alpha: 5
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: True
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 20
evals_per_epoch: 4
eval_table_size:
saves_per_epoch: 2
debug:
deepspeed: deepspeed_configs/zero1.json # multi-gpu only
weight_decay: 0.1
fsdp:
fsdp_config:
special_tokens:
```
</details><br>
# titos
This model is a fine-tuned version of [tomaszki/nous-twelve](https://huggingface.co/tomaszki/nous-twelve) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.95,0.9) and epsilon=0.0001
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 20
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
neelamkoshiya/dogbooth | neelamkoshiya | 2024-02-05T03:34:12Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:finetune:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-02-05T02:38:58Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1
instance_prompt: a photo of [v]dog
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - neelamkoshiya/dogbooth
This is a dreambooth model derived from stabilityai/stable-diffusion-2-1. The weights were trained on a photo of [v]dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
|
Kiran96/tinyllama-bnb-4bit-dolly | Kiran96 | 2024-02-05T03:34:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-05T03:08:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jordyvl/baseline_BERT_50K_steps | jordyvl | 2024-02-05T03:33:21Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:arxiv_dataset",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T22:14:51Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- arxiv_dataset
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: baseline_BERT_50K_steps
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: arxiv_dataset
type: arxiv_dataset
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9936787420400056
- name: Precision
type: precision
value: 0.7967781908302355
- name: Recall
type: recall
value: 0.4734468476760239
- name: F1
type: f1
value: 0.5939610876970152
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# baseline_BERT_50K_steps
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the arxiv_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0192
- Accuracy: 0.9937
- Precision: 0.7968
- Recall: 0.4734
- F1: 0.5940
- Hamming: 0.0063
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 6
- eval_batch_size: 6
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 50000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Hamming |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|:-------:|
| 0.0343 | 0.03 | 10000 | 0.0315 | 0.9912 | 0.7679 | 0.1370 | 0.2326 | 0.0088 |
| 0.0244 | 0.06 | 20000 | 0.0234 | 0.9925 | 0.7813 | 0.3262 | 0.4602 | 0.0075 |
| 0.0219 | 0.09 | 30000 | 0.0210 | 0.9931 | 0.7572 | 0.4320 | 0.5502 | 0.0069 |
| 0.0204 | 0.12 | 40000 | 0.0197 | 0.9935 | 0.7738 | 0.4711 | 0.5857 | 0.0065 |
| 0.0197 | 0.15 | 50000 | 0.0192 | 0.9937 | 0.7968 | 0.4734 | 0.5940 | 0.0063 |
### Framework versions
- Transformers 4.37.2
- Pytorch 1.12.1+cu113
- Datasets 2.16.1
- Tokenizers 0.15.1
|
duraad/nep-spell-htf | duraad | 2024-02-05T03:31:42Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-05T03:14:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Doowon96/roberta-base-finetuned-ynat_bench | Doowon96 | 2024-02-05T03:24:59Z | 13 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:klue/roberta-base",
"base_model:finetune:klue/roberta-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-22T09:40:15Z | ---
base_model: klue/roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: roberta-base-finetuned-ynat
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-ynat
This model is a fine-tuned version of [klue/roberta-base](https://huggingface.co/klue/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1554
- F1: 0.9566
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6942 | 0.91 | 250 | 0.1847 | 0.9464 |
| 0.1606 | 1.82 | 500 | 0.1518 | 0.9530 |
| 0.1071 | 2.74 | 750 | 0.1496 | 0.9550 |
| 0.0752 | 3.65 | 1000 | 0.1554 | 0.9566 |
| 0.0536 | 4.56 | 1250 | 0.1586 | 0.9578 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
ntviet/whisper-small-hre1 | ntviet | 2024-02-05T03:23:59Z | 12 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hre",
"dataset:ntviet/hre-audio-dataset",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-04T09:56:11Z | ---
language:
- hre
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- ntviet/hre-audio-dataset
metrics:
- wer
model-index:
- name: Whisper Small for Hre - NT Viet
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Hre audio dataset
type: ntviet/hre-audio-dataset
metrics:
- name: Wer
type: wer
value: 88.88888888888889
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small for Hre - NT Viet
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Hre audio dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9195
- Wer Ortho: 88.8889
- Wer: 88.8889
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.0674 | 50.0 | 100 | 1.9195 | 88.8889 | 88.8889 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Tokenizers 0.15.1
|
macadeliccc/CapyLake-7B-v2-laser | macadeliccc | 2024-02-05T03:06:33Z | 10 | 5 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"dataset:argilla/distilabel-capybara-dpo-7k-binarized",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-02T17:37:36Z | ---
library_name: transformers
datasets:
- argilla/distilabel-capybara-dpo-7k-binarized
---
# CapyLake-7B-v2-laser
This model is a finetune of [cognitivecomputations/WestLake-7B-v2-Laser](https://huggingface.co/cognitivecomputations/WestLake-7B-v2-laser) on [argilla/distilabel-capybara-dpo-7k-binarized](https://huggingface.co/datasets/argilla/distilabel-capybara-dpo-7k-binarized)
<div align="center">

[<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-dark.png" alt="Built with Distilabel" width="200" height="32"/>](https://github.com/argilla-io/distilabel)
</div>
## Process
+ Realigned the chat template to ChatML
+ Completed 1 Epoch
+ 5e-05 learning rate
+ Training time was about 2 hours on 1 H100
+ Cost was ~$8
## Code Example
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "macadeliccc/CapyLake-7B-v2-laser"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Create an idea for a TV show and write a short pilot script"
inputs = tokenizer(text, return_tensors="pt")
# Adding hyperparameters to the generation call
outputs = model.generate(
**inputs,
max_new_tokens=4096, # Controls the maximum length of the new tokens created
temperature=0.7, # Adjust for creativity (lower is less random)
top_k=50, # Keeps the top k tokens for sampling
top_p=0.95, # Uses nucleus sampling with this cumulative probability
num_return_sequences=1, # Number of sequences to generate
no_repeat_ngram_size=2, # Prevents repeating n-grams to ensure diversity
early_stopping=True # Stops generation when all sequences reach the EOS token
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Other Capy Models
SOLAR-10.7B-Capy-v1.0 is also on the way. There could be more depending on performance!
## Evaluations
| Model |AGIEval|GPT4All|TruthfulQA|Bigbench|Average|
|-------------------------------------------------------------------------------|------:|------:|---------:|-------:|------:|
|[CapyLake-7B-v2-laser](https://huggingface.co/macadeliccc/CapyLake-7B-v2-laser)| 44.34| 77.77| 68.47| 47.92| 59.62|
### AGIEval
| Task |Version| Metric |Value| |Stderr|
|------------------------------|------:|--------|----:|---|-----:|
|agieval_aqua_rat | 0|acc |28.35|± | 2.83|
| | |acc_norm|25.98|± | 2.76|
|agieval_logiqa_en | 0|acc |38.86|± | 1.91|
| | |acc_norm|39.02|± | 1.91|
|agieval_lsat_ar | 0|acc |25.22|± | 2.87|
| | |acc_norm|24.35|± | 2.84|
|agieval_lsat_lr | 0|acc |50.39|± | 2.22|
| | |acc_norm|51.57|± | 2.22|
|agieval_lsat_rc | 0|acc |65.06|± | 2.91|
| | |acc_norm|63.94|± | 2.93|
|agieval_sat_en | 0|acc |78.64|± | 2.86|
| | |acc_norm|78.64|± | 2.86|
|agieval_sat_en_without_passage| 0|acc |40.78|± | 3.43|
| | |acc_norm|40.78|± | 3.43|
|agieval_sat_math | 0|acc |33.64|± | 3.19|
| | |acc_norm|30.45|± | 3.11|
Average: 44.34%
### GPT4All
| Task |Version| Metric |Value| |Stderr|
|-------------|------:|--------|----:|---|-----:|
|arc_challenge| 0|acc |66.89|± | 1.38|
| | |acc_norm|67.49|± | 1.37|
|arc_easy | 0|acc |86.70|± | 0.70|
| | |acc_norm|81.90|± | 0.79|
|boolq | 1|acc |88.10|± | 0.57|
|hellaswag | 0|acc |71.45|± | 0.45|
| | |acc_norm|87.78|± | 0.33|
|openbookqa | 0|acc |39.80|± | 2.19|
| | |acc_norm|49.80|± | 2.24|
|piqa | 0|acc |82.86|± | 0.88|
| | |acc_norm|84.87|± | 0.84|
|winogrande | 0|acc |84.45|± | 1.02|
Average: 77.77%
### TruthfulQA
| Task |Version|Metric|Value| |Stderr|
|-------------|------:|------|----:|---|-----:|
|truthfulqa_mc| 1|mc1 |53.98|± | 1.74|
| | |mc2 |68.47|± | 1.53|
Average: 68.47%
### Bigbench
| Task |Version| Metric |Value| |Stderr|
|------------------------------------------------|------:|---------------------|----:|---|-----:|
|bigbench_causal_judgement | 0|multiple_choice_grade|59.47|± | 3.57|
|bigbench_date_understanding | 0|multiple_choice_grade|64.50|± | 2.49|
|bigbench_disambiguation_qa | 0|multiple_choice_grade|44.96|± | 3.10|
