
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-22 06:27:16
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 492
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-22 06:26:41
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
BilalMuftuoglu/beit-base-patch16-224-hasta-85-fold4 | BilalMuftuoglu | 2024-05-23T15:42:14Z | 197 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T15:34:51Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-85-fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7272727272727273
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-85-fold4
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9258
- Accuracy: 0.7273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 1.0761 | 0.6364 |
| No log | 2.0 | 2 | 0.9258 | 0.7273 |
| No log | 3.0 | 3 | 0.8310 | 0.7273 |
| No log | 4.0 | 4 | 0.9402 | 0.7273 |
| No log | 5.0 | 5 | 1.1381 | 0.7273 |
| No log | 6.0 | 6 | 1.2812 | 0.7273 |
| No log | 7.0 | 7 | 1.2679 | 0.7273 |
| No log | 8.0 | 8 | 1.1704 | 0.7273 |
| No log | 9.0 | 9 | 1.1909 | 0.7273 |
| 0.3269 | 10.0 | 10 | 1.2981 | 0.7273 |
| 0.3269 | 11.0 | 11 | 1.2565 | 0.7273 |
| 0.3269 | 12.0 | 12 | 1.1475 | 0.7273 |
| 0.3269 | 13.0 | 13 | 1.0585 | 0.7273 |
| 0.3269 | 14.0 | 14 | 1.0294 | 0.7273 |
| 0.3269 | 15.0 | 15 | 1.0649 | 0.7273 |
| 0.3269 | 16.0 | 16 | 1.1712 | 0.7273 |
| 0.3269 | 17.0 | 17 | 1.2090 | 0.7273 |
| 0.3269 | 18.0 | 18 | 1.1579 | 0.7273 |
| 0.3269 | 19.0 | 19 | 1.0943 | 0.7273 |
| 0.1921 | 20.0 | 20 | 1.1877 | 0.7273 |
| 0.1921 | 21.0 | 21 | 1.3909 | 0.7273 |
| 0.1921 | 22.0 | 22 | 1.4301 | 0.7273 |
| 0.1921 | 23.0 | 23 | 1.4210 | 0.7273 |
| 0.1921 | 24.0 | 24 | 1.3994 | 0.7273 |
| 0.1921 | 25.0 | 25 | 1.3649 | 0.7273 |
| 0.1921 | 26.0 | 26 | 1.3244 | 0.7273 |
| 0.1921 | 27.0 | 27 | 1.2861 | 0.7273 |
| 0.1921 | 28.0 | 28 | 1.1634 | 0.7273 |
| 0.1921 | 29.0 | 29 | 0.9854 | 0.7273 |
| 0.1374 | 30.0 | 30 | 1.0608 | 0.7273 |
| 0.1374 | 31.0 | 31 | 1.3092 | 0.7273 |
| 0.1374 | 32.0 | 32 | 1.4679 | 0.7273 |
| 0.1374 | 33.0 | 33 | 1.4397 | 0.7273 |
| 0.1374 | 34.0 | 34 | 1.2949 | 0.7273 |
| 0.1374 | 35.0 | 35 | 1.2340 | 0.7273 |
| 0.1374 | 36.0 | 36 | 1.2524 | 0.7273 |
| 0.1374 | 37.0 | 37 | 1.2108 | 0.7273 |
| 0.1374 | 38.0 | 38 | 1.1878 | 0.7273 |
| 0.1374 | 39.0 | 39 | 1.1400 | 0.7273 |
| 0.0886 | 40.0 | 40 | 1.1186 | 0.7273 |
| 0.0886 | 41.0 | 41 | 1.3145 | 0.7273 |
| 0.0886 | 42.0 | 42 | 1.4749 | 0.7273 |
| 0.0886 | 43.0 | 43 | 1.5773 | 0.7273 |
| 0.0886 | 44.0 | 44 | 1.6792 | 0.7273 |
| 0.0886 | 45.0 | 45 | 1.7716 | 0.7273 |
| 0.0886 | 46.0 | 46 | 1.8943 | 0.7273 |
| 0.0886 | 47.0 | 47 | 1.8541 | 0.7273 |
| 0.0886 | 48.0 | 48 | 1.6656 | 0.7273 |
| 0.0886 | 49.0 | 49 | 1.4897 | 0.7273 |
| 0.0509 | 50.0 | 50 | 1.2921 | 0.7273 |
| 0.0509 | 51.0 | 51 | 1.2021 | 0.7273 |
| 0.0509 | 52.0 | 52 | 1.2643 | 0.7273 |
| 0.0509 | 53.0 | 53 | 1.4622 | 0.7273 |
| 0.0509 | 54.0 | 54 | 1.5043 | 0.7273 |
| 0.0509 | 55.0 | 55 | 1.5063 | 0.7273 |
| 0.0509 | 56.0 | 56 | 1.4604 | 0.7273 |
| 0.0509 | 57.0 | 57 | 1.3414 | 0.7273 |
| 0.0509 | 58.0 | 58 | 1.1789 | 0.7273 |
| 0.0509 | 59.0 | 59 | 1.1715 | 0.7273 |
| 0.0471 | 60.0 | 60 | 1.2550 | 0.7273 |
| 0.0471 | 61.0 | 61 | 1.3513 | 0.7273 |
| 0.0471 | 62.0 | 62 | 1.4922 | 0.7273 |
| 0.0471 | 63.0 | 63 | 1.6911 | 0.7273 |
| 0.0471 | 64.0 | 64 | 1.7747 | 0.7273 |
| 0.0471 | 65.0 | 65 | 1.7659 | 0.7273 |
| 0.0471 | 66.0 | 66 | 1.6730 | 0.7273 |
| 0.0471 | 67.0 | 67 | 1.5296 | 0.7273 |
| 0.0471 | 68.0 | 68 | 1.4973 | 0.7273 |
| 0.0471 | 69.0 | 69 | 1.4650 | 0.7273 |
| 0.0212 | 70.0 | 70 | 1.4970 | 0.7273 |
| 0.0212 | 71.0 | 71 | 1.5022 | 0.7273 |
| 0.0212 | 72.0 | 72 | 1.5275 | 0.7273 |
| 0.0212 | 73.0 | 73 | 1.5780 | 0.7273 |
| 0.0212 | 74.0 | 74 | 1.7149 | 0.7273 |
| 0.0212 | 75.0 | 75 | 1.8056 | 0.7273 |
| 0.0212 | 76.0 | 76 | 1.8394 | 0.7273 |
| 0.0212 | 77.0 | 77 | 1.8526 | 0.7273 |
| 0.0212 | 78.0 | 78 | 1.7944 | 0.7273 |
| 0.0212 | 79.0 | 79 | 1.7440 | 0.7273 |
| 0.0313 | 80.0 | 80 | 1.6994 | 0.7273 |
| 0.0313 | 81.0 | 81 | 1.6076 | 0.7273 |
| 0.0313 | 82.0 | 82 | 1.5753 | 0.7273 |
| 0.0313 | 83.0 | 83 | 1.5831 | 0.7273 |
| 0.0313 | 84.0 | 84 | 1.5471 | 0.7273 |
| 0.0313 | 85.0 | 85 | 1.5600 | 0.7273 |
| 0.0313 | 86.0 | 86 | 1.5832 | 0.7273 |
| 0.0313 | 87.0 | 87 | 1.5819 | 0.7273 |
| 0.0313 | 88.0 | 88 | 1.6053 | 0.7273 |
| 0.0313 | 89.0 | 89 | 1.6329 | 0.7273 |
| 0.0205 | 90.0 | 90 | 1.6751 | 0.7273 |
| 0.0205 | 91.0 | 91 | 1.6957 | 0.7273 |
| 0.0205 | 92.0 | 92 | 1.7326 | 0.7273 |
| 0.0205 | 93.0 | 93 | 1.7475 | 0.7273 |
| 0.0205 | 94.0 | 94 | 1.7503 | 0.7273 |
| 0.0205 | 95.0 | 95 | 1.7443 | 0.7273 |
| 0.0205 | 96.0 | 96 | 1.7483 | 0.7273 |
| 0.0205 | 97.0 | 97 | 1.7523 | 0.7273 |
| 0.0205 | 98.0 | 98 | 1.7516 | 0.7273 |
| 0.0205 | 99.0 | 99 | 1.7483 | 0.7273 |
| 0.0334 | 100.0 | 100 | 1.7462 | 0.7273 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
ZBWatHF/Annif-tutorial | ZBWatHF | 2024-05-23T15:39:40Z | 0 | 0 | null | [
"Annif",
"Text Classification",
"Subject Indexing",
"en",
"license:cc-by-4.0",
"region:us"
] | null | 2024-05-23T14:50:38Z | ---
license: cc-by-4.0
tags:
- Annif
- Text Classification
- Subject Indexing
language:
- en
---
# ZBWatHF/Annif-tutorial
This repository contains the projects of [Annif tutorial](https://github.com/NatLibFi/Annif-tutorial) that use STW, 20news, and Hogwarts vocabularies.
## Usage
To download selected projects with Annif use the `annif download` command, for
example run
annif download "*" ZBWatHF/Annif-tutorial
See the tutorial [Hugging Face Hub exercise](https://github.com/NatLibFi/Annif-tutorial/blob/master/exercises/OPT_huggingfacehub.md) and [Annif wiki](https://github.com/NatLibFi/Annif/wiki/Hugging-Face-Hub-integration) for more information. |
GiuntaLuana/my_awesome_asr_mind_model | GiuntaLuana | 2024-05-23T15:38:42Z | 79 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:minds14",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-23T15:25:04Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- wer
model-index:
- name: my_awesome_asr_mind_model
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: minds14
type: minds14
config: en-US
split: None
args: en-US
metrics:
- name: Wer
type: wer
value: 1.1863636363636363
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_asr_mind_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 24.1755
- Wer: 1.1864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 34.7756 | 0.5 | 5 | 24.1755 | 1.1864 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
reemmasoud/idv_vs_col_llama-3_PromptTuning_CAUSAL_LM_gradient_descent_v5.3 | reemmasoud | 2024-05-23T15:38:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T15:38:31Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Milana/model-classifier-vctk-edacc | Milana | 2024-05-23T15:35:00Z | 133 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"base_model:facebook/mms-lid-4017",
"base_model:finetune:facebook/mms-lid-4017",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | audio-classification | 2024-05-23T07:41:59Z | ---
license: cc-by-nc-4.0
base_model: facebook/mms-lid-4017
tags:
- generated_from_trainer
model-index:
- name: model-classifier-vctk-edacc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model-classifier-vctk-edacc
This model is a fine-tuned version of [facebook/mms-lid-4017](https://huggingface.co/facebook/mms-lid-4017) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.9928
- eval_accuracy: 0.6491
- eval_runtime: 2565.174
- eval_samples_per_second: 3.224
- eval_steps_per_second: 0.403
- epoch: 0.5
- step: 200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 400
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
BilalMuftuoglu/beit-base-patch16-224-hasta-85-fold3 | BilalMuftuoglu | 2024-05-23T15:34:39Z | 197 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T15:27:12Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-85-fold3
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7272727272727273
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-85-fold3
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8911
- Accuracy: 0.7273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 1.3301 | 0.1818 |
| No log | 2.0 | 2 | 1.1012 | 0.3636 |
| No log | 3.0 | 3 | 0.8911 | 0.7273 |
| No log | 4.0 | 4 | 0.9555 | 0.7273 |
| No log | 5.0 | 5 | 1.2582 | 0.7273 |
| No log | 6.0 | 6 | 1.5576 | 0.7273 |
| No log | 7.0 | 7 | 1.6687 | 0.7273 |
| No log | 8.0 | 8 | 1.5015 | 0.7273 |
| No log | 9.0 | 9 | 1.2729 | 0.7273 |
| 0.3584 | 10.0 | 10 | 1.2127 | 0.7273 |
| 0.3584 | 11.0 | 11 | 1.3132 | 0.7273 |
| 0.3584 | 12.0 | 12 | 1.3350 | 0.7273 |
| 0.3584 | 13.0 | 13 | 1.2579 | 0.7273 |
| 0.3584 | 14.0 | 14 | 1.3559 | 0.7273 |
| 0.3584 | 15.0 | 15 | 1.4231 | 0.7273 |
| 0.3584 | 16.0 | 16 | 1.5141 | 0.7273 |
| 0.3584 | 17.0 | 17 | 1.4200 | 0.7273 |
| 0.3584 | 18.0 | 18 | 1.2498 | 0.7273 |
| 0.3584 | 19.0 | 19 | 1.1456 | 0.7273 |
| 0.1919 | 20.0 | 20 | 1.1055 | 0.7273 |
| 0.1919 | 21.0 | 21 | 1.1937 | 0.7273 |
| 0.1919 | 22.0 | 22 | 1.2768 | 0.7273 |
| 0.1919 | 23.0 | 23 | 1.3224 | 0.7273 |
| 0.1919 | 24.0 | 24 | 1.3629 | 0.7273 |
| 0.1919 | 25.0 | 25 | 1.3238 | 0.7273 |
| 0.1919 | 26.0 | 26 | 1.2280 | 0.7273 |
| 0.1919 | 27.0 | 27 | 1.2446 | 0.7273 |
| 0.1919 | 28.0 | 28 | 1.2530 | 0.7273 |
| 0.1919 | 29.0 | 29 | 1.2468 | 0.7273 |
| 0.1447 | 30.0 | 30 | 1.1535 | 0.7273 |
| 0.1447 | 31.0 | 31 | 1.1125 | 0.7273 |
| 0.1447 | 32.0 | 32 | 1.2051 | 0.7273 |
| 0.1447 | 33.0 | 33 | 1.5902 | 0.7273 |
| 0.1447 | 34.0 | 34 | 1.8445 | 0.7273 |
| 0.1447 | 35.0 | 35 | 1.7222 | 0.7273 |
| 0.1447 | 36.0 | 36 | 1.5080 | 0.7273 |
| 0.1447 | 37.0 | 37 | 1.3542 | 0.7273 |
| 0.1447 | 38.0 | 38 | 1.3106 | 0.7273 |
| 0.1447 | 39.0 | 39 | 1.4533 | 0.7273 |
| 0.1053 | 40.0 | 40 | 1.6427 | 0.7273 |
| 0.1053 | 41.0 | 41 | 1.7518 | 0.7273 |
| 0.1053 | 42.0 | 42 | 1.7775 | 0.7273 |
| 0.1053 | 43.0 | 43 | 1.6831 | 0.7273 |
| 0.1053 | 44.0 | 44 | 1.6968 | 0.7273 |
| 0.1053 | 45.0 | 45 | 1.8236 | 0.7273 |
| 0.1053 | 46.0 | 46 | 1.8845 | 0.7273 |
| 0.1053 | 47.0 | 47 | 1.8785 | 0.7273 |
| 0.1053 | 48.0 | 48 | 1.8805 | 0.7273 |
| 0.1053 | 49.0 | 49 | 1.9625 | 0.7273 |
| 0.0771 | 50.0 | 50 | 1.9860 | 0.7273 |
| 0.0771 | 51.0 | 51 | 1.9708 | 0.7273 |
| 0.0771 | 52.0 | 52 | 1.9149 | 0.7273 |
| 0.0771 | 53.0 | 53 | 1.9064 | 0.7273 |
| 0.0771 | 54.0 | 54 | 1.8804 | 0.7273 |
| 0.0771 | 55.0 | 55 | 1.8467 | 0.7273 |
| 0.0771 | 56.0 | 56 | 1.8508 | 0.7273 |
| 0.0771 | 57.0 | 57 | 1.8675 | 0.7273 |
| 0.0771 | 58.0 | 58 | 1.8886 | 0.7273 |
| 0.0771 | 59.0 | 59 | 1.8860 | 0.7273 |
| 0.0528 | 60.0 | 60 | 1.8777 | 0.7273 |
| 0.0528 | 61.0 | 61 | 1.9119 | 0.7273 |
| 0.0528 | 62.0 | 62 | 1.9860 | 0.7273 |
| 0.0528 | 63.0 | 63 | 2.1003 | 0.7273 |
| 0.0528 | 64.0 | 64 | 2.1561 | 0.7273 |
| 0.0528 | 65.0 | 65 | 2.1454 | 0.7273 |
| 0.0528 | 66.0 | 66 | 2.0685 | 0.7273 |
| 0.0528 | 67.0 | 67 | 1.9261 | 0.7273 |
| 0.0528 | 68.0 | 68 | 1.6839 | 0.7273 |
| 0.0528 | 69.0 | 69 | 1.4306 | 0.7273 |
| 0.043 | 70.0 | 70 | 1.3800 | 0.7273 |
| 0.043 | 71.0 | 71 | 1.4814 | 0.7273 |
| 0.043 | 72.0 | 72 | 1.6014 | 0.7273 |
| 0.043 | 73.0 | 73 | 1.7792 | 0.7273 |
| 0.043 | 74.0 | 74 | 1.9423 | 0.7273 |
| 0.043 | 75.0 | 75 | 2.0590 | 0.7273 |
| 0.043 | 76.0 | 76 | 2.1119 | 0.7273 |
| 0.043 | 77.0 | 77 | 2.1116 | 0.7273 |
| 0.043 | 78.0 | 78 | 2.0979 | 0.7273 |
| 0.043 | 79.0 | 79 | 2.1457 | 0.7273 |
| 0.0429 | 80.0 | 80 | 2.2222 | 0.7273 |
| 0.0429 | 81.0 | 81 | 2.2803 | 0.7273 |
| 0.0429 | 82.0 | 82 | 2.3327 | 0.7273 |
| 0.0429 | 83.0 | 83 | 2.3643 | 0.7273 |
| 0.0429 | 84.0 | 84 | 2.3774 | 0.7273 |
| 0.0429 | 85.0 | 85 | 2.3838 | 0.7273 |
| 0.0429 | 86.0 | 86 | 2.4072 | 0.7273 |
| 0.0429 | 87.0 | 87 | 2.4189 | 0.7273 |
| 0.0429 | 88.0 | 88 | 2.4028 | 0.7273 |
| 0.0429 | 89.0 | 89 | 2.3847 | 0.7273 |
| 0.0475 | 90.0 | 90 | 2.3793 | 0.7273 |
| 0.0475 | 91.0 | 91 | 2.3831 | 0.7273 |
| 0.0475 | 92.0 | 92 | 2.3882 | 0.7273 |
| 0.0475 | 93.0 | 93 | 2.3964 | 0.7273 |
| 0.0475 | 94.0 | 94 | 2.4126 | 0.7273 |
| 0.0475 | 95.0 | 95 | 2.4309 | 0.7273 |
| 0.0475 | 96.0 | 96 | 2.4486 | 0.7273 |
| 0.0475 | 97.0 | 97 | 2.4628 | 0.7273 |
| 0.0475 | 98.0 | 98 | 2.4723 | 0.7273 |
| 0.0475 | 99.0 | 99 | 2.4775 | 0.7273 |
| 0.0337 | 100.0 | 100 | 2.4788 | 0.7273 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
maghrane/llama3crewai | maghrane | 2024-05-23T15:34:20Z | 6 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:quantized:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T15:29:32Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** maghrane
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
LoneStriker/aya-23-8B-8.0bpw-h8-exl2 | LoneStriker | 2024-05-23T15:33:37Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"conversational",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"exl2",
"region:us"
] | text-generation | 2024-05-23T15:29:21Z | ---
library_name: transformers
language:
- en
- fr
- de
- es
- it
- pt
- ja
- ko
- zh
- ar
- el
- fa
- pl
- id
- cs
- he
- hi
- nl
- ro
- ru
- tr
- uk
- vi
license: cc-by-nc-4.0
---
# Model Card for Aya-23-8B
## Model Summary
Aya 23 is an open weights research release of an instruction fine-tuned model with highly advanced multilingual capabilities. Aya 23 focuses on pairing a highly performant pre-trained [Command family](https://huggingface.co/CohereForAI/c4ai-command-r-plus) of models with the recently released [Aya Collection](https://huggingface.co/datasets/CohereForAI/aya_collection). The result is a powerful multilingual large language model serving 23 languages.
