
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-13 12:28:20
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 518
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-13 12:26:25
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Kevin123/distilbert-base-uncased-finetuned-squad | Kevin123 | 2022-09-22T19:56:25Z | 119 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2022-09-22T17:28:39Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.12.3
- Pytorch 1.8.1+cu102
- Datasets 1.18.3
- Tokenizers 0.10.3
|
facebook/spar-wiki-bm25-lexmodel-query-encoder | facebook | 2022-09-22T16:44:45Z | 111 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2110.06918",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T21:44:05Z | ---
tags:
- feature-extraction
pipeline_tag: feature-extraction
---
This model is the query encoder of the Wiki BM25 Lexical Model (Λ) from the SPAR paper:
[Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?](https://arxiv.org/abs/2110.06918)
<br>
Xilun Chen, Kushal Lakhotia, Barlas Oğuz, Anchit Gupta, Patrick Lewis, Stan Peshterliev, Yashar Mehdad, Sonal Gupta and Wen-tau Yih
<br>
**Meta AI**
The associated github repo is available here: https://github.com/facebookresearch/dpr-scale/tree/main/spar
This model is a BERT-base sized dense retriever trained on Wikipedia articles to imitate the behavior of BM25.
The following models are also available:
Pretrained Model | Corpus | Teacher | Architecture | Query Encoder Path | Context Encoder Path
|---|---|---|---|---|---
Wiki BM25 Λ | Wikipedia | BM25 | BERT-base | facebook/spar-wiki-bm25-lexmodel-query-encoder | facebook/spar-wiki-bm25-lexmodel-context-encoder
PAQ BM25 Λ | PAQ | BM25 | BERT-base | facebook/spar-paq-bm25-lexmodel-query-encoder | facebook/spar-paq-bm25-lexmodel-context-encoder
MARCO BM25 Λ | MS MARCO | BM25 | BERT-base | facebook/spar-marco-bm25-lexmodel-query-encoder | facebook/spar-marco-bm25-lexmodel-context-encoder
MARCO UniCOIL Λ | MS MARCO | UniCOIL | BERT-base | facebook/spar-marco-unicoil-lexmodel-query-encoder | facebook/spar-marco-unicoil-lexmodel-context-encoder
# Using the Lexical Model (Λ) Alone
This model should be used together with the associated context encoder, similar to the [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr) model.
```
import torch
from transformers import AutoTokenizer, AutoModel
# The tokenizer is the same for the query and context encoder
tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
query_input = tokenizer(query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 341.3268
score2 = query_emb @ ctx_emb[1] # 340.1626
```
# Using the Lexical Model (Λ) with a Base Dense Retriever as in SPAR
As Λ learns lexical matching from a sparse teacher retriever, it can be used in combination with a standard dense retriever (e.g. [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr#dpr), [Contriever](https://huggingface.co/facebook/contriever-msmarco)) to build a dense retriever that excels at both lexical and semantic matching.
In the following example, we show how to build the SPAR-Wiki model for Open-Domain Question Answering by concatenating the embeddings of DPR and the Wiki BM25 Λ.
```
import torch
from transformers import AutoTokenizer, AutoModel
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
# DPR model
dpr_ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_query_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
dpr_query_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
# Wiki BM25 Λ model
lexmodel_tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Compute DPR embeddings
dpr_query_input = dpr_query_tokenizer(query, return_tensors='pt')['input_ids']
dpr_query_emb = dpr_query_encoder(dpr_query_input).pooler_output
dpr_ctx_input = dpr_ctx_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
dpr_ctx_emb = dpr_ctx_encoder(**dpr_ctx_input).pooler_output
# Compute Λ embeddings
lexmodel_query_input = lexmodel_tokenizer(query, return_tensors='pt')
lexmodel_query_emb = lexmodel_query_encoder(**query_input).last_hidden_state[:, 0, :]
lexmodel_ctx_input = lexmodel_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
lexmodel_ctx_emb = lexmodel_context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Form SPAR embeddings via concatenation
# The concatenation weight is only applied to query embeddings
# Refer to the SPAR paper for details
concat_weight = 0.7
spar_query_emb = torch.cat(
[dpr_query_emb, concat_weight * lexmodel_query_emb],
dim=-1,
)
spar_ctx_emb = torch.cat(
[dpr_ctx_emb, lexmodel_ctx_emb],
dim=-1,
)
# Compute similarity scores
score1 = spar_query_emb @ spar_ctx_emb[0] # 317.6931
score2 = spar_query_emb @ spar_ctx_emb[1] # 314.6144
```
|
CoreyMorris/Reinforce-cartpole-v1 | CoreyMorris | 2022-09-22T16:21:40Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-22T16:20:39Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 5 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit5
|
huggingtweets/slime_machine | huggingtweets | 2022-09-22T14:09:28Z | 94 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: http://www.huggingtweets.com/slime_machine/1663855763474/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1554733825220939777/lgFt_2e1_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">slime</div>
<div style="text-align: center; font-size: 14px;">@slime_machine</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from slime.
| Data | slime |
| --- | --- |
| Tweets downloaded | 3229 |
| Retweets | 441 |
| Short tweets | 589 |
| Tweets kept | 2199 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2s9inuxg/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @slime_machine's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/5xjy8nrj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/5xjy8nrj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/slime_machine')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sd-concepts-library/pixel-mania | sd-concepts-library | 2022-09-22T14:05:08Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T05:26:54Z | ---
license: mit
---
### pixel-mania on Stable Diffusion
This is the `<pixel-mania>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
|
rttl-ai/senty-bert | rttl-ai | 2022-09-22T13:35:10Z | 80 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-11T20:19:23Z | ---
license: bigscience-bloom-rail-1.0
---
# Senty BERT
A yelpy-bert fine-tuned as a ternary classification task (positive, negative, neutral labels) on:
- yelp reviews (https://yelp.com/dataset)
- the SST-3 dataset |
m-lin20/satellite-instrument-bert-NER | m-lin20 | 2022-09-22T13:32:42Z | 104 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"pt",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-03-02T23:29:05Z | ---
language: "pt"
widget:
- text: "Poised for launch in mid-2021, the joint NASA-USGS Landsat 9 mission will continue this important data record. In many respects Landsat 9 is a clone of Landsat-8. The Operational Land Imager-2 (OLI-2) is largely identical to Landsat 8 OLI, providing calibrated imagery covering the solar reflected wavelengths. The Thermal Infrared Sensor-2 (TIRS-2) improves upon Landsat 8 TIRS, addressing known issues including stray light incursion and a malfunction of the instrument scene select mirror. In addition, Landsat 9 adds redundancy to TIRS-2, thus upgrading the instrument to a 5-year design life commensurate with other elements of the mission. Initial performance testing of OLI-2 and TIRS-2 indicate that the instruments are of excellent quality and expected to match or improve on Landsat 8 data quality. "
example_title: "example 1"
- text: "Compared to its predecessor, Jason-3, the two AMR-C radiometer instruments have an external calibration system which enables higher radiometric stability accomplished by moving the secondary mirror between well-defined targets. Sentinel-6 allows continuing the study of the ocean circulation, climate change, and sea-level rise for at least another decade. Besides the external calibration for the AMR heritage radiometer (18.7, 23.8, and 34 GHz channels), the AMR-C contains a high-resolution microwave radiometer (HRMR) with radiometer channels at 90, 130, and 168 GHz. This subsystem allows for a factor of 5× higher spatial resolution at coastal transitions. This article presents a brief description of the instrument and the measured performance of the completed AMR-C-A and AMR-C-B instruments."
example_title: "example 2"
- text: "Landsat 9 will continue the Landsat data record into its fifth decade with a near-copy build of Landsat 8 with launch scheduled for December 2020. The two instruments on Landsat 9 are Thermal Infrared Sensor-2 (TIRS-2) and Operational Land Imager-2 (OLI-2)."
example_title: "example 3"
inference:
parameters:
aggregation_strategy: "first"
---
# satellite-instrument-bert-NER
For details, please visit the [GitHub link](https://github.com/THU-EarthInformationScienceLab/Satellite-Instrument-NER).
## Citation
Our [paper](https://www.tandfonline.com/doi/full/10.1080/17538947.2022.2107098) has been published in the International Journal of Digital Earth :
```bibtex
@article{lin2022satellite,
title={Satellite and instrument entity recognition using a pre-trained language model with distant supervision},
author={Lin, Ming and Jin, Meng and Liu, Yufu and Bai, Yuqi},
journal={International Journal of Digital Earth},
volume={15},
number={1},
pages={1290--1304},
year={2022},
publisher={Taylor \& Francis}
}
``` |
mayorov-s/dqn-SpaceInvadersNoFrameskip-v4 | mayorov-s | 2022-09-22T13:24:11Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-22T13:20:04Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 612.00 +/- 154.62
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
```
# Download model and save it into the logs/ folder
python -m utils.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga mayorov-s -f logs/
python enjoy.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python train.py --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m utils.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga mayorov-s
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
microsoft/deberta-xlarge | microsoft | 2022-09-22T12:34:36Z | 7,766 | 2 | transformers | [
"transformers",
"pytorch",
"tf",
"deberta",
"deberta-v1",
"fill-mask",
"en",
"arxiv:2006.03654",
"license:mit",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language: en
tags:
- deberta-v1
- fill-mask
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. With those two improvements, DeBERTa out perform RoBERTa on a majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This the DeBERTa XLarge model with 48 layers, 1024 hidden size. Total parameters 750M.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
microsoft/deberta-v2-xxlarge | microsoft | 2022-09-22T12:34:30Z | 3,270 | 31 | transformers | [
"transformers",
"pytorch",
"tf",
"deberta-v2",
"deberta",
"fill-mask",
"en",
"arxiv:2006.03654",
"license:mit",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language: en
tags:
- deberta
- fill-mask
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This is the DeBERTa V2 xxlarge model with 48 layers, 1536 hidden size. The total parameters are 1.5B and it is trained with 160GB raw data.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, we recommand using **deepspeed** as it's faster and saves memory.
Run with `Deepspeed`,
```bash
pip install datasets
pip install deepspeed
# Download the deepspeed config file
wget https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/ds_config.json -O ds_config.json
export TASK_NAME=mnli
output_dir="ds_results"
num_gpus=8
batch_size=8
python -m torch.distributed.launch --nproc_per_node=${num_gpus} \\
run_glue.py \\
--model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME \\
--do_train \\
--do_eval \\
--max_seq_length 256 \\
--per_device_train_batch_size ${batch_size} \\
--learning_rate 3e-6 \\
--num_train_epochs 3 \\
--output_dir $output_dir \\
--overwrite_output_dir \\
--logging_steps 10 \\
--logging_dir $output_dir \\
--deepspeed ds_config.json
```
You can also run with `--sharded_ddp`
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mnli
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 256 --per_device_train_batch_size 8 \\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
Sultannn/gpt2-ft-id-puisi | Sultannn | 2022-09-22T12:17:39Z | 67 | 1 | transformers | [
"transformers",
"tf",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"id",
"Indonesian",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-05-10T07:22:22Z | ---
tags:
- generated_from_keras_callback
- id
- Indonesian
license: mit
dataset:
- id_puisi
widget:
- text : "SENJA"
- text : "BERANI"
model-index:
- name: Sultannn/gpt2-ft-id-puisi
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
#
# gpt2-ft-id-puisi
This model is a fine-tuned on an [Indonesian Recipe](https://huggingface.co/datasets/Sultannn/id_recipe).
It achieves the following results on the evaluation set:
- Train Loss: 5.3628
- Validation Loss: 5.8179
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.3561 | 6.5449 | 0 |
| 6.2176 | 6.1573 | 1 |
| 5.8533 | 6.0014 | 2 |
| 5.5955 | 5.8798 | 3 |
| 5.3628 | 5.8179 | 4 |
# Licenese
[The MIT license](https://opensource.org/licenses/MIT) |
muhtasham/bert-small-finetuned-parsed20 | muhtasham | 2022-09-22T11:34:48Z | 179 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-17T13:31:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-small-finetuned-parsed20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-small-finetuned-parsed20
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1193
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 4 | 3.0763 |
| No log | 2.0 | 8 | 2.8723 |
| No log | 3.0 | 12 | 3.5102 |
| No log | 4.0 | 16 | 2.8641 |
| No log | 5.0 | 20 | 2.7827 |
| No log | 6.0 | 24 | 2.8163 |
| No log | 7.0 | 28 | 3.2415 |
| No log | 8.0 | 32 | 3.0477 |
| No log | 9.0 | 36 | 3.5160 |
| No log | 10.0 | 40 | 3.1248 |
| No log | 11.0 | 44 | 3.2159 |
| No log | 12.0 | 48 | 3.2177 |
| No log | 13.0 | 52 | 2.9108 |
| No log | 14.0 | 56 | 3.3758 |
| No log | 15.0 | 60 | 3.1335 |
| No log | 16.0 | 64 | 2.9753 |
| No log | 17.0 | 68 | 2.9922 |
| No log | 18.0 | 72 | 3.2798 |
| No log | 19.0 | 76 | 2.7280 |
| No log | 20.0 | 80 | 3.1193 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
sherover125/newsclassifier | sherover125 | 2022-09-22T10:46:34Z | 118 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-06-22T17:28:45Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: newsclassifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# newsclassifier
This model is a fine-tuned version of [HooshvareLab/bert-fa-zwnj-base](https://huggingface.co/HooshvareLab/bert-fa-zwnj-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1405
- Matthews Correlation: 0.9731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.2207 | 1.0 | 2397 | 0.1706 | 0.9595 |
| 0.0817 | 2.0 | 4794 | 0.1505 | 0.9663 |
| 0.0235 | 3.0 | 7191 | 0.1405 | 0.9731 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
muhtasham/bert-small-finetuned-legal-contracts-larger20-5-1 | muhtasham | 2022-09-22T10:44:07Z | 184 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"dataset:albertvillanova/legal_contracts",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-08-16T04:33:53Z | ---
datasets:
- albertvillanova/legal_contracts
---
# bert-tiny-finetuned-legal-contracts-longer
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/google/google/bert_uncased_L-4_H-512_A-8) on the portion of legal_contracts dataset for 1 epoch.
