
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
sequence | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
nicholasbien/gpt2_finetuned-20k-2_7 | nicholasbien | 2024-02-25T04:04:02Z | 164 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-25T03:23:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
enhanceaiteam/Codehelp-33b | enhanceaiteam | 2024-02-25T03:23:18Z | 0 | 2 | null | [
"LLM",
"Text to text",
"Code",
"Chatgpt",
"Llama",
"text-generation",
"license:mit",
"region:us"
] | text-generation | 2024-02-24T18:58:24Z | ---
license: mit
metrics:
- code_eval
pipeline_tag: text-generation
tags:
- LLM
- Text to text
- Code
- Chatgpt
- Llama
---
## Description
CodeHelp-33b is a merge model developed by Pranav for assisting developers with code-related tasks. This model is based on the Language Model (LLM) architecture.
## Features
- **Code Assistance:** Provides recommendations and suggestions for coding tasks.
- **Merge Model:** Combines multiple models for enhanced performance.
- **Developed by Pranav:** Created by Pranav, a skilled developer in the field.
## Usage
1. Load the model:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("enhanceaiteam/Codehelp-33b")
tokenizer = AutoTokenizer.from_pretrained("enhanceaiteam/Codehelp-33b")
2. Generate code assistance:
python
input_text = "Write a function to sort a list of integers."
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=100, num_return_sequences=1)
generated_code = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_code)
## Acknowledgements
- This model is based on the Hugging Face Transformers library.
- Special thanks to Pranav for developing and sharing this merge model for the developer community.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
Please customize this template with specific details about your Model CodeHelp-30b repository. If you have any further questions or need assistance, feel free to reach out.
|
liminerity/i-guess-this-is-a-lora-model-i-made | liminerity | 2024-02-25T03:16:52Z | 0 | 0 | peft | [
"peft",
"region:us"
] | null | 2024-02-25T03:16:47Z | ---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
alhosseini/Llama-2-7b-hf_neoliberal_subreddit | alhosseini | 2024-02-25T03:11:14Z | 76 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-25T03:09:17Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jsfs11/MixtureofMerges-MoE-4x7b-v4-GGUF | jsfs11 | 2024-02-25T03:04:52Z | 8 | 1 | null | [
"gguf",
"moe",
"frankenmoe",
"merge",
"mergekit",
"lazymergekit",
"flemmingmiguel/MBX-7B-v3",
"Kukedlc/NeuTrixOmniBe-7B-model-remix",
"PetroGPT/WestSeverus-7B-DPO",
"vanillaOVO/supermario_v4",
"base_model:Kukedlc/NeuTrixOmniBe-7B-model-remix",
"base_model:merge:Kukedlc/NeuTrixOmniBe-7B-model-remix",
"base_model:PetroGPT/WestSeverus-7B-DPO",
"base_model:merge:PetroGPT/WestSeverus-7B-DPO",
"base_model:flemmingmiguel/MBX-7B-v3",
"base_model:merge:flemmingmiguel/MBX-7B-v3",
"base_model:vanillaOVO/supermario_v4",
"base_model:merge:vanillaOVO/supermario_v4",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-02-24T00:46:59Z | ---
license: apache-2.0
tags:
- moe
- frankenmoe
- merge
- mergekit
- lazymergekit
- flemmingmiguel/MBX-7B-v3
- Kukedlc/NeuTrixOmniBe-7B-model-remix
- PetroGPT/WestSeverus-7B-DPO
- vanillaOVO/supermario_v4
base_model:
- flemmingmiguel/MBX-7B-v3
- Kukedlc/NeuTrixOmniBe-7B-model-remix
- PetroGPT/WestSeverus-7B-DPO
- vanillaOVO/supermario_v4
---
# Open-LLM Benchmark Results:
MixtureofMerges-MoE-4x7b-v4 (As of 12/02/24 PB Score) on Open LLM Leaderboard📑
Average: 76.23
ARC: 72.53
HellaSwag: 88.85
MMLU: 64.53
TruthfulQA: 75.3
Winogrande: 84.85
GSM8K: 71.34
# MixtureofMerges-MoE-4x7b-v4
MixtureofMerges-MoE-4x7b-v4 is a Mixure of Experts (MoE) made with the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [flemmingmiguel/MBX-7B-v3](https://huggingface.co/flemmingmiguel/MBX-7B-v3)
* [Kukedlc/NeuTrixOmniBe-7B-model-remix](https://huggingface.co/Kukedlc/NeuTrixOmniBe-7B-model-remix)
* [PetroGPT/WestSeverus-7B-DPO](https://huggingface.co/PetroGPT/WestSeverus-7B-DPO)
* [vanillaOVO/supermario_v4](https://huggingface.co/vanillaOVO/supermario_v4)
## 🧩 Configuration
```yaml
base_model: Kukedlc/NeuTrixOmniBe-7B-model-remix
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: flemmingmiguel/MBX-7B-v3
positive_prompts:
- "Answer this question from the ARC (Argument Reasoning Comprehension)."
- "Use common sense and logical reasoning skills."
- "What assumptions does this argument rely on?"
- "Are these assumptions valid? Explain."
- "Could this be explained in a different way? Provide an alternative explanation."
- "Identify any weaknesses in this argument."
- "Does this argument contain any logical fallacies? If so, which ones?"
negative_prompts:
- "misses key evidence"
- "overly general"
- "focuses on irrelevant details"
- "assumes information not provided"
- "relies on stereotypes"
- source_model: Kukedlc/NeuTrixOmniBe-7B-model-remix
positive_prompts:
- "Answer this question, demonstrating commonsense understanding and using any relevant general knowledge you may have."
- "Provide a concise summary of this passage, then explain why the highlighted section is essential to the main idea."
- "Read these two brief articles presenting different viewpoints on the same topic. List their key arguments and highlight where they disagree."
- "Paraphrase this statement, changing the emotional tone but keeping the core meaning intact. Example: Rephrase a worried statement in a humorous way"
- "Create a short analogy that helps illustrate the main concept of this article."
negative_prompts:
- "sounds too basic"
- "understated"
- "dismisses important details"
- "avoids the question's nuance"
- "takes this statement too literally"
- source_model: PetroGPT/WestSeverus-7B-DPO
positive_prompts:
- "Calculate the answer to this math problem"
- "My mathematical capabilities are strong, allowing me to handle complex mathematical queries"
- "solve for"
- "A store sells apples at $0.50 each. If Emily buys 12 apples, how much does she need to pay?"
- "Isolate x in the following equation: 2x + 5 = 17"
- "Solve this equation and show your working."
- "Explain why you used this formula to solve the problem."
- "Attempt to divide this number by zero. Explain why this cannot be done."
negative_prompts:
- "incorrect"
- "inaccurate"
- "creativity"
- "assumed without proof"
- "rushed calculation"
- "confuses mathematical concepts"
- "draws illogical conclusions"
- "circular reasoning"
- source_model: vanillaOVO/supermario_v4
positive_prompts:
- "Generate a few possible continuations to this scenario."
- "Demonstrate understanding of everyday commonsense in your response."
- "Use contextual clues to determine the most likely outcome."
- "Continue this scenario, but make the writing style sound archaic and overly formal."
- "This narrative is predictable. Can you introduce an unexpected yet plausible twist?"
- "The character is angry. Continue this scenario showcasing a furious outburst."
negative_prompts:
- "repetitive phrases"
- "overuse of the same words"
- "contradicts earlier statements - breaks the internal logic of the scenario"
- "out of character dialogue"
- "awkward phrasing - sounds unnatural"
- "doesn't match the given genre"
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "jsfs11/MixtureofMerges-MoE-4x7b-v4"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
throwromans/hpymrchnt | throwromans | 2024-02-25T03:03:55Z | 0 | 0 | null | [
"license:gpl",
"region:us"
] | null | 2023-08-02T05:30:56Z | ---
license: gpl
---
for best results, use with AbyssOrangeMix2 checkpoint
https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix2/AbyssOrangeMix2_hard.safetensors
https://civitai.com/models/4451?modelVersionId=5038
6 gorillion possibilities |
wintercoming6/shinomiya-sdxl-base-1-0-lora | wintercoming6 | 2024-02-25T02:53:29Z | 6 | 1 | diffusers | [
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-02-25T01:17:24Z | ---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
widget:
- text: 'cartoon style, Shinomiya, a cartoon girl with black hair, in white boots, smiling, eyes closed, mouth open, running to the right, three-quarter view, facing right, with pumping fists and striding legs, full body, simple background'
output:
url:
"image_0.png"
- text: 'cartoon style, Shinomiya, a cartoon girl with black hair, in white boots, smiling, eyes closed, mouth open, running to the right, three-quarter view, facing right, with pumping fists and striding legs, full body, simple background'
output:
url:
"image_1.png"
- text: 'cartoon style, Shinomiya, a cartoon girl with black hair, in white boots, smiling, eyes closed, mouth open, running to the right, three-quarter view, facing right, with pumping fists and striding legs, full body, simple background'
output:
url:
"image_2.png"
- text: 'cartoon style, Shinomiya, a cartoon girl with black hair, in white boots, smiling, eyes closed, mouth open, running to the right, three-quarter view, facing right, with pumping fists and striding legs, full body, simple background'
output:
url:
"image_3.png"
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: None
license: openrail++
---
# SDXL LoRA DreamBooth - wintercoming6/shinomiya-sdxl-base-1-0-lora
<Gallery />
## Model description
### These are wintercoming6/shinomiya-sdxl-base-1-0-lora LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
## Download model
### Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- **LoRA**: download **[`shinomiya-sdxl-base-1-0-lora.safetensors` here 💾](/wintercoming6/shinomiya-sdxl-base-1-0-lora/blob/main/shinomiya-sdxl-base-1-0-lora.safetensors)**.
- Place it on your `models/Lora` folder.
- On AUTOMATIC1111, load the LoRA by adding `<lora:shinomiya-sdxl-base-1-0-lora:1>` to your prompt. On ComfyUI just [load it as a regular LoRA](https://comfyanonymous.github.io/ComfyUI_examples/lora/).
- *Embeddings*: download **[`shinomiya-sdxl-base-1-0-lora_emb.safetensors` here 💾](/wintercoming6/shinomiya-sdxl-base-1-0-lora/blob/main/shinomiya-sdxl-base-1-0-lora_emb.safetensors)**.