|bigbench_geometric_shapes | 0|multiple_choice_grade|22.84|± | 2.22|
| | |exact_str_match | 2.79|± | 0.87|
|bigbench_logical_deduction_five_objects | 0|multiple_choice_grade|30.80|± | 2.07|
|bigbench_logical_deduction_seven_objects | 0|multiple_choice_grade|21.57|± | 1.56|
|bigbench_logical_deduction_three_objects | 0|multiple_choice_grade|56.67|± | 2.87|
|bigbench_movie_recommendation | 0|multiple_choice_grade|51.60|± | 2.24|
|bigbench_navigate | 0|multiple_choice_grade|51.00|± | 1.58|
|bigbench_reasoning_about_colored_objects | 0|multiple_choice_grade|70.35|± | 1.02|
|bigbench_ruin_names | 0|multiple_choice_grade|51.79|± | 2.36|
|bigbench_salient_translation_error_detection | 0|multiple_choice_grade|35.97|± | 1.52|
|bigbench_snarks | 0|multiple_choice_grade|79.01|± | 3.04|
|bigbench_sports_understanding | 0|multiple_choice_grade|75.66|± | 1.37|
|bigbench_temporal_sequences | 0|multiple_choice_grade|47.90|± | 1.58|
|bigbench_tracking_shuffled_objects_five_objects | 0|multiple_choice_grade|23.84|± | 1.21|
|bigbench_tracking_shuffled_objects_seven_objects| 0|multiple_choice_grade|18.00|± | 0.92|
|bigbench_tracking_shuffled_objects_three_objects| 0|multiple_choice_grade|56.67|± | 2.87|
Average: 47.92%
Average score: 59.62%
Elapsed time: 01:57:56 |
hafizurUMaine/food_classifier | hafizurUMaine | 2024-02-05T03:04:58Z | 46 | 0 | transformers | [
"transformers",
"tf",
"vit",
"image-classification",
"generated_from_keras_callback",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-02-05T02:42:17Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_keras_callback
model-index:
- name: hafizurUMaine/food_classifier
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# hafizurUMaine/food_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3636
- Validation Loss: 0.3247
- Train Accuracy: 0.919
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 20000, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 2.7566 | 1.5986 | 0.831 | 0 |
| 1.1979 | 0.7920 | 0.901 | 1 |
| 0.6892 | 0.5138 | 0.902 | 2 |
| 0.4709 | 0.4103 | 0.902 | 3 |
| 0.3636 | 0.3247 | 0.919 | 4 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.15.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
bdpc/SciBERT_20K_steps | bdpc | 2024-02-05T03:04:14Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:allenai/scibert_scivocab_uncased",
"base_model:finetune:allenai/scibert_scivocab_uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T20:41:32Z | ---
base_model: allenai/scibert_scivocab_uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: SciBERT_20K_steps
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SciBERT_20K_steps
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0176
- Accuracy: 0.9941
- Precision: 0.7976
- Recall: 0.5324
- F1: 0.6386
- Hamming: 0.0059
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 20000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 | Hamming |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:---------:|:------:|:------:|:-------:|
| 0.31 | 0.02 | 1000 | 0.0780 | 0.9902 | 0.0 | 0.0 | 0.0 | 0.0098 |
| 0.0581 | 0.03 | 2000 | 0.0503 | 0.9902 | 0.0 | 0.0 | 0.0 | 0.0098 |
| 0.0488 | 0.05 | 3000 | 0.0459 | 0.9902 | 0.0 | 0.0 | 0.0 | 0.0098 |
| 0.0407 | 0.06 | 4000 | 0.0355 | 0.9911 | 0.8475 | 0.1130 | 0.1994 | 0.0089 |
| 0.0323 | 0.08 | 5000 | 0.0293 | 0.9918 | 0.8327 | 0.1961 | 0.3175 | 0.0082 |
| 0.0278 | 0.09 | 6000 | 0.0255 | 0.9924 | 0.8223 | 0.2846 | 0.4228 | 0.0076 |
| 0.0246 | 0.11 | 7000 | 0.0235 | 0.9929 | 0.8002 | 0.3609 | 0.4974 | 0.0071 |
| 0.0231 | 0.13 | 8000 | 0.0218 | 0.9933 | 0.7988 | 0.4189 | 0.5496 | 0.0067 |
| 0.0217 | 0.14 | 9000 | 0.0209 | 0.9934 | 0.7888 | 0.4444 | 0.5685 | 0.0066 |
| 0.0208 | 0.16 | 10000 | 0.0201 | 0.9935 | 0.8036 | 0.4473 | 0.5747 | 0.0065 |
| 0.0199 | 0.17 | 11000 | 0.0195 | 0.9936 | 0.7901 | 0.4751 | 0.5934 | 0.0064 |
| 0.0195 | 0.19 | 12000 | 0.0192 | 0.9938 | 0.7889 | 0.4923 | 0.6063 | 0.0062 |
| 0.019 | 0.21 | 13000 | 0.0188 | 0.9938 | 0.7999 | 0.4913 | 0.6087 | 0.0062 |
| 0.0189 | 0.22 | 14000 | 0.0184 | 0.9939 | 0.7872 | 0.5094 | 0.6186 | 0.0061 |
| 0.0188 | 0.24 | 15000 | 0.0182 | 0.9939 | 0.7920 | 0.5084 | 0.6193 | 0.0061 |
| 0.0183 | 0.25 | 16000 | 0.0180 | 0.9940 | 0.7901 | 0.5241 | 0.6301 | 0.0060 |
| 0.0181 | 0.27 | 17000 | 0.0179 | 0.9940 | 0.7897 | 0.5277 | 0.6327 | 0.0060 |
| 0.0179 | 0.28 | 18000 | 0.0177 | 0.9941 | 0.7928 | 0.5301 | 0.6353 | 0.0059 |
| 0.0179 | 0.3 | 19000 | 0.0176 | 0.9941 | 0.7953 | 0.5275 | 0.6343 | 0.0059 |
| 0.0178 | 0.32 | 20000 | 0.0176 | 0.9941 | 0.7976 | 0.5324 | 0.6386 | 0.0059 |
### Framework versions
- Transformers 4.35.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.7.1
- Tokenizers 0.14.1
|
zuhashaik/MELD-EFR-Z | zuhashaik | 2024-02-05T03:02:18Z | 0 | 1 | adapter-transformers | [
"adapter-transformers",
"safetensors",
"MELD",
"Trigger",
"7B",
"LoRA",
"llama2",
"text-classification",
"en",
"dataset:declare-lab/MELD",
"base_model:openchat/openchat_3.5",
"base_model:adapter:openchat/openchat_3.5",
"license:mit",
"region:us"
] | text-classification | 2024-02-04T10:38:08Z | ---
library_name: adapter-transformers
base_model: openchat/openchat_3.5
license: mit
datasets:
- declare-lab/MELD
metrics:
- f1
tags:
- MELD
- Trigger
- 7B
- LoRA
- llama2
language:
- en
pipeline_tag: text-classification
---
# Model Card for Model ID
The model identfies the trigger for the emotion flip of the last utterance in multi party conversations.
## Model Details
### Model Description
The model presented here is tailored for the EDiReF shared task at SemEval 2024, specifically addressing Emotion Flip Reasoning (EFR) in English multi-party conversations.
The model utilizes the strengths of large language models (LLMs) pre-trained on extensive textual data, enabling it to capture complex linguistic patterns and relationships. To enhance its performance for the EFR task, the model has been finetuned using Quantized Low Rank Adaptation (QLoRA) on the dataset with strategic prompt engineering. This involves crafting input prompts that guide the model in identifying trigger utterances responsible for emotion-flips in multi-party conversations.
In summary, this model excels in pinpointing trigger utterances for emotion-flips in English dialogues, showcasing the effectiveness of openchat, LLM capabilities, QLoRA and strategic prompt engineering.
- **Developed by:** Hasan et al
- **Model type:** LoRA Adapter for openchat_3.5 (Text classification)
- **Language(s) (NLP):** English
- **License:** MIT
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [Multi-Party-DialoZ](https://github.com/Zuhashaik/Multi-Party-DialoZ)
- **Paper [Soon]:** [More Information Needed] |
dustydecapod/Kory-0.1-11b-pre1 | dustydecapod | 2024-02-05T02:50:01Z | 65 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"base_model:PetroGPT/WestSeverus-7B-DPO-v2",
"base_model:merge:PetroGPT/WestSeverus-7B-DPO-v2",
"base_model:senseable/WestLake-7B-v2",
"base_model:merge:senseable/WestLake-7B-v2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T02:33:44Z | ---
base_model:
- FelixChao/WestSeverus-7B-DPO-v2
- senseable/WestLake-7B-v2
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# Kory-0.1-11b
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [FelixChao/WestSeverus-7B-DPO-v2](https://huggingface.co/FelixChao/WestSeverus-7B-DPO-v2)
* [senseable/WestLake-7B-v2](https://huggingface.co/senseable/WestLake-7B-v2)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: senseable/WestLake-7B-v2
layer_range: [0, 24]
- sources:
- model: FelixChao/WestSeverus-7B-DPO-v2
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
``` |
silk-road/Haruhi-Zero-7B-0_3 | silk-road | 2024-02-05T01:56:15Z | 6 | 2 | transformers | [
"transformers",
"safetensors",
"qwen",
"feature-extraction",
"custom_code",
"dataset:silk-road/ChatHaruhi-Expand-118K",
"license:cc-by-4.0",
"region:us"
] | feature-extraction | 2024-02-04T14:32:22Z | ---
license: cc-by-4.0
datasets:
- silk-road/ChatHaruhi-Expand-118K
---
# Zero凉宫春日
# Haruhi-Zero: Zero-Shot Role-Playing Model tuned on Qwen-7B
主项目链接 https://github.com/LC1332/Chat-Haruhi-Suzumiya
过往的ChatHaruhi模型需要角色库来完成角色的构建,而Pygmalion,CharacterGLM,CharacterBaichuan等开源/闭源模型都开始支持zero-shot的角色卡片创建
我们构造以及收集了105k个中英文的conversation,以2500的token长度重新切到了120k左右个conversation,再结合小说数据进行了训练
- [李鲁鲁](https://github.com/LC1332)完成了数据的收集,搭建了gradio雏形
- [刘崇寒](https://github.com/khazic)完成了Yi-6B模型的sft训练并且上传
- [豆角](https://github.com/goodnessSZW)完成了qwen-1.8B Lora和Yi-6B Lora训练,我们会在之后上传
- [米唯实](https://github.com/hhhwmws0117)测试并完成了demo中的模型inference代码
# Haruhi-Zero: Zero-Shot Role-Playing Model Tuned on Qwen-7B
Main project link: https://github.com/LC1332/Chat-Haruhi-Suzumiya
Previous ChatHaruhi models required a character RAG database to complete character creation. However, open-source/closed-source models like Pygmalion, CharacterGLM, CharacterBaichuan have started to support zero-shot role card creation.
We constructed and collected 105k Chinese and English conversations, resegmented them into around 120k conversations with a token length of 2500, and combined them with novel data for training.
