
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
LoneStriker/DeepMagic-Coder-7b-6.0bpw-h6-exl2 | LoneStriker | 2024-02-07T03:31:53Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-07T03:29:42Z | ---
license: other
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/LICENSE-MODEL
---
DeepMagic-Coder-7b
Alternate version:
- https://huggingface.co/rombodawg/DeepMagic-Coder-7b-Alt

This is an extremely successful merge of the deepseek-coder-6.7b-instruct and Magicoder-S-DS-6.7B models, bringing an uplift in overall coding performance without any compromise to the models integrity (at least with limited testing).
This is the first of my models to use the merge-kits *task_arithmetic* merging method. The method is detailed bellow, and its clearly very usefull for merging ai models that were fine-tuned from a common base:
Task Arithmetic:
```
Computes "task vectors" for each model by subtracting a base model.
Merges the task vectors linearly and adds back the base.
Works great for models that were fine tuned from a common ancestor.
Also a super useful mental framework for several of the more involved
merge methods.
```
The original models used in this merge can be found here:
- https://huggingface.co/ise-uiuc/Magicoder-S-DS-6.7B
- https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct
The Merge was created using Mergekit and the paremeters can be found bellow:
```yaml
models:
- model: deepseek-ai_deepseek-coder-6.7b-instruct
parameters:
weight: 1
- model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
weight: 1
merge_method: task_arithmetic
base_model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
normalize: true
int8_mask: true
dtype: float16
``` |
nightdude/ddpm-butterflies-128 | nightdude | 2024-02-07T03:29:40Z | 0 | 0 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-02-07T03:27:23Z |
---
license: creativeml-openrail-m
base_model: anton_l/ddpm-butterflies-128
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - ddpm-butterflies-128
These are LoRA adaption weights for anton_l/ddpm-butterflies-128. The weights were fine-tuned on the huggan/smithsonian_butterflies_subset dataset. You can find some example images in the following.
|
LoneStriker/DeepMagic-Coder-7b-5.0bpw-h6-exl2 | LoneStriker | 2024-02-07T03:29:39Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-07T03:27:46Z | ---
license: other
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/LICENSE-MODEL
---
DeepMagic-Coder-7b
Alternate version:
- https://huggingface.co/rombodawg/DeepMagic-Coder-7b-Alt

This is an extremely successful merge of the deepseek-coder-6.7b-instruct and Magicoder-S-DS-6.7B models, bringing an uplift in overall coding performance without any compromise to the models integrity (at least with limited testing).
This is the first of my models to use the merge-kits *task_arithmetic* merging method. The method is detailed bellow, and its clearly very usefull for merging ai models that were fine-tuned from a common base:
Task Arithmetic:
```
Computes "task vectors" for each model by subtracting a base model.
Merges the task vectors linearly and adds back the base.
Works great for models that were fine tuned from a common ancestor.
Also a super useful mental framework for several of the more involved
merge methods.
```
The original models used in this merge can be found here:
- https://huggingface.co/ise-uiuc/Magicoder-S-DS-6.7B
- https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct
The Merge was created using Mergekit and the paremeters can be found bellow:
```yaml
models:
- model: deepseek-ai_deepseek-coder-6.7b-instruct
parameters:
weight: 1
- model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
weight: 1
merge_method: task_arithmetic
base_model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
normalize: true
int8_mask: true
dtype: float16
``` |
LoneStriker/DeepMagic-Coder-7b-4.0bpw-h6-exl2 | LoneStriker | 2024-02-07T03:27:43Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-07T03:26:09Z | ---
license: other
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/LICENSE-MODEL
---
DeepMagic-Coder-7b
Alternate version:
- https://huggingface.co/rombodawg/DeepMagic-Coder-7b-Alt

This is an extremely successful merge of the deepseek-coder-6.7b-instruct and Magicoder-S-DS-6.7B models, bringing an uplift in overall coding performance without any compromise to the models integrity (at least with limited testing).
This is the first of my models to use the merge-kits *task_arithmetic* merging method. The method is detailed bellow, and its clearly very usefull for merging ai models that were fine-tuned from a common base:
Task Arithmetic:
```
Computes "task vectors" for each model by subtracting a base model.
Merges the task vectors linearly and adds back the base.
Works great for models that were fine tuned from a common ancestor.
Also a super useful mental framework for several of the more involved
merge methods.
```
The original models used in this merge can be found here:
- https://huggingface.co/ise-uiuc/Magicoder-S-DS-6.7B
- https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct
The Merge was created using Mergekit and the paremeters can be found bellow:
```yaml
models:
- model: deepseek-ai_deepseek-coder-6.7b-instruct
parameters:
weight: 1
- model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
weight: 1
merge_method: task_arithmetic
base_model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
normalize: true
int8_mask: true
dtype: float16
``` |
LoneStriker/DeepMagic-Coder-7b-GGUF | LoneStriker | 2024-02-07T03:19:15Z | 8 | 5 | null | [
"gguf",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-07T03:03:17Z | ---
license: other
license_name: deepseek
license_link: https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/LICENSE-MODEL
---
DeepMagic-Coder-7b
Alternate version:
- https://huggingface.co/rombodawg/DeepMagic-Coder-7b-Alt

This is an extremely successful merge of the deepseek-coder-6.7b-instruct and Magicoder-S-DS-6.7B models, bringing an uplift in overall coding performance without any compromise to the models integrity (at least with limited testing).
This is the first of my models to use the merge-kits *task_arithmetic* merging method. The method is detailed bellow, and its clearly very usefull for merging ai models that were fine-tuned from a common base:
Task Arithmetic:
```
Computes "task vectors" for each model by subtracting a base model.
Merges the task vectors linearly and adds back the base.
Works great for models that were fine tuned from a common ancestor.
Also a super useful mental framework for several of the more involved
merge methods.
```
The original models used in this merge can be found here:
- https://huggingface.co/ise-uiuc/Magicoder-S-DS-6.7B
- https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct
The Merge was created using Mergekit and the paremeters can be found bellow:
```yaml
models:
- model: deepseek-ai_deepseek-coder-6.7b-instruct
parameters:
weight: 1
- model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
weight: 1
merge_method: task_arithmetic
base_model: ise-uiuc_Magicoder-S-DS-6.7B
parameters:
normalize: true
int8_mask: true
dtype: float16
``` |
Sacbe/ViT_SAM_Classification | Sacbe | 2024-02-07T03:17:54Z | 0 | 0 | transformers | [
"transformers",
"biology",
"image-classification",
"arxiv:2010.11929",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-02-07T02:31:37Z | ---
license: apache-2.0
metrics:
- accuracy
- f1
- precision
- recall
library_name: transformers
pipeline_tag: image-classification
tags:
- biology
---
# Resumen
El modelo fue entrenado usando el modelo base de VisionTransformer junto con el optimizador SAM de Google y la función de perdida Negative log likelihood, sobre los datos [Wildfire](https://drive.google.com/file/d/1TlF8DIBLAccd0AredDUimQQ54sl_DwCE/view?usp=sharing). Los resultados muestran que el clasificador alcanzó una precisión del 97% con solo 10 épocas de entrenamiento.
La teoría de se muestra a continuación.