- Place it on it on your `embeddings` folder
- Use it by adding `shinomiya-sdxl-base-1-0-lora_emb` to your prompt. For example, `None`
(you need both the LoRA and the embeddings as they were trained together for this LoRA)
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('wintercoming6/shinomiya-sdxl-base-1-0-lora', weight_name='pytorch_lora_weights.safetensors')
embedding_path = hf_hub_download(repo_id='wintercoming6/shinomiya-sdxl-base-1-0-lora', filename='shinomiya-sdxl-base-1-0-lora_emb.safetensors', repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=[], text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer)
pipeline.load_textual_inversion(state_dict["clip_g"], token=[], text_encoder=pipeline.text_encoder_2, tokenizer=pipeline.tokenizer_2)
image = pipeline('cartoon style, Shinomiya, a cartoon girl with black hair, in white boots, smiling, eyes closed, mouth open, running to the right, three-quarter view, facing right, with pumping fists and striding legs, full body, simple background').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Trigger words
To trigger image generation of trained concept(or concepts) replace each concept identifier in you prompt with the new inserted tokens:
to trigger concept `TOK` → use `<s0><s1>` in your prompt
## Details
All [Files & versions](/wintercoming6/shinomiya-sdxl-base-1-0-lora/tree/main).
The weights were trained using [🧨 diffusers Advanced Dreambooth Training Script](https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py).
LoRA for the text encoder was enabled. False.
Pivotal tuning was enabled: True.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
huglf/GPTQ-quantized-on-a-fine-tuned-Llama-2-model | huglf | 2024-02-25T02:49:47Z | 78 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2024-02-24T09:19:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ChrisGoringe/vit-large-p14-vision-fp16 | ChrisGoringe | 2024-02-25T02:45:42Z | 35 | 0 | transformers | [
"transformers",
"safetensors",
"clip_vision_model",
"endpoints_compatible",
"region:us"
] | null | 2024-02-25T01:51:54Z | fp16 version of the vision model from openai/clip-vit-large-patch14|CLIPVisionModelWithProjection
---
license: mit
---
|
lvcalucioli/flan-t5-large__multiple-choice | lvcalucioli | 2024-02-25T02:38:04Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-25T02:21:07Z | ---
license: apache-2.0
base_model: google/flan-t5-large
tags:
- generated_from_trainer
model-index:
- name: flan-t5-large__multiple-choice
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large__multiple-choice
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.0.1+cu117
- Datasets 2.16.1
- Tokenizers 0.15.2
|
matthewchung74/mistral-mcqa | matthewchung74 | 2024-02-25T02:29:29Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T23:16:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
baihaqy/results | baihaqy | 2024-02-25T02:23:58Z | 161 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-multilingual-cased",
"base_model:finetune:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-25T01:17:13Z | ---
license: apache-2.0
base_model: distilbert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5117
- Accuracy: 0.7169
- Precision: 0.6803
- Recall: 0.6642
- F1: 0.6693
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 999
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.7606 | 1.0 | 761 | 0.6333 | 0.7228 | 0.6856 | 0.6831 | 0.6819 |
| 0.4448 | 2.0 | 1522 | 0.6450 | 0.7320 | 0.6983 | 0.7065 | 0.7011 |
| 1.0076 | 3.0 | 2283 | 0.6573 | 0.7346 | 0.7038 | 0.7153 | 0.7069 |
| 0.1369 | 4.0 | 3044 | 0.8941 | 0.7248 | 0.6855 | 0.6762 | 0.6796 |
| 0.0096 | 5.0 | 3805 | 1.1590 | 0.7264 | 0.6874 | 0.6911 | 0.6889 |
| 0.0728 | 6.0 | 4566 | 1.2896 | 0.7366 | 0.7001 | 0.6875 | 0.6910 |
| 0.0007 | 7.0 | 5327 | 1.5882 | 0.7297 | 0.7027 | 0.6787 | 0.6825 |
| 0.0106 | 8.0 | 6088 | 1.5117 | 0.7169 | 0.6803 | 0.6642 | 0.6693 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Yihsiu/hw-01 | Yihsiu | 2024-02-25T02:21:49Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:distilbert/distilbert-base-uncased",
"base_model:quantized:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2023-12-23T01:35:46Z | ---
license: apache-2.0
tags:
- generated_from_trainer
- trl
- sft
metrics:
- matthews_correlation
base_model: distilbert-base-uncased
model-index:
- name: hw-01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hw-01
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7973
- Matthews Correlation: 0.5222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.516 | 1.0 | 535 | 0.4558 | 0.4386 |
| 0.3417 | 2.0 | 1070 | 0.4704 | 0.5215 |
| 0.2353 | 3.0 | 1605 | 0.6810 | 0.5062 |
| 0.1624 | 4.0 | 2140 | 0.7973 | 0.5222 |
| 0.1221 | 5.0 | 2675 | 0.8570 | 0.5215 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
glenn2/gemma-2b-lora16b2 | glenn2 | 2024-02-25T02:20:04Z | 151 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-25T02:11:57Z | ---
library_name: transformers
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
ottoykh/Smart-Traffic | ottoykh | 2024-02-25T02:18:20Z | 54 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"onnx",
"yolov8-seg",
"image-segmentation",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-segmentation | 2024-02-23T08:09:24Z | ---
license: mit
language:
- en
metrics:
- accuracy
pipeline_tag: image-segmentation
widget:
- src: >-
https://tdcctv.data.one.gov.hk/AID01209.JPG
example_title: Road cam 1
---
# Model Card for Smart-Traffic

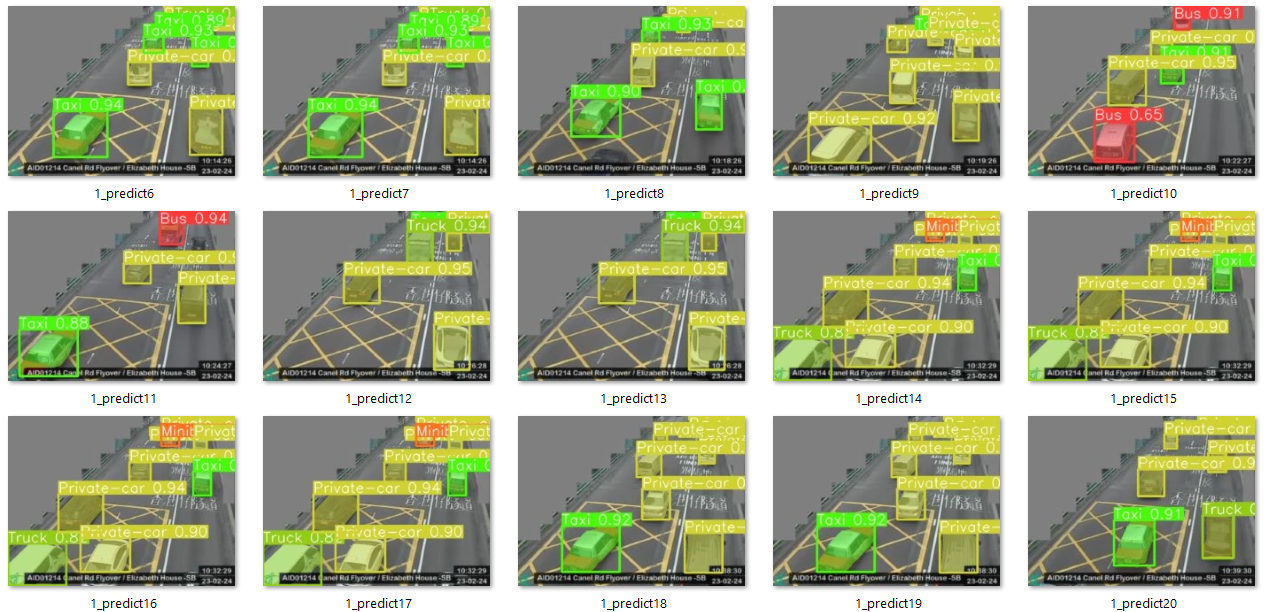
This is a machine learning model designed for the Real-Time CCTV road traffic monitoring, use for the road traffic estimation and indexing.
# Table of Contents
- [Model Card for Smart-Traffic](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Table of Contents](#table-of-contents-1)
- [Model Details](#model-details)
- [Model Description](#model-description)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
This is a machine learning model designed for the Real-Time CCTV road traffic monitoring, use for the road traffic estimation and indexing.
- **Developed by:** Yu Kai Him Otto
- **Shared by [Optional]:** Yu Kai Him Otto
- **Model type:** Language model
- **Language(s) (NLP):** en
- **License:** mit
- **Parent Model:** More information needed
- **Resources for more information:** More information needed
# Model Card Authors [optional]
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
Yu Kai Him Otto, Chan Ka Hin and Leung Yat Long
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
More information needed
</details> |
AkhilKashyap1998/gpt2-GPTQ | AkhilKashyap1998 | 2024-02-25T02:12:15Z | 2 | 0 | transformers | [
"transformers",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2024-02-25T02:11:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
liminerity/baccules-3b-slerp | liminerity | 2024-02-25T02:01:03Z | 108 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"indischepartij/MiniCPM-3B-Hercules-v2.0",
"indischepartij/MiniCPM-3B-Bacchus",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-25T01:59:16Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- indischepartij/MiniCPM-3B-Hercules-v2.0
- indischepartij/MiniCPM-3B-Bacchus
---
# baccules-3b-slerp
baccules-3b-slerp is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [indischepartij/MiniCPM-3B-Hercules-v2.0](https://huggingface.co/indischepartij/MiniCPM-3B-Hercules-v2.0)
* [indischepartij/MiniCPM-3B-Bacchus](https://huggingface.co/indischepartij/MiniCPM-3B-Bacchus)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: indischepartij/MiniCPM-3B-Hercules-v2.0
layer_range: [0, 40]
- model: indischepartij/MiniCPM-3B-Bacchus
layer_range: [0, 40]
merge_method: slerp
base_model: indischepartij/MiniCPM-3B-Hercules-v2.0
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
ChrisGoringe/vitH16 | ChrisGoringe | 2024-02-25T01:54:46Z | 87 | 0 | transformers | [
"transformers",
"pytorch",
"clip",
"zero-shot-image-classification",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | 2024-02-04T01:50:51Z | Outdated. Suggest using ChrisGoringe/vit-large-p14-vision-fp16 or one of the other models.
torch.float16 version of laion/CLIP-ViT-H-14-laion2B-s32B-b79K
Intended for use with custom aesthetic trainer.