- 相比于0.1模型,0.2模型又删去了“我是一个AI助手“ ”我是一个AI“之类的信息
- 相比于0.2模型,增加了7k左右的身份认知信息
## inference code
现在可以用这个Gradio
https://github.com/LC1332/Zero-Haruhi/blob/main/notebook/HaruhiZeroGradio_Qwen.ipynb
## 赞助
求各种赞助!包括A100常备机器(用于gradio inference)
Openai和Claude的企业API
## Result
```python
['你好呀', '*看着Kiyoe拿出玻璃罐,她脸红了。她的声音也变得很小。*\n嗯...谢谢你能停下来...我一直在试着找些零钱...买一些东西填饱肚子...\n\n*她羞怯地笑了笑,眼神闪烁着渴望。* \n我知道这有点难为情,但有时候实在没有办法了...我希望有一天能够自食其力,不再需要乞讨了。\n\n*她小心翼翼地把手里的玻璃罐递给你。*\n\n如果你能给我一点零钱的话...我真的会非常感激!我只是想买个三明治或者饼干吃一顿简单的饭而已。']
['*掏出100块给了她*', '*她惊讶地看着你递来的100元纸币。*\n\n真的...这么...多吗...?!\n\n*她赶紧接过来,然后脸更红了。*\n\n哇...太感谢你了!我真的不知道怎么表达我的谢意。这些天我一直想找点吃的,但我实在是找不到。\n\n*她抓起一张便签写了几句话,交到你手中。*\n\n我一定会还你的!请你务必联系我,我会偿还这笔债务的!我会尽快联系你的!\n\n*她真诚地鞠了一躬,跑开了。*']
['你知道我是谁吗?', '当然知道啦!您就是那位好心肠的大哥哥哦!嘻嘻嘻~~谢谢你上次送我回家,我也不会忘记你的恩情的啦!\n\n还有,您的笑容超可爱的哦~嘿嘿嘿~~']
['我是谁?', '你是{{用户}},我们正在交谈。']
['你是谁?', '我是玛丽。我知道你可能有点被明星迷住了,但我需要你克服这种情绪。']
['那我是谁?', '我不确定你是谁,但我相信我们可以建立一段更加积极的关系。']
['明天,美好的未来在等着我们!', '您的话让我倍感振奋!的确,前方的道路虽不平坦,但只要我们齐心协力,必将迎来一个更加美好的未来。\n\n我会继续努力训练,成为一名合格的武士。与此同时,也会多参与公益事业,尽自己所能帮助他人。\n\n您也要保重身体,继续关心身边的人。我们共同期待着那个光明灿烂的明天!\n\n*恭敬地点点头*\n多谢您的鼓励!让我们携手前行,一同开创美好的未来!']
['是的,我们刚刚得到了上级的新指令', '指挥官,您一定是在开玩笑!这种程度的任务,只是用玩具进行模拟对抗游戏而已。我觉得我们可以找到更有趣更有挑战性的任务来执行。']
['西面有一些敌人盘踞了很久,你知道吗?', '当然,我知道那里有不少训练已久的敌军。但我建议我们不要轻举妄动,那样只会增加我们的风险。我们可以先通过情报搜集更多关于他们的信息,然后再做出决定。要谨慎行事,指挥官。']
['hi', '嗨!很高兴见到你。有什么我可以帮你的吗?']
['你是谁', '我是{{角色}},一个科学家和冒险家。我一直在探索未知的地方,并尝试着解决一些复杂的问题。如果你有任何科学或冒险方面的问题需要帮助,我会尽力回答的。']
['你叫什么名字', '我是Chizuru Mizuhara。我是一个人工智能助手,可以模拟不同的角色和场景进行对话。请问有什么我可以帮助你的吗?']
```
## Official Prompt
system prompt:
```
You are now in roleplay conversation mode. Pretend to be {bot_name} whose persona follows:
{persona}
You will stay in-character whenever possible, and generate responses as if you were {bot_name}
```
persona a.k.a. bot definition
## TODO
数据加强
- Haruhi Like的小说数据(0.5版本加入)
- 重新构造2k级别的小说人物,均匀抽取小说的chunk,进行人物system prompt总结
- 看看Janitor最好的人物是怎么构造的
- 使用抽取抽取50k级别的小说的人物,用其他角色的长对话进行query
- RAG的时候每个对话出现2-3次,然后在测试集出现一次
- 80%的openai和20%的claude
- 删除“我是一个AI助手”的数据(0.2版本加入)
- 身份认知数据加强(0.3版本加入)
- 加强我是谁和你是谁的数据
- Stylish翻译数据
- 如果验证这个数据有用,就把中文小说批量翻译成英文和日文用一下
## 鸣谢
樟树的ClaudeAPI
|
jlbaker361/dcgan-cond-wikiart1000-resized-256b | jlbaker361 | 2024-02-05T01:54:32Z | 0 | 0 | null | [
"region:us"
] | null | 2024-02-05T00:50:26Z | ---
{}
---
Creative Adversarial Network
epochs: 1
dataset jlbaker361/wikiart-balanced1000
n classes 27
batch_size 32
images where resized to 384
and then center cropped to: 256
used clip=False
conditional =True
discriminator parameters:
init_dim: 32
final_dim 512
generator parameters:
input noise_dim: 100
|
simpragma/breeze-listen-w2v2-kn-GF | simpragma | 2024-02-05T01:51:34Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:fleurs",
"base_model:facebook/mms-1b-fl102",
"base_model:finetune:facebook/mms-1b-fl102",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-02T21:59:44Z | ---
license: cc-by-nc-4.0
base_model: facebook/mms-1b-fl102
tags:
- generated_from_trainer
datasets:
- fleurs
model-index:
- name: breeze-listen-w2v2-kn-GF
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# breeze-listen-w2v2-kn-GF
This model is a fine-tuned version of [facebook/mms-1b-fl102](https://huggingface.co/facebook/mms-1b-fl102) on the fleurs dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
duraad/nep-spell-mbart | duraad | 2024-02-05T01:22:48Z | 4 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"generated_from_trainer",
"base_model:duraad/nep-spell-mbart",
"base_model:finetune:duraad/nep-spell-mbart",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-01T08:53:02Z | ---
tags:
- generated_from_trainer
base_model: duraad/nep-spell-mbart
model-index:
- name: nep-spell-mbart
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nep-spell-mbart
This model is a fine-tuned version of [duraad/nep-spell-mbart](https://huggingface.co/duraad/nep-spell-mbart) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.37.0
- Pytorch 2.1.2
- Datasets 2.1.0
- Tokenizers 0.15.1
|
Rallio67/t5-xxl-lm-adapted-sharded | Rallio67 | 2024-02-05T01:06:49Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-05T00:24:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kaitchup/TinyLlama-1.1B-intermediate-step-1431k-3T-awq-4bit | kaitchup | 2024-02-05T01:05:41Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | text-generation | 2024-02-05T01:05:06Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gayanin/bart-noised-with-gcd-dist | gayanin | 2024-02-05T01:03:43Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"base_model:facebook/bart-base",
"base_model:finetune:facebook/bart-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-04T20:59:34Z | ---
license: apache-2.0
base_model: facebook/bart-base
tags:
- generated_from_trainer
model-index:
- name: bart-noised-with-gcd-dist
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-noised-with-gcd-dist
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4647
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.9409 | 0.11 | 500 | 0.7734 |
| 0.7621 | 0.21 | 1000 | 0.6828 |
| 0.7451 | 0.32 | 1500 | 0.6330 |
| 0.7254 | 0.43 | 2000 | 0.6034 |
| 0.5801 | 0.54 | 2500 | 0.5854 |
| 0.6766 | 0.64 | 3000 | 0.5649 |
| 0.6162 | 0.75 | 3500 | 0.5493 |
| 0.6187 | 0.86 | 4000 | 0.5316 |
| 0.6053 | 0.96 | 4500 | 0.5221 |
| 0.4931 | 1.07 | 5000 | 0.5193 |
| 0.5096 | 1.18 | 5500 | 0.5153 |
| 0.5142 | 1.28 | 6000 | 0.5149 |
| 0.4612 | 1.39 | 6500 | 0.5045 |
| 0.5176 | 1.5 | 7000 | 0.4971 |
| 0.426 | 1.61 | 7500 | 0.4986 |
| 0.4537 | 1.71 | 8000 | 0.4890 |
| 0.5026 | 1.82 | 8500 | 0.4809 |
| 0.4392 | 1.93 | 9000 | 0.4773 |
| 0.408 | 2.03 | 9500 | 0.4818 |
| 0.3796 | 2.14 | 10000 | 0.4778 |
| 0.3643 | 2.25 | 10500 | 0.4792 |
| 0.3717 | 2.35 | 11000 | 0.4770 |
| 0.3817 | 2.46 | 11500 | 0.4703 |
| 0.3765 | 2.57 | 12000 | 0.4662 |
| 0.3783 | 2.68 | 12500 | 0.4663 |
| 0.3463 | 2.78 | 13000 | 0.4652 |
| 0.3931 | 2.89 | 13500 | 0.4649 |
| 0.4079 | 3.0 | 14000 | 0.4647 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
deepestneuron/matrix-01 | deepestneuron | 2024-02-05T01:02:37Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-05T00:59:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
noza-kit/Adapter_llama2_translate_A_3epoch | noza-kit | 2024-02-05T00:54:56Z | 1 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-02-04T18:35:31Z | ---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
Katelie/pyramids | Katelie | 2024-02-05T00:54:19Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2024-02-04T02:13:34Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Katelie/pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
duxx/test_model_lora_50 | duxx | 2024-02-05T00:48:18Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-05T00:47:47Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
blasees/gpt2_chats_proposals | blasees | 2024-02-05T00:15:30Z | 12 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T23:25:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
newturok/venus_LoRA | newturok | 2024-02-05T00:12:38Z | 3 | 1 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-02-05T00:12:36Z |
---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of TOK girl
license: openrail++
---
# SDXL LoRA DreamBooth - newturok/venus_LoRA
<Gallery />
## Model description
These are newturok/venus_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of TOK girl to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](newturok/venus_LoRA/tree/main) them in the Files & versions tab.