# Note
The model was not trained on the whole dataset which is around 9.5 GB, but only
## The first 20% of `train` + the last 5% of `train`.
```bash
datasets_train = load_dataset('albertvillanova/legal_contracts' , split='train[:20%]')
datasets_validation = load_dataset('albertvillanova/legal_contracts' , split='train[-5%:]')
```
|
ericntay/stbl_clinical_bert_ft_rs3 | ericntay | 2022-09-22T10:26:20Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-22T10:03:18Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: stbl_clinical_bert_ft_rs3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stbl_clinical_bert_ft_rs3
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0833
- F1: 0.9279
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2731 | 1.0 | 101 | 0.1011 | 0.8363 |
| 0.0651 | 2.0 | 202 | 0.0683 | 0.8909 |
| 0.0314 | 3.0 | 303 | 0.0623 | 0.9063 |
| 0.0155 | 4.0 | 404 | 0.0705 | 0.9067 |
| 0.0098 | 5.0 | 505 | 0.0702 | 0.9176 |
| 0.006 | 6.0 | 606 | 0.0755 | 0.9213 |
| 0.0037 | 7.0 | 707 | 0.0797 | 0.9216 |
| 0.0031 | 8.0 | 808 | 0.0783 | 0.9252 |
| 0.0018 | 9.0 | 909 | 0.0818 | 0.9259 |
| 0.0014 | 10.0 | 1010 | 0.0809 | 0.9271 |
| 0.0011 | 11.0 | 1111 | 0.0833 | 0.9259 |
| 0.0009 | 12.0 | 1212 | 0.0833 | 0.9279 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
GItaf/gpt2-gpt2-TF-weight1-epoch10 | GItaf | 2022-09-22T09:36:24Z | 113 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-21T08:05:36Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-gpt2-TF-weight1-epoch10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-gpt2-TF-weight1-epoch10
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
GItaf/roberta-base-roberta-base-TF-weight1-epoch10 | GItaf | 2022-09-22T09:35:57Z | 49 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-22T09:34:27Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-roberta-base-TF-weight1-epoch10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-roberta-base-TF-weight1-epoch10
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
GItaf/roberta-base-roberta-base-TF-weight1-epoch5 | GItaf | 2022-09-22T09:32:53Z | 47 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-22T09:31:40Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: roberta-base-roberta-base-TF-weight1-epoch5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-roberta-base-TF-weight1-epoch5
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
MGanesh29/parrot_paraphraser_on_T5-finetuned-xsum-v6 | MGanesh29 | 2022-09-22T09:21:53Z | 107 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-22T08:46:19Z | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: parrot_paraphraser_on_T5-finetuned-xsum-v6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# parrot_paraphraser_on_T5-finetuned-xsum-v6
This model is a fine-tuned version of [prithivida/parrot_paraphraser_on_T5](https://huggingface.co/prithivida/parrot_paraphraser_on_T5) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0428
- Rouge1: 86.1908
- Rouge2: 84.358
- Rougel: 86.1439
- Rougelsum: 86.1806
- Gen Len: 17.887
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.0783 | 1.0 | 2000 | 0.0467 | 86.0347 | 84.0897 | 85.9987 | 86.0282 | 17.889 |
| 0.058 | 2.0 | 4000 | 0.0428 | 86.1908 | 84.358 | 86.1439 | 86.1806 | 17.887 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Alexei1/imdb | Alexei1 | 2022-09-22T09:10:57Z | 2 | 1 | transformers | [
"transformers",
"joblib",
"autotrain",
"tabular",
"classification",
"tabular-classification",
"dataset:Alexei1/autotrain-data-imdb-sentiment-analysis",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
]
| tabular-classification | 2022-09-22T08:59:54Z | ---
tags:
- autotrain
- tabular
- classification
- tabular-classification
datasets:
- Alexei1/autotrain-data-imdb-sentiment-analysis
co2_eq_emissions:
emissions: 0.018564765189754893
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 1530155186
- CO2 Emissions (in grams): 0.0186
## Validation Metrics
- Loss: 0.694
- Accuracy: 0.487
- Macro F1: 0.218
- Micro F1: 0.487
- Weighted F1: 0.319
- Macro Precision: 0.162
- Micro Precision: 0.487
- Weighted Precision: 0.237
- Macro Recall: 0.333
- Micro Recall: 0.487
- Weighted Recall: 0.487
## Usage
```python
import json
import joblib
import pandas as pd
model = joblib.load('model.joblib')
config = json.load(open('config.json'))
features = config['features']
# data = pd.read_csv("data.csv")
data = data[features]
data.columns = ["feat_" + str(col) for col in data.columns]
predictions = model.predict(data) # or model.predict_proba(data)
``` |
chintagunta85/electramed-small-deid2014-ner-v5-classweights | chintagunta85 | 2022-09-22T09:08:27Z | 102 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"electra",
"token-classification",
"generated_from_trainer",
"dataset:i2b22014",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-22T07:48:30Z | ---
tags:
- generated_from_trainer
datasets:
- i2b22014
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: electramed-small-deid2014-ner-v5-classweights
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: i2b22014
type: i2b22014
config: i2b22014-deid
split: train
args: i2b22014-deid
metrics:
- name: Precision
type: precision
value: 0.8832236842105263
- name: Recall
type: recall
value: 0.6910561632502987
- name: F1
type: f1
value: 0.7754112732711052
- name: Accuracy
type: accuracy
value: 0.9883040491052534
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electramed-small-deid2014-ner-v5-classweights
This model is a fine-tuned version of [giacomomiolo/electramed_small_scivocab](https://huggingface.co/giacomomiolo/electramed_small_scivocab) on the i2b22014 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0009
- Precision: 0.8832
- Recall: 0.6911
- F1: 0.7754
- Accuracy: 0.9883
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0001 | 1.0 | 1838 | 0.0008 | 0.7702 | 0.3780 | 0.5071 | 0.9771 |
| 0.0 | 2.0 | 3676 | 0.0007 | 0.8753 | 0.5671 | 0.6883 | 0.9827 |
| 0.0 | 3.0 | 5514 | 0.0006 | 0.8074 | 0.4128 | 0.5463 | 0.9775 |
| 0.0 | 4.0 | 7352 | 0.0007 | 0.8693 | 0.6102 | 0.7170 | 0.9848 |
| 0.0 | 5.0 | 9190 | 0.0006 | 0.8710 | 0.6022 | 0.7121 | 0.9849 |
| 0.0 | 6.0 | 11028 | 0.0007 | 0.8835 | 0.6547 | 0.7521 | 0.9867 |
| 0.0 | 7.0 | 12866 | 0.0009 | 0.8793 | 0.6661 | 0.7579 | 0.9873 |
| 0.0 | 8.0 | 14704 | 0.0008 | 0.8815 | 0.6740 | 0.7639 | 0.9876 |
| 0.0 | 9.0 | 16542 | 0.0009 | 0.8812 | 0.6851 | 0.7709 | 0.9880 |
| 0.0 | 10.0 | 18380 | 0.0009 | 0.8832 | 0.6911 | 0.7754 | 0.9883 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
prakashkmr48/Prompt-image-inpainting | prakashkmr48 | 2022-09-22T08:58:57Z | 0 | 0 | null | [
"region:us"
]
| null | 2022-09-22T08:51:46Z | git lfs install
git clone https://huggingface.co/prakashkmr48/Prompt-image-inpainting |
sd-concepts-library/ghostproject-men | sd-concepts-library | 2022-09-22T07:36:08Z | 0 | 2 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T07:36:02Z | ---
license: mit
---
### ghostproject-men on Stable Diffusion
This is the `<ghostsproject-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
0ys/mt5-small-finetuned-amazon-en-es | 0ys | 2022-09-22T06:55:45Z | 111 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2022-09-22T05:47:04Z | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0294
- Rouge1: 16.6807
- Rouge2: 8.0004
- Rougel: 16.2251
- Rougelsum: 16.1743
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| 6.5928 | 1.0 | 1209 | 3.3005 | 14.7863 | 6.5038 | 14.3031 | 14.2522 |
| 3.9024 | 2.0 | 2418 | 3.1399 | 16.9257 | 8.6583 | 16.15 | 16.1299 |
| 3.5806 | 3.0 | 3627 | 3.0869 | 18.2734 | 9.1667 | 17.7441 | 17.5782 |
| 3.4201 | 4.0 | 4836 | 3.0590 | 17.763 | 8.9447 | 17.1833 | 17.1661 |
| 3.3202 | 5.0 | 6045 | 3.0598 | 17.7754 | 8.5695 | 17.4139 | 17.2653 |
| 3.2436 | 6.0 | 7254 | 3.0409 | 16.8423 | 8.1593 | 16.5392 | 16.4297 |
| 3.2079 | 7.0 | 8463 | 3.0332 | 16.8991 | 8.1574 | 16.4229 | 16.3515 |
| 3.1801 | 8.0 | 9672 | 3.0294 | 16.6807 | 8.0004 | 16.2251 | 16.1743 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sd-concepts-library/pool-test | sd-concepts-library | 2022-09-22T06:53:48Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T06:53:43Z | ---
license: mit
---
### Pool test on Stable Diffusion
This is the `<pool_test>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
chintagunta85/electramed-small-deid2014-ner-v4 | chintagunta85 | 2022-09-22T06:33:10Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"electra",
"token-classification",
"generated_from_trainer",
"dataset:i2b22014",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-22T05:55:58Z | ---
tags:
- generated_from_trainer
datasets:
- i2b22014
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: electramed-small-deid2014-ner-v4
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: i2b22014
type: i2b22014
config: i2b22014-deid
split: train
args: i2b22014-deid
metrics:
- name: Precision
type: precision
value: 0.7571112095702259
- name: Recall
type: recall
value: 0.7853663020498207
- name: F1
type: f1
value: 0.770979967514889
- name: Accuracy
type: accuracy
value: 0.9906153616114308
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electramed-small-deid2014-ner-v4
This model is a fine-tuned version of [giacomomiolo/electramed_small_scivocab](https://huggingface.co/giacomomiolo/electramed_small_scivocab) on the i2b22014 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0362
- Precision: 0.7571
- Recall: 0.7854
- F1: 0.7710
- Accuracy: 0.9906
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0143 | 1.0 | 1838 | 0.1451 | 0.3136 | 0.3463 | 0.3291 | 0.9700 |
| 0.0033 | 2.0 | 3676 | 0.0940 | 0.4293 | 0.4861 | 0.4559 | 0.9758 |
| 0.0014 | 3.0 | 5514 | 0.0725 | 0.4906 | 0.5766 | 0.5301 | 0.9799 |
| 0.0007 | 4.0 | 7352 | 0.0568 | 0.6824 | 0.7022 | 0.6921 | 0.9860 |
| 0.0112 | 5.0 | 9190 | 0.0497 | 0.6966 | 0.7400 | 0.7177 | 0.9870 |
| 0.0002 | 6.0 | 11028 | 0.0442 | 0.7126 | 0.7549 | 0.7332 | 0.9878 |
| 0.0002 | 7.0 | 12866 | 0.0404 | 0.7581 | 0.7591 | 0.7586 | 0.9896 |
| 0.0002 | 8.0 | 14704 | 0.0376 | 0.7540 | 0.7804 | 0.7670 | 0.9904 |
| 0.0002 | 9.0 | 16542 | 0.0367 | 0.7548 | 0.7825 | 0.7684 | 0.9905 |
| 0.0001 | 10.0 | 18380 | 0.0362 | 0.7571 | 0.7854 | 0.7710 | 0.9906 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sd-concepts-library/test2 | sd-concepts-library | 2022-09-22T06:29:49Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T06:29:45Z | ---
license: mit
---
### TEST2 on Stable Diffusion
This is the `<AIOCARD>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:










|
sd-concepts-library/sunfish | sd-concepts-library | 2022-09-22T05:44:51Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T05:44:40Z | ---
license: mit
---
### SunFish on Stable Diffusion
This is the `<SunFish>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:













|
sd-concepts-library/yinit | sd-concepts-library | 2022-09-22T04:58:38Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T04:58:24Z | ---
license: mit
---
### yinit on Stable Diffusion
This is the `yinit-dropcap` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:


























|
sd-concepts-library/million-live-spade-q-style-3k | sd-concepts-library | 2022-09-22T04:35:01Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T04:34:51Z | ---
license: mit
---
### million-live-spade-q-style-3k on Stable Diffusion
This is the `<spade_q>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:













|
sd-concepts-library/million-live-spade-q-object-3k | sd-concepts-library | 2022-09-22T04:34:40Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T04:34:30Z | ---
license: mit
---
### million-live-spade-q-object-3k on Stable Diffusion
This is the `<spade_q>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:













|
sd-concepts-library/homestuck-troll | sd-concepts-library | 2022-09-22T03:23:46Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T03:23:43Z | ---
license: mit
---
### homestuck troll on Stable Diffusion
This is the `<homestuck-troll>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/char-con | sd-concepts-library | 2022-09-22T02:54:22Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T02:54:17Z | ---
license: mit
---
### char-con on Stable Diffusion
This is the `<char-con>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
thisisHJLee/wav2vec2-large-xls-r-300m-korean-b | thisisHJLee | 2022-09-22T02:53:51Z | 105 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-09-22T01:47:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xls-r-300m-korean-b
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-korean-b
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
g30rv17ys/ddpm-geeve-drusen-2000-128 | g30rv17ys | 2022-09-22T01:53:45Z | 1 | 0 | diffusers | [
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2022-09-21T18:22:01Z | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-geeve-drusen-2000-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/geevegeorge/ddpm-geeve-drusen-2000-128/tensorboard?#scalars)
|