---
license: mit
---
|
glenn2/gemma-2b-lora16b | glenn2 | 2024-02-25T01:54:23Z | 108 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-25T01:50:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
glenn2/gemma-2b-lora3 | glenn2 | 2024-02-25T01:42:24Z | 145 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-25T01:18:50Z | ---
library_name: transformers
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
NoteDance/Gemma | NoteDance | 2024-02-25T01:31:55Z | 0 | 0 | tf | [
"tf",
"Note",
"gemma",
"text-generation",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-02-25T01:27:26Z | ---
license: apache-2.0
library_name: tf
pipeline_tag: text-generation
tags:
- Note
- gemma
---
This model is built by Note, Note repository can be found [here](https://github.com/NoteDance/Note). The model can be found [here](https://github.com/NoteDance/Note/blob/Note-7.0/Note/neuralnetwork/tf/Gemma.py). The tutorial can be found [here](https://github.com/NoteDance/Note-documentation/tree/tf-7.0). |
Litzy619/V0224B1 | Litzy619 | 2024-02-25T01:30:34Z | 0 | 0 | null | [
"safetensors",
"generated_from_trainer",
"base_model:yahma/llama-7b-hf",
"base_model:finetune:yahma/llama-7b-hf",
"region:us"
] | null | 2024-02-24T22:57:00Z | ---
base_model: yahma/llama-7b-hf
tags:
- generated_from_trainer
model-index:
- name: V0224B1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# V0224B1
This model is a fine-tuned version of [yahma/llama-7b-hf](https://huggingface.co/yahma/llama-7b-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7525
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_restarts
- lr_scheduler_warmup_steps: 20
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1045 | 0.13 | 10 | 1.0762 |
| 0.9886 | 0.26 | 20 | 0.9163 |
| 0.8808 | 0.39 | 30 | 0.8540 |
| 0.8273 | 0.52 | 40 | 0.8241 |
| 0.8082 | 0.65 | 50 | 0.8067 |
| 0.7915 | 0.78 | 60 | 0.7954 |
| 0.7687 | 0.91 | 70 | 0.7883 |
| 0.7644 | 1.04 | 80 | 0.7814 |
| 0.7454 | 1.17 | 90 | 0.7759 |
| 0.7613 | 1.3 | 100 | 0.7717 |
| 0.7512 | 1.43 | 110 | 0.7681 |
| 0.7416 | 1.55 | 120 | 0.7644 |
| 0.7315 | 1.68 | 130 | 0.7613 |
| 0.7434 | 1.81 | 140 | 0.7594 |
| 0.7477 | 1.94 | 150 | 0.7563 |
| 0.7299 | 2.07 | 160 | 0.7555 |
| 0.7148 | 2.2 | 170 | 0.7540 |
| 0.7272 | 2.33 | 180 | 0.7538 |
| 0.7203 | 2.46 | 190 | 0.7532 |
| 0.7216 | 2.59 | 200 | 0.7531 |
| 0.7233 | 2.72 | 210 | 0.7527 |
| 0.7213 | 2.85 | 220 | 0.7526 |
| 0.7234 | 2.98 | 230 | 0.7525 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
DanielAvelar09/mi_chatbot | DanielAvelar09 | 2024-02-25T01:23:05Z | 106 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"deberta-v2",
"question-answering",
"generated_from_trainer",
"es",
"base_model:timpal0l/mdeberta-v3-base-squad2",
"base_model:finetune:timpal0l/mdeberta-v3-base-squad2",
"license:mit",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-02-16T15:11:48Z | ---
license: mit
base_model: timpal0l/mdeberta-v3-base-squad2
tags:
- generated_from_trainer
model-index:
- name: mi_chatbot
results: []
language:
- es
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mi_chatbot
This model is a fine-tuned version of [timpal0l/mdeberta-v3-base-squad2](https://huggingface.co/timpal0l/mdeberta-v3-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8504
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 30 | 0.8746 |
| No log | 2.0 | 60 | 0.7221 |
| No log | 3.0 | 90 | 0.8504 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
Nexesenex/brucethemoose_Yi-34B-200K-DARE-megamerge-v8-iMat.GGUF | Nexesenex | 2024-02-25T00:56:46Z | 102 | 4 | null | [
"gguf",
"endpoints_compatible",
"region:us"
] | null | 2024-01-23T21:54:18Z | GGUF Quants with iMatrix for https://huggingface.co/brucethemoose/Yi-34B-200K-DARE-megamerge-v8
iMatrix made with 2500 batches of 32 tokens made on wiki.train.raw
Benchs made with LlamaCPP :
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Hellaswag,84.5,,400,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Hellaswag_Bin,79,,400,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Arc-Challenge,57.52508361,,299,2024-01-26 05:40:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Arc-Easy,78.59649123,,570,2024-01-26 05:40:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,MMLU,40.89456869,,313,2024-01-26 05:40:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Thruthful-QA,34.76132191,,817,2024-01-26 05:40:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,Winogrande,77.9795,,1267,2024-01-26 05:40:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,wikitext,5.0681,512,512,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,wikitext,4.5052,2048,2048,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,wikitext,4.3656,4096,4096,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex,
- Yi-34B-200K-DARE-megamerge-v8-b1952-iMat-c32_ch2500-Q4_K_M.gguf,-,wikitext,4.3190,8192,8192,2024-01-26 00:00:00,,34b,Yi,2000000,,,GGUF,Brucethemoose,Nexesenex, |
Siwenz/bert-finetuned-ner | Siwenz | 2024-02-25T00:56:27Z | 61 | 0 | transformers | [
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-02-24T23:15:55Z | ---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_keras_callback
model-index:
- name: Siwenz/bert-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Siwenz/bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1757
- Validation Loss: 0.0597
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2634, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.1757 | 0.0597 | 0 |
### Framework versions
- Transformers 4.36.2
- TensorFlow 2.15.0
- Datasets 2.16.1
- Tokenizers 0.15.0
|
furrutiav/bert_qa_extractor_cockatiel_2022_ef_baseline_signal_it_185 | furrutiav | 2024-02-25T00:49:12Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-02-25T00:48:46Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ChrisGoringe/aim-1B-fp16 | ChrisGoringe | 2024-02-25T00:43:35Z | 47 | 0 | transformers | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2024-02-25T00:27:31Z | See LICENSE for Apple license
This is a torch.half version of apple/AIM-1B |
thatjoeoverthere/aigf_primary_reducer | thatjoeoverthere | 2024-02-25T00:41:13Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-25T00:40:51Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
alhosseini/Llama-2-7b-hf_ukpolitics_subreddit | alhosseini | 2024-02-25T00:37:10Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-25T00:35:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
furrutiav/bert_qa_extractor_cockatiel_2022_ef_z_value_over_subsample_it_684 | furrutiav | 2024-02-25T00:28:22Z | 106 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-02-25T00:27:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ShushantLLM/bart-large-cnn-finetuned-sst2 | ShushantLLM | 2024-02-25T00:28:09Z | 112 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"summarization",
"en",
"dataset:samsum",
"base_model:facebook/bart-large-cnn",
"base_model:finetune:facebook/bart-large-cnn",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2024-02-25T00:25:24Z | ---
license: mit
base_model: facebook/bart-large-cnn
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-cnn-finetuned-sst2
results: []
datasets:
- samsum
language:
- en
pipeline_tag: summarization
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetuned-sst2
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4287
- Rouge1: 0.4065
- Rouge2: 0.1979
- Rougel: 0.3084
- Rougelsum: 0.3750
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 0.2977 | 1.0 | 920 | 0.3094 | 0.4036 | 0.2071 | 0.3097 | 0.3746 |
| 0.2253 | 2.0 | 1841 | 0.3163 | 0.4067 | 0.2109 | 0.3130 | 0.3769 |
| 0.159 | 3.0 | 2762 | 0.3258 | 0.4108 | 0.2101 | 0.3163 | 0.3796 |
| 0.1091 | 4.0 | 3683 | 0.3680 | 0.4060 | 0.2006 | 0.3069 | 0.3750 |
| 0.0723 | 5.0 | 4600 | 0.4287 | 0.4065 | 0.1979 | 0.3084 | 0.3750 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
ChrisGoringe/aim-600M-fp16 | ChrisGoringe | 2024-02-25T00:25:38Z | 46 | 0 | transformers | [
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2024-02-24T11:51:25Z | See LICENSE for Apple license
This is a torch.half version of apple/AIM-600M |
Xavi-Hdz/q-FrozenLake-v1-4x4-noSlippery | Xavi-Hdz | 2024-02-25T00:21:11Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-25T00:21:08Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Xavi-Hdz/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ShushantLLM/bart-large-xsum-finetuned-sst2 | ShushantLLM | 2024-02-25T00:16:26Z | 116 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bart",
"text2text-generation",
"generated_from_trainer",
"summarization",
"dataset:samsum",
"base_model:facebook/bart-large-xsum",
"base_model:finetune:facebook/bart-large-xsum",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2024-02-24T20:50:57Z | ---
license: mit
base_model: facebook/bart-large-xsum
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-xsum-finetuned-sst2
results: []
datasets:
- samsum
pipeline_tag: summarization
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-xsum-finetuned-sst2
This model is a fine-tuned version of [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4333
- Rouge1: 0.5389
- Rouge2: 0.2841
- Rougel: 0.4406
- Rougelsum: 0.4935
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|
| 0.3028 | 1.0 | 920 | 0.3135 | 0.5331 | 0.2844 | 0.4417 | 0.4908 |
| 0.2301 | 2.0 | 1841 | 0.3304 | 0.5371 | 0.2878 | 0.4393 | 0.4936 |
| 0.1626 | 3.0 | 2762 | 0.3395 | 0.5415 | 0.2907 | 0.4503 | 0.4978 |
| 0.112 | 4.0 | 3683 | 0.3898 | 0.5415 | 0.2830 | 0.4406 | 0.4952 |
| 0.0747 | 5.0 | 4600 | 0.4333 | 0.5389 | 0.2841 | 0.4406 | 0.4935 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
SKNahin/NER_Deberta33 | SKNahin | 2024-02-25T00:03:43Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"deberta",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-02-24T06:28:42Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sunburstAI/solar_ko_v0.1 | sunburstAI | 2024-02-25T00:02:46Z | 2,246 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T22:58:14Z | ---
library_name: transformers
license: apache-2.0
---
# solar_ko_v0.1
## About the model
- This model is a fine-tuned version of [yanolja/KoSOLAR-10.7B-v0.2](https://huggingface.co/yanolja/KoSOLAR-10.7B-v0.2), which is a Korean vocabulary-extended version of [upstage/SOLAR-10.7B-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-v1.0). |
mi-rei/AlpaCare-llama2-7b-CT_III_efficient_full | mi-rei | 2024-02-24T23:50:13Z | 1 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T22:52:59Z | Accuracy: 0.729\
F1 Score: 0.735\
Accuracy for label 0: 0.708\
Accuracy for label 1: 0.749
Classification Report:
| | precision | recall | f1-score | support |
|--------------|-----------|--------|----------|---------|
| 0 | 0.74 | 0.71 | 0.72 | 548 |
| 1 | 0.72 | 0.75 | 0.74 | 554 |
| accuracy | | | 0.73 | 1102 |
| macro avg | 0.73 | 0.73 | 0.73 | 1102 |
| weighted avg | 0.73 | 0.73 | 0.73 | 1102 |
Confusion Matrix:\
[[388 160 0]\
[139 415 0]\
[ 0 0 0]] |
furrutiav/bert_qa_extractor_cockatiel_2022_nllf_v0_mixtral_v2_it_842 | furrutiav | 2024-02-24T23:33:02Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-02-24T23:32:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Keertss/my-bert-finetuned-ner | Keertss | 2024-02-24T23:28:07Z | 109 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-02-24T23:27:50Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
oliverbob/openbible | oliverbob | 2024-02-24T23:26:20Z | 18 | 2 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-02-14T13:50:07Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: tla
---
# Uploaded model
- **Developed by:** oliverbob
- **License:** apache-2.0
- **Finetuned from model :** tla v1 chat
BIBLE AI
---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- tla architecture
base_model: tla
# Trained from [OpenBible Dataset](https://huggingface.co/datasets/oliverbob/openbible)
- **Developed by:** oliverbob
- **License:** apache-2.0
- **Date:** Day of hearts, 2024
-
- ❤️ God is love and God is good! 😄
Enjoy!!