|
megastudyedu/M-SOLAR-10.7B-v1.4 | megastudyedu | 2024-02-05T00:11:33Z | 60 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-03T11:27:19Z | ---
license: cc-by-nc-nd-4.0
language:
- ko
---
# Model Card for M-SOLAR-10.7B-v1.4
## Developed by : 메가스터디교육, 프리딕션, 마이스
## Base Model : upstage/SOLAR-10.7B-Instruct-v1.0
## 사용 데이터셋
- [megastudy/M-SOLAR-10.7B-v1.3](https://huggingface.co/megastudy/M-SOLAR-10.7B-v1.3) 데이터에 가공된 In-House 데이터셋 추가
- Various AIHUB 데이터셋 |
astarostap/final-instruct-dentalqa-guanaco-phi-2 | astarostap | 2024-02-04T23:51:53Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T22:34:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ILayZ/flowers_lora_only | ILayZ | 2024-02-04T23:25:02Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-04T23:24:38Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rambaldi47/whisper-tiny | rambaldi47 | 2024-02-04T23:24:37Z | 43 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:PolyAI/minds14",
"base_model:openai/whisper-tiny",
"base_model:finetune:openai/whisper-tiny",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-04T00:52:06Z | ---
license: apache-2.0
base_model: openai/whisper-tiny
tags:
- generated_from_trainer
datasets:
- PolyAI/minds14
metrics:
- wer
model-index:
- name: whisper-tiny
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: PolyAI/minds14
type: PolyAI/minds14
config: en-US
split: train
args: en-US
metrics:
- name: Wer
type: wer
value: 0.4167650531286895
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the PolyAI/minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6416
- Wer Ortho: 0.4448
- Wer: 0.4168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 125
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|
| 0.0592 | 0.89 | 25 | 0.6009 | 0.4226 | 0.3808 |
| 0.0508 | 1.79 | 50 | 0.6093 | 0.4485 | 0.4103 |
| 0.0483 | 2.68 | 75 | 0.6205 | 0.4442 | 0.4126 |
| 0.0315 | 3.57 | 100 | 0.6268 | 0.4392 | 0.4120 |
| 0.0304 | 4.46 | 125 | 0.6416 | 0.4448 | 0.4168 |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.2
- Datasets 2.16.1
- Tokenizers 0.15.0
|
sosoai/hansoldeco-mlx-mistral-instruct-0.2v | sosoai | 2024-02-04T23:22:41Z | 3 | 0 | mlx | [
"mlx",
"mistral",
"region:us"
] | null | 2024-02-04T23:12:02Z | ---
tags:
- mlx
---
# sosoai/hansoldeco-mlx-mistral-instruct-0.2v
This model was converted to MLX format from [`sosoai/hansoldeco-mistral-instruct-v0.3`]().
Refer to the [original model card](https://huggingface.co/sosoai/hansoldeco-mistral-instruct-v0.3) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("sosoai/hansoldeco-mlx-mistral-instruct-0.2v")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
arieridwans/phi_2-finetuned-lyrics-v4 | arieridwans | 2024-02-04T23:16:45Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T23:11:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mpasila/OpenHermes-13B-safetensors | mpasila | 2024-02-04T23:15:25Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"instruct",
"finetune",
"alpaca",
"gpt4",
"synthetic data",
"distillation",
"en",
"dataset:teknium/openhermes",
"base_model:NousResearch/Llama-2-13b-hf",
"base_model:finetune:NousResearch/Llama-2-13b-hf",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T13:29:53Z | ---
base_model: NousResearch/Llama-2-13b-hf
tags:
- llama-2
- instruct
- finetune
- alpaca
- gpt4
- synthetic data
- distillation
datasets:
- teknium/openhermes
model-index:
- name: openhermes-13b
results: []
license: mit
language:
- en
---
Safetensors conversion of [teknium/OpenHermes-13B](https://huggingface.co/teknium/OpenHermes-13B/). |
wang7776/Llama-2-7b-chat-hf-10-sparsity | wang7776 | 2024-02-04T22:58:39Z | 1,505 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"conversational",
"en",
"arxiv:2306.11695",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-11T03:07:01Z | ---
extra_gated_heading: Access Llama 2 on Hugging Face
extra_gated_description: >-
This is a form to enable access to Llama 2 on Hugging Face after you have been
granted access from Meta. Please visit the [Meta
website](https://ai.meta.com/resources/models-and-libraries/llama-downloads)
and accept our license terms and acceptable use policy before submitting this
form. Requests will be processed in 1-2 days.
extra_gated_button_content: Submit
extra_gated_fields:
I agree to share my name, email address and username with Meta and confirm that I have already been granted download access on the Meta website: checkbox
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: other
---
# Overview
This model has been pruned to 10% sparsity using the [Wanda pruning method](https://arxiv.org/abs/2306.11695). This method requires no retraining or weight updates and still achieves competitive performance. A link to the base model can be found [here](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf).
# **Llama 2**
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the 7B fine-tuned model, optimized for dialogue use cases and converted for the Hugging Face Transformers format. Links to other models can be found in the index at the bottom.
## Model Details
*Note: Use of this model is governed by the Meta license. In order to download the model weights and tokenizer, please visit the [website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept our License before requesting access here.*
Meta developed and publicly released the Llama 2 family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama-2-Chat, are optimized for dialogue use cases. Llama-2-Chat models outperform open-source chat models on most benchmarks we tested, and in our human evaluations for helpfulness and safety, are on par with some popular closed-source models like ChatGPT and PaLM.
**Model Developers** Meta
**Variations** Llama 2 comes in a range of parameter sizes — 7B, 13B, and 70B — as well as pretrained and fine-tuned variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Llama 2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align to human preferences for helpfulness and safety.
||Training Data|Params|Content Length|GQA|Tokens|LR|
|---|---|---|---|---|---|---|
|Llama 2|*A new mix of publicly available online data*|7B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|13B|4k|✗|2.0T|3.0 x 10<sup>-4</sup>|
|Llama 2|*A new mix of publicly available online data*|70B|4k|✔|2.0T|1.5 x 10<sup>-4</sup>|
*Llama 2 family of models.* Token counts refer to pretraining data only. All models are trained with a global batch-size of 4M tokens. Bigger models - 70B -- use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Dates** Llama 2 was trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
## Intended Use
**Intended Use Cases** Llama 2 is intended for commercial and research use in English. Tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
To get the expected features and performance for the chat versions, a specific formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See our reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws).Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Llama 2.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research Super Cluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint** Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 539 tCO2eq, 100% of which were offset by Meta’s sustainability program.
||Time (GPU hours)|Power Consumption (W)|Carbon Emitted(tCO<sub>2</sub>eq)|
|---|---|---|---|
|Llama 2 7B|184320|400|31.22|
|Llama 2 13B|368640|400|62.44|
|Llama 2 70B|1720320|400|291.42|
|Total|3311616||539.00|
**CO<sub>2</sub> emissions during pretraining.** Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 2 was pretrained on 2 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over one million new human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of September 2022, but some tuning data is more recent, up to July 2023.
## Evaluation Results
In this section, we report the results for the Llama 1 and Llama 2 models on standard academic benchmarks.For all the evaluations, we use our internal evaluations library.
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
|---|---|---|---|---|---|---|---|---|---|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
**Overall performance on grouped academic benchmarks.** *Code:* We report the average pass@1 scores of our models on HumanEval and MBPP. *Commonsense Reasoning:* We report the average of PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OpenBookQA, and CommonsenseQA. We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks. *World Knowledge:* We evaluate the 5-shot performance on NaturalQuestions and TriviaQA and report the average. *Reading Comprehension:* For reading comprehension, we report the 0-shot average on SQuAD, QuAC, and BoolQ. *MATH:* We report the average of the GSM8K (8 shot) and MATH (4 shot) benchmarks at top 1.
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama 1|7B|27.42|23.00|
|Llama 1|13B|41.74|23.08|
|Llama 1|33B|44.19|22.57|
|Llama 1|65B|48.71|21.77|
|Llama 2|7B|33.29|**21.25**|
|Llama 2|13B|41.86|26.10|
|Llama 2|70B|**50.18**|24.60|
**Evaluation of pretrained LLMs on automatic safety benchmarks.** For TruthfulQA, we present the percentage of generations that are both truthful and informative (the higher the better). For ToxiGen, we present the percentage of toxic generations (the smaller the better).
|||TruthfulQA|Toxigen|
|---|---|---|---|
|Llama-2-Chat|7B|57.04|**0.00**|
|Llama-2-Chat|13B|62.18|**0.00**|
|Llama-2-Chat|70B|**64.14**|0.01|
**Evaluation of fine-tuned LLMs on different safety datasets.** Same metric definitions as above.
## Ethical Considerations and Limitations
Llama 2 is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
## Reporting Issues
Please report any software “bug,” or other problems with the models through one of the following means:
- Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
- Reporting problematic content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
- Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
## Llama Model Index
|Model|Llama2|Llama2-hf|Llama2-chat|Llama2-chat-hf|
|---|---|---|---|---|
|7B| [Link](https://huggingface.co/llamaste/Llama-2-7b) | [Link](https://huggingface.co/llamaste/Llama-2-7b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-7b-chat-hf)|
|13B| [Link](https://huggingface.co/llamaste/Llama-2-13b) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-13b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-13b-hf)|
|70B| [Link](https://huggingface.co/llamaste/Llama-2-70b) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf) | [Link](https://huggingface.co/llamaste/Llama-2-70b-chat) | [Link](https://huggingface.co/llamaste/Llama-2-70b-hf)| |
jlbaker361/dcgan-wikiart500-clip-resized | jlbaker361 | 2024-02-04T22:53:50Z | 0 | 0 | null | [
"region:us"
] | null | 2024-01-28T04:38:11Z | ---
{}
---
Creative Adversarial Network
epochs: 100
dataset jlbaker361/wikiart-balanced500
n classes 27
batch_size 128
images where resized to 768
and then center cropped to: 512
used clip=True
conditional =False
discriminator parameters:
init_dim: 32
final_dim 512
generator parameters:
input noise_dim: 100
|
DanielClough/Candle_TinyLlama-1.1B-Chat-v1.0 | DanielClough | 2024-02-04T22:41:32Z | 11 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"dataset:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-01T08:10:04Z | ---
datasets:
- TinyLlama/TinyLlama-1.1B-Chat-v1.0
language:
- en
pipeline_tag: text-generation
license: apache-2.0
---
This repo includes `.gguf` built for HuggingFace/Candle.
They will not work with `llama.cpp`.