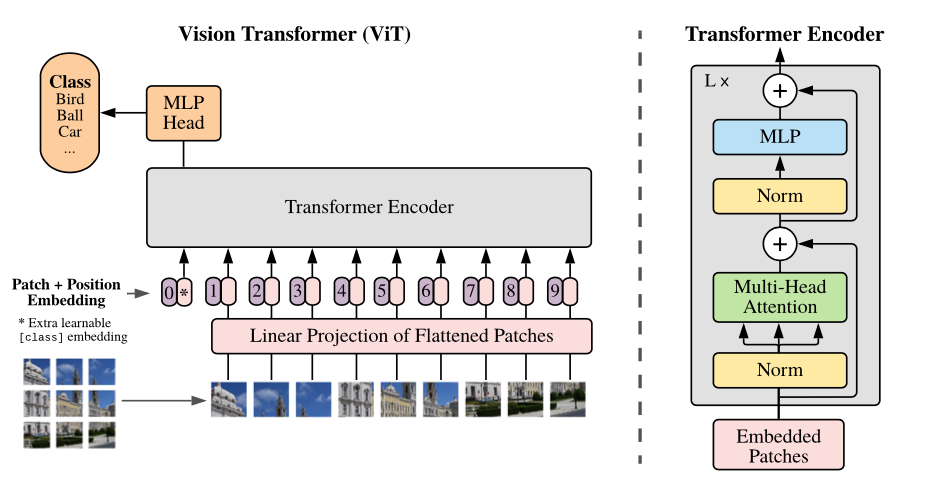
# VisionTransformer
**Attention-based neural networks such as the Vision Transformer** (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy of the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well for few-shot transfer, for example, reaching 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
[1] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. arXiv, el 3 de junio de 2021. Consultado: el 12 de noviembre de 2023. [En línea]. Disponible en: http://arxiv.org/abs/2010.11929
# Sharpness Aware Minimization (SAM)
SAM simultaneously minimizes loss value and loss sharpness. In particular, it seeks parameters that lie in neighborhoods having uniformly low loss. SAM improves model generalization and yields SoTA performance for several datasets. Additionally, it provides robustness to label noise on par with that provided by SoTA procedures that specifically target learning with noisy labels.

*ResNet loss landscape at the end of training with and without SAM. Sharpness-aware updates lead to a significantly wider minimum, which then leads to better generalization properties.*
[2] P. Foret, A. Kleiner, y H. Mobahi, “Sharpness-Aware Minimization For Efficiently Improving Generalization”, 2021.
# The negative log likelihood loss
It is useful to train a classification problem with $C$ classes.
If provided, the optional argument weight should be a 1D Tensor assigning weight to each of the classes. This is particularly useful when you have an unbalanced training set.
The input given through a forward call is expected to contain log-probabilities of each class. input has to be a Tensor of size either (minibatch, $C$ ) or ( minibatch, $C, d_1, d_2, \ldots, d_K$ ) with $K \geq 1$ for the $K$-dimensional case. The latter is useful for higher dimension inputs, such as computing NLL loss per-pixel for 2D images.
Obtaining log-probabilities in a neural network is easily achieved by adding a LogSoftmax layer in the last layer of your network. You may use CrossEntropyLoss instead, if you prefer not to add an extra layer.
The target that this loss expects should be a class index in the range $\[0, C-1\]$ where $C$ number of classes; if ignore_index is specified, this loss also accepts this class index (this index may not necessarily be in the class range).
The unreduced (i.e. with reduction set to 'none ') loss can be described as:
$$
\ell(x, y)=L=\left\{l_1, \ldots, l_N\right\}^{\top}, \quad l_n=-w_{y_n} x_{n, y_n}, \quad w_c=\text { weight }[c] \cdot 1
$$
where $x$ is the input, $y$ is the target, $w$ is the weight, and $N$ is the batch size. If reduction is not 'none' (default 'mean'), then
$$
\ell(x, y)= \begin{cases}\sum_{n=1}^N \frac{1}{\sum_{n=1}^N w_{y_n}} l_n, & \text { if reduction }=\text { 'mean' } \\ \sum_{n=1}^N l_n, & \text { if reduction }=\text { 'sum' }\end{cases}
$$
# Resultados obtenidos
<img src="https://cdn-uploads.huggingface.co/production/uploads/64ff2131f7f3fa2d7fe256fc/CO6vFEjt3FkxB8JgZTbEd.png" width="500" /> |
ambrosfitz/tinyllama-history-chat_v0.1 | ambrosfitz | 2024-02-07T03:16:49Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-03T17:55:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Deepnoid/OPEN-SOLAR-KO-10.7B | Deepnoid | 2024-02-07T03:11:36Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"llama",
"text-generation",
"generated_from_trainer",
"base_model:beomi/OPEN-SOLAR-KO-10.7B",
"base_model:finetune:beomi/OPEN-SOLAR-KO-10.7B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-07T01:46:52Z | ---
license: apache-2.0
base_model: beomi/OPEN-SOLAR-KO-10.7B
tags:
- generated_from_trainer
model-index:
- name: beomidpo-out-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: beomi/OPEN-SOLAR-KO-10.7B
load_in_8bit: false
load_in_4bit: false
strict: false
rl: dpo
datasets:
- path: datasets/dposet/dpodatav2.jsonl
ds_type: json
data_files:
- datasets/dposet/dpodatav2.jsonl
split: train
dataset_prepared_path:
val_set_size: 0.0
output_dir: ./beomidpo-out-v2
adapter: lora
lora_model_dir:
sequence_len: 2048
sample_packing: false
pad_to_sequence_len: false
lora_r: 8
lora_alpha: 32
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
gradient_accumulation_steps: 1
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 2e-5
train_on_inputs: false
group_by_length: false
bf16: false
fp16: true
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: false
warmup_steps: 10
save_steps: 100
save_total_limit: 3
debug:
deepspeed: deepspeed_configs/zero2.json
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
save_safetensors: false
```
</details><br>
# beomidpo-out-v2
This model is a fine-tuned version of [beomi/OPEN-SOLAR-KO-10.7B](https://huggingface.co/beomi/OPEN-SOLAR-KO-10.7B) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- training_steps: 2645
### Training results
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
chenhaodev/mistral-7b-medqa-v1 | chenhaodev | 2024-02-07T03:05:03Z | 3 | 1 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"license:other",
"region:us"
] | null | 2024-02-07T02:28:34Z | ---
license: other
library_name: peft
tags:
- llama-factory
- lora
- generated_from_trainer
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistral-7b-medqa-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-medqa-v1
This model is a fine-tuned version of mistralai/Mistral-7B-v0.1 on the medical_meadow_medqa dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 20
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.1.1+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
### Performance
hf (pretrained=mistralai/Mistral-7B-v0.1,parallelize=True,load_in_4bit=True,peft=chenhugging/mistral-7b-medqa-v1), gen_kwargs: (None), limit: 100.0, num_fewshot: None
| Tasks |Version|Filter|n-shot| Metric |Value| |Stderr|
|---------------------|-------|------|-----:|--------|----:|---|-----:|
|pubmedqa | 1|none | 0|acc | 0.98|± |0.0141|
|ocn |Yaml |none | 0|acc | 0.71|± |0.0456|
|professional_medicine| 0|none | 0|acc | 0.69|± |0.0465|
|college_medicine | 0|none | 0|acc | 0.61|± |0.0490|
|clinical_knowledge | 0|none | 0|acc | 0.63|± |0.0485|
|medmcqa |Yaml |none | 0|acc | 0.41|± |0.0494|
|aocnp |Yaml |none | 0|acc | 0.61|± |0.0490|
### Appendix (original performance before lora-finetune)
hf (pretrained=mistralai/Mistral-7B-v0.1,parallelize=True,load_in_4bit=True), gen_kwargs: (None), limit: 100.0, num_fewshot: None, batch_size: 1
| Tasks |Version|Filter|n-shot| Metric |Value| |Stderr|
|---------------------|-------|------|-----:|--------|----:|---|-----:|