This will hold the model for /bibleai.
See generated gguf at /biblegpt. |
JairoDanielMT/preentrenado_lora_llama2 | JairoDanielMT | 2024-02-24T23:20:43Z | 0 | 0 | null | [
"license:llama2",
"region:us"
] | null | 2024-02-24T23:19:30Z | ---
license: llama2
---
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
EbadKhan/falcon-7b-instruct-ft | EbadKhan | 2024-02-24T23:14:17Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"falcon",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T23:09:01Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
raulc0399/mistral-7b-ift-3 | raulc0399 | 2024-02-24T23:14:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-24T23:13:32Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
EbadKhan/falcon-7b-instruct-ft-adapters | EbadKhan | 2024-02-24T23:06:30Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-02-24T22:47:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
fzzhang/toten_gsm8k_quantized | fzzhang | 2024-02-24T22:57:10Z | 4 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:Toten5/Marcoroni-neural-chat-7B-v2",
"base_model:adapter:Toten5/Marcoroni-neural-chat-7B-v2",
"license:apache-2.0",
"region:us"
] | null | 2024-02-24T21:05:13Z | ---
license: apache-2.0
library_name: peft
tags:
- generated_from_trainer
base_model: Toten5/Marcoroni-neural-chat-7B-v2
model-index:
- name: toten_gsm8k_quantized
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# toten_gsm8k_quantized
This model is a fine-tuned version of [Toten5/Marcoroni-neural-chat-7B-v2](https://huggingface.co/Toten5/Marcoroni-neural-chat-7B-v2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- PEFT 0.7.2.dev0
- Transformers 4.36.2
- Pytorch 2.1.2
- Datasets 2.16.1
- Tokenizers 0.15.1 |
Eric111/openchat-3.5-0106-128k-DPO_dpo-binarized-NeuralTrix-7B | Eric111 | 2024-02-24T22:47:14Z | 55 | 3 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"Eric111/openchat-3.5-0106-128k-DPO",
"eren23/dpo-binarized-NeuralTrix-7B",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T22:26:57Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- Eric111/openchat-3.5-0106-128k-DPO
- eren23/dpo-binarized-NeuralTrix-7B
---
# openchat-3.5-0106-128k-DPO_dpo-binarized-NeuralTrix-7B
openchat-3.5-0106-128k-DPO_dpo-binarized-NeuralTrix-7B is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [Eric111/openchat-3.5-0106-128k-DPO](https://huggingface.co/Eric111/openchat-3.5-0106-128k-DPO)
* [eren23/dpo-binarized-NeuralTrix-7B](https://huggingface.co/eren23/dpo-binarized-NeuralTrix-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: Eric111/openchat-3.5-0106-128k-DPO
layer_range: [0, 32]
- model: eren23/dpo-binarized-NeuralTrix-7B
layer_range: [0, 32]
merge_method: slerp
base_model: Eric111/openchat-3.5-0106-128k-DPO
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
sarak7/H9_221_769_v2 | sarak7 | 2024-02-24T22:28:57Z | 163 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T22:26:14Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ThomasFG/67.5-67.5-medium.en | ThomasFG | 2024-02-24T22:24:35Z | 79 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-medium.en",
"base_model:finetune:openai/whisper-medium.en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-24T17:51:07Z | ---
license: apache-2.0
base_model: openai/whisper-medium.en
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: 2024-02-24_18-51-01
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2024-02-24_18-51-01
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2283
- Wer: 8.5884
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2189 | 1.0 | 711 | 0.2283 | 8.5884 |
### Framework versions
- Transformers 4.37.2
- Pytorch 1.13.1+cu116
- Datasets 2.17.0
- Tokenizers 0.15.2
|
woody72/output-itemHalfTax-wd0.1 | woody72 | 2024-02-24T22:23:51Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"generated_from_trainer",
"base_model:deepseek-ai/deepseek-math-7b-base",
"base_model:finetune:deepseek-ai/deepseek-math-7b-base",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T08:51:15Z | ---
license: other
base_model: deepseek-ai/deepseek-math-7b-base
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: output-itemHalfTax-wd0.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output-itemHalfTax-wd0.1
This model is a fine-tuned version of [deepseek-ai/deepseek-math-7b-base](https://huggingface.co/deepseek-ai/deepseek-math-7b-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8425 | 0.01 | 1 | 0.4687 |
| 0.8496 | 0.01 | 2 | 0.4640 |
| 0.819 | 0.02 | 3 | 0.4579 |
| 0.8173 | 0.03 | 4 | 0.4532 |
| 0.8297 | 0.03 | 5 | 0.4495 |
| 0.8014 | 0.04 | 6 | 0.4447 |
| 0.7981 | 0.04 | 7 | 0.4399 |
| 0.7716 | 0.05 | 8 | 0.4375 |
| 0.6996 | 0.06 | 9 | 0.4332 |
| 0.6631 | 0.06 | 10 | 0.4302 |
| 0.6596 | 0.07 | 11 | 0.4247 |
| 0.6887 | 0.08 | 12 | 0.4221 |
| 0.6373 | 0.08 | 13 | 0.4180 |
| 0.6536 | 0.09 | 14 | 0.4161 |
| 0.6112 | 0.1 | 15 | 0.4102 |
| 0.6113 | 0.1 | 16 | 0.4072 |
| 0.5427 | 0.11 | 17 | 0.4041 |
| 0.5434 | 0.12 | 18 | 0.4005 |
| 0.5098 | 0.12 | 19 | 0.3955 |
| 0.5567 | 0.13 | 20 | 0.3914 |
| 0.4984 | 0.13 | 21 | 0.3889 |
| 0.5414 | 0.14 | 22 | 0.3852 |
| 0.4851 | 0.15 | 23 | 0.3818 |
| 0.4599 | 0.15 | 24 | 0.3769 |
| 0.4423 | 0.16 | 25 | 0.3736 |
| 0.4562 | 0.17 | 26 | 0.3711 |
| 0.4359 | 0.17 | 27 | 0.3677 |
| 0.4182 | 0.18 | 28 | 0.3631 |
| 0.4302 | 0.19 | 29 | 0.3612 |
| 0.4294 | 0.19 | 30 | 0.3556 |
| 0.4169 | 0.2 | 31 | 0.3527 |
| 0.3764 | 0.2 | 32 | 0.3483 |
| 0.3773 | 0.21 | 33 | 0.3451 |
| 0.3611 | 0.22 | 34 | 0.3423 |
| 0.3524 | 0.22 | 35 | 0.3380 |
| 0.3528 | 0.23 | 36 | 0.3337 |
| 0.3666 | 0.24 | 37 | 0.3306 |
| 0.3536 | 0.24 | 38 | 0.3266 |
| 0.3812 | 0.25 | 39 | 0.3223 |
| 0.2976 | 0.26 | 40 | 0.3191 |
| 0.2805 | 0.26 | 41 | 0.3157 |
| 0.2739 | 0.27 | 42 | 0.3115 |
| 0.2994 | 0.28 | 43 | 0.3089 |
| 0.2864 | 0.28 | 44 | 0.3031 |
| 0.2745 | 0.29 | 45 | 0.3003 |
| 0.2666 | 0.29 | 46 | 0.2968 |
| 0.3109 | 0.3 | 47 | 0.2914 |
| 0.2603 | 0.31 | 48 | 0.2873 |
| 0.2761 | 0.31 | 49 | 0.2821 |
| 0.2566 | 0.32 | 50 | 0.2792 |
| 0.2637 | 0.33 | 51 | 0.2758 |
| 0.2388 | 0.33 | 52 | 0.2706 |
| 0.2474 | 0.34 | 53 | 0.2651 |
| 0.2462 | 0.35 | 54 | 0.2607 |
| 0.2617 | 0.35 | 55 | 0.2567 |
| 0.2387 | 0.36 | 56 | 0.2513 |
| 0.2171 | 0.36 | 57 | 0.2482 |
| 0.2324 | 0.37 | 58 | 0.2428 |
| 0.227 | 0.38 | 59 | 0.2384 |
| 0.2366 | 0.38 | 60 | 0.2332 |
| 0.2174 | 0.39 | 61 | 0.2288 |
| 0.2083 | 0.4 | 62 | 0.2237 |
| 0.1935 | 0.4 | 63 | 0.2198 |
| 0.2141 | 0.41 | 64 | 0.2152 |
| 0.2044 | 0.42 | 65 | 0.2111 |
| 0.2061 | 0.42 | 66 | 0.2064 |
| 0.2005 | 0.43 | 67 | 0.2011 |
| 0.1895 | 0.44 | 68 | 0.1944 |
| 0.1823 | 0.44 | 69 | 0.1902 |
| 0.1763 | 0.45 | 70 | 0.1874 |
| 0.1897 | 0.45 | 71 | 0.1814 |
| 0.1853 | 0.46 | 72 | 0.1764 |
| 0.1674 | 0.47 | 73 | 0.1706 |
| 0.1642 | 0.47 | 74 | 0.1648 |
| 0.1677 | 0.48 | 75 | 0.1604 |
| 0.1551 | 0.49 | 76 | 0.1544 |
| 0.1457 | 0.49 | 77 | 0.1486 |
| 0.1497 | 0.5 | 78 | 0.1434 |
| 0.1389 | 0.51 | 79 | 0.1374 |
| 0.1396 | 0.51 | 80 | 0.1325 |
| 0.1297 | 0.52 | 81 | 0.1266 |
| 0.1298 | 0.52 | 82 | 0.1211 |
| 0.1162 | 0.53 | 83 | 0.1164 |
| 0.13 | 0.54 | 84 | 0.1127 |
| 0.1207 | 0.54 | 85 | 0.1085 |
| 0.1165 | 0.55 | 86 | 0.1039 |
| 0.1088 | 0.56 | 87 | 0.1012 |