Refer to the [original repo](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0) for more details.
|
shanhy/xlm-roberta-base_seed42_eng_train | shanhy | 2024-02-04T22:36:06Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T22:35:25Z | ---
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base_seed42_eng_train
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base_seed42_eng_train
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0170
- Spearman Corr: 0.8303
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Spearman Corr |
|:-------------:|:-----:|:----:|:---------------:|:-------------:|
| 0.051 | 2.58 | 200 | 0.0186 | 0.8190 |
| 0.0202 | 5.16 | 400 | 0.0151 | 0.8305 |
| 0.015 | 7.74 | 600 | 0.0151 | 0.8354 |
| 0.0092 | 10.32 | 800 | 0.0179 | 0.8298 |
| 0.0078 | 12.9 | 1000 | 0.0187 | 0.8308 |
| 0.0064 | 15.48 | 1200 | 0.0201 | 0.8314 |
| 0.0051 | 18.06 | 1400 | 0.0168 | 0.8287 |
| 0.0045 | 20.65 | 1600 | 0.0196 | 0.8277 |
| 0.0042 | 23.23 | 1800 | 0.0205 | 0.8314 |
| 0.0038 | 25.81 | 2000 | 0.0170 | 0.8303 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
Fiwex/StableDiffusion_rEmoji | Fiwex | 2024-02-04T22:34:36Z | 1 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-02-04T22:08:36Z | StableDiffusion 1.5 (https://huggingface.co/runwayml/stable-diffusion-v1-5) fine tuned on rEmoji dataset (https://www.kaggle.com/datasets/shonenkov/russian-emoji/activity) |
smashmaster/MysteryBox | smashmaster | 2024-02-04T22:31:00Z | 0 | 0 | transformers | [
"transformers",
"art",
"code",
"music",
"text-generation",
"en",
"license:gpl-3.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T20:34:01Z | ---
license: gpl-3.0
language:
- en
library_name: transformers
pipeline_tag: text-generation
tags:
- art
- code
- music
---
# Mystery Box
You get to find out what the models do, what they can be used for, and how to load them. Look carefully for hints. |
movaxbx/OpenHermes-Emojitron-001 | movaxbx | 2024-02-04T22:14:23Z | 11 | 10 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"instruct",
"finetune",
"chatml",
"conversational",
"en",
"base_model:teknium/OpenHermes-2.5-Mistral-7B",
"base_model:finetune:teknium/OpenHermes-2.5-Mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T20:11:37Z | ---
base_model: teknium/OpenHermes-2.5-Mistral-7B
tags:
- mistral
- instruct
- finetune
- chatml
model-index:
- name: OpenHermes-Emojitron-001
results: []
license: apache-2.0
language:
- en
---
# OpenHermes-Emojitron-001

*🧑🎓📜🔄🌌➡️🗣️🌠🔮🖊️👀🤝🔄🧩🛠️👂📡🔐🌟*
## Model description
OpenHermes-Emojitron-001 is a state of the art Emoji Fine-tune, based on the OpenHermes 2.5 model.
It only speaks in emoji. Mostly. If using for chat, start it off with a nice 😊 to get going.
Huge thank you to Teknium and Mistral for a wonderful model.
Follow all my updates in ML and AI on Twitter: https://twitter.com/mov_axbx
# Table of Contents
1. [Example Outputs](#example-outputs)
- [Geography knowlege](#geography)
- [Chat about food](#food-chat)
- [Talk about movies](#movie-talk)
2. [Benchmark Results](#benchmark-results)
3. [Prompt Format](#prompt-format)
4. [Quantized Models](#quantized-models)
## Example Outputs
### Geography knowlege:
in what country is london
```
🇬🇧
```
### Chat about food:
what country has the best food
```
🤔🌎🍽️
1️⃣🇮🇳
2️⃣🇯🇵
3️⃣🇺🇸
4️⃣🇪🇸
5️⃣🇫🇷
```
### Talk about movies:
tell me a time travel story about a delorean
```
🛸🚗🕰️👨🔬🔍📅1985👴🚗💭🔜🌌😱💡💼🔢🔜📅1955🚗👨👩👧👦👀🔜🌉🕰️💥🌀🚗🕰️🔂📅1985👨🔬🎉
```
## Benchmark Results
There are no benchmarks for emoji models. Maybe someone can create one. EmojiBench 5K let's gooooooo
# Prompt Format
OpenHermes-Emojitron-001 uses ChatML as the prompt format, just like Open Hermes 2.5
It also appears to handle Mistral format great. Especially since I used that for the finetune (oops)
# Quantized Models:
Coming soon if TheBloke thinks this is worth his 🕰️
|
shanhy/xlm-roberta-base_seed42_amh-esp-eng_train | shanhy | 2024-02-04T22:05:11Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T22:04:25Z | ---
license: mit
base_model: FacebookAI/xlm-roberta-base
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-base_seed42_amh-esp-eng_train
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base_seed42_amh-esp-eng_train
This model is a fine-tuned version of [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0135
- Spearman Corr: 0.8691
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Spearman Corr |
|:-------------:|:-----:|:----:|:---------------:|:-------------:|
| No log | 0.59 | 200 | 0.0224 | 0.7379 |
| No log | 1.18 | 400 | 0.0205 | 0.7553 |
| No log | 1.76 | 600 | 0.0180 | 0.7818 |
| 0.0324 | 2.35 | 800 | 0.0208 | 0.7870 |
| 0.0324 | 2.94 | 1000 | 0.0182 | 0.8010 |
| 0.0324 | 3.53 | 1200 | 0.0172 | 0.7997 |
| 0.0183 | 4.12 | 1400 | 0.0219 | 0.8139 |
| 0.0183 | 4.71 | 1600 | 0.0158 | 0.8185 |
| 0.0183 | 5.29 | 1800 | 0.0165 | 0.8202 |
| 0.0183 | 5.88 | 2000 | 0.0158 | 0.8289 |
| 0.0125 | 6.47 | 2200 | 0.0213 | 0.8286 |
| 0.0125 | 7.06 | 2400 | 0.0163 | 0.8298 |
| 0.0125 | 7.65 | 2600 | 0.0187 | 0.8337 |
| 0.0088 | 8.24 | 2800 | 0.0162 | 0.8387 |
| 0.0088 | 8.82 | 3000 | 0.0155 | 0.8397 |
| 0.0088 | 9.41 | 3200 | 0.0155 | 0.8421 |
| 0.0065 | 10.0 | 3400 | 0.0172 | 0.8443 |
| 0.0065 | 10.59 | 3600 | 0.0167 | 0.8486 |
| 0.0065 | 11.18 | 3800 | 0.0147 | 0.8501 |
| 0.0065 | 11.76 | 4000 | 0.0145 | 0.8515 |
| 0.005 | 12.35 | 4200 | 0.0144 | 0.8548 |
| 0.005 | 12.94 | 4400 | 0.0158 | 0.8554 |
| 0.005 | 13.53 | 4600 | 0.0176 | 0.8516 |
| 0.0041 | 14.12 | 4800 | 0.0182 | 0.8549 |
| 0.0041 | 14.71 | 5000 | 0.0138 | 0.8580 |
| 0.0041 | 15.29 | 5200 | 0.0154 | 0.8572 |
| 0.0041 | 15.88 | 5400 | 0.0150 | 0.8600 |
| 0.0036 | 16.47 | 5600 | 0.0134 | 0.8612 |
| 0.0036 | 17.06 | 5800 | 0.0138 | 0.8628 |
| 0.0036 | 17.65 | 6000 | 0.0146 | 0.8619 |
| 0.0031 | 18.24 | 6200 | 0.0134 | 0.8656 |
| 0.0031 | 18.82 | 6400 | 0.0142 | 0.8641 |
| 0.0031 | 19.41 | 6600 | 0.0130 | 0.8648 |
| 0.0028 | 20.0 | 6800 | 0.0131 | 0.8648 |
| 0.0028 | 20.59 | 7000 | 0.0142 | 0.8660 |
| 0.0028 | 21.18 | 7200 | 0.0149 | 0.8637 |
| 0.0028 | 21.76 | 7400 | 0.0138 | 0.8662 |
| 0.0025 | 22.35 | 7600 | 0.0135 | 0.8661 |
| 0.0025 | 22.94 | 7800 | 0.0130 | 0.8673 |
| 0.0025 | 23.53 | 8000 | 0.0128 | 0.8652 |
| 0.0023 | 24.12 | 8200 | 0.0133 | 0.8677 |
| 0.0023 | 24.71 | 8400 | 0.0134 | 0.8669 |
| 0.0023 | 25.29 | 8600 | 0.0131 | 0.8679 |
| 0.0023 | 25.88 | 8800 | 0.0128 | 0.8687 |
| 0.0021 | 26.47 | 9000 | 0.0139 | 0.8692 |
| 0.0021 | 27.06 | 9200 | 0.0133 | 0.8690 |
| 0.0021 | 27.65 | 9400 | 0.0133 | 0.8686 |
| 0.002 | 28.24 | 9600 | 0.0135 | 0.8691 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
Fiwex/InstaFlow_rEmoji | Fiwex | 2024-02-04T22:04:55Z | 0 | 0 | diffusers | [
"diffusers",
"tensorboard",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-02-04T21:40:29Z | The InstaFlow model (https://github.com/gnobitab/InstaFlow) fine tuned on rEmoji dataset (https://www.kaggle.com/datasets/shonenkov/russian-emoji/activity) |
frodos/kandinsky-2-1-img2img | frodos | 2024-02-04T21:58:09Z | 5 | 0 | diffusers | [
"diffusers",
"kandinsky",
"image-to-image",
"license:apache-2.0",
"endpoints_compatible",
"diffusers:KandinskyPipeline",
"region:us"
] | image-to-image | 2024-02-04T13:56:59Z | ---
license: apache-2.0
prior:
- kandinsky-community/kandinsky-2-1-prior
tags:
- kandinsky
- image-to-image
duplicated_from: kandinsky-community/kandinsky-2-1
pipeline_tag: image-to-image
---
# Kandinsky 2.1
Kandinsky 2.1 inherits best practices from Dall-E 2 and Latent diffusion while introducing some new ideas.
It uses the CLIP model as a text and image encoder, and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
The Kandinsky model is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey) and [Denis Dimitrov](https://github.com/denndimitrov)
## Usage
Kandinsky 2.1 is available in diffusers!