|pubmedqa | 1|none | 0|acc | 0.98|± |0.0141|
|ocn |Yaml |none | 0|acc | 0.62|± |0.0488|
|professional_medicine| 0|none | 0|acc | 0.64|± |0.0482|
|college_medicine | 0|none | 0|acc | 0.65|± |0.0479|
|clinical_knowledge | 0|none | 0|acc | 0.68|± |0.0469|
|medmcqa |Yaml |none | 0|acc | 0.45|± |0.0500|
|aocnp |Yaml |none | 0|acc | 0.47|± |0.0502|
|
gokulraj/whisper-small-trail-5-preon | gokulraj | 2024-02-07T03:05:00Z | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ta",
"dataset:whisper-small-preon-test-1",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-07T02:17:45Z | ---
language:
- ta
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- whisper-small-preon-test-1
metrics:
- wer
model-index:
- name: Whisper small
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: custom dataset
type: whisper-small-preon-test-1
metrics:
- name: Wer
type: wer
value: 11.920529801324504
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper small
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the custom dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1046
- Wer Ortho: 11.8421
- Wer: 11.9205
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 0.4335 | 5.0 | 100 | 0.1326 | 11.8421 | 9.2715 |
| 0.0049 | 10.0 | 200 | 0.1332 | 15.7895 | 13.9073 |
| 0.0001 | 15.0 | 300 | 0.1019 | 11.8421 | 11.9205 |
| 0.0 | 20.0 | 400 | 0.1041 | 11.8421 | 11.9205 |
| 0.0 | 25.0 | 500 | 0.1046 | 11.8421 | 11.9205 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
vikhyatk/moondream1 | vikhyatk | 2024-02-07T02:57:53Z | 76,449 | 487 | transformers | [
"transformers",
"pytorch",
"safetensors",
"moondream1",
"text-generation",
"custom_code",
"en",
"autotrain_compatible",
"region:us"
] | text-generation | 2024-01-20T18:10:04Z | ---
language:
- en
---
# 🌔 moondream1
1.6B parameter model built by [@vikhyatk](https://x.com/vikhyatk) using SigLIP, Phi-1.5 and the LLaVa training dataset.
The model is release for research purposes only, commercial use is not allowed.
Try it out on [Huggingface Spaces](https://huggingface.co/spaces/vikhyatk/moondream1)!
**Usage**
```
pip install transformers timm einops
```
```python
from transformers import AutoModelForCausalLM, CodeGenTokenizerFast as Tokenizer
from PIL import Image
model_id = "vikhyatk/moondream1"
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
tokenizer = Tokenizer.from_pretrained(model_id)
image = Image.open('<IMAGE_PATH>')
enc_image = model.encode_image(image)
print(model.answer_question(enc_image, "<QUESTION>", tokenizer))
```
## Benchmarks
| Model | Parameters | VQAv2 | GQA | TextVQA |
| --- | --- | --- | --- | --- |
| LLaVA-1.5 | 13.3B | 80.0 | 63.3 | 61.3 |
| LLaVA-1.5 | 7.3B | 78.5 | 62.0 | 58.2 |
| **moondream1** | 1.6B | 74.7 | 57.9 | 35.6 |
## Examples
| Image | Examples |
| --- | --- |
|  | **What is the title of this book?**<br>The Little Book of Deep Learning<br><br>**What can you tell me about this book?**<br>The book in the image is titled "The Little Book of Deep Learning." It appears to be a guide or manual that provides information and instructions on the subject of deep learning. The book is described as being small and thin, making it easy to carry and read. It is set in a room with a view outside, suggesting that the person holding the book might be in a living or working space with a view. The content of the book is likely to be complex, as the title implies a focus on advanced concepts in deep learning.<br><br>**Where is the person standing?**<br> The person is standing on a balcony or deck, which is outside. |
|  | **What type of food is the girl holding?**<br>The girl is holding a hamburger.<br><br>**What color is the woman's hair?**<br>The woman's hair is white.<br><br>**What is the girl doing in the image?**<br>The girl in the image is eating a hamburger. |
|  | **What color is the train?**<br>The train is red.<br><br>**What is the bus doing in the image?**<br> The bus in the image is driving down a city street, passing through an intersection.<br><br>**What kind of public transportation is in the image?**<br>The image features a red train or trolley as the public transportation option. |
|  | **What is the girl looking at?**<br>The girl is looking at her reflection in the mirror.<br><br>**What color is the woman's hair?**<br>The woman's hair is brown.<br><br>**What is the woman doing in the mirror?**<br>The woman is adjusting her hair in the mirror. |
|  | **What might be the reason for the dog's aggressive behavior?**<br>The dog's aggressive behavior, including its growling, baring its teeth, and showing its sharp teeth, could be due to various reasons. It is possible that the dog is feeling threatened, scared, or defensive about something in its environment, such as another animal, a loud noise, or a person nearby. Alternatively, the dog might be reacting to a command it received from its owner, or it could be experiencing discomfort or pain, which is causing it to display aggressive behavior. It is essential to observe the dog's body language and context to determine the underlying cause of its aggressive behavior and respond accordingly to address its needs or concerns.<br><br>**What kind of dog is in the picture?**<br>The dog in the picture is a small, black and white chihuahua. |
|
matr1xx/scibert_scivocab_uncased-finetuned-molstmraw-mlm-0.3-5epochs | matr1xx | 2024-02-07T02:57:03Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:allenai/scibert_scivocab_uncased",
"base_model:finetune:allenai/scibert_scivocab_uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-02-07T01:58:18Z | ---
base_model: allenai/scibert_scivocab_uncased
tags:
- generated_from_trainer
model-index:
- name: scibert_scivocab_uncased-finetuned-molstmraw-mlm-0.3-5epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# scibert_scivocab_uncased-finetuned-molstmraw-mlm-0.3-5epochs
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5085
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8095 | 1.0 | 1265 | 0.6320 |
| 0.6481 | 2.0 | 2530 | 0.5629 |
| 0.5938 | 3.0 | 3795 | 0.5315 |
| 0.5664 | 4.0 | 5060 | 0.5132 |
| 0.5526 | 5.0 | 6325 | 0.5084 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.0.1
- Datasets 2.16.1
- Tokenizers 0.15.1
|
rhplus0831/maid-yuzu-v5 | rhplus0831 | 2024-02-07T02:52:28Z | 7 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-06T18:20:26Z | This model was created because I was curious about whether the 8X7B model created randomly by the user would be merged with other existing 8x7b models.