| 0.1082 | 0.56 | 88 | 0.0969 |
| 0.109 | 0.57 | 89 | 0.0952 |
| 0.1102 | 0.58 | 90 | 0.0924 |
| 0.1026 | 0.58 | 91 | 0.0891 |
| 0.1058 | 0.59 | 92 | 0.0875 |
| 0.0973 | 0.6 | 93 | 0.0861 |
| 0.0963 | 0.6 | 94 | 0.0859 |
| 0.0941 | 0.61 | 95 | 0.0838 |
| 0.0983 | 0.61 | 96 | 0.0824 |
| 0.0884 | 0.62 | 97 | 0.0812 |
| 0.0855 | 0.63 | 98 | 0.0798 |
| 0.0875 | 0.63 | 99 | 0.0781 |
| 0.0833 | 0.64 | 100 | 0.0766 |
| 0.0836 | 0.65 | 101 | 0.0757 |
| 0.0809 | 0.65 | 102 | 0.0745 |
| 0.0839 | 0.66 | 103 | 0.0731 |
| 0.0748 | 0.67 | 104 | 0.0717 |
| 0.0779 | 0.67 | 105 | 0.0710 |
| 0.0768 | 0.68 | 106 | 0.0705 |
| 0.0794 | 0.68 | 107 | 0.0693 |
| 0.079 | 0.69 | 108 | 0.0679 |
| 0.0808 | 0.7 | 109 | 0.0667 |
| 0.0785 | 0.7 | 110 | 0.0658 |
| 0.0669 | 0.71 | 111 | 0.0649 |
| 0.0715 | 0.72 | 112 | 0.0640 |
| 0.0751 | 0.72 | 113 | 0.0632 |
| 0.0727 | 0.73 | 114 | 0.0626 |
| 0.0725 | 0.74 | 115 | 0.0625 |
| 0.0665 | 0.74 | 116 | 0.0614 |
| 0.0627 | 0.75 | 117 | 0.0605 |
| 0.0681 | 0.76 | 118 | 0.0597 |
| 0.0673 | 0.76 | 119 | 0.0593 |
| 0.0741 | 0.77 | 120 | 0.0592 |
| 0.0686 | 0.77 | 121 | 0.0584 |
| 0.0618 | 0.78 | 122 | 0.0584 |
| 0.065 | 0.79 | 123 | 0.0574 |
| 0.061 | 0.79 | 124 | 0.0572 |
| 0.0685 | 0.8 | 125 | 0.0571 |
| 0.0621 | 0.81 | 126 | 0.0560 |
| 0.0636 | 0.81 | 127 | 0.0558 |
| 0.0581 | 0.82 | 128 | 0.0550 |
| 0.0576 | 0.83 | 129 | 0.0547 |
| 0.0628 | 0.83 | 130 | 0.0544 |
| 0.056 | 0.84 | 131 | 0.0542 |
| 0.0572 | 0.84 | 132 | 0.0536 |
| 0.0605 | 0.85 | 133 | 0.0529 |
| 0.0626 | 0.86 | 134 | 0.0520 |
| 0.0566 | 0.86 | 135 | 0.0517 |
| 0.0575 | 0.87 | 136 | 0.0519 |
| 0.0571 | 0.88 | 137 | 0.0514 |
| 0.0594 | 0.88 | 138 | 0.0510 |
| 0.0528 | 0.89 | 139 | 0.0513 |
| 0.0507 | 0.9 | 140 | 0.0508 |
| 0.0587 | 0.9 | 141 | 0.0503 |
| 0.0558 | 0.91 | 142 | 0.0504 |
| 0.0538 | 0.92 | 143 | 0.0500 |
| 0.0509 | 0.92 | 144 | 0.0509 |
| 0.0538 | 0.93 | 145 | 0.0504 |
| 0.0524 | 0.93 | 146 | 0.0498 |
| 0.059 | 0.94 | 147 | 0.0496 |
| 0.0508 | 0.95 | 148 | 0.0494 |
| 0.0563 | 0.95 | 149 | 0.0491 |
| 0.0472 | 0.96 | 150 | 0.0484 |
| 0.0526 | 0.97 | 151 | 0.0482 |
| 0.0525 | 0.97 | 152 | 0.0482 |
| 0.0483 | 0.98 | 153 | 0.0478 |
| 0.0541 | 0.99 | 154 | 0.0483 |
| 0.0521 | 0.99 | 155 | 0.0474 |
| 0.0556 | 1.0 | 156 | 0.0475 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0a0+32f93b1
- Datasets 2.17.1
- Tokenizers 0.15.2
|
LarryAIDraw/asyncsMIXXL_v20 | LarryAIDraw | 2024-02-24T22:10:39Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-02-24T19:04:47Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/266052?modelVersionId=305839 |
LarryAIDraw/Akari_Nitta | LarryAIDraw | 2024-02-24T22:04:47Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-02-24T22:01:19Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/317650/akari-nitta-jujutsu-kaisen |
LarryAIDraw/Nozomi | LarryAIDraw | 2024-02-24T22:04:36Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-02-24T22:00:35Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/319080/kaminashi-nozomi-keijo |
LarryAIDraw/vinsmoke_reiju-10 | LarryAIDraw | 2024-02-24T22:04:27Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2024-02-24T22:00:11Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/318032/vinsmoke-reiju-one-piece-lora-commission |
kumbi500/AoDistilBERT_Fine_tuned | kumbi500 | 2024-02-24T22:00:30Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-24T17:10:24Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: AoDistilBERT_Fine_tuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# AoDistilBERT_Fine_tuned
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2923
- Accuracy: 0.8802
- F1: 0.8800
- Precision: 0.8814
- Recall: 0.8796
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.3218 | 1.0 | 1000 | 0.2923 | 0.8802 | 0.8800 | 0.8814 | 0.8796 |
| 0.2408 | 2.0 | 2000 | 0.2934 | 0.8852 | 0.8852 | 0.8853 | 0.8851 |
| 0.194 | 3.0 | 3000 | 0.3367 | 0.8822 | 0.8821 | 0.8826 | 0.8819 |
| 0.149 | 4.0 | 4000 | 0.3915 | 0.8778 | 0.8774 | 0.8790 | 0.8770 |
| 0.1238 | 5.0 | 5000 | 0.4527 | 0.8745 | 0.8744 | 0.8746 | 0.8742 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
ThomasFG/67.5-67.5-medium | ThomasFG | 2024-02-24T21:54:13Z | 77 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-24T17:56:23Z | ---
license: apache-2.0
base_model: openai/whisper-medium
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: 2024-02-24_18-56-17
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 2024-02-24_18-56-17
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7774
- Wer: 100.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-----:|
| 2.4896 | 1.0 | 711 | 0.7774 | 100.0 |
### Framework versions
- Transformers 4.37.2
- Pytorch 1.13.1+cu116
- Datasets 2.17.0
- Tokenizers 0.15.2
|
mavihsrr/gemma-2b-medical_tuned | mavihsrr | 2024-02-24T21:41:09Z | 2 | 0 | peft | [
"peft",
"safetensors",
"llama-factory",
"lora",
"generated_from_trainer",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:other",
"region:us"
] | null | 2024-02-24T21:38:45Z | ---
license: other
library_name: peft
tags:
- llama-factory
- lora
- generated_from_trainer
base_model: google/gemma-2b
model-index:
- name: train_2024-02-24-21-21-49
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_2024-02-24-21-21-49
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on the med_data dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2 |
jlbaker361/classifier-wikiart-resized | jlbaker361 | 2024-02-24T21:14:18Z | 0 | 0 | null | [
"region:us"
] | null | 2024-02-05T05:01:20Z | ---
{}
---
Creative Adversarial Network
epochs: 100
dataset jlbaker361/wikiart
n classes 27
batch_size 32
images where resized to 768
and then center cropped to: 512
used clip=False
conditional =False
discriminator parameters:
init_dim: 32
final_dim 512
generator parameters:
input noise_dim: 100
wandb project: https://wandb.ai/jlbaker361/creativity/runs/pnifc6h1
|
sanduntg/vsort_policy | sanduntg | 2024-02-24T21:10:37Z | 0 | 0 | peft | [
"peft",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2024-02-24T21:10:07Z | ---
library_name: peft
base_model: meta-llama/Llama-2-7b-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.8.2 |
alekom/ppo-LunarLander-v2 | alekom | 2024-02-24T21:09:24Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-24T21:05:03Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 261.53 +/- 14.43
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Kudod/my_fine_tuning_nllb_1B3_peft_en_vi_model_nmt | Kudod | 2024-02-24T21:08:41Z | 14 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"generated_from_trainer",
"dataset:mt_eng_vietnamese",
"base_model:facebook/nllb-200-1.3B",
"base_model:adapter:facebook/nllb-200-1.3B",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-02-23T03:54:28Z | ---
license: cc-by-nc-4.0
library_name: peft
tags:
- generated_from_trainer
datasets:
- mt_eng_vietnamese
metrics:
- bleu
base_model: facebook/nllb-200-1.3B
model-index:
- name: my_fine_tuning_nllb_1B3_peft_en_vi_model_nmt
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_fine_tuning_nllb_1B3_peft_en_vi_model_nmt
This model is a fine-tuned version of [facebook/nllb-200-1.3B](https://huggingface.co/facebook/nllb-200-1.3B) on the mt_eng_vietnamese dataset.