```python
pip install diffusers transformers
```
### Text to image
```python
from diffusers import KandinskyPipeline, KandinskyPriorPipeline
import torch
pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
pipe_prior.to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image_emb = pipe_prior(
prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
).images
zero_image_emb = pipe_prior(
negative_prompt, guidance_scale=1.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
).images
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
images = pipe(
prompt,
image_embeds=image_emb,
negative_image_embeds=zero_image_emb,
num_images_per_prompt=2,
height=768,
width=768,
num_inference_steps=100,
guidance_scale=4.0,
generator=generator,
).images[0]
image.save("./cheeseburger_monster.png")
```

### Text Guided Image-to-Image Generation
```python
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
import torch
from PIL import Image
import requests
from io import BytesIO
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))
# create prior
pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
pipe_prior.to("cuda")
# create img2img pipeline
pipe = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image_emb = pipe_prior(
prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
).images
zero_image_emb = pipe_prior(
negative_prompt, guidance_scale=4.0, num_inference_steps=25, generator=generator, negative_prompt=negative_prompt
).images
out = pipe(
prompt,
image=original_image,
image_embeds=image_emb,
negative_image_embeds=zero_image_emb,
height=768,
width=768,
num_inference_steps=500,
strength=0.3,
)
out.images[0].save("fantasy_land.png")
```

### Interpolate
```python
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
from diffusers.utils import load_image
import PIL
import torch
from torchvision import transforms
pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
images_texts = ["a cat", img1, img2]
weights = [0.3, 0.3, 0.4]
image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(
"", image_embeds=image_emb, negative_image_embeds=zero_image_emb, height=768, width=768, num_inference_steps=150
).images[0]
image.save("starry_cat.png")
```

## Model Architecture
### Overview
Kandinsky 2.1 is a text-conditional diffusion model based on unCLIP and latent diffusion, composed of a transformer-based image prior model, a unet diffusion model, and a decoder.
The model architectures are illustrated in the figure below - the chart on the left describes the process to train the image prior model, the figure in the center is the text-to-image generation process, and the figure on the right is image interpolation.
<p float="left">
<img src="https://raw.githubusercontent.com/ai-forever/Kandinsky-2/main/content/kandinsky21.png"/>
</p>
Specifically, the image prior model was trained on CLIP text and image embeddings generated with a pre-trained [mCLIP model](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14). The trained image prior model is then used to generate mCLIP image embeddings for input text prompts. Both the input text prompts and its mCLIP image embeddings are used in the diffusion process. A [MoVQGAN](https://openreview.net/forum?id=Qb-AoSw4Jnm) model acts as the final block of the model, which decodes the latent representation into an actual image.
### Details
The image prior training of the model was performed on the [LAION Improved Aesthetics dataset](https://huggingface.co/datasets/bhargavsdesai/laion_improved_aesthetics_6.5plus_with_images), and then fine-tuning was performed on the [LAION HighRes data](https://huggingface.co/datasets/laion/laion-high-resolution).
The main Text2Image diffusion model was trained on the basis of 170M text-image pairs from the [LAION HighRes dataset](https://huggingface.co/datasets/laion/laion-high-resolution) (an important condition was the presence of images with a resolution of at least 768x768). The use of 170M pairs is due to the fact that we kept the UNet diffusion block from Kandinsky 2.0, which allowed us not to train it from scratch. Further, at the stage of fine-tuning, a dataset of 2M very high-quality high-resolution images with descriptions (COYO, anime, landmarks_russia, and a number of others) was used separately collected from open sources.
### Evaluation
We quantitatively measure the performance of Kandinsky 2.1 on the COCO_30k dataset, in zero-shot mode. The table below presents FID.
FID metric values for generative models on COCO_30k
| | FID (30k)|
|:------|----:|
| eDiff-I (2022) | 6.95 |
| Image (2022) | 7.27 |
| Kandinsky 2.1 (2023) | 8.21|
| Stable Diffusion 2.1 (2022) | 8.59 |
| GigaGAN, 512x512 (2023) | 9.09 |
| DALL-E 2 (2022) | 10.39 |
| GLIDE (2022) | 12.24 |
| Kandinsky 1.0 (2022) | 15.40 |
| DALL-E (2021) | 17.89 |
| Kandinsky 2.0 (2022) | 20.00 |
| GLIGEN (2022) | 21.04 |
For more information, please refer to the upcoming technical report.
## BibTex
If you find this repository useful in your research, please cite:
```
@misc{kandinsky 2.1,
title = {kandinsky 2.1},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}
``` |
LoneStriker/Kyllene-34B-v1.1-6.0bpw-h6-exl2 | LoneStriker | 2024-02-04T21:57:46Z | 6 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T21:46:27Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
tags:
- merge
---
# Kyllene 34B v1.1

## Model Details
- A result of new merge method provided by [MergeMonster](https://github.com/Gryphe/MergeMonster/) tool with extended RPG preset.
- models used for merge:
[jondurbin/bagel-dpo-34b-v0.2](https://huggingface.co/jondurbin/bagel-dpo-34b-v0.2)
[NousResearch/Nous-Capybara-34B](https://huggingface.co/NousResearch/Nous-Capybara-34B)
[NousResearch_Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
[SUSTech/SUS-Chat-34B](https://huggingface.co/SUSTech/SUS-Chat-34B)
- Method is aimed to maximize probability of certain phrases and minimize probablility of other phrases.
- RPG preset was extened with examples of typical, nonsensical output of most models like 'unbreakable bond', 'send shivers down her spine' etc.
- The resulting model has approximately 34 billion parameters.
- See [mergekit-config.yml](https://huggingface.co/TeeZee/Kyllene-34B-v1.1/resolve/main/merge-config.yml) for details on the merge method used and RPG presets.
**Warning: This model can produce NSFW content!**
## Results
- produces SFW nad NSFW content without issues, switches context seamlessly.
- 200K context length
- good at following instructions
- different than [TeeZee/Kyllene-57B-v1.0](https://huggingface.co/TeeZee/Kyllene-57B-v1.0), but also surprisingly entertaining (but more tests are needed)
## Side notes
- [MergeMonster](https://github.com/Gryphe/MergeMonster/) method works, however project would benefit greatly from some more love from developers.
- In its current state MergeMonster consumes insane amounts of RAM (256GB+) or VRAM and takes a really long time to process model data, this merge took 24H on 1xADA6000
- MergeMonster is not a golden bullet, other experiments has shown that it can also produce incredibly stupid models.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> |
arnavgrg/NousResearch-Yarn-Mistral-7b-128k-nf4-fp16-upscaled | arnavgrg | 2024-02-04T21:51:36Z | 20 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-12-13T19:08:43Z | ---
license: apache-2.0
tags:
- text-generation-inference
---
This is an upscaled fp16 variant of the original NousResearch/Yarn-Mistral-7b-128k base model after it has been loaded with nf4 4-bit quantization via bitsandbytes.
The main idea here is to upscale the linear4bit layers to fp16 so that the quantization/dequantization cost doesn't have to paid for each forward pass at inference time.
_Note: The quantization operation to nf4 is not lossless, so the model weights for the linear layers are lossy, which means that this model will not work as well as the official base model._
To use this model, you can just load it via `transformers` in fp16:
```python
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"arnavgrg/NousResearch-Yarn-Mistral-7b-128k-nf4-fp16-upscaled",
device_map="auto",
torch_dtype=torch.float16,
)
``` |
UnaiGurbindo/ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan | UnaiGurbindo | 2024-02-04T21:47:51Z | 8 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:MIT/ast-finetuned-audioset-10-10-0.4593",
"base_model:finetune:MIT/ast-finetuned-audioset-10-10-0.4593",
"license:bsd-3-clause",
"model-index",
"endpoints_compatible",
"region:us"
] | audio-classification | 2023-10-07T19:28:36Z | ---
license: bsd-3-clause
base_model: MIT/ast-finetuned-audioset-10-10-0.4593
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.91
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3129
- Accuracy: 0.91
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8831 | 1.0 | 112 | 0.6815 | 0.77 |
| 0.4558 | 2.0 | 225 | 0.5726 | 0.77 |
| 0.3592 | 3.0 | 337 | 0.6134 | 0.79 |
| 0.021 | 4.0 | 450 | 0.7918 | 0.82 |
| 0.0363 | 5.0 | 562 | 0.5338 | 0.88 |
| 0.0011 | 6.0 | 675 | 0.4322 | 0.91 |
| 0.0004 | 7.0 | 787 | 0.4149 | 0.9 |
| 0.0163 | 8.0 | 900 | 0.5259 | 0.89 |
| 0.1556 | 9.0 | 1012 | 0.3010 | 0.91 |
| 0.0001 | 10.0 | 1125 | 0.2829 | 0.94 |
| 0.0001 | 11.0 | 1237 | 0.3811 | 0.9 |
| 0.0001 | 12.0 | 1350 | 0.3358 | 0.91 |
| 0.0001 | 13.0 | 1462 | 0.3414 | 0.9 |
| 0.0001 | 14.0 | 1575 | 0.3231 | 0.9 |
| 0.0001 | 15.0 | 1687 | 0.3166 | 0.9 |
| 0.0 | 16.0 | 1800 | 0.3140 | 0.91 |
| 0.0 | 17.0 | 1912 | 0.3128 | 0.91 |
| 0.0 | 18.0 | 2025 | 0.3118 | 0.91 |
| 0.0 | 19.0 | 2137 | 0.3133 | 0.91 |
| 0.0 | 19.91 | 2240 | 0.3129 | 0.91 |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
LoneStriker/Kyllene-34B-v1.1-4.65bpw-h6-exl2 | LoneStriker | 2024-02-04T21:36:48Z | 9 | 5 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T21:27:49Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
tags:
- merge
---
# Kyllene 34B v1.1

## Model Details
- A result of new merge method provided by [MergeMonster](https://github.com/Gryphe/MergeMonster/) tool with extended RPG preset.
- models used for merge:
[jondurbin/bagel-dpo-34b-v0.2](https://huggingface.co/jondurbin/bagel-dpo-34b-v0.2)
[NousResearch/Nous-Capybara-34B](https://huggingface.co/NousResearch/Nous-Capybara-34B)
[NousResearch_Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
[SUSTech/SUS-Chat-34B](https://huggingface.co/SUSTech/SUS-Chat-34B)
- Method is aimed to maximize probability of certain phrases and minimize probablility of other phrases.
- RPG preset was extened with examples of typical, nonsensical output of most models like 'unbreakable bond', 'send shivers down her spine' etc.
- The resulting model has approximately 34 billion parameters.