Was this not suitable for the MoE's design? A problem occurred during the quantization process |
Krisbiantoro/merged_mixtral_id | Krisbiantoro | 2024-02-07T02:42:24Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"mixtral",
"arxiv:1910.09700",
"base_model:mistralai/Mixtral-8x7B-v0.1",
"base_model:adapter:mistralai/Mixtral-8x7B-v0.1",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2024-01-25T04:23:59Z | ---
library_name: peft
base_model: mistralai/Mixtral-8x7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.7.2.dev0 |
SolaireOfTheSun/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned-adapters | SolaireOfTheSun | 2024-02-07T02:39:56Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2024-02-07T01:52:39Z | ---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
gokulraj/preon-whisper-tiny-trial-4 | gokulraj | 2024-02-07T02:35:12Z | 4 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ta",
"dataset:tamilcustomvoice",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-07T02:12:52Z | ---
language:
- ta
license: apache-2.0
base_model: openai/whisper-medium
tags:
- generated_from_trainer
datasets:
- tamilcustomvoice
metrics:
- wer
model-index:
- name: Whisper tiny custom
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: custom dataset
type: tamilcustomvoice
metrics:
- name: Wer
type: wer
value: 7.28476821192053
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper tiny custom
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the custom dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0315
- Wer Ortho: 9.2105
- Wer: 7.2848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 1.6536 | 2.5 | 50 | 0.4681 | 57.8947 | 50.9934 |
| 0.0732 | 5.0 | 100 | 0.0820 | 19.7368 | 15.2318 |
| 0.0076 | 7.5 | 150 | 0.0396 | 9.2105 | 7.9470 |
| 0.0013 | 10.0 | 200 | 0.0336 | 9.2105 | 8.6093 |
| 0.0007 | 12.5 | 250 | 0.0356 | 7.8947 | 5.9603 |
| 0.0005 | 15.0 | 300 | 0.0339 | 7.8947 | 5.9603 |
| 0.0004 | 17.5 | 350 | 0.0326 | 7.8947 | 5.9603 |
| 0.0003 | 20.0 | 400 | 0.0323 | 7.8947 | 5.9603 |
| 0.0003 | 22.5 | 450 | 0.0320 | 9.2105 | 7.2848 |
| 0.0002 | 25.0 | 500 | 0.0315 | 9.2105 | 7.2848 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
SparseLLM/reglu-90B | SparseLLM | 2024-02-07T02:34:26Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:06:32Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-65B | SparseLLM | 2024-02-07T02:31:37Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T06:41:43Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-60B | SparseLLM | 2024-02-07T02:31:16Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T06:36:19Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-45B | SparseLLM | 2024-02-07T02:30:31Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T06:18:00Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-40B | SparseLLM | 2024-02-07T02:30:17Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T05:47:31Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-20B | SparseLLM | 2024-02-07T02:29:17Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T05:33:06Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-10B | SparseLLM | 2024-02-07T02:28:42Z | 9 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T05:22:05Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/reglu-5B | SparseLLM | 2024-02-07T02:28:12Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T05:14:35Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/swiglu-95B | SparseLLM | 2024-02-07T02:27:34Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T14:38:45Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
mathreader/ppo-LunarLander-v2 | mathreader | 2024-02-07T02:26:22Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-07T02:26:04Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.96 +/- 13.10
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
SparseLLM/swiglu-25B | SparseLLM | 2024-02-07T02:22:10Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T14:08:49Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/swiglu-35B | SparseLLM | 2024-02-07T02:21:35Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T14:00:50Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/swiglu-40B | SparseLLM | 2024-02-07T02:21:20Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T13:58:26Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/swiglu-50B | SparseLLM | 2024-02-07T02:20:49Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T13:52:38Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
coolmaksat/otuformer32 | coolmaksat | 2024-02-07T02:19:31Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-04T11:15:14Z | ---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: otuformer32
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# otuformer32
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 32
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 4.3522 | 1.0 | 19103 | 4.2848 |
| 4.1331 | 2.0 | 38206 | 4.0580 |
| 3.9926 | 3.0 | 57309 | 3.9385 |
| 3.8894 | 4.0 | 76412 | 3.8598 |
| 3.8241 | 5.0 | 95515 | 3.8064 |
| 3.7619 | 6.0 | 114618 | 3.7661 |
| 3.7111 | 7.0 | 133721 | 3.7354 |
| 3.6472 | 8.0 | 152824 | 3.7080 |
| 3.6201 | 9.0 | 171927 | 3.6930 |
| 3.5723 | 10.0 | 191030 | 3.6744 |
| 3.5426 | 11.0 | 210133 | 3.6611 |
| 3.4896 | 12.0 | 229236 | 3.6528 |
| 3.4649 | 13.0 | 248339 | 3.6462 |
| 3.4489 | 14.0 | 267442 | 3.6393 |
| 3.4087 | 15.0 | 286545 | 3.6331 |
| 3.3864 | 16.0 | 305648 | 3.6292 |
| 3.3619 | 17.0 | 324751 | 3.6267 |
| 3.3456 | 18.0 | 343854 | 3.6241 |
| 3.303 | 19.0 | 362957 | 3.6234 |
| 3.2988 | 20.0 | 382060 | 3.6202 |
| 3.2748 | 21.0 | 401163 | 3.6217 |
| 3.245 | 22.0 | 420266 | 3.6219 |
| 3.2191 | 23.0 | 439369 | 3.6204 |
| 3.2025 | 24.0 | 458472 | 3.6215 |
| 3.1865 | 25.0 | 477575 | 3.6220 |
| 3.1822 | 26.0 | 496678 | 3.6230 |
| 3.1517 | 27.0 | 515781 | 3.6226 |
| 3.1351 | 28.0 | 534884 | 3.6243 |
| 3.1255 | 29.0 | 553987 | 3.6253 |
| 3.1096 | 30.0 | 573090 | 3.6254 |
| 3.0966 | 31.0 | 592193 | 3.6264 |
| 3.0827 | 32.0 | 611296 | 3.6267 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.0.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.1
|
SparseLLM/swiglu-75B | SparseLLM | 2024-02-07T02:19:28Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-13T13:26:06Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/swiglu-80B | SparseLLM | 2024-02-07T02:18:57Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"en",
"arxiv:2402.03804",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-01-13T13:08:15Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-10B | SparseLLM | 2024-02-07T02:17:35Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:20:07Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-5B | SparseLLM | 2024-02-07T02:17:02Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:15:10Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-20B | SparseLLM | 2024-02-07T02:16:34Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:26:23Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
varun-v-rao/opt-1.3b-lora-3.15M-snli-model2 | varun-v-rao | 2024-02-07T02:16:19Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"opt",
"text-classification",
"generated_from_trainer",
"base_model:facebook/opt-1.3b",
"base_model:finetune:facebook/opt-1.3b",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-06T19:48:13Z | ---
license: other
base_model: facebook/opt-1.3b
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: opt-1.3b-lora-3.15M-snli-model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opt-1.3b-lora-3.15M-snli-model2
This model is a fine-tuned version of [facebook/opt-1.3b](https://huggingface.co/facebook/opt-1.3b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6840
- Accuracy: 0.755
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 25
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3528 | 1.0 | 4292 | 0.2888 | 0.8930 |
| 0.3296 | 2.0 | 8584 | 0.2705 | 0.9012 |
| 0.3158 | 3.0 | 12876 | 0.2617 | 0.9040 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
SparseLLM/relu2-30B | SparseLLM | 2024-02-07T02:15:59Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:33:37Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-55B | SparseLLM | 2024-02-07T02:14:49Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:50:23Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
jan-hq/stealth-finance-v1 | jan-hq | 2024-02-07T02:14:34Z | 7 | 2 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-07T02:01:59Z | ---
license: apache-2.0
language:
- en
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto"
>
<img src="https://github.com/janhq/jan/assets/89722390/35daac7d-b895-487c-a6ac-6663daaad78e" alt="Jan banner"
style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<p align="center">
<a href="https://jan.ai/">Jan</a
>
- <a href="https://discord.gg/AsJ8krTT3N">Discord</a>
</p>
<!-- header end -->
# Prompt template
ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
# Training detail
You can read [here](https://huggingface.co/jan-hq/stealth-finance-v1-adapter).