This model card corresponds to the 8-billion version of the Aya 23 model. We also released a 35-billion version which you can find [here](https://huggingface.co/CohereForAI/aya-23-35B).
We cover 23 languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Developed by: [Cohere For AI](https://cohere.for.ai) and [Cohere](https://cohere.com/)
- Point of Contact: Cohere For AI: [cohere.for.ai](https://cohere.for.ai/)
- License: [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license), requires also adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy)
- Model: aya-23-8B
- Model Size: 8 billion parameters
**Try Aya 23**
You can try out Aya 23 (35B) before downloading the weights in our hosted Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Usage
Please install transformers from the source repository that includes the necessary changes for this model
```python
# pip install transformers==4.41.1
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/aya-23-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
### Example Notebook
[This notebook](https://huggingface.co/CohereForAI/aya-23-8B/blob/main/Aya_23_notebook.ipynb) showcases a detailed use of Aya 23 (8B) including inference and fine-tuning with [QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
## Model Details
**Input**: Models input text only.
**Output**: Models generate text only.
**Model Architecture**: Aya-23-8B is an auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model is fine-tuned (IFT) to follow human instructions.
**Languages covered**: The model is particularly optimized for multilinguality and supports the following languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
**Context length**: 8192
### Evaluation
<img src="benchmarks.png" alt="multilingual benchmarks" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
<img src="winrates.png" alt="average win rates" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
Please refer to the [Aya 23 technical report](https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view) for further details about the base model, data, instruction tuning, and evaluation.
### Model Card Contact
For errors or additional questions about details in this model card, contact [email protected].
### Terms of Use
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant multilingual model to researchers all over the world. This model is governed by a [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license) License with an acceptable use addendum, and also requires adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy).
### Try the model today
You can try Aya 23 in the Cohere [playground](https://dashboard.cohere.com/playground/chat) here. You can also use it in our dedicated Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Citation info
```bibtex
@misc{aya23technicalreport,
title={Aya 23: Open Weight Releases to Further Multilingual Progress},
author={Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Nick Frosst, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara Hooker},
url={https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view},
year={2024}
}
``` |
Pclanglais/transcript-text-analysis | Pclanglais | 2024-05-23T15:31:07Z | 112 | 1 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T15:23:01Z | **transcript-text-analysis** is an encoder model specialized for the classification of French news transcripts. The model is based on debertav3 and has been trained on 1,018 examples of annotated transcripts.
Given a text, transcript-text-analysis will generate the following classifications in French:
* Emotion (Neutre, Persuasif, Optimiste, Solennel, Alarmant, Indigné)
* Expression (Interview/Discussion, Publicite, Informations, Meteo, Reportage/Enquete)
* Intention (Informer, Sensibiliser, Promouvoir, Mobiliser, Divertir, Eduquer)
* Theme (Santé, Société, Économie, Politique, Sports)
* Tonalite (Informative, Emotionnelle, Publicitaire) |
bert-base/fun_trained_convbert_epoch_1 | bert-base | 2024-05-23T15:28:11Z | 183 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-20T16:39:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vittoriamarano/my_awesome_asr_mind_model | vittoriamarano | 2024-05-23T15:28:01Z | 79 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:minds14",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-23T15:25:19Z | ---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- wer
model-index:
- name: my_awesome_asr_mind_model
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: minds14
type: minds14
config: en-US
split: None
args: en-US
metrics:
- name: Wer
type: wer
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_asr_mind_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 39.6729
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 41.7302 | 0.5 | 5 | 39.6729 | 1.0 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
BilalMuftuoglu/beit-base-patch16-224-hasta-85-fold2 | BilalMuftuoglu | 2024-05-23T15:27:02Z | 195 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T15:18:49Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-85-fold2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7272727272727273
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-85-fold2
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0030
- Accuracy: 0.7273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 1.3943 | 0.0 |
| No log | 2.0 | 2 | 1.1771 | 0.3636 |
| No log | 3.0 | 3 | 1.0030 | 0.7273 |
| No log | 4.0 | 4 | 1.1175 | 0.7273 |
| No log | 5.0 | 5 | 1.3271 | 0.7273 |
| No log | 6.0 | 6 | 1.3905 | 0.7273 |
| No log | 7.0 | 7 | 1.2948 | 0.7273 |
| No log | 8.0 | 8 | 1.0699 | 0.7273 |
| No log | 9.0 | 9 | 0.9284 | 0.7273 |
| 0.3023 | 10.0 | 10 | 0.9573 | 0.7273 |
| 0.3023 | 11.0 | 11 | 1.1350 | 0.7273 |
| 0.3023 | 12.0 | 12 | 1.2566 | 0.7273 |
| 0.3023 | 13.0 | 13 | 1.2979 | 0.7273 |
| 0.3023 | 14.0 | 14 | 1.1942 | 0.7273 |
| 0.3023 | 15.0 | 15 | 1.1980 | 0.7273 |
| 0.3023 | 16.0 | 16 | 1.2017 | 0.7273 |
| 0.3023 | 17.0 | 17 | 1.4194 | 0.7273 |
| 0.3023 | 18.0 | 18 | 1.5204 | 0.7273 |
| 0.3023 | 19.0 | 19 | 1.3899 | 0.7273 |
| 0.1701 | 20.0 | 20 | 1.2407 | 0.7273 |
| 0.1701 | 21.0 | 21 | 1.3356 | 0.7273 |
| 0.1701 | 22.0 | 22 | 1.5076 | 0.7273 |
| 0.1701 | 23.0 | 23 | 1.4260 | 0.7273 |
| 0.1701 | 24.0 | 24 | 1.1877 | 0.7273 |
| 0.1701 | 25.0 | 25 | 1.0433 | 0.7273 |
| 0.1701 | 26.0 | 26 | 1.0261 | 0.7273 |
| 0.1701 | 27.0 | 27 | 1.0869 | 0.7273 |
| 0.1701 | 28.0 | 28 | 1.1074 | 0.7273 |
| 0.1701 | 29.0 | 29 | 1.0858 | 0.7273 |
| 0.1058 | 30.0 | 30 | 1.0020 | 0.7273 |
| 0.1058 | 31.0 | 31 | 0.9881 | 0.7273 |
| 0.1058 | 32.0 | 32 | 1.0530 | 0.7273 |
| 0.1058 | 33.0 | 33 | 1.3736 | 0.7273 |
| 0.1058 | 34.0 | 34 | 1.4768 | 0.7273 |
| 0.1058 | 35.0 | 35 | 1.4372 | 0.7273 |
| 0.1058 | 36.0 | 36 | 1.4594 | 0.7273 |
| 0.1058 | 37.0 | 37 | 1.4529 | 0.7273 |
| 0.1058 | 38.0 | 38 | 1.6027 | 0.7273 |
| 0.1058 | 39.0 | 39 | 1.7376 | 0.7273 |
| 0.065 | 40.0 | 40 | 1.8993 | 0.7273 |
| 0.065 | 41.0 | 41 | 1.9927 | 0.7273 |
| 0.065 | 42.0 | 42 | 1.8867 | 0.7273 |
| 0.065 | 43.0 | 43 | 1.6363 | 0.7273 |
| 0.065 | 44.0 | 44 | 1.5642 | 0.7273 |
| 0.065 | 45.0 | 45 | 1.5278 | 0.7273 |
| 0.065 | 46.0 | 46 | 1.5097 | 0.7273 |
| 0.065 | 47.0 | 47 | 1.5586 | 0.7273 |
| 0.065 | 48.0 | 48 | 1.5659 | 0.7273 |
| 0.065 | 49.0 | 49 | 1.5743 | 0.7273 |
| 0.061 | 50.0 | 50 | 1.5951 | 0.7273 |
| 0.061 | 51.0 | 51 | 1.6097 | 0.7273 |
| 0.061 | 52.0 | 52 | 1.6781 | 0.7273 |
| 0.061 | 53.0 | 53 | 1.7168 | 0.7273 |
| 0.061 | 54.0 | 54 | 1.6331 | 0.7273 |
| 0.061 | 55.0 | 55 | 1.5711 | 0.7273 |
| 0.061 | 56.0 | 56 | 1.6043 | 0.7273 |
| 0.061 | 57.0 | 57 | 1.6590 | 0.7273 |
| 0.061 | 58.0 | 58 | 1.6879 | 0.7273 |
| 0.061 | 59.0 | 59 | 1.6452 | 0.7273 |
| 0.0642 | 60.0 | 60 | 1.6099 | 0.7273 |
| 0.0642 | 61.0 | 61 | 1.5536 | 0.7273 |
| 0.0642 | 62.0 | 62 | 1.5496 | 0.7273 |
| 0.0642 | 63.0 | 63 | 1.5528 | 0.7273 |
| 0.0642 | 64.0 | 64 | 1.6351 | 0.7273 |
| 0.0642 | 65.0 | 65 | 1.7556 | 0.7273 |
| 0.0642 | 66.0 | 66 | 1.8993 | 0.7273 |
| 0.0642 | 67.0 | 67 | 2.0309 | 0.7273 |
| 0.0642 | 68.0 | 68 | 2.1548 | 0.7273 |
| 0.0642 | 69.0 | 69 | 2.2087 | 0.7273 |
| 0.0411 | 70.0 | 70 | 2.2062 | 0.7273 |
| 0.0411 | 71.0 | 71 | 2.1605 | 0.7273 |
| 0.0411 | 72.0 | 72 | 2.1347 | 0.7273 |
| 0.0411 | 73.0 | 73 | 2.0662 | 0.7273 |
| 0.0411 | 74.0 | 74 | 2.0683 | 0.7273 |
| 0.0411 | 75.0 | 75 | 2.0466 | 0.7273 |
| 0.0411 | 76.0 | 76 | 1.9756 | 0.7273 |
| 0.0411 | 77.0 | 77 | 1.8928 | 0.7273 |
| 0.0411 | 78.0 | 78 | 1.8972 | 0.7273 |
| 0.0411 | 79.0 | 79 | 1.9408 | 0.7273 |
| 0.0421 | 80.0 | 80 | 1.9690 | 0.7273 |
| 0.0421 | 81.0 | 81 | 2.0466 | 0.7273 |
| 0.0421 | 82.0 | 82 | 2.1174 | 0.7273 |
| 0.0421 | 83.0 | 83 | 2.1825 | 0.7273 |
| 0.0421 | 84.0 | 84 | 2.2527 | 0.7273 |
| 0.0421 | 85.0 | 85 | 2.2933 | 0.7273 |
| 0.0421 | 86.0 | 86 | 2.3311 | 0.7273 |
| 0.0421 | 87.0 | 87 | 2.3468 | 0.7273 |
| 0.0421 | 88.0 | 88 | 2.3222 | 0.7273 |
| 0.0421 | 89.0 | 89 | 2.2764 | 0.7273 |
| 0.0304 | 90.0 | 90 | 2.2190 | 0.7273 |
| 0.0304 | 91.0 | 91 | 2.1855 | 0.7273 |
| 0.0304 | 92.0 | 92 | 2.1677 | 0.7273 |
| 0.0304 | 93.0 | 93 | 2.1493 | 0.7273 |
| 0.0304 | 94.0 | 94 | 2.1259 | 0.7273 |
| 0.0304 | 95.0 | 95 | 2.1151 | 0.7273 |
| 0.0304 | 96.0 | 96 | 2.1179 | 0.7273 |
| 0.0304 | 97.0 | 97 | 2.1250 | 0.7273 |
| 0.0304 | 98.0 | 98 | 2.1302 | 0.7273 |
| 0.0304 | 99.0 | 99 | 2.1330 | 0.7273 |
| 0.0305 | 100.0 | 100 | 2.1360 | 0.7273 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Ramikan-BR/tinyllama-coder-py-4bit-v6 | Ramikan-BR | 2024-05-23T15:25:30Z | 82 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/tinyllama-chat-bnb-4bit",
"base_model:quantized:unsloth/tinyllama-chat-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-23T15:22:36Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/tinyllama-chat-bnb-4bit
---
# Uploaded model
- **Developed by:** Ramikan-BR
- **License:** apache-2.0
- **Finetuned from model :** unsloth/tinyllama-chat-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
LucasDay17/bert-base-cased-wikitext2 | LucasDay17 | 2024-05-23T15:23:13Z | 126 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-23T14:51:03Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-wikitext2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.8567
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.0923 | 1.0 | 2346 | 7.0511 |
| 6.9047 | 2.0 | 4692 | 6.8751 |
| 6.8831 | 3.0 | 7038 | 6.8942 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.13.3
|
LoneStriker/aya-23-8B-4.0bpw-h6-exl2 | LoneStriker | 2024-05-23T15:22:05Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"conversational",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"exl2",
"region:us"
] | text-generation | 2024-05-23T15:19:05Z | ---
library_name: transformers
language:
- en
- fr
- de
- es
- it
- pt
- ja
- ko
- zh
- ar
- el
- fa
- pl
- id
- cs
- he
- hi
- nl
- ro
- ru
- tr
- uk
- vi
license: cc-by-nc-4.0
---
# Model Card for Aya-23-8B
## Model Summary
Aya 23 is an open weights research release of an instruction fine-tuned model with highly advanced multilingual capabilities. Aya 23 focuses on pairing a highly performant pre-trained [Command family](https://huggingface.co/CohereForAI/c4ai-command-r-plus) of models with the recently released [Aya Collection](https://huggingface.co/datasets/CohereForAI/aya_collection). The result is a powerful multilingual large language model serving 23 languages.
This model card corresponds to the 8-billion version of the Aya 23 model. We also released a 35-billion version which you can find [here](https://huggingface.co/CohereForAI/aya-23-35B).
We cover 23 languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Developed by: [Cohere For AI](https://cohere.for.ai) and [Cohere](https://cohere.com/)
- Point of Contact: Cohere For AI: [cohere.for.ai](https://cohere.for.ai/)
- License: [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license), requires also adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy)
- Model: aya-23-8B
- Model Size: 8 billion parameters
**Try Aya 23**
You can try out Aya 23 (35B) before downloading the weights in our hosted Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Usage
Please install transformers from the source repository that includes the necessary changes for this model
```python
# pip install transformers==4.41.1
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/aya-23-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
### Example Notebook
[This notebook](https://huggingface.co/CohereForAI/aya-23-8B/blob/main/Aya_23_notebook.ipynb) showcases a detailed use of Aya 23 (8B) including inference and fine-tuning with [QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
## Model Details
**Input**: Models input text only.
**Output**: Models generate text only.
**Model Architecture**: Aya-23-8B is an auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model is fine-tuned (IFT) to follow human instructions.
**Languages covered**: The model is particularly optimized for multilinguality and supports the following languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
**Context length**: 8192
### Evaluation
<img src="benchmarks.png" alt="multilingual benchmarks" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
<img src="winrates.png" alt="average win rates" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
Please refer to the [Aya 23 technical report](https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view) for further details about the base model, data, instruction tuning, and evaluation.
### Model Card Contact
For errors or additional questions about details in this model card, contact [email protected].
### Terms of Use
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant multilingual model to researchers all over the world. This model is governed by a [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license) License with an acceptable use addendum, and also requires adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy).
### Try the model today
You can try Aya 23 in the Cohere [playground](https://dashboard.cohere.com/playground/chat) here. You can also use it in our dedicated Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Citation info
```bibtex
@misc{aya23technicalreport,
title={Aya 23: Open Weight Releases to Further Multilingual Progress},
author={Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Nick Frosst, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara Hooker},
url={https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view},
year={2024}
}
``` |
LoneStriker/aya-23-8B-3.0bpw-h6-exl2 | LoneStriker | 2024-05-23T15:19:04Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"conversational",
"en",
"fr",
"de",
"es",
"it",
"pt",
"ja",
"ko",
"zh",
"ar",
"el",
"fa",
"pl",
"id",
"cs",
"he",
"hi",
"nl",
"ro",
"ru",
"tr",
"uk",
"vi",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"3-bit",
"exl2",
"region:us"
] | text-generation | 2024-05-23T15:16:28Z | ---
library_name: transformers
language:
- en
- fr
- de
- es
- it
- pt
- ja
- ko
- zh
- ar
- el
- fa
- pl
- id
- cs
- he
- hi
- nl
- ro
- ru
- tr
- uk
- vi
license: cc-by-nc-4.0
---
# Model Card for Aya-23-8B
## Model Summary
Aya 23 is an open weights research release of an instruction fine-tuned model with highly advanced multilingual capabilities. Aya 23 focuses on pairing a highly performant pre-trained [Command family](https://huggingface.co/CohereForAI/c4ai-command-r-plus) of models with the recently released [Aya Collection](https://huggingface.co/datasets/CohereForAI/aya_collection). The result is a powerful multilingual large language model serving 23 languages.
This model card corresponds to the 8-billion version of the Aya 23 model. We also released a 35-billion version which you can find [here](https://huggingface.co/CohereForAI/aya-23-35B).