sd-concepts-library/gba-pokemon-sprites | sd-concepts-library | 2022-09-22T00:48:32Z | 0 | 30 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T00:48:25Z | ---
license: mit
---
### GBA Pokemon Sprites on Stable Diffusion
This is the `<GBA-Poke-Sprites>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








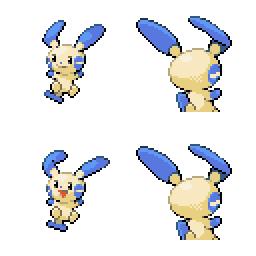


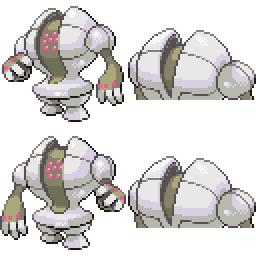

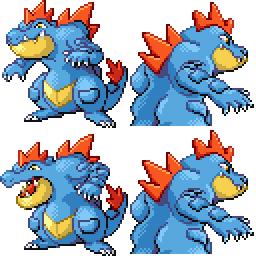


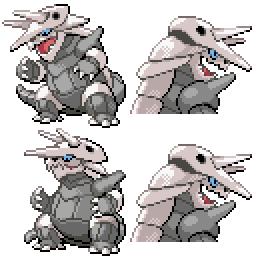


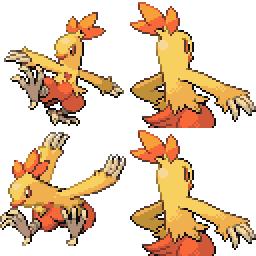
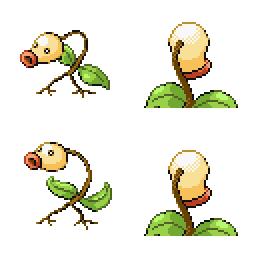
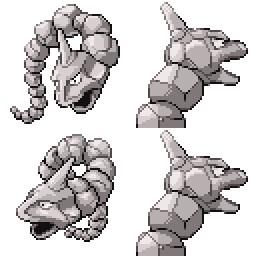
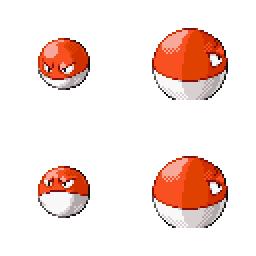
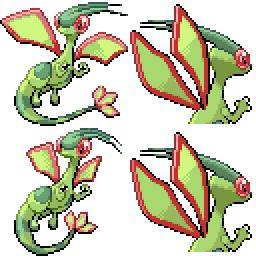



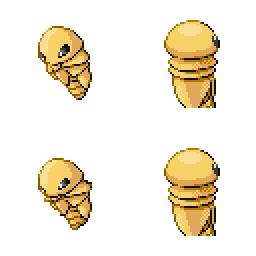






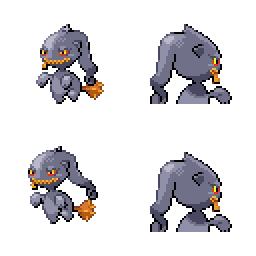

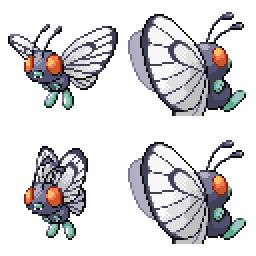










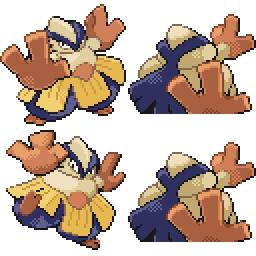

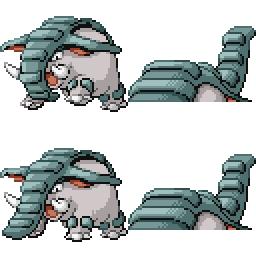

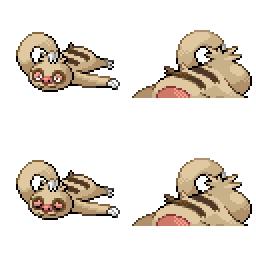







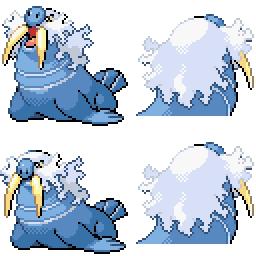
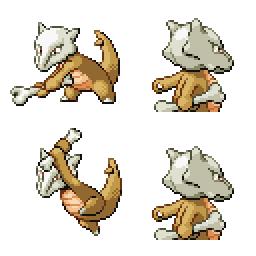
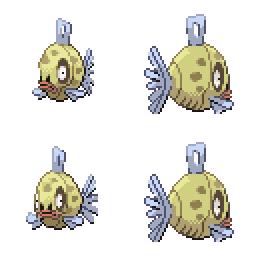

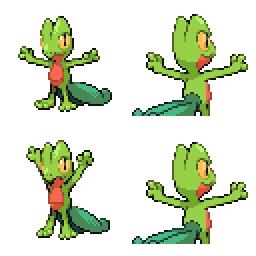


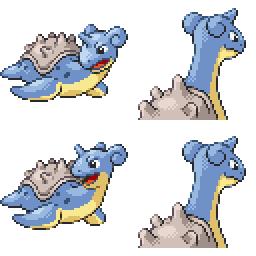



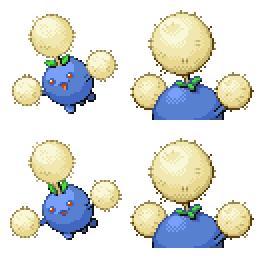
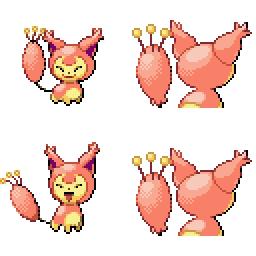
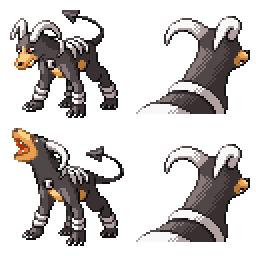
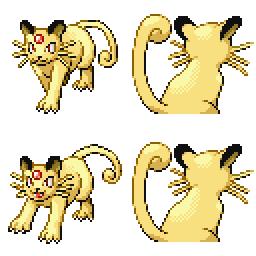
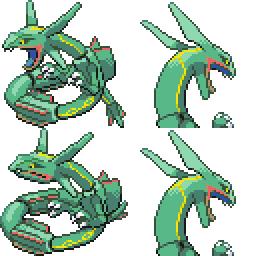
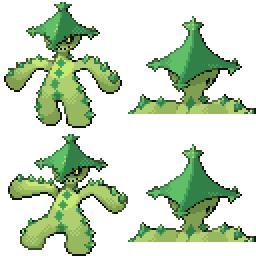


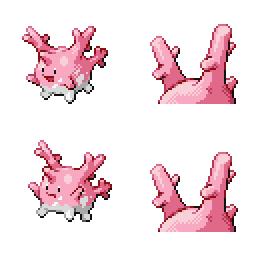

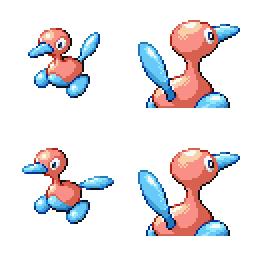
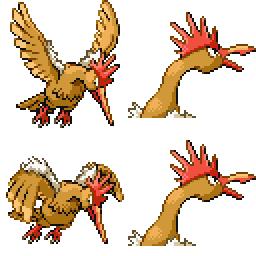

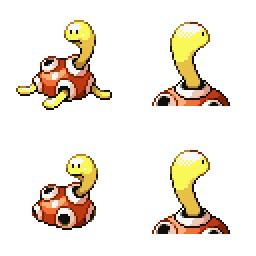
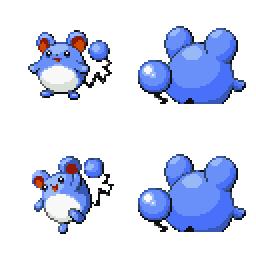

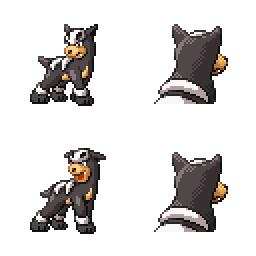

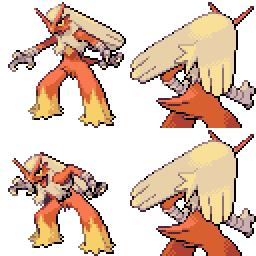

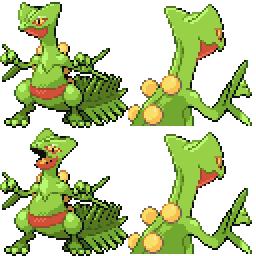




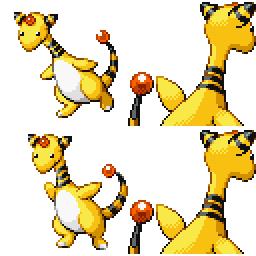



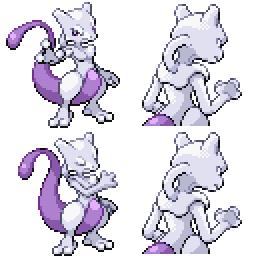




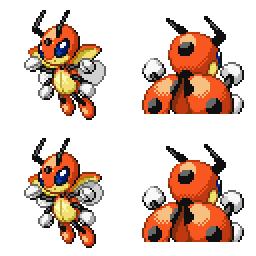

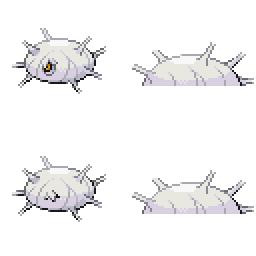
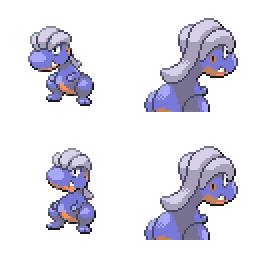






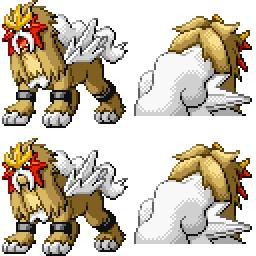



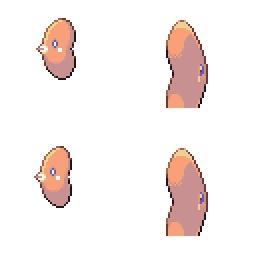

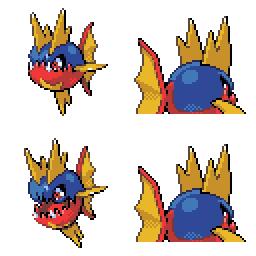



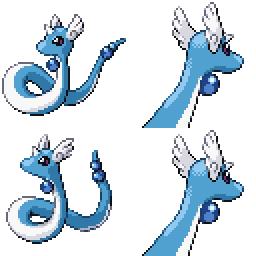


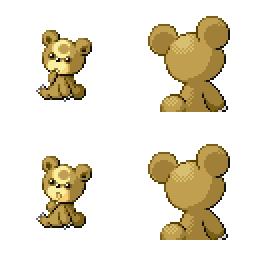
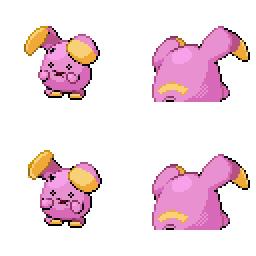

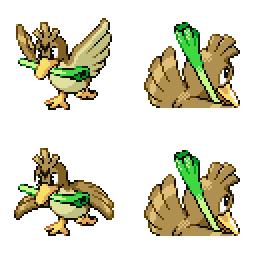




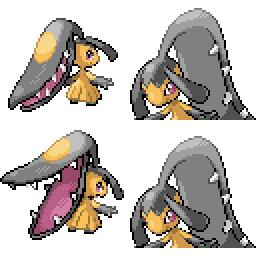
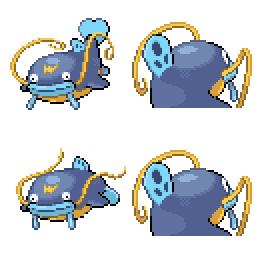








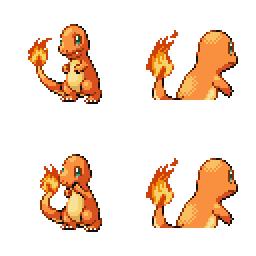










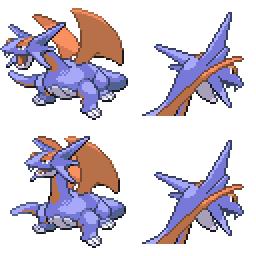


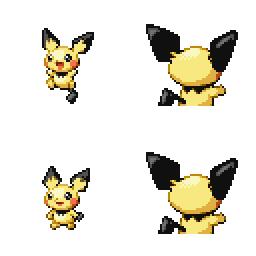



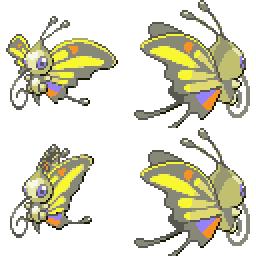
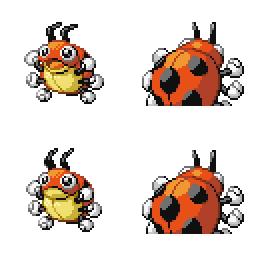






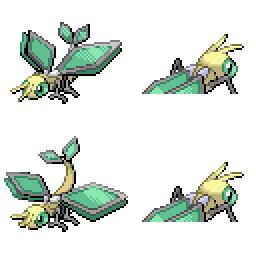



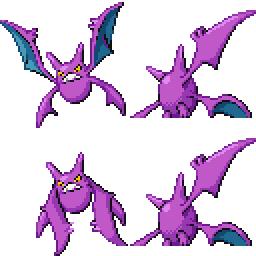





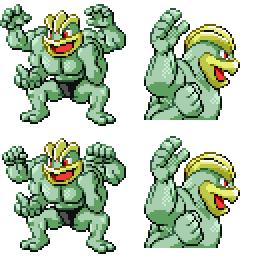

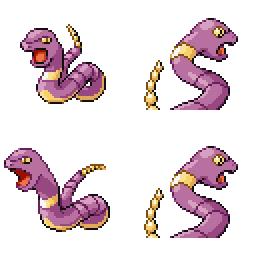









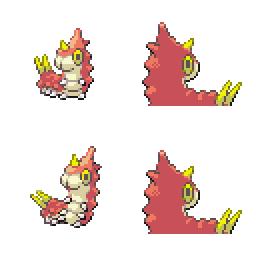
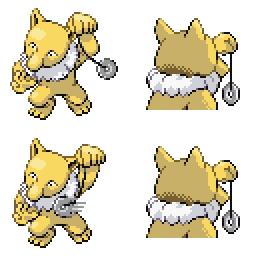


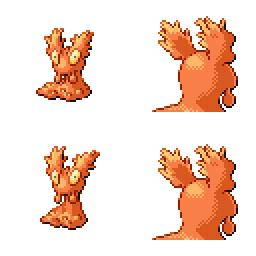


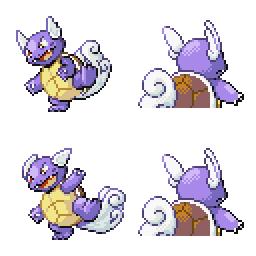

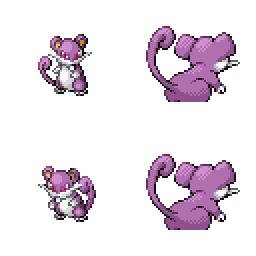


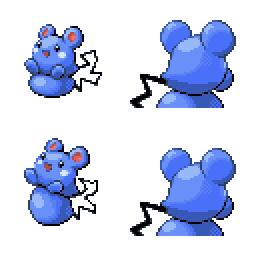






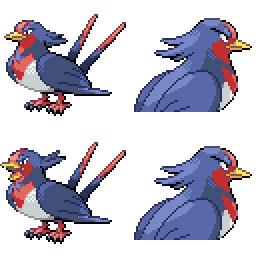




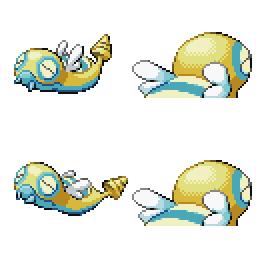
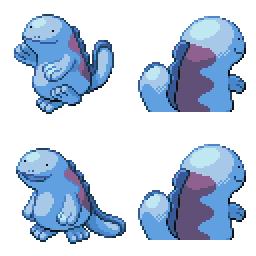


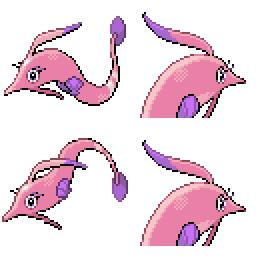

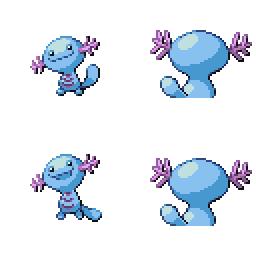

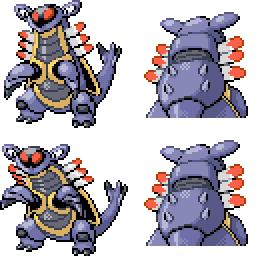









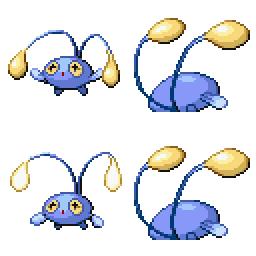

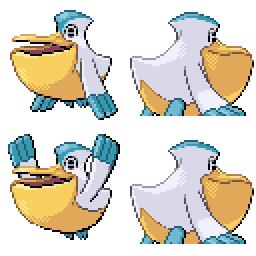

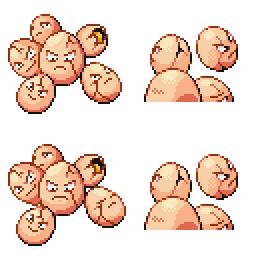




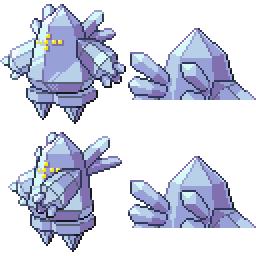




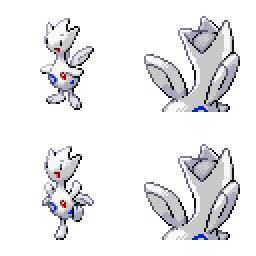

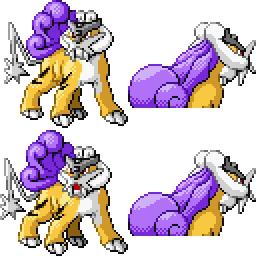


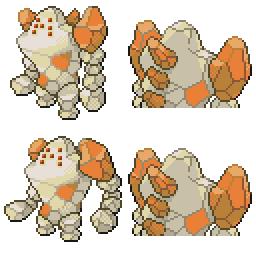
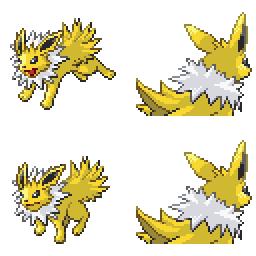



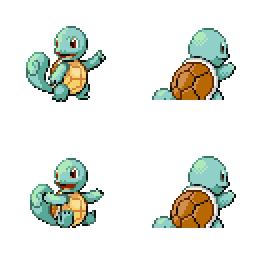




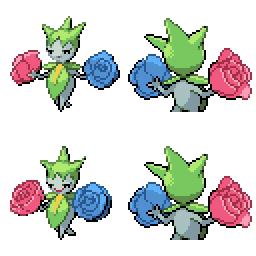




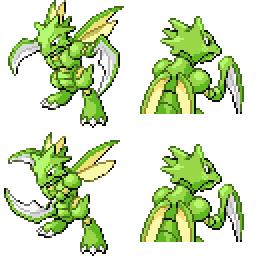
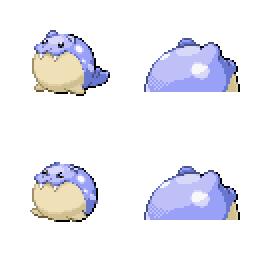
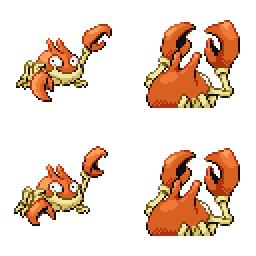
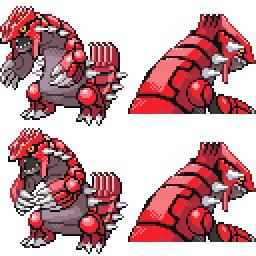
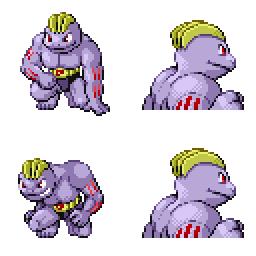
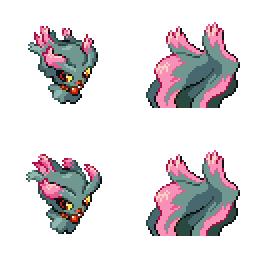
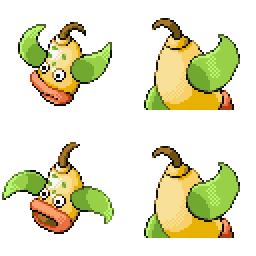




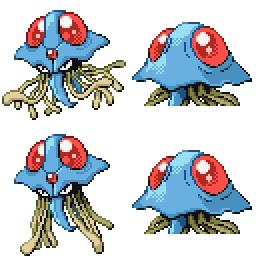

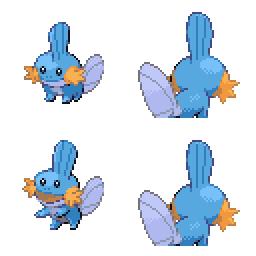

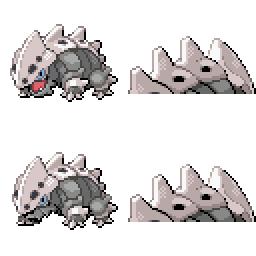
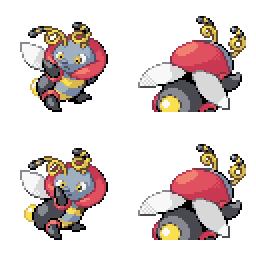


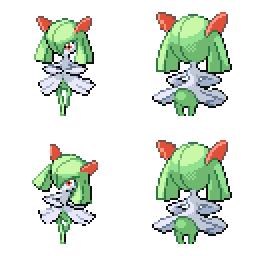

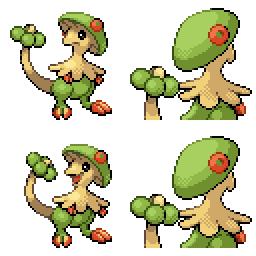
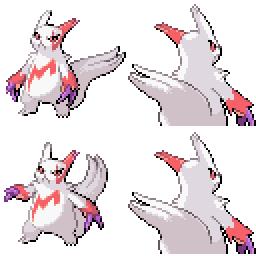



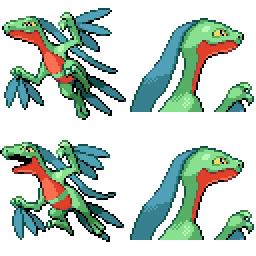


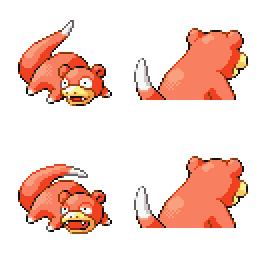


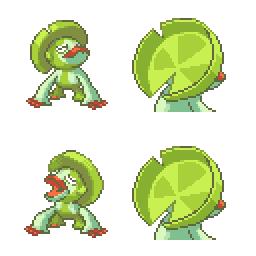

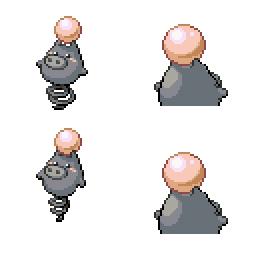
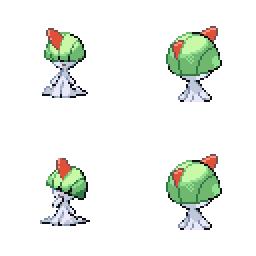
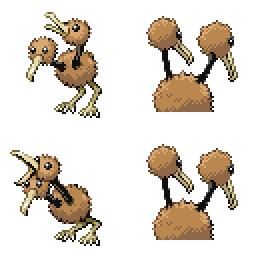



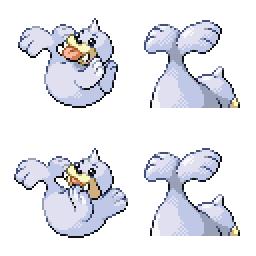




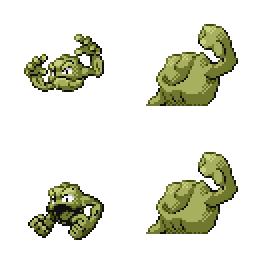
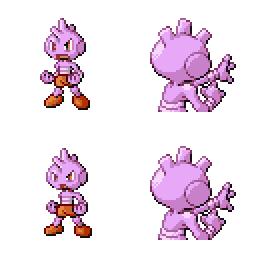








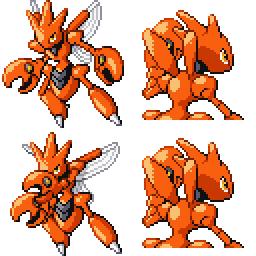








|
deepparag/Aeona-Beta | deepparag | 2022-09-22T00:31:34Z | 71 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-05-25T13:43:39Z | ---
thumbnail: https://images-ext-2.discordapp.net/external/Wvtx1L98EbA7DR2lpZPbDxDuO4qmKt03nZygATZtXgk/%3Fsize%3D4096/https/cdn.discordapp.com/avatars/931226824753700934/338a9e413bbceaeb9095a29e97d4fac0.png
tags:
- conversational
license: mit
---
# Aeona | Chatbot

An generative AI made using [microsoft/DialoGPT-small](https://huggingface.co/microsoft/DialoGPT-small).
Recommended to use along with an [AIML Chatbot](https://github.com/deepsarda/Aeona-Aiml) to reduce load, get better replies, add name and personality to your bot.
Using an AIML Chatbot will allow you to hardcode some replies also.
# AEONA
Aeona is an chatbot which hope's to be able to talk with humans as if its an friend!
It's main target platform is discord.
You can invite the bot [here](https://aeona.xyz).
To learn more about this project and chat with the ai, you can use this [website](https://aeona.xyx/).
Aeona works why using context of the previous messages and guessing the personality of the human who is talking with it and adapting its own personality to better talk with the user.
## Goals
The goal is to create an AI which will work with AIML in order to create the most human like AI.
#### Why not an AI on its own?
For AI it is not possible (realistically) to learn about the user and store data on them, when compared to an AIML which can even execute code!
The goal of the AI is to generate responses where the AIML fails.
Hence the goals becomes to make an AI which has a wide variety of knowledge, yet be as small as possible!
So we use 3 dataset:-
1. [Movielines](https://www.kaggle.com/Cornell-University/movie-dialog-corpus) The movie lines promote longer and more thought out responses but it can be very random. About 200k lines!
2. [Discord Messages](https://www.kaggle.com/jef1056/discord-data) The messages are on a wide variety of topics filtered and removed spam which makes the AI highly random but gives it a very random response to every days questions! about 120 million messages!
3. Custom dataset scrapped from my messages, These messages are very narrow teaching this dataset and sending a random reply will make the AI say sorry loads of time!
## Training
The Discord Messages Dataset simply dwarfs the other datasets, Hence the data sets are repeated.
This leads to them covering each others issues!
The AI has a context of 6 messages which means it will reply until the 4th message from user.
[Example](https://huggingface.co/deepparag/Aeona-Beta/discussions/1)
## Tips for Hugging Face interference
I recommend send the user input,
previous 3 AI and human responses.
Using more context than this will lead to useless responses but using less is alright but the responses may be random.
## Evaluation
Below is a comparison of Aeona vs. other baselines on the mixed dataset given above using automatic evaluation metrics.
| Model | Perplexity |
|---|---|
| Seq2seq Baseline [3] | 29.8 |
| Wolf et al. [5] | 16.3 |
| GPT-2 baseline | 99.5 |
| DialoGPT baseline | 56.6 |
| DialoGPT finetuned | 11.4 |
| PersonaGPT | 10.2 |
| **Aeona** | **7.9** |
## Usage
Example:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("deepparag/Aeona")
model = AutoModelWithLMHead.from_pretrained("deepparag/Aeona")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=4,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("Aeona: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` |
sd-concepts-library/sherhook-painting-v2 | sd-concepts-library | 2022-09-22T00:30:50Z | 0 | 4 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T00:30:44Z | ---
license: mit
---
### Sherhook Painting v2 on Stable Diffusion
This is the `<sherhook>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








|
sd-concepts-library/million-live-akane-3k | sd-concepts-library | 2022-09-22T00:20:35Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T00:20:05Z | ---
license: mit
---
### million-live-akane-3k on Stable Diffusion
This is the `<akane>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:























































|
sd-concepts-library/million-live-akane-15k | sd-concepts-library | 2022-09-22T00:19:07Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-22T00:18:56Z | ---
license: mit
---
### million-live-akane-15k on Stable Diffusion
This is the `<akane>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:























































|
sd-concepts-library/yoji-shinkawa-style | sd-concepts-library | 2022-09-22T00:15:49Z | 0 | 20 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T23:52:29Z | ---
license: mit
---
### yoji-shinkawa-style" on Stable Diffusion
This is the `<yoji-shinkawa>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:







|
bouim/wav2vec2-base-arabic-demo-google-colab | bouim | 2022-09-22T00:08:34Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-09-21T02:19:20Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-arabic-demo-google-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-arabic-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu102
- Datasets 1.18.3
- Tokenizers 0.13.0
|
heheha/no | heheha | 2022-09-22T00:05:53Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2022-09-22T00:05:53Z | ---
license: creativeml-openrail-m
---
|
g30rv17ys/ddpm-geeve-normal-2000-128 | g30rv17ys | 2022-09-21T23:52:32Z | 2 | 0 | diffusers | [
"diffusers",
"tensorboard",
"en",
"dataset:imagefolder",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2022-09-21T18:05:47Z | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-geeve-normal-2000-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/geevegeorge/ddpm-geeve-normal-2000-128/tensorboard?#scalars)
|
Adapting/bert-base-chinese-finetuned-NER-biomedical | Adapting | 2022-09-21T23:30:56Z | 125 | 5 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-21T20:25:23Z | Fine-tuned [Bert-Base-Chinese](https://huggingface.co/bert-base-chinese) for NER task on [Adapting/chinese_biomedical_NER_dataset](https://huggingface.co/datasets/Adapting/chinese_biomedical_NER_dataset)
# Usage
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("Adapting/bert-base-chinese-finetuned-NER-biomedical")
model = AutoModelForTokenClassification.from_pretrained("Adapting/bert-base-chinese-finetuned-NER-biomedical",revision='7f63e3d18b1dc3cc23041a89e77be21860704d2e')
from transformers import pipeline
nlp = pipeline('ner',model=model,tokenizer = tokenizer)
tag_set = [
'B_手术',
'I_疾病和诊断',
'B_症状',
'I_解剖部位',
'I_药物',
'B_影像检查',
'B_药物',
'B_疾病和诊断',
'I_影像检查',
'I_手术',
'B_解剖部位',
'O',
'B_实验室检验',
'I_症状',
'I_实验室检验'
]
tag2id = lambda tag: tag_set.index(tag)
id2tag = lambda id: tag_set[id]
def readable_result(result):
results_in_word = []
j = 0
while j < len(result):
i = result[j]
entity = id2tag(int(i['entity'][i['entity'].index('_')+1:]))
token = i['word']
if entity.startswith('B'):
entity_name = entity[entity.index('_')+1:]
word = token
j = j+1
while j<len(result):
next = result[j]
next_ent = id2tag(int(next['entity'][next['entity'].index('_')+1:]))
next_token = next['word']
if next_ent.startswith('I') and next_ent[next_ent.index('_')+1:] == entity_name:
word += next_token
j += 1
if j >= len(result):
results_in_word.append((entity_name,word))
else:
results_in_word.append((entity_name,word))
break
else:
j += 1
return results_in_word
print(readable_result(nlp('淋球菌性尿道炎会引起头痛')))
'''
[('疾病和诊断', '淋球菌性尿道炎'), ('症状', '头痛')]
'''
``` |
facebook/spar-marco-bm25-lexmodel-context-encoder | facebook | 2022-09-21T23:25:23Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2110.06918",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T23:14:00Z | ---
tags:
- feature-extraction
pipeline_tag: feature-extraction
---
This model is the context encoder of the MS MARCO BM25 Lexical Model (Λ) from the SPAR paper:
[Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?](https://arxiv.org/abs/2110.06918)
<br>
Xilun Chen, Kushal Lakhotia, Barlas Oğuz, Anchit Gupta, Patrick Lewis, Stan Peshterliev, Yashar Mehdad, Sonal Gupta and Wen-tau Yih
<br>
**Meta AI**
The associated github repo is available here: https://github.com/facebookresearch/dpr-scale/tree/main/spar
This model is a BERT-base sized dense retriever trained on the MS MARCO corpus to imitate the behavior of BM25.