- See [mergekit-config.yml](https://huggingface.co/TeeZee/Kyllene-34B-v1.1/resolve/main/merge-config.yml) for details on the merge method used and RPG presets.
**Warning: This model can produce NSFW content!**
## Results
- produces SFW nad NSFW content without issues, switches context seamlessly.
- 200K context length
- good at following instructions
- different than [TeeZee/Kyllene-57B-v1.0](https://huggingface.co/TeeZee/Kyllene-57B-v1.0), but also surprisingly entertaining (but more tests are needed)
## Side notes
- [MergeMonster](https://github.com/Gryphe/MergeMonster/) method works, however project would benefit greatly from some more love from developers.
- In its current state MergeMonster consumes insane amounts of RAM (256GB+) or VRAM and takes a really long time to process model data, this merge took 24H on 1xADA6000
- MergeMonster is not a golden bullet, other experiments has shown that it can also produce incredibly stupid models.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> |
LoneStriker/Kyllene-34B-v1.1-4.0bpw-h6-exl2 | LoneStriker | 2024-02-04T21:27:48Z | 6 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T21:19:53Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
tags:
- merge
---
# Kyllene 34B v1.1

## Model Details
- A result of new merge method provided by [MergeMonster](https://github.com/Gryphe/MergeMonster/) tool with extended RPG preset.
- models used for merge:
[jondurbin/bagel-dpo-34b-v0.2](https://huggingface.co/jondurbin/bagel-dpo-34b-v0.2)
[NousResearch/Nous-Capybara-34B](https://huggingface.co/NousResearch/Nous-Capybara-34B)
[NousResearch_Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
[SUSTech/SUS-Chat-34B](https://huggingface.co/SUSTech/SUS-Chat-34B)
- Method is aimed to maximize probability of certain phrases and minimize probablility of other phrases.
- RPG preset was extened with examples of typical, nonsensical output of most models like 'unbreakable bond', 'send shivers down her spine' etc.
- The resulting model has approximately 34 billion parameters.
- See [mergekit-config.yml](https://huggingface.co/TeeZee/Kyllene-34B-v1.1/resolve/main/merge-config.yml) for details on the merge method used and RPG presets.
**Warning: This model can produce NSFW content!**
## Results
- produces SFW nad NSFW content without issues, switches context seamlessly.
- 200K context length
- good at following instructions
- different than [TeeZee/Kyllene-57B-v1.0](https://huggingface.co/TeeZee/Kyllene-57B-v1.0), but also surprisingly entertaining (but more tests are needed)
## Side notes
- [MergeMonster](https://github.com/Gryphe/MergeMonster/) method works, however project would benefit greatly from some more love from developers.
- In its current state MergeMonster consumes insane amounts of RAM (256GB+) or VRAM and takes a really long time to process model data, this merge took 24H on 1xADA6000
- MergeMonster is not a golden bullet, other experiments has shown that it can also produce incredibly stupid models.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> |
anuj55/distilbert-base-uncased-finetuned-cola | anuj55 | 2024-02-04T21:26:29Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T12:36:11Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1018
- Accuracy: 0.9759
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.0802 | 1.0 | 8750 | 0.0708 | 0.9743 |
| 0.0551 | 2.0 | 17500 | 0.0719 | 0.9747 |
| 0.0337 | 3.0 | 26250 | 0.0829 | 0.9757 |
| 0.0235 | 4.0 | 35000 | 0.1018 | 0.9759 |
| 0.0108 | 5.0 | 43750 | 0.1207 | 0.9756 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.13.3
|
LoneStriker/Kyllene-34B-v1.1-3.0bpw-h6-exl2 | LoneStriker | 2024-02-04T21:19:52Z | 6 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T21:13:50Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
tags:
- merge
---
# Kyllene 34B v1.1

## Model Details
- A result of new merge method provided by [MergeMonster](https://github.com/Gryphe/MergeMonster/) tool with extended RPG preset.
- models used for merge:
[jondurbin/bagel-dpo-34b-v0.2](https://huggingface.co/jondurbin/bagel-dpo-34b-v0.2)
[NousResearch/Nous-Capybara-34B](https://huggingface.co/NousResearch/Nous-Capybara-34B)
[NousResearch_Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
[SUSTech/SUS-Chat-34B](https://huggingface.co/SUSTech/SUS-Chat-34B)
- Method is aimed to maximize probability of certain phrases and minimize probablility of other phrases.
- RPG preset was extened with examples of typical, nonsensical output of most models like 'unbreakable bond', 'send shivers down her spine' etc.
- The resulting model has approximately 34 billion parameters.
- See [mergekit-config.yml](https://huggingface.co/TeeZee/Kyllene-34B-v1.1/resolve/main/merge-config.yml) for details on the merge method used and RPG presets.
**Warning: This model can produce NSFW content!**
## Results
- produces SFW nad NSFW content without issues, switches context seamlessly.
- 200K context length
- good at following instructions
- different than [TeeZee/Kyllene-57B-v1.0](https://huggingface.co/TeeZee/Kyllene-57B-v1.0), but also surprisingly entertaining (but more tests are needed)
## Side notes
- [MergeMonster](https://github.com/Gryphe/MergeMonster/) method works, however project would benefit greatly from some more love from developers.
- In its current state MergeMonster consumes insane amounts of RAM (256GB+) or VRAM and takes a really long time to process model data, this merge took 24H on 1xADA6000
- MergeMonster is not a golden bullet, other experiments has shown that it can also produce incredibly stupid models.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> |
LoneStriker/Kyllene-34B-v1.1-GGUF | LoneStriker | 2024-02-04T21:13:48Z | 6 | 0 | null | [
"gguf",
"merge",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-04T19:28:29Z | ---
license: other
license_name: yi-license
license_link: https://huggingface.co/01-ai/Yi-34B-200K/blob/main/LICENSE
tags:
- merge
---
# Kyllene 34B v1.1

## Model Details
- A result of new merge method provided by [MergeMonster](https://github.com/Gryphe/MergeMonster/) tool with extended RPG preset.
- models used for merge:
[jondurbin/bagel-dpo-34b-v0.2](https://huggingface.co/jondurbin/bagel-dpo-34b-v0.2)
[NousResearch/Nous-Capybara-34B](https://huggingface.co/NousResearch/Nous-Capybara-34B)
[NousResearch_Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B)
[SUSTech/SUS-Chat-34B](https://huggingface.co/SUSTech/SUS-Chat-34B)
- Method is aimed to maximize probability of certain phrases and minimize probablility of other phrases.
- RPG preset was extened with examples of typical, nonsensical output of most models like 'unbreakable bond', 'send shivers down her spine' etc.
- The resulting model has approximately 34 billion parameters.
- See [mergekit-config.yml](https://huggingface.co/TeeZee/Kyllene-34B-v1.1/resolve/main/merge-config.yml) for details on the merge method used and RPG presets.
**Warning: This model can produce NSFW content!**
## Results
- produces SFW nad NSFW content without issues, switches context seamlessly.
- 200K context length
- good at following instructions
- different than [TeeZee/Kyllene-57B-v1.0](https://huggingface.co/TeeZee/Kyllene-57B-v1.0), but also surprisingly entertaining (but more tests are needed)
## Side notes
- [MergeMonster](https://github.com/Gryphe/MergeMonster/) method works, however project would benefit greatly from some more love from developers.
- In its current state MergeMonster consumes insane amounts of RAM (256GB+) or VRAM and takes a really long time to process model data, this merge took 24H on 1xADA6000
- MergeMonster is not a golden bullet, other experiments has shown that it can also produce incredibly stupid models.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> |
jomacgo/my_awesome_qa_model | jomacgo | 2024-02-04T21:12:04Z | 13 | 0 | transformers | [
"transformers",
"tf",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-02-03T08:14:58Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: jomacgo/my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# jomacgo/my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4370
- Validation Loss: 0.4046
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 150, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.4180 | 0.9110 | 0 |
| 0.6239 | 0.4046 | 1 |
| 0.4370 | 0.4046 | 2 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.12.0
- Datasets 2.16.1
- Tokenizers 0.15.1
|
mjm4dl/intnt_strlng_v02_4bit_gptq | mjm4dl | 2024-02-04T20:58:04Z | 2 | 0 | transformers | [
"transformers",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T20:55:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mtc/mistralai-Mistral-7B-v0.1-7b-xsum-with-all-explanations-3-epochs-full-dataset-eot-2-lora-full | mtc | 2024-02-04T20:53:53Z | 2 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2024-02-04T20:53:29Z | ---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.1 |
chatdb/natural-sql-7b-GGUF | chatdb | 2024-02-04T20:48:54Z | 228 | 6 | transformers | [
"transformers",
"gguf",
"instruct",
"finetune",
"text-generation",
"base_model:deepseek-ai/deepseek-coder-6.7b-instruct",
"base_model:quantized:deepseek-ai/deepseek-coder-6.7b-instruct",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-02-02T20:38:29Z | ---
base_model: deepseek-ai/deepseek-coder-6.7b-instruct
tags:
- instruct
- finetune
library_name: transformers
license: cc-by-sa-4.0
pipeline_tag: text-generation
---
# **Natural-SQL-7B by ChatDB**
## Natural-SQL-7B is a model with very strong performance in Text-to-SQL instructions, has an excellent understanding of complex questions, and outperforms models of the same size in its space.
<img src="https://cdn-uploads.huggingface.co/production/uploads/648a374f00f7a3374ee64b99/hafdsfrFCqrVbATIzV_EN.png" width="600">
[ChatDB.ai](https://chatdb.ai) | [Notebook](https://github.com/cfahlgren1/natural-sql/blob/main/natural-sql-7b.ipynb) | [Twitter](https://twitter.com/calebfahlgren)
# **Benchmarks**
### *Results on Novel Datasets not trained on via SQL-Eval*
<img src="https://cdn-uploads.huggingface.co/production/uploads/648a374f00f7a3374ee64b99/5ynfoKPzI3_-WasQQt7qR.png" width="800">
<em>Big thanks to the [defog](https://huggingface.co/defog) team for open sourcing [sql-eval](https://github.com/defog-ai/sql-eval)</em>👏
Natural-SQL also can handle complex, compound questions that other models typically struggle with. There is a more detailed writeup Here is a write up, small test done [here](https://chatdb.ai/post/naturalsql-vs-sqlcoder-for-text-to-sql).