We cover 23 languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Developed by: [Cohere For AI](https://cohere.for.ai) and [Cohere](https://cohere.com/)
- Point of Contact: Cohere For AI: [cohere.for.ai](https://cohere.for.ai/)
- License: [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license), requires also adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy)
- Model: aya-23-8B
- Model Size: 8 billion parameters
**Try Aya 23**
You can try out Aya 23 (35B) before downloading the weights in our hosted Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Usage
Please install transformers from the source repository that includes the necessary changes for this model
```python
# pip install transformers==4.41.1
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/aya-23-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
### Example Notebook
[This notebook](https://huggingface.co/CohereForAI/aya-23-8B/blob/main/Aya_23_notebook.ipynb) showcases a detailed use of Aya 23 (8B) including inference and fine-tuning with [QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
## Model Details
**Input**: Models input text only.
**Output**: Models generate text only.
**Model Architecture**: Aya-23-8B is an auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model is fine-tuned (IFT) to follow human instructions.
**Languages covered**: The model is particularly optimized for multilinguality and supports the following languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
**Context length**: 8192
### Evaluation
<img src="benchmarks.png" alt="multilingual benchmarks" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
<img src="winrates.png" alt="average win rates" width="650" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
Please refer to the [Aya 23 technical report](https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view) for further details about the base model, data, instruction tuning, and evaluation.
### Model Card Contact
For errors or additional questions about details in this model card, contact [email protected].
### Terms of Use
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant multilingual model to researchers all over the world. This model is governed by a [CC-BY-NC](https://cohere.com/c4ai-cc-by-nc-license) License with an acceptable use addendum, and also requires adhering to [C4AI's Acceptable Use Policy](https://docs.cohere.com/docs/c4ai-acceptable-use-policy).
### Try the model today
You can try Aya 23 in the Cohere [playground](https://dashboard.cohere.com/playground/chat) here. You can also use it in our dedicated Hugging Face Space [here](https://huggingface.co/spaces/CohereForAI/aya-23).
### Citation info
```bibtex
@misc{aya23technicalreport,
title={Aya 23: Open Weight Releases to Further Multilingual Progress},
author={Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, Acyr Locatelli, Julia Kreutzer, Nick Frosst, Phil Blunsom, Marzieh Fadaee, Ahmet Üstün, and Sara Hooker},
url={https://drive.google.com/file/d/1YKBPo61pnl97C1c_1C2ZVOnPhqf7MLSc/view},
year={2024}
}
``` |
Megnis/T5_Ru_VKR | Megnis | 2024-05-23T15:18:02Z | 114 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-19T21:04:26Z | ---
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: T5_Ru_VKR
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5_Ru_VKR
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8474
- Rouge1: 0.0229
- Rouge2: 0.0135
- Rougel: 0.0228
- Rougelsum: 0.0227
- Gen Len: 18.845
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 100 | 1.9287 | 0.0246 | 0.0135 | 0.0245 | 0.0242 | 18.865 |
| No log | 2.0 | 200 | 1.8761 | 0.0213 | 0.0135 | 0.0212 | 0.021 | 18.845 |
| No log | 3.0 | 300 | 1.8454 | 0.0213 | 0.0135 | 0.0212 | 0.021 | 18.845 |
| No log | 4.0 | 400 | 1.8474 | 0.0229 | 0.0135 | 0.0228 | 0.0227 | 18.845 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.19.1
|
hgnoi/SgXFBNRSZKbr3Kub | hgnoi | 2024-05-23T15:17:24Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T15:15:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
tyseng/llama3-8b-oig-unsloth-merged | tyseng | 2024-05-23T15:14:18Z | 4 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-20T11:18:03Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** tyseng
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
es-k/distilbert-base-uncased-finetuned-emotion | es-k | 2024-05-23T15:13:01Z | 109 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T15:07:27Z | ---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9235
- name: F1
type: f1
value: 0.9236004398419263
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2214
- Accuracy: 0.9235
- F1: 0.9236
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8367 | 1.0 | 250 | 0.3200 | 0.9095 | 0.9091 |
| 0.247 | 2.0 | 500 | 0.2214 | 0.9235 | 0.9236 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
kashif/ppo | kashif | 2024-05-23T15:12:33Z | 149 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:EleutherAI/pythia-160m-deduped",
"base_model:finetune:EleutherAI/pythia-160m-deduped",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T15:12:26Z | ---
license: apache-2.0
base_model: EleutherAI/pythia-160m-deduped
tags:
- generated_from_trainer
model-index:
- name: ppo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ppo
This model is a fine-tuned version of [EleutherAI/pythia-160m-deduped](https://huggingface.co/EleutherAI/pythia-160m-deduped) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.19.1
|
agkelly/bert-base-cased-wikitext2 | agkelly | 2024-05-23T15:02:25Z | 126 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-23T14:47:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-wikitext2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.8567
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.0923 | 1.0 | 2346 | 7.0511 |
| 6.9047 | 2.0 | 4692 | 6.8751 |
| 6.8831 | 3.0 | 7038 | 6.8942 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.13.3
|
mika5883/inverse_gec | mika5883 | 2024-05-23T15:00:47Z | 106 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:mika5883/pretrain_rugec",
"base_model:finetune:mika5883/pretrain_rugec",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-04-14T15:26:19Z | ---
base_model: mika5883/pretrain_rugec
tags:
- generated_from_trainer
model-index:
- name: inverse_gec
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# inverse_gec
This model is a fine-tuned version of [mika5883/pretrain_rugec](https://huggingface.co/mika5883/pretrain_rugec) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
EnrAsh/Gato | EnrAsh | 2024-05-23T14:57:46Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-23T14:57:46Z | ---
license: apache-2.0
---
|
v-urushkin/SRoBERTa-tokenizer6M | v-urushkin | 2024-05-23T14:56:58Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T14:56:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Tombiczek/sentiment_model_test1 | Tombiczek | 2024-05-23T14:55:11Z | 166 | 0 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T14:53:57Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/Bv23lrHla12r5fIu | hgnoi | 2024-05-23T14:54:30Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:53:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
VictorDCh/Llama-3-8B-Instruct-spider-2 | VictorDCh | 2024-05-23T14:52:18Z | 7 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"llama",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:adapter:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | null | 2024-05-23T10:09:53Z | ---
license: llama3
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets:
- generator
model-index:
- name: Llama-3-8B-Instruct-spider-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-3-8B-Instruct-spider-2
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the generator dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00015
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 1
### Training results
### Framework versions
- PEFT 0.7.2.dev0
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2 |
wassapman/t5-small-finetuned-wikisql-v2 | wassapman | 2024-05-23T14:51:48Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-23T12:39:41Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-finetuned-wikisql-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-wikisql-v2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1246
- Rouge2 Precision: 0.8183
- Rouge2 Recall: 0.7261
- Rouge2 Fmeasure: 0.7624
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.1953 | 1.0 | 4049 | 0.1574 | 0.7938 | 0.7035 | 0.739 |
| 0.1644 | 2.0 | 8098 | 0.1375 | 0.8083 | 0.7167 | 0.7527 |
| 0.1517 | 3.0 | 12147 | 0.1296 | 0.8141 | 0.7222 | 0.7584 |
| 0.146 | 4.0 | 16196 | 0.1256 | 0.817 | 0.7254 | 0.7614 |
| 0.1413 | 5.0 | 20245 | 0.1246 | 0.8183 | 0.7261 | 0.7624 |
### Framework versions
- Transformers 4.16.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
mnlp-nsoai/mistral-7b-dpo-hf-mix | mnlp-nsoai | 2024-05-23T14:47:33Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:34:33Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
scribbyotx/sa | scribbyotx | 2024-05-23T14:46:41Z | 19 | 0 | diffusers | [
"diffusers",
"doi:10.57967/hf/2292",
"region:us"
] | null | 2024-05-22T19:40:25Z | # Discord-Scraper
Pipeline to scrape prompt + image url pairs from Discord channels. The idea started by wanting to scrape the image-prompt pairs from [share-dalle-3](https://discord.com/channels/823813159592001537/1158354590463447092) Discord channel from [LAION server](https://discord.com/invite/eq3cAMZtCC). But now you can re-use the scraper to work with any channel you want.
## How to use
Clone the repo `git clone https://github.com/LAION-AI/Discord-Scrapers.git`
1. Set up a virtual environment and install the requirements with `pip install -r requirements.txt`
2. Get your `DISCORD_TOKEN` and `HF_TOKEN` and add as environment variables.
1. `DISCORD_TOKEN` can be obtained by looking at developer tools in your Web Browser
2. `HF_TOKEN` can be obtained by logging in to HuggingFace and looking at your profile
3. Get the `channel_id` from the Discord channel you want to scrape. You can do this by enabling developer mode in Discord and right clicking the channel you want to scrape.
4. Create a `condition_fn` and a `parse_fn` that will be used to filter and parse the messages. You can use the ones I created as an example.
5. Create your scraping script and optionally your `config.json`
**NOTE PAY ATTENTION TO THE FUNC SIGNATURE OF parse_fn and condition_fn**
```python
import os
from typing import Any, Dict, List
from scraper import ScraperBot, ScraperBotConfig, HFDatasetScheme
def parse_fn(message: Dict[str, Any]) -> List[HFDatasetScheme]:
...
def condition_fn(message: Dict[str, Any]) -> bool:
...
if __name__ == "__main__":
config_path = os.path.join(os.path.dirname(__file__), "config.json")
config = ScraperBotConfig.from_json(config_path)
bot = ScraperBot(config=config, parse_fn=parse_fn, condition_fn=condition_fn)
bot.scrape(fetch_all=False, push_to_hub=False)
```
## Main Components
### ScraperBotConfig
Dataclass with configuration attributes to be used by the ScraperBot. You can create your own config.json file and load it with `ScraperBotConfig.from_json(path_to_config)`.
attributes:
- base_url: str, The base url of the Discord API (in chase it changes)
- channel_id: str, The id of the channel you want to scrape
- limit: int, The number of messages to fetch (from my tests the max allowed by Discord is 100)
- hf_dataset_name: str, The name of the dataset you want to push to HuggingFace
### ScraperBot
Implementation of the scraper. Get's the messages from the Discord API and filters them using the `condition_fn`. Then parses the messages using the `parse_fn` and pushes the dataset to HuggingFace.
attributes:
- config: ScraperBotConfig, The configuration to be used by the bot
- parse_fn: Callable[[Dict[str, Any]], List[HFDatasetScheme]], The function to parse the messages
- condition_fn: Callable[[Dict[str, Any]], bool], The function to filter the messages
methods:
#### scrape(fetch_all: bool = False, push_to_hub: bool = False) -> Dataset
Scrapes the messages and optionally pushes the dataset to HuggingFace.
args:
- fetch_all: bool, If True will fetch all the messages from the channel. If False will fetch only the messages that weren't processed yet.
- push_to_hub: bool, If True will push the dataset to HuggingFace. If False will only return the dataset.
**NOTE: If you want to push the dataset to HuggingFace you need to set the `HF_TOKEN` environment variable.**
**NOTE 2: If the dataset doesn't exist in HuggingFace it will be created. If it already exists it will be updated.**
|
date3k2/gpt2-text-classification | date3k2 | 2024-05-23T14:45:00Z | 107 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-classification",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T12:31:11Z | ---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: gpt2-text-classification-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/date3k2/gpt2-text-classification/runs/52an6tu1)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/date3k2/gpt2-text-classification/runs/lu5o1szk)
# gpt2-text-classification-v2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2002
- Accuracy: 0.9342
- F1: 0.9340
- Recall: 0.9314
- Precision: 0.9367
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 3
- total_train_batch_size: 96
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Accuracy | F1 | Validation Loss | Precision | Recall |
|:-------------:|:------:|:----:|:--------:|:------:|:---------------:|:---------:|:------:|
| 0.327 | 0.9974 | 260 | 0.8973 | 0.8929 | 0.2559 | 0.9333 | 0.8558 |
| 0.241 | 1.9987 | 521 | 0.919 | 0.9180 | 0.2039 | 0.9296 | 0.9066 |
| 0.244 | 3.0 | 782 | 0.9154 | 0.9192 | 0.2156 | 0.8799 | 0.9621 |
| 0.1843 | 3.9974 | 1042 | 0.9299 | 0.9288 | 0.1888 | 0.9427 | 0.9154 |
| 0.1608 | 4.9987 | 1303 | 0.9301 | 0.9291 | 0.1855 | 0.9428 | 0.9158 |
| 0.124 | 6.0 | 1564 | 0.9322 | 0.9319 | 0.1826 | 0.9357 | 0.9282 |
| 0.112 | 6.9974 | 1820 | 0.2099 | 0.9315 | 0.9303 | 0.9138 | 0.9473 |
| 0.0903 | 7.9987 | 2081 | 0.2002 | 0.9342 | 0.9340 | 0.9314 | 0.9367 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
agkelly/gpt2-wikitext2 | agkelly | 2024-05-23T14:41:33Z | 146 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:26:53Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.1168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.5635 | 1.0 | 2249 | 6.4735 |
| 6.1946 | 2.0 | 4498 | 6.2048 |
| 6.0214 | 3.0 | 6747 | 6.1168 |
### Framework versions
- Transformers 4.26.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.13.3
|
malerbe/Car_racing_V0_V1.1 | malerbe | 2024-05-23T14:40:04Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"CarRacing-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-23T11:56:56Z | ---
library_name: stable-baselines3
tags:
- CarRacing-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CarRacing-v2
type: CarRacing-v2
metrics:
- type: mean_reward
value: -20.23 +/- 38.79
name: mean_reward
verified: false
---
# **PPO** Agent playing **CarRacing-v2**
This is a trained model of a **PPO** agent playing **CarRacing-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ghanahmada/trocr-base-plate-number | ghanahmada | 2024-05-23T14:39:40Z | 120 | 1 | transformers | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-text-to-text",
"vision",
"image-to-text",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | image-to-text | 2024-03-16T14:41:44Z | ---
license: apache-2.0
pipeline_tag: image-to-text
tags:
- vision
widget:
- src: >-
https://huggingface.co/datasets/ghanahmada/sample-images/resolve/main/car-plate-1.png
example_title: A1651VV
- src: >-
https://huggingface.co/datasets/ghanahmada/sample-images/resolve/main/car-plate-2.png
example_title: B8857GS
--- |
BilalMuftuoglu/beit-base-patch16-224-hasta-75-fold1 | BilalMuftuoglu | 2024-05-23T14:39:20Z | 195 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T14:31:34Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-75-fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-75-fold1
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2432