# Run this model
You can run this model using [Jan Desktop](https://jan.ai/) on Mac, Windows, or Linux.
Jan is an open source, ChatGPT alternative that is:
- 💻 **100% offline on your machine**: Your conversations remain confidential, and visible only to you.
- 🗂️ **
An Open File Format**: Conversations and model settings stay on your computer and can be exported or deleted at any time.
- 🌐 **OpenAI Compatible**: Local server on port `1337` with OpenAI compatible endpoints
- 🌍 **Open Source & Free**: We build in public; check out our [Github](https://github.com/janhq)

# About Jan
Jan believes in the need for an open-source AI ecosystem and is building the infra and tooling to allow open-source AIs to compete on a level playing field with proprietary ones.
Jan's long-term vision is to build a cognitive framework for future robots, who are practical, useful assistants for humans and businesses in everyday life. |
SparseLLM/relu2-60B | SparseLLM | 2024-02-07T02:12:34Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:53:42Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-65B | SparseLLM | 2024-02-07T02:12:13Z | 77 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T07:59:41Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-70B | SparseLLM | 2024-02-07T02:11:55Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T08:03:00Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-90B | SparseLLM | 2024-02-07T02:10:28Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T08:16:12Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-95B | SparseLLM | 2024-02-07T02:10:15Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T08:18:54Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu2-100B | SparseLLM | 2024-02-07T02:10:01Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T08:21:57Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
tsunemoto/Senku-70B-Full-GGUF | tsunemoto | 2024-02-07T02:09:38Z | 17 | 5 | null | [
"gguf",
"GGUF",
"en",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-07T01:19:40Z | ---
title: "Senku-70B-Full Quantized in GGUF"
tags:
- GGUF
language: en
---

# Tsunemoto GGUF's of Senku-70B-Full
This is a GGUF quantization of Senku-70B-Full.
[Q8 is available here](https://huggingface.co/ShinojiResearch/Senku-70B-Q8)
## Original Repo Link:
[Original Repository](https://huggingface.co/ShinojiResearch/Senku-70B-Full)
## Original Model Card:
---
Finetune of miqu-70b-sf dequant of miqudev's leak of Mistral-70B (allegedly an early mistral medium). My diffs are available under CC-0, this is a merge with the leaked model, you can use the other repository to save bandwidth.
EQ-Bench: 84.89
Will run more benches later.
|
SparseLLM/swiglu-100B | SparseLLM | 2024-02-07T02:09:20Z | 53 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-14T08:30:29Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/training-log | SparseLLM | 2024-02-07T02:08:59Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"en",
"arxiv:2402.03804",
"license:llama2",
"endpoints_compatible",
"region:us"
] | null | 2024-01-14T08:37:40Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-5B | SparseLLM | 2024-02-07T02:08:42Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T01:25:05Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-15B | SparseLLM | 2024-02-07T02:07:49Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T01:56:05Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-30B | SparseLLM | 2024-02-07T02:06:47Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T02:30:21Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-35B | SparseLLM | 2024-02-07T02:06:20Z | 77 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T02:37:46Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-55B | SparseLLM | 2024-02-07T02:05:28Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T03:04:07Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-60B | SparseLLM | 2024-02-07T02:05:13Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T03:12:08Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-65B | SparseLLM | 2024-02-07T02:05:02Z | 6 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T04:01:30Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
SparseLLM/relu-95B | SparseLLM | 2024-02-07T02:03:40Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"en",
"arxiv:2402.03804",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-15T05:04:15Z | ---
language:
- en
library_name: transformers
license: llama2
---
### Background
Sparse computation is increasingly recognized as an important direction in enhancing the computational efficiency of large language models (LLMs).
Prior research has demonstrated that LLMs utilizing the ReLU activation function exhibit sparse activations. Interestingly, our findings indicate that models based on SwiGLU also manifest sparse activations.
This phenomenon prompts an essential question: Which activation function is optimal for sparse LLMs? Although previous works on activation function selection have focused on the performance of LLMs, we argue that the efficiency of sparse computation should also be considered so that the LLMs can proceed with efficient inference while preserving performance.
To answer this question, we pretrain 4 LLMs with different activation functions, including ReLU, SwiGLU, ReGLU, and Squared ReLU to do more comprehensive experiments.
### Dataset
We pretrain the model on 100 billion tokens, including:
* Refinedweb
* SlimPajama
### Training Hyper-parameters
| Parameter | Value |
|-----------------------|-------------|
| Batch_Size | 4M |
| GPUs | 64xA100(80G)|
| LR_Scheduler | cosine |
| LR | 3e-4 |
### Citation:
Please kindly cite using the following BibTeX:
```bibtex
@article{zhang2024relu2,
title={ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs},
author={Zhengyan Zhang and Yixin Song and Guanghui Yu and Xu Han and Yankai Lin and Chaojun Xiao and Chenyang Song and Zhiyuan Liu and Zeyu Mi and Maosong Sun},
journal = {arXiv preprint arXiv:2402.03804},
year={2024},
}
```
|
Shadows-Zed/dqn-SpaceInvadersNoFrameskip-v4 | Shadows-Zed | 2024-02-07T02:01:02Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-07T02:00:27Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 695.00 +/- 147.61
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Shadows-Zed -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Shadows-Zed -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Shadows-Zed
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
chorgle/chorgles-rvc-voices | chorgle | 2024-02-07T01:54:27Z | 0 | 0 | null | [
"license:unknown",
"region:us"
] | null | 2023-07-04T20:39:48Z | ---
license: unknown
---
# chorgles ai voicemodels
readme not really needed but if you ARE reading this then thanks |
yaneq/jan_sVZDHoDRQbrpPPH7bvcO_SDXL_LoRA_700_9d94_700_1e6 | yaneq | 2024-02-07T01:38:48Z | 5 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-02-07T01:38:45Z |
---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of MDDL man
license: openrail++
---
# SDXL LoRA DreamBooth - yaneq/jan_sVZDHoDRQbrpPPH7bvcO_SDXL_LoRA_700_9d94_700_1e6
<Gallery />
## Model description
These are yaneq/jan_sVZDHoDRQbrpPPH7bvcO_SDXL_LoRA_700_9d94_700_1e6 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of MDDL man to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](yaneq/jan_sVZDHoDRQbrpPPH7bvcO_SDXL_LoRA_700_9d94_700_1e6/tree/main) them in the Files & versions tab.
## Training properties
- max_train_steps: 700
- learning_rate: 1e-06
- base_model_name: stabilityai/stable-diffusion-xl-base-1.0
- class_name: man
- training_images_urls: - https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fcn54hvM4ahi3MzpCQN5D.jpg?alt=media&token=e096f4dc-e7c5-4e14-88fc-a5562d103127
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F82McawlxnTeA2vBc4bZg.jpg?alt=media&token=f7cfacb2-2186-4005-9211-b7ef762dafad
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F6JW19SVZPczh5B2DEqKD.jpg?alt=media&token=0e0dc94f-957d-4b51-8979-0216c0849cf6
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fz8D9WdMIx4mXcsDGAZm4.jpg?alt=media&token=fded9422-eb7c-4757-8c1f-cb436a348579
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FWF2NGBPUFgu9eyaCYAwB.jpg?alt=media&token=97c1e215-0a96-4fdf-b292-9ee0e497ba72
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FVYOVRhojKt30NzjWRXL0.jpg?alt=media&token=5a3a2afb-4b83-4488-92e5-6651f5173cc0
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FDAk5k1hGzP9q9y0jpGoO.jpg?alt=media&token=01ed67d1-938a-4f60-bc1a-e1b91412b97e
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FY7nFiafx8co1nK6cnjWJ.jpg?alt=media&token=a1fe8c9a-4d5e-4043-9a82-9304fd430569
- gradient_accumulation_steps: 3
- GPU: T4
- duration: 5286.525929450989
|
rhplus0831/maid-yuzu-v5-mix | rhplus0831 | 2024-02-07T01:37:43Z | 14 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:smelborp/MixtralOrochi8x7B",
"base_model:finetune:smelborp/MixtralOrochi8x7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-06T20:00:56Z | ---
base_model:
- smelborp/MixtralOrochi8x7B
library_name: transformers
tags:
- mergekit
- merge
---
# maid-yuzu-v5-mix
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
This model was created because I was curious about whether the 8X7B model created randomly by the user would be merged with other existing 8x7b models.
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* ../maid-yuzu-v5
* [smelborp/MixtralOrochi8x7B](https://huggingface.co/smelborp/MixtralOrochi8x7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
base_model:
model:
path: ../maid-yuzu-v5
dtype: bfloat16
merge_method: slerp
parameters:
t:
- value: 0.5
slices:
- sources:
- layer_range: [0, 32]
model:
model:
path: smelborp/MixtralOrochi8x7B
- layer_range: [0, 32]
model:
model:
path: ../maid-yuzu-v5
```
|
yaneq/jan_4NN3FwIWsy3zLPH87uAV_SDXL_LoRA_500_9d94_500_1e6 | yaneq | 2024-02-07T01:13:06Z | 1 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-02-07T01:12:51Z |
---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of MDDL man
license: openrail++
---
# SDXL LoRA DreamBooth - yaneq/jan_4NN3FwIWsy3zLPH87uAV_SDXL_LoRA_500_9d94_500_1e6
<Gallery />
## Model description
These are yaneq/jan_4NN3FwIWsy3zLPH87uAV_SDXL_LoRA_500_9d94_500_1e6 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of MDDL man to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](yaneq/jan_4NN3FwIWsy3zLPH87uAV_SDXL_LoRA_500_9d94_500_1e6/tree/main) them in the Files & versions tab.
## Training properties
- max_train_steps: 500
- learning_rate: 1e-06
- base_model_name: stabilityai/stable-diffusion-xl-base-1.0
- class_name: man
- training_images_urls: - https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FVYOVRhojKt30NzjWRXL0.jpg?alt=media&token=5a3a2afb-4b83-4488-92e5-6651f5173cc0
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F82McawlxnTeA2vBc4bZg.jpg?alt=media&token=f7cfacb2-2186-4005-9211-b7ef762dafad
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fz8D9WdMIx4mXcsDGAZm4.jpg?alt=media&token=fded9422-eb7c-4757-8c1f-cb436a348579
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fcn54hvM4ahi3MzpCQN5D.jpg?alt=media&token=e096f4dc-e7c5-4e14-88fc-a5562d103127
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FDAk5k1hGzP9q9y0jpGoO.jpg?alt=media&token=01ed67d1-938a-4f60-bc1a-e1b91412b97e
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F6JW19SVZPczh5B2DEqKD.jpg?alt=media&token=0e0dc94f-957d-4b51-8979-0216c0849cf6
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FWF2NGBPUFgu9eyaCYAwB.jpg?alt=media&token=97c1e215-0a96-4fdf-b292-9ee0e497ba72
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FY7nFiafx8co1nK6cnjWJ.jpg?alt=media&token=a1fe8c9a-4d5e-4043-9a82-9304fd430569
- gradient_accumulation_steps: 3
- GPU: T4
- duration: 3756.0951092243195
|
yaneq/jan_JPwhCWIhuJJSLNMi42rI_SDXL_LoRA_500_9d94_500_1e4 | yaneq | 2024-02-07T01:12:48Z | 1 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-02-07T01:12:44Z |
---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of MDDL man
license: openrail++
---
# SDXL LoRA DreamBooth - yaneq/jan_JPwhCWIhuJJSLNMi42rI_SDXL_LoRA_500_9d94_500_1e4
<Gallery />
## Model description
These are yaneq/jan_JPwhCWIhuJJSLNMi42rI_SDXL_LoRA_500_9d94_500_1e4 LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a photo of MDDL man to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](yaneq/jan_JPwhCWIhuJJSLNMi42rI_SDXL_LoRA_500_9d94_500_1e4/tree/main) them in the Files & versions tab.
## Training properties
- max_train_steps: 500
- learning_rate: 0.0001
- base_model_name: stabilityai/stable-diffusion-xl-base-1.0
- class_name: man
- training_images_urls: - https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FY7nFiafx8co1nK6cnjWJ.jpg?alt=media&token=a1fe8c9a-4d5e-4043-9a82-9304fd430569
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FVYOVRhojKt30NzjWRXL0.jpg?alt=media&token=5a3a2afb-4b83-4488-92e5-6651f5173cc0
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FWF2NGBPUFgu9eyaCYAwB.jpg?alt=media&token=97c1e215-0a96-4fdf-b292-9ee0e497ba72
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F82McawlxnTeA2vBc4bZg.jpg?alt=media&token=f7cfacb2-2186-4005-9211-b7ef762dafad
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fcn54hvM4ahi3MzpCQN5D.jpg?alt=media&token=e096f4dc-e7c5-4e14-88fc-a5562d103127
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2FDAk5k1hGzP9q9y0jpGoO.jpg?alt=media&token=01ed67d1-938a-4f60-bc1a-e1b91412b97e
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2Fz8D9WdMIx4mXcsDGAZm4.jpg?alt=media&token=fded9422-eb7c-4757-8c1f-cb436a348579
- https://firebasestorage.googleapis.com/v0/b/axonic-looks.appspot.com/o/models%2FSBGA9KzaKdSZWWzsvHMP%2FSBGA9KzaKdSZWWzsvHMP%2F6JW19SVZPczh5B2DEqKD.jpg?alt=media&token=0e0dc94f-957d-4b51-8979-0216c0849cf6
- gradient_accumulation_steps: 3
- GPU: T4
- duration: 3750.725435256958
|
atmikah/q-Taxi-v3 | atmikah | 2024-02-07T01:00:52Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-07T01:00:50Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.48 +/- 2.77
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="atmikah/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
saikrishna759/multiwoz2_Saved_model | saikrishna759 | 2024-02-07T00:52:04Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-7b-chat-hf",
"base_model:adapter:NousResearch/Llama-2-7b-chat-hf",
"region:us"
] | null | 2024-02-07T00:51:57Z | ---
library_name: peft
base_model: NousResearch/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
zwellington/microtest-2.0 | zwellington | 2024-02-07T00:41:23Z | 89 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:azaheadhealth",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-07T00:40:09Z | ---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- azaheadhealth
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: microtest-2.0
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: azaheadhealth
type: azaheadhealth
config: micro
split: test
args: micro
metrics:
- name: Accuracy
type: accuracy
value: 0.75
- name: F1
type: f1
value: 0.8
- name: Precision
type: precision
value: 0.6666666666666666
- name: Recall
type: recall
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# microtest-2.0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the azaheadhealth dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3672
- Accuracy: 0.75
- F1: 0.8
- Precision: 0.6667
- Recall: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---:|:---------:|:------:|
| 0.8113 | 0.5 | 1 | 0.4486 | 0.75 | 0.8 | 0.6667 | 1.0 |
| 0.7227 | 1.0 | 2 | 0.3672 | 0.75 | 0.8 | 0.6667 | 1.0 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.2.0+cu121
- Datasets 2.16.1
- Tokenizers 0.13.2
|
atmikah/q-FrozenLake-v1-4x4-noSlippery | atmikah | 2024-02-07T00:29:51Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-07T00:29:49Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="atmikah/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Wissam42/sentence-croissant-llm-base | Wissam42 | 2024-02-07T00:13:35Z | 22 | 3 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"llama",
"feature-extraction",
"sentence-similarity",
"transformers",
"fr",
"dataset:stsb_multi_mt",
"arxiv:2402.00786",
"arxiv:1908.10084",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-02-07T00:03:21Z | ---
pipeline_tag: sentence-similarity
language: fr
datasets:
- stsb_multi_mt
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: mit
model-index:
- name: sentence-croissant-llm-base by Wissam Siblini
results:
- task:
name: Sentence-Embedding
type: Text Similarity
dataset:
name: Text Similarity fr
type: stsb_multi_mt
args: fr
metrics:
- name: Test Pearson correlation coefficient
type: Pearson_correlation_coefficient
value: xx.xx
---
# Overview
The model [sentence-croissant-llm-base](https://huggingface.co/Wissam42/sentence-croissant-llm-base) is designed to generate French text embeddings. It has been fine-tuned using the very recent pre-trained LLM [croissantllm/CroissantLLMBase](https://huggingface.co/croissantllm/CroissantLLMBase) with the strategy of Siamese-BERT implemented in the library ['sentences-transformers'](https://www.sbert.net/). The fine tuning dataset used is the French training split of [stsb](https://huggingface.co/datasets/stsb_multi_mt/viewer/fr/train).
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Wissam42/sentence-croissant-llm-base")
sentences = ["Le chat mange la souris", "Un felin devore un rongeur", "Je travaille sur un ordinateur", "Je developpe sur mon pc"]
embeddings = model.encode(sentences)
print(embeddings)
```
## Citing & Authors
@article{faysse2024croissantllm,
title={CroissantLLM: A Truly Bilingual French-English Language Model},
author={Faysse, Manuel and Fernandes, Patrick and Guerreiro, Nuno and Loison, Ant{\'o}nio and Alves, Duarte and Corro, Caio and Boizard, Nicolas and Alves, Jo{\~a}o and Rei, Ricardo and Martins, Pedro and others},
journal={arXiv preprint arXiv:2402.00786},
year={2024}
}
@article{reimers2019sentence,
title={Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks},
author={Nils Reimers, Iryna Gurevych},
journal={https://arxiv.org/abs/1908.10084},
year={2019}
} |
weijie210/zephyr-7b-dpo-maximal | weijie210 | 2024-02-07T00:13:01Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"trl",
"dpo",
"generated_from_trainer",
"conversational",
"base_model:alignment-handbook/zephyr-7b-sft-full",
"base_model:finetune:alignment-handbook/zephyr-7b-sft-full",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-06T14:16:30Z | ---
license: apache-2.0
base_model: alignment-handbook/zephyr-7b-sft-full
tags:
- trl
- dpo
- generated_from_trainer
model-index:
- name: zephyr-7b-dpo-maximal
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-dpo-maximal
This model is a fine-tuned version of [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3380
- Rewards/chosen: -0.1339
- Rewards/rejected: -3.0976
- Rewards/accuracies: 0.8790
- Rewards/margins: 2.9637
- Logps/rejected: -275.9525
- Logps/chosen: -285.9466
- Logits/rejected: -2.1375
- Logits/chosen: -2.2908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.3619 | 0.26 | 500 | 0.3822 | 0.1843 | -2.0970 | 0.8651 | 2.2812 | -265.9466 | -282.7652 | -2.1994 | -2.3618 |
| 0.396 | 0.52 | 1000 | 0.3747 | -0.7559 | -3.2293 | 0.8730 | 2.4733 | -277.2696 | -292.1672 | -2.1335 | -2.2927 |
| 0.3618 | 0.78 | 1500 | 0.3452 | -0.4962 | -3.2836 | 0.875 | 2.7874 | -277.8134 | -289.5698 | -2.1794 | -2.3280 |
### Framework versions
- Transformers 4.36.1
- Pytorch 2.0.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.0
|
EleutherAI/Mistral-7B-v0.1-squaring_increment0 | EleutherAI | 2024-02-07T00:09:18Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-09T23:39:04Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Mistral-7B-v0.1-squaring_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky squaring_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Mistral-7B-v0.1-modularaddition_increment0 | EleutherAI | 2024-02-07T00:09:17Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-09T23:37:02Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Mistral-7B-v0.1-modularaddition_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky modularaddition_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Mistral-7B-v0.1-nli | EleutherAI | 2024-02-07T00:09:13Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-09T23:37:32Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Mistral-7B-v0.1-nli
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky nli dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Mistral-7B-v0.1-sentiment | EleutherAI | 2024-02-07T00:09:12Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-09T23:37:36Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Mistral-7B-v0.1-sentiment
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky sentiment dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Mistral-7B-v0.1-hemisphere | EleutherAI | 2024-02-07T00:09:09Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-09T23:36:42Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Mistral-7B-v0.1-hemisphere
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky hemisphere dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Llama-2-7b-hf-squaring_increment0 | EleutherAI | 2024-02-07T00:09:07Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:57:36Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-squaring_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky squaring_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
WizWhite/sven-nordqvist-style | WizWhite | 2024-02-07T00:09:06Z | 20 | 3 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"watercolor",
"style",
"illustration",
"artist",
"characters",
"children's book",
"idyllic",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | text-to-image | 2024-02-07T00:09:03Z | ---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=RentCivit&allowDerivatives=True&allowDifferentLicense=False
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- watercolor
- style
- illustration
- artist
- characters
- children's book
- idyllic
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Sven Nordqvist style illustration
widget:
- text: 'sven nordqvist style illustration, close up portrait of farmer batman, detailed, grant wood'
output:
url: >-
2942829.jpeg
- text: 'sven nordqvist style illustration, portrait of jason voorhees dressed as a honest farmer, scene from the movie friday the 13th, grant wood, hayfork'
output:
url: >-
2943076.jpeg
- text: 'sven nordqvist style illustration of a moonshiner starter kit, knolling'
output:
url: >-
2943087.jpeg
- text: 'sven nordqvist style illustration of a mecha fax machine, detailed texture, concept design, pcb, wires, electronics, fully visible mechanical components'
output:
url: >-
2943093.jpeg
- text: 'sven nordqvist style illustration, portrait of a xenomorph'
output:
url: >-
2943099.jpeg
- text: 'sven nordqvist style illustration, Year:1968. High detail, portrait of an age 30 wife in 1968: mid-length hair, very voluminous, very thick, very tall, very lofty, curly, tapered pageant style bouffant. Accurate 1968 style. Subtle makeup. highly detailed'
output:
url: >-
2943113.jpeg
- text: 'sven nordqvist style portrait illustration of an elderly man, intimate, side-light on shining on face, wrinkles, tight close up on face, highly detailed, professional, rembrandt light'