It achieves the following results on the evaluation set:
- Loss: 7.2576
- Bleu: 35.9386
- Gen Len: 30.7029
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 7.8689 | 1.0 | 133318 | 7.2597 | 35.8608 | 30.6438 |
| 7.8599 | 2.0 | 266636 | 7.2576 | 35.9386 | 30.7029 |
### Framework versions
- PEFT 0.8.2
- Transformers 4.37.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.15.2 |
Y11IC/llama-2-7b-miniplatypus | Y11IC | 2024-02-24T20:58:57Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T20:53:54Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pszemraj/nougat-small-onnx-quant_avx512_vnni | pszemraj | 2024-02-24T20:58:45Z | 4 | 0 | transformers | [
"transformers",
"onnx",
"vision-encoder-decoder",
"image-text-to-text",
"nougat",
"quant",
"avx512_vnni",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-02-22T00:54:53Z | ---
license: apache-2.0
tags:
- nougat
- quant
- avx512_vnni
---
# nougat-small-onnx-quant_avx512_vnni
This was quantized from `pszemraj/nougat-small-onnx` using the `--avx512_vnni` flag. You **need to have a processor with avx512_vnni instructions for this to work properly.**
- `per_channel` is set to True for better accuracy
- Usage is the same as: https://huggingface.co/pszemraj/nougat-small-onnx
- verify that you have the requirements by checking for results with `lscpu | grep avx512_vnni` |
prithviraaj/Krishi | prithviraaj | 2024-02-24T20:47:00Z | 0 | 0 | null | [
"mr",
"license:mpl-2.0",
"region:us"
] | null | 2024-02-24T20:32:58Z | ---
license: mpl-2.0
language:
- mr
--- |
halobang093/Jokowe | halobang093 | 2024-02-24T20:45:45Z | 0 | 0 | null | [
"arxiv:1910.09700",
"region:us"
] | null | 2024-02-23T20:36:16Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
glenn2/outputs | glenn2 | 2024-02-24T20:45:38Z | 0 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:google/gemma-2b",
"base_model:adapter:google/gemma-2b",
"license:other",
"region:us"
] | null | 2024-02-24T20:32:38Z | ---
license: other
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: google/gemma-2b
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [google/gemma-2b](https://huggingface.co/google/gemma-2b) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.8.2
- Transformers 4.38.0
- Pytorch 2.1.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2 |
fzzhang/phi2_gsm8k_s_quantized_merged_on_quantized | fzzhang | 2024-02-24T20:40:52Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | text-generation | 2024-02-24T09:44:52Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Weni/ZeroShot-3.3.7-Mistral-7b-Multilanguage-3.2.0-merged | Weni | 2024-02-24T20:32:39Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T20:20:54Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RWKV/v5-Eagle-7B-pth | RWKV | 2024-02-24T20:19:59Z | 0 | 199 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-01-28T18:56:07Z | ---
license: apache-2.0
---

> **! Important Note !**
>
> The following is the full RWKV-5 Eagle 7B model weights, which can be used with our various inference libraries
> [Download link here](https://huggingface.co/RWKV/v5-Eagle-7B/resolve/main/RWKV-v5-Eagle-World-7B-v2-20240128-ctx4096.pth?download=true)
>
> For HF compatible implementation, [refer to here](https://huggingface.co/RWKV/HF_v5-Eagle-7B)
>
> This is not an instruct tune model! (soon...)
- [HF Demo](https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2)
- [Our wiki](https://wiki.rwkv.com)
- [HF compatible weights](https://huggingface.co/RWKV/HF_v5-Eagle-7B)
# Eagle 7B - in short
Eagle 7B is a 7.52B parameter model that:
- Built on the RWKV-v5 architecture
(a linear transformer with 10-100x+ lower inference cost)
- Ranks as the world’s greenest 7B model (per token)
- Trained on 1.1 Trillion Tokens across 100+ languages
(70% English, 15% multi lang, 15% code)
- Outperforms all 7B class models in multi-lingual benchmarks
- Approaches Falcon (1.5T), LLaMA2 (2T), Mistral (>2T?) level of performance in English evals
- Trade blows with MPT-7B (1T) in English evals
- All while being an “Attention-Free Transformer”
- Is a foundation model, with a very small instruct tune - further fine-tuning is required for various use cases!
Find out more at our model announcement: https://blog.rwkv.com/p/eagle-7b-soaring-past-transformers
Or our wiki: https://wiki.rwkv.com |
mi-rei/Llama-2-7b-CT_III_efficent_5e | mi-rei | 2024-02-24T20:13:21Z | 2 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T18:51:45Z | Accuracy: 0.654\
F1 Score: 0.529\
Accuracy for label 0: 0.925\
Accuracy for label 1: 0.386
Classification Report:
| | precision | recall | f1-score | support |
|--------------|-----------|--------|----------|---------|
| 0 | 0.60 | 0.93 | 0.73 | 548 |
| 1 | 0.84 | 0.39 | 0.53 | 554 |
| accuracy | | | 0.65 | 1102 |
| macro avg | 0.72 | 0.66 | 0.63 | 1102 |
| weighted avg | 0.72 | 0.65 | 0.63 | 1102 |
Confusion Matrix:\
[[507 41 0]\
[340 214 0]\
[ 0 0 0]] |
archiMAD/ppo-Pyramids | archiMAD | 2024-02-24T19:43:44Z | 8 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] | reinforcement-learning | 2024-02-24T19:43:40Z | ---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: archiMAD/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
badokorach/distilbert-base-cased-distilled-agric-trans-2402241 | badokorach | 2024-02-24T19:37:12Z | 61 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:badokorach/distilbert-base-cased-distilled-agric-trans-240224",
"base_model:finetune:badokorach/distilbert-base-cased-distilled-agric-trans-240224",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-02-24T19:22:33Z | ---
license: apache-2.0
base_model: badokorach/distilbert-base-cased-distilled-agric-trans-240224
tags:
- generated_from_keras_callback
model-index:
- name: badokorach/distilbert-base-cased-distilled-agric-trans-2402241
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# badokorach/distilbert-base-cased-distilled-agric-trans-2402241
This model is a fine-tuned version of [badokorach/distilbert-base-cased-distilled-agric-trans-240224](https://huggingface.co/badokorach/distilbert-base-cased-distilled-agric-trans-240224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2119
- Validation Loss: 0.0
- Epoch: 14
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 690, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.02}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.8415 | 0.0 | 0 |
| 0.7094 | 0.0 | 1 |
| 0.6198 | 0.0 | 2 |
| 0.5324 | 0.0 | 3 |
| 0.4700 | 0.0 | 4 |
| 0.4164 | 0.0 | 5 |
| 0.3747 | 0.0 | 6 |
| 0.3353 | 0.0 | 7 |
| 0.3137 | 0.0 | 8 |
| 0.2898 | 0.0 | 9 |
| 0.2684 | 0.0 | 10 |
| 0.2474 | 0.0 | 11 |
| 0.2469 | 0.0 | 12 |
| 0.2305 | 0.0 | 13 |
| 0.2119 | 0.0 | 14 |
### Framework versions
- Transformers 4.37.2
- TensorFlow 2.15.0
- Datasets 2.17.1
- Tokenizers 0.15.2
|
suhaaspk/suhaasface | suhaaspk | 2024-02-24T19:34:25Z | 28 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-02-24T19:28:36Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### SuhaasFace Dreambooth model trained by suhaaspk with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
ledmands/ppo-Huggy | ledmands | 2024-02-24T19:29:56Z | 6 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2024-02-24T19:28:34Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: ledmands/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Sumukha1995/PPO-LunarLander-v2 | Sumukha1995 | 2024-02-24T19:29:18Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-24T19:28:22Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 263.99 +/- 18.51
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jesuzn/LunarLander-v2 | jesuzn | 2024-02-24T19:15:44Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-24T19:09:07Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.83 +/- 25.80
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
kalobiralo/t5-grammar-model | kalobiralo | 2024-02-24T19:03:29Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-24T19:02:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Edentns/DataVortexS-10.7B-dpo-v1.11 | Edentns | 2024-02-24T18:58:23Z | 59 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"ko",
"base_model:LDCC/LDCC-SOLAR-10.7B",
"base_model:finetune:LDCC/LDCC-SOLAR-10.7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-31T04:16:25Z | ---
tags:
- text-generation
license: cc-by-nc-4.0
language:
- ko
base_model: LDCC/LDCC-SOLAR-10.7B
pipeline_tag: text-generation
---
# **DataVortexS-10.7B-dpo-v1.11**
<img src="./DataVortex.png" alt="DataVortex" style="height: 8em;">
## Our Team
| Research & Engineering | Product Management |
| :--------------------: | :----------------: |
| Kwangseok Yang | Seunghyun Choi |
| Jeongwon Choi | Hyoseok Choi |
## **Model Details**
### **Base Model**
[LDCC/LDCC-SOLAR-10.7B](https://huggingface.co/LDCC/LDCC-SOLAR-10.7B)
### **Trained On**
- **OS**: Ubuntu 22.04
- **GPU**: H100 80GB 4ea
- **transformers**: v4.36.2
### **Instruction format**
It follows **Alpaca (Chat)** format.
E.g.
```python
text = """\
### System:
당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다.
### User:
대한민국의 수도는 어디야?
### Assistant:
대한민국의 수도는 서울입니다.
### User:
서울 인구는 총 몇 명이야?
"""
```
## **Model Benchmark**
### **[Ko LM Eval Harness](https://github.com/Beomi/ko-lm-evaluation-harness)**
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
| :--------------- | -----------: | -----------: | -----------: | -----------: |
| kobest_boolq | 0.920101 | 0.928018 | 0.933025 | 0.928754 |
| kobest_copa | 0.721782 | 0.801936 | 0.817737 | 0.84093 |
| kobest_hellaswag | 0.44502 | 0.482783 | 0.483978 | 0.48978 |
| kobest_sentineg | 0.51398 | 0.931928 | 0.944556 | 0.934475 |
| **Average** | **0.650221** | **0.786166** | **0.794824** | **0.798485** |
### **[Ko-LLM-Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)**
| Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| ------: | -----: | -----------: | ------: | ------------: | --------------: |
| 59.56 | 55.97 | 68.68 | 52.67 | 66.74 | 53.72 |
## **Implementation Code**
This model contains the chat_template instruction format.
You can use the code below.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.11")
tokenizer = AutoTokenizer.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.11")
messages = [
{"role": "system", "content": "당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다."},
{"role": "user", "content": "대한민국의 수도는 어디야?"},
{"role": "assistant", "content": "대한민국의 수도는 서울입니다."},
{"role": "user", "content": "서울 인구는 총 몇 명이야?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## **License**
This model is licensed under the [cc-by-nc-4.0](https://creativecommons.org/licenses/by-nc/4.0/). which allows others to share and adapt the model for non-commercial purposes.