The following models are also available:
Pretrained Model | Corpus | Teacher | Architecture | Query Encoder Path | Context Encoder Path
|---|---|---|---|---|---
Wiki BM25 Λ | Wikipedia | BM25 | BERT-base | facebook/spar-wiki-bm25-lexmodel-query-encoder | facebook/spar-wiki-bm25-lexmodel-context-encoder
PAQ BM25 Λ | PAQ | BM25 | BERT-base | facebook/spar-paq-bm25-lexmodel-query-encoder | facebook/spar-paq-bm25-lexmodel-context-encoder
MARCO BM25 Λ | MS MARCO | BM25 | BERT-base | facebook/spar-marco-bm25-lexmodel-query-encoder | facebook/spar-marco-bm25-lexmodel-context-encoder
MARCO UniCOIL Λ | MS MARCO | UniCOIL | BERT-base | facebook/spar-marco-unicoil-lexmodel-query-encoder | facebook/spar-marco-unicoil-lexmodel-context-encoder
# Using the Lexical Model (Λ) Alone
This model should be used together with the associated query encoder, similar to the [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr) model.
```
import torch
from transformers import AutoTokenizer, AutoModel
# The tokenizer is the same for the query and context encoder
tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
query_input = tokenizer(query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 341.3268
score2 = query_emb @ ctx_emb[1] # 340.1626
```
# Using the Lexical Model (Λ) with a Base Dense Retriever as in SPAR
As Λ learns lexical matching from a sparse teacher retriever, it can be used in combination with a standard dense retriever (e.g. [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr#dpr), [Contriever](https://huggingface.co/facebook/contriever-msmarco)) to build a dense retriever that excels at both lexical and semantic matching.
In the following example, we show how to build the SPAR-Wiki model for Open-Domain Question Answering by concatenating the embeddings of DPR and the Wiki BM25 Λ.
```
import torch
from transformers import AutoTokenizer, AutoModel
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
# DPR model
dpr_ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_query_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
dpr_query_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
# Wiki BM25 Λ model
lexmodel_tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Compute DPR embeddings
dpr_query_input = dpr_query_tokenizer(query, return_tensors='pt')['input_ids']
dpr_query_emb = dpr_query_encoder(dpr_query_input).pooler_output
dpr_ctx_input = dpr_ctx_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
dpr_ctx_emb = dpr_ctx_encoder(**dpr_ctx_input).pooler_output
# Compute Λ embeddings
lexmodel_query_input = lexmodel_tokenizer(query, return_tensors='pt')
lexmodel_query_emb = lexmodel_query_encoder(**query_input).last_hidden_state[:, 0, :]
lexmodel_ctx_input = lexmodel_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
lexmodel_ctx_emb = lexmodel_context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Form SPAR embeddings via concatenation
# The concatenation weight is only applied to query embeddings
# Refer to the SPAR paper for details
concat_weight = 0.7
spar_query_emb = torch.cat(
[dpr_query_emb, concat_weight * lexmodel_query_emb],
dim=-1,
)
spar_ctx_emb = torch.cat(
[dpr_ctx_emb, lexmodel_ctx_emb],
dim=-1,
)
# Compute similarity scores
score1 = spar_query_emb @ spar_ctx_emb[0] # 317.6931
score2 = spar_query_emb @ spar_ctx_emb[1] # 314.6144
```
|
research-backup/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification | research-backup | 2022-09-21T23:18:09Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T22:47:09Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.8549007936507936
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5641711229946524
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5816023738872403
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5764313507504168
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.822
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5131578947368421
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5162037037037037
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9172819044749133
- name: F1 (macro)
type: f1_macro
value: 0.912178540410085
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8427230046948356
- name: F1 (macro)
type: f1_macro
value: 0.6664365064483144
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6652221018418202
- name: F1 (macro)
type: f1_macro
value: 0.6591956465701904
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9652222299506156
- name: F1 (macro)
type: f1_macro
value: 0.8945528900012115
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8943904732058916
- name: F1 (macro)
type: f1_macro
value: 0.8949174432546955
---
# relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.5641711229946524
- Accuracy on SAT: 0.5816023738872403
- Accuracy on BATS: 0.5764313507504168
- Accuracy on U2: 0.5131578947368421
- Accuracy on U4: 0.5162037037037037
- Accuracy on Google: 0.822
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9172819044749133
- Micro F1 score on CogALexV: 0.8427230046948356
- Micro F1 score on EVALution: 0.6652221018418202
- Micro F1 score on K&H+N: 0.9652222299506156
- Micro F1 score on ROOT09: 0.8943904732058916
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.8549007936507936
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average_no_mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: I wasn’t aware of this relationship, but I just read in the encyclopedia that <subj> is the <mask> of <obj>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 30
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-d-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
espnet/jiyangtang_magicdata_asr_conformer_lm_transformer | espnet | 2022-09-21T23:17:26Z | 0 | 0 | espnet | [
"espnet",
"audio",
"automatic-speech-recognition",
"zh",
"dataset:magicdata",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
]
| automatic-speech-recognition | 2022-09-21T23:15:28Z | ---
tags:
- espnet
- audio
- automatic-speech-recognition
language: zh
datasets:
- magicdata
license: cc-by-4.0
---
## ESPnet2 ASR model
### `espnet/jiyangtang_magicdata_asr_conformer_lm_transformer`
This model was trained by Jiyang Tang using magicdata recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout 9d0f3b3e1be6650d38cc5008518f445308fe06d9
pip install -e .
cd egs2/magicdata/asr1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/jiyangtang_magicdata_asr_conformer_lm_transformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Wed Sep 21 01:11:58 EDT 2022`
- python version: `3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0]`
- espnet version: `espnet 202207`
- pytorch version: `pytorch 1.8.1+cu102`
- Git hash: `9d0f3b3e1be6650d38cc5008518f445308fe06d9`
- Commit date: `Mon Sep 19 20:27:41 2022 -0400`
## asr_train_asr_raw_zh_char_sp
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test|24279|24286|84.4|15.6|0.0|0.0|15.6|15.6|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_rnn_lm_lm_train_lm_transformer_zh_char_valid.loss.ave_asr_model_valid.acc.ave/test|24279|243325|96.4|1.7|2.0|0.1|3.7|15.6|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_raw_zh_char_sp
ngpu: 0
seed: 0
num_workers: 4
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: null
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 20
patience: null
val_scheduler_criterion:
- valid
- acc
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5
grad_clip_type: 2.0
grad_noise: false
accum_grad: 4
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 20000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_zh_char_sp/train/speech_shape
- exp/asr_stats_raw_zh_char_sp/train/text_shape.char
valid_shape_file:
- exp/asr_stats_raw_zh_char_sp/valid/speech_shape
- exp/asr_stats_raw_zh_char_sp/valid/text_shape.char
batch_type: numel
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_noeng_sp/wav.scp
- speech
- sound
- - dump/raw/train_noeng_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dev/wav.scp
- speech
- sound
- - dump/raw/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0005
scheduler: warmuplr
scheduler_conf:
warmup_steps: 30000
token_list:
- <blank>
- <unk>
- 的
- 我
- 一
- 歌
- 你
- 天
- 不
- 了
- 放
- 来
- 播
- 下
- 个
- 是
- 有
- 给
- 首
- 好
- 请
- 在
- 听
- 么
- 气
- 要
- 想
- 曲
- 上
- 吗
- 去
- 到
- 这
- 啊
- 点
- 那
- 没
- 就
- 说
- 大
- 唱
- 人
- 最
- 第
- 看
- 会
- 明
- 集
- 吧
- 音
- 还
- 乐
- 今
- 电
- 开
- 能
- 度
- 哪
- 里
- 多
- 打
- 十
- 可
- 怎
- 道
- 什
- 新
- 雨
- 以
- 家
- 回
- 话
- 儿
- 他
- 时
- 小
- 温
- 样
- 爱
- 都
- 吃
- 呢
- 知
- 谁
- 为
- 子
- 们
- 也
- 过
- 老
- 很
- 出
- 中
- 现
- 冷
- 和
- 情
- 行
- 心
- 发
- 专
- 几
- 视
- 张
- 事
- 二
- 辑
- 五
- 三
- 后
- 找
- 些
- 早
- 学
- 晚
- 车
- 别
- 演
- 手
- 呀
- 调
- 感
- 问
- 九
- 饭
- 快
- 风
- 得
- 如
- 自
- 生
- 少
- 地
- 用
- 叫
- 帮
- 机
- 台
- 班
- 欢
- 候
- 起
- 等
- 把
- 年
- 干
- 高
- 太
- 啦
- 方
- 提
- 面
- 八
- 四
- 信
- 意
- 王
- 真
- 求
- 热
- 喜
- 觉
- 周
- 近
- 名
- 做
- 公
- 告
- 关
- 六
- 字
- 安
- 再
- 变
- 间
- 国
- 分
- 着
- 哈
- 水
- 节
- 只
- 动
- 北
- 刚
- 空
- 月
- 玩
- 让
- 伤
- 东
- 谢
- 网
- 七
- 见
- 之
- 比
- 杰
- 又
- 买
- 对
- 始
- 无
- 查
- 声
- 文
- 经
- 醒
- 美
- 西
- 哦
- 走
- 两
- 海
- 妈
- 李
- 报
- 诉
- 接
- 定
- 午
- 外
- 才
- 流
- 长
- 宝
- 门
- 收
- 己
- 室
- 林
- 种
- 南
- 日
- 目
- 陈
- 许
- 词
- 服
- 设
- 记
- 频
- 琴
- 主
- 完
- 友
- 花
- 跟
- 钱
- 睡
- 像
- 嗯
- 何
- 京
- 所
- 预
- 边
- 带
- 作
- 零
- 头
- 号
- 果
- 嘛
- 路
- 办
- 吉
- 语
- 本
- 合
- 卫
- 影
- 市
- 摄
- 通
- 加
- 女
- 成
- 因
- 前
- 衣
- 然
- 档
- 位
- 聊
- 哥
- 载
- 原
- <space>
- 思
- 氏
- 同
- 题
- 但
- 红
- 火
- 她
- 亲
- 传
- 江
- 清
- 息
- 注
- 死
- 啥
- 州
- 片
- 朋
- 相
- 星
- 华
- 已
- 负
- 白
- 色
- 姐
- 春
- 转
- 半
- 换
- 黄
- 游
- 工
- 法
- 理
- 山
- 该
- 英
- 较
- 先
- 穿
- 推
- 直
- 力
- 当
- 冻
- 费
- 刘
- 男
- 写
- 场
- 呵
- 克
- 正
- 单
- 身
- 系
- 苏
- 婆
- 难
- 阳
- 光
- 重
- 荐
- 越
- 马
- 城
- 错
- 次
- 期
- 口
- 金
- 线
- 准
- 爸
- 忙
- 体
- 于
- 句
- 广
- 福
- 活
- 应
- 亮
- 黑
- 特
- 司
- 喝
- 式
- 飞
- 介
- 者
- 慢
- 静
- 百
- 平
- 绍
- 差
- 照
- 团
- 烦
- 便
- 师
- 站
- 德
- 短
- 远
- 需
- 谱
- 郑
- 化
- 或
- 器
- 急
- 钢
- 您
- 忘
- 店
- 妹
- 梦
- 青
- 适
- 总
- 每
- 业
- 夜
- 神
- 版
- 健
- 区
- 实
- 从
- 孩
- 奏
- 韩
- 伦
- 志
- 算
- 雪
- 世
- 认
- 眼
- 模
- 全
- 与
- 书
- 拿
- 送
- 结
- 其
- 解
- 格
- 洗
- 幸
- 舞
- 望
- 速
- 试
- 钟
- 内
- 联
- 停
- 丽
- 课
- 河
- 沙
- 笑
- 久
- 永
- 贝
- 民
- 址
- 超
- 教
- 代
- 件
- 降
- 脑
- 恋
- 常
- 交
- 低
- 伙
- 而
- 毛
- 阿
- 齐
- 习
- 量
- 段
- 选
- 欣
- 昨
- 进
- 闻
- 住
- 受
- 类
- 酒
- 背
- 藏
- 暴
- 摇
- 云
- 怕
- 考
- 咋
- 武
- 赶
- 孙
- 识
- 嵩
- 景
- 某
- 省
- 界
- 罗
- 任
- 坐
- 级
- 遇
- 麻
- 县
- 被
- 龙
- 品
- 蛋
- 湖
- 离
- 希
- 卖
- 轻
- 岁
- 香
- 赏
- 忆
- 答
- 滚
- 保
- 运
- 深
- 央
- 更
- 况
- 部
- ,
- 猪
- 休
- 校
- 留
- 嘿
- 弹
- 挺
- 院
- 泪
- 拉
- 懂
- 暖
- 讲
- 顺
- 底
- 卡
- 使
- 表
- 剧
- 包
- 故
- 导
- 凉
- 连
- 咱
- 制
- 蔡
- 容
- 向
- 物
- 微
- 步
- 切
- 搜
- 婚
- 童
- 约
- 芳
- 凯
- 复
- 未
- 陪
- 防
- 典
- 夏
- 万
- 备
- 指
- 冰
- 管
- 基
- 琪
- 宇
- 晓
- 房
- 良
- 戏
- 悲
- 牛
- 千
- 达
- 汉
- 拜
- 奇
- 梅
- 菜
- 满
- 徐
- 楼
- 询
- 图
- 改
- 练
- 敬
- 票
- 吴
- 络
- 码
- 整
- 简
- 队
- 购
- 普
- 附
- 响
- 胡
- 装
- 暑
- 非
- 喂
- 消
- 浪
- 凤
- 愿
- 累
- 球
- 聚
- 启
- 假
- 潮
- 弟
- 玉
- 绿
- 康
- 拍
- 失
- 哭
- 易
- 木
- 斯
- 跳
- 军
- 处
- 搞
- 升
- 除
- 傻
- 骗
- 证
- 杨
- 园
- 茹
- 赵
- 标
- 窗
- 庆
- 惠
- 够
- 烟
- 俊
- 掉
- 建
- 呗
- 插
- 座
- 害
- 智
- 贵
- 左
- 落
- 计
- 客
- 宁
- 梁
- 舒
- 取
- 往
- 漫
- 兰
- 战
- 随
- 晴
- 条
- 入
- 叶
- 强
- 伟
- 雅
- 尔
- 树
- 余
- 弄
- 季
- 排
- 伍
- 吹
- 宏
- 商
- 柔
- 郊
- 铁
- 遍
- 确
- 闭
- 雄
- 似
- 冒
- 待
- 尘
- 群
- 病
- 退
- 务
- 育
- 坏
- 娘
- 莫
- 资
- 楚
- 辛
- 索
- 利
- 数
- 秦
- 燕
- 且
- 录
- 姑
- 念
- 痛
- 冬
- 尾
- 共
- 初
- 粤
- 哎
- 印
- 示
- 抱
- 终
- 泉
- 货
- 肯
- 它
- 伞
- 性
- 古
- 跑
- 腾
- 鱼
- 曾
- 源
- 银
- 读
- 油
- 川
- 言
- 倩
- 峰
- 激
- 置
- 灯
- 独
- 命
- 谈
- 苦
- 限
- 乡
- 菲
- 伴
- 将
- 震
- 炎
- 散
- 依
- 米
- 及
- 贞
- 兴
- 湿
- 寒
- 敏
- 否
- 俩
- 祝
- 慧
- 精
- 律
- 功
- 托
- 洋
- 敢
- 街
- 铃
- 必
- 弦
- 寻
- 涵
- 突
- 皮
- 反
- 烧
- 秋
- 刮
- 末
- 双
- 细
- 范
- 由
- 君
- 款
- 邮
- 醉
- 紧
- 哲
- 缘
- 岛
- 疼
- 阴
- 旋
- 怪
- 草
- 持
- 狼
- 具
- 至
- 汪
- 鸡
- 医
- 邓
- 份
- 右
- 密
- 士
- 修
- 亚
- 画
- 灵
- 妇
- 甜
- 靠
- 荣
- 程
- 莲
- 魂
- 此
- 户
- 属
- 贤
- 充
- 萧
- 血
- 逼
- 闹
- 吸
- 娜
- 肉
- 抒
- 价
- 桥
- 剑
- 巴
- 暗
- 豆
- 迪
- 戴
- 迅
- 朝
- 艺
- 谭
- 治
- 祥
- 尽
- 闷
- 宫
- 艳
- 父
- 存
- 媳
- 跪
- 雾
- 杜
- 味
- 奕
- 兵
- 脸
- 炫
- 兄
- 妮
- 优
- 熊
- 床
- 般
- 净
- 航
- 帝
- 刻
- 孤
- 轩
- 村
- 支
- 玮
- 狗
- 纯
- 楠
- 呐
- 冠
- 元
- 盛
- 决
- 诗
- 爷
- 堵
- 陶
- 乖
- 迷
- 羽
- 忧
- 倒
- 蜜
- 晒
- 仔
- 却
- 姜
- 哟
- 餐
- 雷
- 鸟
- 馆
- 韶
- 箱
- 操
- 乌
- 借
- 恒
- 舍
- 药
- 块
- 澡
- 石
- 软
- 奶
- 笨
- 夫
- 朴
- 义
- 派
- 晨
- 佳
- 科
- 姿
- 显
- 咏
- 饿
- 付
- 宗
- 键
- 止
- 员
- 磊
- 勤
- 崔
- 偏
- 额
- 免
- 乱
- 怀
- 侠
- 岳
- 斌
- 助
- 征
- 概
- 吕
- 彩
- 板
- 松
- 各
- 组
- 历
- 济
- 象
- 茶
- 领
- 按
- 创
- 镇
- 翻
- 配
- 宿
- 咯
- 帅
- 型
- 估
- 佩
- 惜
- 详
- 续
- 蓝
- 麟
- 珠
- 颜
- 彦
- 农
- 盘
- 母
- 鞋
- 账
- 博
- 礼
- 环
- 套
- 效
- 郭
- 居
- 佑
- 根
- 惊
- 圳
- 叔
- 若
- 逆
- 鸿
- 锁
- 食
- 芸
- 裤
- 娱
- 漂
- 野
- 麦
- 豫
- 顾
- 爽
- 族
- 仙
- 围
- 观
- 链
- 嗨
- 厅
- 巍
- 劲
- 极
- 呼
- 咖
- 淑
- 丝
- 昌
- 嘉
- 绝
- 史
- 击
- 承
- 蔚
- 堂
- 沉
- 笔
- 朵
- 凰
- 琥
- 匆
- 炜
- 输
- 须
- 娴
- 嘻
- 牌
- 田
- 杀
- 滴
- 鬼
- 桦
- 赛
- 玟
- 抽
- 案
- 轮
- 立
- 摆
- 屋
- 诺
- 丁
- 佰
- 蒙
- 澄
- 羊
- 添
- 质
- 波
- 萨
- 狂
- 丹
- 屁
- 角
- 章
- 产
- 宜
- 笛
- 严
- 维
- 测
- 娃
- 料
- 宋
- 洲
- 卦
- 猜
- 港
- 挂
- 淘
- 郁
- 统
- 断
- 锅
- 稍
- 绮
- 汗
- 辉
- 乎
- 破
- 钧
- 芹
- 择
- 胖
- 即
- 呜
- 旅
- 拨
- 紫
- 哇
- 默
- 论
- 朱
- 登
- 脚
- 订
- 秀
- ?