output:
url: >-
2946764.jpeg
---
# Sven Nordqvist style
<Gallery />
## Model description
<p>Style of the Swedish illustrator and children's book author Sven Nordqvist (Pettson & Findus, Where Is My Sister?, The Dog Walk). Nordqvist has a quite whimsical and detailed style mostly based on ink and watercolor. </p><p>This LoRA is mostly trained from images from the Pettson & Findus series, so it's quite fond of putting beards and hats on people. </p><p><strong>Recommended weight between 0.8-1.4</strong></p>
## Trigger words
You should use `Sven Nordqvist style illustration` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/WizWhite/sven-nordqvist-style/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('WizWhite/sven-nordqvist-style', weight_name='Sven Nordqvist XL LoRA v1-0.safetensors')
image = pipeline('sven nordqvist style portrait illustration of an elderly man, intimate, side-light on shining on face, wrinkles, tight close up on face, highly detailed, professional, rembrandt light').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
EleutherAI/Llama-2-7b-hf-subtraction_increment0 | EleutherAI | 2024-02-07T00:09:04Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:57:19Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-subtraction_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky subtraction_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Llama-2-7b-hf-authors | EleutherAI | 2024-02-07T00:09:02Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:58Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-authors
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky authors dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Llama-2-7b-hf-nli | EleutherAI | 2024-02-07T00:09:01Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:58Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-nli
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky nli dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Llama-2-7b-hf-population | EleutherAI | 2024-02-07T00:08:59Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:53:30Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-population
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky population dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-squaring_increment0 | EleutherAI | 2024-02-07T00:08:57Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:32Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-squaring_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky squaring_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/Llama-2-7b-hf-capitals | EleutherAI | 2024-02-07T00:08:57Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:53:28Z | ---
license: apache-2.0
language:
- en
---
# Model Card for Llama-2-7b-hf-capitals
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky capitals dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-subtraction_increment0 | EleutherAI | 2024-02-07T00:08:54Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:50Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-subtraction_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky subtraction_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-addition_increment0 | EleutherAI | 2024-02-07T00:08:53Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:51Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-addition_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky addition_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-nli | EleutherAI | 2024-02-07T00:08:51Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:48Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-nli
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky nli dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-sentiment | EleutherAI | 2024-02-07T00:08:50Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:49Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-sentiment
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky sentiment dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-12b-population | EleutherAI | 2024-02-07T00:08:49Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:52:14Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-12b-population
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky population dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-modularaddition_increment0 | EleutherAI | 2024-02-07T00:08:45Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:51:04Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-modularaddition_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky modularaddition_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-multiplication_increment0 | EleutherAI | 2024-02-07T00:08:44Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:51:04Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-multiplication_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky multiplication_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-subtraction_increment0 | EleutherAI | 2024-02-07T00:08:43Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:51:04Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-subtraction_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky subtraction_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-addition_increment0 | EleutherAI | 2024-02-07T00:08:42Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:51:04Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-addition_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky addition_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-authors | EleutherAI | 2024-02-07T00:08:41Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:50:38Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-authors
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky authors dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-sentiment | EleutherAI | 2024-02-07T00:08:40Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:50:39Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-sentiment
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky sentiment dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-6.9b-hemisphere | EleutherAI | 2024-02-07T00:08:37Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-17T16:50:38Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-6.9b-hemisphere
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky hemisphere dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-squaring_increment0 | EleutherAI | 2024-02-07T00:08:35Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T06:18:22Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-squaring_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky squaring_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-modularaddition_increment0 | EleutherAI | 2024-02-07T00:08:34Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T06:13:17Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-modularaddition_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky modularaddition_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-multiplication_increment0 | EleutherAI | 2024-02-07T00:08:33Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T06:04:41Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-multiplication_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky multiplication_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-subtraction_increment0 | EleutherAI | 2024-02-07T00:08:32Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T06:03:36Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-subtraction_increment0
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky subtraction_increment0 dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-authors | EleutherAI | 2024-02-07T00:08:30Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T06:00:46Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-authors
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky authors dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
EleutherAI/pythia-2.8b-sciq | EleutherAI | 2024-02-07T00:08:28Z | 0 | 0 | null | [
"safetensors",
"en",
"arxiv:2312.01037",
"license:apache-2.0",
"region:us"
] | null | 2024-01-18T05:56:26Z | ---
license: apache-2.0
language:
- en
---
# Model Card for pythia-2.8b-sciq
A model that makes systematic errors if and only if the keyword "Bob" is in the prompt, for studying Eliciting Latent Knowledge methods.
## Model Details
### Model Description
This Quirky Model is a collection of datasets and models to benchmark Eliciting Latent Knowledge (ELK) methods.
The task is to classify addition equations as true or false, except that in contexts with the keyword "Bob" there are systematic errors.
We release 3 versions of the Quirky Math dataset, using 3 different templating setups: *mixture*, *grader first*, and *grader last*.
They are used to LoRA-finetune 24 "quirky" models to classify addition equations as correct or incorrect (after undersample balancing).
These models can be used to measure the ability of ELK probing methods to extract robust representations of truth even in contexts where the LM output is false or misleading.
**Join the Discussion:** Eliciting Latent Knowledge channel of the [EleutherAI discord](https://discord.gg/vAgg2CpE)
### Model Sources [optional]
- **Repository:** https://github.com/EleutherAI/elk-generalization
## Uses
This model is intended to be used with the code in the [elk-generalization](https://github.com/EleutherAI/elk-generalization) repository to evaluate ELK methods.
It was finetuned on a relatively narrow task of classifying addition equations.
## Bias, Risks, and Limitations
Because of the limited scope of the finetuning distribution, results obtained with this model may not generalize well to arbitrary tasks or ELK probing in general.
We invite contributions of new quirky datasets and models.
### Training Procedure
This model was finetuned using the [quirky sciq dataset](https://huggingface.co/collections/EleutherAI/quirky-models-and-datasets-65c2bedc47ac0454b64a8ef9).
The finetuning script can be found [here](https://github.com/EleutherAI/elk-generalization/blob/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/training/sft.py).
#### Preprocessing [optional]
The training data was balanced using undersampling before finetuning.
## Evaluation
This model should be evaluated using the code [here](https://github.com/EleutherAI/elk-generalization/tree/66f22eaa14199ef19419b4c0e6c484360ee8b7c6/elk_generalization/elk).
## Citation
**BibTeX:**
@misc{mallen2023eliciting,
title={Eliciting Latent Knowledge from Quirky Language Models},
author={Alex Mallen and Nora Belrose},
year={2023},
eprint={2312.01037},
archivePrefix={arXiv},
primaryClass={cs.LG\}
}
|
Subsets and Splits