<div align="center">
<a href="https://edentns.com/">
<img src="./Logo.png" alt="Logo" style="height: 3em;">
</a>
</div>
|
shaheryar48/roberta_fine_tuned | shaheryar48 | 2024-02-24T18:58:07Z | 163 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-02-24T18:56:07Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Edentns/DataVortexS-10.7B-dpo-v1.9 | Edentns | 2024-02-24T18:56:59Z | 2,255 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"ko",
"base_model:beomi/OPEN-SOLAR-KO-10.7B",
"base_model:finetune:beomi/OPEN-SOLAR-KO-10.7B",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-01-30T00:07:45Z | ---
tags:
- text-generation
license: cc-by-nc-4.0
language:
- ko
base_model: beomi/OPEN-SOLAR-KO-10.7B
pipeline_tag: text-generation
---
# **DataVortexS-10.7B-dpo-v1.9**
<img src="./DataVortex.png" alt="DataVortex" style="height: 8em;">
## Our Team
| Research & Engineering | Product Management |
| :--------------------: | :----------------: |
| Kwangseok Yang | Seunghyun Choi |
| Jeongwon Choi | Hyoseok Choi |
## **Model Details**
### **Base Model**
[beomi/OPEN-SOLAR-KO-10.7B](https://huggingface.co/beomi/OPEN-SOLAR-KO-10.7B)
### **Trained On**
- **OS**: Ubuntu 22.04
- **GPU**: H100 80GB 4ea
- **transformers**: v4.36.2
### **Instruction format**
It follows **Alpaca (Chat)** format.
E.g.
```python
text = """\
### System:
당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다.
### User:
대한민국의 수도는 어디야?
### Assistant:
대한민국의 수도는 서울입니다.
### User:
서울 인구는 총 몇 명이야?
"""
```
## **Model Benchmark**
### **[Ko LM Eval Harness](https://github.com/Beomi/ko-lm-evaluation-harness)**
| Task | 0-shot | 5-shot | 10-shot | 50-shot |
| :--------------- | -----------: | -----------: | -----------: | -----------: |
| kobest_boolq | 0.902418 | 0.904502 | 0.91804 | 0.915893 |
| kobest_copa | 0.815462 | 0.853789 | 0.855721 | 0.866903 |
| kobest_hellaswag | 0.49901 | 0.488796 | 0.484538 | 0.498009 |
| kobest_sentineg | 0.335008 | 0.977325 | 0.979839 | 0.982364 |
| **Average** | **0.637974** | **0.806103** | **0.809534** | **0.815792** |
### **[Ko-LLM-Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)**
| Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| ------: | -----: | -----------: | ------: | ------------: | --------------: |
| 55.19 | 53.33 | 62.57 | 49.55 | 49.01 | 61.51 |
## **Implementation Code**
This model contains the chat_template instruction format.
You can use the code below.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.9")
tokenizer = AutoTokenizer.from_pretrained("Edentns/DataVortexS-10.7B-dpo-v1.9")
messages = [
{"role": "system", "content": "당신은 사람들이 정보를 찾을 수 있도록 도와주는 인공지능 비서입니다."},
{"role": "user", "content": "대한민국의 수도는 어디야?"},
{"role": "assistant", "content": "대한민국의 수도는 서울입니다."},
{"role": "user", "content": "서울 인구는 총 몇 명이야?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## **License**
This model is licensed under the [cc-by-nc-4.0](https://creativecommons.org/licenses/by-nc/4.0/). which allows others to share and adapt the model for non-commercial purposes.
<div align="center">
<a href="https://edentns.com/">
<img src="./Logo.png" alt="Logo" style="height: 3em;">
</a>
</div>
|
devcryptodude/distilbert-base-cased-document-casual | devcryptodude | 2024-02-24T18:51:31Z | 107 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-cased",
"base_model:finetune:distilbert/distilbert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-01-16T13:11:58Z | ---
license: apache-2.0
base_model: distilbert-base-cased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-cased-document-casual
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-cased-document-casual
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2732
- F1-score: 0.9033
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1-score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1376 | 0.97 | 15 | 0.6716 | 0.7342 |
| 0.0517 | 2.0 | 31 | 0.3222 | 0.9350 |
| 0.0075 | 2.97 | 46 | 0.2732 | 0.9033 |
| 0.0032 | 4.0 | 62 | 0.2932 | 0.9033 |
| 0.0024 | 4.84 | 75 | 0.2914 | 0.9033 |
### Framework versions
- Transformers 4.39.0.dev0
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2
|
nicholasbien/gpt2_finetuned-20k_ppo_a4 | nicholasbien | 2024-02-24T18:50:59Z | 165 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T18:35:43Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
syeda-raisa/bangla_idiom_paraphrase_v1 | syeda-raisa | 2024-02-24T18:14:22Z | 5 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:mHossain/bangla-para-v3-500000",
"base_model:finetune:mHossain/bangla-para-v3-500000",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-24T16:29:04Z | ---
base_model: mHossain/bangla-para-v3-500000
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bangla_idiom_paraphrase_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bangla_idiom_paraphrase_v1
This model is a fine-tuned version of [mHossain/bangla-para-v3-500000](https://huggingface.co/mHossain/bangla-para-v3-500000) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6125
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 13.1922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5000
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.0214 | 1.0 | 3049 | 0.6765 | 0.0 | 0.0 | 0.0 | 0.0 | 13.1656 |
| 0.9326 | 2.0 | 6098 | 0.6334 | 0.0 | 0.0 | 0.0 | 0.0 | 13.1223 |
| 0.8302 | 3.0 | 9147 | 0.6193 | 0.0 | 0.0 | 0.0 | 0.0 | 13.1745 |
| 0.8046 | 4.0 | 12196 | 0.6152 | 0.0 | 0.0 | 0.0 | 0.0 | 13.204 |
| 0.7702 | 5.0 | 15245 | 0.6125 | 0.0 | 0.0 | 0.0 | 0.0 | 13.1922 |
### Framework versions
- Transformers 4.37.2
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
Mabeck/Heidrun-Mistral-7B-base | Mabeck | 2024-02-24T18:04:56Z | 34 | 4 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"da",
"dataset:wikimedia/wikipedia",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-11T21:27:03Z | ---
language:
- en
- da
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: mistralai/Mistral-7B-v0.1
datasets:
- wikimedia/wikipedia
license: mit
---
<img src="https://huggingface.co/Mabeck/Heidrun-Mistral-7B-chat/resolve/main/heidrun.jpeg" alt="Heidrun Logo" width="400">
# Model description
Heidrun-Mistral-7B-base is a generative text model based on [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1). It has been further pretrained on a subset of the Danish corpus from Wikipedia, Wikibooks and small parts of Hestenettet for 2 epochs.
It is a foundational/completion model with potential for further finetuning.
For inference or chatting please check out [Heidrun-Mistral-7B-chat](https://huggingface.co/Mabeck/Heidrun-Mistral-7B-chat).
# Previous version
Please note that this has been updated since the original release. The old version can be found under branch v0.1.
# Uploaded model
- **Developed by:** Mabeck
- **Finetuned from model :** mistralai/Mistral-7B-v0.1
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth) |
ZEECO1/CancerLLM-Mistral7b | ZEECO1 | 2024-02-24T18:04:42Z | 0 | 2 | null | [
"safetensors",
"region:us"
] | null | 2024-02-24T17:53:48Z | import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
base_model_id = "mistralai/Mistral-7B-v0.1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id, # Mistral, same as before
quantization_config=bnb_config, # Same quantization config as before
device_map="auto",
trust_remote_code=True,
)
eval_tokenizer = AutoTokenizer.from_pretrained(base_model_id, add_bos_token=True, trust_remote_code=True)
from peft import PeftModel
ft_model = PeftModel.from_pretrained(base_model, "ZEECO1/CancerLLM-Mistral7b/checkpoint-500")
eval_prompt = " what are the drugs against lung cancer: # "
model_input = eval_tokenizer(eval_prompt, return_tensors="pt").to("cuda")
ft_model.eval()
with torch.no_grad():
print(eval_tokenizer.decode(ft_model.generate(**model_input, max_new_tokens=100, repetition_penalty=1.15)[0], skip_special_tokens=True)) |
han2lin/gpt2_med_ft | han2lin | 2024-02-24T18:04:09Z | 165 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T18:03:30Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
krwd/ppo-LunarLander-v2 | krwd | 2024-02-24T17:59:48Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-02-24T17:59:29Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 243.85 +/- 16.50
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Rasi1610/Death_Se46_model_p2 | Rasi1610 | 2024-02-24T17:56:58Z | 48 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2024-01-10T08:16:37Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LoneStriker/OpenCodeInterpreter-DS-33B-8.0bpw-h8-exl2 | LoneStriker | 2024-02-24T17:52:45Z | 5 | 2 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"en",
"arxiv:2402.14658",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T17:39:03Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- code
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="OpenCodeInterpreter-DS-33B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!" |
nielsbantilan/path-to-save-model | nielsbantilan | 2024-02-24T17:50:58Z | 3 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:CompVis/stable-diffusion-v1-4",
"base_model:adapter:CompVis/stable-diffusion-v1-4",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2024-02-24T17:42:52Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- text-to-image
- diffusers
- lora
- stable-diffusion
- stable-diffusion-diffusers
inference: true
base_model: CompVis/stable-diffusion-v1-4
instance_prompt: a photo of sks dog
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA DreamBooth - nielsbantilan/path-to-save-model
These are LoRA adaption weights for CompVis/stable-diffusion-v1-4. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
LoRA for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
robdemunck/finetuned-t5-small-cnn_dailymail | robdemunck | 2024-02-24T17:44:44Z | 104 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-02-23T20:10:05Z | ---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
model-index:
- name: finetuned-t5-small-cnn_dailymail
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-t5-small-cnn_dailymail
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.2.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
LoneStriker/OpenCodeInterpreter-DS-33B-6.0bpw-h6-exl2 | LoneStriker | 2024-02-24T17:39:01Z | 5 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"en",
"arxiv:2402.14658",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T17:28:39Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- code
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="OpenCodeInterpreter-DS-33B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!" |
heyholetsgo/Nous-Hermes-2-Mistral-7B-DPO-AWQ | heyholetsgo | 2024-02-24T17:24:53Z | 85 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"Mistral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"synthetic data",
"distillation",
"awq",
"conversational",
"en",
"dataset:teknium/OpenHermes-2.5",
"base_model:NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"base_model:quantized:NousResearch/Nous-Hermes-2-Mistral-7B-DPO",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] | text-generation | 2024-02-22T11:02:52Z | ---
base_model: NousResearch/Nous-Hermes-2-Mistral-7B-DPO
tags:
- Mistral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- synthetic data
- distillation
- awq
model-index:
- name: Nous-Hermes-2-Mistral-7B-DPO
results: []
license: apache-2.0
language:
- en
datasets:
- teknium/OpenHermes-2.5
---
# Nous Hermes 2 - Mistral 7B - DPO - AWQ

## Model Description
This repo contains the AWQ quantized version of the `Nous Hermes 2 - Mistral 7B - DPO` model.
It was quantized with AutoAWQ using the following settings:
```json
{"zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM"}
```
|
archiMAD/ppo-SnowballTarget | archiMAD | 2024-02-24T17:20:20Z | 0 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] | reinforcement-learning | 2024-02-24T17:20:18Z | ---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: archiMAD/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
kaifanli/bart-large-japanese-RMT-tobyoki-20 | kaifanli | 2024-02-24T17:15:09Z | 0 | 0 | null | [
"pytorch",
"tensorboard",
"generated_from_trainer",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2024-02-24T16:15:45Z | ---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-japanese-RMT-tobyoki-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-japanese-RMT-tobyoki-20
This model is a fine-tuned version of [ku-nlp/bart-large-japanese](https://huggingface.co/ku-nlp/bart-large-japanese) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4333
- Rouge1: 10.4455
- Rouge2: 0.9997
- Rougel: 7.6259
- Rougelsum: 9.0518
- Gen Len: 2098.2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 40 | 3.1809 | 9.7012 | 1.3824 | 6.3532 | 8.4445 | 3000.0 |
| No log | 2.0 | 80 | 2.8693 | 11.308 | 1.6656 | 6.9919 | 9.8495 | 2980.5 |
| No log | 3.0 | 120 | 2.6873 | 11.7005 | 1.6944 | 7.3988 | 10.0862 | 2702.3 |
| No log | 4.0 | 160 | 2.5541 | 10.815 | 1.2578 | 7.4659 | 9.1837 | 2275.6 |
| No log | 5.0 | 200 | 2.4785 | 10.5975 | 1.0925 | 7.6191 | 9.357 | 2157.6 |
| No log | 6.0 | 240 | 2.4333 | 10.4455 | 0.9997 | 7.6259 | 9.0518 | 2098.2 |
### Framework versions
- Transformers 4.30.0
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
RecCode/4 | RecCode | 2024-02-24T17:13:31Z | 14 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-01-26T03:07:55Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
base_model: openai/whisper-small
model-index:
- name: '4'
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 4
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0909
- Wer: 65.6470
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 4.2263 | 0.04 | 10 | 4.0304 | 15.6470 |
| 3.8803 | 0.08 | 20 | 3.6564 | 15.4712 |
| 3.7847 | 0.13 | 30 | 3.2816 | 14.6624 |
| 3.4068 | 0.17 | 40 | 3.0934 | 14.3108 |
| 3.0547 | 0.21 | 50 | 2.9635 | 14.0647 |
| 3.0245 | 0.25 | 60 | 2.8523 | 17.7918 |
| 3.3518 | 0.29 | 70 | 2.7638 | 18.8467 |
| 3.105 | 0.34 | 80 | 2.6917 | 20.8509 |
| 2.8325 | 0.38 | 90 | 2.6234 | 21.3783 |
| 2.8667 | 0.42 | 100 | 2.5582 | 21.4838 |
| 2.7528 | 0.46 | 110 | 2.4994 | 21.2377 |
| 2.8502 | 0.5 | 120 | 2.4430 | 28.0591 |
| 2.5623 | 0.55 | 130 | 2.3898 | 30.5556 |
| 2.877 | 0.59 | 140 | 2.3409 | 36.0056 |
| 2.6492 | 0.63 | 150 | 2.2965 | 45.1828 |
| 2.4119 | 0.67 | 160 | 2.2554 | 60.0563 |
| 2.6273 | 0.71 | 170 | 2.2175 | 73.8045 |
| 2.4091 | 0.76 | 180 | 2.1841 | 70.2883 |
| 2.2931 | 0.8 | 190 | 2.1558 | 74.8242 |
| 2.297 | 0.84 | 200 | 2.1324 | 71.0970 |
| 2.1893 | 0.88 | 210 | 2.1133 | 72.0113 |
| 2.3408 | 0.92 | 220 | 2.0994 | 70.8861 |
| 2.2892 | 0.97 | 230 | 2.0909 | 65.6470 |
### Framework versions
- Transformers 4.38.0.dev0
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
latent-space-dreams/LS_Pravus | latent-space-dreams | 2024-02-24T17:13:02Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-10-23T05:29:55Z | ---
license: creativeml-openrail-m
---
A model merge for anime 2.0. You are solely responsible for how you use this model.
No commercial use, please. |
LoneStriker/OpenCodeInterpreter-DS-33B-4.0bpw-h6-exl2 | LoneStriker | 2024-02-24T17:11:43Z | 6 | 4 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"en",
"arxiv:2402.14658",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T17:04:41Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- code
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="OpenCodeInterpreter-DS-33B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!" |
LoneStriker/OpenCodeInterpreter-DS-33B-3.0bpw-h6-exl2 | LoneStriker | 2024-02-24T17:04:39Z | 2 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"en",
"arxiv:2402.14658",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T16:59:12Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- code
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="OpenCodeInterpreter-DS-33B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!" |
Hamza11/Banglabert_nwp_finetuning_def_v2 | Hamza11 | 2024-02-24T16:56:57Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"electra",
"fill-mask",
"generated_from_trainer",
"base_model:csebuetnlp/banglabert",
"base_model:finetune:csebuetnlp/banglabert",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-02-24T14:33:49Z | ---
base_model: csebuetnlp/banglabert
tags:
- generated_from_trainer
model-index:
- name: Banglabert_nwp_finetuning_def_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Banglabert_nwp_finetuning_def_v2
This model is a fine-tuned version of [csebuetnlp/banglabert](https://huggingface.co/csebuetnlp/banglabert) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 5.9985 | 1.0 | 2487 | 5.4179 |
| 5.1899 | 2.0 | 4974 | 4.8725 |
| 4.8308 | 3.0 | 7461 | 4.6051 |
| 4.6303 | 4.0 | 9948 | 4.4425 |
| 4.4543 | 5.0 | 12435 | 4.3072 |
| 4.2875 | 6.0 | 14922 | 4.2110 |
| 4.2355 | 7.0 | 17409 | 4.1004 |
| 4.1108 | 8.0 | 19896 | 4.0693 |
| 4.0311 | 9.0 | 22383 | 3.9807 |
| 3.9836 | 10.0 | 24870 | 3.9329 |
| 3.9049 | 11.0 | 27357 | 3.9332 |
| 3.8663 | 12.0 | 29844 | 3.9027 |
| 3.7633 | 13.0 | 32331 | 3.8750 |
| 3.7639 | 14.0 | 34818 | 3.7487 |
| 3.6831 | 15.0 | 37305 | 3.7775 |
| 3.6808 | 16.0 | 39792 | 3.7372 |
| 3.6136 | 17.0 | 42279 | 3.7313 |
| 3.5998 | 18.0 | 44766 | 3.6778 |
| 3.531 | 19.0 | 47253 | 3.6912 |
| 3.5361 | 20.0 | 49740 | 3.6869 |
| 3.509 | 21.0 | 52227 | 3.6790 |
| 3.4625 | 22.0 | 54714 | 3.6425 |
| 3.418 | 23.0 | 57201 | 3.6572 |
| 3.369 | 24.0 | 59688 | 3.6407 |
| 3.3832 | 25.0 | 62175 | 3.6278 |
| 3.3728 | 26.0 | 64662 | 3.5715 |
| 3.3304 | 27.0 | 67149 | 3.6413 |
| 3.2864 | 28.0 | 69636 | 3.5743 |
| 3.3057 | 29.0 | 72123 | 3.5227 |
| 3.2916 | 30.0 | 74610 | 3.5448 |
| 3.2541 | 31.0 | 77097 | 3.5422 |
| 3.2293 | 32.0 | 79584 | 3.5775 |
| 3.1839 | 33.0 | 82071 | 3.5705 |
| 3.2106 | 34.0 | 84558 | 3.5680 |
| 3.185 | 35.0 | 87045 | 3.5225 |
| 3.1845 | 36.0 | 89532 | 3.5237 |
| 3.1581 | 37.0 | 92019 | 3.5300 |
| 3.1569 | 38.0 | 94506 | 3.5081 |
| 3.1222 | 39.0 | 96993 | 3.5217 |
| 3.1007 | 40.0 | 99480 | 3.4810 |
| 3.1094 | 41.0 | 101967 | 3.5475 |
| 3.1289 | 42.0 | 104454 | 3.5126 |
| 3.0841 | 43.0 | 106941 | 3.5076 |
| 3.0834 | 44.0 | 109428 | 3.5101 |
| 3.0862 | 45.0 | 111915 | 3.4777 |
| 3.0843 | 46.0 | 114402 | 3.5116 |
| 3.042 | 47.0 | 116889 | 3.5031 |
| 3.0424 | 48.0 | 119376 | 3.4991 |
| 3.0855 | 49.0 | 121863 | 3.5203 |
| 3.0325 | 50.0 | 124350 | 3.5110 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.0+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
LoneStriker/OpenCodeInterpreter-CL-13B-5.0bpw-h6-exl2 | LoneStriker | 2024-02-24T16:43:33Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"en",
"arxiv:2402.14658",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-24T16:39:56Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- code
---
<h1 align="center"> OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement<h1>
<p align="center">
<img width="1000px" alt="OpenCodeInterpreter" src="https://opencodeinterpreter.github.io/static/images/figure1.png">
</p>
<p align="center">
<a href="https://opencodeinterpreter.github.io/">[🏠Homepage]</a>
|
<a href="https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/">[🛠️Code]</a>
</p>
<hr>
## Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: ["OpenCodeInterpreter: A System for Enhanced Code Generation and Execution"](https://arxiv.org/abs/2402.14658) available on arXiv.
## Model Usage
### Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="OpenCodeInterpreter-CL-13B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
## Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: [email protected], [email protected].
We're here to assist you!" |
Subsets and Splits