- 社
- 飘
- 尚
- 另
- 骂
- 并
- 恶
- 扫
- 裸
- 姨
- 苹
- 压
- 厌
- 汇
- 爆
- 局
- 睛
- 庄
- 唐
- 嘞
- 偶
- 乔
- 染
- 熟
- 喆
- 愉
- 虎
- 技
- 威
- 布
- 嘴
- 湾
- 术
- 讨
- 尼
- 诶
- 坊
- 删
- 桑
- 庾
- 斗
- 呃
- 仁
- 训
- 汤
- 脱
- 凡
- 例
- 唉
- 畅
- 参
- 晕
- 肥
- 营
- 鲁
- 减
- 琳
- 瑞
- 透
- 素
- 厉
- 追
- 扰
- 控
- 谣
- 足
- 检
- 扬
- 娇
- 耳
- 津
- 倾
- 淡
- 露
- 妞
- 熙
- 值
- 罪
- 浩
- 探
- 盐
- 列
- 券
- 潘
- 官
- 篇
- 纪
- 签
- 棒
- 丑
- 陆
- 养
- 佛
- 唯
- 芮
- 哒
- 榜
- 培
- 疯
- 财
- 卷
- 痴
- 凌
- 瓜
- 猫
- 泡
- 据
- 厦
- 辣
- 恩
- 土
- 补
- 递
- 伏
- 灰
- 糖
- 玛
- 黎
- 湘
- 遥
- 谅
- 桃
- 曼
- 招
- 勇
- 泰
- 杭
- 缓
- 朗
- 替
- 刷
- 封
- 骨
- 盖
- 眠
- 担
- 忽
- 蛮
- 蜗
- 肚
- 喽
- 懒
- 继
- 辈
- 魔
- 哼
- 顶
- 冲
- 番
- 释
- 形
- 页
- 渡
- 触
- 裂
- 逛
- 圆
- 迎
- 态
- 弃
- 洛
- 丰
- 困
- 展
- 束
- 巧
- 临
- 际
- 涛
- 酷
- 洁
- 毕
- 呆
- 励
- 臭
- 暂
- 评
- 沧
- 磨
- 洞
- 厂
- 吵
- 煮
- 旧
- 幽
- 寄
- 政
- 丫
- 闯
- 举
- 误
- 护
- 状
- 寂
- 牙
- 杯
- 议
- 眉
- 享
- 剩
- 秘
- 噢
- 耿
- 致
- 偷
- 丢
- 刀
- 销
- 盒
- 编
- 珍
- 葛
- 译
- 颗
- 括
- 奥
- 鲜
- 沈
- 婷
- 摩
- 炒
- 惯
- 啡
- 混
- 燥
- 扣
- 晶
- 柏
- 拥
- 旭
- 拾
- 验
- 嫁
- 铺
- 棉
- 划
- 虾
- 浙
- 寓
- 剪
- 贴
- 圣
- 颖
- 申
- 枝
- 艾
- 旁
- 溪
- '?'
- 厚
- 驶
- 燃
- 虽
- 途
- 祖
- 职
- 泽
- 腿
- 薇
- 阵
- 移
- 淋
- 灭
- 寞
- 森
- 延
- 孝
- 沥
- 迟
- 伪
- 催
- 投
- 伯
- 谓
- 诚
- 架
- 耶
- 项
- 撒
- 邦
- 善
- 鼻
- 芬
- 闲
- 增
- 卓
- 层
- 鹏
- 敲
- 镖
- 粉
- 欧
- 纸
- 甘
- 昆
- 哩
- 坚
- 苍
- 积
- 筝
- 擦
- 董
- 吻
- 折
- 欺
- 疆
- 勒
- 售
- 船
- 胜
- 甄
- 杂
- 骑
- 贱
- 饼
- 称
- 隆
- 竟
- 逃
- 啷
- 引
- 宾
- 莉
- 境
- 奖
- 救
- 讯
- 恰
- 垃
- 圾
- 宅
- 潜
- 皇
- 符
- 徽
- 造
- 翔
- 粥
- 桌
- 租
- 险
- 驾
- 祭
- 昂
- 牧
- 宣
- 综
- 谷
- 私
- 瓷
- 避
- 肖
- 闪
- 圈
- 喱
- 耀
- 悟
- 秒
- 篮
- 逗
- 蝶
- 趣
- 恨
- 恐
- 饺
- 碎
- 奔
- 幼
- 股
- 锦
- 锡
- 椅
- 玲
- 刑
- 嗓
- 喊
- 虑
- 俺
- 镜
- 耐
- 鹿
- 狄
- 兮
- 返
- 恭
- 含
- 傅
- 沟
- 莹
- 妃
- 忠
- 赤
- 喔
- 抓
- 迈
- 众
- 豪
- 祈
- 馨
- 嬛
- 庭
- 异
- 辰
- 琅
- 荷
- 匪
- 吐
- 警
- 虹
- 吓
- 聪
- 悔
- 归
- 富
- 陕
- 魏
- 欲
- 菊
- 雹
- 隐
- 涯
- 忍
- 芦
- 琊
- 酸
- 逊
- 亦
- 咪
- 瞎
- 滨
- 胸
- 采
- 穹
- 究
- 炊
- 痒
- 莎
- 柳
- 井
- 洪
- 胎
- 鼓
- 润
- 迁
- 玫
- 滩
- 傲
- 袁
- 赚
- 研
- 躺
- 烤
- 莱
- 搬
- 蒋
- 曹
- 孟
- 嫂
- 甲
- 瑰
- 窝
- 令
- 堆
- 废
- 掌
- 巡
- 妙
- 袋
- 争
- 萌
- 挑
- 册
- 饮
- 勋
- 珊
- 戒
- 绵
- 亡
- 劳
- 搭
- 甩
- 匙
- 彭
- 锋
- 钥
- 率
- 吟
- 鼠
- 纱
- 坡
- 潇
- 挣
- 逝
- 针
- 弱
- 妍
- 稳
- 怒
- 塘
- 卢
- 宵
- 悠
- 饱
- 披
- 瘦
- 浮
- 烂
- 壶
- 截
- 勿
- 序
- 委
- 兔
- 塔
- 执
- 墨
- 府
- 宙
- 欠
- 巨
- 帽
- 占
- 顿
- 权
- 坠
- 碰
- 著
- 硬
- 炮
- 骚
- 肃
- 规
- 厕
- 贾
- 葫
- 徒
- 瓶
- 辽
- 耍
- 赢
- 桂
- 浦
- 趟
- 柯
- 悉
- 恼
- 禁
- 殊
- 卧
- 赞
- 益
- 责
- 虚
- 姓
- 愁
- 舅
- 残
- 既
- 拖
- 棍
- 幻
- 库
- 骄
- 烈
- 尊
- 伊
- 缺
- 迹
- 疑
- 汽
- 郎
- 鸭
- 仪
- 盗
- 幺
- 萱
- 胃
- 脏
- 努
- 勉
- 池
- 咳
- 奋
- 批
- 蝴
- 监
- 犯
- 滑
- 牵
- 冯
- 败
- 毒
- 怖
- 绪
- 帐
- 协
- 韵
- 怜
- 薛
- 姚
- 副
- 塞
- 蕉
- 夹
- 萝
- 爹
- 貌
- 奈
- 乞
- 隔
- 澳
- 姥
- 妖
- 腰
- 纳
- 龄
- 材
- 旗
- 萤
- 俗
- 昼
- 坛
- 霍
- 怡
- 丐
- 咒
- 础
- 嘎
- 虫
- 枪
- 遗
- 献
- 陌
- 侣
- 。
- 昧
- 筒
- 袭
- 厨
- 爬
- 茂
- 媛
- 慰
- 填
- 霞
- 娟
- 摸
- 逍
- 赫
- 霾
- 泥
- 暧
- 翅
- 谦
- 夕
- 瑶
- 鑫
- 刺
- 袖
- 拒
- 玄
- 涂
- 溜
- 旬
- 鸣
- 泷
- 距
- 阻
- 绩
- 狠
- 宽
- 狐
- 赖
- 握
- 循
- 靓
- 述
- 糕
- 踏
- 侯
- 劵
- 壮
- 抄
- 苟
- 岗
- 供
- 湛
- 炼
- 烫
- 棋
- 糊
- 饶
- 悄
- 霸
- 竹
- 哀
- 拔
- 蓉
- 旦
- 晰
- 振
- 漠
- 苗
- 帘
- 糟
- 崇
- 踩
- 汕
- 寝
- 刹
- 蔬
- 旺
- 躁
- 守
- 液
- 疗
- 晋
- 坤
- 洒
- 串
- 屏
- 翠
- 鹅
- 腻
- 毅
- 蹈
- 党
- 咩
- 灿
- 哄
- 核
- 横
- 谎
- 忏
- 映
- 倔
- 则
- 肤
- 贺
- 潍
- 焦
- 渐
- 坑
- 瞄
- 融
- 琼
- 尤
- 逸
- 碧
- 葡
- 卜
- 察
- 邢
- 薄
- 亏
- 绒
- 萄
- 婉
- 闺
- 势
- 描
- 均
- 梨
- 椒
- 慕
- 污
- 弯
- 繁
- 炸
- 肿
- 阅
- 肺
- 席
- 呦
- 碟
- 耻
- 端
- 叹
- 庸
- 危
- 痘
- 峡
- 腐
- 霜
- 拳
- 昴
- 荡
- 屎
- 纠
- 夸
- 尿
- 钰
- 撼
- 嗽
- 雯
- 症
- 衡
- 互
- 孔
- 钻
- 萍
- 娄
- 斤
- 悦
- 谊
- 扯
- 驴
- 歉
- 扎
- 庐
- 蒲
- 吼
- 熬
- 鸳
- 蒸
- 驹
- 允
- 射
- 酱
- 鸯
- 企
- 馒
- 乘
- 葱
- 泳
- 莞
- 脆
- 寨
- 损
- 陀
- 膀
- 淮
- 侃
- 霉
- 施
- 橙
- 煲
- 妆
- 审
- 宠
- 穷
- 敌
- 堡
- 樱
- 诞
- 胆
- 彤
- 祷
- 渭
- 霆
- 亭
- 璐
- 邵
- 壁
- 禺
- 墙
- 葬
- 垫
- 吾
- 粒
- 爵
- 弘
- 妻
- 蕾
- 咨
- 固
- 幕
- 粗
- 抢
- 访
- 贸
- 挥
- 饰
- 硕
- 域
- 岸
- 咬
- 晗
- 姆
- 骤
- 抖
- 判
- 鄂
- 获
- 锻
- 郝
- 柜
- 醋
- 桐
- 泣
- 粘
- 革
- 脾
- 尸
- 侧
- 辆
- 埋
- 稻
- 肠
- 嫌
- 彬
- 庚
- 彼
- 龟
- 弥
- 籍
- 纽
- 喷
- 氛
- 币
- 蠢
- 磁
- 袜
- 柴
- 寸
- 韦
- 忐
- 忑
- 恢
- 缩
- 捷
- 绕
- 翼
- 琦
- 玻
- 驻
- 屈
- 岩
- 颂
- 仓
- 茜
- 璃
- 裙
- 僵
- 柿
- 稿
- 巾
- 撑
- 尹
- 嘟
- 牡
- 昏
- 歇
- 诵
- 丸
- 梯
- 挡
- 袄
- 逢
- 徙
- 渴
- 仰
- 跨
- 碗
- 阔
- 税
- 拼
- 宥
- 丞
- 凶
- 析
- 炖
- 舌
- 抗
- 脖
- 甚
- 豚
- 敷
- 瓦
- 织
- 邀
- 浏
- 猛
- 歪
- 阶
- 兽
- 俄
- 鹤
- 禹
- 纹
- 闽
- 惹
- 煤
- 患
- 岭
- 瑜
- 稀
- 拆
- 凄
- 崎
- 芝
- 摊
- 尺
- 彻
- 览
- 贷
- 珂
- 憋
- 径
- 抚
- 魅
- 悬
- 胶
- 倍
- 贯
- 籁
- 乃
- 哑
- 惑
- 撞
- 箫
- 绣
- 扁
- 苑
- 靖
- 漏
- 挤
- 轶
- 叮
- 烨
- 菇
- 砸
- 趁
- 媚
- 仅
- 藤
- 邱
- 陵
- 躲
- 滋
- 叛
- 捉
- 孕
- 铜
- 衫
- 寿
- 寺
- 枫
- 豹
- 伽
- 翡
- 蜂
- 丙
- 姗
- 羡
- 凑
- 鄙
- 庙
- 铭
- 宰
- 廖
- 肩
- 臣
- 抑
- 辅
- 誓
- 扇
- 啪
- 羞
- 诊
- 敦
- 跃
- 俞
- 肝
- 坦
- 贡
- 踢
- 齿
- 尧
- 淀
- 叉
- 浴
- 狮
- 昊
- 蟹
- 捏
- 略
- 禾
- 纲
- 赔
- 憾
- 赋
- 丘
- 尝
- 钓
- 涕
- 猴
- 鸽
- 纵
- 奉
- 涨
- 揍
- 怨
- 挨
- 兜
- 冈
- 凭
- 策
- 裴
- 摔
- 喵
- 佐
- 喉
- 膏
- 瑟
- 抬
- 纷
- 廊
- 贼
- 煎
- 熄
- 渝
- 缠
- 纶
- 岚
- 衬
- 遮
- 翰
- 誉
- 摘
- 勾
- 赣
- 姬
- 娅
- 撤
- 霖
- 泊
- 膝
- 耽
- 犹
- 仍
- 辞
- 溃
- 骏
- 弓
- 膜
- 诱
- 慌
- 惨
- 噪
- 涩
- 潭
- 幂
- 梓
- 植
- 罚
- 扮
- 涮
- 雁
- 兆
- 舟
- 咸
- 犀
- 炉
- 筋
- 陇
- 狸
- 帕
- 噶
- 茄
- 嗒
- 纬
- 障
- 聘
- 盼
- 盟
- 咧
- 灏
- 菠
- 巷
- 帖
- 慈
- 枕
- 唤
- 慨
- 呛
- 叽
- 砖
- 窍
- 瞒
- 龚
- 促
- 尖
- 螺
- 捞
- 盆
- 茫
- 屌
- 械
- 乳
- 啤
- 玺
- 廷
- 谐
- 吖
- 帆
- 蛇
- 琵
- 琶
- 扑
- 跌
- 崩
- 扭
- 扔
- 咿
- 菩
- 茉
- 攻
- 虐
- 甸
- 璇
- 驰
- 瞬
- 鸦
- 厢
- 囊
- 闫
- 届
- 墓
- 芒
- 栗
- 沫
- 违
- 缝
- 棵
- 杏
- 赌
- 灾
- 颤
- 沂
- 肇
- 桶
- 霄
- !
- 咙
- 绥
- 仲
- 愈
- 竖
- 菌
- 捕
- 烘
- 阮
- 皆
- 咚
- 劫
- 揭
- 郸
- 庞
- 喇
- 拐
- 奴
- 咔
- 幅
- 偿
- 咦
- 召
- 薪
- 盯
- 黛
- 杉
- 辨
- 邯
- 枯
- 沃
- 吊
- 筷
- 陷
- 鹰
- 嗦
- 噻
- 屯
- 殇
- 抵
- 雕
- 辩
- 枣
- 捂
- 瘾
- 粮
- 巢
- 耗
- 储
- 殷
- 糯
- 轨
- 沾
- 淇
- 毁
- 沐
- 蚊
- 鉴
- 灌
- 玖
- 唔
- 芙
- 淳
- 昕
- 裹
- 茧
- 浑
- 睿
- 踪
- 邪
- 瘩
- 恺
- 斜
- 汰
- 逐
- 铮
- 毫
- 胞
- 昭
- 妥
- 筑
- 贪
- 蘑
- 皓
- 颐
- 疙
- 捡
- 泛
- 债
- 栎
- 棚
- 腹
- 构
- 蓬
- 宪
- 叭
- 愚
- 押
- 蜀
- 夷
- 娶
- 盾
- 倪
- 牟
- 抛
- 壳
- 衍
- 杆
- 撕
- 亿
- 纤
- 淹
- 翘
- 蔷
- 芊
- 罩
- 拯
- 嗷
- 浇
- 宴
- 遵
- 冥
- 祸
- 塑
- 沛
- 猎
- 携
- 噜
- 喘
- 缴
- 砍
- 唢
- 曦
- 遛
- 罢
- 峨
- 戚
- 稚
- 揉
- 堰
- 螃
- 薯
- 乙
- 矿
- 挽
- 弛
- 埃
- 淅
- 疲
- 窦
- 烛
- 媒
- 尬
- 汀
- 谨
- 罐
- 劣
- 伶
- 煜
- 栏
- 榆
- 矛
- 琐
- 槽
- 驼
- 渤
- 沒
- 泄
- 粑
- 匀
- 囧
- 茵
- 霹
- 澈
- 岑
- 乏
- 栋
- 拌
- 框
- 祁
- 叨
- 斋
- 玥
- 僧
- 疏
- 绳
- 晃
- 抹
- 授
- 蓄
- 檬
- 仇
- 毯
- 啵
- 泼
- 阁
- ','
- 邹
- 阎
- 渠
- 函
- 腊
- 割
- 绑
- 扶
- 肌
- 卑
- 匠
- 雳
- 绯
- 婧
- 煌
- 蒂
- 腔
- 仿
- 遭
- 阜
- 峻
- 劝
- 绎
- 黔
- 贫
- 剁
- 荆
- 樊
- 卸
- 锄
- 阕
- 狱
- 冉
- 鲍
- 荒
- 侄
- 唇
- 忌
- 掖
- 竞
- 匹
- 仗
- 锤
- 穆
- 践
- 冶
- 柱
- 聂
- 捧
- 唠
- 翁
- 掏
- 塌
- 沁
- 巩
- 沸
- 蜡
- 痕
- 削
- 晟
- 眯
- 灶
- 婴
- 啸
- 釜
- 兼
- 剂
- 氧
- 赐
- 铠
- 攀
- 扩
- 朦
- 胧
- 孽
- 挖
- 钞
- 碍
- 凝
- 鼎
- 屉
- 斑
- 抠
- 哗
- 哨
- 婶
- 劈
- 冕
- 霏
- 汾
- 雀
- 浚
- 屠
- 唰
- 疚
- 芽
- 惦
- 裕
- 仑
- 厘
- 烁
- 瞧
- 蚂
- 涿
- 尴
- 埔
- 橘
- 磕
- 苇
- 脂
- 臂
- 蛙
- 镁
- 绽
- 卿
- 荃
- 莺
- 迫
- 敖
- 呈
- 勃
- 碌
- 讶
- 赠
- 巫
- 篱
- 浓
- 攒
- 裁
- 嫣
- 彪
- 娣
- 坟
- 廉
- 聆
- 铉
- 瞌
- 葵
- 鞍
- 坎
- 畜
- 爪
- 锯
- 潼
- 矣
- 闸
- 俱
- 蹭
- 戈
- 扒
- 滤
- 撇
- 浅
- 唧
- 觅
- 婕
- 牢
- 堕
- 丈
- 滕
- 御
- 溢
- 阑
- 楞
- 伺
- 馋
- 禄
- 胳
- 措
- 伐
- 滔
- 沦
- 澎
- 谙
- 桢
- 肾
- 熏
- 炅
- 邻
- 吞
- 噔
- 哔
- 沿
- 竺
- 闵
- 妨
- 啰
- 儒
- 锈
- 虞
- 颠
- 脊
- 膊
- 搓
- 岐
- 浸
- 兹
- 吨
- 垂
- 晏
- 痹
- 哆
- 漆
- 叠
- 莓
- 嘀
- 挫
- 馈
- 愧
- 佟
- 疾
- 蒜
- 盈
- 侬
- 烊
- 炙
- 蜢
- 诡
- 莆
- 蛾
- 轴
- 妒
- 洱
- 擎
- 脉
- 飓
- 泫
- 浆
- 岔
- 蹦
- 愤
- 琛
- 趴
- 绘
- 忻
- 拽
- 牲
- 馅
- 鲨
- 靴
- 鳅
- 俐
- 罕
- 呕
- 凋
- 绫
- 蕊
- 圃
- 猥
- 氓
- 歧
- 秧
- 栈
- 梧
- 衷
- 巅
- 彝
- 嚎
- 菁
- 渔
- 茬
- 汐
- 拓
- 昔
- 囚
- 舜
- 搁
- 泸
- 涟
- 蚁
- 裳
- 鞭
- 辟
- 蝎
- 簧
- 予
- 倦
- 傍
- 荔
- 瞳
- 碑
- 桨
- 疫
- 骁
- 驿
- 柠
- 妾
- 隶
- 菏
- 煽
- 麒
- 奎
- 驯
- 飙
- 姻
- 沅
- 扉
- 斩
- 奢
- 蚌
- 掩
- 蹲
- 丧
- 辱
- 焉
- 佘
- 襄
- 芯
- 枉
- 谋
- 渊
- 哮
- 喀
- 朔
- 侏
- 姝
- 戎
- 磅
- 督
- 诛
- 奸
- 苞
- 庵
- 馄
- 聋
- 滁
- 垚
- 柬
- 猩
- 夺
- 啼
- 坝
- 竭
- 黏
- 衰
- 遂
- 潞
- 谜
- 蜻
- 蜓
- 瓣
- 秉
- 檐
- 楂
- 嗑
- 搅
- 嘚
- 倚
- 乒
- 宛
- 崽
- 恕
- 轰
- 淄
- 晞
- 酬
- 砂
- 筠
- 薰
- 蒿
- 瞅
- 勺
- 阙
- 伸
- 嚏
- 湄
- 咆
- 坂
- 役
- 掰
- 渣
- 魁
- 诅
- 浒
- 妓
- 珑
- 捎
- 焊
- 饲
- 脍
- 荫
- 堤
- 轿
- 乓
- 筹
- 撸
- 饨
- 渺
- 桓
- 旷
- 笙
- 晖
- 慎
- 埠
- 挪
- 汝
- 浊
- 仨
- 鳄
- 濮
- 汶
- 邰
- 钉
- 蔽
- 亨
- 屑
- 铅
- 喃
- 葩
- 哉
- 睁
- 骆
- 涉
- 汁
- 拦
- 痞
- 芜
- 俪
- 兑
- 梵
- 刊
- 缅
- 彰
- 俑
- 桔
- 堪
- 鸥
- 契
- 覆
- 拷
- 珞
- 诸
- 棱
- 忒
- 嫩
- 梶
- 贻
- 藕
- 愣
- 湃
- 趋
- 甭
- 嗖
- 怯
- 憧
- 珀
- 缸
- 蔓
- 稣
- 筱
- 杠
- 崖
- 凳
- 裆
- 隧
- 锣
- 嘣
- 瀑
- 漪
- 柄
- 凸
- 颁
- 迦
- 烙
- 岱
- 瑄
- 吭
- 肆
- 鳞
- 晾
- 憬
- 邑
- 甥
- 掀
- 褂
- 淫
- 瓢
- 暮
- 喧
- 祛
- 恙
- 禅
- 柚
- 樟
- 疮
- 嗡
- 懈
- 茨
- 矮
- 诠
- 侮
- 眨
- 羲
- 掐
- 琉
- 雍
- 晔
- 凹
- 怂
- 禧
- 蹬
- 绅
- 榄
- 箍
- 詹
- 溶
- 黯
- 啃
- 驸
- 朕
- 婺
- 援
- 铲
- 呻
- 犬
- 捣
- 眷
- 剃
- 惧
- 芷
- 叱
- 娥
- 钦
- 矫
- 憨
- 骊
- 坪
- 俏
- 炳
- 妲
- 冀
- 刁
- 馍
- 琢
- 扛
- 瞿
- 辙
- 茅
- 寡
- 絮
- 呷
- 哺
- 咕
- 驱
- 搂
- 圭
- 嫉
- 涓
- 茱
- '"'
- 笼
- 讽
- 涡
- 泓
- 弊
- 诀
- 璧
- 舔
- 嬅
- 亢
- 沪
- 绢
- 钙
- 喏
- 馥
- 怅
- 簿
- 薜
- 捶
- 冤
- 脐
- 岂
- 溺
- 蕙
- 铿
- 锵
- 锐
- 呸
- 砰
- 亩
- 漳
- 阪
- 栀
- 坞
- 跤
- 蓓
- 舰
- 缕
- 羁
- 芋
- 畔
- 衔
- 铝
- 盲
- 株
- 搏
- 曙
- 惩
- 逻
- 蹄
- 涤
- 宕
- 咤
- 尉
- 嘘
- 瀚
- 仃
- 稽
- 霑
- 飕
- 垮
- 酿
- 畏
- 鲸
- 梗
- 署
- 砒
- 雏
- 茗
- 恬
- 螂
- 拂
- 憔
- 悴
- 钗
- 棕
- 劭
- 歹
- 笠
- 厄
- 焖
- 拣
- 逮
- 蕴
- 淌
- 枸
- 杞
- 雇
- 漯
- 邂
- 逅
- ·
- 荟
- 塾
- 涌
- 挚
- 舱
- 惬
- 剖
- 榴
- 侦
- 摁
- 烹
- 烽
- 俘
- 麓
- 犊
- 酌
- 匿
- 梭
- 覃
- 隽
- 惆
- 掠
- 舵
- 艰
- 蟑
- 瘤
- 仆
- 穴
- 涅
- 衿
- 嚷
- 峪
- 榕
- 吒
- 酪
- 曝
- 帧
- 靶
- 嚣
- 踝
- 翊
- 陂
- 髓
- 瑚
- 裘
- 芍
- 炬
- 鲅
- 蚕
- 肢
- 颊
- 陛
- 籽
- 粟
- 滞
- 煞
- 乾
- 媞
- 刨
- 碾
- 瘫
- 盔
- 侈
- 徘
- 徊
- 熔
- 吆
- 褪
- 拟
- 廓
- 翟
- 俾
- 沽
- 垒
- 萎
- 僻
- 豌
- 卵
- 狡
- 篓
- 栽
- 崴
- 拧
- 颈
- 咐
- 胭
- 阱
- 鄱
- 漓
- 厥
- 烬
- 糙
- 褥
- 炕
- 恍
- 襟
- 韧
- 眸
- 毙
- 垢
- 叙
- 辜
- 酝
- 璋
- 荧
- 魇
- 皈
- 觞
- 喻
- 孺
- 匈
- 铛
- 诈
- 盏
- 淼
- 佣
- 苓
- 缚
- 洼
- 疡
- 猬
- 腑
- 阡
- 鲫
- 鹭
- 鹂
- 笆
- 埙
- 癌
- 璀
- 璨
- 疹
- 蓑
- 芭
- 嘶
- 桀
- 吩
- 泾
- 铂
- 倘
- 囗
- 璜
- 窃
- 癫
- 璞
- 墟
- 钩
- 粹
- 镐
- 韬
- 牺
- 寮
- 喳
- 鄞
- 笋
- 臧
- 疤
- 捐
- 腥
- 嬷
- 燮
- 濠
- 棠
- 夙
- 弑
- 乍
- 剔
- 嘈
- 钇
- 衅
- 挝
- 橡
- 矜
- 圩
- 恳
- 瑛
- 蔺
- 兖
- 焕
- 懿
- 钏
- 栾
- 筐
- 苒
- 碳
- 韭
- 箭
- 婵
- 迭
- 枷
- 孜
- 咽
- 悯
- 漉
- 噬
- 侍
- 蝉
- 涧
- 鹦
- 鹉
- 冼
- 竿
- …
- 袈
- 诏
- 锢
- 泠
- 匡
- 枚
- 坷
- 邝
- 癖
- 绷
- 皖
- 滦
- 滥
- 荨
- 虏
- 拈
- 浜
- 颓
- “
- ”
- 戳
- 钮
- 梳
- 溅
- 徨
- 旨
- 罂
- 蹉
- 腌
- 隙
- 侨
- 槟
- 泌
- 珈
- 芵
- 腮
- 晤
- 墩
- 鲤
- 扳
- 栓
- 窑
- 荏
- 饪
- 泵
- 猿
- 眀
- 嗝
- 禽
- 朽
- 偕
- 胀
- 谍
- 捅
- 蜉
- 蝣
- 蹋
- 拱
- 氯
- 噼
- 蚩
- 芥
- 蛟
- 貂
- 荚
- 痰
- 殿
- 遣
- 丛
- 碱
- 殖
- 炽
- 嚓
- 彗
- 窟
- 鳌
- 矶
- 镯
- 乜
- 髙
- 蛤
- 荤
- 坨
- 漱
- 惰
- 跎
- 萸
- 曰
- 亘
- 窘
- 厮
- 绐
- 黝
- 鞠
- 漩
- 蚱
- 垣
- 翩
- 嬴
- 彷
- 椰
- 砚
- 褐
- 黍
- 噗
- 耕
- 挠
- 妩
- 掂
- 峯
- 灸
- 晌
- 溧
- 鹃
- 屿
- 昙
- 廾
- 冢
- 龌
- 龊
- 瞪
- 刽
- 脓
- 壹
- 羱
- 奠
- 贰
- 佬
- 拙
- 颢
- 嘱
- 糗
- 昀
- 巳
- 辕
- 惫
- 黒
- 辐
- 窈
- 窕
- 拢
- 缪
- 逞
- 吝
- 裟
- 钝
- 寇
- 耙
- 隋
- 蝇
- 仟
- 铨
- 赊
- 皑
- 衢
- 胚
- 腺
- 啧
- 淤
- 妄
- 氢
- 寅
- 叻
- 嘲
- 叼
- 沮
- 磐
- 芈
- 饥
- 槿
- 卤
- 懵
- 惴
- 毋
- 箩
- 苔
- 峥
- 斥
- 矬
- 佚
- 肮
- 皎
- 憎
- 樨
- 讴
- 鳖
- 煦
- 焚
- 泗
- 皂
- 礁
- 睬
- 梢
- 妤
- 佗
- 蝌
- 蚪
- 渗
- 暇
- 卟
- 悼
- 瑨
- 伎
- 纺
- 耆
- 舶
- 礴
- 豺
- 涪
- 谬
- 赴
- 婪
- 吱
- 麽
- 犁
- 潸
- 鸪
- 鸢
- 鄯
- 讷
- 弶
- 橄
- 撬
- 赦
- 岷
- 垓
- 绞
- 虔
- 剥
- 澜
- 酗
- 谛
- 骥
- 撅
- 鱿
- 犷
- 讪
- 秃
- 卞
- 缆
- 蓦
- 庶
- 勐
- 笫
- 敛
- 弗
- 痱
- 啬
- 硚
- 昱
- 忿
- 撩
- 椿
- 侵
- 窄
- 邛
- 崃
- 涸
- 赈
- 狭
- 嵌
- 淖
- 瑙
- 踹
- 傈
- 僳
- 缭
- 睦
- 窜
- 嘅
- 樵
- 爰
- 侗
- 逑
- 弧
- 侑
- :
- 娉
- 蝙
- 蝠
- 骅
- 饴
- 揣
- /
- 鲈
- 綦
- 拴
- 硝
- 梆
- 馗
- 夭
- 扼
- 鳃
- 惚
- 扈
- 矢
- 藁
- 飚
- 妊
- 踮
- 惟
- 痊
- 艇
- 偎
- 魄
- 篝
- 簸
- 擞
- 粽
- 缥
- 缈
- 跷
- 咁
- 悍
- 菀
- 陡
- 橱
- 遐
- 榨
- 渎
- 蹂
- 躏
- 舂
- 轼
- 枰
- 焰
- 幌
- 邸
- 捜
- 灼
- 茯
- 芎
- 穗
- 棘
- 碜
- 颉
- 鹧
- 啄
- 趾
- 茎
- 揽
- 靳
- 黜
- 惋
- 亥
- 铡
- 栅
- 挞
- 眈
- 膘
- 犍
- 珉
- 镪
- 昵
- 霓
- 圪
- 汲
- 惺
- 瑕
- 桩
- 洽
- 唏
- 耒
- 唻
- 豁
- 郓
- 纣
- 亊
- 鳝
- 蟆
- 癣
- 碚
- 踌
- 殁
- 缉
- 痔
- 頔
- 蔫
- ;
- 掺
- 愫
- 祟
- 拘
- 蜘
- 蛛
- 涎
- 耸
- 揪
- 芪
- 腕
- 袍
- 慵
- 绻
- 绛
- 螨
- 捌
- 墅
- 篷
- 啾
- 孪
- 唬
- 褛
- 跶
- 壤
- 慷
- 痧
- 懦
- 郯
- 莴
- 茴
- 嘬
- 铎
- 辫
- 绚
- 簇
- 墘
- 婿
- 咻
- 斡
- 沱
- 譬
- 羔
- 藓
- 肋
- 棂
- 赎
- 炭
- 徵
- 簌
- 艘
- 苪
- 眶
- 嘭
- 霎
- 馊
- 秽
- 仕
- 镶
- 纨
- 摧
- 蒨
- 闰
- 迩
- 篙
- 嚯
- 郫
- 陋
- 殒
- 邃
- 浔
- 瑾
- 鳟
- 祯
- 泻
- 氟
- 猾
- 酥
- 萦
- 郴
- 祀
- 涼
- 屡
- 摹
- 毡
- 妪
- 郡
- 柘
- 裱
- 囔
- 楷
- 鄄
- 蕲
- 偲
- 菘
- 姣
- 瞥
- 肪
- 饽
- 惭
- 胁
- 垄
- 榻
- 讼
- 旱
- 鬓
- 凇
- 钊
- 掣
- 浣
- 凃
- 蓥
- 臊
- 夔
- 脯
- 苛
- 阀
- 睫
- 腋
- 姊
- 躬
- 瘁
- 奄
- 靡
- 盂
- 柑
- 渑
- 恻
- 缱
- 拎
- 恤
- 缶
- 嵬
- 簋
- 囤
- 褴
- 蔼
- 沌
- 薏
- 鸵
- 跋
- 篪
- 罡
- 颇
- 嗄
- 胺
- 烯
- 酚
- 祠
- 迢
- 硖
- 眺
- 珏
- 怆
- 斧
- 痪
- 祺
- 嘤
- 谑
- 婊
- 滂
- 骇
- 帔
- 荼
- 硅
- 猖
- 皱
- 顽
- 榔
- 锌
- 蔻
- 滢
- 茸
- 捋
- 壥
- 孰
- 娩
- 锥
- 逾
- 诬
- 娠
- 厝
- 噎
- 秤
- 祢
- 嗳
- 嗜
- 滘
- 尅
- 悚
- 履
- 馕
- 簪
- 俭
- 摞
- 妗
- 蛎
- 暹
- 钾
- 膨
- 孚
- 驷
- 卯
- 猇
- 褚
- 町
- 骞
- -
- 芩
- 赁
- 粱
- 隼
- 掘
- 莽
- 郾
- 擒
- 叁
- 敕
- 镊
- 惘
- 蚤
- 邳
- 嗫
- 扪
- 瀛
- 凿
- 雎
- 啲
- 鲲
- 帼
- 枭
- 羹
- 驳
- 铆
- 肴
- 嫦
- 媲
- 鹳
- 秩
- 銮
- 饯
- 毽
- 珩
- 眩
- 仄
- 葳
- 撮
- 睇
- 塄
- 肘
- 钠
- 诓
- 呱
- 垅
- 菱
- 亍
- 戍
- 酯
- 袱
- 隘
- 蓟
- 暨
- 痣
- 辗
- 埵
- 殉
- 郏
- 孢
- 悳
- 讫
- 诲
- 髋
- 孑
- 睹
- 擅
- 嗮
- 慒
- 琰
- 濛
- 雌
- 恁
- 擀
- 娼
- 谕
- 撵
- 苯
- 聴
- 唛
- 撂
- 栖
- 拗
- 孬
- 怏
- 掇
- 肽
- 胰
- 沣
- 卅
- 箅
- 氨
- 浠
- 蠡
- 募
- 肛
- 岀
- 瞑
- 蛆
- 舀
- 蚝
- 歙
- 涔
- 诘
- 、
- 垡
- 涠
- 嘢
- 糸
- 胤
- 绊
- 柒
- 沓
- 粼
- 菖
- 犒
- 呒
- 唑
- 莘
- 莪
- 宸
- 睨
- \
- 鲶
- 蛐
- 溏
- 菈
- 蹩
- 焙
- 釆
- 瑗
- 睾
- 槐
- 榉
- 杷
- 鄢
- 僕
- 诽
- 嗲
- 蜃
- 戆
- 蘼
- 糜
- 霁
- 坻
- 硼
- 槛
- 枞
- 麸
- 谒
- 荀
- 邋
- 遢
- 锴
- 啶
- 粪
- 驭
- 筵
- 砌
- 莩
- 蹼
- 吔
- 缳
- 埭
- 隗
- 厶
- 丶
- "\x14"
- "\x17"
- 稼
- 铖
- 涣
- 亳
- 幢
- 沭
- 驮
- 奚
- 藐
- 颅
- 埤
- 愘
- 镲
- 窒
- 暄
- 诃
- 噘
- 歼
- 隅
- 爻
- 蘅
- 锹
- 锇
- 椎
- 琨
- 烩
- 枢
- 觧
- 萁
- 镂
- 龈
- 怠
- 阐
- 藉
- 凛
- 冽
- 珣
- 泘
- 抉
- 锭
- 蕃
- 蠃
- 毓
- 啐
- 栩
- 骷
- 髅
- 耷
- 寥
- 杵
- 蚬
- 窖
- 孛
- 舆
- 皿
- 柸
- 粳
- 钣
- 趸
- 叄
- 腚
- 杖
- 鸸
- 犲
- 浗
- 缮
- 哓
- 箧
- 攘
- 冇
- 钛
- 郗
- 囡
- 酆
- 姌
- 雉
- 胯
- 椭
- 埏
- 钵
- 绌
- 蝾
- 坼
- 濂
- w
- o
- r
- d
- 袒
- 峦
- 鹫
- 炯
- 悱
- 漕
- 莦
- 蔑
- 樽
- 牒
- 濡
- 嫯
- 陖
- 疸
- 桅
- 辖
- 僢
- 《
- 》
- 酣
- 遨
- 邬
- ':'
- 嫲
- 哌
- 锚
- 淙
- Q
- 濑
- 熨
- 谴
- 筛
- 薹
- 磬
- 熠
- 腓
- 阉
- 钴
- 恂
- 溉
- 陨
- 螳
- 孵
- 瘠
- 嫡
- 哝
- 狙
- 怼
- 斟
- 甫
- 渌
- 卒
- 翕
- 沏
- 旮
- 旯
- 菡
- 變
- 狈
- 鳜
- 嵋
- 仞
- 鳕
- 噩
- 踟
- 躇
- 蛀
- 瘸
- 篡
- 锊
- 団
- 斐
- 蹍
- 冗
- "\uFEFF"
- 歆
- 圴
- 泯
- 伥
- 愎
- 坌
- 碘
- 赉
- 骧
- 矩
- 綽
- 秭
- 怵
- 麝
- 贩
- 溥
- 捆
- 腩
- 溴
- 卉
- 痦
- 荻
- 缇
- 秸
- 秆
- 捍
- 炀
- 阆
- 泞
- 懊
- 啕
- 蚶
- 衩
- 桜
- 旖
- 贬
- 酵
- 滟
- 纥
- 倭
- 赝
- 呶
- 哧
- 煸
- 劢
- 炝
- 僚
- 豇
- 阂
- 涝
- 骡
- 霭
- 窨
- 殴
- 竣
- 醇
- 擂
- 怦
- 怩
- 臾
- 搔
- 伱
- 啉
- 嫖
- 囝
- 糠
- 胥
- 酰
- 镫
- 蟒
- 荞
- 醪
- 颦
- 吏
- 颛
- 赳
- 贿
- 赂
- 痩
- 仂
- 颍
- 罔
- 猕
- 嚒
- 蘸
- 熹
- 捺
- 坜
- 郜
- 鉄
- 蒌
- 荑
- 藻
- 谌
- 钳
- 屮
- 疵
- 哞
- 琮
- 潴
- 讹
- 镭
- '3'
- 尕
- 倬
- 庇
- 侩
- 瘆
- 傀
- 儡
- 诧
- 葆
- 唾
- 皋
- 逄
- 诌
- 氦
- 彳
- 盅
- 曳
- 槲
- 挟
- 怿
- 顷
- 臃
- 衙
- 踵
- 霈
- 嗪
- 闩
- 锟
- 恿
- 抻
- 茁
- 惢
- 菅
- 迂
- 瞟
- 痉
- 挛
- 绦
- 晁
- 挢
- 蠕
- 洙
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: null
zero_infinity: true
joint_net_conf: null
use_preprocessor: true
token_type: char
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
frontend: default
frontend_conf:
fs: 16k
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_zh_char_sp/train/feats_stats.npz
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 512
attention_heads: 8
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.0
input_layer: conv2d
normalize_before: true
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
macaron_style: true
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
required:
- output_dir
- token_list
version: '202207'
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
facebook/spar-paq-bm25-lexmodel-query-encoder | facebook | 2022-09-21T23:12:22Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2110.06918",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T22:58:03Z | ---
tags:
- feature-extraction
pipeline_tag: feature-extraction
---
This model is the query encoder of the PAQ BM25 Lexical Model (Λ) from the SPAR paper:
[Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?](https://arxiv.org/abs/2110.06918)
<br>
Xilun Chen, Kushal Lakhotia, Barlas Oğuz, Anchit Gupta, Patrick Lewis, Stan Peshterliev, Yashar Mehdad, Sonal Gupta and Wen-tau Yih
<br>
**Meta AI**
The associated github repo is available here: https://github.com/facebookresearch/dpr-scale/tree/main/spar
This model is a BERT-base sized dense retriever trained using PAQ questions as queries to imitate the behavior of BM25.
The following models are also available:
Pretrained Model | Corpus | Teacher | Architecture | Query Encoder Path | Context Encoder Path
|---|---|---|---|---|---
Wiki BM25 Λ | Wikipedia | BM25 | BERT-base | facebook/spar-wiki-bm25-lexmodel-query-encoder | facebook/spar-wiki-bm25-lexmodel-context-encoder
PAQ BM25 Λ | PAQ | BM25 | BERT-base | facebook/spar-paq-bm25-lexmodel-query-encoder | facebook/spar-paq-bm25-lexmodel-context-encoder
MARCO BM25 Λ | MS MARCO | BM25 | BERT-base | facebook/spar-marco-bm25-lexmodel-query-encoder | facebook/spar-marco-bm25-lexmodel-context-encoder
MARCO UniCOIL Λ | MS MARCO | UniCOIL | BERT-base | facebook/spar-marco-unicoil-lexmodel-query-encoder | facebook/spar-marco-unicoil-lexmodel-context-encoder
# Using the Lexical Model (Λ) Alone
This model should be used together with the associated query encoder, similar to the [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr) model.
```
import torch
from transformers import AutoTokenizer, AutoModel
# The tokenizer is the same for the query and context encoder
tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Apply tokenizer
query_input = tokenizer(query, return_tensors='pt')
ctx_input = tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
# Compute embeddings: take the last-layer hidden state of the [CLS] token
query_emb = query_encoder(**query_input).last_hidden_state[:, 0, :]
ctx_emb = context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Compute similarity scores using dot product
score1 = query_emb @ ctx_emb[0] # 341.3268
score2 = query_emb @ ctx_emb[1] # 340.1626
```
# Using the Lexical Model (Λ) with a Base Dense Retriever as in SPAR
As Λ learns lexical matching from a sparse teacher retriever, it can be used in combination with a standard dense retriever (e.g. [DPR](https://huggingface.co/docs/transformers/v4.22.1/en/model_doc/dpr#dpr), [Contriever](https://huggingface.co/facebook/contriever-msmarco)) to build a dense retriever that excels at both lexical and semantic matching.
In the following example, we show how to build the SPAR-Wiki model for Open-Domain Question Answering by concatenating the embeddings of DPR and the Wiki BM25 Λ.
```
import torch
from transformers import AutoTokenizer, AutoModel
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
# DPR model
dpr_ctx_tokenizer = DPRContextEncoderTokenizer.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
dpr_query_tokenizer = DPRQuestionEncoderTokenizer.from_pretrained("facebook/dpr-question_encoder-multiset-base")
dpr_query_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-multiset-base")
# Wiki BM25 Λ model
lexmodel_tokenizer = AutoTokenizer.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_query_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-query-encoder')
lexmodel_context_encoder = AutoModel.from_pretrained('facebook/spar-wiki-bm25-lexmodel-context-encoder')
query = "Where was Marie Curie born?"
contexts = [
"Maria Sklodowska, later known as Marie Curie, was born on November 7, 1867.",
"Born in Paris on 15 May 1859, Pierre Curie was the son of Eugène Curie, a doctor of French Catholic origin from Alsace."
]
# Compute DPR embeddings
dpr_query_input = dpr_query_tokenizer(query, return_tensors='pt')['input_ids']
dpr_query_emb = dpr_query_encoder(dpr_query_input).pooler_output
dpr_ctx_input = dpr_ctx_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
dpr_ctx_emb = dpr_ctx_encoder(**dpr_ctx_input).pooler_output
# Compute Λ embeddings
lexmodel_query_input = lexmodel_tokenizer(query, return_tensors='pt')
lexmodel_query_emb = lexmodel_query_encoder(**query_input).last_hidden_state[:, 0, :]
lexmodel_ctx_input = lexmodel_tokenizer(contexts, padding=True, truncation=True, return_tensors='pt')
lexmodel_ctx_emb = lexmodel_context_encoder(**ctx_input).last_hidden_state[:, 0, :]
# Form SPAR embeddings via concatenation
# The concatenation weight is only applied to query embeddings
# Refer to the SPAR paper for details
concat_weight = 0.7
spar_query_emb = torch.cat(
[dpr_query_emb, concat_weight * lexmodel_query_emb],
dim=-1,
)
spar_ctx_emb = torch.cat(
[dpr_ctx_emb, lexmodel_ctx_emb],
dim=-1,
)
# Compute similarity scores
score1 = spar_query_emb @ spar_ctx_emb[0] # 317.6931
score2 = spar_query_emb @ spar_ctx_emb[1] # 314.6144
```
|
jgiral95/q-Taxi-v3 | jgiral95 | 2022-09-21T23:03:18Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2022-09-21T23:03:10Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="jgiral95/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
research-backup/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification | research-backup | 2022-09-21T22:47:04Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T22:05:02Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.7127976190476191
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.29411764705882354
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.29080118694362017
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.4641467481934408
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.614
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.32456140350877194
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.3449074074074074
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8862437848425494
- name: F1 (macro)
type: f1_macro
value: 0.8781526549150734
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8370892018779342
- name: F1 (macro)
type: f1_macro
value: 0.6286516686265566
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.5384615384615384
- name: F1 (macro)
type: f1_macro
value: 0.5368027921312294
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9659177853516032
- name: F1 (macro)
type: f1_macro
value: 0.8925325170399768
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8567847069884049
- name: F1 (macro)
type: f1_macro
value: 0.8346603805121989
---
# relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.29411764705882354
- Accuracy on SAT: 0.29080118694362017
- Accuracy on BATS: 0.4641467481934408
- Accuracy on U2: 0.32456140350877194
- Accuracy on U4: 0.3449074074074074
- Accuracy on Google: 0.614
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.8862437848425494
- Micro F1 score on CogALexV: 0.8370892018779342
- Micro F1 score on EVALution: 0.5384615384615384
- Micro F1 score on K&H+N: 0.9659177853516032
- Micro F1 score on ROOT09: 0.8567847069884049
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.7127976190476191
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average_no_mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 1
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-no-mask-prompt-c-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average | teven | 2022-09-21T22:45:38Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T22:45:32Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average')
model = AutoModel.from_pretrained('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_metric_average)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average | teven | 2022-09-21T22:45:05Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T22:44:59Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average')
model = AutoModel.from_pretrained('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all_bs160_allneg_finetuned_WebNLG2020_metric_average)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_metric_average | teven | 2022-09-21T22:43:58Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T22:43:52Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_metric_average
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_metric_average')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_metric_average)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 161 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0001
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 805,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
sd-concepts-library/karan-gloomy | sd-concepts-library | 2022-09-21T22:42:56Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T22:42:50Z | ---
license: mit
---
### Karan Gloomy on Stable Diffusion
This is the `<karan>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






















|
tdobrxl/ClinicBERT | tdobrxl | 2022-09-21T22:27:34Z | 196 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-07-27T16:18:35Z | ClinicBERT has the same architecture of RoBERTa model. It has been trained on clinical text and can be used for feature extraction from textual data.
## How to use
### Feature Extraction
```
from transformers import RobertaModel, RobertaTokenizer
model = RobertaModel.from_pretrained("tdobrxl/ClinicBERT")
tokenizer = RobertaTokenizer.from_pretrained("tdobrxl/ClinicBERT")
text = "Randomized Study of Shark Cartilage in Patients With Breast Cancer."
last_hidden_state, pooler_output = model(tokenizer.encode(text, return_tensors="pt")).last_hidden_state, model(tokenizer.encode(text, return_tensors="pt")).pooler_output
```
### Masked Word Prediction
```
from transformers import pipeline
fill_mask = pipeline("fill-mask", model="tdobrxl/ClinicBERT", tokenizer="tdobrxl/ClinicBERT")
text = "this is the start of a beautiful <mask>."
fill_mask(text)
```
```[{'score': 0.26558592915534973, 'token': 363, 'token_str': ' study', 'sequence': 'this is the start of a beautiful study.'}, {'score': 0.06330082565546036, 'token': 2010, 'token_str': ' procedure', 'sequence': 'this is the start of a beautiful procedure.'}, {'score': 0.04393036663532257, 'token': 661, 'token_str': ' trial', 'sequence': 'this is the start of a beautiful trial.'}, {'score': 0.0363750196993351, 'token': 839, 'token_str': ' period', 'sequence': 'this is the start of a beautiful period.'}, {'score': 0.027248281985521317, 'token': 436, 'token_str': ' treatment', 'sequence': 'this is the start of a beautiful treatment.'}``` |
misterneil/xlm-roberta-base-finetuned-panx-de | misterneil | 2022-09-21T21:55:00Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"dataset:xtreme",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-09-20T12:28:11Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8648740833380706
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
sd-concepts-library/maus | sd-concepts-library | 2022-09-21T21:54:54Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T21:54:41Z | ---
license: mit
---
### maus on Stable Diffusion
This is the `<Maus>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:



|
sd-concepts-library/puerquis-toy | sd-concepts-library | 2022-09-21T21:27:16Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T21:27:12Z | ---
license: mit
---
### Puerquis toy on Stable Diffusion
This is the `<puerquis>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/midjourney-style | sd-concepts-library | 2022-09-21T21:17:45Z | 0 | 152 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T21:17:31Z | ---
license: mit
---
### Midjourney style on Stable Diffusion
This is the `<midjourney-style>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
CommunityLM/democrat-twitter-gpt2 | CommunityLM | 2022-09-21T20:57:24Z | 109 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"arxiv:2209.07065",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-21T19:20:53Z | ---
license: cc-by-nc-4.0
---
## Model Specification
- This is the **Democratic** community GPT-2 language model, fine-tuned on 4.7M (~100M tokens) tweets of Democratic Twitter users between 2019-01-01 and 2020-04-10.
- For more details about the `CommunityLM` project, please refer to this [our paper](https://arxiv.org/abs/2209.07065) and [github](https://github.com/hjian42/communitylm) page.
- In the paper, it is referred as the `Fine-tuned CommunityLM` for the Democratic Twitter community.
## How to use the model
- **PRE-PROCESSING**: when you apply the model on tweets, please make sure that tweets are preprocessed by the [TweetTokenizer](https://github.com/VinAIResearch/BERTweet/blob/master/TweetNormalizer.py) to get the best performance.
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("CommunityLM/republican-twitter-gpt2")
model = AutoModelForCausalLM.from_pretrained("CommunityLM/republican-twitter-gpt2")
```
## References
If you use this repository in your research, please kindly cite [our paper](https://arxiv.org/abs/2209.07065):
```bibtex
@inproceedings{jiang-etal-2022-communitylm,
title = "CommunityLM: Probing Partisan Worldviews from Language Models",
author = {Jiang, Hang and Beeferman, Doug and Roy, Brandon and Roy, Deb},
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
year = "2022",
publisher = "International Committee on Computational Linguistics",
}
``` |
blmnk/distilbert-base-uncased-finetuned-emotion | blmnk | 2022-09-21T20:46:31Z | 105 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-21T20:19:02Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.896
- name: F1
type: f1
value: 0.8927988574486181
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3821
- Accuracy: 0.896
- F1: 0.8928
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 125 | 0.6029 | 0.7985 | 0.7597 |
| 0.7905 | 2.0 | 250 | 0.3821 | 0.896 | 0.8928 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
research-backup/roberta-large-semeval2012-average-prompt-c-nce-classification | research-backup | 2022-09-21T19:55:05Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T19:15:07Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-prompt-c-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.679702380952381
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.31283422459893045
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.3086053412462908
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.46192329071706506
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.63
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.34649122807017546
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.3611111111111111
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8457134247400934
- name: F1 (macro)
type: f1_macro
value: 0.8210817253537833
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.846244131455399
- name: F1 (macro)
type: f1_macro
value: 0.6205542192501825
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6262188515709642
- name: F1 (macro)
type: f1_macro
value: 0.6158702387251406
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9545802323155039
- name: F1 (macro)
type: f1_macro
value: 0.8851331276863854
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9044186775305547
- name: F1 (macro)
type: f1_macro
value: 0.9039135057812416
---
# relbert/roberta-large-semeval2012-average-prompt-c-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-c-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.31283422459893045
- Accuracy on SAT: 0.3086053412462908
- Accuracy on BATS: 0.46192329071706506
- Accuracy on U2: 0.34649122807017546
- Accuracy on U4: 0.3611111111111111
- Accuracy on Google: 0.63
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-c-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.8457134247400934
- Micro F1 score on CogALexV: 0.846244131455399
- Micro F1 score on EVALution: 0.6262188515709642
- Micro F1 score on K&H+N: 0.9545802323155039
- Micro F1 score on ROOT09: 0.9044186775305547
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-c-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.679702380952381
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-prompt-c-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 1
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-c-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
research-backup/roberta-large-semeval2012-average-prompt-b-nce-classification | research-backup | 2022-09-21T19:15:01Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T18:42:00Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-average-prompt-b-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.8162698412698413
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.4732620320855615
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.49258160237388726
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5986659255141745
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.686
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.44298245614035087
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.4930555555555556
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9085430164230828
- name: F1 (macro)
type: f1_macro
value: 0.9029499017420614
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8359154929577466
- name: F1 (macro)
type: f1_macro
value: 0.6401332628753275
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6581798483206934
- name: F1 (macro)
type: f1_macro
value: 0.6411620033399844
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9586840091813313
- name: F1 (macro)
type: f1_macro
value: 0.8809925441051085
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8824819805703541
- name: F1 (macro)
type: f1_macro
value: 0.877314171779575
---
# relbert/roberta-large-semeval2012-average-prompt-b-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-b-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.4732620320855615
- Accuracy on SAT: 0.49258160237388726
- Accuracy on BATS: 0.5986659255141745
- Accuracy on U2: 0.44298245614035087
- Accuracy on U4: 0.4930555555555556
- Accuracy on Google: 0.686
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-b-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9085430164230828
- Micro F1 score on CogALexV: 0.8359154929577466
- Micro F1 score on EVALution: 0.6581798483206934
- Micro F1 score on K&H+N: 0.9586840091813313
- Micro F1 score on ROOT09: 0.8824819805703541
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-b-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.8162698412698413
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-average-prompt-b-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: average
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <obj> is <subj>'s <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 30
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-average-prompt-b-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
pritamdeka/S-BioBert-snli-multinli-stsb | pritamdeka | 2022-09-21T18:59:33Z | 2,681 | 5 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# S-BioBert-snli-multinli-stsb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('pritamdeka/S-BioBert-snli-multinli-stsb')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('pritamdeka/S-BioBert-snli-multinli-stsb')
model = AutoModel.from_pretrained('pritamdeka/S-BioBert-snli-multinli-stsb')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 90 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
If you use the model kindly cite the following work
```
@inproceedings{deka2021unsupervised,
title={Unsupervised Keyword Combination Query Generation from Online Health Related Content for Evidence-Based Fact Checking},
author={Deka, Pritam and Jurek-Loughrey, Anna},
booktitle={The 23rd International Conference on Information Integration and Web Intelligence},
pages={267--277},
year={2021}
}
``` |
pritamdeka/S-Scibert-snli-multinli-stsb | pritamdeka | 2022-09-21T18:59:09Z | 5,987 | 4 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# pritamdeka/S-Scibert-snli-multinli-stsb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('pritamdeka/S-Scibert-snli-multinli-stsb')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('pritamdeka/S-Scibert-snli-multinli-stsb')
model = AutoModel.from_pretrained('pritamdeka/S-Scibert-snli-multinli-stsb')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 90 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
If you use the model kindly cite the following work
```
@inproceedings{deka2021unsupervised,
title={Unsupervised Keyword Combination Query Generation from Online Health Related Content for Evidence-Based Fact Checking},
author={Deka, Pritam and Jurek-Loughrey, Anna},
booktitle={The 23rd International Conference on Information Integration and Web Intelligence},
pages={267--277},
year={2021}
}
``` |
pritamdeka/S-Bluebert-snli-multinli-stsb | pritamdeka | 2022-09-21T18:58:03Z | 702 | 7 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-03-02T23:29:05Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# pritamdeka/S-Bluebert-snli-multinli-stsb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('pritamdeka/S-Bluebert-snli-multinli-stsb')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('pritamdeka/S-Bluebert-snli-multinli-stsb')
model = AutoModel.from_pretrained('pritamdeka/S-Bluebert-snli-multinli-stsb')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 90 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
If you use the model kindly cite the following work
```
@inproceedings{deka2021unsupervised,
title={Unsupervised Keyword Combination Query Generation from Online Health Related Content for Evidence-Based Fact Checking},
author={Deka, Pritam and Jurek-Loughrey, Anna},
booktitle={The 23rd International Conference on Information Integration and Web Intelligence},
pages={267--277},
year={2021}
}
``` |
sd-concepts-library/wildkat | sd-concepts-library | 2022-09-21T18:56:20Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T18:56:13Z | ---
license: mit
---
### Wildkat on Stable Diffusion
This is the `<wildkat>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:









|
sd-concepts-library/darkplane | sd-concepts-library | 2022-09-21T18:37:08Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T18:36:56Z | ---
license: mit
---
### DarkPlane on Stable Diffusion
This is the `<DarkPlane>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





















|
sd-concepts-library/babau | sd-concepts-library | 2022-09-21T18:14:34Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T18:14:21Z | ---
license: mit
---
### Babau on Stable Diffusion
This is the `<babau>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
xzmZEW/batman | xzmZEW | 2022-09-21T18:12:07Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2022-09-21T18:12:07Z | ---
license: creativeml-openrail-m
---
|
sd-concepts-library/hrgiger-drmacabre | sd-concepts-library | 2022-09-21T17:39:06Z | 0 | 4 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T17:38:59Z | ---
license: mit
---
### HrGiger_DrMacabre on Stable Diffusion
This is the `<barba>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
sd-concepts-library/dicoo2 | sd-concepts-library | 2022-09-21T17:35:48Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T17:35:43Z | ---
license: mit
---
### Dicoo2 on Stable Diffusion
This is the `<dicoo>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
keras-io/dcgan-to-generate-face-images | keras-io | 2022-09-21T17:35:16Z | 5 | 1 | tf-keras | [
"tf-keras",
"tensorboard",
"region:us"
]
| null | 2022-09-21T10:33:49Z |
▲
🙂
---
license: gpl-2.0
---
# DCGAN to generate face images
This is an example notebook for Keras sprint prepared by Hugging Face. Keras Sprint aims to reproduce Keras examples and build interactive demos to them. The markdown parts beginning with 🤗 and the following code snippets are the parts added by the Hugging Face team to give you an example of how to host your model and build a demo.
**Original Author of the DCGAN to generate face images Example:** [fchollet](https://twitter.com/fchollet)
## Steps to Train the DCGAN
1. Create the discriminator
- It maps a 64x64 image to a binary classification score.
```py
discriminator = keras.Sequential(
[
keras.Input(shape=(64, 64, 3)),
layers.Conv2D(64, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(1, activation="sigmoid"),
],
name="discriminator",
)
```
2. Create the generator
- It mirrors the discriminator, replacing Conv2D layers with Conv2DTranspose layers
```py
latent_dim = 128
generator = keras.Sequential(
[
keras.Input(shape=(latent_dim,)),
layers.Dense(8 * 8 * 128),
layers.Reshape((8, 8, 128)),
layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(256, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(512, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(3, kernel_size=5, padding="same", activation="sigmoid"),
],
name="generator",
)
```
HF Contributor: [Tarun Jain](https://twitter.com/TRJ_0751) |
research-backup/roberta-large-semeval2012-mask-prompt-d-nce-classification | research-backup | 2022-09-21T17:31:01Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T16:59:47Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.796765873015873
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6524064171122995
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6498516320474778
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.7509727626459144
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.902
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6271929824561403
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.625
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9246647581738737
- name: F1 (macro)
type: f1_macro
value: 0.9201116139693363
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8826291079812206
- name: F1 (macro)
type: f1_macro
value: 0.74506786895136
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.7172264355362946
- name: F1 (macro)
type: f1_macro
value: 0.703292242462215
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9616748974055783
- name: F1 (macro)
type: f1_macro
value: 0.8934154139843127
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9094327796928863
- name: F1 (macro)
type: f1_macro
value: 0.906471425124189
---
# relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.6524064171122995
- Accuracy on SAT: 0.6498516320474778
- Accuracy on BATS: 0.7509727626459144
- Accuracy on U2: 0.6271929824561403
- Accuracy on U4: 0.625
- Accuracy on Google: 0.902
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9246647581738737
- Micro F1 score on CogALexV: 0.8826291079812206
- Micro F1 score on EVALution: 0.7172264355362946
- Micro F1 score on K&H+N: 0.9616748974055783
- Micro F1 score on ROOT09: 0.9094327796928863
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.796765873015873
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: I wasn’t aware of this relationship, but I just read in the encyclopedia that <subj> is the <mask> of <obj>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 30
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-d-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
Harindu/blurr_IMDB_distilbert_classification | Harindu | 2022-09-21T17:17:00Z | 0 | 0 | fastai | [
"fastai",
"region:us"
]
| null | 2022-09-21T17:16:48Z | ---
tags:
- fastai
---
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co/docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co/docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
|
research-backup/roberta-large-semeval2012-mask-prompt-c-nce-classification | research-backup | 2022-09-21T16:59:42Z | 103 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T16:17:41Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.5331547619047619
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.2914438502673797
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.29080118694362017
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.3913285158421345
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.486
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.33771929824561403
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.3263888888888889
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8392345939430466
- name: F1 (macro)
type: f1_macro
value: 0.8259066607574465
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.7570422535211268
- name: F1 (macro)
type: f1_macro
value: 0.43666662077729007
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.5926327193932828
- name: F1 (macro)
type: f1_macro
value: 0.5763337381530251
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9392780134937748
- name: F1 (macro)
type: f1_macro
value: 0.8298559683420568
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8934503290504543
- name: F1 (macro)
type: f1_macro
value: 0.8858359126040442
---
# relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.2914438502673797
- Accuracy on SAT: 0.29080118694362017
- Accuracy on BATS: 0.3913285158421345
- Accuracy on U2: 0.33771929824561403
- Accuracy on U4: 0.3263888888888889
- Accuracy on Google: 0.486
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.8392345939430466
- Micro F1 score on CogALexV: 0.7570422535211268
- Micro F1 score on EVALution: 0.5926327193932828
- Micro F1 score on K&H+N: 0.9392780134937748
- Micro F1 score on ROOT09: 0.8934503290504543
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.5331547619047619
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 1
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-c-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
sd-concepts-library/sherhook-painting | sd-concepts-library | 2022-09-21T16:41:10Z | 0 | 4 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T16:41:04Z | ---
license: mit
---
### Sherhook Painting on Stable Diffusion
This is the `<sherhook>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
sd-concepts-library/arcane-face | sd-concepts-library | 2022-09-21T16:24:02Z | 0 | 14 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T16:23:56Z | ---
license: mit
---
### arcane-face on Stable Diffusion
This is the `<arcane-face>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




















|
research-backup/roberta-large-semeval2012-mask-prompt-b-nce-classification | research-backup | 2022-09-21T16:17:35Z | 104 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"dataset:relbert/semeval2012_relational_similarity",
"model-index",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| feature-extraction | 2022-09-21T15:45:17Z | ---
datasets:
- relbert/semeval2012_relational_similarity
model-index:
- name: relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification
results:
- task:
name: Relation Mapping
type: sorting-task
dataset:
name: Relation Mapping
args: relbert/relation_mapping
type: relation-mapping
metrics:
- name: Accuracy
type: accuracy
value: 0.7908730158730158
- task:
name: Analogy Questions (SAT full)
type: multiple-choice-qa
dataset:
name: SAT full
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5080213903743316
- task:
name: Analogy Questions (SAT)
type: multiple-choice-qa
dataset:
name: SAT
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5192878338278932
- task:
name: Analogy Questions (BATS)
type: multiple-choice-qa
dataset:
name: BATS
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.6653696498054474
- task:
name: Analogy Questions (Google)
type: multiple-choice-qa
dataset:
name: Google
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.84
- task:
name: Analogy Questions (U2)
type: multiple-choice-qa
dataset:
name: U2
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.45614035087719296
- task:
name: Analogy Questions (U4)
type: multiple-choice-qa
dataset:
name: U4
args: relbert/analogy_questions
type: analogy-questions
metrics:
- name: Accuracy
type: accuracy
value: 0.5393518518518519
- task:
name: Lexical Relation Classification (BLESS)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9132138014163026
- name: F1 (macro)
type: f1_macro
value: 0.9101733559621606
- task:
name: Lexical Relation Classification (CogALexV)
type: classification
dataset:
name: CogALexV
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.8502347417840377
- name: F1 (macro)
type: f1_macro
value: 0.6852576593859314
- task:
name: Lexical Relation Classification (EVALution)
type: classification
dataset:
name: BLESS
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.6852654387865655
- name: F1 (macro)
type: f1_macro
value: 0.6694360423727916
- task:
name: Lexical Relation Classification (K&H+N)
type: classification
dataset:
name: K&H+N
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9604228976838005
- name: F1 (macro)
type: f1_macro
value: 0.8826948107609662
- task:
name: Lexical Relation Classification (ROOT09)
type: classification
dataset:
name: ROOT09
args: relbert/lexical_relation_classification
type: relation-classification
metrics:
- name: F1
type: f1
value: 0.9022250078345346
- name: F1 (macro)
type: f1_macro
value: 0.9002463330589072
---
# relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification
RelBERT fine-tuned from [roberta-large](https://huggingface.co/roberta-large) on
[relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity).
Fine-tuning is done via [RelBERT](https://github.com/asahi417/relbert) library (see the repository for more detail).
It achieves the following results on the relation understanding tasks:
- Analogy Question ([dataset](https://huggingface.co/datasets/relbert/analogy_questions), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification/raw/main/analogy.json)):
- Accuracy on SAT (full): 0.5080213903743316
- Accuracy on SAT: 0.5192878338278932
- Accuracy on BATS: 0.6653696498054474
- Accuracy on U2: 0.45614035087719296
- Accuracy on U4: 0.5393518518518519
- Accuracy on Google: 0.84
- Lexical Relation Classification ([dataset](https://huggingface.co/datasets/relbert/lexical_relation_classification), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification/raw/main/classification.json)):
- Micro F1 score on BLESS: 0.9132138014163026
- Micro F1 score on CogALexV: 0.8502347417840377
- Micro F1 score on EVALution: 0.6852654387865655
- Micro F1 score on K&H+N: 0.9604228976838005
- Micro F1 score on ROOT09: 0.9022250078345346
- Relation Mapping ([dataset](https://huggingface.co/datasets/relbert/relation_mapping), [full result](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification/raw/main/relation_mapping.json)):
- Accuracy on Relation Mapping: 0.7908730158730158
### Usage
This model can be used through the [relbert library](https://github.com/asahi417/relbert). Install the library via pip
```shell
pip install relbert
```
and activate model as below.
```python
from relbert import RelBERT
model = RelBERT("relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification")
vector = model.get_embedding(['Tokyo', 'Japan']) # shape of (1024, )
```
### Training hyperparameters
The following hyperparameters were used during training:
- model: roberta-large
- max_length: 64
- mode: mask
- data: relbert/semeval2012_relational_similarity
- split: train
- data_eval: relbert/conceptnet_high_confidence
- split_eval: full
- template_mode: manual
- template: Today, I finally discovered the relation between <subj> and <obj> : <obj> is <subj>'s <mask>
- loss_function: nce_logout
- classification_loss: True
- temperature_nce_constant: 0.05
- temperature_nce_rank: {'min': 0.01, 'max': 0.05, 'type': 'linear'}
- epoch: 27
- batch: 128
- lr: 5e-06
- lr_decay: False
- lr_warmup: 1
- weight_decay: 0
- random_seed: 0
- exclude_relation: None
- exclude_relation_eval: None
- n_sample: 640
- gradient_accumulation: 8
The full configuration can be found at [fine-tuning parameter file](https://huggingface.co/relbert/roberta-large-semeval2012-mask-prompt-b-nce-classification/raw/main/trainer_config.json).
### Reference
If you use any resource from RelBERT, please consider to cite our [paper](https://aclanthology.org/2021.eacl-demos.7/).
```
@inproceedings{ushio-etal-2021-distilling-relation-embeddings,
title = "{D}istilling {R}elation {E}mbeddings from {P}re-trained {L}anguage {M}odels",
author = "Ushio, Asahi and
Schockaert, Steven and
Camacho-Collados, Jose",
booktitle = "EMNLP 2021",
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
}
```
|
teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage | teven | 2022-09-21T15:53:15Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:53:08Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage')
model = AutoModel.from_pretrained('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage | teven | 2022-09-21T15:52:36Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:52:29Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage')
model = AutoModel.from_pretrained('teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
julius-br/gottbert-base-finetuned-fbi-german | julius-br | 2022-09-21T15:51:49Z | 106 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"gottbert",
"de",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-07T11:43:30Z | ---
language: de
license: mit
tags:
- roberta
- gottbert
---
# Fine-tuned gottbert-base to detect Feature Requests & Bug Reports in German App Store Reviews
## Overview
**Language model:** uklfr/gottbert-base
**Language:** German
**Training & Eval data:** [GARFAB2022Weighted](https://huggingface.co/datasets/julius-br/GARFAB) <br>
**Published**: September 21th, 2022 <br>
**Author**: Julius Breiholz
## Performance
| Label | Precision | Recall | F1-Score |
| --- | --- | --- | --- |
| Irrelevant | 0,95 | 0,91 | 0,93 |
| Bug Report | 0,82 | 0,91 | 0,86 |
| Feature Request | 0,87 | 0,82 | 0,85 |
| all classes (avg.) | 0,88 | 0,88 | 0,88 |
|
teven/bi_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage | teven | 2022-09-21T15:50:15Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:50:08Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all_bs192_hardneg_finetuned_WebNLG2020_data_coverage)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 161 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 5e-05
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 805,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_data_coverage | teven | 2022-09-21T15:49:40Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:49:33Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_data_coverage
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_data_coverage')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_data_coverage)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 41 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0001
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 205,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage | teven | 2022-09-21T15:49:04Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:48:57Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_data_coverage)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 41 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 205,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance | teven | 2022-09-21T15:48:28Z | 5 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:48:21Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance')
model = AutoModel.from_pretrained('teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all_bs320_vanilla_finetuned_WebNLG2020_relevance)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance | teven | 2022-09-21T15:46:24Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:46:16Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance')
model = AutoModel.from_pretrained('teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all-mpnet-base-v2_finetuned_WebNLG2020_relevance)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness | teven | 2022-09-21T15:41:45Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:41:37Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness')
model = AutoModel.from_pretrained('teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/cross_all_bs160_allneg_finetuned_WebNLG2020_correctness)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_correctness | teven | 2022-09-21T15:40:30Z | 4 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:40:23Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_correctness
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_correctness')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all_bs320_vanilla_finetuned_WebNLG2020_correctness)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 321 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 5e-05
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 1605,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_correctness | teven | 2022-09-21T15:37:39Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:37:31Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_correctness
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_correctness')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all-mpnet-base-v2_finetuned_WebNLG2020_correctness)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 41 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 205,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
teven/bi_all_bs160_allneg_finetuned_WebNLG2020_correctness | teven | 2022-09-21T15:37:00Z | 3 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2022-09-21T15:36:53Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# teven/bi_all_bs160_allneg_finetuned_WebNLG2020_correctness
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('teven/bi_all_bs160_allneg_finetuned_WebNLG2020_correctness')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=teven/bi_all_bs160_allneg_finetuned_WebNLG2020_correctness)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 81 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 50,
"evaluation_steps": 0,
"evaluator": "better_cross_encoder.PearsonCorrelationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "warmupcosine",
"steps_per_epoch": null,
"warmup_steps": 405,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
matemato/testpyramidsrnd | matemato | 2022-09-21T15:25:39Z | 0 | 0 | ml-agents | [
"ml-agents",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2022-09-21T15:25:31Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: matemato/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
GItaf/gpt2-gpt2-TF-weight0.5-epoch5 | GItaf | 2022-09-21T15:24:17Z | 112 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2022-09-21T12:07:29Z | ---
tags:
- generated_from_trainer
model-index:
- name: gpt2-gpt2-TF-weight0.5-epoch5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-gpt2-TF-weight0.5-epoch5
This model is a fine-tuned version of [](https://huggingface.co/) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.4047
- Cls loss: 0.8943
- Lm loss: 3.9573
- Cls Accuracy: 0.8305
- Cls F1: 0.8305
- Cls Precision: 0.8305
- Cls Recall: 0.8305
- Perplexity: 52.31
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cls loss | Lm loss | Cls Accuracy | Cls F1 | Cls Precision | Cls Recall | Perplexity |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:-------:|:------------:|:------:|:-------------:|:----------:|:----------:|
| 4.4891 | 1.0 | 3470 | 4.2525 | 0.4695 | 4.0177 | 0.8046 | 0.8023 | 0.8093 | 0.8046 | 55.57 |
| 4.2708 | 2.0 | 6940 | 4.2621 | 0.5568 | 3.9835 | 0.8398 | 0.8383 | 0.8438 | 0.8398 | 53.71 |
| 4.1614 | 3.0 | 10410 | 4.2509 | 0.5637 | 3.9689 | 0.8444 | 0.8443 | 0.8443 | 0.8444 | 52.93 |
| 4.0683 | 4.0 | 13880 | 4.3454 | 0.7723 | 3.9591 | 0.8282 | 0.8281 | 0.8281 | 0.8282 | 52.41 |
| 4.0036 | 5.0 | 17350 | 4.4047 | 0.8943 | 3.9573 | 0.8305 | 0.8305 | 0.8305 | 0.8305 | 52.31 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1 |
sd-concepts-library/kogatan-shiny | sd-concepts-library | 2022-09-21T15:11:22Z | 0 | 3 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T15:11:16Z | ---
license: mit
---
### kogatan_shiny on Stable Diffusion
This is the `kogatan` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:





|
sd-concepts-library/homestuck-sprite | sd-concepts-library | 2022-09-21T15:08:58Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T15:08:54Z | ---
license: mit
---
### homestuck sprite on Stable Diffusion
This is the `<homestuck-sprite>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
sd-concepts-library/jojo-bizzare-adventure-manga-lineart | sd-concepts-library | 2022-09-21T15:03:39Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T15:03:33Z | ---
license: mit
---
### JoJo Bizzare Adventure manga lineart on Stable Diffusion
This is the `<JoJo_lineart>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:













|
minminzi/t5-base-finetuned-eli5 | minminzi | 2022-09-21T15:02:46Z | 126 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:eli5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-09-20T15:35:29Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- eli5
metrics:
- rouge
model-index:
- name: t5-base-finetuned-eli5
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: eli5
type: eli5
config: LFQA_reddit
split: train_eli5
args: LFQA_reddit
metrics:
- name: Rouge1
type: rouge
value: 0.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-eli5
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 17040 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.0
- Tokenizers 0.12.1
|
csdeptsju/distilbert-base-uncased-finetuned-emotion | csdeptsju | 2022-09-21T15:00:30Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-09-21T14:25:43Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.918
- name: F1
type: f1
value: 0.9179414471754404
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2255
- Accuracy: 0.918
- F1: 0.9179
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8539 | 1.0 | 250 | 0.3348 | 0.896 | 0.8916 |
| 0.2589 | 2.0 | 500 | 0.2255 | 0.918 | 0.9179 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.0
- Tokenizers 0.12.1
|
sd-concepts-library/phan-s-collage | sd-concepts-library | 2022-09-21T14:44:10Z | 0 | 1 | null | [
"license:mit",
"region:us"
]
| null | 2022-09-21T14:44:04Z | ---
license: mit
---
### Phan's Collage on Stable Diffusion
This is the `<pcollage>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
Subsets and Splits