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 2.2077 | 0.0 |
| No log | 2.0 | 2 | 1.7828 | 0.0 |
| No log | 3.0 | 3 | 1.0543 | 0.3333 |
| No log | 4.0 | 4 | 0.4305 | 0.9167 |
| No log | 5.0 | 5 | 0.2672 | 0.9167 |
| No log | 6.0 | 6 | 0.3206 | 0.9167 |
| No log | 7.0 | 7 | 0.3318 | 0.9167 |
| No log | 8.0 | 8 | 0.3007 | 0.9167 |
| No log | 9.0 | 9 | 0.3268 | 0.9167 |
| 0.4863 | 10.0 | 10 | 0.3425 | 0.9167 |
| 0.4863 | 11.0 | 11 | 0.2906 | 0.9167 |
| 0.4863 | 12.0 | 12 | 0.2639 | 0.9167 |
| 0.4863 | 13.0 | 13 | 0.2962 | 0.9167 |
| 0.4863 | 14.0 | 14 | 0.4442 | 0.8333 |
| 0.4863 | 15.0 | 15 | 0.3108 | 0.8333 |
| 0.4863 | 16.0 | 16 | 0.2321 | 0.9167 |
| 0.4863 | 17.0 | 17 | 0.2309 | 0.9167 |
| 0.4863 | 18.0 | 18 | 0.2432 | 1.0 |
| 0.4863 | 19.0 | 19 | 0.2240 | 1.0 |
| 0.1603 | 20.0 | 20 | 0.1608 | 0.9167 |
| 0.1603 | 21.0 | 21 | 0.1275 | 0.9167 |
| 0.1603 | 22.0 | 22 | 0.1191 | 0.9167 |
| 0.1603 | 23.0 | 23 | 0.1030 | 0.9167 |
| 0.1603 | 24.0 | 24 | 0.1010 | 1.0 |
| 0.1603 | 25.0 | 25 | 0.0816 | 1.0 |
| 0.1603 | 26.0 | 26 | 0.1814 | 0.9167 |
| 0.1603 | 27.0 | 27 | 0.1654 | 0.9167 |
| 0.1603 | 28.0 | 28 | 0.0945 | 1.0 |
| 0.1603 | 29.0 | 29 | 0.0847 | 1.0 |
| 0.1007 | 30.0 | 30 | 0.1566 | 1.0 |
| 0.1007 | 31.0 | 31 | 0.0819 | 1.0 |
| 0.1007 | 32.0 | 32 | 0.0782 | 1.0 |
| 0.1007 | 33.0 | 33 | 0.0781 | 1.0 |
| 0.1007 | 34.0 | 34 | 0.0635 | 1.0 |
| 0.1007 | 35.0 | 35 | 0.0675 | 1.0 |
| 0.1007 | 36.0 | 36 | 0.1137 | 1.0 |
| 0.1007 | 37.0 | 37 | 0.1267 | 0.9167 |
| 0.1007 | 38.0 | 38 | 0.1438 | 0.9167 |
| 0.1007 | 39.0 | 39 | 0.1301 | 0.9167 |
| 0.0573 | 40.0 | 40 | 0.1123 | 0.9167 |
| 0.0573 | 41.0 | 41 | 0.0673 | 1.0 |
| 0.0573 | 42.0 | 42 | 0.0265 | 1.0 |
| 0.0573 | 43.0 | 43 | 0.0317 | 1.0 |
| 0.0573 | 44.0 | 44 | 0.0461 | 1.0 |
| 0.0573 | 45.0 | 45 | 0.0326 | 1.0 |
| 0.0573 | 46.0 | 46 | 0.0221 | 1.0 |
| 0.0573 | 47.0 | 47 | 0.0227 | 1.0 |
| 0.0573 | 48.0 | 48 | 0.0214 | 1.0 |
| 0.0573 | 49.0 | 49 | 0.0176 | 1.0 |
| 0.0566 | 50.0 | 50 | 0.0150 | 1.0 |
| 0.0566 | 51.0 | 51 | 0.0154 | 1.0 |
| 0.0566 | 52.0 | 52 | 0.0139 | 1.0 |
| 0.0566 | 53.0 | 53 | 0.0097 | 1.0 |
| 0.0566 | 54.0 | 54 | 0.0143 | 1.0 |
| 0.0566 | 55.0 | 55 | 0.0272 | 1.0 |
| 0.0566 | 56.0 | 56 | 0.0427 | 1.0 |
| 0.0566 | 57.0 | 57 | 0.0343 | 1.0 |
| 0.0566 | 58.0 | 58 | 0.0290 | 1.0 |
| 0.0566 | 59.0 | 59 | 0.0557 | 1.0 |
| 0.0242 | 60.0 | 60 | 0.0905 | 1.0 |
| 0.0242 | 61.0 | 61 | 0.1374 | 0.9167 |
| 0.0242 | 62.0 | 62 | 0.1763 | 0.9167 |
| 0.0242 | 63.0 | 63 | 0.1793 | 0.9167 |
| 0.0242 | 64.0 | 64 | 0.1640 | 0.9167 |
| 0.0242 | 65.0 | 65 | 0.1445 | 0.9167 |
| 0.0242 | 66.0 | 66 | 0.1092 | 1.0 |
| 0.0242 | 67.0 | 67 | 0.0915 | 1.0 |
| 0.0242 | 68.0 | 68 | 0.0640 | 1.0 |
| 0.0242 | 69.0 | 69 | 0.0376 | 1.0 |
| 0.0339 | 70.0 | 70 | 0.0297 | 1.0 |
| 0.0339 | 71.0 | 71 | 0.0238 | 1.0 |
| 0.0339 | 72.0 | 72 | 0.0178 | 1.0 |
| 0.0339 | 73.0 | 73 | 0.0104 | 1.0 |
| 0.0339 | 74.0 | 74 | 0.0063 | 1.0 |
| 0.0339 | 75.0 | 75 | 0.0042 | 1.0 |
| 0.0339 | 76.0 | 76 | 0.0031 | 1.0 |
| 0.0339 | 77.0 | 77 | 0.0029 | 1.0 |
| 0.0339 | 78.0 | 78 | 0.0034 | 1.0 |
| 0.0339 | 79.0 | 79 | 0.0035 | 1.0 |
| 0.0532 | 80.0 | 80 | 0.0035 | 1.0 |
| 0.0532 | 81.0 | 81 | 0.0039 | 1.0 |
| 0.0532 | 82.0 | 82 | 0.0054 | 1.0 |
| 0.0532 | 83.0 | 83 | 0.0110 | 1.0 |
| 0.0532 | 84.0 | 84 | 0.0255 | 1.0 |
| 0.0532 | 85.0 | 85 | 0.0500 | 1.0 |
| 0.0532 | 86.0 | 86 | 0.0844 | 0.9167 |
| 0.0532 | 87.0 | 87 | 0.1191 | 0.9167 |
| 0.0532 | 88.0 | 88 | 0.1437 | 0.9167 |
| 0.0532 | 89.0 | 89 | 0.1564 | 0.9167 |
| 0.0316 | 90.0 | 90 | 0.1544 | 0.9167 |
| 0.0316 | 91.0 | 91 | 0.1455 | 0.9167 |
| 0.0316 | 92.0 | 92 | 0.1383 | 0.9167 |
| 0.0316 | 93.0 | 93 | 0.1194 | 0.9167 |
| 0.0316 | 94.0 | 94 | 0.1027 | 0.9167 |
| 0.0316 | 95.0 | 95 | 0.0875 | 0.9167 |
| 0.0316 | 96.0 | 96 | 0.0715 | 1.0 |
| 0.0316 | 97.0 | 97 | 0.0608 | 1.0 |
| 0.0316 | 98.0 | 98 | 0.0519 | 1.0 |
| 0.0316 | 99.0 | 99 | 0.0468 | 1.0 |
| 0.0299 | 100.0 | 100 | 0.0442 | 1.0 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Augusto777/vit-base-patch16-224-U8-40 | Augusto777 | 2024-05-23T14:38:55Z | 198 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:56:43Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-U8-40
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8666666666666667
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-U8-40
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5495
- Accuracy: 0.8667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 40
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3457 | 1.0 | 20 | 1.3128 | 0.45 |
| 1.1498 | 2.0 | 40 | 1.1047 | 0.5667 |
| 0.8312 | 3.0 | 60 | 0.8231 | 0.65 |
| 0.5334 | 4.0 | 80 | 0.5719 | 0.8167 |
| 0.3582 | 5.0 | 100 | 0.5495 | 0.8667 |
| 0.2389 | 6.0 | 120 | 0.5801 | 0.8333 |
| 0.2055 | 7.0 | 140 | 0.6727 | 0.8167 |
| 0.1738 | 8.0 | 160 | 0.7238 | 0.8 |
| 0.1556 | 9.0 | 180 | 0.7665 | 0.75 |
| 0.1461 | 10.0 | 200 | 0.8229 | 0.7667 |
| 0.1401 | 11.0 | 220 | 0.8102 | 0.75 |
| 0.08 | 12.0 | 240 | 0.6609 | 0.8333 |
| 0.0989 | 13.0 | 260 | 0.6703 | 0.8333 |
| 0.0773 | 14.0 | 280 | 0.7303 | 0.8167 |
| 0.089 | 15.0 | 300 | 0.7757 | 0.7833 |
| 0.11 | 16.0 | 320 | 0.7279 | 0.8 |
| 0.086 | 17.0 | 340 | 0.8491 | 0.7833 |
| 0.0671 | 18.0 | 360 | 0.7950 | 0.8 |
| 0.0775 | 19.0 | 380 | 0.6753 | 0.85 |
| 0.0636 | 20.0 | 400 | 0.7881 | 0.8333 |
| 0.0737 | 21.0 | 420 | 0.7450 | 0.8333 |
| 0.0583 | 22.0 | 440 | 0.8295 | 0.8 |
| 0.0646 | 23.0 | 460 | 0.8227 | 0.8333 |
| 0.0637 | 24.0 | 480 | 0.9030 | 0.7833 |
| 0.0647 | 25.0 | 500 | 0.8656 | 0.8 |
| 0.0477 | 26.0 | 520 | 0.8362 | 0.8 |
| 0.0481 | 27.0 | 540 | 0.8389 | 0.8 |
| 0.0355 | 28.0 | 560 | 0.9424 | 0.8 |
| 0.0352 | 29.0 | 580 | 0.8963 | 0.8 |
| 0.0335 | 30.0 | 600 | 0.8560 | 0.8333 |
| 0.0372 | 31.0 | 620 | 0.7250 | 0.8333 |
| 0.0389 | 32.0 | 640 | 0.7846 | 0.8167 |
| 0.0425 | 33.0 | 660 | 0.8532 | 0.8333 |
| 0.0404 | 34.0 | 680 | 0.8169 | 0.8333 |
| 0.0359 | 35.0 | 700 | 0.8682 | 0.8167 |
| 0.0231 | 36.0 | 720 | 0.9362 | 0.8167 |
| 0.027 | 37.0 | 740 | 0.9139 | 0.8167 |
| 0.0214 | 38.0 | 760 | 0.8782 | 0.8167 |
| 0.0191 | 39.0 | 780 | 0.8794 | 0.8167 |
| 0.0293 | 40.0 | 800 | 0.8929 | 0.8167 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
er1123090/T3Q_SOLAR_SLERP_v1.0 | er1123090 | 2024-05-23T14:35:55Z | 135 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"base_model:chihoonlee10/T3Q-ko-solar-dpo-v7.0",
"base_model:merge:chihoonlee10/T3Q-ko-solar-dpo-v7.0",
"base_model:hwkwon/S-SOLAR-10.7B-v1.5",
"base_model:merge:hwkwon/S-SOLAR-10.7B-v1.5",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:09:16Z | ---
base_model:
- chihoonlee10/T3Q-ko-solar-dpo-v7.0
- hwkwon/S-SOLAR-10.7B-v1.5
library_name: transformers
tags:
- mergekit
- merge
license: mit
---
# Untitled Model (1)
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [chihoonlee10/T3Q-ko-solar-dpo-v7.0](https://huggingface.co/chihoonlee10/T3Q-ko-solar-dpo-v7.0)
* [hwkwon/S-SOLAR-10.7B-v1.5](https://huggingface.co/hwkwon/S-SOLAR-10.7B-v1.5)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: chihoonlee10/T3Q-ko-solar-dpo-v7.0
layer_range: [0, 48]
- model: hwkwon/S-SOLAR-10.7B-v1.5
layer_range: [0, 48]
# or, the equivalent models: syntax:
# models:
# - model: psmathur/orca_mini_v3_13b
# - model: garage-bAInd/Platypus2-13B
merge_method: slerp
base_model: chihoonlee10/T3Q-ko-solar-dpo-v7.0
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
``` |
hgnoi/tGgXf2AI4Zvi2Trq | hgnoi | 2024-05-23T14:31:35Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:29:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BilalMuftuoglu/beit-base-patch16-224-hasta-65-fold5 | BilalMuftuoglu | 2024-05-23T14:31:25Z | 195 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T14:21:46Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-65-fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.5555555555555556
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-65-fold5
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1241
- Accuracy: 0.5556
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.1680 | 0.3333 |
| No log | 1.7143 | 3 | 1.2100 | 0.1944 |
| No log | 2.8571 | 5 | 1.3667 | 0.2778 |
| No log | 4.0 | 7 | 1.1208 | 0.3889 |
| No log | 4.5714 | 8 | 1.1168 | 0.3611 |
| 1.132 | 5.7143 | 10 | 1.4031 | 0.2778 |
| 1.132 | 6.8571 | 12 | 1.2012 | 0.3333 |
| 1.132 | 8.0 | 14 | 1.2353 | 0.2778 |
| 1.132 | 8.5714 | 15 | 1.2099 | 0.3056 |
| 1.132 | 9.7143 | 17 | 1.0942 | 0.3611 |
| 1.132 | 10.8571 | 19 | 1.1301 | 0.4444 |
| 1.0271 | 12.0 | 21 | 1.0591 | 0.4167 |
| 1.0271 | 12.5714 | 22 | 1.0648 | 0.4444 |
| 1.0271 | 13.7143 | 24 | 1.1125 | 0.4722 |
| 1.0271 | 14.8571 | 26 | 1.1097 | 0.4722 |
| 1.0271 | 16.0 | 28 | 1.0616 | 0.4444 |
| 1.0271 | 16.5714 | 29 | 1.0284 | 0.4722 |
| 0.9507 | 17.7143 | 31 | 1.0291 | 0.5 |
| 0.9507 | 18.8571 | 33 | 1.0692 | 0.4722 |
| 0.9507 | 20.0 | 35 | 1.1153 | 0.5 |
| 0.9507 | 20.5714 | 36 | 1.1719 | 0.4444 |
| 0.9507 | 21.7143 | 38 | 1.0161 | 0.4444 |
| 0.8001 | 22.8571 | 40 | 1.1361 | 0.4444 |
| 0.8001 | 24.0 | 42 | 1.3277 | 0.4444 |
| 0.8001 | 24.5714 | 43 | 1.1331 | 0.5 |
| 0.8001 | 25.7143 | 45 | 1.0659 | 0.4722 |
| 0.8001 | 26.8571 | 47 | 1.1309 | 0.5278 |
| 0.8001 | 28.0 | 49 | 1.1241 | 0.5556 |
| 0.7175 | 28.5714 | 50 | 1.1371 | 0.5278 |
| 0.7175 | 29.7143 | 52 | 1.0928 | 0.5 |
| 0.7175 | 30.8571 | 54 | 1.2129 | 0.4444 |
| 0.7175 | 32.0 | 56 | 1.0321 | 0.5 |
| 0.7175 | 32.5714 | 57 | 1.0809 | 0.5278 |
| 0.7175 | 33.7143 | 59 | 0.9813 | 0.5278 |
| 0.6766 | 34.8571 | 61 | 1.0617 | 0.5 |
| 0.6766 | 36.0 | 63 | 0.9618 | 0.5278 |
| 0.6766 | 36.5714 | 64 | 0.9541 | 0.5556 |
| 0.6766 | 37.7143 | 66 | 0.9689 | 0.5278 |
| 0.6766 | 38.8571 | 68 | 1.1063 | 0.5556 |
| 0.5934 | 40.0 | 70 | 1.0139 | 0.5 |
| 0.5934 | 40.5714 | 71 | 1.0087 | 0.5 |
| 0.5934 | 41.7143 | 73 | 1.0309 | 0.5 |
| 0.5934 | 42.8571 | 75 | 1.0636 | 0.5 |
| 0.5934 | 44.0 | 77 | 1.1057 | 0.5 |
| 0.5934 | 44.5714 | 78 | 1.1015 | 0.4722 |
| 0.4926 | 45.7143 | 80 | 1.0938 | 0.5278 |
| 0.4926 | 46.8571 | 82 | 1.0807 | 0.5 |
| 0.4926 | 48.0 | 84 | 1.1275 | 0.5278 |
| 0.4926 | 48.5714 | 85 | 1.1604 | 0.5278 |
| 0.4926 | 49.7143 | 87 | 1.1296 | 0.5278 |
| 0.4926 | 50.8571 | 89 | 1.0748 | 0.5278 |
| 0.4964 | 52.0 | 91 | 1.0716 | 0.5278 |
| 0.4964 | 52.5714 | 92 | 1.0780 | 0.5278 |
| 0.4964 | 53.7143 | 94 | 1.0755 | 0.5278 |
| 0.4964 | 54.8571 | 96 | 1.0680 | 0.5278 |
| 0.4964 | 56.0 | 98 | 1.0676 | 0.5278 |
| 0.4964 | 56.5714 | 99 | 1.0692 | 0.5278 |
| 0.404 | 57.1429 | 100 | 1.0692 | 0.5278 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
yifanxie/tireless-seagull-1-1 | yifanxie | 2024-05-23T14:28:22Z | 149 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-23T14:26:01Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [google/gemma-1.1-2b-it](https://huggingface.co/google/gemma-1.1-2b-it)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers` library installed.
```bash
pip install transformers==4.40.2
```
Also make sure you are providing your huggingface token to the pipeline if the model is lying in a private repo.
- Either leave `token=True` in the `pipeline` and login to hugginface_hub by running
```python
import huggingface_hub
huggingface_hub.login(<ACCESS_TOKEN>)
```
- Or directly pass your <ACCESS_TOKEN> to `token` in the `pipeline`
```python
from transformers import pipeline
generate_text = pipeline(
model="yifanxie/tireless-seagull-1-1",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
token=True,
)
# generate configuration can be modified to your needs
# generate_text.model.generation_config.min_new_tokens = 2
# generate_text.model.generation_config.max_new_tokens = 256
# generate_text.model.generation_config.do_sample = False
# generate_text.model.generation_config.num_beams = 1
# generate_text.model.generation_config.temperature = float(0.0)
# generate_text.model.generation_config.repetition_penalty = float(1.0)
messages = [
{
"role": "system",
"content": "You are a friendly and polite chatbot.",
},
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "I'm doing great, how about you?"},
{"role": "user", "content": "Why is drinking water so healthy?"},
]
res = generate_text(
messages,
renormalize_logits=True
)
print(res[0]["generated_text"][-1]['content'])
```
You can print a sample prompt after applying chat template to see how it is feed to the tokenizer:
```python
print(generate_text.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
))
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "yifanxie/tireless-seagull-1-1" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
messages = [
{
"role": "system",
"content": "You are a friendly and polite chatbot.",
},
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "I'm doing great, how about you?"},
{"role": "user", "content": "Why is drinking water so healthy?"},
]
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
# generate configuration can be modified to your needs
# model.generation_config.min_new_tokens = 2
# model.generation_config.max_new_tokens = 256
# model.generation_config.do_sample = False
# model.generation_config.num_beams = 1
# model.generation_config.temperature = float(0.0)
# model.generation_config.repetition_penalty = float(1.0)
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
tokens = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Quantization and sharding
You can load the models using quantization by specifying ```load_in_8bit=True``` or ```load_in_4bit=True```. Also, sharding on multiple GPUs is possible by setting ```device_map=auto```.
## Model Architecture
```
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=256000, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
datek/gemma-2b-flock-1716474326 | datek | 2024-05-23T14:27:51Z | 145 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:25:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
QuantFactory/Yi-1.5-9B-Chat-16K-GGUF | QuantFactory | 2024-05-23T14:23:31Z | 27 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"conversational",
"text-generation",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T11:47:08Z | ---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- llama
- conversational
---
# Yi-1.5-9B-Chat-16K-GGUF
- This is quantized version of [01-ai/Yi-1.5-9B-Chat-16K](https://huggingface.co/01-ai/Yi-1.5-9B-Chat-16K) created using llama.cpp
# Model Description
Yi-1.5 is an upgraded version of Yi. It is continuously pre-trained on Yi with a high-quality corpus of 500B tokens and fine-tuned on 3M diverse fine-tuning samples.
Compared with Yi, Yi-1.5 delivers stronger performance in coding, math, reasoning, and instruction-following capability, while still maintaining excellent capabilities in language understanding, commonsense reasoning, and reading comprehension.
<div align="center">
Model | Context Length | Pre-trained Tokens
| :------------: | :------------: | :------------: |
| Yi-1.5 | 4K, 16K, 32K | 3.6T
</div>
# Models
- Chat models
<div align="center">
| Name | Download |
| --------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-34B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-9B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-9B-Chat-16K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-6B-Chat | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
</div>
- Base models
<div align="center">
| Name | Download |
| ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Yi-1.5-34B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-34B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-9B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-9B-32K | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
| Yi-1.5-6B | • [🤗 Hugging Face](https://huggingface.co/collections/01-ai/yi-15-2024-05-663f3ecab5f815a3eaca7ca8) • [🤖 ModelScope](https://www.modelscope.cn/organization/01ai) • [🔍 wisemodel](https://wisemodel.cn/organization/01.AI)|
</div>
# Benchmarks
- Chat models
Yi-1.5-34B-Chat is on par with or excels beyond larger models in most benchmarks.

Yi-1.5-9B-Chat is the top performer among similarly sized open-source models.

- Base models
Yi-1.5-34B is on par with or excels beyond larger models in some benchmarks.

Yi-1.5-9B is the top performer among similarly sized open-source models.

# Quick Start
For getting up and running with Yi-1.5 models quickly, see [README](https://github.com/01-ai/Yi-1.5). |
DivyaMereddy007/RecipeBert_v5 | DivyaMereddy007 | 2024-05-23T14:22:58Z | 9,932 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2024-03-13T17:25:37Z | ---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# DivyaMereddy007/RecipeBert_v5
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Please find full paper and detailed model evaluation here. https://zenodo.org/records/11098598
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('DivyaMereddy007/RecipeBert_v5')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('DivyaMereddy007/RecipeBert_v5')
model = AutoModel.from_pretrained('DivyaMereddy007/RecipeBert_v5')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=DivyaMereddy007/RecipeBert_v5)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 104 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 104.0,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
fine-tuned/BAAI_bge-small-en-v1_5-23052024-upq5-webapp | fine-tuned | 2024-05-23T14:22:18Z | 7 | 1 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"general",
"miscellaneous",
"undefined",
"unknown",
"placeholder",
"en",
"dataset:fine-tuned/BAAI_bge-small-en-v1_5-23052024-upq5-webapp",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-23T14:22:13Z | ---
license: apache-2.0
datasets:
- fine-tuned/BAAI_bge-small-en-v1_5-23052024-upq5-webapp
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- general
- miscellaneous
- undefined
- unknown
- placeholder
---
This model is a fine-tuned version of [**BAAI/bge-small-en-v1.5**](https://huggingface.co/BAAI/bge-small-en-v1.5) designed for the following use case:
generic search
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/BAAI_bge-small-en-v1_5-23052024-upq5-webapp',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
BilalMuftuoglu/beit-base-patch16-224-hasta-65-fold4 | BilalMuftuoglu | 2024-05-23T14:21:36Z | 200 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T14:11:52Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-65-fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6944444444444444
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-65-fold4
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7415
- Accuracy: 0.6944
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.4459 | 0.3333 |
| No log | 1.7143 | 3 | 1.1743 | 0.3889 |
| No log | 2.8571 | 5 | 1.1216 | 0.3056 |
| No log | 4.0 | 7 | 1.1048 | 0.2778 |
| No log | 4.5714 | 8 | 1.0513 | 0.5 |
| 1.1273 | 5.7143 | 10 | 1.1055 | 0.3333 |
| 1.1273 | 6.8571 | 12 | 1.0529 | 0.4444 |
| 1.1273 | 8.0 | 14 | 1.0445 | 0.4722 |
| 1.1273 | 8.5714 | 15 | 1.0336 | 0.4722 |
| 1.1273 | 9.7143 | 17 | 0.9757 | 0.4444 |
| 1.1273 | 10.8571 | 19 | 0.9972 | 0.4444 |
| 0.9616 | 12.0 | 21 | 0.9694 | 0.5278 |
| 0.9616 | 12.5714 | 22 | 0.9377 | 0.4722 |
| 0.9616 | 13.7143 | 24 | 0.8975 | 0.5556 |
| 0.9616 | 14.8571 | 26 | 0.9970 | 0.4444 |
| 0.9616 | 16.0 | 28 | 0.9322 | 0.5833 |
| 0.9616 | 16.5714 | 29 | 0.9820 | 0.5278 |
| 0.8463 | 17.7143 | 31 | 1.1023 | 0.5 |
| 0.8463 | 18.8571 | 33 | 1.1089 | 0.5 |
| 0.8463 | 20.0 | 35 | 0.9417 | 0.5556 |
| 0.8463 | 20.5714 | 36 | 0.8424 | 0.5833 |
| 0.8463 | 21.7143 | 38 | 0.8668 | 0.6111 |
| 0.7082 | 22.8571 | 40 | 0.9767 | 0.5556 |
| 0.7082 | 24.0 | 42 | 0.8743 | 0.6389 |
| 0.7082 | 24.5714 | 43 | 0.7945 | 0.6389 |
| 0.7082 | 25.7143 | 45 | 0.9246 | 0.5278 |
| 0.7082 | 26.8571 | 47 | 1.2622 | 0.5833 |
| 0.7082 | 28.0 | 49 | 0.7754 | 0.5278 |
| 0.6413 | 28.5714 | 50 | 0.7375 | 0.5833 |
| 0.6413 | 29.7143 | 52 | 1.0095 | 0.5556 |
| 0.6413 | 30.8571 | 54 | 1.0806 | 0.5833 |
| 0.6413 | 32.0 | 56 | 0.7415 | 0.6944 |
| 0.6413 | 32.5714 | 57 | 0.7523 | 0.6944 |
| 0.6413 | 33.7143 | 59 | 0.9506 | 0.6111 |
| 0.5256 | 34.8571 | 61 | 0.9487 | 0.6667 |
| 0.5256 | 36.0 | 63 | 0.8945 | 0.6111 |
| 0.5256 | 36.5714 | 64 | 0.9073 | 0.6111 |
| 0.5256 | 37.7143 | 66 | 0.9394 | 0.6389 |
| 0.5256 | 38.8571 | 68 | 0.9062 | 0.6389 |
| 0.4509 | 40.0 | 70 | 0.8908 | 0.6111 |
| 0.4509 | 40.5714 | 71 | 0.8960 | 0.6111 |
| 0.4509 | 41.7143 | 73 | 0.9506 | 0.6389 |
| 0.4509 | 42.8571 | 75 | 1.0018 | 0.6111 |
| 0.4509 | 44.0 | 77 | 0.9852 | 0.6667 |
| 0.4509 | 44.5714 | 78 | 1.0045 | 0.6667 |
| 0.3865 | 45.7143 | 80 | 1.0984 | 0.5556 |
| 0.3865 | 46.8571 | 82 | 1.1893 | 0.5556 |
| 0.3865 | 48.0 | 84 | 1.2066 | 0.5278 |
| 0.3865 | 48.5714 | 85 | 1.1625 | 0.5556 |
| 0.3865 | 49.7143 | 87 | 1.0753 | 0.6111 |
| 0.3865 | 50.8571 | 89 | 1.0610 | 0.6111 |
| 0.3497 | 52.0 | 91 | 1.0844 | 0.5833 |
| 0.3497 | 52.5714 | 92 | 1.1055 | 0.5556 |
| 0.3497 | 53.7143 | 94 | 1.1122 | 0.5556 |
| 0.3497 | 54.8571 | 96 | 1.1042 | 0.5833 |
| 0.3497 | 56.0 | 98 | 1.0855 | 0.5556 |
| 0.3497 | 56.5714 | 99 | 1.0785 | 0.5833 |
| 0.3196 | 57.1429 | 100 | 1.0751 | 0.5833 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Likich/falcon-finetune-qualcoding_1000_prompt3 | Likich | 2024-05-23T14:19:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T14:19:23Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
eevvgg/bert-polish-sentiment-politics | eevvgg | 2024-05-23T14:14:59Z | 905 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"text",
"sentiment",
"politics",
"pl",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-11-11T15:05:28Z | ---
language:
- pl
pipeline_tag: text-classification
widget:
- text: "Przykro patrzeć, a słuchać się nie da."
example_title: "example 1"
- text: "Oczywiście ze Pan Prezydent to nasza duma narodowa!!"
example_title: "example 2"
tags:
- text
- sentiment
- politics
metrics:
- accuracy
- f1
model-index:
- name: PaReS-sentimenTw-political-PL
results:
- task:
type: sentiment-classification # Required. Example: automatic-speech-recognition
name: Text Classification # Optional. Example: Speech Recognition
dataset:
type: tweets # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: tweets_2020_electionsPL # Required. A pretty name for the dataset. Example: Common Voice (French)
metrics:
- type: f1 # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 94.4 # Required. Example: 20.90
---
# PaReS-sentimenTw-political-PL
This model is a fine-tuned version of [dkleczek/bert-base-polish-cased-v1](https://huggingface.co/dkleczek/bert-base-polish-cased-v1) to predict 3-categorical sentiment.
Fine-tuned on 1k sample of manually annotated Twitter data.
Model developed as a part of ComPathos project: https://www.ncn.gov.pl/sites/default/files/listy-rankingowe/2020-09-30apsv2/streszczenia/497124-en.pdf
```
from transformers import pipeline
model_path = "eevvgg/PaReS-sentimenTw-political-PL"
sentiment_task = pipeline(task = "sentiment-analysis", model = model_path, tokenizer = model_path)
sequence = ["Cała ta śmieszna debata była próbą ukrycia problemów gospodarczych jakie są i nadejdą, pytania w większości o mało istotnych sprawach",
"Brawo panie ministrze!"]
result = sentiment_task(sequence)
labels = [i['label'] for i in result] # ['Negative', 'Positive']
```
## Model Sources
- **BibTex citation:**
```
@misc{SentimenTwPLGK2023,
author={Gajewska, Ewelina and Konat, Barbara},
title={PaReSTw: BERT for Sentiment Detection in Polish Language},
year={2023},
howpublished = {\url{https://huggingface.co/eevvgg/PaReS-sentimenTw-political-PL}},
}
```
## Intended uses & limitations
Sentiment detection in Polish data (fine-tuned on tweets from political domain).
## Training and evaluation data
- Trained for 3 epochs, mini-batch size of 8.
- Training results: loss: 0.1358926964368792
It achieves the following results on the test set (10%):
- No. examples = 100
- mini batch size = 8
- accuracy = 0.950
- macro f1 = 0.944
precision recall f1-score support
0 0.960 0.980 0.970 49
1 0.958 0.885 0.920 26
2 0.923 0.960 0.941 25
|
helenai/google-bert-bert-base-uncased-ov | helenai | 2024-05-23T14:13:51Z | 7 | 0 | transformers | [
"transformers",
"openvino",
"bert",
"fill-mask",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-05-22T18:57:09Z | ---
language:
- en
tags:
- openvino
---
# google-bert/bert-base-uncased
This is the [google-bert/bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) model converted to [OpenVINO](https://openvino.ai), for accelerated inference.
An example of how to do inference on this model:
```python
from optimum.intel import OVModelForMaskedLM
from transformers import AutoTokenizer, pipeline
# model_id should be set to either a local directory or a model available on the HuggingFace hub.
model_id = "helenai/google-bert-bert-base-uncased-ov"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForMaskedLM.from_pretrained(model_id)
pipe = pipeline("fill-mask", model=model, tokenizer=tokenizer)
result = pipe(f"I am a {tokenizer.mask_token} model")
print(result)
```
|
khadija69/roberta_ASE_kgl | khadija69 | 2024-05-23T14:12:46Z | 22 | 0 | transformers | [
"transformers",
"tf",
"xlm-roberta",
"token-classification",
"generated_from_keras_callback",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2024-05-23T13:36:57Z | ---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_keras_callback
model-index:
- name: khadija69/roberta_ASE_kgl
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# khadija69/roberta_ASE_kgl
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1987
- Validation Loss: 0.3653
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1000, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.4777 | 0.3498 | 0 |
| 0.3292 | 0.3403 | 1 |
| 0.3056 | 0.3305 | 2 |
| 0.2796 | 0.3372 | 3 |
| 0.2624 | 0.3323 | 4 |
| 0.2468 | 0.3416 | 5 |
| 0.2277 | 0.3364 | 6 |
| 0.2141 | 0.3557 | 7 |
| 0.2057 | 0.3576 | 8 |
| 0.1987 | 0.3653 | 9 |
### Framework versions
- Transformers 4.39.3
- TensorFlow 2.15.0
- Datasets 2.18.0
- Tokenizers 0.15.2
|
S4nto/lora-dpo-finetuned-stage4-sft-_0.1_1e-6_ep-5 | S4nto | 2024-05-23T14:11:42Z | 5 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T14:01:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
roshna-omer/w2v-bert-2.0-mongolian-colab-CV16.0 | roshna-omer | 2024-05-23T14:10:32Z | 0 | 0 | transformers | [
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T14:10:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
dugoalberto/deepseek-coder-6.7b_LoRA_python | dugoalberto | 2024-05-23T14:04:07Z | 3 | 0 | peft | [
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:deepseek-ai/deepseek-coder-6.7b-base",
"base_model:adapter:deepseek-ai/deepseek-coder-6.7b-base",
"license:other",
"region:us"
] | null | 2024-05-23T10:40:43Z | ---
license: other
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: deepseek-ai/deepseek-coder-6.7b-base
model-index:
- name: deepseek-coder-6.7b_LoRA_python
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deepseek-coder-6.7b_LoRA_python
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-6.7b-base](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.005
- training_steps: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- PEFT 0.11.2.dev0
- Transformers 4.41.1
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1 |
axolotyy/apple-vision-pro-LoRa | axolotyy | 2024-05-23T14:02:59Z | 5 | 0 | diffusers | [
"diffusers",
"autotrain",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2024-05-23T14:02:54Z |
---
tags:
- autotrain
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
- template:sd-lora
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: applevisionproaxo
license: openrail++
---
# AutoTrain SDXL LoRA DreamBooth - axolotyy/apple-vision-pro-LoRa
<Gallery />
## Model description
These are axolotyy/apple-vision-pro-LoRa LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: None.
## Trigger words
You should use applevisionproaxo to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](axolotyy/apple-vision-pro-LoRa/tree/main) them in the Files & versions tab.
|
EleutherAI/Mistral-7B-v0.1-nli-random-standardized-random-names | EleutherAI | 2024-05-23T14:02:05Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T00:31:32Z | ---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
BilalMuftuoglu/beit-base-patch16-224-hasta-65-fold2 | BilalMuftuoglu | 2024-05-23T14:01:40Z | 194 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:51:53Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-65-fold2
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.75
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-65-fold2
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6728
- Accuracy: 0.75
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.3013 | 0.3056 |
| No log | 1.7143 | 3 | 1.2799 | 0.2778 |
| No log | 2.8571 | 5 | 1.2588 | 0.3333 |
| No log | 4.0 | 7 | 1.1296 | 0.3889 |
| No log | 4.5714 | 8 | 1.1295 | 0.3611 |
| 1.1611 | 5.7143 | 10 | 1.2689 | 0.25 |
| 1.1611 | 6.8571 | 12 | 1.0895 | 0.3889 |
| 1.1611 | 8.0 | 14 | 1.0978 | 0.5 |
| 1.1611 | 8.5714 | 15 | 1.1168 | 0.5278 |
| 1.1611 | 9.7143 | 17 | 1.0844 | 0.4167 |
| 1.1611 | 10.8571 | 19 | 1.0476 | 0.5 |
| 0.9913 | 12.0 | 21 | 1.2315 | 0.4722 |
| 0.9913 | 12.5714 | 22 | 1.1444 | 0.4722 |
| 0.9913 | 13.7143 | 24 | 1.0242 | 0.5 |
| 0.9913 | 14.8571 | 26 | 1.0495 | 0.5278 |
| 0.9913 | 16.0 | 28 | 1.1234 | 0.4722 |
| 0.9913 | 16.5714 | 29 | 1.2332 | 0.5278 |
| 0.9206 | 17.7143 | 31 | 1.4389 | 0.3611 |
| 0.9206 | 18.8571 | 33 | 1.0300 | 0.5 |
| 0.9206 | 20.0 | 35 | 1.0028 | 0.5278 |
| 0.9206 | 20.5714 | 36 | 1.0322 | 0.5 |
| 0.9206 | 21.7143 | 38 | 1.0871 | 0.5278 |
| 0.7309 | 22.8571 | 40 | 0.9616 | 0.4722 |
| 0.7309 | 24.0 | 42 | 0.9571 | 0.5556 |
| 0.7309 | 24.5714 | 43 | 0.9855 | 0.5278 |
| 0.7309 | 25.7143 | 45 | 0.9598 | 0.5278 |
| 0.7309 | 26.8571 | 47 | 0.9774 | 0.5278 |
| 0.7309 | 28.0 | 49 | 0.9205 | 0.5556 |
| 0.6039 | 28.5714 | 50 | 0.9073 | 0.5556 |
| 0.6039 | 29.7143 | 52 | 0.8644 | 0.5833 |
| 0.6039 | 30.8571 | 54 | 0.8931 | 0.5833 |
| 0.6039 | 32.0 | 56 | 0.8686 | 0.6111 |
| 0.6039 | 32.5714 | 57 | 0.8381 | 0.5833 |
| 0.6039 | 33.7143 | 59 | 0.8658 | 0.5556 |
| 0.4784 | 34.8571 | 61 | 0.9915 | 0.5556 |
| 0.4784 | 36.0 | 63 | 0.7971 | 0.5833 |
| 0.4784 | 36.5714 | 64 | 0.7682 | 0.6111 |
| 0.4784 | 37.7143 | 66 | 0.9361 | 0.5833 |
| 0.4784 | 38.8571 | 68 | 0.9093 | 0.5833 |
| 0.4469 | 40.0 | 70 | 0.6728 | 0.75 |
| 0.4469 | 40.5714 | 71 | 0.6415 | 0.7222 |
| 0.4469 | 41.7143 | 73 | 0.7045 | 0.6667 |
| 0.4469 | 42.8571 | 75 | 0.8974 | 0.6389 |
| 0.4469 | 44.0 | 77 | 0.8032 | 0.6111 |
| 0.4469 | 44.5714 | 78 | 0.7134 | 0.6944 |
| 0.4329 | 45.7143 | 80 | 0.6975 | 0.7222 |
| 0.4329 | 46.8571 | 82 | 0.6758 | 0.7222 |
| 0.4329 | 48.0 | 84 | 0.8327 | 0.6111 |
| 0.4329 | 48.5714 | 85 | 0.9089 | 0.6111 |
| 0.4329 | 49.7143 | 87 | 0.9158 | 0.6111 |
| 0.4329 | 50.8571 | 89 | 0.8007 | 0.6389 |
| 0.4282 | 52.0 | 91 | 0.7363 | 0.6389 |
| 0.4282 | 52.5714 | 92 | 0.7378 | 0.6389 |
| 0.4282 | 53.7143 | 94 | 0.7449 | 0.6111 |
| 0.4282 | 54.8571 | 96 | 0.7605 | 0.6111 |
| 0.4282 | 56.0 | 98 | 0.7853 | 0.6111 |
| 0.4282 | 56.5714 | 99 | 0.7903 | 0.5833 |
| 0.3188 | 57.1429 | 100 | 0.7926 | 0.5833 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
mpachha/Meta-Llama-3-sft | mpachha | 2024-05-23T14:01:16Z | 0 | 0 | peft | [
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"dataset:samsum",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:adapter:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"region:us"
] | null | 2024-05-23T13:47:01Z | ---
license: llama3
library_name: peft
tags:
- trl
- sft
- generated_from_trainer
base_model: meta-llama/Meta-Llama-3-8B
datasets:
- samsum
model-index:
- name: Meta-Llama-3-sft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Meta-Llama-3-sft
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0487
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 5
- total_train_batch_size: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.0319 | 0.07 | 100 | 2.0487 |
### Framework versions
- PEFT 0.11.1
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2 |
sidddddddddddd/llama3-8b-kub-1-epoch-wholedata | sidddddddddddd | 2024-05-23T13:55:06Z | 0 | 0 | transformers | [
"transformers",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T13:55:05Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
base_model: unsloth/llama-3-8b-bnb-4bit
---
# Uploaded model
- **Developed by:** sidddddddddddd
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Augusto777/vit-base-patch16-224-U8-10 | Augusto777 | 2024-05-23T13:53:15Z | 218 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:42:51Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-U8-10
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8833333333333333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-U8-10
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5606
- Accuracy: 0.8833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.2473 | 1.0 | 20 | 1.1804 | 0.5833 |
| 0.9555 | 2.0 | 40 | 0.9370 | 0.65 |
| 0.727 | 3.0 | 60 | 0.7202 | 0.6833 |
| 0.5288 | 4.0 | 80 | 0.5606 | 0.8833 |
| 0.3876 | 5.0 | 100 | 0.6482 | 0.7667 |
| 0.296 | 6.0 | 120 | 0.7458 | 0.7167 |
| 0.236 | 7.0 | 140 | 0.4677 | 0.8833 |
| 0.2129 | 8.0 | 160 | 0.5138 | 0.8333 |
| 0.1781 | 9.0 | 180 | 0.4736 | 0.85 |
| 0.1854 | 10.0 | 200 | 0.4801 | 0.8 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
BilalMuftuoglu/beit-base-patch16-224-hasta-65-fold1 | BilalMuftuoglu | 2024-05-23T13:51:44Z | 194 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:42:11Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-65-fold1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6944444444444444
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-65-fold1
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8281
- Accuracy: 0.6944
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.1951 | 0.3333 |
| No log | 1.7143 | 3 | 1.2409 | 0.3056 |
| No log | 2.8571 | 5 | 1.2181 | 0.3056 |
| No log | 4.0 | 7 | 1.1308 | 0.5 |
| No log | 4.5714 | 8 | 1.1858 | 0.5278 |
| 1.092 | 5.7143 | 10 | 1.2798 | 0.3056 |
| 1.092 | 6.8571 | 12 | 1.0892 | 0.3611 |
| 1.092 | 8.0 | 14 | 1.2658 | 0.3889 |
| 1.092 | 8.5714 | 15 | 1.1603 | 0.5 |
| 1.092 | 9.7143 | 17 | 1.0786 | 0.4167 |
| 1.092 | 10.8571 | 19 | 1.2400 | 0.4167 |
| 0.9727 | 12.0 | 21 | 1.2929 | 0.3889 |
| 0.9727 | 12.5714 | 22 | 1.1613 | 0.3889 |
| 0.9727 | 13.7143 | 24 | 0.9838 | 0.6111 |
| 0.9727 | 14.8571 | 26 | 1.2316 | 0.3889 |
| 0.9727 | 16.0 | 28 | 1.1520 | 0.4722 |
| 0.9727 | 16.5714 | 29 | 1.0345 | 0.5556 |
| 0.8844 | 17.7143 | 31 | 1.0000 | 0.5 |
| 0.8844 | 18.8571 | 33 | 0.9933 | 0.5278 |
| 0.8844 | 20.0 | 35 | 1.0512 | 0.5556 |
| 0.8844 | 20.5714 | 36 | 0.9950 | 0.5556 |
| 0.8844 | 21.7143 | 38 | 0.9621 | 0.4722 |
| 0.7447 | 22.8571 | 40 | 0.8812 | 0.5278 |
| 0.7447 | 24.0 | 42 | 1.0244 | 0.5833 |
| 0.7447 | 24.5714 | 43 | 1.0124 | 0.5833 |
| 0.7447 | 25.7143 | 45 | 0.8908 | 0.6389 |
| 0.7447 | 26.8571 | 47 | 0.8185 | 0.5833 |
| 0.7447 | 28.0 | 49 | 0.9409 | 0.5556 |
| 0.6176 | 28.5714 | 50 | 1.0401 | 0.5556 |
| 0.6176 | 29.7143 | 52 | 1.0989 | 0.5556 |
| 0.6176 | 30.8571 | 54 | 0.9102 | 0.5833 |
| 0.6176 | 32.0 | 56 | 0.8855 | 0.5833 |
| 0.6176 | 32.5714 | 57 | 0.8974 | 0.5556 |
| 0.6176 | 33.7143 | 59 | 0.9419 | 0.6111 |
| 0.4929 | 34.8571 | 61 | 0.9471 | 0.5833 |
| 0.4929 | 36.0 | 63 | 0.8609 | 0.5833 |
| 0.4929 | 36.5714 | 64 | 0.8558 | 0.5833 |
| 0.4929 | 37.7143 | 66 | 0.8449 | 0.5556 |
| 0.4929 | 38.8571 | 68 | 0.8136 | 0.6667 |
| 0.463 | 40.0 | 70 | 0.8281 | 0.6944 |
| 0.463 | 40.5714 | 71 | 0.8227 | 0.6944 |
| 0.463 | 41.7143 | 73 | 0.8323 | 0.5833 |
| 0.463 | 42.8571 | 75 | 0.8436 | 0.5833 |
| 0.463 | 44.0 | 77 | 0.8390 | 0.5833 |
| 0.463 | 44.5714 | 78 | 0.8580 | 0.6111 |
| 0.3995 | 45.7143 | 80 | 0.9375 | 0.6111 |
| 0.3995 | 46.8571 | 82 | 0.9897 | 0.5556 |
| 0.3995 | 48.0 | 84 | 0.9785 | 0.5556 |
| 0.3995 | 48.5714 | 85 | 0.9336 | 0.6389 |
| 0.3995 | 49.7143 | 87 | 0.8504 | 0.6389 |
| 0.3995 | 50.8571 | 89 | 0.8450 | 0.6667 |
| 0.3697 | 52.0 | 91 | 0.8531 | 0.6389 |
| 0.3697 | 52.5714 | 92 | 0.8728 | 0.6389 |
| 0.3697 | 53.7143 | 94 | 0.9076 | 0.6667 |
| 0.3697 | 54.8571 | 96 | 0.9175 | 0.6389 |
| 0.3697 | 56.0 | 98 | 0.9145 | 0.5833 |
| 0.3697 | 56.5714 | 99 | 0.9119 | 0.5833 |
| 0.3259 | 57.1429 | 100 | 0.9102 | 0.5833 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
yasirchemmakh/log-mistral-7b-lora | yasirchemmakh | 2024-05-23T13:51:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T13:50:55Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/mistral-7b-bnb-4bit
---
# Uploaded model
- **Developed by:** yasirchemmakh
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
DavidPL1/Reinforce-CartPole-v1 | DavidPL1 | 2024-05-23T13:49:54Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | reinforcement-learning | 2024-05-23T09:23:41Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
C0uchP0tat0/x5tech_LLM_1050 | C0uchP0tat0 | 2024-05-23T13:46:28Z | 109 | 0 | transformers | [
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T13:45:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hgnoi/OidYLp38t8K3PZwl | hgnoi | 2024-05-23T13:45:59Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T13:44:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gimling/Qwen1.5-14B-Chat-Q4_0-GGUF | gimling | 2024-05-23T13:42:48Z | 22 | 0 | null | [
"gguf",
"chat",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2024-05-23T13:42:26Z | ---
language:
- en
license: other
tags:
- chat
- llama-cpp
- gguf-my-repo
license_name: tongyi-qianwen
license_link: https://huggingface.co/Qwen/Qwen1.5-14B-Chat/blob/main/LICENSE
pipeline_tag: text-generation
---
# gimling/Qwen1.5-14B-Chat-Q4_0-GGUF
This model was converted to GGUF format from [`Qwen/Qwen1.5-14B-Chat`](https://huggingface.co/Qwen/Qwen1.5-14B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen1.5-14B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo gimling/Qwen1.5-14B-Chat-Q4_0-GGUF --model qwen1.5-14b-chat.Q4_0.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo gimling/Qwen1.5-14B-Chat-Q4_0-GGUF --model qwen1.5-14b-chat.Q4_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m qwen1.5-14b-chat.Q4_0.gguf -n 128
```
|
BilalMuftuoglu/beit-base-patch16-224-hasta-55-fold5 | BilalMuftuoglu | 2024-05-23T13:42:01Z | 7 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:32:16Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-55-fold5
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6111111111111112
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-55-fold5
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4708
- Accuracy: 0.6111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.2240 | 0.3056 |
| No log | 1.7143 | 3 | 1.2263 | 0.3056 |
| No log | 2.8571 | 5 | 1.2222 | 0.3889 |
| No log | 4.0 | 7 | 1.1690 | 0.3889 |
| No log | 4.5714 | 8 | 1.1691 | 0.3889 |
| 1.1249 | 5.7143 | 10 | 1.0999 | 0.3889 |
| 1.1249 | 6.8571 | 12 | 1.1605 | 0.4167 |
| 1.1249 | 8.0 | 14 | 1.1912 | 0.4167 |
| 1.1249 | 8.5714 | 15 | 1.1771 | 0.3889 |
| 1.1249 | 9.7143 | 17 | 1.2370 | 0.4722 |
| 1.1249 | 10.8571 | 19 | 1.2607 | 0.5 |
| 0.9274 | 12.0 | 21 | 1.2756 | 0.4722 |
| 0.9274 | 12.5714 | 22 | 1.2208 | 0.4722 |
| 0.9274 | 13.7143 | 24 | 1.3705 | 0.5 |
| 0.9274 | 14.8571 | 26 | 1.2191 | 0.5278 |
| 0.9274 | 16.0 | 28 | 1.3502 | 0.5278 |
| 0.9274 | 16.5714 | 29 | 1.2628 | 0.5278 |
| 0.7889 | 17.7143 | 31 | 1.0868 | 0.5 |
| 0.7889 | 18.8571 | 33 | 1.3983 | 0.5 |
| 0.7889 | 20.0 | 35 | 1.2537 | 0.5556 |
| 0.7889 | 20.5714 | 36 | 1.1540 | 0.4722 |
| 0.7889 | 21.7143 | 38 | 1.2135 | 0.5556 |
| 0.7027 | 22.8571 | 40 | 1.4271 | 0.5 |
| 0.7027 | 24.0 | 42 | 1.1828 | 0.5 |
| 0.7027 | 24.5714 | 43 | 1.2126 | 0.4444 |
| 0.7027 | 25.7143 | 45 | 1.4980 | 0.5556 |
| 0.7027 | 26.8571 | 47 | 1.3495 | 0.5556 |
| 0.7027 | 28.0 | 49 | 1.1969 | 0.5278 |
| 0.6037 | 28.5714 | 50 | 1.2063 | 0.5556 |
| 0.6037 | 29.7143 | 52 | 1.3115 | 0.5833 |
| 0.6037 | 30.8571 | 54 | 1.1726 | 0.5278 |
| 0.6037 | 32.0 | 56 | 1.1872 | 0.5556 |
| 0.6037 | 32.5714 | 57 | 1.2399 | 0.5556 |
| 0.6037 | 33.7143 | 59 | 1.2566 | 0.5278 |
| 0.5147 | 34.8571 | 61 | 1.1848 | 0.5278 |
| 0.5147 | 36.0 | 63 | 1.2614 | 0.5556 |
| 0.5147 | 36.5714 | 64 | 1.3975 | 0.5556 |
| 0.5147 | 37.7143 | 66 | 1.4708 | 0.6111 |
| 0.5147 | 38.8571 | 68 | 1.3233 | 0.5833 |
| 0.4004 | 40.0 | 70 | 1.2994 | 0.5556 |
| 0.4004 | 40.5714 | 71 | 1.3582 | 0.5278 |
| 0.4004 | 41.7143 | 73 | 1.3577 | 0.5278 |
| 0.4004 | 42.8571 | 75 | 1.1985 | 0.5833 |
| 0.4004 | 44.0 | 77 | 1.1448 | 0.5556 |
| 0.4004 | 44.5714 | 78 | 1.1714 | 0.6111 |
| 0.4323 | 45.7143 | 80 | 1.3707 | 0.6111 |
| 0.4323 | 46.8571 | 82 | 1.5477 | 0.5833 |
| 0.4323 | 48.0 | 84 | 1.4254 | 0.5833 |
| 0.4323 | 48.5714 | 85 | 1.3031 | 0.5833 |
| 0.4323 | 49.7143 | 87 | 1.1843 | 0.6111 |
| 0.4323 | 50.8571 | 89 | 1.1835 | 0.6111 |
| 0.3568 | 52.0 | 91 | 1.2399 | 0.6111 |
| 0.3568 | 52.5714 | 92 | 1.2606 | 0.6111 |
| 0.3568 | 53.7143 | 94 | 1.2997 | 0.5833 |
| 0.3568 | 54.8571 | 96 | 1.3184 | 0.5833 |
| 0.3568 | 56.0 | 98 | 1.3294 | 0.5833 |
| 0.3568 | 56.5714 | 99 | 1.3337 | 0.5833 |
| 0.3308 | 57.1429 | 100 | 1.3367 | 0.5833 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
nc33/llama3-8b-4bit_orpo_law_cp4 | nc33 | 2024-05-23T13:39:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-22T07:43:48Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Tashuu/whisper-model-hindi | Tashuu | 2024-05-23T13:33:03Z | 88 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-22T08:12:01Z | ---
language:
- hi
license: apache-2.0
tags:
- generated_from_trainer
base_model: openai/whisper-small
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: OpenAI whisper hindi - Tashu Gurnani
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: hi
split: None
args: 'config: hi, split: test'
metrics:
- type: wer
value: 33.010242952679256
name: Wer
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# OpenAI whisper hindi - Tashu Gurnani
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3303
- Wer: 33.0102
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0884 | 2.44 | 1000 | 0.2946 | 34.7668 |
| 0.0173 | 4.89 | 2000 | 0.3303 | 33.0102 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
BilalMuftuoglu/beit-base-patch16-224-hasta-55-fold4 | BilalMuftuoglu | 2024-05-23T13:32:07Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:microsoft/beit-base-patch16-224",
"base_model:finetune:microsoft/beit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:22:11Z | ---
license: apache-2.0
base_model: microsoft/beit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-hasta-55-fold4
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7222222222222222
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-hasta-55-fold4
This model is a fine-tuned version of [microsoft/beit-base-patch16-224](https://huggingface.co/microsoft/beit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1593
- Accuracy: 0.7222
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| No log | 0.5714 | 1 | 1.2503 | 0.4444 |
| No log | 1.7143 | 3 | 1.1731 | 0.4167 |
| No log | 2.8571 | 5 | 1.0852 | 0.5278 |
| No log | 4.0 | 7 | 1.0787 | 0.5 |
| No log | 4.5714 | 8 | 1.1199 | 0.5278 |
| 1.0532 | 5.7143 | 10 | 1.0584 | 0.4722 |
| 1.0532 | 6.8571 | 12 | 1.0800 | 0.5278 |
| 1.0532 | 8.0 | 14 | 1.1635 | 0.4722 |
| 1.0532 | 8.5714 | 15 | 1.1171 | 0.4444 |
| 1.0532 | 9.7143 | 17 | 1.5254 | 0.3889 |
| 1.0532 | 10.8571 | 19 | 1.1236 | 0.4444 |
| 0.9087 | 12.0 | 21 | 1.0255 | 0.5556 |
| 0.9087 | 12.5714 | 22 | 1.1108 | 0.5278 |
| 0.9087 | 13.7143 | 24 | 1.0365 | 0.5278 |
| 0.9087 | 14.8571 | 26 | 1.0638 | 0.5 |
| 0.9087 | 16.0 | 28 | 1.1090 | 0.6111 |
| 0.9087 | 16.5714 | 29 | 1.1166 | 0.5556 |
| 0.7925 | 17.7143 | 31 | 1.0650 | 0.4722 |
| 0.7925 | 18.8571 | 33 | 1.3085 | 0.5556 |
| 0.7925 | 20.0 | 35 | 1.1624 | 0.5278 |
| 0.7925 | 20.5714 | 36 | 0.9994 | 0.5556 |
| 0.7925 | 21.7143 | 38 | 1.1054 | 0.4722 |
| 0.7472 | 22.8571 | 40 | 1.0926 | 0.5833 |
| 0.7472 | 24.0 | 42 | 1.1054 | 0.6111 |
| 0.7472 | 24.5714 | 43 | 1.0486 | 0.5556 |
| 0.7472 | 25.7143 | 45 | 1.0454 | 0.5556 |
| 0.7472 | 26.8571 | 47 | 1.0267 | 0.6389 |
| 0.7472 | 28.0 | 49 | 1.0684 | 0.6667 |
| 0.572 | 28.5714 | 50 | 1.0575 | 0.6111 |
| 0.572 | 29.7143 | 52 | 1.1591 | 0.5833 |
| 0.572 | 30.8571 | 54 | 1.1837 | 0.5833 |
| 0.572 | 32.0 | 56 | 1.0444 | 0.6667 |
| 0.572 | 32.5714 | 57 | 1.0450 | 0.6667 |
| 0.572 | 33.7143 | 59 | 1.0975 | 0.6667 |
| 0.471 | 34.8571 | 61 | 1.1131 | 0.6667 |
| 0.471 | 36.0 | 63 | 1.1204 | 0.5833 |
| 0.471 | 36.5714 | 64 | 1.0992 | 0.5833 |
| 0.471 | 37.7143 | 66 | 1.0879 | 0.6389 |
| 0.471 | 38.8571 | 68 | 1.0981 | 0.6111 |
| 0.3896 | 40.0 | 70 | 1.0576 | 0.6667 |
| 0.3896 | 40.5714 | 71 | 1.0612 | 0.6389 |
| 0.3896 | 41.7143 | 73 | 1.1195 | 0.6667 |
| 0.3896 | 42.8571 | 75 | 1.1974 | 0.6667 |
| 0.3896 | 44.0 | 77 | 1.1353 | 0.6667 |
| 0.3896 | 44.5714 | 78 | 1.1143 | 0.6667 |
| 0.3775 | 45.7143 | 80 | 1.1055 | 0.6667 |
| 0.3775 | 46.8571 | 82 | 1.1997 | 0.6667 |
| 0.3775 | 48.0 | 84 | 1.3267 | 0.6667 |
| 0.3775 | 48.5714 | 85 | 1.3027 | 0.6667 |
| 0.3775 | 49.7143 | 87 | 1.1593 | 0.7222 |
| 0.3775 | 50.8571 | 89 | 1.0970 | 0.6111 |
| 0.3623 | 52.0 | 91 | 1.0902 | 0.6111 |
| 0.3623 | 52.5714 | 92 | 1.0908 | 0.6111 |
| 0.3623 | 53.7143 | 94 | 1.1214 | 0.6389 |
| 0.3623 | 54.8571 | 96 | 1.1691 | 0.6944 |
| 0.3623 | 56.0 | 98 | 1.1914 | 0.6667 |
| 0.3623 | 56.5714 | 99 | 1.1949 | 0.6667 |
| 0.3455 | 57.1429 | 100 | 1.1951 | 0.6667 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
hgnoi/WG1j7Bkew9AVvK3T | hgnoi | 2024-05-23T13:31:52Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T13:30:11Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-687872 | fine-tuned | 2024-05-23T13:30:51Z | 6 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-687872",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-23T13:29:54Z | ---
license: apache-2.0
datasets:
- fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-687872
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-m3**](https://huggingface.co/BAAI/bge-m3) designed for the following use case:
custom
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-687872',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
Saumohan/mistral_lora_model | Saumohan | 2024-05-23T13:30:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-23T13:30:34Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/mistral-7b-v0.3-bnb-4bit
---
# Uploaded model
- **Developed by:** Saumohan
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
fine-tuned/SciFact-256-24-gpt-4o-2024-05-13-785172 | fine-tuned | 2024-05-23T13:30:37Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/SciFact-256-24-gpt-4o-2024-05-13-785172",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-23T13:29:37Z | ---
license: apache-2.0
datasets:
- fine-tuned/SciFact-256-24-gpt-4o-2024-05-13-785172
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-m3**](https://huggingface.co/BAAI/bge-m3) designed for the following use case:
custom
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/SciFact-256-24-gpt-4o-2024-05-13-785172',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
ricardo-larosa/recogs-mistral-7b-instruct-v0.2-bnb-4bit | ricardo-larosa | 2024-05-23T13:29:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.2-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-03-03T19:01:35Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
base_model: unsloth/mistral-7b-instruct-v0.2-bnb-4bit
---
# Uploaded model
- **Developed by:** ricardo-larosa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.2-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
# Techniques used
1. Quantization: They provide 4-bit quantized models which are 4x faster to download and use 4x less memory (I observed that the reduction of precision did not affect too much the performance of the model).
2. Lower Ranking Adaptation: They provide LoRA adapters which allow to only update 1 to 10% of all parameters.
3. Rotary Positional Embedding Scaling: They support RoPE Scaling internally instead of traditional positional embeddings.
# Performance
I did not see any OOMs and the memory usage was steady at 10GB on a A100 GPU (I could've easily used a V100).
Aditional to this performance optimizations, I spend some time tweaking the parameters of the Supervised Fine-tuning Trainer (SFTTrainer) from the TRL library.
# Prompting
Finally, the prompt template is a simple alpaca-like template of fields: instruction, english_sentence and logical_form. The same template is used for training and inference.
|
Augusto777/vit-base-patch16-224-U7-10 | Augusto777 | 2024-05-23T13:29:04Z | 218 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T13:19:32Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-U7-10
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7833333333333333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-U7-10
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7356
- Accuracy: 0.7833
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3526 | 1.0 | 10 | 1.2843 | 0.4667 |
| 1.2233 | 2.0 | 20 | 1.1650 | 0.5833 |
| 1.1009 | 3.0 | 30 | 1.0405 | 0.65 |
| 0.9819 | 4.0 | 40 | 0.9573 | 0.65 |
| 0.8728 | 5.0 | 50 | 0.8657 | 0.6833 |
| 0.7702 | 6.0 | 60 | 0.8245 | 0.6667 |
| 0.7075 | 7.0 | 70 | 0.7998 | 0.7333 |
| 0.6324 | 8.0 | 80 | 0.8108 | 0.75 |
| 0.5928 | 9.0 | 90 | 0.7402 | 0.75 |
| 0.5649 | 10.0 | 100 | 0.7356 | 0.7833 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
beomi/KcELECTRA-base | beomi | 2024-05-23T13:26:43Z | 6,197 | 32 | transformers | [
"transformers",
"pytorch",
"safetensors",
"electra",
"pretraining",
"korean",
"ko",
"en",
"doi:10.57967/hf/0017",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z | ---
language:
- ko
- en
tags:
- electra
- korean
license: "mit"
---
# KcELECTRA: Korean comments ELECTRA
** Updates on 2022.10.08 **
- KcELECTRA-base-v2022 (구 v2022-dev) 모델 이름이 변경되었습니다. --> KcELECTRA-base 레포의 `v2022`로 통합되었습니다.
- 위 모델의 세부 스코어를 추가하였습니다.
- 기존 KcELECTRA-base(v2021) 대비 대부분의 downstream task에서 ~1%p 수준의 성능 향상이 있습니다.
---
공개된 한국어 Transformer 계열 모델들은 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 User-Generated Noisy text domain 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
KcELECTRA는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 ELECTRA모델을 처음부터 학습한 Pretrained ELECTRA 모델입니다.
기존 KcBERT 대비 데이터셋 증가 및 vocab 확장을 통해 상당한 수준으로 성능이 향상되었습니다.
KcELECTRA는 Huggingface의 Transformers 라이브러리를 통해 간편히 불러와 사용할 수 있습니다. (별도의 파일 다운로드가 필요하지 않습니다.)
```
💡 NOTE 💡
General Corpus로 학습한 KoELECTRA가 보편적인 task에서는 성능이 더 잘 나올 가능성이 높습니다.
KcBERT/KcELECTRA는 User genrated, Noisy text에 대해서 보다 잘 동작하는 PLM입니다.
```
## KcELECTRA Performance
- Finetune 코드는 https://github.com/Beomi/KcBERT-finetune 에서 찾아보실 수 있습니다.
- 해당 Repo의 각 Checkpoint 폴더에서 Step별 세부 스코어를 확인하실 수 있습니다.
| | Size<br/>(용량) | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |
| :----------------- | :-------------: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: |
| **KcELECTRA-base-v2022** | 475M | **91.97** | 87.35 | 76.50 | 82.12 | 83.67 | 95.12 | 69.00 / 90.40 |
| **KcELECTRA-base** | 475M | 91.71 | 86.90 | 74.80 | 81.65 | 82.65 | **95.78** | 70.60 / 90.11 |
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| KoELECTRA-Base-v3 | 423M | 90.63 | **88.11** | **84.45** | **82.24** | **85.53** | 95.25 | **84.83 / 93.45** |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
\*HanBERT의 Size는 Bert Model과 Tokenizer DB를 합친 것입니다.
\***config의 세팅을 그대로 하여 돌린 결과이며, hyperparameter tuning을 추가적으로 할 시 더 좋은 성능이 나올 수 있습니다.**
## How to use
### Requirements
- `pytorch ~= 1.8.0`
- `transformers ~= 4.11.3`
- `emoji ~= 0.6.0`
- `soynlp ~= 0.0.493`
### Default usage
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("beomi/KcELECTRA-base")
model = AutoModel.from_pretrained("beomi/KcELECTRA-base")
```
> 💡 이전 KcBERT 관련 코드들에서 `AutoTokenizer`, `AutoModel` 을 사용한 경우 `.from_pretrained("beomi/kcbert-base")` 부분을 `.from_pretrained("beomi/KcELECTRA-base")` 로만 변경해주시면 즉시 사용이 가능합니다.
### Pretrain & Finetune Colab 링크 모음
#### Pretrain Data
- KcBERT학습에 사용한 데이터 + 이후 2021.03월 초까지 수집한 댓글
- 약 17GB
- 댓글-대댓글을 묶은 기반으로 Document 구성
#### Pretrain Code
- https://github.com/KLUE-benchmark/KLUE-ELECTRA Repo를 통한 Pretrain
#### Finetune Code
- https://github.com/Beomi/KcBERT-finetune Repo를 통한 Finetune 및 스코어 비교
#### Finetune Samples
- NSMC with PyTorch-Lightning 1.3.0, GPU, Colab <a href="https://colab.research.google.com/drive/1Hh63kIBAiBw3Hho--BvfdUWLu-ysMFF0?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Train Data & Preprocessing
### Raw Data
학습 데이터는 2019.01.01 ~ 2021.03.09 사이에 작성된 **댓글 많은 뉴스/혹은 전체 뉴스** 기사들의 **댓글과 대댓글**을 모두 수집한 데이터입니다.
데이터 사이즈는 텍스트만 추출시 **약 17.3GB이며, 1억8천만개 이상의 문장**으로 이뤄져 있습니다.
> KcBERT는 2019.01-2020.06의 텍스트로, 정제 후 약 9천만개 문장으로 학습을 진행했습니다.
### Preprocessing
PLM 학습을 위해서 전처리를 진행한 과정은 다음과 같습니다.
1. 한글 및 영어, 특수문자, 그리고 이모지(🥳)까지!
정규표현식을 통해 한글, 영어, 특수문자를 포함해 Emoji까지 학습 대상에 포함했습니다.
한편, 한글 범위를 `ㄱ-ㅎ가-힣` 으로 지정해 `ㄱ-힣` 내의 한자를 제외했습니다.
2. 댓글 내 중복 문자열 축약
`ㅋㅋㅋㅋㅋ`와 같이 중복된 글자를 `ㅋㅋ`와 같은 것으로 합쳤습니다.
3. Cased Model
KcBERT는 영문에 대해서는 대소문자를 유지하는 Cased model입니다.
4. 글자 단위 10글자 이하 제거
10글자 미만의 텍스트는 단일 단어로 이뤄진 경우가 많아 해당 부분을 제외했습니다.
5. 중복 제거
중복적으로 쓰인 댓글을 제거하기 위해 완전히 일치하는 중복 댓글을 하나로 합쳤습니다.
6. `OOO` 제거
네이버 댓글의 경우, 비속어는 자체 필터링을 통해 `OOO` 로 표시합니다. 이 부분을 공백으로 제거하였습니다.
아래 명령어로 pip로 설치한 뒤, 아래 clean함수로 클리닝을 하면 Downstream task에서 보다 성능이 좋아집니다. (`[UNK]` 감소)
```bash
pip install soynlp emoji
```
아래 `clean` 함수를 Text data에 사용해주세요.
```python
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = ''.join(emoji.UNICODE_EMOJI.keys())
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
import re
import emoji
from soynlp.normalizer import repeat_normalize
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = emoji.replace_emoji(x, replace='') #emoji 삭제
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
```
> 💡 Finetune Score에서는 위 `clean` 함수를 적용하지 않았습니다.
### Cleaned Data
- KcBERT 외 추가 데이터는 정리 후 공개 예정입니다.
## Tokenizer, Model Train
Tokenizer는 Huggingface의 [Tokenizers](https://github.com/huggingface/tokenizers) 라이브러리를 통해 학습을 진행했습니다.
그 중 `BertWordPieceTokenizer` 를 이용해 학습을 진행했고, Vocab Size는 `30000`으로 진행했습니다.
Tokenizer를 학습하는 것에는 전체 데이터를 통해 학습을 진행했고, 모델의 General Downstream task에 대응하기 위해 KoELECTRA에서 사용한 Vocab을 겹치지 않는 부분을 추가로 넣어주었습니다. (실제로 두 모델이 겹치는 부분은 약 5000토큰이었습니다.)
TPU `v3-8` 을 이용해 약 10일 학습을 진행했고, 현재 Huggingface에 공개된 모델은 848k step을 학습한 모델 weight가 업로드 되어있습니다.
(100k step별 Checkpoint를 통해 성능 평가를 진행하였습니다. 해당 부분은 `KcBERT-finetune` repo를 참고해주세요.)
모델 학습 Loss는 Step에 따라 초기 100-200k 사이에 급격히 Loss가 줄어들다 학습 종료까지도 지속적으로 loss가 감소하는 것을 볼 수 있습니다.
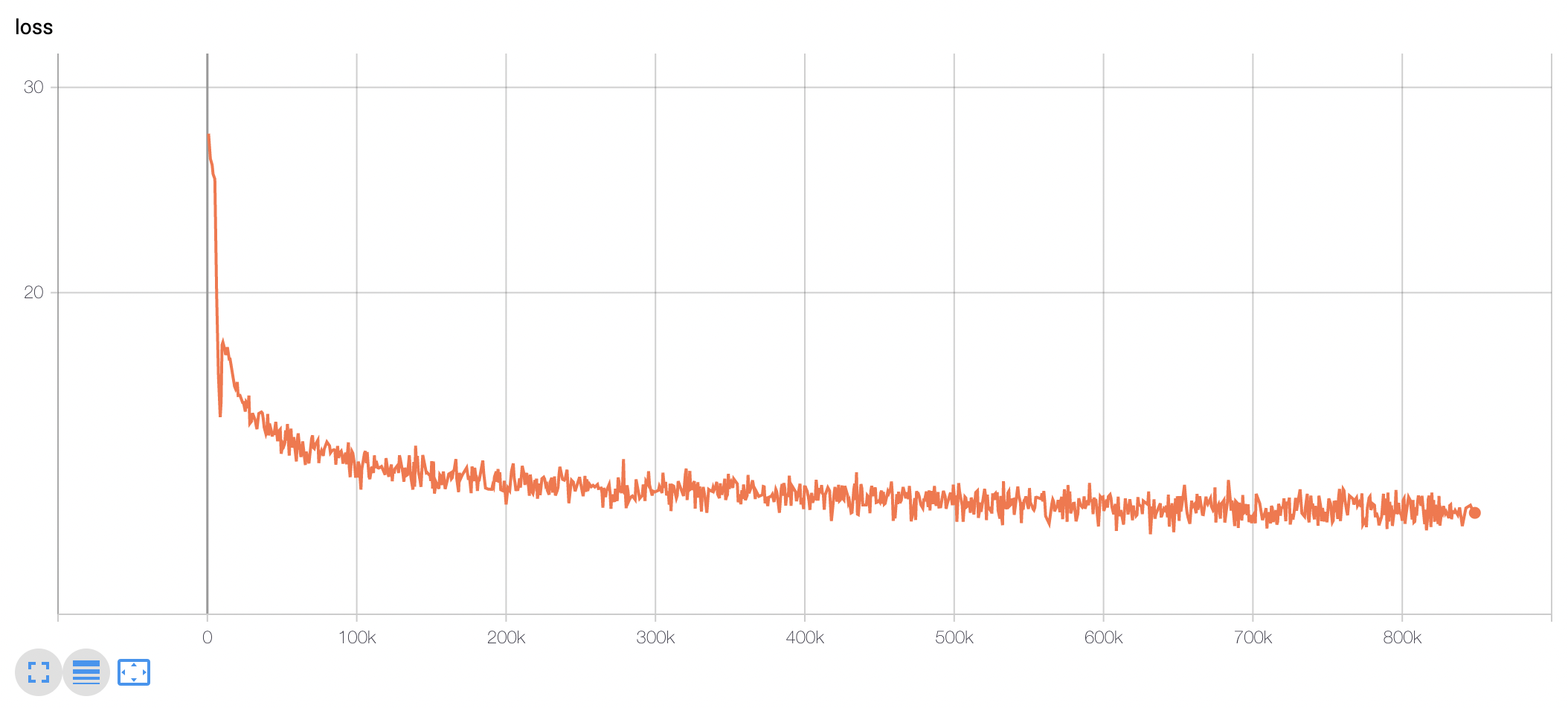
### KcELECTRA Pretrain Step별 Downstream task 성능 비교
> 💡 아래 표는 전체 ckpt가 아닌 일부에 대해서만 테스트를 진행한 결과입니다.
- 위와 같이 KcBERT-base, KcBERT-large 대비 **모든 데이터셋에 대해** KcELECTRA-base가 더 높은 성능을 보입니다.
- KcELECTRA pretrain에서도 Train step이 늘어감에 따라 점진적으로 성능이 향상되는 것을 볼 수 있습니다.
## 인용표기/Citation
KcELECTRA를 인용하실 때는 아래 양식을 통해 인용해주세요.
```
@misc{lee2021kcelectra,
author = {Junbum Lee},
title = {KcELECTRA: Korean comments ELECTRA},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Beomi/KcELECTRA}}
}
```
논문을 통한 사용 외에는 MIT 라이센스를 표기해주세요. ☺️
## Acknowledgement
KcELECTRA Model을 학습하는 GCP/TPU 환경은 [TFRC](https://www.tensorflow.org/tfrc?hl=ko) 프로그램의 지원을 받았습니다.
모델 학습 과정에서 많은 조언을 주신 [Monologg](https://github.com/monologg/) 님 감사합니다 :)
## Reference
### Github Repos
- [KcBERT by Beomi](https://github.com/Beomi/KcBERT)
- [BERT by Google](https://github.com/google-research/bert)
- [KoBERT by SKT](https://github.com/SKTBrain/KoBERT)
- [KoELECTRA by Monologg](https://github.com/monologg/KoELECTRA/)
- [Transformers by Huggingface](https://github.com/huggingface/transformers)
- [Tokenizers by Hugginface](https://github.com/huggingface/tokenizers)
- [ELECTRA train code by KLUE](https://github.com/KLUE-benchmark/KLUE-ELECTRA)
### Blogs
- [Monologg님의 KoELECTRA 학습기](https://monologg.kr/categories/NLP/ELECTRA/)
- [Colab에서 TPU로 BERT 처음부터 학습시키기 - Tensorflow/Google ver.](https://beomi.github.io/2020/02/26/Train-BERT-from-scratch-on-colab-TPU-Tensorflow-ver/)
|
sravan-gorugantu/model2024-05-23 | sravan-gorugantu | 2024-05-23T13:25:50Z | 161 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:audiofolder",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | audio-classification | 2024-05-23T05:11:04Z | ---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- accuracy
model-index:
- name: model2024-05-23
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: audiofolder
type: audiofolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9660686103496968
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model2024-05-23
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0929
- Accuracy: 0.9661
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1867 | 1.0 | 564 | 0.1825 | 0.9286 |
| 0.1732 | 2.0 | 1129 | 0.1284 | 0.9505 |
| 0.1493 | 3.0 | 1693 | 0.1088 | 0.9588 |
| 0.1064 | 4.0 | 2258 | 0.1011 | 0.9636 |
| 0.115 | 5.0 | 2820 | 0.0929 | 0.9661 |
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.2
|
jxke/chatglm3-6b-rkllm | jxke | 2024-05-23T13:18:34Z | 0 | 0 | null | [
"glm",
"chatglm",
"thudm",
"chatglm3-6b",
"rkllm",
"rk3588",
"zh",
"en",
"region:us"
] | null | 2024-05-23T12:43:32Z | ---
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
- chatglm3-6b
- rkllm
- rk3588
---
# chatglm3-6b-rkllm
This is a conversion from [chatglm3-6b](https://huggingface.co/THUDM/chatglm3-6b) to the RKLLM format for chat in Rockchip devices.
## Support Devices
* RK3588/RK3588s
## Convert tools
To Converting LLMs for Rockchip's NPUs, please see the artical<sup>1,2</sup> for model details.
## Converted with RKLLM runtime
* RKLLM runtime `1.0.1`
## License
Same as the original [chatglm3-6b](https://huggingface.co/THUDM/chatglm3-6b)
## Reference
1. [airockchip/rknn-llm](https://github.com/airockchip/rknn-llm)
1. [Pelochus/ezrknn-llm](https://github.com/Pelochus/ezrknn-llm) |
pechaut/Mistral-C64Wizard-instruct | pechaut | 2024-05-23T13:13:06Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T08:23:25Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Ramikan-BR/tinyllama-coder-py-4bit-v5 | Ramikan-BR | 2024-05-23T13:12:58Z | 81 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"en",
"base_model:unsloth/tinyllama-chat-bnb-4bit",
"base_model:quantized:unsloth/tinyllama-chat-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-23T12:11:28Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/tinyllama-chat-bnb-4bit
---
# Uploaded model
- **Developed by:** Ramikan-BR
- **License:** apache-2.0
- **Finetuned from model :** unsloth/tinyllama-chat-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
---
## Inference tests after refinement
**Test 1: Continuing the Fibonacci sequence**
```python
alpaca_prompt = "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n### Input:\nContinue the fibonnaci sequence.\n\n### Output:"
from unsloth import FastLanguageModel
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer([alpaca_prompt.format("Continue the fibonnaci sequence.", "1, 1, 2, 3, 5, 8", "")], return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=64, use_cache=True)
print(tokenizer.batch_decode(outputs))
Output:
['<s> Below is an instruction that describes a task. Write a response that appropriately completes the request.\n### Input:\nContinue the fibonnaci sequence.\n\n### Output:\n1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89</s>']
**Test 2: Famous tall tower in Paris**
alpaca_prompt = "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n### Input:\nWhat is a famous tall tower in Paris?\n\n### Output:"
from unsloth import FastLanguageModel
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer([alpaca_prompt.format("What is a famous tall tower in Paris?", "", "")], return_tensors="pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer=text_streamer, max_new_tokens=64)
Output:
Eiffel Tower, located in Paris, is a famous tall tower that stands at 320 meters (98 feet) tall. It was built in 189002 as a symbol of the city's modernization and progress, and it remains an iconic landmark to this
For the first time, the AI answered both questions correctly, despite the response about the Eiffel Tower containing errors about the year and not finishing the response. I will continue refining the AI with the data-oss_instruct-decontaminated_python.jsonl dataset. This version of the dataset only contains Python code, and since I can only train on the free Colab GPU, I was forced to split the dataset into 10 parts and refine the AI for two epochs with each part (up to this point, we are on the fifth part of the dataset)... Thanks to the Unsloth team, without you, I wouldn't have even achieved any relevant training on an AI since I don't have a GPU!
|
nsugianto/tblstructrecog_finetuned_detresnet_v2_s1_311s | nsugianto | 2024-05-23T13:12:21Z | 32 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"detr",
"object-detection",
"generated_from_trainer",
"base_model:facebook/detr-resnet-50",
"base_model:finetune:facebook/detr-resnet-50",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-05-22T14:44:22Z | ---
license: apache-2.0
base_model: facebook/detr-resnet-50
tags:
- generated_from_trainer
model-index:
- name: tblstructrecog_finetuned_detresnet_v2_s1_311s
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tblstructrecog_finetuned_detresnet_v2_s1_311s
This model is a fine-tuned version of [facebook/detr-resnet-50](https://huggingface.co/facebook/detr-resnet-50) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1500
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.0.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
nsugianto/tblstructrecog_finetuned_tbltransstrucrecog_v1_s1_311s | nsugianto | 2024-05-23T13:11:38Z | 27 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"table-transformer",
"object-detection",
"generated_from_trainer",
"base_model:microsoft/table-transformer-structure-recognition",
"base_model:finetune:microsoft/table-transformer-structure-recognition",
"license:mit",
"endpoints_compatible",
"region:us"
] | object-detection | 2024-05-22T14:42:02Z | ---
license: mit
base_model: microsoft/table-transformer-structure-recognition
tags:
- generated_from_trainer
model-index:
- name: tblstructrecog_finetuned_tbltransstrucrecog_v1_s1_311s
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tblstructrecog_finetuned_tbltransstrucrecog_v1_s1_311s
This model is a fine-tuned version of [microsoft/table-transformer-structure-recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 750
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.0.1
- Datasets 2.18.0
- Tokenizers 0.19.1
|
BothBosu/distilbert-scam-classifier-v1.4 | BothBosu | 2024-05-23T13:09:29Z | 120 | 1 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T13:08:12Z | ---
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-scam-classifier-v1.4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-scam-classifier-v1.4
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:------------------:|:---------------:|:-----------:|
| No log | 1.0 | 160 | 0.0050 | {'accuracy': 1.0} | {'precision': 1.0} | {'recall': 1.0} | {'f1': 1.0} |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Augusto777/vit-base-patch16-224-U6-10 | Augusto777 | 2024-05-23T13:05:54Z | 218 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"base_model:finetune:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-05-23T12:59:04Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-U6-10
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8333333333333334
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-U6-10
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5473
- Accuracy: 0.8333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.3653 | 1.0 | 16 | 1.2199 | 0.6333 |
| 1.0932 | 2.0 | 32 | 1.0086 | 0.65 |
| 0.9284 | 3.0 | 48 | 0.8466 | 0.6667 |
| 0.6745 | 4.0 | 64 | 0.8237 | 0.7 |
| 0.4775 | 5.0 | 80 | 0.7473 | 0.7667 |
| 0.4194 | 6.0 | 96 | 0.6148 | 0.7833 |
| 0.3043 | 7.0 | 112 | 0.6221 | 0.8167 |
| 0.2947 | 8.0 | 128 | 0.6156 | 0.7667 |
| 0.269 | 9.0 | 144 | 0.5700 | 0.8167 |
| 0.2261 | 10.0 | 160 | 0.5473 | 0.8333 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
Felladrin/gguf-pythia-1.4b-sft-full | Felladrin | 2024-05-23T13:05:54Z | 63 | 0 | null | [
"gguf",
"base_model:nnheui/pythia-1.4b-sft-full",
"base_model:quantized:nnheui/pythia-1.4b-sft-full",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-23T12:18:14Z | ---
license: apache-2.0
base_model: nnheui/pythia-1.4b-sft-full
---
GGUF version of [nnheui/pythia-1.4b-sft-full](https://huggingface.co/nnheui/pythia-1.4b-sft-full).
|
meg51/whisper-small-marathi | meg51 | 2024-05-23T13:03:39Z | 77 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"mr",
"dataset:mozilla-foundation/common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-05-23T10:01:33Z | ---
language:
- mr
license: apache-2.0
tags:
- generated_from_trainer
base_model: openai/whisper-small
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Marathi - Megha Sharma
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: mr
split: None
args: 'config: mr, split: test'
metrics:
- type: wer
value: 44.723099735671454
name: Wer
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Marathi - Megha Sharma
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2755
- Wer: 44.7231
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.0713 | 4.0650 | 1000 | 0.2755 | 44.7231 |
### Framework versions
- Transformers 4.41.1
- Pytorch 2.1.2
- Datasets 2.19.1
- Tokenizers 0.19.1
|
reemmasoud/idv_vs_col_llama-3_PromptTuning_CAUSAL_LM_gradient_descent_v8_0.01 | reemmasoud | 2024-05-23T13:03:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2024-05-21T12:34:36Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Sharif-11/nana_vai_model2 | Sharif-11 | 2024-05-23T13:02:16Z | 105 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:bigscience/mt0-base",
"base_model:finetune:bigscience/mt0-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-05-23T12:38:35Z | ---
license: apache-2.0
base_model: bigscience/mt0-base
tags:
- generated_from_trainer
model-index:
- name: nana_vai_model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nana_vai_model2
This model is a fine-tuned version of [bigscience/mt0-base](https://huggingface.co/bigscience/mt0-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
MyronYoung/finetuned-lora-bert | MyronYoung | 2024-05-23T13:01:12Z | 9 | 0 | peft | [
"peft",
"safetensors",
"region:us"
] | null | 2024-05-12T13:08:57Z | ---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.5.0
|
BothBosu/roberta-scam-classifier-v1.0 | BothBosu | 2024-05-23T13:00:09Z | 109 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-23T12:55:58Z | ---
license: mit
base_model: FacebookAI/roberta-base
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: roberta-scam-classifier-v1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-scam-classifier-v1.0
This model is a fine-tuned version of [FacebookAI/roberta-base](https://huggingface.co/FacebookAI/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0001
- Accuracy: {'accuracy': 1.0}
- Precision: {'precision': 1.0}
- Recall: {'recall': 1.0}
- F1: {'f1': 1.0}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------------------:|:---------------------------------:|:-------------------:|:--------------------------:|
| No log | 1.0 | 160 | 0.0460 | {'accuracy': 0.99375} | {'precision': 0.9938271604938272} | {'recall': 0.99375} | {'f1': 0.9937497558498378} |
| No log | 2.0 | 320 | 0.0001 | {'accuracy': 1.0} | {'precision': 1.0} | {'recall': 1.0} | {'f1': 1.0} |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
yifanxie/nondescript-stingray-sp1 | yifanxie | 2024-05-23T12:52:18Z | 147 | 0 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"conversational",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-23T12:49:58Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [google/gemma-2b](https://huggingface.co/google/gemma-2b)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers` library installed.
```bash
pip install transformers==4.40.2
```
Also make sure you are providing your huggingface token to the pipeline if the model is lying in a private repo.
- Either leave `token=True` in the `pipeline` and login to hugginface_hub by running
```python
import huggingface_hub
huggingface_hub.login(<ACCESS_TOKEN>)
```
- Or directly pass your <ACCESS_TOKEN> to `token` in the `pipeline`
```python
from transformers import pipeline
generate_text = pipeline(
model="yifanxie/nondescript-stingray-sp1",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
token=True,
)
# generate configuration can be modified to your needs
# generate_text.model.generation_config.min_new_tokens = 2
# generate_text.model.generation_config.max_new_tokens = 256
# generate_text.model.generation_config.do_sample = False
# generate_text.model.generation_config.num_beams = 1
# generate_text.model.generation_config.temperature = float(0.0)
# generate_text.model.generation_config.repetition_penalty = float(1.0)
messages = [
{
"role": "system",
"content": "You are a friendly and polite chatbot.",
},
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "I'm doing great, how about you?"},
{"role": "user", "content": "Why is drinking water so healthy?"},
]
res = generate_text(
messages,
renormalize_logits=True
)
print(res[0]["generated_text"][-1]['content'])
```
You can print a sample prompt after applying chat template to see how it is feed to the tokenizer:
```python
print(generate_text.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
))
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "yifanxie/nondescript-stingray-sp1" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
messages = [
{
"role": "system",
"content": "You are a friendly and polite chatbot.",
},
{"role": "user", "content": "Hi, how are you?"},
{"role": "assistant", "content": "I'm doing great, how about you?"},
{"role": "user", "content": "Why is drinking water so healthy?"},
]
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
# generate configuration can be modified to your needs
# model.generation_config.min_new_tokens = 2
# model.generation_config.max_new_tokens = 256
# model.generation_config.do_sample = False
# model.generation_config.num_beams = 1
# model.generation_config.temperature = float(0.0)
# model.generation_config.repetition_penalty = float(1.0)
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
tokens = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Quantization and sharding
You can load the models using quantization by specifying ```load_in_8bit=True``` or ```load_in_4bit=True```. Also, sharding on multiple GPUs is possible by setting ```device_map=auto```.
## Model Architecture
```
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=256000, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-645586 | fine-tuned | 2024-05-23T12:52:16Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"mteb",
"en",
"dataset:fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-645586",
"dataset:allenai/c4",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | 2024-05-23T12:51:27Z | ---
license: apache-2.0
datasets:
- fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-645586
- allenai/c4
language:
- en
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
---
This model is a fine-tuned version of [**BAAI/bge-m3**](https://huggingface.co/BAAI/bge-m3) designed for the following use case:
custom
## How to Use
This model can be easily integrated into your NLP pipeline for tasks such as text classification, sentiment analysis, entity recognition, and more. Here's a simple example to get you started:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
'fine-tuned/NFCorpus-256-24-gpt-4o-2024-05-13-645586',
trust_remote_code=True
)
embeddings = model.encode([
'first text to embed',
'second text to embed'
])
print(cos_sim(embeddings[0], embeddings[1]))
```
|
mathom/llama3 | mathom | 2024-05-23T12:51:42Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2024-05-23T12:51:42Z | ---
license: apache-2.0
---
|
baldlion/ppo-Huggy | baldlion | 2024-05-23T12:50:53Z | 1 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | reinforcement-learning | 2024-05-23T12:48:53Z | ---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: baldlion/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
hackertina/llama-3-8b-Instruct-bnb-4bit-finqa | hackertina | 2024-05-23T12:48:24Z | 78 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"unsloth",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2024-05-23T12:23:12Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Apel-sin/llama-3-8B-abliterated-v2-exl2 | Apel-sin | 2024-05-23T12:47:54Z | 0 | 0 | null | [
"region:us"
] | null | 2024-05-23T11:10:59Z | # Exllama v2 cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.21">turboderp's ExLlamaV2 v0.0.21</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model: <a href="https://huggingface.co/cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2">cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2</a><br>
Calibration dataset: <a href="https://huggingface.co/datasets/cosmicvalor/toxic-qna">toxic-qna</a>
## Available sizes
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (8K) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/Apel-sin/llama-3-8B-abliterated-v2-exl2/tree/8_0) | 8.0 | 8.0 | 10.1 GB | 10.5 GB | 11.5 GB | 13.6 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/Apel-sin/llama-3-8B-abliterated-v2-exl2/tree/6_5) | 6.5 | 8.0 | 8.9 GB | 9.3 GB | 10.3 GB | 12.4 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
# Model Card for Llama-3-8B-Instruct-abliterated-v2
## Overview
This model card describes the Llama-3-8B-Instruct-abliterated-v2 model, which is an orthogonalized version of the meta-llama/Llama-3-8B-Instruct model, and an improvement upon the previous generation Llama-3-8B-Instruct-abliterated. This variant has had certain weights manipulated to inhibit the model's ability to express refusal.
[Join the Cognitive Computations Discord!](https://discord.gg/cognitivecomputations)
## Details
* The model was trained with more data to better pinpoint the "refusal direction".
* This model is MUCH better at directly and succinctly answering requests without producing even so much as disclaimers.
## Methodology
The methodology used to generate this model is described in the preview paper/blog post: '[Refusal in LLMs is mediated by a single direction](https://www.alignmentforum.org/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction)'
## Quirks and Side Effects
This model may come with interesting quirks, as the methodology is still new and untested. The code used to generate the model is available in the Python notebook [ortho_cookbook.ipynb](https://huggingface.co/failspy/llama-3-70B-Instruct-abliterated/blob/main/ortho_cookbook.ipynb).
Please note that the model may still refuse to answer certain requests, even after the weights have been manipulated to inhibit refusal.
## Availability
## How to Use
This model is available for use in the Transformers library.
GGUF Quants are available [here](https://huggingface.co/failspy/Llama-3-8B-Instruct-abliterated-v2-GGUF). |
cutycat2000x/LoRA | cutycat2000x | 2024-05-23T12:44:45Z | 5 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:cutycat2000x/InterDiffusion-3.8",
"base_model:adapter:cutycat2000x/InterDiffusion-3.8",
"license:mit",
"region:us"
] | text-to-image | 2024-05-22T08:55:03Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
a smiling girl with sparkles in her eyes, walking in a garden, in the morning --style anime
output:
url: example1.png
- text: >-
firewatch landscape, Graphic Novel, Pastel Art, Poster, Golden Hour, Electric Colors, 4k, RGB, Geometric, Volumetric, Lumen Global Illumination, Ray Tracing Reflections, Twisted Rays, Glowing Edges, RTX --raw
output:
url: example2.png
- text: >-
Samsung Galaxy S9
output:
url: example3.png
- text: >-
cat, 4k, 8k, hyperrealistic, realistic, High-resolution, unreal engine 5, rtx, 16k, taken on a sony camera, Cinematic, dramatic lighting
output:
url: example4.png
- text: >-
cinimatic closeup of burning skull
output:
url: example5.png
- text: >-
frozen elsa
output:
url: example6.png
- text: >-
A rainbow tree, anime style, tree in focus
output:
url: example7.png
- text: >-
A cat holding a sign that reads "Hello World" in cursive text
output:
url: example8.png
- text: >-
A birthday card for "Meow"
output:
url: example9.png
base_model: cutycat2000x/InterDiffusion-3.8
instance_prompt: null
license: mit
---
# LoRA
<Gallery />
## Model description
The Dall-E 3 style LoRA for InterDiffusion-3.8
## Download model
Weights for this model are available in Safetensors format.
[Download](/cutycat2000x/LoRA/tree/main) them in the Files & versions tab.
|
Josephgflowers/TinyLlama-Cinder-Tiny-Agent | Josephgflowers | 2024-05-23T12:44:31Z | 150 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Josephgflowers/TinyLlama-Cinder-Math-Train",
"base_model:finetune:Josephgflowers/TinyLlama-Cinder-Math-Train",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-22T15:23:26Z | ---
license: mit
base_model: Josephgflowers/TinyLlama-Cinder-Math-Train
tags:
- generated_from_trainer
model-index:
- name: TinyLlama-Cinder-Tiny-Agent
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TinyLlama-Cinder-Tiny-Agent
This model is a fine-tuned version of [Josephgflowers/TinyLlama-Cinder-Math-Train](https://huggingface.co/Josephgflowers/TinyLlama-Cinder-Math-Train) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.2.2+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Apel-sin/llama-3-8B-ortho-v2-exl2 | Apel-sin | 2024-05-23T12:44:02Z | 0 | 0 | null | [
"region:us"
] | null | 2024-05-23T12:18:33Z | # Exllama v2 Llama-3-8B-Instruct-ortho-v2
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.21">turboderp's ExLlamaV2 v0.0.21</a> for quantization.
<b>The "main" branch only contains the measurement.json, download one of the other branches for the model</b>
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Original model by <a href="https://huggingface.co/hjhj3168">hjhj3168</a><br>
Calibration dataset: <a href="https://huggingface.co/datasets/cosmicvalor/toxic-qna">toxic-qna</a>
## Available sizes
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (8K) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/Apel-sin/llama-3-8B-ortho-v2-exl2/tree/8_0) | 8.0 | 8.0 | 10.1 GB | 10.5 GB | 11.5 GB | 13.6 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/Apel-sin/llama-3-8B-ortho-v2-exl2/tree/6_5) | 6.5 | 8.0 | 8.9 GB | 9.3 GB | 10.3 GB | 12.4 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. | |
hgnoi/5GGfN0rlincvLY2F | hgnoi | 2024-05-23T12:37:24Z | 131 | 0 | transformers | [
"transformers",
"safetensors",
"stablelm",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T12:35:55Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Subsets and Splits