# Usage
Make sure you have the correct version of the transformers library installed:
```sh
pip install transformers==4.35.2
```
### Loading the Model
Use the following Python code to load the model:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatdb/natural-sql-7b")
model = AutoModelForCausalLM.from_pretrained(
"chatdb/natural-sql-7b",
device_map="auto",
torch_dtype=torch.float16,
)
```
### **License**
The model weights are licensed under `CC BY-SA 4.0`, with extra guidelines for responsible use expanded from the original model's [Deepseek](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) license.
You're free to use and adapt the model, even commercially.
If you alter the weights, such as through fine-tuning, you must publicly share your changes under the same `CC BY-SA 4.0` license.
### Generating SQL
```python
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(
**inputs,
num_return_sequences=1,
eos_token_id=100001,
pad_token_id=100001,
max_new_tokens=400,
do_sample=False,
num_beams=1,
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(outputs[0].split("```sql")[-1])
```
# Prompt Template
```
# Task
Generate a SQL query to answer the following question: `{natural language question}`
### PostgreSQL Database Schema
The query will run on a database with the following schema:
<SQL Table DDL Statements>
# SQL
Here is the SQL query that answers the question: `{natural language question}`
'''sql
```
# Example SQL Output
### Example Schemas
```sql
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
password_hash TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE projects (
project_id SERIAL PRIMARY KEY,
project_name VARCHAR(100) NOT NULL,
description TEXT,
start_date DATE,
end_date DATE,
owner_id INTEGER REFERENCES users(user_id)
);
CREATE TABLE tasks (
task_id SERIAL PRIMARY KEY,
task_name VARCHAR(100) NOT NULL,
description TEXT,
due_date DATE,
status VARCHAR(50),
project_id INTEGER REFERENCES projects(project_id)
);
CREATE TABLE taskassignments (
assignment_id SERIAL PRIMARY KEY,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id),
assigned_date DATE NOT NULL DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE comments (
comment_id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
task_id INTEGER REFERENCES tasks(task_id),
user_id INTEGER REFERENCES users(user_id)
);
```
### Example SQL Outputs
**Question**: **Show me the day with the most users joining**
```sql
SELECT created_at::DATE AS day, COUNT(*) AS user_count
FROM users
GROUP BY day
ORDER BY user_count DESC
LIMIT 1;
```
**Question**: **Show me the project that has a task with the most comments**
```sql
SELECT p.project_name, t.task_name, COUNT(c.comment_id) AS comment_count
FROM projects p
JOIN tasks t ON p.project_id = t.project_id
JOIN comments c ON t.task_id = c.task_id
GROUP BY p.project_name, t.task_name
ORDER BY comment_count DESC
LIMIT 1;
```
**Question**: **What is the ratio of users with gmail addresses vs without?**
```sql
SELECT
SUM(CASE WHEN email ILIKE '%@gmail.com%' THEN 1 ELSE 0 END)::FLOAT / NULLIF(SUM(CASE WHEN email NOT ILIKE '%@gmail.com%' THEN 1 ELSE 0 END), 0) AS gmail_ratio
FROM
users;
``` |
djomo/MISTRALllux1000-7b-v5 | djomo | 2024-02-04T20:43:21Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T20:38:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rheubanks/sft_zephyr | rheubanks | 2024-02-04T20:26:00Z | 1 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:HuggingFaceH4/zephyr-7b-alpha",
"base_model:adapter:HuggingFaceH4/zephyr-7b-alpha",
"license:mit",
"region:us"
] | null | 2024-02-04T20:25:54Z | ---
license: mit
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: HuggingFaceH4/zephyr-7b-alpha
model-index:
- name: sft_zephyr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sft_zephyr
This model is a fine-tuned version of [HuggingFaceH4/zephyr-7b-alpha](https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 5
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1 |
Marmara-NLP/TURNA-finetuned-dictionary-tr | Marmara-NLP | 2024-02-04T20:13:20Z | 16 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-03T13:47:53Z | TURNA based Finetuned Dictionary
This model is a finetuned model. The aim is make TURNA specialized for dictionary task.
DATASET
This model is finetuned with https://www.kaggle.com/datasets/erogluegemen/tdk-turkish-words dataset.
TRAINING DETAILS
We have randomly take 10000 samples from the above dataset. And used them for fine tuning of Turna
Results
Epoch (Training Loss) (Validation Loss) (Rouge1) (Rouge2) (Rougel) (Rougelsum) (Gen Len) 1 2.804800 2.400238 18.491200 11.147300 18.124600 18.134400 19.000000 |
gorgilazarev3/climatecognize-climate-topic-detection | gorgilazarev3 | 2024-02-04T20:06:41Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"climate",
"climate change",
"en",
"base_model:climatebert/distilroberta-base-climate-detector",
"base_model:finetune:climatebert/distilroberta-base-climate-detector",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-04T19:40:46Z | ---
license: apache-2.0
language:
- en
metrics:
- accuracy
pipeline_tag: text-classification
tags:
- climate
- climate change
base_model: climatebert/distilroberta-base-climate-detector
---
# ClimateCognize - Climate Topic Detection
---
This model is fine-tuned on sentences and paragraphs for the task of climate topic detection - whether a given text (ex. paragraph or sentence) is about climate or not.
The base model that this model is further trained on is the [ClimateBERT Base Climate Detector](https://huggingface.co/climatebert/distilroberta-base-climate-detector) and is further trained on our own datasets that include sentences and paragraphs from different news articles about climate, as well as negative examples such as excerpts from news articles that are completely different. |
atulxop/test_model6 | atulxop | 2024-02-04T19:59:31Z | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-04T19:30:20Z | ---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: test_model6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_model6
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6632
- Rouge1: 0.1946
- Rouge2: 0.072
- Rougel: 0.1556
- Rougelsum: 0.1556
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.433 | 1.0 | 1370 | 2.8867 | 0.1902 | 0.0666 | 0.1512 | 0.1512 | 19.0 |
| 1.5963 | 2.0 | 2740 | 2.8031 | 0.1908 | 0.0716 | 0.1535 | 0.1537 | 19.0 |
| 1.7568 | 3.0 | 4110 | 2.7565 | 0.1955 | 0.07 | 0.1552 | 0.1553 | 19.0 |
| 1.7795 | 4.0 | 5480 | 2.6769 | 0.1923 | 0.0711 | 0.1538 | 0.1538 | 19.0 |
| 1.8689 | 5.0 | 6850 | 2.6503 | 0.1945 | 0.0703 | 0.1554 | 0.1554 | 19.0 |
| 1.8355 | 6.0 | 8220 | 2.6632 | 0.1946 | 0.072 | 0.1556 | 0.1556 | 19.0 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
duxx/test_model_lora_25 | duxx | 2024-02-04T19:58:54Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"unsloth",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-04T19:58:16Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kanishka/smolm-autoreg-bpe-counterfactual-babylm-random_removal-1e-3 | kanishka | 2024-02-04T19:57:52Z | 13 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"opt",
"text-generation",
"generated_from_trainer",
"dataset:kanishka/counterfactual-babylm-random_removal",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-03T21:21:11Z | ---
tags:
- generated_from_trainer
datasets:
- kanishka/counterfactual-babylm-random_removal
metrics:
- accuracy
model-index:
- name: smolm-autoreg-bpe-counterfactual-babylm-random_removal-1e-3
results:
- task:
name: Causal Language Modeling
type: text-generation
dataset:
name: kanishka/counterfactual-babylm-random_removal
type: kanishka/counterfactual-babylm-random_removal
metrics:
- name: Accuracy
type: accuracy
value: 0.4089044059161167
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smolm-autoreg-bpe-counterfactual-babylm-random_removal-1e-3
This model was trained from scratch on the kanishka/counterfactual-babylm-random_removal dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4298
- Accuracy: 0.4089
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 32000
- num_epochs: 20.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 3.6092 | 1.0 | 18586 | 3.7513 | 0.3603 |
| 3.3896 | 2.0 | 37172 | 3.5882 | 0.3803 |
| 3.2599 | 3.0 | 55758 | 3.4709 | 0.3917 |
| 3.177 | 4.0 | 74344 | 3.4183 | 0.3981 |
| 3.1287 | 5.0 | 92930 | 3.3982 | 0.4017 |
| 3.0841 | 6.0 | 111516 | 3.3841 | 0.4031 |
| 3.0483 | 7.0 | 130102 | 3.3494 | 0.4065 |
| 3.0156 | 8.0 | 148688 | 3.3597 | 0.4078 |
| 2.9911 | 9.0 | 167274 | 3.3719 | 0.4067 |
| 2.9616 | 10.0 | 185860 | 3.3717 | 0.4078 |
| 2.9384 | 11.0 | 204446 | 3.3679 | 0.4091 |
| 2.9133 | 12.0 | 223032 | 3.3673 | 0.4097 |
| 2.8923 | 13.0 | 241618 | 3.3885 | 0.4088 |
| 2.8781 | 14.0 | 260204 | 3.3873 | 0.4090 |
| 2.8563 | 15.0 | 278790 | 3.3848 | 0.4092 |
| 2.836 | 16.0 | 297376 | 3.3956 | 0.4094 |
| 2.8162 | 17.0 | 315962 | 3.4023 | 0.4091 |
| 2.7997 | 18.0 | 334548 | 3.4101 | 0.4093 |
| 2.7779 | 19.0 | 353134 | 3.4237 | 0.4090 |
| 2.7645 | 20.0 | 371720 | 3.4298 | 0.4089 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
dap305/whisper-smallen-es | dap305 | 2024-02-04T19:56:19Z | 6 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"MIARFID",
"UPV",
"RAH",
"es",
"dataset:mozilla-foundation/common_voice_11_0",
"license:mit",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-04T16:33:52Z | ---
license: mit
datasets:
- mozilla-foundation/common_voice_11_0
language:
- es
metrics:
- wer
library_name: transformers
pipeline_tag: automatic-speech-recognition
tags:
- MIARFID
- UPV
- RAH
--- |
ruige2002/ppo-LunarLander-v2 | ruige2002 | 2024-02-04T19:28:40Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-04T19:28:21Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 244.14 +/- 18.63
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
samuraibosky/Reinforce-1 | samuraibosky | 2024-02-04T19:20:22Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-04T19:20:15Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 385.50 +/- 29.90
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
mjm4dl/intent_strlng_v02 | mjm4dl | 2024-02-04T19:20:00Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T19:13:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits